Anti-ngf Compositions And Use Thereof
Dutzar; Benjamin H. ; et al.
U.S. patent application number 16/504602 was filed with the patent office on 2020-02-27 for anti-ngf compositions and use thereof. The applicant listed for this patent is ALDERBIO HOLDINGS LLC. Invention is credited to Corinne C. Akatsuka, Jens J. Billgren, Betty Yu-Ching Chang, Benjamin H. Dutzar, Pei Fan, Leon F. Garcia-Martinez, Brian R. Kovacevich, John A. Latham, Patricia Dianne McNeill, Danielle M. Mitchell, Ethan W. Ojala, Erica A. Stewart.
| Application Number | 20200062837 16/504602 |
| Document ID | / |
| Family ID | 46162451 |
| Filed Date | 2020-02-27 |












View All Diagrams
| United States Patent Application | 20200062837 |
| Kind Code | A1 |
| Dutzar; Benjamin H. ; et al. | February 27, 2020 |
ANTI-NGF COMPOSITIONS AND USE THEREOF
Abstract
The present invention is directed to antibodies and fragments thereof having binding specificity for NGF. Another embodiment of this invention relates to the antibodies described herein, and binding fragments thereof, comprising the sequences of the V.sub.H, V.sub.L and CDR polypeptides described herein, and the polynucleotides encoding them. The invention also contemplates conjugates of anti-NGF antibodies and binding fragments thereof conjugated to one or more functional or detectable moieties. The invention also contemplates methods of making said anti-NGF antibodies and binding fragments thereof. Embodiments of the invention also pertain to the use of anti-NGF antibodies, and binding fragments thereof, for the diagnosis, assessment and treatment of diseases and disorders associated with NGF.
| Inventors: | Dutzar; Benjamin H.; (Seattle, WA) ; Kovacevich; Brian R.; (Snohomish, WA) ; McNeill; Patricia Dianne; (Federal Way, WA) ; Mitchell; Danielle M.; (Seattle, WA) ; Ojala; Ethan W.; (Snohomish, WA) ; Fan; Pei; (Bothell, WA) ; Billgren; Jens J.; (Seattle, WA) ; Stewart; Erica A.; (Seattle, WA) ; Akatsuka; Corinne C.; (Hilo, HI) ; Chang; Betty Yu-Ching; (Cupertino, CA) ; Latham; John A.; (Seattle, WA) ; Garcia-Martinez; Leon F.; (Woodinville, WA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 46162451 | ||||||||||
| Appl. No.: | 16/504602 | ||||||||||
| Filed: | July 8, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15294016 | Oct 14, 2016 | 10344083 | ||
| 16504602 | ||||
| 13309295 | Dec 1, 2011 | 9783602 | ||
| 15294016 | ||||
| 61418832 | Dec 1, 2010 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | C07K 2317/55 20130101; A61P 17/00 20180101; A61P 15/00 20180101; A61P 1/00 20180101; A61P 37/08 20180101; C07K 2317/565 20130101; C07K 2317/92 20130101; A61K 45/06 20130101; A61P 25/00 20180101; A61P 43/00 20180101; C07K 16/22 20130101; A61P 25/06 20180101; A61P 25/04 20180101; A61P 19/00 20180101; A61P 29/00 20180101; A61P 27/02 20180101; Y02A 50/30 20180101; A61K 51/1021 20130101; A61P 31/04 20180101; A61P 1/18 20180101; A61P 19/10 20180101; A61P 35/00 20180101; C07K 2317/24 20130101; A61K 39/3955 20130101; C07K 16/2875 20130101; A61K 2039/505 20130101; A61P 21/00 20180101; C07K 2317/41 20130101; C07K 2317/622 20130101; A61P 1/16 20180101; A61P 19/02 20180101; C07K 2317/76 20130101; C07K 2317/94 20130101; Y02A 50/466 20180101 |
| International Class: | C07K 16/22 20060101 C07K016/22; A61K 51/10 20060101 A61K051/10; C07K 16/28 20060101 C07K016/28; A61K 39/395 20060101 A61K039/395; A61K 45/06 20060101 A61K045/06 |
Claims
1. An anti-human NGF antibody or antibody fragment which comprises the same CDR polypeptides as an anti-human NGF antibody selected from Ab1, Ab2, Ab3, Ab4, Ab5, Ab6, Ab7, Ab8, Ab9, Ab10, Ab11, Ab12, Ab13, Ab14, Ab15, Ab16, Ab17, Ab18, Ab19, Ab20, and Ab21.
2-5. (canceled)
6. The anti-human NGF antibody or fragment according to claim 1, wherein said fragment is a Fab fragment comprising a V.sub.H polypeptide at least 90% identical to one selected from those in SEQ ID NO: 3, 13, 23, 33, 43, 53, 63, 73, 83, 93, 103, 113, 123, 133, 143, 153, 163, 173, 183, 193, or 402 and/or V.sub.L polypeptide sequence at least 90% identical to one selected from: SEQ ID NO: 1, 11, 21, 31, 41, 51, 61, 71, 81, 91, 101, 111, 121, 131, 141, 151, 161, 171, 181, 191, or 401.
7-21. (canceled)
22. The anti-human NGF antibody or fragment of claim 1, which is directly or indirectly attached to a detectable label or therapeutic agent.
23. A nucleic acid sequence or nucleic acid sequences which result in the expression of an anti-human NGF antibody or antibody fragment according to claim 1.
24-26. (canceled)
27. A recombinant cell which expresses an antibody or antibody fragment according to claim 1.
28-31. (canceled)
32. A method of treatment comprising administering to a patient with a disease or condition associated with NGF expressing cells a therapeutically effective amount of at least one anti-human NGF antibody or fragment according to claim 1.
33. The method of claim 32 wherein the disease is selected from inflammatory pain, post-operative incision pain, complex regional pain syndrome, cancer pain, primary or metastatic bone cancer pain, fracture pain, osteoporotic fracture pain, pain resulting from burn, osteoporosis, gout joint pain, pain associated with sickle cell crises, and other nociceptic pain, as well as hepatocellular carcinoma, breast cancer, liver cirrhosis, neurogenic pain, neuropathic pain, nociceptic pain, trigeminal neuralgia, post-herpetic neuralgia, phantom limb pain, fibromyalgia, menstrual pain, ovarialgia, reflex sympathetic dystrophy, neurogenic pain, osteoarthritis or rheumatoid arthritis pain, lower back pain, diabetic neuropathy, sciatica, or migraine.
34-57. (canceled)
58. A method of making an antibody according to claim 1, in a recombinant host cell or non-human transgenic animal or plant containing one or more heterologous polynucleotides encoding said antibody.
59-117. (canceled)
118. An anti-NGF antibody or antibody fragment according to claim 1, comprising a variable light chain polypeptide sequence and a variable heavy chain polypeptide sequence selected from the following: TABLE-US-00177 Variable Light Variable Heavy Chain Chain A Seq ID No: 1 Seq ID No: 3 B Seq ID No: 11 Seq ID No: 13 C Seq ID No: 21 Seq ID No: 23 D Seq ID No: 31 Seq ID No: 33 E Seq ID No: 41 Seq ID No: 43 F Seq ID No: 51 Seq ID No: 53 G Seq ID No: 61 Seq ID No: 63 H Seq ID No: 71 Seq ID No: 73 I Seq ID No: 81 Seq ID No: 83 J Seq ID No: 91 Seq ID No: 93 K Seq ID No: 101 Seq ID No: 103 L Seq ID No: 111 Seq ID No: 113 M Seq ID No: 121 Seq ID No: 123 N Seq ID No: 131 Seq ID No: 133 O Seq ID No: 141 Seq ID No: 143 P Seq ID No: 151 Seq ID No: 153 Q Seq ID No: 161 Seq ID No: 163 R Seq ID No: 171 Seq ID No: 173 S Seq ID No: 181 Seq ID No: 183 T Seq ID No: 191 Seq ID No: 193
119. An anti-NGF antibody or antibody fragment according to claim 1, comprising a light chain polypeptide sequence and a heavy chain polypeptide sequence selected from the following: TABLE-US-00178 Light Chain Heavy Chain Ab1 Seq ID No: 2 Seq ID No: 4 Ab2 Seq ID No: 12 Seq ID No: 14 Ab3 Seq ID No: 22 Seq ID No: 24 Ab4 Seq ID No: 32 Seq ID No: 34 Ab5 Seq ID No: 42 Seq ID No: 44 Ab6 Seq ID No: 52 Seq ID No: 54 Ab7 Seq ID No: 62 Seq ID No: 64 Ab8 Seq ID No: 72 Seq ID No: 74 Ab9 Seq ID No: 82 Seq ID No: 84 Ab10 Seq ID No: 92 Seq ID No: 94 Ab11 Seq ID No: 102 Seq ID No: 104 Ab12 Seq ID No: 112 Seq ID No: 114 Ab13 Seq ID No: 122 Seq ID No: 124 Ab14 Seq ID No: 132 Seq ID No: 134 Ab15 Seq ID No: 142 Seq ID No: 144 Ab16 Seq ID No: 152 Seq ID No: 154 Ab17 Seq ID No: 162 Seq ID No: 164 Ab18 Seq ID No: 172 Seq ID No: 174 Ab19 Seq ID No: 182 Seq ID No: 184 Ab20 Seq ID No: 192 Seq ID No: 194 Ab21 Seq ID No: 401 Seq ID No: 402
120-144. (canceled)
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application claims the benefit of priority to U.S. provisional patent application No. 61/418,832, filed Dec. 1, 2010, the contents of which are incorporated herein by reference in its entirety. In addition this application relates to Attorney Docket No. 67858-740003 (Serial Number to be assigned); entitled "METHODS OF PREVENTING OR TREATING PAIN USING ANTI-NGF ANTIBODIES THAT SELECTIVELY INHIBIT THE ASSOCIATION OF NGF WITH TRKA, WITHOUT AFFECTING THE ASSOCIATION OF NGF WITH P75"; Docket No. 67858-740004 (Serial Number to be assigned); entitled "METHODS OF PREVENTING INFLAMMATION AND TREATING PAIN USING ANTI-NGF COMPOSITIONS"; Docket No. 67858-740005 (Serial Number to be assigned); entitled "METHODS OF PREVENTING OR TREATING PAIN USING ANTI-NGF ANTIBODIES", all assigned to Alder Biopharmaceuticals, and all filed on Dec. 1, 2011, the contents of which are all incorporated by reference in their entireties.
BACKGROUND OF THE INVENTION
Field of the Invention
[0002] This invention pertains to antibodies and fragments thereof (including Fab fragments) having binding specificity to human Nerve Growth Factor (hereinafter "NGF"). The invention also pertains to methods of screening for diseases and disorders associated with NGF, and methods of preventing or treating diseases and disorders associated with NGF by administering said antibodies or fragments thereof.
Description of Related Art
[0003] Nerve Growth Factor (NGF) (also known as beta nerve growth factor (Beta-NGF)) is produced as a mature protein of 222 amino acids in length, following cleavage of a 18 amino acid signal peptide. The gene encoding NGF is located on chromosome 1p13.1. A biologically active form of NGF is a secreted protein which homodimerizes and is incorporated into a larger complex. NGF is a member of the neurotrophins (NTs), which are a group of structurally-related proteins further including brain-derived neurotrophic factor (BDNF), NT-3, and NT-4/5. (Wyman et al., Gene Therapy (1999), 6:1648-1660). NTs support the survival of specific types of neurons and neurotransmitter systems, being produced by cells that are targeted by innervating neurons. Id. Basal forebrain, substantia nigra, brain stem, cortex, and spinal cord are nervous system regions having demonstrated responsiveness to NGF. Id.
[0004] All NTs bind to a low-affinity receptor identified as p75. (Sarchielli et al., Expert Rev. Neurotherapeutics (2004), 4(1):115-127). NGF selectively binds to, and displays a high affinity for, the high affinity neurotrophin receptor TrkA. Id. It has recently been demonstrated that NGF acts through its low-affinity receptor p75 in a developmentally-regulated signaling pathway necessary for myogenic differentiation and muscle repair in vivo. (Deponti et al., Mol. Biol. Cell (2009), 20:3620-3627).
[0005] NGF has also been demonstrated to interact with pain-signalling systems in adult animals, and is responsible for hyperalgesia when administered either locally or systemically in many species. (Sarchielli et al., Expert Rev. Neurotherapeutics (2004), 4(1):115-127). NGF has been shown to induce a pain-like response when infused into the CSF in rats, and has been demonstrated to maintain chronic pain. Furthermore, NGF has been demonstrated to contribute to the development of mechanical allodynia occurring 8-12 hours later, and to the secondary pain response. Id.
[0006] Pain may often be addressed through the administration of certain narcotics or non-steroidal anti-inflammatory drugs (NSAIDs). However, the administration of these treatments may occur at the cost of certain negative consequences. NSAIDs have the potential to cause kidney failure, intestinal bleeding, and liver dysfunction. Narcotics have the potential to cause nausea, vomiting, impaired mental functioning, and addiction. Therefore, it is desirable to identify alternative treatments for pain in order to avoid certain of these negative consequences.
[0007] NGF is believed to play a role in a multitude of diseases and disorders, including but not limited to pain associated with a broad range of diseases and disorders, such as pain associated with cancers, neuropathic pain, and neurogenic pain. Due to the perceived involvement of NGF in a wide range of pain-related diseases and disorders, there remains a need in the art for compositions and methods useful for preventing or treating diseases and disorders associated with NGF, and particularly those associated with pain. Particularly preferred anti-NGF compositions are those having minimal or minimizing adverse reactions, such as inflammation when administered to the patient. Compositions or methods that reduce or inhibit diseases or disorders associated with NGF, such as pain, are beneficial to the patient in need thereof.
BRIEF SUMMARY OF THE INVENTION
[0008] The present invention is directed to specific antibodies and fragments thereof having binding specificity for NGF, in particular antibodies having desired epitopic specificity, high affinity or avidity and/or functional properties. Another embodiment of this invention relates to the antibodies described herein, comprising the sequences of the V.sub.H, V.sub.L and CDR polypeptides described herein, and the polynucleotides encoding them.
[0009] A preferred embodiment of the invention is directed to chimeric or humanized antibodies and fragments thereof (including Fab fragments) capable of binding to NGF and/or inhibiting the biological activities mediated by the binding of NGF to p75 and/or the TrkA receptor. In another preferred embodiment of the invention, full length antibodies and Fab fragments thereof are capable of significantly reducing pain in vivo in murine models, as measured by Gait analysis (as described in the examples herein).
[0010] In another embodiment of the invention, chimeric or humanized antibodies and fragments thereof (including Fab fragments) capable of binding to NGF inhibit TF1 cell proliferation. In another embodiment of the invention, chimeric or humanized antibodies and fragments thereof (including Fab fragments) capable of binding to NGF inhibit PC-12 neurite outgrowth.
[0011] In another embodiment of the invention these antibodies and humanized versions may be derived from rabbit immune cells (B lymphocytes) and may be selected based on their homology (sequence identity) to human germ line sequences. These antibodies may require minimal or no sequence modifications, thereby facilitating retention of functional properties after humanization. A further embodiment of the invention is directed to fragments from anti-NGF antibodies encompassing V.sub.H, V.sub.L and CDR polypeptides, e.g., derived from rabbit immune cells and the polynucleotides encoding the same, as well as the use of these antibody fragments and the polynucleotides encoding them in the creation of novel antibodies and polypeptide compositions capable of binding to NGF and/or NGF/TrkA and/or anti-NGF/p75 complexes or multimers thereof.
[0012] The invention also contemplates conjugates of anti-NGF antibodies and binding fragments thereof conjugated to one or more functional or detectable moieties. The invention also contemplates methods of making said chimeric or humanized anti-NGF or anti-NGF/TrkA and/or anti-NGF/p75 complex antibodies and binding fragments thereof. In one embodiment, binding fragments include, but are not limited to, Fab, Fab', F(ab').sub.2, Fv, scFv fragments, SMIPs (small molecule immunopharmaceuticals), camelbodies, nanobodies, MetMab like monovalent agents, and IgNAR.
[0013] Embodiments of the invention pertain to the use of anti-NGF antibodies and binding fragments thereof for the diagnosis, assessment and treatment of diseases and disorders associated with NGF or aberrant expression thereof. The invention also contemplates the use of fragments of anti-NGF antibodies for the diagnosis, assessment and treatment of diseases and disorders associated with NGF or aberrant expression thereof. Other embodiments of the invention relate to the production of anti-NGF antibodies or fragments thereof in recombinant host cells, for example mammalian cells such as CHO, NSO or HEK 293 cells, or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains.
BRIEF DESCRIPTION OF THE SEVERAL VIEWS OF THE DRAWINGS
[0014] FIG. 1 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab1.
[0015] FIG. 2 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab2.
[0016] FIG. 3 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab3.
[0017] FIG. 4 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab4.
[0018] FIG. 5 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab5.
[0019] FIG. 6 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab6.
[0020] FIG. 7 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab7.
[0021] FIG. 8 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab8.
[0022] FIG. 9 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab9.
[0023] FIG. 10 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab10.
[0024] FIG. 11 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab11.
[0025] FIG. 12 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab12.
[0026] FIG. 13 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab13.
[0027] FIG. 14 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab14.
[0028] FIG. 15 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab15.
[0029] FIG. 16 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab16.
[0030] FIG. 17 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab17.
[0031] FIG. 18 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab18.
[0032] FIG. 19 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab19.
[0033] FIG. 20 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab20.
[0034] FIG. 21 provides polynucleotide and polypeptide sequences corresponding to the full-length Antibody Ab21, produced by expression in Pichia pastoris.
[0035] FIG. 22 provides the heavy and light chain polypeptide sequences of Fab1.
[0036] FIG. 23 provides the heavy and light chain polypeptide sequences of Fab2.
[0037] FIG. 24 provides the NGF ELISA binding data obtained following the protocol described infra for antibodies Ab1 and Ab2.
[0038] FIG. 25 provides the NGF ELISA binding data obtained following the protocol described infra for antibody Ab3.
[0039] FIG. 26 provides the NGF ELISA binding data obtained following the protocol described infra for antibody Ab4.
[0040] FIG. 27 provides the NGF ELISA binding data obtained following the protocol described infra for antibodies Ab5 and Ab6.
[0041] FIG. 28 provides the NGF ELISA binding data obtained following the protocol described infra for Fab1.
[0042] FIG. 29 provides the NGF ELISA binding data obtained following the protocol described infra for Fab2.
[0043] FIG. 30 provides the NGF ELISA binding data obtained following the protocol described infra for antibodies Ab7 and Ab8.
[0044] FIG. 31 provides the NGF ELISA binding data obtained following the protocol described infra for antibodies Ab9 and Ab10.
[0045] FIG. 32 provides the NGF ELISA binding data obtained following the protocol described infra for antibody Ab11.
[0046] FIG. 33 provides the NGF ELISA binding data obtained following the protocol described infra for antibody Ab12.
[0047] FIG. 34 provides the NGF ELISA binding data obtained following the protocol described infra for antibody Ab13.
[0048] FIG. 35 provides the NGF ELISA binding data obtained following the protocol described infra for antibody Ab14.
[0049] FIG. 36 provides the NGF ELISA binding data obtained following the protocol described infra for antibody Ab15.
[0050] FIG. 37 provides the NGF ELISA binding data obtained following the protocol described infra for antibody Ab16.
[0051] FIG. 38 provides the NGF ELISA binding data obtained following the protocol described infra for antibodies Ab17 and Ab18.
[0052] FIG. 39 provides the NGF ELISA binding data obtained following the protocol described infra for antibody Ab19.
[0053] FIG. 40 provides the NGF ELISA binding data obtained following the protocol described infra for antibody Ab20.
[0054] FIG. 41 provides the TF1 cell proliferation data obtained following example 1 for antibodies Ab1 and Ab2.
[0055] FIG. 42 provides the TF1 cell proliferation data obtained following example 1 for antibodies Ab3 and Ab4.
[0056] FIG. 43 provides the TF1 cell proliferation data obtained following example 1 for antibodies Ab5 and Ab6.
[0057] FIG. 44 provides the TF1 cell proliferation data obtained following example 1 for the Fab1 and Fab2 antibody fragments.
[0058] FIG. 45 provides the TF1 cell proliferation data obtained following example 1 for antibodies Ab7 and Ab8.
[0059] FIG. 46 provides the TF1 cell proliferation data obtained following example 1 for antibodies Ab9 and Ab10.
[0060] FIG. 47 provides the TF1 cell proliferation data obtained following example 1 for antibodies Ab11 and Ab12.
[0061] FIG. 48 provides the TF1 cell proliferation data obtained following example 1 for antibodies Ab13 and Ab14.
[0062] FIG. 49 provides the TF1 cell proliferation data obtained following example 1 for antibody Ab15.
[0063] FIG. 50 provides the TF1 cell proliferation data obtained following example 1 for antibody Ab16.
[0064] FIG. 51 provides the TF1 cell proliferation data obtained following example 1 for antibodies Ab17 and Ab18.
[0065] FIG. 52 provides the TF1 cell proliferation data obtained following example 1 for antibodies Ab19 and Ab20.
[0066] FIG. 53 provides the inhibition of NGF-p75 interaction data obtained following example 5 for antibodies Ab3 and Ab4. Antibodies Ab3 and Ab4 do not demonstrate the ability to inhibit the interaction of NGF and p75.
[0067] FIG. 54 provides the inhibition of NGF-p75 interaction data obtained following example 5 for antibodies Ab15 and Ab16. Antibodies Ab15 and Ab16 do not demonstrate the ability to inhibit the interaction of NGF and p75.
[0068] FIG. 55 provides the inhibition of NGF-p75 interaction data obtained following example 5 for antibody Ab5. Antibody Ab5 demonstrates the ability to inhibit the interaction of NGF and p75.
[0069] FIG. 56 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab1 obtained following example 6.
[0070] FIG. 57 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab2 obtained following example 6.
[0071] FIG. 58 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab3 obtained following example 6. The results further demonstrate that the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab3 obtained following example 6 is less than that seen with anti-NGF antibodies which exhibit different NGF binding selectivity.
[0072] FIG. 59 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab5 obtained following example 6.
[0073] FIG. 60 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab6 obtained following example 6.
[0074] FIG. 61 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab7 obtained following example 6.
[0075] FIG. 62 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab8 obtained following example 6.
[0076] FIG. 63 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab9 obtained following example 6.
[0077] FIG. 64 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab10 obtained following example 6.
[0078] FIG. 65 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab11 obtained following example 6.
[0079] FIG. 66 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab13 obtained following example 6.
[0080] FIG. 67 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab17 obtained following example 6.
[0081] FIG. 68 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab18 obtained following example 6.
[0082] FIG. 69 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab19 obtained following example 6.
[0083] FIG. 70 demonstrates a statistically significant reduction in pain as assessed by Gait analysis following administration of antibodies Ab2, Ab6, and Ab8, when compared with results obtained with the controls following example 7.
[0084] FIG. 71 demonstrates a statistically significant reduction in pain as assessed by Gait analysis following administration of antibody Ab6 and Fab1, when compared with results obtained with the controls following example 7.
[0085] FIG. 72 demonstrates a statistically significant reduction in pain as assessed by Gait analysis following administration of antibody Ab3, when compared with results obtained with the controls following example 7.
[0086] FIG. 73 demonstrates a statistically significant reduction in pain as assessed by Gait analysis following administration of antibody Ab6 and antibody Ab21, when compared with results obtained with the controls following example 7.
[0087] FIG. 74 demonstrates an increase in inflammation following administration of each of antibodies Ab2, Ab6, and Ab8, when compared with inflammation results for the controls following example 8.
[0088] FIG. 75 demonstrates no significant increase in inflammation following administration of the Fab1 antibody fragment, when compared with inflammation results for the control. In contrast, administration of antibody Ab6 resulted in increased inflammation, when compared with inflammation results for the controls following example 8.
[0089] FIG. 76 demonstrates an increase in inflammation following administration of antibody Ab3, when compared with inflammation results for the controls following example 8.
[0090] FIG. 77 also demonstrates an increase in inflammation following administration of antibody Ab6 and antibody Ab21, when compared with inflammation results for the controls following example 8.
[0091] FIG. 78 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab16 obtained following example 6. The results further demonstrate that the inhibition of PC-12 neurite outgrowth at the same concentrations of antibody is less than that seen with anti-NGF antibodies which exhibit different NGF binding selectivity.
[0092] FIG. 79 demonstrates the inhibition of PC-12 neurite outgrowth in the presence of increasing concentrations of antibody Ab15 obtained following example 6. The results further demonstrate that the inhibition of PC-12 neurite outgrowth at the same concentrations of antibody is less than that seen with anti-NGF antibodies which exhibit different NGF binding selectivity.
DETAILED DESCRIPTION OF PREFERRED EMBODIMENTS
Definitions
[0093] It is to be understood that this invention is not limited to the particular methodology, protocols, cell lines, animal species or genera, and reagents described, as such may vary. It is also to be understood that the terminology used herein is for the purpose of describing particular embodiments only, and is not intended to limit the scope of the present invention which will be limited only by the appended claims. As used herein the singular forms "a", "and", and "the" include plural referents unless the context clearly dictates otherwise. Thus, for example, reference to "a cell" includes a plurality of such cells and reference to "the protein" includes reference to one or more proteins and equivalents thereof known to those skilled in the art, and so forth. All technical and scientific terms used herein have the same meaning as commonly understood to one of ordinary skill in the art to which this invention belongs unless clearly indicated otherwise.
[0094] Nerve Growth Factor (NGF): As used herein, NGF (also referred to as Beta-NGF; HSAN5; and NGFB) encompasses not only the following mature amino acid sequence available from R&D Systems (Minneapolis, Minn.) as Homo sapiens Beta-Nerve Growth Factor (.beta.-NGF): SSSHPIFHRGEFSVCDSVSVWVGDKTTATDIKGKEVMVLGEVNINNSVFKQYFFET KCRDPNPVDSGCRGIDSKHWNSYCTTTHTFVKALTMDGKQAAWRFIRIDTACVC VLSRKAVRRA (SEQ ID NO: 411), but also any pro-, mature, soluble, and/or membrane-bound forms of this NGF amino acid sequence, as well as mutants (mutiens), splice variants, isoforms, orthologues, homologues and variants of this sequence.
[0095] Host Cell: In the present invention this is generally intended to include any cell that provides for the expression of antibodies or antibody fragments according to the invention. This includes by way of example bacterial, yeast, fungi, avian, mammalian, plants, and insect cell expression systems. Typically antibodies are expressed in mammalian, bacterial and yeast cells. In a preferred embodiment the subject antibodies or antibody fragments are expressed in a proprietary secretory expression system that uses diploid Pichia yeast cultures for antibody expression. This expression system is disclosed in U.S. Pat. No. 7,927,863, by Cregg, issued Apr. 19, 2011, the contents of which are incorporated by reference herein.
[0096] Transgenic Animal: In the present invention this refers to any animal (non-human) that has been genetically modified, e.g., by mutation of an endogenous gene, gene knock-in, gene knock-out, and the like. As is well known in the art transgenic animals, e.g., rodents, bovines, et al. can be engineered with human immunoglobulin genes and thereby express human antibodies. Accordingly transgenic animals includes non-human animals engineered to express anti-NGF antibodies.
[0097] Mating competent yeast species: In the present invention this is intended to broadly encompass any diploid or tetraploid yeast which can be grown in culture. Such species of yeast may exist in a haploid, diploid, or other polyploid form. The cells of a given ploidy may, under appropriate conditions, proliferate for an indefinite number of generations in that form. Diploid cells can also sporulate to form haploid cells. Sequential mating can result in tetraploid strains through further mating or fusion of diploid strains. The present invention contemplates the use of haploid yeast, as well as diploid or other polyploid yeast cells produced, for example, by mating or spheroplast fusion.
[0098] In one embodiment of the invention, the mating competent yeast is a member of the Saccharomycetaceae family, which includes the genera Arxiozyma; Ascobotryozyma; Citeromyces; Debaryomyces; Dekkera; Eremothecium; Issatchenkia; Kazachstania; Kluyveromyces; Kodamaea; Lodderomyces; Pachysolen; Pichia; Saccharomyces; Saturnispora; Tetrapisispora; Torulaspora; Williopsis; and Zygosaccharomyces. Other types of yeast potentially useful in the invention include Yarrowia; Rhodosporidium; Candida; Hansenula; Filobasium; Sporidiobohis; Bullera; Leucosporidium and Filobasidella.
[0099] In a preferred embodiment of the invention, the mating competent yeast is a member of the genus Pichia. In a further preferred embodiment of the invention, the mating competent yeast of the genus Pichia is one of the following species: Pichia pastoris, Pichia methanolica, and Hansenula polymorpha (Pichia angusta). In a particularly preferred embodiment of the invention, the mating competent yeast of the genus Pichia is the species Pichia pastoris.
[0100] Haploid Yeast Cell: A cell having a single copy of each gene of its normal genomic (chromosomal) complement.
[0101] Polyploid Yeast Cell: A cell having more than one copy of its normal genomic (chromosomal) complement.
[0102] Diploid Yeast Cell: A cell having two copies (alleles) of essentially every gene of its normal genomic complement, typically formed by the process of fusion (mating) of two haploid cells.
[0103] Tetraploid Yeast Cell: A cell having four copies (alleles) of essentially every gene of its normal genomic complement, typically formed by the process of fusion (mating) of two haploid cells. Tetraploids may carry two, three, four or more different expression cassettes. Such tetraploids might be obtained in S. cerevisiae by selective mating homozygotic heterothallic a/a and alpha/alpha diploids and in Pichia by sequential mating of haploids to obtain auxotrophic diploids. For example, a [met his] haploid can be mated with [ade his] haploid to obtain diploid [his]; and a [met arg] haploid can be mated with [ade arg] haploid to obtain diploid [arg]; then the diploid [his].times.diploid [arg] to obtain a tetraploid prototroph. It will be understood by those of skill in the art that reference to the benefits and uses of diploid cells may also apply to tetraploid cells.
[0104] Yeast Mating: The process by which two haploid yeast cells naturally fuse to form one diploid yeast cell.
[0105] Meiosis: The process by which a diploid yeast cell undergoes reductive division to form four haploid spore products. Each spore may then germinate and form a haploid vegetatively growing cell line.
[0106] Selectable Marker: A selectable marker is a gene or gene fragment that confers a growth phenotype (physical growth characteristic) on a cell receiving that gene as, for example through a transformation event. The selectable marker allows that cell to survive and grow in a selective growth medium under conditions in which cells that do not receive that selectable marker gene cannot grow. Selectable marker genes generally fall into several types, including positive selectable marker genes such as a gene that confers on a cell resistance to an antibiotic or other drug, temperature when two ts mutants are crossed or a ts mutant is transformed; negative selectable marker genes such as a biosynthetic gene that confers on a cell the ability to grow in a medium without a specific nutrient needed by all cells that do not have that biosynthetic gene, or a mutagenized biosynthetic gene that confers on a cell inability to grow by cells that do not have the wild type gene; and the like. Suitable markers include but are not limited to: ZEO; G418; LYS3; MET1; MET3a; ADE1; ADE3; URA3; and the like.
[0107] Expression Vector: These DNA vectors contain elements that facilitate manipulation for the expression of a foreign protein within the target host cell. Conveniently, manipulation of sequences and production of DNA for transformation is first performed in a bacterial host, e.g. E. coli, and usually vectors will include sequences to facilitate such manipulations, including a bacterial origin of replication and appropriate bacterial selection marker. Selection markers encode proteins necessary for the survival or growth of transformed host cells grown in a selective culture medium. Host cells not transformed with the vector containing the selection gene will not survive in the culture medium. Typical selection genes encode proteins that (a) confer resistance to antibiotics or other toxins, (b) complement auxotrophic deficiencies, or (c) supply critical nutrients not available from complex media. Exemplary vectors and methods for transformation of yeast are described, for example, in Burke, D., Dawson, D., & Stearns, T. (2000). Methods in yeast genetics: a Cold Spring Harbor Laboratory course manual. Plainview, N.Y.: Cold Spring Harbor Laboratory Press.
[0108] Expression vectors for use in the methods of the invention will further include yeast specific sequences, including a selectable auxotrophic or drug marker for identifying transformed yeast strains. A drug marker may further be used to amplify copy number of the vector in a yeast host cell.
[0109] The polypeptide coding sequence of interest is operably linked to transcriptional and translational regulatory sequences that provide for expression of the polypeptide in yeast cells. These vector components may include, but are not limited to, one or more of the following: an enhancer element, a promoter, and a transcription termination sequence. Sequences for the secretion of the polypeptide may also be included, e.g. a signal sequence, and the like. A yeast origin of replication is optional, as expression vectors are often integrated into the yeast genome. In one embodiment of the invention, the polypeptide of interest is operably linked, or fused, to sequences providing for optimized secretion of the polypeptide from yeast diploid cells.
[0110] Nucleic acids are "operably linked" when placed into a functional relationship with another nucleic acid sequence. For example, DNA for a signal sequence is operably linked to DNA for a polypeptide if it is expressed as a preprotein that participates in the secretion of the polypeptide; a promoter or enhancer is operably linked to a coding sequence if it affects the transcription of the sequence. Generally, "operably linked" means that the DNA sequences being linked are contiguous, and, in the case of a secretory leader, contiguous and in reading frame. However, enhancers do not have to be contiguous. Linking is accomplished by ligation at convenient restriction sites or alternatively via a PCR/recombination method familiar to those skilled in the art (Gateway.RTM. Technology; Invitrogen, Carlsbad Calif.). If such sites do not exist, the synthetic oligonucleotide adapters or linkers are used in accordance with conventional practice.
[0111] Promoters are untranslated sequences located upstream (5') to the start codon of a structural gene (generally within about 100 to 1000 bp) that control the transcription and translation of particular nucleic acid sequences to which they are operably linked. Such promoters fall into several classes: inducible, constitutive, and repressible promoters (that increase levels of transcription in response to absence of a repressor). Inducible promoters may initiate increased levels of transcription from DNA under their control in response to some change in culture conditions, e.g., the presence or absence of a nutrient or a change in temperature.
[0112] The yeast promoter fragment may also serve as the site for homologous recombination and integration of the expression vector into the same site in the yeast genome; alternatively a selectable marker is used as the site for homologous recombination. Pichia transformation is described in Cregg et al. (1985) Mol. Cell. Biol. 5:3376-3385.
[0113] Examples of suitable promoters from Pichia include the AOX1 and promoter (Cregg et al. (1989) Mol. Cell. Biol. 9:1316-1323); ICL1 promoter (Menendez et al. (2003) Yeast 20(13):1097-108); glyceraldehyde-3-phosphate dehydrogenase promoter (GAP) (Waterham et al. (1997) Gene 186(1):37-44); and FLD1 promoter (Shen et al. (1998) Gene 216(1):93-102). The GAP promoter is a strong constitutive promoter and the AOX and FLD1 promoters are inducible.
[0114] Other yeast promoters include ADH1, alcohol dehydrogenase II, GAL4, PHO3, PHO5, Pyk, and chimeric promoters derived therefrom. Additionally, non-yeast promoters may be used in the invention such as mammalian, insect, plant, reptile, amphibian, viral, and avian promoters. Most typically the promoter will comprise a mammalian promoter (potentially endogenous to the expressed genes) or will comprise a yeast or viral promoter that provides for efficient transcription in yeast systems.
[0115] The polypeptides of interest may be produced recombinantly not only directly, but also as a fusion polypeptide with a heterologous polypeptide, e.g. a signal sequence or other polypeptide having a specific cleavage site at the N-terminus of the mature protein or polypeptide. In general, the signal sequence may be a component of the vector, or it may be a part of the polypeptide coding sequence that is inserted into the vector. The heterologous signal sequence selected preferably is one that is recognized and processed through one of the standard pathways available within the host cell. The S. cerevisiae alpha factor pre-pro signal has proven effective in the secretion of a variety of recombinant proteins from P. pastoris. Other yeast signal sequences include the alpha mating factor signal sequence, the invertase signal sequence, and signal sequences derived from other secreted yeast polypeptides. Additionally, these signal peptide sequences may be engineered to provide for enhanced secretion in diploid yeast expression systems. Other secretion signals of interest also include mammalian signal sequences, which may be heterologous to the protein being secreted, or may be a native sequence for the protein being secreted. Signal sequences include pre-peptide sequences, and in some instances may include propeptide sequences. Many such signal sequences are known in the art, including the signal sequences found on immunoglobulin chains, e.g., K28 preprotoxin sequence, PHA-E, FACE, human MCP-1, human serum albumin signal sequences, human Ig heavy chain, human Ig light chain, and the like. For example, see Hashimoto et. al. Protein Eng 11(2) 75 (1998); and Kobayashi et. al. Therapeutic Apheresis 2(4) 257 (1998).
[0116] Transcription may be increased by inserting a transcriptional activator sequence into the vector. These activators are cis-acting elements of DNA, usually about from 10 to 300 bp, which act on a promoter to increase its transcription. Transcriptional enhancers are relatively orientation and position independent, having been found 5' and 3' to the transcription unit, within an intron, as well as within the coding sequence itself. The enhancer may be spliced into the expression vector at a position 5' or 3' to the coding sequence, but is preferably located at a site 5' from the promoter.
[0117] Expression vectors used in eukaryotic host cells may also contain sequences necessary for the termination of transcription and for stabilizing the mRNA. Such sequences are commonly available from 3' to the translation termination codon, in untranslated regions of eukaryotic or viral DNAs or cDNAs. These regions contain nucleotide segments transcribed as polyadenylated fragments in the untranslated portion of the mRNA.
[0118] Construction of suitable vectors containing one or more of the above-listed components employs standard ligation techniques or PCR/recombination methods. Isolated plasmids or DNA fragments are cleaved, tailored, and re-ligated in the form desired to generate the plasmids required or via recombination methods. For analysis to confirm correct sequences in plasmids constructed, the ligation mixtures are used to transform host cells, and successful transformants selected by antibiotic resistance (e.g. ampicillin or Zeocin) where appropriate. Plasmids from the transformants are prepared, analyzed by restriction endonuclease digestion and/or sequenced.
[0119] As an alternative to restriction and ligation of fragments, recombination methods based on att sites and recombination enzymes may be used to insert DNA sequences into a vector. Such methods are described, for example, by Landy (1989) Ann. Rev. Biochem. 58:913-949; and are known to those of skill in the art. Such methods utilize intermolecular DNA recombination that is mediated by a mixture of lambda and E. coli-encoded recombination proteins. Recombination occurs between specific attachment (att) sites on the interacting DNA molecules. For a description of att sites see Weisberg and Landy (1983) Site-Specific Recombination in Phage Lambda, in Lambda II, Weisberg, ed. (Cold Spring Harbor, N.Y.:Cold Spring Harbor Press), pp. 211-250. The DNA segments flanking the recombination sites are switched, such that after recombination, the att sites are hybrid sequences comprised of sequences donated by each parental vector. The recombination can occur between DNAs of any topology.
[0120] Att sites may be introduced into a sequence of interest by ligating the sequence of interest into an appropriate vector; generating a PCR product containing att B sites through the use of specific primers; generating a cDNA library cloned into an appropriate vector containing att sites; and the like.
[0121] Folding, as used herein, refers to the three-dimensional structure of polypeptides and proteins, where interactions between amino acid residues act to stabilize the structure. While non-covalent interactions are important in determining structure, usually the proteins of interest will have intra- and/or intermolecular covalent disulfide bonds formed by two cysteine residues. For naturally occurring proteins and polypeptides or derivatives and variants thereof, the proper folding is typically the arrangement that results in optimal biological activity, and can conveniently be monitored by assays for activity, e.g. ligand binding, enzymatic activity, etc.
[0122] In some instances, for example where the desired product is of synthetic origin, assays based on biological activity will be less meaningful. The proper folding of such molecules may be determined on the basis of physical properties, energetic considerations, modeling studies, and the like.
[0123] The expression host may be further modified by the introduction of sequences encoding one or more enzymes that enhance folding and disulfide bond formation, i.e. foldases, chaperonins, etc. Such sequences may be constitutively or inducibly expressed in the yeast host cell, using vectors, markers, etc. as known in the art. Preferably the sequences, including transcriptional regulatory elements sufficient for the desired pattern of expression, are stably integrated in the yeast genome through a targeted methodology.
[0124] For example, the eukaryotic PDI is not only an efficient catalyst of protein cysteine oxidation and disulfide bond isomerization, but also exhibits chaperone activity. Co-expression of PDI can facilitate the production of active proteins having multiple disulfide bonds. Also of interest is the expression of BIP (immunoglobulin heavy chain binding protein); cyclophilin; and the like. In one embodiment of the invention, each of the haploid parental strains expresses a distinct folding enzyme, e.g. one strain may express BIP, and the other strain may express PDI or combinations thereof.
[0125] The terms "desired protein" or "desired antibody" are used interchangeably and refer generally to a parent antibody specific to a target, i.e., NGF or a chimeric or humanized antibody or a binding portion thereof derived therefrom as described herein. The term "antibody" is intended to include any polypeptide chain-containing molecular structure with a specific shape that fits to and recognizes an epitope, where one or more non-covalent binding interactions stabilize the complex between the molecular structure and the epitope. The archetypal antibody molecule is the immunoglobulin, and all types of immunoglobulins, IgG, IgM, IgA, IgE, IgD, etc., from all sources, e.g. human, rodent, rabbit, cow, sheep, pig, dog, other mammals, chicken, other avians, etc., are considered to be "antibodies." A preferred source for producing antibodies useful as starting material according to the invention is rabbits. Numerous antibody coding sequences have been described; and others may be raised by methods well-known in the art. Examples thereof include chimeric antibodies, human antibodies and other non-human mammalian antibodies, humanized antibodies, single chain antibodies (such as scFvs), camelbodies, nanobodies, MetMab like monovalent agents, IgNAR (single-chain antibodies derived from sharks), small-modular immunopharmaceuticals (SMIPs), and antibody fragments such as Fabs, Fab', F(ab').sub.2 and the like. See Streltsov V A, et al., Structure of a shark IgNAR antibody variable domain and modeling of an early-developmental isotype, Protein Sci. 2005 November; 14(11):2901-9. Epub 2005 Sep. 30; Greenberg A S, et al., A new antigen receptor gene family that undergoes rearrangement and extensive somatic diversification in sharks, Nature. 1995 Mar. 9; 374(6518):168-73; Nuttall S D, et al., Isolation of the new antigen receptor from wobbegong sharks, and use as a scaffold for the display of protein loop libraries, Mol Immunol. 2001 August; 38(4):313-26; Hamers-Casterman C, et al., Naturally occurring antibodies devoid of light chains, Nature. 1993 Jun. 3; 363(6428):446-8; Gill D S, et al., Biopharmaceutical drug discovery using novel protein scaffolds, Curr Opin Biotechnol. 2006 December; 17(6):653-8. Epub 2006 Oct. 19.
[0126] The present invention includes in particular includes monovalent antibody molecules that bind NGF, which are analogous to MetMab molecules. MetMab is a monovalent antibody specific to Met. (Met is a protein encoded by the nucleotide sequence set forth in Park et al., Proc. Natl. Acad. Sci. 84, 7479-(1987), or fragments thereof, as well as related polypeptides, which include, but are not limited to, allelic variants, splice variants, derivative variants, substitution variants, deletion variants, and/or insertion variants, fusion polypeptides, and interspecies homologs). The MetMab antibody, is a monovalent antibody known by different names including OA-5d5 (Genentech) and is also called One Armed 5d5, 5d5, MetMab, PRO143966, among others). Antibody OA-5d5, including its structure and properties, and methods for making and using it, are described in U.S. Publication No. 2007/0092520. In one embodiment, an anti-NGF antibody according to the invention may comprise a single Fab region linked to an Fc region. In such embodiment, an antibody of the invention may comprise light and heavy chain variable domains as described herein. In such an embodiment, the antibody is monovalent and may comprise an intact Fc region. In another such embodiment, the Fc region may comprise at least one protuberance (knob) and at least one cavity (hole), wherein the presence of the protuberance and cavity enhances formation of a complex between an Fc polypeptide comprising the protuberance and an Fc polypeptide comprising the cavity, for example as described in WO 2005/063816. In one embodiment, the Fc region of an antibody of the invention may comprise a first and a second Fc polypeptide, wherein the first and second polypeptide each comprises one or more mutations with respect to wild type human Fc. In one embodiment, a cavity mutation is T366S, L368A and/or Y407V. In another embodiment, a protuberance mutation is T366W. In a specific embodiment, a monovalent antibody according to the subject invention may comprise a one-armed antibody synthesized as described in WO2005/063816. In such embodiment, the one-armed antibody may comprise Fc mutations constituting "knobs" and "holes" as described in WO2005/063816. For example, a hole mutation can be one or more of T366A, L368A and/or Y407V in an Fc polypeptide, and a cavity mutation can be T366W.
[0127] The invention is also directed to an anti-human NGF monovalent agent that binds with the same NGF epitope and/or competes with an anti-NGF antibody for binding to NGF as an antibody or antibody fragment disclosed herein, including but not limited to an anti-NGF antibody selected from Ab1, Ab2, Ab3, Ab4, Ab5, Ab6, Ab7, Ab8, Ab9, Ab10, Ab11, Ab12, Ab13, Ab14, Ab15, Ab16, Ab17, Ab18, Ab19, Ab20 or Ab21.
[0128] For example, antibodies or antigen binding fragments may be produced by genetic engineering. In this technique, as with other methods, antibody-producing cells are sensitized to the desired antigen or immunogen. The messenger RNA isolated from antibody producing cells is used as a template to make cDNA using PCR amplification. A library of vectors, each containing one heavy chain gene and one light chain gene retaining the initial antigen specificity, is produced by insertion of appropriate sections of the amplified immunoglobulin cDNA into the expression vectors. A combinatorial library is constructed by combining the heavy chain gene library with the light chain gene library. This results in a library of clones which co-express a heavy and light chain (resembling the Fab fragment or antigen binding fragment of an antibody molecule). The vectors that carry these genes are co-transfected into a host cell. When antibody gene synthesis is induced in the transfected host, the heavy and light chain proteins self-assemble to produce active antibodies that can be detected by screening with the antigen or immunogen.
[0129] Antibody coding sequences of interest include those encoded by native sequences, as well as nucleic acids that, by virtue of the degeneracy of the genetic code, are not identical in sequence to the disclosed nucleic acids, and variants thereof. Variant polypeptides can include amino acid (aa) substitutions, additions or deletions. The amino acid substitutions can be conservative amino acid substitutions or substitutions to eliminate non-essential amino acids, such as to alter a glycosylation site, or to minimize misfolding by substitution or deletion of one or more cysteine residues that are not necessary for function. Variants can be designed so as to retain or have enhanced biological activity of a particular region of the protein (e.g., a functional domain, catalytic amino acid residues, etc). Variants also include fragments of the polypeptides disclosed herein, particularly biologically active fragments and/or fragments corresponding to functional domains. Techniques for in vitro mutagenesis of cloned genes are known. Also included in the subject invention are polypeptides that have been modified using ordinary molecular biological techniques so as to improve their resistance to proteolytic degradation or to optimize solubility properties or to render them more suitable as a therapeutic agent.
[0130] Chimeric antibodies herein broadly includes any antibody or antibody fragment produced by combining portions of one or more antibodies of the same or different species. containing. Typically chimeric antibodies comprise the variable regions of one non-human antibody and the constant regions of another human antibody. Chimeric antibodies herein further include humanized antibodies, as humanized antibodies comprise a portion of at least one human antibody and a portion of a non-human antibody, i.e., they typically comprise the CDRs of a non-human antibody and all or most of the framework residues of a human antibody. Therefore, humanized and chimericantibodies are sometimes referred to interchangeably herein. Chimeric antibodies may be made by recombinant means by combining the variable light and heavy chain regions (V.sub.L and V.sub.H), obtained from antibody producing cells of one species with the constant light and heavy chain regions from another. Typically chimeric antibodies utilize rodent or rabbit variable regions and human constant regions, in order to produce an antibody with predominantly human domains. The production of such chimeric antibodies is well known in the art, and may be achieved by standard means (as described, e.g., in U.S. Pat. No. 5,624,659, incorporated herein by reference in its entirety). It is further contemplated that the human constant regions of chimeric antibodies of the invention may be selected from IgG1, IgG2, IgG3, IgG4, IgG5, IgG6, IgG7, IgG8, IgG9, IgG10, IgG11, IgG12, IgG13, IgG14, IgG15, IgG16, IgG17, IgG18 or IgG19 constant regions.
[0131] Humanized antibodies are engineered to contain even more human-like immunoglobulin domains, and incorporate only the complementarity-determining regions of the animal-derived antibody. This is accomplished by carefully examining the sequence of the hyper-variable loops of the variable regions of the monoclonal antibody, and fitting them to the structure of the human antibody chains. Although facially complex, the process is straightforward in practice. See, e.g., U.S. Pat. No. 6,187,287, incorporated fully herein by reference.
[0132] In addition to entire immunoglobulins (or their recombinant counterparts), immunoglobulin fragments comprising the epitope binding site (e.g., Fab', F(ab').sub.2, or other fragments) may be synthesized. "Fragment," or minimal immunoglobulins may be designed utilizing recombinant immunoglobulin techniques. For instance "Fv" immunoglobulins for use in the present invention may be produced by synthesizing a fused variable light chain region and a variable heavy chain region. Combinations of antibodies are also of interest, e.g. diabodies, which comprise two distinct Fv specificities. In another embodiment of the invention, SMIPs (small molecule immunopharmaceuticals), camelbodies, nanobodies, MetMab like monovalent agents, and IgNAR are encompassed by immunoglobulin fragments.
[0133] Immunoglobulins and fragments thereof may be modified post-translationally, e.g. to add effector moieties such as chemical linkers, detectable moieties, such as fluorescent dyes, enzymes, toxins, substrates, bioluminescent materials, radioactive materials, chemiluminescent moieties and the like, or specific binding moieties, such as streptavidin, avidin, or biotin, and the like may be utilized in the methods and compositions of the present invention. Examples of additional effector molecules are provided infra.
[0134] A polynucleotide sequence "corresponds" to a polypeptide sequence if translation of the polynucleotide sequence in accordance with the genetic code yields the polypeptide sequence (i.e., the polynucleotide sequence "encodes" the polypeptide sequence), one polynucleotide sequence "corresponds" to another polynucleotide sequence if the two sequences encode the same polypeptide sequence.
[0135] A "heterologous" region or domain of a DNA construct is an identifiable segment of DNA within a larger DNA molecule that is not found in association with the larger molecule in nature. Thus, when the heterologous region encodes a mammalian gene, the gene will usually be flanked by DNA that does not flank the mammalian genomic DNA in the genome of the source organism. Another example of a heterologous region is a construct where the coding sequence itself is not found in nature (e.g., a cDNA where the genomic coding sequence contains introns, or synthetic sequences having codons different than the native gene). Allelic variations or naturally-occurring mutational events do not give rise to a heterologous region of DNA as defined herein.
[0136] A "coding sequence" is an in-frame sequence of codons that (in view of the genetic code) correspond to or encode a protein or peptide sequence. Two coding sequences correspond to each other if the sequences or their complementary sequences encode the same amino acid sequences. A coding sequence in association with appropriate regulatory sequences may be transcribed and translated into a polypeptide. A polyadenylation signal and transcription termination sequence will usually be located 3' to the coding sequence. A "promoter sequence" is a DNA regulatory region capable of binding RNA polymerase in a cell and initiating transcription of a downstream (3' direction) coding sequence. Promoter sequences typically contain additional sites for binding of regulatory molecules (e.g., transcription factors) which affect the transcription of the coding sequence. A coding sequence is "under the control" of the promoter sequence or "operatively linked" to the promoter when RNA polymerase binds the promoter sequence in a cell and transcribes the coding sequence into mRNA, which is then in turn translated into the protein encoded by the coding sequence.
[0137] Vectors are used to introduce a foreign substance, such as DNA, RNA or protein, into an organism or host cell. Typical vectors include recombinant viruses (for polynucleotides) and liposomes (for polypeptides). A "DNA vector" is a replicon, such as plasmid, phage or cosmid, to which another polynucleotide segment may be attached so as to bring about the replication of the attached segment. An "expression vector" is a DNA vector which contains regulatory sequences which will direct polypeptide synthesis by an appropriate host cell. This usually means a promoter to bind RNA polymerase and initiate transcription of mRNA, as well as ribosome binding sites and initiation signals to direct translation of the mRNA into a polypeptide(s). Incorporation of a polynucleotide sequence into an expression vector at the proper site and in correct reading frame, followed by transformation of an appropriate host cell by the vector, enables the production of a polypeptide encoded by said polynucleotide sequence.
[0138] "Amplification" of polynucleotide sequences is the in vitro production of multiple copies of a particular nucleic acid sequence. The amplified sequence is usually in the form of DNA. A variety of techniques for carrying out such amplification are described in a review article by Van Brunt (1990, Bio/Technol., 8(4):291-294). Polymerase chain reaction or PCR is a prototype of nucleic acid amplification, and use of PCR herein should be considered exemplary of other suitable amplification techniques.
[0139] The general structure of antibodies in vertebrates now is well understood (Edelman, G. M., Ann. N.Y. Acad. Sci., 190: 5 (1971)). Antibodies consist of two identical light polypeptide chains of molecular weight approximately 23,000 daltons (the "light chain"), and two identical heavy chains of molecular weight 53,000-70,000 (the "heavy chain"). The four chains are joined by disulfide bonds in a "Y" configuration wherein the light chains bracket the heavy chains starting at the mouth of the "Y" configuration. The "branch" portion of the "Y" configuration is designated the F.sub.ab region; the stem portion of the "Y" configuration is designated the F.sub.C region. The amino acid sequence orientation runs from the N-terminal end at the top of the "Y" configuration to the C-terminal end at the bottom of each chain. The N-terminal end possesses the variable region having specificity for the antigen that elicited it, and is approximately 100 amino acids in length, there being slight variations between light and heavy chain and from antibody to antibody.
[0140] The variable region is linked in each chain to a constant region that extends the remaining length of the chain and that within a particular class of antibody does not vary with the specificity of the antibody (i.e., the antigen eliciting it). There are five known major classes of constant regions that determine the class of the immunoglobulin molecule (IgG, IgM, IgA, IgD, and IgE corresponding to .gamma., .mu., .alpha., .delta., and .epsilon. (gamma, mu, alpha, delta, or epsilon) heavy chain constant regions). The constant region or class determines subsequent effector function of the antibody, including activation of complement (Kabat, E. A., Structural Concepts in Immunology and Immunochemistry, 2nd Ed., p. 413-436, Holt, Rinehart, Winston (1976)), and other cellular responses (Andrews, D. W., et al., Clinical Immunobiology, pp 1-18, W. B. Sanders (1980); Kohl, S., et al., Immunology, 48: 187 (1983)); while the variable region determines the antigen with which it will react. Light chains are classified as either .kappa. (kappa) or .lamda. (lambda). Each heavy chain class can be prepared with either kappa or lambda light chain. The light and heavy chains are covalently bonded to each other, and the "tail" portions of the two heavy chains are bonded to each other by covalent disulfide linkages when the immunoglobulins are generated either by hybridomas or by B cells.
[0141] The expression "variable region" or "VR" refers to the domains within each pair of light and heavy chains in an antibody that are involved directly in binding the antibody to the antigen. Each heavy chain has at one end a variable domain (V.sub.H) followed by a number of constant domains. Each light chain has a variable domain (V.sub.L) at one end and a constant domain at its other end; the constant domain of the light chain is aligned with the first constant domain of the heavy chain, and the light chain variable domain is aligned with the variable domain of the heavy chain.
[0142] The expressions "complementarity determining region," "hypervariable region," or "CDR" refer to one or more of the hyper-variable or complementarity determining regions (CDRs) found in the variable regions of light or heavy chains of an antibody (See Kabat, E. A. et al., Sequences of Proteins of Immunological Interest, National Institutes of Health, Bethesda, Md., (1987)). These expressions include the hypervariable regions as defined by Kabat et al. ("Sequences of Proteins of Immunological Interest," Kabat E., et al., US Dept. of Health and Human Services, 1983) or the hypervariable loops in 3-dimensional structures of antibodies (Chothia and Lesk, J Mol. Biol. 196 901-917 (1987)). The CDRs in each chain are held in close proximity by framework regions and, with the CDRs from the other chain, contribute to the formation of the antigen binding site. Within the CDRs there are select amino acids that have been described as the selectivity determining regions (SDRs) which represent the critical contact residues used by the CDR in the antibody-antigen interaction (Kashmiri, S., Methods, 36:25-34 (2005)).
[0143] The expressions "framework region" or "FR" refer to one or more of the framework regions within the variable regions of the light and heavy chains of an antibody (See Kabat, E. A. et al., Sequences of Proteins of Immunological Interest, National Institutes of Health, Bethesda, Md., (1987)). These expressions include those amino acid sequence regions interposed between the CDRs within the variable regions of the light and heavy chains of an antibody.
Anti-NGF Antibodies and Binding Fragments Thereof Having Binding Activity for NGF
Antibody Ab1
[0144] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00001 (SEQ ID NO: 1) ALVMTQTPSSVSAAVGGTVTINCQASQNIYSNLAWYQQRPGQRPKLLIYG ASNLDAGVPSRFRGSGSGTEYTLTISDLECDDVGTYYCQSAFDSDSTENT FGGGTEVVVKR.
[0145] The invention particularly contemplates antibodies and fragments suitable for treating inflammation, pain and the specific pain associated disorders alone or in association with another active agent, e.g., an NSAID or opioid analgesic, wherein the antibodies include chimeric antibodies having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00002 (SEQ ID NO: 2) ALVMTQTPSSVSAAVGGTVTINCQASQNIYSNLAWYQQRPGQRPKLLIYG ASNLDAGVPSRFRGSGSGTEYTLTISDLECDDVGTYYCQSAFDSDSTENT FGGGTEVVVKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQ WKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVT HQGLSSPVTKSFNRGEC.
[0146] The invention particularly contemplates antibodies and fragments suitable for treating inflammation, pain and the specific pain associated disorders alone or in association with another active agent, e.g., an NSAID or opioid analgesic, wherein the antibodies include chimeric antibodies having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00003 (SEQ ID NO: 3) QSLEESGGRLVTPGTPLTLTCTVSGFSLSSYAMSWVRQAPGKGLEWIGVI TSIGSTVYASWAKGRFTISKTSTTVDLKITSPTTEDTATYFCARGYDDYD EMTYFNIWGQGTLVTVSS.
[0147] The invention particularly contemplates antibodies and fragments suitable for treating inflammation, pain and the specific pain associated disorders alone or in association with another active agent, e.g., an NSAID or opioid analgesic, wherein the antibodies include chimeric antibodies having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00004 (SEQ ID NO: 4) QSLEESGGRLVTPGTPLTLTCTVSGFSLSSYAMSWVRQAPGKGLEWIGVI TSIGSTVYASWAKGRFTISKTSTTVDLKITSPTTEDTATYFCARGYDDYD EMTYFNIWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYI CNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKD TLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYAST YRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVY TLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLD SDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK.
[0148] The invention particularly contemplates antibodies and fragments suitable for treating inflammation, pain and the specific pain associated disorders alone or in association with another active agent, e.g., an NSAID or opioid analgesic, wherein the antibodies comprise one or more of the polypeptide sequences of SEQ ID NO: 5; SEQ ID NO: 6; and SEQ ID NO: 7 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 1 or the light chain sequence of SEQ ID NO: 2, and/or one or more of the polypeptide sequences of SEQ ID NO: 8; SEQ ID NO: 9; and SEQ ID NO: 10 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 3 or the heavy chain sequence of SEQ ID NO: 4, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0149] The invention particularly contemplates antibodies and fragments suitable for treating pain and specific pain or inflammation associated disorders alone or in association with another active agent, e.g., an NSAID or opioid analgesic, wherein the antibody is a fragment having binding specificity to NGF. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 1 or SEQ ID NO: 2. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 3 or SEQ ID NO: 4.
[0150] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 5; SEQ ID NO: 6; and SEQ ID NO: 7 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 1 or the light chain sequence of SEQ ID NO: 2.
[0151] The invention particularly contemplates antibodies and fragments suitable for treating inflammation, pain and the specific pain associated disorders alone or in association with another active agent, e.g., an NSAID or opioid analgesic, wherein the antibodies include fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 8; SEQ ID NO: 9; and SEQ ID NO: 10 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 3 or the heavy chain sequence of SEQ ID NO: 4.
[0152] The invention also contemplates antibody fragments which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 1; the variable heavy chain region of SEQ ID NO: 3; the complementarity-determining regions (SEQ ID NO: 5; SEQ ID NO: 6; and SEQ ID NO: 7) of the variable light chain region of SEQ ID NO: 1; and the complementarity-determining regions (SEQ ID NO: 8; SEQ ID NO: 9; and SEQ ID NO: 10) of the variable heavy chain region of SEQ ID NO: 3.
[0153] In a particularly preferred embodiment of the invention, the chimeric anti-NGF antibody is Ab1, comprising, or alternatively consisting of, SEQ ID NO: 2 and SEQ ID NO: 4, and having at least one of the biological activities set forth herein.
[0154] In a further particularly preferred embodiment of the invention, antibody fragments for use herein comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and monovalent antibody molecules analogous to MetMab. With respect to antibody Ab1, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 1 and the variable heavy chain sequence of SEQ ID NO: 3. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 1 and/or SEQ ID NO: 3 in said Fab while retaining binding specificity for NGF.
[0155] In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab1. In another embodiment of the invention, anti-NGF antibodies such as Ab1 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, transgenic plants or animals, or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab2
[0156] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric or humanized antibodies having binding specificity to NGF wherein the antibody is antibody Ab2 or fragments thereof, for example as set forth below, in a therapeutically effective amount which inhibits the association of NGF with TrkA and further inhibits the association of NGF with p75. In one embodiment, the invention includes chimeric or humanized antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00005 (SEQ ID NO: 11) DIQMTQSPSTLSASVGDRVTITCQASQNIYSNLAWYQQKPGKAPKLLIYG ASNLDAGVPSRFSGSGSGTEYTLTISSLQPDDFATYYCQSAFDSDSTENT FGGGTKVEIKR.
