Fc VARIANTS WITH ALTERED BINDING TO FcRn
Chamberlain; Aaron Keith ; et al.
U.S. patent application number 16/985119 was filed with the patent office on 2021-04-22 for fc variants with altered binding to fcrn. The applicant listed for this patent is Xencor, Inc.. Invention is credited to Aaron Keith Chamberlain, Bassil Dahiyat, John Desjarlais, Sher Bahadur Karki, Gregory Lazar.
| Application Number | 20210115147 16/985119 |
| Document ID | / |
| Family ID | 1000005312725 |
| Filed Date | 2021-04-22 |



View All Diagrams
| United States Patent Application | 20210115147 |
| Kind Code | A1 |
| Chamberlain; Aaron Keith ; et al. | April 22, 2021 |
Fc VARIANTS WITH ALTERED BINDING TO FcRn
Abstract
The present application relates to optimized IgG immunoglobulin variants, engineering methods for their generation, and their application, particularly for therapeutic purposes.
| Inventors: | Chamberlain; Aaron Keith; (San Diego, CA) ; Dahiyat; Bassil; (Altadena, CA) ; Desjarlais; John; (Pasadena, CA) ; Karki; Sher Bahadur; (Santa Monica, CA) ; Lazar; Gregory; (Pacifica, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 1000005312725 | ||||||||||
| Appl. No.: | 16/985119 | ||||||||||
| Filed: | August 4, 2020 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15709334 | Sep 19, 2017 | |||
| 16985119 | ||||
| 14318001 | Jun 27, 2014 | |||
| 15709334 | ||||
| 11932151 | Oct 31, 2007 | 8802820 | ||
| 14318001 | ||||
| 60951536 | Jul 24, 2007 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | C07K 16/2863 20130101; C07K 16/2878 20130101; C07K 16/32 20130101; C07K 2317/90 20130101; C07K 16/082 20130101; C07K 2317/524 20130101; A61K 2039/505 20130101; C07K 2317/526 20130101; C07K 16/22 20130101; C07K 2317/24 20130101; C07K 2317/52 20130101; C07K 16/2893 20130101 |
| International Class: | C07K 16/28 20060101 C07K016/28; C07K 16/08 20060101 C07K016/08; C07K 16/22 20060101 C07K016/22; C07K 16/32 20060101 C07K016/32 |
Claims
1.-24. (canceled)
25. A protein comprising an Fc variant as compared to a parent IgG Fc region, said variant Fc region comprising an amino acid substitution selected from the group consisting of Q311V, H285D and N286D, wherein numbering is according to the EU index in Kabat et al.
26. An antibody comprising an Fc variant as compared to a parent IgG Fc region, said variant Fc region comprising an amino acid substitution selected from the group consisting of Q311V, H285D and N286D, wherein numbering is according to the EU index in Kabat et al.
27. A nucleic acid encoding the protein of claim 25.
28. A nucleic acid encoding the heavy chain of said antibody of claim 26.
29. An expression vector comprising the nucleic acid of claim 27.
30. A host cell comprising the expression vector of claim 29.
31. A method of making a protein comprising an Fc variant as compared to a parent IgG Fc region, said variant Fc region comprising an amino acid substitution selected from the group consisting of Q311V, H285D and N286D, wherein numbering is according to the EU index in Kabat et al., said method comprising culturing the host cell of claim 30 under conditions wherein said antibody is expressed and recovering said antibody.
Description
[0001] This application is a continuation of U.S. patent application Ser. No. 15/709,334, filed Sep. 19, 2017, which is a divisional of U.S. patent application Ser. No. 14/318,001, filed Jun. 27, 2014, now abandoned, which is a continuation of U.S. patent application Ser. No. 11/932,151, filed Oct. 31, 2007, now U.S. Pat. No. 8,802,820 which claims benefit under 35 U.S.C. .sctn. 119(e) to U.S. Ser. No. 60/951,536 filed Jul. 24, 2007, both entirely incorporated by reference.
[0002] The instant application contains a Sequence Listing which has been submitted electronically in ASCII format and is hereby incorporated by reference in its entirety. Said ASCII copy, created on Aug. 4, 2020, is named 067461-5026-US29_Sequence_Listing_ST25.txt and is 59,371 bytes in size.
FIELD OF THE INVENTION
[0003] The present application relates to optimized IgG immunoglobulin variants, engineering methods for their generation, and their application, particularly for therapeutic purposes.
BACKGROUND OF THE INVENTION
[0004] Antibodies are immunological proteins that bind a specific antigen. In most mammals, including humans and mice, antibodies are constructed from paired heavy and light polypeptide chains. Each chain is made up of individual immunoglobulin (Ig) domains, and thus the generic term immunoglobulin is used for such proteins. Each chain is made up of two distinct regions, referred to as the variable and constant regions. The light and heavy chain variable regions show significant sequence diversity between antibodies, and are responsible for binding the target antigen. The constant regions show less sequence diversity, and are responsible for binding a number of natural proteins to elicit important biochemical events. In humans there are five different classes of antibodies including IgA (which includes subclasses IgA1 and IgA2), IgD, IgE, IgG (which includes subclasses IgG1, IgG2, IgG3, and IgG4), and IgM. The distinguishing feature between these antibody classes is their constant regions, although subtler differences may exist in the V region. FIG. 1 shows an IgG1 antibody, used here as an example to describe the general structural features of immunoglobulins. IgG antibodies are tetrameric proteins composed of two heavy chains and two light chains. The IgG heavy chain is composed of four immunoglobulin domains linked from N- to C-terminus in the order VH-CH1-CH2-CH3, referring to the heavy chain variable domain, heavy chain constant domain 1, heavy chain constant domain 2, and heavy chain constant domain 3 respectively (also referred to as VH-C.gamma.1-C.gamma.2-C.gamma.3, referring to the heavy chain variable domain, constant gamma 1 domain, constant gamma 2 domain, and constant gamma 3 domain respectively). The IgG light chain is composed of two immunoglobulin domains linked from N- to C-terminus in the order VL-CL, referring to the light chain variable domain and the light chain constant domain respectively.
[0005] The variable region of an antibody contains the antigen binding determinants of the molecule, and thus determines the specificity of an antibody for its target antigen. The variable region is so named because it is the most distinct in sequence from other antibodies within the same class. The majority of sequence variability occurs in the complementarity determining regions (CDRs). There are 6 CDRs total, three each per heavy and light chain, designated VH CDR1, VH CDR2, VH CDR3, VL CDR1, VL CDR2, and VL CDR3. The variable region outside of the CDRs is referred to as the framework (FR) region. Although not as diverse as the CDRs, sequence variability does occur in the FR region between different antibodies. Overall, this characteristic architecture of antibodies provides a stable scaffold (the FR region) upon which substantial antigen binding diversity (the CDRs) can be explored by the immune system to obtain specificity for a broad array of antigens. A number of high-resolution structures are available for a variety of variable region fragments from different organisms, some unbound and some in complex with antigen. The sequence and structural features of antibody variable regions are well characterized (Morea et al., 1997, Biophys Chem 68:9-16; Morea et al., 2000, Methods 20:267-279, entirely incorporated by reference), and the conserved features of antibodies have enabled the development of a wealth of antibody engineering techniques (Maynard et al., 2000, Annu Rev Biomed Eng 2:339-376, entirely incorporated by reference). For example, it is possible to graft the CDRs from one antibody, for example a murine antibody, onto the framework region of another antibody, for example a human antibody. This process, referred to in the art as "humanization", enables generation of less immunogenic antibody therapeutics from nonhuman antibodies. Fragments including the variable region can exist in the absence of other regions of the antibody, including for example the antigen binding fragment (Fab) including VH-C.gamma.1 and VH-CL, the variable fragment (Fv) including VH and VL, the single chain variable fragment (scFv) including VH and VL linked together in the same chain, as well as a variety of other variable region fragments (Little et al., 2000, Immunol Today 21:364-370, entirely incorporated by reference).
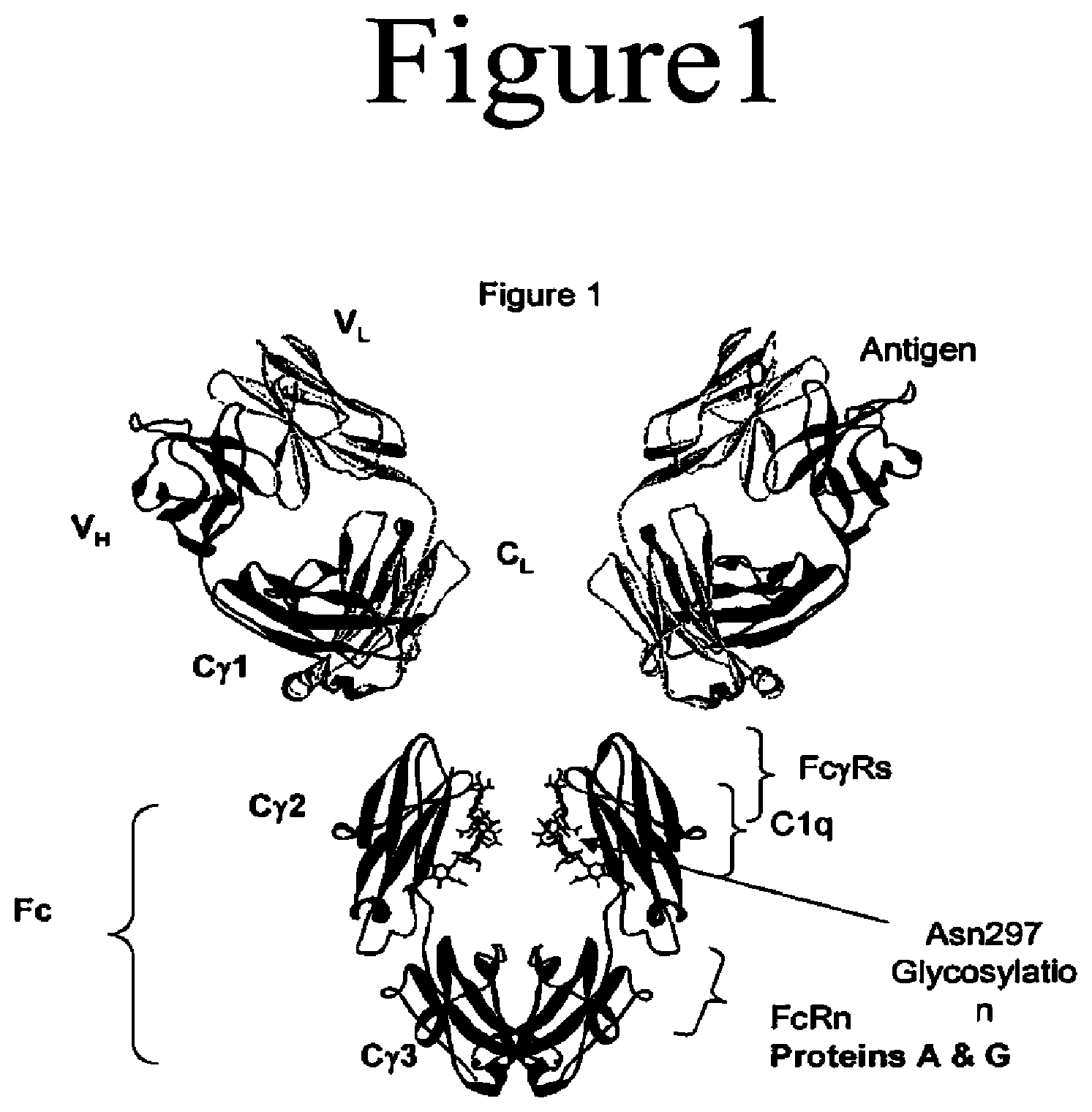
[0006] The Fc region of an antibody interacts with a number of Fc receptors and ligands, imparting an array of important functional capabilities referred to as effector functions. For IgG the Fc region, as shown in FIGS. 1 and 2, comprises Ig domains C.gamma.2 and C.gamma.3 and the N-terminal hinge leading into C.gamma.2. An important family of Fc receptors for the IgG class is the Fc gamma receptors (Fc.gamma.Rs). These receptors mediate communication between antibodies and the cellular arm of the immune system (Raghavan et al., 1996, Annu Rev Cell Dev Biol 12:181-220; Ravetch et al., 2001, Annu Rev Immunol 19:275-290, both entirely incorporated by reference). In humans this protein family includes Fc.gamma.RI (CD64), including isoforms Fc.gamma.RIa, Fc.gamma.RIb, and Fc.gamma.RIc; Fc.gamma.RII (CD32), including isoforms Fc.gamma.RIIa (including allotypes H131 and R131), Fc.gamma.RIIb (including Fc.gamma.RIIb-1 and Fc.gamma.RIIb-2), and Fc.gamma.RIIc; and Fc.gamma.RIII (CD16), including isoforms Fc.gamma.RIIIa (including allotypes V158 and F158) and Fc.gamma.RIIIb (including allotypes Fc.gamma.RIIIb-NA1 and Fc.gamma.RIIIb-NA2) (Jefferis et al., 2002, Immunol Lett 82:57-65, entirely incorporated by reference). These receptors typically have an extracellular domain that mediates binding to Fc, a membrane spanning region, and an intracellular domain that may mediate some signaling event within the cell. These receptors are expressed in a variety of immune cells including monocytes, macrophages, neutrophils, dendritic cells, eosinophils, mast cells, platelets, B cells, large granular lymphocytes, Langerhans' cells, natural killer (NK) cells, and .gamma..gamma. T cells. Formation of the Fc/Fc.gamma.R complex recruits these effector cells to sites of bound antigen, typically resulting in signaling events within the cells and important subsequent immune responses such as release of inflammation mediators, B cell activation, endocytosis, phagocytosis, and cytotoxic attack. The ability to mediate cytotoxic and phagocytic effector functions is a potential mechanism by which antibodies destroy targeted cells. The cell-mediated reaction wherein nonspecific cytotoxic cells that express Fc.gamma.Rs recognize bound antibody on a target cell and subsequently cause lysis of the target cell is referred to as antibody dependent cell-mediated cytotoxicity (ADCC) (Raghavan et al., 1996, Annu Rev Cell Dev Biol 12:181-220; Ghetie et al., 2000, Annu Rev Immunol 18:739-766; Ravetch et al., 2001, Annu Rev Immunol 19:275-290, all entirely incorporated by reference). The cell-mediated reaction wherein nonspecific cytotoxic cells that express Fc.gamma.Rs recognize bound antibody on a target cell and subsequently cause phagocytosis of the target cell is referred to as antibody dependent cell-mediated phagocytosis (ADCP). A number of structures have been solved of the extracellular domains of human Fc.gamma.Rs, including Fc.gamma.RIIa (pdb accession code 1 H9V, entirely incorporated by reference)(Sondermann et al., 2001, J Mol Biol 309:737-749, entirely incorporated by reference) (pdb accession code 1FCG, entirely incorporated by reference)(Maxwell et al., 1999, Nat Struct Biol 6:437-442, entirely incorporated by reference), Fc.gamma.RIIb (pdb accession code 2FCB, entirely incorporated by reference)(Sondermann et al., 1999, Embo J 18:1095-1103, entirely incorporated by reference); and Fc.gamma.RIIIb (pdb accession code 1 E4J, entirely incorporated by reference)(Sondermann et al., 2000, Nature 406:267-273, entirely incorporated by reference.). All Fc.gamma.Rs bind the same region on Fc, at the N-terminal end of the C.gamma.2 domain and the preceding hinge, shown in FIG. 1. This interaction is well characterized structurally (Sondermann et al., 2001, J Mol Biol 309:737-749, entirely incorporated by reference), and several structures of the human Fc bound to the extracellular domain of human Fc.gamma.RIIIb have been solved (pdb accession code 1 E4K, entirely incorporated by reference)(Sondermann et al., 2000, Nature 406:267-273, entirely incorporated by reference) (pdb accession codes 1 IIS and 1 IIX, entirely incorporated by reference)(Radaev et al., 2001, J Biol Chem 276:16469-16477, entirely incorporated by reference), as well as has the structure of the human IgE Fc/Fc.epsilon.RI.alpha. complex (pdb accession code 1F6A, entirely incorporated by reference)(Garman et al., 2000, Nature 406:259-266, entirely incorporated by reference). The effector function response may be modified by variant in the Fc region (Lazar et al. 2006 Proc. Nat. Acad. Sci USA. 103(111):4005-4010, entirely incorporated by reference).
[0007] The different IgG subclasses have different affinities for the Fc.gamma.Rs, with IgG1 and IgG3 typically binding substantially better to the receptors than IgG2 and IgG4 (Jefferis et al., 2002, Immunol Lett 82:57-65, entirely incorporated by reference). All Fc.gamma.Rs bind the same region on IgG Fc, yet with different affinities: the high affinity binder Fc.gamma.RI has a Kd for IgG1 of 10.sup.-8 M.sup.-1, whereas the low affinity receptors Fc.gamma.RII and Fc.gamma.RII generally bind at 10.sup.-6 and 10.sup.-5 respectively. The extracellular domains of Fc.gamma.RIIIa and Fc.gamma.RIIIb are 96% identical; however Fc.gamma.RIIIb does not have an intracellular signaling domain. Furthermore, whereas Fc.gamma.RI, Fc.gamma.RIIa/c, and Fc.gamma.RIIIa are positive regulators of immune complex-triggered activation, characterized by having an intracellular domain that has an immunoreceptor tyrosine-based activation motif (ITAM), Fc.gamma.RIIb has an immunoreceptor tyrosine-based inhibition motif (ITIM) and is therefore inhibitory. Thus the former are referred to as activation receptors, and Fc.gamma.RIIb is referred to as an inhibitory receptor. The receptors also differ in expression pattern and levels on different immune cells. Yet another level of complexity is the existence of a number of Fc.gamma.R polymorphisms in the human proteome. A particularly relevant polymorphism with clinical significance is V158/F158 Fc.gamma.RIIIa. Human IgG1 binds with greater affinity to the V158 allotype than to the F158 allotype. This difference in affinity, and presumably its effect on ADCC and/or ADCP, has been shown to be a significant determinant of the efficacy of the anti-CD20 antibody rituximab (Rituxan.RTM., Biogenldec). Patients with the V158 allotype respond favorably to rituximab treatment; however, patients with the lower affinity F158 allotype respond poorly (Cartron et al., 2002, Blood 99:754-758, entirely incorporated by reference). Approximately 10-20% of humans are V158/V158 homozygous, 45% are V158/F158 heterozygous, and 35-45% of humans are F158/F158 homozygous (Lehrnbecher et al., 1999, Blood 94:4220-4232; Cartron et al., 2002, Blood 99:754-758, all entirely incorporated by reference). Thus 80-90% of humans are poor responders, i.e., they have at least one allele of the F158 Fc.gamma.RIIIa.
[0008] An overlapping but separate site on Fc, shown in FIG. 1, serves as the interface for the complement protein C1q. In the same way that Fc/Fc.gamma.R binding mediates ADCC, Fc/C1q binding mediates complement dependent cytotoxicity (CDC). C1q forms a complex with the serine proteases C1r and C1s to form the C1 complex. C1q is capable of binding six antibodies, although binding to two IgGs is sufficient to activate the complement cascade. Similar to Fc interaction with Fc.gamma.Rs, different IgG subclasses have different affinity for C1q, with IgG1 and IgG3 typically binding substantially better to the Fc.gamma.Rs than IgG2 and IgG4 (Jefferis et al., 2002, Immunol Lett 82:57-65, entirely incorporated by reference).
[0009] In IgG, a site on Fc between the Cg2 and Cg3 domains (FIG. 1) mediates interaction with the neonatal receptor FcRn, the binding of which recycles endocytosed antibody from the endosome back to the bloodstream (Raghavan et al., 1996, Annu Rev Cell Dev Biol 12:181-220; Ghetie et al., 2000, Annu Rev Immunol 18:739-766, both entirely incorporated by reference). This process, coupled with preclusion of kidney filtration due to the large size of the full-length molecule, results in favorable antibody serum half-lives ranging from one to three weeks. Binding of Fc to FcRn also plays a key role in antibody transport. The binding site on Fc for FcRn is also the site at which the bacterial proteins A and G bind. The tight binding by these proteins is typically exploited as a means to purify antibodies by employing protein A or protein G affinity chromatography during protein purification. Thus the fidelity of this region on Fc is important for both the clinical properties of antibodies and their purification. Available structures of the rat Fc/FcRn complex (Burmeister et al., 1994, Nature, 372:379-383; Martin et al., 2001, Mol Cell 7:867-877, both entirely incorporated by reference), and of the complexes of Fc with proteins A and G (Deisenhofer, 1981, Biochemistry 20:2361-2370; Sauer-Eriksson et al., 1995, Structure 3:265-278; Tashiro et al., 1995, Curr Opin Struct Biol 5:471-481, all entirely incorporated by reference), provide insight into the interaction of Fc with these proteins. The FcRn receptor is also responsible for the transfer of IgG to the neo-natal gut and to the lumen of the intestinal epithelia in adults (Ghetie and Ward, Annu. Rev. Immunol., 2000, 18:739-766; Yoshida et al., Immunity, 2004, 20(6):769-783, both entirely incorporated by reference).
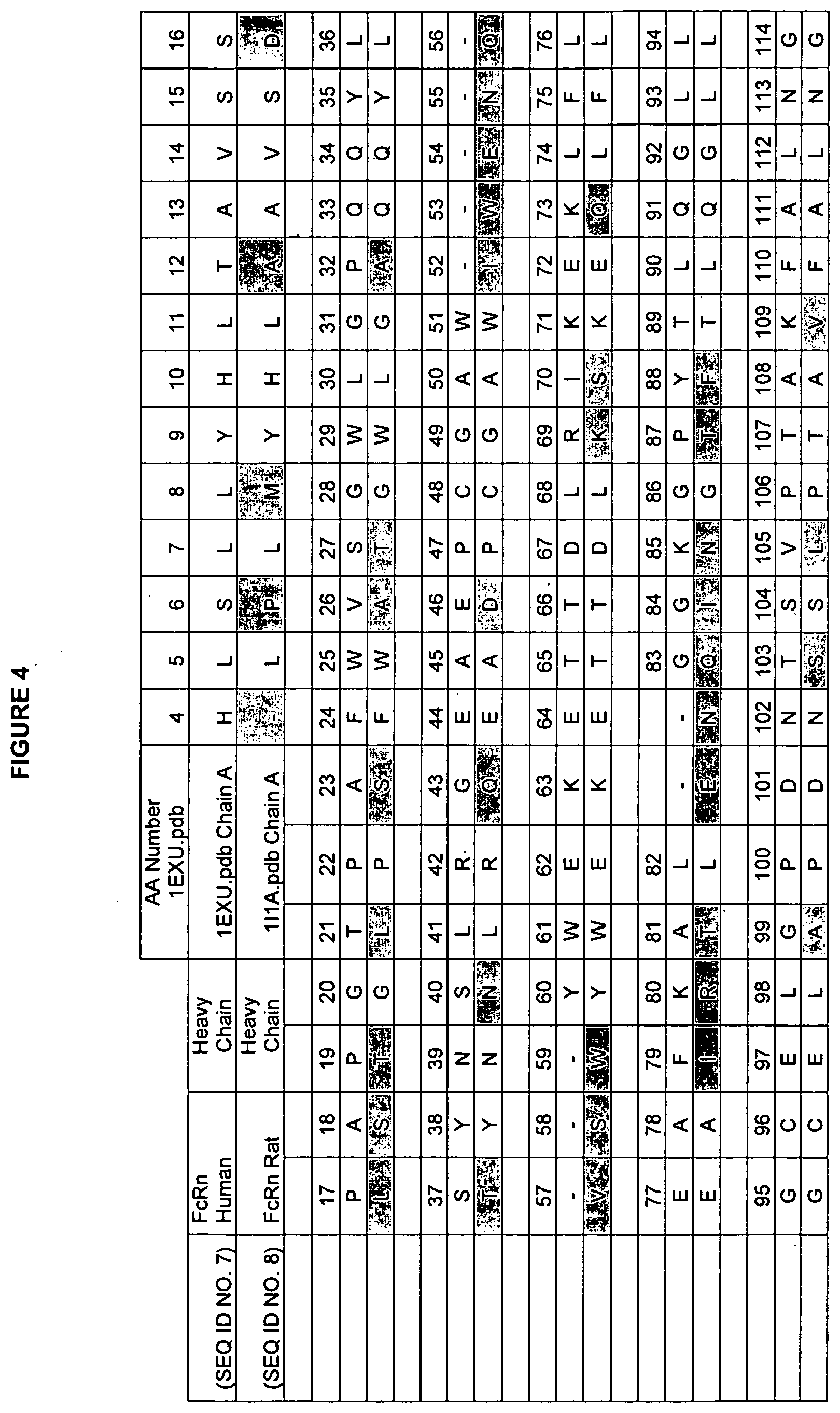
[0010] Studies of rat and human Fc domains have demonstrated the importance of some Fc residues to the binding of FcRn. The rat and human sequences have about 64% sequence identity in the Fc regions (residues 237-443 in the numbering of Kabat et al.). See FIGS. 3, 4, and 5 for the rat/human alignments of Fc, FcRn heavy chain, and FcRn light chain (beta-2-microglobulin). A model of the human Fc/FcRn complex has been built from the existing structure of the rat Fc/FcRn complex (Martin et al., 2001, Mol Cell 7:867-877, entirely incorporated by reference). The rat and human sequences share some residues that are critical for FcRn binding, such as H310 and H435 (Medesan et al., 1997 J. Immunol. 158(5):221-7; Shields et al., 2001, J. Biol. Chem. 276(9):6591-6604, both entirely incorporated by reference). In many positions, however, the human and rat proteins have different amino acids, giving the residues in the human sequence different environments, and possibly a different identities, than in the rat sequence. This variability limits the ability to transfer characteristics from one homolog to the other homolog.
[0011] In the murine Fc, random mutation and phage display selection at the sites, T252, T254, and T256 lead to a triple mutant, T252L/T254S/T256F, that has a 3.5-fold increase in FcRn affinity and a 1.5-fold increase in serum half-life (Ghetie et al., 1997, Nat. Biotech. 15(7): 637-640, entirely incorporated by reference). Disruption of the Fc/FcRn interaction by mutations at positions 253, 310 and 435 also lead to decreased in vivo half-life (Medesan et al J. Immunol. 1997 158(5):2211-7, entirely incorporated by reference).
[0012] The crystal structures of the rat Fc/FcRn complex identified important Fc residues for FcRn binding (Burmeister et al. Nature. 372:379-383 (1994); Martin et al. Molecular Cell. 7:867-877 (2001), both entirely incorporated by reference). The original Fc/FcRn complex structure was solved in 1994 to a resolution of 6 .ANG. (Table 2a, Burmeister et al. Nature. 372:379-383 (1994), entirely incorporated by reference). The higher resolution structure, solved in 2001 by Mann et al, showed a more detailed view of the side chains positions (Martin et al. Molecular Cell. 7:867-877 (2001), entirely incorporated by reference). This crystal structure of rat Fc bound to rat FcRn was solved using an Fc dimer with one monomer containing the mutations T252G/I253G/T254G/H310E/H433E/H435E, which disrupt FcRn binding, and one monomer containing a wild-type Fc monomer.
[0013] Mutational studies in human Fc.gamma. have been done on some of the residues that are important for binding to FcRn and have demonstrated an increased serum half-life. In human Fc.gamma.1, Hinton et al. mutated three residues individually to the other 19 common amino acids. Hinton et al., found that some point mutants a double mutant increased the FcRn binding affinity (Hinton et al., 2004, J. Biol. Chem. 279(8): 6213-6216. Hinton et al. Journal of Immunology 2006, 176:346-356, both entirely incorporated by reference). Two mutations had increased half-lives in monkeys. Shields et al. mutated residues, almost exclusively to Ala, and studied their binding to FcRn and the Fc.gamma.R's (Shields et al., 2001, J. Biol. Chem., 276(9):6591-6604, entirely incorporated by reference).
[0014] Dall'Acqua et al. used phage display to select for Fc mutations that bound FcRn with increased affinity (Dall'Acqua et al. 2002, J. Immunol. 169:5171-5180, entirely incorporated by reference). The DNA sequences selected for were primarily double and triple mutants. The reference expressed the proteins encoded by many of their selected sequences and found some that bound to FcRn more tightly than the wild-type Fc.
[0015] The administration of antibodies and Fc fusion proteins as therapeutics requires injections with a prescribed frequency relating to the clearance and half-life characteristics of the protein. Longer in vivo half-lives allow more seldom injections or lower dosing, which is clearly advantageous. Although the past mutations in the Fc domain have lead to some proteins with increased FcRn binding affinity and in vivo half-lives, these mutations have not identified the optimal mutations and enhanced in vivo half-life.
[0016] One feature of the Fc region is the conserved N-linked glycosylation that occurs at N297, shown in FIG. 1. This carbohydrate, or oligosaccharide as it is sometimes referred, plays a critical structural and functional role for the antibody, and is one of the principle reasons that antibodies must be produced using mammalian expression systems. Umana et al., 1999, Nat Biotechnol 17:176-180; Davies et al., 2001, Biotechnol Bioeng 74:288-294; Mimura et al., 2001, J Biol Chem 276:45539-45547.; Radaev et al., 2001, J Biol Chem 276:16478-16483; Shields et al., 2001, J Biol Chem 276:6591-6604; Shields et al., 2002, J Biol Chem 277:26733-26740; Simmons et al., 2002, J Immunol Methods 263:133-147; Radaev et al., 2001, J Biol Chem 276:16469-16477; and Krapp et al., 2003, J Mol Biol 325:979-989, all entirely incorporated by reference).
[0017] Antibodies have been developed for therapeutic use. Representative publications related to such therapies include Chamow et al., 1996, Trends Biotechnol 14:52-60; Ashkenazi et al., 1997, Curr Opin Immunol 9:195-200, Cragg et al., 1999, Curr Opin Immunol 11:541-547; Glennie et al., 2000, Immunol Today 21:403-410, McLaughlin et al., 1998, J Clin Oncol 16:2825-2833, and Cobleigh et al., 1999, J Clin Oncol 17:2639-2648, all entirely incorporated by reference. Currently for anticancer therapy, any small improvement in mortality rate defines success. Certain IgG variants disclosed herein enhance the capacity of antibodies to limit further growth or destroy at least partially, targeted cancer cells.
[0018] Anti-tumor potency of antibodies is via enhancement of their ability to mediate cytotoxic effector functions such as ADCC, ADCP, and CDC. Examples include Clynes et al., 1998, Proc Natl Acad Sci USA 95:652-656; Clynes et al., 2000, Nat Med 6:443-446 and Carton et al., 2002, Blood 99:754-758, both entirely incorporated by reference.
[0019] Human IgG1 is the most commonly used antibody for therapeutic purposes, and the majority of engineering studies have been constructed in this context. The different isotypes of the IgG class however, including IgG1, IgG2, IgG3, and IgG4, have unique physical, biological, and clinical properties. There is a need in the art to design improved IgG1, IgG2, IgG3, and IgG4 variants. There is a further need to design such variants to improve binding to FcRn and/or increase in vivo half-life as compared to native IgG polypeptides. Additionally, there is a need to combine variants with improved pharmacokinetic properties with variants comprising modifications to improve efficacy through altered FcgammaR binding. The present application meets these and other needs.
SUMMARY OF THE INVENTION
[0020] The present application is directed to Fc variants of a parent polypeptide including at least one modification in the Fc region of the polypeptide. In various embodiments, the variant polypeptides exhibit altered binding to FcRn as compared to a parent polypeptide. In certain variations, the modification can be selected from the group consisting of: 246H, 246S, 247D, 247T, 248H, 248P, 248Q, 248R, 248Y, 249T, 249W, 250E, 250I, 250Q, 250V, 251D, 251E, 251H, 251I, 251K, 251M, 251N, 251T, 251V, 251Y, 252Q, 252Y, 253L, 253T, 253V, 254H, 254L, 254N, 254T, 254V, A254N, 255E, 255F, 255H, 255K, 255S, 255V, 256E, 256V, 257A, 257C, 257D, 257E, 257F, 257G, 257H, 257I, 257K, 257L, 257M, 257N, 257Q, 257R, 257S, 257T, 257V, 257W, 257Y, 258R, 258V, 259I, 279A, 279D, 279C, 279F, 279G, 279H, 279I, 279K, 279M, 279N, 279P, 279Q, 279Q, 279R, 279S, 279T, 279W, 279Y, 280H, {circumflex over ( )}281A, {circumflex over ( )}281 D, {circumflex over ( )}281S, {circumflex over ( )}281I, 282D, 282F, 282H, 282I, 282T, 283F, 283I, 283L, 283Y, 284H, 284K, 284P, 284Q, 284R, 284S, 284Y, 285S, 285V, 286D, 286#, 286L, 287H, 287S, 287V, 287Y, 288H, 288Q, 288S, 305H, 305T, 306F, 306H, 306I, 306N, 306T, 306V, 306Y, 307D, 307P, 307Q, 307S, 307V, 307Y, 308C, 308D, 308E, 308F, 308G, 308H, 308I, 308K, 308L, 308M, 308N, 308Q, 308P, 308R, 308S, 308W, 308Y, 309F, 309H, 309N, 309Q, 309V, 309Y, 310K, 310N, 310T, 311A, 311L, 311P, 311T, 311V, 311W, 312H, 313Y, 315E, 315G, 315H, 315Q, 315S, 315T, 317H, 317S, 319F, 319F, 319L, 339P, 340P, 341S, 374H, 374S, 376H, 376L, 378H, 378N, 380A, 380T, 380Y, 382H, 383H, 383K, 383Q, 384E, 384G, 384H, 385A, 385C, 385F, 385H, 385I, 385K, 385L, 385M, 385N, 385P, 385Q, 385S, 385T, 385V, 385W, 385Y, 386E, 386K, 387#, 387A, 387H, 387K, 387Q, 389E, 389H, 426E, 426H, 426L, 426N, 426R, 426V, 426Y, 427I, 428F, 428L, 429D, 429F, 429K, 429N, 429Q, 429S, 429T, 429Y, 430D, 430H, 430K, 430L, 430Q, 430Y, 431G, 431H, 431I, 431P, 431P, 431S, 432F, 432H, 432N, 432S, 432V, 433E, 433P, 433S, 434A, 434F, 434H, 434L, 434M, 434Q, 434S, 434Y, 435N, 436E, 436F, 436L, 436V, 436W, 437E, 437V, 438H, and 438K, where the numbering is according to the EU Index in Kabat et al. and {circumflex over ( )} is an insertion after the identified position and # is a deletion of the identified position.
[0021] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 250Q/252Y, 250Q/256E, 250Q/286D, 250Q/308F, 250Q/308Y, 250Q/311A, 250Q/311V, 250Q/380A, 250Q/428L, 250Q/428F, 250Q/434H, 250Q/434F, 250Q/434Y, 250Q/434A, 250Q/434M, and 250Q/434S.
[0022] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 250E/252Y, 250E/256E, 250E/286D, 250E/308F, 250E/308Y, 250E/311A, 250E/311V, 250E/380A, 250E/428L, 250E/428F, 250E/434H, 250E/434F, 250E/434Y, 250E/434A, 250E/434M, and 250E/434S.
[0023] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 252Y/250Q, 252Y/250E, 252Y/256E, 252Y/286D, 252Y/308F, 252Y/308Y, 252Y/311A, 252Y/311V, 252Y/380A, 252Y/428L, 252Y/428F, 252Y/434H, 252Y/434F, 252Y/434Y, 252Y/434A, 252Y/434M, and 252Y/434S.
[0024] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 256E/250Q, 256E/250E, 256E/252Y, 256E/286D, 256E/308F, 256E/308Y, 256E/311A, 256E/311V, 256E/380A, 256E/428L, 256E/428F, 256E/434H, 256E/434F, 256E/434Y, 256E/434A, 256E/434M, and 256E/434S.
[0025] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 286D/250Q, 286D/250E, 286D/252Y, 286D/256E, 286D/308F, 286D/308Y, 286D/311A, 286D/311V, 286D/380A, 286D/428L, 286D/428F, 286D/434H, 286D/434F, 286D/434Y, 286D/434A, 286D/434M, and 286D/434S.
[0026] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 308F/250Q, 308F/250E, 308F/252Y, 308F/256E, 308F/286D, 308F/311A, 308F/311V, 308F/380A, 308F/428L, 308F/428F, 308F/434H, 308F/434F, 308F/434Y, 308F/434A, 308F/434M, and 308F/434S.
[0027] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 308Y/250Q, 308Y/250E, 308Y/252Y, 308Y/256E, 308Y/286D, 308Y/311A, 308Y/311V, 308Y/380A, 308Y/428L, 308Y/428F, 308Y/434H, 308Y/434F, 308Y/434Y, 308Y/434A, 308Y/434M, and 308Y/434S.
[0028] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 311A/250Q, 311A/250E, 311A/252Y, 311A/256E, 311A/286D, 311A/308F, 311A/308Y, 311A/380A, 311A/428L, 311A/428F, 311A/434H, 311A/434F, 311A/434Y, 311A/434A, 311A/434M, and 311A/434S.
[0029] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 311V/250Q, 311V/250E, 311V/252Y, 311V/256E, 311V/286D, 311V/308F, 311V/308Y, 311V/380A, 311V/428L, 311V/428F, 311V/434H, 311V/434F, 311V/434Y, 311V/434A, 311V/434M, and 311V/434S.
[0030] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 380A/250Q, 380A/250E, 380A/252Y, 380A/256E, 380A/286D, 380A/308F, 380A/308Y, 380A/311A, 380A/311V, 380A/428L, 380A/428F, 380A/434H, 380A/434F, 380A/434Y, 380A/434A, 380A/434M, and 380A/434S.
[0031] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 428L/250Q, 428L/250E, 428L/252Y, 428L/256E, 428L/286D, 428L/308F, 428L/308Y, 428L/311A, 428L/311V, 428L/380A, 428L/434H, 428L/434F, 428L/434Y, 428L/434A, 428L/434M, and 428L/434S.
[0032] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 434H/250Q, 434H/250E, 434H/252Y, 434H/256E, 434H/286D, 434H/308F, 434H/308Y, 434H/311A, 434H/311V, 434H/380A, 434H/428L, and 434H/428F.
[0033] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 434F/250Q, 434F/250E, 434F/252Y, 434F/256E, 434F/286D, 434F/308F, 434F/308Y, 434F/311A, 434F/311V, 434F/380A, 434F/428L, and 434F/428F.
[0034] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 434Y/250Q, 434Y/250E, 434Y/252Y, 434Y/256E, 434Y/286D, 434Y/308F, 434Y/308Y, 434Y/311A, 434Y/311V, 434Y/380A, 434Y/428L, and 434Y/428F.
[0035] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 434A/250Q, 434A/250E, 434A/252Y, 434A/256E, 434A/286D, 434A/308F, 434A/308Y, 434A/311A, 434A/311V, 434A/380A, 434A/428L, and 434A/428F.
[0036] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 434M/250Q, 434M/250E, 434M/252Y, 434M/256E, 434M/286D, 434M/308F, 434M/308Y, 434M/311A, 434M/311V, 434M/380A, 434M/428L, and 434M/428F.
[0037] In another variation, the Fc variant includes at least two modifications selected from the group consisting of: 434S/250Q, 434S/250E, 434S/252Y, 434S/256E, 434S/286D, 434S/308F, 434S/308Y, 434S/311A, 434S/311V, 434S/380A, 434S/428L, and 434S/428F.
[0038] In another variation, the Fc variant includes at least one modification selected from the group consisting of: Y319L, T307Q, V259I, M252Y, V259I/N434S, M428L/N434S, V308F/N434S, M252Y/S254T/T256E/N434S, M252Y/S254T/T256E/V308F, M252Y/S254T/T256E/M428L, V308F/M428L/N434S, V259I/V308F/N434S, T307QN308F/N434S, T250I/V308F/N434S, V308F/Y319L/N434S, V259I/V308F/M428L, V259I/T307Q/V308F, T250I/V259I/V308F, V259I/V308F/Y319L, T307Q/V308F/L309Y, T307Q/V308F/Y319L, and T250Q/V308F/M428L.
[0039] In another variation, the Fc variant includes at least one modification selected from the group consisting of: Y319L, T307Q, V259I, M252Y, V259I/N434S, M428L/N434S, V308F/N434S, V308F/M428L/N434S, V259I/V308F/N434S, T307Q/V308F/N434S, T250I/V308F/N434S, V308F/Y319L/N434S, V259I/V308F/M428L, V259I/T307Q/V308F, T250I/V2591/V308F, V259I/V308F/Y319L, T307Q/V308F/L309Y, T307Q/V308F/Y319L, and T250Q/V308F/M428L.
[0040] In another variation, the Fc variant includes at least one modification selected from the group consisting of: 250I, 250V, 252Q, 252Y, 254T, 256V, 259I, 307P, 307Q, 307S, 308F, 309N, 309Y, 311P, 319F, 319L, 428L, and 434S.
[0041] In another variation, the Fc variant includes at least one modification selected from the group consisting of: 250V/308F, 250I/308F, 254T/308F, 256V/308F, 259I/308F, 307P/208F, 307Q/308F, 307S/308F, 308F/309Y, 308F/309Y, V308F/311P, 308F/319L, 308F/319F, 308F/428L, 252Q/308F, M252Y/S254T/T256E, 259I/434S, 428L/434S, 308F/434S, 308F/428L/434S, 259I/308F/434S, 307Q/308F/434S, 250I/308F/434S, 308F/319L/434S, 259I/308F/428L, 259I/307Q/308F, 250I/259I/308F, 259I/308F/319L, 307Q/308F/309Y, 307Q/308F/319L, and 250Q/308F/428L.
[0042] In another variation, the invention includes a method of treating a patient in need of said treatment comprising administering an effective amount of an Fc variant described herein.
[0043] In another variation, the invention includes a method of increasing the half-life of an antibody or immunoadhesin by modifying an Fc according to the modifications described herein.
BRIEF DESCRIPTION OF THE DRAWINGS
[0044] FIG. 1. Antibody structure and function. Shown is a model of a full length human IgG1 antibody, modeled using a humanized Fab structure from pdb accession code 1CE1 (James et al., 1999, J Mol Biol 289:293-301, entirely incorporated by reference) and a human IgG1 Fc structure from pdb accession code 1DN2 (DeLano et al., 2000, Science 287:1279-1283, entirely incorporated by reference). The flexible hinge that links the Fab and Fc regions is not shown. IgG1 is a homodimer of heterodimers, made up of two light chains and two heavy chains. The Ig domains that comprise the antibody are labeled, and include V.sub.L and C.sub.Lfor the light chain, and V.sub.H, Cgamma1 (C.gamma.1), Cgamma2 (C.gamma.2), and Cgamma3 (C.gamma.3) for the heavy chain. The Fc region is labeled. Binding sites for relevant proteins are labeled, including the antigen binding site in the variable region, and the binding sites for Fc.gamma.Rs, FcRn, C1q, and proteins A and G in the Fc region.
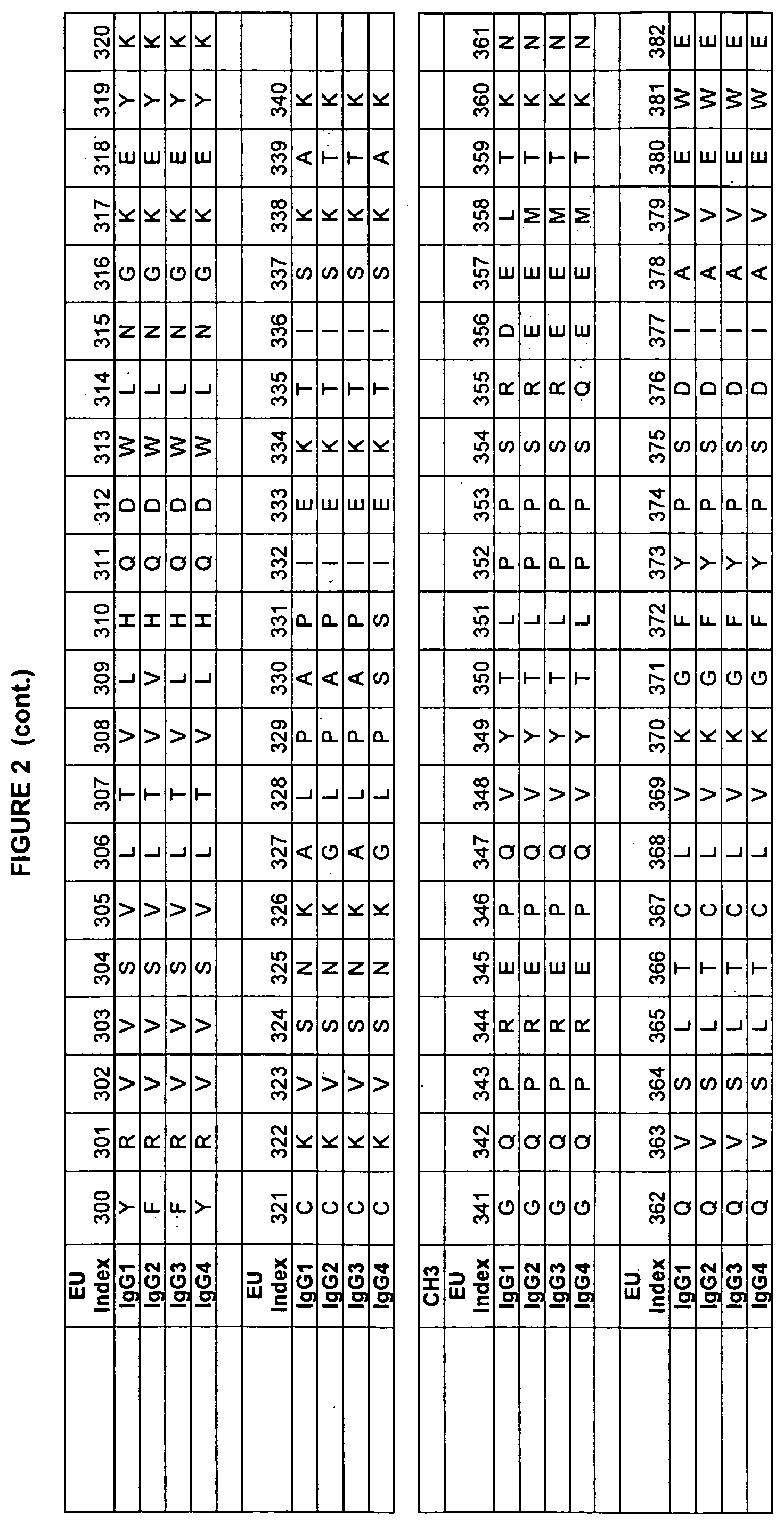
[0045] FIG. 2. Human IgG sequences used in the present invention with the EU numbering as in Kabat et al.
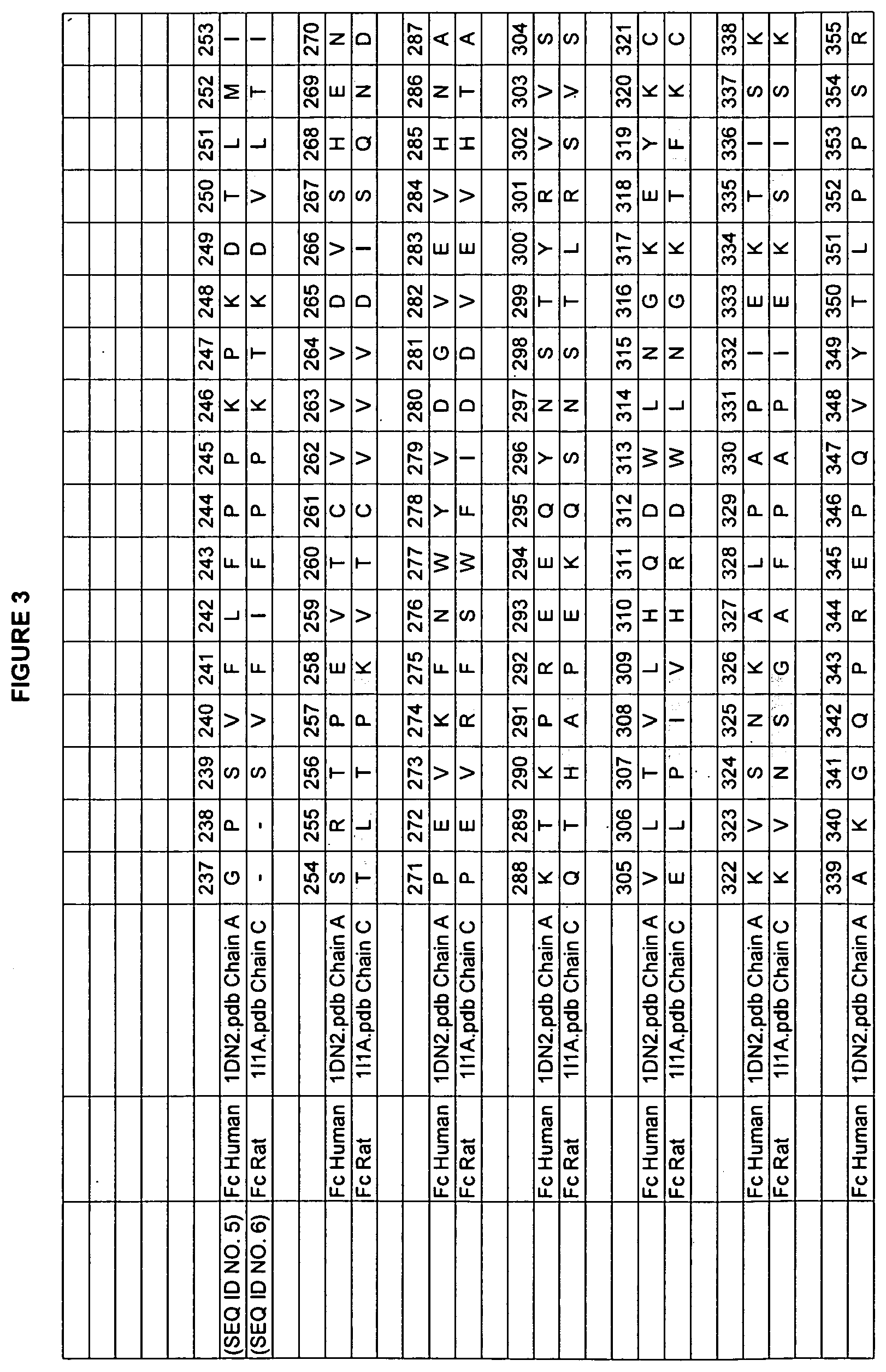
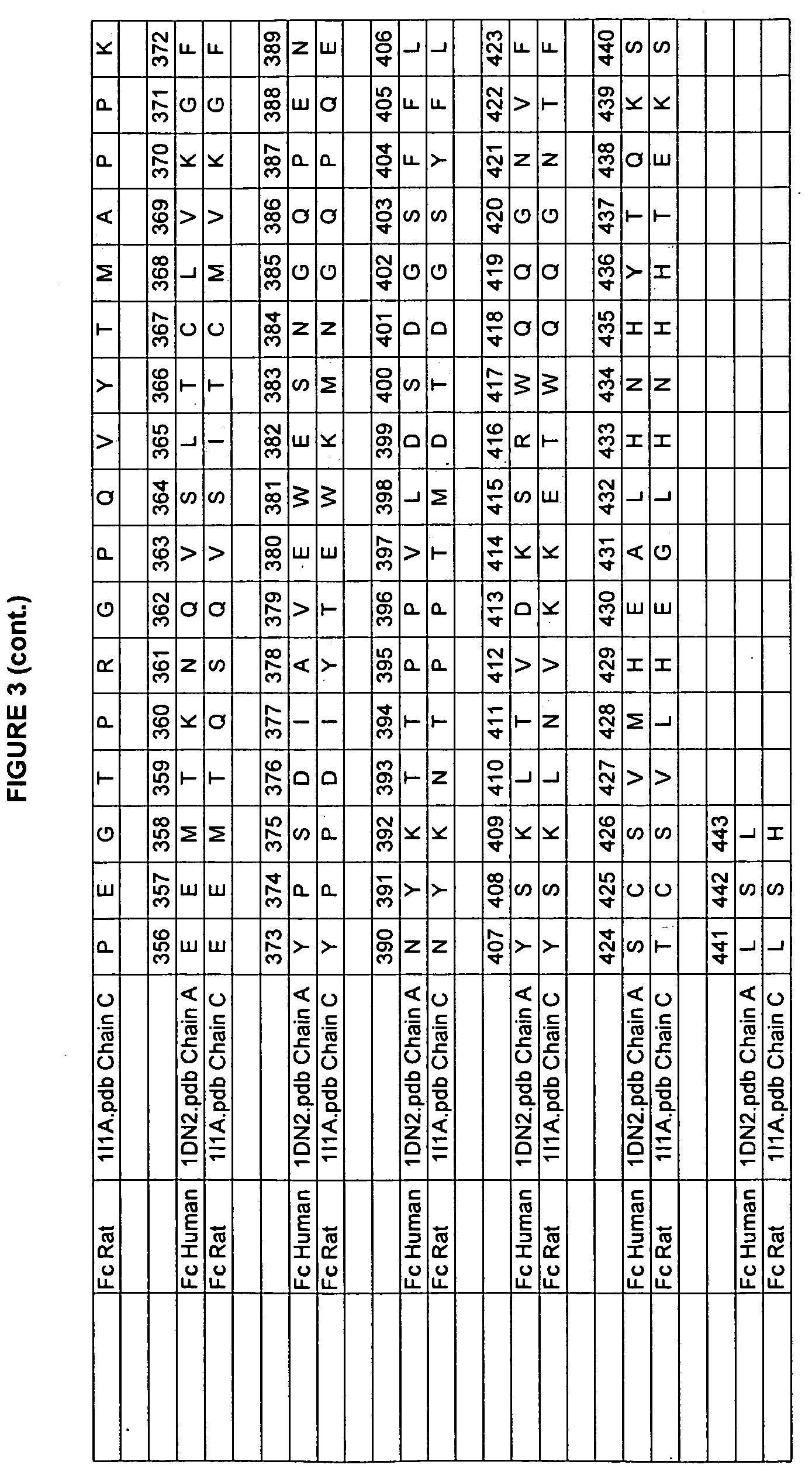
[0046] FIG. 3. Example human and rodent IgG sequences used in the present invention with the EU numbering as in Kabat.
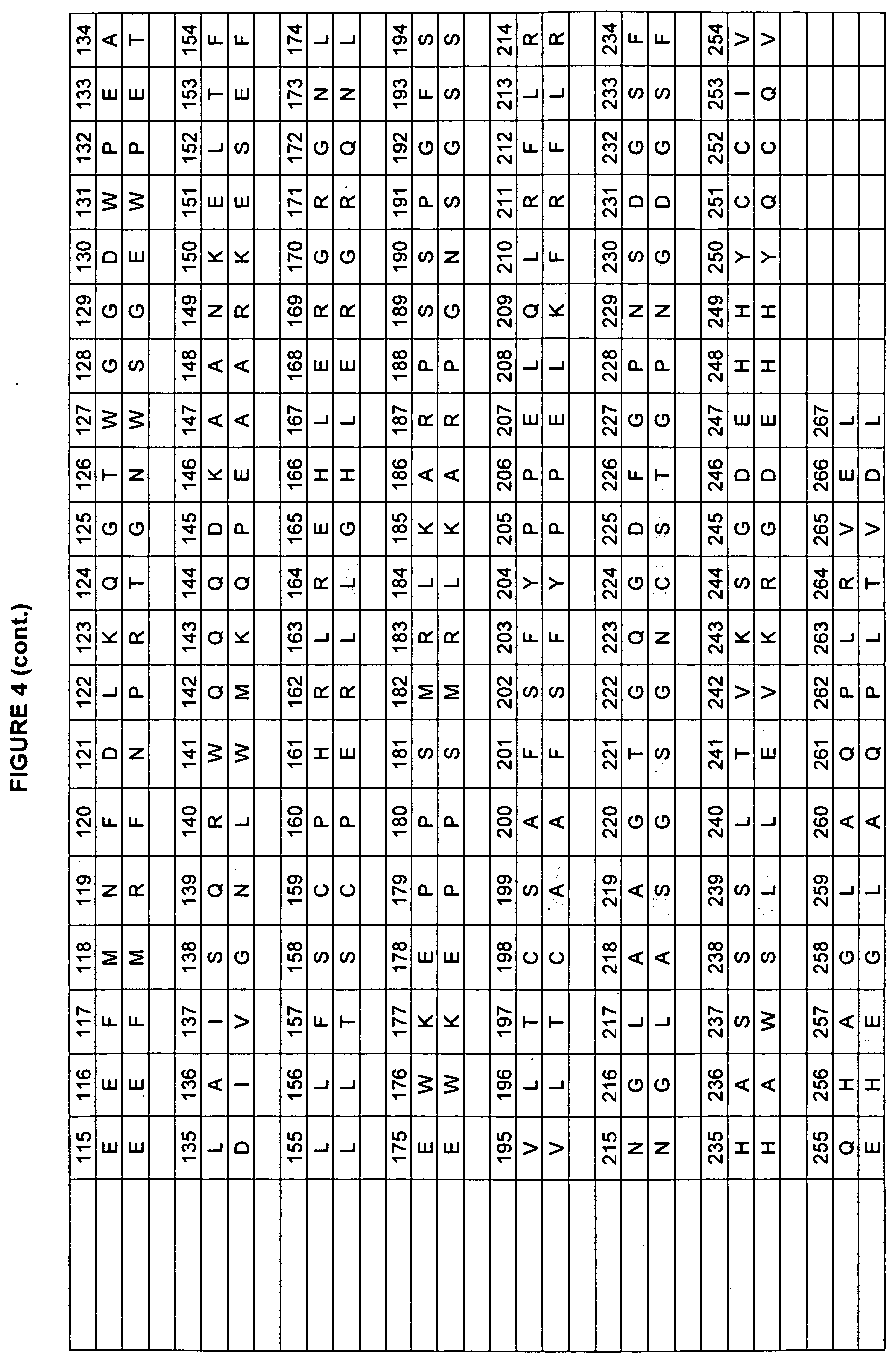
[0047] FIG. 4. Example human and rodent FcRn heavy chain sequences used in the present invention.
[0048] FIG. 5. Example human and rodent beta-2-microglobulin sequences used in the present invention.
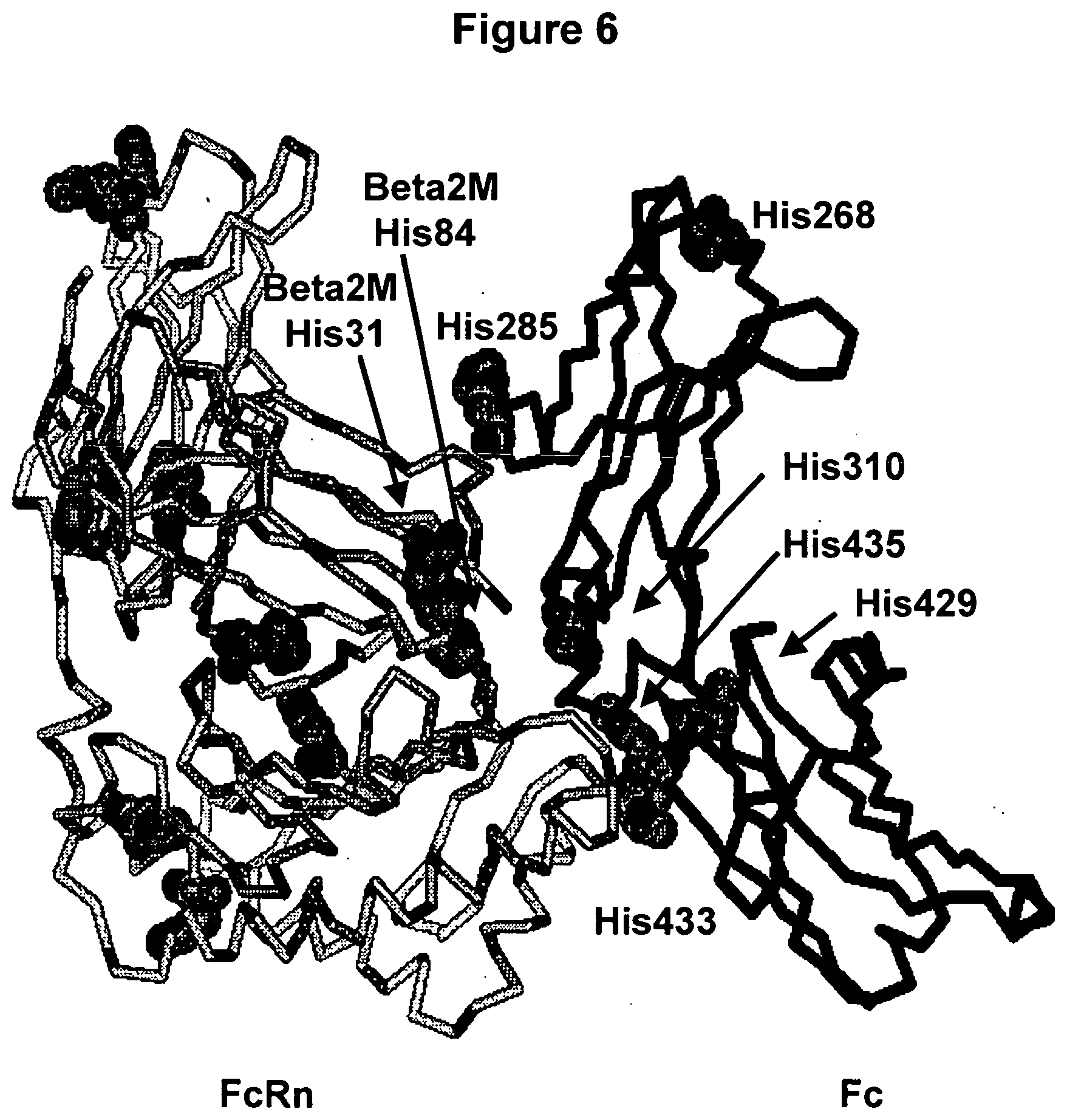
[0049] FIG. 6. A human Fc/FcRn complex model created from the rat structures (Burmeister et al., 1994, Nature, 372:379-383; Martin et al., 2001, Mol Cell 7:867-877, both entirely incorporated by reference). Some histidine residues are shown in space-filling atoms on the FcRn chains (light grey) and Fc polypeptide (dark grey).
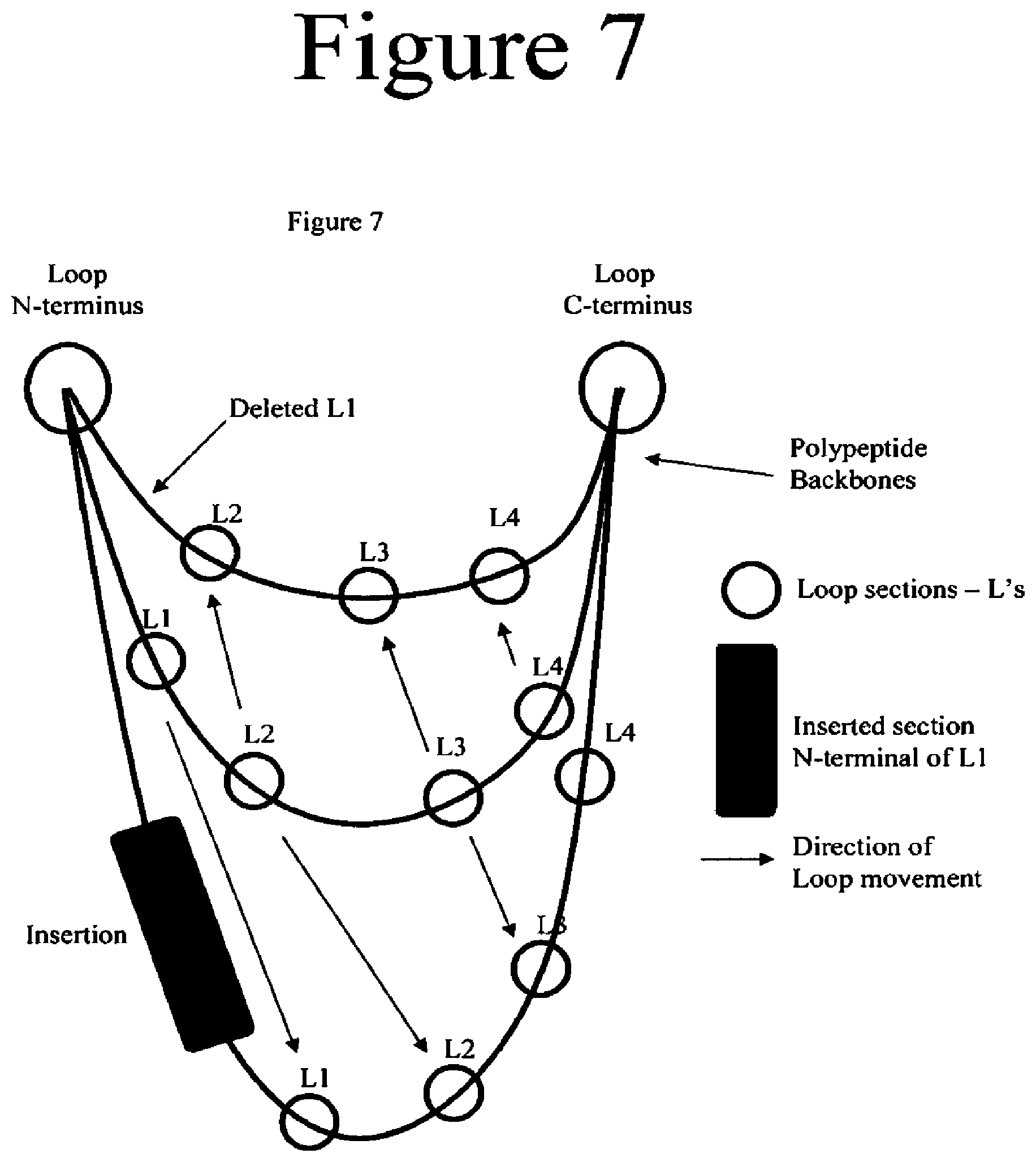
[0050] FIG. 7. IIlustration of some concepts used in the design of variants comprising insertions or deletions.
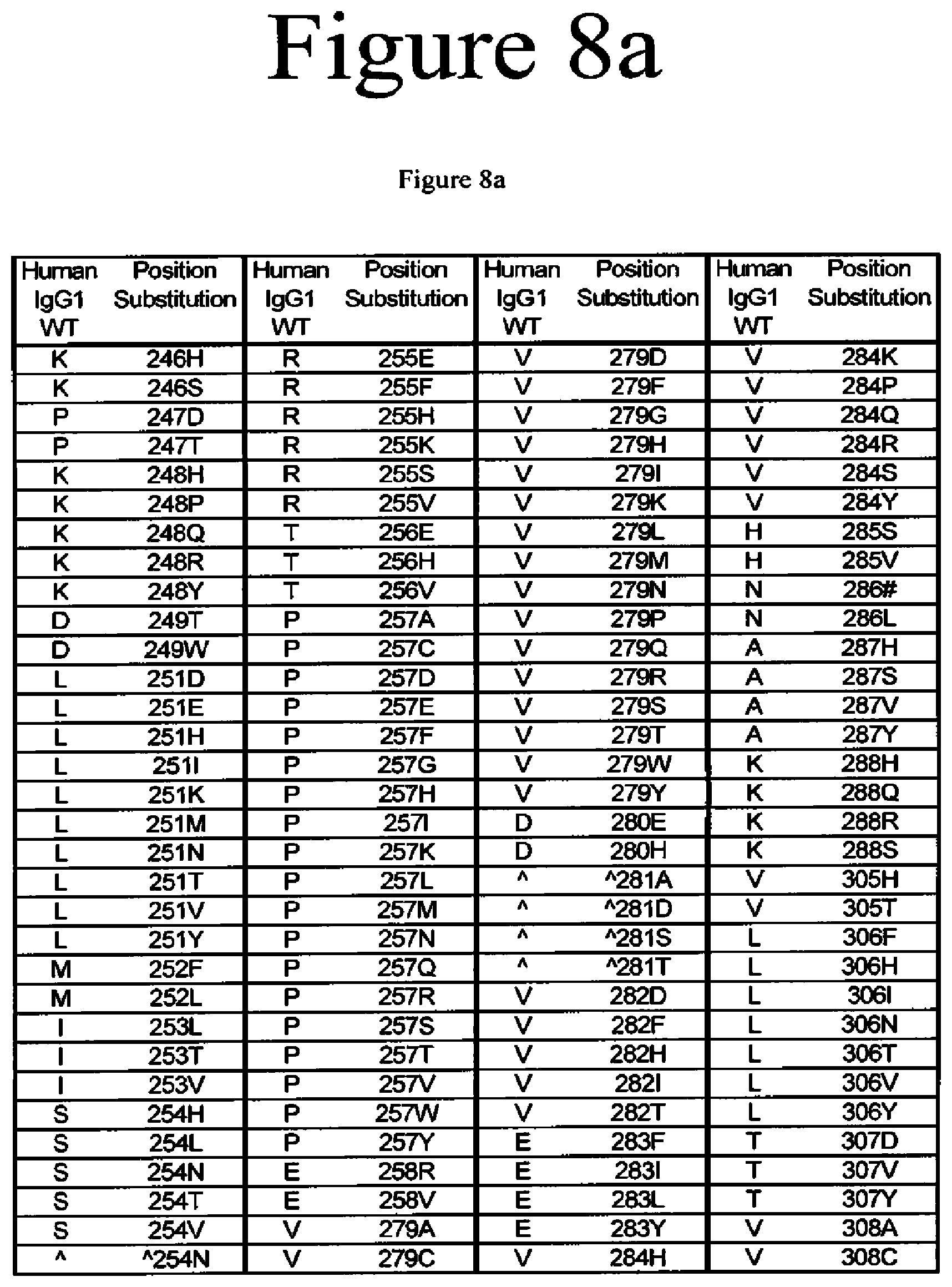
[0051] FIG. 8a-8b. Variants of the present invention.
[0052] FIG. 9a-9b. Variants of the present invention.
[0053] FIG. 10a-10b. Variants of the present invention.
[0054] FIG. 11. Diagram of the vector pcDNA3.1 Zeo+, which may be used in the construct of Fc variants.
[0055] FIG. 12a-12b. Competition FcRn binding data of wild-type Fc and Fc variants of the present invention. In each panel, the Fc variants of the present invention are shown as the left (red or dark grey) curve and the wild-type anti-HER2 antibody is shown as the right (blue or light grey) curve.
[0056] FIGS. 13a-13j. Summary of FcRn binding properties of the Fc variants. The columns from left to right show the FcRn binding modifications, the immunoglobulin used, other modifications, the relative FcRn affinity by AlphaScreen.TM. competition assays compared to wild type (median value), and the number of assays performed. Relative FcRn affinity numbers greater than 1.0 demonstrate increased binding over wild type. Data were collected at pH 6.0 (0.1M sodium phosphate, 25 mM sodium chloride).
[0057] FIG. 14a-14d. FcRn binding data of Fc variants. The Fc variants are in alemtuzumab or anti-HER2 antibody. Shown are the fold-increases in binding compared to wild type, that is, numbers greater than one indicate tighter binding to FcRn whereas numbers less than one indicate reduced binding to FcRn.
[0058] FIG. 15. Summary of surface plasmon resonance experiments of Fc variants with improved binding to FcRn. The bar graph shows the fold-increase in FcRn binding affinity of each variant relative to wild-type Fc domain.
[0059] FIG. 16a-16b. Surface plasmon resonance experiments of wild-type antibody and variants of the present invention. The traces shown are the association and dissociation of the Fc variant antibody to FcRn at pH6.0.
[0060] FIG. 17a-17c. Binding assays of Fc variants of the present invention to FcRn. Shown are direct binding assays measured by AlphaScreen.TM. at pH 6.0 (a and b) and pH 7.0 (c).
[0061] FIG. 18. Binding assays of Fc variants of the present invention to FcRn. Shown are the surface plasmon resonance units created upon binding of the variant Fc to surface-bound FcRn.
