System And Method For Performance Evaluation Of Probability Forecast
Zhang; Xiaoping ; et al.
U.S. patent application number 17/066695 was filed with the patent office on 2021-01-28 for system and method for performance evaluation of probability forecast. The applicant listed for this patent is FinancialSharp, Inc.. Invention is credited to David Kedmey, Fang Wang, Xiaoping Zhang.
| Application Number | 20210027183 17/066695 |
| Document ID | / |
| Family ID | 1000005137407 |
| Filed Date | 2021-01-28 |



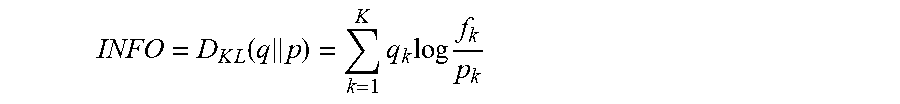






View All Diagrams
| United States Patent Application | 20210027183 |
| Kind Code | A1 |
| Zhang; Xiaoping ; et al. | January 28, 2021 |
SYSTEM AND METHOD FOR PERFORMANCE EVALUATION OF PROBABILITY FORECAST
Abstract
A method and system for probability distribution forecast evaluation are disclosed. The present disclosure is directed to embodiments of a system that evaluates probability distribution forecasts by acquiring one or more of a probability distribution forecast, a probability distribution realization, and a prior knowledge of the probability distribution forecast. The system disclosed herein may then compute an accuracy score and an information score based on the acquired forecast, realization, and prior knowledge. In evaluating the forecast, a performance score may also be computed based on the accuracy score and the information score.
| Inventors: | Zhang; Xiaoping; (Toronto, CA) ; Kedmey; David; (Brooklyn, NY) ; Wang; Fang; (Toronto, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 1000005137407 | ||||||||||
| Appl. No.: | 17/066695 | ||||||||||
| Filed: | October 9, 2020 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15478910 | Apr 4, 2017 | 10803393 | ||
| 17066695 | ||||
| 62317774 | Apr 4, 2016 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06N 5/02 20130101; G06N 7/005 20130101; G06F 17/18 20130101; G06N 5/04 20130101 |
| International Class: | G06N 5/04 20060101 G06N005/04; G06N 5/02 20060101 G06N005/02; G06F 17/18 20060101 G06F017/18; G06N 7/00 20060101 G06N007/00 |
Claims
1. A probability distribution forecast evaluation system comprising: at least one processor; at least one memory device that stores a plurality of instructions which, when executed by the at least one processor, cause the at least one processor to operate with the at least one memory device to: acquire a probability distribution forecast and a prior knowledge of the probability distribution forecast; compute an information score based on the probability distribution forecast and the prior knowledge of the probability distribution forecast; and compute a performance score based on the information score.
2. The probability distribution forecast evaluation system of claim 1, further comprising instructions that, when executed by the at least one processor, cause the at least one processor to operate with the at least one memory device to: acquire a probability distribution realization corresponding to the probability distribution forecast; compute an accuracy score based on one or more of the probability distribution forecast, the probability distribution realization corresponding to the probability distribution forecast, and the prior knowledge of the probability distribution forecast; and compute the performance score based on the accuracy score and the information score.
3. The probability distribution forecast evaluation system of claim 2, wherein the accuracy score is computed based on the probability distribution forecast and the probability distribution realization.
4. The probability distribution forecast evaluation system of claim 3, wherein the accuracy score is computed by calculating a dissimilarity score between the probability distribution forecast and the probability distribution realization.
5. The probability distribution forecast evaluation system of claim 4, wherein the dissimilarity score is either (1) the Kullback-Leibler (KL) divergence between the probability distribution forecast and the probability distribution realization, or (2) a quadratic approximation of the KL divergence between the probability distribution forecast and the probability distribution realization.
6. The probability distribution forecast evaluation system of claim 2, wherein the performance score is computed by subtracting the accuracy score from the information score.
7. The probability distribution forecast evaluation system of claim 2, wherein a relative performance score is further computed based on the computed performance score and an entropy of the prior knowledge of the probability distribution forecast.
8. The probability distribution forecast evaluation system of claim 1, wherein the information score is computed by calculating a dissimilarity score between the probability distribution realization and the prior knowledge of the probability distribution forecast.
9. The probability distribution forecast evaluation system of claim 8, wherein the dissimilarity score is either (1) the Kullback-Leibler (KL) divergence between the probability distribution realization and the prior knowledge of the probability distribution forecast, or (2) a quadratic approximation of the KL divergence between the probability distribution realization and the prior knowledge of the probability distribution forecast.
10. The probability distribution forecast evaluation system of claim 1, wherein one or more of the probability distribution forecast and the prior knowledge of the probability distribution forecast are computed based on samples.
11. The probability distribution forecast evaluation system of claim 10, wherein one or more of the probability distribution forecast and the prior knowledge of the probability distribution forecast are partitioned into discrete probability bins.
