Document Processing System And Method
Eveland; Christopher K. ; et al.
U.S. patent application number 16/750904 was filed with the patent office on 2020-05-21 for document processing system and method. This patent application is currently assigned to ISQFT, INC.. The applicant listed for this patent is ISQFT, INC.. Invention is credited to John W. Caven, III, Christopher K. Eveland, Robert B. Menzel.
| Application Number | 20200159985 16/750904 |
| Document ID | / |
| Family ID | 53838465 |
| Filed Date | 2020-05-21 |








View All Diagrams
| United States Patent Application | 20200159985 |
| Kind Code | A1 |
| Eveland; Christopher K. ; et al. | May 21, 2020 |
DOCUMENT PROCESSING SYSTEM AND METHOD
Abstract
A computer-implemented method comprises storing a plurality of construction project specification documents in a data storage system. The method further comprises, for each of the plurality of construction project specification documents, extracting a plurality of blocks of text from the document, extracting formatting information for the document based on the extracted text blocks, generating a location descriptor for each of the text blocks based on the formatting information, the location descriptor indicating the location of the text block within the document, determining the type of text contained in each of the text blocks, and storing the location descriptor and the type of text contained in the text block for each of the text blocks.
| Inventors: | Eveland; Christopher K.; (Wyoming, OH) ; Caven, III; John W.; (Jacksonville, FL) ; Menzel; Robert B.; (Jacksonville, FL) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assignee: | ISQFT, INC. Cincinnati OH |
||||||||||
| Family ID: | 53838465 | ||||||||||
| Appl. No.: | 16/750904 | ||||||||||
| Filed: | January 23, 2020 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 13327648 | Dec 15, 2011 | |||
| 16750904 | ||||
| 61527581 | Aug 25, 2011 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06F 16/447 20190101; G06Q 50/08 20130101; G06F 16/29 20190101; G06F 16/438 20190101; G06F 16/93 20190101; G06F 16/254 20190101; G06F 40/295 20200101; G06F 16/248 20190101; G06F 40/103 20200101; G06F 16/444 20190101; G06F 3/0482 20130101 |
| International Class: | G06F 40/103 20060101 G06F040/103; G06F 40/295 20060101 G06F040/295; G06F 16/93 20060101 G06F016/93; G06F 16/25 20060101 G06F016/25; G06Q 50/08 20060101 G06Q050/08 |
Claims
1.-18. (canceled)
19. A system for efficiently managing a database of construction project specification documents, the system comprising: the database having a plurality of construction project specification documents stored therein, wherein the construction project specification documents are formatted to have a predefined uniform organizational structure, the predefined uniform organizational structure defining different parts of the construction project specification documents according to a specific standard for organizing construction specification documents; memory; a processor; a machine-readable storage medium having a program of instructions thereon, wherein, for each of the plurality of construction project specification documents, the program of instructions, when executed by the processor, causes the system to: extract a plurality of blocks of text from each construction project specification document, extract formatting information for each construction project specification document based on the extracted text blocks, generate a location descriptor for each of the text blocks based on the formatting information, the location descriptor indicating the location of the text block within each construction project specification document, the location descriptor including an indication of a specific part of the different parts of a given construction project specification document of the plurality of construction project specification documents, wherein to generate the location descriptor, the program of instructions utilizes the predefined uniform organizational structure of the plurality of construction project specification documents according to the specific standard for organizing construction specification documents and a sequential offset, determine a type of text contained in each of the text blocks, recognize a plurality of entities contained in the plurality of blocks of text, and store, for each of the text blocks, the location descriptor and the type of text contained in the text block in the database; and generate a plurality of relatedness scores by comparing each of the plurality of entities against each of the remaining plurality of entities, each of the plurality of relatedness scores corresponding to each pair of compared entities, each of the plurality of relatedness scores based on a likelihood of the compared entities appearing in a common block of text, and store each relatedness score in the database; and, the system further including a named entity recognition system configured to perform entity identification and entity extraction, the named entity recognition system identifies entities as one of a plurality of different types of entities, the plurality of different types of entities including named entities, structure indicating entities, and relationship indicating entities.
20. A system as defined in claim 19, wherein, to extract the plurality of blocks of text from the document, the program of instructions dissects pages of the document into the text blocks based on headings, subheadings, and indenting within the document.
21. A system as defined in claim 19, wherein the specific standard for organizing construction specification documents is a MasterFormat standard.
22. A system as defined in claim 21, wherein the location descriptor includes a hierarchical descriptor generated based on the predefined uniform organizational structure of the plurality of construction project specification documents, and wherein the hierarchical descriptor reflects the location of the text block by indicating a division of the predefined uniform organizational structure and a code of the predefined uniform organizational structure.
23. A system as defined in claim 19, wherein the program of instructions is further configured to identify construction project specification documents that satisfy search criteria received from a user; and wherein the system further comprises user interface logic configured to generate a user interface, the user interface logic configured to generate a plurality of charts for display to the user, wherein the user can interact with the charts to specify modified search criteria, and wherein the user interface logic is configured to receive modified search criteria from the user via one of the charts and update the remaining charts to reflect the modified search criteria.
24. A system as defined in claim 23, wherein the plurality of charts include a timeline reflecting the number of construction project specification documents that satisfy the search criteria as a function of time.
25. A system as defined in claim 23, wherein the plurality of charts include a map reflecting the number of construction project specification documents that satisfy the search criteria as a function of geographic region.
26. A system as defined in claim 23, wherein the plurality of charts include a chart reflecting the number of construction project specification documents associated with projects that are at a specified stage of completion.
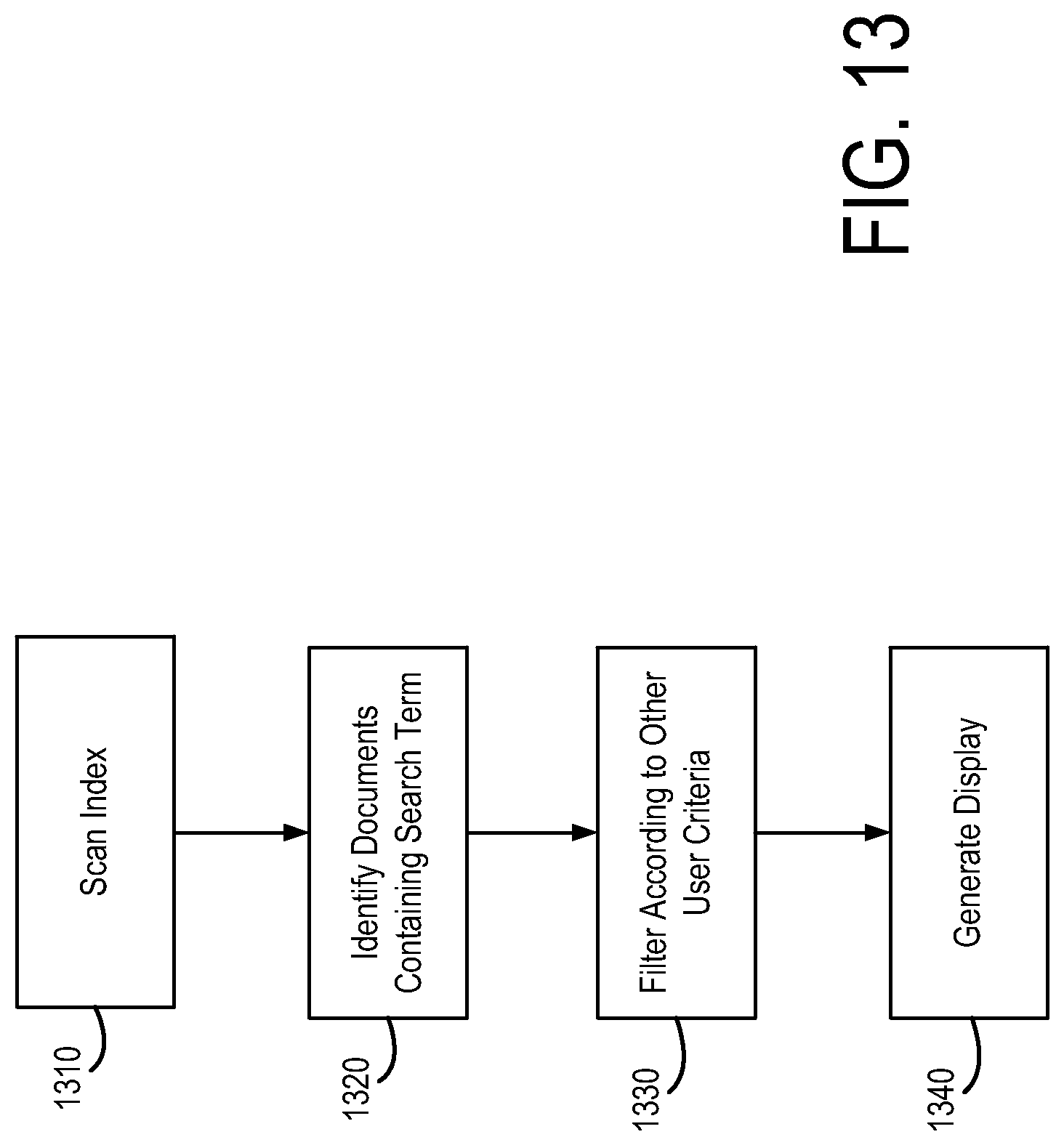
27. A computer-implemented method for efficiently managing a database of construction project specification documents, the method comprising: storing a plurality of construction project specification documents in the database, wherein the construction project specification documents are formatted to have a predefined uniform organizational structure, the predefined uniform organizational structure defining different parts of the construction project specification documents according to a specific standard for organizing construction project specification documents; for each of the plurality of construction project specification documents: extracting a plurality of blocks of text from the documents, extracting formatting information for the documents based on the extracted text blocks, generating a location descriptor for each of the text blocks based on the formatting information, the location descriptor indicating the location of the text block within the documents, the location descriptor including an indication of a specific part of the different parts of a given construction project specification document of the plurality of construction project specification documents, wherein the predefined uniform organizational structure of the plurality of construction project specification documents according to the specific standard for organizing construction specification documents and a sequential offset are utilized to generate the location descriptor, determining a type of text contained in each of the text blocks, recognizing a plurality of entities contained in the plurality of blocks of text, via a named entity recognition system configured to perform entity identification and entity extraction, the named entity recognition system identifies entities as one of a plurality of different types of entities, the plurality of different types of entities including named entities, structure indicating entities, and relationship indicating entities, and storing, for each of the text blocks, the location descriptor and the type of text contained in the text block in the database; generate a plurality of relatedness scores by comparing each of the plurality of entities against each of the remaining plurality of entities, each of the plurality of relatedness scores corresponding to each pair of compared entities, each of the plurality of relatedness scores based on a likelihood of the compared entities appearing in a common block of text; and store each relatedness score in the database.
