Systems And Methods For Assessment And Visualization Of Supply Chain Management System Data
BAJAJ; Mudit ; et al.
U.S. patent application number 16/616376 was filed with the patent office on 2020-04-23 for systems and methods for assessment and visualization of supply chain management system data. This patent application is currently assigned to JABIL INC.. The applicant listed for this patent is JABIL INC.. Invention is credited to Mudit BAJAJ, Paul DOCHERTY, Andrew JOYNER, Ancha KOTESWARARAO, Erin MORRIS, Ross VALENTINE.
| Application Number | 20200126014 16/616376 |
| Document ID | / |
| Family ID | 64395871 |
| Filed Date | 2020-04-23 |






View All Diagrams
| United States Patent Application | 20200126014 |
| Kind Code | A1 |
| BAJAJ; Mudit ; et al. | April 23, 2020 |
SYSTEMS AND METHODS FOR ASSESSMENT AND VISUALIZATION OF SUPPLY CHAIN MANAGEMENT SYSTEM DATA
Abstract
Apparatus, system and method for supply chain management (SCM) system processing. A SCM operating platform is operatively coupled to SCM modules for collecting, storing, distributing and processing SCM data to determine statistical opportunities and risk in a SCM hierarchy. SCM risk processing may be utilized to determine risk values that are dependent upon SCM attributes. Multiple SCM risk processing results may be produced for further drill-down by a user. SCM network nodes, their relation and status may further be produced for fast and efficient status determination.
| Inventors: | BAJAJ; Mudit; (St. Petersburg, FL) ; JOYNER; Andrew; (St. Petersburg, FL) ; VALENTINE; Ross; (St. Petersburg, FL) ; MORRIS; Erin; (St. Petersburg, FL) ; DOCHERTY; Paul; (St. Petersburg, FL) ; KOTESWARARAO; Ancha; (St. Petersburg, FL) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assignee: | JABIL INC. St. Petersburg FL |
||||||||||
| Family ID: | 64395871 | ||||||||||
| Appl. No.: | 16/616376 | ||||||||||
| Filed: | May 22, 2018 | ||||||||||
| PCT Filed: | May 22, 2018 | ||||||||||
| PCT NO: | PCT/US2018/033807 | ||||||||||
| 371 Date: | November 22, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 62509675 | May 22, 2017 | |||
| 62509665 | May 22, 2017 | |||
| 62509660 | May 22, 2017 | |||
| 62509669 | May 22, 2017 | |||
| 62509653 | May 22, 2017 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06Q 50/28 20130101; G06Q 10/063114 20130101; G06Q 10/0637 20130101; G06N 20/00 20190101; G06Q 10/06315 20130101; G06Q 10/0635 20130101; G06F 16/904 20190101; G06Q 10/06375 20130101; G06Q 10/087 20130101 |
| International Class: | G06Q 10/06 20060101 G06Q010/06 |
Claims
1. A supply chain management system for at least partially individually managing a plurality of nodes in a supply chain comprising the plurality of nodes, comprising: a plurality of data inputs capable of receiving primary hardware and software data from at least ones of the supply chain nodes at least two hierarchical levels in the supply chain over at least one computer network upon indication by at least one processor; a plurality of rules stored in at least one memory element associated with the at least one processor and capable of performing operations on the primary hardware and software data to produce secondary data upon direction from the at least one processor; and a plurality of data outputs capable of: interfacing with a plurality of application inputs, and capable of providing the secondary data, comprised of at least one of node-centric supply chain risk data, supply chain management data, and supply chain analytics data individually particular to the ones of the nodes; and interfacing with the user to provide the secondary data as each of the data cascaded as supply chain risk data, supply chain management data, and supply chain analytics as between multiple ones of the ones of the nodes.
Description
RELATED APPLICATIONS
[0001] The present application claims the benefit of priority to International Application No. PCT/US2018/033807, filed May 22, 2018, entitled "Systems and Methods for Assessment and Visualization of Supply Chain Management System Data" which claims priority to, is related to, and incorporates by reference, U.S. provisional application No. 62/509,675, filed May 22, 2017, entitled "Systems and Methods for Assessment and Visualization of Supply Chain Management System Data"; U.S. provisional application No. 62/509,665, filed May 22, 2017, entitled "Systems and Methods for Interfaces to a Supply Chain Management System"; U.S. provisional application No. 62/509,660, filed May 22, 2017, entitled "Systems and Methods for Risk Processing of Supply Chain Management System Data"; U.S. provisional application No. 62/509,669, filed May 22, 2017, entitled "Systems and Methods Optimized Design of a Supply Chain"; U.S. provisional application No. 62/509,653, filed May 22, 2017, entitled Systems and Methods for Providing Diagnostics for a Supply Chain; U.S. patent application Ser. No. 14/523,642, filed Oct. 24, 2014, to Valentine, et al., entitled "Systems and Methods for Risk Processing and Visualization of Supply Chain Management System Data," which claims priority to U.S. provisional patent application Ser. No. 61/895,636, to Valentine, et al., entitled "Power Supply With Balanced Current Sharing," filed Oct. 28, 2013, U.S. provisional patent application Ser. No. 61/895,665, to Joyner et al., entitled "System and Method for Managing Supply Chain Risk," filed Oct. 25, 2013, and U.S. provisional patent application Ser. No. 61/896,251 to McLellan et al., entitled "Method for Identifying and Presenting Risk Mitigation Opportunities in a Supply Chain," filed Oct. 28, 2013. Each of these are incorporated by reference in their respective entireties herein.
BACKGROUND
Field of the Disclosure
[0002] The present disclosure relates to supply chain management (SCM) system processing. More specifically, the present disclosure is related to processing SCM data to reduce cost, optimize data processing and networked communications, improving flexibility, and identifying and mitigating risk in a supply chain. Furthermore, the SCM data may be structured using visualization, analytics and frameworks.
Background of the Disclosure
[0003] Supply chains have become increasingly complex, and product companies are faced with numerous challenges such as globalization, shortening product lifecycles, high mix product offerings and countless supply chain procurement models. In addition, challenging economic conditions have placed additional pressure on companies to reduce cost to maximize margin or profit. Focus areas of supply chain-centric companies include reducing cost in the supply chain, maximizing flexibility across the supply chain, and mitigating risks in the supply chain to prevent lost revenue.
[0004] Supply chain risk, or the likelihood of supply chain disruptions, is emerging as a key challenge to SCM. The ability to identify which supplier has a greater potential of a disruption is an important first step in managing the frequency and impact of these disruptions that often significantly impact a supply chain. Currently, supply chain risk management approaches seek to measure either supplier attributes or the supply chain structure, where the findings are used to compare suppliers and predict disruption. The results are then used to prepare proper mitigation and response strategies associated with these suppliers. Ideally, such risk management and assessment would be performed during the design of a supply chain for a product or line of products, but design tools and data analysis to allow for such design capabilities are not available in the known art.
[0005] Rather than the data- and algorithm-centric supply chain design and risk analysis discussed above, supply chain risk management is instead most often a formal, largely manual process that involves identifying potential losses, understanding the likelihood of potential losses, assigning significance to these losses, and taking steps to proactively prevent these losses. A conventional example of such an approach is the purchasing risk and mitigation (PRAM) methodology developed by the Dow Chemical Company to measure supply chain risks and its impacts. This approach examines supply market risk, supplier risk, organization risk and supply strategy risk as factors for supply chain analysis. Generally speaking, this approach is based on the belief that supplier problems account for the large majority of shutdowns and supply chain failures.
[0006] Such conventional systems are needlessly complicated and somewhat disorganized in that multiple layers of classification risks are utilized and, too often, the systems focus mainly on proactively endeavoring to predict disruptive events instead of analyzing and processing underlying root causes and large-scale accumulated data to assess potential disruptions. Further, these conventional systems fail to provide tools to aid in the design of a supply chain at the outset to address potential breakdown and disruption, and they also give little insight or visibility into the actual supply chain over its entirety. Thus, what is needed is an efficient, simplified SCM processing system for aiding in the design of the supply chain, and thereby maximizing opportunities to address potential supply chain risks at the outset and during the life cycle of a supply chain.
[0007] Moreover, conventional supply chain management has historically been based on various assumptions that may prove incorrect. By way of example, it has generally been understood that the highest risk in the supply chain resides with suppliers with whom the highest spend occurs--however, the most significant risk in a supply chain may actually reside with small suppliers, particularly if language barriers reside between the supplier and the supply chain manager, or with sole source suppliers, or in relation to suppliers highly likely to be subject to catastrophic events, such as earthquakes, for example. Further, it has typically been the case that increased inventory results in improved delivery performance--however, this, too, may prove to be an incorrect assumption upon analysis of large-scale data over time and across multiple suppliers, at least in that this assumption is true only if an inventory buffer is placed on the correct part or parts, and at the correct service level. Needless to say, such information would be difficult to glean absent automated review of large-scale data over time, and without visibility across an entire supply chain.
[0008] Yet further, present supply chain management fails to account for much of the available large-scale data information. By way of example, social media or other third party data sources may be highly indicative of supply chain needs or prospective disruptions. For example, if a provider expresses a desire for increased inventory levels, but social media expresses a largely negative customer sentiment, sales are likely to fall and the increased inventory levels will likely not be necessary. Similarly, large scale data inclusive of third party data may indicate that a supplier previously deemed high risk, such as due to the threat of earthquake, is actually lower risk because that supplier has not been hit with an earthquake over magnitude 5 for that last 20 years, and earthquakes of less than magnitude 5 have only a minimal probability of affecting the supply chain in a certain vertical. As such, large scale data, such as may include social media or other third party data, may complement supply chain management in ways not provided by conventional supply chain management.
[0009] By way of further example, conventional systems often deem certain events, such as significant geopolitical events, to pose a very high risk to the supply chain. However, large scale data analysis, such as from the inception of the design of many supply chains in a given vertical and from end-to-end of such supply chains throughout their respective life cycles, may reveal that this supposition has generally not been the case--rather, the supply chain risk may instead be revealed as far more dependent on sole source items and the size and language spoken by certain suppliers than on geopolitical events, by way of non-limiting example.
SUMMARY OF THE DISCLOSURE
[0010] Disclosed is an apparatus, system and method for supply chain management (SCM) system processing. A SCM operating platform is operatively coupled to SCM modules for collecting, storing, distributing and processing SCM data to determine statistical opportunities and risk in a SCM hierarchy. SCM risk processing may be utilized to determine risk values that are dependent upon SCM attributes. Multiple SCM risk processing results may be produced for further drill-down by a user. SCM network nodes, their relation and status may further be produced for fast and efficient status determination.
[0011] More particularly, a supply chain management operating platform is disclosed for managing a supply chain that includes a plurality of supply chain nodes. The platform, and its associated system and method, may include a plurality of data inputs capable of receiving primary hardware and software data from at least one third party data source and at least one supply chain node upon indication by at least one processor. The platform and its associated system and method may also include a plurality of rules stored in at least one memory element associated with at least one processor and capable of performing operations on the primary hardware and software data to produce secondary data upon direction from the processor(s). The platform and its associated system and method may also include a plurality of data outputs capable of at least one of interfacing with a plurality of application inputs, and capable of providing the secondary data, comprised of at least one of supply chain risk data, supply chain management data, and supply chain analytics, to ones of the plurality of application inputs for interfacing to a user; and interfacing with the user to provide the secondary data comprised of at least one of supply chain risk data, supply chain management data, and supply chain analytics.
[0012] Further included may be a supply chain management system for at least partially individually managing a plurality of nodes in a supply chain comprising the plurality of supply chain nodes. The system may include a plurality of data inputs capable of receiving primary hardware and software data from at least ones of the supply chain nodes at least two hierarchical levels in the supply chain over at least one computer network upon indication by at least one processor; a plurality of rules stored in at least one memory element associated with the at least one processor and capable of performing operations on the primary hardware and software data to produce secondary data upon direction from the at least one processor; and a plurality of data outputs. The data outputs may be capable of: interfacing with a plurality of application inputs, and capable of providing the secondary data, comprised of at least one of node-centric supply chain risk data, supply chain management data, and supply chain analytics data individually particular to the ones of the nodes; and interfacing with the user to provide the secondary data as each of the data cascaded as supply chain risk data, supply chain management data, and supply chain analytics as between multiple ones of the ones of the nodes.
BRIEF DESCRIPTION OF THE DRAWINGS
[0013] The present invention is illustrated by way of example and not limitation in the figures of the accompanying drawings, in which like references indicate similar elements and in which:
[0014] FIG. 1 illustrates a computer system for transmitting and processing data, and particularly supply chain management (SCM) data under an exemplary embodiment;
[0015] FIG. 2 illustrates an exemplary processing device suitable for use in the embodiment of FIG. 1 for processing and presenting SCM data;
[0016] FIG. 3A illustrates an exemplary SCM platform comprising a plurality of plug-in applications/modules, including a control tower module, a network optimization module, a supply chain analytics module, a supplier radar module, and a supply/demand processing module under one embodiment;
[0017] FIG. 3B illustrates the SCM platform utilizing extended plug-in applications/modules under another exemplary embodiment;
[0018] FIG. 4 illustrates exemplary data points and variables modules operatively coupled to a SCM platform under one embodiment;
[0019] FIGS. 5A-5F illustrate logical processing outcomes for a variety of exemplary embodiments;
[0020] FIG. 6 illustrates an exemplary automation process suitable for utilization in the embodiment of FIG. 1;
[0021] FIG. 7 illustrates an exemplary data visualization example for actionable-measurable-proactive (AMP) SCM processing;
[0022] FIG. 8A illustrates a further data visualization and "one-click" report generation under one embodiment;
[0023] FIG. 8B illustrates a functional action input module associated with report generation from the data visualization of FIG. 8A;
[0024] FIG. 9 illustrates an exemplary data table providing for attribute naming, attribute description and applicable weight attribution for SCM processing;
[0025] FIG. 10 illustrates an exemplary risk assembly detail for commodities/parts, wherein part and supplier attributes are processed to determine an overall risk;
[0026] FIG. 11 illustrates an exemplary risk part detail for commodities/parts, wherein various attributes are processed together with attribute weights and selection scores to calculate a weighted risk score;
[0027] FIG. 12 illustrates an exemplary data visualization heat map for various assemblies and associated parts, wherein specific assemblies and/or parts are presented as color-coded objects to indicate a level of risk;
[0028] FIG. 13 illustrates an exemplary analytics engine for use with the embodiments;
[0029] FIG. 14 illustrates an exemplary interface;
[0030] FIG. 15 illustrates an exemplary interface;
[0031] FIG. 16 illustrates an exemplary interface;
[0032] FIG. 17 illustrates an exemplary interface;
[0033] FIG. 18 illustrates an exemplary interface;
[0034] FIG. 19 illustrates an exemplary interface;
[0035] FIG. 20 illustrates an exemplary interface;
[0036] FIG. 21 illustrates an exemplary interface;
[0037] FIG. 22 illustrates an exemplary interface;
[0038] FIG. 23 illustrates an exemplary interface;
[0039] FIG. 24 illustrates an exemplary interface;
[0040] FIG. 25 illustrates an exemplary interface;
[0041] FIG. 26 illustrates an exemplary interface;
[0042] FIG. 27 illustrates an exemplary interface;
[0043] FIG. 28 illustrates an exemplary interface;
[0044] FIG. 29 illustrates an exemplary interface;
[0045] FIG. 30 illustrates an exemplary interface;
[0046] FIG. 31 illustrates an exemplary interface;
[0047] FIG. 32 illustrates an exemplary interface; and
[0048] FIG. 33 illustrates an exemplary interface.
DETAILED DESCRIPTION
[0049] The figures and descriptions provided herein may have been simplified to illustrate aspects that are relevant for a clear understanding of the herein described devices, systems, and methods, while eliminating, for the purpose of clarity, other aspects that may be found in typical devices, systems, and methods. Those of ordinary skill may recognize that other elements and/or operations may be desirable and/or necessary to implement the devices, systems, and methods described herein. Because such elements and operations are well known in the art, and because they do not facilitate a better understanding of the present disclosure, a discussion of such elements and operations may not be provided herein. However, the present disclosure is deemed to inherently include all such elements, variations, and modifications to the described aspects that would be known to those of ordinary skill in the art.
