Anti-pd-l1 Antibodies And Uses Thereof
Fang; Lei ; et al.
U.S. patent application number 17/563502 was filed with the patent office on 2022-04-21 for anti-pd-l1 antibodies and uses thereof. The applicant listed for this patent is I-Mab Biopharma US Limited. Invention is credited to Lei Fang, Bingshi Guo, Yongqiang Wang, Zhengyi Wang, Jingwu Zang.
| Application Number | 20220119531 17/563502 |
| Document ID | / |
| Family ID | |
| Filed Date | 2022-04-21 |








View All Diagrams
| United States Patent Application | 20220119531 |
| Kind Code | A1 |
| Fang; Lei ; et al. | April 21, 2022 |
ANTI-PD-L1 ANTIBODIES AND USES THEREOF
Abstract
Provided are anti-PD-L1 antibodies or fragments thereof. The antibodies or fragments thereof specifically bind to the immunoglobulin C domain of the PD-L1 protein. In various example, the antibodies or fragments thereof include a VH CDR1 of SEQ ID NO: 1, a VH CDR2 of SEQ ID NO: 116, a VH CDR3 of SEQ ID NO: 117, a VL CDR1 of SEQ ID NO: 4, a VL CDR2 of SEQ ID NO: 5, and a VL CDR3 of SEQ ID NO: 6, or variants of each thereof. Methods of using the antibodies or fragments thereof for treating and diagnosing diseases such as cancer and infectious diseases are also provided.
| Inventors: | Fang; Lei; (Shanghai, CN) ; Wang; Yongqiang; (Shanghai, CN) ; Wang; Zhengyi; (Shanghai, CN) ; Guo; Bingshi; (Shanghai, CN) ; Zang; Jingwu; (Shanghai, CN) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Appl. No.: | 17/563502 | ||||||||||
| Filed: | December 28, 2021 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 16610071 | Oct 31, 2019 | 11220546 | ||
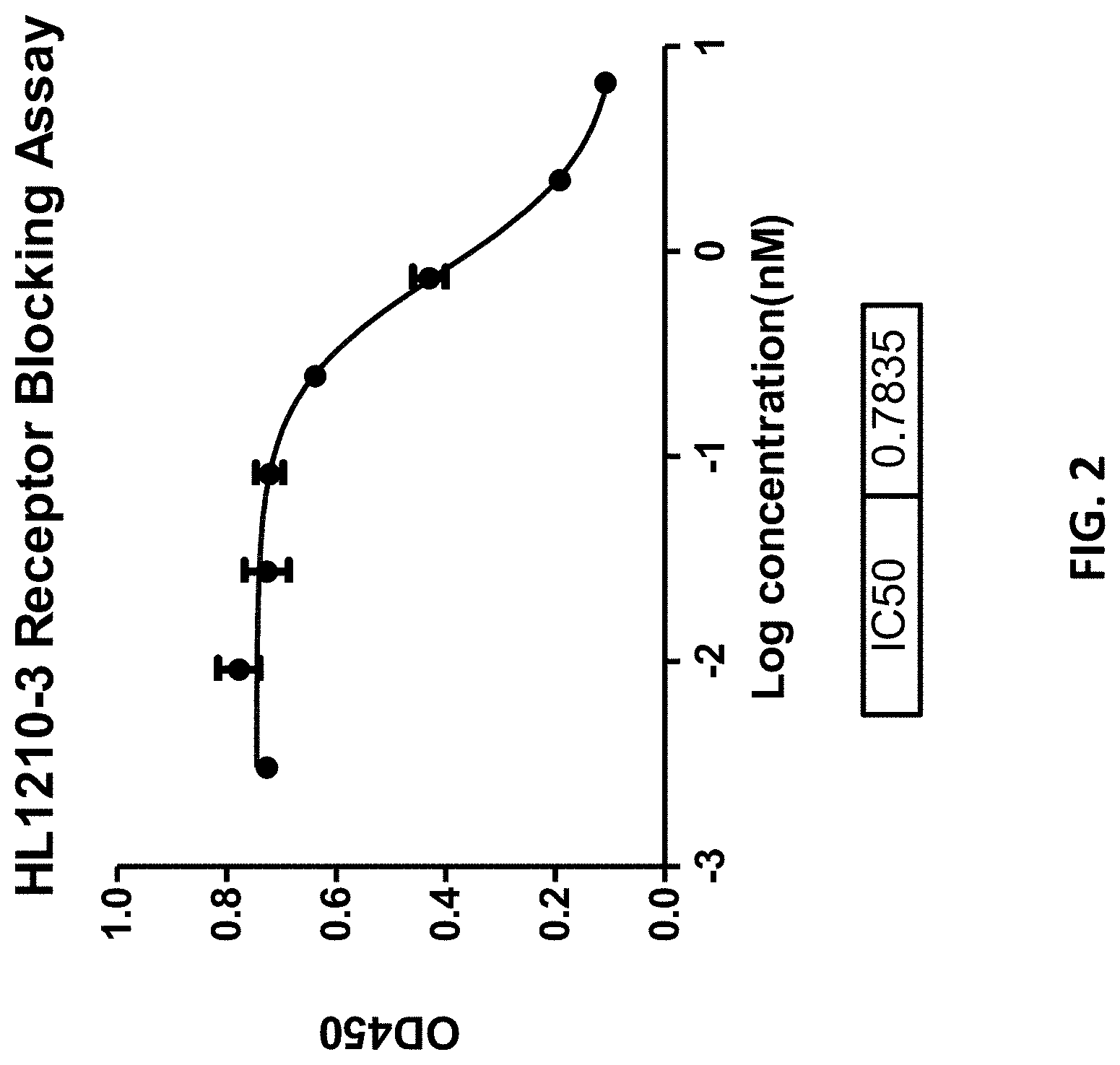
| PCT/CN2019/080458 | Mar 29, 2019 | |||
| 17563502 | ||||
| International Class: | C07K 16/28 20060101 C07K016/28; A61P 35/00 20060101 A61P035/00 |
Foreign Application Data
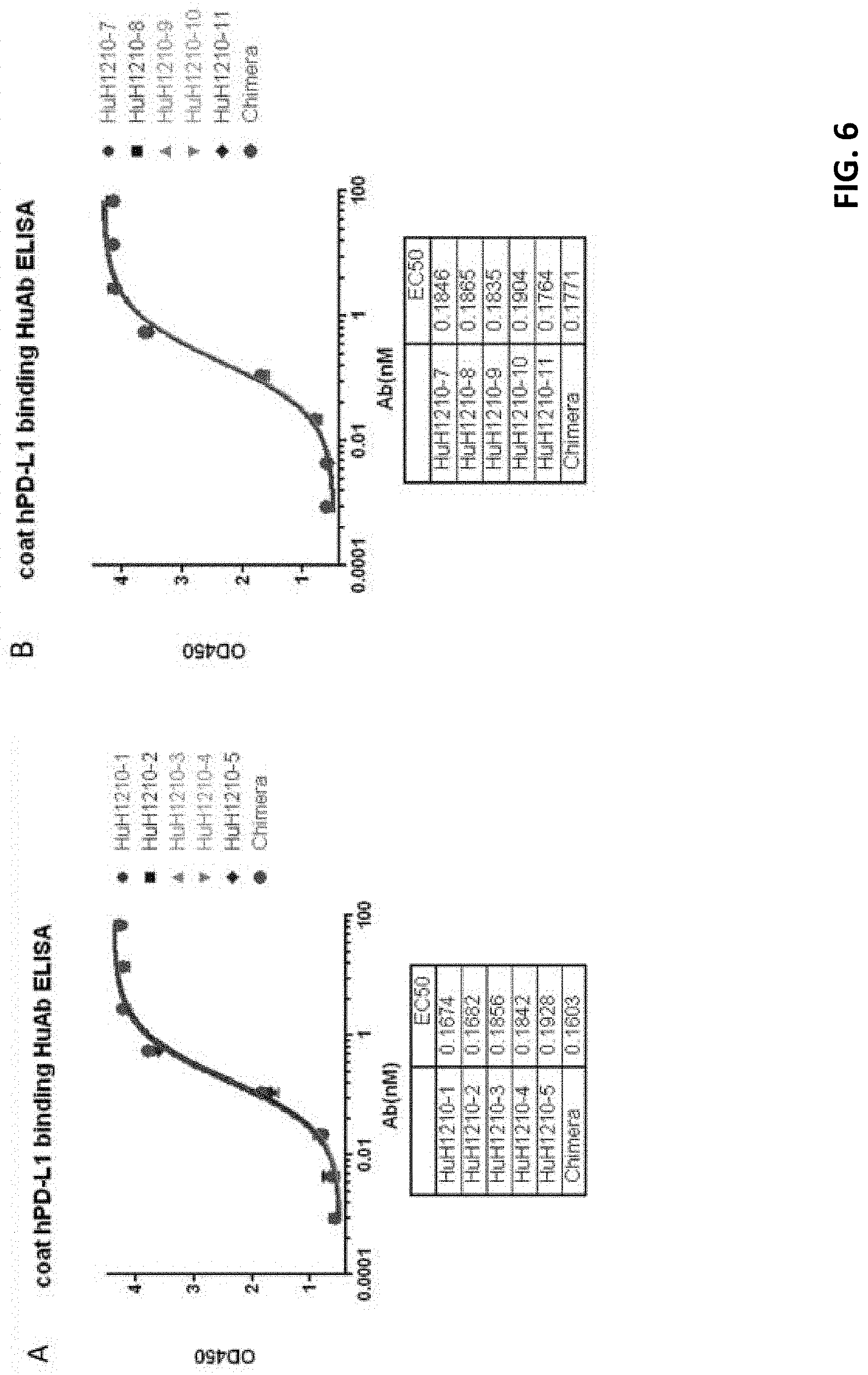
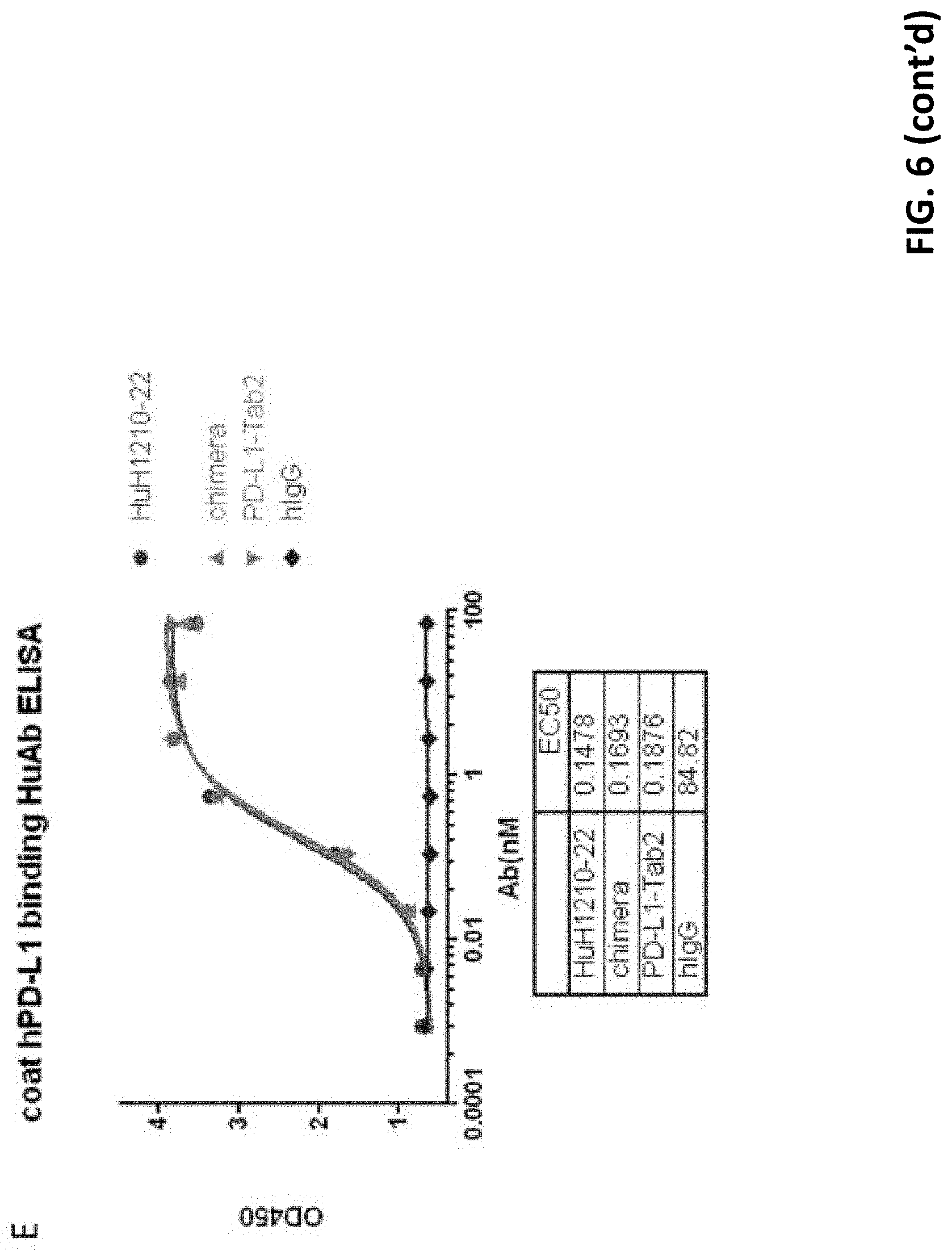
| Date | Code | Application Number |
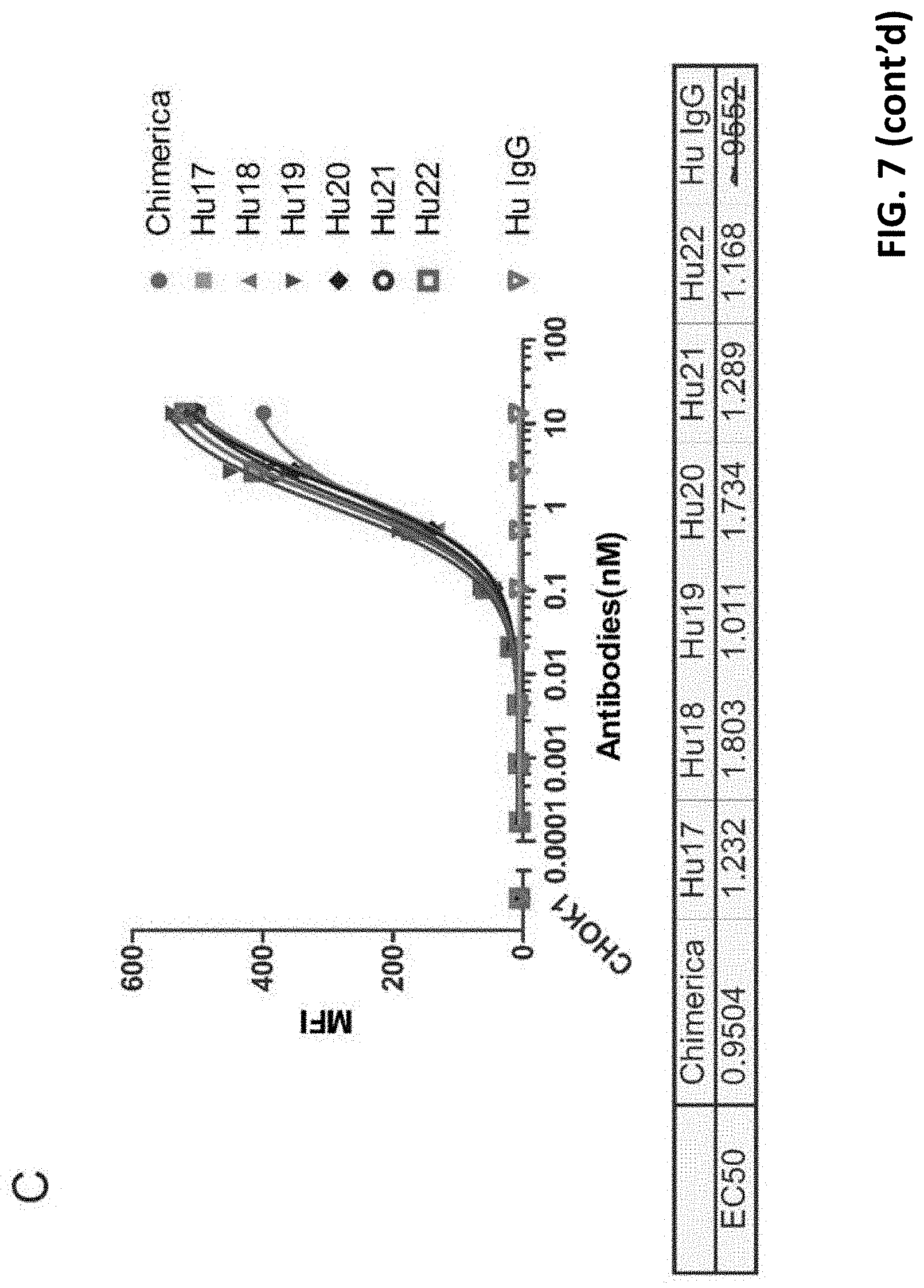
|---|---|---|
| Mar 29, 2018 | CN | PCT/CN2018/081079 |
Claims
1. An antibody or fragment thereof, wherein the antibody or fragment thereof has specificity to a human PD-L1 protein and comprises: (a) a VH CDR1 comprising the amino acid sequence of SEQ ID NO: 1 or a variant of SEQ ID NO: 1 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 1; (b) a VH CDR2 comprising the amino acid sequence of SEQ ID NO: 116 or a variant of SEQ ID NO: 116 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 116, wherein amino acid residue 12 of the VH CDR3 is Arg; (c) a VH CDR3 comprising the amino acid sequence of SEQ ID NO: 3 or a variant of SEQ ID NO: 3 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 3; (d) a VL CDR1 comprising the amino acid sequence of SEQ ID NO: 4 or a variant of SEQ ID NO: 4 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 4; (e) a VL CDR2 comprising the amino acid sequence of SEQ ID NO: 5 or a variant of SEQ ID NO: 5 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 5; and (f) a VL CDR3 comprising the amino acid sequence of SEQ ID NO: 6 or a variant of SEQ ID NO: 6 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 6.
2. The antibody or fragment thereof of claim 1, wherein the variant of SEQ ID NO: 1 is selected from the group consisting of SEQ ID NO: 61-67.
3. The antibody or fragment thereof of claim 1, wherein the variant of SEQ ID NO: 116 is selected from the group consisting of SEQ ID NO: 118-127.
4. The antibody or fragment thereof of claim 1, wherein the variant of SEQ ID NO: 3 is selected from the group consisting of SEQ ID NO: 117 and 128-139.
5. The antibody or fragment thereof of claim 1, wherein the variant of SEQ ID NO: 4 is selected from the group consisting of SEQ ID NO: 91-92.
6. The antibody or fragment thereof of claim 1, wherein the variant of SEQ ID NO: 5 is selected from the group consisting of SEQ ID NO: 93-105.
7. The antibody or fragment thereof of claim 1, wherein the variant of SEQ ID NO: 6 is selected from the group consisting of SEQ ID NO: 140 and 106-111.
8. The antibody or fragment thereof of claim 1, wherein the VH CDR1 comprises the amino acid sequence of SEQ ID NO: 1, the VH CDR2 comprises the amino acid sequence of SEQ ID NO: 116, the VH CDR3 comprises the amino acid sequence of SEQ ID NO: 3, the VL CDR1 comprises the amino acid sequence of SEQ ID NO: 4, the VL CDR2 comprises the amino acid sequence of SEQ ID NO: 5, and the VL CDR3 comprises the amino acid sequence of SEQ ID NO: 6.
9. The antibody or fragment thereof of claim 8, comprising a heavy chain variable region comprising the amino acid sequence of SEQ IN NO: 141 and a light chain variable region comprising the amino acid sequence of SEQ ID NO: 142.
10. The antibody or fragment thereof of claim 1, wherein amino acid residues 4, 5 and 6 of the VL CDR3 are Ser, Asp and Ala, respectively.
11. The antibody or fragment thereof of claim 10, wherein the VL CDR3 comprises the amino acid sequence of SEQ ID NO: 140.
12. The antibody or fragment thereof of claim 11, wherein the VH CDR1 comprises the amino acid sequence of SEQ ID NO: 1, the VH CDR2 comprises the amino acid sequence of SEQ ID NO: 116, the VH CDR3 comprises the amino acid sequence of SEQ ID NO: 3, the VL CDR1 comprises the amino acid sequence of SEQ ID NO: 4, the VL CDR2 comprises the amino acid sequence of SEQ ID NO: 5, and the VL CDR3 comprises the amino acid sequence of SEQ ID NO: 140.
13. The antibody or fragment thereof of claim 12, comprising a heavy chain variable region comprising the amino acid sequence of SEQ IN NO: 159 and a light chain variable region comprising the amino acid sequence of SEQ ID NO: 160.
14. The antibody or fragment thereof of claim 1, wherein the second amino acid residue of the VH CDR3 is Leu.
15. The antibody or fragment thereof of claim 14, wherein the VH CDR3 comprises the amino acid sequence of SEQ ID NO: 117.
16. The antibody or fragment thereof of claim 15, wherein the VH CDR1 comprises the amino acid sequence of SEQ ID NO: 1, the VH CDR2 comprises the amino acid sequence of SEQ ID NO: 116, the VH CDR3 comprises the amino acid sequence of SEQ ID NO: 117, the VL CDR1 comprises the amino acid sequence of SEQ ID NO: 4, the VL CDR2 comprises the amino acid sequence of SEQ ID NO: 5, and the VL CDR3 comprises the amino acid sequence of SEQ ID NO: 6.
17. The antibody or fragment thereof of claim 16, comprising a heavy chain variable region comprising the amino acid sequence of SEQ IN NO: 149 and a light chain variable region comprising the amino acid sequence of SEQ ID NO: 150.
18. One or more polynucleotide encoding the antibody or fragment thereof of claim 1.
19. A method of treating cancer or infection in a patient in need thereof, comprising administering to the patient an effective amount of the antibody or fragment thereof of claim 1.
20. The method of claim 19, which is for treating cancer characterized with expression of PD-L1.
Description
CROSS REFERENCE TO RELATED APPLICATIONS
[0001] The present application is a continuation of U.S. patent application Ser. No. 16/610,071, filed Oct. 31, 2019, which is the U.S. national stage application of International Application PCT/CN2019/080458, filed Mar. 29, 2019, which claims priority to Chinese Patent Application PCT/CN2018/081079, filed Mar. 29, 2018, the contents of each of which are incorporated herein by reference in their entireties in the present disclosure.
SEQUENCE LISTING
[0002] The instant application contains a Sequence Listing which has been submitted in ASCII format via EFS-Web and is hereby incorporated by reference in its entirety. Said ASCII copy, created on Dec. 22, 2021, is named 54LW-269085-US2_ST25.txt and is 87,662 bytes in size.
BACKGROUND
[0003] Programmed death-ligand 1 (PD-L1), also known as cluster of differentiation 274 (CD274) or B7 homolog 1 (B7-H1), is a 40 kDa type 1 transmembrane protein believed to play a major role in suppressing the immune system during particular events such as pregnancy, tissue allografts, autoimmune disease and other disease states such as hepatitis. The binding of PD-L1 to PD-1 or B7.1 transmits an inhibitory signal which reduces the proliferation of CD8+ T cells at the lymph nodes and supplementary to that PD-1 is also able to control the accumulation of foreign antigen specific T cells in the lymph nodes through apoptosis which is further mediated by a lower regulation of the gene Bcl-2.
[0004] It has been shown that upregulation of PD-L1 may allow cancers to evade the host immune system. An analysis of tumor specimens from patients with renal cell carcinoma found that high tumor expression of PD-L1 was associated with increased tumor aggressiveness and an increased risk of death. Many PD-L1 inhibitors are in development as immuno-oncology therapies and are showing good results in clinical trials.
[0005] In addition to treatment of cancers, PD-L1 inhibition has also shown promises in treating infectious diseases. In a mouse model of intracellular infection, L. monocytogenes induced PD-L1 protein expression in T cells, NK cells, and macrophages. PD-L1 blockade (e.g., using blocking antibodies) resulted in increased mortality for infected mice. Blockade reduced TNF.alpha. and nitric oxide production by macrophages, reduced granzyme B production by NK cells, and decreased proliferation of L. monocytogenes antigen-specific CD8 T cells (but not CD4 T cells). This evidence suggests that PD-L1 acts as a positive costimulatory molecule in intracellular infection.
SUMMARY
[0006] The present disclosure provides anti-PD-L1 antibodies having high binding affinity to human PD-L1 proteins and can effectively block the interaction between PD-L1 and its receptor PD-1. Also importantly, the examples demonstrate that these anti-PD-L1 antibodies promote T cell immune response and inhibit tumor growth. Different from known anti-PD-L1 antibodies that bind to the immunoglobulin V domain of the extracellular portion of the PD-L1 protein, these antibodies bind to the immunoglobulin C domain, in particular amino acid residues Y134, K162, and N183. These anti-PD-L1 antibodies are useful for therapeutic purposes such as treating various types of cancer, as well as infections, and can also be used for diagnostic and prognostic purposes.
[0007] One embodiment of the present disclosure provides an anti-PD-L1 antibody or fragment thereof, which antibody or fragment thereof can specifically bind to an immunoglobulin C (Ig C) domain of a human Programmed death-ligand 1 (PD-L1) protein. In some embodiments, the Ig C domain consists of amino acid residues 133-225. In some embodiments, the antibody or fragment thereof can bind to at least one of amino acid residues Y134, K162, or N183 of the PD-L1 protein. In some embodiments, the antibody or fragment thereof can bind to at least one of amino acid residues Y134, K162, and N183 of the PD-L1 protein. In some embodiments, the antibody or fragment thereof does not bind to an immunoglobulin V (Ig V) domain of the PD-L1 protein, wherein the Ig V domain consists of amino acid residues 19-127.
[0008] One embodiment of the present disclosure provides an anti-PD-L1 antibody or fragment thereof, wherein the antibody or fragment thereof has specificity to a human Programmed death-ligand 1 (PD-L1) protein and comprises a VH CDR1 of SEQ ID NO: 1, a VH CDR2 of SEQ ID NO: 2, a VH CDR3 of SEQ ID NO: 3, a VL CDR1 of SEQ ID NO: 4, a VL CDR2 of SEQ ID NO: 5, and a VL CDR3 of SEQ ID NO: 6. In some embodiments, the antibody or fragment thereof further comprises a heavy chain constant region, a light chain constant region, an Fc region, or the combination thereof. In some embodiments, the light chain constant region is a kappa or lambda chain constant region. In some embodiments, the antibody or fragment thereof is of an isotype of IgG, IgM, IgA, IgE or IgD. In some embodiments, the isotype is IgG1, IgG2, IgG3 or IgG4. Without limitation, the antibody or fragment thereof is a chimeric antibody, a humanized antibody, or a fully human antibody. In one aspect, antibody or fragment thereof is a humanized antibody.
[0009] Through mutagenesis, the present disclosure has further identified mutation hotspot residues in the VH CDR3 (see, e.g., antibodies A1, A2, C3, C4, C6, B1 and B6 in Examples 13-17) and VL CDR3 (see, e.g., antibodies B3, C4 and A3 in Examples 13-17). Therefore, the present disclosure also provides antibodies that incorporate one or more of mutations at these hotspots.
[0010] In some embodiments, provided is an antibody or fragment thereof, wherein the antibody or fragment thereof has specificity to a human PD-L1 protein and comprises (a) a VH CDR1 comprising the amino acid sequence of SEQ ID NO: 1 or a variant of SEQ ID NO: 1 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 1; (b) a VH CDR2 comprising the amino acid sequence of SEQ ID NO: 116 or a variant of SEQ ID NO: 116 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 116; (c) a VH CDR3 comprising the amino acid sequence of SEQ ID NO: 117 or a variant of SEQ ID NO: 117 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 117, wherein the second amino acid residue of the VH CDR3 is Leu; (d) a VL CDR1 comprising the amino acid sequence of SEQ ID NO: 4 or a variant of SEQ ID NO: 4 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 4; (e) a VL CDR2 comprising the amino acid sequence of SEQ ID NO: 5 or a variant of SEQ ID NO: 5 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 5; and (f) a VL CDR3 comprising the amino acid sequence of SEQ ID NO: 6 or a variant of SEQ ID NO: 6 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 6.
[0011] In one embodiment, the VH CDR1 comprises the amino acid sequence of SEQ ID NO: 1, the VH CDR2 comprises the amino acid sequence of SEQ ID NO: 116, the VH CDR3 comprises the amino acid sequence of SEQ ID NO: 117, the VL CDR1 comprises the amino acid sequence of SEQ ID NO: 4, the VL CDR2 comprises the amino acid sequence of SEQ ID NO: 5, and the VL CDR3 comprises the amino acid sequence of SEQ ID NO: 6.
[0012] In one embodiment, the antibody or fragment thereof comprises a heavy chain variable region comprising the amino acid sequence of SEQ IN NO: 149 and a light chain variable region comprising the amino acid sequence of SEQ ID NO: 150.
[0013] Also provided, in one embodiment, is an antibody or fragment thereof, wherein the antibody or fragment thereof has specificity to a human PD-L1 protein and comprises: (a) a VH CDR1 comprising the amino acid sequence of SEQ ID NO: 1 or a variant of SEQ ID NO: 1 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 1; (b) a VH CDR2 comprising the amino acid sequence of SEQ ID NO: 116 or a variant of SEQ ID NO: 116 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 116; (c) a VH CDR3 comprising the amino acid sequence of SEQ ID NO: 3 or a variant of SEQ ID NO: 3 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 3; (d) a VL CDR1 comprising the amino acid sequence of SEQ ID NO: 4 or a variant of SEQ ID NO: 4 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 4; (e) a VL CDR2 comprising the amino acid sequence of SEQ ID NO: 5 or a variant of SEQ ID NO: 5 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 5; and (f) a VL CDR3 comprising the amino acid sequence of SEQ ID NO: 140 or a variant of SEQ ID NO: 140 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 140, wherein at least (i) amino acid residue 4 of the VL CDR3 is Ser, (ii) amino acid residue 5 of the VL CDR3 is Asp, or (iii) amino acid residue 6 of the VL CDR3 is Ala.
[0014] In one embodiment, the VH CDR1 comprises the amino acid sequence of SEQ ID NO: 1, the VH CDR2 comprises the amino acid sequence of SEQ ID NO: 116, the VH CDR3 comprises the amino acid sequence of SEQ ID NO: 3, the VL CDR1 comprises the amino acid sequence of SEQ ID NO: 4, the VL CDR2 comprises the amino acid sequence of SEQ ID NO: 5, and the VL CDR3 comprises the amino acid sequence of SEQ ID NO: 140.
[0015] In one embodiment, the antibody or fragment thereof comprises a heavy chain variable region comprising the amino acid sequence of SEQ IN NO: 159 and a light chain variable region comprising the amino acid sequence of SEQ ID NO: 160.
[0016] One embodiment provides an antibody or fragment thereof, wherein the antibody or fragment thereof has specificity to a human PD-L1 protein and comprises: (a) a VH CDR1 comprising the amino acid sequence of SEQ ID NO: 1 or a variant of SEQ ID NO: 1 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 1; (b) a VH CDR2 comprising the amino acid sequence of SEQ ID NO: 116 or a variant of SEQ ID NO: 116 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 116; (c) a VH CDR3 comprising the amino acid sequence of SEQ ID NO: 3 or a variant of SEQ ID NO: 3 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 3; (d) a VL CDR1 comprising the amino acid sequence of SEQ ID NO: 4 or a variant of SEQ ID NO: 4 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 4; (e) a VL CDR2 comprising the amino acid sequence of SEQ ID NO: 5 or a variant of SEQ ID NO: 5 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 5; and (f) a VL CDR3 comprising the amino acid sequence of SEQ ID NO: 6 or a variant of SEQ ID NO: 6 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 6.
[0017] In some embodiments, the VH CDR1 comprises the amino acid sequence of SEQ ID NO: 1, the VH CDR2 comprises the amino acid sequence of SEQ ID NO: 116, the VH CDR3 comprises the amino acid sequence of SEQ ID NO: 3, the VL CDR1 comprises the amino acid sequence of SEQ ID NO: 4, the VL CDR2 comprises the amino acid sequence of SEQ ID NO: 5, and the VL CDR3 comprises the amino acid sequence of SEQ ID NO: 6.
[0018] In some embodiments, the antibody or fragment thereof comprises a heavy chain variable region comprising the amino acid sequence of SEQ IN NO: 141 and a light chain variable region comprising the amino acid sequence of SEQ ID NO: 142.
[0019] Also provided, in some embodiments, is a composition comprising the antibody or fragment thereof of the present disclosure and a pharmaceutically acceptable carrier. Still also provided, in some embodiments, is an isolated cell comprising one or more polynucleotide encoding the antibody or fragment thereof of the present disclosure.
[0020] Treatment methods and uses are also provided. In one embodiment, a method of treating cancer or infection in a patient in need thereof is provided, comprising administering to the patient an effective amount of the antibody or fragment thereof of the present disclosure. In some embodiments, the cancer is a solid tumor. In some embodiments, the cancer is selected from the group consisting of bladder cancer, liver cancer, colon cancer, rectal cancer, endometrial cancer, leukemia, lymphoma, pancreatic cancer, small cell lung cancer, non-small cell lung cancer, breast cancer, urethral cancer, head and neck cancer, gastrointestinal cancer, stomach cancer, oesophageal cancer, ovarian cancer, renal cancer, melanoma, prostate cancer and thyroid cancer. In some embodiments, the cancer is selected from the group consisting of bladder cancer, liver cancer, pancreatic cancer, non-small cell lung cancer, breast cancer, urethral cancer, colorectal cancer, head and neck cancer, squamous cell cancer, Merkel cell carcinoma, gastrointestinal cancer, stomach cancer, oesophageal cancer, ovarian cancer, renal cancer, and small cell lung cancer. In some embodiments, the method further comprises administering to the patient a second cancer therapeutic agent. In some embodiments, the infection is viral infection, bacterial infection, fungal infection or infection by a parasite.
[0021] In another embodiment, a method of treating cancer or infection in a patient in need thereof is provided, comprising: (a) treating a cell, in vitro, with the antibody or fragment thereof of the present disclosure; and (b) administering the treated cell to the patient. In some embodiments, the method further comprises, prior to step (a), isolating the cell from an individual. In some embodiments, the cell is isolated from the patient. In some embodiments, the cell is isolated from a donor individual different from the patient. In some embodiments, the cell is a T cell, non-limiting examples of which include a tumor-infiltrating T lymphocyte, a CD4+ T cell, a CD8+ T cell, or the combination thereof.
[0022] Diagnostic methods and uses are also provided. In one embodiment, a method of detecting expression of PD-L1 in a sample is provided, comprising contacting the sample with an antibody or fragment thereof under conditions for the antibody or fragment thereof to bind to the PD-L1, and detecting the binding which indicates expression of PD-L1 in the sample. In some embodiments, the sample comprises a tumor cell, a tumor tissue, an infected tissue, or a blood sample.
[0023] Antibodies and fragment of the present disclosure can be used to prepare bispecific antibodies. In one embodiment, a bispecific antibody is provided, comprising a fragment of the present disclosure and a second antigen-binding fragment having specificity to a molecular on an immune cell. In some embodiments, the molecule is selected from the group consisting of PD-1, CTLA-4, LAG-3, CD28, CD122, 4-1BB, TIM3, OX-40, OX40L, CD40, CD40L, LIGHT, ICOS, ICOSL, GITR, GITRL, TIGIT, CD27, VISTA, B7H3, B7H4, HEVM or BTLA, CD47 and CD73. In some embodiments, the fragment and the second fragment each is independently selected from a Fab fragment, a single-chain variable fragment (scFv), or a single-domain antibody. In some embodiments, the bispecific antibody further comprises a Fc fragment.
BRIEF DESCRIPTION OF THE DRAWINGS
[0024] FIG. 1 shows that HL1210-3 can bind to human PD-L1 with high affinity.
[0025] FIG. 2 shows that HL1210-3 can efficiently inhibit the binding of human PD-L1 to human PD1.
[0026] FIG. 3 shows the HL1210-3 antibody can highly efficiently inhibit the binding of PD-1 on PD-L1 expressed on mammalian cells.
[0027] FIG. 4 shows that the tested anti-PD-L1 antibodies can promote human T cell response.
[0028] FIG. 5 shows the binding kinetics of HL1210-3 to recombinant PD-L1.
[0029] FIG. 6 shows that all tested humanized antibodies had comparable binding efficacy to human PD-L1 in contact to chimeric antibody.
[0030] FIG. 7 shows that all tested humanized antibodies can high efficiently bind to PD-L1 expressed on mammalian cells, comparable with chimeric antibody.
[0031] FIG. 8 shows that humanized antibody Hu1210-41 can bind to rhesus PD-L1 with lower affinity and cannot bind to rat and mouse PD-L1.
[0032] FIG. 9 shows that Hu1210-41 antibody can only specifically binding to B7-H1 (PD-L1), not B7-DC, B7-1, B7-2, B7-H2, PD-1, CD28, CTLA4, ICOS and BTLA.
[0033] FIG. 10 shows that Hu1210-41 can efficiently inhibit the binding of human PD-L1 to human PD1 and B7-1.
[0034] FIG. 11 shows that Hu1210-41 can efficiently inhibit the binding of human PD-L1 to human PD1 and B7-1.
[0035] FIG. 12 shows that the Hu1210-8, Hu1210-9, Hu1210-16, Hu1210-17, Hu1210-21 and Hu1210-36 humanized antibodies can dose dependently promote the IFN.gamma. and IL-2 production in mix lymphocyte reaction.
[0036] FIG. 13 shows that the Hu1210-40, Hu1210-41 and Hu1210-17 humanized antibodies can dose dependently promote the IFN.gamma. production in CMV recall assay.
[0037] FIG. 14 shows that Hu1210-31 can inhibit the tumor growth by 30% at 5 mg/kg in HCC827-NSG-xenograft model.
[0038] FIG. 15 shows that Hu1210-41 antibody can dose-dependently inhibit the tumor growth in HCC827-NSG-xenograft model, while the tumor weight was also dose-dependently suppressed by Hu1210-41 antibody.
[0039] FIG. 16 plots, for each PD-L1 mutant, the mean binding value as a function of expression (control anti-PD-L1 mAb reactivity).
[0040] FIG. 17 illustrates the locations of Y134, K162, and N183, the residues (spheres) involved in binding to the anti-PD-L1 Hu1210-41 antibody.
[0041] FIG. 18 compares the S60R mutant to parental antibody Hu1210-41 in terms of binding efficiency to PD-L1 expressed on mammalian cells.
[0042] FIG. 19 shows the results of a binding assay (to human PD-L1) for the derived antibodies.
[0043] FIG. 20 shows that antibody B6 more highly efficiently bound to PD-L1 expressed on mammalian cells, as compared to the parental antibody and Tecentriq.TM. (atezolizumab).
[0044] FIG. 21 shows the antibodies' effect on IL2 production in Jurkat cells in which B6 also exhibited higher potency.
[0045] FIG. 22 shows the antibodies' in vitro activity to promote IFN.gamma. production in a mixed lymphocyte setting.
[0046] FIG. 23 shows the antibodies' in vivo activity to inhibit tumor growth.
DETAILED DESCRIPTION
Definitions
[0047] It is to be noted that the term "a" or "an" entity refers to one or more of that entity; for example, "an antibody," is understood to represent one or more antibodies. As such, the terms "a" (or "an"), "one or more," and "at least one" can be used interchangeably herein.
[0048] As used herein, the term "polypeptide" is intended to encompass a singular "polypeptide" as well as plural "polypeptides," and refers to a molecule composed of monomers (amino acids) linearly linked by amide bonds (also known as peptide bonds). The term "polypeptide" refers to any chain or chains of two or more amino acids, and does not refer to a specific length of the product. Thus, peptides, dipeptides, tripeptides, oligopeptides, "protein," "amino acid chain," or any other term used to refer to a chain or chains of two or more amino acids, are included within the definition of "polypeptide," and the term "polypeptide" may be used instead of, or interchangeably with any of these terms. The term "polypeptide" is also intended to refer to the products of post-expression modifications of the polypeptide, including without limitation glycosylation, acetylation, phosphorylation, amidation, derivatization by known protecting/blocking groups, proteolytic cleavage, or modification by non-naturally occurring amino acids. A polypeptide may be derived from a natural biological source or produced by recombinant technology, but is not necessarily translated from a designated nucleic acid sequence. It may be generated in any manner, including by chemical synthesis.
[0049] The term "isolated" as used herein with respect to cells, nucleic acids, such as DNA or RNA, refers to molecules separated from other DNAs or RNAs, respectively, that are present in the natural source of the macromolecule. The term "isolated" as used herein also refers to a nucleic acid or peptide that is substantially free of cellular material, viral material, or culture medium when produced by recombinant DNA techniques, or chemical precursors or other chemicals when chemically synthesized. Moreover, an "isolated nucleic acid" is meant to include nucleic acid fragments which are not naturally occurring as fragments and would not be found in the natural state. The term "isolated" is also used herein to refer to cells or polypeptides which are isolated from other cellular proteins or tissues. Isolated polypeptides is meant to encompass both purified and recombinant polypeptides.
[0050] As used herein, the term "recombinant" as it pertains to polypeptides or polynucleotides intends a form of the polypeptide or polynucleotide that does not exist naturally, a non-limiting example of which can be created by combining polynucleotides or polypeptides that would not normally occur together.
[0051] "Homology" or "identity" or "similarity" refers to sequence similarity between two peptides or between two nucleic acid molecules. Homology can be determined by comparing a position in each sequence which may be aligned for purposes of comparison. When a position in the compared sequence is occupied by the same base or amino acid, then the molecules are homologous at that position. A degree of homology between sequences is a function of the number of matching or homologous positions shared by the sequences. An "unrelated" or "non-homologous" sequence shares less than 40% identity, though preferably less than 25% identity, with one of the sequences of the present disclosure.
[0052] A polynucleotide or polynucleotide region (or a polypeptide or polypeptide region) has a certain percentage (for example, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 98% or 99%) of "sequence identity" to another sequence means that, when aligned, that percentage of bases (or amino acids) are the same in comparing the two sequences. This alignment and the percent homology or sequence identity can be determined using software programs known in the art, for example those described in Ausubel et al. eds. (2007) Current Protocols in Molecular Biology. Preferably, default parameters are used for alignment. One alignment program is BLAST, using default parameters. In particular, programs are BLASTN and BLASTP, using the following default parameters: Genetic code=standard; filter=none; strand=both; cutoff=60; expect=10; Matrix=BLOSUM62; Descriptions=50 sequences; sort by=HIGH SCORE; Databases=non-redundant, GenBank+EMBL+DDBJ+PDB+GenBank CDS translations+SwissProtein+SPupdate+PIR. Biologically equivalent polynucleotides are those having the above-noted specified percent homology and encoding a polypeptide having the same or similar biological activity.
[0053] The term "an equivalent nucleic acid or polynucleotide" refers to a nucleic acid having a nucleotide sequence having a certain degree of homology, or sequence identity, with the nucleotide sequence of the nucleic acid or complement thereof. A homolog of a double stranded nucleic acid is intended to include nucleic acids having a nucleotide sequence which has a certain degree of homology with or with the complement thereof. In one aspect, homologs of nucleic acids are capable of hybridizing to the nucleic acid or complement thereof. Likewise, "an equivalent polypeptide" refers to a polypeptide having a certain degree of homology, or sequence identity, with the amino acid sequence of a reference polypeptide. In some aspects, the sequence identity is at least about 70%, 75%, 80%, 85%, 90%, 95%, 98%, or 99%. In some aspects, the equivalent polypeptide or polynucleotide has one, two, three, four or five addition, deletion, substitution and their combinations thereof as compared to the reference polypeptide or polynucleotide. In some aspects, the equivalent sequence retains the activity (e.g., epitope-binding) or structure (e.g., salt-bridge) of the reference sequence.
[0054] Hybridization reactions can be performed under conditions of different "stringency". In general, a low stringency hybridization reaction is carried out at about 40.degree. C. in about 10.times.SSC or a solution of equivalent ionic strength/temperature. A moderate stringency hybridization is typically performed at about 50.degree. C. in about 6.times.SSC, and a high stringency hybridization reaction is generally performed at about 60.degree. C. in about 1.times.SSC. Hybridization reactions can also be performed under "physiological conditions" which is well known to one of skill in the art. A non-limiting example of a physiological condition is the temperature, ionic strength, pH and concentration of Mg.sup.2+ normally found in a cell.
[0055] A polynucleotide is composed of a specific sequence of four nucleotide bases: adenine (A); cytosine (C); guanine (G); thymine (T); and uracil (U) for thymine when the polynucleotide is RNA. Thus, the term "polynucleotide sequence" is the alphabetical representation of a polynucleotide molecule. This alphabetical representation can be input into databases in a computer having a central processing unit and used for bioinformatics applications such as functional genomics and homology searching. The term "polymorphism" refers to the coexistence of more than one form of a gene or portion thereof. A portion of a gene of which there are at least two different forms, i.e., two different nucleotide sequences, is referred to as a "polymorphic region of a gene". A polymorphic region can be a single nucleotide, the identity of which differs in different alleles.
[0056] The terms "polynucleotide" and "oligonucleotide" are used interchangeably and refer to a polymeric form of nucleotides of any length, either deoxyribonucleotides or ribonucleotides or analogs thereof. Polynucleotides can have any three-dimensional structure and may perform any function, known or unknown. The following are non-limiting examples of polynucleotides: a gene or gene fragment (for example, a probe, primer, EST or SAGE tag), exons, introns, messenger RNA (mRNA), transfer RNA, ribosomal RNA, ribozymes, cDNA, dsRNA, siRNA, miRNA, recombinant polynucleotides, branched polynucleotides, plasmids, vectors, isolated DNA of any sequence, isolated RNA of any sequence, nucleic acid probes and primers. A polynucleotide can comprise modified nucleotides, such as methylated nucleotides and nucleotide analogs. If present, modifications to the nucleotide structure can be imparted before or after assembly of the polynucleotide. The sequence of nucleotides can be interrupted by non-nucleotide components. A polynucleotide can be further modified after polymerization, such as by conjugation with a labeling component. The term also refers to both double- and single-stranded molecules. Unless otherwise specified or required, any embodiment of this disclosure that is a polynucleotide encompasses both the double-stranded form and each of two complementary single-stranded forms known or predicted to make up the double-stranded form.
[0057] The term "encode" as it is applied to polynucleotides refers to a polynucleotide which is said to "encode" a polypeptide if, in its native state or when manipulated by methods well known to those skilled in the art, it can be transcribed and/or translated to produce the mRNA for the polypeptide and/or a fragment thereof. The antisense strand is the complement of such a nucleic acid, and the encoding sequence can be deduced therefrom.
[0058] As used herein, an "antibody" or "antigen-binding polypeptide" refers to a polypeptide or a polypeptide complex that specifically recognizes and binds to an antigen. An antibody can be a whole antibody and any antigen binding fragment or a single chain thereof. Thus the term "antibody" includes any protein or peptide containing molecule that comprises at least a portion of an immunoglobulin molecule having biological activity of binding to the antigen. Examples of such include, but are not limited to a complementarity determining region (CDR) of a heavy or light chain or a ligand binding portion thereof, a heavy chain or light chain variable region, a heavy chain or light chain constant region, a framework (FR) region, or any portion thereof, or at least one portion of a binding protein.
[0059] The terms "antibody fragment" or "antigen-binding fragment", as used herein, is a portion of an antibody such as F(ab').sub.2, F(ab).sub.2, Fab', Fab, Fv, scFv and the like. Regardless of structure, an antibody fragment binds with the same antigen that is recognized by the intact antibody. The term "antibody fragment" includes aptamers, spiegelmers, and diabodies. The term "antibody fragment" also includes any synthetic or genetically engineered protein that acts like an antibody by binding to a specific antigen to form a complex.
[0060] A "single-chain variable fragment" or "scFv" refers to a fusion protein of the variable regions of the heavy (V.sub.H) and light chains (V.sub.L) of immunoglobulins. In some aspects, the regions are connected with a short linker peptide of ten to about 25 amino acids. The linker can be rich in glycine for flexibility, as well as serine or threonine for solubility, and can either connect the N-terminus of the V.sub.H with the C-terminus of the V.sub.L, or vice versa. This protein retains the specificity of the original immunoglobulin, despite removal of the constant regions and the introduction of the linker. ScFv molecules are known in the art and are described, e.g., in U.S. Pat. No. 5,892,019.