28. A method as defined in claim 27, wherein extracting the plurality of blocks of text comprises dissecting pages of the document into the text blocks based on headings, subheadings, and indenting within the document.
29. A method as defined in claim 27, wherein the location descriptor includes a hierarchical descriptor generated based on the predefined uniform organizational structure of the construction project specification documents, and wherein the hierarchical descriptor reflects the location of the text block by indicating a division of the predefined uniform organizational structure and a code of the predefined uniform organizational structure.
30. A method as defined in claim 27, wherein the system is further configured to identify documents that satisfy search criteria received from a user; and wherein the system further comprises user interface logic configured to generate a user interface, the user interface logic configured to generate a plurality of charts for display to the user, wherein the user can interact with the charts to specify modified search criteria, and wherein the user interface logic is configured to receive modified search criteria from the user via one of the charts and update the remaining charts to reflect the modified search criteria.
31. A computer-implemented method for efficiently managing a database of construction project specification documents, the method comprising: storing a plurality of construction project specification documents in the database, wherein the construction project specification documents are formatted to have a predefined uniform organizational structure, the predefined uniform organizational structure defining different parts of the construction project specification documents according to a specific standard for organizing construction project specification documents; for each of the plurality of construction project specification documents: extracting a plurality of blocks of text from the documents, extracting formatting information for the documents based on the extracted text blocks, generating a location descriptor for each of the text blocks based on the formatting information, the location descriptor indicating the location of the text block within the documents, the location descriptor including an indication of a specific part of the different parts of a given construction project specification document of the plurality of construction project specification documents, wherein the predefined uniform organizational structure of the plurality of construction project specification documents according to the specific standard for organizing construction specification documents and a sequential offset are utilized to generate the location descriptor, determining a type of text contained in each of the text blocks, and storing, for each of the text blocks, the location descriptor and the type of text contained in the text block, recognizing a plurality of entities contained in the plurality of blocks of text, via a named entity recognition system configured to perform entity identification and entity extraction, the named entity recognition system identifies entities as one of a plurality of different types of entities, the plurality of different types of entities including named entities, structure indicating entities, and relationship indicating entities; generate a plurality of relatedness scores by comparing each of the plurality of entities against each of the remaining plurality of entities, each of the plurality of relatedness scores corresponding to each pair of compared entities, each of the plurality of relatedness scores based on a likelihood of the compared entities appearing in a common block of text; receiving a search query comprising search criteria from a user electronically via a graphical user interface; analyzing the construction project specification documents to determine a number of documents that satisfy the search criteria; and responsive to the search query, generating a display reflecting data regarding the number of documents that satisfy the search criteria.
32. The system as defined in claim 19, wherein the named entities includes product names, company names, cities, states, standards or personal names.
33. The system as defined in claim 19, wherein the structure indicating entities includes words or phrases indicating document structure.
Description
CROSS-REFERENCE
[0001] This application is a continuation of U.S. patent application Ser. No. 13/327,648, filed on Dec. 15, 2011, which claims priority to U.S. Provisional Patent Application No. 61/527,581, filed Aug. 25, 2011, the contents of which are incorporated herein by reference in its entirety.
BACKGROUND
[0002] It is sometimes desirable to process and analyze large volumes of documents. As an illustrative example, construction projects are typically described by plans and specifications (herein, "spec documents"). While the plans give a visual representation of the project, the spec documents give all of the details in textual form. A typical spec document is approximately 500 pages in length and covers everything from the bidding procedures that contractors or subcontractors are to follow before being selected, through the types of products, materials, and methods used during construction, to how the site will be cleaned up when completed. Such comprehensive information about active and planned projects makes these spec documents a valuable source of marketing intelligence and sales leads for businesses serving the construction industry.
[0003] As a result, various publication services exist that collect plans and spec documents from various sources. To the extent necessary, the publishers may also digitize hard copies and process them with optical character recognition (OCR) software. Some publishers also annotate the spec documents at a project level with metadata (such as the estimated size and cost of the project, key contacts, the type of construction, and so on). Finally, the publishers aggregate the spec documents in a database and disseminate subsets of the spec documents to subscribers. The subscribers to such services may be, for example, building products manufacturers that use the spec documents for marketing intelligence and sales leads.
[0004] Because a national feed from one of the larger publishers is approximately fifty million pages per year, this is too much information for a single person (or even a reasonably sized team) to analyze to find actionable information or to synthesize new information. The problem is further compounded for manufacturers that subscribe to feeds from more than one publisher.
[0005] Various attempts have been made to process spec documents in a computer-assisted fashion. One technique that has been employed is to use text search with the documents and provide a user with a list of documents that match. For example, a user may be interested in searching for a cleaning product named "409". In basic searching systems, documents containing any copy of those 3 numbers will be returned to the user as matches, although many of those matches will not be for the cleaning product. In places it may be a page number, a section number, an area code in southeast Texas, or other unrelated reference. In an attempt to alleviate this problem, some systems have been built that use a hand labeled table of contents to allow for searches to be limited to specific sections of documents.
[0006] While existing systems for processing and analyzing large volumes of documents have proved useful, further enhancements are needed.
SUMMARY
[0007] According to an example embodiment, a system comprises a data storage system and an indexing and annotation engine. The indexing and annotation engine is configured to perform various operations for each of a plurality of documents stored in the data storage system. Specifically, the indexing and annotation engine is configured to extract a plurality of blocks of text from the document, extract formatting information for the document based on the extracted text blocks, generate a location descriptor for each of the text blocks based on the formatting information, the location descriptor indicating the location of the text block within the document, determine the type of text contained in each of the text blocks, and store the location descriptor and the type of text contained in the text block for each of the text blocks.
[0008] According to another example embodiment, a computer-implemented method comprises storing a plurality of construction project specification documents in a data storage system. The method further comprises, for each of the plurality of construction project specification documents, extracting a plurality of blocks of text from the document, extracting formatting information for the document based on the extracted text blocks, generating a location descriptor for each of the text blocks based on the formatting information, the location descriptor indicating the location of the text block within the document, determining the type of text contained in each of the text blocks, and storing the location descriptor and the type of text contained in the text block for each of the text blocks.
BRIEF DESCRIPTION OF THE DRAWINGS
[0009] FIG. 1 shows a computer system for processing documents according to an example embodiment.
[0010] FIGS. 2-9 show an example of a user interface that may be provided by the system of FIG. 1 according to an example embodiment.
[0011] FIGS. 10A-10B show the operation of an indexing and annotation engine of FIG. 1 according to an example embodiment.
[0012] FIGS. 11A-11B and 12A-12B show an example of a page that may be processed by an indexing and annotation engine of FIG. 1 according to an example embodiment.
[0013] FIG. 13 shows a flowchart showing generation of a screen display using indexing and annotation according to an example embodiment.
[0014] FIG. 14 shows operation of a relatedness engine of FIG. 1 according to an example embodiment.