[0050] The terminology used herein is for the purpose of describing particular example embodiments only and is not intended to be limiting. As used herein, the singular forms "a", "an" and "the" may be intended to include the plural forms as well, unless the context clearly indicates otherwise. The terms "comprises," "comprising," "including," and "having," are inclusive and therefore specify the presence of stated features, integers, steps, operations, elements, and/or components, but do not preclude the presence or addition of one or more other features, integers, steps, operations, elements, components, and/or groups thereof. The method steps, processes, and operations described herein are not to be construed as necessarily requiring their performance in the particular order discussed or illustrated, unless specifically identified as an order of performance. It is also to be understood that additional or alternative steps may be employed.
[0051] When an element or layer is referred to as being "on", "engaged to", "connected to" or "coupled to" another element or layer, it may be directly on, engaged, connected or coupled to the other element or layer, or intervening elements or layers may be present. In contrast, when an element is referred to as being "directly on," "directly engaged to", "directly connected to" or "directly coupled to" another element or layer, there may be no intervening elements or layers present. Other words used to describe the relationship between elements should be interpreted in a like fashion (e.g., "between" versus "directly between," "adjacent" versus "directly adjacent," etc.). As used herein, the term "and/or" includes any and all combinations of one or more of the associated listed items.
[0052] Although the terms first, second, third, etc., may be used herein to describe various elements, components, regions, layers and/or sections, these elements, components, regions, layers and/or sections should not be limited by these terms. These terms may be only used to distinguish one element, component, region, layer or section from another element, component, region, layer or section. Terms such as "first," "second," and other numerical terms when used herein do not imply a sequence or order unless clearly indicated by the context. Thus, a first element, component, region, layer or section discussed below could be termed a second element, component, region, layer or section without departing from the teachings of the exemplary embodiments.
[0053] Computer-implemented platforms, engines, systems and methods of use are disclosed herein that provide networked access to a plurality of types of digital content, including but not limited to video, image, text, audio, metadata, algorithms, interactive and document content, and that track, deliver, manipulate, transform and report the accessed content. Described embodiments of these platforms, engines, systems and methods are intended to be exemplary and not limiting. As such, it is contemplated that the herein described systems and methods may be adapted to provide many types of server and cloud-based valuations, interactions, data exchanges, and the like, and may be extended to provide enhancements and/or additions to the exemplary platforms, engines, systems and methods described. The disclosure is thus intended to include all such extensions.
[0054] Furthermore, it will be understood that the terms "module" or "engine", as used herein does not limit the functionality to particular physical modules, but may include any number of tangibly-embodied software and/or hardware components having a transformative effect on at least a portion of a system. In general, a computer program product in accordance with one embodiment comprises a tangible computer usable medium (e.g., standard RAM, an optical disc, a USB drive, or the like) having computer-readable program code embodied therein, wherein the computer-readable program code is adapted to be executed by a processor (working in connection with an operating system) to implement one or more functions and methods as described below. In this regard, the program code may be implemented in any desired language, and may be implemented as machine code, assembly code, byte code, interpretable source code or the like (e.g., via C, C++, C #, Java, Actionscript, Objective-C, Javascript, CSS, XML, etc.).
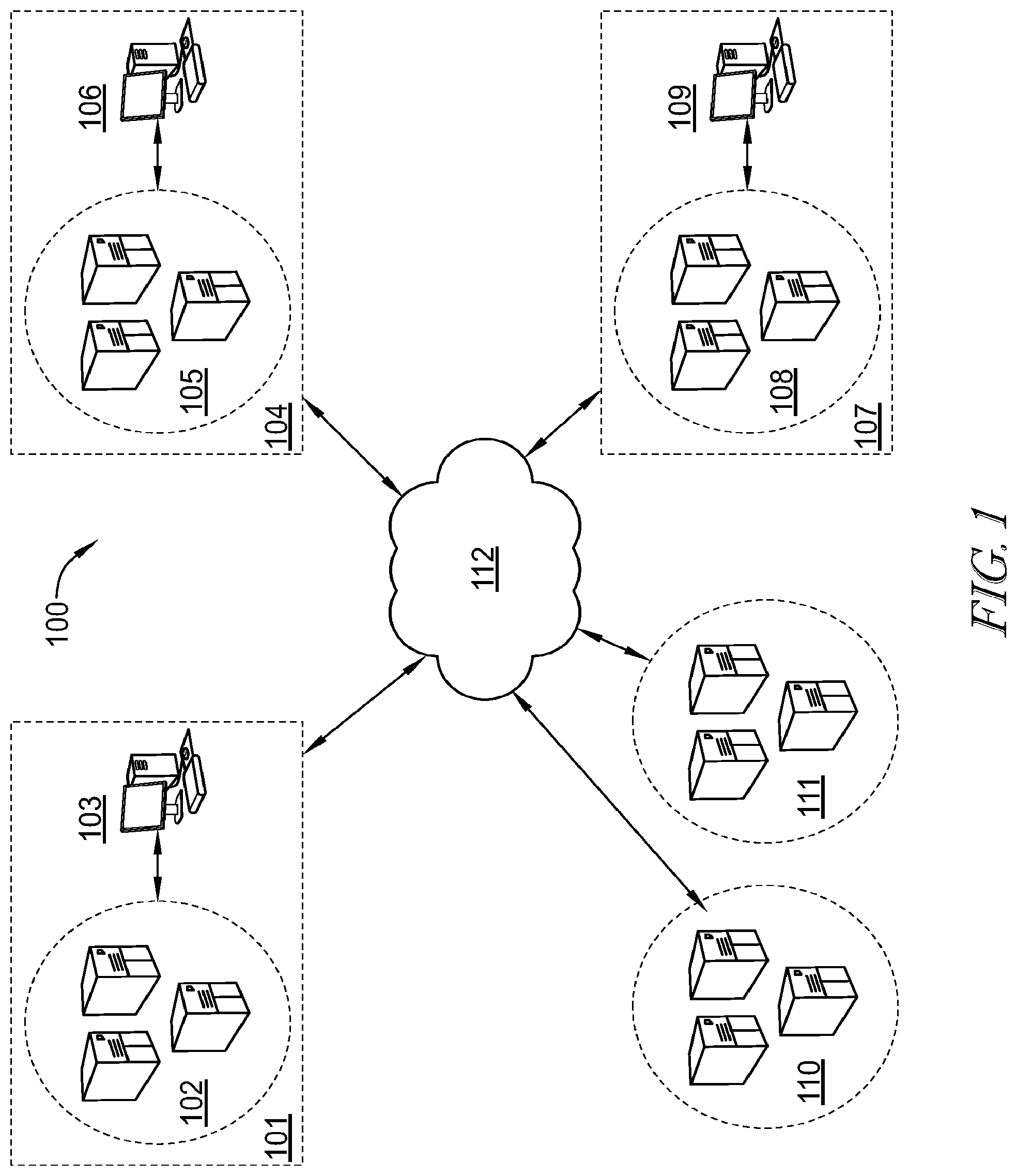
[0055] Turning to FIG. 1, an exemplary computer system is disclosed in an embodiment. In this example, computer system 100 is configured as a SCM processing system, wherein primary processing node 101 is configured to contain an SCM platform for processing data from other nodes (104, 107), which will be described in further detail below. In one embodiment, primary node 101 comprises one or more servers 102 operatively coupled to one or more terminals 103. Primary node 101 is communicatively coupled to network 112, which in turn is operatively coupled to supply chain nodes 104, 107. Nodes 104, 107 may be configured as standalone nodes or, preferably, as network nodes, where each node 104, 107 comprises network servers 105, 108 and terminals 106, 109, respectively.
[0056] As will be explained in the embodiments discussed below, nodes 104, 107 may be configured as assembly nodes, part nodes, supplier nodes, manufacturer nodes and/or any other suitable supply chain node. Each of these nodes may be configured to collect, store, and process relevant supply chain-related data and transmit the SCM data to primary node 101 via network 112. Primary node 101 may further be communicatively coupled to one or more data services 110, 111 which may be associated with governmental, monetary, economic, meteorological, etc., data services. Services 110, 111 may be third-party services configured to provide general environmental data relating to SCM, such as interest rate data, tax/tariff data, weather data, trade data, currency exchange data, and the like, to further assist in SCM processing. Primary node 101 may be "spread" across multiple nodes, rather than comprising a single node, may access data at any one or more of a plurality of layers from nodes 104, 107, and may be capable of applying a selectable one or more algorithms, applications, calculations, or reporting in relation to any one or more data layers from nodes 104, 107.
[0057] FIG. 2 is an exemplary embodiment of a computing device 200 which may function as a computer terminal (e.g., 103), and may be a desktop computer, laptop, tablet computer, smart phone, or the like. Actual devices may include greater or fewer components and/or modules than those explicitly depicted in FIG. 2. Device 200 may include a central processing unit (CPU) 201 (which may include one or more computer readable storage mediums), a memory controller 202, one or more processors 203, a peripherals interface 1204, RF circuitry 205, audio circuitry 206, a speaker 221, a microphone 222, and an input/output (I/O) subsystem 223 having display controller 218, control circuitry for one or more sensors 216 and input device control 214. These components may communicate over one or more communication buses or signal lines in device 200. It should be appreciated that device 200 is only one example of a multifunction device 200, and that device 200 may have more or fewer components than shown, may combine two or more components, or a may have a different configuration or arrangement of the components. The various components shown in FIG. 2 may be implemented in hardware or a combination of hardware and tangibly-embodied, non-transitory software, including one or more signal processing and/or application specific integrated circuits.
[0058] Data communication with device 200 may occur via a direct wired link or data communication through wireless, such as RF, interface 205, or through any other data interface allowing for the receipt of data in digital form. Decoder 213 is capable of providing data decoding or transcoding capabilities for received media, and may also be enabled to provide encoding capabilities as well, depending on the needs of the designer. Memory 208 may also include high-speed random access memory (RAM) and may also include non-volatile memory, such as one or more magnetic disk storage devices, flash memory devices, or other non-volatile solid-state memory devices. Access to memory 208 by other components of the device 200, such as processor 203, decoder 213 and peripherals interface 204, may be controlled by the memory controller 202. Peripherals interface 204 couples the input and output peripherals of the device to the processor 203 and memory 208. The one or more processors 203 run or execute various software programs and/or sets of instructions stored in memory 208 to perform various functions for the device 200 and to process data including SCM data. In some embodiments, the peripherals interface 204, processor(s) 203, decoder 213 and memory controller 202 may be implemented on a single chip, such as a chip 201. In some other embodiments, they may be implemented on separate chips.
[0059] The RF (radio frequency) circuitry 205 receives and sends RF signals, also known as electromagnetic signals. The RF circuitry 205 converts electrical signals to/from electromagnetic signals and communicates with communications networks and other communications devices via the electromagnetic signals. The RF circuitry 205 may include well-known circuitry for performing these functions, including but not limited to an antenna system, an RF transceiver, one or more amplifiers, a tuner, one or more oscillators, a digital signal processor, a CODEC chipset, a subscriber identity module (SIM) card, memory, and so forth. RF circuitry 205 may communicate with networks, such as the Internet, also referred to as the World Wide Web (WWW), an intranet and/or a wireless network, such as a cellular telephone network, a wireless local area network (LAN) and/or a metropolitan area network (MAN), and other devices by wireless communication. The wireless communication may use any of a plurality of communications standards, protocols and technologies, including but not limited to Global System for Mobile Communications (GSM), Enhanced Data GSM Environment (EDGE), high-speed downlink packet access (HSDPA), wideband code division multiple access (W-CDMA), code division multiple access (CDMA), time division multiple access (TDMA), BLE, Bluetooth, Wireless Fidelity (Wi-Fi) (e.g., IEEE 802.11a, IEEE 802.11b, IEEE 802.11g and/or IEEE 802.11n), voice over Internet Protocol (VoIP), Wi-MAX, a protocol for email (e.g., Internet message access protocol (IMAP) and/or post office protocol (POP)), instant messaging (e.g., extensible messaging and presence protocol (XMPP), Session Initiation Protocol for Instant Messaging and Presence Leveraging Extensions (SIMPLE), and/or Instant Messaging and Presence Service (IMPS)), and/or Short Message Service (SMS)), or any other suitable communication protocol, including communication protocols not yet developed as of the filing date of this document.
[0060] Audio circuitry 206, speaker 221, and microphone 222 may provide an audio interface between a user and the device 200. Audio circuitry 1206 may receive audio data from the peripherals interface 204, converts the audio data to an electrical signal, and transmits the electrical signal to speaker 221. The speaker 221 converts the electrical signal to human-audible sound waves. Audio circuitry 206 also receives electrical signals converted by the microphone 221 from sound waves, which may include audio. The audio circuitry 206 converts the electrical signal to audio data and transmits the audio data to the peripherals interface 204 for processing. Audio data may be retrieved from and/or transmitted to memory 208 and/or the RF circuitry 205 by peripherals interface 204. In some embodiments, audio circuitry 206 also includes a headset jack for providing an interface between the audio circuitry 206 and removable audio input/output peripherals, such as output-only headphones or a headset with both output (e.g., a headphone for one or both ears) and input (e.g., a microphone).
[0061] I/O subsystem 223 couples input/output peripherals on the device 200, such as touch screen 215 and other input/control devices 217, to the peripherals interface 204. The I/O subsystem 223 may include a display controller 218 and one or more input controllers 220 for other input or control devices. The one or more input controllers 220 receive/send electrical signals from/to other input or control devices 217. The other input/control devices 217 may include physical buttons (e.g., push buttons, rocker buttons, etc.), dials, slider switches, joysticks, click wheels, and so forth. In some alternate embodiments, input controller(s) 220 may be coupled to any (or none) of the following: a keyboard, infrared port, USB port, and a pointer device such as a mouse, an up/down button for volume control of the speaker 221 and/or the microphone 222. Touch screen 215 may also be used to implement virtual or soft buttons and one or more soft keyboards.
[0062] Touch screen 215 provides an input interface and an output interface between the device and a user. The display controller 218 receives and/or sends electrical signals from/to the touch screen 215. Touch screen 215 displays visual output to the user. The visual output may include graphics, text, icons, video, and any combination thereof (collectively termed "graphics"). In some embodiments, some or all of the visual output may correspond to user-interface objects. Touch screen 215 has a touch-sensitive surface, sensor or set of sensors that accepts input from the user based on haptic and/or tactile contact. Touch screen 215 and display controller 218 (along with any associated modules and/or sets of instructions in memory 208) detect contact (and any movement or breaking of the contact) on the touch screen 215 and converts the detected contact into interaction with user-interface objects (e.g., one or more soft keys, icons, web pages or images) that are displayed on the touch screen. In an exemplary embodiment, a point of contact between a touch screen 215 and the user corresponds to a finger of the user. Touch screen 215 may use LCD (liquid crystal display) technology, or LPD (light emitting polymer display) technology, although other display technologies may be used in other embodiments. Touch screen 215 and display controller 218 may detect contact and any movement or breaking thereof using any of a plurality of touch sensing technologies now known or later developed, including but not limited to capacitive, resistive, infrared, and surface acoustic wave technologies, as well as other proximity sensor arrays or other elements for determining one or more points of contact with a touch screen 215.
[0063] Device 200 may also include one or more sensors 216 such as optical sensors that comprise charge-coupled device (CCD) or complementary metal-oxide semiconductor (CMOS) phototransistors. The optical sensor may capture still images or video, where the sensor is operated in conjunction with touch screen display 215. Device 200 may also include one or more accelerometers 207, which may be operatively coupled to peripherals interface 1204. Alternately, the accelerometer 207 may be coupled to an input controller 214 in the I/O subsystem 211. The accelerometer is preferably configured to output accelerometer data in the x, y, and z axes.
[0064] In one embodiment, the software components stored in memory 208 may include an operating system 209, a communication module 210, a text/graphics module 211, a Global Positioning System (GPS) module 212, audio decoder 1213 and applications 214. Operating system 209 (e.g., Darwin, RTXC, LINUX, UNIX, OS X, Windows, or an embedded operating system such as VxWorks) includes various software components and/or drivers for controlling and managing general system tasks (e.g., memory management, storage device control, power management, etc.) and facilitates communication between various hardware and software components. A SCM processing platform may be integrated as part of operating system 209, or all or some of the disclosed portions of SCM processing may occur within the one or more applications 214. Communication module 210 facilitates communication with other devices over one or more external ports and also includes various software components for handling data received by the RF circuitry 205. An external port (e.g., Universal Serial Bus (USB), Firewire, etc.) may be provided and adapted for coupling directly to other devices or indirectly over a network (e.g., the Internet, wireless LAN, etc.).
