Management and Evaluation of Machine-Learned Models Based on Locally Logged Data
Bonawitz; Keith ; et al.
U.S. patent application number 17/014126 was filed with the patent office on 2020-12-24 for management and evaluation of machine-learned models based on locally logged data. The applicant listed for this patent is Google LLC. Invention is credited to Keith Bonawitz, Daniel Ramage.
| Application Number | 20200401946 17/014126 |
| Document ID | / |
| Family ID | 1000005076845 |
| Filed Date | 2020-12-24 |
| United States Patent Application | 20200401946 |
| Kind Code | A1 |
| Bonawitz; Keith ; et al. | December 24, 2020 |
Management and Evaluation of Machine-Learned Models Based on Locally Logged Data
Abstract
The present disclosure provides systems and methods for the management and/or evaluation of machine-learned models based on locally logged data. In one example, a user computing device can obtain a machine-learned model (e.g., from a server computing device) and can evaluate at least one performance metric for the machine-learned model. In particular, the at least one performance metric for the machine-learned model can be evaluated relative to data that is stored locally at the user computing device. The user computing device and/or the server computing device can determine whether to activate the machine-learned model on the user computing device based at least in part on the at least one performance metric. In another example, the user computing device can evaluate a plurality of machine-learned models against locally stored data. At least one of the models can be selected based on the evaluated performance metrics.
| Inventors: | Bonawitz; Keith; (Watchung, NJ) ; Ramage; Daniel; (Seattle, WA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 1000005076845 | ||||||||||
| Appl. No.: | 17/014126 | ||||||||||
| Filed: | September 8, 2020 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15357559 | Nov 21, 2016 | 10769549 | ||
| 17014126 | ||||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06N 5/022 20130101; G06N 20/00 20190101 |
| International Class: | G06N 20/00 20060101 G06N020/00; G06N 5/02 20060101 G06N005/02 |
Claims
1.-20. (canceled)
21. A computer-implemented method to manage machine-learned models, the method comprising: obtaining, by a user computing device, a plurality of machine-learned models; evaluating, by the user computing device, at least one performance metric for each of the plurality of machine-learned models, wherein the at least one performance metric for each machine-learned model is evaluated relative to data that is stored locally at the user computing device; providing, by the user computing device, the performance metrics respectively evaluated for the plurality of machine-learned models to a server computing device; receiving, by the user computing device, a selection of a first machine-learned model of the plurality of machine-learned models from the server computing device based at least in part on the performance metrics respectively evaluated for the plurality of machine-learned models; and using, by the user computing device, the selected first machine-learned model to obtain one or more predictions.
22. The computer-implemented method of claim 21, wherein evaluating, by the user computing device, the at least one performance metric for each of the plurality of machine-learned models comprises using, by the user computing device, historical data that was previously logged at the user computing device to evaluate the at least one performance metric for each of the plurality of machine-learned models.
23. The computer implemented method of claim 22, wherein using, by the user computing device, the historical data that was previously logged at the user computing device to evaluate the at least one performance metric for each of the plurality of machine-learned models comprises: inputting, by the user computing device, at least a first portion of the historical data into each of the plurality of machine-learned models; receiving, by the user computing device, at least one prediction from each of the plurality of machine-learned models in response to input of the first portion of the historical data; and comparing, by the user computing device, the at least one prediction from each machine-learned model to a second portion of the historical data to respectively determine the at least one performance metric for each of the plurality of machine-learned models.
24. The computer-implemented method of claim 21, wherein evaluating, by the user computing device, the at least one performance metric for each of the plurality of machine-learned models comprises, after obtaining, by the user computing device, the plurality of machine-learned models, using, by the user computing device, new data that is newly logged at the user computing device to evaluate the at least one performance metric for each of the plurality of machine-learned models.
25. The computer-implemented method of claim 24, wherein using, by the user computing device, new data that is newly logged at the user computing device to evaluate the at least one performance metric for each of the plurality of machine-learned models comprises: inputting, by the user computing device, at least a first portion of the new data into each of the plurality of machine-learned models; receiving, by the user computing device, at least one prediction from each of the plurality of machine-learned models in response to input of the first portion of the new data; and comparing, by the user computing device, the at least one prediction from each machine-learned model to a second portion of the new data to respectively determine the at least one performance metric for each of the plurality of machine-learned models.
26. The computer-implemented method of claim 21, wherein obtaining, by the user computing device, the plurality of machine-learned models comprises: receiving, by the user computing device, the plurality of machine-learned models from the server computing device.
27. The computer-implemented method of claim 21, wherein the selection of the first machine-learned model from the plurality of machine-learned models is based at least in part on a global performance that has been aggregated from performance metrics reported by other computing devices.
28. The computer-implemented method of claim 21, wherein evaluating, by the user computing device, at least one performance metric for each of the plurality of machine-learned models comprises evaluating, by the user computing device for each of the plurality of machine-learned models, an average probability of correct prediction.
29. The computer-implemented method of claim 21, wherein the plurality of machine-learned models are evaluated prior to activation of any of the machine-learned models; and after the user computing device receives the selection of the first machine-learned model, the first machine-learned model is activated and used at the user computing device.
30. The computer-implemented method of claim 21, further comprising: reporting, by the user computing device, one or more of the performance metrics evaluated for the plurality of machine-learned models to a server computing device.
31. The computer-implemented method of claim 30, further comprising: aggregating, by the server computing device, the one or more performance metrics received from the user computing device with other performance metrics reported by other computing devices to assess a global performance for each of the plurality of machine-learned models.
32. A computing device, the computing device comprising: one or more processors; and one or more non-transitory computer-readable media that collectively store instructions that, when executed by the one or more processors, cause the computing device to: obtain a machine-learned model, wherein the machine-learned model is one of a plurality of machine-learned models that have been previously trained on different types of training data; train the machine-learned model further based on a first portion of data that is stored locally at the computing device to obtain a user-specific variant of the machine-learned model; evaluate at least one performance metric for the user-specific variant of the machine-learned model, wherein the at least one performance metric for the user-specific variant of the machine-learned model is evaluated relative to a second portion of the data that is stored locally at the computing device; determine whether to activate the user-specific variant of the machine-learned model based at least in part on the at least one performance metric evaluated for the user-specific variant of the machine-learned model; and when it is determined that the user-specific variant of the machine-learned model should be activated, use the user-specific variant of the machine-learned model to obtain one or more predictions.
33. The computing device of claim 32, wherein the computing device uses historical data that was previously logged at the user computing device prior to receipt of the machine-learned model to evaluate the at least one performance metric the machine-learned model.
34. The computing device of claim 32, wherein the computing device uses new data that is newly logged at the user computing device after receipt of the machine-learned model to evaluate the at least one performance metric for each of the plurality of machine-learned models.
35. The computing device of claim 32, wherein to determine whether to activate the user-specific variant of the machine-learned model based at least in part on the at least one performance metric the computing device: compares the at least one performance metric to at least one threshold value; and determines whether the at least one performance metric compares favorably to the at least one threshold value, wherein it is determined that the user-specific variant of the machine-learned model should be activated when the at least one performance metric compares favorably to the at least one threshold value.
36. The computing device of claim 32, wherein to determine whether to activate the user-specific variant of the machine-learned model based at least in part on the at least one performance metric the computing device: provides the at least one performance metric evaluated for the user-specific variant of the machine-learned model to a server computing device; and receives a determination of whether to activate the user-specific variant of the machine-learned model from the server computing device.
37. The computing device of claim 32, wherein the at least one performance metric comprises an average probability of correct prediction.
38. One or more non-transitory computer-readable media that collectively store instructions that, when executed by one or more processors of a server computing system, cause the server computing system to: obtain a plurality of performance metrics respectively associated with a plurality of machine-learned models, wherein the performance metric for each machine-learned model indicates a performance of such machine-learned model when evaluated against a set of data that is stored locally at a user computing device; select at least one of the plurality of machine-learned models based at least in part on the plurality of performance metrics; and cause use of the selected at least one machine-learned model at the user computing device.
39. The one or more non-transitory computer-readable media of claim 38, wherein to obtain the plurality of performance metrics, the server computing device receives the plurality of performance metrics from the user computing device.
40. The one or more non-transitory computer-readable media of claim 39, wherein execution of the instructions further causes the server computing device to aggregate the plurality of performance metrics received from the user computing device with a plurality of additional performance metrics received from additional computing devices to determine a global performance for each of the plurality of machine-learned models.
Description
FIELD
[0001] The present disclosure relates generally to user data and machine learning. More particularly, the present disclosure relates to the management and/or evaluation of machine-learned models based on locally logged data.
BACKGROUND
[0002] User computing devices such as, for example, smart phones, tablets, and/or other mobile computing devices continue to become increasingly: (a) ubiquitous; (b) computationally powerful; (c) endowed with significant local storage; and (d) privy to potentially sensitive data about users, their actions, and their environments. In addition, applications delivered on mobile devices are also increasingly data-driven. For example, in many scenarios, data that is collected from user computing devices is used to train and evaluate new machine-learned models, personalize features, and compute metrics to assess product quality.
[0003] Many of these tasks have traditionally been performed centrally (e.g., by a server computing device). In particular, in some scenarios, data can be uploaded from user computing devices to the server computing device. The server computing device can train various machine-learned models on the centrally collected data and then evaluate the trained models. The trained models can be used by the server computing device or can be downloaded to user computing devices for use at the user computing device. In addition, in some scenarios, personalizable features can be delivered from the server computing device. Likewise, the server computing device can compute metrics across users on centrally logged data for quality assessment.
[0004] However, frequently it is not known exactly how data will be useful in the future and, particularly, which data will be useful. Thus, without a sufficient history of logged data, certain machine-learned models or other data-driven applications may not be realizable. Stated differently, if a certain set or type of data that is needed to train a model, personalize a feature, or compute a metric of interest was not logged, then even after determining that a certain kind of data is useful and should be logged, there is still a significant wait time until enough data to be generated to enable such training, personalization, or computation.
