Financial Documents Examination Methods And Systems
Shah; Naman ; et al.
U.S. patent application number 15/729645 was filed with the patent office on 2020-09-24 for financial documents examination methods and systems. The applicant listed for this patent is Sentieo, Inc.. Invention is credited to Rajdeep Singh Gill, Jed GORE, Jitender Khatri, Vaibhav Negi, Anurag Saxena, Atul Shah, Naman Shah.
| Application Number | 20200302392 15/729645 |
| Document ID | / |
| Family ID | 1000004917387 |
| Filed Date | 2020-09-24 |






View All Diagrams
| United States Patent Application | 20200302392 |
| Kind Code | A1 |
| Shah; Naman ; et al. | September 24, 2020 |
FINANCIAL DOCUMENTS EXAMINATION METHODS AND SYSTEMS
Abstract
A user is able to extract financial data, particularly tables, from a document. The table is stored and the user can compare the data in this table with data from similar tables from previous documents. The user can see how financial data has changed historically by looking only at financial tables from the same type of document, for example, only balance sheet tables from annual reports for a specific public company, over many years, and see how the values have changed or whether any new categories or types of data have been added or deleted. From the time series of financial data, the user can gain real intelligence into an entity's financial health.
| Inventors: | Shah; Naman; (Indian Harbor Beach, FL) ; Shah; Atul; (Indian Harbor Beach, FL) ; Saxena; Anurag; (Paschim Vihar, IN) ; GORE; Jed; (Greenwich, CT) ; Khatri; Jitender; (Punjab Khore Delhi, IN) ; Negi; Vaibhav; (DELHI, IN) ; Gill; Rajdeep Singh; (New Delhi, IN) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 1000004917387 | ||||||||||
| Appl. No.: | 15/729645 | ||||||||||
| Filed: | October 10, 2017 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 62405828 | Oct 7, 2016 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06Q 40/02 20130101; G06Q 10/10 20130101; G06F 16/316 20190101; G06F 40/242 20200101; G06Q 40/12 20131203; G06F 16/93 20190101; G06F 40/205 20200101 |
| International Class: | G06Q 10/10 20060101 G06Q010/10; G06Q 40/02 20060101 G06Q040/02; G06Q 40/00 20060101 G06Q040/00; G06F 16/93 20060101 G06F016/93; G06F 16/31 20060101 G06F016/31; G06F 40/205 20060101 G06F040/205; G06F 40/242 20060101 G06F040/242 |
Claims
1. A method of extracting financial data from a document and analyzing similar financial data from older documents to enhance understanding of the document, the method comprising: inputting a document containing unstructured data; identifying tables and data structures in the document and extracting said tables using a parsing engine; converting tables into dictionaries; verifying that data in a table is financial data and storing dictionaries for valid financial data tables; creating a time series for a selected table wherein a row-based matching algorithm is used to identify similar tables; and storing a time series for a selected table wherein said time series is utilized to examine changes in financial data over time.
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application claims priority to provisional application No. 62/405,828, filed Oct. 7, 2016, which is incorporated herein by reference for all purposes.
BACKGROUND OF THE INVENTION
1. Field of the Invention