[0065] Text/graphics module 211 includes various known software components for rendering and displaying graphics on a screen and/or touch screen 215, including components for changing the intensity of graphics that are displayed. As used herein, the term "graphics" includes any object that can be displayed to a user, including without limitation text, web pages, icons (such as user-interface objects including soft keys), digital images, videos, animations and the like. Additionally, soft keyboards may be provided for entering text in various applications requiring text input. GPS module 212 determines the location of the device and provides this information for use in various applications. Applications 214 may include various modules, including address books/contact list, email, instant messaging, video conferencing, media player, widgets, instant messaging, camera/image management, and the like. Examples of other applications include word processing applications, JAVA-enabled applications, encryption, digital rights management, voice recognition, and voice replication. Under one embodiment, a 3D object may have access to any or all of features in memory 208.
[0066] Turning to FIG. 3A, a SCM operating platform 307 is disclosed, wherein platform 307 may reside at a primary node 101. Platform 307 may be configured to perform and/or control SCM data processing on data received from external nodes 104, 107 and other data sources 110, 111. Platform 307 is operatively coupled to control module 302, which may be configured to process, connect and visualize nodes and their respective geographic locations. Network optimization module 303 processes SCM data to determine which nodes and links meet or exceed predetermined risk thresholds and determines new nodes and/or links that may be added, deleted and/or substituted to establish more efficient network optimization.
[0067] Supply chain analytics module 304 may be configured to process incoming supply chain data and forward results to platform 307 for storage, distribution to other modules and/or for further processing. Supplier radar module 305 may be configured to process SCM data to determine supplier geographic impact and/or geographical risk. Supply/demand processing module 306 may be configured to receive and process supply and demand data for determining supply/demand values for various nodes. Each of modules 302-306 may share data between themselves via platform 307. Platform 307 may further be configured to generate visualizations, such as media, charts, graphs, node trees, and the like, for inspection and/or follow-up action by a user.
[0068] The platform of FIG. 3A is configured to utilize extensive data across many primary and secondary nodes, advanced analytics, logic and visualization to convert extensive, voluminous unstructured data into an easy-to-action, prioritized list of tasks for improved SCM functionality. One advantageous effect of the platform is that it is effective in identifying actual and potential opportunities of improvement, such as based on analysis of extended historical data of similar or related supply chains. These opportunities are designed to streamline and optimize SCM by generating better SCM terms, models and implementation of optimal parameter settings. The techniques described herein, and their advantageous effects are sometimes referred to as "actionable measurable proactive" (AMP) processing techniques.
[0069] FIG. 3B illustrates, at the primary node 101 of a data exchange diagram, platform 307. In the illustration, platform 307 may provide a plurality of rules and processes, such as the aforementioned analytics, exception management, risk management, and visualization techniques, that may be applied by one or more modules. That is, access to the rules and processes provided by the platform may be available to the aforementioned modules. Thus, these applications, also referred to herein as "apps" or modules, may be "thin client", wherein the processes reside entirely within the platform's processing and are accessed by the app; "thick client," wherein the processes reside entirely within the app's processing; or partially thin client, wherein processing and rule application is shared between the app and the platform.
[0070] Data inputs for the one of more modules, also referred to in the pertinent art as "data hooks" for "apps," may be associated with the platform 307, and thus may obtain data that is made available by the platform, such as may be obtained from hardware or software outputs provided from nodes 104, 107 and/or sources 110, 111. As illustrated, data may be received in platform modules for risk management 311, analytics 312, information visualization 313 and exception management 314. The data may be provided in the form of network optimization data 321, supply chain analytics data 322, design/engineering/technology data 315, consumer intelligence data 316, supplier data 317, procurement data 318, operations data 321, and supply and demand data 319, by way of non-limiting example. Output data from any given app may be provided through visualization rules unique to the app and within the app, or via the platform, such as within a discreet display aspect for a given app within the platform. Output data from any given app may be provided, such as through visualization rules unique to the app, within the app, or via the platform, such as within a discreet display aspect, such as a drop down, top line, or side line menu, for a given app within the platform.
[0071] Moreover, primary data employed by the platform and its associated apps may be atypical of that employed by conventional SCM systems. For example, customer intelligence data may include social media trends and/or third party data feeds in relation to a supply chain, or for all supply chains for similar devices, device lines, or for device lines including the same or a similar part. Secondary data derived from the third party data sources for a device, for example, allows for secondary data to be derived therefrom in relation to inventory stock, the need for alternate sourcing, and the like. For example, a negative overall indication on a device, as indicated by social media data drawn from one or more networked social media locations, would indicate a need for decreased inventory (since a negative consumer impression likely indicates an upcoming decrease in sales), notwithstanding any request by the seller of the device to the contrary. This need for decreased inventory may also dictate modifications for the presently disclosed SCM of the approach to other aspects of the supply chain, such as parts needed across multiple customers, the need to de-risk with multiple sources for parts, the need to ship present inventory in a certain timeframe, and the like. This same data may be mined for other purposes, such as to assess geopolitical, weather, and like events.
[0072] The disclosure thus provides a SCM operating platform 307 suitable for receiving base data from the supply chain, and/or from a data store, and/or from third party networked sources, and applying thereto a plurality of rules, algorithms and processes to produce secondary data. This secondary data may be made available within the platform, and/or may be made available to one or more apps, to provide indications to the user based on the applied rules, algorithms and processes. Therefore, the disclosure makes use of significant amounts of data across what may be thousands of supply chain nodes for a single device line to allow for supply chain management, risk management, supply chain monitoring, and supply chain modification, in real time. Further, the platform has the capability to integrate with multiple systems within the firewall of a customer's network and/or outside the firewall. These systems may include, by way of non-limiting example, enterprise resource planning (ERP) systems, Materials Requirement Planning (MRP) systems, point solution systems, and proprietary data source systems. Moreover, based on the significant data available to the platform, the platform and/or its interfaced apps may "learn" from certain of the data received, such as trend data fail point data, or the like, in order to modify the aforementioned rules, algorithms and processes, in real time and for subsequent application. The disclosure herein may thus relate to a platform that has the capability to profile, validate and/or monitor data for its quality.
[0073] Because the apps disclosed make use of the data, rules, algorithms, and processes provided by the platform, any number of different component apps may be provided. Apps may interface with the platform solely to obtain data, and may thereafter apply unique app-based rules, algorithms and processes to the received data; or apps may make use of the data and some or all of the rules, learning algorithms, and processes of the platform and may solely or most significantly provide variations in the visualizations regarding the secondary data produced. Those skilled in the art will thus appreciate, in light of the instant disclosure, that various of the apps and data discussed herein throughout are exemplary only, and thus various other apps, data input, and data output may be provided without departing from the spirit or scope of the invention.
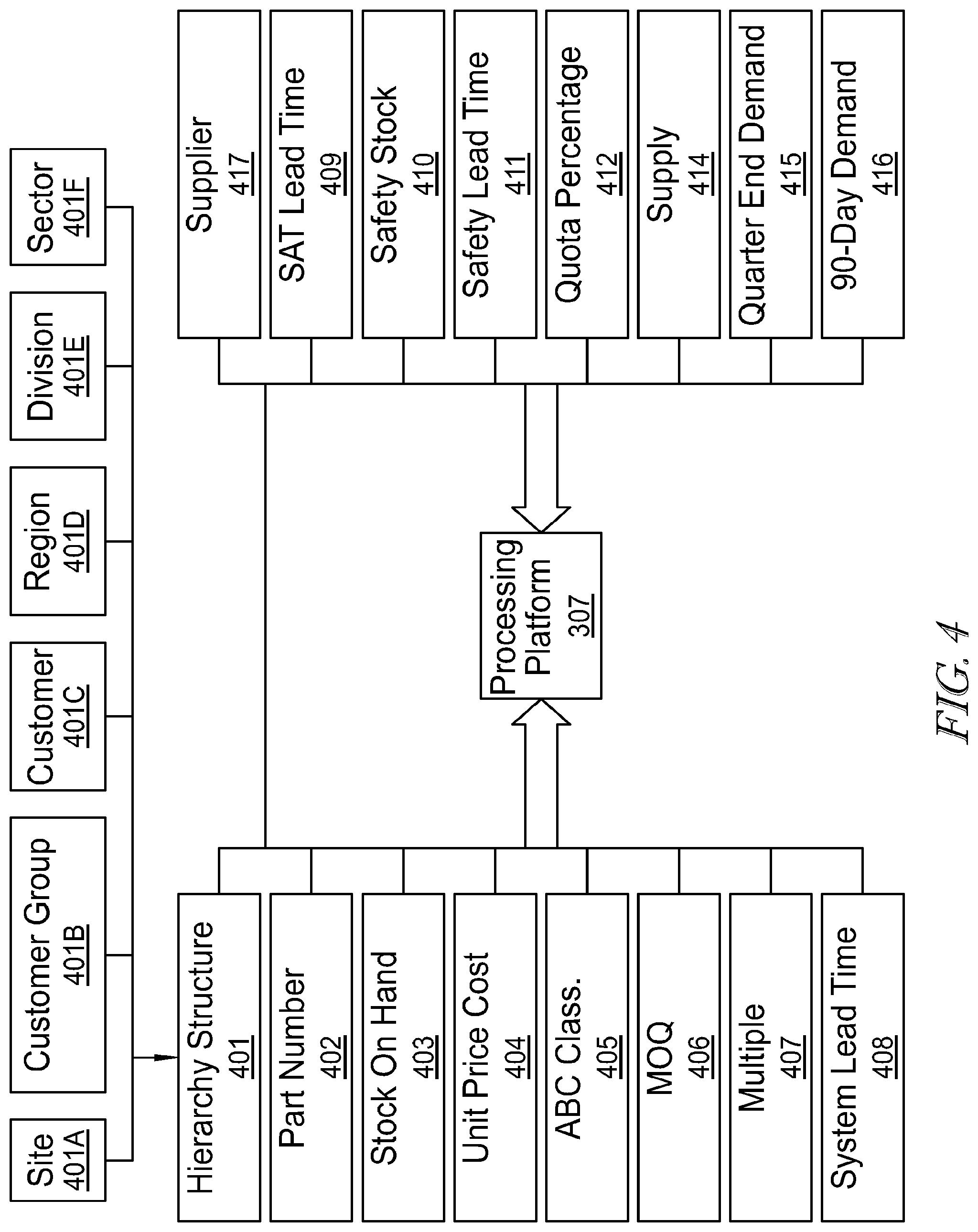
[0074] Turning now to FIG. 4, an embodiment is illustrated for a materials system utilizing the platform 307 of FIG. 3. As SCM data is entered into the system, various data points, variables and loads are entered into the SCM system database for processing and/or distribution to any of the various modules described herein. For each node, a hierarchy structure 401 is determined, which may comprise one or more sites 401A, customer groups 401B, customers 401C, region 401D, division 401E and sector 401E. It is understood by those skilled in the art that the hierarchical structure data points may include additional, other, data points, or may contain fewer data points as the case may be.
[0075] Other entries in the embodiment of FIG. 4 include part number 402, which may comprise unique customer material component numbers for each part. Stock on hand 403 may comprise data relating to a current quantity of each component in stock by ownership. For example, quantity data may be segregated among manufacturers, suppliers and customers. It may be understood by those skilled in the art, in light of the instant disclosure, that other entries and segregations are contemplated by the present disclosure. For example, data may also be segregated among types, such as Raw, Work In Process (WIP) and Finished Goods (FG). Data may likewise be segregated by location, such as by Warehouse, Manufacturing Line, Test, Packout, Shipping, etc., or by using any other methodology that may be contemplated by the skilled artisan in view of the discussion provided herein.
[0076] Unit price 404 may contain data relating to a cost per component. The cost may be determined via a materials cost, labor cost, or some combination. ABC classification 405 may comprise a classification value of procurement frequency (e.g., every 7 days, 14 days, 28 days, etc.).
[0077] ABC Analysis is a term used to define an inventory categorization technique often used in materials management. It is also known as Selective Inventory Control. Policies based on ABC analysis are typically structured such that "A" items are processed under very tight control and accurate records, "B" items are processed under less tightly controlled and good records, and "C" items are processed under the simplest controls possible and minimal records. ABC analysis provides a mechanism for identifying items that will have a significant impact on overall inventory cost, while also providing a mechanism for identifying different categories of stock that will require different management and controls. ABC analysis suggests that inventories of an organization are not of equal value. Thus, the inventory is grouped into three categories (A, B, and C) in order of their estimated importance. Accordingly, "A" items are very important for an organization. Because of the high value of these "A" items, frequent value analysis is required. In addition to that, an organization needs to choose an appropriate order pattern (e.g. "just-in-time") to avoid excess capacity. "B" items are important, but less important than "A" items and more important than "C" items (marginally important). Accordingly, "B" items may be intergroup items. ABC type classifications within the system may help dictate how often materials are procured. By way of non-limiting example, to limit the value of inventory holding and risk, A Classes may be predominantly ordered once per week, B Classes bi-weekly, and C Classes monthly.
[0078] MOQ 406 may comprise data relating to a component minimum order quantity for a predetermined time period. This value may be advantageous in determining, for example, a minimum order quantity that must be procured over a predetermined time period. Multiple 407 may comprise data relating to component multiple quantities, such as multiples for demand more than the MOQ value. System lead time 408 may comprise data relating to a system period of time required to release a purchase order prior to receiving components.
[0079] Continuing with the example of FIG. 4, supplier 417 may comprise identity data relating to a component source supplier. Sourcing Application Tool (SAT) lead time 409 may comprise a supplier quoted period of time required to release a purchase order prior to receiving components. Safety stock 410 may comprise component and FG buffer stock data relating to a buffer stock quantity that will be excluded from available stock until a shortage status is detected. Safety lead time 411 may comprise component buffer lead time data that may be utilized to recommend a component be delivered in an on-time or earlier-than-expected manner. Quota percentage 412 may comprise data relating to a percentage of supply which should be allocated to each component source supplier. Supply 414 may comprise data relating to supply quantity per component over a predetermined (e.g., 90-day) time period. 90-day demand 416 may comprise data relating to customer demand quantity per component over a 90-day time period. Manufacturers of one or more components may also be tracked separately from suppliers. In some cases, a supplier may act as a distributor by stocking parts from different manufacturers to make them quickly available, but typically at a higher price. Here, supply chain models, such as consigned material and/or vendor managed processes, may be used to assist in identifying and potentially offsetting the extra cost.
[0080] Utilizing the exemplary platform illustrated in FIG. 3 and FIG. 4, a number of advantageous SCM processing determinations may be made. In one example, optimal values or actions may be generated based on predetermined logic. For example, a MOQ may be determined to be 10,000 units, while an optimal MOQ quantity is calculated to be 6,000 units. Calculating an area of improvement based on predefined logic, the reduction of current MOQ may be calculated to be 4,000 units (10,000-6,000). Data values calculated for improvement may be determined according to predefined logic, wherein for the exemplary MOQ improvement of 4,000 units, a unit value multiplier of $1 would yield an improvement "opportunity" value of $4,000. As used herein, the phrase "opportunity value" may be used to indicate a particular area of data, such as an item source, a replacement part, an inventory level, or the like, that provides an opportunity to improve an indicated area of the supply chain, such as de-risking, lowering costs, increasing available sources, optimizing inventory levels, or the like.
[0081] In addition, one or more opportunity thresholds may be set for each component, and a resulting prioritization may be determined. For example, the system may be configured to only list components with an opportunity value greater than $1,000, where opportunities are sorted in a descending value. Ownership of each component may be assigned, where the system may notify users associated with an ownership entity. Each component may be assigned to multiple users or a single user, and largest opportunities may be identified and notified first. Owners may assign actions, add comments, and potentially escalate SCM data. For example, owners may advise which actions have been taken or escalate data for resolution, etc. When all options and/or system negotiations are completed or exhausted, the system may manually or automatically close a SCM task associated with the data.
