Method And System For Full Restore Point Creation Using Incremental Backups
Chopra; Shelesh ; et al.
U.S. patent application number 16/562160 was filed with the patent office on 2020-11-05 for method and system for full restore point creation using incremental backups. The applicant listed for this patent is EMC IP Holding Company LLC. Invention is credited to Shelesh Chopra, Kenneth William Owens, Trichy Krishnamurthi Premkumar, Amith Ramachandran, Yasemin Ugur-Ozekinci, Navneet Upadhyay, Hui Yang.
| Application Number | 20200349012 16/562160 |
| Document ID | / |
| Family ID | 1000004303579 |
| Filed Date | 2020-11-05 |






| United States Patent Application | 20200349012 |
| Kind Code | A1 |
| Chopra; Shelesh ; et al. | November 5, 2020 |
METHOD AND SYSTEM FOR FULL RESTORE POINT CREATION USING INCREMENTAL BACKUPS
Abstract
A method and system for full restore point creation using incremental backups. Specifically, the method and system disclosed herein entail performing a modified synthetic full backup operation during processes directed to the protection of database data. The modified synthetic full backup operation, in contrast to traditional synthetic full backup operations, provides a mechanism through which a history of successively stored or synthesized full backups that may be maintained as full restore (or rollback) points for a given database.
| Inventors: | Chopra; Shelesh; (Bangalore, IN) ; Ugur-Ozekinci; Yasemin; (Oakville, CA) ; Owens; Kenneth William; (Burlington, CA) ; Ramachandran; Amith; (Bangalore, IN) ; Upadhyay; Navneet; (Ghaziabad, IN) ; Premkumar; Trichy Krishnamurthi; (Mount Waverley, AU) ; Yang; Hui; (Carlsbad, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 1000004303579 | ||||||||||
| Appl. No.: | 16/562160 | ||||||||||
| Filed: | September 5, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 62841764 | May 1, 2019 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06F 9/547 20130101; G06F 11/1453 20130101; G06F 2201/84 20130101; G06F 11/1451 20130101; G06F 11/1464 20130101 |
| International Class: | G06F 11/14 20060101 G06F011/14; G06F 9/54 20060101 G06F009/54 |
Claims
1. A method for performing backup operations, comprising: receiving a first remote write request comprising a first incremental backup; identifying a first full backup relevant to the first incremental backup; making a determination that a backup tag associated with the first full backup matches a reserved incremental merge tag; cloning, based on the determination, the first full backup to obtain a first full backup copy; and merging the first incremental backup with the first full backup to produce a second full backup.
2. The method of claim 1, wherein the first remote write request is a remote procedure call (RPC) employed in a distributed file system protocol.
3. The method of claim 1, wherein the first full backup copy is a pointer-based snapshot of the first full backup.
4. The method of claim 1, wherein the first full backup is stored in a first directory of a physical file system, wherein the first full backup copy is stored in a second directory of the physical file system following the cloning of the first full backup.
5. The method of claim 4, wherein the second full backup replaces the first full backup in the first directory of the physical file system following the cloning of the first full backup.
6. The method of claim 1, wherein the first full backup and the first incremental backup each exist in deduplicated form.
7. The method of claim 6, wherein the first full backup, in deduplicated form, comprises a full backup content recipe comprising a first sequence of cryptographic fingerprints, wherein the first incremental backup, in deduplicated form, comprises an incremental backup content recipe comprising a second sequence of cryptographic fingerprints.
8. The method of claim 1, further comprising: receiving a second remote write request comprising a second incremental backup; identifying the second full backup as being relevant to the second incremental backup; cloning the second full backup to obtain a second full backup copy; and merging the second incremental backup with the second full backup to produce a third full backup.
9. A system, comprising: a backup storage system comprising a first computer processor configured to: receive a remote write request comprising an incremental backup; identify a first full backup relevant to the incremental backup; make a determination that a backup tag associated with the first full backup matches a reserved incremental merge tag; clone, based on the determination, the first full backup to obtain a first full backup copy; and merge the incremental backup with the first full backup to produce a second full backup.
10. The system of claim 9, wherein the backup storage system further comprises a backup file system service executing on the first computer processor, wherein the backup file system service implements a portion of a distributed file system.
11. The system of claim 10, further comprising: a client device operatively connected to the backup storage system and comprising a second computer processor configured to: submit the remote write request to the backup storage system using a distributed file system protocol employed by the distributed file system.
12. The system of claim 11, wherein the client device further comprises a backup file system interface executing on the second computer processor, wherein the backup file system interface implements another portion of the distributed file system.
13. A non-transitory computer readable medium (CRM) comprising computer readable program code, which when executed by a computer processor, enables the computer processor to: receive a first remote write request comprising a first incremental backup; identify a first full backup relevant to the first incremental backup; make a determination that a backup tag associated with the first full backup matches a reserved incremental merge tag; clone, based on the determination, the first full backup to obtain a first full backup copy; and merge the first incremental backup with the first full backup to produce a second full backup.
14. The non-transitory CRM of claim 13, wherein the first remote write request is a remote procedure call (RPC) employed in a distributed file system protocol.
15. The non-transitory CRM of claim 13, wherein the first full backup copy is a pointer-based snapshot of the first full backup.
16. The non-transitory CRM of claim 13, wherein the first full backup is stored in a first directory of a physical file system, wherein the first full backup copy is stored in a second directory of the physical file system following the cloning of the first full backup.
17. The non-transitory CRM of claim 16, wherein the second full backup replaces the first full backup in the first directory of the physical file system following the cloning of the first full backup.
18. The non-transitory CRM of claim 13, wherein the first full backup and the first incremental backup each exist in deduplicated form.
19. The non-transitory CRM of claim 18, wherein the first full backup, in deduplicated form, comprises a full backup content recipe comprising a first sequence of cryptographic fingerprints, wherein the first incremental backup, in deduplicated form, comprises an incremental backup content recipe comprising a second sequence of cryptographic fingerprints.
20. The non-transitory CRM of claim 13, comprising computer readable program code, which when executed by the computer processor, further enables the computer processor to: receive a second remote write request comprising a second incremental backup; identify the second full backup as being relevant to the second incremental backup; clone the second full backup to obtain a second full backup copy; and merge the second incremental backup with the second full backup to produce a third full backup.
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application claims priority under 35 U.S.C. .sctn. 119(e) to U.S. Provisional Patent Application No. 62/841,764, filed on May 1, 2019, which is incorporated herein by reference in its entirety.
BACKGROUND
[0002] In traditional synthetic full backup operations, full backups are synthesized on the backup storage system through the merging of one or more incremental backups with the current full backup, which had previously been stored or synthesized thereon. The merging of the current full backup with the incremental backup(s) produces a new current full backup, which replaces the previous current full backup.
