Ligand Discovery For T Cell Receptors
Birnbaum; Michael Edward ; et al.
U.S. patent application number 17/011899 was filed with the patent office on 2020-12-24 for ligand discovery for t cell receptors. The applicant listed for this patent is The Board of Trustees of the Leland Stanford Junior University, California Institute of Technology. Invention is credited to David Baltimore, Michael Thomas Bethune, Michael Edward Birnbaum, Kenan Christopher Garcia, Juan Luis Mendoza.
| Application Number | 20200400679 17/011899 |
| Document ID | / |
| Family ID | 1000005063204 |
| Filed Date | 2020-12-24 |










View All Diagrams
| United States Patent Application | 20200400679 |
| Kind Code | A1 |
| Birnbaum; Michael Edward ; et al. | December 24, 2020 |
LIGAND DISCOVERY FOR T CELL RECEPTORS
Abstract
Compositions and methods are provided for the identification of peptide sequences that are ligands for a T cell receptor (TCR) of interest, in a given MHC context.
| Inventors: | Birnbaum; Michael Edward; (Stanford, CA) ; Mendoza; Juan Luis; (Redwood City, CA) ; Bethune; Michael Thomas; (Pasadena, CA) ; Baltimore; David; (Pasadena, CA) ; Garcia; Kenan Christopher; (Menlo Park, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 1000005063204 | ||||||||||
| Appl. No.: | 17/011899 | ||||||||||
| Filed: | September 3, 2020 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15301930 | Oct 4, 2016 | 10816554 | ||
| PCT/US2015/024244 | Apr 3, 2015 | |||
| 17011899 | ||||
| 61975646 | Apr 4, 2014 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G01N 2333/7051 20130101; C07K 14/00 20130101; G01N 33/6845 20130101; G01N 2333/70539 20130101 |
| International Class: | G01N 33/68 20060101 G01N033/68; C07K 14/00 20060101 C07K014/00 |
Claims
1.-27. (canceled)
28. A method of identifying a set of peptide ligands that bind to a T cell receptor (TCR) of interest in a specific MHC protein context, the method comprising: contacting the TCR of interest with a population of host cells comprising a cell surface library of single chain polypeptides each comprising (a) a peptide ligand and (b) a binding domain of an MHC protein; selecting host cells expressing a single chain polypeptide that binds to the TCR of interest; iterating the selecting step for at least three rounds to obtain a selected population of host cells; and performing deep sequencing of the selected population of host cells to provide a dataset of sequences of the set of peptide ligands.
29. The method of claim 28, wherein the single chain polypeptides each have a structure of P-L.sub.1-.beta.-L.sub.2-.alpha.-L.sub.3-T, wherein P is the peptide ligand; each of L.sub.1, L.sub.2 and L.sub.3 are flexible linkers of from about 4 to about 12 amino acids in length; .alpha. is a soluble form of an .alpha. domain of a human class I MHC protein or of a human class II MHC protein; .beta. is a soluble form of human class I MHC .beta.2 microglobulin or a soluble form of a .beta. domain of a human class II MHC .beta. protein; when .alpha. is the soluble form of an .alpha. domain of a human class I MHC protein, then .beta. is the soluble form of human class I MHC .beta.2 microglobulin; when .alpha. is the soluble form of an .alpha. domain of a human class II MHC protein, then .beta. is the soluble form of a .beta. domain of a human class II MHC .beta. protein; and T is a domain that tethers the single chain polypeptide to the surface of a host cell in the population of host cells.
30. The method of claim 28, further comprising using the dataset to generate a computational algorithm to predict naturally occurring TCR ligands.
31. The method of claim 28, further comprising identifying TCR contact residue hotspots and predicting cross-reactivity of the TCR of interest to the set of peptide ligands.
32. The method of claim 28, wherein the TCR of interest is multimerized.
33. The method of claim 28, wherein the TCR of interest is an orphan TCR.
34. The method of claim 28, wherein the peptide ligand is from about 8 to about 20 amino acids in length.
35. The method of claim 28, wherein the peptide ligand is randomized at multiple positions, and wherein the peptide ligand has limited diversity at MHC anchor positions.
36. The method of claim 28, wherein the MHC binding domain comprises .alpha.1 and .alpha.2 domains of a class I MHC protein, and .beta.2 microglobulin.
37. The method of claim 28, wherein the MHC binding domain comprises .alpha.1 and .beta.1 domains of a class II MHC protein.
38. The method of claim 37, wherein the binding domain is encoded by an allele of HLA-DRA and an allele of HLA-DRB4.
39. The method of claim 37, wherein the binding domain is encoded by an allele of HLA-DRA and an allele of HLA-DRB15.
40. The method of claim 28, wherein the host cells are yeast cells.
41. The method of claim 28, where the cell surface library comprises at least 10.sup.6 of the single chain polypeptides.
42. The method of claim 29, wherein the host cells are yeast cells.
43. The method of claim 29, where the cell surface library comprises at least 10.sup.8 of the single chain polypeptides.
44. The method of claim 42, wherein the T is Aga2.
45. The method of claim 29, wherein the flexible linkers are Gly-Ser linkers.
46. The method of claim 29, wherein the peptide ligand is from about 8 to about 20 amino acids in length and is randomized at multiple positions and has limited diversity at MHC anchor positions; the .alpha. is the soluble form of an .alpha. domain of a human class I MHC protein comprising .alpha.1 and .alpha.2 domains of the human class I MHC protein; the .beta. is the soluble form of the human class I MHC .beta.2 microglobulin; the T is Aga2; and the host cells are yeast cells.
47. The method of claim 29, wherein the peptide ligand is from about 8 to about 20 amino acids in length and is randomized at multiple positions and has limited diversity at MHC anchor positions; the .alpha. is the soluble form of an .alpha. domain of a human class II MHC protein; the .beta. is a soluble form of the human class II MHC .beta. protein; the T is Aga2; and the host cells are yeast cells.
Description
BACKGROUND OF THE INVENTION
[0001] T cells are the central mediators of adaptive immunity, through both direct effector functions and coordination and activation of other immune cells. Each T cell expresses a unique T cell receptor (TCR), selected for the ability to bind to major histocompatibility complex (MHC) molecules presenting peptides. TCR recognition of peptide-MHC (pMHC) drives T cell development, survival, and effector functions. Even though TCR ligands are relatively low affinity (1-100 .mu.M), the TCRs are remarkably sensitive, requiring as few as 10 agonist peptides to fully activate a T cell.
[0002] Extensive structural studies of TCR recognition of pMHC show the vast majority of studied TCR-pMHC complexes share a consistent binding orientation, driven by conserved contacts between the tops of the MHC helices and the germline-encoded TCR CDR1 and CDR2 loops (see Garcia and Adams (2005) Cell 122, 333-336; Garcia et al. (2009) Nat Immunol 10, 143-147; and Rudolph et al. (2006) Annual Review of Immunology 24, 419-466). These conserved contacts have likely coevolved throughout the development of the adaptive immune system and serve as the basis of MHC restriction of the .alpha..beta. TCR repertoire (Scott-Browne et al., 2011). Alteration to the typical TCR-pMHC interaction has been shown to correlate with abrogated signaling and, when present in development, skewed TCR repertoires (Adams et al. (2011) Immunity 35(5):681-93; Birnbaum et al. (2012) Immunol. Rev. 250(1):82-101).
[0003] An additional important feature of the TCR is the ability to balance cross-reactivity with specificity. Since the number of T cells that would be necessary to uniquely recognize every possible pMHC combination is extremely high, and since there are few if any `holes` characterized in the TCR repertoire, it has been posited that a large degree of TCR cross-reactivity is a requirement of functional antigen recognition. How the T cell repertoire can simultaneously be MHC restricted, cross-reactive enough to ensure all potential antigenic challenges can be met, yet still specific enough to avoid aberrant autoimmunity, has remained an open and pressing question in immunology.
[0004] The present invention provides materials and methods for the identification of T cell receptor ligands.
RELATED PUBLICATIONS
[0005] U.S. Pat. No. 8,450,247, Peelle et al.; Patent Application Publication; Pub. No. US 2010/0210473, Bowley et al.; US 2004/0146976, Dane et al.; International Application WO2004015395; International Application WO2005116646; International Application WO2012022975.
SUMMARY OF THE INVENTION
[0006] Compositions and methods are provided for the identification of peptide sequences that are ligands for a T cell receptor (TCR) of interest, in a given MHC context. In the methods of the invention, a library of single chain polypeptides are generated that comprise: the binding domains of a major histocompatibility complex protein; and diverse peptide ligands. The library is initially generated as a population of polynucleotides encoding the single chain polypeptide operably linked to an expression vector, which library may comprise at least 10.sup.6, at least 10.sup.7, more usually at least 10.sup.8 different peptide ligand coding sequences, and may contain up to about 10.sup.13, 10.sup.14 or more different ligand sequences. The library is introduced into a suitable host cell that expresses the encoded polypeptide, which host cells include, without limitation, yeast cells. The number of unique host cells expressing the polypeptide is generally less than the total predicted diversity of polynucleotides, e.g. up to about 5.times.10.sup.9 different specificities, up to about 10.sup.9, up to about 5.times.10.sup.8, up to about 10.sup.8, etc.
[0007] A TCR of interest is multimerized to enhance binding, and used to select for host cells expressing those single chain polypeptides that bind to the T cell receptor. Iterative rounds of selection are performed, i.e. the cells that are selected in the first round provide the starting population for the second round, etc. until the selected population has a signal above background, usually at least three and more usually at least four rounds of selection are performed. Polynucleotides encoding the final selected population from the library of single chain polypeptides are subjected to high throughput sequencing. It is shown herein that the selected set of peptide ligands exhibit a restricted choice of amino acids at residues, e.g. the residues that contact the TCR, which information can be input into an algorithm that can be used to analyze public databases for all peptides that meet the criteria for binding, and which provides a set of peptides that meet these criteria.
[0008] The peptide ligand is from about 8 to about 20 amino acids in length, usually from about 8 to about 18 amino acids, from about 8 to about 16 amino acids, from about 8 to about 14 amino acids, from about 8 to about 12 amino acids, from about 10 to about 14 amino acids, from about 10 to about 12 amino acids. It will be appreciated that a fully random library would represent an extraordinary number of possible combinations. In preferred methods, the diversity is limited at the residues that anchor the peptide to the MHC binding domains, which are referred to herein as MHC anchor residues. The position of the anchor residues in the peptide are determined by the specific MHC binding domains. Class I binding domains have anchor residues at the P2 position, and at the last contact residue. Class II binding domains have an anchor residue at P1, and depending on the allele, at one of P4, P6 or P9. For example, the anchor residues for IE.sup.k are P1 {I, L, V} and P9 {K}; the anchor residues for HLA-DR15 are P1 {I, L, V} and P4 {F, Y}. Anchor residues for DR alleles are shared at P1, with allele-specific anchor residues at P4, P6, P7, and/or P9.
[0009] In some embodiments, the binding domains of a major histocompatibility complex protein are soluble domains of Class II alpha and beta chain. In some such embodiments the binding domains have been subjected to mutagenesis and selected for amino acid changes that enhance the solubility of the single chain polypeptide, without altering the peptide binding contacts. In certain specific embodiments, the binding domains are HLA-DR4.alpha. comprising the set of amino acid changes {M36L, V132M}; and HLA-DR4.beta. comprising the set of amino acid changes {H62N, D72E}. In certain specific embodiments, the binding domains are HLA-DR15.alpha. comprising the set of amino acid changes {F12S, M23K}; and HLA-DR15.beta. comprising the amino acid change {PUS}. In certain specific embodiments, the binding domains are H2 IE.sup.k.alpha. comprising the set of amino acid changes {I8T, F12S, L14T, A56V} and H2 IE.sup.k.beta. comprising the set of amino acid changes {W6S, L8T, L34S}.
[0010] In some embodiments, the binding domains of a major histocompatibility complex protein comprise the alpha 1 and alpha 2 domains of a Class I MHC protein, which are provided in a single chain with .beta.2 microglobulin. In some such embodiments the Class I protein has been subjected to mutagenesis and selected for amino acid changes that enhance the solubility of the single chain polypeptide, without altering the peptide binding contacts. In certain specific embodiments, the binding domains are HLA-A2 alpha 1 and alpha 2 domains, comprising the amino acid change {Y84A}. In certain specific embodiments, the binding domains are H2-L.sup.d alpha 1 and alpha 2 domains, comprising the amino acid change {M31R}. In certain specific embodiments the binding domains are HLA-B57 alpha 1, alpha 2 and alpha 3 domains, comprising the amino acid change {Y84A}.
[0011] In some embodiments of the invention, a library is provided of polypeptides, or of nucleic acids encoding such polypeptides, wherein the polypeptide structure has the formula:
P-L.sub.1-.beta.-L.sub.2-.alpha.-L.sub.3-T
[0012] wherein each of L.sub.1, L.sub.2 and L.sub.3 are flexible linkers of from about 4 to about 12 amino acids in length, e.g. comprising glycine, serine, alanine, etc.
[0013] .alpha. is a soluble form of a domains of a class I MHC protein, or class II a MHC protein;
[0014] .beta. is a soluble form of (i) a .beta. chain of a class II MHC protein or (ii) .beta..sub.2 microglobulin for a class I MHC protein;
[0015] T is a domain that allows the polypeptide to be tethered to a cell surface, including without limitation yeast Aga2, or is a transmembrane domain that allows display on a cell surface; and
[0016] P is a peptide ligand, usually a library of different peptide ligands as described above, where at least 10.sup.6, at least 10.sup.7, more usually at least 10.sup.8 different peptide ligands are present in the library. The MHC binding domains are as described above. The library can be provided as a nucleic acid composition, e.g. operably linked to an expression vector. The library can be provided as a population of host cells transfected with the nucleic acid composition. In some embodiments the host cells are yeast (S. cerevisae) cells. The MHC portion of the construct may be a "mini" MHC where the boundaries for inclusion of the protein are set to be the end of the MHC peptide binding domain; or may be set at the end of the Beta2/Alpha2/Alpha3 domains as judged by structure and/or sequence for the `full length` MHCs.
[0017] The multimerized T cell receptor for selection is a soluble protein comprising the binding domains of a TCR of interest, e.g. TCR.alpha./.beta., TCR.gamma./.delta., and can be synthesized by any convenient method. The TCR can be provided as a single chain, or a heterodimer. In some embodiments, the soluble TCR is modified by the addition of a biotin acceptor peptide sequence at the C terminus of one polypeptide. After biotinylation at the acceptor peptide, the TCR can be multimerized by binding to biotin binding partner, e.g. avidin, streptavidin, traptavidin, neutravidin, etc. The biotin binding partner can comprise a detectable label, e.g. a fluorophore, mass label, etc., or can be bound to a particle, e.g. a paramagnetic particle. Selection of ligands bound to the TCR can be performed by flow cytometry, magnetic selection, and the like as known in the art.
[0018] Also provided herein is a method of determining the set of polypeptide ligands that bind to a T cell receptor of interest, comprising the steps of: performing multiple rounds of selection of a polypeptide library as set forth herein with a T cell receptor of interest; performing deep sequencing of the peptide ligands that are selected; inputting the sequence data to computer readable medium, where it is used to generate a search algorithm embodied as a program of instructions executable by computer and performed by means of software components loaded into the computer.
[0019] Also provided herein are software products tangibly embodied in a machine-readable medium, the software product comprising instructions operable to cause one or more data processing apparatus to perform operations comprising: generating a n.times.20 matrix from the positional frequencies of selected peptide ligands obtained by the screening methods of the invention, where n is the number of amino acid positions in the peptide ligand library. A cutoff of amino acid frequencies is set, e.g. less than 0.1, less than 0.05, less than 0.01, and frequencies below the cutoff are set to zero. A database of sequences, e.g. a set of human polypeptide sequences; a set of pathogen polypeptide sequences, a set of microbial polypeptide sequences, a set of allergen polypeptide sequences; etc. are searched with the algorithm using an n-position sliding window alignment with scoring the product of positional amino acid frequencies from the substitution matrix. An aligned segment containing at least one amino acid where the frequency is below the cutoff is excluded as a match.
[0020] In some embodiments, a kit is provided for the identification of peptide sequences that are ligands for a T cell receptor (TCR) of interest. Such a kit may comprise a library of polynucleotides encoding a polypeptide of the formula P-L.sub.1-.beta.-L.sub.2-.alpha.-L.sub.3-T, where a diverse set of peptide ligands is provided, e.g. at least 10.sup.6, at least 10.sup.7, more usually at least 10.sup.8, at least 10.sup.9, at least 10.sup.10 different peptide ligands are present in the library and may contain up to about 10.sup.14 different ligands, usually up to about 10.sup.13 different ligands. The polynucleotide library can be provided as a population of transfected cells, or as an isolated population of nucleic acids. Reagents for labeling and multimerizing a TCR can be included. In some embodiments the kit will further comprise a software package for analysis of a sequence database.
BRIEF DESCRIPTION OF THE DRAWINGS
[0021] The invention is best understood from the following detailed description when read in conjunction with the accompanying drawings. It is emphasized that, according to common practice, the various features of the drawings are not to-scale. On the contrary, the dimensions of the various features are arbitrarily expanded or reduced for clarity. Included in the drawings are the following figures.
[0022] FIG. 1: Library design and selection of I-E.sup.k, a murine class II MHC molecule. (A) Schematic of the murine class II MHC I-E.sup.k displayed on yeast, as .beta.1.alpha.1 `mini` MHC with peptide covalently linked to MHC N-terminus. (B) Mutations required for correct folding of the .beta.1.alpha.1 `mini` I-E.sup.k (top). Mutations found via error prone mutagenesis and selection are colored purple. Rationally introduced mutations are colored red. Staining with 2B4 and 226 tetramers demonstrate function of error prone-only construct (1.sup.st gen MHC) as well as error prone+designed mutant construct (2nd gen MHC) (bottom). (C) Design of the peptide library displayed by I-E.sup.k. Design is based upon the structure of 2B4 bound to MCC/I-E.sup.k (left). Residues from P(-2) to P10 are randomized, with limited diversity at P(-2), P10, and the P1/P9 anchors (right). Residues are colored corresponding to TCR contacts (magenta), MHC contacts (brown), MHC anchors (black), or neutral contacts (grey). (D) TCR tetramer staining of three clones selected for binding to 2B4 TCR compared to MCC (wild-type). TCR contacts are colored red. See also FIG. 8.
[0023] FIG. 2: Deep sequencing of peptide selections on I-E.sup.k converges on one dominant epitope for 2B4 TCR recognition. (A) Plots for amino acid prevalence at the three primary TCR contact positions (P3 (cyan), P5 (magenta), and P8 (orange)) show the peptide library enriches from even representation of all amino acids in the pre-selection library to a WT-like motif at each position. A secondary preference can be seen at P5 and P8 in round 3 but is outcompeted by round 4. (B) Sequence enrichment of 250 most abundant peptides show a convergence from a broad array of sequences to a few related clones. Area in grey represents all clones other than the most prevalent 250. (C) Comparison of total number of peptides and prevalence of 10 most abundant peptides for each round of selection. See also FIG. 9.
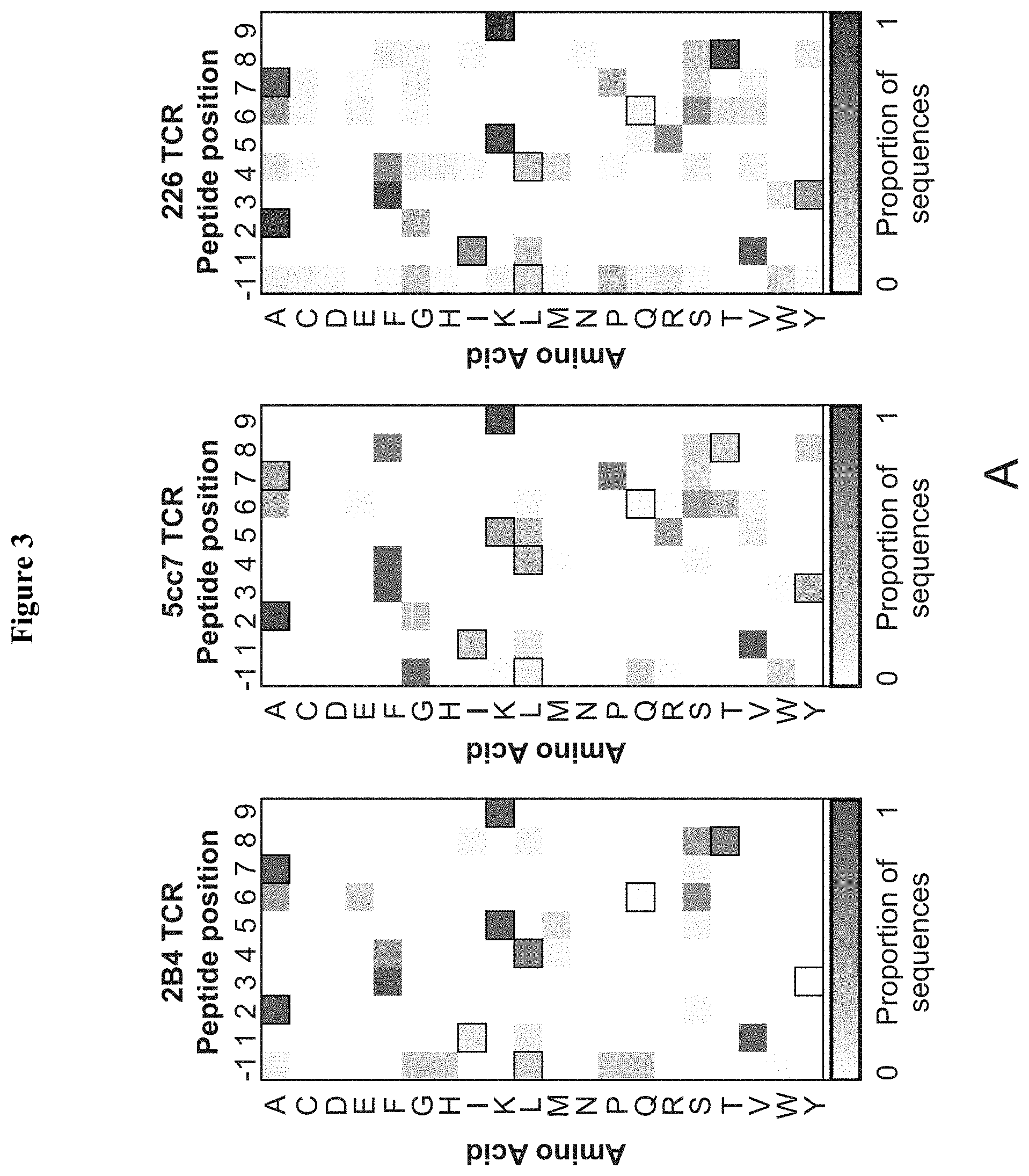
[0024] FIG. 3: Three different MCC/I-E.sup.k reactive TCRs require a WT-like recognition motif in the peptide antigens. (A) Heatmaps of amino acid preference by position for 2B4 (left, red) 5cc7 (center, green) and 226 (right, blue) TCRs. The sequence for MCC is represented via outlined boxes. TCR contact residues are labeled red on x axis. (B) Covariation analysis of TCR contact positions P5 (x axis) and P8 (y axis) show distinct coupling of amino acid preferences. (C) Minimum distance clustering of all TCR sequences selected above background show sequences for all TCRs form one large cluster with MCC (black circle, not represented in library but added for reference). Sequence cluster placed in a representation of whole-library sequence space (left: 1.times. magnification, center: 1000.times. magnification) for reference. See also FIG. 10.
[0025] FIG. 4: Relationships between affinity and activity of peptides selected for binding to IE.sup.k-reactive TCRs. (A) EC50s of IL-2 release and CD69 upregulation for 2B4 T cells with either peptides selected from library, plus MCC (red) (left), or peptides selected for a TCR other than the one tested (right). Sequences with close homology to MCC are represented in blue. Sequences that do not share 3/3 TCR contacts with MCC are in black. (B) EC50s as in A, but for 5cc7 T cells. (C) Correlation between pMHC-TCR affinity and peptide signaling potency. Each data point represents one peptide. See also FIG. 11.
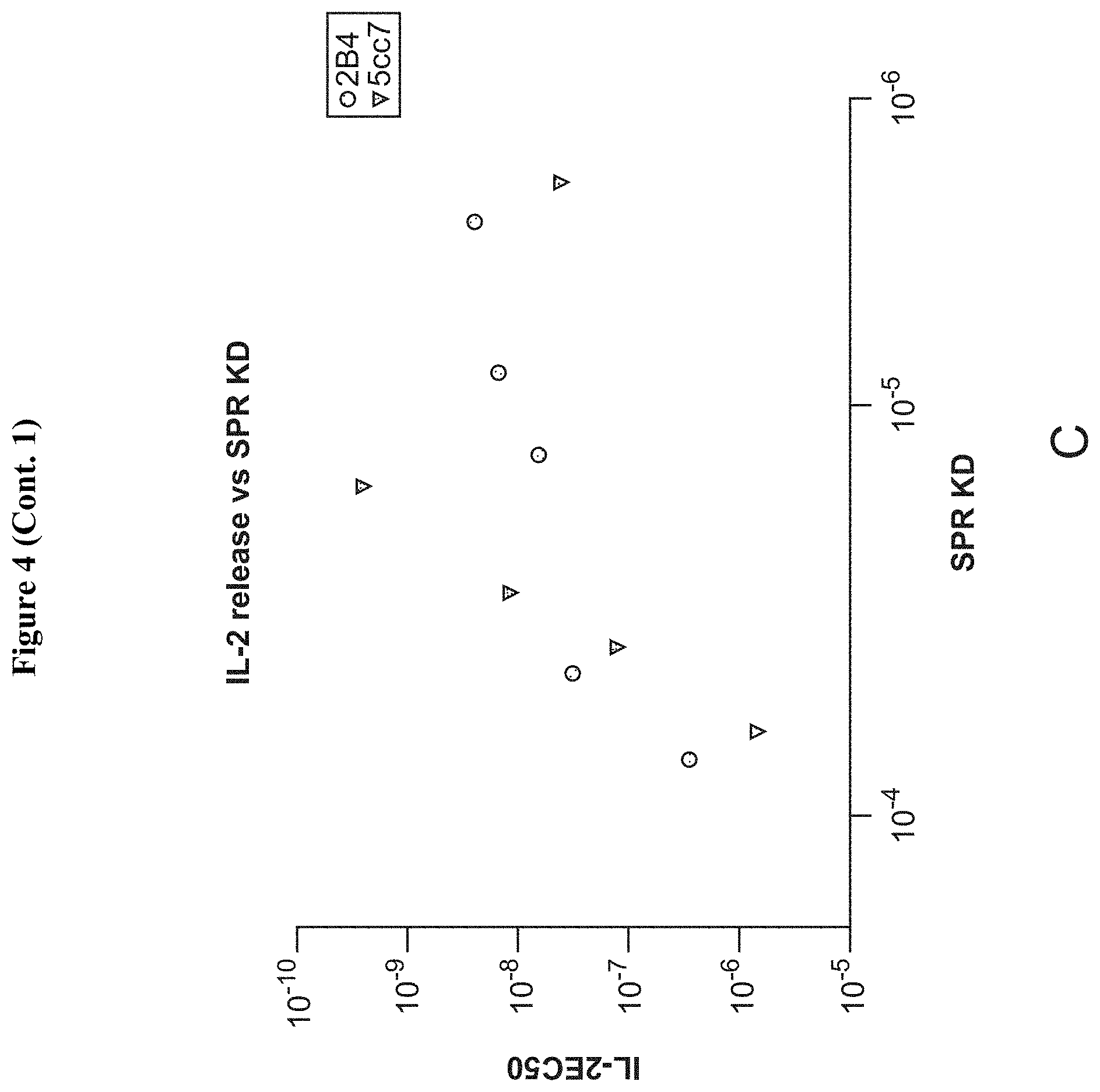
[0026] FIG. 5: Peptides distantly related to MCC show highly similar mechanism of recognition and linkages to the cognate antigen. Crystal structures of peptide-MHC/TCR complexes for 2A-I-E.sup.k/2B4 and MCC-I-E.sup.k/2B4 (PDB ID: 3QIB) (A) as well as 5c1-I-Ek/5cc7 and MCC-I-E.sup.k/226 (PDB ID: 3QIU) (B) compared. TCR contacts are shown in magenta (noted with triangles). Each structure aligned based on MHC (top) shows very little change in overall binding geometry despite significant variation of peptide sequence. The TCRs accommodate differences in peptide sequence primarily through rearrangement of the TCR CDR3.beta. (bottom). (C) TCR CDR loop footprints for 2B4 recognizing MCC and 2A peptides, 226 recognizing MCC and MCC K99E peptides, and 5cc7 recognizing 5c1 and 5c2 peptide show very little deviation. (D) Progression of sequences from MCC and 2A peptides. Each peptide is represented in deep sequencing results and differs by one TCR contact from the previous sequence. See also Table 1.
[0027] FIG. 6: Design and selection of HLA-DR15 based libraries for myelin basic protein (MBP)-reactive human TCRs. (A) HLA-DR15 library design based upon structure of MBP-HLA-DR15/Ob.1A12 complex crystal structure (PDB ID:1YMM). All residues (P(-4)-P10) are fully randomized, except for the P1 and P4 anchors (in black). TCR contacts are colored magenta. (B) Heatmap of amino acid preference by position for Ob.1A12 TCR. The sequence for MBP is represented via outlined boxes. TCR contacts are labeled red on the x axis. (C) Design and selection results of library that suppresses central `HF` TCR recognition motif at P2-P3 of peptide. Resulting register shift is shown in blue on x axis. (D) Sequence clustering shows distinct, related clusters of selected peptides. Sequence cluster placed in a representation of whole-library sequence space (left: 1.times. magnification, center: 1000.times. magnification) for reference.
[0028] FIG. 7: Discovery of naturally occurring TCR ligands through deep sequencing and substitution matrix-based homology search. (A) Schematic for ligand search strategy, in which a positional substitution matrix is generated from deep sequencing data and then used to find naturally occurring peptides that are represented within the matrix. (B) Functional characterization of a selection of naturally occurring peptides with predicted activity. The peptides comprise a variety of microbial, environmental, and self antigens. Activity is tested via proliferation of T cells when exposed to peptide. Heatmaps are normalized to 10 .mu.M dose of MBP peptide for each T cell clone.
[0029] FIG. 8: Affinity measurement of `mini` MCC-I-E.sup.k. SPR measurement using soluble 226 TCR flowed over a surface containing either full length MCC-I-Ek (green) or "mini" MCC-I-Ek, as used for yeast selections
[0030] FIG. 9: Statistics and reads for 2B4 selections of I-Ek library. (A) Summary of total number of Illumina reads by round for 2B4 selections. Corrected sequences correspond to reads which were in frame with no stop codons. Corrected unique peptides were the number of peptides present with greater than 4 unique sequence reads, after corrections for frame, stop codons, and 1 nt read errors (which were coalesced into the parent peptides). (B) Relative enrichment for 25 most abundant peptide after 4 rounds of selection with 2B4 TCR.
[0031] FIG. 10: Reads and distance clustering for selections of I-Ek library. (A) Total number of unique peptide sequences (top) and relative enrichment for 25 most abundant peptides (bottom) through 4 rounds of selection with 5cc7 and 226 TCRs. (B) Minimum distance clustering of all TCR sequences selected with maximum distance of 2 (left) and 3 (right) show different network topologies that coalesce into a single group. Compare to FIG. 3C.
[0032] FIG. 11: Characterization of library selected peptides via signaling and affinity. (A) Dose response curves of IL-2 release assay for 2B4 and 5cc7 T cell blasts. (B) and (C) Dose response curves of CD69 upregulation assay for 2B4 and 5cc7 T cell blasts. Curves in black represent peptides for which there were no sequencing reads for the given TCR. (D) Good correlation between EC50 of CD69 upregulation and IL-2 release for library selected peptide. (E) Sequence of peptides tested for binding via SPR. (F) SPR titrations for selected peptides using refolded 2B4 (left), 5cc7 (center), and 226 (right) TCRs.
[0033] FIG. 12: Features of TCR recognition of MCC and library-derived peptides bound to I-Ek. (A) A shared contact exists between Arg29.alpha. of CDR1.alpha. and the peptide in all four complexes. (B) Side chain flip of 2B4 Glu101.beta. repurposes former peptide-binding contact to intra-loop contact between MCC and 2A complexes. (C) Alignment of 5c1-I-Ek/5cc7 and 5c2-I-Ek/5cc7 complexes shows essentially identical binding footprint. (D) Conversion of a hydrogen bond between Gln50.beta. of 226 and P8 Thr in MCC (black) to a .pi.-cation interaction between Gln50.beta. of 5cc7 and P8 Phe in 5c1 (red). (E) Significant deviation of TCR C.beta. FG loop between MCC-I-Ek/226 and 5c1-I-Ek/5cc7 complexes correlates with reduced signaling potency.