[0002] The present invention relates to financial software. More specifically, the invention relates to software for analyzing similar financial data from multiple documents over time thereby gaining insights into the financial data.
2. Description of the Related Art
[0003] Current financial and corporate document examination software platforms lack efficient and intuitive features for their users, and do not possess the ability to process unstructured financial data into coherent structures. The user experience for many of these tools do not facilitate quick and in-depth analysis of financial and corporate data, particularly in the instance where such data are contained in free form text, or in data tables that are specific to an industry or a single company. Users are therefore prevented from gaining meaningful insights into what the numbers and statements contained in these financial and corporate documents mean. There is, effectively, an "intelligence-gathering" limit that is reached with current tools. What is needed is a platform for facilitating analysis of similar and sometimes unstructured financial data over a period of time so that changes and trends can be easily detected.
BRIEF DESCRIPTION OF THE DRAWINGS
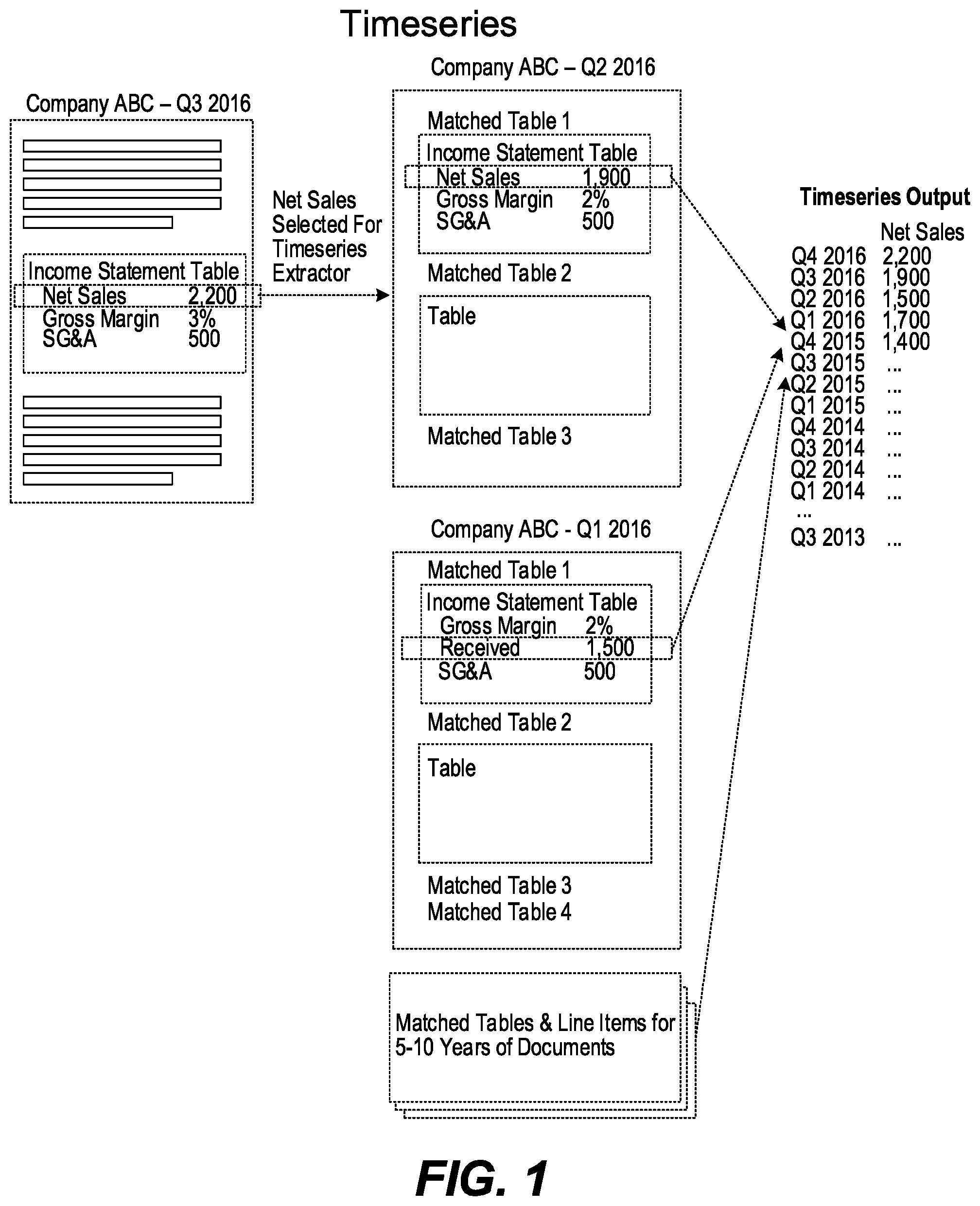
[0004] FIG. 1 is a high-level diagram of a time series feature in accordance with one embodiment;
[0005] FIG. 2 shows a financial table with a column of marks along the left side for each row and a row of marks at the top of the table;
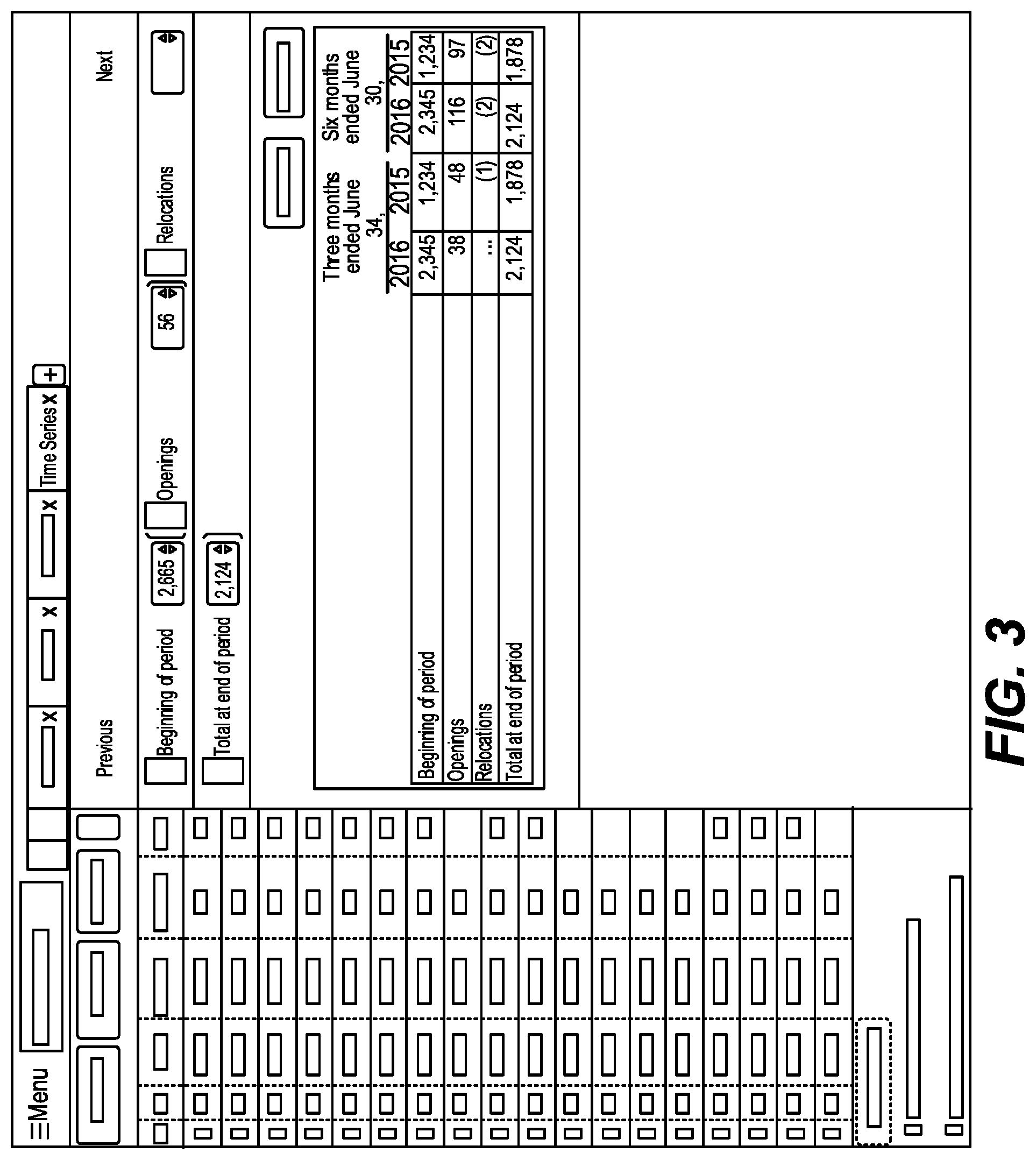
[0006] FIG. 3 is a screenshot showing how auditing modifies the table on the right pane to display a source table from an original document in accordance with one embodiment;
[0007] FIG. 4 is a block diagram showing a high-level view of similar tables;
[0008] FIG. 5 shows a screenshot when a user clicks Similar Tables in a document and showing tables from five years of quarterly filings and presenting in a split screen view;
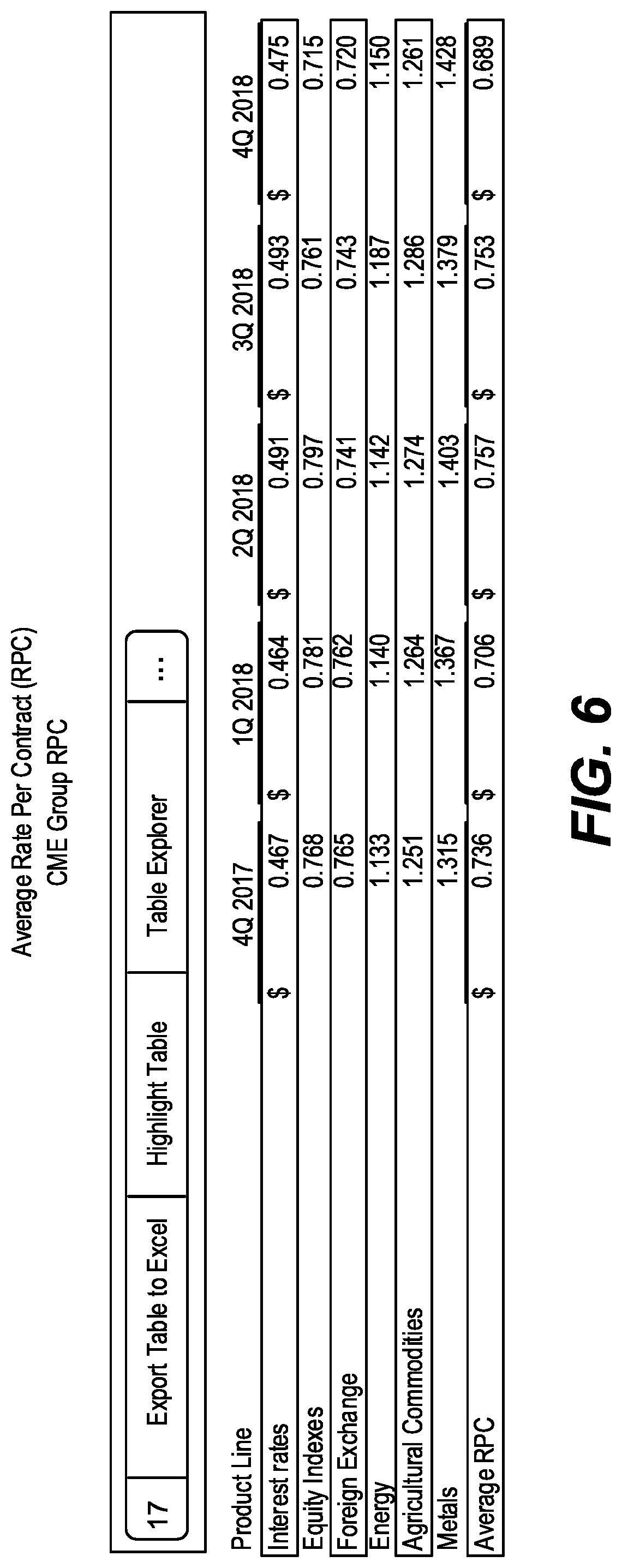
[0009] FIG. 6 is a screenshot of one feature of a similar tables tool in accordance with one embodiment;
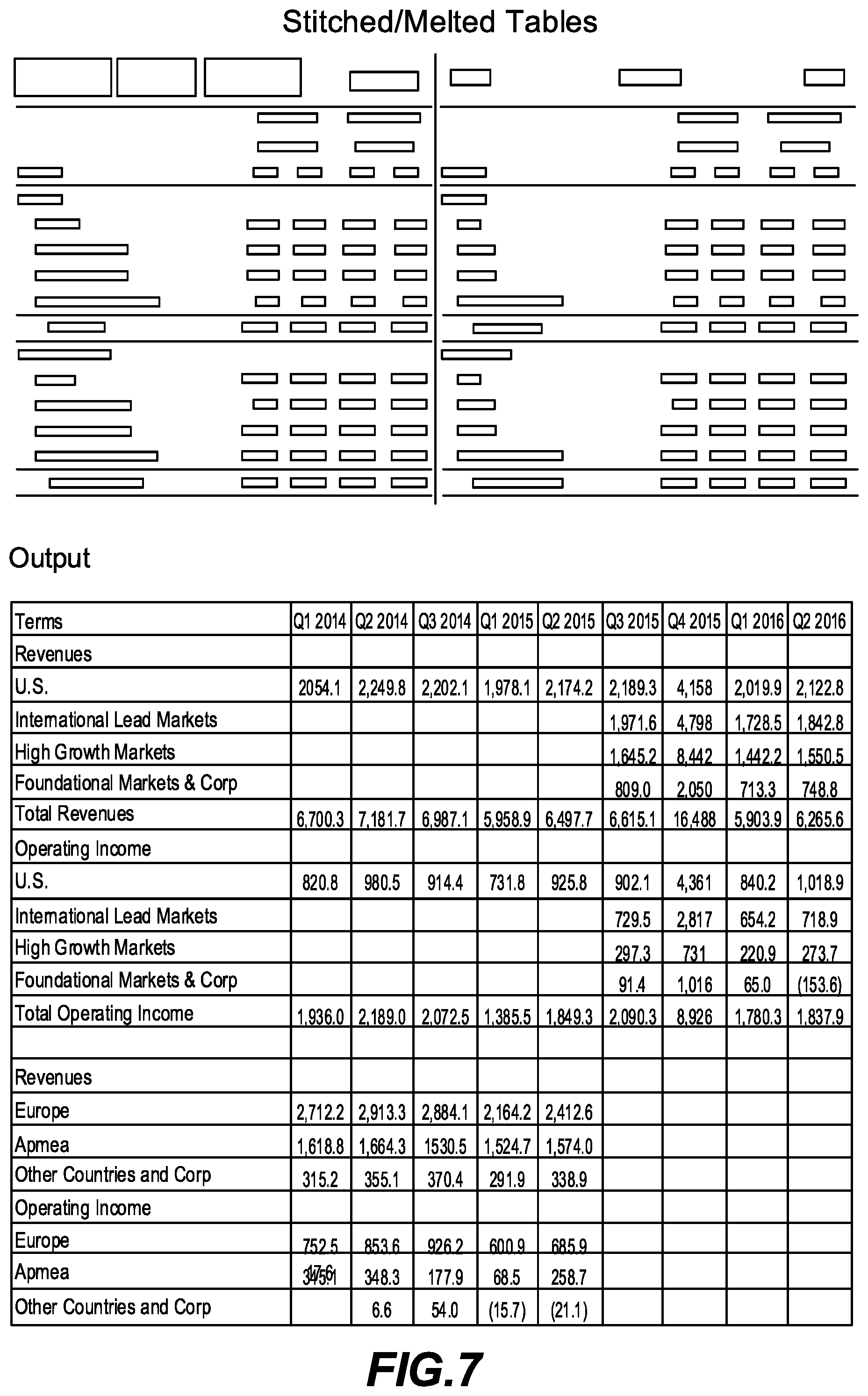
[0010] FIG. 7 is a screenshot of a stitched tables feature in accordance with one embodiment;
[0011] FIG. 8 is a screenshot of a melted tables feature in accordance with one embodiment;
[0012] FIG. 9 is a flow diagram of a process of pre-processing a document and creating dictionaries for tables in the document;
[0013] FIG. 10 is a flow diagram of a process of creating a time series of tables in accordance with one embodiment;
[0014] FIG. 11 is a flow diagram showing options of what can be viewed through the platform user interface and exported into a spreadsheet in accordance with one embodiment;
[0015] FIG. 12 is a block diagram of a system of the financial document intelligence platform in accordance with various embodiments; and
[0016] FIG. 13 is a block diagram illustrating an example of a computer system capable of implementing various processes in the described embodiments;
SUMMARY OF THE EMBODIMENTS