SUMMARY
[0003] In general, in one aspect, the invention relates to a method for performing backup operations. The method includes receiving a first remote write request including a first incremental backup, identifying a first full backup relevant to the first incremental backup, making a determination that a backup tag associated with the first full backup matches a reserved incremental merge tag, cloning, based on the determination, the first full backup to obtain a first full backup copy, and merging the first incremental backup with the first full backup to produce a second full backup.
[0004] In general, in one aspect, the invention relates to a system. The system includes a backup storage system including a first computer processor configured to receive a remote write request including an incremental backup, identify a first full backup relevant to the incremental backup, make a determination that a backup tag associated with the first full backup matches a reserved incremental merge tag, clone, based on the determination, the first full backup to obtain a first full backup copy, and merge the incremental backup with the first full backup to produce a second full backup.
[0005] In general, in one aspect, the invention relates to a non-transitory computer readable medium (CRM). The non-transitory CRM includes computer readable program code, which when executed by a computer processor, enables the computer processor to receive a first remote write request including a first incremental backup, identify a first full backup relevant to the first incremental backup, make a determination that a backup tag associated with the first full backup matches a reserved incremental merge tag, clone, based on the determination, the first full backup to obtain a first full backup copy, and merge the first incremental backup with the first full backup to produce a second full backup.
[0006] Other aspects of the invention will be apparent from the following description and the appended claims.
BRIEF DESCRIPTION OF DRAWINGS
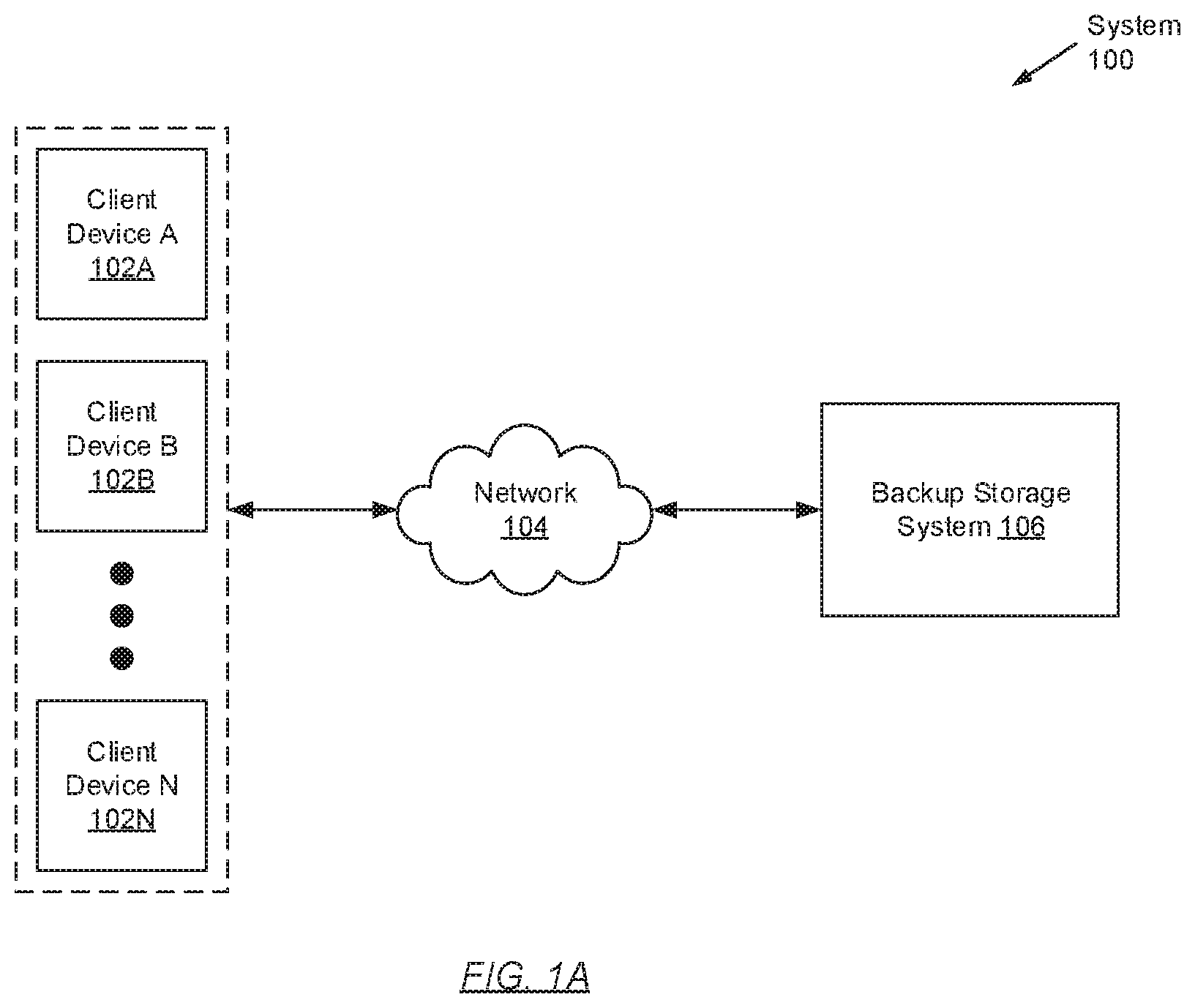
[0007] FIG. 1A shows a system in accordance with one or more embodiments of the invention.
[0008] FIG. 1B shows a client device in accordance with one or more embodiments of the invention.
[0009] FIG. 1C shows a backup storage system in accordance with one or more embodiments of the invention.
