Tomographic Reconstruction System
Liu; Junshi ; et al.
U.S. patent application number 17/033065 was filed with the patent office on 2021-04-15 for tomographic reconstruction system. This patent application is currently assigned to Purdue Research Foundation. The applicant listed for this patent is Purdue Research Foundation. Invention is credited to Charles A. Bouman, Junshi Liu, Anand Raghunathan, Singanallur V. Venkatakrishnan, Swagath Venkataramani.
| Application Number | 20210110581 17/033065 |
| Document ID | / |
| Family ID | 1000005293281 |
| Filed Date | 2021-04-15 |











View All Diagrams
| United States Patent Application | 20210110581 |
| Kind Code | A1 |
| Liu; Junshi ; et al. | April 15, 2021 |
TOMOGRAPHIC RECONSTRUCTION SYSTEM
Abstract
A tomography system having a central processing unit, a system memory communicatively connected to the central processing unit, and a hardware acceleration unit communicatively connected to the central processing unit and the system memory, the hardware accelerator configured to perform at least a portion of an MBIR process on computer tomography data. The hardware accelerator unit may include one or more voxel evaluation modules which evaluate an updated value of a voxel given a voxel location in a reconstructed volume. By processing voxel data for voxels in a voxel neighborhood, processing time is reduces.
| Inventors: | Liu; Junshi; (West Lafayette, IN) ; Venkataramani; Swagath; (West Lafayette, IN) ; Venkatakrishnan; Singanallur V.; (Orinda, CA) ; Bouman; Charles A.; (West Lafayette, IN) ; Raghunathan; Anand; (West Lafayette, IN) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assignee: | Purdue Research Foundation West Lafayette IN |
||||||||||
| Family ID: | 1000005293281 | ||||||||||
| Appl. No.: | 17/033065 | ||||||||||
| Filed: | September 25, 2020 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 16233066 | Dec 26, 2018 | |||
| 17033065 | ||||
| 15063054 | Mar 7, 2016 | 10163232 | ||
| 16233066 | ||||
| 62129018 | Mar 5, 2015 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06T 11/006 20130101; G06T 2211/432 20130101; G06T 2211/424 20130101 |
| International Class: | G06T 11/00 20060101 G06T011/00 |
Goverment Interests
GOVERNMENT RIGHTS
[0002] This invention was made with government support under Grant Number CNS-1018621 awarded by National Science Foundation. The government has certain rights in the invention.
Claims
1. A tomography system, comprising: a central processing unit; a system memory communicatively connected to the central processing unit; and a hardware acceleration unit communicatively connected to the central processing unit and the system memory, the hardware accelerator configured to perform at least a portion of an MBIR process on computer tomography data.
2. The system according to claim 1, further comprising one or more voxel evaluation modules that evaluates an updated value of a voxel given a voxel location in a reconstructed volume.
3. The system according to claim 1, further comprising an electronic display, the display operatively connected to the central processing unit, the electronic display configured to display a reconstructed image based on the computer tomography data.
4. The system according to claim 1, further comprising a computer tomography scanner, wherein the computer tomography scanner is configured to irradiate a test object, measure resulting radiation, and provide measured data corresponding to the resulting radiation.
5. The system according to claim 1, wherein hardware acceleration unit comprises a control unit which generates a pseudo-random sequence of voxel locations.
6. The system of claim 1, wherein the hardware acceleration unit is configured to identify voxel data required to update a voxel and fetch the voxel data from the system memory.
7. The system of claim 2, wherein the VEM contains VEM memory blocks internal to the VEM, which stores the data needed to compute the updated voxel value.
8. The system of claim 2, wherein the VEM is configured to assess the data stored in the VEM memory blocks, re-use said data stored in the VEM memory blocks across multiple voxel evaluations, and partially fetch unavailable data from the system memory.
9. The system of claim 2, wherein the VEM is configured to perform data transfer operations and data processing operations in parallel.
10. The system of claim 2 wherein the VEM is configured to perform data transfer operations and data processing operations in a pipelined manner.
11. The system of claim 2, wherein the hardware accelerator unit fetches data required for a voxel from the system memory, while computations corresponding to a different voxel are in progress.