DETAILED DESCRIPTION OF EXAMPLE EMBODIMENTS
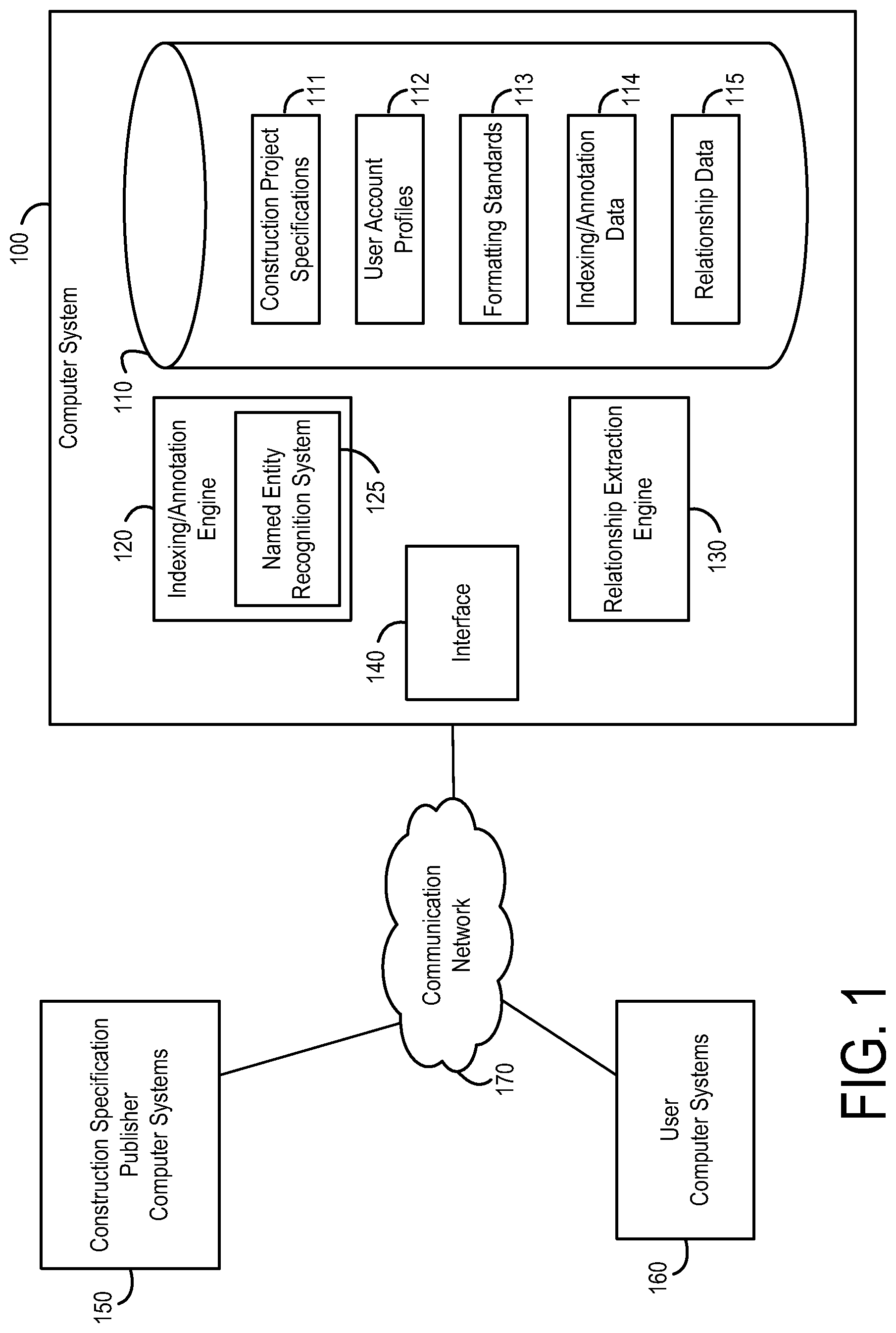
[0015] Referring now to FIG. 1, FIG. 1 shows a computer system 100 for processing documents, such as large volumes of unstructured or weakly structured documents according to an example embodiment. System 100 enhances the ability to search within the documents and also synthesizes information about the relationships between entities mentioned in the documents.
[0016] As shown in FIG. 1, the computer system 100 comprises a data storage system 110, an indexing and annotation engine 120, a relationship extraction engine 130 and an interface 140. The data storage system stores construction project specifications 111 which are received as input from computer system(s) 150 of one or more publishers of construction specifications. User account profile information 112 may be stored which indicates which users are licensed to access which standards. The documents may be digital text (e.g. in ASCII format), formatted text (e.g. PDF or Microsoft Word documents), or physical paper documents. The documents may be of any length and may be unstructured beyond the conventions of written text (i.e. words, sentences, paragraphs, sections, chapters, etc.).
[0017] In an example embodiment, the documents in the data storage system 110 may be loosely structured to the extent that content in the documents follows a predefined uniform organizational structure. The predefined uniform organizational structure need not dictate all organization structure of the content in the documents, however, it may provide a level of uniformity at least at a high level. For example, if the documents are books, the books may have a predefined uniform organizational structure if each of the books uses a uniform table of contents that specifies parts of the book, chapters within each part, and headings within each chapter. The predefined uniform organizational structure need not dictate all organization structure of the content in the books, in as much as there may be further subheadings and content within each heading the structure of which is not defined by the predefined uniform organizational structure. Additionally, the uniform organizational structure may be violated according to the author's preference or custom. For example, some authors may intentionally violate the uniform organizational structure in situations where the uniform organizational structure does not provide what the author considers to be an optimal structure for the document being authored (e.g., is considered incomplete in some respect). Assuming a uniform table of contents is used, then text found under a particular heading of a particular chapter of a particular part of the book will relate to the same topic, regardless which book in which the text is located. Information 113 regarding the predefined uniform organizational structure may be stored in the data storage system 110, either explicitly or implicitly (e.g., via the manner in which the indexing/annotation engine 114 is configured to operate).
[0018] In an example embodiment, the documents are spec documents relating to the construction industry, and the predefined uniform organizational structure is the Construction Specifications Institute (CSI) MasterFormat standard, which is a standard for organizing spec documents and other written information for commercial and institutional building projects. MasterFormat provides a master list of divisions, and section numbers and titles within each division, to follow in organizing information about a facility's construction requirements and associated activities. Each division contains a number of sections. Each section is divided into three parts--"general," "products," and "execution." Each part is organized by a standardized system of articles and paragraphs. The division and section within a spec document where a particular piece of text is located is indicative of the subject matter of the pertinent text. For example, text found in Division 09, Section 3000 of a spec document that follows the MasterFormat standard relates to tiling. As indicated above, the uniform organizational structure may sometimes be violated according to the author's preference or custom. In the case of the MasterFormat standard, for example, some authors may add divisions or CSI codes if their application is not covered in the official MasterFormat.
[0019] The data storage system 110 also stores indexing and annotation data 114 and relationship data 115 generated by the indexing and annotation engine 120 and the relationship extraction engine 130, respectively. As described in greater detail below, the indexing and annotation engine 120 takes the spec documents as input, processes their natural structure, and identifies named entities and other phrases of interest. The output of the indexing and annotation engine 120 includes a list of entities (words and multi-word phrases), paired with location information. "Words" in this context refers to strings of characters within the document separated by white-space or punctuation. Each such entity is additionally paired with its type (e.g., one of company-name, product-name, place, heading, etc.). The location information includes the document, page number, section number (which may be assigned sequentially in the event that the source document does not have numbered sections), and so on. The output of the indexing and annotation engine 120 (i.e., the indexing and annotation data 114) is stored in the data storage system 110. Further details regarding the indexing and annotation engine 120 are discussed below in connection with FIGS. 10A-10B, 11A-11B, and 12A-12B.
