Gpu-based Third-order Low-rank Tensor Completion Method And The Apparatus
Zhang; Tao ; et al.
U.S. patent application number 16/818140 was filed with the patent office on 2020-09-17 for gpu-based third-order low-rank tensor completion method and the apparatus. This patent application is currently assigned to Tensor & Deep Learning Lab L.L.C.. The applicant listed for this patent is Tensor & Deep Learning Lab L.L.C.. Invention is credited to Xiaoyang Liu, Da Xu, Tao Zhang.
| Application Number | 20200294184 16/818140 |
| Document ID | / |
| Family ID | 1000004841418 |
| Filed Date | 2020-09-17 |



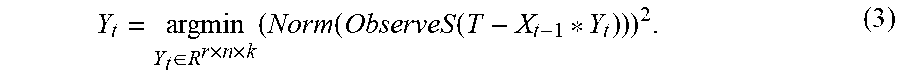
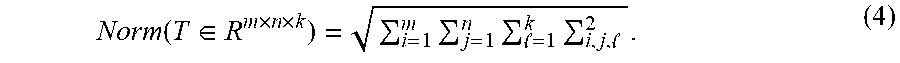
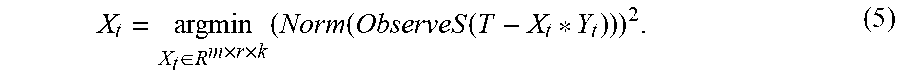
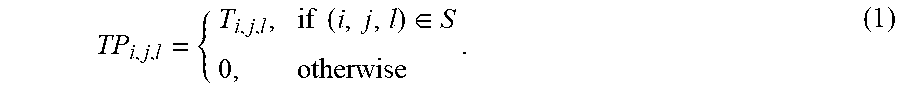

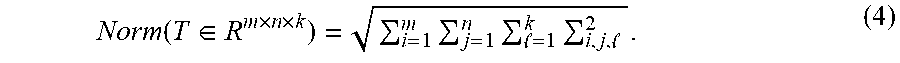
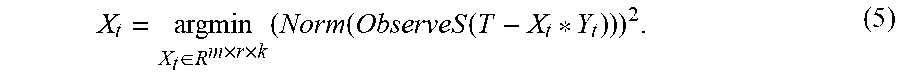
View All Diagrams
| United States Patent Application | 20200294184 |
| Kind Code | A1 |
| Zhang; Tao ; et al. | September 17, 2020 |
GPU-BASED THIRD-ORDER LOW-RANK TENSOR COMPLETION METHOD AND THE APPARATUS
Abstract
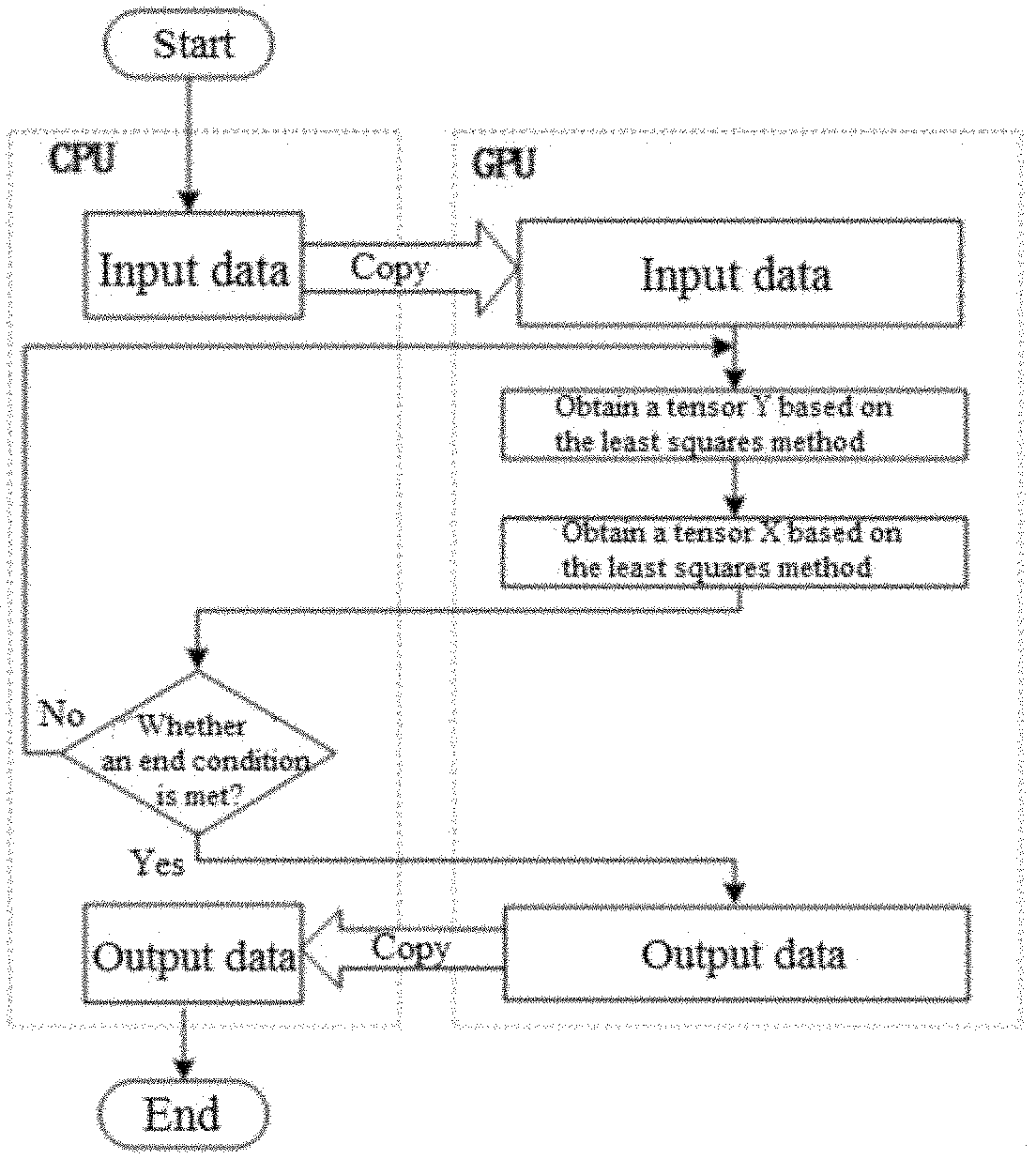
The present disclosure provides a GPU-based third-order low-rank tensor completion method. Operation steps of the method includes: (1) transmitting, by a CPU, input data DATA1 to a GPU, and initializing the loop count t=1; (2) obtaining, by the GPU, a third-order tensor Y.sub.t of a current loop t based on the least squares method; (3) obtaining, by the GPU, a third-order tensor X.sub.t of the current loop t based on the least squares method; (4) checking, by the CPU, whether an end condition is met; and if the end condition is met, turning to (5); otherwise, increasing the loop count t by 1 and turning to (2) to continue the loop; and (5) outputting, by the GPU, output data DATA2 to the CPU. In the present disclosure, in the third-order low-rank tensor completion, a computational task with high concurrent processes is accelerated by using the GPU to improve computational efficiency.
| Inventors: | Zhang; Tao; (New York, NY) ; Xu; Da; (New York, NY) ; Liu; Xiaoyang; (New York, NY) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assignee: | Tensor & Deep Learning Lab
L.L.C. New York NY |
||||||||||
| Family ID: | 1000004841418 | ||||||||||
| Appl. No.: | 16/818140 | ||||||||||
| Filed: | March 13, 2020 |
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06T 1/20 20130101; G06F 17/16 20130101 |
| International Class: | G06T 1/20 20060101 G06T001/20; G06F 17/16 20060101 G06F017/16 |
Foreign Application Data
| Date | Code | Application Number |
|---|---|---|
| Mar 15, 2019 | CN | 201910195941.8 |
Claims
1. A GPU-based third-order low-rank tensor completion method, wherein operation steps comprise: Step 1: transmitting, by a CPU, input data DATA1 to a GPU, and initializing the loop count t=1; Step 2: obtaining, by the GPU, a third-order tensor Y.sub.t of a current loop t based on the least squares method; Step 3: obtaining, by the GPU, a third-order tensor X.sub.1 of the current loop t based on the least squares method; Step 4: checking, by the CPU, whether an end condition is met; and if the end condition is met, turning to Step 5; otherwise, increasing the loop count t by 1 and turning to Step 2 to continue the loop; and Step 5: outputting, by the GPU, output data DATA2 to the CPU.
