Antisense Oligonucleotide Directed Removal Of Proteolytic Cleavage Sites From Proteins
van Roon-Mom; Wilhelmina M.C. ; et al.
U.S. patent application number 16/439390 was filed with the patent office on 2020-10-22 for antisense oligonucleotide directed removal of proteolytic cleavage sites from proteins. The applicant listed for this patent is Academisch Ziekenhuis Leiden h.o.d.n. LUMC. Invention is credited to Annemieke Aartsma-Rus, Melvin Maurice Evers, Barry Antonius Pepers, Garrit-Jan Boudewijn Van Ommen, Wilhelmina M.C. van Roon-Mom.
| Application Number | 20200332298 16/439390 |
| Document ID | / |
| Family ID | 1000004932362 |
| Filed Date | 2020-10-22 |





| United States Patent Application | 20200332298 |
| Kind Code | A1 |
| van Roon-Mom; Wilhelmina M.C. ; et al. | October 22, 2020 |
ANTISENSE OLIGONUCLEOTIDE DIRECTED REMOVAL OF PROTEOLYTIC CLEAVAGE SITES FROM PROTEINS
Abstract
The invention relates to means and methods for removing a proteolytic cleavage site from a protein comprising providing a cell that expresses pre-mRNA encoding the protein with an anti-sense oligonucleotide that induces skipping of the exonic sequence that encodes the proteolytic cleavage site, the method further comprising allowing translation of mRNA produced from the pre-mRNA.
| Inventors: | van Roon-Mom; Wilhelmina M.C.; (Beverwijk, NL) ; Evers; Melvin Maurice; (Utrecht, NL) ; Pepers; Barry Antonius; (Leiden, NL) ; Aartsma-Rus; Annemieke; (Hoofddorp, NL) ; Van Ommen; Garrit-Jan Boudewijn; (Amsterdam, NL) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 1000004932362 | ||||||||||
| Appl. No.: | 16/439390 | ||||||||||
| Filed: | June 12, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15439776 | Feb 22, 2017 | 10364432 | ||
| 16439390 | ||||
| 13814203 | Apr 12, 2013 | 9611471 | ||
| PCT/NL2011/050549 | Aug 4, 2011 | |||
| 15439776 | ||||
| 61370855 | Aug 5, 2010 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | C12N 2310/346 20130101; C12N 2310/11 20130101; C12Y 304/19012 20130101; C12N 15/113 20130101; C12N 2320/33 20130101; C12N 2310/315 20130101; C12N 2310/321 20130101; C12N 15/111 20130101; C12N 15/1137 20130101 |
| International Class: | C12N 15/113 20060101 C12N015/113; C12N 15/11 20060101 C12N015/11 |
Foreign Application Data
| Date | Code | Application Number |
|---|---|---|
| Aug 5, 2010 | EP | 10172076.1 |
Claims
1.-20. (canceled)
21. An oligonucleotide of between fourteen (14) and forty (40) nucleotides that induces skipping of an exon or a part thereof that encodes a proteolytic cleavage site in a protein involved in a disease that is associated with a proteolytic cleavage product of the protein, wherein the oligonucleotide binds to pre-mRNA of the protein to form a double-stranded nucleic acid complex, wherein the oligonucleotide is chemically modified to render the double-stranded nucleic acid complex RNase H resistant, and wherein the disease is a polyglutamine disorder.
22. The oligonucleotide of claim 21, wherein the polyglutamine disorder is Huntington's disease ("HD") or Alzheimer's disease ("AD").
23. The oligonucleotide of claim 21, wherein the polyglutamine disorder is Huntington's disease ("HD"), and wherein part of exon 12 of human huntingtin pre-mRNA is skipped.
24. The oligonucleotide of claim 21, wherein the polyglutamine disorder is Huntington's disease ("HD"), and wherein nucleotides 207 to 341 of exon 12 of human huntingtin pre-mRNA is skipped.
25. The oligonucleotide of claim 21, wherein the polyglutamine disorder is Huntington's disease ("HD"), and wherein the oligonucleotide comprises a polynucleotide selected from the group consisting of SEQ ID NO: 170, SEQ ID NO: 172, SEQ ID NO: 174, SEQ ID NO: 176, SEQ ID NO: 178, SEQ ID NO: 180, SEQ ID NO: 182, SEQ ID NO: 184, SEQ ID NO: 186, and SEQ ID NO: 188.
26. The oligonucleotide of claim 21, wherein the polyglutamine disorder is Huntington's disease ("HD"), and wherein the oligonucleotide consists of a polynucleotide selected from the group consisting of SEQ ID NO: 170, SEQ ID NO: 172, SEQ ID NO: 174, SEQ ID NO: 176, SEQ ID NO: 178, SEQ ID NO: 180, SEQ ID NO: 182, SEQ ID NO: 184, SEQ ID NO: 186, and SEQ ID NO: 188.
27. The oligonucleotide of claim 21, wherein the proteolytic cleavage site is a caspase-3 cleavage site or a caspase-6 cleavage site.
28. The oligonucleotide of claim 21, wherein at least one nucleotide of the oligonucleotide is chemically modified by a 2'-O-methyl substitution.
29. The oligonucleotide of claim 27, wherein each nucleotide of the oligonucleotide is chemically modified by a 2'-O-methyl substitution.
30. The oligonucleotide of claim 21, wherein at least one nucleotide of the oligonucleotide is chemically modified by a 2'-O-methoxyethyl substitution.
31. The oligonucleotide of claim 29, wherein each nucleotide of the oligonucleotide is chemically modified by a 2'-O-methoxyethyl substitution.
32. The oligonucleotide of claim 21, wherein all internucleoside linkages of the oligonucleotide are phosphorothioated.
33. The oligonucleotide of claim 21, wherein the oligonucleotide is a uniformly 2'-O-methoxyethylribose modified phosphorothioate oligonucleotide.
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application is a continuation of U.S. patent application Ser. No. 15/439,776, filed Feb. 22, 2017, pending, which is a continuation of U.S. patent application Ser. No. 13/814,203, filed Apr. 12, 2013, now U.S. Pat. No. 9,611,471, issued Apr. 4, 2017, which is a national phase entry under 35 U.S.C. .sctn. 371 of International Patent Application PCT/NL2011/050549, filed Aug. 4, 2011, designating the United States of America and published in English as International Patent Publication WO 2012/018257 A1 on Feb. 9, 2012, which claims the benefit under Article 8 of the Patent Cooperation Treaty and under 35 U.S.C. .sctn. 119(e) to U.S. Provisional Patent Application Ser. No. 61/370,855, filed Aug. 5, 2010, and to European Patent Application Serial No. 10172076.1, filed Aug. 5, 2010, the contents of the entirety of each of which are hereby incorporated herein by this reference.
STATEMENT ACCORDING TO 37 C.F.R. .sctn. 1.821(c) or (e)--SEQUENCE LISTING SUBMITTED AS A TXT AND PDF FILES
[0002] Pursuant to 37 C.F.R. .sctn. 1.821(c) or (e), files containing a TXT version and a PDF version of the Sequence Listing have been submitted concomitant with this application, the contents of which are hereby incorporated by reference.
TECHNICAL FIELD
[0003] This application relates to the field of biotechnology and genetic and acquired diseases. In particular, it relates to the alteration of mRNA processing of specific pre-mRNA to remove a proteolytic cleavage site from a protein encoded by the pre-mRNA.
BACKGROUND
[0004] Proteolytic processing is a major form of post-translational modification that occurs when a protease cleaves one or more bonds in a target protein to modify its activity. This processing may lead to activation, inhibition, alteration or destruction of the protein's activity. Many cellular processes are controlled by proteolytic processing. The attacking protease may remove a peptide segment from either end of the target protein, but it may also cleave internal bonds in the protein that lead to major changes in the structure and function of the protein.
[0005] Proteolytic processing is a highly specific process. The mechanism of proteolytic processing varies according to the protein being processed, location of the protein, and the protease.
[0006] Proteolytic processing can have various functions. For instance, proteolysis of precursor proteins regulates many cellular processes including gene expression, embryogenesis, the cell cycle, programmed cell death, intracellular protein targeting and endocrine/neural functions. In all of these processes, proteolytic cleavage of precursor proteins is necessary. The proteolysis is often done by serine proteases in the secretory pathways. These proteases are calcium-dependent serine endoproteases and are related to yeast and subtilisin proteases and, therefore, called Subtilisin-like Proprotein Convertases (SPCs) or PCs. Seven members of this family have been identified and characterized and each have conserved signal peptides, pro-regions, catalytic and P-domains but differ in their C-terminal domains in mammals.
[0007] Autocatalytic cleavage of an N-terminal propeptide activates these proteases, which is required for folding, and activity also causes the release of prodomain. Other examples of function associated with proteolytic processing are the blood clotting cascades, the metaloendopeptidases, the secretases and the caspases. Yet other examples are the viral proteases that specifically process viral polyproteins.
[0008] The prior art describes various strategies to inhibit the various proteases. For instance, gamma-secretase inhibitors are presently being developed for the treatment of T cell acute lymphoblastic leukemia (Nature Medicine 2009, 15:50-58). Caspase inhibitors are being developed for a variety of different applications (The Journal of Biological Chemistry 1998, 273:32608-32613), for instance, in the treatment of sepsis (Nature Immunology 2000, 1:496-501).
[0009] A problem with the use of protease inhibitors is that these proteins typically have a range of targets in the human body and, associated therewith, a range of effects. Inhibiting a protease in the human body through the action of a protease inhibitor thus, not only inhibits the desired effect, but typically also has a range of other effects that may or may not affect the utility of the protease inhibitor for the indicated disease. Another problem associated with protease inhibitors is that it is not always easy to produce an inhibitor that is sufficiently specific for the target protease and, therefore, may also inhibit other proteases.
DISCLOSURE
[0010] The disclosure provides an alternative approach to interfere with the proteolytic processing of target proteins. Instead of designing inhibitors to the proteases, the target protein itself is modified. In the art, it is known to modify a protease cleavage site in a target protein. This is typically done by introducing point mutations into the coding region of a protein. These mutations typically break up the recognition sequence of the protease. These types of modification are usually introduced into a cDNA copy of the gene and this altered copy is inserted into the DNA of cells by recombinant DNA technology. Although this can be done in the laboratory, it is difficult to implement such strategies in the clinic, if only because gene therapy applications that rely on the introduction of a complete gene are, at present, not very efficient, and the original gene associated with the problem is not removed.
[0011] Provided herein is a method for removing a proteolytic cleavage site from a protein comprising providing a cell that expresses a pre-mRNA encoding the protein with an antisense oligonucleotide (AON) that induces skipping of the exon sequence that encodes the proteolytic cleavage site, the method further comprising allowing translation of mRNA produced from the pre-mRNA.
[0012] A method hereof is particularly useful for removing proteolytic cleavage sites from proteins. It does not require removal or modification of the gene itself, but rather, prevents the incorporation of the genetic code for the proteolytic cleavage site into the coding region of the protein in the mature mRNA. In this way, the process is reversible. The oligonucleotide has a finite life span in the cell and, therefore, has a finite effect on the removal. Another advantage is that the removal is not absolute. Not all pre-mRNA coding for the target protein that is generated by the cell is typically targeted. It is possible to achieve high levels of skipping. The skipping efficiency depends, for instance, on the particular target, the particular exon sequence to be skipped, the particular AON design, and/or the amount of AON used. Skipping percentages are typically expressed as the ratio of mRNA that does not have the coding part of the proteolytic cleavage site (skipped mRNA) versus the sum of skipped mRNA and unmodified mRNA coding for the unmodified target protein (unmodified mRNA). The possibility of tailoring the percentage of skipping is advantageous; for instance, when the unmodified protein is associated with a toxic phenotype but also has a positive function to perform that is not performed (as well) by the modified protein. By removing the proteolytic cleavage site only from a fraction of the protein formed, it is possible to reduce the toxic property, while leaving the positive or desired function of the unmodified protein at least partially intact.
[0013] A method hereof modulates the splicing of a pre-mRNA into an mRNA, such that an exon sequence that codes for a proteolytic cleavage site that is present in the exons encoded by the pre-mRNA is not included in the mature mRNA produced from the pre-mRNA. Protein that is subsequently translated from this mRNA does not contain the proteolytic cleavage site. The invention, thus, does not actually remove a proteolytic cleavage site from a protein that has already been formed. Rather, it promotes the production of a novel protein that does not contain the proteolytic cleavage site. However, when looking at a cell as an entity wherein protein synthesis and degradation are at equilibrium, the result of a method of the invention can be seen as removing a proteolytic cleavage site from a protein. Unmodified target protein is gradually replaced by target protein that does not contain the proteolytic cleavage site. Thus, provided is a method for producing a cell that contains a modified protein that lacks a proteolytic cleavage site, when compared to the unmodified protein encoded in the genome, the method comprising providing a cell that expresses pre-mRNA encoding the protein with an AON that induces skipping of the exon sequence or part of the exon sequence that encodes the proteolytic cleavage site, the method further comprising allowing translation of mRNA produced from the pre-mRNA in the cell. The novel mRNA from which the coding sequence for the proteolytic cleavage site is removed is a shortened or smaller coding sequence that codes for a shorter or smaller version of the unmodified protein. Often, the modified protein is an internally deleted version of the unmodified protein, wherein the internal deletion at least breaks up and, preferably, deletes the proteolytic cleavage site.
