High Speed Fpga Boot-up Through Concurrent Multi-frame Configuration Scheme
Tan; Jun Pin ; et al.
U.S. patent application number 16/194991 was filed with the patent office on 2019-05-23 for high speed fpga boot-up through concurrent multi-frame configuration scheme. The applicant listed for this patent is Altera Corporation. Invention is credited to Kiun Kiet Jong, Jun Pin Tan, Lai Pheng Tan.
| Application Number | 20190156873 16/194991 |
| Document ID | / |
| Family ID | 55754114 |
| Filed Date | 2019-05-23 |





| United States Patent Application | 20190156873 |
| Kind Code | A1 |
| Tan; Jun Pin ; et al. | May 23, 2019 |
HIGH SPEED FPGA BOOT-UP THROUGH CONCURRENT MULTI-FRAME CONFIGURATION SCHEME
Abstract
Systems and methods are provided herein for implementing a programmable integrated circuit device that enables high-speed FPGA boot-up through a significant reduction of configuration time. By enabling high-speed FPGA boot-up, the programmable integrated circuit device will be able to accommodate applications that require faster boot-up time than conventional programmable integrated circuit devices are able to accommodate. In order to enable high-speed boot-up, dedicated address registers are implemented for each data line segment of a data line, which in turn significantly reduces configuration random access memory (CRAM) write time (e.g., by a factor of at least two).
| Inventors: | Tan; Jun Pin; (Kepong, MY) ; Jong; Kiun Kiet; (Bayan Lepas, MY) ; Tan; Lai Pheng; (Gelugor, MY) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 55754114 | ||||||||||
| Appl. No.: | 16/194991 | ||||||||||
| Filed: | November 19, 2018 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15489535 | Apr 17, 2017 | 10186305 | ||
| 16194991 | ||||
| 15197356 | Jun 29, 2016 | 9627019 | ||
| 15489535 | ||||
| 14685098 | Apr 13, 2015 | 9401190 | ||
| 15197356 | ||||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | H03K 19/1776 20130101; H03K 19/17758 20200101; G11C 7/00 20130101; G11C 7/1039 20130101; G06F 9/4403 20130101; G11C 8/04 20130101 |
| International Class: | G11C 8/04 20060101 G11C008/04; H03K 19/177 20060101 H03K019/177; G06F 9/4401 20060101 G06F009/4401; G11C 7/00 20060101 G11C007/00; G11C 7/10 20060101 G11C007/10 |
Claims
1-20. (canceled)
21. A programmable integrated circuit device, comprising: a first data line segment of a plurality of data line segments, wherein the first data line segment comprises: a first plurality of configuration random access memory (CRAM) cells; and a first pipeline column coupled to the first plurality of CRAMs, wherein the first pipeline column is configured to: receive a plurality of data frames; transmit a first data frame of the plurality of data frames to the first plurality of CRAMs, wherein the first data frame is associated with the first data line segment; and transmit a second data frame of the plurality of data frames to a second data line segment of the plurality of data line segments, wherein the second data frame is associated with the second data line segment, and wherein the second data line segment comprises a second pipeline column coupled to a second plurality of CRAMs.
22. The programmable integrated circuit device of claim 21, wherein the first data line segment is configured to load the first data frame into the first plurality of CRAMs, and wherein the second data line segment is configured to load the second data frame into the second plurality of CRAMs at a substantially similar time as the loading of the first data frame into the first plurality of CRAMs.
23. The programmable integrated circuit device of claim 21, wherein the first data line segment is coupled to a first address register, and wherein the second data line segment is coupled to a second address register.
24. The programmable integrated circuit device of claim 23, wherein the first data line segment is coupled to the first address register via a first plurality of address lines, wherein the second data line segment is coupled to the second address register via a second plurality of address lines.
25. The programmable integrated circuit device of claim 23, wherein the first data line segment and the second data line segment are configured to load the first data frame and the second data frame, respectively, in response to receiving a respective activation signal at a substantially similar time from the first address register and from the second address register, respectively.
26. The programmable integrated circuit device of claim 25, wherein the respective activation signal is transmitted by the first address register and by the second address register in response to the first data line segment transmitting the first data frame associated to the first plurality of CRAMs and the second data line segment transmitting the second data frame to the second plurality of CRAMs.
27. The programmable integrated circuit device of claim 21, wherein the first pipeline column is configured to receive the plurality of data frames via a plurality of data lines coupled to the first pipeline column.
28. The programmable integrated circuit device of claim 21, wherein the first pipeline column comprises one or more flip flop latches.
29. The programmable integrated circuit device of claim 21, comprising a data register configured to transmit the plurality of data frames to the plurality of data lines.