[0034] FIG. 13: Development of MBP-HLA-DR15 platform and selection with Ob.1A12 and Ob.2F3 TCRs. (A) Staining of WT HLA-DR15 as well as multiple potential variants with Ob.1A12 tetramer as well as anti HLA-DR15 antibodies. "Mut3" was the final construct used for all studies. (B) Mutations required for functional display of MBP-HLA-DR15 yeast display platform. (C) Plots for amino acid prevalence at the three primary TCR contact positions (P2 (magenta), P3 (green), and P5 (cyan)) show the peptide library enriches from even representation of all amino acids in the pre-selection library to a WT-like motif at each position. (D) Heatmap of amino acid preference by position for Ob.2F3 TCR (orange) shows little change from Ob.1A12 selections (see FIGS. 6B and 6C). (E) Minimum distance clustering of all TCR-selected with maximum distance of 3. Compare to FIGS. 3C, 10B, and 6D.
[0035] FIG. 14: Creation of substitution matrix based upon TCR selection of HLA-DR15 libraries for prediction of naturally occurring peptide ligands. (A) Heatmaps for selection of library with P2 His, P3 Phe, and P5 Lys/Arg set to determine relative importance of residues more distal to TCR binding hotspot. Selections for Ob.1A12 (purple, right) and Ob.2F3 (orange, right) look extremely similar. (B) Covariation analysis between P(-2) and P(-1) positions for Ob.1A12 (purple, left) and Ob.2F3 (orange, right) show no significant covariation between residues, allowing for assumption of independently varying positions. No covariation for any other positions noted.
[0036] FIG. 15: Sequences of constructs, SEQ ID NO:1-6.
[0037] FIG. 16: Schematic of HLA-B5703 library and construct. The library was constructed with the P2 anchor of the peptide ligand fixed to A, T or S and the P11 anchor fixed to F, Y or W.
[0038] FIG. 17: shows a heatmap of the search matrix after 3 rounds of selection from the HLA-B5703 library in FIG. 16.
DETAILED DESCRIPTION OF THE EMBODIMENTS
[0039] Before the subject invention is described further, it is to be understood that the invention is not limited to the particular embodiments of the invention described below, as variations of the particular embodiments may be made and still fall within the scope of the appended claims. It is also to be understood that the terminology employed is for the purpose of describing particular embodiments, and is not intended to be limiting. In this specification and the appended claims, the singular forms "a," "an" and "the" include plural reference unless the context clearly dictates otherwise.
[0040] Where a range of values is provided, it is understood that each intervening value, to the tenth of the unit of the lower limit unless the context clearly dictates otherwise, between the upper and lower limit of that range, and any other stated or intervening value in that stated range, is encompassed within the invention. The upper and lower limits of these smaller ranges may independently be included in the smaller ranges, and are also encompassed within the invention, subject to any specifically excluded limit in the stated range. Where the stated range includes one or both of the limits, ranges excluding either or both of those included limits are also included in the invention.
[0041] Unless defined otherwise, all technical and scientific terms used herein have the same meaning as commonly understood to one of ordinary skill in the art to which this invention belongs. Although any methods, devices and materials similar or equivalent to those described herein can be used in the practice or testing of the invention, illustrative methods, devices and materials are now described.
[0042] All publications mentioned herein are incorporated herein by reference for the purpose of describing and disclosing the subject components of the invention that are described in the publications, which components might be used in connection with the presently described invention.
[0043] The present invention has been described in terms of particular embodiments found or proposed by the present inventor to comprise preferred modes for the practice of the invention. It will be appreciated by those of skill in the art that, in light of the present disclosure, numerous modifications and changes can be made in the particular embodiments exemplified without departing from the intended scope of the invention. For example, due to codon redundancy, changes can be made in the underlying DNA sequence without affecting the protein sequence. Moreover, due to biological functional equivalency considerations, changes can be made in protein structure without affecting the biological action in kind or amount. All such modifications are intended to be included within the scope of the appended claims.
[0044] MHC Proteins.
[0045] Major histocompatibility complex proteins (also called human leukocyte antigens, HLA, or the H2 locus in the mouse) are protein molecules expressed on the surface of cells that confer a unique antigenic identity to these cells. MHC/HLA antigens are target molecules that are recognized by T-cells and natural killer (NK) cells as being derived from the same source of hematopoietic reconstituting stem cells as the immune effector cells ("self") or as being derived from another source of hematopoietic reconstituting cells ("non-self"). Two main classes of HLA antigens are recognized: HLA class I and HLA class II.
[0046] The MHC proteins used in the libraries and methods of the invention may be from any mammalian or avian species, e.g. primate sp., particularly humans; rodents, including mice, rats and hamsters; rabbits; equines, bovines, canines, felines; etc. Of particular interest are the human HLA proteins, and the murine H-2 proteins. Included in the HLA proteins are the class II subunits HLA-DP.alpha., HLA-DP.beta., HLA-DQ.alpha., HLA-DQ.beta., HLA-DR.alpha. and HLA-DR.beta., and the class I proteins HLA-A, HLA-B, HLA-C, and .beta.2-microglobulin. Included in the murine H-2 subunits are the class I H-2K, H-2D, H-2L, and the class II I-A.alpha., I-A.beta., I-E.alpha. and I-E.beta., and .beta.2-microglobulin.
[0047] The MHC binding domains are typically a soluble form of the normally membrane-bound protein. The soluble form is derived from the native form by deletion of the transmembrane domain. Conveniently, the protein is truncated, removing both the cytoplasmic and transmembrane domains. In some embodiments, the binding domains of a major histocompatibility complex protein are soluble domains of Class II alpha and beta chain. In some such embodiments the binding domains have been subjected to mutagenesis and selected for amino acid changes that enhance the solubility of the single chain polypeptide, without altering the peptide binding contacts.
[0048] An "allele" is one of the different nucleic acid sequences of a gene at a particular locus on a chromosome. One or more genetic differences can constitute an allele. An important aspect of the HLA gene system is its polymorphism. Each gene, MHC class I (A, B and C) and MHC class II (DP, DQ and DR) exists in different alleles. Current nomenclature for HLA alleles are designated by numbers, as described by Marsh et al.: Nomenclature for factors of the HLA system, 2010. Tissue Antigens 75:291-455, herein specifically incorporated by reference. For HLA protein and nucleic acid sequences, see Robinson et al. (2011), The IMGT/HLA database. Nucleic Acids Research 39 Suppl 1:D1171-6, herein specifically incorporated by reference.
[0049] The numbering of amino acid residues on the various MHC proteins and variants disclosed herein is made to be consistent with the full length polypeptide. Boundaries were set to either be the end of the MHC peptide binding domain (as judged by examining crystal structures) for the `mini` MHCs, e.g. as exemplified herein with I-Ek, H2-Ld, and HLA-DR15, and the end of the Beta2/Alpha2/Alpha3 domains as judged by structure and/or sequence for the `full length` MHCs, as exemplified herein with HLA-A2, -B57, and -DR4.
[0050] In some embodiments, the MHC portion of a construct is the MHC portion delineated in any of SEQ ID NO:1-6. It will be understood by one of skill in the art that the peptide and linker portions can be varied from the provided sequences.
[0051] MHC Context.
[0052] The function of MHC molecules is to bind peptide fragments derived from pathogens and display them on the cell surface for recognition by the appropriate T cells. Thus T cell receptor recognition can be influenced by the MHC protein that is presenting the antigen. The term MHC context refers to the recognition by a TCR of a given peptide, when it is presented by a specific MHC protein.
[0053] Class II HLA/MHC.
[0054] Class II binding domains generally comprise the .alpha.1 and .alpha.2 domains for the .alpha. chain, and the .beta.1 and .beta.2 domains for the .beta. chain. Not more than about 10, usually not more than about 5, preferably none of the amino acids of the transmembrane domain will be included. The deletion will be such that it does not interfere with the ability of the .alpha.2 or .beta.2 domain to bind peptide ligands.
[0055] In some embodiments, the binding domains of a major histocompatibility complex protein are soluble domains of Class II alpha and beta chain. In some such embodiments the binding domains have been subjected to mutagenesis and selected for amino acid changes that enhance the solubility of the single chain polypeptide, without altering the peptide binding contacts.
[0056] In certain specific embodiments, the binding domains are an HLA-DR allele. The HLA-DRA protein can be selected, without limitation, from the binding domains of DRA*01:01:01:01; DRA*01:01:01:02; DRA*01:01:01:03; DRA*01:01:02; DRA*01:02:01; DRA*01:02:02; and DRA*01:02:03, which may be modified to comprise the amino acid changes {M36L, V132M}; or {F125, M23K}, depending on whether it is provided in the context of a full-length or mini-allele. The HLA-DRA binding domains can be combined with any one of the HLA-DRB binding domains.
[0057] In certain such embodiments, the HLA-DRA allele is paired with the binding domains of an HLA-DRB4 allele. The HLA-DRB4 allele can be selected from the publicly available DRB4 alleles, including without limitation: DRB1*04:01:01; DRB1*04:01:02; DRB1*04:01:03; DRB1*04:01:04; DRB1*04:01:05; DRB1*04:01:06; DRB1*04:01:07; DRB1*04:01:08; DRB1*04:01:09; DRB1*04:01:10; DRB1*04:01:11; DRB1*04:01:12; DRB1*04:01:13; DRB1*04:01:14; DRB1*04:02:01; DRB1*04:02:02; DRB1*04:02:03; DRB1*04:03:01; DRB1*04:03:02; DRB1*04:03:03; DRB1*04:03:04; DRB1*04:03:05; DRB1*04:03:06; DRB1*04:03:07; DRB1*04:03:08; DRB1*04:04:01; DRB1*04:04:02; DRB1*04:04:03; DRB1*04:04:04; DRB1*04:04:05; DRB1*04:04:06; DRB1*04:04:07; DRB1*04:04:08; DRB1*04:05:01; DRB1*04:05:02; DRB1*04:05:03; DRB1*04:05:04; DRB1*04:05:05; DRB1*04:05:06; DRB1*04:05:07; DRB1*04:05:08; DRB1*04:05:09; DRB1*04:05:10; DRB1*04:05:11; DRB1*04:05:13; DRB1*04:05:14; DRB1*04:05:15; DRB1*04:05:16; DRB1*04:06:01; DRB1*04:06:02; DRB1*04:06:03; DRB1*04:06:04; DRB1*04:06:05; DRB1*04:07:01; DRB1*04:07:02; DRB1*04:07:03; DRB1*04:07:04; DRB1*04:08:01; DRB1*04:08:02; DRB1*04:08:03; DRB1*04:09; DRB1*04:10:01; DRB1*04:10:02; DRB1*04:11:01; DRB1*04:11:02; DRB1*04:11:03; DRB1*04:12; DRB1*04:13; DRB1*04:14; DRB1*04:15; DRB1*04:16; DRB1*04:17:01; DRB1*04:17:02; DRB1*04:18; DRB1*04:19; DRB1*04:20; DRB1*04:21; DRB1*04:22; DRB1*04:23; DRB1*04:24; DRB1*04:25; DRB1*04:26; DRB1*04:27; DRB1*04:28; DRB1*04:29; DRB1*04:30; DRB1*04:31; DRB1*04:32; DRB1*04:33; DRB1*04:34; DRB1*04:35; DRB1*04:36; DRB1*04:37; DRB1*04:38; DRB1*04:39; DRB1*04:40; DRB1*04:41; DRB1*04:42; DRB1*04:43; DRB1*04:44; DRB1*04:45; DRB1*04:46; DRB1*04:47; DRB1*04:48; DRB1*04:49; DRB1*04:50; DRB1*04:51; DRB1*04:52; DRB1*04:53; DRB1*04:54; DRB1*04:55; DRB1*04:56; DRB1*04:57; DRB1*04:58; DRB1*04:59; DRB1*04:60; DRB1*04:61; DRB1*04:62; DRB1*04:63; DRB1*04:64; DRB1*04:65; DRB1*04:66; DRB1*04:67; DRB1*04:68; DRB1*04:69; DRB1*04:70; DRB1*04:71; DRB1*04:72:01; DRB1*04:72:02; DRB1*04:73; DRB1*04:74; DRB1*04:75; DRB1*04:76; DRB1*04:77; DRB1*04:78; DRB1*04:79; DRB1*04:80; DRB1*04:81N; DRB1*04:82; DRB1*04:83; DRB1*04:84; DRB1*04:85; DRB1*04:86; DRB1*04:87; DRB1*04:88; DRB1*04:89; DRB1*04:90; DRB1*04:91; DRB1*04:92; DRB1*04:93; DRB1*04:94N; DRB1*04:95:01; DRB1*04:95:02; DRB1*04:96; DRB1*04:97; DRB1*04:98:01; DRB1*04:98:02; DRB1*04:99; DRB1*04:100; DRB1*04:101; DRB1*04:102; DRB1*04:103; DRB1*04:104; DRB1*04:105:01; DRB1*04:105:02; DRB1*04:106; DRB1*04:107; DRB1*04:108; DRB1*04:109; DRB1*04:110; DRB1*04:111; DRB1*04:112; DRB1*04:113; DRB1*04:114; DRB1*04:115; DRB1*04:116; DRB1*04:117; DRB1*04:118; DRB1*04:119N; DRB1*04:120N; DRB1*04:121; DRB1*04:122; DRB1*04:123; DRB1*04:124; DRB1*04:125; DRB1*04:126; DRB1*04:127; DRB1*04:128; DRB1*04:129; DRB1*04:130; DRB1*04:131; DRB1*04:132; DRB1*04:133; DRB1*04:134; DRB1*04:135; DRB1*04:136; DRB1*04:137; DRB1*04:138; DRB1*04:139; DRB1*04:140; DRB1*04:141; DRB1*04:142N; DRB1*04:143; DRB1*04:144; DRB1*04:145; DRB1*04:146; DRB1*04:147; DRB1*04:148; DRB1*04:149; DRB1*04:150; DRB1*04:151; DRB1*04:152; DRB1*04:153; DRB1*04:154; DRB1*04:155; DRB1*04:156; DRB1*04:157N; DRB1*04:158N; DRB1*04:159; DRB1*04:160; DRB1*04:161; DRB1*04:162; DRB1*04:163; DRB1*04:164; DRB1*04:165; DRB1*04:166; DRB1*04:167; DRB1*04:168; DRB1*04:169; DRB1*04:170; DRB1*04:171; and DRB1*04:172; which may be modified to comprise the amino acid changes {H62N, D72E}.
[0058] In other such embodiments the HLA-DRA allele is paired with the binding domains of an HLA-DRB15 allele. The HLA-DRB15 allele can be selected from the publicly available DRB15 alleles, including without limitation: DRB1*15:01:01:01; DRB1*15:01:01:02; DRB1*15:01:01:03; DRB1*15:01:01:04; DRB1*15:01:02; DRB1*15:01:03; DRB1*15:01:04; DRB1*15:01:05; DRB1*15:01:06; DRB1*15:01:07; DRB1*15:01:08; DRB1*15:01:09; DRB1*15:01:10; DRB1*15:01:11; DRB1*15:01:12; DRB1*15:01:13; DRB1*15:01:14; DRB1*15:01:15; DRB1*15:01:16; DRB1*15:01:17; DRB1*15:01:18; DRB1*15:01:19; DRB1*15:01:20; DRB1*15:01:21; DRB1*15:01:22; DRB1*15:02:01; DRB1*15:02:02; DRB1*15:02:03; DRB1*15:02:04; DRB1*15:02:05; DRB1*15:02:06; DRB1*15:02:07; DRB1*15:02:08; DRB1*15:02:09; DRB1*15:02:10; DRB1*15:03:01:01; DRB1*15:03:01:02; DRB1*15:03:02; DRB1*15:04; DRB1*15:05; DRB1*15:06:01; DRB1*15:06:02; DRB1*15:07:01; DRB1*15:07:02; DRB1*15:08; DRB1*15:09; DRB1*15:10; DRB1*15:11; DRB1*15:12; DRB1*15:13; DRB1*15:14; DRB1*15:15; DRB1*15:16; DRB1*15:17N; DRB1*15:18; DRB1*15:19; DRB1*15:20; DRB1*15:21; DRB1*15:22; DRB1*15:23; DRB1*15:24; DRB1*15:25; DRB1*15:26; DRB1*15:27; DRB1*15:28; DRB1*15:29; DRB1*15:30; DRB1*15:31; DRB1*15:32; DRB1*15:33; DRB1*15:34; DRB1*15:35; DRB1*15:36; DRB1*15:37:01; DRB1*15:37:02; DRB1*15:38; DRB1*15:39; DRB1*15:40; DRB1*15:41; DRB1*15:42; DRB1*15:43; DRB1*15:44; DRB1*15:45; DRB1*15:46; DRB1*15:47; DRB1*15:48; DRB1*15:49; DRB1*15:50N; DRB1*15:51; DRB1*15:52; DRB1*15:53; DRB1*15:54; DRB1*15:55; DRB1*15:56; DRB1*15:57; DRB1*15:58; DRB1*15:59; DRB1*15:60; DRB1*15:61; DRB1*15:62; DRB1*15:63; DRB1*15:64; DRB1*15:65; DRB1*15:66; DRB1*15:67; DRB1*15:68; DRB1*15:69; DRB1*15:70; DRB1*15:71; DRB1*15:72; DRB1*15:73; DRB1*15:74; DRB1*15:75; DRB1*15:76; DRB1*15:77; DRB1*15:78; DRB1*15:79; DRB1*15:80N; DRB1*15:81; DRB1*15:82; DRB1*15:83; DRB1*15:84; DRB1*15:85; DRB1*15:86; DRB1*15:87; DRB1*15:88; DRB1*15:89; DRB1*15:90; DRB1*15:91; DRB1*15:92; DRB1*15:93; DRB1*15:94; DRB1*15:95; DRB1*15:96; DRB1*15:97; DRB1*15:98; DRB1*15:99; DRB1*15:100; DRB1*15:101; DRB1*15:102; DRB1*15:103; and DRB1*15:104; which may be modified to comprise the amino acid changes {P11S}.
[0059] In other embodiments the Class II binding domains are an H2 protein, e.g. I-A.alpha., I-A.beta., I-E.alpha. and I-E.beta.. In some such embodiments, the binding domains are H2 IE.sup.k.alpha. which may comprise the set of amino acid changes {I8T, F12S, L14T, A56V}; and H2 IE.sup.k.beta. which may comprise the set of amino acid changes {W6S, L8T, L34S}.
[0060] Class I HLA/MHC.
[0061] For class I proteins, the binding domains may include the .alpha.1, .alpha.2 and .alpha.3 domain of a Class I allele, including without limitation HLA-A, HLA-B, HLA-C, H-2K, H-2D, H-2L, which are combined with .beta..sub.2-microglobulin. Not more than about 10, usually not more than about 5, preferably none of the amino acids of the transmembrane domain will be included. The deletion will be such that it does not interfere with the ability of the domains to bind peptide ligands.
[0062] In certain specific embodiments, the binding domains are HLA-A2 binding domains, e.g. comprising at least the alpha 1 and alpha 2 domains of an A2 protein. A large number of alleles have been identified in HLA-A2, including without limitation HLA-A*02:01:01:01 to HLA-A*02:478, which sequences are available at, for example, Robinson et al. (2011), The IMGT/HLA database. Nucleic Acids Research 39 Suppl 1:D1171-6. Among the HLA-A2 allelic variants, HLA-A*02:01 is the most prevalent. The binding domains may comprise the amino acid change {Y84A}.
[0063] In certain specific embodiments, the binding domains are HLA-B57 binding domains, e.g. comprising at least the alpha1 and alpha 2 domains of a B57 protein. The HLA-B57 allele can be selected from the publicly available B57 alleles, including without limitation: B*57:01:01; B*57:01:02; B*57:01:03; B*57:01:04; B*57:01:05; B*57:01:06; B*57:01:07; B*57:01:08; B*57:01:09; B*57:01:10; B*57:01:11; B*57:01:12; B*57:01:13; B*57:01:14; B*57:01:15; B*57:01:16; B*57:01:17; B*57:02:01; B*57:02:02; B*57:03:01; B*57:03:02; B*57:04; B*57:05; B*57:06; B*57:07; B*57:08; B*57:09; B*57:10; B*57:11; B*57:12; B*57:13; B*57:14; B*57:15; B*57:16; B*57:17; B*57:18; B*57:19; B*57:20; B*57:21; B*57:22; B*57:23; B*57:24; B*57:25; B*57:26; B*57:27; B*57:28N; B*57:29; B*57:30; B*57:31; B*57:32; B*57:33; B*57:34; B*57:35; B*57:36; B*57:37; B*57:38; B*57:39; B*57:40; B*57:41; B*57:42; B*57:43; B*57:44; B*57:45; B*57:46; B*57:47; B*57:48; B*57:49; B*57:50; B*57:51; B*57:52; B*57:53; B*57:54; B*57:55; B*57:56; B*57:57; B*57:58; B*57:59; B*57:60; B*57:61; B*57:62; B*57:63; B*57:64; B*57:65; B*57:66; B*57:67; B*57:68; and B*57:69; which may be modified to comprise the amino acid change {Y84A}.
[0064] In other embodiments, the binding domains comprise H2-L.sup.d alpha 1 and alpha 2 domains, which may comprise the amino acid change {M31R}.
[0065] T cell receptor, refers to the antigen/MHC binding heterodimeric protein product of a vertebrate, e.g. mammalian, TCR gene complex, including the human TCR .alpha., .beta., .gamma. and .delta. chains. For example, the complete sequence of the human .beta. TCR locus has been sequenced, as published by Rowen et al. (1996) Science 272(5269):1755-1762; the human .alpha. TCR locus has been sequenced and resequenced, for example see Mackelprang et al. (2006) Hum Genet. 119(3):255-66; see a general analysis of the T-cell receptor variable gene segment families in Arden Immunogenetics. 1995; 42(6):455-500; each of which is herein specifically incorporated by reference for the sequence information provided and referenced in the publication.
[0066] The multimerized T cell receptor for selection in the methods of the invention is a soluble protein comprising the binding domains of a TCR of interest, e.g. TCR.alpha./.beta., TCR.gamma./.delta.. The soluble protein may be a single chain, or more usually a heterodimer. In some embodiments, the soluble TCR is modified by the addition of a biotin acceptor peptide sequence at the C terminus of one polypeptide. After biotinylation at the acceptor peptide, the TCR can be multimerized by binding to biotin binding partner, e.g. avidin, streptavidin, traptavidin, neutravidin, etc. The biotin binding partner can comprise a detectable label, e.g. a fluorophore, mass label, etc., or can be bound to a particle, e.g. a paramagnetic particle. Selection of ligands bound to the TCR can be performed by flow cytometry, magnetic selection, and the like as known in the art.
[0067] Peptide ligands of the TCR are peptide antigens against which an immune response involving T lymphocyte antigen specific response can be generated. Such antigens include antigens associated with autoimmune disease, infection, foodstuffs such as gluten, etc., allergy or tissue transplant rejection. Antigens also include various microbial antigens, e.g. as found in infection, in vaccination, etc., including but not limited to antigens derived from virus, bacteria, fungi, protozoans, parasites and tumor cells. Tumor antigens include tumor specific antigens, e.g. immunoglobulin idiotypes and T cell antigen receptors; oncogenes, such as p21/ras, p53, p210/bcr-abl fusion product; etc.; developmental antigens, e.g. MART-1/Melan A; MAGE-1, MAGE-3; GAGE family; telomerase; etc.; viral antigens, e.g. human papilloma virus, Epstein Barr virus, etc.; tissue specific self-antigens, e.g. tyrosinase; gp100; prostatic acid phosphatase, prostate specific antigen, prostate specific membrane antigen; thyroglobulin, .alpha.-fetoprotein; etc.; and self-antigens, e.g. her-2/neu; carcinoembryonic antigen, muc-1, and the like.
[0068] In the methods of the invention, a library of diverse peptide antigens is generated. The peptide ligand is from about 8 to about 20 amino acids in length, usually from about 8 to about 18 amino acids, from about 8 to about 16 amino acids, from about 8 to about 14 amino acids, from about 8 to about 12 amino acids, from about 10 to about 14 amino acids, from about 10 to about 12 amino acids. It will be appreciated that a fully random library would represent an extraordinary number of possible combinations. In preferred methods, the diversity is limited at the residues that anchor the peptide to the MHC binding domains, which are referred to herein as MHC anchor residues. The position of the anchor residues in the peptide are determined by the specific MHC binding domains. Diversity may also be limited at other positions as informed by binding studies, e.g. at TCR anchors.
[0069] Library.
[0070] In some embodiments of the invention, a library is provided of polypeptides, or of nucleic acids encoding such polypeptides, wherein the polypeptide structure has the formula:
polynucleotide composition encoding the P-L.sub.1-.beta.-L.sub.2-.alpha.-L.sub.3-T polypeptide
[0071] wherein each of L.sub.1, L.sub.2 and L.sub.3 are flexible linkers of from about 4 to about 12 amino acids in length, e.g. comprising glycine, serine, alanine, etc.
[0072] .alpha. is a soluble form of a domains of a class I MHC protein, or class II a MHC protein;
[0073] .beta. is a soluble form of (i) a .beta. chain of a class II MHC protein or (ii) .beta.2 microglobulin for a class I MHC protein;
[0074] T is a domain that allows the polypeptide to be tethered to a cell surface, including without limitation yeast Aga2; and
[0075] P is a peptide ligand, usually a library of different peptide ligands as described above, where at least 10.sup.6, at least 10', more usually at least 10.sup.8 different peptide ligands are present in the library.
[0076] Conventional methods of assembling the coding sequences can be used. In order to generate the diversity of peptide ligands, randomization, error prone PCR, mutagenic primers, and the like as known in the art are used to create a set of polynucleotides. The library of polynucleotides is typically ligated to a vector suitable for the host cell of interest. In various embodiments the library is provided as a purified polynucleotide composition encoding the P-L.sub.1-.beta.-L.sub.2-.alpha.-L.sub.3-T polypeptides; as a purified polynucleotide composition encoding the P-L.sub.1-.beta.-L.sub.2-.alpha.-L.sub.3-T polypeptides operably linked to an expression vector, where the vector can be, without limitation, suitable for expression in yeast cells; as a population of cells comprising the library of polynucleotides encoding the P-L.sub.1-.beta.-L.sub.2-.alpha.-L.sub.3-T polypeptides, where the population of cells can be, without limitation yeast cells, and where the yeast cells may be induced to express the polypeptide library.
[0077] "Suitable conditions" shall have a meaning dependent on the context in which this term is used. That is, when used in connection with binding of a T cell receptor to a polypeptide of the formula polynucleotide composition encoding the P-L.sub.1-.beta.-L.sub.2-.alpha.-L.sub.3-T polypeptide, the term shall mean conditions that permit a TCR to bind to a cognate peptide ligand. When this term is used in connection with nucleic acid hybridization, the term shall mean conditions that permit a nucleic acid of at least 15 nucleotides in length to hybridize to a nucleic acid having a sequence complementary thereto. When used in connection with contacting an agent to a cell, this term shall mean conditions that permit an agent capable of doing so to enter a cell and perform its intended function. In one embodiment, the term "suitable conditions" as used herein means physiological conditions.
[0078] The term "specificity" refers to the proportion of negative test results that are true negative test result. Negative test results include false positives and true negative test results.
[0079] The term "sensitivity" is meant to refer to the ability of an analytical method to detect small amounts of analyte. Thus, as used here, a more sensitive method for the detection of amplified DNA, for example, would be better able to detect small amounts of such DNA than would a less sensitive method. "Sensitivity" refers to the proportion of expected results that have a positive test result.
[0080] The term "reproducibility" as used herein refers to the general ability of an analytical procedure to give the same result when carried out repeatedly on aliquots of the same sample.
[0081] Sequencing platforms that can be used in the present disclosure include but are not limited to: pyrosequencing, sequencing-by-synthesis, single-molecule sequencing, second-generation sequencing, nanopore sequencing, sequencing by ligation, or sequencing by hybridization. Preferred sequencing platforms are those commercially available from Illumina (RNA-Seq) and Helicos (Digital Gene Expression or "DGE"). "Next generation" sequencing methods include, but are not limited to those commercialized by: 1) 454/Roche Lifesciences including but not limited to the methods and apparatus described in Margulies et al., Nature (2005) 437:376-380 (2005); and U.S. Pat. Nos. 7,244,559; 7,335,762; 7,211,390; 7,244,567; 7,264,929; 7,323,305; 2) Helicos BioSciences Corporation (Cambridge, Mass.) as described in U.S. application Ser. No. 11/167,046, and U.S. Pat. Nos. 7,501,245; 7,491,498; 7,276,720; and in U.S. Patent Application Publication Nos. US20090061439; US20080087826; US20060286566; US20060024711; US20060024678; US20080213770; and US20080103058; 3) Applied Biosystems (e.g. SOLiD sequencing); 4) Dover Systems (e.g., Polonator G.007 sequencing); 5) IIlumina as described U.S. Pat. Nos. 5,750,341; 6,306,597; and 5,969,119; and 6) Pacific Biosciences as described in U.S. Pat. Nos. 7,462,452; 7,476,504; 7,405,281; 7,170,050; 7,462,468; 7,476,503; 7,315,019; 7,302,146; 7,313,308; and US Application Publication Nos. US20090029385; US20090068655; US20090024331; and US20080206764. All references are herein incorporated by reference. Such methods and apparatuses are provided here by way of example and are not intended to be limiting.
METHODS AND COMPOSITIONS
[0082] Compositions and methods are provided for accurately identifying the set of peptides recognized by a T cell receptor in a given MHC context. The methods involve the generation of a library of polypeptides in which specific MHC binding domains, which provide the MHC context, are combined in a single polypeptide chain with a diverse library of peptide ligands. The diversity of the library is as previously defined. The single chain polypeptide may further comprise a domain that allows the peptide to be tethered to, or otherwise inserted into a cell surface.