[0014] Antisense-mediated modulation of splicing (also referred to as exon-skipping) is one of the fields where AONs have been able to live up to their expectations. In this approach, AONs are implemented to facilitate cryptic splicing, to change levels of alternatively spliced genes, or, in case of Duchenne muscular dystrophy (DMD), to skip an exon in order to restore a disrupted reading frame. The latter allows the generation of internally deleted, but largely functional, dystrophin proteins and would convert a severe DMD into a milder Becker muscular dystrophy phenotype. In fact, exon skipping is currently one of the most promising therapeutic tools for DMD, and a successful first-in-man trial has recently been completed. The antisense-mediated modulation of splicing has been diversified since its first introduction and now many different kinds of manipulations are possible. Apart from classical exon skipping where typically an entire exon is skipped from the mature mRNA, it is, for instance, possible to skip a part of an exon. Exon inclusion is also possible. The latter occurs when AONs targeted toward appropriate intron sequences are coupled to the business end of SR-proteins.
[0015] Exon skipping has been used to restore cryptic splicing, to change levels of alternatively spliced genes, and to restore disrupted open reading frames. This approach has been employed with a number of genes including Apolipoprotein B, Bcl-X, Collagen type 7, dystrophin, dysferlin, prostate-specific membrane antigen, IL-5 receptor alpha, MyD88, Tau, TNFalpha2 receptor, Titin, WT1, beta-globulin, and CFTR. Accordingly, in preferred embodiments, methods are provided for removing a proteolytic cleavage site from a protein, wherein the protein is not Apolipoprotein B, Bcl-X, Collagen type 7, dystrophin, dysferlin, prostate-specific membrane antigen, IL-5 receptor alpha, MyD88, Tau, TNFalpha2 receptor, Titin, WT1, beta-globulin, or CFTR; more preferably, the protein is not dystrophin.
[0016] In contrast to the previous uses for exon-skipping, provided is a method for removing a proteolytic cleavage site in order to treat an individual, restore function to a protein, or reduce toxicity of a protein. The methods and oligonucleotides described herein are particularly useful for removing proteolytic cleavage sites from a protein, wherein the protein is involved in a neurodegenerative disorder.
[0017] Prevention of inclusion of a coding part for a proteolytic cleavage site into mature mRNA is, in the present invention, typically achieved by means of exon-skipping. Antisense oligonucleotides for exon-skipping typically enable skipping of an exon or the 5' or 3' part of it. Antisense oligonucleotides can be directed toward the 5' splice site, the 3' splice site, to both splice sites, to one or more exon-internal sites and to intron sequences, for instance, specific for the branch point. The latter enables skipping of the upstream exon.
[0018] Skipping of the nucleotides that code for the proteolytic cleavage site is typically achieved by skipping the exon that contains the nucleotides that code for the proteolytic cleavage site. The proteolytic cleavage site comprises the recognition sequence for the specific protease and the two amino acids between which the peptide linkage is cleaved by the protease. The proteolytic cleavage site can overlap the boundary of two adjacent exons or, if a part of the exon is skipped, overlap the exon sequence that contains the cryptic splice acceptor/donor sequence. In this embodiment, it is preferred to skip the exon sequence that codes for the peptide linkage that is cleaved by the protease. Whether or not a recognition sequence for a protease is actually used in nature depends, not only on the presence of the recognition sequence itself, but also on the location of the site in the folded protein. An internally located recognition site is typically not used in nature. In the invention, a proteolytic cleavage site is an active proteolytic cleavage site that is actually used in nature.
[0019] Skipping of the exon that contains the nucleotides that code for the proteolytic cleavage site is preferably achieved by means of an AON that is directed toward an exon internal sequence. An oligonucleotide is said to be directed toward an exon internal sequence if the complementarity region that contains the sequence identity to the reverse complement of the target pre-mRNA is within the exon boundary. Presently, all exons that have been targeted by means of exon-skipping can be induced to be skipped from the mature mRNA, often with one AON and sometimes with two AONs directed toward the exon. However, not all AONs that can be designed induce detectable amounts of skipping. The most experience with exon-skipping has been gained in the DMD system. Using AON directed toward exon-internal sequences, it has been shown that all exons can be skipped (with the exception, of course, of the first and the last exon). However, not all AON designed against an exon-internal sequence actually induce detectable amounts of skipping of the targeted exon. The frequency of randomly selected exon-internal AON that induce skipping is around 30%, depending on the actual exon that is targeted. Since the first trials, however, the experience gained from AON that successfully induced skipping has resulted in a significant improvement of the success ratio of a designed AON (PMID: 18813282, Aartsma-Rus et al., Mol. Ther. 17(3):548 (2009). The factors that improve the success ratio include, among others, the predicted structure of the exon RNA at the target site, the exact sequence targeted, and the predicted presence or absence of specific SR-protein binding sites in the target site (ibid).
[0020] Skipping of an exon sequence encoding a proteolytic cleavage site is preferably such that downstream amino acids of the target protein are present in the newly formed protein. In this way, the proteolytic cleavage site is removed while leaving much of the downstream protein intact. In this embodiment, the functionality of the modified protein is at least part of the functionality of the protein as present in normal individuals. Thus, preferably, the modified protein contains an "in frame" deletion of the proteolytic cleavage site. Preferably, the "in frame" deleted protein has at least 20%, preferably at least 50% of the functionality of the unmodified protein in a normal individual. Thus, in certain embodiments, the number of nucleotides that is skipped is dividable by three. Skipping of an exon sequence that codes for a proteolytic cleavage site is typically achieved by skipping the exon that contains this sequence. Skipping of the target exon is sufficient if this exon contains a number of nucleotides that is dividable by three. If the exon contains another number, it is preferred to also skip an adjacent exon, such that the total number of skipped nucleotides is again dividable by three. In most cases, the skipping of an adjacent exon is sufficient; however, if this also does not result in a number of skipped nucleotides that is dividable by three, the skipping of yet a further exon, adjacent to the two mentioned, may be necessary. Skipping of four or more exons is possible but often does not yield a lot of the correct protein. Sometimes, it is possible to skip only a part of an exon. This is either the 5' part of the 3' part of the exon. This occurs when the exon contains a cryptic 3' or 5' splice site that can be activated.
[0021] The term "pre-mRNA" refers to a non-processed or partly processed precursor mRNA that is synthesized from a DNA template in the cell nucleus by transcription. Within the context of the invention, inducing and/or promoting skipping of an exon sequence that codes for a proteolytic cleavage site, as indicated herein, means that at least 1%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90% or more of the mRNA encoding of the targeted protein in a cell will not contain the skipped exon sequence (modified/(modified+unmodified) mRNA). This is preferably assessed by PCR as described in the examples.
[0022] An AON hereof that induces skipping of an exon sequence that encodes a proteolytic cleavage site, preferably, comprises a sequence that is complementary to the exon. In some embodiments, the AON induces skipping of an exon in its entirety. In other embodiments, the AON induces skipping of a part of an exon, preferably, the part encodes a proteolytic cleavage site. Preferably, the AON contains a continuous stretch of between 8-50 nucleotides that is complementary to the exon. An AON hereof preferably comprises a stretch of at least 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49 or 50 nucleotides that is complementary to the exon. In certain embodiments, the AON contains a continuous stretch of between 12-45 nucleotides that is complementary to the exon. More preferably, a stretch of between 15-41 nucleotides. Depending on the chemical modification introduced into the AON the complementary stretch may be at the smaller side of the range or at the larger side. A preferred antisense oligonucleotide, according to the invention, comprises a T-O alkyl phosphorothioate antisense oligonucleotide, such as 2'-O-methyl modified ribose (RNA), 2'-O-ethyl modified ribose, 2'-O-propyl modified ribose, and/or substituted derivatives of these modifications, such as halogenated derivatives. A most preferred AON, comprises of 2'-O-methyl phosphorothioate ribose. Such AON, typically, do not need to have a very large complementary stretch. Such AON, typically, contain a stretch of between 15-25 complementary nucleotides. As described herein below, another preferred AON hereof comprises a morpholino backbone. AON comprising such backbones typically contain somewhat larger stretches of complementarity. Such AON, typically, contain a stretch of between 25-40 complementary nucleotides. When in this invention reference is made to the range of nucleotides, this range includes the number(s) mentioned. Thus, by way of example, when reference is made to a stretch of between 8-50, this includes 8 and 50.
[0023] An AON hereof that is complementary to a target RNA is capable of hybridizing to the target RNA under stringent conditions. Typically, this means that the reverse complement of the AON is at least 90% and, preferably, at least 95% and, more preferably, at least 98% and, most preferably, at least 100% identical to the nucleotide sequence of the target at the targeted sited. An AON hereof, thus preferably, has two or less mismatches with the reverse complement of the target RNA, preferably, it has one or no mismatches with the reverse complement of the target RNA. In another preferred embodiment, the AON may be specifically designed to have one or more mismatches, preferably, one or two mismatches, e.g., in cases where it is necessary to reduce the affinity when the skipping of the 100% complementary AON is more effective than biologically desired in view of the necessary remaining protein activity. A mismatch is defined herein as a nucleotide or nucleotide analogue that does not have the same base pairing capacity in kind, not necessarily in amount, as the nucleotide it replaces. For instance, the base of uracil that replaces a thymine and vice versa, is not a mismatch. A preferred mismatch comprises an inosine. An inosine nucleotide is capable of pairing with any natural base in an RNA, i.e., capable of pairing with an A, C, G or U in the target RNA.
[0024] In certain embodiments, the nucleotide analogue or equivalent comprises a modified backbone. Examples of such backbones are provided by morpholino backbones, carbamate backbones, siloxane backbones, sulfide, sulfoxide and sulfone backbones, formacetyl and thioformacetyl backbones, methyleneformacetyl backbones, riboacetyl backbones, alkene containing backbones, sulfamate, sulfonate and sulfonamide backbones, methyleneimino and methylenehydrazino backbones, and amide backbones. Phosphorodiamidate morpholino oligomers are modified backbone oligonucleotides that have previously been investigated as antisense agents. Morpholino oligonucleotides have an uncharged backbone in which the deoxyribose sugar of DNA is replaced by a six-membered ring, and the phosphodiester linkage is replaced by a phosphorodiamidate linkage. Morpholino oligonucleotides are resistant to enzymatic degradation and appear to function as antisense agents by arresting translation or interfering with pre-mRNA splicing rather than by activating RNase H. Morpholino oligonucleotides have been successfully delivered to tissue culture cells by methods that physically disrupt the cell membrane. One study comparing several of these methods, found that scrape loading was the most efficient method of delivery; however, because the morpholino backbone is uncharged, cationic lipids are not effective mediators of morpholino oligonucleotide uptake in cells. A recent report demonstrated triplex formation by a morpholino oligonucleotide and, because of the non-ionic backbone, these studies showed that the morpholino oligonucleotide was capable of triplex formation in the absence of magnesium. A modified backbone is typically preferred to increase nuclease resistance of the AON, the target RNA or the AON/target RNA hybrid, or a combination thereof. A modified backbone can also be preferred because of its altered affinity for the target sequence compared to an unmodified backbone. An unmodified backbone can be RNA or DNA, preferably it is an RNA backbone.
[0025] It is further preferred that the linkage between the residues in a backbone does not include a phosphorus atom, such as a linkage that is formed by short chain alkyl or cycloalkyl internucleoside linkages, mixed heteroatom and alkyl or cycloalkyl internucleoside linkages, or one or more short chain heteroatomic or heterocyclic internucleoside linkages.
[0026] A preferred nucleotide analogue or equivalent, comprises a Peptide Nucleic Acid (PNA), having a modified polyamide backbone (Nielsen, et al. (1991) Science 254, 1497-1500). PNA-based molecules are true mimics of DNA molecules in terms of base-pair recognition. The backbone of the PNA is composed of 7V-(2-aminoethyl)-glycine units linked by peptide bonds, wherein the nucleobases are linked to the backbone by methylene carbonyl bonds. An alternative backbone comprises a one-carbon extended pyrrolidine PNA monomer (Govindaraju and Kumar (2005) Chem. Commun. 495-497). Since the backbone of a PNA molecule contains no charged phosphate groups, PNA-RNA hybrids are usually more stable than RNA-RNA or RNA-DNA hybrids, respectively, (Egholm et al. (1993) Nature 365:566-568).
[0027] A further preferred backbone, comprises a morpholino nucleotide analog or equivalent, in which the ribose or deoxyribose sugar is replaced by a six-membered morpholino ring. A most preferred nucleotide analog or equivalent, comprises a phosphorodiamidate morpholino oligomer (PMO), in which the ribose or deoxyribose sugar is replaced by a six-membered morpholino ring, and the anionic phosphodiester linkage between adjacent morpholino rings is replaced by a non-ionic phosphorodiamidate linkage.