30. A method for operating a programmable integrated circuit device, comprising: receiving, via a pipeline column of a data line segment, a plurality of data frames; transmitting, via the pipeline column, a first data frame of the plurality of data frames to a plurality of configuration random access memory (CRAM) cells of the data line segment, wherein the first data frame is associated with the data line segment; and transmitting, via the pipeline column, a second data frame of the plurality of data frames to an additional plurality of CRAMs of an additional data line segments, wherein the second data frame is associated with the additional data line segment.
31. The method of claim 30, wherein an activation signal is transmitted to the data line segment and the additional data line segment to trigger loading of the first data frame into the data line segment and the second data frame into the second data line segment at a substantially similar time in response to the data line segment and the additional data line segment receiving the first data frame and the second data frame, respectively.
32. The method of claim 31, wherein loading the first data frame into the data line segment comprises loading the first data frame into the plurality of CRAMs, and wherein loading the second data frame into the additional line segment comprises loading the second data frame into the additional plurality of CRAMs.
33. The method of claim 30, wherein receiving the plurality data frames is received via a plurality of data lines associated with the pipeline column.
34. The method of claim 30, wherein transmitting the second data frame comprises pipelining, via the pipeline column, the second data frame to an additional pipeline column of the additional data line segment located downstream of the pipeline column.
35. A non-transitory machine-readable medium comprising instructions stored thereon for configuring a programmable integrated circuit device, the instructions comprising: instructions to receive a plurality of data frames at a pipeline column of a data line segment; instructions to transmit, via the pipeline column, a first data frame of the plurality of data frames to a plurality of memory cells of the data line segment, wherein the first data frame is associated with the data line segment; and instructions to transmit, via the pipeline column, a second data frame of the plurality of data frames to an additional pipeline column of an additional data line segment.
36. The non-transitory machine-readable medium of claim 35, wherein the first data frame comprises null data, and wherein the second frame of data comprises null data.
37. The non-transitory machine-readable medium of claim 35, comprising instructions for transmitting an activation signal to the data line segment and to the additional data line segment to trigger loading of the first data frame into the data line segment and the second data frame into the additional data line segment at a substantially similar time in response to the data line segment and the additional data line segment receiving the first data frame and the second data frame, respectively.
38. The non-transitory machine-readable medium of claim 37, wherein loading the first data frame into the data line segment comprises loading the first data frame into the plurality of memory cells, and wherein loading the second data frame into the additional data line segment comprises loading the second data frame into a second plurality of CRAMs of the additional data line segment.
39. The non-transitory machine-readable medium of claim 35, wherein the instructions comprise instructions to: scrub data previously loaded into the plurality of memory cells in response to the first data frame being transmitted in the data line segment; and scrub data previously loaded into an additional plurality of memory cells of the additional data line segment in response to the second data frame being transmitted in the additional data line segment.
40. The non-transitory machine-readable medium of claim 35, wherein instructions to receive the plurality data frames occurs via a plurality of data lines associated with the pipeline column.
Description
CROSS REFERENCE TO RELATED APPLICATIONS
[0001] This application is a Continuation of U.S. patent application Ser. No. 15/197,356, entitled "High Speed FPGA Boot-Up Through Concurrent Multi-Frame Configuration Scheme", filed on Jun. 29, 2016, which claims priority to U.S. patent application Ser. No. 14/685,098, entitled "High Speed FPGA Boot-Up Through Concurrent Multi-Frame Configuration Scheme", filed on Apr. 13, 2015. Both of these applications are herein incorporated by reference in its entirety and for all purposes.
BACKGROUND
[0002] Integrated circuit devices such as field programmable gate array (FPGA) devices are known to suffer bottlenecks that prevent high-speed boot-up by causing less than optimal configuration random access memory (CRAM) programming time. Accordingly, applications that require boot-up time that is faster than a programming time offered in a programmable integrated circuit device, such as an FPGA device, cannot be implemented in such a device. Typically, these bottlenecks are formed because configuration time is not scalable in conventional programmable integrated circuit devices, and therefore, the larger the device required to run an application, the larger the configuration time per data frame becomes. For example, as FPGA designs are scaled larger, data lines and address lines become larger, thus requiring more time to be configured.
SUMMARY
[0003] Systems and methods are provided herein for implementing a programmable integrated circuit device that enables high-speed FPGA boot-up through a significant reduction of configuration time. By enabling high-speed FPGA boot-up, the programmable integrated circuit device is able to accommodate applications that require faster boot-up time than conventional programmable integrated circuit devices are able to accommodate.
[0004] In order to enable high-speed boot-up, dedicated address registers are implemented for each data line segment of a data line, which in turn significantly reduces configuration random access memory (CRAM) write time (e.g., by a factor of at least two).
