Syntax Reuse For Affine Mode With Adaptive Motion Vector Resolution
LIU; Hongbin ; et al.
U.S. patent application number 16/814840 was filed with the patent office on 2020-07-02 for syntax reuse for affine mode with adaptive motion vector resolution. The applicant listed for this patent is Beijing Bytedance Network Technology Co., Ltd. Bytedance Inc.. Invention is credited to Hongbin LIU, Yue WANG, Kai ZHANG, Li ZHANG.
| Application Number | 20200213612 16/814840 |
| Document ID | / |
| Family ID | 68051876 |
| Filed Date | 2020-07-02 |










View All Diagrams
| United States Patent Application | 20200213612 |
| Kind Code | A1 |
| LIU; Hongbin ; et al. | July 2, 2020 |
SYNTAX REUSE FOR AFFINE MODE WITH ADAPTIVE MOTION VECTOR RESOLUTION
Abstract
A method for video processing is disclosed to include: determining, for a conversion between a coded representation of a current block of a video and the current block, a motion vector difference (MVD) precision to be used for the conversion from a set of allowed multiple MVD precisions applicable to a video region containing the current video block; and performing the conversion based on the MVD precision.
| Inventors: | LIU; Hongbin; (Beijing, CN) ; ZHANG; Li; (San Diego, CA) ; ZHANG; Kai; (San Diego, CA) ; WANG; Yue; (Beijing, CN) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 68051876 | ||||||||||
| Appl. No.: | 16/814840 | ||||||||||
| Filed: | March 10, 2020 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| PCT/IB2019/057897 | Sep 19, 2019 | |||
| 16814840 | ||||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | H04N 19/174 20141101; H04N 19/52 20141101; H04N 19/184 20141101; H04N 19/567 20141101; H04N 19/137 20141101; H04N 19/147 20141101; H04N 19/159 20141101; H04N 19/139 20141101; H04N 19/186 20141101; H04N 19/96 20141101; H04N 19/109 20141101; H04N 19/132 20141101; H04N 19/523 20141101; H04N 19/176 20141101; H04N 19/537 20141101; H04N 19/70 20141101; H04N 19/53 20141101 |
| International Class: | H04N 19/52 20060101 H04N019/52; H04N 19/176 20060101 H04N019/176; H04N 19/184 20060101 H04N019/184; H04N 19/70 20060101 H04N019/70 |
Foreign Application Data
| Date | Code | Application Number |
|---|---|---|
| Sep 19, 2018 | CN | PCT/CN2018/106513 |
| Feb 1, 2019 | CN | PCT/CN2019/074433 |
Claims
1. A method of coding video data, the method comprising: determining that a coding mode for a first video block is an affine inter mode; determining, for motion information of the first video block, a motion precision from a motion precision set including multiple motion precisions; and coding the first video block based on the determined coding mode and the determined motion precision; wherein multiple syntax elements are selectively present in a video bitstream to indicate the motion precision in the motion precision set.
2. The method of claim 1, wherein the coding includes encoding the first video block into the video bitstream.
3. The method of claim 1, wherein the coding includes decoding the first video block from a video bitstream.
4. The method of claim 1, wherein semantics of at least one syntax element of the multiple syntax elements are different in a normal inter mode and in the affine inter mode.
5. The method of claim 1, wherein the multiple syntax elements include a first syntax element and a second syntax element, wherein present of the second syntax element is based on at least one of a value of the first syntax element, or whether the first syntax element is absent from the bitstream representation.
6. The method of claim 5, wherein whether the first syntax element is present in the video bitstream based on at least one of: 1) whether multiple MVD precisions for affine inter coded blocks is enabled or disabled; 2) motion vector differences (MVDs) of control point motion vectors of the first video block.
7. The method of claim 6, wherein the first syntax element is not present in the video bitstream based on the at least one condition being satisfied: motion vector differences (MVDs) of all control point motion vectors of the first video block being zero; multiple MVD precisions for affine inter coded blocks being disabled.
8. The method of claim 6, wherein the first syntax element is present in the video bitstream based on the at least one condition being satisfied: multiple MVD precisions for affine inter coded blocks being enabled; the coding mode for the first block being determined as the affine inter mode; at least one motion vector difference of at least one control point motion vectors of the first video block being non-zero.
9. The method of claim 6, wherein the motion vector differences (MVDs) of control point motion vectors of the first video block comprises an MVD in each valid prediction direction for each control point motion vector, wherein when both the horizontal component and the vertical component of the MVD are zero, the MVD is a zero MVD.
10. The method of claim 5, wherein the motion precision for the first block is a first motion precision which is a default precision, in respond to the first syntax element being not present in the video bitstream or the first syntax element being equal to zero.
11. The method of claim 10, wherein the first motion precision is 1/4 luma sample.
12. The method of claim 5, wherein the second syntax element is present in the video bitstream based on the at least one condition being satisfied: the first syntax element being equal to non-zero; the coding mode of the first video block being the affine inter mode.
13. The method of claim 5, wherein the second syntax element is equal to zero corresponding to the motion precision being 1/16 luma sample, and is equal to non-zero corresponding to the motion precision being integer luma sample.
14. The method of claim 5, wherein a same value of the second syntax element indicates different motion precisions for blocks coded with the affine inter mode and for blocks coded with a normal inter mode.
15. The method of claim 5, wherein the second syntax element is selectively present in a video bitstream to indicate a motion precision in a motion precision set for a block coded with an intra block copy mode, wherein the first syntax element is skipped for the block coded with the intra block copy mode.
16. The method of claim 5, wherein the first syntax element is coded using context-based coding that includes a use of at least one context model and at least one context, wherein at least one same context model is used for the first syntax element of both blocks coded with the affine inter mode and blocks coded with the normal inter mode, and selection of context is dependent on whether the coding mode of the block is the affine inter mode or normal inter mode.
17. The method of claim 5, wherein the second syntax element is coded using context-based coding that includes a use of at least one context model and at least one context, wherein at least one same context model and at least one same context are used for the second syntax element of both blocks coded with the affine inter mode and blocks coded with the normal inter mode.
18. The method of claim 1, wherein the motion information comprises at least one of a motion vector difference (MVD), motion vector predictor (MVP) and motion vector (MV).
19. A video coding apparatus comprising a processor and a non-transitory memory with instructions thereon, wherein the instructions upon execution by the processor, cause the processor to: determine that a coding mode for a first video block is an affine inter mode; determine, for motion information of the first video block, a motion precision from a motion precision set including multiple motion precisions; and code the first video block based on the determined coding mode and the determined motion precision; wherein multiple syntax elements are selectively present in a video bitstream to indicate the motion precision in the motion precision set.
20. A non-transitory computer-readable storage medium storing instructions that cause a processor to: determine that a coding mode for a first video block is an affine inter mode; determine, for motion information of the first video block, a motion precision from a motion precision set including multiple motion precisions; and code the first video block based on the determined coding mode and the determined motion precision; wherein multiple syntax elements are selectively present in a video bitstream to indicate the motion precision in the motion precision set.
Description
CROSS-REFERENCE TO RELATED DOCUMENTS
[0001] This application is a continuation of International Application No. PCT/IB2019/057897 filed Sep. 19, 2019, which claims the priority to and benefits of International Patent Application No. PCT/CN2018/106513, filed on Sep. 19, 2018, and International Patent Application No. PCT/CN2019/074433, filed on Feb. 1, 2019. For all purposes under the law, the entire disclosure of the aforementioned application is incorporated by reference as part of the disclosure of this application.
TECHNICAL FIELD
[0002] This patent document relates to video processing techniques, devices and systems.
BACKGROUND
[0003] In spite of the advances in video compression, digital video still accounts for the largest bandwidth use on the internet and other digital communication networks. As the number of connected user devices capable of receiving and displaying video increases, it is expected that the bandwidth demand for digital video usage will continue to grow.
SUMMARY
[0004] Devices, systems and methods related to digital video coding, and specifically, to motion vector predictor derivation and signaling for affine mode with adaptive motion vector resolution (AMVR) are described. The described methods may be applied to both the existing video coding standards (e.g., High Efficiency Video Coding (HEVC)) and future video coding standards or video codecs.
[0005] In one representative aspect, the disclosed technology may be used to provide a method for video processing. This method includes determining, for a conversion between a coded representation of a current block of a video and the current block, a motion vector difference (MVD) precision to be used for the conversion from a set of allowed multiple MVD precisions applicable to a video region containing the current video block; and performing the conversion based on the MVD precision.
[0006] In one representative aspect, the disclosed technology may be used to provide a method for video processing. This method includes determining, for a video region comprising one or more video blocks of a video and a coded representation of the video, a usage of multiple motion vector difference (MVD) precisions for the conversion of the one or more video blocks in the video region; and performing the conversion based on the determining.
[0007] In another representative aspect, the disclosed technology may be used to provide a method for video processing. This method includes determining, for a video region comprising one or more video blocks of a video and a coded representation of the video, whether to apply an adaptive motion vector resolution (AMVR) process to a current video block for a conversion between the current video block and the coded representation of the video; and performing the conversion based on the determining.
[0008] In another representative aspect, the disclosed technology may be used to provide a method for video processing. This method includes determining, for a video region comprising one or more video blocks of a video and a coded representation of the video, how to apply an adaptive motion vector resolution (AMVR) process to a current video block for a conversion between the current video block and the coded representation of the video; and performing the conversion based on the determining.
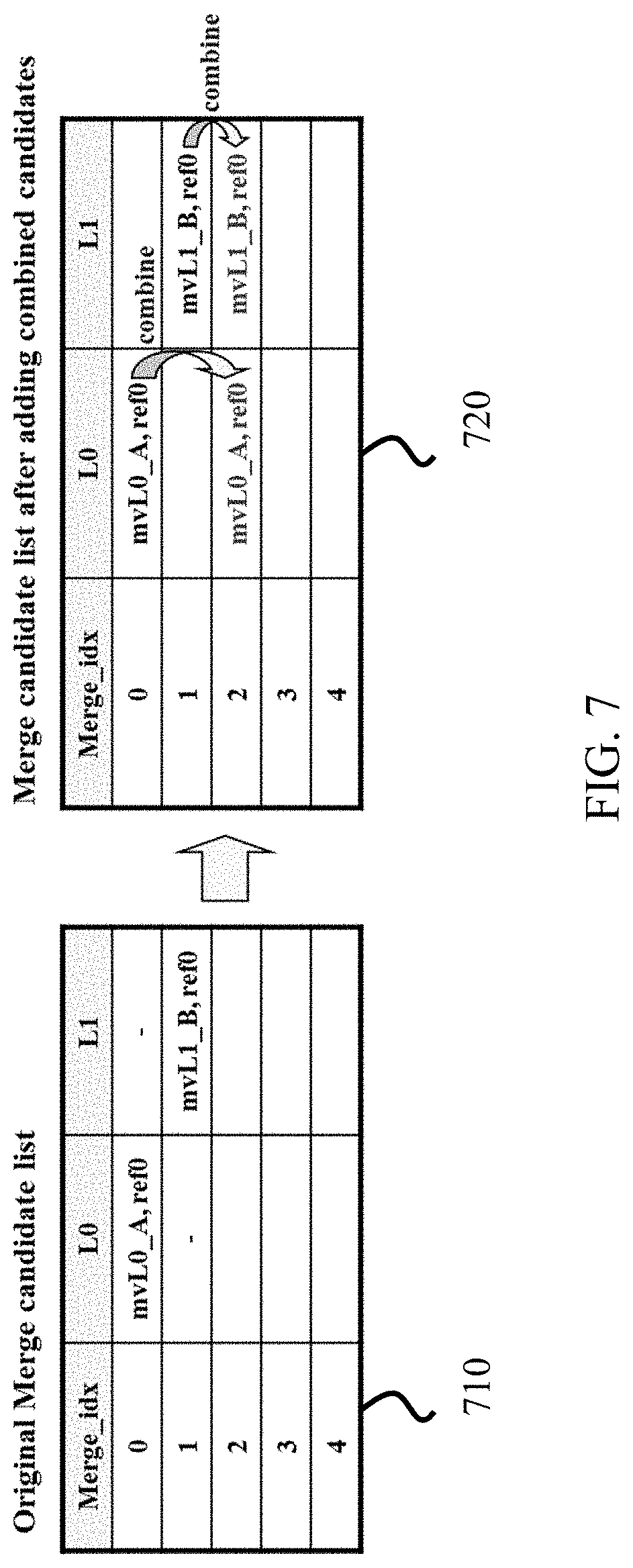
[0009] In one representative aspect, the disclosed technology may be used to provide a method for video processing. This method includes determining, based on a coding mode of a parent coding unit of a current coding unit that uses an affine coding mode or a rate-distortion (RD) cost of the affine coding mode, a usage of an adaptive motion vector resolution (AMVR) for a conversion between a coded representation of a current block of a video and the current block; and performing the conversion according to a result of the determining.
[0010] In one representative aspect, the disclosed technology may be used to provide a method for video processing. This method includes determining a usage of an adaptive motion vector resolution (AMVR) for a conversion between a coded representation of a current block of a video and the current block that uses an advanced motion vector prediction (AMVP) coding mode, the determining based on a rate-distortion (RD) cost of the AMVP coding mode; and performing the conversion according to a result of the determining.
[0011] In one representative aspect, the disclosed technology may be used to provide a method for video processing. This method includes generating, for a conversion between a coded representation of a current block of a video and the current block, a set of MV (Motion Vector) precisions using a 4-parameter affine model or 6-parameter affine model; and performing the conversion based on the set of MV precisions.
[0012] In one representative aspect, the disclosed technology may be used to provide a method for video processing. This method includes determining, based on a coding mode of a parent block of a current block that uses an affine coding mode, whether an adaptive motion vector resolution (AMVR) tool is used for a conversion, wherein the AMVR tool is used to refine motion vector resolution during decoding; and performing the conversion according to a result of the determining.
[0013] In one representative aspect, the disclosed technology may be used to provide a method for video processing. This method includes determining, based on a usage of MV precisions for previous blocks that has been previously coded using an affine coding mode, a termination of a rate-distortion (RD) calculations of MV precisions for a current block that uses the affine coding mode for a conversion between a coded representation of the current block and the current block; and performing the conversion according to a result of the determining.
[0014] In another representative aspect, the above-described method is embodied in the form of processor-executable code and stored in a computer-readable program medium.
[0015] In yet another representative aspect, a device that is configured or operable to perform the above-described method is disclosed. The device may include a processor that is programmed to implement this method.
[0016] In yet another representative aspect, a video decoder apparatus may implement a method as described herein.
[0017] The above and other aspects and features of the disclosed technology are described in greater detail in the drawings, the description and the claims.
BRIEF DESCRIPTION OF THE DRAWINGS
[0018] FIG. 1 shows an example of constructing a merge candidate list.
[0019] FIG. 2 shows an example of positions of spatial candidates.
[0020] FIG. 3 shows an example of candidate pairs subject to a redundancy check of spatial merge candidates.
[0021] FIGS. 4A and 4B show examples of the position of a second prediction unit (PU) based on the size and shape of the current block.
[0022] FIG. 5 shows an example of motion vector scaling for temporal merge candidates.
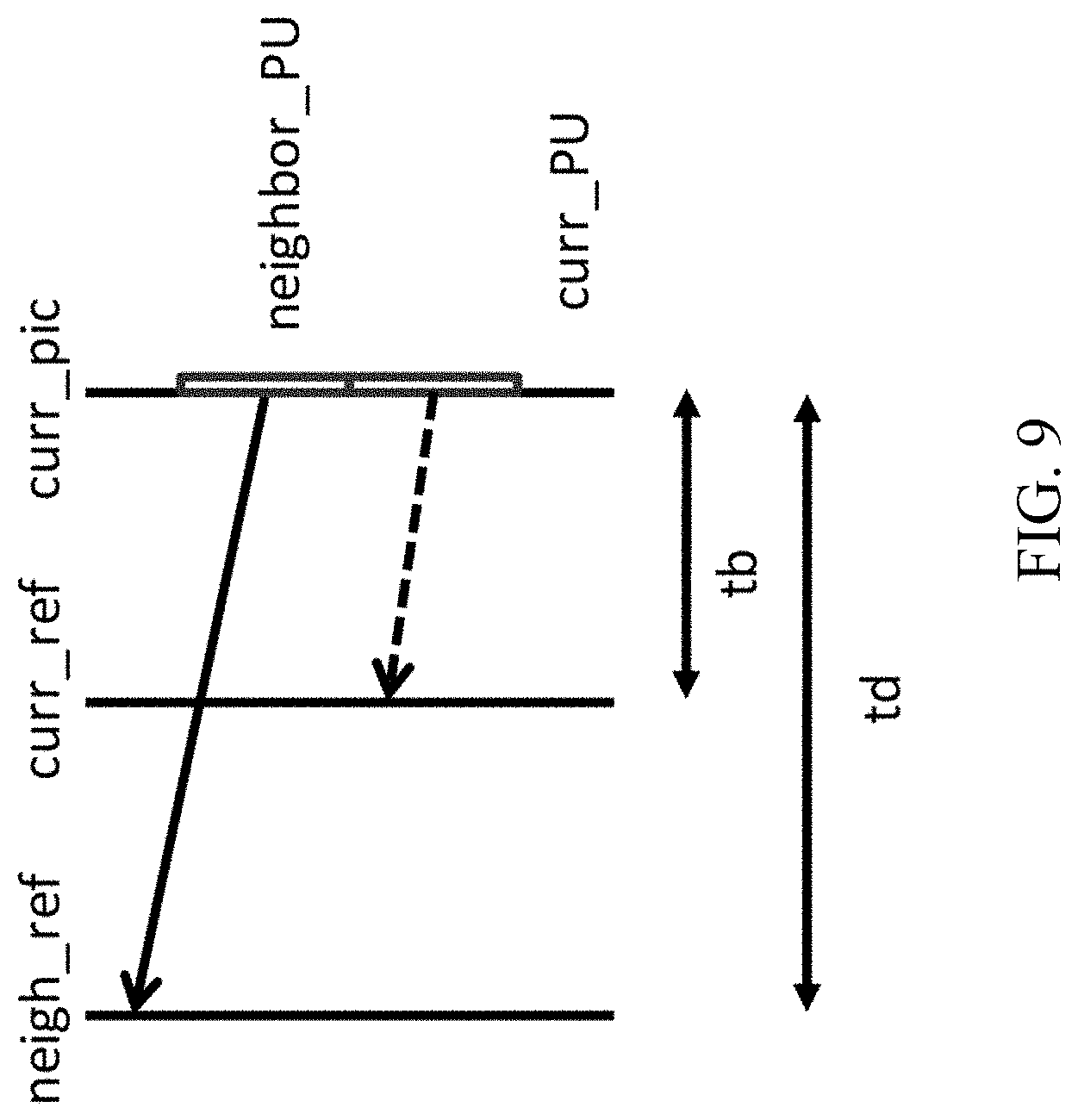
[0023] FIG. 6 shows an example of candidate positions for temporal merge candidates.
[0024] FIG. 7 shows an example of generating a combined bi-predictive merge candidate.
[0025] FIG. 8 shows an example of constructing motion vector prediction candidates.
[0026] FIG. 9 shows an example of motion vector scaling for spatial motion vector candidates.
[0027] FIG. 10 shows an example of motion prediction using the alternative temporal motion vector prediction (ATMVP) algorithm for a coding unit (CU).
[0028] FIG. 11 shows an example of a coding unit (CU) with sub-blocks and neighboring blocks used by the spatial-temporal motion vector prediction (STMVP) algorithm.
[0029] FIG. 12 shows an example flowchart for encoding with different MV precisions.
[0030] FIGS. 13A and 13B show example snapshots of sub-block when using the overlapped block motion compensation (OBMC) algorithm.
[0031] FIG. 14 shows an example of neighboring samples used to derive parameters for the local illumination compensation (LIC) algorithm.
[0032] FIG. 15 shows an example of a simplified affine motion model.
[0033] FIG. 16 shows an example of an affine motion vector field (MVF) per sub-block.
[0034] FIG. 17 shows an example of motion vector prediction (MVP) for the AF_INTER affine motion mode.
[0035] FIGS. 18A and 18B show examples of the 4-parameter and 6-parameter affine models, respectively.
[0036] FIGS. 19A and 19B show example candidates for the AF_MERGE affine motion mode.
[0037] FIG. 20 shows an example of bilateral matching in pattern matched motion vector derivation (PMMVD) mode, which is a special merge mode based on the frame-rate up conversion (FRUC) algorithm.
[0038] FIG. 21 shows an example of template matching in the FRUC algorithm.
[0039] FIG. 22 shows an example of unilateral motion estimation in the FRUC algorithm.
[0040] FIG. 23 shows an example of an optical flow trajectory used by the bi-directional optical flow (BIO) algorithm.
[0041] FIGS. 24A and 24B show example snapshots of using of the bi-directional optical flow (BIO) algorithm without block extensions.
[0042] FIG. 25 shows an example of the decoder-side motion vector refinement (DMVR) algorithm based on bilateral template matching.
[0043] FIGS. 26A-261 show flowcharts of example methods for video processing based on some implementations of the disclosed technology.
[0044] FIG. 27 is a block diagram of an example of a hardware platform for implementing a visual media decoding or a visual media encoding technique described in the present document.
[0045] FIG. 28 shows an example of symmetrical mode.
[0046] FIG. 29 shows another block diagram of an example of a hardware platform for implementing a video processing system described in the present document.
DETAILED DESCRIPTION
[0047] Due to the increasing demand of higher resolution video, video coding methods and techniques are ubiquitous in modern technology. Video codecs typically include an electronic circuit or software that compresses or decompresses digital video, and are continually being improved to provide higher coding efficiency. A video codec converts uncompressed video to a compressed format or vice versa. There are complex relationships between the video quality, the amount of data used to represent the video (determined by the bit rate), the complexity of the encoding and decoding algorithms, sensitivity to data losses and errors, ease of editing, random access, and end-to-end delay (latency). The compressed format usually conforms to a standard video compression specification, e.g., the High Efficiency Video Coding (HEVC) standard (also known as H.265 or MPEG-H Part 2), the Versatile Video Coding standard to be finalized, or other current and/or future video coding standards.
[0048] Embodiments of the disclosed technology may be applied to existing video coding standards (e.g., HEVC, H.265) and future standards to improve compression performance. Section headings are used in the present document to improve readability of the description and do not in any way limit the discussion or the embodiments (and/or implementations) to the respective sections only.
1. EXAMPLES OF INTER-PREDICTION IN HEVC/H.265
[0049] Video coding standards have significantly improved over the years, and now provide, in part, high coding efficiency and support for higher resolutions. Recent standards such as HEVC and H.265 are based on the hybrid video coding structure wherein temporal prediction plus transform coding are utilized.
1.1 Examples of Prediction Modes
[0050] Each inter-predicted PU (prediction unit) has motion parameters for one or two reference picture lists. In some embodiments, motion parameters include a motion vector and a reference picture index. In other embodiments, the usage of one of the two reference picture lists may also be signaled using inter_pred_idc. In yet other embodiments, motion vectors may be explicitly coded as deltas relative to predictors.
[0051] When a CU is coded with skip mode, one PU is associated with the CU, and there are no significant residual coefficients, no coded motion vector delta or reference picture index. A merge mode is specified whereby the motion parameters for the current PU are obtained from neighboring PUs, including spatial and temporal candidates. The merge mode can be applied to any inter-predicted PU, not only for skip mode. The alternative to merge mode is the explicit transmission of motion parameters, where motion vector, corresponding reference picture index for each reference picture list and reference picture list usage are signaled explicitly per each PU.
[0052] When signaling indicates that one of the two reference picture lists is to be used, the PU is produced from one block of samples. This is referred to as `uni-prediction`. Uni-prediction is available both for P-slices and B-slices.
[0053] When signaling indicates that both of the reference picture lists are to be used, the PU is produced from two blocks of samples. This is referred to as `bi-prediction`. Bi-prediction is available for B-slices only.
1.1.1 Embodiments of Constructing Candidates for Merge Mode
[0054] When a PU is predicted using merge mode, an index pointing to an entry in the merge candidates list is parsed from the bitstream and used to retrieve the motion information. The construction of this list can be summarized according to the following sequence of steps:
[0055] Step 1: Initial candidates derivation [0056] Step 1.1: Spatial candidates derivation [0057] Step 1.2: Redundancy check for spatial candidates [0058] Step 1.3: Temporal candidates derivation
[0059] Step 2: Additional candidates insertion [0060] Step 2.1: Creation of bi-predictive candidates [0061] Step 2.2: Insertion of zero motion candidates
[0062] FIG. 1 shows an example of constructing a merge candidate list based on the sequence of steps summarized above. For spatial merge candidate derivation, a maximum of four merge candidates are selected among candidates that are located in five different positions. For temporal merge candidate derivation, a maximum of one merge candidate is selected among two candidates. Since constant number of candidates for each PU is assumed at decoder, additional candidates are generated when the number of candidates does not reach to maximum number of merge candidate (MaxNumMergeCand) which is signalled in slice header. Since the number of candidates is constant, index of best merge candidate is encoded using truncated unary binarization (TU). If the size of CU is equal to 8, all the PUs of the current CU share a single merge candidate list, which is identical to the merge candidate list of the 2N.times.2N prediction unit.
1.1.2 Constructing Spatial Merge Candidates
[0063] In the derivation of spatial merge candidates, a maximum of four merge candidates are selected among candidates located in the positions depicted in FIG. 2. The order of derivation is A.sub.1, B.sub.1, B.sub.0, A.sub.0 and B.sub.2. Position B.sub.2 is considered only when any PU of position A.sub.1, B.sub.1, B.sub.0, A.sub.0 is not available (e.g. because it belongs to another slice or tile) or is intra coded. After candidate at position A.sub.1 is added, the addition of the remaining candidates is subject to a redundancy check which ensures that candidates with same motion information are excluded from the list so that coding efficiency is improved.
[0064] To reduce computational complexity, not all possible candidate pairs are considered in the mentioned redundancy check. Instead only the pairs linked with an arrow in FIG. 3 are considered and a candidate is only added to the list if the corresponding candidate used for redundancy check has not the same motion information. Another source of duplicate motion information is the "second PU" associated with partitions different from 2N.times.2N. As an example, FIGS. 4A and 4B depict the second PU for the case of N.times.2N and 2N.times.N, respectively. When the current PU is partitioned as N.times.2N, candidate at position A.sub.1 is not considered for list construction. In some embodiments, adding this candidate may lead to two prediction units having the same motion information, which is redundant to just have one PU in a coding unit. Similarly, position B.sub.1 is not considered when the current PU is partitioned as 2N.times.N.
1.1.3 Constructing Temporal Merge Candidates
[0065] In this step, only one candidate is added to the list. Particularly, in the derivation of this temporal merge candidate, a scaled motion vector is derived based on co-located PU belonging to the picture which has the smallest POC difference with current picture within the given reference picture list. The reference picture list to be used for derivation of the co-located PU is explicitly signaled in the slice header.
