Using Output Equalization In Training An Artificial Intelligence Model In A Semiconductor Solution
Ren; Yongxiong ; et al.
U.S. patent application number 16/586432 was filed with the patent office on 2020-09-24 for using output equalization in training an artificial intelligence model in a semiconductor solution. This patent application is currently assigned to Gyrfalcon Technology Inc.. The applicant listed for this patent is Gyrfalcon Technology Inc.. Invention is credited to Tianran Chen, Yi Fan, Xiaochun Li, Yongxiong Ren, Yinbo Shi, Lin Yang, Yequn Zhang.
| Application Number | 20200302288 16/586432 |
| Document ID | / |
| Family ID | 1000004376467 |
| Filed Date | 2020-09-24 |










View All Diagrams
| United States Patent Application | 20200302288 |
| Kind Code | A1 |
| Ren; Yongxiong ; et al. | September 24, 2020 |
USING OUTPUT EQUALIZATION IN TRAINING AN ARTIFICIAL INTELLIGENCE MODEL IN A SEMICONDUCTOR SOLUTION
Abstract
A system for training an artificial intelligence (AI) model for an AI chip may include an AI training unit to train weights of an AI model in floating point, and one or more quantization units for updating the weights of the AI model while accounting for the hardware constraints in the AI chip. The system may also include customization unit for performing one or more linear transformations on the updated weights. The system may also perform output equalization for one or more convolution layers of the AI model to equalize the inputs and/or outputs of each layer of the AI model to within the range allowed in the physical AI chip. The system may further update the weights by performing shift-based quantization that mimics the characteristics of a hardware chip. The updated weights may be stored in fixed point and uploadable to an AI chip implementing an AI task.
| Inventors: | Ren; Yongxiong; (San Jose, CA) ; Fan; Yi; (Fremont, CA) ; Zhang; Yequn; (San Jose, CA) ; Chen; Tianran; (San Jose, CA) ; Shi; Yinbo; (Santa Clara, CA) ; Li; Xiaochun; (San Ramon, CA) ; Yang; Lin; (Milpitas, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assignee: | Gyrfalcon Technology Inc. Milpitas CA |
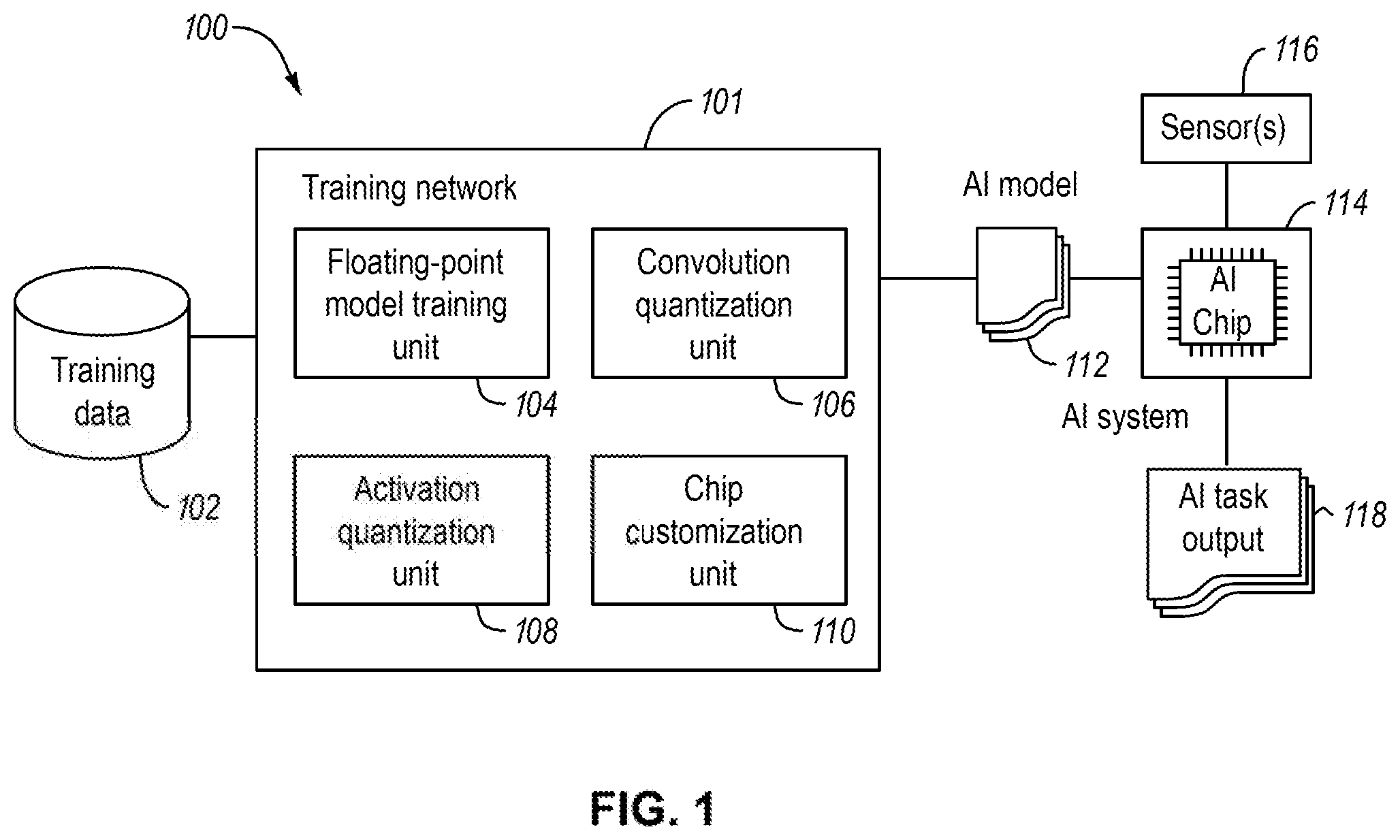
||||||||||
| Family ID: | 1000004376467 | ||||||||||
| Appl. No.: | 16/586432 | ||||||||||
| Filed: | September 27, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 62821437 | Mar 20, 2019 | |||
| 62830269 | Apr 5, 2019 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06N 3/063 20130101; G06N 3/04 20130101; G06N 3/08 20130101 |
| International Class: | G06N 3/08 20060101 G06N003/08; G06N 3/063 20060101 G06N003/063; G06N 3/04 20060101 G06N003/04 |
Claims
1. A system comprising, a processor; and non-transitory computer readable medium contain programming instructions that, when executed, will cause the processor to: access eights of a convolution neural network (CNN) model; perform one or more linear transformations on the weights; perform a output equalization operation to update the weights of the CNN model to cause output of one or more convolution layers of the CNN model to be equalized; and upload the updated weights of the CNN model to an artificial intelligence (AI) chip capable of executing an AI task.
2. The system of claim 1, wherein the programming instructions for performing one or more linear transformations comprise programming instructions configured to perform one or more operations of: performing a batch normalization merge; performing an image mean merge; or performing an image scale merge.
3. The system of claim 1, wherein the programming instructions for performing the output equalization operation comprise programming instructions configured to: based on a training image set, use the weights of the CNN model to determine a first maximum output value of a first convolution layer of the CNN model and determine a second maximum, output value of a second convolution layer of the CNN model; and update the weights of the second layer of the CNN model based on the first and second maximum output values.
4. The system of claim 3, wherein each convolution layer of the CNN model comprises a bias value, and the programming instructions for performing the gain edition operation also comprise programming instructions configured to: update the bias value of the second. convolution layer based on the second maximum value and a bit-size of the second convolution layer corresponding to a convolution layer of the AI chip.
5. The system of claim 1 further comprising additional programming instructions configured to, before uploading the updated weights to the AI chip, perform a fine-tuning operation comprising: accessing the updated weights of the CNN model from the output equalization operation; in one or more iterations until a stopping criteria is met, performing operations comprising: performing shift-based quantization to quantize the updated weights of the CNN model; determining output of the AI model based on the quantized weights of the CNN model and a training data set; determining a change of weights based on the output of the CNN model; and updating the weights of the CNN model based on the change of weights.
6. The system of claim 5, wherein programming instructions for performing the shift-based quantization comprise programing instructions configured to: determine a shift value for a convolution layer of the CNN model corresponding to a convolution layer of the AI chip, based on a bit-size of the corresponding convolution layer of the AI chip and a maximum value of the weights of the CNN model; and quantize the updated weights of the convolution layer of the CNN model based on the determined shift value.
7. The system of claim 5, wherein the programming instructions for determining the change of weights of the CNN model comprise using a gradient descent method, wherein a loss function in the gradient descent method is based on a sum of loss values over a plurality of training instances in the training data set, wherein the loss value of each of the plurality of training instances is a difference between the quantized output of the CNN model for the training instance and a ground truth of the training instance.