[0017] In one aspect of the invention, a method of extracting financial data from a document and analyzing similar financial data from older documents to enhance understanding of the document is described. A financial document intelligence system receives a document containing unstructured data. Tables in the document are identified and extracted using a parsing engine. Each table is converted to a dictionary. The system then verifies that data in a table is financial data and, once verified, the dictionaries for valid financial data tables are stored. A series of stitched tables, also referred to as a time series, is created for a selected table using a row-based, "next best" matching algorithm. Tables that are similar to the selected table with respect to type and schema are identified and used to create a time series for the selected table. This time series allows users to easily see how certain financial data has changed over time.
DETAILED DESCRIPTION
[0018] Example embodiments of methods and systems for examining and analyzing financial and corporate documents are described. These examples and embodiments are provided solely to add context and aid in the understanding of the invention. Thus, it will be apparent to one skilled in the art of software and financial document processing that the present invention may be practiced without some or all of the specific details described herein. In other instances, well-known concepts have not been described in detail in order to avoid unnecessarily obscuring the present invention. Although these embodiments are described in sufficient detail to enable one skilled in the art to practice the invention, these examples, illustrations, and contexts are not limiting, and other embodiments may be used and changes may be made without departing from the spirit and scope of the invention.
[0019] One aspect of the present invention is the ability to perform what is referred to as time series and table extraction. Time series is a function that allows users to select line item rows from a document or HTMUXBRL table and automatically retrieve historical values of those line items from previous documents. A high-level diagram of the time series feature is shown in FIG. 1. The user selects either a specific row from a table to be extracted or the entire table. In one embodiment, the selection of a row can also be done automatically by the software. Logic behind the software finds that particular table in previous versions of the document and extracts those lines and builds what is referred to as a composite table.
[0020] The user interface for a time series table allows the user to perform an audit easily by enabling the user to go back to the table from which the highlighted figure originated. In one embodiment, the system can auto-update the composite table whenever a new table is created. Referring now to FIGS. 2 and 3, first FIG. 2 shows a table with a column of marks along the left side for each row and a row of marks at the top of the table. In one embodiment, line items from the original table become columns in the composite table. Each value can be audited by clicking on the table row on the left side of the screen. Referring to FIG. 3, auditing modifies the table on the right pane to display the source table from the original document. The user can also edit the resulting table on the left. The entire table may be exported to a spreadsheet or saved in another suitable format. Additionally, the resulting table can be set to auto-update with new values when new versions of the document are made available.
