Non-human Animals Having A Hexanucleotide Repeat Expansion In A C9orf72 Locus
Heslin; David ; et al.
U.S. patent application number 16/986077 was filed with the patent office on 2020-11-26 for non-human animals having a hexanucleotide repeat expansion in a c9orf72 locus. The applicant listed for this patent is Regeneron Pharmaceuticals, Inc.. Invention is credited to Roxanne Ally, Gustavo Droguett, David Frendewey, Chunguang Guo, David Heslin, Daisuke Kajimura, Michael LaCroix-Fralish, Ka-Man Venus Lai, Lynn Macdonald, Alexander O. Mujica, Aarti Sharma-Kanning, Chia-Jen Siao, David M. Valenzuela.
| Application Number | 20200370054 16/986077 |
| Document ID | / |
| Family ID | 1000005008392 |
| Filed Date | 2020-11-26 |

View All Diagrams
| United States Patent Application | 20200370054 |
| Kind Code | A1 |
| Heslin; David ; et al. | November 26, 2020 |
NON-HUMAN ANIMALS HAVING A HEXANUCLEOTIDE REPEAT EXPANSION IN A C9ORF72 LOCUS
Abstract
A non-human animal (e.g., a rodent) model for diseases associated with a C9ORF72 heterologous hexanucleotide repeat expansion sequence is provided, which non-human animal comprises a heterologous hexanucleotide repeat (GGGGCC) in an endogenous C9ORF72 locus. A non-human animal disclosed herein comprising a heterologous hexanucleotide repeat expansion sequence comprising at least one instance, e.g., repeat, of a hexanucleotide (GGGGCC) sequence may further exhibit a characteristic and/or phenotype associated with one or more neurodegenerative disorders (e.g., amyotrophic lateral sclerosis (ALS) and/or frontotemporal dementia (FTD), etc.). Methods of identifying therapeutic candidates that may be used to prevent, delay or treat one or more neurodegenerative (e.g., amyotrophic lateral sclerosis (ALS, also referred to as Lou Gehrig's disease) and frontotemporal dementia (FTD)) are also provided.
| Inventors: | Heslin; David; (Closter, NJ) ; Ally; Roxanne; (Briarwood, NY) ; Siao; Chia-Jen; (New York, NY) ; Lai; Ka-Man Venus; (Seattle, WA) ; Valenzuela; David M.; (Yorktown Heights, NY) ; Guo; Chunguang; (Thornwood, NY) ; LaCroix-Fralish; Michael; (Yorktown Heights, NY) ; Macdonald; Lynn; (Harrison, NY) ; Sharma-Kanning; Aarti; (New York, NY) ; Kajimura; Daisuke; (New York, NY) ; Droguett; Gustavo; (New City, NY) ; Frendewey; David; (New York, NY) ; Mujica; Alexander O.; (Elmsford, NY) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 1000005008392 | ||||||||||
| Appl. No.: | 16/986077 | ||||||||||
| Filed: | August 5, 2020 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15721517 | Sep 29, 2017 | 10781453 | ||
| 16986077 | ||||
| 62452795 | Jan 31, 2017 | |||
| 62402613 | Sep 30, 2016 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | A01K 67/0278 20130101; C12N 2310/20 20170501; A01K 2267/0318 20130101; C12N 5/0619 20130101; C12N 15/907 20130101; C12N 5/0623 20130101; C12N 15/625 20130101; C12N 9/22 20130101; C12N 2800/30 20130101; C12N 15/113 20130101; A01K 2217/072 20130101; A01K 2227/105 20130101 |
| International Class: | C12N 15/62 20060101 C12N015/62; A01K 67/027 20060101 A01K067/027; C12N 15/113 20060101 C12N015/113; C12N 15/90 20060101 C12N015/90; C12N 5/0793 20060101 C12N005/0793; C12N 5/0797 20060101 C12N005/0797 |
Claims
1. A non-human animal or non-human animal cell comprising in its genome a heterologous hexanucleotide repeat expansion sequence inserted at an endogenous C9orf7 2 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises at least one repeat of the hexanucleotide sequence set forth as SEQ ID NO: 1.
2.-32. (canceled)
33. A method of identifying a therapeutic candidate for the treatment of a disease or condition associated with the presence of a hexanucleotide repeat expansion sequence, the method comprising (a) administering a candidate agent to a non-human animal or a non-human animal cell comprising a C9orf72 locus genetically modified to comprise a hexanucleotide repeat expansion sequence comprising at least one repeat of the hexanucleotide sequence set forth as SEQ ID NO:1; (b) performing one or more assays to determine if the candidate agent has an effect on one or more signs, symptoms and/or conditions associated with the disease or condition; and (c) identifying the candidate agent that has an effect on the one or more signs, symptoms and/or conditions associated with the disease or condition as the therapeutic candidate.
34.-40. (canceled)
41. A host cell comprising a heterologous hexanucleotide repeat expansion sequence.
42. The host cell of claim 41, wherein the host cell is a bacterial cell.
43. A CRISPR/Cas system comprising a Cas protein and/or one or more gRNA, wherein the one or more gRNA is encoded by a DNA comprising a sequence selected from the group consisting of SEQ ID NO:38, SEQ ID NO:39, SEQ ID NO:40, SEQ ID NO:41, SEQ ID NO:42, SEQ ID NO:43, SEQ ID NO:44, SEQ ID NO:45, SEQ ID NO:46, SEQ ID NO:47, SEQ ID NO:48, SEQ ID NO:49; SEQ ID NO:50, and a combination thereof.
44. The CRISPR/Cas system of claim 43, wherein the one or more gRNA comprises a first, second and third gRNA, wherein the first gRNA is encoded by a DNA comprising the sequence set forth as SEQ ID NO: 39, wherein the second gRNA is encoded by a DNA comprising the sequence set forth as SEQ ID NO: 44, and wherein the third gRNA is encoded by a DNA comprising the sequence set forth as SEQ ID NO: 50.
45. The CRISPR/Cas system of claim 44, further comprising a fourth gRNA encoded by a DNA comprising the sequence set forth as SEQ ID NO: 47.
46. The CRISPR/Cas system of claim 45, further comprising a fifth, sixth, and seventh gRNA, wherein the fifth gRNA is encoded by a DNA comprising the sequence set forth as SEQ ID NO: 46, the sixth gRNA is encoded by a DNA comprising the sequence set forth as SEQ ID NO: 48, and the seventh gRNA is encoded by a DNA comprising the sequence set forth as SEQ ID NO: 49.
47. The CRISPR/Cas system of claim 42, wherein the gRNA comprises a tracrRNA encoding by a DNA comprising a sequence set forth as SEQ ID NO:63, 64 or 65.
48. The CRISPR/Cas system of claim 47, wherein the tracrRNA is encoded by a DNA comprising the sequence set forth as SEQ ID NO:63.
49. The CRISPR/Cas system of claim 47, wherein the tracrRNA is encoded by a DNA comprising the sequence set forth as SEQ ID NO:64.
50. The CRISPR/Cas system of claim 47, wherein the tracrRNA is encoded by a DNA comprising the sequence set forth as SEQ ID NO:65.
51. The CRISPR/Cas system of claim 43, further comprising an expression construct, wherein the expression construct comprises a nucleic acid encoding the Cas protein and/or DNA encoding the at least one gRNA, and wherein the expression construct optionally further comprises a drug resistance gene.
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application claims the benefit of U.S. Provisional Application No. 62/402,613, filed Sep. 30, 2016, and U.S. Provisional Application No. 62/452,795, filed Jan. 31, 2017, each of which is hereby incorporated herein in its entirety by reference.
INCORPORATION BY REFERENCE OF SEQUENCE LISTING
[0002] An official copy of the sequence listing is submitted concurrently with the specification electronically via EFS-Web as an ASCII formatted sequence listing with a file name of "2017-09-29-10267US01-SEQ-LIST_ST25", a creation date of Sep. 29, 2017, and a size of about 94 KB. The sequence listing contained in this ASCII formatted document is part of the specification and is herein incorporated by reference in its entirety.
BACKGROUND
[0003] Neurodegenerative diseases are major contributors to disability and disease. In particular, amyotrophic lateral sclerosis (ALS, also referred to as Lou Gehrig's disease) and frontotemporal dementia (FTD) are rare nervous system disorders characterized by progressive neuronal loss and/or death.
[0004] Although aging is viewed as the greatest risk factor for neurodegenerative disease, several genetic components have been discovered. For example, mutations in the copper-zinc superoxide dismutase (SOD1) gene have long been associated with ALS. Also, expanded hexanucleotide repeats of GGGGCC within a non-coding region of the C9ORF72 gene have been linked to both ALS and FTD. Currently, there is no cure for either disease, although some treatments are able to prolong life by about 3-5 months.
[0005] While various laboratory animal models are extensively used in the development of most therapeutics, very few if any models exist that address neurodegenerative and inflammatory diseases in ways that provide for elucidation of the exact molecular mechanism by which identified genetic components cause disease, which elucidation in turn may uncover potential therapeutic modalities for not only ALS or other neurodegenerative diseases having a similar clinical presentation. Thus, the manner in which genetic mutations cause neurodegenerative disease remains largely unknown. Ideal animal models would contain the same genetic components and represent similar characteristics of human disease. Given the genetic differences between species, there is a high unmet need for the development of improved animal models that closely recapitulate human neurodegenerative and/or inflammatory disease. Of course, such improved animal models provide significant value in the development of effective therapeutic and/or prophylactic agents.
SUMMARY
[0006] The present invention encompasses the recognition that it is desirable to engineer non-human animals or non-human animal cells (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) to permit improved in vivo or in vitro systems for identifying and developing new therapeutics and, in some embodiments, therapeutic regimens, which can be used for the treatment of neurodegenerative diseases, disorders and conditions. In some embodiments, the in vivo or in vitro systems as described herein can be used for identifying and developing new therapeutics for treating diseases, disorders, and/or conditions associated with the C9ORF72 locus, particularly a heterologous hexanucleotide repeat expansion sequence in the locus, such as, e.g., neurodegenerative disorders. Further, non-human animals or non-human animal cells (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein that comprise an insertion of a hexanucleotide repeat expansion sequence in a C9ORF72 locus are desirable, for example, for use in identifying and developing therapeutics that target a GGGGCC hexanucleotide repeat (SEQ ID NO:1), products derived therefrom, e.g., sense or antisense RNA transcribed therefrom, a RAN translation product and/or dipeptide repeat protein encoded by the hexanucleotide repeat, etc. In some embodiments, non-human animals and non-human animal cells (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) as described herein respectively provide improved in vivo and in vitro systems (or models) for neurodegenerative diseases, disorders and conditions (e.g., ALS and/or FTD).
[0007] A non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein comprises in its genome a heterologous hexanucleotide repeat expansion sequence inserted into an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises at least one repeat of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein comprises in its germline genome a heterologous hexanucleotide repeat expansion sequence inserted into an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises at least one repeat of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous hexanucleotide expansion sequence is a non-rodent (e.g., non-rat or non-mouse, e.g., a human) hexanucleotide expansion sequence that comprises at least one instance, e.g., repeat, of the hexanucleotide sequence set forth as SEQ ID NO:1. In some embodiments, the (human) heterologous hexanucleotide repeat expansion sequence comprises more than one, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the (human) heterologous hexanucleotide repeat expansion sequence comprises at least about three, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous (human) hexanucleotide repeat expansion sequence comprises at least about five, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous (human) hexanucleotide repeat expansion sequence comprises at least about ten, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous (human) hexanucleotide repeat expansion sequence comprises at least about fifteen, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous (human) hexanucleotide repeat expansion sequence comprises at least about twenty, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous (human) hexanucleotide repeat expansion sequence comprises at least about thirty, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous (human) hexanucleotide repeat expansion sequence comprises at least about forty, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous (human) hexanucleotide repeat expansion sequence comprises at least about fifty, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous (human) hexanucleotide repeat expansion sequence comprises at least about sixty, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous (human) hexanucleotide repeat expansion sequence comprises at least about seventy, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous (human) hexanucleotide repeat expansion sequence comprises at least about eighty, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous (human) hexanucleotide repeat expansion sequence comprises at least about ninety, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the heterologous (human) hexanucleotide repeat expansion sequence comprises at least about one-hundred, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1. In some embodiments, the non-human animal comprises the heterologous (human) hexanucleotide repeat expansion sequence in its germline genome.
[0008] In some embodiments, the heterologous (e.g., non-rodent, non-rat, non-mouse and/or human) hexanucleotide repeat expansion sequence comprises heterologous (e.g., non-rodent, non-rat, non-mouse and/or human) sequences that flank the at least one, e.g., at least about three, at least about five, at least about ten, at least about fifteen, at least about twenty, at least about thirty, at least about forty, at least about fifty, at least about sixty, at least about seventy, at least about eighty, at least about ninety or at least about one-hundred, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO:1. Accordingly, a heterologous (e.g., non-rodent, non-rat, non-mouse, and/or human) hexanucleotide repeat expansion sequence may comprise from 5' to 3': a first heterologous hexanucleotide flanking sequence, one or more (preferably contiguous) instances of the hexanucleotide set forth as SEQ ID NO:1, and a second heterologous hexanucleotide flanking sequence. In some embodiments, a heterologous hexanucleotide repeat expansion sequence is identical to or substantially identical to a naturally occurring genomic sequence comprising a first heterologous hexanucleotide flanking sequence, one or more instances of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second heterologous hexanucleotide flanking sequence. Naturally occurring first and/or second heterologous hexanucleotide flanking sequences may each independently be, e.g., at least 4 base pairs in length, e.g., at least 10 base pairs in length, e.g., at least 20 base pairs in length etc.
[0009] In some embodiments, a heterologous human hexanucleotide expansion sequence spans (and optionally encompasses) all or portions of exons 1a and/or exon 1b of a human C9orf72 gene. In some embodiments, a first heterologous hexanucleotide flanking sequence comprises all or part of the sequence of exon 1a of a human C9orf72 gene (set forth as SEQ ID NO:34) and/or a second heterologous hexanucleotide flanking sequence comprises all or part of the sequence of exon 1b of a human C9orf72 gene (set forth as SEQ ID NO:35). In some embodiments, a first heterologous hexanucleotide flanking sequence comprises the sequence set forth as SEQ ID NO:36, or a portion thereof, and/or a second heterologous hexanucleotide flanking sequence comprises the sequence set forth as SEQ ID NO:37, or a portion thereof.
[0010] An exemplary human hexanucleotide repeat expansion sequence is set forth as SEQ ID NO:2 (comprising from 5' to 3': a first heterologous hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36, 3 repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second heterologous hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37). Another exemplary human hexanucleotide repeat expansion sequence is set forth as SEQ ID NO:3 (comprising from 5' to 3': a first heterologous hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36, 100 repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second heterologous hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37). Accordingly, disclosed herein are non-human animals, e.g., rodents such as a rat or a mouse, whose genomes comprise in an endogenous C9orf72 locus a sequence set forth as SEQ ID NO:2, a variant of SEQ ID NO:2, a sequence set forth as SEQ ID NO:3, or a variant of SEQ ID NO:3.
[0011] In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) comprises in its genome a hexanucleotide repeat expansion sequence comprising a sequence that is a SEQ ID NO:2 variant, which comprises from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:34), one or two contiguous repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:35). In some embodiments, a non-human animal or a non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) as described herein comprises in its genome a hexanucleotide repeat expansion sequence comprising a sequence that is a SEQ ID NO:3 variant, which comprises from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:34), more than one and less than 100 contiguous repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:35). In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) comprises in its (germline) genome a hexanucleotide repeat expansion sequence comprising a sequence that is a SEQ ID NO:3 variant, comprises from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:34), 36 contiguous repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:35). In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) as described herein comprises in its genome a hexanucleotide repeat expansion sequence comprising a sequence that is a SEQ ID NO:3 variant, which comprises from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:34), 92 contiguous repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:35).
[0012] In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) as disclosed herein is heterozygous or homozygous for a hexanucleotide repeat expansion sequence comprising a sequence that is a SEQ ID NO:2 variant, which comprises from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:34), one or two contiguous repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:35). In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) comprises in its (germline) genome a hexanucleotide repeat expansion sequence comprising a sequence that is a SEQ ID NO:3 variant, which comprises from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:34), more than one and less than 100 contiguous repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:35). In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) comprises in its (germline) genome a hexanucleotide repeat expansion sequence comprising a sequence that is a SEQ ID NO:3 variant, comprises from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:34), 36 contiguous repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:35). In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) comprises in its (germline) genome a hexanucleotide repeat expansion sequence comprising a sequence that is a SEQ ID NO:3 variant, which comprises from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:34), 92 contiguous repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37 (or a portion thereof, e.g., a sequence set forth as SEQ ID NO:35).
[0013] In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) comprises in its (germline) genome a replacement of 5' untranslated and/or non-coding endogenous non-human sequences of the endogenous C9orf72 locus with the heterologous (human) hexanucleotide repeat expansion sequence. In some embodiments, the untranslated and/or non-coding sequence spanning between (and optionally encompassing at least a portion of) endogenous exon 1 (e.g., exon 1a and/or 1b) and the ATG start codon of the endogenous non-human C9orf72 locus, or a portion thereof, is replaced with the heterologous hexanucleotide repeat expansion sequence. Additional sequences (e.g., recombinase recognition sequences, a drug resistance cassette, a reporter gene, etc.) linked to the heterologous (human) hexanucleotide expansion sequence, may also replace the untranslated and/or non-coding sequence spanning between (and optionally encompassing) endogenous exon 1 (e.g., exon 1a and/or exon 1b) and the ATG start codon of the endogenous non-human C9orf72 locus, or a portion thereof.
[0014] Accordingly, in some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) as disclosed herein may comprise a heterozygous or homozygous replacement of an endogenous sequence that (1) starts from the 5' end, within, or the 3' end of an endogenous exon 1 and (2) ends 5' of the endogenous ATG start codon, or a portion thereof, with a heterologous hexanucleotide repeat expansion sequence, e.g., a hexanucleotide repeat expansion sequence comprising a least one repeat of the hexanucleotide sequence set forth as SEQ ID NO:1. In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) as disclosed herein may comprise a heterozygous or homozygous replacement of an endogenous sequence that (i) starts from the 5' end of, within, or from the 3' end of an endogenous exon 1 and (ii) ends 5' of the endogenous ATG start codon, or a portion thereof, with a heterologous hexanucleotide repeat expansion comprising from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 34, at least one instance of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:35. In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) as disclosed herein may comprise a heterozygous or homozygous replacement of an endogenous sequence that (ii) starts from the 5' end of, within, or the 3' end of an endogenous exon 1 and (ii) ends 5' of the endogenous ATG start codon, or a portion thereof, with a heterologous hexanucleotide repeat expansion sequence comprising from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36, at least one instance of the hexanucleotide sequence set forth as SEQ ID NO:1, and a second human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37. In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) as disclosed herein may comprise a heterozygous or homozygous replacement of an endogenous sequence that (ii) starts from the 5' end of, within, or the 3' end of an endogenous exon 1 and (ii) ends 5' of the endogenous ATG start codon, or a portion thereof, with a heterologous hexanucleotide repeat expansion sequence comprising the sequence set forth as SEQ ID NO:2, a variant thereof, SEQ ID NO:3 or a variant thereof.
[0015] In some embodiments, a non-human animal or non-human animal cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein comprises in its (germline) genome a heterologous hexanucleotide repeat expansion sequence inserted at an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises one or more repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1, and wherein the non-human animal or cell exhibits one or more of the following characteristics: (i) increased expression of C9orf72 RNA sense and/or antisense transcripts compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by quantitative PCR (ii) an increased number of RNA foci comprising a C9orf72 RNA sense and/or antisense transcript compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by fluorescence activated in situ hybridization, (iii) an increased level of dipeptide repeat proteins compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by immunofluorescence or (iv) any combination of (i)-(iii). In some embodiments, a non-human animal or cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein comprises in its (germline) genome a heterologous hexanucleotide repeat expansion sequence inserted at an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises three or more repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1, and wherein the non-human animal or cell exhibits one or more of the following characteristics: (i) increased expression of C9orf72 RNA sense and/or antisense transcripts compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by quantitative PCR (ii) an increased number of RNA foci an increased number of RNA foci comprising a C9orf72 RNA sense and/or antisense transcript compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by fluorescence activated in situ hybridization, (iii) an increased level of dipeptide repeat proteins compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by immunofluorescence or (iv) any combination of (i)-(iii). In some embodiments, a non-human animal or cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein comprises in its (germline) genome a heterologous hexanucleotide repeat expansion sequence inserted at an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises at least thirty repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1, and wherein the non-human animal or cell exhibits one or more of the following characteristics: (i) increased expression of C9orf72 RNA sense and/or antisense transcripts compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by quantitative PCR (ii) an increased number of RNA foci comprising an increased number of RNA foci comprising a C9orf72 RNA sense and/or antisense transcript compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by fluorescence activated in situ hybridization, (iii) an increased level of dipeptide repeat proteins compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by immunofluorescence or (iv) any combination of (i)-(iii). In some embodiments, a non-human animal or cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein comprises in its (germline) genome a heterologous hexanucleotide repeat expansion sequence inserted at an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises ninety or more repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1, and wherein the non-human animal or cell exhibits one or more of the following characteristics: (i) increased expression of C9orf72 RNA sense and/or antisense transcripts compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by quantitative PCR (ii) an increased number of RNA foci an increased number of RNA foci comprising a C9orf72 RNA sense and/or antisense transcript compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by fluorescence activated in situ hybridization, (iii) an increased level of dipeptide repeat proteins compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by immunofluorescence or (iv) any combination of (i)-(iii). In some embodiments, a non-human animal or cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein comprises in its (germline) genome a heterologous hexanucleotide repeat expansion sequence inserted at an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises ninety-two repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1, and wherein the non-human animal or cell exhibits all of the following three characteristics: (i) increased expression of C9orf72 RNA sense and/or antisense transcripts compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by quantitative PCR (ii) an increased number of RNA foci comprising an increased number of RNA foci comprising a C9orf72 RNA sense and/or antisense transcript compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by fluorescence activated in situ hybridization, and (iii) an increased level of dipeptide repeat proteins compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by immunofluorescence. In some embodiments, a non-human animal or cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein comprises in its (germline) genome a heterologous hexanucleotide repeat expansion sequence inserted at an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises more than ninety repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1, and wherein the non-human animal or cell exhibits all of the following three characteristics: (i) increased expression of C9orf72 RNA sense and/or antisense transcripts compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by quantitative PCR (ii) an increased number of RNA foci comprising an increased number of RNA foci comprising a C9orf72 RNA sense and/or antisense transcript compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by fluorescence activated in situ hybridization, and (iii) an increased level of dipeptide repeat proteins compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by immunofluorescence. In some embodiments, a non-human animal or cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein comprises in its genome a heterologous hexanucleotide repeat expansion sequence inserted at an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises at least 92 repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1, and wherein the non-human animal or cell exhibits all of the following three characteristics: (i) increased expression of C9orf72 RNA sense and/or antisense transcripts compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by quantitative PCR (ii) an increased number of RNA foci comprising an increased number of RNA foci comprising a C9orf72 RNA sense and/or antisense transcript compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by fluorescence activated in situ hybridization, and (iii) an increased level of dipeptide repeat proteins compared to a control animal or cell comprising a wildtype C9orf72 locus, e.g., as evaluated by immunofluorescence.
[0016] In some embodiments, a non-human animal or cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein comprises in its genome a heterologous hexanucleotide repeat expansion sequence inserted at an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises a repeat of the hexanucleotide sequence set forth as SEQ ID NO: 1, and wherein one or more of the following characteristics of the non-human animal or cell is not significantly different compared to a control non-human animal or cell comprising a wildtype C9orf72 locus: (i) the amount of C9orf72 RNA sense and/or antisense transcripts compared, e.g., as evaluated by quantitative PCR (ii) the number of RNA foci comprising a C9orf72 RNA sense and/or antisense transcript, e.g., as evaluated by fluorescence activated in situ hybridization, (iii) the level of dipeptide repeat proteins, e.g., as evaluated by immunofluorescence or (iv) any combination of (i)-(iii). In some embodiments, a non-human animal or cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein comprises in its genome a heterologous hexanucleotide repeat expansion sequence inserted at an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises three repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1, and wherein one or more of the following characteristics of the non-human animal or cell is not significantly different compared to a control non-human animal or cell comprising a wildtype C9orf72 locus: (i) the amount of C9orf72 RNA sense and/or antisense transcripts compared, e.g., as evaluated by quantitative PCR (ii) the number of RNA foci comprising a C9orf72 RNA sense and/or antisense transcript, e.g., as evaluated by fluorescence activated in situ hybridization, (iii) the level of dipeptide repeat proteins, e.g., as evaluated by immunofluorescence or (iv) any combination of (i)-(iii). In some embodiments, a non-human animal or cell (e.g., embryonic stem cell, embryonic stem cell derived-motor neuron, brain cell, neuronal cell, muscle cell, heart cell) described herein comprises in its genome a heterologous hexanucleotide repeat expansion sequence inserted at an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises thirty repeats of the hexanucleotide sequence set forth as SEQ ID NO: 1, and wherein one or more of the following characteristics of the non-human animal or cell is not significantly different compared to a control non-human animal or cell comprising a wildtype C9orf72 locus: (i) the amount of C9orf72 RNA sense and/or antisense transcripts compared, e.g., as evaluated by quantitative PCR (ii) the number of RNA foci comprising a C9orf72 RNA sense and/or antisense transcript, e.g., as evaluated by fluorescence activated in situ hybridization, (iii) the level of dipeptide repeat proteins, e.g., as evaluated by immunofluorescence or (iv) any combination of (i)-(iii).
[0017] In some embodiments, a nucleic acid construct (or targeting construct, or targeting vector) as described herein is provided.
[0018] In some embodiments, a nucleic acid construct as described herein comprises, from 5' to 3', a 5' non-human targeting arm comprising a polynucleotide that is homologous to a 5' portion of a non-human (e.g., a rodent such as a mouse or a rat) C9ORF72 locus, a heterologous hexanucleotide repeat expansion sequence comprising at least one of a hexanucleotide sequence set forth as SEQ ID NO:1, a first recombinase recognition site; a first promoter operably linked to a selectable marker, a second recombinase recognition site, and a 3' non-human targeting arm comprising a polynucleotide that is homologous to a 3' portion of a non-human (e.g., a rodent such as a mouse or a rat) C9ORF72 locus. In some embodiments, the 5' portion of a non-human (e.g., a rodent such as a mouse or rat) C9ORF72 locus includes a genomic sequence upstream of exon 1 of the non-human (e.g., rodent such as mouse or rat) C9ORF72 gene.
[0019] In some embodiments, recombinase recognition sites include loxP, lox511, lox2272, lox2372, lox66, lox71, loxM2, lox5171, FRT, FRT11, FRT71, attp, att, FRT, rox, or a combination thereof. In some embodiments, a recombinase gene is included in the construct, e.g., under the control of an inducible promoter. The recombinase gene may be selected from the group consisting of Cre, Flp (e.g., Flpe, Flpo), and Dre. In some certain embodiments, first and second recombinase recognition sites are lox (e.g., loxP) sites, and a recombinase gene encodes a Cre recombinase.
[0020] In some embodiments, a first promoter is selected from the group consisting of protamine (Prot; e.g., Prot1 or Prot5), Blimp1, Blimp1 (1 kb fragment), Blimp1 (2 kb fragment), Gata6, Gata4, Igf2, Lhx2, Lhx5, hUB1, Em7 and Pax3. In some certain embodiments, a first promoter is a hUB1 promoter in combination with an Em7 promoter.
[0021] In some embodiments, a selectable marker is selected from group consisting of neomycin phosphotransferase (neo.sup.r), hygromycin B phosphotransferase (hyg.sup.r), puromycin-N-acetyltransferase (puro.sup.r), blasticidin S deaminase (bsr.sup.r), xanthine/guanine phosphoribosyl transferase (gpt), and Herpes simplex virus thymidine kinase (HSV-tk). In some certain embodiments, a selectable marker is neo.sup.r.
[0022] In some embodiments, the nucleic acid construct comprises the sequence set forth as SEQ ID NO:8, which comprises from 5' to 3': a 5' non-human (mouse) targeting arm, a first human hexanucleotide flanking sequence comprising the sequence set forth as SEQ ID NO:36, three repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, a second human hexanucleotide flanking sequence comprising the sequence set forth as SEQ ID NO:37, a floxed drug resistance (neo.sup.r) cassette and a 3' non-human (mouse) targeting arm. In some embodiments, the nucleic acid construct comprises the sequence set forth as SEQ ID NO:9, which comprises from 5' to 3': a 5' non-human (mouse) targeting arm, a first human hexanucleotide flanking sequence comprising the sequence set forth as SEQ ID NO:36, one-hundred repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, a second human hexanucleotide flanking sequence comprising the sequence set forth as SEQ ID NO:37, a floxed drug resistance (neo.sup.r) cassette and a 3' non-human (mouse) targeting arm.
[0023] In some embodiments, a method of making a non-human animal or non-human animal cell is provided whose genome comprises an insertion of a heterologous hexanucleotide repeat expansion sequence into an endogenous C9orf72 locus, wherein the heterologous hexanucleotide repeat expansion sequence comprises at least one, e.g., at least about 3 repeats, e.g., at least about 30 repeats, e.g., at least about 90 repeats, of a hexanucleotide sequence set forth as SEQ ID NO:1, the method comprising (a) introducing a nucleic acid sequence, e.g., a nucleic acid construct as described herein (e.g., a nucleic acid construct comprising a sequence set forth as SEQ ID NO:8 or a nucleic acid construct comprising a sequence set forth as SEQ ID NO:9), into a non-human embryonic stem cell so that the heterologous hexanucleotide repeat expansion sequence is inserted into an endogenous C9ORF72 locus, which nucleic acid comprises a polynucleotide that is homologous to the C9ORF72 locus; (b) obtaining a genetically modified non-human embryonic stem cell from (a); and optionally, (c) creating a non-human animal using the genetically modified non-human embryonic stem cell of (b). In some embodiments, a method of making a non-human animal described herein further comprises a step of breeding a non-human animal generated in (c) so that a non-human animal homozygous for the insertion is created.
[0024] In some embodiments, a method for making a non-human animal whose genome comprises an insertion of a heterologous hexanucleotide repeat expansion sequence, which comprises at least one repeat of the hexanucleotide sequence set forth as SEQ ID NO:1, in an endogenous C9ORF72 locus is provided, the method comprising modifying the genome of a non-human animal so that it comprises an inserted heterologous hexanucleotide repeat expansion sequence in an endogenous C9ORF72 locus, thereby making said non-human animal.
[0025] In some embodiments, a non-human animal is provided which is obtainable by, generated from, or produced from a method as described herein. In some embodiments, a non-human animal as disclosed herein is produced using a nucleic acid construct comprising a sequence set forth as SEQ ID NO:8. Such a non-human animal comprises a heterozygous or homozygous replacement of about 853 bp of an endogenous C9orf72 locus starting from within endogenous exon 1 with a heterologous nucleotide sequence comprising from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36, one to three repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, a human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37, and a floxed drug resistance (neo.sup.r) cassette, or upon excision of the neo gene, a lox recombination recognition sequence. In some embodiments, a non-human animal as disclosed herein is produced using a nucleic acid construct comprising a sequence set forth as SEQ ID NO:9. Such a non-human animal comprises a heterozygous or homozygous replacement of about 853 bp of an endogenous C9orf72 locus starting from within endogenous exon 1 with a heterologous nucleotide sequence comprising from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36, one to one-hundred (e.g., 36 or 92) repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, a human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37, and a floxed drug resistance (neo.sup.r) cassette, or upon excision of the neo gene, a lox recombination recognition sequence. In some embodiments, a non-human animal comprises a heterologous nucleotide sequence set forth as SEQ ID NO:4 (8026), a heterologous nucleotide sequence set forth as SEQ ID NO:5 (8027), a heterologous nucleotide sequence set forth as SEQ ID NO:6 (8028), or a heterologous nucleotide sequence set forth as SEQ ID NO:7 (8029), wherein the heterologous nucleotide sequence optionally replaces about 853 bp of an untranslated and/or non-coding sequence of an endogenous C9orf72 locus that starts within endogenous exon 1. In some embodiments, a non-human animal as disclosed herein is produced, e.g., by breeding an animal created using a nucleic acid construct comprising a sequence set forth as SEQ ID NO:8 with an animal created using a nucleic acid construct comprising a sequence set forth as SEQ ID NO:9. Such animals may comprise both (1) a heterozygous replacement of about 853 bp of an endogenous C9orf72 locus starting from within endogenous exon 1 with a heterologous nucleotide sequence comprising from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36, one to three repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, a human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37, and a floxed drug resistance (neo.sup.r) cassette, or upon excision of the neo gene, a lox recombination recognition sequence and (2) a heterozygous replacement of about 853 bp of an endogenous C9orf72 locus starting from within endogenous exon 1 with a heterologous nucleotide sequence comprising from 5' to 3': a first human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO: 36, one to one-hundred (e.g., 36 or 92) repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, a human hexanucleotide flanking sequence comprising a sequence set forth as SEQ ID NO:37, and a floxed drug resistance (neo.sup.r) cassette, or upon excision of the neo gene, a lox recombinase recognition sequence.
[0026] In some embodiments, an isolated non-human cell or tissue of a non-human animal as described herein, or as made by a method described herein, is provided. In some embodiments, an isolated cell or tissue comprises a C9ORF72 locus as described herein. In some embodiments, a cell is a neuronal cell or a cell from a neuronal lineage. In some embodiments, an immortalized cell line is provided, which is made from an isolated cell of a non-human animal as described herein.
[0027] In some embodiments, a non-human embryonic stem cell is provided whose genome comprises a C9ORF72 locus as described herein. In some embodiments, a non-human embryonic stem cell is a rodent embryonic stem cell. In some certain embodiments, a rodent embryonic stem cell is a mouse embryonic stem cell and is from a 129 strain, C57BL strain, or a mixture thereof. In some certain embodiments, a rodent embryonic stem cell is a mouse embryonic stem cell and is a mixture of 129 and C57BL strains.
[0028] Also described herein is a Clustered Regularly Interspersed Short Palindromic Repeats (CRISPR)/CRISPR-associated (Cas) system, or one or more components of a CRISPR/Cas system, which may be used to delete from a cell, e.g., an embryonic stem cell, a heterologous hexanucleotide repeat expansion sequence (or portion thereof) inserted an endogenous C9ORF72 locus as described herein. Such components include, for example, Cas proteins and/or guide RNAs (gRNAs), which gRNA may include two separate RNA molecules; e.g., targeter-RNA (e.g., CRISPR RNAs (crRNA) and activator RNA (e.g., tracrRNAs); or a single-guide RNA (e.g., single-molecule gRNA (sgRNA)).
[0029] CRISPR/Cas systems include transcripts and other elements involved in the expression of, or directing the activity of, Cas genes. A CRISPR/Cas system can be, for example, a type I, a type II, or a type III system. Alternatively, a CRISPR/Cas system can be a type V system (e.g., subtype V-A or subtype V-B). A heterologous hexanucleotide repeat expansion sequence (or portion thereof) inserted an endogenous C9ORF72 locus as described herein may be deleted by utilizing CRISPR complexes (comprising a guide RNA (gRNA) complexed with a Cas protein) for site-directed cleavage of nucleic acids.
[0030] A CRISPR/Cas system as described herein may comprise a Cas protein (e.g., Cas1, Cas1B, Cas2, Cas3, Cas4, Cas5, Cas5e (CasD), Cas6, Cas6e, Cas6f, Cas7, Cas8a1, Cas8a2, Cas8b, Cas8c, Cas9 (Csn1 or Csx12), Cas10, Cas10d, CasF, CasG, CasH, Csy1, Csy2, Csy3, Cse1 (CasA), Cse2 (CasB), Cse3 (CasE), Cse4 (CasC), Csc1, Csc2, Csa5, Csn2, Csm2, Csm3, Csm4, Csm5, Csm6, Cmr1, Cmr3, Cmr4, Cmr5, Cmr6, Csb1, Csb2, Csb3, Csx17, Csx14, Csx10, Csx16, CsaX, Csx3, Csx1, Csx15, Csf1, Csf2, Csf3, Csf4, Cu1966, and homologs or modified versions thereof) and/or one or more guide RNA (gRNA), which target(s) a gRNA recognition sequence. A CRISPR/Cas system as described herein may further comprise at least one expression construct, which comprises a nucleic acid encoding a Cas protein (e.g., which may be operably linked to a promoter) and/or DNA encoding a gRNA as described herein.
[0031] In some embodiments a gRNA recognition sequence, e.g., a target nucleic acid sequence to which a DNA-targeting segment of a gRNA will bind provided sufficient conditions for binding exist, is found in SEQ ID NO:45, or portion thereof. Site-specific binding and cleavage of SEQ ID NO:45 by Cas proteins can occur at locations determined by both (i) base-pairing complementarity between the gRNA and the target DNA and (ii) a short motif, called the protospacer adjacent motif (PAM), in the target DNA. The PAM can flank the guide RNA recognition sequence. Optionally, the guide RNA recognition sequence can be flanked on the 3' end by the PAM. Alternatively, the guide RNA recognition sequence can be flanked on the 5' end by the PAM. For example, the cleavage site of Cas proteins can be about 1 to about 10 or about 2 to about 5 base pairs (e.g., 3 base pairs) upstream or downstream of the PAM sequence. In some cases (e.g., when Cas9 from S. pyogenes or a closely related Cas9 is used), the PAM sequence of the non-complementary strand can be 5'-N.sub.1GG-3', where N.sub.1 is any DNA nucleotide and is immediately 3' of the guide RNA recognition sequence of the non-complementary strand of the target DNA. As such, the PAM sequence of the complementary strand would be 5'-CCN.sub.2-3', where N.sub.2 is any DNA nucleotide and is immediately 5' of the guide RNA recognition sequence of the complementary strand of the target DNA. In some such cases, N.sub.1 and N.sub.2 can be complementary and the N.sub.1-N.sub.2 base pair can be any base pair (e.g., N.sub.1=C and N.sub.2=G; N.sub.1=G and N.sub.2=C; N.sub.1=A and N.sub.2=T; or N.sub.1=T, and N.sub.2=A). In the case of Cas9 from S. aureus, the PAM can be NNGRRT or NNGRR, where N can A, G, C, or T, and R can be G or A. In some cases (e.g., for FnCpf1), the PAM sequence can be upstream of the 5' end and have the sequence 5'-TTN-3'. In some embodiments, a gRNA recognition sequence starts at position 190, 196, 274, 899, 905, 1006, or 1068 of SEQ ID NO:45.
[0032] As disclosed herein, guide RNAs may be provided in any form. In some embodiments, gRNA can be provided in the form of RNA, either as two molecules (a separate crRNA and tracrRNA) or as one molecule (sgRNA), and optionally in the form of a complex with a Cas protein. The gRNA can also be provided in the form of DNA encoding the gRNA. In some embodiments, the DNA encoding the gRNA can encode a single RNA molecule (sgRNA) or separate RNA molecules (e.g., separate crRNA and tracrRNA) (wherein the separate RNA molecules may be provided as one DNA molecule, or as separate DNA molecules encoding the crRNA and tracrRNA, respectively).
[0033] In one embodiment, a CRISPR/Cas system as described herein comprises Cas9 protein or a protein derived from a Cas9 from a type II CRISPR/Cas system and/or at least one gRNA, wherein the at least one gRNA is encoded by DNA that encodes a crRNA and/or a tracrRNA. In some embodiments, a DNA encoding a crRNA comprises a sequence selected from the group consisting of AGTACTGTGAGAGCAAGTAG (R) (SEQ ID NO:38), GCTCTCACAGTACTCGCTGA (SEQ ID NO:39), CCGCAGCCTGTAGCAAGCTC (SEQ ID NO:40), CGGCCGCTAGCGCGATCGCG (SEQ ID NO:41), ACGCCCCGCGATCGCGCTAG (R) (SEQ ID NO:42), TGGCGAGTGGGTGAGTGAGG (SEQ ID NO:43), GGAAGAGGCGCGGGTAGAAG (SEQ ID NO:44), GAGTACTGTGAGAGCAAGTAG (R) (SEQ ID NO:46), GCCGCAGCCTGTAGCAAGCTC (SEQ ID NO:47), GCGGCCGCTAGCGCGATCGCG (SEQ ID NO:48), GACGCCCCGCGATCGCGCTAG (R) (SEQ ID NO:49), and GTGGCGAGTGGGTGAGTGAGG (SEQ ID NO:50). In one embodiment, a CRISPR/Cas system described herein comprises a combination of at least seven crRNA encoding sequences, wherein each of the seven crRNA encoding sequences comprises a sequence set forth as SEQ ID NO: 38, 39, 40, 41, 42, 43 or 44. In one embodiment, a CRISPR/Cas 9 system described herein comprises a combination of at least seven distinct crRNA encoding sequences, wherein each of the seven crRNA encoding sequences comprises a sequence set forth as SEQ ID NO: 46, 39, 47, 48, 49, 50 or 44. In one embodiment, a CRISPR/Cas 9 system described herein comprises a combination of at least three distinct crRNA encoding sequences, each comprising a sequence set forth as SEQ ID NO: 40, 43 or 44. In one embodiment, a CRISPR/Cas 9 system described herein comprises a combination of at least three distinct crRNA encoding sequences, each comprising a sequence set forth as SEQ ID NO: 47, 50 or 44. In one embodiment, a CRISPR/Cas 9 system described herein comprises a combination of at least four distinct crRNA encoding sequences, each comprising a sequence set forth as SEQ ID NO: 38, 39, 41 or 42. In one embodiment, a CRISPR/Cas 9 system described herein comprises a combination of at least four distinct crRNA encoding sequences, each comprising a sequence set forth as SEQ ID NO: 46, 39, 48, or 49.
[0034] In some embodiments, a gRNA disclosed herein is encoded by DNA encoding a tracrRNA. In some embodiments, the tracrRNA encoding sequence comprises a sequence set forth as SEQ ID NO:63, 64 or 65. In some embodiments a gRNA as described herein comprises a crRNA and a tracrRNA. In some embodiments, a gRNA as disclosed herein comprises one or more crRNA (e.g., encoded by DNA comprising a sequence set forth as SEQ ID NO: 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 49 or 50) and a tracrRNA, e.g., a DNA comprising a sequence set forth as SEQ ID NO:63, 64 or 65. In some embodiments, the DNA encoding the gRNA can encode a single RNA molecule (sgRNA) or separate RNA molecules (e.g., separate crRNA and tracrRNA) (wherein the separate RNA molecules may be provided as one DNA molecule, or as separate DNA molecules encoding the crRNA and tracrRNA, respectively).
[0035] Targeted genetic modifications can be generated by contacting a cell with a Cas protein and one or more guide RNAs that hybridize to one or more guide RNA recognition sequences within a target genomic locus. At least one of the one or more guide RNAs can form a complex with and can guide the Cas protein to at least one of the one or more guide RNA recognition sequences, and the Cas protein can cleave the target genomic locus within at least one of the one or more guide RNA recognition sequences. Cleavage by the Cas protein can create a double-strand break or a single-strand break (e.g., if the Cas protein is a nickase). The end sequences generated by the double-strand break or the single-strand break can then undergo recombination.
[0036] In some embodiments, a non-human germ cell is provided whose genome comprises a C9ORF72 locus as described herein. In some embodiments, a non-human germ cell is a rodent germ cell. In some certain embodiments, a rodent germ cell is a mouse germ cell and is from a 129 strain, C57BL strain, or a mixture thereof. In some certain embodiments, a rodent germ cell is a mouse germ cell and is a mixture of 129 and C57BL strains.
[0037] In some embodiments, the use of a non-human embryonic stem cell or germ cell as described herein is provided to make a genetically modified non-human animal. In some certain embodiments, a non-human embryonic stem cell or germ cell is a mouse embryonic stem cell or germ cell and is used to make a mouse comprising a C9ORF72 locus as described herein. In some certain embodiments, a non-human embryonic stem cell or germ cell is a rat embryonic stem cell germ cell and is used to make a rat comprising a C9ORF72 locus as described herein.
[0038] In some embodiments, a non-human embryo is provided comprising, made from, obtained from, or generated from a non-human embryonic stem cell comprising a C9ORF72 locus as described herein. In some certain embodiments, a non-human embryo is a rodent embryo; in some embodiments, a mouse embryo; in some embodiments, a rat embryo.
[0039] In some embodiments, the use of a non-human embryo as described herein is provided to make a genetically modified non-human animal. In some certain embodiments, a non-human embryo is a mouse embryo and is used to make a mouse comprising a C9ORF72 locus as described herein. In some certain embodiments, a non-human embryo is a rat embryo and is used to make a rat comprising a C9ORF72 locus as described herein.
[0040] In some embodiments, a non-human animal model of amyotrophic lateral sclerosis (ALS) or frontotemporal dementia (FTD) is provided, which non-human animal has an endogenous C9ORF72 locus comprising a heterologous hexanucleotide repeat expansion sequence as disclosed herein.
[0041] In some embodiments, a non-human animal model of amyotrophic lateral sclerosis (ALS) or frontotemporal dementia (FTD) is provided, which is obtained by an insertion of a heterologous hexanucleotide repeat expansion sequence in an endogenous C9ORF72 locus.
[0042] In some embodiments, a method for identifying a therapeutic candidate for the treatment of a neurodegenerative disease, disorder or condition is provided, the method comprising (a) administering a candidate agent to a non-human animal or non-human animal cell (e.g., embryonic stem cell, an embryonic stem cell-derived motor neuron, a brain cell, a cortical cell, a neuronal cell, a muscle cell, a heart cell) whose genome comprises an endogenous C9ORF72 locus modified as described herein; (b) performing one or more assays to determine if the candidate agent has a modulating effect on one or more signs, symptoms and/or conditions associated with the disease, disorder or condition (e.g., increased transcription of sense or antisense C9orf72 RNA from the C9orf72 locus, increased nuclear and/or cytoplasmic RNA foci comprising sense or antisense C9orf72 RNA, increased RAN translation products (e.g., dipeptide repeat proteins); and (c) identifying the candidate agent that has a modulating effect on the one or more signs, symptoms and/or conditions associated with the disease, disorder or condition as the therapeutic candidate. In some embodiments, the disease or condition is selected from the group consisting of a neurodegenerative disease or condition. In some embodiments, the candidate agent is administered in vivo to a non-human animal as described herein, and one or more assays are performed on tissue comprising a brain cell, a cortical cell, a neuronal cell, a muscle cell, a heart cell, or a germ cell isolated from the non-human animal after administration. In some embodiments, the candidate agent is administered to a cell (e.g., an embryonic stem cell, an embryonic stem cell-derived motor neuron, a brain cell, a cortical cell, a neuronal cell, a muscle cell, a heart cell) comprising a hexanucleotide repeat expansion sequence at the C9orf72 locus as described herein, and the assay performed, in vitro. In some embodiments, the assay is quantitative polymerase chain reaction (qPCR) to detect C9orf72 gene products, e.g., sense and antisense C9orf72 RNA. In some embodiments, qPCR may be performed with a primer and/or probe having a nucleotide sequence set forth in SEQ ID NO:66, SEQ ID NO:67, SEQ ID NO:68, SEQ ID NO:69, SEQ ID NO:70, SEQ ID NO:71, SEQ ID NO:72, SEQ ID NO:73, SEQ ID NO:74, SEQ ID NO:75, SEQ ID NO:76, SEQ ID NO:77, SEQ ID NO:78, SEQ ID NO:79, SEQ ID NO:80, or any combination thereof. In some embodiments, the assay measures RNA foci comprising a C9orf72 sense or antisense RNA transcript, e.g., an RNA transcript of a hexanucleotide repeat expansion sequence. In some embodiments, the assay that measures RNA foci comprising a C9orf72 sense or antisense RNA transcript, e.g., an RNA transcript of a hexanucleotide repeat expansion sequence, using one or more probes having a nucleotide sequence as set forth in any one of SEQ ID NO:81, SEQ ID NO:82, SEQ ID NO:83, and/or SEQ ID NO:84. In some embodiments, the assay is measures RAN translation products, e.g., the assay is immunofluorescence and RAN translation products (e.g., dipeptide repeat proteins, e.g., polyGA dipeptide repeat proteins) are measured with an anti-polyGA antibody. In some embodiments, the assay is measures C9orf72 protein levels.
[0043] In some embodiments, use of a non-human animal as described herein is provided in the manufacture of a medicament for the treatment of a neurodegenerative disease, disorder or condition.
[0044] In some embodiments, a neurodegenerative disease, disorder or condition is amyotrophic lateral sclerosis (ALS). In some embodiments, a neurodegenerative disease, disorder or condition is frontotemporal dementia (FTD).
[0045] In various embodiments, one or more phenotypes as described herein is or are as compared to a reference or control. In some embodiments, a reference or control includes a non-human animal having a modification as described herein, a modification that is different than a modification as described herein, or no modification (e.g., a wild type non-human animal). Non-human animals comprising a heterologous hexanucleotide repeat expansion sequence comprising a sequence set forth as SEQ ID NO:2, a variant thereof, SEQ ID NO: 4, a variant thereof, or SEQ ID NO:5, or a variant thereof, may exhibit a wildtype phenotype, e.g., may be used as a reference, or control, non-human animal in the methods described herein.
[0046] In various embodiments, a non-human animal is homozygous for the C9orf72 locus described herein. In various embodiments, the non-human animal is heterozygous for the C9orf72 locus described herein.
[0047] In various embodiments, a non-human animal described herein is a rodent; in some embodiments, a mouse; in some embodiments, a rat.
[0048] As used in this application, the terms "about" and "approximately" are used as equivalents. Any numerals used in this application with or without about/approximately are meant to cover any normal fluctuations appreciated by one of ordinary skill in the relevant art.
[0049] Other features, objects, and advantages of non-human animals, cells and methods provided herein are apparent in the detailed description of certain embodiments that follows. It should be understood, however, that the detailed description, while indicating certain embodiments, is given by way of illustration only, not limitation. Various changes and modifications within the scope of the invention will become apparent to those skilled in the art from the detailed description.
BRIEF DESCRIPTION OF THE DRAWINGS
[0050] The Drawings included herein, which is composed of the following Figures, is for illustration purposes only and not for limitation. The patent or application file contains at least one drawing executed in color. Copies of this patent or patent application publication with the color drawing(s) will be provided by the United States Patent and Trademark Office upon request and payment of the necessary fee.
