Site Specific Her2 Antibody Drug Conjugates
MA; Dangshe ; et al.
U.S. patent application number 16/891460 was filed with the patent office on 2020-12-03 for site specific her2 antibody drug conjugates. This patent application is currently assigned to Pfizer Inc.. The applicant listed for this patent is Pfizer Inc.. Invention is credited to Edmund Idris GRAZIANI, Frank LOGANZO, Jr., Dangshe MA, Kimberly Ann MARQUETTE, Puja SAPRA, Pavel STROP.
| Application Number | 20200377615 16/891460 |
| Document ID | / |
| Family ID | 1000004974776 |
| Filed Date | 2020-12-03 |












View All Diagrams
| United States Patent Application | 20200377615 |
| Kind Code | A1 |
| MA; Dangshe ; et al. | December 3, 2020 |
SITE SPECIFIC HER2 ANTIBODY DRUG CONJUGATES
Abstract
The present invention provides site specific HER2 antibody drug conjugates and methods for preparing and using the same.
| Inventors: | MA; Dangshe; (Millwood, NY) ; LOGANZO, Jr.; Frank; (New City, NY) ; MARQUETTE; Kimberly Ann; (Somerville, MA) ; GRAZIANI; Edmund Idris; (Chestnut Ridge, NY) ; SAPRA; Puja; (River Edge, NJ) ; STROP; Pavel; (San Mateo, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assignee: | Pfizer Inc. New York NY |
||||||||||
| Family ID: | 1000004974776 | ||||||||||
| Appl. No.: | 16/891460 | ||||||||||
| Filed: | June 3, 2020 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15356750 | Nov 21, 2016 | 10689458 | ||
| 16891460 | ||||
| 62409105 | Oct 17, 2016 | |||
| 62289727 | Feb 1, 2016 | |||
| 62289744 | Feb 1, 2016 | |||
| 62260854 | Nov 30, 2015 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | C07K 2317/565 20130101; A61K 47/6863 20170801; A61K 47/6857 20170801; C07K 16/303 20130101; A61K 47/6811 20170801; A61K 47/6803 20170801; C07K 2317/92 20130101; C07K 2317/73 20130101; C07K 16/32 20130101; C07K 16/3015 20130101; C07K 16/30 20130101; A61K 2039/505 20130101; C07K 16/3069 20130101; C07K 16/3023 20130101; A61K 47/6855 20170801; C07K 2317/732 20130101; C07K 2317/52 20130101; C07K 2317/94 20130101; C07K 16/3053 20130101 |
| International Class: | C07K 16/32 20060101 C07K016/32; A61K 47/68 20060101 A61K047/68; C07K 16/30 20060101 C07K016/30 |
Claims
1-23. (canceled)
24. A method of treating a HER2 expressing cancer in a subject, comprising administering to the subject in need thereof a therapeutically effective amount of a composition comprising an antibody drug conjugate of the formula: Ab-(L-D), wherein: (a) Ab is an antibody that binds to HER2 and comprises (1) a heavy chain variable region comprising three CDRs comprising SEQ ID NOs:2, 3 and 4; (2) a heavy chain constant region of any of SEQ ID NOs:17, 5, 13, 21, 23, 25, 27, 29, 31, 33, 35, 37 or 39; (3) a light chain variable region comprising three CDRs comprising SEQ ID NOs:8, 9 and 10; (4) a light chain constant region of any of SEQ ID NOs:41, 11 or 43; and (b) L-D is a linker-drug moiety, wherein L is a linker, and D is a drug, with the proviso that when the heavy chain constant region is SEQ ID NO:5 the light chain constant region is not SEQ ID NO:11.
25. The method of claim 24, wherein the cancer is a solid tumor.
26. (canceled)
27. The method of claim 24, wherein the solid tumor is selected from the group consisting of breast cancer, ovarian cancer, lung cancer and gastric cancer.
28. The method of claim 27, wherein the breast cancer is estrogen and progesterone receptor negative or triple negative breast cancer (TNBC).
29. The method of claim 27, wherein the lung cancer is non-small cell cancer (NSLC).
30. The method of claim 24, wherein the subject has been previously treated with trastuzumab and/or trastuzumab emtansine either of which alone or in combination with another therapeutic agent.
31. The method of claim 30, wherein the therapeutic agent is a taxane.
32. The method of claim 30, wherein the cancer is resistant to, refractory to and/or relapsed from treatment with trastuzumab and/or trastuzumab emtansine either of which alone or in combination with another therapeutic agent.
33. The method of claim 32, wherein the therapeutic agent is a taxane.
34. The method of claim 24, wherein the cancer expresses HER2 at a high level.
35. The method of claim 34, wherein the cancer expresses HER2 at a 3+ level as determined by immunohistochemistry (IHC) and/or a fluorescence in situ hybridization (FISH) amplification ratio of .gtoreq.2.0.
36. The method of claim 24, wherein the cancer expresses HER2 at a moderate level.
37. The method of claim 36, wherein the cancer expresses HER2 at a 2+ level as determined by immunohistochemistry (IHC) and/or a fluorescence in situ hybridization (FISH) amplification ratio of <2.0
38. The method of claim 24, wherein the cancer expresses HER2 at a low level.
39. The method of claim 38, wherein the cancer expresses HER2 at a 1+ level as determined by immunohistochemistry (IHC) and/or a fluorescence in situ hybridization (FISH) amplification ratio of <2.0.
40. The method of claim 35, wherein IHC is performed using a Dako Hercptest.TM. assay and FISH is performed using a Dako HER2 FISH Pharm Dx' assay.
41. The method of claim 37, wherein IHC is performed using a Dako Hercptest.TM. assay and FISH is performed using a Dako HER2 FISH Pharm Dx' assay.
42. The method of claim 39, wherein IHC is performed using a Dako Hercptest.TM. assay and FISH is performed using a Dako HER2 FISH Pharm Dx' assay.
43. The method of claim 24, wherein: (a) the antibody comprises a heavy chain comprising SEQ ID NO:18 and a light chain comprising SEQ ID NO:42; and (b) L is a linker of vc and D is an auristatin of 2-methylalanyl-N-[(3R,4S,5S)-3-methoxy-1-{(2S)-2-[(1R,2R)-1-methoxy-2-met- hyl-3-oxo-3-{[(1 S)-2-phenyl-1-(1,3-thiazol-2-yl)ethyl]amino}propyl]pyrrolidin-1-yl}-5-met- hyl-1-oxoheptan-4-yl]-N-methyl-L-valinamide or a pharmaceutically acceptable salt or solvate thereof.
44. The method of claim 24, wherein: (a) the antibody comprises a heavy chain comprising SEQ ID NO:14 and a light chain comprising SEQ ID NO:44; and (b) L is a linker of AcLysvc and D is an auristatin of 2-methylalanyl-N-[(3R,4S,5S)-3-methoxy-1-{(2S)-2-[(1R,2R)-1-methoxy-2-met- hyl-3-oxo-3-{[(1 S)-2-phenyl-1-(1,3-thiazol-2-yl)ethyl]amino}propyl]pyrrolidin-1-yl}-5-met- hyl-1-oxoheptan-4-yl]-N-methyl-L-valinamide or a pharmaceutically acceptable salt or solvate thereof.
Description
RELATED APPLICATIONS
[0001] This application claims the benefit of U.S. Provisional Application No. 62/260,854, filed Nov. 30, 2015, U.S. Provisional Application No. 62/289,744, filed Feb. 1, 2016, U.S. Provisional Application No. 62/289,727, filed Feb. 1, 2016, and U.S. Provisional Application No. 62/409,105, filed Oct. 17, 2016, which are hereby incorporated by referenced in their entireties.
SEQUENCE LISTING
[0002] This application is being filed electronically via EFS-Web and includes an electronically submitted sequence listing in .txt format. The .txt file contains a sequence listing entitled "PC72091A_SequenceListing.txt" created on Oct. 18, 2016, and having a size of 171 KB. The sequence listing contained in this .txt file is part of the specification and is incorporated herein by reference in its entirety.
FIELD OF THE INVENTION
[0003] The present invention relates to site specific HER2 antibody drug conjugates. The present invention further relates to the methods of using such antibody drug conjugates for the treatment of cancer.
BACKGROUND OF THE INVENTION
[0004] Members of the ErbB family of transmembrane receptor tyrosine kinases are important mediators of cell growth, cell differentiation, cell migration, and apoptosis. The receptor family includes four distinct members, including epidermal growth factor receptor (EGFR or ErbB1), HER2 (ErbB2 or p185), HER3 (ErbB3) and HER4 (ErbB4 or tyro2).
[0005] HER2 was originally identified as the product of the transforming gene from neuroblastomas of chemically treated rats. HER2 overexpression has been validated as tumorigenic both in vitro (Di Fiore et al., 1987, Science 237(4811):178-82; Hudziak et al., 1987, PNAS 84(20):7159-63; Chazin et al., 1992, Oncogene 7(9):1859-66) and in animal models (Guy et al., 1992, PNAS 89(22):10578-82). Amplification of the gene encoding HER2 with consequent overexpression of the receptor occurs in breast and ovarian cancers and correlates with a poor prognosis (Slamon et al., 1987, Science 235(4785):177-82; Slamon et al., 1989, Science 244:707-12; Anbazhagan et al., 1991, Annals Oncology 2(1):47-53; Andrulis et al., 1998, J Clinical Oncology 16(4):1340-9). Overexpression of HER2 (frequently but not necessarily due to gene amplification) has also been observed in other tumor types including gastric, endometrial, non-small cell lung cancer, colon, pancreatic, bladder, kidney, prostate and cervical (Scholl et al., 2001, Annals Oncology 12 (Suppl. 1):581-7; Menard et al., 2001, Ann Oncol 12(Suppl 1):515-9; Martin et al., 2014, Future Oncology 10:1469-86).
[0006] Herceptin.RTM. (trastuzumab) is a humanized monoclonal antibody that binds to the extracellular domain of HER2 (Carter et al. 1992, PNAS 89:4285-9 and U.S. Pat. No. 5,821,337). Herceptin.RTM. received marketing approval from the Food and Drug Administration on Sep. 25, 1998 for the treatment of patients with metastatic breast cancer whose tumors overexpress the HER2 protein. Although Herceptin.RTM. is a breakthrough in treating patients with HER2-overexpressing breast cancers that have received extensive prior anti-cancer therapy, segments of patients in this population fail to respond, respond only poorly or become resistant to Herceptin.RTM. treatment.
[0007] Kadcyla.RTM. (trastuzumab-DM1 or T-DM1) is an antibody drug conjugate consisting of trastuzumab conjugated to the maytansinoid agent DM1 via the stable thioether linker MCC (4-[N-maleimidomethyl] cyclohexane-1-carboxylate) (Lewis et al., 2008, Cancer Res. 68:9280-90; Krop et al., 2010, J Clin Oncol. 28:2698-2704; U.S. Pat. No. 8,337,856). Kadcyla.RTM. received marketing approval from the Food and Drug Administration on Feb. 22, 2013 for the treatment of HER2 positive metastatic breast cancer in patients who had been previously treated with Herceptin.RTM. and a taxane drug and became Herceptin.RTM. refractory. Like seen with Herceptin.RTM., there are segments of the patients in the HER2-overexpressing breast cancer population that do not experience successful long term therapy with Kadcyla.RTM..
[0008] Therefore, there is a significant clinical need for developing further HER2-directed cancer therapies for those patients with HER2-overexpressing tumors or other diseases associated with HER2 overexpression that do not respond, respond poorly or become resistant to Herceptin.RTM. and/or Kadcyla.RTM. treatment.
SUMMARY OF THE INVENTION
[0009] The present invention provides site specific HER2 antibody drug conjugates (ADCs) and their use in treatment of HER2-expressing cancers. ADCs enable targeted delivery of therapeutics to cancer cells and offer potential for more selective therapy while reducing known off-target toxicities.
[0010] A site specific HER2 ADC of the invention is generally of the formula: Ab-(L-D), wherein Ab is an antibody, or antigen-binding fragment thereof, that binds to HER2; and L-D is a linker-drug moiety, wherein L is a linker, and D is a drug.
[0011] The antibody (Ab) of the ADCs of the invention can be any HER2-binding antibody. In some aspects of the invention, the Ab binds to the same epitope on HER2 as trastuzumab (Herceptin.RTM.). In other aspects of the invention, the Ab has the same heavy chain and light chain CDRs as trastuzumab. In specific aspects of the invention, the Ab has the same heavy chain variable region (V.sub.H) and the same light chain variable region (V.sub.L) as trastuzumab.
[0012] The HER2 ADCs of the present invention are conjugated to the drug in a site specific manner. To accommodate this type of conjugation, the antibody must be derivatized to provide for either a reactive cysteine residue engineered at one or more specific sites or an acyl donor glutamine residue (either engineered at one or more specific sites or in an attached peptide tag). Such modifications should be at sites that do not disrupt the antigen binding capability of the antibody. In preferred embodiments, the one or more modifications are made in the constant region of the heavy and/or light chains of the antibody.
[0013] In some embodiments of the present invention, the site specific HER2 ADCs can use antibodies comprising heavy chain variable region CDRs and light chain variable region CDRs of trastuzumab (V.sub.H CDRs of SEQ ID NOs:2-4 and V.sub.L CDRs of SEQ ID NOs:8-10) and any combination of heavy and light chain constant regions disclosed in Table 1 with the proviso that when the heavy chain constant region is SEQ ID NO:5 then the light chain constant region is not SEQ ID NO:11. In such embodiments, the heavy chain constant region can be selected from any of SEQ ID NOs:17, 5, 13, 21, 23, 25, 27, 29, 31, 33, 35, 37 or 39 while the light chain constant region can be selected from any of SEQ ID NOs:41, 11 or 43 providing that the combination is not SEQ ID NO:5 and SEQ ID NO:11.
[0014] In a specific embodiment, the antibody used to make the site specific HER2 ADC comprises a V.sub.H domain with CDRs of SEQ ID NOs:2-4 and a V.sub.L domain with CDRs of SEQ ID NOs:8-10 attached to a heavy chain constant region of SEQ ID NO:17 and a light chain constant region of SEQ ID NO:41. In another specific embodiment, the antibody used to make the site specific HER2 ADC comprises a V.sub.H domain with CDRs of SEQ ID NOs:2-4 and a V.sub.L domain with CDRs of SEQ ID NOs:8-10 attached to a heavy chain constant region of SEQ ID NO:13 and a light chain constant region of SEQ ID NO:43.
[0015] In other embodiments, the ADCs of the invention can use antibodies comprising of any combination of heavy and light chains disclosed in Table 1 with the proviso that if the heavy chain is SEQ ID NO:6 then the light chain is not SEQ ID NO:12. In such embodiments, the heavy chain can be selected from any of SEQ ID NOs:18, 6, 14, 22, 24, 26, 28, 30, 32, 34, 36, 38 or 40 while the light chain can be selected from any of SEQ ID NOs: 42, 12 or 44 providing that the combination is not SEQ ID NO:6 and SEQ ID NO:12.
[0016] In a specific embodiment, the ADCs of the invention can use an antibody comprising a heavy chain of SEQ ID NO:18 and a light chain of SEQ ID NO:42. In another specific embodiment, the ADCs of the invention can use an antibody comprising a heavy chain of SEQ ID NO:14 and a light chain of SEQ ID NO:44.
[0017] Any of the site specific HER2 ADCs disclosed herein can be prepared with a drug (D) that is a therapeutic agent useful for treating cancer. In a specific embodiment, the therapeutic agent is an anti-mitotic agent. In another specific embodiment, the anti-mitotic agent drug component in the ADCs of the invention is an auristatin (e.g., 0101, 8261, 6121, 8254, 6780 and 0131). In a more specific embodiment, the auristatin drug component in the ADCs of the invention is 2-methylalanyl-N-[(3R,4S,5S)-3-methoxy-1-{(2S)-2-[(1R,2R)-1-methoxy-2-met- hyl-3-oxo-3-{[(1S)-2-phenyl-1-(1,3-thiazol-2-yl)ethyl]amino}propyl]pyrroli- din-1-yl}-5-methyl-1-oxoheptan-4-yl]-N-methyl-L-valinamide (also known as 0101). Preferably, the drug component of the ADCs of the invention is membrane permeable.
[0018] Any of the site specific HER2 ADCs disclosed herein can be prepared with a linker (L) that is cleavable or non-cleavable. Preferably, the linker is cleavable. Cleavable linkers include, but are not limited to, vc, AcLysvc and m(H20)c-vc. More preferably, the linker is vc or AcLysvc.
[0019] In a particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:18 and a light chain of SEQ ID NO:42; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is vc and wherein the drug is 0101.
[0020] In another particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:14 and a light chain of SEQ ID NO:44; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is AcLysvc and wherein the drug is 0101.
[0021] Another aspect of the invention includes methods of making, methods of preparing, methods of synthesis, methods of conjugation and methods of purification of the antibody drug conjugates disclosed herein and the intermediates for the preparation, synthesis and conjugation of the antibody drug conjugates disclosed herein.
[0022] Further provided are pharmaceutical compositions comprising a site specific HER2 ADC disclosed herein and a pharmaceutically acceptable carrier.
[0023] Nucleic acids encoding the antibody portion of the site specific HER2 ADCs are contemplated by the invention. Additional vectors and host cells comprising the nucleic acids are also contemplate by the invention.
[0024] The present invention also provides method of use of the site specific HER2 ADCs in the treatment of HER2-expressing cancers. HER2-expressing cancer to be treated with the site specific HER2 ADCs of the invention can express HER2 at a high, moderate or low level. In some embodiments, the cancer to be treated is resistant to, refractory to and/or relapsed from treatment with trastuzumab and/or trastuzumab emtansine (T-DM1) either of which alone or in combination with a taxane. Cancers to be treated include, but are not limited to, breast cancer, ovarian cancer, lung cancer, gastric cancer, esophageal cancer, colorectal cancer, urothelial cancer, pancreatic cancer, salivary gland cancer and brain cancer or metastases of the aforementioned cancers. In a more specific embodiment, the breast cancer is estrogen receptor and progesterone receptor negative breast cancer or triple negative breast cancer (TNBC). In another embodiment, the lung cancer is non-small cell lung cancer (NSCLC).
[0025] These and other aspects of the invention will be appreciated by a review of the application as a whole.
BRIEF DESCRIPTION OF THE DRAWINGS
[0026] FIGS. 1A-1B depict (A) T(kK183C+K290C)-vc0101 ADC and (B) T(LCQ05+K222R)-AcLysvc0101 ADC. Each black circle represents a linker/payload that is conjugated to the monoclonal antibody. The structure of one such linker/payload is shown for each ADC. The underlined entity is supplied by the amino acid residue on the antibody through which conjugation occurs.
[0027] FIGS. 2A-2E depict spectra of selected ADCs from hydrophobic interaction chromatography (HIC) showing changes in retention times upon conjugation of trastuzumab derived antibodies to different linker payloads.
[0028] FIGS. 3A-3B depict graphs of ADCs binding to HER2. (A) direct binding to HER2 positive BT474 cells and (B) competitive binding with PE labelled trastuzumab to BT474 cells. These results indicate that the binding properties of antibody in these ADCs were unaltered by the conjugation process.
[0029] FIG. 4 depicts ADCC activities of trastuzumab derived ADCs.
[0030] FIG. 5 depicts in vitro cytotoxicity data (IC.sub.50) reported in nM payload concentration for a number of trastuzumab derived ADCs on a number of cell lines with different levels of HER2 expression.
[0031] FIG. 6 depicts in vitro cytotoxicity data (IC.sub.50) reported in ng/ml antibody concentration for a number of trastuzumab derived ADCs on a number of cell lines with different levels of HER2 expression.
[0032] FIGS. 7A-7I depict anti-tumor activity of nine trastuzumab derived ADCs on N87 xenografts with tumor volume was plotted over time. (A) T(kK183C+K290C)-vc0101; (B) T(kK183C)-vc0101; (C) T(K290C)-vc0101; (D) T(LCQ05+K222R)-AcLysvc0101; (E) T(K290C+K334C)-vc0101; (F) T(K334C+K392C)-vc0101; (G) T(N297Q+K222R)-AcLysvc0101; (H) T-vc0101; (I) T-DM1. N87 gastric cancer cells express high levels of HER2.
[0033] FIGS. 8A-8E depict anti-tumor activity of six trastuzumab derived ADCs on HCC1954 xenografts with tumor volume plotted over time. (A) T(LCQ05+K222R)-AcLysvc0101; (B) T(K290C+K334C)-vc0101; (C) T(K334C+K392C)-vc0101; (D) T(N297Q+K222R)-AcLysvc0101; (E) T-DM1. HCC1954 breast cancer cells express high levels of HER2.
[0034] FIGS. 9A-9G depict anti-tumor activity of seven trastuzumab derived ADCs on JIMT-1 xenografts with tumor volume plotted over time. (A) T(kK183C+K290C)-vc0101; (B) T(LCQ05+K222R)-AcLysvc0101; (C) T(K290C+K334C)-vc0101; (D) T(K334C+K392C)-vc0101; (E) T(N297Q+K222R)-AcLysvc0101; (F) T-vc0101; (G) T-DM1. JIMT-1 breast cancer cells express moderate/low levels of HER2.
[0035] FIGS. 10A-10D depict anti-tumor activity of five trastuzumab derived ADCs on MDA-MB-361(DYT2) xenografts with tumor volume plotted over time. (A) T(LCQ05+K222R)-AcLysvc0101; (B) T(N297Q+K222R)-AcLysvc0101; (C) T-vc0101; (D) T-DM1. MDA-MB-361(DYT2) breast cancer cells express moderate/low levels of HER2.
[0036] FIGS. 11A-11E depict anti-tumor activity of five trastuzumab derived ADCs on PDX-144580 patient derived xenografts with tumor volume plotted over time. (A) T(kK183C+K290C)-vc0101; (B) T(LCQ05+K222R)-AcLysvc0101; (C) T(N297Q+K222R)-AcLysvc0101; (D) T-vc0101; (E) T-DM1. PDX-144580 patient derived cells are a TNBC PDX model.
[0037] FIGS. 12A-12D depict anti-tumor activity of four trastuzumab derived ADCs on PDX-37622 patient derived xenografts with tumor volume plotted over time. (A) T(kK183C+K290C)-vc0101; (B) T(N297Q+K222R)-AcLysvc0101; (C) T(K297C+K334C)-vc0101; (D) T-DM1. PDX-37622 patient derived cells are a NSCLC PDX model expressing moderate levels of HER2.
[0038] FIGS. 13A-13B depict immunohistocytochemistry of N87 tumor xenografts treated with either (A) T-DM1 or (B) T-vc0101 and stained for phosphohistone H3 and IgG antibody. Bystander activity is observed with T-vc0101.
[0039] FIG. 14 depicts in vitro cytotoxicity data (IC.sub.50) reported in nM payload concentration and ng/ml antibody concentration for a number of trastuzumab derived ADCs and free payloads on cells made resistant to T-DM1 in vitro (N87-TM1 and N87-TM2) or parental cells sensitive to T-DM1 (N87cells). N87 gastric cancer cells express high levels of HER2.
[0040] FIGS. 15A-15G depict anti-tumor activity of seven trastuzumab derived ADCs on T-DM1 sensitive (N87 cells) and resistant (N87-TM1 and N87-TM2) gastric cancer cells. (A) T-DM1; (B) T-mc8261; (C) T(297Q+K222R)-AcLysvc0101; (D) T(LCQ05+K222R)-AcLysvc0101; (E) T(K290C+K334C)-vc0101; (F) T(K334C+K392C)-vc0101; (G) T(kK183C+K290C)-vc0101.
[0041] FIGS. 16A-16B depict western blots showing (A) MRP1 drug efflux pump and (B) MDR1 drug efflux pump protein expression on T-DM1 sensitive (N87 cells) and resistant (N87-TM1 and N87-TM2) gastric cancer cells.
[0042] FIGS. 17A-17B depict HER2 expression and binding to trastuzumab of T-DM1 sensitive (N87 cells) and resistant (N87-TM1 and N87-TM2) gastric cancer cells. (A) a western blot showing HER2 protein expression and (B) trastuzumab binding to cell surface HER2.
[0043] FIGS. 18A-18D depict characterization of protein expression levels in T-DM1 sensitive (N87 cells) and resistant (N87-TM1 and N87-TM2) gastric cancer cells. (A) protein expression level changes in 523 proteins; (B) western blots showing protein expression of IGF2R, LAMP1 and CTSB; (C) western blot showing protein expression of CAV1; (D) IHC of CAV1 protein expression in tumors generated in vivo from implantation of N87 cells (left panel) and N87-TM2 cells (right panel).
[0044] FIGS. 19A-19C depict sensitivity to trastuzumab and various trastuzumab derived ADCs of tumors generated in vivo from implantation of (A) T-DM1 sensitive N87 parental cells; (B) T-DM1 resistant N87-TM1 cells; (C) T-DM1 resistant N87-TM2 cells.
[0045] FIGS. 20A-20F depict sensitivity to trastuzumab and various trastuzumab derived ADCs of tumors generated in vivo from implantation of T-DM1 sensitive N87 parental cells and T-DM1 resistant N87-TM2 or N87-TM1 cells. (A) N87 tumor size was plotted over time in the presence of trastuzumab or two trastuzumab derived ADCs; (B) N87-TM2 tumor size was plotted over time in the presence of trastuzumab or two trastuzumab derived ADCs; (C) time for N87 cell tumor to double in size in the presence of in the presence of trastuzumab or two trastuzumab derived ADCs; (D) time for N87-TM2 cell tumor to double in size in the presence of trastuzumab or two trastuzumab derived ADCs; (E) N87-TM2 tumor size was plotted over time in the presence of seven different trastuzumab derived ADCs; (F) N87-TM1 tumor size was plotted over time with a trastuzumab derived ADC added at day 14.
[0046] FIGS. 21A-21E depict generation and characterization of T-DM1 resistant cells generated in vivo. (A) N87 gastric cancer cells were initially sensitive to T-DM1 when implanted in vivo. (B) Over time, the implanted N87 cells became resistant to T-DM1 but remained sensitive to (C) T-vc0101, (D) T(N297Q+K222R)-AcLysvc0101 and (E) T(kK183+K290C)-vc0101.
[0047] FIGS. 22A-22D depict in vitro cytotoxicity of four trastuzumab derived ADCs on T-DM1 resistant cells (N87-TDM) generated in vivo compared to T-DM1 sensitive parental N87 cells with tumor volume plotted over time. (A) T-DM1; (B) T(kK183+K290C)-vc0101; (C) T(LCQ05+K222R)-AcLysvc0101; (D) T(N297Q+K222R)-AcLysvc0101.
[0048] FIGS. 23A-23B depict HER2 protein expression levels on T-DM1 resistant cells (N87-TDM1, from mice 2, 17 and 18) generated in vivo compared to T-DM1 sensitive parental N87 cells. (A) FACS analysis and (B) western blot analysis. No significant difference in HER2 protein expression was observed.
[0049] FIGS. 24A-24D depict that T-DM1 resistance in N87-TDM1 (mice 2, 7 and 17) is not due to drug efflux pumps. (A) a western blot showing MDR1 protein expression. In vitro cytotoxicity of T-DM1 resistant cells (N87-TDM1) and T-DM1 sensitive N87 parental cells in the presence of free drug (B) 0101; (C) doxorubicin; (D) T-DM1.
[0050] FIGS. 25A-25B depict concentration vs time profiles and pharmacokinetics/toxicokinetics of (A) both total Ab and trastuzumab ADC (T-vc0101) or T(kK183C+K290C) site specific ADC after dose administration to cynomolgus monkeys and (B) the ADC analyte of trastuzumab (T-vc0101) or various site specific ADCs after dose administration to cynomolgus monkeys.
[0051] FIG. 26 depicts relative retention values by hydrophobic interaction chromatography (HIC) vs exposure (AUC) in rats. The X-axis represents Relative Retention Time by HIV; while the Y-axis represents pharmacokinetic dose-normalized exposure in rats ("area under curve", AUC for antibody, from 0 to 336 hours, divided by drug dose of 10 mg/kg). Symbol shape denotes approximate drug loading (DAR): diamond=DAR 2; circle=DAR 4. Arrow indicates T(kK183C+K290C)-vc0101.
[0052] FIG. 27 depicts a toxicity study using T-vc0101 conventional conjugate ADC and T(kK183C+K290C)-vc0101 site specific ADC. T-vc0101 induced severe neutropenia at 5 mg/kg while the T(kK183C+K290C)-vc0101 caused a minimal drop in neutrophil counts at 9 mg/kg.
[0053] FIGS. 28A-28C depict the crystal structure of (A) T(K290C+K334C)-vc0101; (B) T(K290C+K392C)-vc0101; and (C) T(K334C+K392C)-vc0101.
[0054] FIG. 29 depicts in vivo efficacy on a xenograft model using the N87 cell line. All ADCs tested showed efficacy at 3mpk.
[0055] FIG. 30 depicts anti-tumor activity of trastuzumab and two trastuzumab derived ADCs on PDX-GA0044 patient derived xenografts with tumor volume plotted over time. Animals were treated with vehicle (hollow diamonds), trastuzumab (hollow triangles), T-DM1 (hollow circles), or T(kK183C+K290C)-vc0101 (solid circles and solid squares). PDX-GA0044 patient derived cells are a Gastric PDX model expressing moderate levels of HER2.
DETAILED DESCRIPTION OF THE INVENTION
[0056] The present invention provides site specific HER2 antibody drug conjugates (ADCs), processes for preparing the conjugates using HER2 antibodies, linkers, and drug payloads and nucleic acids encoding the antibodies used in making the ADCs. The ADCs of the invention are useful for the preparation and manufacture of compositions, such as medicaments, that can be used in the treatment of HER2-expressing cancers.
[0057] ADCs consist of an antibody component conjugated to a drug payload through the use of a linker. Conventional conjugation strategies for ADCs rely on randomly conjugating the drug payload to the antibody through lysines or cysteines that are endogenously on the antibody heavy and/or light chain. Accordingly, such ADCs are a heterogeneous mixture of species showing different drug:antibody ratios (DAR). In contrast, the ADCs disclosed herein are site specific ADCs that conjugate the drug payload to the antibody at particular engineered residues on the antibody heavy and/or light chain. As such, the site specific ADCs are a homogeneous population of ADCs comprised of a species with a defined drug:antibody ratio (DAR). Thus, the site specific ADCs demonstrate uniform stoichiometry resulting in improved pharmacokinetics, biodistribution and safety profile of the conjugate. ADCs of the invention include antibodies of the invention conjugated to one or more linker/payload moieties.
[0058] The present invention provides antibody drug conjugates of the formula Ab-(L-D), wherein (a) Ab is an antibody, or antigen-binding fragment thereof, that binds to HER2, and (b) L-D is a linker-drug moiety, wherein L is a linker, and D is a drug.
[0059] Also encompassed by the present invention are antibody drug conjugates of the formula Ab-(L-D).sub.p, wherein (a) Ab is an antibody, or antigen-binding fragment thereof, that binds to HER2, (b) L-D is a linker-drug moiety, wherein L is a linker, and D is a drug and (c) p is the number of linker/drug moieties are attached to the antibody. For site specific ADCs, p is a whole number due to the homogeneous nature of the ADC. In some embodiments, p is 4. In other embodiments, p is 3. In other embodiments, p is 2. In other embodiments, p is 1. In other embodiments, p is greater than 4.
[0060] As used herein, the term "HER2" refers to a transmembrane tyrosine kinase receptor that belongs to the EGFR family. HER2 is also known as ErbB2, p185 and CD340. This family of receptors includes four members (EGFR/HER1, HER2, HER3 and HER4) that function by stimulating growth factor signaling pathways such as the PI3K-AKT-mTOR pathway. Amplification and/or overexpression of HER2 is associated with multiple human malignancies. The wild type human HER2 protein is described, for example, in Semba et al., 1985, PNAS 82:6497-6501 and Yamamoto et al., 1986, Nature 319:230-4 and Genbank Accession Number X03363.
[0061] As used herein, the term "Antibody (Ab)" refers to an immunoglobulin molecule capable of recognizing and binding to a specific target or antigen, such as a polypeptide, through at least one antigen recognition site located in the variable region of the immunoglobulin molecule. The term can encompass any type of antibody, including but not limited to monoclonal antibodies, antigen-binding fragments of intact antibodies that retain the ability to specifically bind to a given antigen (i.e., Fab, Fab', F(ab').sub.2, Fd, Fv, Fc, etc.) and mutants thereof.
[0062] Native or naturally occurring antibodies, and native immunoglobulins, are typically heterotetrameric glycoproteins of about 150,000 daltons, composed of two identical light (L) chains and two identical heavy (H) chains. Each light chain is linked to a heavy chain by one covalent disulfide bond, while the number of disulfide linkages varies among the heavy chains of different immunoglobulin isotypes. Each heavy and light chain also has regularly spaced intrachain disulfide bridges. Each heavy chain has at one end a variable domain (V.sub.H) followed by a number of constant domains. Each light chain has a variable domain at one end (V.sub.L) and a constant domain at its other end; the constant domain of the light chain is aligned with the first constant domain of the heavy chain, and the light chain variable domain is aligned with the variable domain of the heavy chain. The term "variable" refers to the fact that certain portions of the variable domains differ extensively in sequence among antibodies.
[0063] The antibody used in the present invention specifically binds to HER2. In a specific embodiment, the HER2 antibody binds to the same epitope on HER2 as trastuzumab (Herceptin.RTM.). In a more specific embodiment, the HER2 antibody has the same variable region CDRs as trastuzumab (Herceptin.RTM.). In yet a more specific embodiment, the HER2 antibody has the same variable regions (i.e., V.sub.H and V.sub.L) as trastuzumab (Herceptin.RTM.).
[0064] As used herein, the term "Linker (L)" describes the direct or indirect linkage of the antibody to the drug payload. Attachment of a linker to an antibody can be accomplished in a variety of ways, such as through surface lysines, reductive-coupling to oxidized carbohydrates, cysteine residues liberated by reducing interchain disulfide linkages, reactive cysteine residues engineered at specific sites, and acyl donor glutamine-containing tag or an endogenous glutamine made reactive by polypeptide engineering in the presence of transglutaminase and an amine. The present invention uses site specific methods to link the antibody to the drug payload. In one embodiment, conjugation occurs through cysteine residues that have been engineered into the antibody constant region. In another embodiment, conjugation occurs through acyl donor glutamine residues that have either been a) added to the antibody constant region via a peptide tag, b) engineered into the antibody constant region or c) made accessible/reactive by engineering surrounding residues. Linkers can be cleavable (i.e., susceptible to cleavage under intracellular conditions) or non-cleavable. In some embodiments, the linker is a cleavable linker.
[0065] As used herein, the term "Drug (D)" refers to any therapeutic agent useful in treating cancer. The drug has biological or detectable activity, for example, cytotoxic agents, chemotherapeutic agents, cytostatic agents, and immunomodulatory agents. In preferred embodiments, therapeutic agents have a cytotoxic effect on tumors including the depletion, elimination and/or the killing of tumor cells. The terms drug, payload, and drug payload are used interchangeably. In a specific embodiment, the drug is an anti-mitotic agent. In a more specific embodiment, the drug is an auristatin. In a yet more specific embodiment, the drug is 2-methylalanyl-N-[(3R,4S,5S)-3-methoxy-1-{(2S)-2-[(1R,2R)-1-methoxy-2-met- hyl-3-oxo-3-{[(1S)-2-phenyl-1-(1,3-thiazol-2-yl)ethyl]amino}propyl]pyrroli- din-1-yl}-5-methyl-1-oxoheptan-4-yl]-N-methyl-L-valinamide (also known as 0101). In some embodiments, the drug is preferably membrane permeable.
[0066] As used herein, the term "L-D" refers to a linker-drug moiety resulting from a drug (D) linked to a linker (L).
[0067] Additional scientific and technical terms used in connection with the present invention, unless indicated otherwise herein, shall have the meanings that are commonly understood by those of ordinary skill in the art. Further, unless otherwise required by context, singular terms shall include pluralities and plural terms shall include the singular. Generally, nomenclature used in connection with, and techniques of, cell and tissue culture, molecular biology, immunology, microbiology, genetics and protein and nucleic acid chemistry and hybridization described herein are those well-known and commonly used in the art.
I. HER2 Antibodies
[0068] For preparation of site specific HER2 ADCs of the invention, the antibody can be any antibody that specifically binds to the extracellular domain of HER2. In one embodiment, the antibody used to make the ADC binds to the same epitope of HER2 as trastuzumab and/or competes with trastuzumab for HER2 binding. In another embodiment, the antibody used to make the ADC has the same heavy chain variable region CDRs and light chain variable region CDRs as trastuzumab. In yet another embodiment, the antibody used to make the ADC has the same heavy chain variable region and light chain variable region as trastuzumab.
[0069] The term "compete", as used herein with regard to an antibody, means that a first antibody, or an antigen-binding fragment thereof, binds to an epitope in a manner sufficiently similar to the binding of a second antibody, or an antigen-binding fragment thereof, such that the result of binding of the first antibody with its cognate epitope is detectably decreased in the presence of the second antibody compared to the binding of the first antibody in the absence of the second antibody. The alternative, where the binding of the second antibody to its epitope is also detectably decreased in the presence of the first antibody, can, but need not be the case. That is, a first antibody can inhibit the binding of a second antibody to its epitope without that second antibody inhibiting the binding of the first antibody to its respective epitope. However, where each antibody detectably inhibits the binding of the other antibody with its cognate epitope or ligand, whether to the same, greater, or lesser extent, the antibodies are said to "cross-compete" with each other for binding of their respective epitope(s). Both competing and cross-competing antibodies are encompassed by the present invention. Regardless of the mechanism by which such competition or cross-competition occurs (e.g., steric hindrance, conformational change, or binding to a common epitope, or portion thereof), the skilled artisan would appreciate, based upon the teachings provided herein, that such competing and/or cross-competing antibodies are encompassed and can be useful for the methods disclosed herein.
[0070] Trastuzumab (trade name Herceptin.RTM.) is a humanized monoclonal antibody that binds to the extracellular domain of HER2. The amino acid sequences of its variable domains are disclosed in U.S. Pat. No. 5,821,337 (V.sub.H is SEQ ID NO:42 and V.sub.L is SEQ ID NO:41 of U.S. Pat. No. 5,821,337) as well as in Table 1 infra (SEQ ID NOs:1 and 7, respectively). The amino acid sequences of the heavy chain variable region CDRs are SEQ ID NOs:2-4 while the amino acid sequences of the light chain CDRs are SEQ ID NOs:6-10 (Table 1 infra). The amino acid sequences of the complete heavy and light chains are SEQ ID NOs:6 and 12, respectively (Table 1 infra).
[0071] T-DM1 (trade name Kadcyla.RTM.) is an antibody drug conjugate consisting of trastuzumab conjugated to the maytansinoid agent DM1 via the stable thioether linker MCC (4-[N-maleimidomethyl] cyclohexane-1-carboxylate) (U.S. Pat. No. 8,337,856). The antibody component of this ADC is identical to trastuzumab. Payload conjugation to trastuzumab is accomplished using conventional conjugation (rather than site specific) techniques such that the ADC is a heterogeneous population of species with different amounts of DM1 conjugated to each one. The DM1 payload inhibits cell proliferation by inhibiting the formation of microtubules during mitosis through inhibition of tubulin polymerization (Remillard et al., 1975, Science 189:1002-5). Kadcyla.RTM. is approved for the treatment of HER2 positive metastatic breast cancer in patients who had been previously treated with Herceptin.RTM. and a taxane drug and became Herceptin.RTM. refractory. T-DM1 used in the experiments described in the Examples Section was made internally using publically available information.
[0072] The ADCs of the present invention are conjugated to the payload in a site specific manner. To accommodate this type of conjugation, the antibody must be derivatized to provide for either a reactive cysteine residue engineered at one or more specific sites, an acyl donor glutamine-containing tag or an endogenous glutamine made reactive by polypeptide engineering in the presence of transglutaminase and an amine. Amino acid modifications can be made by any method known in the art and many such methods are well known and routine for the skilled artisan. For example, but not by way of limitation, amino acid substitutions, deletions and insertions may be accomplished using any well-known PCR-based technique. Amino acid substitutions may be made by site-directed mutagenesis (see, for example, Zoller and Smith, 1982, Nucl. Acids Res. 10:6487-6500; and Kunkel, 1985, PNAS 82:488).
[0073] In applications where retention of antigen binding is required, such modifications should be at sites that do not disrupt the antigen binding capability of the antibody. In preferred embodiments, the one or more modifications are made in the constant region of the heavy and/or light chains.
[0074] As used herein, the term "constant region" of an antibody refers to the constant region of the antibody light chain or the constant region of the antibody heavy chain, either alone or in combination. The constant regions of the antibodies used to make the ADCs of the invention may be derived from constant regions of any one of IgA, IgD, IgE, IgG, IgM, or any isotypes thereof as well as subclasses and mutated versions thereof.
[0075] The constant domains are not involved directly in binding an antibody to an antigen, but exhibit various effector functions, such as Fc receptor (FcR) binding, participation of the antibody in antibody-dependent cellular toxicity (ADCC), opsonization, initiation of complement dependent cytotoxicity, and mast cell degranulation. As known in the art, the term "Fc region" is used to define a C-terminal region of an immunoglobulin heavy chain. The "Fc region" may be a native sequence Fc region or a variant Fc region. Although the boundaries of the Fc region of an immunoglobulin heavy chain might vary, the human IgG heavy chain Fc region is usually defined to stretch from an amino acid residue at position Cys226, or from Pro230, to the carboxyl-terminus thereof. The numbering of the residues in the Fc region is that of the EU Index of Kabat (Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md., 1991). The Fc region of an immunoglobulin generally has two constant regions, CH2 and CH3.
[0076] There are two different light chains constant regions for use in antibodies, CL.kappa. and CL.LAMBDA.. CL.kappa. has known polymorphic loci CL.kappa.-V/A.sup.45 and CL.kappa.-L/V.sup.83 (using the Kabat numbering system as set forth in Kabat et al. (1991, NIH Publication 91-3242, National Technical Information Service, Springfield, Va.), so all Kappa and Lambda positions are numbered according to the Kabat system.) thus allowing for polymorphisms Km(1): CL.kappa.-V.sup.48/L.sup.83; Km(1,2): CL.kappa.-A.sup.45/L.sup.83; and Km(3): CL.kappa.-A.sup.48/V.sup.83 Polypeptides, antibodies and ADCs of the invention can have antibody components with any of these light chain constant regions.
[0077] For clarity, unless otherwise specified, amino acid residues in the human IgG heavy constant domain of an antibody are numbered according the EU index of Edelman et al., 1969, Proc. Natl. Acad. Sci. USA 63(1):78-85 as described in Kabat et al., 1991, referred to herein as the "EU index of Kabat". Typically, the Fc domain comprises from about amino acid residue 236 to about 447 of the human IgG1 constant domain. Correspondence between C numberings can be found, e.g., at IGMT database. Amino acid residues of the light chain constant domain are numbered according to Kabat et al., 1991. Numbering of antibody constant domain amino acid residues is also shown in International Patent Publication No. WO 2013/093809. The only exception to the use of EU index of Kabat in IgG heavy constant domain is residue A114 described in the examples. A114 refers to Kabat numbering, and the corresponding EU index number is 118. This is because the initial publication of site specific conjugating at this site used Kabat numbering and referred this site as A114C, and has since been widely used in the art as the "114" site. See Junutula et al., Nature Biotechnology 26, 925-932 (2008). To be consistent with the common usage of this site in the art, "A114," "A114C," "C114" or "114C" are used in the examples.
[0078] Nucleic acids encoding the heavy and light chains of the antibodies used to make the ADCs of the invention can be cloned into a vector for expression or propagation. The sequence encoding the antibody of interest may be maintained in vector in a host cell and the host cell can then be expanded and frozen for future use.
[0079] As used herein, the term "vector" refers to a construct which is capable of delivering, and preferably, expressing, one or more gene(s) or sequence(s) of interest in a host cell. Examples of vectors include, but are not limited to, viral vectors, naked DNA or RNA expression vectors, plasmid, cosmid or phage vectors, DNA or RNA expression vectors associated with cationic condensing agents, DNA or RNA expression vectors encapsulated in liposomes, and certain eukaryotic cells, such as producer cells.
[0080] As used herein, the term "host cell" includes an individual cell or cell culture that can be or has been a recipient for vector(s) for incorporation of polynucleotide inserts. Host cells include progeny of a single host cell, and the progeny may not necessarily be completely identical (in morphology or in genomic DNA complement) to the original parent cell due to natural, accidental, or deliberate mutation. A host cell includes cells transfected in vivo with a nucleic acids or vectors of this invention.
[0081] Table 1 provides the amino acid (protein) sequences and associated nucleic acid (DNA) sequences of humanized HER2 antibodies used in constructing the site specific ADCs of the invention. The CDRs shown are defined by Kabat numbering scheme.
[0082] The antibody heavy chains and light chains shown in Table 1 have the trastuzumab heavy chain variable region (V.sub.H) and light chain variable region (V.sub.L). The heavy chain constant region and light chain constant region are derivatized from trastuzumab and contain on or more modification to allow for site specific conjugation when making the ADCs of the invention.
[0083] Modifications to the amino acid sequences in the antibody constant region to allow for site specific conjugation are underlined and bolded. The nomenclature for the antibodies derivatized from trastuzumab is T (for trastuzumab) and then in parenthesis the position of the amino acid of modification flanked by the single letter amino acid code for the wild type residue and the single letter amino acid code for the residue that is now in that position in the derivatized antibody. Two exceptions to this nomenclature are "kK183C" which denotes that position 183 on the light (kappa) chain has been modified from a lysine to a cysteine and "LCQ05" which denotes an eight amino acid glutamine-containing tag that has been attached to the C terminus of the light chain constant region.
[0084] One of the modifications shown in Table 1 is not used for conjugation. The residue at position 222 on the heavy chain (using the EU Index of Kabat numbering scheme) can be altered to result in a more homogenous antibody and payload conjugate, better intermolecular crosslinking between the antibody and the payload and/or significant decrease in interchain crosslinking.
TABLE-US-00001 TABLE 1 Sequences of humanized HER2 antibodies SEQ ID NO. Description Sequence 1 Trastuzumab EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR VH protein IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG GDGFYAMDYWGQGTLVTVSS 2 VH CDR1 DTYIH protein 3 VH CDR2 RIYPTNGYTRYADSVKG protein 4 VH CDR3 WGGDGFYAMDY protein 5 Trastuzumab ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV heavy chain HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK constant SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE region DPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKE protein YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPG 6 Trastuzumab EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR heavy chain IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG protein GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG 7 Trastuzumab DIQMTQSPSSLSASVGDRVTITCRASQDVNTAVAWYQQKPGKAPKLLIYSA VL protein SFLYSGVPSRFSGSRSGTDFTLTISSLQPEDFATYYCQQHYTTPPTFGQGT KVEIK 8 VL CDR1 RASQDVNTAVA protein 9 VL CRD2 SASFLYS protein 10 VL CDR3 QQHYTTPPT protein 11 Trastuzumab RTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSG light chain NSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKS constant FNRGEC region protein 12 Trastuzumab DIQMTQSPSSLSASVGDRVTITCRASQDVNTAVAWYQQKPGKAPKLLIYSA light chain SFLYSGVPSRFSGSRSGTDFTLTISSLQPEDFATYYCQQHYTTPPTFGQGT protein KVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNA LQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSS PVTKSFNRGEC 13 T(K222R) ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV heavy chain HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK constant SCDRTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE region DPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKE protein YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPGK 14 T(K222R) EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR heavy chain IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG protein GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDRTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK 15 T(K246C) ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV heavy chain HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK constant SCDKTHTCPPCPAPELLGGPSVFLFPPCPKDTLMISRTPEVTCVVVDVSHE region DPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKE protein YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPG 16 T(K246C) EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR heavy chain IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG protein GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPCP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG 17 T(K290C) ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV heavy chain HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK constant SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE region DPEVKFNWYVDGVEVHNAKTCPREEQYNSTYRVVSVLTVLHQDWLNGKE protein YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPG 18 T(K290C) EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR heavy chain IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG protein GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTCPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG 19 T(N297A) ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV heavy chain HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK constant SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE region DPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKE protein YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPGK 20 T(N297A) EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR heavy chain IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG protein GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYA STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK 21 T(N297Q) ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV heavy chain HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK constant SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE region DPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKE protein YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPGK 22 T(N297Q) EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR heavy chain IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG protein GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQ STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK 23 T(K334C) ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV heavy chain HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK constant SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE region DPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKE protein YKCKVSNKALPAPIECTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPG 24 T(K334C) EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR heavy chain IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG protein GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIECTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG 25 T(K392C) ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV heavy chain HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK constant SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE region DPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKE protein YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV KGFYPSDIAVEWESNGQPENNYCTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPG 26 T(K392C) EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR heavy chain IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG protein GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYCTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG 27 T(L443C) ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV heavy chain HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK constant SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE region DPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKE protein YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSCSPG 28 T(L443C) EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR heavy chain IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG protein GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSCSPG 29 T(K290C + ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV K334C) HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK heavy chain SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE constant DPEVKFNWYVDGVEVHNAKTCPREEQYNSTYRVVSVLTVLHQDWLNGKE region YKCKVSNKALPAPIECTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV protein KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPG 30 T(K290C + EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR K334C) IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG heavy chain GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV protein KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTCPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIECTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG 31 T(K290C + ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV K392C) HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK heavy chain SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE constant DPEVKFNWYVDGVEVHNAKTCPREEQYNSTYRVVSVLTVLHQDWLNGKE region YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV protein KGFYPSDIAVEWESNGQPENNYCTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPG 32 T(K290C + EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR K392C) IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG heavy chain GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV protein KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTCPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYCTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG 33 T(N297A + ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV K222R) HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK heavy chain SCDRTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE constant DPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKE region YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV protein KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPGK
34 T(N297A + EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR K222R) IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG heavy chain GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV protein KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDRTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYA STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK 35 T(N297Q + ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV K222R) HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK heavy chain SCDRTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE constant DPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKE region YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV protein KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPGK 36 T(N297Q + EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR K222R) IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG heavy chain GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV protein KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDRTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQ STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK 37 T(K334C + ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV K392C) HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK heavy chain SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE constant DPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKE region YKCKVSNKALPAPIECTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV protein KGFYPSDIAVEWESNGQPENNYCTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSLSPG 38 T(K334C + EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR K392C) IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG heavy chain GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV protein KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIECTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYCTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG 39 T(K392C + ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV L443C) HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK heavy chain SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE constant DPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKE region YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLV protein KGFYPSDIAVEWESNGQPENNYCTTPPVLDSDGSFFLYSKLTVDKSRWQQ GNVFSCSVMHEALHNHYTQKSLSCSPG 40 T(K392C + EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTYIHWVRQAPGKGLEWVAR L443C) IYPTNGYTRYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSRWG heavy chain GDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV protein KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV YTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYCTTPPVL DSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSCSPG 41 T(kK183C) RTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSG light chain NSQESVTEQDSKDSTYSLSSTLTLSCADYEKHKVYACEVTHQGLSSPVTK constant SFNRGEC region protein 42 T(kK183C) DIQMTQSPSSLSASVGDRVTITCRASQDVNTAVAWYQQKPGKAPKLLIYSA light chain SFLYSGVPSRFSGSRSGTFTLTISSLQPEDFATYYCQQHYTTPPTFGQGTK protein VEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNAL QSGNSQESVTEQDSKDSTYSLSSTLTLSCADYEKHKVYACEVTHQGLSSP VTKSFNRGEC 43 T(LCQ05) RTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSG light chain NSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKS constant FNRGECGGLLQGPP region protein 44 T(LCQ05) DIQMTQSPSSLSASVGDRVTITCRASQDVNTAVAWYQQKPGKAPKLLIYSA light chain SFLYSGVPSRFSGSRSGTDFTLTISSLQPEDFATYYCQQHYTTPPTFGQGT protein KVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNA LQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSS PVTKSFNRGECGGLLQGPP 45 Trastuzumab GAGGTGCAGCTGGTGGAATCCGGCGGAGGCCTGGTCCAGCCTGGCGG VH DNA ATCTCTGCGGCTGTCTTGCGCCGCCTCCGGCTTCAACATCAAGGACAC CTACATCCACTGGGTCCGACAGGCACCTGGCAAGGGACTGGAATGGGT GGCCCGGATCTACCCCACCAACGGCTACACCAGATACGCCGACTCCGT GAAGGGCCGGTTCACCATCTCCGCCGACACCTCCAAGAACACCGCCTA CCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTG CTCCAGATGGGGAGGCGACGGCTTCTACGCCATGGACTACTGGGGCC AGGGCACCCTGGTCACCGTGTCTAGC 46 Trastuzumab GAGGTGCAGCTGGTGGAATCCGGCGGAGGCCTGGTCCAGCCTGGCGG heavy chain ATCTCTGCGGCTGTCTTGCGCCGCCTCCGGCTTCAACATCAAGGACAC DNA CTACATCCACTGGGTCCGACAGGCACCTGGCAAGGGACTGGAATGGGT GGCCCGGATCTACCCCACCAACGGCTACACCAGATACGCCGACTCCGT GAAGGGCCGGTTCACCATCTCCGCCGACACCTCCAAGAACACCGCCTA CCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTG CTCCAGATGGGGAGGCGACGGCTTCTACGCCATGGACTACTGGGGCC AGGGCACCCTGGTCACCGTGTCTAGCGCGTCGACCAAGGGCCCATCG GTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCG GCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGT GTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGG CTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCG TGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATC ACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCA TGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGC CACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAG GTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCAC GTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAA TGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCC CATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACA GGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGG TCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCG TGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACG CCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCA CCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCC GTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCC CTGTCCCCGGGT 47 Trastuzumab GACATCCAGATGACCCAGTCCCCCTCCAGCCTGTCCGCCTCTGTGGGC VL DNA GACAGAGTGACCATCACCTGTCGGGCCTCCCAGGACGTGAACACCGC CGTGGCCTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGA TCTACTCCGCCTCCTTCCTGTACTCCGGCGTGCCCTCCCGGTTCTCCG GCTCCAGATCTGGCACCGACTTTACCCTGACCATCTCCAGCCTGCAGC CCGAGGACTTCGCCACCTACTACTGCCAGCAGCACTACACCACCCCCC 48 Trastuzumab GACATCCAGATGACCCAGTCCCCCTCCAGCCTGTCCGCCTCTGTGGGC light chain GACAGAGTGACCATCACCTGTCGGGCCTCCCAGGACGTGAACACCGC DNA CGTGGCCTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGA TCTACTCCGCCTCCTTCCTGTACTCCGGCGTGCCCTCCCGGTTCTCCG GCTCCAGATCTGGCACCGACTTTACCCTGACCATCTCCAGCCTGCAGC CCGAGGACTTCGCCACCTACTACTGCCAGCAGCACTACACCACCCCCC CCACCTTTGGCCAGGGCACCAAGGTGGAAATCAAGCGGACCGTGGCC GCTCCCTCCGTGTTCATCTTCCCACCCTCCGACGAGCAGCTGAAGTCC GGCACCGCCTCCGTCGTGTGCCTGCTGAACAACTTCTACCCCCGCGAG GCCAAGGTGCAGTGGAAGGTGGACAACGCCCTGCAGTCCGGCAACTC CCAGGAATCCGTCACCGAGCAGGACTCCAAGGACAGCACCTACTCCCT GTCCTCCACCCTGACCCTGTCCAAGGCCGACTACGAGAAGCACAAGGT GTACGCCTGCGAAGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCA AGTCCTTCAACCGGGGCGAGTGC 49 T(K222R) GCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG heavy chain AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA constant CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA region DNA GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT CCCTCAGCAGCGTAGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACCGTACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGG GAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTC CTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC AACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAA GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGA GGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCT TCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGG GGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTA CACGCAGAAGAGCCTCTCCCTGTCTCCGGGAAAA 50 T(K222R) GAGGTGCAGCTGGTGGAGTCCGGCGGCGGCCTGGTTCAGCCCGGCG heavy chain GATCACTGAGGCTCTCCTGTGCCGCCAGCGGCTTCAACATCAAGGACA DNA CATACATCCACTGGGTTCGCCAGGCTCCTGGCAAGGGACTGGAGTGG GTCGCTAGGATCTACCCCACCAATGGGTACACCAGGTACGCCGACTCC GTGAAGGGGCGGTTCACAATCTCAGCCGATACTAGCAAAAATACAGCC TACTTGCAGATGAACTCCCTGAGAGCAGAGGATACCGCCGTGTACTATT GCTCTCGCTGGGGCGGCGACGGCTTCTACGCTATGGATTATTGGGGCC AGGGAACCTTGGTCACCGTCTCCTCAGCCTCCACCAAGGGCCCATCGG TCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGG CCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGT CGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCT GTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTAGTGACCGTG CCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCAC AAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGT GACCGTACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGG GGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATG ATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCA CGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGT GCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTA CCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGG CAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCAT CGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGT GTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCA GCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGG AGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCT CCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCACC GTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGT GATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCT GTCTCCGGGAAAA 51 T(K246C) GCGTCGACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG heavy chain AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA constant CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA region DNA GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CATGCCCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGG GAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTC CTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC AACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAA GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGA GGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCT TCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGG GGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTA CACGCAGAAGAGCCTCTCCCTGTCCCCGGGT 52 T(K246C) GAGGTGCAGCTGGTGGAATCCGGCGGAGGCCTGGTCCAGCCTGGCGG heavy chain ATCTCTGCGGCTGTCTTGCGCCGCCTCCGGCTTCAACATCAAGGACAC DNA CTACATCCACTGGGTCCGACAGGCACCTGGCAAGGGACTGGAATGGGT GGCCCGGATCTACCCCACCAACGGCTACACCAGATACGCCGACTCCGT GAAGGGCCGGTTCACCATCTCCGCCGACACCTCCAAGAACACCGCCTA CCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTG CTCCAGATGGGGAGGCGACGGCTTCTACGCCATGGACTACTGGGGCC AGGGCACCCTGGTCACCGTGTCTAGCGCGTCGACCAAGGGCCCATCG GTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCG GCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGT GTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGG CTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCG TGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATC ACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCATGCCCCAAGGACACCCTCA TGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGC CACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAG GTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCAC GTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAA TGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCC CATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACA GGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGG TCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCG TGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACG CCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCA CCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCC
GTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCC CTGTCCCCGGGT 53 T(K290C) GCGTCGACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG heavy chain AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA constant CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA region DNA GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACATGCCCGCGG GAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTC CTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC AACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAA GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGA GGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCT TCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGG GGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTA CACGCAGAAGAGCCTCTCCCTGTCCCCGGGT 54 T(K290C) GAGGTGCAGCTGGTGGAATCCGGCGGAGGCCTGGTCCAGCCTGGCGG heavy chain ATCTCTGCGGCTGTCTTGCGCCGCCTCCGGCTTCAACATCAAGGACAC DNA CTACATCCACTGGGTCCGACAGGCACCTGGCAAGGGACTGGAATGGGT GGCCCGGATCTACCCCACCAACGGCTACACCAGATACGCCGACTCCGT GAAGGGCCGGTTCACCATCTCCGCCGACACCTCCAAGAACACCGCCTA CCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTG CTCCAGATGGGGAGGCGACGGCTTCTACGCCATGGACTACTGGGGCC AGGGCACCCTGGTCACCGTGTCTAGCGCGTCGACCAAGGGCCCATCG GTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCG GCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGT GTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGG CTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCG TGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATC ACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCA TGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGC CACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAG GTGCATAATGCCAAGACATGCCCGCGGGAGGAGCAGTACAACAGCAC GTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAA TGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCC CATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACA GGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGG TCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCG TGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACG CCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCA CCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCC GTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCC CTGTCCCCGGGT 55 T(N297A) GCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG heavy chain AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA constant CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA region DNA GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT CCCTCAGCAGCGTAGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGG GAGGAGCAGTACGCCAGCACGTACCGTGTGGTCAGCGTCCTCACCGT CCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTC CAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAA AGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGG AGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCT TCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCG GAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCC TTCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAG GGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCAC TACACGCAGAAGAGCCTCTCCCTGTCTCCGGGAAAA 56 T(N297A) GAGGTGCAGCTGGTGGAGTCCGGCGGCGGCCTGGTTCAGCCCGGCG heavy chain GATCACTGAGGCTCTCCTGTGCCGCCAGCGGCTTCAACATCAAGGACA DNA CATACATCCACTGGGTTCGCCAGGCTCCTGGCAAGGGACTGGAGTGG GTCGCTAGGATCTACCCCACCAATGGGTACACCAGGTACGCCGACTCC GTGAAGGGGCGGTTCACAATCTCAGCCGATACTAGCAAAAATACAGCC TACTTGCAGATGAACTCCCTGAGAGCAGAGGATACCGCCGTGTACTATT GCTCTCGCTGGGGCGGCGACGGCTTCTACGCTATGGATTATTGGGGCC AGGGAACCTTGGTCACCGTCTCCTCAGCCTCCACCAAGGGCCCATCGG TCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGG CCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGT CGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCT GTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTAGTGACCGTG CCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCAC AAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGT GACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGG GGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATG ATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCA CGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGT GCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACGT ACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATG GCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCA TCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGG TGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCA GCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGG AGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCT CCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCACC GTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGT GATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCT GTCTCCGGGAAAA 57 T(N297Q) GCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG heavy chain AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA constant CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA region GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT DNA CCCTCAGCAGCGTAGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGG GAGGAGCAGTACCAAAGCACGTACCGTGTGGTCAGCGTCCTCACCGTC CTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC AACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAA GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGA GGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCT TCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGG GGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTA CACGCAGAAGAGCCTCTCCCTGTCTCCGGGAAAAGCCGCCAGCGGCTT CAACATCAAGGACACATACATCCACTGGGTTCGCCAGGCTCCTGGCAA GGG 58 T(N297Q) GAGGTGCAGCTGGTGGAGTCCGGCGGCGGCCTGGTTCAGCCCGGCG heavy chain GATCACTGAGGCTCTCCTGTGCCGCCAGCGGCTTCAACATCAAGGACA DNA CATACATCCACTGGGTTCGCCAGGCTCCTGGCAAGGGACTGGAGTGG GTCGCTAGGATCTACCCCACCAATGGGTACACCAGGTACGCCGACTCC GTGAAGGGGCGGTTCACAATCTCAGCCGATACTAGCAAAAATACAGCC TACTTGCAGATGAACTCCCTGAGAGCAGAGGATACCGCCGTGTACTATT GCTCTCGCTGGGGCGGCGACGGCTTCTACGCTATGGATTATTGGGGCC AGGGAACCTTGGTCACCGTCTCCTCAGCCTCCACCAAGGGCCCATCGG TCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGG CCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGT CGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCT GTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTAGTGACCGTG CCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCAC AAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGT GACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGG GGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATG ATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCA CGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGT GCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAAAGCACGTA CCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGG CAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCAT CGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGT GTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCA GCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGG AGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCT CCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCACC GTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGT GATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCT GTCTCCGGGAAAAGCCGCCAGCGGCTTCAACATCAAGGACACATACAT CCACTGGGTTCGCCAGGCTCCTGGCAAGGG 59 T(K334C) GCGTCGACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG heavy chain AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA constant CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA region GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT DNA CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGG GAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTC CTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC AACAAAGCCCTCCCAGCCCCCATCGAGTGCACCATCTCCAAAGCCAAA GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGA GGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCT TCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGG GGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTA 60 T(K334C) GAGGTGCAGCTGGTGGAATCCGGCGGAGGCCTGGTCCAGCCTGGCGG heavy chain ATCTCTGCGGCTGTCTTGCGCCGCCTCCGGCTTCAACATCAAGGACAC DNA CTACATCCACTGGGTCCGACAGGCACCTGGCAAGGGACTGGAATGGGT GGCCCGGATCTACCCCACCAACGGCTACACCAGATACGCCGACTCCGT GAAGGGCCGGTTCACCATCTCCGCCGACACCTCCAAGAACACCGCCTA CCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTG CTCCAGATGGGGAGGCGACGGCTTCTACGCCATGGACTACTGGGGCC AGGGCACCCTGGTCACCGTGTCTAGCGCGTCGACCAAGGGCCCATCG GTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCG GCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGT GTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGG CTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCG TGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATC ACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCA TGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGC CACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAG GTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCAC GTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAA TGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCC CATCGAGTGCACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACA GGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGG TCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCG TGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACG CCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCA CCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCC GTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCC CTGTCCCCGGGT 61 T(K392C) GCGTCGACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG heavy chain AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA constant CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA region GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT DNA CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGG GAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTC CTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC AACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAA GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGA GGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACTGCACCACGCCTCCCGTGCTGGACTCCGACGGCTCCT TCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGG GGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTA CACGCAGAAGAGCCTCTCCCTGTCCCCGGGT 62 T(K392C) GAGGTGCAGCTGGTGGAATCCGGCGGAGGCCTGGTCCAGCCTGGCGG heavy chain ATCTCTGCGGCTGTCTTGCGCCGCCTCCGGCTTCAACATCAAGGACAC DNA CTACATCCACTGGGTCCGACAGGCACCTGGCAAGGGACTGGAATGGGT GGCCCGGATCTACCCCACCAACGGCTACACCAGATACGCCGACTCCGT GAAGGGCCGGTTCACCATCTCCGCCGACACCTCCAAGAACACCGCCTA CCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTG CTCCAGATGGGGAGGCGACGGCTTCTACGCCATGGACTACTGGGGCC AGGGCACCTTGGTCACCGTGTCTAGCGCGTCGACCAAGGGCCCATCG GTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCG GCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGT GTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGG CTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCG TGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATC ACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCA
TGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGC CACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAG GTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCAC GTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAA TGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCC CATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACA GGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGG TCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCG TGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACTGCACCACG CCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCA CCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCC GTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCC CTGTCCCCGGGT 63 T(L443C) GCGTCGACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG heavy chain AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA constant CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA region GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT DNA CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGG GAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTC CTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC AACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAA GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGA GGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCT TCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGG GGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTA CACGCAGAAGAGCCTCTCCTGCTCCCCGGGT 64 T(L443C) GAGGTGCAGCTGGTGGAATCCGGCGGAGGCCTGGTCCAGCCTGGCGG heavy chain ATCTCTGCGGCTGTCTTGCGCCGCCTCCGGCTTCAACATCAAGGACAC DNA CTACATCCACTGGGTCCGACAGGCACCTGGCAAGGGACTGGAATGGGT GGCCCGGATCTACCCCACCAACGGCTACACCAGATACGCCGACTCCGT GAAGGGCCGGTTCACCATCTCCGCCGACACCTCCAAGAACACCGCCTA CCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTG CTCCAGATGGGGAGGCGACGGCTTCTACGCCATGGACTACTGGGGCC AGGGCACCCTGGTCACCGTGTCTAGCGCGTCGACCAAGGGCCCATCG GTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCG GCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGT GTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGG CTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCG TGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATC ACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCA TGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGC CACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAG GTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCAC GTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAA TGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCC CATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACA GGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGG TCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCG TGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACG CCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCA CCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCC GTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCC TGCTCCCCGGGT 65 T(K290C + GCGTCGACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG K334C) AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA heavy chain CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA constant GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT region CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG DNA ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACATGCCCGCGG GAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTC CTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC AACAAAGCCCTCCCAGCCCCCATCGAGTGCACCATCTCCAAAGCCAAA GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGA GGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCT TCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGG GGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTA CACGCAGAAGAGCCTCTCCCTGTCCCCGGGT 66 T(K290C + GAGGTGCAGCTGGTGGAATCCGGCGGAGGCCTGGTCCAGCCTGGCGG K334C) ATCTCTGCGGCTGTCTTGCGCCGCCTCCGGCTTCAACATCAAGGACAC heavy chain CTACATCCACTGGGTCCGACAGGCACCTGGCAAGGGACTGGAATGGGT DNA GGCCCGGATCTACCCCACCAACGGCTACACCAGATACGCCGACTCCGT GAAGGGCCGGTTCACCATCTCCGCCGACACCTCCAAGAACACCGCCTA CCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTG CTCCAGATGGGGAGGCGACGGCTTCTACGCCATGGACTACTGGGGCC AGGGCACCCTGGTCACCGTGTCTAGCGCGTCGACCAAGGGCCCATCG GTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCG GCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGT GTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGG CTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCG TGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATC ACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCA TGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGC CACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAG GTGCATAATGCCAAGACATGCCCGCGGGAGGAGCAGTACAACAGCAC GTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAA TGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCC CATCGAGTGCACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACA GGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGG TCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCG TGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACG CCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCA CCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCC GTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCC CTGTCCCCGGGT 67 T(K290C + GCGTCGACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG K392C) AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA heavy chain CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA constant GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT region CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG DNA ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACATGCCCGCGG GAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTC CTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC AACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAA GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGA GGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACTGCACCACGCCTCCCGTGCTGGACTCCGACGGCTCCT TCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGG GGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTA CACGCAGAAGAGCCTCTCCCTGTCCCCGGGT 68 T(K290C + GAGGTGCAGCTGGTGGAATCCGGCGGAGGCCTGGTCCAGCCTGGCGG K392C) ATCTCTGCGGCTGTCTTGCGCCGCCTCCGGCTTCAACATCAAGGACAC heavy chain CTACATCCACTGGGTCCGACAGGCACCTGGCAAGGGACTGGAATGGGT DNA GGCCCGGATCTACCCCACCAACGGCTACACCAGATACGCCGACTCCGT GAAGGGCCGGTTCACCATCTCCGCCGACACCTCCAAGAACACCGCCTA CCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTG CTCCAGATGGGGAGGCGACGGCTTCTACGCCATGGACTACTGGGGCC AGGGCACCCTGGTCACCGTGTCTAGCGCGTCGACCAAGGGCCCATCG GTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCG GCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGT GTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGG CTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCG TGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATC ACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCA TGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGC CACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAG GTGCATAATGCCAAGACATGCCCGCGGGAGGAGCAGTACAACAGCAC GTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAA TGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCC CATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACA GGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGG TCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCG TGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACTGCACCACG CCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCA CCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCC GTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCC CTGTCCCCGGGT 69 T(N297A + GCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG K222R) AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA heavy chain CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA constant GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT region CCCTCAGCAGCGTAGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG DNA ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACCGTACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGG GAGGAGCAGTACGCCAGCACGTACCGTGTGGTCAGCGTCCTCACCGT CCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTC CAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAA AGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGG AGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCT TCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCG GAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCC TTCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAG GGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCAC TACACGCAGAAGAGCCTCTCCCTGTCTCCGGGAAAA 70 T(N297A + GAGGTGCAGCTGGTGGAGTCCGGCGGCGGCCTGGTTCAGCCCGGCG K222R) GATCACTGAGGCTCTCCTGTGCCGCCAGCGGCTTCAACATCAAGGACA heavy chain CATACATCCACTGGGTTCGCCAGGCTCCTGGCAAGGGACTGGAGTGG DNA GTCGCTAGGATCTACCCCACCAATGGGTACACCAGGTACGCCGACTCC GTGAAGGGGCGGTTCACAATCTCAGCCGATACTAGCAAAAATACAGCC TACTTGCAGATGAACTCCCTGAGAGCAGAGGATACCGCCGTGTACTATT GCTCTCGCTGGGGCGGCGACGGCTTCTACGCTATGGATTATTGGGGCC AGGGAACCTTGGTCACCGTCTCCTCAGCCTCCACCAAGGGCCCATCGG TCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGG CCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGT CGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCT GTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTAGTGACCGTG CCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCAC AAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGT GACCGTACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGG GGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATG ATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCA CGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGT GCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACGT ACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATG GCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCA TCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGG TGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCA GCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGG AGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCT CCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCACC GTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGT GATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCT GTCTCCGGGAAAA 71 T(N297Q + GCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG K222R) AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA heavy chain CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA constant GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT region CCCTCAGCAGCGTAGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG DNA ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACCGTACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGG GAGGAGCAGTACCAAAGCACGTACCGTGTGGTCAGCGTCCTCACCGTC CTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC AACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAA GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGA GGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCT TCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGG GGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTA CACGCAGAAGAGCCTCTCCCTGTCTCCGGGAAAAGCCGCCAGCGGCTT CAACATCAAGGACACATACATCCACTGGGTTCGCCAGGCTCCTGGCAA GGG 72 T(N297Q + GAGGTGCAGCTGGTGGAGTCCGGCGGCGGCCTGGTTCAGCCCGGCG K222R) GATCACTGAGGCTCTCCTGTGCCGCCAGCGGCTTCAACATCAAGGACA heavy chain CATACATCCACTGGGTTCGCCAGGCTCCTGGCAAGGGACTGGAGTGG DNA GTCGCTAGGATCTACCCCACCAATGGGTACACCAGGTACGCCGACTCC GTGAAGGGGCGGTTCACAATCTCAGCCGATACTAGCAAAAATACAGCC
TACTTGCAGATGAACTCCCTGAGAGCAGAGGATACCGCCGTGTACTATT GCTCTCGCTGGGGCGGCGACGGCTTCTACGCTATGGATTATTGGGGCC AGGGAACCTTGGTCACCGTCTCCTCAGCCTCCACCAAGGGCCCATCGG TCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGG CCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGT CGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCT GTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTAGTGACCGTG CCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCAC AAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGT GACCGTACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGG GGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATG ATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCA CGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGT GCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACCAAAGCACGTA CCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGG CAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCAT CGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGT GTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCA GCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGG AGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCT CCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCACC GTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGT GATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCT GTCTCCGGGAAAAGCCGCCAGCGGCTTCAACATCAAGGACACATACAT CCACTGGGTTCGCCAGGCTCCTGGCAAGGG 73 T(K334C + GCGTCGACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG K39C2) AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA heavy chain CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA region GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT constant CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG DNA ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGG GAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTC CTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC AACAAAGCCCTCCCAGCCCCCATCGAGTGCACCATCTCCAAAGCCAAA GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGA GGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACTGCACCACGCCTCCCGTGCTGGACTCCGACGGCTCCT TCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGG GGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTA CACGCAGAAGAGCCTCTCCCTGTCCCCGGGT 74 T(K334C + GAGGTGCAGCTGGTGGAATCCGGCGGAGGCCTGGTCCAGCCTGGCGG K392C) ATCTCTGCGGCTGTCTTGCGCCGCCTCCGGCTTCAACATCAAGGACAC heavy chain CTACATCCACTGGGTCCGACAGGCACCTGGCAAGGGACTGGAATGGGT DNA GGCCCGGATCTACCCCACCAACGGCTACACCAGATACGCCGACTCCGT GAAGGGCCGGTTCACCATCTCCGCCGACACCTCCAAGAACACCGCCTA CCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTG CTCCAGATGGGGAGGCGACGGCTTCTACGCCATGGACTACTGGGGCC AGGGCACCCTGGTCACCGTGTCTAGCGCGTCGACCAAGGGCCCATCG GTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCG GCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGT GTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGG CTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCG TGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATC ACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCA TGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGC CACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAG GTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCAC GTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAA TGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCC CATCGAGTGCACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACA GGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGG TCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCG TGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACTGCACCACG CCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCA CCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCC GTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCC CTGTCCCCGGGT 75 T(K392C + GCGTCGACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAG L443C) AGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTA heavy chain CTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCA constant GCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT region CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG DNA ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGAC AAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCC CAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACAT GCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACT GGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGG GAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTC CTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCC AACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAA GGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGA GGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACTGCACCACGCCTCCCGTGCTGGACTCCGACGGCTCCT TCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGG GGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTA CACGCAGAAGAGCCTCTCCTGCTCCCCGGGT 76 T(K392C + GAGGTGCAGCTGGTGGAATCCGGCGGAGGCCTGGTCCAGCCTGGCGG L443C) ATCTCTGCGGCTGTCTTGCGCCGCCTCCGGCTTCAACATCAAGGACAC heavy chain CTACATCCACTGGGTCCGACAGGCACCTGGCAAGGGACTGGAATGGGT DNA GGCCCGGATCTACCCCACCAACGGCTACACCAGATACGCCGACTCCGT GAAGGGCCGGTTCACCATCTCCGCCGACACCTCCAAGAACACCGCCTA CCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTG CTCCAGATGGGGAGGCGACGGCTTCTACGCCATGGACTACTGGGGCC AGGGCACCCTGGTCACCGTGTCTAGCGCGTCGACCAAGGGCCCATCG GTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCG GCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGT GTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGG CTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCG TGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATC ACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTT GTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCA TGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGC CACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAG GTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCAC GTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAA TGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCC CATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACA GGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGG TCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCG TGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACTGCACCACG CCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCA CCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCC GTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCC TGCTCCCCGGGT 77 T(kK183C) CGGACCGTGGCCGCTCCCTCCGTGTTCATCTTCCCACCCTCCGACGAG light chain CAGCTGAAGTCCGGCACCGCCTCCGTCGTGTGCCTGCTGAACAACTTC constant TACCCCCGCGAGGCCAAGGTGCAGTGGAAGGTGGACAACGCCCTGCA region GTCCGGCAACTCCCAGGAATCCGTCACCGAGCAGGACTCCAAGGACA DNA GCACCTACTCCCTGTCCTCCACCCTGACCCTGTCCTGCGCCGACTACG AGAAGCACAAGGTGTACGCCTGCGAAGTGACCCACCAGGGCCTGTCCA GCCCCGTGACCAAGTCCTTCAACCGGGGCGAGTGC 78 T(kK183C) GACATCCAGATGACCCAGTCCCCCTCCAGCCTGTCCGCCTCTGTGGGC light chain GACAGAGTGACCATCACCTGTCGGGCCTCCCAGGACGTGAACACCGC DNA CGTGGCCTGGTATCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGA TCTACTCCGCCTCCTTCCTGTACTCCGGCGTGCCCTCCCGGTTCTCCG GCTCCAGATCTGGCACCGACTTTACCCTGACCATCTCCAGCCTGCAGC CCGAGGACTTCGCCACCTACTACTGCCAGCAGCACTACACCACCCCCC CCACCTTTGGCCAGGGCACCAAGGTGGAAATCAAGCGGACCGTGGCC GCTCCCTCCGTGTTCATCTTCCCACCCTCCGACGAGCAGCTGAAGTCC GGCACCGCCTCCGTCGTGTGCCTGCTGAACAACTTCTACCCCCGCGAG GCCAAGGTGCAGTGGAAGGTGGACAACGCCCTGCAGTCCGGCAACTC CCAGGAATCCGTCACCGAGCAGGACTCCAAGGACAGCACCTACTCCCT GTCCTCCACCCTGACCCTGTCCTGCGCCGACTACGAGAAGCACAAGGT GTACGCCTGCGAAGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCA AGTCCTTCAACCGGGGCGAGTGC 79 T(LCQ05) CGTACGGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGC light chain AGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTAT constant CCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCG region GGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCAC DNA CTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAA ACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCC CGTCACAAAGAGCTTCAACAGGGGAGAGTGT GGTGGCCTGCTTCAGGGCCCACCA 80 T(LCQ05) GATATCCAGATGACACAGTCCCCCTCCAGCCTCTCCGCTAGTGTCGGA light chain GATAGAGTGACAATTACATGTCGGGCAAGCCAGGACGTCAATACCGCC DNA GTGGCCTGGTATCAGCAGAAGCCAGGAAAGGCCCCAAAACTCCTGATC TACTCCGCCTCCTTCCTGTACTCAGGGGTCCCTTCACGCTTCTCCGGTT CCCGGAGCGGCACCGACTTCACTCTGACTATCTCAAGCTTGCAGCCCG AGGACTTCGCCACATACTATTGCCAGCAGCACTATACCACCCCCCCTAC CTTCGGTCAGGGAACTAAGGTGGAAATTAAACGTACGGTGGCTGCACC ATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACT GCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAG TACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGA GTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCA CCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCT GCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCA ACAGGGGAGAGTGTGGTGGCCTGCTTCAGGGCCCACCA
[0085] In some embodiments, the ADCs of the invention can use antibodies comprising heavy chain variable region CDRs and light chain variable region CDRs of trastuzumab (V.sub.H CDRs of SEQ ID NOs:2-4 and V.sub.L CDRs of SEQ ID NOs:8-10) and any combination of heavy and light chain constant regions disclosed in Table 1 with the proviso that when the heavy chain constant region is SEQ ID NO:5 then the light chain constant region is not SEQ ID NO:11 (due to the fact that this combination recreates wild type trastuzumab and would thus not allow for site specific conjugation). In such embodiments, the heavy chain constant region can be selected from any of SEQ ID NOs:17, 5, 13, 21, 23, 25, 27, 29, 31, 33, 35, 37 or 39 while the light chain constant region can be selected from any of SEQ ID NOs:41, 11 or 43 providing that the combination is not SEQ ID NO:5 and SEQ ID NO:11 as discussed supra.
[0086] In more specific embodiments, the ADCs of the invention can use antibodies comprising heavy chain variable region CDRs and light chain variable region CDRs of trastuzumab (V.sub.H CDRs of SEQ ID NOs:2-4 and V.sub.L CDRs of SEQ ID NOs:8-10) and a heavy and light chain constant region combination selected from:
(a) a heavy chain constant region of SEQ ID NO:17 and a light chain constant region of SEQ ID NO:41; (b) a heavy chain constant region of SEQ ID NO:5 and a light chain constant region of SEQ ID NO:41; (c) a heavy chain constant region of SEQ ID NO:17 and a light chain constant region of SEQ ID NO:11; (d) a heavy chain constant region of SEQ ID NO:21 and a light chain constant region of SEQ ID NO:11; (e) a heavy chain constant region of SEQ ID NO:23 and a light chain constant region of SEQ ID NO:11; (f) a heavy chain constant region of SEQ ID NO:25 and a light chain constant region of SEQ ID NO:11; (g) a heavy chain constant region of SEQ ID NO:27 and a light chain constant region of SEQ ID NO:11; (h) a heavy chain constant region of SEQ ID NO:23 and a light chain constant region of SEQ ID NO:41; (i) a heavy chain constant region of SEQ ID NO:25 and a light chain constant region of SEQ ID NO:41; (j) a heavy chain constant region of SEQ ID NO:27 and a light chain constant region of SEQ ID NO:41; (k) a heavy chain constant region of SEQ ID NO:29 and a light chain constant region of SEQ ID NO:11; (l) a heavy chain constant region of SEQ ID NO:31 and a light chain constant region of SEQ ID NO:11; (m) a heavy chain constant region of SEQ ID NO:33 and a light chain constant region of SEQ ID NO:43; (n) a heavy chain constant region of SEQ ID NO:35 and a light chain constant region of SEQ ID NO:11; (o) a heavy chain constant region of SEQ ID NO:37 and a light chain constant region of SEQ ID NO:11; (p) a heavy chain constant region of SEQ ID NO:39 and a light chain constant region of SEQ ID NO:11; or (q) a heavy chain constant region of SEQ ID NO:13 and a light chain constant region of SEQ ID NO:43.
[0087] In yet a more specific embodiment, an ADC of the invention comprises an antibody with V.sub.H CDRs of SEQ ID NOs:2-4 and V.sub.L CDRs of SEQ ID NOs:8-10 and a heavy chain constant region of SEQ ID NO:17 and a light chain constant region of SEQ ID NO:41.
[0088] In another more specific embodiment, an ADC of the invention comprises an antibody with V.sub.H CDRs of SEQ ID NOs:2-4 and V.sub.L CDRs of SEQ ID NOs:8-10 and a heavy chain constant region of SEQ ID NO:13 and a light chain constant region of SEQ ID NO:43.
[0089] In other embodiments, the ADCs of the invention can use antibodies comprising any combination of heavy and light chains disclosed in Table 1 with the proviso that if the heavy chain is SEQ ID NO:6 then the light chain is not SEQ ID NO:12 (due to the fact that this combination recreates wild type trastuzumab and would thus not allow for site specific conjugation). In such embodiments, the heavy chain can be selected from any of SEQ ID NOs:18, 6, 14, 22, 24, 26, 28, 30, 32, 34, 36, 38 or 40 while the light chain can be selected from any of SEQ ID NOs: 42, 12 or 44 providing that the combination is not SEQ ID NO:6 and SEQ ID NO:12 as discussed supra.
[0090] In more specific embodiments, the ADCs of the invention can use antibodies comprising a heavy chain and light chain combination selected from:
(a) a heavy chain of SEQ ID NO:18 and a light chain of SEQ ID NO:42; (b) a heavy chain of SEQ ID NO:6 and a light chain of SEQ ID NO:42; (c) a heavy chain of SEQ ID NO:18 and a light chain of SEQ ID NO:12; (d) a heavy chain of SEQ ID NO:22 and a light chain of SEQ ID NO:12; (e) a heavy chain of SEQ ID NO:24 and a light chain of SEQ ID NO:12; (f) a heavy chain of SEQ ID NO:26 and a light chain of SEQ ID NO:12; (g) a heavy chain of SEQ ID NO:28 and a light chain of SEQ ID NO:12; (h) a heavy chain of SEQ ID NO:24 and a light chain of SEQ ID NO:42; (i) a heavy chain of SEQ ID NO:26 and a light chain of SEQ ID NO:42; (j) a heavy chain of SEQ ID NO:28 and a light chain of SEQ ID NO:42; (k) a heavy chain of SEQ ID NO:30 and a light chain of SEQ ID NO:12; (l) a heavy chain of SEQ ID NO:32 and a light chain of SEQ ID NO:12; (m) a heavy chain of SEQ ID NO:34 and a light chain of SEQ ID NO:44; (n) a heavy chain of SEQ ID NO:36 and a light chain of SEQ ID NO:12; (o) a heavy chain of SEQ ID NO:38 and a light chain of SEQ ID NO:12; (p) a heavy chain of SEQ ID NO:40 and a light chain of SEQ ID NO:12; or (q) a heavy chain of SEQ ID NO:14 and a light chain of SEQ ID NO:44.
[0091] In yet a more specific embodiment, an ADC of the invention comprises an antibody with a heavy chain of SEQ ID NO:18 and a light chain of SEQ ID NO:42. Plasmids containing nucleic acids encoding the heavy chain of SEQ ID NO:18 and the light chain of SEQ ID NO:42 have been deposited with the American Type Culture Collection (ATCC), 10801 University Blvd., Manassas, Va. 20110-2209 on Nov. 17, 2015 and given Accession Nos. PTA-122672 and PTA-122673, respectively. The deposits were made under the provisions of the Budapest Treaty on the International Recognition of the Deposit of Microorganisms for the Purpose of Patent Procedure and Regulations thereunder (Budapest Treaty). This assures maintenance of a viable culture of the deposit for 30 years from the date of deposit. The deposit will be made available by ATCC under the terms of the Budapest Treaty, and subject to an agreement between Pfizer Inc. and ATCC, which assures permanent and unrestricted availability of the progeny of the culture of the deposit to the public upon issuance of the pertinent U.S. patent or upon laying open to the public of any U.S. or foreign patent application, whichever comes first, and assures availability of the progeny to one determined by the U.S. Commissioner of Patents and Trademarks to be entitled thereto according to 35 U.S.C. Section 122 and the Commissioner's rules pursuant thereto (including 37 C.F.R. Section 1.14 with particular reference to 886 OG 638).
