Oligonucleotides For Modulating Erc1 Expression
HAGEDORN; Peter ; et al.
U.S. patent application number 15/733391 was filed with the patent office on 2021-04-01 for oligonucleotides for modulating erc1 expression. This patent application is currently assigned to Roche Innovation Center Copenhagen A/S. The applicant listed for this patent is Roche Innovation Center Copenhagen A/S. Invention is credited to Peter HAGEDORN, Lykke PEDERSEN.
| Application Number | 20210095276 15/733391 |
| Document ID | / |
| Family ID | 1000005302946 |
| Filed Date | 2021-04-01 |



| United States Patent Application | 20210095276 |
| Kind Code | A1 |
| HAGEDORN; Peter ; et al. | April 1, 2021 |
OLIGONUCLEOTIDES FOR MODULATING ERC1 EXPRESSION
Abstract
The present invention relates to antisense oligonucleotides that are capable of reducing expression of ERC1 in a target cell. The oligonucleotides hybridize to ERC1 pre-mRNA. The present invention further relates to conjugates of the oligonucleotide and pharmaceutical compositions and methods for treatment of disease associated with ERC1 overexpression, such as cancer or Dengue virus infection using the antisense oligonucleotide.
| Inventors: | HAGEDORN; Peter; (Horsholm, DK) ; PEDERSEN; Lykke; (US) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assignee: | Roche Innovation Center Copenhagen
A/S Horsholm DK |
||||||||||
| Family ID: | 1000005302946 | ||||||||||
| Appl. No.: | 15/733391 | ||||||||||
| Filed: | January 15, 2019 | ||||||||||
| PCT Filed: | January 15, 2019 | ||||||||||
| PCT NO: | PCT/EP2019/050881 | ||||||||||
| 371 Date: | July 17, 2020 |
| Current U.S. Class: | 1/1 |
| Current CPC Class: | C12N 2310/11 20130101; C12N 2310/315 20130101; C12N 15/113 20130101; C12N 2310/3231 20130101 |
| International Class: | C12N 15/113 20060101 C12N015/113 |
Foreign Application Data
| Date | Code | Application Number |
|---|---|---|
| Jan 17, 2018 | EP | 18152080.0 |
Claims
1. An antisense oligonucleotide of 10 to 50 nucleotides in length, which comprises a contiguous nucleotide sequence of 10 to 30 nucleotides in length with at least 90% complementarity, such as fully complementary to a mammalian ERC1 target nucleic acid, wherein the antisense oligonucleotide is capable of reducing the expression of the mammalian ERC1 target nucleic acid, in a cell.
2. The antisense oligonucleotide according to claim 1, wherein the contiguous nucleotide sequence is at least 90% complementary to a sequence selected from the group consisting of SEQ ID NO: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 and 13, or a naturally occurring variant thereof.
3. The antisense oligonucleotide according to claim 1, wherein the contiguous nucleotide sequence is fully complementary to the mammalian ERC1 target nucleic acid.
4. The antisense oligonucleotide according to claim 1, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to an intron region present in the pre-mRNA of a mammalian ERC1 nucleic acid (e.g. SEQ ID NO:1).
5. The antisense oligonucleotide according to claim 1, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to an intron region present in the pre-mRNA of human ERC1, selected from position 815-37239 on SEQ ID NO: 1, position 38065-92655 on SEQ ID NO: 1, position 93073-114241 on SEQ ID NO: 1, position 114317-119683 on SEQ ID NO: 1, position 119840-125357 on SEQ ID NO: 1, position 125526-151111 on SEQ ID NO: 1, position 151280-190031 on SEQ ID NO: 1, position 190170-191416 on SEQ ID NO: 1, position 191558-192772 on SEQ ID NO:1, position 192914-199350 on SEQ ID NO: 1, position 199545-246260 on SEQ ID NO: 1, position 246397-272525 on SEQ ID NO: 1, position 272658-299343 on SEQ ID NO: 1, position 299505-381324 on SEQ ID NO:1, position 381470-417640 on SEQ ID NO: 1, position 417740-454053 on SEQ ID NO: 1, and position 454243-499584 on SEQ ID NO: 1.
6. The antisense oligonucleotide according to claim 1, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to position 38065-92655 of SEQ ID NO: 1.
7. The antisense oligonucleotide according to claim 1, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to SEQ ID NO: 14, 12, 24, 25 or 26.
8. The antisense oligonucleotide of claim 1, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to a target region of SEQ ID NO 1, selected from the group consisting of position 88284-88297, 88378-88391, 88425-88438, 88472-88485, 88517-88530, 88656-88669, 88703-88716, 88750-88763, 88795-88808, 88842-88855, 88889-88902, 88936-88949, 88983-88996, 89030-89043, 89077-89090, 89124-89137, 89171-89184, 89265-89278, 89312-89325, 89359-88372; 88374-88393, 88421-88440, 88468-88487, 88513-88532, 88652-88671, 88699-88718, 88746-88765, 88791-88810, 88838-88857, 88885-88904, 88932-88951, 88979-88998, 89026-89045, 89073-89092, 89120-89139, 89167-89186, 89261-89280, 89308-89327, 89355-89374; 88374-88391, 88421-88438, 88468-88485, 88513-88530, 88652-88669, 88699-88716, 88746-88763, 88791-88808, 88838-88855, 88885-88902, 88932-88949, 88979-88996, 89026-89043, 89073-89090, 89120-89137, 89167-89184, 89261-89278, 89308-89325, 89355-89372; 88376-88391, 88423-88438, 88470-88485, 88515-88530, 88654-88669, 88701-88716, 88748-88763, 88793-88808, 88840-88855, 88887-88902, 88934-88949, 88981-88996, 89028-89043, 89075-89090, 89122-89137, 89169-89184, 89263-89278, 89310-89325, 89357-89372, 451815-451834, 451816-451833, 451818-451833, 451818-451831 of SEQ ID NO: 1.
9. The antisense oligonucleotide according to claim 1, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to a target region of 10-22, such as 14-20, nucleotides in length of the target nucleic acid of SEQ ID NO: 1, wherein the target region is repeated at least 2 times across the target nucleic acid.
10. The antisense oligonucleotide according to claim 1, wherein the contiguous nucleotide sequence is at least 90% identical, such as is 100% identical to a sequence selected from the group consisting of SEQ ID NO: 15, 16, 17, and 18.
11. The antisense oligonucleotide according claim 1, wherein the contiguous nucleotide sequence consists or comprises of a sequence selected from the group consisting of SEQ ID NO: 15, 16, 17, and 18.
12. The antisense oligonucleotide of claim 1, wherein the contiguous nucleotide sequence comprises one or more 2'sugar modified nucleosides.
13. The antisense oligonucleotide of claim 12, wherein the one or more 2' sugar modified nucleosides is independently selected from the group consisting of 2'-O-alkyl-RNA, 2'-O-methyl-RNA, 2'-alkoxy-RNA, 2'-O-methoxyethyl-RNA, 2'-amino-DNA, 2'-fluoro-DNA, arabino nucleic acid (ANA), 2'-fluoro-ANA and LNA nucleosides.
14. The antisense oligonucleotide of claim 12, wherein the one or more 2' sugar modified nucleosides is a LNA nucleoside.
15. The antisense oligonucleotide of claim 1, wherein the contiguous nucleotide sequence comprises at least one modified internucleoside linkage.
16. The antisense oligonucleotide of claim 1, wherein at least 50%, such as at least 75%, such as at least 90%, such as all of the internucleoside linkages within the contiguous nucleotide sequence are phosphorothioate internucleoside linkages.
17. The antisense oligonucleotide of claim 1, wherein the antisense oligonucleotide is capable of recruiting RNase H.
18. The antisense oligonucleotide of claim 1, wherein the antisense oligonucleotide or contiguous nucleotide sequence thereof, consists or comprises of a gapmer of formula 5'-F-G-F'-3', where region F and F' independently comprise 1-8 nucleosides, of which 1-5 are 2' sugar modified nucleosides and defines the 5' and 3' end of the F and F' region, and G is a region between 6 and 17 nucleosides which are capable of recruiting RNaseH, such as a region comprising 6-17 DNA nucleosides.
19. The antisense oligonucleotide of claim 1, wherein the antisense oligonucleotide, or contiguous nucleotide sequence thereof is selected from the group consisting of TCATttctatCTGT (Compound 15_1); AATCatttctatctgtaTCT (Compound 16_1); TCAtttctatctgtATCT (Compound 17_1); and TCATttctatctGTAT (Compound 18_1), wherein capital letters represent LNA nucleosides, such as beta-D-oxy LNA nucleosides, lower case letters represent DNA nucleosides, optionally, all LNA C are 5-methyl cytosine, and all the internucleoside linkages are phosphorothioate linkages.
20. A conjugate comprising the antisense oligonucleotide according to claim 1, and at least one conjugate moiety covalently attached to said oligonucleotide.
21. A pharmaceutically acceptable salt of the antisense oligonucleotide according to claim 1.
22. A pharmaceutical composition comprising the antisense oligonucleotide of claim 1 and a pharmaceutically acceptable diluent, solvent, carrier, salt and/or adjuvant.
23. An in vivo or in vitro method for inhibiting a mammalian ERC1 expression in a target cell which is expressing the mammalian ERC1, said method comprising administering an antisense oligonucleotide of claim 1 in an effective amount to said cell.
24. The antisense oligonucleotide of claim 1 for use in medicine.
25. The antisense oligonucleotide of claim 1, for use in the treatment or prevention of dengue virus infection or cancer, such as thyroid carcinoma, breast cancer, head and neck cancer, colorectal cancer, renal cancer, testis cancer, melanoma or metastatic cancer.
26. Use of the antisense oligonucleotide of claim 1, for the preparation of a medicament for treatment or prevention of dengue virus infection or cancer, such as thyroid carcinoma, breast cancer, head and neck cancer, colorectal cancer, renal cancer testis cancer, melanoma or metastatic cancer.
27. A pharmaceutically acceptable salt of the antisense oligonucleotide conjugate according to claim 20.
28. A pharmaceutical composition comprising the conjugate of claim 20 and a pharmaceutically acceptable diluent, solvent, carrier, salt and/or adjuvant.
29. An in vivo or in vitro method for inhibiting a mammalian ERC1 expression in a target cell which is expressing the mammalian ERC1, said method comprising administering the conjugate according to claim 20 in an effective amount to said cell.
30. The conjugate according to claim 20, for use in the treatment or prevention of dengue virus infection or cancer, such as thyroid carcinoma, breast cancer, head and neck cancer, colorectal cancer, renal cancer, testis cancer, melanoma or metastatic cancer.
Description
FIELD OF INVENTION
[0001] The present invention relates to oligonucleotides (oligomers) that are complementary to ELKS/RAB6-Interacting/CAST Family Member 1 (ERC1) transcript, leading to modulation of the expression of ERC1 in a cell. Such oligonucleotides may be used for reducing ERC1 transcript in a target cell. Modulation of ERC1 expression is beneficial for a range of medical disorders, such as dengue virus or cancer, such as thyroid carcinoma, breast cancer, head and neck cancer, colorectal cancer, renal cancer testis cancer, melanoma or metastasis formation.
BACKGROUND
[0002] ELKS/RAB6-Interacting/CAST Family Member 1 (ERC1) is a member of a family of RIM-binding proteins, which are active zone proteins that regulate neurotransmitter release.
[0003] Astro et al. J Cell Sci, 2014, 127: 3862-3876; used siRNA targeting ERC1 to show that a complex comprising Liprin-alphal, ERC1 and LL5 is important in cell migration in vitro, which is a fundamental process for tumor metastasis formation.
[0004] Alpay et al 2015 Breast Cancer Res. Vol 151 p. 75-87 shows that in vitro knock down of ERC1 with shRNA influences NF-kappaB signaling in breast cancer cell lines.
[0005] ERC1 has also been shown to rearrange with oncogenes or kinases in a varios cancers such as melanoma and papillary thyroid carcinomas, see for example WO2014130975 ERC1 and Nakata et al 1999 Genes, Chromosomes and Cancer Vol 25 p. 97-103.ERC1. Khadka et al. 2011, showed that downregulation of ERC1 using siRNA in Dengue virus infected cells caused a significant decrease in virus replication in the cells.
[0006] ERC1 None of the references above disclose a single stranded antisense oligonucleotides targeting ERC1, and in particular they do not disclose the concept of targeting intron sequences or repeated sequences in the ERC1 transcript.
[0007] Antisense oligonucleotides targeting repeated sites in the same RNA have been shown to have enhanced potency for downregulation of target mRNA in some cases of in vitro transfection experiments. This has been the case for GCGR, STST3, MAPT, OGFR, and BOK RNA (Vickers at al. PLOS one, October 2014, Volume 9, Issue 10). WO 2013/120003 also refers to modulation of RNA by repeat targeting.
OBJECTIVE OF THE INVENTION
[0008] ERC1 is involved in the development and progression of a number of tumors as well as a host factor in dengue virus infections. The present invention provides antisense oligonucleotides capable of modulating ERC1 mRNA and protein expression in vivo and in vitro. Accordingly, the present invention can potentially be used in combination therapy together with the standard cancer care therapies and potentially can alleviate symptoms of cancers, such as metastatic cancer, or cancers such as thyroid carcinoma breast cancer, head and neck cancer, colorectal cancer, renal cancer testis cancer and melanoma. Furthermore, the antisense oligonucleotides of the present invention may be used for treatment or alleviation of Dengue virus infection.
SUMMARY OF INVENTION
[0009] The present invention provides antisense oligonucleotides, such as gapmer oligonucleotides, which are complementary to a target mammalian ERC1 nucleic acids, and uses thereof.
[0010] The present invention provides oligonucleotides which comprise contiguous nucleotide sequences which are complementary to certain regions or sequences present in target mammalian ERC1 nucleic acids.
[0011] The compounds of the invention are capable of inhibiting mammalian ERC1 nucleic acids in a cell which is expressing the mammalian ERC1 nucleic acid.
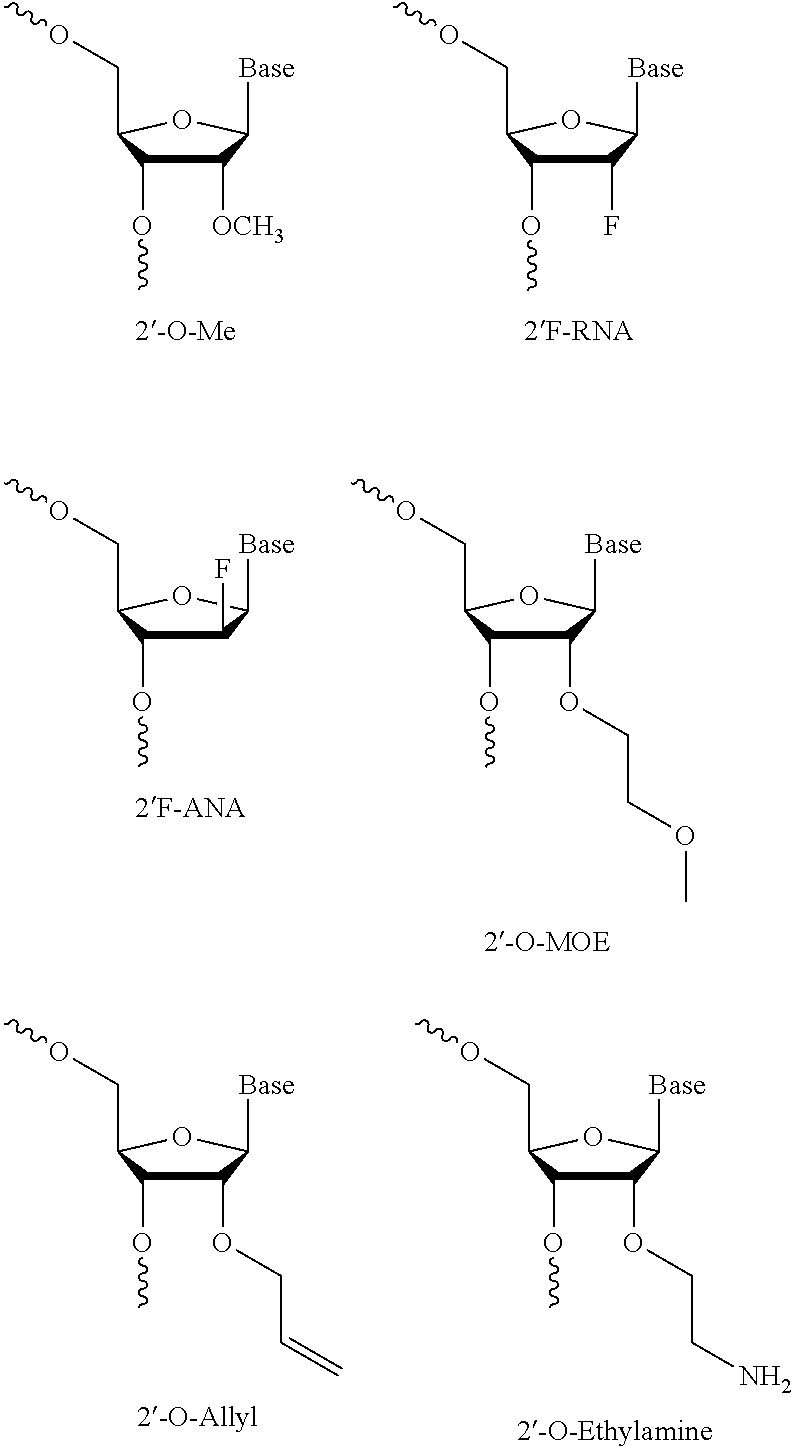
[0012] The present invention provides for an antisense oligonucleotide compound targeting a mammalian ERC1 nucleic acid, and in vitro and in vivo uses thereof, and their use in medicine.
[0013] Accordingly, a first aspect the invention provides an antisense oligonucleotide of 10 to 50 nucleotides in length, which comprises a contiguous nucleotide sequence of 10 to 30 nucleotides in length with at least 90% complementarity, such as fully complementary, to a mammalian ERC1 target nucleic acid, wherein the antisense oligonucleotide is capable of reducing the expression of the mammalian ERC1 target nucleic acid, in a cell.
[0014] In a further aspect the invention provides an antisense oligonucleotide, wherein the contiguous nucleotide sequence is at least 90% complementary to a sequence selected from the group consisting of SEQ ID NO: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 and 13 or a naturally occurring variant thereof.
[0015] In a further aspect, the invention provides an antisense oligonucleotide, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to an intron region present in the pre-mRNA of mammalian ERC1 target nucleic acid (e.g. SEQ ID NO 1).
[0016] In a further aspect the invention provides the antisense oligonucleotide, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to a region of SEQ ID NO 1, selected from the group consisting of position 88284-88297, 88378-88391, 88425-88438, 88472-88485, 88517-88530, 88656-88669, 88703-88716, 88750-88763, 88795-88808, 88842-88855, 88889-88902, 88936-88949, 88983-88996, 89030-89043, 89077-89090, 89124-89137, 89171-89184, 89265-89278, 89312-89325, 89359-88372; 88374-88393, 88421-88440, 88468-88487, 88513-88532, 88652-88671, 88699-88718, 88746-88765, 88791-88810, 88838-88857, 88885-88904, 88932-88951, 88979-88998, 89026-89045, 89073-89092, 89120-89139, 89167-89186, 89261-89280, 89308-89327, 89355-89374; 88374-88391, 88421-88438, 88468-88485, 88513-88530, 88652-88669, 88699-88716, 88746-88763, 88791-88808, 88838-88855, 88885-88902, 88932-88949, 88979-88996, 89026-89043, 89073-89090, 89120-89137, 89167-89184, 89261-89278, 89308-89325, 89355-89372; 88376-88391, 88423-88438, 88470-88485, 88515-88530, 88654-88669, 88701-88716, 88748-88763, 88793-88808, 88840-88855, 88887-88902, 88934-88949, 88981-88996, 89028-89043, 89075-89090, 89122-89137, 89169-89184, 89263-89278, 89310-89325, 89357-89372, 451815-451834, 451816-451833, 451818-451833, 451818-4518310f SEQ ID NO: 1.
[0017] In a further aspect, the invention provides antisense oligonucleotides which comprises a wherein the contiguous nucleotide sequence is 95% complementary, such as fully complementary, to a target region of 10-22, such as 14-20, nucleotides in length of the target nucleic acid of SEQ ID NO: 1, wherein the target region is repeated at least 5 or more times across the target nucleic acid.
[0018] In a further aspect the invention provides the antisense oligonucleotide, wherein the antisense oligonucleotide, or contiguous nucleotide sequence thereof is selected from the group consisting of TCATttctatCTGT (Compound 15_1); AATCatttctatctgtaTCT (Compound 16_1); TCAtttctatctgtATCT (Compound 17_1); and TCATttctatctGTAT (Compound 18_1; wherein capital letters represent LNA nucleosides, such as beta-D-oxy LNA nucleosides, lower case letters represent DNA nucleosides, optionally all LNA C are 5-methyl cytosine, and all internucleoside linkages are phosphorothioate internucleoside linkages.