8. The system of claim 1 further comprising additional programming instructions configured to cause the AI chip to; perform the AI task to generate output of the AI task; and presenting the output of the AI task on an output device; wherein the updated weights of the CNN model are uploaded into an embedded cellular neural network architecture in the AI chip.
9. A method comprising, at a processing device: accessing weights of a convolution neural network (CNN) model; performing one or more linear transformations on the weights; performing a output equalization operation to update the weights of the CNN model to cause output of one or more convolution layers of the CNN model to be equalized; and uploading the updated weights of the CNN model to an artificial intelligence (AI) system comprising an AI chip capable of executing an AI task; and at the AI system: causing the AI chip to perform the AI task to generate output of the AI task; and presenting the output of the AI task on an output device; wherein the updated weights of the CNN model are uploaded into an embedded cellular neural network architecture in the AI chip.
10. The method of claim 9, wherein performing the linear transformations comprises performing one or more operations comprising: performing a batch normalization merge; performing an image mean merge; and performing an image scale merge.
11. The method of claim 9, wherein performing the output equalization operation comprises: based on a training image set, using the weights of the CNN model to determine a first maximum output value of a first convolution layer of the CNN model and determine a second maximum output value of a second convolution layer of the CNN model; and updating the weights of the second convolution layer of the CNN model based on the first and second maximum output values.
12. The method of claim 11, wherein each convolution layer of the CNN model comprises a bias value, and performing the gain edition operation also comprises: updating the bias value of the second convolution layer based on the second maximum value and a bit-size of the second convolution layer corresponding to a convolution layer of the AI chip.
13. The method of claim 9 further comprising, before uploading the updated weights to the AI chip: accessing the updated weights of the CNN model from the output equalization operation; and in one or more iterations until a stopping criteria is met, performing operations comprising: performing shift-based quantization to quantize the updated weights of the CNN model; determining output of the AI model based on the quantized weights of the CNN model and a training data set; determining a change of weights based on the output of the CNN model; and updating the weights of the CNN model based on the change of weights.
14. The method of claim 13, wherein perforating the shift-based quantization comprises: determining a shift value for a convolution layer of the CNN model corresponding to a convolution layer of the AI chip, based on a bit-size of the corresponding convolution layer of the AI chip and a maximum value of the weights of the CNN model; and quantizing weights of the convolution layer of the CNN model based on the determined shift value.
15. The method of claim 13, wherein determining the change of weights comprises using a gradient descent method, wherein a loss function in the gradient descent method is based on a sum of loss values over a plurality of training instances in the training data set, wherein the loss value of each of the plurality of training instances is a difference between the quantized output of the CNN model for the training instance and a ground truth of the training instance.
16. A method comprising, at a processing device: accessing weights of a convolution neural network (CNN) model; performing one or more linear transformations on the weights, the linear transformations comprising performing one or more operations comprising: performing a batch normalization merge; performing an image mean merge; and performing an image scale merge; performing a output equalization operation to update the weights of the CNN model by updating the weights of a first convolution layer of the CNN model based on statistical output values of the first convolution layer and a second convolution layer preceding the first convolution layer based on a training image set; and uploading the updated weights of the CNN model to an artificial intelligence (AI) system comprising an AI chip capable of executing an AI task.
17. The method of claim 16 further comprising, at the AI system: causing the AI chip to perform the AI task to generate output of the AI task; and presenting the output of the AI task on an output device; wherein the updated weights of the CNN model are uploaded into an embedded cellular neural network architecture in the AI chip.
18. The method of claim 16, wherein, performing the output equalization operation comprises: based on the training image set, using the weights of the CNN model to determine a first maximum output value of the first convolution layer and determine a second maximum output value of the second convolution layer; and updating the weights of the first convolution layer of the CNN model based on the first and second maximum output values.
19. The method of claim 18, wherein each convolution layer of the CNN model comprises, a bias value, and performing the output equalization operation also comprises: updating the bias value of the second convolution layer based on the second maximum value and a bit-size of the second convolution layer corresponding to a convolution layer of the AI chip.
20. The method of claim 16 further comprising, before uploading the updated weights to the AI chip: accessing the updated weights of the CNN model form the output equalization operation; and in one or more iterations until a stopping criteria is met, performing operations comprising: performing shift-based quantization on the weights of the CNN model; determining output of the AI model based on the updated weights of the CNN model and a training data set; determining a change of weights based on the output of the CNN model; and updating the weights of the CNN model based on the change of weights.
Description
PRIORITY CLAIM
[0001] This application claims the filing benefit of U.S. Provisional Application No. 62/821,437, filed Mar. 20, 2019 and U.S. Provisional Application No. 62/830,269, filed Apr. 5, 2019. These applications are incorporated by reference herein in their entirety and for all purposes.
FIELD
[0002] This patent document relates generally to systems and methods for providing artificial intelligence solutions. Examples of training a convolution neural network model for uploading to an artificial intelligence semiconductor are provided.
BACKGROUND
[0003] Artificial intelligence (AI) semiconductor solutions include using embedded hardware in an AI integrated circuit (IC) to perform NI tasks. Hardware-based solutions, as well as software solutions, still encounter the challenges of obtaining an optimal AI model, such as a convolutional neural network (CNN) for the hardware. For example, if the weights of a CNN model are trained outside the chip, they are usually stored in floating point. When the weights of a CNN model in floating point are loaded into an AI chip they usually lose data bits from quantization, for example, from 16- or 32-bits to 1- to 8-bits. The loss of data bits in an AI chip compromises the performance of the AI chip due to lost information and data precision. Further, existing training methods are often performed in a high performance computing environment, such as on a desktop, without accounting for the hardware constraints in a physical AI chip. This often causes performance degradation when a trained AI model is loaded into an AI chip.
BRIEF DESCRIPTION OF THE DRAWINGS
[0004] The present solution will be described with reference to the following figures, in which like numerals represent like items throughout the figures.
[0005] FIG. 1 illustrates an example training system in accordance with various examples described herein.
[0006] FIG. 2 illustrates a flow diagram of an example process of training that may be implemented in a convolution quantization unit in accordance with various examples described herein.
[0007] FIG. 3 illustrates an example of mask values in a 3-bit configuration in accordance with various examples described herein.
[0008] FIG. 4 illustrates a flow diagram of an example process of training that may be implemented in an activation quantization unit in accordance with various examples described herein.
[0009] FIG. 5 illustrates a diagram of an example convolution neural network in an AI chip in accordance with various examples described herein.
[0010] FIG. 6A illustrates a flow diagram of an example process of training an AI model for executing in an AI chip in accordance with various examples described herein.
[0011] FIG. 6B illustrates an example distribution of output values of an AI model in accordance with various examples described herein.
[0012] FIG. 7 illustrates a flow diagram of an example process of training that may be implemented in a chip customization unit in accordance with various examples described herein.
[0013] FIG. 8 illustrates a flow diagram of an example process of fine tuning in accordance with various examples described herein.
[0014] FIG. 9 illustrates various embodiments of one or more electronic devices for implementing the various methods and processes described herein.
DETAILED DESCRIPTION
[0015] As used in this document, the singular forms "a", "an", and "the" include plural references unless the context clearly dictates otherwise. Unless defined otherwise, technical and scientific terms used herein have the same meanings as commonly understood by one of ordinary skill in the art. As used in this document, the term "comprising" means "including, but not limited to."
[0016] An example of "artificial intelligence logic circuit" and "AI logic circuit" includes a logic circuit that is configured to execute certain AI functions such as a neural network in AI or machine learning tasks. An AI logic circuit can be a processor. An AI logic circuit can also be a logic circuit that is controlled by an external processor and executes certain AI functions.
[0017] Examples of "integrated circuit" "semiconductor chip," "chip," and "semiconductor device" include integrated circuits (ICs) that contain electronic circuits on semiconductor materials, such as silicon, for performing certain functions. For example, an integrated circuit can be a microprocessor, a memory, a programmable array logic (PAL) device, are application-specific integrated circuit (ASIC), or others, An AI integrated circuit may include an integrated circuit that contains an AI logic circuit.
[0018] Examples of "AI chip" include hardware- or software-based device that is capable of performing functions of an AI logic circuit. An AI chip may be a physical IC. For example, a physical AI chip may include a CNN, which may contain weights and/or parameters. The AI chip may also be a virtual chip, i.e., software-based. For example, a virtual AI chip may include one or more processor simulators to implement functions of a desired AI logic circuit.
[0019] Examples of "AI model" include data containing one or more parameters that, when loaded inside an AI chip, are used for executing the AI chip. For example, an AI model for a given CNN may include the weights, biases, and other parameters for one or more convolutional layers of the CNN. Here, the weights and parameters of an AI model are interchangeable.