[0066] FIG. 5 shows an example of the derivation of the scaled motion vector for a temporal merge candidate (as the dotted line), which is scaled from the motion vector of the co-located PU using the POC distances, tb and td, where tb is defined to be the POC difference between the reference picture of the current picture and the current picture and td is defined to be the POC difference between the reference picture of the co-located picture and the co-located picture. The reference picture index of temporal merge candidate is set equal to zero. For a B-slice, two motion vectors, one is for reference picture list 0 and the other is for reference picture list 1, are obtained and combined to make the bi-predictive merge candidate.
[0067] In the co-located PU (Y) belonging to the reference frame, the position for the temporal candidate is selected between candidates C.sub.0 and C.sub.1, as depicted in FIG. 6. If PU at position C.sub.0 is not available, is intra coded, or is outside of the current CTU, position C.sub.1 is used. Otherwise, position C.sub.0 is used in the derivation of the temporal merge candidate.
1.1.4 Constructing Additional Types of Merge Candidates
[0068] Besides spatio-temporal merge candidates, there are two additional types of merge candidates: combined bi-predictive merge candidate and zero merge candidate. Combined bi-predictive merge candidates are generated by utilizing spatio-temporal merge candidates. Combined bi-predictive merge candidate is used for B-Slice only. The combined bi-predictive candidates are generated by combining the first reference picture list motion parameters of an initial candidate with the second reference picture list motion parameters of another. If these two tuples provide different motion hypotheses, they will form a new bi-predictive candidate.
[0069] FIG. 7 shows an example of this process, wherein two candidates in the original list (710, on the left), which have mvL0 and refIdxL0 or mvL1 and refIdxL1, are used to create a combined bi-predictive merge candidate added to the final list (720, on the right).
[0070] Zero motion candidates are inserted to fill the remaining entries in the merge candidates list and therefore hit the MaxNumMergeCand capacity. These candidates have zero spatial displacement and a reference picture index which starts from zero and increases every time a new zero motion candidate is added to the list. The number of reference frames used by these candidates is one and two for uni- and bi-directional prediction, respectively. In some embodiments, no redundancy check is performed on these candidates.
1.1.5 Examples of Motion Estimation Regions for Parallel Processing
[0071] To speed up the encoding process, motion estimation can be performed in parallel whereby the motion vectors for all prediction units inside a given region are derived simultaneously. The derivation of merge candidates from spatial neighborhood may interfere with parallel processing as one prediction unit cannot derive the motion parameters from an adjacent PU until its associated motion estimation is completed. To mitigate the trade-off between coding efficiency and processing latency, a motion estimation region (MER) may be defined. The size of the MER may be signaled in the picture parameter set (PPS) using the "log_2_parallel_merge_level_minus2" syntax element. When a MER is defined, merge candidates falling in the same region are marked as unavailable and therefore not considered in the list construction.
1.2 Embodiments of Advanced Motion Vector Prediction (AMVP)
[0072] AMVP exploits spatio-temporal correlation of motion vector with neighboring PUs, which is used for explicit transmission of motion parameters. It constructs a motion vector candidate list by firstly checking availability of left, above temporally neighboring PU positions, removing redundant candidates and adding zero vector to make the candidate list to be constant length. Then, the encoder can select the best predictor from the candidate list and transmit the corresponding index indicating the chosen candidate. Similarly with merge index signaling, the index of the best motion vector candidate is encoded using truncated unary. The maximum value to be encoded in this case is 2 (see FIG. 8). In the following sections, details about derivation process of motion vector prediction candidate are provided.
1.2.1 Examples of Constructing Motion Vector Prediction Candidates
[0073] FIG. 8 summarizes derivation process for motion vector prediction candidate, and may be implemented for each reference picture list with refidx as an input.
[0074] In motion vector prediction, two types of motion vector candidates are considered: spatial motion vector candidate and temporal motion vector candidate. For spatial motion vector candidate derivation, two motion vector candidates are eventually derived based on motion vectors of each PU located in five different positions as previously shown in FIG. 2.
[0075] For temporal motion vector candidate derivation, one motion vector candidate is selected from two candidates, which are derived based on two different co-located positions. After the first list of spatio-temporal candidates is made, duplicated motion vector candidates in the list are removed. If the number of potential candidates is larger than two, motion vector candidates whose reference picture index within the associated reference picture list is larger than 1 are removed from the list. If the number of spatio-temporal motion vector candidates is smaller than two, additional zero motion vector candidates is added to the list.
1.2.2 Constructing Spatial Motion Vector Candidates
[0076] In the derivation of spatial motion vector candidates, a maximum of two candidates are considered among five potential candidates, which are derived from PUs located in positions as previously shown in FIG. 2, those positions being the same as those of motion merge. The order of derivation for the left side of the current PU is defined as A.sub.0, A.sub.1, and scaled A.sub.0, scaled A.sub.1. The order of derivation for the above side of the current PU is defined as B.sub.0, B.sub.1, B.sub.2, scaled B.sub.0, scaled B.sub.1, scaled B.sub.2. For each side there are therefore four cases that can be used as motion vector candidate, with two cases not required to use spatial scaling, and two cases where spatial scaling is used. The four different cases are summarized as follows: [0077] No spatial scaling [0078] (1) Same reference picture list, and same reference picture index (same POC) [0079] (2) Different reference picture list, but same reference picture (same POC) [0080] Spatial scaling [0081] (3) Same reference picture list, but different reference picture (different POC) [0082] (4) Different reference picture list, and different reference picture (different POC)
[0083] The no-spatial-scaling cases are checked first followed by the cases that allow spatial scaling. Spatial scaling is considered when the POC is different between the reference picture of the neighbouring PU and that of the current PU regardless of reference picture list. If all PUs of left candidates are not available or are intra coded, scaling for the above motion vector is allowed to help parallel derivation of left and above MV candidates. Otherwise, spatial scaling is not allowed for the above motion vector.
[0084] As shown in the example in FIG. 9, for the spatial scaling case, the motion vector of the neighbouring PU is scaled in a similar manner as for temporal scaling. One difference is that the reference picture list and index of current PU is given as input; the actual scaling process is the same as that of temporal scaling.
1.2.3 Constructing Temporal Motion Vector Candidates
[0085] Apart from the reference picture index derivation, all processes for the derivation of temporal merge candidates are the same as for the derivation of spatial motion vector candidates (as shown in the example in FIG. 6). In some embodiments, the reference picture index is signaled to the decoder.
2. EXAMPLE OF INTER PREDICTION METHODS IN JOINT EXPLORATION MODEL (JEM)
[0086] In some embodiments, future video coding technologies are explored using a reference software known as the Joint Exploration Model (JEM). In JEM, sub-block based prediction is adopted in several coding tools, such as affine prediction, alternative temporal motion vector prediction (ATMVP), spatial-temporal motion vector prediction (STMVP), bi-directional optical flow (BIO), Frame-Rate Up Conversion (FRUC), Locally Adaptive Motion Vector Resolution (LAMVR), Overlapped Block Motion Compensation (OBMC), Local Illumination Compensation (LIC), and Decoder-side Motion Vector Refinement (DMVR).
2.1 Examples of Sub-CU Based Motion Vector Prediction
[0087] In the JEM with quadtrees plus binary trees (QTBT), each CU can have at most one set of motion parameters for each prediction direction. In some embodiments, two sub-CU level motion vector prediction methods are considered in the encoder by splitting a large CU into sub-CUs and deriving motion information for all the sub-CUs of the large CU. Alternative temporal motion vector prediction (ATMVP) method allows each CU to fetch multiple sets of motion information from multiple blocks smaller than the current CU in the collocated reference picture. In spatial-temporal motion vector prediction (STMVP) method motion vectors of the sub-CUs are derived recursively by using the temporal motion vector predictor and spatial neighbouring motion vector. In some embodiments, and to preserve more accurate motion field for sub-CU motion prediction, the motion compression for the reference frames may be disabled.
2.1.1 Examples of Alternative Temporal Motion Vector Prediction (ATMVP)
[0088] In the ATMVP method, the temporal motion vector prediction (TMVP) method is modified by fetching multiple sets of motion information (including motion vectors and reference indices) from blocks smaller than the current CU.
[0089] FIG. 10 shows an example of ATMVP motion prediction process for a CU 1000. The ATMVP method predicts the motion vectors of the sub-CUs 1001 within a CU 1000 in two steps. The first step is to identify the corresponding block 1051 in a reference picture 1050 with a temporal vector. The reference picture 1050 is also referred to as the motion source picture. The second step is to split the current CU 1000 into sub-CUs 1001 and obtain the motion vectors as well as the reference indices of each sub-CU from the block corresponding to each sub-CU.
[0090] In the first step, a reference picture 1050 and the corresponding block is determined by the motion information of the spatial neighboring blocks of the current CU 1000. To avoid the repetitive scanning process of neighboring blocks, the first merge candidate in the merge candidate list of the current CU 1000 is used. The first available motion vector as well as its associated reference index are set to be the temporal vector and the index to the motion source picture. This way, the corresponding block may be more accurately identified, compared with TMVP, wherein the corresponding block (sometimes called collocated block) is always in a bottom-right or center position relative to the current CU.
[0091] In the second step, a corresponding block of the sub-CU 1051 is identified by the temporal vector in the motion source picture 1050, by adding to the coordinate of the current CU the temporal vector. For each sub-CU, the motion information of its corresponding block (e.g., the smallest motion grid that covers the center sample) is used to derive the motion information for the sub-CU. After the motion information of a corresponding N.times.N block is identified, it is converted to the motion vectors and reference indices of the current sub-CU, in the same way as TMVP of HEVC, wherein motion scaling and other procedures apply. For example, the decoder checks whether the low-delay condition (e.g. the POCs of all reference pictures of the current picture are smaller than the POC of the current picture) is fulfilled and possibly uses motion vector MVx (e.g., the motion vector corresponding to reference picture list X) to predict motion vector MVy (e.g., with X being equal to 0 or 1 and Y being equal to 1-X) for each sub-CU.
2.1.2 Examples of Spatial-Temporal Motion Vector Prediction (STMVP)
[0092] In the STMVP method, the motion vectors of the sub-CUs are derived recursively, following raster scan order. FIG. 11 shows an example of one CU with four sub-blocks and neighboring blocks. Consider an 8.times.8 CU 1100 that includes four 4.times.4 sub-CUs A (1101), B (1102), C (1103), and D (1104). The neighboring 4.times.4 blocks in the current frame are labelled as a (1111), b (1112), c (1113), and d (1114).
[0093] The motion derivation for sub-CU A starts by identifying its two spatial neighbors. The first neighbor is the N.times.N block above sub-CU A 1101 (block c 1113). If this block c (1113) is not available or is intra coded the other N.times.N blocks above sub-CU A (1101) are checked (from left to right, starting at block c 1113). The second neighbor is a block to the left of the sub-CU A 1101 (block b 1112). If block b (1112) is not available or is intra coded other blocks to the left of sub-CU A 1101 are checked (from top to bottom, staring at block b 1112). The motion information obtained from the neighboring blocks for each list is scaled to the first reference frame for a given list. Next, temporal motion vector predictor (TMVP) of sub-block A 1101 is derived by following the same procedure of TMVP derivation as specified in HEVC. The motion information of the collocated block at block D 1104 is fetched and scaled accordingly. Finally, after retrieving and scaling the motion information, all available motion vectors are averaged separately for each reference list. The averaged motion vector is assigned as the motion vector of the current sub-CU.
2.1.3 Examples of Sub-CU Motion Prediction Mode Signaling
[0094] In some embodiments, the sub-CU modes are enabled as additional merge candidates and there is no additional syntax element required to signal the modes. Two additional merge candidates are added to merge candidates list of each CU to represent the ATMVP mode and STMVP mode. In other embodiments, up to seven merge candidates may be used, if the sequence parameter set indicates that ATMVP and STMVP are enabled. The encoding logic of the additional merge candidates is the same as for the merge candidates in the HM, which means, for each CU in P or B slice, two more RD checks may be needed for the two additional merge candidates. In some embodiments, e.g., JEM, all bins of the merge index are context coded by CABAC (Context-based Adaptive Binary Arithmetic Coding). In other embodiments, e.g., HEVC, only the first bin is context coded and the remaining bins are context by-pass coded.
2.2 Examples of Adaptive Motion Vector Difference Resolution
[0095] In some embodiments, motion vector differences (MVDs) (between the motion vector and predicted motion vector of a PU) are signalled in units of quarter luma samples when use_integer_mv_flag is equal to 0 in the slice header. In the JEM, a locally adaptive motion vector resolution (LAMVR) is introduced. In the JEM, MVD can be coded in units of quarter luma samples, integer luma samples or four luma samples. The MVD resolution is controlled at the coding unit (CU) level, and MVD resolution flags are conditionally signalled for each CU that has at least one non-zero MVD components.
[0096] For a CU that has at least one non-zero MVD components, a first flag is signalled to indicate whether quarter luma sample MV precision is used in the CU. When the first flag (equal to 1) indicates that quarter luma sample MV precision is not used, another flag is signalled to indicate whether integer luma sample MV precision or four luma sample MV precision is used.
[0097] When the first MVD resolution flag of a CU is zero, or not coded for a CU (meaning all MVDs in the CU are zero), the quarter luma sample MV resolution is used for the CU. When a CU uses integer-luma sample MV precision or four-luma-sample MV precision, the MVPs in the AMVP candidate list for the CU are rounded to the corresponding precision.
[0098] In the encoder, CU-level RD checks are used to determine which MVD resolution is to be used for a CU. That is, the CU-level RD check is performed three times for each MVD resolution. To accelerate encoder speed, the following encoding schemes are applied in the JEM: [0099] During RD check of a CU with normal quarter luma sample MVD resolution, the motion information of the current CU (integer luma sample accuracy) is stored. The stored motion information (after rounding) is used as the starting point for further small range motion vector refinement during the RD check for the same CU with integer luma sample and 4 luma sample MVD resolution so that the time-consuming motion estimation process is not duplicated three times. [0100] RD check of a CU with 4 luma sample MVD resolution is conditionally invoked. For a CU, when RD cost integer luma sample MVD resolution is much larger than that of quarter luma sample MVD resolution, the RD check of 4 luma sample MVD resolution for the CU is skipped.
[0101] The encoding process is shown in FIG. 12. First, 1/4 pel MV is tested and the RD cost is calculated and denoted as RDCost0, then integer MV is tested and the RD cost is denoted as RDCost1. If RDCost1<th*RDCost0 (wherein th is a positive valued threshold), then 4-pel MV is tested; otherwise, 4-pel MV is skipped. Basically, motion information and RD cost etc. are already known for 1/4 pel MV when checking integer or 4-pel MV, which can be reused to speed up the encoding process of integer or 4-pel MV.
2.3 Examples of Higher Motion Vector Storage Accuracy
[0102] In HEVC, motion vector accuracy is one-quarter pel (one-quarter luma sample and one-eighth chroma sample for 4:2:0 video). In the JEM, the accuracy for the internal motion vector storage and the merge candidate increases to 1/16 pel. The higher motion vector accuracy ( 1/16 pel) is used in motion compensation inter prediction for the CU coded with skip/merge mode. For the CU coded with normal AMVP mode, either the integer-pel or quarter-pel motion is used.
[0103] SHVC upsampling interpolation filters, which have same filter length and normalization factor as HEVC motion compensation interpolation filters, are used as motion compensation interpolation filters for the additional fractional pel positions. The chroma component motion vector accuracy is 1/32 sample in the JEM, the additional interpolation filters of 1/32 pel fractional positions are derived by using the average of the filters of the two neighbouring 1/16 pel fractional positions.
2.4 Examples of Overlapped Block Motion Compensation (OBMC)
[0104] In the JEM, OBMC can be switched on and off using syntax at the CU level. When OBMC is used in the JEM, the OBMC is performed for all motion compensation (MC) block boundaries except the right and bottom boundaries of a CU. Moreover, it is applied for both the luma and chroma components. In the JEM, an MC block corresponds to a coding block. When a CU is coded with sub-CU mode (includes sub-CU merge, affine and FRUC mode), each sub-block of the CU is a MC block. To process CU boundaries in a uniform fashion, OBMC is performed at sub-block level for all MC block boundaries, where sub-block size is set equal to 4.times.4, as shown in FIGS. 13A and 13B.
[0105] FIG. 13A shows sub-blocks at the CU/PU boundary, and the hatched sub-blocks are where OBMC applies. Similarly, FIG. 13B shows the sub-Pus in ATMVP mode.
[0106] When OBMC applies to the current sub-block, besides current motion vectors, motion vectors of four connected neighboring sub-blocks, if available and are not identical to the current motion vector, are also used to derive prediction block for the current sub-block. These multiple prediction blocks based on multiple motion vectors are combined to generate the final prediction signal of the current sub-block.
[0107] Prediction block based on motion vectors of a neighboring sub-block is denoted as PN, with N indicating an index for the neighboring above, below, left and right sub-blocks and prediction block based on motion vectors of the current sub-block is denoted as PC. When PN is based on the motion information of a neighboring sub-block that contains the same motion information to the current sub-block, the OBMC is not performed from PN. Otherwise, every sample of PN is added to the same sample in PC, i.e., four rows/columns of PN are added to PC. The weighting factors {1/4, 1/8, 1/16, 1/32} are used for PN and the weighting factors {3/4, 7/8, 15/16, 31/32} are used for PC. The exception are small MC blocks, (i.e., when height or width of the coding block is equal to 4 or a CU is coded with sub-CU mode), for which only two rows/columns of PN are added to PC. In this case weighting factors {1/4, 1/8} are used for PN and weighting factors {3/4, 7/8} are used for PC. For PN generated based on motion vectors of vertically (horizontally) neighboring sub-block, samples in the same row (column) of PN are added to PC with a same weighting factor.
[0108] In the JEM, for a CU with size less than or equal to 256 luma samples, a CU level flag is signaled to indicate whether OBMC is applied or not for the current CU. For the CUs with size larger than 256 luma samples or not coded with AMVP mode, OBMC is applied by default. At the encoder, when OBMC is applied for a CU, its impact is taken into account during the motion estimation stage. The prediction signal formed by OBMC using motion information of the top neighboring block and the left neighboring block is used to compensate the top and left boundaries of the original signal of the current CU, and then the normal motion estimation process is applied.
2.5 Examples of Local Illumination Compensation (LIC)
[0109] LIC is based on a linear model for illumination changes, using a scaling factor a and an offset b. And it is enabled or disabled adaptively for each inter-mode coded coding unit (CU).
[0110] When LIC applies for a CU, a least square error method is employed to derive the parameters a and b by using the neighboring samples of the current CU and their corresponding reference samples. FIG. 14 shows an example of neighboring samples used to derive parameters of the IC algorithm. Specifically, and as shown in FIG. 14, the subsampled (2:1 subsampling) neighbouring samples of the CU and the corresponding samples (identified by motion information of the current CU or sub-CU) in the reference picture are used. The IC parameters are derived and applied for each prediction direction separately.
[0111] When a CU is coded with merge mode, the LIC flag is copied from neighboring blocks, in a way similar to motion information copy in merge mode; otherwise, an LIC flag is signaled for the CU to indicate whether LIC applies or not.
[0112] When LIC is enabled for a picture, an additional CU level RD check is needed to determine whether LIC is applied or not for a CU. When LIC is enabled for a CU, the mean-removed sum of absolute difference (MR-SAD) and mean-removed sum of absolute Hadamard-transformed difference (MR-SATD) are used, instead of SAD and SATD, for integer pel motion search and fractional pel motion search, respectively.
[0113] To reduce the encoding complexity, the following encoding scheme is applied in the JEM: [0114] LIC is disabled for the entire picture when there is no obvious illumination change between a current picture and its reference pictures. To identify this situation, histograms of a current picture and every reference picture of the current picture are calculated at the encoder. If the histogram difference between the current picture and every reference picture of the current picture is smaller than a given threshold, LIC is disabled for the current picture; otherwise, LIC is enabled for the current picture.
2.6 Examples of Affine Motion Compensation Prediction
[0115] In HEVC, only a translation motion model is applied for motion compensation prediction (MCP). However, the camera and objects may have many kinds of motion, e.g. zoom in/out, rotation, perspective motions, and/or other irregular motions. JEM, on the other hand, applies a simplified affine transform motion compensation prediction. FIG. 15 shows an example of an affine motion field of a block 1400 described by two control point motion vectors V.sub.0 and V.sub.1. The motion vector field (MVF) of the block 1400 can be described by the following equation:
{ v x = ( v 1 x - v 0 x ) w x - ( v 1 y - v 0 y ) w y + v 0 x v y = ( v 1 y - v 0 y ) w x + ( v 1 x - v 0 x ) w y + v 0 y Eq . ( 1 ) ##EQU00001##
[0116] As shown in FIG. 15, (v.sub.0x, v.sub.0y) is motion vector of the top-left corner control point, and (v.sub.1x, v.sub.1y) is motion vector of the top-right corner control point. To simplify the motion compensation prediction, sub-block based affine transform prediction can be applied. The sub-block size M.times.N is derived as follows:
{ M = clip 3 ( 4 , w , w .times. MvPre max ( abs ( v 1 x - v 0 x ) , abs ( v 1 y - v 0 y ) ) ) N = clip 3 ( 4 , h , h .times. MvPre max ( abs ( v 2 x - v 0 x ) , abs ( v 2 y - v 0 y ) ) ) Eq . ( 2 ) ##EQU00002##
[0117] Here, MvPre is the motion vector fraction accuracy (e.g., 1/16 in JEM). (v.sub.2x, v.sub.2y) is motion vector of the bottom-left control point, calculated according to Eq. (1). M and N can be adjusted downward if necessary to make it a divisor of w and h, respectively.
[0118] FIG. 16 shows an example of affine MVF per sub-block for a block 1500. To derive motion vector of each M.times.N sub-block, the motion vector of the center sample of each sub-block can be calculated according to Eq. (1), and rounded to the motion vector fraction accuracy (e.g., 1/16 in JEM). Then the motion compensation interpolation filters can be applied to generate the prediction of each sub-block with derived motion vector. After the MCP, the high accuracy motion vector of each sub-block is rounded and saved as the same accuracy as the normal motion vector.
2.6.1 Embodiments of the AF_INTER Mode
[0119] In the JEM, there are two affine motion modes: AF_INTER mode and AF_MERGE mode. For CUs with both width and height larger than 8, AF_INTER mode can be applied. An affine flag in CU level is signaled in the bitstream to indicate whether AF_INTER mode is used. In the AF_INTER mode, a candidate list with motion vector pair {(v.sub.0, v.sub.1)|v.sub.0={v.sub.A, v.sub.B, v.sub.c}, v.sub.1={v.sub.D,v.sub.E}} is constructed using the neighboring blocks.
[0120] FIG. 17 shows an example of motion vector prediction (MVP) for a block 1600 in the AF_INTER mode. As shown in FIG. 17, v.sub.0 is selected from the motion vectors of the sub-block A, B, or C. The motion vectors from the neighboring blocks can be scaled according to the reference list. The motion vectors can also be scaled according to the relationship among the Picture Order Count (POC) of the reference for the neighboring block, the POC of the reference for the current CU, and the POC of the current CU. The approach to select v.sub.1 from the neighboring sub-block D and E is similar. If the number of candidate list is smaller than 2, the list is padded by the motion vector pair composed by duplicating each of the AMVP candidates. When the candidate list is larger than 2, the candidates can be firstly sorted according to the neighboring motion vectors (e.g., based on the similarity of the two motion vectors in a pair candidate). In some implementations, the first two candidates are kept. In some embodiments, a Rate Distortion (RD) cost check is used to determine which motion vector pair candidate is selected as the control point motion vector prediction (CPMVP) of the current CU. An index indicating the position of the CPMVP in the candidate list can be signaled in the bitstream. After the CPMVP of the current affine CU is determined, affine motion estimation is applied and the control point motion vector (CPMV) is found. Then the difference of the CPMV and the CPMVP is signaled in the bitstream.
[0121] In AF_INTER mode, when 4/6 parameter affine mode is used, 2/3 control points are required, and therefore 2/3 MVD needs to be coded for these control points, as shown in FIGS. 18A and 18B. In an existing implementation, the MV may be derived as follows, e.g., it predicts mvd.sub.1 and mvd.sub.2 from mvd.sub.0.
mv.sub.0=mv.sub.0+mvd.sub.0
mv.sub.1=mv.sub.1+mvd.sub.1+mvd.sub.0
mv.sub.2=mv.sub.2+mvd.sub.2+mvd.sub.0
[0122] Herein, mv.sub.i, mvd.sub.i and mv.sub.i are the predicted motion vector, motion vector difference and motion vector of the top-left pixel (i=0), top-right pixel (i=1) or left-bottom pixel (i=2) respectively, as shown in FIG. 18B. In some embodiments, the addition of two motion vectors (e.g., mvA(xA, yA) and mvB(xB, yB)) is equal to summation of two components separately. For example, newMV=mvA+mvB implies that the two components of newMV are set to (xA+xB) and (yA+yB), respectively.
2.6.2 Examples of Fast Affine ME Algorithms in AF_INTER Mode
[0123] In some embodiments of the affine mode, MV of 2 or 3 control points needs to be determined jointly. Directly searching the multiple MVs jointly is computationally complex. In an example, a fast affine ME algorithm is proposed and is adopted into VTM/BMS.
[0124] For example, the fast affine ME algorithm is described for the 4-parameter affine model, and the idea can be extended to 6-parameter affine model:
{ x ' = ax + by + c y ' = - bx + ay + d Eq . ( 3 ) { mv ( x , y ) h = x ' - x = ( a - 1 ) x + by + c mv ( x , y ) v = y ' - y = - bx + ( a - 1 ) y + d Eq . ( 4 ) ##EQU00003##
[0125] Replacing (a-1) with a' enables the motion vectors to be rewritten as:
{ mv ( x , y ) h = x ' - x = a ' x + by + c mv ( x , y ) v = y ' - y = - bx + a ' y + d Eq . ( 5 ) ##EQU00004##
[0126] If it is assumed that the motion vectors of the two controls points (0, 0) and (0, w) are known, from Equation (5) the affine parameters may be derived as:
{ c = mv ( 0 , 0 ) h d = mv ( 0 , 0 ) v . Eq . ( 6 ) ##EQU00005##
[0127] The motion vectors can be rewritten in vector form as:
MV(p)=A(P)*MV.sub.c.sup.T. Eq. (7)
[0128] Herein, P=(x, y) is the pixel position,
A ( P ) = [ 1 x 0 y 0 y 1 - x ] , and Eq . ( 8 ) MV C = [ mv ( 0 , 0 ) h a mv ( 0 , 0 ) v b ] . Eq . ( 9 ) ##EQU00006##
[0129] In some embodiments, and at the encoder, the MVD of AF_INTER may be derived iteratively. Denote MV.sup.i(P) as the MV derived in the ith iteration for position P and denote dMV.sub.C.sup.i as the delta updated for MV.sub.C in the ith iteration. Then in the (i+1)th iteration,
MV i + 1 ( P ) = A ( P ) * ( ( MV C i ) T + ( dMV C i ) T ) = A ( P ) * ( MV C i ) T + A ( P ) * ( dMV C i ) T = MV i ( P ) + A ( P ) * ( dMV C i ) T . Eq . ( 10 ) ##EQU00007##
[0130] Denote Pic.sub.ref as the reference picture and denote Pic.sub.cur as the current picture and denote Q=P+MV.sup.i (P). If the MSE is used as the matching criterion, then the function that needs to be minimized may be written as:
min .SIGMA..sub.p(Pic.sub.cur(P)-Pic.sub.ref(P+MV.sup.i+1(P))).sup.2=min- >.SIGMA..sub.P(Pic.sub.cur(P)-Pic.sub.ref(Q+A(P)*(dMV.sub.C.sup.i).sup.- T)).sup.2 Eq. (11)
[0131] If it is assumed that (dMV.sub.C.sup.i).sup.T is small enough, Pic.sub.ref (Q+A(P)*(dMV.sub.C.sup.i).sup.T) may be rewritten, as an approximation based on a 1-st order Taylor expansion, as:
Pic.sub.ref(Q+A(P)*(dMV.sub.C.sup.i).sup.T).apprxeq.Pic.sub.ref(Q)+Pic.s- ub.ref'(Q)*A(P)*(dMV.sub.C.sup.i).sup.T. (12)
[0132] Herein,
Pic ref ' ( Q ) = [ dPic ref ( Q ) dx dPic ref ( Q ) dy ] . ##EQU00008##
If the notation E.sub.i+1(P)=Pic.sub.cur(P)-Pic.sub.ref(Q) is adopted, then:
min .SIGMA..sub.P(Pic.sub.cur(P)-Pic.sub.ref(Q)-Pic.sub.ref'(Q)*A(P)*(dM- V.sub.C.sup.i).sup.T).sup.2=min .SIGMA..sub.P(E.sup.i+1(P)-Pic.sub.ref'(Q)*A(P)*(dMV.sub.C.sup.i).sup.T).- sup.2) Eq. (13)
[0133] The term dMV.sub.C.sup.i may be derived by setting the derivative of the error function to zero, and then computing delta MV of the control points (0, 0) and (0, w) according to A(P)*(dMV.sub.C.sup.i).sup.T, as follows:
dMV.sub.(0,0).sup.h=dMV.sub.C.sup.i[0] Eq. (14)
dMV.sub.(0,w).sup.h=dMV.sub.C.sup.i[1]*w+dMV.sub.C.sup.i[2] Eq. (15)
dMV.sub.(0,0).sup.v=dMV.sub.C.sup.i[2] Eq. (16)
dMV.sub.(0,w).sup.v=dMV.sub.C.sup.i[3]*w+dMV.sub.C.sup.i[2] Eq. (17)
[0134] In some embodiments, this MVD derivation process may be iterated n times, and the final MVD may be calculated as follows:
fdMV.sub.(0,0).sup.h=.SIGMA..sub.i=0.sup.n-1dMV.sub.C.sup.i[0] Eq. (18)
fdMV.sub.(0,w).sup.h=.SIGMA..sub.i=0.sup.n-1dMV.sub.C.sup.i[1]*w+.SIGMA.- .sub.i=0.sup.n-1dMV.sub.C.sup.i[0] Eq. (19)
fdMV.sub.(0,0).sup.v=.SIGMA..sub.i=0.sup.n-1dMV.sub.C.sup.i[2] Eq. (20)
fdMV.sub.(0,w).sup.v=.SIGMA..sub.i=0.sup.n-1-dMV.sub.C.sup.i[3]*w+.SIGMA- ..sub.i=0.sup.n-1dMV.sub.C.sup.i[2] Eq. (21)
[0135] In the aforementioned implementation, predicting delta MV of control point (0, w), denoted by mvd.sub.1 from delta MV of control point (0, 0), denoted by mvd.sub.0, results in only (.SIGMA..sub.i=0.sup.n-1dMV.sub.C.sup.i[1]*w, -.SIGMA..sub.i=0.sup.n-1-dMV.sub.C.sup.i[3]*w) being encoded for mvd.sub.1.
2.6.3 Embodiments of the AF_MERGE Mode
[0136] When a CU is applied in AF_MERGE mode, it gets the first block coded with an affine mode from the valid neighboring reconstructed blocks. FIG. 19A shows an example of the selection order of candidate blocks for a current CU 1800. As shown in FIG. 19A, the selection order can be from left (1801), above (1802), above right (1803), left bottom (1804) to above left (1805) of the current CU 1800. FIG. 19B shows another example of candidate blocks for a current CU 1800 in the AF_MERGE mode. If the neighboring left bottom block 1801 is coded in affine mode, as shown in FIG. 19B, the motion vectors v.sub.2, v.sub.3 and v.sub.4 of the top left corner, above right corner, and left bottom corner of the CU containing the sub-block 1801 are derived. The motion vector v.sub.0 of the top left corner on the current CU 1800 is calculated based on v2, v3 and v4. The motion vector v1 of the above right of the current CU can be calculated accordingly.
[0137] After the CPMV of the current CU v0 and v1 are computed according to the affine motion model in Eq. (1), the MVF of the current CU can be generated. In order to identify whether the current CU is coded with AF_MERGE mode, an affine flag can be signaled in the bitstream when there is at least one neighboring block is coded in affine mode.
2.7 Examples of Pattern Matched Motion Vector Derivation (PMMVD)
[0138] The PMMVD mode is a special merge mode based on the Frame-Rate Up Conversion (FRUC) method. With this mode, motion information of a block is not signaled but derived at decoder side.
[0139] A FRUC flag can be signaled for a CU when its merge flag is true. When the FRUC flag is false, a merge index can be signaled and the regular merge mode is used. When the FRUC flag is true, an additional FRUC mode flag can be signaled to indicate which method (e.g., bilateral matching or template matching) is to be used to derive motion information for the block.
[0140] At the encoder side, the decision on whether using FRUC merge mode for a CU is based on RD cost selection as done for normal merge candidate. For example, multiple matching modes (e.g., bilateral matching and template matching) are checked for a CU by using RD cost selection. The one leading to the minimal cost is further compared to other CU modes. If a FRUC matching mode is the most efficient one, FRUC flag is set to true for the CU and the related matching mode is used.
[0141] Typically, motion derivation process in FRUC merge mode has two steps: a CU-level motion search is first performed, then followed by a Sub-CU level motion refinement. At CU level, an initial motion vector is derived for the whole CU based on bilateral matching or template matching. First, a list of MV candidates is generated and the candidate that leads to the minimum matching cost is selected as the starting point for further CU level refinement. Then a local search based on bilateral matching or template matching around the starting point is performed. The MV results in the minimum matching cost is taken as the MV for the whole CU. Subsequently, the motion information is further refined at sub-CU level with the derived CU motion vectors as the starting points.
[0142] For example, the following derivation process is performed for a W.times.H CU motion information derivation. At the first stage, MV for the whole W.times.H CU is derived. At the second stage, the CU is further split into M.times.M sub-CUs. The value of M is calculated as in Eq. (3), D is a predefined splitting depth which is set to 3 by default in the JEM. Then the MV for each sub-CU is derived.
M = max { 4 , min { M 2 D , N 2 D } } Eq . ( 3 ) ##EQU00009##
[0143] FIG. 20 shows an example of bilateral matching used in the Frame-Rate Up Conversion (FRUC) method. The bilateral matching is used to derive motion information of the current CU by finding the closest match between two blocks along the motion trajectory of the current CU (1900) in two different reference pictures (1910, 1911). Under the assumption of continuous motion trajectory, the motion vectors MV0 (1901) and MV1 (1902) pointing to the two reference blocks are proportional to the temporal distances, e.g., TD0 (1903) and TD1 (1904), between the current picture and the two reference pictures. In some embodiments, when the current picture 1900 is temporally between the two reference pictures (1910, 1911) and the temporal distance from the current picture to the two reference pictures is the same, the bilateral matching becomes mirror based bi-directional MV.
[0144] FIG. 21 shows an example of template matching used in the Frame-Rate Up Conversion (FRUC) method. Template matching can be used to derive motion information of the current CU 2000 by finding the closest match between a template (e.g., top and/or left neighboring blocks of the current CU) in the current picture and a block (e.g., same size to the template) in a reference picture 2010. Except the aforementioned FRUC merge mode, the template matching can also be applied to AMVP mode. In both JEM and HEVC, AMVP has two candidates. With the template matching method, a new candidate can be derived. If the newly derived candidate by template matching is different to the first existing AMVP candidate, it is inserted at the very beginning of the AMVP candidate list and then the list size is set to two (e.g., by removing the second existing AMVP candidate). When applied to AMVP mode, only CU level search is applied.
[0145] The MV candidate set at CU level can include the following: (1) original AMVP candidates if the current CU is in AMVP mode, (2) all merge candidates, (3) several MVs in the interpolated MV field (described later), and top and left neighboring motion vectors.
[0146] When using bilateral matching, each valid MV of a merge candidate can be used as an input to generate a MV pair with the assumption of bilateral matching. For example, one valid MV of a merge candidate is (MVa, ref.sub.a) at reference list A. Then the reference picture ref.sub.b of its paired bilateral MV is found in the other reference list B so that ref.sub.a and ref.sub.b are temporally at different sides of the current picture. If such a ref.sub.b is not available in reference list B, ref.sub.b is determined as a reference which is different from ref.sub.a and its temporal distance to the current picture is the minimal one in list B. After ref.sub.b is determined, MVb is derived by scaling MVa based on the temporal distance between the current picture and ref.sub.a, ref.sub.b.
[0147] In some implementations, four MVs from the interpolated MV field can also be added to the CU level candidate list. More specifically, the interpolated MVs at the position (0, 0), (W/2, 0), (0, H/2) and (W/2, H/2) of the current CU are added. When FRUC is applied in AMVP mode, the original AMVP candidates are also added to CU level MV candidate set. In some implementations, at the CU level, 15 MVs for AMVP CUs and 13 MVs for merge CUs can be added to the candidate list.
[0148] The MV candidate set at sub-CU level includes an MV determined from a CU-level search, (2) top, left, top-left and top-right neighboring MVs, (3) scaled versions of collocated MVs from reference pictures, (4) one or more ATMVP candidates (e.g., up to four), and (5) one or more STMVP candidates (e.g., up to four). The scaled MVs from reference pictures are derived as follows. The reference pictures in both lists are traversed. The MVs at a collocated position of the sub-CU in a reference picture are scaled to the reference of the starting CU-level MV. ATMVP and STMVP candidates can be the four first ones. At the sub-CU level, one or more MVs (e.g., up to 17) are added to the candidate list.
[0149] Generation of an Interpolated MV Field.
[0150] Before coding a frame, interpolated motion field is generated for the whole picture based on unilateral ME. Then the motion field may be used later as CU level or sub-CU level MV candidates.
[0151] In some embodiments, the motion field of each reference pictures in both reference lists is traversed at 4.times.4 block level. FIG. 22 shows an example of unilateral Motion Estimation (ME) 2100 in the FRUC method. For each 4.times.4 block, if the motion associated to the block passing through a 4.times.4 block in the current picture and the block has not been assigned any interpolated motion, the motion of the reference block is scaled to the current picture according to the temporal distance TD0 and TD1 (the same way as that of MV scaling of TMVP in HEVC) and the scaled motion is assigned to the block in the current frame. If no scaled MV is assigned to a 4.times.4 block, the block's motion is marked as unavailable in the interpolated motion field.
[0152] Interpolation and Matching Cost.
[0153] When a motion vector points to a fractional sample position, motion compensated interpolation is needed. To reduce complexity, bi-linear interpolation instead of regular 8-tap HEVC interpolation can be used for both bilateral matching and template matching.
[0154] The calculation of matching cost is a bit different at different steps. When selecting the candidate from the candidate set at the CU level, the matching cost can be the absolute sum difference (SAD) of bilateral matching or template matching. After the starting MV is determined, the matching cost C of bilateral matching at sub-CU level search is calculated as follows:
C=SAD+w(|MV.sub.x-MV.sub.x.sup.s|+|MV.sub.y-MV.sub.y.sup.s|) Eq. (4)
[0155] Here, w is a weighting factor. In some embodiments, w can be empirically set to 4. MV and MVS indicate the current MV and the starting MV, respectively. SAD may still be used as the matching cost of template matching at sub-CU level search.
[0156] In FRUC mode, MV is derived by using luma samples only. The derived motion will be used for both luma and chroma for MC inter prediction. After MV is decided, final MC is performed using 8-taps interpolation filter for luma and 4-taps interpolation filter for chroma.
[0157] MV refinement is a pattern based MV search with the criterion of bilateral matching cost or template matching cost. In the JEM, two search patterns are supported--an unrestricted center-biased diamond search (UCBDS) and an adaptive cross search for MV refinement at the CU level and sub-CU level, respectively. For both CU and sub-CU level MV refinement, the MV is directly searched at quarter luma sample MV accuracy, and this is followed by one-eighth luma sample MV refinement. The search range of MV refinement for the CU and sub-CU step are set equal to 8 luma samples.
[0158] In the bilateral matching merge mode, bi-prediction is applied because the motion information of a CU is derived based on the closest match between two blocks along the motion trajectory of the current CU in two different reference pictures. In the template matching merge mode, the encoder can choose among uni-prediction from list0, uni-prediction from list1, or bi-prediction for a CU. The selection ca be based on a template matching cost as follows:
[0159] If costBi<=factor*min (cost0, cost1) [0160] bi-prediction is used; [0161] Otherwise, if cost0<=cost1 [0162] uni-prediction from list0 is used; [0163] Otherwise, [0164] uni-prediction from list1 is used;
[0165] Here, cost0 is the SAD of list0 template matching, cost1 is the SAD of list1 template matching and costBi is the SAD of bi-prediction template matching. For example, when the value of factor is equal to 1.25, it means that the selection process is biased toward bi-prediction. The inter prediction direction selection can be applied to the CU-level template matching process.
2.8 Examples of Bi-Directional Optical Flow (BIO)
[0166] The bi-directional optical flow (BIO) method is a sample-wise motion refinement performed on top of block-wise motion compensation for bi-prediction. In some implementations, the sample-level motion refinement does not use signaling.
[0167] Let I.sup.(k) be the luma value from reference k (k=0, 1) after block motion compensation, and denote .differential.I.sup.(k)/.differential.x and .differential.I.sup.(k)/.differential.y as the horizontal and vertical components of the I.sup.(k) gradient, respectively. Assuming the optical flow is valid, the motion vector field (v.sub.x, v.sub.y) is given by:
.differential.I.sup.(k)/.differential.t+v.sub.x.differential.I.sup.(k)/.- differential.x+v.sub.y.differential.I.sup.(k)/.differential.y=0. Eq. (5)
[0168] Combining this optical flow equation with Hermite interpolation for the motion trajectory of each sample results in a unique third-order polynomial that matches both the function values I.sup.(k) and derivatives .differential.I.sup.(k)/.differential.x and .differential.I.sup.(k)/.differential.y at the ends. The value of this polynomial at t=0 is the BIO prediction:
pred.sub.BIO=1/2(I.sup.(0)+I.sup.(1)+v.sub.x/2(.tau..sub.1.differential.- I.sup.(1)/.differential.x-.tau..sub.0.differential.I.sup.(0)/.differential- .x)+v.sub.y/2(.tau..sub.1.differential.I.sup.(1)/.differential.y-.tau..sub- .0.differential.I.sup.(0)/.differential.y)). Eq. (6)
[0169] FIG. 23 shows an example optical flow trajectory in the Bi-directional Optical flow (BIO) method. Here, .tau..sub.0 and .tau..sub.1 denote the distances to the reference frames. Distances .tau..sub.0 and .tau..sub.1 are calculated based on POC for Ref.sub.0 and Ref.sub.1: .tau..sub.0=POC(current)-POC(Ref.sub.0), .tau..sub.1=POC(Ref.sub.1)-POC(current). If both predictions come from the same time direction (either both from the past or both from the future) then the signs are different (e.g., .tau..sub.0.tau..sub.1<0). In this case, BIO is applied if the prediction is not from the same time moment (e.g., .tau..sub.0.noteq..tau..sub.1). Both referenced regions have non-zero motion (e.g. MVx.sub.0, MVy.sub.0, MVx.sub.1, MVy.noteq.0) and the block motion vectors are proportional to the time distance (e.g. MVx.sub.0/MVx.sub.1=MVy.sub.0/MVy.sub.1=-.tau..sub.0/.tau..sub.1).
[0170] The motion vector field (v.sub.x, v.sub.y) is determined by minimizing the difference .DELTA. between values in points A and B. FIGS. 9A-9B show an example of intersection of motion trajectory and reference frame planes. Model uses only first linear term of a local Taylor expansion for .DELTA.:
.DELTA.=(I.sup.(0)-I.sup.(1).sub.0+v.sub.x(.tau..sub.1.differential.I.su- p.(1)/.differential.x+.tau..sub.0.differential.I.sup.(0)/.differential.x)+- v.sub.y(.tau..sub.1.differential.I.sup.(1)/.differential.y+.tau..sub.0.dif- ferential.I.sup.(0)/.differential.y)) Eq. (7)
[0171] All values in the above equation depend on the sample location, denoted as (i', j'). Assuming the motion is consistent in the local surrounding area, .DELTA. can be minimized inside the (2M+1).times.(2M+1) square window .OMEGA. centered on the currently predicted point (i,j), where M is equal to 2:
( v x , v y ) = arg min v x , v y [ i ' , j ] .di-elect cons. .OMEGA. .DELTA. 2 [ i ' , j ' ] Eq . ( 8 ) ##EQU00010##
[0172] For this optimization problem, the JEM uses a simplified approach making first a minimization in the vertical direction and then in the horizontal direction. This results in the following:
v x = ( s 1 + r ) > m ? clip 3 ( - thBIO , thBIO , - s 3 ( s 1 + r ) ) : 0 Eq . ( 9 ) v y = ( s 5 + r ) > m ? clip 3 ( - thBIO , thBIO , - s 6 - v x s 2 / 2 ( s 5 + r ) ) : 0 where , Eq . ( 10 ) s 1 = [ i ' , j ] .di-elect cons. .OMEGA. ( .tau. 1 .differential. I ( 1 ) / .differential. x + .tau. 0 .differential. I ( 0 ) / .differential. x ) 2 ; s 3 = [ i ' , j ] .di-elect cons. .OMEGA. ( I ( 1 ) - I ( 0 ) ) ( .tau. 1 .differential. I ( 1 ) / .differential. x + .tau. 0 .differential. I ( 0 ) / .differential. x ) ; s 2 = [ i ' , j ] .di-elect cons. .OMEGA. ( .tau. 1 .differential. I ( 1 ) / .differential. x + .tau. 0 .differential. I ( 0 ) / .differential. x ) ( .tau. 1 .differential. I ( 1 ) / .differential. y + .tau. 0 .differential. I ( 0 ) / .differential. y ) ; s 5 = [ i ' , j ] .di-elect cons. .OMEGA. ( .tau. 1 .differential. I ( 1 ) / .differential. y + .tau. 0 .differential. I ( 0 ) / .differential. y ) 2 ; s 6 = [ i ' , j ] .di-elect cons. .OMEGA. ( I ( 1 ) - I ( 0 ) ) ( .tau. 1 .differential. I ( 1 ) / .differential. y + .tau. 0 .differential. I ( 0 ) / .differential. y ) Eq . ( 11 ) ##EQU00011##
[0173] In order to avoid division by zero or a very small value, regularization parameters r and m can be introduced in Eq. (9) and Eq. (10), where:
r=5004.sup.d-8 Eq. (12)
m=7004.sup.d-8 Eq. (13)
[0174] Here, d is bit depth of the video samples.
[0175] In order to keep the memory access for BIO the same as for regular bi-predictive motion compensation, all prediction and gradients values, I.sup.(k), .differential.I.sup.(k)/.differential.x, .differential.I.sup.(k)/.differential.y, are calculated for positions inside the current block. FIG. 24A shows an example of access positions outside of a block 2300. As shown in FIG. 24A, in Eq. (9), (2M+1).times.(2M+1) square window .OMEGA. centered in currently predicted point on a boundary of predicted block needs to accesses positions outside of the block. In the JEM, values of I.sup.(k), .differential.I.sup.(k)/.differential.x, .differential.I.sup.(k)/.differential.y outside of the block are set to be equal to the nearest available value inside the block. For example, this can be implemented as a padding area 2301, as shown in FIG. 24B.