[0019] In a further aspect the invention provides a conjugate comprising the antisense oligonucleotide according to the invention, and at least one conjugate moiety covalently attached to said oligonucleotide.
[0020] In a further aspect the invention provides a pharmaceutical composition comprising the oligonucleotide according to the invention or the conjugate according to some aspects of the invention, and a pharmaceutically acceptable diluent, solvent, carrier, salt and/or adjuvant.
[0021] In a further aspect, the invention provides a pharmaceutically acceptable salt of the antisense oligonucleotide or conjugate according to the invention the invention.
[0022] In a further aspect the invention provides an in vivo or in vitro method for inhibiting mammalian ERC1 expression in a target cell which is expressing the mammalian ERC1, said method comprising administering an oligonucleotide, the conjugate, the pharmaceutically acceptable salt, or the pharmaceutical composition according to the invention in an effective amount to said cell.
[0023] In a further aspect the invention provides a method for treating or preventing a disease comprising administering a therapeutically or prophylactically effective amount of an oligonucleotide, the conjugate, the pharmaceutically acceptable salt, or the pharmaceutical composition according to the invention to a subject suffering from or susceptible to the disease.
[0024] In a further aspect the invention provides a use of the oligonucleotide, the conjugate, the pharmaceutically acceptable salt, or the pharmaceutical composition of the invention for the preparation of a medicament for treatment or prevention of cancers, such as metastatic cancer, or cancers such as thyroid carcinoma breast cancer, head and neck cancer, colorectal cancer, renal cancer testis cancer and melanoma. Furthermore, the antisense oligonucleotides of the present invention may be used for treatment or alleviation of Dengue virus infection.
Definitions
Oligonucleotide
[0025] The term "oligonucleotide" as used herein is defined as it is generally understood by the skilled person as a molecule comprising two or more covalently linked nucleosides. Such covalently bound nucleosides may also be referred to as nucleic acid molecules or oligomers. Oligonucleotides are commonly made in the laboratory by solid-phase chemical synthesis followed by purification. When referring to a sequence of the oligonucleotide, reference is made to the sequence or order of nucleobase moieties, or modifications thereof, of the covalently linked nucleotides or nucleosides. The oligonucleotide of the invention is man-made, and is chemically synthesized, and is typically purified or isolated. The oligonucleotide of the invention may comprise one or more modified nucleosides or nucleotides.
Antisense Oligonucleotides
[0026] The term "Antisense oligonucleotide" as used herein is defined as oligonucleotides capable of modulating expression of a target gene by hybridizing to a target nucleic acid, in particular to a contiguous sequence on a target nucleic acid. The antisense oligonucleotides are not essentially double stranded and are therefore not siRNAs or shRNAs. Preferably, the antisense oligonucleotides of the present invention are single stranded. It is understood that single stranded oligonucleotides of the present invention can form hairpins or intermolecular duplex structures (duplex between two molecules of the same oligonucleotide), as long as the degree of intra or inter self-complementarity is less than 50% across of the full length of the oligonucleotide
[0027] Advantageously, the antisense oligonucleotide of the invention comprises one or more modified nucleosides or nucleotides.
Contiguous Nucleotide Sequence
[0028] The term "contiguous nucleotide sequence" refers to the region of the oligonucleotide which is complementary to the target nucleic acid. The term is used interchangeably herein with the term "contiguous nucleobase sequence" and the term "oligonucleotide motif sequence". In some embodiments all the nucleotides of the oligonucleotide constitute the contiguous nucleotide sequence. In some embodiments the oligonucleotide comprises the contiguous nucleotide sequence, such as a F-G-F' gapmer region, and may optionally comprise further nucleotide(s), for example a nucleotide linker region which may be used to attach a functional group to the contiguous nucleotide sequence. The nucleotide linker region may or may not be complementary to the target nucleic acid.
Nucleotides
[0029] Nucleotides are the building blocks of oligonucleotides and polynucleotides, and for the purposes of the present invention include both naturally occurring and non-naturally occurring nucleotides. In nature, nucleotides, such as DNA and RNA nucleotides comprise a ribose sugar moiety, a nucleobase moiety and one or more phosphate groups (which is absent in nucleosides). Nucleosides and nucleotides may also interchangeably be referred to as "units" or "monomers".
Modified Nucleoside
[0030] The term "modified nucleoside" or "nucleoside modification" as used herein refers to nucleosides modified as compared to the equivalent DNA or RNA nucleoside by the introduction of one or more modifications of the sugar moiety or the (nucleo)base moiety. In a preferred embodiment the modified nucleoside comprise a modified sugar moiety. The term modified nucleoside may also be used herein interchangeably with the term "nucleoside analogue" or modified "units" or modified "monomers". Nucleosides with an unmodified DNA or RNA sugar moiety are termed DNA or RNA nucleosides herein. Nucleosides with modifications in the base region of the DNA or RNA nucleoside are still generally termed DNA or RNA if they allow Watson Crick base pairing.
Modified Internucleoside Linkage
[0031] The term "modified internucleoside linkage" is defined as generally understood by the skilled person as linkages other than phosphodiester (PO) linkages, that covalently couples two nucleosides together. The oligonucleotides of the invention may therefore comprise modified internucleoside linkages. In some embodiments, the modified internucleoside linkage increases the nuclease resistance of the oligonucleotide compared to a phosphodiester linkage. For naturally occurring oligonucleotides, the internucleoside linkage includes phosphate groups creating a phosphodiester bond between adjacent nucleosides. Modified internucleoside linkages are particularly useful in stabilizing oligonucleotides for in vivo use, and may serve to protect against nuclease cleavage at regions of DNA or RNA nucleosides in the oligonucleotide of the invention, for example within the gap region of a gapmer oligonucleotide, as well as in regions of modified nucleosides, such as region F and F'.
[0032] In an embodiment, the oligonucleotide comprises one or more internucleoside linkages modified from the natural phosphodiester, such one or more modified internucleoside linkages that is for example more resistant to nuclease attack. Nuclease resistance may be determined by incubating the oligonucleotide in blood serum or by using a nuclease resistance assay (e.g. snake venom phosphodiesterase (SVPD)), both are well known in the art. Internucleoside linkages which are capable of enhancing the nuclease resistance of an oligonucleotide are referred to as nuclease resistant internucleoside linkages. In some embodiments at least 50% of the internucleoside linkages in the oligonucleotide, or contiguous nucleotide sequence thereof, are modified, such as at least 60%, such as at least 70%, such as at least 80 or such as at least 90% of the internucleoside linkages in the oligonucleotide, or contiguous nucleotide sequence thereof, are nuclease resistant internucleoside linkages. In some embodiments all of the internucleoside linkages of the oligonucleotide, or contiguous nucleotide sequence thereof, are nuclease resistant internucleoside linkages. It will be recognized that, in some embodiments the nucleosides which link the oligonucleotide of the invention to a non-nucleotide functional group, such as a conjugate, may be phosphodiester.
[0033] A preferred modified internucleoside linkage for use in the oligonucleotide of the invention is phosphorothioate.
[0034] Phosphorothioate internucleoside linkages are particularly useful due to nuclease resistance, beneficial pharmacokinetics and ease of manufacture. In some embodiments at least 50% of the internucleoside linkages in the oligonucleotide, or contiguous nucleotide sequence thereof, are phosphorothioate, such as at least 60%, such as at least 70%, such as at least 80% or such as at least 90% of the internucleoside linkages in the oligonucleotide, or contiguous nucleotide sequence thereof, are phosphorothioate. In some embodiments, other than the phosphorodithioate internucleoside linkages, all of the internucleoside linkages of the oligonucleotide, or contiguous nucleotide sequence thereof, are phosphorothioate. In some embodiments, the oligonucleotide of the invention comprises both phosphorothioate internucleoside linkages and at least one phosphodiester linkage, such as 2, 3 or 4 phosphodiester linkages, in addition to the phosphorodithioate linkage(s). In a gapmer oligonucleotide, phosphodiester linkages, when present, are suitably not located between contiguous DNA nucleosides in the gap region G.
[0035] Nuclease resistant linkages, such as phosphorothioate linkages, are particularly useful in oligonucleotide regions capable of recruiting nuclease when forming a duplex with the target nucleic acid, such as region G for gapmers. Phosphorothioate linkages may, however, also be useful in non-nuclease recruiting regions and/or affinity enhancing regions such as regions F and F' for gapmers. Gapmer oligonucleotides may, in some embodiments comprise one or more phosphodiester linkages in region F or F', or both region F and F', which the internucleoside linkage in region G may be fully phosphorothioate.
[0036] Advantageously, all the internucleoside linkages in the contiguous nucleotide sequence of the oligonucleotide, or all the internucleoside linkages of the oligonucleotide, are phosphorothioate linkages.
[0037] It is recognized that, as disclosed in EP 2 742 135, antisense oligonucleotides may comprise other internucleoside linkages (other than phosphodiester and phosphorothioate), for example alkyl phosphonate/methyl phosphonate internucleosides, which according to EP 2 742 135 may for example be tolerated in an otherwise DNA phosphorothioate the gap region.
Nucleobase
[0038] The term nucleobase includes the purine (e.g. adenine and guanine) and pyrimidine (e.g. uracil, thymine and cytosine) moiety present in nucleosides and nucleotides which form hydrogen bonds in nucleic acid hybridization. In the context of the present invention the term nucleobase also encompasses modified nucleobases which may differ from naturally occurring nucleobases, but are functional during nucleic acid hybridization. In this context "nucleobase" refers to both naturally occurring nucleobases such as adenine, guanine, cytosine, thymidine, uracil, xanthine and hypoxanthine, as well as non-naturally occurring variants. Such variants are for example described in Hirao et al (2012) Accounts of Chemical Research vol 45 page 2055 and Bergstrom (2009) Current Protocols in Nucleic Acid Chemistry Suppl. 37 1.4.1.
[0039] In a some embodiments the nucleobase moiety is modified by changing the purine or pyrimidine into a modified purine or pyrimidine, such as substituted purine or substituted pyrimidine, such as a nucleobased selected from isocytosine, pseudoisocytosine, 5-methyl cytosine, 5-thiozolo-cytosine, 5-propynyl-cytosine, 5-propynyl-uracil, 5-bromouracil 5-thiazolo-uracil, 2-thio-uracil, 2'thio-thymine, inosine, diaminopurine, 6-aminopurine, 2-aminopurine, 2,6-diaminopurine and 2-chloro-6-aminopurine.
[0040] The nucleobase moieties may be indicated by the letter code for each corresponding nucleobase, e.g. A, T, G, C or U, wherein each letter may optionally include modified nucleobases of equivalent function. For example, in the exemplified oligonucleotides, the nucleobase moieties are selected from A, T, G, C, and 5-methyl cytosine. Optionally, for LNA gapmers, 5-methyl cytosine LNA nucleosides may be used.
Modified Oligonucleotide
[0041] The term modified oligonucleotide describes an oligonucleotide comprising one or more sugar-modified nucleosides and/or modified internucleoside linkages. The term "chimeric" oligonucleotide is a term that has been used in the literature to describe oligonucleotides with modified nucleosides.
Complementarity
[0042] The term "complementarity" describes the capacity for Watson-Crick base-pairing of nucleosides/nucleotides. Watson-Crick base pairs are guanine (G)-cytosine (C) and adenine (A)-thymine (T)/uracil (U). It will be understood that oligonucleotides may comprise nucleosides with modified nucleobases, for example 5-methyl cytosine is often used in place of cytosine, and as such the term complementarity encompasses Watson Crick base-paring between non-modified and modified nucleobases (see for example Hirao et al (2012) Accounts of Chemical Research vol 45 page 2055 and Bergstrom (2009) Current Protocols in Nucleic Acid Chemistry Suppl. 37 1.4.1).
[0043] The term "% complementary" as used herein, refers to the proportion of nucleotides (in percent) of a contiguous nucleotide sequence in a nucleic acid molecule (e.g. oligonucleotide) which across the contiguous nucleotide sequence, are complementary to a reference sequence (e.g. a target sequence or sequence motif). The percentage of complementarity is thus calculated by counting the number of aligned nucleobases that are complementary (from Watson Crick base pair) between the two sequences (when aligned with the target sequence 5'-3' and the oligonucleotide sequence from 3'-5'), dividing that number by the total number of nucleotides in the oligonucleotide and multiplying by 100. In such a comparison a nucleobase/nucleotide which does not align (form a base pair) is termed a mismatch. Insertions and deletions are not allowed in the calculation of % complementarity of a contiguous nucleotide sequence. It will be understood that in determining complementarity, chemical modifications of the nucleobases are disregarded as long as the functional capacity of the nucleobase to form Watson Crick base pairing is retained (e.g. 5'-methyl cytosine is considered identical to a cytosine for the purpose of calculating % identity).
[0044] The term "fully complementary", refers to 100% complementarity.
[0045] The following is an example of an oligonucleotide (SEQ ID NO: 15) that is fully complementary to the target nucleic acid (SEQ ID NO: 24):
TABLE-US-00001 (SEQ ID NO: 24) 5' aagtcgatatacagagatacagatagaaatgatttgtaatat 3' (SEQ ID NO: 15) 3' TGTCTATCTTTACT 5'
Identity
[0046] The term "Identity" as used herein, refers to the proportion of nucleotides (expressed in percent) of a contiguous nucleotide sequence in a nucleic acid molecule (e.g. oligonucleotide) which across the contiguous nucleotide sequence, are identical to a reference sequence (e.g. a sequence motif). The percentage of identity is thus calculated by counting the number of aligned bases that are identical (a match) between two sequences (in the contiguous nucleotide sequence of the compound of the invention and in the reference sequence), dividing that number by the total number of nucleotides in the oligonucleotide and multiplying by 100.
[0047] Therefore, Percentage of Identity=(Matches.times.100)/Length of aligned region (e.g. the contiguous nucleotide sequence). Insertions and deletions are not allowed in the calculation the percentage of identity of a contiguous nucleotide sequence. It will be understood that in determining identity, chemical modifications of the nucleobases are disregarded as long as the functional capacity of the nucleobase to form Watson Crick base pairing is retained (e.g. 5-methyl cytosine is considered identical to a cytosine for the purpose of calculating % identity).
Hybridization
[0048] The term "hybridizing" or "hybridizes" as used herein is to be understood as two nucleic acid strands (e.g. an oligonucleotide and a target nucleic acid) forming hydrogen bonds between base pairs on opposite strands thereby forming a duplex. The affinity of the binding between two nucleic acid strands is the strength of the hybridization. It is often described in terms of the melting temperature (T.sub.m) defined as the temperature at which half of the oligonucleotides are duplexed with the target nucleic acid. At physiological conditions T.sub.m is not strictly proportional to the affinity (Mergny and Lacroix, 2003, Oligonucleotides 13:515-537). The standard state Gibbs free energy .DELTA.G.degree. is a more accurate representation of binding affinity and is related to the dissociation constant (K.sub.d) of the reaction by .DELTA.G.degree.=-RTIn(K.sub.d), where R is the gas constant and T is the absolute temperature. Therefore, a very low .DELTA.G.degree. of the reaction between an oligonucleotide and the target nucleic acid reflects a strong hybridization between the oligonucleotide and target nucleic acid. .DELTA.G.degree. is the energy associated with a reaction where aqueous concentrations are 1M, the pH is 7, and the temperature is 37.degree. C. The hybridization of oligonucleotides to a target nucleic acid is a spontaneous reaction and for spontaneous reactions .DELTA.G.degree. is less than zero. .DELTA.G.degree. can be measured experimentally, for example, by use of the isothermal titration calorimetry (ITC) method as described in Hansen et al., 1965, Chem. Comm. 36-38 and Holdgate et al., 2005, Drug Discov Today. The skilled person will know that commercial equipment is available for .DELTA.G.degree. measurements. .DELTA.G.degree. can also be estimated numerically by using the nearest neighbor model as described by SantaLucia, 1998, Proc Natl Acad Sci USA. 95: 1460-1465 using appropriately derived thermodynamic parameters described by Sugimoto et al., 1995, Biochemistry 34:11211-11216 and McTigue et al., 2004, Biochemistry 43:5388-5405. In order to have the possibility of modulating its intended nucleic acid target by hybridization, oligonucleotides of the present invention hybridize to a target nucleic acid with estimated .DELTA.G.degree. values below -10 kcal for oligonucleotides that are 10-30 nucleotides in length. In some embodiments the degree or strength of hybridization is measured by the standard state Gibbs free energy .DELTA.G.degree.. The oligonucleotides may hybridize to a target nucleic acid with estimated .DELTA.G.degree. values below the range of -10 kcal, such as below -15 kcal, such as below -20 kcal and such as below -25 kcal for oligonucleotides that are 8-30 nucleotides in length. In some embodiments the oligonucleotides hybridize to a target nucleic acid with an estimated .DELTA.G.degree. value of -10 to -60 kcal, such as -12 to -40, such as from -15 to -30 kcal or -16 to -27 kcal such as -18 to -25 kcal.
Target Nucleic Acid
[0049] According to the present invention, the target nucleic acid is a nucleic acid which encodes mammalian ERC1 and may for example be a gene, a RNA, a mRNA, and pre-mRNA, a mature mRNA or a cDNA sequence. The target may therefore be referred to as an ERC1 target nucleic acid.
[0050] The oligonucleotide of the invention may, for example, target exon regions of a mammalian ERC1RNA, or may, for example, target any intron region in the ERC1pre-mRNA (see, for example, Table 1).
TABLE-US-00002 TABLE 1 Human ERC1Exon and Intron regions of one of the splice variants. Exon regions in the human Intron regions in the human ERC1premRNA (SEQ ID NO: 1) ERC1premRNA (SEQ ID NO: 1) ID start end ID start end E1 700 814 I1 815 37239 E2 37240 38064 I2 38065 92655 E3 92656 93072 I3 93073 114241 E4 114242 114316 I4 114317 119683 E5 119684 119839 I5 119840 125357 E6 125358 125525 I6 125526 1151111 E7 151112 151279 I7 151280 190031 E8 190032 190169 I8 190170 191416 E9 191417 191557 I9 191558 192772 E10 192773 192913 I10 192914 199350 E11 199351 199544 I11 199545 246260 E12 246261 246396 I12 246397 272525 E13 272526 272657 I13 272658 299343 E14 299344 299504 I14 299505 381324 E15 381325 381469 I15 381470 417640 E16 417641 417739 I16 417740 454053 E17 454054 454242 I17 454243 499584 E18 499585 505425
[0051] Suitably, the target nucleic acid encodes an ERC1 protein, in particular mammalian ERC1, such as human ERC1 (See for example Tables 2 and 3) which provides the genomic sequence, the mature mRNA and pre-mRNA sequences for human, mice rat and monkey ERC1).
[0052] In some embodiments, the target nucleic acid is selected from the group consisting of SEQ ID NO: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 and 13 or naturally occurring variants thereof (e.g. sequences encoding a mammalian ERC1 protein.
[0053] The target nucleic acid many, in some embodiments, be a RNA or DNA, such as a messenger RNA, such as a mature mRNA or a pre-mRNA which encodes mammalian ERC1 protein, such as human ERC1, e.g. the human pre-mRNA sequence, such as that disclosed as SEQ ID NO:1 or human mature mRNA as disclosed in SEQ ID NO:2, SEQ ID NO:3, SEQ ID NO:4, SEQ ID NO:5, SEQ ID NO:6, SEQ ID NO:7, SEQ ID NO:8, SEQ ID NO:9, SEQ ID NO:10, SEQ ID NO:11, and SEQ ID NO:12, or naturally occurring variants thereof (e.g. sequences encoding a mammalian ERC1 protein).
[0054] If employing the oligonucleotide of the invention in research or diagnostics the target nucleic acid may be a cDNA or a synthetic nucleic acid derived from DNA or RNA.
[0055] For in vivo or in vitro application, the oligonucleotide of the invention is typically capable of inhibiting the expression of the ERC1 target nucleic acid in a cell which is expressing the ERC1 target nucleic acid. The contiguous sequence of nucleobases of the oligonucleotide of the invention is typically complementary to the ERC1 target nucleic acid, as measured across the length of the oligonucleotide, optionally with the exception of one or two mismatches, and optionally excluding nucleotide based linker regions which may link the oligonucleotide to an optional functional group such as a conjugate, or other non-complementary terminal nucleotides (e.g. region D' or D'').
[0056] Further information on exemplary target nucleic acids is provided in tables 2 and 3.
TABLE-US-00003 TABLE 2 Genome and assembly information for ERC1 across species. Genomic coordinates Species Chr. Strand Start End Assembly Ensembl ID Human 12 fwd 990509 1495933 GRCh38.p7 release 107 ENSG00000082805 MusMusculus 6 rev 119570796 119848167 GRCm38.p5 ENSMUSG00000030172 rnorvegicus 4 rev 152087379 152380184 Rnor_6.0 ENSRNOG00000009264 Cynomolgus monkey 11 fwd 1015931 1585322 Macaca_fascicularis_5.0 release 100 (GCF_000364345.1) Fwd = forward strand. The genome coordinates provide the pre-mRNA sequence (genomic sequence).