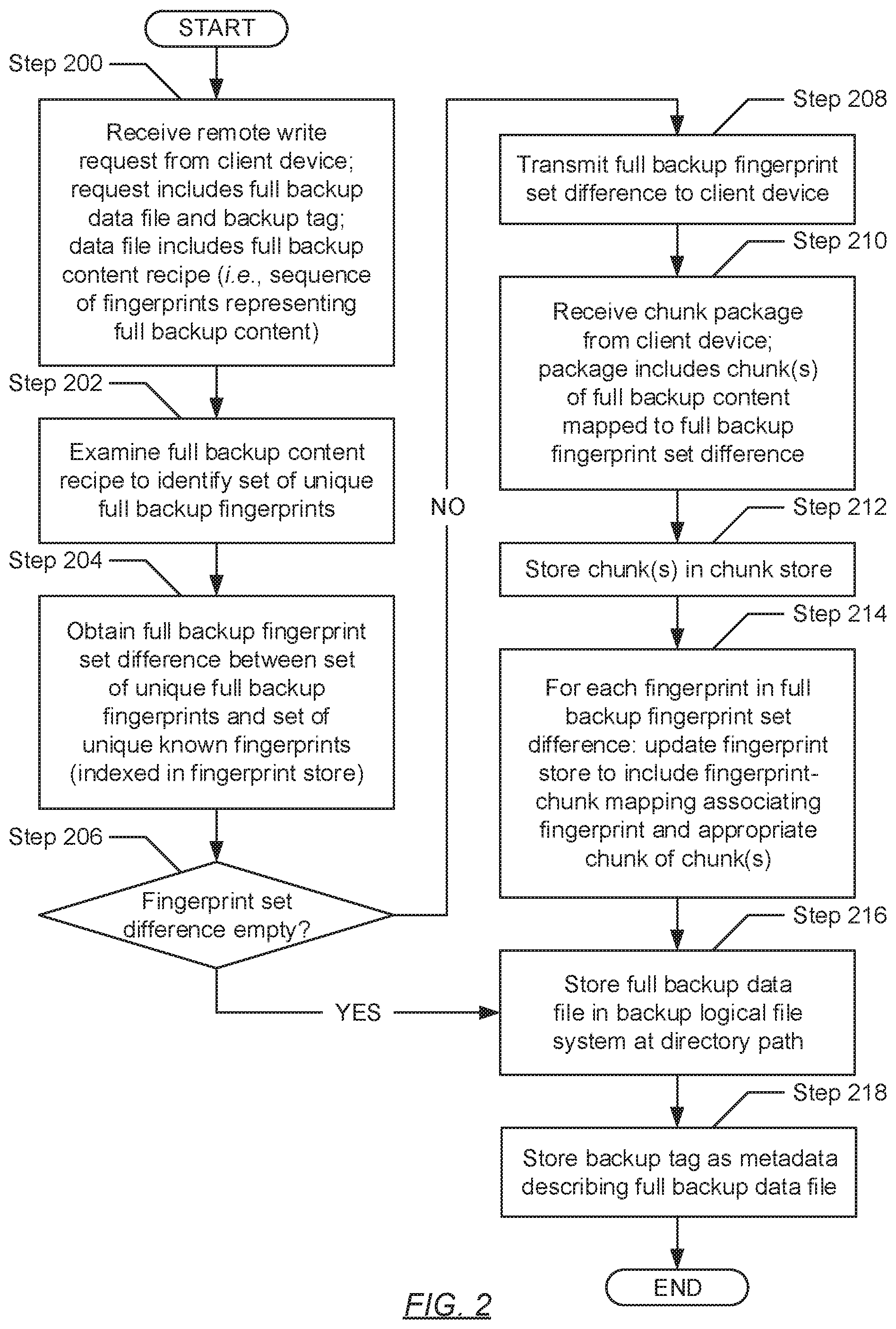
[0010] FIG. 2 shows a flowchart describing a method for processing a remote write request in accordance with one or more embodiments of the invention.
[0011] FIGS. 3A and 3B show flowcharts describing a method for processing a remote write request in accordance with one or more embodiments of the invention.
[0012] FIG. 4 shows an exemplary computing system in accordance with one or more embodiments of the invention.
DETAILED DESCRIPTION
[0013] Specific embodiments of the invention will now be described in detail with reference to the accompanying figures. In the following detailed description of the embodiments of the invention, numerous specific details are set forth in order to provide a more thorough understanding of the invention. However, it will be apparent to one of ordinary skill in the art that the invention may be practiced without these specific details. In other instances, well-known features have not been described in detail to avoid unnecessarily complicating the description.
[0014] In the following description of FIGS. 1A-4, any component described with regard to a figure, in various embodiments of the invention, may be equivalent to one or more like-named components described with regard to any other figure. For brevity, descriptions of these components will not be repeated with regard to each figure. Thus, each and every embodiment of the components of each figure is incorporated by reference and assumed to be optionally present within every other figure having one or more like-named components. Additionally, in accordance with various embodiments of the invention, any description of the components of a figure is to be interpreted as an optional embodiment which may be implemented in addition to, in conjunction with, or in place of the embodiments described with regard to a corresponding like-named component in any other figure.
[0015] Throughout the application, ordinal numbers (e.g., first, second, third, etc.) may be used as an adjective for an element (i.e., any noun in the application). The use of ordinal numbers is not to necessarily imply or create any particular ordering of the elements nor to limit any element to being only a single element unless expressly disclosed, such as by the use of the terms "before", "after", "single", and other such terminology. Rather, the use of ordinal numbers is to distinguish between the elements. By way of an example, a first element is distinct from a second element, and a first element may encompass more than one element and succeed (or precede) the second element in an ordering of elements.
[0016] In general, embodiments of the invention relate to a method and system for full restore point creation using incremental backups. Specifically, one or more embodiments of the invention entails performing a modified synthetic full backup operation during processes directed to the protection of database data. The modified synthetic full backup operation, in contrast to traditional synthetic full backup operations, provides a mechanism through which a history of successively stored or synthesized full backups that may be maintained as full restore (or rollback) points for a given database.
[0017] FIG. 1A shows a system in accordance with one or more embodiments of the invention. The system (100) may include one or more client devices (102A-102N) operatively connected to a backup storage system (106). Each of these system (100) components is described below.
[0018] In one embodiment of the invention, the above-mentioned system (100) components may operatively connect to one another through a network (104) (e.g., a local area network (LAN), a wide area network (WAN) such as the Internet, a mobile network, etc.). The network may be implemented using any combination of wired and/or wireless connections. Further, the network may encompass various interconnected, network-enabled subcomponents (or systems) (e.g., switches, routers, gateways, etc.) that may facilitate communications between the above-mentioned system (100) components. Moreover, the above-mentioned system (100) components may communicate with one another using any combination of wired and/or wireless communication protocols.
[0019] In one embodiment of the invention, a client device (102A-102N) may represent any physical appliance or computing system designed and configured to receive, generate, process, store, and/or transmit digital data, as well as to provide an environment in which one or more computer programs may execute thereon. The computer programs (not shown) may, for example, implement large-scale and complex data processing; or implement one or more services offered locally or over the network (104). Further, in providing an execution environment for any computer programs installed thereon, a client device (102A-102N) may include and allocate various resources (e.g., computer processors, memory, storage, virtualization, network bandwidth, etc.), as needed, to the computer programs and the tasks (or processes) instantiated thereby. One of ordinary skill will appreciate that a client device (102A-102N) may perform other functionalities without departing from the scope of the invention. Examples of a client device (102A-102N) may include, but are not limited to, a desktop computer, a laptop computer, a server, a mainframe, or any other computing system similar to the exemplary computing system shown in FIG. 4. Moreover, client devices (102A-102N) are described in further detail below with respect to FIG. 1B.
[0020] In one embodiment of the invention, the backup storage system (106) may represent a data backup, archiving, and/or disaster recovery storage system. The backup storage system (106) may be implemented using one or more servers (not shown). Each server may refer to a physical server, which may reside in a datacenter, or a virtual server, which may reside in a cloud computing environment. Additionally or alternatively, the backup storage system (106) may be implemented using one or more computing systems similar to the exemplary computing system shown in FIG. 4. Furthermore, the backup storage system (106) is described in further detail below with respect to FIG. 1C.