[0005] One possible response to this problem would be to log any and all data centrally. However, this response comes with its own drawbacks. In particular, users use their mobile devices for all manner of privacy-sensitive activities. Mobile devices are also increasingly sensor-rich, which can result in giving the device access to further privacy-sensitive data streams from their surroundings. Thus, privacy considerations suggest that logging should be done prudently--rather than wholesale--to minimize the privacy risks to the user.
[0006] Beyond privacy, the data streams these devices can produce are becoming increasingly high bandwidth. Thus, in many cases it is simply infeasible to stream any and all user data to a centralized database, even if doing so was desirable.
SUMMARY
[0007] Aspects and advantages of embodiments of the present disclosure will be set forth in part in the following description, or can be learned from the description, or can be learned through practice of the embodiments.
[0008] One example aspect of the present disclosure is directed to a computer-implemented method to manage machine-learned models. The method includes obtaining, by a user computing device, a plurality of machine-learned models. The method includes evaluating, by the user computing device, at least one performance metric for each of the plurality of machine-learned models. The at least one performance metric for each machine-learned model is evaluated relative to data that is stored locally at the user computing device. The method includes determining, by the user computing device, a selection of a first machine-learned model from the plurality of machine-learned models based at least in part on the performance metrics respectively evaluated for the plurality of machine-learned models. The method includes using, by the user computing device, the selected first machine-learned model to obtain one or more predictions.
[0009] Another example aspect of the present disclosure is directed to a computing device. The computing device includes one or more processors and one or more non-transitory computer-readable media that collectively store instructions that, when executed by the one or more processors, cause the computing device to perform operations. Execution of the instructions causes the computing device to obtain a machine-learned model. Execution of the instructions causes the computing device to evaluate at least one performance metric for the machine-learned model. The at least one performance metric for the machine-learned model is evaluated relative to data that is stored locally at the computing device. Execution of the instructions causes the computing device to determine whether to activate the machine-learned model based at least in part on the at least one performance metric evaluated for the machine-learned model. Execution of the instructions causes the computing device to use the machine-learned model to obtain one or more predictions when it is determined that the machine-learned model should be activated.
[0010] Another example aspect of the present disclosure is directed to one or more non-transitory computer-readable media that collectively store instructions that, when executed by one or more processors of a computing system, cause the computing system to perform operations. Execution of the instructions causes the computing system to obtain a plurality of performance metrics respectively associated with a plurality of machine-learned models. The performance metric for each machine-learned model indicates a performance of such machine-learned model when evaluated against a set of data that is stored locally at a user computing device. Execution of the instructions causes the computing system to select at least one of the plurality of machine-learned models based at least in part on the plurality of performance metrics. Execution of the instructions causes the computing system to cause use of the selected at least one machine-learned model at the user computing device.
[0011] Other aspects of the present disclosure are directed to various systems, apparatuses, non-transitory computer-readable media, user interfaces, and electronic devices.
[0012] These and other features, aspects, and advantages of various embodiments of the present disclosure will become better understood with reference to the following description and appended claims. The accompanying drawings, which are incorporated in and constitute a part of this specification, illustrate example embodiments of the present disclosure and, together with the description, serve to explain the related principles.
BRIEF DESCRIPTION OF THE DRAWINGS
[0013] Detailed discussion of embodiments directed to one of ordinary skill in the art is set forth in the specification, which makes reference to the appended figures, in which:
[0014] FIG. 1A depicts a block diagram of an example computing system that performs model management and evaluation based on locally logged data according to example embodiments of the present disclosure.
[0015] FIG. 1B depicts a block diagram of an example computing device that performs model management and evaluation based on locally logged data according to example embodiments of the present disclosure.
[0016] FIG. 1C depicts a block diagram of an example computing device that performs model management and evaluation based on locally logged data according to example embodiments of the present disclosure.
[0017] FIG. 2 depicts a flow chart diagram of an example method to manage a machine-learned model according to example embodiments of the present disclosure.
[0018] FIG. 3 depicts a flow chart diagram of an example method to evaluate a machine-learned model according to example embodiments of the present disclosure.
[0019] FIG. 4 depicts a flow chart diagram of an example method to manage a plurality of machine-learned models according to example embodiments of the present disclosure.
[0020] FIG. 5 depicts a flow chart diagram of an example method to manage a plurality of machine-learned models according to example embodiments of the present disclosure.
DETAILED DESCRIPTION
[0021] Generally, the present disclosure is directed to the management and/or evaluation of machine-learned models based on locally logged data. In particular, the systems and methods of the present disclosure can leverage the availability of significant amounts of data that have been logged locally at a user computing device, as opposed to the traditional centralized collection of data. In one example, a user computing device can obtain a machine-learned model (e.g., from a server computing device) and can evaluate at least one performance metric for the machine-learned model. In particular, the at least one performance metric for the machine-learned model can be evaluated relative to data that is stored locally at the user computing device. The user computing device and/or the server computing device can determine whether to activate the machine-learned model on the user computing device based at least in part on the at least one performance metric. In another example, the user computing device can obtain a plurality of machine-learned models and can evaluate at least one performance metric for each of the plurality of machine-learned models relative to the data that is stored locally at the user computing device. The user computing device and/or server computing device can select at least one of machine-learned models for use at the user computing device based at least in part on the performance metrics. For example, the model with the best performance metric(s) can be selected for activation and use at the user computing device.
[0022] Thus, the present disclosure provides improved techniques for model management and evaluation which leverage the existence of locally logged user data. For example, one or more models can be evaluated prior to activation to determine how much value each of such models would bring if it were enabled as a user-visible feature. As a result of such evaluation process, the systems of the present disclosure can make decisions regarding use and activation of machine-learned models that are more informed and user-specific. In addition, since the user data is stored locally at the user computing device, rather than uploaded for storage at a central server, user privacy is enhanced.
[0023] More particularly, aspects of the present disclosure are based on a recognition that that the traditional `log centrally` vs. `don't log` tension is a false dichotomy. Instead, according to aspects of the present disclosure, user data can be logged locally to on-device storage. In such fashion, the data stays with the user, thereby increasing user privacy.
[0024] In particular, according to an aspect of the present disclosure, applications and/or operating systems implemented on a user computing device (e.g., a mobile computing device such as a smartphone) can provide a local, on-device database to which log entries are written. In some implementations, the database(s) may or may not be inspectable by a user. Log entries in the database may or may not expire (e.g., due to time-to-live constraints, storage space constraints, or other constraints). Furthermore, log entries may or may not be expungable by a user. Logging to the database(s) can be logically similar to logging to a central, server-stored database, but logs can be placed in secure local storage that does not leave the device.
[0025] According to an aspect of the present disclosure, when it is desirable to train a model, personalize a feature, or compute a metric, the computation can be sent to the data, rather than vice versa. According to this approach, only a minimal amount of information necessary to perform the specific action is collected centrally. In some instances, the use of locally logged data to provide personalized features and/or perform model training and/or management can result in no central collection of user data at all. In particular, in some implementations, application libraries and/or operating systems of the user computing device can provide support for running analyses against this local database, thereby eliminating the need to upload data centrally for analysis or use.
[0026] As one example, in some implementations, a new machine-learned model can be trained by the user computing device based on the locally logged data. In particular, an untrained model structure and a training algorithm can be provided to the user computing device (e.g., from a server computing device). The user computing device can be instructed to use the entries in the local database (or some subset thereof) as training data for the training algorithm. Thereafter, the newly trained machine intelligence model can be used immediately to deliver predictions, which may be useful in any number of scenarios. Alternatively, as will be discussed further below, the trained model can be evaluated prior to activation.
[0027] In some implementations, the machine-learned model can be delivered to the user computing device partially or fully pre-trained. For example, the server computing device can partially or fully train the model on centrally collected data prior to transmitting the model to the user computing device. In some of such implementations, the user computing device can further train the model against the local log database. In some instances, this additional local training can be viewed as personalizing the model.
[0028] In some implementations, some information about the trained model's parameters can be delivered by the user computing device back to the server computing device. For example, the server computing device can use the returned parameter information to construct a cross-population model.
[0029] According to another aspect of the present disclosure, in some implementations, the user computing device can evaluate at least one performance metric for the machine-learned model relative to data that is stored locally at the user computing device. For example, the performance metric can be used to determine how much value the new model would bring if it were activated as a user-visible feature. One example performance metric is an average probability of correct prediction. Another example performance metric is expected utility of the model. For example, the expected utility can include a number of user interactions saved/eliminated. Statistics about the prediction performance could either be logged locally for future analysis or logged centrally.
[0030] As one example, the user computing device can evaluate the machine-learned model based on its ability to predict future user behavior. In particular, the user computing device can use new local data that is newly logged after receipt and/or training of the machine-learned model to evaluate the at least one performance metric for the machine-learned model. For example, the model can be employed to make predictions based on newly received data. In some implementations, the predictions are not used to provide user features or otherwise affect the performance of the device or application, but instead are compared to new ground truth data to assess the predictions' correctness.
[0031] Alternatively or additionally, the user computing device can evaluate the machine-learned model against previously logged local data. In particular, the user computing device can use historical data that was previously logged at the user computing device to evaluate the at least one performance metric. Thus, a machine-learned model can be evaluated against previously collected historical data and/or against newly collected data.
[0032] According to another aspect of the present disclosure, the user computing device and/or server computing device can determine whether to activate the machine-learned model based at least in part on the at least one performance metric. For example, if the performance metric(s) compare favorably to one or more performance thresholds, then the model can be activated for use at the user computing device. In various implementations, the user computing device can determine whether to activate the model or the user computing device can provide the performance metric(s) to the server computing device and the server computing device can determine whether to activate the model.