TABLE-US-00004 TABLE 3 Sequence details for ERC1 across species. Species RNA type Length (nt) SEQ ID NO Human premRNA 505425 1 Human mRNA 5789 2 Human mRNA 5796 3 Human mRNA 4390 4 Human mRNA 9118 5 Human mRNA 550 6 Human mRNA 546 7 Human mRNA 9241 8 Human mRNA 9202 9 Human mRNA 868 10 Human mRNA 2832 11 Human mRNA 1275 12 Cyno premRNA 569392 13 Note SEQ ID NO 13 comprises regions of multiple NNNNs, where the sequencing has been unable to accurately refine the sequence, and a degenerate sequence is therefore included. For the avoidance of doubt the compounds of the invention are complementary to the actual target sequence and are not therefore degenerate compounds
Target Sequence
[0057] The term "target sequence" as used herein refers to a sequence of nucleotides present in the target nucleic acid, which comprises the nucleobase sequence, which is complementary to the antisense oligonucleotide of the invention. In some embodiments, the target sequence consists of a region on the target nucleic acid, which is complementary to the contiguous nucleotide sequence of the antisense oligonucleotide of the invention. This region of the target nucleic acid may be referred to as the target nucleotide sequence. In some embodiments the target sequence is longer than the contiguous complementary sequence of a single oligonucleotide, and may, for example represent a preferred region of the target nucleic acid which may be targeted by several oligonucleotides of the invention.
[0058] The antisense oligonucleotide of the invention comprises a contiguous nucleotide sequence, which is complementary to the target nucleic acid, such as a target sequence described herein.
[0059] In some embodiments the target sequence is conserved between human and monkey, in particular a sequence that is present in both SEQ ID NO: 1 and SEQ ID NO: 13. In a preferred embodiment, the target sequence is present in SEQ ID NO: 14.
[0060] The target sequence to which the oligonucleotide is complementary generally comprises a contiguous nucleobase sequence of at least 10 nucleotides. The contiguous nucleotide sequence is between 10 to 50 nucleotides, such as 12 to 30, such as 14 to 20, such as 15 to 18 contiguous nucleotides
[0061] In one embodiment of the invention the target sequence is SEQ ID NO: 14.
[0062] In another embodiment of the invention the target sequence is SEQ ID NO: 23.
[0063] In another embodiment of the invention the target sequence is SEQ ID NO: 24.
[0064] In another embodiment of the invention the target sequence is SEQ ID NO: 25.
[0065] In another embodiment of the invention the target sequence is SEQ ID NO: 26.
Repeated Target Region
[0066] The target region or target sequence can be unique for the target nucleic acid (only present once).
[0067] In some aspects of the invention the target region is repeated at least two times over the span of target nucleic acid. Repeated as encompassed by the present invention means that there are at least two identical nucleotide sequences (target regions) of at least 10, such as at least 11, or at least 12, nucleotides in length which occur in the target nucleic acid at different positions. Each repeated target region is separated from the identical region by at least one nucleobase on the contiguous sequence of target nucleic acid and is positioned at different and non-overlapping positions within the target nucleic acid.
Target Cell
[0068] The term a "target cell" as used herein refers to a cell which is expressing the target nucleic acid. In some embodiments the target cell may be in vivo or in vitro. In some embodiments the target cell is a mammalian cell such as a rodent cell, such as a mouse cell or a rat cell, or a primate cell such as a monkey cell or a human cell.
[0069] In some preferred embodiments the target cell expresses ERC1 mRNA, such as the ERC1 pre-mRNA or ERC1 mature mRNA. The poly A tail of ERC1 mRNA is typically disregarded for antisense oligonucleotide targeting.
Naturally Occurring Variant
[0070] The term "naturally occurring variant" refers to variants of ERC1 gene or transcripts which originate from the same genetic loci as the target nucleic acid and is a directional transcript from the same chromosomal position and direction as the target nucleic acid, but may differ for example, by virtue of degeneracy of the genetic code causing a multiplicity of codons encoding the same amino acid, or due to alternative splicing of pre-mRNA, or the presence of polymorphisms, such as single nucleotide polymorphisms, and allelic variants. Based on the presence of the sufficient complementary sequence to the oligonucleotide, the oligonucleotide of the invention may therefore target the target nucleic acid and naturally occurring variants thereof.
[0071] In some embodiments, the naturally occurring variants have at least 95% such as at least 98% or at least 99% homology to a mammalian ERC1 target nucleic acid, such as a target nucleic acid selected form the group consisting of SEQ ID NO: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 13 and 14 (or any other pre-mRNA or mRNAs disclosed herein).
Modulation of Expression
[0072] The term "modulation of expression" as used herein is to be understood as an overall term for an oligonucleotide's ability to alter the amount of ERC1 when compared to the amount of ERC1 before administration of the oligonucleotide. Alternatively modulation of expression may be determined by reference to a control experiment. It is generally understood that the control is an individual or target cell treated with a saline composition or an individual or target cell treated with a non-targeting oligonucleotide (mock). It is generally understood that the control is a target cell treated with a saline composition or a target cell treated with a non-targeting oligonucleotide (mock).
[0073] A modulation according to the present invention shall be understood as an antisense oligonuclleotide's ability to inhibit, down-regulate, reduce, suppress, remove, stop, block, prevent, lessen, lower, avoid or terminate expression of ERC1, e.g. by degradation of mRNA or blockage of transcription.
High Affinity Modified Nucleosides
[0074] A high affinity modified nucleoside is a modified nucleotide which, when incorporated into the oligonucleotide enhances the affinity of the oligonucleotide for its complementary target, for example as measured by the melting temperature (T.sup.m). A high affinity modified nucleoside of the present invention preferably result in an increase in melting temperature between +0.5 to +12.degree. C., more preferably between +1.5 to +10.degree. C. and most preferably between +3 to +8.degree. C. per modified nucleoside. Numerous high affinity modified nucleosides are known in the art and include for example, many 2' substituted nucleosides as well as locked nucleic acids (LNA) (see e.g. Freier & Altmann; Nucl. Acid Res., 1997, 25, 4429-4443 and Uhlmann; Curr. Opinion in Drug Development, 2000, 3(2), 293-213).
Sugar Modifications
[0075] The oligomer of the invention may comprise one or more nucleosides which have a modified sugar moiety, i.e. a modification of the sugar moiety when compared to the ribose sugar moiety found in DNA and RNA.
[0076] Numerous nucleosides with modification of the ribose sugar moiety have been made, primarily with the aim of improving certain properties of oligonucleotides, such as affinity and/or nuclease resistance.
[0077] Such modifications include those where the ribose ring structure is modified, e.g. by replacement with a hexose ring (HNA), or a bicyclic ring, which typically have a biradicle bridge between the C2 and C4 carbons on the ribose ring (LNA), or an unlinked ribose ring which typically lacks a bond between the C2 and C3 carbons (e.g. UNA). Other sugar modified nucleosides include, for example, bicyclohexose nucleic acids (WO2011/017521) or tricyclic nucleic acids (WO2013/154798). Modified nucleosides also include nucleosides where the sugar moiety is replaced with a non-sugar moiety, for example in the case of peptide nucleic acids (PNA), or morpholino nucleic acids.
[0078] Sugar modifications also include modifications made via altering the substituent groups on the ribose ring to groups other than hydrogen, or the 2'--OH group naturally found in DNA and RNA nucleosides. Substituents may, for example be introduced at the 2', 3', 4' or 5' positions.
[0079] Nucleosides with modified sugar moieties also include 2' modified nucleosides, such as 2' substituted nucleosides. Indeed, much focus has been spent on developing 2' substituted nucleosides, and numerous 2' substituted nucleosides have been found to have beneficial properties when incorporated into oligonucleotides, such as enhanced nucleoside resistance and enhanced affinity.
2' Sugar Modified Nucleosides.
[0080] A 2' sugar modified nucleoside is a nucleoside which has a substituent other than H or --OH at the 2' position (2' substituted nucleoside) or comprises a 2' linked biradicle capable of forming a bridge between the 2' carbon and a second carbon in the ribose ring, such as LNA (2'-4' biradicle bridged) nucleosides.
[0081] Indeed, much focus has been spent on developing 2' sugar substituted nucleosides, and numerous 2' substituted nucleosides have been found to have beneficial properties when incorporated into oligonucleotides. Examples of 2' substituted modified nucleosides are 2'-O-alkyl-RNA, 2'-O-methyl-RNA, 2'-alkoxy-RNA, 2'-O-methoxyethyl-RNA (MOE), 2'-amino-DNA, 2'-Fluoro-RNA, and 2'-F-ANA nucleoside. For further examples, please see e.g. Freier & Altmann; Nucl. Acid Res., 1997, 25, 4429-4443 and Uhlmann; Curr. Opinion in Drug Development, 2000, 3(2), 293-213, and Deleavey and Damha, Chemistry and Biology 2012, 19, 937. Below are illustrations of some 2' substituted modified nucleosides.
##STR00001##
Locked Nucleic Acid Nucleosides (LNA).
[0082] A "LNA nucleoside" is a 2'-modified nucleoside which comprises a biradical linking the C2' and C4' of the ribose sugar ring of said nucleoside (also referred to as a "2'-4' bridge"), which restricts or locks the conformation of the ribose ring. These nucleosides are also termed bridged nucleic acid or bicyclic nucleic acid (BNA) in the literature. The locking of the conformation of the ribose is associated with an enhanced affinity of hybridization (duplex stabilization) when the LNA is incorporated into an oligonucleotide for a complementary RNA or DNA molecule. This can be routinely determined by measuring the melting temperature of the oligonucleotide/complement duplex.
[0083] Non limiting, exemplary LNA nucleosides are disclosed in WO 99/014226, WO 00/66604, WO 98/039352, WO 2004/046160, WO 00/047599, WO 2007/134181, WO 2010/077578, WO 2010/036698, WO 2007/090071, WO 2009/006478, WO 2011/156202, WO 2008/154401, WO 2009/067647, WO 2008/150729, Morita et al., Bioorganic & Med. Chem. Lett. 12, 73-76, Seth et al. J. Org. Chem. 2010, Vol 75(5) pp. 1569-81 and Mitsuoka et al., Nucleic Acids Research 2009, 37(4), 1225-1238.
[0084] The 2'-4' bridge comprises 2 to 4 bridging atoms and is in particular of formula --X--Y--, X being linked to C4' and Y linked to C2', [0085] wherein [0086] X is oxygen, sulfur, --CR.sup.aR.sup.b--, --C(R.sup.a).dbd.C(R.sup.b)--, --C(.dbd.CR.sup.aR.sup.b)--, --C(R.sup.a).dbd.N--, --Si(R.sup.a).sub.2--, --SO.sub.2--, --NR.sup.a--; --O--NR.sup.a--, --NR.sup.a--O--, --C(=J)-, Se, --O--NR.sup.a--, --NR.sup.a--CR.sup.aR.sup.b--, --N(R.sup.a)--O-- or --O--CR.sup.aR.sup.b-- [0087] Y is oxygen, sulfur, --(CR.sup.aR.sup.b).sub.n--, --CR.sup.aR.sup.b--O--CR.sup.aR.sup.b--, --C(R.sup.a).dbd.C(R.sup.b)--, --C(R.sup.a).dbd.N--, --Si(R.sup.a).sub.2--, --SO.sub.2--, --NR.sup.a--, --C(=J)-, Se, --O--NR.sup.a--, --NR.sup.a--CR.sup.aR.sup.b--, --N(R.sup.a)--O-- or --O--CR.sup.aR.sup.b--; [0088] with the proviso that --X--Y-- is not --O--O--, Si(R.sup.a).sub.2--Si(R.sup.a).sub.2--, --SO.sub.2--SO.sub.2--, --C(R.sup.a).dbd.C(R.sup.b)--C(R.sup.a).dbd.C(R.sup.b), --C(R.sup.a).dbd.N--C(R.sup.a).dbd.N--, --C(R.sup.a).dbd.N--C(R.sup.a).dbd.C(R.sup.b), --C(R.sup.a).dbd.C(R.sup.b)--C(R.sup.a).dbd.N-- or --Se--Se--; [0089] J is oxygen, sulfur, .dbd.CH.sub.2 or .dbd.N(R.sup.a); [0090] R.sup.a and R.sup.b are independently selected from hydrogen, halogen, hydroxyl, cyano, thiohydroxyl, alkyl, substituted alkyl, alkenyl, substituted alkenyl, alkynyl, substituted alkynyl, alkoxy, substituted alkoxy, alkoxyalkyl, alkenyloxy, carboxyl, alkoxycarbonyl, alkylcarbonyl, formyl, aryl, heterocyclyl, amino, alkylamino, carbamoyl, alkylaminocarbonyl, aminoalkylaminocarbonyl, alkylaminoalkylaminocarbonyl, alkylcarbonylamino, carbamido, alkanoyloxy, sulfonyl, alkylsulfonyloxy, nitro, azido, thiohydroxylsulfidealkylsulfanyl, aryloxycarbonyl, aryloxy, arylcarbonyl, heteroaryl, heteroaryloxycarbonyl, heteroaryloxy, heteroarylcarbonyl, --OC(.dbd.X.sup.a)R.sup.c, --OC(.dbd.X.sup.a)R.sup.cR.sup.d and --NR.sup.eC(.dbd.X.sup.a)R.sup.cR.sup.d; [0091] or two geminal R.sup.a and R.sup.b together form optionally substituted methylene; [0092] or two geminal R.sup.a and R.sup.b, together with the carbon atom to which they are attached, form cycloalkyl or halocycloalkyl, with only one carbon atom of --X--Y--; [0093] wherein substituted alkyl, substituted alkenyl, substituted alkynyl, substituted alkoxy and substituted methylene are alkyl, alkenyl, alkynyl and methylene substituted with 1 to 3 substituents independently selected from halogen, hydroxyl, alkyl, alkenyl, alkynyl, alkoxy, alkoxyalkyl, alkenyloxy, carboxyl, alkoxycarbonyl, alkylcarbonyl, formyl, heterocylyl, aryl and heteroaryl; [0094] X.sup.a is oxygen, sulfur or --NR.sup.c; [0095] R.sup.c, R.sup.d and R.sup.e are independently selected from hydrogen and alkyl; and [0096] n is 1, 2 or 3.
[0097] In a further particular embodiment of the invention, X is oxygen, sulfur, --NR.sup.a--, --CR.sup.aR.sup.b-- or --C(.dbd.CR.sup.aR.sup.b)--, particularly oxygen, sulfur, --NH--, --CH.sub.2-- or --C(.dbd.CH.sub.2)--, more particularly oxygen.
[0098] In another particular embodiment of the invention, Y is --CR.sup.aR.sup.b--, --CR.sup.aR.sup.b--CR.sup.aR.sup.b-- or --CR.sup.aR.sup.b--, --CR.sup.aR.sup.b--CR.sup.aR.sup.b--, particularly --CH.sub.2--CHCH.sub.3--, --CHCH.sub.3--CH.sub.2--, --CH.sub.2--CH.sub.2-- or --CH.sub.2--CH.sub.2--CH.sub.2--.
[0099] In a particular embodiment of the invention, --X--Y-- is --O--(CR.sup.aR.sup.b).sub.n--, --S--CR.sup.aR.sup.b--, --N(R.sup.a)CR.sup.aR.sup.b--, --CR.sup.aR.sup.b--CR.sup.aR.sup.b--, --O--CR.sup.aR.sup.b--O--CR.sup.aR.sup.b--, --CR.sup.aR.sup.b--O--CR.sup.aR.sup.b--, --C(.dbd.CR.sup.aR.sup.b)--CR.sup.aR.sup.b--, --N(R.sup.a)(CR.sup.aR.sup.b--, --O--N(R.sup.a)--CR.sup.aR.sup.b-- or --N(R.sup.a)--O--CR.sup.aR.sup.b--.
[0100] In a particular embodiment of the invention, R.sup.a and R.sup.b are independently selected from the group consisting of hydrogen, halogen, hydroxyl, alkyl and alkoxyalkyl, in particular hydrogen, halogen, alkyl and alkoxyalkyl.
[0101] In another embodiment of the invention, R.sup.a and R.sup.b are independently selected from the group consisting of hydrogen, fluoro, hydroxyl, methyl and --CH.sub.2--O--CH.sub.3, in particular hydrogen, fluoro, methyl and --CH.sub.2--O--CH.sub.3.
[0102] Advantageously, one of R.sup.a and R.sup.b of --X--Y-- is as defined above and the other ones are all hydrogen at the same time.
[0103] In a further particular embodiment of the invention, R.sup.a is hydrogen or alkyl, in particular hydrogen or methyl.
[0104] In another particular embodiment of the invention, R.sup.b is hydrogen or or alkyl, in particular hydrogen or methyl.
[0105] In a particular embodiment of the invention, one or both of R.sup.a and R.sup.b are hydrogen.
[0106] In a particular embodiment of the invention, only one of R.sup.a and R.sup.b is hydrogen.
[0107] In one particular embodiment of the invention, one of R.sup.a and R.sup.b is methyl and the other one is hydrogen.
[0108] In a particular embodiment of the invention, R.sup.a and R.sup.b are both methyl at the same time.
[0109] In a particular embodiment of the invention, --X--Y-- is --O--CH.sub.2--, --S--CH.sub.2--, --S--CH(CH.sub.3)--, --NH--CH.sub.2--, --O--CH.sub.2CH.sub.2--, --O--CH(CH.sub.2--O--CH.sub.3)--, --O--CH(CH.sub.2CH.sub.3)--, --O--CH(CH.sub.3)--, --O--CH.sub.2O--CH.sub.2--, --O--CH.sub.2--O--CH.sub.2--, --CH.sub.2--O--CH.sub.2--, --C(.dbd.CH.sub.2)CH.sub.2--, --C(.dbd.CH.sub.2)CH(CH.sub.3)--, --N(OCH.sub.3)CH.sub.2-- or --N(CH.sub.3)CH.sub.2--;
[0110] In a particular embodiment of the invention, --X--Y-- is --O--CR.sup.aR.sup.b-- wherein R.sup.a and R.sup.b are independently selected from the group consisting of hydrogen, alkyl and alkoxyalkyl, in particular hydrogen, methyl and --CH.sub.2--O--CH.sub.3.
[0111] In a particular embodiment, --X--Y-- is --O--CH.sub.2-- or --O--CH(CH.sub.3)--, particularly --O--CH.sub.2--.
[0112] The 2'-4' bridge may be positioned either below the plane of the ribose ring (beta-D-configuration), or above the plane of the ring (alpha-L- configuration), as illustrated in formula (A) and formula (B) respectively.
[0113] The LNA nucleoside according to the invention is in particular of formula (A) or (B)
##STR00002## [0114] wherein [0115] W is oxygen, sulfur, --N(R.sup.a)-- or --CR.sup.aR.sup.b--, in particular oxygen; [0116] B is a nucleobase or a modified nucleobase; [0117] Z is an internucleoside linkage to an adjacent nucleoside or a 5'-terminal group; [0118] Z* is an internucleoside linkage to an adjacent nucleoside or a 3'-terminal group; [0119] R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are independently selected from hydrogen, halogen, alkyl, haloalkyl, alkenyl, alkynyl, hydroxy, alkoxy, alkoxyalkyl, azido, alkenyloxy, carboxyl, alkoxycarbonyl, alkylcarbonyl, formyl and aryl; and [0120] X, Y, R.sup.a and R.sup.b are as defined above.
[0121] In a particular embodiment, in the definition of --X--Y--, R.sup.a is hydrogen or alkyl, in particular hydrogen or methyl. In another particular embodiment, in the definition of --X--Y--, R.sup.b is hydrogen or alkyl, in particular hydrogen or methyl. In a further particular embodiment, in the definition of --X--Y--, one or both of R.sup.a and R.sup.b are hydrogen. In a particular embodiment, in the definition of --X--Y--, only one of R.sup.a and R.sup.b is hydrogen. In one particular embodiment, in the definition of --X--Y--, one of R.sup.a and R.sup.b is methyl and the other one is hydrogen. In a particular embodiment, in the definition of --X--Y--, R.sup.a and R.sup.b are both methyl at the same time.
[0122] In a further particular embodiment, in the definition of X, R.sup.a is hydrogen or alkyl, in particular hydrogen or methyl. In another particular embodiment, in the definition of X, R.sup.b is hydrogen or alkyl, in particular hydrogen or methyl. In a particular embodiment, in the definition of X, one or both of R.sup.a and R.sup.b are hydrogen. In a particular embodiment, in the definition of X, only one of R.sup.a and R.sup.b is hydrogen. In one particular embodiment, in the definition of X, one of R.sup.a and R.sup.b is methyl and the other one is hydrogen. In a particular embodiment, in the definition of X, R.sup.a and R.sup.b are both methyl at the same time.