12. The system of claim 2, wherein the hardware accelerator unit comprises a plurality of VEMs, the VEMs configured to update multiple voxels in parallel.
13. The system of claim 12, wherein the sequence of voxels updated on a VEM is constrained to enhance data reuse within the accelerator.
14. The system of claim 12 in which at least one next voxel processed on a given VEM is constrained to lie within a common slice as the previous voxel processed on the VEM, thereby enabling the error sinogram memory to be reused.
15. The system of claim 12 in which voxels updated concurrently on multiple VEMs are constrained such that they share at least one entry of an A matrix of the tomography data.
16. The system of claim 15 where the said shared entry of the A matrix is fetched only once from the system memory and used by multiple VEMs.
17. The system of claim 12 in which adjacent voxels are updated on the same VEM, enabling neighborhood voxel data to be shared between the voxels.
18. The system of claim 12 where each VEM is configured to update a voxel neighborhood around a given voxel, the neighborhood comprising voxels adjacent to the given voxel.
Description
RELATED APPLICATIONS
[0001] The present patent application is a continuation of U.S. patent application Ser. No. 16/233,066, filed Dec. 26, 2018, which is a continuation of U.S. patent application Ser. No. 15/063,054, filed Mar. 7, 2016, which claims the priority benefit of U.S. Provisional Patent Application Ser. No. 62/129,018, filed Mar. 5, 2015. The contents of all of the these applications is hereby incorporated by reference in its entirety into the present disclosure.
TECHNICAL FIELD
[0003] The present application relates to tomography imaging devices, e.g., computed tomography devices, and to tomography control systems.
BACKGROUND
[0004] Tomographic reconstruction is an important inverse problem in a wide range of imaging systems, including medical scanners, explosive detection systems and electron and X-ray microscopy for scientific and materials imaging. The objective of tomographic reconstruction is to compute a three-dimensional volume (a physical object or a scene) from two-dimensional observations that are acquired using an imaging system. An example of tomographic reconstruction is found in computed tomography (CT) scans, in which X-ray radiation is passed from several angles to record 2D radiographic images of specific parts of the scanned patient. These radiographic images are then processed using a reconstruction algorithm to form a 3D volumetric view of the scanned region, which is subsequently used for medical diagnosis.
[0005] Model Based Iterative Reconstruction (MBIR) is a promising approach to realize tomographic reconstruction. The MBIR framework formulates the problem of reconstruction as minimization of a high-dimensional cost function, in which each voxel in the 3D volume is a variable. An iterative algorithm is employed to optimize the cost function such that a pre-specified error threshold is met.
[0006] MBIR has demonstrated state-of-the art reconstruction quality on various applications and has been utilized commercially in GE's healthcare systems. In addition to improved image quality, MBIR has enabled significant reduction in X-ray dosage in the context of lung cancer screening (.about.80% reduction) and pediatric imaging (30-50% reduction). In other application domains, MBIR offers additional advantages such as improved output resolution, precise definition with reduced impact of undesired artifacts in images, and the ability to reconstruct even with sparse view angles. These capabilities are extremely critical in applications such as explosive detection systems (e.g. baggage and cargo scanners), where there is a need to reduce cost due to false alarm rates, operate under non-ideal view angles, and extend deployed systems to cover new threat scenarios.
[0007] While MBIR shows great potential, its high compute and data requirements are key bottlenecks to its widespread commercial adoption. For instance, reconstructing a 512.times.512.times.256 volume of nanoparticles viewed from different angles through an electron microscope requires 50.33 GOPS (Giga operations) and 15G memory accesses per iteration of MBIR. Further, the algorithm may take 10s of iterations to converge depending on the threshold. Clearly, this places significant compute demand. One tested software implementation required .about.1700 seconds per iteration on a 2.3 GHz AMD Opteron server with 196 GB memory, which is unacceptable for many practical applications. Thus, technologies that enable orders of magnitude improvement in MBIR's implementation efficiency are needed.
SUMMARY
[0008] According to various aspects, a tomography system is provided, comprising a central processing unit, a system memory communicatively connected to the central processing unit and a hardware acceleration unit communicatively connected to the central processing unit and the system memory, the hardware accelerator configured to perform at least a portion of an MBIR process on computer tomography data. The system may comprise one or more voxel evaluation modules that evaluates an updated value of a voxel given a voxel location in a reconstructed volume. The operations may further include determining a reconstructed image for the selected voxel using the updated value of the voxel. The system may also include a computer tomography scanner, wherein the computer tomography scanner is configured to irradiate a test object, measure resulting radiation, and provide measured data corresponding to the resulting radiation.