12. The probability distribution forecast evaluation system of claim 10, wherein one or more of the probability distribution forecast and the prior knowledge of the probability distribution forecast contain sample errors and the performance score is normalized to account for the sample errors.
13. A method comprising: acquiring a probability distribution forecast and a prior knowledge of the probability distribution forecast; computing an information score based on the probability distribution forecast and the prior knowledge of the probability distribution forecast; and computing a performance score based on the information score.
14. The method of claim 13, further comprising: acquiring a probability distribution realization corresponding to the probability distribution forecast; computing an accuracy score based on one or more of the probability distribution forecast, the probability distribution realization corresponding to the probability distribution forecast, and the prior knowledge of the probability distribution forecast; and computing the performance score based on the accuracy score and the information score.
15. The method of claim 14, wherein the accuracy score is computed based on the probability distribution forecast and the probability distribution realization.
16. The method of claim 14, wherein the performance score is computed by subtracting the accuracy score from the information score.
17. The method of claim 14, wherein a relative performance score is further computed based on the computed performance score and an entropy of the prior knowledge of the probability distribution forecast.
18. The method of claim 13, wherein the information score is computed by calculating a dissimilarity score between the probability distribution realization and the prior knowledge of the probability distribution forecast.
19. The method of claim 13, wherein one or more of the probability distribution forecast and the prior knowledge of the probability distribution forecast are computed based on samples, and wherein one or more of the probability distribution forecast and the prior knowledge of the probability distribution forecast are partitioned into discrete probability bins.
20. The method of claim 13, wherein one or more of the probability distribution forecast and the prior knowledge of the probability distribution forecast are computed based on samples, and wherein one or more of the probability distribution forecast and the prior knowledge of the probability distribution forecast contain sample errors and the performance score is normalized to account for the sample errors.
Description
PRIORITY CLAIM
[0001] This application claims priority to and the benefit of U.S. Provisional Patent Application Ser. No. 62/317,774, filed on Apr. 4, 2016, and U.S. patent application Ser. No. 15/478,910, filed on Apr. 4, 2017, both of which are incorporated herein by reference in their entirety.
TECHNICAL FIELD
[0002] The present application relates in general to evaluating probability distribution forecasts. More specifically, the present application refers to a system and method for evaluating probability distribution forecasts by computing an accuracy score and an information score and further computing a performance score based on the accuracy score and information score.
BACKGROUND
[0003] Modern forecasting techniques and technologies have resulted in a large number of forecasts and predictions across a variety of industries and applications. The widespread availability of such forecasts enables businesses, groups, and individuals to better plan their behavior and generally prepare for the future. However, these forecasts are only useful to the extent they are accurate. It is therefore important for users of these forecasts to have a way to evaluate these forecasts.
[0004] The large number of available forecasts and large number of predictions inherent in each forecast means that any forecast evaluation must be systematic and repeatable between multiple forecasts. Existing forecast evaluation strategies focus primarily on the forecasts' accuracy, or how far the forecast's predictions tend to be from what actually happens. However, focusing on accuracy alone fails to measure whether the forecast provides more information than what is already available. A forecast that provides more information may be more useful even if it is less accurate. For example, a forecast that tells you it rains on 30% of the days in July may be highly accurate. However, a forecast that predicts an 80% chance of rain tomorrow may be much more useful, even if it is inaccurate and there is actually a 90% chance of rain tomorrow. Therefore, a forecast evaluation strategy that takes into account both a forecast's accuracy and the additional information it provides is needed.
SUMMARY
[0005] A system and method to enable probability distribution forecast evaluation are disclosed. The probability distribution forecast evaluation system comprises at least one processor and at least one memory device. The at least one memory device may store a plurality of instructions which, when executed by the at least one processor, cause the at least one processor to operate with the at least one memory device to acquire one or more of a probability distribution forecast, a probability distribution realization corresponding to the probability distribution forecast, and a prior knowledge of the probability distribution forecast; compute an accuracy score based on the one or more of a probability distribution forecast, a probability distribution realization corresponding to the probability distribution forecast, and a prior knowledge of the probability distribution forecast; compute an information score based on the one or more of a probability distribution forecast, a probability distribution realization corresponding to the probability distribution forecast, and a prior knowledge of the probability distribution forecast; and compute a performance score based on the accuracy score and the information score.
[0006] The accuracy score may be computed based on the probability distribution forecast and the probability distribution realization. The accuracy score may further be computed by calculating a dissimilarity score between the probability distribution forecast and the probability distribution realization. The probability distribution forecast evaluation system may calculate a dissimilarity score that is either (1) the Kullback-Leibler (KL) divergence between the probability distribution forecast and the probability distribution realization, or (2) a quadratic approximation of the KL divergence between the probability distribution forecast and the probability distribution realization.