[0062] FIG. 19. Surface plasmon resonance measurement of the binding affinity of Fc variants of the present invention to human FcRn at pH 6.0.
[0063] FIG. 20. Summary of surface plasmon resonance (SPR) measurements of the binding affinity of Fc variants of the present invention with human, macaque and mouse FcRn. Numbers greater than one indicate increased binding of the variant Fc to FcRn as determined by fitting SPR curves to a 1:1 Langmuir binding model.
[0064] FIG. 21a-21b. Summary of FcRn binding properties of the Fc variants. The columns from left to right show the FcRn binding modifications, the immunoglobulin used, other modifications, the relative FcRn affinity by AlphaScreen.TM. competition assays compared to wild type (median value), and the number of assays performed. Relative FcRn affinity numbers greater than 1.0 demonstrate increased binding over wild type. Data were collected at pH 6.0 (0.1M sodium phosphate, 125mM sodium chloride).
[0065] FIG. 22. Amino acid sequences of the anti-HER2 antibody heavy and light chains.
[0066] FIG. 23. Amino acid sequences of the constant regions (CH1 to CH3) of the some IgG1 heavy chains used herein.
[0067] FIG. 24. Amino acid sequences of the constant regions (CH1 to CH3) of the some hybrid IgG1/2 heavy chains used herein.
[0068] FIG. 25. Fc variants binding to the human FcgammaRIIIA (V158 Allotype) as determined with AlphaScreen.TM. competition assays.
[0069] FIG. 26. Fc variants binding binding to protein A as determined with AlphaScreen.TM. competition assays.
[0070] FIG. 27. Serum concentrations of WT and variants of antibodies in human FcRn knockin mice. Anti-VEGF antibodies used were the WT (open squares), V308F (closed squares), P257L (closed triagles) and P257N (crosses).
[0071] FIG. 28. Examples of FcRn binding variants of the present invention. Anti-VEGF antibodies are listed with the volume of culture media and the yield of purified protein.
[0072] FIG. 29. Binding affinity of variants of the present invention to human FcRn at pH6.0. The values shown are fold increase in binding strength of the variant in question to the wild-type antibody. For example, the variant 434S binds to FcRn 4.4-fold more tightly than does the wild-type antibody.
[0073] FIG. 30. Binding of WT and variant antibodies to FcRn on the surface of 293T cells.
[0074] FIG. 31a-31b. Combination variants of the present invention comprising multiple substitutions.
[0075] FIG. 32. A picture of the intereactions of a variant human CH3 domain comprising 434S, labeled Ser434, and human FcRn.
DETAILED DESCRIPTION OF THE INVENTION
[0076] The present invention discloses the generation of novel variants of Fc domains, including those found in antibodies, Fc fusions, and immuno-adhesions, which have an increased binding to the FcRn receptor. As noted herein, binding to FcRn results in longer serum retention in vivo.
[0077] In order to increase the retention of the Fc proteins in vivo, the increase in binding affinity must be at around pH 6 while maintaining lower affinity at around pH 7.4. Although still under examination, Fc regions are believed to have longer half-lives in vivo, because binding to FcRn at pH 6 in an endosome sequesters the Fc (Ghetie and Ward, 1997 Immunol Today. 18(12): 592-598, entirely incorporated by reference). The endosomal compartment then recycles the Fc to the cell surface. Once the compartment opens to the extracellular space, the higher pH, .about.7.4, induces the release of Fc back into the blood. In mice, Dall'Acqua et al. showed that Fc mutants with increased FcRn binding at pH 6 and pH 7.4 actually had reduced serum concentrations and the same half life as wild-type Fc (Dall' Acqua et al. 2002, J. Immunol. 169:5171-5180, entirely incorporated by reference). The increased affinity of Fc for FcRn at pH 7.4 is thought to forbid the release of the Fc back into the blood. Therefore, the Fc mutations that will increase Fc's half-life in vivo will ideally increase FcRn binding at the lower pH while still allowing release of Fc at higher pH. The amino acid histidine changes its charge state in the pH range of 6.0 to 7.4. Therefore, it is not surprising to find His residues at important positions in the Fc/FcRn complex (FIG. 6.)
[0078] An additional aspect of the invention is the increase in FcRn binding over wild type specifically at lower pH, about pH 6.0, to facilitate Fc/FcRn binding in the endosome. Also disclosed are Fc variants with altered FcRn binding and altered binding to another class of Fc receptors, the Fc.gamma.R's (sometimes written FcgammaR's) as differential binding to Fc.gamma.Rs, particularly increased binding to Fc.gamma.RIIIb and decreased binding to Fc.gamma.RIIb, has been shown to result in increased efficacy.
[0079] Definitions
[0080] In order that the application may be more completely understood, several definitions are set forth below. Such definitions are meant to encompass grammatical equivalents.
[0081] By "ADCC" or "antibody dependent cell-mediated cytotoxicity" as used herein is meant the cell-mediated reaction wherein nonspecific cytotoxic cells that express Fc.gamma.Rs recognize bound antibody on a target cell and subsequently cause lysis of the target cell.
[0082] By "ADCP" or antibody dependent cell-mediated phagocytosis as used herein is meant the cell-mediated reaction wherein nonspecific cytotoxic cells that express Fc.gamma.Rs recognize bound antibody on a target cell and subsequently cause phagocytosis of the target cell.
[0083] By "modification" herein is meant an amino acid substitution, insertion, and/or deletion in a polypeptide sequence or an alteration to a moiety chemically linked to a protein. For example, a modification may be an altered carbohydrate or PEG structure attached to a protein. By "amino acid modification" herein is meant an amino acid substitution, insertion, and/or deletion in a polypeptide sequence.
[0084] By "amino acid substitution" or "substitution" herein is meant the replacement of an amino acid at a particular position in a parent polypeptide sequence with another amino acid. For example, the substitution E272Y refers to a variant polypeptide, in this case an Fc variant, in which the glutamic acid at position 272 is replaced with tyrosine.
[0085] By "amino acid insertion" or "insertion" as used herein is meant the addition of an amino acid sequence at a particular position in a parent polypeptide sequence. For example, -233E or {circumflex over ( )}233E designates an insertion of glutamic acid after position 233 and before position 234. Additionally, -233ADE or {circumflex over ( )}233ADE designates an insertion of AlaAspGlu after position 233 and before position 234.
[0086] By "amino acid deletion" or "deletion" as used herein is meant the removal of an amino acid sequence at a particular position in a parent polypeptide sequence. For example, E233- or E233# designates a deletion of glutamic acid at position 233. Additionally, EDA233- or EDA233# designates a deletion of the sequence GluAspAla that begins at position 233.
[0087] By "variant protein" or "protein variant", or "variant" as used herein is meant a protein that differs from that of a parent protein by virtue of at least one amino acid modification. Protein variant may refer to the protein itself, a composition comprising the protein, or the amino sequence that encodes it. Preferably, the protein variant has at least one amino acid modification compared to the parent protein, e.g. from about one to about ten amino acid modifications, and preferably from about one to about five amino acid modifications compared to the parent. The protein variant sequence herein will preferably possess at least about 80% homology with a parent protein sequence, and most preferably at least about 90% homology, more preferably at least about 95% homology. Variant protein can refer to the variant protein itself, compositions comprising the protein variant, or the DNA sequence that encodes it. Accordingly, by "antibody variant" or "variant antibody" as used herein is meant an antibody that differs from a parent antibody by virtue of at least one amino acid modification, "IgG variant" or "variant IgG" as used herein is meant an antibody that differs from a parent IgG by virtue of at least one amino acid modification, and "immunoglobulin variant" or "variant immunoglobulin" as used herein is meant an immunoglobulin sequence that differs from that of a parent immunoglobulin sequence by virtue of at least one amino acid modification. "Fc variant" or "variant Fc" as used herein is meant a protein comprising a modification in an Fc domain. The Fc variants of the present invention are defined according to the amino acid modifications that compose them. Thus, for example, I332E is an Fc variant with the substitution I332E relative to the parent Fc polypeptide. Likewise, S239D/I332E/G236A defines an Fc variant with the substitutions S239D, I332E, and G236A relative to the parent Fc polypeptide. The identity of the WT amino acid may be unspecified, in which case the aforementioned variant is referred to as 239D/332E/236A. It is noted that the order in which substitutions are provided is arbitrary, that is to say that, for example, S239D/I332E/G236A is the same Fc variant as G236A/S239D/I332E, and so on. For all positions discussed in the present invention, numbering is according to the EU index or EU numbering scheme (Kabat et al., 1991, Sequences of Proteins of Immunological Interest, 5th Ed., United States Public Health Service, National Institutes of Health, Bethesda, hereby entirely incorporated by reference). The EU index or EU index as in Kabat or EU numbering scheme refers to the numbering of the EU antibody (Edelman et al., 1969, Proc Natl Acad Sci USA 63:78-85, hereby entirely incorporated by reference.) The modification can be an addition, deletion, or substitution. Substitutions can include naturally occurring amino acids and non-naturally occurring amino acids. Variants may comprise non-natural amino acids. Examples include U.S. Pat. No. 6,586,207; WO 98/48032; WO 03/073238; US2004-0214988A1; WO 05/35727A2; WO 05/74524A2; J. W. Chin et al., (2002), Journal of the American Chemical Society 124:9026-9027; J. W. Chin, & P. G. Schultz, (2002), ChemBioChem 11:1135-1137; J. W. Chin, et al., (2002), PICAS United States of America 99:11020-11024; and, L. Wang, & P. G. Schultz, (2002), Chem. 1-10, all entirely incorporated by reference.
[0088] As used herein, "protein" herein is meant at least two covalently attached amino acids, which includes proteins, polypeptides, oligopeptides and peptides. The peptidyl group may comprise naturally occurring amino acids and peptide bonds, or synthetic peptidomimetic structures, i.e. "analogs", such as peptoids (see Simon et al., PNAS USA 89(20):9367 (1992), entirely incorporated by reference). The amino acids may either be naturally occurring or non-naturally occurring; as will be appreciated by those in the art. For example, homo-phenylalanine, citrulline, and noreleucine are considered amino acids for the purposes of the invention, and both D- and L-(R or S) configured amino acids may be utilized. The variants of the present invention may comprise modifications that include the use of unnatural amino acids incorporated using, for example, the technologies developed by Schultz and colleagues, including but not limited to methods described by Cropp & Shultz, 2004, Trends Genet. 20(12):625-30, Anderson et al., 2004, Proc Natl Acad Sci USA 101(2):7566-71, Zhang et al., 2003, 303(5656):371-3, and Chin et al., 2003, Science 301(5635):964-7, all entirely incorporated by reference. In addition, polypeptides may include synthetic derivatization of one or more side chains or termini, glycosylation, PEGylation, circular permutation, cyclization, linkers to other molecules, fusion to proteins or protein domains, and addition of peptide tags or labels.
[0089] By "residue" as used herein is meant a position in a protein and its associated amino acid identity. For example, Asparagine 297 (also referred to as Asn297, also referred to as N297) is a residue in the human antibody IgG1.
[0090] By "Fab" or "Fab region" as used herein is meant the polypeptide that comprises the VH, CH1, VL, and CL immunoglobulin domains. Fab may refer to this region in isolation, or this region in the context of a full length antibody, antibody fragment or Fab fusion protein.
[0091] By "IgG subclass modification" as used herein is meant an amino acid modification that converts one amino acid of one IgG isotype to the corresponding amino acid in a different, aligned IgG isotype. For example, because IgG1 comprises a tyrosine and IgG2 a phenylalanine at EU position 296, a F296Y substitution in IgG2 is considered an IgG subclass modification.
[0092] By "non-naturally occurring modification" as used herein is meant an amino acid modification that is not isotypic. For example, because none of the IgGs comprise a glutamic acid at position 332, the substitution I332E in IgG1, IgG2, IgG3, or IgG4 is considered a non-naturally occuring modification.
[0093] By "amino acid" and "amino acid identity" as used herein is meant one of the 20 naturally occurring amino acids or any non-natural analogues that may be present at a specific, defined position.
[0094] By "effector function" as used herein is meant a biochemical event that results from the interaction of an antibody Fc region with an Fc receptor or ligand. Effector functions include but are not limited to ADCC, ADCP, and CDC.
[0095] By "effector cell" as used herein is meant a cell of the immune system that expresses one or more Fc receptors and mediates one or more effector functions. Effector cells include but are not limited to monocytes, macrophages, neutrophils, dendritic cells, eosinophils, mast cells, platelets, B cells, large granular lymphocytes, Langerhans' cells, natural killer (NK) cells, and .gamma..delta.T cells, and may be from any organism including but not limited to humans, mice, rats, rabbits, and monkeys.
[0096] By "IgG Fc ligand" as used herein is meant a molecule, preferably a polypeptide, from any organism that binds to the Fc region of an IgG antibody to form an Fc/Fc ligand complex. Fc ligands include but are not limited to Fc.gamma.Rs, Fc.gamma.Rs, Fc.gamma.Rs, FcRn, C1q, C3, mannan binding lectin, mannose receptor, staphylococcal protein A, streptococcal protein G, and viral Fc.gamma.R. Fc ligands also include Fc receptor homologs (FcRH), which are a family of Fc receptors that are homologous to the Fc.gamma.Rs (Davis et al., 2002, Immunological Reviews 190:123-136, entirely incorporated by reference). Fc ligands may include undiscovered molecules that bind Fc. Particular IgG Fc ligands are FcRn and Fc gamma receptors. By "Fc ligand" as used herein is meant a molecule, preferably a polypeptide, from any organism that binds to the Fc region of an antibody to form an Fc/Fc ligand complex.
[0097] By "Fc gamma receptor", "Fc.gamma.R" or "FcgammaR" as used herein is meant any member of the family of proteins that bind the IgG antibody Fc region and is encoded by an Fc.gamma.R gene. In humans this family includes but is not limited to Fc.gamma.RI (CD64), including isoforms Fc.gamma.RIa, Fc.gamma.RIb, and Fc.gamma.RIc; Fc.gamma.RII (CD32), including isoforms Fc.gamma.RIIa (including allotypes H131 and R131), Fc.gamma.RIIb (including Fc.gamma.RIIb-1 and Fc.gamma.RIIb-2), and Fc.gamma.RIIc; and Fc.gamma.RIII (CD16), including isoforms Fc.gamma.RIIIa (including allotypes V158 and F158) and Fc.gamma.RIIIb (including allotypes Fc.gamma.RIIIb-NA1 and Fc.gamma.RIIIb-NA2) (Jefferis et al., 2002, Immunol Lett 82:57-65, entirely incorporated by reference), as well as any undiscovered human Fc.gamma.Rs or Fc.gamma.R isoforms or allotypes. An Fc.gamma.R may be from any organism, including but not limited to humans, mice, rats, rabbits, and monkeys. Mouse Fc.gamma.Rs include but are not limited to Fc.gamma.RI (CD64), Fc.gamma.RII (CD32), Fc.gamma.RIII (CD16), and Fc.gamma.RIII-2 (CD16-2), as well as any undiscovered mouse Fc.gamma.Rs or Fc.gamma.R isoforms or allotypes.
[0098] By "FcRn" or "neonatal Fc Receptor" as used herein is meant a protein that binds the IgG antibody Fc region and is encoded at least in part by an FcRn gene. The FcRn may be from any organism, including but not limited to humans, mice, rats, rabbits, and monkeys. As is known in the art, the functional FcRn protein comprises two polypeptides, often referred to as the heavy chain and light chain. The light chain is beta-2-microglobulin and the heavy chain is encoded by the FcRn gene. Unless other wise noted herein, FcRn or an FcRn protein refers to the complex of FcRn heavy chain with beta-2-microglobulin. Sequences of particular interest of FcRn are shown in the Figures, particularly the human species.
[0099] By "parent polypeptide" as used herein is meant an unmodified polypeptide that is subsequently modified to generate a variant. The parent polypeptide may be a naturally occurring polypeptide, or a variant or engineered version of a naturally occurring polypeptide. Parent polypeptide may refer to the polypeptide itself, compositions that comprise the parent polypeptide, or the amino acid sequence that encodes it. Accordingly, by "parent immunoglobulin" as used herein is meant an unmodified immunoglobulin polypeptide that is modified to generate a variant, and by "parent antibody" as used herein is meant an unmodified antibody that is modified to generate a variant antibody. It should be noted that "parent antibody" includes known commercial, recombinantly produced antibodies as outlined below.
[0100] By "position" as used herein is meant a location in the sequence of a protein. Positions may be numbered sequentially, or according to an established format, for example the EU index as in Kabat. For example, position 297 is a position in the human antibody IgG1.
[0101] By "target antigen" as used herein is meant the molecule that is bound specifically by the variable region of a given antibody. A target antigen may be a protein, carbohydrate, lipid, or other chemical compound.
[0102] By "target cell" as used herein is meant a cell that expresses a target antigen.
[0103] By "variable region" as used herein is meant the region of an immunoglobulin that comprises one or more Ig domains substantially encoded by any of the V.THETA., V.lamda., and/or VH genes that make up the kappa, lambda, and heavy chain immunoglobulin genetic loci respectively.
[0104] By "wild type or WT" herein is meant an amino acid sequence or a nucleotide sequence that is found in nature, including allelic variations. A WT protein has an amino acid sequence or a nucleotide sequence that has not been intentionally modified.
[0105] The present invention is directed to antibodies that exhibit moduluated binding to FcRn (modulation including increased as well as decreased binding). For example, in some instances, increased binding results in cellular recycling of the antibody and hence increased half-life, for example for therapeutic antibodies. Alternatively, decreased FcRn binding is desirable, for example for diagnostic antibodies or therapeutic antibodies that contain radiolabels. In addition, antibodies exhibiting increased binding to FcRn and altered binding to other Fc receptors, eg. Fc.gamma.Rs, find use in the present invention. Accordingly, the present invention provides antibodies.
Antibodies
[0106] The present application is directed to antibodies that include amino acid modifications that modulate binding to FcRn. Of particular interest are antibodies that minimally comprise an Fc region, or functional variant thereof, that displays increased binding affinity to FcRn at lowered pH, and do not exhibit substantially altered binding at higher pH.
[0107] Traditional antibody structural units typically comprise a tetramer. Each tetramer is typically composed of two identical pairs of polypeptide chains, each pair having one "light" (typically having a molecular weight of about 25 kDa) and one "heavy" chain (typically having a molecular weight of about 50-70 kDa). Human light chains are classified as kappa and lambda light chains. Heavy chains are classified as mu, delta, gamma, alpha, or epsilon, and define the antibody's isotype as IgM, IgD, IgG, IgA, and IgE, respectively. IgG has several subclasses, including, but not limited to IgG1, IgG2, IgG3, and IgG4. IgM has subclasses, including, but not limited to, IgM1 and IgM2. Thus, "isotype" as used herein is meant any of the subclasses of immunoglobulins defined by the chemical and antigenic characteristics of their constant regions. The known human immunoglobulin isotypes are IgG1, IgG2, IgG3, IgG4, IgA1, IgA2, IgM1, IgM2, IgD, and IgE.
[0108] The amino-terminal portion of each chain includes a variable region of about 100 to 110 or more amino acids primarily responsible for antigen recognition. In the variable region, three loops are gathered for each of the V domains of the heavy chain and light chain to form an antigen-binding site. Each of the loops is referred to as a complementarity-determining region (hereinafter referred to as a "CDR"), in which the variation in the amino acid sequence is most significant.
[0109] The carboxy-terminal portion of each chain defines a constant region primarily responsible for effector function. Kabat et al. collected numerous primary sequences of the variable regions of heavy chains and light chains. Based on the degree of conservation of the sequences, they classified individual primary sequences into the CDR and the framework and made a list thereof (see SEQUENCES OF IMMUNOLOGICAL INTEREST, 5th edition, NIH publication, No. 91-3242, E.A. Kabat et al., entirely incorporated by reference).
[0110] In the IgG subclass of immunoglobulins, there are several immunoglobulin domains in the heavy chain. By "immunoglobulin (Iq) domain" herein is meant a region of an immunoglobulin having a distinct tertiary structure. Of interest in the present invention are the heavy chain domains, including, the constant heavy (CH) domains and the hinge domains. In the context of IgG antibodies, the IgG isotypes each have three CH regions. Accordingly, "CH" domains in the context of IgG are as follows: "CH1" refers to positions 118-220 according to the EU index as in Kabat. "CH2" refers to positions 237-340 according to the EU index as in Kabat, and "CH3" refers to positions 341-447 according to the EU index as in Kabat.
[0111] Another type of Ig domain of the heavy chain is the hinge region. By "hinge" or "hinge region" or "antibody hinge region" or "immunoglobulin hinge region" herein is meant the flexible polypeptide comprising the amino acids between the first and second constant domains of an antibody. Structurally, the IgG CH1 domain ends at EU position 220, and the IgG CH2 domain begins at residue EU position 237. Thus for IgG the antibody hinge is herein defined to include positions 221 (D221 in IgG1) to 236 (G236 in IgG1), wherein the numbering is according to the EU index as in Kabat. In some embodiments, for example in the context of an Fc region, the lower hinge is included, with the "lower hinge" generally referring to positions 226 or 230.
[0112] Of particular interest in the present invention are the Fc regions. By "Fc" or "Fc region", as used herein is meant the polypeptide comprising the constant region of an antibody excluding the first constant region immunoglobulin domain and in some cases, part of the hinge. Thus Fc refers to the last two constant region immunoglobulin domains of IgA, IgD, and IgG, the last three constant region immunoglobulin domains of IgE and IgM, and the flexible hinge N-terminal to these domains. For IgA and IgM, Fc may include the J chain. For IgG, as illustrated in FIG. 1, Fc comprises immunoglobulin domains Cgamma2 and Cgamma3 (Cg2 and Cg3) and the lower hinge region between Cgamma1 (Cg1) and Cgamma2 (Cg2). Although the boundaries of the Fc region may vary, the human IgG heavy chain Fc region is usually defined to include residues C226 or P230 to its carboxyl-terminus, wherein the numbering is according to the EU index as in Kabat. Fc may refer to this region in isolation, or this region in the context of an Fc polypeptide, as described below. By "Fc polypeptide" as used herein is meant a polypeptide that comprises all or part of an Fc region. Fc polypeptides include antibodies, Fc fusions, isolated Fcs, and Fc fragments.
[0113] In some embodiments, the antibodies are full length. By "full length antibody" herein is meant the structure that constitutes the natural biological form of an antibody, including variable and constant regions, including one or more modifications as outlined herein.
[0114] Alternatively, the antibodies can be a variety of structures, including, but not limited to, antibody fragments, monoclonal antibodies, bispecific antibodies, minibodies, domain antibodies, synthetic antibodies (sometimes referred to herein as "antibody mimetics"), chimeric antibodies, humanized antibodies, antibody fusions (sometimes referred to as "antibody conjugates"), and fragments of each, respectively.
[0115] Antibody Fragments
[0116] In one embodiment, the antibody is an antibody fragment. Of particular interest are antibodies that comprise Fc regions, Fc fusions, and the constant region of the heavy chain (CH1-hinge-CH2-CH3), again also including constant heavy region fusions.
[0117] Specific antibody fragments include, but are not limited to, (i) the Fab fragment consisting of VL, VH, CL and CH1 domains, (ii) the Fd fragment consisting of the VH and CH1 domains, (iii) the Fv fragment consisting of the VL and VH domains of a single antibody; (iv) the dAb fragment (Ward et al., 1989, Nature 341:544-546, entirely incorporated by reference) which consists of a single variable, (v) isolated CDR regions, (vi) F(ab')2 fragments, a bivalent fragment comprising two linked Fab fragments (vii) single chain Fv molecules (scFv), wherein a VH domain and a VL domain are linked by a peptide linker which allows the two domains to associate to form an antigen binding site (Bird et al., 1988, Science 242:423-426, Huston et al., 1988, Proc. Natl. Acad. Sci. U.S.A. 85:5879-5883, entirely incorporated by reference), (viii) bispecific single chain Fv (WO 03/11161, hereby incorporated by reference) and (ix) "diabodies" or "triabodies", multivalent or multispecific fragments constructed by gene fusion (Tomlinson et. al., 2000, Methods Enzymol. 326:461-479; WO94/13804; Holliger et al., 1993, Proc. Natl. Acad. Sci. U.S.A. 90:6444-6448, all entirely incorporated by reference). The antibody fragments may be modified. For example, the molecules may be stabilized by the incorporation of disulphide bridges linking the VH and VL domains (Reiter et al., 1996, Nature Biotech. 14:1239-1245, entirely incorporated by reference).
[0118] Chimeric and Humanized Antibodies
[0119] In some embodiments, the scaffold components can be a mixture from different species. As such, if the protein is an antibody, such antibody may be a chimeric antibody and/or a humanized antibody. In general, both "chimeric antibodies" and "humanized antibodies" refer to antibodies that combine regions from more than one species. For example, "chimeric antibodies" traditionally comprise variable region(s) from a mouse (or rat, in some cases) and the constant region(s) from a human. "Humanized antibodies" generally refer to non-human antibodies that have had the variable-domain framework regions swapped for sequences found in human antibodies. Generally, in a humanized antibody, the entire antibody, except the CDRs, is encoded by a polynucleotide of human origin or is identical to such an antibody except within its CDRs. The CDRs, some or all of which are encoded by nucleic acids originating in a non-human organism, are grafted into the beta-sheet framework of a human antibody variable region to create an antibody, the specificity of which is determined by the engrafted CDRs. The creation of such antibodies is described in, e.g., WO 92/11018, Jones, 1986, Nature 321:522-525, Verhoeyen et al., 1988, Science 239:1534-1536, all entirely incorporated by reference. "Backmutation" of selected acceptor framework residues to the corresponding donor residues is often required to regain affinity that is lost in the initial grafted construct (U.S. Pat. Nos. 5,530,101; 5,585,089; 5,693,761; 5,693,762; 6,180,370; 5,859,205; 5,821,337; 6,054,297; 6,407,213, all entirely incorporated by reference). The humanized antibody optimally also will comprise at least a portion of an immunoglobulin constant region, typically that of a human immunoglobulin, and thus will typically comprise a human Fc region. Humanized antibodies can also be generated using mice with a genetically engineered immune system. Roque et al., 2004, Biotechnol. Prog. 20:639-654, entirely incorporated by reference. A variety of techniques and methods for humanizing and reshaping non-human antibodies are well known in the art (See Tsurushita & Vasquez, 2004, Humanization of Monoclonal Antibodies, Molecular Biology of B Cells, 533-545, Elsevier Science (USA), and references cited therein, all entirely incorporated by reference). Humanization methods include but are not limited to methods described in Jones et al., 1986, Nature 321:522-525; Riechmann et al., 1988; Nature 332:323-329; Verhoeyen et al., 1988, Science, 239:1534-1536; Queen et al., 1989, Proc Natl Acad Sci, USA 86:10029-33; He et al., 1998, J. Immunol. 160: 1029-1035; Carter et al., 1992, Proc Natl Acad Sci USA 89:4285-9, Presta et al., 1997, Cancer Res. 57(20):4593-9; Gorman et al., 1991, Proc. Natl. Acad. Sci. USA 88:4181-4185; O'Connor et al., 1998, Protein Eng 11:321-8, all entirely incorporated by reference. Humanization or other methods of reducing the immunogenicity of nonhuman antibody variable regions may include resurfacing methods, as described for example in Roguska et al., 1994, Proc. Natl. Acad. Sci. USA 91:969-973, entirely incorporated by reference. In one embodiment, the parent antibody has been affinity matured, as is known in the art. Structure-based methods may be employed for humanization and affinity maturation, for example as described in U.S. Ser. No. 11/004,590. Selection based methods may be employed to humanize and/or affinity mature antibody variable regions, including but not limited to methods described in Wu et al., 1999, J. Mol. Biol. 294:151-162; Baca et al., 1997, J. Biol. Chem. 272(16):10678-10684; Rosok et al., 1996, J. Biol. Chem. 271(37): 22611-22618; Rader et al., 1998, Proc. Natl. Acad. Sci. USA 95: 8910-8915; Krauss et al., 2003, Protein Engineering 16(10):753-759, all entirely incorporated by reference. Other humanization methods may involve the grafting of only parts of the CDRs, including but not limited to methods described in U.S. Ser. No. 09/810,510; Tan et al., 2002, J. Immunol. 169:1119-1125; De Pascalis et al., 2002, J. Immunol. 169:3076-3084, all entirely incorporated by reference.
[0120] Bispecific Antibodies
[0121] In one embodiment, the antibodies of the invention multispecific antibody, and notably a bispecific antibody, also sometimes referred to as "diabodies". These are antibodies that bind to two (or more) different antigens. Diabodies can be manufactured in a variety of ways known in the art (Holliger and Winter, 1993, Current Opinion Biotechnol. 4:446-449, entirely incorporated by reference), e.g., prepared chemically or from hybrid hybridomas.
[0122] Minibodies
[0123] In one embodiment, the antibody is a minibody. Minibodies are minimized antibody-like proteins comprising a scFv joined to a CH3 domain. Hu et al., 1996, Cancer Res. 56:3055-3061, entirely incorporated by reference. In some cases, the scFv can be joined to the Fc region, and may include some or the entire hinge region.
[0124] Human Antibodies
[0125] In one embodiment, the antibody is a fully human antibody with at least one modification as outlined herein. "Fully human antibody" or "complete human antibody" refers to a human antibody having the gene sequence of an antibody derived from a human chromosome with the modifications outlined herein.
[0126] Antibody Fusions
[0127] In one embodiment, the antibodies of the invention are antibody fusion proteins (sometimes referred to herein as an "antibody conjugate"). One type of antibody fusions comprises Fc fusions, which join the Fc region with a conjugate partner. By "Fc fusion" as used herein is meant a protein wherein one or more polypeptides is operably linked to an Fc region. Fc fusion is herein meant to be synonymous with the terms "immunoadhesin", "Ig fusion", "Ig chimera", and "receptor globulin" (sometimes with dashes) as used in the prior art (Chamow et al., 1996, Trends Biotechnol 14:52-60; Ashkenazi et al., 1997, Curr Opin Immunol 9:195-200, both entirely incorporated by reference). An Fc fusion combines the Fc region of an immunoglobulin with a fusion partner, which in general can be any protein or small molecule. Virtually any protein or small molecule may be linked to Fc to generate an Fc fusion. Protein fusion partners may include, but are not limited to, the variable region of any antibody, the target-binding region of a receptor, an adhesion molecule, a ligand, an enzyme, a cytokine, a chemokine, or some other protein or protein domain. Small molecule fusion partners may include any therapeutic agent that directs the Fc fusion to a therapeutic target. Such targets may be any molecule, preferably an extracellular receptor, which is implicated in disease. Thus, the IgG variants can be linked to one or more fusion partners. In one alternate embodiment, the IgG variant is conjugated or operably linked to another therapeutic compound. The therapeutic compound may be a cytotoxic agent, a chemotherapeutic agent, a toxin, a radioisotope, a cytokine, or other therapeutically active agent. The IgG may be linked to one of a variety of nonproteinaceous polymers, e.g., polyethylene glycol, polypropylene glycol, polyoxyalkylenes, or copolymers of polyethylene glycol and polypropylene glycol.
[0128] In addition to Fc fusions, antibody fusions include the fusion of the constant region of the heavy chain with one or more fusion partners (again including the variable region of any antibody), while other antibody fusions are substantially or completely full length antibodies with fusion partners. In one embodiment, a role of the fusion partner is to mediate target binding, and thus it is functionally analogous to the variable regions of an antibody (and in fact can be). Virtually any protein or small molecule may be linked to Fc to generate an Fc fusion (or antibody fusion). Protein fusion partners may include, but are not limited to, the target-binding region of a receptor, an adhesion molecule, a ligand, an enzyme, a cytokine, a chemokine, or some other protein or protein domain. Small molecule fusion partners may include any therapeutic agent that directs the Fc fusion to a therapeutic target. Such targets may be any molecule, preferably an extracellular receptor, which is implicated in disease.
[0129] The conjugate partner can be proteinaceous or non-proteinaceous; the latter generally being generated using functional groups on the antibody and on the conjugate partner. For example linkers are known in the art; for example, homo-or hetero-bifunctional linkers as are well known (see, 1994 Pierce Chemical Company catalog, technical section on cross-linkers, pages 155-200, incorporated herein by reference).
[0130] Suitable conjugates include, but are not limited to, labels as described below, drugs and cytotoxic agents including, but not limited to, cytotoxic drugs (e.g., chemotherapeutic agents) or toxins or active fragments of such toxins. Suitable toxins and their corresponding fragments include diptheria A chain, exotoxin A chain, ricin A chain, abrin A chain, curcin, crotin, phenomycin, enomycin and the like. Cytotoxic agents also include radiochemicals made by conjugating radioisotopes to antibodies, or binding of a radionuclide to a chelating agent that has been covalently attached to the antibody. Additional embodiments utilize calicheamicin, auristatins, geldanamycin, maytansine, and duocarmycins and analogs; for the latter, see U.S. 2003/0050331A1, entirely incorporated by reference.
[0131] Covalent Modifications of Antibodies
[0132] Covalent modifications of antibodies are included within the scope of this invention, and are generally, but not always, done post-translationally. For example, several types of covalent modifications of the antibody are introduced into the molecule by reacting specific amino acid residues of the antibody with an organic derivatizing agent that is capable of reacting with selected side chains or the N- or C-terminal residues.
[0133] Cysteinyl residues most commonly are reacted with a-haloacetates (and corresponding amines), such as chloroacetic acid or chloroacetamide, to give carboxymethyl or carboxyamidomethyl derivatives. Cysteinyl residues may also be derivatized by reaction with bromotrifluoroacetone, .alpha.-bromo-.beta.-(5-imidozoyl)propionic acid, chloroacetyl phosphate, N-alkylmaleimides, 3-nitro-2-pyridyl disulfide, methyl 2-pyridyl disulfide, p-chloromercuribenzoate, 2-chloromercuri-4-nitrophenol, or chloro-7-nitrobenzo-2-oxa-1,3-diazole and the like.
[0134] Histidyl residues are derivatized by reaction with diethylpyrocarbonate at pH 5.5-7.0 because this agent is relatively specific for the histidyl side chain. Para-bromophenacyl bromide also is useful; the reaction is preferably performed in 0.1 M sodium cacodylate at pH 6.0.