[0021] While FIG. 1A shows a configuration of components, other system (100) configurations may be used without departing from the scope of the invention.
[0022] FIG. 1B shows a client device in accordance with one or more embodiments of the invention. The client device (102) may include one or more user programs (110A-110N), a client protection agent (112), a client dedupe agent (114), a client operating system (116), and a client storage array (124). Each of these client device (102) components is described below.
[0023] In one embodiment of the invention, a user program (110A-110N) may refer to a computer program that may execute on the underlying hardware of the client device (102). Specifically, a user program (110A-110N) may be designed and configured to perform one or more functions, tasks, and/or activities instantiated by a user of the client device (102). Accordingly, towards performing these operations, a user program (110A-110N) may include functionality to request and consume client device (102) resources (e.g., computer processors, memory, storage (124), virtualization, network bandwidth, etc.) by way of service calls to the client operating system (116). One of ordinary skill will appreciate that a user program (110A-110N) may perform other functionalities without departing from the scope of the invention. Examples of a user program (110A-110N) may include, but are not limited to, a word processor, an email client, a database client, a web browser, a media player, a file viewer, an image editor, a simulator, a computer game, or any other computer executable application.
[0024] In one embodiment of the invention, the client protection agent (112) may refer to a computer program that may execute on the underlying hardware of the client device (102). Specifically, the client protection agent (112) may be designed and configured to perform client-side database backup and recovery operations. To that extent, the client protection agent (112) may protect one or more databases (also referred herein as assets (126A-126N)) on the client device (102) against data loss (i.e., backup the database(s)); and reconstruct one or more databases on the client device (102) following such data loss (i.e., recover the database(s)). One of ordinary skill will appreciate that the client protection agent (112) may perform other functionalities without departing from the scope of the invention.
[0025] In one embodiment of the invention, the client dedupe agent (114) may refer to a computer program that may execute on the underlying hardware of the client device (102). Specifically, the client dedupe agent (114) may be designed and configured to perform client- or source-side data deduplication. Source-side data deduplication may refer to the identification and subsequent elimination of redundant data prior to transmission of the data to the backup storage system (106). To that extent, the client dedupe agent (114) may include functionality to: obtain database data selected for backup from and by the client protection agent (112); apply data deduplication on the obtained database data to render deduplicated database data; and remotely write the deduplicated database data onto the backup storage system (106) by way of the backup file system interface (122) (described below). One of ordinary skill will appreciate that the client dedupe agent (114) may perform other functionalities without departing from the scope of the invention.
[0026] In one embodiment of the invention, the client operating system (116) may refer to a computer program that may execute on the underlying hardware of the client device (102). Specifically, the client operating system (116) may be designed and configured to oversee client device (102) operations. To that extent, the client operating system (116) may include functionality to, for example, support fundamental client device (102) functions; schedule tasks; mediate interactivity between logical (e.g., software) and physical (e.g., hardware) client device (102) components; allocate client device (102) resources; and execute or invoke other computer programs executing on the client device (102). One of ordinary skill will appreciate that the client operating system (116) may perform other functionalities without departing from the scope of the invention.
[0027] For example, the client operating system (116) may facilitate user program (110A-110N) interaction with asset (126A-126N) data stored locally on the client device (102) or remotely over the network (104). In facilitating the aforementioned interaction, the client operating system (116) may implement a client logical file system (118). The client logical file system (118) may represent a collection of in-memory data structures maintained, by the client operating system (116), to manage the various accessible asset (126A-126N) data stored locally on the client device (102) and/or remotely on the backup storage system (106). Further, the client logical file system (118) may expose an application programming interface (API) through which the user program(s) (110A-110N) may manipulate--i.e., via one or more file operations--any granularity of locally and/or remotely stored asset (126A-126N) data. These file operations, requested by the user program(s) (110A-110N), may subsequently be delivered to the client file system (120) or backup file system interface (122) for processing.
[0028] In one embodiment of the invention, the client file system (120) may represent a physical file system (also referred to as a file system implementation). A physical file system may refer to a collection of subroutines concerned with the physical operation of one or more physical storage devices (described below). The client file system (120), in this respect, may be concerned with the physical operation of the client storage array (124). Accordingly, the client file system (120) may employ client storage array (124) device drivers (or firmware) to process requested file operations from the user program(s) (110A-110N). Device drivers enable the client file system (120) to manipulate physical storage or disk blocks as appropriate.
[0029] In one embodiment of the invention, the backup file system interface (122) may represent a computer program that may execute on the underlying hardware of the client device (102). Specifically, the backup file system interface (122) may be designed and configured to facilitate the access and manipulation of remotely stored database data as if the aforementioned database data were stored locally on the client device (102). Accordingly, the backup file system interface (122) may, in part, implement a distributed file system (DFS), which may employ any known distributed file system protocol (e.g., the network file system (NFS) protocol). A distributed file system may refer to a mechanism through which files (e.g., database data) may be stored and accessed based on client-server architecture over a network (104). Particularly, in a distributed file system, one or more central appliances (e.g., the backup storage system (106)) store files that can be accessed, with proper authorization permissions, by any number of remote clients (e.g., the client device (102)) across the network (104). Furthermore, the backup file system interface (122) may include functionality to issue remote procedure calls (RPCs) directed to accessing and manipulating any granularity of database data remotely stored on the backup storage system (106).
[0030] In one embodiment of the invention, the client storage array (124) may refer to a collection of one or more physical storage devices (not shown) on which various forms of digital data--e.g., one or more assets (126A-126N) (described below)--may be consolidated. Each physical storage device may encompass non-transitory computer readable storage media on which data may be stored in whole or in part, and temporarily or permanently. Further, each physical storage device may be designed and configured based on a common or different storage device technology--examples of which may include, but are not limited to, flash based storage devices, fibre-channel (FC) based storage devices, serial-attached small computer system interface (SCSI) (SAS) based storage devices, and serial advanced technology attachment (SATA) storage devices. Moreover, any subset or all of the client storage array (124) may be implemented using persistent (i.e., non-volatile) storage. Examples of persistent storage may include, but are not limited to, optical storage, magnetic storage, NAND Flash Memory, NOR Flash Memory, Magnetic Random Access Memory (M-RAM), Spin Torque Magnetic RAM (ST-MRAM), Phase Change Memory (PCM), or any other storage defined as non-volatile Storage Class Memory (SCM).
[0031] In one embodiment of the invention, an asset (126A-126N) may represent a database, or a logical container to and from which related digital data, or any granularity thereof, may be stored and retrieved, respectively. An asset (126A-126N) may occupy a portion of a physical storage device or, alternatively, may span across multiple physical storage devices, of the client storage array (124). Furthermore, an asset (126A-126N) may refer to a composite of various database objects including, but not limited to, one or more data files, one or more control files, and one or more redo log files (all not shown). Each of these asset (126A-126N) subcomponents is described below.