[0082] In the field of SCM processing, various data points have been used to improve a supply chain. However, the present applicants have identified a number of data areas that are relatively efficient to obtain and process. These data areas are opportunity value areas that have potentially been overlooked by conventional approaches, but have been found to be useful in determining better days in inventory, inventory turn and cash flow, among others. One data area includes MOQ, which provides opportunities to reduce MOQ to an optimal quantity using logic based on order frequency, multiple quantities and demand profiles. Another data area includes safety stock, which provides opportunities to reduce safety stock levels using logic based on order frequency and demand profiles to an optimal safety stock (buffer quantity). Yet another data point includes lead time, which may provide opportunities to reduce procurement lead times with higher system parameters versus an active quotes database.
[0083] A still further data point includes safety lead time, which may provide opportunities to reduce safety lead times based on removal of system parameters and/or reducing excessive parameters. Excess inventory data points may also provide opportunities to reduce owned excess inventory based on a rolling measurement and highlight supplier returns privileges. Supply not required data points may also provide opportunity to reduce, divert, cancel, etc., material arriving within a certain period which is not required to meet customer demand. Of course the aforementioned data points are not exclusive and may be combined with other data points discussed in the present disclosure or other data points known in the art.
[0084] Thus, for example and as further illustrated with regard to FIGS. 5A-5F, 6-7, and 8A and B, described below, derived secondary data may be provided to indicate, for example, a recommended buffer for an inventoried part. A risk calculation, as discussed in more detail below with regard to FIGS. 9-12, may indicate that a particular part is a high risk part (such as because it is from a small, sole source, foreign supplier). Further, as is often the case with a high risk part, the indication may be that the part is relatively inexpensive in relation to other parts for a given device. Consequently, the presently disclosed SCM platform 307, notwithstanding a calculation that the optimal procurement time may be 14 days, may derive secondary data from the combinations of the optimal procurement secondary data, the risk associated with the part, and the cost of the part, that a 28 day buffer should be ordered for the part at each of the next two 14 day procurement windows--thereby increasing the buffer for this key, high risk part using the learning algorithms of the platform 307. That is, the disclosed embodiments may perform balancing of input primary and derived secondary data to arrive at a solution that is optimal when considering a wide range of factors, but which is not necessarily optimal for any given factor.
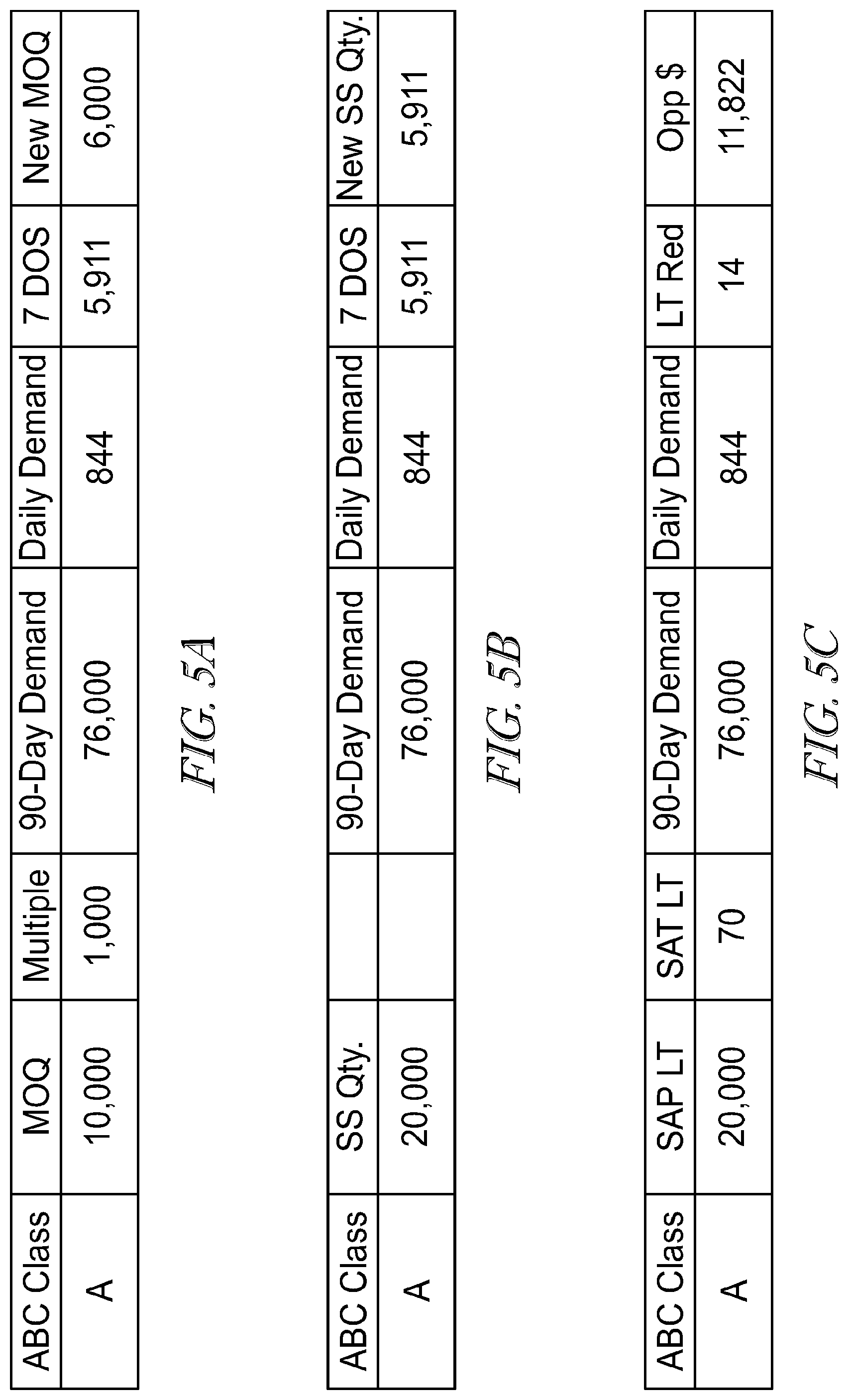
[0085] FIGS. 5A-5F illustrates various examples of data processing under various embodiments. FIG. 5A provides an exemplary process based on MOQ data points. In this example, the logic is to process an ABC classification, indicating how often a component is procured. For example, an "A" class part may be procured every 7 days, class "B" 14 days and class "C" 28 days. The MOQ and multiple (Pack Size) data points are then processed in the system over a predetermined time period (e.g., 90 days). Referring to FIG. 5A, the system calculates a 7 day-of-service (DOS) quantity of 5,911 based on a daily forward looking demand of 844. If the system is configured to have a DOS threshold of 7 days, the respective multiple quantity of 1,000 may be rounded up to greater than the 7 DOS quantity, which results in a new MOQ of 6,000 (6.times. multiple qty. 1,000). Here, the supplier may be notified to reduce MOQ to 6,000, as the purchaser will not want to purchase more than 7 DOS for a class "A" part. Furthermore, if a multiple quantity is a genuine pack size, then the purchaser may be able to purchase 6 units instead of 10. Since the unit reduction is calculated to be 4,000 (10,000-6,000), the reduction value may be multiplied by the unit value to determine a total opportunity value. This calculation in turn may be used by the system to effect monthly/quarterly ending inventory values. Such a configuration advantageously improves end-of-life situation and reduce liability within a supply chain.
[0086] Turning to FIG. 5B, the exemplary embodiment provides an illustrative process based on safety stock data points. In this example, the system determines if a safety stock is available, and, if one is available, a similar ABC and daily demand logic described above is applied. The daily demand quantity is used to calculate what seven, fourteen and 28 DOSs should be, and, if the part safety stock quantity is greater than this value, then a new safety stock quantity is established. In one example, class "A" part of 5,911 quantity is determined to have a 7 DOS. Accordingly, the system automatically sets a new SS quantity at 5,911. One reason for this is that, for class "A" parts, a location should not be holding more than 7 days safety stock, (unless otherwise configured by the system), as this pulls the full order book from suppliers early and may affect ending inventory values. In the example of FIG. 5B, the same process may be repeated for "B" and "C" classes for 14 and 28 day time periods, respectively.
[0087] FIG. 5C illustrates an exemplary embodiment using lead time data points. Lead time data is more straightforward to process, where the system simply takes a SAT quote for the part and supplier combination. If the system finds a quote and the lead time is less than what is entered in the system, additional processing steps may be taken. First, daily demand quantity is calculated, and, based on this, the system uses the difference between the current lead time and the SAT lead time to calculate an opportunity value. As an example, assuming a unit cost is $1, and a lead time reduction is 84 days in SAP versus 70 days in SAT (14 days), the 14 day reduction may be processed with a daily demand value such that 844.times.$1=$844.times.14 days=$11,822.
[0088] In FIG. 5D, an exemplary embodiment is provided using safety lead time data points. Similar to lead time, safety lead time is straightforward for the system to process, where the system looks for the removal of the full SLT if the SLT indicator is set. In this case, the system calculates a daily demand quantity, and, based on this, it uses a reduction of a current SLT to calculate an opportunity value. For example, assuming a unit cost is $1, and the SLT is 10 days in SAP, the daily demand value (844.times.$1=$844) is multiplied by the reduction of 10 days, which results in $8,444.
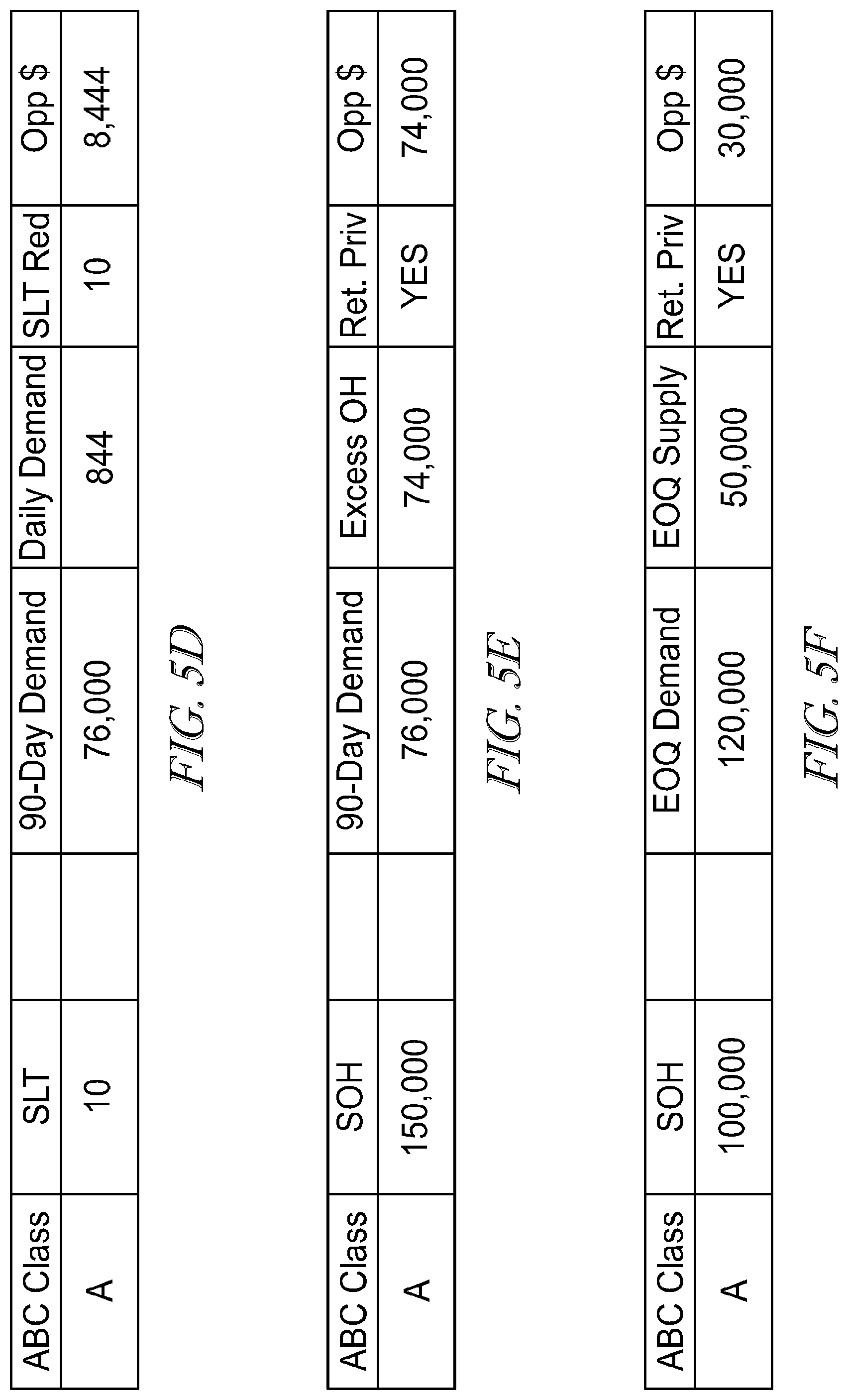
[0089] In FIG. 5E, an exemplary embodiment is illustrated for the system utilizing excess stock data points. Here the owned stock on hand is compared to the next 90 days of demand. If the stock is greater than the specified demand, then the remaining quantity is then used as an excess quantity. As such, an opportunity value may be calculated, based on a product of the standard unit cost. For example, if 150,000 units of stock is on hand, and the next 90 days demand (which may include past demand) is only 76,000, the system would process the data such that 150,000-76,000=74,000. Again assuming a unit cost of $1, the opportunity value may be determined to be $74,000. In one embodiment, the system may also highlight is the part/unit has potential supplier returns privileges in place via a connection to SAT.
[0090] In FIG. 5F, a supply not required data point processing embodiment is shown. In this example, certain supplier purchase orders are not required to meet current quarter demands. Here, the opportunity value is not necessarily limited the purchase order quantity (e.g., use exception); the system calculates a quantity arriving within a quarter which is greater that a needed quantity. For example, assuming a unit cost is $1 and the stock on hand is 100,000, the demand unit quarter end is 12,000 and a supply unit QTR end is 50,000. Here the system would process the data points as (100,000+50,000)-120,000=30,000 (or $30,000 that is not required, representing $30,000 of opportunity)
[0091] In addition to the examples provided in FIGS. 5A-F, other variables may be utilized by the system for optimization. For example, master production schedule (MPS) tactical rules may be employed to generate a scorecard format in order to identify areas of concern and opportunity. By using a plurality of variables as inputs, an MPS may be configured to generate a set of outputs for decision making within the system. Inputs may include any of the data points disclosed herein, as well as forecast demand, production costs, inventory money, customer needs, inventory progress, supply, lot size, production lead time, and capacity. Inputs may be automatically generated by the system by linking one or more departments at a node with a production department. For instance, when a sale is recorded, the forecast demand may be automatically shifted to meet the new demand. Inputs may also be inputted manually from forecasts that have also been calculated manually. Outputs may include amounts to be produced, staffing levels, quantity available to promise, and projected available balance. Outputs may be used to create a MRP schedule.
[0092] Other variables may include product lead-time stack data, where procurement and manufacturing lead times are stacked (which may also include safety lead times) to an end product level to identify areas of concern and opportunity. Supply chain models may also be used to optimize inventory. For example, if a sub-optimal supply chain model is not in place with current suppliers, arrangements with customers may be processed to improve the supply chain model, which in turn could allow for identification and/or quantification for potential inventory reduction or inventory avoidance opportunities. Supplier payment term data may also be cross-referenced to identify potential extended payment terms to produce better cash flow.
[0093] Generally speaking, certain features and processes described herein are based on a "plan-do-check-act" (PDCA) methodology, where the PDCA cycle may be thought of as a checklist of multiple stages to solve SCM issues. The AMP methodology described above may effectively be used to identify opportunities, and, when no suitable opportunities are available, cycle the system to flag the lack of opportunity and move to another suitable area. The AMP categories should be arranged to prioritize opportunities to highlight the best ones, allowing the user to concentrate on areas having the greatest impact.