[0028] In yet a further embodiment, a nucleotide analogue or equivalent of the invention, comprises a substitution of one of the non-bridging oxygens in the phosphodiester linkage. This modification slightly destabilizes base-pairing but adds significant resistance to nuclease degradation. A preferred nucleotide analogue or equivalent, comprises phosphorothioate, chiral phosphorothioate, phosphorodithioate, phosphotriester, aminoalkylphosphotriester, H-phosphonate, methyl and other alkyl phosphonate including 3'-alkylene phosphonate, 5'-alkylene phosphonate and chiral phosphonate, phosphinate, phosphoramidate including 3'-amino phosphoramidate and aminoalkylphosphoramidate, thionophosphoramidate, thionoalkylphosphonate, thionoalkylphosphotriester, selenophosphate or boranophosphate.
[0029] A further preferred nucleotide analogue or equivalent of the invention, comprises one or more sugar moieties that are mono- or disubstituted at the 2',3' and/or 5' position, such as a --OH; --F; substituted or unsubstituted, linear or branched lower (Cl-ClO) alkyl, alkenyl, alkynyl, alkaryl, allyl, aryl, or aralkyl that may be interrupted by one or more heteroatoms; O-, S-, or N-alkyl; O-, S-, or N-alkenyl; O-, S- or N-alkynyl; O-, S-, or N-allyl; O-alkyl-O-alkyl, -methoxy, -aminopropoxy; -amino xy; methoxyethoxy; -dimethyl-aminooxyethoxy; and -dimethylaminoethoxyethoxy. The sugar moiety can be a pyranose or derivative thereof, or a deoxypyranose or derivative thereof, preferably, a ribose or a derivative thereof, or a deoxyribose or a derivative thereof. Such preferred derivatized sugar moieties comprise Locked Nucleic Acid (LNA), in which the 2'-carbon atom is linked to the 3' or 4' carbon atom of the sugar ring, thereby, forming a bicyclic sugar moiety. A preferred LNA comprises 2'-0,4'-C-ethylene-bridged nucleic acid (Morita et al. 2001, Nucleic Acid Res., Supplement No. 1:241-242). These substitutions render the nucleotide analogue, or equivalent RNase H and nuclease, resistant and increase the affinity for the target RNA. As is apparent to one of skill in the art, the substitutions provided herein render the double-stranded complex of the antisense oligonucleotide with its target pre-mRNA RNase H resistant. Accordingly, preferred oligonucleotides bind to the pre-mRNA of the protein to form a double-stranded nucleic acid complex and are chemically modified to render the double-stranded nucleic acid complex RNAse H resistant.
[0030] It is understood by a skilled person that it is not necessary for all positions in an antisense oligonucleotide to be modified uniformly. In addition, more than one of the aforementioned analogues or equivalents, may be incorporated in a single antisense oligonucleotide or even at a single position within an antisense oligonucleotide. In certain embodiments, an antisense oligonucleotide hereof has at least two different types of analogues or equivalents.
[0031] As mentioned hereinabove, a preferred AON hereof, comprises a T-O alkyl phosphorothioate antisense oligonucleotide, such as 2'-O-methyl modified ribose (RNA), 2'-O-ethyl modified ribose, 2'-O-propyl modified ribose, and/or substituted derivatives of these modifications, such as halogenated derivatives. A most preferred AON, comprises of 2'-O-methyl phosphorothioate ribose.
[0032] An AON can be linked to a moiety that enhances uptake of the antisense oligonucleotide in cells. Examples of such moieties are cholesterols, carbohydrates, vitamins, biotin, lipids, phospholipids, cell-penetrating peptides including but not limited to antennapedia, TAT, transportan and positively charged amino acids, such as oligoarginine, poly-arginine, oligolysine or polylysine, antigen-binding domains, such as provided by an antibody, a Fab fragment of an antibody, or a single chain antigen binding domain, such as a cameloid single domain antigen-binding domain.
[0033] Additional flanking sequences may be used to modify the binding of a protein to the AON, or to modify a thermodynamic property of the AON, more preferably, to modify target RNA binding affinity.
[0034] AON administration in humans is typically well-tolerated. Clinical manifestations of the administration of AON in human clinical trials have been limited to the local side effects following subcutaneous (SC) injection (on the whole intravenous (i.v.) administration seems to be better tolerated) and generalized side effects, such as fever and chills that similar to the response to interferon administration, respond well to paracetamol. More than 4000 patients with different disorders have been treated so far using systemic delivery of first generation AON (phosphorothioate backbone), and approximately 500 following local administration. The typical dosage used ranged from 0.5 mg/kg every other day for one month in Crohn's disease, to 200 mg twice weekly for three months in rheumatoid arthritis, to higher dosages of 2 mg/kg day in other protocols dealing with malignancies. Fewer patients (approx. 300) have been treated so far using new generation AON (uniform phosphorothioated backbone with flanking 2' methoxyethoxy wing) delivered systemically at doses comprised between 0.5 and 9 mg/kg per week for up to three weeks.
[0035] Delivery of AON to cells of the brain can be achieved by various means. For instance, they can be delivered directly to the brain via intracerebral inoculation (Schneider et al., Journal of Neuroimmunology (2008) 195:21-27), intraparenchymal infusion (Broaddus et al., J. Neurosurg. 1998 April; 88(4):734-42), intrathecal, or intraventricularly. Alternatively, the AON can be coupled to a single domain antibody or the variable domain thereof (VHH) that has the capacity to pass the Blood Brain barrier. Nanotechnology has also been used to deliver oligonucleotides to the brain, e.g., a nanogel consisting of cross-linked PEG and polyethylenimine. Encapsulation of AON in liposomes is also well known to one of skill in the art.
[0036] An AON hereof may comprise a sequence that is complementary to part of the pre-mRNA, as defined herein. In a more preferred embodiment, the length of the complementary part of the oligonucleotide is of at least 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50 nucleotides. Additional flanking sequences may be used to modify the binding of a protein to the molecule or oligonucleotide, or to modify a thermodynamic property of the oligonucleotide, more preferably, to modify target RNA binding affinity. An AON hereof may further comprise additional nucleotides that are not complementary to the target site on the target pre-mRNA. In certain embodiments, an AON contains between 8-50 nucleotides. An AON hereof preferably comprises a stretch of at least 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49 or 50 nucleotides. In certain embodiments, the AON contains a continuous stretch of between 12-45 nucleotides, more preferably, a stretch of between 15-41 nucleotides. Depending on the chemistry of the backbone, as indicated hereinabove, an AON hereof contains between 15-25 nucleotides. An AON hereof with a morpholino backbone typically contains a stretch of between 25-40 nucleotides. In certain embodiments, the indicated amounts for the number of nucleotides in the AON refers to the length of the complementarity to the target pre-mRNA, preferably to an exon internal sequence, however, the target sequence can also be a 5' or a 3' splice site of an exon or an intron sequence, such as preferably a branch point. In another preferred embodiment, the indicated amounts refer to the total number of nucleotides in the AON.
[0037] Preferably, the complementary part is at least 50% of the length of the oligonucleotide hereof, more preferably, at least 60%, even more preferably, at least 70%, even more preferably, at least 80%, even more preferably, at least 90% or even more preferably, at least 95%, or even more preferably, 98% and most preferably, up to 100% of the length of the oligonucleotide hereof, with the putative exception of deliberately introduced specific mismatches, e.g., for down-regulating affinity when necessary.
[0038] With respect to AON that also contain additional nucleotides, the total number of nucleotides typically does not exceed 50, and the additional nucleotides preferably range in number from between 5-25, preferably from 10-25, more preferably, from 15-25. The additional nucleotides typically are not complementary to the target site on the pre-mRNA but may be complementary to another site on the pre-mRNA or may serve a different purpose and not be complementary to the target pre-mRNA, i.e., less than 95% sequence identity of the additional nucleotides to the reverse complement of the target pre-mRNA.
[0039] The proteolytic cleavage site that is to be removed from a protein by a method or AON hereof is preferably a serine endoprotease cleavage site, a metaloendopeptidase cleavage site, a secretase cleavage site and/or a caspase cleavage site. In a particularly preferred embodiment, the cleavage site is a caspase cleavage site or secretase cleavage site. Caspases are a family of intracellular cysteine proteases that play a central role in the initiation and execution of programmed cell death. The term caspases is a short form for Cysteine Aspartate-specific Proteases: their catalytical activity depends on a critical cysteine-residue within a highly conserved active-site pentapeptide QACRG, and the caspases specifically cleave their substrates after Asp residues (also the serine-protease granzyme B has specificity for Asp in the P1 position of substrates). More than ten different members of the caspase family have been identified in mammals. According to a unified nomenclature, the caspases are referred to in the order of their publication: so Caspase-1 is ICE (Interleukin-lbeta-Converting Enzyme), the first aspartate-specific cysteine protease described. The secretase family of proteases is subdivided into three groups, the alpha-, beta- and gamma-secretases. In certain embodiments, the secretase is a gamma-secretase.
[0040] The protein from which the proteolytic cleavage site is to be removed can be any protein that contains a proteolytic cleavage site. In certain embodiments, the protein is a mammalian protein, more preferably, a primate protein. In a particularly preferred embodiment, the protein is a human protein. In certain embodiments, the protein is associated with a disease in humans. In a particularly preferred embodiment, the protein is associated with a triplet repeat disease in humans. Preferably, a polyglutamine repeat disease.
[0041] In certain embodiments, the protein comprises a caspase cleavage site or secretase cleavage site. Preferably, the protein comprises a caspase-3 or -6 proteolytic cleavage site. Preferably, the protein is a protein that is normally present in the brain of a mammal. In a particularly preferred embodiment, the gene encoding the protein is a mutant gene that encodes a trinucleotide repeat expansion when compared to the gene of a normal individual.
[0042] In a particularly preferred embodiment, the protein is a protein encoded by one of the genes listed in Table 1a or 1b. In a particularly preferred embodiment, the gene is a mutant gene that is the causative gene in a polyglutamine disorder, preferably a gene of Table 1a. In a particularly preferred embodiment, the gene is the huntingtin (Htt) gene. Htt is expressed in all mammalian cells. The highest concentrations are found in the brain and testes, with moderate amounts in the liver, heart, and lungs. The function of Htt in humans is as yet not entirely resolved. Htt interacts among others with proteins, which are involved in transcription, cell signaling and intracellular transporting. In humans the gene, and in particular mutants thereof, is associated with Huntington's disease (HD). HD is a progressive neurodegenerative genetic disorder, which affects muscle movement and muscle coordination and leads to cognitive decline and dementia. It typically becomes noticeable in middle age. HD is the most common genetic cause of abnormal involuntary writhing movements called chorea and is much more common in people of Western European descent than in those from Asia or Africa. The disease is caused by an autosomal dominant mutation of the Htt-gene. A child of an affected parent has a 50% risk of inheriting the disease.
[0043] For the Htt gene, it is preferred that the caspase-6 proteolytic cleave site encoded by exon Htt exon 12 is removed from the Huntingtin protein. It is preferred that the coding region that codes for the proteolytic cleavage site is removed "in frame," so as to allow incorporation of the normal downstream amino acid sequence into the mutant protein. In one embodiment, the "in frame" removal is achieved by providing the cell with an AON that enables skipping of exon 12 and an AON that enables skipping of exon 13 of the Htt gene. In another preferred embodiment, the "in frame" removal is achieved by providing the cell with an AON capable of inducing exon skipping directed toward the region delimited by nucleotides 269-297 of exon 12 of the Htt gene. In certain embodiments, the AON is directed toward region delimited by nucleotides 207 until 341 of exon 12. It is preferred that the AON is directed toward the internal region delimited by nucleotides 207 until 341 of exon 12. This includes nucleotides 207 and 341. It has been found in the present invention that AON directed toward the preferred regions induce skipping of the last 135 nucleotides of exon 12, thereby producing an "in frame" complete deletion of two active caspase 3 cleavage sites at amino acid 513 and 552, and removal of the first amino acid of an active caspase 6 site, partially located in exon 12 and partially in exon 13. AON HDEx12_1 (Table 2) activates a cryptic splice site at nucleotide 206 in exon 12, leading to the absence of the remainder of exon 12 from the formed mRNA.
[0044] Further provided is an isolated and/or recombinant modified Htt mRNA having a deletion of at least nucleotides 207 until 341 of exon 12. The modified Htt mRNA preferably comprises the exons 1-11, the first 206 nucleotides of exon 12 and exons 13-67. In another preferred embodiment, the modified Htt mRNA comprises the exons 1-11, 14-67.
[0045] In another embodiment provided is an isolated and/or recombinant modified Htt protein comprising a deletion of amino acids 538-583. The modified Htt protein preferably comprises the amino acid sequence encoded by exons 1-11, the first 206 nucleotides of exon 12, and exons 13-67. In another preferred embodiment, the modified Htt protein comprises the amino acid sequence encoded by exons 1-11, 14-67.