[0007] The probability distribution forecast evaluation system may compute the information score based on the probability distribution realization and the prior knowledge of the probability distribution forecast. The information score may be computed by calculating a dissimilarity score between the probability distribution realization and the prior knowledge of the probability distribuion forecast. The probability distribution forecast evaluation system may calculate a dissimilarity score that is either (1) the Kullback-Leibler (KL) divergence between the probability distribution realization and the prior knowledge of the probability distribution forecast, or (2) a quadratic approximation of the KL divergence between the probability distribution realization and the prior knowledge of the probability distribution forecast.
[0008] The probability distribution forecast evaluation system may compute the performance score by subtracting the accuracy score from the information score. Further, one or more of the probability distribution forecast, the probability distribution realization corresponding to the probability distribution forecast, and the prior knowledge of the probability distribution forecast are computed based on samples. Still further, one or more of the probability distribution forecast, the probability distribution realization corresponding to the probability distribution forecast, and the prior knowledge of the probability distribution forecast may be partitioned into discrete probability bins. In some embodiments, one or more of the probability distribution forecast, the probability distribution realization corresponding to the probability distribution forecast, and the prior knowledge of the probability distribution forecast contain sample errors and the performance score may be normalized to account for the sample errors. Lastly, a relative performance score may be further computed based on the computed performance score and the entropy of the prior knowledge of the probability distribution forecast.
BRIEF DESCRIPTION OF THE FIGURES
[0009] FIG. 1 is a schematic diagram of an example implementation of the presently described probability distribution forecast evaluation system.
[0010] FIG. 2 is a flowchart of an example method for implementing the presently described probability distribution forecast evaluation system.
DETAILED DESCRIPTION
[0011] The systems and method disclosed herein rely in different capacities on scoring and manipulating probability distributions. These probability distributions may correspond to any set of financial, business, weather, or other data. The probability distributions may be forecasts or predictions of a given probability distribution, actual realizations of a probability distributions, or prior knowledge of a given probability distribution, which may also comprise a reference probability distribution. The probability distributions may be stored either as continuous probability density functions, as discretized probability mass functions stored in vectors, or as samples that correspond to the probability distribution. It should be understood that the probability distributions may also be stored in other manners without departing from the scope of the present disclosure.
[0012] Throughout this detailed description, multiple equations are used to illustrate potential embodiments of the system disclosed herein. To aid in understanding these exemplary equations, Table 1 below sets out definitions for terms used in the equations.
TABLE-US-00001 TABLE 1 Term Definition K Number of bins in a given probability distribution, or a number of possible outcomes N Total number of realized samples or total number of forecasts M.sub.k Total number of forecasts for the k-th bin. f.sub.k Forecast probability (frequency) for k-th bin f.sub.nk Forecast probability (frequency) for the k-th bin at the n-th sample p.sub.k Realized probability (frequency) for the k-th bin .sub.k Observed frequency for the k-th bin; i.e., an empirical ex post estimate of p.sub.k o.sub.nk For the n-th sample, if it falls in the k-th bin, o.sub.nk = 1; otherwise, o.sub.nk = 0 .sub.k|p Observed frequency for the k-th bin, according to a bin division of p q.sub.k Prior knowledge for the k-th bin, or a reference probability distribution used as the prior knowledge f, p, , q The probability density functions with the definitions as described above (i.e., f-forecast, p-realization, -observed realization estimate, and q-prior knowledge) f, p, , q Vectors representing the probability mass functions with the definitions as described above (i.e., the discretized version of the probability density functions f, p, , q with a certain bin division)
[0013] Those skilled in the art will understand that these exemplary equations are not the only way to implement embodiments of the system disclosed herein, and various changes and modifications to the preferred embodiments will be apparent to them. Such changes and modifications can be made without departing from the spirit and scope of the present subject matter and without diminishing its intended advantages. It is therefore intended that such changes and modifications be covered by the appended claims.