[0061] The term antibody encompasses various broad classes of polypeptides that can be distinguished biochemically. Those skilled in the art will appreciate that heavy chains are classified as gamma, mu, alpha, delta, or epsilon (.gamma., .mu., .alpha., .delta., .epsilon.) with some subclasses among them (e.g., .gamma.1-.gamma.4). It is the nature of this chain that determines the "class" of the antibody as IgG, IgM, IgA IgG, or IgE, respectively. The immunoglobulin subclasses (isotypes) e.g., IgG.sub.1, IgG.sub.2, IgG.sub.3, IgG4, IgG5, etc. are well characterized and are known to confer functional specialization. Modified versions of each of these classes and isotypes are readily discernable to the skilled artisan in view of the instant disclosure and, accordingly, are within the scope of the instant disclosure. All immunoglobulin classes are clearly within the scope of the present disclosure, the following discussion will generally be directed to the IgG class of immunoglobulin molecules. With regard to IgG, a standard immunoglobulin molecule comprises two identical light chain polypeptides of molecular weight approximately 23,000 Daltons, and two identical heavy chain polypeptides of molecular weight 53,000-70,000. The four chains are typically joined by disulfide bonds in a "Y" configuration wherein the light chains bracket the heavy chains starting at the mouth of the "Y" and continuing through the variable region.
[0062] Antibodies, antigen-binding polypeptides, variants, or derivatives thereof of the disclosure include, but are not limited to, polyclonal, monoclonal, multispecific, human, humanized, primatized, or chimeric antibodies, single chain antibodies, epitope-binding fragments, e.g., Fab, Fab' and F(ab').sub.2, Fd, Fvs, single-chain Fvs (scFv), single-chain antibodies, disulfide-linked Fvs (sdFv), fragments comprising either a VK or VH domain, fragments produced by a Fab expression library, and anti-idiotypic (anti-Id) antibodies (including, e.g., anti-Id antibodies to LIGHT antibodies disclosed herein). Immunoglobulin or antibody molecules of the disclosure can be of any type (e.g., IgG, IgE, IgM, IgD, IgA, and IgY), class (e.g., IgG1, IgG2, IgG3, IgG4, IgA1 and IgA2) or subclass of immunoglobulin molecule.
[0063] Light chains are classified as either kappa or lambda (K, .delta.). Each heavy chain class may be bound with either a kappa or lambda light chain. In general, the light and heavy chains are covalently bonded to each other, and the "tail" portions of the two heavy chains are bonded to each other by covalent disulfide linkages or non-covalent linkages when the immunoglobulins are generated either by hybridomas, B cells or genetically engineered host cells. In the heavy chain, the amino acid sequences run from an N-terminus at the forked ends of the Y configuration to the C-terminus at the bottom of each chain.
[0064] Both the light and heavy chains are divided into regions of structural and functional homology. The terms "constant" and "variable" are used functionally. In this regard, it will be appreciated that the variable domains of both the light (VK) and heavy (VH) chain portions determine antigen recognition and specificity. Conversely, the constant domains of the light chain (CK) and the heavy chain (CH1, CH2 or CH3) confer important biological properties such as secretion, transplacental mobility, Fc receptor binding, complement binding, and the like. By convention the numbering of the constant region domains increases as they become more distal from the antigen-binding site or amino-terminus of the antibody. The N-terminal portion is a variable region and at the C-terminal portion is a constant region; the CH3 and CK domains actually comprise the carboxy-terminus of the heavy and light chain, respectively.
[0065] As indicated above, the variable region allows the antibody to selectively recognize and specifically bind epitopes on antigens. That is, the VK domain and VH domain, or subset of the complementarity determining regions (CDRs), of an antibody combine to form the variable region that defines a three dimensional antigen-binding site. This quaternary antibody structure forms the antigen-binding site present at the end of each arm of the Y. More specifically, the antigen-binding site is defined by three CDRs on each of the VH and VK chains (i.e. CDR-H1, CDR-H2, CDR-H3, CDR-L1, CDR-L2 and CDR-L3). In some instances, e.g., certain immunoglobulin molecules derived from camelid species or engineered based on camelid immunoglobulins, a complete immunoglobulin molecule may consist of heavy chains only, with no light chains. See, e.g., Hamers-Casterman et al., Nature 363:446-448 (1993).
[0066] In naturally occurring antibodies, the six "complementarity determining regions" or "CDRs" present in each antigen-binding domain are short, non-contiguous sequences of amino acids that are specifically positioned to form the antigen-binding domain as the antibody assumes its three dimensional configuration in an aqueous environment. The remainder of the amino acids in the antigen-binding domains, referred to as "framework" regions, show less inter-molecular variability. The framework regions largely adopt a .beta.-sheet conformation and the CDRs form loops which connect, and in some cases form part of, the .beta.-sheet structure. Thus, framework regions act to form a scaffold that provides for positioning the CDRs in correct orientation by inter-chain, non-covalent interactions. The antigen-binding domain formed by the positioned CDRs defines a surface complementary to the epitope on the immunoreactive antigen. This complementary surface promotes the non-covalent binding of the antibody to its cognate epitope. The amino acids comprising the CDRs and the framework regions, respectively, can be readily identified for any given heavy or light chain variable region by one of ordinary skill in the art, since they have been precisely defined (see "Sequences of Proteins of Immunological Interest," Kabat, E., et al., U.S. Department of Health and Human Services, (1983); and Chothia and Lesk, J. Mol. Biol., 196:901-917 (1987)).
[0067] In the case where there are two or more definitions of a term which is used and/or accepted within the art, the definition of the term as used herein is intended to include all such meanings unless explicitly stated to the contrary. A specific example is the use of the term "complementarity determining region" ("CDR") to describe the non-contiguous antigen combining sites found within the variable region of both heavy and light chain polypeptides. This particular region has been described by Kabat et al., U.S. Dept. of Health and Human Services, "Sequences of Proteins of Immunological Interest" (1983) and by Chothia et al., J. Mol. Biol. 196:901-917 (1987), which are incorporated herein by reference in their entireties. The CDR definitions according to Kabat and Chothia include overlapping or subsets of amino acid residues when compared against each other. Nevertheless, application of either definition to refer to a CDR of an antibody or variants thereof is intended to be within the scope of the term as defined and used herein. The appropriate amino acid residues which encompass the CDRs as defined by each of the above cited references are set forth in the table below as a comparison. The exact residue numbers which encompass a particular CDR will vary depending on the sequence and size of the CDR. Those skilled in the art can routinely determine which residues comprise a particular CDR given the variable region amino acid sequence of the antibody.
TABLE-US-00001 Kabat Chothia CDR-H1 31-35 26-32 CDR-H2 50-65 52-58 CDR-H3 95-102 95-102 CDR-L1 24-34 26-32 CDR-L2 50-56 50-52 CDR-L3 89-97 91-96
[0068] Kabat et al. also defined a numbering system for variable domain sequences that is applicable to any antibody. One of ordinary skill in the art can unambiguously assign this system of "Kabat numbering" to any variable domain sequence, without reliance on any experimental data beyond the sequence itself. As used herein, "Kabat numbering" refers to the numbering system set forth by Kabat et al., U.S. Dept. of Health and Human Services, "Sequence of Proteins of Immunological Interest" (1983).
[0069] In addition to table above, the Kabat number system describes the CDR regions as follows: CDR-H1 begins at approximately amino acid 31 (i.e., approximately 9 residues after the first cysteine residue), includes approximately 5-7 amino acids, and ends at the next tryptophan residue. CDR-H2 begins at the fifteenth residue after the end of CDR-H1, includes approximately 16-19 amino acids, and ends at the next arginine or lysine residue. CDR-H3 begins at approximately the thirty third amino acid residue after the end of CDR-H2; includes 3-25 amino acids; and ends at the sequence W-G-X-G, where X is any amino acid. CDR-L1 begins at approximately residue 24 (i.e., following a cysteine residue); includes approximately 10-17 residues; and ends at the next tryptophan residue. CDR-L2 begins at approximately the sixteenth residue after the end of CDR-L1 and includes approximately 7 residues. CDR-L3 begins at approximately the thirty third residue after the end of CDR-L2 (i.e., following a cysteine residue); includes approximately 7-11 residues and ends at the sequence F or W-G-X-G, where X is any amino acid.
[0070] Antibodies disclosed herein may be from any animal origin including birds and mammals. Preferably, the antibodies are human, murine, donkey, rabbit, goat, guinea pig, camel, llama, horse, or chicken antibodies. In another embodiment, the variable region may be condricthoid in origin (e.g., from sharks).
[0071] As used herein, the term "heavy chain constant region" includes amino acid sequences derived from an immunoglobulin heavy chain. A polypeptide comprising a heavy chain constant region comprises at least one of: a CH1 domain, a hinge (e.g., upper, middle, and/or lower hinge region) domain, a CH2 domain, a CH3 domain, or a variant or fragment thereof. For example, an antigen-binding polypeptide for use in the disclosure may comprise a polypeptide chain comprising a CH1 domain; a polypeptide chain comprising a CH1 domain, at least a portion of a hinge domain, and a CH2 domain; a polypeptide chain comprising a CH1 domain and a CH3 domain; a polypeptide chain comprising a CH1 domain, at least a portion of a hinge domain, and a CH3 domain, or a polypeptide chain comprising a CH1 domain, at least a portion of a hinge domain, a CH2 domain, and a CH3 domain. In another embodiment, a polypeptide of the disclosure comprises a polypeptide chain comprising a CH3 domain. Further, an antibody for use in the disclosure may lack at least a portion of a CH2 domain (e.g., all or part of a CH2 domain). As set forth above, it will be understood by one of ordinary skill in the art that the heavy chain constant region may be modified such that they vary in amino acid sequence from the naturally occurring immunoglobulin molecule.
[0072] The heavy chain constant region of an antibody disclosed herein may be derived from different immunoglobulin molecules. For example, a heavy chain constant region of a polypeptide may comprise a CH1 domain derived from an IgG1 molecule and a hinge region derived from an IgG3 molecule. In another example, a heavy chain constant region can comprise a hinge region derived, in part, from an IgG1 molecule and, in part, from an IgG3 molecule. In another example, a heavy chain portion can comprise a chimeric hinge derived, in part, from an IgG1 molecule and, in part, from an IgG4 molecule.
[0073] As used herein, the term "light chain constant region" includes amino acid sequences derived from antibody light chain. Preferably, the light chain constant region comprises at least one of a constant kappa domain or constant lambda domain.
[0074] A "light chain-heavy chain pair" refers to the collection of a light chain and heavy chain that can form a dimer through a disulfide bond between the CL domain of the light chain and the CH1 domain of the heavy chain.
[0075] As previously indicated, the subunit structures and three dimensional configuration of the constant regions of the various immunoglobulin classes are well known. As used herein, the term "VH domain" includes the amino terminal variable domain of an immunoglobulin heavy chain and the term "CH1 domain" includes the first (most amino terminal) constant region domain of an immunoglobulin heavy chain. The CH1 domain is adjacent to the VH domain and is amino terminal to the hinge region of an immunoglobulin heavy chain molecule.
[0076] As used herein the term "CH2 domain" includes the portion of a heavy chain molecule that extends, e.g., from about residue 244 to residue 360 of an antibody using conventional numbering schemes (residues 244 to 360, Kabat numbering system; and residues 231-340, EU numbering system; see Kabat et al., U.S. Dept. of Health and Human Services, "Sequences of Proteins of Immunological Interest" (1983). The CH2 domain is unique in that it is not closely paired with another domain. Rather, two N-linked branched carbohydrate chains are interposed between the two CH2 domains of an intact native IgG molecule. It is also well documented that the CH3 domain extends from the CH2 domain to the C-terminal of the IgG molecule and comprises approximately 108 residues.
[0077] As used herein, the term "hinge region" includes the portion of a heavy chain molecule that joins the CH1 domain to the CH2 domain. This hinge region comprises approximately 25 residues and is flexible, thus allowing the two N-terminal antigen-binding regions to move independently. Hinge regions can be subdivided into three distinct domains: upper, middle, and lower hinge domains (Roux et al., J. Immunol 161:4083 (1998)).
[0078] As used herein the term "disulfide bond" includes the covalent bond formed between two sulfur atoms. The amino acid cysteine comprises a thiol group that can form a disulfide bond or bridge with a second thiol group. In most naturally occurring IgG molecules, the CH1 and CK regions are linked by a disulfide bond and the two heavy chains are linked by two disulfide bonds at positions corresponding to 239 and 242 using the Kabat numbering system (position 226 or 229, EU numbering system).
[0079] As used herein, the term "chimeric antibody" will be held to mean any antibody wherein the immunoreactive region or site is obtained or derived from a first species and the constant region (which may be intact, partial or modified in accordance with the instant disclosure) is obtained from a second species. In certain embodiments the target binding region or site will be from a non-human source (e.g. mouse or primate) and the constant region is human.
[0080] As used herein, "percent humanization" is calculated by determining the number of framework amino acid differences (i.e., non-CDR difference) between the humanized domain and the germline domain, subtracting that number from the total number of amino acids, and then dividing that by the total number of amino acids and multiplying by 100.
[0081] By "specifically binds" or "has specificity to," it is generally meant that an antibody binds to an epitope via its antigen-binding domain, and that the binding entails some complementarity between the antigen-binding domain and the epitope. According to this definition, an antibody is said to "specifically bind" to an epitope when it binds to that epitope, via its antigen-binding domain more readily than it would bind to a random, unrelated epitope. The term "specificity" is used herein to qualify the relative affinity by which a certain antibody binds to a certain epitope. For example, antibody "A" may be deemed to have a higher specificity for a given epitope than antibody "B," or antibody "A" may be said to bind to epitope "C" with a higher specificity than it has for related epitope "D."
[0082] As used herein, the terms "treat" or "treatment" refer to both therapeutic treatment and prophylactic or preventative measures, wherein the object is to prevent or slow down (lessen) an undesired physiological change or disorder, such as the progression of cancer. Beneficial or desired clinical results include, but are not limited to, alleviation of symptoms, diminishment of extent of disease, stabilized (i.e., not worsening) state of disease, delay or slowing of disease progression, amelioration or palliation of the disease state, and remission (whether partial or total), whether detectable or undetectable. "Treatment" can also mean prolonging survival as compared to expected survival if not receiving treatment. Those in need of treatment include those already with the condition or disorder as well as those prone to have the condition or disorder or those in which the condition or disorder is to be prevented.
[0083] By "subject" or "individual" or "animal" or "patient" or "mammal," is meant any subject, particularly a mammalian subject, for whom diagnosis, prognosis, or therapy is desired. Mammalian subjects include humans, domestic animals, farm animals, and zoo, sport, or pet animals such as dogs, cats, guinea pigs, rabbits, rats, mice, horses, cattle, cows, and so on.
[0084] As used herein, phrases such as "to a patient in need of treatment" or "a subject in need of treatment" includes subjects, such as mammalian subjects, that would benefit from administration of an antibody or composition of the present disclosure used, e.g., for detection, for a diagnostic procedure and/or for treatment.
Anti-PD-L1 Antibodies
[0085] The present disclosure provides anti-PD-L1 antibodies with high affinity to the human PD-L1 protein. The tested antibodies exhibited potent binding and inhibitory activities and are useful for therapeutic and diagnostics uses.
[0086] The PD-L1 protein is a 40 kDa type 1 transmembrane protein. Its extracellular portion includes an N-terminal immunoglobulin V (IgV) domain (amino acids 19-127) and a C-terminal immunoglobulin C (IgC) domain (amino acids 133-225). PD-1 and PD-L1 interact through the conserved front and side of their IgV domains, as do the IgV domains of antibodies and T cell receptors. Not surprisingly, the current anti-PD-L1 antibodies all bind to the IgV domain which can disrupt the binding between PD-1 and PD-L1 . It is therefore a surprising and unexpected finding of the present disclosure that antibodies, such as many disclosed herein, that bind to the IgC domain of the PD-L1 protein can still effectively, and perhaps even more so, inhibit PD-L1, leading to even further improved therapeutic effects.
[0087] One embodiment of the present disclosure, therefore, provides an anti-PD-L1 antibody or fragment thereof, which antibody or fragment thereof can specifically bind to an immunoglobulin C (Ig C) domain of a human Programmed death-ligand 1 (PD-L1) protein. In some embodiments, the Ig C domain consists of amino acid residues 133-225.
[0088] In some embodiments, the antibody or fragment thereof can bind to at least one of amino acid residues Y134, K162, or N183 of the PD-L1 protein. In some embodiments, the antibody or fragment thereof can bind to at least two of amino acid residues Y134, K162, or N183 of the PD-L1 protein. In some embodiments, the antibody or fragment thereof can bind to at least one of amino acid residues Y134, K162, and N183 of the PD-L1 protein. In some embodiments, the antibody or fragment thereof does not bind to an immunoglobulin V (Ig V) domain of the PD-L1 protein, wherein the Ig V domain consists of amino acid residues 19-127.
[0089] In accordance with one embodiment of the present disclosure, provided is an antibody that includes the heavy chain and light chain variable domains with the CDR regions as defined in SEQ ID NO: 1-6.
TABLE-US-00002 TABLE 1 Sequences of the CDR regions Name Sequence SEQ ID NO: VH CDR1 SYDMS 1 VH CDR2 TISDGGGYIYYSDSVKG 2 VH CDR3 EFGKRYALDY 3 VL CDR1 KASQDVTPAVA 4 VL CDR2 STSSRYT 5 VL CDR3 QQHYTTPLT 6
[0090] As demonstrated in the experimental examples, the antibodies that contained these CDR regions, whether mouse, humanized or chimeric, had potent PD-L1 binding and inhibitory activities. Further computer modeling indicated that certain residues within the CDR can be modified to retain or improve the property of the antibodies. Such residues are referred to as "hot spots" which are underlined in Table 1. In some embodiments, an anti-PD-L1 antibody of the present disclosure includes the VH and VL CDR as listed in Table 1, with one, two or three further modifications. Such modifications can be addition, deletion or substation of amino acids.
[0091] In some embodiments, the modification is substitution at no more than one hot spot position from each of the CDRs. In some embodiments, the modification is substitution at one, two or three such hot spot positions. In one embodiment, the modification is substitution at one of the hot spot positions. Such substitutions, in some embodiments, are conservative substitutions.
[0092] A "conservative amino acid substitution" is one in which the amino acid residue is replaced with an amino acid residue having a similar side chain. Families of amino acid residues having similar side chains have been defined in the art, including basic side chains (e.g., lysine, arginine, histidine), acidic side chains (e.g., aspartic acid, glutamic acid), uncharged polar side chains (e.g., glycine, asparagine, glutamine, serine, threonine, tyrosine, cysteine), nonpolar side chains (e.g., alanine, valine, leucine, isoleucine, proline, phenylalanine, methionine, tryptophan), beta-branched side chains (e.g., threonine, valine, isoleucine) and aromatic side chains (e.g., tyrosine, phenylalanine, tryptophan, histidine). Thus, a nonessential amino acid residue in an immunoglobulin polypeptide is preferably replaced with another amino acid residue from the same side chain family. In another embodiment, a string of amino acids can be replaced with a structurally similar string that differs in order and/or composition of side chain family members.
[0093] Non-limiting examples of conservative amino acid substitutions are provided in the table below, where a similarity score of 0 or higher indicates conservative substitution between the two amino acids.
TABLE-US-00003 TABLE 2 Amino Acid Similarity Matrix C G P S A T D E N Q H K R V M I L F Y W W -8 -7 -6 -2 -6 -5 -7 -7 -4 -5 -3 -3 2 -6 -4 -5 -2 0 0 17 Y 0 -5 -5 -3 -3 -3 -4 -4 -2 -4 0 -4 -5 -2 -2 -1 -1 7 10 F -4 -5 -5 -3 -4 -3 -6 -5 -4 -5 -2 -5 -4 -1 0 1 2 9 L -6 -4 -3 -3 -2 -2 -4 -3 -3 -2 -2 -3 -3 2 4 2 6 I -2 -3 -2 -1 -1 0 -2 -2 -2 -2 -2 -2 -2 4 2 5 M -5 -3 -2 -2 -1 -1 -3 -2 0 -1 -2 0 0 2 6 V -2 -1 -1 -1 0 0 -2 -2 -2 -2 -2 -2 -2 4 R -4 -3 0 0 -2 -1 -1 -1 0 1 2 3 6 K -5 -2 -1 0 -1 0 0 0 1 1 0 5 H -3 -2 0 -1 -1 -1 1 1 2 3 6 Q -5 -1 0 -1 0 -1 2 2 1 4 N -4 0 -1 1 0 0 2 1 2 E -5 0 -1 0 0 0 3 4 D -5 1 -1 0 0 0 4 T -2 0 0 1 1 3 A -2 1 1 1 2 S 0 1 1 1 P -3 -1 6 G -3 5 C 12
TABLE-US-00004 TABLE 3 Conservative Amino Acid Substitutions For Amino Acid Substitution With Alanine D-Ala, Gly, Aib, .beta.-Ala, L-Cys, D-Cys Arginine D-Arg, Lys, D-Lys, Orn D-Orn Asparagine D-Asn, Asp, D-Asp, Glu, D-Glu Gln, D-Gln Aspartic Acid D-Asp, D-Asn, Asn, Glu, D-Glu, Gln, D-Gln Cysteine D-Cys, S-Me-Cys, Met, D-Met, Thr, D-Thr, L-Ser, D-Ser Glutamine D-Gln, Asn, D-Asn, Glu, D-Glu, Asp, D-Asp Glutamic Acid D-Glu, D-Asp, Asp, Asn, D-Asn, Gln, D-Gln Glycine Ala, D-Ala, Pro, D-Pro, Aib, .beta.-Ala Isoleucine D-Ile, Val, D-Val, Leu, D-Leu, Met, D-Met Leucine Val, D-Val, Met, D-Met, D-Ile, D-Leu, Ile Lysine D-Lys, Arg, D-Arg, Orn, D-Orn Methionine D-Met, S-Me-Cys, Ile, D-Ile, Leu, D-Leu, Val, D-Val Phenylalanine D-Phe, Tyr, D-Tyr, His, D-His, Trp, D-Trp Proline D-Pro Serine D-Ser, Thr, D-Thr, allo-Thr, L-Cys, D-Cys Threonine D-Thr, Ser, D-Ser, allo-Thr, Met, D-Met, Val, D-Val Tyrosine D-Tyr, Phe, D-Phe, His, D-His, Trp, D-Trp Valine D-Val, Leu, D-Leu, Ile, D-Ile, Met, D-Met
[0094] Specific examples of CDRs with suitable substitutions are provided in SEQ ID NO: 61-111 of Example 11. In some embodiments, therefore, an antibody of the present disclosure includes a VH CDR1 of SEQ ID NO: 1 or any one of 61-67. In some embodiments, an antibody of the present disclosure includes a VH CDR2 of SEQ ID NO: 2 or any one of 68-77. In some embodiments, an antibody of the present disclosure includes a VH CDR3 of SEQ ID NO: 1 or any one of 78-90. In some embodiments, an antibody of the present disclosure includes a VL CDR1 of SEQ ID NO: 4 or any one of 91-92. In some embodiments, an antibody of the present disclosure includes a VL CDR2 of SEQ ID NO: 5 or any one of 93-105. In some embodiments, an antibody of the present disclosure includes a VL CDR3 of SEQ ID NO: 6 or any one of 106-110.
[0095] In some embodiments, an antibody or fragment thereof includes no more than one, no more than two, or no more than three of the above substitutions. In some embodiments, the antibody or fragment thereof includes a VH CDR1 of SEQ ID NO: 1 or any one of SEQ ID NO: 61-67, a VH CDR2 of SEQ ID NO: 2, a VH CDR3 of SEQ ID NO: 3, a VL CDR1 of SEQ ID NO: 4, a VL CDR2 of SEQ ID NO: 5, and a VL CDR3 of SEQ ID NO: 6.
[0096] In some embodiments, the antibody or fragment thereof includes a VH CDR1 of SEQ ID NO: 1, a VH CDR2 of SEQ ID NO: 2 or any one of SEQ ID NO: 68-77, a VH CDR3 of SEQ ID NO: 3, a VL CDR1 of SEQ ID NO: 4, a VL CDR2 of SEQ ID NO: 5, and a VL CDR3 of SEQ ID NO: 6.
[0097] In some embodiments, the antibody or fragment thereof includes a VH CDR1 of SEQ ID NO: 1, a VH CDR2 of SEQ ID NO: 2, a VH CDR3 of SEQ ID NO: 3 or any one of SEQ ID NO: 78-90, a VL CDR1 of SEQ ID NO: 4, a VL CDR2 of SEQ ID NO: 5, and a VL CDR3 of SEQ ID NO: 6.
[0098] In some embodiments, the antibody or fragment thereof includes a VH CDR1 of SEQ ID NO: 1, a VH CDR2 of SEQ ID NO: 2, a VH CDR3 of SEQ ID NO: 3, a VL CDR1 of SEQ ID NO: 4 or any one of SEQ ID NO: 91-92, a VL CDR2 of SEQ ID NO: 5, and a VL CDR3 of SEQ ID NO: 6.
[0099] In some embodiments, the antibody or fragment thereof includes a VH CDR1 of SEQ ID NO: 1, a VH CDR2 of SEQ ID NO: 2, a VH CDR3 of SEQ ID NO: 3, a VL CDR1 of SEQ ID NO: 4, a VL CDR2 of SEQ ID NO: 5 or any one of SEQ ID NO: 93-105, and a VL CDR3 of SEQ ID NO: 6.
[0100] In some embodiments, the antibody or fragment thereof includes a VH CDR1 of SEQ ID NO: 1, a VH CDR2 of SEQ ID NO: 2, a VH CDR3 of SEQ ID NO: 3, a VL CDR1 of SEQ ID NO: 4, a VL CDR2 of SEQ ID NO: 5, and a VL CDR3 of SEQ ID NO: 6 or any one of SEQ ID NO: 106-111.
[0101] Non-limiting examples of VH are provided in SEQ ID NO: 7-26 and 113, out of which SEQ ID NO: 113 is the mouse VH, and SEQ ID NO: 7-26 are humanized ones. Further, among the humanized VH, SEQ ID NO: 9-15, 17-21 and 23-26 include one or more back-mutations to the mouse version. Likewise, non-limiting examples of VL (VK) are provided in SEQ ID NO: 27-33. SEQ ID NO: 28 and 30 are the originally derived, CDR-grafted, humanized sequences as shown in the examples. SEQ ID NO: 29 and 31-33 are humanized VL with back-mutations.
[0102] The back-mutations are shown to be useful for retaining certain characteristics of the anti-PD-L1 antibodies. Accordingly, in some embodiments, the anti-PD-L1 antibodies of the present disclosure, in particular the human or humanized ones, include one or more of the back-mutations. In some embodiments, the VH back-mutation (i.e., included amino acid at the specified position) is one or more selected from (a) Ser at position 44, (b) Ala at position 49, (c) Ala at position 53, (d) Ile at position 91, (e) Glu at position 1, (f) Val at position 37, (g) Thr at position 40 (h) Val at position 53, (i) Glu at position 54, (j) Asn at position 77, (k) Arg at position 94, and (1) Thr at position 108, according to Kabat numbering, and combinations thereof In some embodiments, the back-mutations are selected from (a) Ser at position 44, (b) Ala at position 49, (c) Ala at position 53, and/or (d) Ile at position 91, according to Kabat numbering, and combinations thereof.
[0103] In some embodiments, the VL back-mutation is one or more selected from (a) Ser at position 22, (b) Gln at position 42, (c) Ser at position 43, (d) Asp at position 60, and (e) Thr at position 63, according to Kabat numbering, and combinations thereof.
[0104] In some embodiments, the anti-PD-L1 antibody of the present disclosure includes a VH of SEQ ID NO: 7-26, a VL of SEQ ID NO: 27-33, or their respective biological equivalents. A biological equivalent of a VH or VL is a sequence that includes the designated amino acids while having an overall 80%, 85%, 90%, 95%, 98% or 99% sequence identity. A biological equivalent of SEQ ID NO: 20, for instance, can be a VH that has an overall 80%, 85%, 90%, 95%, 98% or 99% sequence identity to SEQ ID NO: 20 but retains the CDRs (SEQ ID NO: 1-6 or their variants), and optionally retains one or more, or all of the back-mutations. In one embodiment, the VH has the amino acid sequence of SEQ ID NO: 20 and the VL has the amino acid sequence of SEQ ID NO: 28.
Further Improved PD-L1 Antibodies
[0105] Through random mutagenesis with controlled mutation rates, Examples 13-17 were able to identify a number of hotspot residues in particular in the CDR3 of both the heavy chain (e.g., B6, C3, C6, and Al) and the light chain (e.g., A3) variable regions (see Tables 14 and 15). The mutagenesis was performed on a template antibody derived from Hu1210-41 (as noted in the footnote of Table 14, the template antibody WT has a S60R (Kabat numbering) substitution in the heavy chain CDR2). Also, compared to the chimeric antibody, Hu1210-41 included a G53A substitution (see SEQ ID NO:20) in VH CDR2. Among the tested mutant antibodies, antibody B6 exhibited greatly improved binding affinity to human PD-L1 and biological activities.
[0106] In one embodiment, therefore, provided are antibodies and antigen-binding fragment that include the following CDRs (from the S60R mutant) and their variants.
TABLE-US-00005 Name Sequence SEQ ID NO: VH CDR1 SYDMS 1 VH CDR2 TISDAGGYIYYRDSVKG 116 VH CDR3 EFGKRYALDY 3 VL CDR1 KASQDVTPAVA 4 VL CDR2 STSSRYT 5 VL CDR3 QQHYTTPLT 6
[0107] In one embodiment, therefore, provided are antibodies and antigen-binding fragment that include the following CDRs (from B6) and their variants.
TABLE-US-00006 Name Sequence SEQ ID NO: VH CDR1 SYDMS 1 VH CDR2 TISDAGGYIYYRDSVKG 116 VH CDR3 ELPWRYALDY 117 VL CDR1 KASQDVTPAVA 4 VL CDR2 STSSRYT 5 VL CDR3 QQHYTTPLT 6
[0108] In one embodiment, provided is an antibody or fragment thereof, wherein the antibody or fragment thereof has specificity to a human PD-L1 protein and comprises: (a) a VH CDR1 comprising the amino acid sequence of SEQ ID NO: 1 or a variant of SEQ ID NO: 1 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 1; (b) a VH CDR2 comprising the amino acid sequence of SEQ ID NO: 116 or a variant of SEQ ID NO: 116 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 116; (c) a VH CDR3 comprising the amino acid sequence of SEQ ID NO: 3 or a variant of SEQ ID NO: 3 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 3, wherein the second amino acid residue of the VH CDR3 is Leu; (d) a VL CDR1 comprising the amino acid sequence of SEQ ID NO: 4 or a variant of SEQ ID NO: 4 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 4; (e) a VL CDR2 comprising the amino acid sequence of SEQ ID NO: 5 or a variant of SEQ ID NO: 5 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 5; and (f) a VL CDR3 comprising the amino acid sequence of SEQ ID NO: 6 or a variant of SEQ ID NO: 6 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 6.
[0109] In one embodiment, provided is an antibody or fragment thereof, wherein the antibody or fragment thereof has specificity to a human PD-L1 protein and comprises: (a) a VH CDR1 comprising the amino acid sequence of SEQ ID NO: 1 or a variant of SEQ ID NO: 1 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 1; (b) a VH CDR2 comprising the amino acid sequence of SEQ ID NO: 116 or a variant of SEQ ID NO: 116 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 116; (c) a VH CDR3 comprising the amino acid sequence of SEQ ID NO: 117 or a variant of SEQ ID NO: 117 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 117, wherein the second amino acid residue of the VH CDR3 is Leu; (d) a VL CDR1 comprising the amino acid sequence of SEQ ID NO: 4 or a variant of SEQ ID NO: 4 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 4; (e) a VL CDR2 comprising the amino acid sequence of SEQ ID NO: 5 or a variant of SEQ ID NO: 5 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 5; and (f) a VL CDR3 comprising the amino acid sequence of SEQ ID NO: 6 or a variant of SEQ ID NO: 6 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 6.
[0110] Example variants of SEQ ID NO: 1 have one amino acid substitution at one of amino acid residues 1, 2 and 5, such as SEQ ID NO: 61-67:
TABLE-US-00007 Name Sequence SEQ ID NO: VH CDR1 SYDMS 1 TYDMS 61 CYDMS 62 SFDMS 63 SHDMS 64 SWDMS 65 SYDMT 66 SYDMC 67
[0111] Example variants of SEQ ID NO: 116 have one or more amino acid substitutions, such as SEQ ID NO: 118-127, 2 and 68-77. In some embodiments, the variants are SEQ ID NO: 118-127.
TABLE-US-00008 Name Sequence SEQ ID NO: VH CDR2 TISDAGGYIYYRDSVKG 116 TISDAGAYIYYRDSVKG 118 TISDAGPYIYYRDSVKG 119 TISDAGGFIYYRDSVKG 120 TISDAGGHIYYRDSVKG 121 TISDAGGWIYYRDSVKG 122 TISDAGGYIYYRDTVKG 123 TISDAGGYIYYRDCVKG 124 TISDAGGYIYYRDSLKG 125 TISDAGGYIYYRDSIKG 126 TISDAGGYIYYRDSMKG 127 TISDGGGYIYYSDSVKG 2 TISDGGAYIYYSDSVKG 68 TISDGGPYIYYSDSVKG 69 TISDGGGFIYYSDSVKG 70 TISDGGGHIYYSDSVKG 71 TISDGGGWIYYSDSVKG 72 TISDGGGYIYYSDTVKG 73 TISDGGGYIYYSDCVKG 74 TISDGGGYIYYSDSLKG 75 TISDGGGYIYYSDSIKG 76 TISDGGGYIYYSDSMKG 77
[0112] In some embodiments, the third amino acid residue of the VH CDR3 variant is Pro. In some embodiments, the fourth amino acid residue of the VH CDR3 variant is Trp.
[0113] Example variants of SEQ ID NO: 3 have one or more amino acid substitution at amino acid residues 1-6, such as SEQ ID NO: 78-90:
TABLE-US-00009 Name Sequence SEQ ID NO: VH CDR3 EFGKRYALDY 3 QFGKRYALDY 78 DFGKRYALDY 79 NFGKRYALDY 80 EYGKRYALDY 81 EHGKRYALDY 82 EWGKRYALDY 83 EFAKRYALDY 84 EFPKRYALDY 85 EFGRRYALDY 86 EFGKKYALDY 87 EFGKRFALDY 88 EFGKRHALDY 89 EFGKRWALDY 90
[0114] Example variants of SEQ ID NO: 117 have one or more amino acid substitution at amino acid residues 1, 5 and 6, such as SEQ ID NO: 128-139:
TABLE-US-00010 Name Sequence SEQ ID NO: VH CDR3 ELPWRYALDY (B6) 117 ELFNRYALDY (B1) 128 ELHFRYALDY (C3) 129 ELYFRYALDY (C6) 130 ELLHRYALDY (A1) 131 ELRGRYALDY (A2) 132 QLPWRYALDY 133 DLPWRYALDY 134 NLPWRYALDY 135 ELPWKYALDY 136 ELPWRFALDY 137 ELPWRHALDY 138 ELPWRWALDY 139
[0115] In some embodiments, the variant of SEQ ID NO: 4 has one amino acid substitution at amino acid residue 3, such as SEQ ID NO: 91-92:
TABLE-US-00011 Name Sequence SEQ ID NO: VL CDR1 KASQDVTPAVA 4 KATQDVTPAVA 91 KACQDVTPAVA 92
[0116] In some embodiments, the variant of SEQ ID NO: 5 has one amino acid substitution at one of amino acid residues 1-6, such as SEQ ID NO: 93-105:
TABLE-US-00012 Name Sequence SEQ ID NO: VL CDR2 STSSRYT 5 TTSSRYT 93 CTSSRYT 94 SSSSRYT 95 SMSSRYT 96 SVSSRYT 97 STTSRYT 98 STCSRYT 99 STSTRYT 100 STSCRYT 101 STSSKYT 102 STSSRFT 103 STSSRHT 104 STSSRWT 105
[0117] Example variants of SEQ ID NO: 6 have one amino acid substitution at one of amino acid residues 1 and 2, such as SEQ ID NO: 106-111. Another example variant is SEQ ID NO: 140.
TABLE-US-00013 Name Sequence SEQ ID NO: VL CDR3 QQHYTTPLT 6 EQHYTTPLT 106 DQHYTTPLT 107 NQHYTTPLT 108 QEHYTTPLT 109 QDHYTTPLT 110 QNHYTTPLT 111 QQHSDAPLT (A3) 140
[0118] Mutant A3, which has substitutions at three residues in the VL CDR3, also exhibited excellent binding affinity to human PD-L1. In one embodiment, therefore, provided are antibodies and antigen-binding fragment that include the following CDRs and their variants:
TABLE-US-00014 Name Sequence SEQ ID NO: VH CDR1 SYDMS 1 VH CDR2 TISDAGGYIYYRDSVKG 116 VH CDR3 EFGKRYALDY 3 VL CDR1 KASQDVTPAVA 4 VL CDR2 STSSRYT 5 VL CDR3 QQHSDAPLT 140
[0119] In one embodiment, therefore, provided is an antibody or fragment thereof, wherein the antibody or fragment thereof has specificity to a human PD-L1 protein and comprises: (a) a VH CDR1 comprising the amino acid sequence of SEQ ID NO: 1 or a variant of SEQ ID NO: 1 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 1; (b) a VH CDR2 comprising the amino acid sequence of SEQ ID NO: 116 or a variant of SEQ ID NO: 116 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 116; (c) a VH CDR3 comprising the amino acid sequence of SEQ ID NO: 3 or a variant of SEQ ID NO: 3 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 3; (d) a VL CDR1 comprising the amino acid sequence of SEQ ID NO: 4 or a variant of SEQ ID NO: 4 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 4; (e) a VL CDR2 comprising the amino acid sequence of SEQ ID NO: 5 or a variant of SEQ ID NO: 5 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 5; and (f) a VL CDR3 comprising the amino acid sequence of SEQ ID NO: 140 or a variant of SEQ ID NO: 140 having one, two or three substitution, deletion or insertion as compared to SEQ ID NO: 140, wherein at least (i) amino acid residue 4 of the VL CDR3 is Ser, (ii) amino acid residue 5 of the VL CDR3 is Asp, or (iii) amino acid residue 6 of the VL CDR3 is Ala.