[0046] In yet another embodiment provided is an isolated and/or recombinant cell comprising a modified Htt mRNA and/or a modified Htt protein as indicated herein above. Preferably, the cell comprises an Htt gene comprising a coding region of a polyglutamine repeat, the length of which is associated with HD.
[0047] For the ATXN3 gene, it is preferred that the caspase cleavage sites in exon 7 is removed from the protein. It is preferred that the coding region that codes for the proteolytic cleavage site is removed "in frame," so as to allow incorporation of the normal downstream amino acid into the mutant protein. In one embodiment, the "in frame" removal is achieved by providing the cell with an AON that enables skipping of exon 7 and an AON that enables skipping of exon 8 of the ATXN3 gene.
[0048] For the ATN1 gene, it is preferred that the caspase 3 cleavage site near the N-terminus of the protein and the polyglutamine tract (.sup.106DSLD.sup.109) in exon 5 is removed from the protein. It is preferred that the coding region that codes for the proteolytic cleavage site is removed "in frame," so as to allow incorporation of the normal downstream amino acid into the mutant protein. In one embodiment, the "in frame" removal is achieved by providing the cell with an AON that enables skipping of exon 5 and an AON that enables skipping of exon 6 of the ATN1 gene. In certain embodiments, the AON comprises a sequence as depicted in Table 2 under DPRLA AON.
[0049] Further provided is an AON, of preferably between 14-40 nucleotides that induces skipping of an exon that encodes a proteolytic cleavage site in a protein. In certain embodiments, provided is an AON comprising a sequence as depicted in Table 2. The AON is suitable for skipping the indicated exon of the gene. In a particularly preferred embodiment, the AON comprises the sequence of HDEx12_1 of Table 2. In another preferred embodiment, provided is an AON as indicated herein above that is specific for the region identified by a sequence of an AON depicted in Table 2. In certain embodiments, the AON comprises at least 10 consecutive nucleotides of the region identified by an oligonucleotide as depicted in Table 2. In a particularly preferred embodiment, provided is an AON, as indicated hereinabove, that is specific for the region identified by a sequence of HDEx12_1 of Table 2.
[0050] Further provided is the use of exon-skipping in a cell for removing a proteolytic cleavage site from a protein. Further provided is the use of an AON that induces skipping of an exon that encodes a proteolytic cleavage site in a protein, for removing the proteolytic cleavage site from the protein in a cell that produces pre-mRNA encoding the protein. Further provided is an oligonucleotide of between 14-40 nucleotides that induces skipping of an exon that encodes a proteolytic cleavage site in a protein for use in the treatment of a disease that is associated with a proteolytic cleavage product of the protein.
[0051] In another embodiment, provided is a method for altering the proteolytic processing of a protein that comprises a proteolytic cleavage site comprising providing a cell that produces a pre-mRNA that codes for the protein with an AON that is specific for the pre-mRNA; and that prevents inclusion of the code for the proteolytic cleavage site into mature mRNA produced from the pre-mRNA, the method further comprising allowing translation of the mRNA to produce the protein of which the proteolytic processing is altered.
[0052] Further provided is a non-human animal comprising an oligonucleotide hereof. Preferably, the non-human animal comprises a mutant gene that encodes a trinucleotide repeat expansion when compared to the gene of a normal individual.
[0053] Further provided is a modified human protein from which a proteolytic cleavage site is removed by means of exon skipping. Further provided is an mRNA encoding a modified human protein from which a proteolytic cleavage site is removed by means of exon skipping.
[0054] Further provided is a cell encoding a human protein comprising a proteolytic cleavage site, wherein the cell contains an AON hereof for removing the proteolytic cleavage site from the protein in the cell.
[0055] The general nomenclature of cleavage site positions of the substrate were formulated by Schecter and Berger, 1967-68 [Schechter and Berger, 1967], [Schechter and Berger, 1968]. They designate the cleavage site between P1-P1', incrementing the numbering in the N-terminal direction of the cleaved peptide bond (P2, P3, P4, etc.). On the carboxyl side of the cleavage site, numbering are likewise incremented (P1', P2', P3', etc.).
BRIEF DESCRIPTION OF THE DRAWINGS
[0056] FIGS. 1A and 1B: Exon skipping after transfection with various concentrations HDEx12_1 AON. FIG. 1A) Patient derived HD fibroblasts were treated with 1, 25, 150, and 1000 nM HDEx12_1. .beta.-Actin was taken along as loading control. Increasing the AON concentration from 1 nM to 25 nM resulted in a higher skip percentage from 16% to 92% as was measured by Lab-on-a-Chip. The highest skip percentage of 95% was obtained with 150 nM HDEx12_1. Too high concentration of AON resulted in inefficient skip. In the Mock I control (transfection agent only) no skip is visible as expected. The potency of HDEx12_1 exon 12 skip was also seen in another HD and control fibroblast cell line and human neuroblastoma SH-SY5Y cells. FIG. 1B) Schematic representation of PCR of HD exons 9 to 14. Both schematic representation of normal (top) and shorter, skipped exon 12 (bottom) products are shown.
[0057] FIG. 2: Log dose response curve of HDEx12_1 AON in a HD fibroblast cell line. X-axis displays the log concentration (nM) and y-axis the percentage of skip. The half maximum inhibitory value (IC50) of the HDEx12_1 AON was found to be 40 nM. The optimal percentage exon 12 skip was achieved with an AON concentration of 150 nM and higher. Results shown as mean.+-.SEM (n=2-3).
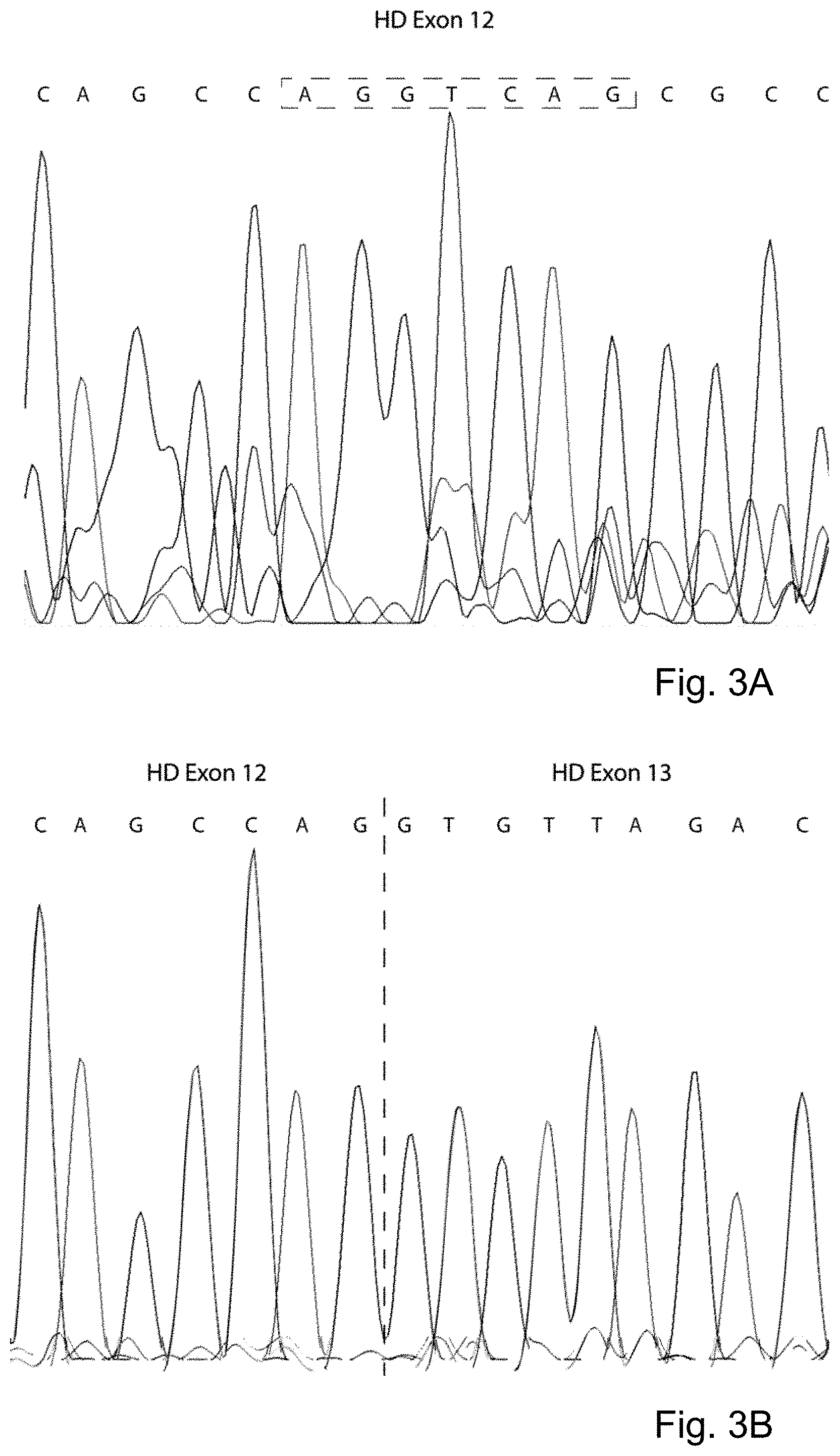
[0058] FIGS. 3A and 3B: Sanger sequencing of normal (FIG. 3A) and skipped (SEQ ID NO:228) (FIG. 3B) PCR product (SEQ ID NO:229). HDEx12_1 AON transfection in a HD fibroblast cell line resulted in an in-frame skip of 135 nucleotides, which corresponds with 45 amino acids. The observed skip is caused by the activation of an alternative splice site (AG|GTRAG, see dashed box (positions 6-12 of SEQ ID NO:228)), resulting in an alternative splice site exon isoform. This partial exon 12 skip results in the deletion of an active caspase-3 site .sup.549DLND.sup.552 and partial removal of the first amino acid (Isoleucine) of an active caspase-6 site (.sup.583IVLD.sup.586).
[0059] FIG. 4: Partial amino acid sequence of the huntingtin protein (see SEQ ID NO:227). Underlined are the amino acids encoded by exon 12 and 13. Highlighted is the part of the protein that is currently skipped by the exon 12 AON. In bold is the caspase-3 site .sup.510DSVD.sup.513, caspase-3 site .sup.549DLND.sup.552 and caspase-6 site .sup.583IVLD.sup.586.
[0060] FIGS. 5A-5D: Schematic diagram of huntingtin. FIG. 5A) Diagram of complete htt protein. PolyQ indicates the polyglutamine tract. The arrows indicate the caspase cleavage sites and their amino acid positions. FIG. 5B) Amino-terminal part of the htt protein. Htt exon 1 to 17 are depicted. The arrows indicate the caspase cleavage sites and their amino acid positions. FIG. 5C) Schematic representation and amino acid sequence of htt exon 12 and 13 with the caspase cleavage motifs depicted in bold. Exon boundaries are shown with vertical grey bars (SEQ ID NO:230). FIG. 5D) Partial amino acid and nucleotide sequence of htt exon 12 and 13 (SEQ ID NOS:231 and 233). Caspase cleavage motifs are depicted in bold and exon boundary is shown with vertical grey bar. The light grey highlighted sequence denotes the part which is skipped after HDEx12_1 AON treatment.
DETAILED DESCRIPTION
Examples
[0061] AON-Mediated Exon Skipping in Neurodegenerative Diseases to Remove Proteolytic Cleavage Sites. AON-Mediated Exon Skipping in Huntington's Disease to Remove Proteolytic Cleavage Sites from the Huntingtin Protein
Methods
AONs and Primers
[0062] All AONs consisted of 2'-O-methyl RNA and full length phosphorothioate backbones.
Cell Cultures and AON Transfection
[0063] Patient fibroblast cells and human neuroblastoma cells were transfected with AONs at concentrations ranging between 1-1000 nM, using Polyethylenemine (PEI) ExGen500 according to the manufacturer's instructions, with 3.3 .mu.l PEI per .mu.g of transfected AON. A second transfection was performed 24 hours after the first transfection. RNA was isolated 24 hours after the second transfection and cDNA was synthesized using random hexamer primers.
Cell Lines Used:
[0064] FLB73 Human Fibroblast Control
[0065] GM04022 Human Fibroblast HD
[0066] GM02173 Human Fibroblast HD
[0067] SH-SY5Y Neuroblastoma Control
[0068] Quantitative Real-Time PCR (qRT-PCR) was carried out using the LIGHTCYCLER.RTM. 480 System (Roche) allowing for quantification of gene expression.
Agarose Gel and Sanger Sequencing
[0069] All PCR products were run on 2% agarose gel with 100 base pair ladders. Bands were isolated using the QIAGEN.RTM. PCR purification kit according to manufacturer's instructions. The samples were then sequenced by Sanger sequencing using the Applied Biosystems BigDyeTerminator v3.1 kit.