[0176] With BIO, it is possible that the motion field can be refined for each sample. To reduce the computational complexity, a block-based design of BIO is used in the JEM. The motion refinement can be calculated based on a 4.times.4 block. In the block-based BIO, the values of s.sub.n in Eq. (9) of all samples in a 4.times.4 block can be aggregated, and then the aggregated values of s.sub.n in are used to derived BIO motion vectors offset for the 4.times.4 block. More specifically, the following formula can used for block-based BIO derivation:
s 1 , b k = ( x , y ) .di-elect cons. b k [ i ' , j ] .di-elect cons. .OMEGA. ( x , y ) ( .tau. 1 .differential. I ( 1 ) / .differential. x + .tau. 0 .differential. I ( 0 ) / .differential. x ) 2 ; s 3 , b k = ( x , y ) .di-elect cons. b k [ i ' , j ] .di-elect cons. .OMEGA. ( I ( 1 ) - I ( 0 ) ) ( .tau. 1 .differential. I ( 1 ) / .differential. x + .tau. 0 .differential. I ( 0 ) / .differential. x ) ; s 2 , b k = ( x , y ) .di-elect cons. b k [ i ' , j ] .di-elect cons. .OMEGA. ( .tau. 1 .differential. I ( 1 ) / .differential. x + .tau. 0 .differential. I ( 0 ) / .differential. x ) ( .tau. 1 .differential. I ( 1 ) / .differential. y + .tau. 0 .differential. I ( 0 ) / .differential. y ) ; s 5 , b k = ( x , y ) .di-elect cons. b k [ i ' , j ] .di-elect cons. .OMEGA. ( .tau. 1 .differential. I ( 1 ) / .differential. y + .tau. 0 .differential. I ( 0 ) / .differential. y ) 2 ; s 6 , b k = ( x , y ) .di-elect cons. b k [ i ' , j ] .di-elect cons. .OMEGA. ( I ( 1 ) - I ( 0 ) ) ( .tau. 1 .differential. I ( 1 ) / .differential. y + .tau. 0 .differential. I ( 0 ) / .differential. y ) Eq . ( 14 ) ##EQU00012##
[0177] Here, b.sub.k denotes the set of samples belonging to the k-th 4.times.4 block of the predicted block. s.sub.n in Eq (9) and Eq (10) are replaced by ((s.sub.n,bk)>>4) to derive the associated motion vector offsets.
[0178] In some scenarios, MV regiment of BIO may be unreliable due to noise or irregular motion. Therefore, in BIO, the magnitude of MV regiment is clipped to a threshold value. The threshold value is determined based on whether the reference pictures of the current picture are all from one direction. For example, if all the reference pictures of the current picture are from one direction, the value of the threshold is set to 12.times.2.sup.14-d; otherwise, it is set to 12.times.2.sup.13-d.
[0179] Gradients for BIO can be calculated at the same time with motion compensation interpolation using operations consistent with HEVC motion compensation process (e.g., 2D separable Finite Impulse Response (FIR)). In some embodiments, the input for the 2D separable FIR is the same reference frame sample as for motion compensation process and fractional position (fracX, fracY) according to the fractional part of block motion vector. For horizontal gradient .differential.I/.differential.x, a signal is first interpolated vertically using BIOfilterS corresponding to the fractional position fracY with de-scaling shift d-8. Gradient filter BIOfilterG is then applied in horizontal direction corresponding to the fractional position fracX with de-scaling shift by 18-d. For vertical gradient .differential.I/.differential.y, a gradient filter is applied vertically using BIOfilterG corresponding to the fractional position fracY with de-scaling shift d-8. The signal displacement is then performed using BIOfilterS in horizontal direction corresponding to the fractional position fracX with de-scaling shift by 18-d. The length of interpolation filter for gradients calculation BIOfilterG and signal displacement BIOfilterF can be shorter (e.g., 6-tap) in order to maintain reasonable complexity. Table 1 shows example filters that can be used for gradients calculation of different fractional positions of block motion vector in BIO. Table 2 shows example interpolation filters that can be used for prediction signal generation in BIO.
TABLE-US-00001 TABLE 1 Exemplary filters for gradient calculations in BIO Interpolation filter for Fractional pel position gradient(BIOfilterG) 0 {8, -39, -3, 46, -17, 5} 1/16 {8, -32, -13, 50, -18, 5} 1/8 {7, -27, -20, 54, -19, 5} 3/16 {6, -21, -29, 57, -18, 5} 1/4 {4, -17, -36, 60, -15, 4} 5/16 {3, -9, -44, 61, -15, 4} 3/8 {1, -4, -48, 61, -13, 3} 7/16 {0, 1, -54, 60, -9, 2} 1/2 {-1, 4, -57, 57, -4, 1}
TABLE-US-00002 TABLE 2 Exemplary interpolation filters for prediction signal generation in BIO Interpolation filter for Fractional pel position prediction signal(BIOfilterS) 0 {0, 0, 64, 0, 0, 0} 1/16 {1, -3, 64, 4, -2, 0} 1/8 {1, -6, 62, 9, -3, 1} 3/16 {2, -8, 60, 14, -5, 1} 1/4 {2, -9, 57, 19, -7, 2} 5/16 {3, -10, 53, 24, -8, 2} 3/8 {3, -11, 50, 29, -9, 2} 7/16 {3, -11, 44, 35, -10, 3} 1/2 {3, -10, 35, 44, -11, 3}
[0180] In the JEM, BIO can be applied to all bi-predicted blocks when the two predictions are from different reference pictures. When Local Illumination Compensation (LIC) is enabled for a CU, BIO can be disabled.
[0181] In some embodiments, OBMC is applied for a block after normal MC process. To reduce the computational complexity, BIO may not be applied during the OBMC process. This means that BIO is applied in the MC process for a block when using its own MV and is not applied in the MC process when the MV of a neighboring block is used during the OBMC process.
2.9 Examples of Decoder-Side Motion Vector Refinement (DMVR)
[0182] In a bi-prediction operation, for the prediction of one block region, two prediction blocks, formed using a motion vector (MV) of list0 and a MV of list1, respectively, are combined to form a single prediction signal. In the decoder-side motion vector refinement (DMVR) method, the two motion vectors of the bi-prediction are further refined by a bilateral template matching process. The bilateral template matching applied in the decoder to perform a distortion-based search between a bilateral template and the reconstruction samples in the reference pictures in order to obtain a refined MV without transmission of additional motion information.
[0183] In DMVR, a bilateral template is generated as the weighted combination (i.e. average) of the two prediction blocks, from the initial MV0 of list0 and MV1 of list1, respectively, as shown in FIG. 25. The template matching operation consists of calculating cost measures between the generated template and the sample region (around the initial prediction block) in the reference picture. For each of the two reference pictures, the MV that yields the minimum template cost is considered as the updated MV of that list to replace the original one. In the JEM, nine MV candidates are searched for each list. The nine MV candidates include the original MV and 8 surrounding MVs with one luma sample offset to the original MV in either the horizontal or vertical direction, or both. Finally, the two new MVs, i.e., MV0' and MV1' as shown in FIG. 25, are used for generating the final bi-prediction results. A sum of absolute differences (SAD) is used as the cost measure.
[0184] DMVR is applied for the merge mode of bi-prediction with one MV from a reference picture in the past and another from a reference picture in the future, without the transmission of additional syntax elements. In the JEM, when LIC, affine motion, FRUC, or sub-CU merge candidate is enabled for a CU, DMVR is not applied.
2.2.9 Examples of Symmetric Motion Vector Difference
[0185] Symmetric motion vector difference (SMVD) is proposed to encode the MVD more efficiently.
[0186] Firstly, in slice level, variables BiDirPredFlag, RefIdxSymL0 and RefIdxSymL1 are derived as follows:
[0187] The forward reference picture in reference picture list 0 which is nearest to the current picture is searched. If found, RefIdxSymL0 is set equal to the reference index of the forward picture.
[0188] The backward reference picture in reference picture list 1 which is nearest to the current picture is searched. If found, RefIdxSymL1 is set equal to the reference index of the backward picture.
[0189] If both forward and backward picture are found, BiDirPredFlag is set equal to 1.
[0190] Otherwise, following applies:
[0191] The backward reference picture in reference picture list 0 which is nearest to the current one is searched. If found, RefIdxSymL0 is set equal to the reference index of the backward picture.
[0192] The forward reference picture in reference picture list 1 which is nearest to the current one is searched. If found, RefIdxSymL1 is set equal to the reference index of the forward picture.
[0193] If both backward and forward picture are found, BiDirPredFlag is set equal to 1. Otherwise, BiDirPredFlag is set equal to 0.
[0194] Secondly, in CU level, a symmetrical mode flag indicating whether symmetrical mode is used or not is explicitly signaled if the prediction direction for the CU is bi-prediction and BiDirPredFlag is equal to 1.
[0195] When the flag is true, only mvp_l0_flag, mvp_l1_flag and MVD0 are explicitly signaled. The reference indices are set equal to RefIdxSymL0, RefIdxSymL1 for list 0 and list 1, respectively. MVD1 is just set equal to -MVD0. The final motion vectors are shown in below formula.
{ ( mvx 0 , mvy 0 ) = ( mvpx 0 + mvdx 0 , mvpy 0 + mvdy 0 ) ( mvx 1 , mvy 1 ) = ( mvpx 1 - mvdx 0 , mvpy 1 - mvdy 0 ) ##EQU00013##
[0196] FIG. 28 shows examples of symmetrical mode.
[0197] The modifications in coding unit syntax are shown in Table 3.
TABLE-US-00003 TABLE 3 Modifications in coding unit syntax Descriptor coding_umt( x0, y0, cbWidth, cbHeight, treeType ) { ... if( slice_type = = B ) inter_pred_idc[ x0 ][ y0 ] ae(v) if( sps_affine_enabled_flag && cbWidth >= 16 && cbHeight >= 16 ) { inter_affine_flag[ x0 ][ y0 ] ae(v) if( sps_affine_type_flag && inter_affine_flag[ x0 ][ y0 ] ) cu_affine_type_flag[ x0 ][ y0 ] ae(v) } if( inter_pred_idc[ x0 ][ y0 ] == PRED_BI && BiDirPredFlag && inter_affine_flag[ x0 ][ y0 ] == 0 ) symmetric_mvd_flag[ x0 ][ y0 ] ae(v) if( inter_pred_idc[ x0 ][ y0 ] != PRED_L1 ) { if( num_ref_idx_l0_active_minus1 > 0 && !symmetric_mvd_flag[ x0 ][ y0 ] ) ref_idx_l0[ x0 ][ y0 ] ae(v) mvd_coding( x0, y0, 0, 0 ) if( MotionModelIdc[ x0 ][ y0 ] > 0 ) mvd_coding( x0, y0, 0, 1 ) if(MotionModelIdc[ x0 ][ y0 ] > 1 ) mvd_coding( x0, y0, 0, 2 ) mvp_l0_flag[ x0 ][ y0 ] ae(v) } else { MvdL0[ x0 ][ y0 ][ 0 ] = 0 MvdL0[ x0 ][ y0 ][ 1 ] = 0 } if( inter_pred_idc[ x0 ][ y0 ] != PRED_L0 ) { if( num_ref_idx_l1_active_minus1 > 0 && !symmetric_mvd_flag[ x0 ][ y0 ] ) ref_idx_l1[ x0 ][ y0 ] ae(v) if( mvd_l1_zero_flag && inter_pred_idc[ x0 ][ y0 ] = = PRED_BI ) { ... } else { if( !symmetric_mvd_flag[ x0 ][ y0 ] ) { mvd_coding( x0, y0, 1, 0 ) if( MotionModelIdc[ x0 ][ y0 ] > 0 ) mvd_coding( x0, y0, 1, 1 ) if(MotionModelIdc[ x0 ][ y0 ] > 1 ) mvd_coding( x0, y0, 1, 2 ) } mvp_l1_flag[ x0 ][ y0 ] ae(v) } else { MvdL1[ x0 ][ y0 ][ 0 ] = 0 MvdL1[ x0 ][ y0 ][ 1 ] = 0 } ... } } ... }
2.2.11 Symmetric MVD for Affine Bi-Prediction Coding
[0198] SMVD for affine mode is proposed in [9].
2.3 Context-Adaptive Binary Arithmetic Coding (CABAC)
2.3.1 CABAC Design in HEVC
2.3.1.1 Context Representation and Initialization Process in HEVC
[0199] In HEVC, for each context variable, the two variables pStateIdx and valMps are initialized.
[0200] From the 8 bit table entry initValue, the two 4 bit variables slopeIdx and offsetIdx are derived as follows:
slopeIdx=initValue>>4
offsetIdx=initValue & 15 (34)
[0201] The variables m and n, used in the initialization of context variables, are derived from slopeIdx and offsetIdx as follows:
m=slopeIdx*5-45
n=(offsetIdx<<3)-16 (35)
[0202] The two values assigned to pStateIdx and valMps for the initialization are derived from the luma's quantization parameter of slice denoted by SliceQpY. Given the variables m and n, the initialization is specified as follows:
preCtxState=Clip3(1,126,((m*Clip3(0,51,SliceQpY))>>4)+n)
valMps=(preCtxState<=63)?0:1
pStateIdx=valMps?(preCtxState-64):(63-preCtxState) (36)
2.3.1.2 State Transition Process in HEVC
[0203] Inputs to this process are the current pStateIdx, the decoded value binVal and valMps values of the context variable associated with ctxTable and ctxIdx.
[0204] Outputs of this process are the updated pStateIdx and valMps of the context variable associated with ctxIdx.
[0205] Depending on the decoded value binVal, the update of the two variables pStateIdx and valMps associated with ctxIdx is derived as follows in (37):
TABLE-US-00004 if( binVal == valMps ) pStateIdx = transIdxMps( pStateIdx ) else { (37) if( pStateIdx == 0 ) valMps = 1 - valMps pStateIdx = transIdxLps( pStateIdx ) }
2.3.2 CABAC Design in VVC
[0206] The context-adaptive binary arithmetic coder (BAC) in VVC has been changed in VVC which is different from that in HEVC in terms of both context updating process and arithmetic coder.
[0207] Here is the summary of recently adopted proposal (JVET-M0473, CE test 5.1.13).
TABLE-US-00005 TABLE 4 Summary of CABAC modifications in VVC State representation 10 + 14 bit linear, reduced range rLPS computation 5 .times. 4 bit multiplier Initialization 128 .times. 16 bit to map HEVC-like state to linear representation, retrained initialization values Rate estimation 256 .times. 2 .times. 19 bit table Window size Variable, defined per context a = 2 . . . (controlling probability 5 b = a + 3 . . . 6 updating speed) That is, each context has two variables for recording the associated probabilities, and each probability is updated with its own speed (faster speed based on the variable a and lower speed based on the variable b) Other rMPS >= 128 is guaranteed
2.3.2.1 Context Initialization Process in VVC
[0208] n VVC, two values assigned to pStateIdx0 and pStateIdx1 for the initialization are derived from SliceQpY. Given the variables m and n, the initialization is specified as follows:
preCtxState=Clip3(0,127,((m*Clip3(0,51,SliceQpY))>>4)+n)
pStateIdx0=initStateIdxToState[preCtxState]>>4
pStateIdx1=initStateIdxToState[preCtxState] (38)
2.3.2.2 State Transition Process in VVC
[0209] Inputs to this process are the current pStateIdx0 and pStateIdx1, and the decoded value binVal.
[0210] Outputs of this process are the updated pStateIdx0 and pStateIdx1 of the context variable associated with ctxIdx.
[0211] The variables shift0 (corresponding to variable a in Summary of CABAC modifications in VVCTable 4) and shift1 (corresponding to variable b in Summary of CABAC modifications in VVC Table 4e) are derived from the shiftIdx value associated with ctxTable and ctxInc.
shift0=(shiftIdx>>2)+2
shift1=(shiftIdx &3)+3+shift0 (39)
[0212] Depending on the decoded value binVal, the update of the two variables pStateIdx0 and pStateIdx1 associated with ctxIdx is derived as follows:
pStateIdx0=pStateIdx0-(pStateIdx0>>shift0)+(1023*binVal>>shi- ft0)
pStateIdx1=pStateIdx1-(pStateIdx1>>shift1)+(16383*binVal>>sh- ift1) (40)
3. DRAWBACKS OF EXISTING IMPLEMENTATIONS
[0213] In some existing implementations, when MV/MV difference (MVD) could be selected from a set of multiple MV/MVD precisions for affine coded blocks, it remains uncertain how more accurate motion vectors may be obtained.
[0214] In other existing implementations, the MV/MVD precision information also plays an important role in determination of the overall coding gain of AMVR applied to affine mode, but achieving this goal remains uncertain.
4. EXAMPLE METHODS FOR MV PREDICTORS FOR AFFINE MODE WITH AMVR
[0215] Embodiments of the presently disclosed technology overcome the drawbacks of existing implementations, thereby providing video coding with higher coding efficiencies. The derivation and signaling of motion vector predictors for affine mode with adaptive motion vector resolution (AMVR), based on the disclosed technology, may enhance both existing and future video coding standards, is elucidated in the following examples described for various implementations. The examples of the disclosed technology provided below explain general concepts, and are not meant to be interpreted as limiting. In an example, unless explicitly indicated to the contrary, the various features described in these examples may be combined.
[0216] In some embodiments, the following examples may be applied to affine mode or normal mode when AMVR is applied. These examples assume that a precision Prec (i.e., MV is with 1/(2{circumflex over ( )}Prec) precision) is used for encoding MVD in AF_INTER mode or for encoding MVD in normal inter mode. A motion vector predictor (e.g., inherited from a neighboring block MV) and its precision are denoted by MVPred(MVPred.sub.X, MVPred.sub.Y) and PredPrec, respectively.
Improvement of Affine Mode with AMVR Supported [0217] 1. The set of allowed MVD precisions may be different from picture to picture, from slice to slice, or from block to block. [0218] a. In one example, the set of allowed MVD precisions may depend on coded information, such as block size, block shape. etc. al. [0219] b. A set of allowed MV precisions may be pre-defined, such as { 1/16, 1/4, 1}. [0220] c. Indications of allowed MV precisions may be signaled in SPS/PPS/VPS/sequence header/picture header/slice header/group of CTUs, etc. al. [0221] d. The signaling of selected MV precision from a set of allowed MV precisions further depend on number of allowed MV precisions for a block. [0222] 2. A syntax element is signaled to the decoder to indicate the used MVD precision in affine inter mode. [0223] a. In one example, only one single syntax element is used to indicate the MVD precisions applied to the affine mode and the AMVR mode. [0224] i. In one example, same semantics are used, that is, the same value of syntax element is mapped to the same MVD precision for the AMVR and affine mode. [0225] ii. Alternatively, the semantics of the single syntax element is different for the AMVR mode and the affine mode. That is, the same value of syntax element could be mapped to different MVD precision for the AMVR and affine mode. [0226] b. In one example, when affine mode uses same set of MVD precisions with AMVR (e.g., MVD precision set is {1, 1/4, 4}-pel), the MVD precision syntax element in AMVR is reused in affine mode, i.e., only one single syntax element is used. [0227] i. Alternatively, furthermore, when encoding/decoding this syntax element in CABAC encoder/decoder, same or different context models may be used for AMVR and affine mode. [0228] ii. Alternatively, furthermore, this syntax element may have different semantics in AMVR and affine mode. For example, the syntax element equal to 0, 1 and 2 indicates 1/4-pel, 1-pel and 4-pel MV precision respectively in AMVR, while in affine mode, the syntax element equal to 0, 1 and 2 indicates 1/4-pel, 1/16-pel and 1-pel MV precision respectively. [0229] c. In one example, when affine mode uses same number of MVD precisions with AMVR but different sets of MVD precisions (e.g., MVD precision set for AMVR is {1, 1/4, 4}-pel while for affine, it is { 1/16, 1/4, 1}-pel), the MVD precision syntax element in AMVR is reused in affine mode, i.e., only one single syntax element is used. [0230] i. Alternatively, furthermore, when encoding/decoding this syntax element in CABAC encoder/decoder, same or different context models may be used for AMVR and affine mode. [0231] ii. Alternatively, furthermore, this syntax element may have different semantics in AMVR and affine mode. [0232] d. In one example, affine mode uses less MVD precisions than AMVR, the MVD precision syntax element in AMVR is reused in affine mode. However, only a subset of the syntax element values is valid for affine mode. [0233] i. Alternatively, furthermore, when encoding/decoding this syntax element in CABAC encoder/decoder, same or different context models may be used for AMVR and affine mode. [0234] ii. Alternatively, furthermore, this syntax element may have different semantics in AMVR and affine mode. [0235] e. In one example, affine mode uses more MVD precisions than AMVR, the MVD precision syntax element in AMVR is reused in affine mode. However, such syntax element is extended to allow more values in affine mode. [0236] i. Alternatively, furthermore, when encoding/decoding this syntax element in CABAC encoder/decoder, same or different context models may be used for AMVR and affine mode. [0237] ii. Alternatively, furthermore, this syntax element may have different semantics in AMVR and affine mode. [0238] f. In one example, a new syntax element is used for coding the MVD precision of affine mode, i.e., two different syntax elements are used for coding the MVD precision of AMVR and affine mode. [0239] g. The syntax for indication of MVD precisions for the affine mode may be signaled under one or all of the following conditions are true: [0240] i. MVDs for all control points are non-zero. [0241] ii. MVDs for at least one control point is non-zero. [0242] iii. MVD of one control point (e.g., the first CPMV) are non-zero [0243] In this case, when either one of the above conditions or all of them fail, there is no need to signal the MVD precisions. [0244] h. The syntax element for indication of MVD precisions for either affine mode or the AMVR mode may be coded with contexts and the contexts are dependent on coded information. [0245] i. In one example, when there is only one single syntax element, the contexts may depend on whether current block is coded with affine mode or not. [0246] i. In one example, the context may depend on the block size/block shape/MVD precisions of neighboring blocks/temporal layer index/prediction directions, etc. al. [0247] j. Whether to enable or disable the usage of multiple MVD precisions for the affine mode may be signaled in SPS/PPS/VPS/sequence header/picture header/slice header/group of CTUs, etc. al. [0248] i. In one example, whether to signal the information of enable or disable the usage of multiple MVD precisions for the affine mode may depend on other syntax elements. For example, the information of enable or disable the usage of multiple MV and/or MVP and/or MVD precisions for the affine mode is signaled when affine mode is enabled; and is not signaled and inferred to be 0 when affine mode is disabled. [0249] k. Alternatively, multiple syntax elements may be signaled to indicate the used MV and/or MVP and/or MVD precision (in the following discussion, they are all referred to as "MVD precision") in affine inter mode. [0250] i. In one example, the syntax elements used to indicate the used MVD precision in affine inter mode and normal inter mode may be different. [0251] 1. The number of syntax elements to indicate the used MVD precision in affine inter mode and normal inter mode may be different. [0252] 2. The semantics of the syntax elements to indicate the used MVD precision in affine inter mode and normal inter mode may be different. [0253] 3. The context models in arithmetic coding to code one syntax elements to indicate the used MVD precision in affine inter mode and normal inter mode may be different. [0254] 4. The methods to derive context models in arithmetic coding to code one syntax element to indicate the used MVD precision in affine inter mode and normal inter mode may be different. [0255] ii. In one example, a first syntax element (e.g. amvr_flag) may be signaled to indicate whether to apply AMVR in an affine-coded block. [0256] 1. The first syntax element is conditionally signaled. a. In one example, signalling of the first syntax element (amvr_flag) is skipped when current block is coded with certain mode (e.g., CPR/IBC mode). b. In one example, signalling of the first syntax element (amvr_flag) is skipped when all CPMVs' MVDs (including both horizontal and vertical components) are all zero. c. In one example, signalling of the first syntax element (amvr_flag) is skipped when one selected CPMVs' MVDs (including both horizontal and vertical components) are all zero. i. In one example, the selected CPMV's MVD is the first CPMV's MVD to be coded/decoded. d. In one example, signalling of the first syntax element (amvr_flag) is skipped when the usage of enabling multiple MVD precisions for affine-coded block is false. e. In one example, the first syntax element may be signaled under the following conditions: i. Usage of enabling multiple MVD precisions for affine-coded block is true and current block is coded with affine mode; ii. Alternatively, usage of enabling multiple MVD precisions for affine-coded block is true, current block is coded with affine mode, and at least one component of a CPMV's MVD is unequal to 0. iii. Alternatively, usage of enabling multiple MVD precisions for affine-coded block is true, current block is coded with affine mode, and at least one component of a selected CPMV's MVD is unequal to 0. [0257] 1. In one example, the selected CPMV's MVD is the first CPMV's MVD to be coded/decoded. [0258] 2. When AMVR is not applied to an affine-coded block or the first syntax element is not present, a