[0120] Example variants of SEQ ID NO: 1 have one amino acid substitution at one of amino acid residues 1, 2 and 5, such as SEQ ID NO: 61-67.
[0121] Example variants of SEQ ID NO: 116 have one or more amino acid substitutions, such as SEQ ID NO: 118-127, 2 and 68-77.
[0122] Example variants of SEQ ID NO: 3 have one or more amino acid substitutions such as SEQ ID NO: 117 and 128-139.
TABLE-US-00015 Name Sequence SEQ ID NO: VH CDR3 ELPWRYALDY (B6) 117 ELFNRYALDY (B1) 128 ELHFRYALDY (C3) 129 ELYFRYALDY (C6) 130 ELLHRYALDY (A1) 131 ELRGRYALDY (A2) 132 QLPWRYALDY 133 DLPWRYALDY 134 NLPWRYALDY 135 ELPWKYALDY 136 ELPWRFALDY 137 ELPWRHALDY 138 ELPWRWALDY 139
[0123] Example variants of SEQ ID NO: 4 have one amino acid substitution at amino acid residue 3, such as SEQ ID NO: 91-92.
[0124] Example variants of SEQ ID NO: 5 has one amino acid substitution at one of amino acid residues 1-6, such as SEQ ID NO: 93-105.
[0125] In some embodiments, amino acid residue 4 of the VL CDR3 variant is Ser. In some embodiments, amino acid residue 5 of the VL CDR3 variant is Asp. In some embodiments, amino acid residue 6 of the VL CDR3 variant is Ala. Example variants of SEQ ID NO: 140 has one amino acid substitution at one of amino acid residues 1 and 2, such as SEQ ID NO: 161-166.
TABLE-US-00016 Name Sequence SEQ ID NO: VL CDR3 QQHSDAPLT 140 EQHSDAPLT 161 DQHSDAPLT 162 NQHSDAPLT 163 QEHSDAPLT 164 QDHSDAPLT 165 QNHSDAPLT 166
[0126] Examples of antibodies derived from the mutagenesis study or their antigen-binding fragments include those having the heavy chain and light chain variable regions provided in Table 15. In one embodiment, the heavy chain variable region includes SEQ ID NO: 141 and the light chain variable region includes SEQ ID NO: 142. In one embodiment, the heavy chain variable region includes SEQ ID NO: 143 and the light chain variable region includes SEQ ID NO: 144. In one embodiment, the heavy chain variable region includes SEQ ID NO: 145 and the light chain variable region includes SEQ ID NO: 146. In one embodiment, the heavy chain variable region includes SEQ ID NO: 147 and the light chain variable region includes SEQ ID NO: 148. In one embodiment, the heavy chain variable region includes SEQ ID NO: 149 and the light chain variable region includes SEQ ID NO: 150. In one embodiment, the heavy chain variable region includes SEQ ID NO: 151 and the light chain variable region includes SEQ ID NO: 152. In one embodiment, the heavy chain variable region includes SEQ ID NO: 153 and the light chain variable region includes SEQ ID NO: 154. In one embodiment, the heavy chain variable region includes SEQ ID NO: 155 and the light chain variable region includes SEQ ID NO: 156. In one embodiment, the heavy chain variable region includes SEQ ID NO: 157 and the light chain variable region includes SEQ ID NO: 158. In one embodiment, the heavy chain variable region includes SEQ ID NO: 159 and the light chain variable region includes SEQ ID NO: 160.
[0127] It will also be understood by one of ordinary skill in the art that antibodies as disclosed herein may be modified such that they vary in amino acid sequence from the naturally occurring binding polypeptide from which they were derived. For example, a polypeptide or amino acid sequence derived from a designated protein may be similar, e.g., have a certain percent identity to the starting sequence, e.g., it may be 60%, 70%, 75%, 80%, 85%, 90%, 95%, 98%, or 99% identical to the starting sequence.
[0128] In certain embodiments, the antibody comprises an amino acid sequence or one or more moieties not normally associated with an antibody. Exemplary modifications are described in more detail below. For example, an antibody of the disclosure may comprise a flexible linker sequence, or may be modified to add a functional moiety (e.g., PEG, a drug, a toxin, or a label).
[0129] Antibodies, variants, or derivatives thereof of the disclosure include derivatives that are modified, i.e., by the covalent attachment of any type of molecule to the antibody such that covalent attachment does not prevent the antibody from binding to the epitope. For example, but not by way of limitation, the antibodies can be modified, e.g., by glycosylation, acetylation, pegylation, phosphorylation, phosphorylation, amidation, derivatization by known protecting/blocking groups, proteolytic cleavage, linkage to a cellular ligand or other protein, etc. Any of numerous chemical modifications may be carried out by known techniques, including, but not limited to specific chemical cleavage, acetylation, formylation, metabolic synthesis of tunicamycin, etc. Additionally, the antibodies may contain one or more non-classical amino acids.
[0130] In some embodiments, the antibodies may be conjugated to therapeutic agents, prodrugs, peptides, proteins, enzymes, viruses, lipids, biological response modifiers, pharmaceutical agents, or PEG.
[0131] The antibodies may be conjugated or fused to a therapeutic agent, which may include detectable labels such as radioactive labels, an immunomodulator, a hormone, an enzyme, an oligonucleotide, a photoactive therapeutic or diagnostic agent, a cytotoxic agent, which may be a drug or a toxin, an ultrasound enhancing agent, a non-radioactive label, a combination thereof and other such agents known in the art.
[0132] The antibodies can be detectably labeled by coupling it to a chemiluminescent compound. The presence of the chemiluminescent-tagged antigen-binding polypeptide is then determined by detecting the presence of luminescence that arises during the course of a chemical reaction. Examples of particularly useful chemiluminescent labeling compounds are luminol, isoluminol, theromatic acridinium ester, imidazole, acridinium salt and oxalate ester.
[0133] The antibodies can also be detectably labeled using fluorescence emitting metals such as .sup.152Eu, or others of the lanthanide series. These metals can be attached to the antibody using such metal chelating groups as diethylenetriaminepentacetic acid (DTPA) or ethylenediaminetetraacetic acid (EDTA). Techniques for conjugating various moieties to an antibody are well known, see, e.g., Arnon et al., "Monoclonal Antibodies For Immunotargeting Of Drugs In Cancer Therapy", in Monoclonal Antibodies And Cancer Therapy, Reisfeld et al. (eds.), pp. 243-56 (Alan R. Liss, Inc. (1985); Hellstrom et al., "Antibodies For Drug Delivery", in Controlled Drug Delivery (2nd Ed.), Robinson et al., (eds.), Marcel Dekker, Inc., pp. 623-53 (1987); Thorpe, "Antibody Carriers Of Cytotoxic Agents In Cancer Therapy: A Review", in Monoclonal Antibodies '84: Biological And Clinical Applications, Pinchera et al. (eds.), pp. 475-506 (1985); "Analysis, Results, And Future Prospective Of The Therapeutic Use Of Radiolabeled Antibody In Cancer Therapy", in Monoclonal Antibodies For Cancer Detection And Therapy, Baldwin et al. (eds.), Academic Press pp. 303-16 (1985), and Thorpe et al., "The Preparation And Cytotoxic Properties Of Antibody-Toxin Conjugates", Immunol. Rev. (52:119-58 (1982)).
Bi-Functional Molecules
[0134] PD-L1 is an immune checkpoint molecule and is also a tumor antigen. As a tumor antigen targeting molecule, an antibody or antigen-binding fragment specific to PD-L1 can be combined with a second antigen-binding fragment specific to an immune cell to generate a bispecific antibody.
[0135] In some embodiments, the immune cell is selected from the group consisting of a T cell, a B cell, a monocyte, a macrophage, a neutrophil, a dendritic cell, a phagocyte, a natural killer cell, an eosinophil, a basophil, and a mast cell. Molecules on the immune cell which can be targeted include, for example, CD3, CD16, CD19, CD28, and CD64. Other examples include PD-1, CTLA-4, LAG-3 (also known as CD223), CD28, CD122, 4-1BB (also known as CD137), TIM3, OX-40 or OX40L, CD40 or CD40L, LIGHT, ICOS/ICOSL, GITR/GITRL, TIGIT, CD27, VISTA, B7H3, B7H4, HEVM or BTLA (also known as CD272), killer-cell immunoglobulin-like receptors (KIRs), and CD47. Specific examples of bispecificity include, without limitation, PD-L1/PD-1, PD-L1/LAG3, PD-L1/TIGIT, and PD-L1/CD47.
[0136] As an immune checkpoint inhibitor, an antibody or antigen-binding fragment specific to PD-L1 can be combined with a second antigen-binding fragment specific to a tumor antigen to generate a bispecific antibody. A "tumor antigen" is an antigenic substance produced in tumor cells, i.e., it triggers an immune response in the host. Tumor antigens are useful in identifying tumor cells and are potential candidates for use in cancer therapy. Normal proteins in the body are not antigenic. Certain proteins, however, are produced or overexpressed during tumorigenesis and thus appear "foreign" to the body. This may include normal proteins that are well sequestered from the immune system, proteins that are normally produced in extremely small quantities, proteins that are normally produced only in certain stages of development, or proteins whose structure is modified due to mutation.
[0137] An abundance of tumor antigens are known in the art and new tumor antigens can be readily identified by screening. Non-limiting examples of tumor antigens include EGFR, Her2, EpCAM, CD20, CD30, CD33, CD47, CD52, CD133, CD73, CEA, gpA33, Mucins, TAG-72, CIX, PSMA, folate-binding protein, GD2, GD3, GM2, VEGF, VEGFR, Integrin, .alpha.V.beta.3, .alpha.5.beta.1, ERBB2, ERBB3, MET, IGF1R, EPHA3, TRAILR1, TRAILR2, RANKL, FAP and Tenascin.
[0138] In some aspects, the monovalent unit has specificity to a protein that is overexpressed on a tumor cell as compared to a corresponding non-tumor cell. A "corresponding non-tumor cell" as used here, refers to a non-tumor cell that is of the same cell type as the origin of the tumor cell. It is noted that such proteins are not necessarily different from tumor antigens. Non-limiting examples include carcinoembryonic antigen (CEA), which is overexpressed in most colon, rectum, breast, lung, pancreas and gastrointestinal tract carcinomas; heregulin receptors (HER-2, neu or c-erbB-2), which is frequently overexpressed in breast, ovarian, colon, lung, prostate and cervical cancers; epidermal growth factor receptor (EGFR), which is highly expressed in a range of solid tumors including those of the breast, head and neck, non-small cell lung and prostate; asialoglycoprotein receptor; transferrin receptor; serpin enzyme complex receptor, which is expressed on hepatocytes; fibroblast growth factor receptor (FGFR), which is overexpressed on pancreatic ductal adenocarcinoma cells; vascular endothelial growth factor receptor (VEGFR), for anti-angiogenesis gene therapy; folate receptor, which is selectively overexpressed in 90% of nonmucinous ovarian carcinomas; cell surface glycocalyx; carbohydrate receptors; and polymeric immunoglobulin receptor, which is useful for gene delivery to respiratory epithelial cells and attractive for treatment of lung diseases such as Cystic Fibrosis. Non-limiting examples of bispecificity in this respect include PD-L1/EGFR, PD-L1/Her2, PD-L1/CD33, PD-L1/CD133, PD-L1/CEA and PD-L1/VEGF.
[0139] Different format of bispecific antibodies are also provided. In some embodiments, each of the anti-PD-L1 fragment and the second fragment each is independently selected from a Fab fragment, a single-chain variable fragment (scFv), or a single-domain antibody. In some embodiments, the bispecific antibody further includes a Fc fragment.
[0140] Bifunctional molecules that include not just antibody or antigen binding fragment are also provided. As a tumor antigen targeting molecule, an antibody or antigen-binding fragment specific to PD-L1, such as those described here, can be combined with an immune cytokine or ligand optionally through a peptide linker. The linked immune cytokines or ligands include, but not limited to, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-10, IL-12, IL-13, IL-15, GM-CSF, TNF-.alpha., CD40L, OX40L, CD27L, CD30L, 4-1BBL, LIGHT and GITRL. Such bi-functional molecules can combine the immune checkpoint blocking effect with tumor site local immune modulation.
Polynucleotides Encoding the Antibodies and Methods of Preparing the Antibodies
[0141] The present disclosure also provides isolated polynucleotides or nucleic acid molecules (e.g., SEQ ID NO: 34-60, 112, and 114) encoding the antibodies, variants or derivatives thereof of the disclosure. The polynucleotides of the present disclosure may encode the entire heavy and light chain variable regions of the antigen-binding polypeptides, variants or derivatives thereof on the same polynucleotide molecule or on separate polynucleotide molecules. Additionally, the polynucleotides of the present disclosure may encode portions of the heavy and light chain variable regions of the antigen-binding polypeptides, variants or derivatives thereof on the same polynucleotide molecule or on separate polynucleotide molecules.
[0142] Methods of making antibodies are well known in the art and described herein. In certain embodiments, both the variable and constant regions of the antigen-binding polypeptides of the present disclosure are fully human. Fully human antibodies can be made using techniques described in the art and as described herein. For example, fully human antibodies against a specific antigen can be prepared by administering the antigen to a transgenic animal which has been modified to produce such antibodies in response to antigenic challenge, but whose endogenous loci have been disabled. Exemplary techniques that can be used to make such antibodies are described in U.S. Pat. Nos. 6,150,584; 6,458,592; 6,420,140 which are incorporated by reference in their entireties.
[0143] In certain embodiments, the prepared antibodies will not elicit a deleterious immune response in the animal to be treated, e.g., in a human. In one embodiment, antigen-binding polypeptides, variants, or derivatives thereof of the disclosure are modified to reduce their immunogenicity using art-recognized techniques. For example, antibodies can be humanized, primatized, deimmunized, or chimeric antibodies can be made. These types of antibodies are derived from a non-human antibody, typically a murine or primate antibody, that retains or substantially retains the antigen-binding properties of the parent antibody, but which is less immunogenic in humans. This may be achieved by various methods, including (a) grafting the entire non-human variable domains onto human constant regions to generate chimeric antibodies; (b) grafting at least a part of one or more of the non-human complementarity determining regions (CDRs) into a human framework and constant regions with or without retention of critical framework residues; or (c) transplanting the entire non-human variable domains, but "cloaking" them with a human-like section by replacement of surface residues. Such methods are disclosed in Morrison et al., Proc. Natl. Acad. Sci. USA 57:6851-6855 (1984); Morrison et al., Adv. Immunol. 44:65-92 (1988); Verhoeyen et al., Science 239:1534-1536 (1988); Padlan, Molec. Immun. 25:489-498 (1991); Padlan, Molec. Immun. 31:169-217 (1994), and U.S. Pat. Nos. 5,585,089, 5,693,761, 5,693,762, and 6,190,370, all of which are hereby incorporated by reference in their entirety.
[0144] De-immunization can also be used to decrease the immunogenicity of an antibody. As used herein, the term "de-immunization" includes alteration of an antibody to modify T-cell epitopes (see, e.g., International Application Publication Nos. WO/9852976 A1 and WO/0034317 A2). For example, variable heavy chain and variable light chain sequences from the starting antibody are analyzed and a human T-cell epitope "map" from each V region showing the location of epitopes in relation to complementarity-determining regions (CDRs) and other key residues within the sequence is created. Individual T-cell epitopes from the T-cell epitope map are analyzed in order to identify alternative amino acid substitutions with a low risk of altering activity of the final antibody. A range of alternative variable heavy and variable light sequences are designed comprising combinations of amino acid substitutions and these sequences are subsequently incorporated into a range of binding polypeptides. Typically, between 12 and 24 variant antibodies are generated and tested for binding and/or function. Complete heavy and light chain genes comprising modified variable and human constant regions are then cloned into expression vectors and the subsequent plasmids introduced into cell lines for the production of whole antibody. The antibodies are then compared in appropriate biochemical and biological assays, and the optimal variant is identified.
[0145] The binding specificity of antigen-binding polypeptides of the present disclosure can be determined by in vitro assays such as immunoprecipitation, radioimmunoassay (RIA) or enzyme-linked immunoabsorbent assay (ELISA).
[0146] Alternatively, techniques described for the production of single-chain units (U.S. Pat. No. 4,694,778; Bird, Science 242:423-442 (1988); Huston et al., Proc. Natl. Acad. Sci. USA 55:5879-5883 (1988); and Ward et al., Nature 334:544-554 (1989)) can be adapted to produce single-chain units of the present disclosure. Single-chain units are formed by linking the heavy and light chain fragments of the Fv region via an amino acid bridge, resulting in a single-chain fusion peptide. Techniques for the assembly of functional Fv fragments in E. coli may also be used (Skerra et al., Science 242: 1038-1041 (1988)).
[0147] Examples of techniques which can be used to produce single-chain Fvs (scFvs) and antibodies include those described in U.S. Pat. Nos. 4,946,778 and 5,258,498; Huston et al., Methods in Enzymology 203:46-88 (1991); Shu et al., Proc. Natl. Sci. USA 90:1995-1999 (1993); and Skerra et al., Science 240:1038-1040 (1988). For some uses, including in vivo use of antibodies in humans and in vitro detection assays, it may be preferable to use chimeric, humanized, or human antibodies. A chimeric antibody is a molecule in which different portions of the antibody are derived from different animal species, such as antibodies having a variable region derived from a murine monoclonal antibody and a human immunoglobulin constant region. Methods for producing chimeric antibodies are known in the art. See, e.g., Morrison, Science 229:1202 (1985); Oi et al., BioTechniques 4:214 (1986); Gillies et al., J. Immunol. Methods 125:191-202 (1989); U.S. Pat. Nos. 5,807,715; 4,816,567; and 4,816397, which are incorporated herein by reference in their entireties.
[0148] Humanized antibodies are antibody molecules derived from a non-human species antibody that bind the desired antigen having one or more complementarity determining regions (CDRs) from the non-human species and framework regions from a human immunoglobulin molecule. Often, framework residues in the human framework regions will be substituted with the corresponding residue from the CDR donor antibody to alter, preferably improve, antigen-binding. These framework substitutions are identified by methods well known in the art, e.g., by modeling of the interactions of the CDR and framework residues to identify framework residues important for antigen-binding and sequence comparison to identify unusual framework residues at particular positions. (See, e.g., Queen et al., U.S. Pat. No. 5,585,089; Riechmann et al., Nature 332:323 (1988), which are incorporated herein by reference in their entireties.) Antibodies can be humanized using a variety of techniques known in the art including, for example, CDR-grafting (EP 239,400; PCT publication WO 91/09967; U.S. Pat. Nos. 5,225,539; 5,530,101; and 5,585,089), veneering or resurfacing (EP 592,106; EP 519,596; Padlan, Molecular Immunology 28(4/5):489-498 (1991); Studnicka et al., Protein Engineering 7(6):805-814 (1994); Roguska. et al., Proc. Natl. Sci. USA 91:969-973 (1994)), and chain shuffling (U.S. Pat. No. 5,565,332, which is incorporated by reference in its entirety).
[0149] Completely human antibodies are particularly desirable for therapeutic treatment of human patients. Human antibodies can be made by a variety of methods known in the art including phage display methods using antibody libraries derived from human immunoglobulin sequences. See also, U.S. Pat. Nos. 4,444,887 and 4,716,111; and PCT publications WO 98/46645, WO 98/50433, WO 98/24893, WO 98/16654, WO 96/34096, WO 96/33735, and WO 91/10741; each of which is incorporated herein by reference in its entirety.
[0150] Human antibodies can also be produced using transgenic mice which are incapable of expressing functional endogenous immunoglobulins, but which can express human immunoglobulin genes. For example, the human heavy and light chain immunoglobulin gene complexes may be introduced randomly or by homologous recombination into mouse embryonic stem cells. Alternatively, the human variable region, constant region, and diversity region may be introduced into mouse embryonic stem cells in addition to the human heavy and light chain genes. The mouse heavy and light chain immunoglobulin genes may be rendered non-functional separately or simultaneously with the introduction of human immunoglobulin loci by homologous recombination. In particular, homozygous deletion of the JH region prevents endogenous antibody production. The modified embryonic stem cells are expanded and microinjected into blastocysts to produce chimeric mice. The chimeric mice are then bred to produce homozygous offspring that express human antibodies. The transgenic mice are immunized in the normal fashion with a selected antigen, e.g., all or a portion of a desired target polypeptide. Monoclonal antibodies directed against the antigen can be obtained from the immunized, transgenic mice using conventional hybridoma technology. The human immunoglobulin transgenes harbored by the transgenic mice rearrange during B-cell differentiation, and subsequently undergo class switching and somatic mutation. Thus, using such a technique, it is possible to produce therapeutically useful IgG, IgA, IgM and IgE antibodies. For an overview of this technology for producing human antibodies, see Lonberg and Huszar Int. Rev. Immunol. 73:65-93 (1995). For a detailed discussion of this technology for producing human antibodies and human monoclonal antibodies and protocols for producing such antibodies, see, e.g., PCT publications WO 98/24893; WO 96/34096; WO 96/33735; U.S. Pat. Nos. 5,413,923; 5,625,126; 5,633,425; 5,569,825; 5,661,016; 5,545,806; 5,814,318; and 5,939,598, which are incorporated by reference herein in their entirety. In addition, companies such as Abgenix, Inc. (Freemont, Calif.) and GenPharm (San Jose, Calif.) can be engaged to provide human antibodies directed against a selected antigen using technology similar to that described above.
[0151] Completely human antibodies which recognize a selected epitope can also be generated using a technique referred to as "guided selection." In this approach a selected non-human monoclonal antibody, e.g., a mouse antibody, is used to guide the selection of a completely human antibody recognizing the same epitope. (Jespers et al., Bio/Technology 72:899-903 (1988). See also, U.S. Pat. No. 5,565,332, which is incorporated by reference in its entirety.)
[0152] In another embodiment, DNA encoding desired monoclonal antibodies may be readily isolated and sequenced using conventional procedures (e.g., by using oligonucleotide probes that are capable of binding specifically to genes encoding the heavy and light chains of murine antibodies). The isolated and subcloned hybridoma cells serve as a preferred source of such DNA. Once isolated, the DNA may be placed into expression vectors, which are then transfected into prokaryotic or eukaryotic host cells such as E. coli cells, simian COS cells, Chinese Hamster Ovary (CHO) cells or myeloma cells that do not otherwise produce immunoglobulins. More particularly, the isolated DNA (which may be synthetic as described herein) may be used to clone constant and variable region sequences for the manufacture antibodies as described in Newman et al., U.S. Pat. No. 5,658,570, filed Jan. 25, 1995, which is incorporated by reference herein. Essentially, this entails extraction of RNA from the selected cells, conversion to cDNA, and amplification by PCR using Ig specific primers. Suitable primers for this purpose are also described in U.S. Pat. No. 5,658,570. As will be discussed in more detail below, transformed cells expressing the desired antibody may be grown up in relatively large quantities to provide clinical and commercial supplies of the immunoglobulin.
[0153] Additionally, using routine recombinant DNA techniques, one or more of the CDRs of the antigen-binding polypeptides of the present disclosure, may be inserted within framework regions, e.g., into human framework regions to humanize a non-human antibody. The framework regions may be naturally occurring or consensus framework regions, and preferably human framework regions (see, e.g., Chothia et al., J. Mol. Biol. 278:457-479 (1998) for a listing of human framework regions). Preferably, the polynucleotide generated by the combination of the framework regions and CDRs encodes an antibody that specifically binds to at least one epitope of a desired polypeptide, e.g., LIGHT. Preferably, one or more amino acid substitutions may be made within the framework regions, and, preferably, the amino acid substitutions improve binding of the antibody to its antigen. Additionally, such methods may be used to make amino acid substitutions or deletions of one or more variable region cysteine residues participating in an intrachain disulfide bond to generate antibody molecules lacking one or more intrachain disulfide bonds. Other alterations to the polynucleotide are encompassed by the present disclosure and within the skill of the art.
[0154] In addition, techniques developed for the production of "chimeric antibodies" (Morrison et al., Proc. Natl. Acad. Sci. USA:851-855 (1984); Neuberger et al., Nature 372:604-608 (1984); Takeda et al., Nature 314:452-454 (1985)) by splicing genes from a mouse antibody molecule, of appropriate antigen specificity, together with genes from a human antibody molecule of appropriate biological activity can be used. As used herein, a chimeric antibody is a molecule in which different portions are derived from different animal species, such as those having a variable region derived from a murine monoclonal antibody and a human immunoglobulin constant region.
[0155] Yet another highly efficient means for generating recombinant antibodies is disclosed by Newman, Biotechnology 10: 1455-1460 (1992). Specifically, this technique results in the generation of primatized antibodies that contain monkey variable domains and human constant sequences. This reference is incorporated by reference in its entirety herein. Moreover, this technique is also described in commonly assigned U.S. Pat. Nos. 5,658,570, 5,693,780 and 5,756,096 each of which is incorporated herein by reference.
[0156] Alternatively, antibody-producing cell lines may be selected and cultured using techniques well known to the skilled artisan. Such techniques are described in a variety of laboratory manuals and primary publications. In this respect, techniques suitable for use in the disclosure as described below are described in Current Protocols in Immunology, Coligan et al., Eds., Green Publishing Associates and Wiley-Interscience, John Wiley and Sons, New York (1991) which is herein incorporated by reference in its entirety, including supplements.
[0157] Additionally, standard techniques known to those of skill in the art can be used to introduce mutations in the nucleotide sequence encoding an antibody of the present disclosure, including, but not limited to, site-directed mutagenesis and PCR-mediated mutagenesis which result in amino acid substitutions. Preferably, the variants (including derivatives) encode less than 50 amino acid substitutions, less than 40 amino acid substitutions, less than 30 amino acid substitutions, less than 25 amino acid substitutions, less than 20 amino acid substitutions, less than 15 amino acid substitutions, less than 10 amino acid substitutions, less than 5 amino acid substitutions, less than 4 amino acid substitutions, less than 3 amino acid substitutions, or less than 2 amino acid substitutions relative to the reference variable heavy chain region, CDR-H1, CDR-H2, CDR-H3, variable light chain region, CDR-L1, CDR-L2, or CDR-L3. Alternatively, mutations can be introduced randomly along all or part of the coding sequence, such as by saturation mutagenesis, and the resultant mutants can be screened for biological activity to identify mutants that retain activity.
Cancer Treatment
[0158] As described herein, the antibodies, variants or derivatives of the present disclosure may be used in certain treatment and diagnostic methods.
[0159] The present disclosure is further directed to antibody-based therapies which involve administering the antibodies of the disclosure to a patient such as an animal, a mammal, and a human for treating one or more of the disorders or conditions described herein. Therapeutic compounds of the disclosure include, but are not limited to, antibodies of the disclosure (including variants and derivatives thereof as described herein) and nucleic acids or polynucleotides encoding antibodies of the disclosure (including variants and derivatives thereof as described herein).
[0160] The antibodies of the disclosure can also be used to treat or inhibit cancer. PD-L1 can be overexpressed in tumor cells. Tumor-derived PD-L1 can bind to PD-1 on immune cells thereby limiting antitumor T-cell immunity. Results with small molecule inhibitors, or monoclonal antibodies targeting PD-L1 in murine tumor models, indicate that targeted PD-L1 therapy is an important alternative and realistic approach to effective control of tumor growth. As demonstrated in the experimental examples, the anti-PD-L1 antibodies activated the adaptive immune response machinery, which can lead to improved survival in cancer patients.
[0161] Accordingly, in some embodiments, provided are methods for treating a cancer in a patient in need thereof. The method, in one embodiment, entails administering to the patient an effective amount of an antibody of the present disclosure. In some embodiments, at least one of the cancer cells (e.g., stromal cells) in the patient expresses, over-express, or is induced to express PD-L1. Induction of PD-L1 expression, for instance, can be done by administration of a tumor vaccine or radiotherapy.
[0162] Tumors that express the PD-L1 protein include those of bladder cancer, non-small cell lung cancer, renal cancer, breast cancer, urethral cancer, colorectal cancer, head and neck cancer, squamous cell cancer, Merkel cell carcinoma, gastrointestinal cancer, stomach cancer, oesophageal cancer, ovarian cancer, renal cancer, and small cell lung cancer. Accordingly, the presently disclosed antibodies can be used for treating any one or more such cancers.
[0163] Cellular therapies, such as chimeric antigen receptor (CAR) T-cell therapies, are also provided in the present disclosure. A suitable cell can be used, that is put in contact with an anti-PD-L1 antibody of the present disclosure (or alternatively engineered to express an anti-PD-L1 antibody of the present disclosure). Upon such contact or engineering, the cell can then be introduced to a cancer patient in need of a treatment. The cancer patient may have a cancer of any of the types as disclosed herein. The cell (e.g., T cell) can be, for instance, a tumor-infiltrating T lymphocyte, a CD4+ T cell, a CD8+ T cell, or the combination thereof, without limitation.
[0164] In some embodiments, the cell was isolated from the cancer patient him- or her-self. In some embodiments, the cell was provided by a donor or from a cell bank. When the cell is isolated from the cancer patient, undesired immune reactions can be minimized.
[0165] Additional diseases or conditions associated with increased cell survival, that may be treated, prevented, diagnosed and/or prognosed with the antibodies or variants, or derivatives thereof of the disclosure include, but are not limited to, progression, and/or metastases of malignancies and related disorders such as leukemia (including acute leukemias (e.g., acute lymphocytic leukemia, acute myelocytic leukemia (including myeloblastic, promyelocytic, myelomonocytic, monocytic, and erythroleukemia)) and chronic leukemias (e.g., chronic myelocytic (granulocytic) leukemia and chronic lymphocytic leukemia)), polycythemia vera, lymphomas (e.g., Hodgkin's disease and non-Hodgkin's disease), multiple myeloma, Waldenstrom's macroglobulinemia, heavy chain disease, and solid tumors including, but not limited to, sarcomas and carcinomas such as fibrosarcoma, myxosarcoma, liposarcoma, chondrosarcoma, osteogenic sarcoma, chordoma, angiosarcoma, endotheliosarcoma, lymphangiosarcoma, lymphangioendotheliosarcoma, synovioma, mesothelioma, Ewing's tumor, leiomyosarcoma, rhabdomyo sarcoma, colon carcinoma, pancreatic cancer, breast cancer, thyroid cancer, endometrial cancer, melanoma, prostate cancer, ovarian cancer, prostate cancer, squamous cell carcinoma, basal cell carcinoma, adenocarcinoma, sweat gland carcinoma, sebaceous gland carcinoma, papillary carcinoma, papillary adenocarcinomas, cystadenocarcinoma, medullary carcinoma, bronchogenic carcinoma, renal cell carcinoma, hepatoma, bile duct carcinoma, choriocarcinoma, seminoma, embryonal carcinoma, Wilm's tumor, cervical cancer, testicular tumor, lung carcinoma, small cell lung carcinoma, bladder carcinoma, epithelial carcinoma, glioma, astrocytoma, medulloblastoma, craniopharyngioma, ependymoma, pinealoma, hemangioblastoma, acoustic neuroma, oligodendroglioma, menangioma, melanoma, neuroblastoma and retinoblastoma.
Combination Therapies
[0166] In a further embodiment, the compositions of the disclosure are administered in combination with an antineoplastic agent, an antiviral agent, antibacterial or antibiotic agent or antifungal agents. Any of these agents known in the art may be administered in the compositions of the current disclosure.
[0167] In another embodiment, compositions of the disclosure are administered in combination with a chemotherapeutic agent. Chemotherapeutic agents that may be administered with the compositions of the disclosure include, but are not limited to, antibiotic derivatives (e.g., doxorubicin, bleomycin, daunorubicin, and dactinomycin); antiestrogens (e.g., tamoxifen); antimetabolites (e.g., fluorouracil, 5-FU, methotrexate, floxuridine, interferon alpha-2b, glutamic acid, plicamycin, mercaptopurine, and 6-thioguanine); cytotoxic agents (e.g., carmustine, BCNU, lomustine, CCNU, cytosine arabinoside, cyclophosphamide, estramustine, hydroxyurea, procarbazine, mitomycin, busulfan, cis-platin, and vincristine sulfate); hormones (e.g., medroxyprogesterone, estramustine phosphate sodium, ethinyl estradiol, estradiol, megestrol acetate, methyltestosterone, diethylstilbestrol diphosphate, chlorotrianisene, and testolactone); nitrogen mustard derivatives (e.g., mephalen, chorambucil, mechlorethamine (nitrogen mustard) and thiotepa); steroids and combinations (e.g., bethamethasone sodium phosphate); and others (e.g., dicarbazine, asparaginase, mitotane, vincristine sulfate, vinblastine sulfate, and etoposide).
[0168] In an additional embodiment, the compositions of the disclosure are administered in combination with cytokines. Cytokines that may be administered with the compositions of the disclosure include, but are not limited to, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-10, IL-12, IL-13, IL-15, anti-CD40, CD40L, and TNF-.alpha..
[0169] In additional embodiments, the compositions of the disclosure are administered in combination with other therapeutic or prophylactic regimens, such as, for example, radiation therapy.