Lab-On-a-Chip
[0070] Lab-on-a-Chip automated electrophoresis was used to quantify the PCR products using a 2100 Bioanalyzer. Samples were made 1 part .beta.-Actin primed product, as a reference transcript, to 5 parts experimental PCR products. The samples were run on a DNA 1000 chip.
Western Blot
[0071] Protein was isolated from cells 72 hours after the first transfection and run on a Western blots, transferred onto a PVDF membrane and immunolabelled with primary antibodies recognizing htt, 1H6 or 4C8 (both 1:1,000 diluted)
Materials
[0072] AONs and primers were obtained from Eurogentec, Liege, Belgium.
[0073] AON sequences:
TABLE-US-00001 HDEx12_1: (SEQ ID NO: 1) CGGUGGUGGUCUGGGAGCUGUCGCUGAUG HDEx12_2: (SEQ ID NO: 2) UCACAGCACACACUGCAGG HDEx13_1: (SEQ ID NO: 3) GUUCCUGAAGGCCUCCGAGGCUUCAUCA HDEx13_2: (SEQ ID NO: 4) GGUCCUACUUCUACUCCUUCGGUGU
[0074] Patient fibroblast cell lines GM04022 and GM02173 were obtained from Coriell, Institute for Medical Research, Camden, USA and control fibroblast cell line FLB73 from Maaike Vreeswijk, LUMC.
Results
[0075] Transfection of AON HDEx12_1 in both patient derived HD fibroblast and human neuroblastoma cells showed an efficient skip (see FIGS. 1A and 1B) of exon 12. The optimal percentage exon 12 skip was achieved with a concentration of 150 nM, but a skip was already visible at 1 nM (see FIG. 2). Sanger sequencing confirmed that the last 135 nucleotides of exon 12 were skipped after transfection of the cells with AON HDEx12_1. This corresponded to deletion of 45 amino acids containing two active caspase 3 sites and the first amino acid of an active caspase 6 site (see FIGS. 3A, 3B, and 4). In silico analysis revealed that the observed skip is likely due to the activation of the alternative splice site AG|GTRAG (positions 6-12 of SEQ ID NO:228) resulting in an alternative splice site exon isoform (see FIGS. 3A and 3B).
CONCLUSIONS
[0076] With AON HDEx12_1, we have shown a partial skip of exon 12 of the huntingtin transcript that result in a truncated but in frame protein product. Using different cell lines we have confirmed this partial exon 12 skip by Sanger sequencing and in silico analysis revealed an alternative splice site in exon 12 that is likely the cause of this partial skip. This skipped protein product misses two complete caspase-3 cleavage sites located in exon 12, and the first amino acid of the caspase-6 cleavage site that is located on the border of exon 12 and 13. Recent mouse model data showed that the preferred site of in vivo htt cleavage to be at amino acid 552, which is used in vitro by either caspase-3 or caspase-2.sup.1 and that mutation of the last amino acid of the caspase 6 cleavage site at amino acid position 586 reduces toxicity in an HD model..sup.2
[0077] Functional analysis will be performed to determine whether AON HDEx12_1 can reduce the toxicity of mutant huntingtin and to determine the level of prevention of formation of toxic N-terminal huntingtin fragments. Also other AONs will be tested to completely skip exons 12 and 13 of the huntingtin transcript.
REFERENCES CITED
[0078] 1. Wellington, C. L. et al. Inhibiting caspase cleavage of huntingtin reduces toxicity and aggregate formation in neuronal and nonneuronal cells. J. Biol. Chem. 275:19831-19838 (2000). [0079] 2. Graham, R. K. et al. Cleavage at the Caspase-6 Site Is Required for Neuronal Dysfunction and Degeneration Due to Mutant Huntingtin. Cell 125:1179-1191 (2006).
TABLE-US-00002 [0079] TABLE 1a Polyglutamine (PolyQ) Diseases Normal Pathogenic PolyQ PolyQ Type Gene repeats repeats DRPLA (Dentatorubropallidoluysian ATN1 or DRPLA 6-35 49-88 atrophy) HD (Huntington's disease) Htt (Huntingtin) 10-35 35+ SBMA (Spinobulbar muscular atrophy Androgen receptor on 9-36 38-62 or Kennedy disease) the X chromosome. SCA1 (Spinocerebellar ataxia Type 1) ATXN1 6-35 49-88 SCA2 (Spinocerebellar ataxia Type 2) ATXN2 14-32 33-77 SCA3 (Spinocerebellar ataxia Type 3 or ATXN3 12-40 55-86 Machado-Joseph disease) SCA6 (Spinocerebellar ataxia Type 6) CACNA1A 4-18 21-30 SCA7 (Spinocerebellar ataxia Type 7) ATXN7 7-17 38-120 SCA17 (Spinocerebellar ataxia Type 17) TBP 25-42 47-63
TABLE-US-00003 TABLE 1b Non-Polyglutamine Diseases Unstable repeat disorders caused by loss-of-function, RNA-mediated, or unknown mechanism MIM Repeat Gene Normal Expanded Main clinical features Disease Number unit product repeat repeat length Loss of function mechanism FRAXA 309550 (CGC).sub.n FMRP 6-60 >200 (full Mental retardation, mutation) macroorchidsm, connective tissue defects, behavioral abnormalities FRAXE 309548 (CCG).sub.n FMR2 4-39 200-900 Mental retardation FRDA 229300 (GAA).sub.n Frataxin 6-32 200-1700 Sensory ataxia, cardiomyopathy, diabetes RNA-mediated pathogenesis DM1 160900 (CTG).sub.n DMPK 5-37 50-10,000 Myotonia, weakness, cardiac conduction defects, insulin resistance, cataracts, testicular atrophy, and mental retardation in congenital form FXTAS 309550 (CGG).sub.n FMR1 RNA 6-60 60-200 Ataxia, tremor, (premutation) Parkinsonism, and dementia Unknown pathogenic mechanism SCA8 608768 (CTG).sub.n SCA8 RNA 16-34 >74 Ataxia, slurred speech, nystagmus SCA12 604326 (CAG).sub.n PPP2R2B 7-45 55-78 Ataxia and seizures HDL2 606438 (CTG).sub.n Junctophilin 7-28 66-78 Similar to HD Annual Review of Neuroscience, Vol. 30: 575-621 (Volume publication date July 2007) Trinucleotide Repeat Disorders, Harry T. Orr and Huda Y. Zoghbi
TABLE-US-00004 TABLE 2 List of AON HDEx12_1: CGGUGGUGGUCUGGGAGCUGUCGCUGAUG (SEQ ID NO: 1) HDEx12_2: UCACAGCACACACUGCAGG (SEQ ID NO: 2) HDEx13_1: GUUCCUGAAGGCCUCCGAGGCUUCAUCA (SEQ ID NO: 3) HDEx13_2: GGUCCUACUUCUACUCCUUCGGUGU (SEQ ID NO:4) HDEx12_2 is a comparative example of an oligo- nucleotide having the nucleotide sequence of Htt in the sense strand. DRPLA AONs: 1 DRPLAEx5_18 GUC GCU GCU GCC AUC AUC AU (SEQ ID NO: 5) 2 DRPLAEx5_128 AAG AGG AAG CAG GAG GCA GA (SEQ ID NO: 6) 3 DRPLAEx5_81 GGA GGA GCC UGG AAC AUU CG (SEQ ID NO: 7) 1 DRPLAEx6_80 AAG CUC GCG CUC CUU CUC GC (SEQ ID NO: 8) 2 DRPLAEx6_1 CGA GUU GAA GCC GCG AUC CA (SEQ ID NO: 9) 3 DRPLAEx6_84 GUU CAA GCU CGC GCU CCU UC (SEQ ID NO: 10) HDEx AON are oligonucleotides for skipping exons 12 or 13 of the Htt gene. DRPLA AON are oligonucleotides for skipping exons 5 or 6 of the DRPLA/ATN1 gene.
[0080] Table 3 provides further oligonucleotides for exon skipping.
[0081] APP: amyloid precursor protein in Alzheimer's disease (AD); ATN1: Atrophin 1 in DRPLA; ATNX3: Ataxin 3 for SCA3; ATXN7: Ataxin 7 in SCAT; TBP: TATA binding protein for SCA17; and HTT in Huntington's disease (HD)
TABLE-US-00005 TABLE 3 AON sequences targeting proteins involved in neurodegenerative diseases SEQ ID SEQ ID Disease AON Name Target Sequence NO: AON Sequence NO: AD hAPPEx15_1 GTTCTGGGTTGACAAATATCAAG 11 CUUGAUAUUUGUCAACCCAGAAC 12 AD hAPPEx15_2 CGGAGGAGATCTCTGAAGTGAAG 13 CUUCACUUCAGAGAUCUCCUCCG 14 AD hAPPEx15_3 GATGCAGAATTCCGACATGAC 15 GUCAUGUCGGAAUUCUGCAUC 16 AD hAPPEx15_4 CTCAGGATATGAAGTTCATCATC 17 GAUGAUGAACUUCAUAUCCUGAG 18 AD hAPPEx16_1 GCAATCATTGGACTCATGGT 19 ACCAUGAGUCCAAUGAUUGC 20 AD hAPPEx16_2 GATCGTCATCACCTTGGTGA 21 UCACCAAGGUGAUGACGAUC 22 AD hAPPEx16_3 GTACACATCCATTCATCATGGTG 23 CACCAUGAUGAAUGGAUGUGUAC 24 AD hAPPEx16_4 GCAGAAGATGTGGGTTCAAAC 25 GUUUGAACCCACAUCUUCUGC 26 AD hAPPEx16_5 GGTGATGCTGAAGAAGAAACAG 27 CUGUUUCUUCUUCAGCAUCACC 28 AD hAPPEx16_6 TCATCATGGTGTGGTGGAGGTAG 29 CUACCUCCACCACACCAUGAUGA 30 DRPLA hATN1Ex5_1 CTCCCTCGGCCACAGTCTCCCT 31 AGGGAGACUGUGGCCGAGGGAG 32 DRPLA hATN1Ex5_2 GCGGAGCCTTAATGATGATGGC 33 GCCAUCAUCAUUAAGGCUCCGC 34 DRPLA hATN1Ex5_3 AGCAGCGACCCTAGGGATATCG 35 CGAUAUCCCUAGGGUCGCUGCU 36 DRPLA hATN1Ex5_4 AGGACAACCGAAGCACGTCCC 37 GGGACGUGCUUCGGUUGUCCU 38 DRPLA hATN1Ex5_5 TGGAAGTGTGGAGAATGACTCTG 39 CAGAGUCAUUCUCCACACUUCCA 40 DRPLA hATN1Ex5_6 ATCTTCTGGCCTGTCCCAGGGC 41 GCCCUGGGACAGGCCAGAAGAU 42 DRPLA hATN1Ex5_7 CGACAGCCAGAGGCTAGCTTTGA 43 UCAAAGCUAGCCUCUGGCUGUCG 44 DRPLA hATN1Ex5_8 