[0032] In one embodiment of the invention, a data file may refer to a database object for storing database data. Database data may encompass computer readable content (e.g., images, text, video, audio, machine code, any other form of computer readable content, or a combination thereof), which may be generated, interpreted, and/or processed by any given user program (110A-110N). Further, a data file may store database data in (a) undeduplicated form or (b) deduplicated form. In brief, the latter form of database data may be produced through the application of data deduplication on the former form of the database data. That is, undeduplicated database data may entail computer readable content that may or may not include redundant information. In contrast, deduplicated database data may result from the elimination of any redundant information found throughout the undeduplicated computer readable content and, accordingly, may instead reflect a content recipe of the undeduplicated computer readable content. A content recipe may refer to a sequence of chunk identifiers (or pointers) associated with (or directed to) unique database data chunks consolidated in physical storage. Collectively, the sequence of chunk identifiers (or pointers)--representative of the deduplicated database data--may be used to reconstruct the corresponding undeduplicated database data. Moreover, a given chunk identifier for a given database data chunk may encompass a cryptographic fingerprint or hash of the given database data chunk.
[0033] In one embodiment of the invention, a control file may refer to a database object for storing asset (126A-126N) metadata (also referred to as database metadata). Database metadata may encompass information descriptive of the database (or asset (126A-126N)) status and structure. By way of examples, database metadata may include, but are not limited to, a database name assigned to the asset (126A-126N), the name(s) and storage location(s) of one or more data files and redo log files associated with the asset (126A-126N), a creation timestamp encoding the date and/or time marking the creation of the asset (126A-126N), a log sequence number associated with a current redo log file, etc.
[0034] In one embodiment of the invention, a redo log file may refer to a database object for storing a history of changes made to the database data. A redo log file may include one or more redo entries (or redo records), which may include a set of change vectors. Each change vector subsequently describes or represents a modification made to a single asset (126A-126N) data block. Furthermore, a redo log file may serve to recover the asset (126A-126N) should a failover occur, or to apply recent changes to a recovered asset (126A-126N) which may have transpired during the database recovery process.
[0035] While FIG. 1B shows a configuration of components, other client device (102) configurations may be used without departing from the scope of the invention.
[0036] FIG. 1C shows a backup storage system in accordance with one or more embodiments of the invention. The backup storage system (106) may include a backup operating system (140), a backup protection agent (148), and a backup storage array (150). Each of these backup storage system (106) components is described below.
[0037] In one embodiment of the invention, the backup operating system (140) may refer to a computer program that may execute on the underlying hardware of the backup storage system (106). Specifically, the backup operating system (140) may be designed and configured to oversee backup storage system (106) operations. To that extent, the backup operating system (140) may include functionality to, for example, support fundamental backup storage system (106) functions; schedule tasks; mediate interactivity between logical (e.g., software) and physical (e.g., hardware) backup storage system (106) components; allocate backup storage system (106) resources; and execute or invoke other computer programs executing on the backup storage system (106). One of ordinary skill will appreciate that the backup operating system (140) may perform other functionalities without departing from the scope of the invention.
[0038] For example, the backup operating system (140) may facilitate backup asset (156A-156N) access and manipulation by one or more computer programs (e.g., backup protection agent (148)) executing locally on the backup storage system (106) or, alternatively, by one or more remote computing systems (e.g., client device(s) (102A-102N)) over the network (104). In facilitating the aforementioned interaction, the backup operating system (140) may implement a backup logical file system (142). The backup logical file system (142) may represent a collection of in-memory data structures maintained, by the backup operating system (140), to manage the various accessible backup asset (156A-156N) data stored locally on the backup storage system (106). Further, the backup logical file system (142) may expose an application programming interface (API) through which the local computer programs and/or remote computing systems may manipulate--i.e., via one or more file operations--any granularity of locally stored backup asset (156A-156N) data. File operations, requested by the local computer programs, may be delivered to the backup file system (146) for processing, whereas file operations, requested by the remote computing systems, may be received and processed by the backup file system service (144).
[0039] In one embodiment of the invention, the backup file system service (144) may represent a computer program that may execute on the underlying hardware of the backup storage system (106). Specifically, the backup file system service (144) may be designed and configured to facilitate the authorized, remote access and manipulation of locally stored backup database data. Accordingly, the backup file system service (144) may, in part, implement a distributed file system (DFS), which may employ any known distributed file system protocol (e.g., the network file system (NFS) protocol). A distributed file system may refer to a mechanism through which files (e.g., database data) may be stored and accessed based on client-server architecture over a network (104). Particularly, in a distributed file system, one or more central appliances (e.g., the backup storage system (106)) store files that can be accessed, with proper authorization permissions, by any number of remote clients (e.g., the client device(s) (102A-102N)) across the network (104). Furthermore, the backup file system service (144) may include functionality to service remote procedure calls (RPCs) directed to accessing and manipulating any granularity of backup database data locally stored on the backup storage system (106).
[0040] In one embodiment of the invention, the backup file system (146) may represent a physical file system (also referred to as a file system implementation). A physical file system may refer to a collection of subroutines concerned with the physical operation of one or more physical storage devices (described below). The backup file system (146), in this respect, may be concerned with the physical operation of the backup storage array (150). Accordingly, the backup file system (146) may employ backup storage array (150) device drivers (or firmware) to process requested file operations from the local computer programs or the remote computing systems (via the backup file system service (144)). Device drivers enable the backup file system (146) to manipulate physical storage or disk blocks as appropriate.
[0041] In one embodiment of the invention, the backup protection agent (148) may refer to a computer program that may execute on the underlying hardware of the backup storage system (106). Specifically, the backup protection agent (148) may be designed and configured to perform server-side database backup and recovery operations. To that extent, the backup protection agent (148) may receive database data, submitted by the client device(s) (102A-102N), to store as backup assets (156A-156N) on the backup storage array (150) during database backup operations; and, conversely, may retrieve backup database data from the backup storage array (150) during database recovery operations. One of ordinary skill will appreciate that the backup protection agent (148) may perform other functionalities without departing from the scope of the invention.
[0042] In one embodiment of the invention, the backup storage array (150) may refer to a collection of one or more physical storage devices (not shown) on which various forms of digital data--e.g., one or more backup assets (156A-156N) (described below)--may be consolidated. Each physical storage device may encompass non-transitory computer readable storage media on which data may be stored in whole or in part, and temporarily or permanently. Further, each physical storage device may be designed and configured based on a common or different storage device technology--examples of which may include, but are not limited to, flash based storage devices, fibre-channel (FC) based storage devices, serial-attached small computer system interface (SCSI) (SAS) based storage devices, and serial advanced technology attachment (SATA) storage devices. Moreover, any subset or all of the backup storage array (150) may be implemented using persistent (i.e., non-volatile) storage. Examples of persistent storage may include, but are not limited to, optical storage, magnetic storage, NAND Flash Memory, NOR Flash Memory, Magnetic Random Access Memory (M-RAM), Spin Torque Magnetic RAM (ST-MRAM), Phase Change Memory (PCM), or any other storage defined as non-volatile Storage Class Memory (SCM).