[0157] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00006 (SEQ ID NO: 12) DIQMTQSPSTLSASVGDRVTITCQASQNIYSNLAWYQQKPGKAPKLLIYG ASNLDAGVPSRFSGSGSGTEYTLTISSLQPDDFATYYCQSAFDSDSTENT FGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQ WKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVT HQGLSSPVTKSFNRGEC.
[0158] The invention further includes chimeric or humanized antibodies having binding specificity to NGF e.g., for treatment or prevention of inflammation, pain and pain associated conditions and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00007 (SEQ ID NO: 13) EVQLVESGGGLVQPGGSLRLSCAASGFTVSSYAMSWVRQAPGKGLEWVGV ITSIGSTVYASSAKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARGYD DYDEMTYFNIWGQGTLVTVSS.
[0159] The invention also includes chimeric or humanized antibodies having binding specificity to NGF e.g., for treatment or prevention of inflammation, pain and pain associated conditions and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00008 (SEQ ID NO: 14) EVQLVESGGGLVQPGGSLRLSCAASGFTVSSYAMSWVRQAPGKGLEWVGV ITSIGSTVYASSAKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARGYD DYDEMTYFNIWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPK PKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY ASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREP QVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPP VLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG K.
[0160] The invention further contemplates antibodies e.g., for treatment or prevention of pain, inflammation and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 15; SEQ ID NO: 16; and SEQ ID NO: 17 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 11 or the light chain sequence of SEQ ID NO: 12, and/or one or more of the polypeptide sequences of SEQ ID NO: 18; SEQ ID NO: 19; and SEQ ID NO: 20 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 13 or the heavy chain sequence of SEQ ID NO: 14, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0161] The invention also contemplates fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 11 or SEQ ID NO: 12. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 13 or SEQ ID NO: 14.
[0162] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF, e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 15; SEQ ID NO: 16; and SEQ ID NO: 17 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 11 or the light chain sequence of SEQ ID NO: 12.
[0163] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF, e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 18; SEQ ID NO: 19; and SEQ ID NO: 20 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 13 or the heavy chain sequence of SEQ ID NO: 14.
[0164] The invention also contemplates antibody fragments which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 11; the variable heavy chain region of SEQ ID NO: 13; the complementarity-determining regions (SEQ ID NO: 15; SEQ ID NO: 16; and SEQ ID NO: 17) of the variable light chain region of SEQ ID NO: 11; and the complementarity-determining regions (SEQ ID NO: 18; SEQ ID NO: 19; and SEQ ID NO: 20) of the variable heavy chain region of SEQ ID NO: 13.
[0165] In a particularly preferred embodiment of the invention, the chimeric or humanized anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab2, comprising, or alternatively consisting of, SEQ ID NO: 12 and SEQ ID NO: 14, and having at least one of the biological activities set forth herein.
[0166] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and monovalent antibody molecules analogous to MetMab. With respect to antibody Ab2, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 11 and the variable heavy chain sequence of SEQ ID NO: 13. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 11 and/or SEQ ID NO: 13 in said Fab while retaining binding specificity for NGF.
[0167] In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab2. In another embodiment of the invention, anti-NGF antibodies such as Ab2 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, transgenic plants or animals, or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab3
[0168] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which do not appreciably inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric antibodies having binding specificity to NGF wherein the antibody is Ab3 or fragments thereof, for example as set forth below, in a therapeutically effective amount which inhibits the association of NGF with TrkA without appreciably inhibiting the association of NGF with p75. In one embodiment, the invention includes chimeric antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00009 (SEQ ID NO: 21) AVLTQTPSPVSAAMGDTVTIKCQSSQSVYKNNYLSWYQQKPGQPPRLLIY DASNLPSGVPSRFSGSGSGTQFTLTISGVQCDDAATYYCLGDYDDDADNA FGGGTEVVVKR.
[0169] The invention also includes chimeric antibodies, e.g., e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00010 (SEQ ID NO: 22) AVLTQTPSPVSAAMGDTVTIKCQSSQSVYKNNYLSWYQQKPGQPPRLLIY DASNLPSGVPSRFSGSGSGTQFTLTISGVQCDDAATYYCLGDYDDDADNA FGGGTEVVVKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQ WKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVT HQGLSSPVTKSFNRGEC.
[0170] The invention further includes chimeric antibodies e.g., e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00011 (SEQ ID NO: 23) QSVEESGGRLVTPGTPLTLTCTVSGFSLSSYVMIWVRQAPGKGLEYIGIT WSAGTYYASWAKGRFTISKTSSTTVDLKITSPTTEDTATYFCAGGGGSIY DIWGPGTLVTVSS.
[0171] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00012 (SEQ ID NO: 24) QSVEESGGRLVTPGTPLTLTCTVSGFSLSSYVMIWVRQAPGKGLEYIGIT WSAGTYYASWAKGRFTISKTSSTTVDLKITSPTTEDTATYFCAGGGGSIY DIWGPGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPV TVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNH KPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMIS RTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVS VLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPS REEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSF FLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK.
[0172] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 25; SEQ ID NO: 26; and SEQ ID NO: 27 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 21 or the light chain sequence of SEQ ID NO: 22, and/or one or more of the polypeptide sequences of SEQ ID NO: 28; SEQ ID NO: 29; and SEQ ID NO: 30 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 23 or the heavy chain sequence of SEQ ID NO: 24, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0173] The invention also contemplates fragments of the antibody e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 21 or SEQ ID NO: 22. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 23 or SEQ ID NO: 24.
[0174] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 25; SEQ ID NO: 26; and SEQ ID NO: 27 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 21 or the light chain sequence of SEQ ID NO: 22.
[0175] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 28; SEQ ID NO: 29; and SEQ ID NO: 30 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 23 or the heavy chain sequence of SEQ ID NO: 24.
[0176] The invention also contemplates antibody fragments which include one or more of the antibody fragments described herein e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 21; the variable heavy chain region of SEQ ID NO: 23; the complementarity-determining regions (SEQ ID NO: 25; SEQ ID NO: 26; and SEQ ID NO: 27) of the variable light chain region of SEQ ID NO: 21; and the complementarity-determining regions (SEQ ID NO: 28; SEQ ID NO: 29; and SEQ ID NO: 30) of the variable heavy chain region of SEQ ID NO: 23.
[0177] In a particularly preferred embodiment of the invention, the chimeric anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab3, comprising, or alternatively consisting of, SEQ ID NO: 22 and SEQ ID NO: 24, and having at least one of the biological activities set forth herein.
[0178] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and monovalent antibody molecules analogous to MetMab. With respect to antibody Ab3, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 21 and the variable heavy chain sequence of SEQ ID NO: 23. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 21 and/or SEQ ID NO: 23 in said Fab while retaining binding specificity for NGF.
[0179] In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab3. In another embodiment of the invention, anti-NGF antibodies such as Ab3 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, transgenic plants or animals, or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab4
[0180] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which do not appreciably inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention provides chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00013 (SEQ ID NO: 31) DIQMTQSPSTLSASVGDRVTITCQSSQSVYKNNYLSWYQQKPGKAPKLLI YDASNLPSGVPSRFSGSGSGTEFTLTISSLQPDDFATYYCLGDYDDDADN AFGGGTKVEIKR.
[0181] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00014 (SEQ ID NO: 32) DIQMTQSPSTLSASVGDRVTITCQSSQSVYKNNYLSWYQQKPGKAPKLLI YDASNLPSGVPSRFSGSGSGTEFTLTISSLQPDDFATYYCLGDYDDDADN AFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKV QWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEV THQGLSSPVTKSFNRGEC.
[0182] The invention further includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00015 (SEQ ID NO: 33) EVQLVESGGGLVQPGGSLRLSCAASGFTVSSYVMIWVRQAPGKGLEYIGI TWSAGTYYASSAKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAGGGGS IYDIWGQGTLVTVSS.
[0183] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00016 (SEQ ID NO: 34) EVQLVESGGGLVQPGGSLRLSCAASGFTVSSYVMIWVRQAPGKGLEYIGI TWSAGTYYASSAKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAGGGGS IYDIWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPE PVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNV NHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLM ISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRV VSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLP PSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDG SFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK.
[0184] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 35; SEQ ID NO: 36; and SEQ ID NO: 37 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 31 or the light chain sequence of SEQ ID NO: 32, and/or one or more of the polypeptide sequences of SEQ ID NO: 38; SEQ ID NO: 39; and SEQ ID NO: 40 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 33 or the heavy chain sequence of SEQ ID NO: 34, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0185] The invention also contemplates fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 31 or SEQ ID NO: 32. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 33 or SEQ ID NO: 34.
[0186] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 35; SEQ ID NO: 36; and SEQ ID NO: 37 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 31 or the light chain sequence of SEQ ID NO: 32.
[0187] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 38; SEQ ID NO: 39; and SEQ ID NO: 40 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 33 or the heavy chain sequence of SEQ ID NO: 34.
[0188] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 31; the variable heavy chain region of SEQ ID NO: 33; the complementarity-determining regions (SEQ ID NO: 35; SEQ ID NO: 36; and SEQ ID NO: 37) of the variable light chain region of SEQ ID NO: 31; and the complementarity-determining regions (SEQ ID NO: 38; SEQ ID NO: 39; and SEQ ID NO: 40) of the variable heavy chain region of SEQ ID NO: 33.
[0189] In a particularly preferred embodiment of the invention, the chimeric or humanized anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab4, comprising, or alternatively consisting of, SEQ ID NO: 32 and SEQ ID NO: 34, and having at least one of the biological activities set forth herein.
[0190] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and monovalent antibody molecules analogous to MetMab. With respect to antibody Ab4, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 31 and the variable heavy chain sequence of SEQ ID NO: 33. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 31 and/or SEQ ID NO: 33 in said Fab while retaining binding specificity for NGF.
[0191] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab4. In another embodiment of the invention, anti-NGF antibodies such as Ab4 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, transgenic plants or animals, or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab5
[0192] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which further inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00017 (SEQ ID NO: 41) AYDMTQTPASVEVAVGGTVTIKCQASQSIYSNLAWYQQRPGQPPKLLIYD ASTLESGVPSRFKGSGSGTEYTLTISGVECADAASYYCQQGFTVSDIDNA FGGGTEVVVKR.
[0193] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00018 (SEQ ID NO: 42) AYDMTQTPASVEVAVGGTVTIKCQASQSIYSNLAWYQQRPGQPPKLLIYD ASTLESGVPSRFKGSGSGTEYTLTISGVECADAASYYCQQGFTVSDIDNA FGGGTEVVVKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQ WKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVT HQGLSSPVTKSFNRGEC.
[0194] The invention further includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00019 (SEQ ID NO: 43) QSVEESGGRLVTPGTPLTLTCTVSGFSLSNYAVGWVRQAPGKGLEWIGII GRNGNTWYASWARGRFTISKTSTTVDLKITSPTSEDTATYFCARGYGRSV AYYVFNIWGPGTLVTVSS.
[0195] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00020 (SEQ ID NO: 44) QSVEESGGRLVTPGTPLTLTCTVSGFSLSNYAVGWVRQAPGKGLEWIGII GRNGNTWYASWARGRFTISKTSTTVDLKITSPTSEDTATYFCARGYGRSV AYYVFNIWGPGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYI CNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKD TLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYAST YRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVY TLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLD SDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK.
[0196] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 45; SEQ ID NO: 46; and SEQ ID NO: 47 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 41 or the light chain sequence of SEQ ID NO: 42, and/or one or more of the polypeptide sequences of SEQ ID NO: 48; SEQ ID NO: 49; and SEQ ID NO: 50 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 43 or the heavy chain sequence of SEQ ID NO: 44, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0197] The invention also contemplates fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 41 or SEQ ID NO: 42. In another embodiment of the invention, antibody fragments of the invention e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 43 or SEQ ID NO: 44.
[0198] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 45; SEQ ID NO: 46; and SEQ ID NO: 47 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 41 or the light chain sequence of SEQ ID NO: 42.
[0199] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 48; SEQ ID NO: 49; and SEQ ID NO: 50 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 43 or the heavy chain sequence of SEQ ID NO: 44.
[0200] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 41; the variable heavy chain region of SEQ ID NO: 43; the complementarity-determining regions (SEQ ID NO: 45; SEQ ID NO: 46; and SEQ ID NO: 47) of the variable light chain region of SEQ ID NO: 41; and the complementarity-determining regions (SEQ ID NO: 48; SEQ ID NO: 49; and SEQ ID NO: 50) of the variable heavy chain region of SEQ ID NO: 43.
[0201] In a particularly preferred embodiment of the invention, the included chimeric anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab5, comprising, or alternatively consisting of, SEQ ID NO: 42 and SEQ ID NO: 44, and having at least one of the biological activities set forth herein.
[0202] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and monovalent antibody molecules analogous to MetMab. With respect to antibody Ab5, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 41 and the variable heavy chain sequence of SEQ ID NO: 43. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 41 and/or SEQ ID NO: 43 in said Fab while retaining binding specificity for NGF.
[0203] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab5. In another embodiment of the invention, anti-NGF antibodies such as Ab5 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plants, animals, or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab6
[0204] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric or humanized antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00021 (SEQ ID NO: 51) DIQMTQSPSTLSASVGDRVTITCQASQSIYSNLAWYQQKPGKAPKLLIYD ASTLESGVPSRFSGSGSGTEYTLTISSLQPDDFATYYCQQGFTVSDIDNA FGGGTKVEIKR.
[0205] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00022 (SEQ ID NO: 52) DIQMTQSPSTLSASVGDRVTITCQASQSIYSNLAWYQQKPGKAPKLLIYD ASTLESGVPSRFSGSGSGTEYTLTISSLQPDDFATYYCQQGFTVSDIDNA FGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQ WKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVT HQGLSSPVTKSFNRGEC.
[0206] The invention further includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00023 (SEQ ID NO: 53) EVQLVESGGGLVQPGGSLRLSCAASGFTVSNYAVGWVRQAPGKGLEWVGI IGRNGNTWYASSARGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARGYG RSVAYYVFNIWGPGTLVTVSS.
[0207] The invention also includes chimeric antibodies or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00024 (SEQ ID NO: 54) EVQLVESGGGLVQPGGSLRLSCAASGFTVSNYAVGWVRQAPGKGLEWVGI IGRNGNTWYASSARGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARGYG RSVAYYVFNIWGPGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPK PKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY ASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREP QVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPP VLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG K.
[0208] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 55; SEQ ID NO: 56; and SEQ ID NO: 57 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 52, and/or one or more of the polypeptide sequences of SEQ ID NO: 58; SEQ ID NO: 59; and SEQ ID NO: 60 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 54, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0209] The invention also contemplates fragments of the antibody e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 51 or SEQ ID NO: 52. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 53 or SEQ ID NO: 54.
[0210] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 55; SEQ ID NO: 56; and SEQ ID NO: 57 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 52.
[0211] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 58; SEQ ID NO: 59; and SEQ ID NO: 60 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 54.
[0212] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 51; the variable heavy chain region of SEQ ID NO: 53; the complementarity-determining regions (SEQ ID NO: 55; SEQ ID NO: 56; and SEQ ID NO: 57) of the variable light chain region of SEQ ID NO: 51; and the complementarity-determining regions (SEQ ID NO: 58; SEQ ID NO: 59; and SEQ ID NO: 60) of the variable heavy chain region of SEQ ID NO: 53.
[0213] In a particularly preferred embodiment of the invention, the anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab6, comprising, or alternatively consisting of, SEQ ID NO: 52 and SEQ ID NO: 54, and having at least one of the biological activities set forth herein.
[0214] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and monovalent antibody molecules analogous to MetMab. With respect to antibody Ab6, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 51 and the variable heavy chain sequence of SEQ ID NO: 53. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 51 and/or SEQ ID NO: 53 in said Fab while retaining binding specificity for NGF.
[0215] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab6. In another embodiment of the invention, anti-NGF antibodies such as Ab6 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab7
[0216] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00025 (SEQ ID NO: 61) ADVVMTQTPASVSQPVGGTVTIKCQASEDIYNLLAWYQQKPGQPPKLLIY SASTLASGVPSRFKGSGSGTEYTLTISGLECADAATYYCQNNYLVTTYGV AFGGGTEVVVKR.
[0217] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00026 (SEQ ID NO: 62) ADVVMTQTPASVSQPVGGTVTIKCQASEDIYNLLAWYQQKPGQPPKLLIY SASTLASGVPSRFKGSGSGTEYTLTISGLECADAATYYCQNNYLVTTYGV AFGGGTEVVVKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKV QWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEV THQGLSSPVTKSFNRGEC.
[0218] The invention further includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00027 (SEQ ID NO: 63) QEQLKESGGRLVTPGTPLTLTCTVSGFSLSSYAMIWVRQAPGKGLEYIGY IDTDTSAYYASWVKGRFTISRTSTTVDLKITSPTTEDTATYFCARSYAAY GGYPATFDPWGPGTLVTVSS.
[0219] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00028 (SEQ ID NO: 64) QEQLKESGGRLVTPGTPLTLTCTVSGFSLSSYAMIWVRQAPGKGLEYIGY IDTDTSAYYASWVKGRFTISRTSTTVDLKITSPTTEDTATYFCARSYAAY GGYPATFDPWGPGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVK DYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQT YICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYA STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQ VYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPV LDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG K.
[0220] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 65; SEQ ID NO: 66; and SEQ ID NO: 67 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 61 or the light chain sequence of SEQ ID NO: 62, and/or one or more of the polypeptide sequences of SEQ ID NO: 68; SEQ ID NO: 69; and SEQ ID NO: 70 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 63 or the heavy chain sequence of SEQ ID NO: 64, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0221] The invention also contemplates fragments of the antibody e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 61 or SEQ ID NO: 62. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 63 or SEQ ID NO: 64.
[0222] In a further embodiment of the invention, fragments of the antibody e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 65; SEQ ID NO: 66; and SEQ ID NO: 67 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 61 or the light chain sequence of SEQ ID NO: 62.
[0223] In a further embodiment of the invention, fragments of the antibody e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 68; SEQ ID NO: 69; and SEQ ID NO: 70 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 63 or the heavy chain sequence of SEQ ID NO: 64.
[0224] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 61; the variable heavy chain region of SEQ ID NO: 63; the complementarity-determining regions (SEQ ID NO: 65; SEQ ID NO: 66; and SEQ ID NO: 67) of the variable light chain region of SEQ ID NO: 61; and the complementarity-determining regions (SEQ ID NO: 68; SEQ ID NO: 69; and SEQ ID NO: 70) of the variable heavy chain region of SEQ ID NO: 63.
[0225] In a particularly preferred embodiment of the invention, the chimeric anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab7, comprising, or alternatively consisting of, SEQ ID NO: 62 and SEQ ID NO: 64, and having at least one of the biological activities set forth herein.
[0226] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and monovalent antibody molecules analogous to MetMab. With respect to antibody Ab7, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 61 and the variable heavy chain sequence of SEQ ID NO: 63. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 61 and/or SEQ ID NO: 63 in said Fab while retaining binding specificity for NGF.
[0227] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab7. In another embodiment of the invention, anti-NGF antibodies such as Ab7 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, transgenic plants or animals, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab8
[0228] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which further inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes humanized or chimeric antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00029 (SEQ ID NO: 71) DIQMTQSPSSLSASVGDRVTITCQASEDIYNLLAWYQQKPGKVPKLLIYS ASTLASGVPSRFSGSGSGTDYTLTISSLQPEDVATYYCQNNYLVTTYGVA FGGGTKVEIKR.
[0229] The invention also includes humanized or chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00030 (SEQ ID NO: 72) DIQMTQSPSSLSASVGDRVTITCQASEDIYNLLAWYQQKPGKVPKLLIYS ASTLASGVPSRFSGSGSGTDYTLTISSLQPEDVATYYCQNNYLVTTYGVA FGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQ WKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVT HQGLSSPVTKSFNRGEC.
[0230] The invention further includes humanized or chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00031 (SEQ ID NO: 73) QVQLVESGGGVVQPGRSLRLSCAASGFTFSSYAMIWVRQAPGKGLEYIGY IDTDTSAYYASSVKGRFTISRDNSKNTLYLQMSSLRAEDTAVYYCARSYA AYGGYPATFDPWGQGTLVTVSS.
[0231] The invention also includes humanized or chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00032 (SEQ ID NO: 74) QVQLVESGGGVVQPGRSLRLSCAASGFTFSSYAMIWVRQAPGKGLEYIGY IDTDTSAYYASSVKGRFTISRDNSKNTLYLQMSSLRAEDTAVYYCARSYA AYGGYPATFDPWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL VKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGT QTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPP KPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQ YASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPRE PQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTP PVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK.
[0232] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 75; SEQ ID NO: 76; and SEQ ID NO: 77 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 71 or the light chain sequence of SEQ ID NO: 72, and/or one or more of the polypeptide sequences of SEQ ID NO: 78; SEQ ID NO: 79; and SEQ ID NO: 80 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 73 or the heavy chain sequence of SEQ ID NO: 74, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0233] The invention also contemplates fragments of the antibody e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 71 or SEQ ID NO: 72. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 73 or SEQ ID NO: 74.
[0234] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 75; SEQ ID NO: 76; and SEQ ID NO: 77 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 71 or the light chain sequence of SEQ ID NO: 72.
[0235] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 78; SEQ ID NO: 79; and SEQ ID NO: 80 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 73 or the heavy chain sequence of SEQ ID NO: 74.
[0236] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 71; the variable heavy chain region of SEQ ID NO: 73; the complementarity-determining regions (SEQ ID NO: 75; SEQ ID NO: 76; and SEQ ID NO: 77) of the variable light chain region of SEQ ID NO: 71; and the complementarity-determining regions (SEQ ID NO: 78; SEQ ID NO: 79; and SEQ ID NO: 80) of the variable heavy chain region of SEQ ID NO: 73.
[0237] In a particularly preferred embodiment of the invention, the anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is chimeric or humanized Ab8, comprising, or alternatively consisting of, SEQ ID NO: 72 and SEQ ID NO: 74, and having at least one of the biological activities set forth herein.
[0238] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and monovalent antibody molecules analogous to MetMab. With respect to antibody Ab8, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 71 and the variable heavy chain sequence of SEQ ID NO: 73. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 71 and/or SEQ ID NO: 73 in said Fab while retaining binding specificity for NGF.
[0239] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab8. In another embodiment of the invention, anti-NGF antibodies such as Ab8 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cell, transgenic plant or animal or microbial systems such as bacterial yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab9
[0240] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention chimeric antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below comprising the sequence set forth below:
TABLE-US-00033 (SEQ ID NO: 81) AYDMTQTPASVSAAVGGTVTIKCQASENIGSYLAWYQQKPGQPPELLIYR ASTLASGVPSRFKGSGSGTQFTLTISGVECADAATYYCQQGYNSENLDNA FGGGTEVVVKR.
[0241] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00034 (SEQ ID NO: 82) AYDMTQTPASVSAAVGGTVTIKCQASENIGSYLAWYQQKPGQPPELLIYR ASTLASGVPSRFKGSGSGTQFTLTISGVECADAATYYCQQGYNSENLDNA FGGGTEVVVKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQ WKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVT HQGLSSPVTKSFNRGEC.
[0242] The invention further includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00035 (SEQ ID NO: 83) QSVEESGGRLVTPGTPLTLTCTVSGIDLSMYSMGWVRQAPGKGLEYIGWI SYGGTAYYASWAKGRFTISKTSTTVELKITSPTIEDTATYFCARETPVNY YLDIWGQGTLVTVSS.
[0243] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00036 (SEQ ID NO: 84) QSVEESGGRLVTPGTPLTLTCTVSGIDLSMYSMGWVRQAPGKGLEYIGWI SYGGTAYYASWAKGRFTISKTSTTVELKITSPTIEDTATYFCARETPVNY YLDIWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPE PVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNV NHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLM ISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRV VSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLP PSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDG SFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK.
[0244] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 85; SEQ ID NO: 86; and SEQ ID NO: 87 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 81 or the light chain sequence of SEQ ID NO: 82, and/or one or more of the polypeptide sequences of SEQ ID NO: 88; SEQ ID NO: 89; and SEQ ID NO: 90 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 83 or the heavy chain sequence of SEQ ID NO: 84, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0245] The invention also contemplates fragments of the antibody e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 81 or SEQ ID NO: 82. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 83 or SEQ ID NO: 84.
[0246] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 85; SEQ ID NO: 86; and SEQ ID NO: 87 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 81 or the light chain sequence of SEQ ID NO: 82.
[0247] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 88; SEQ ID NO: 89; and SEQ ID NO: 90, which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 83 or the heavy chain sequence of SEQ ID NO: 84.
[0248] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 81; the variable heavy chain region of SEQ ID NO: 83; the complementarity-determining regions (SEQ ID NO: 85; SEQ ID NO: 86; and SEQ ID NO: 87) of the variable light chain region of SEQ ID NO: 81; and the complementarity-determining regions (SEQ ID NO: 88; SEQ ID NO: 89; and SEQ ID NO: 90) of the variable heavy chain region of SEQ ID NO: 83.
[0249] In a particularly preferred embodiment of the invention, the chimeric anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab9, comprising, or alternatively consisting of, SEQ ID NO: 82 and SEQ ID NO: 84, and having at least one of the biological activities set forth herein.
[0250] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and other monovalent agents analogous to MetMab. With respect to antibody Ab9, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 81 and the variable heavy chain sequence of SEQ ID NO: 83. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 81 and/or SEQ ID NO: 83 in said Fab while retaining binding specificity for NGF.
[0251] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab9. In another embodiment of the invention, anti-NGF antibodies such as Ab9 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, transgenic plant or animal, or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab10
[0252] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric or humanized antibodies for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00037 (SEQ ID NO: 91) AYDMTQSPSSLSASVGDRVTITCQASENIGSYLAWYQQKPGKVPKLLIYR ASTLASGVPSRFSGSGSGTDFTLTISSLQPEDVATYYCQQGYNSENLDNA FGGGTKVEIKR.
[0253] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00038 (SEQ ID NO: 92) AYDMTQSPSSLSASVGDRVTITCQASENIGSYLAWYQQKPGKVPKLLIYR ASTLASGVPSRFSGSGSGTDFTLTISSLQPEDVATYYCQQGYNSENLDNA FGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQ WKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVT HQGLSSPVTKSFNRGEC.
[0254] The invention further includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00039 (SEQ ID NO: 93) QVQLVESGGGVVQPGRSLRLSCAASGFTFSMYSMGWVRQAPGKGLEYIGW ISYGGTAYYASSAKGRFTISRDNSKNTLYLQMSSLRAEDTAVYYCARETP VNYYLDIWGQGTLVTVSS.
[0255] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00040 (SEQ ID NO: 94) QVQLVESGGGVVQPGRSLRLSCAASGFTFSMYSMGWVRQAPGKGLEYIGW ISYGGTAYYASSAKGRFTISRDNSKNTLYLQMSSLRAEDTAVYYCARETP VNYYLDIWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYI CNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKD TLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYAST YRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVY TLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLD SDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK.
[0256] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 95; SEQ ID NO: 96; and SEQ ID NO: 97 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 91 or the light chain sequence of SEQ ID NO: 92, and/or one or more of the polypeptide sequences of SEQ ID NO: 98; SEQ ID NO: 99; and SEQ ID NO: 100 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 93 or the heavy chain sequence of SEQ ID NO: 94, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0257] The invention also contemplates fragments of the antibody e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 91 or SEQ ID NO: 92. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 93 or SEQ ID NO: 94.
[0258] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 95; SEQ ID NO: 96; and SEQ ID NO: 97 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 91 or the light chain sequence of SEQ ID NO: 92.
[0259] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 98; SEQ ID NO: 99; and SEQ ID NO: 100 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 93 or the heavy chain sequence of SEQ ID NO: 94.
[0260] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 91; the variable heavy chain region of SEQ ID NO: 93; the complementarity-determining regions (SEQ ID NO: 95; SEQ ID NO: 96; and SEQ ID NO: 97) of the variable light chain region of SEQ ID NO: 91; and the complementarity-determining regions (SEQ ID NO: 98; SEQ ID NO: 99; and SEQ ID NO: 100) of the variable heavy chain region of SEQ ID NO: 93.
[0261] In a particularly preferred embodiment of the invention, the anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is chimeric or humanized Ab10, comprising, or alternatively consisting of, SEQ ID NO: 92 and SEQ ID NO: 94, and having at least one of the biological activities set forth herein.
[0262] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and other monovalent agents analogous to MetMab. With respect to antibody Ab10, the Fab fragment e.g., for treatment or prevention of pain and pain associated conditions includes the variable light chain sequence of SEQ ID NO: 91 and the variable heavy chain sequence of SEQ ID NO: 93. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 91 and/or SEQ ID NO: 93 in said Fab while retaining binding specificity for NGF.
[0263] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab10. In another embodiment of the invention, anti-NGF antibodies such as Ab10 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, transgenic plant or animal, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab11
[0264] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00041 (SEQ ID NO: 101) AFELTQTPSSVEAAVGGTVTIKCQASQNIVTNLAWYQQKPGQPPKLLIYG ASTLASGVSSRFKGSGSGTQFTLTISDLECADAATYFCQSYDGFNSAGFG GGTEVVVKR.
[0265] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00042 (SEQ ID NO: 102) AFELTQTPSSVEAAVGGTVTIKCQASQNIVTNLAWYQQKPGQPPKLLIYG ASTLASGVSSRFKGSGSGTQFTLTISDLECADAATYFCQSYDGFNSAGFG GGTEVVVKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWK VDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQ GLSSPVTKSFNRGEC.
[0266] The invention further includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00043 (SEQ ID NO: 103) QSLEESGGRLVTPGTPLTLTCTASGFSLSGYDMSWVRQAPGKGLEYIGLI SYDGNTYYATWAKGRFTISKTSTTVDLKITSPTTEDTATYFCARSLYAGP NAGIGPFNIWGQGTLVTVSS.
[0267] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00044 (SEQ ID NO: 104) QSLEESGGRLVTPGTPLTLTCTASGFSLSGYDMSWVRQAPGKGLEYIGLI SYDGNTYYATWAKGRFTISKTSTTVDLKITSPTTEDTATYFCARSLYAGP NAGIGPFNIWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVK DYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQT YICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYA STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQ VYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPV LDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG K.
[0268] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 105; SEQ ID NO: 106; and SEQ ID NO: 107 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 101 or the light chain sequence of SEQ ID NO: 102, and/or one or more of the polypeptide sequences of SEQ ID NO: 108; SEQ ID NO: 109; and SEQ ID NO: 110 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 103 or the heavy chain sequence of SEQ ID NO: 104, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0269] The invention also contemplates fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 101 or SEQ ID NO: 102. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 103 or SEQ ID NO: 104.
[0270] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 105; SEQ ID NO: 106; and SEQ ID NO: 107 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 101 or the light chain sequence of SEQ ID NO: 102.
[0271] In a further embodiment of the invention, fragments of the antibody e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 108; SEQ ID NO: 109; and SEQ ID NO: 110 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 103 or the heavy chain sequence of SEQ ID NO: 104.
[0272] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 101; the variable heavy chain region of SEQ ID NO: 103; the complementarity-determining regions (SEQ ID NO: 105; SEQ ID NO: 106; and SEQ ID NO: 107) of the variable light chain region of SEQ ID NO: 101; and the complementarity-determining regions (SEQ ID NO: 108; SEQ ID NO: 109; and SEQ ID NO: 110) of the variable heavy chain region of SEQ ID NO: 103.
[0273] In a particularly preferred embodiment of the invention, the chimeric anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab11, comprising, or alternatively consisting of, SEQ ID NO: 102 and SEQ ID NO: 104, and having at least one of the biological activities set forth herein.
[0274] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and other monovalent agents analogous to MetMab. With respect to antibody Ab11, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 101 and the variable heavy chain sequence of SEQ ID NO: 103. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 101 and/or SEQ ID NO: 103 in said Fab while retaining binding specificity for NGF.
[0275] In one embodiment of the invention described herein (infra), Fab fragments may e.g., for treatment or prevention of pain and pain associated conditions be produced by enzymatic digestion (e.g., papain) of Ab11. In another embodiment of the invention, anti-NGF antibodies such as Ab11 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, transgenic plant or animal, or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab12
[0276] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric or humanized antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00045 (SEQ ID NO: 111) AFQMTQSPSSLSASVGDRVTITCQASQNIVTNLAWYQQKPGKVPKLLIYG ASTLASGVPSRFSGSGSGTDFTLTISSLQPEDVATYYCQSYDGFNSAGFG GGTKVEIKR.
[0277] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00046 (SEQ ID NO: 112) AFQMTQSPSSLSASVGDRVTITCQASQNIVTNLAWYQQKPGKVPKLLIYG ASTLASGVPSRFSGSGSGTDFTLTISSLQPEDVATYYCQSYDGFNSAGFG GGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWK VDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQ GLSSPVTKSFNRGEC.
[0278] The invention further includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00047 (SEQ ID NO: 113) QVQLVESGGGVVQPGRSLRLSCAASGFSLSGYDMSWVRQAPGKGLEWVGL ISYDGNTYYATSAKGRFTISRDNSKNTLYLQMSSLRAEDTAVYYCARSLY AGPNAGIGPFNIWGQGTLVTVSS.
[0279] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00048 (SEQ ID NO: 114) QVQLVESGGGVVQPGRSLRLSCAASGFSLSGYDMSWVRQAPGKGLEWVGL ISYDGNTYYATSAKGRFTISRDNSKNTLYLQMSSLRAEDTAVYYCARSLY AGPNAGIGPFNIWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGC LVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLG TQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFP PKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREE QYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPR EPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTT PPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLS PGK.
[0280] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 115; SEQ ID NO: 116; and SEQ ID NO: 117 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 111 or the light chain sequence of SEQ ID NO: 112, and/or one or more of the polypeptide sequences of SEQ ID NO: 118; SEQ ID NO: 119; and SEQ ID NO: 120 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 113 or the heavy chain sequence of SEQ ID NO: 114, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0281] The invention also contemplates fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 111 or SEQ ID NO: 112. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 113 or SEQ ID NO: 114.
[0282] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 115; SEQ ID NO: 116; and SEQ ID NO: 117 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 111 or the light chain sequence of SEQ ID NO: 112.
[0283] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 118; SEQ ID NO: 119; and SEQ ID NO: 120 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 113 or the heavy chain sequence of SEQ ID NO: 114.
[0284] The invention also contemplates antibody fragments which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 111; the variable heavy chain region of SEQ ID NO: 113; the complementarity-determining regions (SEQ ID NO: 115; SEQ ID NO: 116; and SEQ ID NO: 117) of the variable light chain region of SEQ ID NO: 111; and the complementarity-determining regions (SEQ ID NO: 118; SEQ ID NO: 119; and SEQ ID NO: 120) of the variable heavy chain region of SEQ ID NO: 113.
[0285] In a particularly preferred embodiment of the invention, the anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is chimeric or humanized Ab12, comprising, or alternatively consisting of, SEQ ID NO: 112 and SEQ ID NO: 114, and having at least one of the biological activities set forth herein.
[0286] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and other monovalent agents analogous to MetMab. With respect to antibody Ab12, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 111 and the variable heavy chain sequence of SEQ ID NO: 113. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 111 and/or SEQ ID NO: 113 in said Fab while retaining binding specificity for NGF.
[0287] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab12. In another embodiment of the invention, anti-NGF antibodies such as Ab12 or Fab fragments thereof e.g., for treatment or prevention of pain and pain associated conditions may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cell, transgenic plants or animals, or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab13
[0288] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00049 (SEQ ID NO: 121) AAVLTQTPSPVSAAVGGTVSISCQSSQNVYKNNYLSWYQQKPGQPPKLLI YKASTLASGVPSRFKGGGSGTDFTLTISDVQCDAAATYYCAGGYTSSSDN AFGGGTEVVVKR.
[0289] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00050 (SEQ ID NO: 122) AAVLTQTPSPVSAAVGGTVSISCQSSQNVYKNNYLSWYQQKPGQPPKLLI YKASTLASGVPSRFKGGGSGTDFTLTISDVQCDAAATYYCAGGYTSSSDN AFGGGTEVVVKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKV QWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEV THQGLSSPVTKSFNRGEC.
[0290] The invention further includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00051 (SEQ ID NO: 123) QSVEASGGRLVTPGTPLTLTCTASGFSLSTYWMSWVRQAPGKGLEWIGDI YFSNEETNYASWAKGRFTISKTSTTVDLNVISPTTEDTATYFCARGSPDV DIGIDMWGPGTLVTVSS.
[0291] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00052 (SEQ ID NO: 124) QSVEASGGRLVTPGTPLTLTCTASGFSLSTYWMSWVRQAPGKGLEWIGDI YFSNEETNYASWAKGRFTISKTSTTVDLNVISPTTEDTATYFCARGSPDV DIGIDMWGPGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYF PEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYIC NVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDT LMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTY RVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYT LPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDS DGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK.
[0292] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 125; SEQ ID NO: 126; and SEQ ID NO: 127 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 121 or the light chain sequence of SEQ ID NO: 122, and/or one or more of the polypeptide sequences of SEQ ID NO: 128; SEQ ID NO: 129; and SEQ ID NO: 130 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 123 or the heavy chain sequence of SEQ ID NO: 124, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0293] The invention also contemplates fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 121 or SEQ ID NO: 122. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 123 or SEQ ID NO: 124.
[0294] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 125; SEQ ID NO: 126; and SEQ ID NO: 127 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 121 or the light chain sequence of SEQ ID NO: 122.
[0295] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 128; SEQ ID NO: 129; and SEQ ID NO: 130 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 123 or the heavy chain sequence of SEQ ID NO: 124.
[0296] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 121; the variable heavy chain region of SEQ ID NO: 123; the complementarity-determining regions (SEQ ID NO: 125; SEQ ID NO: 126; and SEQ ID NO: 127) of the variable light chain region of SEQ ID NO: 121; and the complementarity-determining regions (SEQ ID NO: 128; SEQ ID NO: 129; and SEQ ID NO: 130) of the variable heavy chain region of SEQ ID NO: 123.
[0297] In a particularly preferred embodiment of the invention, the chimeric anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab13, comprising, or alternatively consisting of, SEQ ID NO: 122 and SEQ ID NO: 124, and having at least one of the biological activities set forth herein.
[0298] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and other monovalent agents analagous to MetMab. With respect to antibody Ab13, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 121 and the variable heavy chain sequence of SEQ ID NO: 123. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 121 and/or SEQ ID NO: 123 in said Fab while retaining binding specificity for NGF.
[0299] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab13. In another embodiment of the invention, anti-NGF antibodies such as Ab13 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, plants, animals, or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab14
[0300] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric or humanized antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below
TABLE-US-00053 (SEQ ID NO: 131) DIQMTQSPSSLSASVGDRVTITCQSSQNVYKNNYLSWYQQKPGKVPKLLI YKASTLASGVPSRFSGSGSGTDFTLTISSLQPEDVATYYCAGGYTSSSDN AFGGGTKVEIKR.
[0301] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00054 (SEQ ID NO: 132) DIQMTQSPSSLSASVGDRVTITCQSSQNVYKNNYLSWYQQKPGKVPKLLI YKASTLASGVPSRFSGSGSGTDFTLTISSLQPEDVATYYCAGGYTSSSDN AFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKV QWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEV THQGLSSPVTKSFNRGEC.
[0302] The invention further includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00055 (SEQ ID NO: 133) EVQLVESGGGLVQPGGSLRLSCAASGFTVSTYWMSWVRQAPGKGLEWVGD IYFSNEETNYASSAKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARGS PDVDIGIDMWGPGTLVTVSS.
[0303] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00056 (SEQ ID NO: 134) EVQLVESGGGLVQPGGSLRLSCAASGFTVSTYWMSWVRQAPGKGLEWVGD IYFSNEETNYASSAKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARGS PDVDIGIDMWGPGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVK DYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQT YICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYA STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQ VYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPV LDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG K.
[0304] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 135; SEQ ID NO: 136; and SEQ ID NO: 137 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 131 or the light chain sequence of SEQ ID NO: 132, and/or one or more of the polypeptide sequences of SEQ ID NO: 138; SEQ ID NO: 139; and SEQ ID NO: 140 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 133 or the heavy chain sequence of SEQ ID NO: 134, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0305] The invention also contemplates fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 131 or SEQ ID NO: 132. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 133 or SEQ ID NO: 134.
[0306] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 135; SEQ ID NO: 136; and SEQ ID NO: 137 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 131 or the light chain sequence of SEQ ID NO: 132.
[0307] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 138; SEQ ID NO: 139; and SEQ ID NO: 140 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 133 or the heavy chain sequence of SEQ ID NO: 134.
[0308] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 131; the variable heavy chain region of SEQ ID NO: 133; the complementarity-determining regions (SEQ ID NO: 135; SEQ ID NO: 136; and SEQ ID NO: 137) of the variable light chain region of SEQ ID NO: 131; and the complementarity-determining regions (SEQ ID NO: 138; SEQ ID NO: 139; and SEQ ID NO: 140) of the variable heavy chain region of SEQ ID NO: 133.
[0309] In a particularly preferred embodiment of the invention, the anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is chimeric or humanized Ab14, comprising, or alternatively consisting of, SEQ ID NO: 132 and SEQ ID NO: 134, and having at least one of the biological activities set forth herein.
[0310] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and other monovalent agents analogous to MetMab. With respect to antibody Ab14, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 131 and the variable heavy chain sequence of SEQ ID NO: 133. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 131 and/or SEQ ID NO: 133 in said Fab while retaining binding specificity for NGF.
[0311] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab14. In another embodiment of the invention, anti-NGF antibodies such as Ab14 or Fab fragments thereof e.g., for treatment or prevention of pain and pain associated conditions may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cell, plant, animal, or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab15
[0312] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which do not appreciably inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below
TABLE-US-00057 (SEQ ID NO: 141) AAVLTQTPSPVSAAVGDTVTIKCQSSQSVYKNNYLSWYQQKPGQPPKLLI YDASNLPSGVPSRFSGSGSGTQFTLTISGVQCDDAATYYCLGDYDDDTDN GFGGGTEVVVKR.
[0313] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00058 (SEQ ID NO: 142) AAVLTQTPSPVSAAVGDTVTIKCQSSQSVYKNNYLSWYQQKPGQPPKLLI YDASNLPSGVPSRFSGSGSGTQFTLTISGVQCDDAATYYCLGDYDDDTDN GFGGGTEVVVKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKV QWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEV THQGLSSPVTKSFNRGEC.
[0314] The invention further includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00059 (SEQ ID NO: 143) QSVEESGGRLVTPGTPLTLTCTVSGIDLSSYAMIWVRQAPGKGLEYIGII WSGGTYYATWAKGRFTISKTSTTVDLQITSPTTEDAATYFCAAGGGSIYD VWGPGTLVTVSS.
[0315] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00060 (SEQ ID NO: 144) QSVEESGGRLVTPGTPLTLTCTVSGIDLSSYAMIWVRQAPGKGLEYIGII WSGGTYYATWAKGRFTISKTSTTVDLQITSPTTEDAATYFCAAGGGSIYD VWGPGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVT VSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHK PSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISR TPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSV LTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSR EEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFF LYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK.
[0316] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 145; SEQ ID NO: 146; and SEQ ID NO: 147 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 141 or the light chain sequence of SEQ ID NO: 142, and/or one or more of the polypeptide sequences of SEQ ID NO: 148; SEQ ID NO: 149; and SEQ ID NO: 150 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 143 or the heavy chain sequence of SEQ ID NO: 144, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0317] The invention also contemplates fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 141 or SEQ ID NO: 142. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 143 or SEQ ID NO: 144.
[0318] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 145; SEQ ID NO: 146; and SEQ ID NO: 147 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 141 or the light chain sequence of SEQ ID NO: 142.
[0319] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 148; SEQ ID NO: 149; and SEQ ID NO: 150 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 143 or the heavy chain sequence of SEQ ID NO: 144.
[0320] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 141; the variable heavy chain region of SEQ ID NO: 143; the complementarity-determining regions (SEQ ID NO: 145; SEQ ID NO: 146; and SEQ ID NO: 147) of the variable light chain region of SEQ ID NO: 141; and the complementarity-determining regions (SEQ ID NO: 148; SEQ ID NO: 149; and SEQ ID NO: 150) of the variable heavy chain region of SEQ ID NO: 143.
[0321] In a particularly preferred embodiment of the invention, the chimeric anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab15, comprising, or alternatively consisting of, SEQ ID NO: 142 and SEQ ID NO: 144, and having at least one of the biological activities set forth herein.
[0322] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and other monovalent agents analogous to MetMab. With respect to antibody Ab15, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 141 and the variable heavy chain sequence of SEQ ID NO: 143. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 141 and/or SEQ ID NO: 143 in said Fab while retaining binding specificity for NGF.
[0323] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab15. In another embodiment of the invention, anti-NGF antibodies e.g., for treatment or prevention of pain and pain associated conditions such as Ab15 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, transgenic plants or animals, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab16
[0324] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which do not appreciably inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric or humanized antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below
TABLE-US-00061 (SEQ ID NO: 151) ALVMTQTPSSTSEPVGGTVTINCQASQNIGNDLSWYQQKPGQPPELLIYS TSKLATGVPKRFSGSRSGTQFTLTISDLECDDAATYYCLGVYSYISDDGN AFGGGTEVVVKR.
[0325] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00062 (SEQ ID NO: 152) ALVMTQTPSSTSEPVGGTVTINCQASQNIGNDLSWYQQKPGQPPELLIYS TSKLATGVPKRFSGSRSGTQFTLTISDLECDDAATYYCLGVYSYISDDGN AFGGGTEVVVKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKV QWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEV THQGLSSPVTKSFNRGEC.
[0326] The invention further includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00063 (SEQ ID NO: 153) QSVEEFGGRLVTPGTPLTLTCTVSGFSLNNYAMTWVRQAPGKGLEWIGII GSIGTTYYASWAKGRFFISKTSTTVDLKIISPTTEDTATYFCARDAGVTV DGYGYYFNIWGPGTLVTVSS.
[0327] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00064 (SEQ ID NO: 154) QSVEEFGGRLVTPGTPLTLTCTVSGFSLNNYAMTWVRQAPGKGLEWIGII GSIGTTYYASWAKGRFFISKTSTTVDLKIISPTTEDTATYFCARDAGVTV DGYGYYFNIWGPGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVK DYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQT YICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYA STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQ VYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPV LDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSL SPGK.
[0328] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 155; SEQ ID NO: 156; and SEQ ID NO: 157 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 151 or the light chain sequence of SEQ ID NO: 152, and/or one or more of the polypeptide sequences of SEQ ID NO: 158; SEQ ID NO: 159; and SEQ ID NO: 160 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 153 or the heavy chain sequence of SEQ ID NO: 154, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0329] The invention also contemplates fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 151 or SEQ ID NO: 152. In another embodiment of the invention, antibody fragments of the invention e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 153 or SEQ ID NO: 154.
[0330] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 155; SEQ ID NO: 156; and SEQ ID NO: 157 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 151 or the light chain sequence of SEQ ID NO: 152.
[0331] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 158; SEQ ID NO: 159; and SEQ ID NO: 160 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 153 or the heavy chain sequence of SEQ ID NO: 154.
[0332] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 151; the variable heavy chain region of SEQ ID NO: 153; the complementarity-determining regions (SEQ ID NO: 155; SEQ ID NO: 156; and SEQ ID NO: 157) of the variable light chain region of SEQ ID NO: 151; and the complementarity-determining regions (SEQ ID NO: 158; SEQ ID NO: 159; and SEQ ID NO: 160) of the variable heavy chain region of SEQ ID NO: 153.
[0333] In a particularly preferred embodiment of the invention, the anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab16, comprising, or alternatively consisting of, SEQ ID NO: 152 and SEQ ID NO: 154, and having at least one of the biological activities set forth herein.
[0334] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and other monovalent agents analogous to MetMab. With respect to antibody Ab16, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 151 and the variable heavy chain sequence of SEQ ID NO: 153. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 151 and/or SEQ ID NO: 153 in said Fab while retaining binding specificity for NGF.
[0335] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab16. In another embodiment of the invention, anti-NGF antibodies e.g., for treatment or prevention of pain and pain associated conditions such as Ab16 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, transgenic plants or animals, or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab17
[0336] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00065 (SEQ ID NO: 161) AIEMTQTPFSVSAAVGGTVTIKCQASQTISNYLAWYQQKPGQPPKLLIYG ASNLESGVPSRFKGSGSGTQFTLTISDLECDDAATYYCQQGYTISNVDNN VFGGGTEVVVKR.
[0337] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00066 (SEQ ID NO: 162) AIEMTQTPFSVSAAVGGTVTIKCQASQTISNYLAWYQQKPGQPPKLLIYG ASNLESGVPSRFKGSGSGTQFTLTISDLECDDAATYYCQQGYTISNVDNN VFGGGTEVVVKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKV QWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEV THQGLSSPVTKSFNRGEC.
[0338] The invention further includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00067 (SEQ ID NO: 163) QSLEESGGRLVTPGGSLTLTCAASGFSLTGYNLVWVRQAPGKGLEWIGFI SYGDTTYYASWAKGRFTISKTSTTVTLTITDLQPSDTGTYFCARETANTY DYGIWGPGTLVTVSS.
[0339] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00068 (SEQ ID NO: 164) QSLEESGGRLVTPGGSLTLTCAASGFSLTGYNLVWVRQAPGKGLEWIGFI SYGDTTYYASWAKGRFTISKTSTTVTLTITDLQPSDTGTYFCARETANTY DYGIWGPGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPE PVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNV NHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLM ISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRV VSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLP PSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDG SFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK.
[0340] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 165; SEQ ID NO: 166; and SEQ ID NO: 167 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 161 or the light chain sequence of SEQ ID NO: 162, and/or one or more of the polypeptide sequences of SEQ ID NO: 168; SEQ ID NO: 169; and SEQ ID NO: 170 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 163 or the heavy chain sequence of SEQ ID NO: 164, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0341] The invention also contemplates fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 161 or SEQ ID NO: 162. In another optional embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 163 or SEQ ID NO: 164.
[0342] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 165; SEQ ID NO: 166; and SEQ ID NO: 167 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 161 or the light chain sequence of SEQ ID NO: 162.
[0343] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 168; SEQ ID NO: 169; and SEQ ID NO: 170 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 163 or the heavy chain sequence of SEQ ID NO: 164.
[0344] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 161; the variable heavy chain region of SEQ ID NO: 163; the complementarity-determining regions (SEQ ID NO: 165; SEQ ID NO: 166; and SEQ ID NO: 167) of the variable light chain region of SEQ ID NO: 161; and the complementarity-determining regions (SEQ ID NO: 168; SEQ ID NO: 169; and SEQ ID NO: 170) of the variable heavy chain region of SEQ ID NO: 163.
[0345] In a particularly preferred embodiment of the invention, the chimeric anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab17, comprising, or alternatively consisting of, SEQ ID NO: 162 and SEQ ID NO: 164, and having at least one of the biological activities set forth herein.
[0346] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and other monovalent agents analogous to MetMab. With respect to antibody Ab17, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 161 and the variable heavy chain sequence of SEQ ID NO: 163. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 161 and/or SEQ ID NO: 163 in said Fab while retaining binding specificity for NGF.
[0347] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab17. In another embodiment of the invention, anti-NGF antibodies such as Ab17 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, plants, animals, or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab18
[0348] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric or humanized antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00069 (SEQ ID NO: 171) DIQMTQSPSTLSASVGDRVTITCQASQTISNYLAWYQQKPGKAPKLLIYG ASNLESGVPSRFSGSGSGTEFTLTISSLQPDDFATYYCQQGYTISNVDNN VFGGGTKVEIKR.
[0349] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00070 (SEQ ID NO: 172) DIQMTQSPSTLSASVGDRVTITCQASQTISNYLAWYQQKPGKAPKLLIYG ASNLESGVPSRFSGSGSGTEFTLTISSLQPDDFATYYCQQGYTISNVDNN VFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKV QWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEV THQGLSSPVTKSFNRGEC.
[0350] The invention further includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00071 (SEQ ID NO: 173) EVQLVESGGGLVQPGGSLRLSCAASGFTVSGYNLVWVRQAPGKGLEWVGF ISYGDTTYYASSAKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARETA NTYDYGIWGQGTLVTVSS.
[0351] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00072 (SEQ ID NO: 174) EVQLVESGGGLVQPGGSLRLSCAASGFTVSGYNLVWVRQAPGKGLEWVGF ISYGDTTYYASSAKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARETA NTYDYGIWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYI CNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKD TLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYAST YRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVY TLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLD SDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK.
[0352] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 175; SEQ ID NO: 176; and SEQ ID NO: 177 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 171 or the light chain sequence of SEQ ID NO: 172, and/or one or more of the polypeptide sequences of SEQ ID NO: 178; SEQ ID NO: 179; and SEQ ID NO: 180 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 173 or the heavy chain sequence of SEQ ID NO: 174, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0353] The invention also contemplates fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 171 or SEQ ID NO: 172. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 173 or SEQ ID NO: 174.
[0354] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 175; SEQ ID NO: 176; and SEQ ID NO: 177 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 171 or the light chain sequence of SEQ ID NO: 172.
[0355] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 178; SEQ ID NO: 179; and SEQ ID NO: 180 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 173 or the heavy chain sequence of SEQ ID NO: 174.
[0356] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 171; the variable heavy chain region of SEQ ID NO: 173; the complementarity-determining regions (SEQ ID NO: 175; SEQ ID NO: 176; and SEQ ID NO: 177) of the variable light chain region of SEQ ID NO: 171; and the complementarity-determining regions (SEQ ID NO: 178; SEQ ID NO: 179; and SEQ ID NO: 180) of the variable heavy chain region of SEQ ID NO: 173.
[0357] In a particularly preferred embodiment of the invention, the anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab18, comprising, or alternatively consisting of, SEQ ID NO: 172 and SEQ ID NO: 174, and having at least one of the biological activities set forth herein.
[0358] In a further particularly preferred embodiment of the invention, antibody fragments comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and other monovalent agents analogous to MetMab. With respect to antibody Ab18, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 171 and the variable heavy chain sequence of SEQ ID NO: 173. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 171 and/or SEQ ID NO: 173 in said Fab while retaining binding specificity for NGF.
[0359] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab18. In another embodiment of the invention, anti-NGF antibodies such as Ab18 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, plants, animals, or microbial systems such as bacteria or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab19
[0360] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below
TABLE-US-00073 (SEQ ID NO: 181) AAVLTQTPSPVSAAVGGTVSISCQSSQNVYKNNYLSWYQQKPGQPPKLLI YKASTLASGVPSRFKGSGSGTDFTLTISDVQCDAAATYYCAGGYSSSSDN AFGGGTEVVVKR.
[0361] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00074 (SEQ ID NO: 182) AAVLTQTPSPVSAAVGGTVSISCQSSQNVYKNNYLSWYQQKPGQPPKLLI YKASTLASGVPSRFKGSGSGTDFTLTISDVQCDAAATYYCAGGYSSSSDN AFGGGTEVVVKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKV QWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEV THQGLSSPVTKSFNRGEC.
[0362] The invention further includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00075 (SEQ ID NO: 183) QSVEASGGRLVMPGGSLTLTCTASGFSLSTYWMSWVRQAPGKGLEWIGDI YFSNEETNYATWAKGRFTISKTSTTVDLNVISPTTEDTATYFCARGSPDV EIAIDMWGQGTLVTVSS.
[0363] The invention also includes chimeric antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00076 (SEQ ID NO: 184) QSVEASGGRLVMPGGSLTLTCTASGFSLSTYWMSWVRQAPGKGLEWIGDI YFSNEETNYATWAKGRFTISKTSTTVDLNVISPTTEDTATYFCARGSPDV EIAIDMWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYF PEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYIC NVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDT LMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTY RVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYT LPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDS DGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK.
[0364] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 185; SEQ ID NO: 186; and SEQ ID NO: 187 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 181 or the light chain sequence of SEQ ID NO: 182, and/or one or more of the polypeptide sequences of SEQ ID NO: 188; SEQ ID NO: 189; and SEQ ID NO: 190 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 183 or the heavy chain sequence of SEQ ID NO: 184, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0365] The invention also contemplates fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 181 or SEQ ID NO: 182. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 183 or SEQ ID NO: 184.
[0366] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 185; SEQ ID NO: 186; and SEQ ID NO: 187 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 181 or the light chain sequence of SEQ ID NO: 182.
[0367] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 188; SEQ ID NO: 189; and SEQ ID NO: 190 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 183 or the heavy chain sequence of SEQ ID NO: 184.
[0368] The invention also contemplates antibody fragments which include one or more of the antibody fragments described herein e.g., for treatment or prevention of pain and pain associated conditions. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 181; the variable heavy chain region of SEQ ID NO: 183; the complementarity-determining regions (SEQ ID NO: 185; SEQ ID NO: 186; and SEQ ID NO: 187) of the variable light chain region of SEQ ID NO: 181; and the complementarity-determining regions (SEQ ID NO: 188; SEQ ID NO: 189; and SEQ ID NO: 190) of the variable heavy chain region of SEQ ID NO: 183.
[0369] In a particularly preferred embodiment of the invention, the chimeric anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab19, comprising, or alternatively consisting of, SEQ ID NO: 182 and SEQ ID NO: 184, and having at least one of the biological activities set forth herein.
[0370] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and other monovalent agents analogous to MetMab. With respect to antibody Ab19, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 181 and the variable heavy chain sequence of SEQ ID NO: 183. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 181 and/or SEQ ID NO: 183 in said Fab while retaining binding specificity for NGF.
[0371] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab19. In another embodiment of the invention, anti-NGF antibodies such as Ab19 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, plants, animals, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab20
[0372] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric or humanized antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00077 (SEQ ID NO: 191) DIQMTQSPSSLSASVGDRVTITCQSSQNVYKNNYLSWYQQKPGKVPKLLI YKASTLASGVPSRFSGSGSGTDFTLTISSLQPEDVATYYCAGGYTSSSDN AFGGGTKVEIKR.
[0373] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00078 (SEQ ID NO: 192) DIQMTQSPSSLSASVGDRVTITCQSSQNVYKNNYLSWYQQKPGKVPKLLI YKASTLASGVPSRFSGSGSGTDFTLTISSLQPEDVATYYCAGGYTSSSDN AFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKV QWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEV THQGLSSPVTKSFNRGEC.
[0374] The invention further includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00079 (SEQ ID NO: 193) EVQLVESGGGLVQPGGSLRLSCAASGFTVSTYWMSWVRQAPGKGLEWVGD IYFSNEETNYATSAKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARGS PDVEIAIDMWGQGTLVTVSS.
[0375] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00080 (SEQ ID NO: 194) EVQLVESGGGLVQPGGSLRLSCAASGFTVSTYWMSWVRQAPGKGLEWVGD IYFSNEETNYATSAKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARGS PDVEIAIDMWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVK DYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQT YICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYA STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQ VYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPV LDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG K.
[0376] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 195; SEQ ID NO: 196; and SEQ ID NO: 197 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 191 or the light chain sequence of SEQ ID NO: 192, and/or one or more of the polypeptide sequences of SEQ ID NO: 198; SEQ ID NO: 199; and SEQ ID NO: 200 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 193 or the heavy chain sequence of SEQ ID NO: 194, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0377] The invention also contemplates fragments of the antibody having binding specificity to NGF. In one embodiment of the invention, antibody fragments of the invention e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 191 or SEQ ID NO: 192. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 193 or SEQ ID NO: 194.
[0378] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 195; SEQ ID NO: 196; and SEQ ID NO: 197 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 191 or the light chain sequence of SEQ ID NO: 192.
[0379] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 198; SEQ ID NO: 199; and SEQ ID NO: 200 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 193 or the heavy chain sequence of SEQ ID NO: 194.
[0380] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 191; the variable heavy chain region of SEQ ID NO: 193; the complementarity-determining regions (SEQ ID NO: 195; SEQ ID NO: 196; and SEQ ID NO: 197) of the variable light chain region of SEQ ID NO: 191; and the complementarity-determining regions (SEQ ID NO: 198; SEQ ID NO: 199; and SEQ ID NO: 200) of the variable heavy chain region of SEQ ID NO: 193.
[0381] In a particularly preferred embodiment of the invention, the chimeric or humanized anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab20, comprising, or alternatively consisting of, SEQ ID NO: 192 and SEQ ID NO: 194, and having at least one of the biological activities set forth herein.
[0382] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF and other monovalent agents analogous to MetMab. With respect to antibody Ab20, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 191 and the variable heavy chain sequence of SEQ ID NO: 193. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 191 and/or SEQ ID NO: 193 in said Fab while retaining binding specificity for NGF.
[0383] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab20. In another embodiment of the invention, anti-NGF antibodies e.g., for treatment or prevention of pain and pain associated conditions such as Ab20 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, plants, animals, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab21
[0384] The invention provides novel anti-NGF antibodies and antibody fragments and compositions containing, that specifically bind NGF which inhibit the association of NGF with TrkA and which further inhibit the association of NGF with p75. These novel antibodies and antibody fragments are e.g., suitable for detecting NGF, and for treating pain and pain-associated disorders and conditions, e.g., pain associated with inflammation, cancer, specific pain and inflammation associated disorders, especially pain-associated disorders associated with elevated NGF levels, and may be administered alone or in association with another active agent, e.g., another biologic, an NSAID or opioid analgesic. In one embodiment, the invention includes chimeric or humanized antibodies having binding specificity to NGF and possessing a variable light chain sequence comprising the sequence set forth below:
TABLE-US-00081 (SEQ ID NO: 51) DIQMTQSPSTLSASVGDRVTITCQASQSIYSNLAWYQQKPGKAPKLLIYD ASTLESGVPSRFSGSGSGTEYTLTISSLQPDDFATYYCQQGFTVSDIDNA FGGGTKVEIKR.
[0385] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00082 (SEQ ID NO: 401) DIQMTQSPSTLSASVGDRVTITCQASQSIYSNLAWYQQKPGKAPKLLIYD ASTLESGVPSRFSGSGSGTEYTLTISSLQPDDFATYYCQQGFTVSDIDNA FGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQ WKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVT HQGLSSPVTKSFNRGEC.