BRIEF DESCRIPTION OF DRAWINGS
[0005] Further features of the invention, its nature and various advantages will be apparent upon consideration of the following detailed description, taken in conjunction with the accompanying drawings, in which like reference characters refer to like parts throughout, and in which:
[0006] FIG. 1 depicts a programmable integrated circuit device including a configuration source, a data register, data line segments, and an address register, in accordance with some embodiments of this disclosure;
[0007] FIG. 2 depicts a timing diagram that demonstrates a length of time of which each activity described with respect to FIG. 1 requires, in accordance with some embodiments of this disclosure;
[0008] FIG. 3 depicts a timing diagram that demonstrates a length of time of which each activity described with respect to FIG. 1 would require if the time it took to transfer data from a configuration source to a data register were accelerated, in accordance with some embodiments of this disclosure;
[0009] FIG. 4 is a system diagram that depicts a programmable integrated circuit device including a configuration source, a data register, data line segments, and multiple address registers, in accordance with some embodiments of this disclosure;
[0010] FIG. 5 depicts a timing diagram that demonstrates a length of time of which each activity described with respect to FIG. 4 requires, in accordance with some embodiments of this disclosure;
[0011] FIG. 6 is a flowchart that depicts a process for writing data into CRAM of a programmable integrated circuit device in a scalable manner, in accordance with some embodiments of the disclosure;
[0012] FIG. 7 is a simplified block diagram of an exemplary system employing a programmable logic device incorporating systems and methods of the present disclosure, in accordance with some embodiments of this disclosure;
[0013] FIG. 8 is a cross-sectional view of a magnetic data storage medium encoded with a set of machine-executable instructions for performing methods described herein, in accordance with some embodiments of this disclosure; and
[0014] FIG. 9 is a cross-sectional view of an optically-readable data storage medium encoded with a set of machine executable instructions for performing methods described herein, in accordance with some embodiments of this disclosure.
DETAILED DESCRIPTION
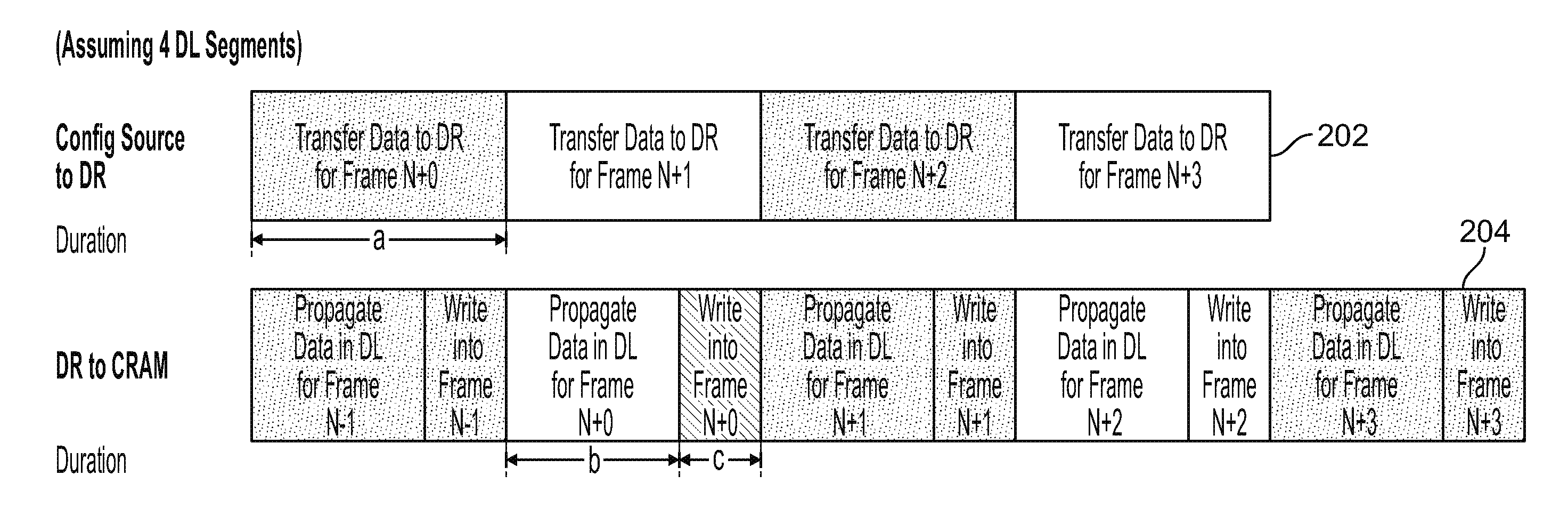
[0015] FIG. 1 depicts a programmable integrated circuit device including a configuration source, a data register, data line segments, and an address register, in accordance with some embodiments of this disclosure. Programmable integrated circuit device 100 may include configuration source 102, data register 104, data line segments 106, address register 108, CRAM 110, and buffer columns 112. Configuration source 102 contains data that is to be transmitted to data register 104. As indicated, the letter "a" corresponds to the amount of time necessary to transfer data from configuration source 102 through data register 104. Once data register 104 has received the data from configuration source 102, data register 104 propagates the data from data register 104 to each data line segment 106 in order to write the data to each CRAM 110. Buffer columns 112 re-buffer data as it propagates along a data line in order to ensure the strength of the signal does not deteriorate as data propagates through a data line. The letter "b" corresponds to the amount of time needed to charge or discharge a segment of a data line. When the data is fully propagated to all CRAM 110, address register 108 is activated, which causes data to be written into CRAM 110. In FIG. 1, the acronym "DR" stands for "Data Register," the acronym "DL" stands for "Data Line," and the acronym "AL" stands for "Address Line."