[0092] The assignee of the present application has agreed that if a culture of the materials on deposit should die or be lost or destroyed when cultivated under suitable conditions, the materials will be promptly replaced on notification with another of the same. Availability of the deposited material is not to be construed as a license to practice the invention in contravention of the rights granted under the authority of any government in accordance with its patent laws.
[0093] In another more specific embodiment, an ADC of the invention comprises an antibody with a heavy chain of SEQ ID NO:14 and a light chain of SEQ ID NO:44.
[0094] In some aspects of the invention, the ADC of the invention includes an antibody having a heavy chain and/or a light chain comprising an amino acid sequence that is at least 90%, 95%, 98%, or 99% identical to any of the heavy or light chains disclosed supra. Residues that have been altered can be in the variable region or in the constant region of the antibody. In some embodiments, there are no more than 1, 2, 3, 4 or 5 residues that have been altered as compared to any of the heavy or light chains disclosed supra. In other embodiments, there are no altered residues in any of the variable region CDRs.
[0095] The term "percent identical" (or "% identical") in the context of amino acid sequences means the number of residues in two sequences that are the same when aligned for maximum correspondence. There are a number of different algorithms known in the art which can be used to measure amino acid percent identity (i.e., the Basic Local Alignment Tool or BLAST.RTM.). Unless otherwise specified, default parameters for a particular program or algorithm are used.
[0096] For use in preparation of ADCs, HER2 antibodies described herein may be substantially pure, i.e., at least 50% pure (i.e., free from contaminants), more preferably, at least 90% pure, more preferably, at least 95% pure, yet more preferably, at least 98% pure, and most preferably, at least 99% pure.
II. Drugs
[0097] Drugs useful in preparation of the site specific HER2 ADCs of the invention include any therapeutic agent useful in the treatment of cancer including, but not limited to, cytotoxic agents, cytostatic agents, immunomodulating agents and chemotherapeutic agents. A cytotoxic effect refers to the depletion, elimination and/or the killing of a target cell (i.e., tumor cell). A cytotoxic agent refers to an agent that has a cytotoxic effect on a cell. A cytostatic effect refers to the inhibition of cell proliferation. A cytostatic agent refers to an agent that has a cytostatic effect on a cell, thereby inhibiting the growth and/or expansion of a specific subset of cells (i.e., tumor cells). An immunomodulating agent refers to an agent that stimulates the immune response through the production of cytokines and/or antibodies and/or modulating T cell function thereby inhibiting or reducing the growth of a subset of cells (i.e., tumor cells) either directly or indirectly by allowing another agent to be more efficacious. A chemotherapeutic agent refers to an agent that is a chemical compound useful in the treatment of cancer. A drug may also be a drug derivative, wherein a drug has been functionalized to enable conjugation with an antibody of the invention.
[0098] In some embodiments the drug is a membrane permeable drug. In such embodiments, the payload (i.e. drug) can elicit a bystander effect wherein cells surrounding the cell that initially internalized the ADC are killed by the payload. This occurs when the payload is released from the antibody (i.e., by cleaving of a cleavable linker) and crosses the cellular membrane and, upon diffusion, induces the killing of surrounding cells.
[0099] In accordance with the disclosed methods, the drugs are used to prepare antibody drug conjugates of the formula Ab-(L-D), wherein (a) Ab is an antibody that binds to HER2; and (b) L-D is a linker-drug moiety, wherein L is a linker, and D is a drug.
[0100] The drug-to-antibody ratio (DAR) or drug loading indicates the number of drug (D) molecules that are conjugated per antibody. The antibody drug conjugates of the present invention use site specific conjugation such that there is essentially a homogeneous population of ADCs having one DAR in a composition of ADCs. In some embodiments, the DAR is 1. In some embodiments, the DAR is 2. In other embodiments, the DAR is 3. In other embodiments, the DAR is 4. In other embodiments, the DAR is greater than 4.
[0101] Using conventional conjugation (rather than site specific conjugation) results in a heterogeneous population of different species of ADCs, each of which has a different individual DAR. Compositions of ADCs prepared in this way include a plurality of antibodies, each antibody conjugated to a particular number of drug molecules. As such, the compositions have an average DAR. T-DM1 (Kadcyla.RTM.) uses conventional conjugation on lysine residues and has an average DAR of around 4 with a broad distribution which includes ADCs loaded with 0, 1, 2, 3, 4, 5, 6, 7 or 8 drug molecules (Kim et al., 2014, Bioconj Chem 25(7):1223-32).
[0102] Compositions, batches, and/or formulations of a plurality of ADCs may be characterized by an average DAR. DAR and average DAR can be determined by various conventional means such as UV spectroscopy, mass spectroscopy, ELISA assay, radiometric methods, hydrophobic interaction chromatography (HIC), electrophoresis and HPLC.
[0103] In aspects of the invention, an HER2 ADC may have a DAR of 1, a DAR of 2, a DAR of 3, a DAR of 4, a DAR of 5, a DAR of 6, a DAR of 7, a DAR of 8, a DAR of 9, a DAR of 10, a DAR of 11, a DAR of 12 or a DAR greater than 12. In aspects of the invention, an HER2 ADC may have one drug molecule, or 2 drug molecules, or 3 drug molecules, or 4 drug molecules, or 5 drug molecules, or 6 drug molecules, or 7 drug molecules, or 8 drug molecules, or 9 drug molecules, or 10 drug molecules, or 11 drug molecules, or 12 drug molecules or greater than 12 molecules.
[0104] In aspects of the invention, an HER2 ADC may have average DAR in the range of about 2 to about 4, or an average DAR in the range of about 3 to about 5, or an average DAR in the range of about 4 to about 6, or an average DAR in the range of about 5 to about 7, or an average DAR in the range of about 6 to about 8, or an average DAR in the range of about 7 to about 9, or an average DAR in the range of about 8 to about 10, or an average DAR in the range of about 9 to about 11, or an average DAR in the range of about 10 to about 12, etc. In some aspects the compositions, batches and/or formulations of HER2 ADCs may have an average DAR of about 1, or an average DAR of about 2, an average DAR of about 3, or an average DAR of about 4, or an average DAR of about 5, or an average DAR of about 6, or an average DAR of about 7, or an average DAR of about 8, or an average DAR of about 9, or an average DAR of about 10, or an average DAR of about 11, or an average DAR of about 12 or an average DAR greater than 12. As used in the foregoing ranges of average DAR, the term "about" means +/-0.5%.
[0105] A composition, batch, and/or formulation of HER2 ADCs may be characterized by a preferred range of average DAR, e.g., an average DAR in the range of about 3 to about 5, an average DAR in the range of about 3 to about 4, or an average DAR in the range of about 4 to about 5. Further, a composition, batch, and/or formulation of HER2 ADCs may be characterized by a preferred range of average DAR, e.g., an average DAR in the range of 3 to 5, an average DAR in the range of 3 to 4, or an average DAR in the range of 4 to 5.
[0106] In some aspects of the invention, a composition, batch, and/or formulation of HER2 ADCs may be characterized by an average DAR of about 1.0, or an average DAR of 1.0, or an average DAR of 1.1, or an average DAR of 1.2, or an average DAR of 1.3, or an average DAR of 1.4, or an average DAR of 1.5, or an average DAR of 1.6, or an average DAR of 1.7, or an average DAR of 1.8, or an average DAR of 1.9. In another aspect, a composition, batch, and/or formulation of HER2 ADCs may be characterized by an average DAR of about 2.0, or an average DAR of 2.0, or an average DAR of 2.1, or an average DAR of 2.2, or an average DAR of 2.3, or an average DAR of 2.4, or an average DAR of 2.5, or an average DAR of 2.6, or an average DAR of 2.7, or an average DAR of 2.8, or an average DAR of 2.9. In another aspect, a composition, batch, and/or formulation of HER2 ADCs may be characterized by an average DAR of about 3.0, or an average DAR of 3.0, or an average DAR of 3.1, or an average DAR of 3.2, or an average DAR of 3.3, or an average DAR of 3.4, or an average DAR of 3.5, or an average DAR of 3.6, or an average DAR of 3.7, or an average DAR of 3.8, or an average DAR of 3.9. In another aspect, a composition, batch, and/or formulation of HER2 ADCs may be characterized by an average DAR of about 4.0, or an average DAR of 4.0, or an average DAR of 4.1, or an average DAR of 4.2, or an average DAR of 4.3, or an average DAR of 4.4, or an average DAR of 4.5, or an average DAR of 4.6, or an average DAR of 4.7, or an average DAR of 4.8, or an average DAR of 4.9, or an average DAR of 5.0.
[0107] In another aspect, a composition, batch, and/or formulation of HER2 ADCs may be characterized by an average DAR of 12 or less, an average DAR of 11 or less, an average DAR of 10 or less, an average DAR of 9 or less, an average DAR of 8 or less, an average DAR of 7 or less, an average DAR of 6 or less, an average DAR of 5 or less, an average DAR of 4 or less, an average DAR of 3 or less, an average DAR of 2 or less or an average DAR of 1 or less.
[0108] In other aspects, a composition, batch, and/or formulation of HER2 ADCs may be characterized by an average DAR of 11.5 or less, an average DAR of 10.5 or less, an average DAR of 9.5 or less, an average DAR of 8.5 or less, an average DAR of 7.5 or less, an average DAR of 6.5 or less, an average DAR of 5.5 or less, an average DAR of 4.5 or less, an average DAR of 3.5 or less, an average DAR of 2.5 or less, an average DAR of 1.5 or less.
[0109] In some aspects of the present invention, the methods for conventional conjugation via cysteine residues and purification conditions disclosed herein provide a composition, batch, and/or formulation of HER2 ADCs with an optimized average DAR in the range of about 3 to 5, preferably about 4.
[0110] In some aspects of the present invention, the methods for site-specific conjugation via engineered cysteine residues and purification conditions disclosed herein provide a composition, batch, and/or formulation of HER2 ADCs with an optimized average DAR in the range of about 3 to 5, preferably about 4.
[0111] In some aspects of the present invention, the methods for site-specific conjugation via transglutaminase-based conjugation and purification conditions disclosed herein provide a composition, batch, and/or formulation of HER2 ADCs with an optimized average DAR in the range of about 1 to 3, preferably about 2.
[0112] Also encompassed by the present invention are antibody drug conjugates of the formula Ab-(L-D)p, wherein (a) Ab is an antibody, or antigen-binding fragment thereof, that binds to HER2, (b) L-D is a linker-drug moiety, wherein L is a linker, and D is a drug and (c) p is the number of linker/drug moieties that are attached to the antibody. For site specific ADCs, p is a whole number due to the homogeneous nature of the ADC. In some embodiments, p is 4. In other embodiments, p is 3. In other embodiments, p is 2. In other embodiments, p is 1. In other embodiments, p is greater than 4.
[0113] In one embodiment, the drug component of the ADCs of the invention is an anti-mitotic drug. In a specific embodiment, the anti-mitotic drug is an auristatin (e.g., 0101, 8261, 6121, 8254, 6780 and 0131; see Table 2 infra). In a more specific embodiment, the auristatin drug is 2-methylalanyl-N-[(3R,4S,5S)-3-methoxy-1-{(2S)-2-[(1R,2R)-1-methoxy-2-met- hyl-3-oxo-3-{[(1S)-2-phenyl-1-(1,3-thiazol-2-yl)ethyl]amino}propyl]pyrroli- din-1-yl}-5-methyl-1-oxoheptan-4-yl]-N-methyl-L-valinamide (also known as 0101).
[0114] Auristatins inhibit cell proliferation by inhibiting the formation of microtubules during mitosis through inhibition of tubulin polymerization. PCT International Publication No. WO 2013/072813, which is incorporated by reference in its entirety, discloses auristatins that are useful in the manufacture of the ADCs of the invention and provides methods of producing those auristatins.
TABLE-US-00002 TABLE 2 Drugs Name Structure IUPAC Name 0101 ##STR00001## 2-methylalanyl-N-[(3R,4S,5S)-3-methoxy- 1-{(2S)-2-[(1R,2R)-1-methoxy-2-methyl-3- oxo-3-{[(1S)-2-phenyl-1-(1,3-thiazol-2- yl)ethyl]amino}propyl]pyrrolidin-1-yl}-5- methyl-1-oxoheptan-4-yl]-N-methyl-L- valinamide 8261 ##STR00002## 2-methylalanyl-N-[(3R,4S,5S)-1-{(2S)-2- [(1R,2R)-3-{[(1S)-1-carboxy-2- phenylethyl]amino}-1-methoxy-2-methyl- 3-oxopropyl]pyrrolidin-1-yl}-3-methoxy-5- methyl-1-oxoheptan-4-yl]-N-methyl-L- valinamide 6121 ##STR00003## 2-methyl-L-prolyl-N-[(3R,4S,5S)-3- methoxy-1-{(2S)-2-[(1R,2R)-1-methoxy-3- {[(2S)-1-methoxy-1-oxo-3-phenylpropan- 2-yl]amino}-2-methyl-3- oxopropyl]pyrrolidin-1-yl}-5-methyl-1- oxoheptan-4-yl]-N-methyl-L-valinamide 8254 ##STR00004## 2-methylalanyl-N-[(3R,4S,5S)-3-methoxy- 1-{(2S)-2-[(1R,2R)-1-methoxy-3-{[(2S)-1- methoxy-1-oxo-3-phenylpropan-2- yl]amino}-2-methyl-3-oxopropyl]pyrrolidin- 1-yl}-5-methyl-1-oxoheptan-4-yl]-N- methyl-L-valinamide 6780 ##STR00005## 2-methylalanyl-N-[(3R,4S,5S)-1-{(2S)-2- [(1R,2R)-3-{[(1S,2R)-1-hydroxy-1- phenylpropan-2-yl]amino}-1-methoxy-2- methyl-3-oxopropyl]pyrrolidin-1-yl}-3- methoxy-5-methyl-1-oxoheptan-4-yl]-N- methyl-L-valinamide 0131 ##STR00006## 2-methyl-L-prolyl-N-[(3R,4S,5S)-1-{(2S)- 2-[(1R,2R)-3-{[(1S)-1-carboxy-2- phenylethyl]amino}-1-methoxy-2-methyl- 3-oxopropyl]pyrrolidin-1-yl}-3-methoxy-5- methyl-1-oxoheptan-4-yl]-N-methyl-L- valinamide MMAD ##STR00007## N-methyl-L-valyl-N-[(3R,4S,5S)-3- methoxy-1-{(2S)-2-[(1R,2R)-1-methoxy-2- methyl-3-oxo-3-{[(1S)-2-phenyl-1-(1,3- thiazol-2-yl)ethyl]amino}propyl]pyrrolidin- 1-yl}-5-methyl-1-oxoheptan-4-yl]-N- methyl-L-valinamide MMAE ##STR00008## N-methyl-L-valyl-N-[(3R,4S,5S)-1-{(2S)-2- [(1R,2R)-3-{[(1S,2R)-1-hydroxy-1- phenylpropan-2-yl]amino}-1-methoxy-2- methyl-3-oxopropyl]pyrrolidin-1-yl}-3- methoxy-5-methyl-1-oxoheptan-4-yl]-N- methyl-L-valinamide MMAF ##STR00009## N-methyl-L-valyl-N-[(3R,4S,5S)-1-{(2S)-2- [(1R,2R)-3-{[(1S)-1-carboxy-2- phenylethyl]amino}-1-methoxy-2-methyl- 3-oxopropyl]pyrrolidin-1-yl}-3-methoxy-5- methyl-1-oxoheptan-4-yl]-N-methyl-L- valinamide
[0115] In some aspects of the invention, the cytotoxic agent can be made using a liposome or biocompatible polymer. The HER2 antibodies as described herein can be conjugated to the biocompatible polymer to increase serum half-life and bioactivity, and/or to extend in vivo half-lives. Examples of biocompatible polymers include water-soluble polymers, such as polyethylene glycol (PEG) or derivatives thereof and zwitterion-containing biocompatible polymers (e.g., a phosphorylcholine containing polymer).
III. Linkers
[0116] Site specific HER2 ADCs of the invention are prepared using a linker to link or conjugate a drug to an HER2 antibody. A linker is a bifunctional compound which can be used to link a drug and an antibody to form an antibody drug conjugate (ADC). Such conjugates allow the selective delivery of drugs to tumor cells. Suitable linkers include, for example, cleavable and non-cleavable linkers. A cleavable linker is typically susceptible to cleavage under intracellular conditions. Major mechanisms by which a conjugated drug is cleaved from an antibody include hydrolysis in the acidic pH of the lysosomes (hydrazones, acetals, and cis-aconitate-like amides), peptide cleavage by lysosomal enzymes (the cathepsins and other lysosomal enzymes), and reduction of disulfides. As a result of these varying mechanisms for cleavage, mechanisms of linking the drug to the antibody also vary widely and any suitable linker can be used.
[0117] Suitable cleavable linkers include, but are not limited to, a peptide linker cleavable by an intracellular protease, such as lysosomal protease or an endosomal protease such as maleimidocaproyl-valine-citrulline-p-aminobenzyloxycarbonyl (vc), N.about.2.about.-acetyl-L-lysyl-L-valyl-L-citruline-p-aminobenzyloxycarbo- nyl-N,N'-dimethylaminoethyl-CO-(AcLysvc) and m(H20)c-vc (Table 3 infra). In specific embodiments, the linker is a cleavable linker such that the payload can induce a bystander effect once the linker is cleaved. The bystander effect is when a membrane permeable drug is released from the antibody (i.e., by cleaving of a cleavable linker) and crosses the cellular membrane and, upon diffusion, induces killing of cells surrounding the cell that initially internalized the ADC.
[0118] Suitable non-cleavable linkers include, but are not limited to, maleimidocaproyl (mc), maleimide-(polyethylene glycol).sub.6 (MalPeg6), Mal-PEG2C2, Mal-PEG3C2 and m(H20)c (Table 3 infra).
[0119] Other suitable linkers include linkers hydrolyzable at a specific pH or a pH range, such as a hydrazone linker. Additional suitable cleavable linkers include disulfide linkers. The linker may be covalently bound to the antibody to such an extent that the antibody must be degraded intracellularly in order for the drug to be released e.g. the mc linker and the like.
[0120] In particular aspects of the invention, the linkers in the site specific HER2 ADCs of the invention are cleavable and may be vc or AcLysvc.
[0121] Many of the therapeutic agents (drugs) conjugated to antibodies have little, if any, solubility in water and that can limit drug loading on the conjugate due to aggregation of the conjugate. One approach to overcoming this is to add solublizing groups to the linker. Conjugates made with a linker consisting of PEG and a dipeptide can been used, including those having a PEG di-acid, thiol-acid, or maleimide-acid attached to the antibody, a dipeptide spacer, and an amide bond to the amine of an anthracycline or a duocarmycin analogue. Another example is a conjugate prepared with a PEG-containing linker disulfide bonded to a cytotoxic agent and amide bonded to an antibody. Approaches that incorporate PEG groups may be beneficial in overcoming aggregation and limits in drug loading.
TABLE-US-00003 TABLE 3 Linkers Name Structure vc ##STR00010## AcLysvc ##STR00011## mc ##STR00012## MalPeg6 ##STR00013## m(H20)c ##STR00014## m(H20)c- vc ##STR00015## ##STR00016##
[0122] Linkers are attached to the monoclonal antibody via the left side of the molecule and the drug via the right side of the molecule as depicted in Table 3.
IV. Methods of Preparing Site Specific HER2 ADCs
[0123] Also provided are methods for preparing antibody drug conjugates of the present invention. For example, a process for producing a site specific HER2 ADC as disclosed herein can include (a) linking the linker to the drug; (b) conjugating the linker-drug moiety to the antibody; and (c) purifying the antibody drug conjugate.
[0124] The HER2 ADCs of the present invention use site specific methods to conjugate the HER2 antibody to the drug payload.
[0125] In one embodiment, the site specific conjugation occurs through one or more cysteine residues that have been engineered into an antibody constant region. Methods of preparing HER2 antibodies for site specific conjugation through cysteine residues can be performed as described in PCT Publication No. WO2013/093809, which is incorporated by reference in its entirety. One or more of the following positions (using EU Index of Kabat numbering for the IgG1 constant region and Kabat numbering for the Kappa chain constant region) can be altered to be a cysteine and thus serve as a site for conjugation: a) on the heavy chain constant region, residues 114, 246, 249, 265, 267, 270, 276, 278, 283, 290, 292, 293, 294, 300, 302, 303, 314, 315, 318, 320, 327, 332, 333, 334, 336, 345, 347, 354, 355, 358, 360, 362, 370, 373, 375, 376, 378, 380, 382, 386, 388, 390, 392, 393, 401, 404, 411, 413, 414, 416, 418, 419, 421, 428, 431, 432, 437, 438, 439, 443, and 444 and/or b) on the Kappa chain constant region, residues 111, 149, 183, 188, 207, and 210.
[0126] In a specific embodiment, the one or more positions (using EU Index of Kabat numbering) that can be altered to be a cysteine a) on the heavy chain constant region are 290, 334, 392 and/or 443 and/or b) on the light chain constant region is 183 (Kabat numbering).
[0127] In a more specific embodiment, positions 290 on the heavy chain constant region and position 183 on the light chain constant region are altered to cysteine for conjugation.
[0128] In another embodiment, the site specific conjugation occurs through one or more acyl donor glutamine residues that have been engineered into the antibody constant region. Methods of preparing HER2 antibodies for site specific conjugation through glutamine residues can be performed as described in PCT Publication No. WO2012/059882, which is incorporated by reference in its entirety. Antibodies can be engineered to express the glutamine residue used for site specific conjugation in three different ways.
[0129] The short peptide tag containing the glutamine residue can be incorporated into a number of different positions of the light and/or heavy chain (i.e., at the N-terminus, at the C-terminus, internally). In a first embodiment, a short peptide tag containing the glutamine residue can be attached to the C-terminus of the heavy and/or light chain. One or more of the following glutamine containing tags can be attached to serve as the acyl donor for drug conjugation: GGLLQGPP (SEQ ID NO:81), GGLLQGG (SEQ ID NO:82), LLQGA (SEQ ID NO:83), GGLLQGA (SEQ ID NO:84), LLQG (SEQ ID NO: 85), LLQGPG (SEQ ID NO: 86), LLQGPA (SEQ ID NO: 87), LLQGP (SEQ ID NO: 88), LLQP (SEQ ID NO: 89), LLQPGK (SEQ ID NO: 90), LLQGAPGK (SEQ ID NO: 91), LLQGAPG (SEQ ID NO: 92), LLQGAP (SEQ ID NO: 93), LLQX.sub.1X.sub.2X.sub.3X.sub.4X.sub.5, wherein X.sub.1 is G or P, wherein X.sub.2 is A, G, P, or absent, wherein X.sub.3 is A, G, K, P, or absent, wherein X.sub.4 is G, K or absent, and wherein X.sub.5 is K or absent (SEQ ID NO: 94), or LLQX.sub.1X.sub.2X.sub.3X.sub.4X.sub.5, wherein X.sub.1 is any naturally occurring amino acid and wherein X.sub.2, X.sub.3, X.sub.4, and X.sub.5 are any naturally occurring amino acids or absent (SEQ ID NO: 95).
[0130] In a specific embodiment, GGLLQGPP (SEQ ID NO:81) is attached to the C-terminus of the light chain.
[0131] In a second embodiment, a residue on the heavy and/or light chain can be altered to a glutamine residue by site directed mutagenesis. In a specific embodiment, the residue at position 297 on the heavy chain (using EU Index of Kabat numbering) can be altered to be a glutamine (Q) and thus serve as a site for conjugation.
[0132] In a third embodiment, a residue on the heavy chain or light chain can be altered resulting in a glycosylation at that position such that one or more endogenous glutamine becomes accessible/reactive for conjugation. In a specific embodiment, the residue at position 297 on the heavy chain (using EU Index of Kabat numbering) is altered to an alanine (A). In such cases, the glutamine (Q) at position 295 on the heavy chain is then capable for use in conjugation.
[0133] Optimal reaction conditions for formation of a conjugate may be empirically determined by variation of reaction variables such as temperature, pH, linker-payload moiety input, and additive concentration. Conditions suitable for conjugation of other drugs may be determined by those skilled in the art without undue experimentation. Site specific conjugation through engineered cysteine residues is exemplified in Example 5A infra. Site specific conjugation through glutamine residues is exemplified in Example 5B infra.
[0134] To further increase the number of drug molecules per antibody drug conjugate, the drug may be conjugated to polyethylene glycol (PEG), including straight or branched polyethylene glycol polymers and monomers. A PEG monomer is of the formula: --(CH.sub.2CH.sub.2O)--. Drugs and/or peptide analogs may be bound to PEG directly or indirectly, i.e. through appropriate spacer groups such as sugars. A PEG-antibody drug composition may also include additional lipophilic and/or hydrophilic moieties to facilitate drug stability and delivery to a target site in vivo. Representative methods for preparing PEG-containing compositions may be found in, e.g., U.S. Pat. Nos. 6,461,603; 6,309,633; and 5,648,095.
[0135] Following conjugation, the conjugates may be separated and purified from unconjugated reactants and/or aggregated forms of the conjugates by conventional methods. This can include processes such as size exclusion chromatography (SEC), ultrafiltration/diafiltration, ion exchange chromatography (IEC), chromatofocusing (CF) HPLC, FPLC, or Sephacryl S-200 chromatography. The separation may also be accomplished by hydrophobic interaction chromatography (HIC). Suitable HIC media includes Phenyl Sepharose 6 Fast Flow chromatographic medium, Butyl Sepharose 4 Fast Flow chromatographic medium, Octyl Sepharose 4 Fast Flow chromatographic medium, Toyopearl Ether-650M chromatographic medium, Macro-Prep methyl HIC medium or Macro-Prep t-Butyl HIC medium.
[0136] Table 4 infra shows HER2 ADCs used to generate data in the Examples Section set forth herein. The site specific HER2 ADCs shown in Table 4 (in rows 1-17) are examples of site specific ADCs of the invention.
[0137] To make a site specific HER2 ADC of the invention any HER2 antibody disclosed in Section I supra can be conjugated using site specific techniques to any drug disclosed in Section II supra via any linker disclosed in Section III supra. In preferred embodiments, the linker is cleavable (e.g., vc or AcLysvc). In other preferred embodiments, the drug is an auristatin (e.g., 0101).
[0138] In a particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:18 and a light chain of SEQ ID NO:42; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is vc and wherein the drug is 0101. A schematic of such an ADC is shown in FIG. 1A.
[0139] In another particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:14 and a light chain of SEQ ID NO:44; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is AcLysvc and wherein the drug is 0101. A schematic of such an ADC is shown in FIG. 1B.
[0140] In another particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:24 and a light chain of SEQ ID NO:42; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is vc and wherein the drug is 0101.
[0141] In another particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:26 and a light chain of SEQ ID NO:42; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is vc and wherein the drug is 0101.
[0142] In another particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:28 and a light chain of SEQ ID NO:42; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is vc and wherein the drug is 0101.
[0143] In another particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:30 and a light chain of SEQ ID NO:12; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is vc and wherein the drug is 0101.
[0144] In another particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:32 and a light chain of SEQ ID NO:12; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is vc and wherein the drug is 0101.
[0145] In another particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:34 and a light chain of SEQ ID NO:44; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is AcLysvc and wherein the drug is 0101.
[0146] In another particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:36 and a light chain of SEQ ID NO:12; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is AcLysvc and wherein the drug is 0101.
[0147] In another particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:38 and a light chain of SEQ ID NO:12; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is vc and wherein the drug is 0101.
[0148] In another particular aspect of the invention, site specific HER2 ADC of the formula Ab-(L-D) comprises (a) an antibody, Ab, comprising a heavy chain of SEQ ID NO:40 and a light chain of SEQ ID NO:12; and (b) a linker-drug moiety, L-D, wherein L is a linker, and D is a drug, wherein the linker is vc and wherein the drug is 0101.
TABLE-US-00004 TABLE 4 HER2 ADCs Heavy Heavy Light Light Chain Chain Chain Chain variable constant Heavy variable constant Light Linker ADC region region Chain region region Chain Linker Payload Type.sup.1 T(kK183C) - 1 5 6 7 41 42 vc 0101 C vc0101 T(K290C) - 1 17 18 7 11 12 vc 0101 C vc0101 T(N297Q) - 1 21 22 7 11 12 AcLysvc 0101 C AcLysvc0101 T(K334C) - 1 23 24 7 11 12 vc 0101 C vc0101 T(K392C) - 1 25 26 7 11 12 vc 0101 C vc0101 T(L443C) - 1 27 28 7 11 12 vc 0101 C vc0101 T(kK183C + 1 17 18 7 41 42 vc 0101 C K290C) - vc0101 T(kK183C + 1 23 24 7 41 42 vc 0101 C K334C) - vc0101 T(kK183C + 1 25 26 7 41 42 vc 0101 C K392C) - vc0101 T(kK183C + 1 27 28 7 41 42 vc 0101 C L443C) - vc0101 T(K290C + 1 29 30 7 11 12 vc 0101 C K334C) - vc0101 T(K290C + 1 31 32 7 11 12 vc 0101 C K392C) - vc0101 T(N297A + 1 33 34 7 43 44 AcLysvc 0101 C K222R + LC Q05) - AcLysvc0101 T(N297Q + 1 35 36 7 11 12 AcLysvc 0101 C K222R) - AcLysvc0101 T(K334C + 1 37 38 7 11 12 vc 0101 C K392C) - vc0101 T(K392C + 1 39 40 7 11 12 vc 0101 C L443C) - vc0101 T(LCQ05 + 1 13 14 7 43 44 AcLysvc 0101 C K222R) - AcLysvc0101 T - mc8261 1 5 6 7 11 12 mc 8261 N T - m(H20)c8261 1 5 6 7 11 12 m(H20)c 8261 N T - MalPeg8261 1 5 6 7 11 12 MalPeg6 8261 N T - vc8261 1 5 6 7 11 12 vc 8261 C T - mc6121 1 5 6 7 11 12 mc 6121 N T - MalPeg6121 1 5 6 7 11 12 MalPeg6 6121 N T - mc0101 1 5 6 7 11 12 mc 0101 N T - vc0101 1 5 6 7 11 12 vc 0101 C T - vc8254 1 5 6 7 11 12 vc 8254 C T - vc6780 1 5 6 7 11 12 vc 6780 C T - vc0131 1 5 6 7 11 12 vc 0131 C T - MalPegM 1 5 6 7 11 12 MalPeg6 MMAD N MAD T - vcMMAE 1 5 6 7 11 12 vc MMAE C T - DM1 1 5 6 7 11 12 mcc DM1 N .sup.1C = cleavable; N = non-cleavable
V. Use of Site Specific HER2 Antibody Drug Conjugates
[0149] The antibody drug conjugates of the present invention are useful in therapeutic methods to treat HER2-expressing cancer. In some aspects of the invention, provided is a method of inhibiting tumor growth or progression in a subject who has a HER2-expressing tumor, including administering to the subject in need thereof an effective amount of a composition (i.e., a pharmaceutical composition) having one or more ADCs described herein. In other aspects of the invention, provided is a method of inhibiting metastasis of HER2-expressing cancer cells in a subject, including administering to the subject in need thereof an effective amount of a composition (i.e., a pharmaceutical composition) having one or more ADCs described herein. In other aspects of the invention, provided is a method of inducing regression of a HER2-expressing tumor in a subject, including administering to the subject in need thereof an effective amount of a composition (i.e., a pharmaceutical composition) having one or more ADCs described herein. In other aspects, the invention provides a pharmaceutical composition comprising one or more ADCs described herein for use in a method as described above. In other aspects, the invention provides the use of one or more ADCs as described herein or a pharmaceutical composition comprising the ADCs as described herein in the manufacture of a medicament for use in the methods described above.
[0150] Desired outcomes of the disclosed therapeutic methods are generally quantifiable measures as compared to a control or baseline measurement. As used herein, relative terms such as "improve," "increase," or "reduce" indicate values relative to a control, such as a measurement in the same individual prior to initiation of treatment described herein, or a measurement in a control individual (or multiple control individuals) in the absence of the treatment described herein. A representative control individual is an individual afflicted with the same form of cancer as the individual being treated, who is about the same age as the individual being treated (to ensure that the stages of the disorder in the treated individual and the control individual are comparable).
[0151] Changes or improvements in response to therapy are generally statistically significant. As used herein, the term "significance" or "significant" relates to a statistical analysis of the probability that there is a non-random association between two or more entities. To determine whether or not a relationship is "significant" or has "significance," statistical manipulations of the data can be "p-value." Those p-values that fall below a user-defined cut-off point are regarded as significant. A p-value less than or equal to 0.1, less than 0.05, less than 0.01, less than 0.005, or less than 0.001 may be regarded as significant.
[0152] V.A. Cancers
[0153] The ADCs of the present invention are useful in treating HER2-expressing cancers. In one embodiment, the HER2-expressing cancer is a solid tumor. In a more specific embodiment, HER2-expressing solid tumors include, but are not limited to, breast cancer (e.g., estrogen and progesterone receptor negative breast cancer, triple negative breast cancer), ovarian cancer, lung cancer (e.g., non-small cell lung cancer (including adenocarcinomas, squamous cell carcinomas and large cell carcinomas) and small cell lung cancer), gastric cancer, esophageal cancer, colorectal cancer, urothelial cancer (e.g., micropapillary urothelial cancer and typical urothelial cancer), pancreatic cancer, salivary gland cancer (e.g., mucoepidermoid carcinomas, adenoid cystic carcinomas and terminal duct adenocarcinoma) and brain cancer or metastases of the aforementioned cancers (i.e., lung metastasis from HER2+ breast cancer) (Martin et al., 2014, Future Oncol. 10(8):1469-86).
[0154] In an even more specific embodiment, HER2-expressing solid tumors include, but are not limited to, breast cancer, ovarian cancer, lung cancer and gastric cancer.
[0155] In another embodiment, the breast cancer is estrogen receptor and progesterone receptor negative. In a more specific embodiment, the breast cancer is triple negative breast cancer (TNBC).
[0156] In another embodiment, the lung cancer is non-small cell lung cancer (NSCLC).
[0157] In one aspect of the invention, ADCs disclosed herein can be used to treat HER2-expressing cancers that have not been previously treated with a therapeutic agent (i.e., as a first line treatment).
[0158] In another aspect of the invention, ADCs disclosed herein can be used to treat HER2-expressing cancers that are resistant to, refractory to and/or relapsed from treatment with another therapeutic agent (i.e., as a second line treatment). In one embodiment, the prior treatment was trastuzumab (trastuzumab or Herceptin.RTM.) either alone or in combination with an additional therapeutic agent (i.e., a taxane such as paclitaxel, docetaxel, cabazitaxel, etc.). In another embodiment, the prior treatment was trastuzumab emtansine (T-DM1 or Kadcyla.RTM.) either alone or in combination with an additional therapeutic agent (i.e., a taxane such as paclitaxel, docetaxel, cabazitaxel, etc.).
[0159] In another aspect of the invention, ADCs disclosed herein can be used to treat HER2-expressing cancers that are resistant to, refractory to and/or relapsed from treatment with more than one other therapeutic agent (i.e., as a third line treatment or a fourth line treatment, etc.).
[0160] ADCs of the present invention can be used to treat cancers that express high levels of HER2 (i.e., IHC 3+), moderate levels of HER2 (i.e., 2+ IHC or 2+/3+ IHC) or low levels of HER2 (i.e., IHC 1+, IHC 2+ or IHC 1+/2+) (see Section IVB for methods of HER2 detection). This is in contrast to trastuzumab and T-DM1 where they are not efficacious in low or moderate HER2-expressing cancers (Burris et al., 2011, J Clinical Oncology 29(4):398-405).
[0161] ADCs of the present invention can be used to treat cancers that are homogeneous in nature where the majority of tumor cells express a similar amount of HER2. Alternatively, the ADCs of the present invention can be used to treat cancers that are heterogeneous in nature where there are different tumor cell populations expressing different levels of HER2.
[0162] V.B. HER2 Detection Methods
[0163] Aspects regarding the best way to assess HER2 expression levels on a tumor have been discussed and clinical implications have been outlined (Sauter et al., 2009, J Clin Oncol. 27:1323-33; Wolff et al., 2007, J Clinical Oncology 25:118-45; Wolff et al., 2013, J Clinical Oncology 31:3997-4014). Currently, HER2 status can be assessed by immunohistochemistry (IHC), fluorescent in situ hybridization (FISH) and chromogenic in situ hybridization (CISH).
[0164] IHC identifies HER2 protein expression on the cell membrane. Results are usually expressed using a semiquantitative scoring system ranging from 0+(no expression) to 3+(high expression). Tumors that show no (0+) or low levels (1+) of expression are considered HER2-negative; vice-versa tumors that show high levels (3+) of expression should be considered as HER2-positive. This method is economically advantageous and readily available, but suffers from low sensitivity and high interobserver variability (Gancberg et al., 2002, Breast Cancer Res Treat. 74:113-20).
[0165] There are four FDA-approved commercial kits available for HER2 detection using IHC: HercepTest.TM. (by Dako Denmark A/S); Pathway (by Ventana Medical Systems, Inc.); Insite HER2/NEU kit (by Biogenex Laboratories, Inc.) and Bond Oracle HER2 IHC System (by Leica Biosystems). These are highly standardized, semi-quantitative assays which stratify HER2 expression levels into; 0 (<20,000 receptors per cell, no visible expression), 1+(.about.100,000 receptors per cell, partial membrane staining, <10% of cells overexpressing HER-2), 2+(.about.500,000 receptors per cell, light to moderate complete membrane staining, >10% of cells overexpressing HER-2), and 3+(.about.2,000,000 receptors per cell, strong complete membrane staining, >10% of cells overexpressing HER-2). The presence of cytoplasmic expression is disregarded.
[0166] FISH detects HER2 gene amplification with a DNA probe and is more specific and sensitive than IHC (Owens et al., 2004, Clin Breast Cancer. 5:63-69; Press et al., 2005, Clin Cancer Res. 11:6598-6607; Vogel et al., 2002, J Clinical Oncology 20(3):719-726). FISH offers quantitative results on the number of HER2 gene copies per chromosome 17 centromeres. Results are reported as a ratio of the number of HER2 signals to chromosome 17 centromere signals. A ratio of less than 1.8 is considered within normal limits. A ratio of 1.8-2.0 is equivocal and requires further testing. A ratio of greater than 2.0 is consistent with amplification of HER2 gene sequences.
[0167] There are four FDA-approved commercial kits available for HER2 detection using FISH: HER2 FISH Pharm Dx.TM. kit (by Dako Denmark A/S); Pathvysion HER2 DNA Probe Kit (by Abbott Molecular Inc.); Inform HER2/NEU and Inform HER2 Dual ISH DNA Probe Cocktail (both by Ventana Medical Systems, Inc.).
[0168] Another method to assess HER2 gene amplification is CISH. CISH is very similar to FISH but utilizes conventional peroxidase or alkaline phosphatase reactions visualized under a standard bright-field microscope. There are two FDA-approved commercial kits available for HER2 detection using CISH: HER2 CISH PharmDx Kit (by Dako Denmark A/S) and Spot-Light HER2 CISH Kit (by Life Technologies, Inc.).
[0169] Both gene amplification detected by FISH or CISH and protein expression by IHC are commonly used as initial test to assess HER2 status. There is a good correlation between the two methods (Jacobs et al., 1999, J Clinical Oncology 17(7):1974-82). However in cases where the tumor is scored as equivocal (i.e., IHC 2+ or FISH/CISH ratio of 1.8-2.2 or average HER2 gene copy number of four to six signals per nucleus), a common approach is to test the tumor with an alternative method (Wolff et al., 2007, J Clinical Oncology 25:118-45).
[0170] Thus, HER2 expression is considered high in tumors with a 3+ level as determined by immunohistochemistry (IHC) and/or a fluorescence in situ hybridization (FISH) amplification ratio of 2.0. HER2 expression is considered moderate in tumors with a 2+ level as determined by immunohistochemistry (IHC) and/or a fluorescence in situ hybridization (FISH) amplification ratio of <2.0. HER2 expression is considered low in tumors with a 1+ level as determined by immunohistochemistry (IHC) and/or a fluorescence in situ hybridization (FISH) amplification ratio of <2.0.
[0171] In one embodiment, HER2 levels are determined by IHC. In a more specific embodiment, IHC is performed using a Dako Hercptest.TM. assay.
[0172] In another embodiment, HER2 levels are determined by FISH. In a more specific embodiment, FISH is performed using a Dako HER2 FISH Pharm Dx.TM. assay.
[0173] Representative tumor samples include any biological or clinical sample which contains tumor cells, for example, a tissue sample, a biopsy, a blood sample, a plasma sample, a saliva sample, a urine sample, etc.
VI. Formulations
[0174] The present invention provides pharmaceutical compositions including any of the site specific HER2 antibody drug conjugates disclosed herein and a pharmaceutically acceptable carrier. Further, the compositions can include more than one of the site specific HER2 ADCs disclosed herein.
[0175] The compositions used in the present invention can further include pharmaceutically acceptable carriers, excipients, or stabilizers (Remington: The Science and practice of Pharmacy 21st Ed., 2005, Lippincott Williams and Wilkins, Ed. K. E. Hoover), in the form of lyophilized formulations or aqueous solutions. Acceptable carriers, excipients, or stabilizers are nontoxic to recipients at the dosages and concentrations, and may include buffers such as phosphate, citrate, and other organic acids; antioxidants including ascorbic acid and methionine; preservatives (such as octadecyldimethylbenzyl ammonium chloride; hexamethonium chloride; benzalkonium chloride, benzethonium chloride; phenol, butyl or benzyl alcohol; alkyl parabens such as methyl or propyl paraben; catechol; resorcinol; cyclohexanol; 3-pentanol; and m-cresol); low molecular weight (less than about 10 residues) polypeptides; proteins, such as serum albumin, gelatin, or immunoglobulins; hydrophilic polymers such as polyvinylpyrrolidone; amino acids such as glycine, glutamine, asparagine, histidine, arginine, or lysine; monosaccharides, disaccharides, and other carbohydrates including glucose, mannose, or dextrans; chelating agents such as EDTA; sugars such as sucrose, mannitol, trehalose or sorbitol; salt-forming counter-ions such as sodium; metal complexes (e.g. Zn-protein complexes); and/or non-ionic surfactants such as TWEEN.TM., PLURONICS.TM. or polyethylene glycol (PEG). "Pharmaceutically acceptable salt" as used herein refers to pharmaceutically acceptable organic or inorganic salts of a molecule or macromolecule. Pharmaceutically acceptable excipients are further described herein.
[0176] Various formulations of one or more site specific HER2 ADCs may be used for administration including, but not limited to formulations comprising one or more pharmaceutically acceptable excipients. Pharmaceutically acceptable excipients are known in the art, and are relatively inert substances that facilitate administration of a pharmacologically effective substance. For example, an excipient can give form or consistency, or act as a diluent. Suitable excipients include but are not limited to stabilizing agents, wetting and emulsifying agents, salts for varying osmolarity, encapsulating agents, buffers, and skin penetration enhancers. Excipients as well as formulations for parenteral and nonparenteral drug delivery are set forth in Remington, The Science and Practice of Pharmacy 20th Ed. Mack Publishing, 2000.
[0177] In some aspects of the invention, these agents are formulated for administration by injection (e.g., intraperitoneally, intravenously, subcutaneously, intramuscularly, etc.). Accordingly, these agents can be combined with pharmaceutically acceptable vehicles such as saline, Ringer's solution, dextrose solution, and the like. The particular dosage regimen, i.e., dose, timing and repetition, will depend on the particular individual and that individual's medical history.
[0178] Therapeutic formulations of the site specific HER2 ADCs used in accordance with the present invention are prepared for storage by mixing an ADC having the desired degree of purity with optional pharmaceutically acceptable carriers, excipients or stabilizers (Remington, The Science and Practice of Pharmacy 21st Ed. Mack Publishing, 2005), in the form of lyophilized formulations or aqueous solutions. Acceptable carriers, excipients, or stabilizers are nontoxic to recipients at the dosages and concentrations employed, and may include buffers such as phosphate, citrate, and other organic acids; salts such as sodium chloride; antioxidants including ascorbic acid and methionine; preservatives (such as octadecyldimethylbenzyl ammonium chloride; hexamethonium chloride; benzalkonium chloride, benzethonium chloride; phenol, butyl or benzyl alcohol; alkyl parabens, such as methyl or propyl paraben; catechol; resorcinol; cyclohexanol; 3-pentanol; and m-cresol); low molecular weight (less than about 10 residues) polypeptides; proteins, such as serum albumin, gelatin, or immunoglobulins; hydrophilic polymers such as polyvinylpyrrolidone; amino acids such as glycine, glutamine, asparagine, histidine, arginine, or lysine; monosaccharides, disaccharides, and other carbohydrates including glucose, mannose, or dextrins; chelating agents such as EDTA; sugars such as sucrose, mannitol, trehalose or sorbitol; salt-forming counter-ions such as sodium; metal complexes (e.g. Zn-protein complexes); and/or non-ionic surfactants such as TWEEN.TM., PLURONICS.TM. or polyethylene glycol (PEG).
[0179] Liposomes containing the site specific HER2 ADCs can be prepared by methods known in the art, such as described in Eppstein, et al., 1985, PNAS 82:3688-92; Hwang, et al., 1908, PNAS 77:4030-4; and U.S. Pat. Nos. 4,485,045 and 4,544,545. Liposomes with enhanced circulation time are disclosed in U.S. Pat. No. 5,013,556. Particularly useful liposomes can be generated by the reverse phase evaporation method with a lipid composition including phosphatidylcholine, cholesterol and PEG-derivatized phosphatidylethanolamine (PEG-PE). Liposomes are extruded through filters of defined pore size to yield liposomes with the desired diameter.
[0180] The active ingredients may also be entrapped in microcapsules prepared, for example, by coacervation techniques or by interfacial polymerization, for example, hydroxymethylcellulose or gelatin-microcapsules and poly-(methylmethacrylate) microcapsules, respectively, in colloidal drug delivery systems (for example, liposomes, albumin microspheres, microemulsions, nanoparticles and nanocapsules) or in macroemulsions. Such techniques are disclosed in Remington, The Science and Practice of Pharmacy 21st Ed. Mack Publishing, 2005.
[0181] Sustained-release preparations may be prepared. Suitable examples of sustained-release preparations include semipermeable matrices of solid hydrophobic polymers containing the antibody, which matrices are in the form of shaped articles, e.g. films, or microcapsules. Examples of sustained-release matrices include polyesters, hydrogels (for example, poly(2-hydroxyethyl-methacrylate), or poly(vinylalcohol)), polylactides (U.S. Pat. No. 3,773,919), copolymers of L-glutamic acid and 7 ethyl-L-glutamate, non-degradable ethylene-vinyl acetate, degradable lactic acid-glycolic acid copolymers such as the LUPRON DEPOT.TM. (injectable microspheres composed of lactic acid-glycolic acid copolymer and leuprolide acetate), sucrose acetate isobutyrate, and poly-D-(-)-3-hydroxybutyric acid.
[0182] The formulations to be used for in vivo administration must be sterile. This is readily accomplished by, for example, filtration through sterile filtration membranes. Therapeutic site specific HER2 ADC compositions are generally placed into a container having a sterile access port, for example, an intravenous solution bag or vial having a stopper pierceable by a hypodermic injection needle.
[0183] Suitable surface-active agents include, in particular, non-ionic agents, such as polyoxyethylenesorbitans (e.g. TWEEN.TM. 20, 40, 60, 80 or 85) and other sorbitans (e.g. Span.TM. 20, 40, 60, 80 or 85). Compositions with a surface-active agent will conveniently include between 0.05 and 5% surface-active agent, and can be between 0.1 and 2.5%. It will be appreciated that other ingredients may be added, for example mannitol or other pharmaceutically acceptable vehicles, if necessary.
[0184] Suitable emulsions may be prepared using commercially available fat emulsions, such as INTRALIPID.TM., LIPOSYN.TM., INFONUTROL.TM., LIPOFUNDIN.TM. and LIPIPHYSAN.TM.. The active ingredient may be either dissolved in a pre-mixed emulsion composition or alternatively it may be dissolved in an oil (e.g. soybean oil, safflower oil, cottonseed oil, sesame oil, corn oil or almond oil) and an emulsion formed upon mixing with a phospholipid (e.g. egg phospholipids, soybean phospholipids or soybean lecithin) and water. It will be appreciated that other ingredients may be added, for example glycerol or glucose, to adjust the tonicity of the emulsion. Suitable emulsions will typically contain up to 20% oil, for example, between 5 and 20%. The fat emulsion can include fat droplets between 0.1 and 1.0 .mu.m, particularly 0.1 and 0.5 .mu.m, and have a pH in the range of 5.5 to 8.0. The emulsion compositions can be those prepared by mixing a site specific HER2 ADC with INTRALIPID.TM. or the components thereof (soybean oil, egg phospholipids, glycerol and water).
[0185] The invention also provides kits for use in the instant methods. Kits of the invention include one or more containers including one or more site specific HER2 ADCs as described herein and instructions for use in accordance with any of the methods of the invention described herein. Generally, these instructions include a description of administration of the site specific HER2 ADC for the above described therapeutic treatments.
[0186] The instructions relating to the use of the site specific HER2 ADCs as described herein generally include information as to dosage, dosing schedule, and route of administration for the intended treatment. The containers may be unit doses, bulk packages (e.g., multi-dose packages) or sub-unit doses. Instructions supplied in the kits of the invention are typically written instructions on a label or package insert (e.g., a paper sheet included in the kit), but machine-readable instructions (e.g., instructions carried on a magnetic or optical storage disk) are also acceptable.
[0187] The kits of this invention are in suitable packaging. Suitable packaging includes, but is not limited to, vials, bottles, jars, flexible packaging (e.g., sealed Mylar or plastic bags), and the like. Also contemplated are packages for use in combination with a specific device, such as an infusion device such as a minipump. A kit may have a sterile access port (for example the container may be an intravenous solution bag or a vial having a stopper pierceable by a hypodermic injection needle). The container may also have a sterile access port (for example the container may be an intravenous solution bag or a vial having a stopper pierceable by a hypodermic injection needle). At least one active agent in the composition is a site specific HER2 ADC. The container may further include a second pharmaceutically active agent.
[0188] Kits may optionally provide additional components such as buffers and interpretive information. Normally, the kit includes a container and a label or package insert(s) on or associated with the container.
VII. Dose and Administration