[0020] FIG. 1 illustrates an example training system in accordance with various examples described herein. In some example, a training system 100 may include a training network 101 to train an AI model. The system 100 may upload the AI model 112 to an AI chip in an AI system 114. In some examples, an AI model may include a convolutional neural network (CNN) that is trained to perform AI tasks, e.g., voice or image recognition tasks. A CNN may include multiple convolutional layers, each of which may include multiple parameters, such as weights and/or other parameters. In such case, an AI model may include parameters of the CNN model. In some examples, a CNN model may include weights, such as a mask and a scalar for a given layer of the CNN model. For example, a kernel in a CNN layer may be represented by a mask that has multiple values in lower precision multiplied by a scalar in higher precision. In some examples, a CNN model may include other parameters. For example, a CNN layer may include one or more bias values that, when added to the output of the output channel, adjust the output values to a desired range.
[0021] In a non-limiting, example, in a CNN model, a computation in a given layer in the CNN may be expressed by Y=W* X+b, where X is input data. Y is output data, W is a kernel, and b is a bias; all variables are relative to the given layer. Both the input data and the output data may have a number of channels. Operation "*" is a convolution. Kernel W may include weights. For example, a kernel may include 9 cells in a 3.times.3 mask, where each cell may have a binary value, such as "1" and "-1." In such case, a kernel may be expressed by multiple binary values in the 3.times.3 mask multiplied by a scalar. In other examples, for some or all kernels, each cell may be a signed 2 or 8 bit integer. Alternatively, and/or additionally, a kernel may contain data with non-binary values, such as 7-value. Other bit length or values may also be possible. The scalar may include a value having a bit width, such as 12-bit or 16-bit. Other bit length may also be possible. The bias b may contain a value having multiple bits, such as 18 bits. Other bit length or values may also be possible. In a non-limiting example, the output Y may be further discretized into a signed 5-bit or 10-bit integer. Other bit length or values may also be possible.
[0022] In some examples, the AI chip in the AI system 114 may include an embedded cellular neural network that has memory containing the multiple parameters in the CNN. In some scenarios, the memory in an AI chip may be a one-time-programmable (OTP) memory that allows a user to load a CNN model into the physical AI chip once. Alternatively, the AI chip may have a random access memory (RAM), magneto-resistive random access memory (MRAM), other types of memory that allows a user to update and load a CNN model into the physical AI chip multiple times. In a non-limiting example, the AI chip may include convolutional, Pooling, and ReLU layers in a CNN model. In such case, the AI chip may perform all computations in an AI task. In other examples, the AI chip may include a subset of the convolutional, Pooling, and ReLU layers in a CNN model. In such case, the AI chip may perform certain computations in an AI task, leaving the remaining, computations in the AI task performed in a CPU/GPU or other host processors outside the AI chip.
[0023] In some examples, the training network 101 may be configured to include, a forward propagation neural network, in which information may flow from the input layer to one or more hidden layers of the network to the output layer. An AI training system may also be configured to include a backward propagation network to update the weights of the AI model based on the output of the AI chip. In some examples, an AI training system may include a combination of forward and backward propagation networks.
[0024] In some examples, training data 102 may be provided for use in training the AI model 112. For example, training data 102 may be used for training an AI model that is suitable for face recognition tasks, and the training data may contain any suitable dataset collected for performing face recognition tasks. In another example, the training data may be used for training an AI model suitable for scene recognition in video and images, and thus the training data may contain any suitable scene dataset collected for performing scene recognition tasks. In some scenarios, training data may reside in a memory in a host device. In one or more other scenarios, training data may reside in a central data repository and is available for access the training network 101 via the communication network 103. In some examples, an AI model may be trained by using one or more devices to implement one or more training units 104-110 as shown in FIG. 1. Details are further described with reference to FIGS. 1-9.
[0025] In some examples, the training network 101 may include a floating-point model training unit 104, which may be configured to train an AI model, e.g., a CNN model using one or more sets of training data 102. For example, the floating-point model training unit may be implemented on a desktop computer (CPU, and/or GPU) in floating point, in which one or more weights of the CNN model are in floating point. Any known or later developed methods may be used to train a CNN model. The training system 400 may further include one or more units to convert the floating-point model to a hardware-supported model, as further illustrated in FIG. 1.
[0026] In some examples, the training system 100 may include a convolution quantization unit 106 and/or activation quantization unit 108, each of which may be configured to update the weights of a CNN model to adapt to an AI chip. For example, the convolution quantization unit 106 may convert the trained weights in floating-point to weights in fixed-point so that the weights can be supported by the AI chip. The activation quantization unit 108 may further update the weights of the CNN so that the CNN output values based on the updated weights are also supported by the AI chip. Alternatively, and/or additionally, the order of the convolution quantization unit 106 and the activation quantization unit 108 may not matter. For example, the activation quantization unit 108 may access the training weights (e.g., from the floating-point model training unit 104) in floating-point and generate updated weights in fixed-point. Conversely, the convolution quantization unit 106 may access the updated weights in fixed-point from the activation quantization unit 108 and further update the weights to those the can be supported by the AI chip. For, example, the updated weights from the convolution quantization unit 106 and/or the activation quantization unit 108 may be in fixed-point and have the bit-width, equal to that supported by the AI chip, such as 1-bit, 2-bit, 5-bit, 8-bit etc. The output values that are generated by the AI model based on the updated weights from the convolution quantization unit 106 and/or the activation quantization unit 108 may also result in fixed-point values and have the bit-width equal to that supported by activation layers in the AI chip, such as 5-bit, or 10-bit.
[0027] In some examples, the training network 101 may include a chip customization unit 110 which may be configured to further update the weights of the AI model to maximize the resources supported by the hardware AI chip. For example, the chip customization unit 110 may be configured to perform batch normalization merge, image mean merge, scalar mean merge, and/or a combination thereof, which are described in the present disclosure. The chip customization unit 110 may further train the weights in a manner that mimics the characteristics of the hardware in the AI chip. For example, the training may include shift-based quantization which may mimic the features of the hardware. In some examples, the one or more units in the training network 101 may be serially coupled in that the output of one unit is fed to the input of another unit. For example, the one or more units may be coupled in the order of 104, 108, 106 and 110, where 104 receives the training data and produces a floating-point AI model, where each of the units 105, 108 and 110 further converts or updates the weights of the AI model and unit 110 produces the final AI model 112 uploadable to an AI chip for executing an AI task. Alternatively, the one or more units may be coupled in the order of 104, 106, 108 and 110. In other scenarios, a lesser of 104, 106, 108 and 110 may be serially coupled. For example, boxes 104, 106 and 110, or boxes 104, 108 and 110 may be respectively serially coupled to train and update the weights of the AI model and generate the final AI model 112.
[0028] With further reference to FIG. 1, the AI system 114 may be coupled to one or more sensors 116. The sensor(s) 116 may be configured to capture various types of data, such as image, video, audio, text, or any information in various media formats. The AI system 114 may be executed to implement an AI task in the AI chip based on the captured sensor data from sensor(s) 116, and generate AI task output 118. For example, in some scenarios, the AI chip in the AI system 114 may contain an AI model for performing certain AI tasks. Executing an AI chip or an AI model may include causing the AI chip to perform an AI task based on the AI model inside the AI chip and generate an output. Examples of an AI task may include image recognition, voice recognition, object recognition, data processing and analyzing, or any recognition, classification, processing tasks that employ artificial intelligence technologies. An example of an AI system, such as a camera having a built-in AI chip, is described in the present disclosure. Now, each of the units in the training network 101 is further described in detail with reference to FIGS. 2-9.
