De-duplication Of Client-side Data Cache For Virtual Disks
Lakshman; Avinash ; et al.
U.S. patent application number 16/937401 was filed with the patent office on 2020-11-12 for de-duplication of client-side data cache for virtual disks. The applicant listed for this patent is Commvault Systems, Inc.. Invention is credited to Avinash Lakshman, Gaurav Yadav.
| Application Number | 20200356277 16/937401 |
| Document ID | / |
| Family ID | 1000004976568 |
| Filed Date | 2020-11-12 |


| United States Patent Application | 20200356277 |
| Kind Code | A1 |
| Lakshman; Avinash ; et al. | November 12, 2020 |
DE-DUPLICATION OF CLIENT-SIDE DATA CACHE FOR VIRTUAL DISKS
Abstract
A computer receives a write request including an offset within a virtual disk. The computer writes the data block to a remote platform and calculates a hash value of the data. If the hash value does not exist in a first table of a block cache of the computer, the computer adds a pair to the first table: hash value/block cache data offset. Next, the computer adds a pair in a second table of the block cache: virtual disk offset of the data/hash value. A read request uses these tables to find the data in the cache without accessing the storage platform. The read consults the second table to find the hash value corresponding to the virtual disk offset of block. The hash value is used as a key into the first table to find the block cache data offset of the data; the data is read from the block cache at that offset.
| Inventors: | Lakshman; Avinash; (Fremont, CA) ; Yadav; Gaurav; (Mountain View, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 1000004976568 | ||||||||||
| Appl. No.: | 16/937401 | ||||||||||
| Filed: | July 23, 2020 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15156015 | May 16, 2016 | |||
| 16937401 | ||||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06F 3/0641 20130101; G06F 9/45558 20130101; G06F 3/0665 20130101; G06F 2009/45583 20130101; G06F 3/067 20130101; G06F 3/0608 20130101; G06F 3/0689 20130101 |
| International Class: | G06F 3/06 20060101 G06F003/06; G06F 9/455 20060101 G06F009/455 |
Claims
1. A method of using deduplicated client-side caching for a storage platform, the system comprising: by a first computer server, intercepting a write request to write a first block of data to a first virtual disk configured on the storage platform, wherein the write request is issued by an application executing at one of: the first computer server and one of a plurality of other computer servers that use the storage platform; by the first computer server, based on determining that the first virtual disk is administered with client-side caching enabled: calculating a hash value for the first block of data, querying first metadata that tracks contents of a client-side cache maintained by the first computer server, if the first metadata comprises the hash value, refraining by the first computer server from storing the first block of data to the client-side cache, and if the first metadata does not comprise the hash value, (a) storing the first block of data in the client-side cache at a second offset, and (b) updating the first metadata to indicate that a block of data having the hash value is stored in the client-side cache at the second offset; and wherein the client-side cache is not used for write requests to a virtual disk administered without client-side caching, wherein the client-side cache is configured in persistent storage of the first computer server, and wherein the persistent storage is distinct from data storage resources configured in the storage platform.
2. The method of claim 1, wherein the client-side cache provides global cache deduplication for all virtual disks in the storage platform that are configured with client-side caching enabled.
3. The method of claim 1 further comprising: if the first metadata comprises the hash value, updating second metadata that tracks virtual disk offsets within the storage platform with a key-value pair that comprises: a first offset for the first block of data within the first virtual disk and the hash value of the first block of data.
4. The method of claim 1 further comprising: by the first computer server, intercepting a read request for the first block of data from the first offset within the first virtual disk configured on the storage platform, wherein the read request is issued by an application executing at one of: the first computer server and one of a plurality of other computer servers that use the storage platform; by the first computer server, based on determining that the first virtual disk is administered with client-side caching enabled: querying the first metadata for the hash value of the first block of data, if the first metadata lacks the hash value, issuing a read request to a storage node of the storage platform to read the first data block from the first offset on the first virtual disk, and serving the first data block received from the storage platform in response to the read request, and if the first metadata comprises the hash value, serving a data block having the hash value from the client-side cache in response to the read request; and wherein the client-side cache is not used for read requests from a virtual disk administered without client-side caching.
5. The method of claim 1, wherein the first offset for the first block of data within the first virtual disk is calculated by the first computer server based on an amount of data in the write request.
6. The method of claim 1, wherein the client-side cache is used for all virtual disks in the storage platform that are configured with client-side caching enabled.
7. The method of claim 1, wherein the client-side cache is used for all virtual disks in the storage platform that are configured at the application level with client-side caching enabled.
8. The method of claim 1 further comprising: writing the first block of data to the first virtual disk at the first offset.
9. The method of claim 1 further comprising: writing the first block of data to the first virtual disk at the first offset regardless of whether client-side caching is enabled for the first virtual disk.
10. A method of using deduplicated client-side caching for a storage platform, the system comprising: by a first computer server, intercepting a write request to write a first block of data to a first virtual disk configured on the storage platform, wherein the write request is issued by an application executing at one of: the first computer server and one of a plurality of other computer servers that use the storage platform; by the first computer server, based on determining that the first virtual disk is administered with client-side caching enabled: calculating a hash value for the first block of data, querying first metadata for the hash value, wherein the first metadata tracks contents of a client-side cache configured in persistent storage at the first computing server, and wherein the persistent storage is distinct from data storage resources configured in the storage platform, and if the first metadata comprises the hash value, refraining from writing the first block of data to the client-side cache, and updating second metadata that tracks virtual disk offsets within the storage platform with a key-value pair comprising a first offset for the first block of data within the first virtual disk and the hash value of the first block of data; by the first computer server, intercepting a read request for the first block of data from the first offset within the first virtual disk, wherein the read request is issued by an application executing at one of: the first computer server and one of a plurality of other computer servers that use the storage platform; by the first computer server, based on determining that the first virtual disk is administered with client-side caching enabled: querying the first metadata for the hash value of the first block of data, and if the first metadata comprises the hash value, serving from the client-side cache a data block having the hash value of the first block of data in response to the read request.
11. The method of claim 10 further comprising: if the first metadata does not comprise the hash value, by the first computer server, storing the first block of data in the client-side cache at a second offset, and updating the first metadata to indicate that a block of data having the hash value is stored in the client-side cache at the second offset.
12. The method of claim 10 further comprising: if the second metadata lacks an entry for the first offset, by the first computer server, issuing a read request to a storage node of the storage platform to read the first block of data from the first offset on the first virtual disk, and serving the first block of data received from the storage platform in response to the read request.