[0386] The invention further includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a variable heavy chain sequence comprising the sequence set forth below:
TABLE-US-00083 (SEQ ID NO: 53) EVQLVESGGGLVQPGGSLRLSCAASGFTVSNYAVGWVRQAPGKGLEWVGI IGRNGNTWYASSARGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARGYG RSVAYYVFNIWGPGTLVTVSS.
[0387] The invention also includes chimeric or humanized antibodies e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00084 (SEQ ID NO: 402) EVQLVESGGGLVQPGGSLRLSCAASGFTVSNYAVGWVRQAPGKGLEWVGI IGRNGNTWYASSARGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARGY GRSVAYYVFNIWGPGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL VKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGT QTYICNVNHKPSNTKVDARVEPKSCDKTHTCPPCPAPELLGGPSVFLFPP KPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQ YASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPRE PQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTP PVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK.
[0388] The invention further contemplates antibodies e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 55; SEQ ID NO: 56; and SEQ ID NO: 57 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 401, and/or one or more of the polypeptide sequences of SEQ ID NO: 58; SEQ ID NO: 59; and SEQ ID NO: 60 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 402, or combinations of these polypeptide sequences. In another embodiment of the invention, the antibodies of the invention or fragments thereof comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0389] The invention also contemplates fragments of the antibody e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF. In one embodiment of the invention, antibody fragments of the invention e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 51 or SEQ ID NO: 401. In another embodiment of the invention, antibody fragments of the invention e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 53 or SEQ ID NO: 402.
[0390] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 55; SEQ ID NO: 56; and SEQ ID NO: 57 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 401 and monovalent antibody molecules analogous to MetMab.
[0391] In a further embodiment of the invention, fragments of the antibody having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 58; SEQ ID NO: 59; and SEQ ID NO: 60 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 402.
[0392] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 51; the variable heavy chain region of SEQ ID NO: 53; the complementarity-determining regions (SEQ ID NO: 55; SEQ ID NO: 56; and SEQ ID NO: 57) of the variable light chain region of SEQ ID NO: 51; and the complementarity-determining regions (SEQ ID NO: 58; SEQ ID NO: 59; and SEQ ID NO: 60) of the variable heavy chain region of SEQ ID NO: 53.
[0393] In a particularly preferred embodiment of the invention, the anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions is Ab21, comprising, or alternatively consisting of, SEQ ID NO: 401 and SEQ ID NO: 402, and having at least one of the biological activities set forth herein.
[0394] In a particularly preferred embodiment of the invention, monovalent agents are utilized in methods of treating pain in a patient without substantially increasing inflammation in said patient. Exemplary monovalent agents include, but are not limited to, Fab, Fab', MetMab like monovalent agents, Fv, scFv fragments, SMIPs (small molecule immunopharmaceuticals), camelbodies, nanobodies, IgNAR, or one or more combinations thereof.
[0395] In a further particularly preferred embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab21, the Fab fragment includes the variable light chain sequence of SEQ ID NO: 51 and the variable heavy chain sequence of SEQ ID NO: 53. This embodiment of the invention further contemplates additions, deletions, and variants of SEQ ID NO: 51 and/or SEQ ID NO: 53 in said Fab while retaining binding specificity for NGF.
[0396] In one embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced by enzymatic digestion (e.g., papain) of Ab21. In another embodiment of the invention, anti-NGF antibodies e.g., for treatment or prevention of pain and pain associated conditions such as Ab21 or Fab fragments thereof may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant, animal or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Fragment Fab1
[0397] The invention contemplates methods of treating pain using antibody fragment Fab1 or fragments thereof, for example as set forth below, in a therapeutically effective amount which inhibits the association of NGF with TrkA and further inhibit the association of NGF with p75. In one embodiment, the invention includes Fab antibody fragments e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00085 (SEQ ID NO: 405) DIQMTQSPSTLSASVGDRVTITCQASQSIYSNLAWYQQKPGKAPKLLIYD ASTLESGVPSRFSGSGSGTEYTLTISSLQPDDFATYYCQQGFTVSDIDNA FGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQ WKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVT HQGLSSPVTKSFNRGEC.
[0398] The invention further includes Fab antibody fragments e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00086 (SEQ ID NO: 406) EVQLVESGGGLVQPGGSLRLSCAASGFTVSNYAVGWVRQAPGKGLEWVGI IGRNGNTWYASSARGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARGYG RSVAYYVFNIWGPGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDARVEPKSCDKTH.
[0399] The invention further contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 55; SEQ ID NO: 56; and SEQ ID NO: 57 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 405, and/or one or more of the polypeptide sequences of SEQ ID NO: 58; SEQ ID NO: 59; and SEQ ID NO: 60 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 406, or combinations of these polypeptide sequences. In another embodiment of the invention, antibody fragments of the invention e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0400] The invention also contemplates fragments of the antibody e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF. In one embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 51 or SEQ ID NO: 405. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 53 or SEQ ID NO: 406.
[0401] In a further embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 55; SEQ ID NO: 56; and SEQ ID NO: 57 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 405.
[0402] In a further embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 58; SEQ ID NO: 59; and SEQ ID NO: 60 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 406.
[0403] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 51; the variable heavy chain region of SEQ ID NO: 53; the complementarity-determining regions (SEQ ID NO: 55; SEQ ID NO: 56; and SEQ ID NO: 57) of the variable light chain region of SEQ ID NO: 51; and the complementarity-determining regions (SEQ ID NO: 58; SEQ ID NO: 59; and SEQ ID NO: 60) of the variable heavy chain region of SEQ ID NO: 53.
[0404] In a particularly preferred embodiment of the invention, the anti-NGF antibody fragment e.g., for treatment or prevention of pain and pain associated conditions is Fab1, comprising SEQ ID NO: 405 and SEQ ID NO: 406, and having at least one of the biological activities set forth herein or a monovalent agent analogous to MetMab. In one embodiment of the invention, antibody fragment Fab1 may be produced by enzymatic digestion (e.g., papain) of Ab21.
Antibody Fragment Fab2
[0405] The invention contemplates methods of treating pain using antibody fragment Fab2 or fragments thereof, for example as set forth below, in a therapeutically effective amount which inhibits the association of NGF with TrkA and further inhibit the association of NGF with p75. In one embodiment, the invention includes Fab antibody fragments e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a light chain sequence comprising the sequence set forth below:
TABLE-US-00087 (SEQ ID NO: 407) DIQMTQSPSTLSASVGDRVTITCQASQSIYSNLAWYQQKPGKAPKLLIYD ASTLESGVPSRFSGSGSGTEYTLTISSLQPDDFATYYCQQGFTVSDIDNA FGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQ WKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVT HQGLSSPVTKSFNRGEC.
[0406] The invention further includes Fab antibody fragments e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF and possessing a heavy chain sequence comprising the sequence set forth below:
TABLE-US-00088 (SEQ ID NO: 408) EVQLVESGGGLVQPGGSLRLSCAASGFTVSNYAVGWVRQAPGKGLEWVGI IGRNGNTWYASSARGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARGYG RSVAYYVFNIWGPGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLV KDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ TYICNVNHKPSNTKVDARVEPKSCDKTH.
[0407] The invention further contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions comprising one or more of the polypeptide sequences of SEQ ID NO: 55; SEQ ID NO: 56; and SEQ ID NO: 57 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 407, and/or one or more of the polypeptide sequences of SEQ ID NO: 58; SEQ ID NO: 59; and SEQ ID NO: 60 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 408, or combinations of these polypeptide sequences. In another embodiment of the invention, antibody fragments of the invention comprise, or alternatively consist of, combinations of one or more of the CDRs, the variable heavy and variable light chain sequences, and the heavy and light chain sequences set forth above, including all of them.
[0408] The invention also contemplates fragments of the antibody e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF. In one embodiment of the invention, antibody fragments of the invention e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 51 or SEQ ID NO: 407. In another embodiment of the invention, antibody fragments of the invention e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, the polypeptide sequence of SEQ ID NO: 53 or SEQ ID NO: 408.
[0409] In a further embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 55; SEQ ID NO: 56; and SEQ ID NO: 57 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable light chain sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 407.
[0410] In a further embodiment of the invention, antibody fragments e.g., for treatment or prevention of pain and pain associated conditions having binding specificity to NGF comprise, or alternatively consist of, one or more of the polypeptide sequences of SEQ ID NO: 58; SEQ ID NO: 59; and SEQ ID NO: 60 which correspond to the complementarity-determining regions (CDRs, or hypervariable regions) of the variable heavy chain sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 408.
[0411] The invention also contemplates antibody fragments e.g., for treatment or prevention of pain and pain associated conditions which include one or more of the antibody fragments described herein. In one embodiment of the invention, fragments of the antibodies having binding specificity to NGF e.g., for treatment or prevention of pain and pain associated conditions comprise, or alternatively consist of, one, two, three or more, including all of the following antibody fragments: the variable light chain region of SEQ ID NO: 51; the variable heavy chain region of SEQ ID NO: 53; the complementarity-determining regions (SEQ ID NO: 55; SEQ ID NO: 56; and SEQ ID NO: 57) of the variable light chain region of SEQ ID NO: 51; and the complementarity-determining regions (SEQ ID NO: 58; SEQ ID NO: 59; and SEQ ID NO: 60) of the variable heavy chain region of SEQ ID NO: 53.
[0412] In a particularly preferred embodiment of the invention, the anti-NGF antibody fragment e.g., for treatment or prevention of pain and pain associated conditions is Fab2, comprising SEQ ID NO: 407 and SEQ ID NO: 408, and having at least one of the biological activities set forth herein.
[0413] In another embodiment of the invention described herein (infra), Fab fragments e.g., for treatment or prevention of pain and pain associated conditions may be produced via expression in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, plant cells, plants, animals or microbial systems such as bacterial or yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention, antibody fragment Fab2 may be produced by expression in Pichia pastoris using protocols set forth herein in the examples.
[0414] In another embodiment, antibody fragments may be present in one or more of the following non-limiting forms: Fab, Fab', F(ab')2, Fv and single chain Fv antibody forms. In a preferred embodiment, the anti-NGF antibodies described herein further comprises the kappa constant light chain sequence comprising the sequence set forth below:
TABLE-US-00089 (SEQ ID NO: 412) VAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNS QESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSF NRGEC.
[0415] In another preferred embodiment, the anti-NGF antibodies described herein e.g., for treatment or prevention of pain and pain associated conditions further comprises the gamma-1 constant heavy chain polypeptide sequence comprising the sequence set forth below:
TABLE-US-00090 (SEQ ID NO: 413) ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKRVEP KSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVS HEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGK EYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTC LVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRW QQGNVFSCSVMHEALHNHYTQKSLSLSPGK.
[0416] In another embodiment, the invention contemplates an isolated anti-NGF antibody e.g., for treatment or prevention of pain and pain associated conditions comprising a V.sub.H polypeptide sequence selected from: SEQ ID NO: 3, 13, 23, 33, 43, 53, 63, 73, 83, 93, 103, 113, 123, 133, 143, 153, 163, 173, 183, 193, or 402, or a variant thereof; and further comprising a V.sub.L polypeptide sequence selected from: SEQ ID NO: 1, 11, 21, 31, 41, 51, 61, 71, 81, 91, 101, 111, 121, 131, 141, 151, 161, 171, 181, 191, or 401, or a variant thereof, wherein one or more of the framework residues (FR residues) in said V.sub.H or V.sub.L polypeptide has been substituted with another amino acid residue resulting in an anti-NGF antibody that specifically binds NGF. The invention contemplates humanized and chimeric forms of these antibodies e.g., for treatment or prevention of pain and pain associated conditions. The chimeric antibodies may include an Fc derived from IgG1, IgG2, IgG3, IgG4, IgG5, IgG6, IgG7, IgG8, IgG9, IgG10, IgG11, IgG12, IgG13, IgG14, IgG15, IgG16, IgG17, IgG18 or IgG19 constant regions.
[0417] In one embodiment of the invention, the antibodies or V.sub.H or V.sub.L polypeptides originate or are selected from one or more rabbit B cell populations prior to initiation of the humanization process referenced herein.
[0418] In another embodiment of the invention, the anti-NGF antibodies and fragments thereof e.g., for treatment or prevention of pain and pain associated conditions do not have binding specificity for p75 and/or TrkA and/or multimers thereof, and desirably will antagonize one or more of the biological effects elicited by NGF and/or more specifically biological functions elicited by NGF's interaction with p75 and/or TrkA. In a further embodiment of the invention, there is contemplated methods for treating pain comprising using the anti-NGF antibodies and fragments thereof to inhibit the association of NGF with p75 and/or TrkA. In another embodiment of the invention, there is contemplated methods for treating pain comprising using anti-NGF antibodies and fragments thereof to inhibit the association of NGF with TrkA and/or multimers thereof and/or antagonizes the biological effects thereof. In another embodiment of the invention, there is contemplated methods for treating pain comprising using anti-NGF antibodies and fragments thereof to inhibit the association of NGF with p75 and/or multimers thereof and the association of NGF with TrkA and/or multimers thereof, and antagonize the biological effects of p75 and TrkA. In another embodiment of the invention, there is contemplated methods for treating pain using NGF antagonists, e.g., anti-NGF antibodies or fragments thereof, that selectively inhibit the association of NGF with TrkA and/or multimers thereof, that do not appreciably inhibit the association of NGF with p75 and/or multimers thereof.
[0419] As stated supra, antibodies and fragments thereof may be modified post-translationally to add effector moieties such as chemical linkers, detectable moieties such as for example fluorescent dyes, enzymes, substrates, bioluminescent materials, radioactive materials, and chemiluminescent moieties, or functional moieties such as for example streptavidin, avidin, biotin, a cytotoxin, a cytotoxic agent, and radioactive materials. Regarding detectable moieties, further exemplary enzymes include, but are not limited to, horseradish peroxidase, acetylcholinesterase, alkaline phosphatase, beta-galactosidase and luciferase. Further exemplary fluorescent materials include, but are not limited to, rhodamine, fluorescein, fluorescein isothiocyanate, umbelliferone, dichlorotriazinylamine, phycoerythrin and dansyl chloride. Further exemplary chemiluminescent moieties include, but are not limited to, luminol. Further exemplary bioluminescent materials include, but are not limited to, luciferin and aequorin. u Further exemplary radioactive materials include, but are not limited to, Iodine 125 (.sup.125I) Carbon 14 (.sup.14C), Sulfur 35 (.sup.35S), Tritium (.sup.3H) and Phosphorus 32 (.sup.32P). Regarding functional moieties, exemplary cytotoxic agents include, but are not limited to, methotrexate, aminopterin, 6-mercaptopurine, 6-thioguanine, cytarabine, 5-fluorouracil decarbazine; alkylating agents such as mechlorethamine, thioepa chlorambucil, melphalan, carmustine (BSNU), mitomycin C, lomustine (CCNU), 1-methylnitrosourea, cyclothosphamide, mechlorethamine, busulfan, dibromomannitol, streptozotocin, mitomycin C, cis-dichlorodiamine platinum (II) (DDP) cisplatin and carboplatin (paraplatin); anthracyclines include daunorubicin (formerly daunomycin), doxorubicin (adriamycin), detorubicin, carminomycin, idarubicin, epirubicin, mitoxantrone and bisantrene; antibiotics include dactinomycin (actinomycin D), bleomycin, calicheamicin, mithramycin, and anthramycin (AMC); and antimytotic agents such as the vinca alkaloids, vincristine and vinblastine. Other cytotoxic agents include paclitaxel (taxol), ricin, pseudomonas exotoxin, gemcitabine, cytochalasin B, gramicidin D, ethidium bromide, emetine, etoposide, tenoposide, colchicin, dihydroxy anthracin dione, 1-dehydrotestosterone, glucocorticoids, procaine, tetracaine, lidocaine, propranolol, puromycin, procarbazine, hydroxyurea, asparaginase, corticosteroids, mytotane (O,P'-(DDD)), interferons, and mixtures of these cytotoxic agents. Further cytotoxic agents include, but are not limited to, chemotherapeutic agents such as carboplatin, cisplatin, paclitaxel, gemcitabine, calicheamicin, doxorubicin, 5-fluorouracil, mitomycin C, actinomycin D, cyclophosphamide, vincristine and bleomycin. Toxic enzymes from plants and bacteria such as ricin, diphtheria toxin and Pseudomonas toxin may be conjugated to the humanized or chimeric antibodies, or binding fragments thereof, to generate cell-type-specific-killing reagents (Youle, et al., Proc. Nat'l Acad. Sci. USA 77:5483 (1980); Gilliland, et al., Proc. Nat'l Acad. Sci. USA 77:4539 (1980); Krolick, et al., Proc. Nat'l Acad. Sci. USA 77:5419 (1980)). Other cytotoxic agents include cytotoxic ribonucleases as described by Goldenberg in U.S. Pat. No. 6,653,104. Embodiments of the invention also relate to radioimmunoconjugates where a radionuclide that emits alpha or beta particles is stably coupled to the antibody, or binding fragments thereof, with or without the use of a complex-forming agent. Such radionuclides include beta-emitters such as Phosphorus-32 (.sup.32P), Scandium-47 (.sup.47Sc), Copper-67 (.sup.67Cu), Gallium-67 (.sup.67Ga), Yttrium-88 (.sup.88Y), Yttrium-90 (.sup.90Y), Iodine-125 (.sup.125) Iodine-131 (.sup.131I) Samarium-153 (.sup.153Sm), Lutetium-177 (.sup.177Lu), Rhenium-186 (.sup.186Re) or Rhenium-188 (.sup.188Re), and alpha-emitters such as Astatine-211 (.sup.211At), Lead-212 (.sup.212Pb), Bismuth-212 (.sup.212Bi) or -213 (.sup.213Bi) or Actinium-225 (.sup.225Ac).
[0420] Methods are known in the art for conjugating an antibody or binding fragment thereof to a detectable moiety and the like, such as for example those methods described by Hunter et al, Nature 144:945 (1962); David et al, Biochemistry 13:1014 (1974); Pain et al, J. Immunol. Meth. 40:219 (1981); and Nygren, J., Histochem. and Cytochem. 30:407 (1982).
[0421] Also, the antibodies or antibody fragments may be modified to affect half-life or circulation time such as by PEGylation. Antibodies or fragments thereof may also be chemically modified to provide additional advantages such as increased solubility, stability and circulating time (in vivo half-life) of the polypeptide, or decreased immunogenicity (See U.S. Pat. No. 4,179,337). The chemical moieties for derivatization may be selected from water soluble polymers such as polyethylene glycol, ethylene glycol/propylene glycol copolymers, carboxymethylcellulose, dextran, polyvinyl alcohol and the like. The antibodies and fragments thereof may be modified at random positions within the molecule, or at predetermined positions within the molecule and may include one, two, three or more attached chemical moieties.
[0422] The polymer may be of any molecular weight, and may be branched or unbranched. For polyethylene glycol, the preferred molecular weight is between about 1 kDa and about 100 kDa (the term "about" indicating that in preparations of polyethylene glycol, some molecules will weigh more, some less, than the stated molecular weight) for ease in handling and manufacturing. Other sizes may be used, depending on the desired therapeutic profile (e.g., the duration of sustained release desired, the effects, if any on biological activity, the ease in handling, the degree or lack of antigenicity and other known effects of the polyethylene glycol to a therapeutic protein or analog). For example, the polyethylene glycol may have an average molecular weight of about 200, 500, 1000, 1500, 2000, 2500, 3000, 3500, 4000, 4500, 5000, 5500, 6000, 6500, 7000, 7500, 8000, 8500, 9000, 9500, 10,000, 10,500, 11,000, 11,500, 12,000, 12,500, 13,000, 13,500, 14,000, 14,500, 15,000, 15,500, 16,000, 16,500, 17,000, 17,500, 18,000, 18,500, 19,000, 19,500, 20,000, 25,000, 30,000, 35,000, 40,000, 50,000, 55,000, 60,000, 65,000, 70,000, 75,000, 80,000, 85,000, 90,000, 95,000, or 100,000 kDa. Branched polyethylene glycols are described, for example, in U.S. Pat. No. 5,643,575; Morpurgo et al., Appl. Biochem. Biotechnol. 56:59-72 (1996); Vorobjev et al., Nucleosides Nucleotides 18:2745-2750 (1999); and Caliceti et al., Bioconjug. Chem. 10:638-646 (1999), the disclosures of each of which are incorporated herein by reference.
[0423] There are a number of attachment methods available to those skilled in the art, See e.g., EP 0 401 384, herein incorporated by reference (coupling PEG to G-CSF), See also Malik et al., Exp. Hematol. 20:1028-1035 (1992) (reporting PEGylation of GM-CSF using tresyl chloride). For example, polyethylene glycol may be covalently bound through amino acid residues via a reactive group, such as, a free amino or carboxyl group. Reactive groups are those to which an activated polyethylene glycol molecule may be bound. The amino acid residues having a free amino group may include lysine residues and the N-terminal amino acid residues; those having a free carboxyl group may include aspartic acid residues glutamic acid residues and the C-terminal amino acid residue. Sulfhydryl groups may also be used as a reactive group for attaching the polyethylene glycol molecules. Preferred for therapeutic purposes is attachment at an amino group, such as attachment at the N-terminus or lysine group.
[0424] As suggested above, polyethylene glycol may be attached to proteins via linkage to any of a number of amino acid residues. For example, polyethylene glycol can be linked to polypeptides via covalent bonds to lysine, histidine, aspartic acid, glutamic acid, or cysteine residues. One or more reaction chemistries may be employed to attach polyethylene glycol to specific amino acid residues (e.g., lysine, histidine, aspartic acid, glutamic acid, or cysteine) or to more than one type of amino acid residue (e.g., lysine, histidine, aspartic acid, glutamic acid, cysteine and combinations thereof).
[0425] Alternatively, antibodies or fragments thereof may have increased in vivo half lives via fusion with albumin (including but not limited to recombinant human serum albumin or fragments or variants thereof (see, e.g., U.S. Pat. No. 5,876,969, issued Mar. 2, 1999, EP Patent 0 413 622, and U.S. Pat. No. 5,766,883, issued Jun. 16, 1998, herein incorporated by reference in their entirety)) or other circulating blood proteins such as transferrin or ferritin. In a preferred embodiment, polypeptides and/or antibodies of the present invention (including fragments or variants thereof) are fused with the mature form of human serum albumin (i.e., amino acids 1-585 of human serum albumin as shown in FIGS. 1 and 2 of EP Patent 0 322 094) which is herein incorporated by reference in its entirety. Polynucleotides encoding fusion proteins of the invention are also encompassed by the invention.
[0426] Embodiments described herein further include variants and equivalents that are substantially homologous to the antibodies, antibody fragments, diabodies, SMIPs, camelbodies, MetMab like monovalent antibody fragments, nanobodies, MetMab like monovalent agents, IgNAR, polypeptides, variable regions and CDRs set forth herein. These may contain, e.g., conservative substitution mutations, (i.e., the substitution of one or more amino acids by similar amino acids). For example, conservative substitution refers to the substitution of an amino acid with another within the same general class, e.g., one acidic amino acid with another acidic amino acid, one basic amino acid with another basic amino acid, or one neutral amino acid by another neutral amino acid. What is intended by a conservative amino acid substitution is well known in the art.
[0427] In another embodiment, the invention contemplates polypeptide sequences having at least 90% or greater sequence homology to any one or more of the polypeptide sequences of antibody fragments, variable regions and CDRs set forth herein. More preferably, the invention contemplates polypeptide sequences having at least 95% or greater sequence homology, even more preferably at least 98% or greater sequence homology, and still more preferably at least 99% or greater sequence homology to any one or more of the polypeptide sequences of antibody fragments, variable regions and CDRs set forth herein. Methods for determining homology between nucleic acid and amino acid sequences are well known to those of ordinary skill in the art.
[0428] In another embodiment, the invention further contemplates the above-recited polypeptide homologs of the antibody fragments, variable regions and CDRs set forth herein further having anti-NGF activity. Non-limiting examples of anti-NGF activity are set forth herein.
[0429] In another embodiment, the invention further contemplates the generation and use of anti-idiotypic antibodies that bind any of the foregoing sequences. In an exemplary embodiment, such an anti-idiotypic antibody could be administered to a subject who has received an anti-NGF antibody to modulate, reduce, or neutralize, the effect of the anti-NGF antibody. Such anti-idiotypic antibodies could also be useful e.g., for treatment of an autoimmune disease characterized by the presence of anti-NGF antibodies. A further exemplary use of such anti-idiotypic antibodies is for detection of the anti-NGF antibodies of the present invention, for example to monitor the levels of the anti-NGF antibodies present in a subject's blood or other bodily fluids.
[0430] The present invention also contemplates anti-NGF antibodies comprising any of the polypeptide or polynucleotide sequences described herein substituted for any of the other polynucleotide sequences described herein. For example, without limitation thereto, the present invention contemplates antibodies comprising the combination of any of the variable light chain and variable heavy chain sequences described herein, and further contemplates antibodies resulting from substitution of any of the CDR sequences described herein for any of the other CDR sequences described herein.
Additional Exemplary Embodiments of the Invention
[0431] In another embodiment, the invention contemplates one or more anti-human NGF antibodies or antibody fragments thereof which specifically bind to the same linear or conformational epitope(s) and/or competes for binding to the same or overlapping linear or conformational epitope(s) on an intact human NGF polypeptide or fragment thereof as an anti-human NGF antibody selected from Ab1, Ab2, Ab3, Ab4, Ab5, Ab6, Ab7, Ab8, Ab9, Ab10, Ab11, Ab12, Ab13, Ab14, Ab15, Ab16, Ab17, Ab18, Ab19, Ab20, or Ab21. In a preferred embodiment, the anti-human NGF antibody or fragment thereof specifically binds to the same or overlapping linear or conformational epitope(s) and/or competes for binding to the same or overlapping linear or conformational epitope(s) on an intact human NGF polypeptide or a fragment thereof as Ab3, Ab4, Ab5, Ab6, Ab15, or Ab16.
[0432] A preferred embodiment of the invention is directed to chimeric or humanized antibodies and fragments thereof (including Fab fragments) having binding specificity for NGF and inhibiting biological activities mediated by the binding of NGF to the TrkA receptor.
[0433] Another preferred embodiment of the invention is directed to a method of treating diseases or disorders associated with NGF by affecting those biological activities mediated by TrkA. In one embodiment, the disease or disorder associated with NGF is pain. A further listing of diseases and disorders associated with NGF is provided herein.
[0434] In another preferred embodiment of the invention, full length antibodies and Fab fragments thereof are capable of significantly reducing pain in vivo in murine models as assessed by using Gait analysis (as described in Example 5 herein), compared to results obtained with controls.
[0435] A particularly preferred embodiment of the invention contemplates the use of Fab polypeptide sequences for the treatment of pain in a patient. Non-limiting types of pain that may be treated using Fab polypeptide sequences are provided elsewhere in this disclosure.
[0436] In another embodiment of the invention, chimeric or humanized anti-NGF antibodies and fragments thereof (including Fab fragments) having binding specificity for NGF inhibit TF1 cell proliferation.
[0437] The invention is also directed to an anti-NGF antibody that binds with the same or overlapping NGF epitope and/or competes with an anti-NGF antibody for binding to NGF as an antibody or antibody fragment disclosed herein, including but not limited to an anti-NGF antibody selected from Ab1, Ab2, Ab3, Ab4, Ab5, Ab6, Ab7, Ab8, Ab9, Ab10, Ab11, Ab12, Ab13, Ab14, Ab15, Ab16, Ab17, Ab18, Ab19, or Ab20 or Ab21.
[0438] In another embodiment, the invention is also directed to an isolated anti-NGF antibody or antibody fragment comprising one or more of the CDRs contained in the V.sub.H polypeptide sequences selected from: 3, 13, 23, 33, 43, 53, 63, 73, 83, 93, 103, 113, 123, 133, 143, 153, 163, 173, 183, 193, or 402, or a variant thereof, and/or one or more of the CDRs contained in the V.sub.L polypeptide sequences selected from: 1, 11, 21, 31, 41, 51, 61, 71, 81, 91, 101, 111, 121, 131, 141, 151, 161, 171, 181, 191, or 401, or a variant thereof.
[0439] In one embodiment of the invention, the anti-human NGF antibody discussed above comprises at least 2 complementarity determining regions (CDRs) in each the variable light and the variable heavy regions which are identical to those contained in an anti-human NGF antibody selected from the group consisting of Ab1, Ab2, Ab3, Ab4, Ab5, Ab6, Ab7, Ab8, Ab9, Ab10, Ab11, Ab12, Ab13, Ab14, Ab15, Ab16, Ab17, Ab18, Ab19, or Ab20 or Ab21.
[0440] In a preferred embodiment, the anti-human NGF antibody discussed above comprises at least 2 complementarity determining regions (CDRs) in each the variable light and the variable heavy regions which are identical to those contained in Ab3, Ab4, Ab5, or Ab6. In another embodiment, all of the CDRs of the anti-human NGF antibody discussed above are identical to the CDRs contained in an anti-human NGF antibody selected from Ab1, Ab2, Ab3, Ab4, Ab5, Ab6, Ab7, Ab8, Ab9, Ab10, Ab11, Ab12, Ab13, Ab14, Ab15, Ab16, Ab17, Ab18, Ab19, or Ab20 or Ab21. In a preferred embodiment of the invention, all of the CDRs of the anti-human NGF antibody discussed above are identical to the CDRs contained in an anti-human NGF antibody selected from Ab3, Ab4, Ab5, or Ab6.
[0441] The invention further contemplates that the one or more anti-human NGF antibodies discussed above are aglycosylated; that contain an Fc region that has been modified to alter effector function, half-life, proteolysis, and/or glycosylation; are human, humanized, single chain or chimeric; and are a humanized antibody derived from a rabbit (parent) anti-human NGF antibody.
[0442] The invention further contemplates one or more anti-human NGF antibodies wherein the framework regions (FRs) in the variable light region and the variable heavy regions of said antibody respectively are human FRs which are unmodified or which have been modified by the substitution of at most 2 or 3 human FR residues in the variable light or heavy chain region with the corresponding FR residues of the parent rabbit antibody, and wherein said human FRs have been derived from human variable heavy and light chain antibody sequences which have been selected from a library of human germline antibody sequences based on their high level of homology to the corresponding rabbit variable heavy or light chain regions relative to other human germline antibody sequences contained in the library.
[0443] In one embodiment of the invention, the anti-human NGF antibody or fragment specifically binds to NGF expressing human cells and/or to circulating soluble NGF molecules in vivo, including NGF expressed on or by human cells in a patient with a disease associated with cells that express NGF.
[0444] In another embodiment, the disease is selected from inflammatory pain, post-operative incision pain, complex regional pain syndrome, cancer pain, primary or metastatic bone cancer pain, fracture pain, osteoporotic fracture pain, pain resulting from burn, osteoporosis, gout joint pain, pain associated with sickle cell crises, and other nociceptic pain, as well as hepatocellular carcinoma, breast cancer, liver cirrhosis, neurogenic pain, neuropathic pain, nociceptic pain, trigeminal neuralgia, post-herpetic neuralgia, phantom limb pain, fibromyalgia, menstrual pain, ovarialgia, reflex sympathetic dystrophy, neurogenic pain, osteoarthritis or rheumatoid arthritis pain, lower back pain, diabetic neuropathy, sciatica, or migraine.
[0445] The invention further contemplates anti-human NGF antibodies or fragments directly or indirectly attached to a detectable label or therapeutic agent.
[0446] The invention also contemplates one or more nucleic acid sequences which result in the expression of an anti-human NGF antibody or antibody fragment as set forth above, including those comprising, or alternatively consisting of, yeast or human preferred codons. The invention also contemplates vectors (including plasmids or recombinant viral vectors) comprising said nucleic acid sequence(s). The invention also contemplates host cells or recombinant host cells expressing at least one of the antibodies set forth above, including a mammalian, yeast, bacterial, and insect cells. In a preferred embodiment, the host cell is a yeast cell. In a further preferred embodiment, the yeast cell is a diploidal yeast cell. In a more preferred embodiment, the yeast cell is a Pichia yeast.
[0447] The invention also contemplates a method of treatment comprising administering to a patient with a disease or condition associated with NGF expressing cells a therapeutically effective amount of at least one anti-human NGF antibody or fragment described herein. The invention also contemplates that the treatment method may involve the administration of two or more anti-NGF antibodies or fragments thereof and disclosed herein. If more than one antibody is administered to the patient, the multiple antibodies may be administered simultaneously or concurrently, or may be staggered in their administration. The diseases that may be treated are presented in the non-limiting list set forth above and elsewhere herein. In a preferred embodiment, the disease is selected from cancer pain or neuropathic pain. In a particularly preferred embodiment, the disease is cancer pain. In another embodiment the treatment further includes the administration of another therapeutic agent or regimen selected from chemotherapy, radiotherapy, cytokine administration or gene therapy.
[0448] In a non-limiting embodiment of the invention, another therapeutic agent or regimen includes Taxol (paclitaxel) or its derivatives, platinum compounds such as carboplatin or cisplatin, anthrocyclines such as doxorubicin, alkylating agents such as cyclophosphamide, anti-metabolites such as 5-fluorouracil, or etoposide.
[0449] The invention further contemplates a method of in vivo imaging which detects the presence of cells which express NGF comprising administering a diagnostically effective amount of at least one anti-human NGF antibody. In one embodiment, said administration further includes the administration of a radionuclide or fluorophore that facilitates detection of the antibody at NGF expressing disease sites. In another embodiment of the invention, the method of in vivo imaging is used to detect NGF expressing tumors or metastases, or tumors or metastases expressing TrkA and/or p75 capable of binding to NGF. In a further embodiment, the results of said in vivo imaging method are used to facilitate the design of an appropriate therapeutic regimen, including therapeutic regimens including radiotherapy, chemotherapy or a combination thereof.
Polynucleotides Encoding Anti-NGF Antibody Polypeptides
Antibody Ab1
[0450] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 1:
TABLE-US-00091 (SEQ ID NO: 201) GCCCTTGTGATGACCCAGACTCCATCCTCCGTGTCTGCAGCTGTGGGAGG CACAGTCACCATCAATTGCCAGGCCAGTCAGAACATTTACAGCAATTTAG CCTGGTATCAACAGAGACCAGGGCAGCGTCCCAAGCTCCTGATCTATGGT GCATCCAATCTGGATGCTGGGGTCCCATCGCGGTTCAGAGGCAGTGGATC TGGGACAGAGTACACTCTCACCATCAGCGACCTGGAGTGTGACGATGTTG GCACTTACTACTGTCAAAGTGCTTTTGATAGTGATAGTACTGAAAATACT TTCGGCGGAGGGACCGAGGTGGTGGTCAAACGT.
[0451] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 2:
TABLE-US-00092 (SEQ ID NO: 202) GCCCTTGTGATGACCCAGACTCCATCCTCCGTGTCTGCAGCTGTGGGAGG CACAGTCACCATCAATTGCCAGGCCAGTCAGAACATTTACAGCAATTTAG CCTGGTATCAACAGAGACCAGGGCAGCGTCCCAAGCTCCTGATCTATGGT GCATCCAATCTGGATGCTGGGGTCCCATCGCGGTTCAGAGGCAGTGGATC TGGGACAGAGTACACTCTCACCATCAGCGACCTGGAGTGTGACGATGTTG GCACTTACTACTGTCAAAGTGCTTTTGATAGTGATAGTACTGAAAATACT TTCGGCGGAGGGACCGAGGTGGTGGTCAAACGTACGGTAGCGGCCCCATC TGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCT CTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAG TGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCAC AGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGC TGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACC CATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTG TTAG.
[0452] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 3:
TABLE-US-00093 (SEQ ID NO: 203) CAGTCGCTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGTCTCTGGCTTCTCCCTCAGTAGCTATGCAATGA GCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATGGATCGGAGTCATT ACTAGTATTGGTAGCACAGTCTACGCGAGCTGGGCGAAAGGCCGATTCAC CATCTCCAAAACCTCGACCACGGTGGATCTGAAAATCACCAGTCCGACAA CCGAGGACACGGCCACCTATTTCTGTGCCAGAGGCTACGATGACTATGAT GAGATGACCTACTTTAACATCTGGGGCCAGGGGACCCTCGTCACCGTCTC GAGC.
[0453] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 4:
TABLE-US-00094 (SEQ ID NO: 204) CAGTCGCTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGTCTCTGGCTTCTCCCTCAGTAGCTATGCAATGA GCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATGGATCGGAGTCATT ACTAGTATTGGTAGCACAGTCTACGCGAGCTGGGCGAAAGGCCGATTCAC CATCTCCAAAACCTCGACCACGGTGGATCTGAAAATCACCAGTCCGACAA CCGAGGACACGGCCACCTATTTCTGTGCCAGAGGCTACGATGACTATGAT GAGATGACCTACTTTAACATCTGGGGCCAGGGGACCCTCGTCACCGTCTC GAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCA AGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTAC TTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGG CGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCA GCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATC TGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGA GCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTG AACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGAC ACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGT GAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGG AGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACG TACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGG CAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCG AGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTAC ACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGAC CTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGA GCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGAC TCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAG GTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGC ACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA.
[0454] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 205; SEQ ID NO: 206; and SEQ ID NO: 207 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 1 or the light chain sequence of SEQ ID NO: 2.
[0455] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 208; SEQ ID NO: 209; and SEQ ID NO: 210 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 3 or the heavy chain sequence of SEQ ID NO: 4.
[0456] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 201 encoding the light chain variable sequence of SEQ ID NO: 1; the polynucleotide SEQ ID NO: 202 encoding the light chain sequence of SEQ ID NO: 2; the polynucleotide SEQ ID NO: 203 encoding the heavy chain variable sequence of SEQ ID NO: 3; the polynucleotide SEQ ID NO: 204 encoding the heavy chain sequence of SEQ ID NO: 4; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 205; SEQ ID NO: 206; and SEQ ID NO: 207) of the light chain variable sequence of SEQ ID NO: 1 or the light chain sequence of SEQ ID NO: 2; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 208; SEQ ID NO: 209; and SEQ ID NO: 210) of the heavy chain variable sequence of SEQ ID NO: 3 or the heavy chain sequence of SEQ ID NO: 4.
[0457] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab1, the polynucleotides encoding the full length Ab1 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 202 encoding the light chain sequence of SEQ ID NO: 2 and the polynucleotide SEQ ID NO: 204 encoding the heavy chain sequence of SEQ ID NO: 4.
[0458] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab1 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab1 or Fab fragments thereof may be produced via expression of Ab1 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab2
[0459] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 11:
TABLE-US-00095 (SEQ ID NO: 211) GACATCCAGATGACCCAGTCTCCTTCCACCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTCAGAACATTTACAGCAACTTAG CCTGGTATCAGCAGAAACCAGGAAAAGCCCCTAAGCTCCTGATCTATGGT GCATCCAATCTGGATGCTGGAGTCCCATCAAGGTTCTCTGGCAGTGGATC TGGGACAGAGTACACTCTCACCATCAGCAGCCTGCAGCCTGATGATTTTG CAACTTACTACTGCCAAAGTGCTTTTGATAGTGATAGTACTGAAAACACT TTCGGCGGAGGAACCAAGGTGGAAATCAAACGT.
[0460] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 12:
TABLE-US-00096 (SEQ ID NO: 212) GACATCCAGATGACCCAGTCTCCTTCCACCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTCAGAACATTTACAGCAACTTAG CCTGGTATCAGCAGAAACCAGGAAAAGCCCCTAAGCTCCTGATCTATGGT GCATCCAATCTGGATGCTGGAGTCCCATCAAGGTTCTCTGGCAGTGGATC TGGGACAGAGTACACTCTCACCATCAGCAGCCTGCAGCCTGATGATTTTG CAACTTACTACTGCCAAAGTGCTTTTGATAGTGATAGTACTGAAAACACT TTCGGCGGAGGAACCAAGGTGGAAATCAAACGTACGGTAGCGGCCCCATC TGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCT CTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAG TGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCAC AGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGC TGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACC CATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTG TTAG.
[0461] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 13:
TABLE-US-00097 (SEQ ID NO: 213) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTAGCTATGCAA TGAGCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGAGTC ATTACTAGTATTGGTAGCACAGTCTACGCGAGCAGCGCGAAAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGAACA GCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGGCTACGAT GACTATGATGAGATGACCTACTTTAACATCTGGGGCCAAGGGACCCTCGT CACCGTCTCGAGC.
[0462] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 14:
TABLE-US-00098 (SEQ ID NO: 214) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTAGCTATGCAA TGAGCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGAGTC ATTACTAGTATTGGTAGCACAGTCTACGCGAGCAGCGCGAAAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGAACA GCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGGCTACGAT GACTATGATGAGATGACCTACTTTAACATCTGGGGCCAAGGGACCCTCGT CACCGTCTCGAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCAC CCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTC AAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCT GACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCT ACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAA GAGAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCC CAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAA CCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGT GGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGG ACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTAC GCCAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTG GCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAG CCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCA CAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGT CAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGG AGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCC GTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGA CAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATG AGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGT AAATGA.
[0463] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 215; SEQ ID NO: 216; and SEQ ID NO: 217 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 11 or the light chain sequence of SEQ ID NO: 12.
[0464] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 218; SEQ ID NO: 219; and SEQ ID NO: 220 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 13 or the heavy chain sequence of SEQ ID NO: 14.
[0465] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 211 encoding the light chain variable sequence of SEQ ID NO: 11; the polynucleotide SEQ ID NO: 212 encoding the light chain sequence of SEQ ID NO: 12; the polynucleotide SEQ ID NO: 213 encoding the heavy chain variable sequence of SEQ ID NO: 13; the polynucleotide SEQ ID NO: 214 encoding the heavy chain sequence of SEQ ID NO: 14; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 215; SEQ ID NO: 216; and SEQ ID NO: 217) of the light chain variable sequence of SEQ ID NO: 11 or the light chain sequence of SEQ ID NO: 12; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 218; SEQ ID NO: 219; and SEQ ID NO: 220) of the heavy chain variable sequence of SEQ ID NO: 13 or the heavy chain sequence of SEQ ID NO: 14.
[0466] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab2, the polynucleotides encoding the full length Ab2 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 212 encoding the light chain sequence of SEQ ID NO: 12 and the polynucleotide SEQ ID NO: 214 encoding the heavy chain sequence of SEQ ID NO: 14.
[0467] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab2 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab2 or Fab fragments thereof may be produced via expression of Ab2 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab3
[0468] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 21:
TABLE-US-00099 (SEQ ID NO: 221) GCAGCCGTGCTGACCCAGACACCATCGCCCGTGTCTGCAGCTATGGGAGA CACAGTCACCATCAAGTGCCAGTCCAGTCAGAGTGTTTATAAGAACAACT ACTTATCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAGGCTCCTGATC TATGATGCATCCAATCTGCCATCTGGGGTCCCATCACGGTTCAGCGGCAG TGGATCTGGGACACAGTTCACTCTCACCATCAGCGGCGTGCAGTGTGACG ATGCTGCCACTTACTACTGTCTAGGCGATTATGATGATGATGCTGATAAT GCTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGT.
[0469] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 22:
TABLE-US-00100 (SEQ ID NO: 222) GCAGCCGTGCTGACCCAGACACCATCGCCCGTGTCTGCAGCTATGGGAGA CACAGTCACCATCAAGTGCCAGTCCAGTCAGAGTGTTTATAAGAACAACT ACTTATCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAGGCTCCTGATC TATGATGCATCCAATCTGCCATCTGGGGTCCCATCACGGTTCAGCGGCAG TGGATCTGGGACACAGTTCACTCTCACCATCAGCGGCGTGCAGTGTGACG ATGCTGCCACTTACTACTGTCTAGGCGATTATGATGATGATGCTGATAAT GCTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGTACGGTAGCGGCCCC ATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTG CCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTA CAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGT CACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGA CGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTC ACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGA GTGTTAG.
[0470] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 23:
TABLE-US-00101 (SEQ ID NO: 223) CAGTCGGTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGTCTCTGGATTCTCCCTCAGTAGCTATGTAATGA TCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGAATCACT TGGAGTGCTGGTACATACTACGCGAGCTGGGCGAAAGGCCGATTCACCAT CTCCAAAACCTCGTCGACCACGGTGGATCTGAAAATCACCAGTCCGACAA CCGAGGACACGGCCACCTATTTCTGTGCCGGAGGTGGTGGTAGTATTTAT GATATTTGGGGCCCGGGCACCCTGGTCACCGTCTCGAGC.
[0471] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 24:
TABLE-US-00102 (SEQ ID NO: 224) CAGTCGGTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGTCTCTGGATTCTCCCTCAGTAGCTATGTAATGA TCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGAATCACT TGGAGTGCTGGTACATACTACGCGAGCTGGGCGAAAGGCCGATTCACCAT CTCCAAAACCTCGTCGACCACGGTGGATCTGAAAATCACCAGTCCGACAA CCGAGGACACGGCCACCTATTTCTGTGCCGGAGGTGGTGGTAGTATTTAT GATATTTGGGGCCCGGGCACCCTGGTCACCGTCTCGAGCGCCTCCACCAA GGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGG GCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTG ACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCC GGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCG TGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCAC AAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGA CAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGAC CGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCC CGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCC TGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCA AGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACGTACCGTGTGGTCAGC GTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTG CAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCA AAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCC CGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGG CTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGG AGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTC TTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAA CGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGC AGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA.
[0472] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 225; SEQ ID NO: 226; and SEQ ID NO: 227 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 21 or the light chain sequence of SEQ ID NO: 22.
[0473] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 228; SEQ ID NO: 229; and SEQ ID NO: 230 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 23 or the heavy chain sequence of SEQ ID NO: 24.
[0474] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 221 encoding the light chain variable sequence of SEQ ID NO: 21; the polynucleotide SEQ ID NO: 222 encoding the light chain sequence of SEQ ID NO: 22; the polynucleotide SEQ ID NO: 223 encoding the heavy chain variable sequence of SEQ ID NO: 23; the polynucleotide SEQ ID NO: 224 encoding the heavy chain sequence of SEQ ID NO: 24; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 225; SEQ ID NO: 226; and SEQ ID NO: 227) of the light chain variable sequence of SEQ ID NO: 21 or the light chain sequence of SEQ ID NO: 22; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 228; SEQ ID NO: 229; and SEQ ID NO: 230) of the heavy chain variable sequence of SEQ ID NO: 23 or the heavy chain sequence of SEQ ID NO: 24.
[0475] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab3, the polynucleotides encoding the full length Ab3 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 222 encoding the light chain sequence of SEQ ID NO: 22 and the polynucleotide SEQ ID NO: 224 encoding the heavy chain sequence of SEQ ID NO: 24.
[0476] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab3 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab3 or Fab fragments thereof may be produced via expression of Ab3 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab4
[0477] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 31:
TABLE-US-00103 (SEQ ID NO: 231) GACATCCAGATGACCCAGTCTCCTTCCACCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGTCCAGTCAGAGTGTCTATAAGAACAACT ACTTATCCTGGTATCAGCAGAAACCAGGAAAAGCCCCTAAGCTCCTGATC TATGATGCATCCAATCTGCCATCTGGAGTCCCATCAAGGTTCAGCGGCAG TGGATCTGGAACAGAATTCACTCTCACCATCAGCAGCCTGCAGCCTGATG ATTTTGCAACTTATTACTGCCTAGGCGATTATGATGATGATGCTGATAAT GCTTTCGGCGGAGGAACCAAGGTGGAAATCAAACGT.
[0478] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 32:
TABLE-US-00104 (SEQ ID NO: 232) GACATCCAGATGACCCAGTCTCCTTCCACCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGTCCAGTCAGAGTGTCTATAAGAACAACT ACTTATCCTGGTATCAGCAGAAACCAGGAAAAGCCCCTAAGCTCCTGATC TATGATGCATCCAATCTGCCATCTGGAGTCCCATCAAGGTTCAGCGGCAG TGGATCTGGAACAGAATTCACTCTCACCATCAGCAGCCTGCAGCCTGATG ATTTTGCAACTTATTACTGCCTAGGCGATTATGATGATGATGCTGATAAT GCTTTCGGCGGAGGAACCAAGGTGGAAATCAAACGTACGGTAGCGGCCCC ATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTG CCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTA CAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGT CACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGA CGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTC ACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGA GTGTTAG.
[0479] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 33:
TABLE-US-00105 (SEQ ID NO: 233) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTAGCTATGTAA TGATCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTACATCGGAATC ACTTGGAGTGCTGGTACATACTACGCGAGCAGTGCGAAAGGCCGATTCAC CATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGAACAGCC TGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTGGAGGTGGTGGTAGT ATCTATGATATTTGGGGCCAAGGGACCCTCGTCACCGTCTCGAGC.
[0480] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 34:
TABLE-US-00106 (SEQ ID NO: 234) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTAGCTATGTAA TGATCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTACATCGGAATC ACTTGGAGTGCTGGTACATACTACGCGAGCAGTGCGAAAGGCCGATTCAC CATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGAACAGCC TGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTGGAGGTGGTGGTAGT ATCTATGATATTTGGGGCCAAGGGACCCTCGTCACCGTCTCGAGCGCCTC CACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCT CTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAA CCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACAC CTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGG TGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTG AATCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATC TTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATG ATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGA AGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATA ATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACGTACCGTGTG GTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTA CAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCA TCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCC CCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGT CAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGC AGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGC TCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCA GGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACT ACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA.
[0481] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 235; SEQ ID NO: 236; and SEQ ID NO: 237 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 31 or the light chain sequence of SEQ ID NO: 32.
[0482] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 238; SEQ ID NO: 239; and SEQ ID NO: 240 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 33 or the heavy chain sequence of SEQ ID NO: 34.
[0483] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 231 encoding the light chain variable sequence of SEQ ID NO: 31; the polynucleotide SEQ ID NO: 232 encoding the light chain sequence of SEQ ID NO: 32; the polynucleotide SEQ ID NO: 233 encoding the heavy chain variable sequence of SEQ ID NO: 33; the polynucleotide SEQ ID NO: 234 encoding the heavy chain sequence of SEQ ID NO: 34; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 235; SEQ ID NO: 236; and SEQ ID NO: 237) of the light chain variable sequence of SEQ ID NO: 31 or the light chain sequence of SEQ ID NO: 32; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 238; SEQ ID NO: 239; and SEQ ID NO: 240) of the heavy chain variable sequence of SEQ ID NO: 33 or the heavy chain sequence of SEQ ID NO: 34.
[0484] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab4, the polynucleotides encoding the full length Ab4 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 232 encoding the light chain sequence of SEQ ID NO: 32 and the polynucleotide SEQ ID NO: 234 encoding the heavy chain sequence of SEQ ID NO: 34.
[0485] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab4 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab4 or Fab fragments thereof may be produced via expression of Ab4 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab5
[0486] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 41:
TABLE-US-00107 (SEQ ID NO: 241) GCCTATGATATGACCCAGACTCCAGCCTCTGTGGAGGTAGCTGTGGGAGG CACAGTCACCATCAAGTGCCAGGCCAGTCAGAGCATTTACAGCAATTTAG CCTGGTATCAGCAGAGACCAGGGCAGCCTCCCAAGCTCCTGATCTATGAT GCATCCACTCTGGAATCTGGGGTCCCATCGCGGTTCAAAGGCAGTGGATC TGGGACAGAGTACACTCTCACCATCAGCGGCGTGGAGTGTGCCGATGCTG CCTCTTACTACTGTCAACAGGGTTTTACTGTTAGTGATATTGATAATGCT TTCGGCGGAGGGACCGAGGTGGTGGTCAAACGT.
[0487] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 42:
TABLE-US-00108 (SEQ ID NO: 242) GCCTATGATATGACCCAGACTCCAGCCTCTGTGGAGGTAGCTGTGGGAGG CACAGTCACCATCAAGTGCCAGGCCAGTCAGAGCATTTACAGCAATTTAG CCTGGTATCAGCAGAGACCAGGGCAGCCTCCCAAGCTCCTGATCTATGAT GCATCCACTCTGGAATCTGGGGTCCCATCGCGGTTCAAAGGCAGTGGATC TGGGACAGAGTACACTCTCACCATCAGCGGCGTGGAGTGTGCCGATGCTG CCTCTTACTACTGTCAACAGGGTTTTACTGTTAGTGATATTGATAATGCT TTCGGCGGAGGGACCGAGGTGGTGGTCAAACGTACGGTAGCGGCCCCATC TGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCT CTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAG TGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCAC AGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGC TGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACC CATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTG TTAG.
[0488] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 43:
TABLE-US-00109 (SEQ ID NO: 243) CAGTCGGTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGTCTCTGGATTCTCCCTCAGTAACTATGCAGTGG GCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATGGATCGGAATCATT GGTCGTAATGGTAACACATGGTACGCGAGCTGGGCAAGAGGCCGATTCAC CATCTCCAAAACCTCGACCACGGTGGATCTGAAAATCACCAGTCCGACAA GCGAGGACACGGCCACATATTTCTGTGCCAGAGGATATGGCCGTAGTGTT GCTTATTACGTCTTTAACATCTGGGGCCCAGGCACCCTCGTCACCGTCTC GAGC.
[0489] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 44:
TABLE-US-00110 (SEQ ID NO: 244) CAGTCGGTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGTCTCTGGATTCTCCCTCAGTAACTATGCAGTGG GCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATGGATCGGAATCATT GGTCGTAATGGTAACACATGGTACGCGAGCTGGGCAAGAGGCCGATTCAC CATCTCCAAAACCTCGACCACGGTGGATCTGAAAATCACCAGTCCGACAA GCGAGGACACGGCCACATATTTCTGTGCCAGAGGATATGGCCGTAGTGTT GCTTATTACGTCTTTAACATCTGGGGCCCAGGCACCCTCGTCACCGTCTC GAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCA AGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTAC TTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGG CGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCA GCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATC TGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGA GCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTG AACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGAC ACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGT GAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGG AGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACG TACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGG CAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCG AGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTAC ACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGAC CTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGA GCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGAC TCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAG GTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGC ACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA.
[0490] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 245; SEQ ID NO: 246; and SEQ ID NO: 247 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 41 or the light chain sequence of SEQ ID NO: 42.
[0491] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 248; SEQ ID NO: 249; and SEQ ID NO: 250 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 43 or the heavy chain sequence of SEQ ID NO: 44.
[0492] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 241 encoding the light chain variable sequence of SEQ ID NO: 41; the polynucleotide SEQ ID NO: 242 encoding the light chain sequence of SEQ ID NO: 42; the polynucleotide SEQ ID NO: 243 encoding the heavy chain variable sequence of SEQ ID NO: 43; the polynucleotide SEQ ID NO: 244 encoding the heavy chain sequence of SEQ ID NO: 44; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 245; SEQ ID NO: 246; and SEQ ID NO: 247) of the light chain variable sequence of SEQ ID NO: 41 or the light chain sequence of SEQ ID NO: 42; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 248; SEQ ID NO: 249; and SEQ ID NO: 250) of the heavy chain variable sequence of SEQ ID NO: 43 or the heavy chain sequence of SEQ ID NO: 44.
[0493] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab5, the polynucleotides encoding the full length Ab5 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 242 encoding the light chain sequence of SEQ ID NO: 42 and the polynucleotide SEQ ID NO: 244 encoding the heavy chain sequence of SEQ ID NO: 44.
[0494] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab5 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab5 or Fab fragments thereof may be produced via expression of Ab5 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab6
[0495] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 51:
TABLE-US-00111 (SEQ ID NO: 251) GACATCCAGATGACCCAGTCTCCTTCCACCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTCAGAGCATTTACAGCAATCTTG CCTGGTATCAGCAGAAACCAGGAAAAGCCCCTAAGCTCCTGATCTATGAT GCATCCACTCTGGAATCTGGAGTCCCATCAAGGTTCAGCGGCAGTGGATC TGGGACAGAGTACACTCTCACCATCAGCAGCCTGCAGCCTGATGATTTTG CAACTTACTACTGCCAACAGGGTTTTACTGTTAGTGATATTGATAATGCT TTCGGCGGAGGAACCAAGGTGGAAATCAAACGT.
[0496] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 52:
TABLE-US-00112 (SEQ ID NO: 252) GACATCCAGATGACCCAGTCTCCTTCCACCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTCAGAGCATTTACAGCAATCTTG CCTGGTATCAGCAGAAACCAGGAAAAGCCCCTAAGCTCCTGATCTATGAT GCATCCACTCTGGAATCTGGAGTCCCATCAAGGTTCAGCGGCAGTGGATC TGGGACAGAGTACACTCTCACCATCAGCAGCCTGCAGCCTGATGATTTTG CAACTTACTACTGCCAACAGGGTTTTACTGTTAGTGATATTGATAATGCT TTCGGCGGAGGAACCAAGGTGGAAATCAAACGTACGGTAGCGGCCCCATC TGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCT CTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAG TGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCAC AGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGC TGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACC CATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTG TTAG.
[0497] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 53:
TABLE-US-00113 (SEQ ID NO: 253) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTAACTATGCAG TGGGCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGAATC ATTGGTCGTAATGGTAACACATGGTACGCGAGCTCTGCAAGAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGAACA GCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGGATATGGC CGTAGTGTTGCTTATTACGTCTTTAACATCTGGGGCCCAGGGACCCTCGT CACCGTCTCGAGC.
[0498] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 54:
TABLE-US-00114 (SEQ ID NO: 254) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTAACTATGCAG TGGGCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGAATC ATTGGTCGTAATGGTAACACATGGTACGCGAGCTCTGCAAGAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGAACA GCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGGATATGGC CGTAGTGTTGCTTATTACGTCTTTAACATCTGGGGCCCAGGGACCCTCGT CACCGTCTCGAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCAC CCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTC AAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCT GACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCT ACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAA GAGAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCC CAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAA CCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGT GGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGG ACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTAC GCCAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTG GCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAG CCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCA CAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGT CAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGG AGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCC GTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGA CAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATG AGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGT AAATGA.
[0499] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 255; SEQ ID NO: 256; and SEQ ID NO: 257 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 52.
[0500] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 258; SEQ ID NO: 259; and SEQ ID NO: 260 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 54.
[0501] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 251 encoding the light chain variable sequence of SEQ ID NO: 51; the polynucleotide SEQ ID NO: 252 encoding the light chain sequence of SEQ ID NO: 52; the polynucleotide SEQ ID NO: 253 encoding the heavy chain variable sequence of SEQ ID NO: 53; the polynucleotide SEQ ID NO: 254 encoding the heavy chain sequence of SEQ ID NO: 54; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 255; SEQ ID NO: 256; and SEQ ID NO: 257) of the light chain variable sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 52; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 258; SEQ ID NO: 259; and SEQ ID NO: 260) of the heavy chain variable sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 54.
[0502] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab6, the polynucleotides encoding the full length Ab6 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 252 encoding the light chain sequence of SEQ ID NO: 52 and the polynucleotide SEQ ID NO: 254 encoding the heavy chain sequence of SEQ ID NO: 54.
[0503] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab6 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab6 or Fab fragments thereof may be produced via expression of Ab6 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab7
[0504] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 61:
TABLE-US-00115 (SEQ ID NO: 261) GCCGATGTTGTGATGACCCAGACTCCAGCCTCCGTGTCTCAACCTGTGGG AGGCACAGTCACCATCAAGTGCCAGGCCAGTGAGGACATTTATAACTTAT TGGCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTAT TCTGCATCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAAAGGCAGTGG ATCTGGGACAGAGTACACTCTCACCATCAGCGGCCTGGAGTGTGCCGATG CTGCCACTTACTACTGTCAAAACAATTATCTTGTTACTACTTATGGTGTT GCTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGT.
[0505] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 62:
TABLE-US-00116 (SEQ ID NO: 262) GCCGATGTTGTGATGACCCAGACTCCAGCCTCCGTGTCTCAACCTGTGGG AGGCACAGTCACCATCAAGTGCCAGGCCAGTGAGGACATTTATAACTTAT TGGCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTAT TCTGCATCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAAAGGCAGTGG ATCTGGGACAGAGTACACTCTCACCATCAGCGGCCTGGAGTGTGCCGATG CTGCCACTTACTACTGTCAAAACAATTATCTTGTTACTACTTATGGTGTT GCTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGTACGGTAGCGGCCCC ATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTG CCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTA CAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGT CACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGA CGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTC ACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGA GTGTTAG.
[0506] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 63:
TABLE-US-00117 (SEQ ID NO: 263) CAGGAGCAGCTGAAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACC CCTGACACTCACCTGTACAGTCTCTGGATTCTCCCTCAGTAGCTATGCAA TGATCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGATAC ATTGATACTGATACTAGCGCATACTACGCGAGCTGGGTGAAAGGCCGATT CACCATCTCCAGAACCTCGACCACGGTGGATCTCAAAATCACTAGTCCGA CAACCGAGGACACGGCCACCTATTTCTGTGCCAGATCTTATGCTGCTTAT GGTGGTTATCCTGCTACTTTTGATCCCTGGGGCCCAGGCACCCTGGTCAC CGTCTCGAGC.
[0507] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 64:
TABLE-US-00118 (SEQ ID NO: 264) CAGGAGCAGCTGAAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACC CCTGACACTCACCTGTACAGTCTCTGGATTCTCCCTCAGTAGCTATGCAA TGATCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGATAC ATTGATACTGATACTAGCGCATACTACGCGAGCTGGGTGAAAGGCCGATT CACCATCTCCAGAACCTCGACCACGGTGGATCTCAAAATCACTAGTCCGA CAACCGAGGACACGGCCACCTATTTCTGTGCCAGATCTTATGCTGCTTAT GGTGGTTATCCTGCTACTTTTGATCCCTGGGGCCCAGGCACCCTGGTCAC CGTCTCGAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCT CCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAG GACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGAC CAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACC TACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAG AGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAG CACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCC AAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGT GGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACG GCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCC AGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCT GAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCC CCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAG GTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAG CCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGT GGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTG CTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAA GAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGG CTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA TGA.
[0508] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 265; SEQ ID NO: 266; and SEQ ID NO: 267 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 61 or the light chain sequence of SEQ ID NO: 62.
[0509] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 268; SEQ ID NO: 269; and SEQ ID NO: 270 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 63 or the heavy chain sequence of SEQ ID NO: 64.