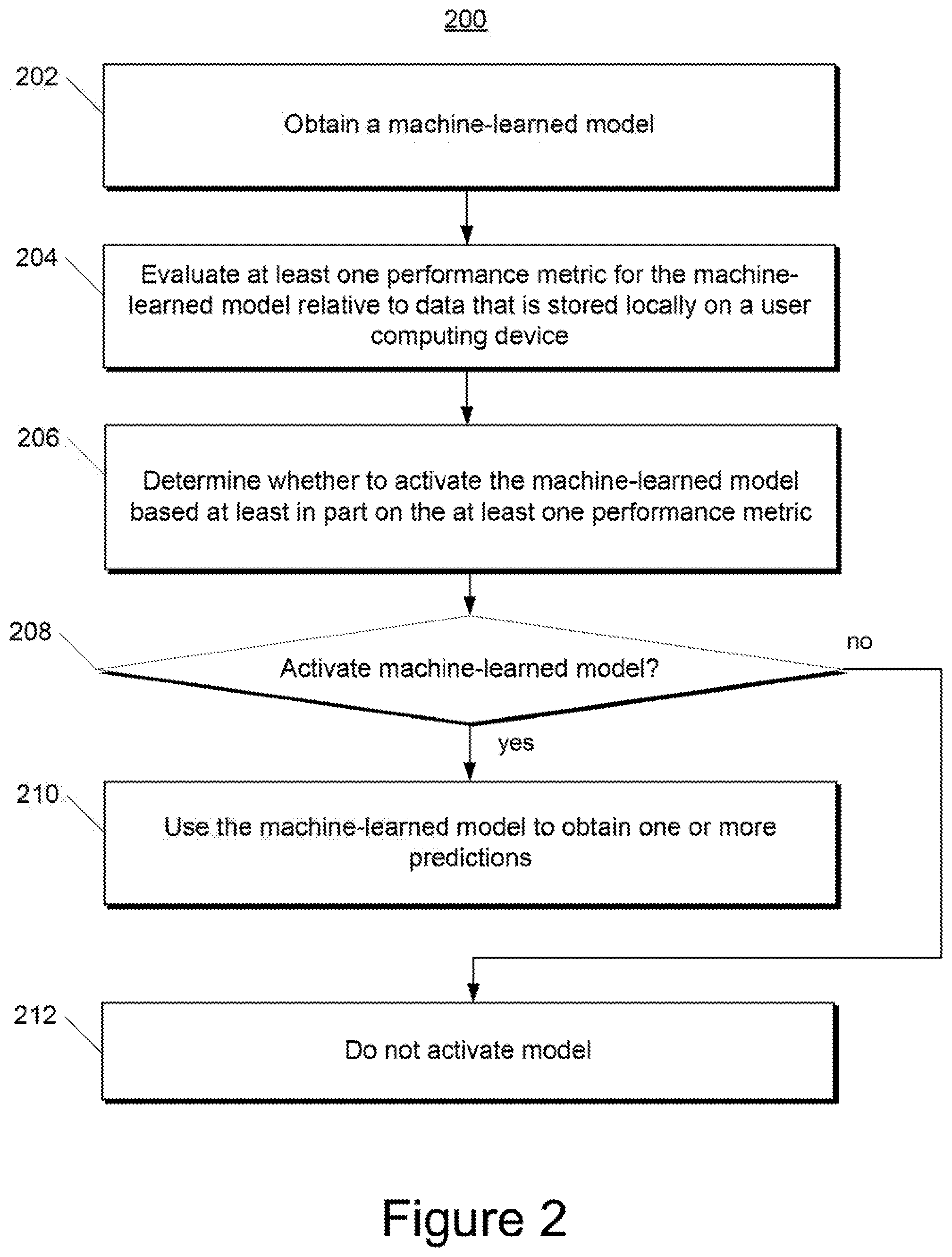
[0033] According to another aspect of the present disclosure, in some implementations, rather than receive and/or train a single machine-learned model, the user computing device can receive and/or train a plurality of machine-learned models. For example, the server computing device can have trained the plurality of machine-learned models on different types of training data.
[0034] The user computing device can evaluate at least one performance metric for each of the plurality of machine-learned models. In particular, the user computing device can evaluate the at least one performance metric for each machine-learned model relative to data that is stored locally at the user computing device. For example, the locally stored data can be newly received data or can be previously logged data, as described above.
[0035] The user computing device and/or server computing device can select one of the machine-learned models based at least in part on the performance metrics. For example, the model with the best performance metric(s) can be selected for activation and use at the user computing device. As noted, the user computing device can perform the selection or the user computing device can provide the performance metrics to the server computing device and the server computing device can perform the selection.
[0036] To provide a particular example, a server computing device can have trained three different machine-learned models to predict a next word will be entered into a text messaging application (e.g., based on a previously entered string). However, the machine-learned models can have been trained on different types of training data. For example, a first model can have been trained on publically-available literature (e.g., books); a second model can have been trained on publically-available social media posts; and a third model can have been trained on publically-available electronic mail conversations. The server computing device can provide the three models to the user computing device.
[0037] Prior to activating any of the models, the user computing device can evaluate at least one performance metric for each of the three models relative to locally stored data. For example, the locally stored data can include previously logged instances of text input by the user into the text messaging application and/or newly logged instances of text input by the user into the text messaging application. As an example, the user computing device can determine, for each of the models, an average probability of correctly predicting the next word when given a portion of one of the logged instances of text input.
[0038] The user computing device and/or server computing device can select one of the three models based on the evaluated performance metrics. As an example, if the model trained on the publically-available electronic mail conversations was found to have the highest average probability of correctly predicting the next word, then such model can be activated and used at the user computing device. For example, the selected model can be used to predict a next word which can be surfaced within an autocomplete feature of the text messaging application on the user computing device.
[0039] In further implementations, the selected model can be personalized based on the locally stored data prior to activation. In yet further implementations, if two or more models perform favorably relative to one or more thresholds, then the two or more models can be aggregated to form a single model that is then activated (or personalized and activated). As an example, the two or more models that performed favorably relative to the one or more thresholds can be aggregated according to a weighted average, where the weight respectively applied to each of the two or more models is a function of the respective performance metric evaluated for such model (e.g., more favorably performing models can receive increased weight).
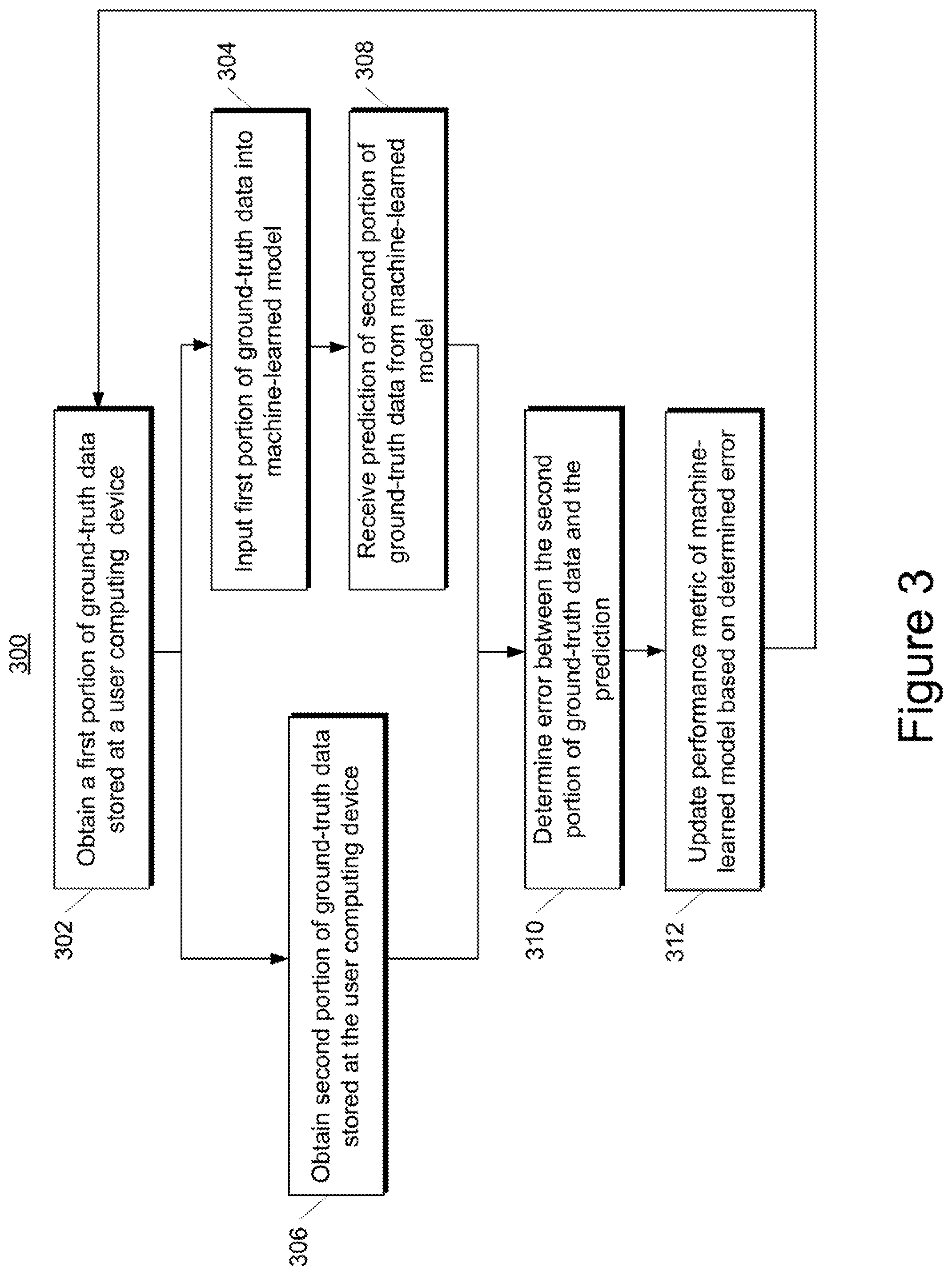
[0040] According to yet another aspect of the present disclosure, metrics based on typical aggregating queries can also be computed against the locally logged data. The contribution from each user to the overall metric can be computed on the user computing device. In some instances, these per-user aggregates are sufficiently small and de-privatized that they can be delivered to a central server for further cross-user aggregation without exposure of sensitive data. In other instances, to enhance user privacy, differential privacy can be used to introduce noise into the per-user aggregates before they are delivered to the central server for cross-user aggregation.