CTCGAATGTTCCAGGCTCCTCC 45 GGAGGAGCCUGGAACAUUCGAG 46 DRPLA hATN1Ex5_9 TCTATCCTGGGGGCACTGGTGG 47 CCACCAGUGCCCCCAGGAUAGA 48 DRPLA hATN1Ex5_10 TGGACCCCCAATGGGTCCCAAG 49 CUUGGGACCCAUUGGGGGUCCA 50 DRPLA hATN1Ex5_11 AGGGGCTGCCTCATCAGTGG 51 CCACUGAUGAGGCAGCCCCU 52 DRPLA hATN1Ex5_12 AAGCTCTGGGGCTAGTGGTGCTC 53 GAGCACCACUAGCCCCAGAGCUU 54 DRPLA hATN1Ex5_13 ACAAAGCCGCCTACCACTCCAG 55 CUGGAGUGGUAGGCGGCUUUGU 56 DRPLA hATN1Ex5_14 CTCCACCACCAGCCAACTTCC 57 GGAAGUUGGCUGGUGGUGGAG 58 DRPLA hATN1Ex5_15 CCAACCACTACCTGGTCATCTG 59 CAGAUGACCAGGUAGUGGUUGG 60 DRPLA hATN1Ex5_16 TGGCCCAGAGAAGGGCCCAAC 61 GUUGGGCCCUUCUCUGGGCCA 62 DRPLA hATN1Ex5_17 TTCCTCTTCTGCTCCAGCGCC 63 GGCGCUGGAGCAGAAGAGGAA 64 DRPLA hATN1Ex5_18 GTTTCCTTATTCATCCTCTAG 65 CUAGAGGAUGAAUAAGGAAAC 66 DRPLA hATN1Ex5_19 GCCTCTCTGTCTCCAATCAGC 67 GCUGAUUGGAGACAGAGAGGC 68 DRPLA hATN1Ex5_20 CCATCCCAGGCTGTGTGGAG 69 CUCCACACAGCCUGGGAUGG 70 DRPLA hATN1Ex5_21 TCTACTGGGGCCCAGTCCACCG 71 CGGUGGACUGGGCCCCAGUAGA 72 DRPLA hATN1Ex5_22 GCATCACGGAAACTCTGGGCC 73 GGCCCAGAGUUUCCGUGAUGC 74 DRPLA hATN1Ex5_23 CCACTGGAGGGCGGTAGCTCC 75 GGAGCUACCGCCCUCCAGUGG 76 DRPLA hATN1Ex5_24 CTCCCTGGGGTCTCTGAGGCC 77 GGCCUCAGAGACCCCAGGGAG 78 DRPLA hATN1Ex5_25 CACCAGGGCCAGCACACCTGC 79 GCAGGUGUGCUGGCCCUGGUG 80 DRPLA hATN1Ex5_26 GTGTCCTACAGCCAAGCAGGCC 81 GGCCUGCUUGGCUGUAGGACAC 82 DRPLA hATN1Ex5_27 CAAGGGTCCTACCCATGTTCAC 83 GUGAACAUGGGUAGGACCCUUG 84 DRPLA hATN1Ex5_28 CACCGGTGCCTACGGTCACCAC 85 GUGGUGACCGUAGGCACCGGUG 86 DRPLA hATN1Ex5_29 CTCTTCGGCTACCCTTTCCAC 87 GUGGAAAGGGUAGCCGAAGAG 88 DRPLA hATN1Ex5_30 GGTCATTGCCACCGTGGCTTC 89 GAAGCCACGGUGGCAAUGACC 90 DRPLA hATN1Ex5_31 CCACCGTACGGAAAGAGAGCC 91 GGCUCUCUUUCCGUACGGUGG 92 DRPLA hATN1Ex5_32 CCACCGGGCTATCGAGGAACCTC 93 GAGGUUCCUCGAUAGCCCGGUGG 94 DRPLA hATN1Ex5_33 CAGGCCCAGGGACCTTCAAGCC 95 GGCUUGAAGGUCCCUGGGCCUG 96 DRPLA hATN1Ex5_34 CCACCGTGGGACCTGGGCCCCTG 97 CAGGGGCCCAGGUCCCACGGUGG 98 DRPLA hATN1Ex5_35 GCCACCTGCGGGGCCCTCAGGC 99 GCCUGAGGGCCCCGCAGGUGGC 100 DRPLA hATN1Ex5_36 CCATCGCTGCCACCACCACCT 101 AGGUGGUGGUGGCAGCGAUGG 102 DRPLA hATN1Ex5_37 CCTGCCTCAGGGCCGCCCCTG 103 CAGGGGCGGCCCUGAGGCAGG 104 DRPLA hATN1Ex5_38 GCCGGCTGAGGAGTATGAGACC 105 GGUCUCAUACUCCUCAGCCGGC 106 DRPLA hATN1Ex5_39 CCAAGGTGGTAGATGTACCCA 107 UGGGUACAUCUACCACCUUGG 108 DRPLA hATN1Ex5_40 GCCATGCCAGTCAGTCTGCCAG 109 CUGGCAGACUGACUGGCAUGGC 110 DRPLA hATN1Ex6_1 CCTGGATCGCGGCTTCAACTC 111 GAGUUGAAGCCGCGAUCCAGG 112 DRPLA hATN1Ex6_2 CCTGTACTTCGTGCCACTGGAGG 113 CCUCCAGUGGCACGAAGUACAGG 114 DRPLA hATN1Ex6_3 GACCTGGTGGAGAAGGTGCGGCG 115 CGCCGCACCUUCUCCACCAGGUC 116 DRPLA hATN1Ex6_4 CGCGAAGAAAAGGAGCGCGAGCG 117 CGCUCGCGCUCCUUUUCUUCGCG 118 DRPLA hATN1Ex6_5 GCGAGCGGGAACGCGAGAAAG 119 CUUUCUCGCGUUCCCGCUCGC 120 DRPLA hATN1Ex6_6 GCGAGAAGGAGCGCGAGCTTG 121 CAAGCUCGCGCUCCUUCUCGC 122 S CA3 hATXN3Ex7_1 TTGTCGTTAAGGGTGATCTGC 123 GCAGAUCACCCUUAACGACAA 124 S CA3 hATXN3Ex7_2 CTGCCAGATTGCGAAGCTGA 125 UCAGCUUCGCAAUCUGGCAG 126 S CA3 hATXN3Ex7_3 GACCAACTCCTGCAGATGATT 127 AAUCAUCUGCAGGAGUUGGUC 128 S CA3 hATXN3Ex7_4 GGTCCAACAGATGCATCGAC 129 GUCGAUGCAUCUGUUGGACC 130 S CA3 hATXN3Ex7_5 GCACAACTAAAAGAGCAAAG 131 CUUUGCUCUUUUAGUUGUGC 132 S CA3 hATXN3Ex8_1 GTTAGAAGCAAATGATGGCTC 133 GAGCCAUCAUUUGCUUCUAAC 134 S CA3 hATXN3Ex8_2 CTCAGGAATGTTAGACGAAG 135 CUUCGUCUAACAUUCCUGAG 136 S CA3 hATXN3Ex8_3 GAGGAGGATTTGCAGAGGGC 137 GCCCUCUGCAAAUCCUCCUC 138 S CA3 hATXN3Ex8_4 GAGGAAGCAGATCTCCGCAG 139 CUGCGGAGAUCUGCUUCCUC 140 S CA3 hATXN3Ex8_5 GGCTATTCAGCTAAGTATGCAAG 141 CUUGCAUACUUAGCUGAAUAGCC 142 S CA3 hATXN3Ex9_1 GGTAGTTCCAGAAACATATCTC 143 GAGAUAUGUUUCUGGAACUACC 144 S CA3 hATXN3Ex9_2 GCTTCGGAAGAGACGAGAAGC 145 GCUUCUCGUCUCUUCCGAAGC 146 S CA3 hATXN3Ex10_1 CAGCAGCAAAAGCAGCAACAGC 147 GCUGUUGCUGCUUUUGCUGCUG 148 S CA3 hATXN3Ex10_2 GACCTATCAGGACAGAGTTC 149 GAACUCUGUCCUGAUAGGUC 150 S CA7 hATXN7Ex3_1 GAGCGGAAAGAATGTCGGAGC 151 GCUCCGACAUUCUUUCCGCUC 152 S CA7 hATXN7Ex3_2 AGCGGGCCGCGGATGACGTCA 153 UGACGUCAUCCGCGGCCCGCU 154 S CA7 hATXN7Ex3_3 AGCAGCCGCCGCCTCCGCAG 155 CUGCGGAGGCGGCGGCUGCU 156 S CA7 hATXN7Ex3_4 ACACGGCCGGAGGACGGCG 157 CGCCGUCCUCCGGCCGUGU 158 S CA7 hATXN7Ex3_5 GCGCCGCCTCCACCTCGGCCG 159 CGGCCGAGGUGGAGGCGGCGC 160 S CA7 hATXN7Ex3_6 ACCTCGGCCGCCGCAATGGCGA 161 UCGCCAUUGCGGCGGCCGAGGU 162 S CA7 hATXN7Ex3_7 GGCCTCTGCCCAGTCCTGAAGT 163 ACUUCAGGACUGGGCAGAGGCC 164 S CA7 hATXN7Ex3_8 TGATGCTGGGACAGTCGTGGAAT 165 AUUCCACGACUGUCCCAGCAUCA 166 S CA7 hATXN7Ex3_9 AGGCTTCCAAACTTCCTGGGAAG 167 CUUCCCAGGAAGUUUGGAAGCCU 168 HD hHTTEx12_1 CATCAGCGACAGCTCCCAGACCACCACCG 169 CGGUGGUGGUCUGGGAGCUGUCGCUGAUG 170 HD hHTTEx12_2 TCACAGCACACACTGCAGGC 171 GCCUGCAGUGUGUGCUGUGA 172 HD hHTTEx12_3 GGTCAGCAGGTCATGACATCAT 173 AUGAUGUCAUGACCUGCUGACC 174 HD hHTTEx12_4 AGAGCTGGCTGCTTCTTCAG 175 CUGAAGAAGCAGCCAGCUCU 176 HD hHTTEx12_5 GATGAGGAGGATATCTTGAG 177 CUCAAGAUAUCCUCCUCAUC 178 HD hHTTEx12_6 TCAGTGAAGGATGAGATCAGTGG 179 CCACUGAUCUCAUCCUUCACUGA 180 HD hHTTEx12_7 ATGGACCTGAATGATGGGAC 181 GUCCCAUCAUUCAGGUCCAU 182 HD hHTTEx12_8 TGACAAGCTCTGCCACTGAT 183 AUCAGUGGCAGAGCUUGUCA 184 HD hHTTEx12_9 TCCAGCCAGGTCAGCGCCGT 185 ACGGCGCUGACCUGGCUGGA 186 HD hHTTEx12_10 ACTCAGTGGATCTGGCCAGCT 187 AGCUGGCCAGAUCCACUGAGU 188 HD hHTTEx13_1 CCTGCAGATTGGACAGCC 189 GGCUGUCCAAUCUGCAGG 190 HD hHTTEx13_2 GGTACCGACAACCAGTATTT 191 AAAUACUGGUUGUCGGUACC 192 HD hHTTEx14_1 AACATGAGTCACTGCAGGCAG 193 CUGCCUGCAGUGACUCAUGUU 194 HD hHTTEx14_2 GCCTTCTGACAGCAGTGTTGAT 195 AUCAACACUGCUGUCAGAAGGC 196 HD hHTTEx14_3 GTTGAGAGATGAAGCTACTG 197 CAGUAGCUUCAUCUCUCAAC 198 SCA17 hTBPEx3_1: GCCATGACTCCCGGAATCCCTA 199 UAGGGAUUCCGGGAGUCAUGGC 200 SCA17 hTBPEx3_2: CCTATCTTTAGTCCAATGATGC 201 GCAUCAUUGGACUAAAGAUAGG 202 SCA17 hTBPEx3_3: TATGGCACTGGACTGACCCCAC 203 GUGGGGUCAGUCCAGUGCCAUA 204 SCA17 hTBPEx3_4: GCAGCTGCAGCCGTTCAGCAG 205 CUGCUGAACGGCUGCAGCUGC 206 SCA17 hTBPEx3_5: GTTCAGCAGTCAACGTCCCAGC 207 GCUGGGACGUUGACUGCUGAAC 208 SCA17 hTBPEx3_6: AACCTCAGGCCAGGCACCACAG 209 CUGUGGUGCCUGGCCUGAGGUU 210 SCA17 hTBPEx3_7: GCACCACAGCTCTTCCACTCA 211 UGAGUGGAAGAGCUGUGGUGC 212 SCA17 hTBPEx3_8: CTCACAGACTCTCACAACTGC 213 GCAGUUGUGAGAGUCUGUGAG 214 SCA17 hTBPEx3_9: GGCACCACTCCACTGTATCCCT 215 AGGGAUACAGUGGAGUGGUGCC 216 SCA17 hTBPEx3_10: CATCACTCCTGCCACGCCAGCT 217 AGCUGGCGUGGCAGGAGUGAUG 218 SCA17 hTBPEx3_11: AGAGTTCTGGGATTGTACCGCA 219 UGCGGUACAAUCCCAGAACUCU 220 SCA17 hTBPEx4_1: TGTATCCACAGTGAATCTTGGT 221 ACCAAGAUUCACUGUGGAUACA 222 SCA17 hTBPEx4_2: GGTTGTAAACTTGACCTAAAG 223 CUUUAGGUCAAGUUUACAACC 224 SCA17 hTBPEx4_3: CATTGCACTTCGTGCCCGAAACG 225 CGUUUCGGGCACGAAGUGCAAUG 226
Sequence CWU 1
1
234129RNAArtificialAON HDEx12_1 1cggugguggu cugggagcug ucgcugaug
29219RNAArtificialAON HDEx12_2 2ucacagcaca cacugcagg
19328RNAArtificialAON HDEx13_1 3guuccugaag gccuccgagg cuucauca
28425RNAArtificialAON HDEx13_2 4gguccuacuu cuacuccuuc ggugu
25520RNAArtificialAON DRPLAEx5_18 5gucgcugcug ccaucaucau
20620RNAArtificialAON DRPLAEx5_128 6aagaggaagc aggaggcaga
20720RNAArtificialAON DRPLAEx5_81 7ggaggagccu ggaacauucg
20820RNAArtificialAON DRPLAEx6_80 8aagcucgcgc uccuucucgc
20920RNAArtificialAON DRPLAEx6_1 9cgaguugaag ccgcgaucca
201020RNAArtificialAON DRPLAEx6_84 10guucaagcuc gcgcuccuuc
201123DNAArtificialtarget hAPPEx15_1 11gttctgggtt gacaaatatc aag
231223RNAArtificialAON hAPPEx15_1 12cuugauauuu gucaacccag aac
231323DNAArtificialtarget hAPPEx15_2 13cggaggagat ctctgaagtg aag
231423RNAArtificialAON hAPPEx15_2 14cuucacuuca gagaucuccu ccg
231521DNAArtificialtarget hAPPEx15_3 15gatgcagaat tccgacatga c
211621RNAArtificialAON hAPPEx15_3 16gucaugucgg aauucugcau c
211723DNAArtificialtarget hAPPEx15_4 17ctcaggatat gaagttcatc atc
231823RNAArtificialAON hAPPEx15_4 18gaugaugaac uucauauccu gag
231920DNAArtificialtarget hAPPEx16_1 19gcaatcattg gactcatggt
202020RNAArtificialAON hAPPEx16_1 20accaugaguc caaugauugc
202120DNAArtificialtarget hAPPEx16_2 21gatcgtcatc accttggtga
202220RNAArtificialAON hAPPEx16_2 22ucaccaaggu gaugacgauc
202323DNAArtificialtarget hAPPEx16_3 23gtacacatcc attcatcatg gtg
232423RNAArtificialAON hAPPEx16_3 24caccaugaug aauggaugug uac
232521DNAArtificialtarget hAPPEx16_4 25gcagaagatg tgggttcaaa c
212621RNAArtificialAON hAPPEx16_4 26guuugaaccc acaucuucug c