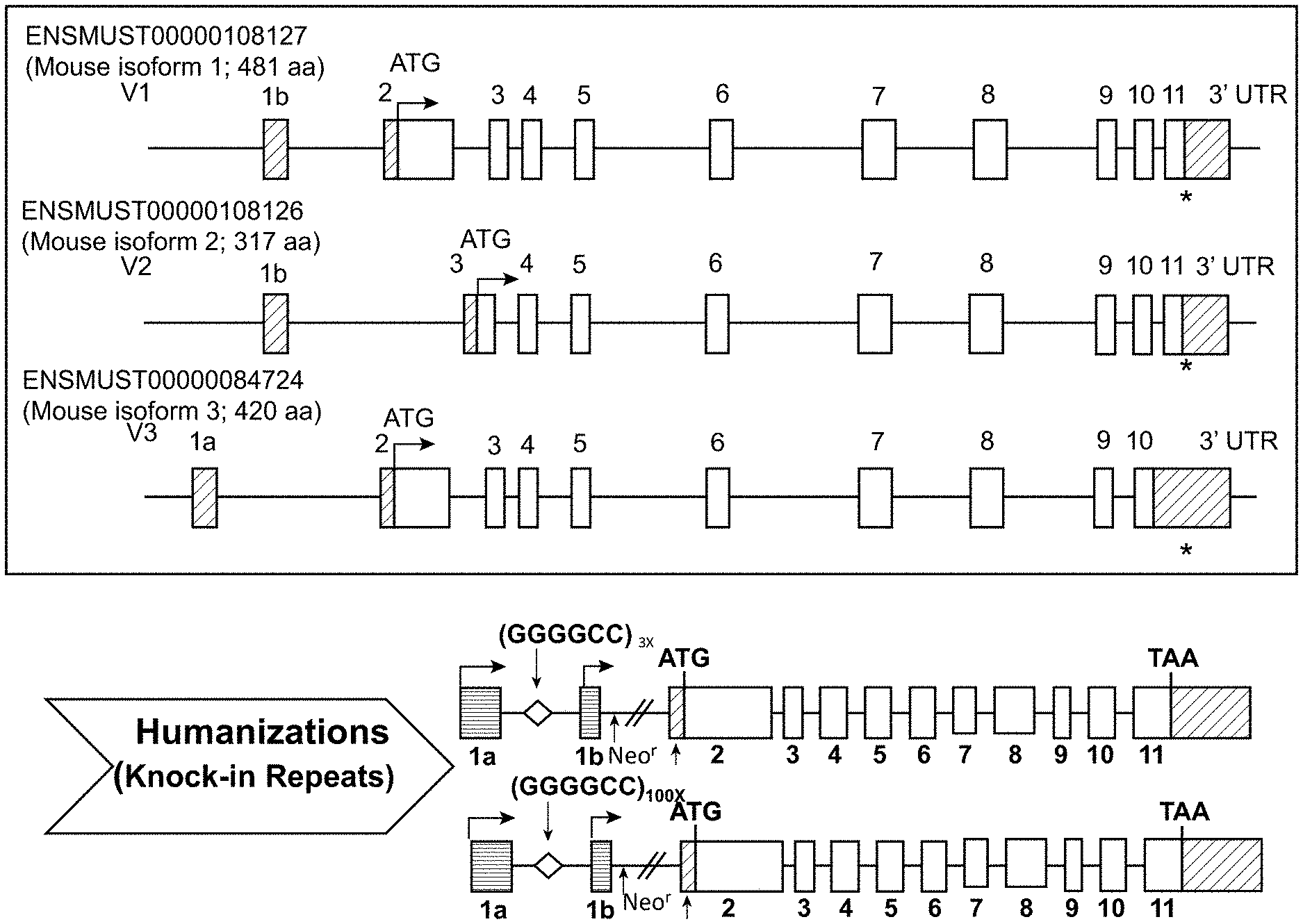
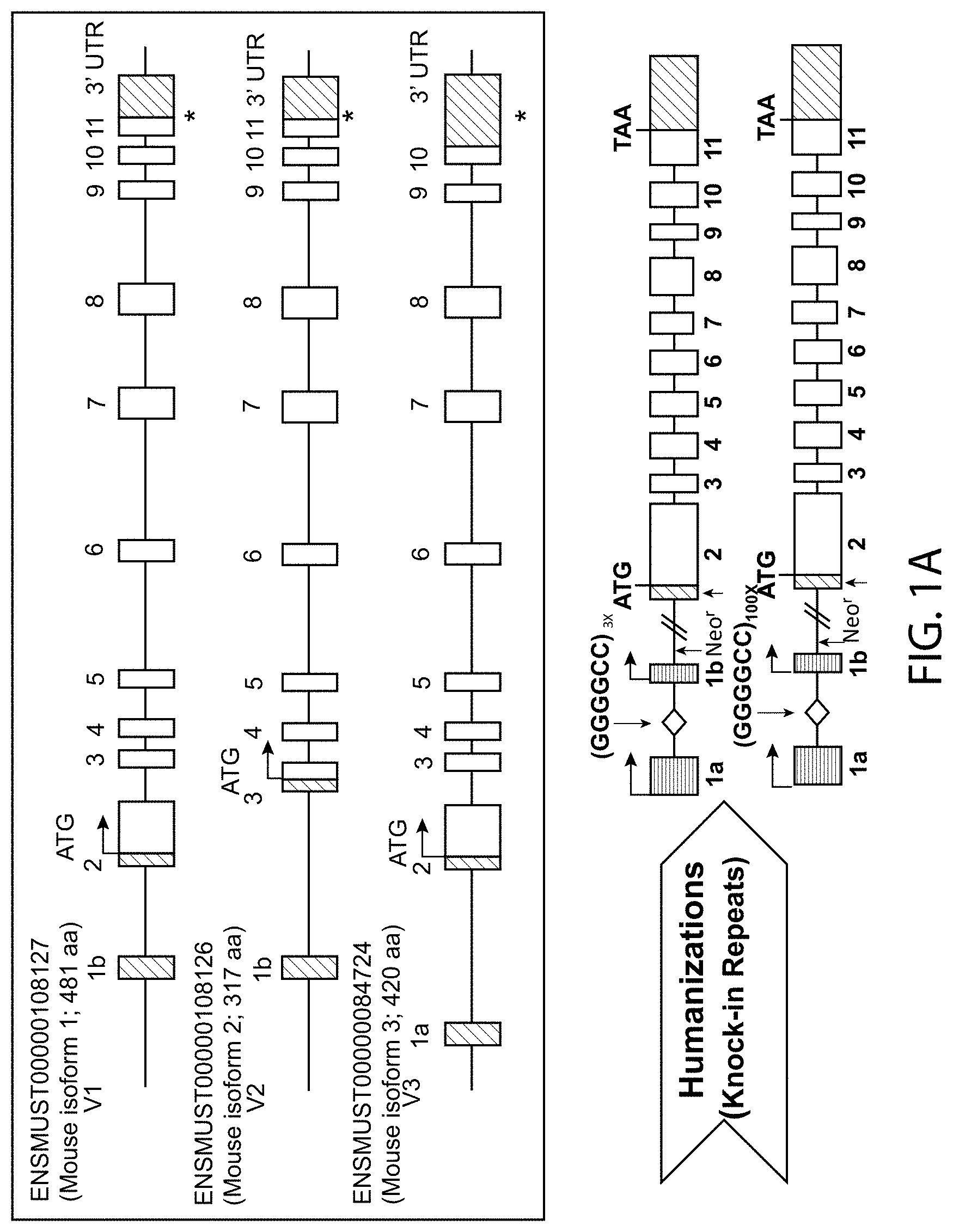
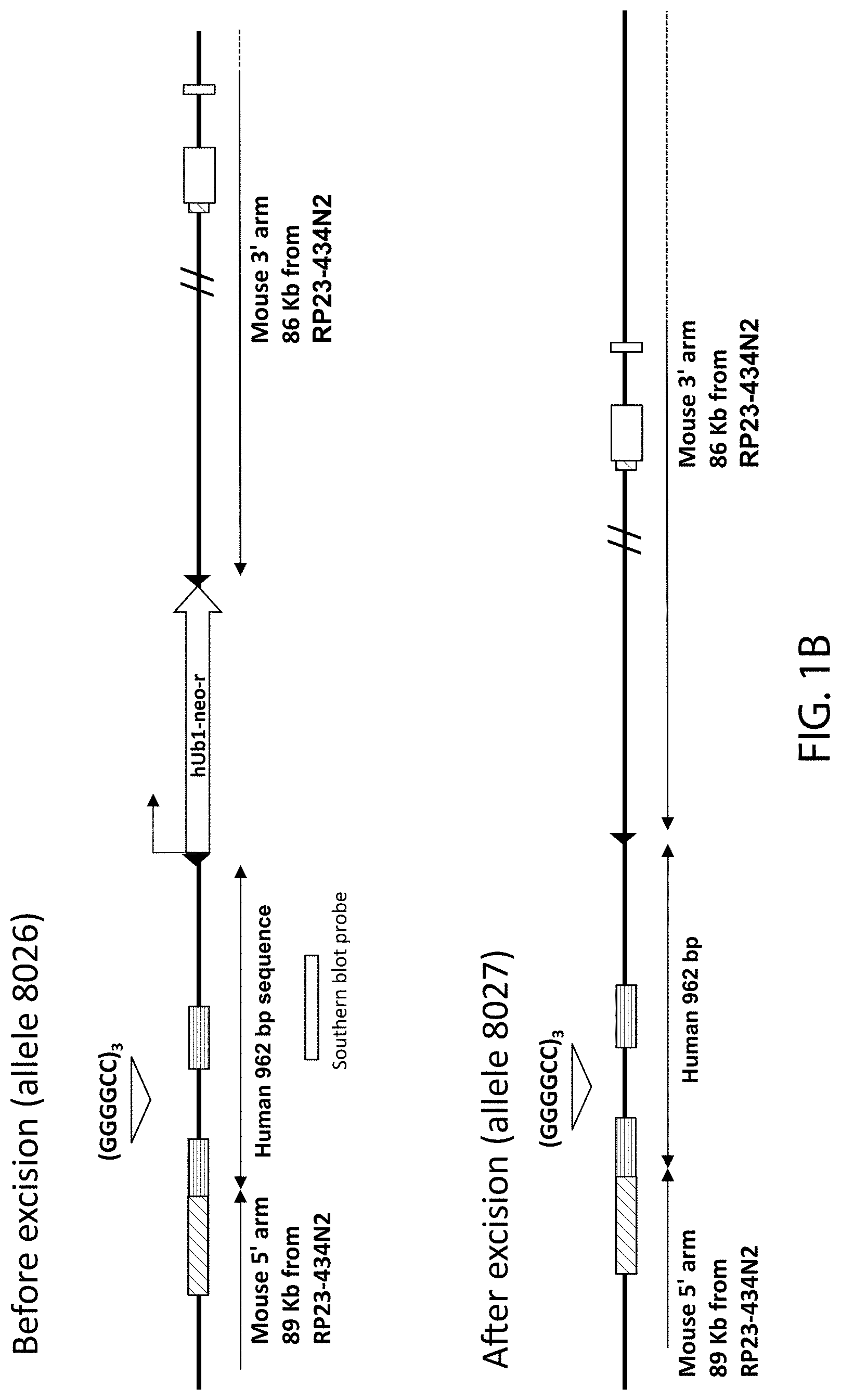
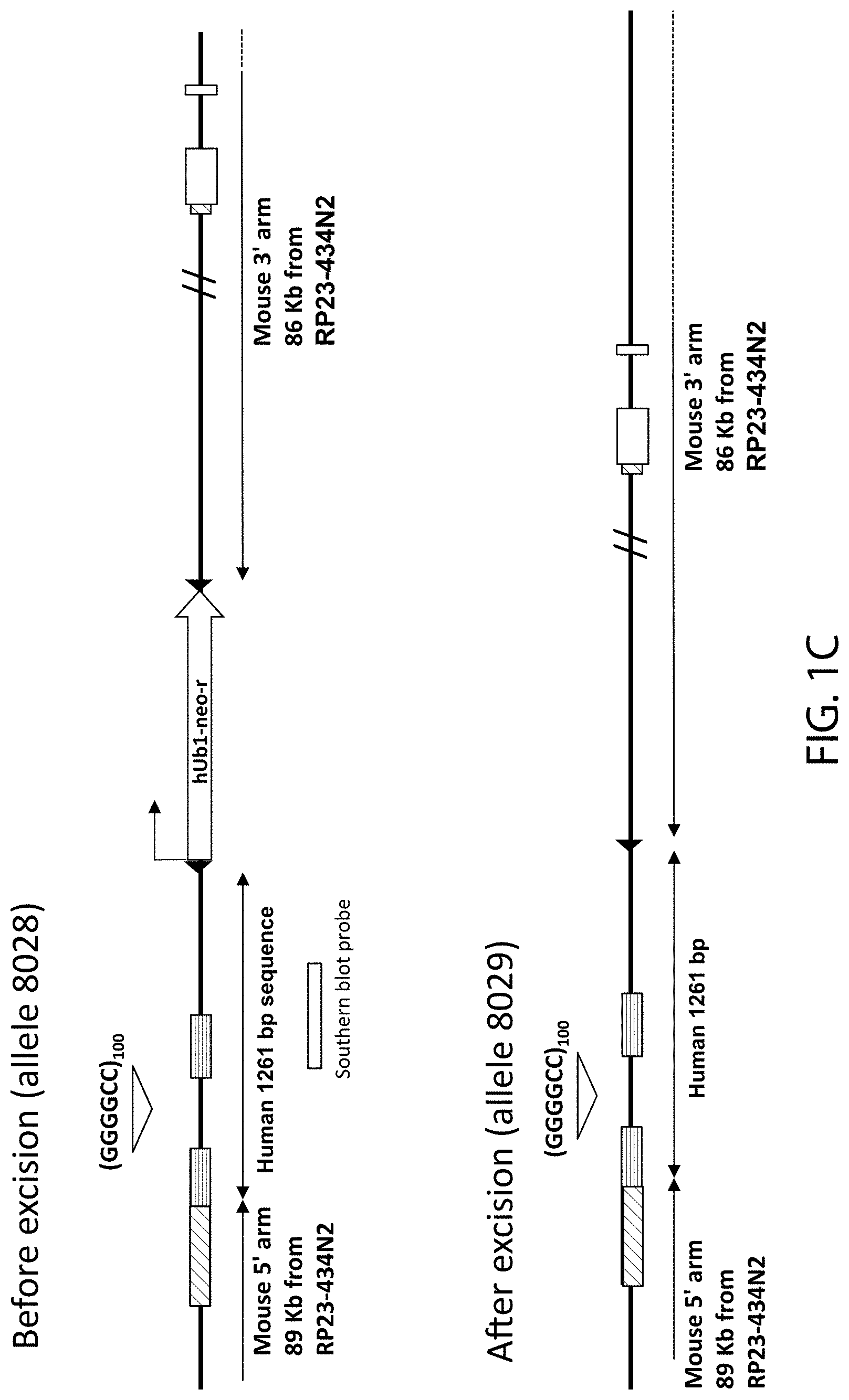
[0051] FIG. 1A shows a schematic illustration, not to scale, of the three reported mouse C9orf72 transcript isoforms (V1, V2 and V3) in the top box and a schematic illustration, not to scale, of a targeting strategy for insertion of one of two human heterologous hexanucleotide repeat expansion sequences spanning exons 1a and 1b of the human C9orf72 gene and comprising 3 or 100 repeats into an endogenous mouse C9orf72 locus. In FIG. 1A, white filled boxes represent mouse exons, with white diagonally striped boxes representing non-coding mouse exons of the mouse C9orf72 locus. Horizontally striped boxes are non-coding exons of a human C9orf72 locus and the diamond represents the hexanucleotide repeat. A first targeting vector comprising a sequence set forth as SEQ ID NO:2 and a second targeting vector comprising a sequence set forth as SEQ ID NO:4 were generated. The first targeting vector includes from 5' to 3': a mouse homology arm 89 Kb upstream from RP23-434N2 of mouse the 3110043021Rik gene and comprising SEQ ID NO:6, a human sequence set forth as SEQ ID NO:8 which spans non-coding exons 1a and 1b of human C9orf72 and includes the intervening intron containing three repeats of the hexanucleotide sequence GGGGCC; a drug selection cassette that comprises a promoter from the human ubiquitin 1 gene (hUb1) and the bacterial Em7 gene operably linked to a neomycin phosphotransferase resistance gene (neo-r) and is flanked by loxP sites), and a mouse homology arm 86 Kb downstream from RP23-434N2 of mouse the 3110043021Rik gene and comprising SEQ ID NO:7. The second targeting vector includes from 5' to 3': a mouse homology arm 89 Kb upstream from RP23-434N2 of mouse the 3110043021Rik gene and comprising SEQ ID NO:6; a human sequence set forth as SEQ ID NO:9 which spans non-coding exons 1a and 1b of human C9orf72 and includes the intervening intron containing 100 repeats of the hexanucleotide sequence GGGGCC; a drug selection cassette that comprises a promoter from the human ubiquitin 1 gene (hUb1) and the bacterial Em7 gene operably linked to a neomycin phosphotransferase resistance gene (neo-r) and is flanked by loxP sites); and a mouse homology arm 86 Kb downstream from RP23-434N2 of mouse the 3110043021Rik gene and comprising SEQ ID NO:7. Upon homologous recombination with the first or second targeting vector, a mouse genomic region of about 853 bp, including a portion of exon 1 and part of intron 1 of mouse 3110043021Rik is replaced with a sequence comprising the genomic sequence spanning exons 1a-1b of the human C9orf72 non-coding sequence. The resulting modified mouse C9orf72-HRE.sub.3 loci before and after excision of the drug resistance cassette are depicted in FIG. 1B. The resulting modified mouse C9orf72-HRE.sub.100 loci before and after excision of the drug resistance cassette are depicted in FIG. 1C. In FIGS. 1B and 1C, murine non-coding regions are represented by diagonally striped boxes, human non-coding exons are represented by horizontally striped boxes, and mouse coding exons are represented by white boxes. Also shown in the top panels of FIGS. 1B and 1C is an approximate location of a probe (vertical white rectangle) used for Southern blot analysis (SEQ ID NO:29).
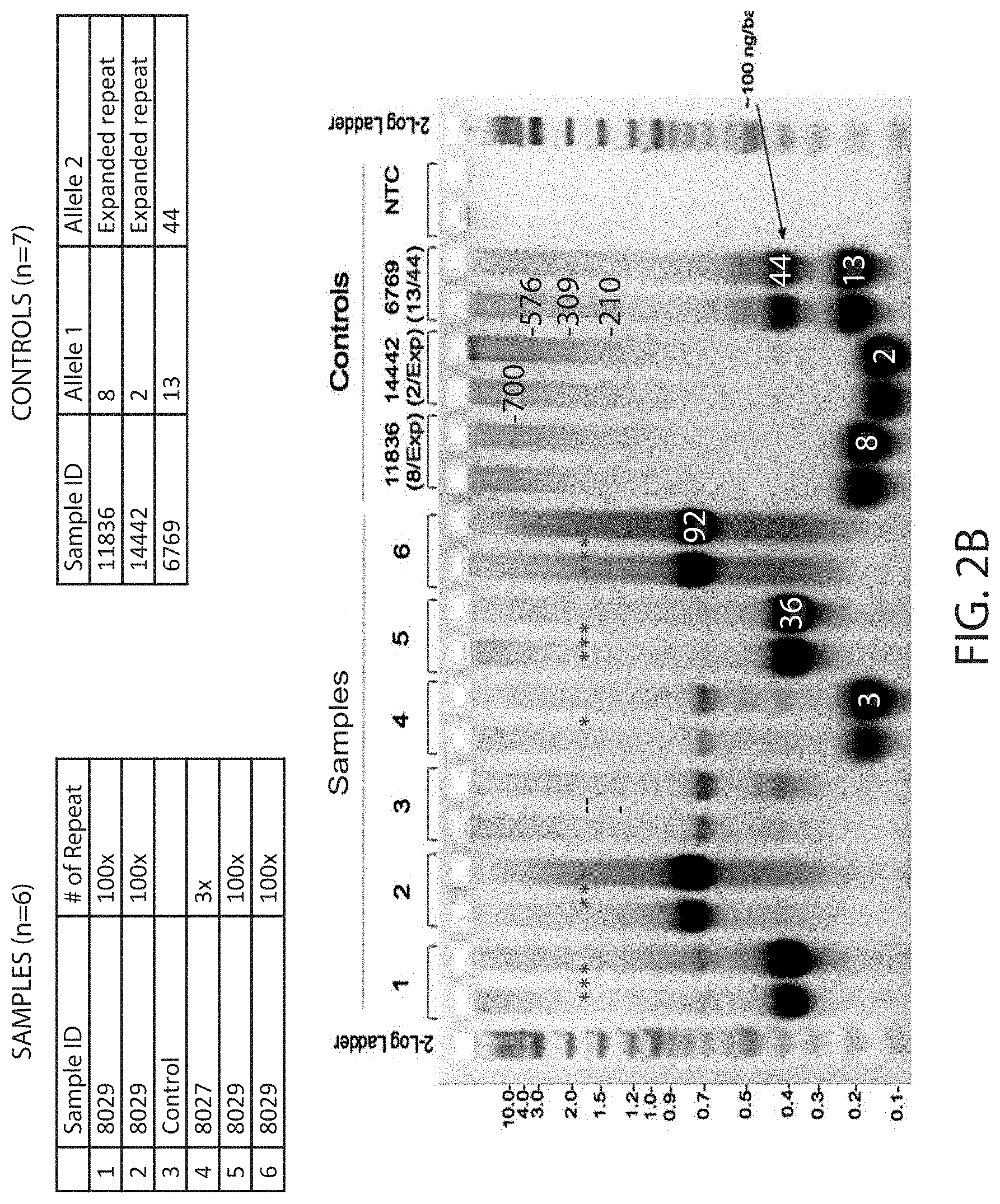
[0052] Shown in FIG. 2A is the result of Southern blot analysis of genomic DNA isolated from control ES cell clones, ES cell clones targeted with a targeting vector comprising a heterologous repeat expansion sequence comprising three repeats of the hexanucleotide sequence (8026) and after excision of the drug cassette (8027 A-C4), or ES cell clones targeted with a targeting vector comprising a heterologous repeat expansion sequence comprising 100 repeats of the hexanucleotide sequence (8028) and after excision of the drug cassette (8029 A-A3, 8029 A-A6, 8029 B-A4, 8029 B-A10). FIG. 2B shows the genotypic results of genotyping samples (n=6) including a control ES cell clone, the 8027 A-C4 clone, the 8029 A-A3 clone, the 8029 A-A6 clone, the 8029 B-A4 clone, the 8029 B-A10 clone, and controls (n=7) obtained from human samples containing three hexanucleotide repeat expansion sequences.
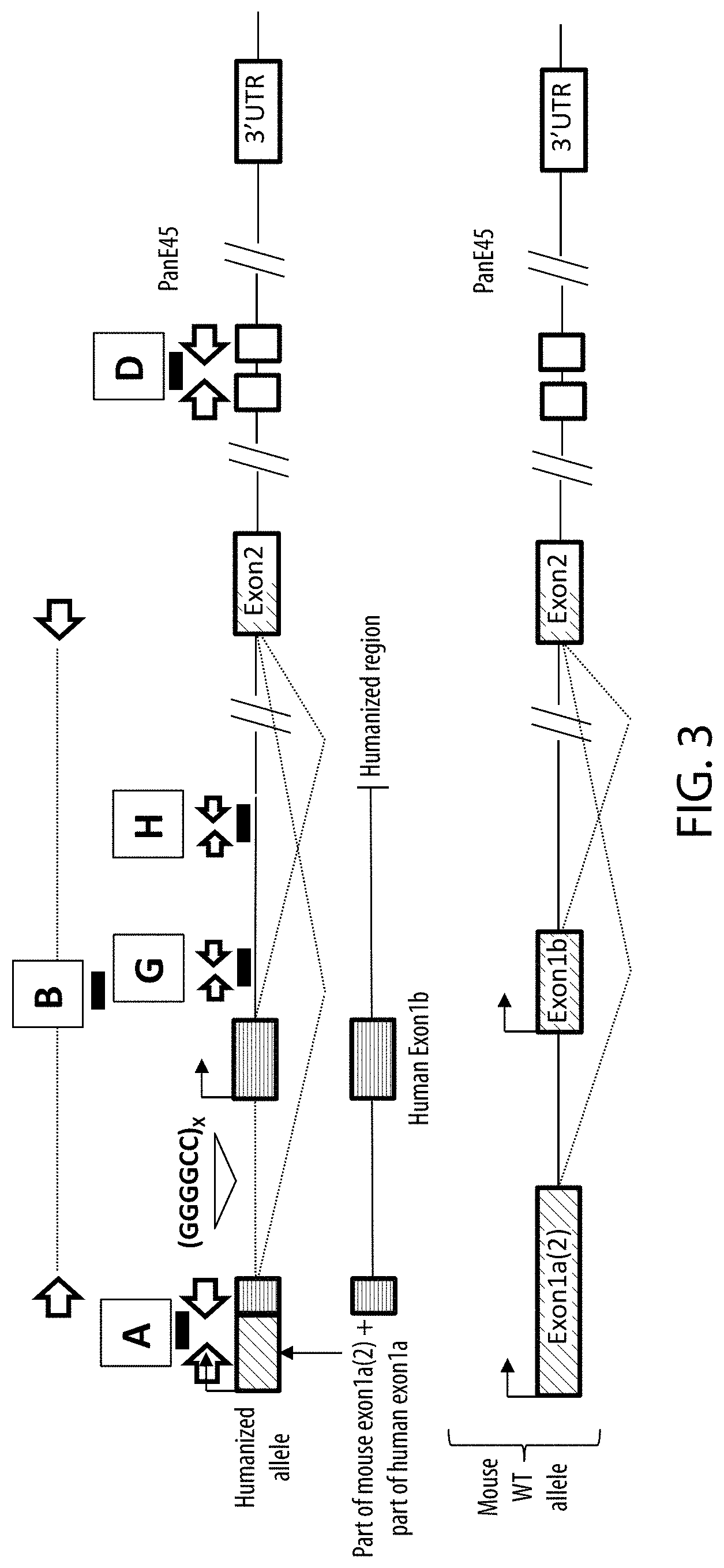
[0053] FIG. 3 shows a schematic illustration, not to scale, of the humanized C9orf72-HREx (where x.gtoreq.1), the humanized region, and the wildtype (WT) C9orf72 mouse loci. Also shown in FIG. 3 are the approximate locations of 5'- and 3'-primers (white arrows) and probes (filled rectangles) used in the TAQMAN.RTM. qualitative PCR analyses A, B, G, H, and D described in Table 1 to quantify gene expression products from the modified C9orf72-HRE loci (A, B, G, H) or both the modified and wildtype C9orf72 loci (D). In FIG. 3, murine non-coding regions are represented by diagonally striped boxes, human non-coding exons are represented by horizontally striped boxes, and mouse coding exons are represented by white boxes. The sequences for the primers and probes depicted in FIG. 3 and described in Table 1 are provided in Table 5.
Table 1
TABLE-US-00001 [0054] TABLE 1 Location Location Analyses of 5'-primer of 3'-primer Location of probe A Mouse exon 1a Human exon 1a Spans junction of mouse exon 1a and human exon 1a B Human exon 1a Mouse exon 2 Human intron 2 G Human Intron 2 Human Intron 2 Human Intron 2 H Human Intron 2 Human Intron 2 Human Intron 2 D Mouse Exon 5 Mouse Exon 6 Mouse Intron 6
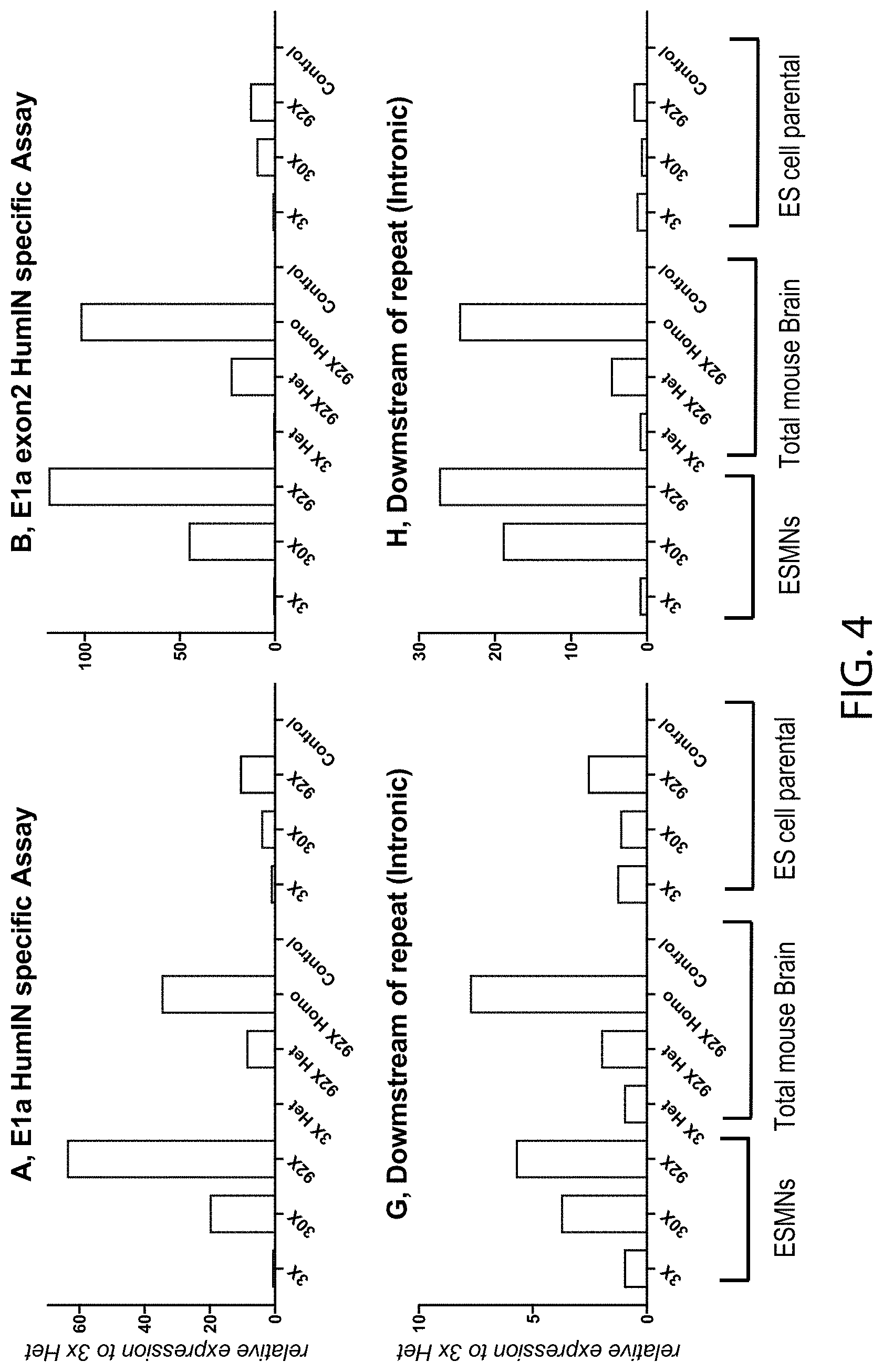
[0055] FIG. 4 provides bar graphs showing expression levels (as determined by the TAQMAN.RTM. qualitative PCR assays A, B, G, and H depicted in FIG. 3) of the C9orf72 locus (y-axis) by embryonic stem cell derived motor neurons (ESMNs), total brain tissue, or parental embryonic stem (ES) cells that are heterozygous (Het) or homozygous (Homo) for a wildtype C9orf72 locus (control) or a modified C9orf72 locus comprising three (3.times.), thirty (30.times.) or ninety-two (92.times.) repeats of the hexanucleotide sequence set forth as SEQ ID NO:1 relative to ESMNs, brain, or parental ESCs, respectively, that are heterozygous for a modified C9orf72 locus comprising three (3.times.) repeats of the hexanucleotide sequence set forth as SEQ ID NO:1. All ESMNs and parental ES cells were heterozygous for the modified C9orf72 loci, and all controls were homozygous for the wildtype C9orf72 locus.
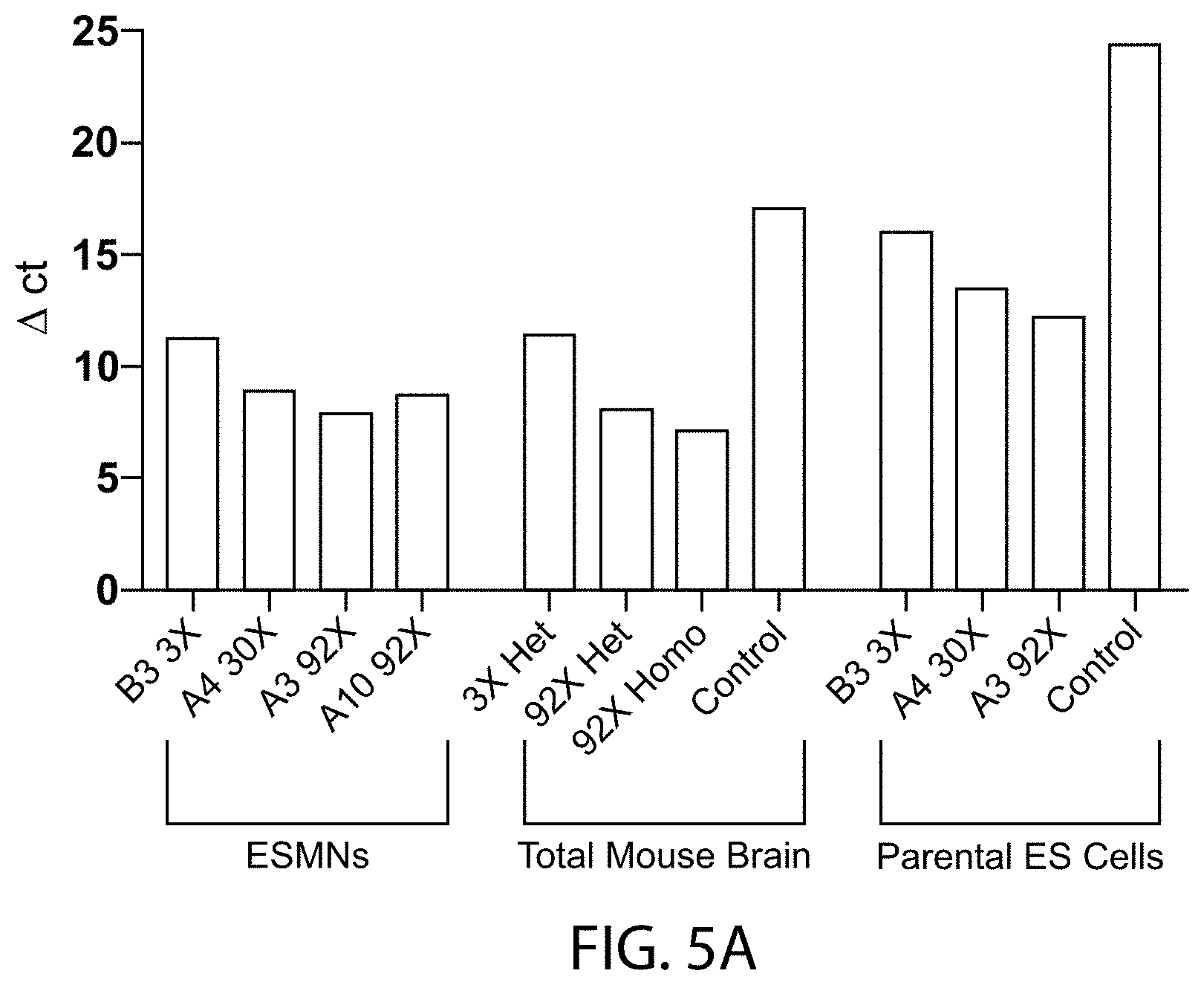
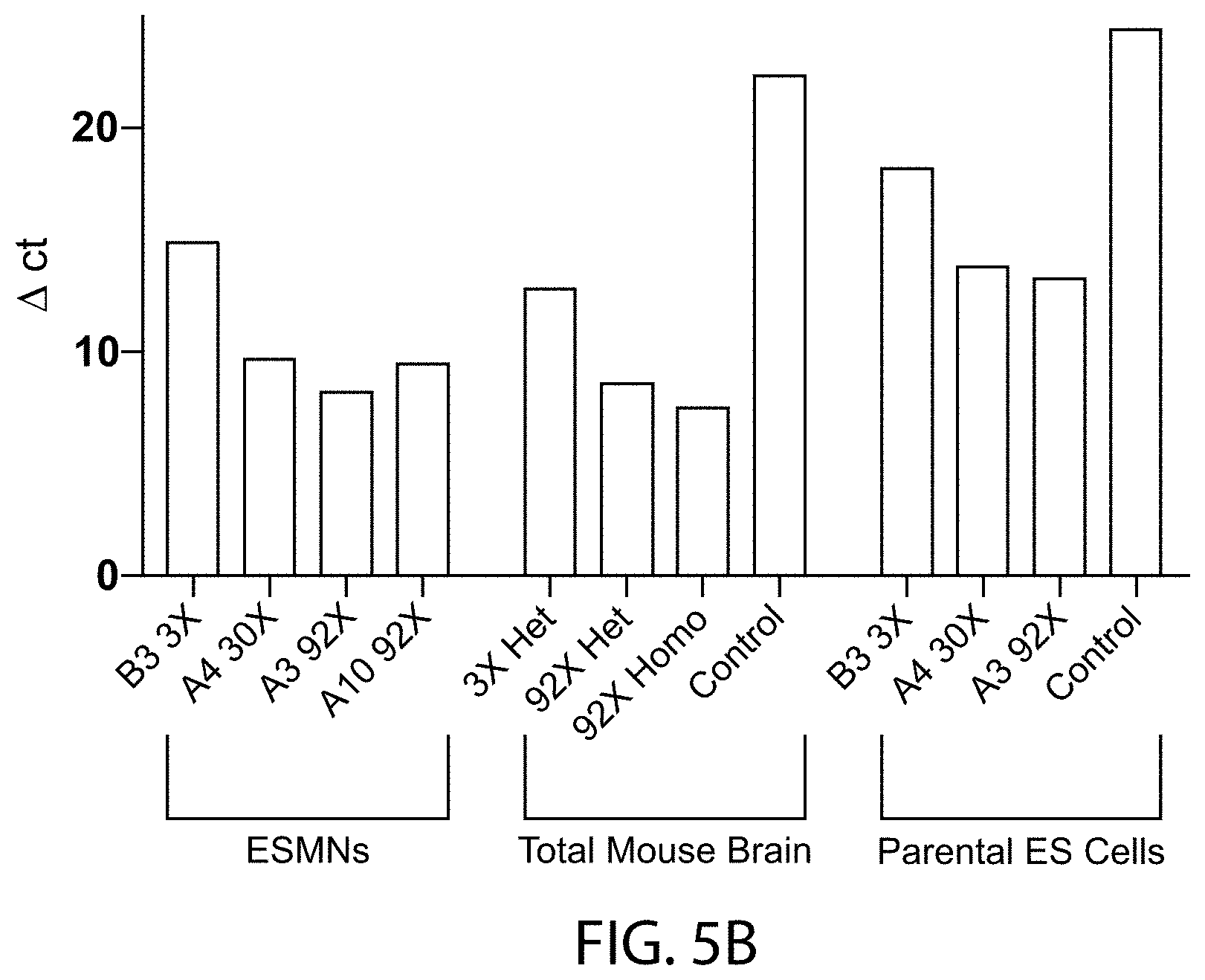
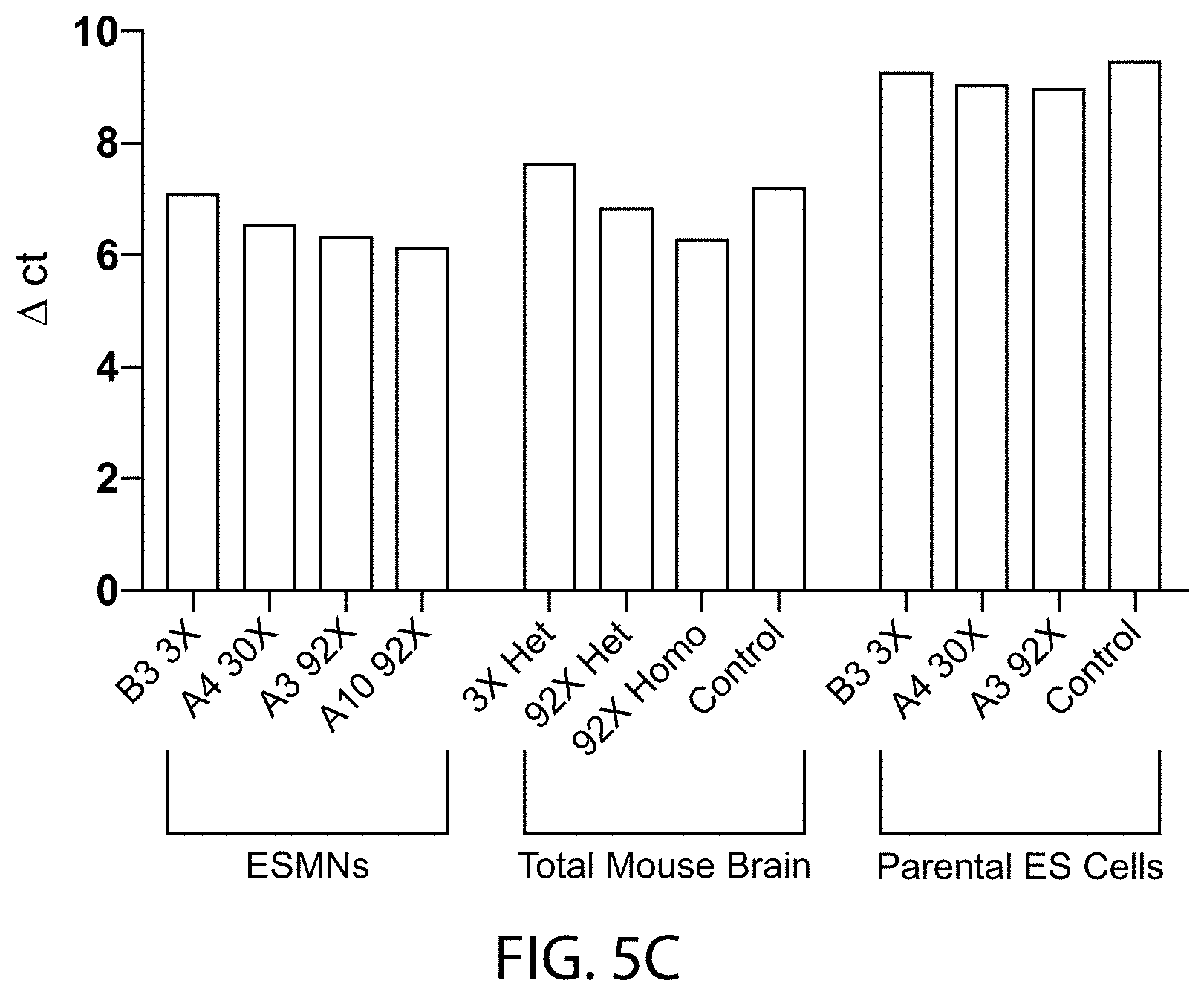
[0056] FIGS. 5A-5C provides bar graphs showing the differences in the count values (.DELTA. ct; y-axis) of C9orf72 gene products (detected by the TAQMAN.RTM. qualitative PCR assay A (FIG. 5A), assay B (FIG. 5B), or assay D (FIG. 5C) as depicted in FIG. 3) by embryonic stem cell derived motor neurons (ESMNs), total mouse brain, or parental embryonic stem (ES) cells that are heterozygous (het) or homozygous (homo) for a wildtype C9orf72 locus (Controls) or a modified C9orf72 locus comprising three (3.times.), thirty (30.times.) or ninety-two (92.times.) repeats of the hexanucleotide sequence set forth as SEQ ID NO:1 and the count values of GAPDH gene products. All ESMNs and parental ES cells were heterozygous for the modified C9orf72 loci, and all controls were homozygous for the wildtype C9orf72 locus.
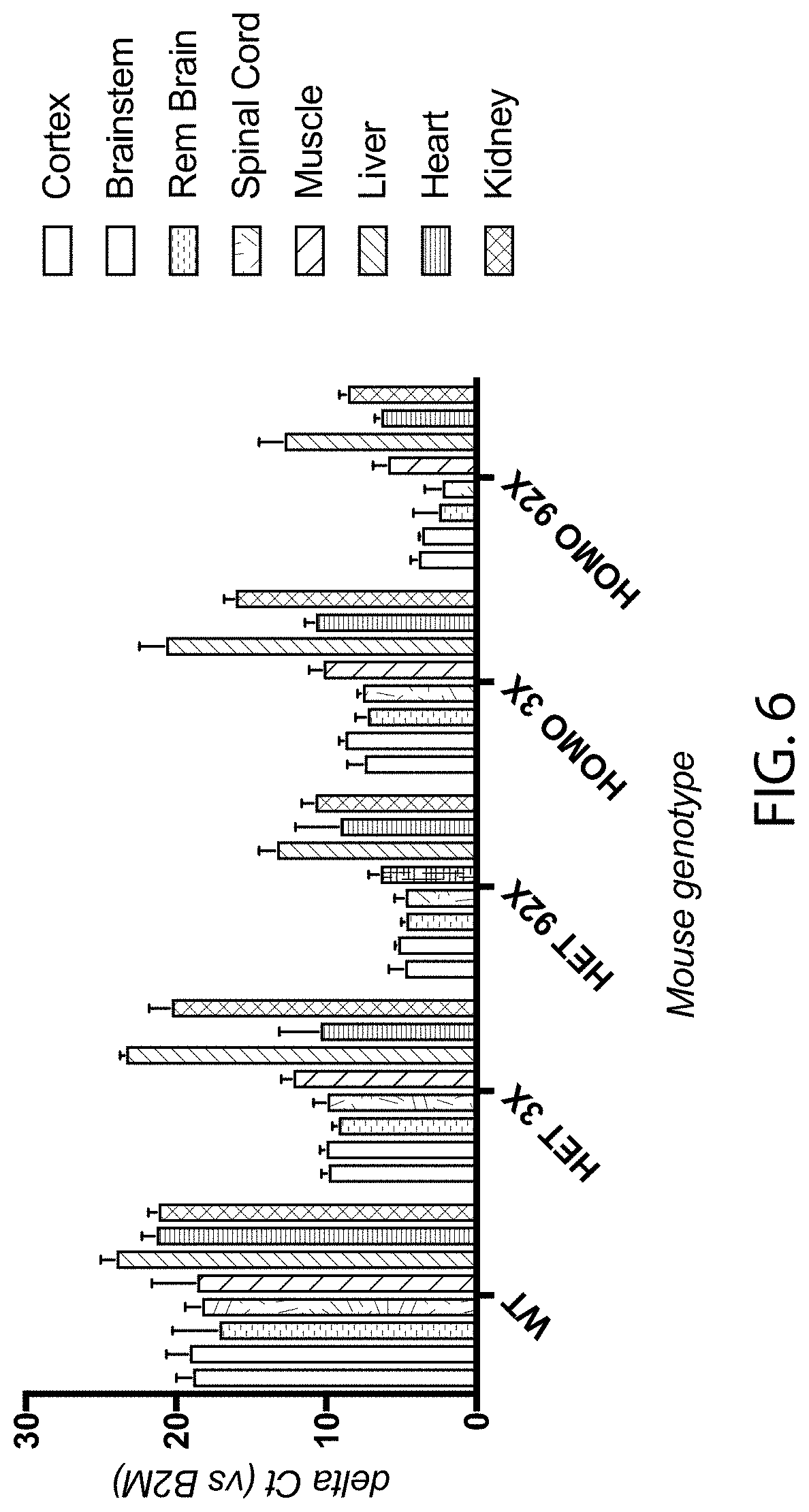
[0057] FIG. 6 provides bar graphs showing the differences in the count values (.DELTA. ct; y-axis) of C9orf72 gene products (detected by the TAQMAN.RTM. qualitative PCR assay B as depicted in FIG. 3) in tissues isolated from the cortex, brainstem, remaining (rem) brain, spinal cord, muscle, liver, heart, or kidneys of mice heterozygous (het) or homozygous (homo) for a wildtype C9orf72 locus (WT) or a modified c9orf72 locus comprising three (3.times.) or ninety-two (92.times.) repeats of the hexanucleotide sequence set forth as SEQ ID NO:1 and the count values of .beta.2-microglobulin (B2M) gene products.
[0058] FIG. 7 shows Western blot images (top) from reducing SDS-PAGE analysis of lysates from embryonic stem cell-derived motor neurons (ESMNs) homozygous for a wildtype C9orf72 locus (CTRL) or heterozygous for a modified C9orf72 locus comprising three (G.sub.4C.sub.23.times.), thirty (G.sub.4C.sub.230.times.) or ninety-two (G.sub.4C.sub.292.times.) repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, blotted with anti-C9orf72 antibody (top) or anti-GAPDH antibody (bottom). Bar graphs (bottom panel) of the protein levels of C9orf72 of these samples normalized to protein levels of C9orf72 of ESMNs heterozygous for a modified C9orf72 locus comprising three repeats of the hexanucleotide sequence set forth as SEQ ID NO:1 are also provided, as are molecular weight markers.
[0059] FIG. 8 shows a Western blot image (top) from reducing SDS-PAGE analysis of lysates of from embryonic stem cell-derived motor neurons (ESMNs) heterozygous for a modified C9orf72 locus comprising three (G.sub.4C.sub.23.times.) or ninety-two (G.sub.4C.sub.292.times.) repeats of the hexanucleotide sequence set forth as SEQ ID NO:1. Lysates containing 0 .mu.g, 1.25 .mu.g, 2.5 .mu.g, 5 .mu.g, or 10 .mu.g total proteins are blotted with anti-C9orf72 antibody (shown) or anti-GAPDH antibody (data not shown). Bar graphs (bottom) of the protein levels of C9orf72 of these samples normalized to protein levels of GAPDH by these samples are also provided, as are molecular weight markers.