[0123] In a further particular embodiment, in the definition of Y, R.sup.a is hydrogen or alkyl, in particular hydrogen or methyl. In another particular embodiment, in the definition of Y, R.sup.b is hydrogen or alkyl, in particular hydrogen or methyl. In a particular embodiment, in the definition of Y, one or both of R.sup.a and R.sup.b are hydrogen. In a particular embodiment, in the definition of Y, only one of R.sup.a and R.sup.b is hydrogen. In one particular embodiment, in the definition of Y, one of R.sup.a and R.sup.b is methyl and the other one is hydrogen. In a particular embodiment, in the definition of Y, R.sup.a and R.sup.b are both methyl at the same time.
[0124] In a particular embodiment of the invention R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are independently selected from hydrogen and alkyl, in particular hydrogen and methyl.
[0125] In a further particular advantageous embodiment of the invention, R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time.
[0126] In another particular embodiment of the invention, R.sup.1, R.sup.2, R.sup.3, are all hydrogen at the same time, one of R.sup.5 and R.sup.5* is hydrogen and the other one is as defined above, in particular alkyl, more particularly methyl.
[0127] In a particular embodiment of the invention, R.sup.5 and R.sup.5* are independently selected from hydrogen, halogen, alkyl, alkoxyalkyl and azido, in particular from hydrogen, fluoro, methyl, methoxyethyl and azido. In particular advantageous embodiments of the invention, one of R.sup.5 and R.sup.5* is hydrogen and the other one is alkyl, in particular methyl, halogen, in particular fluoro, alkoxyalkyl, in particular methoxyethyl or azido; or R.sup.5 and R.sup.5* are both hydrogen or halogen at the same time, in particular both hydrogen of fluoro at the same time. In such particular embodiments, W can advantageously be oxygen, and --X--Y-- advantageously --O--CH.sub.2--.
[0128] In a particular embodiment of the invention, --X--Y-- is --O--CH.sub.2--, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time. Such LNA nucleosides are disclosed in WO 99/014226, WO 00/66604, WO 98/039352 and WO 2004/046160 which are all hereby incorporated by reference, and include what are commonly known in the art as beta-D-oxy LNA and alpha-L-oxy LNA nucleosides.
[0129] In another particular embodiment of the invention, --X--Y-- is --S--CH.sub.2--, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time. Such thio LNA nucleosides are disclosed in WO 99/014226 and WO 2004/046160 which are hereby incorporated by reference.
[0130] In another particular embodiment of the invention, --X--Y-- is --NH--CH.sub.2--, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time. Such amino LNA nucleosides are disclosed in WO 99/014226 and WO 2004/046160 which are hereby incorporated by reference.
[0131] In another particular embodiment of the invention, --X--Y-- is --O--CH.sub.2CH.sub.2-- or --OCH.sub.2CH.sub.2CH.sub.2--, W is oxygen, and R.sup.1, R.sup.2, R.sup.3, Wand R.sup.5* are all hydrogen at the same time. Such LNA nucleosides are disclosed in WO 00/047599 and Morita et al., Bioorganic & Med. Chem. Lett. 12, 73-76, which are hereby incorporated by reference, and include what are commonly known in the art as 2'-O-4'C-ethylene bridged nucleic acids (ENA).
[0132] In another particular embodiment of the invention, --X--Y-- is --O--CH.sub.2--, W is oxygen, R.sup.1, R.sup.2, R.sup.3 are all hydrogen at the same time, one of R.sup.5 and R.sup.5* is hydrogen and the other one is not hydrogen, such as alkyl, for example methyl. Such 5' substituted LNA nucleosides are disclosed in WO 2007/134181 which is hereby incorporated by reference.
[0133] In another particular embodiment of the invention, --X--Y-- is --O--CR.sup.aR.sup.b--, wherein one or both of R.sup.a and R.sup.b are not hydrogen, in particular alkyl such as methyl, W is oxygen, R.sup.1, R.sup.2, R.sup.3 are all hydrogen at the same time, one of R.sup.5 and R.sup.5* is hydrogen and the other one is not hydrogen, in particular alkyl, for example methyl. Such bis modified LNA nucleosides are disclosed in WO 2010/077578 which is hereby incorporated by reference.
[0134] In another particular embodiment of the invention, --X--Y-- is --O--CHR.sup.a--, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time. Such 6'-substituted LNA nucleosides are disclosed in WO 2010/036698 and WO 2007/090071 which are both hereby incorporated by reference. In such 6'-substituted LNA nucleosides, R.sup.a is in particular C.sub.1-C.sub.6 alkyl, such as methyl.
[0135] In another particular embodiment of the invention, --X--Y-- is --O--CH(CH.sub.2--O--CH.sub.3)-- ("2' O-methoxyethyl bicyclic nucleic acid", Seth et al. J. Org. Chem. 2010, Vol 75(5) pp. 1569-81).
[0136] In another particular embodiment of the invention, --X--Y-- is --O--CH(CH.sub.2CH.sub.3)-- ("2'O-ethyl bicyclic nucleic acid", Seth at al., J. Org. Chem. 2010, Vol 75(5) pp. 1569-81).
[0137] In another particular embodiment of the invention, --X--Y-- is --O--CH(CH.sub.2--O--CH.sub.3)--, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time. Such LNA nucleosides are also known in the art as cyclic MOEs (cMOE) and are disclosed in WO 2007/090071.
[0138] In another particular embodiment of the invention, --X--Y-- is --O--CH(CH.sub.3)--.
[0139] In another particular embodiment of the invention, --X--Y-- is --O--CH.sub.2--O--CH.sub.2-- (Seth et al., J. Org. Chem 2010 op. cit.)
[0140] In another particular embodiment of the invention, --X--Y-- is --O--CH(CH.sub.3)--, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time. Such 6'-methyl LNA nucleosides are also known in the art as cET nucleosides, and may be either (S)-cET or (R)-cET diastereoisomers, as disclosed in WO 2007/090071 (beta-D) and WO 2010/036698 (alpha-L) which are both hereby incorporated by reference.
[0141] In another particular embodiment of the invention, --X--Y-- is --O--CR.sup.aR.sup.b--, wherein neither R.sup.a nor R.sup.b is hydrogen, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5' are all hydrogen at the same time. In a particular embodiment, R.sup.a and R.sup.b are both alkyl at the same time, in particular both methyl at the same time. Such 6'-di-substituted LNA nucleosides are disclosed in WO 2009/006478 which is hereby incorporated by reference.
[0142] In another particular embodiment of the invention, --X--Y-- is --S--CHR.sup.a--, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time. Such 6'-substituted thio LNA nucleosides are disclosed in WO 2011/156202 which is hereby incorporated by reference. In a particular embodiment of such 6'-substituted thio LNA, R.sup.a is alkyl, in particular methyl.
[0143] In a particular embodiment of the invention, --X--Y-- is --C(.dbd.CH.sub.2)C(R.sup.aR.sup.b)--, --C(.dbd.CHF)C(R.sup.aR.sup.b)-- or --C(.dbd.CF.sub.2)C(R.sup.aR.sup.b)--, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time. R.sup.a and R.sup.b are advantagesously independently selected from hydrogen, halogen, alkyl and alkoxyalkyl, in particular hydrogen, methyl, fluoro and methoxymethyl. R.sup.a and R.sup.b are in particular both hydrogen or methyl at the same time or one of R.sup.a and R.sup.b is hydrogen and the other one is methyl. Such vinyl carbo LNA nucleosides are disclosed in WO 2008/154401 and WO 2009/067647 which are both hereby incorporated by reference.
[0144] In a particular embodiment of the invention, --X--Y-- is --N(OR.sup.a)--CH.sub.2--, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time. In a particular embodiment, R.sup.a is alkyl such as methyl. Such LNA nucleosides are also known as N substituted LNAs and are disclosed in WO 2008/150729 which is hereby incorporated by reference.
[0145] In a particular embodiment of the invention, --X--Y-- is --O--N(R.sup.a)--, --N(R.sup.a)--O--, --NR.sup.a--CR.sup.aR.sup.b--CR.sup.aR.sup.b-- or --NR.sup.a--CR.sup.aR.sup.b--, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time. R.sup.a and R.sup.b are advantagesously independently selected from hydrogen, halogen, alkyl and alkoxyalkyl, in particular hydrogen, methyl, fluoro and methoxymethyl. In a particular embodiment, R.sup.a is alkyl, such as methyl, R.sup.b is hydrogen or methyl, in particular hydrogen. (Seth et al., J. Org. Chem 2010 op. cit.).
[0146] In a particular embodiment of the invention, --X--Y-- is --O--N(CH.sub.3)-- (Seth et al., J. Org. Chem 2010 op. cit.).
[0147] In a particular embodiment of the invention, R.sup.5 and R.sup.5* are both hydrogen at the same time. In another particular embodiment of the invention, one of R.sup.5 and R.sup.5* is hydrogen and the other one is alkyl, such as methyl. In such embodiments, R.sup.1, R.sup.2 and R.sup.3 can be in particular hydrogen and --X--Y-- can be in particular --O--CH.sub.2-- or --O--CHC(R.sup.a).sub.3--, such as --O--CH(CH.sub.3)--.
[0148] In a particular embodiment of the invention, --X--Y-- is --CR.sup.aR.sup.b--O--CR.sup.aR.sup.b--, such as --CH.sub.2--O--CH.sub.2--, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time. In such particular embodiments, R.sup.a can be in particular alkyl such as methyl, R.sup.b hydrogen or methyl, in particular hydrogen. Such LNA nucleosides are also known as conformationally restricted nucleotides (CRNs) and are disclosed in WO 2013/036868 which is hereby incorporated by reference.
[0149] In a particular embodiment of the invention, --X--Y-- is --O--CR.sup.aR.sup.b--O--CR.sup.aR.sup.b--, such as --O--CH.sub.2--O--CH.sub.2--, W is oxygen and R.sup.1, R.sup.2, R.sup.3, R.sup.5 and R.sup.5* are all hydrogen at the same time. R.sup.a and R.sup.b are advantageously independently selected from hydrogen, halogen, alkyl and alkoxyalkyl, in particular hydrogen, methyl, fluoro and methoxymethyl. In such a particular embodiment, R.sup.a can be in particular alkyl such as methyl, R.sup.b hydrogen or methyl, in particular hydrogen. Such LNA nucleosides are also known as COC nucleotides and are disclosed in Mitsuoka et al., Nucleic Acids Research 2009, 37(4), 1225-1238, which is hereby incorporated by reference.
[0150] It will be recognized that, unless specified, the LNA nucleosides may be in the beta-D or alpha-L stereoisoform.
[0151] Particular examples of LNA nucleosides of the invention are presented in Scheme 1 (wherein B is as defined above).
##STR00003## ##STR00004##
[0152] Particular LNA nucleosides are beta-D-oxy-LNA, 6'-methyl-beta-D-oxy LNA such as (S)-6'-methyl-beta-D-oxy-LNA (ScET) and ENA.
[0153] If one of the starting materials or compounds of the invention contain one or more functional groups which are not stable or are reactive under the reaction conditions of one or more reaction steps, appropriate protecting groups (as described e.g. in "Protective Groups in Organic Chemistry" by T. W. Greene and P. G. M. Wuts, 3rd Ed., 1999, Wiley, New York) can be introduced before the critical step applying methods well known in the art. Such protecting groups can be removed at a later stage of the synthesis using standard methods described in the literature. Examples of protecting groups are tert-butoxycarbonyl (Boc), 9-fluorenylmethyl carbamate (Fmoc), 2-trimethylsilylethyl carbamate (Teoc), carbobenzyloxy (Cbz) and p-methoxybenzyloxycarbonyl (Moz).
[0154] The compounds described herein can contain several asymmetric centers and can be present in the form of optically pure enantiomers, mixtures of enantiomers such as, for example, racemates, mixtures of diastereoisomers, diastereoisomeric racemates or mixtures of diastereoisomeric racemates.
[0155] The term "asymmetric carbon atom" means a carbon atom with four different substituents. According to the Cahn-Ingold-Prelog Convention an asymmetric carbon atom can be of the "R" or "S" configuration.
Chemical Group Definitions
[0156] In the present description the term "alkyl", alone or in combination, signifies a straight-chain or branched-chain alkyl group with 1 to 8 carbon atoms, particularly a straight or branched-chain alkyl group with 1 to 6 carbon atoms and more particularly a straight or branched-chain alkyl group with 1 to 4 carbon atoms. Examples of straight-chain and branched-chain C.sub.1-C.sub.8 alkyl groups are methyl, ethyl, propyl, isopropyl, butyl, isobutyl, tert.-butyl, the isomeric pentyls, the isomeric hexyls, the isomeric heptyls and the isomeric octyls, particularly methyl, ethyl, propyl, butyl and pentyl. Particular examples of alkyl are methyl, ethyl and propyl.
[0157] The term "cycloalkyl", alone or in combination, signifies a cycloalkyl ring with 3 to 8 carbon atoms and particularly a cycloalkyl ring with 3 to 6 carbon atoms. Examples of cycloalkyl are cyclopropyl, cyclobutyl, cyclopentyl, cyclohexyl, cycloheptyl and cyclooctyl, more particularly cyclopropyl and cyclobutyl. A particular example of "cycloalkyl" is cyclopropyl.
[0158] The term "alkoxy", alone or in combination, signifies a group of the formula alkyl-O-- in which the term "alkyl" has the previously given significance, such as methoxy, ethoxy, n-propoxy, isopropoxy, n-butoxy, isobutoxy, sec.butoxy and tert.butoxy. Particular "alkoxy" are methoxy and ethoxy. Methoxyethoxy is a particular example of "alkoxyalkoxy".
[0159] The term "oxy", alone or in combination, signifies the --O-- group.
[0160] The term "alkenyl", alone or in combination, signifies a straight-chain or branched hydrocarbon residue comprising an olefinic bond and up to 8, preferably up to 6, particularly preferred up to 4 carbon atoms. Examples of alkenyl groups are ethenyl, 1-propenyl, 2-propenyl, isopropenyl, 1-butenyl, 2-butenyl, 3-butenyl and isobutenyl.
[0161] The term "alkynyl", alone or in combination, signifies a straight-chain or branched hydrocarbon residue comprising a triple bond and up to 8, preferably up to 6, particularly preferred up to 4 carbon atoms.
[0162] The terms "halogen" or "halo", alone or in combination, signifies fluorine, chlorine, bromine or iodine and particularly fluorine, chlorine or bromine, more particularly fluorine. The term "halo", in combination with another group, denotes the substitution of said group with at least one halogen, particularly substituted with one to five halogens, particularly one to four halogens, i.e. one, two, three or four halogens.
[0163] The term "haloalkyl", alone or in combination, denotes an alkyl group substituted with at least one halogen, particularly substituted with one to five halogens, particularly one to three halogens. Examples of haloalkyl include monofluoro-, difluoro- or trifluoro-methyl, -ethyl or -propyl, for example 3,3,3-trifluoropropyl, 2-fluoroethyl, 2,2,2-trifluoroethyl, fluoromethyl or trifluoromethyl. Fluoromethyl, difluoromethyl and trifluoromethyl are particular "haloalkyl".
[0164] The term "halocycloalkyl", alone or in combination, denotes a cycloalkyl group as defined above substituted with at least one halogen, particularly substituted with one to five halogens, particularly one to three halogens. Particular example of "halocycloalkyl" are halocyclopropyl, in particular fluorocyclopropyl, difluorocyclopropyl and trifluorocyclopropyl.
[0165] The terms "hydroxyl" and "hydroxy", alone or in combination, signify the --OH group.
[0166] The terms "thiohydroxyl" and "thiohydroxy", alone or in combination, signify the --SH group.
[0167] The term "carbonyl", alone or in combination, signifies the --C(O)-- group.
[0168] The term "carboxy" or "carboxyl", alone or in combination, signifies the --COOH group.
[0169] The term "amino", alone or in combination, signifies the primary amino group (--NH.sub.2), the secondary amino group (--NH--), or the tertiary amino group (--N--).
[0170] The term "alkylamino", alone or in combination, signifies an amino group as defined above substituted with one or two alkyl groups as defined above.
[0171] The term "sulfonyl", alone or in combination, means the --SO.sub.2 group.
[0172] The term "sulfinyl", alone or in combination, signifies the --SO-- group.
[0173] The term "sulfanyl", alone or in combination, signifies the --S-- group.
[0174] The term "cyano", alone or in combination, signifies the --CN group.
[0175] The term "azido", alone or in combination, signifies the --N.sub.3 group.
[0176] The term "nitro", alone or in combination, signifies the NO.sub.2 group.
[0177] The term "formyl", alone or in combination, signifies the --C(O)H group.
[0178] The term "carbamoyl", alone or in combination, signifies the --C(O)NH.sub.2 group.
[0179] The term "cabamido", alone or in combination, signifies the --NH--C(O)--NH.sub.2 group.
[0180] The term "aryl", alone or in combination, denotes a monovalent aromatic carbocyclic mono- or bicyclic ring system comprising 6 to 10 carbon ring atoms, optionally substituted with 1 to 3 substituents independently selected from halogen, hydroxyl, alkyl, alkenyl, alkynyl, alkoxy, alkoxyalkyl, alkenyloxy, carboxyl, alkoxycarbonyl, alkylcarbonyl and formyl. Examples of aryl include phenyl and naphthyl, in particular phenyl.
[0181] The term "heteroaryl", alone or in combination, denotes a monovalent aromatic heterocyclic mono- or bicyclic ring system of 5 to 12 ring atoms, comprising 1, 2, 3 or 4 heteroatoms selected from N, O and S, the remaining ring atoms being carbon, optionally substituted with 1 to 3 substituents independently selected from halogen, hydroxyl, alkyl, alkenyl, alkynyl, alkoxy, alkoxyalkyl, alkenyloxy, carboxyl, alkoxycarbonyl, alkylcarbonyl and formyl. Examples of heteroaryl include pyrrolyl, furanyl, thienyl, imidazolyl, oxazolyl, thiazolyl, triazolyl, oxadiazolyl, thiadiazolyl, tetrazolyl, pyridinyl, pyrazinyl, pyrazolyl, pyridazinyl, pyrimidinyl, triazinyl, azepinyl, diazepinyl, isoxazolyl, benzofuranyl, isothiazolyl, benzothienyl, indolyl, isoindolyl, isobenzofuranyl, benzimidazolyl, benzoxazolyl, benzoisoxazolyl, benzothiazolyl, benzoisothiazolyl, benzooxadiazolyl, benzothiadiazolyl, benzotriazolyl, purinyl, quinolinyl, isoquinolinyl, quinazolinyl, quinoxalinyl, carbazolyl or acridinyl.
[0182] The term "heterocyclyl", alone or in combination, signifies a monovalent saturated or partly unsaturated mono- or bicyclic ring system of 4 to 12, in particular 4 to 9 ring atoms, comprising 1, 2, 3 or 4 ring heteroatoms selected from N, O and S, the remaining ring atoms being carbon, optionally substituted with 1 to 3 substituents independently selected from halogen, hydroxyl, alkyl, alkenyl, alkynyl, alkoxy, alkoxyalkyl, alkenyloxy, carboxyl, alkoxycarbonyl, alkylcarbonyl and formyl. Examples for monocyclic saturated heterocyclyl are azetidinyl, pyrrolidinyl, tetrahydrofuranyl, tetrahydro-thienyl, pyrazolidinyl, imidazolidinyl, oxazolidinyl, isoxazolidinyl, thiazolidinyl, piperidinyl, tetrahydropyranyl, tetrahydrothiopyranyl, piperazinyl, morpholinyl, thiomorpholinyl, 1,1-dioxo-thiomorpholin-4-yl, azepanyl, diazepanyl, homopiperazinyl, or oxazepanyl. Examples for bicyclic saturated heterocycloalkyl are 8-aza-bicyclo[3.2.1]octyl, quinuclidinyl, 8-oxa-3-aza-bicyclo[3.2.1]octyl, 9-aza-bicyclo[3.3.1]nonyl, 3-oxa-9-aza-bicyclo[3.3.1]nonyl, or 3-thia-9-aza-bicyclo[3.3.1]nonyl. Examples for partly unsaturated heterocycloalkyl are dihydrofuryl, imidazolinyl, dihydro-oxazolyl, tetrahydro-pyridinyl or dihydropyranyl.
Pharmaceutically Acceptable Salts
[0183] The term "pharmaceutically acceptable salts" refers to those salts which retain the biological effectiveness and properties of the free bases or free acids, which are not biologically or otherwise undesirable. The salts are formed with inorganic acids such as hydrochloric acid, hydrobromic acid, sulfuric acid, nitric acid, phosphoric acid, particularly hydrochloric acid, and organic acids such as acetic acid, propionic acid, glycolic acid, pyruvic acid, oxalic acid, maleic acid, malonic acid, succinic acid, fumaric acid, tartaric acid, citric acid, benzoic acid, cinnamic acid, mandelic acid, methanesulfonic acid, ethanesulfonic acid, p-toluenesulfonic acid, salicylic acid, N-acetylcystein. In addition these salts may be prepared form addition of an inorganic base or an organic base to the free acid. Salts derived from an inorganic base include, but are not limited to, the sodium, potassium, lithium, ammonium, calcium, magnesium salts. Salts derived from organic bases include, but are not limited to salts of primary, secondary, and tertiary amines, substituted amines including naturally occurring substituted amines, cyclic amines and basic ion exchange resins, such as isopropylamine, trimethylamine, diethylamine, triethylamine, tripropylamine, ethanolamine, lysine, arginine, N-ethylpiperidine, piperidine, polyamine resins. The compound of formula (I) can also be present in the form of zwitterions. Particularly preferred pharmaceutically acceptable salts of compounds of formula (I) are the salts of hydrochloric acid, hydrobromic acid, sulfuric acid, phosphoric acid and methanesulfonic acid.