[0094] By automating the AMP process, a system may quickly and efficiently identify opportunities. In FIG. 6, an exemplary block diagram of an automatic AMP process is illustrated, where a supply chain dashboard and AMP scorecard for SCM data is generated by the system in 601 and forwarded to automated subscription 602. In certain instances when a process cannot be automated, a manual run and export function 603 may be provided. SCM data may then be processed in a supply chain development manager (SCDM) module/global planning manager (GPM) module that may be part of the system platform. The modules allow for business team analytics and review, where part ownership is assigned and used to provide one or more summary/detail reports issued at predetermined times (e.g., weekly). Once the system has reviewed the relevant data, a process owner utilizing the system may drive action for subsequent negotiation/implementation 609. In instances where unresolved issues arise, an escalation process may flag the issue for higher level system review. As processes are completed (or left unresolved), the system closes the current process.
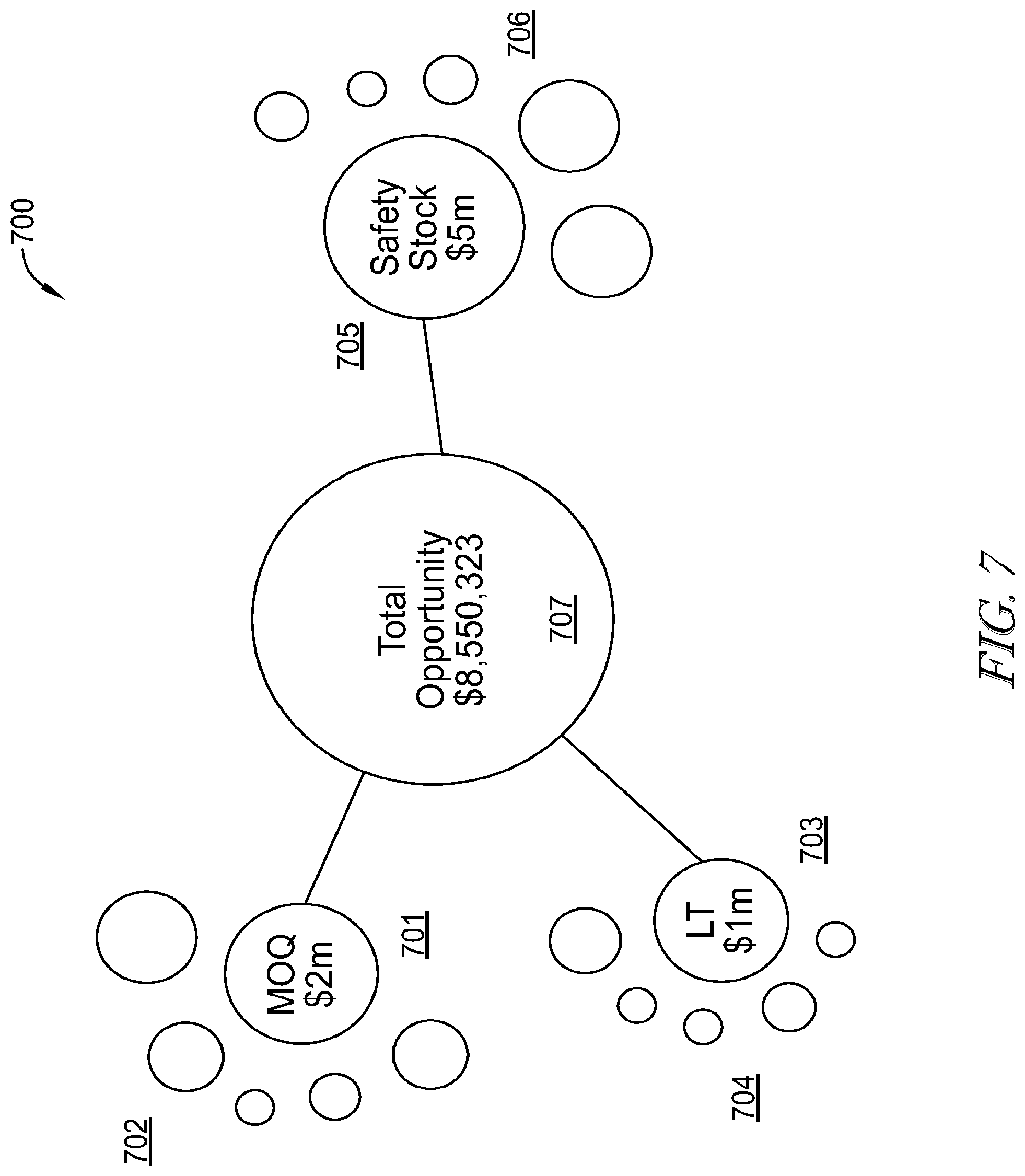
[0095] In addition to data processing, the SCM platform system advantageously packages processed data to be uniquely visualized on a user's screen. In the example of FIG. 7, an exemplary bubble chart 700 is illustrated, where a total opportunity visualization is provided using MOQ, lead time and safety stock data points. Here, various opportunities identified in the system relating to MOQ using any of the techniques described herein. The various identified opportunities are visualized in the system as "bubbles" of varying size 702, where the size of the bubble is dependent upon the size of the opportunity. In this example, MOQ opportunity 701 is identified as having the largest opportunity ($2 M). The remaining bubbles in the exemplary illustration, as well as in certain other examples disclosed herein, may, of course, represent other opportunities available.
[0096] Similarly, lead time opportunities identified by the system are visualized 704, where lead-time opportunity 703 is identified as the largest opportunity ($1 M). Likewise, safety stock opportunities 706 are identified and opportunity 705 is identified as the largest opportunity ($5 M). As each of the largest opportunities are identified (701, 703, 705), they are linked to total opportunity bubble 707 which visualizes a total opportunity value ($8,550,323). The system may be configured such that, as other opportunities (i.e., opportunities other than the largest) are selected, the total opportunity bubble 707 automatically recalculates the total opportunity value for immediate review by a user. Such a configuration is particularly advantageous for analyzing primary and secondary opportunities quickly and efficiently.
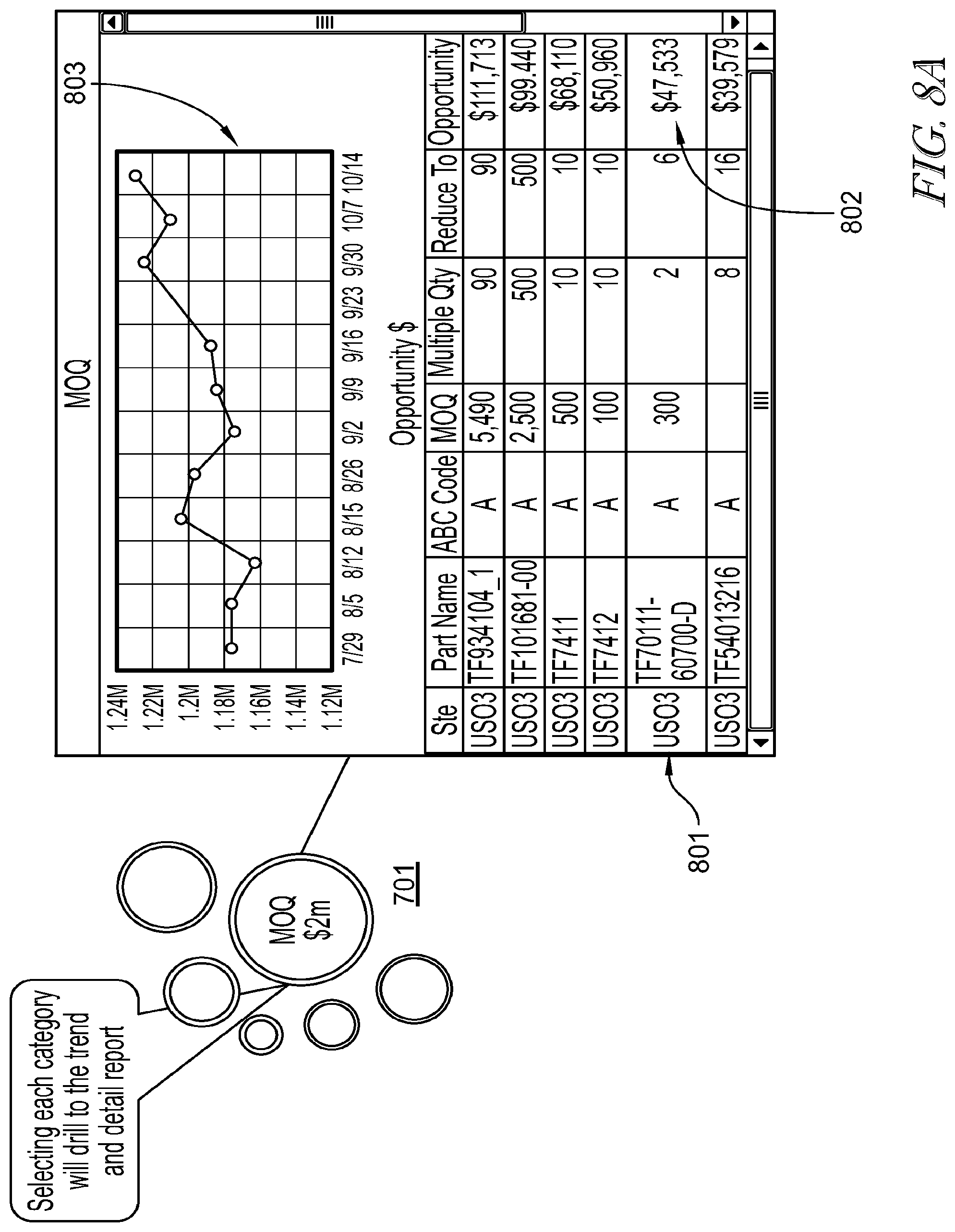
[0097] The bubble data visualization of FIG. 7 may be advantageously configured to provide immediate analytics generated from one or more modules in the system. Turning to FIG. 8A, an exemplary embodiment is provided where opportunity bubble 701 is selected, which in turn launches analytics window 801 comprising graphical 803 and textual 802 representations of the underlying data. In this example, graphical representation 803 comprises a chart illustrating a dollar value opportunity trend spanning a predetermined time period. Textual representation 802 comprises a table, indicating a site location (Ste), part name, ABC code, MOQ, multiple quantity value, reduction value and opportunity value, similar to the embodiments discussed above in connection with FIGS. 5A-F. In chart 802, the component opportunities making up the total MOQ opportunity may be simultaneously viewed to determine greater details surrounding the opportunity.
[0098] FIG. 8B illustrates an embodiment, where, if a system component is selected in section 802, a functionality window 804 is provided for assigning ownership, comments, entering actions and escalation to components of 802. In this example, window 804 enables entry of ownership ("owner") for a part number, and an "assigned by" and assignment date entry for each area (safety stock, MOQ). Comments may be entered into window 804 as shown, together with an action drop-down menu allowing automated action entries such as "not started", "started", "achieved", "unachievable" and "in escalation". For the escalation drop-down menu, escalation system managers may be assigned via the interface for further action.
[0099] As part of the embodiments disclosed herein, the system is further enabled to process and calculate risk(s), and various other factors and related factors, within supply chains, automatically and based on real time data from a variety of sources. Generally speaking, supply chain risks may emanate from geographic risk and attribute-based risk, among others. For geographic risks, manufacturing locations are registered within the system for parts purchased so that when an area becomes volatile because of socio-political, geographic, (macro-) economic, and/or weather-related disruption, related variables may be processed to determine an effect on, or risk to, a supply chain.
[0100] For attribute risk, the system may be configured to calculate a risk-in-supply chain (risk attribute) value, where a risk attribute value is based on a framework that analyzes various different risk categories of the supply chain. FIG. 9 illustrates an exemplary embodiment in which attributes 901-906, along with their respective descriptions 907, are assigned risk weight values 908 to calculate risk. In one embodiment, a total risk attribute score may be based on a 1-5 scale, with 1 representing the least risk and 5 representing the most risk. The weights may be applied to stress attributes that may be more important than others in calculating supply chain risk. After multiplying a score in each category by the associated weight, scores for each part on an end product or assembly may be added up and divided by the number of parts to determine a risk attribute score for each assembly. Next, scores for each assembly for a customer are added up and then divided by the number of assemblies to determine a risk attribute score for the customer.
[0101] In the embodiment of FIG. 9, the example illustrates six attributes: alternative sourcing 901, part change risk 902, part manufacturing risk 903, lead time 904, spend leverage 905 and strategic status 906. It should be understood by those skilled in the art that additional attributes or fewer attributes may be utilized by the system. Moreover, in the illustration, the attributes are weighted by a weighting algorithm (applied at platform 307 or one of its associated apps) at 36%, 19%, 9%, 19%, 19%, and 0%, respectively, although those skilled in the art will appreciate that these weightings may be varied. Additional attributes may comprise defects per million, lot return rate, corrective action count, inventory performance, environmental and regulatory items, security programs (e.g., Customs-Trade Partnership Against Terrorism (C-TPAT)), supplier financial status, supplier audit results and component life cycle stages, among others. It is also worth noting that attributes and weighting may be dependent upon data availability, i.e., algorithms and selected attributes may be modified based on availability, and the data selection and/or aspects of the applied algorithm may be controlled automatically and in real time by platform, and/or control may include or be exclusively indicated by manual inputs of data or aspects of the algorithms.
[0102] An exemplary risk attribute score detail is provided in the embodiment of FIG. 10. The embodiment of FIG. 10 illustrates an exemplary report for an assembly, where the report is based on each of the parts making up the assembly and the associated risk attribute scores. In FIG. 10, a part level report is provided which provides additional detail by part to show risk attribute score specifics. Such a report may break out each category score so that a user may see where, and to what extent, risk exists, and potential courses of action that may be taken to lessen the risk. As is illustrated in FIG. 10, the platform 307, and/or the individual app, may receive primary data and generate therefrom secondary data, such as calculation of the risk attribute score. In the example shown, the primary and secondary data used to generate the risk attribute score is the same as that of FIG. 9, although those skilled in the art will appreciate that other primary and/or derived secondary data may be used in supply chain risk calculations.
[0103] For example, and as illustrated in FIG. 11, if an alternative sourcing category contains a high risk attribute score, a user may investigate the parts where the user requires purchase from only one manufacturer ("sourced parts") which may be causing a high risk attribute score. The user may configure the system to enable or suggest other manufacturers as suppliers which will lower the risk attribute score by diversifying the supply base. Long lead times may increase a risk attribute score as well. As such, a user may configure the system to communicate or order suppliers to lower lead times so that a manufacturer may react quicker to demand changes if the parts can be bought and received in a shorter time period. In either case, the risk attribute system module allows a manufacturer to be a proactive party in the chain and suggest alternative sourcing using an extended supply base to lessen the amount of sole source parts and reduce lead times for a customer. Of course, it is understood by those skilled in the art that the risk attribute calculations disclosed herein may be applied to any aspect or attribute of a supply chain system including parts, suppliers, manufacturers, geography, and so forth.
[0104] FIG. 11 additionally serves to illustrate that a weighting algorithm may be employed with regard to primary and/or secondary data to arrive at requested information, and further that such weighting algorithm may be adjusted over time, such as by platform 307, based on "learning" that occurs upon application of the algorithm. For example, if actual risk is repeatedly indicated as higher than a generated risk attribute score, the weighting algorithm shown in FIG. 11 may be adjusted, and/or the primary and secondary data that is used in the score calculation may be modified, etc., in real time by the platform 307 (and/or by the app making use of the primary data, secondary data, and algorithms provided by the platform 307).
[0105] The risk attribute processing may subsequently be utilized by, and/or may utilize, the SCM platform 307 to generate a heat map to visualize risk attribute scores and their impact easily and quickly for a user. In certain embodiments, heat maps may allow the display of multiple variables, such as revenues and risk. In the illustrative example of FIG. 12, a heat map 1200 is shown for a plurality of assemblies (Assy 101-105), where each assembly is associated with one or more parts. Thus, assembly Assy 101 comprises five primary parts ("parts 201-205"), Assy 102 comprises "parts 206-210", Assy 103 comprises "parts 211-215 and so on.
[0106] In one embodiment, assemblies or parts with higher revenue over a predetermined time period (e.g., 90 days) are visualized with bigger boxes compared to assemblies and/or parts having lower revenue. In addition to size, the heat map may color code boxes to reflect risk attribute scores. The color codes may be configured to show green for low risk, yellow for medium-low risk, orange for medium-high risk and red for high risk. As shown in FIG. 12, the risk attribute module may be configured to utilize a nested "heat map" format for inserting one set of heat maps into a higher level heat map. Thus, the heat maps for parts may be simultaneously visualized with their associated assembly.