[0189] For in vivo applications, site specific HER2 ADCs are provided or administered in an effective dosage. The phrases "effective dosage" or "effective amount" as used herein refer to an amount of a drug, compound or pharmaceutical composition necessary to achieve any one or more beneficial or desired therapeutic results either directly or indirectly. For example, when administered to a cancer-bearing subject, an effective dosage includes an amount sufficient to elicit anti-cancer activity, including cancer cell cytolysis, inhibition of cancer cell proliferation, induction of cancer cell apoptosis, reduction of cancer cell antigens, delayed tumor growth, and/or inhibition of metastasis. Tumor shrinkage is well accepted as a clinical surrogate marker for efficacy. Another well accepted marker for efficacy is progression-free survival.
[0190] An effective dosage can be administered in one or more administrations. An effective dosage of a drug, compound, or pharmaceutical composition may or may not be achieved in conjunction with another drug, compound, or pharmaceutical composition. Thus, an effective dosage may be considered in the context of administering one or more therapeutic agents, and a single agent may be considered to be given in an effective amount if, in conjunction with one or more other agents, a desirable result may be or is achieved.
[0191] The site specific HER2 ADCs can be administered to an individual via any suitable route. It should be understood by persons skilled in the art that the examples described herein are not intended to be limiting but to be illustrative of the techniques available. Accordingly, in some aspects of the invention, the site specific HER2 ADC is administered to an individual in accord with known methods, such as intravenous administration, e.g., as a bolus or by continuous infusion over a period of time, by intramuscular, intraperitoneal, intracerebrospinal, intracranial, transdermal, subcutaneous, intra-articular, sublingually, intrasynovial, via insufflation, intrathecal, oral, inhalation or topical routes. Administration can be systemic, e.g., intravenous administration, or localized. Commercially available nebulizers for liquid formulations, including jet nebulizers and ultrasonic nebulizers are useful for administration. Liquid formulations can be directly nebulized and lyophilized powder can be nebulized after reconstitution. Alternatively, the site specific HER2 ADC can be aerosolized using a fluorocarbon formulation and a metered dose inhaler, or inhaled as a lyophilized and milled powder.
[0192] In some aspects of the invention, the site specific HER2 ADC is administered via site-specific or targeted local delivery techniques. Examples of site-specific or targeted local delivery techniques include various implantable depot sources of site specific HER2 ADC or local delivery catheters, such as infusion catheters, indwelling catheters, or needle catheters, synthetic grafts, adventitial wraps, shunts and stents or other implantable devices, site specific carriers, direct injection, or direct application. See, e.g. PCT International Publication No. WO 2000/53211 and U.S. Pat. No. 5,981,568.
[0193] For the purpose of the present invention, the appropriate dosage of the site specific HER2 ADCs will depend on the particular ADC (or compositions thereof) employed, the type and severity of symptoms to be treated, whether the agent is administered for therapeutic purposes, previous therapy, the patient's clinical history and response to the agent, the patient's clearance rate for the administered agent, and the discretion of the attending physician. The clinician may administer a site specific HER2 ADC until a dosage is reached that achieves the desired result and beyond. Dose and/or frequency can vary over course of treatment, but may stay constant as well. Empirical considerations, such as the half-life, generally will contribute to the determination of the dosage. For example, antibodies that are compatible with the human immune system, such as humanized antibodies or fully human antibodies, may be used to prolong half-life of the antibody and to prevent the antibody being attacked by the host's immune system. Frequency of administration may be determined and adjusted over the course of therapy, and is generally, but not necessarily, based on treatment and/or suppression and/or amelioration of symptoms, e.g., tumor growth inhibition or delay, etc. Alternatively, sustained continuous release formulations of site specific HER2 ADCs may be appropriate. Various formulations and devices for achieving sustained release are known in the art.
[0194] Generally, for administration of a site specific HER2 ADC, an initial candidate dosage can be about 2 mg/kg. For the purpose of the present invention, a typical daily dosage might range from about any of 3 .mu.g/kg to 30 .mu.g/kg to 300 .mu.g/kg to 3 mg/kg, to 30 mg/kg, to 100 mg/kg or more. For example, dosage of about 1 mg/kg, about 2.5 mg/kg, about 5 mg/kg, about 10 mg/kg, and about 25 mg/kg may be used. For repeated administrations over several days or longer, depending on the disorder, the treatment is sustained until a desired suppression of symptoms occurs or until sufficient therapeutic levels are achieved, for example, to inhibit or delay tumor growth/progression or metastases of cancer cells. An exemplary dosing regimen includes administering an initial dose of about 2 mg/kg, followed by a weekly maintenance dose of about 1 mg/kg of the site specific HER2 ADC, or followed by a maintenance dose of about 1 mg/kg every other week. Other exemplary dosing regimens include administering increasing doses (e.g., initial dose of 1 mg/kg and gradual increase to one or more higher doses every week or longer time period). Other dosage regimens may also be useful, depending on the pattern of pharmacokinetic decay that the practitioner wishes to achieve. For example, in some aspects of the invention, dosing from one to four times a week is contemplated. In other aspects, dosing once a month or once every other month or every three months is contemplated, as well as weekly, bi-weekly and every three weeks. The progress of this therapy may be easily monitored by conventional techniques and assays. The dosing regimen (including the particular site specific HER2 ADC used) can vary over time.
VIII. Combination Therapies
[0195] In some aspects of the invention, the methods described herein further include a step of treating a subject with an additional form of therapy. In some aspects, the additional form of therapy is an additional anti-cancer therapy including, but not limited to, chemotherapy, radiation, surgery, hormone therapy, and/or additional immunotherapy.
[0196] The disclosed site specific HER2 ADCs may be administered as an initial treatment, or for treatment of cancers that are unresponsive to conventional therapies. In addition, the site specific HER2 ADCs may be used in combination with other therapies (e.g., surgical excision, radiation, additional anti-cancer drugs etc.) to thereby elicit additive or potentiated therapeutic effects and/or reduce cytotoxicity of some anti-cancer agents. Site specific HER2 ADCs of the invention may be co-administered or co-formulated with additional agents, or formulated for consecutive administration with additional agents in any order.
[0197] Site specific HER2 ADCs of the invention may be used in combination with other therapeutic agents including, but not limited to, therapeutic antibodies, ADCs, immunomodulating agents, cytotoxic agents, and cytostatic agents. A cytotoxic effect refers to the depletion, elimination and/or the killing of a target cells (i.e., tumor cells). A cytotoxic agent refers to an agent that has a cytotoxic and/or cytostatic effect on a cell. A cytostatic effect refers to the inhibition of cell proliferation. A cytostatic agent refers to an agent that has a cytostatic effect on a cell, thereby inhibiting the growth and/or expansion of a specific subset of cells (i.e., tumor cells). An immunomodulating agent refers to an agent that stimulates the immune response though the production of cytokines and/or antibodies and/or modulating T cell function thereby inhibiting or reducing the growth of a subset of cells (i.e., tumor cells) either directly or indirectly by allowing another agent to be more efficacious.
[0198] For combination therapies, a site specific HER2 ADC and/or one or more additional therapeutic agents are administered within any time frame suitable for performance of the intended therapy. Thus, the single agents may be administered substantially simultaneously (i.e., as a single formulation or within minutes or hours) or consecutively in any order. For example, single agent treatments may be administered within about 1 year of each other, such as within about 10, 8, 6, 4, or 2 months, or within 4, 3, 2 or 1 week(s), or within about 5, 4, 3, 2 or 1 day(s).
[0199] The disclosed combination therapies may elicit a synergistic therapeutic effect, i.e., an effect greater than the sum of their individual effects or therapeutic outcomes. For example, a synergistic therapeutic effect may be an effect of at least about two-fold greater than the therapeutic effect elicited by a single agent, or the sum of the therapeutic effects elicited by the single agents of a given combination, or at least about five-fold greater, or at least about ten-fold greater, or at least about twenty-fold greater, or at least about fifty-fold greater, or at least about one hundred-fold greater. A synergistic therapeutic effect may also be observed as an increase in therapeutic effect of at least 10% compared to the therapeutic effect elicited by a single agent, or the sum of the therapeutic effects elicited by the single agents of a given combination, or at least 20%, or at least 30%, or at least 40%, or at least 50%, or at least 60%, or at least 70%, or at least 80%, or at least 90%, or at least 100%, or more. A synergistic effect is also an effect that permits reduced dosing of therapeutic agents when they are used in combination.
Examples
[0200] The following examples are offered for illustrative purposes only, and are not intended to limit the scope of the present invention in any way. Indeed, various modifications of the invention in addition to those shown and described herein will become apparent to those skilled in the art from the foregoing description and fall within the scope of the appended claims.
Example 1: Preparation of Trastuzumab Derived Antibodies for Site Specific Conjugation
[0201] A. For Conjugation Via Cysteine
[0202] Methods of preparing trastuzumab derivatives for site specific conjugation through cysteine residues were generally performed as described in PCT Publication WO2013/093809 (which is incorporated herein in its entirety). One or more residues on either the light chain (183 using the Kabat numbering scheme) or the heavy chain (290, 334, 392 and/or 443 using the EU index of Kabat numbering scheme) were altered to a cysteine (C) residue by site directed mutagenesis.
[0203] B. For Conjugation Via Transglutaminase
[0204] Methods of preparing trastuzumab derivatives for site specific conjugation through glutamine residues were generally performed as described in PCT Publication WO2012/059882 (which is incorporated herein in its entirety). Trastuzumab was engineered to express the glutamine residue used for conjugation in three different ways.
[0205] For the first method, an 8 amino acid residue tag (LCQ05) containing the glutamine residue was attached to the C-terminus of the light chain (i.e., SEQ ID NO:81).
[0206] For the second method, a residue on the heavy chain (position 297 using the EU index of Kabat numbering scheme) was altered from an asparagine (N) to a glutamine (Q) residue by site directed mutagenesis.
[0207] For the third method, a residue on the heavy chain (position 297 using the EU index of Kabat numbering system) was altered from an asparagine (N) to an alanine (A). This results in aglycosylation at position 297 and accessible/reactive endogenous glutamine at position 295.
[0208] Additionally, some of the trastuzumab derivatives have an alteration that is not used for conjugation. The residue at position 222 on the heavy chain (using the EU Index of Kabat numbering scheme) was altered from a lysine (K) to an arginine (R) residue. The K222R substitution was found to result in more homogenous antibody and payload conjugate, better intermolecular crosslinking between the antibody and the payload, and/or significant decrease in interchain crosslinking with the glutamine tag on the C terminus of the antibody light chain.
Example 2: Production of Stably Transfected Cells Expressing Trastuzumab Derived Antibodies
[0209] A. Cysteine Mutants
[0210] To determine that the single and double cysteine engineered trastuzumab derived antibody variants could be stably expressed in cells and large-scale produced, CHO cells were transfected with DNA encoding nine trastuzumab derived antibody variants (T(.kappa.K183C), T(K290C), T(K334C), T(K392C), T(.kappa.K183C+K290C), T(.kappa.K183C+K392C), T(K290C+K334C), T(K334C+K392C) and T(K290C+K392C)) and stable high production pools were isolated using standard procedures well-known in the art. To produce T(.kappa.K183C+K334C) for conjugation studies, HEK-293 cells (ATCC Accession # CRL-1573) were transiently co-transfected with heavy and light chain DNA encoding this double-cysteine engineered antibody variant using standard methods. A two-column process, i.e. Protein-A affinity capture followed by a TMAE column or a three-column process, i.e. Protein-A affinity capture followed by a TMAE column and then CHA-TI column, was used to isolate these trastuzumab variants from the concentrated CHO pool starting material. Using these purification process, all engineered cysteine trastuzumab derived antibody variant preparations contained >97% peak-of-interest (POI) as determined by analytical size-exclusion chromatography (Table 5). These results shown in Table 5 demonstrate that acceptable levels of high molecular weight (HMW) aggregated species were detected following elution from Protein A resin for all ten trastuzumab derived cysteine variants and that this undesirable HMW species could be removed using size exclusion chromatography. Additionally, the data demonstrated that the Protein A binding site in the human IgG1 constant region was not altered by the presence of the engineered cysteine residues.
TABLE-US-00005 TABLE 5 Production of Trastuzumab Derived Cysteine Antibody Variants ProA Purification Eluate Yield Final Yield Variant Process (% POI) (ProA) (% POI) (Final) T(.kappa.K183C) 2 column ND ND >99% 768 mg/L T(K290C) 2 column >99% ND >99% 100 mg/L T(K334C) 2 column >99% ND >99% 100 mg/L T(K392C 2 column >99% ND >99% 110 mg/L T(.kappa.K183C + 3 column 93% 567 mg/L >99% 248 mg/L K290C) T(K290C + 3 column 91.2% 470 mg/L >99% 240 mg/L K334C) T(K334C + 3 column 92.4% 410 mg/L >99% 220 mg/L K392C) T(.kappa.K183C + 3 column ND ND >99% 64 mg/L K334C) T(K290C + 2 column 93.1% 700 mg/L 97.9% 420 mg/L K392C) T(.kappa.K183C + 2 column 91.4 ND 97.8 600 mg/L K392C) ND = Not Determined
Example 3: Integrity of Trastuzumab Derived Antibodies
[0211] Molecular assessment of the engineered cysteine and transglutaminase variants was performed to evaluate key biophysical properties relative to the trastuzumab wild type antibody to ensure the variants would be amenable to a standard antibody manufacturing platform process.
[0212] A. Cysteine Mutants
[0213] To determine integrity of the purified engineered cysteine antibody variant preparations produced via stable CHO expression, the percent purity of peaks was calculated using non-reduced capillary gel electrophoresis (Caliper LabChip GXII: Perkin Elmer Waltham, Mass.). Results show that the engineered cysteine antibody variants T(.kappa.K183C+K290C) and T(K290C+K334C) contained low levels of both fragments and high molecular mass species (HMMS) similar to the trastuzumab wild type antibody. In contrast, T(K334C+K392C) contained high levels of fragmented antibody peaks relative to the other double engineered cysteine variants evaluated (Table 6). These results suggest that specific combinations of engineered cysteines can impact integrity of the antibody intended for site-specific conjugation.
TABLE-US-00006 TABLE 6 Percent Purity of Peaks Calculated from Non-Reduced Electropherogram Antibody Main Peak (%) Fragments (%) HMMS (%) trastuzumab WT 95 5 0 T(.kappa.K183C + K290C) 95.78 4.18 0.04 T(K290C + K334C) 94.6 5.2 0.2 T(K334C + K392C) 80.7 19.3 0
Example 4: Generation of Payload Drug Compounds
[0214] The auristatin drug compounds 0101, 0131, 8261, 6121, 8254 and 6780 were made according to the methods described in PCT Publication WO2013/072813 (which is incorporated herein in its entirety). In published application, the auristatin compounds are indicated by the numbering system shown in Table 7.
TABLE-US-00007 TABLE 7 Auristatin Drug Compound Designation in WO2013/072813 0101 #54 0131 #118 8261 #69 6121 #117 8254 #70 6780 #112
[0215] According to PCT Publication WO2013/072813 drug compound 0101 was made according to the following procedure.
##STR00017##
[0216] Step 1. Synthesis of N-[(9H-fluoren-9-ylmethoxy)carbonyl]-2-methylalanyl-N-[(3R,4S,5S)-3-metho- xy-1-{(2S)-2-[(1R,2R)-1-methoxy-2-methyl-3-oxo-3-{[(1S)-2-phenyl-1-(1,3-th- iazol-2-yl)ethyl]amino}propyl]pyrrolidin-1-yl}-5-methyl-1-oxoheptan-4-yl]-- N-methyl-L-valinamide (#53). According to general procedure D, from #32 (2.05 g, 2.83 mmol, 1 eq.) in dichloromethane (20 mL, 0.1 M) and N,N-dimethylformamide (3 mL), the amine #19 (2.5 g, 3.4 mmol, 1.2 eq.), HATU (1.29 g, 3.38 mmol, 1.2 eq.) and triethylamine (1.57 mL, 11.3 mmol, 4 eq.) was synthesized the crude desired material, which was purified by silica gel chromatography (Gradient: 0% to 55% acetone in heptane), producing #53 (2.42 g, 74%) as a solid. LC-MS: m/z 965.7 [M+H.sup.+], 987.6 [M+Na.sup.+], retention time=1.04 minutes; HPLC (Protocol A): m/z 965.4 [M+H.sup.+], retention time=11.344 minutes (purity >97%); .sup.1H NMR (400 MHz, DMSO-d.sub.6), presumed to be a mixture of rotamers, characteristic signals: .delta. 7.86-7.91 (m, 2H), [7.77 (d, J=3.3 Hz) and 7.79 (d, J=3.2 Hz), total 1H], 7.67-7.74 (m, 2H), [7.63 (d, J=3.2 Hz) and 7.65 (d, J=3.2 Hz), total 1H], 7.38-7.44 (m, 2H), 7.30-7.36 (m, 2H), 7.11-7.30 (m, 5H), [5.39 (ddd, J=11.4, 8.4, 4.1 Hz) and 5.52 (ddd, J=11.7, 8.8, 4.2 Hz), total 1H], [4.49 (dd, J=8.6, 7.6 Hz) and 4.59 (dd, J=8.6, 6.8 Hz), total 1H], 3.13, 3.17, 3.18 and 3.24 (4 s, total 6H), 2.90 and 3.00 (2 br s, total 3H), 1.31 and 1.36 (2 br s, total 6H), [1.05 (d, J=6.7 Hz) and 1.09 (d, J=6.7 Hz), total 3H].
[0217] Step 2. Synthesis of 2-methylalanyl-N-[(3R,4S,5S)-3-methoxy-1-{(2S)-2-[(1R,2R)-1-methoxy-2-met- hyl-3-oxo-3-{[(1S)-2-phenyl-1-(1,3-thiazol-2-yl)ethyl]amino}propyl]pyrroli- din-1-yl}-5-methyl-1-oxoheptan-4-yl]-N-methyl-L-valinamide (#54 or 0101). According to general procedure A, from #53 (701 mg, 0.726 mmol) in dichloromethane (10 mL, 0.07 M) was synthesized the crude desired material, which was purified by silica gel chromatography (Gradient: 0% to 10% methanol in dichloromethane). The residue was diluted with diethyl ether and heptane and was concentrated in vacuo to afford #54 (or 0101) (406 mg, 75%) as a white solid. LC-MS: m/z 743.6 [M+H.sup.+], retention time=0.70 minutes; HPLC (Protocol A): m/z 743.4 [M+H.sup.+], retention time=6.903 minutes, (purity >97%); .sup.1H NMR (400 MHz, DMSO-d.sub.6), presumed to be a mixture of rotamers, characteristic signals: .delta. [8.64 (br d, J=8.5 Hz) and 8.86 (br d, J=8.7 Hz), total 1H], [8.04 (br d, J=9.3 Hz) and 8.08 (br d, J=9.3 Hz), total 1H], [7.77 (d, J=3.3 Hz) and 7.80 (d, J=3.2 Hz), total 1H], [7.63 (d, J=3.3 Hz) and 7.66 (d, J=3.2 Hz), total 1H], 7.13-7.31 (m, 5H), [5.39 (ddd, J=11, 8.5, 4 Hz) and 5.53 (ddd, J=12, 9, 4 Hz), total 1H], [4.49 (dd, J=9, 8 Hz) and 4.60 (dd, J=9, 7 Hz), total 1H], 3.16, 3.20, 3.21 and 3.25 (4 s, total 6H), 2.93 and 3.02 (2 br s, total 3H), 1.21 (s, 3H), 1.13 and 1.13 (2 s, total 3H), [1.05 (d, J=6.7 Hz) and 1.10 (d, J=6.7 Hz), total 3H], 0.73-0.80 (m, 3H).
[0218] Drug compounds MMAD, MMAE and MMAF were made in-house according to methods disclosed in PCT Publication WO 2013/072813.
[0219] Drug compound DM1 was made in-house from purchased maytansinol via procedures outlined in U.S. Pat. No. 5,208,020.
Example 5: Bioconjugation of Trastuzumab-Derived Antibodies
[0220] The trastuzumab-derived antibodies of the present invention were conjugated to payload via linkers to generate ADCs. The conjugation method used was either site specific (i.e., via particular cysteine residues or particular glutamine residues) or conventional conjugation.
[0221] A. Cysteine Site Specific
[0222] The ADCs of Table 8 were conjugated via cysteine site specific methods described below.
TABLE-US-00008 TABLE 8 T(.kappa.K183C)-vc0101 T(.kappa.K183C + K334C)-vc0101 T(K290C)-vc0101 T(.kappa.K183C + K392C)-vc0101 T(K334C)-vc0101 T(K290C + K334C)-vc0101 T(K392C)-vc0101 T(K290C + K392C)-vc0101 T(.kappa.K183C + K290C)-vc0101 T(K334C + K392C)-vc0101
[0223] A 500 mM tris(2-carboxyethyl)phosphine hydrochloride (TCEP) solution (50 to 100 molar equivalents) was added to the antibody (5 mg) such that the final antibody concentration was 5-15 mg/mL in PBS containing 20 mM EDTA. After allowing the reaction to stand at 37.degree. C. for 2.5 hour, the antibody was buffer exchanged into PBS containing 5 mM EDTA using a gel filtration column (PD-10 desalting column, GE Healthcare). The resulting antibody (5-10 mg/mL) in PBS containing 5 mM EDTA was treated with a freshly prepared 50 mM solution of DHA in 1:1 PBS/EtOH (final DHA concentration=1 mM-4 mM) and allowed to stand at 4.degree. C. overnight.
[0224] The antibody/DHA mixture was buffer exchanged into PBS containing 5 mM EDTA (pH of the equilibration buffer adjusted to .about.7.0 using phosphoric acid) and concentrated using a 50 kD MW cutoff spin concentration device. The resulting antibody in PBS (antibody concentration .about.5-10 mg/ml) containing 5 mM EDTA was treated with 5-7 molar equivalents of 10 mM maleimide payload in DMA. After standing for 1.5-2.5 hours, the material was buffer exchanged (PD-10). Purification by SEC was performed (as needed) to remove any aggregated material and remaining free payload.
[0225] B. Transglutaminase Site Specific
[0226] The ADCs of Table 9 were conjugated via transglutaminase site specific methods described below.
TABLE-US-00009 TABLE 9 T(N297Q)-AcLysvc0101 T(LCQ05 + K222R)-AcLysvc0101 T(N297Q + K222R)-AcLysvc0101 T(N297A + K222R - LCQ05)-AcLysvc0101
[0227] In the transamidation reaction, the glutamine on the antibody acted as an acyl donor, and the amine-containing compound acted as an acyl acceptor (amine donor). Purified HER2 antibody in the concentration of 33 .mu.M was incubated with a 10-25 M excess acyl acceptor, ranging between 33-83.3 .mu.M AcLysvc-0101, in the presence of 2% (w/v) Streptoverticillium mobaraense transglutaminase (ACTIVA.TM., Ajinomoto, Japan) in 150-mM sodium chloride and Tris HCl buffer at pH range 7.5-8, with 0.31 mM reduced glutathione unless noted. The reaction conditions were adjusted for individual acyl donors, with T(LCQ05+K222R) using 10M excess acyl acceptor at pH 8.0 without reduced glutathione, T(N297Q+K222R) and T(N297Q) using 20M excess acyl acceptor at pH 7.5 and T(N297A+K222R+LCQ05) using 25M excess acyl acceptor at pH 7.5. Following incubation at 37.degree. C. for 16-20 hours, the antibody was purified on MabSelect SuReO resin or Butyl Sepharose High Performance (GE Healthcare, Piscataway, N.J.) using standard chromatography methods known to persons skilled in the art, such as commercial affinity chromatography and hydrophobic interaction chromatography from GE Healthcare.
[0228] C. Conventional Conjugation
[0229] The ADCs of Tables 10 and 11 were conjugated via conventional conjugation methods described below.
TABLE-US-00010 TABLE 10 T-DM1 T-mc0101 T-mc8261 T-vc0101 T-MalPeg8261 T-vc8261 T-mc6121 T-vc8254 T-MalPeg6121 T-vc6780 T-MalPegMMAD T-vc0131 T-vcMMAE
TABLE-US-00011 TABLE 11 T-m(H20)c8261 T-m(H20)cvc0101
[0230] The antibody was dialyzed into Dulbecco's Phosphate Buffered Saline (DPBS, Lonza). The dialyzed antibody was diluted to 15 mg/mL with PBS containing 5 mM 2, 2', 2'', 2''-(ethane-1, 2-diyldinitrilo)tetraacetic acid (EDTA), pH 7. The resulting antibody was treated with 2-3 equivalents of tris(2-carboxyethyl)phosphine hydrochloride (TCEP, 5 mM in distilled water) and allowed to stand 37.degree. C. for 1-2 hours. Upon cooling to room temperature, dimethylacetamide (DMA) was added to achieve 10% (v/v) total organic. The mixture was treated with 8-10 equivalents of the appropriate linker-payload as a 10 mM stock solution in DMA. The reaction was allowed to stand for 1-2 hours at room temperature and then buffer exchanged into DPBS (pH 7. 4) using GE Healthcare Sephadex G-25 M buffer exchange columns per manufacturer's instructions.
[0231] Material that was to remain ring-closed (ADCs of Table 10) was purified by size exclusion chromatography (SEC) using GE AKTA Explorer system with GE Superdex200 column and PBS (pH 7. 4) eluent. Final samples were concentrated to .about.5 mg/mL protein, filter sterilized, and checked for loading using the mass spectroscopy conditions outlined below.
[0232] Material used for succinimide ring hydrolysis (ADCs of Table 11) were immediately buffer exchanged into a 50 mM borate buffer (pH 9.2) using an ultrafiltration device (50 kd MW cutoff). The resulting solution was heated to 45.degree. C. for 48 h. The resulting solution was cooled, buffer-exchanged into PBS, and purified by SEC (as described below) in order to remove any aggregated material. Final samples were concentrated to .about.5 mg/mL protein and filter sterilized and checked for loading using the mass spectroscopy conditions outlined below.
[0233] D. T-DM1 Conjugation
[0234] Trastuzumab-maytansinoid conjugate (T-DM1) is structurally similar to trastuzumab emtansine (Kadcyla.RTM.). T-DM1 is comprised of the trastuzumab antibody covalently bound to the DM1 maytansinoid through the bifunctional linker sulfosuccinimidyl 4-(N-maleimidomethyl) cyclohexane-1-carboxylate (sulfo-SMCC). Sulfo-SMCC is first conjugated to the free amines on the antibody for one hour at 25.degree. C. in 50 mM potassium phosphate, 2 mM EDTA, pH 6.8, at a 10:1 reaction stoichiometry, and unbound linker is then desalted from the conjugated antibody. This antibody-MCC intermediate is then conjugated to the DM1 sulfide at the free maleimido end on the MCC linker antibody overnight at 25.degree. C. in 50 mM potassium phosphate, 50 mM NaCl, 2 mM EDTA, pH 6.8, at a 10:1 reaction stoichiometry. Remaining unreacted maleimide is then capped with L-cysteine, and the ADC is fractionated through a Superdex200 column to remove non-monomeric species (Chari et al., 1992, Cancer Res 52:127-31).
Example 6: Purification of ADCs
[0235] The ADCs were generally purified and characterized using size-exclusion chromatography (SEC) as described below. The loading of the drug onto the intended site of conjugation was determined using a variety of methods including mass spectrometry (MS), reverse phase HPLC, and hydrophobic interaction chromatography (HIC), as more fully described below. The combination of these three analytical methods provides a variety of ways to verify and quantitate the loading of the payload onto the antibody thereby providing an accurate determination of the DAR for each conjugate.
[0236] A. Preparative SEC
[0237] ADCs were generally purified using SEC chromatography using a Waters Superdex200 10/300GL column on an Akta Explorer FPLC system in order to remove protein aggregate and to remove traces of payload-linker left in the reaction mixture. On occasion, ADCs were free of aggregate and small molecule prior to SEC purification and were therefore not subjected to preparative SEC. The eluent used was PBS at 1 mL/min flow. Under these conditions, aggregated material (eluting at about 10 minutes at room temperature) was easily separated from non-aggregated material (eluting at about 15 minutes at room temperature). Hydrophobic payload-linker combinations frequently resulted in a "right-shift" of the SEC peaks. Without wishing to be bound by any particular theory, this SEC peak shift may be due to hydrophobic interactions of the linker-payload with the stationary phase. In some cases, this right-shift allowed for conjugated protein to be partially resolved from non-conjugated protein.
[0238] B. Analytical SEC
[0239] Analytical SEC was carried out on an Agilent 1100 HPLC using PBS as eluent to assess the purity and monomeric status of the ADCs. The eluent was monitored at 220 and 280 nM. When the column was a TSKGel G3000SW column (7.8.times.300 mm, catalog number R874803P), the mobile phase used was PBS with a flow rate of 0.9 mL/min for 30 minutes When the column was a BiosepSEC3000 column (7.8.times.300 mm), the mobile phase used was PBS with a flow rate of 1.0 mL/min for 25 minutes.
Example 7: Characterization of ADCs
[0240] A. Mass Spectroscopy (MS)
[0241] Samples were prepped for LCMS analysis by combining approximately 20 .mu.l of sample (approximately 1 mg/ml ADC in PBS) with 20 .mu.l of 20 mM dithiothreitol (DTT). After allowing the mixture to stand at room temperature for 5 minutes, the samples were injected into an Agilent 110 HPLC system fitted with an Agilent Poroshell 300SB-C8 (2.1.times.75 mm) column. The system temperature was set to 60.degree. C. A 5 minute gradient from 20% to 45% acetonitrile in water (with 0.1% formic acid modifier) was utilized. The eluent was monitored by UV (220 nM) and by a Waters Micromass ZQ mass spectrometer (ESI ionization; cone voltage: 20V; Source temp: 120.degree. C.; Desolvation temp: 350.degree. C.). The crude spectrum containing the multiple-charged species was deconvoluted using MaxEnt1 within MassLynx 4.1 software package according to the manufacturer's instructions.
[0242] B. MS Determination of Loading Per Antibody
[0243] The total loading of the payload to the antibody to make an ADC is referred to as the Drug Antibody Ratio or DAR. The DAR was calculated for each of the ADCs made (Table 12).
[0244] The spectra for the entire elution window (usually 5 minutes) were combined into a single summed spectrum (i.e., a mass spectrum that represents the MS of the entire sample). MS results for ADC samples were compared directly to the corresponding MS of the identical non-loaded control antibody. This allowed for the identification of loaded/nonloaded heavy chain (HC) peaks and loaded/nonloaded light chain (LC) peaks. The ratio of the various peaks can be used to establish loading based on the equation below (Equation 1). Calculations are based on the assumption that loaded and non-loaded chains ionize equally which has been determined to be a generally valid assumption.
[0245] The following calculation was performed in order to establish the DAR:
Loading=2*[LC1/(LC1+LC0)]+2*[HC1/(HC0+HC1+HC2)]+4*[HC2/(HC0+HC1+HC2)] Equation 1:
Where the indicated variables are the relative abundance of: LC0=unloaded light chain, LC1=single loaded light chain, HC0=unloaded heavy chain, HC1=single loaded heavy chain, and HC2=double loaded heavy chain. One of ordinary skill in the art would appreciate that the invention encompasses expansion of this calculation to encompass higher loaded species such as LC2, LC3, HC3, HC4, HC5, and the like.
[0246] Equation 2, below, is used to estimate the amount of loading onto non-engineered cysteine residues. For engineered Fc mutants, loading onto the light chain (LC) was considered, by definition, to be nonspecific loading. Moreover, it was assumed that loading only the LC was the result of inadvertent reduction of the HC-LC disulfide bridge (i.e., the antibody was "over-reduced"). Given that a large excess of maleimide electrophile was used for the conjugation reactions (generally approximately 5 equivalents for single mutants and 10 equivalents for double mutants), it was assumed that any nonspecific loading onto the light chain was accompanied by a corresponding amount of non-specific loading onto the heavy chain (i.e., the other "half" of the broken HC-LC disulfide). With these assumptions in mind, the following equation (Equation 2) was used to estimate the amount of non-specific loading onto the protein:
Nonspecific loading=4*[LC1/(LC1+LC0)] Equation 2:
Where the indicated variables are the relative abundance of: LC0=unloaded light chain, LC1=single loaded light chain.
TABLE-US-00012 TABLE 12 Drug Antibody Ratio (DAR) of ADCs ADC DAR T(.kappa.K183C)-vc0101 2 T(K290C)-vc0101 2 T(K334C)-vc0101 2 T(K392C)-vc0101 2 T(.kappa.K183C + K290C)-vc0101 4 T(.kappa.K183C + K334C)-vc0101 4 T(.kappa.K183C + K392C)-vc0101 4 T(K290C + K334C)-vc0101 4 T(K290C + K392C)-vc0101 4 T(K334C + K392C)-vc0101 4 T(N297Q)-AcLysvc0101 4 T(N297Q + K222R)-AcLysvc0101 4 T(N297A + K222R + LCQ05)-AcLysvc0101 4 T(LCQ05 + K222R)-AcLysvc0101 2 T-mc8261 4.2 T-m(H20)c8261 3.6 T-MalPeg8261 3.1 T-vc8261 4.3 T-mc6121 3.5 T-MalPeg6121 3.6 T-mc0101 4.8 T-vc0101 4.2 T-vc8254 4 T-vc6780 4.2 T-vc0131 4.5 T-MalPegMMAD 4.4 T-vcMMAE 3.8 T-DM1 4.2
[0247] C. Proteolysis with FabRICATOR.RTM. to Establish the Site of Loading
[0248] For the cysteine mutant ADCs, any nonspecific loading of the electrophillic payload onto the antibody is presumed to occur at the "interchain" also referred to as the "internal" cysteine residues (i.e., those that are typically part of the HC-HC or HC-LC disulfide bridges). In order to distinguish loading of electrophile onto the engineered cysteines in the Fc domain versus loading onto the internal cysteine residues (otherwise typically forming the S--S bonds between HC-HC or HC-LC), the conjugates were treated with a protease known to cleave between the Fab domains and the Fc domain of the antibody. One such protease is the cysteine protease IdeS, marketed as "FabRICATOR.RTM." by Genovis, and described in von Pawel-Rammingen et al., 2002, EMBO J. 21:1607.
[0249] Briefly, following the manufacturer's suggested conditions, the ADC was treated with FabRICATOR.RTM. protease and the sample was incubated at 37.degree. C. for 30 minutes. Samples were prepped for LCMS analysis by combining approximately 20 .mu.l of sample (approximately 1 mg/mL in PBS) with 20 .mu.l of 20 mM dithiothreitol (DTT) and allowing the mixture to stand at room temperature for 5 minutes. This treatment of human IgG1 resulted in three antibody fragments, all ranging from about 23 to 26 kD in size: the LC fragment comprising an internal cysteine which typically forms an LC-HC interchain disulfide bond; the N-terminal HC fragment comprising three internal cysteines (where one typically forms an LC-HC disulfide bond and the other two cysteines found in the hinge region of the antibody and which typically form HC-HC disulfide bonds between the two heavy chains of the antibody); and the C-terminal HC fragment which contains no reactive cysteines other than those introduced by mutation in the constructs disclosed herein. The samples were analyzed by MS as described above. Loading calculations were performed in the same manner as previously described (above) in order to quantitate the loading of the LC, the N-terminal HC, and the C-terminal HC. Loading on the C-terminal HC is considered "specific" loading while loading onto the LC and the N-terminal HC is considered "nonspecific" loading.
[0250] To cross-check the loading calculations, a subset of ADCs were also assessed for loading using alternative methods (reverse phase high performance liquid chromatography [rpHPLC]-based and hydrophobic interaction chromatography [HIC]-based methods) as more fully described in the sections below.
[0251] D. Reverse Phase HPLC Analysis
[0252] Samples were prepped for reverse-phase HPLC analysis by combining approximately 20 .mu.l of sample (approximately 1 mg/mL in PBS) with 20 .mu.l of 20 mM dithiothreitol (DTT). After allowing the mixture to stand at room temperature for 5 minutes, the samples were injected into an Agilent 1100 HPLC system fitted with an Agilent Poroshell 300SB-C8 (2.1.times.75 mm) column. The system temperature was set to 60.degree. C. and the eluent was monitored by UV (220 nM and 280 nM). A 20-minute gradient from 20% to 45% acetonitrile in water (with 0.1% TFA modifier) was utilized: T=0 min:25% acetonitrile; T=2 min:25% acetonitrile; T=19 min:45% acetonitrile; and T=20 min:25% acetonitrile. Using these conditions, the HC and LC of the antibody were baseline separated. The results of this analysis indicate that the LC remains largely unmodified (except for T(kK183C) and T(LCQ05) containing antibodies) while the HC is modified (data not shown).
[0253] E. Hydrophobic Interaction Chromatography (HIC)
[0254] Compounds were prepared for HIC analysis by diluting samples to approximately 1 mg/ml with PBS. The samples were analyzed by auto-injection of 15 .mu.l onto an Agilent 1200 HPLC with a TSK-GEL Butyl NPR column (4.6.times.3.5 mm, 2.5 .mu.m pore size; Tosoh Biosciences part #14947). The system includes an auto-sampler with a thermostat, a column heater and a UV detector.
[0255] The gradient method was used as follows:
[0256] Mobile phase A: 1.5M ammonium sulfate, 50 mM potassium phosphate dibasic (pH7); Mobile phase B: 20% isopropyl alcohol, 50 mM potassium phosphate dibasic (pH 7); T=0 min. 100% A; T=12 min., 0% A.
[0257] Retention times are shown in Table 13. Selected spectra are shown in FIGS. 2A-2E. ADCs using site-specific conjugation (T(kK183C+K290C)-vc0101, T(K334C+K392C)-vc0101 and T(LCQ05+K222R)-AcLysvc0101) (FIGS. 1A-1C) showed primarily one peak while ADCs using conventional conjugation (T-vc0101 and T-DM1) (FIGS. 2D-2E) showed a mixture of differentially loaded conjugates.
TABLE-US-00013 TABLE 13 ADC retention times by hydrophobic interaction chromatography (HIC) ADC RT (min) RRT T-vc0101 8.8 .+-. 0.1 1.68 T(.kappa.K183C)-vc0101 7.2 .+-. 0.1 1.40 T(K334C)-vc0101 ND T(K392C)-vc0101 6.7 .+-. 0.1 1.29 T(L443C)-vc0101 10.1 .+-. 0.1 1.98 T(.kappa.K183C + K290C)-vc0101 9.0 .+-. 0.0 1.77 T(.kappa.K183C + K334C)-vc0101 ND T(.kappa.K183C + K392C)-vc0101 7.7 .+-. 0.1 1.54 T(.kappa.K183C + L443C)-vc0101 10.6 2.04 T(K290C + K334C)-vc0101 6.3 .+-. 0.0 1.21 T(K290C + K392C)-vc0101 7.8 .+-. 0.0 1.54 T(K334C + K392C)-vc0101 6.0 .+-. 0.3 1.18 T(K392C + L443C)-vc0101 10.8 .+-. 0.0 2.08 T(LCQ05 + K222R)-AcLys-vc0101 6.5 1.27 T(N297A + K222R + LCQ05)-AcLys-vc0101 6.3 .+-. 0.1 1.24 ND = not determined RT = retention time (min) on HIC RRT = mean relative retention time, calculated by RT of ADC divided by RT of benchmark unconjugated wild type trastuzumab having a typical retention time of 5.0-5.2 min
[0258] F. Thermostability
[0259] Differential Scanning calorimetry (DCS) was used to determine the thermal stability of the engineered cysteine and transglutaminase antibody variants, and corresponding Aur-06380101 site-specific conjugates. For this analysis, samples formulated in PBS-CMF pH 7.2 were dispensed into the sample tray of a MicroCal VP-Capillary DSC with Autosampler (GE Healthcare Bio-Sciences, Piscataway, N.J.), equilibrated for 5 minutes at 10.degree. C. and then scanned up to 110.degree. C. at a rate of 100.degree. C. per hour. A filtering period of 16 seconds was selected. Raw data was baseline corrected and the protein concentration was normalized. Origin Software 7.0 (OriginLab Corporation, Northampton, Mass.) was used to fit the data to an MN2-State Model with an appropriate number of transitions.
[0260] All single and double cysteine engineered antibody variants as well as the engineered LCQ05 acyl donor glutamine-containing tag antibody exhibited excellent thermal stability as determined by the first melting transition (Tm1) >65.degree. C. (Table 14).
[0261] Trastuzumab derived monoclonal antibodies conjugated to 0101 using site specific conjugation methods were also evaluated and shown to have exceptional thermal stability as well (Table 15). However, the Tm1 for T(K392C+L443C)-vc0101 ADC was most impacted by conjugation of the payload since it was -4.35.degree. C. relative to the unconjugated antibody.
[0262] Taken together these results demonstrated that both the engineered cysteine and acyl donor glutamine-containing tag antibody variants were thermally stable and that site-specific conjugation of 0101 via a vc linker yielded conjugates with excellent thermal stability. Furthermore, the lower thermal stability observed for T(K392C+L443C)-vc0101 relative to the unconjugated antibody indicated that conjugation of 0101 via a vc linker to certain combinations of engineered cysteine residues can impact stability of the ADC.
TABLE-US-00014 TABLE 14 Thermal Stability of Engineered Trastuzumab Derived Variants Antibody Tm1 (.degree. C.) Tm2 (.degree. C.) Tm3 (.degree. C.) T(.kappa.K183C) 72.17 .+-. 0.029 80.78 .+-. 0.37 82.81 .+-. 0.055 T(L443C) 72.02 .+-. 0.06 80.98 .+-. 1.10 82.96 .+-. 0.11 T(LCQ05) 72.22 .+-. 0.027 81.16 .+-. 0.19 82.88 .+-. 0.033 T(.kappa.K183C + K290C) 75.4 81.1 82.9 T(.kappa.K183C + K392C) 75 81 83 T(.kappa.K183C + L443C) 72.24 .+-. 0.05 80.89 .+-. 0.89 82.87 .+-. 0.16 T(K290C + K334C) 75.0 .+-. 0.14 83.0 .+-. 0.1 81.1 .+-. 0.4 T(K334C + K392C) 75.3 .+-. 0.25 82.7 .+-. 0.53 81.0 .+-. 2.9 T(K290C + K392C) 77 81 83 T(K392C + L443C) 73.95 .+-. 0.29 80.54 .+-. 0.70 82.81 .+-. 0.17
TABLE-US-00015 TABLE 15 Thermal Stability of Site-Specific Conjugates Conjugated to Auristatin 0101 Tm1.sub.SSC - Site-Specific Conjugate Tm1 (.degree. C.) Tm2 (.degree. C.) Tm3 (.degree. C.) Tm1.sub.Ab T(.kappa.K183C)-vc0101 70.16 .+-. 80.45 .+-. 82.04 .+-. -2.01 0.03 0.12 0.03 T(L443C)-vc0101 72.34 .+-. 80.20 .+-. 82.44 .+-. 0.32 0.10 0.59 0.10 T(.kappa.K183C + L443C)- 70.11 .+-. 78.89 .+-. 81.38 .+-. -2.13 vc0101 0.02 0.59 0.10 T(K392C + L443C)- 69.60 .+-. 79.21 .+-. 82.10 .+-. -4.35 vc0101 0.35 0.43 0.05
Example 8: ADC Binding to HER2
[0263] A. Direct Binding
[0264] BT474 cells (HTB-20) were trypsinized, spun down and re-suspended in fresh media. The cells were then incubated with a serial of dilutions of either the ADCs or unconjugated trastuzumab with starting concentration of 1 pg/ml for one hour at 4.degree. C. The cells were then washed twice with ice cold PBS and incubated with anti-human Alexafluor 488 secondary antibody (Cat# A-11013, Life technologies) for 30 min. The cells were then washed twice and then re-suspended in PBS. The mean fluorescence intensity was read using Accuri flow cytometer (BD Biosciences San Jose, Calif.).
TABLE-US-00016 TABLE 16 ADC binding to HER2 ADC/Ab EC.sub.50 trastuzumab 0.37 T(.kappa.K183C + K392C)-vc0101 0.56 T(.kappa.K183C + K290C)-vc0101 0.47 T(K290C + K392C)-vc0101 0.32 T-DM1 (Kadcyla) 0.40 T(LCQ05 + K222R)-AcLysvc0101 0.37 T(N297Q + K222R)-AcLysvc0101 0.36 EC50 = the concentration of an antibody or ADC that gives half-maximal binding.
[0265] As shown in FIG. 3A and Table 16, ADCs T(LCQ05+K222R)-AcLysvc0101, T(N297Q+K222R)-AcLysvc0101, T(kK183C+K290C)-vc0101, T(kK183C+K392C)-vc0101, T(K290C+K392C)-vc0101 had similar binding affinities as T-DM1 and trastuzumab by direct binding. This indicates that the modifications to the antibody in the ADCs of the present invention and the addition of the linker-payload did not significantly affect binding.
[0266] B. Competitive Binding by FACS
[0267] BT474 cells were trypsinized, spun down and re-suspended in fresh media. The cells were then incubated for one hour at 4.degree. C. with serial dilutions of either the ADCs or the unconjugated trastuzumab combined with 1 .mu.g/mL of trastuzumab-PE (custom synthesized 1:1 PE labeled trastuzumab by eBiosciences (San Diego, Calif.)). The cells were then washed twice and then re-suspended in PBS. The mean fluorescence intensity was read using Accuri flow cytometer (BD Biosciences San Jose, Calif.).
[0268] As shown in FIG. 3B, ADCs T(LCQ05+K222R)-AcLysvc0101, T(N297Q+K222R)-AcLysvc0101, T(kK183C+K290C)-vc0101, T(kK183C+K392C)-vc0101, T(K290C+K392C)-vc0101 had similar binding affinities as T-DM1 and trastuzumab by competition binding to PE labeled trastuzumab. This indicates that the modifications to the antibody in the ADCs of the present invention and the addition of the linker-payload did not significantly affect binding.
Example 9: ADC Binding to Human FcRn
[0269] It is believed in the art that FcRn interacts with IgG regardless of subtype in a pH dependent manner and protects the antibody from degradation by preventing it from entering the lysosomal compartment where it is degraded. Therefore, a consideration for selecting positions for introduction of reactive cysteines into the wild type IgG1-Fc region was to avoid altering the FcRn binding properties and half-life of the antibody comprising the engineered cysteine.
[0270] BIAcore.RTM. analysis was performed to determine the steady-state affinity (KD) for the trastuzumab derived monoclonal antibodies and their respective ADCs for binding to human FcRn. BIAcore.RTM. technology utilizes changes in the refractive index at the surface layer of a sensor upon binding of the trastuzumab derived monoclonal antibodies or their respective ADCs to human FcRn protein immobilized on the layer. Binding was detected by surface plasmon resonance (SPR) of laser light refracting from the surface. Human FcRn was specifically biotinylated through an engineered Avi-tag using the BirA reagent (Catalog #: BIRA500, Avidity, LLC, Aurora, Colo.) and immobilized onto a streptavidin (SA) sensor chip to enable uniform orientation of the FcRn protein on the sensor. Next, various concentrations of the trastuzumab derived monoclonal antibodies or their respective ADCs or in 20 mM MES (2-(N-morpholino)ethanesulfonic acid pH 6.0, with 150 mM NaCl, 3 mM EDTA (ethylenediaminetetraacetic acid), 0.5% Surfactant P20 (MES-EP) were injected over the chip surface. The surface was regenerated using HBS-EP+0.05% Surfactant P20 (GE Healthcare, Piscataway, N.J.), pH 7.4, between injection cycles. The steady-state binding affinities were determined for the trastuzumab derived monoclonal antibodies or their respective ADCs, and these were compared with the wild type trastuzumab antibody (comprising no cysteine mutations in the IgG1 Fc region, no TGase engineered tag or site-specific conjugation of a payload).
[0271] These data demonstrated that incorporation of engineered cysteine residues into the IgG-Fc region at the indicated positions of the invention did not alter affinity to FcRn (Table 17).
TABLE-US-00017 TABLE 17 Steady-State Affinities of Site-Specific Conjugates Binding Human FcRn KD [nM] KD [nM] KD [nM] Experiment 1 Experiment 2 Experiment 3 Trastuzumab WT 1050.0 705.8 859.2 T-DM1 ND 500.8 ND T(K290C + K334C) 987.0 ND ND T(K290C + K334C)-vc0101 1218.0 ND ND T(K334C + K392C) 834.1 ND ND T(K334C + K392C)-vc0101 1404.0 ND ND T(.kappa.K183C + K290C) 1173.0 ND ND T(.kappa.K183C + K290C)-vc0101 473.8 ND ND T(.kappa.K183C + K392C) 1009.0 ND ND T(.kappa.K183C + K392C)-vc0101 672.5 ND ND T(.kappa.K183C)-vc0101 961.5 ND ND T(LCQ05) 900.9 ND ND T(LCQ05)-vc0101 1050.0 ND ND T(K392C) ND 468.3 ND T(K392C)-vc0101 ND 518.8 ND T(N297Q)-vc0101 ND 647.9 ND T(.kappa.K183C + K334C)-vc0101 ND 416.5 ND T(.kappa.K183C + K443C) ND 542.8 ND T(.kappa.K183C + K443C)-vc0101 ND 287.5 ND T(K290C) ND ND 650.3 T(K290C)-vc0101 ND ND 874.6 T(K290C + K392C)-vc0101 ND ND 554.7 T(K334C) ND ND 631.6 T(K334C)-vc0101 ND ND 791.2 T(K392C + K443C) ND ND 601.7 T(K392C + K443C)-vc0101 ND ND 197.9 ND = Not Determined
Example 10: ADC Binding to Fc.gamma. Receptors
[0272] Binding of the ADCs using site-specific conjugation to human Fc-.gamma. receptors was evaluated in order to understand if conjugation to a payload alters binding which can impact antibody related functionality properties such as antibody-dependent cell-mediated cytotoxicity (ADCC). Fc.gamma.IIIa (CD16) is expressed on NK cells and macrophages, and co-engagement of this receptor with the target expressing cells via antibody binding induces ADCC. BIAcore.RTM. analysis was used to examine binding of the trastuzumab derived monoclonal antibodies and their respective ADCs to Fc-.gamma. receptors IIa (CD32a), IIb(CD32b), IIIa (CD16) and Fc.gamma.RI (CD64).
[0273] For this surface plasmon resonance (SPR) assay, recombinant human epidermal growth factor receptor 2 (Her2/neu) extra-cellular domain protein (Sino Biological Inc., Beijing, P.R. China) was immobilized on a CM5 chip (GE Healthcare, Piscataway, N.J.) and .about.300-400 response units (RU) of either a trastuzumab derived monoclonal antibody or its respective ADC was captured. The T-DM1 was included in this evaluation as a positive control since it has been shown to retain binding properties post-conjugation to Fc.gamma. receptors comparable to the unconjugated trastuzumab antibody. Next, various concentrations of the Fc.gamma. receptors Fc.gamma.IIa (CD32a), Fc.gamma.IIb(CD32b), Fc.gamma.IIIa (CD16a) and Fc.gamma.RI (CD64) were injected over the surface and binding was determined.
[0274] Fc.gamma.Rs IIa, IIb and IIIa exhibited rapid on/off rates and therefore the sensorgrams were fit to steady state model to obtain Kd values. Fc.gamma.RI exhibited slower on/off rates so data was fit to a kinetic model to obtain Kd values.
[0275] Conjugation of payload at the engineered cysteine positions 290 and 334 showed a moderate loss in Fc.gamma.R affinity, specifically to CD16a, CD32a and CD64 compared to their unconjugated counterpart antibodies and T-DM1 (Table 18). However, simultaneous conjugation at sites 290, 334 and 392 resulted in a substantial loss of affinity to CD16a, CD32a and CD32b, but not CD64 as observed with the T(K290C+K334C)-vc0101 and T(K334C+K392C)-vc0101 (Table 18). Interestingly, T(.kappa.K183C+K290C)-vc0101 exhibited comparable binding to all Fc.gamma.R evaluated in this study despite harboring drug payload on the K290C position (Table 18). As expected the transglutaminase mediated conjugated T(N297Q+K222R)-AcLysvc0101 did not bind to any of the Fc.gamma. receptors evaluated since location of the acyl donor glutamine-containing tag removes N-linked glycosylation. Contrary, T(LCQ05+K222R)-AcLysvc0101 retained full binding to the Fc.gamma. receptors as the glutamine-containing tag is engineered within the human Kappa light chain constant region.
[0276] Taken together, these results suggested that location of the conjugated payload can impact binding of the ADC to Fc.gamma.R and may impact the antibody functionality of the conjugate.
TABLE-US-00018 TABLE 18 Binding Affinity of Site-Specific Conjugates for Fc.gamma. Receptors binding to the CD16a, CD32a, CD32b and CD64 K.sub.D [M] Fc.gamma.RIIIa Fc.gamma.RIIa Fc.gamma.RIIb Fc.gamma.RI (CD16a) (CD32a) (CD32b) (CD64) [.mu.M] [.mu.M] [.mu.M] [pM] Trastuzumab WT mAb 0.36 0.74 4.08 23 T-DM1 ADC 0.30 0.53 2.97 27 T(K290C)-vc0101 1.20 1.70 3.74 185 T(K334C)-vc0101 0.81 1.42 4.74 ND T(K290C + K334C)-vc0101 5.14 6.30 6.38 110 T(K334C + K392C)-vc0101 2.38 4.18 11.30 43 T(K392C)-vc0101 0.45 0.73 4.33 ND T(.kappa.K183C + K290C)-0101 0.47 0.70 3.63 37 T(LCQ05 + K222R)-AcLysvc0101 0.43 0.62 3.41 32 T(N297Q - K222R)-AcLysvc0101 NB NB NB NB ND = Not Determined, NB = No Binding
Example 11: ADCC Activities
[0277] In ADCC assays, Her2-expressing cell lines BT474 and SKBR3 were used as target cells while NK-92 cells (an interleukin-2 dependent natural killer cell line derived from peripheral blood mononuclear cells from a 50 year old Caucasian male by Conkwest) or human peripheral blood mononucleocytes (PBMC) isolated from the freshly drawn blood from a healthy donor (#179) were used as effector cells.
[0278] Target cells (BT474 or SKBR3) of 1.times.10.sup.4 cells/100 .mu.l/well were placed in 96-well plate and cultured overnight in RPMI1640 media at 37.degree. C./5% CO.sub.2. The next day, the media was removed and replaced with 60 .mu.l assay buffer (RPMI1640 media containing 10 mM HEPES), 20 .mu.l of 1 .mu.g/ml antibody or ADC, followed by addition of 20 .mu.l 1.times.10.sup.5 (for SKBR3) or 5.times.10.sup.5 (for BT474) PBMC suspension or 2.5.times.10.sup.5 NK92 cells for both cell lines to each well to achieve effector to target ratio of 50:1 for BT474 or of 25:1 for SKBR3 for PBMC, 10:1 for NK92. All samples were run in triplicate.
[0279] Assay plates were incubated at 37.degree. C./5% CO.sub.2 for 6 hours and then equilibrated to room temperature. LDH release from cell lysis was measured using CytoTox-One.TM. reagent at an excitation wavelength of 560 nm and an emission wavelength of 590 nm. As a positive control, 8 .mu.L of Triton was added to generate a maximum LDH release in control wells. The specific cytotoxicity shown in FIG. 4 was calculated using the following formula:
% Specific Cytotoxicity = Experimental - effector spontaneous - target spontaneous Target maximum - Target spontaneous .times. 100 ##EQU00001##
[0280] "Experimental" corresponds to the signal measured in one of the condition described above.
[0281] "Effector spontaneous" corresponds to the signal measured in the presence of PBMC alone.
[0282] "Target spontaneous" corresponds to the signal measured in the presence of target cells alone.
[0283] "Target Maximum" corresponds to the signal measured in the presence of detergent-lysed target cells alone.
[0284] FIG. 4 shows the ADCC activities tested for trastuzumab, T-DM1 and vc0101 ADC conjugates. The data conform the reported ADCC activities of Trastuzumab and T-DM1. Since the mutation of N297Q is at the glycosylation site, T(N297Q+K222R)-AcLysvc0101 was not expected to have ADCC activities which was also confirmed in the assays. For single mutant (K183C, K290C, K334C, K392C including LCQ05) ADCs, ADCC activities were maintained. Surprisingly, for double mutant (K183C+K290C, K183C+K392C, K183C+K334C K290C+K392C, K290C+K334C, K334C+K392C) ADCs, ADCC activities were maintained in all except two double mutant ADCs associated with K334C site (K290C+K334C and K334C+K392C).
Example 12: In Vitro Cytotoxicity Assays
[0285] Antibody-drug conjugates were prepared as indicated in Example 3. Cells were seeded in 96-well plates at low density, then treated the following day with ADCs and unconjugated payloads at 3-fold serial dilutions at 10 concentrations in duplicate. Cells were incubated for 4 days in a humidified 37.degree. C./5% CO.sub.2 incubator. The plates were harvested by incubating with CellTiter.RTM. 96 AQueous One MTS Solution (Promega, Madison, Wis.) for 1.5 hours and absorbance measured on a Victor plate reader (Perkin-Elmer, Waltham, Mass.) at wavelength 490 nm. IC.sub.50 values were calculated using a four-parameter logistic model with XLfit (IDBS, Bridgewater, N.J.) and reported as nM payload concentration in FIG. 5 and ng/ml antibody concentration in FIG. 6. The IC.sub.50 are shown +/-the standard deviation with the number of independent determinations in parenthesis.
[0286] The ADCs containing vc-0101 or AcLysv-0101 linker-payloads were highly potent against Her2-positive cell models and selective against Her2-negative cells, compared with the benchmark ADC, T-DM1 (Kadcyla).
[0287] ADCs synthesized with site-specific conjugation to trastuzumab showed high level potency and selectivity against Her2 cell models. Notably, several trastuzumab-vc0101 ADCs are more potent than T-DM1 in moderate or low Her2-expressing cell models. For example, the in vitro cytotoxicity IC.sub.50 for T(kK183C+K290C)-vc0101 in MDA-MB-175-VII cells (with 1+Her2 expression) is 351 ng/ml, compared with 3626 ng/ml for T-DM1 (.about.10-fold lower). For cells with 2++ level Her2 expression such as MDA-MB-361-DYT2 and MDA-MB-453 cells, the IC.sub.50 for T(kK183C+K290C)-vc0101 is 12-20 ng/ml, compared with 38-40 ng/ml for T-DM1.
Example 13: Xenograft Models
[0288] Trastuzumab derived ADCs of the invention tested in an N87 gastric cancer xenograft model, 37622 lung cancer xenograft model, and a number of breast cancer xenograft models (i.e., HCC 1954, JIMT-1, MDA-MB-361(DYT2) and 144580 (PDX) models). For each model described below the first dose was given on Day 1. The tumors were measured at least once a week and their volume was calculated with the formula: tumor volume (mm.sup.3)=0.5.times.(tumor width.sup.2)(tumor length). The mean tumor volumes (.+-.S.E.M.) for each treatment group were calculated having a maximum of 8-10 animals and a minimum of 6-8 animals to be included.
[0289] A. N87 Gastric Xenografts
[0290] The effects of Trastuzumab derived ADCs were examined in immunodeficient mice on the in vivo growth of human tumor xenografts that were established from the N87 cell line (ATCC CRL-5822) which has high level HER2 expression. To generate xenografts, nude (Nu/Nu, Charles River Lab, Wilmington, Mass.) female mice were implanted subcutaneously with 7.5.times.10.sup.6 N87 cells in 50% Matrigel (BD Biosciences). When the tumors reached a volume of 250 to 450 mm.sup.3, the tumors were staged to ensure uniformity of the tumor mass among various treatment groups. The N87 gastric model was dosed 4 times intravenously 4 days apart (Q4dx4) with PBS vehicle, Trastuzumab ADCs (at 0.3, 1 and 3 mg/kg) or T-DM1 (1, 3 and 10 mg/kg) (FIG. 7).
[0291] The data demonstrates that Trastuzumab derived ADCs inhibited growth of N87 gastric xenografts in a dose-dependent manner (FIGS. 7A-7H).
[0292] As illustrated in FIG. 7I, T-DM1 had delayed tumor growth at 1 and 3 mg/kg and had complete regression of tumors at 10 mg/kg. However, T(kK183C+K290C)-vc0101 provided complete regression at 1 and 3 mg/kg and partial regression at 0.3 mg/kg (FIG. 7A). The data shows that T(kK183C+K290C)-vc0101 is significantly more potent (.about.10 times) than T-DM1 in this model.
[0293] Similar in vivo efficacy from ADCs with DAR4 (FIGS. 6E, 6F and 6G) were obtained compared to 183+290 (FIG. 7A). In addition, single mutants were evaluated that are DAR2 ADCs (FIGS. 7B, 7C and 7D). In general, these ADCs are less efficacious compared to DAR4 ADCs but more efficacious than T-DM1. Among DAR2 ADCs, it appears LCQ05 is the most potent ADC based on the in vivo efficacy data.
[0294] B. HCC1954 Breast Xenografts
[0295] HCC1954 (ATCC# CRL-2338) is a high HER2 expression breast cancer cell line. To generate xenografts, SHO female mice (Charles River, Wilmington, Mass.) were implanted subcutaneously with 5.times.10.sup.6 HCC1954 cells in 50% Matrigel (BD Biosciences). When the tumors reached a volume of 200 to 250 mm.sup.3, the tumors were staged to ensure uniformity of the tumor mass among various treatment groups. The HCC1954 breast model was dosed intravenously Q4dx4 with PBS vehicle, Trastuzumab derived ADCs and negative control ADC (FIGS. 8A-8E).
[0296] The data demonstrates that Trastuzumab ADCs inhibited growth of HCC1954 breast xenografts in a dose-dependent manner. Comparing the 1 mg/kg dose, vc0101 conjugates were more efficacious than T-DM1. Comparing the 0.3 mg/kg dose, DAR4 loaded ADCs (FIGS. 8B, 8C and 8D) are more efficacious than a DAR2 loaded ADC (FIG. 8A). Further, the negative control ADC at 1 mg/kg had very minimal impact on tumor growth compared to vehicle control (FIG. 8D). However, T(N297Q+K222R)-AcLysvc0101 completely regressed the tumors indicating the target specificity.
[0297] C. JIMT-1 Breast Xenografts
[0298] JIMT-1 is a breast cancer cell line expressing moderate/low Her2 and is inherently resistant to trastuzumab. To generate xenografts, nude (Nu/Nu) female mice were implanted subcutaneously with 5.times.10.sup.6 JIMT-1 cells (DSMZ# ACC-589) in 50% Matrigel (BD Biosciences). When the tumors reached a volume of 200 to 250 mm.sup.3, the tumors were staged to ensure uniformity of the tumor mass among various treatment groups. The JIMT-1 breast model was dosed intravenously Q4dx4 with PBS vehicle, T-DM1 (FIG. 9G), trastuzumab derived ADCs using site specific conjugation (FIGS. 9A-9E), trastuzumab derived ADC using conventional conjugation (FIG. 9F) and negative control huNeg-8.8 ADC.
[0299] The data demonstrates that all the tested vc0101 conjugates cause tumor reduction in a dose-dependent manner. These ADCs can cause tumor regression at 1 mg/kg. However, T-DM1 is inactive in this moderate/low Her2 expressing model even at 6 mg/kg.
[0300] D. MDA-MB-361(DYT2) Breast Xenografts
[0301] MDA-MB-361(DYT2) is a breast cancer cell line expressing moderate/low Her2. To generate xenografts, nude (Nu/Nu) female mice were irradiated at 100 cGy/min for 4 minutes and three days later implanted subcutaneously with 1.0.times.10.sup.7 MDA-MB-361(DYT2) cells (ATCC# HTB-27) in 50% Matrigel (BD Biosciences). When the tumors reached a volume of 300 to 400 mm.sup.3, the tumors were staged to ensure uniformity of the tumor mass among various treatment groups. The DYT2 breast model was dosed intravenously Q4dx4 with PBS vehicle, trastuzumab derived ADCs using site specific and conventional conjugation, T-DM1 and negative control ADC (FIGS. 10A-10D).
[0302] The data demonstrates that trastuzumab ADCs inhibited growth of DYT2 breast xenografts in a dose-dependent manner. Although DYT2 is moderate/low Her2 expression cell lines, it is more sensitive to micro-tubule inhibitors than other Her2 low/moderate expressing cell lines.
[0303] E. 144580 Patient-Derived Breast Cancer Xenografts
[0304] The effects of Trastuzumab derived ADCs were examined in immunodeficient mice on the in vivo growth of human tumor xenografts that were established from fragments of freshly resected 144580 breast tumors obtained in accordance with appropriate consent procedures. The tumor characterization of 144580 when fresh biopsy was taken was as a triple negative (ER-, PR-, and HER2-) breast cancer tumor. The 144580 breast patient-derived xenografts were subcutaneously passaged in vivo as fragments from animal to animal in nude (Nu/Nu) female mice. When the tumors reached a volume of 150 to 300 mm.sup.3, they were staged to ensure uniformity of the tumor size among various treatment groups. The 144580 breast model was dosed intravenously four times every four days (Q4dx4) with PBS vehicle, trastuzumab ADCs using site specific conjugation, trastuzumab derived ADC using conventional conjugation and negative control ADC (FIGS. 11A-11E).
[0305] In this HER2- (by clinical definition) PDX model, T-DM1 was ineffective at all doses tested (1, 5, 3 and 6 mg/kg) (FIG. 10E). For DAR4 vc0101 ADCs (FIGS. 11A, 11C and 11D), 3 mg/kg is able to cause tumor regression (even at 1 mg/kg in FIG. 11C). The DAR2 vc0101 ADC (FIG. 11B) is less efficacious than DAR4 ADCs at 3 mg/kg. However, the DAR 2 vc0101 ADC is efficacious at 6 mg/kg unlike T-DM1.
[0306] F. 37622 Patient-Derived Non-Small Cell Lund Cancer Xenograft
[0307] Several ADCs were tested in patient-derived Non-Small Cell Lung Cancer xenograft model of 37622 obtained in accordance with appropriate consent procedures. The 37622 patient-derived xenografts were subcutaneously passaged in vivo as fragments from animal to animal in nude (Nu/Nu) female mice. When the tumors reached a volume of 150 to 300 mm.sup.3, they were staged to ensure uniformity of the tumor size among various treatment groups. The 37622 PDX model was dosed intravenously four times every four days (Q4dx4) with PBS vehicle, trastuzumab derived ADCs using site specific conjugation, T-DM1 and negative control ADC (FIGS. 12A-12D).
[0308] Expression of Her2 was profiled by modified Hercept test and was classified as 2+ with more heterogeneity than seen in cell lines. The ADCs conjugated with vc0101 as a linker-payload (FIGS. 12A-12C) were efficacious at 1 and 3 mg/kg causing tumor regression. However, T-DM1 only provided some therapeutic benefit at 10 mg/kg (FIG. 12D). It appears vc0101 ADCs are 10-times more potent than T-DM1 by comparing results at 10 mg/kg from T-DM1 to 1 mg/kg from vc0101 ADCs. It is possible that the bystander effect is important for efficacy for a heterogeneic tumor.
[0309] G. GA0044 Patient-Derived Gastric Cancer Xenograft
[0310] Trastuzumab and anti-HER2 ADCs were tested in a patient-derived Gastric xenograft model (GA0044) obtained in accordance with appropriate consent procedures. The GA0044 patient-derived xenografts were subcutaneously passaged in vivo as fragments from animal to animal in nude (Nu/Nu) female mice. When the tumors reached a volume of 150 to 300 mm.sup.3, they were staged to ensure uniformity of the tumor size among various treatment groups. The GA0044 PDX model was dosed intravenously four times every four days (Q4dx4) with PBS vehicle, trastuzumab, T-DM1or a trastuzumab derived ADC using site-specific conjugation to vc0101 (FIG. 30).
[0311] Expression of HER2 in GA0044 was profiled by modified Hercept test and was classified as 2+ with heterogeneous distribution. The ADC conjugated with vc0101 as the payload (namely, T(kK183C+K290C)-vc0101) was efficacious and resulted in complete tumor regressions at 1 and 3 mg/kg doses. Trastuzumab and T-DM1 showed no appreciable difference in tumor growth as compared to vehicle treated tumors. It is possible that the bystander effect is important for efficacy in this tumor with heterogenous target (i.e. HER2) expression.
[0312] H. Demonstration of Bystander Effect of T-vc0101 ADC in N87 Gastric Xenograft
[0313] The released metabolite of the T-DM1 ADC has been shown to be the lysine-capped mcc-DM1 linker payload (i.e., Lys-mcc-DM1) which is a membrane impermeable compound (Kovtun et al., 2006, Cancer Res 66:3214-21; Xie et al., 2004, J Pharmacol Exp Ther 310:844). However, the released metabolite from the T-vc0101 ADC is auristatin 0101, a compound with more membrane permeability than Lys-mcc-DM1. The ability of a released ADC payload to kill neighboring cells is known as the bystander effect. Due to a release of a membrane permeable payload, T-vc0101 is able to elicit a strong bystander effect whereas T-DM1 is not. FIG. 13 shows immunohistocytochemistry from N87 cell line xenograft tumors which received a single dose of either T-DM1 at 6 mg/kg (FIG. 13A) or T-vc0101 at 3 mg/kg (FIG. 13B) and then harvested and processed in formalin fixation 96 hours later. Tumor sections were stained for human IgG to detect ADC bound to tumor cells and phospho-histone H3 (pHH3) to detect mitotic cells as a readout of the proposed mechanism of action for the payloads of both ADCs.
[0314] ADC is detected in the periphery of the tumors in both cases. In T-DM1 treated tumors (FIG. 13A), the majority of pHH3 positive tumor cells are located near the ADC. However, in T-vc0101 treated tumors (FIG. 13B), the majority of pHH3 positive tumor cells extend beyond the location of the ADC (black arrows highlight a few examples) and are in the tumor interior. These data suggest that an ADC with a cleavable linker and a membrane permeable payload can elicit a strong bystander effect in vivo.
Example 14: In Vitro T-DM1 Resistance Models
[0315] A. Generation of T-DM1 Resistant Cells In Vitro
[0316] N87 cells were passaged into two separate flasks and each flask was treated identically with respect to the resistance-generation protocol to enable biological duplicates. Cells were exposed to five cycles of T-DM1 conjugate at approximately IC.sub.80 concentrations (10 nM payload concentration) for 3 days, followed by approximately 4 to 11 days recovery without treatment. After the five cycles at 10 nM of the T-DM1 conjugate, the cells were exposed to six additional cycles of 100 nM T-DM1 in a similar fashion. The procedure was intended to simulate the chronic, multi-cycle (on/off) dosing at maximally tolerated doses typically used for cytotoxic therapeutics in the clinic, followed by a recovery period. Parental cells derived from N87 are referred to as N87, and cells chronically exposed to T-DM1 are referred to as N87-TM. Moderate- to high-level drug resistance developed within 4 months for N87-TM cells. Drug selection pressure was removed after .about.3-4 months of cycle treatments when the level of resistance no longer increased after continued drug exposure. Responses and phenotypes remained stable in the cultured cell lines for approximately 3-6 months thereafter. Thereafter, a reduction in the magnitude of the resistance phenotype as measured by cytotoxicity assays was occasionally observed, in which case early passage cryo-preserved T-DM1 resistant cells were thawed for additional studies. All reported characterizations were conducted after removal of T-DM1 selection pressure for at least 2-8 weeks to ensure stabilization of the cells. Data were collected from various thawed cryopreserved populations derived from a single selection, over approximately 1-2 years after model development to ensure consistency in the results. The gastric cancer cell line N87 was selected for resistance to trastuzumab-maytansinoid antibody-drug conjugate (T-DM1) by treatment cycles at doses that were approximately the IC.sub.80 (.about.10 nM payload concentration) for the respective cell line. Parental N87 cells were inherently sensitive to the conjugate (IC.sub.50=1.7 nM payload concentration; 62 ng/ml antibody concentration) (FIG. 14). Two populations of parental N87 cells were exposed to the treatment cycles and, after only approximately four months exposure cycling at 100 nM T-DM1, these two populations (henceforth named N87-TM-1 and N87-TM-2) became refractory to the ADC by 114- and 146-fold, respectively, compared with parental cells (FIG. 14 and FIG. 15A). Interestingly, minimal cross-resistance (.about.2.2-2.5.times.) to the corresponding unconjugated maytansinoid free drug, DM1, was observed (FIG. 14).
[0317] B. Cytotoxicity Studies
[0318] ADCs were prepared as indicated in Example 3. Unconjugated maytansine analog (DM1) and auristatin analogs were prepared by Pfizer Worldwide Medicinal Chemistry (Groton, Conn.). Other standard-of-care chemotherapeutics were purchased from Sigma (St. Louis, Mo.). Cells were seeded in 96-well plates at low density, then treated the following day with ADCs and unconjugated payloads at 3-fold serial dilutions at 10 concentrations in duplicate. Cells were incubated for 4 days in a humidified 37.degree. C./5% CO.sub.2 incubator. The plates were harvested by incubating with CellTiter.RTM. 96 AQueous One MTS Solution (Promega, Madison, Wis.) for 1.5 hours and absorbance measured on a Victor plate reader (Perkin-Elmer, Waltham, Mass.) at wavelength 490 nm. IC.sub.50 values were calculated using a four-parameter logistic model with XLfit (IDBS, Bridgewater, N.J.).
[0319] The cross-resistance profile to other trastuzumab derived ADCs was determined. Significant cross-resistance to many trastuzumab derived ADCs composed of non-cleavable linkers and delivering payloads with anti-tubulin mechanisms of action was observed (FIG. 14). For example, in N87-TM vs. N87-parental cells, >330- and >272-fold reduced potency was observed to T-mc8261 (FIG. 14 and FIG. 15B) and T-MalPeg8261 (FIG. 14), which represent an auristatin-based payload linked to trastuzumab via non-cleavable maleimidocaproyl or Mal-PEG linkers, respectively. Over 235-fold resistance was observed in N87-TM cells against T-mcMalPegMMAD, another trastuzumab ADC with a different non-cleavable linker delivering monomethyl dolastatin (MMAD) (FIG. 14).
[0320] Remarkably, it was observed that the N87-TM cell line retained sensitivity to payloads when delivered via a cleavable linker, even though these drugs functionally inhibit similar targets (i.e., microtubule depolymerization). Examples of ADCs which overcome resistance include, but are not limited to, T(N297Q+K222R)-AcLysvc0101 (FIG. 14 and FIG. 15C), T(LCQ05+K222R)-AcLysvc0101 (FIG. 14 and FIG. 15D), T(K290C+K334C)-vc0101 (FIG. 10 and FIG. 11E), T(K334C+K392C)-vc0101 (FIG. 14 and FIG. 15F) and T(kK183C+K290C)-vc0101 (FIG. 14 and FIG. 15G). These represent trastuzumab-based ADCs delivering the auristatin analog 0101, but where the payloads are released intracellularly by proteolytic cleavage of the vc linker.
[0321] In order to determine whether these ADC-resistant cancer cells were broadly resistant to other therapies, the N87-TM cell models were treated with a panel of standard-of-care chemotherapeutics with various mechanisms of action. In general, small molecule inhibitors of microtubule and DNA function remained effective against the N87-TM resistant cell lines (FIG. 14). While these cells were made resistant against an ADC delivering an analog of the microtubule depolymerizing agent, maytansine, minimal or no cross-resistance was observed to several tubulin depolymerizing or polymerizing agents. Similarly, both cell lines retained sensitivity to agents which interfere with DNA function, including topoisomerase inhibitors, anti-metabolites, and alklyating/cross-linking agents. In general, the N87-TM cells were not refractory to a broad range of cytotoxics, ruling out generic growth or cell cycle defects which might mimic drug resistance.
[0322] Both N87-TM populations also retained sensitivity to the corresponding unconjugated drugs (i.e., DM1 and 0101; FIG. 14). Hence, N87-TM cells made refractory to a trastuzumab-maytansinoid conjugate displayed cross-resistance to other microtubule-based ADCs when delivered via non-cleavable linkers, but remained sensitive to unconjugated microtubule inhibitors and other chemotherapeutics.
[0323] To determine the molecular mechanism of resistance to T-DM1 in the N87-TM cells protein expression levels of MDR1 and MRP1 drug efflux pumps were determined. This was because small molecule tubulin inhibitors are known substrates of the MDR1 and MRP1 drug efflux pumps (Thomas and Coley, 2003, Cancer Control 10(2):159-165). The protein expression levels of these two proteins from total cell lysates of the parental N87 and N87-TM resistant cells was determined (FIG. 16). Immunoblot analysis showed that the N87-TM resistant cells do not significantly overexpress the MRP1 (FIG. 16A) or MDR1 (FIG. 16B) proteins. Taken together, these data combined with the lack of cross-resistance to known substrates of drug efflux pumps (e.g. paclitaxel, doxorubicin) in the N87-TM cells suggests that drug efflux pump overexpression is not the molecular mechanism of T-DM1 resistance in N87-TM cells.
[0324] Since the mechanism of action for ADCs requires binding to a specific antigen, antigen depletion or reduced antibody binding may account for T-DM1 resistance in N87-TM cells. To determine if the antigen for T-DM1 had been significantly depleted in N87-TM cells, HER2 protein expression levels from total cell lysates of the parental N87 and N87-TM resistant cells were compared (FIG. 17A). Immunoblot analysis showed that the N87-TM cells did not have a markedly reduced amount of HER2 protein expression compared with the parental N87 cells.
[0325] The amount of antibody binding to cell surface HER2 antigens of the N87-TM cells was determined. In a cell surface binding study using fluorescence activated cell sorting, the N87-TM cells did have .about.50% decrease in trastuzumab binding to cell surface antigens (FIG. 17B). Since N87 cells are high expressers of HER2 protein among cancer cell lines (Fujimoto-Ouchi et al., 2007, Cancer Chemother Pharmacol 59(6):795-805), a .about.50% reduction in HER2 antibody binding in these cells probably does not represent the driving mechanism of resistance to T-DM1 in N87-TM cells. Evidence supporting this interpretation is that the N87-TM resistant cells remain sensitive to other HER2 binding trastuzumab derived ADCs with different linkers and payloads (FIG. 14).
[0326] In order to determine potential mechanisms of T-DM1 resistance in an unbiased approach, the parental N87 and N87-TM resistant cell models were profiled via a proteomic approach in order to globally identify changes in membrane protein expression levels that may be responsible for T-DM1 resistance. Significant expression level changes in 523 proteins between both cell line models was observed (FIG. 18A). To validate a selection of these predicted protein changes, immunoblots on N87 and N87-TM whole cell lysates were performed for proteins predicted to be under-expressed (IGF2R, LAMP1, CTSB) (FIG. 18B) and over-expressed (CAV1) (FIG. 18C) in the N87-TM cells relative to the N87 cells. In vivo tumors were generated by subcutaneous implantation of the N87 and N87-TM-2 cells into NSG mice to assess if protein changes observed in vivo mimic those seen in vitro. N87-TM-2 tumors retained over-expression of the CAV1 protein compared with the N87 tumors (FIG. 18D). While CAV1 staining in the mouse stroma in both models is expected, epithelial CAV1 staining was only seen in the N87-TM-2 model.
[0327] C. In Vivo Efficacy Studies
[0328] In order to determine if the resistance observed in cell culture was recapitulated in vivo, parental N87 cells and N87-TM-2 cells were expanded and injected into the flanks of Female NOD scid gamma (NSG) immunodeficient mice (NOD.Cg-Prkdcscid II2rgtm1Wjl/SzJ) obtained from The Jackson Laboratory (Bar Harbor, Me.). Mice were injected subcutaneously in the right flank with suspensions of either N87 or N87-TM cells (7.5.times.10.sup.6 cells per injection, with 50% Matrigel). Mice were randomized into study groups when tumors reached .about.0.3 g (.about.250 mm.sup.3). T-DM1 conjugate or vehicle, were administered intravenously in saline on day 0 and repeated for a total of four doses, four days apart (Q4Dx4). Tumors were measured weekly and mass calculated as volume=(width.times.width.times.length)/2. Time-to-event analysis (tumor doubling) was conducted and significance evaluated by Log-rank (Mantel-Cox) test. No weight loss was observed in mice in all treatment groups in these studies.
[0329] Mice were treated with the following agents: (1) vehicle control PBS, (2) trastuzumab antibody at 13 mg/kg, followed by 4.5 mg/kg; (3) T-DM1 at 6 mg/kg; (4) T-DM1 at 10 mg/kg; (5) T-DM1 at 10 mg/kg, then T(N297Q+K222R)-AcLysvc0101 at 3 mg/kg; (6) T(N297Q+K222R)-AcLysvc0101 at 3 mg/kg. Tumor sizes were monitored and results are indicated in FIG. 20. The N87 (FIG. 19 and FIG. 20A) and N87-TM-2 (FIG. 19 and FIG. 20B) tumors showed an ADC efficacy profile similar to that seen in the in vitro cytotoxicity assays (FIGS. 19 and 20B), wherein the N87-TM drug resistant cells were refractory to T-DM1 but still responded to trastuzumab derived ADCs with cleavable linkers. In fact, tumors that were refractory to T-DM1 and grew to about 1 gram were switched to therapy with T(N297Q+K222R)-AcLysvc0101 and effectively regressed (FIG. 20B). In a time-to-event analysis of this study, T-DM1 at 6 and 10 mg/kg prevented tumor doubling in >50% of mice for at least 60 days in the N87 model, but T-DM1 failed to do so in the N87-TM-2 model (FIGS. 20C and 20D). T(N297Q+K222R)-AcLysvc0101 dosed at 3 mg/kg prevented any tumor doubling of both N87 and N87-TM tumors in the mice for the duration of the study (.about.80 days) (FIGS. 20C and 20D).
[0330] In another study, all cleavable linked ADCs that overcame T-DM1 resistance in vitro remained effective in this N87-TM2 tumor model that was non-responsive to T-DM1 (FIG. 19 and FIG. 20E).
[0331] It was then assessed whether T(kK183+K290C)-vc0101 ADC could inhibit the growth of tumors which were refractory to TDM1. N87-TM tumors treated with either vehicle or T-DM1 grew through these treatments, however tumors switched to T(kK183C+K290C)-vc0101 therapy at day 14 immediately regressed (FIG. 20F).
Example 15: In Vivo T-DM1 Resistant Models
[0332] A. Generation of T-DM1 Resistant Cells In Vivo
[0333] All animal studies were approved by the Pfizer Pearl River Institutional Animal Care and Use Committee according to established guidelines. To generate xenografts, nude (Nu/Nu) female mice were implanted subcutaneously with 7.5.times.10.sup.6 N87 cells in 50% Matrigel (BD Biosciences). The animals were randomized when average tumor volume reach .about.300 mm.sup.3 into two groups: 1) vehicle control (n=10) and 2) T-DM1 treated (n=20). T-DM1 ADC (6.5 mg/kg) or vehicle (PBS) were administered intravenously in saline on day 0 and then the animals were dosed weekly with 6.5 mg/kg for up to 30 weeks. Tumors were measured twice per week or weekly and mass calculated as volume=(width.times.width.times.length)/2. No weight loss was observed in mice in all treatment groups in these studies.
[0334] Animals were considered refractory or relapsed under T-DM1 treatment when the individual tumor volume reached .about.600 mm.sup.3 (doubled original size of tumor at randomization). Compared to control group, most tumors initially responded to T-DM1 treatment as shown in FIG. 21A. More specifically, 17 out of 20 mice responded to initial T-DM1 treatment but significant number of tumors (13 out of 20) relapsed under T-DM1 treatment. Over time the implanted N87 tumor cells became resistant to T-DM1 (FIG. 21B). Three tumors that did not initially responded to T-DM1 treatment were harvested for Her2 expression determination by IHC indicating no HER2 expression changes. The remaining 10 relapsed tumors are described below.
[0335] Four tumors which initially responded to T-DM1 treatment and then relapsed were switched to T-vc0101 treatment weekly at 2.6 mg/kg on day 77 (mice 1 and 16), 91 (mouse 19), 140 (mouse 6). As shown in FIG. 19C, T-DM1 resistant tumors generated in vivo responded to T-vc0101 indicating acquired T-DM1 resistant tumors are sensitive to vc0101 ADC treatment.
[0336] Another three tumors initially responded to T-DM1 treatment and then relapsed were switched to T(N297Q+K222R)-AcLysvc0101 treatment weekly at 2.6 mg/kg on day 110 (mice 4, 13, and 18). As shown in FIG. 21D, T-DM1 resistant tumors generated in vivo also responded to T(N297Q+K222R)-AcLysvc0101. A follow-on experiment was performed to evaluate T(kK183C+K290C)-vc0101, similar results were obtained indicating that T-DM1 resistant tumors generated in vivo were sensitive to T(kK183C+K290C)-vc0101 treatment as shown in FIG. 21E.
[0337] In summary, all T-DM1 refractory tumors having follow-on treatment were sensitive to the vc0101 ADC treatment (7 of 7) indicating that in vivo resistant T-DM1 tumors can be treated with cleavable vc0101 conjugates.
[0338] Additional three tumors (mouse 7, 17 and 2 as shown in FIG. 21B) initially responded to T-DM1 and then relapsed were excised for in vitro characterization. After 2-5 months of culturing the excised tumors in vitro these cells were evaluated for resistance to T-DM1 and characterized in vitro (see Sections B and C of this Example below).
[0339] B. Cytotoxicity Studies
[0340] Cells relapsed from T-DM1 treatment and cultured in vitro (as described in Section A of this Example) were seeded in 96-well plates and dosed the following day with 4-fold serial dilutions of the ADCs or unconjugated payloads. Cells were incubated for 96 hours in a humidified 37.degree. C./5% CO.sub.2 incubator. CellTiter Glo Solution (Promega, Madison, Wis.) was added to the plates and absorbance measured on a Victor plate reader (Perkin-Elmer, Waltham, Mass.) at wavelength 490 nm. IC.sub.50 values were calculated using a four-parameter logistic model with XLfit (IDBS, Bridgewater, N.J.).
[0341] Cytotoxicity screening results are summarized in Tables 19 and 20. The cells were resistant to T-DM1 (FIG. 22A) when compared to the parental but sensitive to cleavable vc0101 conjugates T-vc0101 (data not shown), T(kK183C+K290C)-vc0101 (FIG. 22B), T(LCQ05+K222R)-AcLysvc0101 (FIG. 22C) and T(N297Q+K222R)-AcLysvc0101 (FIG. 22D) (Table 19). The T-DM1 resistant cells were surprisingly sensitive to the parent payload DM1 as well as the 0101 payload (Table 20).
TABLE-US-00019 TABLE 19 Resistant Cell Sensitivity to ADCs N87-T- N87-T- N87-T- N87 DM1 DM1 DM1 Fold ADC parental Mouse #7 Mouse #17 Mouse #2 Resistance T-DM1 16 1388 944 3700 ~60-230 T(.kappa.K183C + 5 -- -- 5 1 K290C)-vc0101 T(LCQ05 + 25 9 10 18 ~1 K222R)- AcLysvc0101 T(N297Q + 9 7 13 16 ~1 K222R)- AcLysvc0101 T(K334C + 6 -- 11 4 ~1 K392C)-vc0101 T(K290C + 6 -- 16 4 ~1-2 K334C)-vc0101 IC.sub.50 values are shown for each of the cell lines
TABLE-US-00020 TABLE 20 Resistant Cell Line Sensitivity to Free Payload Cell Line DMI-Sme Aur-0101 Doxorubicin N87 10 0.5 48 N87-T-DM1_Ms2 23 0.40 46 N87-T-DM1_Ms7 20 0.60 79 N87-T-DM1_Ms17 27 0.28 34
[0342] C. Her2 Expression by FACS and Western Blot
[0343] Her2 expression was characterized on cells relapsed from T-DM1 treatment and cultured in vitro (as described in Section A of this Example). For FACS analysis, cells were trypsinized, spun down and resuspended in fresh media. The cells were then incubated for one hour at 4.degree. C. with 5 .mu.g/mL of Trastuzumab-PE (custom synthesized 1:1 PE labeled Trastuzumab by eBiosciences (San Diego, Calif.)). The cells were then washed twice and then resuspended in PBS. The mean fluorescence intensity was read using Accuri flow cytometer (BD Biosciences San Jose, Calif.).
[0344] For western blot analysis, the cells were lysed using RIPA lysis buffer (with protease inhibitors and phosphatase inhibitor) on ice for 15 minutes then vortexed and spun down at maximum speed in a microcentrifuge at 4.degree. C. The supernatant was collected and 4.times. sample buffer and reducing agent were added to the samples normalizing for total protein in each sample. The samples were run on a 4-12% Bis tris gel and transferred on to nitrocellulose membrane. The membranes were blocked for an hour and incubated with HER2 antibody (Cell Signalling, 1:1000) over night at 4.degree. C. The membranes were then washed 3 times in 1.times.TBST and incubated with an anti-mouse HRP antibody (Cell Signalling, 1:5000) for 1 hour washed 3 times and probed.
[0345] The HER2 expression levels of the T-DM1 relapsed tumors were similar to the control tumors (without T-DM1 treatment) as evaluated by FACS (FIG. 23A) and western blot (FIG. 23B).
[0346] D. T-DM1 Resistance is not Due to Expression of Drug Efflux Pumps
[0347] The cell lines do not express MDR1 by western blot (FIG. 24A) and cells are not resistant to MDR-1 substrate free drug 0101 (FIG. 24B). No resistance to doxorubicin (FIG. 24C) was observed indicating that resistant mechanism is not through MRP1. However, the cells are still resistant to free DM1 (FIG. 24D).
Example 16: Pharmacokinetics (PK)
[0348] Exposure of conventional or site specific vc0101 antibody drug conjugates were determined after an IV bolus dose administration of either 5 or 6 mg/kg to cynomolgus monkeys. Concentrations of total antibody (total Ab; measurement of both conjugated mAb and unconjugated mAb) and ADC (mAb that is conjugated to at least one drug molecule) was measured using ligand binding assays (LBA). The ADC in was made using vc0101 in all cases except for T(LCQ05) were AcLysvc0101 was used. Conventional conjugation (not site specific conjugation) was used to make the ADC from trastuzumab.
[0349] Concentration vs time profiles and pharmacokinetics/toxicokinetics of both total Ab and trastuzumab ADC (T-vc0101) (5 mg/kg) or T(kK183C+K290C) site specific ADC (6 mg/kg) after dose administration to cynomolgus monkeys (FIG. 25A and Table 21). Exposure of the T(kK183C+K290C) site specific ADC has both increased exposure and stability when compared to the conventional conjugate.
[0350] Concentration vs time profiles and pharmacokinetics/toxicokinetics of the ADC analyte of trastuzumab (T-vc0101) (5 mg/kg) or T(kK183C+K290C), T(LCQ05), T(K334C+K392C), T(K290C+K334C), T(K290C+K392C) and T(kK183C+K392C) site specific ADC (6 mg/kg) after dose administration to cynomolgus monkeys (FIG. 25B and Table 21). Exposure several site specific ADC (T(LCQ05), T(kK183C+K290C), T(K290C+K392C) and T(kK183C+K392C)) are higher compared to that of the trastuzumab ADC using conventional conjugation. However, exposure of two other site specific ADC (T(K290C+K334C) and T(K334C+K392C)) do not have higher exposure than the trastuzumab ADC indicating that not all site specific ADCs will have pharmacokinetic properties better than the trastuzumab ADC made using conventional conjugation.
TABLE-US-00021 TABLE 21 Pharmacokinetics Dose Cmax AUC( 0-336 h) mAb/ADC (mg/kg) Analyte (.mu.g/mL) (.mu.g h/mL) trastuzumab 5 Total Ab 157 11100 ADC 154 7660 T(K290C + K334C) 6 Total Ab 165 5770 ADC 163 5060 T(K334C + K392C) 6 Total Ab 159 5320 ADC 157 4770 T(LCQ05) 5 Total Ab 165 .+-. 19 16400 .+-. 1020 ADC 164 .+-. 22 16300 .+-. 989 T(.kappa.K183C + K290C) 6 Total Ab 187 16800 ADC 181 15300 T(K183C + K392C) 6 Total Ab 195 18500 ADC 196 16900 T(K290C + K392C) 6 Total Ab 205 13300 ADC 208 12300
Example 17: Relative Retention Values by Hydrophobic Interaction Chromatography Vs. Exposure (AUC) in Rats
[0351] Hydrophobicity is a physical property of a protein that can be assessed by hydrophobicity interaction chromatography (HIC), and the retention times of protein samples differ based on their relative hydrophobicity. ADCs can be compared with their respective antibody by calculating a relative retention time (RRT), which is the ratio of the HIC retention time of the ADC divided by the HIC retention time of the respective antibody. Highly hydrophobic ADCs have higher RRT, and it is possible that these ADCs may also have more pharmacokinetic liability, specifically lower area-under-the-curve (AUC, or exposure). When the HIC values of ADCs with various site mutations were compared with their measured AUC in rats, the distribution in FIG. 26 was observed.
[0352] ADCs with RRT 1.9 showed lower AUC values, while ADCs with lower RRT tended to have higher AUC, although the relationship was not direct. The ADC T(kK183C+K290C)-vc0101 was observed to have a relatively higher RRT (mean value of 1.77) and therefore was expected to have a relatively lower AUC. Surprisingly, the observed AUC was relatively high, hence it was not obvious to predict the exposure of this ADC from the hydrophobicity data.
Example 18:Toxicity Studies
[0353] In two independent exploratory toxicity studies, a total of ten male and female cynomolgus monkeys were divided into 5 dosage groups (1/gender/dosage) and dosed IV once every 3 weeks (study days 1, 22 and 43). On study day 46 (3 days after the 3.sup.rd dose administration) animals were euthanized and protocol specified blood and tissue samples were collected. Clinical observations, clinical pathology, macroscopic and microscopic pathology evaluations were conducted in life and post necropsy. For anatomic pathology evaluation, severity of histopathology findings was recorded on a subjective, relative, study specific basis.
[0354] In cynomolgus monkey exploratory toxicity studies at 3 and 5 mg/kg, T-vc0101 caused transient but marked (390/.mu.l) to severe (40/.mu.l to non-detectable) neutropenia at Day 11 post the first dose. In contrast at 9 mg/kg, all cynomolgus monkeys dosed with T(kK183C+K290C)-vc0101 had none to minimal neutropenia with neutrophil counts well above 500/.mu.l at any time-points tested (FIG. 27). In fact, T(kK183C+K290C)-vc0101 dosed animals showed average neutrophil counts (>1000 .mu.L) at day 11 and 14 as compared to vehicle controls.
[0355] Microscopically in the bone marrow at 3 and 5 mg/kg, the cynomolgus monkey dosed with T-vc0101 had compound-related increased M/E ratio. Increased myeloid/erythroid (M/E) ratio consisted of decreased erythroid precursors combined with an increase of primarily mature granulocytes. In contrast, at 6 and 9 mg/kg, only the male dosed with T(kK183C+K290C)-vc0101 at 6 mg/kg/dose had minimal to mild increased cellularity of mature granulocytes (data not shown).
[0356] Therefore, the hematologic and microscopic data clearly indicated that the ADC conjugate based on site-specific-mutation technology, T(kK183C+K290C)-vc010 clearly improved the T-vc010 induced bone marrow toxicity and neutropenia.
Example 19: ADC Crystal Structure
[0357] The crystal structures were obtained for T(K290C+K334C)-vc0101, T(K290C+K392C)-vc0101 and T(K334C+K392C)-vc0101. These particular ADCs were chosen for crystallography since conjugation to the K290C+K334C and K334C+K392C double cysteine-variants, but not the K290C+K392C, abolished ADCC activity.
[0358] The conjugated Fc regions were prepared for crystallography using papain cleavage of the ADCs. Crystals of the same morphology were obtained for the three conjugated IgG1-Fc regions using the same conditions: 100 mM NaCitrate pH 5.0+100 mM MgCl.sub.2+15% PEG 4K.
[0359] Wild type human IgG1-Fc structures deposited in the PDB are relatively similar showing that the CH2-CH2 domains contact each other through Asn297-linked glycans (carbohydrate or glycan antennas) and that the CH3-CH3 domains form a stable interface that is relatively constant between structures. Fc structures exist in either a "closed" or "open" confirmation and the deglycosylated Fc structure adopts the "open" structure conformation thus demonstrating that the glycan antennas hold the CH2 regions together. Additionally, a published structure of an unconjugated Phe241Ala-IgG1 Fc mutant (Yu et al. "Engineering Hydrophobic Protein-Carbohydrate interactions to fine-tune monoclonal antibodies". JACS 2013) shows one partially disordered CH2 domain since this mutation leads to destabilization of CH2-glycan interface and CH2-CH2 interface since aromatic Phe residue cannot stabilize the carbohydrate.
[0360] The "CH2 domain" of a human IgG Fc region (also referred to as "Cy2" domain) usually extends from about amino acid 231 to about amino acid 340. The CH2 domain is unique in that it is not closely paired with another domain. Rather, two N-linked branched carbohydrate chains are interposed between the two CH2 domains of an intact native IgG molecule. It has been speculated that the carbohydrate may provide a substitute for the domain-domain pairing and help stabilize the CH2 domain (Burton et al., 1985, Molec. Immunol. 22: 161-206).
[0361] The "CH3 domain" comprises the stretch of residues C-terminal to a CH2 domain in an Fc region (i.e. from about amino acid residue 341 to about amino acid residue 447 of an IgG).
[0362] The solved structures for both T(K290C+K334C)-vc0101 and T(K290C+K392C)-vc0101 Fc regions were similar showing that the Fc dimer contained one CH2 and both CH3s that were highly ordered (like wild type Fc). However, they also contain a disordered CH2 with glycan attached (FIG. 28A and FIG. 28B). The higher degree of destabilization of one CH2 domain was attributed to the close proximity of conjugation sites to glycan antennas. Considering 0101 payload geometry, conjugation at any of K290, K334, K392 sites could perturb the overall trajectory of the glycan away from the CH2 surface destabilizing the glycan and the CH2 structure itself and as a result the CH2-CH2 interface (FIG. 28C). A higher degree of heterogeneity is available to these 0101 site-specifically conjugated double cysteine-Fc-variants relative to WT-Fc, Phe241Ala-Fc or deglycosylated-Fc. When engineered cysteine-variant positions were mapped on the structure of WT-Fc in complex with Fc.gamma.R type IIb, it showed that conjugation at C334 could directly interfere with binding to Fc.gamma.RIIb (FIG. 28C). This heterogeneity in CH2 positioning caused by mutation or conjugation could result in significant decrease in FcRIIb binding. Therefore these results suggested that either conformation heterogeneity or conjugation of 0101 to certain combinations of engineered cysteines within the IgG1-Fc could affect ADCC activity for the double cysteine variants containing the K334C site, or perhaps both.
Example 20: Different Conjugation Sites Results in Different ADC Properties
[0363] A. General Procedure for the Synthesis of Cys-Mutant ADCs
[0364] A solution of trastuzumab incorporating one or more engineered cyststeine residues (as shown in the Table 22) was prepared in 50 mM phosphate buffer, pH 7.4. PBS, EDTA (0.5 M stock), and TCEP (0.5 M stock) were added such that the final protein concentration was 10 mg/mL, the final EDTA concentration was 20 mM, and the final TCEP concentration was approximately 6.6 mM (100 molar eq.). The reaction was allowed to stand at rt for 48 h then buffer exchanged into PBS using GE PD-10 Sephadex G25 columns per the manufacturer's instructions. The resulting solution was treated with approximately 50 equivalents of dehydroascorbate (50 mM stock in 1:1 EtOH/water). The antibody was allowed to stand at 4.degree. C. overnight and subsequently buffer exchanged into PBS using GE PD-10 Sephadex G25 columns per the manufacturer's instructions. Slight variations of the above procedure were employed on some mutants.
[0365] The antibody thus prepared was diluted to .about.2.5 mg/mL in PBS containing 10% DMA (vol/vol) and treated with vc0101 (10 molar eq.) as a 10 mM stock solution in DMA. After 2 h at rt, the mixture was buffer exchanged into PBS (per above) and purified by size-exclusion chromatography on a Superdex200 column. The monomeric fractions were concentrated and filter sterilized to give the final ADC. See Table 22 below for product characterization.
TABLE-US-00022 TABLE 22 Summary of ADC properties HIC HIC LCMS LCMS RT relative LCMS Observed Expected % Main retention DAR HIC DAR Mass Mass mono Peak time ADC (mol/mol) (mol/mol) Shift Shift mer (min) (RRT) T(A114C) - vc0101 1.9 1.74 1342 1341 94% 7.15 1.40 T(kK183C) - vc0101 2 2 1341 1341 99% 7.05 1.38 T(K290C) - vc0101 2.1 2.1 1341 1341 99% 7.85 1.53 T(K334C) - vc0101 2.1 2.1 1341 1341 99% 5.90 1.15 T(Q347C) - vc0101 1.9 NA 1341 1341 99% 8.41 1.64 T(S375C) - vc0101 2 NA 1340 1341 99% 6.23 1.22 T(E380C) - vc0101 2 1.9 1341 1341 99% 7.93 1.55 T(K388C) - vc0101 1.9 NA 1340 1341 97% 8.75 1.71 T(K392C) - vc0101 2.1 2.1 1341 1341 98% 6.60 1.29 T(N421C) - vc0101 1.9 NA 1342 1341 93% 8.20 1.60 T(L443C) - vc0101 2 2 1344 1341 90% 9.10 1.78 T(kK183C + K334C) - vc0101 3.7 NA 1341 1341 95% 7.00 1.37 T(kK183C + K392C) - vc0101 4 4 1342 1341 97% 7.70 1.50 T(K290C + K334C) - vc0101 4 4 1342 1341 97% 6.03 1.18 T(K334C + K392C) - vc0101 4 4 1343 1341 97% 5.91 1.15 T(K392C + L443C) - vc0101 3.2 NA 1340 1341.68 97% 10.85 2.12 Trastuzumab mAb 5.12 1.00
[0366] B. General Analytical Methods for Conjugation Examples
[0367] LCMS: Column=Waters BEH300-C4, 2.1.times.100 mm (P/N=186004496); Instrument=Acquity UPLC with an SQD2 mass spec detector; Flow rate=0.7 mL/min; Temperature=80.degree. C.; Buffer A=water+0.1% formic acid; Buffer B=acetonitrile+0.1% formic acid. The gradient ran from 3% B to 95% B over 2 minutes, holds at 95% B for 0.75 min, and then re-equilibrates at 3% B. The sample was reduced with TCEP or DTT immediately prior to injection. The eluate was monitored by LCMS (400-2000 daltons) and the protein peak was deconvoluted using MaxEnt1. DAR was reported as a weight average loading.
[0368] SEC: Column: Superdex200 (5/150 GL); Mobile phase: Phosphate buffered saline containing 2% acetonitrile, pH 7.4; Flow rate=0.25 mL/min; Temperature=ambient; Instrument: Agilent 1100 HPLC.
[0369] HIC:_Column: TSKGel Butyl NPR, 4.6 mm.times.3.5 cm (P/N=S0557-835); Buffer A=1.5 M ammonium sulfate containing 10 mM phosphate, pH 7; Buffer B=10 mM phosphate, pH 7+20% isopropyl alcohol; Flow rate=0.8 mL/min; Temperature=ambient; Gradient=0% B to 100% B over 12 minutes, hold at 100% B for 2 minutes, then re-equilibrate at 100% A; Instrument: Agilent 1100 HPLC.
[0370] C. Determination of Hydrophobicity of Site Specific vc0101 Conjugates
[0371] ADCs of Table 22 were evaluated by hydrophobic interaction chromatography (method above) in order to determine the relative hydrophobicity of the various conjugates. ADC hydrophobicity has been reported to correlate with total antibody exposure.
[0372] Conjugates to sites 334, 375, and 392 exhibited to smallest shift in retention time as compared to the unmodified antibody while conjugates to sites 421, 443, and 347 showed the largest shift in retention time. The relative hydrophobicity of each ADC was calculated by dividing the retention time of the ADC by the retention time of the unmodified antibody, thus resulting in a "relative retention time" or "RRT". An RRT of .about.1 indicates that the ADC has approximately the same hydrophobicity as the unmodified antibody. The RRT for each ADC is shown in Table 22.
[0373] D. ADC Plasma Stability of Site Specific vc0101 Conjugates
[0374] ADC samples (.about.1.5 mg/mL) were diluted into mouse, rat or human plasma to yield a final solution of 50 .mu.g/mL ADC in plasma. Samples were incubated at 37.degree. C. under 5% CO.sub.2, and aliquots were taken at three time points (0, 24 h, and 72 h). Each time point of ADC samples from the plasma incubation (25 .mu.L) was deglycosylated with IgG0 at 37.degree. C. for 1 h. Following the deglycosylation, a capture antibody (biotinylated goat anti-human IgG1 Fc.gamma. fragment specific at 1 mg/mL for mouse and rat plasma, or biotinylated anti-trastuzumab antibody at 1 mg/mL for human plasma) was added and the mixture was heated at 37.degree. C. for 1 h followed by gentle shaking at room temperature for a second hour. Dynabead MyOne Streptavidin T1 magnetic beads were added to the samples and incubated at room temperature for 1 h with gentle shaking. The sample plate was then washed with 200 .mu.L PBS+0.05% Tween-20, 200 .mu.L PBS and HPLC grade water. The bound ADC was eluted with 55 .mu.L of 2% of formic acid (FA) (v/v). 50 .mu.L aliquot of each sample were transferred into a new plate followed by an additional 5 .mu.L of 200 mM TCEP.
[0375] The intact protein analysis was carried out with Xevo G2 Q-TOF mass spectrometer coupled with nanoAcquity UPLC (Waters) using BEH300 C4, 1.7 .mu.m, 0.3.times.100 mm iKey column. The mobile phase A (MPA) consisted of 0.1% FA in water (v/v) and the mobile phase B (MPB) consisted of 0.1% FA in acetonitrile (v/v). The chromatographic separation was achieved at a flow rate of 0.3 .mu.L/min using a linear gradient of MPB from 5% to 90% over 7 min. The LC column temperature was set at 85.degree. C. Data acquisition was conducted with MassLynx software version 4.1. The mass acquisition range was from 700 Da to 2400 Da. Data analysis including deconvolution was performed using Biopharmalynx version 1.33.
[0376] Loading and succinimide ring opening (a +18 dalton peak) was monitored over time. The loading data is reported as % DAR loss compared to 0 h DAR. The ring-opening data is reported as the % of ring-opened species as compared to total species present at 72 h. Several site mutants resulted in very stable ADCs (334C, 421C, and 443C) while some sites lost significant amounts of linker-payload (380C and 114C). The rate of ring-opening varied considerably between the sites. Several sites such as 392C, 183C, and 334C resulted in very little ring opening while other sites such as 421C, 388C, and 347C resulted in rapid and spontaneous ring opening.
[0377] Sites that result in rapid and spontaneous ring opening may be useful for the generation of conjugates that have reduced hydrophobicity and/or increased PK exposure. This finding runs counter to the prevailing understanding that ring stability correlates with plasma stability. In some aspects therefore, conjugation at one or more of sites 421C, 388C, and 347C can be particularly advantageous when using a linker-payload with a high hydrophobicity. In some aspects, high hydrophobicity is a relative retention time (RRT) value (as measured by HIC) of 1.5 or more. In some aspects, high hydrophobicity is a RRT value of 1.7 or more. In some aspects, high hydrophobicity is a RRT value of 1.8 or more. In some aspects, high hydrophobicity is a RRT value of 1.9 or more. In some aspects, high hydrophobicity is a RRT value of 2.0 or more.
TABLE-US-00023 TABLE 23 Plasma stability of various ADCs % Succinamide ADC % DAR Loss @ 72-h hydrolysis @ 72-h T(K334C)-vc0101 0% 18% T(N421C)-vc0101 0% 100 T(L443C)-vc0101 0% 40% T(K388C)-vc0101 -1.3% 100% T(K392C)-vc0101 3.0% 0% T(K290C)-vc0101 9.5% 21% T(Q347C)-vc0101 10% 66% T(.kappa.K183C)-vc0101 11% 29% T(S375C)-vc0101 12% 46% T(A114C)-vc0101 20% 33% T(E380C)-vc0101 49% 29%
[0378] E. Glutathione Stability of Site Specific vc0101 Conjugates
[0379] The ADC samples were diluted into aqueous glutathione to yield a final GSH concentration of 0.5 mM and final protein concentration of .about.0.1 mg/mL in a phosphate buffer, pH 7.4. The samples were then incubated at 37.degree. C. and aliquots were removed at three time points to determine the DAR (T-0, T-3 day, T-6 day). The aliquot from each time point was treated with TCEP and analyzed by LC-MS per the method described in Example 20.A.
[0380] Loading and succinimide ring opening (a +18 dalton peak) was monitored over time. The loading data is reported as % DAR loss compared to 0 h DAR. (Table 24) The ring-opening data is reported as the % of ring-opened species as compared to total species present at 72 h. Several site mutants resulted in very stable ADCs (334C, 421C, and 443C) while some sites lost significant amounts of linker-payload (380C and 114C). The rate of ring-opening varied considerably between the sites. Several sites such as 392C, 183C, and 334C resulted in very little ring opening while other sites such as 421C, 388C, and 347C resulted in considerable ring-opening. The results of this assay correlates quite well with the plasma stability results (Example 20.D) suggesting that thiol-mediated deconjugation is the major pathway of payload loss in plasma. Combined, these results suggest that particular sites such as 334, 443, 290, and 392 may be especially useful for the conjugation of payload-linkers that are readily lost through a thiol-mediated deconjugation. Such payload-linkers include those that utilize the common mc and vc linkages (e.g. vc-101, vc-MMAE, mc-MMAF etc).