[0170] Combination therapies are also provided, which includes the use of one or more of the anti-PD-L1 antibody of the present disclosure along with a second anticancer (chemotherapeutic) agent. Chemotherapeutic agents may be categorized by their mechanism of action into, for example, the following groups:
[0171] anti-metabolites/anti-cancer agents such as pyrimidine analogs floxuridine, capecitabine, and cytarabine;
[0172] purine analogs, folate antagonists, and related inhibitors;
[0173] antiproliferative/antimitotic agents including natural products such as vinca alkaloid (vinblastine, vincristine) and microtubule such as taxane (paclitaxel, docetaxel), vinblastin, nocodazole, epothilones, vinorelbine (NAVELBINE.RTM.), and epipodophyllotoxins (etoposide, teniposide);
[0174] DNA damaging agents such as actinomycin, amsacrine, busulfan, carboplatin, chlorambucil, cisplatin, cyclophosphamide (CYTOXAN.RTM.), dactinomycin, daunorubicin, doxorubicin, epirubicin, iphosphamide, melphalan, merchlorethamine, mitomycin, mitoxantrone, nitrosourea, procarbazine, taxol, taxotere, teniposide, etoposide, and triethylenethiophosphoramide;
[0175] antibiotics such as dactinomycin, daunorubicin, doxorubicin, idarubicin, anthracyclines, mitoxantrone, bleomycins, plicamycin (mithramycin), and mitomycin;
[0176] enzymes such as L-asparaginase which systemically metabolizes L-asparagine and deprives cells which do not have the capacity to synthesize their own asparagine;
[0177] antiplatelet agents;
[0178] antiproliferative/antimitotic alkylating agents such as nitrogen mustards cyclophosphamide and analogs (melphalan, chlorambucil, hexamethylmelamine, and thiotepa), alkyl nitrosoureas (carmustine) and analogs, streptozocin, and triazenes (dacarbazine);
[0179] antiproliferative/antimitotic antimetabolites such as folic acid analogs (methotrexate);
[0180] platinum coordination complexes (cisplatin, oxiloplatinim, and carboplatin), procarbazine, hydroxyurea, mitotane, and aminoglutethimide;
[0181] hormones, hormone analogs (estrogen, tamoxifen, goserelin, bicalutamide, and nilutamide), and aromatase inhibitors (letrozole and anastrozole);
[0182] anticoagulants such as heparin, synthetic heparin salts, and other inhibitors of thrombin;
[0183] fibrinolytic agents such as tissue plasminogen activator, streptokinase, urokinase, aspirin, dipyridamole, ticlopidine, and clopidogrel;
[0184] antimigratory agents;
[0185] antisecretory agents (breveldin);
[0186] immunosuppressives tacrolimus, sirolimus, azathioprine, and mycophenolate;
[0187] compounds (TNP-470, genistein) and growth factor inhibitors (vascular endothelial growth factor inhibitors and fibroblast growth factor inhibitors);
[0188] angiotensin receptor blockers, nitric oxide donors;
[0189] anti-sense oligonucleotides;
[0190] antibodies such as trastuzumab and rituximab;
[0191] cell cycle inhibitors and differentiation inducers such as tretinoin;
[0192] inhibitors, topoisomerase inhibitors (doxorubicin, daunorubicin, dactinomycin, eniposide, epirubicin, etoposide, idarubicin, irinotecan, mitoxantrone, topotecan, and irinotecan), and corticosteroids (cortisone, dexamethasone, hydrocortisone, methylprednisolone, prednisone, and prednisolone);
[0193] growth factor signal transduction kinase inhibitors;
[0194] dysfunction inducers;
[0195] toxins such as Cholera toxin, ricin, Pseudomonas exotoxin, Bordetella pertussis adenylate cyclase toxin, diphtheria toxin, and caspase activators;
[0196] and chromatin.
[0197] Further examples of chemotherapeutic agents include:
[0198] alkylating agents such as thiotepa and cyclophosphamide (CYTOXAN.RTM.);
[0199] alkyl sulfonates such as busulfan, improsulfan, and piposulfan;
[0200] aziridines such as benzodopa, carboquone, meturedopa, and uredopa;
[0201] emylerumines and memylamelamines including alfretamine, triemylenemelamine, triethylenephosphoramide, triethylenethiophosphoramide, and trimemylolomelamine;
[0202] acetogenins, especially bullatacin and bullatacinone;
[0203] a camptothecin, including synthetic analog topotecan;
[0204] bryostatin;
[0205] callystatin;
[0206] CC-1065, including its adozelesin, carzelesin, and bizelesin synthetic analogs; cryptophycins, particularly cryptophycin 1 and cryptophycin 8;
[0207] dolastatin;
[0208] duocarmycin, including the synthetic analogs KW-2189 and CBI-TMI;
[0209] eleutherobin;
[0210] pancratistatin;
[0211] a sarcodictyin;
[0212] spongistatin;
[0213] nitrogen mustards such as chlorambucil, chlornaphazine, cyclophosphamide, estramustine, ifosfamide, mechlorethamine, mechlorethamine oxide hydrochloride, melphalan, novembichin, phenesterine, prednimustine, trofosfamide, and uracil mustard;
[0214] nitrosoureas such as carmustine, chlorozotocin, foremustine, lomustine, nimustine, and ranimustine;
[0215] antibiotics such as the enediyne antibiotics (e.g., calicheamicin, especially calicheamicin gammaII and calicheamicin phiI1), dynemicin including dynemicin A, bisphosphonates such as clodronate, an esperamicin, neocarzinostatin chromophore and related chromoprotein enediyne antibiotic chromomophores, aclacinomycins, actinomycin, authramycin, azaserine, bleomycins, cactinomycin, carabicin, carrninomycin, carzinophilin, chromomycins, dactinomycin, daunorubicin, detorubicin, 6-diazo-5-oxo-L-norleucine, doxorubicin (including morpholino-doxorubicin, cyanomorpholino-doxorubicin, 2-pyrrolino-doxorubicin, and deoxydoxorubicin), epirubicin, esorubicin, idarubicin, marcellomycin, mitomycins such as mitomycin C, mycophenolic acid, nogalamycin, olivomycins, peplomycin, porfiromycin, puromycin, quelamycin, rodorubicin, streptonigrin, streptozocin, tubercidin, ubenimex, zinostatin, and zorubicin;
[0216] anti-metabolites such as methotrexate and 5-fluorouracil (5-FU);
[0217] folic acid analogs such as demopterin, methotrexate, pteropterin, and trimetrexate;
[0218] purine analogs such as fludarabine, 6-mercaptopurine, thiamiprine, and thioguanine;
[0219] pyrimidine analogs such as ancitabine, azacitidine, 6-azauridine, carmofur, cytarabine, dideoxyuridine, doxifluridine, enocitabine, and floxuridine;
[0220] androgens such as calusterone, dromostanolone propionate, epitiostanol, mepitiostane, and testolactone;
[0221] anti-adrenals such as aminoglutethimide, mitotane, and trilostane;
[0222] folic acid replinishers such as frolinic acid;
[0223] trichothecenes, especially T-2 toxin, verracurin A, roridin A, and anguidine;
[0224] taxoids such as paclitaxel (TAXOL.RTM.) and docetaxel (TAXOTERE.RTM.);
[0225] platinum analogs such as cisplatin and carboplatin;
[0226] aceglatone; aldophosphamide glycoside; aminolevulinic acid; eniluracil; amsacrine; hestrabucil; bisantrene; edatraxate; defofamine; demecolcine; diaziquone; elformthine; elliptinium acetate; an epothilone; etoglucid; gallium nitrate; hydroxyurea; lentinan; leucovorin; lonidamine; maytansinoids such as maytansine and ansamitocins; mitoguazone; mitoxantrone; mopidamol; nitracrine; pentostatin; phenamet; pirarubicin; losoxantrone; fluoropyrimidine; folinic acid; podophyllinic acid; 2-ethylhydrazide; procarbazine; polysaccharide-K (PSK); razoxane; rhizoxin; sizofiran; spirogermanium; tenuazonic acid; triaziquone; 2,2',2''-tricUorotriemylamine; urethane; vindesine; dacarbazine; mannomustine; mitobronitol; mitolactol; pipobroman; gacytosine; arabinoside ("Ara-C"); cyclophosphamide; thiopeta; chlorambucil; gemcitabine (GEMZAR.RTM.); 6-thioguanine; mercaptopurine; methotrexate; vinblastine; platinum; etoposide (VP-16); ifosfamide; mitroxantrone; vancristine; vinorelbine (NAVELBINE.RTM.); novantrone; teniposide; edatrexate; daunomycin; aminopterin; xeoloda; ibandronate; CPT-11; topoisomerase inhibitor RFS 2000; difluoromethylornithine (DFMO); retinoids such as retinoic acid; capecitabine; FOLFIRI (fluorouracil, leucovorin, and irinotecan);
[0227] and pharmaceutically acceptable salts, acids, or derivatives of any of the above.
[0228] Also included in the definition of "chemotherapeutic agent" are anti-hormonal agents such as anti-estrogens and selective estrogen receptor modulators (SERMs), inhibitors of the enzyme aromatase, anti-androgens, and pharmaceutically acceptable salts, acids or derivatives of any of the above that act to regulate or inhibit hormone action on tumors.
[0229] Examples of anti-estrogens and SERMs include, for example, tamoxifen (including NOLVADEX.TM.), raloxifene, droloxifene, 4-hydroxytamoxifen, trioxifene, keoxifene, LY117018, onapristone, and toremifene (FARESTON.RTM.)).
[0230] Inhibitors of the enzyme aromatase regulate estrogen production in the adrenal glands. Examples include 4(5)-imidazoles, aminoglutethimide, megestrol acetate (MEGACE.RTM.), exemestane, formestane, fadrozole, vorozole (RIVISOR.RTM.)), letrozole (FEMARA.RTM.), and anastrozole)(ARIMIDEX.RTM.).
[0231] Examples of anti-androgens include flutamide, nilutamide, bicalutamide, leuprohde, and goserelin.
[0232] Examples of chemotherapeutic agents also include anti-angiogenic agents including, but are not limited to, retinoid acid and derivatives thereof, 2-methoxyestradiol, ANGIOSTATIN.RTM., ENDOSTATIN.RTM., suramin, squalamine, tissue inhibitor of metalloproteinase-1, tissue inhibitor of metalloproteinase-2, plasminogen activator inhibitor-1, plasminogen activator inbibitor-2, cartilage-derived inhibitor, paclitaxel (nab-paclitaxel), platelet factor 4, protamine sulphate (clupeine), sulphated chitin derivatives (prepared from queen crab shells), sulphated polysaccharide peptidoglycan complex (sp-pg), staurosporine, modulators of matrix metabolism including proline analogs ((1-azetidine-2-carboxylic acid (LACA)), cishydroxyproline, d,I-3,4-dehydroproline, thiaproline, .alpha.,.alpha.'-dipyridyl, beta-aminopropionitrile fumarate, 4-propyl-5-(4-pyridinyl)-2(3h)-oxazolone, methotrexate, mitoxantrone, heparin, interferons, 2 macroglobulin-serum, chicken inhibitor of metalloproteinase-3 (ChIMP-3), chymostatin, beta-cyclodextrin tetradecasulfate, eponemycin, fumagillin, gold sodium thiomalate, d-penicillamine, beta-1-anticollagenase-serum, alpha-2-antiplasmin, bisantrene, lobenzarit disodium, n-2-carboxyphenyl-4-chloroanthronilic acid disodium or "CCA", thalidomide, angiostatic steroid, carboxy aminoimidazole, and metalloproteinase inhibitors such as BB-94. Other anti-angiogenesis agents include antibodies, preferably monoclonal antibodies against these angiogenic growth factors: beta-FGF, alpha-FGF, FGF-5, VEGF isoforms, VEGF-C, HGF/SF, and Ang-1/Ang-2.
[0233] Examples of chemotherapeutic agents also include anti-fibrotic agents including, but are not limited to, the compounds such as beta-aminoproprionitrile (BAPN), as well as the compounds disclosed in U.S. Pat. No. 4,965,288 (Palfreyman, et al.) relating to inhibitors of lysyl oxidase and their use in the treatment of diseases and conditions associated with the abnormal deposition of collagen and U.S. Pat. No. 4,997,854 (Kagan et al.) relating to compounds which inhibit LOX for the treatment of various pathological fibrotic states, which are herein incorporated by reference. Further exemplary inhibitors are described in U.S. Pat. No. 4,943,593 (Palfreyman et al.) relating to compounds such as 2-isobutyl-3-fluoro-, chloro-, or bromo-allylamine, U.S. Pat. No. 5,021,456 (Palfreyman et al.), U.S. Pat. No. 5,059,714 (Palfreyman et al.), U.S. Pat. No. 5,120,764 (Mccarthy et al.), U.S. Pat. No. 5,182,297 (Palfreyman et al.), U.S. Pat. No. 5,252,608 (Palfreyman et al.) relating to 2-(1-naphthyloxymemyl)-3-fluoroallylamine, and U.S. Pub. No. 2004/0248871 (Farjanel et al.), which are herein incorporated by reference.
[0234] Exemplary anti-fibrotic agents also include the primary amines reacting with the carbonyl group of the active site of the lysyl oxidases, and more particularly those which produce, after binding with the carbonyl, a product stabilized by resonance, such as the following primary amines: emylenemamine, hydrazine, phenylhydrazine, and their derivatives; semicarbazide and urea derivatives; aminonitriles such as BAPN or 2-nitroethylamine; unsaturated or saturated haloamines such as 2-bromo-ethylamine, 2-chloroethylamine, 2-trifluoroethyl amine, 3-bromopropylamine, and p-halobenzylamines; and selenohomocysteine lactone.
[0235] Other anti-fibrotic agents are copper chelating agents penetrating or not penetrating the cells. Exemplary compounds include indirect inhibitors which block the aldehyde derivatives originating from the oxidative deamination of the lysyl and hydroxylysyl residues by the lysyl oxidases. Examples include the thiolamines, particularly D-penicillamine, and its analogs such as 2-amino-5-mercapto-5-methylhexanoic acid, D-2-amino-3-methyl-3-((2-acetamidoethyl)dithio)butanoic acid, p-2-amino-3-methyl-3-((2-aminoethyl)dithio)butanoic acid, sodium-4-((p-1-dimethyl-2-amino-2-carboxyethyl)dithio)butane sulphurate, 2-acetamidoethyl-2-acetamidoethanethiol sulphanate, and sodium-4-mercaptobutanesulphinate trihydrate.
[0236] Examples of chemotherapeutic agents also include immunotherapeutic agents including and are not limited to therapeutic antibodies suitable for treating patients. Some examples of therapeutic antibodies include simtuzumab, abagovomab, adecatumumab, afutuzumab, alemtuzumab, altumomab, amatuximab, anatumomab, arcitumomab, bavituximab, bectumomab, bevacizumab, bivatuzumab, blinatumomab, brentuximab, cantuzumab, catumaxomab, cetuximab, citatuzumab, cixutumumab, clivatuzumab, conatumumab, daratumumab, drozitumab, duligotumab, dusigitumab, detumomab, dacetuzumab, dalotuzumab, ecromeximab, elotuzumab, ensituximab, ertumaxomab, etaracizumab, farletuzumab, ficlatuzumab, figitumumab, flanvotumab, futuximab, ganitumab, gemtuzumab, girentuximab, glembatumumab, ibritumomab, igovomab, imgatuzumab, indatuximab, inotuzumab, intetumumab, ipilimumab, iratumumab, labetuzumab, lexatumumab, lintuzumab, lorvotuzumab, lucatumumab, mapatumumab, matuzumab, milatuzumab, minretumomab, mitumomab, moxetumomab, narnatumab, naptumomab, necitumumab, nimotuzumab, nofetumomab, ocaratuzumab, ofatumumab, olaratumab, onartuzumab, oportuzumab, oregovomab, panitumumab, parsatuzumab, patritumab, pemtumomab, pertuzumab, pintumomab, pritumumab, racotumomab, radretumab, rilotumumab, rituximab, robatumumab, satumomab, sibrotuzumab, siltuximab, solitomab, tacatuzumab, taplitumomab, tenatumomab, teprotumumab, tigatuzumab, tositumomab, trastuzumab, tucotuzumab, ublituximab, veltuzumab, vorsetuzumab, votumumab, zalutumumab, CC49, and 3F8. Rituximab can be used for treating indolent B-cell cancers, including marginal-zone lymphoma, WM, CLL and small lymphocytic lymphoma. A combination of Rituximab and chemotherapy agents is especially effective.
[0237] The exemplified therapeutic antibodies may be further labeled or combined with a radioisotope particle such as indium-111, yttrium-90, or iodine-131.
[0238] In a one embodiment, the additional therapeutic agent is a nitrogen mustard alkylating agent. Nonlimiting examples of nitrogen mustard alkylating agents include chlorambucil.
[0239] In one embodiment, the compounds and compositions described herein may be used or combined with one or more additional therapeutic agents. The one or more therapeutic agents include, but are not limited to, an inhibitor of Abl, activated CDC kinase (ACK), adenosine A2B receptor (A2B), apoptosis signal-regulating kinase (ASK), Auroa kinase, Bruton's tyrosine kinase (BTK), BET-bromodomain (BRD) such as BRD4, c-Kit, c-Met, CDK-activating kinase (CAK), calmodulin-dependent protein kinase (CaMK), cyclin-dependent kinase (CDK), casein kinase (CK), discoidin domain receptor (DDR), epidermal growth factor receptors (EGFR), focal adhesion kinase (FAK), Flt-3, FYN, glycogen synthase kinase (GSK), HCK, histone deacetylase (HDAC), IKK such as IKK.beta..epsilon., isocitrate dehydrogenase (IDH) such as IDH1, Janus kinase (JAK), KDR, lymphocyte-specific protein tyrosine kinase (LCK), lysyl oxidase protein, lysyl oxidase-like protein (LOXL), LYN, matrix metalloprotease (MMP), MEK, mitogen-activated protein kinase (MAPK), NEK9, NPM-ALK, p38 kinase, platelet-derived growth factor (PDGF), phosphorylase kinase (PK), polo-like kinase (PLK), phosphatidylinositol 3-kinase (PI3K), protein kinase (PK) such as protein kinase A, B, and/or C, PYK, spleen tyrosine kinase (SYK), serine/threonine kinase TPL2, serine/threonine kinase STK, signal transduction and transcription (STAT), SRC, serine/threonine-protein kinase (TBK) such as TBK1, TIE, tyrosine kinase (TK), vascular endothelial growth factor receptor (VEGFR), YES, or any combination thereof
[0240] ASK inhibitors include ASK1 inhibitors. Examples of ASK1 inhibitors include, but are not limited to, those described in WO 2011/008709 (Gilead Sciences) and WO 2013/112741 (Gilead Sciences).
[0241] Examples of BTK inhibitors include, but are not limited to, ibrutinib, HM71224, ONO-4059, and CC-292.
[0242] DDR inhibitors include inhibitors of DDR1 and/or DDR2. Examples of DDR inhibitors include, but are not limited to, those disclosed in WO 2014/047624 (Gilead Sciences), US 2009/0142345 (Takeda Pharmaceutical), US 2011/0287011 (Oncomed Pharmaceuticals), WO 2013/027802 (Chugai Pharmaceutical), and WO 2013/034933 (Imperial Innovations).
[0243] Examples of HDAC inhibitors include, but are not limited to, pracinostat and panobinostat.
[0244] JAK inhibitors inhibit JAK1, JAK2, and/or JAK3. Examples of JAK inhibitors include, but are not limited to, filgotinib, ruxolitinib, fedratinib, tofacitinib, baricitinib, lestaurtinib, pacritinib, XL019, AZD1480, INCB039110, LY2784544, BMS911543, and NS018.
[0245] LOXL inhibitors include inhibitors of LOXL1, LOXL2, LOXL3, LOXL4, and/or LOXLS. Examples of LOXL inhibitors include, but are not limited to, the antibodies described in WO 2009/017833 (Arresto Biosciences).
[0246] Examples of LOXL2 inhibitors include, but are not limited to, the antibodies described in WO 2009/017833 (Arresto Biosciences), WO 2009/035791 (Arresto Biosciences), and WO 2011/097513 (Gilead Biologics).
[0247] MMP inhibitors include inhibitors of MMP1 through 10. Examples of MMP9 inhibitors include, but are not limited to, marimastat (BB-2516), cipemastat (Ro 32-3555), and those described in WO 2012/027721 (Gilead Biologics).
[0248] PI3K inhibitors include inhibitors of PI3K.gamma., PI3K.delta., PI3K.beta., PI3K.alpha., and/or pan-PI3K. Examples of PI3K inhibitors include, but are not limited to, wortmannin, BKM120, CH5132799, XL756, and GDC-0980.
[0249] Examples of PI3K.gamma. inhibitors include, but are not limited to, ZSTK474, AS252424, LY294002, and TG100115.
[0250] Examples of PI3K.delta. inhibitors include, but are not limited to, PI3K II, TGR-1202, AMG-319, GSK2269557, X-339, X-414, RP5090, KAR4141, XL499, OXY111A, IPI-145, IPI-443, and the compounds described in WO 2005/113556 (ICOS), WO 2013/052699 (Gilead Calistoga), WO 2013/116562 (Gilead Calistoga), WO 2014/100765 (Gilead Calistoga), WO 2014/100767 (Gilead Calistoga), and WO 2014/201409 (Gilead Sciences).
[0251] Examples of PI3K.beta. inhibitors include, but are not limited to, GSK2636771, BAY 10824391, and TGX221.
[0252] Examples of PI3K.alpha. inhibitors include, but are not limited to, buparlisib, BAY 80-6946, BYL719, PX-866, RG7604, MLN1117, WX-037, AEZA-129, and PA799.
[0253] Examples of pan-PI3K inhibitors include, but are not limited to, LY294002, BEZ235, XL147 (SAR245408), and GDC-0941.
[0254] Examples of SYK inhibitors include, but are not limited to, tamatinib (R406), fostamatinib (R788), PRT062607, BAY-61-3606, NVP-QAB 205 AA, R112, R343, and those described in U.S. Pat. No. 8,450,321 (Gilead Connecticut).
[0255] TKIs may target epidermal growth factor receptors (EGFRs) and receptors for fibroblast growth factor (FGF), platelet-derived growth factor (PDGF), and vascular endothelial growth factor (VEGF). Examples of TKIs that target EGFR include, but are not limited to, gefitinib and erlotinib. Sunitinib is a non-limiting example of a TKI that targets receptors for FGF, PDGF, and VEGF.
[0256] The anti-PD-L1 antibodies of the present disclosure can be used, in some embodiments, together with an immune checkpoint inhibitor. Immune checkpoints are molecules in the immune system that either turn up a signal (co-stimulatory molecules) or turn down a signal (co-inhibitory molecules). Many cancers protect themselves from the immune system by inhibiting the T cell signal through agonist for co-inhibitory molecules or antagonist for co-stimulatory molecules. An immune checkpoint agonist or antagonist can help stop such a protective mechanism by the cell cells. An immune checkpoint agonist or antagonist may target any one or more of the following checkpoint molecules, PD-1, CTLA-4, LAG-3 (also known as CD223), CD28, CD122, 4-1BB (also known as CD137), TIM3, OX-40/OX40L, CD40/CD40L, LIGHT, ICOS/ICOSL, GITR/GITRL, TIGIT, CD27, VISTA, B7H3, B7H4, HEVM or BTLA (also known as CD272).
[0257] Programmed T cell death 1 (PD-1) is a trans-membrane protein found on the surface of T cells, which, when bound to programmed T cell death ligand 1 (PD-L1) on tumor cells, results in suppression of T cell activity and reduction of T cell-mediated cytotoxicity. Thus, PD-1 and PD-L1 are immune down-regulators or immune checkpoint "off switches". Example PD-1 inhibitor include, without limitation, nivolumab, (Opdivo) (BMS-936558), pembrolizumab (Keytruda), pidilizumab, AMP-224, MEDI0680 (AMP-514), PDR001, MPDL3280A, MEDI4736, BMS-936559 and MSB0010718C.
[0258] CTLA-4 is a protein receptor that downregulates the immune system. Non-limiting examples of CTLA-4 inhibitors include ipilimumab (Yervoy) (also known as BMS-734016, MDX-010, MDX-101) and tremelimumab (formerly ticilimumab, CP-675,206).
[0259] Lymphocyte-activation gene 3 (LAG-3) is an immune checkpoint receptor on the cell surface works to suppress an immune response by action to Tregs as well as direct effects on CD8+ T cells. LAG-3 inhibitors include, without limitation, LAG525 and BMS-986016.
[0260] CD28 is constitutively expressed on almost all human CD4+ T cells and on around half of all CD8 T cells. prompts T cell expansion. Non-limiting examples of CD28 inhibitors include TGN1412.
[0261] CD122 increases the proliferation of CD8+ effector T cells. Non-limiting examples include NKTR-214.
[0262] 4-1BB (also known as CD137) is involved in T-cell proliferation. CD137-mediated signaling is also known to protect T cells, and in particular, CD8+ T cells from activation-induced cell death. PF-05082566, Urelumab (BMS-663513) and lipocalin are example CD137 inhibitors.
[0263] For any of the above combination treatments, the anti-PD-L1 antibody can be administered concurrently or separately from the other anticancer agent. When administered separately, the anti-PD-L1 antibody can be administered before or after the other anticancer agent.
Treatment of Infections
[0264] As demonstrated in the experimental examples, the antibodies of the present disclosure can activate immune response which can then be useful for treating infections.
[0265] Infection is the invasion of an organism's body tissues by disease-causing agents, their multiplication, and the reaction of host tissues to these organisms and the toxins they produce. An infection can be caused by infectious agents such as viruses, viroids, prions, bacteria, nematodes such as parasitic roundworms and pinworms, arthropods such as ticks, mites, fleas, and lice, fungi such as ringworm, and other macroparasites such as tapeworms and other helminths. In one aspect, the infectious agent is a bacterium, such as Gram negative bacterium. In one aspect, the infectious agent is virus, such as DNA viruses, RNA viruses, and reverse transcribing viruses. Non-limiting examples of viruses include Adenovirus, Coxsackievirus, Epstein-Barr virus, Hepatitis A virus, Hepatitis B virus, Hepatitis C virus, Herpes simplex virus, type 1, Herpes simplex virus, type 2, Cytomegalovirus, Human herpesvirus, type 8, HIV, Influenza virus, Measles virus, Mumps virus, Human papillomavirus, Parainfluenza virus, Poliovirus, Rabies virus, Respiratory syncytial virus, Rubella virus, Varicella-zoster virus.
[0266] The antibodies of the present disclosure can also be used to treat an infectious disease caused by a microorganism, or kill a microorganism, by targeting the microorganism and an immune cell to effect elimination of the microorganism. In one aspect, the microorganism is a virus including RNA and DNA viruses, a Gram positive bacterium, a Gram negative bacterium, a protozoa or a fungus. Non-limiting examples of infectious diseases and related microorganisms are provided in Table 4 below.
TABLE-US-00017 TABLE 4 Infectious diseases and related microorganism sources. Infectious Disease Microorganism Source Acinetobacter infections Acinetobacter baumannii Actinomycosis Actinomyces israelii, Actinomyces gerencseriae and Propionibacterium propionicus African sleeping sickness Trypanosoma brucei (African trypanosomiasis) AIDS (Acquired immunodeficiency syndrome) HIV (Human immunodeficiency virus) Amebiasis Entamoeba histolytica Anaplasmosis Anaplasma genus Anthrax Bacillus anthracis Arcanobacterium haemolyticum infection Arcanobacterium haemolyticum Argentine hemorrhagic fever Junin virus Ascariasis Ascaris lumbricoides Aspergillosis Aspergillus genus Astrovirus infection Astroviridae family Babesiosis Babesia genus Bacillus cereus infection Bacillus cereus Bacterial pneumonia multiple bacteria Bacterial vaginosis (BV) multiple bacteria Bacteroides infection Bacteroides genus Balantidiasis Balantidium coli Baylisascaris infection Baylisascaris genus BK virus infection BK virus Black piedra Piedraia hortae Blastocystis hominis infection Blastocystis hominis Blastomycosis Blastomyces dermatitidis Bolivian hemorrhagic fever Machupo virus Borrelia infection Borrelia genus Botulism (and Infant botulism) Clostridium botulinum Brazilian hemorrhagic fever Sabia Brucellosis Brucella genus Burkholderia infection usually Burkholderia cepacia and other Burkholderia species Buruli ulcer Mycobacterium ulcerans Calicivirus infection Caliciviridae family (Norovirus and Sapovirus) Campylobacteriosis Campylobacter genus Candidiasis (Moniliasis; Thrush) usually Candida albicans and other Candida species Cat-scratch disease Bartonella henselae Cellulitis usually Group A Streptococcus and Staphylococcus Chagas Disease (American trypanosomiasis) Trypanosoma cruzi Chancroid Haemophilus ducreyi Chickenpox Varicella zoster virus (VZV) Chlamydia Chlamydia trachomatis Chlamydophila pneumoniae infection Chlamydophila pneumoniae Cholera Vibrio cholerae Chromoblastomycosis usually Fonsecaea pedrosoi Clonorchiasis Clonorchis sinensis Clostridium difficile infection Clostridium difficile Coccidioidomycosis Coccidioides immitis and Coccidioides posadasii Colorado tick fever (CTF) Colorado tick fever virus (CTFV) Common cold (Acute viral rhinopharyngitis; usually rhinoviruses and coronaviruses. Acute coryza) Creutzfeldt-Jakob disease (CJD) CJD prion Crimean-Congo hemorrhagic fever Crimean-Congo hemorrhagic fever virus (CCHF) Cryptococcosis Cryptococcus neoformans Cryptosporidiosis Cryptosporidium genus Cutaneous larva migrans (CLM) usually Ancylostoma braziliense; multiple other parasites Cyclosporiasis Cyclospora cayetanensis Cysticercosis Taenia solium Cytomegalovirus infection Cytomegalovirus Dengue fever Dengue viruses (DEN-1, DEN-2, DEN-3 and DEN-4)- Flaviviruses Dientamoebiasis Dientamoeba fragilis Diphtheria Corynebacterium diphtheriae Diphyllobothriasis Diphyllobothrium Dracunculiasis Dracunculus medinensis Ebola hemorrhagic fever Ebolavirus (EBOV) Echinococcosis Echinococcus genus Ehrlichiosis Ehrlichia genus Enterobiasis (Pinworm infection) Enterobius vermicularis Enterococcus infection Enterococcus genus Enterovirus infection Enterovirus genus Epidemic typhus Rickettsia prowazekii Erythema infectiosum (Fifth disease) Parvovirus B19 Exanthem subitum (Sixth disease) Human herpesvirus 6 (HHV-6) and Human herpesvirus 7 (HHV-7) Fasciolopsiasis Fasciolopsis buski Fasciolosis Fasciola hepatica and Fasciola gigantica Fatal familial insomnia (FFI) FFI prion Filariasis Filarioidea superfamily Food poisoning by Clostridium perfringens Clostridium perfringens Free-living amebic infection multiple Fusobacterium infection Fusobacterium genus Gas gangrene (Clostridial myonecrosis) usually Clostridium perfringens; other Clostridium species Geotrichosis Geotrichum candidum Gerstmann-Straussler-Scheinker GSS prion syndrome (GSS) Giardiasis Giardia intestinalis Glanders Burkholderia mallei Gnathostomiasis Gnathostoma spinigerum and Gnathostoma hispidum Gonorrhea Neisseria gonorrhoeae Granuloma inguinale (Donovanosis) Klebsiella granulomatis Group A streptococcal infection Streptococcus pyogenes Group B streptococcal infection Streptococcus agalactiae Haemophilus influenzae infection Haemophilus influenzae Hand, foot and mouth disease Enteroviruses, mainly Coxsackie A virus and Enterovirus (HFMD) 71 (EV71) Hantavirus Pulmonary Syndrome (HPS) Sin Nombre virus Helicobacter pylori infection Helicobacter pylori Hemolytic-uremic syndrome (HUS) Escherichia coli O157:H7, O111 and O104:H4 Hemorrhagic fever with renal Bunyaviridae family syndrome (HFRS) Hepatitis A Hepatitis A Virus Hepatitis B Hepatitis B Virus Hepatitis C Hepatitis C Virus Hepatitis D Hepatitis D Virus Hepatitis E Hepatitis E Virus Herpes simplex Herpes simplex virus 1 and 2 (HSV-1 and HSV-2) Histoplasmosis Histoplasma capsulatum Hookworm infection Ancylostoma duodenale and Necator americanus Human bocavirus infection Human bocavirus (HBoV) Human ewingii ehrlichiosis Ehrlichia ewingii Human granulocytic anaplasmosis Anaplasma phagocytophilum (HGA) Human metapneumovirus infection Human metapneumovirus (hMPV) Human monocytic ehrlichiosis Ehrlichia chaffeensis Human papillomavirus (HPV) Human papillomavirus (HPV) infection Human parainfluenza virus infection Human parainfluenza viruses (HPIV) Hymenolepiasis Hymenolepis nana and Hymenolepis diminuta Epstein-Barr Virus Infectious Epstein-Barr Virus (EBV) Mononucleosis (Mono) Influenza (flu) Orthomyxoviridae family Isosporiasis Isospora belli Kawasaki disease unknown; evidence supports that it is infectious Keratitis multiple Kingella kingae infection Kingella kingae Kuru Kuru prion Lassa fever Lassa virus Legionellosis (Legionnaires' disease) Legionella pneumophila Legionellosis (Pontiac fever) Legionella pneumophila Leishmaniasis Leishmania genus Leprosy Mycobacterium leprae and Mycobacterium lepromatosis Leptospirosis Leptospira genus Listeriosis Listeria monocytogenes Lyme disease (Lyme borreliosis) usually Borrelia burgdorferi and other Borrelia species Lymphatic filariasis (Elephantiasis) Wuchereria bancrofti and Brugia malayi Lymphocytic choriomeningitis Lymphocytic choriomeningitis virus (LCMV) Malaria Plasmodium genus Marburg hemorrhagic fever (MHF) Marburg virus Measles Measles virus Melioidosis (Whitmore's disease) Burkholderia pseudomallei Meningitis multiple Meningococcal disease Neisseria meningitidis Metagonimiasis usually Metagonimus yokagawai Microsporidiosis Microsporidia phylum Molluscum contagiosum (MC) Molluscum contagiosum virus (MCV) Mumps Mumps virus Murine typhus (Endemic typhus) Rickettsia typhi Mycoplasma pneumonia Mycoplasma pneumoniae Mycetoma numerous species of bacteria (Actinomycetoma) and fungi (Eumycetoma) Myiasis parasitic dipterous fly larvae Neonatal conjunctivitis most commonly Chlamydia trachomatis and Neisseria (Ophthalmia neonatorum) gonorrhoeae (New) Variant Creutzfeldt-Jakob vCID prion disease (vCJD, nvCJD) Nocardiosis usually Nocardia asteroides and other Nocardia species Onchocerciasis (River blindness) Onchocerca volvulus Paracoccidioidomycosis Paracoccidioides brasiliensis (South American blastomycosis) Paragonimiasis usually Paragonimus westermani and other Paragonimus species Pasteurellosis Pasteurella genus Pediculosis capitis (Head lice) Pediculus humanus capitis Pediculosis corporis (Body lice) Pediculus humanus corporis Pediculosis pubis (Pubic lice, Crab lice) Phthirus pubis Pelvic inflammatory disease (PID) multiple Pertussis (Whooping cough) Bordetella pertussis Plague Yersinia pestis Pneumococcal infection Streptococcus pneumoniae Pneumocystis pneumonia (PCP) Pneumocystis jirovecii Pneumonia multiple Poliomyelitis Poliovirus Prevotella infection Prevotella genus Primary amoebic usually Naegleria fowleri meningoencephalitis (PAM) Progressive multifocal JC virus leukoencephalopathy Psittacosis Chlamydophila psittaci Q fever Coxiella burnetii Rabies Rabies virus Rat-bite fever Streptobacillus moniliformis and Spirillum minus Respiratory syncytial virus infection Respiratory syncytial virus (RSV) Rhinosporidiosis Rhinosporidium seeberi Rhinovirus infection Rhinovirus Rickettsial infection Rickettsia genus Rickettsialpox Rickettsia akari Rift Valley fever (RVF) Rift Valley fever virus Rocky mountain spotted fever (RMSF) Rickettsia rickettsii Rotavirus infection Rotavirus Rubella Rubella virus Salmonellosis Salmonella genus SARS (Severe Acute Respiratory Syndrome) SARS coronavirus Scabies Sarcoptes scabiei Schistosomiasis Schistosoma genus Sepsis multiple Shigellosis (Bacillary dysentery) Shigella genus Shingles (Herpes zoster) Varicella zoster virus (VZV) Smallpox (Variola) Variola major or Variola minor Sporotrichosis Sporothrix schenckii Staphylococcal food poisoning Staphylococcus genus Staphylococcal infection Staphylococcus genus Strongyloidiasis Strongyloides stercoralis Syphilis Treponema pallidum Taeniasis Taenia genus Tetanus (Lockjaw) Clostridium tetani Tinea barbae (Barber's itch) usually Trichophyton genus Tinea capitis (Ringworm of the Scalp) usually Trichophyton tonsurans Tinea corporis (Ringworm of the Body) usually Trichophyton genus Tinea cruris (Jock itch) usually Epidermophytonfloccosum, Trichophyton rubrum, and Trichophyton mentagrophytes Tinea manuum (Ringworm of the Hand) Trichophyton rubrum Tinea nigra usually Hortaea werneckii Tinea pedis (Athlete's foot) usually Trichophyton genus Tinea unguium (Onychomycosis) usually Trichophyton genus Tinea versicolor (Pityriasis versicolor) Malassezia genus Toxocariasis (Ocular Larva Migrans (OLM)) Toxocara canis or Toxocara cati Toxocariasis (Visceral Larva Migrans (VLM)) Toxocara canis or Toxocara cati Toxoplasmosis Toxoplasma gondii Trichinellosis Trichinella spiralis Trichomoniasis Trichomonas vaginalis Trichuriasis (Whipworm infection) Trichuris trichiura Tuberculosis usually Mycobacterium tuberculosis Tularemia Francisella tularensis Ureaplasma urealyticum infection Ureaplasma urealyticum Venezuelan equine encephalitis Venezuelan equine encephalitis virus Venezuelan hemorrhagic fever Guanarito virus Viral pneumonia multiple viruses West Nile Fever West Nile virus White piedra (Tinea blanca) Trichosporon beigelii
Yersinia pseudotuberculosis infection Yersinia pseudotuberculosis Yersiniosis Yersinia enterocolitica Yellow fever Yellow fever virus Zygomycosis Mucorales order (Mucormycosis) and Entomophthorales order (Entomophthoramycosis)
[0267] A specific dosage and treatment regimen for any particular patient will depend upon a variety of factors, including the particular antibodies, variant or derivative thereof used, the patient's age, body weight, general health, sex, and diet, and the time of administration, rate of excretion, drug combination, and the severity of the particular disease being treated. Judgment of such factors by medical caregivers is within the ordinary skill in the art. The amount will also depend on the individual patient to be treated, the route of administration, the type of formulation, the characteristics of the compound used, the severity of the disease, and the desired effect. The amount used can be determined by pharmacological and pharmacokinetic principles well known in the art.
[0268] Methods of administration of the antibodies, variants or include but are not limited to intradermal, intramuscular, intraperitoneal, intravenous, subcutaneous, intranasal, epidural, and oral routes. The antigen-binding polypeptides or compositions may be administered by any convenient route, for example by infusion or bolus injection, by absorption through epithelial or mucocutaneous linings (e.g., oral mucosa, rectal and intestinal mucosa, etc.) and may be administered together with other biologically active agents. Thus, pharmaceutical compositions containing the antigen-binding polypeptides of the disclosure may be administered orally, rectally, parenterally, intracistemally, intravaginally, intraperitoneally, topically (as by powders, ointments, drops or transdermal patch), bucally, or as an oral or nasal spray.