[0043] In one embodiment of the invention, the backup storage array (150) may include a fingerprint store (152) and a chunk store (154), which may collectively consolidate deduplicated database data. Recall from above (see e.g., FIG. 1B), that deduplicated database data may result from the elimination of any redundant information found throughout the database data in undeduplicated form. Accordingly, instead of reflecting the binary composition of the undeduplicated database data in its entirety, deduplicated database data may alternatively reflect reduced information in the form of a content recipe of the representative, undeduplicated computer readable content. The aforementioned content recipe may refer to a sequence of chunk identifiers (or pointers) associated with (or directed to) unique database data chunks identified throughout the undeduplicated database data. Any unique database data chunks, along with their respective chunk identifiers (i.e., cryptographic fingerprints or hashes), may be indexed in appropriate physical storages--e.g., the chunk store (154) and the fingerprint store (152), respectively.
[0044] In one embodiment of the invention, the fingerprint store (152) may represent a repository for maintaining chunk identifiers. Each chunk identifier may be indexed by way of a fingerprint store (152) entry (not shown), which may store a mapping relating the chunk identifier to a storage identifier. A chunk identifier (also referred to as a fingerprint or hash) may represent a digital signature that uniquely identifies an associated database data chunk. Further, a chunk identifier may be produced by submitting the associated database data chunk through a hash function, which may employ any existing cryptographic mapping algorithm As such, a chunk identifier may be outputted by the hash function given the associated database data chunk as input. Meanwhile, a storage identifier may represent a character or bit string that uniquely identifies a storage location in the backup storage array (150). By way of an example, a storage identifier may encompass a tuple reflecting (a) a storage device identifier uniquely assigned to a given physical storage device (not shown) of the backup storage array (150); and (b) a binary address assigned to a starting byte (or storage block) in the given physical storage device at which the database data chunk may be physically stored.
[0045] On the other hand, in one embodiment of the invention, the chunk store (154) may represent a repository for maintaining unique database data chunks. Each unique database data chunk may be indexed by way of a chunk store (154) entry (not shown), which may store a mapping relating a storage identifier (described above) to the unique database data chunk. A database data chunk may refer to a fragment or a partition of undeduplicated database data. More specifically, a database data chunk may capture a unique byte pattern that may occur or recur throughout the undeduplicated database data.
[0046] In one embodiment of the invention, a backup asset (156A-156N) may refer to a deduplicated backup copy of a given asset (126A-126N) (see e.g., FIG. 1B). Accordingly, a backup asset (156A-156N) may similarly represent a database, or a logical container to and from which related digital data, or any granularity thereof, may be stored and retrieved, respectively. A backup asset (156A-156N) may occupy a portion of a physical storage device or, alternatively, may span across multiple physical storage devices, of the backup storage array (150). Furthermore, similar to an asset (126A-126N), a backup asset (156A-156N) may refer to a composite of various database objects including, but not limited to, one or more data files, one or more control files, and one or more redo log files (all described above).
[0047] While FIG. 1C shows a configuration of components, other backup storage system (106) configurations may be used without departing from the scope of the invention.
[0048] FIG. 2 shows a flowchart describing a method for processing a remote write request in accordance with one or more embodiments of the invention. The various steps outlined below may be performed by the backup storage system (see e.g., FIGS. 1A and 1C). Further, while the various steps in the flowchart are presented and described sequentially, one of ordinary skill will appreciate that some or all steps may be executed in different orders, may be combined or omitted, and some or all steps may be executed in parallel.
[0049] Turning to FIG. 2, in Step 200, a remote write request is received from a client device. In one embodiment of the invention, the remote write request may include a full backup data file and a corresponding backup tag. The full backup data file may reflect all database data for a given asset (i.e., database) stored on the client device. Further, the full backup data file may arrive in deduplicated form and, thus, may include a full backup content recipe. A content recipe may refer to a sequence of chunk identifiers (or pointers) associated with (or directed to) unique database data chunks indexed in physical storage--e.g., the chunk store of the backup storage array (see e.g., FIG. 1C). In turn, a given chunk identifier for a given database data chunk may encompass a cryptographic fingerprint or hash of the given database data chunk. Accordingly, in one embodiment of the invention, the full backup content recipe may convey a sequence of fingerprints collectively representative of the undeduplicated full backup content. Meanwhile, the backup tag may represent a text attribute (i.e., metadata) that may be associated with or descriptive of the full backup data file.
[0050] In Step 202, the full backup content recipe (received in Step 200) is examined. In one embodiment of the invention, the examination may result in the identification of one or more unique full backup fingerprints (i.e., a set of unique full backup fingerprints), which may occur or recur throughout the full backup content recipe.
[0051] In Step 204, a full backup fingerprint set difference is obtained. In one embodiment of the invention, the full backup fingerprint set difference may refer to zero or more unique fingerprints, included in the set of unique full backup fingerprints (identified in Step 202), that may be excluded from a superset of known (i.e., pre-stored) unique fingerprints indexed in physical storage--e.g., the fingerprint store of the backup storage array (see e.g., FIG. 1C). For example, if the set of unique full backup fingerprints includes a first fingerprint, a second fingerprint, a third fingerprint, and a fourth fingerprint, whereas the superset of known unique fingerprints (indexed in the aforementioned fingerprint store) includes the first fingerprint, the second fingerprint, and the third fingerprint, then the fingerprint set difference of the two sets of fingerprints includes the fourth fingerprint. Alternatively, the superset of known unique fingerprints (indexed in the aforementioned fingerprint store) may include the fourth fingerprint as well and, in such a scenario, the fingerprint set difference of the two sets of fingerprints may result in an empty set.
[0052] In Step 206, a determination is made as to whether the full backup fingerprint set difference (obtained in Step 204) reflects an empty set. Accordingly, in one embodiment of the invention, if it is determined that the full backup fingerprint set difference is indeed an empty set, then the process proceeds to Step 216. On the other hand, in another embodiment of the invention, if it is alternatively determined that the full backup fingerprint set difference includes at least one unknown, unique fingerprint, then the process alternatively proceeds to Step 208.
[0053] In Step 208, after determining (in Step 206), that the full backup fingerprint set difference (obtained in Step 204) includes at least one unknown, unique fingerprint, the aforementioned full backup fingerprint set difference is transmitted to the client device (from which the remote write request had been received in Step 200).