[0021] In one embodiment, the time series and table extraction features are implemented in the following manner. As a financial or other type of document is received in the system, it goes through various preprocessing steps. One of the key stages involves identification of tabular data within the documents. The tabular data is of particular significance as the tables provide a quick structured summary of data mentioned in different places with the document.
[0022] In the next step, each table is fed to a parsing engine which creates a text skeleton of the table and divides it into different parts such as headers, data headers, terms and values. For example, the tables in SEC filings are highly non-standardized, consequently the system goes through a number of preprocessing steps to be able to correctly map a term value to its corresponding column value. In case the table contains data for different periods, the value of each term is identified and saved for each period.
[0023] This skeleton data of each table is then stored in a database from where it can be quickly fetched on demand. The system may maintain these records for all the historical 10-Qs, 10-Ks, 8-K Earnings, XBRL documents and other SEC filings.
[0024] Since the data reported in the filings remain similar from quarter to quarter, the corresponding tables can be identified and matched across the document. The identification logic of the present invention matches the tables on the basis of terms used in the table. Since the order of the tables often varies across documents, and is particularly different in 10-Ks and 10-Qs, the term matching algorithm results in a good match.
[0025] As the user opens a document in the platform, the user has an option to use the time series and table extraction functions on each identified table. The table extraction function identifies the most similar table found in each previous document, based on the term matching algorithm, and returns them.
[0026] Once the results of a time series extraction are returned, they are presented within a table for the user. The user may click on each value and on the right side of the screen, an auditing pane loads the corresponding table from where the value was pulled and is displayed. Extracted valued are color coded to make identifying them within large tables easy. This allows a user to quickly audit the entire table to ensure the values that our algorithm has produced are correct. If multiple tables were returned for the document/value that the user is auditing, the additional tables are displayed below. The user can easily replace values by clicking in any portion of the table and typing the new value or by selecting other matched values from a dropdown menu in the auditing pane.
[0027] Users are normally looking for quarterly values. However, often times values reported within filings are for entire fiscal years or quarter summations of the year to date (3 months, 6 months, 9 months, etc.). Time series allows users to quickly transform these summation values to quarterly values for the entire table by checking specific boxes. If a summation transformation is required only for a single document/value, the user can simply click the YTD box to the left of that value. Once the user is satisfied with the output of the table, they have the option to export the entire table to a spreadsheet. They may also save the output of the time series extraction on the system or open it within a visualization engine, described below.