212722DNAArtificialtarget hAPPEx16_5 27ggtgatgctg aagaagaaac ag
222822RNAArtificialAON hAPPEx16_5 28cuguuucuuc uucagcauca cc
222923DNAArtificialtarget hAPPEx16_6 29tcatcatggt gtggtggagg tag
233023RNAArtificialAON hAPPEx16_6 30cuaccuccac cacaccauga uga
233122DNAArtificialtarget hATN1Ex5_1 31ctccctcggc cacagtctcc ct
223222RNAArtificialAON hATN1Ex5_1 32agggagacug uggccgaggg ag
223322DNAArtificialtarget hATN1Ex5_2 33gcggagcctt aatgatgatg gc
223422RNAArtificialAON hATN1Ex5_2 34gccaucauca uuaaggcucc gc
223522DNAArtificialtarget hATN1Ex5_3 35agcagcgacc ctagggatat cg
223622RNAArtificialAON hATN1Ex5_3 36cgauaucccu agggucgcug cu
223721DNAArtificialtarget hATN1Ex5_4 37aggacaaccg aagcacgtcc c
213821RNAArtificialAON hATN1Ex5_4 38gggacgugcu ucgguugucc u
213923DNAArtificialtarget hATN1Ex5_5 39tggaagtgtg gagaatgact ctg
234023RNAArtificialAON hATN1Ex5_5 40cagagucauu cuccacacuu cca
234122DNAArtificialtarget hATN1Ex5_6 41atcttctggc ctgtcccagg gc
224222RNAArtificialAON hATN1Ex5_6 42gcccugggac aggccagaag au
224323DNAArtificialtarget hATN1Ex5_7 43cgacagccag aggctagctt tga
234423RNAArtificialAON hATN1Ex5_7 44ucaaagcuag ccucuggcug ucg
234522DNAArtificialtarget hATN1Ex5_8 45ctcgaatgtt ccaggctcct cc
224622RNAArtificialAON hATN1Ex5_8 46ggaggagccu ggaacauucg ag
224722DNAArtificialtarget hATN1Ex5_9 47tctatcctgg gggcactggt gg
224822RNAArtificialAON hATN1Ex5_9 48ccaccagugc ccccaggaua ga
224922DNAArtificialtarget hATN1Ex5_10 49tggaccccca atgggtccca ag
225022RNAArtificialAON hATN1Ex5_10 50cuugggaccc auuggggguc ca
225120DNAArtificialtarget hATN1Ex5_11 51aggggctgcc tcatcagtgg
205220RNAArtificialAON hATN1Ex5_11 52ccacugauga ggcagccccu
205323DNAArtificialtarget hATN1Ex5_12 53aagctctggg gctagtggtg ctc
235423RNAArtificialAON hATN1Ex5_12 54gagcaccacu agccccagag cuu
235522DNAArtificialtarget hATN1Ex5_13 55acaaagccgc ctaccactcc ag
225622RNAArtificialAON hATN1Ex5_13 56cuggaguggu aggcggcuuu gu
225721DNAArtificialtarget hATN1Ex5_14 57ctccaccacc agccaacttc c
215821RNAArtificialAON hATN1Ex5_14 58ggaaguuggc ugguggugga g
215922DNAArtificialtarget hATN1Ex5_15 59ccaaccacta cctggtcatc tg
226022RNAArtificialAON hATN1Ex5_15 60cagaugacca gguagugguu gg
226121DNAArtificialtarget hATN1Ex5_16 61tggcccagag aagggcccaa c
216221RNAArtificialAON hATN1Ex5_16 62guugggcccu ucucugggcc a
216321DNAArtificialtarget hATN1Ex5_17 63ttcctcttct gctccagcgc c
216421RNAArtificialAON hATN1Ex5_17 64ggcgcuggag cagaagagga a
216521DNAArtificialtarget hATN1Ex5_18 65gtttccttat tcatcctcta g
216621RNAArtificialAON hATN1Ex5_18 66cuagaggaug aauaaggaaa c
216721DNAArtificialtarget hATN1Ex5_19 67gcctctctgt ctccaatcag c
216821RNAArtificialAON hATN1Ex5_19 68gcugauugga gacagagagg c
216920DNAArtificialtarget hATN1Ex5_20 69ccatcccagg ctgtgtggag
207020RNAArtificialAON hATN1Ex5_20 70cuccacacag ccugggaugg
207122DNAArtificialtarget hATN1Ex5_21 71tctactgggg cccagtccac cg
227222RNAArtificialAON hATN1Ex5_21 72cgguggacug ggccccagua ga
227321DNAArtificialtarget hATN1Ex5_22 73gcatcacgga aactctgggc c
217421RNAArtificialAON hATN1Ex5_22 74ggcccagagu uuccgugaug c
217521DNAArtificialtarget hATN1Ex5_23 75ccactggagg gcggtagctc c
217621RNAArtificialAON hATN1Ex5_23 76ggagcuaccg cccuccagug g
217721DNAArtificialtarget hATN1Ex5_24 77ctccctgggg tctctgaggc c
217821RNAArtificialAON hATN1Ex5_24 78ggccucagag accccaggga g
217921DNAArtificialtarget hATN1Ex5_25 79caccagggcc agcacacctg c
218021RNAArtificialAON hATN1Ex5_25 80gcaggugugc uggcccuggu g
218122DNAArtificialtarget hATN1Ex5_26 81gtgtcctaca gccaagcagg cc
228222RNAArtificialAON hATN1Ex5_26 82ggccugcuug gcuguaggac ac
228322DNAArtificialtarget hATN1Ex5_27 83caagggtcct acccatgttc ac
228422RNAArtificialAON hATN1Ex5_27 84gugaacaugg guaggacccu ug
228522DNAArtificialtarget hATN1Ex5_28 85caccggtgcc tacggtcacc ac
228622RNAArtificialAON hATN1Ex5_28 86guggugaccg uaggcaccgg ug
228721DNAArtificialtarget hATN1Ex5_29 87ctcttcggct accctttcca c
218821RNAArtificialAON hATN1Ex5_29 88guggaaaggg uagccgaaga g
218921DNAArtificialtarget hATN1Ex5_30 89ggtcattgcc accgtggctt c
219021RNAArtificialAON hATN1Ex5_30 90gaagccacgg uggcaaugac c
219121DNAArtificialtarget hATN1Ex5_31 91ccaccgtacg gaaagagagc c
219221RNAArtificialAON hATN1Ex5_31 92ggcucucuuu ccguacggug g
219323DNAArtificialtarget hATN1Ex5_32 93ccaccgggct atcgaggaac ctc
239423RNAArtificialAON hATN1Ex5_32 94gagguuccuc gauagcccgg ugg
239522DNAArtificialtarget hATN1Ex5_33 95caggcccagg gaccttcaag cc
229622RNAArtificialAON hATN1Ex5_33 96ggcuugaagg ucccugggcc ug
229723DNAArtificialtarget hATN1Ex5_34 97ccaccgtggg acctgggccc ctg
239823RNAArtificialAON hATN1Ex5_34 98caggggccca ggucccacgg ugg
239922DNAArtificialtarget hATN1Ex5_35 99gccacctgcg gggccctcag gc
2210022RNAArtificialAON hATN1Ex5_35 100gccugagggc cccgcaggug gc
2210121DNAArtificialtarget hATN1Ex5_36 101ccatcgctgc caccaccacc t
2110221RNAArtificialAON hATN1Ex5_36 102aggugguggu ggcagcgaug g
2110321DNAArtificialtarget hATN1Ex5_37 103cctgcctcag ggccgcccct g
2110421RNAArtificialAON hATN1Ex5_37 104caggggcggc ccugaggcag g
2110522DNAArtificialtarget hATN1Ex5_38 105gccggctgag gagtatgaga cc
2210622RNAArtificialAON hATN1Ex5_38 106ggucucauac uccucagccg gc
2210721DNAArtificialtarget hATN1Ex5_39 107ccaaggtggt agatgtaccc a
2110821RNAArtificialAON hATN1Ex5_ 108uggguacauc uaccaccuug g
2110922DNAArtificialtarget hATN1Ex5_40 109gccatgccag tcagtctgcc ag
2211022RNAArtificialAON hATN1Ex5_40 110cuggcagacu gacuggcaug gc
2211121DNAArtificialtarget hATN1Ex6_1 111cctggatcgc ggcttcaact c
2111221RNAArtificialAON hATN1Ex6_1 112gaguugaagc cgcgauccag g
2111323DNAArtificialtarget hATN1Ex6_2 113cctgtacttc gtgccactgg agg
2311423RNAArtificialAON hATN1Ex6_2 114ccuccagugg cacgaaguac agg
2311523DNAArtificialtarget hATN1Ex6_3 115gacctggtgg agaaggtgcg gcg
2311623RNAArtificialAON hATN1Ex6_3 116cgccgcaccu ucuccaccag guc
2311723DNAArtificialtarget hATN1Ex6_4 117cgcgaagaaa aggagcgcga gcg
2311823RNAArtificialAON hATN1Ex6_4 118cgcucgcgcu ccuuuucuuc gcg
2311921DNAArtificialtarget hATN1Ex6_5 119gcgagcggga acgcgagaaa g
2112021RNAArtificialAON hATN1Ex6_5 120cuuucucgcg uucccgcucg c
2112121DNAArtificialtarget hATN1Ex6_6 121gcgagaagga gcgcgagctt g
2112221RNAArtificialAON hATN1Ex6_6 122caagcucgcg cuccuucucg c
2112321DNAArtificialtarget hATXN3Ex7_1 123ttgtcgttaa gggtgatctg c
2112421RNAArtificialAON hATXN3Ex7_1 124gcagaucacc cuuaacgaca a
2112520DNAArtificialtarget hATXN3Ex7_2 125ctgccagatt gcgaagctga
2012620RNAArtificialAON hATXN3Ex7_2 126ucagcuucgc aaucuggcag
2012721DNAArtificialtarget hATXN3Ex7_3 127gaccaactcc tgcagatgat t
2112821RNAArtificialAON hATXN3Ex7_3 128aaucaucugc aggaguuggu c
2112920DNAArtificialtarget hATXN3Ex7_4 129ggtccaacag atgcatcgac
2013020RNAArtificialAON hATXN3Ex7_4 130gucgaugcau cuguuggacc
2013120DNAArtificialtarget hATXN3Ex7_5 131gcacaactaa aagagcaaag
2013220RNAArtificialAON hATXN3Ex7_5 132cuuugcucuu uuaguugugc
2013321DNAArtificialtarget hATXN3Ex8_1 133gttagaagca aatgatggct c
2113421RNAArtificialAON hATXN3Ex8_1 134gagccaucau uugcuucuaa c
2113520DNAArtificialtarget hATXN3Ex8_2 135ctcaggaatg ttagacgaag
2013620RNAArtificialAON hATXN3Ex8_2 136cuucgucuaa cauuccugag
2013720DNAArtificialtarget hATXN3Ex8_3 137gaggaggatt tgcagagggc
2013820RNAArtificialAON hATXN3Ex8_3 138gcccucugca aauccuccuc
2013920DNAArtificialtarget hATXN3Ex8_4 139gaggaagcag atctccgcag
2014020RNAArtificialAON hATXN3Ex8_4 140cugcggagau cugcuuccuc
2014123DNAArtificialtarget hATXN3Ex8_5 141ggctattcag ctaagtatgc aag
2314223RNAArtificialAON hATXN3Ex8_5 142cuugcauacu uagcugaaua gcc
2314322DNAArtificialtarget hATXN3Ex9_1 143ggtagttcca gaaacatatc tc
2214422RNAArtificialAON hATXN3Ex9_1 144gagauauguu ucuggaacua cc
2214521DNAArtificialtarget hATXN3Ex9_2 145gcttcggaag agacgagaag c
2114621RNAArtificialAON hATXN3Ex9_2 146gcuucucguc ucuuccgaag c
2114722DNAArtificialtarget hATXN3Ex10_1 147cagcagcaaa agcagcaaca gc
2214822RNAArtificialAON hATXN3Ex10_1 148gcuguugcug cuuuugcugc ug
2214920DNAArtificialtarget hATXN3Ex10_2 149gacctatcag gacagagttc
2015020RNAArtificialAON hATXN3Ex10_2 150gaacucuguc cugauagguc
2015121DNAArtificialtarget hATXN7Ex3_1 151gagcggaaag aatgtcggag c