BRIEF DESCRIPTION OF THE DRAWINGS
[0009] In the following description and drawings, identical reference numerals have been used, where possible, to designate identical features that are common to the drawings.
[0010] FIG. 1 is a diagram showing the components of an example tomography system according to one embodiment.
[0011] FIG. 2 is a diagram showing an access pattern for voxel update in an MBIR algorithm useful with various aspects.
[0012] FIG. 3 is a block diagram of an example implementation of hardware specialized to execute the MBIR algorithm useful with various aspects.
[0013] FIG. 4 is a block diagram of a computation engine/Voxel Evaluation Module of FIG. 3 used for voxel update.
[0014] FIG. 5 shows a scheme where constraining voxels on a x-z line enables sharing of A-Matrix Column.
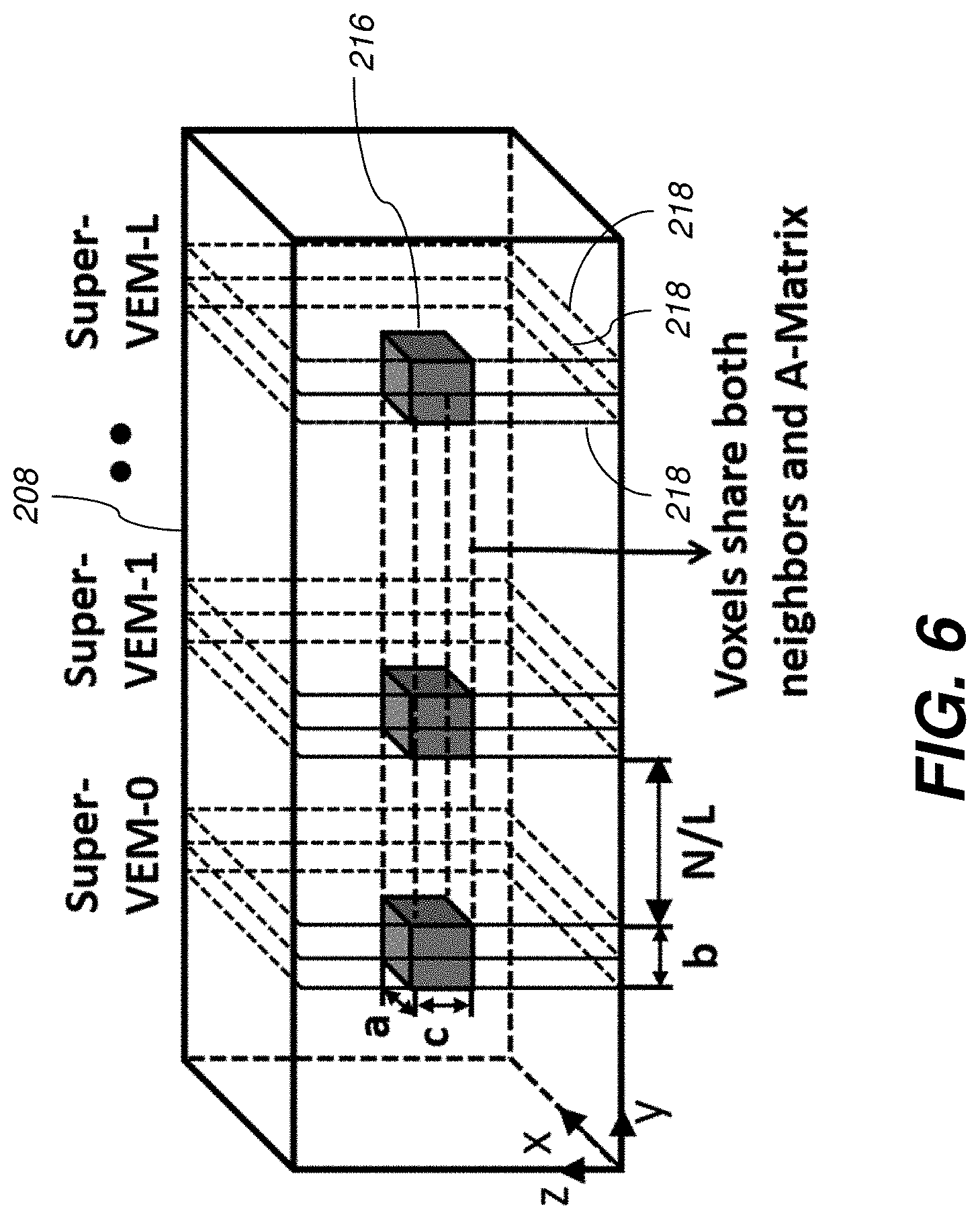
[0015] FIG. 6 shows a scheme where a neighborhood is reused if each computation engine is designed to update a volume around the selected voxel.