Protecting Group
[0184] The term "protecting group", alone or in combination, signifies a group which selectively blocks a reactive site in a multifunctional compound such that a chemical reaction can be carried out selectively at another unprotected reactive site. Protecting groups can be removed. Exemplary protecting groups are amino-protecting groups, carboxy-protecting groups or hydroxy-protecting groups.
Nuclease Mediated Degradation
[0185] Nuclease mediated degradation refers to an oligonucleotide capable of mediating degradation of a complementary nucleotide sequence when forming a duplex with such a sequence.
[0186] In some embodiments, the oligonucleotide may function via nuclease mediated degradation of the target nucleic acid, where the oligonucleotides of the invention are capable of recruiting a nuclease, particularly and endonuclease, preferably endoribonuclease (RNase), such as RNase H. Examples of oligonucleotide designs which operate via nuclease mediated mechanisms are oligonucleotides which typically comprise a region of at least 5 or 6 DNA nucleosides and are flanked on one side or both sides by affinity enhancing nucleosides, for example gapmers, headmers and tailmers.
RNase H Activity and Recruitment
[0187] The RNase H activity of an antisense oligonucleotide refers to its ability to recruit RNase H when in a duplex with a complementary RNA molecule. WO01/23613 provides in vitro methods for determining RNaseH activity, which may be used to determine the ability to recruit RNaseH. Typically an oligonucleotide is deemed capable of recruiting RNase H if it, when provided with a complementary target nucleic acid sequence, has an initial rate, as measured in pmol/l/min, of at least 5%, such as at least 10% or more than 20% of the of the initial rate determined when using a oligonucleotide having the same base sequence as the modified oligonucleotide being tested, but containing only DNA monomers with phosphorothioate linkages between all monomers in the oligonucleotide, and using the methodology provided by Example 91-95 of WO01/23613 (hereby incorporated by reference). For use in determining RHase H activity, recombinant human RNase H1 is available from Lubio Science GmbH, Lucerne, Switzerland.
Gapmer
[0188] The antisense oligonucleotide of the invention, or contiguous nucleotide sequence thereof may be a gapmer. The antisense gapmers are commonly used to inhibit a target nucleic acid via RNase H mediated degradation. A gapmer oligonucleotide comprises at least three distinct structural regions a 5'-flank, a gap and a 3'-flank, F-G-F' in the `5->3` orientation. The "gap" region (G) comprises a stretch of contiguous DNA nucleotides which enable the oligonucleotide to recruit RNase H. The gap region is flanked by a 5' flanking region (F) comprising one or more sugar modified nucleosides, advantageously high affinity sugar modified nucleosides, and by a 3' flanking region (F') comprising one or more sugar modified nucleosides, advantageously high affinity sugar modified nucleosides. The one or more sugar modified nucleosides in region F and F' enhance the affinity of the oligonucleotide for the target nucleic acid (i.e. are affinity enhancing sugar modified nucleosides). In some embodiments, the one or more sugar modified nucleosides in region F and F' are 2' sugar modified nucleosides, such as high affinity 2' sugar modifications, such as independently selected from LNA and 2'-MOE.
[0189] In a gapmer design, the 5' and 3' most nucleosides of the gap region are DNA nucleosides, and are positioned adjacent to a sugar modified nucleoside of the 5' (F) or 3' (F') region respectively. The flanks may further defined by having at least one sugar modified nucleoside at the end most distant from the gap region, i.e. at the 5' end of the 5' flank and at the 3' end of the 3' flank.
[0190] Regions F-G-F' form a contiguous nucleotide sequence. Antisense oligonucleotides of the invention, or the contiguous nucleotide sequence thereof, may comprise a gapmer region of formula F-G-F'.
[0191] The overall length of the gapmer design F-G-F' may be, for example 12 to 32 nucleosides, such as 13 to 24, such as 14 to 22 nucleosides, Such as from 14 to 17, such as 16 to 18 nucleosides.
[0192] By way of example, the gapmer oligonucleotide of the present invention can be represented by the following formulae: [0193] F.sub.1-8-G.sub.5-15-F'.sub.1-8, such as [0194] F.sub.1-8-G.sub.7-15-F.sub.2-8 with the proviso that the overall length of the gapmer regions F-G-F' is at least 12, such as at least 14 nucleotides in length.
[0195] Regions F, G and F' are further defined below and can be incorporated into the F-G-F' formula.
Gapmer--Region G
[0196] Region G (gap region) of the gapmer is a region of nucleosides which enables the oligonucleotide to recruit RNaseH, such as human RNase H1, typically DNA nucleosides. RNaseH is a cellular enzyme which recognizes the duplex between DNA and RNA, and enzymatically cleaves the RNA molecule. Suitably gapmers may have a gap region (G) of at least 5 or 6 contiguous DNA nucleosides, such as 5-16 contiguous DNA nucleosides, such as 6-15 contiguous DNA nucleosides, such as 7-14 contiguous DNA nucleosides, such as 8-12 contiguous DNA nucleotides, such as 8-12 contiguous DNA nucleotides in length. The gap region G may, in some embodiments consist of 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 or 16 contiguous DNA nucleosides. Cytosine (C) DNA in the gap region may in some instances be methylated, such residues are either annotated as 5-methyl-cytosine (meC or with an e instead of a c). Methylation of Cytosine DNA in the gap is advantageous if cg dinucleotides are present in the gap to reduce potential toxicity, the modification does not have significant impact on efficacy of the oligonucleotides.
[0197] In some embodiments the gap region G may consist of 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 or 16 contiguous phosphorothioate linked DNA nucleosides. In some embodiments, all internucleoside linkages in the gap are phosphorothioate linkages.
[0198] Whilst traditional gapmers have a DNA gap region, there are numerous examples of modified nucleosides which allow for RNaseH recruitment when they are used within the gap region. Modified nucleosides which have been reported as being capable of recruiting RNaseH when included within a gap region include, for example, alpha-L-LNA, C4' alkylated DNA (as described in PCT/EP2009/050349 and Vester et al., Bioorg. Med. Chem. Lett. 18 (2008) 2296-2300, both incorporated herein by reference), arabinose derived nucleosides like ANA and 2'F-ANA (Mangos et al. 2003 J. AM. CHEM. SOC. 125, 654-661), UNA (unlocked nucleic acid) (as described in Fluiter et al., Mol. Biosyst., 2009, 10, 1039 incorporated herein by reference). UNA is unlocked nucleic acid, typically where the bond between C2 and C3 of the ribose has been removed, forming an unlocked "sugar" residue. The modified nucleosides used in such gapmers may be nucleosides which adopt a 2' endo (DNA like) structure when introduced into the gap region, i.e. modifications which allow for RNaseH recruitment). In some embodiments the DNA Gap region (G) described herein may optionally contain 1 to 3 sugar modified nucleosides which adopt a 2' endo (DNA like) structure when introduced into the gap region.
Region G--"Gap-Breaker"
[0199] Alternatively, there are numerous reports of the insertion of a modified nucleoside which confers a 3' endo conformation into the gap region of gapmers, whilst retaining some RNaseH activity. Such gapmers with a gap region comprising one or more 3'endo modified nucleosides are referred to as "gap-breaker" or "gap-disrupted" gapmers, see for example WO2013/022984. Gap-breaker oligonucleotides retain sufficient region of DNA nucleosides within the gap region to allow for RNaseH recruitment. The ability of gapbreaker oligonucleotide design to recruit RNaseH is typically sequence or even compound specific--see Rukov et al. 2015 Nucl. Acids Res. Vol. 43 pp. 8476-8487, which discloses "gapbreaker" oligonucleotides which recruit RNaseH which in some instances provide a more specific cleavage of the target RNA. Modified nucleosides used within the gap region of gap-breaker oligonucleotides may for example be modified nucleosides which confer a 3'endo confirmation, such 2'-O-methyl (OMe) or 2'-O-MOE (MOE) nucleosides, or beta-D LNA nucleosides (the bridge between C2' and C4' of the ribose sugar ring of a nucleoside is in the beta conformation), such as beta-D-oxy LNA or ScET nucleosides.
[0200] As with gapmers containing region G described above, the gap region of gap-breaker or gap-disrupted gapmers, have a DNA nucleosides at the 5' end of the gap (adjacent to the 3' nucleoside of region F), and a DNA nucleoside at the 3' end of the gap (adjacent to the 5' nucleoside of region F'). Gapmers which comprise a disrupted gap typically retain a region of at least 3 or 4 contiguous DNA nucleosides at either the 5' end or 3' end of the gap region.
[0201] Exemplary designs for gap-breaker oligonucleotides include [0202] F.sub.1-8-[D.sub.3-4-E.sub.1-D.sub.3-4]-F'.sub.1-8 [0203] F.sub.1-8-[D.sub.1-4-E.sub.1-D.sub.3-4]-F'.sub.1-8 [0204] F.sub.1-8-[D.sub.3-4-E.sub.1-D.sub.1-4]-F'.sub.1-8 wherein region G is within the brackets [D.sub.n-E.sub.r-D.sub.m], D is a contiguous sequence of DNA nucleosides, E is a modified nucleoside (the gap-breaker or gap-disrupting nucleoside), and F and F' are the flanking regions as defined herein, and with the proviso that the overall length of the gapmer regions F-G-F' is at least 12, such as at least 14 nucleotides in length.
[0205] In some embodiments, region G of a gap disrupted gapmer comprises at least 6 DNA nucleosides, such as 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 or 16 DNA nucleosides. As described above, the DNA nucleosides may be contiguous or may optionally be interspersed with one or more modified nucleosides, with the proviso that the gap region G is capable of mediating RNaseH recruitment.
Gapmer--Flanking Regions, F and F'
[0206] Region F is positioned immediately adjacent to the 5' DNA nucleoside of region G. The 3' most nucleoside of region F is a sugar modified nucleoside, such as a high affinity sugar modified nucleoside, for example a 2' substituted nucleoside, such as a MOE nucleoside, or an LNA nucleoside.
[0207] Region F' is positioned immediately adjacent to the 3' DNA nucleoside of region G. The 5' most nucleoside of region F' is a sugar modified nucleoside, such as a high affinity sugar modified nucleoside, for example a 2' substituted nucleoside, such as a MOE nucleoside, or an LNA nucleoside.
[0208] Region F is 1-8 contiguous nucleotides in length, such as 2-6, such as 3-4 contiguous nucleotides in length. Advantageously the 5' most nucleoside of region F is a sugar modified nucleoside. In some embodiments the two 5' most nucleoside of region F are sugar modified nucleoside. In some embodiments the 5' most nucleoside of region F is an LNA nucleoside. In some embodiments the two 5' most nucleoside of region F are LNA nucleosides. In some embodiments the two 5' most nucleoside of region F are 2' substituted nucleoside nucleosides, such as two 3' MOE nucleosides. In some embodiments the 5' most nucleoside of region F is a 2' substituted nucleoside, such as a MOE nucleoside.
[0209] Region F' is 2-8 contiguous nucleotides in length, such as 3-6, such as 4-5 contiguous nucleotides in length. Advantageously, embodiments the 3' most nucleoside of region F' is a sugar modified nucleoside. In some embodiments the two 3' most nucleoside of region F' are sugar modified nucleoside. In some embodiments the two 3' most nucleoside of region F' are LNA nucleosides. In some embodiments the 3' most nucleoside of region F' is an LNA nucleoside. In some embodiments the two 3' most nucleoside of region F' are 2' substituted nucleoside nucleosides, such as two 3' MOE nucleosides. In some embodiments the 3' most nucleoside of region F' is a 2' substituted nucleoside, such as a MOE nucleoside.
[0210] It should be noted that when the length of region F or F' is one, it is advantageously an LNA nucleoside.
[0211] In some embodiments, region F and F' independently consists of or comprises a contiguous sequence of sugar modified nucleosides. In some embodiments, the sugar modified nucleosides of region F may be independently selected from 2'-O-alkyl-RNA units, 2'-O-methyl-RNA, 2'-amino-DNA units, 2'-fluoro-DNA units, 2'-alkoxy-RNA, MOE units, LNA units, arabino nucleic acid (ANA) units and 2'-fluoro-ANA units.
[0212] In some embodiments, region F and F' independently comprises both LNA and a 2' substituted modified nucleosides (mixed wing design).
[0213] In some embodiments, region F and F' consists of only one type of sugar modified nucleosides, such as only MOE or only beta-D-oxy LNA or only ScET. Such designs are also termed uniform flanks or uniform gapmer design.
[0214] In some embodiments, all the nucleosides of region F or F', or F and F' are LNA nucleosides, such as independently selected from beta-D-oxy LNA, ENA or ScET nucleosides. In some embodiments region F consists of 1-5, such as 2-4, such as 3-4 such as 1, 2, 3, 4 or 5 contiguous LNA nucleosides. In some embodiments, all the nucleosides of region F and F' are beta-D-oxy LNA nucleosides.
[0215] In some embodiments, all the nucleosides of region F or F', or F and F' are 2' substituted nucleosides, such as OMe or MOE nucleosides. In some embodiments region F consists of 1, 2, 3, 4, 5, 6, 7, or 8 contiguous OMe or MOE nucleosides. In some embodiments only one of the flanking regions can consist of 2' substituted nucleosides, such as OMe or MOE nucleosides. In some embodiments it is the 5' (F) flanking region that consists 2' substituted nucleosides, such as OMe or MOE nucleosides whereas the 3' (F') flanking region comprises at least one LNA nucleoside, such as beta-D-oxy LNA nucleosides or cET nucleosides. In some embodiments it is the 3' (F') flanking region that consists 2' substituted nucleosides, such as OMe or MOE nucleosides whereas the 5' (F) flanking region comprises at least one LNA nucleoside, such as beta-D-oxy LNA nucleosides or cET nucleosides.
[0216] In some embodiments, all the modified nucleosides of region F and F' are LNA nucleosides, such as independently selected from beta-D-oxy LNA, ENA or ScET nucleosides, wherein region F or F', or F and F' may optionally comprise DNA nucleosides (an alternating flank, see definition of these for more details). In some embodiments, all the modified nucleosides of region F and F' are beta-D-oxy LNA nucleosides, wherein region F or F', or F and F' may optionally comprise DNA nucleosides (an alternating flank, see definition of these for more details).
[0217] In some embodiments the 5' most and the 3' most nucleosides of region F and F' are LNA nucleosides, such as beta-D-oxy LNA nucleosides or ScET nucleosides.
[0218] In some embodiments, the internucleoside linkage between region F and region G is a phosphorothioate internucleoside linkage. In some embodiments, the internucleoside linkage between region F' and region G is a phosphorothioate internucleoside linkage. In some embodiments, the internucleoside linkages between the nucleosides of region F or F', F and F' are phosphorothioate internucleoside linkages.
[0219] Further gapmer designs are disclosed in WO 2004/046160, WO 2007/146511 and WO 2008/113832, hereby incorporated by reference.
LNA Gapmer
[0220] An LNA gapmer is a gapmer wherein either one or both of region F and F' comprises or consists of LNA nucleosides. A beta-D-oxy gapmer is a gapmer wherein either one or both of region F and F' comprises or consists of beta-D-oxy LNA nucleosides.
[0221] In some embodiments the LNA gapmer is of formula: [LNA].sub.1-5-[region G]-[LNA].sub.1-5, wherein region G is as defined in the Gapmer region G definition.
[0222] MOE Gapmers A MOE gapmers is a gapmer wherein regions F and F' consist of MOE nucleosides. In some embodiments the MOE gapmer is of design [MOE].sub.1-8-[Region G]-[MOE].sub.1-8, such as [MOE].sub.2-7-[Region G].sub.5-16-[MOE].sub.2-7, such as [MOE].sub.3-6-[Region G]-[MOE].sub.3-6, wherein region G is as defined in the Gapmer definition. MOE gapmers with a 5-10-5 design (MOE-DNA-MOE) have been widely used in the art.
Mixed Wing Gapmer
[0223] A mixed wing gapmer is an LNA gapmer wherein one or both of region F and F' comprise a 2' substituted nucleoside, such as a 2' substituted nucleoside independently selected from the group consisting of 2'-O-alkyl-RNA units, 2'-O-methyl-RNA, 2'-amino-DNA units, 2'-fluoro-DNA units, 2'-alkoxy-RNA, MOE units, arabino nucleic acid (ANA) units and 2'-fluoro-ANA units, such as a MOE nucleosides. In some embodiments wherein at least one of region F and F', or both region F and F' comprise at least one LNA nucleoside, the remaining nucleosides of region F and F' are independently selected from the group consisting of MOE and LNA. In some embodiments wherein at least one of region F and F', or both region F and F' comprise at least two LNA nucleosides, the remaining nucleosides of region F and F' are independently selected from the group consisting of MOE and LNA. In some mixed wing embodiments, one or both of region F and F' may further comprise one or more DNA nucleosides.
[0224] Mixed wing gapmer designs are disclosed in WO 2008/049085 and WO 2012/109395, both of which are hereby incorporated by reference.
Alternating Flank Gapmers
[0225] Flanking regions may comprise both LNA and DNA nucleoside and are referred to as "alternating flanks" as they comprise an alternating motif of LNA-DNA-LNA nucleosides. Gapmers comprising such alternating flanks are referred to as "alternating flank gapmers". "Alternative flank gapmers" are thus LNA gapmer oligonucleotides where at least one of the flanks (F or F') comprises DNA in addition to the LNA nucleoside(s). In some embodiments at least one of region F or F', or both region F and F', comprise both LNA nucleosides and DNA nucleosides. In such embodiments, the flanking region F or F', or both F and F' comprise at least three nucleosides, wherein the 5' and 3' most nucleosides of the F and/or F' region are LNA nucleosides.
[0226] Alternating flank LNA gapmers are disclosed in WO 2016/127002.
[0227] Oligonucleotides with alternating flanks are LNA gapmer oligonucleotides where at least one of the flanks (F or F') comprises DNA in addition to the LNA nucleoside(s). In some embodiments at least one of region F or F', or both region F and F', comprise both LNA nucleosides and DNA nucleosides. In such embodiments, the flanking region F or F', or both F and F' comprise at least three nucleosides, wherein the 5' and 3' most nucleosides of the F and/or F' region are LNA nucleosides.
[0228] In some embodiments at least one of region F or F', or both region F and F', comprise both LNA nucleosides and DNA nucleosides. In such embodiments, the flanking region F or F', or both F and F' comprise at least three nucleosides, wherein the 5' and 3' most nucleosides of the F or F' region are LNA nucleosides, and the. Flanking regions which comprise both LNA and DNA nucleoside are referred to as alternating flanks, as they comprise an alternating motif of LNA-DNA-LNA nucleosides. Alternating flank LNA gapmers are disclosed in WO2016/127002.
[0229] An alternating flank region may comprise up to 3 contiguous DNA nucleosides, such as 1 to 2 or 1 or 2 or 3 contiguous DNA nucleosides.
[0230] The alternating flak can be annotated as a series of integers, representing a number of LNA nucleosides (L) followed by a number of DNA nucleosides (D), for example [0231] [L].sub.1-3-[D].sub.1-4-[L].sub.1-3 [0232] [L].sub.1-2-[D].sub.1-2-[L].sub.1-2-[D].sub.1-2-[L].sub.1-2
[0233] In oligonucleotide designs these will often be represented as numbers such that 2-2-1 represents 5' [L].sub.2-[D].sub.2-[L] 3', and 1-1-1-1-1 represents 5' [L]-[D]-[L]-[D]-[L] 3'. The length of the flank (region F and F') in oligonucleotides with alternating flanks may independently be 3 to 10 nucleosides, such as 4 to 8, such as 5 to 6 nucleosides, such as 4, 5, 6 or 7 modified nucleosides. In some embodiments only one of the flanks in the gapmer oligonucleotide is alternating while the other is constituted of LNA nucleotides. It may be advantageous to have at least two LNA nucleosides at the 3' end of the 3' flank (F'), to confer additional exonuclease resistance. Some examples of oligonucleotides with alternating flanks are: [0234] [L].sub.1-5-[D].sub.1-4-[L].sub.1-3-[G].sub.5-16-[L].sub.2-6 [0235] [L].sub.1-2-[D].sub.1-2-[L].sub.1-2-[D].sub.1-2-[L].sub.1-2-[G].sub.5-16-- [L].sub.1-2-[D].sub.1-3-[L].sub.2-4 [0236] [L].sub.1-5-[G].sub.5-16-[L]-[D]-[L]-[D]-[L].sub.2 with the proviso that the overall length of the gapmer is at least 12, such as at least 14 nucleotides in length.