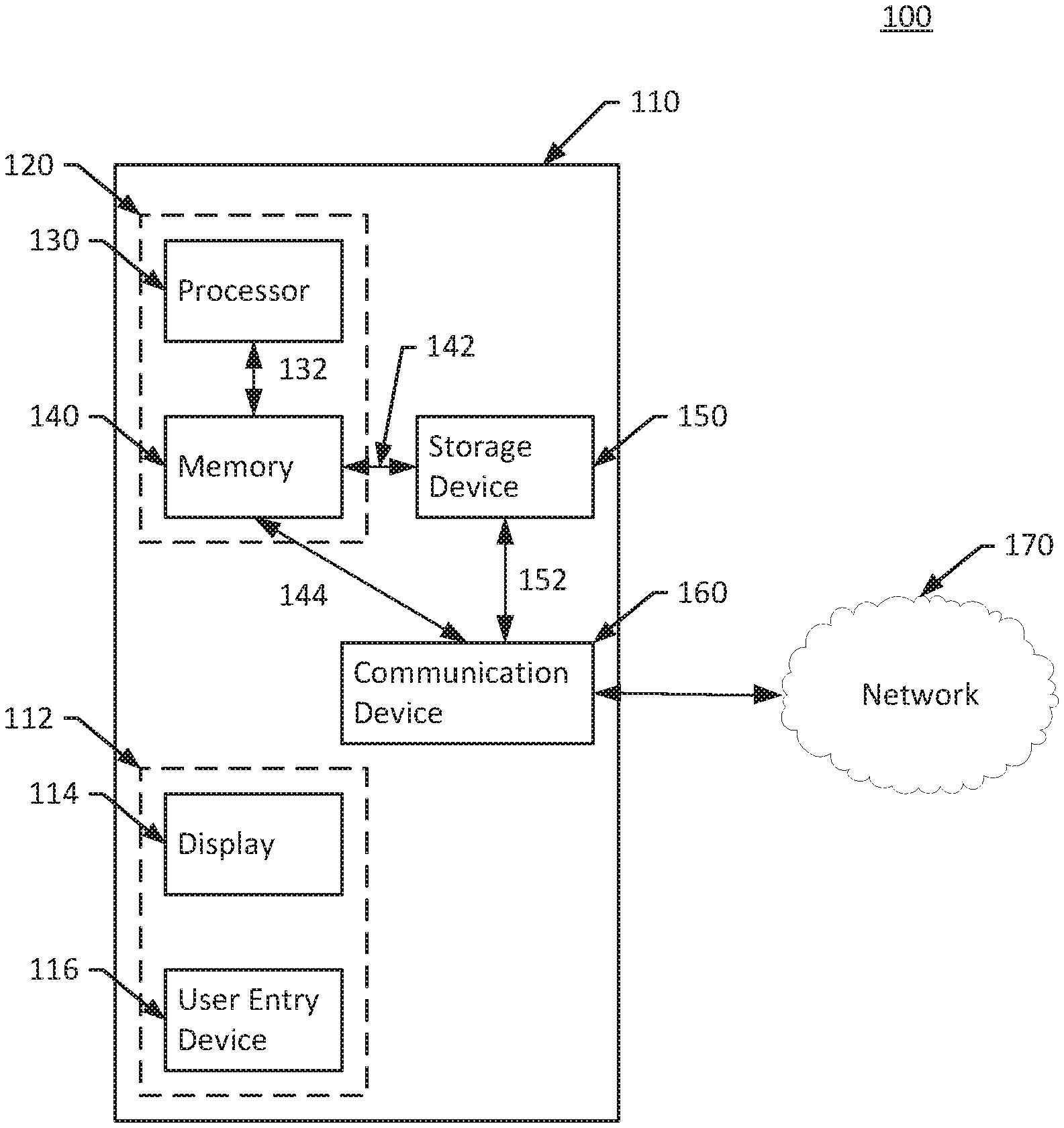
[0014] FIG. 1 is a schematic diagram of an example implementation 100 of the system described herein. The example implementation 100 includes a probability distribution forecast evaluation system 110. The probability distribution forecast evaluation system 110 includes an analysis module 120 comprising a processor 130 coupled to a memory 140. The analysis module 120 is coupled to a storage device 150 via link 142 and a communication device via link 144. The storage device 150 is further connected to the communication device 160 via link 152. The communication device connects the probability distribution forecast evaluation system 110 to the network 170 via link 162. The probability distribution forecast evaluation system 110 further includes a user interface device 112, which includes a display 114 and a user entry device 116.
[0015] The user interface device 112 may consist of a display 114 implemented as a computer monitor and a user entry device 116 implemented as one or more of a computer mouse, keyboard, voice recognition system, touch screen device, or other similar computer input device. In an alternative embodiment not depicted in FIG. 1, the user interface device 112 may be implemented as a physically separate device that connects to the probability distribution system 110 via the network 170 and link 162. For example, the user interface 112 could be a separate computing device such as a laptop, desktop computer, smartphone, or tablet. In this case, the display 114 may include a computer display, smartphone display, or tablet display and the user entry device may include a smartphone or tablet touchscreen, voice recognition system, or keyboard. In still other embodiments, the probability distribution forecast evaluation system 110 may not include any user interface.
[0016] The network 170 may be implemented as a local, closed network, or may include one or more connections to the Internet. The link 162 may be implemented as a wired connection, or as a wireless connection such as Wi-Fi, Bluetooth, 4G/LTE, or any other wireless protocol. The storage device 150 may be implemented as any for of data storage device. For example, the storage device 150 may be implemented as one or more of a hard disk drive (HDD), solid state drive (SSD), flash-based storage, read-only memory (ROM). The storage device 150 may be coupled to the communication device 160 via link 152 to receive information or data from the network 170. The storage device may store one or more of a probability distribution forecast, a realization of a probability distribution forecast, and a prior knowledge of the of the probability distribution forecast. This information may be stored either as a continuous forecast and may also or alternatively be stored as a set of empirical samples.