[0016] The attached drawings are for purposes of illustration and are not necessarily to scale.
DETAILED DESCRIPTION
[0017] X-ray computed tomography, positron-emission tomography, and other tomography imaging systems are referred to herein generically as "CT" systems.
[0018] Throughout this description, some aspects are described in terms that would ordinarily be implemented as software programs. Those skilled in the art will readily recognize that the equivalent of such software can also be constructed in hardware, firmware, or micro-code. Because data-manipulation algorithms and systems are well known, the present description is directed in particular to algorithms and systems forming part of, or cooperating more directly with, systems and methods described herein. Other aspects of such algorithms and systems, and hardware or software for producing and otherwise processing signals or data involved therewith, not specifically shown or described herein, are selected from such systems, algorithms, components, and elements known in the art. Given the systems and methods as described herein, software not specifically shown, suggested, or described herein that is useful for implementation of any aspect is conventional and within the ordinary skill in such arts.
[0019] FIG. 1 shows a tomography system 100 according to one embodiment. As shown, the system 100 includes a CT scanner 102, a central processing unit 104, a system memory 106, a tomography hardware accelerator unit 302, and a user interface 108. The CT scanner 102 may include a rotating gantry having an x-ray radiation source and sensors which direct radiation to an object being scanned at various angles to record 2D radiographic images. The various components shown in FIG. 1 may be communicatively connected by an electronic network.
[0020] Central processing unit 104, hardware accelerator unit 302, and other processors described herein, can each include one or more microprocessors, microcontrollers, field-programmable gate arrays (FPGAs), application-specific integrated circuits (ASICs), programmable logic devices (PLDs), programmable logic arrays (PLAs), programmable array logic devices (PALs), or digital signal processors (DSPs).
[0021] System memory 106 can be a tangible non-transitory computer-readable storage medium, i.e., a non-transitory device or article of manufacture that participates in storing instructions that can be provided to central processing unit 104 or hardware accelerator unit 302 for execution. In one example, the system memory 106 comprises random access memory (RAM). In other examples, the system memory 106 may comprise a hard disk drive.
[0022] The phrase "communicatively connected" includes any type of connection, wired or wireless, for communicating data between devices or processors. These devices or processors can be located in physical proximity or not.
[0023] To better illustrate the technical challenges involved in the implementation of MBIR, an explanation of the mathematical concepts behind the algorithm will be provided. In order to describe the MBIR approach, it is useful to think of all the 2D images (measurements) as well as the unknown 3D volume of voxels as one-dimensional vectors. If y is a M.times.1 vector containing all the measurements, x is a N.times.1 vector containing all the voxels in the 3D volume, and A is a sparse M.times.N matrix implementing the line integral through the 3D volume, then the MBIR reconstruction is obtained by minimizing the following function,
c ( x ) = 1 2 y - Ax 2 + .beta. r , s .di-elect cons. N s w rs .rho. ( x s - x r ) ( 1 ) ##EQU00001##
where N represents the set of all pairs of neighboring voxels in 3D (using say a 26 point neighborhood system), .rho.(.) is a potential function that incorporates a model for the underlying image, A is a diagonal matrix whose entries weight each term by a factor inversely proportional to the noise in the measurement, and .omega..sub.rs is a set of normalized weights depending on the physical distance between neighboring voxels. The first term in equation (1) has the interpretation of enforcing consistency of the desired reconstruction with the measurements while the second term enforces certain desirable characteristics in the reconstruction (sharp edges, low-noise etc.). The term y-Ax, which represents the difference between the original 2D measurements and the 2D projections obtained from the 3D volume, is called the error sinogram (e).