[0028] The time series function allows the user to select a number of terms from the source table. The function identifies the top three similar tables in each previous document (on the basis of the term match algorithm) and then looks for the exact term as the user has requested. If the term is found, that numerical value which corresponds to the latest date in the table is fetched. The output of the time series function is the list of quarter-value pair for the term across documents for the previous five years. The user has an option to load the values for older documents if the user wants the previous data.
[0029] A term may not be used in exactly the same way as in the previous table. This could be because the company has changed the nomenclature for the reported term. For example, a company which stated reporting "Total Members" of its service initially may change it to "Total Membership."
[0030] For such cases, the system first returns an empty value for the missing quarter. The system then goes back to find the similar tables to the source table in the document corresponding to the missing quarter. The system then finds other terms in these similar tables, which are similar to the term that the user has requested. If a term is matched with a high degree of surety, the system finds the corresponding term value for the latest date in the table and returns it with a warning that the actual term and value may be different.
[0031] The similar tables feature allows a user to click a button above a document table to load up the same table from previous filings. A high-level view of similar tables is shown in FIG. 4. For example, a user may click Similar Tables on the Income Statement table in a company's quarterly filing and the tool automatically fetches the Income Statement table from five years of quarterly filings and presents them to the user in a split screen view. This is shown in FIG. 5.
[0032] The similar tables tool identifies these similar, historical tables by applying an algorithm to take the contents of the original table and statistically compare them to the contents of all tables in historical filings of the same type. This is shown in FIG. 6. The table with the highest statistical match is presented as the matched similar table. Once the tool has presented all the similar tables to a user, the user may export the set of tables to a spreadsheet or perform advanced analysis/export through time series, stitched tables and melted tables, features that are described below.
[0033] Another feature of the invention is referred to as stitched tables. This tool generalizes the concepts of time series and similar tables extraction to join entire tables processed at once instead of on a line-by-line basis. Line items that do not match are preserved in sequence rather than discarded. Duplicate line items are separately handled. This method has the advantage of being computationally efficient for large volumes of tables. It also has the advantage of handling, in a user-friendly way, constant changes in financial reporting as business needs evolve over time, for example, due to reorganizations, acquisitions, and new/discounted disclosures. An example is shown in FIG. 7.
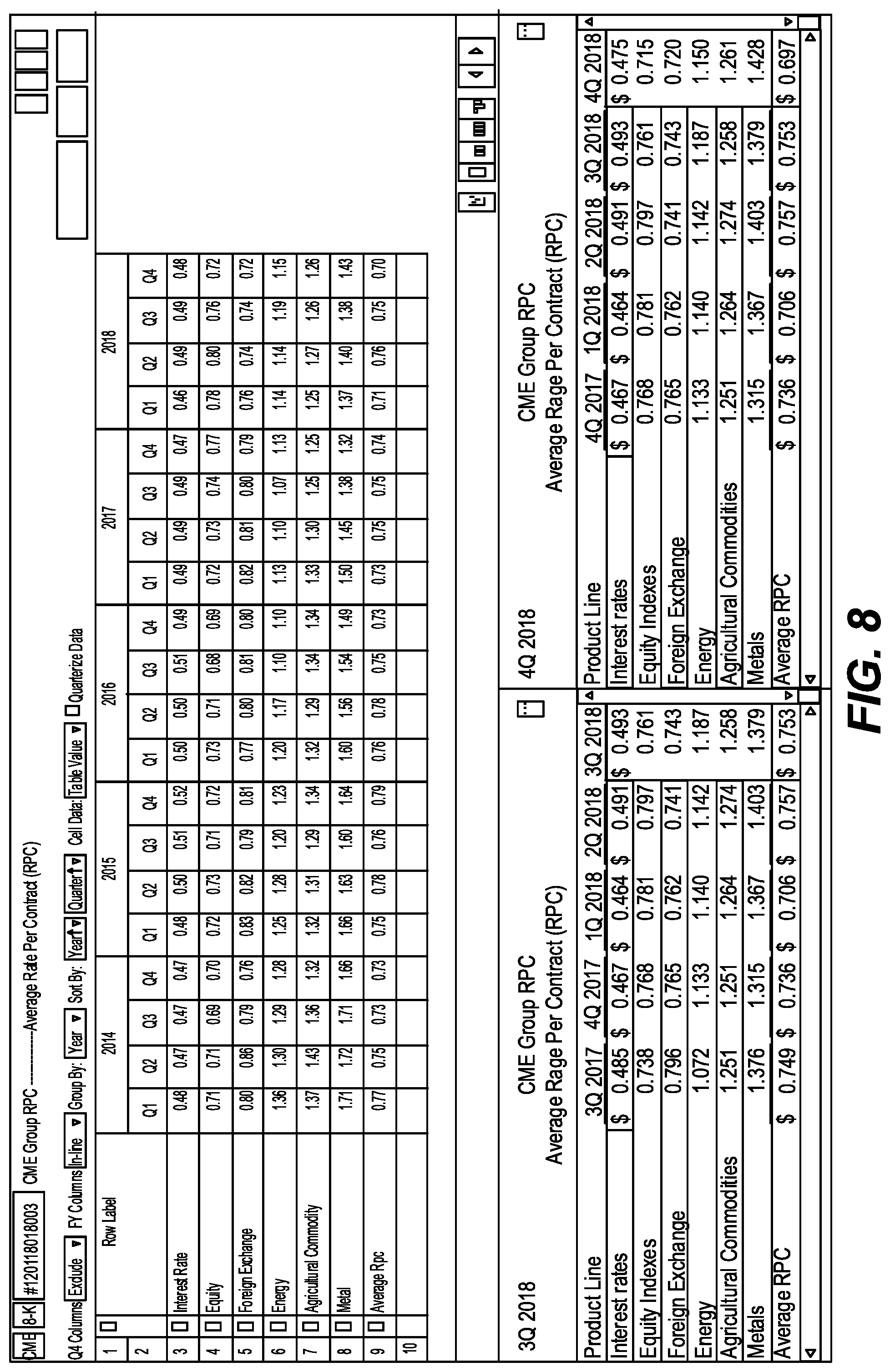
[0034] A feature related to stitched tables may be referred to as melted tables. These tables generalize the concept of stitched tables to encompass multi-dimensional tables where time is not represented in a single column but rather is represented by the entire table. Columns are reshaped into rows and stitched together with their corollaries across time. This has particular applications in a variety of modeling contexts, for example, from Debt Maturity Schedules to property-level ownership breakdowns. An example is shown in FIG. 8.
