Earning Code Classification
Xiao; Min ; et al.
U.S. patent application number 16/358220 was filed with the patent office on 2020-09-24 for earning code classification. The applicant listed for this patent is ADP, LLC. Invention is credited to Manish Karanjavkar, Dmitry Tolstonogov, Xiaojing Wang, Lei Xia, Min Xiao.
| Application Number | 20200302396 16/358220 |
| Document ID | / |
| Family ID | 1000004139767 |
| Filed Date | 2020-09-24 |





View All Diagrams
| United States Patent Application | 20200302396 |
| Kind Code | A1 |
| Xiao; Min ; et al. | September 24, 2020 |
Earning Code Classification
Abstract
Managing and applying human resources data comprising aggregating employee transaction data for an organization. A number of human resources-related attributes are evaluated across heterogeneous transaction data. The employee transaction data is classified via statistical machine learning into a number of normalized codes according to the human resources-related attributes, a user interface is presented to adjust a number of organizational operating procedures according to the normalized codes.
| Inventors: | Xiao; Min; (Florham Park, NJ) ; Xia; Lei; (Parsippany, NJ) ; Karanjavkar; Manish; (Parsippany, NJ) ; Tolstonogov; Dmitry; (Parsippany, NJ) ; Wang; Xiaojing; (Parsippany, NJ) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 1000004139767 | ||||||||||
| Appl. No.: | 16/358220 | ||||||||||
| Filed: | March 19, 2019 |
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06Q 10/105 20130101; G06Q 40/125 20131203; G06Q 10/067 20130101; G06N 20/00 20190101 |
| International Class: | G06Q 10/10 20060101 G06Q010/10; G06Q 40/00 20060101 G06Q040/00; G06N 20/00 20060101 G06N020/00; G06Q 10/06 20060101 G06Q010/06 |
Claims
1. A computer-implemented method for classifying and applying human resources data, the method comprising: aggregating, by a number of processors, employee transaction data for an organization; evaluating, by a number of processors, a number of human resources-related attributes across heterogeneous transaction data; classifying, by a number of processors via statistical machine learning, the employee transaction data into a number of normalized codes according to the human resources-related attributes; and presenting, by a display, a user interface to adjust a number of organizational operating procedures according to the normalized codes.
2. The method of claim 1, wherein the machine learning further comprises: labelling the compensation data by independent first and second labelers according to code descriptions, wherein label agreements between the first and second labelers form a first labeled dataset; resolving label disagreements between the first and second labelers by a third labeler to form a second labeled dataset; labelling the compensation data with a semantic matcher to form a third labeled dataset; combining the first, second, and third labeled datasets into a final labeled dataset; and applying the final labeled dataset to a number of machine learning algorithms.
3. The method of claim 2, wherein machine learning algorithms comprise at least one of: naive Bayes; logistic regression; fully connected neural network; distributed random forest; gradient boosting machine; or XG boost.
4. The method of claim 1, wherein the transaction data is labeled according to code descriptions.
5. The method of claim 1, further comprising deriving, by a number of processors, a number of transaction patterns relative to the normalized codes.
6. The method of claim 5, wherein the transaction patterns comprise at least one of: employee ratio; compensation frequency; earning amount; job category; compensation rate type; employee seniority; working hours; and employee age.
7. The method of claim 1, wherein the normalized codes comprise at one of the following: pay codes; benefits codes; health care costs; or deduction codes.
8. The method of claim 1, wherein adjusting organizational operating procedures according to the normalized codes comprises at least one of: adjusting resource allocation; employee compensation setup.
9. The method of claim 1, further comprising benchmarking the organization according to the normalized codes and sector.
10. A system for classifying and applying human resources data, the system comprising: a bus system; a storage device connected to the bus system, wherein the storage device stores program instructions; and a number of processors connected to the bus system, wherein the number of processors execute the program instructions to: aggregate employee transaction data for an organization; evaluate a number of human resources-related attributes across heterogeneous transaction data; classify, via statistical machine learning, the employee transaction data into a number of normalized codes according to the human resources-related attributes; and present a user interface to adjust a number of organizational operating procedures according to the normalized codes.
11. The system of claim 10, wherein the machine learning further comprises: labelling the compensation data by independent first and second labelers according to code descriptions, wherein label agreements between the first and second labelers form a first labeled dataset; resolving label disagreements between the first and second labelers by a third labeler to form a second labeled dataset; labelling the compensation data with a semantic matcher to form a third labeled dataset; combining the first, second, and third labeled datasets into a final labeled dataset; and applying the final labeled dataset to a number of machine learning algorithms.
12. The system of claim 11, wherein machine learning algorithms comprise at least one of: naive Bayes; logistic regression; fully connected neural network; distributed random forest; gradient boosting machine; or XG boost.
13. The system of claim 10, wherein the transaction data is labeled according to code descriptions.
14. The system of claim 10, wherein the number of processors further execute program instructions to derive a number of transaction patterns relative to the normalized codes.
15. The system of claim 14, wherein the transaction patterns comprise at least one of: employee ratio; compensation frequency; earning amount; job category; compensation rate type; employee seniority; working hours; and employee age.
16. The system of claim 10, wherein the normalized codes comprise at one of the following: pay codes; benefits codes; health care costs; or deduction codes.
17. The system of claim 10, wherein adjusting organizational operating procedures according to the normalized codes comprises at least one of: adjusting resource allocation; employee compensation setup.
18. The system of claim 10, wherein the number of processors further execute program instructions to benchmark the organization according to the normalized codes and sector.
19. A computer program product for classifying and applying human resources data, the computer program product comprising: a non-volatile computer readable storage medium having program instructions embodied therewith, the program instructions executable by a number of processors to cause the computer to perform the steps of: aggregating employee transaction data for an organization; evaluating a number of human resources-related attributes across heterogeneous transaction data; classifying, via statistical machine learning, the employee transaction data into a number of normalized codes according to the human resources-related attributes; and presenting a user interface to adjust a number of organizational operating procedures according to the normalized codes.
20. The computer program product according to claim 19, wherein the machine learning further comprises: labelling the compensation data by independent first and second labelers according to code descriptions, wherein label agreements between the first and second labelers form a first labeled dataset; resolving label disagreements between the first and second labelers by a third labeler to form a second labeled dataset; labelling the compensation data with a semantic matcher to form a third labeled dataset; combining the first, second, and third labeled datasets into a final labeled dataset; and applying the final labeled dataset to a number of machine learning algorithms.
21. The computer program product according to claim 20, wherein machine learning algorithms comprise at least one of: naive Bayes; logistic regression; fully connected neural network; distributed random forest; gradient boosting machine; or XG boost.
22. The computer program product according to claim 19, wherein the transaction data is labeled according to code descriptions.
23. The computer program product according to claim 19, further comprising deriving, by a number of processors, a number of transaction patterns relative to the normalized codes.
24. The computer program product according to claim 23, wherein the transaction patterns comprise at least one of: employee ratio; compensation frequency; earning amount; job category; compensation rate type; employee seniority; working hours; and employee age.
25. The computer program product according to claim 19, wherein the normalized codes comprise at one of the following: pay codes; benefits codes; health care costs; or deduction codes.
26. The computer program product according to claim 19, wherein adjusting organizational operating procedures according to the normalized codes comprises at least one of: adjusting resource allocation; employee compensation setup.
27. The computer program product according to claim 19, further comprising benchmarking the organization according to the normalized codes and sector.
Description
BACKGROUND INFORMATION
1. Field
[0001] The present disclosure relates generally to an improved computer system and, in particular, to classifying and applying human resources data.
2. Background
[0002] Earning codes are very important in human capital management (HCM), especially for payroll transaction. Such codes typically denote the nature of compensation to employees and the circumstances giving rise to the compensation such as regular pay, overtime, sale commission, retirement, etc.
[0003] In addition to the nature of the compensation itself, payroll transactions can also be related to other human resources (HR) related parameters such as job category, position within an organization, tenure, etc.
[0004] Businesses generate large amounts of such payroll data, the data is typically not normalized and used to evaluate and refined business operations.
SUMMARY
[0005] An illustrative embodiment provides a computer-implemented method for classifying and applying human resources data. The method comprises aggregating employee transaction data for an organization and evaluating a number of human resources-related attributes across heterogeneous transaction data. The employee transaction data is classified via statistical machine learning into a number of normalized codes according to the human resources-related attributes, a user interface is presented to adjust a number of organizational operating procedures according to the normalized codes.