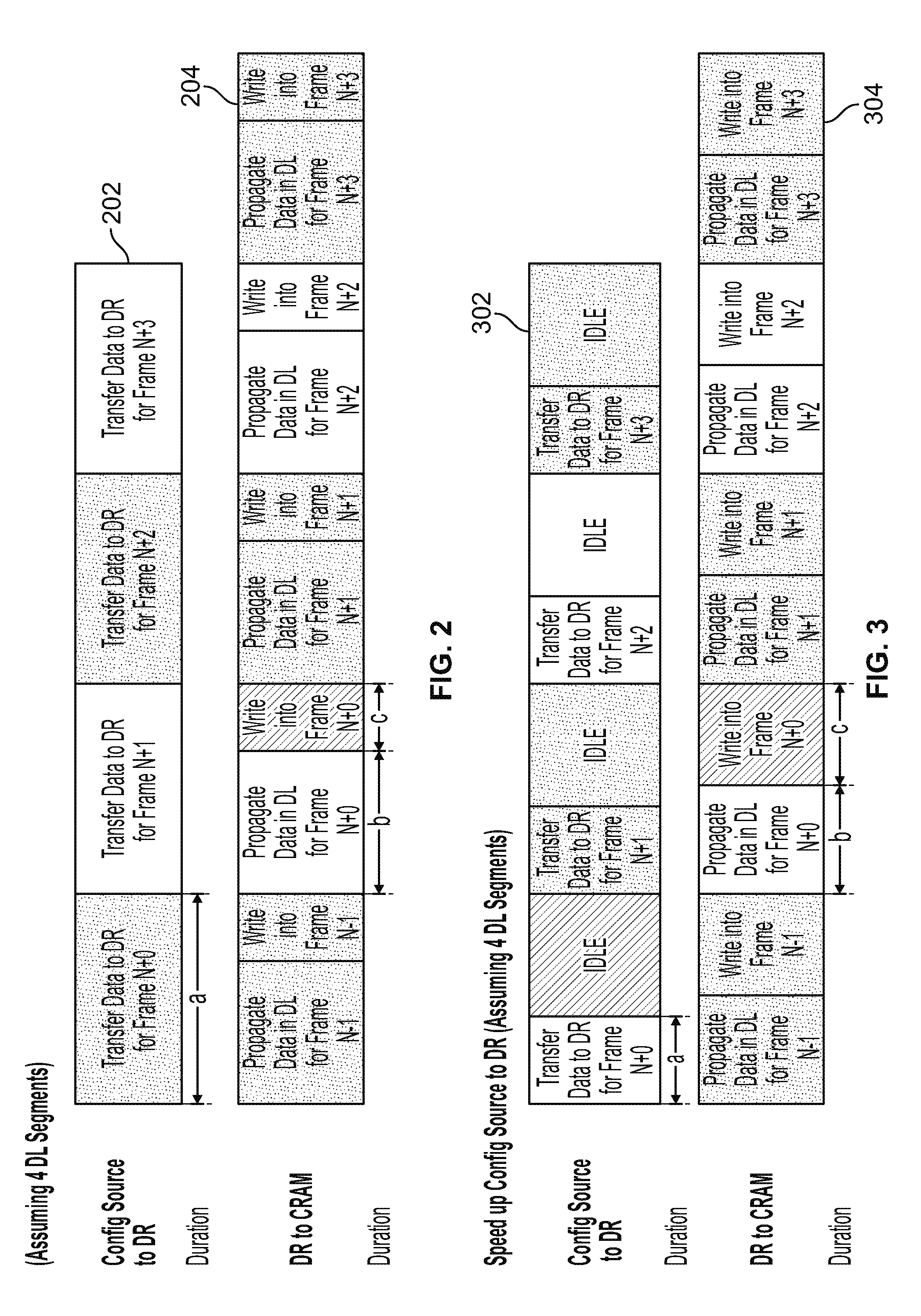
[0016] FIG. 2 depicts a timing diagram that demonstrates a length of time for which each activity described with respect to FIG. 1 requires, in accordance with some embodiments of this disclosure. Block 202 demonstrates the amount of time "a" it takes for data to transfer from configuration source 102 to data register 104. Block 204 demonstrates the amount of time "b" it takes to propagate data from the data register 104 to CRAM 110 (by way of data segments 106), such that a segment of a data line is charged or discharged. Block 204 also demonstrates the amount of time "c" it takes to write the data to CRAM 110 once it has been propagated, such that a data frame is charged or discharged. In FIG. 2, the acronym "DR" stands for "Data Register," and the acronym "DL" stands for "Data Line."