[0269] The term "parenteral" as used herein refers to modes of administration which include intravenous, intramuscular, intraperitoneal, intrasternal, subcutaneous and intra-articular injection and infusion.
[0270] Administration can be systemic or local. In addition, it may be desirable to introduce the antibodies of the disclosure into the central nervous system by any suitable route, including intraventricular and intrathecal injection; intraventricular injection may be facilitated by an intraventricular catheter, for example, attached to a reservoir, such as an Ommaya reservoir. Pulmonary administration can also be employed, e.g., by use of an inhaler or nebulizer, and formulation with an aerosolizing agent.
[0271] It may be desirable to administer the antibodies polypeptides or compositions of the disclosure locally to the area in need of treatment; this may be achieved by, for example, and not by way of limitation, local infusion during surgery, topical application, e.g., in conjunction, with a wound dressing after surgery, by injection, by means of a catheter, by means of a suppository, or by means of an implant, said implant being of a porous, non-porous, or gelatinous material, including membranes, such as sialastic membranes, or fibers. Preferably, when administering a protein, including an antibody, of the disclosure, care must be taken to use materials to which the protein does not absorb.
[0272] In another embodiment, the antibodies or composition can be delivered in a vesicle, in particular a liposome (see Langer, 1990, Science 249:1527-1533; Treat et al., in Liposomes in the Therapy of Infectious Disease and Cancer, Lopez-Berestein and Fidler (eds.), Liss, New York, pp. 353-365 (1989); Lopez-Berestein, ibid., pp. 317-327; see generally ibid.)
[0273] In yet another embodiment, the antigen-binding polypeptide or composition can be delivered in a controlled release system. In one embodiment, a pump may be used (see Sefton, 1987, CRC Crit. Ref. Biomed. Eng. 14:201; Buchwald et al., 1980, Surgery 88:507; Saudek et al., 1989, N. Engl. J. Med. 321:574). In another embodiment, polymeric materials can be used (see Medical Applications of Controlled Release, Langer and Wise (eds.), CRC Pres., Boca Raton, Fla. (1974); Controlled Drug Bioavailability, Drug Product Design and Performance, Smolen and Ball (eds.), Wiley, N.Y. (1984); Ranger and Peppas, J., 1983, Macromol. Sci. Rev. Macromol. Chem. 23:61; see also Levy et al., 1985, Science 228:190; During et al., 1989, Ann. Neurol. 25:351; Howard et al., 1989, J. Neurosurg. 71:105). In yet another embodiment, a controlled release system can be placed in proximity of the therapeutic target, i.e., the brain, thus requiring only a fraction of the systemic dose (see, e.g., Goodson, in Medical Applications of Controlled Release, supra, vol. 2, pp. 115-138 (1984)). Other controlled release systems are discussed in the review by Langer (1990, Science 249:1527-1533).
[0274] In a specific embodiment where the composition of the disclosure comprises a nucleic acid or polynucleotide encoding a protein, the nucleic acid can be administered in vivo to promote expression of its encoded protein, by constructing it as part of an appropriate nucleic acid expression vector and administering it so that it becomes intracellular, e.g., by use of a retroviral vector (see U .S . Pat. No. 4,980,286), or by direct injection, or by use of microparticle bombardment (e.g., a gene gun; Biolistic, Dupont), or coating with lipids or cell-surface receptors or transfecting agents, or by administering it in linkage to a homeobox-like peptide which is known to enter the nucleus (see, e.g., Joliot et al., 1991, Proc. Natl. Acad. Sci. USA 88:1864-1868), etc. Alternatively, a nucleic acid can be introduced intracellularly and incorporated within host cell DNA for expression, by homologous recombination.
[0275] The amount of the antibodies of the disclosure which will be effective in the treatment, inhibition and prevention of an inflammatory, immune or malignant disease, disorder or condition can be determined by standard clinical techniques. In addition, in vitro assays may optionally be employed to help identify optimal dosage ranges. The precise dose to be employed in the formulation will also depend on the route of administration, and the seriousness of the disease, disorder or condition, and should be decided according to the judgment of the practitioner and each patient's circumstances. Effective doses may be extrapolated from dose-response curves derived from in vitro or animal model test systems.
[0276] As a general proposition, the dosage administered to a patient of the antigen-binding polypeptides of the present disclosure is typically 0.1 mg/kg to 100 mg/kg of the patient's body weight, between 0.1 mg/kg and 20 mg/kg of the patient's body weight, or 1 mg/kg to 10 mg/kg of the patient's body weight. Generally, human antibodies have a longer half-life within the human body than antibodies from other species due to the immune response to the foreign polypeptides. Thus, lower dosages of human antibodies and less frequent administration is often possible. Further, the dosage and frequency of administration of antibodies of the disclosure may be reduced by enhancing uptake and tissue penetration (e.g., into the brain) of the antibodies by modifications such as, for example, lipidation.
[0277] The methods for treating an infectious or malignant disease, condition or disorder comprising administration of an antibody, variant, or derivative thereof of the disclosure are typically tested in vitro, and then in vivo in an acceptable animal model, for the desired therapeutic or prophylactic activity, prior to use in humans. Suitable animal models, including transgenic animals, are well known to those of ordinary skill in the art. For example, in vitro assays to demonstrate the therapeutic utility of antigen-binding polypeptide described herein include the effect of an antigen-binding polypeptide on a cell line or a patient tissue sample. The effect of the antigen-binding polypeptide on the cell line and/or tissue sample can be determined utilizing techniques known to those of skill in the art, such as the assays disclosed elsewhere herein. In accordance with the disclosure, in vitro assays which can be used to determine whether administration of a specific antigen-binding polypeptide is indicated, include in vitro cell culture assays in which a patient tissue sample is grown in culture, and exposed to or otherwise administered a compound, and the effect of such compound upon the tissue sample is observed.
[0278] Various delivery systems are known and can be used to administer an antibody of the disclosure or a polynucleotide encoding an antibody of the disclosure, e.g., encapsulation in liposomes, microparticles, microcapsules, recombinant cells capable of expressing the compound, receptor-mediated endocytosis (see, e.g., Wu and Wu, 1987, J. Biol. Chem. 262:4429-4432), construction of a nucleic acid as part of a retroviral or other vector, etc.
Diagnostic Methods
[0279] Over-expression of PD-L1 is observed in certain tumor samples, and patients having PD-L1-over-expressing cells are likely responsive to treatments with the anti-PD-L1 antibodies of the present disclosure. Accordingly, the antibodies of the present disclosure can also be used for diagnostic and prognostic purposes.
[0280] A sample that preferably includes a cell can be obtained from a patient, which can be a cancer patient or a patient desiring diagnosis. The cell be a cell of a tumor tissue or a tumor block, a blood sample, a urine sample or any sample from the patient. Upon optional pre-treatment of the sample, the sample can be incubated with an antibody of the present disclosure under conditions allowing the antibody to interact with a PD-L1 protein potentially present in the sample. Methods such as ELISA can be used, taking advantage of the anti-PD-L1 antibody, to detect the presence of the PD-L1 protein in the sample.
[0281] Presence of the PD-L1 protein in the sample (optionally with the amount or concentration) can be used for diagnosis of cancer, as an indication that the patient is suitable for a treatment with the antibody, or as an indication that the patient has (or has not) responded to a cancer treatment. For a prognostic method, the detection can be done at once, twice or more, at certain stages, upon initiation of a cancer treatment to indicate the progress of the treatment.
Compositions
[0282] The present disclosure also provides pharmaceutical compositions. Such compositions comprise an effective amount of an antibody, and an acceptable carrier. In some embodiments, the composition further includes a second anticancer agent (e.g., an immune checkpoint inhibitor).
[0283] In a specific embodiment, the term "pharmaceutically acceptable" means approved by a regulatory agency of the Federal or a state government or listed in the U.S. Pharmacopeia or other generally recognized pharmacopeia for use in animals, and more particularly in humans. Further, a "pharmaceutically acceptable carrier" will generally be a non-toxic solid, semisolid or liquid filler, diluent, encapsulating material or formulation auxiliary of any type.
[0284] The term "carrier" refers to a diluent, adjuvant, excipient, or vehicle with which the therapeutic is administered. Such pharmaceutical carriers can be sterile liquids, such as water and oils, including those of petroleum, animal, vegetable or synthetic origin, such as peanut oil, soybean oil, mineral oil, sesame oil and the like. Water is a preferred carrier when the pharmaceutical composition is administered intravenously. Saline solutions and aqueous dextrose and glycerol solutions can also be employed as liquid carriers, particularly for injectable solutions. Suitable pharmaceutical excipients include starch, glucose, lactose, sucrose, gelatin, malt, rice, flour, chalk, silica gel, sodium stearate, glycerol monostearate, talc, sodium chloride, dried skim milk, glycerol, propylene, glycol, water, ethanol and the like. The composition, if desired, can also contain minor amounts of wetting or emulsifying agents, or pH buffering agents such as acetates, citrates or phosphates. Antibacterial agents such as benzyl alcohol or methyl parabens; antioxidants such as ascorbic acid or sodium bisulfite; chelating agents such as ethylenediaminetetraacetic acid; and agents for the adjustment of tonicity such as sodium chloride or dextrose are also envisioned. These compositions can take the form of solutions, suspensions, emulsion, tablets, pills, capsules, powders, sustained-release formulations and the like. The composition can be formulated as a suppository, with traditional binders and carriers such as triglycerides. Oral formulation can include standard carriers such as pharmaceutical grades of mannitol, lactose, starch, magnesium stearate, sodium saccharine, cellulose, magnesium carbonate, etc. Examples of suitable pharmaceutical carriers are described in Remington's Pharmaceutical Sciences by E. W. Martin, incorporated herein by reference. Such compositions will contain a therapeutically effective amount of the antigen-binding polypeptide, preferably in purified form, together with a suitable amount of carrier so as to provide the form for proper administration to the patient. The formulation should suit the mode of administration. The parental preparation can be enclosed in ampoules, disposable syringes or multiple dose vials made of glass or plastic.
[0285] In an embodiment, the composition is formulated in accordance with routine procedures as a pharmaceutical composition adapted for intravenous administration to human beings. Typically, compositions for intravenous administration are solutions in sterile isotonic aqueous buffer. Where necessary, the composition may also include a solubilizing agent and a local anesthetic such as lignocaine to ease pain at the site of the injection. Generally, the ingredients are supplied either separately or mixed together in unit dosage form, for example, as a dry lyophilized powder or water free concentrate in a hermetically sealed container such as an ampoule or sachette indicating the quantity of active agent. Where the composition is to be administered by infusion, it can be dispensed with an infusion bottle containing sterile pharmaceutical grade water or saline. Where the composition is administered by injection, an ampoule of sterile water for injection or saline can be provided so that the ingredients may be mixed prior to administration.
[0286] The compounds of the disclosure can be formulated as neutral or salt forms. Pharmaceutically acceptable salts include those formed with anions such as those derived from hydrochloric, phosphoric, acetic, oxalic, tartaric acids, etc., and those formed with cations such as those derived from sodium, potassium, ammonium, calcium, ferric hydroxides, isopropylamine, triethylamine, 2-ethylamino ethanol, histidine, procaine, etc.
EXAMPLES
Example 1
Generation of Human Monoclonal Antibodies Against Human PD-L1
[0287] Anti-human-PD-L1 mouse monoclonal antibodies were generated using the hybridoma technology.
[0288] Antigen: human PDL1-Fc protein and human PD-L1 highly expressed CHOK1 cell line (PDL1-CHOK1 cell line).
[0289] Immunization: To generate mouse monoclonal antibodies to human PD-L1, 6-8 week female BALB/c mice were firstly immunized with 1.5.times.10.sup.7 PDL1-CHOK1 cells. Day 14 and 33 post first immunization, the immunized mice were re-immunized with 1.5.times.10.sup.7 PDL1-CHOK1 cells respectively. To select mice producing antibodies that bond PD-L1 protein, sera from immunized mice were tested by ELISA. Briefly, microtiter plates were coated with human PD-L1 protein at 1 .mu.g/ml in PBS, 100 .mu.l/well at room temperature (RT) overnight, then blocked with 100 .mu.l/well of 5% BSA. Dilutions of plasma from immunized mice were added to each well and incubated for 1-2 hours at RT. The plates were washed with PBS/Tween and then incubate with anti-mouse IgG antibody conjugated with Horse Radish Peroxidase (HRP) for 1 hour at RT. After washing, the plates were developed with ABTS substrate and analyzed by spectrophotometer at OD 405 nm. Mice with sufficient titers of anti-PDL1 IgG were boosted with 50 .mu.g human PDL1-Fc protein at Day 54 post-immunization. The resulting mice were used for fusions. The hybridoma supernatants were tested for anti-PD-L1 IgGs by ELISA.
[0290] Hybridoma clones HL1210-3, HL1207-3, HL1207-9 and HL1120-3 were selected for further analysis. The amino acid and polynucleotide sequences of the variable regions of HL1210-3 are provided in Table 5 below.
TABLE-US-00018 TABLE 5 HL1210-3 variable sequences Name Sequence SEQ ID NO: HL1210-3 VH GAAGTGAAACTGGTGGAGTCTGGGGGAGACTTAGTGAAGC 112 CTGGAGGGTCCCTGAAACTCTCCTGTGCAGCCTCTGGATT CACTTTCAGTAGCTATGACATGTCTTGGGTTCGCCAGACT CCGGAGAAGAGTCTGGAGTGGGTCGCAACCATTAGTGATG GTGGTGGTTACATCTACTATTCAGACAGTGTGAAGGGGCG ATTTACCATCTCCAGAGACAATGCCAAGAACAACCTGTAC CTGCAAATGAGCAGTCTGAGGTCTGAGGACACGGCCTTGT ATATTTGTGCAAGAGAATTTGGTAAGCGCTATGCTTTGGA CTACTGGGGTCAAGGAACCTCAGTCACCGTCTCCTCA HL1210-3 VH EVKLVESGGDLVKPGGSLKLSCAASGFTFSSYDMSWVRQT 113 PEKSLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNNLY LQMSSLRSEDTALYICAREFGKRYALDYWGQGTSVT HL1210-3 VL GACATTGTGATGACCCAGTCTCACAAATTCATGTCCACAT 114 CGGTAGGAGACAGGGTCAGCATCTCCTGCAAGGCCAGTCA GGATGTGACTCCTGCTGTCGCCTGGTATCAACAGAAGCCA GGACAATCTCCTAAACTACTGATTTACTCCACATCCTCCC GGTACACTGGAGTCCCTGATCGCTTCACTGGCAGTGGATC TGGGACGGATTTCACTTTCACCATCAGCAGTGTGCAGGCT GAAGACCTGGCAGTTTATTACTGTCAGCAACATTATACTA CTCCGCTCACGTTCGGTGCTGGGACCAAGCTGGAGCTGAA A HL1210-3 VL DIVMTQSHKFMSTSVGDRVSISCKASQDVTPAVAWYQQKP 115 GQSPKLLIYSTSSRYTGVPDRFTGSGSGTDFTFTISSVQA EDLAVYYCQQHYTTPLTFGAGTKLELK
Example 2
HL1210-3 Mouse Monoclonal Antibody's Binding Activity for Human PD-L1
[0291] To evaluate the binding activity of hybridoma clone HL1210-3, the purified mAb from this clone were subjected to ELISA test. Briefly, microtiter plates were coated with human PD-L1-Fc protein at 0.1 .mu.g/ml in PBS, 100 .mu.l/well at 4.degree. C. overnight, then blocked with 100 .mu.l/well of 5% BSA. Three-fold dilutions of HL1210-3 antibodies starting from 0.2 .mu.g/ml were added to each well and incubated for 1-2 hours at RT. The plates were washed with PBS/Tween and then incubate with goat-anti-mouse IgG antibody conjugated with Horse Radish Peroxidase (HRP) for 1 hour at RT. After washing, the plates were developed with TMB substrate and analyzed by spectrophotometer at OD 450-630 nm. As shown in FIG. 1, HL1210-3 can bind to human PD-L1 with high activity (EC.sub.50=5.539 ng/ml).
Example 3
HL1210-3 Mouse mAb Blocked Human PD-L1 Binding to its Receptor PD-1
Receptor Blocking Assay by Using Recombinant Human PD-L1
[0292] To evaluate the blocking effect of HL1210-3 mouse mAb on recombinant human PD-L1 to bind to its receptor PD-1, the ELISA based receptor blocking assay was employed. Briefly, microtiter plates were coated with human PD-L1-Fc protein at 1 .mu.g/ml in PBS, 100 .mu.l/well at 4.degree. C. overnight, then blocked with 100 .mu.l/well of 5% BSA. 50 .mu.l biotin-labeled human PD-1-Fc protein and 3-fold dilutions of HL1210-3 antibodies starting from 2 .mu.g/ml at 50 .mu.l were added to each well and incubated for 1 hour at 37.degree. C. The plates were washed with PBS/Tween and then incubated with Streptavidin-HRP for 1 hour at 37.degree. C. After washing, the plates were developed with TMB substrate and analyzed by spectrophotometer at OD 450-630 nm. As shown in FIG. 2, HL1210-3 can efficiently inhibit the binding of human PD-L1 to human PD1 at IC.sub.50=0.7835 nM.
Receptor Blocking Assay by Using Mammalian Cell Expressed Human PD-L1
[0293] To evaluate the blocking effect of HL1210-3 mouse mAb on human PD-L1 expressed on mammalian cells to bind to its receptor PD-1, the FACS-based receptor blocking assay was used. Briefly, PDL1-CHOK1 cells were firstly incubated with 3-fold serious diluted HL1210-3 mouse mAb starting at 20 .mu.g/ml at RT for 1 hour. After wash by FACS buffer (PBS with 2% FBS), the biotin-labeled huPD-1 were added to each well and incubated at RT for 1 hour. Then, the Streptavidin-PE were added to each well for 0.5 hour post twice wash with FACS buffer. The mean florescence intensity (MFI)of PE were evaluated by FACSAriaIII. As shown in FIG. 3, the HL1210-3 antibody can highly efficiently inhibit the binding of PD-1 on PD-L1 expressed on mammalian cells at IC50 of 2.56 nM with 92.6% top inhibition rate.
% .times. .times. of .times. .times. inhibition = ( 1 - MFI .times. .times. of .times. .times. testing .times. .times. antibody MFI .times. .times. of .times. .times. vehicle .times. .times. contorl ) .times. 1 .times. 0 .times. 0 .times. % ##EQU00001##
Example 4
HL1210-3 Mouse mAb Promoted Human T Cell Immune Response
[0294] To evaluate the effect of HL1210-3 mouse mAb, the response of human T cells assessed in a mixed lymphocyte reaction setting. Human DCs were differentiated from CD14+ monocytes in the presence of GM-CSF and IL-4 for 7 days. CD4+ T cells isolated from another donor were then co-cultured with the DCs and serial dilutions of anti-PD-L1 blocking antibody. At day 5 post-inoculation, the culture supernatant was assayed for IFN.gamma. production. The results indicated that the HL1210-3 antibodies can dose-dependently promote IFN.gamma. production, suggesting anti-PD-L1 antibody can promote human T cell response (FIG. 4).
Example 5
The Binding Affinity of HL1210-3 Mouse mAb
[0295] The binding of the HL1210-3 antibodies to recombinant PD-L1 protein (human PD-L1-his taq) was tested with BIACORE.TM. using a capture method. The HL1210-3 mouse mAb was captured using anti-mouse Fc antibody coated on a CM5 chip. A series dilution of human PD-L1-his taq protein was injected over captured antibody for 3 mins at a flow rate of 25 .mu.g/ml. The antigen was allowed to dissociate for 900s. All the experiment were carried out on a Biacore T200. Data analysis was carried out using Biacore T200 evaluation software. The result are shown in FIG. 5 and Table 6 below.
TABLE-US-00019 TABLE 6 Binding Kinetics of HL1210-3 to recombinant human PD-L1 ka kd KD Antibody (1/Ms) (1/s) (M) HL1210-3 1.61E+05 4.69E-05 2.93E-10
Example 6
Humanization of the HL1210-3 Mouse mAb
[0296] The mAb HL1210-3 variable region genes were employed to create a humanized MAb. In the first step of this process, the amino acid sequences of the VH and VK of MAb HL1210-3 were compared against the available database of human Ig gene sequences to find the overall best-matching human germline Ig gene sequences. For the light chain, the closest human match was the O18/Jk2 and KV1-39*01/KJ2*04 gene, and for the heavy chain the closest human match was the VH3-21 gene. VH3-11, VH3-23, VH3-7*01 and VH3-48 genes were also selected due to their close matches.
[0297] Humanized variable domain sequences were then designed where the CDR1 (SEQ ID NO.4), 2 (SEQ ID NO.5) and 3 (SEQ ID NO.6) of the HL1210-3 light chain were grafted onto framework sequences of the O18/Jk2 and KV1-39*01/KJ2*04 gene, and the CDR1 (SEQ ID NO.1), 2 (SEQ ID NO.2), and 3 (SEQ ID NO.3) sequences of the HL1210-3 VH were grafted onto framework sequences of the VH3-21, VH3-11, VH3-23, VH3-48 or VH3-7*01 gene. A 3D model was then generated to determine if there were any framework positions where replacing the mouse amino acid to the human amino acid could affect binding and/or CDR conformation. In the case of the light chain, 22S, 43S, 60D, 63T and 42Q (Kabat numbering, see Table 7) in framework were identified. In the case of the heavy chain, 1E, 37V, 40T, 44S, 49A, 77N, 91I, 94R and 108T in the framework was involved in back-mutations.
TABLE-US-00020 TABLE 7 Humanization Design Construct Mutation VH Design I: VH3-21/JH6 Hu1210 VH Chimera Hu1210 VH.1 CDR-grafted Hu1210 VH.1a S49A Hu1210 VH.1b S49A, G44S, Y91I VH Design II: VH3-11/JH6 Hu1210 VH.2 CDR-grafted, Q1E Hu1210 VH.2a Q1E, S49A Hu1210 VH.2b Q1E, I37V, S49A, G44S, Y91I VH Design III: VH3-23/JH6 Hu1210 VH.3 CDR-grafted, K94R Hu1210 VH.3a G44S, S49A, Y91I, K94R VH Design IV: VH3-48/JH6 Hu1210 VH.4 CDR-grafted Hu1210 VH.4a S49A Hu1210 VH.4b S49A, G44S, Y91I Hu1210 VH.4c D52E, S49A, G44S, Y91I Hu1210 VH.4d G53A, S49A, G44S, Y91I Hu1210 VH.4e G53V, S49A, G44S, Y91I VH Design V: VH3-7*01/ HJ1*01 Hu1210 VH.5 CDR-grafted Hu1210 VH.5a H91I Hu1210 VH.5b H91I, H108T Hu1210 VH.5c H91I, H77N Hu1210 VH.5d H91I, H77N, H40T VK Design I: 018/Jk2 Construct Mutation Hu1210 Vk Chimera Hu1210 Vk.1 CDR-grafted Hu1210 Vk.1a A43 S VK Design II: KV1-39*01/KJ2*04 Hu1210 Vk.2 CDR-grafted Hu1210 Vk.2a L60D, L63T Hu1210 Vk.2b L60D, L63T, L42Q, L43S Hu1210 Vk.2c L60D, L63T, L42Q, L43S, T22S
[0298] The amino acid and nucleotide sequences of some of the humanized antibody are listed in Table 8 below.
TABLE-US-00021 TABLE 8 Humanized antibody sequences (bold indicates CDR) SEQ ID Name Sequence NO: HL1210-VH EVKLVESGGDLVKPGGSLKLSCAASGFTFSSYDMSWVRQTPEKSLEWVAT 7 ISDGGGYIYYSDSVKGRFTISRDNAKNNLYLQMSSLRSEDTALYICAREF GKRYALDYWGQGTSVTVSS Hu1210 VH.1 EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVST 8 ISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.1a EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVAT 9 ISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.1b EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT 10 ISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYICAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.2 EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYDMSWIRQAPGKGLEWVST 11 ISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.2a EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYDMSWIRQAPGKGLEWVAT 12 ISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.2b EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT 13 ISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYICAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.3 EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVST 14 ISDGGGYIYYSDSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.3a EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT 15 ISDGGGYIYYSDSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYICAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.4 EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVST 16 ISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYYCAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.4a EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVAT 17 ISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYYCAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.4b EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT 18 ISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.4c EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT 19 ISEGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.4d EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT 20 ISDAGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.4e EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT 21 ISDVGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREF GKRYALDYWGQGTTVTVSS Hu1210 VH.5 EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVAT 22 ISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAREF GKRYALDYWGQGTLVTVSS HU1210 VH.5a EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVAT 23 ISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYICAREF GKRYALDYWGQGTLVTVSS HU1210 VH.5b EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVAT 24 ISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYICAREF GKRYALDYWGQGTTVTVSS HU1210 VH.5C EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVAT 25 ISDGGGYIYYSDSVKGRFTISRDNAKNNLYLQMNSLRAEDTAVYICAREF GKRYALDYWGQGTLVTVSS HU1210 VH.5d EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQTPEKSLEWVAT 26 ISDGGGYIYYSDSVKGRFTISRDNAKNNLYLQMNSLRAEDTAVYICAREF GKRYALDYWGQGTLVTVSS HL1210-VK DIVMTQSNKFMSTSVGDRVSISCKASQDVTPAVAWYQQKPGQSPKLLIYS 27 TSSRYTGVPDRFTGSGSGTDFTFTISSVQAEDLAVYYCQQHYTTPLTFGA GTKLELK Hu1210 VK.1 DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYS 28 TSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQ GTKLEIK Hu1210 VK.1a DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKSPKLLIYS 29 TSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQ GTKLEIK Hu1210 Vk.2 DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYS 30 TSSRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQHYTTPLTFGQ GTKLEIKR Hu1210 Vk.2a DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYS 31 TSSRYTGVPDRFTGSGSGTDFTLTISSLQPEDFATYYCQQHYTTPLTFGQ GTKLEIKR Hu1210 Vk.2b DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGQSPKLLIYS 32 TSSRYTGVPDRFTGSGSGTDFTLTISSLQPEDFATYYCQQHYTTPLTFGQ GTKLEIKR Hu1210 Vk.2c DIQMTQSPSSLSASVGDRVTISCKASQDVTPAVAWYQQKPGQSPKLLIYS 33 TSSRYTGVPDRFTGSGSGTDFTLTISSLQPEDFATYYCQQHYTTPLTFGQ GTKLEIKR HL1210 VH GAGGTGAAGCTGGTGGAGAGCGGCGGAGATCTGGTGAAGCCTGGCGGCAGCCTGAAGCTG 34 AGCTGTGCCGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGGCAGACC CCCGAGAAGAGCCTGGAGTGGGTGGCCACCATCAGCGATGGCGGCGGCTACATCTACTAC AGCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAACCTGTAC CTGCAGATGAGCAGCCTGAGGAGCGAGGACACCGCCCTGTACATCTGCGCCAGGGAGTTC GGCAAGAGGTACGCCCTGGACTACTGGGGACAGGGCACCAGCGTGACCGTGAGCAGC Hu1210 VH.1 GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGAAGCCCGGAGGCAGCCTGAGACTG 35 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCC CCTGGCAAAGGCCTGGAGTGGGTGAGCACCATCTCCGATGGCGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTAC CTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210 VH.1a GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGAAGCCCGGAGGCAGCCTGAGACTG 36 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCC CCTGGCAAAGGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTAC CTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210 VH.1b GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGAAGCCCGGAGGCAGCCTGAGACTG 37 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCC CCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTAC CTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210 VH.2 GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGAAGCCCGGAGGCAGCCTGAGACTG 38 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGATCAGACAGGCC CCTGGCAAAGGCCTGGAGTGGGTGAGCACCATCTCCGATGGCGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTAC CTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210 VH.2a GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGAAGCCCGGAGGCAGCCTGAGACTG 39 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGATCAGACAGGCC CCTGGCAAAGGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTAC CTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210 VH.2b GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGAAGCCCGGAGGCAGCCTGAGACTG 40 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCC CCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTAC CTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210 VH.3 GAGGTGCAGCTGCTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTG 41 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCC CCTGGCAAAGGCCTGGAGTGGGTGAGCACCATCTCCGATGGCGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACAGCAAGAACACCCTGTAC CTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210 VH.3a GAGGTGCAGCTGCTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTG 42 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCC CCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACAGCAAGAACACCCTGTAC CTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210 VH.4 GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTG 43 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCC CCTGGCAAAGGCCTGGAGTGGGTGAGCACCATCTCCGATGGCGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTAC CTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210 VH.4a GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTG 44 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCC CCTGGCAAAGGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTAC CTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210 VH.4b GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTG 45 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCC CCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTAC CTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210 VH.4c GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTG 46 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCC CCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGAAGGCGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTAC CTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210_VH.4d GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTG 47 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCC CCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGCGGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTAC CTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210_VH.4e GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTG 48 AGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCC CCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGTTGGCGGCTACATCTATTAC TCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTAC CTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTC GGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC Hu1210 VH.5 GAGGTGCAGCTGGTGGAGTCCGGAGGAGGCCTGGTGCAACCTGGAGGCTCCCTGAGGCTG 49 TCCTGTGCCGCTTCCGGCTTCACCTTCAGCTCCTACGATATGAGCTGGGTGAGGCAGGCT CCTGGAAAGGGCCTGGAGTGGGTGGCCACCATCTCCGACGGAGGCGGCTACATCTACTAC TCCGACTCCGTGAAGGGCAGGTTCACCATCTCCCGGGACAACGCCAAGAACTCCCTGTAC CTGCAGATGAACTCTCTCAGGGCTGAGGACACCGCCGTGTATTACTGCGCCAGGGAGTTT GGCAAGAGGTACGCCCTGGATTACTGGGGCCAGGGCACACTGGTGACAGTGAGCTCC Hu1210 VH.5a GAGGTGCAGCTGGTGGAGTCCGGAGGAGGCCTGGTGCAACCTGGAGGCTCCCTGAGGCTG 50 TCCTGTGCCGCTTCCGGCTTCACCTTCAGCTCCTACGATATGAGCTGGGTGAGGCAGGCT CCTGGAAAGGGCCTGGAGTGGGTGGCCACCATCTCCGACGGAGGCGGCTACATCTACTAC TCCGACTCCGTGAAGGGCAGGTTCACCATCTCCCGGGACAACGCCAAGAACTCCCTGTAC CTGCAGATGAACTCTCTCAGGGCTGAGGACACCGCCGTGTATATCTGCGCCAGGGAGTTT GGCAAGAGGTACGCCCTGGATTACTGGGGCCAGGGCACACTGGTGACAGTGAGCTCC Hu1210 VH.5b GAGGTGCAGCTGGTGGAGTCCGGAGGAGGCCTGGTGCAACCTGGAGGCTCCCTGAGGCTG
51 TCCTGTGCCGCTTCCGGCTTCACCTTCAGCTCCTACGATATGAGCTGGGTGAGGCAGGCT CCTGGAAAGGGCCTGGAGTGGGTGGCCACCATCTCCGACGGAGGCGGCTACATCTACTAC TCCGACTCCGTGAAGGGCAGGTTCACCATCTCCCGGGACAACGCCAAGAACAACCTGTAC CTGCAGATGAACTCTCTCAGGGCTGAGGACACCGCCGTGTATATCTGCGCCAGGGAGTTT GGCAAGAGGTACGCCCTGGATTACTGGGGCCAGGGCACACTGGTGACAGTGAGCTCC Hu1210 VH.5c GAGGTGCAGCTGGTGGAGTCCGGAGGAGGCCTGGTGCAACCTGGAGGCTCCCTGAGGCTG 52 TCCTGTGCCGCTTCCGGCTTCACCTTCAGCTCCTACGATATGAGCTGGGTGAGGCAGACC CCTGAGAAGAGCCTGGAGTGGGTGGCCACCATCTCCGACGGAGGCGGCTACATCTACTAC TCCGACTCCGTGAAGGGCAGGTTCACCATCTCCCGGGACAACGCCAAGAACAACCTGTAC CTGCAGATGAACTCTCTCAGGGCTGAGGACACCGCCGTGTATATCTGCGCCAGGGAGTTT GGCAAGAGGTACGCCCTGGATTACTGGGGCCAGGGCACACTGGTGACAGTGAGCTCC Hu1210_VH.5d GAGGTGCAGCTGGTGGAGTCCGGAGGAGGCCTGGTGCAACCTGGAGGCTCCCTGAGGCTG 53 TCCTGTGCCGCTTCCGGCTTCACCTTCAGCTCCTACGATATGAGCTGGGTGAGGCAGGCT CCTGGAAAGGGCCTGGAGTGGGTGGCCACCATCTCCGACGGAGGCGGCTACATCTACTAC TCCGACTCCGTGAAGGGCAGGTTCACCATCTCCCGGGACAACGCCAAGAACTCCCTGTAC CTGCAGATGAACTCTCTCAGGGCTGAGGACACCGCCGTGTATATCTGCGCCAGGGAGTTT GGCAAGAGGTACGCCCTGGATTACTGGGGCCAGGGCACAACCGTGACAGTGAGCTCC HL1210 VK GACATCGTGATGACCCAGAGCCACAAGTTCATGAGCACCAGCGTGGGCGATAGGGTGAGC 54 ATCAGCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCC GGCCAGAGCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCGAC AGGTTCACAGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCGTGCAGGCC GAGGACCTGGCCGTGTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCGCC GGCACCAAGCTGGAGCTGAAG Hu1210 VK.1 GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACC 55 ATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCC GGCAAGGCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGC AGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCC GAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAG GGCACCAAGCTGGAGATCAAG Hu1210 VK.1a GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACC 56 ATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCC GGCAAGTCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGC AGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCC GAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAG GGCACCAAGCTGGAGATCAAG Hu1210 VK.2 GACATTCAGATGACCCAGTCCCCTAGCAGCCTGTCCGCTTCCGTGGGCGACAGGGTGACC 57 ATCACCTGCAAGGCCAGCCAGGACGTGACACCTGCTGTGGCCTGGTATCAACAGAAGCCT GGCAAGGCTCCTAAGCTCCTGATCTACAGCACATCCTCCCGGTACACCGGAGTGCCCTCC AGGTTTAGCGGCAGCGGCTCCGGCACCGATTTCACCCTGACCATTTCCTCCCTGCAGCCC GAGGACTTCGCCACCTACTACTGCCAGCAGCACTACACCACACCCCTGACCTTCGGCCAG GGCACCAAGCTGGAGATCAAGCGG Hu1210 VK.2a GACATTCAGATGACCCAGTCCCCTAGCAGCCTGTCCGCTTCCGTGGGCGACAGGGTGACC 58 ATCACCTGCAAGGCCAGCCAGGACGTGACACCTGCTGTGGCCTGGTATCAACAGAAGCCT GGCAAGGCTCCTAAGCTCCTGATCTACAGCACATCCTCCCGGTACACCGGAGTGCCCGAC AGGTTTACCGGCAGCGGCTCCGGCACCGATTTCACCCTGACCATTTCCTCCCTGCAGCCC GAGGACTTCGCCACCTACTACTGCCAGCAGCACTACACCACACCCCTGACCTTCGGCCAG GGCACCAAGCTGGAGATCAAGCGG Hu1210 VK.2b GACATTCAGATGACCCAGTCCCCTAGCAGCCTGTCCGCTTCCGTGGGCGACAGGGTGACC 59 ATCACCTGCAAGGCCAGCCAGGACGTGACACCTGCTGTGGCCTGGTATCAACAGAAGCCT GGCCAGAGCCCTAAGCTCCTGATCTACAGCACATCCTCCCGGTACACCGGAGTGCCCGAC AGGTTTACCGGCAGCGGCTCCGGCACCGATTTCACCCTGACCATTTCCTCCCTGCAGCCC GAGGACTTCGCCACCTACTACTGCCAGCAGCACTACACCACACCCCTGACCTTCGGCCAG GGCACCAAGCTGGAGATCAAGCGG Hu1210 VK.2c GACATTCAGATGACCCAGTCCCCTAGCAGCCTGTCCGCTTCCGTGGGCGACAGGGTGACC 60 ATCAGCTGCAAGGCCAGCCAGGACGTGACACCTGCTGTGGCCTGGTATCAACAGAAGCCT GGCCAGAGCCCTAAGCTCCTGATCTACAGCACATCCTCCCGGTACACCGGAGTGCCCGAC AGGTTTACCGGCAGCGGCTCCGGCACCGATTTCACCCTGACCATTTCCTCCCTGCAGCCC GAGGACTTCGCCACCTACTACTGCCAGCAGCACTACACCACACCCCTGACCTTCGGCCAG GGCACCAAGCTGGAGATCAAGCGG
[0299] The humanized VH and VK genes were produced synthetically and then respectively cloned into vectors containing the human gamma 1 and human kappa constant domains. The pairing of the human VH and the human VK created the 40 humanized antibodies (see Table 9).
TABLE-US-00022 TABLE 9 Humanized antibodies with their VH am VL regions VH Hu1210 Hu1210 Hu1210 Hu1210 Hu1210 Hu1210 Hu1210 Vk VH.1 VH.1a VH.1b VH.2 VH.2a VH 2.b VH Hu1210 Vk.1a Hu1210-1 Hu1210-2 Hu1210-3 Hu1210-4 Hu1210-5 Hu1210 Vk.1a Hu1210-7 Hu1210-8 Hu1210-9 Hu1210-10 Hu1210-11 Hu1210 Vk H1210 chimera VH Hu1210 Hu1210 Hu1210 Hu1210 Hu1210 Vk VH.3 VH.3a VH.4 VH.4a VH.4b Hu1210 Vk.1 Hu1210-13 Hu1210-14 Hu1210-15 Hu1210-16 Hu1210-17 Hu1210 Vk.1a Hu1210-18 Hu1210-19 Hu1210-20 Hu1210-21 Hu1210-22 VH Hu1210 HU1210 HU1210 HU1210 HU1210 VK VH.5 VH.5a VH.5b VH.5c VH.5d Hu1210 Vk.2 Hu1210-23 Hu1210-27 Hu1210-31 Hu1210-32 Hu1210-36 Hu1210 Vk.2a Hu1210-24 Hu1210-28 Hu1210-33 Hu1210-37 Hu1210 Vk.2b Hu1210-25 Hu1210-29 Hu1210-34 Hu1210-38 Hu1210 Vk.2c Hu1210-26 Hu1210-30 Hu1210-35 Hu1210-39 VH Hu1210 Hu1210 Hu1210 Vk VH.4c VH.4d VH.4e Hu1210 Vk.1 Hu1210-40 Hu1210-41 Hu1210-42