[0135] Lysinyl and amino terminal residues are reacted with succinic or other carboxylic acid anhydrides. Derivatization with these agents has the effect of reversing the charge of the lysinyl residues. Other suitable reagents for derivatizing alpha-amino-containing residues include imidoesters such as methyl picolinimidate; pyridoxal phosphate; pyridoxal; chloroborohydride; trinitrobenzenesulfonic acid; O-methylisourea; 2,4-pentanedione; and transaminase-catalyzed reaction with glyoxylate.
[0136] Arginyl residues are modified by reaction with one or several conventional reagents, among them phenylglyoxal, 2,3-butanedione, 1,2-cyclohexanedione, and ninhydrin. Derivatization of arginine residues requires that the reaction be performed in alkaline conditions because of the high pKa of the guanidine functional group. Furthermore, these reagents may react with the groups of lysine as well as the arginine epsilon-amino group.
[0137] The specific modification of tyrosyl residues may be made, with particular interest in introducing spectral labels into tyrosyl residues by reaction with aromatic diazonium compounds or tetranitromethane. Most commonly, N-acetylimidizole and tetranitromethane are used to form O-acetyl tyrosyl species and 3-nitro derivatives, respectively. Tyrosyl residues are iodinated using 125I or 131I to prepare labeled proteins for use in radioimmunoassay, the chloramine T method described above being suitable.
[0138] Carboxyl side groups (aspartyl or glutamyl) are selectively modified by reaction with carbodiimides (R'--N.dbd.C.dbd.N--R'), where R and R' are optionally different alkyl groups, such as 1-cyclohexyl-3-(2-morpholinyl-4-ethyl) carbodiimide or 1-ethyl-3-(4-azonia-4,4-dimethylpentyl) carbodiimide. Furthermore, aspartyl and glutamyl residues are converted to asparaginyl and glutaminyl residues by reaction with ammonium ions.
[0139] Derivatization with bifunctional agents is useful for crosslinking antibodies to a water-insoluble support matrix or surface for use in a variety of methods, in addition to methods described below. Commonly used crosslinking agents include, e.g., 1,1-bis(diazoacetyl)-2-phenylethane, glutaraldehyde, N-hydroxysuccinimide esters, for example, esters with 4-azidosalicylic acid, homobifunctional imidoesters, including disuccinimidyl esters such as 3,3'-dithiobis (succinimidylpropionate), and bifunctional maleimides such as bis-N-maleimido-1,8-octane. Derivatizing agents such as methyl-3-[(p-azidophenyl)dithio]propioimidate yield photoactivatable intermediates that are capable of forming crosslinks in the presence of light. Alternatively, reactive water-insoluble matrices such as cyanogen bromide-activated carbohydrates and the reactive substrates described in U.S. Pat. Nos. 3,969,287; 3,691,016; 4,195,128; 4,247,642; 4,229,537; and 4,330,440, all entirely incorporated by reference, are employed for protein immobilization.
[0140] Glutaminyl and asparaginyl residues are frequently deamidated to the corresponding glutamyl and aspartyl residues, respectively. Alternatively, these residues are deamidated under mildly acidic conditions. Either form of these residues falls within the scope of this invention. Other modifications include hydroxylation of proline and lysine, phosphorylation of hydroxyl groups of seryl or threonyl residues, methylation of the a-amino groups of lysine, arginine, and histidine side chains (T. E. Creighton, Proteins: Structure and Molecular Properties, W. H. Freeman & Co., San Francisco, pp. 79-86 [1983], entirely incorporated by reference), acetylation of the N-terminal amine, and amidation of any C-terminal carboxyl group.
[0141] Glycosylation
[0142] Another type of covalent modification is glycosylation. In another embodiment, the IgG variants disclosed herein can be modified to include one or more engineered glycoforms. By "engineered glycoform" as used herein is meant a carbohydrate composition that is covalently attached to an IgG, wherein said carbohydrate composition differs chemically from that of a parent IgG. Engineered glycoforms may be useful for a variety of purposes, including but not limited to enhancing or reducing effector function. Engineered glycoforms may be generated by a variety of methods known in the art (Umaua et al., 1999, Nat Biotechnol 17:176-180; Davies et al., 2001, Biotechnol Bioeng 74:288-294; Shields et al., 2002, J Biol Chem 277:26733-26740; Shinkawa et al., 2003, J Biol Chem 278:3466-3473; U.S. Pat. No. 6,602,684; U.S. Ser. No. 10/277,370; U.S. Ser. No. 10/113,929; PCT WO 00/61739A1; PCT WO 01/29246A1; PCT WO 02/31140A1; PCT WO 02/30954A1, all entirely incorporated by reference; (Potelligent.RTM. technology [Biowa, Inc., Princeton, N.J.]; GlycoMAb.RTM. glycosylation engineering technology [Glycart Biotechnology AG, Zurich, Switzerland]). Many of these techniques are based on controlling the level of fucosylated and/or bisecting oligosaccharides that are covalently attached to the Fc region, for example by expressing an IgG in various organisms or cell lines, engineered or otherwise (for example Lec-13 CHO cells or rat hybridoma YB2/0 cells), by regulating enzymes involved in the glycosylation pathway (for example FUT8 [.alpha.1,6-fucosyltranserase] and/or .beta.1-4-N-acetylglucosaminyltransferase III [GnTIII]), or by modifying carbohydrate(s) after the IgG has been expressed. Engineered glycoform typically refers to the different carbohydrate or oligosaccharide; thus an IgG variant, for example an antibody or Fc fusion, can include an engineered glycoform. Alternatively, engineered glycoform may refer to the IgG variant that comprises the different carbohydrate or oligosaccharide. As is known in the art, glycosylation patterns can depend on both the sequence of the protein (e.g., the presence or absence of particular glycosylation amino acid residues, discussed below), or the host cell or organism in which the protein is produced. Particular expression systems are discussed below.
[0143] Glycosylation of polypeptides is typically either N-linked or O-linked. N-linked refers to the attachment of the carbohydrate moiety to the side chain of an asparagine residue. The tri-peptide sequences asparagine-X-serine and asparagine-X-threonine, where X is any amino acid except proline, are the recognition sequences for enzymatic attachment of the carbohydrate moiety to the asparagine side chain. Thus, the presence of either of these tri-peptide sequences in a polypeptide creates a potential glycosylation site. O-linked glycosylation refers to the attachment of one of the sugars N-acetylgalactosamine, galactose, or xylose, to a hydroxyamino acid, most commonly serine or threonine, although 5-hydroxyproline or 5-hydroxylysine may also be used.
[0144] Addition of glycosylation sites to the antibody is conveniently accomplished by altering the amino acid sequence such that it contains one or more of the above-described tri-peptide sequences (for N-linked glycosylation sites). The alteration may also be made by the addition of, or substitution by, one or more serine or threonine residues to the starting sequence (for O-linked glycosylation sites). For ease, the antibody amino acid sequence is preferably altered through changes at the DNA level, particularly by mutating the DNA encoding the target polypeptide at preselected bases such that codons are generated that will translate into the desired amino acids.
[0145] Another means of increasing the number of carbohydrate moieties on the antibody is by chemical or enzymatic coupling of glycosides to the protein. These procedures are advantageous in that they do not require production of the protein in a host cell that has glycosylation capabilities for N- and O-linked glycosylation. Depending on the coupling mode used, the sugar(s) may be attached to (a) arginine and histidine, (b) free carboxyl groups, (c) free sulfhydryl groups such as those of cysteine, (d) free hydroxyl groups such as those of serine, threonine, or hydroxyproline, (e) aromatic residues such as those of phenylalanine, tyrosine, or tryptophan, or (f) the amide group of glutamine. These methods are described in WO 87/05330 and in Aplin and Wriston, 1981, CRC Crit. Rev. Biochem., pp. 259-306, both entirely incorporated by reference.
[0146] Removal of carbohydrate moieties present on the starting antibody may be accomplished chemically or enzymatically. Chemical deglycosylation requires exposure of the protein to the compound trifluoromethanesulfonic acid, or an equivalent compound. This treatment results in the cleavage of most or all sugars except the linking sugar (N-acetylglucosamine or N-acetylgalactosamine), while leaving the polypeptide intact. Chemical deglycosylation is described by Hakimuddin et al., 1987, Arch. Biochem. Biophys. 259:52 and by Edge et al., 1981, Anal. Biochem. 118:131, both entirely incorporated by reference. Enzymatic cleavage of carbohydrate moieties on polypeptides can be achieved by the use of a variety of endo- and exo-glycosidases as described by Thotakura et al., 1987, Meth. Enzymol. 138:350, entirely incorporated by reference. Glycosylation at potential glycosylation sites may be prevented by the use of the compound tunicamycin as described by Duskin et al., 1982, J. Biol. Chem. 257:3105, entirely incorporated by reference. Tunicamycin blocks the formation of protein-N-glycoside linkages.
[0147] Another type of covalent modification of the antibody comprises linking the antibody to various nonproteinaceous polymers, including, but not limited to, various polyols such as polyethylene glycol, polypropylene glycol or polyoxyalkylenes, in the manner set forth in, for example, 2005-2006 PEG Catalog from Nektar Therapeutics (available at the Nektar website) U.S. Pat. Nos. 4,640,835; 4,496,689; 4,301,144; 4,670,417; 4,791,192 or 4,179,337, all entirely incorporated by reference. In addition, as is known in the art, amino acid substitutions may be made in various positions within the antibody to facilitate the addition of polymers such as PEG. See for example, U.S. Publication No. 2005/0114037A1, entirely incorporated by reference.
[0148] Labeled Antibodies
[0149] In some embodiments, the covalent modification of the antibodies of the invention comprises the addition of one or more labels. In some cases, these are considered antibody fusions. The term "labelling group" means any detectable label. In some embodiments, the labelling group is coupled to the antibody via spacer arms of various lengths to reduce potential steric hindrance. Various methods for labelling proteins are known in the art and may be used in performing the present invention.
[0150] In general, labels fall into a variety of classes, depending on the assay in which they are to be detected: a) isotopic labels, which may be radioactive or heavy isotopes; b) magnetic labels (e.g., magnetic particles); c) redox active moieties; d) optical dyes; enzymatic groups (e.g. horseradish peroxidase, .beta.-galactosidase, luciferase, alkaline phosphatase); e) biotinylated groups; and f) predetermined polypeptide epitopes recognized by a secondary reporter (e.g., leucine zipper pair sequences, binding sites for secondary antibodies, metal binding domains, epitope tags, etc.). In some embodiments, the labelling group is coupled to the antibody via spacer arms of various lengths to reduce potential steric hindrance. Various methods for labelling proteins are known in the art and may be used in performing the present invention.
[0151] Specific labels include optical dyes, including, but not limited to, chromophores, phosphors and fluorophores, with the latter being specific in many instances. Fluorophores can be either "small molecule" fluores, or proteinaceous fluores.
[0152] By "fluorescent label" is meant any molecule that may be detected via its inherent fluorescent properties. Suitable fluorescent labels include, but are not limited to, fluorescein, rhodamine, tetramethylrhodamine, eosin, erythrosin, coumarin, methyl-coumarins, pyrene, Malacite green, stilbene, Lucifer Yellow, Cascade BlueJ, Texas Red, IAEDANS, EDANS, BODIPY FL, LC Red 640, Cy 5, Cy 5.5, LC Red 705, Oregon green, the Alexa-Fluor dyes (Alexa Fluor 350, Alexa Fluor 430, Alexa Fluor 488, Alexa Fluor 546, Alexa Fluor 568, Alexa Fluor 594, Alexa Fluor 633, Alexa Fluor 660, Alexa Fluor 680), Cascade Blue, Cascade Yellow and R-phycoerythrin (PE) (Molecular Probes, Eugene, Oreg.), FITC, Rhodamine, and Texas Red (Pierce, Rockford, Ill.), Cy5, Cy5.5, Cy7 (Amersham Life Science, Pittsburgh, Pa.). Suitable optical dyes, including fluorophores, are described in Molecular Probes Handbook by Richard P. Haugland, entirely incorporated by reference.
[0153] Suitable proteinaceous fluorescent labels also include, but are not limited to, green fluorescent protein, including a Renilla, Ptilosarcus, or Aequorea species of GFP (Chalfie et al., 1994, Science 263:802-805), EGFP (Clontech Laboratories, Inc., Genbank Accession Number U55762), blue fluorescent protein (BFP, Quantum Biotechnologies, Inc. 1801 de Maisonneuve Blvd. West, 8th Floor, Montreal, Quebec, Canada H3H 1J9; Stauber, 1998, Biotechniques 24:462-471; Heim et al., 1996, Curr. Biol. 6:178-182), enhanced yellow fluorescent protein (EYFP, Clontech Laboratories, Inc.), luciferase (Ichiki et al., 1993, J. Immunol. 150:5408-5417), .beta. galactosidase (Nolan et al., 1988, Proc. Natl. Acad. Sci. U.S.A. 85:2603-2607) and Renilla (WO92/15673, WO95/07463, WO98/14605, WO98/26277, WO99/49019, U.S. Pat. Nos. 5,292,658, 5,418,155, 5,683,888, 5,741,668, 5,777,079, 5,804,387, 5,874,304, 5,876,995, 5,925,558). All of the above-cited references in this paragraph are expressly incorporated herein by reference.
[0154] IgG Variants
[0155] In one embodiment, the invention provides variant IgG proteins. At a minimum, IgG variants comprise an antibody fragment comprising the CH2-CH3 region of the heavy chain. In addition, suitable IgG variants comprise Fc domains (e.g. including the lower hinge region), as well as IgG variants comprising the constant region of the heavy chain (CH1-hinge-CH2-CH3) also being useful in the present invention, all of which can be fused to fusion partners.
[0156] An IgG variant includes one or more amino acid modifications relative to a parent IgG polypeptide, in some cases relative to the wild type IgG. The IgG variant can have one or more optimized properties. An IgG variant differs in amino acid sequence from its parent IgG by virtue of at least one amino acid modification. Thus IgG variants have at least one amino acid modification compared to the parent. Alternatively, the IgG variants may have more than one amino acid modification as compared to the parent, for example from about one to fifty amino acid modifications, preferably from about one to ten amino acid modifications, and most preferably from about one to about five amino acid modifications compared to the parent.
[0157] Thus the sequences of the IgG variants and those of the parent Fc polypeptide are substantially homologous. For example, the variant IgG variant sequences herein will possess about 80% homology with the parent IgG variant sequence, preferably at least about 90% homology, and most preferably at least about 95% homology. Modifications may be made genetically using molecular biology, or may be made enzymatically or chemically.
[0158] Target Antigens for Antibodies
[0159] Virtually any antigen may be targeted by the IgG variants, including but not limited to proteins, subunits, domains, motifs, and/or epitopes belonging to the following list of target antigens, which includes both soluble factors such as cytokines and membrane-bound factors, including transmembrane receptors: 17-IA, 4-1BB, 4Dc, 6-keto-PGF1a, 8-iso-PGF2a, 8-oxo-dG, A1 Adenosine Receptor, A33, ACE, ACE-2, Activin, Activin A, Activin AB, Activin B, Activin C, Activin RIA, Activin RIA ALK-2, Activin RIB ALK-4, Activin RIIA, Activin RIIB, ADAM, ADAM10, ADAM12, ADAM15, ADAM17/TACE, ADAMS, ADAM9, ADAMTS, ADAMTS4, ADAMTS5, Addressins, aFGF, ALCAM, ALK, ALK-1, ALK-7, alpha-1-antitrypsin, alpha-V/beta-1 antagonist, ANG, Ang, APAF-1, APE, APJ, APP, APRIL, AR, ARC, ART, Artemin, anti-Id, ASPARTIC, Atrial natriuretic factor, av/b3 integrin, Axl, b2M, B7-1, B7-2, B7-H, B-lymphocyte Stimulator (BlyS), BACE, BACE-1, Bad, BAFF, BAFF-R, Bag-1, BAK, Bax, BCA-1, BCAM, Bcl, BCMA, BDNF, b-ECGF, bFGF, BID, Bik, BIM, BLC, BL-CAM, BLK, BMP, BMP-2 BMP-2a, BMP-3 Osteogenin, BMP-4 BMP-2b, BMP-5, BMP-6 Vgr-1, BMP-7 (OP-1), BMP-8 (BMP-8a, OP-2), BMPR, BMPR-IA (ALK-3), BMPR-IB (ALK-6), BRK-2, RPK-1, BMPR-II (BRK-3), BMPs, b-NGF, BOK, Bombesin, Bone-derived neurotrophic factor, BPDE, BPDE-DNA, BTC, complement factor 3 (C3), C3a, C4, C5, C5a, C10, CA125, CAD-8, Calcitonin, cAMP, carcinoembryonic antigen (CEA), carcinoma-associated antigen, Cathepsin A, Cathepsin B, Cathepsin C/DPPI, Cathepsin D, Cathepsin E, Cathepsin H, Cathepsin L, Cathepsin O, Cathepsin S, Cathepsin V, Cathepsin X/Z/P, CBL, CCI, CCK2, CCL, CCL1, CCL11, CCL12, CCL13, CCL14, CCL15, CCL16, CCL17, CCL18, CCL19, CCL2, CCL20, CCL21, CCL22, CCL23, CCL24, CCL25, CCL26, CCL27, CCL28, CCL3, CCL4, CCL5, CCL6, CCL7, CCL8, CCL9/10, CCR, CCR1, CCR10, CCR10, CCR2, CCR3, CCR4, CCR5, CCR6, CCR7, CCR8, CCR9, CD1, CD2, CD3, CD3E, CD4, CD5, CD6, CD7, CD8, CD10, CD11a, CD11b, CD11c, CD13, CD14, CD15, CD16, CD18, CD19, CD20, CD21, CD22, CD23, CD25, CD27L, CD28, CD29, CD30, CD30L, CD32, CD33 (p67 proteins), CD34, CD38, CD40, CD40L, CD44, CD45, CD46, CD49a, CD52, CD54, CD55, CD56, CD61, CD64, CD66e, CD74, CD80 (B7-1), CD89, CD95, CD123, CD137, CD138, CD140a, CD146, CD147, CD148, CD152, CD164, CEACAM5, CFTR, cGMP, CINC, Clostridium botulinum toxin, Clostridium perfringens toxin, CKb8-1, CLC, CMV, CMV UL, CNTF, CNTN-1, COX, C-Ret, CRG-2, CT-1, CTACK, CTGF, CTLA-4, CX3CL1, CX3CR1, CXCL, CXCL1, CXCL2, CXCL3, CXCL4, CXCL5, CXCL6, CXCL7, CXCL8, CXCL9, CXCL10, CXCL11, CXCL12, CXCL13, CXCL14, CXCL15, CXCL16, CXCR, CXCR1, CXCR2, CXCR3, CXCR4, CXCR5, CXCR6, cytokeratin tumor-associated antigen, DAN, DCC, DcR3, DC-SIGN, Decay accelerating factor, des(1-3)-IGF-I (brain IGF-1), Dhh, digoxin, DNAM-1, Dnase, Dpp, DPPIV/CD26, Dtk, ECAD, EDA, EDA-A1, EDA-A2, EDAR, EGF, EGFR (ErbB-1), EMA, EMMPRIN, ENA, endothelin receptor, Enkephalinase, eNOS, Eot, eotaxin1, EpCAM, Ephrin B2/EphB4, EPO, ERCC, E-selectin, ET-1, Factor IIa, Factor VII, Factor VIIIc, Factor IX, fibroblast activation protein (FAP), Fas, FcR1, FEN-1, Ferritin, FGF, FGF-19, FGF-2, FGF3, FGF-8, FGFR, FGFR-3, Fibrin, FL, FLIP, Flt-3, Flt-4, Follicle stimulating hormone, Fractalkine, FZD1, FZD2, FZD3, FZD4, FZD5, FZD6, FZD7, FZD8, FZD9, FZD10, G250, Gas 6, GCP-2, GCSF, GD2, GD3, GDF, GDF-1, GDF-3 (Vgr-2), GDF-5 (BMP-14, CDMP-1), GDF-6 (BMP-13, CDMP-2), GDF-7 (BMP-12, CDMP-3), GDF-8 (Myostatin), GDF-9, GDF-15 (MIC-1), GDNF, GDNF, GFAP, GFRa-1, GFR-alpha1, GFR-alpha2, GFR-alpha3, GITR, Glucagon, Glut 4, glycoprotein IIb/IIIa (GP IIb/IIIa), GM-CSF, gp130, gp72, GRO, Growth hormone releasing factor, Hapten (NP-cap or NIP-cap), HB-EGF, HCC, HCMV gB envelope glycoprotein, HCMV) gH envelope glycoprotein, HCMV UL, Hemopoietic growth factor (HGF), Hep B gp120, heparanase, Her2, Her2/neu (ErbB-2), Her3 (ErbB-3), Her4 (ErbB-4), herpes simplex virus (HSV) gB glycoprotein, HSV gD glycoprotein, HGFA, High molecular weight melanoma-associated antigen (HMW-MAA), HIV gp120, HIV IIIB gp 120 V3 loop, HLA, HLA-DR, HM1.24, HMFG PEM, HRG, Hrk, human cardiac myosin, human cytomegalovirus (HCMV), human growth hormone (HGH), HVEM, I-309, IAP, ICAM, ICAM-1, ICAM-3, ICE, ICOS, IFNg, Ig, IgA receptor, IgE, IGF, IGF binding proteins, IGF-1R, IGFBP, IGF-I, IGF-II, IL, IL-1, IL-1R, IL-2, IL-2R, IL-4, IL-4R, IL-5, IL-5R, IL-6, IL-6R, IL-8, IL-9, IL-10, IL-12, IL-13, IL-15, IL-18, IL-18R, IL-23, interferon (INF)-alpha, INF-beta, INF-gamma, Inhibin, iNOS, Insulin A-chain, Insulin B-chain, Insulin-like growth factor 1, integrin alpha2, integrin alpha3, integrin alpha4, integrin alpha4/beta1, integrin alpha4/beta7, integrin alpha5 (alphaV), integrin alpha5/beta1, integrin alpha5/beta3, integrin alpha6, integrin beta1, integrin beta2, interferon gamma, IP-10, I-TAC, JE, Kallikrein 2, Kallikrein 5, Kallikrein 6, Kallikrein 11, Kallikrein 12, Kallikrein 14, Kallikrein 15, Kallikrein L1, Kallikrein L2, Kallikrein L3, Kallikrein L4, KC, KDR, Keratinocyte Growth Factor (KGF), laminin 5, LAMP, LAP, LAP (TGF-1), Latent TGF-1, Latent TGF-1 bp1, LBP, LDGF, LECT2, Lefty, Lewis-Y antigen, Lewis-Y related antigen, LFA-1, LFA-3, Lfo, LIF, LIGHT, lipoproteins, LIX, LKN, Lptn, L-Selectin, LT-a, LT-b, LTB4, LTBP-1, Lung surfactant, Luteinizing hormone, Lymphotoxin Beta Receptor, Mac-1, MAdCAM, MAG, MAP2, MARC, MCAM, MCAM, MCK-2, MCP, M-CSF, MDC, Mer, METALLOPROTEASES, MGDF receptor, MGMT, MHC (HLA-DR), MIF, MIG, MIP, MIP-1-alpha, MK, MMAC1, MMP, MMP-1, MMP-10, MMP-11, MMP-12, MMP-13, MMP-14, MMP-15, MMP-2, MMP-24, MMP-3, MMP-7, MMP-8, MMP-9, MPIF, Mpo, MSK, MSP, mucin (Muc1), MUC18, Muellerian-inhibitin substance, Mug, MuSK, NAIP, NAP, NCAD, N-Cadherin, NCA 90, NCAM, NCAM, Neprilysin, Neurotrophin-3,-4, or -6, Neurturin, Neuronal growth factor (NGF), NGFR, NGF-beta, nNOS, NO, NOS, Npn, NRG-3, NT, NTN, OB, OGG1, OPG, OPN, OSM, OX40L, OX40R, p150, p95, PADPr, Parathyroid hormone, PARC, PARP, PBR, PBSF, PCAD, P-Cadherin, PCNA, PDGF, PDGF, PDK-1, PECAM, PEM, PF4, PGE, PGF, PGI2, PGJ2, PIN, PLA2, placental alkaline phosphatase (PLAP), PIGF, PLP, PP14, Proinsulin, Prorelaxin, Protein C, PS, PSA, PSCA, prostate specific membrane antigen (PSMA), PTEN, PTHrp, Ptk, PTN, R51, RANK, RANKL, RANTES, RANTES, Relaxin A-chain, Relaxin B-chain, renin, respiratory syncytial virus (RSV) F, RSV Fgp, Ret, Rheumatoid factors, RLIP76, RPA2, RSK, S100, SCF/KL, SDF-1, SERINE, Serum albumin, sFRP-3, Shh, SIGIRR, SK-1, SLAM, SLPI, SMAC, SMDF, SMOH, SOD, SPARC, Stat, STEAP, STEAP-II, TACE, TACI, TAG-72 (tumor-associated glycoprotein-72), TARC, TCA-3, T-cell receptors (e.g., T-cell receptor alpha/beta), TdT, TECK, TEM1, TEM5, TEM7, TEM8, TERT, testicular PLAP-like alkaline phosphatase, TfR, TGF, TGF-alpha, TGF-beta, TGF-beta Pan Specific, TGF-beta RI (ALK-5), TGF-beta RII, TGF-beta RIIb, TGF-beta RIII, TGF-beta1, TGF-beta2, TGF-beta3, TGF-beta4, TGF-beta5, Thrombin, Thymus Ck-1, Thyroid stimulating hormone, Tie, TIMP, TIQ, Tissue Factor, TMEFF2, Tmpo, TMPRSS2, TNF, TNF-alpha, TNF-alpha beta, TNF-beta2, TNFc, TNF-RI, TNF-RII, TNFRSF10A (TRAIL R1 Apo-2, DR4), TNFRSF10B (TRAIL R2 DRS, KILLER, TRICK-2A, TRICK-B), TNFRSF10C (TRAIL R3 DcR1, LIT, TRID), TNFRSF10D (TRAIL R4 DcR2, TRUNDD), TNFRSF11A (RANK ODF R, TRANCE R), TNFRSF11B (OPG OCIF, TR1), TNFRSF12 (TWEAK R FN14), TNFRSF13B (TACI), TNFRSF13C (BAFF R), TNFRSF14 (HVEM ATAR, HveA, LIGHT R, TR2), TNFRSF16 (NGFR p75NTR), TNFRSF17 (BCMA), TNFRSF18 (GITR AITR), TNFRSF19 (TROY TAJ, TRADE), TNFRSF19L (RELT), TNFRSF1A (TNF RI CD120a, p55-60), TNFRSF1B (TNF RII CD120b, p75-80), TNFRSF26 (TNFRH3), TNFRSF3 (LTbR TNF RIII, TNFC R), TNFRSF4 (OX40 ACT35, TXGP1 R), TNFRSFS (CD40 p50), TNFRSF6 (Fas Apo-1, APT1, CD95), TNFRSF6B (DcR3 M68, TR6), TNFRSF7 (CD27), TNFRSF8 (CD30), TNFRSF9 (4-1BB CD137, ILA), TNFRSF21 (DR6), TNFRSF22 (DcTRAIL R2 TNFRH2), TNFRST23 (DcTRAIL R1 TNFRH1), TNFRSF25 (DR3 Apo-3, LARD, TR-3, TRAMP, WSL-1), TNFSF10 (TRAIL Apo-2 Ligand, TL2), TNFSF11 (TRANCE/RANK Ligand ODF, OPG Ligand), TNFSF12 (TWEAK Apo-3 Ligand, DR3 Ligand), TNFSF13 (APRIL TALL2), TNFSF13B (BAFF BLYS, TALL1, THANK, TNFSF20), TNFSF14 (LIGHT HVEM Ligand, LTg), TNFSF15 (TL1A/VEGI), TNFSF18 (GITR Ligand AITR Ligand, TL6), TNFSF1A (TNF-a Conectin, DIF, TNFSF2), TNFSF1B (TNF-b LTa, TNFSF1), TNFSF3 (LTb TNFC, p33), TNFSF4 (OX40 Ligand gp34, TXGP1), TNFSF5 (CD40 Ligand CD154, gp39, HIGM1, IMD3, TRAP), TNFSF6 (Fas Ligand Apo-1 Ligand, APT1 Ligand), TNFSF7 (CD27 Ligand CD70), TNFSF8 (CD30 Ligand CD153), TNFSF9 (4-1BB Ligand CD137 Ligand), TP-1, t-PA, Tpo, TRAIL, TRAIL R, TRAIL-R1, TRAIL-R2, TRANCE, transferring receptor, TRF, Trk, TROP-2, TSG, TSLP, tumor-associated antigen CA 125, tumor-associated antigen expressing Lewis Y related carbohydrate, TWEAK, TXB2, Ung, uPAR, uPAR-1, Urokinase, VCAM, VCAM-1, VECAD, VE-Cadherin, VE-cadherin-2, VEFGR-1 (fit-1), VEGF, VEGFR, VEGFR-3 (flt-4), VEGI, VIM, Viral antigens, VLA, VLA-1, VLA-4, VNR integrin, von Willebrands factor, WIF-1, WNT1, WNT2, WNT2B/13, WNT3, WNT3A, WNT4, WNT5A, WNT5B, WNT6, WNT7A, WNT7B, WNT8A, WNT8B, WNT9A, WNT9A, WNT9B, WNT10A, WNT10B, WNT11, WNT16, XCL1, XCL2, XCR1, XCR1, XEDAR, XIAP, XPD, and receptors for hormones and growth factors.
[0160] One skilled in the art will appreciate that the aforementioned list of targets refers not only to specific proteins and biomolecules, but the biochemical pathway or pathways that comprise them. For example, reference to CTLA-4 as a target antigen implies that the ligands and receptors that make up the T cell co-stimulatory pathway, including CTLA-4, B7-1, B7-2, CD28, and any other undiscovered ligands or receptors that bind these proteins, are also targets. Thus target as used herein refers not only to a specific biomolecule, but the set of proteins that interact with said target and the members of the biochemical pathway to which said target belongs. One skilled in the art will further appreciate that any of the aforementioned target antigens, the ligands or receptors that bind them, or other members of their corresponding biochemical pathway, may be operably linked to the Fc variants of the present invention in order to generate an Fc fusion. Thus for example, an Fc fusion that targets EGFR could be constructed by operably linking an Fc variant to EGF, TGF-b, or any other ligand, discovered or undiscovered, that binds EGFR. Accordingly, an Fc variant of the present invention could be operably linked to EGFR in order to generate an Fc fusion that binds EGF, TGF-b, or any other ligand, discovered or undiscovered, that binds EGFR. Thus virtually any polypeptide, whether a ligand, receptor, or some other protein or protein domain, including but not limited to the aforementioned targets and the proteins that compose their corresponding biochemical pathways, may be operably linked to the Fc variants of the present invention to develop an Fc fusion.
[0161] The choice of suitable antigen depends on the desired application. For anti-cancer treatment it is desirable to have a target whose expression is restricted to the cancerous cells. Some targets that have proven especially amenable to antibody therapy are those with signaling functions. Other therapeutic antibodies exert their effects by blocking signaling of the receptor by inhibiting the binding between a receptor and its cognate ligand. Another mechanism of action of therapeutic antibodies is to cause receptor down regulation. Other antibodies do not work by signaling through their target antigen. In some cases, antibodies directed against infectious disease agents are used.
[0162] In one embodiment, the Fc variants of the present invention are incorporated into an antibody against a cytokine. Alternatively, the Fc variants are fused or conjugated to a cytokine. By "cytokine" as used herein is meant a generic term for proteins released by one cell population that act on another cell as intercellular mediators. For example, as described in Penichet et al., 2001, J Immunol Methods 248:91-101, expressly incorporated by reference, cytokines may be fused to antibody to provide an array of desirable properties. Examples of such cytokines are lymphokines, monokines, and traditional polypeptide hormones. Included among the cytokines are growth hormone such as human growth hormone, N-methionyl human growth hormone, and bovine growth hormone; parathyroid hormone; thyroxine; insulin; proinsulin; relaxin; prorelaxin; glycoprotein hormones such as follicle stimulating hormone (FSH), thyroid stimulating hormone (TSH), and luteinizing hormone (LH); hepatic growth factor; fibroblast growth factor; prolactin; placental lactogen; tumor necrosis factor-alpha and -beta; mullerian-inhibiting substance; mouse gonadotropin-associated peptide; inhibin; activin; vascular endothelial growth factor; integrin; thrombopoietin (TPO); nerve growth factors such as NGF-beta; platelet-growth factor; transforming growth factors (TGFs) such as TGF-alpha and TGF-beta; insulin-like growth factor-I and -II; erythropoietin (EPO); osteoinductive factors; interferons such as interferon-alpha, beta, and -gamma; colony stimulating factors (CSFs) such as macrophage-CSF (M-CSF); granulocyte-macrophage-CSF (GM-CSF); and granulocyte-CSF (G-CSF); interleukins (ILs) such as IL-1, IL-1 alpha, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL-9, IL-10, IL-11, IL-12; IL-15, a tumor necrosis factor such as TNF-alpha or TNF-beta; C5a; and other polypeptide factors including LIF and kit ligand (KL). As used herein, the term cytokine includes proteins from natural sources or from recombinant cell culture, and biologically active equivalents of the native sequence cytokines.
[0163] Cytokines and soluble targets, such as TNF superfamily members, are preferred targets for use with the variants of the present invention. For example, anti-VEGF, anti-CTLA-4, and anti-TNF antibodies, or fragments thereof, are particularly good antibodies for the use of Fc variants that increase the FcRn binding. Therapeutics against these targets are frequently involved in the treatment of autoimmune diseases and require multiple injections over long time periods. Therefore, longer serum half-lives and less frequent treatments, brought about from the variants of the present invention, are particularly preferred.
[0164] A number of antibodies and Fc fusions that are approved for use, in clinical trials, or in development may benefit from the Fc variants of the present invention. These antibodies and Fc fusions are herein referred to as "clinical products and candidates". Thus in a preferred embodiment, the Fc polypeptides of the present invention may find use in a range of clinical products and candidates. For example, a number of antibodies that target CD20 may benefit from the Fc polypeptides of the present invention. For example the Fc polypeptides of the present invention may find use in an antibody that is substantially similar to rituximab (Rituxan.RTM., IDEC/Genentech/Roche) (see for example U.S. Pat. No. 5,736,137), a chimeric anti-CD20 antibody approved to treat Non-Hodgkin's lymphoma; HuMax-CD20, an anti-CD20 currently being developed by Genmab, an anti-CD20 antibody described in U.S. Pat. No. 5,500,362, AME-133 (Applied Molecular Evolution), hA20 (Immunomedics, Inc.), HumaLYM (Intracel), and PRO70769 (PCT/US2003/040426, entitled "Immunoglobulin Variants and Uses Thereof"). A number of antibodies that target members of the family of epidermal growth factor receptors, including EGFR (ErbB-1), Her2/neu (ErbB-2), Her3 (ErbB-3), Her4 (ErbB-4), may benefit from the Fc polypeptides of the present invention. For example the Fc polypeptides of the present invention may find use in an antibody that is substantially similar to trastuzumab (Herceptin.RTM., Genentech) (see for example U.S. Pat. No. 5,677,171), a humanized anti-Her2/neu antibody approved to treat breast cancer; pertuzumab (rhuMab-2C4, Omnitarg.TM.), currently being developed by Genentech; an anti-Her2 antibody described in U.S. Pat. No. 4,753,894; cetuximab (Erbitux.RTM., Imclone) (U.S. Pat. No. 4,943,533; PCT WO 96/40210), a chimeric anti-EGFR antibody in clinical trials for a variety of cancers; ABX-EGF (U.S. Pat. No. 6,235,883), currently being developed by Abgenix-Immunex-Amgen; HuMax-EGFr (U.S. Ser. No. 10/172,317), currently being developed by Genmab; 425, EMD55900, EMD62000, and EMD72000 (Merck KGaA) (U.S. Ser. No. 5,558,864; Murthy et al. 1987, Arch Biochem Biophys. 252(2):549-60; Rodeck et al., 1987, J Cell Biochem. 35(4):315-20; Kettleborough et al., 1991, Protein Eng. 4(7):773-83); ICR62 (Institute of Cancer Research) (PCT WO 95/20045; Modjtahedi et al., 1993, J. Cell Biophys. 1993, 22(1-3):129-46; Modjtahedi et al., 1993, Br J Cancer. 1993, 67(2):247-53; Modjtahedi et al, 1996, Br J Cancer, 73(2):228-35; Modjtahedi et al, 2003, Int J Cancer, 105(2):273-80); TheraCIM hR3 (YM Biosciences, Canada and Centro de Immunologia Molecular, Cuba (U.S. Pat. Nos. 5,891,996; 6,506,883; Mateo et al, 1997, Immunotechnology, 3(1):71-81); mAb-806 (Ludwig Institue for Cancer Research, Memorial Sloan-Kettering) (Jungbluth et al. 2003, Proc Natl Acad Sci USA. 100(2):639-44); KSB-102 (KS Biomedix); MR1-1 (IVAX, National Cancer Institute) (PCT WO 0162931A2); and SC100 (Scancell) (PCT WO 01/88138). In another preferred embodiment, the Fc polypeptides of the present invention may find use in alemtuzumab (Campath.RTM., Millenium), a humanized monoclonal antibody currently approved for treatment of B-cell chronic lymphocytic leukemia. The Fc polypeptides of the present invention may find use in a variety of antibodies or Fc fusions that are substantially similar to other clinical products and candidates, including but not limited to muromonab-CD3 (Orthoclone OKT3.RTM.), an anti-CD3 antibody developed by Ortho Biotech/Johnson & Johnson, ibritumomab tiuxetan (Zevalin.RTM.), an anti-CD20 antibody developed by IDEC/Schering AG, gemtuzumab ozogamicin (Mylotarg.RTM.), an anti-CD33 (p67 protein) antibody developed by Celltech/Wyeth, alefacept (Amevive.RTM.), an anti-LFA-3 Fc fusion developed by Biogen), abciximab (ReoPro.RTM.), developed by Centocor/Lilly, basiliximab (Simulect.RTM.), developed by Novartis, palivizumab (Synagis.RTM.), developed by MedImmune, infliximab (Remicade.RTM.), an anti-TNFalpha antibody developed by Centocor, adalimumab (Humira.RTM.), an anti-TNFalpha antibody developed by Abbott, Humicade.TM., an anti-TNFalpha antibody developed by Celltech, etanercept (Enbrel.RTM.), an anti-TNFalpha Fc fusion developed by Immunex/Amgen, ABX-CBL, an anti-CD147 antibody being developed by Abgenix, ABX-IL8, an anti-IL8 antibody being developed by Abgenix, ABX-MA1, an anti-MUC18 antibody being developed by Abgenix, Pemtumomab (R1549, 90Y-muHMFG1), an anti-MUC1 In development by Antisoma, Therex (R1550), an anti-MUC1 antibody being developed by Antisoma, AngioMab (AS1405), being developed by Antisoma, HuBC-1, being developed by Antisoma, Thioplatin (AS1407) being developed by Antisoma, Antegren.RTM. (natalizumab), an anti-alpha-4-beta-1 (VLA-4) and alpha-4-beta-7 antibody being developed by Biogen, VLA-1 mAb, an anti-VLA-1 integrin antibody being developed by Biogen, LTBR mAb, an anti-lymphotoxin beta receptor (LTBR) antibody being developed by Biogen, CAT-152, an anti-TGF-.beta.2 antibody being developed by Cambridge Antibody Technology, J695, an anti-IL-12 antibody being developed by Cambridge Antibody Technology and Abbott, CAT-192, an anti-TGF.beta.1 antibody being developed by Cambridge Antibody Technology and Genzyme, CAT-213, an anti-Eotaxin 1 antibody being developed by Cambridge Antibody Technology, LymphoStat-B.TM. an anti-Blys antibody being developed by Cambridge Antibody Technology and Human Genome Sciences Inc., TRAIL-R1mAb, an anti-TRAIL-R1 antibody being developed by Cambridge Antibody Technology and Human Genome Sciences, Inc., Avastin.TM. (bevacizumab, rhuMAb-VEGF), an anti-VEGF antibody being developed by Genentech, an anti-HER receptor family antibody being developed by Genentech, Anti-Tissue Factor (ATF), an anti-Tissue Factor antibody being developed by Genentech, Xolair.TM. (Omalizumab), an anti-IgE antibody being developed by Genentech, Raptiva.TM. (Efalizumab), an anti-CD11a antibody being developed by Genentech and Xoma, MLN-02 Antibody (formerly LDP-02), being developed by Genentech and Millenium Pharmaceuticals, HuMax CD4, an anti-CD4 antibody being developed by Genmab, HuMax-IL15, an anti-IL15 antibody being developed by Genmab and Amgen, HuMax-Inflam, being developed by Genmab and Medarex, HuMax-Cancer, an anti-Heparanase I antibody being developed by Genmab and Medarex and Oxford GcoSciences, HuMax-Lymphoma, being developed by Genmab and Amgen, HuMax-TAC, being developed by Genmab, IDEC-131, and anti-CD40L antibody being developed by IDEC Pharmaceuticals, IDEC-151 (Clenoliximab), an anti-CD4 antibody being developed by IDEC Pharmaceuticals, IDEC-114, an anti-CD80 antibody being developed by IDEC Pharmaceuticals, IDEC-152, an anti-CD23 being developed by IDEC Pharmaceuticals, anti-macrophage migration factor (MIF) antibodies being developed by IDEC Pharmaceuticals, BEC2, an anti-idiotypic antibody being developed by Imclone, IMC-1C11, an anti-KDR antibody being developed by Imclone, DC101, an anti-flk-1 antibody being developed by Imclone, anti-VE cadherin antibodies being developed by Imclone, CEA-Cide.TM. (labetuzumab), an anti-carcinoembryonic antigen (CEA) antibody being developed by Immunomedics, LymphoCide.TM. (Epratuzumab), an anti-CD22 antibody being developed by Immunomedics, AFP-Cide, being developed by Immunomedics, MyelomaCide, being developed by Immunomedics, LkoCide, being developed by Immunomedics, ProstaCide, being developed by Immunomedics, MDX-010, an anti-CTLA4 antibody being developed by Medarex, MDX-060, an anti-CD30 antibody being developed by Medarex, MDX-070 being developed by Medarex, MDX-018 being developed by Medarex, Osidem.TM. (IDM-1), and anti-Her2 antibody being developed by Medarex and Immuno-Designed Molecules, HuMax.TM.-CD4, an anti-CD4 antibody being developed by Medarex and Genmab, HuMax-IL15, an anti-IL15 antibody being developed by Medarex and Genmab, CNTO 148, an anti-TNF.alpha. antibody being developed by Medarex and Centocor/J&J, CNTO 1275, an anti-cytokine antibody being developed by Centocor/J&J, MOR101 and MOR102, anti-intercellular adhesion molecule-1 (ICAM-1) (CD54) antibodies being developed by MorphoSys, MOR201, an anti-fibroblast growth factor receptor 3 (FGFR-3) antibody being developed by MorphoSys, Nuvion.RTM. (visilizumab), an anti-CD3 antibody being developed by Protein Design Labs, HuZAF.TM., an anti-gamma interferon antibody being developed by Protein Design Labs, Anti-.alpha.5.beta.1 Integrin, being developed by Protein Design Labs, anti-IL-12, being developed by Protein Design Labs, ING-1, an anti-Ep-CAM antibody being developed by Xoma, and MLN01, an anti-Beta2 integrin antibody being developed by Xoma, all of the above-cited references in this paragraph are expressly incorporated herein by reference.