13. The method of claim 10, wherein the client-side cache is not used for write requests to and read requests from a virtual disk administered without client-side caching.
14. The method of claim 10, wherein the client-side cache is used for all virtual disks in the storage platform that are configured with client-side caching enabled.
15. A method of using deduplicated client-side caching for a storage platform, the system comprising: by a first computer server, intercepting a write request to write data to a first virtual disk configured on the storage platform, wherein the write request is issued by an application executing at one of: the first computer server and one of a plurality of other computer servers that use the storage platform; by the first computer server, based on determining that the first virtual disk is administered with client-side caching enabled: calculating a hash value for a first block of the data in the write request, querying first metadata for the hash value, wherein the first metadata tracks contents of a client-side cache configured in persistent storage at the first computing server, and if the first metadata does not comprise the hash value, by the first computer server, storing the first block in the client-side cache at a second offset, and updating the first metadata to indicate that a block of data having the hash value is stored in the client-side cache at the second offset; by the first computer server, intercepting a read request for data from the first offset within the first virtual disk configured on the storage platform, wherein the read request is issued by an application executing at one of: the first computer server and one of a plurality of other computer servers that use the storage platform; by the first computer server, based on determining that the first virtual disk is administered with client-side caching enabled: identifying the first block in the data in the read request, calculating the hash value for the first block, querying the first metadata for the hash value, and if the first metadata comprises the hash value corresponding to the second offset within the client-side cache, serving from the second offset at the client-side cache a data block having the hash value of the first block in response to the read request.
16. The method of claim 15 further comprising: if the first metadata comprises the hash value, refraining from writing the first block of data to the client-side cache.
17. The method of claim 15 further comprising: if the first metadata comprises the hash value, refraining from writing the first block of data to the client-side cache and updating second metadata that tracks virtual disk offsets within the storage platform with a key-value pair comprising a first offset for the first block of data within the first virtual disk and the hash value of the first block of data; and if the second metadata lacks an entry for the first offset, by the first computer server, issuing a read request to a storage node of the storage platform to read the first data block from the first offset on the first virtual disk, and serving the first data block received from the storage platform in response to the read request.
18. The method of claim 15, wherein the client-side cache provides global cache deduplication for all virtual disks in the storage platform that are configured with client-side caching enabled.
19. The method of claim 15, wherein the client-side cache is not used for write requests to and read requests from a virtual disk administered without client-side caching.
20. The method of claim 15, wherein the client-side cache is used for all virtual disks in the storage platform that are configured with client-side caching enabled.
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application is a Continuation of U.S. patent application Ser. No. 15/156,015 filed on May 16, 2016, which is hereby incorporated by reference herein. This application is related to U.S. patent application Ser. Nos. 14/322,813, 14/322,832, 14/684,086, 14/322,850, 14/322,855, 14/322,867, 14/322,868, 14/322,871, and 14/723,380, which are all hereby incorporated by reference. This application is related to U.S. patent application Ser. No. 15/155,838 (Attorney Docket No. COMMV.495A, formerly HEDVP012), filed on May 16, 2016, which is also hereby incorporated by reference.
FIELD OF THE INVENTION
[0002] The present invention relates generally to local caching of data to be stored on a virtual disk within a data center. More specifically, the present invention relates to de-duplication of data stored in the local cache.
BACKGROUND OF THE INVENTION
[0003] In the field of data storage, enterprises have used a variety of techniques in order to store the data that their software applications use. At one point in time, each individual computer server within an enterprise running a particular software application (such as a database or e-mail application) would store data from that application in any number of attached local disks. Although this technique was relatively straightforward, it led to storage manageability problems in that the data was stored in many different places throughout the enterprise.
[0004] These problems led to the introduction of the storage area network in which each computer server within an enterprise communicated with a central storage computer node that included all of the storage disks. The application data that used to be stored locally at each computer server was now stored centrally on the central storage node via a fiber channel switch, for example. Although such a storage area network was easier to manage, changes in computer server architecture created new problems.
[0005] With the advent of virtualization, each computer server can now host dozens of software applications through the use of a hypervisor on each computer server and the use of virtual machines. Thus, computer servers which had been underutilized could now host many different server applications, each application needing to store its data within the storage area network. Weaknesses in the storage area network were revealed by the sheer number of server applications needing to access disks within the central storage node. And, even with the use of remote storage platforms (such as "in-the-cloud" storage), problems still exist.
[0006] For example, the sheer amount of data that applications desire to store in a remote storage platform can overwhelm a local virtual machine if it attempts to cache data to be stored remotely in the storage platform, can raise costs, and can lead to inefficiency. Attempts to remove duplicates of locally-cached data have been tried but are not optimal. Accordingly, further techniques and systems are desired to remove duplicates of data cached at a local computer.
SUMMARY OF THE INVENTION
[0007] To achieve the foregoing, and in accordance with the purpose of the present invention, techniques are disclosed that provide the advantages discussed below.
[0008] Use of a global client-side cache within a computer server of a compute farm allows any client application, software application or virtual machine executing on that computer to make use of this client-side cache. De-duplication of blocks of data within this client-side cache then occurs globally and automatically for all applications executing upon that computer or upon others, regardless of which is the client and regardless of which virtual disk is being accessed within the storage platform. Additionally, each application may decide whether or not to enable client-side caching for each of its virtual disks.
[0009] In addition, the storage resources overhead associated with de-duplication metadata is minimal (<2%) compared to other prior art techniques, and the present invention keeps metadata distributed as well, which means node or disk failures do not lead to a reduction in de-duplication ratios. And, the computing resources overhead is negligible as well: the present invention does not need any specific hardware for de-duplication, and can be run on any commodity hardware. Moreover, the present invention performs global de-duplication, not at the volume or disk level, which means higher de-duplication ratios across the entire storage platform. Finally, the present invention performs in-line de-duplication, which means the invention only writes unique data to the storage platform. Prior art offline or asynchronous de-duplication performs de-duplication in the background, and hence does not provide any real-time guarantees as to reduction in storage. Thus, in-line de-duplication also increases the capacity and life of raw disks.
[0010] In a first embodiment, a method writes a block of data to a virtual disk on a remote storage platform. First, a computer server receives a write request to write the block of data from the computer server to the remote storage platform, the write request includes an offset within the virtual disk and the data. The server writes the block of data to a storage node of the storage platform. After this write, or even prior, the computer server calculates a hash value of the block of data using a hash function or similar function to produce a unique identifier for the block. The computer determines whether the resulting hash value exists in a first metadata table of a block cache of the computer server. If so, the computer adds an entry in a second metadata table of the block cache that includes the virtual disk offset and the hash value as a key/value pair. A later read request uses these tables to find the block of data in the cache without the need to go to the storage platform.