[0041] In some implementations, per-user aggregates can be combined across many users securely using encryption techniques before delivering the resulting cross-user aggregate to the central server. In still other instances, to yet further enhance user privacy, differential privacy can be used to add noise to the cryptographically computed cross-user aggregates during the cryptographic aggregation process before delivering the result to a central server.
[0042] According to another aspect of the present disclosure, user privacy can be further enhanced by not keeping the complete stream of certain forms of data on the user computing device. For example, in some implementations, a summary of the locally logged data can be stored on the user computing device rather than the user data itself. As examples, the summary can be a standard aggregate measure such as maximum value, minimum value, mean value, histogram counts, etc. As another example, the summary could a machine-learned model trained from streaming data.
[0043] As yet another example, the summary itself could be stored and updated in a privacy-preserving manner through the use of pan-private techniques. For example, pan-private techniques can be used that inject noise into a streaming algorithm to achieve differential privacy guarantees on the internal states of that algorithm as well as on its output.
[0044] According to yet another aspect of the present disclosure, in some implementations, the local database of the user computing device or a summarized version of the local database can be stored in an encrypted form. In some implementations, the local database or a summarized version of the local database can be directly accessible only via privileged software (e.g., tasks in the operating system operating with special permissions) or privileged hardware (e.g. trusted computed hardware, such as a Trusted Platform Module).
[0045] With reference now to the Figures, example embodiments of the present disclosure will be discussed in further detail.
Example Devices and Systems
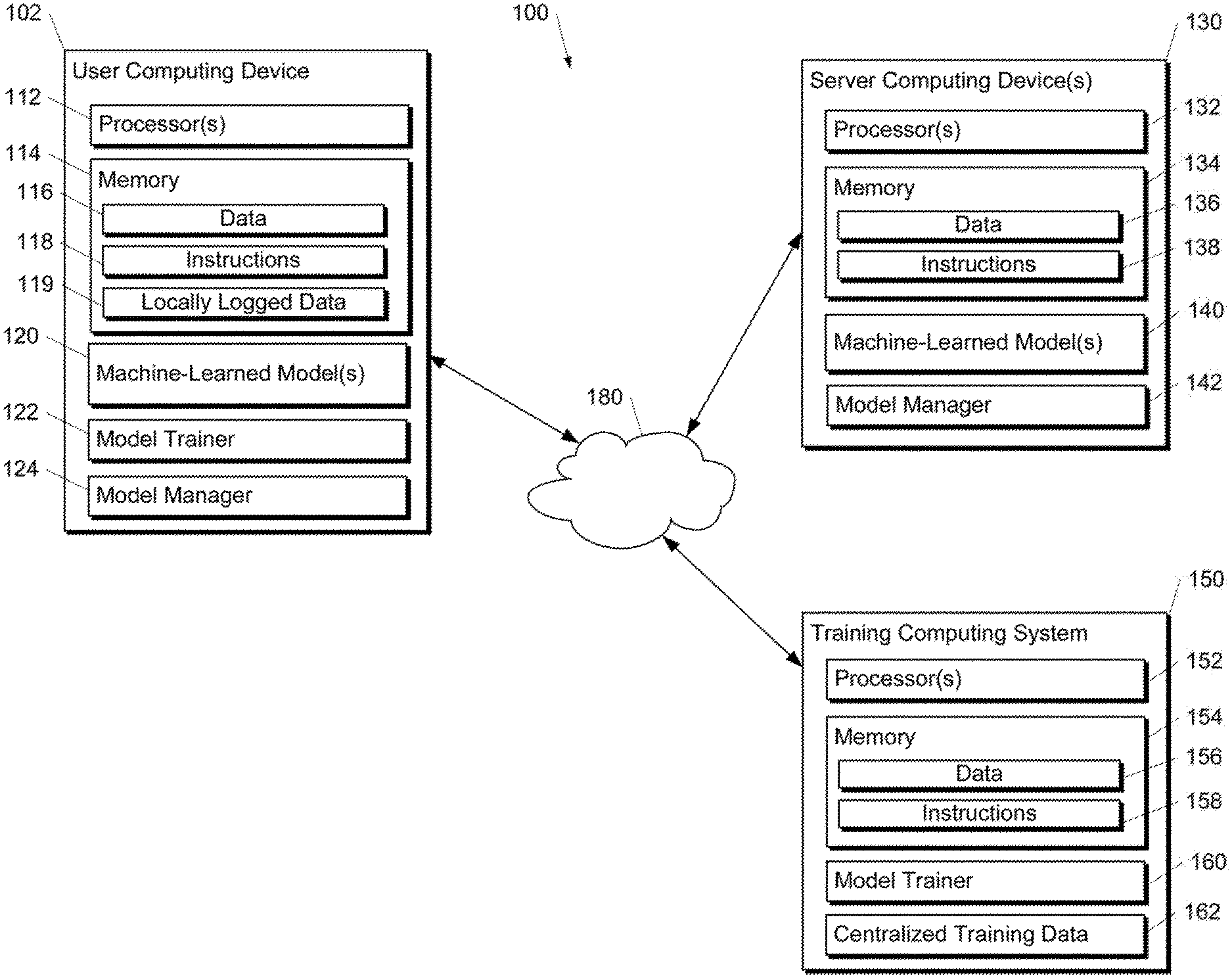
[0046] FIG. 1A depicts a block diagram of an example computing system 100 that performs model management and evaluation based on locally logged data according to example embodiments of the present disclosure. The system 100 includes a user computing device 102, a server computing device 130, and a training computing system 150 that are communicatively coupled over a network 180.
[0047] The user computing device 102 can be any type of computing device, such as, for example, a personal computing device (e.g., laptop or desktop), a mobile computing device (e.g., smartphone or tablet), a gaming console or controller, a wearable computing device, an embedded computing device, a personal assistant computing device, or any other type of computing device.
[0048] The user computing device 102 includes one or more processors 112 and a memory 114. The one or more processors 112 can be any suitable processing device (e.g., a processor core, a microprocessor, an ASIC, a FPGA, a controller, a microcontroller, etc.) and can be one processor or a plurality of processors that are operatively connected. The memory 114 can include one or more non-transitory computer-readable storage mediums, such as RAM, ROM, EEPROM, EPROM, flash memory devices, magnetic disks, etc., and combinations thereof. The memory 114 can store data 116 and instructions 118 which are executed by the processor 112 to cause the user computing device 102 to perform operations.
[0049] Furthermore, according to an aspect of the present disclosure, the memory 114 of the user computing device 102 cam include locally logged data 119. In particular, applications and/or operating systems implemented on the user computing device 102 can provide a local, on-device database in memory 114 to which log entries are written. One database can be used or multiple databases can be used. In some implementations, the database(s) may or may not be inspectable by a user. Log entries in the database may or may not expire (e.g., due to time-to-live constraints, storage space constraints, or other constraints). Furthermore, log entries may or may not be expungable by a user. Logging to the database(s) can be logically similar to logging to a central, server-stored database, but logs can be placed in secure local storage that does not leave the device.
[0050] According to another aspect of the present disclosure, the user computing device 102 can store or include one or more machine-learned models 120. The machine-learned models 120 can be or can otherwise include one or more neural networks (e.g., deep neural networks); Markov models (e.g., hidden Markov models); classifiers; regression models; support vector machines; Bayesian networks; multi-layer non-linear models; or other types of machine-learned models. Neural networks (e.g., deep neural networks) can be feed-forward neural networks, convolutional neural networks, autoencoders, recurrent neural networks (e.g., long short-term memory neural network, gated recurrent units, etc.) and/or various other types of neural networks.