[0024] While several variants of the MBIR algorithm exist based on how the cost function is minimized, a popular variant called the Iterative Coordinate Descent MBIR (ICD-MBIR) is considered. The basic idea in ICD is to update the voxels one at a time so as to monotonically decrease the value of the original function (equation (1)) with each update. Since the cost function is convex and is bounded from below, this method converges to the global minimum.
[0025] The cost function in equation (1) with respect to a single voxel (ignoring constants) indexed by s is given by
c s ( z ) = .theta. 1 z + .theta. 2 2 ( z - x s ) 2 + r .di-elect cons. N s w rs .rho. ( z - x r ) ( 2 ) .theta. 1 = - e t .LAMBDA.A * , s , .theta. 2 = A * , s t .LAMBDA.A s , * ( 3 ) ##EQU00002##
where A.sub.*,s is the s.sup.th column of A, e=y.about.Ax and x.sub.s is the current value of the voxel s.
[0026] Due to the complicated nature of the function .rho.( ), it is typically not possible to find a simple closed form expression for the minimum of (2). Hence, ( ) often replaced by a quadratic surrogate function which makes (2) simpler to minimize. In particular if
a rs = { .rho. ' ( x r - x s ) ( x r - x s ) x s .noteq. x r .rho. '' ( 0 ) x s = x r ( 4 ) ##EQU00003##
then an overall surrogate function to (2) is given by
c s ( z ) = .theta. 1 ( z - x s ) + .theta. 2 ( z - x s ) 2 + .SIGMA. r .di-elect cons. N s w rs a rs ( z - x r ) 2 ( 5 ) ##EQU00004##
[0027] Taking the derivative of this surrogate function and setting it to zero, it can be verified that the minimum of the function is
z * .rarw. .theta. 2 x s - .theta. 1 + .SIGMA. r .di-elect cons. N s w rs a rs x r .theta. 2 + .SIGMA. r .di-elect cons. N s w rs a rs . ( 6 ) ##EQU00005##
[0028] Note that minimizing (5) ensures a decrease of (2) and hence that of the original function (1). The algorithm can be efficiently implemented by keeping track of the error sinogram e along with each update.
[0029] Steps of an MBIR process according to one embodiment are summarized in Table 1 below.
TABLE-US-00001 TABLE 1 Input: 2D Measurements: y Output: Reconstructed 3D volume: x 1: Initialize x at random 2: Error Sinogram: e = y - Ax 3: while Convergence criteria not met do 4: for each voxel v in random order do 5: .theta..sub.1 and .theta..sub.2 = f (e, A.sub.*,.sub.v ) 6: for voxels u .di-elect cons. neighborhood N.sub.v of v do 7: Compute surrogate fn. a.sub.uv for u (Eqn. 5) 8: end for 9: Compute z* = g(.theta..sub.1, .theta..sub.2, x.sub.v, a.sub.*v) (Eqn. 7) 10: Update Error Sinogram: e .rarw. e - (z* - x.sub.v )A.sub.*,.sub.v 11: Update voxel: x.sub.v .rarw. z* 12: end for 13: end while
[0030] Given a set of 2D measurements (y) as inputs, the process produces the reconstructed 3D volume (x) at the output. First, the voxels in x are initialized at random (line 1). Next the error sinogram (e) is computed as the difference between the 2D measurements and the 2D views obtained by projecting the current 3D volume. The process iteratively updates the voxels (lines 4-13) until the convergence criteria is met. In each iteration, every voxel in the volume is updated once in random order.
[0031] Lines 5-11 of the process in Table 1 describe the steps involved in updating a voxel. First, the parameters .theta..sub.1 and .theta..sub.2 are computed using the A matrix and the error sinogram e (line 5). Next, the quadratic surrogate function is evaluated for each of the voxel neighbors (lines 6-8). These are utilized to compute the new value of the voxel z* (line 9). The error sinogram (e) and the 3D volume (x) are then updated the new voxel value (lines 10-11).