[0510] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 261 encoding the light chain variable sequence of SEQ ID NO: 61; the polynucleotide SEQ ID NO: 262 encoding the light chain sequence of SEQ ID NO: 62; the polynucleotide SEQ ID NO: 263 encoding the heavy chain variable sequence of SEQ ID NO: 63; the polynucleotide SEQ ID NO: 264 encoding the heavy chain sequence of SEQ ID NO: 64; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 265; SEQ ID NO: 266; and SEQ ID NO: 267) of the light chain variable sequence of SEQ ID NO: 61 or the light chain sequence of SEQ ID NO: 62; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 268; SEQ ID NO: 269; and SEQ ID NO: 270) of the heavy chain variable sequence of SEQ ID NO: 63 or the heavy chain sequence of SEQ ID NO: 64.
[0511] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab7, the polynucleotides encoding the full length Ab7 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 262 encoding the light chain sequence of SEQ ID NO: 62 and the polynucleotide SEQ ID NO: 264 encoding the heavy chain sequence of SEQ ID NO: 64.
[0512] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab7 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab7 or Fab fragments thereof may be produced via expression of Ab7 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab8
[0513] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 71:
TABLE-US-00119 (SEQ ID NO: 271) GACATCCAGATGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTGAGGACATTTACAACTTATTGG CCTGGTATCAGCAGAAACCAGGGAAAGTCCCTAAGCTCCTGATCTATTCT GCATCCACTCTGGCATCTGGGGTCCCATCTCGTTTCAGTGGCAGTGGATC TGGGACAGATTACACTCTCACCATCAGCAGCCTGCAGCCTGAAGATGTTG CAACTTATTACTGTCAAAACAACTATCTTGTTACTACTTATGGTGTTGCT TTCGGCGGAGGAACCAAGGTGGAAATCAAACGT.
[0514] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 72:
TABLE-US-00120 (SEQ ID NO: 272) GACATCCAGATGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTGAGGACATTTACAACTTATTGG CCTGGTATCAGCAGAAACCAGGGAAAGTCCCTAAGCTCCTGATCTATTCT GCATCCACTCTGGCATCTGGGGTCCCATCTCGTTTCAGTGGCAGTGGATC TGGGACAGATTACACTCTCACCATCAGCAGCCTGCAGCCTGAAGATGTTG CAACTTATTACTGTCAAAACAACTATCTTGTTACTACTTATGGTGTTGCT TTCGGCGGAGGAACCAAGGTGGAAATCAAACGTACGGTAGCGGCCCCATC TGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCT CTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAG TGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCAC AGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGC TGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACC CATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTG TTAG.
[0515] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 73:
TABLE-US-00121 (SEQ ID NO: 273) CAGGTACAGCTGGTGGAGTCTGGTGGAGGCGTGGTCCAGCCTGGGAGGTC CCTGAGACTCTCCTGTGCAGCTTCTGGATTCACCTTCAGTAGCTATGCAA TGATCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGATAC ATTGATACTGATACTAGCGCATACTACGCAAGCAGTGTGAAAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACGCTGTACCTGCAAATGTCTA GCCTGAGAGCCGAGGACACGGCTGTGTATTACTGTGCTAGATCTTATGCT GCTTATGGTGGTTATCCTGCTACTTTTGATCCCTGGGGCCAAGGTACCCT CGTCACCGTCTCGAGC.
[0516] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 74:
TABLE-US-00122 (SEQ ID NO: 274) CAGGTACAGCTGGTGGAGTCTGGTGGAGGCGTGGTCCAGCCTGGGAGGTC CCTGAGACTCTCCTGTGCAGCTTCTGGATTCACCTTCAGTAGCTATGCAA TGATCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGATAC ATTGATACTGATACTAGCGCATACTACGCAAGCAGTGTGAAAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACGCTGTACCTGCAAATGTCTA GCCTGAGAGCCGAGGACACGGCTGTGTATTACTGTGCTAGATCTTATGCT GCTTATGGTGGTTATCCTGCTACTTTTGATCCCTGGGGCCAAGGTACCCT CGTCACCGTCTCGAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGG CACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTG GTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGC CCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGAC TCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACC CAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGA CAAGAGAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGT GCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCA AAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGT GGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACG TGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAG TACGCCAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGA CTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCC CAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAA CCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCA GGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCG TGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCT CCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGT GGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGC ATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCG GGTAAATGA.
[0517] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 275; SEQ ID NO: 276; and SEQ ID NO: 277 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 71 or the light chain sequence of SEQ ID NO: 72.
[0518] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 278; SEQ ID NO: 279; and SEQ ID NO: 280 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 73 or the heavy chain sequence of SEQ ID NO: 74.
[0519] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 271 encoding the light chain variable sequence of SEQ ID NO: 71; the polynucleotide SEQ ID NO: 272 encoding the light chain sequence of SEQ ID NO: 72; the polynucleotide SEQ ID NO: 273 encoding the heavy chain variable sequence of SEQ ID NO: 73; the polynucleotide SEQ ID NO: 274 encoding the heavy chain sequence of SEQ ID NO: 74; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 275; SEQ ID NO: 276; and SEQ ID NO: 277) of the light chain variable sequence of SEQ ID NO: 71 or the light chain sequence of SEQ ID NO: 72; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 278; SEQ ID NO: 279; and SEQ ID NO: 280) of the heavy chain variable sequence of SEQ ID NO: 73 or the heavy chain sequence of SEQ ID NO: 74.
[0520] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab8, the polynucleotides encoding the full length Ab8 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 272 encoding the light chain sequence of SEQ ID NO: 72 and the polynucleotide SEQ ID NO: 274 encoding the heavy chain sequence of SEQ ID NO: 74.
[0521] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab8 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab8 or Fab fragments thereof may be produced via expression of Ab8 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab9
[0522] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 81:
TABLE-US-00123 (SEQ ID NO: 281) GCCTATGATATGACCCAGACTCCAGCCTCCGTGTCTGCAGCTGTGGGAGG CACAGTCACCATCAAGTGCCAGGCCAGTGAGAACATTGGTAGCTACTTAG CCTGGTATCAGCAGAAACCAGGGCAGCCTCCCGAACTCCTGATCTACAGG GCGTCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAAAGGCAGTGGATC TGGGACACAGTTCACTCTCACCATCAGCGGCGTGGAGTGTGCCGATGCTG CCACTTACTACTGTCAACAGGGTTATAATAGTGAGAATCTTGATAATGCT TTCGGCGGAGGGACCGAGGTGGTGGTCAAACGT.
[0523] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 82:
TABLE-US-00124 (SEQ ID NO: 282) GCCTATGATATGACCCAGACTCCAGCCTCCGTGTCTGCAGCTGTGGGAGG CACAGTCACCATCAAGTGCCAGGCCAGTGAGAACATTGGTAGCTACTTAG CCTGGTATCAGCAGAAACCAGGGCAGCCTCCCGAACTCCTGATCTACAGG GCGTCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAAAGGCAGTGGATC TGGGACACAGTTCACTCTCACCATCAGCGGCGTGGAGTGTGCCGATGCTG CCACTTACTACTGTCAACAGGGTTATAATAGTGAGAATCTTGATAATGCT TTCGGCGGAGGGACCGAGGTGGTGGTCAAACGTACGGTAGCGGCCCCATC TGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCT CTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAG TGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCAC AGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGC TGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACC CATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTG TTAG.
[0524] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 83:
TABLE-US-00125 (SEQ ID NO: 283) CAGTCGGTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGTCTCTGGAATCGACCTCAGTATGTATTCAATGG GCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGATGGATT AGTTATGGTGGTACTGCATATTACGCGAGCTGGGCGAAGGGCCGATTCAC CATCTCCAAAACCTCGACCACGGTGGAGCTGAAGATCACCAGTCCGACAA TCGAGGACACGGCCACCTATTTCTGTGCCAGAGAGACTCCTGTTAATTAT TATTTGGACATTTGGGGCCAGGGGACCCTCGTCACCGTCTCGAGC.
[0525] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 84:
TABLE-US-00126 (SEQ ID NO: 284) CAGTCGGTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGTCTCTGGAATCGACCTCAGTATGTATTCAATGG GCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGATGGATT AGTTATGGTGGTACTGCATATTACGCGAGCTGGGCGAAGGGCCGATTCAC CATCTCCAAAACCTCGACCACGGTGGAGCTGAAGATCACCAGTCCGACAA TCGAGGACACGGCCACCTATTTCTGTGCCAGAGAGACTCCTGTTAATTAT TATTTGGACATTTGGGGCCAGGGGACCCTCGTCACCGTCTCGAGCGCCTC CACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCT CTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAA CCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACAC CTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGG TGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTG AATCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATC TTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATG ATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGA AGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATA ATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACGTACCGTGTG GTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTA CAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCA TCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCC CCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGT CAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGC AGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGC TCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCA GGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACT ACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA.
[0526] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 285; SEQ ID NO: 286; and SEQ ID NO: 287 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 81 or the light chain sequence of SEQ ID NO: 82.
[0527] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 288; SEQ ID NO: 289; and SEQ ID NO: 290 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 83 or the heavy chain sequence of SEQ ID NO: 84.
[0528] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 281 encoding the light chain variable sequence of SEQ ID NO: 81; the polynucleotide SEQ ID NO: 282 encoding the light chain sequence of SEQ ID NO: 82; the polynucleotide SEQ ID NO: 283 encoding the heavy chain variable sequence of SEQ ID NO: 83; the polynucleotide SEQ ID NO: 284 encoding the heavy chain sequence of SEQ ID NO: 84; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 285; SEQ ID NO: 286; and SEQ ID NO: 287) of the light chain variable sequence of SEQ ID NO: 81 or the light chain sequence of SEQ ID NO: 82; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 288; SEQ ID NO: 289; and SEQ ID NO: 290) of the heavy chain variable sequence of SEQ ID NO: 83 or the heavy chain sequence of SEQ ID NO: 84.
[0529] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab9, the polynucleotides encoding the full length Ab9 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 282 encoding the light chain sequence of SEQ ID NO: 82 and the polynucleotide SEQ ID NO: 284 encoding the heavy chain sequence of SEQ ID NO: 84.
[0530] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab9 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab9 or Fab fragments thereof may be produced via expression of Ab9 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab10
[0531] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 91:
TABLE-US-00127 (SEQ ID NO: 291) GCCTATGATATGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTGAGAACATTGGTAGCTACTTAG CCTGGTATCAGCAGAAACCAGGGAAAGTCCCTAAGCTCCTGATCTATAGG GCTTCCACTCTGGCATCTGGGGTCCCATCTCGTTTCAGTGGCAGTGGATC TGGGACAGATTTCACTCTCACCATCAGCAGCCTGCAGCCTGAAGATGTTG CAACTTATTACTGTCAACAGGGTTACAATAGTGAGAATCTTGATAATGCT TTCGGCGGAGGAACCAAGGTGGAAATCAAACGT.
[0532] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 92:
TABLE-US-00128 (SEQ ID NO: 292) GCCTATGATATGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTGAGAACATTGGTAGCTACTTAG CCTGGTATCAGCAGAAACCAGGGAAAGTCCCTAAGCTCCTGATCTATAGG GCTTCCACTCTGGCATCTGGGGTCCCATCTCGTTTCAGTGGCAGTGGATC TGGGACAGATTTCACTCTCACCATCAGCAGCCTGCAGCCTGAAGATGTTG CAACTTATTACTGTCAACAGGGTTACAATAGTGAGAATCTTGATAATGCT TTCGGCGGAGGAACCAAGGTGGAAATCAAACGTACGGTAGCGGCCCCATC TGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCT CTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAG TGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCAC AGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGC TGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACC CATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTG TTAG.
[0533] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 93:
TABLE-US-00129 (SEQ ID NO: 293) CAGGTACAGCTGGTGGAGTCTGGTGGAGGCGTGGTCCAGCCTGGGAGGTC CCTGAGACTCTCCTGTGCAGCTTCTGGATTCACCTTCAGTATGTATTCAA TGGGCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGATGG ATTAGTTATGGTGGTACTGCATACTACGCTAGCAGCGCTAAGGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACGCTGTACCTGCAAATGTCTA GCCTGAGAGCCGAGGACACGGCTGTGTATTACTGTGCTAGAGAGACTCCT GTTAATTACTACTTGGACATTTGGGGCCAAGGTACCCTCGTCACCGTCTC GAGC.
[0534] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 94:
TABLE-US-00130 (SEQ ID NO: 294) CAGGTACAGCTGGTGGAGTCTGGTGGAGGCGTGGTCCAGCCTGGGAGGTC CCTGAGACTCTCCTGTGCAGCTTCTGGATTCACCTTCAGTATGTATTCAA TGGGCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGATGG ATTAGTTATGGTGGTACTGCATACTACGCTAGCAGCGCTAAGGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACGCTGTACCTGCAAATGTCTA GCCTGAGAGCCGAGGACACGGCTGTGTATTACTGTGCTAGAGAGACTCCT GTTAATTACTACTTGGACATTTGGGGCCAAGGTACCCTCGTCACCGTCTC GAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCA AGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTAC TTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGG CGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCA GCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATC TGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGA GCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTG AACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGAC ACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGT GAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGG AGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACG TACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGG CAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCG AGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTAC ACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGAC CTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGA GCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGAC TCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAG GTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGC ACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA.
[0535] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 295; SEQ ID NO: 296; and SEQ ID NO: 297 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 91 or the light chain sequence of SEQ ID NO: 92.
[0536] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 298; SEQ ID NO: 299; and SEQ ID NO: 300 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 93 or the heavy chain sequence of SEQ ID NO: 94.
[0537] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 291 encoding the light chain variable sequence of SEQ ID NO: 91; the polynucleotide SEQ ID NO: 292 encoding the light chain sequence of SEQ ID NO: 92; the polynucleotide SEQ ID NO: 293 encoding the heavy chain variable sequence of SEQ ID NO: 93; the polynucleotide SEQ ID NO: 294 encoding the heavy chain sequence of SEQ ID NO: 94; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 295; SEQ ID NO: 296; and SEQ ID NO: 297) of the light chain variable sequence of SEQ ID NO: 91 or the light chain sequence of SEQ ID NO: 92; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 298; SEQ ID NO: 299; and SEQ ID NO: 300) of the heavy chain variable sequence of SEQ ID NO: 93 or the heavy chain sequence of SEQ ID NO: 94.
[0538] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab10, the polynucleotides encoding the full length Ab10 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 292 encoding the light chain sequence of SEQ ID NO: 92 and the polynucleotide SEQ ID NO: 294 encoding the heavy chain sequence of SEQ ID NO: 94.
[0539] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab10 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab10 or Fab fragments thereof may be produced via expression of Ab10 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab11
[0540] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 101:
TABLE-US-00131 (SEQ ID NO: 301) GCATTCGAATTGACCCAGACTCCATCCTCCGTGGAGGCAGCTGTGGGAGG CACAGTCACCATCAAGTGCCAGGCCAGTCAGAACATTGTTACCAATTTAG CCTGGTATCAACAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTATGGT GCATCCACTCTGGCATCTGGGGTCTCATCGCGGTTCAAAGGCAGTGGATC TGGGACACAGTTCACTCTCACCATCAGCGACCTGGAGTGTGCCGATGCTG CCACTTATTTCTGTCAGAGCTATGATGGTTTTAATAGTGCTGGGTTCGGC GGAGGGACCGAGGTGGTGGTCAAACGT.
[0541] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 102:
TABLE-US-00132 (SEQ ID NO: 302) GCATTCGAATTGACCCAGACTCCATCCTCCGTGGAGGCAGCTGTGGGAGG CACAGTCACCATCAAGTGCCAGGCCAGTCAGAACATTGTTACCAATTTAG CCTGGTATCAACAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTATGGT GCATCCACTCTGGCATCTGGGGTCTCATCGCGGTTCAAAGGCAGTGGATC TGGGACACAGTTCACTCTCACCATCAGCGACCTGGAGTGTGCCGATGCTG CCACTTATTTCTGTCAGAGCTATGATGGTTTTAATAGTGCTGGGTTCGGC GGAGGGACCGAGGTGGTGGTCAAACGTACGGTAGCGGCCCCATCTGTCTT CATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTG TGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAG GTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCA GGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCA AAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAG GGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG.
[0542] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 103:
TABLE-US-00133 (SEQ ID NO: 303) CAGTCGCTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGCCTCTGGATTCTCCCTCAGTGGCTACGACATGA GCTGGGTCCGCCAGGCTCCAGGAAAGGGGCTGGAATACATCGGACTCATT AGTTATGATGGTAACACATACTACGCGACCTGGGCGAAAGGCCGATTCAC CATCTCCAAAACCTCGACCACGGTGGATCTGAAAATCACCAGTCCGACAA CCGAGGACACGGCCACCTATTTCTGTGCCAGAAGTCTTTATGCTGGTCCT AATGCTGGTATCGGACCGTTTAACATCTGGGGCCAGGGGACCCTCGTCAC CGTCTCGAGC.
[0543] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 104:
TABLE-US-00134 (SEQ ID NO: 304) CAGTCGCTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGCCTCTGGATTCTCCCTCAGTGGCTACGACATGA GCTGGGTCCGCCAGGCTCCAGGAAAGGGGCTGGAATACATCGGACTCATT AGTTATGATGGTAACACATACTACGCGACCTGGGCGAAAGGCCGATTCAC CATCTCCAAAACCTCGACCACGGTGGATCTGAAAATCACCAGTCCGACAA CCGAGGACACGGCCACCTATTTCTGTGCCAGAAGTCTTTATGCTGGTCCT AATGCTGGTATCGGACCGTTTAACATCTGGGGCCAGGGGACCCTCGTCAC CGTCTCGAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCT CCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAG GACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGAC CAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACC TACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAG AGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAG CACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCC AAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGT GGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACG GCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCC AGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCT GAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCC CCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAG GTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAG CCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGT GGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTG CTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAA GAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGG CTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA TGA.
[0544] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 305; SEQ ID NO: 306; and SEQ ID NO: 307 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 101 or the light chain sequence of SEQ ID NO: 102.
[0545] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 308; SEQ ID NO: 309; and SEQ ID NO: 310 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 103 or the heavy chain sequence of SEQ ID NO: 104.
[0546] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 301 encoding the light chain variable sequence of SEQ ID NO: 101; the polynucleotide SEQ ID NO: 302 encoding the light chain sequence of SEQ ID NO: 102; the polynucleotide SEQ ID NO: 303 encoding the heavy chain variable sequence of SEQ ID NO: 103; the polynucleotide SEQ ID NO: 304 encoding the heavy chain sequence of SEQ ID NO: 104; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 305; SEQ ID NO: 306; and SEQ ID NO: 307) of the light chain variable sequence of SEQ ID NO: 101 or the light chain sequence of SEQ ID NO: 102; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 308; SEQ ID NO: 309; and SEQ ID NO: 310) of the heavy chain variable sequence of SEQ ID NO: 103 or the heavy chain sequence of SEQ ID NO: 104.
[0547] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab11, the polynucleotides encoding the full length Ab11 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 302 encoding the light chain sequence of SEQ ID NO: 102 and the polynucleotide SEQ ID NO: 304 encoding the heavy chain sequence of SEQ ID NO: 104.
[0548] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab11 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab11 or Fab fragments thereof may be produced via expression of Ab11 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab12
[0549] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 111:
TABLE-US-00135 (SEQ ID NO: 311) GCATTCCAGATGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTCAGAACATTGTTACCAACTTAG CCTGGTATCAGCAGAAACCAGGGAAAGTCCCTAAGCTCCTGATCTATGGT GCATCCACTCTGGCATCTGGGGTCCCATCTCGTTTCAGTGGCAGTGGATC TGGGACAGATTTCACTCTCACCATCAGCAGCCTGCAGCCTGAAGATGTTG CAACTTATTACTGTCAGAGCTATGATGGTTTCAATAGTGCTGGTTTCGGC GGAGGAACCAAGGTGGAAATCAAACGT.
[0550] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 112:
TABLE-US-00136 (SEQ ID NO: 312) GCATTCCAGATGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTCAGAACATTGTTACCAACTTAG CCTGGTATCAGCAGAAACCAGGGAAAGTCCCTAAGCTCCTGATCTATGGT GCATCCACTCTGGCATCTGGGGTCCCATCTCGTTTCAGTGGCAGTGGATC TGGGACAGATTTCACTCTCACCATCAGCAGCCTGCAGCCTGAAGATGTTG CAACTTATTACTGTCAGAGCTATGATGGTTTCAATAGTGCTGGTTTCGGC GGAGGAACCAAGGTGGAAATCAAACGTACGGTAGCGGCCCCATCTGTCTT CATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTG TGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAG GTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCA GGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCA AAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAG GGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTAG.
[0551] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 113:
TABLE-US-00137 (SEQ ID NO: 313) CAGGTACAGCTGGTGGAGTCTGGTGGAGGCGTGGTCCAGCCTGGGAGGTC CCTGAGACTCTCCTGTGCAGCTTCTGGATTCTCCCTCAGTGGCTACGACA TGAGCTGGGTCCGTCAGGCTCCAGGCAAGGGACTGGAGTGGGTGGGACTC ATTAGTTATGATGGTAACACATACTACGCGACCTCCGCGAAAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACGCTGTACCTGCAAATGTCTA GCCTGAGAGCCGAGGACACGGCTGTGTATTACTGTGCTAGAAGTCTTTAT GCTGGTCCTAATGCTGGTATCGGACCGTTTAACATCTGGGGCCAAGGTAC CCTCGTCACCGTCTCGAGC.
[0552] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 114:
TABLE-US-00138 (SEQ ID NO: 314) CAGGTACAGCTGGTGGAGTCTGGTGGAGGCGTGGTCCAGCCTGGGAGGTC CCTGAGACTCTCCTGTGCAGCTTCTGGATTCTCCCTCAGTGGCTACGACA TGAGCTGGGTCCGTCAGGCTCCAGGCAAGGGACTGGAGTGGGTGGGACTC ATTAGTTATGATGGTAACACATACTACGCGACCTCCGCGAAAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACGCTGTACCTGCAAATGTCTA GCCTGAGAGCCGAGGACACGGCTGTGTATTACTGTGCTAGAAGTCTTTAT GCTGGTCCTAATGCTGGTATCGGACCGTTTAACATCTGGGGCCAAGGTAC CCTCGTCACCGTCTCGAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCC TGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGC CTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGG CGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAG GACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGC ACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGT GGACAAGAGAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCAC CGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCC CCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATG CGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGT ACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAG CAGTACGCCAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCA GGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCC TCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGA GAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAA CCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCG CCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACG CCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCAC CGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGA TGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCT CCGGGTAAATGA.
[0553] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 315; SEQ ID NO: 316; and SEQ ID NO: 317 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 111 or the light chain sequence of SEQ ID NO: 112.
[0554] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 318; SEQ ID NO: 319; and SEQ ID NO: 320 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 113 or the heavy chain sequence of SEQ ID NO: 114.
[0555] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 311 encoding the light chain variable sequence of SEQ ID NO: 111; the polynucleotide SEQ ID NO: 312 encoding the light chain sequence of SEQ ID NO: 112; the polynucleotide SEQ ID NO: 313 encoding the heavy chain variable sequence of SEQ ID NO: 113; the polynucleotide SEQ ID NO: 314 encoding the heavy chain sequence of SEQ ID NO: 114; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 315; SEQ ID NO: 316; and SEQ ID NO: 317) of the light chain variable sequence of SEQ ID NO: 111 or the light chain sequence of SEQ ID NO: 112; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 318; SEQ ID NO: 319; and SEQ ID NO: 320) of the heavy chain variable sequence of SEQ ID NO: 113 or the heavy chain sequence of SEQ ID NO: 114.
[0556] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab12, the polynucleotides encoding the full length Ab12 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 312 encoding the light chain sequence of SEQ ID NO: 112 and the polynucleotide SEQ ID NO: 314 encoding the heavy chain sequence of SEQ ID NO: 114.
[0557] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab12 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab12 or Fab fragments thereof may be produced via expression of Ab12 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab13
[0558] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 121:
TABLE-US-00139 (SEQ ID NO: 321) GCCGCCGTGCTGACCCAGACTCCATCTCCCGTGTCTGCAGCTGTGGGAGG CACAGTCAGCATCAGTTGCCAGTCCAGTCAGAATGTTTATAAGAACAACT ACTTATCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATC TACAAGGCATCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAAAGGCGG TGGATCTGGGACAGATTTCACTCTCACCATCAGCGACGTGCAGTGTGACG CTGCTGCCACTTACTACTGTGCAGGCGGTTATACCAGTAGTAGTGATAAT GCTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGT.
[0559] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 122:
TABLE-US-00140 (SEQ ID NO: 322) GCCGCCGTGCTGACCCAGACTCCATCTCCCGTGTCTGCAGCTGTGGGAGG CACAGTCAGCATCAGTTGCCAGTCCAGTCAGAATGTTTATAAGAACAACT ACTTATCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATC TACAAGGCATCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAAAGGCGG TGGATCTGGGACAGATTTCACTCTCACCATCAGCGACGTGCAGTGTGACG CTGCTGCCACTTACTACTGTGCAGGCGGTTATACCAGTAGTAGTGATAAT GCTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGTACGGTAGCGGCCCC ATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTG CCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTA CAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGT CACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGA CGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTC ACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGA GTGTTA.
[0560] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 123:
TABLE-US-00141 (SEQ ID NO: 323) CAGTCGGTGGAGGCGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGCCTCTGGATTCTCCCTCAGTACCTACTGGATGA GCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATGGATCGGAGACATT TATTTTAGTAATGAAGAAACAAACTACGCGAGCTGGGCGAAAGGCCGATT TACCATCTCCAAAACCTCGACCACGGTGGATCTGAATGTCATCAGTCCGA CAACCGAGGACACGGCCACCTATTTCTGTGCCAGAGGTTCTCCTGATGTT GATATTGGTATAGATATGTGGGGCCCGGGCACCCTCGTCACCGTCTCGAG C.
[0561] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 124:
TABLE-US-00142 (SEQ ID NO: 324) CAGTCGGTGGAGGCGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGCCTCTGGATTCTCCCTCAGTACCTACTGGATGA GCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATGGATCGGAGACATT TATTTTAGTAATGAAGAAACAAACTACGCGAGCTGGGCGAAAGGCCGATT TACCATCTCCAAAACCTCGACCACGGTGGATCTGAATGTCATCAGTCCGA CAACCGAGGACACGGCCACCTATTTCTGTGCCAGAGGTTCTCCTGATGTT GATATTGGTATAGATATGTGGGGCCCGGGCACCCTCGTCACCGTCTCGAG CGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGA GCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTC CCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGT GCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCA GCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGC AACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCC CAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAAC TCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACC CTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAG CCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGG TGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACGTAC CGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAA GGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGA AAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACC CTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTG CCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCA ATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCC GACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTG GCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACA ACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA.
[0562] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 325; SEQ ID NO: 326; and SEQ ID NO: 327 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 121 or the light chain sequence of SEQ ID NO: 122.
[0563] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 328; SEQ ID NO: 329; and SEQ ID NO: 330 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 123 or the heavy chain sequence of SEQ ID NO: 124.
[0564] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 321 encoding the light chain variable sequence of SEQ ID NO: 121; the polynucleotide SEQ ID NO: 322 encoding the light chain sequence of SEQ ID NO: 122; the polynucleotide SEQ ID NO: 323 encoding the heavy chain variable sequence of SEQ ID NO: 123; the polynucleotide SEQ ID NO: 324 encoding the heavy chain sequence of SEQ ID NO: 124; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 325; SEQ ID NO: 326; and SEQ ID NO: 327) of the light chain variable sequence of SEQ ID NO: 121 or the light chain sequence of SEQ ID NO: 122; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 328; SEQ ID NO: 329; and SEQ ID NO: 330) of the heavy chain variable sequence of SEQ ID NO: 123 or the heavy chain sequence of SEQ ID NO: 124.
[0565] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab13, the polynucleotides encoding the full length Ab13 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 322 encoding the light chain sequence of SEQ ID NO: 122 and the polynucleotide SEQ ID NO: 324 encoding the heavy chain sequence of SEQ ID NO: 124.
[0566] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab13 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab13 or Fab fragments thereof may be produced via expression of Ab13 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab14
[0567] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 131:
TABLE-US-00143 (SEQ ID NO: 331) GACATCCAGATGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGTCCAGTCAGAATGTTTATAAGAACAACT ACTTATCCTGGTATCAGCAGAAACCAGGGAAAGTCCCTAAGCTCCTGATC TATAAGGCATCCACTCTGGCATCTGGGGTCCCATCTCGTTTCAGTGGCAG TGGATCTGGGACAGATTTCACTCTCACCATCAGCAGCCTGCAGCCTGAAG ATGTTGCAACTTATTACTGTGCAGGCGGTTATACCAGTAGTAGTGATAAT GCTTTCGGCGGAGGAACCAAGGTGGAAATCAAACGT.
[0568] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 132:
TABLE-US-00144 (SEQ ID NO: 332) GACATCCAGATGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGTCCAGTCAGAATGTTTATAAGAACAACT ACTTATCCTGGTATCAGCAGAAACCAGGGAAAGTCCCTAAGCTCCTGATC TATAAGGCATCCACTCTGGCATCTGGGGTCCCATCTCGTTTCAGTGGCAG TGGATCTGGGACAGATTTCACTCTCACCATCAGCAGCCTGCAGCCTGAAG ATGTTGCAACTTATTACTGTGCAGGCGGTTATACCAGTAGTAGTGATAAT GCTTTCGGCGGAGGAACCAAGGTGGAAATCAAACGTACGGTAGCGGCCCC ATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTG CCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTA CAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGT CACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGA CGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTC ACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGA GTGTTAG.
[0569] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 133:
TABLE-US-00145 (SEQ ID NO: 333) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTACCTACTGGA TGAGCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGAGAC ATTTACTTTAGTAATGAAGAAACAAACTACGCGAGCAGCGCGAAAGGCCG ATTCACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGA ACAGCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGGTTCT CCTGATGTTGATATTGGTATAGATATGTGGGGCCCAGGGACCCTCGTCAC CGTCTCGAGC.
[0570] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 134:
TABLE-US-00146 (SEQ ID NO: 334) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTACCTACTGGA TGAGCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGAGAC ATTTACTTTAGTAATGAAGAAACAAACTACGCGAGCAGCGCGAAAGGCCG ATTCACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGA ACAGCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGGTTCT CCTGATGTTGATATTGGTATAGATATGTGGGGCCCAGGGACCCTCGTCAC CGTCTCGAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCT CCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAG GACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGAC CAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACC TACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAG AGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAG CACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCC AAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGT GGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACG GCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCC AGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCT GAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCC CCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAG GTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAG CCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGT GGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTG CTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAA GAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGG CTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA TGA.
[0571] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 335; SEQ ID NO: 336; and SEQ ID NO: 337 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 131 or the light chain sequence of SEQ ID NO: 132.
[0572] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 338; SEQ ID NO: 339; and SEQ ID NO: 340 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 133 or the heavy chain sequence of SEQ ID NO: 134.
[0573] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 331 encoding the light chain variable sequence of SEQ ID NO: 131; the polynucleotide SEQ ID NO: 332 encoding the light chain sequence of SEQ ID NO: 132; the polynucleotide SEQ ID NO: 333 encoding the heavy chain variable sequence of SEQ ID NO: 133; the polynucleotide SEQ ID NO: 334 encoding the heavy chain sequence of SEQ ID NO: 134; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 335; SEQ ID NO: 336; and SEQ ID NO: 337) of the light chain variable sequence of SEQ ID NO: 131 or the light chain sequence of SEQ ID NO: 132; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 338; SEQ ID NO: 339; and SEQ ID NO: 340) of the heavy chain variable sequence of SEQ ID NO: 133 or the heavy chain sequence of SEQ ID NO: 134.
[0574] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab14, the polynucleotides encoding the full length Ab14 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 332 encoding the light chain sequence of SEQ ID NO: 132 and the polynucleotide SEQ ID NO: 334 encoding the heavy chain sequence of SEQ ID NO: 134.
[0575] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab14 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab14 or Fab fragments thereof may be produced via expression of Ab14 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab15
[0576] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 141:
TABLE-US-00147 (SEQ ID NO: 341) GCAGCCGTGCTGACCCAGACACCATCGCCCGTGTCTGCAGCTGTGGGAGA CACAGTCACCATCAAGTGCCAGTCCAGTCAGAGTGTTTATAAGAACAACT ACTTATCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATC TATGATGCATCCAATCTGCCATCTGGGGTCCCATCACGGTTCAGCGGCAG TGGATCTGGGACACAGTTCACTCTCACCATCAGCGGCGTGCAGTGTGACG ATGCTGCCACTTACTACTGTCTAGGCGATTATGATGATGATACTGATAAT GGTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGT.
[0577] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 142:
TABLE-US-00148 (SEQ ID NO: 342) GCAGCCGTGCTGACCCAGACACCATCGCCCGTGTCTGCAGCTGTGGGAGA CACAGTCACCATCAAGTGCCAGTCCAGTCAGAGTGTTTATAAGAACAACT ACTTATCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATC TATGATGCATCCAATCTGCCATCTGGGGTCCCATCACGGTTCAGCGGCAG TGGATCTGGGACACAGTTCACTCTCACCATCAGCGGCGTGCAGTGTGACG ATGCTGCCACTTACTACTGTCTAGGCGATTATGATGATGATACTGATAAT GGTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGTACGGTAGCGGCCCC ATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTG CCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTA CAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGT CACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGA CGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTC ACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGA GTGTTAG.
[0578] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 143:
TABLE-US-00149 (SEQ ID NO: 343) CAGTCGGTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGTCTCTGGAATCGACCTCAGTAGCTATGCAATGA TCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGAATCATT TGGAGTGGTGGCACCTACTACGCGACCTGGGCGAAAGGCCGATTCACCAT CTCCAAAACCTCGACCACGGTGGATCTGCAAATCACCAGTCCGACAACCG AGGACGCGGCCACCTATTTCTGTGCCGCAGGTGGTGGTAGTATTTATGAT GTTTGGGGCCCGGGCACCCTGGTCACCGTCTCGAGC.
[0579] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 144:
TABLE-US-00150 (SEQ ID NO: 344) CAGTCGGTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACAGTCTCTGGAATCGACCTCAGTAGCTATGCAATGA TCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATACATCGGAATCATT TGGAGTGGTGGCACCTACTACGCGACCTGGGCGAAAGGCCGATTCACCAT CTCCAAAACCTCGACCACGGTGGATCTGCAAATCACCAGTCCGACAACCG AGGACGCGGCCACCTATTTCTGTGCCGCAGGTGGTGGTAGTATTTATGAT GTTTGGGGCCCGGGCACCCTGGTCACCGTCTCGAGCGCCTCCACCAAGGG CCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCA CAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACG GTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGC TGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGC CCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAG CCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAA AACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGT CAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGG ACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGA GGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGA CAAAGCCGCGGGAGGAGCAGTACGCCAGCACGTACCGTGTGGTCAGCGTC CTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAA GGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAG CCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGG GAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTT CTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGA ACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTC CTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGT CTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGA AGAGCCTCTCCCTGTCTCCGGGTAAATGA.
[0580] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 345; SEQ ID NO: 346; and SEQ ID NO: 347 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 141 or the light chain sequence of SEQ ID NO: 142.
[0581] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 348; SEQ ID NO: 349; and SEQ ID NO: 350 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 143 or the heavy chain sequence of SEQ ID NO: 144.
[0582] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 341 encoding the light chain variable sequence of SEQ ID NO: 141; the polynucleotide SEQ ID NO: 342 encoding the light chain sequence of SEQ ID NO: 142; the polynucleotide SEQ ID NO: 343 encoding the heavy chain variable sequence of SEQ ID NO: 143; the polynucleotide SEQ ID NO: 344 encoding the heavy chain sequence of SEQ ID NO: 144; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 345; SEQ ID NO: 346; and SEQ ID NO: 347) of the light chain variable sequence of SEQ ID NO: 141 or the light chain sequence of SEQ ID NO: 142; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 348; SEQ ID NO: 349; and SEQ ID NO: 350) of the heavy chain variable sequence of SEQ ID NO: 143 or the heavy chain sequence of SEQ ID NO: 144.
[0583] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab15, the polynucleotides encoding the full length Ab15 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 342 encoding the light chain sequence of SEQ ID NO: 142 and the polynucleotide SEQ ID NO: 344 encoding the heavy chain sequence of SEQ ID NO: 144.
[0584] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab15 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab15 or Fab fragments thereof may be produced via expression of Ab15 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab16
[0585] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 151:
TABLE-US-00151 (SEQ ID NO: 351) GCCCTGGTGATGACCCAGACTCCATCCTCCACGTCTGAACCAGTGGGAGG CACAGTCACCATCAATTGCCAGGCTAGTCAGAATATTGGTAACGACCTAT CCTGGTATCAGCAGAAACCAGGGCAGCCTCCCGAGCTCCTAATCTATTCT ACATCCAAACTGGCAACTGGGGTCCCAAAGCGGTTCAGTGGCAGCAGATC TGGGACACAGTTCACTCTCACCATCAGCGACCTGGAGTGTGACGATGCTG CCACTTACTACTGTCTAGGTGTTTATAGTTATATTAGTGATGATGGTAAT GCTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGT.
[0586] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 152:
TABLE-US-00152 (SEQ ID NO: 352) GCCCTGGTGATGACCCAGACTCCATCCTCCACGTCTGAACCAGTGGGAGG CACAGTCACCATCAATTGCCAGGCTAGTCAGAATATTGGTAACGACCTAT CCTGGTATCAGCAGAAACCAGGGCAGCCTCCCGAGCTCCTAATCTATTCT ACATCCAAACTGGCAACTGGGGTCCCAAAGCGGTTCAGTGGCAGCAGATC TGGGACACAGTTCACTCTCACCATCAGCGACCTGGAGTGTGACGATGCTG CCACTTACTACTGTCTAGGTGTTTATAGTTATATTAGTGATGATGGTAAT GCTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGTACGGTAGCGGCCCC ATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTG CCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTA CAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGT CACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGA CGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTC ACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGA GTGTTAG.
[0587] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 153:
TABLE-US-00153 (SEQ ID NO: 353) CAGTCGGTGGAGGAGTTCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACCGTCTCTGGATTCTCCCTCAATAACTATGCAATGA CCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGATCGGGATCATT GGTAGTATTGGTACCACATACTACGCGAGCTGGGCGAAAGGCCGATTCTT CATCTCCAAAACCTCGACCACTGTGGATCTGAAAATCATTAGTCCGACAA CCGAGGACACGGCCACCTATTTCTGTGCCAGAGATGCTGGCGTTACTGTT GATGGTTATGGCTACTACTTTAACATCTGGGGCCCAGGCACCCTCGTCAC CGTCTCGAGC.
[0588] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 154:
TABLE-US-00154 (SEQ ID NO: 354) CAGTCGGTGGAGGAGTTCGGGGGTCGCCTGGTCACGCCTGGGACACCCCT GACACTCACCTGCACCGTCTCTGGATTCTCCCTCAATAACTATGCAATGA CCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGATCGGGATCATT GGTAGTATTGGTACCACATACTACGCGAGCTGGGCGAAAGGCCGATTCTT CATCTCCAAAACCTCGACCACTGTGGATCTGAAAATCATTAGTCCGACAA CCGAGGACACGGCCACCTATTTCTGTGCCAGAGATGCTGGCGTTACTGTT GATGGTTATGGCTACTACTTTAACATCTGGGGCCCAGGCACCCTCGTCAC CGTCTCGAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCT CCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAG GACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGAC CAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACC TACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAG AGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAG CACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCC AAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGT GGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACG GCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCC AGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCT GAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCC CCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAG GTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAG CCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGT GGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTG CTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAA GAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGG CTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA TGA.
[0589] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 355; SEQ ID NO: 356; and SEQ ID NO: 357 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 151 or the light chain sequence of SEQ ID NO: 152.
[0590] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 358; SEQ ID NO: 359; and SEQ ID NO: 360 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 153 or the heavy chain sequence of SEQ ID NO: 154.
[0591] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 351 encoding the light chain variable sequence of SEQ ID NO: 151; the polynucleotide SEQ ID NO: 352 encoding the light chain sequence of SEQ ID NO: 152; the polynucleotide SEQ ID NO: 353 encoding the heavy chain variable sequence of SEQ ID NO: 153; the polynucleotide SEQ ID NO: 354 encoding the heavy chain sequence of SEQ ID NO: 154; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 355; SEQ ID NO: 356; and SEQ ID NO: 357) of the light chain variable sequence of SEQ ID NO: 151 or the light chain sequence of SEQ ID NO: 152; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 358; SEQ ID NO: 359; and SEQ ID NO: 360) of the heavy chain variable sequence of SEQ ID NO: 153 or the heavy chain sequence of SEQ ID NO: 154.
[0592] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab16, the polynucleotides encoding the full length Ab16 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 352 encoding the light chain sequence of SEQ ID NO: 152 and the polynucleotide SEQ ID NO: 354 encoding the heavy chain sequence of SEQ ID NO: 154.
[0593] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab16 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab16 or Fab fragments thereof may be produced via expression of Ab16 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab17
[0594] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 161:
TABLE-US-00155 (SEQ ID NO: 361) GCCATCGAAATGACCCAGACTCCATTCTCCGTGTCTGCAGCTGTGGGAGG CACAGTCACCATCAAGTGCCAGGCCAGTCAGACCATTAGCAACTACTTAG CCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTATGGT GCATCCAATCTGGAATCTGGGGTCCCATCGCGGTTCAAAGGCAGTGGATC TGGGACACAGTTCACTCTCACCATCAGCGACCTGGAGTGTGACGATGCTG CCACTTACTACTGTCAACAGGGTTATACTATCAGTAATGTTGATAACAAT GTTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGT.
[0595] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 162:
TABLE-US-00156 (SEQ ID NO: 362) GCCATCGAAATGACCCAGACTCCATTCTCCGTGTCTGCAGCTGTGGGAGG CACAGTCACCATCAAGTGCCAGGCCAGTCAGACCATTAGCAACTACTTAG CCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATCTATGGT GCATCCAATCTGGAATCTGGGGTCCCATCGCGGTTCAAAGGCAGTGGATC TGGGACACAGTTCACTCTCACCATCAGCGACCTGGAGTGTGACGATGCTG CCACTTACTACTGTCAACAGGGTTATACTATCAGTAATGTTGATAACAAT GTTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGTACGGTAGCGGCCCC ATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTG CCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTA CAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGT CACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGA CGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTC ACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGA GTGTTAG.
[0596] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 163:
TABLE-US-00157 (SEQ ID NO: 363) CAGTCGCTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGGGATCCCT GACACTCACCTGCGCAGCCTCTGGATTCTCCCTCACTGGCTACAACTTGG TCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGATCGGATTCATT AGTTATGGTGATACCACATACTACGCGAGCTGGGCGAAAGGCCGATTCAC CATCTCCAAAACCTCGACCACGGTGACTCTGACGATCACCGATCTGCAAC CTTCAGACACGGGCACCTATTTCTGTGCCAGAGAGACTGCTAATACTTAT GATTATGGCATCTGGGGCCCAGGCACCCTCGTCACCGTCTCGAGC.
[0597] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 164:
TABLE-US-00158 (SEQ ID NO: 364) CAGTCGCTGGAGGAGTCCGGGGGTCGCCTGGTCACGCCTGGGGGATCCCT GACACTCACCTGCGCAGCCTCTGGATTCTCCCTCACTGGCTACAACTTGG TCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAGTGGATCGGATTCATT AGTTATGGTGATACCACATACTACGCGAGCTGGGCGAAAGGCCGATTCAC CATCTCCAAAACCTCGACCACGGTGACTCTGACGATCACCGATCTGCAAC CTTCAGACACGGGCACCTATTTCTGTGCCAGAGAGACTGCTAATACTTAT GATTATGGCATCTGGGGCCCAGGCACCCTCGTCACCGTCTCGAGCGCCTC CACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCT CTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAA CCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACAC CTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGG TGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTG AATCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATC TTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGG GGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATG ATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGA AGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATA ATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACGTACCGTGTG GTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTA CAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCA TCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCC CCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGT CAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGC AGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGC TCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCA GGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACT ACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA.
[0598] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 365; SEQ ID NO: 366; and SEQ ID NO: 367 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 161 or the light chain sequence of SEQ ID NO: 162.
[0599] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 368; SEQ ID NO: 369; and SEQ ID NO: 370 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 163 or the heavy chain sequence of SEQ ID NO: 164.
[0600] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 361 encoding the light chain variable sequence of SEQ ID NO: 161; the polynucleotide SEQ ID NO: 362 encoding the light chain sequence of SEQ ID NO: 162; the polynucleotide SEQ ID NO: 363 encoding the heavy chain variable sequence of SEQ ID NO: 163; the polynucleotide SEQ ID NO: 364 encoding the heavy chain sequence of SEQ ID NO: 164; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 365; SEQ ID NO: 366; and SEQ ID NO: 367) of the light chain variable sequence of SEQ ID NO: 161 or the light chain sequence of SEQ ID NO: 162; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 368; SEQ ID NO: 369; and SEQ ID NO: 370) of the heavy chain variable sequence of SEQ ID NO: 163 or the heavy chain sequence of SEQ ID NO: 164.
[0601] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab17, the polynucleotides encoding the full length Ab17 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 362 encoding the light chain sequence of SEQ ID NO: 162 and the polynucleotide SEQ ID NO: 364 encoding the heavy chain sequence of SEQ ID NO: 164.
[0602] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab17 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab17 or Fab fragments thereof may be produced via expression of Ab17 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab18
[0603] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 171:
TABLE-US-00159 (SEQ ID NO: 371) GACATCCAGATGACCCAGTCTCCTTCCACCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGTCAGGCTAGTCAGACCATTAGCAACTACTTAG CCTGGTATCAGCAGAAACCAGGAAAAGCCCCTAAGCTCCTGATCTATGGT GCATCCAATCTGGAATCTGGAGTCCCATCAAGGTTCAGCGGCAGTGGATC TGGAACAGAATTCACTCTCACCATCAGCAGCCTGCAGCCTGATGATTTTG CAACTTACTACTGTCAACAGGGTTATACTATCAGTAATGTTGATAACAAT GTTTTCGGCGGAGGAACCAAGGTGGAAATCAAACGT.
[0604] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 172:
TABLE-US-00160 (SEQ ID NO: 372) GACATCCAGATGACCCAGTCTCCTTCCACCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGTCAGGCTAGTCAGACCATTAGCAACTACTTAG CCTGGTATCAGCAGAAACCAGGAAAAGCCCCTAAGCTCCTGATCTATGGT GCATCCAATCTGGAATCTGGAGTCCCATCAAGGTTCAGCGGCAGTGGATC TGGAACAGAATTCACTCTCACCATCAGCAGCCTGCAGCCTGATGATTTTG CAACTTACTACTGTCAACAGGGTTATACTATCAGTAATGTTGATAACAAT GTTTTCGGCGGAGGAACCAAGGTGGAAATCAAACGTACGGTAGCGGCCCC ATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTG CCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTA CAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGT CACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGA CGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTC ACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGA GTGTTAG.
[0605] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 173:
TABLE-US-00161 (SEQ ID NO: 373) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTGGCTACAACT TGGTCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGATTC ATTAGTTATGGTGATACCACATACTACGCTAGCTCTGCTAAAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGAACA GCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGAGACTGCT AATACTTATGATTATGGCATCTGGGGCCAAGGGACCCTCGTCACCGTCTC GAGC.
[0606] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 174:
TABLE-US-00162 (SEQ ID NO: 374) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTGGCTACAACT TGGTCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGATTC ATTAGTTATGGTGATACCACATACTACGCTAGCTCTGCTAAAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGAACA GCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGAGACTGCT AATACTTATGATTATGGCATCTGGGGCCAAGGGACCCTCGTCACCGTCTC GAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCA AGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTAC TTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGG CGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCA GCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATC TGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGA GCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTG AACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGAC ACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGT GAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGG AGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACG TACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGG CAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCG AGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTAC ACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGAC CTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGA GCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGAC TCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAG GTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGC ACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA.
[0607] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 375; SEQ ID NO: 376; and SEQ ID NO: 377 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 171 or the light chain sequence of SEQ ID NO: 172.
[0608] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 378; SEQ ID NO: 379; and SEQ ID NO: 380 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 173 or the heavy chain sequence of SEQ ID NO: 174.
[0609] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 371 encoding the light chain variable sequence of SEQ ID NO: 171; the polynucleotide SEQ ID NO: 372 encoding the light chain sequence of SEQ ID NO: 172; the polynucleotide SEQ ID NO: 373 encoding the heavy chain variable sequence of SEQ ID NO: 173; the polynucleotide SEQ ID NO: 374 encoding the heavy chain sequence of SEQ ID NO: 174; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 375; SEQ ID NO: 376; and SEQ ID NO: 377) of the light chain variable sequence of SEQ ID NO: 171 or the light chain sequence of SEQ ID NO: 172; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 378; SEQ ID NO: 379; and SEQ ID NO: 380) of the heavy chain variable sequence of SEQ ID NO: 173 or the heavy chain sequence of SEQ ID NO: 174.
[0610] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab18, the polynucleotides encoding the full length Ab18 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 372 encoding the light chain sequence of SEQ ID NO: 172 and the polynucleotide SEQ ID NO: 374 encoding the heavy chain sequence of SEQ ID NO: 174.
[0611] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab18 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab18 or Fab fragments thereof may be produced via expression of Ab18 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab19
[0612] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 181:
TABLE-US-00163 (SEQ ID NO: 381) GCCGCCGTGCTGACCCAGACTCCATCTCCCGTGTCTGCAGCTGTGGGAGG CACAGTCAGCATCAGTTGCCAGTCCAGTCAGAATGTTTATAAGAACAACT ATTTATCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATC TACAAGGCTTCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAAAGGCAG TGGATCTGGGACAGATTTCACTCTCACCATCAGCGACGTGCAGTGTGACG CTGCTGCCACTTACTACTGTGCAGGCGGTTATAGTAGTAGTAGTGATAAT GCTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGT.
[0613] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 182:
TABLE-US-00164 (SEQ ID NO: 382) GCCGCCGTGCTGACCCAGACTCCATCTCCCGTGTCTGCAGCTGTGGGAGG CACAGTCAGCATCAGTTGCCAGTCCAGTCAGAATGTTTATAAGAACAACT ATTTATCCTGGTATCAGCAGAAACCAGGGCAGCCTCCCAAGCTCCTGATC TACAAGGCTTCCACTCTGGCATCTGGGGTCCCATCGCGGTTCAAAGGCAG TGGATCTGGGACAGATTTCACTCTCACCATCAGCGACGTGCAGTGTGACG CTGCTGCCACTTACTACTGTGCAGGCGGTTATAGTAGTAGTAGTGATAAT GCTTTCGGCGGAGGGACCGAGGTGGTGGTCAAACGTACGGTAGCGGCCCC ATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTG CCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTA CAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGT CACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGA CGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTC ACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGA GTGTTAG.
[0614] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 183:
TABLE-US-00165 (SEQ ID NO: 383) CAGTCGGTGGAGGCGTCCGGGGGTCGTCTGGTCATGCCTGGAGGATCCCT GACACTCACCTGCACAGCCTCTGGATTCTCCCTCAGTACCTACTGGATGT CCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATGGATCGGAGACATT TATTTTAGTAATGAGGAAACAAACTACGCGACCTGGGCGAAAGGCCGATT TACCATCTCCAAAACCTCGACCACGGTGGATCTGAATGTCATCAGTCCGA CAACCGAGGACACGGCCACCTATTTCTGTGCAAGAGGTTCTCCTGATGTT GAGATTGCTATAGATATGTGGGGCCAGGGCACCCTCGTCACCGTCTCGAG C.
[0615] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 184:
TABLE-US-00166 (SEQ ID NO: 384) CAGTCGGTGGAGGCGTCCGGGGGTCGTCTGGTCATGCCTGGAGGATCCCT GACACTCACCTGCACAGCCTCTGGATTCTCCCTCAGTACCTACTGGATGT CCTGGGTCCGCCAGGCTCCAGGGAAGGGGCTGGAATGGATCGGAGACATT TATTTTAGTAATGAGGAAACAAACTACGCGACCTGGGCGAAAGGCCGATT TACCATCTCCAAAACCTCGACCACGGTGGATCTGAATGTCATCAGTCCGA CAACCGAGGACACGGCCACCTATTTCTGTGCAAGAGGTTCTCCTGATGTT GAGATTGCTATAGATATGTGGGGCCAGGGCACCCTCGTCACCGTCTCGAG CGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGA GCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTC CCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGT GCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCA GCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACATCTGC AACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCC CAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAAC TCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACC CTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAG CCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGG TGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCCAGCACGTAC CGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAA GGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGA AAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACC CTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTG CCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCA ATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCC GACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTG GCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACA ACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA.
[0616] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 385; SEQ ID NO: 386; and SEQ ID NO: 387 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 181 or the light chain sequence of SEQ ID NO: 182.
[0617] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 388; SEQ ID NO: 389; and SEQ ID NO: 390 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 183 or the heavy chain sequence of SEQ ID NO: 184.
[0618] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 381 encoding the light chain variable sequence of SEQ ID NO: 181; the polynucleotide SEQ ID NO: 382 encoding the light chain sequence of SEQ ID NO: 182; the polynucleotide SEQ ID NO: 383 encoding the heavy chain variable sequence of SEQ ID NO: 183; the polynucleotide SEQ ID NO: 384 encoding the heavy chain sequence of SEQ ID NO: 184; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 385; SEQ ID NO: 386; and SEQ ID NO: 387) of the light chain variable sequence of SEQ ID NO: 181 or the light chain sequence of SEQ ID NO: 182; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 388; SEQ ID NO: 389; and SEQ ID NO: 390) of the heavy chain variable sequence of SEQ ID NO: 183 or the heavy chain sequence of SEQ ID NO: 184.
[0619] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab19, the polynucleotides encoding the full length Ab19 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 382 encoding the light chain sequence of SEQ ID NO: 182 and the polynucleotide SEQ ID NO: 384 encoding the heavy chain sequence of SEQ ID NO: 184.
[0620] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab19 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab19 or Fab fragments thereof may be produced via expression of Ab19 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab20
[0621] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 191:
TABLE-US-00167 (SEQ ID NO: 391) GACATCCAGATGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGTCCAGTCAGAATGTTTATAAGAACAACT ACTTATCCTGGTATCAGCAGAAACCAGGGAAAGTCCCTAAGCTCCTGATC TATAAGGCATCCACTCTGGCATCTGGGGTCCCATCTCGTTTCAGTGGCAG TGGATCTGGGACAGATTTCACTCTCACCATCAGCAGCCTGCAGCCTGAAG ATGTTGCAACTTATTACTGTGCAGGCGGTTATACCAGTAGTAGTGATAAT GCTTTCGGCGGAGGAACCAAGGTGGAAATCAAACGT.
[0622] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 192:
TABLE-US-00168 (SEQ ID NO: 392) GACATCCAGATGACCCAGTCTCCATCCTCCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGTCCAGTCAGAATGTTTATAAGAACAACT ACTTATCCTGGTATCAGCAGAAACCAGGGAAAGTCCCTAAGCTCCTGATC TATAAGGCATCCACTCTGGCATCTGGGGTCCCATCTCGTTTCAGTGGCAG TGGATCTGGGACAGATTTCACTCTCACCATCAGCAGCCTGCAGCCTGAAG ATGTTGCAACTTATTACTGTGCAGGCGGTTATACCAGTAGTAGTGATAAT GCTTTCGGCGGAGGAACCAAGGTGGAAATCAAACGTACGGTAGCGGCCCC ATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTG CCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTA CAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGT CACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGA CGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTC ACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGA GTGTTAG.
[0623] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 193:
TABLE-US-00169 (SEQ ID NO: 393) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTACCTACTGGA TGAGCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGAGAC ATTTACTTTAGTAATGAAGAAACAAACTACGCGACCAGCGCGAAAGGCCG ATTCACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGA ACAGCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGGTTCT CCTGATGTTGAGATTGCTATAGATATGTGGGGCCAAGGGACCCTCGTCAC CGTCTCGAGC.
[0624] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 194:
TABLE-US-00170 (SEQ ID NO: 394) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTACCTACTGGA TGAGCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGAGAC ATTTACTTTAGTAATGAAGAAACAAACTACGCGACCAGCGCGAAAGGCCG ATTCACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGA ACAGCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGGTTCT CCTGATGTTGAGATTGCTATAGATATGTGGGGCCAAGGGACCCTCGTCAC CGTCTCGAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCT CCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAG GACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGAC CAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACT CCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACC TACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAG AGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAG CACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCC AAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGT GGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACG GCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACGCC AGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCT GAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCC CCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAG GTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAG CCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGT GGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTG CTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAA GAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGG CTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA TGA.
[0625] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 395; SEQ ID NO: 396; and SEQ ID NO: 397 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 191 or the light chain sequence of SEQ ID NO: 192.
[0626] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 398; SEQ ID NO: 399; and SEQ ID NO: 400 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 193 or the heavy chain sequence of SEQ ID NO: 194.
[0627] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 391 encoding the light chain variable sequence of SEQ ID NO: 191; the polynucleotide SEQ ID NO: 392 encoding the light chain sequence of SEQ ID NO: 192; the polynucleotide SEQ ID NO: 393 encoding the heavy chain variable sequence of SEQ ID NO: 193; the polynucleotide SEQ ID NO: 394 encoding the heavy chain sequence of SEQ ID NO: 194; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 395; SEQ ID NO: 396; and SEQ ID NO: 397) of the light chain variable sequence of SEQ ID NO: 191 or the light chain sequence of SEQ ID NO: 192; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 398; SEQ ID NO: 399; and SEQ ID NO: 400) of the heavy chain variable sequence of SEQ ID NO: 193 or the heavy chain sequence of SEQ ID NO: 194.
[0628] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab20, the polynucleotides encoding the full length Ab20 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 392 encoding the light chain sequence of SEQ ID NO: 192 and the polynucleotide SEQ ID NO: 394 encoding the heavy chain sequence of SEQ ID NO: 194.
[0629] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab20 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab20 or Fab fragments thereof may be produced via expression of Ab20 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Ab21
[0630] The invention is further directed to polynucleotides encoding antibody polypeptides having binding specificity to NGF. In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable light chain polypeptide sequence of SEQ ID NO: 51:
TABLE-US-00171 (SEQ ID NO: 251) GACATCCAGATGACCCAGTCTCCTTCCACCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTCAGAGCATTTACAGCAATCTTG CCTGGTATCAGCAGAAACCAGGAAAAGCCCCTAAGCTCCTGATCTATGAT GCATCCACTCTGGAATCTGGAGTCCCATCAAGGTTCAGCGGCAGTGGATC TGGGACAGAGTACACTCTCACCATCAGCAGCCTGCAGCCTGATGATTTTG CAACTTACTACTGCCAACAGGGTTTTACTGTTAGTGATATTGATAATGCT TTCGGCGGAGGAACCAAGGTGGAAATCAAACGT.
[0631] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 401:
TABLE-US-00172 (SEQ ID NO: 403) GACATCCAGATGACCCAGTCTCCTTCCACCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTCAGAGCATTTACAGCAATCTTG CCTGGTATCAGCAGAAACCAGGAAAAGCCCCTAAGCTCCTGATCTATGAT GCATCCACTCTGGAATCTGGAGTCCCATCAAGGTTCAGCGGCAGTGGATC TGGGACAGAGTACACTCTCACCATCAGCAGCCTGCAGCCTGATGATTTTG CAACTTACTACTGCCAACAGGGTTTTACTGTTAGTGATATTGATAATGCT TTCGGCGGAGGAACCAAGGTGGAAATCAAACGTACGGTAGCGGCCCCATC TGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCT CTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAG TGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCAC AGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGC TGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACC CATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTG TTAG.
[0632] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the variable heavy chain polypeptide sequence of SEQ ID NO: 53:
TABLE-US-00173 (SEQ ID NO: 253) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTAACTATGCAG TGGGCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGAATC ATTGGTCGTAATGGTAACACATGGTACGCGAGCTCTGCAAGAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGAACA GCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGGATATGGC CGTAGTGTTGCTTATTACGTCTTTAACATCTGGGGCCCAGGGACCCTCGT CACCGTCTCGAGC.
[0633] In one embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 402:
TABLE-US-00174 (SEQ ID NO: 404) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTAACTATGCAG TGGGCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGAATC ATTGGTCGTAATGGTAACACATGGTACGCGAGCTCTGCAAGAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGAACA GCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGGATATGGC CGTAGTGTTGCTTACTACGTCTTTAACATCTGGGGCCCAGGGACCCTCGT CACCGTCTCGAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCAC CCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTC AAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCT GACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCT ACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACGC GAGAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCC CAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAA CCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGT GGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGG ACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTAC GCCAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTG GCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAG CCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCA CAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGT CAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGG AGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCC GTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGA CAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATG AGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGT AAATGA.
[0634] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 255; SEQ ID NO: 256; and SEQ ID NO: 257 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 401.
[0635] In a further embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one or more of the polynucleotide sequences of SEQ ID NO: 258; SEQ ID NO: 259; and SEQ ID NO: 260 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 402.
[0636] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 251 encoding the light chain variable sequence of SEQ ID NO: 51; the polynucleotide SEQ ID NO: 403 encoding the light chain sequence of SEQ ID NO: 401; the polynucleotide SEQ ID NO: 253 encoding the heavy chain variable sequence of SEQ ID NO: 53; the polynucleotide SEQ ID NO: 404 encoding the heavy chain sequence of SEQ ID NO: 402; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 255; SEQ ID NO: 256; and SEQ ID NO: 257) of the light chain variable sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 401; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 258; SEQ ID NO: 259; and SEQ ID NO: 260) of the heavy chain variable sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 402.
[0637] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody Ab21, the polynucleotides encoding the full length Ab21 antibody comprise, or alternatively consist of, the polynucleotide SEQ ID NO: 403 encoding the light chain sequence of SEQ ID NO: 401 and the polynucleotide SEQ ID NO: 404 encoding the heavy chain sequence of SEQ ID NO: 402.