[0060] FIGS. 9A and 9B are images obtained from fluorescent in situ hybridization (FISH) of embryonic stem cell derived motor neurons (ESMNs) heterozygous for a C9orf72 locus modified to comprise three (C9orf72 G.sub.4C.sub.2 3.times.), thirty (C9orf72 G.sub.4C.sub.2 30.times.) or ninety-two (C9orf72 G.sub.4C.sub.2 92.times.) repeats of the hexanucleotide sequence set forth as SEQ ID NO:1 stained with DNA (FIG. 9A) or LNA (FIG. 9B) probes, which images show the nuclear and cytoplasmic locations of sense (FIG. 9A) or antisense (FIG. 9B) transcripts of the hexanucleotide repeat sequence set forth in SEQ ID NO:1 in the ESMNs. Arrows point to exemplary stained RNA foci.
[0061] FIG. 10 provides images obtained from immunofluorescence of embryonic stem cell derived motor neurons (ESMNs) heterozygous for a C9orf72 locus modified to comprise three (C9orf72 G.sub.4C.sub.2 3.times.) or ninety-two (C9orf72 G.sub.4C.sub.2 92.times.) repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, which images show the nuclear locations of dipeptide repeat proteins (polyGA) translated (through RAN translation, a non-AUG mechanism) from transcripts of the hexanucleotide repeat sequence set forth in SEQ ID NO:1 in the ESMNs. Arrows point to exemplary stained polyGA dipeptide repeat proteins.
[0062] FIG. 11 shows a schematic illustration, not to scale, of about 1300 bp of a mouse C9ORF72 locus comprising a heterologous (human) hexanucleotide repeat expansion comprising about 92 repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, and which may be used as a reference sequence to generate a CRISPR/Cas system for the deletion of the expansion sequence. Also depicted in FIG. 11 are the approximate locations of (1) the 92 repeats of the hexanucleotide sequence depicted by downward pointing arrows, (2) the starting positions (190, 196 and 274) of three sites upstream of the hexanucleotide repeat expansion sequence that may be targeted by gRNA respectively comprising the sequence set forth as SEQ ID NO:38, SEQ ID NO:39, and SEQ ID NO:40, (3) the starting positions (899, 905 1006 and 1068) of four sites downstream of the hexanucleotide repeat expansion sequence that may be targeted by gRNA respectively comprising the sequence set forth as SEQ ID NO:41, SEQ ID NO:42, SEQ ID NO:43 and SEQ ID NO:44, and (4) the approximate locations for forward (F-) and reverse (R-)primers that may be used to confirm the deletion in selected cell clones. The nucleic acid sequence of the reference sequence depicted in FIG. 11 is set forth as SEQ ID NO:45.
[0063] FIG. 12 shows an exemplary 10,718 bp expression construct that may be used in a CRISP/Cas system. The expression construct comprises a nucleic acid encoding a mouse Cas9 protein "mouse opt Cas9" fused with an N-terminal nuclear localization signal (NLS) and C-terminal nuclear localization signal, the expression of the fusion protein being under the control of a CAGG promoter. Upstream of the nucleic acid is a kozak sequence, and downstream of the nucleic acid is a bovine growth hormone polyadenylation (bGHpA) tail. Also shown as part of the expression construct are an EF1 promoter driving the expression of a nucleotide sequence encoding a green fluorescence protein (GFP) fused with a puromycin resistance gene operably linked to an SV40 polyadenylation (SV40 polyA) tail, an origin of replication site (pMB1), and a .beta. lactamase gene providing ampicillin (Amp) resistance. The expression construct allows for the insertion of DNA encoding gRNA, e.g., a crRNA, between a U6 promoter and a termination signal. An expression construct has depicted in FIG. 4 may further comprise, downstream of the U6 promoter and upstream a termination signal, a tracrRNA encoding sequence. Such tracrRNA encoding sequence is placed such that it may be operably linked to the, e.g., crRNA, upon its insertion. In some embodiments, a tracrRNA encoding sequence comprises GTTGGAACCATTCAAAACAGCATAGCAAGTTAAAATAAGGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCG- AGTCGGTGC (SEQ ID NO: 63); GTTTTAGAGCTAGAAATAGCAAGTTAAAATAAGGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGG- TGC (SEQ ID NO:64); GTTTAAGAGCTATGCTGGAAACAGCATAGCAAGTTTAAATAAGGCTAGTCCGTTATCAACTTGAAAAAGTGGC- ACCGAGTCGGTGC (SEQ ID NO:65), or portions thereof.
DEFINITIONS
[0064] This invention is not limited to particular methods and experimental conditions described herein, as such methods and conditions may vary. It is also to be understood that the terminology used herein is for the purpose of describing particular embodiments only, and is not intended to be limiting, since the scope of the present invention is defined by the claims.
[0065] Unless defined otherwise, all terms and phrases used herein include the meanings that the terms and phrases have attained in the art, unless the contrary is clearly indicated or clearly apparent from the context in which the term or phrase is used. Although any methods and materials similar or equivalent to those described herein can be used in the practice or testing of the present invention, particular methods and materials are now described. All publications mentioned herein are hereby incorporated by reference.
[0066] "Administration" includes the administration of a composition to a subject or system (e.g., to a cell, organ, tissue, organism, or relevant component or set of components thereof). Those of ordinary skill will appreciate that route of administration may vary depending, for example, on the subject or system to which the composition is being administered, the nature of the composition, the purpose of the administration, etc. For example, in certain embodiments, administration to an animal subject (e.g., to a human or a rodent) may be bronchial (including by bronchial instillation), buccal, enteral, interdermal, intra-arterial, intradermal, intragastric, intramedullary, intramuscular, intranasal, intraperitoneal, intrathecal, intravenous, intraventricular, mucosal, nasal, oral, rectal, subcutaneous, sublingual, topical, tracheal (including by intratracheal instillation), transdermal, vaginal and/or vitreal. In some embodiments, administration may involve intermittent dosing. In some embodiments, administration may involve continuous dosing (e.g., perfusion) for at least a selected period of time.
[0067] "Amelioration" includes the prevention, reduction or palliation of a state, or improvement of the state of a subject. Amelioration includes, but does not require complete recovery or complete prevention of a disease, disorder or condition (e.g., radiation injury).
[0068] "Approximately", as applied to one or more values of interest, includes to a value that is similar to a stated reference value. In certain embodiments, the term "approximately" or "about" refers to a range of values that fall within 25%, 20%, 19%, 18%, 17%, 16%, 15%, 14%, 13%, 12%, 11%, 10%, 9%, 8%, 7%, 6%, 5%, 4%, 3%, 2%, 1%, or less in either direction (greater than or less than) of the stated reference value unless otherwise stated or otherwise evident from the context (except where such number would exceed 100% of a possible value).
[0069] "Biologically active" includes a characteristic of any agent that has activity in a biological system, in vitro or in vivo (e.g., in an organism). For instance, an agent that, when present in an organism, has a biological effect within that organism is considered to be biologically active. In particular embodiments, where a protein or polypeptide is biologically active, a portion of that protein or polypeptide that shares at least one biological activity of the protein or polypeptide is typically referred to as a "biologically active" portion.
[0070] "Comparable" includes two or more agents, entities, situations, sets of conditions, etc. that may not be identical to one another but that are sufficiently similar to permit comparison there between so that conclusions may reasonably be drawn based on differences or similarities observed. Those of ordinary skill in the art will understand, in context, what degree of identity is required in any given circumstance for two or more such agents, entities, situations, sets of conditions, etc. to be considered comparable.
[0071] "Conservative", when describing a conservative amino acid substitution, includes substitution of an amino acid residue by another amino acid residue having a side chain R group with similar chemical properties (e.g., charge or hydrophobicity). In general, a conservative amino acid substitution will not substantially change the functional properties of interest of a protein, for example, the ability of a receptor to bind to a ligand. Examples of groups of amino acids that have side chains with similar chemical properties include: aliphatic side chains such as glycine, alanine, valine, leucine, and isoleucine; aliphatic-hydroxyl side chains such as serine and threonine; amide-containing side chains such as asparagine and glutamine; aromatic side chains such as phenylalanine, tyrosine, and tryptophan; basic side chains such as lysine, arginine, and histidine; acidic side chains such as aspartic acid and glutamic acid; and sulfur-containing side chains such as cysteine and methionine. Conservative amino acids substitution groups include, for example, valine/leucine/isoleucine, phenylalanine/tyrosine, lysine/arginine, alanine/valine, glutamate/aspartate, and asparagine/glutamine. In some embodiments, a conservative amino acid substitution can be a substitution of any native residue in a protein with alanine, as used in, for example, alanine scanning mutagenesis. In some embodiments, a conservative substitution is made that has a positive value in the PAM250 log-likelihood matrix disclosed in Gonnet, G. H. et al., 1992, Science 256:1443-1445. In some embodiments, a substitution is a moderately conservative substitution wherein the substitution has a nonnegative value in the PAM250 log-likelihood matrix.
[0072] "Control" includes the art-understood meaning of a "control" being a standard against which results are compared. Typically, controls are used to augment integrity in experiments by isolating variables in order to make a conclusion about such variables. In some embodiments, a control is a reaction or assay that is performed simultaneously with a test reaction or assay to provide a comparator. A "control" also includes a "control animal." A "control animal" may have a modification as described herein, a modification that is different as described herein, or no modification (i.e., a wild type animal). In one experiment, a "test" (i.e., a variable being tested) is applied. In a second experiment, the "control," the variable being tested is not applied. In some embodiments, a control is a historical control (i.e., of a test or assay performed previously, or an amount or result that is previously known). In some embodiments, a control is or comprises a printed or otherwise saved record. A control may be a positive control or a negative control.
[0073] "Disruption" includes the result of a homologous recombination event with a DNA molecule (e.g., with an endogenous homologous sequence such as a gene or gene locus). In some embodiments, a disruption may achieve or represent an insertion, deletion, substitution, replacement, missense mutation, or a frame-shift of a DNA sequence(s), or any combination thereof. Insertions may include the insertion of entire genes or fragments of genes, e.g., exons, which may be of an origin other than the endogenous sequence (e.g., a heterologous sequence). In some embodiments, a disruption may increase expression and/or activity of a gene or gene product (e.g., of a protein encoded by a gene). In some embodiments, a disruption may decrease expression and/or activity of a gene or gene product. In some embodiments, a disruption may alter sequence of a gene or an encoded gene product (e.g., an encoded protein). In some embodiments, a disruption may truncate or fragment a gene or an encoded gene product (e.g., an encoded protein). In some embodiments, a disruption may extend a gene or an encoded gene product. In some such embodiments, a disruption may achieve assembly of a fusion protein. In some embodiments, a disruption may affect level, but not activity, of a gene or gene product. In some embodiments, a disruption may affect activity, but not level, of a gene or gene product. In some embodiments, a disruption may have no significant effect on level of a gene or gene product. In some embodiments, a disruption may have no significant effect on activity of a gene or gene product. In some embodiments, a disruption may have no significant effect on either level or activity of a gene or gene product.
[0074] "Determining", "measuring", "evaluating", "assessing", "assaying" and "analyzing" includes any form of measurement, and include determining if an element is present or not. These terms include both quantitative and/or qualitative determinations. Assaying may be relative or absolute. "Assaying for the presence of" can be determining the amount of something present and/or determining whether or not it is present or absent.
[0075] "Endogenous locus" or "endogenous gene" includes a genetic locus found in a parent or reference organism prior to introduction of a disruption, deletion, replacement, alteration, or modification as described herein. In some embodiments, the endogenous locus has a sequence found in nature. In some embodiments, the endogenous locus is a wild type locus. In some embodiments, the reference organism is a wild type organism. In some embodiments, the reference organism is an engineered organism. In some embodiments, the reference organism is a laboratory-bred organism (whether wild type or engineered).
[0076] "Endogenous promoter" includes a promoter that is naturally associated, e.g., in a wild type organism, with an endogenous gene.
[0077] "Gene" includes a DNA sequence in a chromosome that codes for a product (e.g., an RNA product and/or a polypeptide product). In some embodiments, a gene includes coding sequence (i.e., sequence that encodes a particular product). In some embodiments, a gene includes non-coding sequence. In some particular embodiments, a gene may include both coding (e.g., exonic) and non-coding (e.g., intronic) sequence. In some embodiments, a gene may include one or more regulatory sequences (e.g., promoters, enhancers, etc.) and/or intron sequences that, for example, may control or impact one or more aspects of gene expression (e.g., cell-type-specific expression, inducible expression, etc.). For the purpose of clarity we note that, as used in the present application, the term "gene" generally refers to a portion of a nucleic acid that encodes a polypeptide; the term may optionally encompass regulatory sequences, as will be clear from context to those of ordinary skill in the art. This definition is not intended to exclude application of the term "gene" to non-protein-coding expression units but rather to clarify that, in most cases, the term as used in this document refers to a polypeptide-coding nucleic acid.
[0078] "Heterologous" includes an agent or entity from a different source. For example, when used in reference to a polypeptide, nucleic acid sequence, gene, or gene product present in a particular cell or organism, the term clarifies that the relevant polypeptide, nucleic acid sequence, gene, or gene product: 1) was engineered by the hand of man; 2) was introduced into the cell or organism (or a precursor thereof) through the hand of man (e.g., via genetic engineering); and/or 3) is not naturally produced by or present in the relevant cell or organism (e.g., the relevant cell type or organism type). "Heterologous" also includes a polypeptide, nucleic acid sequence, gene or gene product that is normally present in a particular native cell or organism, but has been modified, for example, by mutation or placement under the control of non-naturally associated and, in some embodiments, non-endogenous regulatory elements (e.g., a promoter).
[0079] "Host cell" includes a cell into which a nucleic acid or protein has been introduced. Persons of skill upon reading this disclosure will understand that such terms refer not only to the particular subject cell, but also is used to refer to the progeny of such a cell. Because certain modifications may occur in succeeding generations due to either mutation or environmental influences, such progeny may not, in fact, be identical to the parent cell, but are still included within the scope of the phrase "host cell". In some embodiments, a host cell is or comprises a prokaryotic or eukaryotic cell. In general, a host cell is any cell that is suitable for receiving and/or producing a heterologous nucleic acid or protein, regardless of the Kingdom of life to which the cell is designated. Exemplary cells include those of prokaryotes and eukaryotes (single-cell or multiple-cell), bacterial cells (e.g., strains of Escherichia coli, Bacillus spp., Streptomyces spp., etc.), mycobacteria cells, fungal cells, yeast cells (e.g., Saccharomyces cerevisiae, Schizosaccharomyces pombe, Pichia pastoris, Pichia methanolica, etc.), plant cells, insect cells (e.g., SF-9, SF-21, baculovirus-infected insect cells, Trichoplusia ni, etc.), non-human animal cells, human cells, or cell fusions such as, for example, hybridomas or quadromas. In some embodiments, the cell is a human, monkey, ape, hamster, rat, or mouse cell. In some embodiments, the cell is eukaryotic and is selected from the following cells: CHO (e.g., CHO K1, DXB-11 CHO, Veggie-CHO), COS (e.g., COS-7), retinal cell, Vero, CV1, kidney (e.g., HEK293, 293 EBNA, MSR 293, MDCK, HaK, BHK), HeLa, HepG2, WI38, MRC 5, Colo205, HB 8065, HL-60, (e.g., BHK21), Jurkat, Daudi, A431 (epidermal), CV-1, U937, 3T3, L cell, C127 cell, SP2/0, NS-0, MMT 060562, Sertoli cell, BRL 3A cell, HT1080 cell, myeloma cell, tumor cell, and a cell line derived from an aforementioned cell. In some embodiments, the cell comprises one or more viral genes, e.g., a retinal cell that expresses a viral gene (e.g., a PER.C6.RTM. cell). In some embodiments, a host cell is or comprises an isolated cell. In some embodiments, a host cell is part of a tissue. In some embodiments, a host cell is part of an organism.
[0080] "Identity", in connection with a comparison of sequences, includes identity as determined by a number of different algorithms known in the art that can be used to measure nucleotide and/or amino acid sequence identity. In some embodiments, identities as described herein are determined using a ClustalW v. 1.83 (slow) alignment employing an open gap penalty of 10.0, an extend gap penalty of 0.1, and using a Gonnet similarity matrix (MACVECTOR.TM. 10.0.2, MacVector Inc., 2008).
[0081] "Improve", "increase", "eliminate", or "reduce" includes indicated values that are relative to a baseline measurement, such as a measurement in the same individual (or animal) prior to initiation of a treatment described herein, or a measurement in a control individual (or animal) or multiple control individuals (or animals) in the absence of the treatment described herein.
[0082] "Isolated" includes a substance and/or entity that has been (1) separated from at least some of the components with which it was associated when initially produced (whether in nature and/or in an experimental setting), and/or (2) designed, produced, prepared, and/or manufactured by the hand of man. Isolated substances and/or entities may be separated from about 10%, about 20%, about 30%, about 40%, about 50%, about 60%, about 70%, about 80%, about 90%, about 91%, about 92%, about 93%, about 94%, about 95%, about 96%, about 97%, about 98%, about 99%, or more than about 99% of the other components with which they were initially associated. In some embodiments, isolated agents are about 80%, about 85%, about 90%, about 91%, about 92%, about 93%, about 94%, about 95%, about 96%, about 97%, about 98%, about 99%, or more than about 99% pure. In some embodiments, a substance is "pure" if it is substantially free of other components. In some embodiments, as will be understood by those skilled in the art, a substance may still be considered "isolated" or even "pure", after having been combined with certain other components such as, for example, one or more carriers or excipients (e.g., buffer, solvent, water, etc.); in such embodiments, percent isolation or purity of the substance is calculated without including such carriers or excipients. To give but one example, in some embodiments, a biological polymer such as a polypeptide or polynucleotide that occurs in nature is considered to be "isolated" when: a) by virtue of its origin or source of derivation is not associated with some or all of the components that accompany it in its native state in nature; b) it is substantially free of other polypeptides or nucleic acids of the same species from the species that produces it in nature; or c) is expressed by or is otherwise in association with components from a cell or other expression system that is not of the species that produces it in nature. Thus, for instance, in some embodiments, a polypeptide that is chemically synthesized or is synthesized in a cellular system different from that which produces it in nature is considered to be an "isolated" polypeptide. Alternatively or additionally, in some embodiments, a polypeptide that has been subjected to one or more purification techniques may be considered to be an "isolated" polypeptide to the extent that it has been separated from other components: a) with which it is associated in nature; and/or b) with which it was associated when initially produced.
[0083] "Locus" or "Loci" includes a specific location(s) of a gene (or significant sequence), DNA sequence, polypeptide-encoding sequence, or position on a chromosome of the genome of an organism. For example, a "C9ORF72 locus" may refer to the specific location of a C9ORF72 gene, C9ORF72 DNA sequence, C9ORF72-encoding sequence, or C9ORF72 position on a chromosome of the genome of an organism that has been identified as to where such a sequence resides. A C9ORF72 locus may comprise a regulatory element of a C9ORF72 gene, including, but not limited to, an enhancer, a promoter, 5' and/or 3' UTR, or a combination thereof. Those of ordinary skill in the art will appreciate that chromosomes may, in some embodiments, contain hundreds or even thousands of genes and demonstrate physical co-localization of similar genetic loci when comparing between different species. Such genetic loci can be described as having shared synteny.
[0084] "Non-human animal" includes any vertebrate organism that is not a human. In some embodiments, a non-human animal is a cyclostome, a bony fish, a cartilaginous fish (e.g., a shark or a ray), an amphibian, a reptile, a mammal, and a bird. In some embodiments, a non-human mammal is a primate, a goat, a sheep, a pig, a dog, a cow, or a rodent. In some embodiments, a non-human animal is a rodent such as a rat or a mouse.
[0085] "Nucleic acid" includes any compound and/or substance that is or can be incorporated into an oligonucleotide chain. In some embodiments, a "nucleic acid" is a compound and/or substance that is or can be incorporated into an oligonucleotide chain via a phosphodiester linkage. As will be clear from context, in some embodiments, "nucleic acid" refers to individual nucleic acid residues (e.g., nucleotides and/or nucleosides); in some embodiments, "nucleic acid" refers to an oligonucleotide chain comprising individual nucleic acid residues. In some embodiments, a "nucleic acid" is or comprises RNA; in some embodiments, a "nucleic acid" is or comprises DNA. In some embodiments, a "nucleic acid" is, comprises, or consists of one or more natural nucleic acid residues. In some embodiments, a "nucleic acid" is, comprises, or consists of one or more nucleic acid analogs. In some embodiments, a nucleic acid analog differs from a "nucleic acid" in that it does not utilize a phosphodiester backbone. For example, in some embodiments, a "nucleic acid" is, comprises, or consists of one or more "peptide nucleic acids", which are known in the art and have peptide bonds instead of phosphodiester bonds in the backbone, are considered within the scope of the present invention. Alternatively or additionally, in some embodiments, a "nucleic acid" has one or more phosphorothioate and/or 5'-N-phosphoramidite linkages rather than phosphodiester bonds. In some embodiments, a "nucleic acid" is, comprises, or consists of one or more natural nucleosides (e.g., adenosine, thymidine, guanosine, cytidine, uridine, deoxyadenosine, deoxythymidine, deoxyguanosine, and deoxycytidine). In some embodiments, a "nucleic acid" is, comprises, or consists of one or more nucleoside analogs (e.g., 2-aminoadenosine, 2-thiothymidine, inosine, pyrrolo-pyrimidine, 3-methyl adenosine, 5-methylcytidine, C-5 propynyl-cytidine, C-5 propynyl-uridine, 2-aminoadenosine, C5-bromouridine, C5-fluorouridine, C5-iodouridine, C5-propynyl-uridine, C5-propynyl-cytidine, C5-methylcytidine, 2-aminoadenosine, 7-deazaadenosine, 7-deazaguanosine, 8-oxoadenosine, 8-oxoguanosine, O(6)-methylguanine, 2-thiocytidine, methylated bases, intercalated bases, and combinations thereof). In some embodiments, a "nucleic acid" comprises one or more modified sugars (e.g., 2'-fluororibose, ribose, 2'-deoxyribose, arabinose, and hexose) as compared with those in natural nucleic acids. In some embodiments, a "nucleic acid" has a nucleotide sequence that encodes a functional gene product such as an RNA or protein. In some embodiments, a "nucleic acid" includes one or more introns. In some embodiments, a "nucleic acid" includes one or more exons. In some embodiments, a "nucleic acid" is prepared by one or more of isolation from a natural source, enzymatic synthesis by polymerization based on a complementary template (in vivo or in vitro), reproduction in a recombinant cell or system, and chemical synthesis. In some embodiments, a "nucleic acid" is at least 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 20, 225, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 600, 700, 800, 900, 1000, 1500, 2000, 2500, 3000, 3500, 4000, 4500, 5000 or more residues long. In some embodiments, a "nucleic acid" is single stranded; in some embodiments, a "nucleic acid" is double stranded. In some embodiments, a "nucleic acid" has a nucleotide sequence comprising at least one element that encodes, or is the complement of a sequence that encodes, a polypeptide. In some embodiments, a "nucleic acid" has enzymatic activity.
[0086] "Operably linked" includes a juxtaposition wherein the components described are in a relationship permitting them to function in their intended manner. A control sequence "operably linked" to a coding sequence is ligated in such a way that expression of the coding sequence is achieved under conditions compatible with the control sequences. "Operably linked" sequences include both expression control sequences that are contiguous with the gene of interest and expression control sequences that act in trans or at a distance to control the gene of interest. The term "expression control sequence" includes polynucleotide sequences, which are necessary to affect the expression and processing of coding sequences to which they are ligated. "Expression control sequences" include: appropriate transcription initiation, termination, promoter and enhancer sequences; efficient RNA processing signals such as splicing and polyadenylation signals; sequences that stabilize cytoplasmic mRNA; sequences that enhance translation efficiency (i.e., Kozak consensus sequence); sequences that enhance protein stability; and when desired, sequences that enhance protein secretion. The nature of such control sequences differs depending upon the host organism. For example, in prokaryotes, such control sequences generally include promoter, ribosomal binding site and transcription termination sequence, while in eukaryotes typically such control sequences include promoters and transcription termination sequence. The term "control sequences" is intended to include components whose presence is essential for expression and processing, and can also include additional components whose presence is advantageous, for example, leader sequences and fusion partner sequences.
[0087] "Phenotype" includes a trait, or to a class or set of traits displayed by a cell or organism. In some embodiments, a particular phenotype may correlate with a particular allele or genotype. In some embodiments, a phenotype may be discrete; in some embodiments, a phenotype may be continuous.
[0088] "Physiological conditions" includes its art-understood meaning referencing conditions under which cells or organisms live and/or reproduce. In some embodiments, the term includes conditions of the external or internal milieu that may occur in nature for an organism or cell system. In some embodiments, physiological conditions are those conditions present within the body of a human or non-human animal, especially those conditions present at and/or within a surgical site. Physiological conditions typically include, e.g., a temperature range of 20-40.degree. C., atmospheric pressure of 1, pH of 6-8, glucose concentration of 1-20 mM, oxygen concentration at atmospheric levels, and gravity as it is encountered on earth. In some embodiments, conditions in a laboratory are manipulated and/or maintained at physiologic conditions. In some embodiments, physiological conditions are encountered in an organism.
[0089] "Polypeptide" includes any polymeric chain of amino acids. In some embodiments, a polypeptide has an amino acid sequence that occurs in nature. In some embodiments, a polypeptide has an amino acid sequence that does not occur in nature. In some embodiments, a polypeptide has an amino acid sequence that contains portions that occur in nature separately from one another (i.e., from two or more different organisms, for example, human and non-human portions). In some embodiments, a polypeptide has an amino acid sequence that is engineered in that it is designed and/or produced through action of the hand of man.
[0090] "Prevent" or "prevention" in connection with the occurrence of a disease, disorder, and/or condition, includes reducing the risk of developing the disease, disorder and/or condition and/or to delaying onset of one or more characteristics or symptoms of the disease, disorder or condition. Prevention may be considered complete when onset of a disease, disorder or condition has been delayed for a predefined period of time.
[0091] "Reference" includes a standard or control agent, animal, cohort, individual, population, sample, sequence or value against which an agent, animal, cohort, individual, population, sample, sequence or value of interest is compared. In some embodiments, a reference agent, animal, cohort, individual, population, sample, sequence or value is tested and/or determined substantially simultaneously with the testing or determination of the agent, animal, cohort, individual, population, sample, sequence or value of interest. In some embodiments, a reference agent, animal, cohort, individual, population, sample, sequence or value is a historical reference, optionally embodied in a tangible medium. In some embodiments, a reference may refer to a control. A "reference" also includes a "reference animal". A "reference animal" may have a modification as described herein, a modification that is different as described herein or no modification (i.e., a wild type animal). Typically, as would be understood by those skilled in the art, a reference agent, animal, cohort, individual, population, sample, sequence or value is determined or characterized under conditions comparable to those utilized to determine or characterize the agent, animal (e.g., a mammal), cohort, individual, population, sample, sequence or value of interest.
[0092] "Response" includes any beneficial alteration in a subject's condition that occurs as a result of or correlates with treatment. Such alteration may include stabilization of the condition (e.g., prevention of deterioration that would have taken place in the absence of the treatment), amelioration of symptoms of the condition, and/or improvement in the prospects for cure of the condition, etc. It may refer to a subject's response or to a neuron's response. Neuron or subject response may be measured according to a wide variety of criteria, including clinical criteria and objective criteria. Examination of the motor system of a subject may include examination of one or more of strength, tendon reflexes, superficial reflexes, muscle bulk, coordination, muscle tone, abnormal movements, station and gait. Techniques for assessing response include, but are not limited to, clinical examination, stretch flex (myotatic reflex), Hoffmann's reflex, and/or pressure tests. Methods and guidelines for assessing response to treatment are discussed in Brodal, A.: Neurological Anatomy in Relation to Clinical Medicine, ed. 2, New York, Oxford University Press, 1969; Medical Council of the U.K.: Aids to the Examination of the Peripheral Nervous System, Palo Alto, Calif., Pendragon House, 1978; Monrad-Krohn, G. H., Refsum, S.: The Clinical Examination of the Nervous System, ed. 12, London, H.K. Lewis & Co., 1964; and Wolf, J. K.: Segmental Neurology, A Guide to the Examination and Interpretation of Sensory and Motor Function, Baltimore, University Park Press, 1981. The exact response criteria can be selected in any appropriate manner, provided that when comparing groups of neurons and/or patients, the groups to be compared are assessed based on the same or comparable criteria for determining response rate. One of ordinary skill in the art will be able to select appropriate criteria.
[0093] "Risk", as will be understood from context, of a disease, disorder, and/or condition comprises likelihood that a particular individual will develop a disease, disorder, and/or condition (e.g., a radiation injury). In some embodiments, risk is expressed as a percentage. In some embodiments, risk is from 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30, 40, 50, 60, 70, 80, 90 and up to 100%. In some embodiments, risk is expressed as a risk relative to a risk associated with a reference sample or group of reference samples. In some embodiments, a reference sample or group of reference samples have a known risk of a disease, disorder, condition and/or event (e.g., a radiation injury). In some embodiments a reference sample or group of reference samples are from individuals comparable to a particular individual. In some embodiments, relative risk is 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, or more.
[0094] "Substantially" includes the qualitative condition of exhibiting total or near-total extent or degree of a characteristic or property of interest. One of ordinary skill in the biological arts will understand that biological and chemical phenomena rarely, if ever, go to completion and/or proceed to completeness or achieve or avoid an absolute result. The term "substantially" is therefore used herein to capture the potential lack of completeness inherent in many biological and chemical phenomena.
[0095] "Substantial homology" includes a comparison between amino acid or nucleic acid sequences. As will be appreciated by those of ordinary skill in the art, two sequences are generally considered to be "substantially homologous" if they contain homologous residues in corresponding positions. Homologous residues may be identical residues. Alternatively, homologous residues may be non-identical residues with appropriately similar structural and/or functional characteristics. For example, as is well known by those of ordinary skill in the art, certain amino acids are typically classified as "hydrophobic" or "hydrophilic" amino acids, and/or as having "polar" or "non polar" side chains. Substitution of one amino acid for another of the same type may often be considered a "homologous" substitution. Typical amino acid categorizations are summarized below.
TABLE-US-00002 Alanine Ala A Nonpolar Neutral 1.8 Arginine Arg R Polar Positive -4.5 Asparagine Asn N Polar Neutral -3.5 Aspartic acid Asp D Polar Negative -3.5 Cysteine Cys C Nonpolar Neutral 2.5 Glutamic acid Glu E Polar Negative -3.5 Glutamine Gln Q Polar Neutral -3.5 Glycine Gly G Nonpolar Neutral -0.4 Histidine His H Polar Positive -3.2 Isoleucine Ile I Nonpolar Neutral 4.5 Leucine Leu L Nonpolar Neutral 3.8 Lysine Lys K Polar Positive -3.9 Methionine Met M Nonpolar Neutral 1.9 Phenylalanine Phe F Nonpolar Neutral 2.8 Proline Pro P Nonpolar Neutral -1.6 Serine Ser S Polar Neutral -0.8 Threonine Thr T Polar Neutral -0.7 Tryptophan Trp W Nonpolar Neutral -0.9 Tyrosine Tyr Y Polar Neutral -1.3 Valine Val V Nonpolar Neutral 4.2 Ambiguous Amino Acids 3-Letter 1-Letter Asparagine or aspartic acid Asx B Glutamine or glutamic acid Glx Z Leucine or Isoleucine Xle J Unspecified or unknown amino acid Xaa X
[0096] As is well known in this art, amino acid or nucleic acid sequences may be compared using any of a variety of algorithms, including those available in commercial computer programs such as BLASTN for nucleotide sequences and BLASTP, gapped BLAST, and PSI-BLAST for amino acid sequences. Exemplary such programs are described in Altschul, S. F. et al., 1990, J. Mol. Biol., 215(3): 403-410; Altschul, S. F. et al., 1997, Methods in Enzymology; Altschul, S. F. et al., 1997, Nucleic Acids Res., 25:3389-3402; Baxevanis, A. D., and B. F. F. Ouellette (eds.) Bioinformatics: A Practical Guide to the Analysis of Genes and Proteins, Wiley, 1998; and Misener et al. (eds.) Bioinformatics Methods and Protocols (Methods in Molecular Biology, Vol. 132), Humana Press, 1998. In addition to identifying homologous sequences, the programs mentioned above typically provide an indication of the degree of homology. In some embodiments, two sequences are considered to be substantially homologous if at least 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% or more of their corresponding residues are homologous over a relevant stretch of residues. In some embodiments, the relevant stretch is a complete sequence. In some embodiments, the relevant stretch is at least 9, 10, 11, 12, 13, 14, 15, 16, 17 or more residues. In some embodiments, the relevant stretch includes contiguous residues along a complete sequence. In some embodiments, the relevant stretch includes discontinuous residues along a complete sequence, for example, noncontiguous residues brought together by the folded conformation of a polypeptide or a portion thereof. In some embodiments, the relevant stretch is at least 10, 15, 20, 25, 30, 35, 40, 45, 50, or more residues.
[0097] "Substantial identity" includes a comparison between amino acid or nucleic acid sequences. As will be appreciated by those of ordinary skill in the art, two sequences are generally considered to be "substantially identical" if they contain identical residues in corresponding positions. As is well known in this art, amino acid or nucleic acid sequences may be compared using any of a variety of algorithms, including those available in commercial computer programs such as BLASTN for nucleotide sequences and BLASTP, gapped BLAST, and PSI-BLAST for amino acid sequences. Exemplary such programs are described in Altschul, S. F. et al., 1990, J. Mol. Biol., 215(3): 403-410; Altschul, S. F. et al., 1997, Methods in Enzymology; Altschul, S. F. et al., 1997, Nucleic Acids Res., 25:3389-3402; Baxevanis, A. D., and B. F. F. Ouellette (eds.) Bioinformatics: A Practical Guide to the Analysis of Genes and Proteins, Wiley, 1998; and Misener et al. (eds.) Bioinformatics Methods and Protocols (Methods in Molecular Biology, Vol. 132), Humana Press, 1998. In addition to identifying identical sequences, the programs mentioned above typically provide an indication of the degree of identity. In some embodiments, two sequences are considered to be substantially identical if at least 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% or more of their corresponding residues are identical over a relevant stretch of residues. In some embodiments, the relevant stretch is a complete sequence. In some embodiments, the relevant stretch is at least 10, 15, 20, 25, 30, 35, 40, 45, 50, or more residues.
[0098] "Targeting vector," "targeting construct" or "nucleic acid construct" includes a polynucleotide molecule that comprises a targeting region. A targeting region comprises a sequence that is identical or substantially identical to a sequence in a target cell, tissue or animal and provides for integration of the targeting construct into a position within the genome of the cell, tissue or animal via homologous recombination. Targeting regions that target using site-specific recombinase recognition sites (e.g., loxP or Frt sites) are also included. In some embodiments, a targeting construct as described herein further comprises a nucleic acid sequence or gene (e.g., a reporter gene or homologous or heterologous gene) of particular interest, a selectable marker, control and or regulatory sequences, and other nucleic acid sequences that encodes a recombinase or recombinogenic protein. In some embodiments, a targeting construct may comprise a gene of interest in whole or in part, wherein the gene of interest encodes a polypeptide, in whole or in part, that has a similar function as a protein encoded by an endogenous sequence. In some embodiments, a targeting construct may comprises a humanized gene of interest, in whole or in part, wherein the humanized gene of interest encodes a polypeptide, in whole or in part, that has a similar function as a polypeptide encoded by an endogenous sequence. In some embodiments, a targeting construct may comprise a reporter gene, in whole or in part, wherein the reporter gene encodes a polypeptide that is easily identified and/or measured using techniques known in the art.
[0099] "Transgenic animal", "transgenic non-human animal" or "Tg.sup.+" includes any non-naturally occurring non-human animal in which one or more of the cells of the non-human animal contain heterologous nucleic acid and/or gene encoding a polypeptide of interest, in whole or in part. In some embodiments, a heterologous nucleic acid and/or gene is introduced into the cell, directly or indirectly by introduction into a precursor cell, by way of deliberate genetic manipulation, such as by microinjection or by infection with a recombinant virus. The term genetic manipulation does not include classic breeding techniques, but rather is directed to introduction of recombinant DNA molecule(s). This molecule may be integrated within a chromosome, or it may be extrachromosomally replicating DNA. The term "Tg.sup.+" includes animals that are heterozygous or homozygous for a heterologous nucleic acid and/or gene, and/or animals that have single or multi-copies of a heterologous nucleic acid and/or gene.
[0100] "Treatment", "Treat" or "Treating" includes any administration of a substance (e.g., a therapeutic candidate) that partially or completely alleviates, ameliorates, relives, inhibits, delays onset of, reduces severity of, and/or reduces incidence of one or more symptoms, features, and/or causes of a particular disease, disorder, and/or condition. In some embodiments, such treatment may be administered to a subject who does not exhibit signs of the relevant disease, disorder and/or condition and/or of a subject who exhibits only early signs of the disease, disorder, and/or condition. Alternatively or additionally, in some embodiments, treatment may be administered to a subject who exhibits one or more established signs of the relevant disease, disorder and/or condition. In some embodiments, treatment may be of a subject who has been diagnosed as suffering from the relevant disease, disorder, and/or condition. In some embodiments, treatment may be of a subject known to have one or more susceptibility factors that are statistically correlated with increased risk of development of the relevant disease, disorder, and/or condition.
[0101] "Variant" includes an entity that shows significant structural identity with a reference entity, but differs structurally from the reference entity in the presence or level of one or more chemical moieties as compared with the reference entity. In many embodiments, a "variant" also differs functionally from its reference entity. In general, whether a particular entity is properly considered to be a "variant" of a reference entity is based on its degree of structural identity with the reference entity. As will be appreciated by those skilled in the art, any biological or chemical reference entity has certain characteristic structural elements. A "variant", by definition, is a distinct chemical entity that shares one or more such characteristic structural elements. To give but a few examples, a small molecule may have a characteristic core structural element (e.g., a macrocycle core) and/or one or more characteristic pendent moieties so that a variant of the small molecule is one that shares the core structural element and the characteristic pendent moieties but differs in other pendent moieties and/or in types of bonds present (single vs. double, E vs. Z, etc.) within the core, a polypeptide may have a characteristic sequence element comprised of a plurality of amino acids having designated positions relative to one another in linear or three-dimensional space and/or contributing to a particular biological function, a nucleic acid may have a characteristic sequence element comprised of a plurality of nucleotide residues having designated positions relative to on another in linear or three-dimensional space. For example, a "variant polypeptide" may differ from a reference polypeptide as a result of one or more differences in amino acid sequence and/or one or more differences in chemical moieties (e.g., carbohydrates, lipids, etc.) covalently attached to the polypeptide backbone. In some embodiments, a "variant polypeptide" shows an overall sequence identity with a reference polypeptide that is at least 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, or 99%. Alternatively or additionally, in some embodiments, a "variant polypeptide" does not share at least one characteristic sequence element with a reference polypeptide. In some embodiments, the reference polypeptide has one or more biological activities. In some embodiments, a "variant polypeptide" shares one or more of the biological activities of the reference polypeptide. In some embodiments, a "variant polypeptide" lacks one or more of the biological activities of the reference polypeptide. In some embodiments, a "variant polypeptide" shows a reduced level of one or more biological activities as compared with the reference polypeptide. In many embodiments, a polypeptide of interest is considered to be a "variant" of a parent or reference polypeptide if the polypeptide of interest has an amino acid sequence that is identical to that of the parent but for a small number of sequence alterations at particular positions. Typically, fewer than 20%, 15%, 10%, 9%, 8%, 7%, 6%, 5%, 4%, 3%, or 2% of the residues in the variant are substituted as compared with the parent. In some embodiments, a "variant" has 10, 9, 8, 7, 6, 5, 4, 3, 2, or 1 substituted residue(s) as compared with a parent. Often, a "variant" has a very small number (e.g., fewer than 5, 4, 3, 2, or 1) number of substituted functional residues (i.e., residues that participate in a particular biological activity). Furthermore, a "variant" typically has not more than 5, 4, 3, 2, or 1 additions or deletions, and often has no additions or deletions, as compared with the parent. Moreover, any additions or deletions are typically fewer than about 25, about 20, about 19, about 18, about 17, about 16, about 15, about 14, about 13, about 10, about 9, about 8, about 7, about 6, and commonly are fewer than about 5, about 4, about 3, or about 2 residues. In some embodiments, the parent or reference polypeptide is one found in nature. As will be understood by those of ordinary skill in the art, a plurality of variants of a particular polypeptide of interest may commonly be found in nature, particularly when the polypeptide of interest is an infectious agent polypeptide. In some embodiments, a non-human animal will comprise a variant of a nucleic acid construct used for targeted insertion of a heterologous hexanucleotide expansion sequence. As non-limiting examples, such nucleic acid constructs may comprise a 5' first heterologous hexanucleotide flanking sequence, n repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, a 3' second heterologous hexanucleotide flanking sequence, and optionally, a drug resistance reporter gene preferably flanked by recombinase recognition sequences. As shown in Example 1, an animal resulting from the targeted insertion may comprise in an endogenous locus a variant of the nucleic acid construct, e.g., wherein the variant comprises less than n repeats of the hexanucleotide sequence set forth as SEQ ID NO:1 and/or lacks the drug resistance gene, see, e.g., FIGS. 1B and 1C. Accordingly, a variant of a sequence included herein includes sequences essentially identical to the reference parent sequence, but lacking one or more repeats and/or drug resistance gene(s).
[0102] "Vector" includes a nucleic acid molecule capable of transporting another nucleic acid to which it is associated. In some embodiment, vectors are capable of extra-chromosomal replication and/or expression of nucleic acids to which they are linked in a host cell such as a eukaryotic and/or prokaryotic cell. Vectors capable of directing the expression of operably linked genes are referred to herein as "expression vectors."
[0103] "Wild type" includes an entity having a structure and/or activity as found in nature in a "normal" (as contrasted with mutant, diseased, altered, etc.) state or context. Those of ordinary skill in the art will appreciate that wild type genes and polypeptides often exist in multiple different forms (e.g., alleles).
DETAILED DESCRIPTION OF CERTAIN EMBODIMENTS
[0104] Non-human animals are provided having an insertion of a heterologous hexanucleotide repeat expansion sequence in an endogenous C9ORF72 locus. In some embodiments, non-human animals described herein are heterozygous for a modified C9ORF72 locus as described herein. In some embodiments, non-human animals as described herein comprise a first modified C9orf72 locus and a second modified C9orf72 locus, wherein the first and second loci are different. In some embodiments, non-human animals described herein are homozygous for a modified C9ORF72 locus as described herein. In some embodiments, non-human animals described herein develop ALS- and/or FTD-like disease due to the presence of the heterologous hexanucleotide repeat expansion sequence.
[0105] Various aspects of the invention are described in detail in the following sections. The use of sections is not meant to limit the invention. Each section can apply to any aspect of the invention. In this application, the use of "or" means "and/or" unless stated otherwise.
C9ORF72
[0106] Amyotrophic lateral sclerosis (ALS), also referred to as Lou Gehrig's disease, is the most frequent adult-onset paralytic disorder, characterized by the loss of upper and/or lower motor neurons. ALS occurs in as many as 20,000 individuals across the United States with about 5,000 new cases occurring each year. Frontotemporal dementia (FTD), originally referred to as Pick's disease after physician Arnold Pick, is a group of disorders caused by progressive cell degeneration in the frontal or temporal lobes of the brain. FTD is reported to count for 10-15% of all dementia cases. A hexanucleotide repeat expansion sequence between (and optionally spanning) exons 1a and 1b, two non-coding exons, of the human C9ORF72 gene have been linked to both ALS and FTD (DeJesus-Hernandez, M. et al., 2011, Neuron 72:245-256; Renton, A. E. et al., 2011, Neuron 72:257-268; Majounie, E. et al., 2012, Lancet Neurol. 11:323-330; Waite, A. J. et al., 2014, Neurobiol. Aging 35:1779.e5-1779.e13). It is estimated that the GGGGCC (SEQ ID NO:1) hexanucleotide repeat expansion accounts for about 50% of familial and many non-familial ALS cases. It is present in about 25% of familial FTD cases and about 8% of sporadic.
[0107] Many pathological aspects related to the hexanucleotide repeat expansion sequence in C9ORF72 have been reported such as, for example, repeat length-dependent formation of RNA foci, sequestration of specific RNA-binding proteins, and accumulation and aggregation of dipeptide repeat proteins (e.g., reviewed in Stepto, A. et al., 2014, Acta Neuropathol. 127:377-389; see also Almeida, S. et al., 2013, Acta Neuropathol. 126:385-399; Bieniek, K. F. et al., 2014, JAMA Neurol. 71(6): 775-781; van Blitterswijk, M. et al., 2014, Mol. Neurodegen. 9:38, 10 pages). Knock-in mice that have been generated to contain a heterologous hexanucleotide repeat expansion sequence comprising 66 repeats of the hexanucleotide sequence (GGGGCC; SEQ ID NO:1) exhibit RNA foci and dipeptide protein aggregates in their neurons. These mice showed cortical neuron loss and exhibited behavior and motor deficits at 6 months of age (Chew, J. et al., 2015, Science May 14. Pii:aaa9344). However, the mechanism through which such repeat expansions cause disease, whether through a loss- or gain-of-function of toxicity, remains unclear. Additionally, the contribution of a lower number of repeats in the hexanucleotide repeat expansion sequence to ALS/FTD is also unknown.
[0108] Although C9ORF72 has been reported to regulate endosomal trafficking (Farg, M. A. et al., 2014, Human Mol. Gen. 23(13):3579-3595), much of the cellular function of C9ORF72 remains unknown. Indeed, C9ORF72 is a gene that encodes an uncharacterized protein with unknown function. Despite the lack of understanding surrounding C9ORF72, several animal models, including engineered cell lines, for ALS and/or FTD have been developed (Roberson, E. D., 2012, Ann. Neurol. 72(6):837-849; Panda, S. K. et al., 2013, Genetics 195:703-715; Suzuki, N. et al., 2013, Nature Neurosci. 16(12):1725-1728; Xu, Z. et al., 2013, Proc. Nat. Acad. Sci. U.S.A. 110(19):7778-7783; Hukema, R. K. et al., 2014, Acta Neuropathol. Comm. 2:166, 4 pages). Another report using a transgenic mouse strain containing a heterologous hexanucleotide repeat expansion sequence comprising 80 GGGGCC repeats operably linked with a fluorescent reporter and controlled by a tetracycline responsive element without any surrounding C9orf72 sequences demonstrated neuronal cytoplasmic inclusions similar to those seen in ALS-FTD patients, which suggests that expanded repeats of the hexanucleotide GGGGCC sequence itself may be responsible for disease (Hukema, R. K. et al., 2014, Acta Neuropathol. Comm. 2:166, 4 pages). These mice have been useful to establish an initial C9orf72 expression profile in cells of the CNS and provide some understanding of the mechanism of action associated with the repeat expansion; however, construct design can influence the phenotype of the resulting transgenic animal (see, e.g., Muller, U., 1999, Mech. Develop. 81:3-21). For example, a transgenic mouse strain containing an inducible GGGGCC repeat (Hukema, 2014, supra) was designed without human flanking sequence presumably due to the fact that such surrounding sequence was thought to affect translation of repeat sequences. Thus, such in vivo systems exploiting C9ORF72-mediated biology for therapeutic applications are incomplete.
C9ORF72 and Hexanucleotide Repeat Expansion Sequences
[0109] Mouse C9ORF72 transcript variants have been reported in the art (e.g., Koppers et al., Ann Neurol (2015); 78: 426-438; Atkinson et al., Acta Neuropathologica Communications (2015) 3: 59), and are also depicted in FIG. 1A. The genomic information for the three reported mouse C9ORF72 transcript variants is also available at the Ensembl web site under designations of ENSMUST00000108127 (V1), ENSMUST00000108126 (V2), and ENSMUST00000084724 (V3). Exemplary non-human (e.g., rodent) C9ORF72 mRNA and amino acid sequences are set forth in Table 2. For mRNA sequences, bold font contained within parentheses indicates coding sequence and consecutive exons, where indicated, are separated by alternating lower and upper case letters. For amino acid sequences, mature polypeptide sequences, where indicated, are in bold font.
[0110] Human C9ORF72 transcript variants are known in the art. One human C9ORF72 transcript variant lacks multiple exons in the central and 3' coding regions, and its 3' terminal exon extends beyond a splice site that is used in variant 3 (see below), which results in a novel 3' untranslated region (UTR) as compared to variant 3. This variant encodes a significantly shorter polypeptide and its C-terminal amino acid is distinct as compared to that which is encoded by two other variants. The mRNA and amino acid sequences of this variant can be found at GenBank accession numbers NM_145005.6 and NP_659442.2, respectively, and are hereby incorporated by reference. The sequences of NM_145005.6 and NP_659442.2 are respectively set forth as SEQ ID NO:10 and SEQ ID NO:11. A second human C9ORF72 transcript variant (2) differs in the 5' untranslated region (UTR) compared to variant 3. The mRNA and amino acid sequences of this variant can be found at GenBank accession numbers NM_018325.4 and NP_060795.1, respectively, and are hereby incorporated by reference. The sequences of NM_018325.4 and NP_060795.1 are respectively set forth as SEQ ID NO:12 and SEQ ID NO:13. A third human C9ORF72 transcript variant (3) contains the longest sequence among three reported variants and encodes the longer isoform. The mRNA and amino acid sequences of this variant can be found at GenBank accession numbers NM_001256054.2 and NP_001242983.1, respectively, and are hereby incorporated by reference. The sequences of NM_001256054.2 and NP_001242983.1 are respectively set forth as SEQ ID NO:14 and SEQ ID NO:15. Variants 2 and 3 encode the same protein.
[0111] A hexanucleotide repeat expansion sequence is generally a nucleotide sequence comprising at least one instance, e.g., one repeat, of the hexanucleotide sequence GGGGCC set forth as SEQ ID NO:1. For purposes of insertion into an endogenous non-human C9orf72 locus, a heterologous hexanucleotide repeat expansion sequence comprises at least one instance (repeat) and preferably more than one instance (repeat) of the hexanucleotide sequence set forth as SEQ ID NO:1 and may be identical to, or substantially identical to a genomic nucleic acid sequence spanning (and optionally including) non-coding exons 1a and 1b of a human `chromosome 9 open reading frame 72` (C9orf72), or a portion thereof. Non-limiting examples of heterologous hexanucleotide expansion sequences include the sequences set forth as SEQ ID NO:1, SEQ ID NO:2 (comprising three repeats of the GGGGCC hexanucleotide sequence) and SEQ ID NO:3 (comprising 100 repeats of the GGGGCC hexanucleotide sequence).