[0017] As described above, data transfer and CRAM programming may happen in parallel. Accordingly, the time to program each data frame may be described as the maximum time of (1) the amount of time it takes to transfer data from the configuration source 102 to data register 104, or (2) the amount of time it takes to both propagate data from data register 104 to data line segments 106 and write data into CRAM 110. This amount of time may be alternatively stated as follows:
T.sub.prog(conv)=max(a,(b+c)).
[0018] FIG. 3 depicts a timing diagram that demonstrates a length of time for which each activity described with respect to FIG. 1 would require if the time it took to transfer data from a configuration source to a data register were accelerated, in accordance with some embodiments of this disclosure. In particular, FIG. 3 is designed to illustrate a bottleneck that occurs in the environment of programmable integrated circuit device 100, where, no matter how much an amount of time to transfer data from configuration source 102 to data register 104 is sped up, the amount of time it takes to propagate data from data register 104 to CRAM 110 and then write the data to CRAM 110 is not at all improved. As can be seen in FIG. 3, block 302 demonstrates the amount of time "a" it would take to transfer data from configuration source 102 to data register 104. Note that time "a" is significantly shorter at block 302 than it is at block 202 (corresponding to a speed-up of the time it takes to transfer data from configuration source 102 to data register 104). Block 304 demonstrates the amount of time "b" it takes to propagate data from the data register 104 to CRAM 110 (by way of data segments 106). Block 304 also demonstrates the amount of time "c" it takes to write the data to CRAM 110 once it has been propagated. Note that the combined times "b" and "c" are identical to those depicted in FIG. 2.
[0019] As described above, data transfer and CRAM programming may happen in parallel. Accordingly, with respect to FIG. 3, the time to program each data frame 110 may still be described as the maximum time of the greater of (1) the amount of time it takes to transfer data from the configuration source 102 to data register 104, or (2) the amount of time it takes to both propagate data from data register 104 to data line segments 106 and write data into CRAM 110. As above, this amount of time may be stated as follows: T.sub.prog(conv)=max(a,(b+c)). This is illustrative because even where the time required for data to transfer from configuration source 102 to data register 104 is reduced to less than the time it takes to both propagate data from data register 104 to data line segments 106 and write data into CRAM 110, a bottleneck is formed. Accordingly, in this scenario, the amount of time may be alternatively stated as follows: T.sub.prog(conv)=b+c.
[0020] More recently, programmable integrated circuit devices such as FPGAs have incorporated embedded system-on-chip circuitry, which is able to help speed up the duration of time required to transfer data from configuration source 102 to data register 104 rather easily by using wider data bandwidth. This has not solved the bottleneck described above, which is the time it takes to propagate data from data register 104 through data line segments 106, as well as the enabling and disabling of address register 108 in order to write data to CRAM 110. In order to reduce programmable integrated circuit device (e.g., FPGA) boot-up time even further (e.g., by a factor of at least two times or more), while minimally impacting the amount of chip area that would have to be devoted to the components of the programmable integrated circuit device, dedicated address registers may be assigned for each data line segment, as will be discussed below with respect to FIG. 4.
[0021] FIG. 4 is a system diagram that depicts a programmable integrated circuit device including a configuration source, a data register, data line segments, address registers, CRAM, and pipeline columns, in accordance with some embodiments of this disclosure. Programmable integrated circuit device 400 may include configuration source 402, data register 404, data line (DL) segments 406, address registers 408, CRAM 410, and pipeline columns 412. Programmable integrated circuit device 400 is improved by the inclusion of multiple address registers 408. The address registers 408 are also referred to as ARn, where there may be n address registers, despite only four address registers being depicted. Individual address registers 408 allow one data frame per data line segment to be written at a time. As a result, multiple CRAM 410 may be written per device at one time. Configuration source 402 contains configuration data that is to be transmitted to data register 404. As indicated, the letter "a" corresponds to the amount of time necessary to transfer data from configuration source 402 through data register 404. Once data register 404 has received the data from configuration source 402, data register 404 propagates data from data register 404 to each data line segment 406 in order to write the data to each CRAM 410. Pipeline columns 412 allow new data to propagate down each data line (e.g., new data may be pipelined down the data line each clock cycle). The letter "b" corresponds to the amount of time needed to charge or discharge a segment of a data line (DL) segment 406. When the data is propagated to CRAM 410 of an individual data line segment 406-n, address register 408-n corresponding to data line segment 406-n is activated, which causes data to be written into CRAM 410 in the corresponding data line segment 406-n.