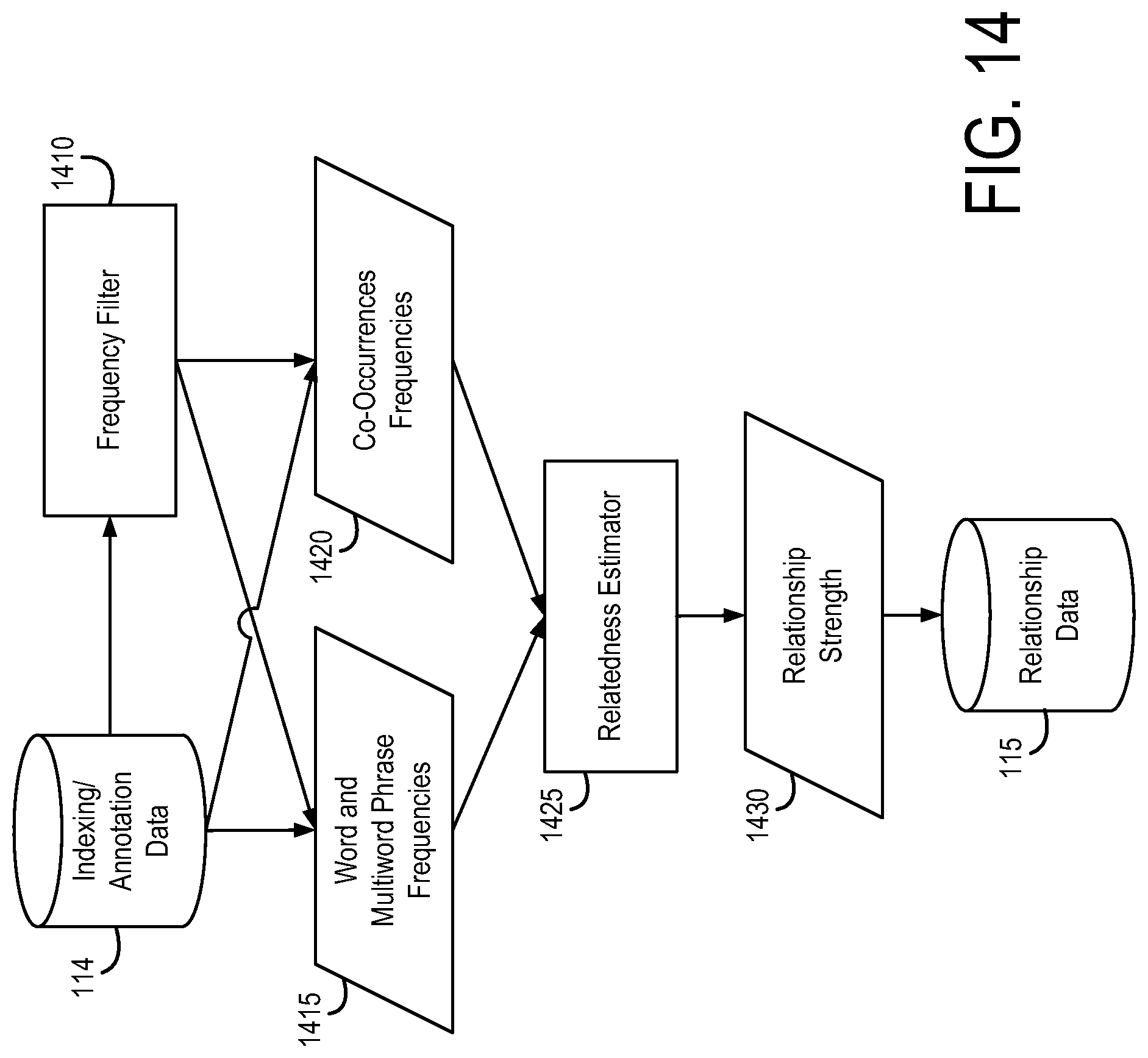
[0020] The relationship extraction engine 130 reads rows from the database and uses them to infer relationships between entities. As described in greater detail below, the relationship extraction engine 130 scans blocks of rows from the output generated by the indexing and annotation engine 120 and uses statistical methods to assign a score indicating the strength of the relationship between two words or entities. For example, Dupont and Tyvek may have a high score because Tyvek is a product sold by Dupont. Conversely, Tyvek and Formula 409 may have a low score, because one is a weather barrier and the other is a cleaning product. This process is performed for all combinations (possible pairs) of entities in the indexing and annotation data 114. These scores may be either requested directly by a user interface, or processed and stored for later access as relationship data 115 in the data storage system 110. Further details regarding the relationship extraction engine 130 are discussed below in connection with FIG. 14.
[0021] The stored indexing and annotation data 114 and the stored relationship data 115 enables the system 100 to provide context sensitive searching for entities (words and multiword phrases) and to provide information regarding relationships between entities. Such information may be made available to users using computing systems 160. For example, interface 140 may provide a web interface that is accessible to via a global communication network 170 (e.g., the Internet). This approach scales well and can be applied to all documents, even in large volumes.
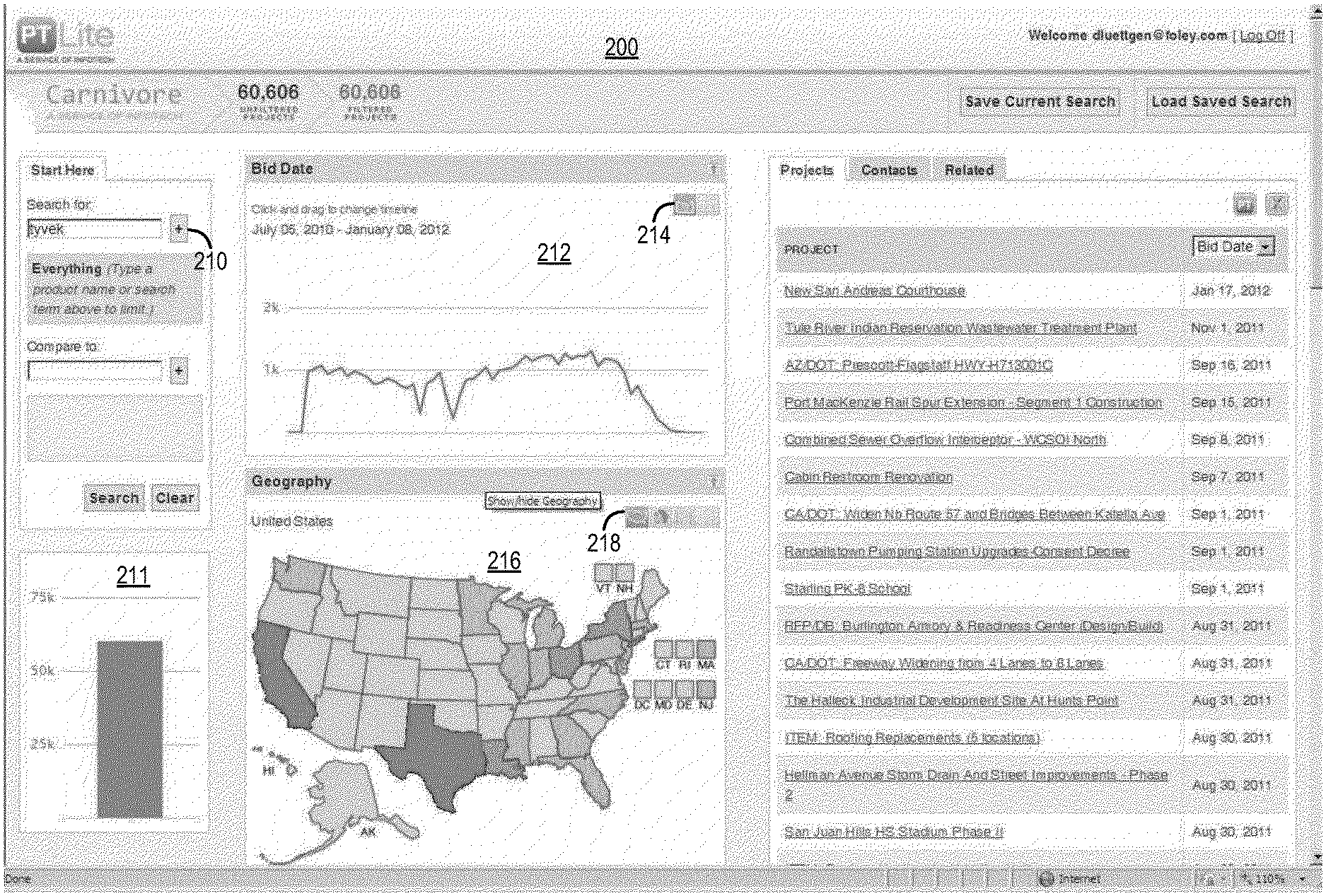
[0022] Referring now to FIGS. 2-9, an example of a user interface that may be provided by the interface 140 is shown according to an example embodiment. Referring first to FIG. 2, FIG. 2 shows a screen display 200 in which a user has entered query ("Tyvek") in a search query field 210. In response, the interface 140 has provided the user (via the screen display 200) with various information regarding the use of the Tyvek product in the construction industry (i.e., as reflected in spec documents). In field 211, a bar graph is shown reflecting the total number of times the term "Tyvek" appears in spec documents stored in data storage system 110. In field 212, a timeline is shown reflecting the number of times the term "Tyvek" appears in spec documents having a bid date during the timeframe Jul. 5, 2010 to Jan. 8, 2012. For example, for projects having a bid date during the week starting Aug. 2, 2010, the term "Tyvek" appears in approximately 1000 spec documents. Buttons 214 are provided that allow the user to change the display format. For example, a button 214 may be pressed by the user to view the data in a tabular format (i.e., a listing of weeks and the number of spec documents using the term "Tyvek" for each week). The user may also be provided with the ability to zoom in and zoom out on the timeline (e.g., to focus in on data for a particular quarter). The data that is shown on screen display 200 is determined by the timeline selected by the user. Hence, when the user changes the timeline in field 212, the rest of the data in screen display 200 is updated and the user is provided with an updated screen display.
[0023] A geography field 216 provides a map reflecting the number of times the term "Tyvek" appears in spec documents for projects in various geographic regions (e.g., states). For example, different states may be color-coded (e.g., different shades of colors may be used) to reflect the varying frequencies of usage of the term "Tyvek" in spec documents. Buttons 218 may be provided that allow the user to display the data in different formats (e.g., map, pie chart, bar graph, tabular, etc.). Initially, all states in the United States are shown. Again, however, the user may be provided with the ability to focus in on certain geographies. For example, if a salesperson's territory is Texas, Oklahoma, and Louisiana, the sales person may select Texas, and then Oklahoma, and then Louisiana (e.g., through a series of three mouse clicks) to be presented with only the data for those three states. Again, the data that is shown on screen display 200 is determined by the geography selected by the user. Hence, when the user changes the geography in field 216, the rest of the data in screen display 200 is updated and the user is provided with an updated screen display. For example, the number of projects that are shown on timeline in field 212 may decrease when only a specific geographic region, such as Texas, is selected.