[0083] The peptide ligand is from about 8 to about 20 amino acids in length, usually from about 8 to about 18 amino acids, from about 8 to about 16 amino acids, from about 8 to about 14 amino acids, from about 8 to about 12 amino acids, from about 10 to about 14 amino acids, from about 10 to about 12 amino acids. In preferred methods, the diversity is limited at the residues that anchor the peptide to the MHC binding domains, which are referred to herein as MHC anchor residues. The position of the anchor residues in the peptide are determined by the specific MHC binding domains. Class I binding domains have anchor residues at the P2 position, and at the last contact residue. Class II binding domains have an anchor residue at P1, and depending on the allele, at one of P4, P6 or P9. For example, the anchor residues for IE.sup.k are P1 {I, L, V} and P9 {K}; the anchor residues for HLA-DR15 are P1 {I, L, V} and P4 {F, Y}. Anchor residues for DR alleles are shared at P1, with allele-specific anchor residues at P4, P6, P7, and/or P9.
[0084] The library can be provided in the form of a polynucleotide, e.g. a coding sequence operably linked to an expression vector; which is introduced by transfection, electroporation, etc. into a suitable host cell. Eukaryotic cells are preferred as a host, and may be any convenient host cell that can be transfected and selected for expression of a protein on the cell surface. Yeast cells are a convenient host, although are not required for practice of the methods.
[0085] Once introduced in the host cells, expression of the library is induced and the cells maintained for a period of time sufficient to provide cell surface display of the polypeptides of the library.
[0086] Selection for a peptide that binds to the TCR of interest is performed by combining a multimerized TCR with the population of host cells expressing the library. The multimerized T cell receptor for selection is a soluble protein comprising the binding domains of a TCR of interest, e.g. .alpha./.beta., TCR.gamma./.delta., and can be synthesized by any convenient method. The TCR may be a single chain, or a heterodimer. In some embodiments, the soluble TCR is modified by the addition of a biotin acceptor peptide sequence at the C terminus of one polypeptide. After biotinylation at the acceptor peptide, the TCR can be multimerized by binding to biotin binding partner, e.g. avidin, streptavidin, traptavidin, neutravidin, etc. The biotin binding partner can comprise a detectable label, e.g. a fluorophore, mass label, etc., or can be bound to a particle, e.g. a paramagnetic particle. Selection of ligands bound to the TCR can be performed by flow cytometry, magnetic selection, and the like as known in the art.
[0087] Rounds of selection are performed until the selected population has a signal above background, usually at least three and more usually at least four rounds of selection are performed. In some embodiments, initial rounds of selection, e.g. until there is a signal above background, are performed with a TCR coupled to a magnetic reagent, such as a superparamagnetic microparticle, which may be referred to as "magnetized". Herein incorporated by reference, Molday (U.S. Pat. No. 4,452,773) describes the preparation of magnetic iron-dextran microparticles and provides a summary describing the various means of preparing particles suitable for attachment to biological materials. A description of polymeric coatings for magnetic particles used in high gradient magnetic separation (HGMS) methods are found in U.S. Pat. No. 5,385,707. Methods to prepare superparamagnetic particles are described in U.S. Pat. No. 4,770,183. The microparticles will usually be less than about 100 nm in diameter, and usually will be greater than about 10 nm in diameter. The exact method for coupling is not critical to the practice of the invention, and a number of alternatives are known in the art. Direct coupling attaches the TCR to the particles. Indirect coupling can be accomplished by several methods. The TCR may be coupled to one member of a high affinity binding system, e.g. biotin, and the particles attached to the other member, e.g. avidin. Alternatively one may also use second stage antibodies that recognize species-specific epitopes of the TCR, e.g. anti-mouse Ig, anti-rat Ig, etc. Indirect coupling methods allow the use of a single magnetically coupled entity, e.g. antibody, avidin, etc., with a variety of separation antibodies.
[0088] Alternatively, and in a preferred embodiment for final rounds of selection, the TCR is multimerized to a reagent having a detectable label, e.g. for flow cytometry, mass cytometry, etc. For example, FACS sorting can be used to increase the concentration of the cells of having a peptide ligand binding to the TCR. Techniques include fluorescence activated cell sorters, which can have varying degrees of sophistication, such as multiple color channels, low angle and obtuse light scattering detecting channels, impedance channels, etc.
[0089] After a final round of selection, polynucleotides are isolated from the selected host cells, and the sequence of the selected peptide ligands are determined, usually by high throughput sequencing. It is shown herein that the selection process results in determination of a set of peptides that are bound by the TCR in the specific HLA context. The biological activity of these ligands in the activation of T cells has been validated. The set of selected ligands provides information about the restrictions on amino acid positions required for binding to the T cell receptor. Usually a plurality of peptide ligands are selected, e.g. up to 10, up to 100, up to 500, up to 1000 or more different peptide sequences.
[0090] The sequence data from this selected set of peptide ligands provides information about the restrictions on amino acids at each position of the peptide ligand. This can be shown graphically, see FIG. 3A-3B, or FIG. 6B-6C for examples. The restrictions can be particularly relevant at the residues contacting the TCR. Data regarding the restrictions on amino acids at positions of the peptide are input to design a search algorithm for analysis of public databases. The results of the search provide a set of peptides that meet the criteria for binding to the TCR in the MHC context. The search algorithm is usually embodied as a program of instructions executable by computer and performed by means of software components loaded into the computer.
[0091] Also provided herein are software products tangibly embodied in a machine-readable medium, the software product comprising instructions operable to cause one or more data processing apparatus to perform operations comprising: generating a n.times.20 matrix from the positional frequencies of selected peptide ligands obtained by the screening methods of the invention, where n is the number of amino acid positions in the peptide ligand library. A cutoff of amino acid frequencies is set, e.g. less than 0.1, less than 0.05, less than 0.01, and frequencies below the cutoff are set to zero. A database of sequences, e.g. a set of human polypeptide sequences; a set of pathogen polypeptide sequences, a set of microbial polypeptide sequences, a set of allergen polypeptide sequences; etc. are searched with the algorithm using an n-position sliding window alignment with scoring the product of positional amino acid frequencies from the substitution matrix. An aligned segment containing at least one amino acid where the frequency is below the cutoff is excluded as a match. The results of the search can be output as a data file in a computer readable medium
[0092] The peptide sequence results and database search results may be provided in a variety of media to facilitate their use. "Media" refers to a manufacture that contains the expression repertoire information of the present invention. The databases of the present invention can be recorded on computer readable media, e.g. any medium that can be read and accessed directly by a computer. Such media include, but are not limited to: magnetic storage media, such as floppy discs, hard disc storage medium, and magnetic tape; optical storage media such as CD-ROM; electrical storage media such as RAM and ROM; and hybrids of these categories such as magnetic/optical storage media. One of skill in the art can readily appreciate how any of the presently known computer readable mediums can be used to create a manufacture comprising a recording of the present database information. "Recorded" refers to a process for storing information on computer readable medium, using any such methods as known in the art. Any convenient data storage structure may be chosen, based on the means used to access the stored information. A variety of data processor programs and formats can be used for storage, e.g. word processing text file, database format, etc.
[0093] As used herein, "a computer-based system" refers to the hardware means, software means, and data storage means used to analyze the information of the present invention. The minimum hardware of the computer-based systems of the present invention comprises a central processing unit (CPU), input means, output means, and data storage means. A skilled artisan can readily appreciate that any one of the currently available computer-based system are suitable for use in the present invention. The data storage means may comprise any manufacture comprising a recording of the present information as described above, or a memory access means that can access such a manufacture.
[0094] A variety of structural formats for the input and output means can be used to input and output the information in the computer-based systems of the present invention. Such presentation provides a skilled artisan with a ranking of similarities and identifies the degree of similarity contained in the test expression repertoire.
[0095] The search algorithm and sequence analysis may be implemented in hardware or software, or a combination of both. In one embodiment of the invention, a machine-readable storage medium is provided, the medium comprising a data storage material encoded with machine readable data which, when using a machine programmed with instructions for using said data, is capable of displaying any of the datasets and data comparisons of this invention. In some embodiments, the invention is implemented in computer programs executing on programmable computers, comprising a processor, a data storage system (including volatile and non-volatile memory and/or storage elements), at least one input device, and at least one output device. Program code is applied to input data to perform the functions described above and generate output information. The output information is applied to one or more output devices, in known fashion. The computer may be, for example, a personal computer, microcomputer, or workstation of conventional design.
[0096] Each program can be implemented in a high level procedural or object oriented programming language to communicate with a computer system. However, the programs can be implemented in assembly or machine language, if desired. In any case, the language may be a compiled or interpreted language. Each such computer program can be stored on a storage media or device (e.g., ROM or magnetic diskette) readable by a general or special purpose programmable computer, for configuring and operating the computer when the storage media or device is read by the computer to perform the procedures described herein. The system may also be considered to be implemented as a computer-readable storage medium, configured with a computer program, where the storage medium so configured causes a computer to operate in a specific and predefined manner to perform the functions described herein.
[0097] Further provided herein is a method of storing and/or transmitting, via computer, sequence, and other, data collected by the methods disclosed herein. Any computer or computer accessory including, but not limited to software and storage devices, can be utilized to practice the present invention. Sequence or other data can be input into a computer by a user either directly or indirectly. Additionally, any of the devices which can be used to sequence DNA or analyze DNA or analyze peptide binding data can be linked to a computer, such that the data is transferred to a computer and/or computer-compatible storage device. Data can be stored on a computer or suitable storage device (e.g., CD). Data can also be sent from a computer to another computer or data collection point via methods well known in the art (e.g., the internet, ground mail, air mail). Thus, data collected by the methods described herein can be collected at any point or geographical location and sent to any other geographical location.
Reagents and Kits
[0098] Also provided are reagents and kits thereof for practicing one or more of the above-described methods. The subject reagents and kits thereof may vary greatly. Reagents of interest include reagents specifically designed for use in the methods of the invention. Such a kit may comprise a library of polynucleotides encoding a polypeptide of the formula P-L.sub.1-.beta.-L.sub.2-.alpha.-L.sub.3-T, where a diverse set of peptide ligands is provided. The polynucleotide library can be provided as a population of transfected cells, or as an isolated population of nucleic acids. Reagents for labeling and multimerizing a TCR can be included. In some embodiments the kit will further comprise a software package for analysis of a sequence database.
[0099] For example, reagents can include primer sets for high throughput sequencing. The kits can further include a software package for sequence analysis. The kit may include reagents employed in the various methods, such as labeled streptavidin, primers for generating target nucleic acids, dNTPs and/or rNTPs, which may be either premixed or separate, one or more uniquely labeled dNTPs and/or rNTPs, such as biotinylated or Cy3 or Cy5 tagged dNTPs, gold or silver particles with different scattering spectra, or other post synthesis labeling reagent, such as chemically active derivatives of fluorescent dyes, enzymes, such as reverse transcriptases, DNA polymerases, RNA polymerases, and the like, various buffer mediums, e.g. hybridization and washing buffers, prefabricated probe arrays, labeled probe purification reagents and components, like spin columns, etc., signal generation and detection reagents, e.g. streptavidin-alkaline phosphatase conjugate, chemifluorescent or chemiluminescent substrate, and the like.
[0100] In addition to the above components, the subject kits will further include instructions for practicing the subject methods. These instructions may be present in the subject kits in a variety of forms, one or more of which may be present in the kit. One form in which these instructions may be present is as printed information on a suitable medium or substrate, e.g., a piece or pieces of paper on which the information is printed, in the packaging of the kit, in a package insert, etc. Yet another means would be a computer readable medium, e.g., diskette, CD, etc., on which the information has been recorded. Yet another means that may be present is a website address which may be used via the internet to access the information at a removed, site. Any convenient means may be present in the kits.
[0101] The above-described analytical methods may be embodied as a program of instructions executable by computer to perform the different aspects of the invention. Any of the techniques described above may be performed by means of software components loaded into a computer or other information appliance or digital device. When so enabled, the computer, appliance or device may then perform the above-described techniques to assist the analysis of sets of values associated with a plurality of peptides in the manner described above, or for comparing such associated values. The software component may be loaded from a fixed media or accessed through a communication medium such as the internet or other type of computer network. The above features are embodied in one or more computer programs may be performed by one or more computers running such programs.
[0102] Software products (or components) may be tangibly embodied in a machine-readable medium, and comprise instructions operable to cause one or more data processing apparatus to perform operations comprising: a) clustering sequence data from a plurality of immunological receptors or fragments thereof; and b) providing a statistical analysis output on said sequence data. Also provided herein are software products (or components) tangibly embodied in a machine-readable medium, and that comprise instructions operable to cause one or more data processing apparatus to perform operations comprising: storing and analyzing sequence data.
EXAMPLES
[0103] The following examples are offered by way of illustration and not by way of limitation.
Example 1
Mechanism for Specificity of T Cell Recognition of Peptide-MHC
[0104] In order to survey a universe of MHC-presented peptide antigens whose numbers greatly exceed the diversity of the T cell repertoire, T cell receptors (TCRs) are thought to be crossreactive. However, experimentally measuring the extent of TCR cross-reactivity has not been achieved. We developed a system to identify MHC-presented peptide ligands by combining TCR selection of highly diverse yeast-displayed peptide-MHC libraries with deep sequencing. While we identified hundreds of peptides reactive with each of five different mouse and human TCRs, the selected peptides possessed TCR recognition motifs that bore a close resemblance to their known antigens. This structural conservation of the TCR interaction surface allowed us to exploit deep sequencing information to computationally identify activating microbial and self-ligands for human autoimmune TCRs. The mechanistic basis of TCR cross-reactivity described here enables effective surveillance of diverse self and foreign antigens, but without requiring degenerate recognition of non-homologous peptides.
[0105] T cells are central to many aspects of adaptive immunity. Each mature T cell expresses a unique .alpha..beta. T cell receptor (TCR) that has been selected for its ability to bind to peptides presented by major histocompatibility complex (MHC) molecules. During the course of T cell development, survival, and effector functions, a given TCR surveys a broad landscape of self and foreign peptides and only responds to ligands whose engagement exceeds certain affinity, kinetic and oligomerization thresholds. Unlike antibodies, TCRs generally have low affinity for ligands (KD.about.1-100 .mu.M), which has been speculated to facilitate rapid scanning of peptide-MHC (pMHC).
[0106] Structural studies of TCR-pMHC complexes have revealed a binding orientation where, generally, the TCR CDR1 and CDR2 loops make the majority of contacts with the tops of the MHC helices while the CDR3 loops, which are conformationally malleable, primarily engage the peptide presented in the MHC groove. The low affinity and fast kinetics of TCR-pMHC binding, combined with conformational plasticity in the CDR3 loops, would seem to facilitate cross-reactivity with structurally distinct peptides presented by MHC. Indeed, given that the calculated diversity of potential peptide antigens is much larger than TCR sequence diversity, and certainly exceeds the number of T cells in an individual, TCR crossreactivity appears to be a biological imperative.
[0107] Crossreactive TCRs have been implicated in the pathogenesis of a number of autoimmune diseases, and have been proposed to explain why sequential infections in mice result in protective differences in immune pathology and the hierarchy of immunodominance. In humans, there is a growing recognition that vaccination can have a more general impact on morbidity and mortality beyond the expected benefit in preventing the targeted disease. Nevertheless, the true extent of TCR cross-reactivity, and its role in T cell immunity, remains a speculative issue, largely due to the absence of quantitative experimental approaches that could definitively address this question. While many examples exist of TCRs recognizing substituted or homologous peptides related to the antigen, such as altered peptide ligands, most of these peptides retain similarities to the wild-type peptides and are recognized in a highly similar fashion. Only a handful of defined examples exist of a single TCR recognizing non-homologous sequences. Examples from nature are rare, and there has not been a robust methodology to identify non-homologous peptides cross-reactive with a given TCR using screening approaches.
[0108] One approach that has been used to estimate cross-reactivity utilizes pooled, chemically synthesized peptide libraries. Based on a calculation taking into account the assumed concentrations of each agonist peptide in the pools, and the aggregate EC50 of the pool in stimulating a T cell clone, it has been extrapolated that .about.10.sup.6 different peptides in mixtures containing .about.10.sup.12 different peptides were agonists. However, while this methodology has successfully isolated a handful of significantly diverse sequences, most studies using the technique find only close homologues to known peptides. Furthermore, these libraries were assayed based solely on bulk stimulatory ability, with only femtomolar concentrations of any given peptide and no knowledge of peptide loading in the MHC or binding to the TCR. Therefore, the contributions of weakly reactive peptides or rare sequences are extremely difficult to isolate.
[0109] A more accurate estimate of cross-reactivity requires the isolation of individual sequences from a library of MHC-presented peptides based upon binding to a TCR. Recently, we and others have created libraries of peptides linked to MHC via yeast and baculovirus display as a method to discover TCR ligands through affinity-based selections that rely on a physical interaction between the peptide-MHC and the TCR (Adams et al. (2011). Immunity 35, 681-693; Birnbaum et al. (2012). Immunol Rev 250, 82-101). However, these methods have so far not been used to address the broader question of TCR cross-reactivity, mainly due to the requirement of manually validating and sequencing individual library `hits`, which has restricted the approach to discovering small numbers of peptides.
[0110] Here, we use deep sequencing of yeast peptide-MHC libraries selected against five murine and human TCRs. Starting with .about.10.sup.8 transformant libraries, we discovered hundreds of unique peptide sequences recognized by each TCR. Strikingly, all peptide sequences bear TCR epitopes with close similarity to their previously known agonist antigens and engage the TCRs in structurally similar ways. With an understanding of this property, we created a computational algorithm to predict naturally occurring TCR ligands using data from our deep sequencing results. The algorithm identified thousands of previously unknown microbial and environmental peptides as well as several peptides of human origin predicted to cross-react with self-reactive TCRs derived from a patient with multiple sclerosis. We tested a diverse set of the putative TCR-reactive peptides and found 94% are able to elicit a T cell response. In general, TCR cross-reactivity does not appear to be characterized by broad degeneracy, but rather is constrained to a small number of TCR contact residue `hotspots` on a peptide, while tolerating greater diversity at other positions. This understanding of the properties of TCR cross-reactivity has broad implications for ligand identification, vaccine design, and immunotherapy.
[0111] We developed a system for the rapid and sensitive detection of TCR-binding peptides presented by the murine class II MHC I-E.sup.k. This represents an advance over previous reports of class II pMHC molecules displayed on the surface of yeast that did not show the ability to bind TCR (Birnbaum et al., supra; Boder et al. (2005). Biotechnol Bioeng 92, 485-491; Esteban and Zhao (2004). J Mol Biol 340, 81-95.; Jiang and Boder, 2010 Proc Natl Acad Sci USA 107, 13258-13263; Starwalt et al., 2003 Protein engineering 16, 147-156; Wen et al., 2008 J Immunol Methods 336, 37-44; Wen et al., 2011 Protein Eng Des Sel 24, 701-709). We were aided by a large compendium of biophysical data for the interaction of I-E.sup.k with several TCRs.
[0112] We designed our construct as a `mini` single-chain MHC Aga2 fusion, with the truncated peptide binding .alpha.1.beta.1 domains fused via a Gly-Ser linker. We linked the wild-type peptide MCC to the N-terminus via a Gly-Ser linker (FIG. 1A). The initial construct was correctly routed to the yeast surface but did not have the ability to bind to TCR, indicating the pMHC was not correctly folded (FIG. 1B). In order to rescue correct folding of the pMHC, we subjected the mini I-E.sup.k to error-prone mutagenesis combined with introduction of solubility-enhancing mutations.
[0113] We selected this mutagenized mini scaffold for binding to the 2B4 TCR, which recognizes MCC-I-E.sup.k with moderate affinity and slow kinetics. Our selections yielded a functional construct with three mutations on the .alpha.1 domain--two solubilizing mutations in what was previously the .alpha.1-.alpha.2 interface and one mutation between the MHC helix and the beta sheets (FIG. 1B). Staining was further improved via introduction of three solubility-enhancing mutations of residues underneath the platform that are normally shielded from solvent by the MHC .alpha.2 and .beta.2 domains (FIG. 1B). None of the MHC residues mutated contacted either the peptide or the TCR. The evolved construct retained specific binding to several MCC-I-E.sup.k recognizing TCRs and showed comparable affinity to the wild-type pMHC (FIG. 1B, 8).
[0114] We then created a peptide library tethered to the MHC construct for display on yeast. Based upon the recently solved 2B4-MCC-I-Ek structure, we mutagenized the peptide from P(-2) to P10 (FIG. 10). Limited diversity was introduced at the two most distal residues and the primary MHC-binding anchor residues at P1 and P9 to maximize the number of peptides capable of being correctly displayed by the MHC (FIG. 10). This library had a theoretical sequence diversity of 5.3.times.10.sup.13, although only 1.8.times.10.sup.8 sequences were represented in our library due to the limits of transformation efficiency.
[0115] Our first attempts at screening involved `manual curation` of selections conducted with multivalent TCR. The library showed enrichment after three rounds of selection using highly avid TCR-coated streptavidin beads followed by a higher stringency `polishing` round of selection using TCR tetramers. The three peptides recovered via sequencing of 12 individual, hand picked clones after selection were related to the WT MCC peptide--the P2, P5, and P8 TCR contacts were all conserved, while P3 showed highly conservative Tyr to Phe mutation (FIG. 1D). These results suggested that a WT-like TCR recognition motif was highly favored. We surmised that these enriched WT sequences present in the later rounds dominated the selections, preventing alternative, potentially non-homologous sequences enriched in early rounds from being recovered. For this reason, we turned to deep sequencing at each step of the selection process to recover all enriched clones.
[0116] Deep Sequencing of Selections for TCR-Binding Peptides.