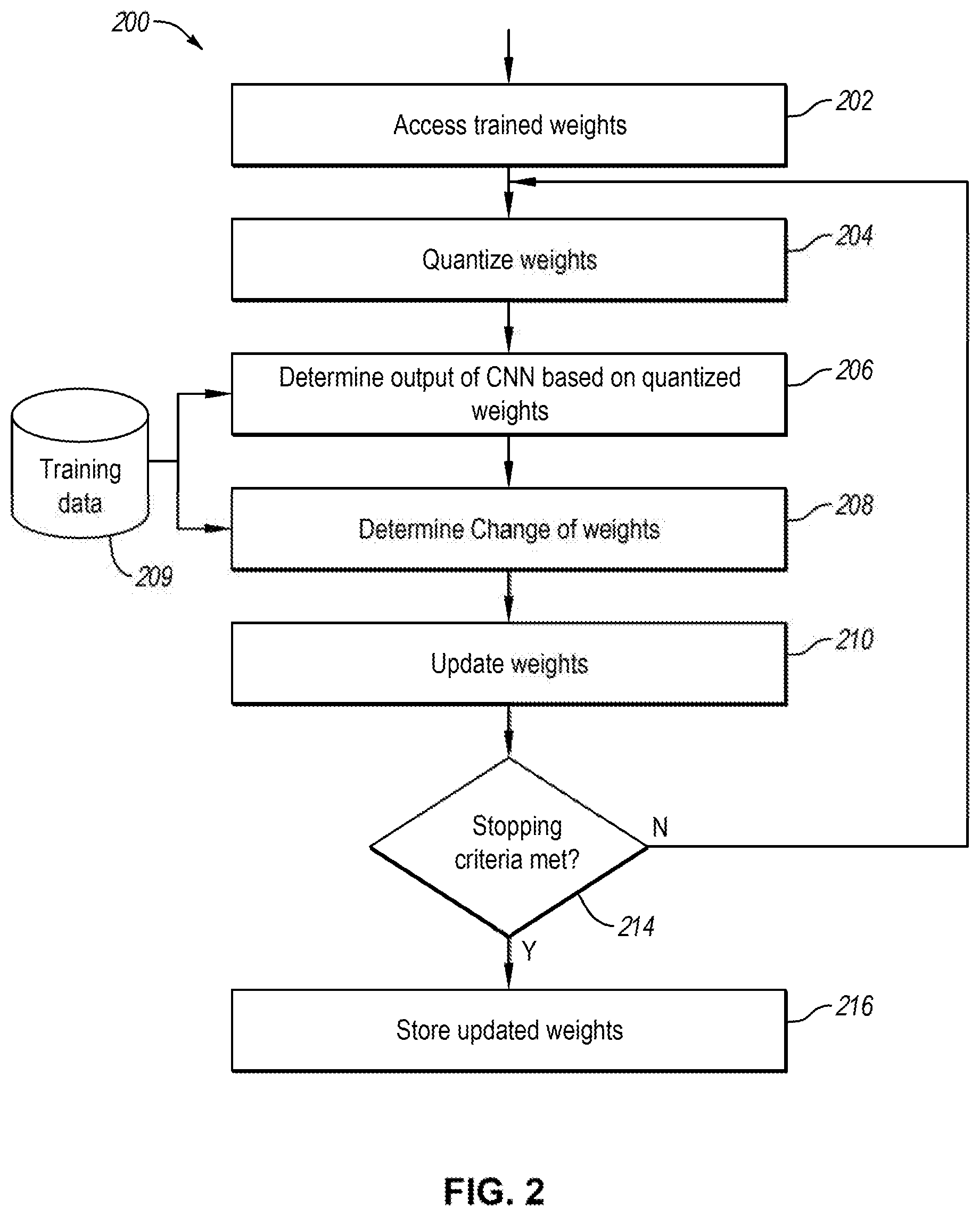
[0029] FIG. 2 illustrates a diagram of an example process of training that may be implemented in a convolution quantization unit, such as 106 in FIG. 1, in accordance with various examples described herein. In some examples, a process 200 may include accessing training weights of an AI model at 202. For example, the AI model may be trained in the floating-point model training unit (104 in FIG. 1) and include weights in floating-point. In a non-limiting example, the trained weights may be the weights of a CNN model and may be stored in floating point. For example, the weights may be stored in 32-bit or 16-bit.
[0030] In some examples, the process 200 may further include quantizing the trained weights at 204, determining output of the AI model based on the quantized weights at 206, determining a change of weights at 208 and updating the weights at 210. In some examples, the quantized weights may correspond to the limit of the hardware, such as the physical AI chip. In a non-limiting example, the quantized weights may be of 1-bit (binary value), 2-bit, 3-bit, 5-bit, or other suitable bits, such as 8-bit. Determining the output of the AI model at 206 may include inferring the AI model using the training data 209 and the quantized trained weights.
[0031] With further reference to FIG. 2, in quantizing the weights at 204, the number of quantization levels may correspond to the hardware constraint of the AI chip so that the quantized weights can be uploaded to the AI chip for execution. For example, the AI chip may include a CNN model. In the CNN model, the weights may include 1-bit (binary value), 2-bit, 3-bit, 5-bit or other suitable bits, such as 8-bit. The structure of the CNN may correspond to that of the hardware in the AI chip. In case of 1-bit, the number of quantization levels will be two. In some scenarios, quantizing the weights to 1-bit may include determining a threshold to properly separate the weights into two groups: one below the threshold and one above the threshold, where each group takes one value, such as {1, -1}.
[0032] In some examples, quantizing the weights at 204 may include a dynamic fixed point conversion. For example, the quantized weights may be determined by:
W Q = W grid .times. grid , where grid = W max 2 nbit - 1 - 1 ##EQU00001##
nbit is the bit-size of the weights in the physical AI chip. For example, nbit may be 8-bit, 12-bit etc. Other values may be possible.
[0033] In some examples, quantizing the weights at 204 may include determining the quantized weights based on the interval in which the values of the weights fall, where the interval is defined depending on the value of nbit. In a non-limiting example, when nbit=1, the weights of a CNN model rimy be quantized into two quantization levels. In other words, the weight values may be divided into two intervals. For example, the first interval is [0, .infin.), and the second interval (-.infin., 0). When W.sub.k.gtoreq.0, W.sub.Q=(W.sub.k).sub.Q=(W.sub.mean).sub.shift-quantized, where W.sub.k represents the weights for a kernel in a convolution layer of the CNN model, W.sub.mean=mean(abs(W.sub.k)), and a shift-quantization of a weight w may be determined by
w 2 shift 2 shift , where shift = log 2 ( 2 nbit - 1 - 1 W max ) ##EQU00002##
where |W|.sub.max is the maximum value of absolute values of the weights. Similarly, when W.sub.k<0, W.sub.Q=-(W.sub.mean).sub.shift-quantized. The mean and maximum values are relative to a convolution layer in the CNN model.
[0034] In a non-limiting example, when nbit=2, the intervals may be defined by (-.infin., -W.sub.mean/4), [-W.sub.mean/4, W.sub.mean/4] and (W.sub.mean/4, .infin.). Thus, the weights may be quantized into:
W.sub.Q=0, when |W.sub.k|.ltoreq.W.sub.mean/4;
W.sub.Q=(W.sub.mean).sub.shift-quantized, when W.sub.k<W.sub.mean/4;
W.sub.Q=-(W.sub.mean).sub.shift-quantized, when W.sub.k<-W.sub.mean/4.
It is appreciated that other variations may also be possible. For example, W.sub.max may be used instead of W.sub.mean. Denominators other than the values of 4 may also be used.
[0035] In another non-limiting example, when nbit=3, the intervals may be defined, as shown in FIG. 3. Define W'.sub.mean=W.sub.mean/4. Thus, the weights may be quantized into:
W.sub.Q=0when |W.sub.k|.ltoreq.W'.sub.mean/2;
W.sub.Q=(W'.sub.mean).sub.shift-quantized, when 3W'.sub.mean2<3W'.sub.mean/2;
W.sub.Q=(2W'.sub.mean).sub.shift-quantized, when 3W'.sub.mean/2<W.sub.k<3W'.sub.mean;
W.sub.Q=(4W'.sub.mean).sub.shift-quantized, when W.sub.k>3W'.sub.mean;
W.sub.Q=-(W'.sub.mean).sub.shift-quantized, when -3W'.sub.mean/2<W.sub.k<-W'.sub.mean/2;
W.sub.Q=-(2W'.sub.mean).sub.shift-quantized, when -3W'.sub.mean<W.sub.k<-3W'.sub.mean/2;
W.sub.Q=-(W'.sub.mean).sub.shift-quantized, when W.sub.k<3W'.sub.mean;
It is appreciated that other variations may also be possible. For example, W.sub.max may be used instead of W.sub.mean. Denominators other than the values of 4 to 2 may also be used.
[0036] Alternatively, and/or additionally, quantizing the weights at 204 may also include compressed-fixed point conversion, where a weight value may be separated into a scalar and a mask, where W=scalar.times.mask. Here, a mask may include a k.times.k kernel and each value in the mask may have a bit-width, such as 1-bit, 2-bit, 3-bit, 5-bit, 8-bit or other bit sizes. In some examples, a quantized weight may be represented by a product of a mask and an associated scalar. The mask may be selected to maximize the bit size of the kernel, where the scalar may be a maximum common denominator among all of the weights. In a non-limiting example, when nbit=5 or above, scalar=min(abs(w.sub.k)) for all weights in kth kernel, and
mask = [ w k scalar ] ##EQU00003##
[0037] The process 200 may further include determining a change of weights at 208 based on the output of the CNN model. In some examples, the output of the CNN model may be the output of the activation layer of the CNN. The process 200 may further update the weights of the CNN model at 210 based on the change of weights. In some examples, the process 200 may be implemented in a forward propagation and backward propagation framework. For example, the process 200 may perform operation 206 in a layer by layer fashion in a forward propagation, in which the inference of the AI model is propagated from the first convolution layer to the last convolution layer in a CNN (or a subset of the convolution layers in the CNN). The output inferred from the first layer will be fed to the second layer, the output inferred from the second layer will be fed to the third layer, so on and so forth until the output of the last layer is inferred.