[0035] Methods and systems for gathering intelligence and understanding financial documents are described in the figures below. FIG. 9 is a flow diagram of a process of pre-processing a document and creating dictionaries for tables in the document. At step 902 the system receives a file of some type of document. The file can come from one of a wide range of sources and may not necessarily be a financial document. For example, it can be a PDF, a PowerPoint document, user notes, an Excel spreadsheet, and so on. In typical cases, the document is some type of financial document such as a 10-K, 10-Q, an annual report, or some other type of conventional financial document for a public company, but may not be.
[0036] The general goal is to extract financial data formatted as tables from a corpus of documents containing unstructured data. The system is a computing system that executes software provided and managed by a third-party financial intelligence service provider. The document is inputted, in most cases, by a client of the service provider. After the file is entered, the first operation by the system is converting it to a suitable format for further processing. In one embodiment, the format is HTML. In other embodiments, different formats can be utilized.
[0037] At step 904 the system identifies tables in the document and extracts them, it separates the tables from the rest of the non-table (or non-tabular) data. This is done by a parsing engine in the system and, in one embodiment, may be implemented by searching for specific tags, such as "TABLE". In other implementations, the parsing engine may search unstructured text for keywords associated with financial data. Some of the tables may not contain financial data or numerical data, in other words, they may not be financial tables. For example, a table may contain only text data, such as names, locations, product names, and so on. However, at step 904, in one embodiment, these tables are still extracted. In addition, the parsing engine is also able to identify and include footnotes. These footnotes may be structurally part of the table or contiguous to the table. The parsing engine is also capable of identifying and processing multi-columnar tables, rendering complex latitudinal (wide) data structures into simplified longitudinal (long) data structures which may be more easily stored and manipulated programmatically.
[0038] At step 906, the system converts each extracted table to what is referred to as a dictionary of table information. In one embodiment, the dictionary includes table data values, number of columns, headers, source document location, relationships between data and column headers (e.g., from which column did the data in this row come from), and other data. A sample of a dictionary is "docid": "123abc", "currency": USD, "section;" "Calculation of Net Leverage Ratio", "period:" "Q1, 2017", value: 18890, field: calculation of net leverage ratiototal debt, alias: "net_leverage_ratio: calculation . . . " subsection, table: Net Leverage Ratio, tickler: amt, unit: null.
[0039] Step 906 is done for each table extracted from the source document. Once all the tables have been converted to dictionaries, the system scans or examines each table, more specifically, the dictionary for each table, to determine if it contains valid financial data at step 908. For example, the system may look for null values or all text data, examples of two indicators that the table does not contain financial data, the only data relevant to embodiments of the present invention. In one embodiment, the system uses what is referred to as identification logic to spot valid financial tables. For example, it can look for specific financial terms that are commonly used, for instance, as column headers, or look for actual numerical data. This is done for each dictionary created at step 906.
[0040] At step 910, the system stores the dictionary for each valid financial data table. The other dictionaries and tables are discarded. The dictionaries and financial tables are written to a central database. From the database, the tables may eventually be displayed in the user interface of the system. For example, a valid financial data table from the source document can be displayed to the user. As described below in FIG. 10, if there is a history of tables that are similar to the table selected by the user, a stitched time series of these similar tables with the selected table may be displayed to the user. One version of the user interface of the system also simply displays the previous tables side by side next to the source table thereby enabling rapid, paginated review. The first stage of the document pre-processing stage is complete after step 910.
[0041] FIG. 10 is a flow diagram of a process of creating a time series of tables for a selected table in accordance with one embodiment. As noted, this may also be referred as stitching a currently selected table with similar tables from previously submitted documents from the user. At step 1002 the system begins by identifying a current table (i.e., a table selected by the user) for a current entity. The dictionary for the selected table is retrieved from the database. The term "entity" can refer to anything for which the service provider has data; it provides an umbrella context for the table. It can be characterized as the top of a schema for a corpus of documents, where all tables (and other data) are subordinate to the entity. For example, an entity could be a private company, a public company's stock ticker, an institution, such the Federal Reserve Bank, a government agency, and so on. As noted, it can be anything for which table data has been collected and stored.
[0042] At step 1004 the system identifies tables from previous documents for that entity that are similar to the current table. The system performs this operation by using data contained in the dictionary for the selected table. In one embodiment, identifying similar tables is performed by looking at table names (e.g., "Balance Sheet") from previous documents, annual reports, for the current entity.
[0043] In one embodiment, this may be done by performing a row-based, "next best" matching algorithm. The "next best match" algorithm can be described as matching the list of rows for the currently selected table against the list of rows for all other tables in previous documents. The best match would be the previous tables for which the number of matched rows is closest to the total number of rows of the currently selected table. At this stage, the system has identified and verified tables that are essentially the same as the current table but from older documents (e.g., from last month, last quarter, last fiscal year, etc.).
[0044] It may not be the case that 100% of the rows in all the tables match. In some cases, perhaps because of a merger between two companies or an internal accounting methodology update where field names change, there may be more than a few non-matching row pairs. In any of these scenarios, at step 1006, the non-matching rows are flagged and included in the tables; they are not discarded by the system. In one embodiment, the non-matching rows are moved to the bottom of the table and displayed in a different color from the matching rows. If there is more than a certain ratio of matching to non-matching rows or there is over a pre-determined percentage of non-matching rows, the tables are flagged or marked for manual review, described in step 1010 below.
[0045] The operation performed by the system in step 1006 creates a multi-table, row-matched schema for the current table. As noted, this may also be described as a stitched time series of tables for the current table. At step 1008 the row mapping, or stitched table, schema is stored in a database as the default stitching schema for that table. Subsequent user modifications may create a new schema associated with a specific user identifier. As mentioned, the user can modify the default schema by moving non-matching flagged rows back to their original place in the table, requesting that the system merge the flagged row with the non-flagged rows, moving them to wherever they want them to be in the table (e.g., at the top), or can discard them.)
[0046] As noted, at step 1008 the system-created, default stitched tables are stored in the dictionary of the current table. Both user-defined and system schemas can be configured for alerts so that when a new table is released that matches the saved schema, the new data is automatically added to the stored stitched tables and the user is notified of the addition.