TABLE-US-00003 TABLE 2 Mus musculus C9orf72 mRNA (NM_001081343; SEQ ID NO: 16) gtgtccggggcggggcggtcccggggcggggcccggagcgg gctgcggttgcggtccctgcgccggcggtgaaggcgcagca gcggcgagtggCTATTGCAAGCGTTCGGATAATGTGAGACC TGGAATGCAGTGAGACCTGGGATGCAGGG(ATGTCGACTAT CTGCCCCCCACCATCTCCTGCTGTTGCCAAGACAGAGATTG CTTTAAGTGGTGAATCACCCTTGTTGGCGGCTACCTTTGCT TACTGGGATAATATTCTTGGTCCTAGAGTAAGGCATATTTG GGCTCCAAAGACAGACCAAGTGCTTCTCAGTGATGGAGAAA TAACTTTTCTTGCCAACCACACTCTAAATGGAGAAATTCTT CGAAATGCAGAGAGTGGGGCTATAGATGTAAAATTTTTTGT CTTATCTGAAAAAGGGGTAATTATTGTTTCATTAATCTTCG ACGGAAACTGGAATGGAGATCGGAGCACTTATGGACTATCA ATTATACTGCCGCAGACAGAGCTGAGCTTCTACCTCCCACT TCACAGAGTGTGTGTTGACAGGCTAACACACATTATTCGAA AAGGAAGAATATGGATGCATAAGgaaagacaagaaaatgtc cagaaaattgtcttggaaggcacagagaggatggaagatca gGGTCAGAGTATCATTCCCATGCTTACTGGGGAAGTCATTC CTGTAATGGAGCTGCTTGCATCTATGAAATCCCACAGTGTT CCTGAAGACATTGATatagctgatacagtgctcaatgatga tgacattggtgacagctgtcacgaaggctttcttctcaaTG CCATCAGCTCACACCTGCAGACCTGTGGCTGTTCCGTTGTA GTTGGCAGCAGTGCAGAGAAAGTAAATAAGatagtaagaac gctgtgcctttttctgacaccagcagagaggaaatgctcca ggctgtgtgaagcagaatcgtcctttaagtacgaatcggga ctctttgtgcaaggcttgctaaagGATGCAACAGGCAGTTT TGTCCTACCCTTCCGGCAAGTTATGTATGCCCCGTACCCCA CCACGCACATTGATGTGGATGTCAACACTGTCAAGCAGATG CCACCGTGTCATGAACATATTTATAATCAACGCAGATACAT GAGGTCAGAGCTGACAGCCTTCTGGAGGGCAACTTCAGAAG AGGACATGGCGCAGGACACCATCATCTACACAGATGAGAGC TTCACTCCTGATTTgaatattttccaagatgtcttacacag agacactctagtgaaagccttcctggatcagGTCTTCCATT TGAAGCCTGGCCTGTCTCTCAGGAGTACTTTCCTTGCACAG TTCCTCCTCATTCTTCACAGAAAAGCCTTGACACTAATCAA GTACATCGAGGATGATACgcagaaggggaaaaagcccttta agtctcttcggaacctgaagatagatcttgatttaacagca gagggcgatcttaacataataatggctctagctgagaaaat taagccaggcctacactctttcatctttgggagacctttct acactagtgtacaagaacgtgatgttctaatgaccttttg a)ccgtgtggtttgctgtgtctgtctcttcacagtcacacc tgctgttacagtgtctcagcagtgtgtgggcacatccttcc tcccgagtcctgctgcaggacagggtacactacacttgtca gtagaagtctgtacctgatgtcaggtgcatcgttacagtga atgactcttcctagaatagatgtactcttttagggccttat gtttacaattatcctaagtactattgctgtcttttaaagat atgaatgatggaatatacacttgaccataactgctgattgg ttttttgttttgttttgtttgttttcttggaaacttatgat tcctggtttacatgtaccacactgaaaccctcgttagcttt acagataaagtgtgagttgacttcctgcccctctgtgttct gtggtatgtccgattacttctgccacagctaaacattagag catttaaagtttgcagttcctcagaaaggaacttagtctga ctacagattagttcttgagagaagacactgatagggcagag ctgtaggtgaaatcagttgttagcccttcctttatagacgt agtccttcagattcggtctgtacagaaatgccgaggggtca tgcatgggccctgagtatcgtgacctgtgacaagttttttg ttggtttattgtagttctgtcaaagaaagtggcatttgttt ttataattgttgccaacttttaaggttaattttcattattt ttgagccgaattaaaatgcgcacctcctgtgcctttcccaa tcttggaaaatataatttcttggcagagggtcagatttcag ggcccagtcactttcatctgaccaccctttgcacggctgcc gtgtgcctggcttagattagaagtccttgttaagtatgtca gagtacattcgctgataagatctttgaagagcagggaagcg tcttgcctctttcctttggtttctgcctgtactctggtgtt tcccgtgtcacctgcatcataggaacagcagagaaatctga cccagtgctatttttctaggtgctactatggcaaactcaag tggtctgtttctgttcctgtaacgttcgactatctcgctag ctgtgaagtactgattagtggagttctgtgcaacagcagtg taggagtatacacaaacacaaatatgtgtttctatttaaaa ctgtggacttagcataaaaagggagaatatatttatttttt acaaaagggataaaaatgggccccgttcctcacccaccaga tttagcgagaaaaagctttctattctgaaaggtcacggtgg ctttggcattacaaatcagaacaacacacactgaccatgat ggcttgtgaactaactgcaaggcactccgtcatggtaagcg agtaggtcccacctcctagtgtgccgctcattgctttacac agtagaatcttatttgagtgctaattgttgtctttgctgct ttactgtgttgttatagaaaatgtaagctgtacagtgaata agttattgaagcatgtgtaaacactgttatatatcttttct cctagatggggaattttgaataaaatacctttgaaattctg tgt Mus musculus C9orf72 amino acid (NP_001074812; SEQ ID NO: 17) MSTICPPPSPAVAKTEIALSGESPLLAATFAYWDNILGPRV RHIWAPKTDQVLLSDGEITFLANHTLNGEILRNAESGAIDV KFFVLSEKGVIIVSLIFDGNWNGDRSTYGLSIILPQTELSF YLPLHRVCVDRLTHIIRKGRIWMHKERQENVQKIVLEGTER MEDQGQSIIPMLTGEVIPVMELLASMKSHSVPEDIDIADTV LNDDDIGDSCHEGFLLNAISSHLQTCGCSVVVGSSAEKVNK IVRTLCLFLTPAERKCSRLCEAESSFKYESGLFVQGLLKDA TGSFVLPFRQVMYAPYPTTHIDVDVNTVKQMPPCHEHIYNQ RRYMRSELTAFWRATSEEDMAQDTIIYTDESFTPDLNIFQD VLHRDTLVKAFLDQVFHLKPGLSLRSTFLAQFLLILHRKAL TLIKYIEDDTQKGKKPFKSLRNLKIDLDLTAEGDLNIIMAL AEKIKPGLHSFIFGRPFYTSVQERDVLMTF Rattus norvegicus C9orf72 mRNA (NM_001007702; SEQ ID NO: 18) CGTTTGTAGTGTCAGCCATCCCAATTGCCTGTTCCTTCTCT GTGGGAGTGGTGTCTAGACAGTCCAGGCAGGGTATGCTAGG CAGGTGCGTTTTGGTTGCCTCAGATCGCAACTTGACTCCAT AACGGTGACCAAAGACAAAAGAAGGAAACCAGATTAAAAAG AACCGGACACAGACCCCTGCAGAATCTGGAGCGGCCGTGGT TGGGGGCGGGGCTACGACGGGGCGGACTCGGGGGCGTGGGA GGGCGGGGCCGGGGCGGGGCCCGGAGCCGGCTGCGGTTGCG GTCCCTGCGCCGGCGGTGAAGGCGCAGCGGCGGCGAGTGGC TATTGCAAGCGTTTGGATAATGTGAGACCTGGGATGCAGG G(ATGTCGACTATCTGCCCCCCACCATCTCCTGCTGTTGCC AAGACAGAGATTGCTTTAAGTGGTGAATCACCCTTGTTGGC GGCTACCTTTGCTTACTGGGATAATATTCTTGGTCCTAGAG TAAGGCACATTTGGGCTCCAAAGACAGACCAAGTACTCCTC AGTGATGGAGAAATCACTTTTCTTGCCAACCACACTCTGAA TGGAGAAATTCTTCGGAATGCGGAGAGTGGGGCAATAGATG TAAAGTTTTTTGTCTTATCTGAAAAGGGCGTCATTATTGTT TCATTAATCTTCGACGGGAACTGGAACGGAGATCGGAGCAC TTACGGACTATCAATTATACTGCCGCAGACGGAGCTGAGTT TCTACCTCCCACTGCACAGAGTGTGTGTTGACAGGCTAACG CACATCATTCGAAAAGGAAGGATATGGATGCACAAGGAAAG ACAAGAAAATGTCCAGAAAATTGTCTTGGAAGGCACCGAGA GGATGGAAGATCAGGGTCAGAGTATCATCCCTATGCTTACT GGGGAGGTCATCCCTGTGATGGAGCTGCTTGCGTCTATGAG ATCACACAGTGTTCCTGAAGACCTCGATATAGCTGATACAG TACTCAATGATGATGACATTGGTGACAGCTGTCATGAAGGC TTTCTTCTCAATGCCATCAGCTCACATCTGCAGACCTGCGG CTGTTCTGTGGTGGTAGGCAGCAGTGCAGAGAAAGTAAATA AGATAGTAAGAACACTGTGCCTTTTTCTGACACCAGCAGAG AGGAAGTGCTCCAGGCTGTGTGAAGCCGAATCGTCCTTTAA ATACGAATCTGGACTCTTTGTACAAGGCTTGCTAAAGGATG CGACTGGCAGTTTTGTACTACCTTTCCGGCAAGTTATGTAT GCCCCTTATCCCACCACACACATCGATGTGGATGTCAACAC TGTCAAGCAGATGCCACCGTGTCATGAACATATTTATAATC AACGCAGATACATGAGGTCAGAGCTGACAGCCTTCTGGAGG GCAACTTCAGAAGAGGACATGGCTCAGGACACCATCATCTA CACAGATGAGAGCTTCACTCCTGATTTGAATATTTTCCAAG ATGTCTTACACAGAGACACTCTAGTGAAAGCCTTTCTGGAT CAGGTCTTCCATTTGAAGCCTGGCCTGTCTCTCAGGAGTAC TTTCCTTGCACAGTTCCTCCTCATTCTTCACAGAAAAGCCT TGACACTAATCAAGTACATAGAGGATGACACGCAGAAGGGG AAAAAGCCCTTTAAGTCTCTTCGGAACCTGAAGATAGATCT TGATTTAACAGCAGAGGGCGACCTTAACATAATAATGGCTC TAGCTGAGAAAATTAAGCCAGGCCTACACTCTTTCATCTTC GGGAGACCTTTCTACACTAGTGTCCAAGAACGTGATGTTCT AATGACTTTTTAA)ACATGTGGTTTGCTCCGTGTGTCTCAT GACAGTCACACTTGCTGTTACAGTGTCTCAGCGCTTTGGAC ACATCCTTCCTCCAGGGTCCTGCCGCAGGACACGTTACACT ACACTTGTCAGTAGAGGTCTGTACCAGATGTCAGGTACATC GTTGTAGTGAATGTCTCTTTTCCTAGACTAGATGTACCCTC GTAGGGACTTATGTTTACAACCCTCCTAAGTACTAGTGCTG TCTTGTAAGGATACGAATGAAGGGATGTAAACTTCACCACA ACTGCTGGTTGGTTTTGTTGTTTTTGTTTTTTGAAACTTAT AATTCATGGTTTACATGCATCACACTGAAACCCTAGTTAGC TTTTTACAGGTAAGCTGTGAGTTGACTGCCTGTCCCTGTGT TCTCTGGCCTGTACGATCTGTGGCGTGTAGGATCACTTTTG CAACAACTAAAAACTAAAGCACTTTGTTTGCAGTTCTACAG AAAGCAACTTAGTCTGTCTGCAGATTCGTTTTTGAAAGAAG ACATGAGAAAGCGGAGTTTTAGGTGAAGTCAGTTGTTGGAT CTTCCTTTATAGACTTAGTCCTTTAGATGTGGTCTGTATAG ACATGCCCAACCATCATGCATGGGCACTGAATATCGTGAAC TGTGGTATGCTTTTTGTTGGTTTATTGTACTTCTGTCAAAG AAAGTGGCATTGGTTTTTATAATTGTTGCCAAGTTTTAAGG TTAATTTTCATTATTTTTGAGCCAAATTAAAATGTGCACCT CCTGTGCCTTTCCCAATCTTGGAAAATATAATTTCTTGGCA GAAGGTCAGATTTCAGGGCCCAGTCACTTTCGTCTGACTTC CCTTTGCACAGTCCGCCATGGGCCTGGCTTAGAAGTTCTTG TAAACTATGCCAGAGAGTACATTCGCTGATAAAATCTTCTT TGCAGAGCAGGAGAGCTTCTTGCCTCTTTCCTTTCATTTCT GCCTGGACTTTGGTGTTCTCCACGTTCCCTGCATCCTAAGG ACAGCAGGAGAACTCTGACCCCAGTGCTATTTCTCTAGGTG CTATTGTGGCAAACTCAAGCGGTCCGTCTCTGTCCCTGTAA CGTTCGTACCTTGCTGGCTGTGAAGTACTGACTGGTAAAGC TCCGTGCTACAGCAGTGTAGGGTATACACAAACACAAGTAA GTGTTTTATTTAAAACTGTGGACTTAGCATAAAAAGGGAGA CTATATTTATTTTTTACAAAAGGGATAAAAATGGAACCCTT TCCTCACCCACCAGATTTAGTCAGAAAAAAACATTCTATTC TGAAAGGTCACAGTGGTTTTGACATGACACATCAGAACAAC GCACACTGTCCATGATGGCTTATGAACTCCAAGTCACTCCA TCATGGTAAATGGGTAGATCCCTCCTTCTAGTGTGCCACAC CATTGCTTCCCACAGTAGAATCTTATTTAAGTGCTAAGTGT TGTCTCTGCTGGTTTACTCTGTTGTTTTAGAGAATGTAAGT TGTATAGTGAATAAGTTATTGAAGCATGTGTAAACACTGTT ATACATCTTTTCTCCTAGATGGGGAATTTGGAATAAAATAC CTTTAAAATTCAAAAAAAAAAAAAAAAAAAAAAAA Rattus norvegicus C9orf72 amino acid (NP_001007703; SEQ ID NO: 19) MSTICPPPSPAVAKTEIALSGESPLLAATFAYWDNILGPRV RHIWAPKTDQVLLSDGEITFLANHTLNGEILRNAESGAIDV KFFVLSEKGVIIVSLIFDGNWNGDRSTYGLSIILPQTELSF YLPLHRVCVDRLTHIIRKGRIWMHKERQENVQKIVLEGTER MEDQGQSIIPMLTGEVIPVMELLASMRSHSVPEDLDIADTV LNDDDIGDSCHEGFLLNAISSHLQTCGCSVVVGSSAEKVNK IVRTLCLFLTPAERKCSRLCEAESSFKYESGLFVQGLLKDA TGSFVLPFRQVMYAPYPTTHIDVDVNTVKQMPPCHEHIYNQ RRYMRSELTAFWRATSEEDMAQDTIIYTDESFTPDLNIFQD VLHRDTLVKAFLDQVFHLKPGLSLRSTFLAQFLLILHRKAL TLIKYIEDDTQKGKKPFKSLRNLKIDLDLTAEGDLNIIMAL AEKIKPGLHSFIFGRPFYTSVQERDVLMTF
C9ORF72 Targeting Vectors and Production of Non-Human Animals Having a Heterologous Hexanucleotide Repeat Expansion Sequence Inserted in a C9ORF72 Locus
[0112] Provided herein are targeting vectors or targeting constructs for the production of non-human animals having a heterologous hexanucleotide expansion sequence inserted into an endogenous C9ORF72 locus as described herein.
[0113] A. Large Targeting Vectors
[0114] In cells other than one-cell stage embryos, a targeting vector that is a "large targeting vector" or "LTVEC" can be used, which includes targeting vectors that comprise homology arms that correspond to and are derived from nucleic acid sequences larger than those typically used by other approaches intended to perform homologous recombination in cells. LTVECs also include targeting vectors comprising nucleic acid inserts having nucleic acid sequences larger than those typically used by other approaches intended to perform homologous recombination in cells. For example, LTVECs make possible the modification of large loci that cannot be accommodated by traditional plasmid-based targeting vectors because of their size limitations. For example, the targeted locus can be (i.e., the 5' and 3' homology arms can correspond to a locus of the cell that is not targetable using a conventional method or that can be targeted only incorrectly or only with significantly low efficiency in the absence of a nick or double-strand break induced by a nuclease agent (e.g., a Cas protein).
[0115] A targeting vector includes homology arms. If the targeting vector also comprises a nucleic acid insert, the homology arms can flank the nucleic acid insert. For ease of reference, the homology arms are referred to herein as 5' and 3' (i.e., upstream and downstream) homology arms. This terminology relates to the relative position of the homology arms to the nucleic acid insert within the exogenous repair template. The 5' and 3' homology arms correspond to regions within the genomic region of interest, which are referred to herein as "5' target sequence" and "3' target sequence," respectively.
[0116] A homology arm and a target sequence "correspond" or are "corresponding" to one another when the two regions share a sufficient level of sequence identity to one another to act as substrates for a homologous recombination reaction. The term "homology" includes DNA sequences that are either identical or share sequence identity to a corresponding sequence. The sequence identity between a given target sequence and the corresponding homology arm found in the exogenous repair template can be any degree of sequence identity that allows for homologous recombination to occur. For example, the amount of sequence identity shared by the homology arm of the exogenous repair template (or a fragment thereof) and the target sequence (or a fragment thereof) can be at least 50%, 55%, 60%, 65%, 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% or 100% sequence identity, such that the sequences undergo homologous recombination. A corresponding region of homology between the homology arm and the corresponding target sequence can be of any length that is sufficient to promote homologous recombination. The homology arms can be symmetrical (each about the same size in length), or they can be asymmetrical (one longer than the other).
[0117] The homology arms can correspond to a locus that is native to a cell (e.g., the targeted locus). Alternatively, for example, they can correspond to a region of a heterologous or exogenous segment of DNA that was integrated into the genome of the cell, including, for example, transgenes, expression cassettes, or heterologous or exogenous regions of DNA. Alternatively, the homology arms of the targeting vector can correspond to a region of a yeast artificial chromosome (YAC), a bacterial artificial chromosome (BAC), a human artificial chromosome, or any other engineered region contained in an appropriate host cell. Still further, the homology arms of the targeting vector can correspond to or be derived from a region of a BAC library, a cosmid library, or a P1 phage library, or can be derived from synthetic DNA.
[0118] Examples of LTVECs include vectors derived from a bacterial artificial chromosome (BAC), a human artificial chromosome, or a yeast artificial chromosome (YAC). Non-limiting examples of LTVECs and methods for making them are described, e.g., in U.S. Pat. Nos. 6,586,251; 6,596,541; and 7,105,348; and in WO 2002/036789, each of which is herein incorporated by reference in its entirety for all purposes. LTVECs can be in linear form or in circular form.
[0119] LTVECs can be of any length and are typically at least 10 kb in length. For example, an LTVEC can be from about 50 kb to about 500 kb, from about 50 kb to about 75 kb, from about 75 kb to about 100 kb, from about 100 kb to about 125 kb, from about 125 kb to about 150 kb, from about 150 kb to about 175 kb, from about 175 kb to about 200 kb, from about 200 kb to about 225 kb, from about 225 kb to about 250 kb, from about 250 kb to about 275 kb, from about 275 kb to about 300 kb, from about 300 kb to about 325 kb, from about 325 kb to about 350 kb, from about 350 kb to about 375 kb, from about 375 kb to about 400 kb, from about 400 kb to about 425 kb, from about 425 kb to about 450 kb, from about 450 kb to about 475 kb, or from about 475 kb to about 500 kb. Alternatively, an LTVEC can be at least 10 kb, at least 15 kb, at least 20 kb, at least 30 kb, at least 40 kb, at least 50 kb, at least 60 kb, at least 70 kb, at least 80 kb, at least 90 kb, at least 100 kb, at least 150 kb, at least 200 kb, at least 250 kb, at least 300 kb, at least 350 kb, at least 400 kb, at least 450 kb, or at least 500 kb or greater. The size of an LTVEC can be too large to enable screening of targeting events by conventional assays, e.g., southern blotting and long-range (e.g., 1 kb to 5 kb) PCR.
[0120] The sum total of the 5' homology arm and the 3' homology arm in an LTVEC is typically at least 10 kb. As an example, the 5' homology arm can range from about 5 kb to about 150 kb and/or the 3' homology arm can range from about 5 kb to about 150 kb. Each homology arm can be, for example, from about 5 kb to about 10 kb, from about 10 kb to about 20 kb, from about 20 kb to about 30 kb, from about 30 kb to about 40 kb, from about 40 kb to about 50 kb, from about 50 kb to about 60 kb, from about 60 kb to about 70 kb, from about 70 kb to about 80 kb, from about 80 kb to about 90 kb, from about 90 kb to about 100 kb, from about 100 kb to about 110 kb, from about 110 kb to about 120 kb, from about 120 kb to about 130 kb, from about 130 kb to about 140 kb, from about 140 kb to about 150 kb, from about 150 kb to about 160 kb, from about 160 kb to about 170 kb, from about 170 kb to about 180 kb, from about 180 kb to about 190 kb, or from about 190 kb to about 200 kb. The sum total of the 5' and 3' homology arms can be, for example, from about 10 kb to about 20 kb, from about 20 kb to about 30 kb, from about 30 kb to about 40 kb, from about 40 kb to about 50 kb, from about 50 kb to about 60 kb, from about 60 kb to about 70 kb, from about 70 kb to about 80 kb, from about 80 kb to about 90 kb, from about 90 kb to about 100 kb, from about 100 kb to about 110 kb, from about 110 kb to about 120 kb, from about 120 kb to about 130 kb, from about 130 kb to about 140 kb, from about 140 kb to about 150 kb, from about 150 kb to about 160 kb, from about 160 kb to about 170 kb, from about 170 kb to about 180 kb, from about 180 kb to about 190 kb, from about 190 kb to about 200 kb, from about 200 kb to about 250 kb, from about 250 kb to about 300 kb, from about 300 kb to about 350 kb, or from about 350 kb to about 400 kb. Alternatively, each homology arm can be at least 5 kb, at least 10 kb, at least 15 kb, at least 20 kb, at least 30 kb, at least 40 kb, at least 50 kb, at least 60 kb, at least 70 kb, at least 80 kb, at least 90 kb, at least 100 kb, at least 110 kb, at least 120 kb, at least 130 kb, at least 140 kb, at least 150 kb, at least 160 kb, at least 170 kb, at least 180 kb, at least 190 kb, or at least 200 kb. Likewise, the sum total of the 5' and 3' homology arms can be at least 10 kb, at least 15 kb, at least 20 kb, at least 30 kb, at least 40 kb, at least 50 kb, at least 60 kb, at least 70 kb, at least 80 kb, at least 90 kb, at least 100 kb, at least 110 kb, at least 120 kb, at least 130 kb, at least 140 kb, at least 150 kb, at least 160 kb, at least 170 kb, at least 180 kb, at least 190 kb, at least 200 kb, at least 250 kb, at least 300 kb, at least 350 kb, or at least 400 kb.
[0121] LTVECs can comprise nucleic acid inserts having nucleic acid sequences larger than those typically used by other approaches intended to perform homologous recombination in cells. For example, an LTVEC can comprise a nucleic acid insert ranging from about 1 kb to about 5 kb, from about 5 kb to about 10 kb, from about 10 kb to about 20 kb, from about 20 kb to about 40 kb, from about 40 kb to about 60 kb, from about 60 kb to about 80 kb, from about 80 kb to about 100 kb, from about 100 kb to about 150 kb, from about 150 kb to about 200 kb, from about 200 kb to about 250 kb, from about 250 kb to about 300 kb, from about 300 kb to about 350 kb, from about 350 kb to about 400 kb, from about 400 kb to about 450 kb, from about 450 kb to about 500 kb, or greater. Alternatively, the nucleic acid insert can be at least 1 kb, at least 5 kb, at least 10 kb, at least 20 kb, at least 30 kb, at least 40 kb, at least 60 kb, at least 80 kb, at least 100 kb, at least 150 kb, at least 200 kb, at least 250 kb, at least 300 kb, at least 350 kb, at least 400 kb, at least 450 kb, or at least 500 kb.
[0122] B. Construction of Large Targeting Vectors
[0123] Many of the techniques used to construct targeting vectors described herein are standard molecular biology techniques well known to the skilled artisan (see, e.g., Sambrook, J., E. F. Fritsch and T. Maniatis. Molecular Cloning: A Laboratory Manual, Second Edition, Vols. 1, 2, and 3, 1989; Current Protocols in, Molecular Biology, Eds. Ausubel et al., Greene Publ. Assoc., Wiley Interscience, NY). Any methods known in the art for constructing large targeting vectors can be used.
[0124] In one example, the method for constructing a large targeting vector (LTVEC) comprises: (a) obtaining a large genomic DNA clone containing the gene/genes or chromosomal locus/loci of interest; and (b) appending homology boxes 1 and 2 to a modification cassette to generate the LTVEC. Optionally, such methods can further comprise verifying that each LTVEC has been engineered correctly. Optionally, such methods can further comprise purification, preparation, and linearization of LTVEC DNA for introduction into eukaryotic cells. Such methods are further described in US 2004/0018626, US 2013/0309670, and WO 2013/163394, each of which is herein incorporated by reference in its entirety for all purposes.
[0125] Genes or loci of interest can be selected based on specific criteria, such as detailed structural or functional data, or they can be selected in the absence of such detailed information as potential genes or gene fragments become predicted through the efforts of the various genome sequencing projects. It is not necessary to know the complete sequence and gene structure of a gene or locus of interest to produce LTVECs. The only sequence information that is required is approximately 80-100 nucleotides so as to obtain the genomic clone of interest as well as to generate the homology boxes used in making the LTVEC and to make probes for use in quantitative modification-of-allele (MOA) assays.
[0126] Once a gene or locus of interest has been selected, a large genomic clone containing this gene or locus can be obtained. This clone can be obtained in any one of several ways including, but not limited to, screening suitable DNA libraries (e.g., BAC, PAC, YAC, or cosmid) by standard hybridization or PCR techniques, or by any other methods familiar to the skilled artisan.
[0127] Homology boxes mark the sites of bacterial homologous recombination that are used to generate LTVECs from large cloned genomic fragments. Homology boxes are short segments of DNA, generally double-stranded and at least 40 nucleotides in length, that are homologous to regions within the large cloned genomic fragment flanking the region to be modified. The homology boxes are appended to the modification cassette so that following homologous recombination in bacteria, the modification cassette replaces the region to be modified. The technique of creating a targeting vector using bacterial homologous recombination can be performed in a variety of systems (see, e.g., Yang et al. (1997) Nat. Biotechnol. 15:859-865, Muyrers et al. (1999) Nucleic Acids Res. 27:1555-1557; Angrand et al. (1999) Nucleic Acids Res. 27:e16; Narayanan et al. (1999) Gene Ther. 6:442-447; Yu, et al. (2000) Proc. Natl. Acad. Sci. U.S.A. 97:5978-5983, each of which is herein incorporated by reference in its entirety for all purposes). One example of such a technology is ET cloning (see, e.g., Zhang et al. (1998) Nat. Genet. 20:123-128; Narayanan et al. (1999) Gene Ther. 6:442-447, each of which is herein incorporated by reference in its entirety for all purposes) and variations of this technology (see, e.g., Yu et al. (2000) Proc. Natl. Acad. Sci. U.S.A. 97:5978-5983, herein incorporated by reference in its entirety for all purposes). ET refers to the recE and recT proteins that carry out the homologous recombination reaction. RecE is an exonuclease that trims one strand of linear double-stranded DNA 5' to 3', thus leaving behind a linear double-stranded fragment with a 3' single-stranded overhang. This single-stranded overhang is coated by recT protein, which has single-stranded DNA (ssDNA) binding activity. ET cloning is performed using E. coli that transiently express the E. coli gene products of recE and recT and the bacteriophage lambda (.lamda.) protein .lamda.gam. The .lamda.gam protein is protects the donor DNA fragment from degradation by the recBC exonuclease system and it is preferred for efficient ET cloning in recBC.sup.+ hosts such as the frequently used E. coli strain DH10b.
[0128] LTVECs can also be generated by DNA assembly methods, such as in vitro DNA assembly methods including Gibson DNA assembly or modifications of Gibson DNA assembly. See, e.g., US 2015/0376628, US 2016/0115486, WO 2015/200334, and US 2010/0035768, each of which is incorporated by reference in its entirety for all purposes.
[0129] Traditional methods of assembling nucleic acids employ time consuming steps of conventional enzymatic digestion with restriction enzymes, cloning of the nucleic acids, and ligating nucleic acids together. These methods are made more difficult when large fragments or vectors are being assembled together. However, the malleable target specificity of nucleases (e.g., guide RNAs and Cas9 nucleases) can be taken advantage of to convert nucleic acids into a form suitable for use in rapid assembly reactions. See, e.g., US 2015/0376628, US 2016/0115486, and WO 2015/200334, each of which is incorporated by reference in its entirety for all purposes.
[0130] Any DNA molecules of interest having overlapping sequences can be assembled by such methods, including DNAs which are naturally occurring, cloned DNA molecules, synthetically generated DNAs, and so forth. Assembling two nucleic acids includes any method of joining strands of two nucleic acids. For example, assembly includes joining digested nucleic acids such that strands from each nucleic acid anneal to the other and extension, in which each strand serves as a template for extension of the other.
[0131] Any in vitro or in vivo DNA assembly methods or rapid combinatorial methods can be used to assemble the nucleic acids. For example, a first and a second nucleic acid having overlapping ends can be combined with a ligase, exonuclease, DNA polymerase, and nucleotides and incubated at a constant temperature, such as at 50.degree. C. Specifically, a T5 exonuclease could be used to remove nucleotides from the 5' ends of dsDNA producing complementary overhangs. The complementary single-stranded DNA overhangs can then be annealed, DNA polymerase used for gap filling, and Taq DNA ligase used to seal the resulting nicks at 50.degree. C. Thus, two nucleic acids sharing overlapping end sequences can be joined into a covalently sealed molecule in a one-step isothermal reaction. See, e.g., Gibson et al. (2009) Nature Methods 6(5): 343-345, herein incorporated by reference in its entirety for all purposes.
[0132] Site-directed nuclease agents (e.g., guide RNA-directed Cas proteins) allow rapid and efficient combination of nucleic acids by selecting and manipulating the end sequences generated by their endonuclease activity. For example, DNA assembly methods can combine a first polynucleotide with a nuclease agent (e.g., a gRNA-Cas complex) specific for a desired target site and an exonuclease. The target site can be chosen such that when the nuclease cleaves the nucleic acid, the resulting ends created by the cleavage have regions complementary to the ends of a second nucleic acid to be assembled with the first nucleic acid (e.g., overlapping ends). These complementary ends can then be assembled to yield a single assembled nucleic acid. Because the nuclease agent (e.g., gRNA-Cas complex) is specific for an individual target site, the method allows for modification of nucleic acids in a precise site-directed manner. By selecting a nuclease agent (e.g., a gRNA-Cas complex) specific for a target site such that, on cleavage, produces end sequences complementary to those of a second nucleic acid, isothermal assembly can be used to assemble the resulting digested nucleic acid. Thus, by selecting nucleic acids and nuclease agents (e.g., gRNA-Cas complexes) that result in overlapping end sequences, nucleic acids can be assembled by rapid combinatorial methods to produce the final assembled nucleic acid in a fast and efficient manner. Alternatively, nucleic acids not having complementary ends can be assembled with joiner oligos designed to have complementary ends to each nucleic acid. By using the joiner oligos, two or more nucleic acids can be seamlessly assembled, thereby reducing unnecessary sequences in the resulting assembled nucleic acid.
[0133] Verification that the LTVEC has been engineered correctly can then be undertaken. For example, diagnostic PCR can be used to verify the novel junctions created by the introduction of the donor fragment into the gene or chromosomal locus of interest. Alternatively or additionally, diagnostic restriction enzyme digestion can be done to make sure that only the desired modifications have been introduced into the LTVEC during the bacterial homologous recombination process. Alternatively or additionally, direct sequencing of the LTVEC can be done, particularly the regions spanning the site of the modification to verify the novel junctions created by the introduction of the donor fragment into the gene or chromosomal locus of interest.
[0134] After any purification and further preparation of the LTVEC DNA for introduction into eukaryotic cells, the LTVEC is preferably linearized in a manner that leaves the modified endogenous gene or chromosomal locus DNA flanked with long homology arms. This can be accomplished by linearizing the LTVEC, preferably in the vector backbone, with any suitable restriction enzyme that digests only rarely. Examples of suitable restriction enzymes include NotI, Pad, SfiI, SrfI, Swal, FseI, and so forth. The choice of restriction enzyme may be determined experimentally (i.e., by testing several different candidate rare cutters) or, if the sequence of the LTVEC is known, by analyzing the sequence and choosing a suitable restriction enzyme based on the analysis.
[0135] C. C9orf72-HRE Nucleic Acid Constructs
[0136] DNA sequences can be used to prepare LTVECs for knock-in animals (e.g., an C9ORF72-HRE). Typically, a polynucleotide molecule (e.g., an insert nucleic acid) comprising a hexanucleotide expansion sequence and/or a selectable marker is inserted into a vector, preferably a DNA vector, in order to replicate the polynucleotide molecule in a suitable host cell.
[0137] A polynucleotide molecule (or insert nucleic acid) comprises a segment of DNA that one desires to integrate into a target locus. In some embodiments, an insert nucleic acid comprises one or more polynucleotides of interest. In some embodiments, an insert nucleic acid comprises one or more expression cassettes. In some certain embodiments, an expression cassette comprises a polynucleotide of interest, a polynucleotide encoding a selection marker and/or a reporter gene along with, in some certain embodiments, various regulatory components that influence expression. Virtually any polynucleotide of interest may be contained within an insert nucleic acid and thereby integrated at a target genomic locus. Methods disclosed herein, provide for at least 1, 2, 3, 4, 5, 6 or more polynucleotides of interest to be integrated into a targeted C9ORF72 genomic locus.
[0138] In some embodiments, a polynucleotide of interest contained in an insert nucleic acid encodes a reporter. In some embodiments, a polynucleotide of interest encodes a selectable marker.
[0139] In some embodiments, a polynucleotide of interest is flanked by or comprises site-specific recombination sites (e.g., loxP, Frt, etc.). In some certain embodiments, site-specific recombination sites flank a DNA segment that encodes a reporter and/or a DNA segment that encodes a selectable marker. Exemplary polynucleotides of interest, including selection markers and reporter genes that can be included within insert nucleic acids are described herein.
[0140] Various methods employed in preparation of plasmids, DNA constructs and/or targeting vectors and transformation of host organisms are known in the art. For other suitable expression systems for both prokaryotic and eukaryotic cells, as well as general recombinant procedures, see Molecular Cloning: A Laboratory Manual, 2nd Ed., ed. by Sambrook, J. et al., Cold Spring Harbor Laboratory Press: 1989.
[0141] As described above, exemplary non-human (e.g., rodent) C9ORF72 nucleic acid and amino acid sequences for use in constructing targeting vectors for knock-in animals are provided in Table 2. Other non-human C9ORF72 sequences can also be found in the GenBank database. C9ORF72 targeting vectors as disclosed herein comprise a heterologous hexanucleotide repeat expansion sequence, and optionally one or more sequences encoding a reporter gene and/or a selectable marker, flanked by sequences that are identical or substantially homologous to flanking sequences of a target region (also referred to as "homology arms") for insertion into the genome of a transgenic non-human animal.
[0142] To give but one example, an insertion start point may be set upstream (5'), within, or downstream (3') of a first exon, e.g., a first non-coding exon, to allow an insert nucleic acid to be operably linked to an endogenous regulatory sequence (e.g., a promoter). A targeting strategy for making a targeted insertion of a heterologous hexanucleotide repeat expansion sequence is provided in FIG. 1B and FIG. 1C. The drug selection cassette is flanked by loxP (LP) recombinase recognition sites that enable Cre-mediated excision of the drug selection cassette. This allows for, among other things, excision of the selection cassette. Thus, prior to phenotypic analysis the drug selection cassette may be removed leaving only the heterologous hexanucleotide repeat expansion sequence, and in some embodiments, one copy of the recombinase recognition site.
[0143] Disclosed herein are nucleic acid constructs useful for the modified mouse C9orf72 alleles depicted in FIGS. 1B and 1C, wherein the nucleic acid constructs comprise the sequences set forth in SEQ ID NO:8 and SEQ ID NO:9. SEQ ID NO:8 comprises from 5' to 3': a 5' homology arm (SEQ ID NO:20), a 962 human bp sequence spanning and including part of exon 1a and all of exon 1b of a human C9orf72 gene (SEQ ID NO:2), a floxed neomycin resistance cassette containing the neomycin resistance gene under the control of a human ubiquitin 1 and/or Em7 promoter (SEQ ID NO:21), and a 3' homology arm (SEQ ID NO:22). SEQ ID NO:9 comprises from 5' to 3': a 5' homology arm (SEQ ID NO:23), a 1261 human bp sequence spanning and including part exon 1a and all of exon 1b of a human C9orf72 gene (SEQ ID NO:3), a floxed neomycin resistance cassette containing the neomycin resistance gene under the control of a human ubiquitin 1 and/or Em7 promoter (SEQ ID NO:24), and a 3' homology arm (SEQ ID NO:25).
[0144] As described herein, insertion of heterologous hexanucleotide repeat expansion sequence into an endogenous C9orf72 locus can comprise a replacement of or an insertion/addition to the C9orf72 locus or a portion thereof with an insert nucleic acid. In some embodiments, an insert nucleic acid comprises a reporter gene. In some certain embodiments, a reporter gene is positioned in operable linkage with an endogenous C9orf72 promoter. Such a modification allows for the expression of a reporter gene driven by an endogenous C9orf72 promoter. Alternatively, a reporter gene is not placed in operable linkage with an endogenous C9orf72 promoter.
[0145] A variety of reporter genes (or detectable moieties) can be used in targeting vectors described herein. Exemplary reporter genes include, for example, .beta.-galactosidase (encoded lacZ gene), Green Fluorescent Protein (GFP), enhanced Green Fluorescent Protein (eGFP), MmGFP, blue fluorescent protein (BFP), enhanced blue fluorescent protein (eBFP), mPlum, mCherry, tdTomato, mStrawberry, J-Red, DsRed, mOrange, mKO, mCitrine, Venus, YPet, yellow fluorescent protein (YFP), enhanced yellow fluorescent protein (eYFP), Emerald, CyPet, cyan fluorescent protein (CFP), Cerulean, T-Sapphire, luciferase, alkaline phosphatase, or a combination thereof. The methods described herein demonstrate the construction of targeting vectors that employ the use of a lacZ reporter gene that encodes .beta.-galactosidase, however, persons of skill upon reading this disclosure will understand that non-human animals described herein can be generated in the absence of a reporter gene or with any reporter gene known in the art.
[0146] Where appropriate, the coding region of the genetic material or polynucleotide sequence(s) encoding a reporter polypeptide, in whole or in part, may be modified to include codons that are optimized for expression in the non-human animal (e.g., see U.S. Pat. Nos. 5,670,356 and 5,874,304). Codon optimized sequences are synthetic sequences, and preferably encode the identical polypeptide (or a biologically active fragment of a full length polypeptide which has substantially the same activity as the full length polypeptide) encoded by the non-codon optimized parent polynucleotide. In some embodiments, the coding region of the genetic material encoding a reporter polypeptide (e.g. lacZ), in whole or in part, may include an altered sequence to optimize codon usage for a particular cell type (e.g., a rodent cell). For example, the codons of the reporter gene to be inserted into the genome of a non-human animal (e.g., a rodent) may be optimized for expression in a cell of the non-human animal. Such a sequence may be described as a codon-optimized sequence.
[0147] Compositions and methods for making non-human animals that comprises an insertion of heterologous hexanucleotide repeat expansion sequence disruption in an endogenous C9ORF72 locus as described herein are provided, including compositions and methods for making non-human animals that express the heterologous hexanucleotide repeat expansion sequence, e.g., from a C9ORF72 promoter, e.g., an endogenous mouse promoter, and a C9ORF72 regulatory sequence, e.g., a human regulatory, e.g., found in exons 1a and 1b. In some embodiments, compositions and methods for making non-human animals that express a heterologous hexanucleotide repeat expansion sequence from an endogenous promoter and an endogenous regulatory sequence are also provided. Methods include inserting a targeting vector, as described herein, encoding a heterologous hexanucleotide repeat expansion sequence into the genome of a non-human animal so that a non-coding sequence of a C9ORF72 locus is deleted, in whole or in part. In some embodiments, a non-human animal described herein comprises an endogenous C9ORF72 locus that comprises a targeting vector as described herein.
[0148] Targeting vectors described herein may be introduced into ES cells and screened for ES clones harboring a disruption in a C9orf72 locus as described in Frendewey, D., et al., 2010, Methods Enzymol. 476:295-307. A variety of host embryos can be employed in the methods and compositions disclosed herein. For example, the pluripotent and/or totipotent cells having the targeted genetic modification can be introduced into a pre-morula stage embryo (e.g., an 8-cell stage embryo) from a corresponding organism. See, e.g., U.S. Pat. Nos. 7,576,259, 7,659,442, 7,294,754, and US 2008/0078000 A1, all of which are incorporated by reference herein in their entireties. In other cases, the donor ES cells may be implanted into a host embryo at the 2-cell stage, 4-cell stage, 8-cell stage, 16-cell stage, 32-cell stage, or 64-cell stage. The host embryo can also be a blastocyst or can be a pre-blastocyst embryo, a pre-morula stage embryo, a morula stage embryo, an uncompacted morula stage embryo, or a compacted morula stage embryo.
[0149] In some embodiments, the VELOCIMOUSE.RTM. method (Poueymirou, W. T. et al., 2007, Nat. Biotechnol. 25:91-99) may be applied to inject positive ES cells into an 8-cell embryo to generate fully ES cell-derived F0 generation heterozygous mice ready for lacZ expression profiling or breeding to homozygosity. Exemplary methods for generating non-human animals having a disruption in a C9orf72 locus are provided in Example 1.
[0150] Methods for generating transgenic non-human animals, including knockouts and knock-ins, are well known in the art (see, e.g., Gene Targeting: A Practical Approach, Joyner, ed., Oxford University Press, Inc. (2000)). For example, generation of transgenic rodents may optionally involve disruption of the genetic loci of an endogenous rodent gene and introduction of a reporter gene into the rodent genome, in some embodiments, at the same location as the endogenous rodent gene.
[0151] A schematic illustration (not to scale) of the genomic organization of a mouse C9orf72 is provided in FIG. 1A (top box). An exemplary targeting strategy for replacement of a non-coding sequence of an endogenous murine C9orf72 locus with a heterologous hexanucleotide repeat expansion sequence is also provided in FIG. 1A (bottom box). As illustrated, genomic DNA spanning between exon 1 and the ATG start codon, or a portion thereof, is replaced with a heterologous hexanucleotide repeat expansion sequence and a drug selection cassette flanked by site-specific recombinase recognition sites. The targeting vector used in this strategy may optionally include a recombinase-encoding sequence that is operably linked to a promoter that is developmentally regulated such that the recombinase is expressed in undifferentiated cells. Exemplary developmentally regulated promoters that can be included in targeting vectors described herein are provided in Table 3. Additional suitable promoters that can be used in targeting vectors described herein include those described in U.S. Pat. Nos. 8,697,851, 8,518,392 and 8,354,389; all of which are herein incorporated by reference). Upon homologous recombination, the non-coding sequence, e.g., approximately 800-1000 bp spanning from exon 1 (or within exon 1) to exon 2, of the endogenous murine C9orf72 locus is replaced by the sequence contained in the targeting vector. The drug selection cassette may be removed, e.g., optionally in a development-dependent manner such that progeny derived from mice whose germ line cells containing a disruption in a C9orf72 locus described above will shed the selectable marker from differentiated cells during development (see U.S. Pat. Nos. 8,697,851, 8,518,392 and 8,354,389, all of which are herein incorporated by reference).
TABLE-US-00004 TABLE 3 Prot promoter (SEQ ID NO: 26) CCAGTAGCAGCACCCACGTCCACCTTCTGTCTAGTAATGTCCAAC ACCTCCCTCAGTCCAAACACTGCTCTGCATCCATGTGGCTCCCAT TTATACCTGAAGCACTTGATGGGGCCTCAATGTTTTACTAGAGCC CACCCCCCTGCAACTCTGAGACCCTCTGGATTTGTCTGTCAGTGC CTCACTGGGGCGTTGGATAATTTCTTAAAAGGTCAAGTTCCCTCA GCAGCATTCTCTGAGCAGTCTGAAGATGTGTGCTTTTCACAGTTC AAATCCATGTGGCTGTTTCACCCACCTGCCTGGCCTTGGGTTATC TATCAGGACCTAGCCTAGAAGCAGGTGTGTGGCACTTAACACCTA AGCTGAGTGACTAACTGAACACTCAAGTGGATGCCATCTTTGTCA CTTCTTGACTGTGACACAAGCAACTCCTGATGCCAAAGCCCTGCC CACCCCTCTCATGCCCATATTTGGACATGGTACAGGTCCTCACTG GCCATGGTCTGTGAGGTCCTGGTCCTCTTTGACTTCATAATTCCT AGGGGCCACTAGTATCTATAAGAGGAAGAGGGTGCTGGCTCCCAG GCCACAGCCCACAAAATTCCACCTGCTCACAGGTTGGCTGGCTCG ACCCAGGTGGTGTCCCCTGCTCTGAGCCAGCTCCCGGCCAAGCCA GCACC Blimpl promoter 1 kb (SEQ ID NO: 27) TGCCATCATCACAGGATGTCCTTCCTTCTCCAGAAGACAGACTGG GGCTGAAGGAAAAGCCGGCCAGGCTCAGAACGAGCCCCACTAATT ACTGCCTCCAACAGCTTTCCACTCACTGCCCCCAGCCCAACATCC CCTTTTTAACTGGGAAGCATTCCTACTCTCCATTGTACGCACACG CTCGGAAGCCTGGCTGTGGGTTTGGGCATGAGAGGCAGGGACAAC AAAACCAGTATATATGATTATAACTTTTTCCTGTTTCCCTATTTC CAAATGGTCGAAAGGAGGAAGTTAGGTCTACCTAAGCTGAATGTA TTCAGTTAGCAGGAGAAATGAAATCCTATACGTTTAATACTAGAG GAGAACCGCCTTAGAATATTTATTTCATTGGCAATGACTCCAGGA CTACACAGCGAAATTGTATTGCATGTGCTGCCAAAATACTTTAGC TCTTTCCTTCGAAGTACGTCGGATCCTGTAATTGAGACACCGAGT TTAGGTGACTAGGGTTTTCTTTTGAGGAGGAGTCCCCCACCCCGC CCCGCTCTGCCGCGACAGGAAGCTAGCGATCCGGAGGACTTAGAA TACAATCGTAGTGTGGGTAAACATGGAGGGCAAGCGCCTGCAAAG GGAAGTAAGAAGATTCCCAGTCCTTGTTGAAATCCATTTGCAAAC AGAGGAAGCTGCCGCGGGTCGCAGTCGGTGGGGGGAAGCCCTGAA CCCCACGCTGCACGGCTGGGCTGGCCAGGTGCGGCCACGCCCCCA TCGCGGCGGCTGGTAGGAGTGAATCAGACCGTCAGTATTGGTAAA GAAGTCTGCGGCAGGGCAGGGAGGGGGAAGAGTAGTCAGTCGCTC GCTCACTCGCTCGCTCGCACAGACACTGCTGCAGTGACACTCGGC CCTCCAGTGTCGCGGAGACGCAAGAGCAGCGCGCAGCACCTGTCC GCCCGGAGCGAGCCCGGCCCGCGGCCGTAGAAAAGGAGGGACCGC CGAGGTGCGCGTCAGTACTGCTCAGCCCGGCAGGGACGCGGGAGG ATGTGGACTGGGTGGAC Blimpl promoter 2 kb (SEQ ID NO: 28) GTGGTGCTGACTCAGCATCGGTTAATAAACCCTCTGCAGGAGGCT GGATTTCTTTTGTTTAATTATCACTTGGACCTTTCTGAGAACTCT TAAGAATTGTTCATTCGGGTTTTTTTGTTTTGTTTTGGTTTGGTT TTTTTGGGTTTTTTTTTTTTTTTTTTTTTTGGTTTTTGGAGACAG GGTTTCTCTGTATATAGCCCTGGCACAAGAGCAAGCTAACAGCCT GTTTCTTCTTGGTGCTAGCGCCCCCTCTGGCAGAAAATGAAATAA CAGGTGGACCTACAACCCCCCCCCCCCCCCCCAGTGTATTCTACT CTTGTCCCCGGTATAAATTTGATTGTTCCGAACTACATAAATTGT AGAAGGATTTTTTAGATGCACATATCATTTTCTGTGATACCTTCC ACACACCCCTCCCCCCCAAAAAAATTTTTCTGGGAAAGTTTCTTG AAAGGAAAACAGAAGAACAAGCCTGTCTTTATGATTGAGTTGGGC TTTTGTTTTGCTGTGTTTCATTTCTTCCTGTAAACAAATACTCAA ATGTCCACTTCATTGTATGACTAAGTTGGTATCATTAGGTTGGGT CTGGGTGTGTGAATGTGGGTGTGGATCTGGATGTGGGTGGGTGTG TATGCCCCGTGTGTTTAGAATACTAGAAAAGATACCACATCGTAA ACTTTTGGGAGAGATGATTTTTAAAAATGGGGGTGGGGGTGAGGG GAACCTGCGATGAGGCAAGCAAGATAAGGGGAAGACTTGAGTTTC TGTGATCTAAAAAGTCGCTGTGATGGGATGCTGGCTATAAATGGG CCCTTAGCAGCATTGTTTCTGTGAATTGGAGGATCCCTGCTGAAG GCAAAAGACCATTGAAGGAAGTACCGCATCTGGTTTGTTTTGTAA TGAGAAGCAGGAATGCAAGGTCCACGCTCTTAATAATAAACAAAC AGGACATTGTATGCCATCATCACAGGATGTCCTTCCTTCTCCAGA AGACAGACTGGGGCTGAAGGAAAAGCCGGCCAGGCTCAGAACGAG CCCCACTAATTACTGCCTCCAACAGCTTTCCACTCACTGCCCCCA GCCCAACATCCCCTTTTTAACTGGGAAGCATTCCTACTCTCCATT GTACGCACACGCTCGGAAGCCTGGCTGTGGGTTTGGGCATGAGAG GCAGGGACAACAAAACCAGTATATATGATTATAACTTTTTCCTGT TTCCCTATTTCCAAATGGTCGAAAGGAGGAAGTTAGGTCTACCTA AGCTGAATGTATTCAGTTAGCAGGAGAAATGAAATCCTATACGTT TAATACTAGAGGAGAACCGCCTTAGAATATTTATTTCATTGGCAA TGACTCCAGGACTACACAGCGAAATTGTATTGCATGTGCTGCCAA AATACTTTAGCTCTTTCCTTCGAAGTACGTCGGATCCTGTAATTG AGACACCGAGTTTAGGTGACTAGGGTTTTCTTTTGAGGAGGAGTC CCCCACCCCGCCCCGCTCTGCCGCGACAGGAAGCTAGCGATCCGG AGGACTTAGAATACAATCGTAGTGTGGGTAAACATGGAGGGCAAG CGCCTGCAAAGGGAAGTAAGAAGATTCCCAGTCCTTGTTGAAATC CATTTGCAAACAGAGGAAGCTGCCGCGGGTCGCAGTCGGTGGGGG GAAGCCCTGAACCCCACGCTGCACGGCTGGGCTGGCCAGGTGCGG CCACGCCCCCATCGCGGCGGCTGGTAGGAGTGAATCAGACCGTCA GTATTGGTAAAGAAGTCTGCGGCAGGGCAGGGAGGGGGAAGAGTA GTCAGTCGCTCGCTCACTCGCTCGCTCGCACAGACACTGCTGCAG TGACACTCGGCCCTCCAGTGTCGCGGAGACGCAAGAGCAGCGCGC AGCACCTGTCCGCCCGGAGCGAGCCCGGCCCGCGGCCGTAGAAAA GGAGGGACCGCCGAGGTGCGCGTCAGTACTGCTCAGCCCGGCAGG GACGCGGGAGGATGTGGACTGGGTGGAC
[0152] D. Introduction of LTVEC into Cells
[0153] LTVEC DNA can be introduced into eukaryotic cells using any standard methodology. "Introducing" includes presenting to the cell the nucleic acid in such a manner that the sequence gains access to the interior of the cell. The introducing can be accomplished by any means.