[0038] In some examples, the operations 208 and 210 may be performed in a layer by layer fashion in a backward propagation, in which a change of weights is determined for each layer in a CNN from the last year to the first layer tor a subset of the convolution layers in the CNN), and the weights in each layer are updated based on the change of weights. In some examples, a loss function may be determined based on the output of the CNN model (e.g., the output of the last convolution layer of the CNN), and the changes of weights may be determined based on the loss function. This is further explained.
[0039] In some examples, the process 200 may repeat updating the weights of the CNN model in one or more iterations. In some examples, blocks 206, 208, 210 may be implemented using a gradient descent method, in which a suitable loss function may be used. In a non-limiting example, a loss function may be defined as:
H p ( q ) = - 1 N i = 1 N y i log ( p ( y i ) ) + ( 1 - y i ) log ( 1 - p ( y i ) ) ##EQU00004##
where y.sub.i is the prediction of the network, e.g., the output of the CNN based on the ith training instance. In a non-limiting example, if the CNN output includes two image labels (e.g., dog or cat), then y.sub.i may have the value of 0 or 1. N is the number of training instances in the training data set. The probability p(y.sub.i) of a training instance being y.sub.iand may be determined from the training. In other words, the loss function h( ) may be defined based on a sum of loss values over a plurality of training instances in the training data set, wherein the loss value of each of the plurality of training instances is a difference between an output of the CNN model for the training instance and a ground truth of the training instance.
[0040] In a non-limiting example, the training data 209 may include a plurality of training input images. The ground truth data may include information about one or more objects in the image, or about whether the image contains a class of objects, such as a cat, a dog, a human face, or a given person's face. Inferring the AI model may include generating a recognition result indicating which class to which the input image belongs. In the training process, such as 200, the loss function may be determined based on the image labels in the ground truth and the recognition result generated from the AI chip based on the training input image.
[0041] In some examples, the gradient descent may be used to determine a change of weight
.DELTA.W=f(W.sub.Q.sup.t)
by minimizing the loss function H( ), where W.sub.Q.sup.t stand for the quantized weights at time t. The process may update the weight from a previous iteration based on the change of weight, e.g., W.sup.t+1=W.sup.t.DELTA.W, where W.sup.tand W.sup.t+1 stand for the weights in a preceding iteration and the weights in the current iteration, respectively. In some examples, the weights (or updated weights) in each iteration, such as W.sup.t and W.sup.t+1 may be stored in floating point. The quantized weights W.sub.Q.sup.t at each iteration t may be stored in fixed point. In some examples, the gradient descent may include known methods, such as stochastic gradient descent method.
[0042] With further reference to FIG. 2, the process 200 may further include repeating blocks 204, 206, 208, 210 iteratively, in one or more iterations, until a stopping criteria is net at 214. In some examples, at each iteration, the process may perform operations 204, 206, 208, 210 in forward and backward propagations as disclosed in the present disclosure. For example, the process 200 may determine the output of the CNN at 206 by inference in a layer by layer fashion in a forward propagation. The process 200 may also determine the change of weights at 208 and update the weights at 210 in a layer by layer fashion in a backward propagation. For each iteration, the process 200 may use a batch of training images selected from the training data 209. The batch size may vary, For example, the batch size may have a value of 32, 64, 128, or other number of images.
[0043] In each iteration, the process 200 may determine whether a stopping criteria has been met at 214. If the stopping criteria has been met, the process may store the updated weights of the CNN model at the current iteration at 216 for use by another unit (e.g., a unit in 101 in FIG. 1). If the stopping criteria has not been met, the process 200 may repeat blocks 204, 206, 208, 210 in a new iteration. In determining whether a stopping criteria has been met, the process 200 may count the number of iterations and determine whether the number of iterations has exceeded a maximum iteration number. For example, the maximum iteration may be set to a suitable number, such as 100, 200, or 1000, or 10,000, or an empirical number. In some examples, determining whether a stopping criteria has been met may also determine whether the value of the loss function at the current iteration is greater than the value of the loss function at a preceding iteration. If the value of the loss function increases, the process 200 may determine that the iterations are diverting and determine to stop the iterations. Alternatively, and/or additionally, if the iterations are diverting, the process 200 may adjust the gradient descent hyper-parameters, such as learning rate, batch size, gradient decent updating mechanism, etc. In some examples, if the value of the loss function does not decrease over a number of iterations, the process 200 may also determine that the stopping criteria is met.
[0044] In some examples, the process 200 may be implemented entirely on a desktop using a CPU or a GPU. Alternatively, certain operations in the process 200 may be implemented in a physical AI chip, where the trained weights or updated weights are uploaded inside the AI chip.
[0045] FIG. 4 illustrates a diagram of an example process of training that may be implemented in an activation quantization unit, such as 108 (in FIG. 1) in accordance with various examples described herein. A training process 400 may perform operations in one or more iterations to train and update the weights of a CNN model, where the trained weights may be output in fixed point, which is suitable for an AI chip, to execute. The process 400 may include accessing trained weights of an AI model at 402. For example, the AI model may include quantized weights from the process 200 (FIG. 2), where the quantized weights are stored in fixed point (at 216 in FIG. 2). Alternatively, the AI model may be trained in the floating-point model training unit (104 in FIG. 1) and include weights in floating-point. In a non-limiting example, the trained weights may be the weights of a CNN model. The process 400 may further include determining output of the AI model based on the weights at 408. If the weights of the CNN are in fixed point, such as determined from the convolution quantization unit 106 in FIG. 1, the operation of determining the output of the CNN may be performed in fixed point. If the weights of the CNN are in floating point, such as trained from the floating-point model training unit (104 in FIG. 1), the operation of determining the output of the CNN may be performed in floating point. Determining the output of the AI model at 408 may include inferring the AI model using the training data 409 and the weights obtained from box 402.
[0046] Similar to FIG. 2, determining the output of the CNN model at 408 may be performed on a CPU or GPU processor outside the AI chip. In some or other scenarios, determining the output of the CNN model may also, be performed directly on an AI chip, where the AI chip may be a physical chip or a virtual AI chip, and executed to produce output. If the weights are in fixed-point and supported by a physical AI chip, the weights may be uploaded into the AI chip. In that case, the process 400 may load quantized weights into the AI chip for execution of the AI model. The training data 409 may be similar to the training data 209 in FIG. 2.
[0047] With further reference to FIG. 4, the process 400 may further include quantizing the output of the CNN at 406. In some examples, quantizing the output of the CNN may include quantizing at least one activation layer. In some examples, an activation layer in an AI chip may include a rectified linear unit (ReLU) of a CNN. The quantization of the activation layer may be based on the hardware constraints of the AI chip so that the quantized output of the activation layer can mimic the characterization of the physical AI chip. FIG. 5 illustrates, a diagram of an example CNN in an AI chip in accordance with various examples described herein. In some example, a CNN 500 in an AI chip may include one, or more convolution layers, e.g., 502, 504, 506 . . . etc. In operation, these convolution layers may include weights stored in fixed point or floating-point. Each of the convolution layers may produce the output in fixed point. In some examples, a convolution layer may also include an activation layer (e.g., ReLU layer), which may also include fix point values.
[0048] FIG. 6A illustrates a diagram of an example process of training an AI model for executing in an AI chip in accordance with various examples described herein. In some examples, a process 600 may quantize the output of one or more convolution layers in a CNN during the training process. The one or more convolution layers in the CNN model may correspond to one or more convolution layers in the AI chip in FIG. 5. By quantizing the output of the convolution layers during the training, the trained CNN model may be expected to achieve a performance in an AI chip close to that achieved in a CPU/GPU during the training. In other words, the quantization effect over the CNN model during the training may mimic that of the AI chip so that performance of the CNN model during the training may accurately reflect the anticipated performance of the physical AI chip when the trained CNN model is uploaded and executed in the AI chip.
[0049] In some examples, the, process 600 may include accessing the input of a first convolution layer at 602 and determining the output of the first convolution layer at 604. For example, the first convolution layer may be any of the convolution layers in a CNN model that corresponds to a convolution layer, e.g. 502, 504, 506 . . . in an AI chip. The output of the convolution may be stored in floating point. Accessing the input of the first convolution layer at 602 may include assessing the input data, if the first convolution layer is the first layer after the input in the CNN, or assessing the output of the preceding layer, if the first convolution layer is an intermediate layer. Determining the output of the first convolution layer at 604 may include executing a CNN model to produce an output at the first convolution layer, in a training process, determining the output of the convolution layer may be performed outside of a chip, e.g., in a CPU/GPU environment. Alternatively, determining the output of the convolution layer may be performed in an AI chip.