TABLE-US-00024 TABLE 24 Glutathione stability of various vc0101 site specific conjugates % Succinamide ADC % DAR Loss @ 72-h hydrolysis @ 72-h T(A114C)-vc0101 12% 41% T(.kappa.K183C)-vc0101 7% 17% T(K334C)-vc0101 4% 26% T(Q347C)-vc0101 10% 71% T(S375C)-vc0101 18% 47% T(E380C)-vc0101 79% 50% T(K388C)-vc0101 19% 100% T(K392C)-vc0101 0% 17% T(N421C)-vc0101 0% 80% T(L443C)-vc0101 12% 41% T(K290C)-vc0101 17% 33%
[0381] F. Pharmacokinetic evaluation of select site specific vc0101 conjugates in mice Non-tumor bearing athymic female nu/nu (nude) mice (6-8 weeks of age) were obtained from Charles River Laboratories. All procedures using mice were approved by the Institutional Animal Care and Use Committee according to established guidelines. Mice (n=3 or 4) were administered a single intravenous dose of an ADC at 3 mg/kg based on the antibody component. Blood samples were collected from each mouse via the tail vein at 0.083, 6, 24, 48, 96, 168 and 336 hours post-dose. The total antibody (T.sub.ab) and ADC concentrations were determined by a LBA where a sheep anti-human IgG antibody was used for capture, a goat anti-human IgG antibody was used for detection of T.sub.ab or an anti-payload antibody was used for detection of ADC. Plasma concentration data for each animal was analyzed using Watson LIMS version 7.4 (Thermo). Exposure varied based on site. The ADCs made from the 290C and 443C mutants exhibited the lowest exposure, while ADCs made from the 183C and 392C sites exhibited the highest exposure. For many applications, sites with a high exposure may be preferred, as this will lead to increased duration of therapeutic agent. However, for certain applications, it may be preferable to use a conjugate with a lower exposure (such as 290C and 443C). In particular, applications where a lower exposure (i.e. lower PK) may include, but are not limited to, use in the brain, the CNS, and the eye. Indications include cancer, especially of the brain, CNS and/or eye.
TABLE-US-00025 TABLE 25 PK exposure of various site-specific vc0101 ADCs tAb AUC (0-last) ADC AUC (0-last) ADC (mg * h/mL) (mg * h/mL) T(.kappa.K183C)-vc0101 7150 5980 T(K290C)-vc0101 4240 3480 T(K334C)-vc0101 5130 4500 T(Q347C)-vc0101 5080 4070 T(K388C)-vc0101 6100 3680 T(K392C)-vc0101 6400 6010 T(L443C)-vc0101 4430 4500
[0382] G. Cathepsin Cleavage of Site Specific vc0101 Conjugates
[0383] Cathepsin B was activated using 6 mM dithiothreitol (DTT) in 150 mM sodium acetate, pH 5.2 for 15 min at 37.degree. C. 50 ng of the activated cathepsin-B was then mixed with 20 uL of 1 mg/mL of ADC at a final concentration of 2 mM DTT, 50 mM sodium acetate, pH 5.2. Reactions were quenched using 10 uM E-64 cysteine protease inhibitor in 250 mM borate buffer, pH 8.5 following incubation at 37.degree. C. for 20 min, 1 h, 2 h and 4 h. After the assay, the samples were reduced using TCEP and analyzed by LC/MS using the conditions described in Example 21.A. The data showed that the rate of linker cleavage depends heavily on the site of conjugation. Particular sites are cleaved very quickly, such as 443C, 388C, and 290C while other sites are cleaved very slowly, such as 334C, 375C, and 392C. In some aspects, it may be advantageous to conjugate to sites that lend themselves to slow cleavage. In other aspects, quick cleavage is preferred. For example, it may be preferable to release the payload quickly to reduce time spent in the endosome. In further aspects rapid payload cleavage can be advantageously permit penetration of the payload where the conjugated molecule may not be able to do so, such as certain solid tumors. In further aspects, rapid cleavage can permit the payload to be delivered to adjacent cells that do not express the antibody's antigen, thus permitting treatment of a heterogenous tumor, for example.
TABLE-US-00026 TABLE 26 Linker cleavage kinetics of various site-specific vc0101 ADCs % Linker % Linker % Linker % Linker cleavage cleavage cleavage cleavage ADC @ 20 min @ 1 h @ 2 h @ 4 h T(A114C)-vc0101 29% 71% 100% 100% T(.kappa.K183C)-vc0101 31% 95% 100% 100% T(K290C)-vc0101 54% 100% 100% 100% T(K334C)-vc0101 0% 0% 0% 13% T(Q347C)-vc0101 42% 89% 100% 100% T(S375C)-vc0101 0% 0% 0% 5% T(E380C)-vc0101 15% 48% 83% 92% T(K388C)-vc0101 82% 100% 100% 100% T(K392C)-vc0101 0% 0% 0% 0% T(N421C)-vc0101 31% 61% 73% 100% T(L443C)-vc0101 100% 100% 100% 100%
[0384] H. Thermal Stability of Site Specific vc0101 Conjugates
[0385] The ADC was diluted to 0.2 mg/mL in PBS (pH 7.4) containing 10 mM EDTA. The ADCs were placed in a sealed vial and heated to 45.degree. C. An aliquot (10 .mu.L) was removed at 1-week increments to evaluate the level of high molecular weight species (HMWS) and low molecular weight species (LMWS) that formed over time by size exclusion chromatography (SEC). The SEC conditions are outlined in Example 21.A. Under these conditions, the monomer eluted at approximately 3.6 minutes. Any protein material eluting to the left of the monomer peak was counted as HMWS and any protein material eluting to the right of the monomer peak was counted as LMWS. Results are shown in Table 27 below. Select ADCs showed excellent thermal stability, such as 183C, 375C, and 334C, while other ADCs showed significant decomposition, such as 443C and 392C+443C.
TABLE-US-00027 TABLE 27 Thermal stability of various site-specific vc0101 ADCs Day 1 Day 1 Day 1 Day 21 Day 21 Day 21 ADC (HMWS) (LMWS) (Monomer) (HMWS) (LMWS) (Monomer) T(A114C) - vc0101 3.31% 3.00% 93.60% 1.70% 5.30% 93.80% T(kK183C) - vc0101 0.40% 0.60% 99.00% 0.40% 1.30% 98.30% T(K290C) - vc0101 0.90% 0.30% 98.70% 2.00% 2.80% 95.20% T(K334C) - vc0101 0.80% 0.40% 98.80% 1.10% 2.60% 96.30% T(Q347C) - vc0101 1.10% 0.40% 98.50% 1.20% 1.50% 97.30% T(S375C) - vc0101 0.70% 0.60% 98.70% 0.80% 2.10% 97.20% T(E380C) - vc0101 0.90% 0.30% 98.80% 1.60% 1.70% 96.60% T(K388C) - vc0101 1.90% 0.70% 97.40% 1.20% 2.10% 96.70% T(K392C) - vc0101 1.20% 0.50% 98.30% 1.40% 2.40% 96.10% T(N421C) - vc0101 2.60% 4.30% 93.00% 2.60% 6.10% 91.30% T(L443C) - vc0101 5.20% 4.60% 90.10% 5.80% 6.30% 87.40% T(kK183C + K334C) - vc0101 4.60% 0.50% 94.90% 5.70% 1.90% 92.40% T(kK183C + K392C) - vc0101 2.10% 0.70% 97.10% 2.10% 1.60% 96.30% T(K290C + K334C) - vc0101 2.80% 0.60% 96.60% 4.30% 1.90% 93.70% T(K334C + K392C) - vc0101 1.90% 0.70% 97.40% 2.70% 2.40% 94.90% T(K392C + L443C) - vc0101 2.80% 0.60% 96.60% 8.80% 2.90% 88.30%
[0386] I. Efficacy of Various vc0101 Site-Mutants
[0387] In vivo efficacy studies of antibody-drug conjugates were performed in a target-expressing xenograft model using the N87 cell line. Approximately 7.5 million tumor cells in 50% matrigel were implanted subcutaneously into 6-8 weeks old nude mice until the tumor sizes reach between 250 and 350 mm.sup.3. The drug was dosed through bolus tail vein injection. Animals were injected with 10, 3, or 1 mg/kg of antibody drug conjugate a total of four times, once every 4 days (on days 1, 5, 9, and 13). All experimental animals are monitored for body weight changes weekly. Tumor volume is measured twice a week for the first 50 days and once weekly thereafter by a Caliper device and calculated with the following formula: Tumor volume=(length.times.width.sup.2)/2. Animals are humanely sacrificed before their tumor volumes reach 2500 mm.sup.3. The tumor size is generally observed to decrease after the first week of treatment. Animals were monitored continuously for tumor re-growth after the treatment has discontinued (up to 100 days post-treatment). Data from the 3mpk dosing group is shown in FIG. 29. ADCs generated from the 388C and 347C mutants exhibited slightly lower potency than ADCs from the 334C, 183C, 392C and 443C mutants.
Sequence CWU 1
1
951120PRTArtificial SequenceSynthetic peptide sequence 1Glu Val Gln
Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu
Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr 20 25 30Tyr
Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40
45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val
50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr Ala
Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val
Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp
Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser Ser 115
12025PRTArtificial SequenceSynthetic peptide sequence 2Asp Thr Tyr
Ile His1 5317PRTArtificial SequenceSynthetic peptide sequence 3Arg
Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val Lys1 5 10
15Gly411PRTArtificial SequenceSynthetic peptide sequence 4Trp Gly
Gly Asp Gly Phe Tyr Ala Met Asp Tyr1 5 105329PRTArtificial
SequenceSynthetic peptide sequence 5Ala Ser Thr Lys Gly Pro Ser Val
Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr Ala
Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val Thr
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His Thr Phe
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser Val
Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75 80Tyr Ile
Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys 85 90 95Lys
Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys 100 105
110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
Thr Cys 130 135 140Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
Lys Phe Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu Val His Asn
Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu Gln Tyr Asn Ser Thr Tyr
Arg Val Val Ser Val Leu Thr Val Leu 180 185 190His Gln Asp Trp Leu
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn 195 200 205Lys Ala Leu
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly 210 215 220Gln
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu225 230
235 240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu Thr Val Asp Lys
Ser Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser Cys Ser Val Met
His Glu Ala Leu His Asn His Tyr Thr305 310 315 320Gln Lys Ser Leu
Ser Leu Ser Pro Gly 3256449PRTArtificial SequenceSynthetic peptide
sequence 6Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro
Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile
Lys Asp Thr 20 25 30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly
Leu Glu Trp Val 35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg
Tyr Ala Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr
Ser Lys Asn Thr Ala Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly
Phe Tyr Ala Met Asp Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150
155 160Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
Val 165 170 175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
Thr Val Pro 180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
Asn Val Asn His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Lys
Val Glu Pro Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro
Cys Pro Ala Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265
270Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
Tyr Arg 290 295 300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
Leu Asn Gly Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys
Ala Leu Pro Ala Pro Ile Glu 325 330 335Lys Thr Ile Ser Lys Ala Lys
Gly Gln Pro Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val385 390
395 400Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
Asp 405 410 415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
Val Met His 420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
Leu Ser Leu Ser Pro 435 440 445Gly7107PRTArtificial
SequenceSynthetic peptide sequence 7Asp Ile Gln Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys
Arg Ala Ser Gln Asp Val Asn Thr Ala 20 25 30Val Ala Trp Tyr Gln Gln
Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Ala Ser Phe
Leu Tyr Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Arg Ser Gly
Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro65 70 75 80Glu Asp
Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro 85 90 95Thr
Phe Gly Gln Gly Thr Lys Val Glu Ile Lys 100 105811PRTArtificial
SequenceSynthetic peptide sequence 8Arg Ala Ser Gln Asp Val Asn Thr
Ala Val Ala1 5 1097PRTArtificial SequenceSynthetic peptide sequence
9Ser Ala Ser Phe Leu Tyr Ser1 5109PRTArtificial SequenceSynthetic
peptide sequence 10Gln Gln His Tyr Thr Thr Pro Pro Thr1
511107PRTArtificial SequenceSynthetic peptide sequence 11Arg Thr
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu1 5 10 15Gln
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe 20 25
30Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
Ser 50 55 60Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
Tyr Glu65 70 75 80Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln
Gly Leu Ser Ser 85 90 95Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 10512214PRTArtificial SequenceSynthetic peptide sequence 12Asp
Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10
15Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Asn Thr Ala
20 25 30Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu
Ile 35 40 45Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Val Pro Ser Arg Phe
Ser Gly 50 55 60Ser Arg Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser
Leu Gln Pro65 70 75 80Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His
Tyr Thr Thr Pro Pro 85 90 95Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
Lys Arg Thr Val Ala Ala 100 105 110Pro Ser Val Phe Ile Phe Pro Pro
Ser Asp Glu Gln Leu Lys Ser Gly 115 120 125Thr Ala Ser Val Val Cys
Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala 130 135 140Lys Val Gln Trp
Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln145 150 155 160Glu
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser 165 170
175Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
Lys Ser 195 200 205Phe Asn Arg Gly Glu Cys 21013330PRTArtificial
SequenceSynthetic peptide sequence 13Ala Ser Thr Lys Gly Pro Ser
Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His Thr
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75 80Tyr
Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys 85 90
95Lys Val Glu Pro Lys Ser Cys Asp Arg Thr His Thr Cys Pro Pro Cys
100 105 110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
Glu Val Thr Cys 130 135 140Val Val Val Asp Val Ser His Glu Asp Pro
Glu Val Lys Phe Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu Val
His Asn Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu Gln Tyr Asn Ser
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu 180 185 190His Gln Asp
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn 195 200 205Lys
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly 210 215
220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu
Glu225 230 235 240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro Val
Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu Thr
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser Cys
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr305 310 315 320Gln
Lys Ser Leu Ser Leu Ser Pro Gly Lys 325 33014450PRTArtificial
SequenceSynthetic peptide sequence 14Glu Val Gln Leu Val Glu Ser
Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys
Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr 20 25 30Tyr Ile His Trp Val
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40 45Ala Arg Ile Tyr
Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val 50 55 60Lys Gly Arg
Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr Ala Tyr65 70 75 80Leu
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys 85 90
95Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
Ser Val 115 120 125Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
Gly Thr Ala Ala 130 135 140Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro
Glu Pro Val Thr Val Ser145 150 155 160Trp Asn Ser Gly Ala Leu Thr
Ser Gly Val His Thr Phe Pro Ala Val 165 170 175Leu Gln Ser Ser Gly
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro 180 185 190Ser Ser Ser
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys 195 200 205Pro
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp 210 215
220Arg Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
Gly225 230 235 240Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
Thr Leu Met Ile 245 250 255Ser Arg Thr Pro Glu Val Thr Cys Val Val
Val Asp Val Ser His Glu 260 265 270Asp Pro Glu Val Lys Phe Asn Trp
Tyr Val Asp Gly Val Glu Val His 275 280 285Asn Ala Lys Thr Lys Pro
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg 290 295 300Val Val Ser Val
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys305 310 315 320Glu
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu 325 330
335Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val
Ser Leu 355 360 365Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
Ala Val Glu Trp 370 375 380Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
Lys Thr Thr Pro Pro Val385 390 395 400Leu Asp Ser Asp Gly Ser Phe
Phe Leu Tyr Ser Lys Leu Thr Val Asp 405 410 415Lys Ser Arg Trp Gln
Gln Gly Asn Val Phe Ser Cys Ser Val Met His 420 425 430Glu Ala Leu
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro 435 440 445Gly
Lys 45015329PRTArtificial SequenceSynthetic peptide sequence 15Ala
Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10
15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu
Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr
His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly Gly
Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Cys Pro Lys Asp Thr Leu
Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135 140Val Val Val Asp
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp145 150 155 160Tyr
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu 165 170
175Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
Ser Asn 195 200
205Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
Glu Glu225 230 235 240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu
Ser Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro
Val Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr305 310 315
320Gln Lys Ser Leu Ser Leu Ser Pro Gly 32516449PRTArtificial
SequenceSynthetic peptide sequence 16Glu Val Gln Leu Val Glu Ser
Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys
Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr 20 25 30Tyr Ile His Trp Val
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40 45Ala Arg Ile Tyr
Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser Val 50 55 60Lys Gly Arg
Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr Ala Tyr65 70 75 80Leu
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys 85 90
95Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
Ser Val 115 120 125Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly
Gly Thr Ala Ala 130 135 140Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro
Glu Pro Val Thr Val Ser145 150 155 160Trp Asn Ser Gly Ala Leu Thr
Ser Gly Val His Thr Phe Pro Ala Val 165 170 175Leu Gln Ser Ser Gly
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro 180 185 190Ser Ser Ser
Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys 195 200 205Pro
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp 210 215
220Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
Gly225 230 235 240Pro Ser Val Phe Leu Phe Pro Pro Cys Pro Lys Asp
Thr Leu Met Ile 245 250 255Ser Arg Thr Pro Glu Val Thr Cys Val Val
Val Asp Val Ser His Glu 260 265 270Asp Pro Glu Val Lys Phe Asn Trp
Tyr Val Asp Gly Val Glu Val His 275 280 285Asn Ala Lys Thr Lys Pro
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg 290 295 300Val Val Ser Val
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys305 310 315 320Glu
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu 325 330
335Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val
Ser Leu 355 360 365Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
Ala Val Glu Trp 370 375 380Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
Lys Thr Thr Pro Pro Val385 390 395 400Leu Asp Ser Asp Gly Ser Phe
Phe Leu Tyr Ser Lys Leu Thr Val Asp 405 410 415Lys Ser Arg Trp Gln
Gln Gly Asn Val Phe Ser Cys Ser Val Met His 420 425 430Glu Ala Leu
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro 435 440
445Gly17329PRTArtificial SequenceSynthetic peptide sequence 17Ala
Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10
15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu
Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr
His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly Gly
Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu
Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135 140Val Val Val Asp
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp145 150 155 160Tyr
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Cys Pro Arg Glu 165 170
175Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
Pro Pro Ser Arg Glu Glu225 230 235 240Met Thr Lys Asn Gln Val Ser
Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295
300Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser Pro Gly
32518449PRTArtificial SequenceSynthetic peptide sequence 18Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr 20 25
30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser
Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr
Ala Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met
Asp Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser Ser Ala
Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro Ser Ser
Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys Leu Val
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155 160Trp Asn
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val 165 170
175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys Pro Ala
Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu Phe Pro
Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr Pro Glu
Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp Pro Glu
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280 285Asn
Ala Lys Thr Cys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg 290 295
300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
Ala Pro Ile Glu 325 330 335Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu Glu
Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys Gly
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn Gly
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val385 390 395 400Leu
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp 405 410
415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
Ser Pro 435 440 445Gly19330PRTArtificial SequenceSynthetic peptide
sequence 19Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser
Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
Ala Leu Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro Ser Ser
Ser Leu Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn His Lys
Pro Ser Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys Ser Cys
Asp Lys Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro Glu Leu
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys Pro Lys
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135 140Val
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp145 150
155 160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
Glu 165 170 175Glu Gln Tyr Ala Ser Thr Tyr Arg Val Val Ser Val Leu
Thr Val Leu 180 185 190His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
Cys Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro Ile Glu Lys
Thr Ile Ser Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu Pro Gln Val
Tyr Thr Leu Pro Pro Ser Arg Glu Glu225 230 235 240Met Thr Lys Asn
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250 255Pro Ser
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn 260 265
270Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
Gly Asn 290 295 300Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
Asn His Tyr Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser Pro Gly
Lys 325 33020450PRTArtificial SequenceSynthetic peptide sequence
20Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1
5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp
Thr 20 25 30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
Trp Val 35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala
Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys
Asn Thr Ala Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp
Thr Ala Val Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr
Ala Met Asp Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser
Ser Ala Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155
160Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
Val Pro 180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
Val Asn His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Lys Val
Glu Pro Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys
Pro Ala Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280
285Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Ala Ser Thr Tyr Arg
290 295 300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
Gly Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
Pro Ala Pro Ile Glu 325 330 335Lys Thr Ile Ser Lys Ala Lys Gly Gln
Pro Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu
Glu Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val385 390 395
400Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
Met His 420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
Ser Leu Ser Pro 435 440 445Gly Lys 45021330PRTArtificial
SequenceSynthetic peptide sequence 21Ala Ser Thr Lys Gly Pro Ser
Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His Thr
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75 80Tyr
Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys 85 90
95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
Glu Val Thr Cys 130 135 140Val Val Val Asp Val Ser His Glu Asp Pro
Glu Val Lys Phe Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu Val
His Asn Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu Gln Tyr Gln Ser
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu 180 185 190His Gln Asp
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn 195 200 205Lys
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly 210 215
220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu
Glu225 230 235 240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro Val
Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu Thr
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr305 310 315
320Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 325
33022450PRTArtificial SequenceSynthetic peptide sequence 22Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr 20 25
30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser
Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr
Ala Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met
Asp Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser Ser Ala
Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro Ser Ser
Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys Leu Val
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155 160Trp Asn
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val 165 170
175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys Pro Ala
Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu Phe Pro
Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr Pro Glu
Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp Pro Glu
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280 285Asn
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Gln Ser Thr Tyr Arg 290 295
300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
Ala Pro Ile Glu 325 330 335Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu Glu
Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys Gly
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn Gly
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val385 390 395 400Leu
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp 405 410
415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
Ser Pro 435 440 445Gly Lys 45023329PRTArtificial SequenceSynthetic
peptide sequence 23Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn
Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu
Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro
Ser Ser Ser Leu Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn
His Lys Pro Ser Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135
140Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
Trp145 150 155 160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
Lys Pro Arg Glu 165 170 175Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
Ser Val Leu Thr Val Leu 180 185 190His Gln Asp Trp Leu Asn Gly Lys
Glu Tyr Lys Cys Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro
Ile Glu Cys Thr Ile Ser Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu225 230 235 240Met
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250
255Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
Phe Phe 275 280 285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
Gln Gln Gly Asn 290 295 300Val Phe Ser Cys Ser Val Met His Glu Ala
Leu His Asn His Tyr Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser
Pro Gly 32524449PRTArtificial SequenceSynthetic peptide sequence
24Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1
5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp
Thr 20 25 30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
Trp Val 35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala
Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys
Asn Thr Ala Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp
Thr Ala Val Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr
Ala Met Asp Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser
Ser Ala Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155
160Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
Val Pro 180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
Val Asn His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Lys Val
Glu Pro Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys
Pro Ala Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280
285Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
Gly Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
Pro Ala Pro Ile Glu 325 330 335Cys Thr Ile Ser Lys Ala Lys Gly Gln
Pro Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu
Glu Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val385 390 395
400Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
Met His 420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
Ser Leu Ser Pro 435 440 445Gly25329PRTArtificial SequenceSynthetic
peptide sequence 25Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn
Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu
Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro
Ser Ser Ser Leu Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn
His Lys Pro Ser Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135
140Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
Trp145 150 155 160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
Lys Pro Arg Glu 165 170 175Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
Ser Val Leu Thr Val Leu 180 185 190His Gln Asp Trp Leu Asn Gly Lys
Glu Tyr Lys Cys Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu225 230 235 240Met
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250
255Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270Asn Tyr Cys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
Phe Phe 275 280 285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
Gln Gln Gly Asn 290 295 300Val Phe Ser Cys Ser Val Met His Glu Ala
Leu His Asn His Tyr Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser
Pro Gly 32526449PRTArtificial SequenceSynthetic peptide sequence
26Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1
5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp
Thr 20 25 30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
Trp Val 35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala
Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys
Asn Thr Ala Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp
Thr Ala Val Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr
Ala Met Asp Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser
Ser Ala Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155
160Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
Val Pro 180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
Val Asn His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Lys Val
Glu Pro Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys
Pro Ala Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280
285Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
Gly Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
Pro Ala Pro Ile Glu 325 330 335Lys Thr Ile Ser Lys Ala Lys Gly Gln
Pro Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu
Glu Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn
Gly Gln Pro Glu Asn Asn Tyr Cys Thr Thr Pro Pro Val385 390 395
400Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
Met His 420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
Ser Leu Ser Pro 435 440 445Gly27329PRTArtificial SequenceSynthetic
peptide sequence 27Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn
Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu
Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro
Ser Ser Ser Leu Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn
His Lys Pro Ser Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135
140Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
Trp145 150 155 160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
Lys Pro Arg Glu 165 170 175Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
Ser Val Leu Thr Val Leu 180 185 190His Gln Asp Trp Leu Asn Gly Lys
Glu Tyr Lys Cys Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu225 230 235 240Met
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250
255Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
Phe Phe 275 280 285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
Gln Gln Gly Asn 290 295 300Val Phe Ser Cys Ser Val Met His Glu Ala
Leu His Asn His Tyr Thr305 310 315 320Gln Lys Ser Leu Ser Cys Ser
Pro Gly 32528449PRTArtificial SequenceSynthetic peptide sequence
28Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1
5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp
Thr 20 25 30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
Trp Val 35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala
Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys
Asn Thr Ala Tyr65
70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met Asp Tyr Trp
Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys
Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr
Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys Leu Val Lys Asp Tyr
Phe Pro Glu Pro Val Thr Val Ser145 150 155 160Trp Asn Ser Gly Ala
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val 165 170 175Leu Gln Ser
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro 180 185 190Ser
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys 195 200
205Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
Gly Gly225 230 235 240Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
Asp Thr Leu Met Ile 245 250 255Ser Arg Thr Pro Glu Val Thr Cys Val
Val Val Asp Val Ser His Glu 260 265 270Asp Pro Glu Val Lys Phe Asn
Trp Tyr Val Asp Gly Val Glu Val His 275 280 285Asn Ala Lys Thr Lys
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg 290 295 300Val Val Ser
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys305 310 315
320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn Gly Gln Pro Glu Asn
Asn Tyr Lys Thr Thr Pro Pro Val385 390 395 400Leu Asp Ser Asp Gly
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp 405 410 415Lys Ser Arg
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His 420 425 430Glu
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Cys Ser Pro 435 440
445Gly29329PRTArtificial SequenceSynthetic peptide sequence 29Ala
Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10
15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu
Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys Ser Cys Asp Lys Thr
His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly Gly
Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu
Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135 140Val Val Val Asp
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp145 150 155 160Tyr
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Cys Pro Arg Glu 165 170
175Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro Ile Glu Cys Thr Ile Ser
Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
Pro Pro Ser Arg Glu Glu225 230 235 240Met Thr Lys Asn Gln Val Ser
Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295
300Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser Pro Gly
32530449PRTArtificial SequenceSynthetic peptide sequence 30Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr 20 25
30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser
Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr
Ala Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met
Asp Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser Ser Ala
Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro Ser Ser
Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys Leu Val
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155 160Trp Asn
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val 165 170
175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys Pro Ala
Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu Phe Pro
Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr Pro Glu
Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp Pro Glu
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280 285Asn
Ala Lys Thr Cys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg 290 295
300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
Ala Pro Ile Glu 325 330 335Cys Thr Ile Ser Lys Ala Lys Gly Gln Pro
Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu Glu
Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys Gly
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn Gly
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val385 390 395 400Leu
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp 405 410
415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
Ser Pro 435 440 445Gly31329PRTArtificial SequenceSynthetic peptide
sequence 31Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser
Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
Ala Leu Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro Ser Ser
Ser Leu Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn His Lys
Pro Ser Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys Ser Cys
Asp Lys Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro Glu Leu
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys Pro Lys
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135 140Val
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp145 150
155 160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Cys Pro Arg
Glu 165 170 175Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
Thr Val Leu 180 185 190His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
Cys Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro Ile Glu Lys
Thr Ile Ser Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu Pro Gln Val
Tyr Thr Leu Pro Pro Ser Arg Glu Glu225 230 235 240Met Thr Lys Asn
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250 255Pro Ser
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn 260 265
270Asn Tyr Cys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
Gly Asn 290 295 300Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
Asn His Tyr Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser Pro Gly
32532449PRTArtificial SequenceSynthetic peptide sequence 32Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr 20 25
30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser
Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr
Ala Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met
Asp Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser Ser Ala
Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro Ser Ser
Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys Leu Val
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155 160Trp Asn
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val 165 170
175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys Pro Ala
Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu Phe Pro
Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr Pro Glu
Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp Pro Glu
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280 285Asn
Ala Lys Thr Cys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg 290 295
300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
Ala Pro Ile Glu 325 330 335Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu Glu
Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys Gly
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn Gly
Gln Pro Glu Asn Asn Tyr Cys Thr Thr Pro Pro Val385 390 395 400Leu
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp 405 410
415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
Ser Pro 435 440 445Gly33330PRTArtificial SequenceSynthetic peptide
sequence 33Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser
Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
Ala Leu Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro Ser Ser
Ser Leu Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn His Lys
Pro Ser Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys Ser Cys
Asp Arg Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro Glu Leu
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys Pro Lys
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135 140Val
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp145 150
155 160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
Glu 165 170 175Glu Gln Tyr Ala Ser Thr Tyr Arg Val Val Ser Val Leu
Thr Val Leu 180 185 190His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
Cys Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro Ile Glu Lys
Thr Ile Ser Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu Pro Gln Val
Tyr Thr Leu Pro Pro Ser Arg Glu Glu225 230 235 240Met Thr Lys Asn
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250 255Pro Ser
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn 260 265
270Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
Gly Asn 290 295 300Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
Asn His Tyr Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser Pro Gly
Lys 325 33034450PRTArtificial SequenceSynthetic peptide sequence
34Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1
5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp
Thr 20 25 30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
Trp Val 35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala
Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys
Asn Thr Ala Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp
Thr Ala Val Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr
Ala Met Asp Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser
Ser Ala Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155
160Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175Leu Gln Ser Ser
Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro 180 185 190Ser Ser
Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys 195 200
205Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
210 215 220Arg Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
Gly Gly225 230 235 240Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
Asp Thr Leu Met Ile 245 250 255Ser Arg Thr Pro Glu Val Thr Cys Val
Val Val Asp Val Ser His Glu 260 265 270Asp Pro Glu Val Lys Phe Asn
Trp Tyr Val Asp Gly Val Glu Val His 275 280 285Asn Ala Lys Thr Lys
Pro Arg Glu Glu Gln Tyr Ala Ser Thr Tyr Arg 290 295 300Val Val Ser
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys305 310 315
320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
325 330 335Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn Gly Gln Pro Glu Asn
Asn Tyr Lys Thr Thr Pro Pro Val385 390 395 400Leu Asp Ser Asp Gly
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp 405 410 415Lys Ser Arg
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His 420 425 430Glu
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro 435 440
445Gly Lys 45035330PRTArtificial SequenceSynthetic peptide sequence
35Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys1
5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu
Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn His Lys Pro Ser
Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys Ser Cys Asp Arg
Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro Glu Leu Leu Gly
Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys Pro Lys Asp Thr
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135 140Val Val Val
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp145 150 155
160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175Glu Gln Tyr Gln Ser Thr Tyr Arg Val Val Ser Val Leu Thr
Val Leu 180 185 190His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
Ile Ser Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu Pro Gln Val Tyr
Thr Leu Pro Pro Ser Arg Glu Glu225 230 235 240Met Thr Lys Asn Gln
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250 255Pro Ser Asp
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn 260 265 270Asn
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe 275 280
285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
Tyr Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 325
33036450PRTArtificial SequenceSynthetic peptide sequence 36Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Thr 20 25
30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala Asp Ser
Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys Asn Thr
Ala Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr Ala Met
Asp Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser Ser Ala
Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro Ser Ser
Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys Leu Val
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155 160Trp Asn
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val 165 170
175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro
Lys Ser Cys Asp 210 215 220Arg Thr His Thr Cys Pro Pro Cys Pro Ala
Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu Phe Pro
Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr Pro Glu
Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp Pro Glu
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280 285Asn
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Gln Ser Thr Tyr Arg 290 295
300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
Ala Pro Ile Glu 325 330 335Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu Glu
Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys Gly
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn Gly
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val385 390 395 400Leu
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp 405 410
415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
Ser Pro 435 440 445Gly Lys 45037329PRTArtificial SequenceSynthetic
peptide sequence 37Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn
Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu
Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro
Ser Ser Ser Leu Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn
His Lys Pro Ser Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135
140Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
Trp145 150 155 160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
Lys Pro Arg Glu 165 170 175Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
Ser Val Leu Thr Val Leu 180 185 190His Gln Asp Trp Leu Asn Gly Lys
Glu Tyr Lys Cys Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro
Ile Glu Cys Thr Ile Ser Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu225 230 235 240Met
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250
255Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270Asn Tyr Cys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
Phe Phe 275 280 285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
Gln Gln Gly Asn 290 295 300Val Phe Ser Cys Ser Val Met His Glu Ala
Leu His Asn His Tyr Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser
Pro Gly 32538449PRTArtificial SequenceSynthetic peptide sequence
38Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1
5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp
Thr 20 25 30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
Trp Val 35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala
Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys
Asn Thr Ala Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp
Thr Ala Val Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr
Ala Met Asp Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser
Ser Ala Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155
160Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
Val Pro 180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
Val Asn His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Lys Val
Glu Pro Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys
Pro Ala Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280
285Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
290 295 300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
Gly Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
Pro Ala Pro Ile Glu 325 330 335Cys Thr Ile Ser Lys Ala Lys Gly Gln
Pro Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu
Glu Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn
Gly Gln Pro Glu Asn Asn Tyr Cys Thr Thr Pro Pro Val385 390 395
400Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
Met His 420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
Ser Leu Ser Pro 435 440 445Gly39329PRTArtificial SequenceSynthetic
peptide sequence 39Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala
Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys
Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn
Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu
Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro
Ser Ser Ser Leu Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn
His Lys Pro Ser Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135
140Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
Trp145 150 155 160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
Lys Pro Arg Glu 165 170 175Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
Ser Val Leu Thr Val Leu 180 185 190His Gln Asp Trp Leu Asn Gly Lys
Glu Tyr Lys Cys Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro
Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu225 230 235 240Met
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250
255Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270Asn Tyr Cys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
Phe Phe 275 280 285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
Gln Gln Gly Asn 290 295 300Val Phe Ser Cys Ser Val Met His Glu Ala
Leu His Asn His Tyr Thr305 310 315 320Gln Lys Ser Leu Ser Cys Ser
Pro Gly 32540449PRTArtificial SequenceSynthetic peptide sequence
40Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1
5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp
Thr 20 25 30Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
Trp Val 35 40 45Ala Arg Ile Tyr Pro Thr Asn Gly Tyr Thr Arg Tyr Ala
Asp Ser Val 50 55 60Lys Gly Arg Phe Thr Ile Ser Ala Asp Thr Ser Lys
Asn Thr Ala Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp
Thr Ala Val Tyr Tyr Cys 85 90 95Ser Arg Trp Gly Gly Asp Gly Phe Tyr
Ala Met Asp Tyr Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser
Ser Ala Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155
160Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
Val Pro 180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
Val Asn His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Lys Val
Glu Pro Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys
Pro Ala Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
Val Glu Val His 275 280 285Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
Tyr Asn Ser Thr Tyr Arg 290 295 300Val Val Ser Val Leu Thr Val Leu
His Gln Asp Trp Leu Asn Gly Lys305 310 315 320Glu Tyr Lys Cys Lys
Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu 325 330 335Lys Thr Ile
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr 340 345 350Thr
Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu 355 360
365Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Cys Thr Thr Pro
Pro Val385 390 395 400Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
Lys Leu Thr Val Asp 405 410 415Lys Ser Arg Trp Gln Gln Gly Asn Val
Phe Ser Cys Ser Val Met His 420 425 430Glu Ala Leu His Asn His Tyr
Thr Gln Lys Ser Leu Ser Cys Ser Pro 435 440
445Gly41107PRTArtificial SequenceSynthetic peptide sequence 41Arg
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu1 5 10
15Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
Gln 35 40 45Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
Asp Ser 50 55 60Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Cys Ala
Asp Tyr Glu65 70 75 80Lys His Lys Val Tyr Ala Cys Glu Val Thr His
Gln Gly Leu Ser Ser 85 90 95Pro Val Thr Lys Ser Phe Asn Arg Gly Glu
Cys 100 10542213PRTArtificial SequenceSynthetic peptide sequence
42Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1
5 10 15Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Val Asn Thr
Ala 20 25 30Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
Leu Ile 35 40 45Tyr Ser Ala Ser Phe Leu Tyr Ser Gly Val Pro Ser Arg
Phe Ser Gly 50 55 60Ser Arg Ser Gly Thr Phe Thr Leu Thr Ile Ser Ser
Leu Gln Pro Glu65 70 75 80Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His
Tyr Thr Thr Pro Pro Thr 85 90 95Phe Gly Gln Gly Thr Lys Val Glu Ile
Lys Arg Thr Val Ala Ala Pro 100 105 110Ser Val Phe Ile Phe Pro Pro
Ser Asp Glu Gln Leu Lys Ser Gly Thr 115 120 125Ala Ser Val Val Cys
Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys 130 135 140Val Gln Trp
Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu145 150 155
160Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175Thr Leu Thr Leu Ser Cys Ala Asp Tyr Glu Lys His Lys Val
Tyr Ala 180 185 190Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
Thr Lys Ser Phe 195 200 205Asn Arg Gly Glu Cys
21043115PRTArtificial SequenceSynthetic peptide sequence 43Arg Thr
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu1 5 10 15Gln
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe 20 25
30Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
Ser 50 55 60Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
Tyr Glu65 70 75 80Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln
Gly Leu Ser Ser 85 90 95Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
Gly Gly Leu Leu Gln 100 105 110Gly Pro Pro 11544222PRTArtificial
SequenceSynthetic peptide sequence 44Asp Ile Gln Met Thr Gln Ser
Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr
Cys Arg Ala Ser Gln Asp Val Asn Thr Ala 20 25 30Val Ala Trp Tyr Gln
Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Ser Ala Ser
Phe Leu Tyr Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Arg Ser
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro65 70 75 80Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Thr Thr Pro Pro 85 90
95Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
Ser Gly 115 120 125Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
Pro Arg Glu Ala 130 135 140Lys Val Gln Trp Lys Val Asp Asn Ala Leu
Gln Ser Gly Asn Ser Gln145 150 155 160Glu Ser Val Thr Glu Gln Asp
Ser Lys Asp Ser Thr Tyr Ser Leu Ser 165 170 175Ser Thr Leu Thr Leu
Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr 180 185 190Ala Cys Glu
Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser 195 200 205Phe
Asn Arg Gly Glu Cys Gly Gly Leu Leu Gln Gly Pro Pro 210 215
22045360DNAArtificial SequenceSynthetic nucleotide sequence
45gaggtgcagc tggtggaatc cggcggaggc ctggtccagc ctggcggatc tctgcggctg
60tcttgcgccg cctccggctt caacatcaag gacacctaca tccactgggt ccgacaggca
120cctggcaagg gactggaatg ggtggcccgg atctacccca ccaacggcta
caccagatac 180gccgactccg tgaagggccg gttcaccatc tccgccgaca
cctccaagaa caccgcctac 240ctgcagatga actccctgcg ggccgaggac
accgccgtgt actactgctc cagatgggga 300ggcgacggct tctacgccat
ggactactgg ggccagggca ccctggtcac cgtgtctagc 360461347DNAArtificial
SequenceSynthetic nucleotide sequence 46gaggtgcagc tggtggaatc
cggcggaggc ctggtccagc ctggcggatc tctgcggctg 60tcttgcgccg cctccggctt
caacatcaag gacacctaca tccactgggt ccgacaggca 120cctggcaagg
gactggaatg ggtggcccgg atctacccca ccaacggcta caccagatac
180gccgactccg tgaagggccg gttcaccatc tccgccgaca cctccaagaa
caccgcctac 240ctgcagatga actccctgcg ggccgaggac accgccgtgt
actactgctc cagatgggga 300ggcgacggct tctacgccat ggactactgg
ggccagggca ccctggtcac cgtgtctagc 360gcgtcgacca agggcccatc
ggtcttcccc ctggcaccct cctccaagag cacctctggg 420ggcacagcgg
ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg
480tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct
acagtcctca 540ggactctact ccctcagcag cgtggtgacc gtgccctcca
gcagcttggg cacccagacc 600tacatctgca acgtgaatca caagcccagc
aacaccaagg tggacaagaa agttgagccc 660aaatcttgtg acaaaactca
cacatgccca ccgtgcccag cacctgaact cctgggggga 720ccgtcagtct
tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct
780gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa
gttcaactgg 840tacgtggacg gcgtggaggt gcataatgcc aagacaaagc
cgcgggagga gcagtacaac 900agcacgtacc gtgtggtcag cgtcctcacc
gtcctgcacc aggactggct gaatggcaag 960gagtacaagt gcaaggtctc
caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 1020aaagccaaag
ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggaggag
1080atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc
cagcgacatc 1140gccgtggagt gggagagcaa tgggcagccg gagaacaact
acaagaccac gcctcccgtg 1200ctggactccg acggctcctt cttcctctat
agcaagctca ccgtggacaa gagcaggtgg 1260cagcagggga acgtcttctc
atgctccgtg atgcatgagg ctctgcacaa ccactacacg 1320cagaagagcc
tctccctgtc cccgggt 134747321DNAArtificial SequenceSynthetic
nucleotide sequence 47gacatccaga tgacccagtc cccctccagc ctgtccgcct
ctgtgggcga cagagtgacc 60atcacctgtc gggcctccca ggacgtgaac accgccgtgg
cctggtatca gcagaagccc 120ggcaaggccc ccaagctgct gatctactcc
gcctccttcc tgtactccgg cgtgccctcc 180cggttctccg gctccagatc
tggcaccgac tttaccctga ccatctccag cctgcagccc 240gaggacttcg
ccacctacta ctgccagcag cactacacca ccccccccac ctttggccag
300ggcaccaagg tggaaatcaa g 32148642DNAArtificial SequenceSynthetic
nucleotide sequence 48gacatccaga tgacccagtc cccctccagc ctgtccgcct
ctgtgggcga cagagtgacc 60atcacctgtc gggcctccca ggacgtgaac accgccgtgg
cctggtatca gcagaagccc 120ggcaaggccc ccaagctgct gatctactcc
gcctccttcc tgtactccgg cgtgccctcc 180cggttctccg gctccagatc
tggcaccgac tttaccctga ccatctccag cctgcagccc 240gaggacttcg
ccacctacta ctgccagcag cactacacca ccccccccac ctttggccag
300ggcaccaagg tggaaatcaa gcggaccgtg gccgctccct ccgtgttcat
cttcccaccc 360tccgacgagc agctgaagtc cggcaccgcc tccgtcgtgt
gcctgctgaa caacttctac 420ccccgcgagg ccaaggtgca gtggaaggtg
gacaacgccc tgcagtccgg caactcccag 480gaatccgtca ccgagcagga
ctccaaggac agcacctact ccctgtcctc caccctgacc 540ctgtccaagg
ccgactacga gaagcacaag gtgtacgcct gcgaagtgac ccaccagggc
600ctgtccagcc ccgtgaccaa gtccttcaac cggggcgagt gc
64249990DNAArtificial SequenceSynthetic nucleotide sequence
49gcctccacca agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
60ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg
120tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct
acagtcctca 180ggactctact ccctcagcag cgtagtgacc gtgccctcca
gcagcttggg cacccagacc 240tacatctgca acgtgaatca caagcccagc
aacaccaagg tggacaagaa agttgagccc 300aaatcttgtg accgtactca
cacatgccca ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct
tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct
420gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa
gttcaactgg 480tacgtggacg gcgtggaggt gcataatgcc aagacaaagc
cgcgggagga gcagtacaac 540agcacgtacc gtgtggtcag cgtcctcacc
gtcctgcacc aggactggct gaatggcaag 600gagtacaagt gcaaggtctc
caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 660aaagccaaag
ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggaggag
720atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc
cagcgacatc 780gccgtggagt gggagagcaa tgggcagccg gagaacaact
acaagaccac gcctcccgtg 840ctggactccg acggctcctt cttcctctat
agcaagctca ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc
atgctccgtg atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc
tctccctgtc tccgggaaaa 990501350DNAArtificial SequenceSynthetic
nucleotide sequence 50gaggtgcagc tggtggagtc cggcggcggc ctggttcagc
ccggcggatc actgaggctc 60tcctgtgccg ccagcggctt caacatcaag gacacataca
tccactgggt tcgccaggct 120cctggcaagg gactggagtg ggtcgctagg
atctacccca ccaatgggta caccaggtac 180gccgactccg tgaaggggcg
gttcacaatc tcagccgata ctagcaaaaa tacagcctac 240ttgcagatga
actccctgag agcagaggat accgccgtgt actattgctc tcgctggggc
300ggcgacggct tctacgctat ggattattgg ggccagggaa ccttggtcac
cgtctcctca 360gcctccacca agggcccatc ggtcttcccc ctggcaccct
cctccaagag cacctctggg 420ggcacagcgg ccctgggctg cctggtcaag
gactacttcc ccgaaccggt gacggtgtcg 480tggaactcag gcgccctgac
cagcggcgtg cacaccttcc cggctgtcct acagtcctca 540ggactctact
ccctcagcag cgtagtgacc gtgccctcca gcagcttggg cacccagacc
600tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagaa
agttgagccc 660aaatcttgtg accgtactca cacatgccca ccgtgcccag
cacctgaact cctgggggga 720ccgtcagtct tcctcttccc cccaaaaccc
aaggacaccc tcatgatctc ccggacccct 780gaggtcacat gcgtggtggt
ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 840tacgtggacg
gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacaac
900agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct
gaatggcaag 960gagtacaagt gcaaggtctc caacaaagcc ctcccagccc
ccatcgagaa aaccatctcc 1020aaagccaaag ggcagccccg agaaccacag
gtgtacaccc tgcccccatc ccgggaggag 1080atgaccaaga accaggtcag
cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 1140gccgtggagt
gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg
1200ctggactccg acggctcctt cttcctctat agcaagctca ccgtggacaa
gagcaggtgg 1260cagcagggga acgtcttctc atgctccgtg atgcatgagg
ctctgcacaa ccactacacg 1320cagaagagcc tctccctgtc tccgggaaaa
135051987DNAArtificial SequenceSynthetic nucleotide sequence
51gcgtcgacca agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
60ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg
120tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct
acagtcctca 180ggactctact ccctcagcag cgtggtgacc gtgccctcca
gcagcttggg cacccagacc 240tacatctgca acgtgaatca caagcccagc
aacaccaagg tggacaagaa agttgagccc 300aaatcttgtg acaaaactca
cacatgccca ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct
tcctcttccc cccatgcccc aaggacaccc tcatgatctc ccggacccct
420gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa
gttcaactgg 480tacgtggacg gcgtggaggt gcataatgcc aagacaaagc
cgcgggagga gcagtacaac 540agcacgtacc gtgtggtcag cgtcctcacc
gtcctgcacc aggactggct gaatggcaag 600gagtacaagt gcaaggtctc
caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 660aaagccaaag
ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggaggag
720atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc
cagcgacatc 780gccgtggagt gggagagcaa tgggcagccg gagaacaact
acaagaccac gcctcccgtg 840ctggactccg acggctcctt cttcctctat
agcaagctca ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc
atgctccgtg atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc
tctccctgtc cccgggt 987521347DNAArtificial SequenceSynthetic
nucleotide sequence 52gaggtgcagc tggtggaatc cggcggaggc ctggtccagc
ctggcggatc tctgcggctg 60tcttgcgccg cctccggctt caacatcaag gacacctaca
tccactgggt ccgacaggca 120cctggcaagg gactggaatg ggtggcccgg
atctacccca ccaacggcta caccagatac 180gccgactccg tgaagggccg
gttcaccatc tccgccgaca cctccaagaa caccgcctac 240ctgcagatga
actccctgcg ggccgaggac accgccgtgt actactgctc cagatgggga
300ggcgacggct tctacgccat ggactactgg ggccagggca ccctggtcac
cgtgtctagc 360gcgtcgacca agggcccatc ggtcttcccc ctggcaccct
cctccaagag cacctctggg 420ggcacagcgg ccctgggctg cctggtcaag
gactacttcc ccgaaccggt gacggtgtcg 480tggaactcag gcgccctgac
cagcggcgtg cacaccttcc cggctgtcct acagtcctca 540ggactctact
ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc
600tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagaa
agttgagccc 660aaatcttgtg acaaaactca cacatgccca ccgtgcccag
cacctgaact cctgggggga 720ccgtcagtct tcctcttccc cccatgcccc
aaggacaccc tcatgatctc ccggacccct 780gaggtcacat gcgtggtggt
ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 840tacgtggacg
gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacaac
900agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct
gaatggcaag 960gagtacaagt gcaaggtctc caacaaagcc ctcccagccc
ccatcgagaa aaccatctcc 1020aaagccaaag ggcagccccg agaaccacag
gtgtacaccc tgcccccatc ccgggaggag 1080atgaccaaga accaggtcag
cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 1140gccgtggagt
gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg
1200ctggactccg acggctcctt cttcctctat agcaagctca ccgtggacaa
gagcaggtgg 1260cagcagggga acgtcttctc atgctccgtg atgcatgagg
ctctgcacaa ccactacacg 1320cagaagagcc tctccctgtc cccgggt
134753987DNAArtificial SequenceSynthetic nucleotide sequence
53gcgtcgacca agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
60ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg
120tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct
acagtcctca 180ggactctact ccctcagcag cgtggtgacc gtgccctcca
gcagcttggg cacccagacc 240tacatctgca acgtgaatca caagcccagc
aacaccaagg tggacaagaa agttgagccc 300aaatcttgtg acaaaactca
cacatgccca ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct
tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct
420gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa
gttcaactgg 480tacgtggacg gcgtggaggt gcataatgcc aagacatgcc
cgcgggagga gcagtacaac 540agcacgtacc gtgtggtcag cgtcctcacc
gtcctgcacc aggactggct gaatggcaag 600gagtacaagt gcaaggtctc
caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 660aaagccaaag
ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggaggag
720atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc
cagcgacatc 780gccgtggagt gggagagcaa tgggcagccg gagaacaact
acaagaccac gcctcccgtg 840ctggactccg acggctcctt cttcctctat
agcaagctca ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc
atgctccgtg atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc
tctccctgtc cccgggt 987541347DNAArtificial SequenceSynthetic
nucleotide sequence 54gaggtgcagc tggtggaatc cggcggaggc ctggtccagc
ctggcggatc tctgcggctg 60tcttgcgccg cctccggctt caacatcaag gacacctaca
tccactgggt ccgacaggca 120cctggcaagg gactggaatg ggtggcccgg
atctacccca ccaacggcta caccagatac 180gccgactccg tgaagggccg
gttcaccatc tccgccgaca cctccaagaa caccgcctac 240ctgcagatga
actccctgcg ggccgaggac accgccgtgt actactgctc cagatgggga
300ggcgacggct tctacgccat ggactactgg ggccagggca ccctggtcac
cgtgtctagc 360gcgtcgacca agggcccatc ggtcttcccc ctggcaccct
cctccaagag cacctctggg 420ggcacagcgg ccctgggctg cctggtcaag
gactacttcc ccgaaccggt gacggtgtcg 480tggaactcag gcgccctgac
cagcggcgtg cacaccttcc cggctgtcct acagtcctca 540ggactctact
ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc
600tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagaa
agttgagccc 660aaatcttgtg acaaaactca cacatgccca ccgtgcccag
cacctgaact cctgggggga 720ccgtcagtct
tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct
780gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa
gttcaactgg 840tacgtggacg gcgtggaggt gcataatgcc aagacatgcc
cgcgggagga gcagtacaac 900agcacgtacc gtgtggtcag cgtcctcacc
gtcctgcacc aggactggct gaatggcaag 960gagtacaagt gcaaggtctc
caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 1020aaagccaaag
ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggaggag
1080atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc
cagcgacatc 1140gccgtggagt gggagagcaa tgggcagccg gagaacaact
acaagaccac gcctcccgtg 1200ctggactccg acggctcctt cttcctctat
agcaagctca ccgtggacaa gagcaggtgg 1260cagcagggga acgtcttctc
atgctccgtg atgcatgagg ctctgcacaa ccactacacg 1320cagaagagcc
tctccctgtc cccgggt 134755990DNAArtificial SequenceSynthetic
nucleotide sequence 55gcctccacca agggcccatc ggtcttcccc ctggcaccct
cctccaagag cacctctggg 60ggcacagcgg ccctgggctg cctggtcaag gactacttcc
ccgaaccggt gacggtgtcg 120tggaactcag gcgccctgac cagcggcgtg
cacaccttcc cggctgtcct acagtcctca 180ggactctact ccctcagcag
cgtagtgacc gtgccctcca gcagcttggg cacccagacc 240tacatctgca
acgtgaatca caagcccagc aacaccaagg tggacaagaa agttgagccc
300aaatcttgtg acaaaactca cacatgccca ccgtgcccag cacctgaact
cctgggggga 360ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc
tcatgatctc ccggacccct 420gaggtcacat gcgtggtggt ggacgtgagc
cacgaagacc ctgaggtcaa gttcaactgg 480tacgtggacg gcgtggaggt
gcataatgcc aagacaaagc cgcgggagga gcagtacgcc 540agcacgtacc
gtgtggtcag cgtcctcacc gtcctgcacc aggactggct gaatggcaag
600gagtacaagt gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa
aaccatctcc 660aaagccaaag ggcagccccg agaaccacag gtgtacaccc
tgcccccatc ccgggaggag 720atgaccaaga accaggtcag cctgacctgc
ctggtcaaag gcttctatcc cagcgacatc 780gccgtggagt gggagagcaa
tgggcagccg gagaacaact acaagaccac gcctcccgtg 840ctggactccg
acggctcctt cttcctctat agcaagctca ccgtggacaa gagcaggtgg
900cagcagggga acgtcttctc atgctccgtg atgcatgagg ctctgcacaa
ccactacacg 960cagaagagcc tctccctgtc tccgggaaaa
990561350DNAArtificial SequenceSynthetic nucleotide sequence
56gaggtgcagc tggtggagtc cggcggcggc ctggttcagc ccggcggatc actgaggctc
60tcctgtgccg ccagcggctt caacatcaag gacacataca tccactgggt tcgccaggct
120cctggcaagg gactggagtg ggtcgctagg atctacccca ccaatgggta
caccaggtac 180gccgactccg tgaaggggcg gttcacaatc tcagccgata
ctagcaaaaa tacagcctac 240ttgcagatga actccctgag agcagaggat
accgccgtgt actattgctc tcgctggggc 300ggcgacggct tctacgctat
ggattattgg ggccagggaa ccttggtcac cgtctcctca 360gcctccacca
agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
420ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt
gacggtgtcg 480tggaactcag gcgccctgac cagcggcgtg cacaccttcc
cggctgtcct acagtcctca 540ggactctact ccctcagcag cgtagtgacc
gtgccctcca gcagcttggg cacccagacc 600tacatctgca acgtgaatca
caagcccagc aacaccaagg tggacaagaa agttgagccc 660aaatcttgtg
acaaaactca cacatgccca ccgtgcccag cacctgaact cctgggggga
720ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc
ccggacccct 780gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc
ctgaggtcaa gttcaactgg 840tacgtggacg gcgtggaggt gcataatgcc
aagacaaagc cgcgggagga gcagtacgcc 900agcacgtacc gtgtggtcag
cgtcctcacc gtcctgcacc aggactggct gaatggcaag 960gagtacaagt
gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa aaccatctcc
1020aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc
ccgggaggag 1080atgaccaaga accaggtcag cctgacctgc ctggtcaaag
gcttctatcc cagcgacatc 1140gccgtggagt gggagagcaa tgggcagccg
gagaacaact acaagaccac gcctcccgtg 1200ctggactccg acggctcctt
cttcctctat agcaagctca ccgtggacaa gagcaggtgg 1260cagcagggga
acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg
1320cagaagagcc tctccctgtc tccgggaaaa 1350571055DNAArtificial
SequenceSynthetic nucleotide sequence 57gcctccacca agggcccatc
ggtcttcccc ctggcaccct cctccaagag cacctctggg 60ggcacagcgg ccctgggctg
cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120tggaactcag
gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca
180ggactctact ccctcagcag cgtagtgacc gtgccctcca gcagcttggg
cacccagacc 240tacatctgca acgtgaatca caagcccagc aacaccaagg
tggacaagaa agttgagccc 300aaatcttgtg acaaaactca cacatgccca
ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct tcctcttccc
cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420gaggtcacat
gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg
480tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga
gcagtaccaa 540agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc
aggactggct gaatggcaag 600gagtacaagt gcaaggtctc caacaaagcc
ctcccagccc ccatcgagaa aaccatctcc 660aaagccaaag ggcagccccg
agaaccacag gtgtacaccc tgcccccatc ccgggaggag 720atgaccaaga
accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc
780gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac
gcctcccgtg 840ctggactccg acggctcctt cttcctctat agcaagctca
ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc atgctccgtg
atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc tctccctgtc
tccgggaaaa gccgccagcg gcttcaacat caaggacaca 1020tacatccact
gggttcgcca ggctcctggc aaggg 1055581415DNAArtificial
SequenceSynthetic nucleotide sequence 58gaggtgcagc tggtggagtc
cggcggcggc ctggttcagc ccggcggatc actgaggctc 60tcctgtgccg ccagcggctt
caacatcaag gacacataca tccactgggt tcgccaggct 120cctggcaagg
gactggagtg ggtcgctagg atctacccca ccaatgggta caccaggtac
180gccgactccg tgaaggggcg gttcacaatc tcagccgata ctagcaaaaa
tacagcctac 240ttgcagatga actccctgag agcagaggat accgccgtgt
actattgctc tcgctggggc 300ggcgacggct tctacgctat ggattattgg
ggccagggaa ccttggtcac cgtctcctca 360gcctccacca agggcccatc
ggtcttcccc ctggcaccct cctccaagag cacctctggg 420ggcacagcgg
ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg
480tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct
acagtcctca 540ggactctact ccctcagcag cgtagtgacc gtgccctcca
gcagcttggg cacccagacc 600tacatctgca acgtgaatca caagcccagc
aacaccaagg tggacaagaa agttgagccc 660aaatcttgtg acaaaactca
cacatgccca ccgtgcccag cacctgaact cctgggggga 720ccgtcagtct
tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct
780gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa
gttcaactgg 840tacgtggacg gcgtggaggt gcataatgcc aagacaaagc
cgcgggagga gcagtaccaa 900agcacgtacc gtgtggtcag cgtcctcacc
gtcctgcacc aggactggct gaatggcaag 960gagtacaagt gcaaggtctc
caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 1020aaagccaaag
ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggaggag
1080atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc
cagcgacatc 1140gccgtggagt gggagagcaa tgggcagccg gagaacaact
acaagaccac gcctcccgtg 1200ctggactccg acggctcctt cttcctctat
agcaagctca ccgtggacaa gagcaggtgg 1260cagcagggga acgtcttctc
atgctccgtg atgcatgagg ctctgcacaa ccactacacg 1320cagaagagcc
tctccctgtc tccgggaaaa gccgccagcg gcttcaacat caaggacaca
1380tacatccact gggttcgcca ggctcctggc aaggg 141559987DNAArtificial
SequenceSynthetic nucleotide sequence 59gcgtcgacca agggcccatc
ggtcttcccc ctggcaccct cctccaagag cacctctggg 60ggcacagcgg ccctgggctg
cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120tggaactcag
gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca
180ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg
cacccagacc 240tacatctgca acgtgaatca caagcccagc aacaccaagg
tggacaagaa agttgagccc 300aaatcttgtg acaaaactca cacatgccca
ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct tcctcttccc
cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420gaggtcacat
gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg
480tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga
gcagtacaac 540agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc
aggactggct gaatggcaag 600gagtacaagt gcaaggtctc caacaaagcc
ctcccagccc ccatcgagtg caccatctcc 660aaagccaaag ggcagccccg
agaaccacag gtgtacaccc tgcccccatc ccgggaggag 720atgaccaaga
accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc
780gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac
gcctcccgtg 840ctggactccg acggctcctt cttcctctat agcaagctca
ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc atgctccgtg
atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc tctccctgtc cccgggt
987601347DNAArtificial SequenceSynthetic nucleotide sequence
60gaggtgcagc tggtggaatc cggcggaggc ctggtccagc ctggcggatc tctgcggctg
60tcttgcgccg cctccggctt caacatcaag gacacctaca tccactgggt ccgacaggca
120cctggcaagg gactggaatg ggtggcccgg atctacccca ccaacggcta
caccagatac 180gccgactccg tgaagggccg gttcaccatc tccgccgaca
cctccaagaa caccgcctac 240ctgcagatga actccctgcg ggccgaggac
accgccgtgt actactgctc cagatgggga 300ggcgacggct tctacgccat
ggactactgg ggccagggca ccctggtcac cgtgtctagc 360gcgtcgacca
agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
420ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt
gacggtgtcg 480tggaactcag gcgccctgac cagcggcgtg cacaccttcc
cggctgtcct acagtcctca 540ggactctact ccctcagcag cgtggtgacc
gtgccctcca gcagcttggg cacccagacc 600tacatctgca acgtgaatca
caagcccagc aacaccaagg tggacaagaa agttgagccc 660aaatcttgtg
acaaaactca cacatgccca ccgtgcccag cacctgaact cctgggggga
720ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc
ccggacccct 780gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc
ctgaggtcaa gttcaactgg 840tacgtggacg gcgtggaggt gcataatgcc
aagacaaagc cgcgggagga gcagtacaac 900agcacgtacc gtgtggtcag
cgtcctcacc gtcctgcacc aggactggct gaatggcaag 960gagtacaagt
gcaaggtctc caacaaagcc ctcccagccc ccatcgagtg caccatctcc
1020aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc
ccgggaggag 1080atgaccaaga accaggtcag cctgacctgc ctggtcaaag
gcttctatcc cagcgacatc 1140gccgtggagt gggagagcaa tgggcagccg
gagaacaact acaagaccac gcctcccgtg 1200ctggactccg acggctcctt
cttcctctat agcaagctca ccgtggacaa gagcaggtgg 1260cagcagggga
acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg
1320cagaagagcc tctccctgtc cccgggt 134761987DNAArtificial
SequenceSynthetic nucleotide sequence 61gcgtcgacca agggcccatc
ggtcttcccc ctggcaccct cctccaagag cacctctggg 60ggcacagcgg ccctgggctg
cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120tggaactcag
gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca
180ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg
cacccagacc 240tacatctgca acgtgaatca caagcccagc aacaccaagg
tggacaagaa agttgagccc 300aaatcttgtg acaaaactca cacatgccca
ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct tcctcttccc
cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420gaggtcacat
gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg
480tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga
gcagtacaac 540agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc
aggactggct gaatggcaag 600gagtacaagt gcaaggtctc caacaaagcc
ctcccagccc ccatcgagaa aaccatctcc 660aaagccaaag ggcagccccg
agaaccacag gtgtacaccc tgcccccatc ccgggaggag 720atgaccaaga
accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc
780gccgtggagt gggagagcaa tgggcagccg gagaacaact actgcaccac
gcctcccgtg 840ctggactccg acggctcctt cttcctctat agcaagctca
ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc atgctccgtg
atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc tctccctgtc cccgggt
987621347DNAArtificial SequenceSynthetic nucleotide sequence
62gaggtgcagc tggtggaatc cggcggaggc ctggtccagc ctggcggatc tctgcggctg
60tcttgcgccg cctccggctt caacatcaag gacacctaca tccactgggt ccgacaggca
120cctggcaagg gactggaatg ggtggcccgg atctacccca ccaacggcta
caccagatac 180gccgactccg tgaagggccg gttcaccatc tccgccgaca
cctccaagaa caccgcctac 240ctgcagatga actccctgcg ggccgaggac
accgccgtgt actactgctc cagatgggga 300ggcgacggct tctacgccat
ggactactgg ggccagggca ccttggtcac cgtgtctagc 360gcgtcgacca
agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
420ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt
gacggtgtcg 480tggaactcag gcgccctgac cagcggcgtg cacaccttcc
cggctgtcct acagtcctca 540ggactctact ccctcagcag cgtggtgacc
gtgccctcca gcagcttggg cacccagacc 600tacatctgca acgtgaatca
caagcccagc aacaccaagg tggacaagaa agttgagccc 660aaatcttgtg
acaaaactca cacatgccca ccgtgcccag cacctgaact cctgggggga
720ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc
ccggacccct 780gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc
ctgaggtcaa gttcaactgg 840tacgtggacg gcgtggaggt gcataatgcc
aagacaaagc cgcgggagga gcagtacaac 900agcacgtacc gtgtggtcag
cgtcctcacc gtcctgcacc aggactggct gaatggcaag 960gagtacaagt
gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa aaccatctcc
1020aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc
ccgggaggag 1080atgaccaaga accaggtcag cctgacctgc ctggtcaaag
gcttctatcc cagcgacatc 1140gccgtggagt gggagagcaa tgggcagccg
gagaacaact actgcaccac gcctcccgtg 1200ctggactccg acggctcctt
cttcctctat agcaagctca ccgtggacaa gagcaggtgg 1260cagcagggga
acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg
1320cagaagagcc tctccctgtc cccgggt 134763987DNAArtificial
SequenceSynthetic nucleotide sequence 63gcgtcgacca agggcccatc
ggtcttcccc ctggcaccct cctccaagag cacctctggg 60ggcacagcgg ccctgggctg
cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120tggaactcag
gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca
180ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg
cacccagacc 240tacatctgca acgtgaatca caagcccagc aacaccaagg
tggacaagaa agttgagccc 300aaatcttgtg acaaaactca cacatgccca
ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct tcctcttccc
cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420gaggtcacat
gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg
480tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga
gcagtacaac 540agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc
aggactggct gaatggcaag 600gagtacaagt gcaaggtctc caacaaagcc
ctcccagccc ccatcgagaa aaccatctcc 660aaagccaaag ggcagccccg
agaaccacag gtgtacaccc tgcccccatc ccgggaggag 720atgaccaaga
accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc
780gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac
gcctcccgtg 840ctggactccg acggctcctt cttcctctat agcaagctca
ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc atgctccgtg
atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc tctcctgctc cccgggt
987641347DNAArtificial SequenceSynthetic nucleotide sequence
64gaggtgcagc tggtggaatc cggcggaggc ctggtccagc ctggcggatc tctgcggctg
60tcttgcgccg cctccggctt caacatcaag gacacctaca tccactgggt ccgacaggca
120cctggcaagg gactggaatg ggtggcccgg atctacccca ccaacggcta
caccagatac 180gccgactccg tgaagggccg gttcaccatc tccgccgaca
cctccaagaa caccgcctac 240ctgcagatga actccctgcg ggccgaggac
accgccgtgt actactgctc cagatgggga 300ggcgacggct tctacgccat
ggactactgg ggccagggca ccctggtcac cgtgtctagc 360gcgtcgacca
agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
420ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt
gacggtgtcg 480tggaactcag gcgccctgac cagcggcgtg cacaccttcc
cggctgtcct acagtcctca 540ggactctact ccctcagcag cgtggtgacc
gtgccctcca gcagcttggg cacccagacc 600tacatctgca acgtgaatca
caagcccagc aacaccaagg tggacaagaa agttgagccc 660aaatcttgtg
acaaaactca cacatgccca ccgtgcccag cacctgaact cctgggggga
720ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc
ccggacccct 780gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc
ctgaggtcaa gttcaactgg 840tacgtggacg gcgtggaggt gcataatgcc
aagacaaagc cgcgggagga gcagtacaac 900agcacgtacc gtgtggtcag
cgtcctcacc gtcctgcacc aggactggct gaatggcaag 960gagtacaagt
gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa aaccatctcc
1020aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc
ccgggaggag 1080atgaccaaga accaggtcag cctgacctgc ctggtcaaag
gcttctatcc cagcgacatc 1140gccgtggagt gggagagcaa tgggcagccg
gagaacaact acaagaccac gcctcccgtg 1200ctggactccg acggctcctt
cttcctctat agcaagctca ccgtggacaa gagcaggtgg 1260cagcagggga
acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg
1320cagaagagcc tctcctgctc cccgggt 134765987DNAArtificial
SequenceSynthetic nucleotide sequence 65gcgtcgacca agggcccatc
ggtcttcccc ctggcaccct cctccaagag cacctctggg 60ggcacagcgg ccctgggctg
cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120tggaactcag
gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca
180ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg
cacccagacc 240tacatctgca acgtgaatca caagcccagc aacaccaagg
tggacaagaa agttgagccc 300aaatcttgtg acaaaactca cacatgccca
ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct tcctcttccc
cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420gaggtcacat
gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg
480tacgtggacg gcgtggaggt gcataatgcc aagacatgcc cgcgggagga
gcagtacaac 540agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc
aggactggct gaatggcaag 600gagtacaagt gcaaggtctc caacaaagcc
ctcccagccc ccatcgagtg caccatctcc 660aaagccaaag ggcagccccg
agaaccacag gtgtacaccc tgcccccatc ccgggaggag 720atgaccaaga
accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc
780gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac
gcctcccgtg 840ctggactccg acggctcctt cttcctctat agcaagctca
ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc atgctccgtg
atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc tctccctgtc cccgggt
987661347DNAArtificial SequenceSynthetic nucleotide sequence
66gaggtgcagc tggtggaatc cggcggaggc ctggtccagc ctggcggatc tctgcggctg
60tcttgcgccg cctccggctt caacatcaag gacacctaca tccactgggt ccgacaggca
120cctggcaagg gactggaatg ggtggcccgg atctacccca ccaacggcta
caccagatac 180gccgactccg tgaagggccg gttcaccatc tccgccgaca
cctccaagaa caccgcctac 240ctgcagatga actccctgcg ggccgaggac
accgccgtgt actactgctc cagatgggga 300ggcgacggct tctacgccat
ggactactgg ggccagggca ccctggtcac cgtgtctagc 360gcgtcgacca
agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
420ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt
gacggtgtcg 480tggaactcag gcgccctgac cagcggcgtg cacaccttcc
cggctgtcct acagtcctca 540ggactctact
ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc
600tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagaa
agttgagccc 660aaatcttgtg acaaaactca cacatgccca ccgtgcccag
cacctgaact cctgggggga 720ccgtcagtct tcctcttccc cccaaaaccc
aaggacaccc tcatgatctc ccggacccct 780gaggtcacat gcgtggtggt
ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 840tacgtggacg
gcgtggaggt gcataatgcc aagacatgcc cgcgggagga gcagtacaac
900agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct
gaatggcaag 960gagtacaagt gcaaggtctc caacaaagcc ctcccagccc
ccatcgagtg caccatctcc 1020aaagccaaag ggcagccccg agaaccacag
gtgtacaccc tgcccccatc ccgggaggag 1080atgaccaaga accaggtcag
cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 1140gccgtggagt
gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg
1200ctggactccg acggctcctt cttcctctat agcaagctca ccgtggacaa
gagcaggtgg 1260cagcagggga acgtcttctc atgctccgtg atgcatgagg
ctctgcacaa ccactacacg 1320cagaagagcc tctccctgtc cccgggt
134767987DNAArtificial SequenceSynthetic nucleotide sequence
67gcgtcgacca agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
60ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg
120tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct
acagtcctca 180ggactctact ccctcagcag cgtggtgacc gtgccctcca
gcagcttggg cacccagacc 240tacatctgca acgtgaatca caagcccagc
aacaccaagg tggacaagaa agttgagccc 300aaatcttgtg acaaaactca
cacatgccca ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct
tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct
420gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa
gttcaactgg 480tacgtggacg gcgtggaggt gcataatgcc aagacatgcc
cgcgggagga gcagtacaac 540agcacgtacc gtgtggtcag cgtcctcacc
gtcctgcacc aggactggct gaatggcaag 600gagtacaagt gcaaggtctc
caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 660aaagccaaag
ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggaggag
720atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc
cagcgacatc 780gccgtggagt gggagagcaa tgggcagccg gagaacaact
actgcaccac gcctcccgtg 840ctggactccg acggctcctt cttcctctat
agcaagctca ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc
atgctccgtg atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc
tctccctgtc cccgggt 987681347DNAArtificial SequenceSynthetic
nucleotide sequence 68gaggtgcagc tggtggaatc cggcggaggc ctggtccagc
ctggcggatc tctgcggctg 60tcttgcgccg cctccggctt caacatcaag gacacctaca
tccactgggt ccgacaggca 120cctggcaagg gactggaatg ggtggcccgg
atctacccca ccaacggcta caccagatac 180gccgactccg tgaagggccg
gttcaccatc tccgccgaca cctccaagaa caccgcctac 240ctgcagatga
actccctgcg ggccgaggac accgccgtgt actactgctc cagatgggga
300ggcgacggct tctacgccat ggactactgg ggccagggca ccctggtcac
cgtgtctagc 360gcgtcgacca agggcccatc ggtcttcccc ctggcaccct
cctccaagag cacctctggg 420ggcacagcgg ccctgggctg cctggtcaag
gactacttcc ccgaaccggt gacggtgtcg 480tggaactcag gcgccctgac
cagcggcgtg cacaccttcc cggctgtcct acagtcctca 540ggactctact
ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc
600tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagaa
agttgagccc 660aaatcttgtg acaaaactca cacatgccca ccgtgcccag
cacctgaact cctgggggga 720ccgtcagtct tcctcttccc cccaaaaccc
aaggacaccc tcatgatctc ccggacccct 780gaggtcacat gcgtggtggt
ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 840tacgtggacg
gcgtggaggt gcataatgcc aagacatgcc cgcgggagga gcagtacaac
900agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct
gaatggcaag 960gagtacaagt gcaaggtctc caacaaagcc ctcccagccc
ccatcgagaa aaccatctcc 1020aaagccaaag ggcagccccg agaaccacag
gtgtacaccc tgcccccatc ccgggaggag 1080atgaccaaga accaggtcag
cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 1140gccgtggagt
gggagagcaa tgggcagccg gagaacaact actgcaccac gcctcccgtg
1200ctggactccg acggctcctt cttcctctat agcaagctca ccgtggacaa
gagcaggtgg 1260cagcagggga acgtcttctc atgctccgtg atgcatgagg
ctctgcacaa ccactacacg 1320cagaagagcc tctccctgtc cccgggt
134769990DNAArtificial SequenceSynthetic nucleotide sequence
69gcctccacca agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
60ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg
120tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct
acagtcctca 180ggactctact ccctcagcag cgtagtgacc gtgccctcca
gcagcttggg cacccagacc 240tacatctgca acgtgaatca caagcccagc
aacaccaagg tggacaagaa agttgagccc 300aaatcttgtg accgtactca
cacatgccca ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct
tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct
420gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa
gttcaactgg 480tacgtggacg gcgtggaggt gcataatgcc aagacaaagc
cgcgggagga gcagtacgcc 540agcacgtacc gtgtggtcag cgtcctcacc
gtcctgcacc aggactggct gaatggcaag 600gagtacaagt gcaaggtctc
caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 660aaagccaaag
ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggaggag
720atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc
cagcgacatc 780gccgtggagt gggagagcaa tgggcagccg gagaacaact
acaagaccac gcctcccgtg 840ctggactccg acggctcctt cttcctctat
agcaagctca ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc
atgctccgtg atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc
tctccctgtc tccgggaaaa 990701350DNAArtificial SequenceSynthetic
nucleotide sequence 70gaggtgcagc tggtggagtc cggcggcggc ctggttcagc
ccggcggatc actgaggctc 60tcctgtgccg ccagcggctt caacatcaag gacacataca
tccactgggt tcgccaggct 120cctggcaagg gactggagtg ggtcgctagg
atctacccca ccaatgggta caccaggtac 180gccgactccg tgaaggggcg
gttcacaatc tcagccgata ctagcaaaaa tacagcctac 240ttgcagatga
actccctgag agcagaggat accgccgtgt actattgctc tcgctggggc
300ggcgacggct tctacgctat ggattattgg ggccagggaa ccttggtcac
cgtctcctca 360gcctccacca agggcccatc ggtcttcccc ctggcaccct
cctccaagag cacctctggg 420ggcacagcgg ccctgggctg cctggtcaag
gactacttcc ccgaaccggt gacggtgtcg 480tggaactcag gcgccctgac
cagcggcgtg cacaccttcc cggctgtcct acagtcctca 540ggactctact
ccctcagcag cgtagtgacc gtgccctcca gcagcttggg cacccagacc
600tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagaa
agttgagccc 660aaatcttgtg accgtactca cacatgccca ccgtgcccag
cacctgaact cctgggggga 720ccgtcagtct tcctcttccc cccaaaaccc
aaggacaccc tcatgatctc ccggacccct 780gaggtcacat gcgtggtggt
ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 840tacgtggacg
gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacgcc
900agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct
gaatggcaag 960gagtacaagt gcaaggtctc caacaaagcc ctcccagccc
ccatcgagaa aaccatctcc 1020aaagccaaag ggcagccccg agaaccacag
gtgtacaccc tgcccccatc ccgggaggag 1080atgaccaaga accaggtcag
cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 1140gccgtggagt
gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg
1200ctggactccg acggctcctt cttcctctat agcaagctca ccgtggacaa
gagcaggtgg 1260cagcagggga acgtcttctc atgctccgtg atgcatgagg
ctctgcacaa ccactacacg 1320cagaagagcc tctccctgtc tccgggaaaa
1350711055DNAArtificial SequenceSynthetic nucleotide sequence
71gcctccacca agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
60ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg
120tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct
acagtcctca 180ggactctact ccctcagcag cgtagtgacc gtgccctcca
gcagcttggg cacccagacc 240tacatctgca acgtgaatca caagcccagc
aacaccaagg tggacaagaa agttgagccc 300aaatcttgtg accgtactca
cacatgccca ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct
tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct
420gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa
gttcaactgg 480tacgtggacg gcgtggaggt gcataatgcc aagacaaagc
cgcgggagga gcagtaccaa 540agcacgtacc gtgtggtcag cgtcctcacc
gtcctgcacc aggactggct gaatggcaag 600gagtacaagt gcaaggtctc
caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 660aaagccaaag
ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggaggag
720atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc
cagcgacatc 780gccgtggagt gggagagcaa tgggcagccg gagaacaact
acaagaccac gcctcccgtg 840ctggactccg acggctcctt cttcctctat
agcaagctca ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc
atgctccgtg atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc
tctccctgtc tccgggaaaa gccgccagcg gcttcaacat caaggacaca
1020tacatccact gggttcgcca ggctcctggc aaggg 1055721415DNAArtificial
SequenceSynthetic nucleotide sequence 72gaggtgcagc tggtggagtc
cggcggcggc ctggttcagc ccggcggatc actgaggctc 60tcctgtgccg ccagcggctt
caacatcaag gacacataca tccactgggt tcgccaggct 120cctggcaagg
gactggagtg ggtcgctagg atctacccca ccaatgggta caccaggtac
180gccgactccg tgaaggggcg gttcacaatc tcagccgata ctagcaaaaa
tacagcctac 240ttgcagatga actccctgag agcagaggat accgccgtgt
actattgctc tcgctggggc 300ggcgacggct tctacgctat ggattattgg
ggccagggaa ccttggtcac cgtctcctca 360gcctccacca agggcccatc
ggtcttcccc ctggcaccct cctccaagag cacctctggg 420ggcacagcgg
ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg
480tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct
acagtcctca 540ggactctact ccctcagcag cgtagtgacc gtgccctcca
gcagcttggg cacccagacc 600tacatctgca acgtgaatca caagcccagc
aacaccaagg tggacaagaa agttgagccc 660aaatcttgtg accgtactca
cacatgccca ccgtgcccag cacctgaact cctgggggga 720ccgtcagtct
tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct
780gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa
gttcaactgg 840tacgtggacg gcgtggaggt gcataatgcc aagacaaagc
cgcgggagga gcagtaccaa 900agcacgtacc gtgtggtcag cgtcctcacc
gtcctgcacc aggactggct gaatggcaag 960gagtacaagt gcaaggtctc
caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 1020aaagccaaag
ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggaggag
1080atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc
cagcgacatc 1140gccgtggagt gggagagcaa tgggcagccg gagaacaact
acaagaccac gcctcccgtg 1200ctggactccg acggctcctt cttcctctat
agcaagctca ccgtggacaa gagcaggtgg 1260cagcagggga acgtcttctc
atgctccgtg atgcatgagg ctctgcacaa ccactacacg 1320cagaagagcc
tctccctgtc tccgggaaaa gccgccagcg gcttcaacat caaggacaca
1380tacatccact gggttcgcca ggctcctggc aaggg 141573987DNAArtificial
SequenceSynthetic nucleotide sequence 73gcgtcgacca agggcccatc
ggtcttcccc ctggcaccct cctccaagag cacctctggg 60ggcacagcgg ccctgggctg
cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120tggaactcag
gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca
180ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg
cacccagacc 240tacatctgca acgtgaatca caagcccagc aacaccaagg
tggacaagaa agttgagccc 300aaatcttgtg acaaaactca cacatgccca
ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct tcctcttccc
cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420gaggtcacat
gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg
480tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga
gcagtacaac 540agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc
aggactggct gaatggcaag 600gagtacaagt gcaaggtctc caacaaagcc
ctcccagccc ccatcgagtg caccatctcc 660aaagccaaag ggcagccccg
agaaccacag gtgtacaccc tgcccccatc ccgggaggag 720atgaccaaga
accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc
780gccgtggagt gggagagcaa tgggcagccg gagaacaact actgcaccac
gcctcccgtg 840ctggactccg acggctcctt cttcctctat agcaagctca
ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc atgctccgtg
atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc tctccctgtc cccgggt
987741347DNAArtificial SequenceSynthetic nucleotide sequence
74gaggtgcagc tggtggaatc cggcggaggc ctggtccagc ctggcggatc tctgcggctg
60tcttgcgccg cctccggctt caacatcaag gacacctaca tccactgggt ccgacaggca
120cctggcaagg gactggaatg ggtggcccgg atctacccca ccaacggcta
caccagatac 180gccgactccg tgaagggccg gttcaccatc tccgccgaca
cctccaagaa caccgcctac 240ctgcagatga actccctgcg ggccgaggac
accgccgtgt actactgctc cagatgggga 300ggcgacggct tctacgccat
ggactactgg ggccagggca ccctggtcac cgtgtctagc 360gcgtcgacca
agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
420ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt
gacggtgtcg 480tggaactcag gcgccctgac cagcggcgtg cacaccttcc
cggctgtcct acagtcctca 540ggactctact ccctcagcag cgtggtgacc
gtgccctcca gcagcttggg cacccagacc 600tacatctgca acgtgaatca
caagcccagc aacaccaagg tggacaagaa agttgagccc 660aaatcttgtg
acaaaactca cacatgccca ccgtgcccag cacctgaact cctgggggga
720ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc
ccggacccct 780gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc
ctgaggtcaa gttcaactgg 840tacgtggacg gcgtggaggt gcataatgcc
aagacaaagc cgcgggagga gcagtacaac 900agcacgtacc gtgtggtcag
cgtcctcacc gtcctgcacc aggactggct gaatggcaag 960gagtacaagt
gcaaggtctc caacaaagcc ctcccagccc ccatcgagtg caccatctcc
1020aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc
ccgggaggag 1080atgaccaaga accaggtcag cctgacctgc ctggtcaaag
gcttctatcc cagcgacatc 1140gccgtggagt gggagagcaa tgggcagccg
gagaacaact actgcaccac gcctcccgtg 1200ctggactccg acggctcctt
cttcctctat agcaagctca ccgtggacaa gagcaggtgg 1260cagcagggga
acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg
1320cagaagagcc tctccctgtc cccgggt 134775987DNAArtificial
SequenceSynthetic nucleotide sequence 75gcgtcgacca agggcccatc
ggtcttcccc ctggcaccct cctccaagag cacctctggg 60ggcacagcgg ccctgggctg
cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120tggaactcag
gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca
180ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg
cacccagacc 240tacatctgca acgtgaatca caagcccagc aacaccaagg
tggacaagaa agttgagccc 300aaatcttgtg acaaaactca cacatgccca
ccgtgcccag cacctgaact cctgggggga 360ccgtcagtct tcctcttccc
cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420gaggtcacat
gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg
480tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga
gcagtacaac 540agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc
aggactggct gaatggcaag 600gagtacaagt gcaaggtctc caacaaagcc
ctcccagccc ccatcgagaa aaccatctcc 660aaagccaaag ggcagccccg
agaaccacag gtgtacaccc tgcccccatc ccgggaggag 720atgaccaaga
accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc
780gccgtggagt gggagagcaa tgggcagccg gagaacaact actgcaccac
gcctcccgtg 840ctggactccg acggctcctt cttcctctat agcaagctca
ccgtggacaa gagcaggtgg 900cagcagggga acgtcttctc atgctccgtg
atgcatgagg ctctgcacaa ccactacacg 960cagaagagcc tctcctgctc cccgggt
987761347DNAArtificial SequenceSynthetic nucleotide sequence
76gaggtgcagc tggtggaatc cggcggaggc ctggtccagc ctggcggatc tctgcggctg
60tcttgcgccg cctccggctt caacatcaag gacacctaca tccactgggt ccgacaggca
120cctggcaagg gactggaatg ggtggcccgg atctacccca ccaacggcta
caccagatac 180gccgactccg tgaagggccg gttcaccatc tccgccgaca
cctccaagaa caccgcctac 240ctgcagatga actccctgcg ggccgaggac
accgccgtgt actactgctc cagatgggga 300ggcgacggct tctacgccat
ggactactgg ggccagggca ccctggtcac cgtgtctagc 360gcgtcgacca
agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg
420ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt
gacggtgtcg 480tggaactcag gcgccctgac cagcggcgtg cacaccttcc
cggctgtcct acagtcctca 540ggactctact ccctcagcag cgtggtgacc
gtgccctcca gcagcttggg cacccagacc 600tacatctgca acgtgaatca
caagcccagc aacaccaagg tggacaagaa agttgagccc 660aaatcttgtg
acaaaactca cacatgccca ccgtgcccag cacctgaact cctgggggga
720ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc
ccggacccct 780gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc
ctgaggtcaa gttcaactgg 840tacgtggacg gcgtggaggt gcataatgcc
aagacaaagc cgcgggagga gcagtacaac 900agcacgtacc gtgtggtcag
cgtcctcacc gtcctgcacc aggactggct gaatggcaag 960gagtacaagt
gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa aaccatctcc
1020aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc
ccgggaggag 1080atgaccaaga accaggtcag cctgacctgc ctggtcaaag
gcttctatcc cagcgacatc 1140gccgtggagt gggagagcaa tgggcagccg
gagaacaact actgcaccac gcctcccgtg 1200ctggactccg acggctcctt
cttcctctat agcaagctca ccgtggacaa gagcaggtgg 1260cagcagggga
acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg
1320cagaagagcc tctcctgctc cccgggt 134777321DNAArtificial
SequenceSynthetic nucleotide sequence 77cggaccgtgg ccgctccctc
cgtgttcatc ttcccaccct ccgacgagca gctgaagtcc 60ggcaccgcct ccgtcgtgtg
cctgctgaac aacttctacc cccgcgaggc caaggtgcag 120tggaaggtgg
acaacgccct gcagtccggc aactcccagg aatccgtcac cgagcaggac
180tccaaggaca gcacctactc cctgtcctcc accctgaccc tgtcctgcgc
cgactacgag 240aagcacaagg tgtacgcctg cgaagtgacc caccagggcc
tgtccagccc cgtgaccaag 300tccttcaacc ggggcgagtg c
32178642DNAArtificial SequenceSynthetic nucleotide sequence
78gacatccaga tgacccagtc cccctccagc ctgtccgcct ctgtgggcga cagagtgacc
60atcacctgtc gggcctccca ggacgtgaac accgccgtgg cctggtatca gcagaagccc
120ggcaaggccc ccaagctgct gatctactcc gcctccttcc tgtactccgg
cgtgccctcc 180cggttctccg gctccagatc tggcaccgac tttaccctga
ccatctccag cctgcagccc 240gaggacttcg ccacctacta ctgccagcag
cactacacca ccccccccac ctttggccag 300ggcaccaagg tggaaatcaa
gcggaccgtg gccgctccct ccgtgttcat cttcccaccc 360tccgacgagc
agctgaagtc cggcaccgcc tccgtcgtgt gcctgctgaa caacttctac
420ccccgcgagg ccaaggtgca gtggaaggtg gacaacgccc tgcagtccgg
caactcccag 480gaatccgtca ccgagcagga ctccaaggac agcacctact
ccctgtcctc caccctgacc 540ctgtcctgcg ccgactacga gaagcacaag
gtgtacgcct gcgaagtgac ccaccagggc 600ctgtccagcc ccgtgaccaa
gtccttcaac cggggcgagt gc 64279321DNAArtificial SequenceSynthetic
nucleotide sequence 79cgtacggtgg ctgcaccatc tgtcttcatc ttcccgccat
ctgatgagca gttgaaatct 60ggaactgcct ctgttgtgtg cctgctgaat aacttctatc
ccagagaggc caaagtacag 120tggaaggtgg ataacgccct ccaatcgggt
aactcccagg agagtgtcac agagcaggac 180agcaaggaca gcacctacag
cctcagcagc accctgacgc tgagcaaagc agactacgag 240aaacacaaag
tctacgcctg cgaagtcacc catcagggcc tgagctcgcc cgtcacaaag
300agcttcaaca
ggggagagtg t 32180666DNAArtificial SequenceSynthetic nucleotide
sequence 80gatatccaga tgacacagtc cccctccagc ctctccgcta gtgtcggaga
tagagtgaca 60attacatgtc gggcaagcca ggacgtcaat accgccgtgg cctggtatca
gcagaagcca 120ggaaaggccc caaaactcct gatctactcc gcctccttcc
tgtactcagg ggtcccttca 180cgcttctccg gttcccggag cggcaccgac
ttcactctga ctatctcaag cttgcagccc 240gaggacttcg ccacatacta
ttgccagcag cactatacca ccccccctac cttcggtcag 300ggaactaagg
tggaaattaa acgtacggtg gctgcaccat ctgtcttcat cttcccgcca
360tctgatgagc agttgaaatc tggaactgcc tctgttgtgt gcctgctgaa
taacttctat 420cccagagagg ccaaagtaca gtggaaggtg gataacgccc
tccaatcggg taactcccag 480gagagtgtca cagagcagga cagcaaggac
agcacctaca gcctcagcag caccctgacg 540ctgagcaaag cagactacga
gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600ctgagctcgc
ccgtcacaaa gagcttcaac aggggagagt gtggtggcct gcttcagggc 660ccacca
666818PRTArtificial SequenceSynthetic peptide sequence 81Gly Gly
Leu Leu Gln Gly Pro Pro1 5827PRTArtificial SequenceSynthetic
peptide sequence 82Gly Gly Leu Leu Gln Gly Gly1 5835PRTArtificial
SequenceSynthetic peptide sequence 83Leu Leu Gln Gly Ala1
5847PRTArtificial SequenceSynthetic peptide sequence 84Gly Gly Leu
Leu Gln Gly Ala1 5854PRTArtificial SequenceSynthetic peptide
sequence 85Leu Leu Gln Gly1866PRTArtificial SequenceSynthetic
peptide sequence 86Leu Leu Gln Gly Pro Gly1 5876PRTArtificial
SequenceSynthetic peptide sequence 87Leu Leu Gln Gly Pro Ala1
5885PRTArtificial SequenceSynthetic peptide sequence 88Leu Leu Gln
Gly Pro1 5894PRTArtificial SequenceSynthetic peptide sequence 89Leu
Leu Gln Pro1906PRTArtificial SequenceSynthetic peptide sequence
90Leu Leu Gln Pro Gly Lys1 5918PRTArtificial SequenceSynthetic
peptide sequence 91Leu Leu Gln Gly Ala Pro Gly Lys1
5927PRTArtificial SequenceSynthetic peptide sequence 92Leu Leu Gln
Gly Ala Pro Gly1 5936PRTArtificial SequenceSynthetic peptide
sequence 93Leu Leu Gln Gly Ala Pro1 5948PRTArtificial
SequenceSynthetic peptide sequenceMISC_FEATURE(4)..(4)Xaa is G or
PMISC_FEATURE(5)..(5)Xaa is A, G, P, or
absentMISC_FEATURE(6)..(6)Xaa is A, G, K, P, or
absentMISC_FEATURE(7)..(7)Xaa is G, K or
absentMISC_FEATURE(8)..(8)Xaa is K or absent 94Leu Leu Gln Xaa Xaa
Xaa Xaa Xaa1 5958PRTArtificial SequenceSynthetic peptide
sequenceMISC_FEATURE(4)..(4)Xaa is any naturally occurring amino
acidMISC_FEATURE(5)..(5)Xaa is any naturally occurring amino acid
or absentMISC_FEATURE(6)..(6)Xaa is any naturally occurring amino
acid or absentMISC_FEATURE(7)..(7)Xaa is any naturally occurring
amino acid or absentMISC_FEATURE(8)..(8)Xaa is any naturally
occurring amino acid or absent 95Leu Leu Gln Xaa Xaa Xaa Xaa Xaa1
5