[0011] In a second embodiment, a method writes a block of data to a virtual disk on a remote storage platform. First, a computer server receives a write request to write the block of data from the computer server to the remote storage platform, the write request includes an offset within the virtual disk and the data. The server writes the block of data to a storage node of the storage platform. After this write, or even prior, the computer server calculates a hash value of the block of data using a hash function or similar function to produce a unique identifier for the block. The computer determines whether the resulting hash value exists in a first metadata table of a block cache of the computer server. If not, the computer writes the block of data into the block cache at a block cache data offset and stores the hash value and the block cache data offset as a key/value pair in the first metadata table. Next the computer adds an entry in a second metadata table of the block cache that includes the virtual disk offset and the hash value as a key/value pair. A later read request uses these tables to find the block of data in the cache without the need to go to the storage platform.
[0012] In a third embodiment, a method reads a block of data from a virtual disk on a remote storage platform. First a computer server receives a read request to read the block of data from the remote storage platform, the read request includes an offset within the virtual disk. Next, the computer server determines whether the virtual disk offset exists as an entry in a first metadata table of a block cache of the computer server. If so, the computer retrieves a unique identifier corresponding to the virtual disk offset in the entry, and then accesses a second metadata table of the block cache and retrieves a block cache data offset using the unique identifier as a key. Finally, the computer reading the block of data from the block cache at the block cache data offset. Thus, it is not necessary to access a remote storage platform to read the block of data.
[0013] In a fourth embodiment, a method reads a block of data from a virtual disk on a remote storage platform. First a computer server receives a read request to read the block of data from the remote storage platform, the read request includes an offset within the virtual disk. Next, the computer server determines whether the virtual disk offset exists as an entry in a first metadata table of a block cache of the computer server. If not, the computer reads the block of data from a remote storage platform. The block is then returned to the requesting application.
BRIEF DESCRIPTION OF THE DRAWINGS
[0014] The invention, together with further advantages thereof, may best be understood by reference to the following description taken in conjunction with the accompanying drawings in which:
[0015] FIG. 1 illustrates a data storage system having a storage platform according to one embodiment of the invention.
[0016] FIG. 2 is a symbolic representation of a virtual disk showing how data within the virtual disk is stored within the storage platform.
[0017] FIG. 3 illustrates in greater detail the computer servers in communication with the storage platform.
[0018] FIG. 4 illustrates one example of a block cache.
[0019] FIG. 5 illustrates a metadata table present within metadata used to store identifiers for blocks of data that have been stored within the block cache.
[0020] FIG. 6 illustrates another metadata table present within metadata used to store MD5s corresponding to a virtual disk offsets.
[0021] FIG. 7 is a flow diagram describing one embodiment by which a virtual machine writes data to the storage platform.
[0022] FIG. 8 is a flow diagram describing one embodiment by which a virtual machine reads data from the storage platform.
[0023] FIGS. 9 and 10 illustrate a computer system suitable for implementing embodiments of the present invention.
DETAILED DESCRIPTION OF THE INVENTION
Storage System
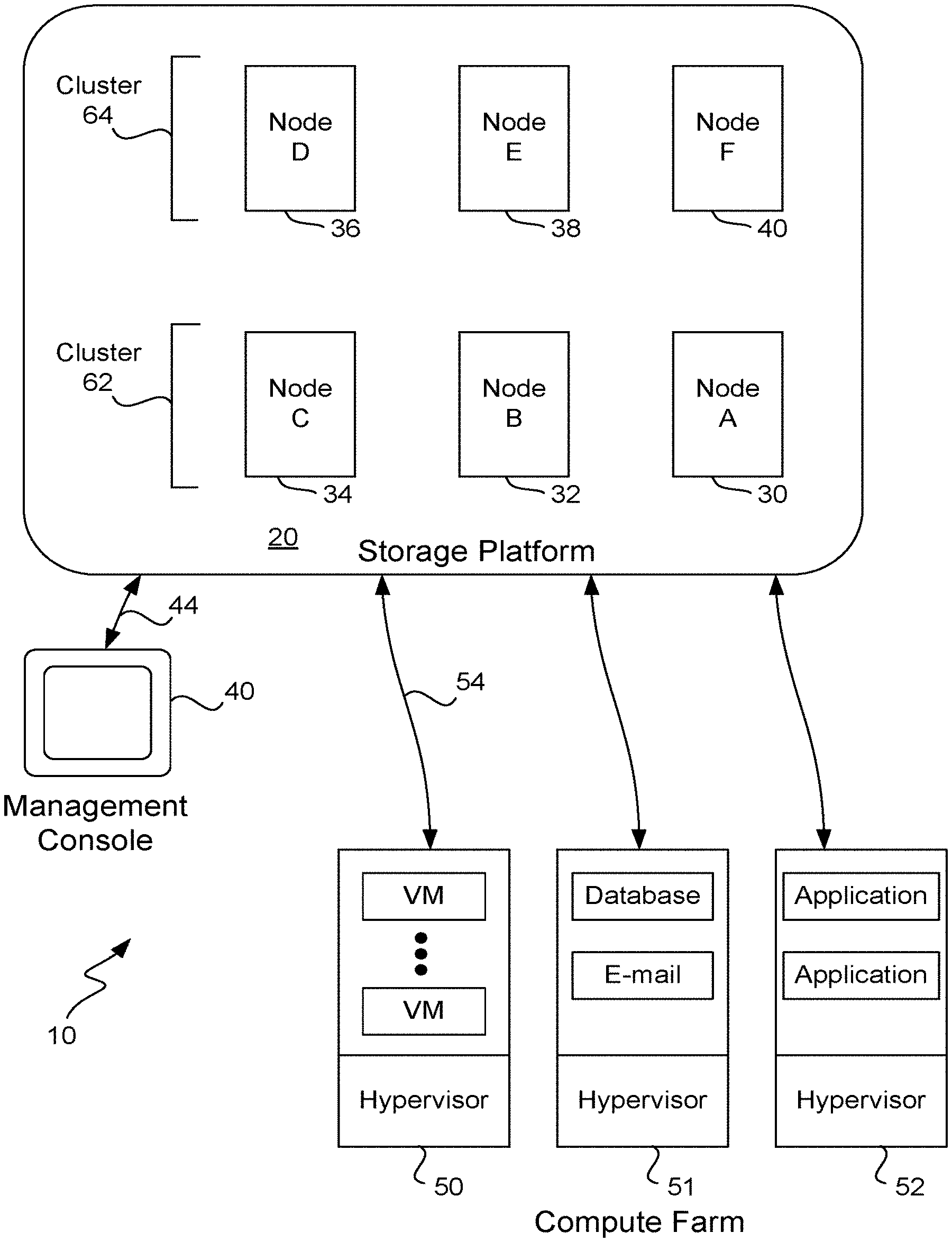
[0024] FIG. 1 illustrates a data storage system 10 according to one embodiment of the invention having a storage platform 20. Included within the storage platform 20 are any number of computer nodes 30-40. Each computer node of the storage platform has a unique identifier (e.g., "A") that uniquely identifies that computer node within the storage platform. Each computer node is a computer having any number of hard drives and solid-state drives (e.g., flash drives), and in one embodiment includes about twenty disks of about 1 TB each. A typical storage platform may include on the order of about 81 TB and may include any number of computer nodes. One advantage is that a platform may start with as few as three nodes and then grow incrementally to as large as 1,000 nodes or more.