[0165] The Fc polypeptides of the present invention may be incorporated into the aforementioned clinical candidates and products, or into antibodies and Fc fusions that are substantially similar to them. The Fc polypeptides of the present invention may be incorporated into versions of the aforementioned clinical candidates and products that are humanized, affinity matured, engineered, or modified in some other way.
[0166] In one embodiment, the Fc polypeptides of the present invention are used for the treatment of autoimmune, inflammatory, or transplant indications. Target antigens and clinical products and candidates that are relevant for such diseases include but are not limited to anti-.alpha.4.beta.7 integrin antibodies such as LDP-02, anti-beta2 integrin antibodies such as LDP-01, anti-complement (C5) antibodies such as 5G1.1, anti-CD2 antibodies such as BTI-322, MEDI-507, anti-CD3 antibodies such as OKT3, SMART anti-CD3, anti-CD4 antibodies such as IDEC-151, MDX-CD4, OKT4A, anti-CD11a antibodies, anti-CD14 antibodies such as IC14, anti-CD18 antibodies, anti-CD23 antibodies such as IDEC 152, anti-CD25 antibodies such as Zenapax, anti-CD40L antibodies such as 5c8, Antova, IDEC-131, anti-CD64 antibodies such as MDX-33, anti-CD80 antibodies such as IDEC-114, anti-CD147 antibodies such as ABX-CBL, anti-E-selectin antibodies such as CDP850, anti-gpIIb/IIIa antibodies such as ReoPro/Abcixima, anti-ICAM-3 antibodies such as ICM3, anti-ICE antibodies such as VX-740, anti-FcR1 antibodies such as MDX-33, anti-IgE antibodies such as rhuMab-E25, anti-IL-4 antibodies such as SB-240683, anti-IL-5 antibodies such as SB-240563, SCH55700, anti-IL-8 antibodies such as ABX-IL8, anti-interferon gamma antibodies, anti-TNF (TNF, TNFa, TNFa, TNF-alpha) antibodies such as CDP571, CDP870, D2E7, Infliximab, MAK-195F, and anti-VLA-4 antibodies such as Antegren.
[0167] Fc variants of the present invention such as those with increased binding to FcRn may be utilized in TNF inhibitor molecules to provide enhanced properties. Useful TNF inhibitor molecules include any molecule that inhibits the action of TNF-alpha in a mammal. Suitable examples include the Fc fusion Enbrel.RTM. (etanercept) and the antibodies Humira.RTM. (adalimumab) and Remicade.RTM. (infliximab). Monoclonal antibodies (such as Remicade and Humira) engineered using the Fc variants of the present invention to increase FcFn binding, may translate to better efficacy through an increased half-life.
[0168] In some embodiments, antibodies against infectious diseases are used. Antibodies against eukaryotic cells include antibodies targeting yeast cells, including but not limited to Saccharomyces cerevisiae, Hansenula polymorpha, Kluyveromyces fragilis and K. lactis, Pichia guillerimondii and P. pastoris, Schizosaccharomyces pombe, plasmodium falciparium, and Yarrowia lipolytica.
[0169] Antibodies against additional fungal cells are also useful, including target antigens associated with Candida strains including Candida glabrata, Candida albicans, C. krusei, C. lusitaniae and C. maltosa, as well as species of Aspergillus, Cryptococcus, Histoplasma, Coccidioides, Blastomyces, and Penicillium, among others
[0170] Antibodies directed against target antigens associated with protozoa include, but are not limited to, antibodies associated with Trypanosoma, Leishmania species including Leishmania donovanii; Plasmodium spp., Pneumocystis carinii, Cryptosporidium parvum, Giardia lamblia, Entamoeba histolytica, and Cyclospora cayetanensis.
[0171] Antibodies against prokaryotic antigens are also useful, including antibodies against suitable bacteria such as pathogenic and non-pathogenic prokaryotes including but not limited to Bacillus, including Bacillus anthracis; Vibrio, e.g. V. cholerae; Escherichia, e.g. Enterotoxigenic E. coli, Shigella, e.g. S. dysenteriae; Salmonella, e.g. S. typhi; Mycobacterium e.g. M. tuberculosis, M. leprae; Clostridium, e.g. C. botulinum, C. tetani, C. difficile, C.perfringens; Cornyebacterium, e.g. C. diphtheriae; Streptococcus, S. pyogenes, S. pneumoniae; Staphylococcus, e.g. S. aureus; Haemophilus, e.g. H. influenzae; Neisseria, e.g. N. meningitidis, N. gonorrhoeae; Yersinia, e.g. Y. lamblia, Y. pestis, Pseudomonas, e.g. P. aeruginosa, P. putida; Chlamydia, e.g. C. trachomatis; Bordetella, e.g. B. pertussis; Treponema, e.g. T palladium; B. anthracis, Y. pestis, Brucella spp., F. tularensis, B. mallei, B. pseudomallei, B. mallei, B. pseudomallei , C. botulinum, Salmonella spp., SEB V. cholerae toxin B, E. coli O157:H7, Listeria spp., Trichosporon beigelii, Rhodotorula species, Hansenula anomala, Enterobacter sp., Klebsiella sp., Listeria sp., Mycoplasma sp. and the like.
[0172] In some aspects, the antibodies are directed against viral infections; these viruses include, but are not limited to, including orthomyxoviruses, (e.g. influenza virus), paramyxoviruses (e.g respiratory syncytial virus, mumps virus, measles virus), adenoviruses, rhinoviruses, coronaviruses, reoviruses, togaviruses (e.g. rubella virus), parvoviruses, poxviruses (e.g. variola virus, vaccinia virus), enteroviruses (e.g. poliovirus, coxsackievirus), hepatitis viruses (including A, B and C), herpesviruses (e.g. Herpes simplex virus, varicella-zoster virus, cytomegalovirus, Epstein-Barr virus), rotaviruses, Norwalk viruses, hantavirus, arenavirus, rhabdovirus (e.g. rabies virus), retroviruses (including HIV, HTLV-I and -II), papovaviruses (e.g. papillomavirus), polyomaviruses, and picornaviruses, and the like.
[0173] Optimized IgG Variant Properties
[0174] The present application also provides IgG variants that are optimized for a variety of therapeutically relevant properties. An IgG variant that is engineered or predicted to display one or more optimized properties is herein referred to as an "optimized IgG variant". The most preferred properties that may be optimized include but are not limited to enhanced or reduced affinity for FcRn and increased or decreased in vivo half-life. Suitable embodiments include antibodies that exhibit increased binding affinity to FcRn at lowered pH, such as the pH associated with endosomes, e.g. pH 6.0, while maintaining the reduced affinity at higher pH, such as 7.4., to allow increased uptake into endosomes but normal release rates. Similarly, these antibodies with modulated FcRn binding may optionally have other desirable properties, such as modulated Fc.gamma.R binding, such as outlined in U.S. Ser. Nos. 11/174,287, 11/124,640, 10/822,231, 10/672,280, 10/379,392, and the patent application entitled IgG Immunoglobulin variants with optimized effector function filed on Oct. 21, 2005 having application Ser. No. 11/256,060. That is, optimized properties also include but are not limited to enhanced or reduced affinity for an Fc.gamma.R. In one optional embodiment, the IgG variants are optimized to possess enhanced affinity for a human activating Fc.gamma.R, preferably Fc.gamma.RIIIa in addition to the FcRn binding profile. In yet another optional alternate embodiment, the IgG variants are optimized to possess reduced affinity for the human inhibitory receptor Fc.gamma.RIIb. That is, particular embodiments embrace the use of antibodies that show increased binding to FcRn, and increased binding to Fc.gamma.RIIIa. Other embodiments utilize use of antibodies that show increased binding to FcRn, and increased binding to Fc.gamma.RIIIa. These embodiments are anticipated to provide IgG polypeptides with enhanced therapeutic properties in humans, for example enhanced effector function and greater anti-cancer potency. In an alternate embodiment, the IgG variants are optimized to have increased or reduced affinity for FcRn and increased or decreased affinity for a human Fc.gamma.R, including but not limited to Fc.gamma.RI, Fc.gamma.RIIa, Fc.gamma.RIIb, Fc.gamma.RIIc, Fc.gamma.RIIIa, and Fc.gamma.RIIIb including their allelic variations. These embodiments are anticipated to provide IgG polypeptides with enhanced therapeutic properties in humans, for example increased serum half-life and reduced effector function. In other embodiments, IgG variants provide enhanced affinity for FcRn and enhanced affinity for one or more Fc.gamma.Rs, yet reduced affinity for one or more other Fc.gamma.Rs. For example, an IgG variant may have enhanced binding to FcRn and Fc.gamma.RIIIa, yet reduced binding to Fc.gamma.RIIb. Alternately, an IgG variant may have reduced binding to FcRn and to Fc.gamma.R's. In another embodiment, an IgG variant may have reduced affinity for FcRn and enhanced affinity for Fc.gamma.RIIb, yet reduced affinity to one or more activating Fc.gamma.Rs. In yet another embodiment, an IgG variant may have increased serum half-life and reduced effector functions.
[0175] Preferred embodiments comprise optimization of binding to a human FcRn and Fc.gamma.R, however in alternate embodiments the IgG variants possess enhanced or reduced affinity for FcRn and Fc.gamma.R from nonhuman organisms, including but not limited to rodents and non-human primates. IgG variants that are optimized for binding to a nonhuman FcRn may find use in experimentation. For example, mouse models are available for a variety of diseases that enable testing of properties such as efficacy, toxicity, and pharmacokinetics for a given drug candidate. As is known in the art, cancer cells can be grafted or injected into mice to mimic a human cancer, a process referred to as xenografting. Testing of IgG variants that comprise IgG variants that are optimized for FcRn may provide valuable information with regard to the clearance characteristics of the protein, its mechanism of clearance, and the like. The IgG variants may also be optimized for enhanced functionality and/or solution properties in aglycosylated form. The Fc ligands include but are not limited to FcRn, Fc.gamma.Rs, C1q, and proteins A and G, and may be from any source including but not limited to human, mouse, rat, rabbit, or monkey, preferably human. In an alternately preferred embodiment, the IgG variants are optimized to be more stable and/or more soluble than the aglycosylated form of the parent IgG variant.
[0176] IgG variants can include modifications that modulate interaction with Fc ligands other than FcRn and Fc.gamma.Rs, including but not limited to complement proteins, and Fc receptor homologs (FcRHs). FcRHs include but are not limited to FcRH1, FcRH2, FcRH3, FcRH4, FcRH5, and FcRH6 (Davis et al., 2002, Immunol. Reviews 190:123-136, entirely incorporated by reference).
[0177] Preferably, the Fc ligand specificity of the IgG variant will determine its therapeutic utility. The utility of a given IgG variant for therapeutic purposes will depend on the epitope or form of the target antigen and the disease or indication being treated. For most targets and indications, enhanced FcRn binding may be preferable as the enhanced FcRn binding may result in an increase in serum half-life. Longer serum half-lives allow less frequent dosing or lower dosing of the therapeutic. This is particularly preferable when the therapeutic agent is given in response to an indication that requires repeated administration. For some targets and indications, decreased FcRn affinity may be preferable. This may be particularly preferable when a variant Fc with increased clearance or decreased serum half-life is desired, for example in Fc polypeptides used as imaging agents or radio-therapeutics.
[0178] IgG variants may be used that comprise IgG variants that provide enhanced affinity for FcRn with enhanced activating Fc.gamma.Rs and/or reduced affinity for inhibitory Fc.gamma.Rs. For some targets and indications, it may be further beneficial to utilize IgG variants that provide differential selectivity for different activating Fc.gamma.Rs; for example, in some cases enhanced binding to Fc.gamma.RIIa and Fc.gamma.RIIIa may be desired, but not Fc.gamma.RI, whereas in other cases, enhanced binding only to Fc.gamma.RIIa may be preferred. For certain targets and indications, it may be preferable to utilize IgG variants that alter FcRn binding and enhance both Fc.gamma.R-mediated and complement-mediated effector functions, whereas for other cases it may be advantageous to utilize IgG variants that enhance FcRn binding, or serum half-life, and either Fc.gamma.R-mediated or complement-mediated effector functions. For some targets or cancer indications, it may be advantageous to reduce or ablate one or more effector functions, for example by knocking out binding to C1q, one or more Fc.gamma.R's, FcRn, or one or more other Fc ligands. For other targets and indications, it may be preferable to utilize IgG variants that provide enhanced binding to the inhibitory Fc.gamma.RIIb, yet VVT level, reduced, or ablated binding to activating Fc.gamma.Rs. This may be particularly useful, for example, when the goal of an IgG variant is to inhibit inflammation or auto-immune disease, or modulate the immune system in some way. Because auto-immune diseases are generally long-lasting and treatment is given in repeated dosing, their treatment with Fc variants with increased half-life from increased FcRn is particularly preferred.
[0179] Modification may be made to improve the IgG stability, solubility, function, or clinical use. In a preferred embodiment, the IgG variants can include modifications to reduce immunogenicity in humans. In a most preferred embodiment, the immunogenicity of an IgG variant is reduced using a method described in U.S. Ser. No. 11/004,590, entirely incorporated by reference. In alternate embodiments, the IgG variants are humanized (Clark, 2000, Immunol Today 21:397-402, entirely incorporated by reference).
[0180] The IgG variants can include modifications that reduce immunogenicity. Modifications to reduce immunogenicity can include modifications that reduce binding of processed peptides derived from the parent sequence to MHC proteins. For example, amino acid modifications would be engineered such that there are no or a minimal number of immune epitopes that are predicted to bind, with high affinity, to any prevalent MHC alleles. Several methods of identifying MHC-binding epitopes in protein sequences are known in the art and may be used to score epitopes in an IgG variant. See for example WO 98/52976; WO 02/079232; WO 00/3317; U.S. Ser. Nos. 09/903,378; 10/039,170; U.S. Ser. No. 60/222,697; U.S. Ser. No. 10/754,296; PCT WO 01/21823; and PCT WO 02/00165; Mallios, 1999, Bioinformatics 15: 432-439; Mallios, 2001, Bioinformatics 17: 942-948; Sturniolo et al., 1999, Nature Biotech. 17: 555-561; WO 98/59244; WO 02/069232; WO 02/77187; Marshall et al., 1995, J. Immunol. 154: 5927-5933; and Hammer et al., 1994, J. Exp. Med. 180: 2353-2358, all entirely incorporated by reference. Sequence-based information can be used to determine a binding score for a given peptide--MHC interaction (see for example Mallios, 1999, Bioinformatics 15: 432-439; Mallios, 2001, Bioinformatics 17: p942-948; Sturniolo et. al., 1999, Nature Biotech. 17: 555-561, all entirely incorporated by reference).
[0181] Engineering IgG Variants
[0182] Variants of the present invention may be designed by various means. The variants, as described herein, may be insertions, deletions, substitutions, other modifications, or combinations of these and other changes. A particularly novel embodiment of the present invention is the design of insertions and deletions that either improve or reduce the binding of an Fc polypeptide to an Fc ligand. As disclosed herein, insertions or deletions may be made that increase or decrease the affinity of the Fc polypeptide for FcRn. Insertions and deletions may be designed by rational approaches or by approaches that include the use or random components, such as random or semi-random library creation or screening. In an alternative embodiment, substitutions are disclosed that increase or decrease the affinity of the Fc polypeptide for FcRn.
[0183] Backbone Modifications: Insertions and Deletions
[0184] Variant Fc polypeptides may be created by substituting a variant amino acid in place of the parent amino acid at a position in the Fc polypeptide. By substituting one or more amino acids for variant amino acids in the Fc polypeptide, the side chains at those positions are altered. Most useful substitutions modify the Fc properties by altering the Fc side chains. The substituted side chains may interact directly or indirectly with an Fc binding partner that is associated with an Fc function or property. The at least one substitution alters the covalent structure of one or more side chains of the parent Fc polypeptide.
[0185] Alternatively, variant Fc polypeptides may be created that change the covalent structure of the backbone of the parent Fc polypeptide. The backbone atoms in proteins are the peptide nitrogen, the alpha carbon, the carbonyl or peptide carbon and the carbonyl oxygen. Changing the covalent structure of the backbone provides additional methods of altering the properties of the Fc polypeptides. The covalent structure of the Fc backbone may be altered by the addition of atoms into the backbone, e.g. by inserting one or more amino acids, or the subtraction of atoms from the backbone, e.g. by deleting one or more amino acids. The covalent structure of the backbone may also be altered by changing individual atoms of the backbone to other atoms (Deechongkit et al., J Am Chem Soc. 2004. 126(51):16762-71, entirely incorporated by reference). As is known in the art and is illustrated herein, insertions or deletions of amino acids in Fc polypeptides may be done by inserting or deleting the corresponding nucleotides in the DNA encoding the Fc polypeptide. Alternatively, as is known in the art, insertions or deletions of amino acids may be done during synthesis of Fc polypeptides.
[0186] The design of insertions or deletions of amino acids that alter the interaction of the Fc polypeptide with one or more binding partners (e.g. FcgammaR's, FcRn, C1q) may be done by considering the structure of the complex of the Fc polypeptide and its binding partner. In a less preferred embodiment, the design may be done by considering the structure of the Fc polypeptide and information about the Fc region involved in binding the binding partner. This information may be obtained by mutagenesis experiments, phage display experiments, homology comparisons, computer modeling or other means.
[0187] Preferred positions in the amino acid sequence for insertions or deletions that affect the Fc binding interactions, but do not affect the overall structure, stability, expression or use of the Fc polypeptide, are in loops that are involved in the Fc/Fc-binding partner interactions. To alter FcRn binding to the Fc polypeptide, positions 244-257, 279-284, 307-317, 383-390, and 428-435 are preferred loop locations for insertions or deletions (numbering from EU index of Kabat et al., Burmeister et al., 1994, Nature, 372:379-383; Martin et al., 2001, Mol Cell 7:867-877, all entirely incorporated by reference). To alter the Fcgamma receptor binding to the Fc polypeptide, positions 229-239, 266-273, 294-299, and 324-331 are preferred loop locations for insertions or deletions (numbering from EU index of Kabat et al., PDB code 1 E4K.pdb Sondermann et al. Nature. 2000 406:267, all entirely incorporated by reference). Loops are regions of the polypeptide not involved in alpha helical or beta sheet structure. Loops positions are positions that are not in either alpha helical or beta sheet structures (van Holde, Johnson and Ho. Principles of Physical Biochemistry. Prentice Hall, New Jersey 1998, Chapter 1 pp2-67, entirely incorporated by reference). Loop positions are preferred because the backbone atoms are typically more flexible and less likely involved in hydrogen bonds compared to the backbone atoms of alpha helices and beta sheets. Therefore, the lengthening or shortening of a loop due to an insertion or deletion of one or more amino acids is less likely to lead to large, disruptive changes to the Fc polypeptide, including stability, expression or other problems.
[0188] Insertions and deletions may be used to alter the length of the polypeptide. For example, in loop regions, altering the loop length results in altered flexibility and conformational entropy of the loop. Insertions in a loop will generally increase the conformational entropy of the loop, which may be defined as Boltzman's constant multiplied by the natural logarithm of the number of possible conformations (van Holde, Johnson and Ho. Principles of Physical Biochemistry. Prentice Hall, New Jersey 1998, pp 78, entirely incorporated by reference). By inserting at least one amino acid into a polypeptide, the total number of conformations available to the polypeptide increases. These additional conformations may be beneficial for forming favorable Fc/Fc-binding partner interactions because the Fc polypeptide may use one of the additional conformations in binding the Fc-binding protein. In this case, the insertion may lead to stronger Fc/Fc-binding partner interactions. If the additional conformations are not used in the binding interface, then the insertion may lead to weaker Fc/Fc-binding partner interactions, because the additional conformations would compete with the binding-competent conformation. Similarly, deletion of a polypeptide segment may also lead to either stronger or weaker Fc/Fc binding-partner interactions. If deletion of a segment, which reduces the possible number of backbone conformations, removes the binding-competent conformation, then the deletion may lead to weaker Fc/Fc-binding partner interactions. If the deletion does not remove the binding-competent conformation, then the deletion may lead to stronger Fc/Fc-binding partner interactions because the deletion may remove conformations that compete with the binding-competent conformation.
[0189] Insertions and deletions may be used to alter the positions and orientations of the amino acids in the Fc polypeptide. Because insertions and deletions cause a change in the covalent structure of the backbone, they necessarily cause a change in the positions of the backbone atoms. FIG. 7 compares the backbone positions at some loop segments, marked L1 to L4, in three different backbones. The reference backbone structure contains four loop segments, whereas the deletion backbone lacks segment L1 and the insertion segment comprises an additional segment before, ie, N-terminal to, segment L1. Deletions and insertions cause the largest change in the backbone structure near the site of the insertion or deletion. By deleting a segment near the N-terminal end of the loop, e.g. segment L1, the loop shortens and the remaining segments shift their position closer to the loop N-terminus. This has the effect of moving the L2 segment toward the prior location of the L1 segment and toward the loop N-terminus. This change in position of the L2 segment toward the L1 segment may strengthen the binding of the Fc/Fc-binding partner complex and is preferred when there is prior information suggesting that the amino acid or amino acids located in L2 make favorable interactions with the Fc-binding partner, when located in L1. For example, if L2 contains alanine and tyrosine and substitution of two L1 amino acids for alanine and tyrosine previously lead to an Fc variant with increased binding, then deletion of L1 may create an Fc variant with increased affinity for the Fc-binding partner.
[0190] Similarly, an insertion of a polypeptide segment into an Fc polypeptide at the N-terminal side of a loop causes the positions of the loop segments to be shifted toward the C-terminal side of the loop. In FIG. 7, an insertion of one or more amino acids before, i.e. N-terminally to, segment L1 alters the backbone conformation including a shift of the L1 segment toward the C-terminal end of the loop. This type of insertion is preferred when the amino acids located in segment L1 are known to make favorable interactions when located in the L2 positions, as the insertion may lead to stronger Fc/Fc-binding partner interactions. If weaker Fc/Fc-binding partner interactions are desired, then the insertion may be used to shift unfavorable amino acid into a new position. The inserted, deleted and reference segments (L1 to L4 in FIG. 7) may be one or more than one amino acid in the Fc polypeptide.
[0191] Alternatively, insertions or deletions may be used at the C-terminal end of loops in a manner analogous to the insertions or deletions at the N-terminal end of loops. Insertions at the loop C-terminus may lead to a movement of the positions N-terminal of the insertion toward the loop N-terminus. Deletions at the loop C-terminus may lead to a movement of the positions N-terminal of the deletion toward the loop C-terminus. The choice of using an insertion or deletion at the N-terminal or C-terminal end of the loop is based on the amino acids located in the loop, the desire for increased or decreased Fc/Fc-binding partner affinity, and the positional shift desired.
[0192] Insertions or deletions may be used in any region of an Fc polypeptide, including the loops, the alpha helical, and the beta sheet regions. Preferred locations for insertions and deletions include loop regions, which are those that are not alpha helical or beta sheet regions. Loops are preferred because they generally accept alterations in the backbone better than alpha helixes or beta sheets. The particularly preferred locations for insertions or deletions that result in stronger protein/protein interactions are at the N-terminal or C-terminal edges of a loop. If the loop side chains are involve in the Fc/Fc-binding partner interactions, then insertions or deletion at the edges are less likely to lead to strongly detrimental changes in the binding interactions. Deletions within the exact center of the loop are more likely to remove important residues in the Fc/Fc-binding partner interface and insertions within the exact center of the loop are more likely to create unfavorable interactions in the Fc/Fc-binding partner interface. The number of residues deleted or inserted may be determined by the size of the backbone change desired with insertions or deletions of 15 or less residues being preferred, insertions or deletions of 10 or less residues being more preferred, and insertions or deletions of 5 or less residues being most preferred.
[0193] Once the position and size of an Fc deletion variant is designed, the entire polypeptide sequence is completely determined and the polypeptide may be constructed by methods known in the art.
[0194] Fc insertion variants, however, have the additional step of designing the sequence of the at least one amino acid to be inserted. Insertions of polar residues, including Ser, Thr, Asn, Gln, Ala, Gly, His, are preferred at positions expected to be exposed in the Fc polypeptide. The smaller amino acids, including Ser, Thr, and Ala, are particularly preferred as the small size is less likely to sterically interfere with the Fc/Fc-binding partner interactions. Ser and Thr also have the capability to hydrogen bond with atoms on the Fc-binding partner.
[0195] Insertions also have the added flexibility that the inserted polypeptide may be designed to make favorable interactions with the Fc-binding partner as would be desire when stronger Fc/Fc-binding partner binding is desired. The length of the backbone insertion may be determined by modeling the variant backbone with a simple, generic sequence to be inserted. For example, polyserine, polyglycine or polyalanine insertions of different lengths may be constructed and modeled. Modeling may be done by a variety of methods, including homology modeling based on known three-dimensional structures of homologues comprising the insertion, and by computer modeling including MODELLER (M. A. Marti-Renom et al. Annu. Rev. Biophys. Biomol. Struct. 29, 291-325, 2000) and ROSETTA (Kuhlman et al. (2003). Science 302, 1364-8), both entirely incorporated by reference. Typically, various backbone conformations are initially generated and the final backbone structure may be determined after the identities of the side chain are established. The side chains may be designed by FDA.RTM. algorithms (U.S. Pat. Nos. 6,188,965; 6,269,312; 6,403,312; 6,801,861; 6,804,611; 6,792,356, 6,950,754, and U.S. Ser. Nos. 09/782,004; 09/927,790; 10/101,499; 10/666,307; 10/666311; 10/218,102, all entirely incorporated by reference).
[0196] Insertions and deletions may be made to alter the binding of Fc polypeptides to FcgammaR in an analogous manner to the described method to alter FcRn-binding properties. Fc domains bind to the FcgammaR at the position indicated in FIG. 1. Structures of the Fc/FcgammaR complex, including PDB codes 1T89 and 1IIS (Radaev S et al. J. Biol. Chem. v276, p.16469-16477 entirely incorporated by reference), demonstrate the interacting residues and loops between the two structures. Mutagenesis results such as those found in U.S. Ser. No. 11/124620 and U.S. Pat. No. 6,737,056, both entirely incorporated by reference) all have utility in determined appropriate shifts of backbone positioning.
[0197] Insertions and deletions may be designed in any polypeptide besides Fc polypeptides by the methods described herein. For example, insertions or deletions in the TNF superfamily member, APRIL, may be designed with the aid of its three-dimensional structure (PDB code 1XU1.pdb, Hymowitz, et al. (2005) J. Biol. Chem. 280:7218, entirely incorporated by reference). Insertions or deletions may be designed to increase APRIL binding to its receptor, TACI. The loop residues preferred as insertion or deletion sites are residues Ser118-Va1124, Asp164-Phe167, Pro192-Ala198, Pro221-Lys226. These loops interact with TACI in the APRIL/TACI complex and mediate binding.
[0198] Polypeptides Incorporating Variants
[0199] The IgG variants can be based on human IgG sequences, and thus human IgG sequences are used as the "base" sequences against which other sequences are compared, including but not limited to sequences from other organisms, for example rodent and primate sequences. IgG variants may also comprise sequences from other immunoglobulin classes such as IgA, IgE, IgD, IgM, and the like. It is contemplated that, although the IgG variants are engineered in the context of one parent IgG, the variants may be engineered in or "transferred" to the context of another, second parent IgG. This is done by determining the "equivalent" or "corresponding" residues and substitutions between the first and second IgG, typically based on sequence or structural homology between the sequences of the IgGs. In order to establish homology, the amino acid sequence of a first IgG outlined herein is directly compared to the sequence of a second IgG. After aligning the sequences, using one or more of the homology alignment programs known in the art (for example using conserved residues as between species), allowing for necessary insertions and deletions in order to maintain alignment (i.e., avoiding the elimination of conserved residues through arbitrary deletion and insertion), the residues equivalent to particular amino acids in the primary sequence of the first IgG variant are defined. Alignment of conserved residues preferably should conserve 100% of such residues. However, alignment of greater than 75% or as little as 50% of conserved residues is also adequate to define equivalent residues. Equivalent residues may also be defined by determining structural homology between a first and second IgG that is at the level of tertiary structure for IgGs whose structures have been determined. In this case, equivalent residues are defined as those for which the atomic coordinates of two or more of the main chain atoms of a particular amino acid residue of the parent or precursor (N on N, CA on CA, C on C and O on O) are within 0.13 nm and preferably 0.1 nm after alignment. Alignment is achieved after the best model has been oriented and positioned to give the maximum overlap of atomic coordinates of non-hydrogen protein atoms of the proteins. Regardless of how equivalent or corresponding residues are determined, and regardless of the identity of the parent IgG in which the IgGs are made, what is meant to be conveyed is that the IgG variants discovered by can be engineered into any second parent IgG that has significant sequence or structural homology with the IgG variant. Thus for example, if a variant antibody is generated wherein the parent antibody is human IgG1, by using the methods described above or other methods for determining equivalent residues, the variant antibody may be engineered in another IgG1 parent antibody that binds a different antigen, a human IgG2 parent antibody, a human IgA parent antibody, a mouse IgG2a or IgG2b parent antibody, and the like. Again, as described above, the context of the parent IgG variant does not affect the ability to transfer the IgG variants to other parent IgGs.
[0200] Methods for engineering, producing, and screening IgG variants are provided. The described methods are not meant to constrain to any particular application or theory of operation. Rather, the provided methods are meant to illustrate generally that one or more IgG variants may be engineered, produced, and screened experimentally to obtain IgG variants with optimized effector function. A variety of methods are described for designing, producing, and testing antibody and protein variants in U.S. Ser. No. 10/754,296, and U.S. Ser. No. 10/672,280, both entirely incorporated by reference.
[0201] A variety of protein engineering methods may be used to design IgG variants with optimized effector function. In one embodiment, a structure-based engineering method may be used, wherein available structural information is used to guide substitutions, insertions or deletions. In a preferred embodiment, a computational screening method may be used, wherein substitutions are designed based on their energetic fitness in computational calculations. See for example U.S. Ser. No. 10/754,296 and U.S. Ser. No. 10/672,280, and references cited therein, all entirely incorporated by reference.
[0202] An alignment of sequences may be used to guide substitutions at the identified positions. One skilled in the art will appreciate that the use of sequence information may curb the introduction of substitutions that are potentially deleterious to protein structure. The source of the sequences may vary widely, and include one or more of the known databases, including but not limited to the Kabat database (Northwestern University); Johnson & Wu, 2001, Nucleic Acids Res. 29:205-206; Johnson & Wu, 2000, Nucleic Acids Res. 28:214-218), the IMGT database (IMGT, the international ImMunoGeneTics information system.RTM.; Lefranc et al., 1999, Nucleic Acids Res. 27:209-212; Ruiz et al., 2000 Nucleic Acids Res. 28:219-221; Lefranc et al., 2001, Nucleic Acids Res. 29:207-209; Lefranc et al., 2003, Nucleic Acids Res. 31:307-310), and VBASE, all entirely incorporated by reference. Antibody sequence information can be obtained, compiled, and/or generated from sequence alignments of germline sequences or sequences of naturally occurring antibodies from any organism, including but not limited to mammals. One skilled in the art will appreciate that the use of sequences that are human or substantially human may further have the advantage of being less immunogenic when administered to a human. Other databases which are more general nucleic acid or protein databases, i.e. not particular to antibodies, include but are not limited to SwissProt, GenBank Entrez, and EMBL Nucleotide Sequence Database. Aligned sequences can include VH, VL, CH, and/or CL sequences. There are numerous sequence-based alignment programs and methods known in the art, and all of these find use in the generation of sequence alignments.
[0203] Alternatively, random or semi-random mutagenesis methods may be used to make amino acid modifications at the desired positions. In these cases positions are chosen randomly, or amino acid changes are made using simplistic rules. For example all residues may be mutated to alanine, referred to as alanine scanning. Such methods may be coupled with more sophisticated engineering approaches that employ selection methods to screen higher levels of sequence diversity. As is well known in the art, there are a variety of selection technologies that may be used for such approaches, including, for example, display technologies such as phage display, ribosome display, cell surface display, and the like, as described below.