[0154] The methods provided herein do not depend on a particular method for introducing a nucleic acid into the cell, only that the nucleic acid gains access to the interior of a least one cell. Methods for introducing nucleic acids into various cell types are known in the art and include, for example, stable transfection methods, transient transfection methods, and virus-mediated methods.
[0155] Transfection protocols as well as protocols for introducing nucleic acids into cells may vary. Non-limiting transfection methods include chemical-based transfection methods using liposomes; nanoparticles; calcium phosphate (see, e.g., Graham et al. (1973) Virology 52 (2): 456-67, Bacchetti et al. (1977) Proc. Natl. Acad. Sci. USA 74 (4): 1590-4, and Kriegler, M (1991). Transfer and Expression: A Laboratory Manual. New York: W. H. Freeman and Company. pp. 96-97, each of which is herein incorporated by reference in its entirety); dendrimers; or cationic polymers such as DEAE-dextran or polyethylenimine. Non-chemical methods include electroporation, Sono-poration, and optical transfection. Particle-based transfection includes the use of a gene gun, or magnet-assisted transfection (see, e.g., Bertram (2006) Current Pharmaceutical Biotechnology 7, 277-285, herein incorporated by reference in its entirety). Viral methods can also be used for transfection.
[0156] Introduction of nucleic acids into a cell can also be mediated by electroporation, by intracytoplasmic injection, by viral infection, by adenovirus, by adeno-associated virus, by lentivirus, by retrovirus, by transfection, by lipid-mediated transfection, or by nucleofection. Nucleofection is an improved electroporation technology that enables nucleic acid substrates to be delivered not only to the cytoplasm but also through the nuclear membrane and into the nucleus. In addition, use of nucleofection in the methods disclosed herein typically requires much fewer cells than regular electroporation (e.g., only about 2 million compared with 7 million by regular electroporation). In one example, nucleofection is performed using the LONZA.RTM. NUCLEOFECTOR.TM. system.
[0157] Introduction of nucleic acids into a cell (e.g., a one-cell stage embryo) can also be accomplished by microinjection. In one-cell stage embryos, microinjection can be into the maternal and/or paternal pronucleus or into the cytoplasm. If the microinjection is into only one pronucleus, the paternal pronucleus is preferable due to its larger size. Microinjection of an mRNA is preferably into the cytoplasm (e.g., to deliver mRNA directly to the translation machinery), while microinjection of a protein or a DNA encoding a DNA encoding a Cas protein is preferably into the nucleus/pronucleus. Alternatively, microinjection can be carried out by injection into both the nucleus/pronucleus and the cytoplasm: a needle can first be introduced into the nucleus/pronucleus and a first amount can be injected, and while removing the needle from the one-cell stage embryo a second amount can be injected into the cytoplasm. If a nuclease agent protein is injected into the cytoplasm, the protein preferably comprises a nuclear localization signal to ensure delivery to the nucleus/pronucleus. Methods for carrying out microinjection are well known. See, e.g., Nagy et al., 2003, Manipulating the Mouse Embryo. Cold Spring Harbor, N.Y.: Cold Spring Harbor Laboratory Press); Meyer et al. (2010) Proc. Natl. Acad. Sci. U.S.A. 107:15022-15026, and Meyer et al. (2012) Proc. Natl. Acad. Sci. USA 109:9354-9359, each of which is herein incorporated by reference in its entirety.
[0158] Other methods for introducing nucleic acid or proteins into a cell can include, for example, vector delivery, particle-mediated delivery, exosome-mediated delivery, lipid-nanoparticle-mediated delivery, cell-penetrating-peptide-mediated delivery, or implantable-device-mediated delivery.
[0159] The introduction of nucleic acids into the cell can be performed one time or multiple times over a period of time. For example, the introduction can be performed at least two times over a period of time, at least three times over a period of time, at least four times over a period of time, at least five times over a period of time, at least six times over a period of time, at least seven times over a period of time, at least eight times over a period of time, at least nine times over a period of times, at least ten times over a period of time, at least eleven times, at least twelve times over a period of time, at least thirteen times over a period of time, at least fourteen times over a period of time, at least fifteen times over a period of time, at least sixteen times over a period of time, at least seventeen times over a period of time, at least eighteen times over a period of time, at least nineteen times over a period of time, or at least twenty times over a period of time.
[0160] E. Screening for and Identifying Cells with Targeted Genetic Modifications
[0161] Cells in which the LTVEC has been introduced successfully can be selected by exposure to selection agents, depending on whether a selectable marker gene that has been engineered into the LTVEC. As a non-limiting example, if the selectable marker is the neomycin phosphotransferase (neo) gene (see, e.g., Beck et al. (1982) Gene 19:327-336, herein incorporated by reference in its entirety for all purposes), then cells that have taken up the LTVEC can be selected in G418-containing media; cells that do not have the LTVEC will die whereas cells that have taken up the LTVEC will survive (see, e.g., Santerre, et al. (1984) Gene 30:147-156, herein incorporated by reference in its entirety for all purposes). Such selection markers can, for example, impart resistance to an antibiotic such as G418, hygromycin, blasticidin, neomycin, or puromycin. Such selection markers include neomycin phosphotransferase (neo.sup.r), hygromycin B phosphotransferase (hyg.sup.r), puromycin-N-acetyltransferase (puro.sup.r), and blasticidin S deaminase (bsr.sup.r). In still other embodiments, the selection marker is operably linked to an inducible promoter and the expression of the selection marker is toxic to the cell. Non-limiting examples of such selection markers include xanthine/guanine phosphoribosyl transferase (gpt), hypoxanthine-guanine phosphoribosyltransferase (HGPRT) or herpes simplex virus thymidine kinase (HSV-TK).
[0162] The methods disclosed herein can further comprise identifying a cell having a modified genome. Various methods can be used to identify cells having a targeted genetic modification, such as a deletion or an insertion. Such methods can comprise identifying one cell having the targeted genetic modification at a target locus.
[0163] Conventional assays for screening for targeted modifications, such as long-range PCR, Sanger sequencing, or Southern blotting, link the inserted targeting vector to the targeted locus. For example, for a long-range PCR assay, one primer can recognize a sequence within the inserted DNA while the other recognizes a genomic region of interest sequence beyond the ends of the targeting vector's homology arms. Because of their large homology arm sizes, however, LTVECs do not permit screening by such conventional assays. To screen LTVEC targeting, modification-of-allele (MOA) assays including loss-of-allele (LOA) and gain-of-allele (GOA) assays can be used (see, e.g., US 2014/0178879 and Frendewey et al. (2010) Methods Enzymol. 476:295-307, each of which is herein incorporated by reference in its entirety for all purposes). The loss-of-allele (LOA) assay inverts the conventional screening logic and quantifies the number of copies of the native locus to which the mutation was directed. In a correctly targeted cell clone, the LOA assay detects one of the two native alleles (for genes not on the X or Y chromosome), the other allele being disrupted by the targeted modification. The same principle can be applied in reverse as a gain-of-allele (GOA) assay to quantify the copy number of the inserted targeting vector. For example, the combined use of GOA and LOA assays will reveal a correctly targeted heterozygous clone as having lost one copy of the native target gene and gained one copy of the drug resistance gene or other inserted marker.
[0164] As an example, quantitative polymerase chain reaction (qPCR) can be used as the method of allele quantification, but any method that can reliably distinguish the difference between zero, one, and two copies of the target gene or between zero, one, and two copies of the nucleic acid insert can be used to develop a MOA assay. For example, TAQMAN.RTM. can be used to quantify the number of copies of a DNA template in a genomic DNA sample, especially by comparison to a reference gene (see, e.g., U.S. Pat. No. 6,596,541, herein incorporated by reference in its entirety for all purposes). The reference gene is quantitated in the same genomic DNA as the target gene(s) or locus(loci). Therefore, two TAQMAN.RTM. amplifications (each with its respective probe) are performed. One TAQMAN.RTM. probe determines the "Ct" (Threshold Cycle) of the reference gene, while the other probe determines the Ct of the region of the targeted gene(s) or locus(loci) which is replaced by successful targeting (i.e., a LOA assay). The Ct is a quantity that reflects the amount of starting DNA for each of the TAQMAN.RTM. probes, i.e. a less abundant sequence requires more cycles of PCR to reach the threshold cycle. Decreasing by half the number of copies of the template sequence for a TAQMAN.RTM. reaction will result in an increase of about one Ct unit. TAQMAN.RTM. reactions in cells where one allele of the target gene(s) or locus(loci) has been replaced by homologous recombination will result in an increase of one Ct for the target TAQMAN.RTM. reaction without an increase in the Ct for the reference gene when compared to DNA from non-targeted cells. For a GOA assay, another TAQMAN.RTM. probe can be used to determine the Ct of the nucleic acid insert that is replacing the targeted gene(s) or locus(loci) by successful targeting.
[0165] The screening step can also comprise arm-specific assays, which are assays used to distinguish between correct targeted insertions of a nucleic acid insert into a target genomic locus from random transgenic insertions of the nucleic acid insert into genomic locations outside of the target genomic locus. Arm-specific assays determine copy numbers of a DNA template in LTVEC homology arms. See, e.g., US 2016/0177339, WO 2016/100819, US 2016/0145646, and WO 2016/081923, each of which is herein incorporated by reference in its entirety for all purposes. It can be useful augment standard LOA and GOA assays to verify correct targeting by LTVECs. For example, LOA and GOA assays alone may not distinguish correctly targeted cell clones from clones in which a deletion of the target genomic locus coincides with random integration of a LTVEC elsewhere in the genome. Because the selection pressure in the targeted cell is based on the selection cassette, random transgenic integration of the LTVEC elsewhere in the genome will generally include the selection cassette and adjacent regions of the LTVEC but may exclude more distal regions of the LTVEC. For example, if a portion of an LTVEC is randomly integrated into the genome, and the LTVEC comprises a nucleic acid insert of around 5 kb or more in length with a selection cassette adjacent to the 3' homology arm, in some cases the 3' homology arm but not the 5' homology arm will be transgenically integrated with the selection cassette. Alternatively, if the selection cassette adjacent to the 5' homology arm, in some cases the 5' homology arm but not the 3' homology arm will be transgenically integrated with the selection cassette. As an example, if LOA and GOA assays are used to assess targeted integration of the LTVEC, and the GOA assay utilizes probes against the selection cassette or any other unique (non-arm) region of the LTVEC, a heterozygous deletion at the target genomic locus combined with a random transgenic integration of the LTVEC will give the same readout as a heterozygous targeted integration of the LTVEC at the target genomic locus. To verify correct targeting by the LTVEC, arm-specific assays can be used in conjunction with LOA and/or GOA assays.
[0166] Other examples of suitable quantitative assays include fluorescence-mediated in situ hybridization (FISH), comparative genomic hybridization, isothermic DNA amplification, quantitative hybridization to an immobilized probe(s), INVADER.RTM. Probes, TAQMAN.RTM. Molecular Beacon probes, or ECLIPSE.TM. probe technology (see, e.g., US 2005/0144655, herein incorporated by reference in its entirety for all purposes).
[0167] Next generation sequencing (NGS) can also be used for screening, particularly in one-cell stage embryos that have been modified. Next-generation sequencing can also be referred to as "NGS" or "massively parallel sequencing" or "high throughput sequencing." Such NGS can be used as a screening tool in addition to the MOA assays and retention assays to define the exact nature of the targeted genetic modification and to detect mosaicism. Mosaicism refers to the presence of two or more populations of cells with different genotypes in one individual who has developed from a single fertilized egg (i.e., zygote). In the methods disclosed herein, it is not necessary to screen for targeted clones using selection markers. For example, the MOA and NGS assays described herein can be relied on without using selection cassettes.
[0168] F. Methods of Making Genetically Modified Non-Human Animals
[0169] Genetically modified non-human animals can be generated employing the various methods disclosed herein. Any convenient method or protocol for producing a genetically modified organism, including the methods described herein, is suitable for producing such a genetically modified non-human animal. Such methods starting with genetically modifying a pluripotent cell such as an embryonic stem (ES) cell generally comprise: (1) modifying the genome of a pluripotent cell that is not a one-cell stage embryo using the methods described herein; (2) identifying or selecting the genetically modified pluripotent cell; (3) introducing the genetically modified pluripotent cell into a host embryo; and (4) implanting and gestating the host embryo comprising the genetically modified pluripotent cell in a surrogate mother. The surrogate mother can then produce F0 generation non-human animals comprising the targeted genetic modification and capable of transmitting the targeted genetic modification though the germline. Animals bearing the genetically modified genomic locus can be identified via a modification of allele (MOA) assay as described herein. The donor cell can be introduced into a host embryo at any stage, such as the blastocyst stage or the pre-morula stage (i.e., the 4 cell stage or the 8 cell stage). Progeny that are capable of transmitting the genetic modification though the germline are generated. The pluripotent cell can be, for example, an ES cell (e.g., a rodent ES cell, a mouse ES cell, or a rat ES cell) as discussed elsewhere herein. See, e.g., U.S. Pat. No. 7,294,754, herein incorporated by reference in its entirety for all purposes.
[0170] Alternatively, such methods starting with genetically modifying a one-cell stage embryo generally comprise: (1) modifying the genome of a one-cell stage embryo using the methods described herein; (2) identifying or selecting the genetically modified embryo; and (3) implanting and gestating the genetically modified embryo in a surrogate mother. The surrogate mother can then produce F0 generation non-human animals comprising the targeted genetic modification and capable of transmitting the targeted genetic modification though the germline. Animals bearing the genetically modified genomic locus can be identified via a modification of allele (MOA) assay as described herein.
[0171] Nuclear transfer techniques can also be used to generate the non-human mammalian animals. Briefly, methods for nuclear transfer can include the steps of: (1) enucleating an oocyte or providing an enucleated oocyte; (2) isolating or providing a donor cell or nucleus to be combined with the enucleated oocyte; (3) inserting the cell or nucleus into the enucleated oocyte to form a reconstituted cell; (4) implanting the reconstituted cell into the womb of a non-human animal to form an embryo; and (5) allowing the embryo to develop. In such methods, oocytes are generally retrieved from deceased animals, although they may be isolated also from either oviducts and/or ovaries of live animals. Oocytes can be matured in a variety of media known to those of ordinary skill in the art prior to enucleation. Enucleation of the oocyte can be performed in a number of manners well known to those of ordinary skill in the art. Insertion of the donor cell or nucleus into the enucleated oocyte to form a reconstituted cell can be by microinjection of a donor cell under the zona pellucida prior to fusion. Fusion may be induced by application of a DC electrical pulse across the contact/fusion plane (electrofusion), by exposure of the cells to fusion-promoting chemicals, such as polyethylene glycol, or by way of an inactivated virus, such as the Sendai virus. A reconstituted cell can be activated by electrical and/or non-electrical means before, during, and/or after fusion of the nuclear donor and recipient oocyte. Activation methods include electric pulses, chemically induced shock, penetration by sperm, increasing levels of divalent cations in the oocyte, and reducing phosphorylation of cellular proteins (as by way of kinase inhibitors) in the oocyte. The activated reconstituted cells, or embryos, can be cultured in medium well known to those of ordinary skill in the art and then transferred to the womb of an animal. See, e.g., US 2008/0092249, WO 1999/005266, US 2004/0177390, WO 2008/017234, and U.S. Pat. No. 7,612,250, each of which is herein incorporated by reference in its entirety for all purposes.
[0172] The various methods provided herein allow for the generation of a genetically modified non-human F0 animal wherein the cells of the genetically modified F0 animal that comprise the targeted genetic modification. It is recognized that depending on the method used to generate the F0 animal, the number of cells within the F0 animal that have the targeted genetic modification will vary. The introduction of the donor ES cells into a pre-morula stage embryo from a corresponding organism (e.g., an 8-cell stage mouse embryo) via, for example, the VELOCIMOUSE.RTM. method allows for a greater percentage of the cell population of the F0 animal to comprise cells having the targeted genetic modification. See, e.g., US 2014/0331340, US 2008/0078001, US 2008/0028479, US 2006/0085866, and WO 2006/044962, each of which is herein incorporated by reference in its entirety for all purposes. For example, at least 50%, 60%, 65%, 70%, 75%, 85%, 86%, 87%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% or 100% of the cellular contribution of the non-human F0 animal can comprise a cell population having the targeted genetic modification. In addition, at least one or more of the germ cells of the F0 animal can have the targeted genetic modification.
[0173] A genetically modified founder non-human animal can be identified based upon the absence of endogenous genomic C9ORF72 sequences in its genome that are replaced with the heterologous hexanucleotide repeat expansion sequence and/or the presence (and/or expression) of the heterologous hexanucleotide repeat expansion sequence, drug resistance gene and/or reporter in tissues or cells of the non-human animal. A transgenic founder non-human animal can then be used to breed additional non-human animals carrying the heterologous hexanucleotide repeat expansion sequence thereby creating a series of non-human animals each carrying one or more copies of a C9ORF72 locus as described herein.
[0174] Transgenic non-human animals may also be produced to contain selected systems that allow for regulated or directed expression of the transgene. Exemplary systems include the Cre/loxP recombinase system of bacteriophage P1 (see, e.g., Lakso, M. et al., 1992, Proc. Natl. Acad. Sci. USA 89:6232-6236) and the FLP/Frt recombinase system of S. cerevisiae (O'Gorman, S. et al, 1991, Science 251:1351-1355). Such animals can be provided through the construction of "double" transgenic animals, e.g., by mating two transgenic animals, one containing a transgene encoding the heterologous hexanucleotide repeat expansion sequence and the other containing a transgene encoding a recombinase (e.g., a Cre recombinase).
[0175] Although embodiments employing an insertion of a heterologous hexanucleotide repeat expansion sequence in an endogenous C9ORF72 locus in a mouse are extensively discussed herein, other non-human animals that comprise a disruption in a C9ORF72 locus are also provided. Such non-human animals include any of those which can be genetically modified to replace a non-coding sequence of a C9ORF72 locus as disclosed herein, including, e.g., mammals, e.g., mouse, rat, rabbit, pig, bovine (e.g., cow, bull, buffalo), deer, sheep, goat, chicken, cat, dog, ferret, primate (e.g., marmoset, rhesus monkey), etc. For example, for those non-human animals for which suitable genetically modifiable ES cells are not readily available, other methods are employed to make a non-human animal comprising the genetic modification. Such methods include, e.g., modifying a non-ES cell genome (e.g., a fibroblast or an induced pluripotent cell) and employing somatic cell nuclear transfer (SCNT) to transfer the genetically modified genome to a suitable cell, e.g., an enucleated oocyte, and gestating the modified cell (e.g., the modified oocyte) in a non-human animal under suitable conditions to form an embryo.
[0176] Briefly, methods for nuclear transfer include steps of: (1) enucleating an oocyte; (2) isolating a donor cell or nucleus to be combined with the enucleated oocyte; (3) inserting the cell or nucleus into the enucleated oocyte to form a reconstituted cell; (4) implanting the reconstituted cell into the womb of an animal to form an embryo; and (5) allowing the embryo to develop. In such methods oocytes are generally retrieved from deceased animals, although they may be isolated also from either oviducts and/or ovaries of live animals. Oocytes may be matured in a variety of medium known to persons of skill in the art prior to enucleation. Enucleation of the oocyte can be performed in a variety of ways known to persons of skill in the art. Insertion of a donor cell or nucleus into an enucleated oocyte to form a reconstituted cell is typically achieved by microinjection of a donor cell under the zona pellucida prior to fusion. Fusion may be induced by application of a DC electrical pulse across the contact/fusion plane (electrofusion), by exposure of the cells to fusion-promoting chemicals, such as polyethylene glycol, or by way of an inactivated virus, such as the Sendai virus. A reconstituted cell is typically activated by electrical and/or non-electrical means before, during, and/or after fusion of the nuclear donor and recipient oocyte. Activation methods include electric pulses, chemically induced shock, penetration by sperm, increasing levels of divalent cations in the oocyte, and reducing phosphorylation of cellular proteins (as by way of kinase inhibitors) in the oocyte. The activated reconstituted cells, or embryos, are typically cultured in medium known to persons of skill in the art and then transferred to the womb of an animal. See, e.g., U.S. Patent Application Publication No. 2008-0092249 A1, WO 1999/005266 A2, U.S. Patent Application Publication No. 2004-0177390 A1, WO 2008/017234 A1, and U.S. Pat. No. 7,612,250, each of which is herein incorporated by reference.
[0177] Methods for modifying a non-human animal genome (e.g., a pig, cow, rodent, chicken, etc.) include, e.g., employing a zinc finger nuclease (ZFN) or a transcription activator-like effector nuclease (TALEN) to modify a genome to include an insertion of a heterologous hexanucleotide repeat expansion sequence in a C9ORF72 locus as described herein.
[0178] In some embodiments, a non-human animal described herein is a mammal. In some embodiments, a non-human animal described herein is a small mammal, e.g., of the superfamily Dipodoidea or Muroidea. In some embodiments, a genetically modified animal described herein is a rodent. In some embodiments, a rodent described herein is selected from a mouse, a rat, and a hamster. In some embodiments, a rodent described herein is selected from the superfamily Muroidea. In some embodiments, a genetically modified animal described herein is from a family selected from Calomyscidae (e.g., mouse-like hamsters), Cricetidae (e.g., hamster, New World rats and mice, voles), Muridae (true mice and rats, gerbils, spiny mice, crested rats), Nesomyidae (climbing mice, rock mice, with-tailed rats, Malagasy rats and mice), Platacanthomyidae (e.g., spiny dormice), and Spalacidae (e.g., mole rates, bamboo rats, and zokors). In some certain embodiments, a genetically modified rodent described herein is selected from a true mouse or rat (family Muridae), a gerbil, a spiny mouse, and a crested rat. In some certain embodiments, a genetically modified mouse described herein is from a member of the family Muridae. In some embodiment, a non-human animal described herein is a rodent. In some certain embodiments, a rodent described herein is selected from a mouse and a rat. In some embodiments, a non-human animal described herein is a mouse.
[0179] In some embodiments, a non-human animal described herein is a rodent that is a mouse of a C57BL strain selected from C57BL/A, C57BL/An, C57BL/GrFa, C57BL/KaLwN, C57BL/6, C57BL/6J, C57BL/6ByJ, C57BL/6NJ, C57BL/10, C57BL/10ScSn, C57BL/10Cr, and C57BL/Ola. In some certain embodiments, a mouse described herein is a 129 strain selected from the group consisting of a strain that is 129P1, 129P2, 129P3, 129X1, 129S1 (e.g., 129S1/SV, 129S1/SvIm), 129S2, 129S4, 129S5, 129S9/SvEvH, 129/SvJae, 129S6 (129/SvEvTac), 129S7, 129S8, 129T1, 129T2 (see, e.g., Festing et al., 1999, Mammalian Genome 10:836; Auerbach, W. et al., 2000, Biotechniques 29(5):1024-1028, 1030, 1032). In some certain embodiments, a genetically modified mouse described herein is a mix of an aforementioned 129 strain and an aforementioned C57BL/6 strain. In some certain embodiments, a mouse described herein is a mix of aforementioned 129 strains, or a mix of aforementioned BL/6 strains. In some certain embodiments, a 129 strain of the mix as described herein is a 129S6 (129/SvEvTac) strain. In some embodiments, a mouse described herein is a BALB strain, e.g., BALB/c strain. In some embodiments, a mouse described herein is a mix of a BALB strain and another aforementioned strain.
[0180] In some embodiments, a non-human animal described herein is a rat. In some certain embodiments, a rat described herein is selected from a Wistar rat, an LEA strain, a Sprague Dawley strain, a Fischer strain, F344, F6, and Dark Agouti. In some certain embodiments, a rat strain as described herein is a mix of two or more strains selected from the group consisting of Wistar, LEA, Sprague Dawley, Fischer, F344, F6, and Dark Agouti.
[0181] A rat pluripotent and/or totipotent cell can be from any rat strain, including, for example, an ACI rat strain, a Dark Agouti (DA) rat strain, a Wistar rat strain, a LEA rat strain, a Sprague Dawley (SD) rat strain, or a Fischer rat strain such as Fisher F344 or Fisher F6. Rat pluripotent and/or totipotent cells can also be obtained from a strain derived from a mix of two or more strains recited above. For example, the rat pluripotent and/or totipotent cell can be from a DA strain or an ACI strain. The ACI rat strain is characterized as having black agouti, with white belly and feet and an RT1.sup.av1 haplotype. Such strains are available from a variety of sources including Harlan Laboratories. An example of a rat ES cell line from an ACI rat is an ACI.G1 rat ES cell. The Dark Agouti (DA) rat strain is characterized as having an agouti coat and an RT1.sup.av1 haplotype. Such rats are available from a variety of sources including Charles River and Harlan Laboratories. Examples of a rat ES cell line from a DA rat are the DA.2B rat ES cell line and the DA.2C rat ES cell line. In some cases, the rat pluripotent and/or totipotent cells are from an inbred rat strain. See, e.g., U.S. 2014/0235933 A1, filed on Feb. 20, 2014, and herein incorporated by reference in its entirety.
[0182] Non-human animals are provided that comprise an insertion of a heterologous hexanucleotide repeat expansion sequence in an endogenous C9ORF72 locus. In some embodiments, insertion of a heterologous hexanucleotide repeat expansion sequence is not pathogenic. In some embodiments, insertion of a heterologous hexanucleotide repeat expansion sequence results in one or more phenotypes as described herein, e.g., a phenotype associated with ALS and/or FTD. Insertion of a heterologous hexanucleotide repeat expansion sequence may be measured directly, e.g., by determining the approximate number of instance, e.g., repeats, of the hexanucleotide sequence set forth as SEQ ID NO:1 in the heterologous hexanucleotide repeat expansion sequence, e.g., by Southern Blot or polymerase chain reaction genotyping reactions.
Methods Employing Non-Human Animals Having an Insertion of a Heterologous Hexanucleotide Repeat Expansion Sequence in an Endogenous C9ORF72 Locus
[0183] Non-human animals as described herein provide improved animal models for neurodegenerative diseases, disorders and conditions. In particular, non-human animals as described herein provide improved animal models that translate to human diseases such as, for example, ALS and/or FTD, characterized by upper motor neuron symptoms and/or non-motor neuron loss.
[0184] Non-human animals as described herein provide an improved in vivo system and source of biological materials (e.g., cells) that comprise and/or express the inserted pathogenic heterologous hexanucleotide repeat expansion sequence in an endogenous C9ORF72 locus that are useful for a variety of assays. In various embodiments, non-human animals described herein may be used to develop therapeutics that treat, prevent and/or inhibit one or more symptoms associated with expression and/or activity of a pathogenic heterologous hexanucleotide repeat expansion. In various embodiments, non-human animals described herein are used to identify, screen and/or develop candidate therapeutics (e.g., antibodies, gRNAs (comprising CRISPR RNA and tracRNA) and siRNA, etc.) that bind a pathogenic heterologous hexanucleotide repeat expansion sequence or expression product thereof, e.g., resulting from RAN translation. In various embodiments, non-human animals described herein are used to screen and develop candidate therapeutics (e.g., antibodies, gRNAs (comprising CRISPR RNA and tracRNA) and siRNA, etc.) that block activity of a pathogenic heterologous hexanucleotide repeat expansion sequence or expression product thereof, e.g., resulting from RAN translation. In various embodiments, non-human animals described herein are used to determine the binding profile of antagonists and/or agonists of a pathogenic heterologous hexanucleotide repeat expansion sequence or expression product thereof (transcript), e.g., resulting from RAN translation, of a non-human animal as described herein. In some embodiments, non-human animals described herein are used to determine the epitope or epitopes of one or more candidate therapeutic antibodies that bind a pathogenic heterologous hexanucleotide repeat expansion sequence or expression product thereof, e.g., resulting from RAN translation.
[0185] In various embodiments, non-human animals described herein are used to determine the pharmacokinetic profiles of a drug targeting a pathogenic heterologous hexanucleotide repeat expansion sequence or expression product thereof, e.g., resulting from RAN translation. In various embodiments, one or more non-human animals described herein and one or more control or reference non-human animals are each exposed to one or more candidate drugs targeting a pathogenic heterologous hexanucleotide repeat expansion sequence or expression product thereof, e.g., resulting from RAN translation, at various doses (e.g., 0.1 mg/kg, 0.2 mg/kg, 0.3 mg/kg, 0.4 mg/kg, 0.5 mg/kg, 1 mg/kg, 2 mg/kg, 3 mg/kg, 4 mg/kg, 5 mg/mg, 7.5 mg/kg, 10 mg/kg, 15 mg/kg, 20 mg/kg, 25 mg/kg, 30 mg/kg, 40 mg/kg, or 50 mg/kg or more). Candidate therapeutic antibodies may be dosed via any desired route of administration including parenteral and non-parenteral routes of administration. Parenteral routes include, e.g., intravenous, intraarterial, intraportal, intramuscular, subcutaneous, intraperitoneal, intraspinal, intrathecal, intracerebroventricular, intracranial, intrapleural or other routes of injection. Non-parenteral routes include, e.g., oral, nasal, transdermal, pulmonary, rectal, buccal, vaginal, ocular. Administration may also be by continuous infusion, local administration, sustained release from implants (gels, membranes or the like), and/or intravenous injection. Blood is isolated from non-human animals (humanized and control) at various time points (e.g., 0 hr, 6 hr, 1 day, 2 days, 3 days, 4 days, 5 days, 6 days, 7 days, 8 days, 9 days, 10 days, 11 days, or up to 30 or more days). Various assays may be performed to determine the pharmacokinetic profiles of administered drugs targeting a pathogenic heterologous hexanucleotide repeat expansion sequence or expression product thereof, e.g., resulting from RAN translation, using samples obtained from non-human animals as described herein including, but not limited to, total IgG, anti-therapeutic antibody response, agglutination, etc.
[0186] In various embodiments, non-human animals as described herein are used to measure the therapeutic effect of blocking, modulating, and/or inhibiting activity of a pathogenic heterologous hexanucleotide repeat expansion sequence or expression product thereof, e.g., resulting from Repeat-associated non-AUG (RAN) translation, and the effect on gene expression as a result of cellular changes. In various embodiments, a non-human animal as described herein or cells isolated therefrom are exposed to a drug targeting a pathogenic heterologous hexanucleotide repeat expansion sequence or expression product thereof, e.g., resulting from RAN translation, of the non-human animal and, after a subsequent period of time, analyzed for effects on processes (or interactions) dependent on the pathogenic heterologous hexanucleotide repeat expansion sequence or expression product thereof, e.g., resulting from RAN translation, for example, formation of RNA foci, protein aggregation from RAN translation products, motor neuron and/or non-motor neuron function, etc.
[0187] Cells from non-human animals as described herein can be isolated and used on an ad hoc basis, or can be maintained in culture for many generations. In various embodiments, cells from a non-human animal as described herein are immortalized (e.g., via use of a virus) and maintained in culture indefinitely (e.g., in serial cultures).
[0188] Non-human animals described herein provide an in vivo system for assessing the pharmacokinetic properties and/or efficacy of a drug (e.g., a drug targeting a pathogenic heterologous hexanucleotide repeat expansion sequence or expression product thereof, e.g., resulting from RAN translation). In various embodiments, a drug may be delivered or administered to one or more non-human animals, cells derived therefrom or having the same genetic modifications thereof, as described herein, followed by monitoring of, or performing one or more assays on, the non-human animals (or cells isolated therefrom) to determine the effect of the drug on the non-human animal. Pharmacokinetic properties include, but are not limited to, how an animal processes the drug into various metabolites (or detection of the presence or absence of one or more drug metabolites, including, but not limited to, toxic metabolites), drug half-life, circulating levels of drug after administration (e.g., serum concentration of drug), anti-drug response (e.g., anti-drug antibodies), drug absorption and distribution, route of administration, routes of excretion and/or clearance of the drug. In some embodiments, pharmacokinetic and pharmacodynamic properties of drugs are monitored in or through the use of non-human animals described herein.
[0189] In some embodiments, performing an assay includes determining the effect on the phenotype and/or genotype of the non-human animal to which the drug is administered. In some embodiments, performing an assay includes determining lot-to-lot variability for a drug. In some embodiments, performing an assay includes determining the differences between the effects of a drug administered to a non-human animal described herein and a reference non-human animal. In various embodiments, reference non-human animals may have a modification as described herein, e.g., insertion of a non-pathogenic heterologous hexanucleotide repeat expansion sequence or no modification (i.e., a wild type non-human animal).
[0190] Exemplary parameters that may be measured in non-human animals (or in and/or using cells isolated therefrom) for assessing the pharmacokinetic properties of a drug include, but are not limited to, agglutination, autophagy, cell division, cell death, complement-mediated hemolysis, DNA integrity, drug-specific antibody titer, drug metabolism, gene expression arrays, metabolic activity, mitochondrial activity, oxidative stress, phagocytosis, protein biosynthesis, protein degradation, protein secretion, stress response, target tissue drug concentration, non-target tissue drug concentration, transcriptional activity, and the like. In various embodiments, non-human animals described herein are used to determine a pharmaceutically effective dose of a drug (e.g., a drug targeting a pathogenic heterologous hexanucleotide repeat expansion sequence or expression product thereof, e.g., resulting from RAN translation).
EXAMPLES
[0191] The following examples are provided so as to describe to those of ordinary skill in the art how to make and use methods and compositions of the invention, and are not intended to limit the scope of what the inventors regard as their invention. Unless indicated otherwise, temperature is indicated in Celsius, and pressure is at or near atmospheric.
Example 1
Insertion of a Heterologous Hexanucleotide Repeat Expansion Sequence in a Non-Human Embryonic Stem Cell at an Endogenous Non-Human C9ORF72 Locus
[0192] This example illustrates a targeted insertion of a heterologous hexanucleotide repeat expansion sequence into an embryonic stem cell at a C9orf72 locus of a non-human animal, particularly rodent. In particular, this example specifically describes the replacement of a part of a non-coding sequence of a mouse C9orf72 locus with a heterologous human hexanucleotide repeat expansion sequence placed in operable linkage with an mouse C9orf72 promoter and/or human regulatory elements, e.g., those that may be found in exons 1a and/or 1b of the human C9orf72 gene. The C9orf72-HRE targeting vector for inserting a heterologous hexanucleotide repeat expansion sequence in an endogenous mouse C9orf72 locus was made as previously described (see, e.g., U.S. Pat. No. 6,586,251; Valenzuela et al., 2003, Nature Biotech. 21(6):652-659; and Adams, N. C. and N. W. Gale, in Mammalian and Avian Transgenesis--New Approaches, ed. Lois, S. P. a. C., Springer Verlag, Berlin Heidelberg, 2006). The resulting modified C9orf72 locus is depicted in FIG. 1A, bottom box.
[0193] Briefly, targeting vectors comprising a sequence set forth in SEQ ID NO:8 or SEQ ID NO:9 were generated using bacterial artificial chromosome (BAC) clones from a mouse RP23 BAC library (Adams, D. J. et al., 2005, Genomics 86:753-758) and introduced into F1 hybrid (129S6SvEvTac/C57BL6NTac) embryonic stem (ES) cells followed by culturing in selection medium containing G418. Drug-resistant colonies were picked 10 days after electroporation and screened for correct targeting as previously described (Valenzuela et al., supra; Frendewey, D. et al., 2010, Methods Enzymol. 476:295-307). Targeted ES cells are analyzed to determine the approximate size of hexanucleotide repeat expansions present in targeted mouse ES cell clones by Southern blot analysis and/or amplification of the C9orf72-HRE locus.
[0194] Specifically, Southern blot analysis was performed to determine the approximate size of hexanucleotide repeat expansions present in targeted C9ORF72 transgenic mouse ES cells. Genomic DNA was extracted from targeted mouse ES clones grown in single wells of a gelatin-coated 96 well plate. Once ES cell clones reached 100% confluence, cells were washed twice with 1.times. PBS and lysed overnight at 37.degree. C. in 50 uL of lysis buffer (1M Tris pH 8.5, 0.5M EDTA, 20% SDS, 5M NaCl, and 1 mg/mL proteinase K). DNA was precipitated with the addition of 125 uL of ice cold 200 proof ethanol to each well, followed by an overnight incubation at 4.degree. C. Precipitated DNA was washed twice with 70% ethanol, air dried, and resuspended in 30 uL 0.5.times. TE pH 8.0.
[0195] Extracted genomic DNAs (gDNA) were digested with HindII and ScaI overnight at 37.degree. C. and size separated on a 1% agarose gel. Post-electrophoresis agarose gels were denatured (1M NaCl, 5% NaOH) and neutralized (1.5M NaCl, 0.5M Tris pH 7.5). Digested gDNAs were then transferred to Hybond-N membranes (Amersham) via overnight capillary transfer.
[0196] A probe corresponding to a 252 bp XmaI fragment (see FIG. 2A) contained within the humanized targeting vector
TABLE-US-00005 (5'- CCGGGGCGGGGCTGCGGTTGCGGTGCCTGCGCCCGCGGCGGCGGAGG CGCAGGCGGTGGCGAGTGGGTGAGTGAGGAGGCGGCATCCTGGCGGG TGGCTGTTTGGGGTTCGGCTGCCGGGAAGAGGCGCGGGTAGAAGCGG GGGCTCTCCTCAGAGCTCGACGCATTTTTACTTTCCCTCTCATTTCT CTGACCGAAGCTGGGTGTCGGGCTTTCGCCTCTAGCGACTGGTGGAA TTGCCTGCATCCGGGCC-3'; SEQ ID NO: 29)
was labeled with .sup.32P using Prime-It II Random Primer Labeling Kit (Agilent). Denatured probe was diluted in ExpressHyb Hybridization Solution (Takara) and incubated with prepared membranes overnight at 65.degree. C. Autoradiography film was exposed to the probed blots for 72 hours.
[0197] As shown in FIG. 2B, an ES cell clone (8027 A-C4) comprising an inserted non-pathogenic heterologous hexanucleotide repeat expansion sequence comprising three repeats of the hexanucleotide sequence set forth as SEQ ID NO:1 is obtained after introduction of the C9orf72-HRE-3 targeting vector comprising a sequence set forth as SEQ ID NO:4 and excision of the drug resistance cassette. After introduction of the C9orf72-HRE-100 targeting vector comprising a sequence set forth as SEQ ID NO:6, at least two ES cell clones (8029 A-A3 and 8029 A-A6) comprising an inserted heterologous hexanucleotide repeat expansion sequence, which is a variant of the sequence set forth as SEQ ID NO:7 and comprises about 92 repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, were obtained. Also at least two ES cell clones (8029 B-A6 and 8029 B-A4) comprising an inserted heterologous hexanucleotide repeat expansion sequence, which is a variant of the sequence set forth as SEQ ID NO:7 and comprises about 30 repeats of the hexanucleotide sequence set forth as SEQ ID NO:1, were obtained after introduction of the C9orf72-HRE-100 targeting vector (8028) and excision of the drug resistance cassette.
[0198] AmplideX PCR/CE C9ORF72 Kit (Asuragen) was also used according to manufacturer's instructions to confirm the number of instances of the hexanucleotide sequence set forth as SEQ ID NO:1 in heterologous hexanucleotide repeat expansion sequence inserted into the endogenous C9orf72 ES cell clones described. Purified mESC genomic total DNA from a 3.times. repeat clone (8027 A-C4), 2 individual 92.times. repeat clones (8029 A-A3, 8029 A-A6), and 2 individual 30.times. repeat clones (8029 B-A4, 8029 B-A10) was used as input DNA. F1H4 mESC genomic total DNA served as negative control, and Coriell Cell Repository purified human blood cell genomic DNA from patients with known C9ORF72 hexanucleotide expanded repeat alleles (samples ND11836 (HRE genotype: 8/expanded), ND14442 (2/expanded), ND6769 (13/44)) served as positive controls (Coriell Institute for Medical Research). PCR using the primers in Table 4 was performed on a ABI 9700 thermal cycler (Thermo Fisher). Amplicons were sized by capillary electrophoresis on a ABI 3500.times.L GeneScan using POP-7 polymer (Thermo Fisher) and NuSieve agarose gels (Lonza). 2-log DNA ladder (New England BioLabs) molecular weight marker was loaded on agarose gels for comparison, and bands were visualized with SYBR Gold Nucleic Acid Stain (Thermo Fisher).
TABLE-US-00006 TABLE 4 Primer name Sequence (SEQ ID NO:) 2-Primer Fwd TGCGCCTCCGCCGCCGCGGGCGCAGGCACCGCAACCGCA (SEQ ID NO: 30) 2-Primer Rev CGCAGCCTGTAGCAAGCTCTGGAACTCAGGAGTCG (SEQ ID NO: 31) 3-Primer Fwd ATGCAGGCAATTCCACCAGTCGCTAGAGGCGAAAGC (SEQ ID NO: 32) 3-Primer Rev TAACCAGAAGAAAACAAGGAGGGAAACAACCGCAGCCTGT (SEQ ID NO: 33)
[0199] FIG. 2B confirms the presence of 3 repeats of the hexanucleotide sequence set forth as SEQ ID NO:1 within the heterologous hexanucleotide repeat expansion sequence inserted into the endogenous C9orf72 locus of mouse ES cell clone 8027 A-C4, about 30 repeats of the hexanucleotide sequence set forth as SEQ ID NO:1 within the heterologous hexanucleotide repeat expansion sequences inserted into the endogenous C9orf72 locus of mouse ES cell clones 8029 B-A9 and 8029 B-A10, and about 92 repeats of the hexanucleotide sequence set forth as SEQ ID NO:1 within the heterologous hexanucleotide repeat expansion sequences at the endogenous C9orf72 locus of mouse ES cell clones 8029 A-A3 and 8029 A-A6.
Example 2
Generation of Embryonic Stem Cell Derived Motor Neurons and Non-Human Animals Comprising a Heterologous Hexanucleotide Repeat Expansion Sequence at an Endogenous Mouse C9ORF72 Locus
[0200] Embryonic Stem Cell Derived Motor Neurons
[0201] Parental embryonic stem cells (ESCs) homozygous for a wildtype C9orf72 locus (control) or heterozygous for a C9orf72 locus genetically modified with about 3 repeats (C9orf72HRE.sub.3.sup.+/-), 30 repeats (C9orf72HRE.sub.30.sup.+/-), or 92 repeats ((C9orf72HRE.sub.92.sup.+/-) of the hexanucleotide sequence set forth as SEQ ID NO:1 were cultured in embryonic stem cell medium (ESM; DMEM+15% Fetal bovine serum+Penicillin/Streptomycin+Glutamine+Non-essential amino acids+nucleosides+.beta.-mercaptoethanol+Sodium pyruvate+LIF) for 2 days, during which the medium was changed daily. ES medium was replaced with 7 ml of ADFNK medium (Advanced DMEM/F12+Neurobasal medium+10% Knockout serum+Penicillin/Streptomycin+Glutamine+.beta.-mercaptoethanol) 1 hour before trypsinization. ADFNK medium was aspirated and ESC were trypsinized with 0.05% trypsin-EDTA. Pelleted cells were resuspended in 12 ml of ADFNK and grown for two days in suspension. Cells were cultured for a further 4 days in ADFNK supplemented with retinoic acid (RA) and smoothened agonist to obtain motor neurons (ESMNs). Dissociated motor neurons were plated and matured in embryonic stem cell-derived motor neuron medium (ESMN; Neurobasal medium+2% Horse serum+B27+Glutamine+Penicillin/Streptomycin+.beta.-mercaptoethanol+10 ng/ml GDNF, BDNF, CNTF).
[0202] Non-Human Animals
[0203] The VELOCIMOUSE.RTM. method (DeChiara, T. M. et al., 2010, Methods Enzymol. 476:285-294; Dechiara, T. M., 2009, Methods Mol. Biol. 530:311-324; Poueymirou et al., 2007, Nat. Biotechnol. 25:91-99) was used, in which targeted ES cells were injected into uncompacted 8-cell stage Swiss Webster embryos, to produce healthy fully ES cell-derived F0 generation mice heterozygous for the C9orf72-HRE (3.times. or 100.times.) insertion. F0 generation heterozygous male were crossed with C57Bl6/NTac females to generate F1 heterozygotes that were intercrossed to produce F2 generation C9orf72-HRE.sup.+/+, C9orf72-HRE.sup.+/- and wild type mice for molecular and phenotypic analyses.
Example 3
Analysis of Motor Neurons or Brain Tissues Having a Heterologous Hexanucleotide Repeat Expansion Sequence in an Endogenous C9orf72 Locus
[0204] Recently, Liu et al. (2017) Cell Chem. Biol. 24:141-148 used quantitative polymerase chain reaction (qPCR) and digital droplet polymerase chain reaction (ddPCR) to quantify the copy number of sense and antisense RNA transcripts from the C9orf72 locus expressed by human fibroblast cell lines, or human astrocytes and motor neurons derived from induced pluripotent stem cells (iPSCs), isolated from patients suffering from ALS. Liu et al. (2017), supra, detected significantly higher numbers of sense intronic, antisense, and sense C9orf72 transcripts in patient-derived fibroblasts compared to fibroblasts derived from healthy patients. On average, three to four copies of C9orf72 intronic and antisense transcripts, and about 15-20 copies of C9orf72 sense mRNA transcripts, were detected per patient-derived fibroblast. Liu et al. (2017) supra. Liu et al. (2017) et al., supra, show that, in contrast, one or less intronic and antisense transcripts, and 5-10 copies of C9orf72 sense mRNA transcripts, were detected in non-disease fibroblast cell lines. Similarly to the fibroblasts, expression of intronic, antisense, and sense C9orf72 transcripts was higher in patient-derived astrocytes and neuronal cells compared to healthy-control derived astrocytes and neuronal cells. Liu et al. (2017) et al., supra. By calculating the percentage of cells that contain RNA foci, the average number of foci per cell, and the distribution of different numbers of foci among cells, and in determining the number of C9orf72 transcripts in disease- or healthy-derived cells, Liu et al. (2017) et al., supra, suggested that the each foci seen in disease-derived cell is a single mutant C9orf72 intronic or antisense transcript, and further, that small numbers of RNA molecules may have a sizable impact on disease.
[0205] In this example, the stability of the size of the hexanucleotide repeat in a breeding colony was confirmed in F2 animals using AmplideX PCR/CE C9ORF72 Kit (Asuragen) as described above (data not shown). Additionally, RNA transcripts in mouse embryonic stem cell derived motor neurons (ESMNs), brain tissues, and parental embryonic stem cells comprising a wildtype C9orf72 locus (control) or a genetically modified C9orf72 locus that comprises three, thirty, or ninety-two repeats of the hexanucleotide sequence set forth in SEQ ID NO:1 were examined. RNA foci and dipeptide repeat protein levels were also evaluated in ESMNs derived from parental embryonic stem cells comprising a wildtype C9orf72 locus (control) or a genetically modified C9orf72 locus that comprises three, thirty, or ninety-two repeats of the hexanucleotide sequence set forth in SEQ ID NO:1.
[0206] Materials and Methods
[0207] Quantitative Polymerase Chain Reaction
[0208] Total RNA from each sample was extracted and reverse transcribed using primers that flank various regions, and probes that detect those regions of the modified C9orf72-HRE locus. Detectable regions include those that span the junction of mouse and human sequences, only human sequences, or only mouse sequences. QPCR of GAPDH or .beta.2-microglobulin was performed using probes and primers of readily available kits.
[0209] Specifically, RNA was isolated from embryonic stem cell-derived motor neurons (ESMN), parental embryonic stem (ES) cells, or total brains isolated from mice comprising a wildtype (WT) C9orf72 locus (control) or a genetically modified C9orf72 locus comprising 3, 30 or 92 repeats of the hexanucleotide sequence set forth as SEQ ID NO:1
[0210] Total RNA was isolated using Direct-zol RNA Miniprep plus kit according to the manufacturer's protocol (Zymo Research). About 1 .mu.g total RNA was t treated with DNase I (ThermoFisher) at 25.degree. C. for 15 min. EDTA was added and the mixture incubated at 65.degree. C. for 10 min. Reverse transcription (RT) reactions were performed with a Maxima H Minus First Strand cDNA Synthesis Kit with dsDNase (ThermoFisher). After DNase I treatment, 10 .mu.L of RT mixture containing RT buffer, random hexamer primers, dNTPs, Maxima H minus enzyme mix was added to make final volume of 20 .mu.L. The RT reaction mixture was incubated at 25.degree. C. for 10 min, then at 50.degree. C. for 15 min, and then 5 min at 85.degree. C. to inactivate the enzyme. The cDNA mix was diluted with water to make 100 .mu.L final volume.