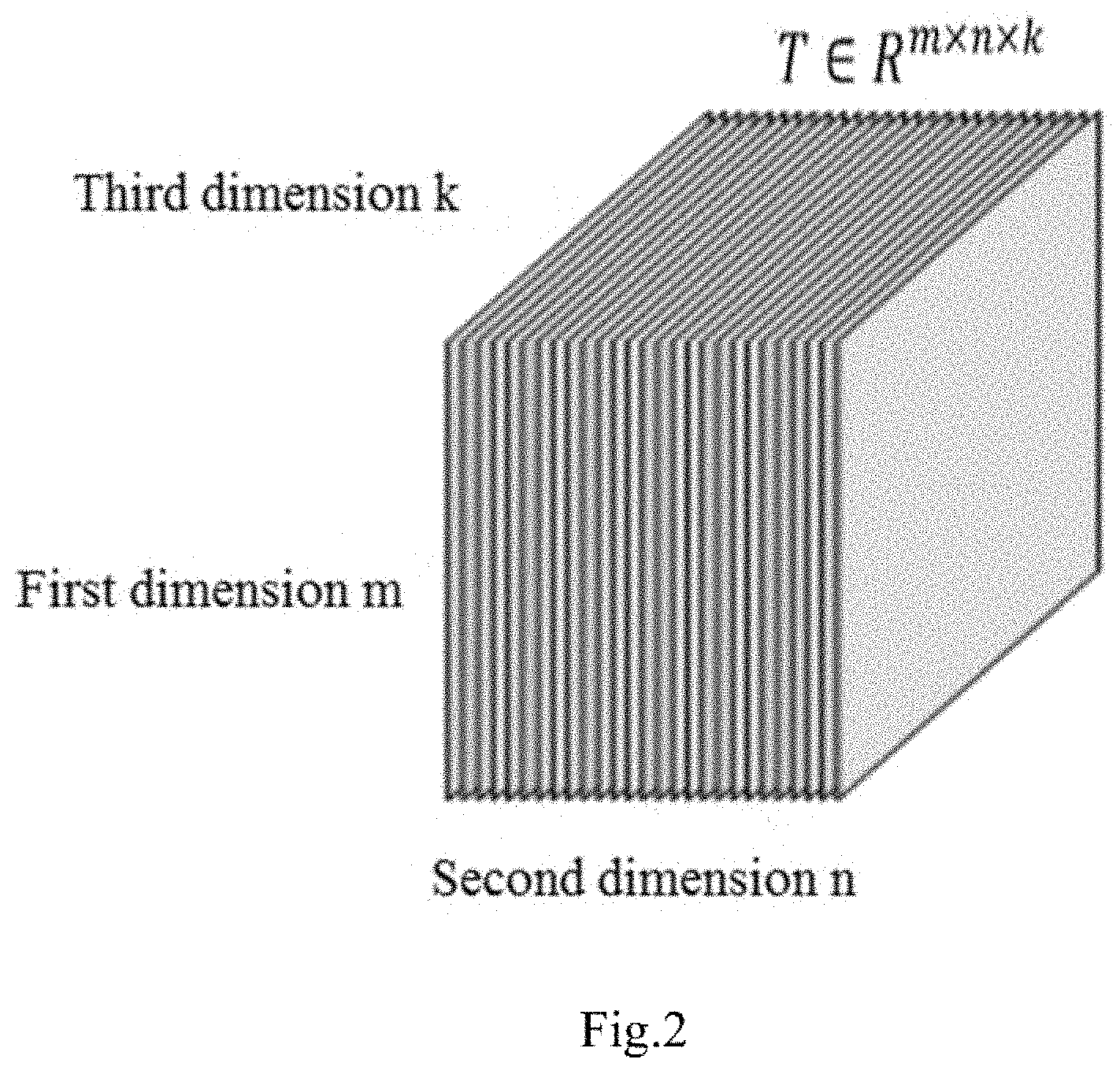
2. The GPU-based third-order low-rank tensor completion method according to claim 1, wherein Step 1 comprises: Step 1.1: allocating memory space in a GPU memory; Step 1.2: transmitting the input data DATA1 in a CPU memory to the allocated memory space in the GPU memory, wherein the DATA1 comprises the following data: (1) a third-order to-be-completed tensor T.di-elect cons.R.sup.m.times.n.times.k, wherein R denotes the set of real numbers, m, n, and k are respectively sizes of the tensor T in the first, second, and third dimensions, the total number of elements of the tensor is m.times.n.times.k, and an element of the tensor that the first, second, and third dimensions are respectively i, j, and l is denoted as T.sub.i,j,l; (2) an observation set S[o].times.[p].times.[q], wherein o.ltoreq.m, p.ltoreq.n, q.ltoreq.k; (3) an observation tensor TP.di-elect cons.R.sup.m.times.n.times.k based on the observation set S and the to-be-completed tensor T.di-elect cons.R.sup.m.times.n.times.k, wherein TP is represented by using an observation function ObserveS( ) for T, that is, TP=ObserveS(T), and the observation function ObserveS( ) is defined as: TP i , j , l = { T i , j , l , if ( i , j , l ) .di-elect cons. S 0 , otherwise , ( 1 ) ##EQU00009## wherein values of those elements TP.sub.i,j,l in TP if (i,j,l).di-elect cons.S need to be accurate and do not need to be completed; and (4) a tubal-rank r of the tensor T, wherein T(i,j,:) is defined as the (i,j).sup.th tube of the tensor T.di-elect cons.R.sup.m.times.n.times.k, and is a vector ((T(i,j,1), T(i,j,2), . . . , T(i,j,k)) with length k; the rank of the third-order tensor is defined as the number of non-zero tubes of .theta. in singular value decomposition of the tensor T=U*.theta.*V, wherein * denotes a multiplication operation of the third-order tensor, and is defined as performing tensor multiplication on third-order tensors A.di-elect cons.R.sup.n1.times.n2.times.k and B.di-elect cons.R.sup.n2.times.n3.times.k to obtain a third-order tensor C.di-elect cons.R.sup.n1.times.n3.times.k: c(i,j,:)=.SIGMA..sub.s=1.sup.n2A(i,s,:)*B(s,j,:), for i.di-elect cons.[n1] and j.di-elect cons.[n3] (2), wherein A(i,s,:)*B(s,j,:) denotes performing a circular convolution for the tubes/vectors; and Step 1.3: initializing the loop variable t=1 on the CPU.