[0204] Methods for production and screening of IgG variants are well known in the art. General methods for antibody molecular biology, expression, purification, and screening are described in Antibody Engineering, edited by Duebel & Kontermann, Springer-Verlag, Heidelberg, 2001; and Hayhurst & Georgiou, 2001, Curr Opin Chem Biol 5:683-689; Maynard & Georgiou, 2000, Annu Rev Biomed Eng 2:339-76. Also see the methods described in U.S. Ser. Nos. 10/754,296; 10/672,280; and 10/822,231; and 11/124,620, all entirely incorporated by reference. Preferred variants of the present invention include those found in FIGS. 8a-8b. Alternatively preferred variants of the present invention include those found in FIGS. 9a-9b. Additionally alternatively preferred variants of the present invention include those found in FIGS. 10a-10b. These variants have shown increased binding to the Fc receptor, FcRn, as illustrated in the examples.
[0205] Making IgG Variants
[0206] The IgG variants can be made by any method known in the art. In one embodiment, the IgG variant sequences are used to create nucleic acids that encode the member sequences, and that may then be cloned into host cells, expressed and assayed, if desired. These practices are carried out using well-known procedures, and a variety of methods that may find use in are described in Molecular Cloning--A Laboratory Manual, 3.sup.rd Ed. (Maniatis, Cold Spring Harbor Laboratory Press, New York, 2001), and Current Protocols in Molecular Biology (John Wiley & Sons), both entirely incorporated by reference. The nucleic acids that encode the IgG variants may be incorporated into an expression vector in order to express the protein. Expression vectors typically include a protein operably linked, that is, placed in a functional relationship, with control or regulatory sequences, selectable markers, any fusion partners, and/or additional elements. The IgG variants may be produced by culturing a host cell transformed with nucleic acid, preferably an expression vector, containing nucleic acid encoding the IgG variants, under the appropriate conditions to induce or cause expression of the protein. A wide variety of appropriate host cells may be used, including but not limited to mammalian cells, bacteria, insect cells, and yeast. For example, a variety of cell lines that may find use are described in the ATCC cell line catalog, available from the American Type Culture Collection, entirely incorporated by reference. The methods of introducing exogenous nucleic acid into host cells are well known in the art, and will vary with the host cell used.
[0207] In a preferred embodiment, IgG variants are purified or isolated after expression. Antibodies may be isolated or purified in a variety of ways known to those skilled in the art. Standard purification methods include chromatographic techniques, electrophoretic, immunological, precipitation, dialysis, filtration, concentration, and chromatofocusing techniques. As is well known in the art, a variety of natural proteins bind antibodies, for example bacterial proteins A, G, and L, and these proteins may find use in purification. Often, purification may be enabled by a particular fusion partner. For example, proteins may be purified using glutathione resin if a GST fusion is employed, Ni.sup.+2 affinity chromatography if a His-tag is employed, or immobilized anti-flag antibody if a flag-tag is used. For general guidance in suitable purification techniques, see Antibody Purification: Principles and Practice, 3.sup.rd Ed., Scopes, Springer-Verlag, NY, 1994, entirely incorporated by reference.
[0208] Screening IgG Variants
[0209] Fc variants may be screened using a variety of methods, including but not limited to those that use in vitro assays, in vivo and cell-based assays, and selection technologies. Automation and high-throughput screening technologies may be utilized in the screening procedures. Screening may employ the use of a fusion partner or label, for example an immune label, isotopic label, or small molecule label such as a fluorescent or colorimetric dye.
[0210] In a preferred embodiment, the functional and/or biophysical properties of Fc variants are screened in an in vitro assay. In a preferred embodiment, the protein is screened for functionality, for example its ability to catalyze a reaction or its binding affinity to its target.
[0211] As is known in the art, subsets of screening methods are those that select for favorable members of a library. The methods are herein referred to as "selection methods", and these methods find use in the present invention for screening Fc variants. When protein libraries are screened using a selection method, only those members of a library that are favorable, that is which meet some selection criteria, are propagated, isolated, and/or observed. A variety of selection methods are known in the art that may find use in the present invention for screening protein libraries. Other selection methods that may find use in the present invention include methods that do not rely on display, such as in vivo methods. A subset of selection methods referred to as "directed evolution" methods are those that include the mating or breading of favorable sequences during selection, sometimes with the incorporation of new mutations.
[0212] In a preferred embodiment, Fc variants are screened using one or more cell-based or in vivo assays. For such assays, purified or unpurified proteins are typically added exogenously such that cells are exposed to individual variants or pools of variants belonging to a library. These assays are typically, but not always, based on the function of the Fc polypeptide; that is, the ability of the Fc polypeptide to bind to its target and mediate some biochemical event, for example effector function, ligand/receptor binding inhibition, apoptosis, and the like. Such assays often involve monitoring the response of cells to the IgG, for example cell survival, cell death, change in cellular morphology, or transcriptional activation such as cellular expression of a natural gene or reporter gene. For example, such assays may measure the ability of Fc variants to elicit ADCC, ADCP, or CDC. For some assays additional cells or components, that is in addition to the target cells, may need to be added, for example example serum complement, or effector cells such as peripheral blood monocytes (PBMCs), NK cells, macrophages, and the like. Such additional cells may be from any organism, preferably humans, mice, rat, rabbit, and monkey. Antibodies may cause apoptosis of certain cell lines expressing the target, or they may mediate attack on target cells by immune cells which have been added to the assay. Methods for monitoring cell death or viability are known in the art, and include the use of dyes, immunochemical, cytochemical, and radioactive reagents. Transcriptional activation may also serve as a method for assaying function in cell-based assays. Alternatively, cell-based screens are performed using cells that have been transformed or transfected with nucleic acids encoding the variants. That is, Fc variants are not added exogenously to the cells.
[0213] The biological properties of the IgG variants may be characterized in cell, tissue, and whole organism experiments. As is known in the art, drugs are often tested in animals, including but not limited to mice, rats, rabbits, dogs, cats, pigs, and monkeys, in order to measure a drug's efficacy for treatment against a disease or disease model, or to measure a drug's pharmacokinetics, toxicity, and other properties. The animals may be referred to as disease models. Therapeutics are often tested in mice, including but not limited to nude mice, SCID mice, xenograft mice, and transgenic mice (including knockins and knockouts). Such experimentation may provide meaningful data for determination of the potential of the protein to be used as a therapeutic. Any organism, preferably mammals, may be used for testing. For example because of their genetic similarity to humans, monkeys can be suitable therapeutic models, and thus may be used to test the efficacy, toxicity, pharmacokinetics, or other property of the IgGs. Tests of the in humans are ultimately required for approval as drugs, and thus of course these experiments are contemplated. Thus the IgGs may be tested in humans to determine their therapeutic efficacy, toxicity, immunogenicity, pharmacokinetics, and/or other clinical properties.
[0214] Methods of Using IgG Variants
[0215] The IgG variants may find use in a wide range of products. In one embodiment the IgG variant is a therapeutic, a diagnostic, or a research reagent, preferably a therapeutic. The IgG variant may find use in an antibody composition that is monoclonal or polyclonal. In a preferred embodiment, the IgG variants are used to kill target cells that bear the target antigen, for example cancer cells. In an alternate embodiment, the IgG variants are used to block, antagonize or agonize the target antigen, for example for antagonizing a cytokine or cytokine receptor. In an alternately preferred embodiment, the IgG variants are used to block, antagonize or agonize the target antigen and kill the target cells that bear the target antigen.
[0216] The IgG variants may be used for various therapeutic purposes. In a preferred embodiment, an antibody comprising the IgG variant is administered to a patient to treat an antibody-related disorder. A "patient" for the purposes includes humans and other animals, preferably mammals and most preferably humans. By "antibody related disorder" or "antibody responsive disorder" or "condition" or "disease" herein are meant a disorder that may be ameliorated by the administration of a pharmaceutical composition comprising an IgG variant. Antibody related disorders include but are not limited to autoimmune diseases, immunological diseases, infectious diseases, inflammatory diseases, neurological diseases, and oncological and neoplastic diseases including cancer. By "cancer" and "cancerous" herein refer to or describe the physiological condition in mammals that is typically characterized by unregulated cell growth. Examples of cancer include but are not limited to carcinoma, lymphoma, blastoma, sarcoma (including liposarcoma), neuroendocrine tumors, mesothelioma, schwanoma, meningioma, adenocarcinoma, melanoma, and leukemia and lymphoid malignancies.
[0217] In one embodiment, an IgG variant is the only therapeutically active agent administered to a patient. Alternatively, the IgG variant is administered in combination with one or more other therapeutic agents, including but not limited to cytotoxic agents, chemotherapeutic agents, cytokines, growth inhibitory agents, anti-hormonal agents, kinase inhibitors, anti-angiogenic agents, cardioprotectants, or other therapeutic agents. The IgG varariants may be administered concomitantly with one or more other therapeutic regimens. For example, an IgG variant may be administered to the patient along with chemotherapy, radiation therapy, or both chemotherapy and radiation therapy. In one embodiment, the IgG variant may be administered in conjunction with one or more antibodies, which may or may not be an IgG variant. In accordance with another embodiment, the IgG variant and one or more other anti-cancer therapies are employed to treat cancer cells ex vivo. It is contemplated that such ex vivo treatment may be useful in bone marrow transplantation and particularly, autologous bone marrow transplantation. It is of course contemplated that the IgG variants can be employed in combination with still other therapeutic techniques such as surgery.
[0218] A variety of other therapeutic agents may find use for administration with the IgG variants. In one embodiment, the IgG is administered with an anti-angiogenic agent. By "anti-angiogenic agent" as used herein is meant a compound that blocks, or interferes to some degree, the development of blood vessels. The anti-angiogenic factor may, for instance, be a small molecule or a protein, for example an antibody, Fc fusion, or cytokine, that binds to a growth factor or growth factor receptor involved in promoting angiogenesis. The preferred anti-angiogenic factor herein is an antibody that binds to Vascular Endothelial Growth Factor (VEGF). In an alternate embodiment, the IgG is administered with a therapeutic agent that induces or enhances adaptive immune response, for example an antibody that targets CTLA-4. In an alternate embodiment, the IgG is administered with a tyrosine kinase inhibitor. By "tyrosine kinase inhibitor" as used herein is meant a molecule that inhibits to some extent tyrosine kinase activity of a tyrosine kinase. In an alternate embodiment, the IgG variants are administered with a cytokine.
[0219] Pharmaceutical compositions are contemplated wherein an IgG variant and one or more therapeutically active agents are formulated. Formulations of the IgG variants are prepared for storage by mixing the IgG having the desired degree of purity with optional pharmaceutically acceptable carriers, excipients or stabilizers (Remington's Pharmaceutical Sciences 16th edition, Osol, A. Ed., 1980, entirely incorporated by reference), in the form of lyophilized formulations or aqueous solutions. The formulations to be used for in vivo administration are preferably sterile. This is readily accomplished by filtration through sterile filtration membranes or other methods. The IgG variants and other therapeutically active agents disclosed herein may also be formulated as immunoliposomes, and/or entrapped in microcapsules.
[0220] The concentration of the therapeutically active IgG variant in the formulation may vary from about 0.1 to 100% by weight. In a preferred embodiment, the concentration of the IgG is in the range of 0.003 to 1.0 molar. In order to treat a patient, a therapeutically effective dose of the IgG variant may be administered. By "therapeutically effective dose" herein is meant a dose that produces the effects for which it is administered. The exact dose will depend on the purpose of the treatment, and will be ascertainable by one skilled in the art using known techniques. Dosages may range from 0.01 to 100 mg/kg of body weight or greater, for example 0.01, 0.1, 1.0, 10, or 50 mg/kg of body weight, with 1 to 10mg/kg being preferred. As is known in the art, adjustments for protein degradation, systemic versus localized delivery, and rate of new protease synthesis, as well as the age, body weight, general health, sex, diet, time of administration, drug interaction and the severity of the condition may be necessary, and will be ascertainable with routine experimentation by those skilled in the art.
[0221] Administration of the pharmaceutical composition comprising an IgG variant, preferably in the form of a sterile aqueous solution, may be done in a variety of ways, including, but not limited to, orally, subcutaneously, intravenously, parenterally, intranasally, intraotically, intraocularly, rectally, vaginally, transdermally, topically (e.g., gels, salves, lotions, creams, etc.), intraperitoneally, intramuscularly, intrapulmonary (e.g., AERx.RTM. inhalable technology commercially available from Aradigm, or Inhance.RTM. pulmonary delivery system commercially available from Nektar Therapeutics, etc.). Therapeutic described herein may be administered with other therapeutics concomitantly, i.e., the therapeutics described herein may be co-administered with other therapies or therapeutics, including for example, small molecules, other biologicals, radiation therapy, surgery, etc.
EXAMPLES
[0222] Examples are provided below to illustrate the present invention. These examples are not meant to constrain the present invention to any particular application or theory of operation. For all positions discussed in the present invention, numbering is according to the EU index as in Kabat (Kabat et al., 1991, Sequences of Proteins of Immunological Interest, 5th Ed., United States Public Health Service, National Institutes of Health, Bethesda, entirely incorporated by reference). Those skilled in the art of antibodies will appreciate that this convention consists of nonsequential numbering in specific regions of an immunoglobulin sequence, enabling a normalized reference to conserved positions in immunoglobulin families. Accordingly, the positions of any given immunoglobulin as defined by the EU index will not necessarily correspond to its sequential sequence.
Example 1: DNA Construction, Expression, and Purification of Fc Variants
[0223] Fc variants were constructed using the human IgG1 Fc domain and the variable domain of trastuzumab (Herceptin.RTM., Genentech). The Fc polypeptides were part of Alemtuzumab, An anti-HER2 antibody or AC10. Alemtuzumab (Campath.RTM., a registered trademark of Millenium) is a humanized monoclonal antibody currently approved for treatment of B-cell chronic lymphocytic leukemia (Hale et al., 1990, Tissue Antigens 35:118-127, entirely incorporated by reference). Trastuzumab (Herceptin.RTM., a registered trademark of Genentech) is an anti-HER2/neu antibody for treatment of metastatic breast cancer. The heavy and light chain sequences of the anti-HER2 antibody are shown in FIG. 22. AC10 is an anti-CD30 monoclonal antibody. The Herceptin variable region was assembled using recursive PCR. This variable region was then cloned with human IgG1 into the pcDNA3.1/Zeo(+) vector (Invitrogen), shown in FIG. 11. Plasmids were propagated in One Shot TOP10 E. coli cells (Invitrogen) and purified using the Hi-Speed Plasmid Maxi Kit (Qiagen). Plasmids were sequenced to verify the presence of the cloned inserts.
[0224] Site-directed mutagenesis was done using the Quikchange.TM. method (Stratagene). Plasmids containing the desired substitutions, insertions, and deletions were propagated in One Shot TOP10 E. coli cells (Invitrogen) and purified using the Hi-Speed Plasmid Maxi Kit (Qiagen). DNA was sequenced to confirm the fidelity of the sequences.
[0225] Plasmids containing heavy chain gene (VH-C.gamma.1-C.gamma.2-C.gamma.3) (wild-type or variants) were co-transfected with plasmid containing light chain gene (VL-C.eta.) into 293T cells. Media were harvested 5 days after transfection, and antibodies were purified from the supernatant using protein A affinity chromatography (Pierce). Protein A binding characteristics of some modified Fc's are shown in FIG. 26. Antibody concentrations were determined by bicinchoninic acid (BCA) assay (Pierce).
Example 2: Binding Affinity Measurements
[0226] Binding of Fc polypeptides to Fc ligands was assayed with surface plasmon resonance measurements. Surface plasmon resonance (SPR) measurements were performed using a BIAcore 3000 instrument (BlAcore AB). Wild-type or variant antibody was captured using immobilized protein L (Pierce Biotechnology, Rockford, Ill.), and binding to receptor analyte was measured. Protein L was covalently coupled to a CM5 sensor chip at a concentration of 1 uM in 10 mM sodium acetate, pH 4.5 on a CM5 sensor chip using N-hydroxysuccinimide/N-ethyl-N'-(-3-dimethylamino-propyl) carbodiimide (NHS/EDC) at a flow rate of 5 ul/min. Flow cell 1 of every sensor chip was mocked with NHS/EDC as a negative control of binding. Running buffer was 0.01 M HEPES pH 7.4, 0.15 M NaCl, 3 mM EDTA, 0.005% v/v Surfactant P20 (HBS-EP, Biacore, Uppsala, Sweden), and chip regeneration buffer was 10 mM glycine-HCl pH 1.5. 125 nM Wild-type or variant anti-HER2 antibody was bound to the protein L CM5 chip in HBS-EP at 1 ul/min for 5 minutes. FcRn-His-GST analyte, a FcRn fused to a His-tag and glutathione S transferase, in serial dilutions between 1 and 250 nM, were injected for 20 minutes association, 10 minutes dissociation, in HBS-EP at 10 ul/min. Response, measured in resonance units (RU), was acquired at 1200 seconds after receptor injection, reflecting near steady state binding. A cycle with antibody and buffer only provided baseline response. RU versus 1/log concentration plots were generated and fit to a sigmoidal dose response using nonlinear regression with GraphPad Prism.
[0227] Binding of Fc polypeptides to Fc ligands was also done with AlphaScreen.TM. (Amplified Luminescent Proximity Homogeneous Assay). AlphaScreen.TM. is a bead-based non-radioactive luminescent proximity assay. Laser excitation of a donor bead excites oxygen, which if sufficiently close to the acceptor bead will generate a cascade of chemiluminescent events, ultimately leading to fluorescence emission at 520-620 nm. The principal advantage of the AlphaScreen.TM. is its sensitivity. Because one donor bead emits up to 60,000 excited oxygen molecules per second, signal amplification is extremely high, allowing detection down to attomolar (10.sup.-18) levels. Wild-type antibody was biotinylated by standard methods for attachment to streptavidin donor beads, and tagged Fc ligand, for example FcRn, FcgammaR or Protein A, was bound to glutathione chelate acceptor beads. The AlphaScreen.TM. was applied as a direct binding assay in which the Fc/Fc ligand interactions bring together the donor and acceptor beads to create the measured signal. Addtionally, the AlphaScreen.TM. was applied as a competition assay for screening designed Fc polypeptides. In the absence of competing Fc polypeptides, wild-type antibody and FcRn interact and produce a signal at 520-620 nm. Untagged Fc domains compete with wild-type Fc/FcRn interaction, reducing fluorescence quantitatively to enable determination of relative binding affinities.
Example 3: FcRn-Binding Properties of Fc Variants
[0228] Binding affinity of IgG1 Fc to FcRn was measured with variant antibodies using AlphaScreen.TM.. The Fc polypeptides were part of Alemtuzumab or Trastuzumab. Alemtuzumab (Campath.RTM., Ilex) is a humanized monoclonal antibody currently approved for treatment of B-cell chronic lymphocytic leukemia (Hale et al., 1990, Tissue Antigens 35:118-127, entirely incorporated by reference). Trastuzumab (Herceptin.RTM., Genentech) is an anti-HER2/neu antibody for treatment of metastatic breast cancer.
[0229] Competitive AlphaScreen.TM. data were collected to measure the relative binding of the Fc variants compared to the wild-type antibody in 0.1 M sodium phosphate pH6.0 with 25 mM sodium chloride. Examples of the AlphaScreen.TM. signal as a function of competitor antibody are shown in FIGS. 12a-12b. The 12 variant curves shown, those of P257L, P257N, V279E, V279Q, V279Y, {circumflex over ( )}281S, E283F, V284E, L306Y, T307V, V308F, and Q311V, demonstrate increased affinity as each variant curve is shifted to the left of the wild-type curve in their box. Competition AphaScreen.TM. data for Fc variants of the present invention are summarized in FIGS. 13a-13j and 14a-14d. Additional competition AlphaScreen.TM. data in 0.1M sodium phosphate pH 6.0 with 125 mM sodium chloride are summarized in FIGS. 21a-21b. The relative FcRn binding of the variant compared to wild type are listed. Values greater than one demonstrate improved binding of the Fc variant to FcRn compared to the wild type. For example, the variant E283L and V284E have 9.5-fold and 26-fold stronger binding than the wild type, respectively. Surface plasmon resonance measurements of many variants also show increased binding to FcRn as shown in FIGS. 15 and 16a-16b.
[0230] At position 257, all variants that remove the imino acid, proline, and substitute an amino acid without the backbone N to side chain covalent bond, allow the backbone more flexibility which allows more freedom for the Fc domain to better bind FcRn. In particular, variants at position 257 to L and N have strong FcRn binding at pH 6, demonstrating that the four atom side chain and gamma branching pattern of the side chain helps the Fc domain make productive, ie strong, FcRn interactions. Position 308 interacts with position 257. Both of these positions in turn interact with H310, which is directly involved in the Fc/FcRn interactions (Table 2, Burmeister et al (1994) Nature 372:379-383, entirely incorporated by reference). The Fc variants V308F and V08Y have a 2.9-fold and 4.3-fold increase in FcRn affinity over wild type (FIGS. 13a-13j). Positions 279 and 385 interact with FcRn as variants V279E, V279Q and V279Y and G385H and G385N all have stronger FcRn interactions. These variants all are to amino acids that are capable of hydrogen bonding. Sequences of the Fc regions of human IgG1 comprising various modifications of the present invention are shown in FIG. 23.
[0231] The Fc variant N434Y has particularly strong binding to FcRn at pH 6.0 as shown in FIG. 13a-13j. The single variant N434Y has 16-fold increased binding. Combinations of this variant with other modifications led to even stronger binding. For example, P257L/N434Y, {circumflex over ( )}281S/N434Y, and V308F/N434Y show 830-fold, 180-fold, and 350-fold increases in FcRn binding.
Example 4: Variants Incorporating Insertions and Deletions
[0232] Insertions and deletions that alter the strength of Fc/FcRn interactions were constructed and their binding properties to various Fc ligands were measured. An Fc variant with an inserted Ser residue between residues 281 and 282, using the EU numbering of Kabat et al, was designed to increase the FcRn binding properties of the Fc domain. This variant is referred to as {circumflex over ( )}2815 with "{circumflex over ( )}" meaning an insertion following the position given. AlphaScreen.TM. data showing the improved binding of {circumflex over ( )}281S is shown in FIGS. 12b and 21a. The inserted sequence, which may be more than one residue, is given after the position number. This Fc variant was constructed in the kappa, IgG1 anti-HER2 antibody trastuzumab (Herceptin.RTM., Genetech) using methods disclosed herein. An insertion at the site between residues 281 and 282 shifts the Fc loop residues C-terminal of residue 281 toward the C-terminus of the loop and alters the side chain positioning. Fc variants comprising substitutions at positions 282, 283, and 284 suggested that the C-terminal shift of this loop was beneficial (See FIGS. 14a-14d). Another variant, a deletion of N286, sometimes referred to as N286#, was also constructed to shift the position of this FcRn-binding loop. This variant shows increased binding to FcRn at pH6.0 (FIG. 14b).
[0233] The AlphaScreen.TM. data shows the binding of the {circumflex over ( )}281S variant and other variants to FcRn. This AlphaScreen.TM. data was collected as a direct binding assay. Higher levels of chemiluminescent signals demonstrate stronger binding. As the concentrations of the variants are raised in the assay, stronger signals are created. These data at pH 6.0, in FIGS. 17a and 17b, demonstrate the increased affinity of {circumflex over ( )}281S, P257L, P257L/{circumflex over ( )}281S (a combination substitution/insertion variant) and other variants over the wild-type Fc. Also shown is a double substitution, T250Q/M428L, shown previously to have an increased serum half in monkeys (Hinton et al., 2004, J. Biol. Chem. 279(8): 6213-6216, entirely incorporated by reference). The insertion, {circumflex over ( )}281S, alone increases the Fc/FcRn binding. Additionally, {circumflex over ( )}281S further increases the binding of P257L when the two modifications are combined in the variant P257L/{circumflex over ( )}281S as shown in the .about.40 nM data points. The data in FIG. 17c demonstrate that these variants do not show increased FcRn binding at pH 7.0. The reduced affinity at pH 7.0 is desired for increased half-life in vivo, because it allows the release of Fc polypeptides from FcRn into the extracellular space, an important step in Fc recycling.
[0234] Surface plasmon resonance experiments also demonstrate the improved binding of {circumflex over ( )}281S to FcRn. FIG. 18 shows the response units created as various Fc variant binding to FcRn on the chip surface. After allowing the variant to fully bind to the chip, the response units are recorded and shown on the ordinate. The insertion, {circumflex over ( )}281S shows binding properties comparable to other variants shown herein to have increased affinity for FcRn over the wild type (See FIGS. 13a-13j, 14a-14d and 15, for examples).
[0235] The deletion variant comprising a deletion of N286, N286#, also shows increased affinity for FcRn over wild type. This variant has a 2.0-fold increase in FcRn affinity as shown in FIG. 13a-13j. The data therein are also AlphaScreen.TM. data collected as a competition experiment at pH 6.0. The variants are used to inhibit the binding of wild-type Fc, linked to the donor bead, with FcRn, linked to the acceptor beads. Two-fold less free N286# was needed than free wild-type Fc to inhibit the binding of the donor/acceptor beads through the Fc/FcRn complex. This demonstrates the 2-fold tighter binding of N286# over the wild type.
[0236] Other Fc variants comprising insertions or deletions have decreased affinity for FcRn. The insertion variant, {circumflex over ( )}254N has greatly decreased FcRn binding as would be expected from the nature and positioning of the variant. This variant places the insertion, an Asn, in the middle of an FcRn binding loop. This insertion has only 1.1% of the binding of the binding affinity of the wild type (FIGS. 13a-13j).
Example 5: Combination Variants with Altered FcRn and FcgammaR Characteristics
[0237] As shown in FIG. 13b for the anti-HER2 antibody, the Fc variant P257L has increased affinity for FcRn relative to VVT. P257L gave a median of 2.6-fold increase in FcRn affinity for human FcRn, pH 6.0 in phosphate buffer with 25 mM NaCl added. The addition of 1332E or S239D/I332E to the P257L variant yielded double and triple variants, P257L/I332E and S239D/P257L/I332E, which retain the increased affinity for FcRn. The variant S239D/I332E has essentially un-altered FcRn binding compared to wild type as shown in the AlphaScreen.TM. assays in FIG. 14b. These double and triple variants had a 5- and 4-fold increased affinity. The I332E and S239D/I332E variants have improved binding to FcgammaR, in particular to FcgammaRIIIa (See U.S. Ser. No. 11/124,620, entirely incorporated by reference). The FcgammaR-binding properties of some variants of the present invention are shown in FIG. 25. The protein A binding properties of some variant of the present invention are shown in FIG. 26. Protein A binding is frequently used during purification of Fc-containing proteins. The substitution V308F also improves FcRn binding at pH 6.0 (FIG. 13e). V308F has 3-fold increased affinity as a single substitution in the anti-HER2 antibody trastuzumab (Herceptin.TM., Genentech) and also has increased affinity when combined with substitutions that increase FcgammaR binding, such as I332E, S239D/I332E, and S298A/E333A/K334A (Lazar et al. 2006 Proc. Nat. Acad. Sci USA. 103(111):4005-4010, Shields et al. 2001 J. Biol. Chem. 276:6591-6604, both entirely incorporated by reference.) The increased FcRn binding of G385H is also maintained when combined with FcgammaR improving substitutions, especially in the triple-substitution variant S239D/I332E/G385H.
[0238] Variants with increased binding to FcRn may be combined with variants that reduce or knock-out binding to FcgammaR and the complement protein, C1q. The improved binding to FcRn increases the effect from a protecting receptor allowing for improved half-life. Fc containing proteins may also be taken into cells and metabolized through their interaction with the FcgammaR and the C1q protein. If the Fc/FcgammaR and Fc/C1q protein interactions are not required for antibody efficacy, deletions of these interactions may be made. Deletions of these interactions may also decrease the effect of a degrading receptor, thereby also allowing for improved half-life. In particular the variants 234G, 235G, 236R, 237K, 267R, 269R, 325A, 325L, and 328R (U.S. Ser. No. 11/396,495 entirely incorporated by reference) may be combined with FcRn-improving variants to create variants with increased FcRn affinity and decreased FcgammaR or C1q affinity. These variants include 235G/257C, 325A/385H, 325A/257L, 234G/308F, 234G/434Y, and 269R/308F/311V. These variants may be made in Fc domains from IgG1, although reduced interactions with the FcgammaR or C1q may also be achieved by placing these mutations into proteins comprising Fc domains from IgG2, IgG4, or IgG3. Putting FcRn modifications, such as 257N, 257L, 257M, 308F, 311V into IgG2 allows for a reduction in FcgammaR binding and increased FcRn interactions.
[0239] Variants with decreased binding to FcRn may be combined with variants that have increased FcgammaR or C1q binding. The decreased FcRn binding combined with increased FcgammaR binding may be beneficial for increasing the amount of the Fc-containing protein available to illicit effector functions. Reducing FcRn binding may reduce the amount of the Fc-containing protein that is sequestered by FcRn and thus affect bioavailability. Modifications such as I253V, S254N, S254# (deletion of 254), T255H, and H435N reduce Fc/FcRn binding (FIG. 13a-13j) and may be combined with variants with improved FcgammaR binding such as S239D, I332E, H268E, G236A. The resulting Fc domains, such as those comprising I253V/S239D/I332E, I332E/H435N, or S254N/H268E, have reduced FcRn binding and increased FcgammaR binding.
[0240] Variants with decreased binding to FcRn may be combined with variants with decreased FcgammaR binding. This combination of decreased FcRn and FcgammaR binding is beneficial in applications such as imaging wherein the Fc-containing protein is labeled with a radioactive or toxic tracer. Ideally the half-life of the protein comprising the radioactive tracer is similar to the half-life of the radionuclide itself. This allows clearance of the tracer from the body in the same time as the decay of the radionuclide. The reduced FcgammaR interactions also allow optimal availability of the Fc-containing protein for its target. For example, if the Fc-containing protein is an antibody, then the reduce FcgammaR binding allow more antibody to be assessable to antigen. Combinations of FcRn- and FcgammaR-affecting variants, such as 235G/254N, 236R/435N, 269R/I253V are good for this application.
Example 6: Fc Variants in Antibody OST577 Binding to Human FcRn
[0241] OST577 is an anti-Hepatitis B surface antigen antibody (Ehrlich et al. (1992) Hum. Antibodies Hybridomas 3:2-7, entirely incorporated by reference). Heavy and light chain sequences were taken from the Kabat Database with KADBID 000653 (heavy) and KADBID 007557(light) (Martin AC, Proteins. 1996 May; 25(1):130-3, entirely incorporated by reference). DNA encoding the heavy and light chains were synthesized by Blue Heron Biolotechnology, Bothell, Wash. Wild-type and variant OST577 antibodies were expressed and purified as in the anti-HER2 (trastuzumab) variants in EXAMPLE 1. Biacore.TM. binding assays were performed as in EXAMPLE 2, with a human FcRn/Glutathione D transferase (GST) fusion protein attached to the chip surface. As shown in FIG. 19, Fc variants of the present invention have altered binding to human FcRn. Variants with increased binding adhere more easily to the FcRn on the surface and cause a greater rise in Response Units (RU's). The variants shown with modification in the FcRn-binding region all have increased affinity for FcRn compared to the wild-type protein. These variants include P257L, P257N, V308F, N434Y, P257L/N434Y and P257L/V308F. The variant with the 3.sup.rd most RU's at 975 seconds, T250Q/M428L, has been shown to increase the half life of OST577 antibodies in macaques (Hinton et al. 2004 Journal of Biological Chemistry 279(8):6213-6216, Hinton et al. 2006 Jounal of Immunology 176:346-356, both entirely incorporated by reference). Included in this data set is an antibody with a hybrid IgG1/IgG2 heavy chain constant region containing the substitutions S239D/I332E. As described in EXAMPLE 5, these substitutions increase the antibody affinity for FcgammaR. As shown in FIG. 19, these substitutions do not alter the FcRn-binding properties, as the hybrid S239D/I332E Biacore.TM. traces overlay the wild-type traces containing kappa or lambda CL1 domains.
Example 7: Affinity of Fc Variants for Human, Monkey and Mouse FcRn
[0242] Fc variants in the anti-HER2 antibody trastuzumab were created as described in EXAMPLE 1. Surface plasmon resonance (SPR) traces were collected as described in EXAMPLE 2, except that human, macaque or mouse FcRn was attached to the chip surface. Two SPR curves were collected for each Fc variant with differing amounts of GST-FcRn attached to the surface. Each curve was fit to a 1:1 Langmuir binding model and the two resulting Kd values were averaged to produce a representative value for each variant-receptor pair. The results are presented in FIG. 20 as the fold-improvement in Kd compared to the wild-type trastuzumab. For example, the variant V308F/Q311V has 3.4-fold tigher binding to human FcRn than does the wild type. V308F/Q311V also has 3.7-fold and 5.1-fold tigher binding to monkey and mouse FcRn, respectively. The variant M428L has been shown to increase the antibody half-life (Hinton et al. 2004 Journal of Biological Chemistry 279(8):6213-6216, entirely incorporated by reference) and has a 2.4-, 2.0, and 2.1-fold increased binding to the human, monkey and mouse FcRn's, respectively. Other variants, including P257L, P257N, N434Y, Q311V, V308F, V308F/N434Y, P257L/V308F, and P257L/N434Y, also show increased binding at pH6.0.
Example 8: FcRn Variants in Various Fc Domains