[0006] Another illustrative embodiment provides a system for classifying and applying human resources data. The system comprises a bus system, a storage device connected to the bus system, wherein the storage device stores program instructions, and a number of processors connected to the bus system, wherein the number of processors execute the program instructions to: aggregate employee transaction data for an organization; evaluate a number of human resources-related attributes across heterogeneous transaction data; classify, via statistical machine learning, the employee transaction data into a number of normalized codes according to the human resources-related attributes; and present a user interface to adjust a number of organizational operating procedures according to the normalized codes.
[0007] Another illustrative embodiment provides a computer program product for classifying and applying human resources data. The computer program product comprises a non-volatile computer readable storage medium having program instructions embodied therewith, the program instructions executable by a number of processors to cause the computer to perform the steps of: aggregating employee transaction data for an organization; evaluating a number of human resources-related attributes across heterogeneous transaction data; classifying, via statistical machine learning, the employee transaction data into a number of normalized codes according to the human resources-related attributes; and presenting a user interface to adjust a number of organizational operating procedures according to the normalized codes.
[0008] The features and functions can be achieved independently in various embodiments of the present disclosure or may be combined in yet other embodiments in which further details can be seen with reference to the following description and drawings.
BRIEF DESCRIPTION OF THE DRAWINGS
[0009] The novel features believed characteristic of the illustrative embodiments are set forth in the appended claims. The illustrative embodiments, however, as well as a preferred mode of use, further objectives and features thereof, will best be understood by reference to the following detailed description of an illustrative embodiment of the present disclosure when read in conjunction with the accompanying drawings, wherein:
[0010] FIG. 1 is an illustration of a block diagram of an information environment in accordance with an illustrative embodiment;
[0011] FIG. 2 is an illustration of a block diagram of a computer system for predictive modeling in accordance with an illustrative embodiment;
[0012] FIG. 3 is a diagram that illustrates a node in a neural network in which illustrative embodiments can be implemented;
[0013] FIG. 4 illustrates a process flow for labeled dataset construction in accordance with an illustrative embodiment;
[0014] FIG. 5 illustrates categorical inputs for earning code classification in accordance with illustrative embodiments;
[0015] FIGS. 6A-6D illustrate categorical outputs of earning code classification in accordance with illustrative embodiments;
[0016] FIG. 7 is a flowchart for a process of predictive modeling and classification of earning codes in accordance with an illustrative embodiment;
[0017] FIG. 8 illustrates a process flow for applying earning code data in accordance with an illustrative embodiment;
[0018] FIG. 9 depicts a graphical comparison of employee ratio versus earning code in accordance with an illustrative embodiment;
[0019] FIG. 10 depicts a graphical comparison of pay frequency versus earning code in accordance with an illustrative embodiment;
[0020] FIG. 11 depicts a graphical comparison of working hours versus earning code in accordance with an illustrative embodiment;
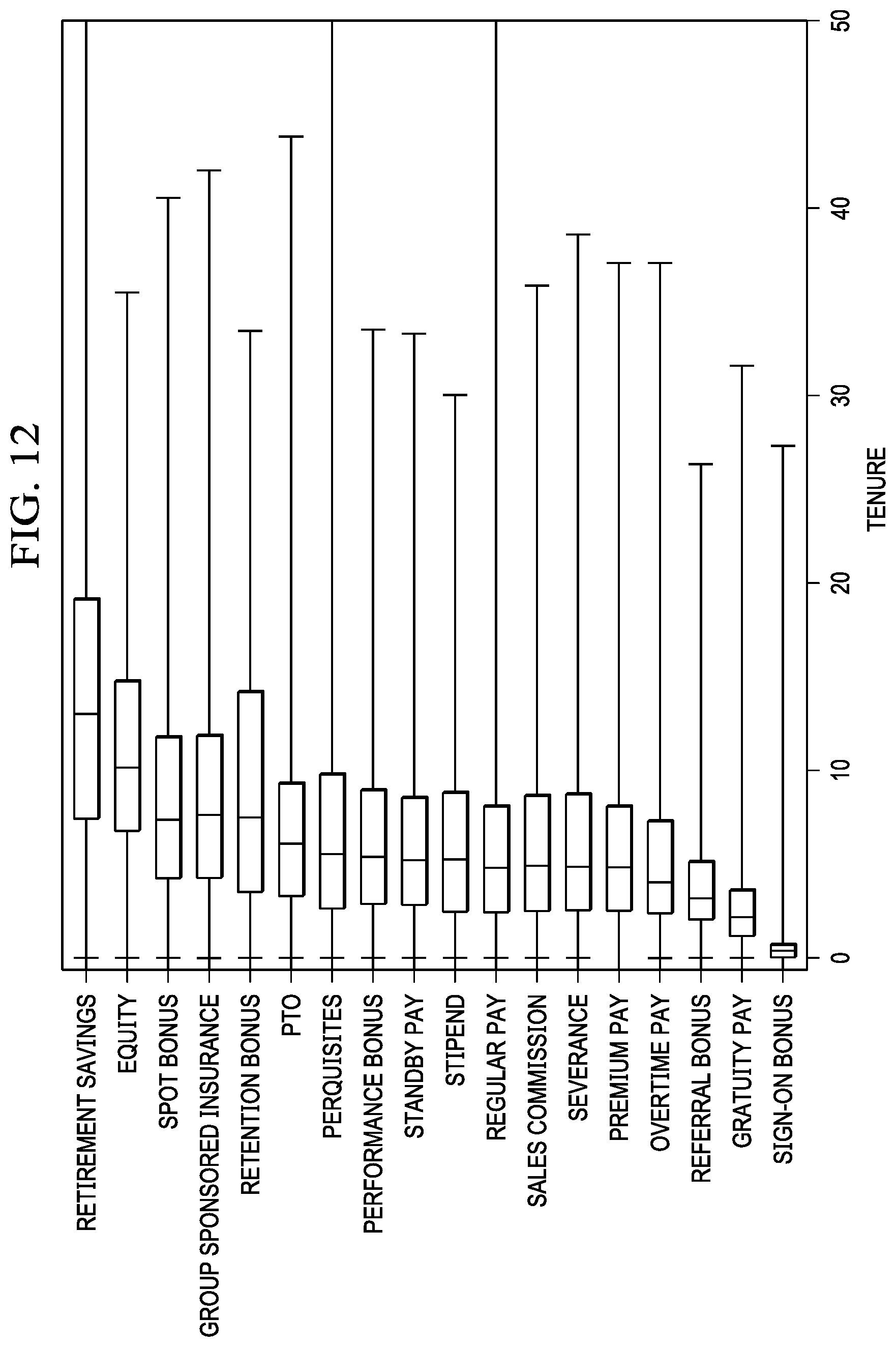
[0021] FIG. 12 depicts a graphical comparison of tenure versus earning code in accordance with an illustrative embodiment;
[0022] FIG. 13 depicts a graphical comparison of employee status versus earning code in accordance with an illustrative embodiment;
[0023] FIG. 14 depicts a graphical comparison of job category versus earning code in accordance with an illustrative embodiment; and
[0024] FIG. 15 is an illustration of a block diagram of a data processing system in accordance with an illustrative embodiment.
DETAILED DESCRIPTION
[0025] The illustrative embodiments recognize and take into account one or more different considerations. For example, the illustrative embodiments recognize and take into account that earning codes are very important to human capital management but that due to the nature of data generation and business operations, those earning codes are not cleaned and normalized with many variations.
[0026] Illustrative embodiments also recognize and take into account that though each single earning amount might be arbitrary, if the information is compressed per earning code, it provides a systematic view of pay patterns. From this, certain groups of features can be derived based on aggregation across all the earnings of each original earning code of a particular organization.
[0027] Illustrative embodiments provide a method to classify and normalize earning codes based on payroll information by using machine learning, which allows downstream applications such resource allocation in terms of earning codes, benchmarking results over detailed earning types, analytical reporting with respect to payroll, and payroll setup recommendations.
[0028] With reference now to the figures and, in particular, with reference to FIG. 1, an illustration of a diagram of a data processing environment is depicted in accordance with an illustrative embodiment. It should be appreciated that FIG. 1 is only provided as an illustration of one implementation and is not intended to imply any limitation with regard to the environments in which the different embodiments may be implemented. Many modifications to the depicted environments may be made.