[0211] After reverse transcription, the PCR reaction solution was reconstituted to a final volume of 8 .mu.L containing 3 .mu.L cDNA and 5 .mu.L of PCR mixture, probe and gene specific primers. Unless otherwise noted final primer and probe concentrations were 0.5 .mu.M and 0.25 .mu.M respectively. qPCR was performed on a ViiA.TM. 7 Real-Time PCR Detection System (ThermoFisher). PCR reactions were done in quadruplicates at 95.degree. C. 10 min and 95.degree. C. 3 s, 60.degree. C. 30 s for 45 cycles in an optical 384-well plate. The sequences of the primers and probes and SEQ ID NO used in each analysis (A, B, F, G, H) are provided in Table 5.
TABLE-US-00007 TABLE 5 Analysis A Forward CATCCCAATTGCCCTTTCC (SEQ ID NO: 66) Primer Reverse CCCACACCTGCTCTTGCTAGA (SEQ ID NO: 67) Primer Probe TCTAGGTGGAAAGTGGG (SEQ ID NO: 68) Analysis B Forward GAGCAGGTGTGGGTTTAGGA (SEQ ID NO: 69) Primer Reverse CCAGGTCTCACTGCATTCCA (SEQ ID NO: 70) Primer Probe ATTGCAAGCGTTCGGATAATGTGAGA (SEQ ID NO: 71) Analysis D Forward GCTGTCACGAAGGCTTTCTTC (SEQ ID NO: 72) Primer Reverse GCACTGCTGCCAACTACAAC (SEQ ID NO: 73) Primer Probe TCAATGCCATCAGCTCACACCTGC (SEQ ID NO: 74) Analysis G Forward AAGAGGCGCGGGTAGAA (SEQ ID NO: 75) Primer Reverse CAGCTTCGGTCAGAGAAATGAG (SEQ ID NO: 76) Primer Probe CTCTCCTCAGAGCTCGACGCATTT (SEQ ID NO: 77) Analysis H Forward CTGCACAATTTCAGCCCAAG (SEQ ID NO: 78) Primer Reverse CAGGTCATGTCCCACAGAAT (SEQ ID NO: 79) Primer Probe CATATGAGGGCAGCAATGCAAGTC (SEQ ID NO: 80)
[0212] Western Blot Analysis
[0213] Differentiated embryoid bodies (EBs) were collected and homogenized in SDS sample buffer (2% SDS, 10% glycerol, 5% .beta.mercaptoethanol, 60 mM TrisHCl, pH 6.8, bromophenol blue). Protein extracts were quantified using the RC DC protein assay (BioRad). Extracts (10 .mu.g) were run on a 4-20% SDS-PAGE gel (ThermoFisher) and transferred onto nitrocellulose membrane using an iBLOT transfer unit (ThermoFisher). Immunoblots were probed with primary antibodies against C9orf72 and GAPDH (Millipore). Bound antibody was detected by incubation with secondary antibodies conjugated to horseradish peroxidase (Abcam) followed by chemiluminescence using a SuperSignal West Pico chemiluminescent substrate (Thermo Scientific). Signal was detected by autoradiography using Full Speed Blue sensitive medical X-Ray film (Ewen Parker XRay Corporation). Relative protein levels were calculated using ImageJ.
[0214] Fluorescent In Situ Hybridization (FISH) and Immunofluorescence (IF) for the Detection of RNA and Translation Products
[0215] Fluorescent in situ hybridization (FISH) and immunofluorescence were respectively used to determine the location of RNA transcribed from the hexanucleotide repeat sequence set forth as SEQ ID NO:1, as well as dipeptide repeat proteins translated therefrom, in embryonic stem cell-derived motor neurons (ESMNs) generated as described in Example 3. Briefly, ESMNs were grown in four-well chamber slide (Lab-Tek II chamber slide system, ThermoFisher Scientific) and fixed with 4% PFA (Electron Microscopy Sciences) in PBS. Cells were then permeabilized with diethyl pyrocarbonate (DEPC) PBS/0.2% Triton X-100 (Fisher Scientific, catalog #BP151) and washed with DEPC-PBS, blocked and stained with LNA or DNA oligonucleotides for the detection of RNA transcription products, or anti-polyGA antibody for the detection of RAN translation products, as described below. After staining, slides were subsequently incubated with an appropriate fluorescent dye, mounted with Fluoromount G (Southern Biotech) and visualized using confocal microscopy.
[0216] Detection of Sense or Antisense RNA Transcription Products
[0217] Slides were pre-hybridized with buffer consisting of 50% formamide (IBI Scientific, catalog #IB72020), DEPC 2.times.SSC [300 mM sodium chloride, 30 mM sodium citrate (pH 7.0)], 10% (w/v) dextran sulfate (Sigma-Aldrich, catalog #D8960), and DEPC 50 mM sodium phosphate (pH 7.0) for 30 min at 66.degree. C. (for LNA probes) or 55.degree. C. (for DNA probes). The hybridization buffer was then drained off, and 400 .mu.l of 40 nM LNA probe mix or 200 ng/ml of DNA probe mix in hybridization buffer was added to each of the slides and incubated in the dark for 3 hours at 66.degree. C. (for LNA probes) or 55.degree. C. (for DNA probes). Slides incubated with LNA probes were rinsed once in DEPC 2.times.SSC/0.1% Tween 20 (Fisher Scientific, catalog no. BP337) at room temperature and in DEPC 0.1.times.SSC three times at 65.degree. C. Slides incubated with DNA probes washed three times with 40% formamide in 2.times.SSC and briefly washed one time in PBS. Slides were subsequently incubated with 1 .mu.g/mL DAPI (Molecular Probes Inc.).
[0218] The sequences and SEQ ID NOs: of the LNA and DNA oligonucleotide probes used in this example, as well as the hybridization conditions of the probes, are provided in Table 6 below.
TABLE-US-00008 TABLE 6 Sequence Probe (SEQ ID NO:) Hybridization method LNA TYE563-CCCCGGCCCCG 66.degree. C. hybridization sense GCCCC and washes in 0.1 X G.sub.4C.sub.2 RNA (SEQ ID NO: 81) SSC LNA TYE563-GGGGCCGGGGC 66.degree. C. hybridization antisense CGGGGGGCCCC and washes in 0.1 X G.sub.4C.sub.2 RNA (SEQ ID NO:82) SSC DNA CCCCGGCCCCGGCCCCG 55.degree. C. hybridization sense G-Cy3 and washes in 2 X SSC G.sub.4C.sub.2 RNA (SEQ ID NO: 83) DNA GGGGCCGGGGCCGGGG 55.degree. C. hybridization antisense C-Cy3 and washes in 2 X SSC G.sub.4C.sub.2 RNA (SEQ ID NO: 84)
[0219] Detection of Dipeptide Repeat Protein Products
[0220] After permeabilization, slides were blocked with 5% normal donkey serum diluted in Tris buffered saline (pH 7.4) with 0.2% Triton X100 (TBS-T). Slides were incubated overnight at 4.degree. C. with primary antibodies against poly-GA (Millipore) diluted in TBS-T with 5% normal donkey. After washing 3 time with TBS-T, slides were incubated with species specific secondary antibodies coupled to Alexa 488 or 555 (1:1000 in TBS-T, ThermoFisher) and DAPI (1 .mu.g/ml) (Molecular Probes Inc.) for 1 hr at room temperature. After washing 3 times with TBS-T slides were mounted with Fluoromount G (Southern Biotech) and visualized using confocal microscopy.
[0221] Results
[0222] As shown in FIGS. 4, 5 and 6, ESMNs, total brain and neuronal tissues from mice comprising the hexanucleotide repeat expansion sequence set forth as SEQ ID NO:1 at the C9orf72 locus showed increased expression of the C9orf72 mRNA transcripts. Such increase appears to be correlated with the number of the hexanucleotide repeats present between exons 1a and 1b of the C9orf72 locus. FIG. 6 also shows that, similar to the neuronal tissues isolated from the mice comprising 3 or 92 repeats of the heterologous hexanucleotide sequence set forth as SEQ ID NO:1 at the endogenous C9orf72 locus and ESMNs comprising the same, C9orf72 expression was also enhanced in non-neuronal tissues, e.g., muscle and heart, in mice comprising 3 or 92 repeats of the heterologous hexanucleotide sequence set forth as SEQ ID NO:1 at the endogenous C9orf72 locus. Furthermore, the enhancement was specific for the humanized C9orf72 allele; no enhanced expression of the mouse C9orf72 allele, which does not contain the repeat sequence, was seen in heterozygous mice (data not shown).
[0223] Preliminary calculations indicate that ESMNs or brain cells with thirty or ninety-two repeats of the hexanucleotide sequence set forth as SEQ ID NO:1 have approximately 17 copies of a C9orf72 mRNA per cell, consistent with the findings of Liu et al. (2017) supra. An increased number of repeats of a hexanucleotide sequence set forth in SEQ ID NO:1 is also directly correlated with an increase in C9orf72 protein levels, (FIGS. 7 and 8), nuclear and cytoplasmic accumulation of sense and antisense C9orf72 RNA foci (FIGS. 9A and 9B), and dipeptide repeat proteins (FIG. 10). The data shown herein indicate that increased number of repeats of a hexanucleotide sequence set forth in SEQ ID NO:1 at the C9orf72 locus results in cells exhibiting a molecular phenotype (e.g., increased transcription, accumulation of RNA foci, and/or increased dipeptide repeat proteins) similar to human cells isolated from patients diagnosed with ALS, and supports the use of the non-human animals disclosed herein as a disease model for neurodegenerative disease.
Example 4
Behavioral Analysis of Non-Human Animals Having a Heterologous Hexanucleotide Repeat Expansion Sequence in an Endogenous C9orf72 Locus
[0224] This example describes behavioral analysis of non-human animals (e.g., rodents) described herein for ALS-like symptoms such as, for example, decreased body weight and/or significant motor abnormalities resulting from an insertion of a heterologous hexanucleotide repeat expansion sequence in an endogenous rodent (e.g., mouse) C9orf72 locus as described in Example 1.
[0225] Phenotypic studies of mice having an a pathogenic heterologous hexanucleotide repeat expansion sequence inserted into an endogenous C9orf72 locus as described above, and/or control mice, e.g., wildtype mice or mice having an a non-pathogenic heterologous hexanucleotide repeat expansion sequence inserted into an endogenous C9orf72 locus as described above, is performed at 8, 18, 37 (female) and 57-60 weeks (male). Body weight is measured on a bi-weekly basis, and body composition is analyzed by .mu.CT scan (Dynamic 60). Standard 24 scan is used to visualize mass of the cervical region of the spine. All animal procedures were conducted in compliance with protocols approved by the Regeneron Pharmaceuticals Institutional Animal Care and Use Committee.
[0226] Assessment of overall motor function is performed using blinded subjective scoring assays. Analysis of motor impairment is conducted using rotarod, open field locomotor, and catwalk testing. Motor impairment score is measure using the system developed by the ALS Therapy Development Institute (ALSTDI, Gill A. et al., 2009, PLoS One 4:e6489). During catwalk testing, subjects walk across an illuminated glass platform while a video camera records from below. Gait related parameters such as stride pattern, individual paw swing speed, stance duration, and pressure are reported for each animal. This test is used to phenotype mice and evaluate novel chemical entities for their effect on motor performance. CatWalk XT is a system for quantitative assessment of footfalls and gait in rats and mice. It is used to evaluate the locomotor ability of rodents in almost any kind of experimental model of central nervous, peripheral nervous, muscular, or skeletal abnormality.
[0227] CatWalk Gait Analysis: Animals are placed at the beginning of the runway of Noldus CatWalk XT 10, with the open end in front of them. Mice spontaneously run to the end of the runway to attempt to escape. The camera records and the software of the system measures the footprints. The footprints are analyzed for abnormalities in paw placement.
[0228] Open Field Test: Mice are placed in the Kinder Scientific open field system and evaluated for 60 minutes. The apparatus uses infrared beams and computer software to calculate fine movements, X+Y ambulation, distance traveled, number of rearing events, time spent rearing, and immobility time.
[0229] Rotorod: The rotorod test (IITC Life Science, Woodland Hills, Calif.) measures the latency for a mouse to fall from a rotating beam. The rotorod is set to the experimental regime that starts at 1 rpm and accelerates up to 15 rpm over 180 seconds. Then, the animals' latency to fall following the incremental regime is recorded. The average and maximum of the three longest durations of time that the animals stay on the beam without falling off are used to evaluate falling latency. Animals that manage to stay on the beam longer than 180 seconds are deemed to be asymptomatic.
[0230] Upper motor neuron impairment presents as spasticity (i.e., rigidity), increased reflexes, tremor, bradykinesia, and Babinski signs. Lower motor neuron impairment presents as muscle weakness, wasting, clasping, curling and dragging of feet, and fasciculations. Bulbar impairment presents as difficulty swallowing, slurring and tongue fasciculations. Overall motor function is also assessed starting at 32 weeks up to 60 weeks of age as percent of living animals at a given week. Mice are weighed weekly and assessment of overall motor function is performed using blinded subjective scoring assays (as described above). Weekly or bi-monthly clinical neurological exams are performed on the two groups of mice looking at their motor impairment, tremor and rigidity of their hind limb muscles. For motor impairment, a blinded neurological scoring scale from of zero (no symptoms) to four (mouse cannot right themselves within 30 seconds of being placed on their side) is used as shown in Table 7.
TABLE-US-00009 TABLE 7 ALS-TDI neurological scoring system Score of 0: Full extension of hind legs away from lateral midline when mouse is suspended by its tail, and mouse can hold this for two seconds, suspended two to three times. Score of 1: Collapse or partial collapse of leg extension towards lateral midline (weakness) or trembling of hind legs during tail suspension. Score of 2: Toes curl under at least twice during walking of 12 inches, or any part of foot is dragging along cage bottom/table. Score of 3: Rigid paralysis or minimal joint movement, foot not being used for generating forward motion. Score of 4: Mouse cannot right itself within 30 seconds after being placed on either side.
[0231] For tremor and rigidity, a scoring system with a scale from zero (no symptoms) to three (severe) is used. Table 8 sets forth the scoring methodology related to motor impairment, tremor and rigidity of animals during testing.
TABLE-US-00010 TABLE 8 0 2 Motor no 1 clapsing & 3 impairment phenotype clasping dragging Paralysis Tremor none mild moderate Severe Rigidity none mild moderate Severe
[0232] In another experiment mice are examined using a grip strength test. Briefly, the grip strength measures the neuromuscular function as maximal muscle strength of forelimbs, and is assessed by the grasping applied by a mouse on a grid that is connected to a sensor. All grip strength values obtained are normalized against mouse body weight.
[0233] In another experiment, the lumbar portion of spinal cords from control mice and mice comprising a pathogenic heterologous hexanucleotide repeat expansion sequence inserted into an endogenous C9orf72 locus at around 60 weeks old are collected for histopathological analysis. The total number of motor neurons in the spinal cords, and mean cell body area of motor neurons are observed in both test and control cohorts.
[0234] The thermal nociception of control mice, and test mice comprising an insertion of a pathogenic heterologous hexanucleotide repeat expansion sequence at 20 weeks of age is tested by placing animals on a metal surface maintained at 48.degree. C., 52.degree. C. or 55.degree. C. (IITC, Woodland Hills, Calif.). Latency to respond, defined as the time elapsed until the animal licked of flicked a hind paw, to the heat stimulus is measured. Mice remain on the plate until they performed either of two nocifensive behaviors: hindpaw licking or hindpaw shaking.
Example 5
Deletion of a Heterologous Hexanucleotide Repeat Expansion Sequence from an Endogenous Non-Human C9ORF72 Locus in a Non-Human Embryonic Stem Cell Using a CRISPR/Cas9 System
[0235] Potential guide RNA (gRNA) sequences for a reference hexanucleotide repeat expansion sequence (comprising at least one, at least about three, at least about five, at least about fifteen, at least about twenty, at least about thirty, at least about forty, at least about fifty, at least about 60 at least about 70, at least about 80, or at least about 90, preferably contiguous, repeats of the hexanucleotide sequence set forth as SEQ ID NO:1) are analyzed and scored. DNA encoding potentially effective gRNA (e.g., crRNA and/or tracRNA) is synthesized and placed into an expression construct, which may also comprise a nucleic acid encoding a Cas protein. See, e.g., FIG. 12. ES cells comprising the reference hexanucleotide repeat expansion sequence are transfected with the expression construct(s) comprising the DNA encoding the gRNA and/or Cas protein, and a drug resistance gene. Drug-resistant clones are obtained by serial dilution, expanded for analysis and frozen. DNA from each drug-resistant ES cell clone is isolated and analyzed by PCR and visualization on an agarose gel. PCR products of a correct size are extracted and further sequenced to confirm deletion of the targeted hexanucleotide repeat expansion sequence.
[0236] FIG. 11 provides a not to scale depiction of a non-limiting exemplary reference hexanucleotide repeat expansion sequence, e.g., as found in 8029 A-A6 ES cells generated in Example 1, e.g., having a sequence as set forth as SEQ ID NO:45, and the positions of which that were more likely to be successfully targeted by gRNA. The DNA sequences encoding crRNA that target the positions depicted in FIG. 11, an exemplary sequence for which is provided as SEQ ID NO:45, and the SEQ ID NO: of each are provided in Table 9. Notably, the sequences set forth as SEQ ID NOs:46-50 contain an initial guanine not found in the reference hexanucleotide repeat expansion sequence set forth as SEQ ID NO:45 for optimal expression with a U6 promoter.
TABLE-US-00011 TABLE 9 Designed gRNA sequences Position in crRNA encoding SEQ ID NO: 45 sequence (SEQ ID NO:) 190 GCTACTTGCTCTCACAGTACT (SEQ ID ON: 46) 196 GCTCTCACAGTACTCGCTGA (SEQ ID NO: 39) 274 GCCGCAGCCTGTAGCAAGCTC (SEQ ID NO: 47) 899 GCGGCCGCTAGCGCGATCGCG (SEQ ID NO: 48) 905 GCTAGCGCGATCGCGGGGCG (SEQ ID NO: 49) 1006 GTGGCGAGTGGGTGAGTGAGG (SEQ ID NO: 50) 1068 GGAAGAGGCGCGGGTAGAAG (SEQ ID NO: 44)
[0237] DNA encoding the crRNA as set forth in Table 9 were made (Integrated DNA Technologies) and inserted into an expression construct in operable linkage with DNA encoding tracrRNA (e.g., DNA comprising the sequence set forth as SEQ ID NO:63). Successful ligation of the crRNA encoding sequences, was confirmed by polymerase chain reaction with the vector screening primers set forth in Table 10, and the sequences of the gRNA (crRNA and tracrRNA) encoding sequences were confirmed with sequence analysis using the vector sequencing primers, also set forth in Table 10. Expression constructs comprising the correct gRNA encoding sequences under the control of a U6 promoter, a nucleic acid encoding a cas9 protein, and a puromycin resistance gene, FIG. 12, were amplified and purified.
TABLE-US-00012 TABLE 10 Vector Screening ACACCGCTCTCACAGTACTCGCTGAG forward primer (SEQ ID NO: 51) Position 190 gRNA Vector Screening ACACCGCCGCAGCCTGTAGCAAGCTCG forward primer (SEQ ID NO: 52) Position 196 gRNA Vector Screening ACACCGAGTACTGTGAGAGCAAGTAGG forward primer (SEQ ID NO: 53) Position 274 gRNA Vector Screening ACACCGACGCCCCGCGATCGCGCTAGG forward primer (SEQ ID NO: 54) Position 899 gRNA Vector Screening ACACCGCGGCCGCTAGCGCGATCGCGG forward primer (SEQ ID NO: 55) Position 905 gRNA Vector Screening ACACCGTGGCGAGTGGGTGAGTGAGGG forward primer (SEQ ID NO: 56) Position 1006 gRNA Vector Screening ACACCGGAAGAGGCGCGGGTAGAAGG forward primer (SEQ ID NO: 57) Position 1068 gRNA Vector Screening GACGCGTTAATGCCAACTTT reverse primer (SEQ ID NO: 58) All gRNA Vector sequencing GAGGGCCTATTTCCCATGAT forward primer (SEQ ID NO: 59) Vector sequencing GACGCGTTAATGCCAACTTT reverse primer (SEQ ID NO: 60) Clone screening GAACTTACGGAGTCCCACGA forward primer (SEQ ID NO: 61) Clone screening GGAGACAGCTCGGGTACTGA reverse primer (SEQ ID NO: 62)
[0238] 8029 A-A6 clones as obtained in Example 1 and comprising a hexanucleotide repeat expansion sequence comprising about 92 repeats of the hexanucleotide sequence set forth as SEQ ID NO:1 (e.g., a reference sequence set forth as SEQ ID NO:45) were transfected with different combinations of the crRNA set forth in Table 9 (plus tracrRNA sequence), a puromycin resistance gene, and a CRISPR/Cas9 endonuclease gene. In one combination, ES cells were transfected with a CRISPR/Cas9 system targeting sequences starting at positions 190, 196, 274, 899, 905, 1006, and 1068 of SEQ ID NO:45 (e.g., the expression construct(s) comprising a nucleic acid encoding cas9 protein and/or gRNA inserts having the sequences set forth as SEQ ID NOs: 39, 44 and 46-50. In a second combination, ES cells were transfected a CRISPR/Cas9 system targeting positions 196, 1006 and 1067 of SEQ ID NO: 45 (e.g., the expression construct(s) comprising a nucleic acid encoding cas9 protein and/or DNA encoding gRNA inserts comprising the sequence set forth as SEQ ID NOs: 39, 50 and 44, respectively). In a third combination, ES cells were transfected with gRNA inserts targeting positions 196, 272 and 1005 and 1067 of SEQ ID NO:45 (e.g., the expression construct(s) comprising a nucleic acid encoding cas9 protein and/or gRNA inserts comprising a sequence set forth as SEQ ID NO: 39, 47, 50 and 44, respectively).
[0239] Puromycin-resistant ES clones were obtained by serial dilution, cultured in media (500 ml KO DMEM media, 95 ml Heat Inactivated FBS, 12 mL L-Glutamine, 6 mL Penn-Step, 6 mL Non-Essential Amino Acids, 1.2 mL B-mercaptoethanol), expanded for analysis, and frozen. DNA from each clone was isolated using the DNAase Blood and Tissue Kit according to the manufacturer's protocol (Qiagen) and analyzed by PCR using the clone screening forward and reverse screening primers set forth in Table 10. PCR products were visualized by agarose gel electrophoresis, and PCR products of a correct size were extracted and further sequenced to confirm deletion of the targeted hexanucleotide repeat expansion sequence.
[0240] Of one-hundred sixty (160) clones, one hundred clones were tested and eleven (11) demonstrated a deletion of the hexanucleotide repeat expansion sequence, e.g. as demonstrated an amplified PCR product between 300 and 700 base pairs (data not shown). Sequence analysis confirmed deletion of the hexanucleotide repeat expansion sequence (data not shown). Of the three combinations tested, a CRISPR/Cas system targeting the combination of positions 196, 1005 and 1067 of SEQ ID NO: 45 proved most efficient in deleting the hexanucleotide repeat expansion sequence; this combination resulted in ten of the eleven positive clones. A CRISPR/Cas system targeting the combination of positions 196, 272. 1005 and 1067 of SEQ ID NO: 45 provided one clone.
EQUIVALENTS
[0241] Having thus described several aspects of at least one embodiment of this invention, it is to be appreciated by those skilled in the art that various alterations, modifications, and improvements will readily occur to those skilled in the art. Such alterations, modifications, and improvements are intended to be part of this disclosure, and are intended to be within the spirit and scope of the invention. Accordingly, the foregoing description and drawing are by way of example only and the invention is described in detail by the claims that follow.
[0242] Use of ordinal terms such as "first," "second," "third," etc., in the claims to modify a claim element does not by itself connote any priority, precedence, or order of one claim element over another or the temporal order in which acts of a method are performed, but are used merely as labels to distinguish one claim element having a certain name from another element having a same name (but for use of the ordinal term) to distinguish the claim elements.
[0243] The articles "a" and "an" in the specification and in the claims, unless clearly indicated to the contrary, should be understood to include the plural referents. Claims or descriptions that include "or" between one or more members of a group are considered satisfied if one, more than one, or all of the group members are present in, employed in, or otherwise relevant to a given product or process unless indicated to the contrary or otherwise evident from the context. The invention includes embodiments in which exactly one member of the group is present in, employed in, or otherwise relevant to a given product or process. The invention also includes embodiments in which more than one, or the entire group members are present in, employed in, or otherwise relevant to a given product or process. Furthermore, it is to be understood that the invention encompasses all variations, combinations, and permutations in which one or more limitations, elements, clauses, descriptive terms, etc., from one or more of the listed claims is introduced into another claim dependent on the same base claim (or, as relevant, any other claim) unless otherwise indicated or unless it would be evident to one of ordinary skill in the art that a contradiction or inconsistency would arise. Where elements are presented as lists, (e.g., in Markush group or similar format) it is to be understood that each subgroup of the elements is also disclosed, and any element(s) can be removed from the group. It should be understood that, in general, where the invention, or aspects of the invention, is/are referred to as comprising particular elements, features, etc., certain embodiments of the invention or aspects of the invention consist, or consist essentially of, such elements, features, etc. For purposes of simplicity those embodiments have not in every case been specifically set forth in so many words herein. It should also be understood that any embodiment or aspect of the invention can be explicitly excluded from the claims, regardless of whether the specific exclusion is recited in the specification.
[0244] Those skilled in the art will appreciate typical standards of deviation or error attributable to values obtained in assays or other processes described herein.
[0245] The publications, websites and other reference materials referenced herein to describe the background of the invention and to provide additional detail regarding its practice are hereby incorporated by reference.
Sequence CWU 1
1
8416DNAArtificial SequenceHeterologous Hexanucleotide sequence
1ggggcc 62964DNAHomo sapiens 2gggtctagca agagcaggtg tgggtttagg
aggtgtgtgt ttttgttttt cccaccctct 60ctccccacta cttgctctca cagtactcgc
tgagggtgaa caagaaaaga cctgataaag 120attaaccaga agaaaacaag
gagggaaaca accgcagcct gtagcaagct ctggaactca 180ggagtcgcgc
gctatgcgat cgcggggccg gggccggggc cgcgatcgcg gggcgtggtc
240ggggcgggcc cgggggcggg cccggggcgg ggctgcggtt gcggtgcctg
cgcccgcggc 300ggcggaggcg caggcggtgg cgagtgggtg agtgaggagg
cggcatcctg gcgggtggct 360gtttggggtt cggctgccgg gaagaggcgc
gggtagaagc gggggctctc ctcagagctc 420gacgcatttt tactttccct
ctcatttctc tgaccgaagc tgggtgtcgg gctttcgcct 480ctagcgactg
gtggaattgc ctgcatccgg gccccgggct tcccggcggc ggcggcggcg
540gcggcggcgc agggacaagg gatggggatc tggcctcttc cttgctttcc
cgccctcagt 600acccgagctg tctccttccc ggggacccgc tgggagcgct
gccgctgcgg gctcgagaaa 660agggagcctc gggtactgag aggcctcgcc
tgggggaagg ccggagggtg ggcggcgcgc 720ggcttctgcg gaccaagtcg
gggttcgcta ggaacccgag acggtccctg ccggcgagga 780gatcatgcgg
gatgagatgg gggtgtggag acgcctgcac aatttcagcc caagcttcta
840gagagtggtg atgacttgca tatgagggca gcaatgcaag tcggtgtgct
ccccattctg 900tgggacatga cctggttgct tcacagctcc gagatgacac
agacttgctt aaaggaagtg 960actc 96431528DNAHomo sapiens 3gggtctagca
agagcaggtg tgggtttagg aggtgtgtgt ttttgttttt cccaccctct 60ctccccacta
cttgctctca cagtactcgc tgagggtgaa caagaaaaga cctgataaag
120attaaccaga agaaaacaag gagggaaaca accgcagcct gtagcaagct
ctggaactca 180ggagtcgcgc gctatgcgat cgccgtctcg gggccggggc
cggggccggg gccggggccg 240gggccggggc cggggccggg gccggggccg
gggccggggc cggggccggg gccggggccg 300gggccggggc cggggccggg
gccggggccg gggccggggc cggggccggg gccggggccg 360gggccggggc
cggggccggg gccggggccg gggccggggc cggggccggg gccggggccg
420gggccggggc cggggccggg gccggggccg gggccggggc cggggccggg
gccggggccg 480gggccggggc cggggccggg gccggggccg gggccggggc
cggggccggg gccggggccg 540gggccggggc cggggccggg gccggggccg
gggccggggc cggggccggg gccggggccg 600gggccggggc cggggccggg
gccggggccg gggccggggc cggggccggg gccggggccg 660gggccggggc
cggggccggg gccggggccg gggccggggc cggggccggg gccggggccg
720gggccggggc cggggccggg gccggggccg gggccggggc cgagaccctc
gagggccggc 780cgctagcgcg atcgcggggc gtggtcgggg cgggcccggg
ggcgggcccg gggcggggct 840gcggttgcgg tgcctgcgcc cgcggcggcg
gaggcgcagg cggtggcgag tgggtgagtg 900aggaggcggc atcctggcgg
gtggctgttt ggggttcggc tgccgggaag aggcgcgggt 960agaagcgggg
gctctcctca gagctcgacg catttttact ttccctctca tttctctgac
1020cgaagctggg tgtcgggctt tcgcctctag cgactggtgg aattgcctgc
atccgggccc 1080cgggcttccc ggcggcggcg gcggcggcgg cggcgcaggg
acaagggatg gggatctggc 1140ctcttccttg ctttcccgcc ctcagtaccc
gagctgtctc cttcccgggg acccgctggg 1200agcgctgccg ctgcgggctc
gagaaaaggg agcctcgggt actgagaggc ctcgcctggg 1260ggaaggccgg
agggtgggcg gcgcgcggct tctgcggacc aagtcggggt tcgctaggaa
1320cccgagacgg tccctgccgg cgaggagatc atgcgggatg agatgggggt
gtggagacgc 1380ctgcacaatt tcagcccaag cttctagaga gtggtgatga
cttgcatatg agggcagcaa 1440tgcaagtcgg tgtgctcccc attctgtggg
acatgacctg gttgcttcac agctccgaga 1500tgacacagac ttgcttaaag gaagtgac
152843621DNAArtificial Sequence8026 insert nucleic acid without
homology arms 4gggtctagca agagcaggtg tgggtttagg aggtgtgtgt
ttttgttttt cccaccctct 60ctccccacta cttgctctca cagtactcgc tgagggtgaa
caagaaaaga cctgataaag 120attaaccaga agaaaacaag gagggaaaca
accgcagcct gtagcaagct ctggaactca 180ggagtcgcgc gctatgcgat
cgcggggccg gggccggggc cgcgatcgcg gggcgtggtc 240ggggcgggcc
cgggggcggg cccggggcgg ggctgcggtt gcggtgcctg cgcccgcggc
300ggcggaggcg caggcggtgg cgagtgggtg agtgaggagg cggcatcctg
gcgggtggct 360gtttggggtt cggctgccgg gaagaggcgc gggtagaagc
gggggctctc ctcagagctc 420gacgcatttt tactttccct ctcatttctc
tgaccgaagc tgggtgtcgg gctttcgcct 480ctagcgactg gtggaattgc
ctgcatccgg gccccgggct tcccggcggc ggcggcggcg 540gcggcggcgc
agggacaagg gatggggatc tggcctcttc cttgctttcc cgccctcagt
600acccgagctg tctccttccc ggggacccgc tgggagcgct gccgctgcgg
gctcgagaaa 660agggagcctc gggtactgag aggcctcgcc tgggggaagg
ccggagggtg ggcggcgcgc 720ggcttctgcg gaccaagtcg gggttcgcta
ggaacccgag acggtccctg ccggcgagga 780gatcatgcgg gatgagatgg
gggtgtggag acgcctgcac aatttcagcc caagcttcta 840gagagtggtg
atgacttgca tatgagggca gcaatgcaag tcggtgtgct ccccattctg
900tgggacatga cctggttgct tcacagctcc gagatgacac agacttgctt
aaaggaagtg 960actcgagata acttcgtata atgtatgcta tacgaagtta
tatgcatggc ctccgcgccg 1020ggttttggcg cctcccgcgg gcgcccccct
cctcacggcg agcgctgcca cgtcagacga 1080agggcgcagc gagcgtcctg
atccttccgc ccggacgctc aggacagcgg cccgctgctc 1140ataagactcg
gccttagaac cccagtatca gcagaaggac attttaggac gggacttggg
1200tgactctagg gcactggttt tctttccaga gagcggaaca ggcgaggaaa
agtagtccct 1260tctcggcgat tctgcggagg gatctccgtg gggcggtgaa
cgccgatgat tatataagga 1320cgcgccgggt gtggcacagc tagttccgtc
gcagccggga tttgggtcgc ggttcttgtt 1380tgtggatcgc tgtgatcgtc
acttggtgag tagcgggctg ctgggctggc cggggctttc 1440gtggccgccg
ggccgctcgg tgggacggaa gcgtgtggag agaccgccaa gggctgtagt
1500ctgggtccgc gagcaaggtt gccctgaact gggggttggg gggagcgcag
caaaatggcg 1560gctgttcccg agtcttgaat ggaagacgct tgtgaggcgg
gctgtgaggt cgttgaaaca 1620aggtgggggg catggtgggc ggcaagaacc
caaggtcttg aggccttcgc taatgcggga 1680aagctcttat tcgggtgaga
tgggctgggg caccatctgg ggaccctgac gtgaagtttg 1740tcactgactg
gagaactcgg tttgtcgtct gttgcggggg cggcagttat ggcggtgccg
1800ttgggcagtg cacccgtacc tttgggagcg cgcgccctcg tcgtgtcgtg
acgtcacccg 1860ttctgttggc ttataatgca gggtggggcc acctgccggt
aggtgtgcgg taggcttttc 1920tccgtcgcag gacgcagggt tcgggcctag
ggtaggctct cctgaatcga caggcgccgg 1980acctctggtg aggggaggga
taagtgaggc gtcagtttct ttggtcggtt ttatgtacct 2040atcttcttaa
gtagctgaag ctccggtttt gaactatgcg ctcggggttg gcgagtgtgt
2100tttgtgaagt tttttaggca ccttttgaaa tgtaatcatt tgggtcaata
tgtaattttc 2160agtgttagac tagtaaattg tccgctaaat tctggccgtt
tttggctttt ttgttagacg 2220tgttgacaat taatcatcgg catagtatat
cggcatagta taatacgaca aggtgaggaa 2280ctaaaccatg ggatcggcca
ttgaacaaga tggattgcac gcaggttctc cggccgcttg 2340ggtggagagg
ctattcggct atgactgggc acaacagaca atcggctgct ctgatgccgc
2400cgtgttccgg ctgtcagcgc aggggcgccc ggttcttttt gtcaagaccg
acctgtccgg 2460tgccctgaat gaactgcagg acgaggcagc gcggctatcg
tggctggcca cgacgggcgt 2520tccttgcgca gctgtgctcg acgttgtcac
tgaagcggga agggactggc tgctattggg 2580cgaagtgccg gggcaggatc
tcctgtcatc tcaccttgct cctgccgaga aagtatccat 2640catggctgat
gcaatgcggc ggctgcatac gcttgatccg gctacctgcc cattcgacca
2700ccaagcgaaa catcgcatcg agcgagcacg tactcggatg gaagccggtc
ttgtcgatca 2760ggatgatctg gacgaagagc atcaggggct cgcgccagcc
gaactgttcg ccaggctcaa 2820ggcgcgcatg cccgacggcg atgatctcgt
cgtgacccat ggcgatgcct gcttgccgaa 2880tatcatggtg gaaaatggcc
gcttttctgg attcatcgac tgtggccggc tgggtgtggc 2940ggaccgctat