[0243] Variants of the present invention may be incorporated into any constant domain, using the molecular biology and purification techniques described herein, including those in EXAMPLE 1. Amino acid sequences of the IgG1, IgG2, IgG3, and IgG4 constant domains may be used as listed in FIG. 2. In addition, combinations of two or more different constant domains may be used. For example, FIG. 24 lists some of the modifications found in the present invention incorporated into a hybrid of IgG1 and IgG2. This hybrid comprises the IgG2 CH1 domain and the IgG1 CH2 and CH3 domains. IgG3 has a lower half-life in humans compared to IgG1, IgG2, and IgG4 (7 days vs .about.21 days, Janeway, Travers, Walport, Shlomchik. Immunology, 5.sup.th ed. Garland Publishing c2001, FIG. 4-16, incorporated by reference) and is therefore desirable in certain applications.
Example 9: Creation of Variant in an Anti-VEGF Antibody
[0244] Anti-VEGF antibodies with altered binding were produced using the methods described herein, including EXAMPLE 1. The wild type anti-VEGF heavy chain comprises the following sequence of amino acids:
TABLE-US-00001 EVQLVESGGGLVQPGGSLRLSCAASGYTFTNYGMNWVRQAPGKGLEW VGWINTYTGEPTYAADFKRRFTFSLDTSKSTAYLQMNSLRAEDTAVY YCAKYPHYYGSSHWYFDVWGQGTLVTVSSASTKGPSVFPLAPSSKST SGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSL SSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPC PAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFN VVYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCK VSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSR WQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
[0245] The wild-type anti-VEGF light chain comprises the following sequence of amino acids:
TABLE-US-00002 DIQMTQSPSSLSASVGDRVTITCSASQDISNYLNWYQQKPGKAPKVL IYFTSSLHSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYSTV PWTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYP REAKVQWKVDNALQSGNSQESVTEQDSKIDSTYSLSSTLTLSKADYE KHKVYACEVTHQGLSSPVTKSFNRGEC
[0246] Single and combination variants with altered binding include the variants shown in FIG. 28, which shows the variants produced, the volume of culture media used, and the resulting yield of the antibody variants. Numbering for the variants follows the EU index as in Kabat et al. The variants listed in FIG. 28 were produced in either IgG1 or hybrid VH comprising sequences from both IgG1 and IgG2. These variants contain the variable region that binds the antigen VEGF. All proteins were judged to be >90% pure by size exclusion chromatography and SDS gel electrophoresis.
Example 10: In Vivo Half-Life of Antibody Variants
[0247] The pharmacokinetics of wild-type and variant antibodies were studied in mice. The mice used were defiecient in the expression of mouse FcRn (B6-Fcgt.sup.Tm1Dcr mice) and were heterozygous for the knock-in of human FcRn (hFcRn Tg--transgene) as described in Petkova et al. International Immunology 2006 December; 18(12):1759-69. Petkova et al showed that the variant N434A has an increased half-life in these human FcRn knock-in mice, which agrees with earilier results showing that the N434A variant has increased half life in monkeys (U.S. application Ser. No. 11/208,422, publication number US26067930A1). Female mice aged 9-12 weeks were injected intravenously with 2 mg/kg antibody in groups of 6 mice per antibody. Blood samples were collected at 1 hr, and days 1, 4, 8, 11, 15, 18, 21, 25 and 28 from the oribital flexus. The concentration of each antiobody in serum was measured with a sandwich ELISA assay using anti-human Fc antibodies and europium detection.
[0248] The results of the study are shown in FIG. 27, which are representative data of two separate studies. The mean and standard deviation of the mean for the four samples are shown. Clearly, the V308F variant has longer half-life, remaining at measurable concentrations out to 25 days. The VVT and P257L and P257N variants are cleared more quickly, only having measurable concentrations out to 15, 8, and 4 days, respectively. The serum concentrations as a function of time were fit to a non-compartimental model using the software package, WinNonLin (Pharsight Inc). The terminal half-life of the V308F variant was 4.9 days, whereas the terminal half-lives of the VVT and P257L and P257N variants were 3.0, 1.9 and 0.9 days, respectively. The area under the curves (AUC) of the V308F variant was 129 day*ug/ml, whereas those of the VVT and P257L and P257N variants were 70, 38 and 38 day*ug/ml, respectively.
Example 11: FcRn Binding Experiments at pH 6.0
[0249] Anti-VEGF variants of the present invention were tested for their binding ability to human FcRn with Biacore assays as described in EXAMPLE 2 with some modifications. Human FcRn was attached covalently to a CM5 chip in 10 mM sodium acetate, pH 4.5 on using N-hydroxysuccinimide/N-ethyl-N'-(-3-dimethylamino-propyl) carbodiimide (NHS/EDC) at a flow rate of 5 ul/min. The human FcRn used contained GST and HIS tagged version to aid in purification and other assys. Approximately 3300 RU of FcRn was attached to the chip. Flow cell 1 was mocked with NHS/EDC as a negative control of binding. Running buffer was 25 mM phosphate buffer pH6.0, 150 mM NaCl, 3 mM EDTA and 0.005% (v/v) Surfactant P20. Antibodies were washed off the FcRn chip with the same buffer at pH7.4, which quickly removed all variants tested. The biacore association and dissociation traces were fit to a conformational exchange model to calculate an apparent equilibrium binding constant, Kd.
[0250] The results demonstrate that the V308F variant and many other variants have improved binding to FcRn. The wild-type anti-VEGF antibody had a Kd of 18 nM, which differs considerably from the value reported in Dall' Acqua et al (Dall' Acqua et al Journal of Immunology 2002, 169:5171-5180) because of the differences in assay design and data fitting. Our assay format gave reproducible results if the FcRn chip was used soon after creation. The FcRn chip, however, degraded with use, possibly from the dissociation of either the two FcRn chains from the surface. The results demonstrate the altered binding of the variants compared to wild-type anti-VEGF. FIG. 29 shows the fold increase in binding strength relative to the wild-type control. Values greater than one show that the variant antibody has has higher affinity for FcRn than the wild-type protein. The variant V308F, for example, binds FcRn 4.5 fold more tightly than the wild-type antibody. The variant V308F/M428L binds FcRn 12.3 fold more tightly and the variant T307P/V308F binds FcRn 3.16 fold more tightly than the wild-type protein. No variants shown in FIG. 29 have reduced affinity for FcRn compared to the wild-type (values would be less than 1.0). The variant N434S has an FcRn binding affinity 4.4 fold stronger than VVT, comparable to V308F.
Example 12: Binding Experiments to Transmembrane FcRn
[0251] FcRn alpha chain and beta-2-microglobulin cDNA was ordered from OriGene Technologies Inc (Rockville, Md.) and transfected in 293T cells to express functional FcRn on the cell surface. 20 ug Fcgrt and 40 ug of beta-2-microglobulin DNA was transfected with lipofectamine (Invitrogen Inc.) and the cells were allowed to grow for 3 days in DMEM media with 10% ultra low IgG serum. Control cells not transfected with the two FcRn chains were also grown. Varying amounts of anti-VEGF antibodies (WT and variants) were bound to the cells for 30 minutes in 25 mM phosphate buffer pH6.0, 150 mM NaCl, 0.5% BSA and then washed 6-9 times in 25 mM phosphate buffer pH6.0, 150 mM NaCl, 0.5% BSA plus 0.003% igepal. After washing, antibodies were fixed to the surface by treatment with the binding with 1% PFA. Bound antibodies were than detected using a PE tagged Fab'.sub.2 against human Fab domains and the mean fluorescence intensity (MFI) was measured using a BD FACS Canto II. The average of two samples per antibody are presented in FIG. 30. The curve fits to the data in FIG. 30 do not provide interpretable EC50 values because many curves did not form an upper baseline by saturating the cells. The antibodies may be ranked in order of their binding affinity, however, by reporting the log[variant] at which the MFI equals 3000, EC(MFI=3000). Using this metric, the antibodies may be listed from strongest to weakest FcRn affinity as follows: V308F/M428L, V2591/V308F, T2501/V308F, T250Q/M428L, N434S, T307Q/V308F, P257L, T307S/V308F, V308F, T256VN308F, V308F/L309Y, and WT.
Example 13: Characteristics of the Variant, 434S
[0252] Antibodies comprising the modification 434S have particularly favorable properties making them preferred variants of the present invention. In human IgG1, the wild-type residue is an asparagine, Asn, at position 434 so that this variant may be referred to as N434S in the context of IgG1 or other Fc domains which contain Asn, N, at position 434. More generally, this variant may be referred to simply as 434S. Herein, the 434S variant has been produced successfully in both the anti-HER2 antibody trastuzumab and the anti-VEGF antibody.
[0253] The Ser at position 434 has the ability to hydrogen bond with FcRn either directly or indirectly, ie, mediated by water or solute molecules. The gamma oxygen of Ser at position 434 is in the vicinity of the carbonyl oxygen atoms of Gly131 and Pro134 on the FcRn molecule, as shown in FIG. 32. FIG. 32 shows a model of the human Fc domain in complex with human FcRn. The Fc domain in the model comprises the 434S substitution, hence residue 434 is Ser in FIG. 32. The model is created with PDA.RTM. technologies (Dahiyat and Mayo Protein Sci. 1996 May; 5(5):895-903), the crystal structure of the rat Fc domain bound to the rat FcRn (Martin et al. Mol Cell. 2001 April; 7(4):867-77), and Pymol (Delano Scientific). The small size of Ser is easily accomidated in the interface between the two proteins.
[0254] The antibody variant N434S has a 4.4-fold increased binding affinity for FcRn compared to the wild-type antibody as shown by biacore.TM. measurements (FIG. 29). The variant also shows increased binding to cell surface bound FcRn as shown by cell counting measurements (FIG. 30).
[0255] Based on the results shown in FIGS. 29 and 30, preferred variants comprising 434S and other modifications are expected to include V308F/434S, 428L/434S, 252Y/434S, 259I/308F/434S, 250I/308F/434S, and 307Q/308F/434S.
Example 14: Additional Variants
[0256] Additional variants may be based on the data contained herein and in the literature (Dall' Acqua et al Journal of Biological Chemistry 2006 Aug. 18; 281(33):23514-24; Petkova et al. International Immunity 2006 December; 18(12):1759-69; Dall' Acqua et al Journal of Immunology 2002, 169:5171-5180; Hinton et al, Journal of Biological Chemistry 2004 279(8): 6213-6216; Shields et al. Journal of Biological Chemistry 2001 276(9):6591-6604; Hinton et al. Journal of Immunology 2006, 176:346-356, all incorporated by reference). These variants include those found in FIGS. 31a-31b.
[0257] Based on the results in FIGS. 29 and 30 and the results of Dall' Acqua et al (Journal of Biological Chemistry 2006 Aug. 18; 281(33):23514-24, incorporated by reference), preferred variants include Y319L, T307Q, V259I, M252Y, V259I/N434S, M428L/N434S, V308F/N434S, M252Y/S254T/T256E/N434S, M252Y/S254T/T256E/V308F, M252Y/S254T/T256E/M428L, V308F/M428L/N434S, V2591/V308F/N434S, T307Q/V308F/N434S, T250I/V308F/N434S, V308F/Y319L/N434S, V259I/V308F/M428L, V259I/T307Q/V308F, T250I/V259I/V308F, V259I/V308F/Y319L, T307Q/V308F/L309Y, T307Q/V308F/Y319L, and T250Q/V308F/M428L.
[0258] Based on the results in FIGS. 29 and 30 more preferred variants include Y319L, T307Q, V259I, M252Y, V259I/N434S, M428L/N434S, V308F/N434S, V308F/M428L/N434S, V259I/V308F/N434S, T307Q/V308F/N434S, T250I/V308F/N434S, V308F/Y319L/N434S, V259I/V308F/M428L, V259I/T307Q/V308F, T250I/V259I/V308F, V259I/V308F/Y319L, T307Q/V308F/L309Y, T307Q/V308F/Y319L, and T250Q/V308F/M428L.
[0259] Whereas particular embodiments of the invention have been described above for purposes of illustration, it will be appreciated by those skilled in the art that numerous variations of the details may be made without departing from the invention as described in the appended claims. All references cited herein are incorporated in their entirety.
Sequence CWU 1
1
241227PRTHomo sapiens 1Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
Pro Glu Leu Leu Gly1 5 10 15Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
Pro Lys Asp Thr Leu Met 20 25 30Ile Ser Arg Thr Pro Glu Val Thr Cys
Val Val Val Asp Val Ser His 35 40 45Glu Asp Pro Glu Val Lys Phe Asn
Trp Tyr Val Asp Gly Val Glu Val 50 55 60His Asn Ala Lys Thr Lys Pro
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr65 70 75 80Arg Val Val Ser Val
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly 85 90 95Lys Glu Tyr Lys
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile 100 105 110Glu Lys
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val 115 120
125Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
Val Glu145 150 155 160Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
Lys Thr Thr Pro Pro 165 170 175Val Leu Asp Ser Asp Gly Ser Phe Phe
Leu Tyr Ser Lys Leu Thr Val 180 185 190Asp Lys Ser Arg Trp Gln Gln
Gly Asn Val Phe Ser Cys Ser Val Met 195 200 205His Glu Ala Leu His
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser 210 215 220Pro Gly
Lys2252223PRTHomo sapiens 2Val Glu Cys Pro Pro Cys Pro Ala Pro Pro
Val Ala Gly Pro Ser Val1 5 10 15Phe Leu Phe Pro Pro Lys Pro Lys Asp
Thr Leu Met Ile Ser Arg Thr 20 25 30Pro Glu Val Thr Cys Val Val Val
Asp Val Ser His Glu Asp Pro Glu 35 40 45Val Gln Phe Asn Trp Tyr Val
Asp Gly Val Glu Val His Asn Ala Lys 50 55 60Thr Lys Pro Arg Glu Glu
Gln Phe Asn Ser Thr Phe Arg Val Val Ser65 70 75 80Val Leu Thr Val
Val His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys 85 90 95Cys Lys Val
Ser Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile 100 105 110Ser
Lys Thr Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro 115 120
125Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
130 135 140Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
Ser Asn145 150 155 160Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
Pro Met Leu Asp Ser 165 170 175Asp Gly Ser Phe Phe Leu Tyr Ser Lys
Leu Thr Val Asp Lys Ser Arg 180 185 190Trp Gln Gln Gly Asn Val Phe
Ser Cys Ser Val Met His Glu Ala Leu 195 200 205His Asn His Tyr Thr
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 210 215 2203229PRTHomo
sapiens 3Leu Gly Asp Thr Thr His Thr Cys Pro Arg Cys Pro Ala Pro
Glu Leu1 5 10 15Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
Lys Asp Thr 20 25 30Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
Val Val Asp Val 35 40 45Ser His Glu Asp Pro Glu Val Gln Phe Lys Trp
Tyr Val Asp Gly Val 50 55 60Glu Val His Asn Ala Lys Thr Lys Pro Arg
Glu Glu Gln Tyr Asn Ser65 70 75 80Thr Phe Arg Val Val Ser Val Leu
Thr Val Leu His Gln Asp Trp Leu 85 90 95Asn Gly Lys Glu Tyr Lys Cys
Lys Val Ser Asn Lys Ala Leu Pro Ala 100 105 110Pro Ile Glu Lys Thr
Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu Pro 115 120 125Gln Val Tyr
Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln 130 135 140Val
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala145 150
155 160Val Glu Trp Glu Ser Ser Gly Gln Pro Glu Asn Asn Tyr Asn Thr
Thr 165 170 175Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
Ser Lys Leu 180 185 190Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
Ile Phe Ser Cys Ser 195 200 205Val Met His Glu Ala Leu His Asn Arg
Phe Thr Gln Lys Ser Leu Ser 210 215 220Leu Ser Pro Gly
Lys2254224PRTHomo sapiens 4Pro Pro Cys Pro Ser Cys Pro Ala Pro Glu
Phe Leu Gly Gly Pro Ser1 5 10 15Val Phe Leu Phe Pro Pro Lys Pro Lys
Asp Thr Leu Met Ile Ser Arg 20 25 30Thr Pro Glu Val Thr Cys Val Val
Val Asp Val Ser Gln Glu Asp Pro 35 40 45Glu Val Gln Phe Asn Trp Tyr
Val Asp Gly Val Glu Val His Asn Ala 50 55 60Lys Thr Lys Pro Arg Glu
Glu Gln Phe Asn Ser Thr Tyr Arg Val Val65 70 75 80Ser Val Leu Thr
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr 85 90 95Lys Cys Lys
Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr 100 105 110Ile
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu 115 120
125Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys
130 135 140Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
Glu Ser145 150 155 160Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
Pro Pro Val Leu Asp 165 170 175Ser Asp Gly Ser Phe Phe Leu Tyr Ser
Arg Leu Thr Val Asp Lys Ser 180 185 190Arg Trp Gln Glu Gly Asn Val
Phe Ser Cys Ser Val Met His Glu Ala 195 200 205Leu His Asn His Tyr
Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys 210 215 2205207PRTHomo
sapiens 5Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
Leu Met1 5 10 15Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
Val Ser His 20 25 30Glu Asn Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
Gly Val Glu Val 35 40 45His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
Tyr Asn Ser Thr Tyr 50 55 60Arg Val Val Ser Val Leu Thr Val Leu His
Gln Asp Trp Leu Asn Gly65 70 75 80Lys Glu Tyr Lys Cys Lys Val Ser
Asn Lys Ala Leu Pro Ala Pro Ile 85 90 95Glu Lys Thr Ile Ser Lys Ala
Lys Gly Gln Pro Arg Glu Pro Gln Val 100 105 110Tyr Thr Leu Pro Pro
Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser 115 120 125Leu Thr Cys
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu 130 135 140Trp
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro145 150
155 160Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
Val 165 170 175Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
Ser Val Met 180 185 190His Glu Ala Leu His Asn His Tyr Thr Gln Lys
Ser Leu Ser Leu 195 200 2056205PRTRattus norvegicus 6Ser Val Phe
Ile Phe Pro Pro Lys Thr Lys Asp Val Leu Thr Ile Thr1 5 10 15Leu Thr
Pro Lys Val Thr Cys Val Val Val Asp Ile Ser Gln Asn Asp 20 25 30Pro
Glu Val Arg Phe Ser Trp Phe Ile Asp Asp Val Glu Val His Thr 35 40
45Ala Gln Thr His Ala Pro Glu Lys Gln Ser Asn Ser Thr Leu Arg Ser
50 55 60Val Ser Glu Leu Pro Ile Val His Arg Asp Trp Leu Asn Gly Lys
Thr65 70 75 80Phe Lys Cys Lys Val Asn Ser Gly Ala Phe Pro Ala Pro
Ile Glu Lys 85 90 95Ser Ile Ser Lys Pro Glu Gly Thr Pro Arg Gly Pro
Gln Val Tyr Thr 100 105 110Met Ala Pro Pro Lys Glu Glu Met Thr Gln
Ser Gln Val Ser Ile Thr 115 120 125Cys Met Val Lys Gly Phe Tyr Pro
Pro Asp Ile Tyr Thr Glu Trp Lys 130 135 140Met Asn Gly Gln Pro Gln
Glu Asn Tyr Lys Asn Thr Pro Pro Thr Met145 150 155 160Asp Thr Asp
Gly Ser Tyr Phe Leu Tyr Ser Lys Leu Asn Val Lys Lys 165 170 175Glu
Thr Trp Gln Gln Gly Asn Thr Phe Thr Cys Ser Val Leu His Glu 180 185
190Gly Leu His Asn His His Thr Glu Lys Ser Leu Ser His 195 200
2057256PRTHomo sapiens 7His Leu Ser Leu Leu Tyr His Leu Thr Ala Val
Ser Ser Pro Ala Pro1 5 10 15Gly Thr Pro Ala Phe Trp Val Ser Gly Trp
Leu Gly Pro Gln Gln Tyr 20 25 30Leu Ser Tyr Asn Ser Leu Arg Gly Glu
Ala Glu Pro Cys Gly Ala Trp 35 40 45Tyr Trp Glu Lys Glu Thr Thr Asp
Leu Arg Ile Lys Glu Lys Leu Phe 50 55 60Leu Glu Ala Phe Lys Ala Leu
Gly Gly Lys Gly Pro Tyr Thr Leu Gln65 70 75 80Gly Leu Leu Gly Cys
Glu Leu Gly Pro Asp Asn Thr Ser Val Pro Thr 85 90 95Ala Lys Phe Ala
Leu Asn Gly Glu Glu Phe Met Asn Phe Asp Leu Lys 100 105 110Gln Gly
Thr Trp Gly Gly Asp Trp Pro Glu Ala Leu Ala Ile Ser Gln 115 120
125Arg Trp Gln Gln Gln Asp Lys Ala Ala Asn Lys Glu Leu Thr Phe Leu
130 135 140Leu Phe Ser Cys Pro His Arg Leu Arg Glu His Leu Glu Arg
Gly Arg145 150 155 160Gly Asn Leu Glu Trp Lys Glu Pro Pro Ser Met
Arg Leu Lys Ala Arg 165 170 175Pro Ser Ser Pro Gly Phe Ser Val Leu
Thr Cys Ser Ala Phe Ser Phe 180 185 190Tyr Pro Pro Glu Leu Gln Leu
Arg Phe Leu Arg Asn Gly Leu Ala Ala 195 200 205Gly Thr Gly Gln Gly
Asp Phe Gly Pro Asn Ser Asp Gly Ser Phe His 210 215 220Ala Ser Ser
Ser Leu Thr Val Lys Ser Gly Asp Glu His His Tyr Cys225 230 235
240Cys Ile Val Gln His Ala Gly Leu Ala Gln Pro Leu Arg Val Glu Leu
245 250 2558265PRTRattus norvegicus 8Leu Pro Leu Met Tyr His Leu
Ala Ala Val Ser Asp Leu Ser Thr Gly1 5 10 15Leu Pro Ser Phe Trp Ala
Thr Gly Trp Leu Gly Ala Gln Gln Tyr Leu 20 25 30Thr Tyr Asn Asn Leu
Arg Gln Glu Ala Asp Pro Cys Gly Ala Trp Ile 35 40 45Trp Glu Asn Gln
Val Ser Trp Tyr Trp Glu Lys Glu Thr Thr Asp Leu 50 55 60Lys Ser Lys
Glu Gln Leu Phe Leu Glu Ala Ile Arg Thr Leu Glu Asn65 70 75 80Gln
Ile Asn Gly Thr Phe Thr Leu Gln Gly Leu Leu Gly Cys Glu Leu 85 90
95Ala Pro Asp Asn Ser Ser Leu Pro Thr Ala Val Phe Ala Leu Asn Gly
100 105 110Glu Glu Phe Met Arg Phe Asn Pro Arg Thr Gly Asn Trp Ser
Gly Glu 115 120 125Trp Pro Glu Thr Asp Ile Val Gly Asn Leu Trp Met
Lys Gln Pro Glu 130 135 140Ala Ala Arg Lys Glu Ser Glu Phe Leu Leu
Thr Ser Cys Pro Glu Arg145 150 155 160Leu Leu Gly His Leu Glu Arg
Gly Arg Gln Asn Leu Glu Trp Lys Glu 165 170 175Pro Pro Ser Met Arg
Leu Lys Ala Arg Pro Gly Asn Ser Gly Ser Ser 180 185 190Val Leu Thr
Cys Ala Ala Phe Ser Phe Tyr Pro Pro Glu Leu Lys Phe 195 200 205Arg
Phe Leu Arg Asn Gly Leu Ala Ser Gly Ser Gly Asn Cys Ser Thr 210 215
220Gly Pro Asn Gly Asp Gly Ser Phe His Ala Trp Ser Leu Leu Glu
Val225 230 235 240Lys Arg Gly Asp Glu His His Tyr Gln Cys Gln Val
Glu His Glu Gly 245 250 255Leu Ala Gln Pro Leu Thr Val Asp Leu 260
265999PRTHomo sapiens 9Ile Gln Arg Thr Pro Lys Ile Gln Val Tyr Ser
Arg His Pro Ala Glu1 5 10 15Asn Gly Lys Ser Asn Phe Leu Asn Cys Tyr
Val Ser Gly Phe His Pro 20 25 30Ser Asp Ile Glu Val Asp Leu Leu Lys
Asn Gly Glu Arg Ile Glu Lys 35 40 45Val Glu His Ser Asp Leu Ser Phe
Ser Lys Asp Trp Ser Phe Tyr Leu 50 55 60Leu Tyr Tyr Thr Glu Phe Thr
Pro Thr Glu Lys Asp Glu Tyr Ala Cys65 70 75 80Arg Val Asn His Val
Thr Leu Ser Gln Pro Lys Ile Val Lys Trp Asp 85 90 95Arg Asp
Met1099PRTRattus norvegicus 10Ile Gln Lys Thr Pro Gln Ile Gln Val
Tyr Ser Arg His Pro Pro Glu1 5 10 15Asn Gly Lys Pro Asn Phe Leu Asn
Cys Tyr Val Ser Gln Phe His Pro 20 25 30Pro Gln Ile Glu Ile Glu Leu
Leu Lys Asn Gly Lys Lys Ile Pro Asn 35 40 45Ile Glu Met Ser Asp Leu
Ser Phe Ser Lys Asp Trp Ser Phe Tyr Ile 50 55 60Leu Ala His Thr Glu
Phe Thr Pro Thr Glu Thr Asp Val Tyr Ala Cys65 70 75 80Arg Val Lys
His Val Thr Leu Lys Glu Pro Lys Thr Val Thr Trp Asp 85 90 95Arg Asp
Met11450PRTArtificial SequenceTrastuzumab Heavy chain 11Glu Val Gln
Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu
Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr 20 25 30Tyr
Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40
45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val
50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr Ala
Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val
Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp
Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser Ser Ala Ser
Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro Ser Ser Lys
Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys Leu Val Lys
Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155 160Trp Asn Ser
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val 165 170 175Leu
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro 180 185
190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
195 200 205Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu Phe Pro Pro Lys
Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr Pro Glu Val Thr
Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp Pro Glu Val Lys
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280 285Asn Ala Lys
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg 290 295 300Val
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys305 310
315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
Glu 325 330 335Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys
Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys Gly Phe Tyr Pro
Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn Gly Gln Pro Glu
Asn Asn Tyr Lys Thr Thr Pro Pro Val385 390 395 400Leu Asp Ser Asp
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp 405 410
415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
Ser Pro 435 440 445Gly Lys 45012214PRTArtificial
SequenceTrastuzumab light chain 12Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys
Arg Ala Ser Gln Asp Val Asn Thr Ala 20 25 30Val Ala Trp Tyr Gln Gln
Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Ala Ser Phe
Leu Tyr Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Arg Ser Gly
Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro65 70 75 80Glu Asp
Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro 85 90 95Thr
Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala 100 105
110Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
Glu Ala 130 135 140Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
Gly Asn Ser Gln145 150 155 160Glu Ser Val Thr Glu Gln Asp Ser Lys
Asp Ser Thr Tyr Ser Leu Ser 165 170 175Ser Thr Leu Thr Leu Ser Lys
Ala Asp Tyr Glu Lys His Lys Val Tyr 180 185 190Ala Cys Glu Val Thr
His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser 195 200 205Phe Asn Arg
Gly Glu Cys 21013330PRTHomo sapiens 13Ala Ser Thr Lys Gly Pro Ser
Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His Thr
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75 80Tyr
Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys 85 90
95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
Glu Val Thr Cys 130 135 140Val Val Val Asp Val Ser His Glu Asp Pro
Glu Val Lys Phe Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu Val
His Asn Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu Gln Tyr Asn Ser
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu 180 185 190His Gln Asp
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn 195 200 205Lys
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly 210 215
220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu
Glu225 230 235 240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro Val
Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu Thr
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser Cys
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr305 310 315 320Gln
Lys Ser Leu Ser Leu Ser Pro Gly Lys 325 33014330PRTArtificial
SequenceP257L IgG1 14Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly
Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp
Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val
Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val
Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120
125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Leu Glu Val Thr Cys
130 135 140Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
Thr Lys Pro Arg Glu 165 170 175Glu Gln Tyr Asn Ser Thr Tyr Arg Val
Val Ser Val Leu Thr Val Leu 180 185 190His Gln Asp Trp Leu Asn Gly
Lys Glu Tyr Lys Cys Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly 210 215 220Gln Pro Arg
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu225 230 235
240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser Cys Ser Val Met His
Glu Ala Leu His Asn His Tyr Thr305 310 315 320Gln Lys Ser Leu Ser
Leu Ser Pro Gly Lys 325 33015330PRTArtificial SequenceP257N IgG1
15Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1
5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu
Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn His Lys Pro Ser
Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys Ser Cys Asp Lys
Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly
Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys Pro Lys Asp Thr
Leu Met Ile Ser Arg Thr Asn Glu Val Thr Cys 130 135 140Val Val Val
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp145 150 155
160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
Val Leu 180 185 190His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
Ile Ser Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu Pro Gln Val Tyr
Thr Leu Pro Pro Ser Arg Glu Glu225 230 235 240Met Thr Lys Asn Gln
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn 260 265 270Asn
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe 275 280
285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
Tyr Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 325
33016330PRTArtificial SequenceV308F IgG1 16Ala Ser Thr Lys Gly Pro
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75
80Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
Phe Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
Pro Glu Val Thr Cys 130 135 140Val Val Val Asp Val Ser His Glu Asp
Pro Glu Val Lys Phe Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu
Val His Asn Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu Gln Tyr Asn
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Phe Leu 180 185 190His Gln
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn 195 200
205Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
Glu Glu225 230 235 240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu
Ser Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro
Val Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr305 310 315
320Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 325
33017330PRTArtificial SequenceQ311V IgG1 17Ala Ser Thr Lys Gly Pro
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75
80Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
Phe Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
Pro Glu Val Thr Cys 130 135 140Val Val Val Asp Val Ser His Glu Asp
Pro Glu Val Lys Phe Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu
Val His Asn Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu Gln Tyr Asn
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu 180 185 190His Val
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn 195 200
205Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
Glu Glu225 230 235 240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu
Ser Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro
Val Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr305 310 315
320Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 325
33018330PRTArtificial SequenceG385H IgG1 18Ala Ser Thr Lys Gly Pro
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75
80Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
Phe Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
Pro Glu Val Thr Cys 130 135 140Val Val Val Asp Val Ser His Glu Asp
Pro Glu Val Lys Phe Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu
Val His Asn Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu Gln Tyr Asn
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu 180 185 190His Gln
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn 195 200
205Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
Glu Glu225 230 235 240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu
Ser Asn His Gln Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro
Val Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr305 310 315
320Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 325
33019330PRTArtificial SequenceWT hybrid 19Ala Ser Thr Lys Gly Pro
Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser
Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75
80Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
Phe Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
Pro Glu Val Thr Cys 130 135 140Val Val Val Asp Val Ser His Glu Asp
Pro Glu Val Gln Phe Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu
Val His Asn Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu Gln Phe Asn
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val 180 185 190His Gln
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
Lys Thr Lys Gly 210 215 220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
Pro Pro Ser Arg Glu Glu225 230 235 240Met Thr Lys Asn Gln Val Ser
Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys
Thr Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295
300Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 325
33020330PRTArtificial SequenceP257L Hybrid 20Ala Ser Thr Lys Gly
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val
His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu
Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75
80Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
Phe Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
Leu Glu Val Thr Cys 130 135 140Val Val Val Asp Val Ser His Glu Asp
Pro Glu Val Gln Phe Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu
Val His Asn Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu Gln Phe Asn
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val 180 185 190His Gln
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn 195 200
205Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly
210 215 220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
Glu Glu225 230 235 240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu
Ser Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro
Met Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr305 310 315
320Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 325
33021330PRTArtificial SequenceP257N Hybrid 21Ala Ser Thr Lys Gly
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val
His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu
Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75
80Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
Phe Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
Asn Glu Val Thr Cys 130 135 140Val Val Val Asp Val Ser His Glu Asp
Pro Glu Val Gln Phe Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu
Val His Asn Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu Gln Phe Asn
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val 180 185 190His Gln
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn 195 200
205Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly
210 215 220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
Glu Glu225 230 235 240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu
Ser Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro
Met Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr305 310 315
320Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 325
33022330PRTArtificial SequenceV308F Hybrid 22Ala Ser Thr Lys Gly
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly
Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val
His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu
Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75
80Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
Phe Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
Pro Glu Val Thr Cys 130 135 140Val Val Val Asp Val Ser His Glu Asp
Pro Glu Val Gln Phe Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu
Val His Asn Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu Gln Phe Asn
Ser Thr Phe Arg Val Val Ser Val Leu Thr Phe Val 180 185 190His Gln
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn 195 200
205Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly
210 215 220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
Glu Glu225 230 235 240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu
Ser Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro
Met Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr305 310 315
320Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 325 33023330PRTHomo
sapiens 23Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser
Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
Ala Leu Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro Ser Ser
Ser Leu Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn His Lys
Pro Ser Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys Ser Cys
Asp Lys Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro Glu Leu
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys Pro Lys
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135 140Val
Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp145 150
155 160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
Glu 165 170 175Glu Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu
Thr Val Val 180 185 190His Val Asp Trp Leu Asn Gly Lys Glu Tyr Lys
Cys Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro Ile Glu Lys
Thr Ile Ser Lys Thr Lys Gly 210 215 220Gln Pro Arg Glu Pro Gln Val
Tyr Thr Leu Pro Pro Ser Arg Glu Glu225 230 235 240Met Thr Lys Asn
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250 255Pro Ser
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn 260 265
270Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
Gly Asn 290 295 300Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
Asn His Tyr Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser Pro Gly
Lys 325 33024330PRTArtificial SequenceG385H Hybrid 24Ala Ser Thr
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr
Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe
Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40
45Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
Thr65 70 75 80Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
Val Asp Lys 85 90 95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
Cys Pro Pro Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
Val Phe Leu Phe Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu Met Ile
Ser Arg Thr Pro Glu Val Thr Cys 130 135 140Val Val Val Asp Val Ser
His Glu Asp Pro Glu Val Gln Phe Asn Trp145 150 155 160Tyr Val Asp
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu
Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val 180 185
190His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr
Lys Gly 210 215 220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
Ser Arg Glu Glu225 230 235 240Met Thr Lys Asn Gln Val Ser Leu Thr
Cys Leu Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu
Trp Glu Ser Asn His Gln Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr
Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295 300Val
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr305 310
315 320Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 325 330
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012
D00013
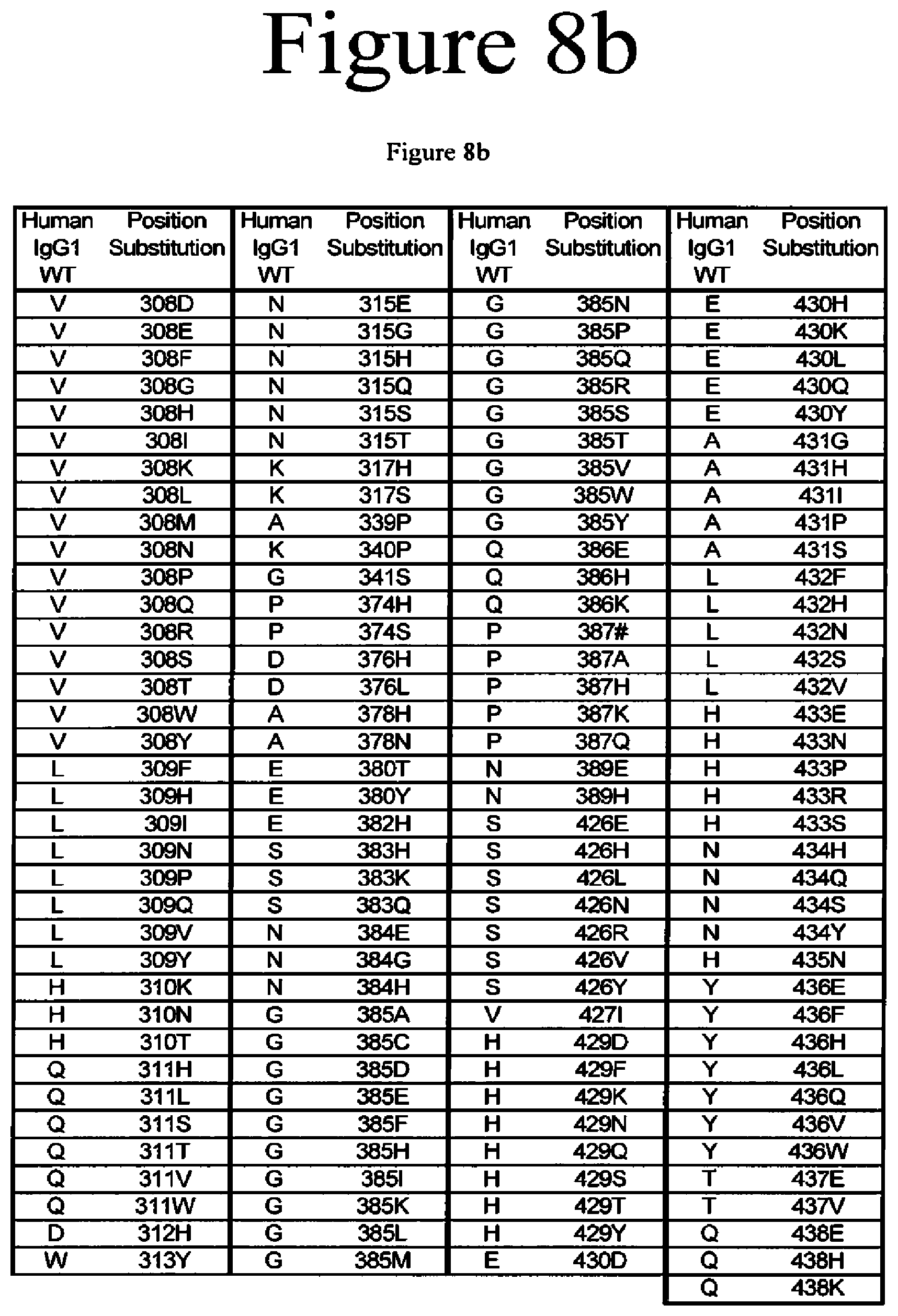
D00014
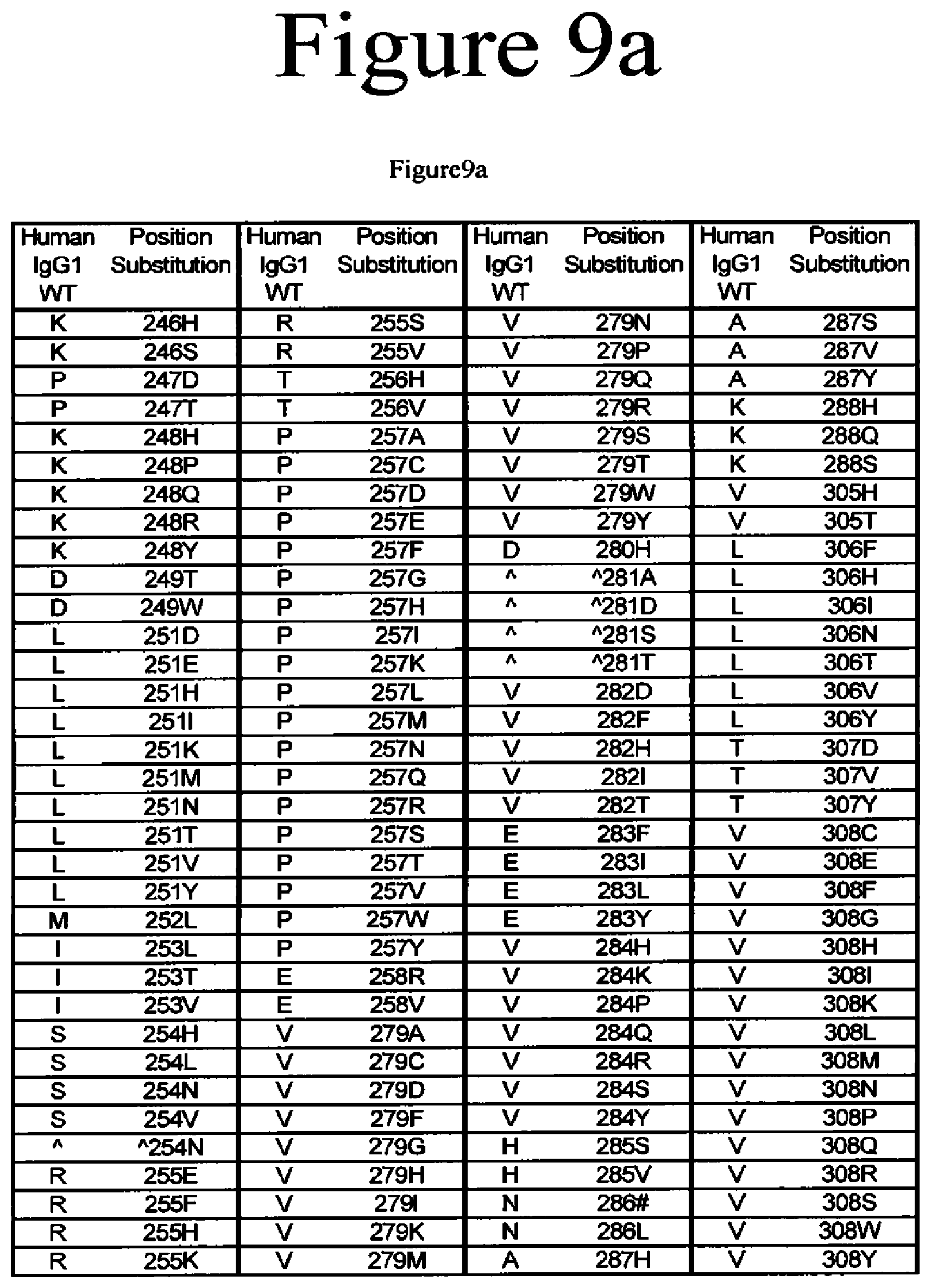
D00015
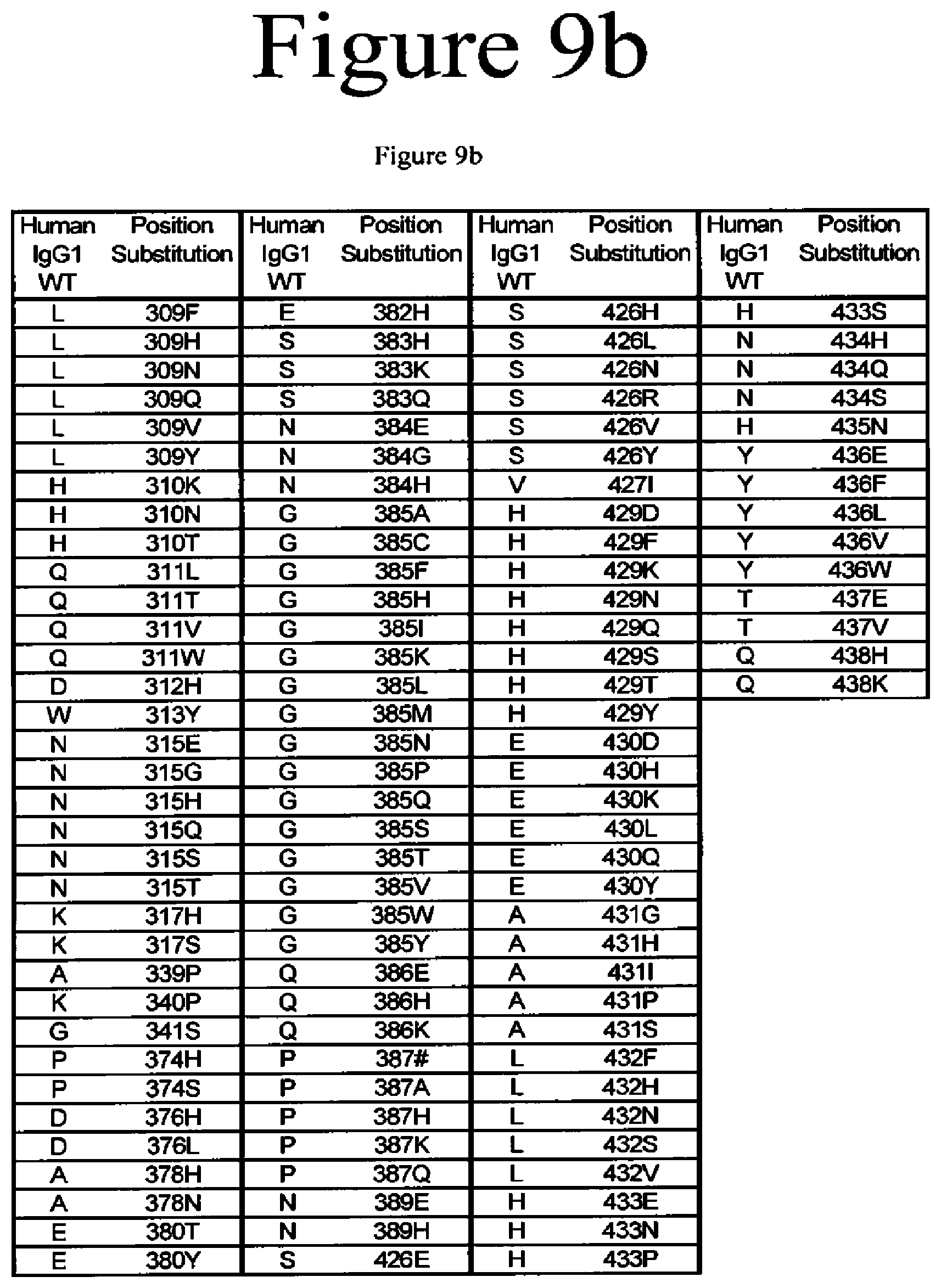
D00016