[0029] The computer-readable program instructions may also be loaded onto a computer, a programmable data processing apparatus, or other device to cause a series of operational steps to be performed on the computer, a programmable apparatus, or other device to produce a computer implemented process, such that the instructions which execute on the computer, the programmable apparatus, or the other device implement the functions and/or acts specified in the flowchart and/or block diagram block or blocks.
[0030] FIG. 1 depicts a pictorial representation of a network of data processing systems in which illustrative embodiments may be implemented. Network data processing system 100 is a network of computers in which the illustrative embodiments may be implemented. Network data processing system 100 contains network 102, which is a medium used to provide communications links between various devices and computers connected together within network data processing system 100. Network 102 may include connections, such as wire, wireless communication links, or fiber optic cables.
[0031] In the depicted example, server computer 104 and server computer 106 connect to network 102 along with storage unit 108. In addition, client computers include client computer 110, client computer 112, and client computer 114. Client computer 110, client computer 112, and client computer 114 connect to network 102. These connections can be wireless or wired connections depending on the implementation. Client computer 110, client computer 112, and client computer 114 may be, for example, personal computers or network computers. In the depicted example, server computer 104 provides information, such as boot files, operating system images, and applications to client computer 110, client computer 112, and client computer 114. Client computer 110, client computer 112, and client computer 114 are clients to server computer 104 in this example. Network data processing system 100 may include additional server computers, client computers, and other devices not shown.
[0032] Program code located in network data processing system 100 may be stored on a computer-recordable storage medium and downloaded to a data processing system or other device for use. For example, the program code may be stored on a computer-recordable storage medium on server computer 104 and downloaded to client computer 110 over network 102 for use on client computer 110.
[0033] In the depicted example, network data processing system 100 is the Internet with network 102 representing a worldwide collection of networks and gateways that use the Transmission Control Protocol/Internet Protocol (TCP/IP) suite of protocols to communicate with one another. At the heart of the Internet is a backbone of high-speed data communication lines between major nodes or host computers consisting of thousands of commercial, governmental, educational, and other computer systems that route data and messages. Of course, network data processing system 100 also may be implemented as a number of different types of networks, such as, for example, an intranet, a local area network (LAN), or a wide area network (WAN). FIG. 1 is intended as an example, and not as an architectural limitation for the different illustrative embodiments.
[0034] The illustration of network data processing system 100 is not meant to limit the manner in which other illustrative embodiments can be implemented. For example, other client computers may be used in addition to or in place of client computer 110, client computer 112, and client computer 114 as depicted in FIG. 1. For example, client computer 110, client computer 112, and client computer 114 may include a tablet computer, a laptop computer, a bus with a vehicle computer, and other suitable types of clients.
[0035] In the illustrative examples, the hardware may take the form of a circuit system, an integrated circuit, an application-specific integrated circuit (ASIC), a programmable logic device, or some other suitable type of hardware configured to perform a number of operations. With a programmable logic device, the device may be configured to perform the number of operations. The device may be reconfigured at a later time or may be permanently configured to perform the number of operations. Programmable logic devices include, for example, a programmable logic array, programmable array logic, a field programmable logic array, a field programmable gate array, and other suitable hardware devices. Additionally, the processes may be implemented in organic components integrated with inorganic components and may be comprised entirely of organic components, excluding a human being. For example, the processes may be implemented as circuits in organic semiconductors.
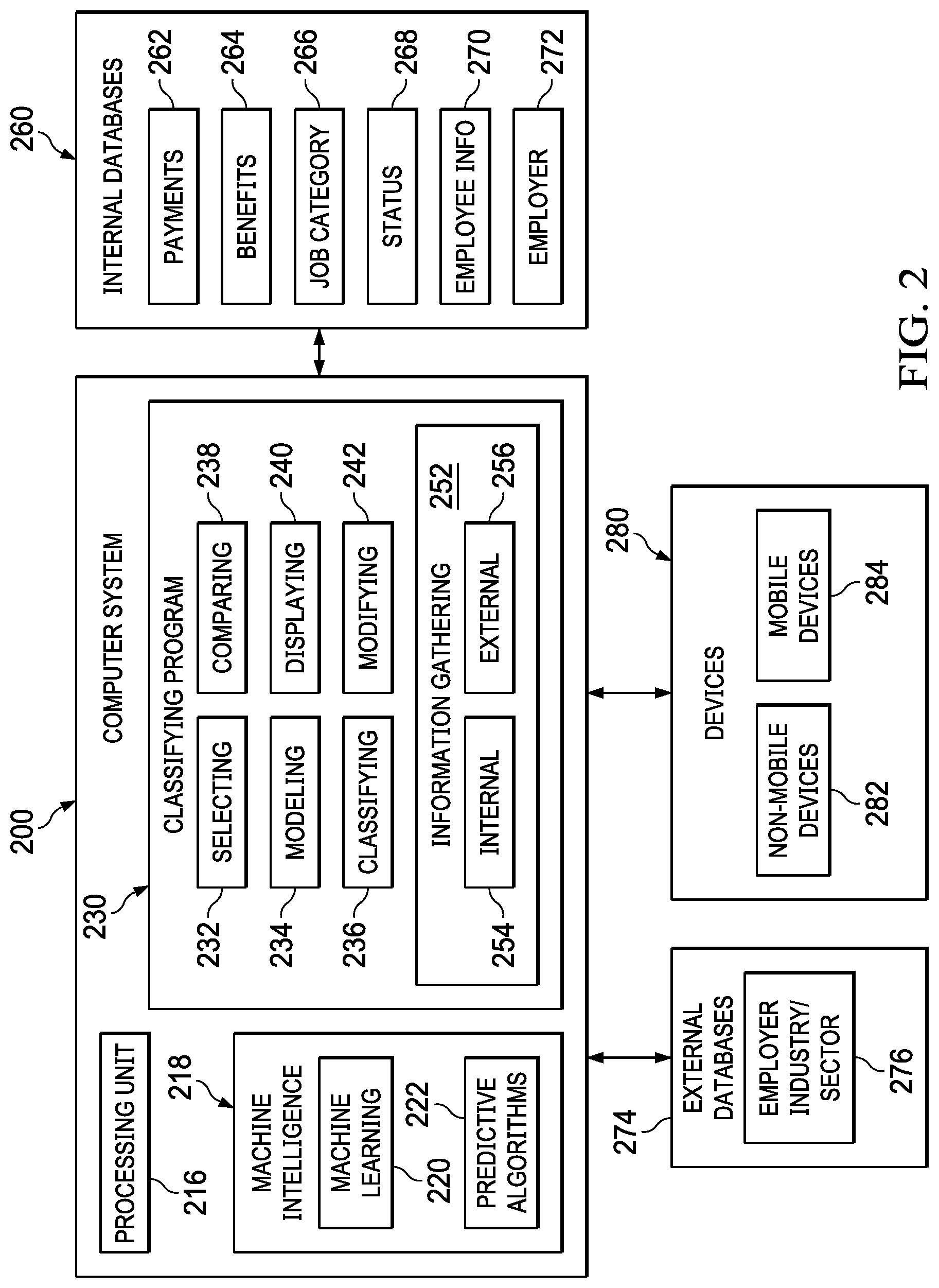
[0036] Turning to FIG. 2, a block diagram of a computer system for predictive modeling is depicted in accordance with an illustrative embodiment. Computer system 200 is connected to internal databases 260, external databases 274 and devices 280. Internal databases 260 comprise HR data such as payments 262, benefits 264, job category 266, employee status 268 (i.e. salaried versus hourly), employee information 720 (e.g., age, tenured, etc.), and employer information 272. External databases 274 comprise employer industry/sector 276, which can be used for benchmarking. Devices 280 comprise non-mobile devices 282 and mobile devices 284.
[0037] Computer system 200 comprises information processing unit 216, machine intelligence 218, and classifying program 230. Machine intelligence 218 comprises machine learning 220 and predictive algorithms 222.
[0038] Machine intelligence 218 can be implemented using one or more systems such as an artificial intelligence system, a neural network, a Bayesian network, an expert system, a fuzzy logic system, a genetic algorithm, or other suitable types of systems. Machine learning 220 and predictive algorithms 222 may make computer system 200 a special purpose computer for dynamic predictive modelling of the probability of financial stress.
[0039] In an embodiment, processing unit 216 comprises one or more conventional general purpose central processing units (CPUs). In an alternate embodiment, processing unit 216 comprises one or more graphical processing units (GPUs). Though originally designed to accelerate the creation of images with millions of pixels whose frames need to be continually recalculated to display output in less than a second, GPUs are particularly well suited to machine learning. Their specialized parallel processing architecture allows them to perform many more floating point operations per second then a CPU, on the order of 100.times. more. GPUs can be clustered together to run neural networks comprising hundreds of millions of connection nodes.