[0638] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced by enzymatic digestion (e.g., papain) of Ab21 following expression of the full-length polynucleotides in a suitable host. In another embodiment of the invention, anti-NGF antibodies such as Ab21 or Fab fragments thereof may be produced via expression of Ab21 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
Antibody Fragment Fab2
[0639] The invention is further directed to polynucleotides encoding antibody fragment polypeptides having binding specificity to NGF. In one embodiment of the invention, Fab polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the light chain polypeptide sequence of SEQ ID NO: 407:
TABLE-US-00175 (SEQ ID NO: 409) GACATCCAGATGACCCAGTCTCCTTCCACCCTGTCTGCATCTGTAGGAGA CAGAGTCACCATCACTTGCCAGGCCAGTCAGAGCATTTACAGCAATCTTG CCTGGTATCAGCAGAAACCAGGAAAAGCCCCTAAGCTCCTGATCTATGAT GCATCCACTCTGGAATCTGGAGTCCCATCAAGGTTCAGCGGCAGTGGATC TGGGACAGAGTACACTCTCACCATCAGCAGCCTGCAGCCTGATGATTTTG CAACTTACTACTGCCAACAGGGTTTTACTGTTAGTGATATTGATAATGCT TTCGGCGGAGGAACCAAGGTGGAAATCAAACGTACGGTAGCGGCCCCATC TGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCT CTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAG TGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCAC AGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGC TGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACC CATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTG TTAG.
[0640] In another embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, the following polynucleotide sequence encoding the heavy chain polypeptide sequence of SEQ ID NO: 408:
TABLE-US-00176 (SEQ ID NO: 410) GAGGTGCAGCTGGTGGAGTCTGGGGGAGGCTTGGTCCAGCCTGGGGGGTC CCTGAGACTCTCCTGTGCAGCCTCTGGATTCACCGTCAGTAACTATGCAG TGGGCTGGGTCCGTCAGGCTCCAGGGAAGGGGCTGGAGTGGGTCGGAATC ATTGGTCGTAATGGTAACACATGGTACGCGAGCTCTGCAAGAGGCCGATT CACCATCTCCAGAGACAATTCCAAGAACACCCTGTATCTTCAAATGAACA GCCTGAGAGCTGAGGACACTGCTGTGTATTACTGTGCTAGAGGATATGGC CGTAGTGTTGCTTACTACGTCTTTAACATCTGGGGCCCAGGGACCCTCGT CACCGTCTCGAGCGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCAC CCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTC AAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCT GACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCT ACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAG ACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACGC GAGAGTTGAGCCCAAATCTTGTGACAAAACTCACTAG.
[0641] In a further embodiment of the invention, polynucleotides encoding Fab antibody fragments having binding specificity to NGF comprise one or more of the polynucleotide sequences of SEQ ID NO: 255; SEQ ID NO: 256; and SEQ ID NO: 257 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the light chain variable sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 409.
[0642] In a further embodiment of the invention, polynucleotides encoding Fab antibody fragments having binding specificity to NGF comprise one or more of the polynucleotide sequences of SEQ ID NO: 258; SEQ ID NO: 259; and SEQ ID NO: 260 which correspond to polynucleotides encoding the complementarity-determining regions (CDRs, or hypervariable regions) of the heavy chain variable sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 410.
[0643] The invention also contemplates polynucleotide sequences including one or more of the polynucleotide sequences encoding antibody fragments described herein. In one embodiment of the invention, polynucleotides encoding antibody fragments having binding specificity to NGF comprise, or alternatively consist of, one, two, three or more, including all of the following polynucleotides encoding antibody fragments: the polynucleotide SEQ ID NO: 251 encoding the light chain variable sequence of SEQ ID NO: 51; the polynucleotide SEQ ID NO: 409 encoding the light chain sequence of SEQ ID NO: 407; the polynucleotide SEQ ID NO: 253 encoding the heavy chain variable sequence of SEQ ID NO: 53; the polynucleotide SEQ ID NO: 410 encoding the heavy chain sequence of SEQ ID NO: 408; polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 255; SEQ ID NO: 256; and SEQ ID NO: 257) of the light chain variable sequence of SEQ ID NO: 51 or the light chain sequence of SEQ ID NO: 407; and polynucleotides encoding the complementarity-determining regions (SEQ ID NO: 258; SEQ ID NO: 259; and SEQ ID NO: 260) of the heavy chain variable sequence of SEQ ID NO: 53 or the heavy chain sequence of SEQ ID NO: 408.
[0644] In a preferred embodiment of the invention, polynucleotides of the invention comprise, or alternatively consist of, polynucleotides encoding Fab (fragment antigen binding) fragments having binding specificity for NGF. With respect to antibody fragment Fab2, the polynucleotides encoding the Fab fragment include the polynucleotide SEQ ID NO: 409 encoding the light chain sequence of SEQ ID NO: 407 and the polynucleotide SEQ ID NO: 410 encoding the heavy chain sequence of SEQ ID NO: 408.
[0645] Another embodiment of the invention contemplates these polynucleotides incorporated into an expression vector for expression in mammalian cells such as CHO, NSO, HEK-293, or in fungal, insect, or microbial systems such as yeast cells such as the yeast Pichia. Suitable Pichia species include, but are not limited to, Pichia pastoris. In one embodiment of the invention described herein (infra), Fab fragments may be produced via expression of Fab2 polynucleotides in mammalian cells such as CHO, NSO or HEK 293 cells, fungal, insect, or microbial systems such as yeast cells (for example diploid yeast such as diploid Pichia) and other yeast strains. Suitable Pichia species include, but are not limited to, Pichia pastoris.
[0646] In one embodiment, the invention is directed to an isolated polynucleotide comprising a polynucleotide encoding an anti-NGF V.sub.H antibody amino acid sequence selected from SEQ ID NO: 3, 13, 23, 33, 43, 53, 63, 73, 83, 93, 103, 113, 123, 133, 143, 153, 163, 173, 183, 193, or 402, or encoding a variant thereof wherein at least one framework residue (FR residue) has been substituted with an amino acid present at the corresponding position in a rabbit anti-NGF antibody V.sub.H polypeptide or a conservative amino acid substitution.
[0647] In another embodiment, the invention is directed to an isolated polynucleotide comprising the polynucleotide sequence encoding an anti-NGF V.sub.L antibody amino acid sequence of 1, 11, 21, 31, 41, 51, 61, 71, 81, 91, 101, 111, 121, 131, 141, 151, 161, 171, 181, 191, or 401, or encoding a variant thereof wherein at least one framework residue (FR residue) has been substituted with an amino acid present at the corresponding position in a rabbit anti-NGF antibody V.sub.L polypeptide or a conservative amino acid substitution.
[0648] In yet another embodiment, the invention is directed to one or more heterologous polynucleotides comprising a sequence encoding the polypeptides contained in SEQ ID NO:1 and SEQ ID NO:3; SEQ ID NO:11 and SEQ ID NO:13; SEQ ID NO:21 and SEQ ID NO:23; SEQ ID NO:31 and SEQ ID NO:33; SEQ ID NO:41 and SEQ ID NO:43; SEQ ID NO:51 and SEQ ID NO:53, SEQ ID NO:61 and SEQ ID NO:63; SEQ ID NO:71 and SEQ ID NO:73; SEQ ID NO:81 and SEQ ID NO:83; SEQ ID NO:91 and SEQ ID NO:93; SEQ ID NO:101 and SEQ ID NO:103; SEQ ID NO:111 and SEQ ID NO:113; SEQ ID NO:121 and SEQ ID NO:123; SEQ ID NO:131 and SEQ ID NO:133; SEQ ID NO:141 and SEQ ID NO:143; SEQ ID NO:151 and SEQ ID NO:153; SEQ ID NO:161 and SEQ ID NO:163; SEQ ID NO:171 and SEQ ID NO:173; SEQ ID NO:181 and SEQ ID NO:183; SEQ ID NO:191 and SEQ ID NO:193; or SEQ ID NO:401 and SEQ ID NO:403.
[0649] In another embodiment, the invention is directed to an isolated polynucleotide that expresses a polypeptide containing at least one CDR polypeptide derived from an anti-NGF antibody wherein said expressed polypeptide alone specifically binds NGF or specifically binds NGF when expressed in association with another polynucleotide sequence that expresses a polypeptide containing at least one CDR polypeptide derived from an anti-NGF antibody wherein said at least one CDR is selected from those contained in the V.sub.L or V.sub.H polypeptides of SEQ ID NO: 1, 3, 11, 13, 21, 23, 31, 33, 41, 43, 51, 53, 61, 63, 71, 73, 81, 83, 91, 93, 101, 103, 111, 113, 121, 123, 131, 133, 141, 143, 151, 153, 161, 163, 171, 173, 181, 183, 191, 193, 401 or SEQ ID NO:403.
[0650] Host cells and vectors comprising said polynucleotides are also contemplated.
[0651] The invention further contemplates vectors comprising the polynucleotide sequences encoding the variable heavy and light chain polypeptide sequences, as well as the individual complementarity-determining regions (CDRs, or hypervariable regions), as set forth herein, as well as host cells comprising said vector sequences. In one embodiment of the invention, the host cell is a yeast cell. In another embodiment of the invention, the yeast host cell belongs to the genus Pichia.
Anti-NGF Activity
[0652] The anti-NGF activity of the anti-NGF antibodies of the present invention, and fragments thereof having binding specificity to NGF, may also be described by their strength of binding or their affinity for NGF. In one embodiment of the invention, the anti-NGF antibodies of the present invention, and fragments thereof having binding specificity to NGF, bind to NGF with a dissociation constant (K.sub.D) of less than or equal to 5.times.10.sup.-7 M, 10.sup.-7 M, 5.times.10.sup.-8 M, 10.sup.-8 M, 5.times.10.sup.-9 M, 10.sup.-9 M, 5.times.10.sup.-10 M, 10.sup.-10 M, 5.times.10.sup.-11 M, 10.sup.-11 M, 5.times.10.sup.-12 M, 10.sup.-12 M, 5.times.10.sup.-13 M, or 10.sup.-13 M. Preferably, the anti-NGF antibodies and fragments thereof bind NGF with a dissociation constant of less than or equal to 5.times.10.sup.-10 M. In another embodiment of the invention, the anti-NGF antibodies of the present invention, and fragments thereof having binding specificity to NGF, bind to a linear or conformational NGF epitope.
[0653] In another embodiment of the invention, the anti-NGF activity of the anti-NGF antibodies of the present invention, and fragments thereof having binding specificity to NGF, bind to NGF with an off-rate of less than or equal to 10.sup.-4 S.sup.-1, 5.times.10.sup.-5 S.sup.-1, 10.sup.-5 S.sup.-1, 5.times.10.sup.-6 S.sup.-1, 10.sup.-6 S.sup.-1, 5.times.10.sup.-7 S.sup.-1, or 10.sup.-7 S.sup.-1.
[0654] In a further embodiment of the invention, the anti-NGF activity of the anti-NGF antibodies of the present invention, and fragments thereof having binding specificity to NGF, exhibit anti-NGF activity by preventing, ameliorating or reducing the symptoms of, or alternatively treating, diseases and disorders associated with NGF. Non-limiting examples of diseases and disorders associated with NGF are set forth infra.
B-Cell Screening and Isolation
[0655] In one embodiment, the present invention contemplates the preparation and isolation of a clonal population of antigen-specific B cells that may be used for isolating at least one NGF antigen-specific cell, which can be used to produce a monoclonal antibody against NGF, which is specific to a desired NGF antigen, or a nucleic acid sequence corresponding to such an antibody. Methods of preparing and isolating said clonal population of antigen-specific B cells are taught, for example, in U.S. patent publication no. US 2007/0269868 to Carvalho-Jensen et al., the disclosure of which is herein incorporated by reference in its entirety. Methods of preparing and isolating said clonal population of antigen-specific B cells are also taught herein in the examples. Methods of "enriching" a cell population by size or density are known in the art. See, e.g., U.S. Pat. No. 5,627,052. These steps can be used in addition to enriching the cell population by antigen-specificity.
Methods of Humanizing Antibodies
[0656] In another embodiment, the present invention contemplates methods for humanizing antibody heavy and light chains. Methods for humanizing antibody heavy and light chains which may be applied to anti-NGF antibodies are taught, for example, in U.S. patent application publication no. US 2009/0022659 to Olson et al., and in U.S. patent application publication no. US 2009/0028784 to Garcia-Martinez et al., the disclosures of each of which are herein incorporated by reference in their entireties.
Methods of Producing Antibodies and Fragments Thereof
[0657] In another embodiment, the present invention contemplates methods for producing anti-NGF antibodies and fragments thereof. Methods for producing anti-NGF antibodies and fragments thereof secreted from polyploidal, preferably diploid or tetraploid strains of mating competent yeast are taught, for example, in U.S. patent application publication no. US 2009/0022659 to Olson et al., and in U.S. patent application publication no. US 2009/0028784 to Garcia-Martinez et al., the disclosures of each of which are herein incorporated by reference in their entireties.
[0658] Other methods of producing antibodies are well known to those of ordinary skill in the art. For example, methods of producing chimeric antibodies are now well known in the art (See, for example, U.S. Pat. No. 4,816,567 to Cabilly et al.; Morrison et al., P.N.A.S. USA, 81:8651-55 (1984); Neuberger, M. S. et al., Nature, 314:268-270 (1985); Boulianne, G. L. et al., Nature, 312:643-46 (1984), the disclosures of each of which are herein incorporated by reference in their entireties).
[0659] Likewise, other methods of producing humanized antibodies are now well known in the art (See, for example, U.S. Pat. Nos. 5,530,101, 5,585,089, 5,693,762, and 6,180,370 to Queen et al; U.S. Pat. Nos. 5,225,539 and 6,548,640 to Winter; U.S. Pat. Nos. 6,054,297, 6,407,213 and 6,639,055 to Carter et al; U.S. Pat. No. 6,632,927 to Adair; Jones, P. T. et al, Nature, 321:522-525 (1986); Reichmann, L., et al, Nature, 332:323-327 (1988); Verhoeyen, M, et al, Science, 239:1534-36 (1988), the disclosures of each of which are herein incorporated by reference in their entireties).
[0660] Antibody polypeptides of the invention having NGF binding specificity may also be produced by constructing, using conventional techniques well known to those of ordinary skill in the art, an expression vector containing an operon and a DNA sequence encoding an antibody heavy chain in which the DNA sequence encoding the CDRs required for antibody specificity is derived from a non-human cell source, preferably a rabbit B-cell source, while the DNA sequence encoding the remaining parts of the antibody chain is derived from a human cell source.
[0661] A second expression vector is produced using the same conventional means well known to those of ordinary skill in the art, said expression vector containing an operon and a DNA sequence encoding an antibody light chain in which the DNA sequence encoding the CDRs required for antibody specificity is derived from a non-human cell source, preferably a rabbit B-cell source, while the DNA sequence encoding the remaining parts of the antibody chain is derived from a human cell source.
[0662] The expression vectors are transfected into a host cell by convention techniques well known to those of ordinary skill in the art to produce a transfected host cell, said transfected host cell cultured by conventional techniques well known to those of ordinary skill in the art to produce said antibody polypeptides.
[0663] The host cell may be co-transfected with the two expression vectors described above, the first expression vector containing DNA encoding an operon and a light chain-derived polypeptide and the second vector containing DNA encoding an operon and a heavy chain-derived polypeptide. The two vectors contain different selectable markers, but preferably achieve substantially equal expression of the heavy and light chain polypeptides. Alternatively, a single vector may be used, the vector including DNA encoding both the heavy and light chain polypeptides. The coding sequences for the heavy and light chains may comprise cDNA, genomic DNA, or both.
[0664] The host cells used to express the antibody polypeptides may be either a bacterial cell such as E. coli, or a eukaryotic cell. In a particularly preferred embodiment of the invention, a mammalian cell of a well-defined type for this purpose, such as a myeloma cell, a Chinese hamster ovary (CHO) cell line, a NSO cell line, or a HEK293 cell line may be used.
[0665] The general methods by which the vectors may be constructed, transfection methods required to produce the host cell and culturing methods required to produce the antibody polypeptides from said host cells all include conventional techniques. Although preferably the cell line used to produce the antibody is a mammalian cell line, any other suitable cell line, such as a bacterial cell line such as an E. coli-derived bacterial strain, or a yeast cell line, may alternatively be used.
[0666] Similarly, once produced the antibody polypeptides may be purified according to standard procedures in the art, such as for example cross-flow filtration, ammonium sulphate precipitation, affinity column chromatography and the like.
[0667] The antibody polypeptides described herein may also be used for the design and synthesis of either peptide or non-peptide mimetics that would be useful for the same therapeutic applications as the antibody polypeptides of the invention. See, for example, Saragobi et al, Science, 253:792-795 (1991), the contents of which is herein incorporated by reference in its entirety.
Epitope Mapping and Related Technologies
[0668] To screen for antibodies that bind to a particular epitope (e.g., those which block binding of IgE to its high affinity receptor), a routine cross-blocking assay such as that described in Harlow and Lane (1990) supra can be performed. Other methods include alanine scanning mutants, peptide blots (Reineke (2004) Methods Mol Biol 248:443-63) (herein specifically incorporated by reference in its entirety), or peptide cleavage analysis. In addition, methods such as epitope excision, epitope extraction and chemical modification of antigens can be employed (Tomer (2000) Protein Science 9: 487-496) (herein specifically incorporated by reference in its entirety).
[0669] As defined supra, the term "epitope" refers to a site on an antigen to which B and/or T cells respond. B-cell epitopes can be formed both from contiguous amino acids or noncontiguous amino acids juxtaposed by tertiary folding of a protein. Epitopes formed from contiguous amino acids are typically retained on exposure to denaturing solvents, whereas epitopes formed by tertiary folding are typically lost on treatment with denaturing solvents. An epitope typically includes at least 3, and more usually, at least 5 or 8-10 amino acids in a unique spatial conformation.
[0670] Modification-Assisted Profiling (MAP), also known as Antigen Structure-based Antibody Profiling (ASAP) is a method that categorizes large numbers of monoclonal antibodies (mAbs) directed against the same antigen according to the similarities of the binding profile of each antibody to chemically or enzymatically modified antigen surfaces (US 2004/0101920, herein specifically incorporated by reference in its entirety). Each category may reflect a unique epitope either distinctly different from or partially overlapping with epitope represented by another category. This technology allows rapid filtering of genetically identical antibodies, such that characterization can be focused on genetically distinct antibodies. When applied to hybridoma screening, MAP may facilitate identification of rare hybridoma clones that produce mAbs having the desired characteristics. MAP may be used to sort the anti-NGF antibodies of the invention into groups of antibodies binding different epitopes.
Immunoconjugates
[0671] The invention encompasses a human anti-NGF monoclonal antibody conjugated to a therapeutic moiety ("immunoconjugate"), such as a cytotoxin, a chemotherapeutic drug, an immunosuppressant or a radioisotope. Cytotoxin agents include any agent that is detrimental to cells. Examples of suitable cytotoxin agents and chemotherapeutic agents for forming immunoconjugates are described herein and are known in the art, see for example, WO 05/103081, herein specifically incorporated by reference in its entirety).
Bispecifics
[0672] The antibodies of the present invention may be monospecific, bispecific, or multispecific. Multispecific antibodies may be specific for different epitopes of one target polypeptide or may contain antigen-binding domains specific for more than one target polypeptide. See, e.g., Tutt et al. (1991) J. Immunol. 147:60-69. The human anti-NGF antibodies can be linked to or co-expressed with another functional molecule, e.g., another peptide or protein. For example, an antibody or fragment thereof can be functionally linked (e.g., by chemical coupling, genetic fusion, noncovalent association or otherwise) to one or more other molecular entities, such as another antibody or antibody fragment, to produce a bispecific or a multispecific antibody with a second binding specificity.
Screening Assays
[0673] The invention also includes screening assays designed to assist in the identification of diseases and disorders associated with NGF in patients exhibiting symptoms of an NGF associated disease or disorder.
[0674] In one embodiment of the invention, the anti-NGF antibodies of the invention, or NGF binding fragments thereof, are used to detect the presence of NGF in a biological sample obtained from a patient exhibiting symptoms of a disease or disorder associated with NGF. The presence of NGF, or elevated levels thereof when compared to pre-disease levels of NGF in a comparable biological sample, may be beneficial in diagnosing a disease or disorder associated with NGF.
[0675] Another embodiment of the invention provides a diagnostic or screening assay to assist in diagnosis of diseases or disorders associated with NGF in patients exhibiting symptoms of an NGF associated disease or disorder identified herein, comprising assaying the level of NGF expression in a biological sample from said patient using a post-translationally modified anti-NGF antibody or binding fragment thereof. The anti-NGF antibody or binding fragment thereof may be post-translationally modified to include a detectable moiety such as set forth previously in the disclosure.
[0676] The NGF level in the biological sample is determined using a modified anti-NGF antibody or binding fragment thereof as set forth herein, and comparing the level of NGF in the biological sample against a standard level of NGF (e.g., the level in normal biological samples). The skilled clinician would understand that some variability may exist between normal biological samples, and would take that into consideration when evaluating results. In one embodiment of the invention, the anti-NGF antibodies of the invention may be used to correlate NGF expression levels with a particular stage of cancerous development. One skilled in the art would be able to measure NGF in numerous subjects in order to establish ranges of NGF expression that correspond to clinically defined stages of cancerous development. These ranges will allow the skilled practitioner to measure NGF in a subject diagnosed with a cancer and correlate the levels in each subject with a range that corresponds to a stage of said cancer. One skilled in the art would understand that by measuring NGF in the patient at different intervals, the progression of the cancer can be determined.
[0677] The above-recited assay may also be useful in monitoring a disease or disorder, where the level of NGF obtained in a biological sample from a patient believed to have a NGF associated disease or disorder is compared with the level of NGF in prior biological samples from the same patient, in order to ascertain whether the NGF level in said patient has changed with, for example, a treatment regimen.
[0678] The invention is also directed to a method of in vivo imaging which detects the presence of cells which express NGF comprising administering a diagnostically effective amount of a diagnostic composition. Said in vivo imaging is useful for the detection or imaging of NGF expressing tumors or metastases, for example, and can be useful as part of a planning regimen for the design of an effective cancer treatment protocol. The treatment protocol may include, for example, one or more of radiation, chemotherapy, cytokine therapy, gene therapy, and antibody therapy, as well as an anti-NGF antibody or fragment thereof.
[0679] The present invention further provides for a kit for detecting binding of an anti-NGF antibody of the invention to NGF. In particular, the kit may be used to detect the presence of a NGF specifically reactive with an anti-NGF antibody of the invention or an immunoreactive fragment thereof. The kit may also include an antibody bound to a substrate, a secondary antibody reactive with the antigen and a reagent for detecting a reaction of the secondary antibody with the antigen. Such a kit may be an ELISA kit and can comprise the substrate, primary and secondary antibodies when appropriate, and any other necessary reagents such as detectable moieties, enzyme substrates, and color reagents, for example as described herein. The diagnostic kit may also be in the form of an immunoblot kit.
[0680] A skilled clinician would understand that a biological sample includes, but is not limited to, sera, plasma, urine, saliva, mucous, pleural fluid, synovial fluid and spinal fluid.
Methods of Ameliorating or Reducing Symptoms of or Treating, or Preventing, Diseases and Disorders Associated with, NGF
[0681] In another embodiment of the invention, anti-NGF antibodies described herein, or fragments thereof, are useful for ameliorating or reducing the symptoms of, or treating, or preventing, diseases and disorders associated with NGF. Anti-NGF antibodies described herein, or fragments thereof, as well as combinations, can also be administered in a therapeutically effective amount to patients in need of treatment of diseases and disorders associated with NGF in the form of a pharmaceutical composition as described in greater detail below.
[0682] In a preferred embodiment of the invention, Fab fragments are utilized for the treatment of pain in a patient, alone or in combination with another active. These Fab fragments desirably will inhibit or block one or more biological activities of NGF, e.g., those involving NGF/p75 and/or NGF/TrkA interaction, preferably without eliciting an inflammatory response.
[0683] In one embodiment of the invention, anti-NGF antibodies or fragments thereof as described herein, alone or with one or more other agents, are useful for ameliorating or reducing the symptoms of, or treating, or preventing, the following non-limiting listing of diseases and disorders: inflammatory pain, post-operative incision pain, complex regional pain syndrome, cancer pain (particularly primary or metastatic bone cancer pain), fracture pain, osteoporotic fracture pain, pain resulting from burn, osteoporosis, gout joint pain, pain associated with sickle cell crises, and other nociceptic pain, as well as hepatocellular carcinoma, breast cancer, liver cirrhosis.
[0684] In another embodiment of the invention, anti-NGF antibodies described herein, or fragments thereof and/or with a second agent, are useful for ameliorating or reducing the symptoms of, or treating, or preventing, the following non-limiting listing of diseases and disorders: neurogenic, neuropathic or nociceptic pain. Neuropathic pain may include, but is not limited to, trigeminal neuralgia, post-herpetic neuralgia, phantom limb pain, fibromyalgia, menstrual pain, ovarialgia, reflex sympathetic dystrophy and neurogenic pain. In other preferred embodiments, osteoarthritis or rheumatoid arthritis pain, lower back pain, diabetic neuropathy, sciatica, migraine, and other neuropathic pain.
[0685] In another embodiment the anti-NGF antibodies described herein, or fragments thereof and/or with a second agent, are useful for ameliorating or reducing the symptoms of, or treating, or preventing, a NGF-related disorder which comprises an inflammatory condition, preferably selected from the group consisting of asthma, arthritis, multiple sclerosis, lupus erythematosus and psoriasis.
[0686] In another embodiment of the invention, one or more anti-NGF monovalent agents are useful in methods of ameliorating or reducing the symptoms of, or treating, or preventing, pain in an individual without substantially raising inflammation in said individual. Exemplary pain is set forth below.
[0687] In another embodiment the anti-NGF antibodies described herein, or fragments thereof and/or with a second agent, are useful for ameliorating or reducing the symptoms of, or treating, or preventing, the following non-limiting listing of diseases and disorders: inflammatory pain, post-operative incision pain, complex regional pain syndrome, cancer pain (particularly primary or metastatic bone cancer pain), fracture pain, osteoporotic fracture pain, pain resulting from burn, osteoporosis, gout joint pain, pain associated with sickle cell crises, and other nociceptic pain, as well as hepatocellular carcinoma, breast cancer, liver cirrhosis.
[0688] In another embodiment the anti-NGF antibodies described herein, or fragments thereof and/or with a second agent, are useful for ameliorating or reducing the symptoms of, or treating, or preventing, the following non-limiting listing of diseases and disorders: neurogenic, neuropathic or nociceptic pain. Neuropathic pain may include, but is not limited to, trigeminal neuralgia, post-herpetic neuralgia, phantom limb pain, fibromyalgia, menstrual pain, ovarialgia, reflex sympathetic dystrophy and neurogenic pain. In other preferred embodiments, osteoarthritis or rheumatoid arthritis pain, lower back pain, diabetic neuropathy, sciatica, migraine, and other neuropathic pain.
[0689] In another embodiment the anti-NGF antibodies described herein, or fragments thereof and/or with a second agent, In general the anti-NGF monovalent agents and/or with a second agent, are useful for ameliorating or reducing the symptoms of, or treating, or preventing, the following non-limiting listing of NGF-associated diseases and disorders wherein the condition is acute pain, dental pain, pain from trauma, surgical pain, pain resulting from amputation or abscess, causalgia, demyelinating diseases, trigeminal neuralgia, cancer, chronic alcoholism, stroke, thalamic pain syndrome, diabetes, acquired immune deficiency syndrome ("AIDS"), toxins, chemotherapy, general headache, migraine, cluster headache, mixed-vascular or non-vascular syndromes, tension headache, general inflammation, arthritis, rheumatic diseases, lupus, osteoarthritis, fibromyalgia, inflammatory bowel disorders, irritable bowel syndrome, inflammatory eye disorders, inflammatory or unstable bladder disorders, psoriasis, skin complaints with inflammatory components, sunburn, carditis, dermatitis, myositis, neuritis, collagen vascular diseases, chronic inflammatory conditions, inflammatory pain and associated hyperalgesia and allodynia, neuropathic pain and associated hyperalgesia or allodynia, diabetic neuropathy pain, causalgia, sympathetically maintained pain, deafferentation syndromes, asthma, epithelial tissue damage or dysfunction, herpes simplex, disturbances of visceral motility at respiratory, genitourinary, gastrointestinal or vascular regions, wounds, burns, allergic skin reactions, pruritis, vitiligo, general gastrointestinal disorders, colitis, gastric ulceration, duodenal ulcers, vasomotor or allergic rhinitis, or bronchial disorders, dysmenorrhea, dyspepsia, gastroesophageal reflux, pancreatitis, or visceralgia
[0690] The terms "NGF-mediated disease" and "NGF-mediated condition" treatable or preventable with the anti-NGF monovalent agents of the invention alone and/or with a second agent, broadly encompass any medical condition or disorder associated with increased levels of NGF or increased sensitivity to NGF including, but not limited to, acute pain, dental pain, pain from trauma, surgical pain, pain resulting from amputation or abscess, causalgia, demyelinating diseases, trigeminal neuralgia, cancer, chronic alcoholism, stroke, thalamic pain syndrome, diabetes, acquired immune deficiency syndrome ("AIDS"), toxins and chemotherapy, general headache, migraine, cluster headache, mixed-vascular and non-vascular syndromes, tension headache, general inflammation, arthritis, rheumatic diseases, lupus, osteoarthritis, inflammatory bowel disorders, irritable bowel syndrome, inflammatory eye disorders, inflammatory or unstable bladder disorders, psoriasis, skin complaints with inflammatory components, sunburn, carditis, dermatitis, myositis, neuritis, collagen vascular diseases, chronic inflammatory conditions, inflammatory pain and associated hyperalgesia and allodynia, neuropathic pain and associated hyperalgesia and allodynia, diabetic neuropathy pain, causalgia, sympathetically maintained pain, deafferentation syndromes, asthma, epithelial tissue damage or dysfunction, herpes simplex, disturbances of visceral motility at respiratory, genitourinary, gastrointestinal or vascular regions, wounds, burns, allergic skin reactions, pruritis, vitiligo, general gastrointestinal disorders, colitis, gastric ulceration, duodenal ulcers, vasomotor or allergic rhinitis, or bronchial disorders, dysmenorrhea, dyspepsia, gastroesophageal reflux, pancreatitis, and visceralgia.
Administration
[0691] In one embodiment of the invention, the anti-NGF antibodies described herein, or NGF binding fragments thereof, as well as combinations of said antibodies or antibody fragments, are administered to a subject at a concentration of between about 0.1 and 100.0 mg/kg of body weight of recipient subject. In a preferred embodiment of the invention, the anti-NGF antibodies described herein, or NGF binding fragments thereof, as well as combinations of said antibodies or antibody fragments, are administered to a subject at a concentration of about 0.4 mg/kg of body weight of recipient subject. In a preferred embodiment of the invention, the anti-NGF antibodies described herein, or NGF binding fragments thereof, as well as combinations of said antibodies or antibody fragments, are administered to a recipient subject with a frequency of once every twenty-six weeks or less, such as once every sixteen weeks or less, once every eight weeks or less, once every four weeks or less, once every two weeks or less, once every week or less, or once daily or less.
[0692] Fab fragments may be administered every two weeks or less, every week or less, once daily or less, multiple times per day, and/or every few hours. In one embodiment of the invention, a patient receives Fab fragments of 0.01 mg/kg to 40 mg/kg per day given in divided doses of 1 to 6 times a day, or in a sustained release form, effective to obtain desired results.
[0693] It is to be understood that the concentration of the antibody or Fab administered to a given patient may be greater or lower than the exemplary administration concentrations set forth above herein.
[0694] A person of skill in the art would be able to determine an effective dosage and frequency of administration through routine experimentation, for example guided by the disclosure herein and the teachings in Goodman, L. S., Gilman, A., Brunton, L. L., Lazo, J. S., & Parker, K. L. (2006). Goodman & Gilman's the pharmacological basis of therapeutics. New York: McGraw-Hill; Howland, R. D., Mycek, M. J., Harvey, R. A., Champe, P. C., & Mycek, M. J. (2006). Pharmacology. Lippincott's illustrated reviews. Philadelphia: Lippincott Williams & Wilkins; and Golan, D. E. (2008). Principles of pharmacology: the pathophysiologic basis of drug therapy. Philadelphia, Pa., [etc.]: Lippincott Williams & Wilkins.
[0695] In another embodiment of the invention, the anti-NGF antibodies described herein, or NGF binding fragments thereof, as well as combinations of said antibodies or antibody fragments, are administered to a subject in a pharmaceutical formulation.
[0696] A "pharmaceutical composition" refers to a chemical or biological composition suitable for administration to a mammal. Such compositions may be specifically formulated for administration via one or more of a number of routes, including but not limited to buccal, epicutaneous, epidural, inhalation, intraarterial, intracardial, intracerebroventricular, intradermal, intramuscular, intranasal, intraocular, intraperitoneal, intraspinal, intrathecal, intravenous, oral, parenteral, rectally via an enema or suppository, subcutaneous, subdermal, sublingual, transdermal, and transmucosal. In addition, administration can occur by means of injection, powder, liquid, gel, drops, or other means of administration.
[0697] In one embodiment of the invention, the anti-NGF antibodies described herein, or NGF binding fragments thereof, as well as combinations of said antibodies or antibody fragments, may be optionally administered in combination with one or more active agents. Such active agents include analgesic, anti-histamine, antipyretic, anti-inflammatory, antibiotic, antiviral, and anti-cytokine agents. Active agents include agonists, antagonists, and modulators of TNF-.alpha., IL-2, IL-4, IL-6, IL-10, IL-12, IL-13, IL-18, IFN-.alpha., IFN-.gamma., BAFF, CXCL13, IP-10, VEGF, EPO, EGF, HRG, Hepatocyte Growth Factor (HGF), Hepcidin, including antibodies reactive against any of the foregoing, and antibodies reactive against any of their receptors. Active agents also include but are not limited to 2-Arylpropionic acids, Aceclofenac, Acemetacin, Acetylsalicylic acid (Aspirin), Alclofenac, Alminoprofen, Amoxiprin, Ampyrone, Arylalkanoic acids, Azapropazone, Benorylate/Benorilate, Benoxaprofen, Bromfenac, Carprofen, Celecoxib, Choline magnesium salicylate, Clofezone, COX-2 inhibitors, Dexibuprofen, Dexketoprofen, Diclofenac, Diflunisal, Droxicam, Ethenzamide, Etodolac, Etoricoxib, Faislamine, fenamic acids, Fenbufen, Fenoprofen, Flufenamic acid, Flunoxaprofen, Flurbiprofen, Ibuprofen, Ibuproxam, Indometacin, Indoprofen, Kebuzone, Ketoprofen, Ketorolac, Lornoxicam, Loxoprofen, Lumiracoxib, Magnesium salicylate, Meclofenamic acid, Mefenamic acid, Meloxicam, Metamizole, Methyl salicylate, Mofebutazone, Nabumetone, Naproxen, N-Arylanthranilic acids, Nerve Growth Factor (NGF), Oxametacin, Oxaprozin, Oxicams, Oxyphenbutazone, Parecoxib, Phenazone, Phenylbutazone, Phenylbutazone, Piroxicam, Pirprofen, profens, Proglumetacin, Pyrazolidine derivatives, Rofecoxib, Salicyl salicylate, Salicylamide, Salicylates, Sulfinpyrazone, Sulindac, Suprofen, Tenoxicam, Tiaprofenic acid, Tolfenamic acid, Tolmetin, and Valdecoxib.
[0698] An anti-histamine can be any compound that opposes the action of histamine or its release from cells (e.g., mast cells). Anti-histamines include but are not limited to acrivastine, astemizole, azatadine, azelastine, betatastine, brompheniramine, buclizine, cetirizine, cetirizine analogues, chlorpheniramine, clemastine, CS 560, cyproheptadine, desloratadine, dexchlorpheniramine, ebastine, epinastine, fexofenadine, HSR 609, hydroxyzine, levocabastine, loratidine, methscopolamine, mizolastine, norastemizole, phenindamine, promethazine, pyrilamine, terfenadine, and tranilast.
[0699] Antibiotics include but are not limited to Amikacin, Aminoglycosides, Amoxicillin, Ampicillin, Ansamycins, Arsphenamine, Azithromycin, Azlocillin, Aztreonam, Bacitracin, Carbacephem, Carbapenems, Carbenicillin, Cefaclor, Cefadroxil, Cefalexin, Cefalothin, Cefalotin, Cefamandole, Cefazolin, Cefdinir, Cefditoren, Cefepime, Cefixime, Cefoperazone, Cefotaxime, Cefoxitin, Cefpodoxime, Cefprozil, Ceftazidime, Ceftibuten, Ceftizoxime, Ceftobiprole, Ceftriaxone, Cefuroxime, Cephalosporins, Chloramphenicol, Cilastatin, Ciprofloxacin, Clarithromycin, Clindamycin, Cloxacillin, Colistin, Co-trimoxazole, Dalfopristin, Demeclocycline, Dicloxacillin, Dirithromycin, Doripenem, Doxycycline, Enoxacin, Ertapenem, Erythromycin, Ethambutol, Flucloxacillin, Fosfomycin, Furazolidone, Fusidic acid, Gatifloxacin, Geldanamycin, Gentamicin, Glycopeptides, Herbimycin, Imipenem, Isoniazid, Kanamycin, Levofloxacin, Lincomycin, Linezolid, Lomefloxacin, Loracarbef, Macrolides, Mafenide, Meropenem, Meticillin, Metronidazole, Mezlocillin, Minocycline, Monobactams, Moxifloxacin, Mupirocin, Nafcillin, Neomycin, Netilmicin, Nitrofurantoin, Norfloxacin, Ofloxacin, Oxacillin, Oxytetracycline, Paromomycin, Penicillin, Penicillins, Piperacillin, Platensimycin, Polymyxin B, Polypeptides, Prontosil, Pyrazinamide, Quinolones, Quinupristin, Rifampicin, Rifampin, Roxithromycin, Spectinomycin, Streptomycin, Sulfacetamide, Sulfamethizole, Sulfanilimide, Sulfasalazine, Sulfisoxazole, Sulfonamides, Teicoplanin, Telithromycin, Tetracycline, Tetracyclines, Ticarcillin, Tinidazole, Tobramycin, Trimethoprim, Trimethoprim-Sulfamethoxazole, Troleandomycin, Trovafloxacin, and Vancomycin.
[0700] Active agents also include Aldosterone, Beclometasone, Betamethasone, Corticosteroids, Cortisol, Cortisone acetate, Deoxycorticosterone acetate, Dexamethasone, Fludrocortisone acetate, Glucocorticoids, Hydrocortisone, Methylprednisolone, Prednisolone, Prednisone, Steroids, and Triamcinolone. Any suitable combination of these active agents is also contemplated.
[0701] A "pharmaceutical excipient" or a "pharmaceutically acceptable excipient" is a carrier, usually a liquid, in which an active therapeutic agent is formulated. In one embodiment of the invention, the active therapeutic agent is a humanized antibody described herein, or one or more fragments thereof. The excipient generally does not provide any pharmacological activity to the formulation, though it may provide chemical and/or biological stability, and release characteristics. Exemplary formulations can be found, for example, in Remington's Pharmaceutical Sciences, 19.sup.th Ed., Grennaro, A., Ed., 1995 which is incorporated by reference.
[0702] As used herein "pharmaceutically acceptable carrier" or "excipient" includes any and all solvents, dispersion media, coatings, antibacterial and antifungal agents, isotonic and absorption delaying agents that are physiologically compatible. In one embodiment, the carrier is suitable for parenteral administration. Alternatively, the carrier can be suitable for intravenous, intraperitoneal, intramuscular, or sublingual administration. Pharmaceutically acceptable carriers include sterile aqueous solutions or dispersions and sterile powders for the extemporaneous preparation of sterile injectable solutions or dispersions. The use of such media and agents for pharmaceutically active substances is well known in the art. Except insofar as any conventional media or agent is incompatible with the active compound, use thereof in the pharmaceutical compositions of the invention is contemplated. Supplementary active compounds can also be incorporated into the compositions.
[0703] Pharmaceutical compositions typically must be sterile and stable under the conditions of manufacture and storage. The invention contemplates that the pharmaceutical composition is present in lyophilized form. The composition can be formulated as a solution, microemulsion, liposome, or other ordered structure suitable to high drug concentration. The carrier can be a solvent or dispersion medium containing, for example, water, ethanol, polyol (for example, glycerol, propylene glycol, and liquid polyethylene glycol), and suitable mixtures thereof. The invention further contemplates the inclusion of a stabilizer in the pharmaceutical composition. The proper fluidity can be maintained, for example, by the use of a coating such as lecithin, by the maintenance of the required particle size in the case of dispersion and by the use of surfactants.
[0704] In many cases, it will be preferable to include isotonic agents, for example, sugars, polyalcohols such as mannitol, sorbitol, or sodium chloride in the composition. Prolonged absorption of the injectable compositions can be brought about by including in the composition an agent which delays absorption, for example, monostearate salts and gelatin. Moreover, the alkaline polypeptide can be formulated in a time release formulation, for example in a composition which includes a slow release polymer. The active compounds can be prepared with carriers that will protect the compound against rapid release, such as a controlled release formulation, including implants and microencapsulated delivery systems. Biodegradable, biocompatible polymers can be used, such as ethylene vinyl acetate, polyanhydrides, polyglycolic acid, collagen, polyorthoesters, polylactic acid and polylactic, polyglycolic copolymers (PLG). Many methods for the preparation of such formulations are known to those skilled in the art.
[0705] For each of the recited embodiments, the compounds can be administered by a variety of dosage forms. Any biologically-acceptable dosage form known to persons of ordinary skill in the art, and combinations thereof, are contemplated. Examples of such dosage forms include, without limitation, reconstitutable powders, elixirs, liquids, solutions, suspensions, emulsions, powders, granules, particles, microparticles, dispersible granules, cachets, inhalants, aerosol inhalants, patches, particle inhalants, implants, depot implants, injectables (including subcutaneous, intramuscular, intravenous, and intradermal), infusions, and combinations thereof.
[0706] The above description of various illustrated embodiments of the invention is not intended to be exhaustive or to limit the invention to the precise form disclosed. While specific embodiments of, and examples for, the invention are described herein for illustrative purposes, various equivalent modifications are possible within the scope of the invention, as those skilled in the relevant art will recognize. The teachings provided herein of the invention can be applied to other purposes, other than the examples described above.
[0707] These and other changes can be made to the invention in light of the above detailed description. In general, in the following claims, the terms used should not be construed to limit the invention to the specific embodiments disclosed in the specification and the claims. Accordingly, the invention is not limited by the disclosure, but instead the scope of the invention is to be determined entirely by the following claims.
[0708] The invention may be practiced in ways other than those particularly described in the foregoing description and examples. Numerous modifications and variations of the invention are possible in light of the above teachings and, therefore, are within the scope of the appended claims.
[0709] Certain teachings related to methods for obtaining a clonal population of antigen-specific B cells were disclosed in U.S. Provisional patent application No. 60/801,412, filed May 19, 2006, the disclosure of which is herein incorporated by reference in its entirety.
[0710] Certain teachings related to humanization of rabbit-derived monoclonal antibodies and preferred sequence modifications to maintain antigen binding affinity were disclosed in International Application No. PCT/US2008/064421, corresponding to International Publication No. WO/2008/144757, entitled "Novel Rabbit Antibody Humanization Methods and Humanized Rabbit Antibodies", filed May 21, 2008, the disclosure of which is herein incorporated by reference in its entirety.
[0711] Certain teachings related to producing antibodies or fragments thereof using mating competent yeast and corresponding methods were disclosed in U.S. patent application Ser. No. 11/429,053, filed May 8, 2006, (U.S. Patent Application Publication No. US2006/0270045), the disclosure of which is incorporated herein by reference in its entirety.
[0712] Certain teachings related to anti-NGF compositions and uses thereof were disclosed in U.S. provisional patent application No. 61/418,832, filed Dec. 1, 2010, the disclosure of which is herein incorporated by reference in its entirety.
[0713] Certain NGF antibody polynucleotides and polypeptides are disclosed in the sequence listing accompanying this patent application filing, and the disclosure of said sequence listing is herein incorporated by reference in its entirety.
[0714] The entire disclosure of each document cited (including patents, patent applications, journal articles, abstracts, manuals, books, or other disclosures) in the Background of the Invention, Detailed Description, and Examples is herein incorporated by reference in their entireties.
[0715] The following examples are put forth so as to provide those of ordinary skill in the art with a complete disclosure and description of how to make and use the subject invention, and are not intended to limit the scope of what is regarded as the invention. Efforts have been made to ensure accuracy with respect to the numbers used (e.g. amounts, temperature, concentrations, etc.) but some experimental errors and deviations should be allowed for. Unless otherwise indicated, parts are parts by weight, molecular weight is average molecular weight, temperature is in degrees centigrade; and pressure is at or near atmospheric.
EXAMPLES
Example 1 Preparation of Antibodies that Bind NGF
[0716] By using the antibody selection protocol described herein, one can generate an extensive panel of antibodies.
Immunization Strategy
[0717] Rabbits were immunized with huNGF (R&D Systems, Minneapolis, Minn.). Immunization consisted of a first subcutaneous (sc) injection of 100 .mu.g in complete Freund's adjuvant (CFA) (Sigma) followed by two boosts, two weeks apart, of 50 .mu.g each in incomplete Freund's adjuvant (IFA) (Sigma). Animals were bled on day 55, and serum titers were determined by ELISA (antigen recognition) and by non-radioactive proliferation assay (Promega) using the T1165 cell line.
Antibody Selection Titer Assessment
[0718] To identify and characterize antibodies that bind to human NGF, antibody containing solutions were tested by ELISA. Briefly, neutravidin coated plates (Thermo Scientific), were blocked with ELISA buffer (0.1 mg/mL BSA, 1.times.PBS pH 7.4, 0.002% Tween 20 and 0.005% sodium azide) for 1 hr at room temperature. The plates were then coated with a 1 .mu.g/mL biotinylated B-NGF solution in ELISA buffer for 1 hour at room temperature. This was followed by a wash step (3.times. using PBS plus 0.05% Tween 20) and a second block with ELISA buffer. The recombinant antibodies were then added onto the plates and incubated for 1 hour at room temperature and then washed 3.times. with PBS/Tween solution. For development, an anti-rabbit Fc-HRP (1:5000 dilution in ELISA buffer) was added onto the wells and incubated for 45 min at RT. After a 3.times. wash step with PBS/Tween solution, the plate was developed using TMB substrate for 3 minutes, stopped using 0.5M HCl and read at 450 nm.
Functional Titer Assessment
[0719] To test for the ability of NGF antibodies to block or inhibit NGF-dependent cell proliferation, we used TF-1 cells (Chevalier et al. Expression and functionality of the trkA proto-oncogene product/NGF receptor in undifferentiated hematopoietic cells. Blood (1994) vol. 83 (6) pp. 1479-85). Briefly, TF-1 cells were maintained in 10% FBS cRPMI media ("complete media") supplemented with rhuGM-CSF. On the day of the assay, the antibodies were serially diluted in complete media in a round bottom 96 well plate. B-NGF (R&D systems) was concomitantly added and the resultant antibody/B-NGF mixture was incubated at 37.degree. C. for 1 hr. While the Ab and B-NGF mixture was incubating, TF-1 cells were washed 3.times. with complete media, counted and plated in a flat bottom 96 well plate using 25,000 cells per well in a 50 .mu.L volume. After 1 hour incubation the NGF-Antibody mixtures were added onto the cells and the plates were incubated for 48 hrs at 37.degree. C. in a humidified 5% CO.sub.2 incubator. Cell proliferation was measured using the "CellTiter" aqueous one solution cell proliferation assay (Promega) according to the manufacturer's instructions. The dependency of the signals on the concentration of antibody was analyzed, and IC50 values were calculated using the GraphPad Prism program.
Tissue Harvesting
[0720] Once acceptable titers were established, the rabbit(s) were sacrificed. Spleen, lymph nodes, and whole blood were harvested and processed as follows:
[0721] Spleen and lymph nodes were processed into a single cell suspension by disassociating the tissue and pushing through sterile wire mesh at 70 .mu.m (Fisher) with a plunger of a 20 cc syringe. Cells were collected in PBS. Cells were washed twice by centrifugation. After the last wash, cell density was determined by trypan blue. Cells were centrifuged at 1500 rpm for 10 minutes; the supernatant was discarded. Cells were resuspended in the appropriate volume of 10% dimethyl sulfoxide (DMSO, Sigma) in FBS (Hyclone) and dispensed at 1 ml/vial. Vials were stored at -70.degree. C. in a slow freezing chamber for 24 hours and stored in liquid nitrogen.
[0722] Peripheral blood mononuclear cells (PBMCs) were isolated by mixing whole blood with equal parts of the low glucose medium described above without FBS. 35 ml of the whole blood mixture was carefully layered onto 8 ml of Lympholyte Rabbit (Cedarlane) into a 45 ml conical tube (Corning) and centrifuged 30 minutes at 2500 rpm at room temperature without brakes. After centrifugation, the PBMC layers were carefully removed using a glass Pasteur pipette (VWR), combined, and placed into a clean 50 ml vial. Cells were washed twice with the modified medium described above by centrifugation at 1500 rpm for 10 minutes at room temperature, and cell density was determined by trypan blue staining. After the last wash, cells were resuspended in an appropriate volume of 10% DMSO/FBS medium and frozen as described above.
B Cell Culture
[0723] On the day of setting up B cell culture, PBMC, splenocyte, or lymph node vials were thawed for use. Vials were removed from LN2 tank and placed in a 37.degree. C. water bath until thawed. Contents of vials were transferred into 15 ml conical centrifuge tube (Corning) and 10 ml of modified RPMI described above was slowly added to the tube. Cells were centrifuged for 5 minutes at 1.5K rpm, and the supernatant was discarded. Cells were resuspended in 10 ml of fresh media. Cell density and viability was determined by trypan blue. Cells were washed again and resuspended at 1E07 cells/80 .mu.L medium. Biotinylated huNGF (B huNGF) was added to the cell suspension at the final concentration of 3 ug/mL and incubated for 30 minutes at 4.degree. C. Unbound B huNGF was removed with two 10 ml washes of phosphate-buffered (PBF):Ca/Mg free PBS (Hyclone), 2 mM ethylenediamine tetraacetic acid (EDTA), 0.5% bovine serum albumin (BSA) (Sigma-biotin free). After the second wash, cells were resuspended at 1E07 cells/80 .mu.l PBF. 20 .mu.l of MACS.RTM. streptavidin beads (Milteni)/10E7 cells were added to the cell suspension. Cells were incubated at 4.degree. C. for 15 minutes. Cells were washed once with 2 ml of PBF/10E7 cells. After washing, the cells were resuspended at 1E08 cells/500 .mu.l of PBF and set aside. A MACS.RTM. MS column (Milteni) was pre-rinsed with 500 ml of PBF on a magnetic stand (Milteni). Cell suspension was applied to the column through a pre-filter, and unbound fraction was collected. The column was washed with 1.5 ml of PBF buffer. The column was removed from the magnet stand and placed onto a clean, sterile 5 ml Polypropylene Falcon tube. 1 ml of PBF buffer was added to the top of the column, and positive selected cells were collected. The yield and viability of positive and negative cell fraction was determined by trypan blue staining. Positive selection yielded an average of 1% of the starting cell concentration.
[0724] A pilot cell screen was established to provide information on seeding levels for the culture. Plates were seeded at 10, 25, 50, 100, or 200 enriched B cells/well. In addition, each well contained 50K cells/well of irradiated EL-4.B5 cells (5,000 Rads) and an appropriate level of activated rabbit T cell supernatant (See U.S. Patent Application Publication No. 20070269868)(ranging from 1-5% depending on preparation) in high glucose modified RPMI medium at a final volume of 250 .mu.l/well. Cultures were incubated for 5 to 7 days at 37.degree. C. in 4% CO.sub.2.
Identification of Selective Antibody Secreting B Cells
[0725] Cultures were tested for antigen recognition and functional activity between days 5 and 7.
Antigen Recognition Screening
[0726] The ELISA format used is as described above except 50 .mu.l of supernatant from the B cell cultures (BCC) wells was used as the source of the antibody. The conditioned medium was transferred to antigen-coated plates. After positive wells were identified, the supernatant was removed and transferred to a 96-well master plate(s). The original culture plates were then frozen by removing all the supernatant except 40 .mu.l/well and adding 60 .mu.l/well of 16% DMSO in FBS. Plates were wrapped in paper towels to slow freezing and frozen after the addition of 10% DMSO at -70.degree. C.
Functional Activity Screening
[0727] To test for the ability of NGF antibodies to block or inhibit NGF-dependent cell proliferation, we used TF-1 cells (Chevalier et al. Expression and functionality of the trkA proto-oncogene product/NGF receptor in undifferentiated hematopoietic cells. Blood (1994) vol. 83 (6) pp. 1479-85). Briefly, TF-1 cells were maintained in 10% FBS cRPMI media ("complete media") supplemented with rhuGM-CSF. On the day of the assay, the antibodies were serially diluted in complete media in a round bottom 96 well plate. B-NGF (R&D systems) was concomitantly added and the resultant antibody/B-NGF mixture was incubated at 37.degree. C. for 1 hr. While the Ab and B-NGF mixture was incubating, TF-1 cells were washed 3.times. with complete media, counted and plated in a flat bottom 96 well plate using 25,000 cells per well in a 50 .mu.L volume. After 1 hour incubation the NGF-Antibody mixtures were added onto the cells and the plates were incubated for 48 hrs at 37.degree. C. in a humidified 5% CO.sub.2 incubator. Cell proliferation was measured using the "CellTiter" aqueous one solution cell proliferation assay (Promega) according to the manufacturer's instructions. The dependency of the signals on the concentration of antibody was analyzed, and IC50 values were calculated using the GraphPad Prism program.
B Cell Recovery
[0728] Plates containing wells of interest were removed from -70.degree. C., and the cells from each well were recovered with 5-200 .mu.l washes of medium/well. The washes were pooled in a 1.5 ml sterile centrifuge tube, and cells were pelleted for 2 minutes at 1500 rpm.
[0729] The tube was inverted, the spin repeated, and the supernatant carefully removed. Cells were resuspended in 100 .mu.l/tube of medium. 100 .mu.l biotinylated NGF coated streptavidin M280 dynabeads (Invitrogen) and 16 .mu.l of goat anti-rabbit H&L IgG-FITC diluted 1:100 in medium was added to the cell suspension.
[0730] 20 .mu.l of cell/beads/FITC suspension was removed, and 5 .mu.l droplets were prepared on a glass slide (Corning) previously treated with Sigmacote (Sigma), 35 to 40 droplets/slide. An impermeable barrier of paraffin oil (JT Baker) was added to submerge the droplets, and the slide was incubated for 90 minutes at 37.degree. C., 4% CO.sub.2 in the dark.
[0731] Specific B cells that produce antibody can be identified by the fluorescent ring around them due to antibody secretion, recognition of the bead-associated biotinylated antigen, and subsequent detection by the fluorescent-IgG detection reagent. Once a cell of interest was identified, the cell in the center of the fluorescent ring was recovered via a micromanipulator (Eppendorf). The single cell synthesizing and exporting the antibody was transferred into a 250 .mu.l microcentrifuge tube and placed in dry ice. After recovering all cells of interest, these were transferred to -70.degree. C. for long-term storage.
Isolation of Antibody Sequences from Antigen-Specific B Cell
[0732] Antibody sequences were recovered using a combined RT-PCR based method from a single isolated B-cell or an antigenic specific B cell isolated from the clonal B cell population. Primers are designed to anneal in conserved and constant regions of the target immunoglobulin genes (heavy and light), such as rabbit immunoglobulin sequences, and a two-step nested PCR recovery step is used to obtain the antibody sequence. Amplicons from each well are analyzed for recovery and size integrity. The resulting fragments are then digested with AluI to fingerprint the sequence clonality. Identical sequences display a common fragmentation pattern in their electrophoretic analysis. The original heavy and light chain amplicon fragments are then restriction enzyme digested with HindIII and XhoI or HindIII and BsiwI to prepare the respective pieces of DNA for cloning. The resulting digestions are then ligated into an expression vector and transformed into bacteria for plasmid propagation and production. Colonies are selected for sequence characterization.
Recombinant Production of Monoclonal Antibody of Desired Antigen Specificity and/or Functional Properties
[0733] Correct full-length antibody sequences for each well containing a single monoclonal antibody are established and miniprep DNA is prepared using Qiagen solid-phase methodology. This DNA is then used to transfect mammalian cells to produce recombinant full-length antibody. Either antibody containing supernatants or protein-A affinity purified antibodies are tested for antigen recognition and functional properties to confirm the original characteristics are found in the recombinant antibody protein.
Antigen Specific ELISA
[0734] To identify and characterize antibodies and Fab fragments that bind to human NGF, antibody- and Fab-containing solutions were tested by ELISA. Briefly, neutravidin coated plates (Thermo Scientific), were blocked with ELISA buffer (0.1 mg/mL BSA, 1.times.PBS pH 7.4, 0.002% Tween 20 and 0.005% sodium azide) for 1 hr at room temperature. The plates were then coated with a 1 .mu.g/mL biotinylated B-NGF solution in ELISA buffer for 1 hour at room temperature. This was followed by a wash step (3.times. using PBS plus 0.05% Tween 20) and a second block with ELISA buffer. The recombinant antibodies or Fabs were then added onto the plates and incubated for 1 hour at room temperature and then washed 3.times. with PBS/Tween solution. For development, an anti-human Fc-HRP or an anti-human Fab-fragment HRP (1:5000 dilution in ELISA buffer) was added onto the wells and incubated for 45 min at RT. After a 3.times. wash step with PBS/Tween solution, the plate was developed using TMB substrate for 3 minutes, stopped using 0.5M HCl, and read at 450 nm.
[0735] Results: FIGS. 24-40 demonstrate that anti-NGF antibodies Ab1-Ab21 bind to NGF. Furthermore, FIGS. 28 and 29 demonstrate that Fab antibody fragments Fab1 and Fab2 bind to NGF.
Functional Activity Screening
[0736] To test for the ability of NGF antibodies to block or inhibit NGF-dependent and TrkA receptor-mediated cell proliferation activity, we used TF-1 cells (Chevalier et al. Expression and functionality of the trkA proto-oncogene product/NGF receptor in undifferentiated hematopoietic cells. Blood (1994) vol. 83 (6) pp. 1479-85). Briefly, TF-1 cells were maintained in 10% FBS cRPMI media ("complete media") supplemented with rhuGM-CSF. On the day of the assay, the antibodies were serially diluted in complete media in a round bottom 96 well plate. B-NGF (R&D systems) was concomitantly added and the resultant antibody/B-NGF mixture was incubated at 37.degree. C. for 1 hr. While the Ab and B-NGF mixture was incubating, TF-1 cells were washed 3.times. with complete media, counted and plated in a flat bottom 96 well plate using 25,000 cells per well in a 50 .mu.L volume. After 1 hour incubation the NGF-Antibody mixtures were added onto the cells and the plates were incubated for 48 hrs at 37.degree. C. in a humidified 5% CO.sub.2 incubator. Cell proliferation was measured using the "CellTiter" aqueous one solution cell proliferation assay (Promega) according to the manufacturer's instructions. The dependency of the signals on the concentration of antibody was analyzed, and IC50 values were calculated using the GraphPad Prism program.
[0737] Results: FIGS. 41-52 demonstrate that anti-NGF antibodies Ab1-Ab20 inhibit the proliferation of TF-1 cells. Furthermore, FIG. 44 demonstrates that Fab antibody fragments also inhibit the proliferation of TF-1 cells. These Fab antibody fragments were produced by: 1.) Pichia pastoris expression of Fab2; and 2.) enzymatic digestion of Ab21 produced in Pichia pastoris (Fab1).
Example 2: Enzymatic Production of Fab Fragments
[0738] Papain digestions were conducted using immobilized papain (Thermo/Pierce) as per manufacturer's instructions. Briefly, purified antibodies were incubated in a cystein/HCl-containing buffer with immobilized papain at 37.degree. C. with gentle rocking. The digestion was monitored by taking an aliquot and analyzing using SDS-PAGE for cleavage of the heavy chain. To stop the reaction, the immobilized papain was spun out and washed using 50 mM Tris pH 7.5 and filtered. Undigested full length antibody and Fc fragments were removed by using a MabSelectSure (GE) column.
Example 3 Yeast Cell Expression
[0739] Antibody genes: Genes were cloned and constructed that directed the synthesis of a chimeric humanized rabbit monoclonal antibody.
Methods
[0740] Construction of Pichia pastoris Expression Vectors for Heavy and Light Chain Antibodies.
[0741] The light and heavy chain fragments (chimera or humanized) were commercially synthesized and subcloned into a pGAP expression vector. The pGAP expression vector uses the GAP promoter to drive expression of the immunoglobulin chain and the human serum albumin (HAS) leader sequence for export. In addition, this vector contains common elements such as a bacterial origin of replication, and a copy of the Sh ble gene which confers resistance to the antibiotic Zeocin.TM. (phleomycin). Zeocin.TM. provides a means of selection for strains that contain the desired expression vector integrated into their genome.
[0742] Transformation of Expression Vectors into Haploid Met1 and Lys3 Host Strains of Pichia pastoris
[0743] All methods used for transformation of haploid P. pastoris strains and manipulation of the P. pastoris sexual cycle were done as described in Pichia Protocols (Methods in Molecular Biology Higgings, D R, and Cregg, J M, Eds. 1998. Humana Press, Totowa, N.J.). Prior to transformation each vector was linearized within the GAP promoter sequences to direct the integration of the vector into the GAP promoter locus of the P. pastoris genome. Haploid strains were transfected using electroporation and successful transformants were selected on YPD Zeocin.TM. plates and then cultured in 96-well plates for two days. Haploid strains were mated and selected for their ability to grow in the absence of the auxotroph markers (i.e., Lys and Met). Diploid strains were then selected for their ability to express either full length or Fab antibody fragments using a ForteBio Octet system fitted with Protein A biosensors to monitor expression.