caggacatag cgttggctac ccgtgatatt gctgaagagc ttggcggcga
3000atgggctgac cgcttcctcg tgctttacgg tatcgccgct cccgattcgc
agcgcatcgc 3060cttctatcgc cttcttgacg agttcttctg aggggatccg
ctgtaagtct gcagaaattg 3120atgatctatt aaacaataaa gatgtccact
aaaatggaag tttttcctgt catactttgt 3180taagaagggt gagaacagag
tacctacatt ttgaatggaa ggattggagc tacgggggtg 3240ggggtggggt
gggattagat aaatgcctgc tctttactga aggctcttta ctattgcttt
3300atgataatgt ttcatagttg gatatcataa tttaaacaag caaaaccaaa
ttaagggcca 3360gctcattcct cccactcatg atctatagat ctatagatct
ctcgtgggat cattgttttt 3420ctcttgattc ccactttgtg gttctaagta
ctgtggtttc caaatgtgtc agtttcatag 3480cctgaagaac gagatcagca
gcctctgttc cacatacact tcattctcag tattgttttg 3540ccaagttcta
attccatcag acctcgacct gcagccccta gataacttcg tataatgtat
3600gctatacgaa gttatgctag c 362151006DNAArtificial Sequence8026
insert nucleic acid without homology arms and after excision of neo
5gggtctagca agagcaggtg tgggtttagg aggtgtgtgt ttttgttttt cccaccctct
60ctccccacta cttgctctca cagtactcgc tgagggtgaa caagaaaaga cctgataaag
120attaaccaga agaaaacaag gagggaaaca accgcagcct gtagcaagct
ctggaactca 180ggagtcgcgc gctatgcgat cgcggggccg gggccggggc
cgcgatcgcg gggcgtggtc 240ggggcgggcc cgggggcggg cccggggcgg
ggctgcggtt gcggtgcctg cgcccgcggc 300ggcggaggcg caggcggtgg
cgagtgggtg agtgaggagg cggcatcctg gcgggtggct 360gtttggggtt
cggctgccgg gaagaggcgc gggtagaagc gggggctctc ctcagagctc
420gacgcatttt tactttccct ctcatttctc tgaccgaagc tgggtgtcgg
gctttcgcct 480ctagcgactg gtggaattgc ctgcatccgg gccccgggct
tcccggcggc ggcggcggcg 540gcggcggcgc agggacaagg gatggggatc
tggcctcttc cttgctttcc cgccctcagt 600acccgagctg tctccttccc
ggggacccgc tgggagcgct gccgctgcgg gctcgagaaa 660agggagcctc
gggtactgag aggcctcgcc tgggggaagg ccggagggtg ggcggcgcgc
720ggcttctgcg gaccaagtcg gggttcgcta ggaacccgag acggtccctg
ccggcgagga 780gatcatgcgg gatgagatgg gggtgtggag acgcctgcac
aatttcagcc caagcttcta 840gagagtggtg atgacttgca tatgagggca
gcaatgcaag tcggtgtgct ccccattctg 900tgggacatga cctggttgct
tcacagctcc gagatgacac agacttgctt aaaggaagtg 960actcgagata
acttcgtata atgtatgcta tacgaagtta tgctag 100664180DNAArtificial
Sequence8026 Insert Nucleic acid without homology arms plus neo
cassette 6ggtctagcaa gagcaggtgt gggtttagga ggtgtgtgtt tttgtttttc
ccaccctctc 60tccccactac ttgctctcac agtactcgct gagggtgaac aagaaaagac
ctgataaaga 120ttaaccagaa gaaaacaagg agggaaacaa ccgcagcctg
tagcaagctc tggaactcag 180gagtcgcgcg ctatgcgatc gccgtctcgg
ggccggggcc ggggccgggg ccggggccgg 240ggccggggcc ggggccgggg
ccggggccgg ggccggggcc ggggccgggg ccggggccgg 300ggccggggcc
ggggccgggg ccggggccgg ggccggggcc ggggccgggg ccggggccgg
360ggccggggcc ggggccgggg ccggggccgg ggccggggcc ggggccgggg
ccggggccgg 420ggccggggcc ggggccgggg ccggggccgg ggccggggcc
ggggccgggg ccggggccgg 480ggccggggcc ggggccgggg ccggggccgg
ggccggggcc ggggccgggg ccggggccgg 540ggccggggcc ggggccgggg
ccggggccgg ggccggggcc ggggccgggg ccggggccgg 600ggccggggcc
ggggccgggg ccggggccgg ggccggggcc ggggccgggg ccggggccgg
660ggccggggcc ggggccgggg ccggggccgg ggccggggcc ggggccgggg
ccggggccgg 720ggccggggcc ggggccgggg ccggggccgg ggccggggcc
gagaccctcg agggccggcc 780gctagcgcga tcgcggggcg tggtcggggc
gggcccgggg gcgggcccgg ggcggggctg 840cggttgcggt gcctgcgccc
gcggcggcgg aggcgcaggc ggtggcgagt gggtgagtga 900ggaggcggca
tcctggcggg tggctgtttg gggttcggct gccgggaaga ggcgcgggta
960gaagcggggg ctctcctcag agctcgacgc atttttactt tccctctcat
ttctctgacc 1020gaagctgggt gtcgggcttt cgcctctagc gactggtgga
attgcctgca tccgggcccc 1080gggcttcccg gcggcggcgg cggcggcggc
ggcgcaggga caagggatgg ggatctggcc 1140tcttccttgc tttcccgccc
tcagtacccg agctgtctcc ttcccgggga cccgctggga 1200gcgctgccgc
tgcgggctcg agaaaaggga gcctcgggta ctgagaggcc tcgcctgggg
1260gaaggccgga gggtgggcgg cgcgcggctt ctgcggacca agtcggggtt
cgctaggaac 1320ccgagacggt ccctgccggc gaggagatca tgcgggatga
gatgggggtg tggagacgcc 1380tgcacaattt cagcccaagc ttctagagag
tggtgatgac ttgcatatga gggcagcaat 1440gcaagtcggt gtgctcccca
ttctgtggga catgacctgg ttgcttcaca gctccgagat 1500gacacagact
tgcttaaagg aagtgactcg agataacttc gtataatgta tgctatacga
1560agttatatgc atggcctccg cgccgggttt tggcgcctcc cgcgggcgcc
cccctcctca 1620cggcgagcgc tgccacgtca gacgaagggc gcagcgagcg
tcctgatcct tccgcccgga 1680cgctcaggac agcggcccgc tgctcataag
actcggcctt agaaccccag tatcagcaga 1740aggacatttt aggacgggac
ttgggtgact ctagggcact ggttttcttt ccagagagcg 1800gaacaggcga
ggaaaagtag tcccttctcg gcgattctgc ggagggatct ccgtggggcg
1860gtgaacgccg atgattatat aaggacgcgc cgggtgtggc acagctagtt
ccgtcgcagc 1920cgggatttgg gtcgcggttc ttgtttgtgg atcgctgtga
tcgtcacttg gtgagtagcg 1980ggctgctggg ctggccgggg ctttcgtggc
cgccgggccg ctcggtggga cggaagcgtg 2040tggagagacc gccaagggct
gtagtctggg tccgcgagca aggttgccct gaactggggg 2100ttggggggag
cgcagcaaaa tggcggctgt tcccgagtct tgaatggaag acgcttgtga
2160ggcgggctgt gaggtcgttg aaacaaggtg gggggcatgg tgggcggcaa
gaacccaagg 2220tcttgaggcc ttcgctaatg cgggaaagct cttattcggg
tgagatgggc tggggcacca 2280tctggggacc ctgacgtgaa gtttgtcact
gactggagaa ctcggtttgt cgtctgttgc 2340gggggcggca gttatggcgg
tgccgttggg cagtgcaccc gtacctttgg gagcgcgcgc 2400cctcgtcgtg
tcgtgacgtc acccgttctg ttggcttata atgcagggtg gggccacctg
2460ccggtaggtg tgcggtaggc ttttctccgt cgcaggacgc agggttcggg
cctagggtag 2520gctctcctga atcgacaggc gccggacctc tggtgagggg
agggataagt gaggcgtcag 2580tttctttggt cggttttatg tacctatctt
cttaagtagc tgaagctccg gttttgaact 2640atgcgctcgg ggttggcgag
tgtgttttgt gaagtttttt aggcaccttt tgaaatgtaa 2700tcatttgggt
caatatgtaa ttttcagtgt tagactagta aattgtccgc taaattctgg
2760ccgtttttgg cttttttgtt agacgtgttg acaattaatc atcggcatag
tatatcggca 2820tagtataata cgacaaggtg aggaactaaa ccatgggatc
ggccattgaa caagatggat 2880tgcacgcagg ttctccggcc gcttgggtgg
agaggctatt cggctatgac tgggcacaac 2940agacaatcgg ctgctctgat
gccgccgtgt tccggctgtc agcgcagggg cgcccggttc 3000tttttgtcaa
gaccgacctg tccggtgccc tgaatgaact gcaggacgag gcagcgcggc
3060tatcgtggct ggccacgacg ggcgttcctt gcgcagctgt gctcgacgtt
gtcactgaag 3120cgggaaggga ctggctgcta ttgggcgaag tgccggggca
ggatctcctg tcatctcacc 3180ttgctcctgc cgagaaagta tccatcatgg
ctgatgcaat gcggcggctg catacgcttg 3240atccggctac ctgcccattc
gaccaccaag cgaaacatcg catcgagcga gcacgtactc 3300ggatggaagc
cggtcttgtc gatcaggatg atctggacga agagcatcag gggctcgcgc
3360cagccgaact gttcgccagg ctcaaggcgc gcatgcccga cggcgatgat
ctcgtcgtga 3420cccatggcga tgcctgcttg ccgaatatca tggtggaaaa
tggccgcttt tctggattca 3480tcgactgtgg ccggctgggt gtggcggacc
gctatcagga catagcgttg gctacccgtg 3540atattgctga agagcttggc
ggcgaatggg ctgaccgctt cctcgtgctt tacggtatcg 3600ccgctcccga
ttcgcagcgc atcgccttct atcgccttct tgacgagttc ttctgagggg
3660atccgctgta agtctgcaga aattgatgat ctattaaaca ataaagatgt
ccactaaaat 3720ggaagttttt cctgtcatac tttgttaaga agggtgagaa
cagagtacct acattttgaa 3780tggaaggatt ggagctacgg gggtgggggt
ggggtgggat tagataaatg cctgctcttt 3840actgaaggct ctttactatt
gctttatgat aatgtttcat agttggatat cataatttaa 3900acaagcaaaa
ccaaattaag ggccagctca ttcctcccac tcatgatcta tagatctata
3960gatctctcgt gggatcattg tttttctctt gattcccact ttgtggttct
aagtactgtg 4020gtttccaaat gtgtcagttt catagcctga agaacgagat
cagcagcctc tgttccacat 4080acacttcatt ctcagtattg ttttgccaag
ttctaattcc atcagacctc gacctgcagc 4140ccctagataa cttcgtataa
tgtatgctat acgaagttat 418071566DNAArtificial Sequence8028 insert
nucleic acid with lox site after excision of neo and without
homology arms 7gggtctagca agagcaggtg tgggtttagg aggtgtgtgt
ttttgttttt cccaccctct 60ctccccacta cttgctctca cagtactcgc tgagggtgaa
caagaaaaga cctgataaag 120attaaccaga agaaaacaag gagggaaaca
accgcagcct gtagcaagct ctggaactca 180ggagtcgcgc gctatgcgat
cgccgtctcg gggccggggc cggggccggg gccggggccg 240gggccggggc
cggggccggg gccggggccg gggccggggc cggggccggg gccggggccg
300gggccggggc cggggccggg gccggggccg gggccggggc cggggccggg
gccggggccg 360gggccggggc cggggccggg gccggggccg gggccggggc
cggggccggg gccggggccg 420gggccggggc cggggccggg gccggggccg
gggccggggc cggggccggg gccggggccg 480gggccggggc cggggccggg
gccggggccg gggccggggc cggggccggg gccggggccg 540gggccggggc
cggggccggg gccggggccg gggccggggc cggggccggg gccggggccg
600gggccggggc cggggccggg gccggggccg gggccggggc cggggccggg
gccggggccg 660gggccggggc cggggccggg gccggggccg gggccggggc
cggggccggg gccggggccg 720gggccggggc cggggccggg gccggggccg
gggccggggc cgagaccctc gagggccggc 780cgctagcgcg atcgcggggc
gtggtcgggg cgggcccggg ggcgggcccg gggcggggct 840gcggttgcgg
tgcctgcgcc cgcggcggcg gaggcgcagg cggtggcgag tgggtgagtg
900aggaggcggc atcctggcgg gtggctgttt ggggttcggc tgccgggaag
aggcgcgggt 960agaagcgggg gctctcctca gagctcgacg catttttact
ttccctctca tttctctgac 1020cgaagctggg tgtcgggctt tcgcctctag
cgactggtgg aattgcctgc atccgggccc 1080cgggcttccc ggcggcggcg
gcggcggcgg cggcgcaggg acaagggatg gggatctggc 1140ctcttccttg
ctttcccgcc ctcagtaccc gagctgtctc cttcccgggg acccgctggg
1200agcgctgccg ctgcgggctc gagaaaaggg agcctcgggt actgagaggc
ctcgcctggg 1260ggaaggccgg agggtgggcg gcgcgcggct tctgcggacc
aagtcggggt tcgctaggaa 1320cccgagacgg tccctgccgg cgaggagatc
atgcgggatg agatgggggt gtggagacgc 1380ctgcacaatt tcagcccaag
cttctagaga gtggtgatga cttgcatatg agggcagcaa 1440tgcaagtcgg
tgtgctcccc attctgtggg acatgacctg gttgcttcac agctccgaga
1500tgacacagac ttgcttaaag gaagtgactc gagataactt cgtataatgt
atgctatacg 1560aagtta 156683821DNAArtificial Sequence8026 targeting
nucleic acid with homology arms and neo cassette 8gaaccgcggc
gcgtcaagca gagacgagtt ccgcccacgt gaaagatggc gtttgtagtg 60acagccatcc
caattgccct ttccttctag gtggaaagtg gggtctagca agagcaggtg
120tgggtttagg aggtgtgtgt ttttgttttt cccaccctct ctccccacta
cttgctctca 180cagtactcgc tgagggtgaa caagaaaaga cctgataaag
attaaccaga agaaaacaag 240gagggaaaca accgcagcct gtagcaagct
ctggaactca ggagtcgcgc gctatgcgat 300cgcggggccg gggccggggc
cgcgatcgcg gggcgtggtc ggggcgggcc cgggggcggg 360cccggggcgg
ggctgcggtt gcggtgcctg cgcccgcggc ggcggaggcg caggcggtgg
420cgagtgggtg agtgaggagg cggcatcctg gcgggtggct gtttggggtt
cggctgccgg 480gaagaggcgc gggtagaagc gggggctctc ctcagagctc
gacgcatttt tactttccct 540ctcatttctc tgaccgaagc tgggtgtcgg
gctttcgcct ctagcgactg gtggaattgc 600ctgcatccgg gccccgggct
tcccggcggc ggcggcggcg gcggcggcgc agggacaagg 660gatggggatc
tggcctcttc cttgctttcc cgccctcagt acccgagctg tctccttccc
720ggggacccgc tgggagcgct gccgctgcgg gctcgagaaa agggagcctc
gggtactgag 780aggcctcgcc tgggggaagg ccggagggtg ggcggcgcgc
ggcttctgcg gaccaagtcg 840gggttcgcta ggaacccgag acggtccctg
ccggcgagga gatcatgcgg gatgagatgg 900gggtgtggag acgcctgcac
aatttcagcc caagcttcta gagagtggtg atgacttgca 960tatgagggca
gcaatgcaag tcggtgtgct ccccattctg tgggacatga cctggttgct
1020tcacagctcc gagatgacac agacttgctt aaaggaagtg actcgagata
acttcgtata 1080atgtatgcta tacgaagtta tatgcatggc ctccgcgccg
ggttttggcg cctcccgcgg 1140gcgcccccct cctcacggcg agcgctgcca
cgtcagacga agggcgcagc gagcgtcctg 1200atccttccgc ccggacgctc
aggacagcgg cccgctgctc ataagactcg gccttagaac 1260cccagtatca
gcagaaggac attttaggac gggacttggg tgactctagg gcactggttt
1320tctttccaga gagcggaaca ggcgaggaaa agtagtccct tctcggcgat
tctgcggagg 1380gatctccgtg
gggcggtgaa cgccgatgat tatataagga cgcgccgggt gtggcacagc
1440tagttccgtc gcagccggga tttgggtcgc ggttcttgtt tgtggatcgc
tgtgatcgtc 1500acttggtgag tagcgggctg ctgggctggc cggggctttc
gtggccgccg ggccgctcgg 1560tgggacggaa gcgtgtggag agaccgccaa
gggctgtagt ctgggtccgc gagcaaggtt 1620gccctgaact gggggttggg
gggagcgcag caaaatggcg gctgttcccg agtcttgaat 1680ggaagacgct
tgtgaggcgg gctgtgaggt cgttgaaaca aggtgggggg catggtgggc
1740ggcaagaacc caaggtcttg aggccttcgc taatgcggga aagctcttat
tcgggtgaga 1800tgggctgggg caccatctgg ggaccctgac gtgaagtttg
tcactgactg gagaactcgg 1860tttgtcgtct gttgcggggg cggcagttat
ggcggtgccg ttgggcagtg cacccgtacc 1920tttgggagcg cgcgccctcg
tcgtgtcgtg acgtcacccg ttctgttggc ttataatgca 1980gggtggggcc
acctgccggt aggtgtgcgg taggcttttc tccgtcgcag gacgcagggt
2040tcgggcctag ggtaggctct cctgaatcga caggcgccgg acctctggtg
aggggaggga 2100taagtgaggc gtcagtttct ttggtcggtt ttatgtacct
atcttcttaa gtagctgaag 2160ctccggtttt gaactatgcg ctcggggttg
gcgagtgtgt tttgtgaagt tttttaggca 2220ccttttgaaa tgtaatcatt
tgggtcaata tgtaattttc agtgttagac tagtaaattg 2280tccgctaaat
tctggccgtt tttggctttt ttgttagacg tgttgacaat taatcatcgg
2340catagtatat cggcatagta taatacgaca aggtgaggaa ctaaaccatg
ggatcggcca 2400ttgaacaaga tggattgcac gcaggttctc cggccgcttg
ggtggagagg ctattcggct 2460atgactgggc acaacagaca atcggctgct
ctgatgccgc cgtgttccgg ctgtcagcgc 2520aggggcgccc ggttcttttt
gtcaagaccg acctgtccgg tgccctgaat gaactgcagg 2580acgaggcagc
gcggctatcg tggctggcca cgacgggcgt tccttgcgca gctgtgctcg
2640acgttgtcac tgaagcggga agggactggc tgctattggg cgaagtgccg
gggcaggatc 2700tcctgtcatc tcaccttgct cctgccgaga aagtatccat
catggctgat gcaatgcggc 2760ggctgcatac gcttgatccg gctacctgcc
cattcgacca ccaagcgaaa catcgcatcg 2820agcgagcacg tactcggatg
gaagccggtc ttgtcgatca ggatgatctg gacgaagagc 2880atcaggggct
cgcgccagcc gaactgttcg ccaggctcaa ggcgcgcatg cccgacggcg
2940atgatctcgt cgtgacccat ggcgatgcct gcttgccgaa tatcatggtg
gaaaatggcc 3000gcttttctgg attcatcgac tgtggccggc tgggtgtggc
ggaccgctat caggacatag 3060cgttggctac ccgtgatatt gctgaagagc
ttggcggcga atgggctgac cgcttcctcg 3120tgctttacgg tatcgccgct
cccgattcgc agcgcatcgc cttctatcgc cttcttgacg 3180agttcttctg
aggggatccg ctgtaagtct gcagaaattg atgatctatt aaacaataaa
3240gatgtccact aaaatggaag tttttcctgt catactttgt taagaagggt
gagaacagag 3300tacctacatt ttgaatggaa ggattggagc tacgggggtg
ggggtggggt gggattagat 3360aaatgcctgc tctttactga aggctcttta
ctattgcttt atgataatgt ttcatagttg 3420gatatcataa tttaaacaag
caaaaccaaa ttaagggcca gctcattcct cccactcatg 3480atctatagat
ctatagatct ctcgtgggat cattgttttt ctcttgattc ccactttgtg
3540gttctaagta ctgtggtttc caaatgtgtc agtttcatag cctgaagaac
gagatcagca 3600gcctctgttc cacatacact tcattctcag tattgttttg
ccaagttcta attccatcag 3660acctcgacct gcagccccta gataacttcg
tataatgtat gctatacgaa gttatgctag 3720cattgtgact tgggcatcac
ttgactgatg gtaatcagtt gcagagagag aagtgcactg 3780attaagtctg
tccacacagg gtctgtctgg ccaggagtgc a 382194387DNAArtificial
Sequence8026 insert nucleic acid with homology arms, hexanucleotide
repeat(s) and neo cassette 9gaaccgcggc gcgtcaagca gagacgagtt
ccgcccacgt gaaagatggc gtttgtagtg 60acagccatcc caattgccct ttccttctag
gtggaaagtg gggtctagca agagcaggtg 120tgggtttagg aggtgtgtgt
ttttgttttt cccaccctct ctccccacta cttgctctca 180cagtactcgc
tgagggtgaa caagaaaaga cctgataaag attaaccaga agaaaacaag
240gagggaaaca accgcagcct gtagcaagct ctggaactca ggagtcgcgc
gctatgcgat 300cgccgtctcg gggccggggc cggggccggg gccggggccg
gggccggggc cggggccggg 360gccggggccg gggccggggc cggggccggg
gccggggccg gggccggggc cggggccggg 420gccggggccg gggccggggc
cggggccggg gccggggccg gggccggggc cggggccggg 480gccggggccg
gggccggggc cggggccggg gccggggccg gggccggggc cggggccggg
540gccggggccg gggccggggc cggggccggg gccggggccg gggccggggc
cggggccggg 600gccggggccg gggccggggc cggggccggg gccggggccg
gggccggggc cggggccggg 660gccggggccg gggccggggc cggggccggg
gccggggccg gggccggggc cggggccggg 720gccggggccg gggccggggc
cggggccggg gccggggccg gggccggggc cggggccggg 780gccggggccg
gggccggggc cggggccggg gccggggccg gggccggggc cggggccggg
840gccggggccg gggccggggc cgagaccctc gagggccggc cgctagcgcg
atcgcggggc 900gtggtcgggg cgggcccggg ggcgggcccg gggcggggct
gcggttgcgg tgcctgcgcc 960cgcggcggcg gaggcgcagg cggtggcgag
tgggtgagtg aggaggcggc atcctggcgg 1020gtggctgttt ggggttcggc
tgccgggaag aggcgcgggt agaagcgggg gctctcctca 1080gagctcgacg
catttttact ttccctctca tttctctgac cgaagctggg tgtcgggctt
1140tcgcctctag cgactggtgg aattgcctgc atccgggccc cgggcttccc
ggcggcggcg 1200gcggcggcgg cggcgcaggg acaagggatg gggatctggc
ctcttccttg ctttcccgcc 1260ctcagtaccc gagctgtctc cttcccgggg
acccgctggg agcgctgccg ctgcgggctc 1320gagaaaaggg agcctcgggt
actgagaggc ctcgcctggg ggaaggccgg agggtgggcg 1380gcgcgcggct
tctgcggacc aagtcggggt tcgctaggaa cccgagacgg tccctgccgg
1440cgaggagatc atgcgggatg agatgggggt gtggagacgc ctgcacaatt
tcagcccaag 1500cttctagaga gtggtgatga cttgcatatg agggcagcaa
tgcaagtcgg tgtgctcccc 1560attctgtggg acatgacctg gttgcttcac
agctccgaga tgacacagac ttgcttaaag 1620gaagtgactc gagataactt
cgtataatgt atgctatacg aagttatatg catggcctcc 1680gcgccgggtt
ttggcgcctc ccgcgggcgc ccccctcctc acggcgagcg ctgccacgtc
1740agacgaaggg cgcagcgagc gtcctgatcc ttccgcccgg acgctcagga
cagcggcccg 1800ctgctcataa gactcggcct tagaacccca gtatcagcag
aaggacattt taggacggga 1860cttgggtgac tctagggcac tggttttctt
tccagagagc ggaacaggcg aggaaaagta 1920gtcccttctc ggcgattctg
cggagggatc tccgtggggc ggtgaacgcc gatgattata 1980taaggacgcg
ccgggtgtgg cacagctagt tccgtcgcag ccgggatttg ggtcgcggtt
2040cttgtttgtg gatcgctgtg atcgtcactt ggtgagtagc gggctgctgg
gctggccggg 2100gctttcgtgg ccgccgggcc gctcggtggg acggaagcgt
gtggagagac cgccaagggc 2160tgtagtctgg gtccgcgagc aaggttgccc
tgaactgggg gttgggggga gcgcagcaaa 2220atggcggctg ttcccgagtc
ttgaatggaa gacgcttgtg aggcgggctg tgaggtcgtt 2280gaaacaaggt
ggggggcatg gtgggcggca agaacccaag gtcttgaggc cttcgctaat
2340gcgggaaagc tcttattcgg gtgagatggg ctggggcacc atctggggac
cctgacgtga 2400agtttgtcac tgactggaga actcggtttg tcgtctgttg
cgggggcggc agttatggcg 2460gtgccgttgg gcagtgcacc cgtacctttg
ggagcgcgcg ccctcgtcgt gtcgtgacgt 2520cacccgttct gttggcttat
aatgcagggt ggggccacct gccggtaggt gtgcggtagg 2580cttttctccg
tcgcaggacg cagggttcgg gcctagggta ggctctcctg aatcgacagg
2640cgccggacct ctggtgaggg gagggataag tgaggcgtca gtttctttgg
tcggttttat 2700gtacctatct tcttaagtag ctgaagctcc ggttttgaac
tatgcgctcg gggttggcga 2760gtgtgttttg tgaagttttt taggcacctt
ttgaaatgta atcatttggg tcaatatgta 2820attttcagtg ttagactagt
aaattgtccg ctaaattctg gccgtttttg gcttttttgt 2880tagacgtgtt
gacaattaat catcggcata gtatatcggc atagtataat acgacaaggt
2940gaggaactaa accatgggat cggccattga acaagatgga ttgcacgcag
gttctccggc 3000cgcttgggtg gagaggctat tcggctatga ctgggcacaa
cagacaatcg gctgctctga 3060tgccgccgtg ttccggctgt cagcgcaggg
gcgcccggtt ctttttgtca agaccgacct 3120gtccggtgcc ctgaatgaac
tgcaggacga ggcagcgcgg ctatcgtggc tggccacgac 3180gggcgttcct
tgcgcagctg tgctcgacgt tgtcactgaa gcgggaaggg actggctgct
3240attgggcgaa gtgccggggc aggatctcct gtcatctcac cttgctcctg
ccgagaaagt 3300atccatcatg gctgatgcaa tgcggcggct gcatacgctt
gatccggcta cctgcccatt 3360cgaccaccaa gcgaaacatc gcatcgagcg
agcacgtact cggatggaag ccggtcttgt 3420cgatcaggat gatctggacg
aagagcatca ggggctcgcg ccagccgaac tgttcgccag 3480gctcaaggcg
cgcatgcccg acggcgatga tctcgtcgtg acccatggcg atgcctgctt
3540gccgaatatc atggtggaaa atggccgctt ttctggattc atcgactgtg
gccggctggg 3600tgtggcggac cgctatcagg acatagcgtt ggctacccgt
gatattgctg aagagcttgg 3660cggcgaatgg gctgaccgct tcctcgtgct
ttacggtatc gccgctcccg attcgcagcg 3720catcgccttc tatcgccttc
ttgacgagtt cttctgaggg gatccgctgt aagtctgcag 3780aaattgatga
tctattaaac aataaagatg tccactaaaa tggaagtttt tcctgtcata
3840ctttgttaag aagggtgaga acagagtacc tacattttga atggaaggat
tggagctacg 3900ggggtggggg tggggtggga ttagataaat gcctgctctt
tactgaaggc tctttactat 3960tgctttatga taatgtttca tagttggata
tcataattta aacaagcaaa accaaattaa 4020gggccagctc attcctccca
ctcatgatct atagatctat agatctctcg tgggatcatt 4080gtttttctct
tgattcccac tttgtggttc taagtactgt ggtttccaaa tgtgtcagtt
4140tcatagcctg aagaacgaga tcagcagcct ctgttccaca tacacttcat
tctcagtatt 4200gttttgccaa gttctaattc catcagacct cgacctgcag
cccctagata acttcgtata 4260atgtatgcta tacgaagtta tgctagcatt
gtgacttggg catcacttga ctgatggtaa 4320tcagttgcag agagagaagt
gcactgatta agtctgtcca cacagggtct gtctggccag 4380gagtgca
4387101957DNAHomo sapiens 10acgtaaccta cggtgtcccg ctaggaaaga
gaggtgcgtc aaacagcgac aagttccgcc 60cacgtaaaag atgacgcttg atatctccgg
agcatttgga taatgtgaca gttggaatgc 120agtgatgtcg actctttgcc
caccgccatc tccagctgtt gccaagacag agattgcttt 180aagtggcaaa
tcacctttat tagcagctac ttttgcttac tgggacaata ttcttggtcc
240tagagtaagg cacatttggg ctccaaagac agaacaggta cttctcagtg
atggagaaat 300aacttttctt gccaaccaca ctctaaatgg agaaatcctt
cgaaatgcag agagtggtgc 360tatagatgta aagttttttg tcttgtctga
aaagggagtg attattgttt cattaatctt 420tgatggaaac tggaatgggg
atcgcagcac atatggacta tcaattatac ttccacagac 480agaacttagt
ttctacctcc cacttcatag agtgtgtgtt gatagattaa cacatataat
540ccggaaagga agaatatgga tgcataagga aagacaagaa aatgtccaga
agattatctt 600agaaggcaca gagagaatgg aagatcaggg tcagagtatt
attccaatgc ttactggaga 660agtgattcct gtaatggaac tgctttcatc
tatgaaatca cacagtgttc ctgaagaaat 720agatatagct gatacagtac
tcaatgatga tgatattggt gacagctgtc atgaaggctt 780tcttctcaag
taagaatttt tcttttcata aaagctggat gaagcagata ccatcttatg
840ctcacctatg acaagatttg gaagaaagaa aataacagac tgtctactta
gattgttcta 900gggacattac gtatttgaac tgttgcttaa atttgtgtta
tttttcactc attatatttc 960tatatatatt tggtgttatt ccatttgcta
tttaaagaaa ccgagtttcc atcccagaca 1020agaaatcatg gccccttgct
tgattctggt ttcttgtttt acttctcatt aaagctaaca 1080gaatcctttc
atattaagtt gtactgtaga tgaacttaag ttatttaggc gtagaacaaa
1140attattcata tttatactga tctttttcca tccagcagtg gagtttagta
cttaagagtt 1200tgtgccctta aaccagactc cctggattaa tgctgtgtac
ccgtgggcaa ggtgcctgaa 1260ttctctatac acctatttcc tcatctgtaa
aatggcaata atagtaatag tacctaatgt 1320gtagggttgt tataagcatt
gagtaagata aataatataa agcacttaga acagtgcctg 1380gaacataaaa
acacttaata atagctcata gctaacattt cctatttaca tttcttctag
1440aaatagccag tatttgttga gtgcctacat gttagttcct ttactagttg
ctttacatgt 1500attatcttat attctgtttt aaagtttctt cacagttaca
gattttcatg aaattttact 1560tttaataaaa gagaagtaaa agtataaagt
attcactttt atgttcacag tcttttcctt 1620taggctcatg atggagtatc
agaggcatga gtgtgtttaa cctaagagcc ttaatggctt 1680gaatcagaag
cactttagtc ctgtatctgt tcagtgtcag cctttcatac atcattttaa
1740atcccatttg actttaagta agtcacttaa tctctctaca tgtcaatttc
ttcagctata 1800aaatgatggt atttcaataa ataaatacat taattaaatg
atattatact gactaattgg 1860gctgttttaa ggctcaataa gaaaatttct
gtgaaaggtc tctagaaaat gtaggttcct 1920atacaaataa aagataacat
tgtgcttata aaaaaaa 195711222PRTHomo sapiens 11Met Ser Thr Leu Cys
Pro Pro Pro Ser Pro Ala Val Ala Lys Thr Glu1 5 10 15Ile Ala Leu Ser
Gly Lys Ser Pro Leu Leu Ala Ala Thr Phe Ala Tyr 20 25 30Trp Asp Asn
Ile Leu Gly Pro Arg Val Arg His Ile Trp Ala Pro Lys 35 40 45Thr Glu
Gln Val Leu Leu Ser Asp Gly Glu Ile Thr Phe Leu Ala Asn 50 55 60His
Thr Leu Asn Gly Glu Ile Leu Arg Asn Ala Glu Ser Gly Ala Ile65 70 75
80Asp Val Lys Phe Phe Val Leu Ser Glu Lys Gly Val Ile Ile Val Ser
85 90 95Leu Ile Phe Asp Gly Asn Trp Asn Gly Asp Arg Ser Thr Tyr Gly
Leu 100 105 110Ser Ile Ile Leu Pro Gln Thr Glu Leu Ser Phe Tyr Leu
Pro Leu His 115 120 125Arg Val Cys Val Asp Arg Leu Thr His Ile Ile
Arg Lys Gly Arg Ile 130 135 140Trp Met His Lys Glu Arg Gln Glu Asn
Val Gln Lys Ile Ile Leu Glu145 150 155 160Gly Thr Glu Arg Met Glu
Asp Gln Gly Gln Ser Ile Ile Pro Met Leu 165 170 175Thr Gly Glu Val
Ile Pro Val Met Glu Leu Leu Ser Ser Met Lys Ser 180 185 190His Ser
Val Pro Glu Glu Ile Asp Ile Ala Asp Thr Val Leu Asn Asp 195 200
205Asp Asp Ile Gly Asp Ser Cys His Glu Gly Phe Leu Leu Lys 210 215
220123261DNAHomo sapiens 12gggcggggct gcggttgcgg tgcctgcgcc
cgcggcggcg gaggcgcagg cggtggcgag 60tggatatctc cggagcattt ggataatgtg
acagttggaa tgcagtgatg tcgactcttt 120gcccaccgcc atctccagct
gttgccaaga cagagattgc tttaagtggc aaatcacctt 180tattagcagc
tacttttgct tactgggaca atattcttgg tcctagagta aggcacattt
240gggctccaaa gacagaacag gtacttctca gtgatggaga aataactttt
cttgccaacc 300acactctaaa tggagaaatc cttcgaaatg cagagagtgg
tgctatagat gtaaagtttt 360ttgtcttgtc tgaaaaggga gtgattattg
tttcattaat ctttgatgga aactggaatg 420gggatcgcag cacatatgga
ctatcaatta tacttccaca gacagaactt agtttctacc 480tcccacttca
tagagtgtgt gttgatagat taacacatat aatccggaaa ggaagaatat
540ggatgcataa ggaaagacaa gaaaatgtcc agaagattat cttagaaggc
acagagagaa 600tggaagatca gggtcagagt attattccaa tgcttactgg
agaagtgatt cctgtaatgg 660aactgctttc atctatgaaa tcacacagtg
ttcctgaaga aatagatata gctgatacag 720tactcaatga tgatgatatt
ggtgacagct gtcatgaagg ctttcttctc aatgccatca 780gctcacactt
gcaaacctgt ggctgttccg ttgtagtagg tagcagtgca gagaaagtaa
840ataagatagt cagaacatta tgcctttttc tgactccagc agagagaaaa
tgctccaggt 900tatgtgaagc agaatcatca tttaaatatg agtcagggct
ctttgtacaa ggcctgctaa 960aggattcaac tggaagcttt gtgctgcctt
tccggcaagt catgtatgct ccatatccca 1020ccacacacat agatgtggat
gtcaatactg tgaagcagat gccaccctgt catgaacata 1080tttataatca
gcgtagatac atgagatccg agctgacagc cttctggaga gccacttcag
1140aagaagacat ggctcaggat acgatcatct acactgacga aagctttact
cctgatttga 1200atatttttca agatgtctta cacagagaca ctctagtgaa
agccttcctg gatcaggtct 1260ttcagctgaa acctggctta tctctcagaa
gtactttcct tgcacagttt ctacttgtcc 1320ttcacagaaa agccttgaca
ctaataaaat atatagaaga cgatacgcag aagggaaaaa 1380agccctttaa
atctcttcgg aacctgaaga tagaccttga tttaacagca gagggcgatc
1440ttaacataat aatggctctg gctgagaaaa ttaaaccagg cctacactct
tttatctttg 1500gaagaccttt ctacactagt gtgcaagaac gagatgttct
aatgactttt taaatgtgta 1560acttaataag cctattccat cacaatcatg
atcgctggta aagtagctca gtggtgtggg 1620gaaacgttcc cctggatcat
actccagaat tctgctctca gcaattgcag ttaagtaagt 1680tacactacag
ttctcacaag agcctgtgag gggatgtcag gtgcatcatt acattgggtg
1740tctcttttcc tagatttatg cttttgggat acagacctat gtttacaata
taataaatat 1800tattgctatc ttttaaagat ataataatag gatgtaaact
tgaccacaac tactgttttt 1860ttgaaataca tgattcatgg tttacatgtg
tcaaggtgaa atctgagttg gcttttacag 1920atagttgact ttctatcttt
tggcattctt tggtgtgtag aattactgta atacttctgc 1980aatcaactga
aaactagagc ctttaaatga tttcaattcc acagaaagaa agtgagcttg
2040aacataggat gagctttaga aagaaaattg atcaagcaga tgtttaattg
gaattgatta 2100ttagatccta ctttgtggat ttagtccctg ggattcagtc
tgtagaaatg tctaatagtt 2160ctctatagtc cttgttcctg gtgaaccaca
gttagggtgt tttgtttatt ttattgttct 2220tgctattgtt gatattctat
gtagttgagc tctgtaaaag gaaattgtat tttatgtttt 2280agtaattgtt
gccaactttt taaattaatt ttcattattt ttgagccaaa ttgaaatgtg
2340cacctcctgt gccttttttc tccttagaaa atctaattac ttggaacaag
ttcagatttc 2400actggtcagt cattttcatc ttgttttctt cttgctaagt
cttaccatgt acctgctttg 2460gcaatcattg caactctgag attataaaat
gccttagaga atatactaac taataagatc 2520tttttttcag aaacagaaaa
tagttccttg agtacttcct tcttgcattt ctgcctatgt 2580ttttgaagtt
gttgctgttt gcctgcaata ggctataagg aatagcagga gaaattttac
2640tgaagtgctg ttttcctagg tgctactttg gcagagctaa gttatctttt
gttttcttaa 2700tgcgtttgga ccattttgct ggctataaaa taactgatta
atataattct aacacaatgt 2760tgacattgta gttacacaaa cacaaataaa
tattttattt aaaattctgg aagtaatata 2820aaagggaaaa tatatttata
agaaagggat aaaggtaata gagcccttct gccccccacc 2880caccaaattt
acacaacaaa atgacatgtt cgaatgtgaa aggtcataat agctttccca
2940tcatgaatca gaaagatgtg gacagcttga tgttttagac aaccactgaa
ctagatgact 3000gttgtactgt agctcagtca tttaaaaaat atataaatac
taccttgtag tgtcccatac 3060tgtgtttttt acatggtaga ttcttattta
agtgctaact ggttattttc tttggctggt 3120ttattgtact gttatacaga
atgtaagttg tacagtgaaa taagttatta aagcatgtgt 3180aaacattgtt
atatatcttt tctcctaaat ggagaatttt gaataaaata tatttgaaat
3240tttaaaaaaa aaaaaaaaaa a 326113481PRTHomo sapiens 13Met Ser Thr
Leu Cys Pro Pro Pro Ser Pro Ala Val Ala Lys Thr Glu1 5 10 15Ile Ala
Leu Ser Gly Lys Ser Pro Leu Leu Ala Ala Thr Phe Ala Tyr 20 25 30Trp
Asp Asn Ile Leu Gly Pro Arg Val Arg His Ile Trp Ala Pro Lys 35 40
45Thr Glu Gln Val Leu Leu Ser Asp Gly Glu Ile Thr Phe Leu Ala Asn
50 55 60His Thr Leu Asn Gly Glu Ile Leu Arg Asn Ala Glu Ser Gly Ala
Ile65 70 75 80Asp Val Lys Phe Phe Val Leu Ser Glu Lys Gly Val Ile
Ile Val Ser 85 90 95Leu Ile Phe Asp Gly Asn Trp Asn Gly Asp Arg Ser
Thr Tyr Gly Leu 100 105 110Ser Ile Ile Leu Pro Gln Thr Glu Leu Ser
Phe Tyr Leu Pro Leu His 115 120 125Arg Val Cys Val Asp Arg Leu Thr
His Ile Ile Arg Lys Gly Arg Ile 130 135 140Trp Met His Lys Glu Arg
Gln Glu Asn Val Gln Lys Ile Ile Leu Glu145 150 155 160Gly Thr Glu
Arg Met Glu Asp Gln Gly Gln Ser Ile Ile Pro Met Leu 165 170 175Thr
Gly Glu Val Ile Pro Val Met Glu Leu Leu Ser Ser Met Lys Ser 180 185
190His Ser Val Pro Glu Glu Ile Asp Ile Ala Asp Thr Val Leu Asn Asp
195 200 205Asp Asp Ile Gly Asp Ser Cys His Glu Gly Phe Leu Leu Asn
Ala Ile 210
215 220Ser Ser His Leu Gln Thr Cys Gly Cys Ser Val Val Val Gly Ser
Ser225 230 235 240Ala Glu Lys Val Asn Lys Ile Val Arg Thr Leu Cys
Leu Phe Leu Thr 245 250 255Pro Ala Glu Arg Lys Cys Ser Arg Leu Cys
Glu Ala Glu Ser Ser Phe 260 265 270Lys Tyr Glu Ser Gly Leu Phe Val
Gln Gly Leu Leu Lys Asp Ser Thr 275 280 285Gly Ser Phe Val Leu Pro
Phe Arg Gln Val Met Tyr Ala Pro Tyr Pro 290 295 300Thr Thr His Ile
Asp Val Asp Val Asn Thr Val Lys Gln Met Pro Pro305 310 315 320Cys
His Glu His Ile Tyr Asn Gln Arg Arg Tyr Met Arg Ser Glu Leu 325 330
335Thr Ala Phe Trp Arg Ala Thr Ser Glu Glu Asp Met Ala Gln Asp Thr
340 345 350Ile Ile Tyr Thr Asp Glu Ser Phe Thr Pro Asp Leu Asn Ile
Phe Gln 355 360 365Asp Val Leu His Arg Asp Thr Leu Val Lys Ala Phe
Leu Asp Gln Val 370 375 380Phe Gln Leu Lys Pro Gly Leu Ser Leu Arg
Ser Thr Phe Leu Ala Gln385 390 395 400Phe Leu Leu Val Leu His Arg
Lys Ala Leu Thr Leu Ile Lys Tyr Ile 405 410 415Glu Asp Asp Thr Gln
Lys Gly Lys Lys Pro Phe Lys Ser Leu Arg Asn 420 425 430Leu Lys Ile
Asp Leu Asp Leu Thr Ala Glu Gly Asp Leu Asn Ile Ile 435 440 445Met
Ala Leu Ala Glu Lys Ile Lys Pro Gly Leu His Ser Phe Ile Phe 450 455
460Gly Arg Pro Phe Tyr Thr Ser Val Gln Glu Arg Asp Val Leu Met
Thr465 470 475 480Phe143356DNAHomo sapiens 14acgtaaccta cggtgtcccg
ctaggaaaga gaggtgcgtc aaacagcgac aagttccgcc 60cacgtaaaag atgacgcttg
gtgtgtcagc cgtccctgct gcccggttgc ttctcttttg 120ggggcggggt
ctagcaagag caggtgtggg tttaggagat atctccggag catttggata
180atgtgacagt tggaatgcag tgatgtcgac tctttgccca ccgccatctc
cagctgttgc 240caagacagag attgctttaa gtggcaaatc acctttatta
gcagctactt ttgcttactg 300ggacaatatt cttggtccta gagtaaggca
catttgggct ccaaagacag aacaggtact 360tctcagtgat ggagaaataa
cttttcttgc caaccacact ctaaatggag aaatccttcg 420aaatgcagag
agtggtgcta tagatgtaaa gttttttgtc ttgtctgaaa agggagtgat
480tattgtttca ttaatctttg atggaaactg gaatggggat cgcagcacat
atggactatc 540aattatactt ccacagacag aacttagttt ctacctccca
cttcatagag tgtgtgttga 600tagattaaca catataatcc ggaaaggaag
aatatggatg cataaggaaa gacaagaaaa 660tgtccagaag attatcttag
aaggcacaga gagaatggaa gatcagggtc agagtattat 720tccaatgctt
actggagaag tgattcctgt aatggaactg ctttcatcta tgaaatcaca
780cagtgttcct gaagaaatag atatagctga tacagtactc aatgatgatg
atattggtga 840cagctgtcat gaaggctttc ttctcaatgc catcagctca
cacttgcaaa cctgtggctg 900ttccgttgta gtaggtagca gtgcagagaa
agtaaataag atagtcagaa cattatgcct 960ttttctgact ccagcagaga
gaaaatgctc caggttatgt gaagcagaat catcatttaa 1020atatgagtca
gggctctttg tacaaggcct gctaaaggat tcaactggaa gctttgtgct
1080gcctttccgg caagtcatgt atgctccata tcccaccaca cacatagatg
tggatgtcaa 1140tactgtgaag cagatgccac cctgtcatga acatatttat
aatcagcgta gatacatgag 1200atccgagctg acagccttct ggagagccac
ttcagaagaa gacatggctc aggatacgat 1260catctacact gacgaaagct
ttactcctga tttgaatatt tttcaagatg tcttacacag 1320agacactcta
gtgaaagcct tcctggatca ggtctttcag ctgaaacctg gcttatctct
1380cagaagtact ttccttgcac agtttctact tgtccttcac agaaaagcct
tgacactaat 1440aaaatatata gaagacgata cgcagaaggg aaaaaagccc
tttaaatctc ttcggaacct 1500gaagatagac cttgatttaa cagcagaggg
cgatcttaac ataataatgg ctctggctga 1560gaaaattaaa ccaggcctac
actcttttat ctttggaaga cctttctaca ctagtgtgca 1620agaacgagat
gttctaatga ctttttaaat gtgtaactta ataagcctat tccatcacaa
1680tcatgatcgc tggtaaagta gctcagtggt gtggggaaac gttcccctgg
atcatactcc 1740agaattctgc tctcagcaat tgcagttaag taagttacac
tacagttctc acaagagcct 1800gtgaggggat gtcaggtgca tcattacatt
gggtgtctct tttcctagat ttatgctttt 1860gggatacaga cctatgttta
caatataata aatattattg ctatctttta aagatataat 1920aataggatgt
aaacttgacc acaactactg tttttttgaa atacatgatt catggtttac
1980atgtgtcaag gtgaaatctg agttggcttt tacagatagt tgactttcta
tcttttggca 2040ttctttggtg tgtagaatta ctgtaatact tctgcaatca
actgaaaact agagccttta 2100aatgatttca attccacaga aagaaagtga
gcttgaacat aggatgagct ttagaaagaa 2160aattgatcaa gcagatgttt
aattggaatt gattattaga tcctactttg tggatttagt 2220ccctgggatt
cagtctgtag aaatgtctaa tagttctcta tagtccttgt tcctggtgaa
2280ccacagttag ggtgttttgt ttattttatt gttcttgcta ttgttgatat
tctatgtagt 2340tgagctctgt aaaaggaaat tgtattttat gttttagtaa
ttgttgccaa ctttttaaat 2400taattttcat tatttttgag ccaaattgaa
atgtgcacct cctgtgcctt ttttctcctt 2460agaaaatcta attacttgga
acaagttcag atttcactgg tcagtcattt tcatcttgtt 2520ttcttcttgc
taagtcttac catgtacctg ctttggcaat cattgcaact ctgagattat
2580aaaatgcctt agagaatata ctaactaata agatcttttt ttcagaaaca
gaaaatagtt 2640ccttgagtac ttccttcttg catttctgcc tatgtttttg
aagttgttgc tgtttgcctg 2700caataggcta taaggaatag caggagaaat
tttactgaag tgctgttttc ctaggtgcta 2760ctttggcaga gctaagttat
cttttgtttt cttaatgcgt ttggaccatt ttgctggcta 2820taaaataact
gattaatata attctaacac aatgttgaca ttgtagttac acaaacacaa
2880ataaatattt tatttaaaat tctggaagta atataaaagg gaaaatatat
ttataagaaa 2940gggataaagg taatagagcc cttctgcccc ccacccacca
aatttacaca acaaaatgac 3000atgttcgaat gtgaaaggtc ataatagctt
tcccatcatg aatcagaaag atgtggacag 3060cttgatgttt tagacaacca
ctgaactaga tgactgttgt actgtagctc agtcatttaa 3120aaaatatata
aatactacct tgtagtgtcc catactgtgt tttttacatg gtagattctt
3180atttaagtgc taactggtta ttttctttgg ctggtttatt gtactgttat
acagaatgta 3240agttgtacag tgaaataagt tattaaagca tgtgtaaaca
ttgttatata tcttttctcc 3300taaatggaga attttgaata aaatatattt
gaaattttaa aaaaaaaaaa aaaaaa 335615481PRTHomo sapiens 15Met Ser Thr
Leu Cys Pro Pro Pro Ser Pro Ala Val Ala Lys Thr Glu1 5 10 15Ile Ala
Leu Ser Gly Lys Ser Pro Leu Leu Ala Ala Thr Phe Ala Tyr 20 25 30Trp
Asp Asn Ile Leu Gly Pro Arg Val Arg His Ile Trp Ala Pro Lys 35 40
45Thr Glu Gln Val Leu Leu Ser Asp Gly Glu Ile Thr Phe Leu Ala Asn
50 55 60His Thr Leu Asn Gly Glu Ile Leu Arg Asn Ala Glu Ser Gly Ala
Ile65 70 75 80Asp Val Lys Phe Phe Val Leu Ser Glu Lys Gly Val Ile