[0040] Classifying program 230 comprises information gathering 252, selecting 232, modeling 234, classifying 236, comparing 238, displaying 240, and modifying 242. Information gathering 252 comprises internal 254 and external 256. Internal 254 is configured to gather data from internal databases 260. External 256 is configured to gather data from external databases 274.
[0041] Thus, processing unit 216, machine intelligence 218, and classifying program 230 transform a computer system into a special purpose computer system as compared to currently available general computer systems that do not have a means to perform machine learning predictive modeling such as computer system 200 of FIG. 2. Currently used general computer systems do not have a means to accurately predict and compare the probability of financial stress without pulling credit bureau data.
[0042] There are three main categories of machine learning: supervised, unsupervised, and reinforcement learning. Supervised machine learning comprises providing the machine with training data and the correct output value of the data. During supervised learning the values for the output are provided along with the training data (labeled dataset) for the model building process. The algorithm, through trial and error, deciphers the patterns that exist between the input training data and the known output values to create a model that can reproduce the same underlying rules with new data. Examples of supervised learning algorithms include regression analysis, decision trees, k-nearest neighbors, neural networks, and support vector machines.
[0043] If unsupervised learning is used, not all of the variables and data patterns are labeled, forcing the machine to discover hidden patterns and create labels on its own through the use of unsupervised learning algorithms. Unsupervised learning has the advantage of discovering patterns in the data with no need for labeled datasets. Examples of algorithms used in unsupervised machine learning include k-means clustering, association analysis, and descending clustering.
[0044] Whereas supervised and unsupervised methods learn from a dataset, reinforcement learning methods learn from feedback to re-learn/retrain the models. Algorithms are used to train the predictive model through interacting with the environment using measurable performance criteria.
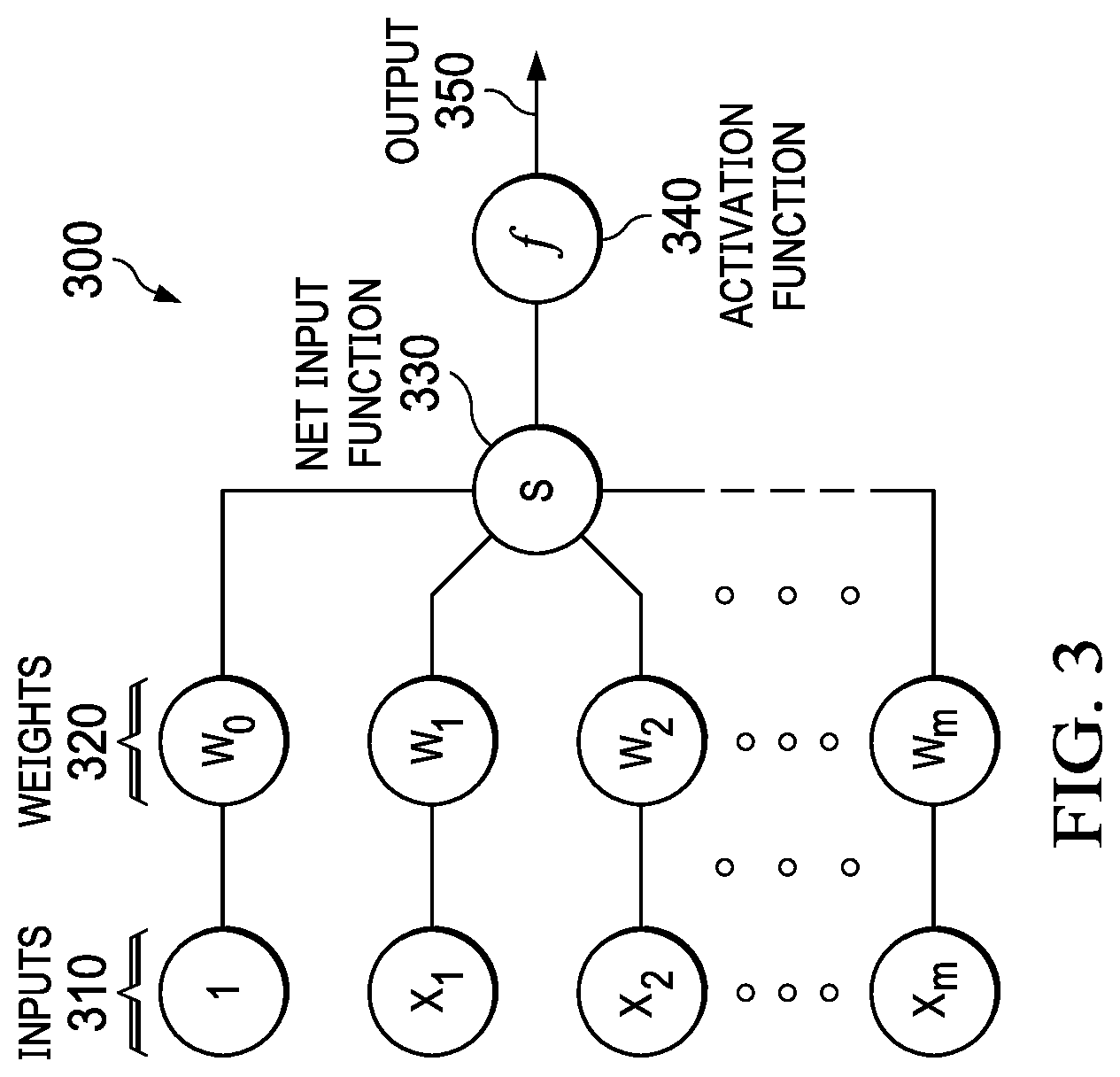
[0045] FIG. 3 is a diagram that illustrates a node in a neural network in which illustrative embodiments can be implemented. Node 300 combines multiple inputs 310 from other nodes. Each input 310 is multiplied by a respective weight 320 that either amplifies or dampens that input, thereby assigning significance to each input for the task the algorithm is trying to learn. The weighted inputs are collected by a net input function 330 and then passed through an activation function 340 to determine the output 350. The connections between nodes are called edges. The respective weights of nodes and edges might change as learning proceeds, increasing or decreasing the weight of the respective signals at an edge. A node might only send a signal if the aggregate input signal exceeds a predefined threshold. Pairing adjustable weights with input features is how significance is assigned to those features with regard to how the network classifies and clusters input data.
[0046] Neural networks are often aggregated into layers, with different layers performing different kinds of transformations on their respective inputs. A node layer is a row of nodes that turn on or off as input is fed through the network. Signals travel from the first (input) layer to the last (output) layer, passing through any layers in between. Each layer's output acts as the next layer's input.
[0047] Stochastic neural networks are a type of network that incorporate random variables, which makes them well suited for optimization problems. This is done by giving the nodes in the network stochastic (randomly determined) weights or transfer functions. A Boltzmann machine is a type of stochastic neural network in which each node is binary valued, and the chance of it firing depends on the other nodes in the network. Each node is a locus of computation that processes an input and begins by making stochastic decisions about whether to transmit that input or not. The weights (coefficients) that modify inputs are randomly initialized.
[0048] It should be emphasized that using neural network-based algorithms is merely an example of one implementation of the illustrative embodiments. Illustrative embodiments can also employ other algorithms such as Random Forest, Gradient-based Machine, XGBoost, etc.
[0049] In machine learning, a cost function estimates how the model is performing. It is a measure of how wrong the model is in terms of its ability to estimate the relationship between input x and output y. This is expressed as a difference or distance between the predicted value and the actual value. The cost function (i.e. loss or error) can be estimated by iteratively running the model to compare estimated predictions against known values of y during supervised learning. The objective of a machine learning model, therefore, is to find parameters, weights, or a structure that minimizes the cost function.
[0050] Gradient descent is an optimization algorithm that attempts to find a local or global minima of a function, thereby enabling the model to learn the gradient or direction that the model should take in order to reduce errors. As the model iterates, it gradually converges towards a minimum where further tweaks to the parameters produce little or zero changes in the loss. At this point the model has optimized the weights such that they minimize the cost function.
[0051] Neural networks can be stacked to created deep networks. After training one neural net, the activities of its hidden nodes can be used as training data for a higher level, thereby allowing stacking of neural networks. Such stacking makes it possible to efficiently train several layers of hidden nodes. Examples of stacked networks include deep belief networks (DBN), deep Boltzmann machines (DBM), convolutional neural networks (CNN), recurrent neural networks (RNN), and spiking neural networks (SNN).