Example 4 Expression of Ab21 and Fab2 in Pichia pastoris
[0744] Two Pichia strains for expression of either full length Ab21 or Fab2 antibody fragment were made. For both the full length or the Fab expressing strains, haploids strains were created and subsequently mated. One haploid strain expressed full length light sequences for Ab21 and another haploid strain expressed either the full length Ab21 or a truncated form of heavy chain to express an Fab fragment (e.g., Fab2). Each diploid strain was used to generate a research cell bank and used for expression in a bioreactor.
[0745] First an inoculum was expanded using the research cell bank using medium comprised of the following nutrients (% w/v): yeast extract 3%, anhydrous dextrose 4%, YNB 1.34%, 0.004% Biotin with 100 mM potassium phosphate. The culture was expanded for approximately 24 hours in a shaking incubator at 30.degree. C. and 300 rpm to generate the inoculum for the fermenters. A 10% inoculum was then added to Labfors 2.5 L working volume vessels containing sterile growth medium. The growth medium for the full length Ab21 was comprised of the following nutrients: potassium sulfate 18.2 g/L, ammonium phosphate monobasic 36.4 g/L, potassium phosphate dibasic 12.8 g/L, magnesium sulfate heptahydrate 3.72 g/L, sodium citrate dihydrate 10 g/L, glycerol 40 g/L, yeast extract 30 g/L, PTM1 trace metals 4.35 mL/L, and antifoam 204 1.67 mL/L. The PTM1 trace metal solution was comprised of the following components: cupric sulfate pentahydrate 6 g/L, sodium iodide 0.08 g/L, manganese sulfate hydrate 3 g/L, sodium molybdate dihyrate 0.2 g/L, boric acid 0.02 g/L, cobalt chloride 0.5 g/L, zinc chloride 20 g/L, ferrous sulfate heptahydrate 65 g/L, biotin 0.2 g/L, and sulfuric acid 5 mL/L.
[0746] The growth medium for the Fab2 fragment was comprised of the following nutrients: potassium sulfate 10.92 g/L, ammonium phosphate monobasic 21.84 g/L, potassium phosphate dibasic 7.68 g/L, magnesium sulfate heptahydrate 3.72 g/L, sodium citrate dihydrate 10 g/L, glycerol 40 g/L, yeast extract 30 g/L, PTM1 trace metal solution 2.61 mL/L, and antifoam 204 1.67 mL/L. The PTM1 trace metal solution was comprised of the following components: cupric sulfate pentahydrate 6 g/L, sodium iodide 0.08 g/L, manganese sulfate hydrate 3 g/L, sodium molybdate dihyrate 0.2 g/L, boric acid 0.02 g/L, cobalt chloride 0.5 g/L, zinc chloride 20 g/L, ferrous sulfate heptahydrate 65 g/L, biotin 0.2 g/L, and sulfuric acid 5 mL/L. Both proteins were expressed under similar conditions. Briefly, the bioreactor process control parameters were set as follows: Agitation 1000 rpm, airflow 1.35 standard liter per minute, temperature 28.degree. C. and pH was controlled at six using ammonium hydroxide. No oxygen supplementation was provided.
[0747] The fermentation cultures were grown for approximately 12 to 16 hours until the initial glycerol was consumed as denoted by a dissolved oxygen spike. The cultures were starved for approximately three hours after the dissolved oxygen spike. After this starvation period, a bolus addition of ethanol was added to the reactor to reach 1% ethanol (w/v). The fermentation cultures were allowed to equilibrate for 15 to 30 minutes. Feed addition was initiated 30 minutes post-ethanol bolus and set at a constant rate of 1 mL/min for 40 minutes, then the feed pump was controlled by an ethanol sensor keeping the concentration of ethanol at 1% for the remainder of the run. The feed was comprised of the following components: yeast extract 50 g/L, dextrose 500 g/L, magnesium sulfate heptahydrate 3 g/L, and PTM1 trace metals 12 mL/L. For fermentation of the full length Ab21, sodium citrate dihydrate (0.5 g/L) was also added to the feed. The total fermentation time was approximately 90 hours.
Example 5 Inhibition of NGF p75 Interactions
[0748] NGF is reported to interact with two receptors on the cell surface: TrkA and p75. A biolayer interferometry assay via the "Octet" was used to characterize the ability of anti-NGF antibodies to inhibit NGF-p75 interactions. Briefly, streptavidin (SA) sensors were pre-wetted in 1.times. kinetics buffer (1.times.PBS ph7.4, 0.002% Tween 20, 0.005% sodium azide and 0.1 mg/mL BSA). A baseline was obtained using again 1.times. kinetics buffer, followed by binding of the biotinylated antibody being tested and another short baseline in 1.times. kinetics buffer. NGF (1 .mu.g/mL) was loaded next and the sensor was then transferred onto 1.times. kinetics buffer. After loading of NGF onto the antibody, on one sensor, all possible sites of NGF were blocked using an un-labeled solution of the biotinylated antibody at 5 .mu.g/mL. As control, a parallel sensor was submerged into 1.times. kinetics buffer during this second blocking step. Both sensors were then exposed to a solution containing p75 (1.2 .mu.g/mL). The ability of an antibody to block or inhibit NGF-p75 interactions was then characterized by monitoring the increase in signal when antibody-immobilized NGF was exposed to soluble p75.
[0749] Results: FIGS. 53 and 54 demonstrates that anti-NGF antibodies Ab3, Ab4, Ab15, and Ab16 do not inhibit binding of NGF to p75, while FIG. 55 demonstrates that antibody Ab5 inhibits binding of NGF to p75.
Example 6 Neurite PC12 Assay
[0750] The ability of anti-NGF antibodies to block or inhibit NGF signaling mediated through the p75 and TrkA receptors was measured in vitro using a rat adrenal medulla cell line, PC12. PC12 cells express both p75 and TrkA receptors on their cell surface (Urdiales et al. Cell cycle phase-specific surface expression of nerve growth factor receptors TrkA and p75(NTR). J Neurosci (1998) vol. 18 (17) pp. 6767-75); (Greene and Tischler. Establishment of a noradrenergic clonal line of rat adrenal pheochromocytoma cells which respond to nerve growth factor. Proc Natl Acad Sci USA (1976) vol. 73 (7) pp. 2424-8). Briefly, PC12 cells were maintained in culture using 15% FBS RPMI and grown on a collagen I-coated flask for 48 hours before priming. The cells were then `primed` for 72 hours by exposing them to 100 ng/mL NGF in differentiation media (1% horse serum RPMI). On the day of the assay, the cells were harvested with a cell scraper, resuspended, rinsed in differentiation media (without NGF) and plated onto a collagen I-coated 24-well plate. The final concentration of NGF in the assay was 100 ng/mL. The antibodies being tested were pre-incubated with the NGF at different molar ratios (from 10.times. to 0.1.times.) for 1 hour in differentiation media prior to adding them onto the PC-12 cells. On day 3, the media was gently removed and antibody-NGF mixtures were replaced. On day 10, the wells were observed under a microscope and representative fields were digitized using a 10.times. magnification lens.
[0751] Results: FIGS. 56-69 and FIGS. 78 and 79 demonstrate that anti-NGF antibodies Ab1-Ab3, Ab5-Ab11, Ab13, Ab15, Ab16, and Ab17-Ab19 inhibit the outgrowth of PC-12 neurite cells at increasing concentrations. It can be seen that antibodies Ab3, Ab15 and Ab16, when assayed at the same antibody concentrations as the other tested anti-NGF antibodies, showed significantly less inhibition of the outgrowth of PC-12 neurite cells. This difference is believed to be attributable to the fact that Ab3, Ab15 and Ab16, all inhibit TrkA/NGF interactions and not NGF/p75 interactions, whereas the remaining tested antibodies inhibit the interaction of NGF with both TrkA and p75.
Example 7 Modulation of Pain Assessed by Gait Analysis
[0752] To assess the effect of anti-NGF agents (full length and Fab fragments) in their ability to modulate pain, a PGPS (peptidoglycan polysaccharide)-induced arthritis model was used. Briefly, male Lewis rats were injected with a solution of PGPS into their right ankle on day (-)17. One day later, ankles were evaluated for an inflammatory response to the PGPS injection and non-responders were eliminated. Responders were allowed to recover for seventeen days before an IV tail vein reactivation with PGPS.
[0753] Full-length antibodies were dosed once, either 2 hours or the night before reactivation. Fab fragments were administered once a day with the first dose administered two hours prior to reactivation. Gait analysis was performed by applying ink to the ventral surface of the foot and documenting weight bearing during movement (footprints) across paper. The rear feet of the rats were placed in blue colored ink, and black ink was applied to the dorsal side of the foot on the suspected painful leg. Rats were placed on paper and allowed to walk. Gaits were scored as follows: 0=normal, equal ink staining on both feet; 1=slight limp, toe staining evident and some heel staining; 2=limping, toes only staining; 3=dragging/carrying leg, black drag marks from dorsal side of foot present; 4=carrying leg, no staining from painful leg.
[0754] Results: FIG. 70 demonstrates a statistically significant reduction in pain as assessed by Gait analysis following administration of antibodies Ab2, Ab6, and Ab8, when compared with results obtained with the controls.
[0755] FIG. 71 demonstrates a statistically significant reduction in pain as assessed by Gait analysis following administration of antibody Ab6 and Fab1, when compared with results obtained with the controls.
[0756] FIG. 72 demonstrates a statistically significant reduction in pain as assessed by Gait analysis following administration of antibody Ab3, when compared with results obtained with the controls.
[0757] FIG. 73 demonstrates a statistically significant reduction in pain as assessed by Gait analysis following administration of antibody Ab6 and antibody Ab21, when compared with results obtained with the controls.
Example 8 Inflammation in PGPS-Induced Arthritis
[0758] The PGPS (peptidoglycan polysaccharide) induced arthritis model used to assess pain (Example 7) also has an associated inflammation response. To assess inflammation, all animals had caliper measurements taken of their ankles prior to reactivation on day 0, and then on days 1, 2, 3 and 4 to determine any anti-inflammatory or pro-inflammatory effects present in treated rats.
[0759] Results: FIG. 74 demonstrates an increase in inflammation following administration of each of antibodies Ab2, Ab6, and Ab8, when compared with inflammation results for the controls.
[0760] FIG. 75 demonstrates no significant increase in inflammation following administration of the Fab1 antibody fragment, when compared with inflammation results for the control. In contrast, administration of antibody Ab6 resulted in increased inflammation, when compared with inflammation results for the controls.
[0761] FIG. 76 demonstrates an increase in inflammation following administration of antibody Ab3, when compared with inflammation results for the controls.
[0762] FIG. 77 also demonstrates an increase in inflammation following administration of antibody Ab6 and antibody Ab21, when compared with inflammation results for the controls.
Sequence CWU 1
1
4131111PRTOryctolagus cuniculus 1Ala Leu Val Met Thr Gln Thr Pro
Ser Ser Val Ser Ala Ala Val Gly1 5 10 15Gly Thr Val Thr Ile Asn Cys
Gln Ala Ser Gln Asn Ile Tyr Ser Asn 20 25 30Leu Ala Trp Tyr Gln Gln
Arg Pro Gly Gln Arg Pro Lys Leu Leu Ile 35 40 45Tyr Gly Ala Ser Asn
Leu Asp Ala Gly Val Pro Ser Arg Phe Arg Gly 50 55 60Ser Gly Ser Gly
Thr Glu Tyr Thr Leu Thr Ile Ser Asp Leu Glu Cys65 70 75 80Asp Asp
Val Gly Thr Tyr Tyr Cys Gln Ser Ala Phe Asp Ser Asp Ser 85 90 95Thr
Glu Asn Thr Phe Gly Gly Gly Thr Glu Val Val Val Lys Arg 100 105
1102217PRTArtificial SequenceChemically Synthesized 2Ala Leu Val
Met Thr Gln Thr Pro Ser Ser Val Ser Ala Ala Val Gly1 5 10 15Gly Thr
Val Thr Ile Asn Cys Gln Ala Ser Gln Asn Ile Tyr Ser Asn 20 25 30Leu
Ala Trp Tyr Gln Gln Arg Pro Gly Gln Arg Pro Lys Leu Leu Ile 35 40
45Tyr Gly Ala Ser Asn Leu Asp Ala Gly Val Pro Ser Arg Phe Arg Gly
50 55 60Ser Gly Ser Gly Thr Glu Tyr Thr Leu Thr Ile Ser Asp Leu Glu
Cys65 70 75 80Asp Asp Val Gly Thr Tyr Tyr Cys Gln Ser Ala Phe Asp
Ser Asp Ser 85 90 95Thr Glu Asn Thr Phe Gly Gly Gly Thr Glu Val Val
Val Lys Arg Thr 100 105 110Val Ala Ala Pro Ser Val Phe Ile Phe Pro
Pro Ser Asp Glu Gln Leu 115 120 125Lys Ser Gly Thr Ala Ser Val Val
Cys Leu Leu Asn Asn Phe Tyr Pro 130 135 140Arg Glu Ala Lys Val Gln
Trp Lys Val Asp Asn Ala Leu Gln Ser Gly145 150 155 160Asn Ser Gln
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr 165 170 175Ser
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His 180 185
190Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
195 200 205Thr Lys Ser Phe Asn Arg Gly Glu Cys 210
2153118PRTOryctolagus cuniculus 3Gln Ser Leu Glu Glu Ser Gly Gly
Arg Leu Val Thr Pro Gly Thr Pro1 5 10 15Leu Thr Leu Thr Cys Thr Val
Ser Gly Phe Ser Leu Ser Ser Tyr Ala 20 25 30Met Ser Trp Val Arg Gln
Ala Pro Gly Lys Gly Leu Glu Trp Ile Gly 35 40 45Val Ile Thr Ser Ile
Gly Ser Thr Val Tyr Ala Ser Trp Ala Lys Gly 50 55 60Arg Phe Thr Ile
Ser Lys Thr Ser Thr Thr Val Asp Leu Lys Ile Thr65 70 75 80Ser Pro
Thr Thr Glu Asp Thr Ala Thr Tyr Phe Cys Ala Arg Gly Tyr 85 90 95Asp
Asp Tyr Asp Glu Met Thr Tyr Phe Asn Ile Trp Gly Gln Gly Thr 100 105
110Leu Val Thr Val Ser Ser 1154448PRTArtificial SequenceChemically
Synthesized 4Gln Ser Leu Glu Glu Ser Gly Gly Arg Leu Val Thr Pro
Gly Thr Pro1 5 10 15Leu Thr Leu Thr Cys Thr Val Ser Gly Phe Ser Leu
Ser Ser Tyr Ala 20 25 30Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
Leu Glu Trp Ile Gly 35 40 45Val Ile Thr Ser Ile Gly Ser Thr Val Tyr
Ala Ser Trp Ala Lys Gly 50 55 60Arg Phe Thr Ile Ser Lys Thr Ser Thr
Thr Val Asp Leu Lys Ile Thr65 70 75 80Ser Pro Thr Thr Glu Asp Thr
Ala Thr Tyr Phe Cys Ala Arg Gly Tyr 85 90 95Asp Asp Tyr Asp Glu Met
Thr Tyr Phe Asn Ile Trp Gly Gln Gly Thr 100 105 110Leu Val Thr Val
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro 115 120 125Leu Ala
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly 130 135
140Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
Asn145 150 155 160Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
Ala Val Leu Gln 165 170 175Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
Val Thr Val Pro Ser Ser 180 185 190Ser Leu Gly Thr Gln Thr Tyr Ile
Cys Asn Val Asn His Lys Pro Ser 195 200 205Asn Thr Lys Val Asp Lys
Arg Val Glu Pro Lys Ser Cys Asp Lys Thr 210 215 220His Thr Cys Pro
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser225 230 235 240Val
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg 245 250
255Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
260 265 270Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
Asn Ala 275 280 285Lys Thr Lys Pro Arg Glu Glu Gln Tyr Ala Ser Thr
Tyr Arg Val Val 290 295 300Ser Val Leu Thr Val Leu His Gln Asp Trp
Leu Asn Gly Lys Glu Tyr305 310 315 320Lys Cys Lys Val Ser Asn Lys
Ala Leu Pro Ala Pro Ile Glu Lys Thr 325 330 335Ile Ser Lys Ala Lys
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu 340 345 350Pro Pro Ser
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys 355 360 365Leu
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser 370 375
380Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
Asp385 390 395 400Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
Val Asp Lys Ser 405 410 415Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
Ser Val Met His Glu Ala 420 425 430Leu His Asn His Tyr Thr Gln Lys
Ser Leu Ser Leu Ser Pro Gly Lys 435 440 445511PRTOryctolagus
cuniculus 5Gln Ala Ser Gln Asn Ile Tyr Ser Asn Leu Ala1 5
1067PRTOryctolagus cuniculus 6Gly Ala Ser Asn Leu Asp Ala1
5712PRTOryctolagus cuniculus 7Gln Ser Ala Phe Asp Ser Asp Ser Thr
Glu Asn Thr1 5 1085PRTOryctolagus cuniculus 8Ser Tyr Ala Met Ser1
5916PRTOryctolagus cuniculus 9Val Ile Thr Ser Ile Gly Ser Thr Val
Tyr Ala Ser Trp Ala Lys Gly1 5 10 151013PRTOryctolagus cuniculus
10Gly Tyr Asp Asp Tyr Asp Glu Met Thr Tyr Phe Asn Ile1 5
1011111PRTArtificial SequenceChemically Synthesized 11Asp Ile Gln
Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg
Val Thr Ile Thr Cys Gln Ala Ser Gln Asn Ile Tyr Ser Asn 20 25 30Leu
Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40
45Tyr Gly Ala Ser Asn Leu Asp Ala Gly Val Pro Ser Arg Phe Ser Gly
50 55 60Ser Gly Ser Gly Thr Glu Tyr Thr Leu Thr Ile Ser Ser Leu Gln
Pro65 70 75 80Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Ser Ala Phe Asp
Ser Asp Ser 85 90 95Thr Glu Asn Thr Phe Gly Gly Gly Thr Lys Val Glu
Ile Lys Arg 100 105 11012217PRTArtificial SequenceChemically
Synthesized 12Asp Ile Gln Met Thr Gln Ser Pro Ser Thr Leu Ser Ala
Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asn
Ile Tyr Ser Asn 20 25 30Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala
Pro Lys Leu Leu Ile 35 40 45Tyr Gly Ala Ser Asn Leu Asp Ala Gly Val
Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly Ser Gly Thr Glu Tyr Thr Leu
Thr Ile Ser Ser Leu Gln Pro65 70 75 80Asp Asp Phe Ala Thr Tyr Tyr
Cys Gln Ser Ala Phe Asp Ser Asp Ser 85 90 95Thr Glu Asn Thr Phe Gly
Gly Gly Thr Lys Val Glu Ile Lys Arg Thr 100 105 110Val Ala Ala Pro
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu 115 120 125Lys Ser
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro 130 135
140Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
Gly145 150 155 160Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
Asp Ser Thr Tyr 165 170 175Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys
Ala Asp Tyr Glu Lys His 180 185 190Lys Val Tyr Ala Cys Glu Val Thr
His Gln Gly Leu Ser Ser Pro Val 195 200 205Thr Lys Ser Phe Asn Arg
Gly Glu Cys 210 21513121PRTArtificial SequenceChemically
Synthesized 13Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
Val Ser Ser Tyr 20 25 30Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys
Gly Leu Glu Trp Val 35 40 45Gly Val Ile Thr Ser Ile Gly Ser Thr Val
Tyr Ala Ser Ser Ala Lys 50 55 60Gly Arg Phe Thr Ile Ser Arg Asp Asn
Ser Lys Asn Thr Leu Tyr Leu65 70 75 80Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg Gly Tyr Asp Asp Tyr
Asp Glu Met Thr Tyr Phe Asn Ile Trp Gly 100 105 110Gln Gly Thr Leu
Val Thr Val Ser Ser 115 12014451PRTArtificial SequenceChemically
Synthesized 14Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
Val Ser Ser Tyr 20 25 30Ala Met Ser Trp Val Arg Gln Ala Pro Gly Lys
Gly Leu Glu Trp Val 35 40 45Gly Val Ile Thr Ser Ile Gly Ser Thr Val
Tyr Ala Ser Ser Ala Lys 50 55 60Gly Arg Phe Thr Ile Ser Arg Asp Asn
Ser Lys Asn Thr Leu Tyr Leu65 70 75 80Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg Gly Tyr Asp Asp Tyr
Asp Glu Met Thr Tyr Phe Asn Ile Trp Gly 100 105 110Gln Gly Thr Leu
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser 115 120 125Val Phe
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala 130 135
140Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
Val145 150 155 160Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
Thr Phe Pro Ala 165 170 175Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu
Ser Ser Val Val Thr Val 180 185 190Pro Ser Ser Ser Leu Gly Thr Gln
Thr Tyr Ile Cys Asn Val Asn His 195 200 205Lys Pro Ser Asn Thr Lys
Val Asp Lys Arg Val Glu Pro Lys Ser Cys 210 215 220Asp Lys Thr His
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly225 230 235 240Gly
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met 245 250
255Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
260 265 270Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
Glu Val 275 280 285His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
Ala Ser Thr Tyr 290 295 300Arg Val Val Ser Val Leu Thr Val Leu His
Gln Asp Trp Leu Asn Gly305 310 315 320Lys Glu Tyr Lys Cys Lys Val
Ser Asn Lys Ala Leu Pro Ala Pro Ile 325 330 335Glu Lys Thr Ile Ser
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val 340 345 350Tyr Thr Leu
Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser 355 360 365Leu
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu 370 375
380Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
Pro385 390 395 400Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
Lys Leu Thr Val 405 410 415Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
Phe Ser Cys Ser Val Met 420 425 430His Glu Ala Leu His Asn His Tyr
Thr Gln Lys Ser Leu Ser Leu Ser 435 440 445Pro Gly Lys
4501511PRTOryctolagus cuniculus 15Gln Ala Ser Gln Asn Ile Tyr Ser
Asn Leu Ala1 5 10167PRTOryctolagus cuniculus 16Gly Ala Ser Asn Leu
Asp Ala1 51712PRTOryctolagus cuniculus 17Gln Ser Ala Phe Asp Ser
Asp Ser Thr Glu Asn Thr1 5 10185PRTOryctolagus cuniculus 18Ser Tyr
Ala Met Ser1 51916PRTArtificial SequenceChemically Synthesized
19Val Ile Thr Ser Ile Gly Ser Thr Val Tyr Ala Ser Ser Ala Lys Gly1
5 10 152013PRTOryctolagus cuniculus 20Gly Tyr Asp Asp Tyr Asp Glu
Met Thr Tyr Phe Asn Ile1 5 1021111PRTOryctolagus cuniculus 21Ala
Val Leu Thr Gln Thr Pro Ser Pro Val Ser Ala Ala Met Gly Asp1 5 10
15Thr Val Thr Ile Lys Cys Gln Ser Ser Gln Ser Val Tyr Lys Asn Asn
20 25 30Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Arg Leu
Leu 35 40 45Ile Tyr Asp Ala Ser Asn Leu Pro Ser Gly Val Pro Ser Arg
Phe Ser 50 55 60Gly Ser Gly Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser
Gly Val Gln65 70 75 80Cys Asp Asp Ala Ala Thr Tyr Tyr Cys Leu Gly
Asp Tyr Asp Asp Asp 85 90 95Ala Asp Asn Ala Phe Gly Gly Gly Thr Glu
Val Val Val Lys Arg 100 105 11022217PRTArtificial
SequenceChemically Synthesized 22Ala Val Leu Thr Gln Thr Pro Ser
Pro Val Ser Ala Ala Met Gly Asp1 5 10 15Thr Val Thr Ile Lys Cys Gln
Ser Ser Gln Ser Val Tyr Lys Asn Asn 20 25 30Tyr Leu Ser Trp Tyr Gln
Gln Lys Pro Gly Gln Pro Pro Arg Leu Leu 35 40 45Ile Tyr Asp Ala Ser
Asn Leu Pro Ser Gly Val Pro Ser Arg Phe Ser 50 55 60Gly Ser Gly Ser
Gly Thr Gln Phe Thr Leu Thr Ile Ser Gly Val Gln65 70 75 80Cys Asp
Asp Ala Ala Thr Tyr Tyr Cys Leu Gly Asp Tyr Asp Asp Asp 85 90 95Ala
Asp Asn Ala Phe Gly Gly Gly Thr Glu Val Val Val Lys Arg Thr 100 105
110Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
115 120 125Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
Tyr Pro 130 135 140Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
Leu Gln Ser Gly145 150 155 160Asn Ser Gln Glu Ser Val Thr Glu Gln
Asp Ser Lys Asp Ser Thr Tyr 165 170 175Ser Leu Ser Ser Thr Leu Thr
Leu Ser Lys Ala Asp Tyr Glu Lys His 180 185 190Lys Val Tyr Ala Cys
Glu Val Thr His Gln Gly Leu Ser Ser Pro Val 195 200 205Thr Lys Ser
Phe Asn Arg Gly Glu Cys 210 21523113PRTOryctolagus cuniculus 23Gln
Ser Val Glu Glu Ser Gly Gly Arg Leu Val Thr Pro Gly Thr Pro1 5 10
15Leu Thr Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Ser Ser Tyr Val
20 25 30Met Ile Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Tyr Ile
Gly 35 40 45Ile Thr Trp Ser Ala Gly Thr Tyr Tyr Ala Ser Trp Ala Lys
Gly Arg 50 55 60Phe Thr Ile Ser Lys Thr Ser Ser Thr Thr Val Asp Leu
Lys Ile Thr65 70 75 80Ser Pro Thr Thr Glu Asp Thr Ala Thr Tyr Phe
Cys Ala Gly Gly Gly 85 90 95Gly Ser Ile Tyr Asp Ile Trp Gly Pro Gly
Thr Leu Val Thr Val Ser 100 105
110Ser24443PRTArtificial SequenceChemically Synthesized 24Gln Ser
Val Glu Glu Ser Gly Gly Arg Leu Val Thr Pro Gly Thr Pro1 5 10 15Leu
Thr Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Ser Ser Tyr Val 20 25
30Met Ile Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Tyr Ile Gly
35 40 45Ile Thr Trp Ser Ala Gly Thr Tyr Tyr Ala Ser Trp Ala Lys Gly
Arg 50 55 60Phe Thr Ile Ser Lys Thr Ser Ser Thr Thr Val Asp Leu Lys
Ile Thr65 70 75 80Ser Pro Thr Thr Glu Asp Thr Ala Thr Tyr Phe Cys
Ala Gly Gly Gly 85 90 95Gly Ser Ile Tyr Asp Ile Trp Gly Pro Gly Thr
Leu Val Thr Val Ser 100 105 110Ser Ala Ser Thr Lys Gly Pro Ser Val
Phe Pro Leu Ala Pro Ser Ser 115 120 125Lys Ser Thr Ser Gly Gly Thr
Ala Ala Leu Gly Cys Leu Val Lys Asp 130 135 140Tyr Phe Pro Glu Pro
Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr145 150 155 160Ser Gly
Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr 165 170
175Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln
180 185 190Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
Val Asp 195 200 205Lys Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His
Thr Cys Pro Pro 210 215 220Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
Ser Val Phe Leu Phe Pro225 230 235 240Pro Lys Pro Lys Asp Thr Leu
Met Ile Ser Arg Thr Pro Glu Val Thr 245 250 255Cys Val Val Val Asp
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn 260 265 270Trp Tyr Val
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg 275 280 285Glu
Glu Gln Tyr Ala Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val 290 295
300Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
Ser305 310 315 320Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
Ser Lys Ala Lys 325 330 335Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
Leu Pro Pro Ser Arg Glu 340 345 350Glu Met Thr Lys Asn Gln Val Ser
Leu Thr Cys Leu Val Lys Gly Phe 355 360 365Tyr Pro Ser Asp Ile Ala
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu 370 375 380Asn Asn Tyr Lys
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe385 390 395 400Phe
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly 405 410
415Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
420 425 430Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 435
4402513PRTOryctolagus cuniculus 25Gln Ser Ser Gln Ser Val Tyr Lys
Asn Asn Tyr Leu Ser1 5 10267PRTOryctolagus cuniculus 26Asp Ala Ser
Asn Leu Pro Ser1 52711PRTOryctolagus cuniculus 27Leu Gly Asp Tyr
Asp Asp Asp Ala Asp Asn Ala1 5 10285PRTOryctolagus cuniculus 28Ser
Tyr Val Met Ile1 52915PRTOryctolagus cuniculus 29Ile Thr Trp Ser
Ala Gly Thr Tyr Tyr Ala Ser Trp Ala Lys Gly1 5 10
15308PRTOryctolagus cuniculus 30Gly Gly Gly Ser Ile Tyr Asp Ile1
531112PRTArtificial SequenceChemically Synthesized 31Asp Ile Gln
Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg
Val Thr Ile Thr Cys Gln Ser Ser Gln Ser Val Tyr Lys Asn 20 25 30Asn
Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu 35 40
45Leu Ile Tyr Asp Ala Ser Asn Leu Pro Ser Gly Val Pro Ser Arg Phe
50 55 60Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser
Leu65 70 75 80Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Leu Gly Asp
Tyr Asp Asp 85 90 95Asp Ala Asp Asn Ala Phe Gly Gly Gly Thr Lys Val
Glu Ile Lys Arg 100 105 11032218PRTArtificial SequenceChemically
Synthesized 32Asp Ile Gln Met Thr Gln Ser Pro Ser Thr Leu Ser Ala
Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Gln Ser Ser Gln Ser
Val Tyr Lys Asn 20 25 30Asn Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly
Lys Ala Pro Lys Leu 35 40 45Leu Ile Tyr Asp Ala Ser Asn Leu Pro Ser
Gly Val Pro Ser Arg Phe 50 55 60Ser Gly Ser Gly Ser Gly Thr Glu Phe
Thr Leu Thr Ile Ser Ser Leu65 70 75 80Gln Pro Asp Asp Phe Ala Thr
Tyr Tyr Cys Leu Gly Asp Tyr Asp Asp 85 90 95Asp Ala Asp Asn Ala Phe
Gly Gly Gly Thr Lys Val Glu Ile Lys Arg 100 105 110Thr Val Ala Ala
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln 115 120 125Leu Lys
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr 130 135
140Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
Ser145 150 155 160Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser
Lys Asp Ser Thr 165 170 175Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser
Lys Ala Asp Tyr Glu Lys 180 185 190His Lys Val Tyr Ala Cys Glu Val
Thr His Gln Gly Leu Ser Ser Pro 195 200 205Val Thr Lys Ser Phe Asn
Arg Gly Glu Cys 210 21533115PRTArtificial SequenceChemically
Synthesized 33Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
Val Ser Ser Tyr 20 25 30Val Met Ile Trp Val Arg Gln Ala Pro Gly Lys
Gly Leu Glu Tyr Ile 35 40 45Gly Ile Thr Trp Ser Ala Gly Thr Tyr Tyr
Ala Ser Ser Ala Lys Gly 50 55 60Arg Phe Thr Ile Ser Arg Asp Asn Ser
Lys Asn Thr Leu Tyr Leu Gln65 70 75 80Met Asn Ser Leu Arg Ala Glu
Asp Thr Ala Val Tyr Tyr Cys Ala Gly 85 90 95Gly Gly Gly Ser Ile Tyr
Asp Ile Trp Gly Gln Gly Thr Leu Val Thr 100 105 110Val Ser Ser
11534445PRTArtificial SequenceChemically Synthesized 34Glu Val Gln
Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Val Ser Ser Tyr 20 25 30Val
Met Ile Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Tyr Ile 35 40
45Gly Ile Thr Trp Ser Ala Gly Thr Tyr Tyr Ala Ser Ser Ala Lys Gly
50 55 60Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
Gln65 70 75 80Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
Cys Ala Gly 85 90 95Gly Gly Gly Ser Ile Tyr Asp Ile Trp Gly Gln Gly
Thr Leu Val Thr 100 105 110Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
Val Phe Pro Leu Ala Pro 115 120 125Ser Ser Lys Ser Thr Ser Gly Gly
Thr Ala Ala Leu Gly Cys Leu Val 130 135 140Lys Asp Tyr Phe Pro Glu
Pro Val Thr Val Ser Trp Asn Ser Gly Ala145 150 155 160Leu Thr Ser
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly 165 170 175Leu
Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly 180 185
190Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
195 200 205Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His
Thr Cys 210 215 220Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
Ser Val Phe Leu225 230 235 240Phe Pro Pro Lys Pro Lys Asp Thr Leu
Met Ile Ser Arg Thr Pro Glu 245 250 255Val Thr Cys Val Val Val Asp
Val Ser His Glu Asp Pro Glu Val Lys 260 265 270Phe Asn Trp Tyr Val
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys 275 280 285Pro Arg Glu
Glu Gln Tyr Ala Ser Thr Tyr Arg Val Val Ser Val Leu 290 295 300Thr
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys305 310
315 320Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
Lys 325 330 335Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
Pro Pro Ser 340 345 350Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu
Thr Cys Leu Val Lys 355 360 365Gly Phe Tyr Pro Ser Asp Ile Ala Val
Glu Trp Glu Ser Asn Gly Gln 370 375 380Pro Glu Asn Asn Tyr Lys Thr
Thr Pro Pro Val Leu Asp Ser Asp Gly385 390 395 400Ser Phe Phe Leu
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln 405 410 415Gln Gly
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn 420 425
430His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 435 440
4453513PRTOryctolagus cuniculus 35Gln Ser Ser Gln Ser Val Tyr Lys
Asn Asn Tyr Leu Ser1 5 10367PRTOryctolagus cuniculus 36Asp Ala Ser
Asn Leu Pro Ser1 53711PRTOryctolagus cuniculus 37Leu Gly Asp Tyr
Asp Asp Asp Ala Asp Asn Ala1 5 10385PRTOryctolagus cuniculus 38Ser
Tyr Val Met Ile1 53915PRTArtificial SequenceChemically Synthesized
39Ile Thr Trp Ser Ala Gly Thr Tyr Tyr Ala Ser Ser Ala Lys Gly1 5 10
15408PRTOryctolagus cuniculus 40Gly Gly Gly Ser Ile Tyr Asp Ile1
541111PRTOryctolagus cuniculus 41Ala Tyr Asp Met Thr Gln Thr Pro
Ala Ser Val Glu Val Ala Val Gly1 5 10 15Gly Thr Val Thr Ile Lys Cys
Gln Ala Ser Gln Ser Ile Tyr Ser Asn 20 25 30Leu Ala Trp Tyr Gln Gln
Arg Pro Gly Gln Pro Pro Lys Leu Leu Ile 35 40 45Tyr Asp Ala Ser Thr
Leu Glu Ser Gly Val Pro Ser Arg Phe Lys Gly 50 55 60Ser Gly Ser Gly
Thr Glu Tyr Thr Leu Thr Ile Ser Gly Val Glu Cys65 70 75 80Ala Asp
Ala Ala Ser Tyr Tyr Cys Gln Gln Gly Phe Thr Val Ser Asp 85 90 95Ile
Asp Asn Ala Phe Gly Gly Gly Thr Glu Val Val Val Lys Arg 100 105
11042217PRTArtificial SequenceChemically Synthesized 42Ala Tyr Asp
Met Thr Gln Thr Pro Ala Ser Val Glu Val Ala Val Gly1 5 10 15Gly Thr
Val Thr Ile Lys Cys Gln Ala Ser Gln Ser Ile Tyr Ser Asn 20 25 30Leu
Ala Trp Tyr Gln Gln Arg Pro Gly Gln Pro Pro Lys Leu Leu Ile 35 40
45Tyr Asp Ala Ser Thr Leu Glu Ser Gly Val Pro Ser Arg Phe Lys Gly
50 55 60Ser Gly Ser Gly Thr Glu Tyr Thr Leu Thr Ile Ser Gly Val Glu
Cys65 70 75 80Ala Asp Ala Ala Ser Tyr Tyr Cys Gln Gln Gly Phe Thr
Val Ser Asp 85 90 95Ile Asp Asn Ala Phe Gly Gly Gly Thr Glu Val Val
Val Lys Arg Thr 100 105 110Val Ala Ala Pro Ser Val Phe Ile Phe Pro
Pro Ser Asp Glu Gln Leu 115 120 125Lys Ser Gly Thr Ala Ser Val Val
Cys Leu Leu Asn Asn Phe Tyr Pro 130 135 140Arg Glu Ala Lys Val Gln
Trp Lys Val Asp Asn Ala Leu Gln Ser Gly145 150 155 160Asn Ser Gln
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr 165 170 175Ser
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His 180 185
190Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
195 200 205Thr Lys Ser Phe Asn Arg Gly Glu Cys 210
21543118PRTOryctolagus cuniculus 43Gln Ser Val Glu Glu Ser Gly Gly
Arg Leu Val Thr Pro Gly Thr Pro1 5 10 15Leu Thr Leu Thr Cys Thr Val
Ser Gly Phe Ser Leu Ser Asn Tyr Ala 20 25 30Val Gly Trp Val Arg Gln
Ala Pro Gly Lys Gly Leu Glu Trp Ile Gly 35 40 45Ile Ile Gly Arg Asn
Gly Asn Thr Trp Tyr Ala Ser Trp Ala Arg Gly 50 55 60Arg Phe Thr Ile
Ser Lys Thr Ser Thr Thr Val Asp Leu Lys Ile Thr65 70 75 80Ser Pro
Thr Ser Glu Asp Thr Ala Thr Tyr Phe Cys Ala Arg Gly Tyr 85 90 95Gly
Arg Ser Val Ala Tyr Tyr Val Phe Asn Ile Trp Gly Pro Gly Thr 100 105
110Leu Val Thr Val Ser Ser 11544448PRTArtificial SequenceChemically
Synthesized 44Gln Ser Val Glu Glu Ser Gly Gly Arg Leu Val Thr Pro
Gly Thr Pro1 5 10 15Leu Thr Leu Thr Cys Thr Val Ser Gly Phe Ser Leu
Ser Asn Tyr Ala 20 25 30Val Gly Trp Val Arg Gln Ala Pro Gly Lys Gly
Leu Glu Trp Ile Gly 35 40 45Ile Ile Gly Arg Asn Gly Asn Thr Trp Tyr
Ala Ser Trp Ala Arg Gly 50 55 60Arg Phe Thr Ile Ser Lys Thr Ser Thr
Thr Val Asp Leu Lys Ile Thr65 70 75 80Ser Pro Thr Ser Glu Asp Thr
Ala Thr Tyr Phe Cys Ala Arg Gly Tyr 85 90 95Gly Arg Ser Val Ala Tyr
Tyr Val Phe Asn Ile Trp Gly Pro Gly Thr 100 105 110Leu Val Thr Val
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro 115 120 125Leu Ala
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly 130 135
140Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
Asn145 150 155 160Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
Ala Val Leu Gln 165 170 175Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
Val Thr Val Pro Ser Ser 180 185 190Ser Leu Gly Thr Gln Thr Tyr Ile
Cys Asn Val Asn His Lys Pro Ser 195 200 205Asn Thr Lys Val Asp Lys
Arg Val Glu Pro Lys Ser Cys Asp Lys Thr 210 215 220His Thr Cys Pro
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser225 230 235 240Val
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg 245 250
255Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
260 265 270Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
Asn Ala 275 280 285Lys Thr Lys Pro Arg Glu Glu Gln Tyr Ala Ser Thr
Tyr Arg Val Val 290 295 300Ser Val Leu Thr Val Leu His Gln Asp Trp
Leu Asn Gly Lys Glu Tyr305 310 315 320Lys Cys Lys Val Ser Asn Lys
Ala Leu Pro Ala Pro Ile Glu Lys Thr 325 330 335Ile Ser Lys Ala Lys
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu 340 345 350Pro Pro Ser
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys 355 360 365Leu
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser 370 375
380Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
Asp385 390 395 400Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
Val Asp Lys Ser 405 410 415Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
Ser Val Met His Glu Ala 420 425 430Leu His Asn His Tyr Thr Gln Lys
Ser Leu Ser Leu Ser Pro Gly Lys 435 440 4454511PRTOryctolagus
cuniculus 45Gln Ala Ser Gln Ser Ile Tyr Ser Asn Leu Ala1 5
10467PRTOryctolagus cuniculus
46Asp Ala Ser Thr Leu Glu Ser1 54712PRTOryctolagus cuniculus 47Gln
Gln Gly Phe Thr Val Ser Asp Ile Asp Asn Ala1 5 10485PRTOryctolagus
cuniculus 48Asn Tyr Ala Val Gly1 54916PRTOryctolagus cuniculus
49Ile Ile Gly Arg Asn Gly Asn Thr Trp Tyr Ala Ser Trp Ala Arg Gly1
5 10 155013PRTOryctolagus cuniculus 50Gly Tyr Gly Arg Ser Val Ala
Tyr Tyr Val Phe Asn Ile1 5 1051111PRTArtificial SequenceChemically
Synthesized 51Asp Ile Gln Met Thr Gln Ser Pro Ser Thr Leu Ser Ala
Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Ser
Ile Tyr Ser Asn 20 25 30Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala
Pro Lys Leu Leu Ile 35 40 45Tyr Asp Ala Ser Thr Leu Glu Ser Gly Val
Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly Ser Gly Thr Glu Tyr Thr Leu
Thr Ile Ser Ser Leu Gln Pro65 70 75 80Asp Asp Phe Ala Thr Tyr Tyr
Cys Gln Gln Gly Phe Thr Val Ser Asp 85 90 95Ile Asp Asn Ala Phe Gly
Gly Gly Thr Lys Val Glu Ile Lys Arg 100 105 11052217PRTArtificial
SequenceChemically Synthesized 52Asp Ile Gln Met Thr Gln Ser Pro
Ser Thr Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys
Gln Ala Ser Gln Ser Ile Tyr Ser Asn 20 25 30Leu Ala Trp Tyr Gln Gln
Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Asp Ala Ser Thr
Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly Ser Gly
Thr Glu Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro65 70 75 80Asp Asp
Phe Ala Thr Tyr Tyr Cys Gln Gln Gly Phe Thr Val Ser Asp 85 90 95Ile
Asp Asn Ala Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr 100 105
110Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
115 120 125Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
Tyr Pro 130 135 140Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
Leu Gln Ser Gly145 150 155 160Asn Ser Gln Glu Ser Val Thr Glu Gln
Asp Ser Lys Asp Ser Thr Tyr 165 170 175Ser Leu Ser Ser Thr Leu Thr
Leu Ser Lys Ala Asp Tyr Glu Lys His 180 185 190Lys Val Tyr Ala Cys
Glu Val Thr His Gln Gly Leu Ser Ser Pro Val 195 200 205Thr Lys Ser
Phe Asn Arg Gly Glu Cys 210 21553121PRTArtificial
SequenceChemically Synthesized 53Glu Val Gln Leu Val Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala
Ala Ser Gly Phe Thr Val Ser Asn Tyr 20 25 30Ala Val Gly Trp Val Arg
Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40 45Gly Ile Ile Gly Arg
Asn Gly Asn Thr Trp Tyr Ala Ser Ser Ala Arg 50 55 60Gly Arg Phe Thr
Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu65 70 75 80Gln Met
Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg
Gly Tyr Gly Arg Ser Val Ala Tyr Tyr Val Phe Asn Ile Trp Gly 100 105
110Pro Gly Thr Leu Val Thr Val Ser Ser 115 12054451PRTArtificial
SequenceChemically Synthesized 54Glu Val Gln Leu Val Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala
Ala Ser Gly Phe Thr Val Ser Asn Tyr 20 25 30Ala Val Gly Trp Val Arg
Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40 45Gly Ile Ile Gly Arg
Asn Gly Asn Thr Trp Tyr Ala Ser Ser Ala Arg 50 55 60Gly Arg Phe Thr
Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu65 70 75 80Gln Met
Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg
Gly Tyr Gly Arg Ser Val Ala Tyr Tyr Val Phe Asn Ile Trp Gly 100 105
110Pro Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
Thr Ala 130 135 140Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
Pro Val Thr Val145 150 155 160Ser Trp Asn Ser Gly Ala Leu Thr Ser
Gly Val His Thr Phe Pro Ala 165 170 175Val Leu Gln Ser Ser Gly Leu
Tyr Ser Leu Ser Ser Val Val Thr Val 180 185 190Pro Ser Ser Ser Leu
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His 195 200 205Lys Pro Ser
Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys 210 215 220Asp
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly225 230
235 240Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
Met 245 250 255Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
Val Ser His 260 265 270Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
Asp Gly Val Glu Val 275 280 285His Asn Ala Lys Thr Lys Pro Arg Glu
Glu Gln Tyr Ala Ser Thr Tyr 290 295 300Arg Val Val Ser Val Leu Thr
Val Leu His Gln Asp Trp Leu Asn Gly305 310 315 320Lys Glu Tyr Lys
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile 325 330 335Glu Lys
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val 340 345
350Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser
355 360 365Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
Val Glu 370 375 380Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
Thr Thr Pro Pro385 390 395 400Val Leu Asp Ser Asp Gly Ser Phe Phe
Leu Tyr Ser Lys Leu Thr Val 405 410 415Asp Lys Ser Arg Trp Gln Gln
Gly Asn Val Phe Ser Cys Ser Val Met 420 425 430His Glu Ala Leu His
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser 435 440 445Pro Gly Lys
4505511PRTOryctolagus cuniculus 55Gln Ala Ser Gln Ser Ile Tyr Ser
Asn Leu Ala1 5 10567PRTOryctolagus cuniculus 56Asp Ala Ser Thr Leu
Glu Ser1 55712PRTOryctolagus cuniculus 57Gln Gln Gly Phe Thr Val
Ser Asp Ile Asp Asn Ala1 5 10585PRTOryctolagus cuniculus 58Asn Tyr
Ala Val Gly1 55916PRTArtificial SequenceChemically Synthesized
59Ile Ile Gly Arg Asn Gly Asn Thr Trp Tyr Ala Ser Ser Ala Arg Gly1
5 10 156013PRTOryctolagus cuniculus 60Gly Tyr Gly Arg Ser Val Ala
Tyr Tyr Val Phe Asn Ile1 5 1061112PRTOryctolagus cuniculus 61Ala
Asp Val Val Met Thr Gln Thr Pro Ala Ser Val Ser Gln Pro Val1 5 10
15Gly Gly Thr Val Thr Ile Lys Cys Gln Ala Ser Glu Asp Ile Tyr Asn
20 25 30Leu Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
Leu 35 40 45Ile Tyr Ser Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg
Phe Lys 50 55 60Gly Ser Gly Ser Gly Thr Glu Tyr Thr Leu Thr Ile Ser
Gly Leu Glu65 70 75 80Cys Ala Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
Asn Tyr Leu Val Thr 85 90 95Thr Tyr Gly Val Ala Phe Gly Gly Gly Thr
Glu Val Val Val Lys Arg 100 105 11062218PRTArtificial
SequenceChemically Synthesized 62Ala Asp Val Val Met Thr Gln Thr
Pro Ala Ser Val Ser Gln Pro Val1 5 10 15Gly Gly Thr Val Thr Ile Lys
Cys Gln Ala Ser Glu Asp Ile Tyr Asn 20 25 30Leu Leu Ala Trp Tyr Gln
Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu 35 40 45Ile Tyr Ser Ala Ser
Thr Leu Ala Ser Gly Val Pro Ser Arg Phe Lys 50 55 60Gly Ser Gly Ser
Gly Thr Glu Tyr Thr Leu Thr Ile Ser Gly Leu Glu65 70 75 80Cys Ala
Asp Ala Ala Thr Tyr Tyr Cys Gln Asn Asn Tyr Leu Val Thr 85 90 95Thr
Tyr Gly Val Ala Phe Gly Gly Gly Thr Glu Val Val Val Lys Arg 100 105
110Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
Phe Tyr 130 135 140Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
Ala Leu Gln Ser145 150 155 160Gly Asn Ser Gln Glu Ser Val Thr Glu
Gln Asp Ser Lys Asp Ser Thr 165 170 175Tyr Ser Leu Ser Ser Thr Leu
Thr Leu Ser Lys Ala Asp Tyr Glu Lys 180 185 190His Lys Val Tyr Ala
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro 195 200 205Val Thr Lys
Ser Phe Asn Arg Gly Glu Cys 210 21563120PRTOryctolagus cuniculus
63Gln Glu Gln Leu Lys Glu Ser Gly Gly Arg Leu Val Thr Pro Gly Thr1
5 10 15Pro Leu Thr Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Ser Ser
Tyr 20 25 30Ala Met Ile Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
Tyr Ile 35 40 45Gly Tyr Ile Asp Thr Asp Thr Ser Ala Tyr Tyr Ala Ser
Trp Val Lys 50 55 60Gly Arg Phe Thr Ile Ser Arg Thr Ser Thr Thr Val
Asp Leu Lys Ile65 70 75 80Thr Ser Pro Thr Thr Glu Asp Thr Ala Thr
Tyr Phe Cys Ala Arg Ser 85 90 95Tyr Ala Ala Tyr Gly Gly Tyr Pro Ala
Thr Phe Asp Pro Trp Gly Pro 100 105 110Gly Thr Leu Val Thr Val Ser
Ser 115 12064450PRTArtificial SequenceChemically Synthesized 64Gln
Glu Gln Leu Lys Glu Ser Gly Gly Arg Leu Val Thr Pro Gly Thr1 5 10
15Pro Leu Thr Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Ser Ser Tyr
20 25 30Ala Met Ile Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Tyr
Ile 35 40 45Gly Tyr Ile Asp Thr Asp Thr Ser Ala Tyr Tyr Ala Ser Trp
Val Lys 50 55 60Gly Arg Phe Thr Ile Ser Arg Thr Ser Thr Thr Val Asp
Leu Lys Ile65 70 75 80Thr Ser Pro Thr Thr Glu Asp Thr Ala Thr Tyr
Phe Cys Ala Arg Ser 85 90 95Tyr Ala Ala Tyr Gly Gly Tyr Pro Ala Thr
Phe Asp Pro Trp Gly Pro 100 105 110Gly Thr Leu Val Thr Val Ser Ser
Ala Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro Ser
Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys Leu
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155 160Trp
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val 165 170
175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro
Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys Pro Ala
Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu Phe Pro
Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr Pro Glu
Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp Pro Glu
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280 285Asn
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Ala Ser Thr Tyr Arg 290 295
300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
Ala Pro Ile Glu 325 330 335Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu Glu
Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys Gly
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn Gly
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val385 390 395 400Leu
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp 405 410
415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
Ser Pro 435 440 445Gly Lys 4506511PRTOryctolagus cuniculus 65Gln
Ala Ser Glu Asp Ile Tyr Asn Leu Leu Ala1 5 10667PRTOryctolagus
cuniculus 66Ser Ala Ser Thr Leu Ala Ser1 56712PRTOryctolagus
cuniculus 67Gln Asn Asn Tyr Leu Val Thr Thr Tyr Gly Val Ala1 5
10685PRTOryctolagus cuniculus 68Ser Tyr Ala Met Ile1
56916PRTOryctolagus cuniculus 69Tyr Ile Asp Thr Asp Thr Ser Ala Tyr
Tyr Ala Ser Trp Val Lys Gly1 5 10 157014PRTOryctolagus cuniculus
70Ser Tyr Ala Ala Tyr Gly Gly Tyr Pro Ala Thr Phe Asp Pro1 5
1071111PRTArtificial SequenceChemically Synthesized 71Asp Ile Gln
Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg
Val Thr Ile Thr Cys Gln Ala Ser Glu Asp Ile Tyr Asn Leu 20 25 30Leu
Ala Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu Leu Ile 35 40
45Tyr Ser Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln
Pro65 70 75 80Glu Asp Val Ala Thr Tyr Tyr Cys Gln Asn Asn Tyr Leu
Val Thr Thr 85 90 95Tyr Gly Val Ala Phe Gly Gly Gly Thr Lys Val Glu
Ile Lys Arg 100 105 11072217PRTArtificial SequenceChemically
Synthesized 72Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala
Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Glu Asp
Ile Tyr Asn Leu 20 25 30Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Val
Pro Lys Leu Leu Ile 35 40 45Tyr Ser Ala Ser Thr Leu Ala Ser Gly Val
Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly Ser Gly Thr Asp Tyr Thr Leu
Thr Ile Ser Ser Leu Gln Pro65 70 75 80Glu Asp Val Ala Thr Tyr Tyr
Cys Gln Asn Asn Tyr Leu Val Thr Thr 85 90 95Tyr Gly Val Ala Phe Gly
Gly Gly Thr Lys Val Glu Ile Lys Arg Thr 100 105 110Val Ala Ala Pro
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu 115 120 125Lys Ser
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro 130 135
140Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
Gly145 150 155 160Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
Asp Ser Thr Tyr 165 170 175Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys
Ala Asp Tyr Glu Lys His 180 185 190Lys Val Tyr Ala Cys Glu Val Thr
His Gln Gly Leu Ser Ser Pro Val 195 200 205Thr Lys Ser Phe Asn Arg
Gly Glu Cys 210 21573122PRTArtificial SequenceChemically
Synthesized 73Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln
Pro Gly Arg1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
Phe Ser Ser Tyr
20 25 30Ala Met Ile Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Tyr
Ile 35 40 45Gly Tyr Ile Asp Thr Asp Thr Ser Ala Tyr Tyr Ala Ser Ser
Val Lys 50 55 60Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr
Leu Tyr Leu65 70 75 80Gln Met Ser Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Tyr Cys Ala 85 90 95Arg Ser Tyr Ala Ala Tyr Gly Gly Tyr Pro
Ala Thr Phe Asp Pro Trp 100 105 110Gly Gln Gly Thr Leu Val Thr Val
Ser Ser 115 12074452PRTArtificial SequenceChemically Synthesized
74Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg1
5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser
Tyr 20 25 30Ala Met Ile Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
Tyr Ile 35 40 45Gly Tyr Ile Asp Thr Asp Thr Ser Ala Tyr Tyr Ala Ser
Ser Val Lys 50 55 60Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn
Thr Leu Tyr Leu65 70 75 80Gln Met Ser Ser Leu Arg Ala Glu Asp Thr
Ala Val Tyr Tyr Cys Ala 85 90 95Arg Ser Tyr Ala Ala Tyr Gly Gly Tyr
Pro Ala Thr Phe Asp Pro Trp 100 105 110Gly Gln Gly Thr Leu Val Thr
Val Ser Ser Ala Ser Thr Lys Gly Pro 115 120 125Ser Val Phe Pro Leu
Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr 130 135 140Ala Ala Leu
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr145 150 155
160Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
Val Thr 180 185 190Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile
Cys Asn Val Asn 195 200 205His Lys Pro Ser Asn Thr Lys Val Asp Lys
Arg Val Glu Pro Lys Ser 210 215 220Cys Asp Lys Thr His Thr Cys Pro
Pro Cys Pro Ala Pro Glu Leu Leu225 230 235 240Gly Gly Pro Ser Val
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu 245 250 255Met Ile Ser
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser 260 265 270His
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu 275 280
285Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Ala Ser Thr
290 295 300Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
Leu Asn305 310 315 320Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
Ala Leu Pro Ala Pro 325 330 335Ile Glu Lys Thr Ile Ser Lys Ala Lys
Gly Gln Pro Arg Glu Pro Gln 340 345 350Val Tyr Thr Leu Pro Pro Ser
Arg Glu Glu Met Thr Lys Asn Gln Val 355 360 365Ser Leu Thr Cys Leu
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val 370 375 380Glu Trp Glu
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro385 390 395
400Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
405 410 415Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
Ser Val 420 425 430Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
Ser Leu Ser Leu 435 440 445Ser Pro Gly Lys 4507511PRTOryctolagus
cuniculus 75Gln Ala Ser Glu Asp Ile Tyr Asn Leu Leu Ala1 5
10767PRTOryctolagus cuniculus 76Ser Ala Ser Thr Leu Ala Ser1
57712PRTOryctolagus cuniculus 77Gln Asn Asn Tyr Leu Val Thr Thr Tyr
Gly Val Ala1 5 10785PRTOryctolagus cuniculus 78Ser Tyr Ala Met Ile1
57916PRTArtificial SequenceChemically Synthesized 79Tyr Ile Asp Thr
Asp Thr Ser Ala Tyr Tyr Ala Ser Ser Val Lys Gly1 5 10
158014PRTOryctolagus cuniculus 80Ser Tyr Ala Ala Tyr Gly Gly Tyr
Pro Ala Thr Phe Asp Pro1 5 1081111PRTOryctolagus cuniculus 81Ala
Tyr Asp Met Thr Gln Thr Pro Ala Ser Val Ser Ala Ala Val Gly1 5 10
15Gly Thr Val Thr Ile Lys Cys Gln Ala Ser Glu Asn Ile Gly Ser Tyr
20 25 30Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Glu Leu Leu
Ile 35 40 45Tyr Arg Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg Phe
Lys Gly 50 55 60Ser Gly Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser Gly
Val Glu Cys65 70 75 80Ala Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Gly