[0117] Analysis of the pooled yeast library DNA after each successive round of selection via deep sequencing showed enrichment from an essentially random distribution of amino acids to a highly WT-like TCR recognition motif (FIGS. 2A, 9A). After the third round, there were nonhomologous amino acids at P5 and P8 selected above background (Met and Ser for P5, Ile and Leu for P8) that were outcompeted by the WT-like motif by the final round of selection. The P3 position converged to Phe, homologous but not identical to the Tyr in the WT peptide (FIG. 2A) Overall, the number of unique peptides observed via deep sequencing progressed from 132,000 unique in-frame peptides observed in the sequenced portion of pre-selection library to only 207 unique peptides after the 3rd round of selection (FIGS. 2B, 2C, 9A, 9B). By the final round of selection, most of the library was dominated by a handful of sequences, matching the result obtained by manual curation (FIGS. 1D, 2B, 2C).
[0118] We therefore chose to conduct all analysis after round 3, since the data consisted of enriched clones that had not yet converged on a small number of sequences. We were also able to track the enrichment profile of individual peptides, finding most peptides enriched roughly 50-fold between rounds (FIGS. 2B, 9B). We repeated the selections with two other TCRs reactive to MCC-I-E.sup.k: 226 and 5cc7. We analyzed enrichment for each TCR after the third round of selection, where there is enrichment for a binding motif but before complete convergence to a small number of sequences (FIGS. 2A, 3A, 9B, 10A). While all three TCRs retain a WT-like TCR recognition motif such as P5 Lys (indicated by the outlined boxes in the heatmaps), each TCR also shows some variation in positional preferences (FIG. 3A). For example, where 2B4 can recognize P5 Met, 5cc7 can accommodate P5 Leu, Val, and Arg. The P3 TCR contact position showed the least variance across all three TCRs, with either Phe or Tyr being required for 2B4 and 5cc7, and Phe, Tyr, or Trp being required for 226 (FIG. 3A).
[0119] While each TCR recognized a largely WT-like motif, each recognized a different number of unique peptide sequences (FIG. 10A). 2B4 showed the highest stringency for its ligands, with only 207 sequences recovered from the selection that had enriched above the maximum background frequency of 1.times.10.sup.-4 observed in any pre-selected clone. 226, as previously reported, showed a greater degree of cross-reactivity, able to recognize 897 unique peptide sequences. The larger number of peptides recognized was largely a function of a higher tolerance for substitutions on TCR-neutral and MHC-contacting residues, such as at positions P(-1) and P4 (FIG. 3A).
[0120] The large collection of peptides recovered via deep sequencing enabled us to apply a co-variation analysis to discover intra-peptide structure-activity relationships that were not previously accessible with traditional single residue substitution analysis (FIG. 3B). By using co-variation analysis of the central P5 residue and the C-terminal P8 residue, a pattern emerged: the native, MCC-like `up-facing` TCR-contact motifs for each TCR (P5 Lys, P8 Ser/Thr) were strongly correlated, while the altered residues (P5 Ser/P8Leu for 2B4, P5 Leu or Arg/P8 Phe for 5cc7) were independently segregated (FIG. 3B). Therefore, the reason some of these TCR contacts were not previously described is that they do not occur independently. Instead, coupled changes across a network of peptide residues may be required to retain TCR binding. These results highlight a degree of cooperativity in the composition of residues comprising a `TCR epitope` that is clearly revealed with deep sequencing. Furthermore, such intra-peptide residue coupling reveals that cross-reactivity can occur through mutually compensatory substitutions to the parent peptide.
[0121] While the selected ligands for all three TCRs possessed shared features, each TCR also selected for a subset of sequences that were not selected by the other two. We wished to determine if these sequences were part of the larger parent MCC-like peptide family or constituted distinct families of peptide sequences. To determine this, we applied distance clustering to all of the peptides selected for all three TCRs (FIG. 3C). We found that while sequences recognized by individual TCRs clustered most closely to each other, essentially all of the selected sequences formed one large cluster of peptides no more than three amino acids different than at least one other peptide in the cluster (FIG. 3C, 10B). This suggests that while each TCR has unique recognition criteria, the three TCRs recognized many of the same peptides. Furthermore, peptides that were recognized by all three TCRs are related to a common specificity domain, and importantly, to the parent MCC ligand.
[0122] Even though we conducted unbiased selections of random libraries, the only ligands that were recovered were remarkably similar to the WT ligand at the TCR interface. Indeed, we attempted to prevent the occurrence of wild-type like peptides from being selected by creating a peptide library that suppressed the Lysine codon at P5, but that retained diversity at all other positions. Nevertheless, these `K-less` libraries failed to select for any TCR tetramer-staining clones when selected with 2B4 TCR. This experiment showed that the recovery of the wild-type TCR binding motifs in the original library was not simply due to wild-type like sequences suppressing the appearance of non-homologous crossreactive peptides.
[0123] Functional Characterization of I-Ek Library Hits.
[0124] We tested the signaling potencies and affinities of a subset of peptides selected for TCR binding. We synthesized 44 of the library peptides selected for binding to various subsets of the TCRs and examined their ability to stimulate T cell blasts from 2B4 and 5cc7 transgenic mice as assayed by CD69 upregulation and IL-2 production. The majority of the peptides predicted to bind 2B4 (19/19) and 5cc7 (17/21) expressing T cells induced CD69 upregulation (FIGS. 4A, 4B, 11A-D). The peptides had a wide range of potencies, with EC50s varying by several logs, including .about.50-fold more potent than the wild-type peptide MCC (colored red). When we compared the presence of the MCC-like TCR recognition epitope with TCR signaling, we found that in general, sequences that shared the MCC-like epitope at all three major TCR contacts (colored blue) were more potent in inducing signaling than those peptides that were more distantly related (colored black) (FIGS. 4A, 4B), speaking to the functional dominance of the wild-type motifs. We also tested the peptides selected for binding to one TCR for their ability to crossreact with the other MCC-reactive T cells. Surprisingly, a large proportion of these peptides potently activated TCR signaling (FIGS. 4A, 4B, 11A-D).
[0125] There was a significant difference in EC50s between peptides that were selected to bind to 2B4 versus the 5cc7/226-selected peptides tested for 2B4 T cell activation. For 5cc7 the EC50s for the two groups (5cc7-selected versus cross-reactive with 2B4/226-selected) are essentially identical. In general, the sequences that showed the most robust activation were again the ones that most closely shared the MCC TCR binding epitope. We additionally chose nine peptides from our initial set of 46 and exchanged them into soluble I-Ek MHC for TCR affinity measurements via surface plasmon resonance (SPR). For 2B4 and 5cc7, TCR bound the pMHC of interest with affinities ranging from KD of .about.1 .mu.M (over 10-fold better than MCC) to those with binding only barely detectable at 100 .mu.M TCR (FIG. 11E-F). When we compared the activity and affinity of our selected peptides, there is a loose but positive correlation between strength of TCR-pMHC binding and potency of activation (FIG. 4C). Several peptides with significantly different affinities show similar potencies (FIG. 4C).
[0126] The Structural Basis of TCR Recognition of Cross-Reactive Peptides.
[0127] To determine the molecular basis of the TCRs' ability to recognize the most diverse of the alternate peptides selected, we determined the crystal structures of 2B4 in complex with the library-derived 2A peptide (containing P5 Ser and P8 Ile) bound to I-E.sup.k, as well as 5cc7 in complex with two library-derived peptides bound to I-E.sup.k, 5c1 and 5c2 (containing P5 Leu/Arg and P8 Phe, respectively) (Table 1). When these complexes were aligned with previously solved complex structures of TCRs (2B4 and 226) binding to MCC-I-E.sup.k, very little deviation in overall TCR-pMHC complex geometry from the parent complexes was observed (FIGS. 5A and 5B). Since the MCC-I-E.sup.k-5cc7 complex is not solved, 5c1 and 5c2 were compared to MCC-I-Ek-226, which shares the TCR.beta. chain with 5cc7 and therefore likely retains a close footprint.
[0128] The contacts between TCR germline-derived CDR1/2 loops and MHC helices, which make up roughly 50% of the binding interface between TCR and pMHC, were essentially unchanged in the new peptide complexes versus MCC despite the difference in TCR contact residues in the peptides (FIG. 5C). When we examined the chemistry of MCC versus 2A, and MCC versus 5c1 peptide recognition by the respective TCRs, we saw the interaction between the TCRa CDR loops and the N-terminal half of the peptides are essentially invariant (FIGS. 5A and 5B, lower panels). Each peptide backbone makes a hydrogen bond at the P3 carbonyl with Arg29.alpha. in the TCR CDR1.alpha. loop. The contacts of 2B4 CDR3a with P2 and P3 in MCC and 2A are essentially identical (FIG. 5A, lower panels).
[0129] While an exact analogy cannot be made between 5cc7 recognizing 5c1 and 226 recognizing MCC due to sequence differences in their CDR3 loops, 5cc7 and 226 CDR3a loop conformations and peptide contacts are extremely similar (FIG. 5B, lower panels). The fact that all three MCC-reactive TCRs enrich for the same peptide residues at P2 and P3 (FIG. 3A) indicates that recognition peptides at their N-terminal contacts are highly conserved within this group (FIG. 5B, lower panels). In contrast, 2B4 and 5cc7 .beta. chain CDR loop interactions with the C termini of the peptides show marked changes to accommodate the non-MCC sequences. For 2B4, the CDR3.beta. loop conformation completely rearranges to engage the alternate P5 and P8 residues on the 2A peptide (FIG. 5A, lower panels). Gln10013, a residue that makes no contact with the peptide in the 2B4-MCC complex structure, flips its side chain by 180 degrees to form hydrogen bonds with the peptide backbone carbonyl oxygens at P5 and P6 (FIG. 5A, lower panels). Similarly, the side chains of Trp98.beta. and Ser99.beta. form hydrogen bonds with the P5 Ser hydroxyl moiety (FIG. 5A). Asp101.beta., one of the main contacts with P5 Lys in MCC, also undergoes a rearrangement. Instead of contacting the peptide, the side chain forms a hydrogen bond with Ser95.beta. on the other end of the CDR3.beta. loop, significantly altering the overall topology of the loop.
[0130] In the 5c1-I-E.sup.k/5cc7 complex, there are far fewer hydrogen bonds formed between the peptide and TCR due to the replacement of P5 Lys with Leu in the 5c1 peptide (FIG. 5B, lower panels). One side chain, Asn98.beta., changes its hydrogen bonding network from engaging only the carbonyl of P6 on the MCC peptide backbone to simultaneously interacting with the carbonyl oxygen of P6 and the amide nitrogen of P8 of the 5c1 peptide (FIG. 5B). The second peptide, 5c2, is recognized essentially identically by 5cc7 as 5c1 despite the substitution of P5 to Arg (Figure S5C). The substitution of a bulkier side chain at P8 (Phe instead of Thr), results in a rocking of 5cc7 such that the TCR C.beta. FG loop is translated by 15 .ANG. relative to the MCC-226 structure (Figure S5D-E). The shift of the TORR chain is correlated with accommodation of a bulky hydrophobic residue Phe at P8 on the peptide. It is interesting to note that 5c1 and MCC differ by several logs in signaling potency (EC50 of 1.5 .mu.M vs 8.4 nM) despite a relatively small difference in affinity (KD of 115 .mu.M vs 41 .mu.M). Indeed, all tested peptides with P8 Phe signal less efficiently than MCC-like peptides, even when affinities are closely matched (such as for 5c3, which binds to 5cc7 with a KD of 62 .mu.M) (FIG. 11E-F). These structures raise the question if a minor tilt of the TCR relative to the MHC can have consequences for signaling.
[0131] Strikingly, upon closer inspection, we find that homologies between what appear to be unrelated peptide sequences emerge from sequence clustering and structural analysis. For example, close structural relationships between the interaction modes of the 2B4-selected peptides MCC and 2A are apparent even though the peptides show little homology at 4/5 TCR contact positions (FIG. 5A). We also set out to determine if we could identify intermediate sequences that would `evolutionarily` link these two peptide sequences during the selection, given that both reside in the same sequence cluster (FIG. 3C).
[0132] Using our dataset of peptide sequences selected for 2B4 binding, we were able to populate a family of peptides that incrementally link MCC and 2A, with each peptide differing by only one TCR contact from the peptide before and after it (FIG. 5D). Thus, connectivity can be established between MCC and 2A through stepwise single amino acid drifts from their parent sequences.
[0133] Collectively, despite differences in peptide sequences, all MCC and library-peptide derived complexes share many common features with regards to docking geometry and interaction chemistry. Up-facing peptide residue sequence changes (e.g. P5, P8) are accommodated `locally` in a structurally parsimonious fashion that preserves most of the parent MCC peptide complex features, as opposed to accommodation through large scale repositioning of the CDR loops on the pMHC surface.
[0134] Development and Selection of a Human MHC Platform for Yeast Display.
[0135] To exploit our technology to find ligands for TCRs relevant to human disease, we also engineered the human MHC HLA-DR15, an allele with genetic linkage to multiple sclerosis. For yeast surface display, HLA-DR15 was constructed comparably to the murine I-Ek .beta.1.alpha.1 `mini` MHC with a peptide fused to the Nterminus (FIG. 6A). We chose to examine two closely-related TCRs, Ob.1A12 and Ob.2F3, that were cloned from a patient with relapsing-remitting multiple sclerosis and recognize HLADR15 bound to an immunodominant epitope of myelin basic protein (MBP, residues 85-99) peptide. These two TCRs utilize the same V.alpha.-J.alpha. and V.beta.-J.beta. gene segments and differ at one position in the CDR3.alpha. loop and two positions in CDR3.beta.. Ob.1A12 TCR is sufficient to cause disease in a humanized TCR transgenic mouse model.
[0136] A structure of Ob.1A12 complexed with HLA-DR15-MBP revealed an atypical docking mode, with the TCR shifted towards the N-terminus of the peptide. Ob.1A12 recognition of the MBP peptide is focused on a P2-His/P3-Phe TCR contact motif, and to a lesser extent on P5 Lys (FIG. 6B). The initial wild-type MBP-HLA-DR15 yeast display construct was not stained by Ob.1A12 TCR tetramers (FIG. 6A). Therefore, as with the I-Ek platform, we subjected this construct to error prone mutagenesis and selected for binding with Ob.1A12. In this fashion, mutations were found that enabled functional display, as measured by tetramer staining.
[0137] Our final construct combined the most heavily selected mutation (Pro11Ser on HLA-DR15.beta.) with two solubility-enhancing mutations on the bottom of the platform that were analogous to mutations required for I-Ek function (FIG. 6B). This construct stained robustly with Ob.1A12 and Ob.2F3 TCRs, as well as two MHC-specific antibodies (FIG. 6A). We designed a peptide library within the HLA-DR15 mini MHC scaffold to find novel Ob.1A12-binding peptides (FIG. 6A). Since Ob.1A12 binds its cognate pMHC shifted towards the N terminus of the peptide, we extended the library, randomizing from P(-4) to P10 compared to P(-2) to P10 for I-Ek (Hahn et al., 2005). The P1 and P4 positions, the strongest peptide anchors for HLA-DR15, were only afforded limited diversity.
[0138] The library was selected for binding to both Ob.1A12 and Ob.2F3 TCR tetramers and then each round was deep sequenced. We observed a strong convergence to a wild-type MBP-like TCR recognition motif for the primary Ob.1A12 TCR contacts (P2 His, P3 Phe, and P5 Lys) (FIG. 6B). Selections conducted with Ob.2F3 produced the same central `HF` MBP-like motif while showing slightly different enrichment patterns at proximal residues (Figure S6D). Given the dominance of `HF` in the selection results, we sought to determine if alternative cross-reactive TCR epitopes for Ob.1A12 would emerge if the up-facing `HF` motif was suppressed.
[0139] We made a library that allowed every amino acid except for His at P2, Phe at P3, and Lys at P5 (FIG. 6C). The selected clones still converged to a central HF motif by register shifting towards the C-terminus of the peptide by one amino acid, allowing the previous P4 Phe anchor to be repurposed as the P3 TCR contact, and the P3 position of the library to become the new P2 His TCR contact (FIG. 6C). Furthermore, when we subsequently prevented both His and Phe at P2 and P3 in a new library to suppress potential register shifting, we did not isolate any Ob.1A12-binding peptides. These results show that the `HF` motif is required for TCR recognition and its enrichment is a function of TCR preference, not any inherent biases caused by the library or MHC anchor positions of the peptide.
[0140] Clustering analysis of the selected peptides for both Ob.1A12 and Ob.2F3 showed that the selected peptides clustered with each other over the unselected peptides from the naive library (FIG. 6D). The overall clustering topology of the selected peptides was different than the I-Ek selections: instead of a single network encompassing all peptides, there were two distinct clusters consisting of peptides no more than 4 amino acids different from each other (FIG. 6D). When the stringency of clustering is increased to allow no more than 3 amino acid differences, matching the analysis done for I-Ek, there were several more sparse clusters. Since Ob1.A12 and Ob.2F3 are so focused on the HF motif, there are fewer total hotspot residues distributed on the peptide compared to the MCC-reactive TCRs we studied.
[0141] High-Confidence Prediction of Naturally Occurring TCR-Reactive Peptides.
[0142] The surprisingly limited tolerance of the TCRs for alternative ligands points to the feasibility of unambiguously identifying natural TCR ligands through selection with a random peptide library. However, library selections and deep sequencing alone are not sufficient to identify naturally occurring ligands for two reasons. First, the size of yeast libraries (.about.2.times.10.sup.8 unique sequences) relative to all possible pMHC-displayed peptides makes it unlikely that any given naturally occurring peptide sequence will exist in the library. Second, the amino acid substitutions that are permitted at each position along the peptide represent a complex, and as our covariation analysis indicated, cooperative interplay between the peptide, MHC, and TCR that may not be well described by common substitution matrices such as BLOSUM. For example, even though manual inspection of Ob.1A12-binding sequences readily shows the WT-like `HF` motif, blastp searches do not find MBP as a match even when constrained to the human proteome.
[0143] We therefore set out to develop an algorithm to use the aggregate data from our selection results to inform searches for candidate TCR antigens. First, we created a substitution matrix that would more accurately describe the probability of specific amino acid substitutions imparted by the selecting TCR. We hypothesized we could use the positional frequency information derived from our Ob.1A12 and Ob.2F3 deep sequencing data as a pMHC-TCR substitution matrix.
[0144] One potential complicating factor in using selection data as a substitution matrix is that the limited coverage of the libraries at every position of the peptide could lead to appearance of residue biases at non-critical (i.e. neutral) peptide positions that do not reflect actual selective pressure. To address this possibility, we created a new HLA-DR15-based library where we fixed the dominant Ob.1A12 binding motif (P2 His, P3 Phe, and P5 Lys/Arg) along with the P1 and P4 MHC-binding anchors, while the remaining residues were fully randomized. In this way, all peptides represented in the library contain the main motif required for Ob.1A12 binding and we could more accurately measure the occurrence of substitutions at other sites along the peptide.
[0145] When the selected libraries were sequenced, we found no dominant sequence, but rather a broad array of peptides that had enriched equally. While some proximal positions such as P(-1) and P(-2) still showed distinct residue preferences, other positions such as P7 and P8 showed less convergence relative to the original HLA-DR15 library. These selections provided critical granularity for what amino acids occur away from the TCR-binding `hotspot` on the peptide, allowing us to construct a more reliable algorithm.
[0146] We compiled the two 14.times.20 matrices consisting of the observed frequencies of the 20 amino acids at each of the 14 positions of the library peptides from the focused DR15 pMHC libraries with the `HF` motif selected by Ob.1A12 and Ob.2F3 (FIG. 7A). Any amino acid with less than 1% prevalence at each position was excluded to minimize possible noise from PCR or read errors. Minimal residue covariation was observed for Ob.1A12 and Ob.2F3 selections, so each position was treated independently.
[0147] With this matrix in hand, we developed a peptide search algorithm. Each protein in the NR (NCBI) or human protein (Uniprot) databases was scanned using a 14 position sliding window and scored as a product of the positional substitution matrix (Cockcroft and Osguthorpe, (1991) FEBS letters 293, 149-152). In this way, a candidate peptide containing even a single disallowed substitution would be excluded as a possible hit. The search using the Ob.1A12 based matrix yielded 2331 unique NR hits and 13 human peptides, both including MBP. For the search based on the Ob.2F3 matrix, we had 4825 unique NR hits and 19 unique human peptides, again both including MBP. The peptide hits shared the central P(-1)-P5 motif of MBP but the flanking residues showed very little sequence homology to either MBP or to each other (FIG. 7B).
[0148] The predicted peptides are from diverse microbial sources, such as bacteria; environmental sources, such as antigens expressed by plants; and several peptides derived from proteins in the human proteome. To test our computationally predicted ligands for Ob.1A12 and Ob.2F3, we synthesized a diverse set comprising 27 of the potential environmental antigens as well as 6 novel human peptides predicted to cross-react with Ob.1A12 and Ob.2F3. The peptides were added to HLADR15 expressing antigen-presenting cells and incubated with the human T cell clones, and T cell proliferation was measured via 3H-thymidine incorporation. Of the 33 putative ligands, 26/27 of the environmental antigens and 5/6 of the human peptides induced proliferation for Ob.1A12 and/or Ob.2F3, a success rate of 94% (FIG. 7B).
[0149] The concept of TCR cross-reactivity is important because key aspects of T cell biology seemingly require recognition of diverse ligands, including thymic development, pathogen surveillance, autoimmunity and transplant rejection. In this study, we aimed to define the mechanisms underlying TCR specificity and cross-reactivity using a combinatorial, biochemical approach that yielded massive datasets based on direct selection. This has given us insight into the structural basis of TCR cross-reactivity and also provides a robust way to discover new peptides (or the original ligand) for a given TCR.
[0150] Our results clarify previous controversies on whether TCRs are highly cross-reactive or highly specific. We find that TCR cross-reactivity can be explained based on structural principles: peptides possess `down-facing` residues that principally fill pockets in the MHC groove and `up-facing` residues that primarily act to engage the TCR. If the criterion of crossreactivity is simply the number of unique peptide sequences that can be recognized by any given TCR, then TCRs do exhibit a high degree of cross-reactivity. Indeed, our selections are able to identify hundreds of peptides for each receptor. Given the fact that the libraries greatly undersample all possible sequence combinations it is likely that our hundreds of discovered peptides are indicative of thousands of different peptides can be recognized by the studied TCRs.
[0151] However, when cross-reactive peptides are examined en masse, we find central conserved TCR-binding (i.e. `up-facing`) motifs. TCR cross-reactivity is not achieved by each receptor recognizing a large number of unrelated peptide epitopes, but rather through greater tolerance for substitutions to peptide residues outside of the TCR interface, differences in residues that contact the MHC, and relatively conservative changes to the residues that contact the TCR CDR loops. The segregation of TCR recognition and MHC binding allow for TCRs to simultaneously accommodate needs for specificity and cross-reactivity, ensuring no `holes` in the TCR repertoire without requiring degenerate recognition of antigen. This conclusion is consistent with previous studies on human self-reactive TCRs from multiple sclerosis patients: all stimulatory microbial peptides were found to share the primary TCR contact residues with the MBP self-peptide while substantial changes were permissible at the MHC interface.
[0152] Although this mechanism is general for a.beta. TCRs, recognition of nonhomologous antigens can occur to varying degrees in the TCR repertoire. The ability for one TCR to bind to multiple MHCs (e.g. alloreactivity); for one TCR to bind in multiple orientations on one MHC; for a peptide to non-canonically bind MHC (e.g. partially-filled peptide grooves); or for a TCR to have TCR-peptide contacts as a disproportionately large or small part of the overall interface (e.g. `super-bulged` peptides) will grant some receptors a greater degree of epitope promiscuity. Class I and class II MHC specific TCRs may exhibit different degrees of cross-reactivity as a consequence of the `low lying` peptides in the class II groove, versus the elevated or `higher profile` peptides presented by class I.
[0153] In retrospect, a close inspection reveals striking commonalities in the peptide binding chemistry by the TCR, in particular a requirement for a hydrophobic contact at the apex of the P7 `bulge` that forms the principal site of contact with the TCR CDR3.beta.. In contrast, a second class I TCR, 2C, was not found to be cross-reactive, instead exhibiting specificity for its endogenous antigen, QL9, in a manner similar to the class II specific TCRs studied here.
[0154] An important implication of these findings is that identification of endogenous antigens of TCRs is feasible using peptide-MHC libraries. In our previous view of cross-reactivity, we assumed that a given TCR would cross-react with so many peptides in a library that elucidation of `natural` leads from a background of degenerately binding sequences would be extremely difficult. Yet we find that we recover essentially only peptides with clear linkages to the natural ligands. The sparse coverage of possible sequences renders it unlikely that any given sequence of interest will be represented with 100% identity in our library.