[0052] FIG. 4 illustrates a process flow for labeled dataset construction in accordance with an illustrative embodiment. Sufficient labeled data of good quality is critical for supervised machine learning. The sources from which payroll transaction data is derived contains certain information such as earning code descriptions, which is highly indicative in terms of normalized earning types. Those descriptions are used as seed information to build a labeled dataset. FIG. 4 is an example of supervised machine learning.
[0053] The process begins with two independent labelers 402 and 404 conducting semi-manual labelling in accordance with expert payroll categories. In this process, automated matching is used to process the initial pool (which is too large for a human to sift) to find likely candidates, which are then manually verified. Such a heuristic matching process has high precision. Each labeler 402, 404 produces an independent preliminary dataset D1 406 and D2 408, respectively, which are compared with each other.
[0054] Data points that are in agreement between D1 402 and D2 406 are added to a first labeled dataset L1 410.
[0055] Discrepancies between the labelers 402, 404 are added to a third preliminary dataset D3 412, which is then resolved by a third independent labeler 414 to produce a second labeled dataset L2 416.
[0056] An unsupervised semantic matcher 418 produces a third preliminary dataset D3 420, which is verified by a labeler 422 to create a third labeled dataset L3 424.
[0057] A final labeled dataset L 426 is generated by combining L1, L2, and L3 by applying quality control to the labeled dataset to remove outliers. This final labeled dataset 426 provides sufficient labeled sample for training and evaluating classifiers during machine learning 428, explained below.
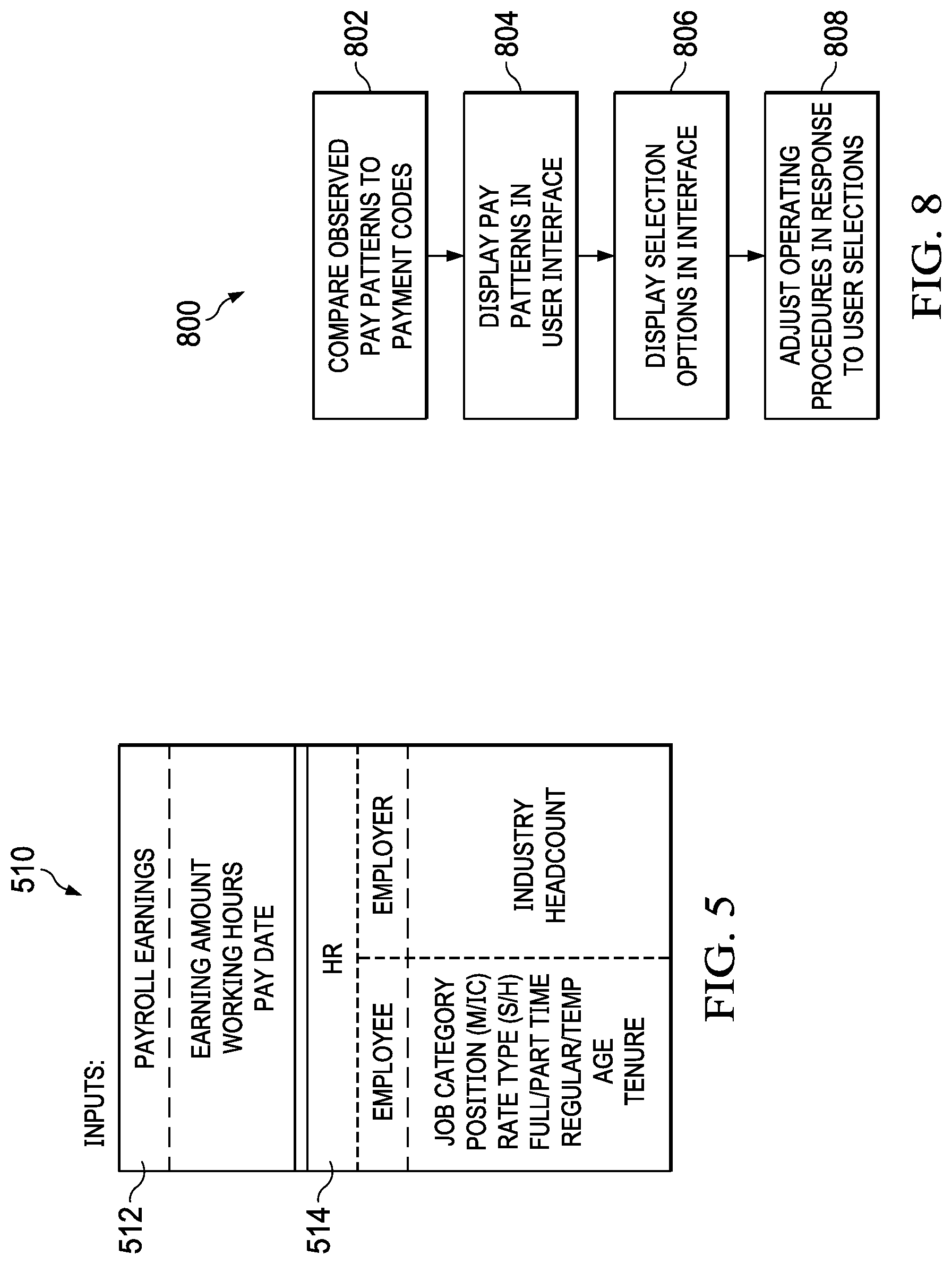
[0058] FIG. 5 illustrates categorical inputs for earning code classification in accordance with illustrative embodiments. The inputs 510 include information about payments made to employees and the conditions under which those payments are made. In the present example, payroll earnings data 512 includes earning amount, working hours, and pay date. In addition, HR attributes 514 are includes which include employee information such as job category, position, rate type (salary/hourly), full or part time status, age, and tenure. HR attributes 514 can also include information about the employer such as industry and employee headcount (size).