3. The GPU-based third-order low-rank tensor completion method according to claim 1, wherein Step 2 comprises: obtaining, based on the least squares method on the GPU, a third-order tensor Y.sub.t of the current loop whose loop count is recorded as t: Y t = argmin Y t .di-elect cons. R r .times. n .times. k ( Norm ( ObserveS ( T - X t - 1 * Y t ) ) ) 2 , ( 3 ) ##EQU00010## wherein the operator * in X.sub.t-1*Y.sub.t in the formula (3) denotes the third-order tensor multiplication defined in the formula (2), and Xt.sub.l-1 is the tensor X.sub.t-1.di-elect cons.R.sup.m.times.r.times.k obtained after the end of the previous loop (that is, the (t-1).sup.th loop), and X.sub.0.di-elect cons.R.sup.m.times.r.times.k required by the first loop is initialized to an arbitrary value, such as a random tensor; the operator--in T-X.sub.t-1*Y.sub.t denotes tensor subtraction, that is, elements with an equal index (i,j,l) that are corresponding to the two tensors are subtracted; ObserveS( ) is an observation function defined in the formula (1), and Norm( ) is a function for obtaining a tensor norm, and is defined as: Norm ( T .di-elect cons. R m .times. n .times. k ) = i = 1 m j = 1 n = 1 k i , j , 2 . ( 4 ) ##EQU00011##
4. The GPU-based third-order low-rank tensor completion method according to claim 1, wherein Step 3 comprises: obtaining, based on the least squares method on the GPU, a third-order tensor X.sub.1 of the current loop whose loop count is recorded as 1: X t = argmin X t .di-elect cons. R m .times. r .times. k ( Norm ( ObserveS ( T - X t * Y t ) ) ) 2 , ( 5 ) ##EQU00012## wherein the operator * in X.sub.t*Y.sub.t in the formula (5) denotes the third-order tensor multiplication defined in the formula (2), Y.sub.t is the tensor Y.sub.t.di-elect cons.R.sup.r.times.n.times.k obtained in Step 2, and the operator--in T-X.sub.t*Y.sub.t denotes tensor subtraction, that is, elements with an equal index (i,j,l) that are corresponding to the two tensors are subtracted; ObserveS( ) is the observation function defined in the formula (1), and Norm( ) is the tensor norm defined in the formula (4).
5. The GPU-based third-order low-rank tensor completion method according to claim 1, wherein Step 4 comprises: checking, by the CPU, whether the end condition is met; and if the end condition is met, turning to Step 5; otherwise, increasing the loop variable t by 1 and turning to Step 2 to continue the loop.
6. The GPU-based third-order low-rank tensor completion method according to claim 1, wherein Step 5 comprises: transmitting, by the GPU, the output data DATA2 to the CPU, wherein the DATA2 comprises third-order tensors X.di-elect cons.R.sup.m.times.r.times.k and Y.di-elect cons.R.sup.r.times.n.times.k obtained in the last loop.
7. An apparatus comprising: a CPU; a GPU, communicably connected with the CPU; and a memory communicably connected with the CPU and GPU for storing instructions executable by the CPU and GPU, to perform the method according to claim 1.