[0054] In Step 210, in response to the above-mentioned transmission (performed in Step 208), a chunk package is received from the client device. In one embodiment of the invention, the chunk package may represent a logical container within which one or more database data chunks may be enclosed. The cardinality of enclosed database data chunks may match the cardinality of unknown, unique fingerprints transmitted to the client device via the full backup fingerprint set difference. Accordingly, each database data chunk, received via the chunk package, may map to a respective unknown, unique fingerprint of the full backup fingerprint set difference, where the unknown, unique fingerprint uniquely identifies the database data chunk. Furthermore, each database data chunk may reflect a different fragment (or byte pattern) that occurs or recurs throughout the undeduplicated full backup content.
[0055] In Step 212, the database data chunk(s) (received in Step 210) is/are indexed in physical storage--e.g., the chunk store of the backup storage array (see e.g., FIG. 1C). In one embodiment of the invention, each database data chunk may be indexed in the chunk store within a new chunk store entry, which may include a mapping relating the database data chunk to a storage identifier (described above) (see e.g., FIG. 1C).
[0056] In Step 214, the unknown, unique fingerprint(s), representative of the full backup fingerprint set difference (obtained in Step 204), is/are subsequently indexed in physical storage--e.g., the fingerprint store of the backup storage array (see e.g., FIG. 1C). Specifically, each unknown, unique fingerprint may be indexed in the fingerprint store within a new fingerprint store entry, which may include a mapping relating the unknown, unique fingerprint to the storage identifier mapped to the database data chunk that which the unknown, unique fingerprint uniquely identifies.
[0057] In Step 216, following the determination that the full backup fingerprint set difference (obtained in Step 204) is an empty set, or following the indexing of the unknown, unique fingerprint(s) (in Step 214), the full backup data file (or more, specifically, the associated full backup content recipe) (received in Step 200) is stored in the backup file system at a prescribed directory path. Thereafter, in Step 218, the backup tag (also received in Step 200) is recorded and stored as associative metadata describing the full backup data file.
[0058] FIGS. 3A and 3B show flowcharts describing a method for processing a remote write request in accordance with one or more embodiments of the invention. The various steps outlined below may be performed by the backup storage system (see e.g., FIGS. 1A and 1C). Further, while the various steps in the flowcharts are presented and described sequentially, one of ordinary skill will appreciate that some or all steps may be executed in different orders, may be combined or omitted, and some or all steps may be executed in parallel.
[0059] Turning to FIG. 3A, in Step 300, a remote write request is received from a client device. In one embodiment of the invention, the remote write request may include an incremental backup data file. The incremental backup data file may reflect any changes made to database data for a given asset (i.e., database), stored on the client device, since a previously submitted remote write request--which may have included another incremental backup data file or a full backup data file (described above) (see e.g., FIG. 2). Further, the incremental backup data file may arrive in deduplicated form and, thus, may include an incremental backup content recipe. A content recipe may refer to a sequence of chunk identifiers (or pointers) associated with (or directed to) unique database data chunks indexed in physical storage--e.g., the chunk store of the backup storage array (see e.g., FIG. 1C). In turn, a given chunk identifier for a given database data chunk may encompass a cryptographic fingerprint or hash of the given database data chunk. Accordingly, in one embodiment of the invention, the incremental backup content recipe may convey a sequence of fingerprints collectively representative of the undeduplicated incremental backup content.
[0060] In Step 302, the incremental backup content recipe (received in Step 300) is examined. In one embodiment of the invention, the examination may result in the identification of one or more unique incremental backup fingerprints (i.e., a set of unique incremental backup fingerprints), which may occur or recur throughout the incremental backup content recipe.
[0061] In Step 304, an incremental backup fingerprint set difference is obtained. In one embodiment of the invention, the incremental backup fingerprint set difference may refer to zero or more unique fingerprints, included in the set of unique incremental backup fingerprints (identified in Step 302), that may be excluded from a superset of known (i.e., pre-stored) unique fingerprints indexed in physical storage--e.g., the fingerprint store of the backup storage array (see e.g., FIG. 1C). For example, if the set of unique incremental backup fmgerprints includes a first fingerprint, a second fingerprint, a third fingerprint, and a fourth fingerprint, whereas the superset of known unique fingerprints (indexed in the aforementioned fingerprint store) includes the first fingerprint, the second fingerprint, and the third fingerprint, then the fingerprint set difference of the two sets of fingerprints includes the fourth fingerprint. Alternatively, the superset of known unique fingerprints (indexed in the aforementioned fingerprint store) may include the fourth fingerprint as well and, in such a scenario, the fingerprint set difference of the two sets of fingerprints may result in an empty set.
[0062] In Step 306, a determination is made as to whether the incremental backup fingerprint set difference (obtained in Step 304) reflects an empty set. Accordingly, in one embodiment of the invention, if it is determined that the incremental backup fingerprint set difference is indeed an empty set, then the process proceeds to Step 316. On the other hand, in another embodiment of the invention, if it is alternatively determined that the incremental backup fingerprint set difference includes at least one unknown, unique fingerprint, then the process alternatively proceeds to Step 308.
[0063] In Step 308, after determining (in Step 306), that the incremental backup fingerprint set difference (obtained in Step 304) includes at least one unknown, unique fingerprint, the aforementioned incremental backup fingerprint set difference is transmitted to the client device (from which the remote write request had been received in Step 300).
[0064] In Step 310, in response to the above-mentioned transmission (performed in Step 308), a chunk package is received from the client device. In one embodiment of the invention, the chunk package may represent a logical container within which one or more database data chunks may be enclosed. The cardinality of enclosed database data chunks may match the cardinality of unknown, unique fingerprints transmitted to the client device via the incremental backup fingerprint set difference. Accordingly, each database data chunk, received via the chunk package, may map to a respective unknown, unique fingerprint of the incremental backup fingerprint set difference, where the unknown, unique fingerprint uniquely identifies the database data chunk. Furthermore, each database data chunk may reflect a different fragment (or byte pattern) that occurs or recurs throughout the undeduplicated incremental backup content.
[0065] In Step 312, the database data chunk(s) (received in Step 310) is/are indexed in physical storage--e.g., the chunk store of the backup storage array (see e.g., FIG. 1C). In one embodiment of the invention, each database data chunk may be indexed in the chunk store within a new chunk store entry, which may include a mapping relating the database data chunk to a storage identifier (described above) (see e.g., FIG. 1C).
[0066] In Step 314, the unknown, unique fingerprint(s), representative of the incremental backup fingerprint set difference (obtained in Step 304), is/are subsequently indexed in physical storage--e.g., the fingerprint store of the backup storage array (see e.g., FIG. 1C). Specifically, each unknown, unique fingerprint may be indexed in the fingerprint store within a new fingerprint store entry, which may include a mapping relating the unknown, unique fingerprint to the storage identifier mapped to the database data chunk that which the unknown, unique fingerprint uniquely identifies.
[0067] In Step 316, following the determination that the incremental backup fingerprint set difference (obtained in Step 304) is an empty set, or following the indexing of the unknown, unique fingerprint(s) (in Step 314), a previously stored full backup data file is identified. In one embodiment of the invention, the identified full backup data file may be relevant to the incremental backup data file (received in Step 300). That is, the incremental backup data file may relate to the full backup data file such that the former reflects database data changes to the latter, which may have transpired since a last database backup operation.