2115221RNAArtificialAON hATXN7Ex3_1 152gcuccgacau ucuuuccgcu c
2115321DNAArtificialtarget hATXN7Ex3_2 153agcgggccgc ggatgacgtc a
2115421RNAArtificialAON hATXN7Ex3_2 154ugacgucauc cgcggcccgc u
2115520DNAArtificialtarget hATXN7Ex3_3 155agcagccgcc gcctccgcag
2015620RNAArtificialAON hATXN7Ex3_3 156cugcggaggc ggcggcugcu
2015719DNAArtificialtarget hATXN7Ex3_4 157acacggccgg aggacggcg
1915819RNAArtificialAON hATXN7Ex3_4 158cgccguccuc cggccgugu
1915921DNAArtificialtarget hATXN7Ex3_5 159gcgccgcctc cacctcggcc g
2116021RNAArtificialAON hATXN7Ex3_5 160cggccgaggu ggaggcggcg c
2116122DNAArtificialtarget hATXN7Ex3_6 161acctcggccg ccgcaatggc ga
2216222RNAArtificialAON hATXN7Ex3_6 162ucgccauugc ggcggccgag gu
2216322DNAArtificialtarget hATXN7Ex3_7 163ggcctctgcc cagtcctgaa gt
2216422RNAArtificialAON hATXN7Ex3_7 164acuucaggac ugggcagagg cc
2216523DNAArtificialtarget hATXN7Ex3_8 165tgatgctggg acagtcgtgg aat
2316623RNAArtificialAON hATXN7Ex3_8 166auuccacgac ugucccagca uca
2316723DNAArtificialtarget hATXN7Ex3_9 167aggcttccaa acttcctggg
aag
2316823RNAArtificialAON hATXN7Ex3_9 168cuucccagga aguuuggaag ccu
2316929DNAArtificialtarget hHTTEx12_1 169catcagcgac agctcccaga
ccaccaccg 2917029RNAArtificialAON hHTTEx12_1 170cggugguggu
cugggagcug ucgcugaug 2917120DNAArtificialtarget hHTTEx12_2
171tcacagcaca cactgcaggc 2017220RNAArtificialAON hHTTEx12_2
172gccugcagug ugugcuguga 2017322DNAArtificialtarget hHTTEx12_3
173ggtcagcagg tcatgacatc at 2217422RNAArtificialAON hHTTEx12_3
174augaugucau gaccugcuga cc 2217520DNAArtificialtarget hHTTEx12_4
175agagctggct gcttcttcag 2017620RNAArtificialAON hHTTEx12_4
176cugaagaagc agccagcucu 2017720DNAArtificialtarget hHTTEx12_5
177gatgaggagg atatcttgag 2017820RNAArtificialAON hHTTEx12_5
178cucaagauau ccuccucauc 2017923DNAArtificialtarget hHTTEx12_6
179tcagtgaagg atgagatcag tgg 2318023RNAArtificialAON hHTTEx12_6
180ccacugaucu cauccuucac uga 2318120DNAArtificialtarget hHTTEx12_7
181atggacctga atgatgggac 2018220RNAArtificialAON hHTTEx12_7
182gucccaucau ucagguccau 2018320DNAArtificialtarget hHTTEx12_8
183tgacaagctc tgccactgat 2018420RNAArtificialAON hHTTEx12_8
184aucaguggca gagcuuguca 2018520DNAArtificialtarget hHTTEx12_9
185tccagccagg tcagcgccgt 2018620RNAArtificialAON hHTTEx12_9
186acggcgcuga ccuggcugga 2018721DNAArtificialtarget hHTTEx12_10
187actcagtgga tctggccagc t 2118821RNAArtificialAON hHTTEx12_10
188agcuggccag auccacugag u 2118918DNAArtificialtarget hHTTEx13_1
189cctgcagatt ggacagcc 1819018RNAArtificialAON hHTTEx13_1
190ggcuguccaa ucugcagg 1819120DNAArtificialtarget hHTTEx13_2
191ggtaccgaca accagtattt 2019220RNAArtificialAON hHTTEx13_2
192aaauacuggu ugucgguacc 2019321DNAArtificialtarget hHTTEx14_1
193aacatgagtc actgcaggca g 2119421RNAArtificialAON hHTTEx14_1
194cugccugcag ugacucaugu u 2119522DNAArtificialtarget hHTTEx14_2
195gccttctgac agcagtgttg at 2219622RNAArtificialAON hHTTEx14_2
196aucaacacug cugucagaag gc 2219720DNAArtificialtarget hHTTEx14_3
197gttgagagat gaagctactg 2019820RNAArtificialAON hHTTEx14_3
198caguagcuuc aucucucaac 2019922DNAArtificialtarget hTBPEx3_1
199gccatgactc ccggaatccc ta 2220022RNAArtificialAON hTBPEx3_1
200uagggauucc gggagucaug gc 2220122DNAArtificialtarget hTBPEx3_2
201cctatcttta gtccaatgat gc 2220222RNAArtificialAON hTBPEx3_2
202gcaucauugg acuaaagaua gg 2220322DNAArtificialtarget hTBPEx3_3
203tatggcactg gactgacccc ac 2220422RNAArtificialAON hTBPEx3_3
204guggggucag uccagugcca ua 2220521DNAArtificialtarget hTBPEx3_4
205gcagctgcag ccgttcagca g 2120621RNAArtificialAON hTBPEx3_4
206cugcugaacg gcugcagcug c 2120722DNAArtificialtarget hTBPEx3_5
207gttcagcagt caacgtccca gc 2220822RNAArtificialAON hTBPEx3_5
208gcugggacgu ugacugcuga ac 2220922DNAArtificialtarget hTBPEx3_6
209aacctcaggc caggcaccac ag 2221022RNAArtificialAON hTBPEx3_6
210cuguggugcc uggccugagg uu 2221121DNAArtificialtarget hTBPEx3_7
211gcaccacagc tcttccactc a 2121221RNAArtificialAON hTBPEx3_7
212ugaguggaag agcuguggug c 2121321DNAArtificialtarget hTBPEx3_8
213ctcacagact ctcacaactg c 2121421RNAArtificialAON hTBPEx3_8
214gcaguuguga gagucuguga g 2121522DNAArtificialtarget hTBPEx3_9
215ggcaccactc cactgtatcc ct 2221622RNAArtificialAON hTBPEx3_9
216agggauacag uggaguggug cc 2221722DNAArtificialtarget hTBPEx3_10
217catcactcct gccacgccag ct 2221822RNAArtificialAON hTBPEx3_10
218agcuggcgug gcaggaguga ug 2221922DNAArtificialtarget hTBPEx3_11
219agagttctgg gattgtaccg ca 2222022RNAArtificialAON hTBPEx3_11
220ugcgguacaa ucccagaacu cu 2222122DNAArtificialtarget hTBPEx4_1
221tgtatccaca gtgaatcttg gt 2222222RNAArtificialAON hTBPEx4_1
222accaagauuc acuguggaua ca 2222321DNAArtificialtarget hTBPEx4_2
223ggttgtaaac ttgacctaaa g 2122421RNAArtificialAON hTBPEx4_2
224cuuuagguca aguuuacaac c 2122523DNAArtificialtarget hTBPEx4_3
225cattgcactt cgtgcccgaa acg 2322623RNAArtificialAON hTBPEx4_3
226cguuucgggc acgaagugca aug 23227240PRTHomo sapiens 227Ser Ile Val
Glu Leu Ile Ala Gly Gly Gly Ser Ser Cys Ser Pro Val1 5 10 15Leu Ser
Arg Lys Gln Lys Gly Lys Val Leu Leu Gly Glu Glu Glu Ala 20 25 30Leu
Glu Asp Asp Ser Glu Ser Arg Ser Asp Val Ser Ser Ser Ala Leu 35 40
45Thr Ala Ser Val Lys Asp Glu Ile Ser Gly Glu Leu Ala Ala Ser Ser
50 55 60Gly Val Ser Thr Pro Gly Ser Ala Gly His Asp Ile Ile Thr Glu
Gln65 70 75 80Pro Arg Ser Gln His Thr Leu Gln Ala Asp Ser Val Asp
Leu Ala Ser 85 90 95Cys Asp Leu Thr Ser Ser Ala Thr Asp Gly Asp Glu
Glu Asp Ile Leu 100 105 110Ser His Ser Ser Ser Gln Val Ser Ala Val
Pro Ser Asp Pro Ala Met 115 120 125Asp Leu Asn Asp Gly Thr Gln Ala
Ser Ser Pro Ile Ser Asp Ser Ser 130 135 140Gln Thr Thr Thr Glu Gly
Pro Asp Ser Ala Val Thr Pro Ser Asp Ser145 150 155 160Ser Glu Ile
Val Leu Asp Gly Thr Asp Asn Gln Tyr Leu Gly Leu Gln 165 170 175Ile
Gly Gln Pro Gln Asp Glu Asp Glu Glu Ala Thr Gly Ile Leu Pro 180 185
190Asp Glu Ala Ser Glu Ala Phe Arg Asn Ser Ser Met Ala Leu Gln Gln
195 200 205Ala His Leu Leu Lys Asn Met Ser His Cys Arg Gln Pro Ser
Asp Ser 210 215 220Ser Val Asp Lys Phe Val Leu Arg Asp Glu Ala Thr
Glu Pro Gly Asp225 230 235 24022816DNAHomo sapiens 228cagccaggtc
agcgcc 1622916DNAArtificialskipped PCR product of HDEx12_1
229cagccaggtg ttagac 16230172PRTHomo sapiensDOMAIN(49)..(52)caspase
cleavage motifDOMAIN(88)..(91)caspase cleavage
motifDOMAIN(122)..(125)caspase cleavage motif 230Asp Val Ser Ser
Ser Ala Leu Thr Ala Ser Val Lys Asp Glu Ile Ser1 5 10 15Gly Glu Leu
Ala Ala Ser Ser Gly Val Ser Thr Pro Gly Ser Ala Gly 20 25 30His Asp
Ile Ile Thr Glu Gln Pro Arg Ser Gln His Thr Leu Gln Ala 35 40 45Asp
Ser Val Asp Leu Ala Ser Cys Asp Leu Thr Ser Ser Ala Thr Asp 50 55
60Gly Asp Glu Glu Asp Ile Leu Ser His Ser Ser Ser Gln Val Ser Ala65
70 75 80Val Pro Ser Asp Pro Ala Met Asp Leu Asn Asp Gly Thr Gln Ala
Ser 85 90 95Ser Pro Ile Ser Asp Ser Ser Gln Thr Thr Thr Glu Gly Pro
Asp Ser 100 105 110Ala Val Thr Pro Ser Asp Ser Ser Glu Ile Val Leu
Asp Gly Thr Asp 115 120 125Asn Gln Tyr Leu Gly Leu Gln Ile Gly Gln
Pro Gln Asp Glu Asp Glu 130 135 140Glu Ala Thr Gly Ile Leu Pro Asp
Glu Ala Ser Glu Ala Phe Arg Asn145 150 155 160Ser Ser Met Ala Leu
Gln Gln Ala His Leu Leu Lys 165 17023178DNAHomo sapiensCDS(1)..(78)
231tcc agc cag gtc agc gcc gtc cca tct gac cct gcc atg gac ctg aat
48Ser Ser Gln Val Ser Ala Val Pro Ser Asp Pro Ala Met Asp Leu Asn1
5 10 15gat ggg acc cag gcc tcg tcg ccc atc agc 78Asp Gly Thr Gln
Ala Ser Ser Pro Ile Ser 20 2523226PRTHomo sapiens 232Ser Ser Gln
Val Ser Ala Val Pro Ser Asp Pro Ala Met Asp Leu Asn1 5 10 15Asp Gly
Thr Gln Ala Ser Ser Pro Ile Ser 20 2523378DNAHomo
sapiensCDS(1)..(78) 233gac agc tcc cag acc acc acc gaa ggg cct gat
tca gct gtt acc cct 48Asp Ser Ser Gln Thr Thr Thr Glu Gly Pro Asp
Ser Ala Val Thr Pro1 5 10 15tca gac agt tct gaa att gtg tta gac ggt
78Ser Asp Ser Ser Glu Ile Val Leu Asp Gly 20 2523426PRTHomo sapiens
234Asp Ser Ser Gln Thr Thr Thr Glu Gly Pro Asp Ser Ala Val Thr Pro1
5 10 15Ser Asp Ser Ser Glu Ile Val Leu Asp Gly 20 25
D00001
D00002
D00003
D00004
D00005
D00006
S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.