default MV and/or MVD precision is utilized. a. In one example, the default precision is 1/4-pel. b. Alternatively, the default precision is set to that used in motion compensation for affine coded blocks. [0259] 3. For example, the MVD precision of affine mode is 1/4-pel if amvr_flag is equal to 0; otherwise the MVD precision of affine mode may be other values. a. Alternatively, furthermore, the additional MVD precisions may be further signaled via a second syntax element. [0260] iii. In one example, a second syntax element (such as amvr_coarse_precision_flag) may be signaled to indicate the MVD precision of affine mode. [0261] 1. In one example, whether the second syntax element is signaled may depend on the first syntax element. For example, the second syntax element is only signaled when the first syntax element is 1. [0262] 2. In one example, the MVD precision of affine mode is 1-pel if the second syntax element is 0; otherwise, the MVD precision of affine mode is 1/16-pel. [0263] 3. In one example, the MVD precision of affine mode is 1/16-pel if the second syntax element is 0; otherwise, the MVD precision of affine mode is full-pixel. [0264] iv. In one example, a syntax element used to indicate the used MVD precision in affine inter mode share the same context models as the syntax element with the same name but used to indicate the used MVD precision in normal inter mode. [0265] 1. Alternatively, a syntax element used to indicate the used MVD precision in affine inter mode use different context models as the syntax element with the same name but used to indicate the used MVD precision in normal inter mode. [0266] 3. Whether to apply or how to apply AMVR on an affine coded block may depend on the reference picture of the current block. [0267] i. In one example, AMVR is not applied if the reference picture is the current picture, i.e., Intra block copying is applied in the current block. [0268] Fast algorithm of AVMR in affine mode for encoder [0269] Denote RD cost (real RD cost, or SATD/SSE/SAD cost plus rough bits cost) of affine mode and AMVP mode as affineCosti and amvpCosti for IMV=i, where in i=0, 1 or 2. Here, IMV=0 means 1/4 pel MV, and IMV=1 means integer MV for AMVP mode and 1/16 pel MV for affine mode, and IMV=2 means 4 pel MV for AMVP mode and integer MV for affine mode. Denote RD cost of merge mode as mergeCost. [0270] 4. It is proposed that AMVR is disabled for affine mode of current CU if the best mode of its parent CU is not AF_INTER mode or AF_MERGE mode. [0271] a. Alternatively, AMVR is disabled for affine mode of current CU if the best mode of its parent CU is not AF_INTER mode [0272] 5. It is proposed that AMVR is disabled for affine mode if affineCost0>th1*amvpCost0, wherein th1 is a positive threshold. [0273] a. Alternatively, in addition, AMVR is disabled for affine mode if min(affineCost0, amvpCost0)>th2*mergeCost, wherein th2 is a positive threshold. [0274] b. Alternatively, in addition, integer MV is disabled for affine mode if affineCost0>th3*affineCost1, wherein th3 is a positive threshold. [0275] 6. It is proposed that AMVR is disabled for AMVP mode if amvpCost0>th4*affineCost0, wherein th4 is a positive threshold. [0276] a. Alternatively, AMVR is disabled for AMVP mode if min(affineCost0, amvpCost0)>th5*mergeCost, wherein th5 is a positive threshold. [0277] 7. It is proposed that 4/6 parameter affine models obtained in one MV precision may be used as a candidate start search point for other MV precisions. [0278] a. In one example, 4/6 parameter affine models obtained in 1/16 MV may be used as a candidate start search point for other MV precisions. [0279] b. In one example, 4/6 parameter affine models obtained in 1/4 MV may be used as a candidate start search point for other MV precisions. [0280] 8. AMVR for affine mode is not checked at encoder for the current block if its parent block does not choose the affine mode. [0281] 9. Statistics of usage of different MV precisions for affine-coded blocks in previously coded frames/slices/tiles/CTU rows may be utilized to early terminate the rate-distortion calculations of MV precisions for affine-coded blocks in current slice/tile/CTU row. [0282] a. In one example, the percentage of affine-coded blocks with a certain MV precision is recorded. If the percentage is too low, then the checking of the corresponding MV precision is skipped. [0283] b. In one example, previously coded frames with the same temporal layer are utilized to decide whether to skip a certain MV precision. [0284] 10. The above proposed method may be applied under certain conditions, such as block sizes, slice/picture/tile types, or motion information. [0285] a. In one example, when a block size contains smaller than M*H samples, e.g., 16 or 32 or 64 luma samples, proposed method is not allowed. [0286] b. Alternatively, when minimum size of a block's width or/and height is smaller than or no larger than X, proposed method is not allowed. In one example, X is set to 8. [0287] c. Alternatively, when minimum size of a block's width or/and height is no smaller than X, proposed method is not allowed. In one example, X is set to 8. [0288] d. Alternatively, when a block's width>th1 or >=th1 and/or a block's height>th2 or >=th2, proposed method is not allowed. In one example, th1 and/or th2 is set to 8. [0289] e. Alternatively, when a block's width<th1 or <=th1 and/or a block's height<th2 or <a=th2, proposed method is not allowed. In one example, th1 and/or th2 is set to 8. [0290] f. Alternatively, whether to enable or disable the above methods and/or which method to be applied may be dependent on block dimension, video processing data unit (VPDU), picture type, low delay check flag, coded information of current block (such as reference pictures, uni or bi-prediction) or previously coded blocks. [0291] 11. The AMVR methods for affine mode may be performed in different ways when intra block copy (IBC, a.k.a. current picture reference (CPR)) is applied or not. [0292] a. In one example, AMVR for affine mode cannot be used if a block is coded by IBC. [0293] b. In one example, AMVR for affine mode may be used if a block is coded by IBC, but the candidate MV/MVD/MVP precisions may be different to those used for non-IBC coded affine-coded block. [0294] 12. All the term "slice" in the document may be replaced by "tile group" or "tile". [0295] 13. In VPS/SPS/PPS/slice header/tile group header, a syntax element (e.g. no_amvr_constraint_flag) equal to 1 specifies that it is a requirement of bitstream conformance that both the syntax element to indicate whether AMVR is enabled (e.g. sps_amvr_enabled_flag) and the syntax element to indicate whether affine AMVR is enabled (e.g. sps_affine_avmr_enabled_flag) shall be equal to 0. The syntax element (e.g. no_amvr_constraint_flag) equal to 0 does not impose a constraint.
[0296] 14. In VPS/SPS/PPS/slice header/tile group header or other video data units, a syntax element (e.g. no_affine_amvr_constraint_flag) may be signalled. [0297] a. In one example, no_affine_amvr_constraint_flag equal to 1 specifies that it is a requirement of bitstream conformance that the syntax element to indicate whether affine AMVR is enabled (e.g. sps_affine_avmr_enabled_flag) shall be equal to 0. The syntax element (e.g. no_affine_amvr_constraint_flag) equal to 0 does not impose a constraint
5. EMBODIMENTS
5.1. Embodiment 1: Indication of Usage of Affine AMVR Mode
[0298] It may be signaled in SPS/PPS/VPS/APS/sequence header/picture header/tile group header, etc. al. This section presents the signalling in SPS.
5.1.1. SPS Syntax Table
TABLE-US-00006 [0299] Descriptor seq_parameter_set_rbsp( ) { sps_seq_parameter_set_id ue(v) ... sps_amvr_enabled_flag u(1) sps_bdof_enabled_flag u(1) sps_affine_amvr_enabled_flag u(1) sps_cclm_enabled_flag u(1) sps_mts_intra_enabled_flag u(1) sps_mts_inter_enabled_flag u(1) sps_affine_enabled_flag u(1) if( sps_affine_enabled_flag ) sps_affine_type_flag u(1) sps_gbi_enabled_flag u(1) sps_cpr_enabled_flag u(1) ... rbsp_trailing_bits( ) }
[0300] An alternative SPS syntax table is given as follows:
TABLE-US-00007 Descriptor seq_parameter_set_rbsp( ) { sps_seq_parameter_set_id ue(v) sps_amvr_enabled_flag u(1) sps_bdof_enabled_flag u(1) sps_cclm_enabled_flag u(1) sps_mts_intra_enabled_flag u(1) sps_mts_inter_enabled_flag u(1) sps_affine_enabled_flag u(1) if( sps_affine_enabled_flag ){ sps_affine_type_flag u(1) sps_affine_amvr_enabled_flag u(1) } sps_gbi_enabled_flag u(1) sps_cpr_enabled_flag u(1) sps_ciip_enabled_flag u(1) sps_triangle_enabled_flag u(1) sps_ladf_enabled_flag u(1) ... rbsp_trailing_bits( ) }
Semantics:
[0301] sps_affine_amvr_enabled_flag equal to 1 specifies that adaptive motion vector difference resolution is used in motion vector coding of affine inter mode. amvr_enabled_flag equal to 0 specifies that adaptive motion vector difference resolution is not used in motion vector coding of affine inter mode.
5.2. Parsing Process of Affine AMVR Mode Information
[0302] Syntax of the affine AMVR mode information may reuse that for the AMVR mode information (applied to normal inter mode). Alternatively, different syntax elements may be utilized. Affine AMVR mode information may be conditionally signaled. Different embodiments below show some examples of the conditions.
5.2.1. Embodiment #1: CU Syntax Table
TABLE-US-00008 [0303] Descriptor coding_unit( x0, y0, cbWidth, cbHeight, treeType ) { if( tile_group_type != I ) { if( treeType != DUAL_TREE_CHROMA ) cu_skip_flag[ x0 ][ y0 ] ae(v) if( cu_skip_flag[ x0 ][ y0 ] = = 0 ) pred_mode_flag ae(v) } if( CuPredMode[ x0 ][ y0 ] = = MODE_INTRA ) { ... } } else if( treeType != DUAL_TREE_CHROMA ) { /* MODE_INTER */ if( cu_skip_flag[ x0 ][ y0 ] = = 0 ) merge_flag[ x0 ][ y0 ] ae(v) if( merge_flag[ x0 ][ y0 ] ) { merge_data( x0, y0, cbWidth, cbHeight ) } else { if( tile_group_type = = B ) inter_pred_idc[ x0 ][ y0 ] ae(v) if( sps_affine_enabled_flag && cbWidth >= 16 && cbHeight >= 16 ) { inter_affine_flag[ x0 ][ y0 ] ae(v) if( sps_affine_type_flag && inter_affine_flag[ x0 ][ y0 ] ) cu_affine_type_flag[ x0 ][ y0 ] ae(v) } if( inter_pred_idc[ x0 ][ y0 ] != PRED_L1 ) { if( num_ref_idx_l0_active_minus1 > 0 ) ref_idx_l0[ x0 ][ y0 ] ae(v) mvd_coding( x0, y0, 0, 0 ) if( MotionModelIdc[ x0 ][ y0 ] > 0 ) mvd_coding( x0, y0, 0, 1 ) if(MotionModelIdc[ x0 ][ y0 ] > 1 ) mvd_coding( x0, y0, 0, 2 ) mvp_l0_flag[ x0 ][ y0 ] ae(v) } else { MvdL0[ x0 ][ y0 ][ 0 ] = 0 MvdL0[ x0 ][ y0 ][ 1 ] = 0 } if( inter_pred_idc[ x0 ][ y0 ] != PRED_L0 ) { if( num_ref_idx_l1_active_minus1 > 0 ) ref_idx_l1[ x0 ][ y0 ] ae(v) if( mvd_l1_zero_flag && inter_pred_idc[ x0 ][ y0 ] = = PRED_BI ) { MvdL1[ x0 ][ y0 ][ 0 ] = 0 MvdL1[ x0 ][ y0 ][ 1 ] = 0 MvdCpL1[ x0 ][ y0 ][ 0 ][ 0 ] = 0 MvdCpL1[ x0 ][ y0 ][ 0 ][ 1 ] = 0 MvdCpL1[ x0 ][ y0 ][ 1 ][ 0 ] = 0 MvdCpL1[ x0 ][ y0 ][ 1 ][ 1 ] = 0 MvdCpL1[ x0 ][ y0 ][ 2 ][ 0 ] = 0 MvdCpL1[ x0 ][ y0 ][ 2 ][ 1 ] = 0 } else { mvd_coding( x0, y0, 1, 0 ) if( MotionModelIdc[ x0 ][ y0 ] > 0 ) mvd_coding( x0, y0, 1, 1 ) if(MotionModelIdc[ x0 ][ y0 ] > 1 ) mvd_coding( x0, y0, 1, 2 ) mvp_l1_flag[ x0 ][ y0 ] ae(v) } else { MvdL1[ x0 ][ y0 ][ 0 ] = 0 MvdL1[ x0 ][ y0 ][ 1 ] = 0 } if( ( sps_amvr_enabled_flag && inter_affine_flag = = 0 && ( MvdL0[ x0 ][ y0 ][ 0 ] != 0 | | MvdL0[ x0 ][ y0 ][ 1 ] != 0 | | MvdL1[ x0 ][ y0 ][ 0 ] != 0 | | MvdL1[ x0 ][ y0 ][ 1 ] != 0 ) ) || ( sps_affine_amvr_enabled_flag && inter_affine_flag = = 1 && ( MvdCpL0[ x0 ][ y0 ][ 0 ] [ 0 ] != 0 | | MvdCpL0[ x0 ][ y0 ][ 0 ] [ 1 ] != 0 | | MvdCpL1[ x0 ][ y0 ][ 0 ] [ 0 ] != 0 | | MvdCpL1[ x0 ][ y0 ][ 0 ] [ 1 ] != 0 | | MvdCpL0[ x0 ][ y0 ][ 1 ] [ 0 ] != 0 | | MvdCpL0[ x0 ][ y0 ][ 1 ] [ 1 ] != 0 | | MvdCpL1[ x0 ][ y0 ][ 1 ] [ 0 ] != 0 | | MvdCpL1[ x0 ][ y0 ][ 1 ] [ 1 ] != 0 | | MvdCpL0[ x0 ][ y0 ][ 2 ] [ 0 ] != 0 | | MvdCpL0[ x0 ][ y0 ][ 2 ] [ 1 ] != 0 | | MvdCpL1[ x0 ][ y0 ][ 2 ] [ 0 ] != 0 | | MvdCpL1[ x0 ][ y0 ][ 2 ] [ 1 ] != 0 ) ) ) { if( !sps_cpr_enabled_flag | | !( inter_pred_idc[ x0 ][ y0 ] == PRED_L0 && ref_idx_l0[ x0 ][ y0 ] = = num_ref_idx_l0_active_minus1 ) ) amvr_flag[ x0 ][ y0 ] ae(v) if( amvr_flag[ x0 ][ y0 ] ) amvr_coarse_precisoin_flag[ x0 ][ y0 ] ae(v) } if( sps_gbi_enabled_flag && inter_pred_idc[ x0 ][ y0 ] = = PRED_BI && cbWidth * cbHeight >= 256 ) gbi_idx[ x0 ][ y0 ] ae(v) } } if( !pcm_flag[ x0 ][ y0 ] ) { if( CuPredMode[ x0 ][ y0 ] != MODE_INTRA && cu_skip_flag[ x0 ][ y0 ] = = 0 ) cu_cbf ae(v) if( cu_cbf ) transform_tree( x0, y0, cbWidth, cbHeight, treeType ) } }
5.2.2. Embodiment 2: An Alternative CU Syntax Table Design
TABLE-US-00009 [0304] Descriptor coding_unit( x0, y0, cbWidth, cbHeight, treeType ) { if( tile_group_type != I ) { if( treeType != DUAL_TREE_CHROMA ) cu_skip_flag[ x0 ][ y0 ] ae(v) if( cu_skip_flag[ x0 ][ y0 ] = = 0 ) pred_mode_flag ae(v) } if( CuPredMode[ x0 ][ y0 ] = = MODE_INTRA ) { ... } } else if( treeType != DUAL_TREE_CHROMA ) { /* MODE_INTER */ if( cu_skip_flag[ x0 ][ y0 ] = = 0 ) merge_flag[ x0 ][ y0 ] ae(v) if( merge_flag[ x0 ][ y0 ] ) { merge_data( x0, y0, cbWidth, cbHeight ) } else { if( tile_group_type = = B ) inter_pred_idc[ x0 ][ y0 ] ae(v) if( sps_affine_enabled_flag && cbWidth >= 16 && cbHeight >= 16 ) { inter_affine_flag[ x0 ][ y0 ] ae(v) if( sps_affine_type_flag && inter_affine_flag[ x0 ][ y0 ] ) cu_affine_type_flag[ x0 ][ y0 ] ae(v) } if( inter_pred_idc[ x0 ][ y0 ] != PRED_L1 ) { if( num_ref_idx_l0_active_minus1 > 0 ) ref_idx_l0[ x0 ][ y0 ] ae(v) mvd_coding( x0, y0, 0, 0 ) if( MotionModelIdc[ x0 ][ y0 ] > 0 ) mvd_coding( x0, y0, 0, 1 ) if(MotionModelIdc[ x0 ][ y0 ] > 1 ) mvd_coding( x0, y0, 0, 2 ) mvp_l0_flag[ x0 ][ y0 ] ae(v) } else { MvdL0[ x0 ][ y0 ][ 0 ] = 0 MvdL0[ x0 ][ y0 ][ 1 ] = 0 } if( inter_pred_idc[ x0 ][ y0 ] != PRED_L0 ) { if( num_ref_idx_l1_active_minus1 > 0 ) ref_idx_l1[ x0 ][ y0 ] ae(v) if( mvd_l1_zero_flag && inter_pred_idc[ x0 ][ y0 ] = = PRED_BI ) { MvdL1[ x0 ][ y0 ][ 0 ] = 0 MvdL1[ x0 ][ y0 ][ 1 ] = 0 MvdCpL1[ x0 ][ y0 ][ 0 ][ 0 ] = 0 MvdCpL1[ x0 ][ y0 ][ 0 ][ 1 ] = 0 MvdCpL1[ x0 ][ y0 ][ 1 ][ 0 ] = 0 MvdCpL1[ x0 ][ y0 ][ 1 ][ 1 ] = 0 MvdCpL1[ x0 ][ y0 ][ 2 ][ 0 ] = 0 MvdCpL1[ x0 ][ y0 ][ 2 ][ 1 ] = 0 } else { mvd_coding( x0, y0, 1, 0 ) if( MotionModelIdc[ x0 ][ y0 ] > 0 ) mvd_coding( x0, y0, 1, 1 ) if(MotionModelIdc[ x0 ][ y0 ] > 1 ) mvd_coding( x0, y0, 1, 2 ) mvp_l1_flag[ x0 ][ y0 ] ae(v) } else { MvdL1[ x0 ][ y0 ][ 0 ] = 0 MvdL1[ x0 ][ y0 ][ 1 ] = 0 } if( ( sps_amvr_enabled_flag && inter_affine_flag = = 0 && ( MvdL0[ x0 ][ y0 ][ 0 ] != 0 | | MvdL0[ x0 ][ y0 ][ 1 ] != 0 | | MvdL1[ x0 ][ y0 ][ 0 ] != 0 | | MvdL1[ x0 ][ y0 ][ 1 ] != 0 ) ) || ( sps_affine_amvr_enabled_flag && inter_affine_flag = = 1 && ( MvdCpL0[ x0 ][ y0 ][ 0 ] [ 0 ] != 0 | | MvdCpL0[ x0 ][ y0 ][ 0 ] [ 1 ] != 0 | | MvdCpL1[ x0 ][ y0 ][ 0 ] [ 0 ] != 0 | | MvdCpL1[ x0 ][ y0 ][ 0 ] [ 1 ] != 0 ) ) ) { if( !sps_cpr_enabled_flag | | !( inter_pred_idc[ x0 ][ y0 ] = = PRED_L0 && ref_idx_l0[ x0 ][ y0 ] = = num_ref_idx_l0_active_minus1 ) ) amvr_flag[ x0 ][ y0 ] ae(v) if( amvr_flag[ x0 ][ y0 ] ) amvr_coarse_precisoin_flag[ x0 ][ y0 ] ae(v) } if( sps_gbi_enabled_flag && inter_pred_idc[ x0 ][ y0 ] = = PRED_BI && cbWidth * cbHeight >= 256 ) gbi_idx[ x0 ][ y0 ] ae(v) } } if( !pcm_flag[ x0 ][ y0 ] ) { if( CuPredMode[ x0 ][ y0 ] != MODE_INTRA && cu_skip_flag[ x0 ][ y0 ] = = 0 ) cu_cbf ae(v) if( cu_cbf ) transform_tree( x0, y0, cbWidth, cbHeight, treeType ) } }
5.2.3. Embodiment 3: a Third CU Syntax Table Design
TABLE-US-00010 [0305] Descriptor coding_unit( x0, y0, cbWidth, cbHeight, treeType ) { if( tile_group_type != I ) { if( treeType != DUAL_TREE_CHROMA ) cu_skip_flag[ x0 ][ y0 ] ae(v) if( cu_skip_flag[ x0 ][ y0 ] = = 0 ) pred_mode_flag ae(v) } if( CuPredMode[ x0 ][ y0 ] = = MODE_INTRA ) { ... } } else if( treeType != DUAL_TREE_CHROMA ) { /* MODE_INTER */ if( cu_skip_flag[ x0 ][ y0 ] = = 0 ) merge_flag[ x0 ][ y0 ] ae(v) if( merge_flag[ x0 ][ y0 ] ) { merge_data( x0, y0, cbWidth, cbHeight ) } else { if( tile_group_type = = B ) inter_pred_idc[ x0 ][ y0 ] ae(v) if( sps_affine_enabled_flag && cbWidth >= 16 && cbHeight >= 16 ) { inter_affine_flag[ x0 ][ y0 ] ae(v) if( sps_affine_type_flag && inter_affine_flag[ x0 ][ y0 ] ) cu_affine_type_flag[ x0 ][ y0 ] ae(v) } if( inter_pred_idc[ x0 ][ y0 ] != PRED_L1 ) { if( num_ref_idx_l0_active_minus1 > 0 ) ref_idx_l0[ x0 ][ y0 ] ae(v) mvd_coding( x0, y0, 0, 0 ) if( MotionModelIdc[ x0 ][ y0 ] > 0 ) mvd_coding( x0, y0, 0, 1 ) if(MotionModelIdc[ x0 ][ y0 ] > 1 ) mvd_coding( x0, y0, 0, 2 ) mvp_l0_flag[ x0 ][ y0 ] ae(v) } else { MvdL0[ x0 ][ y0 ][ 0 ] = 0 MvdL0[ x0 ][ y0 ][ 1 ] = 0 } if( inter_pred_idc[ x0 ][ y0 ] != PRED_L0 ) { if( num_ref_idx_l1_active_minus1 > 0 ) ref_idx_l1[ x0 ][ y0 ] ae(v) if( mvd_l1_zero_flag && inter_pred_idc[ x0 ][ y0 ] = = PRED_BI ) { MvdL1[ x0 ][ y0 ][ 0 ] = 0 MvdL1[ x0 ][ y0 ][ 1 ] = 0 MvdCpL1[ x0 ][ y0 ][ 0 ][ 0 ] = 0 MvdCpL1[ x0 ][ y0 ][ 0 ][ 1 ] = 0 MvdCpL1[ x0 ][ y0 ][ 1 ][ 0 ] = 0 MvdCpL1[ x0 ][ y0 ][ 1 ][ 1 ] = 0 MvdCpL1[ x0 ][ y0 ][ 2 ][ 0 ] = 0 MvdCpL1[ x0 ][ y0 ][ 2 ][ 1 ] = 0 } else { mvd_coding( x0, y0, 1, 0 ) if( MotionModelIdc[ x0 ][ y0 ] > 0 ) mvd_coding( x0, y0, 1, 1 ) if(MotionModelIdc[ x0 ][ y0 ] > 1 ) mvd_coding( x0, y0, 1, 2 ) mvp_l1_flag[ x0 ][ y0 ] ae(v) } else { MvdL1[ x0 ][ y0 ][ 0 ] = 0 MvdL1[ x0 ][ y0 ][ 1 ] = 0 } if( ( sps_amvr_enabled_flag && inter_affine_flag = = 0 && ( MvdL0[ x0 ][ y0 ][ 0 ] != 0 | | MvdL0[ x0 ][ y0 ][ 1 ] != 0 | | MvdL1[ x0 ][ y0 ][ 0 ] != 0 | | MvdL1[ x0 ][ y0 ][ 1 ] != 0 ) ) || ( sps_affine_amvr_enabled_flag && inter_affine_flag = = 1 ) ) { if( !sps_cpr_enabled_flag | | !( inter_pred_idc[ x0 ][ y0 ] = = PRED_L0 && ref_idx_l0[ x0 ][ y0 ] = = num_ref_idx_l0_active_minus1 ) ) amvr_flag[ x0 ][ y0 ] ae(v) if( amvr_flag[ x0 ][ y0 ] ) amvr_coarse_precisoin_flag[ x0 ][ y0 ] ae(v) } if( sps_gbi_enabled_flag && inter_pred_idc[ x0 ][ y0 ] = = PRED_BI && cbWidth * cbHeight >= 256 ) gbi_idx[ x0 ][ y0 ] ae(v) } } if( !pcm_flag[ x0 ][ y0 ] ) { if( CuPredMode[ x0 ][ y0 ] != MODE_INTRA && cu_skip_flag[ x0 ][ y0 ] = = 0 ) cu_cbf ae(v) if( cu_cbf ) transform_tree( x0, y0, cbWidth, cbHeight, treeType ) } }
5.2.4. Embodiment 4: Syntax Table Design with Different Syntax for AMVR and Affine AMVR Mode
TABLE-US-00011 [0306] coding_unit( x0, y0, cbWidth, cbHeight, treeType ) { if( tile_group_type != I ) { if( treeType != DUAL_TREE_CHROMA ) cu_skip_flag[ x0 ][ y0 ] if( cu_skip_flag[ x0 ][ y0 ] = = 0 ) pred_mode_flag } if( CuPredMode[ x0 ][ y0 ] = = MODE_INTRA ) { ... } } else if( treeType != DUAL_TREE_CHROMA ) { /* MODE_INTER */ if( cu_skip_flag[ x0 ][ y0 ] = = 0 ) merge_flag[ x0 ][ y0 ] if( merge_flag[ x0 ][ y0 ] ) { merge_data( x0, y0, cbWidth, cbHeight ) } else { if( tile_group_type = = B ) inter_pred_idc[ x0 ][ y0 ] if( sps_affine_enabled_flag && cbWidth >= 16 && cbHeight >= 16 ) { inter_affine_flag[ x0 ][ y0 ] if( sps affine type flag && inter_affine_flag[ x0 ][ y0 ] ) cu_affine_type_flag[ x0 ][ y0 ] } if( inter_pred_idc[ x0 ][ y0 ] != PRED_L1 ) { if( num_ref_idx_l0_active_minus1 > 0 ) ref_idx_l0[ x0 ][ y0 ] mvd_coding( x0, y0, 0, 0 ) if( MotionModelIdc[ x0 ][ y0 ] > 0 ) mvd_coding( x0, y0, 0, 1 ) if(MotionModelIdc[ x0 ][ y0 ] > 1 ) mvd_coding( x0, y0, 0, 2 ) mvp_l0_flag[ x0 ][ y0 ] } else { MvdL0[ x0 ][ y0 ][ 0 ] = 0 MvdL0[ x0 ][ y0 ][ 1 ] = 0 } if( inter_pred_idc[ x0 ][ y0 ] != PRED_L0 ) { if( num_ref_idx_l1_active_minus1 > 0 ) ref_idx_l1[ x0 ][ y0 ] if( mvd_l1_zero_flag && inter_pred_idc[ x0 ][ y0 ] = = PRED_BI ) { MvdL1[ x0 ][ y0 ][ 0 ] = 0 MMvdL1[ x0 ][ y0 ][ 1 ] = 0 MMvdCpL1[ x0 ][ y0 ][ 0 ][ 0 ] = 0 MMvdCpL1[ x0 ][ y0 ][ 0 ][ 1 ] = 0 MMvdCpL1[ x0 ][ y0 ][ 1 ][ 0 ] = 0 MMvdCpL1[ x0 ][ y0 ][ 1 ][ 1 ] = 0 MMvdCpL1[ x0 ][ y0 ][ 2 ][ 0 ] = 0 MMvdCpL1[ x0 ][ y0 ][ 2 ][ 1 ] = 0 } else { mvd_coding( x0, y0, 1, 0 ) if( MotionModelIdc[ x0 ][ y0 ] > 0 ) mvd_coding( x0, y0, 1, 1 ) if(MotionModelIdc[ x0 ][ y0 ] > 1 ) mvd_coding( x0, y0, 1, 2 ) mvp_l1_flag[ x0 ][ y0 ] } else { MvdL1[ x0 ][ y0 ][ 0 ] = 0 MvdL1[ x0 ][ y0 ][ 1 ] = 0 } if(sps_amvr_enabled_flag && inter_affine_flag = = 0 && ( MvdL0[ x0 ][ y0 ][ 0 ] != 0 | | MvdL0[ x0 ][ y0 ][ 1 ] != 0 | | MvdL1[ x0 ][ y0 ][ 0 ] != 0 | | MvdL1[ x0 ][ y0 ][ 1 ] != 0 ) ) { if( !sps_cpr_enabled_flag | | !( inter_pred_idc[ x0 ][ y0 ] = = PRED_L0 && ref_idx_l0[ x0 ][ y0 ] = = num_ref_idx_l0_active_minus1 ) ) amvr_flag[ x0 ][ y0 ] if( amvr_flag[ x0 ][ y0 ] ) amvr_coarse_precisoin_flag[ x0 ][ y0 ] } else if (conditionsA) { if(conditionsB) affine_amvr_flag[ x0 ][ y0 ] if( amvr_flag[ x0 ][ y0 ] ) affine_amvr_coarse_precisoin_flag[ x0 ][ y0 ] } if( sps_gbi_enabled_flag && inter_pred_idc[ x0 ][ y0 ] = = PRED_BI && cbWidth * cbHeight >= 256 ) gbi_idx[ x0 ][ y0 ] } } if( !pcm_flag[ x0 ][ y0 ] ) { if( CuPredMode[ x0 ][ y0 ] != MODE_INTRA && cu_skip_flag[ x0 ][ y0 ] = = 0 ) cu_cbf if( cu_cbf ) transform_tree( x0, y0, cbWidth, cbHeight, treeType ) } }
[0307] In one example, conditionsA is defined as follows: [0308] (sps_affine_amvr_enabled_flag && inter_affine_flag==1 && [0309] (MvdCpL0[x0][y0][0][0]!=0.parallel. [0310] MvdCpL0[x0][y0][0][1]!=0.parallel. [0311] MvdCpL1[x0][y0][0][0]!=0.parallel. [0312] MvdCpL1[x0][y0][0][1]!=0.parallel. [0313] MvdCpL0[x0][y0][1][0]!=0.parallel. [0314] MvdCpL0[x0][y0][1][1]!=0.parallel. [0315] MvdCpL1[x0][y0][1][0]!=0.parallel. [0316] MvdCpL1[x0][y0][1][1]!=0.parallel. [0317] MvdCpL0[x0][y0][2][0]!=0.parallel. [0318] MvdCpL0[x0][y0][2][1]!=0.parallel. [0319] MvdCpL1[x0][y0][2][0]!=0.parallel. [0320] MvdCpL1[x0][y0][2][1]!=0))
[0321] Alternatively, conditionsA is defined as follows: [0322] (sps_affine_amvr_enabled_flag && inter_affine_flag==1 && [0323] (MvdCpL0[x0][y0][0][0]!=0.parallel. [0324] MvdCpL0[x0][y0][0][1]!=0.parallel. [0325] MvdCpL1[x0][y0][0][0]!=0.parallel. [0326] MvdCpL1[x0][y0][0][1]!=0.parallel.)
[0327] Alternatively, conditionsA is defined as follows: [0328] (sps_affine_amvr_enabled_flag && inter_affine_flag==1 && [0329] (MvdCpLX[x0][y0][0][0]!=0.parallel. [0330] MvdCpLX[x0][y0][0][1]!=0)
[0331] wherein X is being 0 or 1.
[0332] Alternatively, conditionsA is defined as follows: [0333] (sps_affine_amvr_enabled_flag && inter_affine_flag==1) [0334] In one example, conditionsB is defined as follows: [0335] !sps_cpr_enabled_flag.parallel.!(inter_pred_idc[x0][y0]==PRED_L0 && [0336] ref_idx_l0[x0][y0]==num_ref_idx_l0 active_minus1)
[0337] Alternatively, conditionsB is defined as follows: [0338] !sps_cpr_enabled_flag.parallel.!(pred_mode[x0][y0]==CPR).
[0339] Alternatively, conditionsB is defined as follows: [0340] !sps_ibc_enabled_flag.parallel. !(pred_mode[x0][y0]==IBC). When different syntax elements are utilized to code AMVR or Affine AMVR, the context modeling and/or contexts used for the embodiments in 5.5 which are applied to Affine AMVR may be applied accordingly.
5.2.5. Semantics
[0341] amvr_flag[x0][y0] specifies the resolution of motion vector difference. The array indices x0, y0 specify the location (x0, y0) of the top-left luma sample of the considered coding block relative to the top-left luma sample of the picture. amvr_flag[x0][y0] equal to 0 specifies that the resolution of the motion vector difference is 1/4 of a luma sample. amvr_flag[x0][y0] equal to 1 specifies that the resolution of the motion vector difference is further specified by amvr_coarse_precisoin_flag[x0][y0]. When amvr_flag[x0][y0] is not present, it is inferred as follows: [0342] If sps_cpr_enabled_flag is equal to 1, amvr_flag[x0][y0] is inferred to be equal to 1. [0343] Otherwise (sps_cpr_enabled_flag is equal to 0), amvr_flag[x0][y0] is inferred to be equal to 0. amvr_coarse_precisoin_flag[x0][y0] equal to 1 specifies that the resolution of the motion vector difference is four luma samples when inter_affine_flag is equal to 0, and 1 luma samples when inter_affine_flag is equal to 1. The array indices x0, y0 specify the location (x0, y0) of the top-left luma sample of the considered coding block relative to the top-left luma sample of the picture. When amvr_coarse_precisoin_flag[x0][y0] is not present, it is inferred to be equal to 0. If inter_affine_flag[x0][y0] is equal to 0, the variable MvShift is set equal to (amvr_flag[x0][y0]+amvr_coarse_precisoin_flag[x0][y0])<<1 and the variables MvdL0[x0][y0][0], MvdL0[x0][y0][1], MvdL1[x0][y0][0], MvdL1[x0][y0][1] are modified as follows:
[0343] MvdL0[x0][y0][0]=MvdL0[x0][y0][0]<<(MvShift+2) (7-70)
MvdL0[x0][y0][1]=MvdL0[x0][y0][1]<<(MvShift+2) (7-71)
MvdL1[x0][y0][0]=MvdL1[x0][y0][0]<<(MvShift+2) (7-72)
MvdL1[x0][y0][1]=MvdL1[x0][y0][1]<<(MvShift+2) (7-73)
If inter_affine_flag[x0][y0] is equal to 1, the variable MvShift is set equal to (amvr_coarse_precisoin_flag? (amvr_coarse_precisoin_flag<<1):(-(amvr_flag<<1))) and the variables MvdCpL0[x0][y0][0][0], MvdCpL0[x0][y0][0][1], MvdCpL0[x0][y0][1][0], MvdCpL0[x0][y0][1][1], MvdCpL0[x0][y0][2][0], MvdCpL0[x0][y0][2][1] are modified as follows:
MvdCpL0[x0][y0][0][0]=MvdCpL0[x0][y0][0][0]<<(MvShift+2) (7-73)
MvdCpL1[x0][y0][0][1]=MvdCpL1[x0][y0][0][1]<<(MvShift+2) (7-67)
MvdCpL0[x0][y0][1][0]=MvdCpL0[x0][y0][1][0]<<(MvShift+2) (7-66)
MvdCpL1[x0][y0][1][1]=MvdCpL1[x0][y0][1][1]<<(MvShift+2) (7-67)
MvdCpL0[x0][y0][2][0]=MvdCpL0[x0][y0][2][0]<<(MvShift+2) (7-66)
MvdCpL1[x0][y0][2][1]=MvdCpL1[x0][y0][2][1]<<(MvShift+2) (7-67)
[0344] Alternatively, if inter_affine_flag[x0][y0] is equal to 1, the variable MvShift is set equal to (affine_amvr_coarse_precisoin_flag? (affine_amvr_coarse_precisoin_flag<<1):(-(affine_amvr_flag<<1- ))).