[0032] ICD-MBIR offers several advantages over other MBIR variants: (i) It takes lower number of iterations to converge, thereby enabling faster runtimes, and (ii) It is general and can be easily adopted for a variety of applications with different geometries, noise statistics and image models, without the need for custom algorithmic tuning for each application.
[0033] However, a key challenge with ICD-MBIR is that it is not easily amendable to efficient parallel execution on modern multi-cores and many-core accelerators such as general purpose graphical processing units (GPGPUs) for the following reasons. First, there is limited data parallelism within the core computations that evaluate the updated value of the voxel. From a computational standpoint, each voxel update to create a 3D image 208 involves accessing 3 key data-structures as illustrated in FIG. 2: (i) a column 212 of the A matrix 210, wherein the column 212 is indexed by the x and z co-ordinates of a voxel 214, (ii) voxel neighborhood 216, which refers to the voxels adjacent to the current voxel 214 along all directions, and (iii) portions of the error sinogram, which is determined by slice ID or y co-ordinate of the voxel 214. Since the A matrix column 212 is typically sparse (sparsity ratio of 1000:1), the per-voxel update computations are relatively small (Time/Voxel-update: .about.26 .mu.s), and the overheads of parallelization such as task startup time, synchronization between threads, and off-chip memory bandwidth significantly limit performance. In summary, parallelizing computations within each voxel update yields very little performance improvement.
[0034] The present disclosure provides a specialized hardware architecture and associated control system to simultaneously improve both the runtime and energy consumption of the MBIR algorithm by exploiting its computational characteristics.
[0035] FIG. 3 shows a block diagram of the tomography hardware accelerator unit 302 according to one embodiment. The tomography hardware accelerator unit 302 receives as input: 2D measurement data 304, reconstructed 3D volume data 306, A matrix data 308, and error sinogram data 310. In certain embodiments, the 2D measurement data 304, reconstructed 3D volume data 306, A matrix data 308, and error sinogram 310 may be stored in memory blocks external to and operatively connected to the tomography hardware accelerator unit 302. The tomography hardware accelerator unit 302 may also include a global control unit 312 containing appropriate control registers and logic to initialize the location of the external memory blocks and generate interface signals 314 for sending/receiving inputs/outputs to and from the tomography hardware accelerator unit 302.
[0036] At a high level, operation of the tomography hardware accelerator unit 302 can be summarized as follows. First, the global control unit 312 generates a random voxel ID (x,y,z co-ordinates). Based on the co-ordinates, the tomography hardware accelerator unit 302 retrieves the following data from the system memory 106 which is required to update the voxel 214: a column 212 of the A matrix 210, a portion of the error sinogram 310, and the voxel neighbor data 216 (which is a portion of the volume data 306). The tomography hardware accelerator unit 302 may include internal memory blocks to store these data structures. The updated value of the voxel 214 is then computed by the tomography hardware accelerator unit 302 and stored back to the external system memory 106. This process is repeated until the convergence criterion is met.
[0037] The tomography hardware accelerator unit 302 may also comprise one or more voxel evaluation modules 316. Each voxel evaluation module 316 may comprise a theta evaluation module 318, a neighborhood processing element 320, and a voxel update element 322. Each of the theta evaluation module 318, neighborhood processing element 320, and voxel update element 322 may comprise one or more computer processors and associated memory for performing calculations on the received data.
[0038] The TEM 318 evaluates the variables .theta..sub.1 and .theta..sub.2 of the MBIR algorithm. The NPE 320 applies a complex one-to-one function on each of the neighbor voxels. The VUE 322 uses the outputs of TEM and NPE to compute the updated value of the voxel 214 and the error sinogram 310. The processing elements 318, 320 and 322 may comprise hardware functional blocks such as adders, multipliers, registers etc. that are interconnected to achieve the desired functionality, in some cases, over multiple cycles of operation. The VEM 316 may also contain memory blocks that store the column 212 of A matrix 210, portions of the error sinogram 310 and the voxel neighbor data, all of which may be accessed by the TEM 318, NPE 320 and VUE 322. Since the A matrix is sparse, it may be stored as an adjacency list using First-In-First-Out (FIFO) buffers in certain embodiments. A controller present within the engine is designed to fetch the necessary data if it is not already available in the internal memory blocks of the VEM 316.