[0155] However, using selection results to constrain computational searches of protein databases proved to be a highly successful strategy, with 94% of peptides that were predicted to bind showing activity with the TCR of interest. Thus, this approach now opens up peptide ligand discovery for `orphan` TCRs, such as those from regulatory T cells and tumor infiltrating lymphocytes (TILs).
[0156] While the naturally occurring peptides in this study were found as a proof of principle for our methodology, they demonstrate that autoimmune T cells have the ability to be activated by immunogens encountered in the environment, which may serve as the triggers for the initiation of autoimmunity. Several of the peptides in our panel are derived from microorganisms such as Legionella longbeachae and Acinetobacter that have previously been shown to be pathogenic in humans, and thus may have a role in the pathogenesis of multiple sclerosis. Furthermore, a number of other peptides from human pathogens were previously shown to activate human MBP-specific T cell clones. Additionally, the potential for other human peptides to cross-react with autoimmune TCRs with previously `known` antigens presents the intriguing possibility that individual TCRs can recognize multiple self-peptides, potentially contributing to T cell pathologies in autoimmune disease. This notion is supported by the finding that a murine TCR specific for myelin-oligodendrocyte glycoprotein cross-reacts with a second CNS antigen, neurofilament M. Due to this unexpected crossreactivity, these T cells remained pathogenic even in MOG-deficient mice. Our approach for systematic discovery of peptides recognized by human TCRs thus can advance our understanding of complex pathogenesis of immune-mediated diseases.
Methods
[0157] Creation and staining of yeast display constructs I-Ek and HLA-DR15 constructs were codon optimized for yeast expression and synthesized as N-terminal fusions to the yeast surface protein Aga2p (Genscript). Constructs were cloned into the vector pYAL, which contains a Gly-Ser linker and either Myc or Flag epitope tag between the MHC and Aga2p and the Aga2p leader sequence. MHC .alpha.1 and .beta.1 boundaries were determined by examination of previously published structures (PDB 3QIB and 1YMM) and appropriate MHC linker lengths were determined via modeling in Coot. For both constructs, MHC .beta. chain residues 3-96 were used, followed by an eight amino acid Gly-Ser linker, followed by MHC a chain residues 1-83. The peptide was linked to the N terminus of the MHC construct via a 12 amino acid linker. MHC constructs were then electroporated into EBY-100 yeast as previously described (Adams et al., 2011, supra), and induced for expression in SGCAA pH 4.5 media at 20.degree. for 24-60 hours until maximum epitope tag staining was observed (typically 40-70% of total population). To stain pMHC with TCR tetramers, biotinylated TCR was incubated with streptavidin coupled to AlexaFluor 647 (created as described in Ramachandiran et al. (2007). J Immunol Methods 319, 13-20) in a 5:1 ratio for 5 minutes on ice to ensure complete tetramer formation. Yeast cells were then stained with 500 nM tetramer+anti-Myc-alexa fluor 488 or anti-DYKDDDDK-alexa fluor 488 antibodies (Cell Signaling #2279 or #5407, respectively) for 3 hours on ice and washed twice with ice cold PBS+0.5% BSA and 1 mM EDTA (PBE buffer) before analysis via flow cytometry (Accuri C6 flow cytometer).
[0158] Library creation of `mini` 1-Ek and HLA-DR15 `mini` MHC constructs were mutagenized via error prone PCR (Genemorph II kit, Agilent 200550), with a final error rate of .about.3-4 nucleotide substitutions per construct as judged by ligating error prone constructs into a vector and sequencing several clones. Yeast libraries were created by electroporation of competent EBY-100 cells via homologous recombination of linearized pYAL vector and mutagenized pMHC construct essentially as described previously. Final libraries contained approximately 2.times.10.sup.8 yeast transformants. Peptide libraries were created in the same manner as the error prone libraries, except pMHC constructs were instead randomized along the peptide by using mutagenic primers allowing all 20 amino acids via an NNK codon as previously described. The libraries allowed only limited diversity at the known MHC anchor residues to maximize the number of correctly folded and displayed pMHC clones in the library. For I-Ek, P1 and P9 anchors were limited to (ILV) and K using VTT and AAA codons, respectively. P(-2) and P10 were limited to ADNT and AEGKRT using RMA and RVA codons, respectively. For HLA-DR15, P1 and P4 anchors were limited to ILV and FY using VTA and TWT codons, respectively. For the HFK-suppressed DR-15 library, His was suppressed at P2 by using a combination of DNK and NBK codons; Phe was suppressed at P3 by using VNK+NVK; Lys was suppressed at P5 by using BNK+NBK, for a total of 8 primers to construct the library. The resulting PCR product was used as template for a second PCR reaction in which 50 nt of sequence homologous to the vector was added to both ends of the PCR product. .about.100 ug of PCR product and .about.20 ug linearized vector were purified and used for the creation of each library.
[0159] List of primers for error prone libraries:
F (gal promoter f): 5'-ATGCAAAAACTGCATAACCAC-3' R (pyal_rev): 5'-GGGATTTGCTCGCATATAGTTG-3' For the random I-Ek library: F primer (initial randomization PCR):
5'-TATTGCTAGCGTTTTAGCAGCTRMTNNKVTTNNKNNKNNKNNKNNKNNKN NKAAARVAGGCGGTGGTTCGGGCGGTG-3'
[0160] R primer (initial randomization PCR): 5'-CGTCATCATCTTTATAATCGGATC-3' To add overlap for homologous recombination with linearized pYAL vector: F primer:
5'-TTCAATTAAGATGCAGTTACTTCGCTGTTTTTCAATATTTTCTGT TATTGCTAGCGTTTTAGCAGCT-3'
[0161] R primer: 5'-ACCACCAGATCCACCACCACCTTTATCGTCATCATCTTTATAATC GGATC-3' For the random HLA-DR15 library: F primer (initial randomization PCR):
5'-GTTATTGCTAGCGTATTGGCCNNKNNKNNKNNKVTANNKNNKTWTNNKNN KNNKNNKNNKNNKAGAGGTGGTGGTGGTTCAGGT-3'
[0162] F primer (to add homologous recombination region):
5'-TTCAATTAAGATGCAGTTACTTCGCTGTTTTTCAATATTTTCTGTTATTGC TAGCGTATTGGCC-3'
[0163] R primer (used for both PCRs): 5'-ACCGCCACCACCAGATCCACCACCACCCAAGTCTTCTTCAGAAATAAGC TT-5' For the `HF` motif suppression library F primers (all other primers identical to main HLADR15 library, with eight PCR products pooled to serve as second PCR template):
5'-GTTATTGCTAGCGTATTGGCCNNKNNKNNKNNKVTADNKVNKTWTBNKNN KNNKNNKNNKNNKAGAGGTGGTGGTGGTTCAGGT-3'
5'-GTTATTGCTAGCGTATTGGCCNNKNNKNNKNNKVTADNKVNKTWTNBKNN KNNKNNKNNKNNKAGAGGTGGTGGTGGTTCAGGT-3'
5'-GTTATTGCTAGCGTATTGGCCNNKNNKNNKNNKVTADNKNVKTWTBNKNN KNNKNNKNNKNNKAGAGGTGGTGGTGGTTCAGGT-3'
5'-GTTATTGCTAGCGTATTGGCCNNKNNKNNKNNKVTADNKNVKTWTNBKNN KNNKNNKNNKNNKAGAGGTGGTGGTGGTTCAGGT-3'
5'-GTTATTGCTAGCGTATTGGCCNNKNNKNNKNNKVTANBKVNKTWTBNKNN KNNKNNKNNKNNKAGAGGTGGTGGTGGTTCAGGT-3'
5'-GTTATTGCTAGCGTATTGGCCNNKNNKNNKNNKVTANBKVNKTWTNBKNN KNNKNNKNNKNNKAGAGGTGGTGGTGGTTCAGGT-3'
5'-GTTATTGCTAGCGTATTGGCCNNKNNKNNKNNKVTANBKNVKTWTBNKNN KNNKNNKNNKNNKAGAGGTGGTGGTGGTTCAGGT-3'
[0164] 5'-GTTATTGCTAGCGTATTGGCCNNKNNKNNKNNKVTANBKNVKTWTNBKNN KNNKNNKNNKNNKAGAGGTGGTGGTGGTTCAGGT-3' For the `HF` motif optimization library F primer (all other primers identical to main HLADR15 library):
5'-GTTATTGCTAGCGTATTGGCCNNKNNKNNKNNKRTACATTTCTTTARANNK NNKNNKNNKNNKAGAGGTGGTGGTGGTTCAGGT-3'
[0165] Selection of pMHC libraries To maximize sensitivity of selections, all described selection steps were conducted at 4.degree. using cold buffers, and refrigerated centrifuges. All spins were 5,000.times.g for 1 minute. Before each round of selection, a small sample of yeast (.about.1.times.10.sup.6 cells) were stained with an anti-epitope tag antibody. For the first round of selection, .about.2.times.10.sup.9 yeast were washed once with PBS+0.5% BSA and 1 mM EDTA (PBE buffer) and then cleared with unloaded Streptavidin Microbeads (250 uL beads in 5 mL PBE) (Miltenyi, 130-048-101) to eliminate any nonspecifically binding yeast clones by incubating 1 hr at 4.degree. with gentle rotation. The yeast were then spun down, resuspended in 5 mL PBE without a wash, and passed through a Miltenyi LS column. Yeast that did not bind to streptavidin alone were then spun down, resuspended in 5 mL PBE, and incubated with Streptavidin Microbeads loaded with TCR (400 nM TCR were added to 250 uL beads, an amount empirically determined to saturate the streptavidin beads) for 3-4 hrs at 4.degree. with gentle rotation. TCR-binding yeast were then selected via an LS column, washed in SDCAA, and then re-cultured in SDCAA, pH 4.5 at 30.degree. C. overnight. Yeast were re-induced upon reaching OD>2. For each round of selection, at least 10-fold more yeast was used than recovered from the previous round to ensure complete coverage of all selected yeast. Second and third rounds of selection were conducted in the same manner, but with reduced volumes (50 .quadrature.L of beads in 500 .quadrature.L PBE). Progress of selections was monitored by counting of cells selected to TCR-bound streptavidin beads as compared to streptavidin beads alone via an Accuri C6 flow cytometer. Selections typically showed enrichment for TCR binding after 3-4 rounds. For the final round of selection (conducted when the yeast count enriched by TCR loaded beads was higher than background, usually after 3 rounds), the libraries were stained with 500 nM streptavidin-TCR tetramer as described above, washed 3.times. with PBE, then incubated with 50 uL anti-Alexa647 Microbeads (Miltenyi, 130-091-395) in 450 .quadrature.L PBE for 20 minutes. The yeast were washed a final time and passed through a Miltenyi LS column. Enriched yeast were then plated on SDCAA plates for characterization of individual colonies. Individual yeast clones were then screened for tetramer staining as described above. Plasmids containing the selected pMHC were isolated from positive clones via yeast miniprep (Zymoprep II kit, Zymo Research) and sequenced (Sequetech).
[0166] Deep sequencing of selection libraries. Pooled plasmids from 5.times.10.sup.7 yeast from each round of selection were isolated via yeast miniprep (Zymoprep II kit, Zymo Research) and used as PCR template to prepare Illumina samples. Amplicon libraries were designed as follows: (Illumina P5-Truseq read 1-(N8)-Barcode-pMHC-(N8)-Truseq read 2-IlluminaP7). N8 was added immediately after both sequencing primers to generate diversity for low complexity sequencing reads. The adapter and barcode sequences were appended via nested 25-round cycles of PCR of the purified plasmids using Phusion polymerase (NEB). Primers were proximal to the peptide on the pMHC, annealing to the Aga2p leader sequence (5' end) and MHC p1 domain (3' end) to ensure high quality sequence reads of the peptide with double coverage. Final PCR products were run on a high percentage agarose gel and purified via gel extraction. PCR products were then quantitated via nanodrop, normalized for each barcoded round of selection to be equally represented, doped with 5-50% PhiX DNA to ensure sufficient sequence diversity for high quality sequence reads, and run on an Illumina MiSeq with 2.times.150 nt Paired End reads. The initial deep sequencing run, for the 2B4-I-E.sup.k selections, was conducted with 1.times.150 nt Single End reads. When the sequencing data was analyzed as described below, we saw no significant difference in data quality between single and paired-end reads (as judged by comparing the results for 226/5cc7 when analyzed as single reads vs. paired-end reads). Deep sequencing was conducted at the Stanford Stem Cell Institute Genome Center.
[0167] To analyze the sequence data, contigs were generated for each paired end read using PandaSeq. The contigs were then deconvoluted into individual rounds of selections and trimmed to the peptide sequence using Geneious version 6. The number of reads for each unique sequence were then summed and corrected for any potential PCR or sequence read errors by coalescing any sequences differing from only 1 nucleotide from the most dominant representative sequence. Sequences were then translated into peptides, and any reads that contained stop codons or frameshifts were omitted from further analysis. Amino acid frequencies and coevolution analyses were then calculated using scripts and visualized with Matlab (Mathworks Inc.) as previously described.
[0168] List of primers used for deep sequencing. The first PCR was conducted with primers specific to the MHC construct that added N8 sequence for read diversity and a 6-nucleotide barcode. The second PCR was conducted with general primers to add the necessarily Illumina adaptor sequences.
[0169] I-E.sup.k F primer: 5'-CTA CAC GAC GCT CTT CCG ATC TNN NNN NNN XXX XXX CTG TTA TTG CTA GCG TTT TAG CA-3' I-E.sup.k R primer: 5'-GCT GAA CCG CTC TTC CGA TCT NNN NNN NNA ACT CTT TGA GTA CCA TTA TAG AAA-3' HLA-DR15 F primer: 5'-CTA CAC GAC GCT CTT CCG ATC TNN NNN NNN XXX XXX CTG TTA TTG CTA GCG TAT TGG CC-3' HLA-DR15 R primer: 5'-GCT GAA CCG CTC TTC CGA TCT NNN NNN NNC GTT GAA AAA GTG ACA TTC TC-3' Illumina F: 5'-AAT GAT ACG GCG ACC ACC GAG ATC TAC ACT CTT TCC CTA CAC GAC GCT CTT CCG ATC T-3' Illumina R: 5'-CAA GCA GAA GAC GGC ATA CGA GAT CGG TCT CGG CAT TCC TGC TGA ACC GCT CTT CCG ATC-3', Where XXX XXX represents the following barcodes:
TABLE-US-00001 DNA I-E.sup.k round barcode HLA-DR15 Round DNA barcode I-E.sup.k pre- ATCACG HLA-DR15 random lib GTGGCC selection lib pre-selection 284 rd1 CGATGT Random lib Ob.1A12 rd1 GTTTCG 284 rd2 TIAGGC Random lib Ob.1A12 rd2 CGTACG 284 rd3 TGACCA Random lib Ob.1A12 rd3 GAGTGG 284 rd4 ACAGTG Random lib Ob.1A12 rd4 GGTAGC I-E.sup.k pre- GGCTAC Random lib Ob.2F3 rd1 ATGAGC selection lib 5cc7 rd1 CTTGTA Random lib Ob.2F3 rd2 ATTCCT 5cc7 rd2 AGTCAA Random lib Ob.2F3 rd3 CAAAAG 5cc7 rd3 AGTTCC Random lib Ob.2F3 rd4 CAACTA 5cc7 rd4 ATGTCA HLA-DR15 HF-suppressed CACGAT lib pre-selection 226 rd1 CCGTCC HF suppressed Ob.1A12 CACTCA rd1 226 rd2 GTAGAG HF suppressed Ob.1A12 CAGGCG rd2 226 rd3 GTCCGC HF suppressed Ob.1A12 CATGGC rd3 226 rd4 GTGAAA HF suppressed Ob.1A12 CATTTT rd4 HF suppressed Ob.2F3 rd1 CGGAAT HF suppressed Ob.2F3 rd2 CTAGCT HF suppressed OP.2F3 rd3 CTATAC HF suppressed Ob.2F3 rd4 CTCAGA HLA-DR15 HF-motif lib TACAGC pre-selection HF motif Ob.1A12 rd1 TATAAT HF motif Ob.1A12 rd2 TCATTC HF motif Ob.1A12 rd3 TCCCGA HF motif Ob.2F3 rd1 TCGAAG HF motif Ob.2F3 rd2 TCGGCA HF motif Ob.2F3 rd3 AAACAC
[0170] Clustering of selected peptide sequences. To quantify peptide convergence, a random sampling of 1000 pre-enriched library sequences were compared to the top 1000 most enriched sequences from each of the post-TCR selection library sequences. For each set, dispersion was quantified as the minimum hamming distance from each sequence to the next closest non-identical sequence within the set. While in the preselected library the mean minimum distance was 5 amino acids and no identical or distance 1 amino acid sequences were observed, in each of the selected libraries the majority of sequences were significantly more similar to one another than observed pre-selection, with a significant enrichment of distance 1 (p<0.001), distance 2 (p<0.001) and distance 3 (p<0.001) sequences emerging after selection, as determined by both Chi-squared and permutation sampling studies from the preselected library. To distinguish whether TCR selection resulted in a single convergent peptide solution or multiple independent solutions, for each TCR selection all sequences enriched to a frequency above the highest frequency for any clone in the background library were combined and connected by hamming distance into a network using the maximum mutation distance parameter 1, 2, 3, or 4 as obtained from initial sampling. The networks established that all sequences from all three TCRs generate a single dominant graph in which the true ligand was also connected (although never explicitly discovered), while no unselected library sequences converged into the network.
[0171] Profile-based searches for naturally occurring peptide ligands based upon selection results. The positional frequencies from the round 3 fixed HF library were used to generate a 14.times.20 matrix. The positional frequencies for the P1 and P4 anchors from the most abundant unique sequences from the selected fully random library was used instead of the fixed HF library frequencies to increase diversity of sequences in the search at the respective positions. A cutoff of amino acid frequencies less than 0.01 was used and frequencies below the cutoff were set to zero. The NCBI NR database and Human proteome from Uniprot were both downloaded from the respective servers. Both the NR and human databases were searched with the custom algorithm by using a 14-position sliding window alignment with scoring the product of positional amino acid frequencies from the substitution matrix (Cockcroft and Osguthorpe (1991) FEBS letters 293, 149-152; De la Herran-Arita et al. (2013) Science translational medicine 5, 216ra176). An aligned segment containing at least one amino acid where the frequency was below the 0.01 frequency cutoff was excluded as a match regardless of the abundance at other positions. Since the search found thousands of possible unique 14 amino acid peptide matches and the success rate for the functional activation potential of the predicted peptides was unknown, we aligned each of the fixed-HF library peptides with >20 reads to each of the peptide database hits. 26 NR hits and library comparators hits plus 8 human peptide hits (including the WT peptide, MBP) were chosen for functional validation. The peptides were chosen to have diverse statistics such as pairwise identity between search hit and library comparator sequence, search score, counts of the library comparator peptides, and diversity of sequence identity. Broad diversity of statistics was considered to sample the parameters for the hundreds of predicted peptides, the logic was to later use this information to improve our predictions. However, due to the high prediction rate, 94%, no correlations could be made.
[0172] Protein expression of pMHC and TCR for selection, affinity measurements, and structure determination. Proteins for this study were created in multiple formats, described below and separated by use.
[0173] 2B4, 226, and 5cc7 TCR for selection. TCR VmCh chimeras containing an engineered C domain disulfide were cloned into the pAcGP67a insect expression vector (BD Biosciences, 554756) encoding either a C-terminal acidic GCN4-zipper-Biotin acceptor peptide (BAP)-6.times.His tag (for a chain) or a C-terminal basic GCN4 zipper-6.times.His tag (for .beta. chain). Each chain also encoded a 3C protease site between the C-terminus of the TCR ectodomains and the GCN4 zippers to allow for cleavage of zippers. Baculoviruses for each TCR construct were created in SF9 cells via contransfection of BD baculogold linearized baculovirus DNA (BD Biosciences 554739) with Cellfectin II (Life Technologies 10362-100). TCR.alpha. and .beta. chain viruses were coinfected in a small volume (2 mL) of High Five cells in various ratios to find a ratio to ensure 1:1 .alpha.:.beta. stoichiometry.
[0174] To prepare TCRs, 1 L of High Five cells were infected with the appropriate ratio of TCR.alpha. and TCR.beta. viruses for 48 hrs at 28.degree.. Collected culture media was conditioned with 100 mM Tris-HCl pH8.0, 1 mM NiCl2, 5 mM CaCl2) and the subsequent precipitation was cleared via centrifugation. The media is then incubated with Ni-NTA resin (Qiagen 30250) at RT for 3 hours and eluted in 1.times.HBS+200 mM imidazole pH 7.2. TCRs were then site-specifically biotinylated by adding recombinant BirA ligase, 100 .mu.M biotin, 50 mM Bicine pH 8.3, 10 mM ATP, and 10 mM Magnesium Acetate and incubating 4.degree. 0/N. The reaction was then purified via size exclusion chromatography using an AKTAPurifier (GE Healthcare) on a Superdex 200 column (GE Healthcare). Peak fractions were pooled and then tested for biotinylation using an SDS-PAGE gel shift assay. Proteins were typically 100% biotinylated.
[0175] Insect-expressed 2B4 TCR for crystallography. 2B4 TCR was created as described above, except instead of biotinylation, protein was incubated with recombinant 3C protease (10 .mu.g/mg of TCR) and carboxypeptidase A at 4.degree. overnight. Insect-expressed I-E.sup.k MHC I-Ek was cloned into pAcGP67A with acidic/basic zippers as described for TCRs. The I-E.sup.k.beta. construct was modified with an N-terminal extension containing either the 2A peptide via a Gly-Ser linker or CLIP peptide via a Gly-Ser linker containing a thrombin cleavage site.
[0176] Expression, biotinylation, and purification of protein were as described for insect-expressed TCRs, with the exception of 72 hours of protein expression. For crystallography, I-Ek was treated with recombinant 3C protease (10 .mu.g/mg of MHC) and carboxypeptidase A and incubated at 4.degree. overnight before size exclusion chromatography.
[0177] Refolded Murine TCRs for crystallography and affinity measurements. Refolded 2B4, 226, and 5cc7 were created essentially as described. For 5c1 and 5c2 crystal structures, the 5c1 and 5c2 peptides were fused to the N-terminus of 5cc7.beta. via a 10-amino acid GlySer linker. TCRs were purified via size exclusion chromatography and assayed via SDS-PAGE to ensure 1:1 .alpha.:.beta. stoichiometry. If there were an excess of TCR.beta., .beta..beta. homodimer was purified away from .alpha..beta. heterodimer via ion exchange chromatography on a MonoQ column (GE Healthcare) using a 20 mM Tris pH 8/20 mM Tris pH8+500 mM NaCl buffer system. Proteins were then reexchanged into HBS for further use.
[0178] Refolding and biotinylation of Ob.1A12 and Ob.2F3 TCRs. The .alpha. and .beta. chains of Ob.1A12 and Ob.2F3 TCRs were separately cloned into the pET-22b vector (Novagen) and expressed as inclusion bodies in BL21(DE3)Escherichia coli cells (Novagen). The inclusion bodies were purified and dissolved in 6 M guanidine hydrochloride, 10 mM dithiothreitol and 10 mM EDTA. To initiate refolding, solubilized TCR .alpha. and .beta. chains were mixed at a 1:1 molar ratio and diluted to a final concentration of 25 .mu.g/ml of each chain in a refolding buffer containing 5 M urea, 0.5 M L-arginine-HCl, 100 mM Tris-HCl, pH 8.2, 1 mM GSH and 0.1 mM GSSH. After 40 h at 4.degree. C., the refolding mixture was dialyzed twice against deionized water and twice against 10 mM Tris-HCl, pH 8.0. Refolded TCR was purified by anion exchange chromatography using Poros PI (Applied Biosystems) and MonoQ (GE Healthcare) columns. Two cysteines that form the interchain disulfide bond of the C.alpha. and C.beta. Ig domains were repositioned from the C-terminal to the N-terminal part of these domains (via replacement of C.alpha. Thr48 and C.beta. Ser57 with cysteines) in order to enhance refolding of TCR heterodimer (Boulter et al., 2003). In the expression construct, a BirA tag was placed at the C-terminal of the TCR .beta. chain. Site-specific biotinylation of the BirA tag was carried out at a protein concentration of 2 mg/ml at a molar ratio of 20:1 (TCR to BirA). Reactions were incubated for 2 h at 30.degree. C. in the presence of 100 .mu.M biotin, 10 mM ATP, 10 mM magnesium acetate and protease inhibitors, followed by extensive dialysis to remove excess biotin. Biotinylation was confirmed by mobility shift with streptavidin using native polyacrylamide gels.
[0179] Selection of library derived I-Ek peptides for further characterization. Peptides were chosen from the deep sequencing data across a wide range of sequence prevalence for further study via SPR, activity, and structural characterization. Peptides were chosen that were recognized by 1, 2, or all 3 I-E.sup.k reactive TCRs. All peptides were tested for activity with both 2B4 and 5cc7 T cell clones regardless of for which TCR they were initially selected. A subset of peptides was chosen to further characterize via SPR. The 2A peptide that was structurally characterized in FIG. 5A was discovered by manual curation of an I-Ek peptide library. 2A is highly homologous to peptides represented in the deep sequencing data and co-clusters with MCC.
[0180] Surface plasmon resonance. Affinity measurements for peptides bound to I-Ek for 226, 2B4, and 5cc7 TCRs were determined via surface plasmon resonance on a Biacore T100 (GE Healthcare). 10 .mu.M of peptide of interest was added to biotinylated Clip-1-Ek. 1 U thrombin/100 .mu.g MHC was added and incubated at 37.degree.. After 1 hour, pH was lowered by adding sodium cacodylate pH 6.2 to 30 mM and sample was incubated at 37.degree. overnight. Samples were then neutralized with 40 mM HEPES pH 7.2 and stored at 4.degree. until use. pMHC exchanged with the peptide of interest were bound to a Biacore SA chip (GE Healthcare) at a low surface density (100-200 RU) to ensure no recapture of analyte. I-Ek exchanged with a null peptide (MCC K99E) was used as the reference surface. SPR runs were conducted in HBSP+ with 0.1% BSA to reduce nonspecific binding of TCR to the dextran surface. All measurements were made with 3-fold serial dilutions of refolded TCR using 60 s association followed by a 600 s dissociation at 10-30 .mu.L/min flow rate. No regeneration was required because samples returned completely to baseline during dissociation. Measurement of titrations at equilibrium was used to determine KD.
[0181] Activity assay for I-Ek-selected peptides. Lymphocytes were isolated from 5cc7 or 2B4 TCR transgenic Rag-/- mice. All cells were maintained in RPMI+10% FBS, 2 mM L-glutamine, 1 mM sodium pyruvate, 1.times.MEM-NEAA, pen-strep, and 50 .mu.M 2-mercaptoethanol. Antigen specific T cells were stimulated to form blasts with 10 .mu.M MCC added to cells at 1.times.107 cells/mL, with 30 U/mL recombinant IL-2 (R&D Systems) added on day 0 and day 1, splitting on subsequent days as necessary. T cell blasts were used between day 6 and day 10 post-stimulation and isolated with Histopaque 1119 (Sigma) before use to ensure live lymphocytes. T cells were placed into fresh media for 6 hours pre-stimulation to ensure cells were at rest before introduction of peptides of interest. Peptides from library plus positive (MCC) and negative (MCC K99E) controls were synthesized via solid phase peptide synthesis (Genscript) and dissolved at 20 mM in DMSO. 1.times.10.sup.5 CH27 cells (an APC line that expresses I-E.sup.k) per titration point were incubated with peptide diluted in RPMI (Invitrogen) at 37.degree. for 8 hours in a 96 well plate to allow peptide loading. 5.times.10.sup.4 T cell blasts were then added to each well and the plate was briefly pulsed in a swinging bucket centrifuge to ensure good T cell-APC contact. The T cells were stimulated for 18 hours at 37.degree.+5% CO2 in an incubator. After stimulation, cells were pelleted (300.times.g 5 minutes). The conditioned media was collected and frozen to measure IL-2 release and the cells were used to measure CD69 upregulation. To measure CD69 upregulation, T cells were stained with anti CD69-PE (clone H1.2F3, eBioscience 12-0691) and anti CD4-APC (clone GK1.5, eBioscience 17-0041) for 20 minutes at 4.degree.. Cells were then washed in PBS+0.5% BSA and fixed with 1.6% paraformaldehyde in PBS for 15 minutes at room temperature, and washed one final time before analysis. CD69 upregulation was measured using an Accuri C6 flow cytometer with an autosampler (BD) by measuring CD69 MFI in the CD4+ gate. Data was then normalized and EC50s measured via Prism. IL-2 release was measured in technical triplicates via anti-IL-2 Elisa (Ready-setgo mouse IL-2 ELISA kit, eBioscience 88-7024), as recommended by the manufacturer. Media was diluted 1:50 in buffer to obtain measurement within dynamic range of ELISA. Absorbance was measured via SpectraMax Paradigm (Molecular Devices), with EC50 determined via Graphpad Prism.