Region D' or D'' in an Oligonucleotide
[0237] The oligonucleotide of the invention may in some embodiments comprise or consist of the contiguous nucleotide sequence of the oligonucleotide which is complementary to the target nucleic acid, such as the gapmer F-G-F', and further 5' and/or 3' nucleosides. The further 5' and/or 3' nucleosides may or may not be fully complementary to the target nucleic acid. Such further 5' and/or 3' nucleosides may be referred to as region D' and D'' herein.
[0238] The addition of region D' or D'' may be used for the purpose of joining the contiguous nucleotide sequence, such as the gapmer, to a conjugate moiety or another functional group. When used for joining the contiguous nucleotide sequence with a conjugate moiety is can serve as a biocleavable linker. Alternatively it may be used to provide exonucleoase protection or for ease of synthesis or manufacture.
[0239] Region D' and D'' can be attached to the 5' end of region F or the 3' end of region F', respectively to generate designs of the following formulas D'-F-G-F', F-G-F'-D'' or
[0240] D'-F-G-F'-D''. In this instance the F-G-F' is the gapmer portion of the oligonucleotide and region D' or D'' constitute a separate part of the oligonucleotide.
[0241] Region D' or D'' may independently comprise or consist of 1, 2, 3, 4 or 5 additional nucleotides, which may be complementary or non-complementary to the target nucleic acid. The nucleotide adjacent to the F or F' region is not a sugar-modified nucleotide, such as a DNA or RNA or base modified versions of these. The D' or D' region may serve as a nuclease susceptible biocleavable linker (see definition of linkers). In some embodiments the additional 5' and/or 3' end nucleotides are linked with phosphodiester linkages, and are DNA or RNA. Nucleotide based biocleavable linkers suitable for use as region D' or D'' are disclosed in WO 2014/076195, which include by way of example a phosphodiester linked DNA dinucleotide. The use of biocleavable linkers in poly-oligonucleotide constructs is disclosed in WO 2015/113922, where they are used to link multiple antisense constructs (e.g. gapmer regions) within a single oligonucleotide.
[0242] In one embodiment the oligonucleotide of the invention comprises a region D' and/or D'' in addition to the contiguous nucleotide sequence which constitutes the gapmer.
[0243] In some embodiments, the oligonucleotide of the present invention can be represented by the following formulae: [0244] F-G-F'; in particular F.sub.1-8-G.sub.5-16-F'.sub.2-8 [0245] D'-F-G-F', in particular D'.sub.1-3-F.sub.1-8-G.sub.5-16-F'.sub.2-8 [0246] F-G-F'-D'', in particular F.sub.1-8-G.sub.5-16-F'.sub.2-8-D''.sub.1-3 [0247] D'-F-G-F'-D'', in particular D'.sub.1-3-F.sub.1-8-G.sub.5-16-F'.sub.2-8-D''.sub.1-3
[0248] In some embodiments the internucleoside linkage positioned between region D' and region F is a phosphodiester linkage. In some embodiments the internucleoside linkage positioned between region F' and region D'' is a phosphodiester linkage.
Conjugate
[0249] The term conjugate as used herein refers to an oligonucleotide which is covalently linked to a non-nucleotide moiety (conjugate moiety or region C or third region).
[0250] Conjugation of the oligonucleotide of the invention to one or more non-nucleotide moieties may improve the pharmacology of the oligonucleotide, e.g. by affecting the activity, cellular distribution, cellular uptake or stability of the oligonucleotide. In some embodiments the conjugate moiety modify or enhance the pharmacokinetic properties of the oligonucleotide by improving cellular distribution, bioavailability, metabolism, excretion, permeability, and/or cellular uptake of the oligonucleotide. In particular the conjugate may target the oligonucleotide to a specific organ, tissue or cell type and thereby enhance the effectiveness of the oligonucleotide in that organ, tissue or cell type. A the same time the conjugate may serve to reduce activity of the oligonucleotide in non-target cell types, tissues or organs, e.g. off target activity or activity in non-target cell types, tissues or organs. WO 93/07883 and WO2013/033230 provides suitable conjugate moieties, which are hereby incorporated by reference. Further suitable conjugate moieties are those capable of binding to the asialoglycoprotein receptor (ASGPr). In particular tri-valent N-acetylgalactosamine conjugate moieties are suitable for binding to the ASGPr, see for example WO 2014/076196, WO 2014/207232 and WO 2014/179620 (hereby incorporated by reference, in particular, FIG. 13 of WO2014/076196 or claims 158-164 of WO2014/179620).
[0251] Oligonucleotide conjugates and their synthesis has also been reported in comprehensive reviews by Manoharan in Antisense Drug Technology, Principles, Strategies, and Applications, S. T. Crooke, ed., Ch. 16, Marcel Dekker, Inc., 2001 and Manoharan, Antisense and Nucleic Acid Drug Development, 2002, 12, 103, each of which is incorporated herein by reference in its entirety.
[0252] In an embodiment, the non-nucleotide moiety (conjugate moiety) is selected from the group consisting of carbohydrates, cell surface receptor ligands, drug substances, hormones, lipophilic substances, polymers, proteins, peptides, toxins (e.g. bacterial toxins), vitamins, viral proteins (e.g. capsids) or combinations thereof.
Linkers
[0253] A linkage or linker is a connection between two atoms that links one chemical group or segment of interest to another chemical group or segment of interest via one or more covalent bonds. Conjugate moieties can be attached to the oligonucleotide directly or through a linking moiety (e.g. linker or tether). Linkers serve to covalently connect a third region (region C), e.g. a conjugate moiety to to a first region, e.g. an oligonucleotide or contiguous nucleotide sequence complementary to the target nucleic acid (region A), thereby connecting one of the termini of region A to C.
[0254] In some embodiments of the invention the conjugate or oligonucleotide conjugate of the invention may optionally, comprise a linker region (second region or region B and/or region Y) which is positioned between the oligonucleotide or contiguous nucleotide sequence complementary to the target nucleic acid (region A or first region) and the conjugate moiety (region C or third region).
[0255] Region B refers to biocleavable linkers comprising or consisting of a physiologically labile bond that is cleavable under conditions normally encountered or analogous to those encountered within a mammalian body. Conditions under which physiologically labile linkers undergo chemical transformation (e.g., cleavage) include chemical conditions such as pH, temperature, oxidative or reductive conditions or agents, and salt concentration found in or analogous to those encountered in mammalian cells. Mammalian intracellular conditions also include the presence of enzymatic activity normally present in a mammalian cell such as from proteolytic enzymes or hydrolytic enzymes or nucleases. In one embodiment the biocleavable linker is susceptible to S1 nuclease cleavage. In a preferred embodiment the nuclease susceptible linker comprises between 1 and 10 nucleosides, such as 1, 2, 3, 4, 5, 6, 7, 8, 9 or 10 nucleosides, more preferably between 2 and 6 nucleosides and most preferably between 2 and 4 linked nucleosides comprising at least two consecutive phosphodiester linkages, such as at least 3 or 4 or 5 consecutive phosphodiester linkages. Preferably the nucleosides are DNA or RNA. Phosphodiester containing biocleavable linkers are described in more detail in WO 2014/076195 (hereby incorporated by reference).
[0256] Conjugates may also be linked to the oligonucleotide via non-biocleavable linkers, or in some embodiments the conjugate may comprise a non-cleavable linker which is covalently attached to the biocleavable linker (region Y). Linkers that are not necessarily biocleavable but primarily serve to covalently connect a conjugate moiety (region C or third region), to an oligonucleotide (region A or first region), may comprise a chain structure or an oligomer of repeating units such as ethylene glycol, amino acid units or amino alkyl groups The oligonucleotide conjugates of the present invention can be constructed of the following regional elements A-C, A-B--C, A-B--Y--C, A-Y--B--C or A-Y--C. In some embodiments the non-cleavable linker (region Y) is an amino alkyl, such as a C2-C36 amino alkyl group, including, for example C6 to C12 amino alkyl groups. In a preferred embodiment the linker (region Y) is a C6 amino alkyl group. Conjugate linker groups may be routinely attached to an oligonucleotide via use of an amino modified oligonucleotide, and an activated ester group on the conjugate group.
Treatment
[0257] The term `treatment` as used herein refers to both treatment of an existing disease (e.g. a disease or disorder as herein referred to), or prevention of a disease, i.e. prophylaxis. It will therefore be recognized that treatment as referred to herein may, in some embodiments, be prophylactic.
DETAILED DESCRIPTION OF THE INVENTION
The Oligonucleotides of the Invention
[0258] The invention relates to oligonucleotides capable of inhibiting expression of ERC1. The modulation may be achieved by hybridizing to a target nucleic acid encoding ERC1 or which is involved in the regulation of ERC1. The target nucleic acid may be a mammalian ERC1 sequence, such as a sequence selected from the group consisting of SEQ's ID NO's: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 and 13, or naturally occurring variants thereof.
[0259] The oligonucleotide of the invention is an antisense oligonucleotide which targets ERC1 pre-mRNA or mRNA.
[0260] In some embodiments the antisense oligonucleotide of the invention is capable of modulating the expression of the target by inhibiting or reducing target expression. Preferably, such modulation produces an inhibition of expression of at least 20% compared to the normal expression level of the target, more preferably at least 30%, 40%, 50%, 60%, 70%, 80%, or 90%, 95% inhibition compared to the normal expression level of the target. In some embodiments oligonucleotides of the invention may be capable of inhibiting expression levels of ERC1 mRNA by at least 60% or 70% in vitro using HeLa cells. In some embodiments compounds of the invention may be capable of inhibiting expression levels of ERC1 protein by at least 50% in vitro using HeLa cells. Suitably, the examples provide assays which may be used to measure ERC1 RNA or protein inhibition (e.g. example 1). The target modulation is triggered by the hybridization between a contiguous nucleotide sequence of the oligonucleotide and the target nucleic acid. In some embodiments the oligonucleotide of the invention comprises mismatches between the oligonucleotide and the target nucleic acid. Despite mismatches hybridization to the target nucleic acid may still be sufficient to show a desired modulation of ERC1 expression. Reduced binding affinity resulting from mismatches may advantageously be compensated by increased number of nucleotides in the oligonucleotide and/or an increased number of modified nucleosides capable of increasing the binding affinity to the target, such as 2' sugar modified nucleosides, including LNA, present within the oligonucleotide sequence.
[0261] An aspect of the present invention relates to an antisense oligonucleotide of 10 to 50, such as 10-30, nucleotides in length, which comprises a contiguous nucleotide sequence of 10 to 30 nucleotides in length with at least 90% complementarity, such as full complementarity, to a mammalian ERC1 target nucleic acid, wherein the antisense oligonucleotide is capable of reducing the expression of the mammalian ERC1 target nucleic acid in a cell.
[0262] An aspect of the present invention relates to an antisense oligonucleotide of 10 to 30 nucleotides in length, which comprises a contiguous nucleotide sequence of 10 to 22 nucleotides in length with at least 90% complementarity, such as full complementarity, to a mammalian ERC1 target nucleic acid, wherein the antisense oligonucleotide is capable of reducing the expression of the mammalian ERC1 target nucleic acid in a cell.
[0263] In some embodiments, the oligonucleotide comprises a contiguous sequence which is at least 90% complementary, such as at least 91%, such as at least 92%, such as at least 93%, such as at least 94%, such as at least 95%, such as at least 96%, such as at least 97%, such as at least 98%, or 100% complementary with a region of the target nucleic acid or the target sequence.
[0264] In a preferred embodiment the antisense oligonucleotide of the invention, or contiguous nucleotide sequence thereof is fully complementary (100% complementary) to the target nucleic acid or target sequence, or in some embodiments may comprise one or two mismatches between the oligonucleotide and the target nucleic acid.
[0265] Another aspect of the present invention relates to the antisense oligonucleotide, wherein the contiguous nucleotide sequence is at least 90% complementary to a sequence selected from the group consisting of SEQ ID NO1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 and 14, or a naturally occurring variant thereof.
[0266] In some embodiments the oligonucleotide sequence or contiguous nucleotide sequence is at least 90% complementary, such as fully (or 100%) complementary, to a target sequence present in SEQ ID NO: 1 and 13. In some embodiments the contiguous sequence of the antisense oligonucleotide is 100% complementary to the mammalian ERC1 target nucleic acid.
[0267] In a preferred embodiment the oligonucleotide sequence or contiguous nucleotide sequence is 100% complementary to a corresponding target sequence present in SEQ ID NO: 1 and SEQ ID NO: 13.
[0268] Another aspect of the present invention relates to the antisense oligonucleotide, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to an intron region present in the pre-mRNA of mammalian ERC1 target nucleic acid (e.g. SEQ ID NO: 1).
[0269] It shall be understood that intron positions on SEQ ID NO: 1 may vary depending on different splicing of ERC1 pre-mRNA. In the context of the present invention any nucleotide sequence in the gene sequence or pre-mRNA that is removed from the pre-mRNA by RNA splicing during maturation of the final RNA product (mature mRNA) are introns irrespectively on their position on SEQ ID NO: 1. Table 1 provides the most common intron regions in SEQ ID NO: 1.
[0270] In some embodiments the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to an intron region present in the pre-mRNA of human ERC1, selected from position 815-37239 on SEQ ID NO: 1, position 38065-92655 on SEQ ID NO: 1, 93073-114241 on SEQ ID NO: 1, 114317-119683 on SEQ ID NO: 1, 119840-125357 on SEQ ID NO: 1, 125526-1151111 on SEQ ID NO: 1, 151280-190031 on SEQ ID NO: 1, 190170-191416 on SEQ ID NO: 1, 191558-192772 on SEQ ID NO: 1, 192914-199350 on SEQ ID NO: 1, 199545-246260 on SEQ ID NO: 1, 246397-272525 on SEQ ID NO: 1, 272658-299343 on SEQ ID NO: 1, 299505-381324 on SEQ ID NO: 1.
[0271] In some embodiments the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to position 38065-92655 of SEQ ID NO: 1
[0272] In some embodiments the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to position 88376-89391 of SEQ ID NO: 1.
[0273] In some embodiments the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to SEQ ID NO: 14.
[0274] In some embodiments the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to SEQ ID NO: 23.
[0275] In some embodiments the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to SEQ ID NO: 24.
[0276] In some embodiments the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to SEQ ID NO: 25.
[0277] In some embodiments the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to SEQ ID NO: 26.
[0278] In some embodiments, the oligonucleotide or contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to a region of the target nucleic acid, wherein the target nucleic acid region is selected from the group consisting of position 88284-88297, 88378-88391, 88425-88438, 88472-88485, 88517-88530, 88656-88669, 88703-88716, 88750-88763, 88795-88808, 88842-88855, 88889-88902, 88936-88949, 88983-88996, 89030-89043, 89077-89090, 89124-89137, 89171-89184, 89265-89278, 89312-89325, 89359-88372; 88374-88393, 88421-88440, 88468-88487, 88513-88532, 88652-88671, 88699-88718, 88746-88765, 88791-88810, 88838-88857, 88885-88904, 88932-88951, 88979-88998, 89026-89045, 89073-89092, 89120-89139, 89167-89186, 89261-89280, 89308-89327, 89355-89374; 88374-88391, 88421-88438, 88468-88485, 88513-88530, 88652-88669, 88699-88716, 88746-88763, 88791-88808, 88838-88855, 88885-88902, 88932-88949, 88979-88996, 89026-89043, 89073-89090, 89120-89137, 89167-89184, 89261-89278, 89308-89325, 89355-89372; 88376-88391, 88423-88438, 88470-88485, 88515-88530, 88654-88669, 88701-88716, 88748-88763, 88793-88808, 88840-88855, 88887-88902, 88934-88949, 88981-88996, 89028-89043, 89075-89090, 89122-89137, 89169-89184, 89263-89278, 89310-89325, 89357-89372, 451815-451834, 451816-451833, 451818-451833, 451818-451831 of SEQ ID NO: 1.
[0279] According to one aspect of the invention, the target sequence is repeated within the target nucleic acid, i.e. at least two identical target nucleotide sequences (target regions) of at least 10 nucleotides in length occur in the target nucleic acid at different positions. A repeated target region is generally between 10 and 50 nucleotides, such as between 11 and 30 nucleotides, such as between 12 and 25 nucleotides, such as between 13 and 22 nucleotides, such as between 14 and 20 nucleotides, such as between 15 and 19 nucleotides, such as between 16 and 18 nucleotides. In a preferred embodiment the repeated target region is between 14 and 20 nucleotides.
[0280] In one aspect the invention provides antisense oligonucleotides wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to a target region that is repeated at least 2 times across the target nucleic acid of SEQ ID NO: 1. The effect of this is that several oligonucleotide compounds (with the same sequence) can hybridize to one or more target regions on the same target nucleic acid (at the same time), which may result in multiple cleavage events of the target nucleic acid when the oligonucleotide is administered to a cell or an animal or a human.
[0281] In some embodiments the oligonucleotide or the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary to a target region that is repeated at least 5 repeated target regions, such as at least 6, 7, 8, 9, 10, 11, 12, 13, 14 or 15 repeated target regions, or more than 18 repeated target regions. In one embodiment the target region is repeated 19 times within intron 2.
[0282] In a further embodiment the antisense oligonucleotide comprises a contiguous nucleotide sequence that is at least 90% complementary, such as fully complementary, to a target region of 10-22, such as 14-20, nucleotides in length of the target nucleic acid of SEQ ID NO: 1, wherein the target region is repeated at least 5 or more times across the introns of the target nucleic acid.
[0283] In some embodiments, the antisense oligonucleotide of the invention or the contiguous nucleotide sequence thereof is complementary to at least 15, such as 19, repeated target regions in SEQ ID NO: 14.
[0284] In some embodiments, the oligonucleotide of the invention comprises or consists of 10 to 35 nucleotides in length, such as from 10 to 30, such as 11 to 22, such as from 12 to 20, such as from 14 to 18 or 14 to 16 contiguous nucleotides in length. Advantageously, the oligonucleotide comprises or consists of 14 to 20 nucleotides in length.
[0285] In some embodiments, the oligonucleotide or a contiguous nucleotide sequence thereof comprises or consists of 22 or less nucleotides, such as 20 or less nucleotides, such as 18 or less nucleotides, such as 14, 15, 16 or 17 nucleotides.
[0286] In some embodiments, the contiguous nucleotide sequence comprises or consists of 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29 or 30 contiguous nucleotides in length. In a preferred embodiment, the oligonucleotide comprises or consists of 14 to 20 nucleotides in length.
[0287] It is to be understood that any range given herein includes the range endpoints. Accordingly, if an oligonucleotide is said to include from 10 to 30 nucleotides, both 10 and 30 nucleotides are included.
[0288] In some embodiments the contiguous nucleotide sequence of the invention is at least 90% identical, such as 100% identical to a sequence selected from the group consisting of SEQ ID NO: 15, 16, 17 and 18.
[0289] In some embodiments the contiguous nucleotide sequence of the invention is at least 90% identical, such as 100% identical to a sequence selected from the group consisting of SEQ ID NO: 19, 20, 21 and 22.
[0290] In some embodiments the antisense oligonucleotide or contiguous nucleotide sequence thereof consists or comprises of 10 to 30 contiguous nucleotides in length with at least 90% identity, preferably 100% identity to a sequence selected from SEQ ID NO: 15, 16, 17 or 18.
[0291] In some embodiments the antisense oligonucleotide or contiguous nucleotide sequence thereof consists or comprises of 10 to 30 contiguous nucleotides in length with at least 90% identity, preferably 100% identity to a sequence selected from SEQ ID NO: 19, 20, 21 or 22.
[0292] In some embodiments the antisense oligonucleotide or contiguous nucleotide sequence thereof consists or comprises of 12 to 20 contiguous nucleotides in length with at least 90% identity, preferably 100% identity to a sequence selected from SEQ ID NO: 15, 16, 17 or 18.
[0293] In some embodiments the antisense oligonucleotide or contiguous nucleotide sequence thereof consists or comprises of 12 to 20 contiguous nucleotides in length with at least 90% identity, preferably 100% identity to a sequence selected from SEQ ID NO 19, 20, 21 or 22.
[0294] In some embodiments the antisense oligonucleotide or contiguous nucleotide sequence thereof consists or comprises of 14 to 20 contiguous nucleotides in length with at least 90% identity, preferably 100% identity to a sequence selected from SEQ ID NO: 15, 16, 17 or 18.
[0295] In some embodiments the antisense oligonucleotide or contiguous nucleotide sequence thereof consists or comprises of 14 to 20 contiguous nucleotides in length with at least 90% identity, preferably 100% identity to a sequence selected from SEQ ID NO 19, 20, 21 and 22.
[0296] In some embodiments, the antisense oligonucleotide or contiguous nucleotide sequence thereof comprises a sequence selected from SEQ ID NO: 15, 16, 17 or 18.
[0297] In some embodiments, the antisense oligonucleotide or contiguous nucleotide sequence thereof comprises a sequence selected from SEQ ID NO: 19, 20, 21 and 22.