[0025] Computers nodes 30-40 are shown logically being grouped together, although they may be spread across data centers and may be in different geographic locations. A management console 40 used for provisioning virtual disks within the storage platform communicates with the platform over a link 44. Any number of remotely located computer servers 50-52 each typically executes a hypervisor in order to host any number of virtual machines. Server computers 50-52 form what is typically referred to as a compute farm.
[0026] As shown, these virtual machines may be implementing any of a variety of applications such as a database server, an e-mail server, etc., including applications from companies such as Oracle, Microsoft, etc. These applications write to and read data from the storage platform using a suitable storage protocol such as iSCSI or NFS, although each application will not be aware that data is being transferred over link 54 using a different protocol.
[0027] Management console 40 is any suitable computer able to communicate over an Internet connection or link 44 with storage platform 20. When an administrator wishes to manage the storage platform (e.g., provisioning a virtual disk, snapshots, revert, clone, analyze metrics, determine health of cluster, etc.) he or she uses the management console to access the storage platform and is put in communication with a management console routine executing as part of a software module on any one of the computer nodes within the platform. The management console routine is typically a Web server application.
[0028] In order to provision a new virtual disk within storage platform 20 for a particular application running on a virtual machine, the virtual disk is first created and then attached to a particular virtual machine. In order to create a virtual disk, a user uses the management console to first select the size of the virtual disk (e.g., 100 GB), and then selects the individual policies that will apply to that virtual disk. For example, the user selects a replication factor, a data center aware policy and other policies concerning whether or not to compress the data, the type of disk storage, etc. Once the virtual disk has been created, it is then attached to a particular virtual machine within one of the computer servers 50-52 and the provisioning process is complete.
[0029] Advantageously, storage platform 20 is able to simulate prior art central storage nodes (such as the VMax and Clarion products from EMC, VMWare products, etc.) and the virtual machines and software applications will be unaware that they are communicating with storage platform 20 instead of a prior art central storage node. In addition, the provisioning process can be completed on the order of minutes or less, rather than in four to eight weeks as was typical with prior art techniques. The advantage is that one only needs to add metadata concerning a new virtual disk in order to provision the disk and have the disk ready to perform writes and reads.
Provision Virtual Disk
[0030] Typically, an administrator is aware that a particular software application desires a virtual disk within the platform and is aware of the characteristics that the virtual disk should have. The administrator first uses the management console to access the platform and connect with the management console Web server on any one of the computer nodes within the platform. The administrator chooses the characteristics of the new virtual disk such as a name; a size; a replication factor; a residence; compressed; a replication policy; cache enabled (a quality-of-service choice); and a disk type (indicating whether the virtual disk is of a block type--the iSCSI protocol--or of a file type--the NFS protocol).
[0031] As mentioned above, one of the characteristics for the virtual disk that may be chosen is whether or not the client-side cache of the local computer should be enabled for that virtual disk. Applications that do not read or write frequently may not desire the cache to be enabled (as writing to the cache can add overhead), while applications that read and write frequently may desire the cache to be enabled. Cache enablement, thus, is an optional feature that may be turned on or off for each virtual disk.
[0032] Once chosen, these characteristics are stored as "virtual disk information" metadata onto a computer node within the storage platform and may be replicated. In this fashion, the virtual disk metadata has been stored upon metadata nodes within the platform (which might be different from the nodes where the actual data of the virtual disk will be stored). In addition, the identities of the storage nodes which store this metadata for the virtual disk is also sent to the controller virtual machine for placing into a cache.
[0033] The virtual disk that has been created is also attached to a virtual machine of the compute farm. In this step, the administrator is aware of which virtual machine on which computer of the compute farm needs the virtual disk. Thus, information regarding the newly created virtual disk (i.e., name, space available, virtual disk information, etc.) is sent from the management console routine to the appropriate computer within the compute farm. The information is provided to a controller virtual machine which stores the information in a cache, ready for use when the virtual machine needs to write or to read data. The administrator also supplies the name of the virtual disk to the application that will use it.