[0182] T cell Proliferation assays Ob.1A12 and Ob.2F3 T cell clones were restimulated with PHA-L (Roche) in the presence of irradiated peripheral blood mononuclear cells and cultured in RPMI 1640 supplemented with 10% FBS, 2 mM GlutaMAX-I, 10 mM Hepes (all Invitrogen), 1% human serum (Valley Biochemical), and 5 U/ml rIL-2 (Roche), as previously described (Wucherpfennig et al., 1994). T cells were used between 10 and 14 days after restimulation. To determine proliferation, 50.times.10.sup.3 Ob.1A12 or Ob.2F3 T cells were cocultured in a 1:1 ratio with irradiated EBV-transformed MGAR cells that had been treated with 50 .mu.g/ml mitomycin C for 30 min at 37.degree. C. Cells were plated in 0.2 ml/well of a 96-well round bottom plate in AIM-V media (Invitrogen) supplemented with 2 mM GlutaMAX-I. Peptides were tested over a range of concentrations (in triplicates) and proliferation was assessed by [.sup.3H]-thymidine incorporation after 72 h of culture.
[0183] Crystallization and X-ray data collection of I-Ek-TCR complexes. For the 2A-I-E.sup.k-2B4 complex, 2B4 and 2A-I-E.sup.k were expressed and purified separately, as described above, and then mixed at a 1:1 ratio and concentrated to 14 mg/ml. Crystals formed in 100 nl sitting drops in 20 mM sodium/potassium phosphate, 0.1 M Bis-Tris propane pH8.5, 20% PEG-3350. For the 5c1/5c2-I-E.sup.k-5cc7 complexes, tethered pMHC-TCR complexes were produced essentially as described in Newell et al, 2011. Briefly, purified CLIP-I-E.sup.k and 5cc7 with peptide tethered to the N-terminus of TCR were mixed at a 1:3 ratio and concentrated to 4 mg/mL. 1 U thrombin per 100 .quadrature.g CLIP-I-E.sup.k, and carboxypeptidases A and B were incubated with this sample for 3 hours at room temperature (RT). Sodium cacodylate, pH 6.2 was added to a final concentration of 30 mM and incubated at RT for 24-48 hours. Complex was isolated via size exclusion chromatography and concentrated to 10-15 mg/ml. Crystals formed in 100 nl-sitting drops in 0.2 M potassium citrate, 18% PEG-3350. Crystals used to collect datasets included either 4% 1,3 butanediol (for 5c1) or 4% Tert-butanol (for 5c2). All crystals were flash frozen in liquid nitrogen in mother liquor+30% ethylene glycol, and datasets were collected at Stanford Synchrotron Radiation Lightsource (Stanford, Calif.) beamlines 11-1 and 12-2. Data were indexed, integrated, and scaled using either XDS/XSCALE or the HKL-2000 program suite.
[0184] Structure determination and refinement. All structures were solved via molecular replacement using the program Phaser. The molecular replacement search model for the TCRs was the unliganded 2B4 or 5cc7 TCR (PDB ID 3QJF and 3QJH), with the CDR3 loops deleted to avoid model bias. The molecular replacement search model for MHC was the pMHC from the MCC-I-E.sup.k-2B4 complex structure (PDB ID 3QIB) with the peptide deleted to avoid model bias. Manual model building of the peptide and CDR3 loops was performed in COOT followed by iterative rounds of refinement with Phenix, using NCS restraints for the 5cc7 complex structures. For the 5cc7 complex structures, the first complex copy in the asymmetric unit (chains A-E) was used for analysis. Figures were made with PYMOL.
TABLE-US-00002 TABLE 1 2B4-2A-I-E.sup.k 5cc7-5c1-I-E.sup.k 5cc7-5c2-I-E.sup.k Data Collection: Space Group C2 C2 C2 Cell Dimensions a, b, c (.ANG.) 239.94, 60.18, 251.60, 101.87 262.90, 102.21, 78.36 214.64 214.11 .alpha., .beta., .gamma. (.degree.) 90, 104.33, 90 90, 94.88, 90 90, 95.04, 90 Resolution (.ANG.) 50-2.60 39.81-3.29 39.63-3.30 (2.64-2.60) (3.36-3.29) (3.36-3.30) R.sub.sym (%) 9.3 (42.8) 14.3 (135.6) 17.7 (198.0) <l/.sigma.(l)> 13.6 (2.0) 10.9 (1.3) 9.3 (1.0) Completeness (%) 96.8 (88.6) 98.8 (84.9) 99.3 (96.5) Redundancy 3.8 (2.8) 6.8 (5.5) 7.1 (6.7) Refinement Resolution (.ANG.) 50-2.60 40-3.29 40-3.30 (2.68-2.60) (3.33-3.29) (3.34-3.30) Reflections 32548 84239 84648 R.sub.cryst (%) 18.87 (28.13) 21.07 (35.82) 18.81 (36.77) R.sub.free (%) 24.50 (36.43) 24.10 (40.73) 23.57 (40.12) Number of atoms Protein 6493 25581 25597 Ligand 90 70 70 Water 118 0 0 Wilson B-factor 47.84 99.48 102.14 Average B-factors (.ANG..sup.2) All 57.10 119.20 124.70 Protein 57.26 119.20 124.70 Solvent 48.36 -- -- R.m.s. deviations from ideality Bond Lengths (.ANG.) 0.003 0.008 0.005 Bond Angles (.degree.) 0.695 0.831 0.888 Ramachandran statistics Favored (%) 96.49 96.37 95.80 Outliers (%) 0 0 0 Rotamer outliers (%) 0.70 0.54 0.75 Clashscore 4.75 4.98 5.40 PDB accession code 4P2O 4P2R 4P2Q
TABLE-US-00003 TABLE 2 Peptide Position -4 -3 -2 -1 1 2 3 4 5 6 7 8 9 10 Ob.1A12 TCR Amino Acid A 0.06 0.11 0.15 0.05 0 0 0 0 0 0.23 0.03 0.07 0.12 0.1 C 0.02 0.03 0.02 0.04 0 0 0 0 0 0 0.01 0.01 0.11 0. 2 D 0.06 0.01 0 0 0 0 0 0 0 0.02 0 0.02 0 0.02 E 0.13 0.05 0 0 0 0 0 0 0 0 0.05 0.04 0 0.02 F 0.02 0.01 0 0 0.01 0 1 .46 0 0 0.02 0 0 0.03 G 0.0 0.1 0.15 0 0 0 0 0 0 0.23 0.02 0.06 0.0 0.03 H 0.11 0.1 0.07 0.02 0 1 0 0 0 0 0.14 0.05 0 0.03 I 0.01 0.01 0 0 0.45 0 0 0.02 0 0 0.04 0.02 0.05 0.02 K 0.02 0.05 0.02 0.22 0 0 0 0 0.74 0 0 0.04 0 0.05 L 0.03 0.05 0 0 0.19 0 0 0.1 0 0 0.17 0.1 0.23 0.08 M 0.03 0.02 0 0.01 0 0 0.02 0 0.0 0.02 0.04 0.03 0.04 N 0.04 0.04 0.06 0.07 0 0 0 0 0 0.17 0.08 0.02 0 0.02 P 0 0.03 0.1 0 0 0 0 0 0 0 0.1 0.11 0 0.03 Q 0.07 0.06 0.09 0 0 0 0 0 0 0.04 0.07 0.05 0.01 0.03 R 0.07 0.12 0.11 0.25 0 0 0 0 0.28 0 0.0 0.12 0 0.15 S 0.11 0.08 0.14 0.08 0 0 0 0 0 0.17 0.04 0.09 0.04 0.09 T 0.06 0.07 0 0 0 0 0 0 0 0.0 0.02 0.06 0.04 0.05 V 0.03 0.04 0.02 0.24 0.29 0 0 0.02 0 0 0.04 0.07 0.28 0.1 W 0.02 0 0 0 0.01 0 0 0 0 0.05 0 0 0.05 Y 0.04 0.02 0 0 0.01 0 0 0.3 0 0 0.01 0.01 0 0.03 Ob.2F3 TCR Amino Acid A 0.07 0.1 0 0.08 0 0 0 0 0 .25 .07 0. 0.1 C 0.02 0.03 0.02 0.04 0 0 0 0 0 0.01 0.01 0.01 0.0 0.03 D 0.02 0 0 0 0 0 0 0 0.01 0.01 0.02 0 0.02 E 0.12 0 0 0 0 0 0 0 0 0.07 0. 4 0 0.02 F 0.02 0 0 0.01 0 .46 0 0 .01 0 .03 G 0.1 0.1 0 0 0 0 0 0 0.2 0.02 0.04 3 H 0.08 0.0 0.03 0 0 0 0 0 0. 4 0.05 0.0 .03 I 0.01 0.01 0 0.0 0.45 0 0 0. 0 0 .04 0. 2 .07 2 K 0.02 0.02 0.15 0 0 0 0 0.69 0 0 0.04 0 0.04 L 0.03 0.04 0.0 0 0.19 0 0 0.1 0 0 0.17 0.11 0.26 0.08 M 0.03 0.02 0.0 0.01 0.03 0 0 0. 2 0. 3 .01 0. 4 .04 0. 4 N 0.04 0.04 0.0 0.08 0 0 0 0 0 0.11 .02 0.01 2 P 0 0.04 0. 2 0 0 0 0 0 0 0.09 0 0.03 Q 0.07 0 0 0 0 0 0 .03 0.13 .05 0.02 3 R 0.07 0.13 0. 2 0.2 0 0 0 0 31 0 .12 0.12 0 0. 3 S 0.11 0.0 0. 5 0.1 0 0 0 0 0 0. 0.03 .09 0.03 0.1 T 0.07 0 0.0 0 0 0 0 0 0. 5 0. 0.04 0. V 0.04 0.04 0.02 0.28 0.29 0 0 .02 0 0 0. 4 0.07 0.3 0. W 0.02 0 0 0 0.01 0 0 .08 0 0 0.01 0.01 0 0.05 Y 0.02 0 0.0 0.01 0 0 0.03 0 0 0. 1 0.02 0 0.03 indicates data missing or illegible when filed
Example 2
[0185] A library for the HLA protein B5703 was generated with the peptide ligand as shown in FIG. 16. The library was expressed and screened as described above in Example 1, with the AGA1 T cell receptor. After 3 rounds of selection, a heatmap of the search matrix from high throughput sequencing was generated, shown in FIG. 17.
[0186] The top 20 peptides after round 3 has the sequences shown below in Table 3. The number of times the peptides were represented after selection is shown in each column.
TABLE-US-00004 Library Peptide Naive Rd1 Rd2 Rd3 Rd4 NSLKPEIPDYF 11 47 48656 268475 171826 GTIRPEIREMW 5 37 36754 226381 113394 SSGVPEVRMMF 6 38 40422 215079 125041 LSLRPEIPLFF 5 74 63749 183724 189891 KSFVPELKPAF 2 36 37327 157329 120443 WTYRPEVRGVW 4 21 30482 128915 91015 RSFYPEIREYW 7 19 14782 119258 48648 SSFSPELRMRW 3 10 14335 98338 48729 KSCTPEVREYF 0 17 15114 94896 49796 ASFSPELRMAW 0 10 9925 47218 31919 KSLAPEVRDLF 0 8 6502 34865 22054 NSVKPEIRPVW 6 10 10086 33679 32818 NSFRPEVAMKY 6 7 6013 31331 19786 KSLTPEVRGYVV 1 15 13273 30634 38231 YSFKPELKEIF 0 5 5648 28641 20312 ASFRPELAEFW 1 11 14699 24829 42208 GSLAPEIRMYW 9 11 3108 23178 10848 RSFVPEIGMGF 8 18 20370 22329 65722 SALRPEIRLLW 1 50 28840 21235 70740
The data was input into a search algorithm and used to define database hits of potential epitopes for the T cell receptor, shown in Table 4 and Table 5 below: TABLE 4 GAG hits
TABLE-US-00005 JMBlast GI number Reference Score NR Peptide Annotations 255986448 ACU50607.1 278. gag protein [Human 8.71E-10 KAFSPEVXXMF immunodeficiency virus 1] 9. gag protein, partial [Human 9651280 AAF91122.1 2.00E-09 RAFSPEVLPMF immunodeficiency virus 1] 91. gag protein [Human 119361821 ABL66844.1 2.90E-09 KAFSPEVLPMF immunodeficiency virus 1] 190. gag protein, partial [Human 166917908 ABZ03807.1 2.90E-09 KAFSPEVGPMF immunodeficiency virus 1] 41. gag protein, partial [Human 45644268 AAS72819.1 8.71E-09 KAFSPEVXPMF immunodeficiency virus 1] 296. gag protein, partial [Human 269308083 ACZ34129.1 2.90E-08 KAFSPEVKPMF immunodeficiency virus 1]
TABLE-US-00006 TABLE 5 Top 20 NR database hits % ID to Closest Library % ID to Library GI number KF11 GAG NR Peptide Hit (>60%) Peptide 302335486 35.7 RSLAPEVRGYW KSLTPEVRGYW 81.8 345792467 42.9 WTSSPEIRAVF WTSHPEIRAYF 81.8 495145889 28.6 ASSRPELALAY ASFRPELALRY 81.8 459942335 35.7 WTSHPEIKAAF WTSHPEIRAYF 81.8 430749919 42.9 RSLKPEVREVF KSLTPEVREYF 72.7 494716083 42.9 ASLRPEVREAF KSLAPEVRELF 72.7 493030958 42.9 KSLYPEIREVF RSFYPEIREYF 72.7 497464005 28.6 LSGVPEIRERW LSLRPEIREYW 72.7 497193348 35.7 LTIRPEIRPRW GTIRPEIREMW 72.7 488856804 42.9 ASFKPELPDFF NSFKPEIPDYF 72.7 430004692 35.7 STISPEIRLFW GTISPEIREMW 72.7 471573742 42.9 ASLKPEVPLVF LSLRPEVPLFF 72.7 495156089 42.9 SSGAPEVRELF SSGVPEVRMMF 72.7 301092772 35.7 SSVVPELPMAF SSVVPEVRMMF 72.7 348664816 42.9 RSFYPELRLLF RSFYPEIREYF 72.7 497177556 50.0 LTISPEIPPYF GTIRPEIPDYF 72.7 497797312 42.9 ESFRPEIRQYF RSFYPEIREYF 72.7 448510490 50.0 GSLSPELRPIF LSGSPELRMIF 72.7 15790131 35.7 STLSPELRGRW SSFSPELRMRW 72.7 313682157 42.9 KSFRPELKEFY ASFRPELAEFW 72.7
Sequence CWU 1
1
2781420PRTArtificial sequencesynthetic amino acid sequence 1Glu Leu
Ala Gly Ile Gly Ile Leu Thr Val Gly Gly Gly Gly Ser Gly1 5 10 15Gly
Gly Gly Ser Gly Gly Gly Gly Ser Ile Gln Arg Thr Pro Lys Ile 20 25
30Gln Val Tyr Ser Arg His Pro Ala Glu Asn Gly Lys Ser Asn Phe Leu
35 40 45Asn Cys Tyr Val Ser Gly Phe His Pro Ser Asp Ile Glu Val Asp
Leu 50 55 60Leu Lys Asn Gly Glu Arg Ile Glu Lys Val Glu His Ser Asp
Leu Ser65 70 75 80Phe Ser Lys Asp Trp Ser Phe Tyr Leu Leu Tyr Tyr
Thr Glu Phe Thr 85 90 95Pro Thr Glu Lys Asp Glu Tyr Ala Cys Arg Val
Asn His Val Thr Leu 100 105 110Ser Gln Pro Lys Ile Val Lys Trp Asp
Arg Asp Met Gly Gly Gly Gly 115 120 125Ser Gly Gly Gly Gly Ser Gly
Gly Gly Gly Ser Gly Gly Gly Gly Ser 130 135 140His Ser Met Arg Tyr
Phe Phe Thr Ser Val Ser Arg Pro Gly Arg Gly145 150 155 160Glu Pro
Arg Phe Ile Ala Val Gly Tyr Val Asp Asp Thr Gln Phe Val 165 170
175Arg Phe Asp Ser Asp Ala Ala Ser Gln Arg Met Glu Pro Arg Ala Pro
180 185 190Trp Ile Glu Gln Glu Gly Pro Glu Tyr Trp Asp Gly Glu Thr
Arg Lys 195 200 205Val Lys Ala His Ser Gln Thr His Arg Val Asp Leu
Gly Thr Leu Arg 210 215 220Gly Ala Tyr Asn Gln Ser Glu Ala Gly Ser
His Thr Val Gln Arg Met225 230 235 240Tyr Gly Cys Asp Val Gly Ser
Asp Trp Arg Phe Leu Arg Gly Tyr His 245 250 255Gln Tyr Ala Tyr Asp
Gly Lys Asp Tyr Ile Ala Leu Lys Glu Asp Leu 260 265 270Arg Ser Trp
Thr Ala Ala Asp Met Ala Ala Gln Thr Thr Lys His Lys 275 280 285Trp
Glu Ala Ala His Val Ala Glu Gln Leu Arg Ala Tyr Leu Glu Gly 290 295
300Thr Cys Val Glu Trp Leu Arg Arg Tyr Leu Glu Asn Gly Lys Glu
Thr305 310 315 320Leu Gln Arg Thr Asp Ala Pro Lys Thr His Met Thr
His His Ala Val 325 330 335Ser Asp His Glu Ala Thr Leu Arg Cys Trp
Ala Leu Ser Phe Tyr Pro 340 345 350Ala Glu Ile Thr Leu Thr Trp Gln
Arg Asp Gly Glu Asp Gln Thr Gln 355 360 365Asp Thr Glu Leu Val Glu
Thr Arg Pro Ala Gly Asp Gly Thr Phe Gln 370 375 380Lys Trp Ala Ala
Val Val Val Pro Ser Gly Gln Glu Gln Arg Tyr Thr385 390 395 400Cys
His Val Gln His Glu Gly Leu Pro Lys Pro Leu Thr Leu Arg Trp 405 410
415Glu Pro Ser Ser 4202421PRTArtificial sequencesynthetic amino
acid sequence 2Lys Ala Phe Ser Pro Glu Val Ile Pro Met Phe Gly Gly
Gly Gly Ser1 5 10 15Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Gln
Arg Thr Pro Lys 20 25 30Ile Gln Val Tyr Ser Arg His Pro Ala Glu Asn
Gly Lys Ser Asn Phe 35 40 45Leu Asn Cys Tyr Val Ser Gly Phe His Pro
Ser Asp Ile Glu Val Asp 50 55 60Leu Leu Lys Asn Gly Glu Arg Ile Glu
Lys Val Glu His Ser Asp Leu65 70 75 80Ser Phe Ser Lys Asp Trp Ser
Phe Tyr Leu Leu Tyr Tyr Thr Glu Phe 85 90 95Thr Pro Thr Glu Lys Asp
Glu Tyr Ala Cys Arg Val Asn His Val Thr 100 105 110Leu Ser Gln Pro
Lys Ile Val Lys Trp Asp Arg Asp Met Gly Gly Gly 115 120 125Gly Ser
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly 130 135
140Ser His Ser Met Arg Tyr Phe Tyr Thr Ala Met Ser Arg Pro Gly
Arg145 150 155 160Gly Glu Pro Arg Phe Ile Ala Val Gly Tyr Val Asp
Asp Thr Gln Phe 165 170 175Val Arg Phe Asp Ser Asp Ala Ala Ser Pro
Arg Met Ala Pro Arg Ala 180 185 190Pro Trp Ile Glu Gln Glu Gly Pro
Glu Tyr Trp Asp Gly Glu Thr Arg 195 200 205Asn Met Lys Ala Ser Ala
Gln Thr Tyr Arg Glu Asn Leu Arg Ile Ala 210 215 220Leu Arg Ala Tyr
Asn Gln Ser Glu Ala Gly Ser His Ile Ile Gln Val225 230 235 240Met
Tyr Gly Cys Asp Val Gly Pro Asp Gly Arg Leu Leu Arg Gly His 245 250
255Asn Gln Tyr Ala Tyr Asp Gly Lys Asp Tyr Ile Ala Leu Asn Glu Asp
260 265 270Leu Ser Ser Trp Thr Ala Ala Asp Thr Ala Ala Gln Ile Thr
Gln Arg 275 280 285Lys Trp Glu Ala Ala Arg Val Ala Glu Gln Leu Arg
Ala Tyr Leu Glu 290 295 300Gly Leu Cys Val Glu Trp Leu Arg Arg Tyr
Leu Glu Asn Gly Lys Glu305 310 315 320Thr Leu Gln Arg Ala Asp Pro
Pro Lys Thr His Val Thr His His Pro 325 330 335Ile Ser Asp His Glu
Ala Thr Leu Arg Cys Trp Ala Leu Gly Phe Tyr 340 345 350Pro Ala Glu
Ile Thr Leu Thr Trp Gln Arg Asp Gly Glu Asp Gln Thr 355 360 365Gln
Asp Thr Glu Leu Val Glu Thr Arg Pro Ala Gly Asp Arg Thr Phe 370 375
380Gln Lys Trp Ala Ala Val Val Val Pro Ser Gly Glu Glu Gln Arg
Tyr385 390 395 400Thr Cys His Val Gln His Glu Gly Leu Pro Lys Pro
Leu Thr Leu Arg 405 410 415Trp Glu Pro Ser Ser 4203217PRTArtificial
sequencesynthetic amino acid sequence 3Glu Asn Pro Val Val His Phe
Phe Lys Asn Ile Val Thr Pro Arg Gly1 5 10 15Gly Gly Gly Ser Gly Gly
Gly Gly Ser Gly Gly Gly Ser Gly Gly Asp 20 25 30Thr Arg Pro Arg Phe
Leu Trp Gln Ser Lys Arg Glu Cys His Phe Phe 35 40 45Asn Gly Thr Glu
Arg Val Arg Phe Leu Asp Arg Tyr Phe Tyr Asn Gln 50 55 60Glu Glu Ser
Val Arg Phe Asp Ser Asp Val Gly Glu Phe Arg Ala Val65 70 75 80Thr
Glu Leu Gly Arg Pro Asp Ala Glu Tyr Trp Asn Ser Gln Lys Asp 85 90
95Ile Leu Glu Gln Ala Arg Ala Ala Val Asp Thr Tyr Cys Arg His Asn
100 105 110Tyr Gly Val Val Glu Ser Phe Thr Val Gln Arg Arg Val Gln
Gly Gly 115 120 125Gly Gly Ser Gly Gly Gly Ile Lys Glu Glu His Val
Ile Ile Gln Ala 130 135 140Glu Ser Tyr Leu Asn Pro Asp Gln Ser Gly
Glu Phe Lys Phe Asp Phe145 150 155 160Asp Gly Asp Glu Ile Phe His
Val Asp Met Ala Lys Lys Glu Thr Val 165 170 175Trp Arg Leu Glu Glu
Phe Gly Arg Phe Ala Ser Phe Glu Ala Gln Gly 180 185 190Ala Leu Ala
Asn Ile Ala Val Asp Lys Ala Asn Leu Glu Ile Met Thr 195 200 205Lys
Arg Ser Asn Tyr Thr Pro Ile Thr 210 2154207PRTArtificial
sequencesynthetic amino acid sequence 4Gln Leu Ser Pro Phe Pro Phe
Asp Leu Gly Gly Gly Gly Ser Gly Gly1 5 10 15Gly Gly Ser Gly Gly Ser
Tyr Tyr Ile Ala Leu Asn Glu Asp Leu Arg 20 25 30Thr Trp Thr Ala Thr
Asp Met Ala Ala Gln Ile Thr Arg Arg Lys Trp 35 40 45Glu Gln Ala Gly
Ala Ala Glu Tyr Tyr Arg Ala Tyr Leu Glu Gly Glu 50 55 60Cys Val Glu
Trp Leu His Arg Tyr Leu Lys Asn Gly Asn Ala Thr Leu65 70 75 80Leu
Gly Gly Gly Gly Ser Gly Gly Pro His Ser Met Arg Tyr Phe Glu 85 90
95Thr Ala Val Ser Arg Pro Gly Leu Gly Glu Pro Arg Tyr Ile Ser Val
100 105 110Gly Tyr Val Asp Asp Lys Glu Phe Val Arg Phe Asp Ser Asp
Ala Glu 115 120 125Asn Pro Arg Tyr Glu Pro Gln Val Pro Trp Met Glu
Gln Glu Gly Pro 130 135 140Glu Tyr Trp Glu Arg Ile Thr Gln Ile Ala
Lys Gly Gln Glu Gln Trp145 150 155 160Phe Arg Val Asn Leu Arg Thr
Leu Leu Gly Ala Tyr Asn Gln Ser Ala 165 170 175Gly Gly Thr His Thr
Leu Gln Trp Met Tyr Gly Cys Asp Val Gly Ser 180 185 190Asp Gly Arg
Leu Leu Arg Gly Tyr Glu Gln Phe Ala Tyr Asp Gly 195 200
2055210PRTArtificial sequencesynthetic amino acid sequence 5Ala Asp
Leu Ile Ala Tyr Leu Lys Gln Ala Thr Lys Gly Gly Gly Ser1 5 10 15Gly
Gly Gly Gly Ser Gly Gly Gly Ser Gly Arg Pro Ser Phe Thr Glu 20 25
30Tyr Cys Lys Ser Glu Cys His Phe Tyr Asn Gly Thr Gln Arg Val Arg
35 40 45Leu Leu Val Arg Tyr Phe Tyr Asn Ser Glu Glu Asn Leu Arg Phe
Asp 50 55 60Ser Asp Val Gly Glu Phe Arg Ala Val Thr Glu Leu Gly Arg
Pro Asp65 70 75 80Ala Glu Asn Trp Asn Ser Gln Pro Glu Phe Leu Glu
Gln Lys Arg Ala 85 90 95Glu Val Asp Thr Val Cys Arg His Asn Tyr Glu
Ile Phe Asp Asn Phe 100 105 110Leu Val Pro Arg Arg Val Glu Gly Gly
Gly Gly Ser Gly Gly Gly Ile 115 120 125Lys Glu Glu His Thr Ile Thr
Gln Ala Glu Ser Tyr Thr Leu Pro Asp 130 135 140Lys Arg Gly Glu Phe
Met Phe Asp Phe Asp Gly Asp Glu Ile Phe His145 150 155 160Val Asp
Ile Glu Lys Ser Glu Thr Ile Trp Arg Leu Glu Glu Phe Ala 165 170
175Lys Phe Ala Ser Phe Glu Val Gln Gly Ala Leu Ala Asn Ile Ala Val
180 185 190Asp Lys Ala Asn Leu Asp Val Met Lys Glu Arg Ser Asn Asn
Thr Pro 195 200 205Asp Ala 2106490PRTArtificial sequencesynthetic
amino acid sequence 6Met Gln Leu Leu Arg Cys Phe Ser Ile Phe Ser
Val Ile Ala Ser Val1 5 10 15Leu Ala Ile Lys Glu Glu His Val Ile Ile
Gln Ala Glu Phe Tyr Leu 20 25 30Asn Pro Asp Gln Ser Gly Glu Phe Met
Phe Asp Phe Asp Gly Asp Glu 35 40 45Ile Phe His Val Asp Leu Ala Lys
Lys Glu Thr Val Trp Arg Leu Glu 50 55 60Glu Phe Gly Arg Phe Ala Ser
Phe Glu Ala Gln Gly Ala Leu Ala Asn65 70 75 80Ile Ala Val Asp Lys
Ala Asn Leu Glu Ile Met Thr Lys Arg Ser Asn 85 90 95Tyr Thr Pro Ile
Thr Asn Val Pro Pro Glu Val Thr Val Leu Thr Asn 100 105 110Ser Pro
Val Glu Leu Arg Glu Pro Asn Val Leu Ile Cys Phe Ile Asp 115 120
125Lys Phe Thr Pro Pro Val Val Asn Val Thr Trp Leu Arg Asn Gly Lys
130 135 140Pro Val Thr Thr Gly Met Ser Glu Thr Val Phe Leu Pro Arg
Glu Asp145 150 155 160His Leu Phe Arg Lys Phe His Tyr Leu Pro Phe
Leu Pro Ser Thr Glu 165 170 175Asp Val Tyr Asp Cys Arg Val Glu His
Trp Gly Leu Asp Glu Pro Leu 180 185 190Leu Lys His Trp Glu Phe Asp
Ala Pro Ser Pro Leu Pro Glu Thr Thr 195 200 205Glu Gly Ser Gly Ser
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Gly Ser 210 215 220Gly Ala Thr
Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val Glu Glu225 230 235
240Asn Pro Gly Pro Met Gln Leu Leu Arg Cys Phe Ser Ile Phe Ser Val
245 250 255Ile Ala Ser Val Leu Ala Phe Ser Trp Gly Ala Glu Gly Gln
Arg Pro 260 265 270Gly Phe Gly Phe Gly Gly Gly Gly Gly Ser Gly Gly
Gly Gly Ser Gly 275 280 285Gly Gly Ser Gly Gly Asp Thr Arg Pro Arg
Phe Leu Glu Gln Val Lys 290 295 300His Glu Cys His Phe Phe Asn Gly
Thr Glu Arg Val Arg Phe Leu Asp305 310 315 320Arg Tyr Phe Tyr Asn
Gln Glu Glu Tyr Val Arg Phe Asp Ser Glu Val 325 330 335Gly Glu Tyr
Arg Ala Val Thr Glu Leu Gly Arg Pro Asp Ala Glu Tyr 340 345 350Trp
Asn Ser Gln Lys Asp Leu Leu Glu Gln Lys Arg Ala Ala Val Asp 355 360
365Thr Tyr Cys Arg His Asn Tyr Gly Val Gly Glu Ser Phe Thr Val Gln
370 375 380Arg Arg Val Tyr Pro Glu Val Thr Val Tyr Pro Ala Lys Thr
Gln Pro385 390 395 400Leu Gln His His Asn Leu Leu Val Cys Ser Val
Asn Gly Phe Tyr Pro 405 410 415Gly Ser Ile Glu Val Arg Trp Phe Arg
Asn Gly Gln Glu Glu Lys Thr 420 425 430Gly Val Val Ser Thr Gly Leu
Ile Gln Asn Gly Asp Trp Thr Phe Gln 435 440 445Thr Leu Val Met Leu
Glu Thr Val Pro Arg Ser Gly Glu Val Tyr Thr 450 455 460Cys Gln Val
Glu His Pro Ser Leu Thr Ser Pro Leu Thr Val Glu Trp465 470 475
480Arg Ala Arg Ser Glu Ser Ala Gln Ser Lys 485 490713PRTArtificial
sequencesynthetic amino acid sequence 7Ala Asp Leu Ile Ala Tyr Leu
Lys Gln Ala Thr Lys Gly1 5 10813PRTArtificial sequencesynthetic
amino acid sequence 8Ala Thr His Val Ala Phe Leu Lys Ala Ala Thr
Lys Lys1 5 10913PRTArtificial sequencesynthetic amino acid sequence
9Ala Asp Leu Val Ala Phe Phe Lys Glu Ala Ser Lys Arg1 5
101013PRTArtificial sequencesynthetic amino acid sequence 10Ala Asp
Leu Val Ala Phe Phe Lys Ala Ala Thr Lys Thr1 5 101112PRTMus
musculus 11Ala Asp Pro Val Ala Phe Phe Ser Ser Ala Ile Lys1 5
101212PRTMus musculus 12Ala Asp Leu Ile Ala Tyr Leu Lys Gln Ala Thr
Lys1 5 101312PRTMus musculus 13Ala Asn Gly Val Ala Phe Phe Leu Thr
Pro Phe Lys1 5 101412PRTMus musculus 14Ala Asp Leu Ile Ala Tyr Leu
Lys Gln Ala Thr Lys1 5 101510PRTArtificial sequencesynthetic amino
acid sequence 15Leu Ile Ala Tyr Leu Lys Gln Ala Thr Lys1 5
101610PRTArtificial sequencesynthetic amino acid sequence 16Leu Val
Ala Phe Leu Lys Ala Ala Thr Lys1 5 101710PRTArtificial
sequencesynthetic amino acid sequence 17Pro Val Ala Phe Leu Lys Ser
Ala Thr Lys1 5 101810PRTArtificial sequencesynthetic amino acid
sequence 18Pro Ile Ala Phe Met Lys Ser Ala Ile Lys1 5
101910PRTArtificial sequencesynthetic amino acid sequence 19Pro Val
Ala Phe Phe Ser Ser Ala Ile Lys1 5 102014PRTHomo sapiens 20Glu Asn
Pro Val Val His Phe Phe Lys Asn Ile Val Thr Pro1 5
102114PRTSulfurovum sp. NBC37-1 21Ser Leu Gly Asn Ile His Phe Phe
Lys Ser Glu Val Val Arg1 5 102214PRTPopulus trichocarpa 22Ser Val
Ser Val Ile His Phe Phe Lys Ala Pro Ala Ala Ile1 5
102314PRTChlorobium chlorochromatii 23Val Phe Gly Asn Val His Phe
Phe Lys Asn Thr Gly Ser Ala1 5 102414PRTRhodococcus sp. AW25M09
24Ala Ala Gln Arg Ile His Phe Phe Lys Asn Leu Ser Leu Leu1 5
102514PRTSelaginella moellendorffii 25Ser Val Gly Lys Ile His Phe
Phe Lys Met Glu Val Val Ser1 5 102614PRTLegionella longbeachae
26Asn Pro Gln Val Ile His Phe Phe Lys Ser Leu Asp Leu Leu1 5
102714PRTEncephalitozoon romaleae 27Phe Gly Val Lys Ile His Phe Phe
Lys Gln Arg Asn Ser Leu1 5 102814PRTOryzias latipes 28Glu Asn Ala
Val Val His Phe Phe Arg Ser Leu Val Ser Ser1 5
102914PRTKitasatospora setae KM-6054 29Met His Gly Asn Trp His Phe
Phe Arg Asn Phe Leu Ser Asn1 5 103014PRTDesulfotignum 30Val Ser Gly
Tyr Val His Phe Phe Arg Gly Leu Pro Leu Leu1 5 103114PRTVolvox
carteri f. 31Gly Ala His Cys Ile His Phe Phe Lys Ser Ala Val Cys
Arg1 5 103214PRTClostridium papyrosolvens 32Leu Asn Lys Asn Ile His
Phe Phe Lys Asn Leu Pro Leu Pro1 5
103314PRTOryctolagus cuniculus 33Arg Thr Gln Arg Ile His Phe Phe
Lys Gly Asp Lys Val Trp1 5 103414PRTAnoxybacillus flavithermus
34Arg Leu Ser Val Val His Phe Leu Arg Ala Asn Ala Val Ser1 5
103514PRTMacrophomina phaseolina MS6 35Ala Ala Gln Asn Val His Phe
Trp Lys Ala Leu Asn Gln Leu1 5 103614PRTEmiliania huxleyi CCMP1516
36Ser Thr Ala Arg Val His Phe Trp Arg Ser Arg Ser Ser Glu1 5
103714PRTRhizobium leguminosarum 37Asp Val Ser Lys Val His Phe Phe
Lys Gly Asn Gly Gln Thr1 5 103814PRTRunella slithyformis DSM 38His
Arg Ala Lys Leu His Phe Phe Lys Asp Glu Asn Leu Lys1 5
103914PRTBlastococcus saxobsidens DD2 39Ala Arg Ser Val Phe His Phe
Phe Arg Gly Thr Ala Leu Leu1 5 104014PRTDictyostelium fasciculatum
40Tyr Lys His Lys Ile His Phe Phe Lys Asn Glu Val Leu Glu1 5
104114PRTRhodanobacter sp. 116-2 41Thr Glu Gly Ser Val His Phe Phe
Arg Gly His Ala Val Ile1 5 104214PRTOgataea parapolymorpha DL-1
42Ile Glu Ala Ala Ile His Phe Tyr Lys Gly Leu Ala Val Tyr1 5
104314PRTMyxococcus stipitatus DSM 43Ser Ser Ala Arg Leu His Phe
Phe Arg Ala Leu Pro His Pro1 5 104414PRTBacillus clausii KSM-K16
44His Glu Asn Val Val His Phe Phe Lys Asp Gly Glu Leu Val1 5
104514PRTTrichosporon asahii var. 45Leu Glu Ser Val Val His Phe Leu
Arg Gly Gln Lys Val Thr1 5 104614PRTAcinetobacter sp. ADP1 46Ser
Glu Gly Ser Ile His Phe Phe Lys Ala Asp Leu Leu Ser1 5
104714PRTHomo sapiens 47Met Asn Ala Ser Ile His Phe Leu Lys Ala Leu
Glu Thr Tyr1 5 104814PRTHomo sapiens 48Asn Ala Asn Val Leu His Phe
Leu Lys Asn Ile Ile Cys Gln1 5 104914PRTHomo sapiens 49Phe Leu Lys
Lys Phe His Phe Leu Lys Gly Ala Thr Leu Cys1 5 105014PRTHomo
sapiens 50Ile Ile Pro Ala Phe His Phe Leu Lys Ser Glu Lys Gly Leu1
5 105114PRTHomo sapiens 51Ser Ala Asn Asn Ile His Phe Met Arg Gln
Ser Glu Ile Gly1 5 105214PRTHomo sapiens 52Ala Pro Leu Val Ile His
Phe Leu Lys Ala Pro Pro Ala Pro1 5 105314PRTHomo sapiens 53His Met
Leu Ser Phe His Phe Trp Lys Ser Arg Gly Gln Thr1 5
105413PRTArtificial sequencesynthetic amino acid sequence 54Ala Asp
Leu Val Ala Phe Phe Lys Glu Ala Ser Lys Arg1 5 105513PRTArtificial
sequencesynthetic amino acid sequence 55Ala Thr His Val Ala Phe Leu
Lys Ala Ala Thr Lys Lys1 5 105613PRTArtificial sequencesynthetic
amino acid sequence 56Ala Ala Gln Val Ala Phe Leu Lys Ala Ala Thr
Lys Ala1 5 105713PRTArtificial sequencesynthetic amino acid
sequence 57Ala Thr His Val Ala Phe Leu Lys Ala Ala Thr Lys Ala1 5
105813PRTArtificial sequencesynthetic amino acid sequence 58Ala Ala
Gln Val Ala Phe Leu Lys Ala Ala Thr Lys Lys1 5 105913PRTArtificial
sequencesynthetic amino acid sequence 59Ala Asp Trp Val Ala Phe Leu
Lys Gln Ala Thr Lys Gly1 5 106013PRTArtificial sequencesynthetic
amino acid sequence 60Ala Asp Leu Val Ala Phe Phe Lys Glu Ala Ser
Lys Lys1 5 106113PRTArtificial sequencesynthetic amino acid
sequence 61Ala Ala Pro Val Ala Phe Leu Lys Ser Ala Ser Lys Thr1 5
106213PRTArtificial sequencesynthetic amino acid sequence 62Ala Asn
Gly Leu Ala Phe Phe Lys Ser Ala Ser Lys Thr1 5 106313PRTArtificial
sequencesynthetic amino acid sequence 63Ala Thr His Val Ala Phe Leu
Lys Ala Ala Thr Lys Arg1 5 106413PRTArtificial sequencesynthetic
amino acid sequence 64Ala Asp Leu Val Ala Phe Leu Lys Ala Ala Thr
Lys Ala1 5 106513PRTArtificial sequencesynthetic amino acid
sequence 65Ala Asp Leu Val Ala Phe Leu Lys Ala Ala Thr Lys Lys1 5
106613PRTArtificial sequencesynthetic amino acid sequence 66Ala Asp
Gly Val Ala Phe Phe Met Ser Ala Thr Lys Thr1 5 106713PRTArtificial
sequencesynthetic amino acid sequence 67Ala Asp Leu Val Ala Phe Phe
Lys Glu Ala Ser Lys Ala1 5 106813PRTArtificial sequencesynthetic
amino acid sequence 68Ala Asp Leu Val Ala Phe Phe Lys Ala Ala Thr
Lys Ala1 5 106913PRTArtificial sequencesynthetic amino acid
sequence 69Ala Thr His Val Ala Phe Leu Lys Ala Ala Ser Lys Arg1 5
107013PRTArtificial sequencesynthetic amino acid sequence 70Ala Asp
Leu Val Ala Phe Phe Lys Ala Ala Thr Lys Lys1 5 107113PRTArtificial
sequencesynthetic amino acid sequence 71Ala Ala Gln Val Ala Phe Phe
Lys Glu Ala Ser Lys Arg1 5 107213PRTArtificial sequencesynthetic
amino acid sequence 72Ala Thr His Val Ala Phe Leu Lys Glu Ala Ser
Lys Arg1 5 107313PRTArtificial sequencesynthetic amino acid
sequence 73Ala Thr His Val Ala Phe Phe Lys Glu Ala Ser Lys Arg1 5
107413PRTArtificial sequencesynthetic amino acid sequence 74Ala Asp
Leu Val Ala Phe Phe Lys Glu Ala Thr Lys Lys1 5 107513PRTArtificial
sequencesynthetic amino acid sequence 75Ala Asp Ala Ile Ala Phe Phe
Ser Ser Ser Leu Lys Arg1 5 107613PRTArtificial sequencesynthetic
amino acid sequence 76Ala Asp Pro Ile Ala Phe Met Lys Ser Ala Ile
Lys Lys1 5 107713PRTArtificial sequencesynthetic amino acid
sequence 77Ala Asp Leu Val Ala Phe Phe Lys Ser Ala Ser Lys Thr1 5
107813PRTArtificial sequencesynthetic amino acid sequence 78Ala Thr
His Val Ala Phe Leu Lys Ala Ala Thr Lys Thr1 5 107913PRTArtificial
sequencesynthetic amino acid sequence 79Ala Asn Gly Val Ala Phe Phe
Leu Thr Pro Phe Lys Ala1 5 108013PRTArtificial sequencesynthetic
amino acid sequence 80Ala Ala Gln Val Ala Phe Leu Lys Ala Ala Thr
Lys Ala1 5 108113PRTArtificial sequencesynthetic amino acid
sequence 81Ala Asp Gly Val Gly Phe Leu Lys Ala Ala Ser Lys Arg1 5
108213PRTArtificial sequencesynthetic amino acid sequence 82Ala Ala
Gly Val Ala Phe Phe Arg Val Pro Tyr Lys Glu1 5 108313PRTArtificial
sequencesynthetic amino acid sequence 83Ala Asp Gly Val Gly Phe Phe
Val Ser Pro Phe Lys Lys1 5 108413PRTArtificial sequencesynthetic
amino acid sequence 84Ala Asp Trp Ile Ala Tyr Phe Arg Ser Pro Phe
Lys Gly1 5 108513PRTArtificial sequencesynthetic amino acid
sequence 85Ala Asp Gly Leu Ala Tyr Phe Arg Ser Ser Phe Lys Gly1 5
108613PRTArtificial sequencesynthetic amino acid sequence 86Ala Asp
Leu Val Gly Phe Phe Lys Thr Ala Thr Lys Lys1 5 108713PRTArtificial
sequencesynthetic amino acid sequence 87Ala Asn Leu Val Ala Phe Phe
Arg Ser Pro Tyr Lys Ala1 5 108813PRTArtificial sequencesynthetic
amino acid sequence 88Ala Asp Arg Leu Ala Tyr Phe Leu Gln Pro Tyr
Lys Arg1 5 108913PRTArtificial sequencesynthetic amino acid
sequence 89Ala Ala Gln Val Ala Phe Leu Lys Ala Ala Thr Lys Ala1 5
109013PRTArtificial sequencesynthetic amino acid sequence 90Ala Asp
Leu Val Ala Phe Phe Lys Glu Ala Ser Lys Arg1 5 109113PRTArtificial
sequencesynthetic amino acid sequence 91Ala Asp Lys Ile Ala Phe Phe
Lys Ser Val Thr Lys Lys1 5 109213PRTArtificial sequencesynthetic
amino acid sequence 92Ala Asn Leu Leu Gly Tyr His Lys Val Pro Thr
Lys Lys1 5 109313PRTArtificial sequencesynthetic amino acid
sequence 93Ala Asp Pro Val Ala Phe Phe Arg Ser Pro Phe Lys Thr1 5