[0050] With further reference to FIG. 6A, the process 600 may further quantize the output of the first convolution layer at 606. In some examples, the method of quantizing the output of the convolution layer may mimic the configuration of an AI chip such as the number of bits and the quantization behavior of a convolution layer in an AI chip. For example, the quantized output of the CNN model may be stored in fixed point in the same bit-length of the activation layer of the corresponding convolution layer in the AI chip. In a non-limiting example, the output of each convolution layer in an AI chip may have 5 bits (in hardware), where the output values range from 0 to 31. The process 600 may determine a range for quantization based on the bit-width of the output of each convolution layer of the AI chip. In the above example, the range for quantization may be 0-31, which corresponds to 5-bits in the hardware configuration. The process 600 may perform a clipping over the output of a convolution layer in the CNN model, which sets a value beyond a range to a closest minimum or maximum of the range. FIG. 6B illustrates an example of distribution for layout output values of an AI model. In such example, the layer output values from multiple runs of the AI chip over multiple instances of a training set are all greater than zero. A clipping was done at the maximum value y.sub.i.sup..alpha., where i stands for the ith convolution layer. In the above example in which the convolution layer contains 5-bit values, for a value above 31, the process may set the value to the maximum value: 31.
[0051] Returning to FIG. 6A., quantizing the activation layer may include quantizing the output values of one or more convolution layers in the CNN. For example, Y=W*X+b represents the output value of an activation layer, then, the activation layer may be quantized as:
y .varies. = 0.5 ( y - y - .varies. + .varies. ) , i . e . , y .varies. = { 0 , x .di-elect cons. ( - .infin. , 0 ) x , x .di-elect cons. [ 0 , .varies. ] .varies. , x .di-elect cons. ( .varies. , .infin. ) ##EQU00005##
Here, a value of [0, .alpha.] may be represented by a maximum number of bits in the activation layer, e.g., 5-bit, 10-bit, or other values. If a weight is in the range of [0, .alpha.], then the quantization becomes a linear transformation. If a weight has a value of less than zero or a value of greater than .alpha., then the quantization clips the weight at zero or .alpha., respectively. Here, the quantization of activation layer limns the value of the output to the same limit in the hardware. In a non-limiting example, if the bit-width of an activation layer in an AI chip is 5 bits, then [0, .alpha.] may be represented by 5 bits. Accordingly, the quantized value will be represented by 5 bits.
[0052] With further reference to FIG. 6A, the process 600 may further repeat similar operations for a second convolution layer. The process 600 may access input of the second convolution layer at 608, determine the output of the second convolution layer at 610, and quantize the output of the second convolution layer at 612. For example, the second convolution layer may correspond to a convolution layer in the AI chip, such as 504, or 506 in FIG. 5. In accessing the input of the second convolution layer, the process may take the output of the preceding layer. If the first and second convolution layers in the CNN model are consecutive layers, for example, the first layer in the CNN model corresponds to layer 502 in the AI chip and the second layer in the CNN corresponds to layer 504 in the AI chip, then accessing the input of the second layer (e.g., 504) may include accessing the output values of the first layer (e.g., 502). If the values of the output of the first layer are quantized, then accessing the input of the second layer includes accessing the quantized output of the first layer.
[0053] Blocks 610 and 612 may perform in a similar fashion as blocks 604 and 606. Further, the process 600 may repeat blocks 608-612 for one Of more additional layers at 614. In some examples, the process 600 may quantize the output for all convolution layers in a CNN in a layer-by-layer fashion. In some examples, the process 600 may quantize the output of some convolution layers in a CNN model. For example, the process 600 may quantize the output of one or more last few convolution layers in the CNN.
[0054] Returning to FIG. 4, the process 400 may further include determining a change of weights at 408 and updating the weights at 410. The process 400 may further repeat the processes 404, 406, 408, 410 until a stopping criteria is met at 414. Determining the change of weights at 408 and updating the weights at 410 may include a similar training process as in FIG. 2. For example, the process 400 may include determining a change of weights at 408 based on the output of the CNN model. In some examples, the output of the CNN model may be the output of the activation layer of the CNN. The process 400 may further update the weights of the CNN model at 410 based on the change of weights. The process may repeat updating the weights of the CNN model in one or more iterations. Similar to FIG. 2, in each iteration, the process 400 may also be implemented in forward and background propagations in a layer by layer manner. In some examples, blocks 404, 406, 408, 410 may be implemented using a gradient descent method. The gradient descent method may perform in a similar fashion as described in FIG. 2. For example, a loss function may be defined as:
H p ( q ) = - 1 N i = 1 N y i log ( p ( y i ) ) + ( 1 - y i ) log ( 1 - p ( y i ) ) ##EQU00006##
where y.sub.i is the prediction of the network, e.g., the output of the CNN based on the ith training instance. In a non-limiting example, if the CNN output includes two image labels (e.g., dog or cat), then y.sub.i may have the value of 0 or 1. N is the number of training instances in the training data set. The probability p(y.sub.i) of a training instance being y.sub.i and may be determined from the training. In other words, the loss function H( ) may be defined based on a sum of loss values over a plurality of training instances in the training data set, wherein the loss value of each of the plurality of training instances is a difference between an output of the CNN model for the training instance and a ground truth of the training instance.
[0055] In some examples, the gradient descent may be used to determine a change of weights
.DELTA.W=f(W.sub.Q.sup.t)
by minimizing the loss function H( ), where W.sub.Q.sup.t stands for the quantized weights at time t. In other words, W.sub.Q.sup.t=Q(W.sup.t). The process may update the weight from a previous iteration based on the change of weight, e.g., W.sup.t+1=W.sup.t+.DELTA.W, where W.sup.t and W.sup.t+1 stand for the weights in a preceding iteration and the weights in the current iteration, respectively. In some examples, the weights (or updated weights) in each iteration, such as W.sup.t and W.sup.t+1, may be stored in floating point. The quantized weights W.sub.Q.sup.t at each iteration t may be stored in fixed point. In some examples, the gradient descent may include known methods, such as a stochastic gradient descent method.
[0056] With further reference to FIG. 4, once the stopping criteria is met at 414, the process 400 may store the updated weights at 416 for use by another unit (e.g., a unit in 101 in FIG. 1). In some examples, the process 400 may be implemented entirely on a desktop using a CPU or a GPU. Alternatively, certain operations in the process 400 may be implemented in a physical AI chip, where the trained weights or updated weights are uploaded inside the AI chip.
[0057] FIG. 7 illustrates a diagram of an example process of training that may be implemented in a chip customization unit, such as 110 (in FIG. 1) in accordance with various examples described herein. A process 700 may include accessing trained weights at 702. For example, the trained weights may be determined from processes 200 or 400 (in FIGS. 2 or 4, respectively). The process 700 may further including one or more linear transformations, such as performing batch normalization merge at 704, performing image mean merge at 706, performing image scale merge at 708, performing output equalization at 710, and/or performing a combination thereof.
[0058] In some examples, performing batch normalization merge at 704 may include updating the weights and biases of the CNN model by merging the batch normalization into the convolution layers such that the input values of a convolution layer Y=W*X+b are effectively normalized to Y''=W'*X+b where W' and b' are updated weights and biases. In some examples, a hatch normalization may be expressed as:
Y '' = .gamma. ( W * X + b - mean std ) + .beta. ##EQU00007##
where the mean and std are the average and standard deviations of the input values (or output values of previous layers) for each batch of images X. Here, .gamma. and .beta. may be learned from the training process. Accordingly, the weights and biases may be updated based on:
W ' = W .gamma. std ##EQU00008## b ' = b .gamma. std + .beta. - .gamma. mean std ##EQU00008.2##
[0059] In some examples, the weights and biases may be updated per convolution layer. The updating of weights and biases may be performed independently between layers. A batch refers to a data batch, such as a plurality of images. Average values and standard deviations may be determined over the plurality of images in each batch. The values for .gamma. and .beta. are learned during the gradient descent training, independently from the weights and biases of the AI model. A batch normalization may normalize the inputs of each layer to the same range of values. This may help speed up the training process (to converge faster). For example, batch normalization may prevent early saturation of non-linear activation functions. The batch normalization merge at 704 essentially merges the batch normalization parameters into the convolution layer of an AI model. This reduces memory usage on the chip, and increases inference speed when running the AI model on the chip.