[0024] Referring now also to FIGS. 3-6, FIGS. 3-6 show additional graphs that may be displayed to the user. Although the graphs shown in FIGS. 3-6 are presented in separate Figures, as will be appreciated, the graphs shown in FIGS. 3-6 may constitute part of the screen display 200 (e.g., the user may be presented with the graphs upon scrolling down on the screen display shown in FIG. 2).
[0025] Referring first to FIG. 3, a CSI divisions field 220 is shown that reflects the number of times the term "Tyvek" appears in various parts of spec documents. As indicated above, under the MasterFormat standard, spec documents are organized in divisions. "Divisions" in the context of FIG. 3 refers to Masterformat divisions. Hence, the division in which the term appears is indicative of the manner in which Tyvek is being referenced in the spec documents (i.e., the context in which it is being specified). Buttons 222 may be provided that allow the user to display the data in different formats (e.g., pie chart, bar graph, tabular, etc.). Again, the data that is shown on screen display 200 is determined by the division selected by the user. Initially, all divisions are shown. However, if the user selects only certain divisions, then the rest of the data in screen display 200 is updated and the user is provided with an updated screen display. For example, the number of projects that are shown on timeline in field 212, which may have already decreased due to selection of a specific geographic region, may decrease further when only a specific division is selected.
[0026] Referring next to FIG. 4, a project ownership field 224 is shown that reflects the number of spec documents referencing the term "Tyvek" for projects owned by different types of entities (e.g., private, Federal, state, etc.). Buttons 226 may be provided that allow the user to display the data in different formats (e.g., pie chart, bar graph, tabular, etc.). Again, the data that is shown on screen display 200 is determined by the ownership category selected by the user. Initially, all ownership categories are shown. However, if the user selects only certain types of owners, then the rest of the data in screen display 200 is updated and the user is provided with an updated screen display.
[0027] Referring next to FIG. 5, a project stage field 228 is shown that reflects the number of projects referencing the term "Tyvek" for each of various different categories of stages of projects (e.g., bidding, starting, etc.). Buttons 230 may be provided that allow the user to display the data in different formats (e.g., pie chart, bar graph, tabular, etc.). Again, the data that is shown on screen display 200 is determined by the project stage category selected by the user. Initially, all project stages are shown. However, if the user selects only certain types of project stages, then the rest of the data in screen display 200 is updated and the user is provided with an updated screen display.
[0028] Referring next to FIG. 6, a project type field 231 is shown that reflects the number of project types for various different categories of projects (e.g., commercial, retail, roads and bridges, educational, etc.). Buttons 232 may be provided that allow the user to display the data in different formats (e.g., pie chart, bar graph, tabular, etc.). Again, the data that is shown on screen display 200 is determined by the project type category selected by the user. Initially, all project types are shown. However, if the user selects only certain types of project stages, then the rest of the data in screen display 200 is updated and the user is provided with an updated screen display.
[0029] Hence, as shown in FIGS. 2-6, the system 100 provides the user with considerable ability to select and analyze data. The user may zoom down on any one or more of the categories of data discussed above. While certain categories have been described, it will be appreciated that fewer, additional, or different categories may also be provided. It may be noted that data for each spec document (e.g., indicating geography (FIG. 2), project ownership (FIG. 4), project stage (FIG. 5)) may be obtained from meta data provided by publishers, meta data added manually after the spec document is received from publishers, based on analysis of the text data in the spec document, or in another manner. The system 100 then filters all of the spec documents in the data storage system 110 to determine which spec documents fit the user's search criteria, as previously indicated.
[0030] Referring now to FIG. 7, in FIG. 7 a screen display 700 is shown in which the user is conducting comparative research on two products (in this example, Tyvek and Raven). Hence, in FIG. 7, the data described above is shown for both products. For example, a salesperson may compare how often Tyvek is appearing in project specifications with how often Raven is appearing in project specifications for any one or more of a given time period, projects in a given geography, projects owned by certain types of owners, projects that are at certain stages in the construction process, projects of a given type, and/or appearance in specific parts of the project specification.
[0031] Also shown in FIG. 7 is a field 233 that contains a list of projects meeting the parameters specified by the user as discussed above. (A similar field is shown in FIG. 2) The list of projects is presented responsive to selection of a projects tab 234. Colored icons 236 may be used to reflect which projects (i.e., spec documents) refer to which products (i.e., Tyvek and/or Raven). Project names may be displayed as links which may be selected by the user. Upon selecting a link, the user may be provided with a copy of the spec document for the selected project. A selector icon 236 may be provided that causes the interface 140 to sort the data in different dimensions (e.g., bid date, project value, square feet, etc.).
[0032] Referring now to FIG. 8, in FIG. 8, the user has selected a contacts tab 238. Various categories of contacts may be presented to the user (e.g., architects & engineers, consultants, owners, general contractors, etc.). Again, the contacts are entities that are associated with project specifications that meet the user's search criteria, as discussed above. In FIG. 8, the user has selected architects and engineers via a selector icon 240. Hence, a list of architects and engineers is presented to the user, along with the number of projects with which they are associated. The user may be presented with data for all projects or only data for certain types of projects, depending on selector icon 242. Contact names may be displayed as links which may be selected by the user. Upon selecting a link, the user may be provided with additional information (e.g., contact information, etc.) regarding a particular contact (e.g., a particular architect & engineering firm).
[0033] Referring now to FIG. 9, in FIG. 9, the user has selected a related tab 244. In FIG. 9, the user is presented with entities (words and multi-word phrases) that have a high relatedness score relative to the two terms specified by the user (Tyvek and Raven, in this example). The peers column 246 shows products and companies (collectively, "peers" in FIG. 9). As described in greater detail below, for the products and companies listed in FIG. 9, if a block of text spec document lists Tyvek, a high probability exists that the block of text will also include the other products and companies listed in FIG. 9 (i.e., a high probability relative to other products and companies that are not listed). For example, a user may be interested in finding out what other products compete with Tyvek and Raven. The peers column 246 also refers to Typar, which suggests that Typar may be a competing product (as indicated by the fact that spec documents that refer to Tyvek and/or Raven in a given block of text are also highly likely to refer to Typar). Of course, this type of research may be performed for other types of keywords as well (e.g., company names, etc.). While products and companies are grouped together in FIG. 9, as will be appreciated, products and companies may also be listed separately. The standards column 248 shows standards that are considered highly related to Tyvek. Hence, for example, if a block of text in a spec document refers to Tyvek, it is highly likely that the block of text will also include a reference to ANSI Standard Z87.1-1979. It will be appreciated that other categories of terms may also be listed.