Tyr Asn Ser Glu Asn 85 90 95Leu Asp Asn Ala Phe Gly Gly Gly Thr Glu
Val Val Val Lys Arg 100 105 11082217PRTArtificial
SequenceChemically Synthesized 82Ala Tyr Asp Met Thr Gln Thr Pro
Ala Ser Val Ser Ala Ala Val Gly1 5 10 15Gly Thr Val Thr Ile Lys Cys
Gln Ala Ser Glu Asn Ile Gly Ser Tyr 20 25 30Leu Ala Trp Tyr Gln Gln
Lys Pro Gly Gln Pro Pro Glu Leu Leu Ile 35 40 45Tyr Arg Ala Ser Thr
Leu Ala Ser Gly Val Pro Ser Arg Phe Lys Gly 50 55 60Ser Gly Ser Gly
Thr Gln Phe Thr Leu Thr Ile Ser Gly Val Glu Cys65 70 75 80Ala Asp
Ala Ala Thr Tyr Tyr Cys Gln Gln Gly Tyr Asn Ser Glu Asn 85 90 95Leu
Asp Asn Ala Phe Gly Gly Gly Thr Glu Val Val Val Lys Arg Thr 100 105
110Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
115 120 125Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
Tyr Pro 130 135 140Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
Leu Gln Ser Gly145 150 155 160Asn Ser Gln Glu Ser Val Thr Glu Gln
Asp Ser Lys Asp Ser Thr Tyr 165 170 175Ser Leu Ser Ser Thr Leu Thr
Leu Ser Lys Ala Asp Tyr Glu Lys His 180 185 190Lys Val Tyr Ala Cys
Glu Val Thr His Gln Gly Leu Ser Ser Pro Val 195 200 205Thr Lys Ser
Phe Asn Arg Gly Glu Cys 210 21583115PRTOryctolagus cuniculus 83Gln
Ser Val Glu Glu Ser Gly Gly Arg Leu Val Thr Pro Gly Thr Pro1 5 10
15Leu Thr Leu Thr Cys Thr Val Ser Gly Ile Asp Leu Ser Met Tyr Ser
20 25 30Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Tyr Ile
Gly 35 40 45Trp Ile Ser Tyr Gly Gly Thr Ala Tyr Tyr Ala Ser Trp Ala
Lys Gly 50 55 60Arg Phe Thr Ile Ser Lys Thr Ser Thr Thr Val Glu Leu
Lys Ile Thr65 70 75 80Ser Pro Thr Ile Glu Asp Thr Ala Thr Tyr Phe
Cys Ala Arg Glu Thr 85 90 95Pro Val Asn Tyr Tyr Leu Asp Ile Trp Gly
Gln Gly Thr Leu Val Thr 100 105 110Val Ser Ser
11584445PRTArtificial SequenceChemically Synthesized 84Gln Ser Val
Glu Glu Ser Gly Gly Arg Leu Val Thr Pro Gly Thr Pro1 5 10 15Leu Thr
Leu Thr Cys Thr Val Ser Gly Ile Asp Leu Ser Met Tyr Ser 20 25 30Met
Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Tyr Ile Gly 35 40
45Trp Ile Ser Tyr Gly Gly Thr Ala Tyr Tyr Ala Ser Trp Ala Lys Gly
50 55 60Arg Phe Thr Ile Ser Lys Thr Ser Thr Thr Val Glu Leu Lys Ile
Thr65 70 75 80Ser Pro Thr Ile Glu Asp Thr Ala Thr Tyr Phe Cys Ala
Arg Glu Thr 85 90 95Pro Val Asn Tyr Tyr Leu Asp Ile Trp Gly Gln Gly
Thr Leu Val Thr 100 105 110Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
Val Phe Pro Leu Ala Pro 115 120 125Ser Ser Lys Ser Thr Ser Gly Gly
Thr Ala Ala Leu Gly Cys Leu Val 130 135 140Lys Asp Tyr Phe Pro Glu
Pro Val Thr Val Ser Trp Asn Ser Gly Ala145 150 155 160Leu Thr Ser
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly 165 170 175Leu
Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly 180 185
190Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
195 200 205Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His
Thr Cys 210 215 220Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
Ser Val Phe Leu225 230 235 240Phe Pro Pro Lys Pro Lys Asp Thr Leu
Met Ile Ser Arg Thr Pro Glu 245 250 255Val Thr Cys Val Val Val Asp
Val Ser His Glu Asp Pro Glu Val Lys 260 265 270Phe Asn Trp Tyr Val
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys 275 280 285Pro Arg Glu
Glu Gln Tyr Ala Ser Thr Tyr Arg Val Val Ser Val Leu 290 295 300Thr
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys305 310
315 320Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
Lys 325 330 335Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
Pro Pro Ser 340 345 350Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu
Thr Cys Leu Val Lys 355 360 365Gly Phe Tyr Pro Ser Asp Ile Ala Val
Glu Trp Glu Ser Asn Gly Gln 370 375 380Pro Glu Asn Asn Tyr Lys Thr
Thr Pro Pro Val Leu Asp Ser Asp Gly385 390 395 400Ser Phe Phe Leu
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln 405 410 415Gln Gly
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn 420 425
430His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 435 440
4458511PRTOryctolagus cuniculus 85Gln Ala Ser Glu Asn Ile Gly Ser
Tyr Leu Ala1 5 10867PRTOryctolagus cuniculus 86Arg Ala Ser Thr Leu
Ala Ser1 58712PRTOryctolagus cuniculus 87Gln Gln Gly Tyr Asn Ser
Glu Asn Leu Asp Asn Ala1 5 10885PRTOryctolagus cuniculus 88Met Tyr
Ser Met Gly1 58916PRTOryctolagus cuniculus 89Trp Ile Ser Tyr Gly
Gly Thr Ala Tyr Tyr Ala Ser Trp Ala Lys Gly1 5 10
159010PRTOryctolagus cuniculus 90Glu Thr Pro Val Asn Tyr Tyr Leu
Asp Ile1 5 1091111PRTArtificial SequenceChemically Synthesized
91Ala Tyr Asp Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1
5 10 15Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Glu Asn Ile Gly Ser
Tyr 20 25 30Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu
Leu Ile 35 40 45Tyr Arg Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg
Phe Ser Gly 50 55 60Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
Ser Leu Gln Pro65 70 75 80Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln
Gly Tyr Asn Ser Glu Asn 85 90 95Leu Asp Asn Ala Phe Gly Gly Gly Thr
Lys Val Glu Ile Lys Arg 100 105 11092217PRTArtificial
SequenceChemically Synthesized 92Ala Tyr Asp Met Thr Gln Ser Pro
Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys
Gln Ala Ser Glu Asn Ile Gly Ser Tyr 20 25 30Leu Ala Trp Tyr Gln Gln
Lys Pro Gly Lys Val Pro Lys Leu Leu Ile 35 40 45Tyr Arg Ala Ser Thr
Leu Ala Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly Ser Gly
Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro65 70 75 80Glu Asp
Val Ala Thr Tyr Tyr Cys Gln Gln Gly Tyr Asn Ser Glu Asn 85 90 95Leu
Asp Asn Ala Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr 100 105
110Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
115 120 125Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
Tyr Pro 130 135 140Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
Leu Gln Ser Gly145 150 155 160Asn Ser Gln Glu Ser Val Thr Glu Gln
Asp Ser Lys Asp Ser Thr Tyr 165 170 175Ser Leu Ser Ser Thr Leu Thr
Leu Ser Lys Ala Asp Tyr Glu Lys His 180 185 190Lys Val Tyr Ala Cys
Glu Val Thr His Gln Gly Leu Ser Ser Pro Val 195 200 205Thr Lys Ser
Phe Asn Arg Gly Glu Cys 210 21593118PRTArtificial
SequenceChemically Synthesized 93Gln Val Gln Leu Val Glu Ser Gly
Gly Gly Val Val Gln Pro Gly Arg1 5 10 15Ser Leu Arg Leu Ser Cys Ala
Ala Ser Gly Phe Thr Phe Ser Met Tyr 20 25 30Ser Met Gly Trp Val Arg
Gln Ala Pro Gly Lys Gly Leu Glu Tyr Ile 35 40 45Gly Trp Ile Ser Tyr
Gly Gly Thr Ala Tyr Tyr Ala Ser Ser Ala Lys 50 55 60Gly Arg Phe Thr
Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu65 70 75 80Gln Met
Ser Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg
Glu Thr Pro Val Asn Tyr Tyr Leu Asp Ile Trp Gly Gln Gly Thr 100 105
110Leu Val Thr Val Ser Ser 11594448PRTArtificial SequenceChemically
Synthesized 94Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln
Pro Gly Arg1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
Phe Ser Met Tyr 20 25 30Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys
Gly Leu Glu Tyr Ile 35 40 45Gly Trp Ile Ser Tyr Gly Gly Thr Ala Tyr
Tyr Ala Ser Ser Ala Lys 50 55 60Gly Arg Phe Thr Ile Ser Arg Asp Asn
Ser Lys Asn Thr Leu Tyr Leu65 70 75 80Gln Met Ser Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Thr Pro Val Asn
Tyr Tyr Leu Asp Ile Trp Gly Gln Gly Thr 100 105 110Leu Val Thr Val
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro 115 120 125Leu Ala
Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly 130 135
140Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
Asn145 150 155 160Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
Ala Val Leu Gln 165 170 175Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val
Val Thr Val Pro Ser Ser 180 185 190Ser Leu Gly Thr Gln Thr Tyr Ile
Cys Asn Val Asn His Lys Pro Ser 195 200 205Asn Thr Lys Val Asp Lys
Arg Val Glu Pro Lys Ser Cys Asp Lys Thr 210 215 220His Thr Cys Pro
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser225 230 235 240Val
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg 245 250
255Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
260 265 270Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
Asn Ala 275 280 285Lys Thr Lys Pro Arg Glu Glu Gln Tyr Ala Ser Thr
Tyr Arg Val Val 290 295 300Ser Val Leu Thr Val Leu His Gln Asp Trp
Leu Asn Gly Lys Glu Tyr305 310 315 320Lys Cys Lys Val Ser Asn Lys
Ala Leu Pro Ala Pro Ile Glu Lys Thr 325 330 335Ile Ser Lys Ala Lys
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu 340 345 350Pro Pro Ser
Arg Glu Glu Met Thr Lys Asn
Gln Val Ser Leu Thr Cys 355 360 365Leu Val Lys Gly Phe Tyr Pro Ser
Asp Ile Ala Val Glu Trp Glu Ser 370 375 380Asn Gly Gln Pro Glu Asn
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp385 390 395 400Ser Asp Gly
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser 405 410 415Arg
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala 420 425
430Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 4459511PRTOryctolagus cuniculus 95Gln Ala Ser Glu Asn Ile
Gly Ser Tyr Leu Ala1 5 10967PRTOryctolagus cuniculus 96Arg Ala Ser
Thr Leu Ala Ser1 59712PRTOryctolagus cuniculus 97Gln Gln Gly Tyr
Asn Ser Glu Asn Leu Asp Asn Ala1 5 10985PRTOryctolagus cuniculus
98Met Tyr Ser Met Gly1 59916PRTArtificial SequenceChemically
Synthesized 99Trp Ile Ser Tyr Gly Gly Thr Ala Tyr Tyr Ala Ser Ser
Ala Lys Gly1 5 10 1510010PRTOryctolagus cuniculus 100Glu Thr Pro
Val Asn Tyr Tyr Leu Asp Ile1 5 10101109PRTOryctolagus cuniculus
101Ala Phe Glu Leu Thr Gln Thr Pro Ser Ser Val Glu Ala Ala Val Gly1
5 10 15Gly Thr Val Thr Ile Lys Cys Gln Ala Ser Gln Asn Ile Val Thr
Asn 20 25 30Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
Leu Ile 35 40 45Tyr Gly Ala Ser Thr Leu Ala Ser Gly Val Ser Ser Arg
Phe Lys Gly 50 55 60Ser Gly Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser
Asp Leu Glu Cys65 70 75 80Ala Asp Ala Ala Thr Tyr Phe Cys Gln Ser
Tyr Asp Gly Phe Asn Ser 85 90 95Ala Gly Phe Gly Gly Gly Thr Glu Val
Val Val Lys Arg 100 105102215PRTArtificial SequenceChemically
Synthesized 102Ala Phe Glu Leu Thr Gln Thr Pro Ser Ser Val Glu Ala
Ala Val Gly1 5 10 15Gly Thr Val Thr Ile Lys Cys Gln Ala Ser Gln Asn
Ile Val Thr Asn 20 25 30Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Pro
Pro Lys Leu Leu Ile 35 40 45Tyr Gly Ala Ser Thr Leu Ala Ser Gly Val
Ser Ser Arg Phe Lys Gly 50 55 60Ser Gly Ser Gly Thr Gln Phe Thr Leu
Thr Ile Ser Asp Leu Glu Cys65 70 75 80Ala Asp Ala Ala Thr Tyr Phe
Cys Gln Ser Tyr Asp Gly Phe Asn Ser 85 90 95Ala Gly Phe Gly Gly Gly
Thr Glu Val Val Val Lys Arg Thr Val Ala 100 105 110Ala Pro Ser Val
Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser 115 120 125Gly Thr
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu 130 135
140Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
Ser145 150 155 160Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
Thr Tyr Ser Leu 165 170 175Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
Tyr Glu Lys His Lys Val 180 185 190Tyr Ala Cys Glu Val Thr His Gln
Gly Leu Ser Ser Pro Val Thr Lys 195 200 205Ser Phe Asn Arg Gly Glu
Cys 210 215103120PRTOryctolagus cuniculus 103Gln Ser Leu Glu Glu
Ser Gly Gly Arg Leu Val Thr Pro Gly Thr Pro1 5 10 15Leu Thr Leu Thr
Cys Thr Ala Ser Gly Phe Ser Leu Ser Gly Tyr Asp 20 25 30Met Ser Trp
Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Tyr Ile Gly 35 40 45Leu Ile
Ser Tyr Asp Gly Asn Thr Tyr Tyr Ala Thr Trp Ala Lys Gly 50 55 60Arg
Phe Thr Ile Ser Lys Thr Ser Thr Thr Val Asp Leu Lys Ile Thr65 70 75
80Ser Pro Thr Thr Glu Asp Thr Ala Thr Tyr Phe Cys Ala Arg Ser Leu
85 90 95Tyr Ala Gly Pro Asn Ala Gly Ile Gly Pro Phe Asn Ile Trp Gly
Gln 100 105 110Gly Thr Leu Val Thr Val Ser Ser 115
120104450PRTArtificial SequenceChemically Synthesized 104Gln Ser
Leu Glu Glu Ser Gly Gly Arg Leu Val Thr Pro Gly Thr Pro1 5 10 15Leu
Thr Leu Thr Cys Thr Ala Ser Gly Phe Ser Leu Ser Gly Tyr Asp 20 25
30Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Tyr Ile Gly
35 40 45Leu Ile Ser Tyr Asp Gly Asn Thr Tyr Tyr Ala Thr Trp Ala Lys
Gly 50 55 60Arg Phe Thr Ile Ser Lys Thr Ser Thr Thr Val Asp Leu Lys
Ile Thr65 70 75 80Ser Pro Thr Thr Glu Asp Thr Ala Thr Tyr Phe Cys
Ala Arg Ser Leu 85 90 95Tyr Ala Gly Pro Asn Ala Gly Ile Gly Pro Phe
Asn Ile Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser Ser Ala
Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro Ser Ser
Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys Leu Val
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155 160Trp Asn
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val 165 170
175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro
Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys Pro Ala
Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu Phe Pro
Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr Pro Glu
Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp Pro Glu
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280 285Asn
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Ala Ser Thr Tyr Arg 290 295
300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
Ala Pro Ile Glu 325 330 335Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu Glu
Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys Gly
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn Gly
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val385 390 395 400Leu
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp 405 410
415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
Ser Pro 435 440 445Gly Lys 45010511PRTOryctolagus cuniculus 105Gln
Ala Ser Gln Asn Ile Val Thr Asn Leu Ala1 5 101067PRTOryctolagus
cuniculus 106Gly Ala Ser Thr Leu Ala Ser1 510710PRTOryctolagus
cuniculus 107Gln Ser Tyr Asp Gly Phe Asn Ser Ala Gly1 5
101085PRTOryctolagus cuniculus 108Gly Tyr Asp Met Ser1
510916PRTOryctolagus cuniculus 109Leu Ile Ser Tyr Asp Gly Asn Thr
Tyr Tyr Ala Thr Trp Ala Lys Gly1 5 10 1511015PRTOryctolagus
cuniculus 110Ser Leu Tyr Ala Gly Pro Asn Ala Gly Ile Gly Pro Phe
Asn Ile1 5 10 15111109PRTArtificial SequenceChemically Synthesized
111Ala Phe Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1
5 10 15Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asn Ile Val Thr
Asn 20 25 30Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu
Leu Ile 35 40 45Tyr Gly Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg
Phe Ser Gly 50 55 60Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
Ser Leu Gln Pro65 70 75 80Glu Asp Val Ala Thr Tyr Tyr Cys Gln Ser
Tyr Asp Gly Phe Asn Ser 85 90 95Ala Gly Phe Gly Gly Gly Thr Lys Val
Glu Ile Lys Arg 100 105112215PRTArtificial SequenceChemically
Synthesized 112Ala Phe Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala
Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Asn
Ile Val Thr Asn 20 25 30Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Val
Pro Lys Leu Leu Ile 35 40 45Tyr Gly Ala Ser Thr Leu Ala Ser Gly Val
Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly Ser Gly Thr Asp Phe Thr Leu
Thr Ile Ser Ser Leu Gln Pro65 70 75 80Glu Asp Val Ala Thr Tyr Tyr
Cys Gln Ser Tyr Asp Gly Phe Asn Ser 85 90 95Ala Gly Phe Gly Gly Gly
Thr Lys Val Glu Ile Lys Arg Thr Val Ala 100 105 110Ala Pro Ser Val
Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser 115 120 125Gly Thr
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu 130 135
140Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
Ser145 150 155 160Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
Thr Tyr Ser Leu 165 170 175Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp
Tyr Glu Lys His Lys Val 180 185 190Tyr Ala Cys Glu Val Thr His Gln
Gly Leu Ser Ser Pro Val Thr Lys 195 200 205Ser Phe Asn Arg Gly Glu
Cys 210 215113123PRTArtificial SequenceChemically Synthesized
113Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg1
5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser Leu Ser Gly
Tyr 20 25 30Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
Trp Val 35 40 45Gly Leu Ile Ser Tyr Asp Gly Asn Thr Tyr Tyr Ala Thr
Ser Ala Lys 50 55 60Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn
Thr Leu Tyr Leu65 70 75 80Gln Met Ser Ser Leu Arg Ala Glu Asp Thr
Ala Val Tyr Tyr Cys Ala 85 90 95Arg Ser Leu Tyr Ala Gly Pro Asn Ala
Gly Ile Gly Pro Phe Asn Ile 100 105 110Trp Gly Gln Gly Thr Leu Val
Thr Val Ser Ser 115 120114453PRTArtificial SequenceChemically
Synthesized 114Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln
Pro Gly Arg1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ser
Leu Ser Gly Tyr 20 25 30Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys
Gly Leu Glu Trp Val 35 40 45Gly Leu Ile Ser Tyr Asp Gly Asn Thr Tyr
Tyr Ala Thr Ser Ala Lys 50 55 60Gly Arg Phe Thr Ile Ser Arg Asp Asn
Ser Lys Asn Thr Leu Tyr Leu65 70 75 80Gln Met Ser Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg Ser Leu Tyr Ala Gly
Pro Asn Ala Gly Ile Gly Pro Phe Asn Ile 100 105 110Trp Gly Gln Gly
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly 115 120 125Pro Ser
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly 130 135
140Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro
Val145 150 155 160Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly
Val His Thr Phe 165 170 175Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
Ser Leu Ser Ser Val Val 180 185 190Thr Val Pro Ser Ser Ser Leu Gly
Thr Gln Thr Tyr Ile Cys Asn Val 195 200 205Asn His Lys Pro Ser Asn
Thr Lys Val Asp Lys Arg Val Glu Pro Lys 210 215 220Ser Cys Asp Lys
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu225 230 235 240Leu
Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr 245 250
255Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
Gly Val 275 280 285Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
Gln Tyr Ala Ser 290 295 300Thr Tyr Arg Val Val Ser Val Leu Thr Val
Leu His Gln Asp Trp Leu305 310 315 320Asn Gly Lys Glu Tyr Lys Cys
Lys Val Ser Asn Lys Ala Leu Pro Ala 325 330 335Pro Ile Glu Lys Thr
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro 340 345 350Gln Val Tyr
Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln 355 360 365Val
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala 370 375
380Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
Thr385 390 395 400Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
Tyr Ser Lys Leu 405 410 415Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
Asn Val Phe Ser Cys Ser 420 425 430Val Met His Glu Ala Leu His Asn
His Tyr Thr Gln Lys Ser Leu Ser 435 440 445Leu Ser Pro Gly Lys
45011511PRTOryctolagus cuniculus 115Gln Ala Ser Gln Asn Ile Val Thr
Asn Leu Ala1 5 101167PRTOryctolagus cuniculus 116Gly Ala Ser Thr
Leu Ala Ser1 511710PRTOryctolagus cuniculus 117Gln Ser Tyr Asp Gly
Phe Asn Ser Ala Gly1 5 101185PRTOryctolagus cuniculus 118Gly Tyr
Asp Met Ser1 511916PRTArtificial SequenceChemically Synthesized
119Leu Ile Ser Tyr Asp Gly Asn Thr Tyr Tyr Ala Thr Ser Ala Lys Gly1
5 10 1512015PRTOryctolagus cuniculus 120Ser Leu Tyr Ala Gly Pro Asn
Ala Gly Ile Gly Pro Phe Asn Ile1 5 10 15121112PRTOryctolagus
cuniculus 121Ala Ala Val Leu Thr Gln Thr Pro Ser Pro Val Ser Ala
Ala Val Gly1 5 10 15Gly Thr Val Ser Ile Ser Cys Gln Ser Ser Gln Asn
Val Tyr Lys Asn 20 25 30Asn Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly
Gln Pro Pro Lys Leu 35 40 45Leu Ile Tyr Lys Ala Ser Thr Leu Ala Ser
Gly Val Pro Ser Arg Phe 50 55 60Lys Gly Gly Gly Ser Gly Thr Asp Phe
Thr Leu Thr Ile Ser Asp Val65 70 75 80Gln Cys Asp Ala Ala Ala Thr
Tyr Tyr Cys Ala Gly Gly Tyr Thr Ser 85 90 95Ser Ser Asp Asn Ala Phe
Gly Gly Gly Thr Glu Val Val Val Lys Arg 100 105
110122218PRTArtificial SequenceChemically Synthesized 122Ala Ala
Val Leu Thr Gln Thr Pro Ser Pro Val Ser Ala Ala Val Gly1 5 10 15Gly
Thr Val Ser Ile Ser Cys Gln Ser Ser Gln Asn Val Tyr Lys Asn 20 25
30Asn Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
35 40 45Leu Ile Tyr Lys Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg
Phe 50 55 60Lys Gly Gly Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
Asp Val65 70 75 80Gln Cys Asp Ala Ala Ala Thr Tyr Tyr Cys Ala Gly
Gly Tyr Thr Ser 85 90 95Ser Ser Asp Asn Ala Phe Gly Gly Gly Thr Glu
Val Val Val Lys Arg 100 105 110Thr Val Ala Ala Pro Ser Val Phe Ile
Phe Pro Pro Ser Asp Glu Gln 115 120 125Leu Lys Ser Gly Thr Ala Ser
Val Val Cys Leu Leu Asn Asn Phe Tyr 130
135 140Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
Ser145 150 155 160Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser
Lys Asp Ser Thr 165 170 175Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser
Lys Ala Asp Tyr Glu Lys 180 185 190His Lys Val Tyr Ala Cys Glu Val
Thr His Gln Gly Leu Ser Ser Pro 195 200 205Val Thr Lys Ser Phe Asn
Arg Gly Glu Cys 210 215123117PRTOryctolagus cuniculus 123Gln Ser
Val Glu Ala Ser Gly Gly Arg Leu Val Thr Pro Gly Thr Pro1 5 10 15Leu
Thr Leu Thr Cys Thr Ala Ser Gly Phe Ser Leu Ser Thr Tyr Trp 20 25
30Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile Gly
35 40 45Asp Ile Tyr Phe Ser Asn Glu Glu Thr Asn Tyr Ala Ser Trp Ala
Lys 50 55 60Gly Arg Phe Thr Ile Ser Lys Thr Ser Thr Thr Val Asp Leu
Asn Val65 70 75 80Ile Ser Pro Thr Thr Glu Asp Thr Ala Thr Tyr Phe
Cys Ala Arg Gly 85 90 95Ser Pro Asp Val Asp Ile Gly Ile Asp Met Trp
Gly Pro Gly Thr Leu 100 105 110Val Thr Val Ser Ser
115124447PRTArtificial SequenceChemically Synthesized 124Gln Ser
Val Glu Ala Ser Gly Gly Arg Leu Val Thr Pro Gly Thr Pro1 5 10 15Leu
Thr Leu Thr Cys Thr Ala Ser Gly Phe Ser Leu Ser Thr Tyr Trp 20 25
30Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile Gly
35 40 45Asp Ile Tyr Phe Ser Asn Glu Glu Thr Asn Tyr Ala Ser Trp Ala
Lys 50 55 60Gly Arg Phe Thr Ile Ser Lys Thr Ser Thr Thr Val Asp Leu
Asn Val65 70 75 80Ile Ser Pro Thr Thr Glu Asp Thr Ala Thr Tyr Phe
Cys Ala Arg Gly 85 90 95Ser Pro Asp Val Asp Ile Gly Ile Asp Met Trp
Gly Pro Gly Thr Leu 100 105 110Val Thr Val Ser Ser Ala Ser Thr Lys
Gly Pro Ser Val Phe Pro Leu 115 120 125Ala Pro Ser Ser Lys Ser Thr
Ser Gly Gly Thr Ala Ala Leu Gly Cys 130 135 140Leu Val Lys Asp Tyr
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser145 150 155 160Gly Ala
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser 165 170
175Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
Ser Asn 195 200 205Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys
Asp Lys Thr His 210 215 220Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
Leu Gly Gly Pro Ser Val225 230 235 240Phe Leu Phe Pro Pro Lys Pro
Lys Asp Thr Leu Met Ile Ser Arg Thr 245 250 255Pro Glu Val Thr Cys
Val Val Val Asp Val Ser His Glu Asp Pro Glu 260 265 270Val Lys Phe
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys 275 280 285Thr
Lys Pro Arg Glu Glu Gln Tyr Ala Ser Thr Tyr Arg Val Val Ser 290 295
300Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
Lys305 310 315 320Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
Glu Lys Thr Ile 325 330 335Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
Gln Val Tyr Thr Leu Pro 340 345 350Pro Ser Arg Glu Glu Met Thr Lys
Asn Gln Val Ser Leu Thr Cys Leu 355 360 365Val Lys Gly Phe Tyr Pro
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn 370 375 380Gly Gln Pro Glu
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser385 390 395 400Asp
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg 405 410
415Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
Lys 435 440 44512513PRTOryctolagus cuniculus 125Gln Ser Ser Gln Asn
Val Tyr Lys Asn Asn Tyr Leu Ser1 5 101267PRTOryctolagus cuniculus
126Lys Ala Ser Thr Leu Ala Ser1 512711PRTOryctolagus cuniculus
127Ala Gly Gly Tyr Thr Ser Ser Ser Asp Asn Ala1 5
101285PRTOryctolagus cuniculus 128Thr Tyr Trp Met Ser1
512917PRTOryctolagus cuniculus 129Asp Ile Tyr Phe Ser Asn Glu Glu
Thr Asn Tyr Ala Ser Trp Ala Lys1 5 10 15Gly13011PRTOryctolagus
cuniculus 130Gly Ser Pro Asp Val Asp Ile Gly Ile Asp Met1 5
10131112PRTArtificial SequenceChemically Synthesized 131Asp Ile Gln
Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg
Val Thr Ile Thr Cys Gln Ser Ser Gln Asn Val Tyr Lys Asn 20 25 30Asn
Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu 35 40
45Leu Ile Tyr Lys Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg Phe
50 55 60Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser
Leu65 70 75 80Gln Pro Glu Asp Val Ala Thr Tyr Tyr Cys Ala Gly Gly
Tyr Thr Ser 85 90 95Ser Ser Asp Asn Ala Phe Gly Gly Gly Thr Lys Val
Glu Ile Lys Arg 100 105 110132218PRTArtificial SequenceChemically
Synthesized 132Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala
Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Gln Ser Ser Gln Asn
Val Tyr Lys Asn 20 25 30Asn Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly
Lys Val Pro Lys Leu 35 40 45Leu Ile Tyr Lys Ala Ser Thr Leu Ala Ser
Gly Val Pro Ser Arg Phe 50 55 60Ser Gly Ser Gly Ser Gly Thr Asp Phe
Thr Leu Thr Ile Ser Ser Leu65 70 75 80Gln Pro Glu Asp Val Ala Thr
Tyr Tyr Cys Ala Gly Gly Tyr Thr Ser 85 90 95Ser Ser Asp Asn Ala Phe
Gly Gly Gly Thr Lys Val Glu Ile Lys Arg 100 105 110Thr Val Ala Ala
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln 115 120 125Leu Lys
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr 130 135
140Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
Ser145 150 155 160Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser
Lys Asp Ser Thr 165 170 175Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser
Lys Ala Asp Tyr Glu Lys 180 185 190His Lys Val Tyr Ala Cys Glu Val
Thr His Gln Gly Leu Ser Ser Pro 195 200 205Val Thr Lys Ser Phe Asn
Arg Gly Glu Cys 210 215133120PRTArtificial SequenceChemically
Synthesized 133Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
Val Ser Thr Tyr 20 25 30Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys
Gly Leu Glu Trp Val 35 40 45Gly Asp Ile Tyr Phe Ser Asn Glu Glu Thr
Asn Tyr Ala Ser Ser Ala 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp
Asn Ser Lys Asn Thr Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg
Ala Glu Asp Thr Ala Val Tyr Tyr Cys 85 90 95Ala Arg Gly Ser Pro Asp
Val Asp Ile Gly Ile Asp Met Trp Gly Pro 100 105 110Gly Thr Leu Val
Thr Val Ser Ser 115 120134450PRTArtificial SequenceChemically
Synthesized 134Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
Val Ser Thr Tyr 20 25 30Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys
Gly Leu Glu Trp Val 35 40 45Gly Asp Ile Tyr Phe Ser Asn Glu Glu Thr
Asn Tyr Ala Ser Ser Ala 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp
Asn Ser Lys Asn Thr Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg
Ala Glu Asp Thr Ala Val Tyr Tyr Cys 85 90 95Ala Arg Gly Ser Pro Asp
Val Asp Ile Gly Ile Asp Met Trp Gly Pro 100 105 110Gly Thr Leu Val
Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro
Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135
140Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
Ser145 150 155 160Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
Phe Pro Ala Val 165 170 175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser
Ser Val Val Thr Val Pro 180 185 190Ser Ser Ser Leu Gly Thr Gln Thr
Tyr Ile Cys Asn Val Asn His Lys 195 200 205Pro Ser Asn Thr Lys Val
Asp Lys Arg Val Glu Pro Lys Ser Cys Asp 210 215 220Lys Thr His Thr
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly225 230 235 240Pro
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250
255Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
Val His 275 280 285Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Ala
Ser Thr Tyr Arg 290 295 300Val Val Ser Val Leu Thr Val Leu His Gln
Asp Trp Leu Asn Gly Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser
Asn Lys Ala Leu Pro Ala Pro Ile Glu 325 330 335Lys Thr Ile Ser Lys
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro
Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375
380Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
Val385 390 395 400Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
Leu Thr Val Asp 405 410 415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
Ser Cys Ser Val Met His 420 425 430Glu Ala Leu His Asn His Tyr Thr
Gln Lys Ser Leu Ser Leu Ser Pro 435 440 445Gly Lys
45013513PRTOryctolagus cuniculus 135Gln Ser Ser Gln Asn Val Tyr Lys
Asn Asn Tyr Leu Ser1 5 101367PRTOryctolagus cuniculus 136Lys Ala
Ser Thr Leu Ala Ser1 513711PRTOryctolagus cuniculus 137Ala Gly Gly
Tyr Thr Ser Ser Ser Asp Asn Ala1 5 101385PRTOryctolagus cuniculus
138Thr Tyr Trp Met Ser1 513917PRTArtificial SequenceChemically
Synthesized 139Asp Ile Tyr Phe Ser Asn Glu Glu Thr Asn Tyr Ala Ser
Ser Ala Lys1 5 10 15Gly14011PRTOryctolagus cuniculus 140Gly Ser Pro
Asp Val Asp Ile Gly Ile Asp Met1 5 10141112PRTOryctolagus cuniculus
141Ala Ala Val Leu Thr Gln Thr Pro Ser Pro Val Ser Ala Ala Val Gly1
5 10 15Asp Thr Val Thr Ile Lys Cys Gln Ser Ser Gln Ser Val Tyr Lys
Asn 20 25 30Asn Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
Lys Leu 35 40 45Leu Ile Tyr Asp Ala Ser Asn Leu Pro Ser Gly Val Pro
Ser Arg Phe 50 55 60Ser Gly Ser Gly Ser Gly Thr Gln Phe Thr Leu Thr
Ile Ser Gly Val65 70 75 80Gln Cys Asp Asp Ala Ala Thr Tyr Tyr Cys
Leu Gly Asp Tyr Asp Asp 85 90 95Asp Thr Asp Asn Gly Phe Gly Gly Gly
Thr Glu Val Val Val Lys Arg 100 105 110142218PRTArtificial
SequenceChemically Synthesized 142Ala Ala Val Leu Thr Gln Thr Pro
Ser Pro Val Ser Ala Ala Val Gly1 5 10 15Asp Thr Val Thr Ile Lys Cys
Gln Ser Ser Gln Ser Val Tyr Lys Asn 20 25 30Asn Tyr Leu Ser Trp Tyr
Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu 35 40 45Leu Ile Tyr Asp Ala
Ser Asn Leu Pro Ser Gly Val Pro Ser Arg Phe 50 55 60Ser Gly Ser Gly
Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser Gly Val65 70 75 80Gln Cys
Asp Asp Ala Ala Thr Tyr Tyr Cys Leu Gly Asp Tyr Asp Asp 85 90 95Asp
Thr Asp Asn Gly Phe Gly Gly Gly Thr Glu Val Val Val Lys Arg 100 105
110Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
Phe Tyr 130 135 140Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
Ala Leu Gln Ser145 150 155 160Gly Asn Ser Gln Glu Ser Val Thr Glu
Gln Asp Ser Lys Asp Ser Thr 165 170 175Tyr Ser Leu Ser Ser Thr Leu
Thr Leu Ser Lys Ala Asp Tyr Glu Lys 180 185 190His Lys Val Tyr Ala
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro 195 200 205Val Thr Lys
Ser Phe Asn Arg Gly Glu Cys 210 215143112PRTOryctolagus cuniculus
143Gln Ser Val Glu Glu Ser Gly Gly Arg Leu Val Thr Pro Gly Thr Pro1
5 10 15Leu Thr Leu Thr Cys Thr Val Ser Gly Ile Asp Leu Ser Ser Tyr
Ala 20 25 30Met Ile Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Tyr
Ile Gly 35 40 45Ile Ile Trp Ser Gly Gly Thr Tyr Tyr Ala Thr Trp Ala
Lys Gly Arg 50 55 60Phe Thr Ile Ser Lys Thr Ser Thr Thr Val Asp Leu
Gln Ile Thr Ser65 70 75 80Pro Thr Thr Glu Asp Ala Ala Thr Tyr Phe
Cys Ala Ala Gly Gly Gly 85 90 95Ser Ile Tyr Asp Val Trp Gly Pro Gly
Thr Leu Val Thr Val Ser Ser 100 105 110144442PRTArtificial
SequenceChemically Synthesized 144Gln Ser Val Glu Glu Ser Gly Gly
Arg Leu Val Thr Pro Gly Thr Pro1 5 10 15Leu Thr Leu Thr Cys Thr Val
Ser Gly Ile Asp Leu Ser Ser Tyr Ala 20 25 30Met Ile Trp Val Arg Gln
Ala Pro Gly Lys Gly Leu Glu Tyr Ile Gly 35 40 45Ile Ile Trp Ser Gly
Gly Thr Tyr Tyr Ala Thr Trp Ala Lys Gly Arg 50 55 60Phe Thr Ile Ser
Lys Thr Ser Thr Thr Val Asp Leu Gln Ile Thr Ser65 70 75 80Pro Thr
Thr Glu Asp Ala Ala Thr Tyr Phe Cys Ala Ala Gly Gly Gly 85 90 95Ser
Ile Tyr Asp Val Trp Gly Pro Gly Thr Leu Val Thr Val Ser Ser 100 105
110Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
115 120 125Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys
Asp Tyr 130 135 140Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
Ala Leu Thr Ser145 150 155 160Gly Val His Thr Phe Pro Ala Val Leu
Gln Ser Ser Gly Leu Tyr Ser 165 170 175Leu Ser Ser Val Val Thr Val
Pro Ser Ser Ser Leu Gly Thr Gln Thr 180 185 190Tyr Ile Cys Asn Val
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys 195 200 205Arg Val Glu
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys 210 215 220Pro
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro225 230
235 240Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
Thr
Cys 245 250 255Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
Phe Asn Trp 260 265 270Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
Thr Lys Pro Arg Glu 275 280 285Glu Gln Tyr Ala Ser Thr Tyr Arg Val
Val Ser Val Leu Thr Val Leu 290 295 300His Gln Asp Trp Leu Asn Gly
Lys Glu Tyr Lys Cys Lys Val Ser Asn305 310 315 320Lys Ala Leu Pro
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly 325 330 335Gln Pro
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu 340 345
350Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
355 360 365Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
Glu Asn 370 375 380Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
Gly Ser Phe Phe385 390 395 400Leu Tyr Ser Lys Leu Thr Val Asp Lys
Ser Arg Trp Gln Gln Gly Asn 405 410 415Val Phe Ser Cys Ser Val Met
His Glu Ala Leu His Asn His Tyr Thr 420 425 430Gln Lys Ser Leu Ser
Leu Ser Pro Gly Lys 435 44014513PRTOryctolagus cuniculus 145Gln Ser
Ser Gln Ser Val Tyr Lys Asn Asn Tyr Leu Ser1 5 101467PRTOryctolagus
cuniculus 146Asp Ala Ser Asn Leu Pro Ser1 514711PRTOryctolagus
cuniculus 147Leu Gly Asp Tyr Asp Asp Asp Thr Asp Asn Gly1 5
101485PRTOryctolagus cuniculus 148Ser Tyr Ala Met Ile1
514915PRTOryctolagus cuniculus 149Ile Ile Trp Ser Gly Gly Thr Tyr
Tyr Ala Thr Trp Ala Lys Gly1 5 10 151508PRTOryctolagus cuniculus
150Gly Gly Gly Ser Ile Tyr Asp Val1 5151112PRTOryctolagus cuniculus
151Ala Leu Val Met Thr Gln Thr Pro Ser Ser Thr Ser Glu Pro Val Gly1
5 10 15Gly Thr Val Thr Ile Asn Cys Gln Ala Ser Gln Asn Ile Gly Asn
Asp 20 25 30Leu Ser Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Glu Leu
Leu Ile 35 40 45Tyr Ser Thr Ser Lys Leu Ala Thr Gly Val Pro Lys Arg
Phe Ser Gly 50 55 60Ser Arg Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser
Asp Leu Glu Cys65 70 75 80Asp Asp Ala Ala Thr Tyr Tyr Cys Leu Gly
Val Tyr Ser Tyr Ile Ser 85 90 95Asp Asp Gly Asn Ala Phe Gly Gly Gly
Thr Glu Val Val Val Lys Arg 100 105 110152218PRTArtificial
SequenceChemically Synthesized 152Ala Leu Val Met Thr Gln Thr Pro
Ser Ser Thr Ser Glu Pro Val Gly1 5 10 15Gly Thr Val Thr Ile Asn Cys
Gln Ala Ser Gln Asn Ile Gly Asn Asp 20 25 30Leu Ser Trp Tyr Gln Gln
Lys Pro Gly Gln Pro Pro Glu Leu Leu Ile 35 40 45Tyr Ser Thr Ser Lys
Leu Ala Thr Gly Val Pro Lys Arg Phe Ser Gly 50 55 60Ser Arg Ser Gly
Thr Gln Phe Thr Leu Thr Ile Ser Asp Leu Glu Cys65 70 75 80Asp Asp
Ala Ala Thr Tyr Tyr Cys Leu Gly Val Tyr Ser Tyr Ile Ser 85 90 95Asp
Asp Gly Asn Ala Phe Gly Gly Gly Thr Glu Val Val Val Lys Arg 100 105
110Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
Phe Tyr 130 135 140Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
Ala Leu Gln Ser145 150 155 160Gly Asn Ser Gln Glu Ser Val Thr Glu
Gln Asp Ser Lys Asp Ser Thr 165 170 175Tyr Ser Leu Ser Ser Thr Leu
Thr Leu Ser Lys Ala Asp Tyr Glu Lys 180 185 190His Lys Val Tyr Ala
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro 195 200 205Val Thr Lys
Ser Phe Asn Arg Gly Glu Cys 210 215153120PRTOryctolagus cuniculus
153Gln Ser Val Glu Glu Phe Gly Gly Arg Leu Val Thr Pro Gly Thr Pro1
5 10 15Leu Thr Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Asn Asn Tyr
Ala 20 25 30Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
Ile Gly 35 40 45Ile Ile Gly Ser Ile Gly Thr Thr Tyr Tyr Ala Ser Trp
Ala Lys Gly 50 55 60Arg Phe Phe Ile Ser Lys Thr Ser Thr Thr Val Asp
Leu Lys Ile Ile65 70 75 80Ser Pro Thr Thr Glu Asp Thr Ala Thr Tyr
Phe Cys Ala Arg Asp Ala 85 90 95Gly Val Thr Val Asp Gly Tyr Gly Tyr
Tyr Phe Asn Ile Trp Gly Pro 100 105 110Gly Thr Leu Val Thr Val Ser
Ser 115 120154450PRTArtificial SequenceChemically Synthesized
154Gln Ser Val Glu Glu Phe Gly Gly Arg Leu Val Thr Pro Gly Thr Pro1
5 10 15Leu Thr Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Asn Asn Tyr
Ala 20 25 30Met Thr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
Ile Gly 35 40 45Ile Ile Gly Ser Ile Gly Thr Thr Tyr Tyr Ala Ser Trp
Ala Lys Gly 50 55 60Arg Phe Phe Ile Ser Lys Thr Ser Thr Thr Val Asp
Leu Lys Ile Ile65 70 75 80Ser Pro Thr Thr Glu Asp Thr Ala Thr Tyr
Phe Cys Ala Arg Asp Ala 85 90 95Gly Val Thr Val Asp Gly Tyr Gly Tyr
Tyr Phe Asn Ile Trp Gly Pro 100 105 110Gly Thr Leu Val Thr Val Ser
Ser Ala Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser145 150 155
160Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
Val Pro 180 185 190Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
Val Asn His Lys 195 200 205Pro Ser Asn Thr Lys Val Asp Lys Arg Val
Glu Pro Lys Ser Cys Asp 210 215 220Lys Thr His Thr Cys Pro Pro Cys
Pro Ala Pro Glu Leu Leu Gly Gly225 230 235 240Pro Ser Val Phe Leu
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250 255Ser Arg Thr
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu 260 265 270Asp
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His 275 280
285Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Ala Ser Thr Tyr Arg
290 295 300Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn
Gly Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
Pro Ala Pro Ile Glu 325 330 335Lys Thr Ile Ser Lys Ala Lys Gly Gln
Pro Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro Pro Ser Arg Glu
Glu Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr Cys Leu Val Lys
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375 380Glu Ser Asn
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val385 390 395
400Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
405 410 415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
Met His 420 425 430Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
Ser Leu Ser Pro 435 440 445Gly Lys 45015511PRTOryctolagus cuniculus
155Gln Ala Ser Gln Asn Ile Gly Asn Asp Leu Ser1 5
101567PRTOryctolagus cuniculus 156Ser Thr Ser Lys Leu Ala Thr1
515713PRTOryctolagus cuniculus 157Leu Gly Val Tyr Ser Tyr Ile Ser
Asp Asp Gly Asn Ala1 5 101585PRTOryctolagus cuniculus 158Asn Tyr
Ala Met Thr1 515916PRTOryctolagus cuniculus 159Ile Ile Gly Ser Ile
Gly Thr Thr Tyr Tyr Ala Ser Trp Ala Lys Gly1 5 10
1516015PRTOryctolagus cuniculus 160Asp Ala Gly Val Thr Val Asp Gly
Tyr Gly Tyr Tyr Phe Asn Ile1 5 10 15161112PRTOryctolagus cuniculus
161Ala Ile Glu Met Thr Gln Thr Pro Phe Ser Val Ser Ala Ala Val Gly1
5 10 15Gly Thr Val Thr Ile Lys Cys Gln Ala Ser Gln Thr Ile Ser Asn
Tyr 20 25 30Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
Leu Ile 35 40 45Tyr Gly Ala Ser Asn Leu Glu Ser Gly Val Pro Ser Arg
Phe Lys Gly 50 55 60Ser Gly Ser Gly Thr Gln Phe Thr Leu Thr Ile Ser
Asp Leu Glu Cys65 70 75 80Asp Asp Ala Ala Thr Tyr Tyr Cys Gln Gln
Gly Tyr Thr Ile Ser Asn 85 90 95Val Asp Asn Asn Val Phe Gly Gly Gly
Thr Glu Val Val Val Lys Arg 100 105 110162218PRTArtificial
SequenceChemically Synthesized 162Ala Ile Glu Met Thr Gln Thr Pro
Phe Ser Val Ser Ala Ala Val Gly1 5 10 15Gly Thr Val Thr Ile Lys Cys
Gln Ala Ser Gln Thr Ile Ser Asn Tyr 20 25 30Leu Ala Trp Tyr Gln Gln
Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile 35 40 45Tyr Gly Ala Ser Asn
Leu Glu Ser Gly Val Pro Ser Arg Phe Lys Gly 50 55 60Ser Gly Ser Gly
Thr Gln Phe Thr Leu Thr Ile Ser Asp Leu Glu Cys65 70 75 80Asp Asp
Ala Ala Thr Tyr Tyr Cys Gln Gln Gly Tyr Thr Ile Ser Asn 85 90 95Val
Asp Asn Asn Val Phe Gly Gly Gly Thr Glu Val Val Val Lys Arg 100 105
110Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
Phe Tyr 130 135 140Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
Ala Leu Gln Ser145 150 155 160Gly Asn Ser Gln Glu Ser Val Thr Glu
Gln Asp Ser Lys Asp Ser Thr 165 170 175Tyr Ser Leu Ser Ser Thr Leu
Thr Leu Ser Lys Ala Asp Tyr Glu Lys 180 185 190His Lys Val Tyr Ala
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro 195 200 205Val Thr Lys
Ser Phe Asn Arg Gly Glu Cys 210 215163115PRTOryctolagus cuniculus
163Gln Ser Leu Glu Glu Ser Gly Gly Arg Leu Val Thr Pro Gly Gly Ser1
5 10 15Leu Thr Leu Thr Cys Ala Ala Ser Gly Phe Ser Leu Thr Gly Tyr
Asn 20 25 30Leu Val Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
Ile Gly 35 40 45Phe Ile Ser Tyr Gly Asp Thr Thr Tyr Tyr Ala Ser Trp
Ala Lys Gly 50 55 60Arg Phe Thr Ile Ser Lys Thr Ser Thr Thr Val Thr
Leu Thr Ile Thr65 70 75 80Asp Leu Gln Pro Ser Asp Thr Gly Thr Tyr
Phe Cys Ala Arg Glu Thr 85 90 95Ala Asn Thr Tyr Asp Tyr Gly Ile Trp
Gly Pro Gly Thr Leu Val Thr 100 105 110Val Ser Ser
115164445PRTArtificial SequenceChemically Synthesized 164Gln Ser
Leu Glu Glu Ser Gly Gly Arg Leu Val Thr Pro Gly Gly Ser1 5 10 15Leu
Thr Leu Thr Cys Ala Ala Ser Gly Phe Ser Leu Thr Gly Tyr Asn 20 25
30Leu Val Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile Gly
35 40 45Phe Ile Ser Tyr Gly Asp Thr Thr Tyr Tyr Ala Ser Trp Ala Lys
Gly 50 55 60Arg Phe Thr Ile Ser Lys Thr Ser Thr Thr Val Thr Leu Thr
Ile Thr65 70 75 80Asp Leu Gln Pro Ser Asp Thr Gly Thr Tyr Phe Cys
Ala Arg Glu Thr 85 90 95Ala Asn Thr Tyr Asp Tyr Gly Ile Trp Gly Pro
Gly Thr Leu Val Thr 100 105 110Val Ser Ser Ala Ser Thr Lys Gly Pro
Ser Val Phe Pro Leu Ala Pro 115 120 125Ser Ser Lys Ser Thr Ser Gly
Gly Thr Ala Ala Leu Gly Cys Leu Val 130 135 140Lys Asp Tyr Phe Pro
Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala145 150 155 160Leu Thr
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly 165 170
175Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
180 185 190Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn
Thr Lys 195 200 205Val Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys
Thr His Thr Cys 210 215 220Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
Gly Pro Ser Val Phe Leu225 230 235 240Phe Pro Pro Lys Pro Lys Asp
Thr Leu Met Ile Ser Arg Thr Pro Glu 245 250 255Val Thr Cys Val Val
Val Asp Val Ser His Glu Asp Pro Glu Val Lys 260 265 270Phe Asn Trp
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys 275 280 285Pro
Arg Glu Glu Gln Tyr Ala Ser Thr Tyr Arg Val Val Ser Val Leu 290 295
300Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
Lys305 310 315 320Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
Thr Ile Ser Lys 325 330 335Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
Tyr Thr Leu Pro Pro Ser 340 345 350Arg Glu Glu Met Thr Lys Asn Gln
Val Ser Leu Thr Cys Leu Val Lys 355 360 365Gly Phe Tyr Pro Ser Asp
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln 370 375 380Pro Glu Asn Asn
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly385 390 395 400Ser
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln 405 410
415Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 435
440 44516511PRTOryctolagus cuniculus 165Gln Ala Ser Gln Thr Ile Ser
Asn Tyr Leu Ala1 5 101667PRTOryctolagus cuniculus 166Gly Ala Ser
Asn Leu Glu Ser1 516713PRTOryctolagus cuniculus 167Gln Gln Gly Tyr
Thr Ile Ser Asn Val Asp Asn Asn Val1 5 101685PRTOryctolagus
cuniculus 168Gly Tyr Asn Leu Val1 516916PRTOryctolagus cuniculus
169Phe Ile Ser Tyr Gly Asp Thr Thr Tyr Tyr Ala Ser Trp Ala Lys Gly1
5 10 1517010PRTOryctolagus cuniculus 170Glu Thr Ala Asn Thr Tyr Asp
Tyr Gly Ile1 5 10171112PRTArtificial SequenceChemically Synthesized
171Asp Ile Gln Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly1
5 10 15Asp Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Thr Ile Ser Asn
Tyr 20 25 30Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
Leu Ile 35 40 45Tyr Gly Ala Ser Asn Leu Glu Ser Gly Val Pro Ser Arg
Phe Ser Gly 50 55 60Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser
Ser Leu Gln Pro65 70 75 80Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln
Gly Tyr Thr Ile Ser Asn 85 90 95Val Asp Asn Asn Val Phe Gly Gly Gly
Thr Lys Val Glu Ile Lys Arg 100 105 110172218PRTArtificial
SequenceChemically Synthesized 172Asp Ile Gln Met Thr Gln Ser Pro
Ser Thr Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys
Gln Ala Ser Gln Thr Ile Ser Asn Tyr 20 25 30Leu Ala Trp Tyr Gln Gln
Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Gly Ala Ser Asn
Leu Glu Ser
Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly Ser Gly Thr Glu Phe
Thr Leu Thr Ile Ser Ser Leu Gln Pro65 70 75 80Asp Asp Phe Ala Thr
Tyr Tyr Cys Gln Gln Gly Tyr Thr Ile Ser Asn 85 90 95Val Asp Asn Asn
Val Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg 100 105 110Thr Val
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln 115 120
125Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
Gln Ser145 150 155 160Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp
Ser Lys Asp Ser Thr 165 170 175Tyr Ser Leu Ser Ser Thr Leu Thr Leu
Ser Lys Ala Asp Tyr Glu Lys 180 185 190His Lys Val Tyr Ala Cys Glu
Val Thr His Gln Gly Leu Ser Ser Pro 195 200 205Val Thr Lys Ser Phe
Asn Arg Gly Glu Cys 210 215173118PRTArtificial SequenceChemically
Synthesized 173Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
Val Ser Gly Tyr 20 25 30Asn Leu Val Trp Val Arg Gln Ala Pro Gly Lys
Gly Leu Glu Trp Val 35 40 45Gly Phe Ile Ser Tyr Gly Asp Thr Thr Tyr
Tyr Ala Ser Ser Ala Lys 50 55 60Gly Arg Phe Thr Ile Ser Arg Asp Asn
Ser Lys Asn Thr Leu Tyr Leu65 70 75 80Gln Met Asn Ser Leu Arg Ala
Glu Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Thr Ala Asn Thr
Tyr Asp Tyr Gly Ile Trp Gly Gln Gly Thr 100 105 110Leu Val Thr Val
Ser Ser 115174448PRTArtificial SequenceChemically Synthesized
174Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1
5 10 15Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Val Ser Gly
Tyr 20 25 30Asn Leu Val Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
Trp Val 35 40 45Gly Phe Ile Ser Tyr Gly Asp Thr Thr Tyr Tyr Ala Ser
Ser Ala Lys 50 55 60Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn
Thr Leu Tyr Leu65 70 75 80Gln Met Asn Ser Leu Arg Ala Glu Asp Thr
Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Thr Ala Asn Thr Tyr Asp Tyr
Gly Ile Trp Gly Gln Gly Thr 100 105 110Leu Val Thr Val Ser Ser Ala
Ser Thr Lys Gly Pro Ser Val Phe Pro 115 120 125Leu Ala Pro Ser Ser
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly 130 135 140Cys Leu Val
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn145 150 155
160Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln
165 170 175Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
Ser Ser 180 185 190Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn
His Lys Pro Ser 195 200 205Asn Thr Lys Val Asp Lys Arg Val Glu Pro
Lys Ser Cys Asp Lys Thr 210 215 220His Thr Cys Pro Pro Cys Pro Ala
Pro Glu Leu Leu Gly Gly Pro Ser225 230 235 240Val Phe Leu Phe Pro
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg 245 250 255Thr Pro Glu
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro 260 265 270Glu
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala 275 280
285Lys Thr Lys Pro Arg Glu Glu Gln Tyr Ala Ser Thr Tyr Arg Val Val
290 295 300Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
Glu Tyr305 310 315 320Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
Pro Ile Glu Lys Thr 325 330 335Ile Ser Lys Ala Lys Gly Gln Pro Arg
Glu Pro Gln Val Tyr Thr Leu 340 345 350Pro Pro Ser Arg Glu Glu Met
Thr Lys Asn Gln Val Ser Leu Thr Cys 355 360 365Leu Val Lys Gly Phe
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser 370 375 380Asn Gly Gln
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp385 390 395
400Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
405 410 415Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
Glu Ala 420 425 430Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
Ser Pro Gly Lys 435 440 44517511PRTOryctolagus cuniculus 175Gln Ala
Ser Gln Thr Ile Ser Asn Tyr Leu Ala1 5 101767PRTOryctolagus
cuniculus 176Gly Ala Ser Asn Leu Glu Ser1 517713PRTOryctolagus
cuniculus 177Gln Gln Gly Tyr Thr Ile Ser Asn Val Asp Asn Asn Val1 5
101785PRTOryctolagus cuniculus 178Gly Tyr Asn Leu Val1
517916PRTArtificial SequenceChemically Synthesized 179Phe Ile Ser
Tyr Gly Asp Thr Thr Tyr Tyr Ala Ser Ser Ala Lys Gly1 5 10
1518010PRTOryctolagus cuniculus 180Glu Thr Ala Asn Thr Tyr Asp Tyr
Gly Ile1 5 10181112PRTOryctolagus cuniculus 181Ala Ala Val Leu Thr
Gln Thr Pro Ser Pro Val Ser Ala Ala Val Gly1 5 10 15Gly Thr Val Ser
Ile Ser Cys Gln Ser Ser Gln Asn Val Tyr Lys Asn 20 25 30Asn Tyr Leu
Ser Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu 35 40 45Leu Ile
Tyr Lys Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg Phe 50 55 60Lys
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Asp Val65 70 75
80Gln Cys Asp Ala Ala Ala Thr Tyr Tyr Cys Ala Gly Gly Tyr Ser Ser
85 90 95Ser Ser Asp Asn Ala Phe Gly Gly Gly Thr Glu Val Val Val Lys
Arg 100 105 110182218PRTArtificial SequenceChemically Synthesized
182Ala Ala Val Leu Thr Gln Thr Pro Ser Pro Val Ser Ala Ala Val Gly1
5 10 15Gly Thr Val Ser Ile Ser Cys Gln Ser Ser Gln Asn Val Tyr Lys
Asn 20 25 30Asn Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
Lys Leu 35 40 45Leu Ile Tyr Lys Ala Ser Thr Leu Ala Ser Gly Val Pro
Ser Arg Phe 50 55 60Lys Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
Ile Ser Asp Val65 70 75 80Gln Cys Asp Ala Ala Ala Thr Tyr Tyr Cys
Ala Gly Gly Tyr Ser Ser 85 90 95Ser Ser Asp Asn Ala Phe Gly Gly Gly
Thr Glu Val Val Val Lys Arg 100 105 110Thr Val Ala Ala Pro Ser Val
Phe Ile Phe Pro Pro Ser Asp Glu Gln 115 120 125Leu Lys Ser Gly Thr
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr 130 135 140Pro Arg Glu
Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser145 150 155
160Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
Glu Lys 180 185 190His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly
Leu Ser Ser Pro 195 200 205Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215183117PRTOryctolagus cuniculus 183Gln Ser Val Glu Ala Ser
Gly Gly Arg Leu Val Met Pro Gly Gly Ser1 5 10 15Leu Thr Leu Thr Cys
Thr Ala Ser Gly Phe Ser Leu Ser Thr Tyr Trp 20 25 30Met Ser Trp Val
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile Gly 35 40 45Asp Ile Tyr
Phe Ser Asn Glu Glu Thr Asn Tyr Ala Thr Trp Ala Lys 50 55 60Gly Arg
Phe Thr Ile Ser Lys Thr Ser Thr Thr Val Asp Leu Asn Val65 70 75
80Ile Ser Pro Thr Thr Glu Asp Thr Ala Thr Tyr Phe Cys Ala Arg Gly
85 90 95Ser Pro Asp Val Glu Ile Ala Ile Asp Met Trp Gly Gln Gly Thr
Leu 100 105 110Val Thr Val Ser Ser 115184447PRTArtificial
SequenceChemically Synthesized 184Gln Ser Val Glu Ala Ser Gly Gly
Arg Leu Val Met Pro Gly Gly Ser1 5 10 15Leu Thr Leu Thr Cys Thr Ala
Ser Gly Phe Ser Leu Ser Thr Tyr Trp 20 25 30Met Ser Trp Val Arg Gln
Ala Pro Gly Lys Gly Leu Glu Trp Ile Gly 35 40 45Asp Ile Tyr Phe Ser
Asn Glu Glu Thr Asn Tyr Ala Thr Trp Ala Lys 50 55 60Gly Arg Phe Thr