Example 7
The Antigen Binding Properties of Humanized PD-L1 Antibodies
Binding Property to Recombinant Human PD-L1
[0300] To evaluate the antigen binding activity, the humanized antibodies were subjected to ELISA test. Briefly, microtiter plates were coated with human PD-L1-Fc protein at 0.1 .mu.g/ml in PBS, 100 .mu.l/well at 4.degree. C. overnight, then blocked with 100 .mu.l/well of 5% BSA. Five-fold dilutions of humanized antibodies starting from 10 .mu.g/ml were added to each well and incubated for 1-2 hours at RT. The plates were washed with PBS/Tween and then incubate with goat-anti-mouse IgG antibody conjugated with Horse Radish Peroxidase (HRP) for 1 hour at RT. After washing, the plates were developed with TMB substrate and analyzed by spectrophotometer at OD 450-630 nm. As shown in FIG. 6, all the humanized antibodies show comparable binding efficacy to human PD-L1 in contact to chimeric antibody.
Binding Property to Mammalian Expressed Human PD-L1
[0301] To evaluate the antigen binding property, the humanized antibodies were analyzed for its binding to mammalian expressed PD-L1 by FACS. Briefly, PDL1-CHOK1 cells were firstly incubated with 5-fold serious diluted humanized antibodies starting at 2 .mu.g/ml at RT for 1 hour. After wash by FACS buffer (PBS with 2% FBS), the alexa 488-anti-human IgG antibody was added to each well and incubated at RT for 1 hour. The MFI of Alexa 488 were evaluated by FACSAriaIII. As shown in the FIG. 7, all the humanized antibodies can high efficiently bind to PD-L1 expressed on mammalian cells, which was comparable with chimeric antibody.
[0302] To explore the binding kinetics of the humanized antibody, this example performed the affinity ranking by using Octet Red 96. As shown in Table 10, hu1210-3, hu1210-8, hu1210-9, hu1210-14, hu1210-17, hu1210-1 and Hu1210-22 show better affinity, which is comparable with chimeric antibody.
TABLE-US-00023 TABLE 10 Affinity ranking of humanized antibodies Antibody KD (M) kon(1/Ms) kdis(1/s) HU1210 7.16E-09 3.94E+05 2.83E-03 (mIgG) H1210 1.07E-09 1.62E+05 1.73E-04 chimera HU1210-1 4.25E-09 7.10E+04 3.02E-04 HU1210-2 3.23E-09 7.78E+04 2.51E-04 HU1210-3 2.64E-09 8.62E+04 2.28E-04 HU1210-4 7.68E-09 7.12E+04 5.46E-04 HU1210-5 4.83E-09 7.93E+04 3.83E-04 HU1210-7 4.78E-09 8.45E+04 4.04E-04 HU1210-8 1.64E-09 7.72E+04 1.27E-04 HU1210-9 2.33E-09 8.37E+04 1.95E-04 HU1210-10 7.03E-09 8.59E+04 6.04E-04 HU1210-11 4.18E-09 7.54E+04 3.15E-04 HU1210-13 4.36E-09 8.38E+04 3.66E-04 HU1210-14 2.34E-09 8.41E+04 1.97E-04 HU1210-15 4.45E-09 7.87E+04 3.50E-04 HU1210-16 3.14E-09 8.41E+04 2.64E-04 HU1210-17 2.20E-09 8.17E+04 1.80E-04 HU1210-18 4.50E-09 7.92E+04 3.57E-04 HU1210-19 2.50E-09 9.03E+04 2.25E-04 HU1210-20 4.51E-09 8.87E+04 4.00E-04 HU1210-21 3.12E-09 9.39E+04 2.93E-04 HU1210-22 2.56E-09 9.00E+04 2.30E-04
Full Kinetic Affinity of Humanized Antibodies by Biacore.RTM.
[0303] The binding of the humanized antibodies to recombinant PD-L1 protein (human PD-L1-his taq) was tested by BIACORE.TM. using a capture method. The HL1210-3 mouse mAb were captured using anti-mouse Fc antibody coated on a CM5 chip. A series dilution of human PD-L1-his taq protein was injected over captured antibody for 3 mins at a flow rate of 25 .mu.g/ml. The antigen was allowed to dissociate for 900 s. All the experiment were carried out on a Biacore T200. Data analysis was carried out using Biacore T200 evaluation software and is shown in Table 11 below.
TABLE-US-00024 TABLE 11 Affinity by Biacore Antibody ka (1/Ms) kd (1/s) KD (M) Hu1210-8 9.346E+4 7.169E-5 7.671E-10 Hu1210-9 9.856E+4 4.528E-5 4.594E-10 Hu1210-14 1.216E+5 5.293E-5 4.352E-10 Hu1210-16 9.978E+4 6.704E-5 6.720E-10 Hu1210-17 1.101E+5 2.128E-5 1.933E-10 Hu1210-28 1.289E+5 1.080E-4 8.378E-10 Hu1210-31 1.486E+5 1.168E-4 7.862E-10 Hu1210-36 1.461E+5 7.852E-5 5.376E-10 Hu1210-40 8.77E+04 1.31E-04 1.49E-09 Hu1210-41 9.17E+04 3.46E-05 3.78E-10 Hu1210-42 8.68E+04 7.53E-05 8.67E-10 1210 Chimera 1.236E+5 3.265E-5 2.642E-10
Cross Species Activity
[0304] To evaluate the binding of humanized antibodies to huPD-L1, Mouse PD-L1, Rat PD-L1, Rhesus PD-L1, the antibodies were performed for the ELISA testing. Briefly, microtiter plates were coated with human, mouse, rat and rhesus PD-L1-Fc protein at 1 .mu.g/ml in PBS, 100 .mu.l/well at 4.degree. C. overnight, then blocked with 100 .mu.l/well of 5% BSA. Three-fold dilutions of humanized antibodies starting from 1 .mu.g/ml were added to each well and incubated for 1-2 hours at RT. The plates were washed with PBS/Tween and then incubate with goat-anti-mouse IgG antibody conjugated with Horse Radish Peroxidase (HRP) for 1 hour at RT. After washing, the plates were developed with TMB substrate and analyzed by spectrophotometer at OD 450-630 nm. The Hu1210-41 antibody can bind to rhesus PD-L1 with lower affinity and cannot bind to rat and mouse PD-L1 (FIG. 8).
TABLE-US-00025 Human Rhesus Rat Mouse EC50 0.215 nM 0.628 nM No binding No binding
Family Member Specificity
[0305] To evaluate the binding of humanized anti-PD-L1 antibody to human B7 family and other immune checkpoint, the antibody was evaluate for its binding to B7-H1 (PD-L1), B7-DC, B7-1, B7-2, B7-H2, PD-1, CD28, CTLA4, ICOS and BTLA by ELISA. As shown in FIG. 9, the Hu1210-41 antibody can only specifically binding to B7-H1 (PD-L1).
Example 8
Humanized Antibodies Blocked Activity of Human PD-L1 to PD-1
Cell Based Receptor Blocking Assay
[0306] To evaluate the blocking effect of humanized antibodies on human PD-L1 expressed on mammalian cells to bind to its receptor PD-1, the FACS-based receptor blocking assay was employed. Briefly, PDL1-CHOK1 cells were firstly incubated with 3-fold serious diluted HL1210-3 mouse mAb starting at 20 .mu.g/ml at RT for 1 hour. After wash by FACS buffer (PBS with 2% FBS), the biotin-labeled huPD-1 were added to each well and incubated at RT for 1 hour. Then, the Streptavidin-PE were added to each well for 0.5 hour post twice wash with FACS buffer. The mean florescence intensity (MFI)of PE were evaluated by FACSAriaIII.
% .times. .times. of .times. .times. inhibition = ( 1 - MFI .times. .times. of .times. .times. testing .times. .times. antibody MFI .times. .times. of .times. .times. vehicle .times. .times. contorl ) .times. 1 .times. 00 .times. % ##EQU00002##
[0307] As shown in Table 12 below, Hu1210-3, Hu1210-9, Hu1210-8, Hu1210-14, Hu1210-17, Hu1210-19 and Hu1210-22 antibodies show comparable efficacy with chimeric antibody to blocking the binding of PD-L1 to PD-1.
TABLE-US-00026 TABLE 12 PD-1 receptor blocking assay Bio-PD1 (30 .mu.g/ml) TOP EC50 H1210 chimera 87.16 3.961 Hu1210-8 86.35 4.194 Hu1210-9 85.7 4.038 Hu1210-16 88.02 5.436 Hu1210-17 80.88 4.424 Hu1210-3 84.28 3.693 Hu1210-14 79.56 3.572 Hu1210-19 87.45 4.52 Hu1210-22 85.83 4.505 Hu1210-27 103.9 11.48 Hu1210-31 92.91 6.179 Hu1210-36 91.75 8.175
Receptor Blocking Assay by Using Recombinant Human PD-L1
[0308] There are two receptors i.e. PD-1 and B7-1 for human PD-L1. To explore the blocking property of humanized PD-L1 antibody to these two proteins, the protein based receptor blocking assay was employed here. Briefly, microtiter plates were coated with human PD-L1-Fc protein at 1 .mu.g/ml in PBS, 100 .mu.l/well at 4.degree. C. overnight, then blocked with 200 .mu.l/well of 5% BSA at 37.degree. C. for 2 hr. 50 .mu.l biotin-labeled human PD-1-Fc or B7-1vprotein and 5-fold dilutions of PD-L1 antibodies starting from 100 nM at 50 .mu.l were added to each well and incubated for 1 hour at 37.degree. C. The plates were washed with PBS/Tween and then incubate with Streptavidin-HRP for 1 hour at 37.degree. C. After washing, the plates were developed with TMB substrate and analyzed by spectrophotometer at OD 450 nm. As shown in FIGS. 10 and 11, Hu1210-41 can efficiently inhibit the binding of human PD-L1 to human PD1 and B7-1.
Example 9
Humanized Antibody Promoted Human T Cell Immune Response
Mixed Lymphocyte Reaction Assay
[0309] To evaluate the in vitro function of humanized antibodies, the response of human T cells assessed in a mixed lymphocyte reaction setting. Human DCs were differentiated from CD14+ monocytes in the presence of GM-CSF and IL-4 for 7 days. CD4+ T cells isolated from another donor were then co-cultured with the DCs and serial dilutions of anti-PD-L1 blocking antibody. At day 5 post-inoculation, the culture supernatant was assayed for IL-2 and IFN.gamma. production. The results indicated that the Hu1210-8, Hu1210-9, Hu1210-16 and Hu1210-17 antibodies can dose-dependently promote IL-2 and IFN.gamma. production, suggesting anti-PD-L1 antibodies can promote human T cell response.
CMV Recall Assay
[0310] To evaluate the in vitro function of humanized antibodies, the response of human T cells assessed in CMV recall assay. Human PBMCs were stimulated with 1 .mu.g/ml CMV antigen in the presence of serious diluted humanized antibodies. As shown in FIGS. 12 and 13 the Hu1210-40, Hu1210-41 and Hu1210-17 can dose dependently promote the IFN.gamma. production.
Example 10
Tumor Growth Inhibition by Anti-PD-L1 mAb
[0311] Cells from the human lung adenocarcinoma cell line HCC827 will be grafted into NOD scid gamma (NSG) mice. NSG mice are NOD scid gamma deficient and the most immunodeficient mice making them ideal recipients for human tumor cell and PBMC grafting. 10 days post-graft, human PBMCs will be transplanted into the tumor-bearing mice. Approximately 20 days post-graft, once the tumor volume has reached 100-150 mm.sup.3, PD-L1 antibody will be administered to the mice every other day at 5 mg/kg. Tumor volume will be monitored every other day in conjunction with antibody administration. As shown in FIG. 14, Hu1210-31 can inhibit the tumor growth by 30% at 5 mg/kg. Hu1210-41 antibody can dose-dependently inhibit the tumor growth, while the tumor weight was also dose-dependently suppressed by Hu1210-41 antibody (FIG. 15).
Example 11
Computer Simulation of Further Variation and Optimization of the Humanized Antibodies
[0312] It was contemplated that certain amino acid residues within the CDR regions or the framework regions could be changed to further improve or retain the activity and/or stability of the antibodies. Variants were tested, with a computational tool (VectorNTI, available at www.ebi.ac.uk/tools/msa/clustalo/), with respect to their structural, conformational and functional properties, and those (within the CDR regions) that showed promises are listed in the tables blow.
TABLE-US-00027 TABLE 13 VH and VL CDRs and their variants suitable for inclusion in humanized antibodies Name Sequence SEQ ID NO: VH CDR1 SYDMS 1 TYDMS 61 CYDMS 62 SFDMS 63 SHDMS 64 SWDMS 65 SYDMT 66 SYDMC 67 VH CDR2 TISDGGGYIYYSDSVKG 2 TISDGGAYIYYSDSVKG 68 TISDGGPYIYYSDSVKG 69 TISDGGGFIYYSDSVKG 70 TISDGGGHIYYSDSVKG 71 TISDGGGWIYYSDSVKG 72 TISDGGGYIYYSDTVKG 73 TISDGGGYIYYSDCVKG 74 TISDGGGYIYYSDSLKG 75 TISDGGGYIYYSDSIKG 76 TISDGGGYIYYSDSMKG 77 VH CDR3 EFGKRYALDY 3 QFGKRYALDY 78 DFGKRYALDY 79 NFGKRYALDY 80 EYGKRYALDY 81 EHGKRYALDY 82 EWGKRYALDY 83 EFAKRYALDY 84 EFPKRYALDY 85 EFGRRYALDY 86 EFGKKYALDY 87 EFGKRFALDY 88 EFGKRHALDY 89 EFGKRWALDY 90 VL CDR1 KASQDVTPAVA 4 KATQDVTPAVA 91 KACQDVTPAVA 92 VL CDR2 STSSRYT 5 TTSSRYT 93 CTSSRYT 94 SSSSRYT 95 SMSSRYT 96 SVSSRY 97 STTSRYT 98 STCSRYT 99 STSTRYT 100 STSCRYT 101 STSSKYT 102 STSSRFT 103 STSSRHT 104 STSSRWT 105 VL CDR3 QQHYTTPLT 6 EQHYTTPLT 106 DQHYTTPLT 107 NQHYTTPLT 108 QEHYTTPLT 109 QDHYTTPLT 110 QNHYTTPLT 111 Underline: hotspot mutation residues and their substitutes
Example 12
Identification of PD-L1 Epitope
[0313] This study was conducted to identify amino acid residues involved in the binding of PD-L1 to the antibodies of the present disclosure.
[0314] An alanine-scan library of PD-L1 was constructed. Briefly, 217 mutant clones of PD-L1 were generated on Integral Molecular's protein engineering platform. Binding of Hu1210-41 Fab to each variant in the PD-L1 mutation library was determined, in duplicate, by high-throughput flow cytometry. Each raw data point had background fluorescence subtracted and was normalized to reactivity with PD-L1 wild-type (WT). For each PD-L1 variant, the mean binding value was plotted as a function of expression (control anti-PD-L1 mAb reactivity). To identify preliminary critical clones (circles with crosses), thresholds (dashed lines) of >70% WT binding to control MAb and <30% WT reactivity to Hu1210-41 Fab were applied (FIG. 16). Y134, K162, and N183 of PDL1 were identified as required residues for Hu1210-41 binding. The low reactivity of N183A clone with Hu1210-41 Fab suggests that it is the major energetic contributor to Hu1210-41 binding, with lesser contributions by Y134 and K162.
[0315] The critical residues (spheres) were identified on a 3D PD-L1 structure (PDB ID #5JDR, Zhang et al., 2017), illustrated in FIG. 17. These residues, Y134, K162, and N183, therefore, constitute an epitope of PD-L1 responsible for binding to antibodies of various embodiments of the present disclosure.
[0316] It is interesting to note that Y134, K162, and N183 are all located within the IgC domain of the PD-L1 protein. Both PD-1 and PD-L1's extracellular portions have an IgV domain and an IgC domain. It is commonly known that PD-L1 binds to PD-1 through bindings between their IgV domains. Unlike such conventional antibodies, however, Hu1210-41 binds to the IgC domain, which would have been expected to be ineffective in inhibiting PD-1/PD-L1 binding. This different epitope of Hu1210-41, surprisingly, likely contributes to the excellent activities of Hu1210-41.
Example 13
Antibody Engineering of Anti-PDL1 Antibody
[0317] Examples 13-17 attempted to identify further improved antibodies based on Hu1210-41 using mutagenesis.
[0318] A fusion protein of activation-induced cytidine deaminase (AID) with nuclease-inactive clustered regularly interspaced short palindromic repeats (CRISPR)-associated protein 9 (dCas9) was used for high-throughput screening of functional variants in 293 T cells. Briefly, single guide (sg)RNAs recognizing 6 CDRs of antibody can guide dCas9-AID fusion protein to 6 CDRs of antibody and induce mutations in CDR region. The mutated antibodies were displayed in the cell surface of 293 cells. The resulting cells showed better binding potency than the non-mutated counterpart and were FACS sorted out for subsequence sequencing. A mutation of S60 to R in the CDRH2 was identified as potentially having positive effect on the antibody.
[0319] To evaluate the antigen binding property of the S6OR (CDRH2) mutant, the antibodies were analyzed for their binding to mammalian expressed PD-L1 by FACS. Briefly, PD-L1 Raji cells were first incubated with 5-fold serially diluted humanized antibodies starting at 2 .mu.g/ml at RT for 1 hour. After wash by FACS buffer (PBS with 2% FBS), the Alexa 488-anti-human IgG antibody was added to each well and incubated at RT for 1 hour. The MFI of Alexa 488 were evaluated by FACSAriaIII. As shown in the FIG. 18, the S60R mutant highly efficiently bound to PD-L1 expressed on mammalian cells, which was more potent than the parental antibody Hu1210-41. This S60R mutant was then used as the parental antibody for further mutation analyses below, and was referred to as "WT".
[0320] Four sub-libraries were constructed for antibody engineering of anti-PD-L1 monoclonal antibody, using either of the following strategies. In strategy 1, mutagenesis of heavy chain variable domain VH CDR3 or VL-CDR3 was perform by highly random mutation. In strategy 2, two CDR combination libraries composed of (VH-CDR3, VL-CDR3 and VL-CDR1) or (VH-CDR1, VH-CDR2 and VL-CDR2) were generated by CDR walking with controlled mutation rates.
[0321] Bio-Panning: the phage panning methods were adapted by shortening the incubation/binding time prior to the harsh washing condition. Briefly, 100 .mu.l magnetic streptavidin beads (Invitrogen, USA) were blocked with 1 ml of MPBS for 1 hr at room temperature. In another tube, library phage was pre-incubated (5.times.10{circumflex over ( )}11.about.12 for each round) with 100 .mu.l magnetic streptavidin beads in 1 ml of MPBS to remove unwanted binders. Magnet particle concentrator was used to separate the phage and beads. The biotinylated PD-L1 protein was added to the phage and incubated 2 h at room temperature, and gently mixed using an over-head shaker. Beads carrying phage from the solution were separated in the magnetic particle concentrator and the supernatant was discarded. The beads were washed with fresh wash buffer, ten times with PBST and ten times with PBS (pH7.4). 0.8ml, 0.25% Trypsin in PBS (Sigma, USA) was added and incubated for 20 min at 37.degree. C. to elute the phage. The output phage was titrated and rescued for next round panning, decreasing antigen concentration round by round.
ELISA Screening and On/Off Rate Ranking
[0322] Clones were picked and induced from the desired panning output; phage ELISA was conducted for primary screening; positive clones were analyzed by sequencing; unique hotspots were found. Table 14 shows the mutations identified. As shown below, the FGK residues in the CDRH3 are hotpot residues producing improved antibodies.
TABLE-US-00028 TABLE 14 Mutations in the CDRs CDR-H1 CDR-H2 CDR-H3 CDR-L1 CDR-L2 CDR-L3 WT* SYDMS TISDAGGYIYYRDSVKG EFGKRYALDY KASQDVTPAVA STSSRYT QQHYTTPLT SEQ ID NO: 1 116 3 4 5 6 B3 ----- ----------------- ---------- --K-------- ------- M-------- C4 ----- ----------------- ---------S ------W---- ------- ---S----- B1 ----- ----------------- -IFN------ ----------- ------- --------- B6 ----- ----------------- -LPW------ ----------- ------- --------- C3 ----- ----------------- -LHF------ ----------- ------- --------- C6 ----- ----------------- -LYF------ ----------- ------- --------- A1 ----- ----------------- -LLH------ ----------- ------- --------- A2 ----- ----------------- -LRG------ ----------- ------- --------- A3 ----- ----------------- ---------- ----------- ------- ---SDA--- *WT differs from Hu1210-41 by a S60R (Kabat numbering) substitution in the heavy chain to improve affinity.
[0323] The amino acid sequences of the variable regions of these antibodies are shown in Table 15 below.
TABLE-US-00029 TABLE 15 Antibody sequences Name Sequence SEQ ID NO: WT-VH EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT 141 ISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREF GKRYALDYWGQGTTVTVSS WT-Vk DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYS 142 TSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQ GTKLEIK B3-VH EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT ISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREF 143 GKRYALDYWGQGTTVTVSS B3-Vk DIQMTQSPSSLSASVGDRVTITCKAKQDVTPAVAWYQQKPGKAPKLLIYS TSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCMQHYTTPLTFGQ 144 GTKLEIK C4-VH EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT ISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREF 145 GKRYALDSWGQGTTVTVSS C4-Vk DIQMTQSPSSLSASVGDRVTITCKASQDVWPAVAWYQQKPGKAPKLLIYS TSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHSTTPLTFGQ 146 GTKLEIK B1-VH EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT ISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREI 147 FNRYALDYWGQGTTVTVSS B1-Vk DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYS TSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQ 148 GTKLEIK B6-VH EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT ISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREL 149 PWRYALDYWGQGTTVTVSS B6-Vk DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYS TSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQ 150 GTKLEIK C3-VH EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT ISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREL 151 HFRYALDYWGQGTTVTVSS C3-Vk DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYS TSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQ 152 GTKLEIK C6-VH EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT ISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREL 153 YFRYALDYWGQGTTVTVSS C6-Vk DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYS TSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQ 154 GTKLEIK A1-VH EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT ISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREL 155 LHRYALDYWGQGTTVTVSS A1-Vk DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYS TSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQ 156 GTKLEIK A2-VH EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT ISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREL 157 RGRYALDYWGQGTTVTVSS A2-Vk DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYS TSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQ 158 GTKLEIK A3-VH EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVAT ISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREF 159 GKRYALDYWGQGTTVTVSS A3-Vk DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYS TSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHSDAPLTFGQ 160 GTKLEIK
Example 14
Antigen Binding Properties of the PD-L1 Antibodies
[0324] As shown in Tables 14 and 15, totally 9 unique clones were characterized and converted into full-length IgG.
Binding Property to Recombinant Human PD-L1
[0325] To evaluate the antigen binding activity, the antibodies were subjected to ELISA test. Briefly, microtiter plates were coated with human PD-L1-Fc protein at 2 .mu.g/ml in PBS, 100 .mu.l/well at 4.degree. C. overnight, then blocked with 100 .mu.l/well of 5% BSA. 4-fold dilutions of humanized antibodies starting from 10 pg/ml were added to each well and incubated for 1-2 hours at RT. The plates were washed with PBS/Tween and then incubate with goat-anti-mouse IgG antibody conjugated with Horse Radish Peroxidase (HRP) for 1 hour at RT. After washing, the plates were developed with TMB substrate and analyzed by spectrophotometer at OD 450-630 nm. As shown in FIG. 19, all the humanized antibodies showed excellent binding efficacy to human PD-L1, and B6 and C3 behaved better than the parental clone WT.
Binding Property to Mammalian Expressed Human PD-L1
[0326] To evaluate the antigen binding property, the antibodies were analyzed for its binding to mammalian expressed PD-L1 by FACS. Briefly, PDL1-Raji cells were firstly incubated with 5-fold serious diluted humanized antibodies starting at 2 .mu.g/ml at RT for 1 hour. After wash by FACS buffer (PBS with 2% FBS), the Alexa 488-anti-human IgG antibody was added to each well and incubated at RT for 1 hour. The MFI of Alexa 488 were evaluated by FACSAriaIII. As shown in the FIG. 20, B6 highly efficiently bound to PD-L1 expressed on mammalian cells, which was more potent than the parental antibody WT.
Affinity Ranking of Humanized Antibodies by Biacore
[0327] To explore the binding kinetics of the humanized antibody, this example performed the affinity ranking using Biacore. As shown Table 16, B6, C3, C6, A1 and A3 showed better affinity than the parent antibody WT.
TABLE-US-00030 TABLE 16 Affinity ranking Antibody ka (1/Ms) kd (1/s) KD (M) WT 1.77E+05 4.64E-04 2.63E-09 B3 1.19E+05 2.96E-04 2.49E-09 C4 1.13E+05 5.06E-04 4.50E-09 B1 1.63E+05 2.61E-04 1.60E-09 B6 2.42E+05 2.46E-04 1.02E-09 C3 2.18E+05 2.99E-04 1.37E-09 C6 2.06E+05 3.34E-04 1.63E-09 A1 2.03E+05 2.76E-04 1.36E-09 A2 1.87E+05 4.75E-04 2.55E-09 A3 2.18E+05 3.24E-04 1.49E-09
Example 15
Anti-PDL1 Antibody Cell Based Function
[0328] To test the ability of anti-PDL1 antibodies to stimulate T cell response, hPD-1-expressed Jurkat cells were used. Briefly, Jurkat is human T cell leukemia cell line that can produce IL2 upon TCR stimulation. In this assay, Jurkat cells transfected with human PD-1 gene by lentivirus were used as the responder cells. The Raji-PDL1 cells was used as the antigen presenting cells (APC). Staphylococcal Enterotoxins (SE) are used to stimulate TCR signal. In this system, ectopically expressed huPDL1 can suppress SE stimulated IL-2 production by Jurkat cells, while anti-PDL1 antibodies can reverse IL-2 production. In short, APCs (2.5.times.10.sup.4) were co-cultured with PD-1 expressing Jurkat T cells (1.times.10.sup.5) in the presence of SE stimulation. Anti-PDL1 antibodies (starting from 100 nM and 1:4 serially diluted for 8 dose) were added at the beginning of the culture. 48hr later, culture supernatant was evaluated for IL2 production by ELISA. As shown in FIG. 21, the B6 monoclonal antibodies were more potent than parental antibody WT.
Example 16
Mixed Lymphocyte Reaction
[0329] To evaluate the in vitro function of PDL1 antibodies, the response of human T cells was assessed in a mixed lymphocyte reaction setting. Briefly, human DCs were differentiated from CD14+ monocytes in the presence of GM-CSF and IL-4 for 7 days. CD4+ T cells isolated from another donor were then co-cultured with the DCs and serial dilutions of anti-PD-L1 blocking antibody. At day 5 post-inoculation, the culture supernatant was assayed for IFN.gamma. production. The results (FIG. 22) indicated that the B6 antibody was more potent than parental antibody WT in promoting IFN.gamma. production.
Example 17
In Vivo Efficacy of PDL1 Antibody in MC38 Syngeneic Model
[0330] To evaluate the effect of PDL1 on tumor growth, the PDL1 humanized MC38 syngeneic tumor model was applied. In this model, the human PDL1 gene was expressed in mouse MC38 cells, while the extracellular domain of mouse PDL1 gene was replaced by human PDL1 gene. In this regard, the efficacy of human PDL1 antibody on tumor growth could be evaluated in this PDL1 gene humanized MC38 syngeneic model. The huPDL1 MC38 cells were inoculated subcutaneously into PDL1 humanized mice. When tumor reached the volume of 100-150m.sup.3, the parental antibody WT and B6 antibodies were administrated intraperitoneally at 3 mg/kg twice weekly for 6 doses. The result (FIG. 23) showed that B6 antibody was more potent than the parental antibody WT from day 19 to 26.
[0331] The present disclosure is not to be limited in scope by the specific embodiments described which are intended as single illustrations of individual aspects of the disclosure, and any compositions or methods which are functionally equivalent are within the scope of this disclosure. It will be apparent to those skilled in the art that various modifications and variations can be made in the methods and compositions of the present disclosure without departing from the spirit or scope of the disclosure. Thus, it is intended that the present disclosure cover the modifications and variations of this disclosure provided they come within the scope of the appended claims and their equivalents.
[0332] All publications and patent applications mentioned in this specification are herein incorporated by reference to the same extent as if each individual publication or patent application was specifically and individually indicated to be incorporated by reference
Sequence CWU 1
1
16615PRTArtificial SequenceSynthetic 1Ser Tyr Asp Met Ser1
5217PRTArtificial SequenceSynthetic 2Thr Ile Ser Asp Gly Gly Gly
Tyr Ile Tyr Tyr Ser Asp Ser Val Lys1 5 10 15Gly310PRTArtificial
SequenceSynthetic 3Glu Phe Gly Lys Arg Tyr Ala Leu Asp Tyr1 5
10411PRTArtificial SequenceSynthetic 4Lys Ala Ser Gln Asp Val Thr
Pro Ala Val Ala1 5 1057PRTArtificial SequenceSynthetic 5Ser Thr Ser
Ser Arg Tyr Thr1 569PRTArtificial SequenceSynthetic 6Gln Gln His
Tyr Thr Thr Pro Leu Thr1 57119PRTArtificial SequenceSynthetic 7Glu
Val Lys Leu Val Glu Ser Gly Gly Asp Leu Val Lys Pro Gly Gly1 5 10
15Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30Asp Met Ser Trp Val Arg Gln Thr Pro Glu Lys Ser Leu Glu Trp
Val 35 40 45Ala Thr Ile Ser Asp Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp
Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn
Asn Leu Tyr65 70 75 80Leu Gln Met Ser Ser Leu Arg Ser Glu Asp Thr
Ala Leu Tyr Ile Cys 85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu
Asp Tyr Trp Gly Gln Gly 100 105 110Thr Ser Val Thr Val Ser Ser
1158119PRTArtificial SequenceSynthetic 8Glu Val Gln Leu Val Glu Ser
Gly Gly Gly Leu Val Lys Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys
Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp Val
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40 45Ser Thr Ile Ser
Asp Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly Arg
Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75 80Leu
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys 85 90
95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln Gly
100 105 110Thr Thr Val Thr Val Ser Ser 1159119PRTArtificial
SequenceSynthetic 9Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
Lys Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe
Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp Val Arg Gln Ala Pro Gly
Lys Gly Leu Glu Trp Val 35 40 45Ala Thr Ile Ser Asp Gly Gly Gly Tyr
Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg
Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu
Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys 85 90 95Ala Arg Glu Phe Gly
Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln Gly 100 105 110Thr Thr Val
Thr Val Ser Ser 11510119PRTArtificial SequenceSynthetic 10Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25
30Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Ser Leu Glu Trp Val
35 40 45Ala Thr Ile Ser Asp Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser
Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser
Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Ile Cys 85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp
Tyr Trp Gly Gln Gly 100 105 110Thr Thr Val Thr Val Ser Ser
11511119PRTArtificial SequenceSynthetic 11Glu Val Gln Leu Val Glu
Ser Gly Gly Gly Leu Val Lys Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser
Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp
Ile Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40 45Ser Thr Ile
Ser Asp Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75
80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln
Gly 100 105 110Thr Thr Val Thr Val Ser Ser 11512119PRTArtificial
SequenceSynthetic 12Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
Lys Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe
Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp Ile Arg Gln Ala Pro Gly
Lys Gly Leu Glu Trp Val 35 40 45Ala Thr Ile Ser Asp Gly Gly Gly Tyr
Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg
Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu
Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys 85 90 95Ala Arg Glu Phe Gly
Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln Gly 100 105 110Thr Thr Val
Thr Val Ser Ser 11513119PRTArtificial SequenceSynthetic 13Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25
30Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Ser Leu Glu Trp Val
35 40 45Ala Thr Ile Ser Asp Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser
Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser
Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Ile Cys 85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp
Tyr Trp Gly Gln Gly 100 105 110Thr Thr Val Thr Val Ser Ser
11514119PRTArtificial SequenceSynthetic 14Glu Val Gln Leu Leu Glu
Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser
Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp
Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40 45Ser Thr Ile
Ser Asp Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr65 70 75
80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln
Gly 100 105 110Thr Thr Val Thr Val Ser Ser 11515119PRTArtificial
SequenceSynthetic 15Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val
Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe
Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp Val Arg Gln Ala Pro Gly
Lys Ser Leu Glu Trp Val 35 40 45Ala Thr Ile Ser Asp Gly Gly Gly Tyr
Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg
Asp Asn Ser Lys Asn Thr Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu
Arg Ala Glu Asp Thr Ala Val Tyr Ile Cys 85 90 95Ala Arg Glu Phe Gly
Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln Gly 100 105 110Thr Thr Val
Thr Val Ser Ser 11516119PRTArtificial SequenceSynthetic 16Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25
30Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45Ser Thr Ile Ser Asp Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser
Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser
Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Asp Glu Asp Thr Ala
Val Tyr Tyr Cys 85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp
Tyr Trp Gly Gln Gly 100 105 110Thr Thr Val Thr Val Ser Ser
11517119PRTArtificial SequenceSynthetic 17Glu Val Gln Leu Val Glu
Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser
Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp
Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40 45Ala Thr Ile
Ser Asp Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75
80Leu Gln Met Asn Ser Leu Arg Asp Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln
Gly 100 105 110Thr Thr Val Thr Val Ser Ser 11518119PRTArtificial
SequenceSynthetic 18Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe
Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp Val Arg Gln Ala Pro Gly
Lys Ser Leu Glu Trp Val 35 40 45Ala Thr Ile Ser Asp Gly Gly Gly Tyr
Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg
Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu
Arg Asp Glu Asp Thr Ala Val Tyr Ile Cys 85 90 95Ala Arg Glu Phe Gly
Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln Gly 100 105 110Thr Thr Val
Thr Val Ser Ser 11519119PRTArtificial SequenceSynthetic 19Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25
30Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Ser Leu Glu Trp Val
35 40 45Ala Thr Ile Ser Glu Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser
Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser
Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Asp Glu Asp Thr Ala
Val Tyr Ile Cys 85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp
Tyr Trp Gly Gln Gly 100 105 110Thr Thr Val Thr Val Ser Ser
11520119PRTArtificial SequenceSynthetic 20Glu Val Gln Leu Val Glu
Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser
Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp
Val Arg Gln Ala Pro Gly Lys Ser Leu Glu Trp Val 35 40 45Ala Thr Ile
Ser Asp Ala Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75
80Leu Gln Met Asn Ser Leu Arg Asp Glu Asp Thr Ala Val Tyr Ile Cys
85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln
Gly 100 105 110Thr Thr Val Thr Val Ser Ser 11521119PRTArtificial
SequenceSynthetic 21Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe
Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp Val Arg Gln Ala Pro Gly
Lys Ser Leu Glu Trp Val 35 40 45Ala Thr Ile Ser Asp Val Gly Gly Tyr
Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg
Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu
Arg Asp Glu Asp Thr Ala Val Tyr Ile Cys 85 90 95Ala Arg Glu Phe Gly
Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln Gly 100 105 110Thr Thr Val
Thr Val Ser Ser 11522119PRTArtificial SequenceSynthetic 22Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25
30Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45Ala Thr Ile Ser Asp Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser
Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser
Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Tyr Cys 85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp
Tyr Trp Gly Gln Gly 100 105 110Thr Leu Val Thr Val Ser Ser
11523119PRTArtificial SequenceSynthetic 23Glu Val Gln Leu Val Glu
Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser
Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp
Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40 45Ala Thr Ile
Ser Asp Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75
80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Ile Cys
85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln
Gly 100 105 110Thr Leu Val Thr Val Ser Ser 11524119PRTArtificial
SequenceSynthetic 24Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe
Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp Val Arg Gln Ala Pro Gly
Lys Gly Leu Glu Trp Val 35 40 45Ala Thr Ile Ser Asp Gly Gly Gly Tyr
Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg
Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu
Arg Ala Glu Asp Thr Ala Val Tyr Ile Cys 85 90 95Ala Arg Glu Phe Gly
Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln Gly 100 105 110Thr Thr Val
Thr Val Ser Ser 11525119PRTArtificial SequenceSynthetic 25Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25
30Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45Ala Thr Ile Ser Asp Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser
Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Asn
Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Ile Cys 85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp
Tyr Trp Gly Gln Gly 100 105 110Thr Leu Val Thr Val Ser Ser
11526119PRTArtificial SequenceSynthetic 26Glu Val Gln Leu Val Glu
Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser
Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp
Val Arg Gln Thr Pro Glu Lys Ser Leu Glu Trp Val 35
40 45Ala Thr Ile Ser Asp Gly Gly Gly Tyr Ile Tyr Tyr Ser Asp Ser
Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Asn
Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Ile Cys 85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp
Tyr Trp Gly Gln Gly 100 105 110Thr Leu Val Thr Val Ser Ser
11527107PRTArtificial SequenceSynthetic 27Asp Ile Val Met Thr Gln
Ser His Lys Phe Met Ser Thr Ser Val Gly1 5 10 15Asp Arg Val Ser Ile
Ser Cys Lys Ala Ser Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr
Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr
Ser Ser Arg Tyr Thr Gly Val Pro Asp Arg Phe Thr Gly 50 55 60Ser Gly
Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Val Gln Ala65 70 75
80Glu Asp Leu Ala Val Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu
85 90 95Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys 100
10528107PRTArtificial SequenceSynthetic 28Asp Ile Gln Met Thr Gln
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile
Thr Cys Lys Ala Ser Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr
Ser Ser Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly
Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Leu Gln Pro65 70 75
80Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu
85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys 100
10529107PRTArtificial SequenceSynthetic 29Asp Ile Gln Met Thr Gln
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile
Thr Cys Lys Ala Ser Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr
Gln Gln Lys Pro Gly Lys Ser Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr
Ser Ser Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly
Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Leu Gln Pro65 70 75
80Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu
85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys 100
10530108PRTArtificial SequenceSynthetic 30Asp Ile Gln Met Thr Gln
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile
Thr Cys Lys Ala Ser Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr
Ser Ser Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly
Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro65 70 75
80Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu
85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg 100
10531108PRTArtificial SequenceSynthetic 31Asp Ile Gln Met Thr Gln
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile
Thr Cys Lys Ala Ser Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr
Ser Ser Arg Tyr Thr Gly Val Pro Asp Arg Phe Thr Gly 50 55 60Ser Gly
Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro65 70 75
80Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu
85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg 100
10532108PRTArtificial SequenceSynthetic 32Asp Ile Gln Met Thr Gln
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile
Thr Cys Lys Ala Ser Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr
Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr
Ser Ser Arg Tyr Thr Gly Val Pro Asp Arg Phe Thr Gly 50 55 60Ser Gly
Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro65 70 75
80Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu
85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg 100
10533108PRTArtificial SequenceSynthetic 33Asp Ile Gln Met Thr Gln
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile
Ser Cys Lys Ala Ser Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr
Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr
Ser Ser Arg Tyr Thr Gly Val Pro Asp Arg Phe Thr Gly 50 55 60Ser Gly
Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro65 70 75
80Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu
85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Arg 100
10534357DNAArtificial SequenceSynthetic 34gaggtgaagc tggtggagag
cggcggagat ctggtgaagc ctggcggcag cctgaagctg 60agctgtgccg ccagcggctt
caccttcagc agctacgaca tgagctgggt gaggcagacc 120cccgagaaga
gcctggagtg ggtggccacc atcagcgatg gcggcggcta catctactac
180agcgacagcg tgaagggcag gttcaccatc agcagggaca acgccaagaa
caacctgtac 240ctgcagatga gcagcctgag gagcgaggac accgccctgt
acatctgcgc cagggagttc 300ggcaagaggt acgccctgga ctactgggga
cagggcacca gcgtgaccgt gagcagc 35735357DNAArtificial
SequenceSynthetic 35gaggtgcagc tggtggagag cggaggagga ctggtgaagc
ccggaggcag cctgagactg 60agctgcgctg ccagcggctt caccttcagc agctacgaca
tgagctgggt gagacaggcc 120cctggcaaag gcctggagtg ggtgagcacc
atctccgatg gcggcggcta catctattac 180tccgacagcg tgaagggcag
gttcaccatc agcagggaca acgccaagaa cagcctgtac 240ctgcagatga
acagcctgag ggccgaggac accgccgtgt actactgcgc cagggagttc
300ggcaaaaggt acgccctgga ctactggggc cagggcacaa ccgtgaccgt gagcagc
35736357DNAArtificial SequenceSynthetic 36gaggtgcagc tggtggagag
cggaggagga ctggtgaagc ccggaggcag cctgagactg 60agctgcgctg ccagcggctt
caccttcagc agctacgaca tgagctgggt gagacaggcc 120cctggcaaag
gcctggagtg ggtggccacc atctccgatg gcggcggcta catctattac
180tccgacagcg tgaagggcag gttcaccatc agcagggaca acgccaagaa
cagcctgtac 240ctgcagatga acagcctgag ggccgaggac accgccgtgt
actactgcgc cagggagttc 300ggcaaaaggt acgccctgga ctactggggc
cagggcacaa ccgtgaccgt gagcagc 35737357DNAArtificial
SequenceSynthetic 37gaggtgcagc tggtggagag cggaggagga ctggtgaagc
ccggaggcag cctgagactg 60agctgcgctg ccagcggctt caccttcagc agctacgaca
tgagctgggt gagacaggcc 120cctggcaaaa gcctggagtg ggtggccacc
atctccgatg gcggcggcta catctattac 180tccgacagcg tgaagggcag
gttcaccatc agcagggaca acgccaagaa cagcctgtac 240ctgcagatga
acagcctgag ggccgaggac accgccgtgt acatctgcgc cagggagttc
300ggcaaaaggt acgccctgga ctactggggc cagggcacaa ccgtgaccgt gagcagc
35738357DNAArtificial SequenceSynthetic 38gaggtgcagc tggtggagag
cggaggagga ctggtgaagc ccggaggcag cctgagactg 60agctgcgctg ccagcggctt
caccttcagc agctacgaca tgagctggat cagacaggcc 120cctggcaaag
gcctggagtg ggtgagcacc atctccgatg gcggcggcta catctattac
180tccgacagcg tgaagggcag gttcaccatc agcagggaca acgccaagaa
cagcctgtac 240ctgcagatga acagcctgag ggccgaggac accgccgtgt
actactgcgc cagggagttc 300ggcaaaaggt acgccctgga ctactggggc
cagggcacaa ccgtgaccgt gagcagc 35739357DNAArtificial
SequenceSynthetic 39gaggtgcagc tggtggagag cggaggagga ctggtgaagc
ccggaggcag cctgagactg 60agctgcgctg ccagcggctt caccttcagc agctacgaca
tgagctggat cagacaggcc 120cctggcaaag gcctggagtg ggtggccacc
atctccgatg gcggcggcta catctattac 180tccgacagcg tgaagggcag
gttcaccatc agcagggaca acgccaagaa cagcctgtac 240ctgcagatga
acagcctgag ggccgaggac accgccgtgt actactgcgc cagggagttc
300ggcaaaaggt acgccctgga ctactggggc cagggcacaa ccgtgaccgt gagcagc
35740357DNAArtificial SequenceSynthetic 40gaggtgcagc tggtggagag
cggaggagga ctggtgaagc ccggaggcag cctgagactg 60agctgcgctg ccagcggctt
caccttcagc agctacgaca tgagctgggt gagacaggcc 120cctggcaaaa
gcctggagtg ggtggccacc atctccgatg gcggcggcta catctattac
180tccgacagcg tgaagggcag gttcaccatc agcagggaca acgccaagaa
cagcctgtac 240ctgcagatga acagcctgag ggccgaggac accgccgtgt
acatctgcgc cagggagttc 300ggcaaaaggt acgccctgga ctactggggc
cagggcacaa ccgtgaccgt gagcagc 35741357DNAArtificial
SequenceSynthetic 41gaggtgcagc tgctggagag cggaggagga ctggtgcaac
ccggaggcag cctgagactg 60agctgcgctg ccagcggctt caccttcagc agctacgaca
tgagctgggt gagacaggcc 120cctggcaaag gcctggagtg ggtgagcacc
atctccgatg gcggcggcta catctattac 180tccgacagcg tgaagggcag
gttcaccatc agcagggaca acagcaagaa caccctgtac 240ctgcagatga
acagcctgag ggccgaggac accgccgtgt actactgcgc cagggagttc
300ggcaaaaggt acgccctgga ctactggggc cagggcacaa ccgtgaccgt gagcagc
35742357DNAArtificial SequenceSynthetic 42gaggtgcagc tgctggagag
cggaggagga ctggtgcaac ccggaggcag cctgagactg 60agctgcgctg ccagcggctt
caccttcagc agctacgaca tgagctgggt gagacaggcc 120cctggcaaaa
gcctggagtg ggtggccacc atctccgatg gcggcggcta catctattac
180tccgacagcg tgaagggcag gttcaccatc agcagggaca acagcaagaa
caccctgtac 240ctgcagatga acagcctgag ggccgaggac accgccgtgt
acatctgcgc cagggagttc 300ggcaaaaggt acgccctgga ctactggggc
cagggcacaa ccgtgaccgt gagcagc 35743357DNAArtificial
SequenceSynthetic 43gaggtgcagc tggtggagag cggaggagga ctggtgcaac
ccggaggcag cctgagactg 60agctgcgctg ccagcggctt caccttcagc agctacgaca
tgagctgggt gagacaggcc 120cctggcaaag gcctggagtg ggtgagcacc
atctccgatg gcggcggcta catctattac 180tccgacagcg tgaagggcag
gttcaccatc agcagggaca acgccaagaa cagcctgtac 240ctgcagatga
acagcctgag ggatgaggac accgccgtgt actactgcgc cagggagttc
300ggcaaaaggt acgccctgga ctactggggc cagggcacaa ccgtgaccgt gagcagc
35744357DNAArtificial SequenceSynthetic 44gaggtgcagc tggtggagag
cggaggagga ctggtgcaac ccggaggcag cctgagactg 60agctgcgctg ccagcggctt
caccttcagc agctacgaca tgagctgggt gagacaggcc 120cctggcaaag
gcctggagtg ggtggccacc atctccgatg gcggcggcta catctattac
180tccgacagcg tgaagggcag gttcaccatc agcagggaca acgccaagaa
cagcctgtac 240ctgcagatga acagcctgag ggatgaggac accgccgtgt
actactgcgc cagggagttc 300ggcaaaaggt acgccctgga ctactggggc
cagggcacaa ccgtgaccgt gagcagc 35745357DNAArtificial
SequenceSynthetic 45gaggtgcagc tggtggagag cggaggagga ctggtgcaac
ccggaggcag cctgagactg 60agctgcgctg ccagcggctt caccttcagc agctacgaca
tgagctgggt gagacaggcc 120cctggcaaaa gcctggagtg ggtggccacc
atctccgatg gcggcggcta catctattac 180tccgacagcg tgaagggcag
gttcaccatc agcagggaca acgccaagaa cagcctgtac 240ctgcagatga
acagcctgag ggatgaggac accgccgtgt acatctgcgc cagggagttc
300ggcaaaaggt acgccctgga ctactggggc cagggcacaa ccgtgaccgt gagcagc
35746357DNAArtificial SequenceSynthetic 46gaggtgcagc tggtggagag
cggaggagga ctggtgcaac ccggaggcag cctgagactg 60agctgcgctg ccagcggctt
caccttcagc agctacgaca tgagctgggt gagacaggcc 120cctggcaaaa
gcctggagtg ggtggccacc atctccgaag gcggcggcta catctattac
180tccgacagcg tgaagggcag gttcaccatc agcagggaca acgccaagaa
cagcctgtac 240ctgcagatga acagcctgag ggatgaggac accgccgtgt
acatctgcgc cagggagttc 300ggcaaaaggt acgccctgga ctactggggc
cagggcacaa ccgtgaccgt gagcagc 35747357DNAArtificial
SequenceSynthetic 47gaggtgcagc tggtggagag cggaggagga ctggtgcaac
ccggaggcag cctgagactg 60agctgcgctg ccagcggctt caccttcagc agctacgaca
tgagctgggt gagacaggcc 120cctggcaaaa gcctggagtg ggtggccacc
atctccgatg cgggcggcta catctattac 180tccgacagcg tgaagggcag
gttcaccatc agcagggaca acgccaagaa cagcctgtac 240ctgcagatga
acagcctgag ggatgaggac accgccgtgt acatctgcgc cagggagttc
300ggcaaaaggt acgccctgga ctactggggc cagggcacaa ccgtgaccgt gagcagc
35748357DNAArtificial SequenceSynthetic 48gaggtgcagc tggtggagag
cggaggagga ctggtgcaac ccggaggcag cctgagactg 60agctgcgctg ccagcggctt
caccttcagc agctacgaca tgagctgggt gagacaggcc 120cctggcaaaa
gcctggagtg ggtggccacc atctccgatg ttggcggcta catctattac
180tccgacagcg tgaagggcag gttcaccatc agcagggaca acgccaagaa
cagcctgtac 240ctgcagatga acagcctgag ggatgaggac accgccgtgt
acatctgcgc cagggagttc 300ggcaaaaggt acgccctgga ctactggggc
cagggcacaa ccgtgaccgt gagcagc 35749357DNAArtificial
SequenceSynthetic 49gaggtgcagc tggtggagtc cggaggaggc ctggtgcaac
ctggaggctc cctgaggctg 60tcctgtgccg cttccggctt caccttcagc tcctacgata
tgagctgggt gaggcaggct 120cctggaaagg gcctggagtg ggtggccacc
atctccgacg gaggcggcta catctactac 180tccgactccg tgaagggcag
gttcaccatc tcccgggaca acgccaagaa ctccctgtac 240ctgcagatga
actctctcag ggctgaggac accgccgtgt attactgcgc cagggagttt
300ggcaagaggt acgccctgga ttactggggc cagggcacac tggtgacagt gagctcc
35750357DNAArtificial SequenceSynthetic 50gaggtgcagc tggtggagtc
cggaggaggc ctggtgcaac ctggaggctc cctgaggctg 60tcctgtgccg cttccggctt
caccttcagc tcctacgata tgagctgggt gaggcaggct 120cctggaaagg
gcctggagtg ggtggccacc atctccgacg gaggcggcta catctactac
180tccgactccg tgaagggcag gttcaccatc tcccgggaca acgccaagaa
ctccctgtac 240ctgcagatga actctctcag ggctgaggac accgccgtgt
atatctgcgc cagggagttt 300ggcaagaggt acgccctgga ttactggggc
cagggcacac tggtgacagt gagctcc 35751357DNAArtificial
SequenceSynthetic 51gaggtgcagc tggtggagtc cggaggaggc ctggtgcaac
ctggaggctc cctgaggctg 60tcctgtgccg cttccggctt caccttcagc tcctacgata
tgagctgggt gaggcaggct 120cctggaaagg gcctggagtg ggtggccacc
atctccgacg gaggcggcta catctactac 180tccgactccg tgaagggcag
gttcaccatc tcccgggaca acgccaagaa caacctgtac 240ctgcagatga
actctctcag ggctgaggac accgccgtgt atatctgcgc cagggagttt
300ggcaagaggt acgccctgga ttactggggc cagggcacac tggtgacagt gagctcc
35752357DNAArtificial SequenceSynthetic 52gaggtgcagc tggtggagtc
cggaggaggc ctggtgcaac ctggaggctc cctgaggctg 60tcctgtgccg cttccggctt
caccttcagc tcctacgata tgagctgggt gaggcagacc 120cctgagaaga
gcctggagtg ggtggccacc atctccgacg gaggcggcta catctactac
180tccgactccg tgaagggcag gttcaccatc tcccgggaca acgccaagaa
caacctgtac 240ctgcagatga actctctcag ggctgaggac accgccgtgt
atatctgcgc cagggagttt 300ggcaagaggt acgccctgga ttactggggc
cagggcacac tggtgacagt gagctcc 35753357DNAArtificial
SequenceSynthetic 53gaggtgcagc tggtggagtc cggaggaggc ctggtgcaac
ctggaggctc cctgaggctg 60tcctgtgccg cttccggctt caccttcagc tcctacgata
tgagctgggt gaggcaggct 120cctggaaagg gcctggagtg ggtggccacc
atctccgacg gaggcggcta catctactac 180tccgactccg tgaagggcag
gttcaccatc tcccgggaca acgccaagaa ctccctgtac 240ctgcagatga
actctctcag ggctgaggac accgccgtgt atatctgcgc cagggagttt
300ggcaagaggt acgccctgga ttactggggc cagggcacaa ccgtgacagt gagctcc
35754321DNAArtificial SequenceSynthetic 54gacatcgtga tgacccagag
ccacaagttc atgagcacca gcgtgggcga tagggtgagc 60atcagctgca aggccagcca
ggatgtgacc cctgccgtgg cctggtacca gcagaagccc 120ggccagagcc
ccaagctgct gatctacagc accagcagca ggtacaccgg cgtgcccgac
180aggttcacag gaagcggcag cggcaccgac ttcaccttca ccatcagcag
cgtgcaggcc 240gaggacctgg ccgtgtacta ctgccagcag cactacacca
cccctctgac cttcggcgcc 300ggcaccaagc tggagctgaa g
32155321DNAArtificial SequenceSynthetic 55gacatccaga tgacccagag
ccctagcagc ctgagcgcta gcgtgggcga cagggtgacc 60atcacctgca aggccagcca
ggatgtgacc cctgccgtgg cctggtacca gcagaagccc 120ggcaaggccc
ccaagctgct gatctacagc accagcagca ggtacaccgg cgtgcccagc
180aggtttagcg gaagcggcag cggcaccgac ttcaccttca ccatcagcag
cctgcagccc 240gaggacatcg ccacctacta ctgccagcag cactacacca
cccctctgac cttcggccag 300ggcaccaagc tggagatcaa g
32156321DNAArtificial SequenceSynthetic 56gacatccaga tgacccagag
ccctagcagc ctgagcgcta gcgtgggcga cagggtgacc 60atcacctgca aggccagcca
ggatgtgacc cctgccgtgg cctggtacca gcagaagccc 120ggcaagtccc
ccaagctgct gatctacagc accagcagca ggtacaccgg cgtgcccagc
180aggtttagcg gaagcggcag cggcaccgac ttcaccttca ccatcagcag
cctgcagccc 240gaggacatcg ccacctacta ctgccagcag cactacacca
cccctctgac cttcggccag 300ggcaccaagc tggagatcaa g
32157324DNAArtificial SequenceSynthetic 57gacattcaga tgacccagtc
ccctagcagc ctgtccgctt ccgtgggcga cagggtgacc 60atcacctgca aggccagcca
ggacgtgaca cctgctgtgg cctggtatca acagaagcct 120ggcaaggctc
ctaagctcct gatctacagc acatcctccc ggtacaccgg agtgccctcc
180aggtttagcg gcagcggctc cggcaccgat ttcaccctga ccatttcctc
cctgcagccc 240gaggacttcg ccacctacta ctgccagcag cactacacca
cacccctgac cttcggccag 300ggcaccaagc tggagatcaa gcgg
32458324DNAArtificial SequenceSynthetic 58gacattcaga tgacccagtc
ccctagcagc ctgtccgctt ccgtgggcga cagggtgacc 60atcacctgca aggccagcca
ggacgtgaca cctgctgtgg cctggtatca acagaagcct 120ggcaaggctc
ctaagctcct gatctacagc acatcctccc ggtacaccgg agtgcccgac
180aggtttaccg gcagcggctc
cggcaccgat ttcaccctga ccatttcctc cctgcagccc 240gaggacttcg
ccacctacta ctgccagcag cactacacca cacccctgac cttcggccag
300ggcaccaagc tggagatcaa gcgg 32459324DNAArtificial
SequenceSynthetic 59gacattcaga tgacccagtc ccctagcagc ctgtccgctt
ccgtgggcga cagggtgacc 60atcacctgca aggccagcca ggacgtgaca cctgctgtgg
cctggtatca acagaagcct 120ggccagagcc ctaagctcct gatctacagc
acatcctccc ggtacaccgg agtgcccgac 180aggtttaccg gcagcggctc
cggcaccgat ttcaccctga ccatttcctc cctgcagccc 240gaggacttcg
ccacctacta ctgccagcag cactacacca cacccctgac cttcggccag
300ggcaccaagc tggagatcaa gcgg 32460324DNAArtificial
SequenceSynthetic 60gacattcaga tgacccagtc ccctagcagc ctgtccgctt
ccgtgggcga cagggtgacc 60atcagctgca aggccagcca ggacgtgaca cctgctgtgg
cctggtatca acagaagcct 120ggccagagcc ctaagctcct gatctacagc
acatcctccc ggtacaccgg agtgcccgac 180aggtttaccg gcagcggctc
cggcaccgat ttcaccctga ccatttcctc cctgcagccc 240gaggacttcg
ccacctacta ctgccagcag cactacacca cacccctgac cttcggccag
300ggcaccaagc tggagatcaa gcgg 324615PRTArtificial SequenceSynthetic
61Thr Tyr Asp Met Ser1 5625PRTArtificial SequenceSynthetic 62Cys
Tyr Asp Met Ser1 5635PRTArtificial SequenceSynthetic 63Ser Phe Asp
Met Ser1 5645PRTArtificial SequenceSynthetic 64Ser His Asp Met Ser1
5655PRTArtificial SequenceSynthetic 65Ser Trp Asp Met Ser1
5665PRTArtificial SequenceSynthetic 66Ser Tyr Asp Met Thr1
5675PRTArtificial SequenceSynthetic 67Ser Tyr Asp Met Cys1
56817PRTArtificial SequenceSynthetic 68Thr Ile Ser Asp Gly Gly Ala
Tyr Ile Tyr Tyr Ser Asp Ser Val Lys1 5 10 15Gly6917PRTArtificial
SequenceSynthetic 69Thr Ile Ser Asp Gly Gly Pro Tyr Ile Tyr Tyr Ser
Asp Ser Val Lys1 5 10 15Gly7017PRTArtificial SequenceSynthetic
70Thr Ile Ser Asp Gly Gly Gly Phe Ile Tyr Tyr Ser Asp Ser Val Lys1
5 10 15Gly7117PRTArtificial SequenceSynthetic 71Thr Ile Ser Asp Gly
Gly Gly His Ile Tyr Tyr Ser Asp Ser Val Lys1 5 10
15Gly7217PRTArtificial SequenceSynthetic 72Thr Ile Ser Asp Gly Gly
Gly Trp Ile Tyr Tyr Ser Asp Ser Val Lys1 5 10
15Gly7317PRTArtificial SequenceSynthetic 73Thr Ile Ser Asp Gly Gly
Gly Tyr Ile Tyr Tyr Ser Asp Thr Val Lys1 5 10
15Gly7417PRTArtificial SequenceSynthetic 74Thr Ile Ser Asp Gly Gly
Gly Tyr Ile Tyr Tyr Ser Asp Cys Val Lys1 5 10
15Gly7517PRTArtificial SequenceSynthetic 75Thr Ile Ser Asp Gly Gly
Gly Tyr Ile Tyr Tyr Ser Asp Ser Leu Lys1 5 10
15Gly7617PRTArtificial SequenceSynthetic 76Thr Ile Ser Asp Gly Gly
Gly Tyr Ile Tyr Tyr Ser Asp Ser Ile Lys1 5 10
15Gly7717PRTArtificial SequenceSynthetic 77Thr Ile Ser Asp Gly Gly
Gly Tyr Ile Tyr Tyr Ser Asp Ser Met Lys1 5 10
15Gly7810PRTArtificial SequenceSynthetic 78Gln Phe Gly Lys Arg Tyr
Ala Leu Asp Tyr1 5 107910PRTArtificial SequenceSynthetic 79Asp Phe
Gly Lys Arg Tyr Ala Leu Asp Tyr1 5 108010PRTArtificial
SequenceSynthetic 80Asn Phe Gly Lys Arg Tyr Ala Leu Asp Tyr1 5
108110PRTArtificial SequenceSynthetic 81Glu Tyr Gly Lys Arg Tyr Ala
Leu Asp Tyr1 5 108210PRTArtificial SequenceSynthetic 82Glu His Gly
Lys Arg Tyr Ala Leu Asp Tyr1 5 108310PRTArtificial
SequenceSynthetic 83Glu Trp Gly Lys Arg Tyr Ala Leu Asp Tyr1 5
108410PRTArtificial SequenceSynthetic 84Glu Phe Ala Lys Arg Tyr Ala
Leu Asp Tyr1 5 108510PRTArtificial SequenceSynthetic 85Glu Phe Pro
Lys Arg Tyr Ala Leu Asp Tyr1 5 108610PRTArtificial
SequenceSynthetic 86Glu Phe Gly Arg Arg Tyr Ala Leu Asp Tyr1 5
108710PRTArtificial SequenceSynthetic 87Glu Phe Gly Lys Lys Tyr Ala
Leu Asp Tyr1 5 108810PRTArtificial SequenceSynthetic 88Glu Phe Gly
Lys Arg Phe Ala Leu Asp Tyr1 5 108910PRTArtificial
SequenceSynthetic 89Glu Phe Gly Lys Arg His Ala Leu Asp Tyr1 5
109010PRTArtificial SequenceSynthetic 90Glu Phe Gly Lys Arg Trp Ala
Leu Asp Tyr1 5 109111PRTArtificial SequenceSynthetic 91Lys Ala Thr
Gln Asp Val Thr Pro Ala Val Ala1 5 109211PRTArtificial
SequenceSynthetic 92Lys Ala Cys Gln Asp Val Thr Pro Ala Val Ala1 5
10937PRTArtificial SequenceSynthetic 93Thr Thr Ser Ser Arg Tyr Thr1
5947PRTArtificial SequenceSynthetic 94Cys Thr Ser Ser Arg Tyr Thr1
5957PRTArtificial SequenceSynthetic 95Ser Ser Ser Ser Arg Tyr Thr1
5967PRTArtificial SequenceSynthetic 96Ser Met Ser Ser Arg Tyr Thr1
5977PRTArtificial SequenceSynthetic 97Ser Val Ser Ser Arg Tyr Thr1
5987PRTArtificial SequenceSynthetic 98Ser Thr Thr Ser Arg Tyr Thr1
5997PRTArtificial SequenceSynthetic 99Ser Thr Cys Ser Arg Tyr Thr1
51007PRTArtificial SequenceSynthetic 100Ser Thr Ser Thr Arg Tyr
Thr1 51017PRTArtificial SequenceSynthetic 101Ser Thr Ser Cys Arg
Tyr Thr1 51027PRTArtificial SequenceSynthetic 102Ser Thr Ser Ser
Lys Tyr Thr1 51037PRTArtificial SequenceSynthetic 103Ser Thr Ser
Ser Arg Phe Thr1 51047PRTArtificial SequenceSynthetic 104Ser Thr
Ser Ser Arg His Thr1 51057PRTArtificial SequenceSynthetic 105Ser
Thr Ser Ser Arg Trp Thr1 51069PRTArtificial SequenceSynthetic
106Glu Gln His Tyr Thr Thr Pro Leu Thr1 51079PRTArtificial
SequenceSynthetic 107Asp Gln His Tyr Thr Thr Pro Leu Thr1
51089PRTArtificial SequenceSynthetic 108Asn Gln His Tyr Thr Thr Pro
Leu Thr1 51099PRTArtificial SequenceSynthetic 109Gln Glu His Tyr
Thr Thr Pro Leu Thr1 51109PRTArtificial SequenceSynthetic 110Gln
Asp His Tyr Thr Thr Pro Leu Thr1 51119PRTArtificial
SequenceSynthetic 111Gln Asn His Tyr Thr Thr Pro Leu Thr1
5112357DNAArtificial SequenceSynthetic 112gaagtgaaac tggtggagtc
tgggggagac ttagtgaagc ctggagggtc cctgaaactc 60tcctgtgcag cctctggatt
cactttcagt agctatgaca tgtcttgggt tcgccagact 120ccggagaaga
gtctggagtg ggtcgcaacc attagtgatg gtggtggtta catctactat
180tcagacagtg tgaaggggcg atttaccatc tccagagaca atgccaagaa
caacctgtac 240ctgcaaatga gcagtctgag gtctgaggac acggccttgt
atatttgtgc aagagaattt 300ggtaagcgct atgctttgga ctactggggt
caaggaacct cagtcaccgt ctcctca 357113116PRTArtificial
SequenceSynthetic 113Glu Val Lys Leu Val Glu Ser Gly Gly Asp Leu
Val Lys Pro Gly Gly1 5 10 15Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly
Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp Val Arg Gln Thr Pro
Glu Lys Ser Leu Glu Trp Val 35 40 45Ala Thr Ile Ser Asp Gly Gly Gly
Tyr Ile Tyr Tyr Ser Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser
Arg Asp Asn Ala Lys Asn Asn Leu Tyr65 70 75 80Leu Gln Met Ser Ser
Leu Arg Ser Glu Asp Thr Ala Leu Tyr Ile Cys 85 90 95Ala Arg Glu Phe
Gly Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln Gly 100 105 110Thr Ser
Val Thr 115114321DNAArtificial SequenceSynthetic 114gacattgtga
tgacccagtc tcacaaattc atgtccacat cggtaggaga cagggtcagc 60atctcctgca
aggccagtca ggatgtgact cctgctgtcg cctggtatca acagaagcca
120ggacaatctc ctaaactact gatttactcc acatcctccc ggtacactgg
agtccctgat 180cgcttcactg gcagtggatc tgggacggat ttcactttca
ccatcagcag tgtgcaggct 240gaagacctgg cagtttatta ctgtcagcaa
cattatacta ctccgctcac gttcggtgct 300gggaccaagc tggagctgaa a
321115107PRTArtificial SequenceSynthetic 115Asp Ile Val Met Thr Gln
Ser His Lys Phe Met Ser Thr Ser Val Gly1 5 10 15Asp Arg Val Ser Ile
Ser Cys Lys Ala Ser Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr
Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr
Ser Ser Arg Tyr Thr Gly Val Pro Asp Arg Phe Thr Gly 50 55 60Ser Gly
Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Val Gln Ala65 70 75
80Glu Asp Leu Ala Val Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu
85 90 95Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys 100
10511617PRTArtificial SequenceSynthetic 116Thr Ile Ser Asp Ala Gly
Gly Tyr Ile Tyr Tyr Arg Asp Ser Val Lys1 5 10
15Gly11710PRTArtificial SequenceSynthetic 117Glu Leu Pro Trp Arg
Tyr Ala Leu Asp Tyr1 5 1011817PRTArtificial SequenceSynthetic
118Thr Ile Ser Asp Ala Gly Ala Tyr Ile Tyr Tyr Arg Asp Ser Val Lys1
5 10 15Gly11917PRTArtificial SequenceSynthetic 119Thr Ile Ser Asp
Ala Gly Pro Tyr Ile Tyr Tyr Arg Asp Ser Val Lys1 5 10
15Gly12017PRTArtificial SequenceSynthetic 120Thr Ile Ser Asp Ala
Gly Gly Phe Ile Tyr Tyr Arg Asp Ser Val Lys1 5 10
15Gly12117PRTArtificial SequenceSynthetic 121Thr Ile Ser Asp Ala
Gly Gly His Ile Tyr Tyr Arg Asp Ser Val Lys1 5 10
15Gly12217PRTArtificial SequenceSynthetic 122Thr Ile Ser Asp Ala
Gly Gly Trp Ile Tyr Tyr Arg Asp Ser Val Lys1 5 10
15Gly12317PRTArtificial SequenceSynthetic 123Thr Ile Ser Asp Ala
Gly Gly Tyr Ile Tyr Tyr Arg Asp Thr Val Lys1 5 10
15Gly12417PRTArtificial SequenceSynthetic 124Thr Ile Ser Asp Ala
Gly Gly Tyr Ile Tyr Tyr Arg Asp Cys Val Lys1 5 10
15Gly12517PRTArtificial SequenceSynthetic 125Thr Ile Ser Asp Ala
Gly Gly Tyr Ile Tyr Tyr Arg Asp Ser Leu Lys1 5 10
15Gly12617PRTArtificial SequenceSynthetic 126Thr Ile Ser Asp Ala
Gly Gly Tyr Ile Tyr Tyr Arg Asp Ser Ile Lys1 5 10
15Gly12717PRTArtificial SequenceSynthetic 127Thr Ile Ser Asp Ala
Gly Gly Tyr Ile Tyr Tyr Arg Asp Ser Met Lys1 5 10
15Gly12810PRTArtificial SequenceSynthetic 128Glu Leu Phe Asn Arg
Tyr Ala Leu Asp Tyr1 5 1012910PRTArtificial SequenceSynthetic
129Glu Leu His Phe Arg Tyr Ala Leu Asp Tyr1 5 1013010PRTArtificial
SequenceSynthetic 130Glu Leu Tyr Phe Arg Tyr Ala Leu Asp Tyr1 5
1013110PRTArtificial SequenceSynthetic 131Glu Leu Leu His Arg Tyr
Ala Leu Asp Tyr1 5 1013210PRTArtificial SequenceSynthetic 132Glu
Leu Arg Gly Arg Tyr Ala Leu Asp Tyr1 5 1013310PRTArtificial
SequenceSynthetic 133Gln Leu Pro Trp Arg Tyr Ala Leu Asp Tyr1 5
1013410PRTArtificial SequenceSynthetic 134Asp Leu Pro Trp Arg Tyr
Ala Leu Asp Tyr1 5 1013510PRTArtificial SequenceSynthetic 135Asn
Leu Pro Trp Arg Tyr Ala Leu Asp Tyr1 5 1013610PRTArtificial
SequenceSynthetic 136Glu Leu Pro Trp Lys Tyr Ala Leu Asp Tyr1 5
1013710PRTArtificial SequenceSynthetic 137Glu Leu Pro Trp Arg Phe
Ala Leu Asp Tyr1 5 1013810PRTArtificial SequenceSynthetic 138Glu
Leu Pro Trp Arg His Ala Leu Asp Tyr1 5 1013910PRTArtificial
SequenceSynthetic 139Glu Leu Pro Trp Arg Trp Ala Leu Asp Tyr1 5
101409PRTArtificial SequenceSynthetic 140Gln Gln His Ser Asp Ala
Pro Leu Thr1 5141119PRTArtificial SequenceSynthetic 141Glu Val Gln
Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp
Met Ser Trp Val Arg Gln Ala Pro Gly Lys Ser Leu Glu Trp Val 35 40
45Ala Thr Ile Ser Asp Ala Gly Gly Tyr Ile Tyr Tyr Arg Asp Ser Val
50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu
Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Asp Glu Asp Thr Ala Val
Tyr Ile Cys 85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp Tyr
Trp Gly Gln Gly 100 105 110Thr Thr Val Thr Val Ser Ser
115142107PRTArtificial SequenceSynthetic 142Asp Ile Gln Met Thr Gln
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile
Thr Cys Lys Ala Ser Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr
Ser Ser Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly
Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Leu Gln Pro65 70 75
80Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu
85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys 100
105143119PRTArtificial SequenceSynthetic 143Glu Val Gln Leu Val Glu
Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser
Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp
Val Arg Gln Ala Pro Gly Lys Ser Leu Glu Trp Val 35 40 45Ala Thr Ile
Ser Asp Ala Gly Gly Tyr Ile Tyr Tyr Arg Asp Ser Val 50 55 60Lys Gly
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75
80Leu Gln Met Asn Ser Leu Arg Asp Glu Asp Thr Ala Val Tyr Ile Cys
85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp Tyr Trp Gly Gln
Gly 100 105 110Thr Thr Val Thr Val Ser Ser 115144107PRTArtificial
SequenceSynthetic 144Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ala Lys
Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr Gln Gln Lys Pro Gly
Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr Ser Ser Arg Tyr Thr
Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly Ser Gly Thr Asp Phe
Thr Phe Thr Ile Ser Ser Leu Gln Pro65 70 75 80Glu Asp Ile Ala Thr
Tyr Tyr Cys Met Gln His Tyr Thr Thr Pro Leu 85 90 95Thr Phe Gly Gln
Gly Thr Lys Leu Glu Ile Lys 100 105145119PRTArtificial
SequenceSynthetic 145Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu
Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly
Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp Val Arg Gln Ala Pro
Gly Lys Ser Leu Glu Trp Val 35 40 45Ala Thr Ile Ser Asp Ala Gly Gly
Tyr Ile Tyr Tyr Arg Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser
Arg Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75 80Leu Gln Met Asn Ser
Leu Arg Asp Glu Asp Thr Ala Val Tyr Ile Cys 85 90 95Ala Arg Glu Phe
Gly Lys Arg Tyr Ala Leu Asp Ser Trp Gly Gln Gly 100 105 110Thr Thr
Val Thr Val Ser Ser 115146107PRTArtificial SequenceSynthetic 146Asp
Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10
15Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Val Trp Pro Ala
20 25 30Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu
Ile 35 40 45Tyr Ser Thr Ser Ser Arg Tyr Thr Gly Val Pro Ser Arg Phe
Ser Gly 50 55 60Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser
Leu Gln Pro65 70 75 80Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln His
Ser Thr Thr Pro Leu 85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile
Lys 100 105147119PRTArtificial SequenceSynthetic
147Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1
5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser
Tyr 20 25 30Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Ser Leu Glu
Trp Val 35 40 45Ala Thr Ile Ser Asp Ala Gly Gly Tyr Ile Tyr Tyr Arg
Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys
Asn Ser Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Asp Glu Asp
Thr Ala Val Tyr Ile Cys 85 90 95Ala Arg Glu Ile Phe Asn Arg Tyr Ala
Leu Asp Tyr Trp Gly Gln Gly 100 105 110Thr Thr Val Thr Val Ser Ser
115148107PRTArtificial SequenceSynthetic 148Asp Ile Gln Met Thr Gln
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile
Thr Cys Lys Ala Ser Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr
Ser Ser Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly
Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Leu Gln Pro65 70 75
80Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu
85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys 100
105149119PRTArtificial SequenceSynthetic 149Glu Val Gln Leu Val Glu
Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser
Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp
Val Arg Gln Ala Pro Gly Lys Ser Leu Glu Trp Val 35 40 45Ala Thr Ile
Ser Asp Ala Gly Gly Tyr Ile Tyr Tyr Arg Asp Ser Val 50 55 60Lys Gly
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75
80Leu Gln Met Asn Ser Leu Arg Asp Glu Asp Thr Ala Val Tyr Ile Cys
85 90 95Ala Arg Glu Leu Pro Trp Arg Tyr Ala Leu Asp Tyr Trp Gly Gln
Gly 100 105 110Thr Thr Val Thr Val Ser Ser 115150107PRTArtificial
SequenceSynthetic 150Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ala Ser
Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr Gln Gln Lys Pro Gly
Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr Ser Ser Arg Tyr Thr
Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly Ser Gly Thr Asp Phe
Thr Phe Thr Ile Ser Ser Leu Gln Pro65 70 75 80Glu Asp Ile Ala Thr
Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu 85 90 95Thr Phe Gly Gln
Gly Thr Lys Leu Glu Ile Lys 100 105151119PRTArtificial
SequenceSynthetic 151Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu
Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly
Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp Val Arg Gln Ala Pro
Gly Lys Ser Leu Glu Trp Val 35 40 45Ala Thr Ile Ser Asp Ala Gly Gly
Tyr Ile Tyr Tyr Arg Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser
Arg Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75 80Leu Gln Met Asn Ser
Leu Arg Asp Glu Asp Thr Ala Val Tyr Ile Cys 85 90 95Ala Arg Glu Leu
His Phe Arg Tyr Ala Leu Asp Tyr Trp Gly Gln Gly 100 105 110Thr Thr
Val Thr Val Ser Ser 115152107PRTArtificial SequenceSynthetic 152Asp
Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10
15Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Val Thr Pro Ala
20 25 30Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu
Ile 35 40 45Tyr Ser Thr Ser Ser Arg Tyr Thr Gly Val Pro Ser Arg Phe
Ser Gly 50 55 60Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser
Leu Gln Pro65 70 75 80Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln His
Tyr Thr Thr Pro Leu 85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile
Lys 100 105153119PRTArtificial SequenceSynthetic 153Glu Val Gln Leu
Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg
Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met
Ser Trp Val Arg Gln Ala Pro Gly Lys Ser Leu Glu Trp Val 35 40 45Ala
Thr Ile Ser Asp Ala Gly Gly Tyr Ile Tyr Tyr Arg Asp Ser Val 50 55
60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr65
70 75 80Leu Gln Met Asn Ser Leu Arg Asp Glu Asp Thr Ala Val Tyr Ile
Cys 85 90 95Ala Arg Glu Leu Tyr Phe Arg Tyr Ala Leu Asp Tyr Trp Gly
Gln Gly 100 105 110Thr Thr Val Thr Val Ser Ser
115154107PRTArtificial SequenceSynthetic 154Asp Ile Gln Met Thr Gln
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile
Thr Cys Lys Ala Ser Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr
Ser Ser Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly
Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Leu Gln Pro65 70 75
80Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu
85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys 100
105155119PRTArtificial SequenceSynthetic 155Glu Val Gln Leu Val Glu
Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser
Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp
Val Arg Gln Ala Pro Gly Lys Ser Leu Glu Trp Val 35 40 45Ala Thr Ile
Ser Asp Ala Gly Gly Tyr Ile Tyr Tyr Arg Asp Ser Val 50 55 60Lys Gly
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75
80Leu Gln Met Asn Ser Leu Arg Asp Glu Asp Thr Ala Val Tyr Ile Cys
85 90 95Ala Arg Glu Leu Leu His Arg Tyr Ala Leu Asp Tyr Trp Gly Gln
Gly 100 105 110Thr Thr Val Thr Val Ser Ser 115156107PRTArtificial
SequenceSynthetic 156Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ala Ser
Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr Gln Gln Lys Pro Gly
Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr Ser Ser Arg Tyr Thr
Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly Ser Gly Thr Asp Phe
Thr Phe Thr Ile Ser Ser Leu Gln Pro65 70 75 80Glu Asp Ile Ala Thr
Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Leu 85 90 95Thr Phe Gly Gln
Gly Thr Lys Leu Glu Ile Lys 100 105157119PRTArtificial
SequenceSynthetic 157Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu
Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly
Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met Ser Trp Val Arg Gln Ala Pro
Gly Lys Ser Leu Glu Trp Val 35 40 45Ala Thr Ile Ser Asp Ala Gly Gly
Tyr Ile Tyr Tyr Arg Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser
Arg Asp Asn Ala Lys Asn Ser Leu Tyr65 70 75 80Leu Gln Met Asn Ser
Leu Arg Asp Glu Asp Thr Ala Val Tyr Ile Cys 85 90 95Ala Arg Glu Leu
Arg Gly Arg Tyr Ala Leu Asp Tyr Trp Gly Gln Gly 100 105 110Thr Thr
Val Thr Val Ser Ser 115158107PRTArtificial SequenceSynthetic 158Asp
Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10
15Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Val Thr Pro Ala
20 25 30Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu
Ile 35 40 45Tyr Ser Thr Ser Ser Arg Tyr Thr Gly Val Pro Ser Arg Phe
Ser Gly 50 55 60Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser
Leu Gln Pro65 70 75 80Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln His
Tyr Thr Thr Pro Leu 85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile
Lys 100 105159119PRTArtificial SequenceSynthetic 159Glu Val Gln Leu
Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg
Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr 20 25 30Asp Met
Ser Trp Val Arg Gln Ala Pro Gly Lys Ser Leu Glu Trp Val 35 40 45Ala
Thr Ile Ser Asp Ala Gly Gly Tyr Ile Tyr Tyr Arg Asp Ser Val 50 55
60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr65
70 75 80Leu Gln Met Asn Ser Leu Arg Asp Glu Asp Thr Ala Val Tyr Ile
Cys 85 90 95Ala Arg Glu Phe Gly Lys Arg Tyr Ala Leu Asp Tyr Trp Gly
Gln Gly 100 105 110Thr Thr Val Thr Val Ser Ser
115160107PRTArtificial SequenceSynthetic 160Asp Ile Gln Met Thr Gln
Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile
Thr Cys Lys Ala Ser Gln Asp Val Thr Pro Ala 20 25 30Val Ala Trp Tyr
Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Thr
Ser Ser Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly
Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Leu Gln Pro65 70 75
80Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln His Ser Asp Ala Pro Leu
85 90 95Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys 100
1051619PRTArtificial SequenceSynthetic 161Glu Gln His Ser Asp Ala
Pro Leu Thr1 51629PRTArtificial SequenceSynthetic 162Asp Gln His
Ser Asp Ala Pro Leu Thr1 51639PRTArtificial SequenceSynthetic
163Asn Gln His Ser Asp Ala Pro Leu Thr1 51649PRTArtificial
SequenceSynthetic 164Gln Glu His Ser Asp Ala Pro Leu Thr1
51659PRTArtificial SequenceSynthetic 165Gln Asp His Ser Asp Ala Pro
Leu Thr1 51669PRTArtificial SequenceSynthetic 166Gln Asn His Ser
Asp Ala Pro Leu Thr1 5
References
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012