5.3. Rounding Process for Motion Vectors
[0345] The rounding process is modified that when the given rightShift value is equal to 0 (which happens for 1/16-pel precision), the rounding offset is set to 0 instead of (1<<(rightShift-1)).
[0346] For example, the sub-clause of rounding process for MVs is modified as follows:
[0347] Inputs to this process are: [0348] the motion vector mvX, [0349] the right shift parameter rightShift for rounding, [0350] the left shift parameter leftShift for resolution increase.
[0351] Output of this process is the rounded motion vector mvX.
[0352] For the rounding of mvX, the following applies:
offset=(rightShift==0)?0:(1<<(rightShift-1)) (8-371)
mvX[0]=(mvX[0]>=0?(mvX[0]+offset)>>rightShift:-((-mvX[0]+offset- )>>rightShift))<<leftShift (8-372)
mvX[1]=(mvX[1]>=0?(mvX[1]+offset)>>rightShift:-((-mvX[1]+offset- )>>rightShift))<<leftShift (8-373)
5.4. Decoding Process
[0353] The rounding process invoked in the affine motion vector derivation process are performed with the input of (MvShift+2) instead of being fixed to be 2.
Derivation Process for Luma Affine Control Point Motion Vector Predictors
[0354] Inputs to this process are: [0355] a luma location (xCb, yCb) of the top-left sample of the current luma coding block relative to the top-left luma sample of the current picture, [0356] two variables cbWidth and cbHeight specifying the width and the height of the current luma coding block, [0357] the reference index of the current coding unit refIdxLX, with X being 0 or 1, [0358] the number of control point motion vectors numCpMv.
[0359] Output of this process are the luma affine control point motion vector predictors mvpCpLX[cpIdx] with X being 0 or 1, and cpIdx=0 . . . numCpMv-1.
[0360] For the derivation of the control point motion vectors predictor candidate list, cpMvpListLX with X being 0 or 1, the following ordered steps apply:
[0361] The number of control point motion vector predictor candidates in the list numCpMvpCandLX is set equal to 0.
[0362] The variables availableFlagA and availableFlagB are both set equal to FALSE.
[0363] . . . .
[0364] The rounding process for motion vectors as specified in clause 8.4.2.14 is invoked with mvX set equal to cpMvpLX[cpIdx], rightShift set equal to (MvShift+2), and leftShift set equal to (MvShift+2) as inputs and the rounded cpMvpLX[cpIdx] with cpIdx=0 . . . numCpMv-1 as output.
[0365] . . . .
[0366] The variable availableFlagA is set equal to TRUE
[0367] The derivation process for luma affine control point motion vectors from a neighbouring block as specified in clause 8.4.4.5 is invoked with the luma coding block location (xCb, yCb), the luma coding block width and height (cbWidth, cbHeight), the neighbouring luma coding block location (xNb, yNb), the neighbouring luma coding block width and height (nbW, nbH), and the number of control point motion vectors numCpMv as input, the control point motion vector predictor candidates cpMvpLY[cpIdx] with cpIdx=0 . . . numCpMv-1 as output.
[0368] The rounding process for motion vectors as specified in clause 8.4.2.14 is invoked with mvX set equal to cpMvpLY[cpIdx], rightShift set equal to (MvShift+2), and leftShift set equal to (MvShift+2) as inputs and the rounded cpMvpLY[cpIdx] with cpIdx=0 . . . numCpMv-1 as output.
[0369] . . . .
[0370] The derivation process for luma affine control point motion vectors from a neighbouring block as specified in clause 8.4.4.5 is invoked with the luma coding block location (xCb, yCb), the luma coding block width and height (cbWidth, cbHeight), the neighbouring luma coding block location (xNb, yNb), the neighbouring luma coding block width and height (nbW, nbH), and the number of control point motion vectors numCpMv as input, the control point motion vector predictor candidates cpMvpLX[cpIdx] with cpIdx=0 . . . numCpMv-1 as output.
[0371] The rounding process for motion vectors as specified in clause 8.4.2.14 is invoked with mvX set equal to cpMvpLX[cpIdx], rightShift set equal to (MvShift+2), and leftShift set equal to (MvShift+2) as inputs and the rounded cpMvpLX[cpIdx] with cpIdx=0 . . . numCpMv-1 as output.
[0372] The following assignments are made:
cpMvpListLX[numCpMvpCandLX][0]=cpMvpLX[0] (8-618)
cpMvpListLX[numCpMvpCandLX][1]=cpMvpLX[1] (8-619)
cpMvpListLX[numCpMvpCandLX][2]=cpMvpLX[2] (8-620)
numCpMvpCandLX=numCpMvpCandLX+1 (8-621)
Otherwise if PredFlagLY[xNbBk][yNbBk] (with Y=!X) is equal to 1 and DiffPicOrderCnt(RefPicListY[RefIdxLY[xNbBk][yNbBk]], RefPicListX[refIdxLX]) is equal to 0, the following applies:
[0373] The variable availableFlagB is set equal to TRUE
[0374] The derivation process for luma affine control point motion vectors from a neighbouring block as specified in clause 8.4.4.5 is invoked with the luma coding block location (xCb, yCb), the luma coding block width and height (cbWidth, cbHeight), the neighbouring luma coding block location (xNb, yNb), the neighbouring luma coding block width and height (nbW, nbH), and the number of control point motion vectors numCpMv as input, the control point motion vector predictor candidates cpMvpLY[cpIdx] with cpIdx=0 . . . numCpMv-1 as output.
[0375] The rounding process for motion vectors as specified in clause 8.4.2.14 is invoked with mvX set equal to cpMvpLY[cpIdx], rightShift set equal to (MvShift+2), and leftShift set equal to (MvShift+2) as inputs and the rounded cpMvpLY[cpIdx] with cpIdx=0 . . . numCpMv-1 as output.
[0376] The following assignments are made:
cpMvpListLX[numCpMvpCandLX][0]=cpMvpLY[0] (8-622)
cpMvpListLX[numCpMvpCandLX][1]=cpMvpLY[1] (8-623)
cpMvpListLX[numCpMvpCandLX][2]=cpMvpLY[2] (8-624)
numCpMvpCandLX=numCpMvpCandLX+1 (8-625)
[0377] When numCpMvpCandLX is less than 2, the following applies
[0378] The derivation process for constructed affine control point motion vector prediction candidate as specified in clause 8.4.4.8 is invoked with the luma coding block location (xCb, yCb), the luma coding block width cbWidth, the luma coding block height cbHeight, and the reference index of the current coding unit refIdxLX as inputs, and the availability flag availableConsFlagLX, the availability flags availableFlagLX[cpIdx] and cpMvpLX[cpIdx] with cpIdx=0 . . . numCpMv-1 as outputs.
[0379] When availableConsFlagLX is equal to 1, and numCpMvpCandLX is equal to 0, the following assignments are made:
cpMvpListLX[numCpMvpCandLX][0]=cpMvpLX[0] (8-626)
cpMvpListLX[numCpMvpCandLX][1]=cpMvpLX[1] (8-627)
cpMvpListLX[numCpMvpCandLX][2]=cpMvpLX[2] (8-628)
numCpMvpCandLX=numCpMvpCandLX+1 (8-629)
[0380] The following applies for cpIdx=0 . . . numCpMv-1:
[0381] When numCpMvpCandLX is less than 2 and availableFlagLX[cpIdx] is equal to 1, the following assignments are made:
cpMvpListLX[numCpMvpCandLX][0]=cpMvpLX[cpIdx] (8-630)
cpMvpListLX[numCpMvpCandLX][1]=cpMvpLX[cpIdx](8-631)
cpMvpListLX[numCpMvpCandLX][2]=cpMvpLX[cpIdx] (8-632)
numCpMvpCandLX=numCpMvpCandLX+1 (8-633)
When numCpMvpCandLX is less than 2, the following applies:
[0382] The derivation process for temporal luma motion vector prediction as specified in clause 8.4.2.11 is with the luma coding block location (xCb, yCb), the luma coding block width cbWidth, the luma coding block height cbHeight and refIdxLX as inputs, and with the output being the availability flag availableFlagLXCol and the temporal motion vector predictor mvLXCol.
[0383] When availableFlagLXCol is equal to 1, the following applies:
[0384] The rounding process for motion vectors as specified in clause 8.4.2.14 is invoked the with mvX set equal to mvLXCol, rightShift set equal to (MvShift+2), and leftShift set equal to (MvShift+2) as inputs and the rounded mvLXCol as output.
[0385] The following assignments are made:
cpMvpListLX[numCpMvpCandLX][0]=mvLXCol (8-634)
cpMvpListLX[numCpMvpCandLX][1]=mvLXCol (8-635)
cpMvpListLX[numCpMvpCandLX][2]=mvLXCol (8-636)
numCpMvpCandLX=numCpMvpCandLX+1 (8-637)
[0386] When numCpMvpCandLX is less than 2, the following is repeated until numCpMvpCandLX is equal to 2, with mvZero[0] and mvZero[1] both being equal to 0:
cpMvpListLX[numCpMvpCandLX][0]=mvZero (8-638)
cpMvpListLX[numCpMvpCandLX][1]=mvZero (8-639)
cpMvpListLX[numCpMvpCandLX][2]=mvZero (8-640)
numCpMvpCandLX=numCpMvpCandLX+1 (8-641)
[0387] The affine control point motion vector predictor cpMvpLX with X being 0 or 1 is derived as follows:
cpMvpLX=cpMvpListLX[mvp_1X_flag[xCb][yCb]] (8-642)
Derivation Process for Constructed Affine Control Point Motion Vector Prediction Candidates
[0388] Inputs to this process are: [0389] a luma location (xCb, yCb) specifying the top-left sample of the current luma coding block relative to the top-left luma sample of the current picture, [0390] two variables cbWidth and cbHeight specifying the width and the height of the current luma coding block, [0391] the reference index of the current prediction unit partition refIdxLX, with X being 0 or 1,
[0392] Output of this process are: [0393] the availability flag of the constructed affine control point motion vector prediction candidiates availableConsFlagLX with X being 0 or 1, [0394] the availability flags availableFlagLX[cpIdx] with cpIdx=0 . . . 2 and X being 0 or 1, [0395] the constructed affine control point motion vector prediction candidiates cpMvLX[cpIdx] with cpIdx=0 . . . numCpMv-1 and X being 0 or 1.
[0396] The first (top-left) control point motion vector cpMvLX[0] and the availability flag availableFlagLX[0] are derived in the following ordered steps:
[0397] The sample locations (xNbB2, yNbB2), (xNbB3, yNbB3) and (xNbA2, yNbA2) are set equal to (xCb-1, yCb-1), (xCb, yCb-1) and (xCb-1, yCb), respectively.
[0398] The availability flag availableFlagLX[0] is set equal to 0 and both components of cpMvLX[0] are set equal to 0.
[0399] The following applies for (xNbTL, yNbTL) withTL being replaced by B2, B3, and A2:
[0400] The availability derivation process for a coding block as specified in clause is invoked with the luma coding block location (xCb, yCb), the luma coding block width cbWidth, the luma coding block height cbHeight, the luma location (xNbY, yNbY) set equal to (xNbTL, yNbTL) as inputs, and the output is assigned to the coding block availability flag availableTL.
[0401] When availableTL is equal to TRUE and availableFlagLX[0] is equal to 0, the following applies:
[0402] If PredFlagLX[xNbTL][yNbTL] is equal to 1, and DiffPicOrderCnt(RefPicListX[RefIdxLX[xNbTL][yNbTL]], RefPicListX[refIdxLX]) is equal to 0, and the reference picture corresponding to RefIdxLX[xNbTL][yNbTL] is not the current picture, availableFlagLX[0] is set equal to 1 and the following assignments are made:
cpMvLX[0]=MvLX[xNbTL][yNbTL] (8-643)
[0403] Otherwise, when PredFlagLY[xNbTL][yNbTL] (with Y=!X) is equal to 1 and DiffPicOrderCnt(RefPicListY[RefIdxLY[xNbTL][yNbTL]], RefPicListX[refIdxLX]) is equal to 0, and the reference picture corresponding to RefIdxLY[xNbTL][yNbTL] is not the current picture, availableFlagLX[0] is set equal to 1 and the following assignments are made:
cpMvLX[0]=MvLY[xNbTL][yNbTL] (8-644)
[0404] When availableFlagLX[0] is equal to 1, the rounding process for motion vectors as specified in clause 8.4.2.14 is invoked with mvX set equal to cpMvLX[0], rightShift set equal to (MvShift+2), and leftShift set equal to (MvShift+2) as inputs and the rounded cpMvLX[0] as output.
[0405] The second (top-right) control point motion vector cpMvLX[1] and the availability flag availableFlagLX[1] are derived in the following ordered steps:
[0406] The sample locations (xNbB1, yNbB1) and (xNbB0, yNbB0) are set equal to (xCb+cbWidth-1, yCb-1) and (xCb+cbWidth, yCb-1), respectively.
[0407] The availability flag availableFlagLX[1] is set equal to 0 and both components of cpMvLX[1] are set equal to 0.
[0408] The following applies for (xNbTR, yNbTR) withTR being replaced by B1 and B0:
[0409] The availability derivation process for a coding block as specified in clause 6.4.X is invoked with the luma coding block location (xCb, yCb), the luma coding block width cbWidth, the luma coding block height cbHeight, the luma location (xNbY, yNbY) set equal to (xNbTR, yNbTR) as inputs, and the output is assigned to the coding block availability flag availableTR.
[0410] When availableTR is equal to TRUE and availableFlagLX[1] is equal to 0, the following applies:
[0411] If PredFlagLX[xNbTR][yNbTR] is equal to 1, and DiffPicOrderCnt(RefPicListX[RefIdxLX[xNbTR][yNbTR]], RefPicListX[refIdxLX]) is equal to 0, and the reference picture corresponding to RefIdxLX[xNbTR][yNbTR] is not the current picture, availableFlagLX[1] is set equal to 1 and the following assignments are made:
cpMvLX[1]=MvLX[xNbTR][yNbTR] (8-645)
[0412] Otherwise, when PredFlagLY[xNbTR][yNbTR] (with Y=!X) is equal to 1 and DiffPicOrderCnt(RefPicListY[RefIdxLY[xNbTR][yNbTR]], RefPicListX[refIdxLX]) is equal to 0, and the reference picture corresponding to RefIdxLY[xNbTR][yNbTR] is not the current picture, availableFlagLX[1] is set equal to 1 and the following assignments are made:
cpMvLX[1]=MvLY[xNbTR][yNbTR] (8-646)
[0413] When availableFlagLX[1] is equal to 1, the rounding process for motion vectors as specified in clause 8.4.2.14 is invoked with mvX set equal to cpMvLX[1], rightShift set equal to (MvShift+2), and leftShift set equal to (MvShift+2) as inputs and the rounded cpMvLX[1] as output.
[0414] The third (bottom-left) control point motion vector cpMvLX[2] and the availability flag availableFlagLX[2] are derived in the following ordered steps:
[0415] The sample locations (xNbA1, yNbA1) and (xNbA0, yNbA0) are set equal to (xCb-1, yCb+cbHeight-1) and (xCb-1, yCb+cbHeight), respectively.
[0416] The availability flag availableFlagLX[2] is set equal to 0 and both components of cpMvLX[2] are set equal to 0.
[0417] The following applies for (xNbBL, yNbBL) with BL being replaced by A1 and A0:
[0418] The availability derivation process for a coding block as specified in clause 6.4.X invoked with the luma coding block location (xCb, yCb), the luma coding block width cbWidth, the luma coding block height cbHeight, the luma location (xNbY, yNbY) set equal to (xNbBL, yNbBL) as inputs, and the output is assigned to the coding block availability flag availableBL.
[0419] When availableBL is equal to TRUE and availableFlagLX[2] is equal to 0, the following applies:
[0420] If PredFlagLX[xNbBL][yNbBL] is equal to 1, and DiffPicOrderCnt(RefPicListX[RefIdxLX[xNbBL][yNbBL]], RefPicListX[refIdxLX]) is equal to 0, and the reference picture corresponding to RefIdxLY[xNbBL][yNbBL] is not the current picture, availableFlagLX[2] is set equal to 1 and the following assignments are made:
cpMvLX[2]=MvLX[xNbBL][yNbBL] (8-647)
[0421] Otherwise, when PredFlagLY[xNbBL][yNbBL] (with Y=!X) is equal to 1 and DiffPicOrderCnt(RefPicListY[RefIdxLY[xNbBL][yNbBL]], RefPicListX[refIdxLX]) is equal to 0, and the reference picture corresponding to RefIdxLY[xNbBL][yNbBL] is not the current picture, availableFlagLX[2] is set equal to 1 and the following assignments are made:
cpMvLX[2]=MvLY[xNbBL][yNbBL] (8-648)
[0422] When availableFlagLX[2] is equal to 1, the rounding process for motion vectors as specified in clause 8.4.2.14 is invoked with mvX set equal to cpMvLX[2], rightShift set equal to (MvShift+2), and leftShift set equal to (MvShift+2) as inputs and the rounded cpMvLX[2] as output.
5.5. Context Modeling
[0423] Assignment of ctxInc to syntax elements with context coded bins:
TABLE-US-00012 binIdx Syntax element 0 1 2 3 4 >=5 amvr_flag[ ][ ] 0, 1, 2 na na na na na (clause 9.5.4.2.2, when inter_affine_flag[ ][ ] is equal to 0) amvr_coarse_precisoin_flag[ ][ ] 0 na na na na na
[0424] Specification of ctxInc using left and above syntax elements:
[0425] In one example, context increasement offset ctxInc=(condL && availableL)+(condA && availableA)+ctxSetIdx*3.
[0426] Alternatively, ctxInc=((condL && availableL) II (condA && availableA))+ctxSetIdx*3.
ctxInc=(condL && availableL)+M*(condA && availableA)+ctxSetIdx*3. (e.g., M=2)
ctxInc=M*(condL && availableL)+(condA && availableA)+ctxSetIdx*3. (e.g., M=2)
TABLE-US-00013 Syntax element condL condA ctxSetIdx e cu_skip_flag[ xNbL ][ yNbL ] cu_skip_flag[ xNbA ][ yNbA ] 0 e !inter_affine_flag[ x0 ][ y0 ] !inter_affine_flag[ x0 ][ y0 ] 0 && && amvr_flag[ xNbL ][ yNbL ] amvr_flag[ xNbA ][ yNbA ]
[0427] Values of initValue for ctxIdx of amvr_flag:
[0428] Different contexts are used when current block is affine or non-affine.
TABLE-US-00014 ctxIdx of amvr_flag when ctxIdx of amvr_flag when Initialization inter_affine_flag is equal to 0 inter_affine_flag is equal to 1 variable 0 1 2 3 initValue xx xx xx xx
[0429] Values of initValue for ctxIdx of amvr_coarse_precisoin_flag:
[0430] Different contexts are used when current block is affine or non-affine.
TABLE-US-00015 ctxIdx of amvr_coarse_precisoin_flag ctxIdx of amvr_coarse_precisoin_flag when Initialization when inter_affine_flag is equal to 0 inter_affine_flag is equal to 1 variable 0 0 initValue xxx xx
[0431] The examples described above may be incorporated in the context of the method described below, e.g., methods 2610 to 2680, which may be implemented at a video decoder or a video encoder.
[0432] FIG. 26A shows a flowchart of an exemplary method for video processing. The method 2610 includes, at step 2610, determining, for a conversion between a coded representation of a current block of a video and the current block, a motion vector difference (MVD) precision to be used for the conversion from a set of allowed multiple MVD precisions applicable to a video region containing the current video block. The method 2610 includes, at step 2614, performing the conversion based on the MVD precision.
[0433] FIG. 26B shows a flowchart of an exemplary method for video processing. The method 2610 as shown in FIG. 26B includes, at step 2612, determining, for a video region comprising one or more video blocks of a video and a coded representation of the video, a usage of multiple motion vector difference (MVD) precisions for the conversion of the one or more video blocks in the video region. The method 2610 includes, at step 2614, performing the conversion based on the determination.
[0434] FIG. 26C shows a flowchart of an exemplary method for video processing. The method 2620 as shown in FIG. 26C includes, at step 2622, determining, for a video region comprising one or more video blocks of a video and a coded representation of the video, whether to apply an adaptive motion vector resolution (AMVR) process to a current video block for a conversion between the current video block and the coded representation of the video. The method 2620 includes, at step 2624, performing the conversion based on the determining.
[0435] FIG. 26D shows a flowchart of an exemplary method for video processing. The method 2630 as shown in FIG. 26D includes, at step 2632, determining, for a video region comprising one or more video blocks of a video and a coded representation of the video, how to apply an adaptive motion vector resolution (AMVR) process to a current video block for a conversion between the current video block and the coded representation of the video. The method 2630 includes, at step 2634, performing the conversion based on the determining.
[0436] FIG. 26E shows a flowchart of an exemplary method for video processing. The method 2640 as shown in FIG. 26E includes, at step 2642, determining, based on a coding mode of a parent coding unit of a current coding unit that uses an affine coding mode or a rate-distortion (RD) cost of the affine coding mode, a usage of an adaptive motion vector resolution (AMVR) for a conversion between a coded representation of a current block of a video and the current block. The method 2640 includes, at step 2644, performing, the conversion according to a result of the determining.
[0437] FIG. 26F shows a flowchart of an exemplary method for video processing. The method 2650 as shown in FIG. 26F includes, at step 2652, determining a usage of an adaptive motion vector resolution (AMVR) for a conversion between a coded representation of a current block of a video and the current block that uses an advanced motion vector prediction (AMVP) coding mode, the determining based on a rate-distortion (RD) cost of the AMVP coding mode. The method 2650 includes, at step 2654, performing, the conversion according to a result of the determining.
[0438] FIG. 26G shows a flowchart of an exemplary method for video processing. The method 2660 as shown in FIG. 26G includes, at step 2662, generating, for a conversion between a coded representation of a current block of a video and the current block, a set of MV (Motion Vector) precisions using a 4-parameter affine model or 6-parameter affine model. The method 2660 includes, at step 2664, performing, the conversion based on the set of MV precisions.
[0439] FIG. 26H shows a flowchart of an exemplary method for video processing. The method 2670 as shown in FIG. 26H includes, at step 2672, determining, based on a coding mode of a parent block of a current block that uses an affine coding mode, whether an adaptive motion vector resolution (AMVR) tool is used for a conversion, wherein the AMVR tool is used to refine motion vector resolution during decoding. The method 2670 includes, at step 2674, performing the conversion according to a result of the determining.
[0440] FIG. 26I shows a flowchart of an exemplary method for video processing. The method 2680 as shown in FIG. 26I includes, at step 2682, determining, based on a usage of MV precisions for previous blocks that has been previously coded using an affine coding mode, a termination of a rate-distortion (RD) calculations of MV precisions for a current block that uses the affine coding mode for a conversion between a coded representation of the current block and the current block. The method 2680 includes, at step 2684, performing the conversion according to a result of the determining.
5. EXAMPLE IMPLEMENTATIONS OF THE DISCLOSED TECHNOLOGY
[0441] FIG. 27 is an example of a block diagram of a video processing apparatus 2700. The apparatus 2700 may be used to implement one or more of the methods described herein. The apparatus 2700 may be embodied in a smartphone, tablet, computer, Internet of Things (IoT) receiver, and so on. The apparatus 2700 may include one or more processors 2702, one or more memories 2704 and video processing hardware 2706. The processor(s) 2702 may be configured to implement one or more methods (including, but not limited to, methods 2610 to 2680) described in the present document. The memory (memories) 2704 may be used for storing data and code used for implementing the methods and techniques described herein. The video processing hardware 2706 may be used to implement, in hardware circuitry, some techniques described in the present document.
[0442] FIG. 29 is another example of a block diagram of a video processing system in which disclosed techniques may be implemented. FIG. 29 is a block diagram showing an example video processing system 2900 in which various techniques disclosed herein may be implemented. Various implementations may include some or all of the components of the system 2900. The system 2900 may include input 2902 for receiving video content. The video content may be received in a raw or uncompressed format, e.g., 8 or 10 bit multi-component pixel values, or may be in a compressed or encoded format. The input 2902 may represent a network interface, a peripheral bus interface, or a storage interface. Examples of network interface include wired interfaces such as Ethernet, passive optical network (PON), etc. and wireless interfaces such as Wi-Fi or cellular interfaces.
[0443] The system 2900 may include a coding component 2904 that may implement the various coding or encoding methods described in the present document. The coding component 2904 may reduce the average bitrate of video from the input 2902 to the output of the coding component 2904 to produce a coded representation of the video. The coding techniques are therefore sometimes called video compression or video transcoding techniques. The output of the coding component 2904 may be either stored, or transmitted via a communication connected, as represented by the component 2906. The stored or communicated bitstream (or coded) representation of the video received at the input 2902 may be used by the component 2908 for generating pixel values or displayable video that is sent to a display interface 2910. The process of generating user-viewable video from the bitstream representation is sometimes called video decompression. Furthermore, while certain video processing operations are referred to as "coding" operations or tools, it will be appreciated that the coding tools or operations are used at an encoder and corresponding decoding tools or operations that reverse the results of the coding will be performed by a decoder.
[0444] Examples of a peripheral bus interface or a display interface may include universal serial bus (USB) or high definition multimedia interface (HDMI) or Displayport, and so on. Examples of storage interfaces include SATA (serial advanced technology attachment), PCI, IDE interface, and the like. The techniques described in the present document may be embodied in various electronic devices such as mobile phones, laptops, smartphones or other devices that are capable of performing digital data processing and/or video display.