[0022] By way of the steps described above with respect to FIG. 4, CRAM values are propagated through each data line segment to appropriate CRAM cells. Multiple data frames are enabled to be programmed at the same time by the CRAM values being pipelined at every data line segment 406. The frequency of pipelining of the data lines forming the data line segments 406 may depend on a tradeoff between area overhead versus configuration time reduction. In any event, each data line segment 406-n will have its own corresponding address register 408. Each respective address register 408-n is controlled independently by configuration source 402. For example, configuration source 402 may provide one or more input signals to each address register 408-n. This independent control causes write time to be significantly improved by programmable integrated circuit device 400.
[0023] According to the above description, the process of programming the data stream from configuration source 402 to CRAM 410 may be described as follows. First, data register 404 is filled with a configuration bit stream of data from configuration source 402. Next, data of the configuration bit stream (i.e., CRAM values) are shifted from data register 404 to adjacent pipeline registers of data line segments 406 until the data reaches the furthest data line segment 406. In parallel with this process, data corresponding to a next data frame will continue to fill up data register 404 from configuration source 402.
[0024] Following this process, when all pipeline columns 412 of a data line segment 406-n are full with each respective CRAM value, respective address line 408-n will be enabled to write the data into the respective CRAM 410-n. In this manner, multiple data frames are written to CRAM 410 concurrently (i.e., by writing one data frame per data line segment 406 concurrently), thus reducing configuration time (with respect to the configuration time required in known devices).
[0025] FIG. 5 depicts a timing diagram that demonstrates a length of time for which each activity described with respect to FIG. 4 requires, in accordance with some embodiments of this disclosure. FIG. 5 assumes that FIG. 4 includes four data line segments (meaning there will be three pipelining stages). Block 502 demonstrates the amount of time "a" it would take to transfer data from configuration source 402 to data register 404. Note that time "a" is significantly shorter at block 502 than it is at block 202, as it can be easily sped up. Block 504 demonstrates the amount of time it takes to propagate data from the data register 404 to CRAM 410 (by way of data segments 406). Note that the time to propagate data from data register 404 to CRAM 410 is reduced by a factor of 4 in this instance, as each data frame is able to be processed in parallel by the system of FIG. 4, and there are four data segments, each of which may handle a data frame. Accordingly the time it takes to write data to CRAM 410 for any given data frame is "b" divided by four. Block 504 also demonstrates the amount of time "c" it takes to write the data to CRAM 410 once it has been propagated. Similar to the activity described with respect to FIGS. 1-3, time "c" is not significantly sped up by the system of FIG. 4; however, write time only needs to occur once for all address registers, and therefore time "c" is only necessary once for all data line segments, whereas the systems described in FIGS. 1-3 require time "c" to occur once for each segment. Accordingly, the write time is also reduced by a factor of 4. Note that times "b" and "c" are each identical to those depicted in FIG. 2.
[0026] Accordingly, with respect to FIG. 5, the time to program each data frame to CRAM 410 may be described as the amount of time it takes to both propagate data from data register 404 to data line segments 406 and write data into CRAM 410 via data line segments 406. This amount of time may be alternatively stated as follows: T.sub.prog(conv)=(b+c)/4. As a reminder, FIG. 5 depicts an example where four data line segments are used; however, the example of FIG. 5 is exemplary only, and the system can be scaled for N data line segments 406, which would thus cause the programming time to be reduced by a factor of N. In other words, the amount of time may be stated as T.sub.prog(conv)=(b+c)/N where N data line segments 406 are implemented.
[0027] A "saving factor" may also be described with reference to the improved activity described in FIGS. 4 and 5 with respect to the activity described with respect to FIGS. 1-3. In particular, the saving factor is described as follows:
F save = T prog ( conv ) T prog ( new ) = b + c b + c N = N , ##EQU00001##
where N is again the number of data line segments implemented. This further exemplifies that the system described with reference to FIGS. 4 and 5 can improve configuration time of CRAM in direct proportion to a number of data line segments and corresponding data registers implemented.
[0028] As described above and below, the scheme of FIGS. 4 and 5 is advantageous because programming time per data frame is made scalable, where, even for larger devices, by adding sufficient pipeline functionality (i.e., by implementing sufficient data line segments and address registers), the programming time per data frame can be reduced significantly with respect to the scheme described in FIGS. 1-3.
[0029] The scheme of FIGS. 4 and 5 is also advantageous because a certain class of applications require fast boot-up. In particular, larger devices require longer programming time. With the scheme described with respect to FIGS. 4 and 5, larger programmable integrated circuit devices, such as FPGA devices, are able to be competitive in markets where such applications are sold. Finally, this scheme is similarly able to speed up scrubbing operations as multiple data frames may be scrubbed at the same time in the environment of FIGS. 4 and 5.