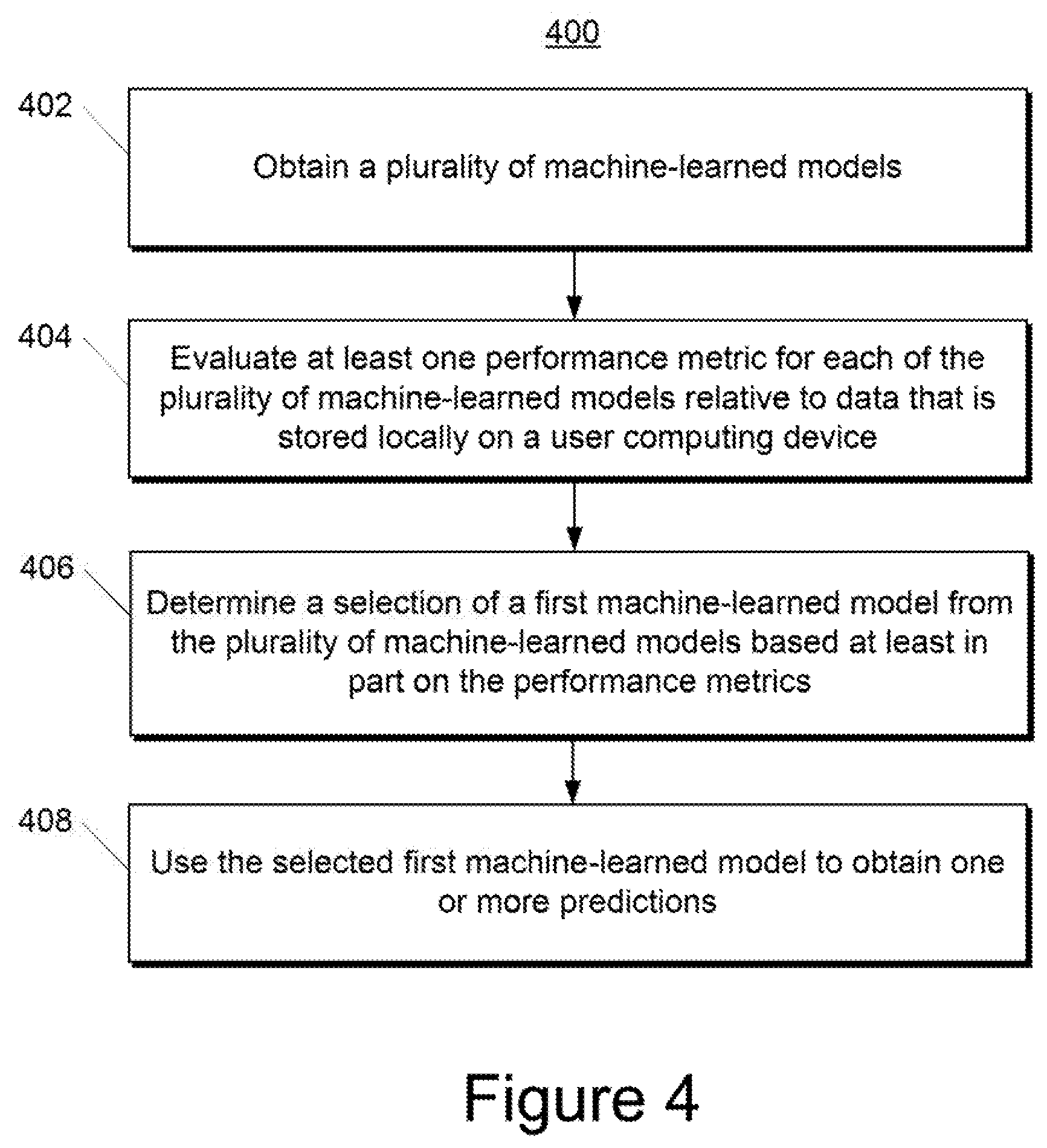
[0051] In some implementations, the one or more machine-learned models 120 can be received from the server computing device 130 over network 180, stored in the user computing device memory 114, and then used or otherwise implemented by the one or more processors 112. In some implementations, the user computing device 102 can implement multiple parallel instances of a single machine-learned model 120.
[0052] More particularly, machine-learned model(s) 120 can be implemented to provide predictions in various situations or applications. As one example, the machine-learned model(s) 120 can be employed within the context of a text messaging application of the user computing device 102, an email application of the user computing device 102, a text composition interface of an application (e.g., a word processing application), or any other application. As other examples, the machine-learned model(s) 120 can be included as a browser plug-in, as an overlay or feature of a keyboard (e.g., a virtual keyboard on the user computing device 102), or in other contexts. Thus, the machine-learned model(s) 120 can receive and analyze data from various applications or other computing device components and can produce predictions on the basis of such data. The predictions can be used for various features.
[0053] Additionally or alternatively, one or more machine-learned models 140 can be included in or otherwise stored and implemented by the server computing device 130 that communicates with the user computing device 102 according to a client-server relationship. For example, the machine-learned models 140 can be implemented by the server computing device 140 as a portion of a web service (e.g., a web email service). Thus, one or more models 120 can be stored and implemented at the user computing device 102 and/or one or more models 140 can be stored and implemented at the server computing device 130.
[0054] The user computing device 102 can also include a model trainer 122. The model trainer 122 can train or re-train one or more of the machine-learned models 120 stored at the user computing device 102 using various training or learning techniques, such as, for example, backwards propagation of errors (e.g., truncated backpropagation through time). In particular, the model trainer 122 can train or re-train one or more of the machine-learned models 120 using the locally logged data 119 as training data. The model trainer 122 can perform a number of generalization techniques (e.g., weight decays, dropouts, etc.) to improve the generalization capability of the models being trained.
[0055] As one example, in some implementations, a new machine-learned model 120 can be trained by the model trainer 122 based on the locally logged data 124. In particular, an untrained model structure and a training algorithm can be provided to the user computing device 102 (e.g., from the server computing device 130). The model trainer 122 can use the locally logged data 119 (or some subset thereof) as training data for the training algorithm. Thereafter, the newly trained machine intelligence model 120 can be used immediately to deliver predictions, which may be useful in any number of scenarios. Alternatively, as will be discussed further below, the trained model 120 can be evaluated prior to activation.
[0056] In some implementations, the machine-learned model 120 can be delivered to the user computing device 102 partially or fully pre-trained. For example, the server computing device 130 can partially or fully train a model 140 (e.g., through cooperation with training computing system 150) on centrally collected data 162 prior to transmitting the model 140 to the user computing device 102, where it is then stored as a model 120. In some of such implementations, the user computing device 102 can implement the model trainer 122 to further train the model 120 against the local log database 119. In some instances, this additional local training can be viewed as personalizing the model 120.
[0057] In some implementations, some information about the trained model's parameters can be delivered by the user computing device 102 back to the server computing device 130. For example, the server computing device 130 can use the returned parameter information to construct a cross-population model.
[0058] According to another aspect of the present disclosure, the user computing device 102 can also include a model manager 124 that performs management and/or evaluation of one or more of the machine-learned models 120. For example, the model manager 124 can evaluate at least one performance metric for each of the machine-learned models 120 based on the locally logged data 119. For example, the performance metric can be used to determine how much value the model 120 would bring if it were activated as a user-visible feature. One example performance metric is an average probability of correct prediction. Statistics about the prediction performance could either be logged locally for future analysis or logged centrally (e.g., at the server computing device 130).
[0059] As one example evaluation technique, the model manager 124 can evaluate the machine-learned model 120 based on its ability to predict future user behavior. In particular, the model manager 124 can use new local data 119 that is newly logged after receipt and/or training of the machine-learned model 120 to evaluate the at least one performance metric for the machine-learned model 120. For example, the model 120 can be employed to make predictions based on newly logged data 119. In some implementations, the predictions are not used to provide user features or otherwise affect the performance of the device or application, but instead are compared to new ground truth data to assess the predictions' correctness.
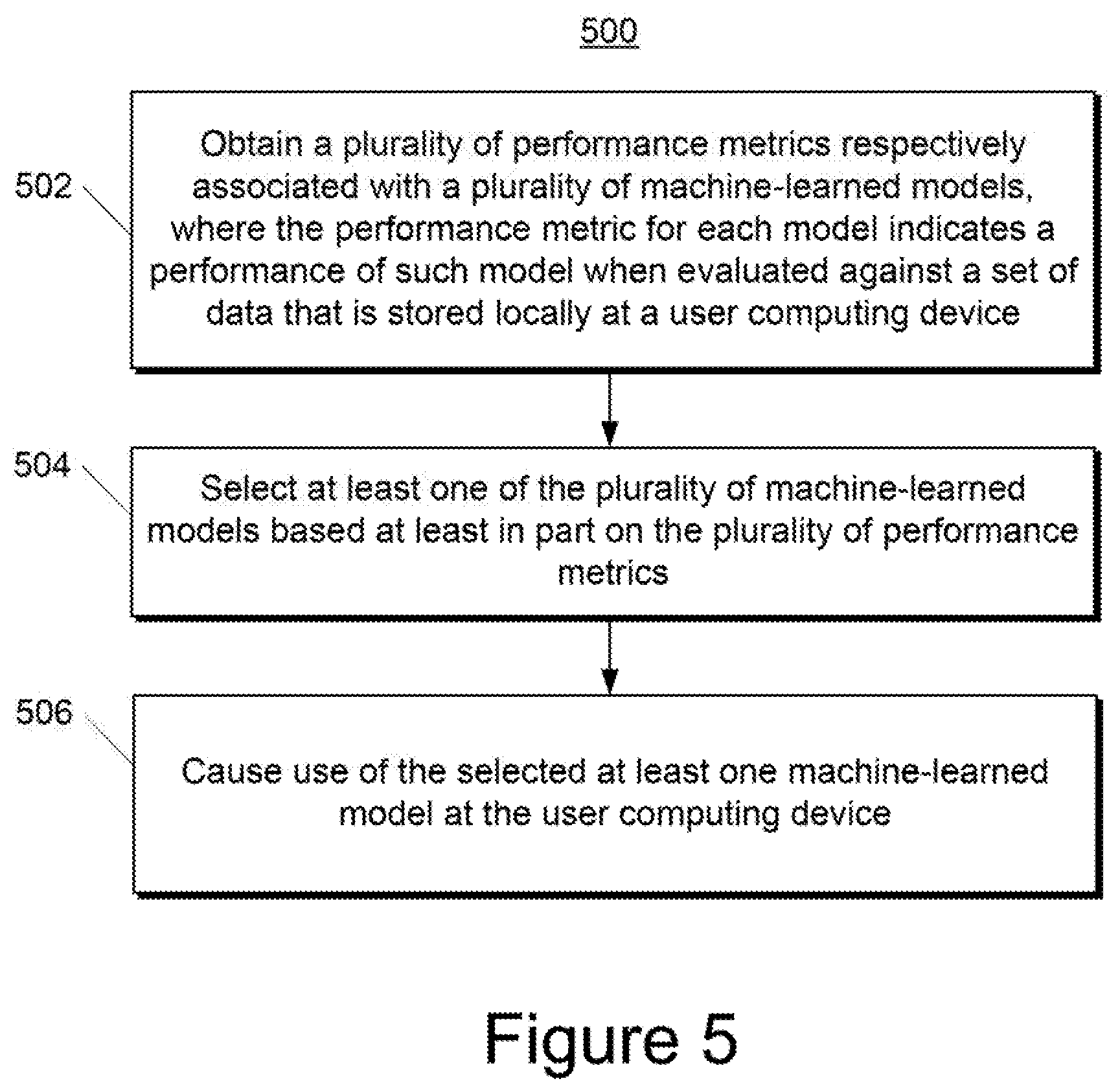
[0060] Alternatively or additionally, the model manager 124 can evaluate the machine-learned model 120 against previously logged local data 119. In particular, the model manager 124 can use historical data 119 that was previously logged at the user computing device 102 to evaluate the at least one performance metric. Thus, a machine-learned model 120 can be evaluated against previously collected historical data and/or against newly collected data.