[0445] In some embodiments, the video processing methods may be implemented using an apparatus that is implemented on a hardware platform as described with respect to FIG. 27 or 29.
[0446] Various techniques and embodiments may be described using the following clause-based format. These clauses may be implemented as preferred features of some embodiments.
[0447] The first set of clauses use some of the techniques described in the previous section, including, for example, items 1, 2, and 13-15 in the previous section.
[0448] 1. A method of video processing, comprising: determining, for a conversion between a coded representation of a current block of a video and the current block, a motion vector difference (MVD) precision to be used for the conversion from a set of allowed multiple MVD precisions applicable to a video region containing the current video block; and performing the conversion based on the MVD precision.
[0449] 2. The method of clause 1, wherein the set of allowed multiple MVD precisions depends on a picture, a slice, or a block of the video data.
[0450] 3. The method of clause 1, wherein the set of allowed multiple MVD precisions depends on coded information of the current block.
[0451] 4. The method of clause 1, wherein the set of allowed multiple MVD precisions is pre-defined.
[0452] 5. The method of clause 1, wherein the set of allowed multiple MVD precisions is signaled in a Sequence Parameter Set (SPS), a Picture Parameter Set (PPS), a Video Parameter Set (VPS), a sequence header, a picture header, a slice header, a group of coding tree unit s (CTUs).
[0453] 6. The method of clause 1, further comprising signaling a determined MVD precision from the set of allowed multiple MVD precision based on a number of allowed MV precisions for the current block.
[0454] 7. The method of clause 1, wherein the determining of the MVD precision is based on one or more syntax elements, and wherein the current block is coded using an affine mode.
[0455] 8. The method of clause 3 or 7, wherein same syntax elements are used to indicate the determined MVD precision from the set of allowed multiple MVD precisions applied to both the affine mode and a non-affine mode.
[0456] 9. The method of clause 3, 7, or 8, wherein when the affine mode and the non-affine mode use a same set of the allowed multiple MVD precisions.
[0457] 10. The method of clause 3, 7, or 8, wherein the affine coded blocks use a different set of the allowed multiple MVD precisions from that used in a non-affine mode.
[0458] 11. The method of clause 10, wherein the different set having a same number of the allowed multiple MVD precisions as that used in the non-affine mode, the syntax elements used in the non-affine mode are reused in the affine mode.
[0459] 12. The method of clause 10, wherein the different set has at least one MVD precision that is different from that used in the non-affine mode.
[0460] 13. The method of clause 3, 7, or 8, wherein semantics of syntax elements used in the non-affine mode and the affine mode are different and the syntax elements have a same decoded value interpreted to different MVD precisions.
[0461] 14. The method of clause 3, 7, or 8, wherein a number of the allowed multiple MVD precisions used in the affine mode is less than that used in a non-affine mode.
[0462] 15. The method of clause 8, wherein one or more subsets of the syntax values for the non-affine mode are not valid in the affine mode.
[0463] 16. The method of claim 8 or 14, wherein semantics of syntax elements used in the non-affine mode and the affine mode are different and the syntax elements with same value is interpreted to different MVD precisions.
[0464] 17. The method of clause 3 or 7, wherein a number of the allowed multiple MVD precisions used in the affine mode is more than that used in a non-affine mode
[0465] 18. The method of clause 17, wherein one or more syntax elements in the non-affine mode are extended to allow more values for the affine mode.
[0466] 19. The method of clause 7, wherein an additional syntax element is used for processing the MVD precision of the affine mode, the additional syntax element being different from that used for processing the MVD precision of a non-affine mode.
[0467] 20. The method of clause 7, wherein indication of the MVD precision for the affine mode is selectively signaled.
[0468] 21. The method of clause 20, wherein indication of the MVD precision for the affine mode is signaled when MVDs for all control point motion vectors (CPMVs) are non-zero.
[0469] 22. The method of clause 20, wherein indication of the MVD precision for the affine mode is signaled when MVDs for at least one CPMV is non-zero.
[0470] 23. The method of clause 20, wherein indication of the MVD precision for the affine mode is signaled when MVD of one selected CPMV is non-zero.
[0471] 24. The method of clause 20, wherein indication of the MVD precision for the affine mode is signaled when MVD of a first CPMV is non-zero.
[0472] 25. The method of clause 20, wherein indication of the MVD precision for the affine mode is not signaled when one or more predetermined conditions are not satisfied.
[0473] 26. The method of clause 7, wherein a syntax element for MVD precision indications associated with either the affine mode or a non-affine mode is coded with contexts that are dependent on coded information of the current block.
[0474] 27. The method of clause 7, wherein a context selection of the syntax element for MVD precision indications associated with either the affine mode or a non-affine mode is dependent on whether the current block is coded with affine mode or not.
[0475] 28. The method of clause 7, wherein one context is used for the syntax element for MVD precision indications for an affine coded block and another context is used for a non-affine coded block.
[0476] 29. The method of clause 7, wherein a context for MVD precision indications is determined based on a size, shape, or MVD precisions of neighboring blocks, a temporal layer index, or prediction directions.
[0477] 30. The method of clause 7, wherein whether to enable or disable a usage of the allowed multiple MVD precisions for the affine mode is signaled in a sequence parameter set (SPS), a picture parameter set (PPS), a video parameter set (VPS), a sequence header, a picture header, a slice header, or a group of coding tree units (CTUs).
[0478] 31. The method of clause 7, wherein whether to enable or disable a usage of the allowed multiple MVD precisions for the affine mode depends on the one or more syntax elements.
[0479] 32. The method of clause 7, wherein information whether to enable or disable a usage of the allowed multiple MVD precisions is signaled upon an enablement of the affine mode and is not signaled upon a disablement of the affine mode.
[0480] 33. The method of any of clauses 7 to 32, wherein the one or more syntax elements are included at a slice level, a picture level, or sequence level.
[0481] 34. The method of clause 5, 30, or 33, wherein the slice is replaced with a tile group or tile.
[0482] 35. The method of any of clauses 1 to 34, wherein, in a VPS, SPS, PPS, slice header, or tile group header, a syntax element equal to 1 specifies a requirement to conform the coded representation, the requirement requiring that both of a first syntax element to indicate whether a first set of multiple MVD precisions is enabled for a non-affine mode and a second syntax element to indicate whether a second set of multiple MVD precisions is enabled for the affine-mode are 0.
[0483] 36. The method of any of clauses 1 to 34, wherein a syntax element is signaled in a VPS, SPS, PPS, slice header, tile group header, or other video data units,
[0484] 37. The method of clause 36, wherein the syntax element equal to 1 specifies a requirement to conform the coded representation, the requirement requiring that the syntax element to indicate whether multiple MVD precisions is enabled for the affine mode is equal to 0.
[0485] 38. The method of any of clauses 7 to 37, wherein a motion vector predictor is utilized in a same MVD precision for affine coded blocks.
[0486] 39. The method of any of clauses 7 to 37, wherein a final motion vector of the current block is utilized in a same MVD precision for affine coded blocks.
[0487] 40. The method of any of clauses 1 to 39, wherein the performing of the conversion includes generating the coded representation from the current block.
[0488] 41. The method of any of clauses 1 to 39, wherein the performing of the conversion includes generating the current block from the coded representation.
[0489] 42. An apparatus in a video system comprising a processor and a non-transitory memory with instructions thereon, wherein the instructions upon execution by the processor, cause the processor to implement the method in any one of clauses 1 to 41.
[0490] 43. A computer program product stored on a non-transitory computer readable media, the computer program product including program code for carrying out the method in any one of clauses 1 to 41.
[0491] The second set of clauses use some of the techniques described in the previous section, including, for example, items 3, 4, and 12 in the previous section.
[0492] 1. A method of video processing, comprising: determining, for a video region comprising one or more video blocks of a video and a coded representation of the video, a usage of multiple motion vector difference (MVD) precisions for the conversion of the one or more video blocks in the video region; and performing the conversion based on the determining.
[0493] 2. The method of clause 1, wherein the conversion of at least some of the one or more video blocks is based on affine mode coding.
[0494] 3. The method of clause 1 or 2, wherein the usage is indicated in the coded representation including a Sequence Parameter Set (SPS), a Picture Parameter Set (PPS), a Video Parameter Set (VPS), a sequence header, a picture header, a slice header, or a group of coding tree units (CTUs)
[0495] 4. The method of clause 3, wherein the usage is indicated depending on a syntax element used to indicate the MVD precisions.
[0496] 5. A method of video processing, comprising: determining, for a video region comprising one or more video blocks of a video and a coded representation of the video, whether to apply an adaptive motion vector resolution (AMVR) process to a current video block for a conversion between the current video block and the coded representation of the video; and performing the conversion based on the determining.
[0497] 6. A method of video processing, comprising: determining, for a video region comprising one or more video blocks of a video and a coded representation of the video, how to apply an adaptive motion vector resolution (AMVR) process to a current video block for a conversion between the current video block and the coded representation of the video; and performing the conversion based on the determining.
[0498] 7. The method of clause 5 or 6, wherein the conversion of the current video block is based on affine mode coding.
[0499] 8. The method of clause 7, wherein the determining depends on a reference picture of the current video block.
[0500] 9. The method of clause 8, wherein, in a case that the reference picture is a current picture, the determining determines not to apply the AMVR process.
[0501] 10. The method of clause 5 or 6, wherein the determining depends on whether an intra block copying (IBC) is applied to the current block or not.
[0502] 11. The method of clause 10, wherein the determining determines to apply the AMVR process to the current block coded by the IBC.
[0503] 12. the method of clause 11, wherein candidate MV (motion vector), MVD, or MVP (motion vector prediction) precisions for IBC coded blocks are different from those used for another video block not coded by the IBC.
[0504] 13. the method of clause 11, wherein candidate MV (motion vector), MVD, or MVP (motion vector prediction) precisions for IBC coded blocks are different from those used for another video block coded with affine mode.
[0505] 14. The method of any of clauses 1 to 13, wherein the performing of the conversion includes generating the coded representation from the current block.
[0506] 15. The method of any of clauses 1 to 13, wherein the performing of the conversion includes generating the current block from the coded representation.
[0507] 16. An apparatus in a video system comprising a processor and a non-transitory memory with instructions thereon, wherein the instructions upon execution by the processor, cause the processor to implement the method in any one of clauses 1 to 15.
[0508] 17. A computer program product stored on a non-transitory computer readable media, the computer program product including program code for carrying out the method in any one of clauses 1 to 15.
[0509] The third set of clauses use some of the techniques described in the previous section, including, for example, items 5-10 and 13 in the previous section.
[0510] 1. A method of video processing, comprising: determining, based on a coding mode of a parent coding unit of a current coding unit that uses an affine coding mode or a rate-distortion (RD) cost of the affine coding mode, a usage of an adaptive motion vector resolution (AMVR) for a conversion between a coded representation of a current block of a video and the current block; and performing the conversion according to a result of the determining.
[0511] 2. The method of clause 1, wherein, in case that the coding mode of the parent coding unit is not AF_Inter mode or AF_MERGE mode, then the determining disables the usage of the AMVR for the current coding unit.
[0512] 3. The method of clause 1, wherein, in case that the coding mode of the parent coding unit is not AF_Inter mode, then the determining disables the usage of the AMVR for the current coding unit.
[0513] 4. The method of clause 1, wherein, in case that the RD of the affine coding mode is greater than a multiplication of a positive threshold and an RD cost of an advanced motion vector prediction (AMVP) mode, then the determining disables the usage of the AMVR for the current coding unit.
[0514] 5. The method of clause 4, wherein the determination is applied for 1/4-pel MV precision.
[0515] 6. The method of clause 1, wherein, in case that a minimum RD cost is greater than a multiplication of a positive threshold and an RD cost of a merge mode, then the determining disables the usage of the AMVR for the current coding unit, wherein the minimum RD cost is a minimum of the RD cost of the affine coding mode and an RD cost of an advanced motion vector prediction (AMVP) mode.
[0516] 7. The method of clause 6, wherein the determination is applied for 1/4-pel MV precision.
[0517] 8. A method of video processing, comprising: determining a usage of an adaptive motion vector resolution (AMVR) for a conversion between a coded representation of a current block of a video and the current block that uses an advanced motion vector prediction (AMVP) coding mode, the determining based on a rate-distortion (RD) cost of the AMVP coding mode; and performing the conversion according to a result of the determining.
[0518] 9. The method of clause 8, wherein, in case that the RD cost of the AMVP coding mode is greater than a multiplication of a positive threshold and an RD cost of an affine mode, the determining disables the usage of the AMVR.
[0519] 10. The method of clause 8, wherein the determination is applied for 1/4-pel MV precision.
[0520] 11. The method of clause 8, wherein, in case that a minimum RD cost is greater than a multiplication of a positive threshold and an RD cost of a merge mode, the determining disables the usage of the AMVR, and wherein the minimum RD cost is a minimum of an RD cost of an affine mode and an RD cost of the AMVP coding mode.
[0521] 12. The method of clause 11, wherein the determination is applied for 1/4-pel MV precision.
[0522] 13. A method of video processing, comprising: generating, for a conversion between a coded representation of a current block of a video and the current block, a set of MV (Motion Vector) precisions using a 4-parameter affine model or 6-parameter affine model; and performing the conversion based on the set of MV precisions.
[0523] 14. The method of clause 13, wherein the 4-parameter affine model or the 6-parameter affine model obtained in a single MV precision is used as a candidate start search point for other MV precisions.
[0524] 15. The method of clause 14, wherein the single MV precision comprises 1/16 MV accuracy.
[0525] 16. The method of clause 14, wherein the single MV precision comprises 1/4 MV accuracy.
[0526] 17. A method of video processing, comprising: determining, based on a coding mode of a parent block of a current block that uses an affine coding mode, whether an adaptive motion vector resolution (AMVR) tool is used for a conversion, wherein the AMVR tool is used to refine motion vector resolution during decoding; and performing the conversion according to a result of the determining.
[0527] 18. The method of clause 17, wherein, in case that the parent block of the current block is not the affine coding mode, the determining causes not to check the AMVR for the current block.
[0528] 19. A method of video processing, comprising: determining, based on a usage of MV precisions for previous blocks that has been previously coded using an affine coding mode, a termination of a rate-distortion (RD) calculations of MV precisions for a current block that uses the affine coding mode for a conversion between a coded representation of the current block and the current block; and performing the conversion according to a result of the determining.
[0529] 20. The method of clause 19, wherein the current block and the previous blocks are included in a current image segment and a previous image segment, respectively, and the current image segment and the previous image segments are pictures, slices, tiles, or CTU (Coding Tree Unit) rows.
[0530] 21. The method of any of clauses 1 to 20, wherein the performing of the conversion includes generating the coded representation from the current block.
[0531] 22. The method of any of clauses 1 to 20, wherein the performing of the conversion includes generating the current block from the coded representation.
[0532] 23. An apparatus in a video system comprising a processor and a non-transitory memory with instructions thereon, wherein the instructions upon execution by the processor, cause the processor to implement the method in any one of clauses 1 to 22.
[0533] 24. A computer program product stored on a non-transitory computer readable media, the computer program product including program code for carrying out the method in any one of claims 1 to 22.
[0534] From the foregoing, it will be appreciated that specific embodiments of the presently disclosed technology have been described herein for purposes of illustration, but that various modifications may be made without deviating from the scope of the invention. Accordingly, the presently disclosed technology is not limited except as by the appended claims.
[0535] Implementations of the subject matter and the functional operations described in this patent document can be implemented in various systems, digital electronic circuitry, or in computer software, firmware, or hardware, including the structures disclosed in this specification and their structural equivalents, or in combinations of one or more of them. Implementations of the subject matter described in this specification can be implemented as one or more computer program products, i.e., one or more modules of computer program instructions encoded on a tangible and non-transitory computer readable medium for execution by, or to control the operation of, data processing apparatus. The computer readable medium can be a machine-readable storage device, a machine-readable storage substrate, a memory device, a composition of matter effecting a machine-readable propagated signal, or a combination of one or more of them. The term "data processing unit" or "data processing apparatus" encompasses all apparatus, devices, and machines for processing data, including by way of example a programmable processor, a computer, or multiple processors or computers. The apparatus can include, in addition to hardware, code that creates an execution environment for the computer program in question, e.g., code that constitutes processor firmware, a protocol stack, a database management system, an operating system, or a combination of one or more of them.
[0536] A computer program (also known as a program, software, software application, script, or code) can be written in any form of programming language, including compiled or interpreted languages, and it can be deployed in any form, including as a stand-alone program or as a module, component, subroutine, or other unit suitable for use in a computing environment. A computer program does not necessarily correspond to a file in a file system. A program can be stored in a portion of a file that holds other programs or data (e.g., one or more scripts stored in a markup language document), in a single file dedicated to the program in question, or in multiple coordinated files (e.g., files that store one or more modules, sub programs, or portions of code). A computer program can be deployed to be executed on one computer or on multiple computers that are located at one site or distributed across multiple sites and interconnected by a communication network.
[0537] The processes and logic flows described in this specification can be performed by one or more programmable processors executing one or more computer programs to perform functions by operating on input data and generating output. The processes and logic flows can also be performed by, and apparatus can also be implemented as, special purpose logic circuitry, e.g., an FPGA (field programmable gate array) or an ASIC (application specific integrated circuit).
[0538] Processors suitable for the execution of a computer program include, by way of example, both general and special purpose microprocessors, and any one or more processors of any kind of digital computer. Generally, a processor will receive instructions and data from a read only memory or a random access memory or both. The essential elements of a computer are a processor for performing instructions and one or more memory devices for storing instructions and data. Generally, a computer will also include, or be operatively coupled to receive data from or transfer data to, or both, one or more mass storage devices for storing data, e.g., magnetic, magneto optical disks, or optical disks. However, a computer need not have such devices. Computer readable media suitable for storing computer program instructions and data include all forms of nonvolatile memory, media and memory devices, including by way of example semiconductor memory devices, e.g., EPROM, EEPROM, and flash memory devices. The processor and the memory can be supplemented by, or incorporated in, special purpose logic circuitry.
[0539] It is intended that the specification, together with the drawings, be considered exemplary only, where exemplary means an example. As used herein, the use of "or" is intended to include "and/or", unless the context clearly indicates otherwise.
[0540] While this patent document contains many specifics, these should not be construed as limitations on the scope of any invention or of what may be claimed, but rather as descriptions of features that may be specific to particular embodiments of particular inventions. Certain features that are described in this patent document in the context of separate embodiments can also be implemented in combination in a single embodiment. Conversely, various features that are described in the context of a single embodiment can also be implemented in multiple embodiments separately or in any suitable subcombination. Moreover, although features may be described above as acting in certain combinations and even initially claimed as such, one or more features from a claimed combination can in some cases be excised from the combination, and the claimed combination may be directed to a subcombination or variation of a subcombination.
[0541] Similarly, while operations are depicted in the drawings in a particular order, this should not be understood as requiring that such operations be performed in the particular order shown or in sequential order, or that all illustrated operations be performed, to achieve desirable results. Moreover, the separation of various system components in the embodiments described in this patent document should not be understood as requiring such separation in all embodiments.
[0542] Only a few implementations and examples are described and other implementations, enhancements and variations can be made based on what is described and illustrated in this patent document.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012