Ile Val Ser 85 90 95Leu Ile Phe Asp Gly Asn Trp Asn Gly Asp Arg Ser
Thr Tyr Gly Leu 100 105 110Ser Ile Ile Leu Pro Gln Thr Glu Leu Ser
Phe Tyr Leu Pro Leu His 115 120 125Arg Val Cys Val Asp Arg Leu Thr
His Ile Ile Arg Lys Gly Arg Ile 130 135 140Trp Met His Lys Glu Arg
Gln Glu Asn Val Gln Lys Ile Ile Leu Glu145 150 155 160Gly Thr Glu
Arg Met Glu Asp Gln Gly Gln Ser Ile Ile Pro Met Leu 165 170 175Thr
Gly Glu Val Ile Pro Val Met Glu Leu Leu Ser Ser Met Lys Ser 180 185
190His Ser Val Pro Glu Glu Ile Asp Ile Ala Asp Thr Val Leu Asn Asp
195 200 205Asp Asp Ile Gly Asp Ser Cys His Glu Gly Phe Leu Leu Asn
Ala Ile 210 215 220Ser Ser His Leu Gln Thr Cys Gly Cys Ser Val Val
Val Gly Ser Ser225 230 235 240Ala Glu Lys Val Asn Lys Ile Val Arg
Thr Leu Cys Leu Phe Leu Thr 245 250 255Pro Ala Glu Arg Lys Cys Ser
Arg Leu Cys Glu Ala Glu Ser Ser Phe 260 265 270Lys Tyr Glu Ser Gly
Leu Phe Val Gln Gly Leu Leu Lys Asp Ser Thr 275 280 285Gly Ser Phe
Val Leu Pro Phe Arg Gln Val Met Tyr Ala Pro Tyr Pro 290 295 300Thr
Thr His Ile Asp Val Asp Val Asn Thr Val Lys Gln Met Pro Pro305 310
315 320Cys His Glu His Ile Tyr Asn Gln Arg Arg Tyr Met Arg Ser Glu
Leu 325 330 335Thr Ala Phe Trp Arg Ala Thr Ser Glu Glu Asp Met Ala
Gln Asp Thr 340 345 350Ile Ile Tyr Thr Asp Glu Ser Phe Thr Pro Asp
Leu Asn Ile Phe Gln 355 360 365Asp Val Leu His Arg Asp Thr Leu Val
Lys Ala Phe Leu Asp Gln Val 370 375 380Phe Gln Leu Lys Pro Gly Leu
Ser Leu Arg Ser Thr Phe Leu Ala Gln385 390 395 400Phe Leu Leu Val
Leu His Arg Lys Ala Leu Thr Leu Ile Lys Tyr Ile 405 410 415Glu Asp
Asp Thr Gln Lys Gly Lys Lys Pro Phe Lys Ser Leu Arg Asn 420 425
430Leu Lys Ile Asp Leu Asp Leu Thr Ala Glu Gly Asp Leu Asn Ile Ile
435 440 445Met Ala Leu Ala Glu Lys Ile Lys Pro Gly Leu His Ser Phe
Ile Phe 450 455 460Gly Arg Pro Phe Tyr Thr Ser Val Gln Glu Arg Asp
Val Leu Met Thr465 470 475 480Phe163198DNAMus musculus 16gtgtccgggg
cggggcggtc ccggggcggg gcccggagcg ggctgcggtt gcggtccctg 60cgccggcggt
gaaggcgcag cagcggcgag tggctattgc aagcgttcgg ataatgtgag
120acctggaatg cagtgagacc tgggatgcag ggatgtcgac tatctgcccc
ccaccatctc 180ctgctgttgc caagacagag attgctttaa gtggtgaatc
acccttgttg gcggctacct 240ttgcttactg ggataatatt cttggtccta
gagtaaggca tatttgggct ccaaagacag 300accaagtgct tctcagtgat
ggagaaataa cttttcttgc caaccacact ctaaatggag 360aaattcttcg
aaatgcagag agtggggcta tagatgtaaa attttttgtc ttatctgaaa
420aaggggtaat tattgtttca ttaatcttcg acggaaactg gaatggagat
cggagcactt 480atggactatc aattatactg ccgcagacag agctgagctt
ctacctccca cttcacagag 540tgtgtgttga caggctaaca cacattattc
gaaaaggaag aatatggatg cataaggaaa 600gacaagaaaa tgtccagaaa
attgtcttgg aaggcacaga gaggatggaa gatcagggtc 660agagtatcat
tcccatgctt actggggaag tcattcctgt aatggagctg cttgcatcta
720tgaaatccca cagtgttcct gaagacattg atatagctga tacagtgctc
aatgatgatg 780acattggtga cagctgtcac gaaggctttc ttctcaatgc
catcagctca cacctgcaga 840cctgtggctg ttccgttgta gttggcagca
gtgcagagaa agtaaataag atagtaagaa 900cgctgtgcct ttttctgaca
ccagcagaga ggaaatgctc caggctgtgt gaagcagaat 960cgtcctttaa
gtacgaatcg ggactctttg tgcaaggctt gctaaaggat gcaacaggca
1020gttttgtcct acccttccgg caagttatgt atgccccgta ccccaccacg
cacattgatg 1080tggatgtcaa cactgtcaag cagatgccac cgtgtcatga
acatatttat aatcaacgca 1140gatacatgag gtcagagctg acagccttct
ggagggcaac ttcagaagag gacatggcgc 1200aggacaccat catctacaca
gatgagagct tcactcctga tttgaatatt ttccaagatg 1260tcttacacag
agacactcta gtgaaagcct tcctggatca ggtcttccat ttgaagcctg
1320gcctgtctct caggagtact ttccttgcac agttcctcct cattcttcac
agaaaagcct 1380tgacactaat caagtacatc gaggatgata cgcagaaggg
gaaaaagccc tttaagtctc 1440ttcggaacct gaagatagat cttgatttaa
cagcagaggg cgatcttaac ataataatgg 1500ctctagctga gaaaattaag
ccaggcctac actctttcat ctttgggaga cctttctaca 1560ctagtgtaca
agaacgtgat gttctaatga ccttttgacc gtgtggtttg ctgtgtctgt
1620ctcttcacag tcacacctgc tgttacagtg tctcagcagt gtgtgggcac
atccttcctc 1680ccgagtcctg ctgcaggaca gggtacacta cacttgtcag
tagaagtctg tacctgatgt 1740caggtgcatc gttacagtga atgactcttc
ctagaataga tgtactcttt tagggcctta 1800tgtttacaat tatcctaagt
actattgctg tcttttaaag atatgaatga tggaatatac 1860acttgaccat
aactgctgat tggttttttg ttttgttttg tttgttttct tggaaactta
1920tgattcctgg tttacatgta ccacactgaa accctcgtta gctttacaga
taaagtgtga 1980gttgacttcc tgcccctctg tgttctgtgg tatgtccgat
tacttctgcc acagctaaac 2040attagagcat ttaaagtttg cagttcctca
gaaaggaact tagtctgact acagattagt 2100tcttgagaga agacactgat
agggcagagc tgtaggtgaa atcagttgtt agcccttcct 2160ttatagacgt
agtccttcag attcggtctg tacagaaatg ccgaggggtc atgcatgggc
2220cctgagtatc gtgacctgtg acaagttttt tgttggttta ttgtagttct
gtcaaagaaa 2280gtggcatttg tttttataat tgttgccaac ttttaaggtt
aattttcatt atttttgagc 2340cgaattaaaa tgcgcacctc ctgtgccttt
cccaatcttg gaaaatataa tttcttggca 2400gagggtcaga tttcagggcc
cagtcacttt catctgacca ccctttgcac ggctgccgtg 2460tgcctggctt
agattagaag tccttgttaa gtatgtcaga gtacattcgc tgataagatc
2520tttgaagagc agggaagcgt cttgcctctt tcctttggtt tctgcctgta
ctctggtgtt 2580tcccgtgtca cctgcatcat aggaacagca gagaaatctg
acccagtgct atttttctag 2640gtgctactat ggcaaactca agtggtctgt
ttctgttcct gtaacgttcg actatctcgc 2700tagctgtgaa gtactgatta
gtggagttct gtgcaacagc agtgtaggag tatacacaaa 2760cacaaatatg
tgtttctatt taaaactgtg gacttagcat aaaaagggag aatatattta
2820ttttttacaa aagggataaa aatgggcccc gttcctcacc caccagattt
agcgagaaaa 2880agctttctat tctgaaaggt cacggtggct ttggcattac
aaatcagaac aacacacact 2940gaccatgatg gcttgtgaac taactgcaag
gcactccgtc atggtaagcg agtaggtccc 3000acctcctagt gtgccgctca
ttgctttaca cagtagaatc ttatttgagt gctaattgtt 3060gtctttgctg
ctttactgtg ttgttataga aaatgtaagc tgtacagtga ataagttatt
3120gaagcatgtg taaacactgt tatatatctt ttctcctaga tggggaattt
tgaataaaat 3180acctttgaaa ttctgtgt 319817481PRTMus musculus 17Met
Ser Thr Ile Cys Pro Pro Pro Ser Pro Ala Val Ala Lys Thr Glu1 5 10
15Ile Ala Leu Ser Gly Glu Ser Pro Leu Leu Ala Ala Thr Phe Ala Tyr
20 25 30Trp Asp Asn Ile Leu Gly Pro Arg Val Arg His Ile Trp Ala Pro
Lys 35 40 45Thr Asp Gln Val Leu Leu Ser Asp Gly Glu Ile Thr Phe Leu
Ala Asn 50 55 60His Thr Leu Asn Gly Glu Ile Leu Arg Asn Ala Glu Ser
Gly Ala Ile65 70 75 80Asp Val Lys Phe Phe Val Leu Ser Glu Lys Gly
Val Ile Ile Val Ser 85 90 95Leu Ile Phe Asp Gly Asn Trp Asn Gly Asp
Arg Ser Thr Tyr Gly Leu 100 105 110Ser Ile Ile Leu Pro Gln Thr Glu
Leu Ser Phe Tyr Leu Pro Leu His 115 120 125Arg Val Cys Val Asp Arg
Leu Thr His Ile Ile Arg Lys Gly Arg Ile 130 135 140Trp Met His Lys
Glu Arg Gln Glu Asn Val Gln Lys Ile Val Leu Glu145 150 155 160Gly
Thr Glu Arg Met Glu Asp Gln Gly Gln Ser Ile Ile Pro Met Leu 165 170
175Thr Gly Glu Val Ile Pro Val Met Glu Leu Leu Ala Ser Met Lys Ser
180 185 190His Ser Val Pro Glu Asp Ile Asp Ile Ala Asp Thr Val Leu
Asn Asp 195 200 205Asp Asp Ile Gly Asp Ser Cys His Glu Gly Phe Leu
Leu Asn Ala Ile 210 215 220Ser Ser His Leu Gln Thr Cys Gly Cys Ser
Val Val Val Gly Ser Ser225 230 235 240Ala Glu Lys Val Asn Lys Ile
Val Arg Thr Leu Cys Leu Phe Leu Thr 245 250 255Pro Ala Glu Arg Lys
Cys Ser Arg Leu Cys Glu Ala Glu Ser Ser Phe 260 265 270Lys Tyr Glu
Ser Gly Leu Phe Val Gln Gly Leu Leu Lys Asp Ala Thr 275 280 285Gly
Ser Phe Val Leu Pro Phe Arg Gln Val Met Tyr Ala Pro Tyr Pro 290 295
300Thr Thr His Ile Asp Val Asp Val Asn Thr Val Lys Gln Met Pro
Pro305 310 315 320Cys His Glu His Ile Tyr Asn Gln Arg Arg Tyr Met
Arg Ser Glu Leu 325 330 335Thr Ala Phe Trp Arg Ala Thr Ser Glu Glu
Asp Met Ala Gln Asp Thr 340 345 350Ile Ile Tyr Thr Asp Glu Ser Phe
Thr Pro Asp Leu Asn Ile Phe Gln 355 360 365Asp Val Leu His Arg Asp
Thr Leu Val Lys Ala Phe Leu Asp Gln Val 370 375 380Phe His Leu Lys
Pro Gly Leu Ser Leu Arg Ser Thr Phe Leu Ala Gln385 390 395 400Phe
Leu Leu Ile Leu His Arg Lys Ala Leu Thr Leu Ile Lys Tyr Ile 405 410
415Glu Asp Asp Thr Gln Lys Gly Lys Lys Pro Phe Lys Ser Leu Arg Asn
420 425 430Leu Lys Ile Asp Leu Asp Leu Thr Ala Glu Gly Asp Leu Asn
Ile Ile 435 440 445Met Ala Leu Ala Glu Lys Ile Lys Pro Gly Leu His
Ser Phe Ile Phe 450 455 460Gly Arg Pro Phe Tyr Thr Ser Val Gln Glu
Arg Asp Val Leu Met Thr465 470 475 480Phe183435DNARattus norvegicus
18cgtttgtagt gtcagccatc ccaattgcct gttccttctc tgtgggagtg gtgtctagac
60agtccaggca gggtatgcta ggcaggtgcg ttttggttgc ctcagatcgc aacttgactc
120cataacggtg accaaagaca aaagaaggaa accagattaa aaagaaccgg
acacagaccc 180ctgcagaatc tggagcggcc gtggttgggg gcggggctac
gacggggcgg actcgggggc 240gtgggagggc ggggccgggg cggggcccgg
agccggctgc ggttgcggtc cctgcgccgg 300cggtgaaggc gcagcggcgg
cgagtggcta ttgcaagcgt ttggataatg tgagacctgg 360gatgcaggga
tgtcgactat ctgcccccca ccatctcctg ctgttgccaa gacagagatt
420gctttaagtg gtgaatcacc cttgttggcg gctacctttg cttactggga
taatattctt 480ggtcctagag taaggcacat ttgggctcca aagacagacc
aagtactcct cagtgatgga 540gaaatcactt ttcttgccaa ccacactctg
aatggagaaa ttcttcggaa tgcggagagt 600ggggcaatag atgtaaagtt
ttttgtctta tctgaaaagg gcgtcattat tgtttcatta 660atcttcgacg
ggaactggaa cggagatcgg agcacttacg gactatcaat tatactgccg
720cagacggagc tgagtttcta cctcccactg cacagagtgt gtgttgacag
gctaacgcac 780atcattcgaa aaggaaggat atggatgcac aaggaaagac
aagaaaatgt ccagaaaatt 840gtcttggaag gcaccgagag gatggaagat
cagggtcaga gtatcatccc tatgcttact 900ggggaggtca tccctgtgat
ggagctgctt
gcgtctatga gatcacacag tgttcctgaa 960gacctcgata tagctgatac
agtactcaat gatgatgaca ttggtgacag ctgtcatgaa 1020ggctttcttc
tcaatgccat cagctcacat ctgcagacct gcggctgttc tgtggtggta
1080ggcagcagtg cagagaaagt aaataagata gtaagaacac tgtgcctttt
tctgacacca 1140gcagagagga agtgctccag gctgtgtgaa gccgaatcgt
cctttaaata cgaatctgga 1200ctctttgtac aaggcttgct aaaggatgcg
actggcagtt ttgtactacc tttccggcaa 1260gttatgtatg ccccttatcc
caccacacac atcgatgtgg atgtcaacac tgtcaagcag 1320atgccaccgt
gtcatgaaca tatttataat caacgcagat acatgaggtc agagctgaca
1380gccttctgga gggcaacttc agaagaggac atggctcagg acaccatcat
ctacacagat 1440gagagcttca ctcctgattt gaatattttc caagatgtct
tacacagaga cactctagtg 1500aaagcctttc tggatcaggt cttccatttg
aagcctggcc tgtctctcag gagtactttc 1560cttgcacagt tcctcctcat
tcttcacaga aaagccttga cactaatcaa gtacatagag 1620gatgacacgc
agaaggggaa aaagcccttt aagtctcttc ggaacctgaa gatagatctt
1680gatttaacag cagagggcga ccttaacata ataatggctc tagctgagaa
aattaagcca 1740ggcctacact ctttcatctt cgggagacct ttctacacta
gtgtccaaga acgtgatgtt 1800ctaatgactt tttaaacatg tggtttgctc
cgtgtgtctc atgacagtca cacttgctgt 1860tacagtgtct cagcgctttg
gacacatcct tcctccaggg tcctgccgca ggacacgtta 1920cactacactt
gtcagtagag gtctgtacca gatgtcaggt acatcgttgt agtgaatgtc
1980tcttttccta gactagatgt accctcgtag ggacttatgt ttacaaccct
cctaagtact 2040agtgctgtct tgtaaggata cgaatgaagg gatgtaaact
tcaccacaac tgctggttgg 2100ttttgttgtt tttgtttttt gaaacttata
attcatggtt tacatgcatc acactgaaac 2160cctagttagc tttttacagg
taagctgtga gttgactgcc tgtccctgtg ttctctggcc 2220tgtacgatct
gtggcgtgta ggatcacttt tgcaacaact aaaaactaaa gcactttgtt
2280tgcagttcta cagaaagcaa cttagtctgt ctgcagattc gtttttgaaa
gaagacatga 2340gaaagcggag ttttaggtga agtcagttgt tggatcttcc
tttatagact tagtccttta 2400gatgtggtct gtatagacat gcccaaccat
catgcatggg cactgaatat cgtgaactgt 2460ggtatgcttt ttgttggttt
attgtacttc tgtcaaagaa agtggcattg gtttttataa 2520ttgttgccaa
gttttaaggt taattttcat tatttttgag ccaaattaaa atgtgcacct
2580cctgtgcctt tcccaatctt ggaaaatata atttcttggc agaaggtcag
atttcagggc 2640ccagtcactt tcgtctgact tccctttgca cagtccgcca
tgggcctggc ttagaagttc 2700ttgtaaacta tgccagagag tacattcgct
gataaaatct tctttgcaga gcaggagagc 2760ttcttgcctc tttcctttca
tttctgcctg gactttggtg ttctccacgt tccctgcatc 2820ctaaggacag
caggagaact ctgaccccag tgctatttct ctaggtgcta ttgtggcaaa
2880ctcaagcggt ccgtctctgt ccctgtaacg ttcgtacctt gctggctgtg
aagtactgac 2940tggtaaagct ccgtgctaca gcagtgtagg gtatacacaa
acacaagtaa gtgttttatt 3000taaaactgtg gacttagcat aaaaagggag
actatattta ttttttacaa aagggataaa 3060aatggaaccc tttcctcacc
caccagattt agtcagaaaa aaacattcta ttctgaaagg 3120tcacagtggt
tttgacatga cacatcagaa caacgcacac tgtccatgat ggcttatgaa
3180ctccaagtca ctccatcatg gtaaatgggt agatccctcc ttctagtgtg
ccacaccatt 3240gcttcccaca gtagaatctt atttaagtgc taagtgttgt
ctctgctggt ttactctgtt 3300gttttagaga atgtaagttg tatagtgaat
aagttattga agcatgtgta aacactgtta 3360tacatctttt ctcctagatg
gggaatttgg aataaaatac ctttaaaatt caaaaaaaaa 3420aaaaaaaaaa aaaaa
343519481PRTRattus norvegicus 19Met Ser Thr Ile Cys Pro Pro Pro Ser
Pro Ala Val Ala Lys Thr Glu1 5 10 15Ile Ala Leu Ser Gly Glu Ser Pro
Leu Leu Ala Ala Thr Phe Ala Tyr 20 25 30Trp Asp Asn Ile Leu Gly Pro
Arg Val Arg His Ile Trp Ala Pro Lys 35 40 45Thr Asp Gln Val Leu Leu
Ser Asp Gly Glu Ile Thr Phe Leu Ala Asn 50 55 60His Thr Leu Asn Gly
Glu Ile Leu Arg Asn Ala Glu Ser Gly Ala Ile65 70 75 80Asp Val Lys
Phe Phe Val Leu Ser Glu Lys Gly Val Ile Ile Val Ser 85 90 95Leu Ile
Phe Asp Gly Asn Trp Asn Gly Asp Arg Ser Thr Tyr Gly Leu 100 105
110Ser Ile Ile Leu Pro Gln Thr Glu Leu Ser Phe Tyr Leu Pro Leu His
115 120 125Arg Val Cys Val Asp Arg Leu Thr His Ile Ile Arg Lys Gly
Arg Ile 130 135 140Trp Met His Lys Glu Arg Gln Glu Asn Val Gln Lys
Ile Val Leu Glu145 150 155 160Gly Thr Glu Arg Met Glu Asp Gln Gly
Gln Ser Ile Ile Pro Met Leu 165 170 175Thr Gly Glu Val Ile Pro Val
Met Glu Leu Leu Ala Ser Met Arg Ser 180 185 190His Ser Val Pro Glu
Asp Leu Asp Ile Ala Asp Thr Val Leu Asn Asp 195 200 205Asp Asp Ile
Gly Asp Ser Cys His Glu Gly Phe Leu Leu Asn Ala Ile 210 215 220Ser
Ser His Leu Gln Thr Cys Gly Cys Ser Val Val Val Gly Ser Ser225 230
235 240Ala Glu Lys Val Asn Lys Ile Val Arg Thr Leu Cys Leu Phe Leu
Thr 245 250 255Pro Ala Glu Arg Lys Cys Ser Arg Leu Cys Glu Ala Glu
Ser Ser Phe 260 265 270Lys Tyr Glu Ser Gly Leu Phe Val Gln Gly Leu
Leu Lys Asp Ala Thr 275 280 285Gly Ser Phe Val Leu Pro Phe Arg Gln
Val Met Tyr Ala Pro Tyr Pro 290 295 300Thr Thr His Ile Asp Val Asp
Val Asn Thr Val Lys Gln Met Pro Pro305 310 315 320Cys His Glu His
Ile Tyr Asn Gln Arg Arg Tyr Met Arg Ser Glu Leu 325 330 335Thr Ala
Phe Trp Arg Ala Thr Ser Glu Glu Asp Met Ala Gln Asp Thr 340 345
350Ile Ile Tyr Thr Asp Glu Ser Phe Thr Pro Asp Leu Asn Ile Phe Gln
355 360 365Asp Val Leu His Arg Asp Thr Leu Val Lys Ala Phe Leu Asp
Gln Val 370 375 380Phe His Leu Lys Pro Gly Leu Ser Leu Arg Ser Thr
Phe Leu Ala Gln385 390 395 400Phe Leu Leu Ile Leu His Arg Lys Ala
Leu Thr Leu Ile Lys Tyr Ile 405 410 415Glu Asp Asp Thr Gln Lys Gly
Lys Lys Pro Phe Lys Ser Leu Arg Asn 420 425 430Leu Lys Ile Asp Leu
Asp Leu Thr Ala Glu Gly Asp Leu Asn Ile Ile 435 440 445Met Ala Leu
Ala Glu Lys Ile Lys Pro Gly Leu His Ser Phe Ile Phe 450 455 460Gly
Arg Pro Phe Tyr Thr Ser Val Gln Glu Arg Asp Val Leu Met Thr465 470
475 480Phe20100DNAMus musculus 20gaaccgcggc gcgtcaagca gagacgagtt
ccgcccacgt gaaagatggc gtttgtagtg 60acagccatcc caattgccct ttccttctag
gtggaaagtg 100212648DNAArtificial Sequencefloxed neo cassette of
8026 plus lox sites 21ataacttcgt ataatgtatg ctatacgaag ttatatgcat
ggcctccgcg ccgggttttg 60gcgcctcccg cgggcgcccc cctcctcacg gcgagcgctg
ccacgtcaga cgaagggcgc 120agcgagcgtc ctgatccttc cgcccggacg
ctcaggacag cggcccgctg ctcataagac 180tcggccttag aaccccagta
tcagcagaag gacattttag gacgggactt gggtgactct 240agggcactgg
ttttctttcc agagagcgga acaggcgagg aaaagtagtc ccttctcggc
300gattctgcgg agggatctcc gtggggcggt gaacgccgat gattatataa
ggacgcgccg 360ggtgtggcac agctagttcc gtcgcagccg ggatttgggt
cgcggttctt gtttgtggat 420cgctgtgatc gtcacttggt gagtagcggg
ctgctgggct ggccggggct ttcgtggccg 480ccgggccgct cggtgggacg
gaagcgtgtg gagagaccgc caagggctgt agtctgggtc 540cgcgagcaag
gttgccctga actgggggtt ggggggagcg cagcaaaatg gcggctgttc
600ccgagtcttg aatggaagac gcttgtgagg cgggctgtga ggtcgttgaa
acaaggtggg 660gggcatggtg ggcggcaaga acccaaggtc ttgaggcctt
cgctaatgcg ggaaagctct 720tattcgggtg agatgggctg gggcaccatc
tggggaccct gacgtgaagt ttgtcactga 780ctggagaact cggtttgtcg
tctgttgcgg gggcggcagt tatggcggtg ccgttgggca 840gtgcacccgt
acctttggga gcgcgcgccc tcgtcgtgtc gtgacgtcac ccgttctgtt
900ggcttataat gcagggtggg gccacctgcc ggtaggtgtg cggtaggctt
ttctccgtcg 960caggacgcag ggttcgggcc tagggtaggc tctcctgaat
cgacaggcgc cggacctctg 1020gtgaggggag ggataagtga ggcgtcagtt
tctttggtcg gttttatgta cctatcttct 1080taagtagctg aagctccggt
tttgaactat gcgctcgggg ttggcgagtg tgttttgtga 1140agttttttag
gcaccttttg aaatgtaatc atttgggtca atatgtaatt ttcagtgtta
1200gactagtaaa ttgtccgcta aattctggcc gtttttggct tttttgttag
acgtgttgac 1260aattaatcat cggcatagta tatcggcata gtataatacg
acaaggtgag gaactaaacc 1320atgggatcgg ccattgaaca agatggattg
cacgcaggtt ctccggccgc ttgggtggag 1380aggctattcg gctatgactg
ggcacaacag acaatcggct gctctgatgc cgccgtgttc 1440cggctgtcag
cgcaggggcg cccggttctt tttgtcaaga ccgacctgtc cggtgccctg
1500aatgaactgc aggacgaggc agcgcggcta tcgtggctgg ccacgacggg
cgttccttgc 1560gcagctgtgc tcgacgttgt cactgaagcg ggaagggact
ggctgctatt gggcgaagtg 1620ccggggcagg atctcctgtc atctcacctt
gctcctgccg agaaagtatc catcatggct 1680gatgcaatgc ggcggctgca
tacgcttgat ccggctacct gcccattcga ccaccaagcg 1740aaacatcgca
tcgagcgagc acgtactcgg atggaagccg gtcttgtcga tcaggatgat
1800ctggacgaag agcatcaggg gctcgcgcca gccgaactgt tcgccaggct
caaggcgcgc 1860atgcccgacg gcgatgatct cgtcgtgacc catggcgatg
cctgcttgcc gaatatcatg 1920gtggaaaatg gccgcttttc tggattcatc
gactgtggcc ggctgggtgt ggcggaccgc 1980tatcaggaca tagcgttggc
tacccgtgat attgctgaag agcttggcgg cgaatgggct 2040gaccgcttcc
tcgtgcttta cggtatcgcc gctcccgatt cgcagcgcat cgccttctat
2100cgccttcttg acgagttctt ctgaggggat ccgctgtaag tctgcagaaa
ttgatgatct 2160attaaacaat aaagatgtcc actaaaatgg aagtttttcc
tgtcatactt tgttaagaag 2220ggtgagaaca gagtacctac attttgaatg
gaaggattgg agctacgggg gtgggggtgg 2280ggtgggatta gataaatgcc
tgctctttac tgaaggctct ttactattgc tttatgataa 2340tgtttcatag
ttggatatca taatttaaac aagcaaaacc aaattaaggg ccagctcatt
2400cctcccactc atgatctata gatctataga tctctcgtgg gatcattgtt
tttctcttga 2460ttcccacttt gtggttctaa gtactgtggt ttccaaatgt
gtcagtttca tagcctgaag 2520aacgagatca gcagcctctg ttccacatac
acttcattct cagtattgtt ttgccaagtt 2580ctaattccat cagacctcga
cctgcagccc ctagataact tcgtataatg tatgctatac 2640gaagttat
264822100DNAMus musculus 22attgtgactt gggcatcact tgactgatgg
taatcagttg cagagagaga agtgcactga 60ttaagtctgt ccacacaggg tctgtctggc
caggagtgca 10023100DNAMus musculus 23gaaccgcggc gcgtcaagca
gagacgagtt ccgcccacgt gaaagatggc gtttgtagtg 60acagccatcc caattgccct
ttccttctag gtggaaagtg 100242648DNAArtificial Sequencefloxed
cassette of 8028 plus lox sites 24ataacttcgt ataatgtatg ctatacgaag
ttatatgcat ggcctccgcg ccgggttttg 60gcgcctcccg cgggcgcccc cctcctcacg
gcgagcgctg ccacgtcaga cgaagggcgc 120agcgagcgtc ctgatccttc
cgcccggacg ctcaggacag cggcccgctg ctcataagac 180tcggccttag
aaccccagta tcagcagaag gacattttag gacgggactt gggtgactct
240agggcactgg ttttctttcc agagagcgga acaggcgagg aaaagtagtc
ccttctcggc 300gattctgcgg agggatctcc gtggggcggt gaacgccgat
gattatataa ggacgcgccg 360ggtgtggcac agctagttcc gtcgcagccg
ggatttgggt cgcggttctt gtttgtggat 420cgctgtgatc gtcacttggt
gagtagcggg ctgctgggct ggccggggct ttcgtggccg 480ccgggccgct
cggtgggacg gaagcgtgtg gagagaccgc caagggctgt agtctgggtc
540cgcgagcaag gttgccctga actgggggtt ggggggagcg cagcaaaatg
gcggctgttc 600ccgagtcttg aatggaagac gcttgtgagg cgggctgtga
ggtcgttgaa acaaggtggg 660gggcatggtg ggcggcaaga acccaaggtc
ttgaggcctt cgctaatgcg ggaaagctct 720tattcgggtg agatgggctg
gggcaccatc tggggaccct gacgtgaagt ttgtcactga 780ctggagaact
cggtttgtcg tctgttgcgg gggcggcagt tatggcggtg ccgttgggca
840gtgcacccgt acctttggga gcgcgcgccc tcgtcgtgtc gtgacgtcac
ccgttctgtt 900ggcttataat gcagggtggg gccacctgcc ggtaggtgtg
cggtaggctt ttctccgtcg 960caggacgcag ggttcgggcc tagggtaggc
tctcctgaat cgacaggcgc cggacctctg 1020gtgaggggag ggataagtga
ggcgtcagtt tctttggtcg gttttatgta cctatcttct 1080taagtagctg
aagctccggt tttgaactat gcgctcgggg ttggcgagtg tgttttgtga
1140agttttttag gcaccttttg aaatgtaatc atttgggtca atatgtaatt
ttcagtgtta 1200gactagtaaa ttgtccgcta aattctggcc gtttttggct
tttttgttag acgtgttgac 1260aattaatcat cggcatagta tatcggcata
gtataatacg acaaggtgag gaactaaacc 1320atgggatcgg ccattgaaca
agatggattg cacgcaggtt ctccggccgc ttgggtggag 1380aggctattcg
gctatgactg ggcacaacag acaatcggct gctctgatgc cgccgtgttc
1440cggctgtcag cgcaggggcg cccggttctt tttgtcaaga ccgacctgtc
cggtgccctg 1500aatgaactgc aggacgaggc agcgcggcta tcgtggctgg
ccacgacggg cgttccttgc 1560gcagctgtgc tcgacgttgt cactgaagcg
ggaagggact ggctgctatt gggcgaagtg 1620ccggggcagg atctcctgtc
atctcacctt gctcctgccg agaaagtatc catcatggct 1680gatgcaatgc
ggcggctgca tacgcttgat ccggctacct gcccattcga ccaccaagcg
1740aaacatcgca tcgagcgagc acgtactcgg atggaagccg gtcttgtcga
tcaggatgat 1800ctggacgaag agcatcaggg gctcgcgcca gccgaactgt
tcgccaggct caaggcgcgc 1860atgcccgacg gcgatgatct cgtcgtgacc
catggcgatg cctgcttgcc gaatatcatg 1920gtggaaaatg gccgcttttc
tggattcatc gactgtggcc ggctgggtgt ggcggaccgc 1980tatcaggaca
tagcgttggc tacccgtgat attgctgaag agcttggcgg cgaatgggct
2040gaccgcttcc tcgtgcttta cggtatcgcc gctcccgatt cgcagcgcat
cgccttctat 2100cgccttcttg acgagttctt ctgaggggat ccgctgtaag
tctgcagaaa ttgatgatct 2160attaaacaat aaagatgtcc actaaaatgg
aagtttttcc tgtcatactt tgttaagaag 2220ggtgagaaca gagtacctac
attttgaatg gaaggattgg agctacgggg gtgggggtgg 2280ggtgggatta
gataaatgcc tgctctttac tgaaggctct ttactattgc tttatgataa
2340tgtttcatag ttggatatca taatttaaac aagcaaaacc aaattaaggg
ccagctcatt 2400cctcccactc atgatctata gatctataga tctctcgtgg
gatcattgtt tttctcttga 2460ttcccacttt gtggttctaa gtactgtggt
ttccaaatgt gtcagtttca tagcctgaag 2520aacgagatca gcagcctctg
ttccacatac acttcattct cagtattgtt ttgccaagtt 2580ctaattccat
cagacctcga cctgcagccc ctagataact tcgtataatg tatgctatac 2640gaagttat
264825100DNAMus musculus 25attgtgactt gggcatcact tgactgatgg
taatcagttg cagagagaga agtgcactga 60ttaagtctgt ccacacaggg tctgtctggc
caggagtgca 10026680DNAMus musculus 26ccagtagcag cacccacgtc
caccttctgt ctagtaatgt ccaacacctc cctcagtcca 60aacactgctc tgcatccatg
tggctcccat ttatacctga agcacttgat ggggcctcaa 120tgttttacta
gagcccaccc ccctgcaact ctgagaccct ctggatttgt ctgtcagtgc
180ctcactgggg cgttggataa tttcttaaaa ggtcaagttc cctcagcagc
attctctgag 240cagtctgaag atgtgtgctt ttcacagttc aaatccatgt
ggctgtttca cccacctgcc 300tggccttggg ttatctatca ggacctagcc
tagaagcagg tgtgtggcac ttaacaccta 360agctgagtga ctaactgaac
actcaagtgg atgccatctt tgtcacttct tgactgtgac 420acaagcaact
cctgatgcca aagccctgcc cacccctctc atgcccatat ttggacatgg
480tacaggtcct cactggccat ggtctgtgag gtcctggtcc tctttgactt
cataattcct 540aggggccact agtatctata agaggaagag ggtgctggct
cccaggccac agcccacaaa 600attccacctg ctcacaggtt ggctggctcg
acccaggtgg tgtcccctgc tctgagccag 660ctcccggcca agccagcacc
680271052DNAMus musculus 27tgccatcatc acaggatgtc cttccttctc
cagaagacag actggggctg aaggaaaagc 60cggccaggct cagaacgagc cccactaatt
actgcctcca acagctttcc actcactgcc 120cccagcccaa catccccttt
ttaactggga agcattccta ctctccattg tacgcacacg 180ctcggaagcc
tggctgtggg tttgggcatg agaggcaggg acaacaaaac cagtatatat
240gattataact ttttcctgtt tccctatttc caaatggtcg aaaggaggaa
gttaggtcta 300cctaagctga atgtattcag ttagcaggag aaatgaaatc
ctatacgttt aatactagag 360gagaaccgcc ttagaatatt tatttcattg
gcaatgactc caggactaca cagcgaaatt 420gtattgcatg tgctgccaaa
atactttagc tctttccttc gaagtacgtc ggatcctgta 480attgagacac
cgagtttagg tgactagggt tttcttttga ggaggagtcc cccaccccgc
540cccgctctgc cgcgacagga agctagcgat ccggaggact tagaatacaa
tcgtagtgtg 600ggtaaacatg gagggcaagc gcctgcaaag ggaagtaaga
agattcccag tccttgttga 660aatccatttg caaacagagg aagctgccgc
gggtcgcagt cggtgggggg aagccctgaa 720ccccacgctg cacggctggg
ctggccaggt gcggccacgc ccccatcgcg gcggctggta 780ggagtgaatc
agaccgtcag tattggtaaa gaagtctgcg gcagggcagg gagggggaag
840agtagtcagt cgctcgctca ctcgctcgct cgcacagaca ctgctgcagt
gacactcggc 900cctccagtgt cgcggagacg caagagcagc gcgcagcacc
tgtccgcccg gagcgagccc 960ggcccgcggc cgtagaaaag gagggaccgc
cgaggtgcgc gtcagtactg ctcagcccgg 1020cagggacgcg ggaggatgtg
gactgggtgg ac 1052282008DNAMus musculus 28gtggtgctga ctcagcatcg
gttaataaac cctctgcagg aggctggatt tcttttgttt 60aattatcact tggacctttc
tgagaactct taagaattgt tcattcgggt ttttttgttt 120tgttttggtt
tggttttttt gggttttttt tttttttttt tttttggttt ttggagacag
180ggtttctctg tatatagccc tggcacaaga gcaagctaac agcctgtttc
ttcttggtgc 240tagcgccccc tctggcagaa aatgaaataa caggtggacc
tacaaccccc cccccccccc 300ccagtgtatt ctactcttgt ccccggtata
aatttgattg ttccgaacta cataaattgt 360agaaggattt tttagatgca
catatcattt tctgtgatac cttccacaca cccctccccc 420ccaaaaaaat
ttttctggga aagtttcttg aaaggaaaac agaagaacaa gcctgtcttt
480atgattgagt tgggcttttg ttttgctgtg tttcatttct tcctgtaaac
aaatactcaa 540atgtccactt cattgtatga ctaagttggt atcattaggt
tgggtctggg tgtgtgaatg 600tgggtgtgga tctggatgtg ggtgggtgtg
tatgccccgt gtgtttagaa tactagaaaa 660gataccacat cgtaaacttt
tgggagagat gatttttaaa aatgggggtg ggggtgaggg 720gaacctgcga
tgaggcaagc aagataaggg gaagacttga gtttctgtga tctaaaaagt
780cgctgtgatg ggatgctggc tataaatggg cccttagcag cattgtttct
gtgaattgga 840ggatccctgc tgaaggcaaa agaccattga aggaagtacc
gcatctggtt tgttttgtaa 900tgagaagcag gaatgcaagg tccacgctct
taataataaa caaacaggac attgtatgcc 960atcatcacag gatgtccttc
cttctccaga agacagactg gggctgaagg aaaagccggc 1020caggctcaga
acgagcccca ctaattactg cctccaacag ctttccactc actgccccca
1080gcccaacatc ccctttttaa ctgggaagca ttcctactct ccattgtacg
cacacgctcg 1140gaagcctggc tgtgggtttg ggcatgagag gcagggacaa
caaaaccagt atatatgatt 1200ataacttttt cctgtttccc tatttccaaa
tggtcgaaag gaggaagtta ggtctaccta 1260agctgaatgt attcagttag
caggagaaat gaaatcctat acgtttaata ctagaggaga 1320accgccttag
aatatttatt tcattggcaa tgactccagg actacacagc gaaattgtat
1380tgcatgtgct gccaaaatac tttagctctt tccttcgaag tacgtcggat
cctgtaattg 1440agacaccgag tttaggtgac tagggttttc ttttgaggag
gagtccccca ccccgccccg 1500ctctgccgcg acaggaagct agcgatccgg
aggacttaga atacaatcgt agtgtgggta 1560aacatggagg gcaagcgcct
gcaaagggaa gtaagaagat tcccagtcct tgttgaaatc
1620catttgcaaa cagaggaagc tgccgcgggt cgcagtcggt ggggggaagc
cctgaacccc 1680acgctgcacg gctgggctgg ccaggtgcgg ccacgccccc
atcgcggcgg ctggtaggag 1740tgaatcagac cgtcagtatt ggtaaagaag
tctgcggcag ggcagggagg gggaagagta 1800gtcagtcgct cgctcactcg
ctcgctcgca cagacactgc tgcagtgaca ctcggccctc 1860cagtgtcgcg
gagacgcaag agcagcgcgc agcacctgtc cgcccggagc gagcccggcc
1920cgcggccgta gaaaaggagg gaccgccgag gtgcgcgtca gtactgctca
gcccggcagg 1980gacgcgggag gatgtggact gggtggac
200829252DNAArtificial SequenceSouthern blot probe 29ccggggcggg
gctgcggttg cggtgcctgc gcccgcggcg gcggaggcgc aggcggtggc 60gagtgggtga
gtgaggaggc ggcatcctgg cgggtggctg tttggggttc ggctgccggg
120aagaggcgcg ggtagaagcg ggggctctcc tcagagctcg acgcattttt
actttccctc 180tcatttctct gaccgaagct gggtgtcggg ctttcgcctc
tagcgactgg tggaattgcc 240tgcatccggg cc 2523039DNAArtificial
SequenceAsuragen 2-Primer Fwd 30tgcgcctccg ccgccgcggg cgcaggcacc
gcaaccgca 393135DNAArtificial SequenceAsuragen 2-Primer Rev
31cgcagcctgt agcaagctct ggaactcagg agtcg 353236DNAArtificial
SequenceAsuragen 3-Primer Fwd 32atgcaggcaa ttccaccagt cgctagaggc
gaaagc 363340DNAArtificial SequenceAsuragen 3-Primer Rev
33taaccagaag aaaacaagga gggaaacaac cgcagcctgt 4034158DNAHomo
sapiens 34acgtaaccta cggtgtcccg ctaggaaaga gaggtgcgtc aaacagcgac
aagttccgcc 60cacgtaaaag atgacgcttg gtgtgtcagc cgtccctgct gcccggttgc
ttctcttttg 120ggggcggggt ctagcaagag caggtgtggg tttaggag
15835487DNAHomo sapiens 35tatctccgga gcatttggat aatgtgacag
ttggaatgca gtgatgtcga ctctttgccc 60accgccatct ccagctgttg ccaagacaga
gattgcttta agtggcaaat cacctttatt 120agcagctact tttgcttact
gggacaatat tcttggtcct agagtaaggc acatttgggc 180tccaaagaca
gaacaggtac ttctcagtga tggagaaata acttttcttg ccaaccacac
240tctaaatgga gaaatccttc gaaatgcaga gagtggtgct atagatgtaa
agttttttgt 300cttgtctgaa aagggagtga ttattgtttc attaatcttt
gatggaaact ggaatgggga 360tcgcagcaca tatggactat caattatact
tccacagaca gaacttagtt tctacctccc 420acttcataga gtgtgtgttg
atagattaac acatataatc cggaaaggaa gaatatggat 480gcataag
48736198DNAHomo sapiens 36gggtctagca agagcaggtg tgggtttagg
aggtgtgtgt ttttgttttt cccaccctct 60ctccccacta cttgctctca cagtactcgc
tgagggtgaa caagaaaaga cctgataaag 120attaaccaga agaaaacaag
gagggaaaca accgcagcct gtagcaagct ctggaactca 180ggagtcgcgc gctatgcg
19837118DNAHomo sapiens 37gcgatcgcgg ggcgtggtcg gggcgggccc
gggggcgggc ccggggcggg gctgcggttg 60cggtgcctgc gcccgcggcg gcggaggcgc
aggcggtggc gagtgggtga gtgaggag 1183820DNAArtificial
SequenceSynthetic 38agtactgtga gagcaagtag 203920DNAArtificial
SequenceSynthetic 39gctctcacag tactcgctga 204020DNAArtificial
SequenceSynthetic 40ccgcagcctg tagcaagctc 204120DNAArtificial
SequenceSynthetic 41cggccgctag cgcgatcgcg 204220DNAArtificial
SequenceSynthetic 42acgccccgcg atcgcgctag 204320DNAArtificial
SequenceSynthetic 43tggcgagtgg gtgagtgagg 204420DNAArtificial
SequenceSynthetic 44ggaagaggcg cgggtagaag 20451302DNAArtificial
SequenceSynthetic 45gaacttacgg agtcccacga gggaaccgcg gcgcgtcaag
cagagacgag ttccgcccac 60gtgaaagatg gcgtttgtag tgacagccat cccaattgcc
ctttccttct aggtggaaag 120tggggtctag caagagcagg tgtgggttta
ggaggtgtgt gtttttgttt ttcccaccct 180ctctccccac tacttgctct
cacagtactc gctgagggtg aacaagaaaa gacctgataa 240agattaacca
gaagaaaaca aggagggaaa caaccgcagc ctgtagcaag ctctggaact
300caggagtcgc gcgctatgcg atcgccgtct cggggccggg gccggggccg
gggccggggc 360cggggccggg gccggggccg gggccggggc cggggccggg
gccggggccg gggccggggc 420cggggccggg gccggggccg gggccggggc
cggggccggg gccggggccg gggccggggc 480cggggccggg gccggggccg
gggccggggc cggggccggg gccggggccg gggccggggc 540cggggccggg
gccggggccg gggccggggc cggggccggg gccggggccg gggccggggc
600cggggccggg gccggggccg gggccggggc cggggccggg gccggggccg
gggccggggc 660cggggccggg gccggggccg gggccggggc cggggccggg
gccggggccg gggccggggc 720cggggccggg gccggggccg gggccggggc
cggggccggg gccggggccg gggccggggc 780cggggccggg gccggggccg
gggccggggc cggggccggg gccggggccg gggccggggc 840cggggccggg
gccggggccg gggccggggc cggggccggg gccgagaccc tcgagggccg
900gccgctagcg cgatcgcggg gcgtggtcgg ggcgggcccg ggggcgggcc
cggggcgggg 960ctgcggttgc ggtgcctgcg cccgcggcgg cggaggcgca
ggcggtgcga gtgggtgagt 1020gaggaggcgg catcctggcg ggtggctgtt
tggggttcgg ctgccgggaa gaggcgcggg 1080tagaagcggg ggctctcctc
agagctcgac gcatttttac tttccctctc atttctctga 1140ccgaagctgg
gtgtcgggct ttcgcctcta gcgactggtg gaattgcctg catccgggcc
1200ccgggcttcc cggcggcggc ggcggcggcg gcggcgcagg gacaagggat
ggggatctgg 1260cctcttcctt gctttcccgc cctcagtacc cgagctgtct cc
13024621DNAArtificial SequenceSynthetic 46gagtactgtg agagcaagta g
214721DNAArtificial SequenceSynthetic 47gccgcagcct gtagcaagct c
214821DNAArtificial SequenceSynthetic 48gcggccgcta gcgcgatcgc g
214921DNAArtificial SequenceSynthetic 49gacgccccgc gatcgcgcta g
215021DNAArtificial SequenceSynthetic 50gtggcgagtg ggtgagtgag g
215126DNAArtificial SequenceSynthetic 51acaccgctct cacagtactc
gctgag 265227DNAArtificial SequenceSynthetic 52acaccgccgc
agcctgtagc aagctcg 275327DNAArtificial SequenceSynthetic
53acaccgagta ctgtgagagc aagtagg 275427DNAArtificial
SequenceSynthetic 54acaccgacgc cccgcgatcg cgctagg
275527DNAArtificial SequenceSynthetic 55acaccgcggc cgctagcgcg
atcgcgg 275627DNAArtificial SequenceSynthetic 56acaccgtggc
gagtgggtga gtgaggg 275726DNAArtificial SequenceSynthetic
57acaccggaag aggcgcgggt agaagg 265820DNAArtificial
SequenceSynthetic 58gacgcgttaa tgccaacttt 205920DNAArtificial
SequenceSynthetic 59gagggcctat ttcccatgat 206020DNAArtificial
SequenceSynthetic 60gacgcgttaa tgccaacttt 206120DNAArtificial
SequenceSynthetic 61gaacttacgg agtcccacga 206220DNAArtificial
SequenceSynthetic 62ggagacagct cgggtactga 206382DNAArtificial
SequenceSynthetic 63gttggaacca ttcaaaacag catagcaagt taaaataagg
ctagtccgtt atcaacttga 60aaaagtggca ccgagtcggt gc
826476DNAArtificial SequenceSynthetic 64gttttagagc tagaaatagc
aagttaaaat aaggctagtc cgttatcaac ttgaaaaagt 60ggcaccgagt cggtgc
766586DNAArtificial SequenceSynthetic 65gtttaagagc tatgctggaa
acagcatagc aagtttaaat aaggctagtc cgttatcaac 60ttgaaaaagt ggcaccgagt
cggtgc 866619DNAArtificial SequenceForward Primer 66catcccaatt
gccctttcc 196721DNAArtificial SequenceReverse Primer 67cccacacctg
ctcttgctag a 216817DNAArtificial SequenceProbe 68tctaggtgga aagtggg
176920DNAArtificial SequenceForward Primer 69gagcaggtgt gggtttagga
207020DNAArtificial SequenceReverse Primer 70ccaggtctca ctgcattcca
207126DNAArtificial SequenceProbe 71attgcaagcg ttcggataat gtgaga
267221DNAArtificial SequenceForward Primer 72gctgtcacga aggctttctt
c 217320DNAArtificial SequenceReverse Primer 73gcactgctgc
caactacaac 207424DNAArtificial SequenceProbe 74tcaatgccat
cagctcacac ctgc 247517DNAArtificial SequenceForward Primer
75aagaggcgcg ggtagaa 177622DNAArtificial SequenceReverse Primer
76cagcttcggt cagagaaatg ag 227724DNAArtificial SequenceProbe
77ctctcctcag agctcgacgc attt 247820DNAArtificial SequenceForward
Primer 78ctgcacaatt tcagcccaag 207920DNAArtificial SequenceReverse
Primer 79caggtcatgt cccacagaat 208024DNAArtificial SequenceProbe
80catatgaggg cagcaatgca agtc 248116DNAArtificial SequenceLNA Probe
for sense G4C2 RNATYE563(1)..(1) 81ccccggcccc ggcccc
168222DNAArtificial SequenceLNA Probe for antisense G4C2
RNATYE563(1)..(1) 82ggggccgggg ccggggggcc cc 228318DNAArtificial
SequenceDNA Probe for sense G4C2 RNACy3(18)..(18) 83ccccggcccc
ggccccgg 188417DNAArtificial SequenceDNA Probe for antisense G4C2
RNACy3(17)..(17) 84ggggccgggg ccggggc 17
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012
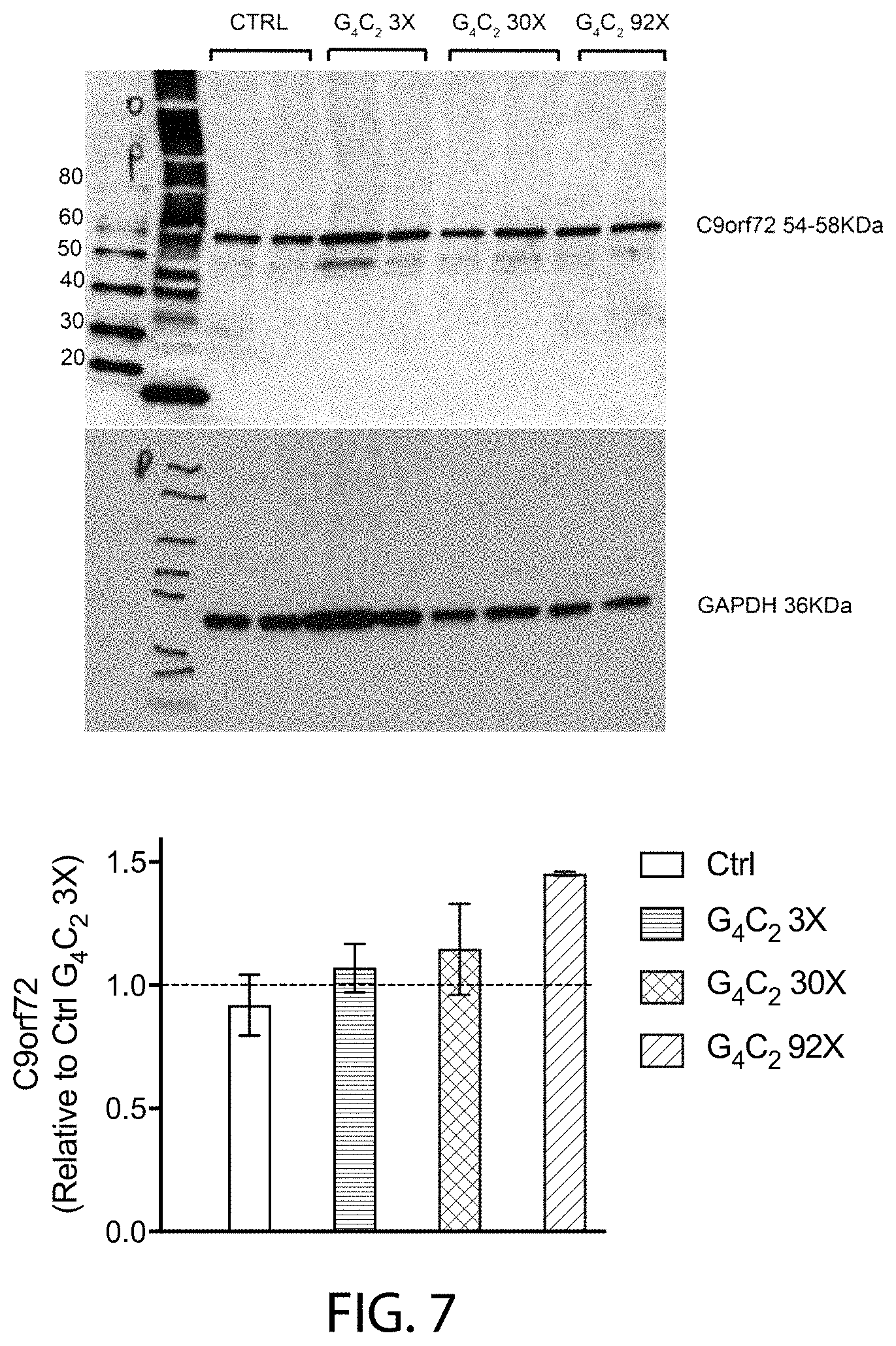
D00013
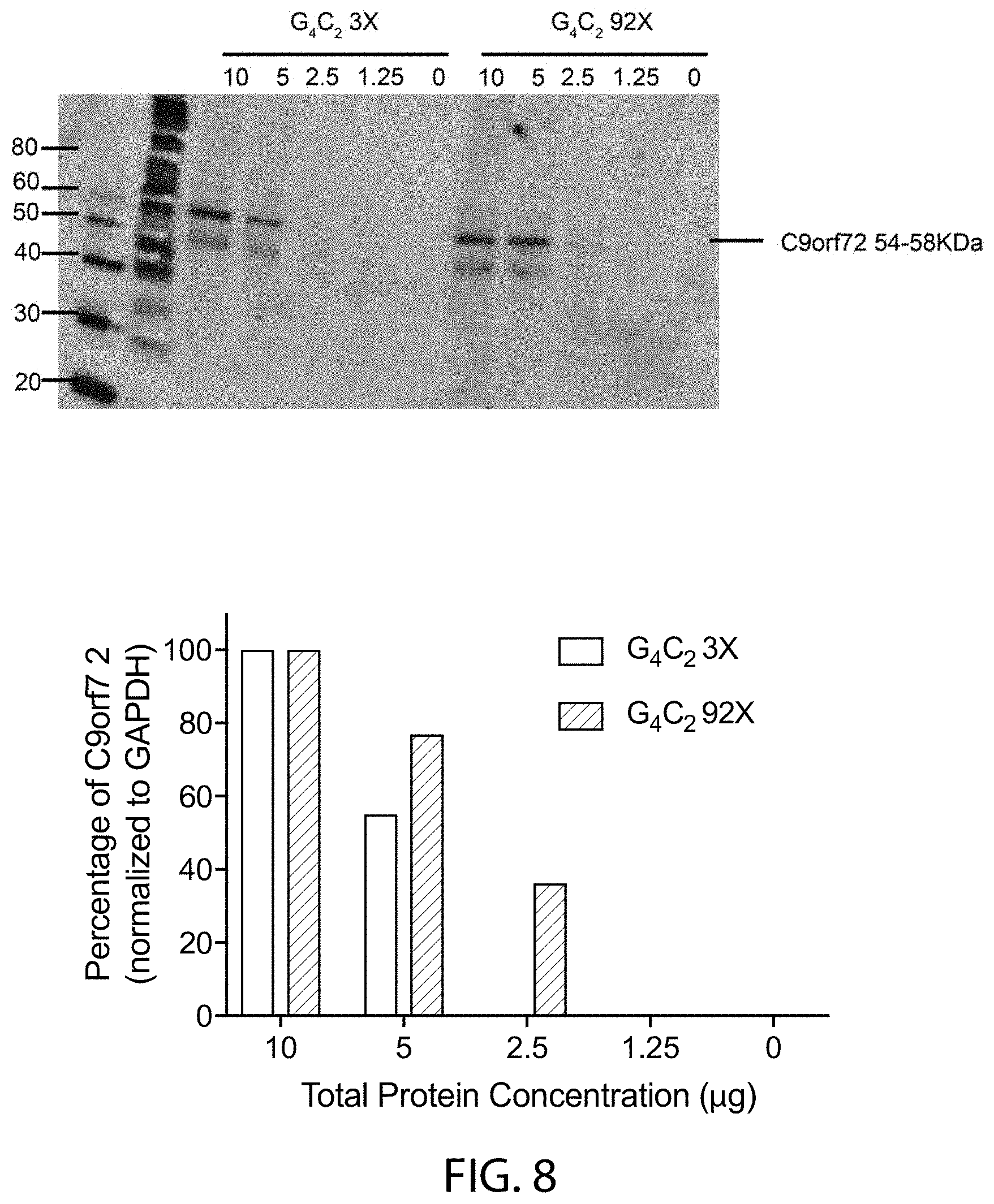
D00014

D00015

D00016
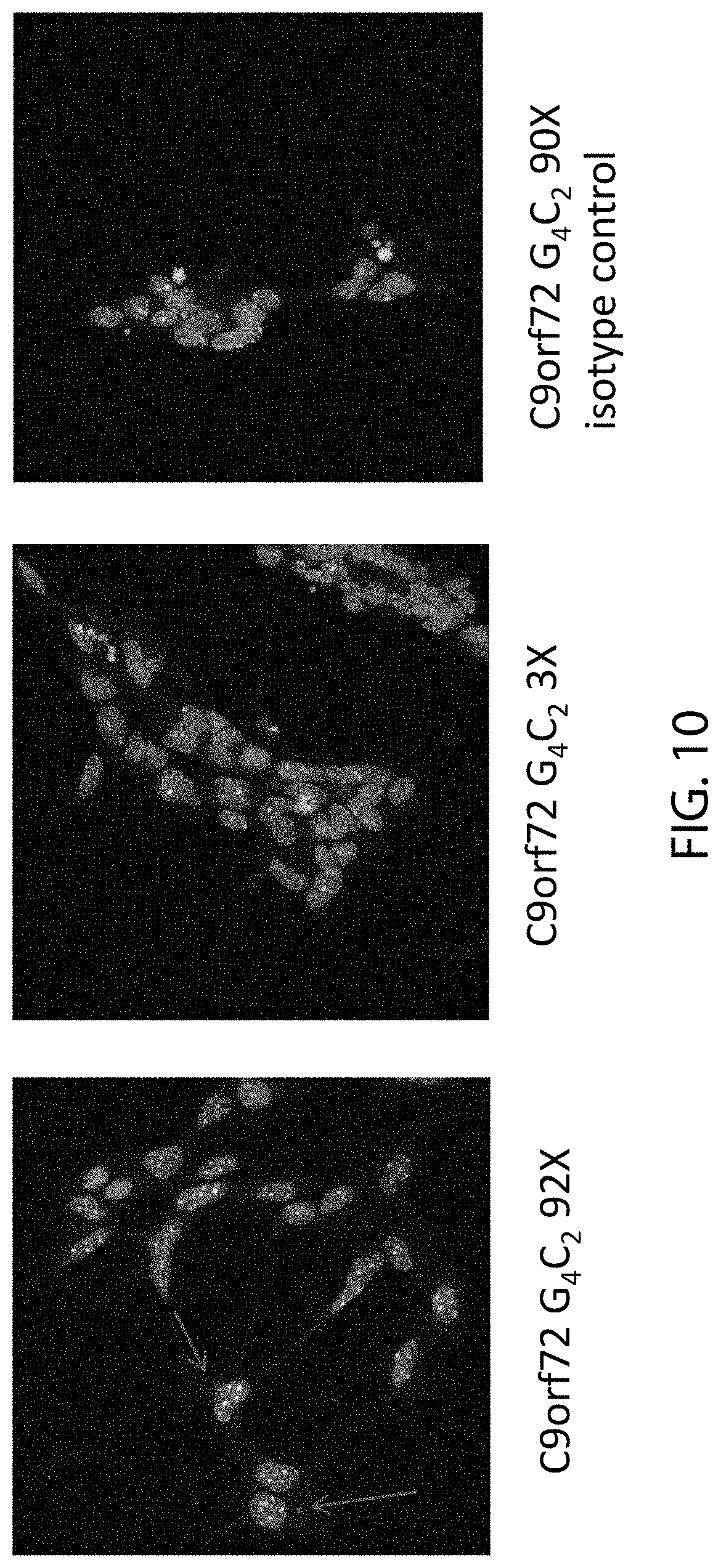
D00017
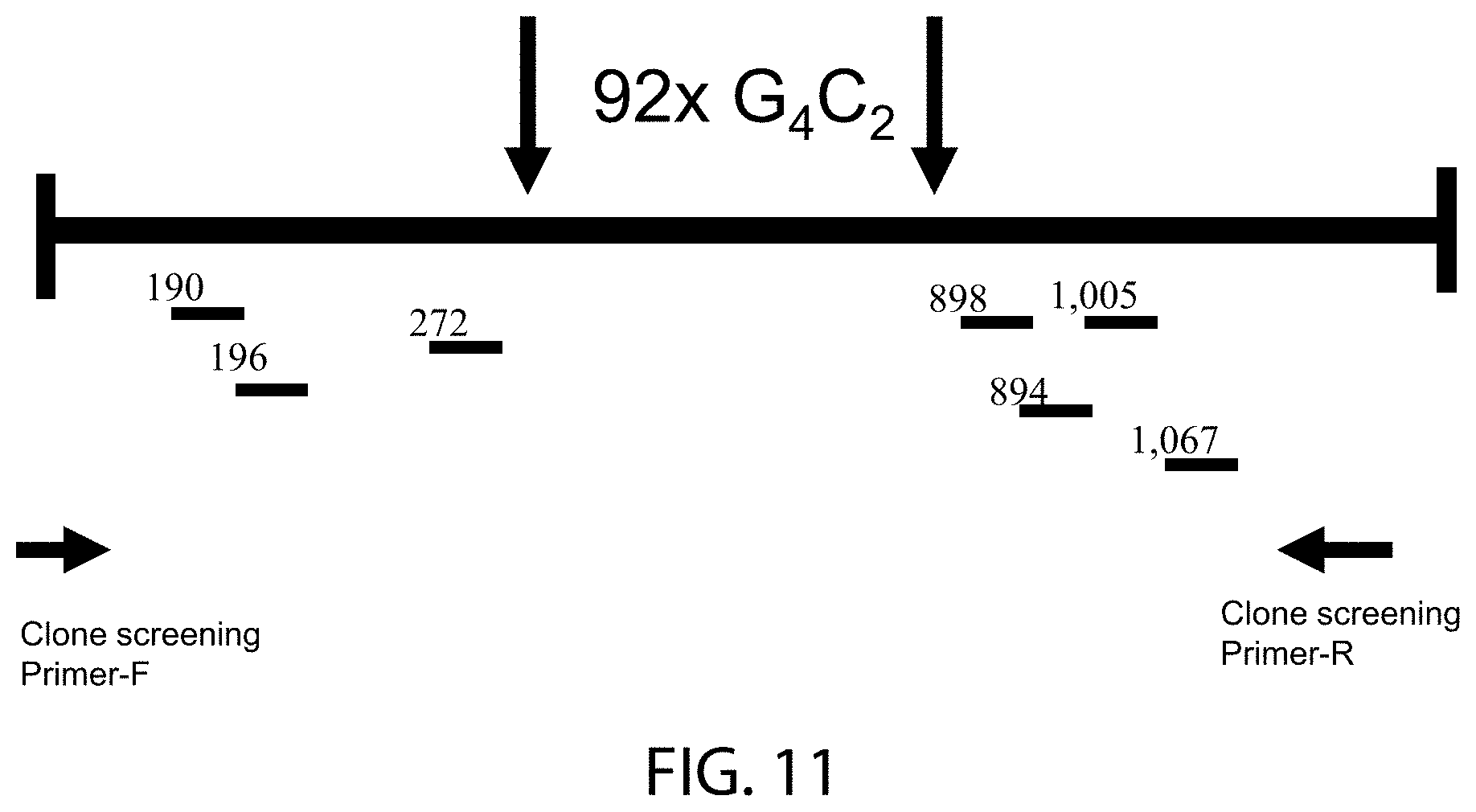
D00018
S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.