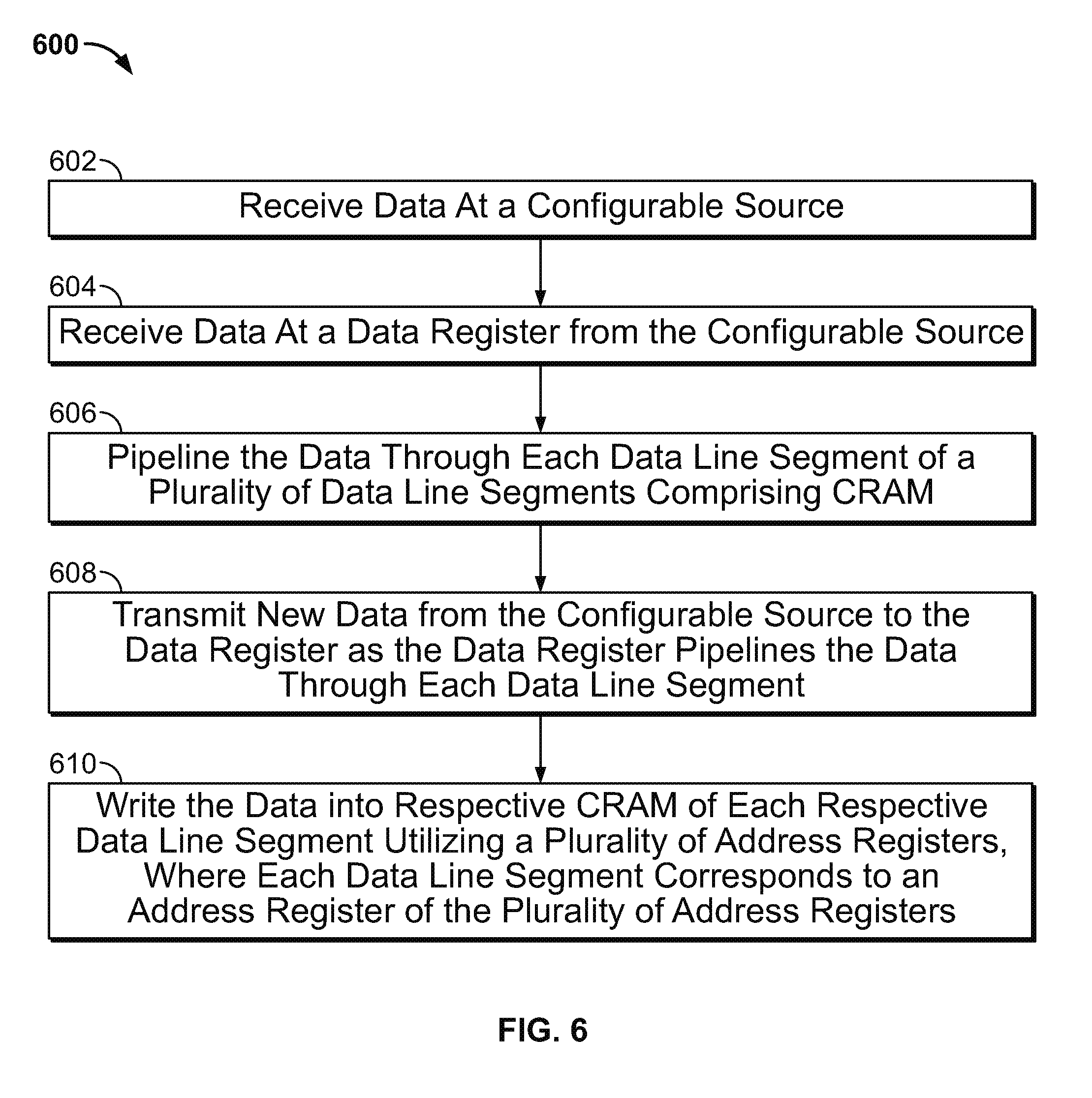
[0030] FIG. 6 is a flow chart that depicts a process for writing data into CRAM of a programmable integrated circuit device in a scalable manner, in accordance with some embodiments of the disclosure. Process 600 begins at 602, where data is received at a configurable source (e.g., configurable source 402). At 604, data is received at a data register (e.g., data register 404) from the configurable source (e.g., configurable source 402). At 606, data is pipelined from the data register (e.g., data register 404) through each data line segment of the device (e.g., data line segments 406), where each data line segment includes CRAM 410.
[0031] At 608, new data is transmitted from the configurable source (e.g., configurable source 402) to the data register (e.g., data register 404) as the data register pipelines the data through each data line segment. In this manner, data is able to be written to CRAM 410 in parallel to configuration source 402 populating data register 404 with new data. At 610, the data is written into respective CRAM of each respective data line segments by way of corresponding address registers 408. In some implementations, address registers 408 correspond one-to-one to data line segments 406, such that each data line segment 406 has an individual address register 408 for the purpose of writing data to CRAM 410 of the particular data line segment.