[0039] The VEM 316 operates as follows. First, the elements of the A matrix column 212 are transferred into the TEM 318. The TEM 318 utilizes the index of the A matrix elements to address the error sinogram 310 memory to obtain the corresponding error sinogram 310 value. The TEM 318 performs a vector reduction operation on the A matrix 212 and error sinogram 310 values to obtain .theta..sub.1 and .theta..sub.2. In parallel to the TEM 318, the NPE 320 operates on each of the voxel's neighbors data and stores the processed neighbor values in a FIFO memory located in the VEM 316. Since the TEM 318 and NPE 216 operate in parallel, the performance of the VEM 316 is maximized when their latencies are equal. This is achieved by proportionately allocating hardware resources in their implementation. The output of the TEM 318 and NPE 320 is directed to the VUE 322, which computes the updated value of the voxel 214. This involves performing a vector reduction operation on the voxel neighborhood 216, followed by multiple scalar operations. The entries in the error sinogram 310 memory are also updated based on the updated value of the voxel 214. Finally, the voxel 214 data is written back to the system memory 106. Thus, the VEM 316 efficiently computes the updated value of a voxel.
[0040] In certain embodiments, the performance of the computation engine can be further improved by operating it as a two-level nested pipeline. The first-level pipeline is within the TEM 318. In this case, the VEM 316 leverages the pipeline parallelism across the different elements of the vector reduction. When the TEM 318 computes on a given A matrix element, the error sinogram value for the successive element is fetched from the error sinogram memory in a pipelined manner. The second level pipelining exploits the parallelism across successive voxels. In this case, the VEM 316 concurrently transfers data required by the subsequent voxel, even as the previous voxel is being processed by the VEM 316. Thus, both pipeline levels improve performance by overlapping data communication with computation.
[0041] Each execution of the VEM 316 requires the A matrix column 212, the error sinogram 310 and the voxel neighbor data 216 to be transferred from the system memory 106 to the VEM 316. To minimize data transfer overhead, in certain embodiments, the VEM 316 reuses the data stored in the internal memory blocks of the VEM 316 across multiple voxels. Since voxels in a slice 218 share the same portion of the error sinogram 310 (FIG. 2), the VEM 316 constrains the sequence in which the voxels 214 are updated in the VEM as follows: First, a slice 218 is selected from the volume 208 at random. Then, all voxels 214 in the slice 218 are updated in a random sequence before the next slice is chosen. In this case, the error sinogram 310 needs to be fetched only once per slice, and all voxels within the slice can re-use the data. Thus the data transfer cost for the error sinogram 310 is amortized across all voxels 214 in the slice 218. This optimization can be simply realized by modifying the global control unit 312 that generates the voxel ID. In other words, the global control unit 312 may be programmed to select voxels for updating in an order that processes a majority of voxels from the same slice together.
[0042] In certain embodiments, the VEMs 316 are arranged as an array of L lanes, each containing a dedicated TEM 318, NPE 318, and VUE 322. To ensure convergence of the MBIR algorithm, the voxels that are to be updated in parallel are chosen to be located far apart in the 3D volume. To maximize the distance of separation, the voxels may be selected from different slices 218 that are equally and entirely spread out across they dimension (FIG. 2) of the 3D volume 208.
[0043] In certain embodiments, as shown in FIG. 5, the tomography hardware accelerator unit 302 restricts concurrently updated voxels to lie on a straight line in the volume. In the embodiment illustrated in FIG. 5, the line 502 is parallel to the y axis of the volume 208 (i.e. they have the same x,z coordinates), although any straight line in the volume may be used. Since A matrix columns are indexed only using the x and z co-ordinates (FIG. 2), concurrently updated voxels 214 share the same A matrix column 212, thereby linearly reducing the A matrix data transfer time. This optimization does not impact convergence, as the slices from which the voxels 214 are picked lie sufficiently far apart (the y dimension of the volume is much larger than the number of parallel voxel updates). As shown in FIG. 3, an A matrix memory 324 may be placed outside the VEMs 316 and shared by all VEMs 316 during operation. Before each execution of the VEM array, the neighborhoods for all voxels 214 and one A matrix column 212 are transferred from the system memory 106 to the memory 324. This results in a net reduction of L.about.1 A matrix column transfers per execution, where L is the number of VEMs 316 in the tomography hardware accelerator unit 302.