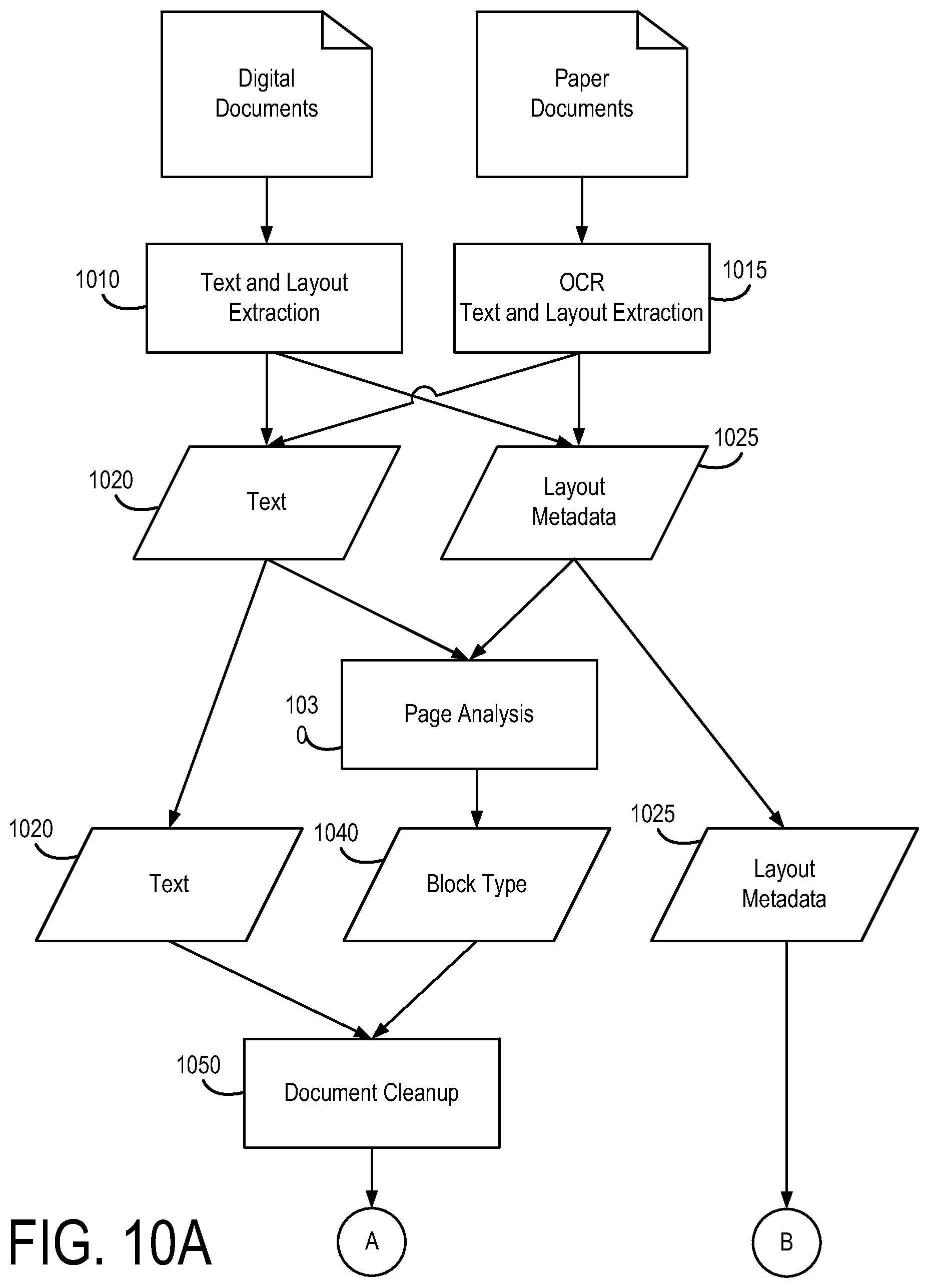
[0034] Referring now to FIGS. 10A-10B, FIGS. 10A-10B show the operation of the indexing and annotation engine 120 in greater detail according to an example embodiment. As described above, the input to engine 120 is a collection of documents, e.g., spec documents. The spec documents may be in either digital or paper format. In the event that the documents are in digital format, the engine 120 extracts blocks of text 1020 and pairs them with location and formatting information 1025, if any, at step 1010. For example, the location information may indicate where on the page a block of text was rendered, and the formatting information may include the font type or size, among other information. Referring now also to FIGS. 11A-11B, an example of a page that may be processed by engine 120 is shown. FIGS. 11A-11B show a page may be dissected into blocks of text 1020.
[0035] Alternatively, in the event that the input is physical paper copies of the documents, then at step 1015 an optical character recognition (OCR) process is performed on the documents. This may produce either raw text (ASCII) or formatted text (e.g. PDF) output. The output of step 1015 is the same as the output of step 1010: blocks of text 1020, with any position and formatting information 1025. In some embodiments, the spec documents may be annotated to provide meta data, as described above.
[0036] At step 1030, using the position and formatting information 1025, a page analysis is performed in which the text and its layout on the page is examined and labels are applied to each text block 1020. The labels indicate the type of text that is in the text block 1020. Referring now also to FIGS. 12A-12B, an example of a page that may be processed by engine 120 is shown. Labels include information such as "header" (for text 1201), "footer" (for text 1202), "marginal note/marking" (for text 1203, in this case markings from a 3-hole punch), or "body text". The body text is shown in FIG. 10B at 1055. Further information extracted from the page analysis may include block labels such as "increase in indent level" (e.g., for text 1204.), or "decrease in indent level" (e.g., for text 1205).
[0037] At step 1050, this information is used to clean up the text stream by removing everything except for the body text 1055, because all other information (e.g., headers, footers, markings) is unlikely to provide useful search or relationship information. In FIGS. 12A-12B, items 1201, 1202, and 1203 would skipped so as to provide a cleaner text stream for the remainder of the indexing process shown in FIGS. 10A-10B.
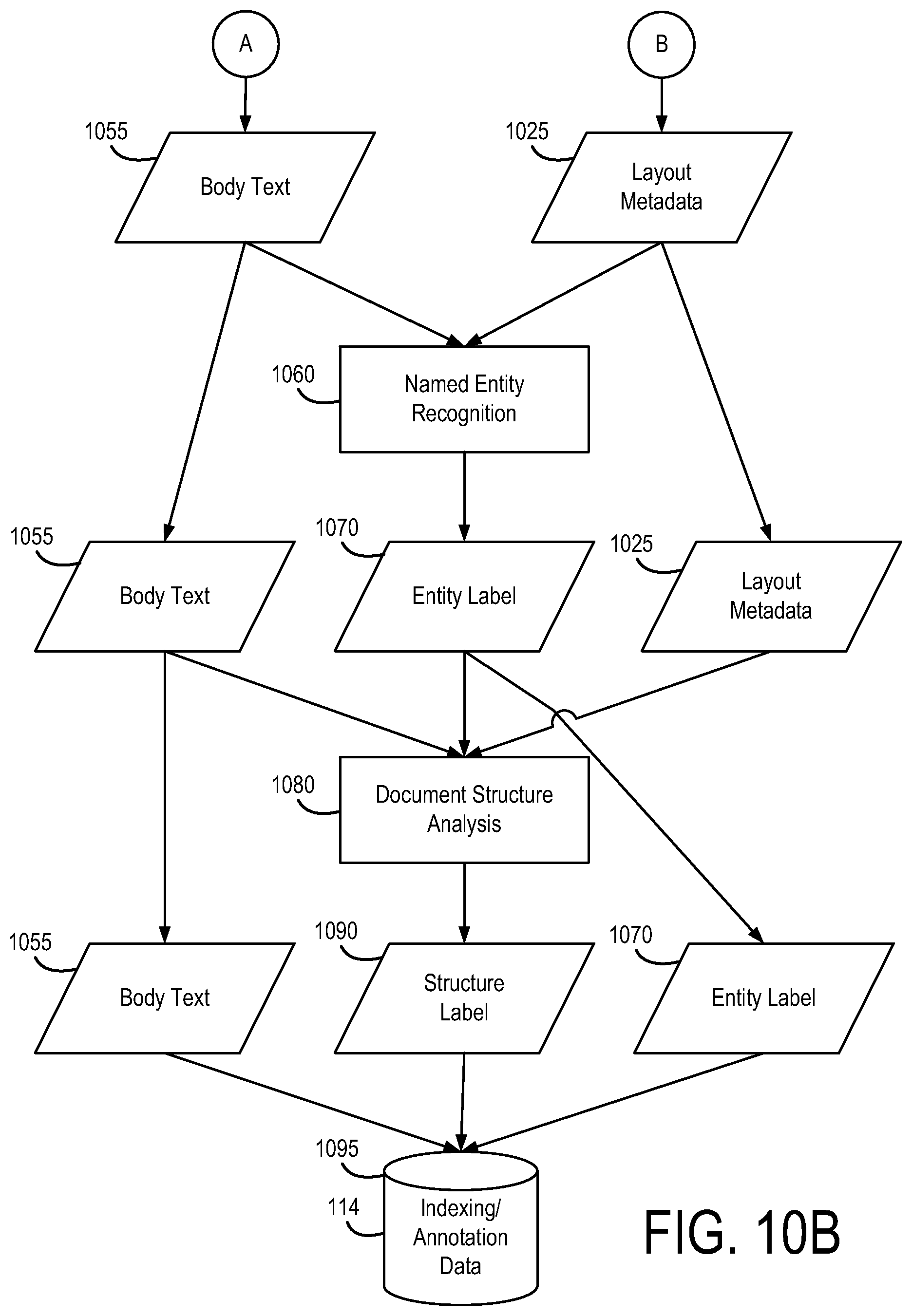
[0038] At step 1060, entity recognition is performed to add entity labels 1070 to the body text 1055. The entity recognition is performed by named entity recognition system 125, which may comprise a trainable software package configured to perform entity identification and entity extraction. The recognized entities may be either named entities, structure indicating entities, or relationship indicating entities. Named entities may include categories such as Product (e.g., text 1206), Company (e.g., text 1207), Place, Standard (e.g., text 1208), and Person. Further examples of named entities are phrases such as "Chemrex, Inc." labeled as a company, "409" labeled as a product, "Beaumont, Tex." labeled as a place, and so on. For example, such categories (company, product, standard) may be used to categories words as shown in FIG. 9, discussed above. Such categories may also be used to reduce false positive matches, e.g., to distinguish the cleaning product "409" from the area code "409," as discussed above. Structure indicating entities are words or phrases that indicate document structure, such as section titles which indicate the start of a section of a document. In FIGS. 12A-12B, the text 1209 are examples of headings that serve as structure indicating entities. As described in greater detail below, when an entity (e.g., a word, a multi-word phrase) is indexed and its location in the spec document is stored in the index, the location of the entity is specified in terms of document structure (e.g., relative to section headings, etc.) as opposed to pagination (i.e., the page upon which the word appears). Hence, the structure indicating entities may later be used in specifying the locations of other (lower level) entities with the spec document. Relationship indicating entities include phrases in the body text such as "by", "a division of", "a product of", and so on. Such information may be used to determine relatedness of entities.