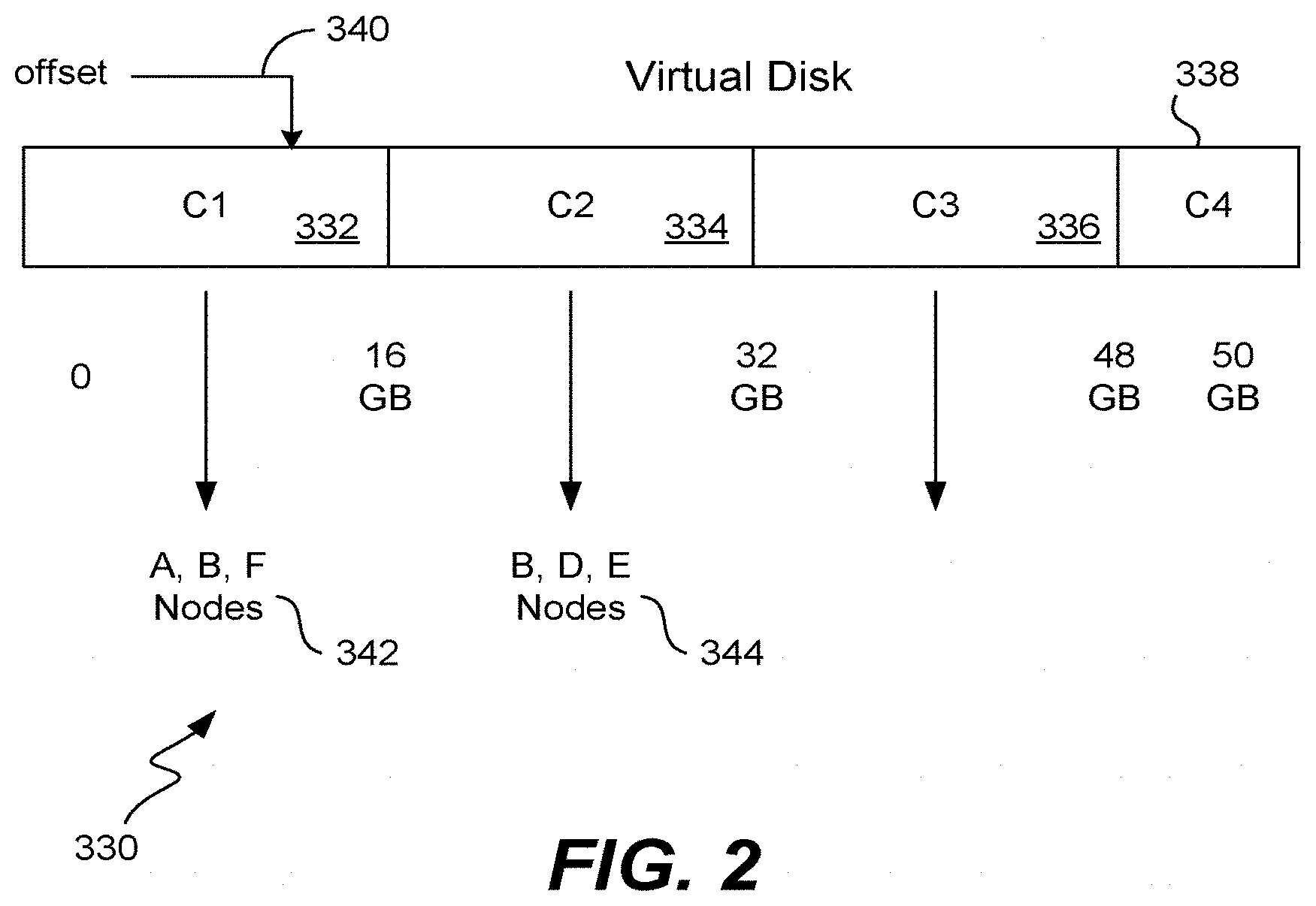
[0034] FIG. 2 is a symbolic representation of a virtual disk 330 showing how data within the virtual disk is stored within the storage platform. As shown, the virtual disk has been provisioned as a disk holding up to 50 GB, and the disk has been logically divided into segments or portions of 16 GB each. Each of these portions is termed a "container," and may range in size from about 4 GB up to about 32 GB, although a size of 16 GB works well. As shown, portions 332-338 are referred to as containers C1, C2, C3 and C4.
[0035] Similar to a traditional hard disk, as data is written to the virtual disk at a particular offset 340 (ranging from 0 up to the size of the virtual disk) the virtual disk will fill up symbolically from left to right. Each container of data will be stored upon a particular node or nodes within the storage platform that are chosen during the write process. In the example of FIG. 2, the replication factor is three, thus, data stored within container 332 will be stored upon the three nodes A, B and F, data stored within the second container 334 will be stored upon the three nodes B, D and E, etc. Note that this storage technique using containers is one of many possible implementations of the storage platform and is transparent to the virtual machines that are storing data.
Controller Virtual Machine
[0036] FIG. 3 illustrates in greater detail one of the computer servers 51 in communication with storage platform 20. As mentioned above, each computer server may host any number of virtual machines, each executing a particular software application. The application may perform I/O handling using a block-based protocol such as iSCSI, using a file-based protocol such as NFS, and the virtual machine communicates using this protocol. Of course, other suitable protocols may also be used by an application. The actual communication protocol used between the server and platform is transparent to these virtual machines.
[0037] As shown, server 51 includes a hypervisor and virtual machines 182 and 186 that desire to perform I/O handling using the iSCSI protocol 187 or the NFS protocol 183. Server 51 also includes a specialized controller virtual machine (CVM) 180 that is adapted to handle communications with the virtual machines using either protocol (and others), yet communicates with the storage platform using a proprietary protocol 189. Protocol 189 may be any suitable protocol for passing data between storage platform 20 and a remote computer server 51 such as TCP. In addition, the CVM may also communicate with public cloud storage using the same or different protocol 191. Advantageously, the CVM need not communicate any "liveness" information between itself and the computer nodes of the platform. There is no need for any CVM to track the status of nodes in the cluster. The CVM need only talk to a node in the platform, which is then able to route requests to other nodes and public storage nodes.
[0038] The CVM also uses a memory cache 181 on the computer server 51. In communication with computer server 51 and with CVM 180 are also any number of solid-state disks (or other similar persistent storage) 195 that will be explained in greater detail below. These disks may be used as a data cache to store data blocks that are written into storage platform 20 and then to rapidly retrieve these data blocks instead of retrieving them from the remote storage platform.
[0039] CVM 180 handles different protocols by simulating an entity that the protocol would expect. For example, when communicating under the iSCSI block protocol, CVM responds to an iSCSI Initiation by behaving as an iSCSI Target. In other words, when virtual machine 186 performs I/O handling, it is the iSCSI Initiator and the controller virtual machine is the iSCSI Target. When an application is using the block protocol, the CVM masquerades as the iSCSI Target, traps the iSCSI CDBs, translates this information into its own protocol, and then communicates this information to the storage platform. Thus, when the CVM presents itself as an iSCSI Target, the application may simply talk to a block device as it would do normally.
[0040] Similarly, when communicating with an NFS client, the CVM behaves as an NFS server. When virtual machine 182 performs I/O handling the controller virtual machine is the NFS server and the NFS client (on behalf of virtual machine 182) executes either in the hypervisor of computer server 51 or in the operating system kernel of virtual machine 182. Thus, when an application is using the NFS protocol, the CVM masquerades as an NFS server, captures NFS packets, and then communicates this information to the storage platform using its own protocol.
[0041] An application is unaware that the CVM is trapping and intercepting its calls under the iSCSI or NFS protocol, or that the CVM even exists. One advantage is that an application need not be changed in order to write to and read from the storage platform. Use of the CVM allows an application executing upon a virtual machine to continue using the protocol it expects, yet allows these applications on the various computer servers to write data to and read data from the same storage platform 20.