8. A method for a GPU-based third-order low-rank tensor completion comprising the steps of: (1) transmitting, by a CPU, input data DATA1 to a GPU, and initializing the loop count t=1; (2) obtaining, by the GPU, a third-order tensor Y.sub.t of a current loop t based on the least squares method; (3) obtaining, by the GPU, a third-order tensor X.sub.t of the current loop t based on the least squares method; (4) checking, by the CPU, whether an end condition is met; and (5) if the end condition is met, outputting, by the GPU, output data DATA2 to the CPU.
9. A method as recited in claim 8, further comprising the steps of: if the end condition is not met, increasing the loop count t by 1; and returning to step (2).
Description
CROSS REFERENCE
[0001] This disclosure is based upon and claims priority to Chinese Patent Application No. 201910195941.8, filed on Mar. 15, 2019, titled "GPU-based third-order low-rank tensor completion method", and the entire contents of which are incorporated herein by reference.
TECHNICAL FIELD
[0002] The present disclosure relates generally to the field of high performance computing technologies, and more specifically, to a GPU (Graphics Processing Unit)-based third-order low-rank tensor completion method.
BACKGROUD
[0003] High-dimensional data in real world can be naturally represented as tensors. Data loss often occurs in transmission of wireless sensor networks, and therefore the collected sensory data is often incomplete. In scenarios where computing and network resources are limited, people use partial measurement to reduce the amount of data that needs to be processed and transmitted, and this also leads to incomplete data. How to recover complete data from the incomplete data is a research hotspot in recent years. A common approach is to model the incomplete data as low-rank tensors and then perform recovery by exploiting redundant features in the data.
[0004] The present disclosure mainly focuses on data completion of third-order low-rank tensors. The existing research proposes some CPU-based third-order low-rank tensor completion methods. For example, calculation for singular value decomposition of a large block diagonal matrix needs to be performed in each iteration of the TNN-ADMM method, and an iteration is performed simultaneously in the time domain and the frequency domain. Therefore, a large number of Fourier transforms and inverse Fourier transforms need to be performed. As a result, algorithm calculation is more time consuming. The accuracy and speed of the Tubal-Alt-Min method based on the alternating least squares method is better than that of the TNN-ADMM method, but computational efficiency of the Tubal-Alt-Min method is still not high. Generally, in the CPU-based third-order low-rank tensor data completion method, the running time increases exponentially with the increase of tensor size. Therefore, the CPU-based method is not suitable for processing of large-scale tensors.
[0005] A GPU has a characteristic of high parallelism and a high memory bandwidth, and therefore the GPU is widely applied to accelerate various calculations. The powerful computing power of the GPU provides a good foundation for accelerating completion of third-order low-rank tensor data.
SUMMARY
[0006] To address existing issues in the prior art, the objective of the present disclosure is to provide a third-order low-rank tensor completion method for the low-tubal-rank tensor model based on GPU.
[0007] The technical solution of the present disclosure is as follows:
[0008] A GPU-based third-order low-rank tensor completion method is provided, and operation steps include:
[0009] Step 1: transmitting, by a CPU, input data DATA1 to a GPU, and initializing the loop count t=1;
[0010] Step 2: obtaining, by the GPU, a third-order tensor Y.sub.t of a current loop t based on the least squares method;
[0011] Step 3: obtaining, by the GPU, a third-order tensor X.sub.t of the current loop t based on the least squares method;
[0012] Step 4: checking, by the CPU, whether an end condition is met; and if the end condition is met, turning to Step 5; otherwise, increasing the loop count t by 1 and turning to Step 2 to continue the loop; and
[0013] Step 5: outputting, by the GPU, output data DATA2 to the CPU.
[0014] Step 1 includes:
[0015] Step 1.1: allocating memory space in a GPU memory;
[0016] Step 1.2: transmitting the input data DATA1 in a CPU memory to the allocated memory space in the GPU memory, wherein the DATA1 includes the following data:
[0017] (1) A third-order to-be-completed tensor T.di-elect cons.R.sup.m.times.n.times.k, wherein R denotes the set of real numbers, m, n, and k are respectively sizes of the tensor T in the first, second, and third dimensions, the total number of elements of the tensor is m.times.n.times.k, and an element of the tensor that the first, second, and third dimensions are respectively i, j, and l is denoted as T.sub.i,j,l.
[0018] (2) An observation set S[o].times.[p].times.[q], where o.ltoreq.m, p.ltoreq.n, and q.ltoreq.k, where [o] denotes the set {1,2, . . . , o}, [p] denotes the set {1,2, . . . , p}, and [q] denotes the set {1,2, . . . , q}.