D00017

D00018

D00019

D00020
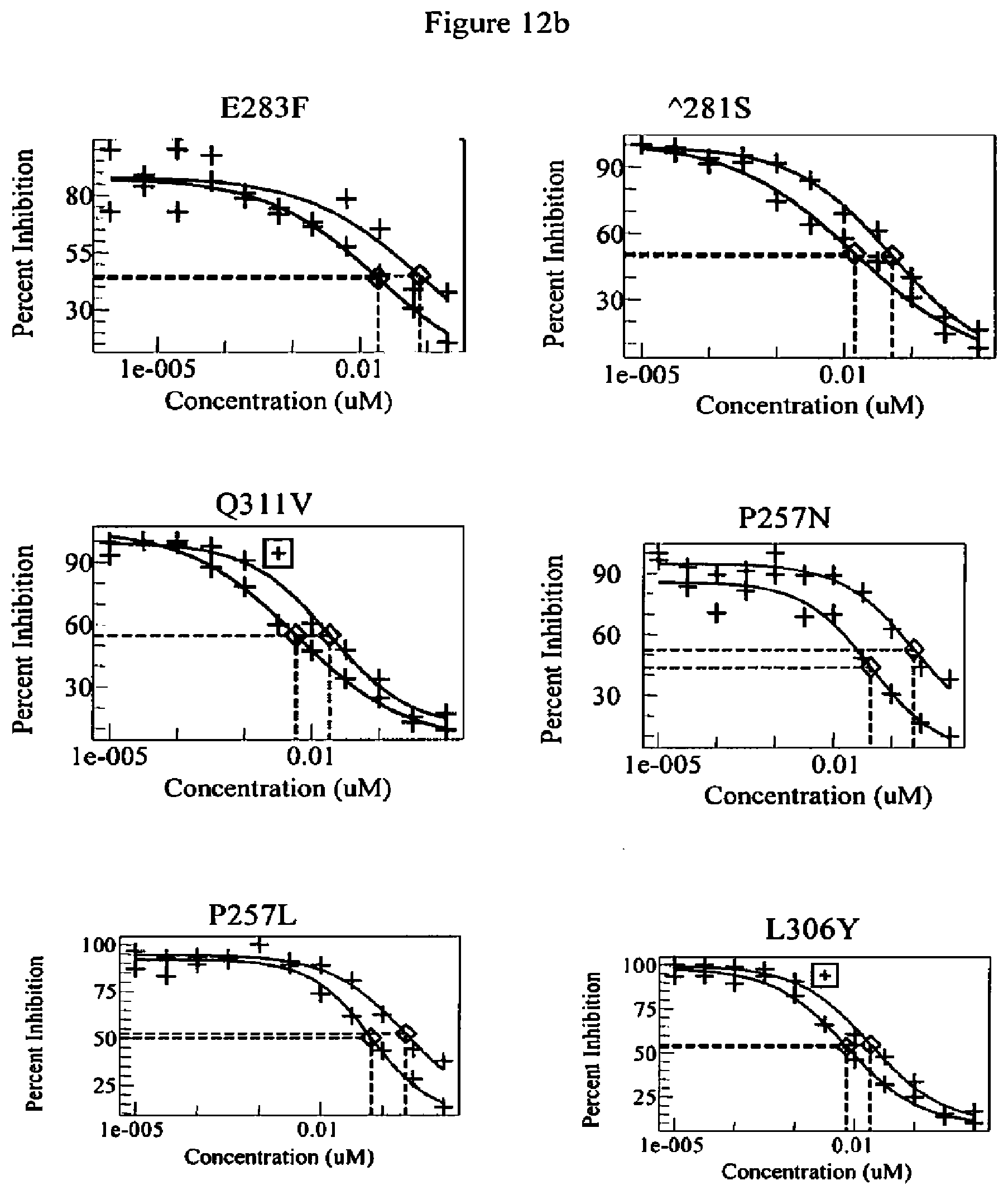
D00021

D00022
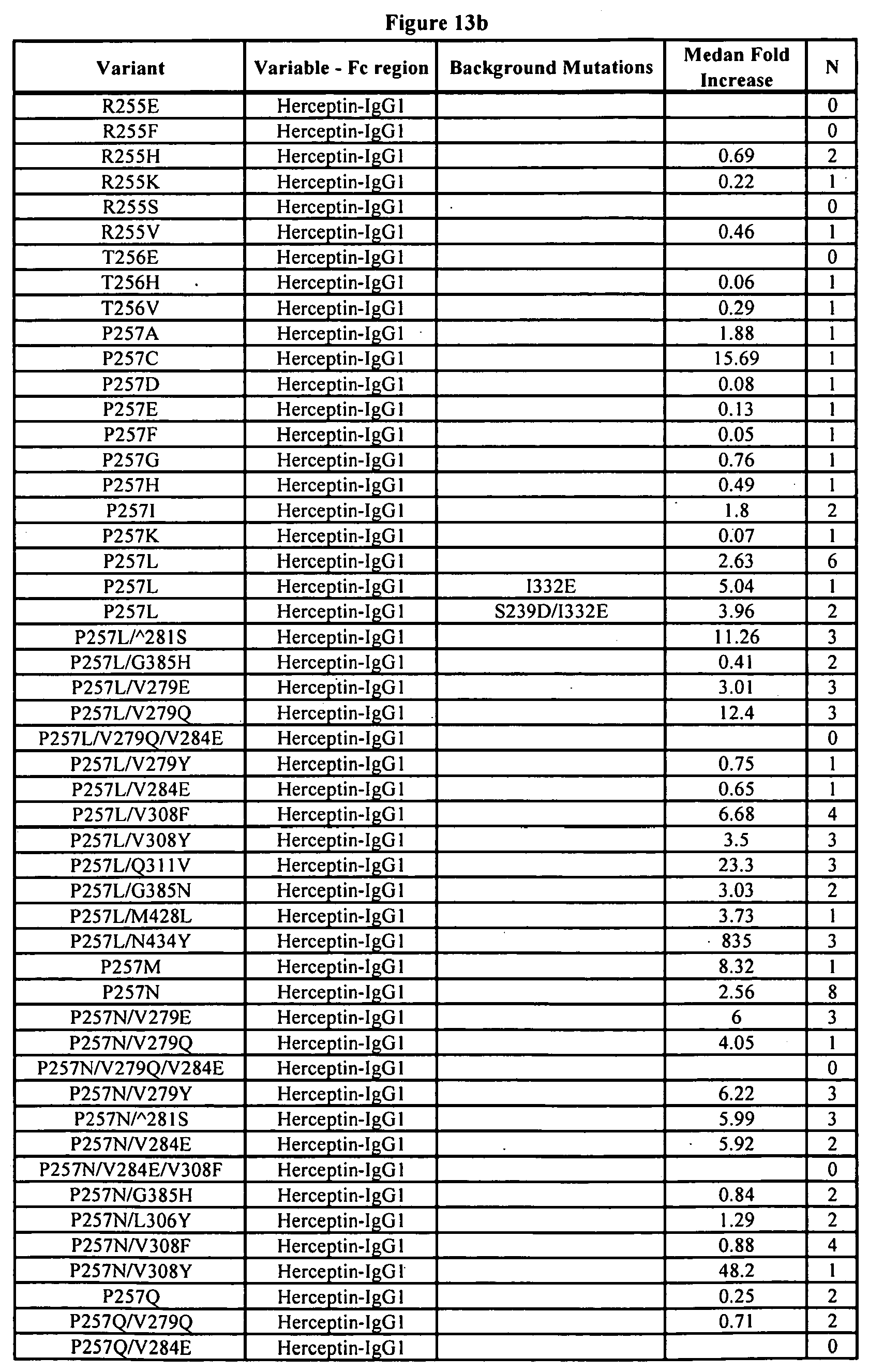
D00023
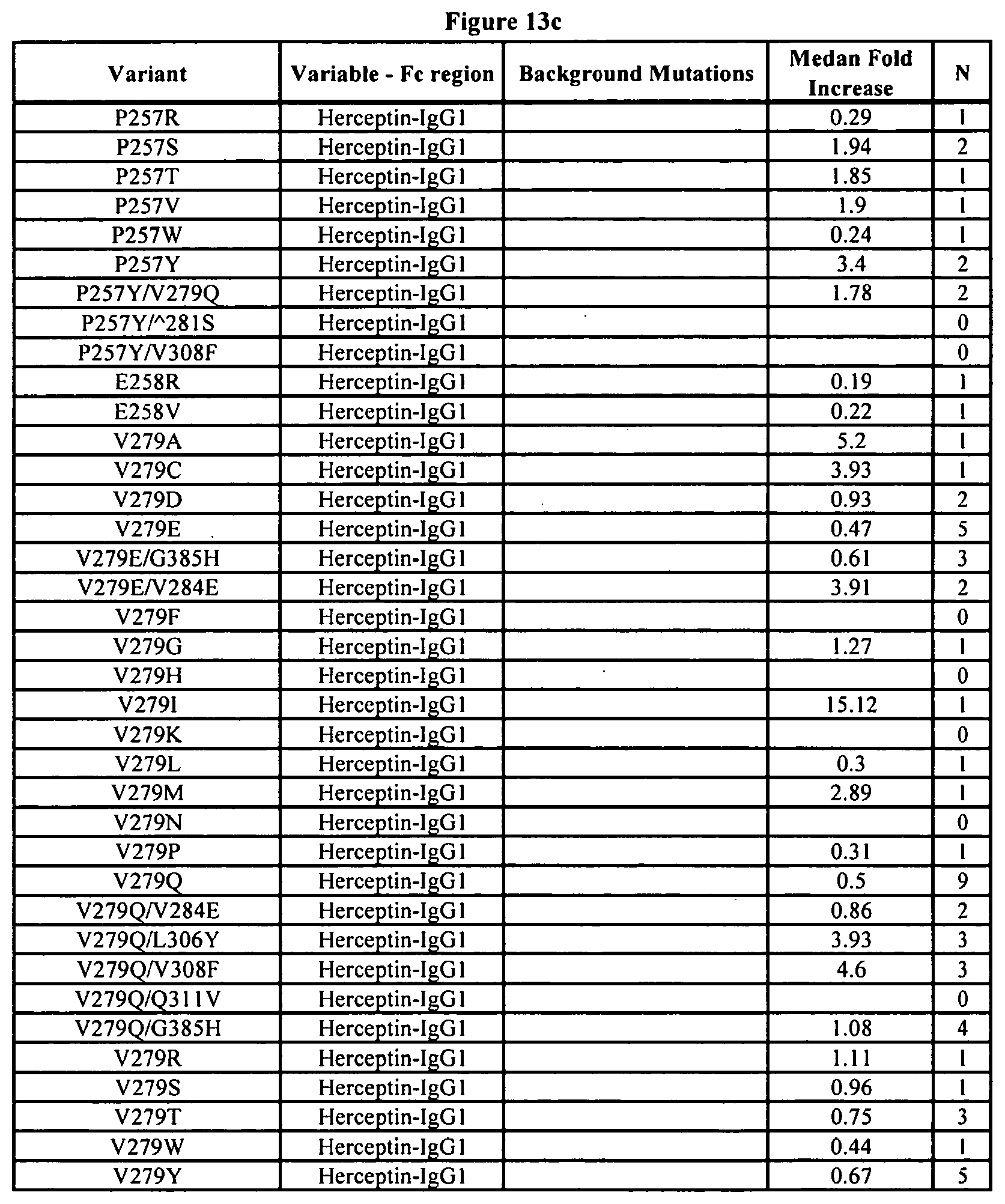
D00024
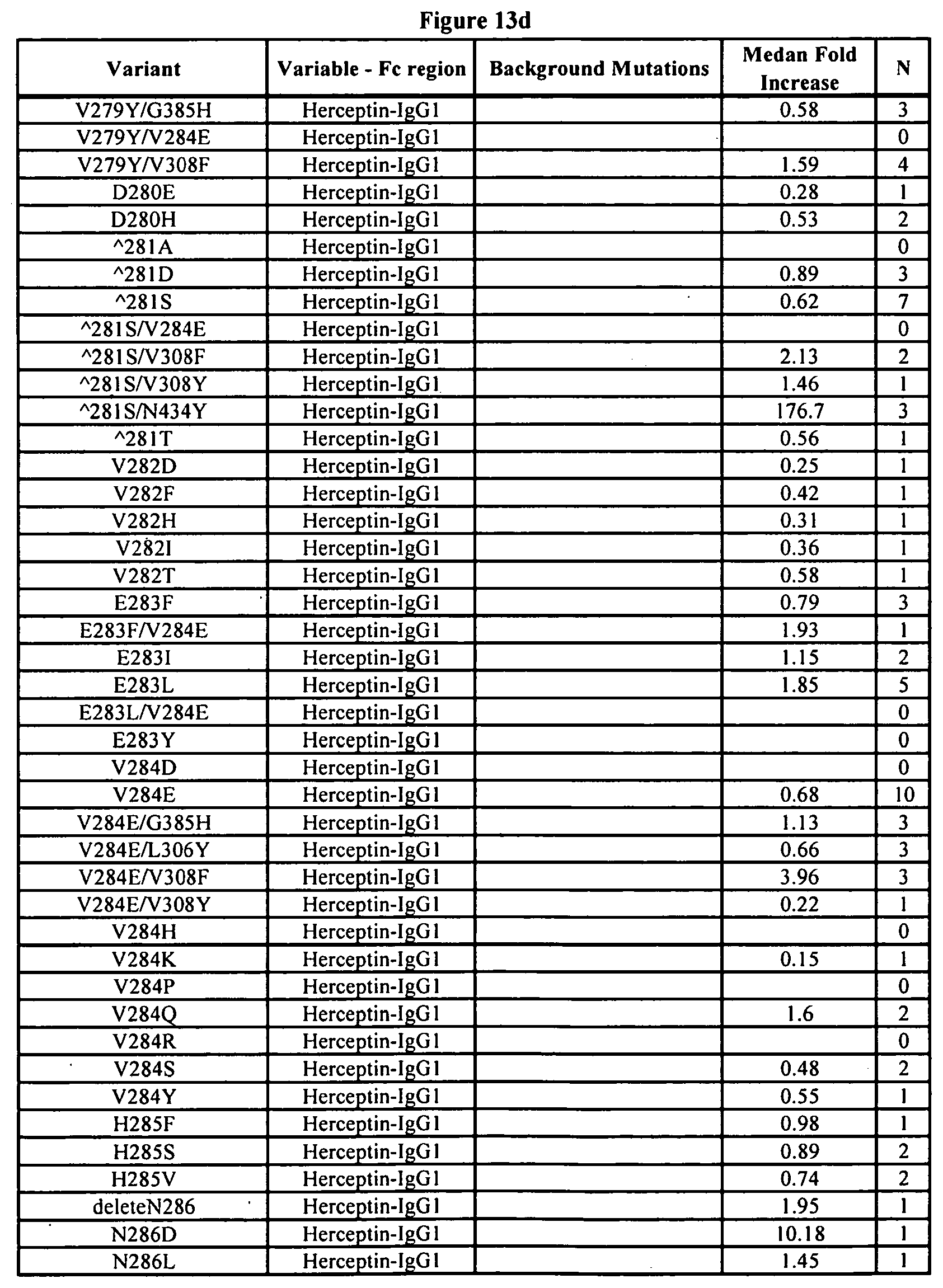
D00025
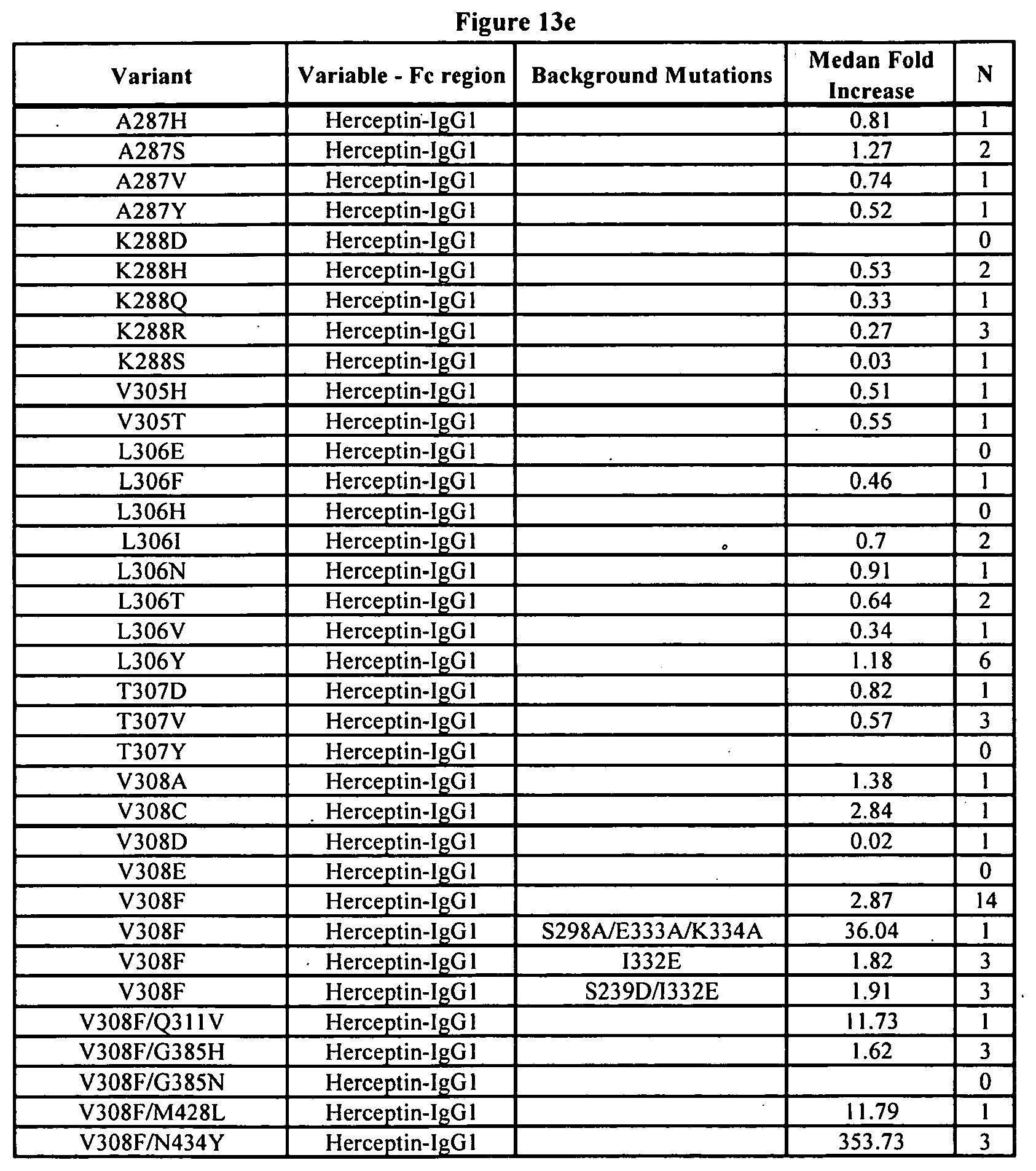
D00026

D00027

D00028
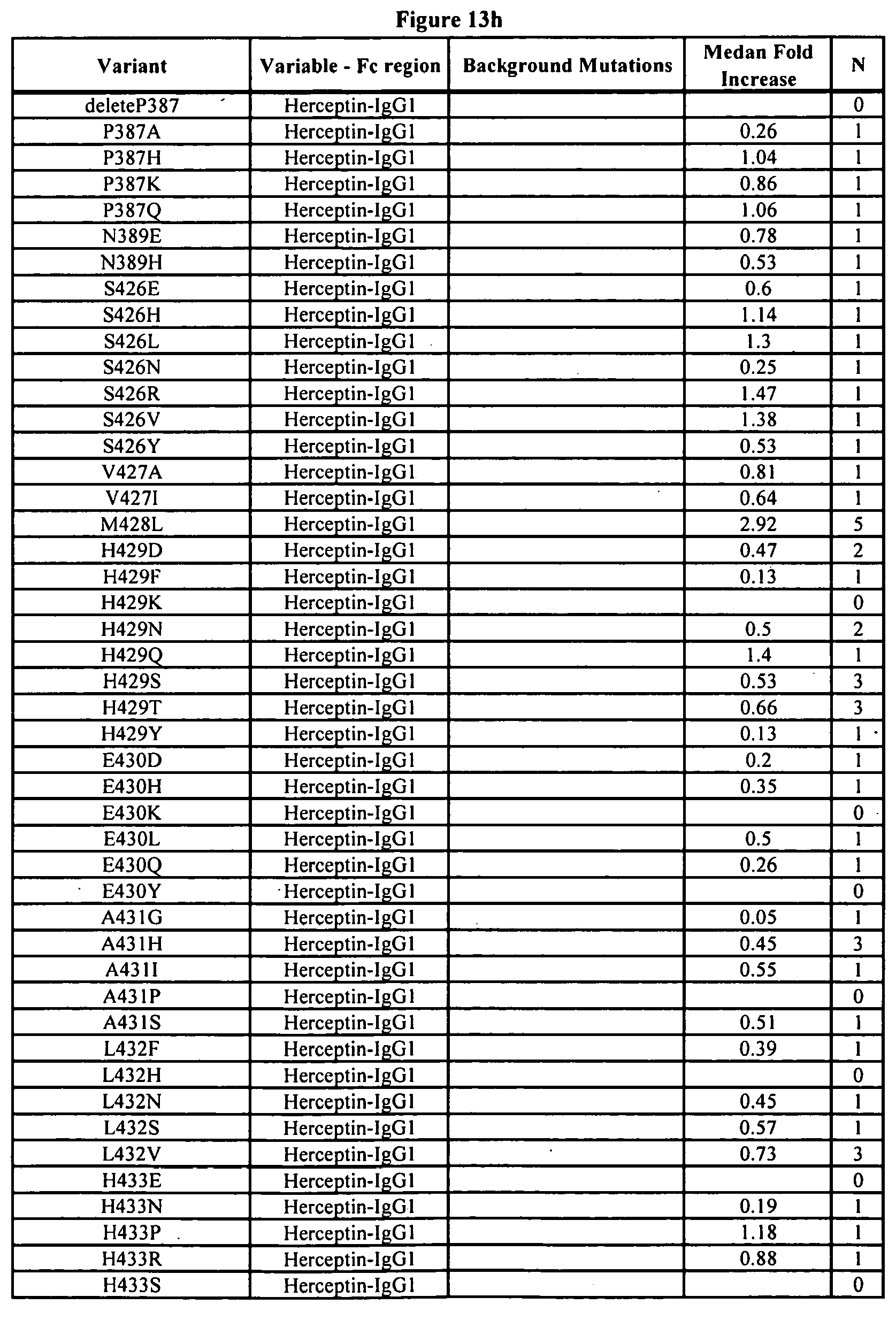
D00029

D00030

D00031

D00032
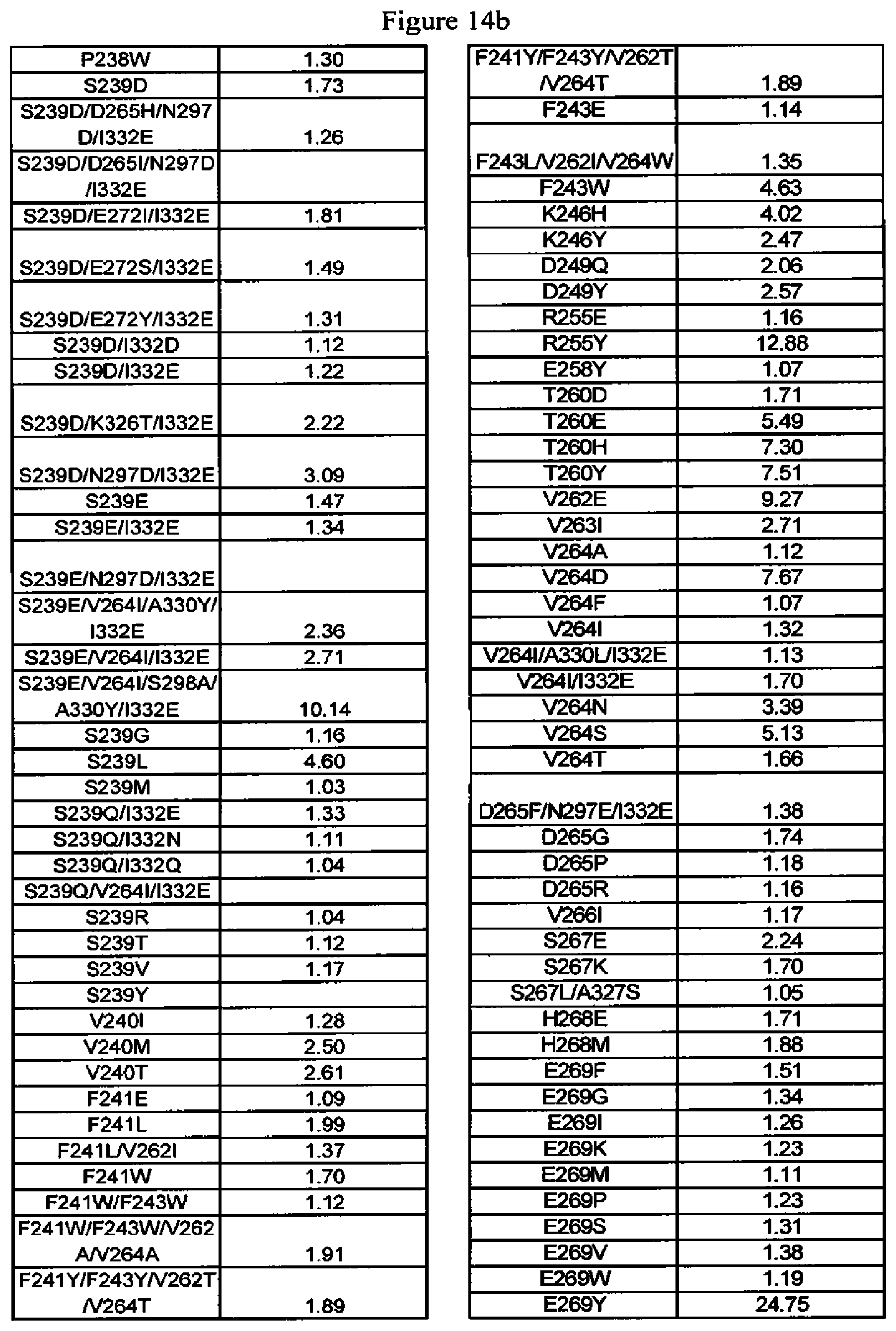
D00033
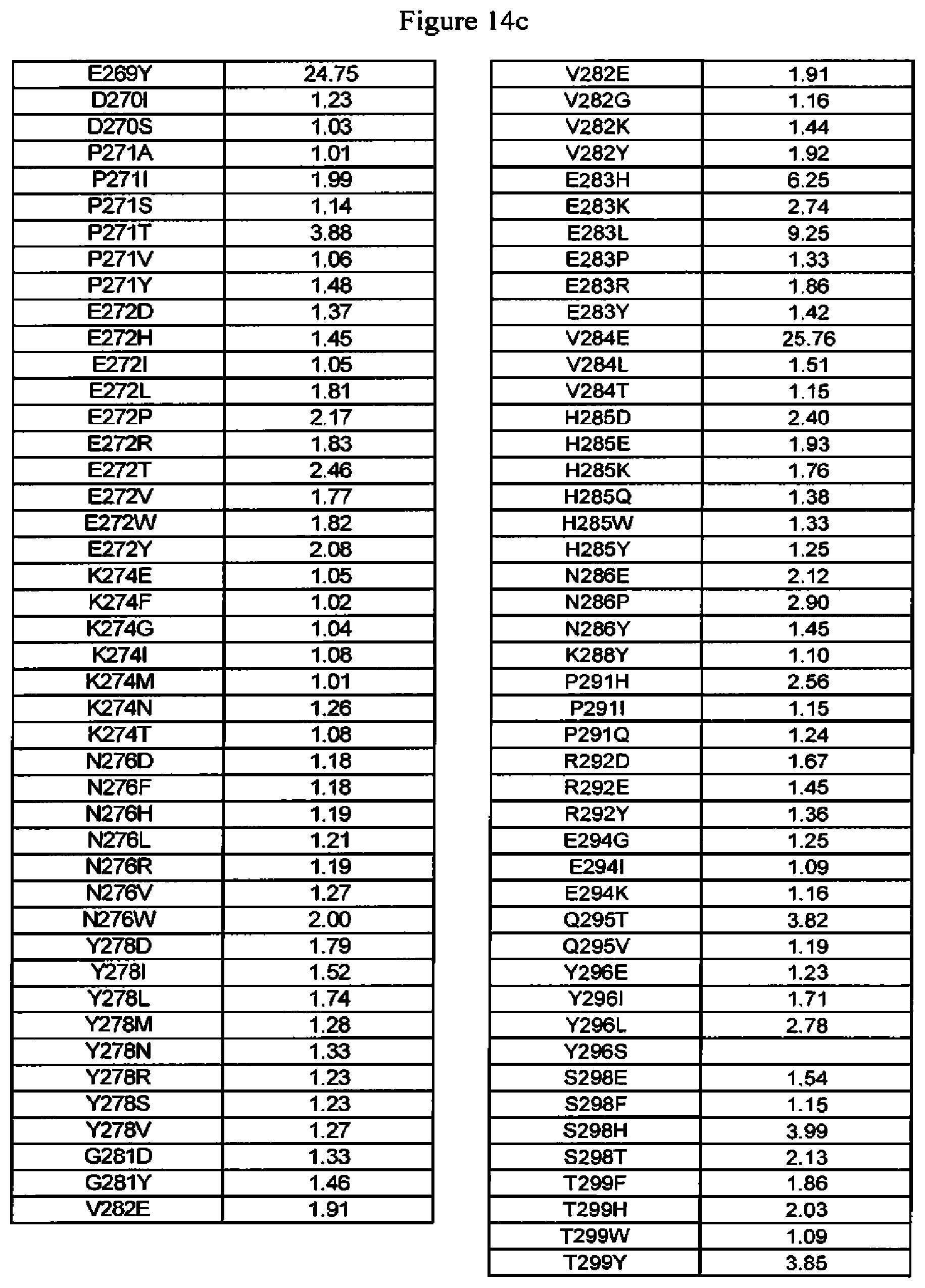
D00034
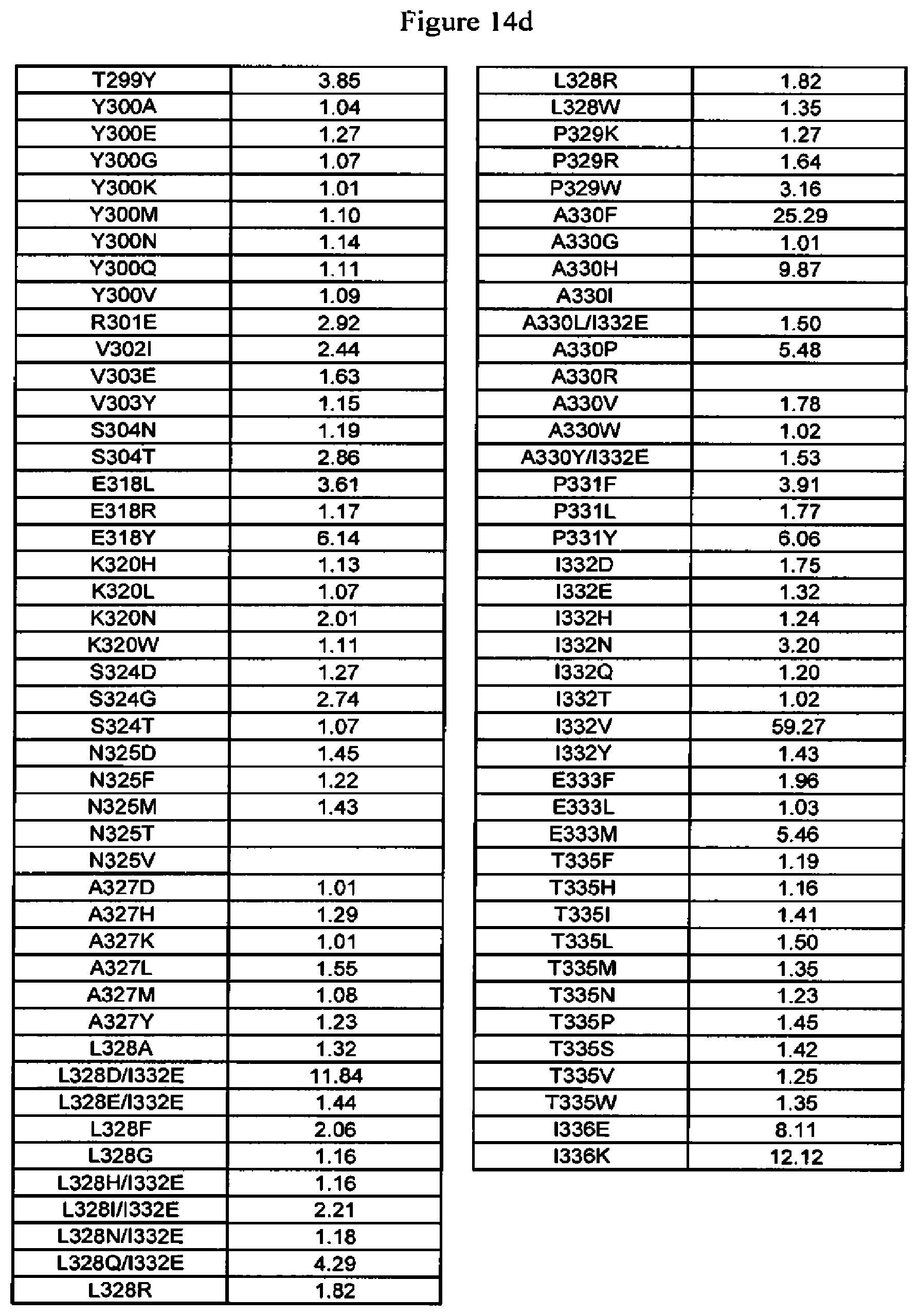
D00035
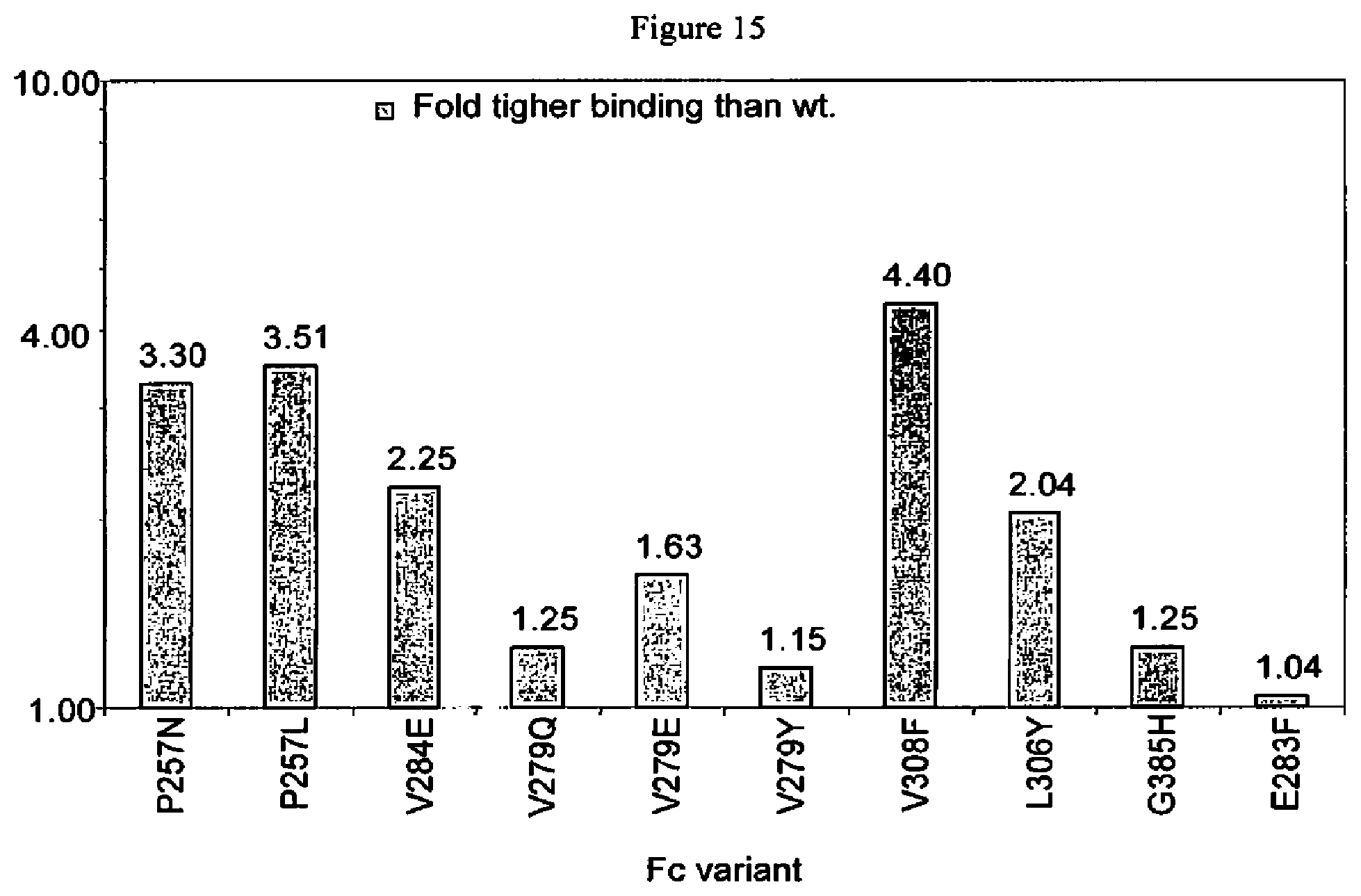
D00036
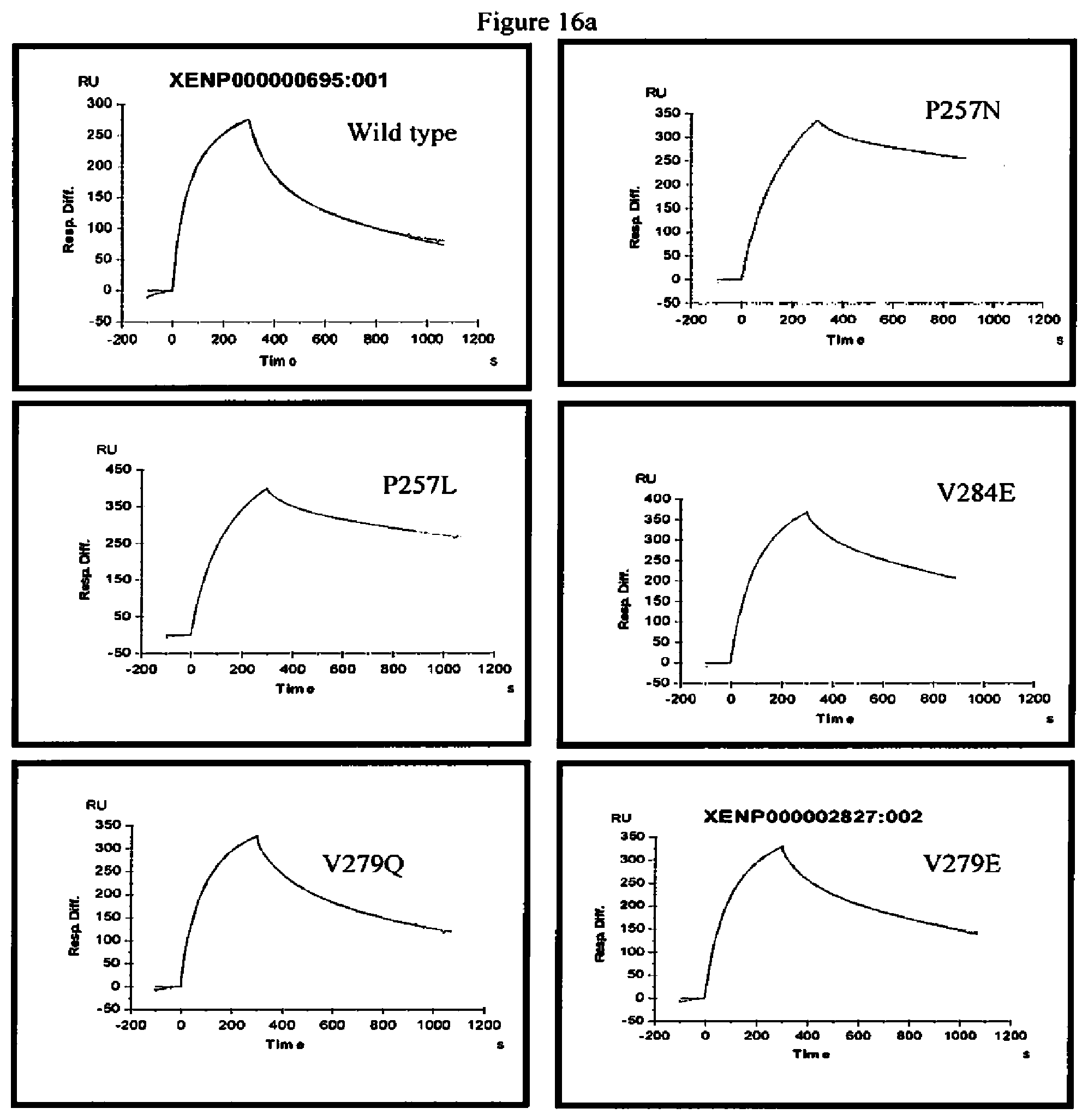
D00037
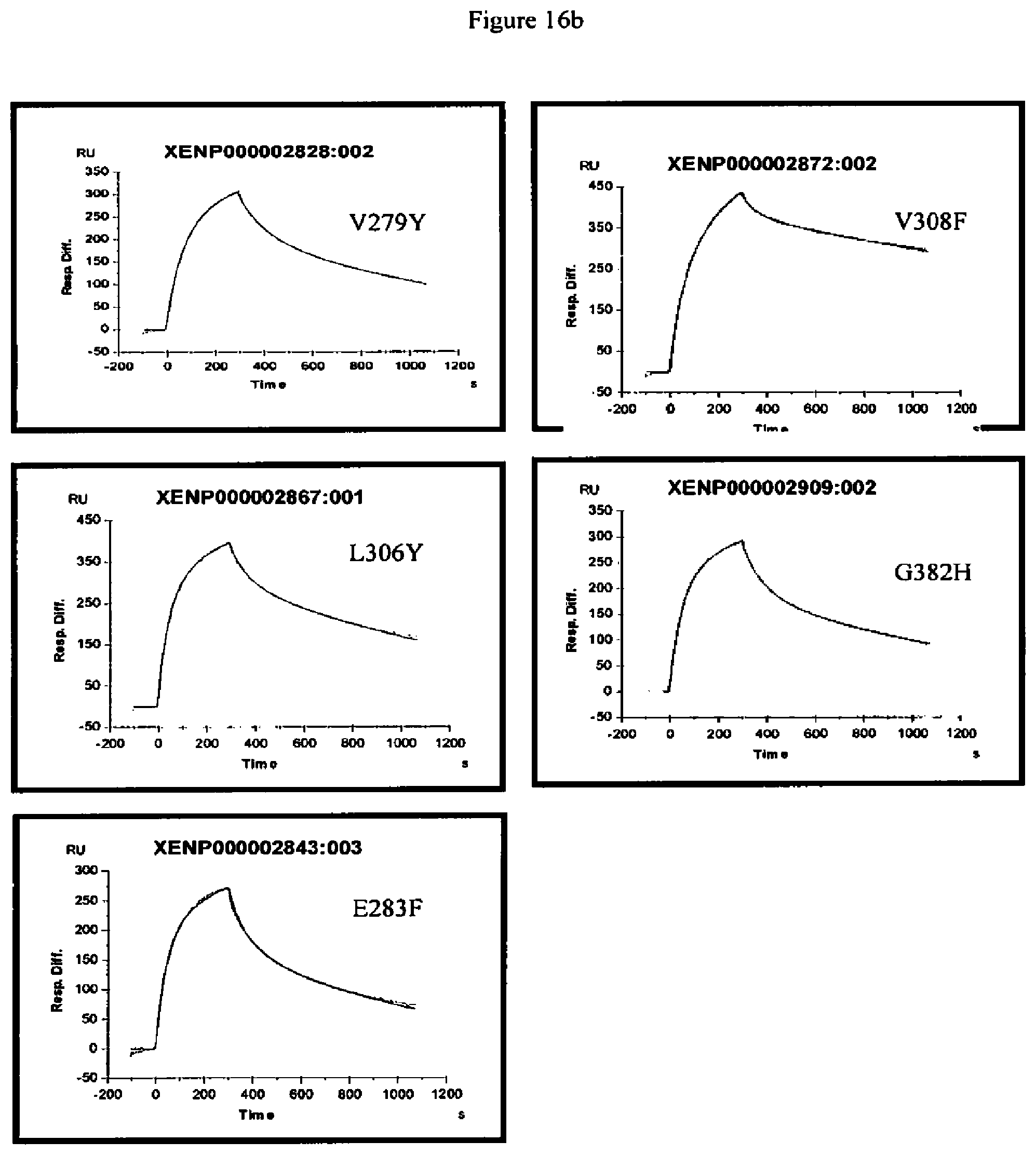
D00038
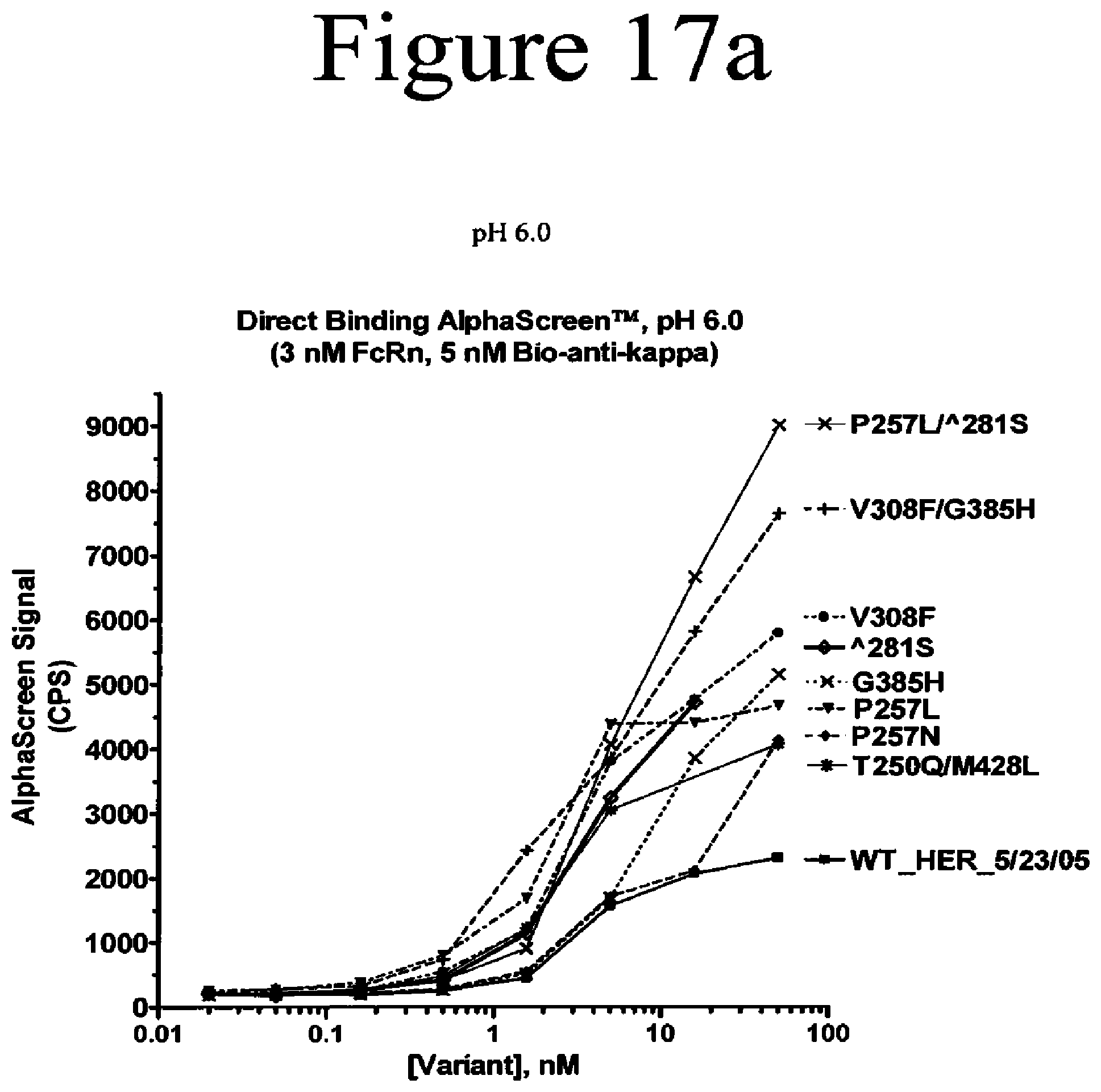
D00039
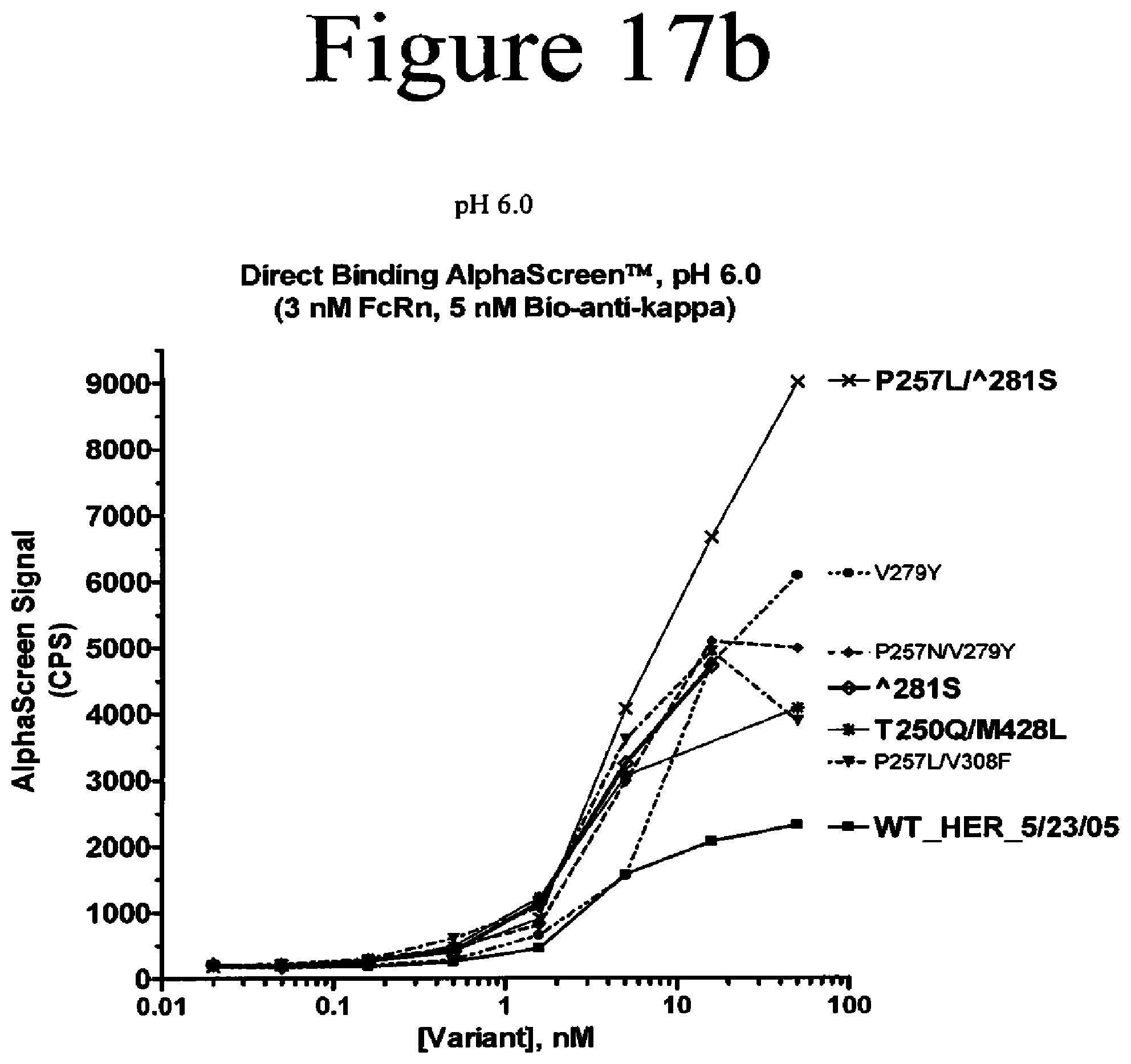
D00040
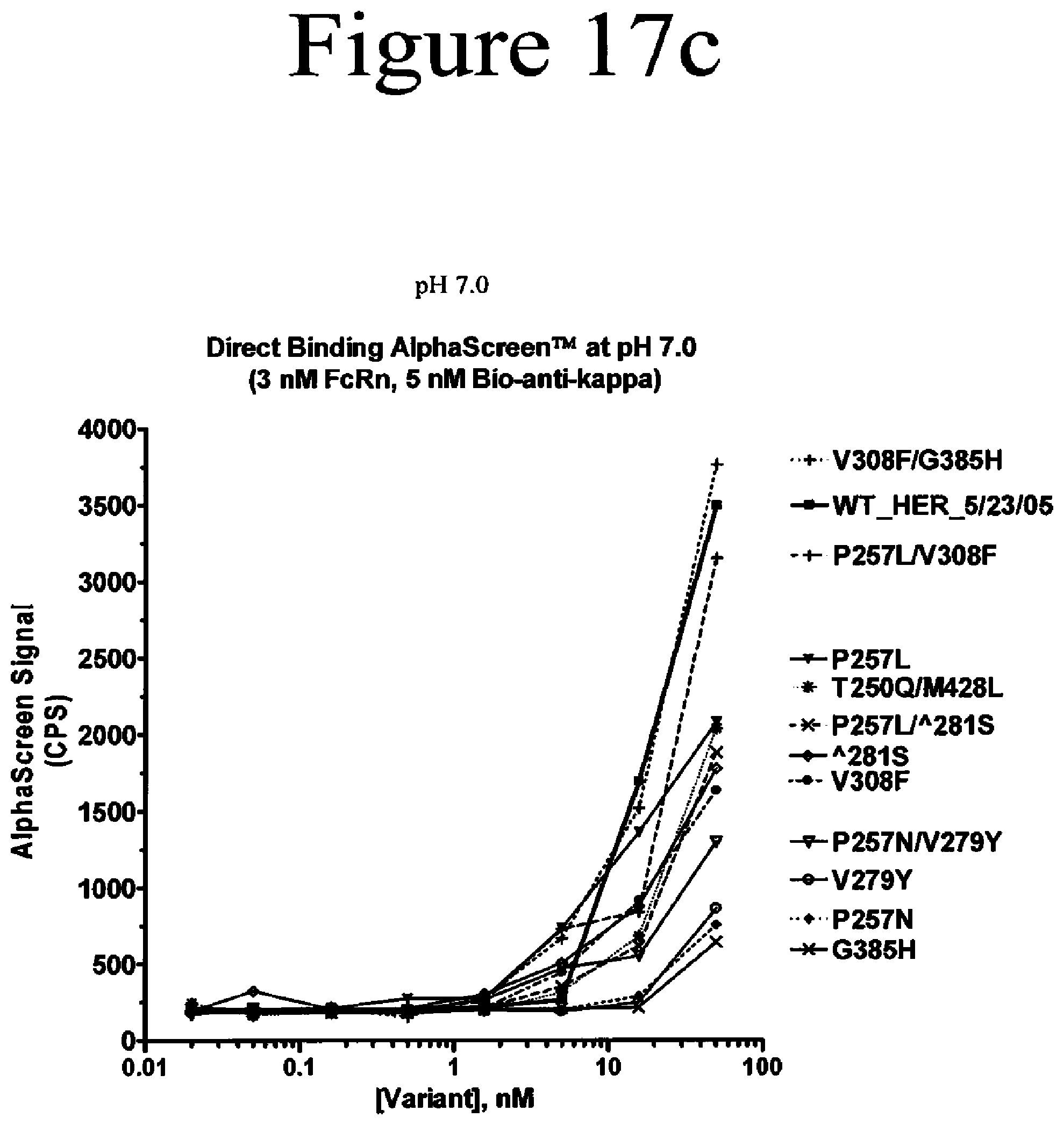
D00041
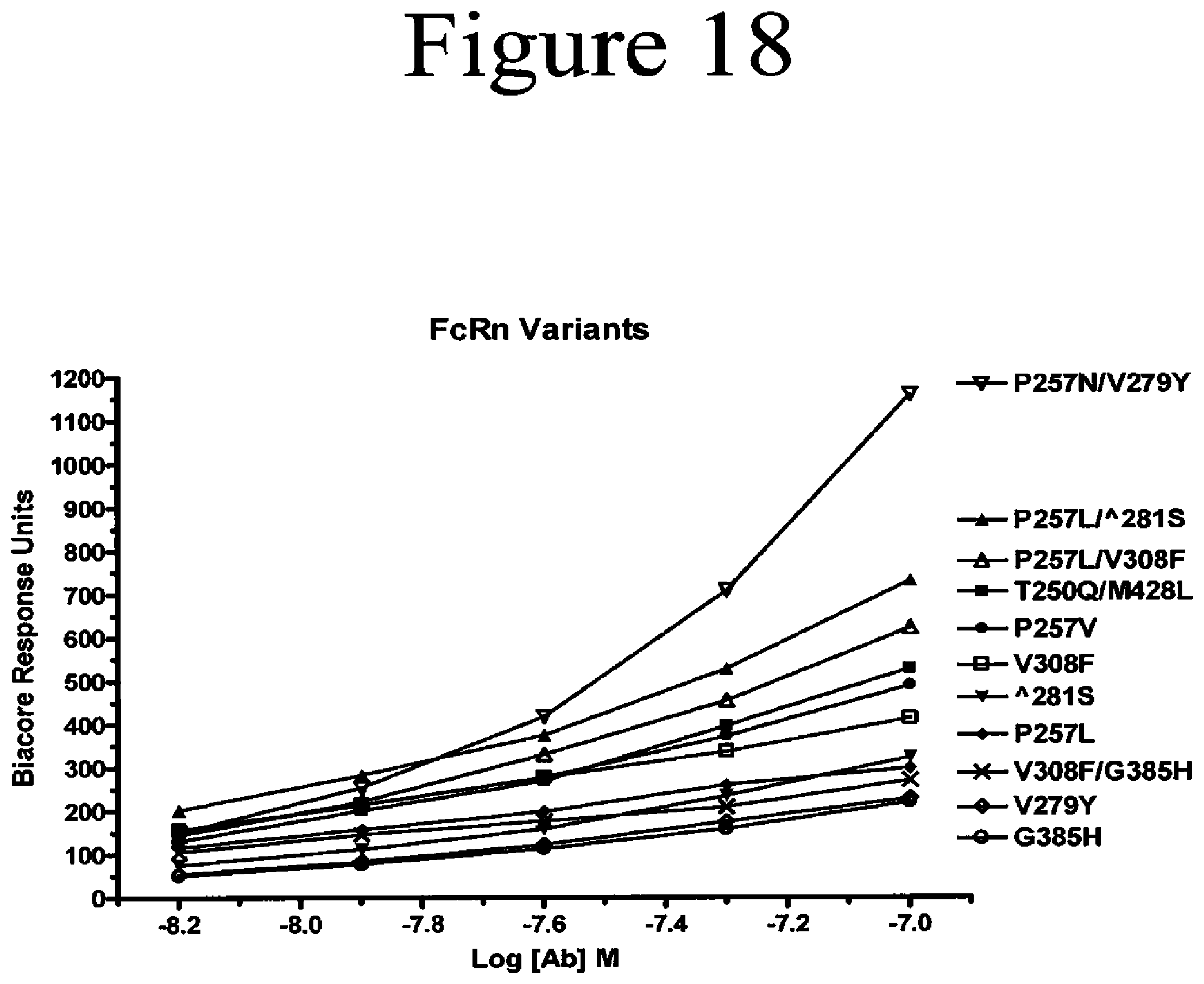
D00042