[0107] In specific reference to the analytics processing described above, node processing may be conducted in the SCM platform to advantageously reflect node-by-node SCM relationships and conditions, wherein each such node may be subjected to analytics. In one embodiment, a node tree is provided to specify a SCM structure and end-to-end supply chains. In one embodiment, processed nodes are associated with data attributes such as metadata, and nodes are linked in the node tree with node connector indicia indicating a relationship or SCM status between nodes. For example, node connectors may be color coded to identify nodes and connections having supply chain issues (e.g., red), supply chain opportunities (e.g., green), both issues and opportunities (e.g., yellow) and neutral (e.g., white) indicating that threshold issue or opportunity does not exist. The visualization may contain interactive and dynamic filtering capabilities to allow users to track upstream and/or downstream nodes from any node in the supply chain. Of note, although the visual presentation and information provided by the node processing app illustrated herein may differ from that provided by the exemplary risk-scoring app discussed above, the same primary and/or secondary data provided by platform 307 may be accessible to both the node-based and risk-scoring apps, as discussed herein.
[0108] Supply chains, and particularly those in the field of high-tech manufacturing, can be very complex, and, from a data standpoint may be made up of hundreds of thousands of records and data points. The node network interactive data visualization disclosed herein advantageously allows a customer to see the entire supply chain in a single depiction. Using such a depiction, non-supply chain professionals from any level may quickly and efficiently determine important aspects of a supply chain.
[0109] In light of the aforementioned complexities in analyzing independent nodes of the supply chain, customers desire insight into the entire supply chain that is unavailable manually because of these complexities and the volume of data these complexities generate. Consequently, the disclosed software as a service may provide overall supply chain insight on a node-by-node basis. Needless to say, these and other disclosed aspects may require significant data driven aspects of the software as a service for supply chain management. More specifically, these data-driven aspects may include, by way of non-limiting example, visibility into the entire supply chain, including all companies, all resellers, all parts, and so on; analytics capable of analyzing big data in order to assess and balance speed, cost, risk, likelihood of failure, recommended replacements and modifications, and to enable the waiting and balancing of the foregoing factors; and an ability to collaborate and dictate action in the supply chain based on the analytics, such as wherein the collaboration may be in the form of multi-point communications that occur automatically or manually, and such as wherein the actions may be subject to manual triggers or may trigger automatically. Accordingly, to meet future supply chain analysis needs, the supply chain and all aspects thereof may be analytically productized, and this may include the people and places that form part of the supply chain.
[0110] By way of example, it is typical that inventory on hand or on order for a supplier, reseller, or manufacture may exceed the demand for those parts. It is also typical that said supplier, reseller, or manufacture may retain these excess and obsolete (E and O) parts in the hopes the parts are necessary to the same or another product owner at a later point in time. Issues caused by such E and O inventory may be further exacerbated by the fact that the definition of E and O may differ as between the supplier, reseller, or manufacture and the product owner/customer.
[0111] Accordingly, the disclosed analytics engine may include, for example, algorithms whereby pattern recognition may be performed across an entire supply chain, or within aspects thereof, to assess patterns that typically lead to E and O. Once learned, these recognized patterns may be applied to the product of a particular customer, such as upon input from the customer at the inception of a design for supply chain. These recognized patterns may also be analytically applied to: a newly input product design, such as in order to give a probability ratio that a part or parts within the design may go E and O; similar products; the same or similar verticals; and/or to any supply chain(s) using the same or similar parts, by way of non-limiting example.
[0112] Such pattern recognition, for E and O and other end-to-end aspects of a supply chain, may be performed by the analytics engine to include part profiles for various parts, including, in certain embodiments, directly competitive parts. Such profiles may include the location of manufacture, generation or shipping of the parts, the history of inclusion of the parts, and the like. Analytic engine profiles may additionally include, for example, typical and/or comparative responses from a particular part provider or providers of that part to variations in demand.
[0113] In accordance with at least the foregoing factors, end-to-end supply chain aspects, such as E and O, may be assessed by the analytics engine before an event that will adversely affect the supply chain occurs. By way of example, to the extent a customer fears being affected by E and O, the analytics engine may assess that the customer has modified demand for a particular part by 50%; that the subject part is from a small province in China; that the subject part is subject to a 90 day lead time; and/or various other factors, such as based on large-volume data regarding the use of that part. Based on this large-volume prior data stored as part of the profile for that part, the analytics engine may assess that, in accordance with the foregoing factors, that part has an 83% chance to experience E and O in the next 60 days. That is, the analytics engine may use particular variables uniquely in relation to a part or parts, and these variables may change dependent on the part, the use of the part, and other factors related to the part. As referenced, the algorithmic application of these variables by the analytics engine then allows for a conclusion by the analytics engine, such as, in this example, a percentage chance that E and O will occur in relation to that part from that given supplier in a given time frame.
[0114] In accordance with the foregoing, the analytics engine may allow for accommodations to be made or charges to be made as a direct result of part consumption that leads to certain outcomes or probabilities in a supply chain, such as E and O. By way of example, in the known art, a customer may request that a given manufacture order 10,000 of a particular part, but may use only 3000 of those parts in that customer's products. However, also in the known art, to the extent that manufacture orders 500,000 of that same part across multiple ones of its customers, there is presently no known automated manner of assessing responsibility to that manufacturer to the extent many of those parts become E and O. In stark contrast to the known art, the disclosed embodiments may allow the analytics engine to apportion responsibility to various customers, such as in the aforementioned example in which one customer is responsible for 7000 E and O parts, such as that the customers may either bear financial responsibility for the E and O rather than the manufacturer, or such that the manufacturer may make more knowledgeable assessments of where accommodations have been provided.
[0115] Specifically in relation to E and O, E and O may be assessed and/or apportioned based on a particular confidence interval for a given part. This confidence interval that E and O may occur may be based by the analytics engine upon numerous analyzed factors, such as those disclosed above, such as particularly time and money. That is, the analytics engine may receive values based on pre-existing knowledge for the various variables related to a given part, such as including time and dollars, and may then generate and/or present to a user a confidence interval that the part will become E and O. The foregoing also allows for modification of the confidence interval that E and O will occur with respect to a given part as time moves on, which enables a snapshot, such as at the request of a user, of likely E and O at any given moment in the supply chain cycle. Due to the volume of data that is analyzed for such E and O assessments, changes in data and or learning by the learning algorithms disclosed may occur continuously or at preset periods. For example, E and O updates may be performed daily, weekly, or continuously.
[0116] Visibility into the end-to-end aspects of the supply chain may be necessary at all times to insure the correct data to adjust the supply chain, such as in the case of E and O discussed above, is in the right hands when needed to enable adjustments to avoid catastrophic occurrences. Thus, key data points should be assessed to enable real time decision-making, either by the analytics engine or by users. These key data points may vary, by example, based on the size of the supply chain, which may vary based on the product that is the outcome of the supply chain. For example, an airplane has a very large supply chain with a great many parts, while a plastic bottle has a very differently sized supply chain.
[0117] Ultimately, the supply chain may be, in essence, treated by the analytics engine as a pipeline. The pipeline may be very wide, such as wherein many suppliers at a particular level feeding a more limited number of manufactures, or may be narrow, such as wherein a limited number of suppliers feed a relatively equivalent number of manufacturers. Accordingly, the supply chain is viewed by the analytics engine level by level, and based upon what aspects of a final outcome are built or what value is added at each level. This level based structure may be provided as a rule-set within a rules engine of the analytics engine.
[0118] More particularly, multiple tiers may appear within certain supply chains, and each of these tiers maybe analyzed independently by the analytics engine, and may be independently provided to the user for viewing. As such, the probabilities and algorithms applied by the analytics engine at each tier may cascade through additional tiers, dependent on the number of additional tiers atop or below the tier then-under analyses. Correspondingly, the processing performed by the disclosed analytics engine provides a multi-level probabilistic cascade for the algorithms applied, such as those discussed herein. This is directly contrary to the known art, in which each level of the supply chain maintains only its own records, and, consequently, to the extent any probabilistic analyses is done at a particular tier or level, that analyses is not and cannot be cascaded through other tiers or levels.
[0119] This multi-tier and individual part breakdown is particularly relevant for supply chains that include highly numerous parts. In the known art, it has generally been assumed that the most expensive parts to purchase or make were also the highest impact parts for risk in the supply chain. However, directly contrary to this thinking, the analytics engine may frequently assess that the highest risk factor parts have no relation to the cost of those parts. This is a result of the probabilistic cascade that can occur even from the least expensive parts through multiple tiers of the supply chain. It should be noted that this probabilistic cascade relates not only to particular parts, but also to customers, suppliers, resellers, manufacturers, outcomes, and products, by way of non-limiting example. Further, it should be noted that this cascade is not unidirectional in all embodiments, but rather maybe vertically and/or horizontally integrated, i.e., may be both "up and down" and/or "left to right" along the continuum of a supply chain "pipeline".
[0120] Further, in order to aid in the comprehensive nature of this probabilistic cascade, the simulation and recommendations discussed throughout may be provided both for design of supply chains and for existing supply chains. Absent this cascade, which is heretofore unknown in the art, true optimization efforts in the design and execution of supply chains cannot be carried out.
[0121] The disclosed probabilistic cascade also allows the analytics engine to expose cause and effect circumstances. For example, consistent receipt of a single part on an average of one day late in a product having 300 parts therein may ultimately cascade to an average 9 day delay in shipping final product. Needless to say, such a delay is significantly impactful to the provider of the product, and as such, the cause of the delay, namely the average one day delay, would be recommended by the analytics engine for correction, such as by the recommendation of cross-sourcing, multiple-sourcing, or alternative-sourcing of that part.
[0122] The analytics engine may make certain of the foregoing assessments by rating key performance indicators in accordance with the referenced rule set, such as subject to or not subject to the input of the user's objectives, and such as based on threshold settings that may automatically alert the user to problems that may affect, positively or detrimentally, the key performance indicators. In certain examples, the effect of the key performance indicators may be visually indicated, such as wherein a green-colored key performance indicator on a display has a positive or no effect based on analytics of existing data, while a yellow KPI may have a possibility of a detrimental effect on the supply chain, and a red KPI may be likely to have a substantial adverse effect on the supply chain.
[0123] KPI analysis may, as referenced above, occur from end-to-end in the supply chain in light of the user's input objectives. Further, KPI analysis may have statistical algorithms applied thereto, such as to provide for the removal of "outlier data" in order to enhance analytic outcomes. For example, abnormal data spikes or dips, such as in inventory levels, may be likely indicative of one-time occurrences, and thus may be dismissed by the analytics engine applying the KPI analysis. Further, rather than dismissing some factors in the KPI analysis, pattern recognition may be performed to assess, for example, repeated variations under the same or similar circumstances. For example, if inventory levels always spike for a particular part of a particular product in the middle of the 3rd quarter of each year, such as in a likely indication of increased product production in the 4th quarter for an upcoming holiday season, the inventory KPI may be assessed as normal notwithstanding yet another spike in inventory in the middle of a 3rd quarter in the given year. That is, the algorithms applied by the analytics engine may perform pattern recognition to assess that this inventory spike is normal for this part and/or product at that given time, and hence it may rate the inventory KPI as not detrimental.
[0124] The algorithms within the analytics engine, as discussed throughout, may perform and/or allow for simulations, such as those provided to a comparator within the analytics engine, that may simulate the outcome of recommended modifications to the supply chain as compared to an unmodified supply chain (as may be input by the user). Such simulated effects on a supply chain may be provided to the user as a snapshot of a one-time modification, or may be supplied to the user over a given horizon, such as the effect of a recommended modification to the supply chain over a six-month horizon.
[0125] More particularly, simulations provided by the analytics engine may allow for the user to change aspects of product design, supply chain design, and/or active supply chain and to be provided with probabilistic, cascaded outcomes of the likely effects of those modifications. Needless to say, numerous variables may be available to the user for changing by the user in a given manually-requested simulation (simulations may also be automated by the analytics engine), and the user may toggle those variables in real time and receive a modified simulated output. By way of non-limiting example, variables may include service level (whether or not part delivery target dates are hit), inventory levels, days of supply, end of life proximity (as may be estimated across many data sets of similar parts), and the like. The user may then modify any of these variables and be provided with a simulated outcome of that modification, or the user may modify a different part metric and be able to see the effect of that modification on one or more of the foregoing variables. By way of example, the user may change an existing service level value, which may toggle the user's risk score for that supply chain factor. Once that occurs, the user may request that the analytics engine provide to the user a list of part providers that are capable of hitting the modified service level, such that the design risk score may be modified to that desired by the user.
[0126] Such simulations may further include predictive modeling. For example, part suppliers may come to understand, based on simulations provided by the analytics engine to users, that a 10% decrease in lead times for that part supplier would enable that part supplier to receive 10% more business from users of the analytics engine. Needless to say, in a similar circumstance, if a part supplier fails to meet criteria to be on 25% of all supplier listings for products using a given part supplied by that part supplier, the part supplier may receive an indication of what characteristics would need to be met by that part supplier to be placed on a certain percentage of the lists that part supplier presently fails to make.
[0127] Moreover, the predictive modeling based in the simulations may be able to make assessments of user goals and interests based on simulations or other interactions by the user in the user interface. For example, if a user repeatedly views various providers for a given part, it may be understood by the analytics engine that that user is particularly interested in that part, and consequently content, suppliers, or other products that include that part may be recommended to the user for viewing by the user through the user interface.
[0128] By way of illustration and as shown in the attached figures, a supply chain analytics engine 1703 may be provided within or in association with platform 307, as is shown in FIG. 13 (AAA). That is, the analytics engine may be, include, be included within, or be distinct from, the supply chain analytics module 304 discussed above. The analytics engine 1703 may include a node-analytics module 1705 that may perform the functionality described in the Figures below, and such as may apply rules indicated for an individual analysis by a rules engine 1707 that applies at least a comparator 1709 having therein comparative algorithms, such as those discussed herein, to the large volume data 1711 from other supply chains, such as may include similar product verticals and dissimilar verticals that integrate similar parts, and from the nodes of the supply chain of interest. The large volume data may be, include, be included within, or be distinct from analytics data 322, discussed above.
[0129] The diagnostics and analytics of analytics engine 1703 are applied on a node-by-node basis to a particular supply chain. That is, each aspect of the supply chain may be treated as a node, regardless of the function of that node within the supply chain. In that way, a variety of comparative and cascading analytics may be assessed on each node, and accordingly recommendations may be provided uniquely for each node, and each aspect of each node, in a supply chain.
[0130] An application 214 may be provided as an aspect of platform 307 in accordance with this node-based processing, which application may apply rules engine 1707 of analytics engine 1703, as shown with greater particularity in the exemplary embodiments of the figures herein, including FIG. 14. Of note, although the visual presentation and information provided by the node processing application illustrated herein may differ from the other applications 214 discussed hereinabove, the same primary and/or secondary data 1711 provided by platform 307 may be accessible to both the node-based and other applications discussed herein.
[0131] This vast data store 1711 that is available to the analytics engine may allow for, for example, global end to end visibility throughout a supply chain for a particular product or group of products, as is illustrated in FIGS. 15(A) and 16(B). As indicated in FIGS. 15 and 16, various suppliers, manufacturers and customers in the supply chain may be visually presented for a given product, and summary information with available drill down detail may be provided at each one of these "nodes within the supply chain." Further available in association with each of these nodes may be a "flowchart" of key elements, such as parts, suppliers, manufacturers, geographies, or the like, such as from the inception of the supply chain to its end upon sale of the product. The end to end visibility throughout the supply chain and its nodes may be enhanced by the providing of alerts, such as based on calculated thresholds by the analytics engine 1703, of areas of enhanced risk within the supply chain, as is illustrated in the exemplary embodiment of FIG. 17 (C).
[0132] Such alerts of generally available end to end visibility data 1711 may be based on calculated trends or analytics, by way of non-limiting example, stored within, uploaded to, and/or "learned" by analytics engine 1703. As illustrated in FIG. 18 (D), a "top 10" of demands, such as for parts by site, by part type, by demand trend, or the like, may be available to the user, such as via one or more pop-up windows upon user access. Similarly, analytics for particular attributes of the supply chain, such as obsoletion of a part, and trending related thereto may likewise be accessible based on the availability of the underlying data and action of the analytics engine 1703, as illustrated in FIG. 19 (E). Such analytics may be available via graphics, trend lines, or hard data, as illustrated additionally with respect to FIG. 20 (F).