[0019] (3) An observation tensor TP.di-elect cons.R.sup.m.times.n.times.k based on the observation set S and the to-be-completed tensor T.di-elect cons.R.sup.m.times.n.times.k, wherein TP is represented by using an observation function ObserveS( ) for T, that is, TP=ObserveS(T), and the observation function ObserveS( ) is defined as:
TP i , j , l = { T i , j , l , if ( i , j , l ) .di-elect cons. S 0 , otherwise . ( 1 ) ##EQU00001##
[0020] In the method of the present disclosure, values of those elements TP.sub.i,j,l in TP if (i,j,l).di-elect cons.S are accurate and do not need to be completed.
[0021] (4) A tubal-rank r of the tensor T, wherein T(i,j,:) is defined as the (i, j).sup.th tube of the tensor T.di-elect cons.R.sup.m.times.n.times.k, and is a vector ((T(i,j,1), T(i,j,2), . . . , T(i,j,k)) with length k; the rank of the third-order tensor is defined as the number of non-zero tubes of .theta. in singular value decomposition of the tensor T=U*.theta.*V, wherein * denotes a multiplication operation of the third-order tensor, and is defined as performing tensor multiplication on third-order tensors A.di-elect cons.R.sup.n1.times.n2.times.k and B.di-elect cons.R.sup.n2.times.n3.times.k to obtain a third-order tensor C.di-elect cons.R.sup.n1.times.n3.times.k:
[0022] C (i,j,:)=.SIGMA..sub.s=1.sup.n2A(i,s,:)*B(s,j,:), for i.di-elect cons.[n1] and j.di-elect cons.[n3] (2), where [n1] denotes the set {1, 2, . . . , n1} and [n3] denotes the set {1, 2, . . . , n3}.
[0023] A(i,s,:)*B(s,j,:) denotes a circular convolution for the tubes/vectors A(i,s,:) and B(s,j,:).
[0024] Step 1.3: initializing the loop variable t=1 on the CPU.
[0025] Step 2 includes:
[0026] obtaining, based on the least squares method on the GPU, a third-order tensor Y.sub.t of the current loop whose loop count is recorded as t:
Y t = argmin Y t .di-elect cons. R r .times. n .times. k ( Norm ( ObserveS ( T - X t - 1 * Y t ) ) ) 2 . ( 3 ) ##EQU00002##
[0027] The operator * in X.sub.t-1*Y.sub.t in the formula (3) denotes the third-order tensor multiplication defined in the formula (2), and X.sub.t-1 is the tensor X.sub.t-1.di-elect cons.R.sup.m.times.r.times.k obtained after the end of the previous loop (that is, the (t-1).sup.th loop), and X.sub.0.di-elect cons.R.sup.m.times.r.times.k required by the first loop is initialized to an arbitrary value, such as a random tensor; the operator--in T-X.sub.t-1*Y.sub.t denotes tensor subtraction, that is, elements with an equal index (i,j,l) that are corresponding to the two tensors are subtracted; ObserveS( ) is an observation function defined in the formula (1), and Norm( ) is a function for obtaining a tensor norm, and is defined as:
Norm ( T .di-elect cons. R m .times. n .times. k ) = i = 1 m j = 1 n = 1 k i , j , 2 . ( 4 ) ##EQU00003##
[0028] Step 3 includes:
[0029] obtaining, based on the least squares method on the GPU, a third-order tensor X.sub.t of the current loop whose loop count is recorded as t:
X t = argmin X t .di-elect cons. R m .times. r .times. k ( Norm ( ObserveS ( T - X t * Y t ) ) ) 2 . ( 5 ) ##EQU00004##
[0030] The operator * in X.sub.t*Y.sub.t in the formula (5) denotes the third-order tensor multiplication defined in the formula (2), Y.sub.t is the tensor Y.sub.t.di-elect cons.R.sup.r.times.n.times.k obtained in Step 2, and the operator--in T-X.sub.t*Y.sub.t denotes tensor subtraction, that is, elements with an equal index (i,j,l) that are corresponding to the two tensors are subtracted; ObserveS( ) is the observation function defined in the formula (1), and Norm( ) is the tensor norm defined in the formula (4).
[0031] Step 4 includes:
[0032] checking, by the CPU, whether the end condition is met; and if the end condition is met, turning to Step 5; otherwise, increasing the loop variable t by 1 and turning to Step 2 to continue the loop.
[0033] Step 5 includes:
[0034] transmitting, by the GPU, the output data DATA2 to the CPU, wherein the DATA2 includes third-order tensors X.di-elect cons.R.sup.m.times.r.times.k and Y.di-elect cons.R.sup.r.times.n.times.k obtained in the last loop.
[0035] Compared with the prior art, the present disclosure has the following prominent substantive features and significant technical progresses.