[0042] Replicas of a virtual disk may be stored within public cloud storage 190. As known in the art, public cloud storage refers to those data centers operated by enterprises that allow the public to store data for a fee. Included within these data centers are those known as Amazon Web Services and Google Compute. During a write request, the write request will include an identifier for each computer node to which a replica should be written. For example, nodes may be identified by their IP address. Thus, the computer node within the platform that first fields the write request from the CVM will then route the data to be written to nodes identified by their IP addresses. Any replica that should be sent to the public cloud can then simply be sent to the DNS name of a particular node which request (and data) is then routed to the appropriate public storage cloud. Any suitable computer router within the storage platform may handle this operation.
Client-Side Cache
[0043] As mentioned above, a client machine, such as computer 51, uses a data cache 195 in order to store blocks of data that it has written to storage platform 20 in order to retrieve those blocks more quickly when a read is performed. The present invention provides an apparatus and technique in order to efficiently cache data on the client side so that during a read operation from a software application it may not be necessary to access the remote storage platform 20. One advantage of the present invention is that very large sizes of a data cache are supported and that blocks of data are stored efficiently. The invention facilitates very large data caches because the invention de-duplicates data in the cache as well, which in turn increases the cache capacity by the factor of the de-duplication ratio.
[0044] FIG. 4 illustrates one example of a block cache 195. Preferably, the block cache is implemented using persistent storage such as any number of hard disks, and most preferably solid-state disks are used. There may be one or more solid-state disks in the block cache. Given a particular size of the block cache (such as 1 TB), FIG. 4 indicates that approximately 10% of the block cache is used for metadata storage 410 and that the remaining portion 420 is used for data storage. A block cache data offset 430 is used to indicate a particular location of a particular block of data within the block cache. The block cache can be many disks one disk. Preferably, the invention takes only one disk as an input. But, users may combine multiple disks into one disk using suitable software such as a Logical Volume Manager (LVM) tool.
[0045] FIG. 5 illustrates a metadata table 440 present within metadata 410 used to store identifiers for blocks of data that have been stored within the block cache. Metadata is stored in pairs, where column 444 indicates the MD5 (or other message digest or unique hash value from a hash function) of a particular block of data, and where column 448 indicates the offset within data 420 where that block of data has been stored.
[0046] FIG. 6 illustrates a metadata table 480 present within metadata 410 used to store MD5s corresponding to a virtual disk offsets. This metadata is stored in pairs, where column 484 indicates a particular offset of a block of data within a particular named virtual disk, and where column 488 indicates the MD5 for the corresponding block of data.
Write Using Client-Side Cache
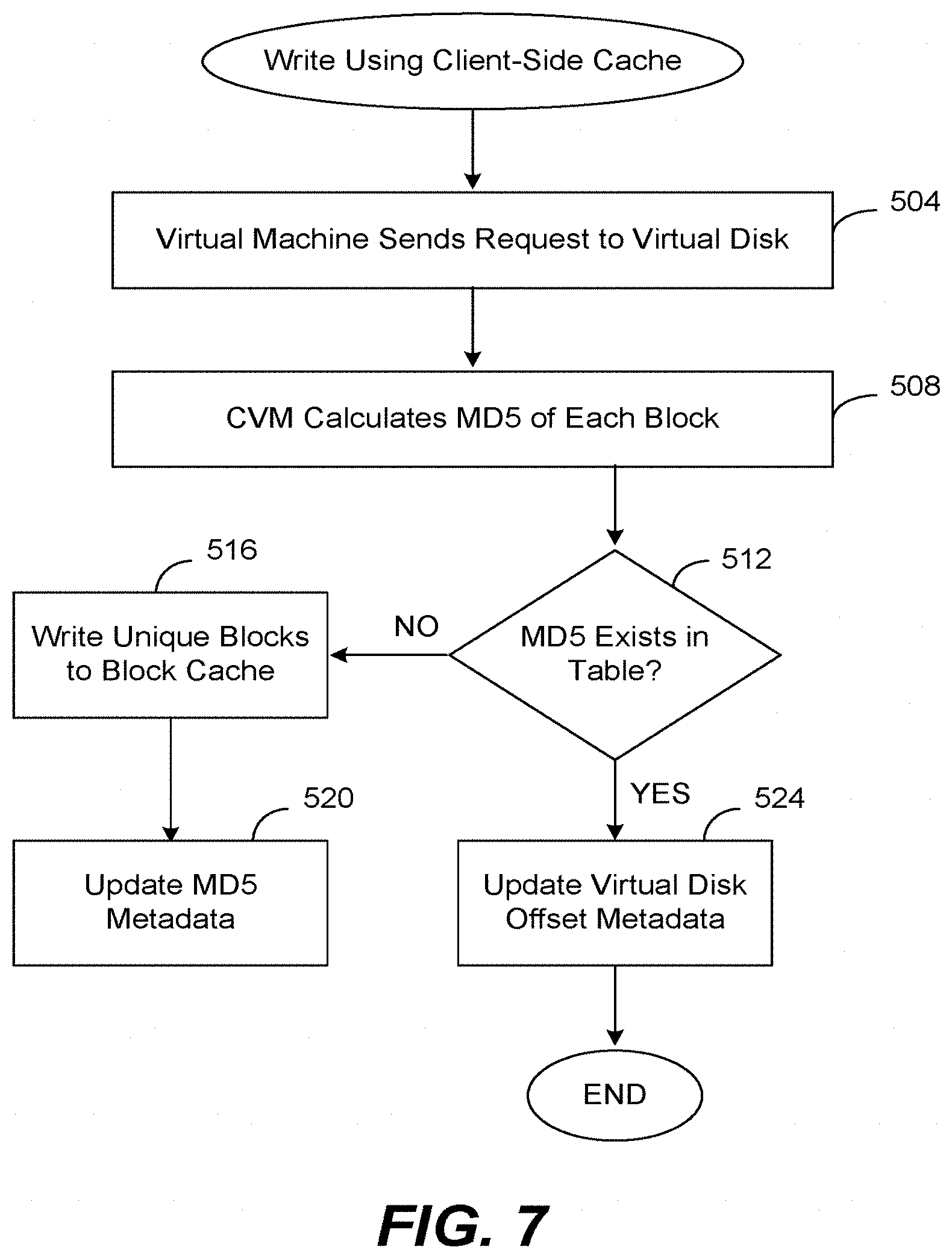
[0047] FIG. 7 is a flow diagram describing one embodiment by which a virtual machine writes data to the storage platform. In this embodiment, an application on a virtual machine is writing to a virtual disk within the platform that has the client-side cache 195 enabled. The CVM is aware of which virtual disks have the cache enabled and which have not because it has stored the virtual disk information into its memory cache 181. This flow may be performed in conjunction with actually sending the data to the storage platform, before sending such data, or after sending such data.