[0061] According to another aspect of the present disclosure, the model manager 124 can determine whether to activate the machine-learned model 120 based at least in part on the at least one performance metric. For example, if the performance metric(s) compare favorably to one or more performance thresholds, then the model 120 can be activated for use at the user computing device 102. In other implementations, the user computing device 102 can provide the performance metric(s) to the server computing device 130 and a model manager 142 located at the server computing device 130 can determine whether to activate the model 120 on the user computing device 102. Thus, decisions regarding activation of a particular model 120 can be performed at the user computing device 102 or the server computing device 130.
[0062] According to another aspect of the present disclosure, in some implementations, rather than receive and/or train a single machine-learned model 120, the user computing device 102 can receive and/or train a plurality of machine-learned models 120. For example, the server computing device 130 can have trained (e.g., through cooperation with training computing system 150) a plurality of machine-learned models 140 on different types of training data and then transmitted such models 140 to the user computing device 102, where they are stored as models 120.
[0063] The model manager 124 can evaluate at least one performance metric for each of the plurality of machine-learned models 120, as described above. The model manager 124 and/or model manager 142 can select one of the machine-learned models 120 based at least in part on the performance metrics. For example, the model 120 with the best performance metric(s) can be selected for activation and use at the user computing device 102. As noted, the model manager 124 can perform the selection or the user computing device 102 can provide the performance metrics to the server computing device 130 and the model manager 142 can perform the selection.
[0064] In further implementations, the selected model 120 can be personalized (e.g., by model trainer 122) based on the locally stored data 119 prior to activation. In yet further implementations, if two or more models 120 perform favorably relative to one or more thresholds, then the two or more models 120 can be aggregated to form a single model 120 that is then activated (or personalized and activated).
[0065] The server computing device 130 includes one or more processors 132 and a memory 134. The one or more processors 132 can be any suitable processing device (e.g., a processor core, a microprocessor, an ASIC, a FPGA, a controller, a microcontroller, etc.) and can be one processor or a plurality of processors that are operatively connected. The memory 134 can include one or more non-transitory computer-readable storage mediums, such as RAM, ROM, EEPROM, EPROM, flash memory devices, magnetic disks, etc., and combinations thereof. The memory 134 can store data 136 and instructions 138 which are executed by the processor 132 to cause the server computing device 130 to perform operations.
[0066] In some implementations, the server computing device 130 includes or is otherwise implemented by one or more server computing devices. In instances in which the server computing device 130 includes plural server computing devices, such server computing devices can operate according to sequential computing architectures, parallel computing architectures, or some combination thereof.
[0067] As described above, the server computing device 130 can store or otherwise includes one or more machine-learned models 140. The machine-learned models 120 can be or can otherwise include one or more neural networks (e.g., deep neural networks); Markov models (e.g., hidden Markov models); classifiers; regression models; support vector machines; Bayesian networks; multi-layer non-linear models; or other types of machine-learned models. Neural networks (e.g., deep neural networks) can be feed-forward neural networks, convolutional neural networks, autoencoders, recurrent neural networks (e.g., long short-term memory neural network, gated recurrent units, etc.) and/or various other types of neural networks.
[0068] The server computing device 130 can train the machine-learned models 140 via interaction with the training computing system 150 that is communicatively coupled over the network 180. The training computing system 150 can be separate from the server computing device 130 or can be a portion of the server computing device 130.
[0069] The training computing system 150 includes one or more processors 152 and a memory 154. The one or more processors 152 can be any suitable processing device (e.g., a processor core, a microprocessor, an ASIC, a FPGA, a controller, a microcontroller, etc.) and can be one processor or a plurality of processors that are operatively connected. The memory 154 can include one or more non-transitory computer-readable storage mediums, such as RAM, ROM, EEPROM, EPROM, flash memory devices, magnetic disks, etc., and combinations thereof. The memory 154 can store data 156 and instructions 158 which are executed by the processor 152 to cause the training computing system 150 to perform operations. In some implementations, the training computing system 150 includes or is otherwise implemented by one or more server computing devices.
[0070] The training computing system 150 can include a model trainer 160 that trains the machine-learned models 140 stored at the server computing device 130 using various training or learning techniques, such as, for example, backwards propagation of errors (e.g., truncated backpropagation through time). The model trainer 160 can perform a number of generalization techniques (e.g., weight decays, dropouts, etc.) to improve the generalization capability of the models being trained. In particular, the model trainer 160 can train a machine-learned model 140 based on a set of training data 162. The training data 162 can includes centrally collected data.
[0071] Each of the model trainer 122, model manager 124, model manager 142, and model trainer 160 can include computer logic utilized to provide desired functionality. Each of the model trainer 122, model manager 124, model manager 142, and model trainer 160 can be implemented in hardware, firmware, and/or software controlling a general purpose processor. For example, in some implementations, each of the model trainer 122, model manager 124, model manager 142, and model trainer 160 includes program files stored on a storage device, loaded into a memory and executed by one or more processors. In other implementations, each of the model trainer 122, model manager 124, model manager 142, and model trainer 160 includes one or more sets of computer-executable instructions that are stored in a tangible computer-readable storage medium such as RAM hard disk or optical or magnetic media.
[0072] The network 180 can be any type of communications network, such as a local area network (e.g., intranet), wide area network (e.g., Internet), or some combination thereof and can include any number of wired or wireless links. In general, communication over the network 180 can be carried via any type of wired and/or wireless connection, using a wide variety of communication protocols (e.g., TCP/IP, HTTP, SMTP, FTP), encodings or formats (e.g., HTML, XML), and/or protection schemes (e.g., VPN, secure HTTP, SSL).
[0073] FIG. 1A illustrates one example computing system that can be used to implement the present disclosure. Other computing systems can be used as well. For example, in some implementations, only the user computing device 102 includes a model trainer and model manager. For example, in some implementations, server computing device 130 does not include manager 142 and the system 100 does not include the training computing system 150. In some implementations, the system 100 includes only the user computing device 102.
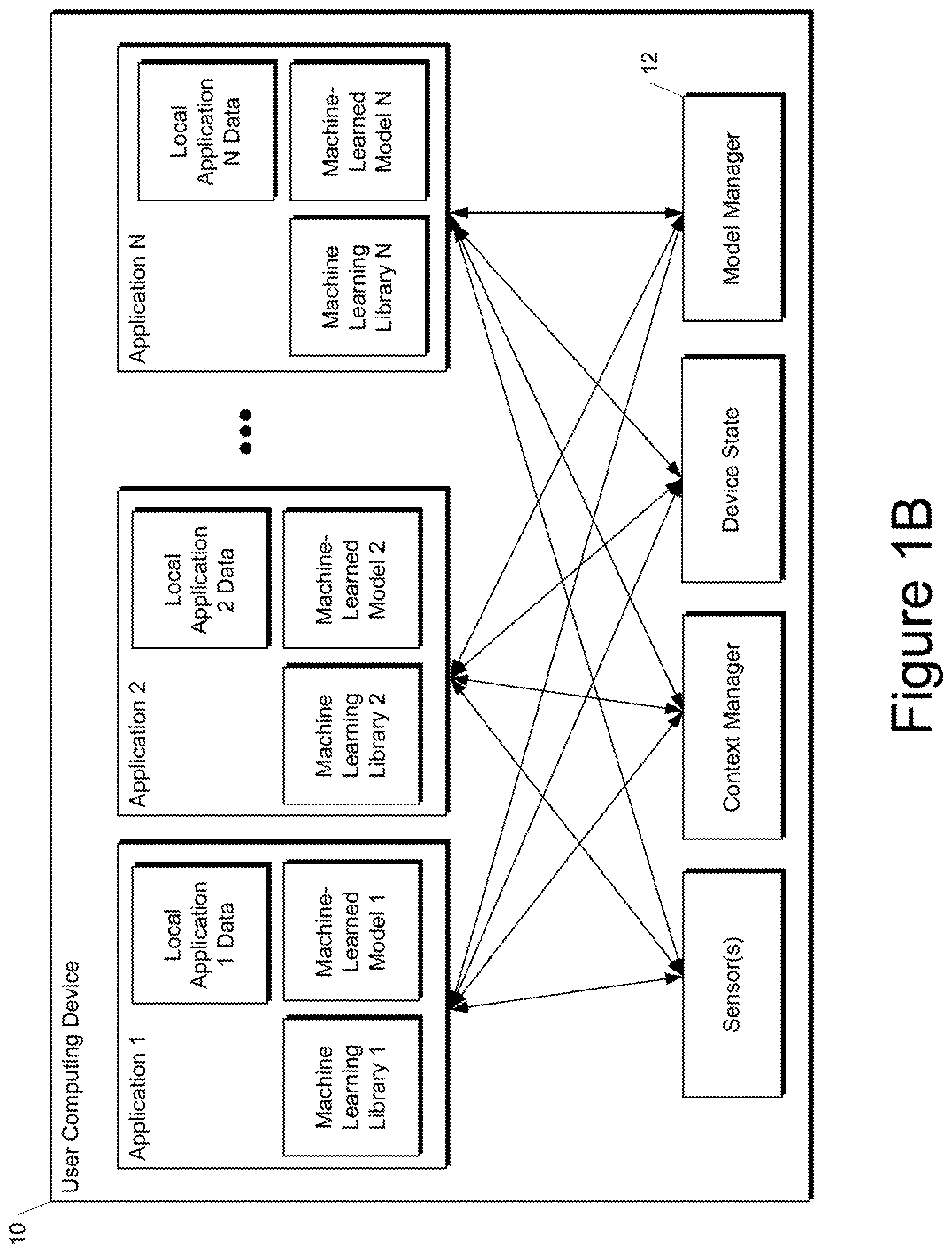
[0074] FIG. 1B depicts a block diagram of an example computing device 10 that performs model management and evaluation based on locally logged data according to example embodiments of the present disclosure.