[0039] In an example embodiment, as part of the entity recognition process discussed above, the named entity recognition system 125 identifies multiword entities. For example, the named entity recognition system 125 may identify "Ceramic Mosaic Tile" and deem it to be a single unit. Such multiword entities may then be indexed in the same manner as single-word entities. In an example embodiment, each word in the document is indexed once as an individual word and once as part of a multiword entity. In an example embodiment, words are assigned to one and only one multiword entity.
[0040] At step 1080, the document structure is analyzed (including text, layout metadata, and any found entities) to build a hierarchical block descriptor for each block of text 1055 deemed to be a single unit. At the root of the hierarchy is the document. The next levels may include chapters (in the case of books), or CSI divisions and codes (in the case of spec documents). In this latter case, one part of the document may have three levels 03, 30, and 00 corresponding to division 03, section 30, subsection 00 ("Cast in Place Concrete") of the MasterFormat 2004 standard. The document structure analysis subprocess may use section headings, tables of contents, information in headers or footers (See FIG. 12B, where "09 3000" (1210) is the CSI code, and "TILING" (1211) is the title of code "09 3000".), etc. to determine the correct section. Beyond the coarse part of the structure, at a minimum, sections listed under headings (1209) are listed with their headings, or in the event of an outline type format in the document with their outline tree descriptor (i.e. the three blocks indicated by 1204 would be "2.01.A", "2.01.A.1", and "2.01.B.1"). As previously indicated, in an example embodiment, the location of entities (e.g., words, multiword phrases) in the spec document is specified in terms of document structure (e.g., relative to section headings, etc.) as opposed to pagination (i.e., the page upon which the word appears). Hence, the hierarchical block descriptors generated at step 1080 may be used as a basis for specifying the locations of entities within spec documents. Additionally, the fact that a word appears in a particular division (under a particular node in the hierarchy) may be used in generating the graph shown in FIG. 3.
[0041] At step 1095, an index is constructed comprising the raw text entities (i.e., individual words, multiword phrases) and other entities (named entities, structure indicating entities, and relationship indicating entities), which are stored along with their position in the document. For each entity, the position includes the location of the entity within the hierarchy (e.g., a unique block ID) as well as an offset (e.g., the location of the entity with the uniquely identified block). For example, the position may include a block ID such as "2.01.B.1 in section 09 300 in document number 3,001" and sequential offset such as "the 5th word in the block" or "the phrase starting 5 words into the block." The detailed position information may be used in a variety of ways in addition to others already mentioned. For example, the detailed position information may permit individual words to be recombined into multiword sequences, e.g., if the user performs a search query using a multiword sequence that was not previously identified as an entity by the entity recognition system 125. This index is stored as the indexing and annotation data 114 in the data storage system 110.
[0042] The process shown in FIG. 10 is performed for every document stored in data storage system 110. As indicated previously, in the context of spec documents for the construction industry, this may be approximately on the order of tens of thousands or hundreds of thousands of documents or more per year, with each document typically being on the order of hundreds of pages or more in length. Hence, the indexing and annotation data 114 in the data storage system 110 comprises a detailed index of the words and other entities contained on the pages of the tens to hundreds of thousands of spec documents generated per year in the construction industry and stored in the data storage system 110, including detailed position information and other information describing the appearances of those entities in the spec documents.
[0043] The indexing and annotation data 114 may be accessed to provide the features described above in connection with FIGS. 2-9 (except for those described in connection with related tab 244 in FIG. 9). For example, and referring to FIG. 13, according to an example embodiment, if the user enters "Tyvek" in search field 210, at step 1310, the system 100 may scan the indexing and annotation data to identify occurrences of the term "Tyvek" in spec documents. Spec documents that contain the term "Tyvek" may be identified at step 1320. The spec documents may be filtered according to any other search criteria at step 1330. Finally, a screen display showing the pertinent data may be generated at step 1340.
[0044] Referring now to FIG. 14, FIG. 14 shows operation of the relatedness engine 130 in greater detail according to an example embodiment. The relatedness engine 130 uses the indexing/annotation data 114 generated by the process of FIG. 10 to the generate relationship data 115. The relatedness engine 130 and the relationship data 115 are used to provide features discussed above in connection with related tab 244 in FIG. 9.
[0045] The relationship data 115 comprises, for each entity (e.g., word, multiword phrase), relatedness scores that reflect the relatedness of that entity to other entities (words, multiword phrases) in the indexing and annotation data 114 (i.e., one relatedness score per entity-entity pair). That is, each entity is compared against every entity, and a related score is generated for each pair.
[0046] According to an example embodiment, the relatedness engine 130 generates a relatedness score for two entities (e.g., two words) based on the likelihood of the two entities appearing in a common text block 920. By way of example, the text under heading 2.03 in the example shown in FIGS. 11B and 12B reads as follows:
[0047] 2.03 GROUT MATERIALS [0048] A. Manufacturers: [0049] 1. Bonsal American, Inc; ProSpec Sanded Tile Grout 700: www.prospec.com. [0050] 2. Custom Building Products; Prism SureColor Grout: www.custombuildingproducts.com. [0051] 3. LATICRETE International, Inc; LATICRETE SpectraLOCK PRO Grout: www.laticrete.com. [0052] 4. Substitutions: See Section 01 6000--Product Requirements.
[0053] B. Grout: Polymer modified cement grout, sanded or unsanded, as specified in ANSI A118.7.
[0054] In the above example, the text located between the two section headings "Manufacturers" and "Grout" is considered a text block. In the above text block, there are certain words that appear, such as "ProSpec," "Prism," and "LATICRETE." The fact that these words appear within the same block of text suggests that these words may be related. In fact, these words are in a common block of text because they are all different types of grout. When this analysis is performed over tens of thousands or hundreds of thousands or more spec documents stored in the data storage system, a reliable relatedness score may be generated. That is, if "ProSpec," "Prism," and "LATICRETE" often appear together in the same blocks of text across many spec documents, then it is likely that they are related.
[0055] Related scores which reflect these probabilities may be generated and stored as the relationship data 115. Such data may be used to provide the features discussed above in connection with related tab 244 in FIG. 9. For example, if the user entered "ProsSpec" as a search term in search query field 210, and selected the related tab 244, the terms "Prism," and "LATICRETE" would appear as peers in column 246. Likewise, because the peers column 246 includes both products and companies, the manufacturers Custom Building Products (which manufactures LATICRETE grout) would also be listed. Conversely, if "ProSpec," "Prism," and "LATICRETE" occur in together in the same block of text only infrequently, then they are considered less related or not related at all, and they would not appear in the peers column 246. The peers column 246 may comprise a predetermined number of entities selected based on their relatedness scores, e.g., the ten products and companies that have the highest relatedness scores for the search term entered by the user. The same approach may be used for the standards column 248.
[0056] In practice, a variety of different mathematical approaches may be used for generating a relatedness score. For example, approaches may be used that are based on the statistics of the document. In a simple example embodiment, a conditional probability approach is used which calculates the condition probability of two entities appearing in the same text block, and conditional probabilities are then used as the relatedness score. That is, for a query word or phrase x, P(Y|X) is computed for each y in the data storage system, and the most related words and phrases are the y's with the highest conditional probabilities given the query x. For example, considering a word or phrase x, a binary random variable X may be defined that is 1 when that word or phrase occurs within a text block, and 0 otherwise. The probability distribution for X may be estimated such that the probability of a word or phrase x occurring in a sample text block, p.sub.x(i), is approximated by the total number of blocks in the construction project specifications 111 in which x occurs (FIG. 14, 1415) divided by the number of blocks in the construction project specifications 111. Similarly the joint probability of the word or phrase x occurring in the same block as word or phrase y, p.sub.x,y(i, j), can be estimated as the number of times in the project specifications 111 that x occurs (i=1), or does not occur (i=0) in the same text block 1320 that y occurs (j=1), or does not occur (j=0) in, divided by the total number of text blocks in the construction project specifications 111. The quality of these estimates can be improved using a smoothing technique such as Good-Turing smoothing. Conditional probabilities of x occurring in a text block, given that y occurs in a text block, can then be computed as P(X=1|Y=1)=p.sub.x,y(1,1)/p.sub.y(1). Frequency filter 1410 may count relevant frequencies and related estimator 1425 may use the frequencies to calculate probabilities. These frequencies and probability estimates can either be stored within the indexing/annotation data 114, or generated on-the-fly by the frequency filter 1410.
[0057] As a concrete example, let x be the word "ProSpec". The relatedness estimator (FIG. 14, 1425) would allow y to take on all possible values, including "Prism". In this case, p.sub.x(1) is the fraction of blocks in which "ProSpec" appears, (FIG. 14, 1415), p.sub.y(1) is the fraction of blocks in which "Prism" (FIG. 14, 1415), and p.sub.x,.sub.y(1,1) is the fraction of blocks in which both "ProSpec" and "Prism" occur (FIG. 14, 1420). Furthermore, the conditional probability P(X=1|Y=1) can be estimated by relatedness estimator 1425 as p.sub.x,y(1,1)/p.sub.y(1). In this simple sample embodiment, these conditional probabilities represent the relationship strength (FIG. 14, 1430) between the entities "ProSpec" and "Prism". Smoothing may be necessary for rare events. If probability is to be estimated on entities that are not indexed with 100% accuracy, then the probability estimate can be adjusted downward to account for false positives, or upward to account for false negatives. This process is performed for all combinations (possible pairs x, y) of entities in the indexing and annotation data 114.