D00001

D00002

D00003

D00004

D00005

D00006

D00007

D00008

D00009

D00010

D00011

D00012

D00013

D00014

D00015

D00016

D00017

D00018

D00019

D00020

D00021

D00022

D00023

D00024

D00025

D00026
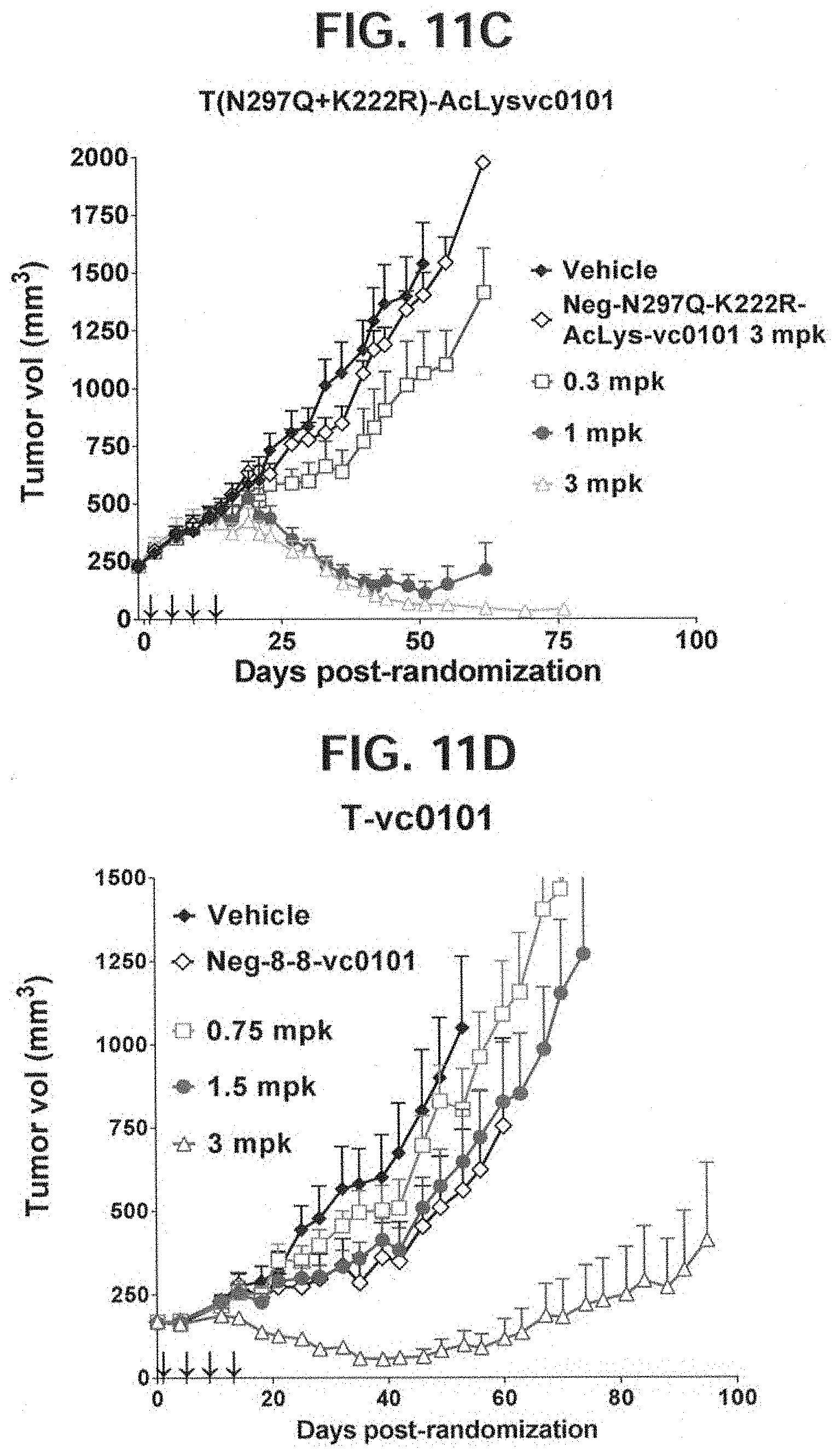
D00027

D00028

D00029

D00030

D00031

D00032

D00033

D00034

D00035

D00036

D00037

D00038

D00039

D00040

D00041

D00042

D00043

D00044

D00045

D00046

D00047

D00048

D00049

D00050

D00051

D00052

D00053

D00054

D00055

D00056

D00057

D00058

D00059

D00060

D00061

D00062


S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.