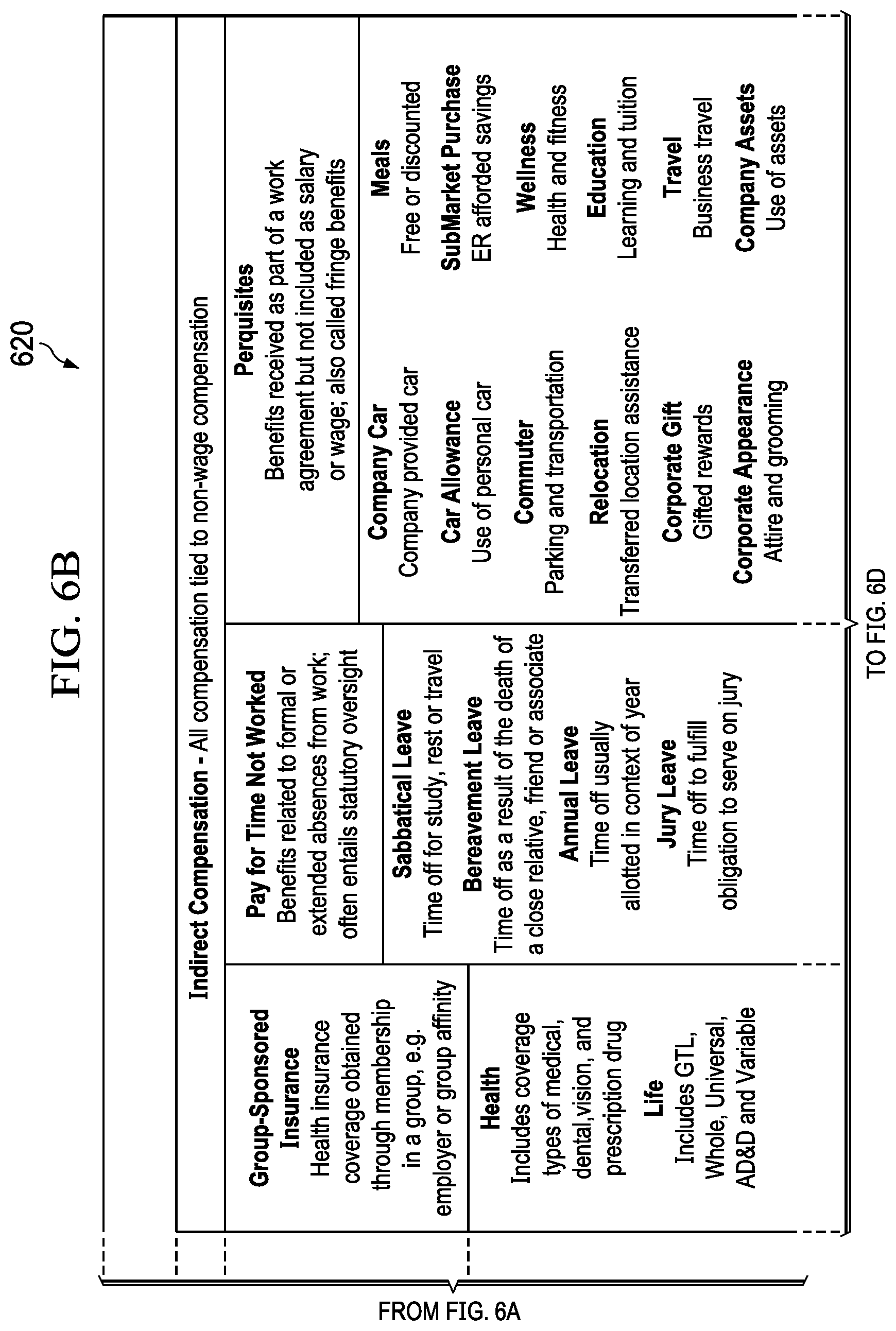
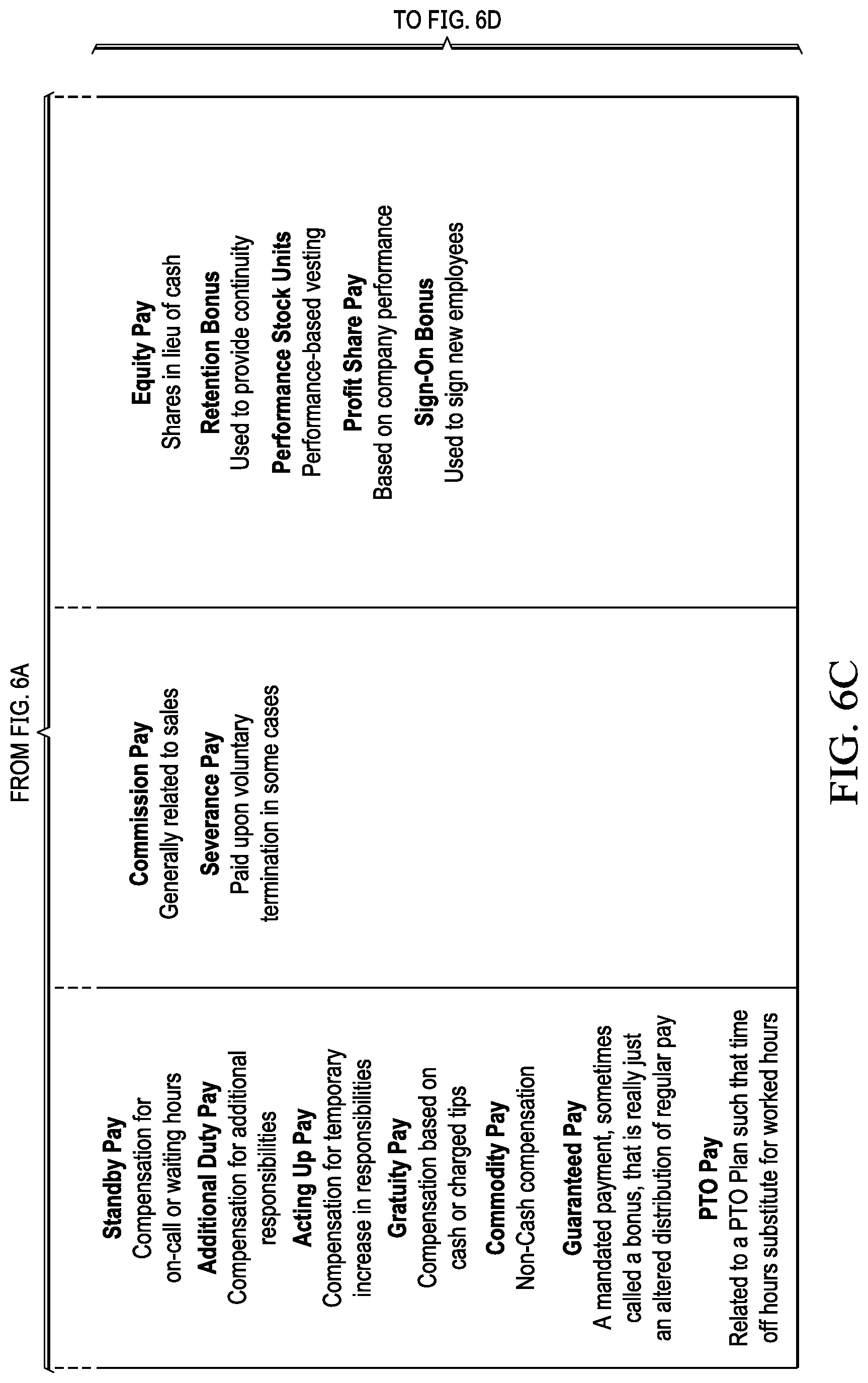
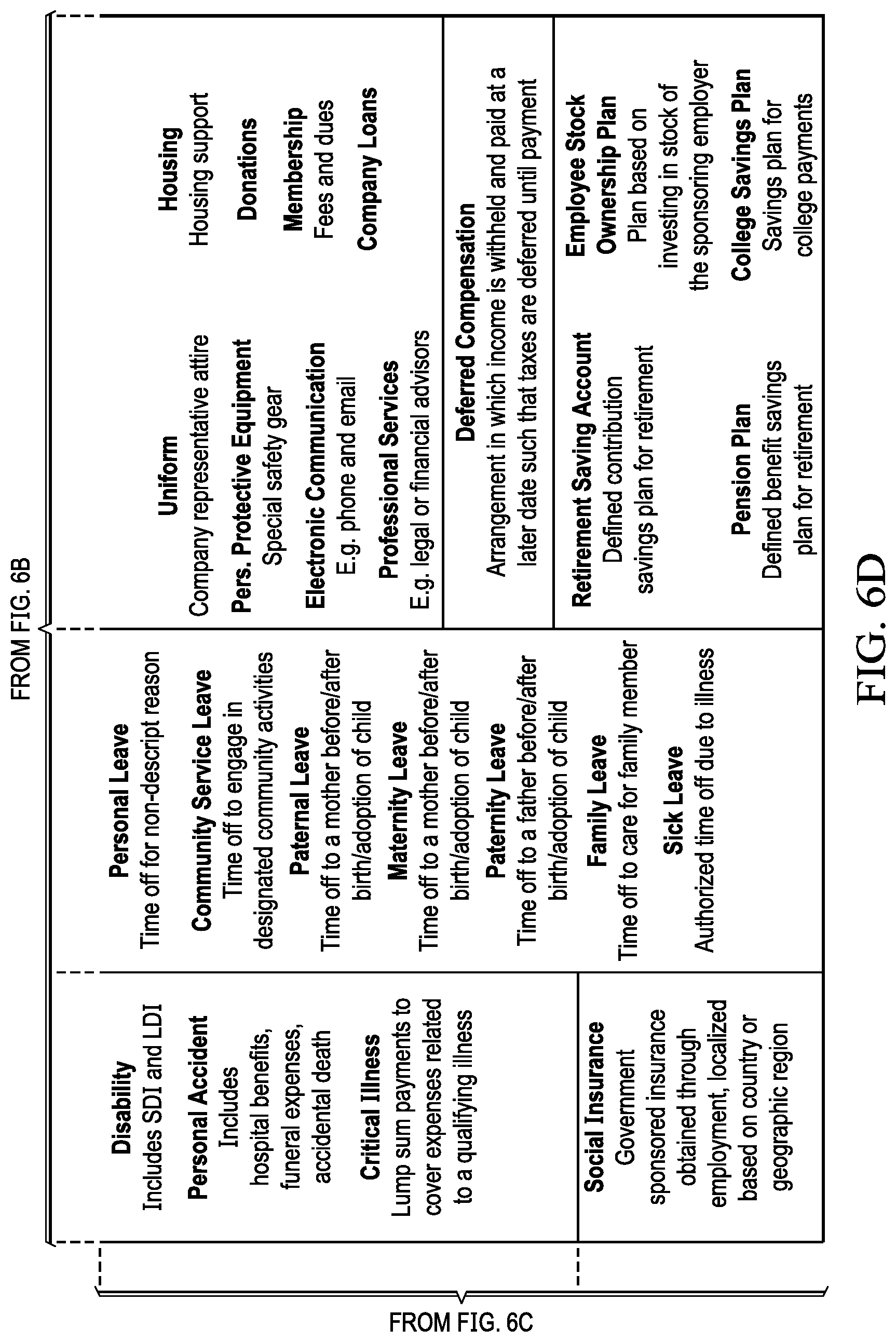
[0059] FIGS. 6A-6D illustrate categorical outputs of earning code classification in accordance with illustrative embodiments.