[0017] The processor 130 may be configured to perform a series of instructions that are stored in the memory 140. The memory 140 may be implemented as one or more random access memories (RAMs). Although depicted in the singular, the processor 130 may be implemented as one or more computer processing units (CPUs). As discussed in greater detail below, the memory 140 may contain a series of instructions that, when executed by the processor 130, cause the processor 130 to acquire one or more of a probability distribution forecast, a probability distribution realization corresponding to the probability distribution forecast, and a prior knowledge of the probability distribution forecast; compute an accuracy score based on the one or more of a probability distribution forecast, a probability distribution realization corresponding to the probability distribution forecast, and a prior knowledge of the probability distribution forecast; compute an information score based on the one or more of a probability distribution forecast, a probability distribution realization corresponding to the probability distribution forecast, and a prior knowledge of the probability distribution forecast; and compute a performance score based on the accuracy score and the information score.
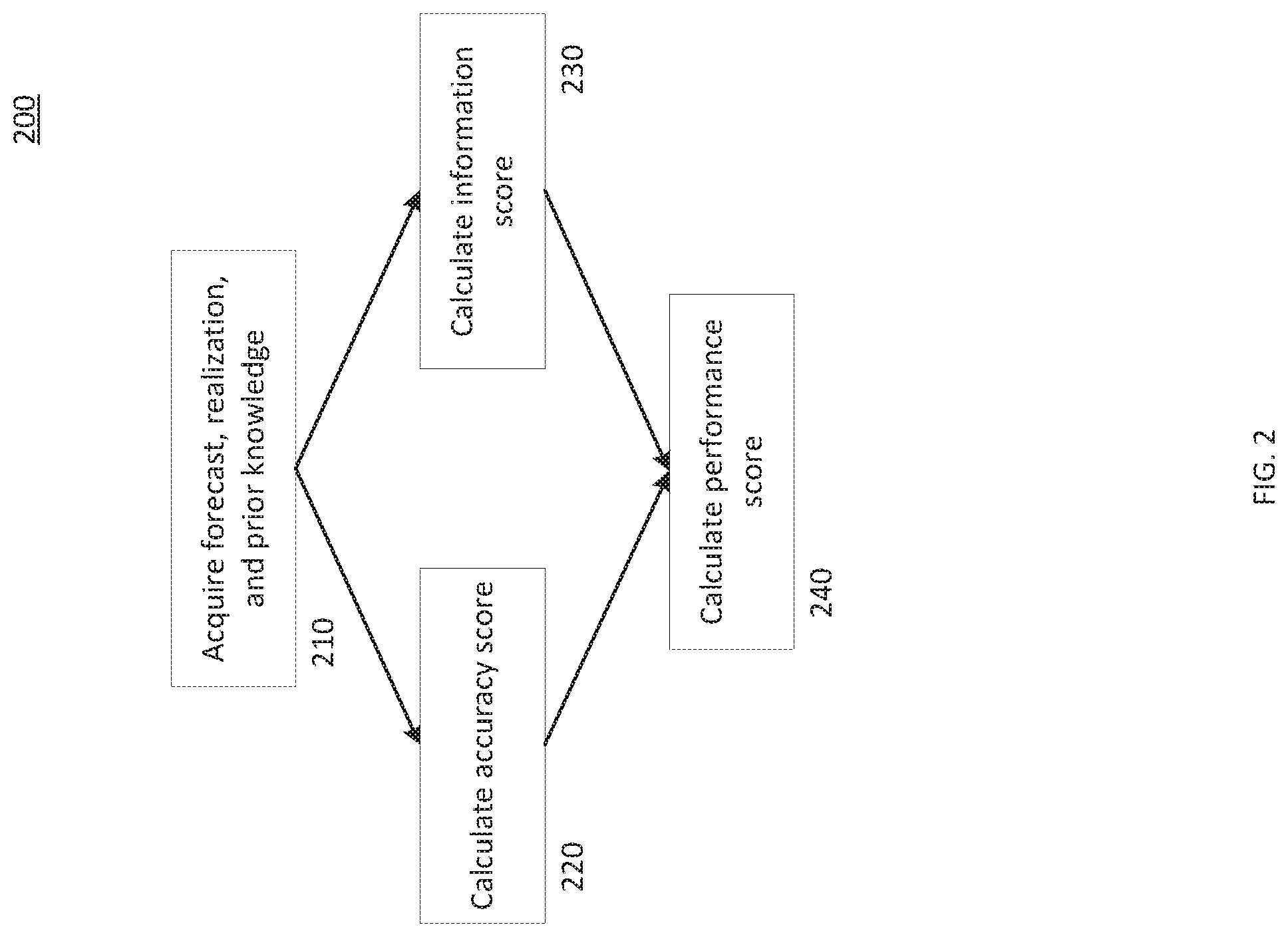
[0018] FIG. 2 depicts a flowchart of an example method 200 for implementing the system described herein. In some embodiments, the method 200 is an implementation of the probability distribution forecast evaluation system 110. For example, the method 200 may be implemented as a series of instructions stored on the memory 140 that cause the processor 130 to perform the method 200 when executed.