[0298] Oligonucleotide compounds represent specific designs of a motif sequence. Capital letters represent beta-D-oxy LNA nucleosides, lowercase letters represent DNA nucleosides, all LNA C are 5-methyl cytosine, and 5-methyl DNA cytosines are presented by "e", all internucleoside linkages are, preferably, phosphorothioate internucleoside linkages. It is understood that the contiguous nucleobase sequences (motif sequence) can be modified to for example increase nuclease resistance and/or binding affinity to the target nucleic acid. Modifications are described in the definitions and in the "Oligonucleotide design" section. Table 4 lists preferred designs of each motif sequence. The pattern in which the modified nucleosides (such as high affinity modified nucleosides) are incorporated into the oligonucleotide sequence is generally termed oligonucleotide design.
[0299] The oligonucleotides of the invention are designed with modified nucleosides and DNA nucleosides. Advantageously, high affinity modified nucleosides are used.
[0300] In an embodiment, the oligonucleotide comprises at least 1 modified nucleoside, such as at least 2, at least 3, at least 4, at least 5, at least 6, at least 7, at least 8, at least 9, at least 10, at least 11, at least 12, at least 13, at least 14, at least 15 or at least 16 modified nucleosides. In an embodiment the oligonucleotide comprises from 1 to 10 modified nucleosides, such as from 2 to 9 modified nucleosides, such as from 3 to 8 modified nucleosides, such as from 4 to 7 modified nucleosides, such as 6 or 7 modified nucleosides. Suitable modifications are described in the "Definitions" section under "modified nucleoside", "high affinity modified nucleosides", "sugar modifications", "2' sugar modifications" and Locked nucleic acids (LNA)".
[0301] In an embodiment, the oligonucleotide comprises one or more sugar modified nucleosides, such as 2' sugar modified nucleosides. Preferably the oligonucleotide of the invention comprise one or more 2' sugar modified nucleoside independently selected from the group consisting of 2'-O-alkyl-RNA, 2'-O-methyl-RNA, 2'-alkoxy-RNA, 2'-O-methoxyethyl-RNA, 2'-amino-DNA, 2'-fluoro-DNA, arabino nucleic acid (ANA), 2'-fluoro-ANA and LNA nucleosides. It is advantageous if one or more of the modified nucleoside(s) is a locked nucleic acid (LNA).
[0302] In a further embodiment the oligonucleotide comprises at least one modified internucleoside linkage. Suitable internucleoside modifications are described in the "Definitions" section under "Modified internucleoside linkage". It is advantageous if at least 75%, such as all, the internucleoside linkages within the contiguous nucleotide sequence are phosphorothioate internucleoside linkages. In some embodiments all the internucleotide linkages in the contiguous sequence of the oligonucleotide are phosphorothioate linkages.
[0303] In some embodiments, the oligonucleotide of the invention comprises at least one LNA nucleoside, such as 1, 2, 3, 4, 5, 6, 7, or 8 LNA nucleosides, such as from 2 to 6 LNA nucleosides, such as from 3 to 7 LNA nucleosides, 4 to 8 LNA nucleosides or 3, 4, 5, 6, 7 or 8 LNA nucleosides. In some embodiments, at least 75% of the modified nucleosides in the oligonucleotide are LNA nucleosides, such as 80%, such as 85%, such as 90% of the modified nucleosides are LNA nucleosides. In a still further embodiment all the modified nucleosides in the oligonucleotide are LNA nucleosides. In a further embodiment, the oligonucleotide may comprise both beta-D-oxy-LNA, and one or more of the following LNA nucleosides: thio-LNA, amino-LNA, oxy-LNA, ScET and/or ENA in either the beta-D or alpha-L configurations or combinations thereof. In a further embodiment, all LNA cytosine units are 5-methyl-cytosine. It is advantageous for the nuclease stability of the oligonucleotide or contiguous nucleotide sequence to have at least 1 LNA nucleoside at the 5' end and at least 2 LNA nucleosides at the 3' end of the nucleotide sequence.
[0304] In an embodiment of the invention the oligonucleotide of the invention is capable of recruiting RNase H.
[0305] In the current invention an advantageous structural design is a gapmer design as described in the "Definitions" section under for example "Gapmer", "LNA Gapmer", "MOE gapmer" and "Mixed Wing Gapmer" "Alternating Flank Gapmer". The gapmer design includes gapmers with uniform flanks, mixed wing flanks, alternating flanks, and gapbreaker designs. In the present invention it is advantageous if the oligonucleotide of the invention is a gapmer with an F-G-F' design. In some embodiments the gapmer is an LNA gapmer with uniform flanks.
[0306] In some embodiments of the invention the LNA gapmer is selected from the following uniform flank designs In preferred embodiments the F-G-F' design is selected from 4-6-4, 4-8-4, 3-11-4; or 4-13-3.
Exemplary Compounds of the Invention In the exemplified oligonucleotide compounds, capital letters represent beta-D-oxy LNA nucleosides, lowercase letters represent DNA nucleosides, all LNA C are 5-methyl cytosine, and 5-methyl DNA cytosines are presented by "e" or .sup.mc, all internucleoside linkages are phosphorothioate internucleoside linkages.
[0307] For certain embodiments of the invention, the oligonucleotide is selected from the group of oligonucleotide compounds with CMP-ID-NO: 15_1, 16_1, 17_1 and 18_1.
[0308] For certain embodiments of the invention, the oligonucleotide is selected from the group of oligonucleotide compounds with CMP-ID-NO: 19_1, 20_1, 21_1 and 22_1.
Method of Manufacture
[0309] In a further aspect, the invention provides methods for manufacturing the oligonucleotides of the invention comprising reacting nucleotide units and thereby forming covalently linked contiguous nucleotide units comprised in the oligonucleotide. Preferably, the method uses phophoramidite chemistry (see for example Caruthers et al, 1987, Methods in Enzymology vol. 154, pages 287-313). In a further embodiment the method further comprises reacting the contiguous nucleotide sequence with a conjugating moiety (ligand). In a further aspect a method is provided for manufacturing the composition of the invention, comprising mixing the oligonucleotide or conjugated oligonucleotide of the invention with a pharmaceutically acceptable diluent, solvent, carrier, salt and/or adjuvant.
Pharmaceutical Salt
[0310] In a further aspect the invention provides a pharmaceutically acceptable salt of the antisense oligonucleotide or a conjugate thereof. In a preferred embodiment, the pharmaceutically acceptable salt is a sodium or a potassium salt.
Pharmaceutical Composition
[0311] In a further aspect, the invention provides pharmaceutical compositions comprising any of the aforementioned oligonucleotides and/or oligonucleotide conjugates or salts thereof and a pharmaceutically acceptable diluent, carrier, salt and/or adjuvant. A pharmaceutically acceptable diluent includes phosphate-buffered saline (PBS) and pharmaceutically acceptable salts include, but are not limited to, sodium and potassium salts. In some embodiments the pharmaceutically acceptable diluent is sterile phosphate buffered saline. In some embodiments the oligonucleotide is used in the pharmaceutically acceptable diluent at a concentration of 50-300 .mu.M solution.
[0312] Suitable formulations for use in the present invention are found in Remington's Pharmaceutical Sciences, Mack Publishing Company, Philadelphia, Pa., 17th ed., 1985. For a brief review of methods for drug delivery, see, e.g., Langer (Science 249:1527-1533, 1990). WO 2007/031091 provides further suitable and preferred examples of pharmaceutically acceptable diluents, carriers and adjuvants (hereby incorporated by reference). Suitable dosages, formulations, administration routes, compositions, dosage forms, combinations with other therapeutic agents, pro-drug formulations are also provided in WO2007/031091.
[0313] Oligonucleotides or oligonucleotide conjugates of the invention may be mixed with pharmaceutically acceptable active or inert substances for the preparation of pharmaceutical compositions or formulations. Compositions and methods for the formulation of pharmaceutical compositions are dependent upon a number of criteria, including, but not limited to, route of administration, extent of disease, or dose to be administered.
[0314] These compositions may be sterilized by conventional sterilization techniques, or may be sterile filtered. The resulting aqueous solutions may be packaged for use as is, or lyophilized, the lyophilized preparation being combined with a sterile aqueous carrier prior to administration. The pH of the preparations typically will be between 3 and 11, more preferably between 5 and 9 or between 6 and 8, and most preferably between 7 and 8, such as 7 to 7.5. The resulting compositions in solid form may be packaged in multiple single dose units, each containing a fixed amount of the above-mentioned agent or agents, such as in a sealed package of tablets or capsules. The composition in solid form can also be packaged in a container for a flexible quantity, such as in a squeezable tube designed for a topically applicable cream or ointment.
[0315] In some embodiments, the oligonucleotide or oligonucleotide conjugate of the invention is a prodrug. In particular with respect to oligonucleotide conjugates the conjugate moiety is cleaved of the oligonucleotide once the prodrug is delivered to the site of action, e.g. the target cell.
Applications
[0316] The oligonucleotides of the invention may be utilized as research reagents for, for example, diagnostics, therapeutics and prophylaxis.
[0317] In research, such oligonucleotides may be used to specifically modulate the synthesis of ERC1 protein in cells (e.g. in vitro cell cultures) and experimental animals thereby facilitating functional analysis of the target or an appraisal of its usefulness as a target for therapeutic intervention. Typically the target modulation is achieved by degrading or inhibiting the pre-mRNA or mRNA producing the protein, thereby prevent protein formation or by degrading or inhibiting a modulator of the gene or mRNA producing the protein. Further advantages may be achieved by targeting pre-mRNA thereby preventing formation of the mature mRNA.
[0318] If employing the oligonucleotide of the invention in research or diagnostics the target nucleic acid may be a cDNA or a synthetic nucleic acid derived from DNA or RNA.
[0319] The present invention provides an in vivo or in vitro method for modulating ERC1 expression in a target cell which is expressing ERC1, said method comprising administering an oligonucleotide of the invention in an effective amount to said cell.
[0320] In some embodiments, the target cell, is a mammalian cell in particular a human cell. The target cell may be an in vitro cell culture or an in vivo cell forming part of a tissue in a mammal. In preferred embodiments the target cell is present in plasma, peripheral blood mononuclear cells, lymph node, breast, head and neck, spleen, liver, colon, thyroid, stomach tissue, salivary gland tissue, adrenal tissue, pancreas, prostate, urinary bladder, placenta, uterus, cervix, testis. In some embodiments, the target cell is a cancer cell or a precancerous cell. In some embodiments the target cell is a premetastatic or a metastatic cancer cell. In some embodiments the target cell is a cell infected with Dengue virus, such as Langerhans cells, monocytes, macrophages, and cells in the bone marrow, liver and spleen. In diagnostics the oligonucleotides may be used to detect and quantitate ERC1 expression in cell and tissues by northern blotting, in-situ hybridisation or similar techniques.
[0321] For therapeutics, an animal or a human, suspected of having a disease or disorder, which can be treated by reducing the expression of ERC1.
[0322] The invention provides methods for treating or preventing a disease, comprising administering a therapeutically or prophylactically effective amount of an antisense oligonucleotide, an oligonucleotide conjugate, a pharmaceutical salt or a pharmaceutical composition of the invention to a subject suffering from or susceptible to the disease.
[0323] The invention also relates to an antisense oligonucleotide, a composition, a pharmaceutical salt or a conjugate as defined herein for use as a medicament.
[0324] The oligonucleotide, oligonucleotide conjugate, pharmaceutical salt or a pharmaceutical composition according to the invention is typically administered in an effective amount.
[0325] The invention also provides for the use of the antisense oligonucleotide or oligonucleotide conjugate of the invention as described for the manufacture of a medicament for the treatment of a disorder as referred to herein, or for a method of the treatment of as a disorder as referred to herein.
[0326] The disease or disorder, as referred to herein, is associated with the increased expression of ERC1.
[0327] The methods of the invention are preferably employed for treatment or prophylaxis against diseases caused by abnormally high levels and/or activity of ERC1.
[0328] The invention further relates to use of an antisense oligonucleotide, oligonucleotide conjugate a pharmaceutical salt or a pharmaceutical composition as defined herein for the manufacture of a medicament for the treatment of abnormally high levels and/or activity of ERC1.
[0329] In one embodiment, the invention relates to oligonucleotides, oligonucleotide conjugates or pharmaceutical compositions for use in the treatment of diseases or disorders is cancer or Dengue virus infection.
[0330] In some embodiments cancer is selected from the group comprising cancers, such as thyroid carcinoma, breast cancer, head and neck cancer, colorectal cancer, renal cancer testis cancer, melanoma or metastatic cancer.
Administration
[0331] The oligonucleotides, conjugates or pharmaceutical compositions of the present invention may be administered enteral (such as, orally or through the gastrointestinal tract) or parenteral (such as, intravenous, subcutaneous, intra-muscular, intracerebral, intracerebroventricular or intrathecal) In a non-limiting embodiment a antisense oligonucleotide, a conjugate, a pharmaceutical salt or pharmaceutical compositions of the present invention are administered by a parenteral route including intravenous, intraarterial, subcutaneous, intraperitoneal or intramuscular injection or infusion.
[0332] In one embodiment the active oligonucleotide or oligonucleotide conjugate is administered intravenously.
[0333] In another embodiment the active oligonucleotide or oligonucleotide conjugate or pharmaceutical composition is administered subcutaneously.
[0334] In some embodiments, the oligonucleotide, oligonucleotide conjugate or pharmaceutical composition of the invention is administered at a dose of 0.1-15 mg/kg, such as from 0.2-10 mg/kg, such as from 0.25-5 mg/kg. The administration can be once a week, every 2.sup.nd week, every third week or even once a month.
[0335] The invention also provides for the use of the oligonucleotide or oligonucleotide conjugate of the invention as described for the manufacture of a medicament wherein the medicament is in a dosage form for intravenous administration
[0336] The invention also provides for the use of the antisense oligonucleotide or oligonucleotide conjugate of the invention as described for the manufacture of a medicament wherein the medicament is in a dosage form for subcutaneous administration
Combination Therapies
[0337] In some embodiments the antisense oligonucleotide, oligonucleotide conjugate or pharmaceutical composition of the invention is for use in a combination treatment with another therapeutic agent. The therapeutic agent can for example be the standard of care for the diseases or disorders described above.
EMBODIMENTS
[0338] The following embodiments of the present invention may be used in combination with any other embodiments described herein.
[0339] 1. An antisense oligonucleotide of 10 to 50 nucleotides in length, which comprises a contiguous nucleotide sequence of 10 to 30 nucleotides in length with at least 90% complementarity to a mammalian ERC1 target nucleic acid, wherein the antisense oligonucleotide is capable of reducing the expression of the mammalian ERC1 target nucleic acid, in a cell.
[0340] 2. The antisense oligonucleotide according to embodiment 1, wherein the contiguous nucleotide sequence is at least 90% complementary to a sequence selected from the group consisting of SEQ ID NO 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 and 13, or a naturally occurring variant thereof.
[0341] 3. The antisense oligonucleotide of embodiment 1 or 2, wherein the contiguous nucleotide sequence is fully complementary to the mammalian ERC1 target nucleic acid.
[0342] 4. The antisense oligonucleotide according to any one of embodiments 1 to 3, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to an intron region present in the pre-mRNA of mammalian ERC1 target nucleic acid (e.g. SEQ ID NO 1).
[0343] 5. The antisense oligonucleotide according to any one of embodiments 1-4, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to an intron region present in the pre-mRNA of human ERC1, selected from position 815-37239 on SEQ ID NO: 1, position 38065-92655 on SEQ ID NO: 1, 93073-114241 on SEQ ID NO: 1, 114317-119683 on SEQ ID NO: 1, 119840-125357 on SEQ ID NO: 1, 125526-151111 on SEQ ID NO: 1, 151280-190031 on SEQ ID NO: 1, 190170-191416 on SEQ ID NO: 1, 191558-192772 on SEQ ID NO:1, 192914-199350 on SEQ ID NO: 1, 199545-246260 on SEQ ID NO: 1, 246397-272525 on SEQ ID NO: 1, 272658-299343 on SEQ ID NO: 1, 299505-381324 on SEQ ID NO:1, 381470-417640 on SEQ ID NO: 1, 417740-454053 on SEQ ID NO: 1, 454243-499584 on SEQ ID NO: 1.
[0344] 6. The antisense oligonucleotide according to any one of embodiments 1-5, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to a position 38065-92655 on SEQ ID NO: 1 or to position 88379-89391 on SEQ ID NO: 1.
[0345] 7. The antisense oligonucleotide according to any one of embodiments 1-6, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to SEQ ID NO: 14, 23 24 25 or 26.
[0346] 8. The antisense oligonucleotide according to any one of embodiments 1-7, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to a target region of SEQ ID NO 1, selected from the group consisting of position 88284-88297, 88378-88391, 88425-88438, 88472-88485, 88517-88530, 88656-88669, 88703-88716, 88750-88763, 88795-88808, 88842-88855, 88889-88902, 88936-88949, 88983-88996, 89030-89043, 89077-89090, 89124-89137, 89171-89184, 89265-89278, 89312-89325, 89359-88372; 88374-88393, 88421-88440, 88468-88487, 88513-88532, 88652-88671, 88699-88718, 88746-88765, 88791-88810, 88838-88857, 88885-88904, 88932-88951, 88979-88998, 89026-89045, 89073-89092, 89120-89139, 89167-89186, 89261-89280, 89308-89327, 89355-89374; 88374-88391, 88421-88438, 88468-88485, 88513-88530, 88652-88669, 88699-88716, 88746-88763, 88791-88808, 88838-88855, 88885-88902, 88932-88949, 88979-88996, 89026-89043, 89073-89090, 89120-89137, 89167-89184, 89261-89278, 89308-89325, 89355-89372; 88376-88391, 88423-88438, 88470-88485, 88515-88530, 88654-88669, 88701-88716, 88748-88763, 88793-88808, 88840-88855, 88887-88902, 88934-88949, 88981-88996, 89028-89043, 89075-89090, 89122-89137, 89169-89184, 89263-89278, 89310-89325, 89357-89372, 451815-451834, 451816-451833, 451818-451833, and 451818-451831 of SEQ ID NO: 1.
[0347] 9. The antisense oligonucleotide according to any one of embodiments 1-8, wherein the contiguous nucleotide sequence is at least 90% complementary, such as fully complementary, to a target sequence of 10-22, such as 14-20 nucleotides in length of the target nucleic acid of SEQ ID NO: 1, wherein the target sequence is repeated at least 5 or more times across the target nucleic acid.
[0348] 10. The antisense oligonucleotide of embodiment 1 to 3, wherein the oligonucleotide is capable of hybridizing to a target nucleic acid selected from the group consisting of SEQ ID NO: 1 to 8 with a .DELTA.G.degree. below -10 kcal.
[0349] 11. The antisense oligonucleotide of embodiment 1 to 10, wherein the target nucleic acid is RNA.
[0350] 12. The antisense oligonucleotide of embodiment 11, wherein the RNA is mRNA.
[0351] 13. The antisense oligonucleotide of embodiment 12, wherein the mRNA is pre-RNA or mature RNA.
[0352] 14. The antisense oligonucleotide of any one of embodiments 1-13, wherein the contiguous nucleotide sequence comprises or consists of at least 10 contiguous nucleotides, particularly 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, or 29 contiguous nucleotides.
[0353] 15. The antisense oligonucleotide of any one of embodiments 1-14, wherein the contiguous nucleotide sequence comprises or consists of from 12 to 22 nucleotides.
[0354] 16. The antisense oligonucleotide of any one of embodiments 1 to 15, wherein the contiguous nucleotide sequence comprises or consists of from 12-18 nucleotides.
[0355] 17. The antisense oligonucleotide of any one of embodiments 1 to-16, wherein the antisense oligonucleotide comprises or consists of 10 to 35 nucleotides in length.
[0356] 18. The antisense oligonucleotide of any one of embodiments 1 to 17, wherein the antisense oligonucleotide comprises or consists of 11 to 22 nucleotides in length.
[0357] 19. The antisense oligonucleotide of any one of embodiments 17 or 18, wherein the oligonucleotide comprises or consists of 12 to 18 nucleotides in length.
[0358] 20. The antisense oligonucleotide of any one of embodiments 1-19, wherein the oligonucleotide or contiguous nucleotide sequence is single stranded.
[0359] 21. The antisense oligonucleotide of any one of embodiments 1-20 wherein the oligonucleotide is not siRNA nor self-complementary.
[0360] 22. The antisense oligonucleotide of embodiment 1-21, wherein the contiguous nucleotide sequence comprises or consists of a sequence selected from SEQ ID NO: 15, 16, 17 and 18.
[0361] 23. The antisense oligonucleotide of any one of embodiments 1-22, wherein the contiguous nucleotide sequence has zero to three mismatches compared to the target nucleic acid it is complementary to.
[0362] 24. The antisense oligonucleotide of embodiment 23, wherein the contiguous nucleotide sequence has one mismatch compared to the target nucleic acid.
[0363] 25. The antisense oligonucleotide of embodiment 24, wherein the contiguous nucleotide sequence has two mismatches compared to the target nucleic acid.
[0364] 26. The antisense oligonucleotide of embodiment 25, wherein the contiguous nucleotide sequence is fully complementary to the target nucleic acid sequence.
[0365] 27. The antisense oligonucleotide of embodiment 1-26, comprising one or more modified nucleosides.