[0060] With further reference to FIG. 7, performing the image mean merge at 706 may include updating the weights and biases of the AI model to give the effect of merging the mean of an image. In other words, in image mean merge, Y=W*(X-mean)+b is equivalent to Y+W'*X+b', where the mean is the average of the images in a batch. In some examples, the mean of multiple images having R, G, B values may be a particular color pixel value (R, G, B). This gives:
W'=W
b'=b-W*mean
[0061] In some examples, the updating of weights and biases in the image mean merge may be performed for the first convolution layer, which is connected to an image layer at the input. As shown, the image mean merge makes sure the input pixel values of the training images are within the pixel value range, e.g., [0, 255]. Further, the image mean is used during the training to adjust the input image pixel range to be balanced around the value of zero to facilitate training convergence.
[0062] With further reference to FIG. 7, performing the image scale merge at 708 may include updating the weights and biases of the AI model to give the effect of scaling the input image. In other words, in image scale merge, Y=W*(X/a)+b is equivalent to W=W'*X+b', where the value a is the average scale of the images in a batch and can be learned from the input images. For example, it the input image is not [0, M], but instead [0, M*scale], where M is the maximum value as allowed in a physical AI chip (e.g., M=255), the value of scale can be learned. Once the value of a is determined, the weights and biases may be updated as:
W ' = W a ##EQU00009## b ' = b ##EQU00009.2##
[0063] In some examples, the updating of weights and biases in the image scale merge may be performed for the first convolution layer, which is connected to an image layer at the input. As shown, the image scale merge gives the effect of adjusting the input image to take values to take full advantage of the size of the input image channel in the AI chip. For example, if the pixel values of the image are above the maximum value allowed in the AI chip, the image scale merge gives the effect of scaling down the image values, or normalizing the image values to within the maximum allowed range of the input image in the AI chip. Conversely, if the pixel values of the image are in a small range, the image scale merge gives the effect of scaling up the image values, or normalizing the values to take full advantage of the maximum allowed range of the input image in the AI chip.
[0064] With further reference to FIG. 7, performing the output 710 may include updating the weights and biases of the AI model so that the output of each convolution layer the AI model has a value within the allowed output value range in the AI chip. In a non-limiting example, the allowed output value range maybe 3-bit. 5-bit, 8-bit, 10-bit, or other values. The operation of output equalization may be performed for one or more, or all of the convolution layers in the AT model.
[0065] In some examples, the maximum output value of the ith layer .alpha..sub.i may be statistically determined from the multiple images in a batch. For example, .alpha..sub.i and .alpha..sub.i-1 may each represent the statistical maximum output value of the ith layer and its preceding layer, the (i-l)th layer, respectively. Then, the weights and biases of the AI model may be updated as:
W i ' = .varies. i - 1 .varies. i W i ##EQU00010## b i ' = 2 nbit - 1 - 1 .varies. i b i ##EQU00010.2##
where nbit is the maximum bit-size of the output value of each layer. In the above example, the quantized value will be in the range of [0, .alpha.] represented in nbit, such as 5-bit. Then the quantization grid is .alpha./(2.sup.nbit . . . 1)=.alpha./31. After output equalization, the quantization value will be in the range of [0, 31], with an effective quantization grid being 31/31 (=1.0). In other words, the output equalization causes the quantization grid to be 1, which is feasible by the AI chip hardware.
[0066] The various linear transformation operations in FIG. 7, such as 704-710 may update the weights and biases of a CNN model so that they are more suitable for a hard ware environment. For example, batch normalization merge normalizes each layer's input data (previous layer's output data) to make the training easy to converge. The output equalization operation may update the weights of the AI model to cause the inputs and/or outputs of each layer of the AI model to be equalized to the same level, and within the range allowed in the physical AI chip. It ensures that the trained/updated model can be loaded onto the physical chip with low degradation of performance. Further, the image mean merge and image scale merge may adjust the input image to an optimal range that maximizes the use of the input image buffer in the physical AI chip.
[0067] With further reference to FIG. 7, the process 700 may further perform fine-tuning at 712 such that the weights and biases of the trained/updated AI model will be even closer to the characteristics of the physical AI chip. In some examples, the fine-tuning at 712 may be based on training data 709.
[0068] FIG. 8 illustrates a diagram of an example process of fine tuning in accordance with various examples described herein. In some examples, a fine tuning process 800 may include accessing trained weights at 802. For example, accessing trained weights may include accessing the updated weights and biases from block 710 or any of the linear transformation operations 704, 706, 708 (in FIG. 7). In another example, accessing training, weights may include accessing the updated weights and biases from one or more units in the training network 101, such as convolution quantization unit 106 or activation quantization unit 108 (in FIG. 1).
[0069] The process 800 may further perform shift-based quantization on the access weights at 804. Shift-based quantization may mimic the characteristics of a hardware chip because shift registers are commonly available inside a chip. In some examples, the weights and biases are updated based on a shift value. The shift value may be an integer. For example,
shift = log 2 ( 2 nbit - 1 - 1 max W ) ##EQU00011## W Q = W 2 shift 2 shift ##EQU00011.2## b Q = b 2 shift 2 shift ##EQU00011.3##
where W.sub.Q and b.sub.Q are the quantized weights and biases, and nbit represents the maximum allowed value in the physical AI chip. In some examples, the weights and biases are updated for one or more convolution layers in a CNN model.
[0070] With further reference to FIG. 8, the process 800 may further include determining the output of the CNN model based on the quantized weights at 808 and determining a change of weights at 810. Determining the output of the AI model at 808 may include inferring the AI model using the training data 809 and the linear transformed weights from one or more operations 704-710 (in FIG. 7). Determining the output of the AI model may be implemented in a CPU, GPU or inside an AI chip (physical or virtual). The process 800 may further include updating the weights at 812 based on the change of weights, and repeating the process until a stopping criteria is met at 814. The training data 809 may be obtained from training data 709 (in FIG. 7) and similar to the training data 209 (in FIG. 2).
[0071] Determining the change of weights at 810 and updating the weights at 812 may include a similar training process as in FIGS. 2 and 4, in which the loss function may be similarly defined and the change of weights may also be similarly determined. For example, blocks 808, 810, 812 may be implemented using a gradient descent method. A loss function may be defined as:
H p ( q ) = - 1 N i = 1 N y i log ( p ( y i ) ) + ( 1 - y i ) log ( 1 - p ( y i ) ) ##EQU00012##
where y.sub.i is the prediction of the network, e.g., the output of the CNN based on the ith training instance. In a non-limiting example, if the CNN output includes two image labels (e.g., dog or cat), then y.sub.i may have the value of 0 or 1. N is the number of training instances in the training data set. The probability p(y.sub.i) of a training instance being y.sub.i and may be determined from the training. In other words, the loss function H( ) may be defined based on a sum of loss values over a plurality of training instances n the training data set, wherein the loss value of each of the plurality of training instances is a difference between an output of the CNN model for the training instance and a ground truth of the training instance.
[0072] In some examples, the gradient descent may be used to determine a change of weights
.DELTA.W=f(W.sub.Q.sup.t)
by minimizing the loss function H( ), where W.sub.Q.sup.t stands for the quantized weights at time t. In other words, W.sub.Q.sup.t=Q(W.sup.t). The process may update the weight from a previous iteration based on the change of weight, e.g., W.sup.t+1=W.sup.t+.DELTA.W, where W.sup.t and W.sup.t+1 stand for the weights in a preceding iteration and the weights in the current iteration, respectively. In some examples, the weights (or updated weights) in each iteration, such as W.sup.t and W.sup.t+1, may be stored in floating point. The quantized weights W.sub.Q.sup.t at each iteration t may be stored in fixed point. In some examples, the gradient descent may include known methods, such as stochastic gradient descent method.
[0073] The stopping criteria may defined in a similar fashion as in FIGS. 2 and 4. For example, in determining whether a stopping criteria has been met, the process 800 may count the number of iterations and determine whether the number of iterations has exceeded a maximum iteration number. The maximum iteration may be set to a suitable number, such as 100, 200, or 1000, or 10,000, of an empirical number. In some examples, determining whether a stopping criteria has been met may also determine whether a value of the loss function at the current iteration is greater than a value of the loss function at a preceding iteration. If the value of the loss function increases, the process 800 may determine that the iterations are diverting and determine to stop the iterations.
[0074] In some examples, the process 800 may be implemented entirely on a desktop using a CPU or a GPU. Alternatively, certain operations in the process 800 may be implemented in a physical AI chip, where the trained weights or updated weights are uploaded inside the AI chip. Once the stopping criteria is met at 814, the process 800 may store the updated weights at 816.
[0075] Returning to FIG. 7, the process 700 may further include uploading the weights to the AI chip at 716. For example, the weights uploaded to the AI chip may be trained and fine-tuned from box 712, and/or any of the operations 704-710 or a combination thereof. Uploading the weights to the AI chip may include uploading the updated weights and biases of the CNN model to the AI chip so that the AI chip may be capable of performing an AI task. Once the trained/updated weights are uploaded to the AI chip, the process 700 may further include executing the AI chip to perform an AI task at 718 in a real-time application, and outputting the result of the AI task at 720. An example of an AI task may include recognizing, one or more classes of object from an input image, such as a crying or smiley face.