[0075] The computing device 10 includes a number of applications (e.g., applications 1 through N). Each application can contain its own machine learning library and machine-learned model(s). Example applications include a text messaging application, an email application, a virtual keyboard application, a browser application, a photograph management application, a music streaming application, a rideshare application, or any other type of application.
[0076] Each application 1 through N also includes local application data. In particular, each application can provide or otherwise communicate with a local, on-device database in memory to which log entries are written. One database can be used for all applications or different respective databases can be used for each application. In some implementations, the database(s) may or may not be inspectable by a user. Log entries in the database(s) may or may not expire (e.g., due to time-to-live constraints, storage space constraints, or other constraints). Furthermore, log entries may or may not be expungable by a user. Logging to the database(s) can be logically similar to logging to a central, server-stored database, but logs can be placed in secure local storage that does not leave the device.
[0077] The user computing device 10 can also include a model manager 12 that performs management and/or evaluation of one or more of the machine-learned models included in the applications. In some implementations, the model manager 12 can be implemented by an operating system of the user computing device 10. In other implementations of the present disclosure, each application 1 through N can include its own respective, dedicated model manager, rather than a single model manager 12 for the entire device 10.
[0078] The model manager 12 can evaluate at least one performance metric for each of the machine-learned models based on the respective local application data. For example, machine-learned model 1 can be evaluated against local application 1 data, and so forth. The evaluated performance metric can be used to determine how much value the machine-learned model 1 would bring if it were activated as a user-visible feature within application 1. The local application 1 data used for evaluation purposes can be previously logged data or newly logged data.
[0079] The model manager 12 can determine whether to activate the machine-learned models based at least in part on the at least one performance metric. For example, if the performance metric evaluated for machine-learned model 1 (e.g., relative to local application 1 data) compares favorably to one or more performance thresholds, then machine-learned model 1 can be activated for use within application 1.
[0080] FIG. 1C depicts a block diagram of an example computing device 50 that performs model management and evaluation based on locally logged data according to example embodiments of the present disclosure.
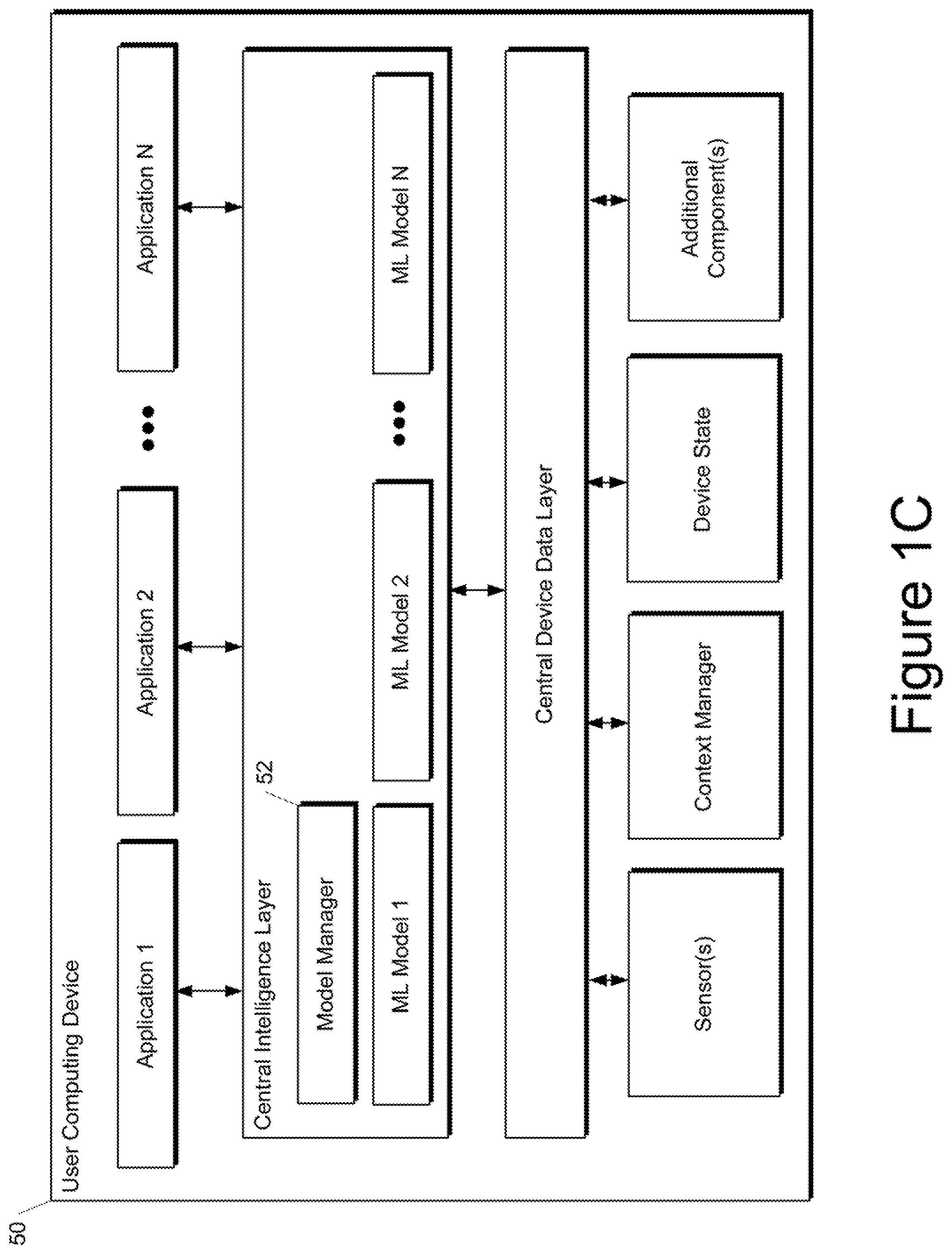
[0081] The computing device 50 includes a number of applications (e.g., applications 1 through N). Each application is in communication with a central intelligence layer. In some implementations, each application can communicate with the central intelligence layer (and model(s) stored therein) using an API (e.g., a common API across all applications).
[0082] The central intelligence layer includes a number of machine-learned models. For example, as illustrated in FIG. 1C, a respective machine-learned model can be provided for each application and managed by the central intelligence layer. In other implementations, two or more applications can share a single machine-learned model. For example, in some implementations, the central intelligence layer can provide a single model for all of the applications.
[0083] The central intelligence layer can also include a model manager 52 that performs management and/or evaluation of one or more of the machine-learned models included in the applications. In some implementations, the model manager 52 can be implemented by an operating system of the user computing device 50.
[0084] The central intelligence layer can communicate with a central device data layer. The central device data layer can be a centralized repository of locally logged data for the computing device 50. As illustrated in FIG. 1C, the central device data layer can communicate with a number of other components of the computing device, such as, for example, one or more sensors, a context manager, a device state component, and/or additional components. In some implementations, the central device data layer can communicate with each device component using an API (e.g., a private API).
[0085] The model manager 52 can evaluate at least one performance metric for one or more of the machine-learned models included in the central intelligence layer based on the locally logged data included in the central device data layer. For example, machine-learned model 1 can be evaluated against the locally logged data included in the central device data layer. The evaluated performance metric can be used to determine how much value the machine-learned model 1 would bring if it were activated as a user-visible feature within application 1. The locally logged data used for evaluation purposes can be previously logged data or newly logged data.
[0086] The model manager 52 can determine whether to activate the machine-learned models based at least in part on the at least one performance metric. For example, if the performance metric evaluated for machine-learned model 1 compares favorably to one or more performance thresholds, then machine-learned model 1 can be activated to provide predictions for use by application 1.
[0087] The computing devices shown in FIGS. 1B and 1C are examples only. Combinations of aspects of such devices can be used to implement the present disclosure as well.
Example Methods
[0088] FIGS. 2-5 illustrate example methods of the present disclosure. Although FIGS. 2-5 respectively depict steps performed in a particular order for purposes of illustration and discussion, the methods of the present disclosure are not limited to the particularly illustrated order or arrangement. The various steps of the methods of FIGS. 2-5 can be omitted, rearranged, combined, and/or adapted in various ways without deviating from the scope of the present disclosure. Further, although the methods of FIGS. 2-4 are discussed as being performed primarily by a user computing device, the methods can be performed by other computing devices (e.g., a server computing device) or combinations of computing devices.
[0089] FIG. 2 depicts a flow chart diagram of an example method 200 to manage a machine-learned model according to example embodiments of the present disclosure.
[0090] At 202, a user computing device obtains a machine-learned model. As one example, in some implementations, a new machine-learned model can be trained by the user computing device based on the locally logged data. In particular, an untrained model structure and a training algorithm can be provided to the user computing device (e.g., from a server computing device). The user computing device can be instructed to use the entries in the local database (or some subset thereof) as training data for the training algorithm.