[0133] Due to the overwhelming number of aspects, nodes, and/or parts that may contribute to a given supply chain, search capabilities to search within the data through a search interface may be provided to the user, as illustrated in FIG. 21 (G). Search capabilities may relate to any one or more aspects of the supply chain, such as parts, purchase orders, customers, shipments, tracking numbers, serial numbers, and the like. Moreover, searches may be hierarchically structured to enhance usability, such as wherein a search for a particular part may include searches for alternative parts, subparts, or the like, and such as wherein searches may include additional pop-up information related to parts, tracking, carriers, or the like, to ensure that the user has accessed the desired information. Such enhanced search capabilities are illustrated with respect to FIGS. 22 (H), 23 (I), and 24 (J), by way of non-limiting example. Alternatives to free-form searches may include, by way of non-limiting example, structured searches, populating drop-downs, or the like, as will be understood by the skilled artisan. A hierarchical search using structured data drop-downs is illustrated, by way of non-limiting example, in FIG. 25 (K).
[0134] More particularly, an exemplary node network is illustrated in FIG. 26 (15), wherein primary (root) company node 1500 is connected in a tree node fashion with assembly nodes, part nodes, supplier nodes and manufacturer nodes as shown. Each node of the supply chain in FIG. 26 may be considered as a separate level. These nodes may be configured such that different supply chains will contain different structures or networks. It is understood by those skilled in the art that the example of FIG. 26 is merely exemplary, and that the nodes and node layers may be arranged in a myriad of ways and structures, and may include additional or fewer layers from those depicted in the example.
[0135] Thus, exemplary node structures may be arranged for various nodes:
Example 11
[0136] Raw Material Mfg..fwdarw.Supplier.fwdarw.Component.fwdarw.Assembly.fwdarw.Customer
Example 21
[0137] Mfg. Plant.fwdarw.Distribution.fwdarw.Customer.fwdarw.End Consumer
Example 3
[0138] Supplier.fwdarw.Vendor Hub.fwdarw.*Mfg. Plant.fwdarw.Customer Hub.fwdarw.End Consumer
[0139] As shown in FIG. 26, each supply chain node is linked by a connection. These connections may be one-to-one, one-to-many and/or many-to-many. The visualization makes it possible to display every node in a given supply chain in a single graphic which allows a user to understand the overall activity and complexity within a supply chain, as well as its overall health. Likewise, displayed nodes may be limited by a user or by the app, and/or by number or by node type, by way of non-limiting example. The exemplary embodiment allows a user to quickly relate to patters being depicted in the node tree visualization. For example, certain nodes may be quickly identified as having high concentrations of demand flowing through them. Nodes may also be identified having existing overall risk and/or opportunity in certain parts of the supply chain. As mentioned previously, a single holistic visualization may allow a company to make quick and efficient assessments of the health of the supply chain, rather than relying on multiple different screens or charts covering hundreds of thousands of data records and/or data points.
[0140] Another advantageous effect of the node tree is the apparent structure of the supply chain is determined quickly. The visualization makes use of data which defines how the supply chain is structured. For example, manufacturers may be linked (e.g., via tags) to suppliers via approved manufacturers lists. Parts may similarly be linked to assemblies via bill of materials (product structures. The complexity of the visualization may be simplified by quickly focusing the node tree to a defined number of nodes. As the nodes and underlying metadata are linked, the selection of one or more nodes may automatically instruct the system to present only the nodes/layers associated with a selected node. This in turn permits focused attention on the nodes that are most relevant (e.g., high demand volume nodes). In one embodiment a predetermined number of "top" nodes may be displayed for each node parent (e.g., based on the top 10 highest demand volume nodes).
[0141] As each node carries pre-calculated data attributes (metadata), the data attributes may be dynamically categorized based on predetermined thresholds. The attributes may further be categorized and color coded as discussed above. For example processed attributes showing issues may be displayed in red, attributes showing opportunities may be displayed as green and neutral attributes (i.e., neither an issue nor an opportunity) may be displayed as white. As such, the overall health of the supply chain may be determined.
[0142] In one exemplary embodiment, an assembly or product determined to carry a high risk would be highlighted as a red node, indicating it is an area of concern meriting a corrective action. In another embodiment a component part containing a large amount of excess inventory would be highlighted as a red node indicating it is an area of concern meriting a corrective action. In another exemplary embodiment, a supplier determined to be a candidate to be moved into a supply chain postponement model (e.g., Supplier Managed Inventory Program) may be highlighted as a green node, since the representative node is indicative of an improvement opportunity.
[0143] The visualization is preferably interactive, allowing data attributes for each node to be drilled down. Dynamic filtering may further be applied to display upstream and downstream nodes by selecting any single node in the supply chain. In the exemplary embodiment of FIG. 27 (16), a selection of supplier node 1600 may cause the system to automatically apply filtering to only display upstream and downstream nodes having dependency on selected node 1600. In the exemplary embodiment of FIG. 28 (17), selection of assembly node 1700 may cause the system to highlight upstream and downstream supply chain nodes.