[0060] When employee payroll transaction data is evaluated in terms of the HR attributes, the resulting output 620 classifies the payroll data into normalized earning codes. In the illustrated example, payroll data is classified into 19 earning codes. However, fewer or greater numbers of codes can be used. A few examples of earning codes include: regular pay associated with regular salary or regular hours worked, overtime pay, paid time off (PTO) such as vacations and sick leave, standby pay associated with inactive periods such as on-call duties, sales commissions, equity, perquisites such as transportation and housing allowances, and retirement.
[0061] Turning to FIG. 7, a flowchart for a process of predictive modeling and classification of earning codes is depicted in accordance with an illustrative embodiment. Process 700 can be implemented in software, hardware, or a combination of the two.
[0062] Process 700 begins by aggregating employee payroll and other transaction data (step 702). After the dataset is aggregated, process 700 scrubs and labels the dataset (step 704). Very large datasets, sometimes referred to as Big Data, often contain noise and complicated data structures. Bordering on the order of petabytes, such datasets comprise a variety, volume, and velocity (rate of change) that defies conventional processing and is impossible for a human to process without advanced machine assistance. Scrubbing refers to the process of refining the dataset before using it to build a predictive model and includes modifying and/or removing incomplete data or data with little predictive value. The dataset can be scrubbed and labeled using the process depicted in FIG. 5.
[0063] After the dataset has been scrubbed and labeled, process 700 divides the data into training, validation, and test datasets to be used for building and testing the predictive model (step 706). To produce optimal results, the same data that is used to test the model should not be the same data used for training. The data is divided with 80% used for training, 10% used for validation, and 10% used for testing. Randomizing the selection of the datasets avoids bias in the model.
[0064] Process 700 then performs iterative analysis on the training date by applying predictive algorithms to construct a predictive model (step 708). Examples of algorithms that can be used include Naive Bayes (NB), Logistic Regression (LR), Fully Connected Neural-Network-based model (NN), and tree-based models such as Distributed Random Forest (DRF), Gradient Boosting Machine (GBM), and XG Boost (XGB). XGB in particular has the advantage of using regularization terms to penalize overfitting and adopts the second-order optimization algorithm.
[0065] As the model is being constructed, it is periodically validated using the validation dataset (step 710). This provides an unbiased evaluation of a model fit on the training dataset. The validation dataset can also play a role in other area of model construction such as feature selection.
[0066] If the model does not adequately fit the training dataset, the process tunes the hyperparameters of the model (step 712). Hyperparameters are the settings of the algorithm that control how fast the model learns patterns and which patterns to identify and analyze.
[0067] After the model is constructed, the test data is fed into model to test its accuracy (step 714). In an embodiment the model is tested using mean absolute error, which examines each prediction in the model and provides an average error score for each prediction. If the error rate between the training and test dataset is below a predetermined threshold, the model has learned the dataset's pattern and passed the test.
[0068] If the model fails the test the training, validation, and test data are re-randomized, and the iterative analysis of the training data is repeated (step 716). Once a model has passed the test stage it is ready for application.
[0069] Whereas supervised and unsupervised learning reach an endpoint after a predictive model is constructed and passes the test in step 714, reinforcement learning continuously improves its model using feedback from application to new empirical data. Algorithms such as Q-learning are used to train the predictive model through continuous learning using measurable performance criteria (discussed in more detail below).
[0070] After the model is constructed and tested for accuracy, process 700 uses the model to classify the payroll data into normalized earning codes (step 718).
[0071] After the data has been classified, process 700 compares observed pay patterns to the earning codes (step 720).
[0072] FIG. 8 illustrates a process flow for applying earning code data in accordance with an illustrative embodiment. Process 800 begins by comparing pay patterns to payment codes (step 802). The different pay patterns are displayed on a user interface (step 804). Examples of displays of pay patterns versus earning are shown in FIGS. 9-14.
[0073] The interface also displays selection options regarding organization procedures that are related to the pay patterns in question (step 806). Examples of such procedures include payroll set up options, allocation of resources, work schedules, the ratio of salaried versus hourly employees assigned to a task, perquisite budgets, etc. In response to input of user selections, the HR system will adjust the operating procedures of the company (step 808).
[0074] FIG. 9 depicts a graphical comparison of employee ratio versus earning code in accordance with an illustrative embodiment. Employee ratio is a very strong indicator to differentiate special payments (e.g., severance, equity) from more common payments (e.g., regular pay, PTO). The employee ratio is calculated as the percentage of employees with that particular earning code over all of the employees in the organization. Intuitively, payments like regular pay or overtime pay could be much more popular than other payments like equity or severance.
[0075] FIG. 10 depicts a graphical comparison of pay frequency versus earning code in accordance with an illustrative embodiment. Pay frequency estimates how frequently each earning code will appear in a 12-month payroll history. For example, regular pay might appear very frequently on each paycheck, while performance bonus like an annual bonus might only appear once a year.
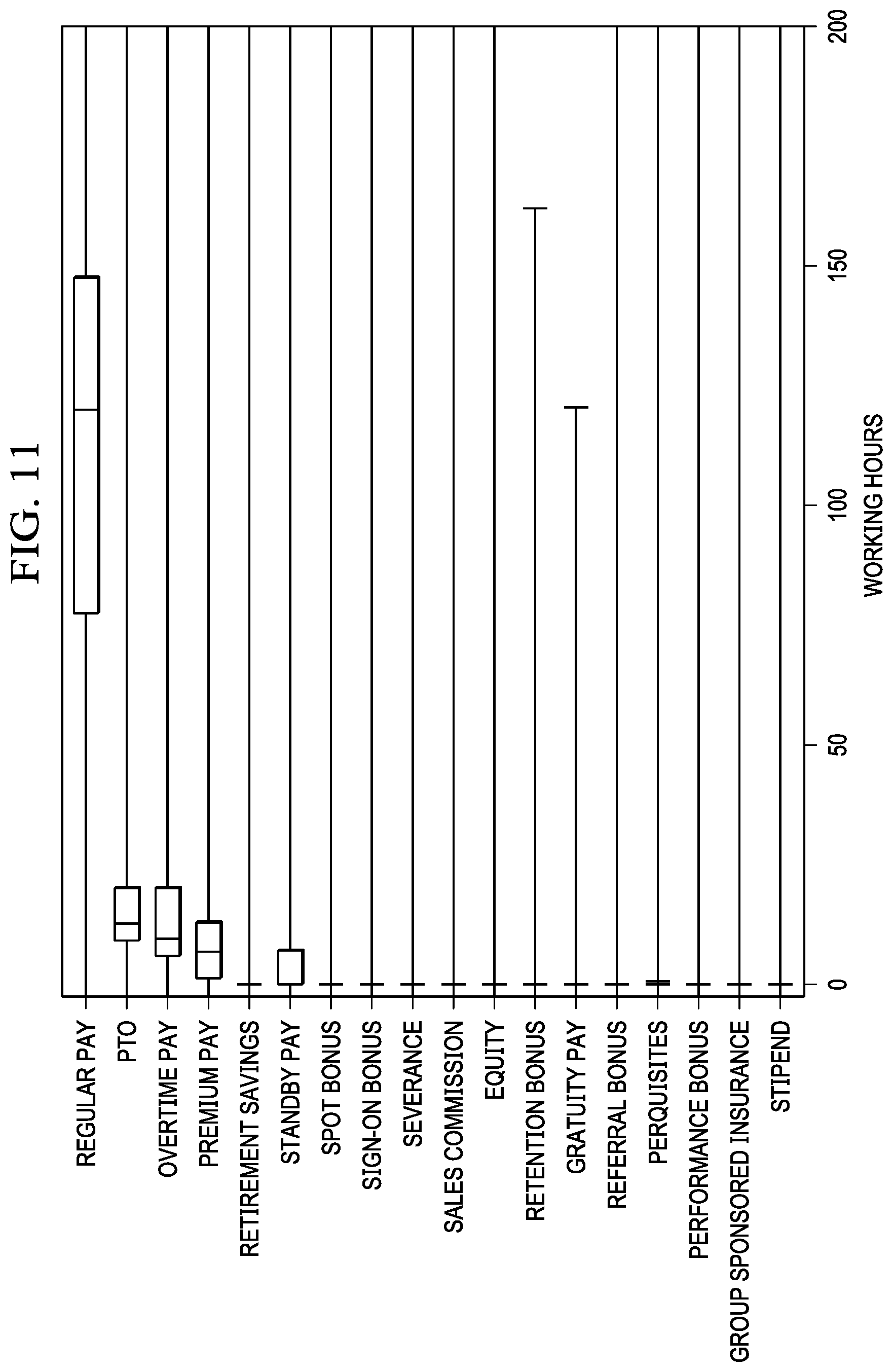
[0076] FIG. 11 depicts a graphical comparison of working hours versus earning code in accordance with an illustrative embodiment. This graph illustrates that payments like regular ray and PTO are estimated based on hours worked while most other types of payments are not associated with working hours such as performance bonuses or stipends.