[0032] It should be understood that one or more elements (such as elements 602, 604, 606, 608, and/or 610) shown in flow diagram 600 may be combined with other elements, performed in any suitable order, performed in parallel (e.g., simultaneously or substantially simultaneously), or removed. For example, elements 606 and 608 of flow diagram 600 may be performed simultaneously, or in a different order than shown in FIG. 6. Process 600 may be implemented using any suitable combination of hardware and/or software in any suitable fashion. For example, flow diagram 600 may be implemented using instructions encoded on a non-transitory machine readable storage medium.
[0033] As depicted in FIG. 7, an Integrated Circuit Programmable Logic Device (PLD) 700 incorporating the multiple network planes according to the present disclosure may be used in many kinds of electronic devices. Integrated Circuit Programmable Logic Device 700 may be an integrated circuit, a processing block, application specific standard product (ASSP), application specific integrated circuit (ASIC), programmable logic device (PLD) such as a field programmable gate array (FPGA), full-custom chip, or a dedicated chip, however, for simplicity, it may be referred to as PLD 700 herein. One possible use is in an exemplary data processing system 700 shown in FIG. 7. Data processing system 700 may include one or more of the following components: a processor 701; memory 702; I/O circuitry 703; and peripheral devices 704. These components are coupled together by a system bus 705 and are populated on a circuit board 706 which is contained in an end-user system 707.
[0034] System 700 can be used in a wide variety of applications, such as computer networking, data networking, instrumentation, video processing, digital signal processing, or any other application where the advantage of using programmable or reprogrammable logic is desirable. PLD 700 can be used to perform a plurality of different logic functions. For example, PLD 700 can be configured as a processor or controller that works in cooperation with processor 701. PLD 700 may also be used as an arbiter for arbitrating access to a shared resource in system 700. In yet another example, PLD 700 can be configured as an interface between processor 701 and one of the other components in system 700. It should be noted that system 700 is only exemplary, and that the true scope and spirit of the invention should be indicated by the following claims.
[0035] Various technologies can be used to implement PLDs 700 as described above and incorporating this disclosure.
[0036] FIG. 8 presents a cross section of a magnetic data storage medium 810 which can be encoded (e.g., a program that includes the steps of FIG. 6) with a machine executable program that can be carried out by systems such as a workstation or personal computer, or other computer or similar device. Medium 810 can be a floppy diskette or hard disk, or magnetic tape, having a suitable substrate 811, which may be conventional, and a suitable coating 812, which may be conventional, on one or both sides, containing magnetic domains (not visible) whose polarity or orientation can be altered magnetically. Except in the case where it is magnetic tape, medium 810 may also have an opening (not shown) for receiving the spindle of a disk drive or other data storage device.
[0037] The magnetic domains of coating 812 of medium 810 are polarized or oriented so as to encode, in manner which may be conventional, a machine-executable program, for execution by a programming system such as a workstation or personal computer or other computer or similar system, having a socket or peripheral attachment into which the PLD to be programmed may be inserted, to configure appropriate portions of the PLD, including its specialized processing blocks, if any, in accordance with the invention.
[0038] FIG. 9 shows a cross section of an optically-readable data storage medium 910 which also can be encoded with such a machine-executable program (e.g., a program that includes the steps of FIG. 6), which can be carried out by systems such as the aforementioned workstation or personal computer, or other computer or similar device. Medium 910 can be a conventional compact disk read-only memory (CD-ROM) or digital video disk read-only memory (DVD-ROM) or a rewriteable medium such as a CD-R, CD-RW, DVD-R, DVD-RW, DVD+R, DVD+RW, or DVD-RAM or a magneto-optical disk which is optically readable and magneto-optically rewriteable. Medium 910 preferably has a suitable substrate 911, which may be conventional, and a suitable coating 912, which may be conventional, usually on one or both sides of substrate 911.
[0039] In the case of a CD-based or DVD-based medium, as is well known, coating 912 is reflective and is impressed with a plurality of pits 913, arranged on one or more layers, to encode the machine-executable program. The arrangement of pits is read by reflecting laser light off the surface of coating 912. A protective coating 914, which preferably is substantially transparent, is provided on top of coating 912.
[0040] In the case of magneto-optical disk, as is well known, coating 912 has no pits 913, but has a plurality of magnetic domains whose polarity or orientation can be changed magnetically when heated above a certain temperature, as by a laser (not shown). The orientation of the domains can be read by measuring the polarization of laser light reflected from coating 912. The arrangement of the domains encodes the program as described above.
[0041] It will be understood that the foregoing is only illustrative of the principles of the disclosure, and that various modifications can be made by those skilled in the art without departing from the scope and spirit of the disclosure. For example, the various elements of this disclosure can be provided on a PLD in any desired number and/or arrangement. One skilled in the art will appreciate that the present disclosure can be practiced by other than the described embodiments, which are presented for purposes of illustration and not of limitation, and the present invention is limited only by the claims that follow.
[0042] No admission is made that any portion of the disclosure, whether in the background or otherwise, forms a part of the prior art.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.