[0036] In the present disclosure, in third-order low-rank tensor completion, a computational task with high concurrent processes is accelerated by using a GPU to improve computational efficiency. Compared with conventional CPU-based third-order low-rank tensor completion, computational efficiency is significantly improved, and same calculation can be completed by using less time.
BRIEF DESCRIPTION OF THE DRAWINGS
[0037] FIG. 1 is a diagram of steps of a GPU-based third-order low-rank tensor completion method of the present disclosure.
[0038] FIG. 2 is a schematic diagram of a third-order tensor.
[0039] FIG. 3 is a schematic diagram illustrating another embodiment of this disclosure wherein the apparatus comprises an input device, an output device, a CPU, a GPU, memory so that the input device and the output device are all communicably connected through a bus.
DETAILED DESCRIPTION
[0040] To make the objectives, technical solutions, and advantages of the present disclosure clearer, the following further describes the present disclosure in detail with reference to the accompanying drawings and the preferred embodiments. It should be understood that, the specific embodiments described herein are merely intended for explaining the present disclosure, but not for limiting the present disclosure.
[0041] A third-order tensor is shown in FIG. 2. A first dimension of the tensor is also referred to as a row, and a size of the row is m, a second dimension is also referred to a column, and a size of the column is n, a size of the third dimension is k. In this way, a real value tensor may be denoted as T.di-elect cons.R.sup.m.times.n.times.k, and a complex value tensor may be denoted as T.di-elect cons.C.sup.m.times.n.times.k, where C denotes the set of complex numbers. T(i,j,l) denotes an element that the first, second, and third dimensions of the tensor T are respectively i, j, l, T(i,j,:) denotes one-dimensional vector formed by k elements: T(i,j,1), T(i,j,2), . . . , T(i,j,k), and the one-dimensional vector T(i,j,:) is along the third dimension, and is referred to the (i,j).sup.th tube of the tensor. The tensor T.di-elect cons.R.sup.m.times.n.times.k has m.times.n tubes.
Embodiment 1
[0042] A GPU-based third-order low-rank tensor completion method is provided. As shown in FIG. 1, steps are as follows:
[0043] Step 1: A CPU transmits input data DATA1 to a GPU, and initializes the loop count t=1.
[0044] Step 2: The GPU obtains a third-order tensor Y.sub.t of a current loop t based on the least squares method.
[0045] Step 3: The GPU obtains a third-order tensor X.sub.t of the current loop t based on the least squares method;
[0046] Step 4: The CPU checks whether an end condition is met; and if the end condition is met, turns to Step 5; otherwise, increases the loop count t by 1 and turns to Step 2 to continue the loop; and
[0047] Step 5: The GPU outputs output data DATA2 to the CPU.
Embodiment 2: This Embodiment Is Basically The Same As Embodiment 1, And Special Features Are As Follows
[0048] Step 1 includes the following steps:
[0049] Step 1.1: Memory space is allocated in a GPU memory.
[0050] Step 1.2: The input data DATA1 in a CPU memory is transmitted to the allocated memory space in the GPU memory. The DATA1 includes the following data:
[0051] (1) A third-order to-be-completed tensor T.di-elect cons.R.sup.m.times.n.times.k, wherein R denotes the set of real numbers, m, n, and k are respectively sizes of the tensor T in the first, second, third dimensions, the total number of elements of the tensor is m.times.n.times.k, and an element of the tensor that the first, second, and third dimensions are respectively i,j, and l is denoted as T.sub.i,j,l.
[0052] (2) An observation set S[o].times.[p].times.[q], wherein o.ltoreq.m, p.ltoreq.n, q.ltoreq.k.
[0053] (3) An observation tensor TP.di-elect cons.R.sup.m.times.n.times.k based on the observation set S and the to-be-completed tensor T.di-elect cons.R.sup.m.times.n.times.k, wherein TP is represented by using an observation function ObserveS( ) for T, that is, TP=ObserveS(T), and the observation function ObserveS( ) is defined as:
TP i , j , l = { T i , j , l , if ( i , j , l ) .di-elect cons. S 0 , otherwise . ( 1 ) ##EQU00005##
[0054] In the method of the present disclosure, values of those elements TP.sub.i,j,l in TP if (i,j,l).di-elect cons.S are accurate and do not need to be completed.