[0058] Conditional probabilities are not symmetric, that is, (i.e. P(X|Y) may not equal P(Y|X)). For example, "it" and "the" will occur in the same block many times, so (using the notation W.sub.word to represent the binary random variable that is 1 when word appears in a block and 0 otherwise) both P(W.sub.it=1, W.sub.the=1) and P(W.sub.it=1|W.sub.the=1) will be high. "InfoTech" and "Carnivore" are much less likely to occur overall, so P(W.sub.InfoText=1, W.sub.Carnivore=1) is likely to be low while P(W.sub.InfoText=1|W.sub.Carnivore=1) should be moderately higher. P(W.sub.Carnivore=1, W.sub.InfoTech=1) could be expected to be low as well, since it is only one of InfoTech's products.
[0059] Hence, while the use of conditional probability provide a useful relatedness measurement, alternative approaches may also be desired in order to enhance the meaningfulness of the relatedness score, such as approaches based on information theory and statistics that build upon and use conditional and joint probabilities as a basis for other relatedness scores. For example, the shared information metric may be used as a relatedness score to take the above-mentioned issues into account. The shared information metric relatedness score between a query x and a candidate can be computed as H(Y.sub.i|X)+H(X|Y.sub.i) for all y in the corpus, where H(B|A) is the conditional entropy. For these binary variables, conditional entropy is defined as:
H ( B A ) = i .di-elect cons. { 0 , 1 } j .di-elect cons. { 0 , 1 } p a , b ( i , j ) log p a ( i , j ) p a , b ( i , j ) ##EQU00001##
Another of many relatedness scores suggested by statistical theory is using the chi-squared test to compare the distribution of the candidate phrases with a null-hypothesis of statistical independence.
[0060] Notably, the relationship extraction engine 130 may rely upon the entities being in the same block as opposed to being on the same page. Hence, the relatedness estimation may be based on proximity in terms of organization of the document as opposed to physical proximity. The fact that two terms appear in the same block of text may be more relevant to determining relatedness than the fact that the two terms are on the same page. For example, if two words appear on either side of a major section heading, the two words are probably not highly related, even though they are close in physical proximity on the page.
[0061] In another embodiment, a relatedness score is calculated using the relationship indicating entities, and to use counts (i.e. voting) or frequencies of phrases such as "<x> by <y>" or "<x>, a division or <y>" in much the same way the block-level conditional probabilities are used.
[0062] The relatedness engine 130 uses probability estimates for various features in the index or database. In some instances, these estimates may be stored in tables in the data storage system 110. A word or entity frequency is neither difficult nor space-prohibitive to store. For more complex relatedness requests received from a user (e.g. requesting relationships limited to a particular CSI division), however, the probabilities are computed "on-the-fly" on an as-needed basis. In this case, a probability estimator scans the database counting relevant frequencies, and using the frequencies to estimate the probabilities. With sufficient storage, joint probabilities (P(X,Y)) may also be stored in tables. If there is not sufficient storage for all pairs, then common pairs may be cached.
[0063] The embodiments of the present invention have been described with reference to drawings. The drawings illustrate certain details of specific embodiments that implement the systems and methods and programs of the present invention. However, describing the invention with drawings should not be construed as imposing on the invention any limitations that may be present in the drawings. The present invention contemplates methods, systems and program products on any machine-readable media for accomplishing its operations. The embodiments of the present invention may be implemented using an existing computer processor, or by a special purpose computer processor incorporated for this or another purpose or by a hardwired system.
[0064] As noted above, embodiments within the scope of the present invention include program products comprising non-transitory machine-readable media for carrying or having machine-executable instructions or data structures stored thereon. Such machine-readable media may be any available media that may be accessed by a general purpose or special purpose computer or other machine with a processor. By way of example, such machine-readable media may comprise RAM, ROM, EPROM, EEPROM, CD-ROM or other optical disk storage, magnetic disk storage or other magnetic storage devices, or any other medium which may be used to carry or store desired program code in the form of machine-executable instructions or data structures and which may be accessed by a general purpose or special purpose computer or other machine with a processor. Thus, any such a connection is properly termed a machine-readable medium. Combinations of the above are also included within the scope of machine-readable media. Machine-executable instructions comprise, for example, instructions and data which cause a general purpose computer, special purpose computer, or special purpose processing machines to perform a certain function or group of functions.
[0065] Embodiments of the present invention have been described in the general context of method steps which may be implemented in one embodiment by a program product including machine-executable instructions, such as program code, for example in the form of program modules executed by machines in networked environments. Generally, program modules include routines, programs, objects, components, data structures, etc. that perform particular tasks or implement particular abstract data types. Machine-executable instructions, associated data structures, and program modules represent examples of program code for executing steps of the methods disclosed herein. The particular sequence of such executable instructions or associated data structures represent examples of corresponding acts for implementing the functions described in such steps.
[0066] As previously indicated, embodiments of the present invention may be practiced in a networked environment using logical connections to one or more remote computers having processors. Those skilled in the art will appreciate that such network computing environments may encompass many types of computers, including personal computers, hand-held devices, multi-processor systems, microprocessor-based or programmable consumer electronics, network PCs, minicomputers, mainframe computers, and so on. Embodiments of the invention may also be practiced in distributed computing environments where tasks are performed by local and remote processing devices that are linked (either by hardwired links, wireless links, or by a combination of hardwired or wireless links) through a communications network. In a distributed computing environment, program modules may be located in both local and remote memory storage devices.
[0067] An exemplary system for implementing the overall system or portions of the invention might include one or more general purpose computers including a processing unit, a system memory or database, and a system bus that couples various system components including the system memory to the processing unit. The database or system memory may include read only memory (ROM) and random access memory (RAM). The database may also include a magnetic hard disk drive for reading from and writing to a magnetic hard disk, a magnetic disk drive for reading from or writing to a removable magnetic disk, and an optical disk drive for reading from or writing to a removable optical disk such as a CD ROM or other optical media. The drives and their associated machine-readable media provide nonvolatile storage of machine-executable instructions, data structures, program modules and other data for the computer. It should also be noted that the word "terminal" as used herein is intended to encompass computer input and output devices. User interfaces, as described herein may include a computer with monitor, keyboard, a keypad, a mouse, joystick or other input devices performing a similar function.
[0068] It should be noted that although the diagrams herein may show a specific order and composition of method steps, it is understood that the order of these steps may differ from what is depicted. For example, two or more steps may be performed concurrently or with partial concurrence. Also, some method steps that are performed as discrete steps may be combined, steps being performed as a combined step may be separated into discrete steps, the sequence of certain processes may be reversed or otherwise varied, and the nature or number of discrete processes may be altered or varied. The order or sequence of any element or apparatus may be varied or substituted according to alternative embodiments. Accordingly, all such modifications are intended to be included within the scope of the present invention. Such variations will depend on the software and hardware systems chosen and on designer choice. It is understood that all such variations are within the scope of the invention. Likewise, software and web implementations of the present invention could be accomplished with standard programming techniques with rule based logic and other logic to accomplish the various database searching steps, correlation steps, comparison steps and decision steps.
[0069] The foregoing description of embodiments of the invention has been presented for purposes of illustration and description. It is not intended to be exhaustive or to limit the invention to the precise form disclosed, and modifications and variations are possible in light of the above teachings or may be acquired from practice of the invention. The embodiments were chosen and described in order to explain the principals of the invention and its practical application to enable one skilled in the art to utilize the invention in various embodiments and with various modifications as are suited to the particular use contemplated. Other substitutions, modifications, changes and omissions may be made in the design, operating conditions and arrangement of the embodiments without departing from the scope of the present invention.
[0070] Throughout the specification, numerous advantages of the exemplary embodiments have been identified. It will be understood of course that it is possible to employ the teachings herein without necessarily achieving the same advantages. Additionally, although many features have been described in the context of a particular data processing unit, it will be appreciated that such features could also be implemented in the context of other hardware configurations.
[0071] While the exemplary embodiments illustrated in the figures and described above are presently preferred, it should be understood that these embodiments are offered by way of example only. Other embodiments may include, for example, structures with different data mapping or different data. The invention is not limited to a particular embodiment, but extends to various modifications, combinations, and permutations that nevertheless fall within the scope and spirit of the appended claims.
* * * * *
References
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012

D00013

D00014

D00015

D00016
D00017
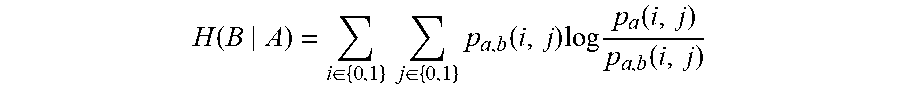
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.