[0144] As can be appreciated by those skilled in the art, the disclosed configurations advantageously provide users with the ability to review end-to-end supply chains and supply chain portions without requiring specialized knowledge. The unique data visualization helps users to truly understand the supply chain network and is relatable for all types of users to identify overall status issues and opportunities. This in turn allows for improved productivity by allowing users to spend time crafting and taking actions instead of analyzing complex data and identifying opportunities/issues. The visualizations further provide standardized definition of issues and opportunities through an entire organization. Drill-down capabilities provide an action-oriented, fact-based analysis with supporting data. The disclosed node network configurations provide a differentiated capability that helps customers understand issues and opportunities that can have meaningful impact on bottom-line performance.
[0145] The figures discussed throughout provide illustrative screenshots of system and system platform operation disclosed herein. The system screen layout may contain a plurality of workspace and navigation areas. A cross-function pane may be provided to present functional areas of a business which are included in the platform. User roles may be assigned in the system to control which functional areas may be made visible to different user groups. A tool pan may likewise be provided for tools that are available within each functional area of the business. User roles may control which tools are visible to different user groups. A main content pane may be provided as a main workspace of the platform which contains data and informational content. In embodiments, a news feed/main page/landing page may also be provided, such as for a chronological timeline of events, facts, occurrences, status, risks, or the like which may be particularly relevant to the user and/or relevant to the particular design/product/similar designs or products. "Pings" may contain alerts such as new critical shortages. In one embodiment, a social data interface may be provided for real-time information from sources such as Twitter. Through various interfaces, data may be filtered by geography, organization level or both.
[0146] FIG. 29 (20A) illustrates an exemplary simplified interactive map screenshot, which allows users to access nodes such as customer nodes, manufacturing nodes and supplier nodes. A graphic overlay on the node geographical location may provide processed data results for the node. Exemplary attributes that may be displayed include, but are not limited to, demand, service level, inventory, excess, obsolete inventory, AMP opportunity, safety stock, risk attribute score and critical shortages. A supplier location count may also be provided to quickly access numbers of suppliers available at a given location.
[0147] For example, as illustrated in FIG. 30 (20B), a plurality of suppliers located about the same geographical location may be visually clustered into a shape, such as a bubble, for manipulation by a user on a map interface, for example. Each cluster, which may contain more than one bubble, may be populated with the number of suppliers based on the level of view such that the number of suppliers may be easily ascertainable by a user. For example, as illustrated in FIG. 30, the map view presented clusters 15 suppliers in the center of the Macau into a single bubble, while also allowing for several smaller clusters which may be readily discernable by the user a separate clusters given the level of map view. In this way, a user may quickly and easily determine at least the general geographic concentration of suppliers in a particular area.
[0148] FIG. 31 (21) illustrates an exemplary screenshot of a node network diagram, similar to those disclosed above. FIG. 32 (34) illustrates an exemplary interactive map that may be displayed as part of the supply radar module. Here, different nodes may be simultaneously displayed, including customer nodes, manufacturing nodes and supplier nodes. The system may be configured to display a global sourcing footprint. In one embodiment, geographic areas containing a large concentration of, e.g., supplier, may be configured to cluster the locations into a bubble, where the cluster may contain a count of the units (suppliers) included in the cluster. To view which units (suppliers) make up the cluster, the cluster bubble may be selected and zoomed to expand the cluster. The map may be toggled between a normal map view and/or a satellite view. The exemplary interactive map of FIG. 32 may be customized to provide maps pertaining to various attributes including, but not limited to, demand, service level, inventory, excess, obsolete inventory, AMP opportunity, safety stock, risk attribute score and critical shortages. FIG. 33 (35) illustrates another exemplary interactive map display, similar to the display in FIG. 32, except that the system configures the map in terms of demand, along with a total value ($26,334,422).
[0149] The exemplary embodiments discussed herein, by virtue of the processing and networked nature of platform 307 and its associated apps, may provide typical data services, in conjunction with the specific features discussed herein. By way of non-limiting example, reports may be made available, such as for download, and data outputs in various formats/file types, and using various visualizations, may be available. Moreover, certain of the aspects discussed herein may be modified in mobile-device based embodiments, such as to ease processing needs and/or to fit modified displays.
[0150] In the foregoing Detailed Description, it can be seen that various features are grouped together in a single embodiment for the purpose of streamlining the disclosure. This method of disclosure is not to be interpreted as reflecting an intention that the claimed embodiments require more features than are expressly recited in each claim. Rather, as the following claims reflect, inventive subject matter lies in less than all features of a single disclosed embodiment. Thus the following claims are hereby incorporated into the Detailed Description, with each claim standing on its own as a separate embodiment.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012
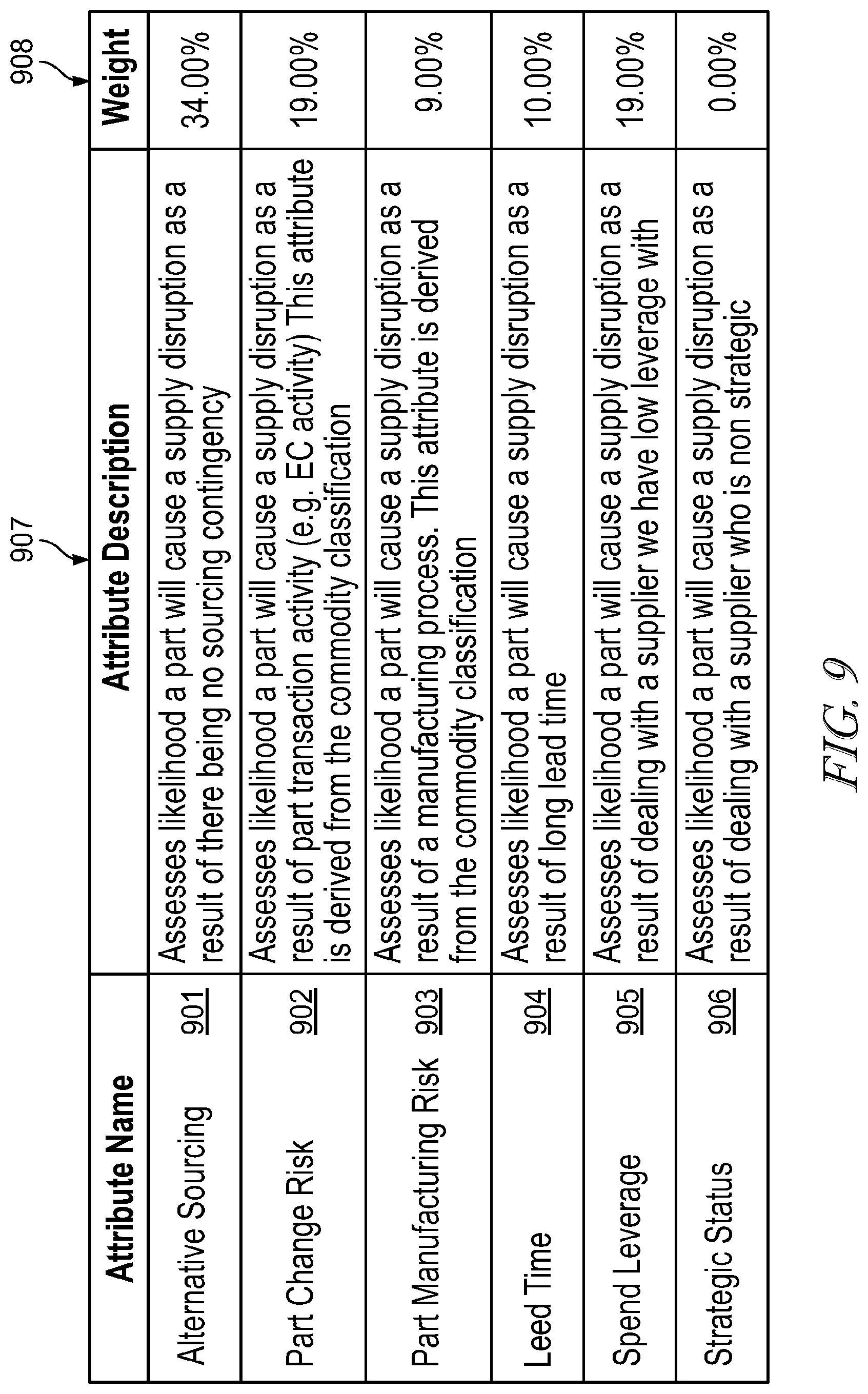
D00013

D00014
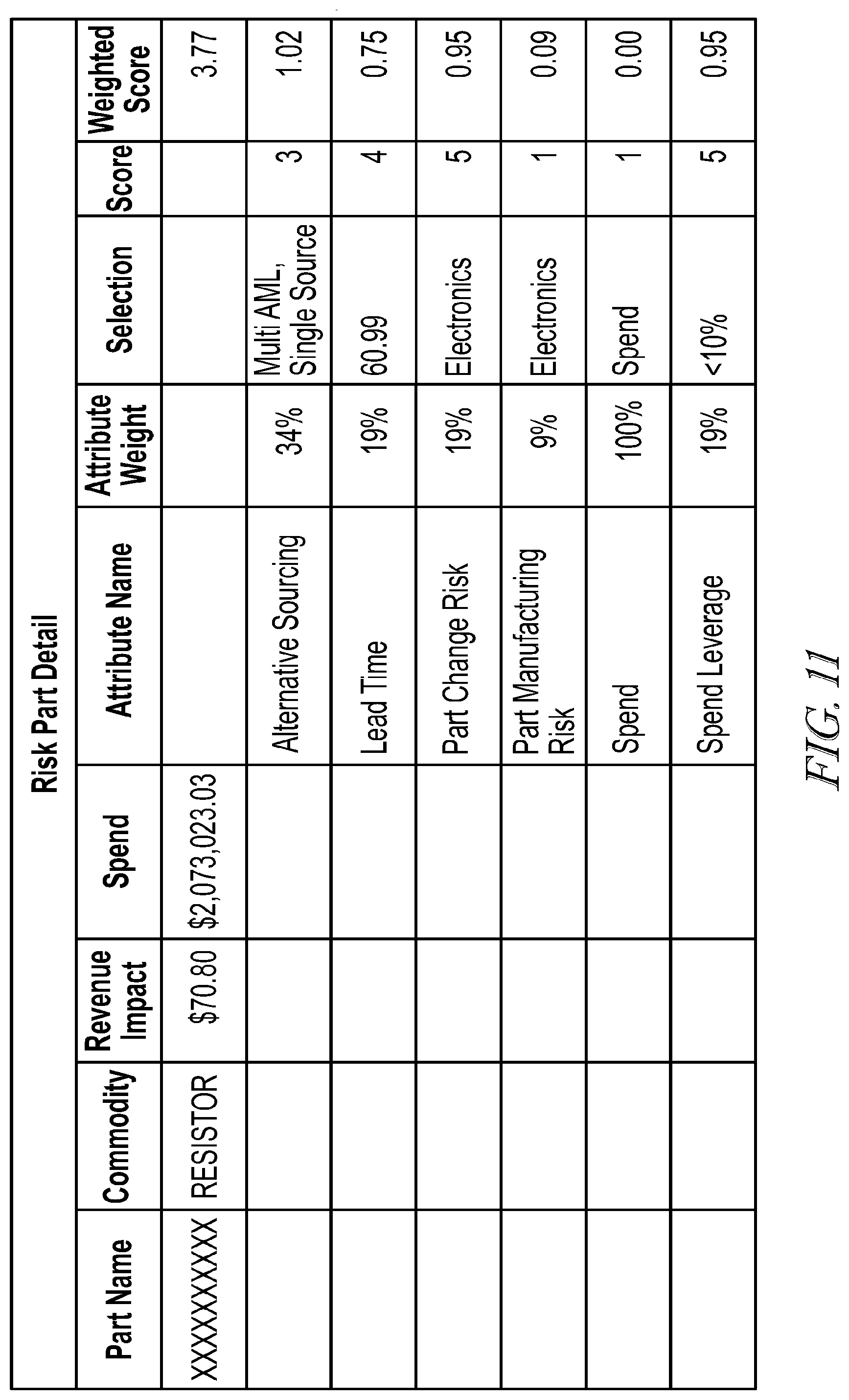
D00015

D00016

D00017

D00018
D00019
D00020

D00021
D00022

D00023

D00024

D00025

D00026
D00027

D00028
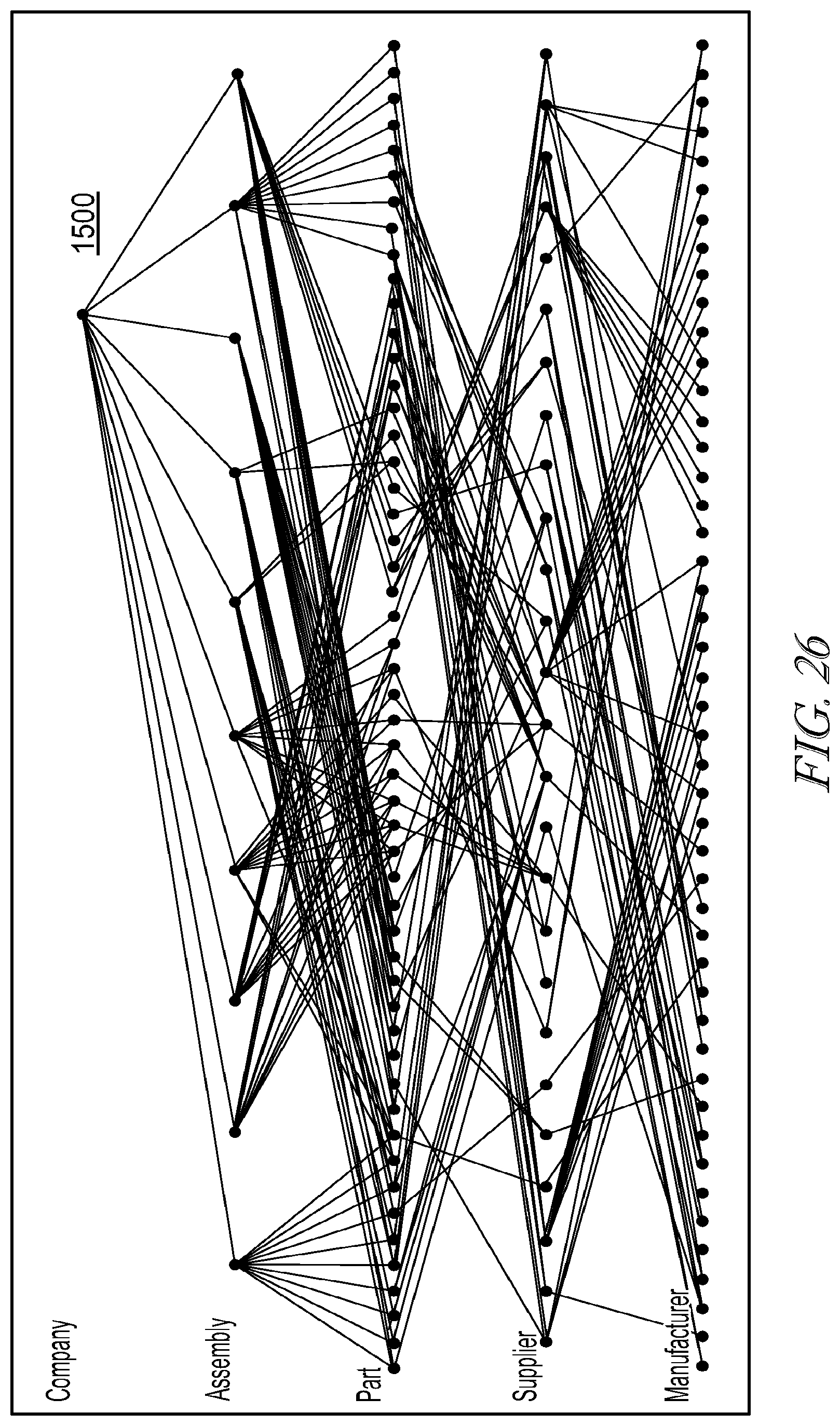
D00029
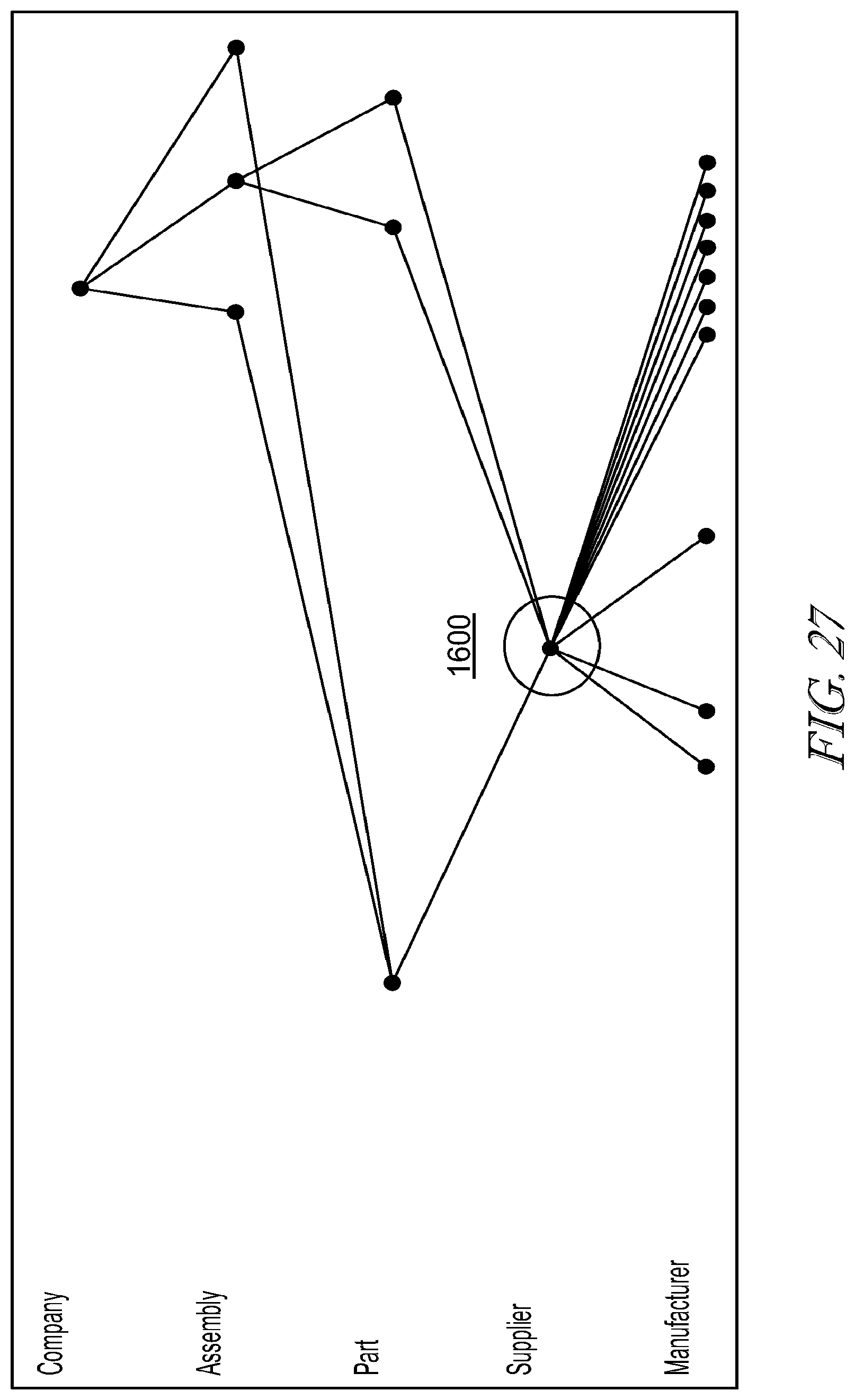
D00030

D00031
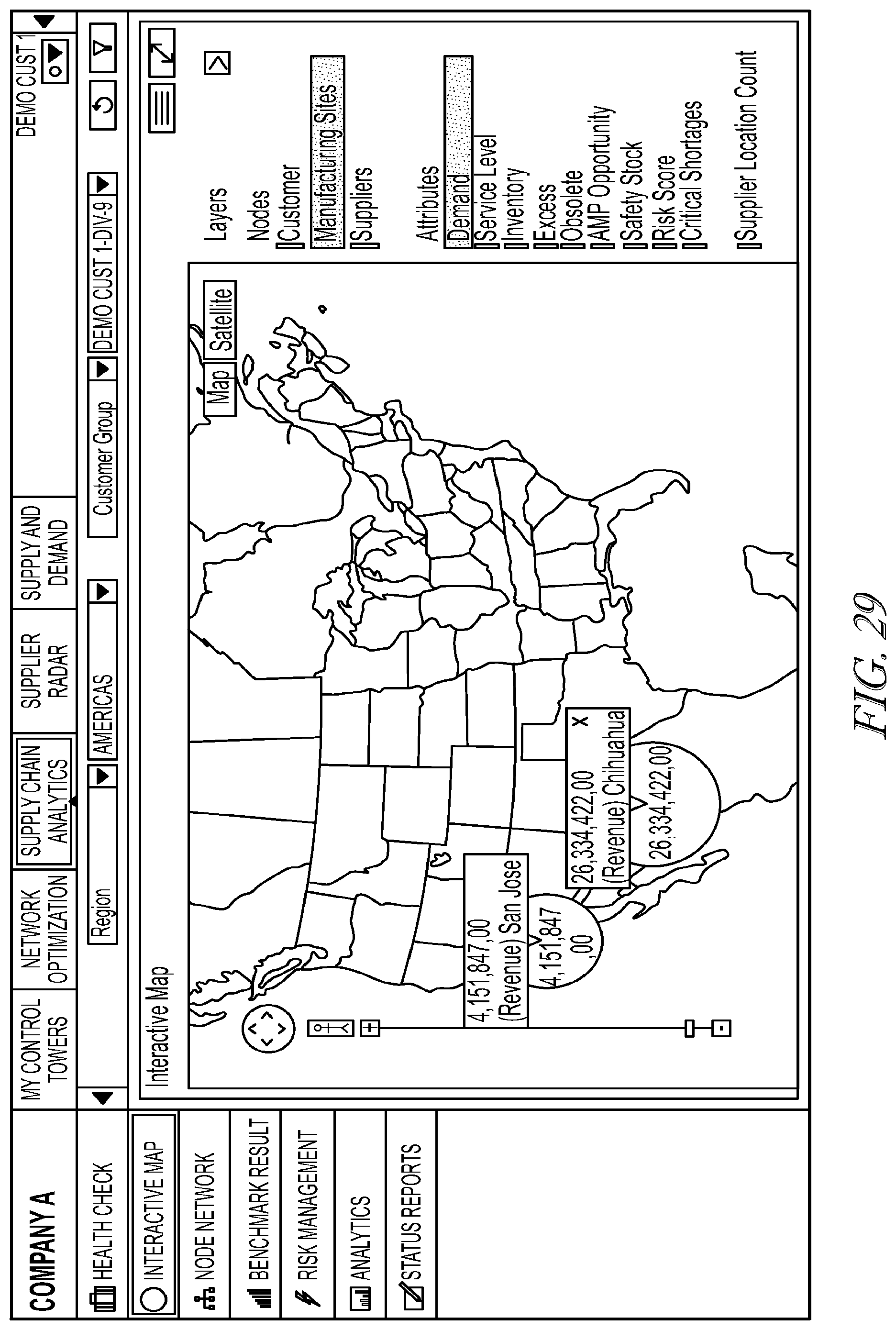
D00032
D00033
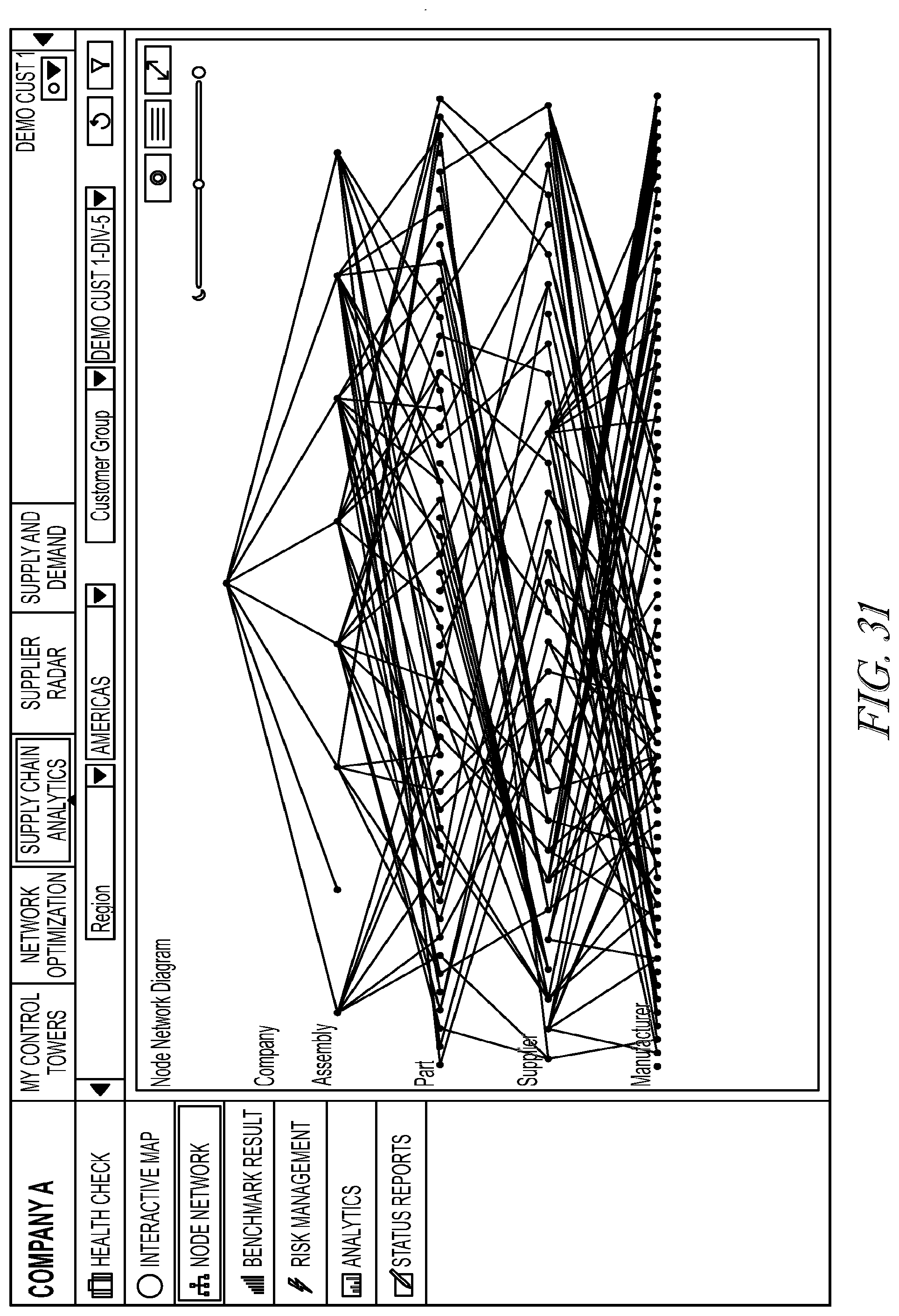
D00034

D00035

XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.