[0055] (4) A tubal-rank r of the tensor T, wherein T(i,j,:) is defined as the (i,j).sup.th tube of the tensor T.di-elect cons.R.sup.m.times.n.times.k, and is a vector ((T(i,j,1), T(i,j,2), . . . , T(i,j,k)) with length k; the tubal-rank of the third-order tensor is defined as the number of non-zero tubes of .theta. in singular value decomposition of the tensor T=U*.theta.*V, wherein * denotes a multiplication operation of the third-order tensor, and is defined as performing tensor multiplication on third-order tensors A.di-elect cons.R.sup.n1.times.n2.times.k and B.di-elect cons.R.sup.n2.times.n3.times.k to obtain a third-order tensor C.di-elect cons.R.sup.n1.times.n3.times.k:
[0056] C(i,j,:)=.SIGMA..sub.s=1.sup.n2A(i,s,:)* B(s,j,:), for i.di-elect cons.[n1] and j.di-elect cons.[n3] (2), where [n1] denotes the set {1, 2, . . . , n1} and [n3] denotes the set {1, 2, . . . , n3}.
[0057] A(i,s,:)*B(s,j,:) denotes performing a circular convolution for the tubes/vectors A(i,s,:) and B(s,j,:).
[0058] Step 2 includes the following step:
[0059] A third-order tensor Y.sub.t of the current loop whose loop count is recorded as 1 is obtained based on the least squares method on the GPU:
Y t = argmin Y t .di-elect cons. R r .times. n .times. k ( Norm ( ObserveS ( T - X t - 1 * Y t ) ) ) 2 . ( 3 ) ##EQU00006##
[0060] The operator * in X.sub.t-1*Y.sub.t in the formula (3) denotes the third-order tensor multiplication defined in the formula (2), and X.sub.t-1 is the tensor X.sub.t-1.di-elect cons.R.sup.m.times.r.times.k obtained after the end of the previous loop (that is, the (t-1).sup.th loop), and X.sub.0.di-elect cons.R.sup.m.times.r.times.k required by the first loop is initialized to an arbitrary value, such as a random tensor; the operator--in T-X.sub.t-1*Y.sub.t denotes tensor subtraction, that is, elements with an equal index (i,j,l) that are corresponding to the two tensors are subtracted; ObserveS( ) is an observation function defined in the formula (1), and Norm( ) is a function for obtaining a tensor norm, and is defined as:
Norm ( T .di-elect cons. R m .times. n .times. k ) = i = 1 m j = 1 n = 1 k i , j , 2 . ( 4 ) ##EQU00007##
[0061] Step 3 includes the following step:
[0062] A third-order tensor X.sub.t of the current loop whose loop count is recorded as t is obtained based on the least squares method on the GPU:
X t = argmin X t .di-elect cons. R m .times. r .times. k ( Norm ( ObserveS ( T - X t * Y t ) ) ) 2 . ( 5 ) ##EQU00008##
[0063] The operator * in X.sub.t*Y.sub.t in the formula (5) denotes the third-order tensor multiplication defined in the formula (2), Y.sub.t is the tensor Y.sub.t.di-elect cons.R.sup.r.times.n.times.k obtained in Step 2, and the operator--in T-X.sub.t*Y.sub.t denotes tensor subtraction, that is, elements with an equal index (i,j,l) that are corresponding to the two tensors are subtracted; ObserveS( ) is the observation function defined in the formula (1), and Norm( ) is the tensor norm defined in the formula (4).
[0064] Step 4 includes the following step:
[0065] The CPU checks whether the end condition is met; and if the end condition is met, turns to Step 5; otherwise, increases the loop variable t by 1 and turns to Step 2 to continue the loop. The end condition may be that a certain loop count or an error threshold is reached.
[0066] Step 5 includes the following step:
[0067] The GPU transmits the output data DATA2 to the CPU, wherein the DATA2 includes third-order tensors X.di-elect cons.R.sup.m.times.r.times.k and Y.di-elect cons.R.sup.r.times.n.times.k obtained in the last loop. A third-order tensor T'=X*Y after completion can be obtained by performing tensor multiplication defined in the formula (2) for X and Y.
[0068] The disclosure further provides an apparatus, comprising a CPU 100; a GPU 200, communicably connected with the CPU 100; a memory 300 communicably connected with the CPU 100 and GPU 200 for storing instructions executable by the CPU 100 and GPU 200, to perform any of the abovementioned methods. Referring to FIG. 3, in one embodiment of this disclosure, the apparatus also comprises an input device 400 and output device 500, and the CPU 100, the GPU 200, the memory 300, the input device 400, and the output device are all communicably connected through a bus 600.
* * * * *
D00000
D00001
D00002
D00003



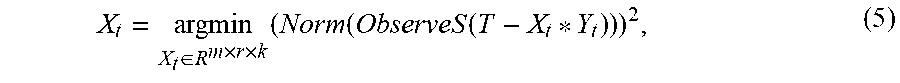
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.