[0366] 28. The antisense oligonucleotide of embodiment 27, wherein the one or more modified nucleoside is a high-affinity modified nucleosides.
[0367] 29. The antisense oligonucleotide of embodiment 28, wherein the one or more modified nucleoside is a 2' sugar modified nucleoside.
[0368] 30. The antisense oligonucleotide of embodiment 29, wherein the one or more 2' sugar modified nucleoside is independently selected from the group consisting of 2'-O-alkyl-RNA, 2'-O-methyl-RNA, 2'-alkoxy-RNA, 2'-O-methoxyethyl-RNA, 2'-amino-DNA, 2'-fluoro-DNA, 2'-fluoro-ANA and LNA nucleosides.
[0369] 31. The antisense oligonucleotide of embodiments 27 to 30, wherein the one or more modified nucleoside is a LNA nucleoside.
[0370] 32. The antisense oligonucleotide of embodiment 31, wherein the modified LNA nucleoside is oxy-LNA.
[0371] 33. The antisense oligonucleotide of embodiment 32, wherein the modified nucleoside is beta-D-oxy-LNA.
[0372] 34. The antisense oligonucleotide of embodiment 31, wherein the modified nucleoside is thio-LNA.
[0373] 35. The antisense oligonucleotide of embodiment 31, wherein the modified nucleoside is amino-LNA.
[0374] 36. The antisense oligonucleotide of embodiment 31, wherein the modified nucleoside is cET.
[0375] 37. The antisense oligonucleotide of embodiment 31, wherein the modified nucleoside is ENA.
[0376] 38. The antisense oligonucleotide of embodiment 31, wherein the modified LNA nucleoside is selected from beta-D-oxy-LNA, alpha-L-oxy-LNA, beta-D-amino-LNA, alpha-L-amino-LNA, beta-D-thio-LNA, alpha-L-thio-LNA, (S)cET, (R)cET beta-D-ENA and alpha-L-ENA.
[0377] 39. The antisense oligonucleotide of any one of embodiments 1-38, wherein the oligonucleotide comprises at least one modified internucleoside linkage.
[0378] 40. The antisense oligonucleotide of embodiment 39, wherein the modified internucleoside linkage is nuclease resistant.
[0379] 41. The antisense oligonucleotide of embodiment 40, wherein at least 50% of the internucleoside linkages within the contiguous nucleotide sequence are phosphorothioate internucleoside linkages or boranophosphate internucleoside linkages.
[0380] 42. The antisense oligonucleotide of embodiment 41, wherein all the internucleoside linkages within the contiguous nucleotide sequence are phosphorothioate internucleoside linkages.
[0381] 43. The antisense oligonucleotide of embodiment 1-42, wherein the antisense oligonucleotide is capable of recruiting RNase H.
[0382] 44. The antisense oligonucleotide of embodiment 43, wherein the antisense oligonucleotide or contiguous nucleotide sequence thereof comprises a gapmer.
[0383] 45. The antisense oligonucleotide of embodiment 43 or 44, wherein the antisense oligonucleotide or contiguous nucleotide sequence thereof consists of or comprises a gapmer of formula 5'-F-G-F'-3', where region F and F' independently comprise or consist of 1-7 modified nucleosides and G is a region between 6 and 17 nucleosides which are capable of recruiting RNaseH, such as a region comprising 6 to 17 DNA nucleosides
[0384] 46. The antisense oligonucleotide of embodiment 45 wherein the modified nucleoside is a 2' sugar modified nucleoside independently selected from the group consisting of 2'-O-alkyl-RNA, 2'-O-methyl-RNA, 2'-alkoxy-RNA, 2'-O-methoxyethyl-RNA, 2'-amino-DNA, 2'-fluoro-DNA, arabino nucleic acid (ANA), 2'-fluoro-ANA and LNA nucleosides.
[0385] 47. The antisense oligonucleotide of embodiment 45 or 46, wherein one or more of the modified nucleosides in region F and F' is a LNA nucleoside.
[0386] 48. The antisense oligonucleotide of embodiment 47, wherein all the modified nucleosides in region F and F' are LNA nucleosides.
[0387] 49. The antisense oligonucleotide of embodiment 48, wherein region F and F' consist of LNA nucleosides.
[0388] 50. The antisense oligonucleotide of embodiment 49, wherein all the modified nucleosides in region F and F' are oxy-LNA nucleosides.
[0389] 51. The antisense oligonucleotide of embodiment 47, wherein at least one of region F or F' further comprises at least one 2' substituted modified nucleoside independently selected from the group consisting of 2'-O-alkyl-RNA, 2'-O-methyl-RNA, 2'-alkoxy-RNA, 2'-O-methoxyethyl-RNA, 2'-amino-DNA and 2'-fluoro-DNA.
[0390] 52. The antisense oligonucleotide of embodiment 47-51, wherein the RNaseH recruiting nucleosides in region G are independently selected from DNA, alpha-L-LNA, C4' alkylated DNA, ANA and 2'F-ANA and UNA.
[0391] 53. The antisense oligonucleotide of embodiment 52, wherein the nucleosides in region G is DNA and/or alpha-L-LNA nucleosides.
[0392] 54. The antisense oligonucleotide of embodiment 52 or 53, wherein region G consists of at least 75% DNA nucleosides.
[0393] 55. The antisense oligonucleotide according to any one of embodiments 1 to 54, wherein the antisense oligonucleotide, or contiguous nucleotide sequence thereof is selected from the group consisting of TCATttctatCTGT; AATCatttctatctgtaTCT; TCAtttctatctgtATCT; and TCATttctatctGTAT, wherein capital letters represent LNA nucleosides, such as beta-D-oxy LNA nucleosides, lower case letters represent DNA nucleosides, optionally, all LNA C are 5-methyl cytosine, and all the internucleoside linkages are phosphorothioate linkages.
[0394] 56. The oligonucleotide of embodiment 55, wherein the oligonucleotide is selected from CMP ID NO: 15_1; 16_1; 17_1 and 18_1.
[0395] 57. A conjugate comprising the antisense oligonucleotide according to any one of claims 1-56, and at least one conjugate moiety covalently attached to said oligonucleotide.
[0396] 58. The antisense oligonucleotide conjugate of embodiment 57, wherein the conjugate moiety is selected from carbohydrates, cell surface receptor ligands, drug substances, hormones, lipophilic substances, polymers, proteins, peptides, toxins, vitamins, viral proteins or combinations thereof.
[0397] 59. The antisense oligonucleotide conjugate of embodiment 57 or 58, wherein the conjugate moiety is capable of binding to the asialoglycoprotein receptor.
[0398] 60. The antisense oligonucleotide conjugate of any one of embodiments 57-59, comprising a linker which is positioned between the antisense oligonucleotide and the conjugate moiety.
[0399] 61. The antisense oligonucleotide conjugate of embodiment 60, wherein the linker is a physiologically labile linker.
[0400] 62. The antisense oligonucleotide conjugate of embodiment 61, wherein the physiologically labile linker is nuclease susceptible linker.
[0401] 63. The antisense oligonucleotide conjugate of embodiment 61 or 62, wherein the oligonucleotide has the formula D'-F-G-F' or F-G-F'-D'', wherein F, F' and G are as defined in embodiments 47-56 and D' or D'' comprises 1, 2 or 3 DNA nucleosides with phosphorothioate internucleoside linkages.
[0402] 64. A pharmaceutically acceptable salt of the antisense oligonucleotide according to any one of embodiments 1-56 or the conjugate according to any of embodiments 57 to 63.
[0403] 65. A pharmaceutical composition comprising the antisense oligonucleotide of embodiment 1-56 or a conjugate of embodiment 57-63 and a pharmaceutically acceptable diluent, carrier, salt and/or adjuvant.
[0404] 66. A method for manufacturing the antisense oligonucleotide of any one of embodiments 1-56, comprising reacting nucleotide units thereby forming covalently linked contiguous nucleotide units comprised in the oligonucleotide.
[0405] 67. The method of embodiment 66, further comprising reacting the contiguous nucleotide sequence with a non-nucleotide conjugation moiety.
[0406] 68. A method for manufacturing the composition of embodiment 65, comprising mixing the oligonucleotide with a pharmaceutically acceptable diluent, carrier, salt and/or adjuvant.
[0407] 69. An in vivo or in vitro method for reducing ERC1 expression in a target cell which is expressing the mammalianERC1, said method comprising administering an antisense oligonucleotide of embodiments 1-56 or a conjugate of embodiments 57-63 or the pharmaceutically acceptable salt of embodiment 64 or the pharmaceutical composition of embodiment 65 in an effective amount to said cell.
[0408] 70. A method for treating, alleviating or preventing a disease comprising administering a therapeutically or prophylactically effective amount of an antisense oligonucleotide of embodiments 1-56 or a conjugate of embodiments 57-63 or the pharmaceutically acceptable salt of embodiment 64 or the pharmaceutical composition of embodiment 65 to a subject suffering from or susceptible to the disease.
[0409] 71. The antisense oligonucleotide of embodiments 1-56 or a conjugate of embodiments 57-63 or the pharmaceutically acceptable salt of embodiment 64 or the pharmaceutical composition of embodiment 65, for use as a medicament for treatment, alleviation or prevention of a disease in a subject.
[0410] 72. Use of the antisense oligonucleotide of embodiments 1-56 or a conjugate of embodiments 57-63 or the pharmaceutically acceptable salt of embodiment 64 for the preparation of a medicament for treatment, alleviation or prevention of a disease in a subject.
[0411] 73. The method, the antisense oligonucleotide or the use of embodiments 70-72, wherein the disease is associated with in vivo activity of ERC1.
[0412] 74. The method, the antisense oligonucleotide or the use of embodiments 70-73, wherein the disease is associated with overexpression of ERC1 gene and/or abnormal levels of ERC1 protein.
[0413] 75. The method, the antisense oligonucleotide or the use of embodiment 74, wherein the ERC1 gene expression is reduced by at least 30%, or at least or at least 40%, or at least 50%, or at least 60%, or at least 70%, or at least 80%, or at least 90%, or at least 95% compared to the expression without the oligonucleotide of embodiments 1-56 or a conjugate of embodiment 57-63 or the pharmaceutically acceptable salt of embodiment 64 or the pharmaceutical composition of embodiment 65.
[0414] 76. The method, the antisense oligonucleotide or the use of embodiments 70-75, wherein the disease is cancer, selected from thyroid carcinoma, breast cancer, head and neck cancer, colorectal cancer, renal cancer testis cancer, melanoma or metastatic cancer.
[0415] 77. The method, the antisense oligonucleotide or the use of embodiments 70-76, wherein the disease is Dengue virus infection.
[0416] 78. The method, the antisense oligonucleotide or the use of embodiments 70-77, wherein the subject is a mammal.
[0417] 79. The method, the antisense oligonucleotide or the use of embodiment 78, wherein the mammal is human.
EXAMPLES
Materials and Methods
[0418] Table 4: list of oligonucleotide motif sequences (indicated by SEQ ID NO), designs of these, as well as specific oligonucleotide compounds (indicated by CMP ID NO) designed based on the motif sequence.
TABLE-US-00005 SEQ CMP ID Oligonucleotide ID Start position on NO Motif sequence Design Compound NO SEQ ID NO: 1* 15 TCATTTCTATCTGT 4-6-4 TCATttctatCTGT 15_1 88284, 88378, 88425, 88472, 88517, 88656, 88703, 88750, 88795, 88842, 88889, 88936, 88983, 89030, 89077, 89124, 89171, 89265, 89312, 89359 16 AATCATTTCTATCTGTATCT 4-13-3 AATCatttctatctgtaTCT 16_1 88374, 88421, 88468, 88513, 88652, 88699, 88746, 88791, 88838, 88885, 88932, 88979, 89026, 89073, 89120, 89167, 89261, 89308, 89355 17 TCATTTCTATCTGTATCT 3-11-4 TCAtttctatctgtATCT 17_1 88374, 88421, 88468, 88513, 88652, 88699, 88746, 88791, 88838, 88885, 88932, 88979, 89026, 89073, 89120, 89167, 89261, 89308, 89355 18 TCATTTCTATCTGTAT 4-8-4 TCATttctatctGTAT 18_1 88376, 88423, 88470, 88515, 88654, 88701, 88748, 88793, 88840, 88887, 88934, 88981, 89028, 89075, 89122, 89169, 89263, 89310, 89357 19 ACAGTGTTTCAATCAAGTAG 4-14-2 ACAGtgtttcaatcaagtAG 19_1 451815 20 CAGTGTTTCAATCAAGTA 4-12-2 CAGTgtttcaatcaagTA 20_1 451816 21 CAGTGTTTCAATCAAG 4-8-4 CAGTgtttcaatCAAG 21_1 451818 22 GTGTTTCAATCAAG 4-6-4 GTGTttcaatCAAG 22_1 451818 *multiple numbers refers to repeat targeting compounds Motif sequences represent the contiguous sequence of nucleobases present in the oligonucleotide. Designs refer to the gapmer design, F-G-F', where each number represents the number of consecutive modified nucleosides, e.g2' modified nucleosides (first number = 5' flank), followed by the number of DNA nucleosides (second number = gap region), followed by the number of modified nucleosides, e.g 2' modified nucleosides (third number = 3' flank), optionally preceded by or followed by further repeated regions of DNA and LNA, which are not necessarily part of the contiguous sequence that is complementary to the target nucleic acid. Oligonucleotide compounds represent specific designs of a motif sequence. Capital letters represent beta-D-oxy LNA nucleosides, lowercase letters represent DNA nucleosides, all LNA C are 5-methyl cytosine, and 5-methyl DNA cytosines are presented by "e", all internucleoside linkages are phosphorothioate internucleoside linkages.
Oligonucleotide Synthesis
[0419] Oligonucleotide synthesis is generally known in the art. Below is a protocol which may be applied. The oligonucleotides of the present invention may have been produced by slightly varying methods in terms of apparatus, support and concentrations used.
[0420] Oligonucleotides are synthesized on uridine universal supports using the phosphoramidite approach on an Oligomaker 48 at 1 .mu.mol scale. At the end of the synthesis, the oligonucleotides are cleaved from the solid support using aqueous ammonia for 5-16 hours at 60.degree. C. The oligonucleotides are purified by reverse phase HPLC (RP-HPLC) or by solid phase extractions and characterized by UPLC, and the molecular mass is further confirmed by ESI-MS.
Elongation of the Oligonucleotide:
[0421] The coupling of .beta.-cyanoethyl- phosphoramidites (DNA-A(Bz), DNA- G(ibu), DNA- C(Bz), DNA-T, LNA-5-methyl-C(Bz), LNA-A(Bz), LNA- G(dmf), or LNA-T) is performed by using a solution of 0.1 M of the 5'-O-DMT-protected amidite in acetonitrile and DCI (4,5-dicyanoimidazole) in acetonitrile (0.25 M) as activator. For the final cycle a phosphoramidite with desired modifications can be used, e.g. a C6 linker for attaching a conjugate group or a conjugate group as such. Thiolation for introduction of phosphorthioate linkages is carried out by using xanthane hydride (0.01 M in acetonitrile/pyridine 9:1). Phosphordiester linkages can be introduced using 0.02 M iodine in THF/Pyridine/water 7:2:1. The rest of the reagents are the ones typically used for oligonucleotide synthesis.
[0422] For post solid phase synthesis conjugation a commercially available C6 aminolinker phorphoramidite can be used in the last cycle of the solid phase synthesis and after deprotection and cleavage from the solid support the aminolinked deprotected oligonucleotide is isolated. The conjugates are introduced via activation of the functional group using standard synthesis methods.
Purification by RP-HPLC:
[0423] The crude compounds are purified by preparative RP-HPLC on a Phenomenex Jupiter C18 10.mu. 150.times.10 mm column. 0.1 M ammonium acetate pH 8 and acetonitrile is used as buffers at a flow rate of 5 mL/min. The collected fractions are lyophilized to give the purified compound typically as a white solid.
Abbreviations:
DCI: 4,5-Dicyanoimidazole
DCM: Dichloromethane
DMF: Dimethylformamide
DMT: 4,4'-Dimethoxytrityl
THF: Tetrahydrofurane
Bz: Benzoyl
Ibu: Isobutyryl
[0424] RP-HPLC: Reverse phase high performance liquid chromatography
T.sub.m Assay:
[0425] Oligonucleotide and RNA target (phosphate linked, PO) duplexes are diluted to 3 mM in 500 ml RNase-free water and mixed with 500 ml 2.times. T.sub.m-buffer (200 mM NaCl, 0.2 mM EDTA, 20 mM Naphosphate, pH 7.0). The solution is heated to 95.degree. C. for 3 min and then allowed to anneal in room temperature for 30 min. The duplex melting temperatures (T.sub.m) is measured on a Lambda 40 UV/VIS Spectrophotometer equipped with a Peltier temperature programmer PTP6 using PE Templab software (Perkin Elmer). The temperature is ramped up from 20.degree. C. to 95.degree. C. and then down to 25.degree. C., recording absorption at 260 nm. First derivative and the local maximums of both the melting and annealing are used to assess the duplex T.sub.m.
Example 1--Testing In Vitro Efficacy and Potency
[0426] Oligonucleotides targeting one region as well as oligonucleotides targeting at least three independent regions on ERC1 were tested in an in vitro experiment in HeLa cells. EC50 (potency) and max kd (efficacy) was assessed for the oligonucleotides.
Cell Lines
[0427] The HeLa cell line was purchased from European Collection of Authenticated Cell Cultures (ECACC) and maintained as recommended by the supplier in a humidified incubator at 37.degree. C. with 5% CO.sub.2. For assays, 2,500 cells/well were seeded in a 96 multi well plate in Eagle's Minimum Essential Medium (Sigma, M4655) with 10% fetal bovine serum (FBS) as recommended by the supplier.
Oligonucleotide Potency and Efficacy
[0428] Cells were incubated for 24 hours before addition of oligonucleotides. The oligonucleotides were dissolved in PBS and added to the cells at final concentrations of oligonucleotides was of 0.01, 0.031, 0.1, 0.31, 1, 3.21, 10, and 32.1 .mu.M, the final culture volume was 100 .mu.l/well. The cells were harvested 3 days after addition of oligonucleotide compounds and total RNA was extracted using the PureLink Pro 96 RNA Purification kit (Thermo Fisher Scientific), according to the manufacturer's instructions. Target transcript levels were quantified using FAM labeled TaqMan assays from Thermo Fisher Scientific in a multiplex reaction with a VIC labelled GAPDH control probe in a technical duplex and biological triplex set up. TaqMan primer assays for the target transcript of interest ERC1 (Hs01553904 ml) and a house keeping gene GAPDH (4326317E VIC.RTM./MGB probe). EC50 and efficacy of the oligonucleotides are shown in Table 6 as % of control sample.
[0429] EC50 calculations were performed in Graph Pad Prism6. The maximum ERC1 knock down level is shown in Table 5 as % of control.
TABLE-US-00006 TABLE 5 EC50 and maximal knock down (Max Kd) % of control CMP ID NO EC50 Std Max kd std Start position(s) on SEQ ID NO: 1 15_1 3.13 0.53 3.84 6.16 88284, 88378, 88425, 88472, 88517, 88656, 88703, 88750, 88795, 88842, 88889, 88936, 88983, 89030, 89077, 89124, 89171, 89265, 89312, 89359 16_1 0.51 0.15 0.00 6.64 88374, 88421, 88468, 88513, 88652, 88699, 88746, 88791, 88838, 88885, 88932, 88979, 89026, 89073, 89120, 89167, 89261, 89308, 89355 17_1 0.39 0.03 2.85 1.75 88374, 88421, 88468, 88513, 88652, 88699, 88746, 88791, 88838, 88885, 88932, 88979, 89026, 89073, 89120, 89167, 89261, 89308, 89355 18_1 1.47 0.17 0.00 3.29 88376, 88423, 88470, 88515, 88654, 88701, 88748, 88793, 88840, 88887, 88934, 88981, 89028, 89075, 89122, 89169, 89263, 89310, 89357 19_1 0.25 0.11 73.49 3.69 451815 20_1 0.71 0.13 56.53 217 451816 21_1 2.49 0.68 334.80 6.56 451818 22_1 12.29 NA 82.19 NA 451818
Sequence CWU 0 SQTB SEQUENCE LISTING The patent application
contains a lengthy "Sequence Listing" section. A copy of the
"Sequence Listing" is available in electronic form from the USPTO
web site
(https://seqdata.uspto.gov/?pageRequest=docDetail&DocID=US20210095276A1).
An electronic copy of the "Sequence Listing" will also be available
from the USPTO upon request and payment of the fee set forth in 37
CFR 1.19(b)(3).
0 SQTB SEQUENCE LISTING The patent application contains a lengthy
"Sequence Listing" section. A copy of the "Sequence Listing" is
available in electronic form from the USPTO web site
(https://seqdata.uspto.gov/?pageRequest=docDetail&DocID=US20210095276A1).
An electronic copy of the "Sequence Listing" will also be available
from the USPTO upon request and payment of the fee set forth in 37
CFR 1.19(b)(3).
References
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.