[0077] FIG. 12 depicts a graphical comparison of tenure versus earning code in accordance with an illustrative embodiment. Seniority can also help to differentiate certain types of earning codes. Using tenure as an example, the value is much smaller for sign-on bonus compared to other types, whereas retention bonuses and retirement savings increase with increasing tenure.
[0078] FIG. 13 depicts a graphical comparison of employee status versus earning code in accordance with an illustrative embodiment. In this example, only the differences between salaried employees and hourly employees are shown in terms of employee status. However, this model uses much more information than that. For example, factors such fulltime/part-time, managerial/individual-contributor indicator, etc. are also taken into account.
[0079] FIG. 14 depicts a graphical comparison of job category versus earning code in accordance with an illustrative embodiment. As can be seen, employees with different job characteristics are clearly associated with different pay patterns. For example, there are more equity payments for salaried employees and more gratuity payments for the hourly employees. Similarly, there are more sales commission payments for the sales workers and more tips payments for the service workers.
[0080] Turning now to FIG. 15, an illustration of a block diagram of a data processing system is depicted in accordance with an illustrative embodiment. Data processing system 1500 may be used to implement one or more computers and client computer system 112 in FIG. 1. In this illustrative example, data processing system 1500 includes communications framework 1502, which provides communications between processor unit 1504, memory 1506, persistent storage 1508, communications unit 1510, input/output unit 1512, and display 1514. In this example, communications framework 1502 may take the form of a bus system.
[0081] Processor unit 1504 serves to execute instructions for software that may be loaded into memory 1506. Processor unit 1504 may be a number of processors, a multi-processor core, or some other type of processor, depending on the particular implementation. In an embodiment, processor unit 1504 comprises one or more conventional general purpose central processing units (CPUs). In an alternate embodiment, processor unit 1504 comprises one or more graphical processing units (CPUs).
[0082] Memory 1506 and persistent storage 1508 are examples of storage devices 1516. A storage device is any piece of hardware that is capable of storing information, such as, for example, without limitation, at least one of data, program code in functional form, or other suitable information either on a temporary basis, a permanent basis, or both on a temporary basis and a permanent basis. Storage devices 1516 may also be referred to as computer-readable storage devices in these illustrative examples. Memory 1516, in these examples, may be, for example, a random access memory or any other suitable volatile or non-volatile storage device. Persistent storage 1508 may take various forms, depending on the particular implementation.
[0083] For example, persistent storage 1508 may contain one or more components or devices. For example, persistent storage 1508 may be a hard drive, a flash memory, a rewritable optical disk, a rewritable magnetic tape, or some combination of the above. The media used by persistent storage 1508 also may be removable. For example, a removable hard drive may be used for persistent storage 1508. Communications unit 1510, in these illustrative examples, provides for communications with other data processing systems or devices. In these illustrative examples, communications unit 1510 is a network interface card.
[0084] Input/output unit 1512 allows for input and output of data with other devices that may be connected to data processing system 1500. For example, input/output unit 1512 may provide a connection for user input through at least one of a keyboard, a mouse, or some other suitable input device. Further, input/output unit 1512 may send output to a printer. Display 1514 provides a mechanism to display information to a user.
[0085] Instructions for at least one of the operating system, applications, or programs may be located in storage devices 1516, which are in communication with processor unit 1504 through communications framework 1502. The processes of the different embodiments may be performed by processor unit 1504 using computer-implemented instructions, which may be located in a memory, such as memory 1506.
[0086] These instructions are referred to as program code, computer-usable program code, or computer-readable program code that may be read and executed by a processor in processor unit 1504. The program code in the different embodiments may be embodied on different physical or computer-readable storage media, such as memory 1506 or persistent storage 1508.
[0087] Program code 1518 is located in a functional form on computer-readable media 1520 that is selectively removable and may be loaded onto or transferred to data processing system 1500 for execution by processor unit 1504. Program code 1518 and computer-readable media 1520 form computer program product 1522 in these illustrative examples. In one example, computer-readable media 1520 may be computer-readable storage media 1524 or computer-readable signal media 1526.
[0088] In these illustrative examples, computer-readable storage media 1524 is a physical or tangible storage device used to store program code 1518 rather than a medium that propagates or transmits program code 1518. Alternatively, program code 1518 may be transferred to data processing system 1500 using computer-readable signal media 1526.
[0089] Computer-readable signal media 1526 may be, for example, a propagated data signal containing program code 1518. For example, computer-readable signal media 1526 may be at least one of an electromagnetic signal, an optical signal, or any other suitable type of signal. These signals may be transmitted over at least one of communications links, such as wireless communications links, optical fiber cable, coaxial cable, a wire, or any other suitable type of communications link.
[0090] The different components illustrated for data processing system 1500 are not meant to provide architectural limitations to the manner in which different embodiments may be implemented. The different illustrative embodiments may be implemented in a data processing system including components in addition to or in place of those illustrated for data processing system 1500. Other components shown in FIG. 15 can be varied from the illustrative examples shown. The different embodiments may be implemented using any hardware device or system capable of running program code 1518.
[0091] As used herein, the phrase "a number" means one or more. The phrase "at least one of", when used with a list of items, means different combinations of one or more of the listed items may be used, and only one of each item in the list may be needed. In other words, "at least one of" means any combination of items and number of items may be used from the list, but not all of the items in the list are required. The item may be a particular object, a thing, or a category.
[0092] For example, without limitation, "at least one of item A, item B, or item C" may include item A, item A and item B, or item C. This example also may include item A, item B, and item C or item B and item C. Of course, any combinations of these items may be present. In some illustrative examples, "at least one of" may be, for example, without limitation, two of item A; one of item B; and ten of item C; four of item B and seven of item C; or other suitable combinations.
[0093] The flowcharts and block diagrams in the different depicted embodiments illustrate the architecture, functionality, and operation of some possible implementations of apparatuses and methods in an illustrative embodiment. In this regard, each block in the flowcharts or block diagrams may represent at least one of a module, a segment, a function, or a portion of an operation or step. For example, one or more of the blocks may be implemented as program code.
[0094] In some alternative implementations of an illustrative embodiment, the function or functions noted in the blocks may occur out of the order noted in the figures. For example, in some cases, two blocks shown in succession may be performed substantially concurrently, or the blocks may sometimes be performed in the reverse order, depending upon the functionality involved. Also, other blocks may be added in addition to the illustrated blocks in a flowchart or block diagram.
[0095] The description of the different illustrative embodiments has been presented for purposes of illustration and description and is not intended to be exhaustive or limited to the embodiments in the form disclosed. The different illustrative examples describe components that perform actions or operations. In an illustrative embodiment, a component may be configured to perform the action or operation described. For example, the component may have a configuration or design for a structure that provides the component an ability to perform the action or operation that is described in the illustrative examples as being performed by the component. Many modifications and variations will be apparent to those of ordinary skill in the art. Further, different illustrative embodiments may provide different features as compared to other desirable embodiments. The embodiment or embodiments selected are chosen and described in order to best explain the principles of the embodiments, the practical application, and to enable others of ordinary skill in the art to understand the disclosure for various embodiments with various modifications as are suited to the particular use contemplated.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012

D00013
D00014
D00015

D00016

D00017

XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.