[0048] In step 504 the virtual machine (on behalf of its software application) that desires to write data into the storage platform sends a write request including the data to be written to a particular virtual disk. The request may originate from a virtual machine on the same computer as the CVM, or from a virtual machine on a different computer. As mentioned, a write request may originate with any of the applications on one of computer servers 50-52 and may use any of a variety of storage protocols. The write request typically takes the form: write (offset, size, virtual disk name). The parameter "virtual disk name" is the name of the virtual disk. The parameter "offset" is an offset within the virtual disk (i.e., a value from 0 up to the size of the virtual disk), and the parameter "size" is the length of the data to be written in bytes. As mentioned above, the CVM will trap or capture this write request sent by the application (in the block protocol or NFS protocol, for example).
[0049] Next, in step 508 the CVM calculates the MD5 of each block within the data to be written. Blocks may be of any size, although typically the size is 4 k bytes. After all of the message digests have been calculated (or perhaps after each one is calculated), in step 512 the CVM performs a lookup in metadata 410 of the block cache 195 to determine if each MD5 exists within table 440 in order to prevent duplicates from being stored. If an MD5 exists, this indicates that that exact block of data has already been written into the client-side cache 195 (for any virtual disk accessed by that CVM) and that it will not be necessary to write that block of data again into the cache. If the MD5 does not exist, this indicates that the block of data does not exist within the block cache yet and that the data block should be written to the cache. It is possible that within the data requested to be written, that some blocks already exist within the block cache and that some do not. It is also possible that the MD5s for certain blocks will be the same (e.g., if all of these blocks are entirely filled with zeros). For each query of table 440 with an MD5, the result returned is whether or not the MD5 exists, and if it exists, the block cache data offset 448.
[0050] For those blocks of data that do not already exist within the block cache, step 516 will write those unique blocks to the data region 420 of the block cache and return the block cache data offset where each block was written in data 420.
[0051] Next, for those unique blocks written in step 516 their metadata will be updated in step 520. In step 520 the CVM updates table 440 with the MD5 of each block written to the block cache and its corresponding block cache data offset, so that the block can later be found in the block cache using its MD5.
[0052] In step 512 if, for any block of data, its MD5 does already exist in table 440, this indicates that the block of data does exist in the block cache, and control moves to step 524. In step 524, table 480 is updated for every block of data in the write request. This table will be updated to include the virtual disk offset of each block along with its corresponding MD5. Knowing the offset from the write request and the block size, it is a simple matter to calculate the virtual disk offset for each block of the write request. In this fashion, the MD5s for all blocks of the write request will be available in table 480 by using the virtual disk offset for each block as a key, which will be useful when reading data from the storage platform and using this client-side cache. In addition, by performing the check in step 512, duplicate blocks of data are not written to the cache.
Read Using Client-Side Cache
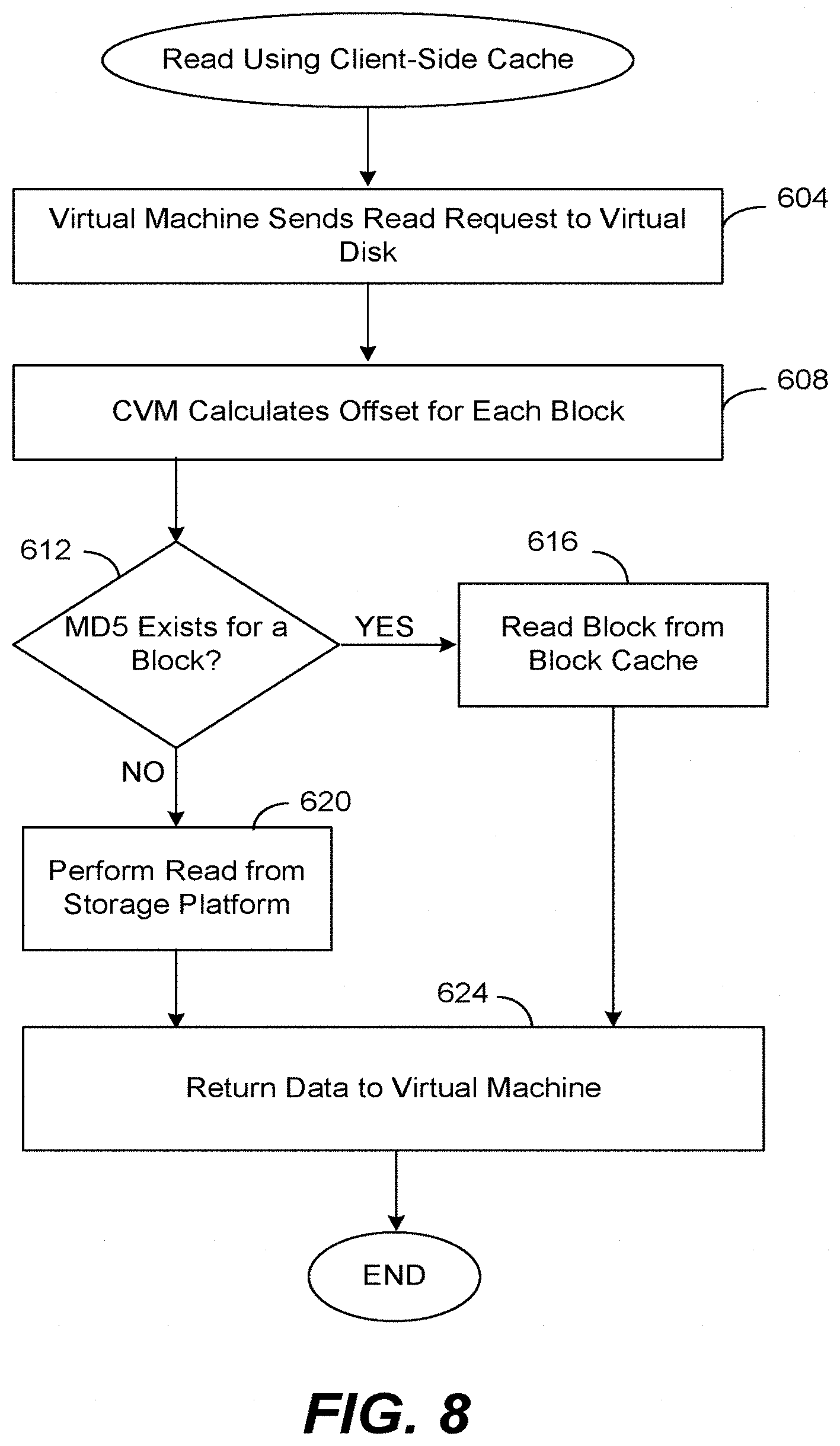
[0053] FIG. 8 is a flow diagram describing one embodiment by which a virtual machine reads data from the storage platform. In this embodiment, an application on a virtual machine is reading from a virtual disk within the platform that has the client-side cache 195 enabled.