[0019] Starting at step 210, the method 200 acquires a probability distribution forecast ("forecast"), a probability distribution realization corresponding to the probability distribution forecast ("realization"), and a prior knowledge of the probability distribution forecast ("prior knowledge"). In some embodiments, the method 200 may not acquire all three of the forecast, realization, and prior knowledge. Instead, it may only acquire a subset, such as just the forecast or both of the forecast and the prior knowledge. The forecast, realization, and prior knowledge may be user entered, such as through the user interface 112; may be stored, such as in storage device 150; or may be looked up, downloaded, or acquired over a network, such as network 170. The system disclosed herein contemplates that each of the forecast, realization, and prior knowledge are acquired by different means. For example, the forecast may be user entered, the realization may be downloaded from the Internet, and the prior knowledge may be stored on a storage device.
[0020] The forecast may be a stored version of a previously-recorded forecast of a statistical probability distribution forecast. The forecast may predict metrics in one or more areas such as financial metrics, economic metrics, business performance metrics, weather metrics, or any other metric that may be useful to predict. The realization may be a stored version of the realized probability distribution of the metrics that the forecast predicted. The prior knowledge may be a stored version of prior knowledge about the probability distribution that the forecast predicted. For example, this may be a reference probability distribution for the forecast.
[0021] Each of the forecast, realization, and prior knowledge may be stored as a probability density function, a probability mass function, or a collection of samples. Further, the forecast, realization, and prior knowledge may be partitioned into one or more bins. Each of the forecast, realization, and prior knowledge may have a different number of bins. Further, each of the forecast, realization, and prior knowledge may be stored in a different function. For example, the forecast and prior knowledge may be stored as a probability density function and the realization may be stored as a collection of samples.
[0022] Once the forecast, realization, and prior knowledge are acquired, at step 220 the method 200 progresses to calculate an accuracy score for the forecast. The accuracy score shows how reliable a forecast is, measuring how reliably the forecast predicts the probability distribution. This measure is important to evaluating a probability distribution forecast because accuracy is an important component of a useful forecast.
[0023] The accuracy score may be based on the forecast and the realization. In some embodiments, the accuracy score is calculated by computing a dissimilarity score between the forecast and the realization. A dissimilarity score may be a measurement of how different two sets of data are. For example, the accuracy score may be calculated by calculating the Kullback-Leibler (KL) divergence between the forecast and the realization, as shown below:
A C C = D K L ( f p ) = k = 1 K f k log f k p k ##EQU00001##
[0024] This implementation of the accuracy score will be lower when a forecast is more accurate.
[0025] In other embodiments, the accuracy score may be calculated using a quadratic approximation of the KL divergence between the forecast and the realization.
[0026] For example, if the accuracy score is calculated based on samples of one or more of the forecast and the realization, it may be useful to calculate the accuracy score using the quadratic approximation of the KL divergence between the samples of the forecast and the realization. Those skilled in the art will recognize that the KL divergence between the samples of the forecast and the realization can be approximated with chi-squared statistics using a quadratic approximation as shown below:
A C C = k = 1 K ( f k - o _ k ) 2 f k ##EQU00002##
[0027] In this instance, if only one of the forecast and the realization is stored as samples, the other may be converted to samples by partitioning it into bins. For example, if the realization distribution is stored as samples, the forecast may be partitioned into bins. In some embodiments, it may be preferable to convert the distribution that was not sampled into the same number of bins as the sampled distribution. In the preceding situation, for example, if the realization distribution is stored as a set of samples in 5 bins, the forecast may be partitioned into 5 bins. In other cases, if neither the forecast nor the realization is stored as samples, the system of the present disclosure may convert both distributions by partitioning them into bins. As described above, it may be beneficial to partition both distributions into the same number of bins.
[0028] At step 230, the method 200 calculates an information score for the forecast. The information score measures the amount of information a forecast contains compared to the prior knowledge about the forecasted metrics. This prior knowledge may include reference probability distributions for the forecasted metrics. The information score is an important part of evaluating forecasts. Conventional techniques, such as the Brier score, treat more certainty (or a better accuracy score) as the better forecast. Such systems fail to properly account for the amount of information in a forecast. For example, even if a forecast is less certain than the prior knowledge, it is still useful to know that the future is more uncertain than the prior knowledge. As a further example, an area may get rain on 30% of the days over the course of the year. However, a forecast that predicted a 30% chance of rain for every day might be very accurate over the course of the year, but it does not contain any information and is therefore not very useful. On the other hand, a forecast that predicts a 90% chance of rain on days when it only rains 80% of the time might not be that accurate, but it does contain information about which days are more likely to receive rain and is therefore more useful. Accordingly, embodiments of the presently disclosed system incorporate an information score into its evaluation.