[0044] In certain embodiments, the neighborhood voxel data transfer time may be reduced by concurrently updating the neighborhood volume 216 of size a.times.b.times.c (x,y,z directions) around the voxel 214. Each VEM 316 is then used to update one of the voxels 214 in the volume 216 in a parallel fashion. To facilitate the neighbor voxel reuse, in certain embodiments, the capacity of the neighborhood memory is sized to hold all of the data for voxels in the neighborhood volume 216. Also, once the updated value of a voxel is computed, it needs to be written to the neighborhood memory 216 within the VEM 316 (in addition to the system memory 106), as subsequent voxels in the volume use the updated value. Also, the since the adjacent voxels along the y direction belong to different slices, the error sinogram memory in the VEM 316 may be replicated to hold data corresponding to each slice 218 in the volume 216. Along similar lines, voxels within the slice 218 use different A matrix columns, and correspondingly the A matrix memory is also replicated. The TEM 318, NPE 320 and VUE 322 are not replicated in the VEM 316 in such embodiments, as voxels in the volume 216 are evaluated sequentially. Finally, the global control unit 312 and VEMs 316 are modified to appropriately index these memories and evaluate all voxels within the neighborhood volume 216.
[0045] Steps of various methods described herein can be performed in any order except when otherwise specified, or when data from an earlier step is used in a later step. Exemplary method(s) described herein are not limited to being carried out by components particularly identified in discussions of those methods.
[0046] Various aspects provide more effective processing of CT data. A technical effect is to improve the functioning of a CT scanner by substantially reducing the time required to process CT data, e.g., by performing MBIR or other processes to determine voxel values. A further technical effect is to transform measured data from a CT scanner into voxel data corresponding to the scanned object.
[0047] Various aspects described herein may be embodied as systems or methods. Accordingly, various aspects herein may take the form of an entirely hardware aspect, an entirely software aspect (including firmware, resident software, micro-code, etc.), or an aspect combining software and hardware aspects These aspects can all generally be referred to herein as a "service," "circuit," "circuitry," "module," or "system."
[0048] Furthermore, various aspects herein may be embodied as computer program products including computer readable program code ("program code") stored on a computer readable medium, e.g., a tangible non-transitory computer storage medium or a communication medium. A computer storage medium can include tangible storage units such as volatile memory, nonvolatile memory, or other persistent or auxiliary computer storage media, removable and non-removable computer storage media implemented in any method or technology for storage of information such as computer-readable instructions, data structures, program modules, or other data. A computer storage medium can be manufactured as is conventional for such articles, e.g., by pressing a CD-ROM or electronically writing data into a Flash memory. In contrast to computer storage media, communication media may embody computer-readable instructions, data structures, program modules, or other data in a modulated data signal, such as a carrier wave or other transmission mechanism. As defined herein, "computer storage media" do not include communication media. That is, computer storage media do not include communications media consisting solely of a modulated data signal, a carrier wave, or a propagated signal, per se.
[0049] The program code can include computer program instructions that can be loaded into processor 186 (and possibly also other processors), and that, when loaded into processor 486, cause functions, acts, or operational steps of various aspects herein to be performed by processor 186 (or other processor). The program code for carrying out operations for various aspects described herein may be written in any combination of one or more programming language(s), and can be loaded from disk 143 into code memory 141 for execution. The program code may execute, e.g., entirely on processor 186, partly on processor 186 and partly on a remote computer connected to network 150, or entirely on the remote computer.
[0050] The invention is inclusive of combinations of the aspects described herein. References to "a particular aspect" (or "embodiment" or "version") and the like refer to features that are present in at least one aspect of the invention. Separate references to "an aspect" (or "embodiment") or "particular aspects" or the like do not necessarily refer to the same aspect or aspects; however, such aspects are not mutually exclusive, unless otherwise explicitly noted. The use of singular or plural in referring to "method" or "methods" and the like is not limiting. The word "or" is used in this disclosure in a non-exclusive sense, unless otherwise explicitly noted.
[0051] The invention has been described in detail with particular reference to certain preferred aspects thereof, but it will be understood that variations, combinations, and modifications can be effected within the spirit and scope of the invention.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.