[0068] Turning to FIG. 3B, in Step 320, a backup tag associated with the full backup data file (identified in Step 316) is obtained. In one embodiment of the invention, the backup tag may represent a text attribute (i.e., metadata) that may be associated with or descriptive of the full backup data file.
[0069] In Step 322, a determination is made as to whether the backup tag (obtained in Step 320) matches a reserved incremental merge tag (described below). Accordingly, in one embodiment of the invention, if it is determined that the backup tag matches the reserved incremental merge tag, then the process proceeds to Step 324. On the other hand, in another embodiment of the invention, if it is alternatively determined that the backup tag does not match the reserved incremental merge tag, then the process alternatively proceeds to Step 330.
[0070] In one embodiment of the invention, the reserved incremental merge tag may represent a unique, prescribed text attribute, which when matched, instructs the backup storage system to perform a modified synthetic full backup operation. In traditional synthetic full backup operations, full backups are synthesized on the backup storage system through the merging of one or more incremental backups with the current full backup, which had previously been stored or synthesized thereon. The aforementioned merging of the current full backup with the incremental backup(s) produces a new current full backup, which replaces the previous current full backup. Subsequently, in traditional synthetic full backup operations, only the new current full backup for any given time may be maintained, whereas any previous current full backups are discarded.
[0071] In one embodiment of the invention, the above-mentioned modified synthetic full backup operation, triggered by a backup tag matching the reserved incremental merge tag, includes the performance of an additional step prior to the execution of a traditional synthetic full backup operation. More specifically, the additional step may entail cloning the current full backup prior to its merger with one or more incremental backups to produce a new current full backup. Accordingly, with the performance of the additional step, a history of successively stored or synthesized full backups may be maintained as full restore (or rollback) points for a given asset.
[0072] In Step 324, after determining (in Step 322) that the backup tag (obtained in Step 320) matches the above-described reserved incremental merge tag, the full backup data file (identified in Step 316) is cloned. In one embodiment of the invention, cloning of the full backup data file may entail generating a pointer-based snapshot of the full backup data file. That is, rather than cloning or copying the physical database data itself, associated with the full backup data file, generation of a pointer-based snapshot exercises the cloning or copying of the full backup content recipe (described above). Subsequently, the cloning process of the full backup data file is rapid despite the physical storage space consumed by the associated physical database data; and, further, the cloning process results in the obtaining of a full backup data file copy, which consumes little to no physical storage capacity.
[0073] In Step 326, the full backup data file copy (or more, specifically, a copy of the associated full backup content recipe) (obtained in Step 324) is stored in the backup file system. More specifically, in one embodiment of the invention, whereas the full backup data file had been stored in a first directory path, the full backup data file copy may be stored in a second (or different) directory path following the cloning process.
[0074] In Step 328, the full backup data file copy (obtained in Step 324) is catalogued with the client device (from which the remote write request had been received in Step 300). In one embodiment of the invention, cataloguing of the full backup data file copy may entail informing the client device of the existence of the full backup data file copy. Further, informing the client device may include relaying metadata pertaining to the full backup data file copy--e.g., a timestamp encoding a date and/or time during which the full backup data file (from which the full backup data file copy depends) had been stored or synthesized; a backup identifier or name associated with the full backup data file copy; a directory path in the backup file system at which the full backup data file copy may be found, etc.
[0075] In Step 330, following the determination that the backup tag (obtained in Step 320) does not match the reserved incremental merge tag, or following the cataloguing of the full backup data file copy with the client device (performed in Step 328), the incremental backup file (received in Step 300) is merged into/with the full backup data file (identified in Step 316). In one embodiment of the invention, the aforementioned merger may entail applying any database data changes, recorded in the incremental backup data file, onto the full backup data file, thereby creating a new full backup data file. Further, the new full backup data file may be retained in deduplicated form, similar to the full backup data file or the incremental backup data file. Accordingly, the new full backup data file may include a new full backup content recipe representative of the new full backup content.
[0076] In Step 332, the full backup data file (identified in Step 316) is overwritten by (or replaced with) the new full backup data file (obtained in Step 330). Thereafter, in Step 334, the backup tag (obtained in Step 320) is recorded as metadata associated with the new full backup data file. That is, in one embodiment of the invention, association of the backup tag--that had been associated with the full backup data file--may be extended to the new full backup data file, which stems from at least the full backup data file.
[0077] FIG. 4 shows an exemplary computing system in accordance with one or more embodiments of the invention. The computing system (400) may include one or more computer processors (402), non-persistent storage (404) (e.g., volatile memory, such as random access memory (RAM), cache memory), persistent storage (406) (e.g., a hard disk, an optical drive such as a compact disk (CD) drive or digital versatile disk (DVD) drive, a flash memory, etc.), a communication interface (412) (e.g., Bluetooth interface, infrared interface, network interface, optical interface, etc.), input devices (410), output devices (408), and numerous other elements (not shown) and functionalities. Each of these components is described below.
[0078] In one embodiment of the invention, the computer processor(s) (402) may be an integrated circuit for processing instructions. For example, the computer processor(s) may be one or more cores or micro-cores of a central processing unit (CPU) and/or a graphics processing unit (GPU). The computing system (400) may also include one or more input devices (410), such as a touchscreen, keyboard, mouse, microphone, touchpad, electronic pen, or any other type of input device. Further, the communication interface (412) may include an integrated circuit for connecting the computing system (400) to a network (not shown) (e.g., a local area network (LAN), a wide area network (WAN) such as the Internet, mobile network, or any other type of network) and/or to another device, such as another computing device.
[0079] In one embodiment of the invention, the computing system (400) may include one or more output devices (408), such as a screen (e.g., a liquid crystal display (LCD), a plasma display, touchscreen, cathode ray tube (CRT) monitor, projector, or other display device), a printer, external storage, or any other output device. One or more of the output devices may be the same or different from the input device(s). The input and output device(s) may be locally or remotely connected to the computer processor(s) (402), non-persistent storage (404), and persistent storage (406). Many different types of computing systems exist, and the aforementioned input and output device(s) may take other forms.
[0080] Software instructions in the form of computer readable program code to perform embodiments of the invention may be stored, in whole or in part, temporarily or permanently, on a non-transitory computer readable medium such as a CD, DVD, storage device, a diskette, a tape, flash memory, physical memory, or any other computer readable storage medium. Specifically, the software instructions may correspond to computer readable program code that, when executed by a processor(s), is configured to perform one or more embodiments of the invention.
[0081] While the invention has been described with respect to a limited number of embodiments, those skilled in the art, having benefit of this disclosure, will appreciate that other embodiments can be devised which do not depart from the scope of the invention as disclosed herein. Accordingly, the scope of the invention should be limited only by the attached claims.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.