[0029] The information score may be based on the forecast and the prior knowledge. In some embodiments, the information score is calculated by computing a dissimilarity score between the forecast and the realization. For example, the information score may be calculated by calculating the KL divergence between the realization and the prior knowledge, as shown below:
INFO = D K L ( q p ) = k = 1 K q k log f k p k ##EQU00003##
[0030] This implementation of the information score will be higher when a forecast provides more information.
[0031] In some embodiments, the forecast may be a conditional distribution. In these cases, both the realization and the forecast may be conditional on the same condition. Similarly, the prior knowledge is generally either an unconditional distribution, or is conditional on a different condition from the forecast and the realization. In this instance, when the accuracy score is high, the forecast may be used as a proxy for the realization in the information score calculation. For example, the information score may be calculated as shown below:
INFO = k = 1 K f k log f k q k ##EQU00004##
[0032] In still further embodiments, the information score may be calculated using a quadratic approximation of the KL divergence between the realization and the prior knowledge. For example, if the accuracy score is calculated based on samples of one or more of the realization and the prior knowledge, it may be useful to calculate the information score using the quadratic approximation of the KL divergence between the samples of the realization and the prior knowledge. Those skilled in the art will recognize that the KL divergence between the samples of the realization and the prior knowledge can be approximated with chi-squared statistics using a quadratic approximation as shown below:
INFO = k = 1 K ( q k - o _ k ) 2 q k ##EQU00005##
[0033] In similar embodiments to those discussed above, if the forecast is accurate (i.e., the accuracy score is small), the forecast may be used as a proxy for the realization in the information score calculation. In this instance, the information score can be calculated with the quadratic approximation of the KL divergence between the samples of the forecast and the prior knowledge as shown below:
INFO = k = 1 K ( q k - f k ) 2 f k ##EQU00006##
[0034] In this instance, if only one of the prior knowledge and the realization is stored as samples, the other may be converted to samples by partitioning it into bins. For example, if the realization distribution is stored as samples, the forecast may be partitioned into bins. In some embodiments, it may be preferable to convert the distribution that was not sampled into the same number of bins as the sampled distribution. In the preceding situation, for example, if the realization distribution is stored as a set of samples in 5 bins, he prior knowledge may be partitioned into 5 bins. In other cases, if neither the prior knowledge nor the realization is stored as samples, the disclosed system may convert both distributions by partitioning them into bins. As described above, it may be beneficial to partition both distributions into the same number of bins.
[0035] After calculating the accuracy and information scores, at step 240, the method 200 calculates a performance score based on the accuracy score and the information score. In some embodiments, the performance score is calculated by subtracting the accuracy score from the information score, as shown below:
PS=INFO-ACC
[0036] When defined like this, the larger the performance score is, the better the forecast is. One benefit of this implementation is that the accuracy score and information score can be calculated independently. This means that, the number of bins used in the accuracy score calculation can differ from the number of bins used in the information score calculation. This improves the simplicity and numerical stability of the calculation.
[0037] Similarly, the above implementation of the performance score calculation does not depend on how each of the information score and the accuracy score are calculated. Accordingly, this implementation may be used even if the accuracy score and information score are calculated based on samples or if the information score is calculated by using the forecast as a proxy for the realization as discussed above. In fact, in some embodiments it may be preferable to use the forecast as a proxy for the realization in the information score calculation. Doing this may result in a simplified, and therefore faster, calculation. Calculating the performance score in this manner may also be more robust if one or more of the forecast, prior knowledge, and realization is stored as samples. An example implementation of this is shown below:
PS = INFO - ACC = k = 1 K f k log f k q k - k = 1 K f k log f k p k = k = 1 K f k log p k q k ##EQU00007##
[0038] In some embodiments, after calculating the performance score, the method 200 will also calculate a relative performance score (not depicted in FIG. 2). The relative performance score may be calculated based on the entropy of the prior knowledge. In some embodiments, the entropy of the prior knowledge may be calculated as defined below:
H Q = - k = 1 K q k log q k = log K - D K L ( q u ) ##EQU00008##
[0039] where u represents a uniform distribution, i.e., u.sub.k=1/K.
[0040] In still further embodiments, after calculating the performance score, the method 200 will also calculate a confidence interval for the performance score. The confidence interval for the performance score may be based on the probability distribution of the performance score. For example, in some embodiments, those with skill in the art will note that one or more of the accuracy score and the information score may have a probability distribution if calculated based on samples. Accordingly, a probability distribution of the performance score may be calculated based on one or more of the probability distribution of the accuracy score and the probability distribution of the information score. The confidence interval for the performance score may then be calculated based on the probability distribution of the performance score. In practice, the confidence interval of the performance score may be valuable because it provides more information on the range of values that the performance score may take. This provides users with a greater understanding of the performance of the forecast.