109413PRTArtificial sequencesynthetic amino acid sequence 94Ala Thr
Asp Ile Ala Phe Phe Arg Ala Cys Thr Lys Gly1 5 109513PRTArtificial
sequencesynthetic amino acid sequence 95Ala Asn Arg Ile Ala Trp Val
Lys Ala Ala Thr Lys Thr1 5 109613PRTArtificial sequencesynthetic
amino acid sequence 96Ala Asp Trp Val Gly Trp Phe Lys Ala Ala Thr
Lys Gly1 5 109713PRTArtificial sequencesynthetic amino acid
sequence 97Ala Asp Trp Ile Ala Tyr Phe Arg Ser Pro Phe Lys Gly1 5
109813PRTArtificial sequencesynthetic amino acid sequence 98Ala Thr
Tyr Val Ala Phe Ser Lys Ser Ala Thr Lys Arg1 5 109912PRTArtificial
sequencesynthetic amino acid sequence 99Ala Asp Leu Ile Ala Tyr Leu
Lys Gln Ala Thr Lys1 5 1010012PRTArtificial sequencesynthetic amino
acid sequence 100Ala Asp Pro Leu Ala Phe Phe Ser Ser Ala Ile Lys1 5
1010112PRTArtificial sequencesynthetic amino acid sequence 101Ala
Thr His Val Ala Phe Leu Lys Ala Ala Thr Lys1 5 1010212PRTArtificial
sequencesynthetic amino acid sequence 102Ala Asp Ala Ile Ala Phe
Phe Ser Ser Ser Leu Lys1 5 1010312PRTArtificial sequencesynthetic
amino acid sequence 103Ala Asn Gly Val Ala Phe Phe Leu Thr Pro Phe
Lys1 5 1010412PRTArtificial sequencesynthetic amino acid sequence
104Ala Asp Gly Leu Ala Tyr Phe Arg Ser Ser Phe Lys1 5
1010512PRTArtificial sequencesynthetic amino acid sequence 105Ala
Asp Gly Val Gly Phe Phe Val Ser Pro Phe Lys1 5 1010612PRTArtificial
sequencesynthetic amino acid sequence 106Ala Asn Leu Leu Gly Tyr
His Lys Val Pro Thr Lys1 5 1010712PRTArtificial sequencesynthetic
amino acid sequence 107Ala Asp Gly Val Ala Phe Leu Lys Ala Ala Thr
Lys1 5 10108190DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(68)..(69)n is a, c, g, or
tmisc_feature(74)..(75)n is a, c, g, or tmisc_feature(77)..(78)n is
a, c, g, or tmisc_feature(80)..(81)n is a, c, g, or
tmisc_feature(83)..(84)n is a, c, g, or tmisc_feature(86)..(87)n is
a, c, g, or tmisc_feature(89)..(90)n is a, c, g, or
tmisc_feature(92)..(93)n is a, c, g, or tmisc_feature(95)..(96)n is
a, c, g, or t 108attttcaatt aagatgcagt tacttcgctg tttttcaata
ttttctgtta ttgctagcgt 60tttggctnnk dcknnknnkn nknnknnknn knnknnktwy
ggtggaggag gttctggagg 120tggtggtagt ggtggtggtg gttccataca
aagaactcca aagatccaag tttacagtag 180acatcctgct
19010963PRTArtificial sequencesynthetic amino acid
sequencemisc_feature(23)..(33)Xaa can be any naturally occurring
amino acid 109Phe Ser Ile Lys Met Gln Leu Leu Arg Cys Phe Ser Ile
Phe Ser Val1 5 10 15Ile Ala Ser Val Leu Ala Xaa Xaa Xaa Xaa Xaa Xaa
Xaa Xaa Xaa Xaa 20 25 30Xaa Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
Gly Gly Gly Gly Ser 35 40 45Ile Gln Arg Thr Pro Lys Ile Gln Val Tyr
Ser Arg His Pro Ala 50 55 6011011PRTHuman immunodeficency virus
110Lys Ala Phe Ser Pro Glu Val Ile Pro Met Phe1 5
101118PRTArtificial sequencesynthetic amino acid sequence 111Asp
Tyr Lys Asp Asp Asp Asp Lys1 51124PRTArtificial sequencesynthetic
amino acid sequence 112Ala Asp Asn Thr11136PRTArtificial
sequencesynthetic amino acid sequence 113Ala Glu Gly Lys Arg Thr1
511421DNAArtificial sequencesynthetic polynucleotide sequence
114atgcaaaaac tgcataacca c 2111522DNAArtificial sequencesynthetic
polynucleotide sequence 115gggatttgct cgcatatagt tg
2211677DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(26)..(27)n is a, c, g, or
tmisc_feature(32)..(33)n is a, c, g, or tmisc_feature(35)..(36)n is
a, c, g, or tmisc_feature(38)..(39)n is a, c, g, or
tmisc_feature(41)..(42)n is a, c, g, or tmisc_feature(44)..(45)n is
a, c, g, or tmisc_feature(47)..(48)n is a, c, g, or
tmisc_feature(50)..(51)n is a, c, g, or t 116tattgctagc gttttagcag
ctrmtnnkvt tnnknnknnk nnknnknnkn nkaaarvagg 60cggtggttcg ggcggtg
7711724DNAArtificial sequencesynthetic polynucleotide sequence
117cgtcatcatc tttataatcg gatc 2411867DNAArtificial
sequencesynthetic polynucleotide sequence 118ttcaattaag atgcagttac
ttcgctgttt ttcaatattt tctgttattg ctagcgtttt 60agcagct
6711950DNAArtificial sequencesynthetic polynucleotide sequence
119accaccagat ccaccaccac ctttatcgtc atcatcttta taatcggatc
5012084DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(22)..(23)n is a, c, g, or
tmisc_feature(25)..(26)n is a, c, g, or tmisc_feature(28)..(29)n is
a, c, g, or tmisc_feature(31)..(32)n is a, c, g, or
tmisc_feature(37)..(38)n is a, c, g, or tmisc_feature(40)..(41)n is
a, c, g, or tmisc_feature(46)..(47)n is a, c, g, or
tmisc_feature(49)..(50)n is a, c, g, or tmisc_feature(52)..(53)n is
a, c, g, or tmisc_feature(55)..(56)n is a, c, g, or
tmisc_feature(58)..(59)n is a, c, g, or tmisc_feature(61)..(62)n is
a, c, g, or t 120gttattgcta gcgtattggc cnnknnknnk nnkvtannkn
nktwtnnknn knnknnknnk 60nnkagaggtg gtggtggttc aggt
8412164DNAArtificial sequencesynthetic polynucleotide sequence
121ttcaattaag atgcagttac ttcgctgttt ttcaatattt tctgttattg
ctagcgtatt 60ggcc 6412251DNAArtificial sequencesynthetic
polynucleotide sequence 122accgccacca ccagatccac caccacccaa
gtcttcttca gaaataagct t 5112384DNAArtificial sequencesynthetic
polynucleotide sequencemisc_feature(22)..(23)n is a, c, g, or
tmisc_feature(25)..(26)n is a, c, g, or tmisc_feature(28)..(29)n is
a, c, g, or tmisc_feature(31)..(32)n is a, c, g, or
tmisc_feature(38)..(38)n is a, c, g, or tmisc_feature(41)..(41)n is
a, c, g, or tmisc_feature(47)..(47)n is a, c, g, or
tmisc_feature(49)..(50)n is a, c, g, or tmisc_feature(52)..(53)n is
a, c, g, or tmisc_feature(55)..(56)n is a, c, g, or
tmisc_feature(58)..(59)n is a, c, g, or tmisc_feature(61)..(62)n is
a, c, g, or t 123gttattgcta gcgtattggc cnnknnknnk nnkvtadnkv
nktwtbnknn knnknnknnk 60nnkagaggtg gtggtggttc aggt
8412484DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(22)..(23)n is a, c, g, or
tmisc_feature(25)..(26)n is a, c, g, or tmisc_feature(28)..(29)n is
a, c, g, or tmisc_feature(31)..(32)n is a, c, g, or
tmisc_feature(38)..(38)n is a, c, g, or tmisc_feature(41)..(41)n is
a, c, g, or tmisc_feature(46)..(46)n is a, c, g, or
tmisc_feature(49)..(50)n is a, c, g, or tmisc_feature(52)..(53)n is
a, c, g, or tmisc_feature(55)..(56)n is a, c, g, or
tmisc_feature(58)..(59)n is a, c, g, or tmisc_feature(61)..(62)n is
a, c, g, or t 124gttattgcta gcgtattggc cnnknnknnk nnkvtadnkv
nktwtnbknn knnknnknnk 60nnkagaggtg gtggtggttc aggt
8412584DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(22)..(23)n is a, c, g, or
tmisc_feature(25)..(26)n is a, c, g, or tmisc_feature(28)..(29)n is
a, c, g, or tmisc_feature(31)..(32)n is a, c, g, or
tmisc_feature(38)..(38)n is a, c, g, or tmisc_feature(40)..(40)n is
a, c, g, or tmisc_feature(47)..(47)n is a, c, g, or
tmisc_feature(49)..(50)n is a, c, g, or tmisc_feature(52)..(53)n is
a, c, g, or tmisc_feature(55)..(56)n is a, c, g, or
tmisc_feature(58)..(59)n is a, c, g, or tmisc_feature(61)..(62)n is
a, c, g, or t 125gttattgcta gcgtattggc cnnknnknnk nnkvtadnkn
vktwtbnknn knnknnknnk 60nnkagaggtg gtggtggttc aggt
8412684DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(22)..(23)n is a, c, g, or
tmisc_feature(25)..(26)n is a, c, g, or tmisc_feature(28)..(29)n is
a, c, g, or tmisc_feature(31)..(32)n is a, c, g, or
tmisc_feature(38)..(38)n is a, c, g, or tmisc_feature(40)..(40)n is
a, c, g, or tmisc_feature(46)..(46)n is a, c, g, or
tmisc_feature(49)..(50)n is a, c, g, or tmisc_feature(52)..(53)n is
a, c, g, or tmisc_feature(55)..(56)n is a, c, g, or
tmisc_feature(58)..(59)n is a, c, g, or tmisc_feature(61)..(62)n is
a, c, g, or t 126gttattgcta gcgtattggc cnnknnknnk nnkvtadnkn
vktwtnbknn knnknnknnk 60nnkagaggtg gtggtggttc aggt
8412784DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(22)..(23)n is a, c, g, or
tmisc_feature(25)..(26)n is a, c, g, or tmisc_feature(28)..(29)n is
a, c, g, or tmisc_feature(31)..(32)n is a, c, g, or
tmisc_feature(37)..(37)n is a, c, g, or tmisc_feature(41)..(41)n is
a, c, g, or tmisc_feature(47)..(47)n is a, c, g, or
tmisc_feature(49)..(50)n is a, c, g, or tmisc_feature(52)..(53)n is
a, c, g, or tmisc_feature(55)..(56)n is a, c, g, or
tmisc_feature(58)..(59)n is a, c, g, or tmisc_feature(61)..(62)n
is
a, c, g, or t 127gttattgcta gcgtattggc cnnknnknnk nnkvtanbkv
nktwtbnknn knnknnknnk 60nnkagaggtg gtggtggttc aggt
8412884DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(22)..(23)n is a, c, g, or
tmisc_feature(25)..(26)n is a, c, g, or tmisc_feature(28)..(29)n is
a, c, g, or tmisc_feature(31)..(32)n is a, c, g, or
tmisc_feature(37)..(37)n is a, c, g, or tmisc_feature(41)..(41)n is
a, c, g, or tmisc_feature(46)..(46)n is a, c, g, or
tmisc_feature(49)..(50)n is a, c, g, or tmisc_feature(52)..(53)n is
a, c, g, or tmisc_feature(55)..(56)n is a, c, g, or
tmisc_feature(58)..(59)n is a, c, g, or tmisc_feature(61)..(62)n is
a, c, g, or t 128gttattgcta gcgtattggc cnnknnknnk nnkvtanbkv
nktwtnbknn knnknnknnk 60nnkagaggtg gtggtggttc aggt
8412984DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(22)..(23)n is a, c, g, or
tmisc_feature(25)..(26)n is a, c, g, or tmisc_feature(28)..(29)n is
a, c, g, or tmisc_feature(31)..(32)n is a, c, g, or
tmisc_feature(37)..(37)n is a, c, g, or tmisc_feature(40)..(40)n is
a, c, g, or tmisc_feature(47)..(47)n is a, c, g, or
tmisc_feature(49)..(50)n is a, c, g, or tmisc_feature(52)..(53)n is
a, c, g, or tmisc_feature(55)..(56)n is a, c, g, or
tmisc_feature(58)..(59)n is a, c, g, or tmisc_feature(61)..(62)n is
a, c, g, or t 129gttattgcta gcgtattggc cnnknnknnk nnkvtanbkn
vktwtbnknn knnknnknnk 60nnkagaggtg gtggtggttc aggt
8413084DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(22)..(23)n is a, c, g, or
tmisc_feature(25)..(26)n is a, c, g, or tmisc_feature(28)..(29)n is
a, c, g, or tmisc_feature(31)..(32)n is a, c, g, or
tmisc_feature(37)..(37)n is a, c, g, or tmisc_feature(40)..(40)n is
a, c, g, or tmisc_feature(46)..(46)n is a, c, g, or
tmisc_feature(49)..(50)n is a, c, g, or tmisc_feature(52)..(53)n is
a, c, g, or tmisc_feature(55)..(56)n is a, c, g, or
tmisc_feature(58)..(59)n is a, c, g, or tmisc_feature(61)..(62)n is
a, c, g, or t 130gttattgcta gcgtattggc cnnknnknnk nnkvtanbkn
vktwtnbknn knnknnknnk 60nnkagaggtg gtggtggttc aggt
8413184DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(22)..(23)n is a, c, g, or
tmisc_feature(25)..(26)n is a, c, g, or tmisc_feature(28)..(29)n is
a, c, g, or tmisc_feature(31)..(32)n is a, c, g, or
tmisc_feature(49)..(50)n is a, c, g, or tmisc_feature(52)..(53)n is
a, c, g, or tmisc_feature(55)..(56)n is a, c, g, or
tmisc_feature(58)..(59)n is a, c, g, or tmisc_feature(61)..(62)n is
a, c, g, or t 131gttattgcta gcgtattggc cnnknnknnk nnkrtacatt
tctttarann knnknnknnk 60nnkagaggtg gtggtggttc aggt
8413259DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 132ctacacgacg
ctcttccgat ctnnnnnnnn atcacgctgt tattgctagc gttttagca
5913359DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 133ctacacgacg
ctcttccgat ctnnnnnnnn cgatgtctgt tattgctagc gttttagca
5913459DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 134ctacacgacg
ctcttccgat ctnnnnnnnn ttaggcctgt tattgctagc gttttagca
5913559DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 135ctacacgacg
ctcttccgat ctnnnnnnnn tgaccactgt tattgctagc gttttagca
5913659DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 136ctacacgacg
ctcttccgat ctnnnnnnnn acagtgctgt tattgctagc gttttagca
5913759DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 137ctacacgacg
ctcttccgat ctnnnnnnnn ggctacctgt tattgctagc gttttagca
5913859DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 138ctacacgacg
ctcttccgat ctnnnnnnnn cttgtactgt tattgctagc gttttagca
5913959DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 139ctacacgacg
ctcttccgat ctnnnnnnnn agtcaactgt tattgctagc gttttagca
5914059DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 140ctacacgacg
ctcttccgat ctnnnnnnnn agttccctgt tattgctagc gttttagca
5914159DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 141ctacacgacg
ctcttccgat ctnnnnnnnn atgtcactgt tattgctagc gttttagca
5914259DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 142ctacacgacg
ctcttccgat ctnnnnnnnn ccgtccctgt tattgctagc gttttagca
5914359DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 143ctacacgacg
ctcttccgat ctnnnnnnnn gtagagctgt tattgctagc gttttagca
5914459DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 144ctacacgacg
ctcttccgat ctnnnnnnnn gtccgcctgt tattgctagc gttttagca
5914559DNAArtificial sequencesynthetic amino acid
sequencemisc_feature(23)..(30)n is a, c, g, or t 145ctacacgacg
ctcttccgat ctnnnnnnnn gtgaaactgt tattgctagc gttttagca
5914659DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 146ctacacgacg
ctcttccgat ctnnnnnnnn gtggccctgt tattgctagc gttttagca
5914759DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 147ctacacgacg
ctcttccgat ctnnnnnnnn gtttcgctgt tattgctagc gttttagca
5914859DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 148ctacacgacg
ctcttccgat ctnnnnnnnn cgtacgctgt tattgctagc gttttagca
5914959DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 149ctacacgacg
ctcttccgat ctnnnnnnnn gagtggctgt tattgctagc gttttagca
5915059DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 150ctacacgacg
ctcttccgat ctnnnnnnnn ggtagcctgt tattgctagc gttttagca
5915159DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 151ctacacgacg
ctcttccgat ctnnnnnnnn atgagcctgt tattgctagc gttttagca
5915259DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 152ctacacgacg
ctcttccgat ctnnnnnnnn attcctctgt tattgctagc gttttagca
5915359DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 153ctacacgacg
ctcttccgat ctnnnnnnnn caaaagctgt tattgctagc gttttagca
5915459DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 154ctacacgacg
ctcttccgat ctnnnnnnnn caactactgt tattgctagc gttttagca
5915559DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 155ctacacgacg
ctcttccgat ctnnnnnnnn cacgatctgt tattgctagc gttttagca
5915659DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 156ctacacgacg
ctcttccgat ctnnnnnnnn cactcactgt tattgctagc gttttagca
5915759DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 157ctacacgacg
ctcttccgat ctnnnnnnnn caggcgctgt tattgctagc gttttagca
5915859DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 158ctacacgacg
ctcttccgat ctnnnnnnnn catggcctgt tattgctagc gttttagca
5915959DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 159ctacacgacg
ctcttccgat ctnnnnnnnn cattttctgt tattgctagc gttttagca
5916059DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 160ctacacgacg
ctcttccgat ctnnnnnnnn cggaatctgt tattgctagc gttttagca
5916159DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 161ctacacgacg
ctcttccgat ctnnnnnnnn ctagctctgt tattgctagc gttttagca
5916259DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 162ctacacgacg
ctcttccgat ctnnnnnnnn ctatacctgt tattgctagc gttttagca
5916359DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 163ctacacgacg
ctcttccgat ctnnnnnnnn ctcagactgt tattgctagc gttttagca
5916459DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 164ctacacgacg
ctcttccgat ctnnnnnnnn tacagcctgt tattgctagc gttttagca
5916559DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 165ctacacgacg
ctcttccgat ctnnnnnnnn tataatctgt tattgctagc gttttagca
5916659DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 166ctacacgacg
ctcttccgat ctnnnnnnnn tcattcctgt tattgctagc gttttagca
5916759DNAArtificial sequencesynthetic amino acid
sequencemisc_feature(23)..(30)n is a, c, g, or t 167ctacacgacg
ctcttccgat ctnnnnnnnn tcccgactgt tattgctagc gttttagca
5916859DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 168ctacacgacg
ctcttccgat ctnnnnnnnn tcgaagctgt tattgctagc gttttagca
5916959DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 169ctacacgacg
ctcttccgat ctnnnnnnnn tcggcactgt tattgctagc gttttagca
5917059DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 170ctacacgacg
ctcttccgat ctnnnnnnnn aaacacctgt tattgctagc gttttagca
5917154DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(22)..(29)n is a, c, g, or t 171gctgaaccgc
tcttccgatc tnnnnnnnna actctttgag taccattata gaaa
5417259DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 172ctacacgacg
ctcttccgat ctnnnnnnnn atcacgctgt tattgctagc gtattggcc
5917359DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 173ctacacgacg
ctcttccgat ctnnnnnnnn cgatgtctgt tattgctagc gtattggcc
5917459DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 174ctacacgacg
ctcttccgat ctnnnnnnnn ttaggcctgt tattgctagc gtattggcc
5917559DNAArtificial sequencesynthetic amino acid
sequencemisc_feature(23)..(30)n is a, c, g, or t 175ctacacgacg
ctcttccgat ctnnnnnnnn tgaccactgt tattgctagc gtattggcc
5917659DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 176ctacacgacg
ctcttccgat ctnnnnnnnn acagtgctgt tattgctagc gtattggcc
5917759DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 177ctacacgacg
ctcttccgat ctnnnnnnnn ggctacctgt tattgctagc gtattggcc
5917859DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 178ctacacgacg
ctcttccgat ctnnnnnnnn cttgtactgt tattgctagc gtattggcc
5917959DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 179ctacacgacg
ctcttccgat ctnnnnnnnn agtcaactgt tattgctagc gtattggcc
5918059DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 180ctacacgacg
ctcttccgat ctnnnnnnnn agttccctgt tattgctagc gtattggcc
5918159DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 181ctacacgacg
ctcttccgat ctnnnnnnnn atgtcactgt tattgctagc gtattggcc
5918259DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 182ctacacgacg
ctcttccgat ctnnnnnnnn ccgtccctgt tattgctagc gtattggcc
5918359DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 183ctacacgacg
ctcttccgat ctnnnnnnnn gtagagctgt tattgctagc gtattggcc
5918459DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 184ctacacgacg
ctcttccgat ctnnnnnnnn gtccgcctgt tattgctagc gtattggcc
5918559DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 185ctacacgacg
ctcttccgat ctnnnnnnnn gtgaaactgt tattgctagc gtattggcc
5918659DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 186ctacacgacg
ctcttccgat ctnnnnnnnn gtggccctgt tattgctagc gtattggcc
5918759DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 187ctacacgacg
ctcttccgat ctnnnnnnnn gtttcgctgt tattgctagc gtattggcc
5918859DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 188ctacacgacg
ctcttccgat ctnnnnnnnn cgtacgctgt tattgctagc gtattggcc
5918959DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 189ctacacgacg
ctcttccgat ctnnnnnnnn gagtggctgt tattgctagc gtattggcc
5919059DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 190ctacacgacg
ctcttccgat ctnnnnnnnn ggtagcctgt tattgctagc gtattggcc
5919159DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 191ctacacgacg
ctcttccgat ctnnnnnnnn atgagcctgt tattgctagc gtattggcc
5919259DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 192ctacacgacg
ctcttccgat ctnnnnnnnn attcctctgt tattgctagc gtattggcc
5919359DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 193ctacacgacg
ctcttccgat ctnnnnnnnn caaaagctgt tattgctagc gtattggcc
5919459DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 194ctacacgacg
ctcttccgat ctnnnnnnnn caactactgt tattgctagc gtattggcc
5919559DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 195ctacacgacg
ctcttccgat ctnnnnnnnn cacgatctgt tattgctagc gtattggcc
5919659DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 196ctacacgacg
ctcttccgat ctnnnnnnnn cactcactgt tattgctagc gtattggcc
5919759DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 197ctacacgacg
ctcttccgat ctnnnnnnnn caggcgctgt tattgctagc gtattggcc
5919859DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 198ctacacgacg
ctcttccgat ctnnnnnnnn catggcctgt tattgctagc gtattggcc
5919959DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 199ctacacgacg
ctcttccgat ctnnnnnnnn cattttctgt tattgctagc gtattggcc
5920059DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 200ctacacgacg
ctcttccgat ctnnnnnnnn cggaatctgt tattgctagc gtattggcc
5920159DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 201ctacacgacg
ctcttccgat ctnnnnnnnn ctagctctgt tattgctagc gtattggcc
5920259DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 202ctacacgacg
ctcttccgat ctnnnnnnnn ctatacctgt tattgctagc gtattggcc
5920359DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 203ctacacgacg
ctcttccgat ctnnnnnnnn ctcagactgt tattgctagc gtattggcc
5920459DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 204ctacacgacg
ctcttccgat ctnnnnnnnn tacagcctgt tattgctagc gtattggcc
5920559DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 205ctacacgacg
ctcttccgat ctnnnnnnnn tataatctgt tattgctagc gtattggcc
5920659DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 206ctacacgacg
ctcttccgat ctnnnnnnnn tcattcctgt tattgctagc gtattggcc
5920759DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 207ctacacgacg
ctcttccgat ctnnnnnnnn tcccgactgt tattgctagc gtattggcc
5920859DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 208ctacacgacg
ctcttccgat ctnnnnnnnn tcgaagctgt tattgctagc gtattggcc
5920959DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 209ctacacgacg
ctcttccgat ctnnnnnnnn tcggcactgt tattgctagc gtattggcc
5921059DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(23)..(30)n is a, c, g, or t 210ctacacgacg
ctcttccgat ctnnnnnnnn aaacacctgt tattgctagc gtattggcc
5921150DNAArtificial sequencesynthetic polynucleotide
sequencemisc_feature(22)..(29)n is a, c, g, or t 211gctgaaccgc
tcttccgatc tnnnnnnnnc gttgaaaaag tgacattctc 5021258DNAArtificial
sequencesynthetic polynucleotide sequence 212aatgatacgg cgaccaccga
gatctacact ctttccctac acgacgctct tccgatct 5821360DNAArtificial
sequencesynthetic polynucleotide sequence 213caagcagaag acggcatacg
agatcggtct cggcattcct gctgaaccgc tcttccgatc 6021411PRTArtificial
sequencesynthetic amino acid sequence 214Asn Ser Leu Lys Pro Glu
Ile Pro Asp Tyr Phe1 5 1021511PRTArtificial sequencesynthetic amino
acid sequence 215Gly Thr Ile Arg Pro Glu Ile Arg Glu Met Trp1 5
1021611PRTArtificial sequencesynthetic amino acid sequence 216Ser
Ser Gly Val Pro Glu Val Arg Met Met Phe1 5 1021711PRTArtificial
sequencesynthetic amino acid sequence 217Leu Ser Leu Arg Pro Glu
Ile Pro Leu Phe Phe1 5 1021811PRTArtificial sequencesynthetic amino
acid sequence 218Lys Ser Phe Val Pro Glu Leu Lys Pro Ala Phe1 5
1021911PRTArtificial sequencesynthetic amino acid sequence 219Trp
Thr Tyr Arg Pro Glu Val Arg Gly Val Trp1 5 1022011PRTArtificial
sequencesynthetic amino acid sequence 220Arg Ser Phe Tyr Pro Glu
Ile Arg Glu Tyr Trp1 5 1022111PRTArtificial sequencesynthetic amino
acid sequence 221Ser Ser Phe Ser Pro Glu Leu Arg Met Arg Trp1 5
1022211PRTArtificial sequencesynthetic amino acid sequence 222Lys
Ser Cys Thr Pro Glu Val Arg Glu Tyr Phe1 5 1022311PRTArtificial
sequencesynthetic amino acid sequence 223Ala Ser Phe Ser Pro Glu
Leu Arg Met Ala Trp1 5 1022411PRTArtificial sequencesynthetic amino
acid sequence 224Lys Ser Leu Ala Pro Glu Val Arg Asp Leu Phe1 5
1022511PRTArtificial sequencesynthetic amino acid sequence 225Asn
Ser Val Lys Pro Glu Ile Arg Pro Val Trp1 5 1022611PRTArtificial
sequencesynthetic amino acid sequence 226Asn Ser Phe Arg Pro Glu
Val Ala Met Lys Tyr1 5 1022711PRTArtificial sequencesynthetic amino
acid sequence 227Lys Ser Leu Thr Pro Glu Val Arg Gly Tyr Trp1 5
1022811PRTArtificial sequencesynthetic amino acid sequence 228Tyr
Ser Phe Lys Pro Glu Leu Lys Glu Ile Phe1 5 1022911PRTArtificial
sequencesynthetic amino acid sequence 229Ala Ser Phe Arg Pro Glu
Leu Ala Glu Phe Trp1 5 1023011PRTArtificial sequencesynthetic amino
acid sequence 230Gly Ser Leu Ala Pro Glu Ile Arg Met Tyr Trp1 5
1023111PRTArtificial sequencesynthetic amino acid sequence 231Arg
Ser Phe Val Pro Glu Ile Gly Met Gly Phe1 5 1023211PRTArtificial
sequencesynthetic amino acid sequence 232Ser Ala Leu Arg Pro Glu
Ile Arg Leu Leu Trp1 5 1023311PRTHuman immunodeficiency virus
1misc_feature(8)..(9)Xaa can be any naturally occurring amino acid
233Lys Ala Phe Ser Pro Glu Val Xaa Xaa Met Phe1 5 1023411PRTHuman
immunodeficiency virus 1 234Arg Ala Phe Ser Pro Glu Val Leu Pro Met
Phe1 5 1023511PRTHuman immunodeficiency virus 1 235Lys Ala Phe Ser
Pro Glu Val Leu Pro Met Phe1 5 1023611PRTHuman immunodeficiency
virus 1 236Lys Ala Phe Ser Pro Glu Val Gly Pro Met Phe1 5
1023711PRTHuman immunodeficiency virus 1misc_feature(8)..(8)Xaa can
be any naturally occurring amino acid 237Lys Ala Phe Ser Pro Glu
Val Xaa Pro Met Phe1 5 1023811PRTHuman immunodeficiency virus 1
238Lys Ala Phe Ser Pro Glu Val Lys Pro Met Phe1 5
1023911PRTOlsenella uli 239Arg Ser Leu Ala Pro Glu Val Arg Gly Tyr
Trp1 5 1024011PRTCanis lupus familiaris 240Trp Thr Ser Ser Pro Glu
Ile Arg Ala Val Phe1 5 1024111PRTPolaromonas sp. CF318 241Ala Ser
Ser Arg Pro Glu Leu Ala Leu Ala Tyr1 5 1024211PRTRicciocarpos
natans 242Trp Thr Ser His Pro Glu Ile Lys Ala Ala Phe1 5
1024311PRTThermobacillus composti KWC4 243Arg Ser Leu Lys Pro Glu
Val Arg Glu Val Phe1 5 1024411PRTStreptomyces coelicoflavus 244Ala
Ser Leu Arg Pro Glu Val Arg Glu Ala Phe1 5
1024511PRTColeofasciculus chthonoplastes 245Lys Ser Leu Tyr Pro Glu
Ile Arg Glu Val Phe1 5 1024611PRTJanibacter sp. HTCC2649 246Leu Ser
Gly Val Pro Glu Ile Arg Glu Arg Trp1 5 1024711PRTOpitutaceae
bacterium TAV5 247Leu Thr Ile Arg Pro Glu Ile Arg Pro Arg Trp1 5
1024811PRTLeptonema illini 248Ala Ser Phe Lys Pro Glu Leu Pro Asp
Phe Phe1 5 1024911PRTRhizobium sp. 249Ser Thr Ile Ser Pro Glu Ile
Arg Leu Phe Trp1 5 1025011PRTEutypa lata UCREL1 250Ala Ser Leu Lys
Pro Glu Val Pro Leu Val Phe1 5 1025111PRTHerbaspirillum sp. CF444
251Ser Ser Gly Ala Pro Glu Val Arg Glu Leu Phe1 5
1025211PRTPhytophthora infestans T30-4 252Ser Ser Val Val Pro Glu
Leu Pro Met Ala Phe1 5 1025311PRTPhytophthora sojae 253Arg Ser Phe
Tyr Pro Glu Leu Arg Leu Leu Phe1 5 1025411PRTSporosarcina
newyorkensis 254Leu Thr Ile Ser Pro Glu Ile Pro Pro Tyr Phe1 5
1025511PRTAcinetobacter sp. P8-3-8 255Glu Ser Phe Arg Pro Glu Ile
Arg Gln Tyr Phe1 5 1025611PRTCandida orthopsilosis Co 90-125 256Gly
Ser Leu Ser Pro Glu Leu Arg Pro Ile Phe1 5 1025711PRTHalobacterium
sp. NRC-1 257Ser Thr Leu Ser Pro Glu Leu Arg Gly Arg Trp1 5
1025811PRTSulfuricurvum kujiense DSM 16994 258Lys Ser Phe Arg Pro
Glu Leu Lys Glu Phe Tyr1 5 1025911PRTArtificial sequencesynthetic
amino acid sequence 259Lys Ser Leu Thr Pro Glu Val Arg Gly Tyr Trp1
5 1026011PRTArtificial sequencesynthetic amino acid sequence 260Trp
Thr Ser His Pro Glu Ile Arg Ala Tyr Phe1 5 1026111PRTArtificial
sequencesynthetic amino acid sequence 261Ala Ser Phe Arg Pro Glu
Leu Ala Leu Arg Tyr1 5 1026211PRTArtificial sequencesynthetic amino
acid sequence 262Trp Thr Ser His Pro Glu Ile Arg Ala Tyr Phe1 5
1026311PRTArtificial sequencesynthetic amino acid sequence 263Lys
Ser Leu Thr Pro Glu Val Arg Glu Tyr Phe1 5 1026411PRTArtificial
sequencesynthetic amino acid sequence 264Lys Ser Leu Ala Pro Glu
Val Arg Glu Leu Phe1 5 1026511PRTArtificial sequencesynthetic amino
acid sequence 265Arg Ser Phe Tyr Pro Glu Ile Arg Glu Tyr Phe1 5
1026611PRTArtificial sequencesynthetic amino acid sequence 266Leu
Ser Leu Arg Pro Glu Ile Arg Glu Tyr Trp1 5 1026711PRTArtificial
sequencesynthetic amino acid sequence 267Gly Thr Ile Arg Pro Glu
Ile Arg Glu Met Trp1 5 1026811PRTArtificial sequencesynthetic amino
acid sequence 268Asn Ser Phe Lys Pro Glu Ile Pro Asp Tyr Phe1 5
1026911PRTArtificial sequencesynthetic amino acid sequence 269Gly
Thr Ile Ser Pro Glu Ile Arg Glu Met Trp1 5 1027011PRTArtificial
sequencesynthetic amino acid sequence 270Leu Ser Leu Arg Pro Glu
Val Pro Leu Phe Phe1 5 1027111PRTArtificial sequencesynthetic amino
acid sequence 271Ser Ser Gly Val Pro Glu Val Arg Met Met Phe1 5
1027211PRTArtificial sequencesynthetic amino acid sequence 272Ser
Ser Val Val Pro Glu Val Arg Met Met Phe1 5 1027311PRTArtificial
sequencesynthetic amino acid sequence 273Arg Ser Phe Tyr Pro Glu
Ile Arg Glu Tyr Phe1 5 1027411PRTArtificial sequencesynthetic amino
acid sequence 274Gly Thr Ile Arg Pro Glu Ile Pro Asp Tyr Phe1 5
1027511PRTArtificial sequencesynthetic amino acid sequence 275Arg
Ser Phe Tyr Pro Glu Ile Arg Glu Tyr Phe1 5 1027611PRTArtificial
sequencesynthetic amino acid sequence 276Leu Ser Gly Ser Pro Glu
Leu Arg Met Ile Phe1 5 1027711PRTArtificial sequencesynthetic amino
acid sequence 277Ser Ser Phe Ser Pro Glu Leu Arg Met Arg Trp1 5
1027811PRTArtificial sequencesynthetic amino acid sequence 278Ala
Ser Phe Arg Pro Glu Leu Ala Glu Phe Trp1 5 10
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012
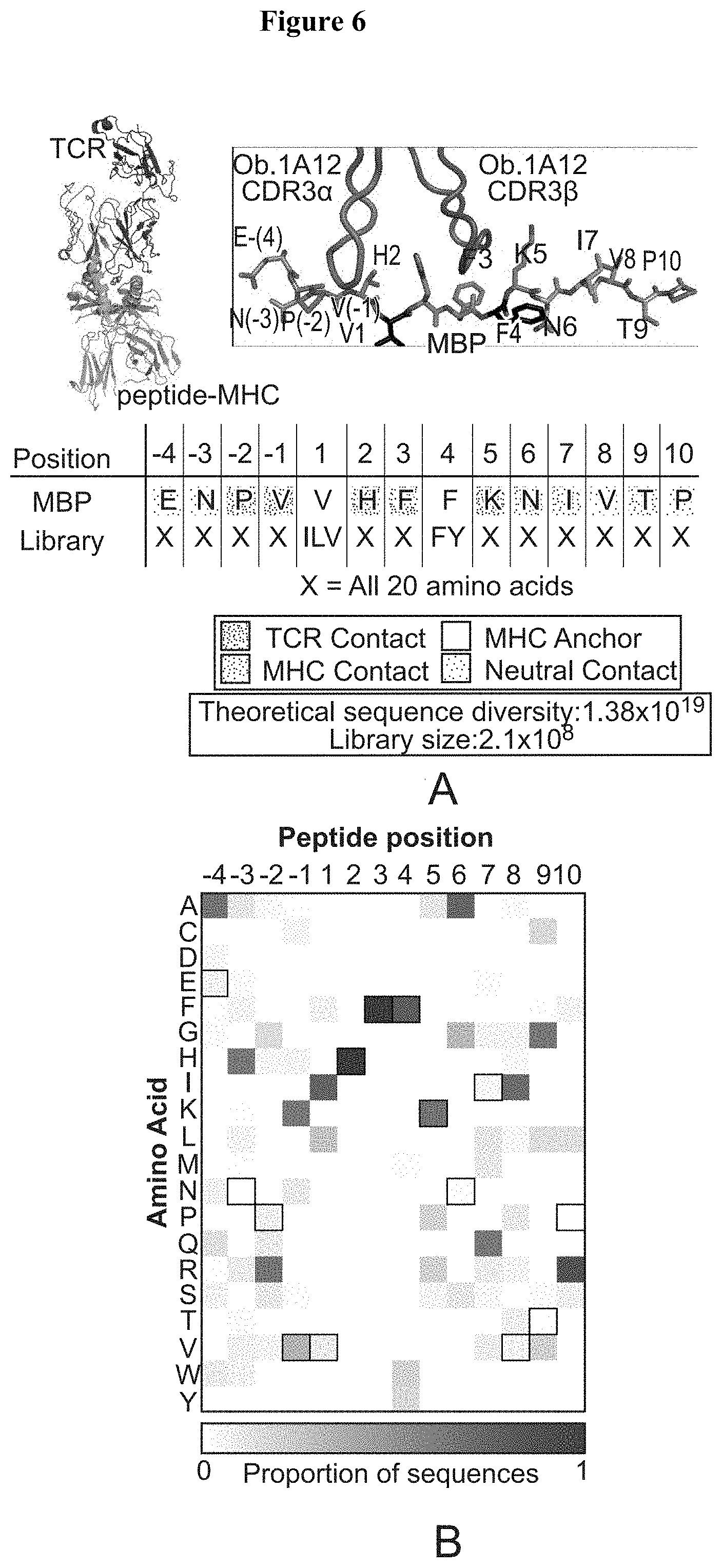
D00013
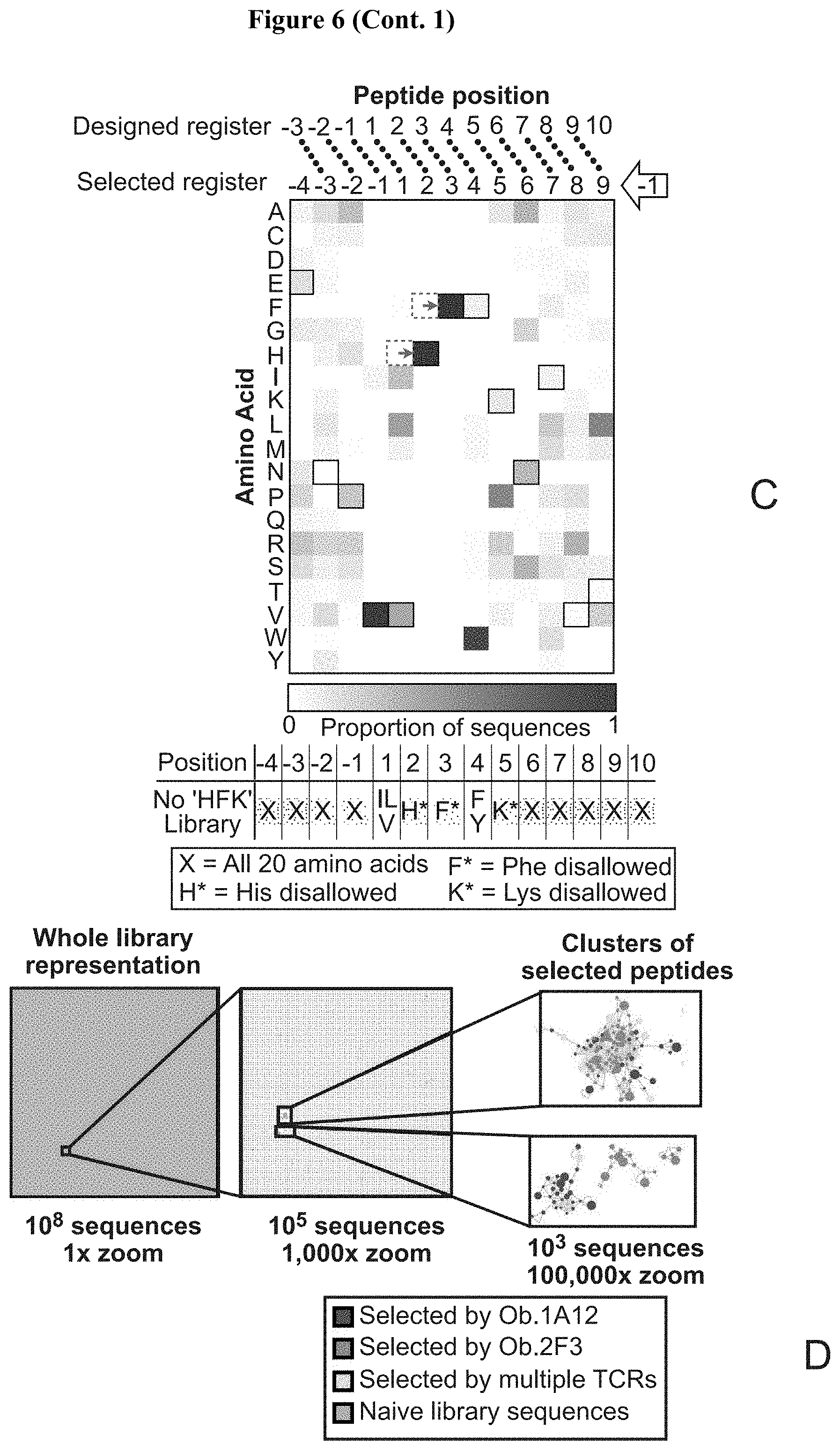
D00014