D00013

D00014

D00015

D00016
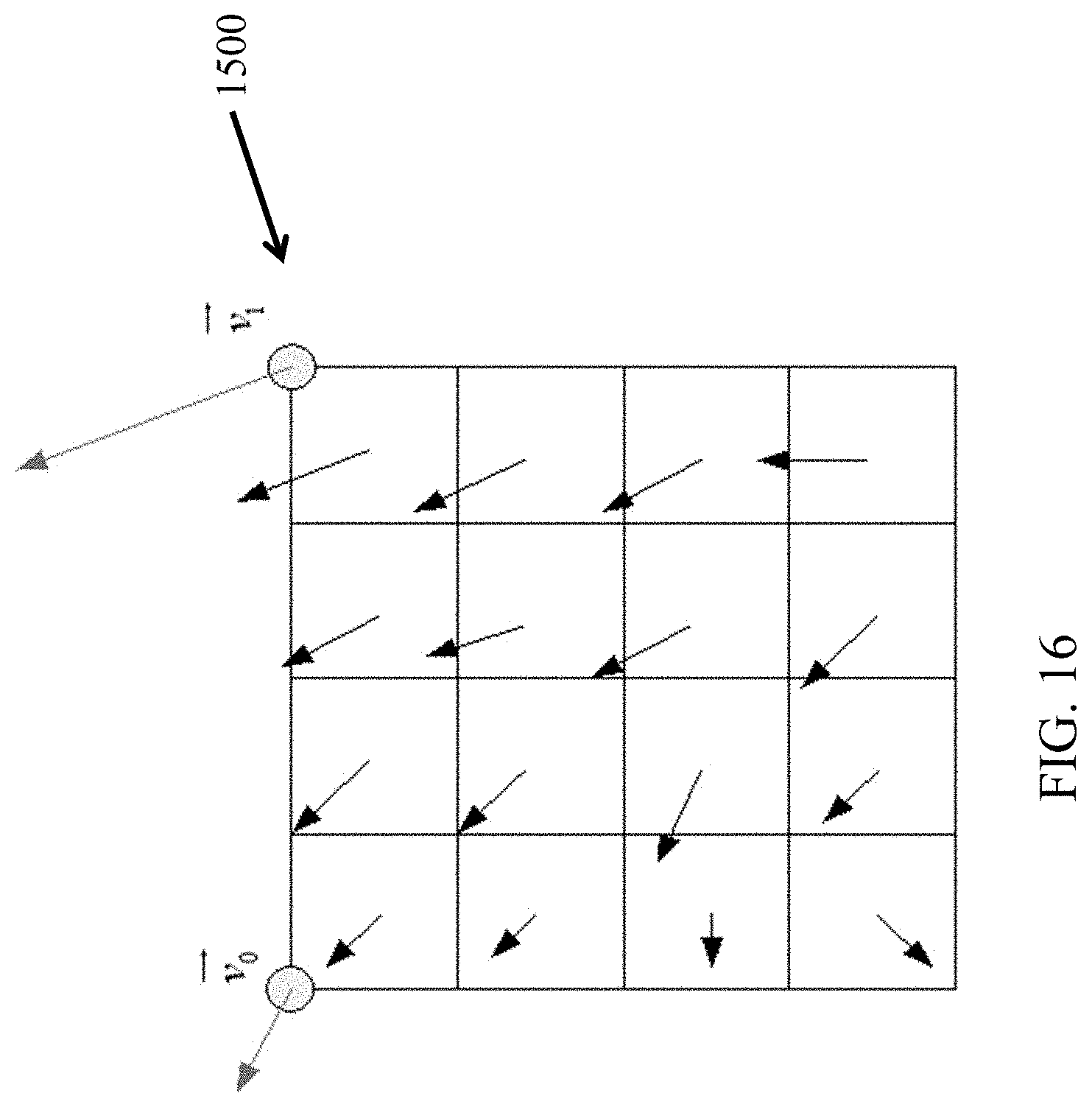
D00017

D00018

D00019

D00020

D00021

D00022

D00023

D00024

D00025

D00026

D00027

D00028

D00029

D00030

D00031

D00032

D00033

D00034

D00035

D00036

D00037














XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.