[0041] The previously-discussed example embodiments of the method 200 focus primarily on analyzing a single forecast at a time. However, the present disclosure also contemplates that the method 200 may also analyze multiple forecasts, where each of the multiple forecasts may differ from one another. In addition, one or more of the prior knowledge and realization could be different for one or more of the multiple forecasts as well. In some embodiments, each of the forecasts may use different bin divisions and the prior knowledge and realization that correspond to each of the forecasts may also use different bin divisions. For example, if the multiple forecasts use different bin divisions, the prior knowledge and realization that correspond to each of the multiple forecasts may use the same division as their corresponding forecast.
[0042] In some embodiments, the method 200 may select bin divisions for each distribution such that the probability bins of the multiple forecasts are the same. In such embodiments, the accuracy and information scores may be calculated as defined below:
A C C = k = 1 K ( f k - o _ k | f ) 2 f k ##EQU00009## I NFO = k = 1 K ( q k - o _ k | q ) 2 q k ##EQU00009.2##
[0043] In the above embodiment, the method 200 may use the forecast as a proxy for the realization in the information score calculation as described above. For example, the information score may be calculated as shown below:
INFO = k = 1 K ( q k | f - f k ) 2 f k ##EQU00010##
[0044] In still further embodiments, the method 200 may select equal quantiles for both the prior knowledge and the realization. In this case, the performance score may be calculated as defined below:
PS = K k = 1 K ( q k - o _ k | q ) 2 - K k = 1 K ( f k - o _ k | f ) 2 = K [ k = 1 K ( 1 K - o _ k | q ) 2 - k = 1 K ( 1 K - o _ k | f ) 2 ] ##EQU00011##
[0045] In the above embodiment, the method 200 may use the forecast as a proxy for the realization in the information score calculation as described above. In such an embodiment, the performance score may be calculated as shown below:
PS = K k = 1 K ( q k | f - f k ) 2 - K k = 1 K ( f k - o _ k | f ) 2 = K [ k = 1 K ( 1 K - q k | f ) 2 - k = 1 K ( 1 K - o _ k | f ) 2 ] ##EQU00012##
[0046] In some cases, it may impractical or impossible to divide the multiple forecasts and their corresponding realizations and prior knowledge into bins with a constant size. For example, it may be impossible to keep bins of a constant size if the outcome is binary. Thus, in some embodiments, the method 200 may calculate the information and accuracy scores as shown below:
INFO = 1 N n = 1 N k = 1 K ( q n k - o n k | q ) 2 q n k ##EQU00013## A C C = 1 N n = 1 N k = 1 K ( f n k - o n k | f ) 2 f n k ##EQU00013.2##
[0047] In the above embodiment, the method 200 may use the forecast as a proxy for the realization in the information score calculation as described above. In such an embodiment, the information score may be calculated as shown below:
INFO = 1 N n = 1 N k = 1 K ( q n k - f n k ) 2 f n k ##EQU00014##
[0048] In similar embodiments, the method 200 may substitute the denominator in the above calculations for 1/K, resulting in the simplified calculations shown below:
INFO = K N n = 1 N k = 1 K ( q n k - o n k | q ) 2 ##EQU00015## ACC = K N n = 1 N k = 1 K ( f n k - o n k | f ) 2 ##EQU00015.2##
[0049] In the above embodiment, the method 200 may use the forecast as a proxy for the realization in the information score calculation as described above. In such an embodiment, the information score may be calculated as shown below:
INFO = K N n = 1 N k = 1 K ( q n k - f n k ) 2 ##EQU00016##
[0050] In some embodiments, after calculating the performance score for the multiple forecasts, the method 200 may also calculate a relative performance score for the multiple forecasts. The relative performance score for the multiple forecasts may be calculated based on the entropy of the prior knowledge corresponding to the multiple forecasts.
* * * * *
D00000
D00001
D00002





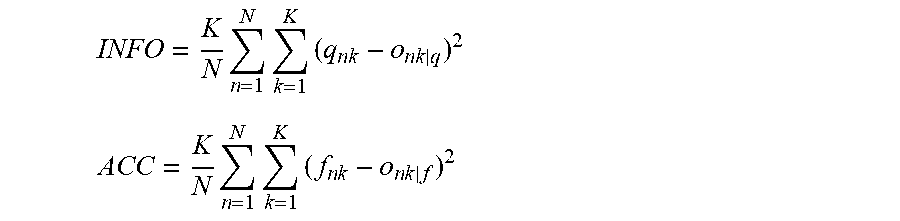
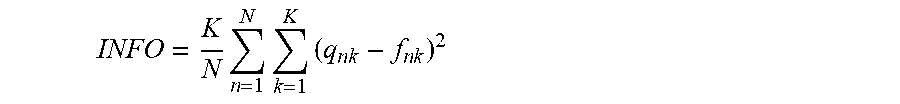
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.