[0047] At step 1010 the service provider via the platform addresses or manually modifies the schema of tables that were marked or somehow distinguished as being heavily flagged tables, tables that have over a pre-determined percentage of flagged rows. A table can also be brought to the attention of the service provider by the user; the user may have a reason or simply want to service provider to audit the table. The tables that are flagged earlier as having too many non-matching rows are still stitched, but may be characterized as insufficiently stitched tables. As such, they are manually reviewed or audited by the service provider who has advanced tools and user interfaces for doing so. During the audit, corrections and updates are made and the insufficiently stitched tables are completed and made into an acceptable time series and stored with the current table in the database and can be displayed or exported, as described below.
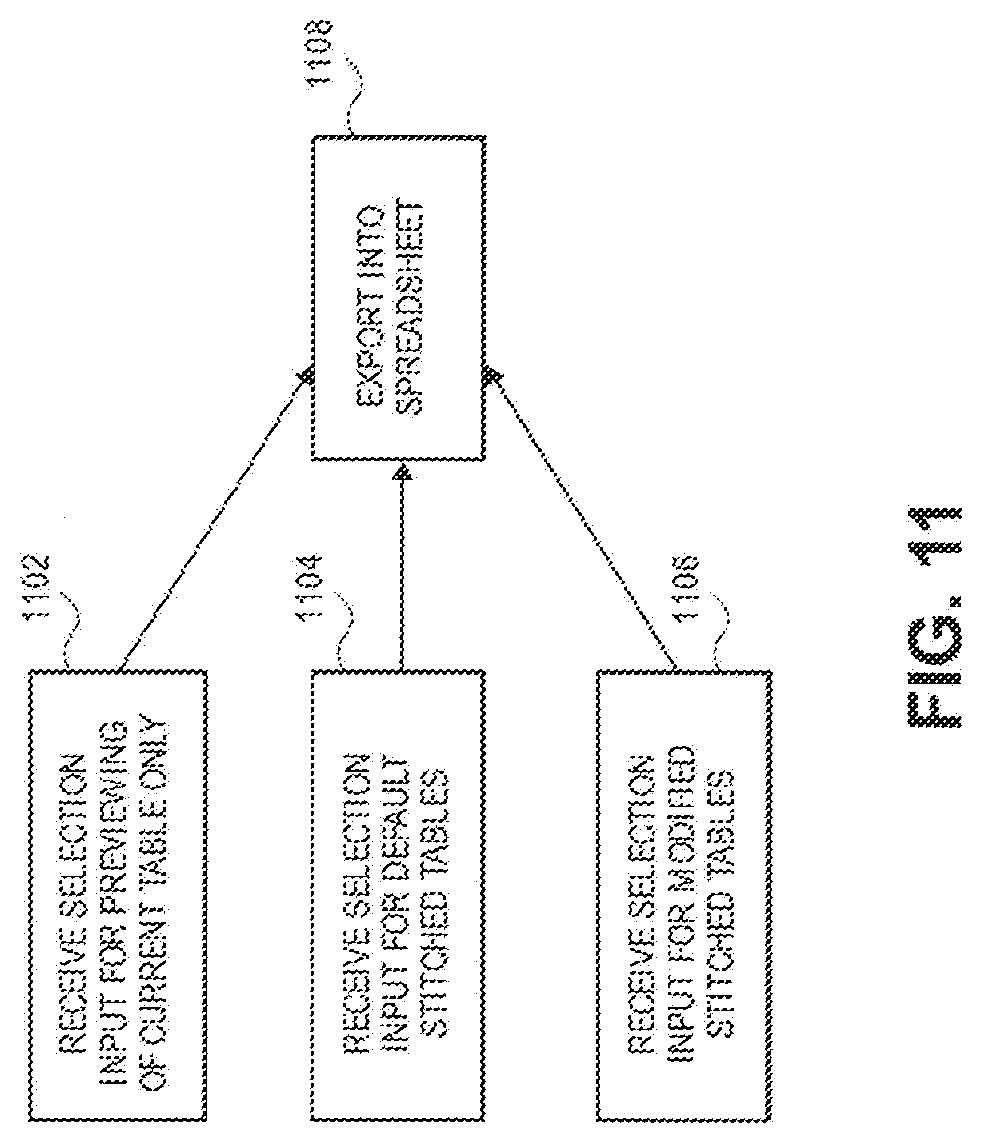
[0048] Once the pre-processing and time series creation are complete, the user has options with regard to what can be viewed through the platform's user interface and exported into a spreadsheet. These options are shown in FIG. 11. One option is that the user can elect to see only the current table on the screen. This is shown in box 1102. The user can then export the current table to an external document, such as a spreadsheet at box 1108. This is the table that was selected by the user at the beginning of FIG. 9 and is the table without any stitched tables. Another option is the user can click through to each cell of the time series and stitched tables and have the source table load up in a popup or a window so that the values of the time series can be audited. Another option is the user can apply filters to the values of the time series and stitched tables to handle instances where a reported number is a year to date number and must be adjusted to match the quarter. A table stitching engine, described below, may determine this in many cases by using an algorithm that uses document type and table headers. The system also provides filters that allow year over year values to be added within the table.
[0049] At step 1104 the system receives selection input for displaying the default stitched tables as described in FIG. 10. As noted, the default current table may have flagged (unmatched) rows at the bottom of the table (or wherever the system designer decides the default location should be) and may be shown in a different color. The default table is shown with its time series of similar tables. The default current table and the stitched tables can be exported into an external spreadsheet, again as shown in step 1108. As described above, the user can modify the default table, for example, by moving the flagged rows to a different location in the table or deleting them. This modified table and the stitched tables can be selected by the user and the system will display the modified table at step 1106. These tables can also be exported into a spreadsheet and utilized by the user outside of the system. In one embodiment, the dictionary for the table, whether the original (step 1102), default stitched (1104) or modified (1106), is used to display the tabulated data and export into an external document.
[0050] FIG. 12 is a block diagram of a system of the financial document intelligence platform in accordance with various embodiments. The platform may be implemented as software executing on a user (e.g., a customer of the financial document intelligence service provider) system or may be operated by the service provider and offered as a service to users. In either case, the platform has various components, modules, and databases most of which have been referenced above and whose functionality has been shown in the flow diagrams.