[0076] In an example application, an AI chip may be installed in a camera and store the trained weights and/or other parameters of the CNN model, such as those trained/quantized/updates weights generated in any of units in the training network 101 (in FIG. 1) or any of the processes 200 (FIG. 2), 400 (FIG. 4), 600 (FIG. 6A), 700 (FIG. 7) or 800 (FIG. 8). The AI chip may be configured to receive a captured image from the camera, perform an image recognition task based on the captured image and the stored CNN model, and present the recognition result on an output device, such as a display. For example, the camera may display, via a user interface, the recognition result. In a face recognition application, the CNN model may be trained for face recognition. A captured image may include one or more facial images associated with one or more persons. The recognition result may include the names associated with each input facial image. The camera may present the output of the recognition result on an output device, such as a display. For example, the user interface may display a person's name next to or overlaid on each of the input facial image associated with the person.
[0077] It is appreciated that the disclosures of various embodiments in FIGS. 1-8 may vary. For example, the number of iterations in process 200 in FIG. 2, process 400 in FIG. 4, and process 800 in FIG. 8 may vary and may be independent. In other examples, the quantization of weights at 204 in FIGS. 2 and 804 in FIG. 8 may be interchangeable. In other examples, the quantization of activation layer 404 in FIG. 4 may be independent from quantization of weights 204 in FIGS. 2 and 804 in FIG. 8 in a training process. In other examples, in a training process, such as process 800 in FIG. 8, quantizing weights at 804 may be optional, while determining the output of the CNN at 808 may be based on the accessed trained weights 802 in FIG. 8. Alternatively, one or more processes 200 (in FIG. 2), 400 (in FIGS. 4) and 800 (in FIG. 8) may be combined. For example, a combined process may perform quantization of activation layer (e.g., 404 in FIG. 4) and quantization of weights (e.g., 204 in FIG. 2) in a single training process. Similarly, a training process, such as 200 (in FIG. 2), 400 (in FIG. 4) or 800 (in FIG. 8) may be performed multiple times, each using a separate training set. Further, the operations in processes 200 (in FIG. 2), 400 (in FIG. 4), 600 (in FIG. 6A), 700 (in FIG. 7) and 800 (in FIG. 8) may be performed entirely on a CPU/GPU processor. Alternatively, certain operations in these processes may be performed on an AI chip. It is appreciated that other variations may be possible.
[0078] FIG. 9 depicts an example of internal hardware that may be included in any electronic device or computing system for implementing various methods in the embodiments described in FIGS. 1-8. An electrical bus 900 serves as an information highway interconnecting the other illustrated components of the hardware. Processor 905 is a central processing device of the system, configured to perform calculations and logic operations required to execute programming instructions. As used in this document and in the claims, the terms "processor" and "processing device" may refer to a single processor or any number of processors in a set of processors that collectively perform a process, whether a central processing unit (CPU) or a graphics processing unit (GPU) or a combination of the two. Read only memory (ROM), random access memory (RAM), flash memory, hard drives, and other devices capable of storing electronic data constitute examples of memory devices 925. A memory device, also referred to as a computer-readable medium, may include a single device or a collection of devices across which data and/or instructions are stored.
[0079] An optional display interface 930 may permit information from the bus 900 to be displayed on a display device 935 in visual, graphic, or alphanumeric format. An audio interface and audio output (such as a speaker) also may be provided. Communication with external devices may occur using various communication ports 940 such as a transmitter and/or receiver, antenna, an RFID tag and/or short-range, or near-field communication circuitry. A communication port 940 may be attached to a communications network, such as the Internet, a local area network, or a cellular telephone data network.
[0080] The hardware may also include a user interface sensor 945 that allows for receipt of data from input devices 950 such as a keyboard, a mouse, a joystick, a touchscreen, a remote control, a pointing device, a video input device, and/or an audio input device, such as a microphone. Digital image flames may also be received from an imaging capturing device 955 such as a video or camera that can either be built-in or external to the system. Other environmental sensors 960, such as a GPS system and/or a temperature sensor, may be installed on system and communicatively accessible by the processor 905, either directly or via the communication ports 940. The communication ports 940 may also communicate with the AI chip to upload or retrieve data to/from the chip. For example, a trained AI model with updated quantized weights obtained from the training system 100 (FIG. 1), or the processes 200 (FIG. 2), 400 (FIG. 4), 600 (FIG. 6A), 700 (FIG. 7) or 800 (FIG. 8) may be shared by one or more processing devices on the network running other training processes or AI applications. For example, a device on the network may receive the trained AI model from the network and upload the trained weights, to an AI chip for performing an AI task via the communication port 940 and an SDK (software development kit). The communication port 940 may also communicate with any other interface circuit or device that is designed for communicating with an integrated circuit.
[0081] Optionally, the hardware may not need to include a memory, but instead programming instructions are run on one or more virtual machines or one or more containers on a cloud. For example, the various methods illustrated above may be implemented by a server on a cloud that includes multiple virtual machines, each virtual machine having an operating system, a virtual disk, virtual network and applications, and the programming instructions for implementing various functions in the robotic system may be stored on one or more of those virtual machines on the cloud.
[0082] Various embodiments described above may be implemented and adapted to various applications. For example, the AI chip having a CNN architecture may be residing in an electronic mobile device. The electronic mobile device may use the built-in AI chip to produce recognition results and generate performance values. In some scenarios, training the CNN model can be performed in the mobile device itself, where the mobile device retrieves training data from a dataset and uses the built-in AI chip to perform the training. In other scenarios, the processing device may be a server device in the communication network (e.g., 102 in FIG. 1 or may be on the cloud. These are only examples of applications in which an AI task can be performed in the AI chip.
[0083] The various systems and methods disclosed in this patent document provide advantages over the prior art, whether implemented standalone or combined. For example, using the systems and methods described in FIGS. 1-9 may help obtain an optimal AI model that may be executed in a physical AI chip with a performance close to an expected performance in the training process by mimicking the hardware configuration in the training process. Further, the quantization of weights and output values of one or more convolution layers may use various methods. The configuration of the training process described herein may facilitate both forward and backward propagations that would take advantage of classical training algorithms, such as gradient decent, in training weights of an AI model. Above illustrated embodiments are described in the context of training a CNN model for an AI chip (physical or virtual), but can also be applied to various other applications, For example, the current solution is not limited to implementing the CNN but can also be applied to other algorithms or architectures inside an AI chip.
[0084] It will be readily understood that the components of the present solution as generally described herein and illustrated in the appended figures could be arranged and designed in a wide variety of different configurations. Thus, the detailed description of various implementations, as represented herein and in the figures, is not intended to limit the scope of the present disclosure, but is merely representative of various implementations. While the various aspects of the present solution are presented in drawings, the drawings are not necessarily drawn to scale unless specifically indicated.
[0085] The present solution may be embodied in other specific forms without departing from its spirit or essential, characteristics. The described embodiments are to be considered in all respects only as illustrative and not restrictive. The scope of the present solution is, therefore, indicated by the appended claims rather than by this detailed description. All changes which come within the meaning and range of equivalency of the claims are to be embraced within their scope.
[0086] Reference throughout this specification to features, advantages, or similar language does not imply that all of the features and advantages that may be realized with the present solution should be or are in any single embodiment thereof. Rather, language referring to the features and advantages is understood to mean that a specific feature, advantage, or characteristic described in connection with an embodiment is included in at least one embodiment of the present solution. Thus, discussions of the features and advantages, and, similar language, throughout the specification may, but do not necessarily, refer to the same embodiment.
[0087] Furthermore, the described features, advantages, and characteristics of the present solution may be combined in any suitable manner in one or more embodiments. One ordinarily skilled in the relevant art will recognize, in light, of the description herein, that the present solution can be practiced without one or more of the specific features or advantages of a particular embodiment. In other instances, additional features and advantages may be recognized in certain embodiments that may not be present in all embodiments of the present solution.
[0088] Other advantages can be apparent to those skilled in the art from the foregoing specification. Accordingly, it will be recognized by those skilled in the art that changes, modifications, or combinations may be made to the above-described embodiments without departing from the broad inventive concepts of the invention. It should therefore be understood that the present solution is not limited to the particular embodiments described herein, but is intended to include all changes, modifications, and all combinations of various embodiments that are within the scope and spirit of the invention as defined in the claims.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
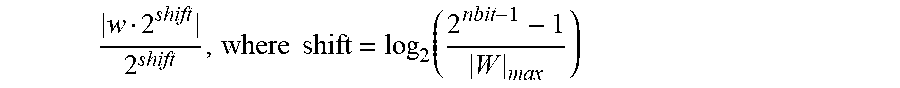










XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.