[0054] In step 604 the virtual machine that desires to read data from the storage platform sends a read request from a particular application to the desired virtual disk. As explained above, the controller virtual machine will then trap or capture the request (depending upon whether it is a block request or an NFS request) and then typically places a request into its own protocol before sending the request to the storage platform.
[0055] As mentioned, a read request may originate with any of the virtual machines on computers 50-52 (for example) and may use any of a variety of storage protocols. The read request typically takes the form: read (offset, size, virtual disk name). The parameter "virtual disk name" is the name of a virtual disk on the storage platform. The parameter "offset" is an offset within the virtual disk (i.e., a value from 0 up to the size of the virtual disk), and the parameter "size" is the length of the data to be read in bytes.
[0056] The CVM is aware of which virtual disks have the client-side cache enabled, and, if so, before sending the read request to the storage platform, the CVM will first check its block cache 195 to determine whether any of the blocks to be read are already present within this cache. Thus, in step 608, the CVM divides up the read request into blocks; e.g., a request of size 64k is divided up into sixteen blocks of 4k each, each block having a corresponding offset within the named virtual disk. Thus, an offset within the named virtual disk is calculated for each block of data.
[0057] Step 612 then checks metadata 410 to determine whether an entry exists in table 480 for each of the calculated offsets of the named virtual disk. If an entry exists, this means that the corresponding data block has been stored in the client-side cache and the MD5 488 corresponding to that entry is returned to the CVM. Thus, in step 616 the CVM consults table 440 using the returned MD5 in order to obtain the block cache data offset for that particular block within data 420. Once obtained, the data block is simply read from the block cache at the block cache data offset, thus obviating the need to read a data block from the remote storage platform 20.
[0058] If an entry does not exist in table 480 for any of the calculated offsets for the named virtual disk, this means that the corresponding data block has not been previously stored in the client-side cache and that the data block must be read from the remote storage platform. Accordingly, in step 620 a read request for that particular data block is sent to the storage platform which then returns the data block.
[0059] It is possible that within a given read request there may be some data blocks that have been stored in the client-side cache and some that have not. Thus, for those data blocks that must be read from the storage platform, the CVM may choose to read those data blocks from the remote storage platform one at a time, or may choose to send a single, combined read request. Those data blocks that do exist within the client-side cache may also be read one by one, or the CVM may issue a single read request for all of those blocks at one time.
[0060] In step 624, after collecting both the data blocks read from the storage platform and the data blocks read from the block cache, the CVM then returns this data corresponding to the original read request to the requesting virtual machine using the appropriate protocol, again masquerading either as a block device or as an NFS device depending upon the protocol used by the particular application.
Computer System Embodiment
[0061] FIGS. 9 and 10 illustrate a computer system 900 suitable for implementing embodiments of the present invention. FIG. 9 shows one possible physical form of the computer system. Of course, the computer system may have many physical forms including an integrated circuit, a printed circuit board, a small handheld device (such as a mobile telephone or PDA), a personal computer or a supercomputer. Computer system 900 includes a monitor 902, a display 904, a housing 906, a disk drive 908, a keyboard 910 and a mouse 912. Disk 914 is a computer-readable medium used to transfer data to and from computer system 900.
[0062] FIG. 10 is an example of a block diagram for computer system 900. Attached to system bus 920 are a wide variety of subsystems. Processor(s) 922 (also referred to as central processing units, or CPUs) are coupled to storage devices including memory 924. Memory 924 includes random access memory (RAM) and read-only memory (ROM). As is well known in the art, ROM acts to transfer data and instructions uni-directionally to the CPU and RAM is used typically to transfer data and instructions in a bi-directional manner. Both of these types of memories may include any suitable of the computer-readable media described below. A fixed disk 926 is also coupled bi-directionally to CPU 922; it provides additional data storage capacity and may also include any of the computer-readable media described below. Fixed disk 926 may be used to store programs, data and the like and is typically a secondary mass storage medium (such as a hard disk, a solid-state drive, a hybrid drive, flash memory, etc.) that can be slower than primary storage but persists data. It will be appreciated that the information retained within fixed disk 926, may, in appropriate cases, be incorporated in standard fashion as virtual memory in memory 924. Removable disk 914 may take the form of any of the computer-readable media described below.
[0063] CPU 922 is also coupled to a variety of input/output devices such as display 904, keyboard 910, mouse 912 and speakers 930. In general, an input/output device may be any of: video displays, track balls, mice, keyboards, microphones, touch-sensitive displays, transducer card readers, magnetic or paper tape readers, tablets, styluses, voice or handwriting recognizers, biometrics readers, or other computers. CPU 922 optionally may be coupled to another computer or telecommunications network using network interface 940. With such a network interface, it is contemplated that the CPU might receive information from the network, or might output information to the network in the course of performing the above-described method steps. Furthermore, method embodiments of the present invention may execute solely upon CPU 922 or may execute over a network such as the Internet in conjunction with a remote CPU that shares a portion of the processing.
[0064] In addition, embodiments of the present invention further relate to computer storage products with a computer-readable medium that have computer code thereon for performing various computer-implemented operations. The media and computer code may be those specially designed and constructed for the purposes of the present invention, or they may be of the kind well known and available to those having skill in the computer software arts. Examples of computer-readable media include, but are not limited to: magnetic media such as hard disks, floppy disks, and magnetic tape; optical media such as CD-ROMs and holographic devices; magneto-optical media such as floptical disks; and hardware devices that are specially configured to store and execute program code, such as application-specific integrated circuits (ASICs), programmable logic devices (PLDs) and ROM and RAM devices. Examples of computer code include machine code, such as produced by a compiler, and files containing higher-level code that are executed by a computer using an interpreter.
[0065] Although the foregoing invention has been described in some detail for purposes of clarity of understanding, it will be apparent that certain changes and modifications may be practiced within the scope of the appended claims. Therefore, the described embodiments should be taken as illustrative and not restrictive, and the invention should not be limited to the details given herein but should be defined by the following claims and their full scope of equivalents.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.