D00013

D00014

D00015

D00016

D00017

D00018

D00019
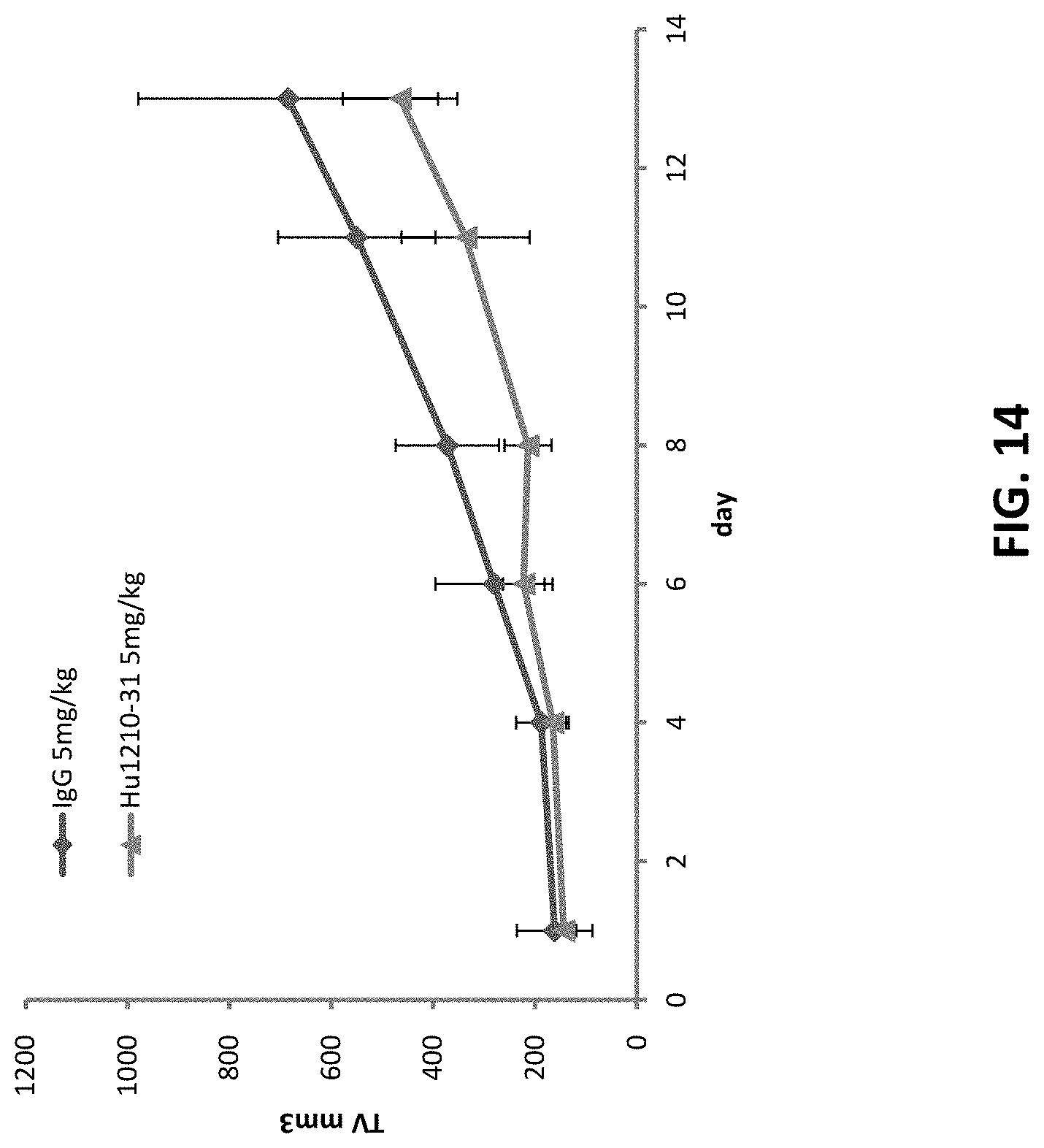
D00020
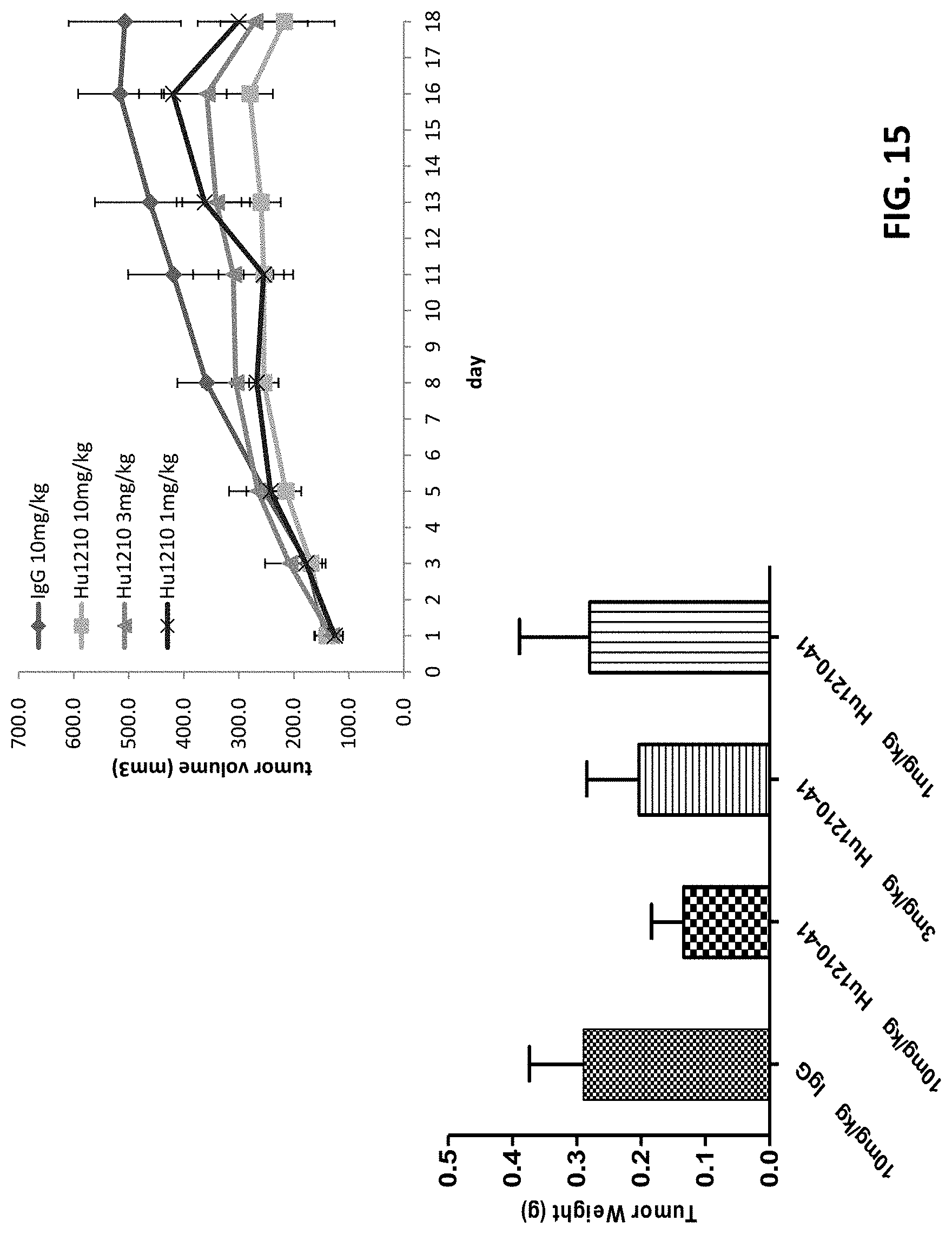
D00021

D00022

D00023

D00024

D00025
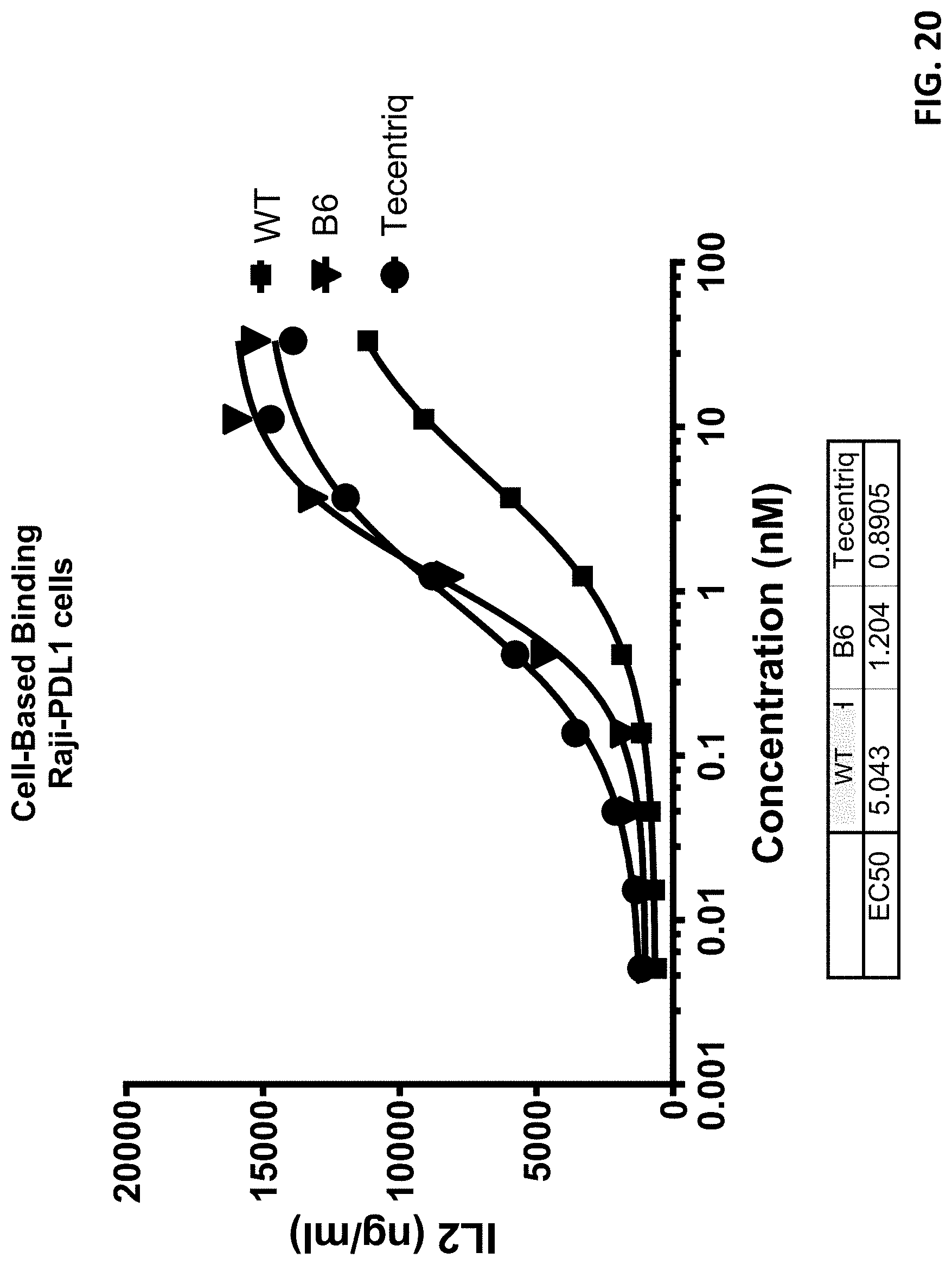
D00026
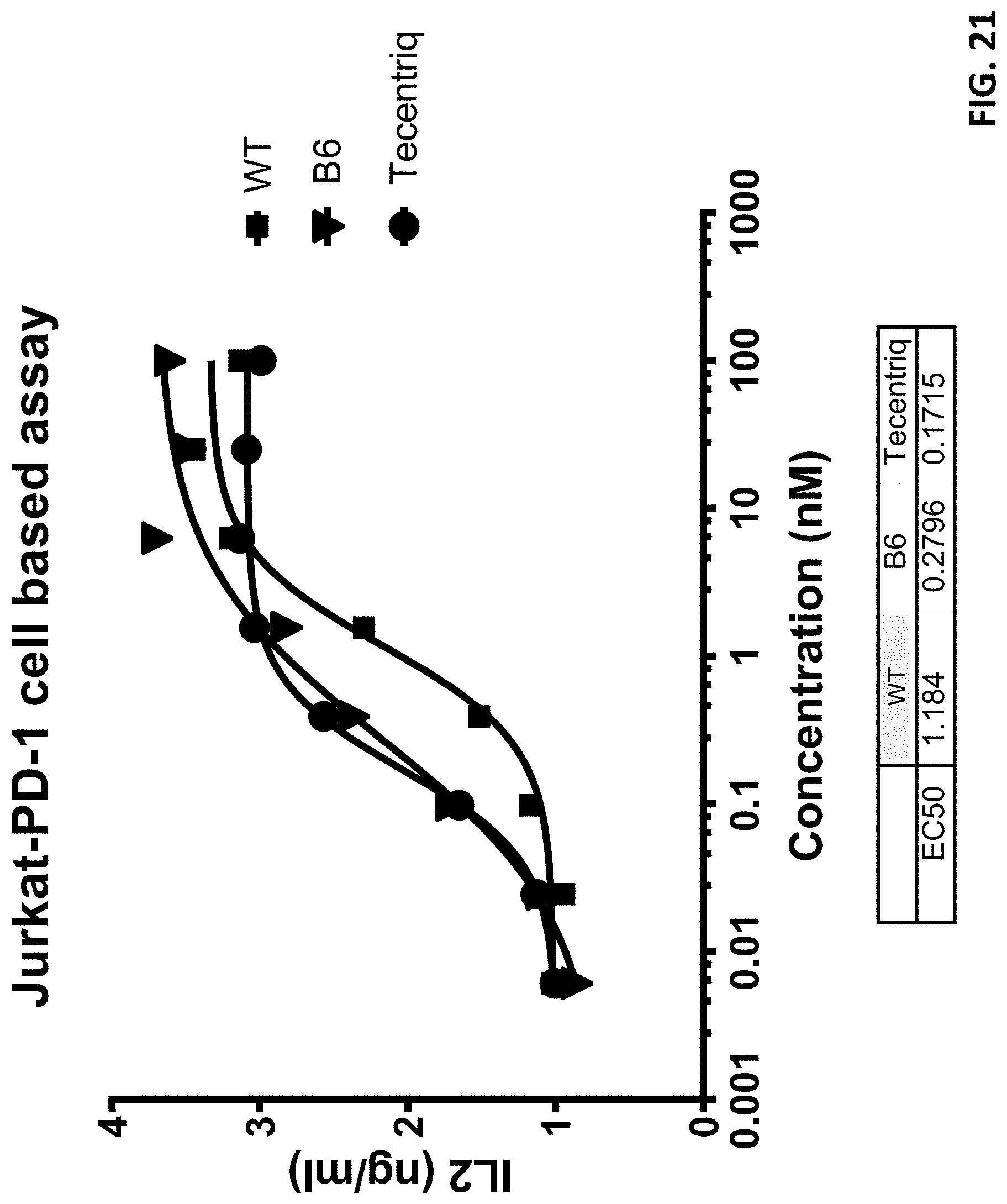
D00027

D00028

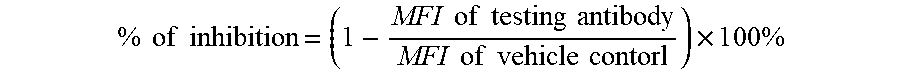

S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.