D00015

D00016

D00017

D00018

D00019

D00020
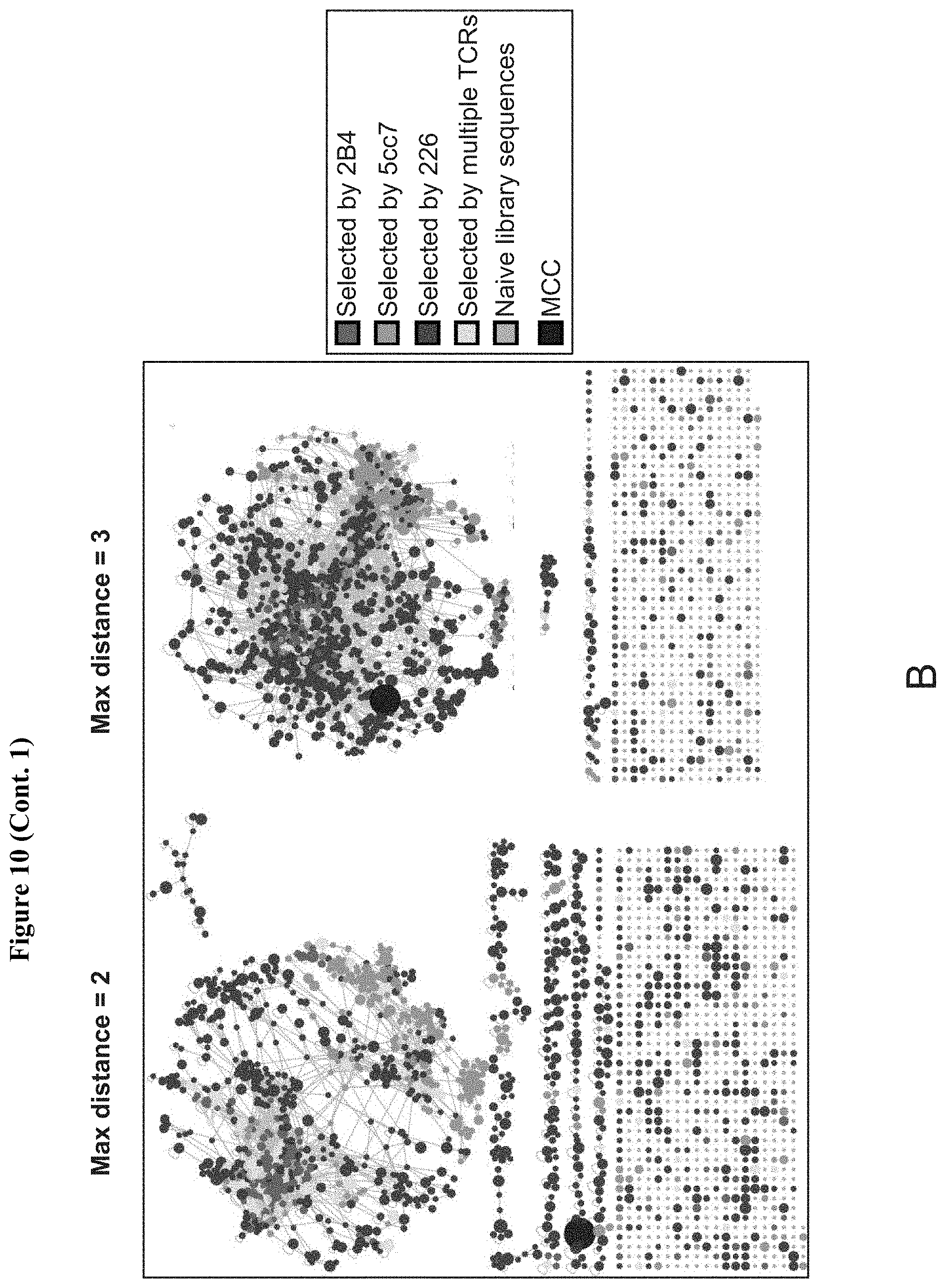
D00021

D00022

D00023

D00024

D00025

D00026

D00027

D00028
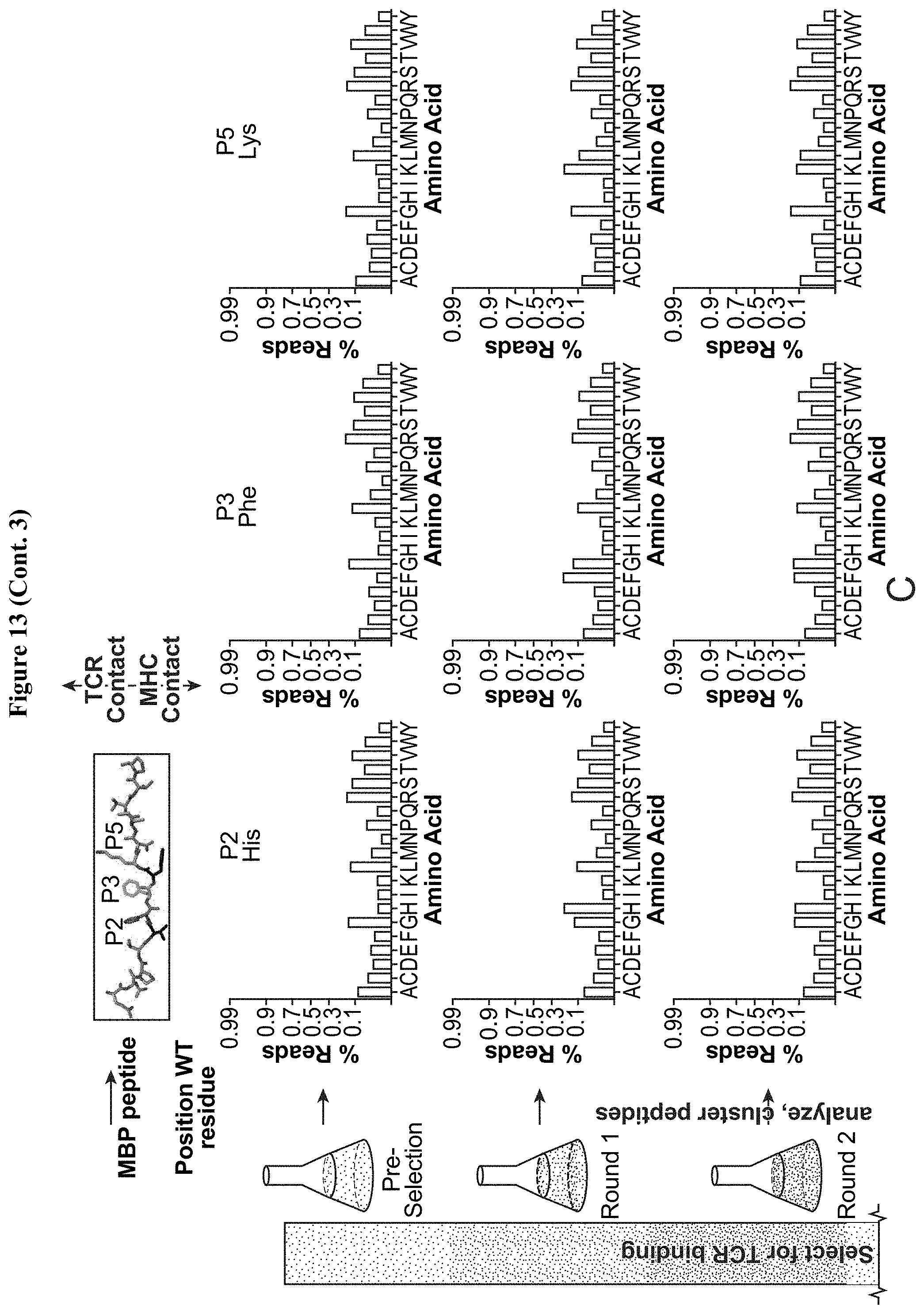
D00029

D00030

D00031

D00032

D00033

D00034

D00035

D00036

P00899
S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.