D00043
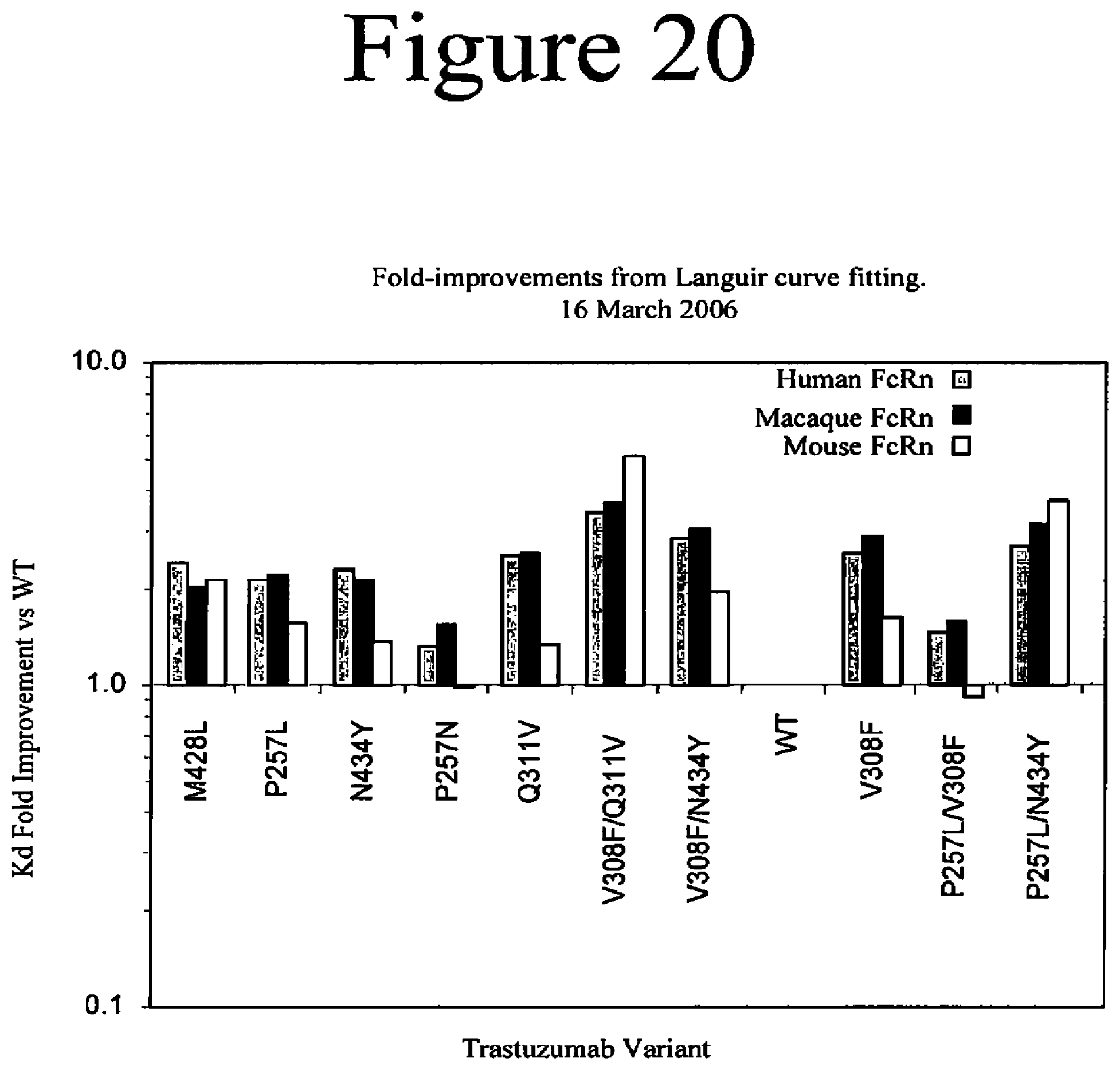
D00044
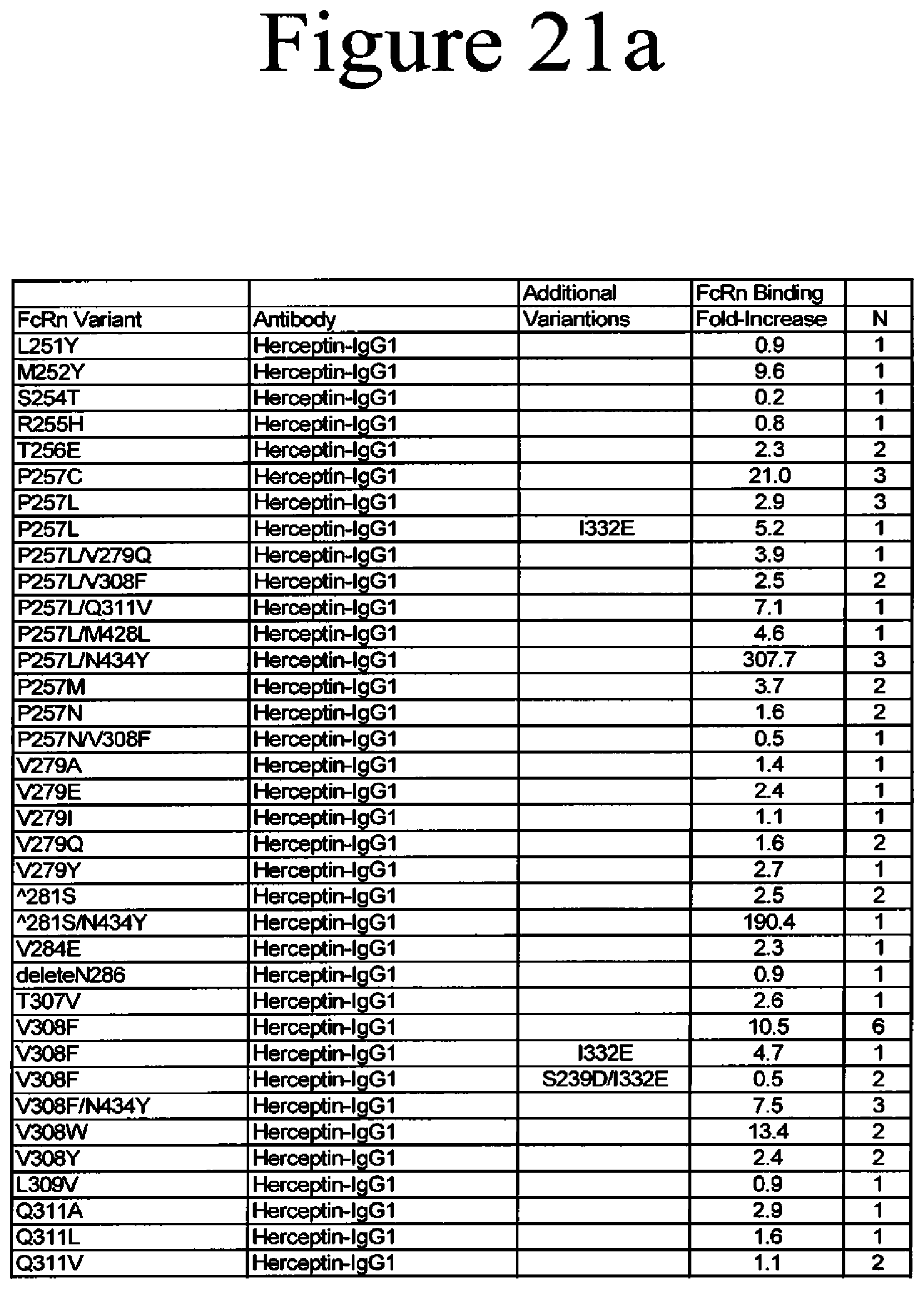
D00045

D00046

D00047

D00048

D00049
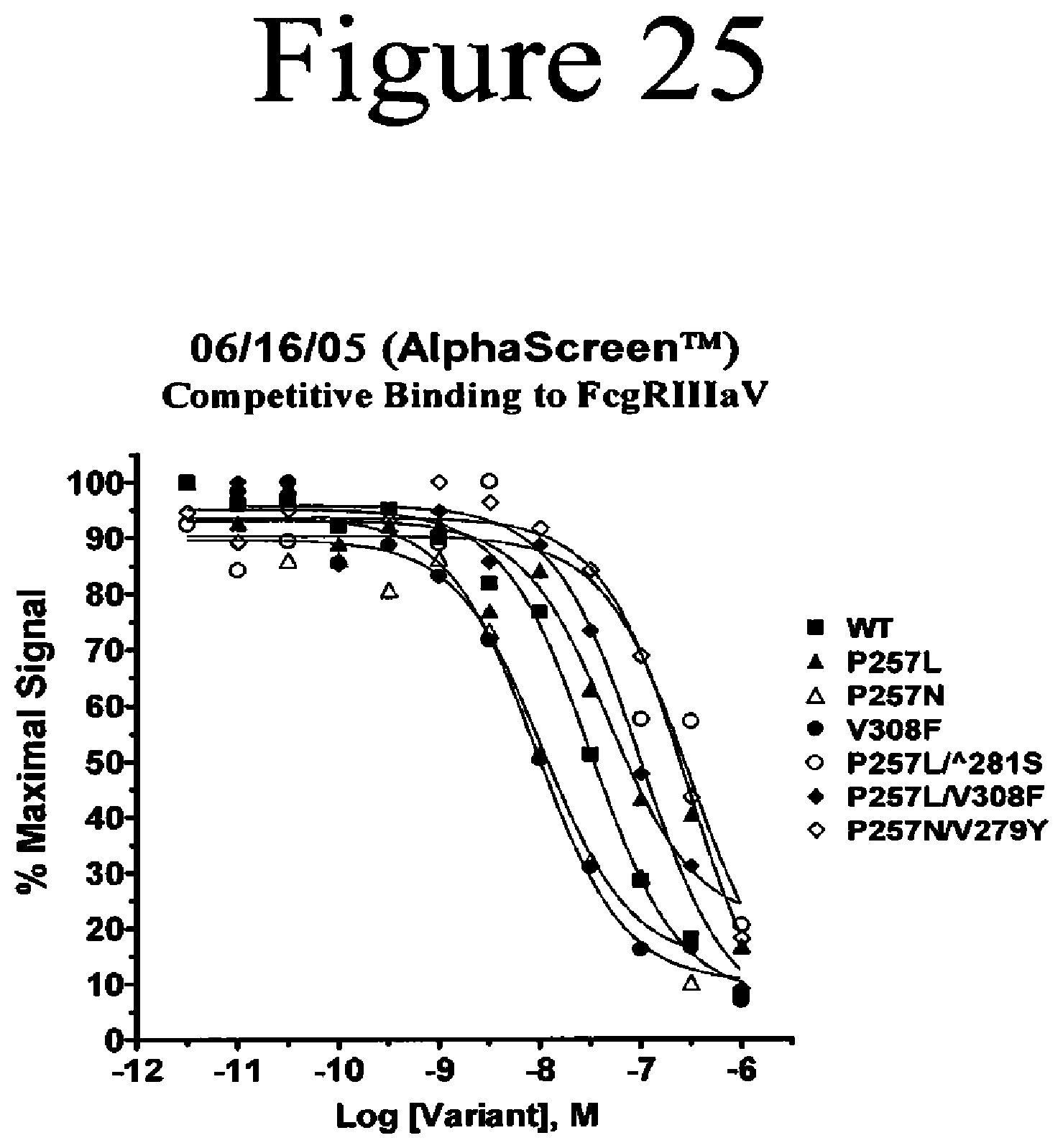
D00050

D00051
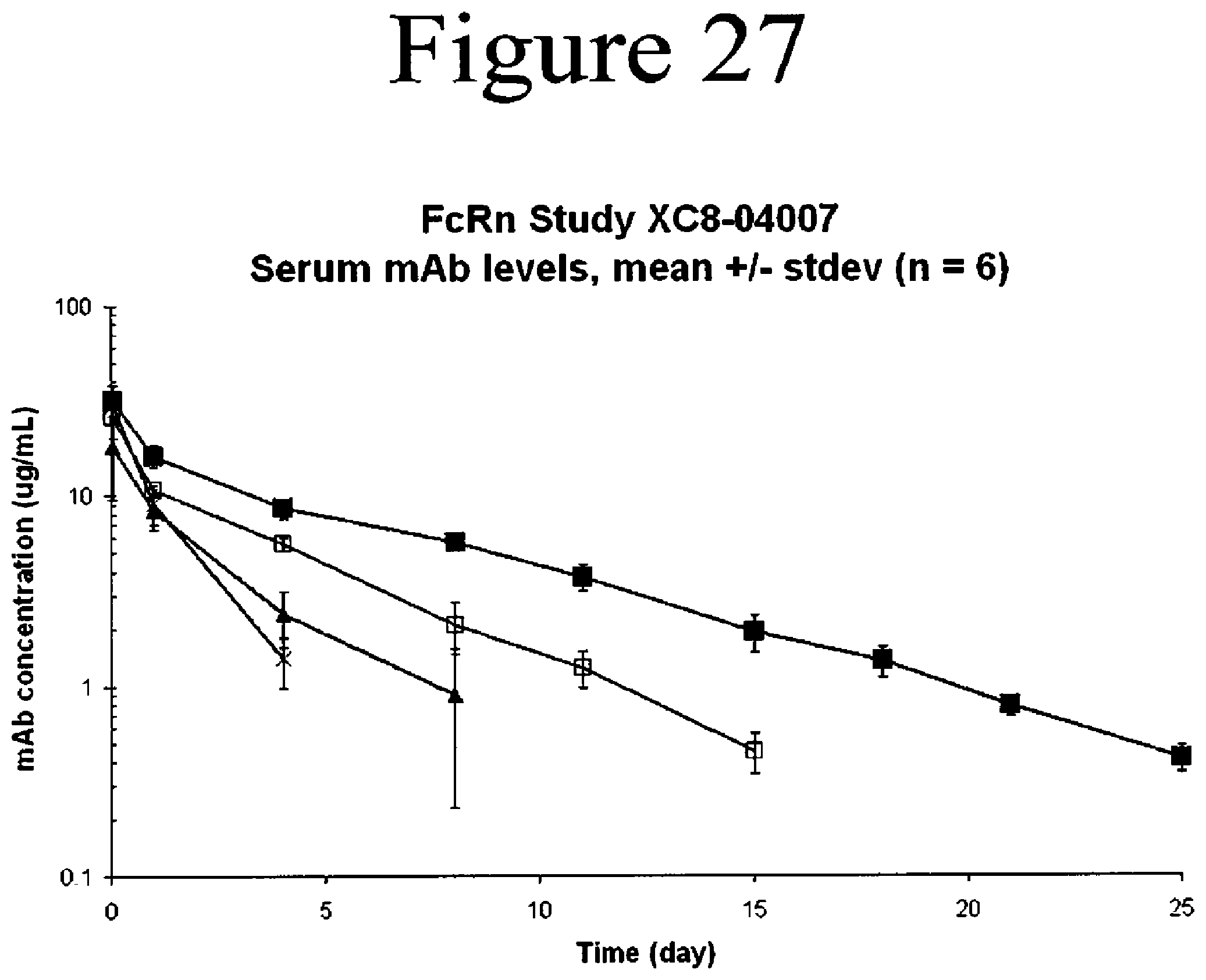
D00052
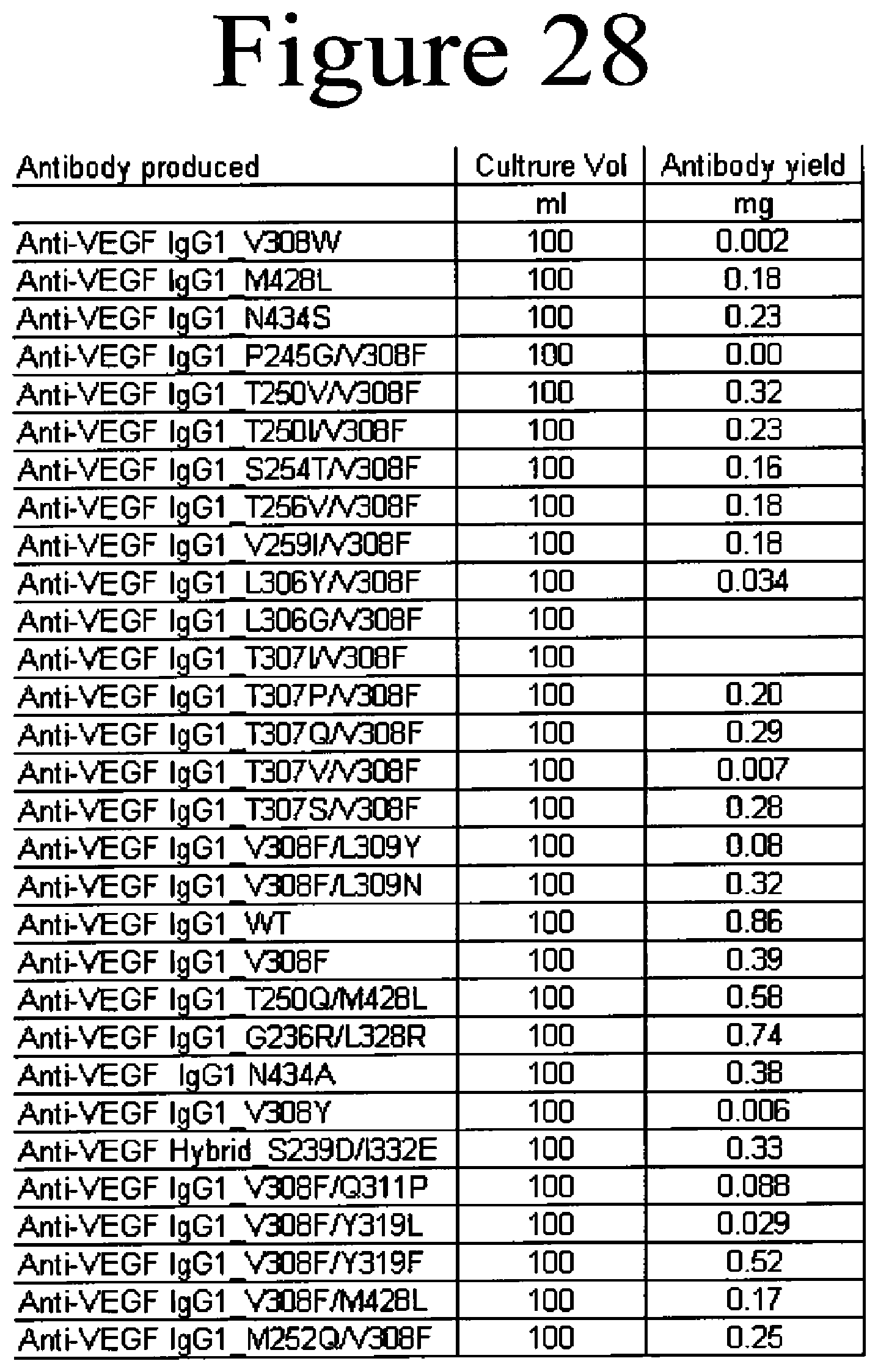
D00053
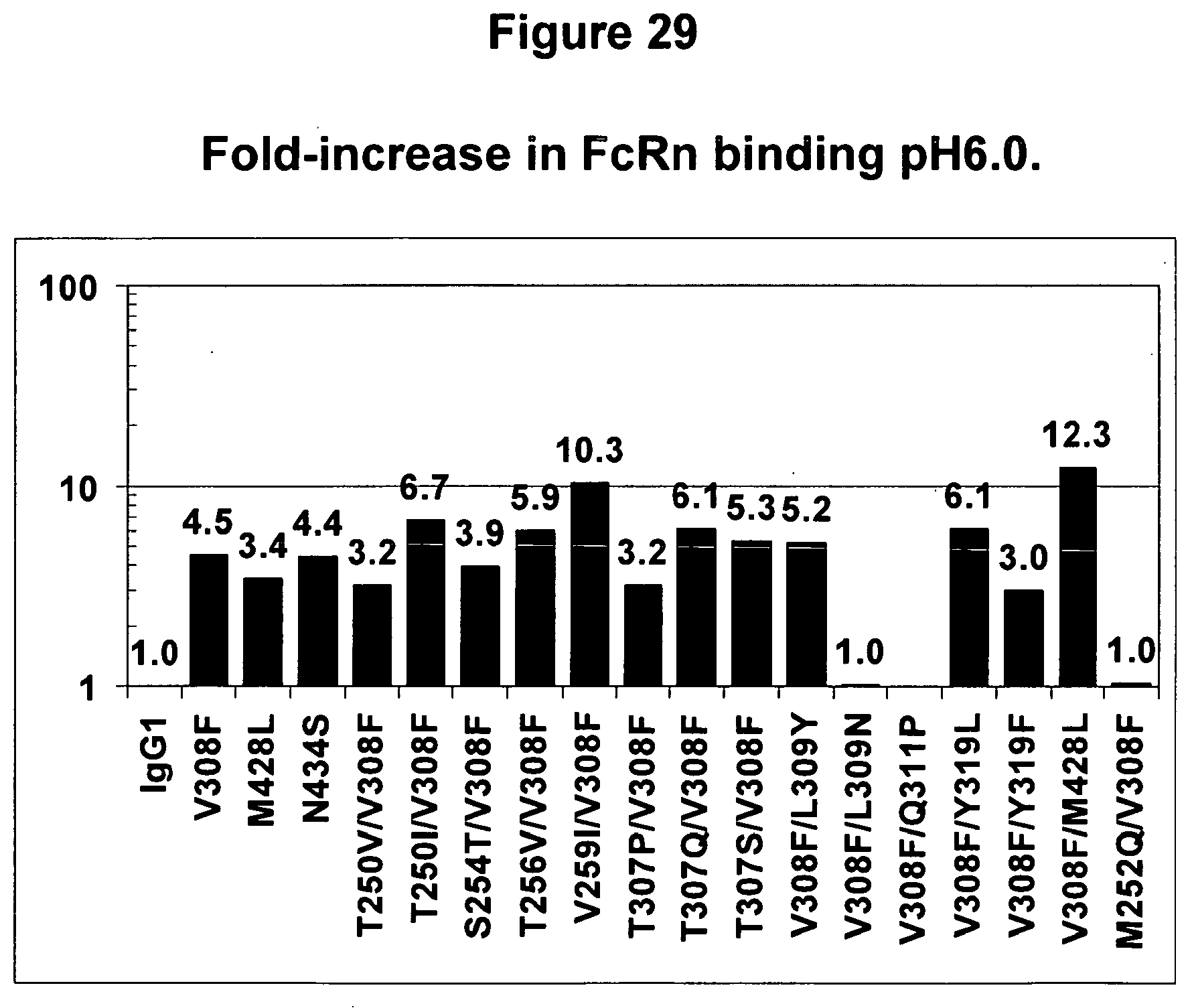
D00054
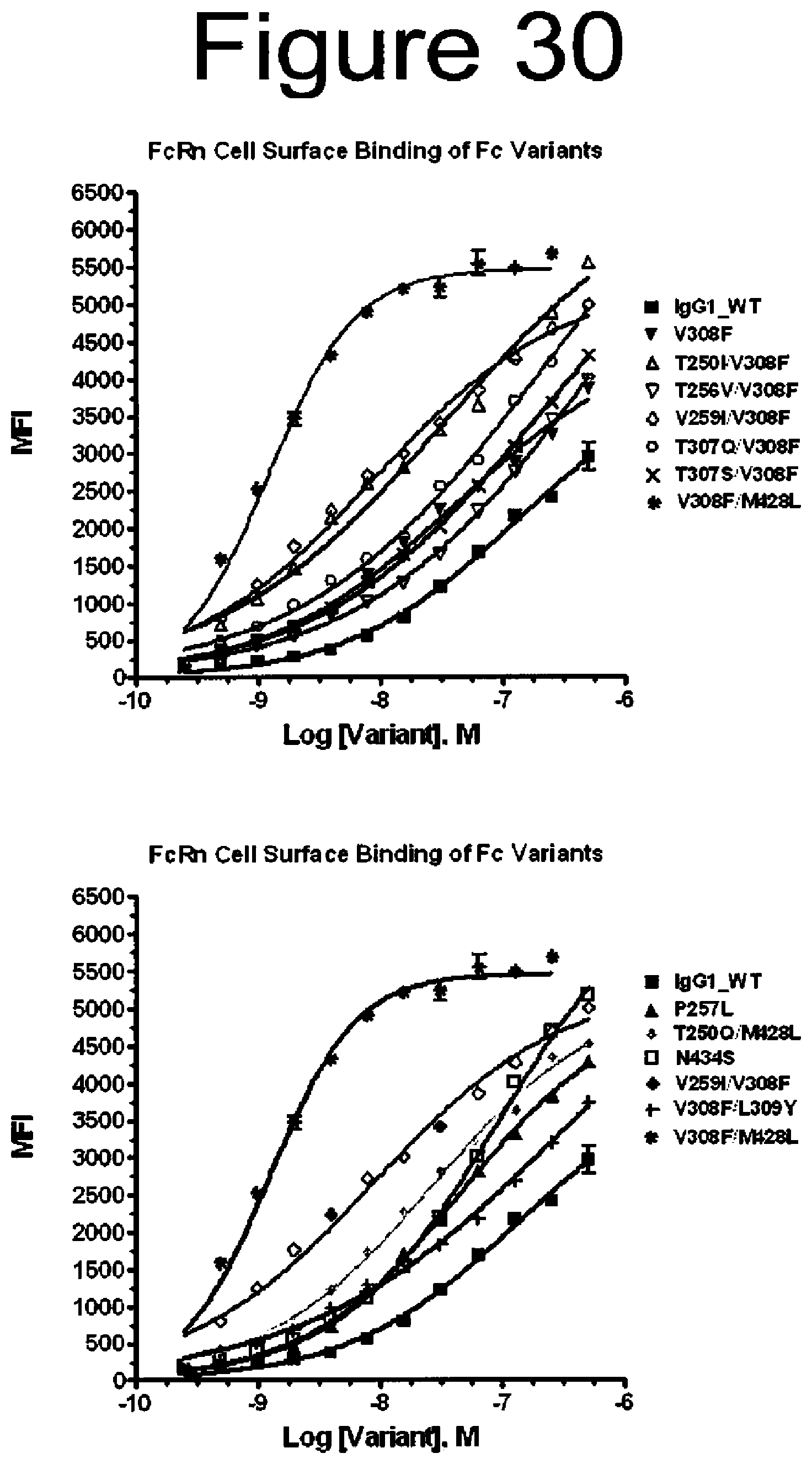
D00055

D00056

D00057
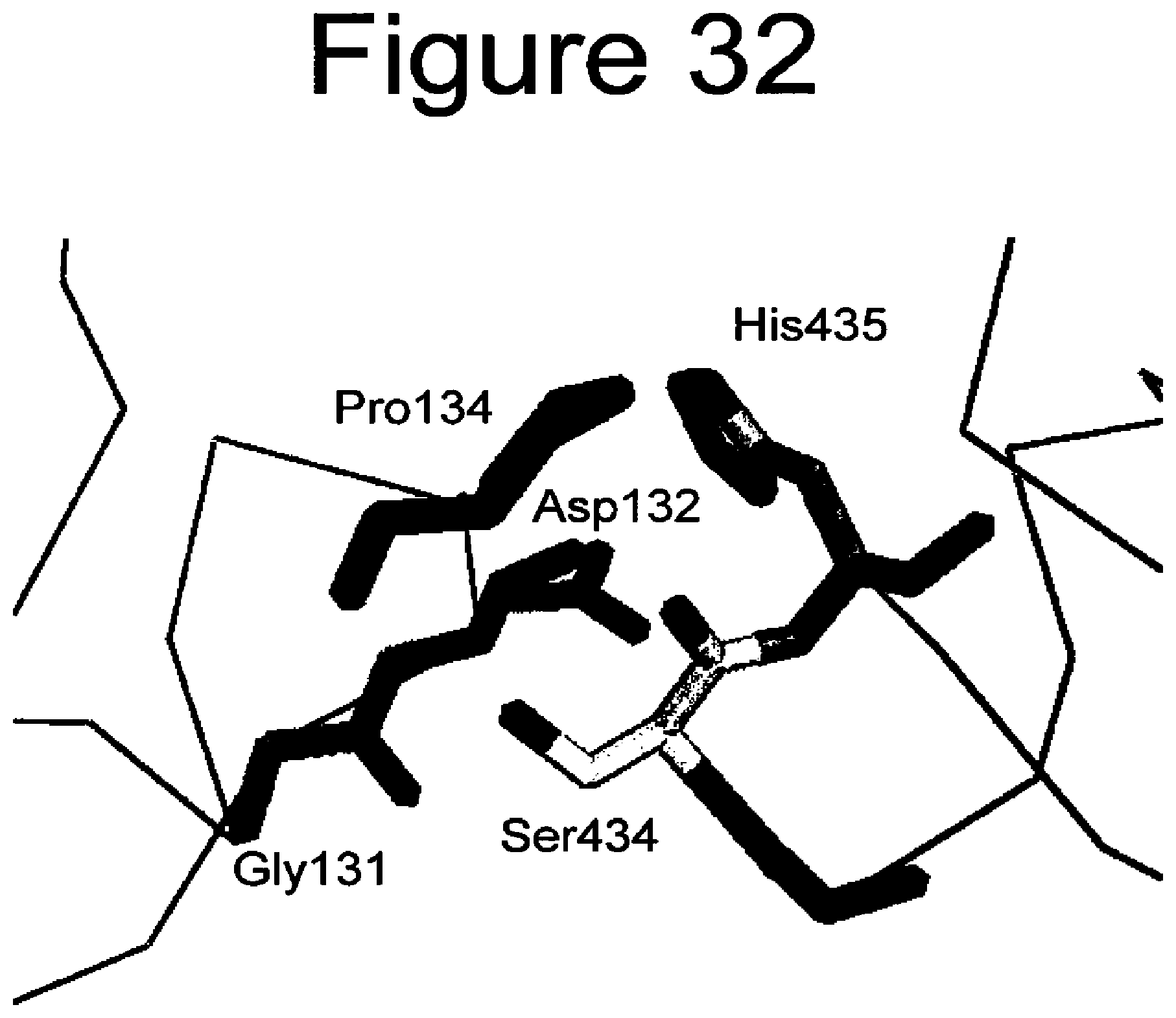
S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.