[0051] A corpus of documents 1202 is inputted into a system or platform 1204. The documents are input one by one and the flow diagrams above explain the steps taken when one document is inputted, such as at step 902, and when one table is selected, as in step 1002. However, a customer is likely to have inputted numerous documents over a period of time. As described above, the only way to obtain a stitched time series of tables is for a user to input numerous documents over time, that is, to have a history of similar documents in the system.
[0052] In financial document intelligence system 1204, a document is received by a document conversion engine 1206. This module converts the document, which may be any type of document and may not even be a financial document and have no tables in it, to HTML. A table extraction engine 1208 identifies and pulls any financial tables from the document. In one embodiment, module 1208 is also responsible for converting each table to a dictionary. As described above, several pre-processing steps occur to ensure that only the dictionaries of valid financial tables are converted to dictionaries.
[0053] Component 1210 is a database used by system 1204 to store all data needed for creating stitched tables. It stores, among other types of data, dictionaries of tables, user data, and table and row data. A table stitching engine 1212 creates the stitched tables. It takes a current table for an entity and, if historical data is available for that table and entity, creates the stitched tables. Engine 1212 performs many of the steps in FIG. 10, such as identifying and verifying historical tables that are similar in type and schema to the current table. This logic is referred to as identification logic above. It also performs the operations of the row-by-row matching between all the verified similar tables, flagging of non-matching rows, and creating the time series. It executes the row-matching algorithm. Once the table stitching is complete, data for the current table is stored in the table dictionary and stored in database 1210.
[0054] Engine 1212 is in communication with a timeseries user interface module 1214 where the user can display various versions of the current table as described in FIG. 11. The user can preview the current table, the default stitched tables, or the modified stitched tables. An export engine module 1216 is used to export tables to a spreadsheet for the user if the export feature is selected.
[0055] FIG. 13 is an illustration of a data processing system 1300 depicted in accordance with some embodiments and as shown in FIG. 12. Data processing system 1300 may be used to implement one or more computers used in a controller or other components of various systems described above. In some embodiments, data processing system 1300 includes communications framework 1302, which provides communications between processor unit 1304, memory 1306, persistent storage 1308, communications unit 1310, input/output (I/O) unit 1312, and display 1314. In this example, communications framework 1302 may take the form of a bus system.
[0056] Processor unit 1304 serves to execute instructions for software that may be loaded into memory 1306. Processor unit 1304 may be a number of processors, a multi-processor core, or some other type of processor, depending on the particular implementation.
[0057] Memory 1306 and persistent storage 1308 are examples of storage devices 1316. A storage device is any piece of hardware that is capable of storing information, such as, for example, without limitation, data, program code in functional form, and/or other suitable information either on a temporary basis and/or a permanent basis. Storage devices 1316 may also be referred to as computer readable storage devices in these illustrative examples. Memory 1306, in these examples, may be, for example, a random access memory or any other suitable volatile or non-volatile storage device. Persistent storage 1308 may take various forms, depending on the particular implementation. For example, persistent storage 1308 may contain one or more components or devices. For example, persistent storage 1308 may be a hard drive, a flash memory, a rewritable optical disk, a rewritable magnetic tape, or some combination of the above. The media used by persistent storage 1308 also may be removable. For example, a removable hard drive may be used for persistent storage 1308.
[0058] Communications unit 1310, in these illustrative examples, provides for communications with other data processing systems or devices. In these illustrative examples, communications unit 1310 is a network interface card.
[0059] Input/output unit 1312 allows for input and output of data with other devices that may be connected to data processing system 1300. For example, input/output unit 1312 may provide a connection for user input through a keyboard, a mouse, and/or some other suitable input device. Further, input/output unit 1312 may send output to a printer. Display 1314 provides a mechanism to display information to a user.
[0060] Instructions for the operating system, applications, and/or programs may be located in storage devices 1316, which are in communication with processor unit 1304 through communications framework 1302. The processes of the different embodiments may be performed by processor unit 1304 using computer-implemented instructions, which may be located in a memory, such as memory 1306.
[0061] These instructions are referred to as program code, computer usable program code, or computer readable program code that may be read and executed by a processor in processor unit 1304. The program code in the different embodiments may be embodied on different physical or computer readable storage media, such as memory 1306 or persistent storage 1308.
[0062] Program code 1318 is located in a functional form on computer readable media 1320 that is selectively removable and may be loaded onto or transmitted to data processing system 1300 for execution by processor unit 1304. Program code 1318 and computer readable media 1320 form computer program product 1322 in these illustrative examples. In one example, computer readable media 1320 may be computer readable storage media 1324 or computer readable signal media 1326.
[0063] In these illustrative examples, computer readable storage media 1324 is a physical or tangible storage device used to store program code 1318 rather than a medium that propagates or transmits program code 1318.
[0064] Alternatively, program code 1318 may be transmitted to data processing system 1300 using computer readable signal media 1326. Computer readable signal media 1326 may be, for example, a propagated data signal containing program code 1318. For example, computer readable signal media 1326 may be an electromagnetic signal, an optical signal, and/or any other suitable type of signal. These signals may be transmitted over communications channels, such as wireless communications channels, optical fiber cable, coaxial cable, a wire, and/or any other suitable type of communications channel.
[0065] The different components illustrated for data processing system 1300 are not meant to provide architectural limitations to the manner in which different embodiments may be implemented. The different illustrative embodiments may be implemented in a data processing system including components in addition to and/or in place of those illustrated for data processing system 1300. Other components shown in FIG. 13 can be varied from the illustrative examples shown. The different embodiments may be implemented using any hardware device or system capable of running program code 1318.
[0066] Therefore, the present disclosure is not to be limited to the specific examples illustrated and that modifications and other examples are intended to be included within the scope of the appended claims. Moreover, although the foregoing description and the associated drawings describe examples of the present disclosure in the context of certain illustrative combinations of elements and/or functions, it should be appreciated that different combinations of elements and/or functions may be provided by alternative implementations without departing from the scope of the appended claims. Accordingly, parenthetical reference numerals in the appended claims are presented for illustrative purposes only and are not intended to limit the scope of the claimed subject matter to the specific examples provided in the present disclosure.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012

D00013

XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.