[0091] As another example, the machine-learned model can be delivered to the user computing device partially or fully pre-trained. For example, the server computing device can partially or fully train the model on centrally collected data prior to transmitting the model to the user computing device. In some of such implementations, the user computing device can further train the model against the local log database. In some instances, this additional local training can be viewed as personalizing the model.
[0092] In some implementations, some information about the trained model's parameters can be delivered by the user computing device back to the server computing device. For example, the server computing device can use the returned parameter information to construct a cross-population model.
[0093] At 204, the user computing device evaluates at least one performance metric for the machine-learned model relative to data that is stored locally on the user computing device. One example performance metric is an average probability of correct prediction by the model. Another example performance metric is expected utility of the model. For example, the expected utility can include a number of user interactions saved/eliminated. As one example, in a predictive keyboard context, use of the model may result in reduction of the number of user taps or other interactions, which can be reflected as expected utility.
[0094] As one example, at 204, the user computing device can evaluate the machine-learned model based on its ability to predict future user behavior. In particular, the user computing device can use new local data that is newly logged after receipt and/or training of the machine-learned model at 202 to evaluate the at least one performance metric for the machine-learned model. For example, the model can be employed to make predictions based on newly received data, which can then be compared to other newly received data.
[0095] Alternatively or additionally, at 204, the user computing device can evaluate the machine-learned model against previously logged local data. In particular, the user computing device can use historical data that was previously logged at the user computing device to evaluate the at least one performance metric. Thus, at 204, a machine-learned model can be evaluated against previously collected historical data and/or against newly collected data.
[0096] As one example evaluation technique, FIG. 3 depicts a flow chart diagram of an example method 300 to evaluate a machine-learned model according to example embodiments of the present disclosure.
[0097] At 302, a user computing device obtains a first portion of ground-truth data stored at the user computing device. The ground-truth data can be previously logged local data or newly logged local data.
[0098] To provide one example, a machine-learned model might be evaluated on its ability to correctly predict a next word that will be entered into a text messaging application based on a previously entered string. Thus, in such example, the ground-truth data might include a first portion that corresponds to a text string entered by a user.
[0099] At 304, the user computing device inputs the first portion of the ground-truth data into a machine-learned model. To continue the example, at 304, the user computing device inputs the text string entered by the user into the machine-learned model.
[0100] At 306, the user computing device obtains a second portion of ground-truth data stored at the user computing device. To continue the example, the second portion of the ground-truth data might include a word that the user entered after entry of the text string. Thus, the model can be evaluated on its ability to correctly predict the second portion of the ground-truth data when given the first portion.
[0101] Block 306 can be done before or after block 304. In particular, as noted, the ground-truth data can be previously logged local data or newly logged local data. As such, when previously logged local data is used, obtaining the ground-truth data can simply include accessing the data from memory. However, in some implementations in which newly logged local data is used, the model can be evaluated in real time. For example, to continue the example, the model can be used to make predictions for evaluation at the same time as the user is entering the text.
[0102] At 308, the user computing device receives a prediction of the second portion of the ground-truth data from the machine-learned model. At 310, the user computing device determines an error between the second portion of the ground-truth data obtained at 306 and the prediction received at 308. As one example, the error can be binary in nature (e.g., does the prediction received at 308 match the second portion of the ground-truth data obtained at 306). As another example, the error can be determined according to an error function that evaluates a (non-binary) magnitude of error between the second portion of the ground-truth data obtained at 306 and the prediction received at 308. Any error function can be used.
[0103] At 312, the user computing device updates a performance metric of the machine-learned model based on the error determined at 310. As one example, the performance metric can be an average of the errors over time. Thus, at 312, the average can be updated based on the newly determined error.
[0104] After 312, the method 300 can terminate or can return to block 302 and again evaluate the machine-learned model relative to a new first and second portion of the ground-truth data. Thus, method 300 can be performed iteratively over a number of corresponding first and second portions of ground-truth data.
[0105] Referring again to FIG. 2, at 206, the user computing device determines whether to activate the machine-learned model based at least in part on the at least one performance metric. For example, if the performance metric(s) compare favorably to one or more performance thresholds, then the model can be activated for use at the user computing device. In some implementations, the user computing device can determine whether to activate the model. In other implementations, the user computing device can provide the performance metric(s) to the server computing device and the server computing device can determine whether to activate the model.
[0106] At 208, the user computing device evaluates the determination made at 206. If the machine-learned model should be activated then method 200 proceeds to 210. At 210, the user computing device uses the machine-learned model to obtain one or more predictions. For example, predictions made by the machine-learned model can be used by one or more applications or other computing device components to provide user features. As one example, the activated model can be used to predict a next word which can be surfaced within an autocomplete feature of the text messaging application on the user computing device.
[0107] However, referring again to bock 208, if the machine-learned model should not be activated, then method 200 proceeds to 212. At 212, the user computing device does not activate the model. Thus, if the model does not perform favorably then it will not be used to provide user facing features.
[0108] FIG. 4 depicts a flow chart diagram of an example method 400 to manage a plurality of machine-learned models according to example embodiments of the present disclosure.
[0109] At 402, a user computing device obtains a plurality of machine-learned models. In particular, rather than receive and/or train a single machine-learned model as described at block 202 of FIG. 2, the user computing device can receive and/or train a plurality of machine-learned models. For example, a server computing device can have trained the plurality of machine-learned models on different types of training data.
[0110] To provide a particular example, a server computing device can have trained three different machine-learned models to predict a next word will be entered into a text messaging application (e.g., based on a previously entered string). However, the machine-learned models can have been trained on different types of training data. For example, a first model can have been trained on publically-available literature (e.g., books); a second model can have been trained on publically-available social media posts; and a third model can have been trained on publically-available electronic mail conversations. The server computing device can provide the three models to the user computing device.
[0111] At 404, the user computing device evaluates at least one performance metric for each of the plurality of machine-learned models relative to data that is stored locally on the user computing device. For example, the locally stored data can be newly received data or can be previously logged data, as described above. As one example, at 404, the user computing device can respectively perform method 300 of FIG. 3 for each of the plurality of machine-learned models.
[0112] To continue the particular example provided above, the user computing device can evaluate at least one performance metric for each of the three models received at 402 relative to locally stored data. For example, the locally stored data can include previously logged instances of text input by the user into the text messaging application and/or newly logged instances of text input by the user into the text messaging application. As an example, the user computing device can determine, for each of the models, an average probability of correctly predicting the next word when given a portion of one of the logged instances of text input.
[0113] At 406, the user computing device determines a selection of a first machine-learned model from the plurality of machine-learned models based at least in part on the performance metrics evaluated at 404. In some implementations, determining the selection at 406 can include performing the selection at locally the user computing device. In other implementations, determining the selection at 406 can include transmitting the performance metrics to the server computing device and then receiving the selection from the server computing device. As an example, the model with the best performance metric(s) can be selected at 406.
[0114] To continue the particular example provided above, the user computing device and/or server computing device can select one of the three models based on the evaluated performance metrics. As an example, if the model trained on the publically-available electronic mail conversations was found to have the highest average probability of correctly predicting the next word, then such model can be activated and used at the user computing device. For example, the selected model can be used to predict a next word which can be surfaced within an autocomplete feature of the text messaging application on the user computing device.
[0115] At 408, the user computing device uses the selected first machine-learned model to obtain one or more predictions. To continue the particular example provided above, the selected model can be used to predict a next word which can be surfaced within an autocomplete feature of the text messaging application on the user computing device. Many different types of models can provide many different types of predictions that can be used for many different uses, including both user-facing features and non-user-facing features.
[0116] In further implementations, the model selected at 406 can be personalized based on the locally stored data prior to use at 408. In yet further implementations, if two or more models perform favorably relative to one or more thresholds, then the two or more models can be aggregated to form a single model that is then activated (or personalized and activated). In one example, the two or more models that performed favorably relative to the one or more thresholds can be aggregated according to a weighted average, where the weight applied to each of the two or more models is a function of the respective performance metric evaluated for such model.
[0117] FIG. 5 depicts a flow chart diagram of an example method 500 to manage a plurality of machine-learned models according to example embodiments of the present disclosure.
[0118] At 502, a server computing device obtains a plurality of performance metrics respectively associated with a plurality of machine-learned models. The performance metric for each model indicates a performance of such model when evaluated against a set of data that is stored locally at a user computing device.
[0119] At 504, the server computing device selects at least one of the plurality of machine-learned models based at least in part on the plurality of performance metrics. As an example, the model with the best performance metric(s) can be selected at 504.
[0120] At 506, the server computing device causes use of the selected at least one machine-learned model at the user computing device. For example, the server computing device can instruct the user computing device to activate and use the selected at least one machine-learned model.
ADDITIONAL DISCLOSURE
[0121] The technology discussed herein makes reference to servers, databases, software applications, and other computer-based systems, as well as actions taken and information sent to and from such systems. The inherent flexibility of computer-based systems allows for a great variety of possible configurations, combinations, and divisions of tasks and functionality between and among components. For instance, processes discussed herein can be implemented using a single device or component or multiple devices or components working in combination. Databases and applications can be implemented on a single system or distributed across multiple systems. Distributed components can operate sequentially or in parallel.
[0122] While the present subject matter has been described in detail with respect to various specific example embodiments thereof, each example is provided by way of explanation, not limitation of the disclosure. Those skilled in the art, upon attaining an understanding of the foregoing, can readily produce alterations to, variations of, and equivalents to such embodiments. Accordingly, the subject disclosure does not preclude inclusion of such modifications, variations and/or additions to the present subject matter as would be readily apparent to one of ordinary skill in the art. For instance, features illustrated or described as part of one embodiment can be used with another embodiment to yield a still further embodiment. Thus, it is intended that the present disclosure cover such alterations, variations, and equivalents.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.