Ile Ser Lys Thr Ser Thr Thr Val Asp Leu Asn Val65 70 75 80Ile Ser
Pro Thr Thr Glu Asp Thr Ala Thr Tyr Phe Cys Ala Arg Gly 85 90 95Ser
Pro Asp Val Glu Ile Ala Ile Asp Met Trp Gly Gln Gly Thr Leu 100 105
110Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
Gly Cys 130 135 140Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
Ser Trp Asn Ser145 150 155 160Gly Ala Leu Thr Ser Gly Val His Thr
Phe Pro Ala Val Leu Gln Ser 165 170 175Ser Gly Leu Tyr Ser Leu Ser
Ser Val Val Thr Val Pro Ser Ser Ser 180 185 190Leu Gly Thr Gln Thr
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn 195 200 205Thr Lys Val
Asp Lys Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His 210 215 220Thr
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val225 230
235 240Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
Thr 245 250 255Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
Asp Pro Glu 260 265 270Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
Val His Asn Ala Lys 275 280 285Thr Lys Pro Arg Glu Glu Gln Tyr Ala
Ser Thr Tyr Arg Val Val Ser 290 295 300Val Leu Thr Val Leu His Gln
Asp Trp Leu Asn Gly Lys Glu Tyr Lys305 310 315 320Cys Lys Val Ser
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile 325 330 335Ser Lys
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro 340 345
350Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
Ser Asn 370 375 380Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
Val Leu Asp Ser385 390 395 400Asp Gly Ser Phe Phe Leu Tyr Ser Lys
Leu Thr Val Asp Lys Ser Arg 405 410 415Trp Gln Gln Gly Asn Val Phe
Ser Cys Ser Val Met His Glu Ala Leu 420 425 430His Asn His Tyr Thr
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 435 440
44518513PRTOryctolagus cuniculus 185Gln Ser Ser Gln Asn Val Tyr Lys
Asn Asn Tyr Leu Ser1 5 101867PRTOryctolagus cuniculus 186Lys Ala
Ser Thr Leu Ala Ser1 518711PRTOryctolagus cuniculus 187Ala Gly Gly
Tyr Ser Ser Ser Ser Asp Asn Ala1 5 101885PRTOryctolagus cuniculus
188Thr Tyr Trp Met Ser1 518917PRTOryctolagus cuniculus 189Asp Ile
Tyr Phe Ser Asn Glu Glu Thr Asn Tyr Ala Thr Trp Ala Lys1 5 10
15Gly19011PRTOryctolagus cuniculus 190Gly Ser Pro Asp Val Glu Ile
Ala Ile Asp Met1 5 10191112PRTArtificial SequenceChemically
Synthesized 191Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala
Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Gln Ser Ser Gln Asn
Val Tyr Lys Asn 20 25 30Asn Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly
Lys Val Pro Lys Leu 35 40 45Leu Ile Tyr Lys Ala Ser Thr Leu Ala Ser
Gly Val Pro Ser Arg Phe 50 55 60Ser Gly Ser Gly Ser Gly Thr Asp Phe
Thr Leu Thr Ile Ser Ser Leu65 70 75 80Gln Pro Glu Asp Val Ala Thr
Tyr Tyr Cys Ala Gly Gly Tyr Thr Ser 85 90 95Ser Ser Asp Asn Ala Phe
Gly Gly Gly Thr Lys Val Glu Ile Lys Arg 100 105
110192218PRTArtificial SequenceChemically Synthesized 192Asp Ile
Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp
Arg Val Thr Ile Thr Cys Gln Ser Ser Gln Asn Val Tyr Lys Asn 20 25
30Asn Tyr Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu
35 40 45Leu Ile Tyr Lys Ala Ser Thr Leu Ala Ser Gly Val Pro Ser Arg
Phe 50 55 60Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
Ser Leu65 70 75 80Gln Pro Glu Asp Val Ala Thr Tyr Tyr Cys Ala Gly
Gly Tyr Thr Ser 85 90 95Ser Ser Asp Asn Ala Phe Gly Gly Gly Thr Lys
Val Glu Ile Lys Arg 100 105 110Thr Val Ala Ala Pro Ser Val Phe Ile
Phe Pro Pro Ser Asp Glu Gln 115 120 125Leu Lys Ser Gly Thr Ala Ser
Val Val Cys Leu Leu Asn Asn Phe Tyr 130 135 140Pro Arg Glu Ala Lys
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser145 150 155 160Gly Asn
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr 165 170
175Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
Ser Pro 195 200 205Val Thr Lys Ser Phe Asn Arg Gly Glu Cys 210
215193120PRTArtificial SequenceChemically Synthesized 193Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Val Ser Thr Tyr 20 25
30Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45Gly Asp Ile Tyr Phe Ser Asn Glu Glu Thr Asn Tyr Ala Thr Ser
Ala 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr
Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Tyr Cys 85 90 95Ala Arg Gly Ser Pro Asp Val Glu Ile Ala Ile
Asp Met Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser Ser 115
120194450PRTArtificial SequenceChemically Synthesized 194Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Val Ser Thr Tyr 20 25
30Trp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45Gly Asp Ile Tyr Phe Ser Asn Glu Glu Thr Asn Tyr Ala Thr Ser
Ala 50 55 60Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr
Leu Tyr65 70 75 80Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
Val Tyr Tyr Cys 85 90 95Ala Arg Gly Ser Pro Asp Val Glu Ile Ala Ile
Asp Met Trp Gly Gln 100 105 110Gly Thr Leu Val Thr Val Ser Ser Ala
Ser Thr Lys Gly Pro Ser Val 115 120 125Phe Pro Leu Ala Pro Ser Ser
Lys Ser Thr Ser Gly Gly Thr Ala Ala 130 135 140Leu Gly Cys Leu Val
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
Ser145 150 155 160Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr
Phe Pro Ala Val 165 170 175Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser
Ser Val Val Thr Val Pro 180 185 190Ser Ser Ser Leu Gly Thr Gln Thr
Tyr Ile Cys Asn Val Asn His Lys 195 200 205Pro Ser Asn Thr Lys Val
Asp Lys Arg Val Glu Pro Lys Ser Cys Asp 210 215 220Lys Thr His Thr
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly225 230 235 240Pro
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile 245 250
255Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
260 265 270Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu
Val His 275 280 285Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Ala
Ser Thr Tyr Arg 290 295 300Val Val Ser Val Leu Thr Val Leu His Gln
Asp Trp Leu Asn Gly Lys305 310 315 320Glu Tyr Lys Cys Lys Val Ser
Asn Lys Ala Leu Pro Ala Pro Ile Glu 325 330 335Lys Thr Ile Ser Lys
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr 340 345 350Thr Leu Pro
Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu 355 360 365Thr
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp 370 375
380Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
Val385 390 395 400Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
Leu Thr Val Asp 405 410 415Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
Ser Cys Ser Val Met His 420 425 430Glu Ala Leu His Asn His Tyr Thr
Gln Lys Ser Leu Ser Leu Ser Pro 435 440 445Gly Lys
45019513PRTOryctolagus cuniculus 195Gln Ser Ser Gln Asn Val Tyr Lys
Asn Asn Tyr Leu Ser1 5 101967PRTOryctolagus cuniculus 196Lys Ala
Ser Thr Leu Ala Ser1 519711PRTOryctolagus cuniculus 197Ala Gly Gly
Tyr Thr Ser Ser Ser Asp Asn Ala1 5 101985PRTOryctolagus cuniculus
198Thr Tyr Trp Met Ser1 519917PRTArtificial SequenceChemically
Synthesized 199Asp Ile Tyr Phe Ser Asn Glu Glu Thr Asn Tyr Ala Thr
Ser Ala Lys1 5 10 15Gly20011PRTArtificial SequenceChemically
Synthesized 200Gly Ser Pro Asp Val Glu Ile Ala Ile Asp Met1 5
10201333DNAOryctolagus cuniculus 201gcccttgtga tgacccagac
tccatcctcc gtgtctgcag ctgtgggagg cacagtcacc 60atcaattgcc aggccagtca
gaacatttac agcaatttag cctggtatca acagagacca 120gggcagcgtc
ccaagctcct gatctatggt gcatccaatc tggatgctgg ggtcccatcg
180cggttcagag gcagtggatc tgggacagag tacactctca ccatcagcga
cctggagtgt 240gacgatgttg gcacttacta ctgtcaaagt gcttttgata
gtgatagtac tgaaaatact 300ttcggcggag ggaccgaggt ggtggtcaaa cgt
333202654DNAArtificial SequenceChemically Synthesized 202gcccttgtga
tgacccagac tccatcctcc gtgtctgcag ctgtgggagg cacagtcacc 60atcaattgcc
aggccagtca gaacatttac agcaatttag cctggtatca acagagacca
120gggcagcgtc ccaagctcct gatctatggt gcatccaatc tggatgctgg
ggtcccatcg 180cggttcagag gcagtggatc tgggacagag tacactctca
ccatcagcga cctggagtgt 240gacgatgttg gcacttacta ctgtcaaagt
gcttttgata gtgatagtac tgaaaatact 300ttcggcggag ggaccgaggt
ggtggtcaaa cgtacggtag cggccccatc tgtcttcatc 360ttcccgccat
ctgatgagca gttgaaatct ggaactgcct ctgttgtgtg cctgctgaat
420aacttctatc ccagagaggc caaagtacag tggaaggtgg ataacgccct
ccaatcgggt 480aactcccagg agagtgtcac agagcaggac agcaaggaca
gcacctacag cctcagcagc 540accctgacgc tgagcaaagc agactacgag
aaacacaaag tctacgcctg cgaagtcacc 600catcagggcc tgagctcgcc
cgtcacaaag agcttcaaca ggggagagtg ttag 654203354DNAOryctolagus
cuniculus 203cagtcgctgg aggagtccgg gggtcgcctg gtcacgcctg ggacacccct
gacactcacc 60tgcacagtct ctggcttctc cctcagtagc tatgcaatga gctgggtccg
ccaggctcca 120gggaaggggc tggaatggat cggagtcatt actagtattg
gtagcacagt ctacgcgagc 180tgggcgaaag gccgattcac catctccaaa
acctcgacca cggtggatct gaaaatcacc 240agtccgacaa ccgaggacac
ggccacctat ttctgtgcca gaggctacga tgactatgat 300gagatgacct
actttaacat ctggggccag gggaccctcg tcaccgtctc gagc
3542041347DNAArtificial SequenceChemically Synthesized
204cagtcgctgg aggagtccgg gggtcgcctg gtcacgcctg ggacacccct
gacactcacc 60tgcacagtct ctggcttctc cctcagtagc tatgcaatga gctgggtccg
ccaggctcca 120gggaaggggc tggaatggat cggagtcatt actagtattg
gtagcacagt ctacgcgagc 180tgggcgaaag gccgattcac catctccaaa
acctcgacca cggtggatct gaaaatcacc 240agtccgacaa ccgaggacac
ggccacctat ttctgtgcca gaggctacga tgactatgat 300gagatgacct
actttaacat ctggggccag gggaccctcg tcaccgtctc gagcgcctcc
360accaagggcc catcggtctt ccccctggca ccctcctcca agagcacctc
tgggggcaca 420gcggccctgg gctgcctggt caaggactac ttccccgaac
cggtgacggt gtcgtggaac 480tcaggcgccc tgaccagcgg cgtgcacacc
ttcccggctg tcctacagtc ctcaggactc 540tactccctca gcagcgtggt
gaccgtgccc tccagcagct tgggcaccca gacctacatc 600tgcaacgtga
atcacaagcc cagcaacacc aaggtggaca agagagttga gcccaaatct
660tgtgacaaaa ctcacacatg cccaccgtgc ccagcacctg aactcctggg
gggaccgtca 720gtcttcctct tccccccaaa acccaaggac accctcatga
tctcccggac ccctgaggtc 780acatgcgtgg tggtggacgt gagccacgaa
gaccctgagg tcaagttcaa ctggtacgtg 840gacggcgtgg aggtgcataa
tgccaagaca aagccgcggg aggagcagta cgccagcacg 900taccgtgtgg
tcagcgtcct caccgtcctg caccaggact ggctgaatgg caaggagtac
960aagtgcaagg tctccaacaa agccctccca gcccccatcg agaaaaccat
ctccaaagcc 1020aaagggcagc cccgagaacc acaggtgtac accctgcccc
catcccggga ggagatgacc 1080aagaaccagg tcagcctgac ctgcctggtc
aaaggcttct atcccagcga catcgccgtg 1140gagtgggaga gcaatgggca
gccggagaac aactacaaga ccacgcctcc cgtgctggac 1200tccgacggct
ccttcttcct ctacagcaag ctcaccgtgg acaagagcag gtggcagcag
1260gggaacgtct tctcatgctc cgtgatgcat gaggctctgc acaaccacta
cacgcagaag 1320agcctctccc tgtctccggg taaatga
134720533DNAOryctolagus cuniculus 205caggccagtc agaacattta
cagcaattta gcc 3320621DNAOryctolagus cuniculus 206ggtgcatcca
atctggatgc t 2120736DNAOryctolagus cuniculus 207caaagtgctt
ttgatagtga tagtactgaa aatact 3620815DNAOryctolagus cuniculus
208agctatgcaa tgagc 1520948DNAOryctolagus cuniculus 209gtcattacta
gtattggtag cacagtctac gcgagctggg cgaaaggc 4821039DNAOryctolagus
cuniculus 210ggctacgatg actatgatga gatgacctac tttaacatc
39211333DNAArtificial SequenceChemically Synthesized 211gacatccaga
tgacccagtc tccttccacc ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc
aggccagtca gaacatttac agcaacttag cctggtatca gcagaaacca
120ggaaaagccc ctaagctcct gatctatggt gcatccaatc tggatgctgg
agtcccatca 180aggttctctg gcagtggatc tgggacagag tacactctca
ccatcagcag cctgcagcct 240gatgattttg caacttacta ctgccaaagt
gcttttgata gtgatagtac tgaaaacact 300ttcggcggag gaaccaaggt
ggaaatcaaa cgt 333212654DNAArtificial SequenceChemically
Synthesized 212gacatccaga tgacccagtc tccttccacc ctgtctgcat
ctgtaggaga cagagtcacc 60atcacttgcc aggccagtca gaacatttac agcaacttag
cctggtatca gcagaaacca 120ggaaaagccc ctaagctcct gatctatggt
gcatccaatc tggatgctgg agtcccatca 180aggttctctg gcagtggatc
tgggacagag tacactctca ccatcagcag cctgcagcct 240gatgattttg
caacttacta ctgccaaagt gcttttgata gtgatagtac tgaaaacact
300ttcggcggag gaaccaaggt ggaaatcaaa cgtacggtag cggccccatc
tgtcttcatc 360ttcccgccat ctgatgagca gttgaaatct ggaactgcct
ctgttgtgtg cctgctgaat 420aacttctatc ccagagaggc caaagtacag
tggaaggtgg ataacgccct ccaatcgggt 480aactcccagg agagtgtcac
agagcaggac agcaaggaca gcacctacag cctcagcagc 540accctgacgc
tgagcaaagc agactacgag aaacacaaag tctacgcctg cgaagtcacc
600catcagggcc tgagctcgcc cgtcacaaag agcttcaaca ggggagagtg ttag
654213363DNAArtificial SequenceChemically Synthesized 213gaggtgcagc
tggtggagtc tgggggaggc ttggtccagc ctggggggtc cctgagactc 60tcctgtgcag
cctctggatt caccgtcagt agctatgcaa tgagctgggt ccgtcaggct
120ccagggaagg ggctggagtg ggtcggagtc attactagta ttggtagcac
agtctacgcg 180agcagcgcga aaggccgatt caccatctcc agagacaatt
ccaagaacac cctgtatctt 240caaatgaaca gcctgagagc tgaggacact
gctgtgtatt actgtgctag aggctacgat 300gactatgatg agatgaccta
ctttaacatc tggggccaag ggaccctcgt caccgtctcg 360agc
3632141356DNAArtificial SequenceChemically Synthesized
214gaggtgcagc tggtggagtc tgggggaggc ttggtccagc ctggggggtc
cctgagactc 60tcctgtgcag cctctggatt caccgtcagt agctatgcaa tgagctgggt
ccgtcaggct 120ccagggaagg ggctggagtg ggtcggagtc attactagta
ttggtagcac agtctacgcg 180agcagcgcga aaggccgatt caccatctcc
agagacaatt ccaagaacac cctgtatctt 240caaatgaaca gcctgagagc
tgaggacact gctgtgtatt actgtgctag aggctacgat 300gactatgatg
agatgaccta ctttaacatc tggggccaag ggaccctcgt caccgtctcg
360agcgcctcca ccaagggccc atcggtcttc cccctggcac cctcctccaa
gagcacctct 420gggggcacag cggccctggg ctgcctggtc aaggactact
tccccgaacc ggtgacggtg 480tcgtggaact caggcgccct gaccagcggc
gtgcacacct tcccggctgt cctacagtcc 540tcaggactct actccctcag
cagcgtggtg accgtgccct ccagcagctt gggcacccag 600acctacatct
gcaacgtgaa tcacaagccc agcaacacca aggtggacaa gagagttgag
660cccaaatctt gtgacaaaac tcacacatgc ccaccgtgcc cagcacctga
actcctgggg 720ggaccgtcag tcttcctctt ccccccaaaa cccaaggaca
ccctcatgat ctcccggacc 780cctgaggtca catgcgtggt ggtggacgtg
agccacgaag accctgaggt caagttcaac 840tggtacgtgg acggcgtgga
ggtgcataat gccaagacaa agccgcggga ggagcagtac 900gccagcacgt
accgtgtggt cagcgtcctc accgtcctgc accaggactg gctgaatggc
960aaggagtaca agtgcaaggt ctccaacaaa gccctcccag cccccatcga
gaaaaccatc 1020tccaaagcca aagggcagcc ccgagaacca caggtgtaca
ccctgccccc atcccgggag 1080gagatgacca agaaccaggt cagcctgacc
tgcctggtca aaggcttcta tcccagcgac 1140atcgccgtgg agtgggagag
caatgggcag ccggagaaca actacaagac cacgcctccc 1200gtgctggact
ccgacggctc cttcttcctc tacagcaagc tcaccgtgga caagagcagg
1260tggcagcagg ggaacgtctt ctcatgctcc gtgatgcatg aggctctgca
caaccactac 1320acgcagaaga gcctctccct gtctccgggt aaatga
135621533DNAOryctolagus cuniculus 215caggccagtc agaacattta
cagcaactta gcc 3321621DNAOryctolagus cuniculus 216ggtgcatcca
atctggatgc t 2121736DNAOryctolagus cuniculus 217caaagtgctt
ttgatagtga tagtactgaa aacact 3621815DNAOryctolagus cuniculus
218agctatgcaa tgagc 1521948DNAArtificial SequenceChemically
Synthesized 219gtcattacta gtattggtag cacagtctac gcgagcagcg cgaaaggc
4822039DNAOryctolagus cuniculus 220ggctacgatg actatgatga gatgacctac
tttaacatc 39221336DNAOryctolagus cuniculus 221gcagccgtgc tgacccagac
accatcgccc gtgtctgcag ctatgggaga cacagtcacc 60atcaagtgcc agtccagtca
gagtgtttat aagaacaact acttatcctg gtatcagcag 120aaaccagggc
agcctcccag gctcctgatc tatgatgcat ccaatctgcc atctggggtc
180ccatcacggt tcagcggcag tggatctggg acacagttca ctctcaccat
cagcggcgtg 240cagtgtgacg atgctgccac ttactactgt ctaggcgatt
atgatgatga tgctgataat 300gctttcggcg gagggaccga ggtggtggtc aaacgt
336222657DNAArtificial SequenceChemically Synthesized 222gcagccgtgc
tgacccagac accatcgccc gtgtctgcag ctatgggaga cacagtcacc 60atcaagtgcc
agtccagtca gagtgtttat aagaacaact acttatcctg gtatcagcag
120aaaccagggc agcctcccag gctcctgatc tatgatgcat ccaatctgcc
atctggggtc 180ccatcacggt tcagcggcag tggatctggg acacagttca
ctctcaccat cagcggcgtg 240cagtgtgacg atgctgccac ttactactgt
ctaggcgatt atgatgatga tgctgataat 300gctttcggcg gagggaccga
ggtggtggtc aaacgtacgg tagcggcccc atctgtcttc 360atcttcccgc
catctgatga gcagttgaaa tctggaactg cctctgttgt gtgcctgctg
420aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc
cctccaatcg 480ggtaactccc aggagagtgt cacagagcag gacagcaagg
acagcaccta cagcctcagc 540agcaccctga cgctgagcaa agcagactac
gagaaacaca aagtctacgc ctgcgaagtc 600acccatcagg gcctgagctc
gcccgtcaca aagagcttca acaggggaga gtgttag 657223339DNAOryctolagus
cuniculus 223cagtcggtgg aggagtccgg gggtcgcctg gtcacgcctg ggacacccct
gacactcacc 60tgcacagtct ctggattctc cctcagtagc tatgtaatga tctgggtccg
ccaggctcca 120gggaaggggc tggaatacat cggaatcact tggagtgctg
gtacatacta cgcgagctgg 180gcgaaaggcc gattcaccat ctccaaaacc
tcgtcgacca cggtggatct gaaaatcacc 240agtccgacaa ccgaggacac
ggccacctat ttctgtgccg gaggtggtgg tagtatttat 300gatatttggg
gcccgggcac cctggtcacc gtctcgagc 3392241332DNAArtificial
SequenceChemically Synthesized 224cagtcggtgg aggagtccgg gggtcgcctg
gtcacgcctg ggacacccct gacactcacc 60tgcacagtct ctggattctc cctcagtagc
tatgtaatga tctgggtccg ccaggctcca 120gggaaggggc tggaatacat
cggaatcact tggagtgctg gtacatacta cgcgagctgg 180gcgaaaggcc
gattcaccat ctccaaaacc tcgtcgacca cggtggatct gaaaatcacc
240agtccgacaa ccgaggacac ggccacctat ttctgtgccg gaggtggtgg
tagtatttat 300gatatttggg gcccgggcac cctggtcacc gtctcgagcg
cctccaccaa gggcccatcg 360gtcttccccc tggcaccctc ctccaagagc
acctctgggg gcacagcggc cctgggctgc 420ctggtcaagg actacttccc
cgaaccggtg acggtgtcgt ggaactcagg cgccctgacc 480agcggcgtgc
acaccttccc ggctgtccta cagtcctcag gactctactc cctcagcagc
540gtggtgaccg tgccctccag cagcttgggc acccagacct acatctgcaa
cgtgaatcac 600aagcccagca acaccaaggt ggacaagaga gttgagccca
aatcttgtga caaaactcac 660acatgcccac cgtgcccagc acctgaactc
ctggggggac cgtcagtctt cctcttcccc 720ccaaaaccca aggacaccct
catgatctcc cggacccctg aggtcacatg cgtggtggtg 780gacgtgagcc
acgaagaccc tgaggtcaag ttcaactggt acgtggacgg cgtggaggtg
840cataatgcca agacaaagcc gcgggaggag cagtacgcca gcacgtaccg
tgtggtcagc 900gtcctcaccg tcctgcacca ggactggctg aatggcaagg
agtacaagtg caaggtctcc 960aacaaagccc tcccagcccc catcgagaaa
accatctcca aagccaaagg gcagccccga 1020gaaccacagg tgtacaccct
gcccccatcc cgggaggaga tgaccaagaa ccaggtcagc 1080ctgacctgcc
tggtcaaagg cttctatccc agcgacatcg ccgtggagtg ggagagcaat
1140gggcagccgg agaacaacta caagaccacg cctcccgtgc tggactccga
cggctccttc 1200ttcctctaca gcaagctcac cgtggacaag agcaggtggc
agcaggggaa cgtcttctca 1260tgctccgtga tgcatgaggc tctgcacaac
cactacacgc agaagagcct ctccctgtct 1320ccgggtaaat ga
133222539DNAOryctolagus cuniculus 225cagtccagtc agagtgttta
taagaacaac tacttatcc 3922621DNAOryctolagus cuniculus 226gatgcatcca
atctgccatc t 2122733DNAOryctolagus cuniculus 227ctaggcgatt
atgatgatga tgctgataat gct 3322815DNAOryctolagus cuniculus
228agctatgtaa tgatc 1522945DNAOryctolagus cuniculus 229atcacttgga
gtgctggtac atactacgcg agctgggcga aaggc 4523024DNAOryctolagus
cuniculus 230ggtggtggta gtatttatga tatt 24231336DNAArtificial
SequenceChemically Synthesized 231gacatccaga tgacccagtc tccttccacc
ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc agtccagtca gagtgtctat
aagaacaact acttatcctg gtatcagcag 120aaaccaggaa aagcccctaa
gctcctgatc tatgatgcat ccaatctgcc atctggagtc 180ccatcaaggt
tcagcggcag tggatctgga acagaattca ctctcaccat cagcagcctg
240cagcctgatg attttgcaac ttattactgc ctaggcgatt atgatgatga
tgctgataat 300gctttcggcg gaggaaccaa ggtggaaatc aaacgt
336232657DNAArtificial SequenceChemically Synthesized 232gacatccaga
tgacccagtc tccttccacc ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc
agtccagtca gagtgtctat aagaacaact acttatcctg gtatcagcag
120aaaccaggaa aagcccctaa gctcctgatc tatgatgcat ccaatctgcc
atctggagtc 180ccatcaaggt tcagcggcag tggatctgga acagaattca
ctctcaccat cagcagcctg 240cagcctgatg attttgcaac ttattactgc
ctaggcgatt atgatgatga tgctgataat 300gctttcggcg gaggaaccaa
ggtggaaatc aaacgtacgg tagcggcccc atctgtcttc 360atcttcccgc
catctgatga gcagttgaaa tctggaactg cctctgttgt gtgcctgctg
420aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc
cctccaatcg 480ggtaactccc aggagagtgt cacagagcag gacagcaagg
acagcaccta cagcctcagc 540agcaccctga cgctgagcaa agcagactac
gagaaacaca aagtctacgc ctgcgaagtc 600acccatcagg gcctgagctc
gcccgtcaca aagagcttca acaggggaga gtgttag 657233345DNAArtificial
SequenceChemically Synthesized 233gaggtgcagc tggtggagtc tgggggaggc
ttggtccagc ctggggggtc cctgagactc 60tcctgtgcag cctctggatt caccgtcagt
agctatgtaa tgatctgggt ccgtcaggct 120ccagggaagg ggctggagta
catcggaatc acttggagtg ctggtacata ctacgcgagc 180agtgcgaaag
gccgattcac catctccaga gacaattcca agaacaccct gtatcttcaa
240atgaacagcc tgagagctga ggacactgct gtgtattact gtgctggagg
tggtggtagt 300atctatgata tttggggcca agggaccctc gtcaccgtct cgagc
3452341338DNAArtificial SequenceChemically Synthesized
234gaggtgcagc tggtggagtc tgggggaggc ttggtccagc ctggggggtc
cctgagactc 60tcctgtgcag cctctggatt caccgtcagt agctatgtaa tgatctgggt
ccgtcaggct 120ccagggaagg ggctggagta catcggaatc acttggagtg
ctggtacata ctacgcgagc 180agtgcgaaag gccgattcac catctccaga
gacaattcca agaacaccct gtatcttcaa 240atgaacagcc tgagagctga
ggacactgct gtgtattact gtgctggagg tggtggtagt 300atctatgata
tttggggcca agggaccctc gtcaccgtct cgagcgcctc caccaagggc
360ccatcggtct tccccctggc accctcctcc aagagcacct ctgggggcac
agcggccctg 420ggctgcctgg tcaaggacta cttccccgaa ccggtgacgg
tgtcgtggaa ctcaggcgcc 480ctgaccagcg
gcgtgcacac cttcccggct gtcctacagt cctcaggact ctactccctc
540agcagcgtgg tgaccgtgcc ctccagcagc ttgggcaccc agacctacat
ctgcaacgtg 600aatcacaagc ccagcaacac caaggtggac aagagagttg
agcccaaatc ttgtgacaaa 660actcacacat gcccaccgtg cccagcacct
gaactcctgg ggggaccgtc agtcttcctc 720ttccccccaa aacccaagga
caccctcatg atctcccgga cccctgaggt cacatgcgtg 780gtggtggacg
tgagccacga agaccctgag gtcaagttca actggtacgt ggacggcgtg
840gaggtgcata atgccaagac aaagccgcgg gaggagcagt acgccagcac
gtaccgtgtg 900gtcagcgtcc tcaccgtcct gcaccaggac tggctgaatg
gcaaggagta caagtgcaag 960gtctccaaca aagccctccc agcccccatc
gagaaaacca tctccaaagc caaagggcag 1020ccccgagaac cacaggtgta
caccctgccc ccatcccggg aggagatgac caagaaccag 1080gtcagcctga
cctgcctggt caaaggcttc tatcccagcg acatcgccgt ggagtgggag
1140agcaatgggc agccggagaa caactacaag accacgcctc ccgtgctgga
ctccgacggc 1200tccttcttcc tctacagcaa gctcaccgtg gacaagagca
ggtggcagca ggggaacgtc 1260ttctcatgct ccgtgatgca tgaggctctg
cacaaccact acacgcagaa gagcctctcc 1320ctgtctccgg gtaaatga
133823539DNAOryctolagus cuniculus 235cagtccagtc agaatgttta
taagaacaac tacttatcc 3923621DNAOryctolagus cuniculus 236aaggcatcca
ctctggcatc t 2123732DNAOryctolagus cuniculus 237gcaggcggtt
ataccagtag tagtgataat gc 3223815DNAOryctolagus cuniculus
238agctatgtaa tgatc 1523945DNAArtificial SequenceChemically
Synthesized 239atcacttgga gtgctggtac atactacgcg agcagtgcga aaggc
4524024DNAOryctolagus cuniculus 240ggtggtggta gtatctatga tatt
24241333DNAOryctolagus cuniculus 241gcctatgata tgacccagac
tccagcctct gtggaggtag ctgtgggagg cacagtcacc 60atcaagtgcc aggccagtca
gagcatttac agcaatttag cctggtatca gcagagacca 120gggcagcctc
ccaagctcct gatctatgat gcatccactc tggaatctgg ggtcccatcg
180cggttcaaag gcagtggatc tgggacagag tacactctca ccatcagcgg
cgtggagtgt 240gccgatgctg cctcttacta ctgtcaacag ggttttactg
ttagtgatat tgataatgct 300ttcggcggag ggaccgaggt ggtggtcaaa cgt
333242654DNAArtificial SequenceChemically Synthesized 242gcctatgata
tgacccagac tccagcctct gtggaggtag ctgtgggagg cacagtcacc 60atcaagtgcc
aggccagtca gagcatttac agcaatttag cctggtatca gcagagacca
120gggcagcctc ccaagctcct gatctatgat gcatccactc tggaatctgg
ggtcccatcg 180cggttcaaag gcagtggatc tgggacagag tacactctca
ccatcagcgg cgtggagtgt 240gccgatgctg cctcttacta ctgtcaacag
ggttttactg ttagtgatat tgataatgct 300ttcggcggag ggaccgaggt
ggtggtcaaa cgtacggtag cggccccatc tgtcttcatc 360ttcccgccat
ctgatgagca gttgaaatct ggaactgcct ctgttgtgtg cctgctgaat
420aacttctatc ccagagaggc caaagtacag tggaaggtgg ataacgccct
ccaatcgggt 480aactcccagg agagtgtcac agagcaggac agcaaggaca
gcacctacag cctcagcagc 540accctgacgc tgagcaaagc agactacgag
aaacacaaag tctacgcctg cgaagtcacc 600catcagggcc tgagctcgcc
cgtcacaaag agcttcaaca ggggagagtg ttag 654243354DNAOryctolagus
cuniculus 243cagtcggtgg aggagtccgg gggtcgcctg gtcacgcctg ggacacccct
gacactcacc 60tgcacagtct ctggattctc cctcagtaac tatgcagtgg gctgggtccg
ccaggctcca 120gggaaggggc tggaatggat cggaatcatt ggtcgtaatg
gtaacacatg gtacgcgagc 180tgggcaagag gccgattcac catctccaaa
acctcgacca cggtggatct gaaaatcacc 240agtccgacaa gcgaggacac
ggccacatat ttctgtgcca gaggatatgg ccgtagtgtt 300gcttattacg
tctttaacat ctggggccca ggcaccctcg tcaccgtctc gagc
3542441347DNAArtificial SequenceChemically Synthesized
244cagtcggtgg aggagtccgg gggtcgcctg gtcacgcctg ggacacccct
gacactcacc 60tgcacagtct ctggattctc cctcagtaac tatgcagtgg gctgggtccg
ccaggctcca 120gggaaggggc tggaatggat cggaatcatt ggtcgtaatg
gtaacacatg gtacgcgagc 180tgggcaagag gccgattcac catctccaaa
acctcgacca cggtggatct gaaaatcacc 240agtccgacaa gcgaggacac
ggccacatat ttctgtgcca gaggatatgg ccgtagtgtt 300gcttattacg
tctttaacat ctggggccca ggcaccctcg tcaccgtctc gagcgcctcc
360accaagggcc catcggtctt ccccctggca ccctcctcca agagcacctc
tgggggcaca 420gcggccctgg gctgcctggt caaggactac ttccccgaac
cggtgacggt gtcgtggaac 480tcaggcgccc tgaccagcgg cgtgcacacc
ttcccggctg tcctacagtc ctcaggactc 540tactccctca gcagcgtggt
gaccgtgccc tccagcagct tgggcaccca gacctacatc 600tgcaacgtga
atcacaagcc cagcaacacc aaggtggaca agagagttga gcccaaatct
660tgtgacaaaa ctcacacatg cccaccgtgc ccagcacctg aactcctggg
gggaccgtca 720gtcttcctct tccccccaaa acccaaggac accctcatga
tctcccggac ccctgaggtc 780acatgcgtgg tggtggacgt gagccacgaa
gaccctgagg tcaagttcaa ctggtacgtg 840gacggcgtgg aggtgcataa
tgccaagaca aagccgcggg aggagcagta cgccagcacg 900taccgtgtgg
tcagcgtcct caccgtcctg caccaggact ggctgaatgg caaggagtac
960aagtgcaagg tctccaacaa agccctccca gcccccatcg agaaaaccat
ctccaaagcc 1020aaagggcagc cccgagaacc acaggtgtac accctgcccc
catcccggga ggagatgacc 1080aagaaccagg tcagcctgac ctgcctggtc
aaaggcttct atcccagcga catcgccgtg 1140gagtgggaga gcaatgggca
gccggagaac aactacaaga ccacgcctcc cgtgctggac 1200tccgacggct
ccttcttcct ctacagcaag ctcaccgtgg acaagagcag gtggcagcag
1260gggaacgtct tctcatgctc cgtgatgcat gaggctctgc acaaccacta
cacgcagaag 1320agcctctccc tgtctccggg taaatga
134724533DNAOryctolagus cuniculus 245caggccagtc agagcattta
cagcaattta gcc 3324621DNAOryctolagus cuniculus 246gatgcatcca
ctctggaatc t 2124736DNAOryctolagus cuniculus 247caacagggtt
ttactgttag tgatattgat aatgct 3624815DNAOryctolagus cuniculus
248aactatgcag tgggc 1524948DNAOryctolagus cuniculus 249atcattggtc
gtaatggtaa cacatggtac gcgagctggg caagaggc 4825039DNAOryctolagus
cuniculus 250ggatatggcc gtagtgttgc ttattacgtc tttaacatc
39251333DNAArtificial SequenceChemically Synthesized 251gacatccaga
tgacccagtc tccttccacc ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc
aggccagtca gagcatttac agcaatcttg cctggtatca gcagaaacca
120ggaaaagccc ctaagctcct gatctatgat gcatccactc tggaatctgg
agtcccatca 180aggttcagcg gcagtggatc tgggacagag tacactctca
ccatcagcag cctgcagcct 240gatgattttg caacttacta ctgccaacag
ggttttactg ttagtgatat tgataatgct 300ttcggcggag gaaccaaggt
ggaaatcaaa cgt 333252654DNAArtificial SequenceChemically
Synthesized 252gacatccaga tgacccagtc tccttccacc ctgtctgcat
ctgtaggaga cagagtcacc 60atcacttgcc aggccagtca gagcatttac agcaatcttg
cctggtatca gcagaaacca 120ggaaaagccc ctaagctcct gatctatgat
gcatccactc tggaatctgg agtcccatca 180aggttcagcg gcagtggatc
tgggacagag tacactctca ccatcagcag cctgcagcct 240gatgattttg
caacttacta ctgccaacag ggttttactg ttagtgatat tgataatgct
300ttcggcggag gaaccaaggt ggaaatcaaa cgtacggtag cggccccatc
tgtcttcatc 360ttcccgccat ctgatgagca gttgaaatct ggaactgcct
ctgttgtgtg cctgctgaat 420aacttctatc ccagagaggc caaagtacag
tggaaggtgg ataacgccct ccaatcgggt 480aactcccagg agagtgtcac
agagcaggac agcaaggaca gcacctacag cctcagcagc 540accctgacgc
tgagcaaagc agactacgag aaacacaaag tctacgcctg cgaagtcacc
600catcagggcc tgagctcgcc cgtcacaaag agcttcaaca ggggagagtg ttag
654253363DNAArtificial SequenceChemically Synthesized 253gaggtgcagc
tggtggagtc tgggggaggc ttggtccagc ctggggggtc cctgagactc 60tcctgtgcag
cctctggatt caccgtcagt aactatgcag tgggctgggt ccgtcaggct
120ccagggaagg ggctggagtg ggtcggaatc attggtcgta atggtaacac
atggtacgcg 180agctctgcaa gaggccgatt caccatctcc agagacaatt
ccaagaacac cctgtatctt 240caaatgaaca gcctgagagc tgaggacact
gctgtgtatt actgtgctag aggatatggc 300cgtagtgttg cttattacgt
ctttaacatc tggggcccag ggaccctcgt caccgtctcg 360agc
3632541356DNAArtificial SequenceChemically Synthesized
254gaggtgcagc tggtggagtc tgggggaggc ttggtccagc ctggggggtc
cctgagactc 60tcctgtgcag cctctggatt caccgtcagt aactatgcag tgggctgggt
ccgtcaggct 120ccagggaagg ggctggagtg ggtcggaatc attggtcgta
atggtaacac atggtacgcg 180agctctgcaa gaggccgatt caccatctcc
agagacaatt ccaagaacac cctgtatctt 240caaatgaaca gcctgagagc
tgaggacact gctgtgtatt actgtgctag aggatatggc 300cgtagtgttg
cttattacgt ctttaacatc tggggcccag ggaccctcgt caccgtctcg
360agcgcctcca ccaagggccc atcggtcttc cccctggcac cctcctccaa
gagcacctct 420gggggcacag cggccctggg ctgcctggtc aaggactact
tccccgaacc ggtgacggtg 480tcgtggaact caggcgccct gaccagcggc
gtgcacacct tcccggctgt cctacagtcc 540tcaggactct actccctcag
cagcgtggtg accgtgccct ccagcagctt gggcacccag 600acctacatct
gcaacgtgaa tcacaagccc agcaacacca aggtggacaa gagagttgag
660cccaaatctt gtgacaaaac tcacacatgc ccaccgtgcc cagcacctga
actcctgggg 720ggaccgtcag tcttcctctt ccccccaaaa cccaaggaca
ccctcatgat ctcccggacc 780cctgaggtca catgcgtggt ggtggacgtg
agccacgaag accctgaggt caagttcaac 840tggtacgtgg acggcgtgga
ggtgcataat gccaagacaa agccgcggga ggagcagtac 900gccagcacgt
accgtgtggt cagcgtcctc accgtcctgc accaggactg gctgaatggc
960aaggagtaca agtgcaaggt ctccaacaaa gccctcccag cccccatcga
gaaaaccatc 1020tccaaagcca aagggcagcc ccgagaacca caggtgtaca
ccctgccccc atcccgggag 1080gagatgacca agaaccaggt cagcctgacc
tgcctggtca aaggcttcta tcccagcgac 1140atcgccgtgg agtgggagag
caatgggcag ccggagaaca actacaagac cacgcctccc 1200gtgctggact
ccgacggctc cttcttcctc tacagcaagc tcaccgtgga caagagcagg
1260tggcagcagg ggaacgtctt ctcatgctcc gtgatgcatg aggctctgca
caaccactac 1320acgcagaaga gcctctccct gtctccgggt aaatga
135625533DNAOryctolagus cuniculus 255caggccagtc agagcattta
cagcaatctt gcc 3325621DNAOryctolagus cuniculus 256gatgcatcca
ctctggaatc t 2125736DNAOryctolagus cuniculus 257caacagggtt
ttactgttag tgatattgat aatgct 3625815DNAOryctolagus cuniculus
258aactatgcag tgggc 1525948DNAArtificial SequenceChemically
Synthesized 259atcattggtc gtaatggtaa cacatggtac gcgagctctg caagaggc
4826039DNAOryctolagus cuniculus 260ggatatggcc gtagtgttgc ttattacgtc
tttaacatc 39261336DNAOryctolagus cuniculus 261gccgatgttg tgatgaccca
gactccagcc tccgtgtctc aacctgtggg aggcacagtc 60accatcaagt gccaggccag
tgaggacatt tataacttat tggcctggta tcagcagaaa 120ccagggcagc
ctcccaagct cctgatctat tctgcatcca ctctggcatc tggggtccca
180tcgcggttca aaggcagtgg atctgggaca gagtacactc tcaccatcag
cggcctggag 240tgtgccgatg ctgccactta ctactgtcaa aacaattatc
ttgttactac ttatggtgtt 300gctttcggcg gagggaccga ggtggtggtc aaacgt
336262657DNAArtificial SequenceChemically Synthesized 262gccgatgttg
tgatgaccca gactccagcc tccgtgtctc aacctgtggg aggcacagtc 60accatcaagt
gccaggccag tgaggacatt tataacttat tggcctggta tcagcagaaa
120ccagggcagc ctcccaagct cctgatctat tctgcatcca ctctggcatc
tggggtccca 180tcgcggttca aaggcagtgg atctgggaca gagtacactc
tcaccatcag cggcctggag 240tgtgccgatg ctgccactta ctactgtcaa
aacaattatc ttgttactac ttatggtgtt 300gctttcggcg gagggaccga
ggtggtggtc aaacgtacgg tagcggcccc atctgtcttc 360atcttcccgc
catctgatga gcagttgaaa tctggaactg cctctgttgt gtgcctgctg
420aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc
cctccaatcg 480ggtaactccc aggagagtgt cacagagcag gacagcaagg
acagcaccta cagcctcagc 540agcaccctga cgctgagcaa agcagactac
gagaaacaca aagtctacgc ctgcgaagtc 600acccatcagg gcctgagctc
gcccgtcaca aagagcttca acaggggaga gtgttag 657263360DNAOryctolagus
cuniculus 263caggagcagc tgaaggagtc cgggggtcgc ctggtcacgc ctgggacacc
cctgacactc 60acctgtacag tctctggatt ctccctcagt agctatgcaa tgatctgggt
ccgccaggct 120ccagggaagg ggctggaata catcggatac attgatactg
atactagcgc atactacgcg 180agctgggtga aaggccgatt caccatctcc
agaacctcga ccacggtgga tctcaaaatc 240actagtccga caaccgagga
cacggccacc tatttctgtg ccagatctta tgctgcttat 300ggtggttatc
ctgctacttt tgatccctgg ggcccaggca ccctggtcac cgtctcgagc
3602641353DNAArtificial SequenceChemically Synthesized
264caggagcagc tgaaggagtc cgggggtcgc ctggtcacgc ctgggacacc
cctgacactc 60acctgtacag tctctggatt ctccctcagt agctatgcaa tgatctgggt
ccgccaggct 120ccagggaagg ggctggaata catcggatac attgatactg
atactagcgc atactacgcg 180agctgggtga aaggccgatt caccatctcc
agaacctcga ccacggtgga tctcaaaatc 240actagtccga caaccgagga
cacggccacc tatttctgtg ccagatctta tgctgcttat 300ggtggttatc
ctgctacttt tgatccctgg ggcccaggca ccctggtcac cgtctcgagc
360gcctccacca agggcccatc ggtcttcccc ctggcaccct cctccaagag
cacctctggg 420ggcacagcgg ccctgggctg cctggtcaag gactacttcc
ccgaaccggt gacggtgtcg 480tggaactcag gcgccctgac cagcggcgtg
cacaccttcc cggctgtcct acagtcctca 540ggactctact ccctcagcag
cgtggtgacc gtgccctcca gcagcttggg cacccagacc 600tacatctgca
acgtgaatca caagcccagc aacaccaagg tggacaagag agttgagccc
660aaatcttgtg acaaaactca cacatgccca ccgtgcccag cacctgaact
cctgggggga 720ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc
tcatgatctc ccggacccct 780gaggtcacat gcgtggtggt ggacgtgagc
cacgaagacc ctgaggtcaa gttcaactgg 840tacgtggacg gcgtggaggt
gcataatgcc aagacaaagc cgcgggagga gcagtacgcc 900agcacgtacc
gtgtggtcag cgtcctcacc gtcctgcacc aggactggct gaatggcaag
960gagtacaagt gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa
aaccatctcc 1020aaagccaaag ggcagccccg agaaccacag gtgtacaccc
tgcccccatc ccgggaggag 1080atgaccaaga accaggtcag cctgacctgc
ctggtcaaag gcttctatcc cagcgacatc 1140gccgtggagt gggagagcaa
tgggcagccg gagaacaact acaagaccac gcctcccgtg 1200ctggactccg
acggctcctt cttcctctac agcaagctca ccgtggacaa gagcaggtgg
1260cagcagggga acgtcttctc atgctccgtg atgcatgagg ctctgcacaa
ccactacacg 1320cagaagagcc tctccctgtc tccgggtaaa tga
135326533DNAOryctolagus cuniculus 265caggccagtg aggacattta
taacttattg gcc 3326621DNAOryctolagus cuniculus 266tctgcatcca
ctctggcatc t 2126736DNAOryctolagus cuniculus 267caaaacaatt
atcttgttac tacttatggt gttgct 3626815DNAOryctolagus cuniculus
268agctatgcaa tgatc 1526948DNAOryctolagus cuniculus 269tacattgata
ctgatactag cgcatactac gcgagctggg tgaaaggc 4827036DNAOryctolagus
cuniculus 270tcttatgctg cttatggtgg ttatcctgct actttt
36271333DNAArtificial SequenceChemically Synthesized 271gacatccaga
tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc
aggccagtga ggacatttac aacttattgg cctggtatca gcagaaacca
120gggaaagtcc ctaagctcct gatctattct gcatccactc tggcatctgg
ggtcccatct 180cgtttcagtg gcagtggatc tgggacagat tacactctca
ccatcagcag cctgcagcct 240gaagatgttg caacttatta ctgtcaaaac
aactatcttg ttactactta tggtgttgct 300ttcggcggag gaaccaaggt
ggaaatcaaa cgt 333272654DNAArtificial SequenceChemically
Synthesized 272gacatccaga tgacccagtc tccatcctcc ctgtctgcat
ctgtaggaga cagagtcacc 60atcacttgcc aggccagtga ggacatttac aacttattgg
cctggtatca gcagaaacca 120gggaaagtcc ctaagctcct gatctattct
gcatccactc tggcatctgg ggtcccatct 180cgtttcagtg gcagtggatc
tgggacagat tacactctca ccatcagcag cctgcagcct 240gaagatgttg
caacttatta ctgtcaaaac aactatcttg ttactactta tggtgttgct
300ttcggcggag gaaccaaggt ggaaatcaaa cgtacggtag cggccccatc
tgtcttcatc 360ttcccgccat ctgatgagca gttgaaatct ggaactgcct
ctgttgtgtg cctgctgaat 420aacttctatc ccagagaggc caaagtacag
tggaaggtgg ataacgccct ccaatcgggt 480aactcccagg agagtgtcac
agagcaggac agcaaggaca gcacctacag cctcagcagc 540accctgacgc
tgagcaaagc agactacgag aaacacaaag tctacgcctg cgaagtcacc
600catcagggcc tgagctcgcc cgtcacaaag agcttcaaca ggggagagtg ttag
654273366DNAArtificial SequenceChemically Synthesized 273caggtacagc
tggtggagtc tggtggaggc gtggtccagc ctgggaggtc cctgagactc 60tcctgtgcag
cttctggatt caccttcagt agctatgcaa tgatctgggt ccgccaggct
120ccagggaagg ggctggaata catcggatac attgatactg atactagcgc
atactacgca 180agcagtgtga aaggccgatt caccatctcc agagacaatt
ccaagaacac gctgtacctg 240caaatgtcta gcctgagagc cgaggacacg
gctgtgtatt actgtgctag atcttatgct 300gcttatggtg gttatcctgc
tacttttgat ccctggggcc aaggtaccct cgtcaccgtc 360tcgagc
3662741359DNAArtificial SequenceChemically Synthesized
274caggtacagc tggtggagtc tggtggaggc gtggtccagc ctgggaggtc
cctgagactc 60tcctgtgcag cttctggatt caccttcagt agctatgcaa tgatctgggt
ccgccaggct 120ccagggaagg ggctggaata catcggatac attgatactg
atactagcgc atactacgca 180agcagtgtga aaggccgatt caccatctcc
agagacaatt ccaagaacac gctgtacctg 240caaatgtcta gcctgagagc
cgaggacacg gctgtgtatt actgtgctag atcttatgct 300gcttatggtg
gttatcctgc tacttttgat ccctggggcc aaggtaccct cgtcaccgtc
360tcgagcgcct ccaccaaggg cccatcggtc ttccccctgg caccctcctc
caagagcacc 420tctgggggca cagcggccct gggctgcctg gtcaaggact
acttccccga accggtgacg 480gtgtcgtgga actcaggcgc cctgaccagc
ggcgtgcaca ccttcccggc tgtcctacag 540tcctcaggac tctactccct
cagcagcgtg gtgaccgtgc cctccagcag cttgggcacc 600cagacctaca
tctgcaacgt gaatcacaag cccagcaaca ccaaggtgga caagagagtt
660gagcccaaat cttgtgacaa aactcacaca tgcccaccgt gcccagcacc
tgaactcctg 720gggggaccgt cagtcttcct cttcccccca aaacccaagg
acaccctcat gatctcccgg 780acccctgagg tcacatgcgt ggtggtggac
gtgagccacg aagaccctga ggtcaagttc 840aactggtacg tggacggcgt
ggaggtgcat aatgccaaga caaagccgcg ggaggagcag 900tacgccagca
cgtaccgtgt ggtcagcgtc ctcaccgtcc tgcaccagga ctggctgaat
960ggcaaggagt acaagtgcaa ggtctccaac aaagccctcc cagcccccat
cgagaaaacc 1020atctccaaag ccaaagggca gccccgagaa ccacaggtgt
acaccctgcc cccatcccgg 1080gaggagatga ccaagaacca ggtcagcctg
acctgcctgg tcaaaggctt ctatcccagc 1140gacatcgccg tggagtggga
gagcaatggg cagccggaga acaactacaa gaccacgcct 1200cccgtgctgg
actccgacgg ctccttcttc ctctacagca agctcaccgt ggacaagagc
1260aggtggcagc aggggaacgt cttctcatgc tccgtgatgc atgaggctct
gcacaaccac 1320tacacgcaga agagcctctc cctgtctccg
ggtaaatga 135927533DNAOryctolagus cuniculus 275caggccagtg
aggacattta caacttattg gcc 3327621DNAOryctolagus cuniculus
276tctgcatcca ctctggcatc t 2127736DNAOryctolagus cuniculus
277caaaacaact atcttgttac tacttatggt gttgct 3627815DNAOryctolagus
cuniculus 278agctatgcaa tgatc 1527948DNAArtificial
SequenceChemically Synthesized 279tacattgata ctgatactag cgcatactac
gcaagcagtg tgaaaggc 4828042DNAOryctolagus cuniculus 280tcttatgctg
cttatggtgg ttatcctgct acttttgatc cc 42281333DNAOryctolagus
cuniculus 281gcctatgata tgacccagac tccagcctcc gtgtctgcag ctgtgggagg
cacagtcacc 60atcaagtgcc aggccagtga gaacattggt agctacttag cctggtatca
gcagaaacca 120gggcagcctc ccgaactcct gatctacagg gcgtccactc
tggcatctgg ggtcccatcg 180cggttcaaag gcagtggatc tgggacacag
ttcactctca ccatcagcgg cgtggagtgt 240gccgatgctg ccacttacta
ctgtcaacag ggttataata gtgagaatct tgataatgct 300ttcggcggag
ggaccgaggt ggtggtcaaa cgt 333282654DNAArtificial SequenceChemically
Synthesized 282gcctatgata tgacccagac tccagcctcc gtgtctgcag
ctgtgggagg cacagtcacc 60atcaagtgcc aggccagtga gaacattggt agctacttag
cctggtatca gcagaaacca 120gggcagcctc ccgaactcct gatctacagg
gcgtccactc tggcatctgg ggtcccatcg 180cggttcaaag gcagtggatc
tgggacacag ttcactctca ccatcagcgg cgtggagtgt 240gccgatgctg
ccacttacta ctgtcaacag ggttataata gtgagaatct tgataatgct
300ttcggcggag ggaccgaggt ggtggtcaaa cgtacggtag cggccccatc
tgtcttcatc 360ttcccgccat ctgatgagca gttgaaatct ggaactgcct
ctgttgtgtg cctgctgaat 420aacttctatc ccagagaggc caaagtacag
tggaaggtgg ataacgccct ccaatcgggt 480aactcccagg agagtgtcac
agagcaggac agcaaggaca gcacctacag cctcagcagc 540accctgacgc
tgagcaaagc agactacgag aaacacaaag tctacgcctg cgaagtcacc
600catcagggcc tgagctcgcc cgtcacaaag agcttcaaca ggggagagtg ttag
654283345DNAOryctolagus cuniculus 283cagtcggtgg aggagtccgg
gggtcgcctg gtcacgcctg ggacacccct gacactcacc 60tgcacagtct ctggaatcga
cctcagtatg tattcaatgg gctgggtccg ccaggctcca 120gggaaggggc
tggaatacat cggatggatt agttatggtg gtactgcata ttacgcgagc
180tgggcgaagg gccgattcac catctccaaa acctcgacca cggtggagct
gaagatcacc 240agtccgacaa tcgaggacac ggccacctat ttctgtgcca
gagagactcc tgttaattat 300tatttggaca tttggggcca ggggaccctc
gtcaccgtct cgagc 3452841338DNAArtificial SequenceChemically
Synthesized 284cagtcggtgg aggagtccgg gggtcgcctg gtcacgcctg
ggacacccct gacactcacc 60tgcacagtct ctggaatcga cctcagtatg tattcaatgg
gctgggtccg ccaggctcca 120gggaaggggc tggaatacat cggatggatt
agttatggtg gtactgcata ttacgcgagc 180tgggcgaagg gccgattcac
catctccaaa acctcgacca cggtggagct gaagatcacc 240agtccgacaa
tcgaggacac ggccacctat ttctgtgcca gagagactcc tgttaattat
300tatttggaca tttggggcca ggggaccctc gtcaccgtct cgagcgcctc
caccaagggc 360ccatcggtct tccccctggc accctcctcc aagagcacct
ctgggggcac agcggccctg 420ggctgcctgg tcaaggacta cttccccgaa
ccggtgacgg tgtcgtggaa ctcaggcgcc 480ctgaccagcg gcgtgcacac
cttcccggct gtcctacagt cctcaggact ctactccctc 540agcagcgtgg
tgaccgtgcc ctccagcagc ttgggcaccc agacctacat ctgcaacgtg
600aatcacaagc ccagcaacac caaggtggac aagagagttg agcccaaatc
ttgtgacaaa 660actcacacat gcccaccgtg cccagcacct gaactcctgg
ggggaccgtc agtcttcctc 720ttccccccaa aacccaagga caccctcatg
atctcccgga cccctgaggt cacatgcgtg 780gtggtggacg tgagccacga
agaccctgag gtcaagttca actggtacgt ggacggcgtg 840gaggtgcata
atgccaagac aaagccgcgg gaggagcagt acgccagcac gtaccgtgtg
900gtcagcgtcc tcaccgtcct gcaccaggac tggctgaatg gcaaggagta
caagtgcaag 960gtctccaaca aagccctccc agcccccatc gagaaaacca
tctccaaagc caaagggcag 1020ccccgagaac cacaggtgta caccctgccc
ccatcccggg aggagatgac caagaaccag 1080gtcagcctga cctgcctggt
caaaggcttc tatcccagcg acatcgccgt ggagtgggag 1140agcaatgggc
agccggagaa caactacaag accacgcctc ccgtgctgga ctccgacggc
1200tccttcttcc tctacagcaa gctcaccgtg gacaagagca ggtggcagca
ggggaacgtc 1260ttctcatgct ccgtgatgca tgaggctctg cacaaccact
acacgcagaa gagcctctcc 1320ctgtctccgg gtaaatga
133828533DNAOryctolagus cuniculus 285caggccagtg agaacattgg
tagctactta gcc 3328621DNAOryctolagus cuniculus 286agggcgtcca
ctctggcatc t 2128736DNAOryctolagus cuniculus 287caacagggtt
ataatagtga gaatcttgat aatgct 3628815DNAOryctolagus cuniculus
288atgtattcaa tgggc 1528948DNAOryctolagus cuniculus 289tggattagtt
atggtggtac tgcatattac gcgagctggg cgaagggc 4829030DNAOryctolagus
cuniculus 290gagactcctg ttaattatta tttggacatt 30291333DNAArtificial
SequenceChemically Synthesized 291gcctatgata tgacccagtc tccatcctcc
ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc aggccagtga gaacattggt
agctacttag cctggtatca gcagaaacca 120gggaaagtcc ctaagctcct
gatctatagg gcttccactc tggcatctgg ggtcccatct 180cgtttcagtg
gcagtggatc tgggacagat ttcactctca ccatcagcag cctgcagcct
240gaagatgttg caacttatta ctgtcaacag ggttacaata gtgagaatct
tgataatgct 300ttcggcggag gaaccaaggt ggaaatcaaa cgt
333292654DNAArtificial SequenceChemically Synthesized 292gcctatgata
tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc
aggccagtga gaacattggt agctacttag cctggtatca gcagaaacca
120gggaaagtcc ctaagctcct gatctatagg gcttccactc tggcatctgg
ggtcccatct 180cgtttcagtg gcagtggatc tgggacagat ttcactctca
ccatcagcag cctgcagcct 240gaagatgttg caacttatta ctgtcaacag
ggttacaata gtgagaatct tgataatgct 300ttcggcggag gaaccaaggt
ggaaatcaaa cgtacggtag cggccccatc tgtcttcatc 360ttcccgccat
ctgatgagca gttgaaatct ggaactgcct ctgttgtgtg cctgctgaat
420aacttctatc ccagagaggc caaagtacag tggaaggtgg ataacgccct
ccaatcgggt 480aactcccagg agagtgtcac agagcaggac agcaaggaca
gcacctacag cctcagcagc 540accctgacgc tgagcaaagc agactacgag
aaacacaaag tctacgcctg cgaagtcacc 600catcagggcc tgagctcgcc
cgtcacaaag agcttcaaca ggggagagtg ttag 654293354DNAArtificial
SequenceChemically Synthesized 293caggtacagc tggtggagtc tggtggaggc
gtggtccagc ctgggaggtc cctgagactc 60tcctgtgcag cttctggatt caccttcagt
atgtattcaa tgggctgggt ccgccaggct 120ccagggaagg ggctggaata
catcggatgg attagttatg gtggtactgc atactacgct 180agcagcgcta
agggccgatt caccatctcc agagacaatt ccaagaacac gctgtacctg
240caaatgtcta gcctgagagc cgaggacacg gctgtgtatt actgtgctag
agagactcct 300gttaattact acttggacat ttggggccaa ggtaccctcg
tcaccgtctc gagc 3542941347DNAArtificial SequenceChemically
Synthesized 294caggtacagc tggtggagtc tggtggaggc gtggtccagc
ctgggaggtc cctgagactc 60tcctgtgcag cttctggatt caccttcagt atgtattcaa
tgggctgggt ccgccaggct 120ccagggaagg ggctggaata catcggatgg
attagttatg gtggtactgc atactacgct 180agcagcgcta agggccgatt
caccatctcc agagacaatt ccaagaacac gctgtacctg 240caaatgtcta
gcctgagagc cgaggacacg gctgtgtatt actgtgctag agagactcct
300gttaattact acttggacat ttggggccaa ggtaccctcg tcaccgtctc
gagcgcctcc 360accaagggcc catcggtctt ccccctggca ccctcctcca
agagcacctc tgggggcaca 420gcggccctgg gctgcctggt caaggactac
ttccccgaac cggtgacggt gtcgtggaac 480tcaggcgccc tgaccagcgg
cgtgcacacc ttcccggctg tcctacagtc ctcaggactc 540tactccctca
gcagcgtggt gaccgtgccc tccagcagct tgggcaccca gacctacatc
600tgcaacgtga atcacaagcc cagcaacacc aaggtggaca agagagttga
gcccaaatct 660tgtgacaaaa ctcacacatg cccaccgtgc ccagcacctg
aactcctggg gggaccgtca 720gtcttcctct tccccccaaa acccaaggac
accctcatga tctcccggac ccctgaggtc 780acatgcgtgg tggtggacgt
gagccacgaa gaccctgagg tcaagttcaa ctggtacgtg 840gacggcgtgg
aggtgcataa tgccaagaca aagccgcggg aggagcagta cgccagcacg
900taccgtgtgg tcagcgtcct caccgtcctg caccaggact ggctgaatgg
caaggagtac 960aagtgcaagg tctccaacaa agccctccca gcccccatcg
agaaaaccat ctccaaagcc 1020aaagggcagc cccgagaacc acaggtgtac
accctgcccc catcccggga ggagatgacc 1080aagaaccagg tcagcctgac
ctgcctggtc aaaggcttct atcccagcga catcgccgtg 1140gagtgggaga
gcaatgggca gccggagaac aactacaaga ccacgcctcc cgtgctggac
1200tccgacggct ccttcttcct ctacagcaag ctcaccgtgg acaagagcag
gtggcagcag 1260gggaacgtct tctcatgctc cgtgatgcat gaggctctgc
acaaccacta cacgcagaag 1320agcctctccc tgtctccggg taaatga
134729533DNAOryctolagus cuniculus 295caggccagtg agaacattgg
tagctactta gcc 3329621DNAOryctolagus cuniculus 296agggcttcca
ctctggcatc t 2129736DNAOryctolagus cuniculus 297caacagggtt
acaatagtga gaatcttgat aatgct 3629815DNAOryctolagus cuniculus
298atgtattcaa tgggc 1529948DNAArtificial SequenceChemically
Synthesized 299tggattagtt atggtggtac tgcatactac gctagcagcg ctaagggc
4830030DNAOryctolagus cuniculus 300gagactcctg ttaattacta cttggacatt
30301327DNAOryctolagus cuniculus 301gcattcgaat tgacccagac
tccatcctcc gtggaggcag ctgtgggagg cacagtcacc 60atcaagtgcc aggccagtca
gaacattgtt accaatttag cctggtatca acagaaacca 120gggcagcctc
ccaagctcct gatctatggt gcatccactc tggcatctgg ggtctcatcg
180cggttcaaag gcagtggatc tgggacacag ttcactctca ccatcagcga
cctggagtgt 240gccgatgctg ccacttattt ctgtcagagc tatgatggtt
ttaatagtgc tgggttcggc 300ggagggaccg aggtggtggt caaacgt
327302648DNAArtificial SequenceChemically Synthesized 302gcattcgaat
tgacccagac tccatcctcc gtggaggcag ctgtgggagg cacagtcacc 60atcaagtgcc
aggccagtca gaacattgtt accaatttag cctggtatca acagaaacca
120gggcagcctc ccaagctcct gatctatggt gcatccactc tggcatctgg
ggtctcatcg 180cggttcaaag gcagtggatc tgggacacag ttcactctca
ccatcagcga cctggagtgt 240gccgatgctg ccacttattt ctgtcagagc
tatgatggtt ttaatagtgc tgggttcggc 300ggagggaccg aggtggtggt
caaacgtacg gtagcggccc catctgtctt catcttcccg 360ccatctgatg
agcagttgaa atctggaact gcctctgttg tgtgcctgct gaataacttc
420tatcccagag aggccaaagt acagtggaag gtggataacg ccctccaatc
gggtaactcc 480caggagagtg tcacagagca ggacagcaag gacagcacct
acagcctcag cagcaccctg 540acgctgagca aagcagacta cgagaaacac
aaagtctacg cctgcgaagt cacccatcag 600ggcctgagct cgcccgtcac
aaagagcttc aacaggggag agtgttag 648303360DNAOryctolagus cuniculus
303cagtcgctgg aggagtccgg gggtcgcctg gtcacgcctg ggacacccct
gacactcacc 60tgcacagcct ctggattctc cctcagtggc tacgacatga gctgggtccg
ccaggctcca 120ggaaaggggc tggaatacat cggactcatt agttatgatg
gtaacacata ctacgcgacc 180tgggcgaaag gccgattcac catctccaaa
acctcgacca cggtggatct gaaaatcacc 240agtccgacaa ccgaggacac
ggccacctat ttctgtgcca gaagtcttta tgctggtcct 300aatgctggta
tcggaccgtt taacatctgg ggccagggga ccctcgtcac cgtctcgagc
3603041353DNAArtificial SequenceChemically Synthesized
304cagtcgctgg aggagtccgg gggtcgcctg gtcacgcctg ggacacccct
gacactcacc 60tgcacagcct ctggattctc cctcagtggc tacgacatga gctgggtccg
ccaggctcca 120ggaaaggggc tggaatacat cggactcatt agttatgatg
gtaacacata ctacgcgacc 180tgggcgaaag gccgattcac catctccaaa
acctcgacca cggtggatct gaaaatcacc 240agtccgacaa ccgaggacac
ggccacctat ttctgtgcca gaagtcttta tgctggtcct 300aatgctggta
tcggaccgtt taacatctgg ggccagggga ccctcgtcac cgtctcgagc
360gcctccacca agggcccatc ggtcttcccc ctggcaccct cctccaagag
cacctctggg 420ggcacagcgg ccctgggctg cctggtcaag gactacttcc
ccgaaccggt gacggtgtcg 480tggaactcag gcgccctgac cagcggcgtg
cacaccttcc cggctgtcct acagtcctca 540ggactctact ccctcagcag
cgtggtgacc gtgccctcca gcagcttggg cacccagacc 600tacatctgca
acgtgaatca caagcccagc aacaccaagg tggacaagag agttgagccc
660aaatcttgtg acaaaactca cacatgccca ccgtgcccag cacctgaact
cctgggggga 720ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc
tcatgatctc ccggacccct 780gaggtcacat gcgtggtggt ggacgtgagc
cacgaagacc ctgaggtcaa gttcaactgg 840tacgtggacg gcgtggaggt
gcataatgcc aagacaaagc cgcgggagga gcagtacgcc 900agcacgtacc
gtgtggtcag cgtcctcacc gtcctgcacc aggactggct gaatggcaag
960gagtacaagt gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa
aaccatctcc 1020aaagccaaag ggcagccccg agaaccacag gtgtacaccc
tgcccccatc ccgggaggag 1080atgaccaaga accaggtcag cctgacctgc
ctggtcaaag gcttctatcc cagcgacatc 1140gccgtggagt gggagagcaa
tgggcagccg gagaacaact acaagaccac gcctcccgtg 1200ctggactccg
acggctcctt cttcctctac agcaagctca ccgtggacaa gagcaggtgg
1260cagcagggga acgtcttctc atgctccgtg atgcatgagg ctctgcacaa
ccactacacg 1320cagaagagcc tctccctgtc tccgggtaaa tga
135330533DNAOryctolagus cuniculus 305caggccagtc agaacattgt
taccaattta gcc 3330621DNAOryctolagus cuniculus 306ggtgcatcca
ctctggcatc t 2130730DNAOryctolagus cuniculus 307cagagctatg
atggttttaa tagtgctggg 3030815DNAOryctolagus cuniculus 308ggctacgaca
tgagc 1530948DNAOryctolagus cuniculus 309ctcattagtt atgatggtaa
cacatactac gcgacctggg cgaaaggc 4831045DNAOryctolagus cuniculus
310agtctttatg ctggtcctaa tgctggtatc ggaccgttta acatc
45311327DNAArtificial SequenceChemically Synthesized 311gcattccaga
tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc
aggccagtca gaacattgtt accaacttag cctggtatca gcagaaacca
120gggaaagtcc ctaagctcct gatctatggt gcatccactc tggcatctgg
ggtcccatct 180cgtttcagtg gcagtggatc tgggacagat ttcactctca
ccatcagcag cctgcagcct 240gaagatgttg caacttatta ctgtcagagc
tatgatggtt tcaatagtgc tggtttcggc 300ggaggaacca aggtggaaat caaacgt
327312648DNAArtificial SequenceChemically Synthesized 312gcattccaga
tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc
aggccagtca gaacattgtt accaacttag cctggtatca gcagaaacca
120gggaaagtcc ctaagctcct gatctatggt gcatccactc tggcatctgg
ggtcccatct 180cgtttcagtg gcagtggatc tgggacagat ttcactctca
ccatcagcag cctgcagcct 240gaagatgttg caacttatta ctgtcagagc
tatgatggtt tcaatagtgc tggtttcggc 300ggaggaacca aggtggaaat
caaacgtacg gtagcggccc catctgtctt catcttcccg 360ccatctgatg
agcagttgaa atctggaact gcctctgttg tgtgcctgct gaataacttc
420tatcccagag aggccaaagt acagtggaag gtggataacg ccctccaatc
gggtaactcc 480caggagagtg tcacagagca ggacagcaag gacagcacct
acagcctcag cagcaccctg 540acgctgagca aagcagacta cgagaaacac
aaagtctacg cctgcgaagt cacccatcag 600ggcctgagct cgcccgtcac
aaagagcttc aacaggggag agtgttag 648313369DNAArtificial
SequenceChemically Synthesized 313caggtacagc tggtggagtc tggtggaggc
gtggtccagc ctgggaggtc cctgagactc 60tcctgtgcag cttctggatt ctccctcagt
ggctacgaca tgagctgggt ccgtcaggct 120ccaggcaagg gactggagtg
ggtgggactc attagttatg atggtaacac atactacgcg 180acctccgcga
aaggccgatt caccatctcc agagacaatt ccaagaacac gctgtacctg
240caaatgtcta gcctgagagc cgaggacacg gctgtgtatt actgtgctag
aagtctttat 300gctggtccta atgctggtat cggaccgttt aacatctggg
gccaaggtac cctcgtcacc 360gtctcgagc 3693141362DNAArtificial
SequenceChemically Synthesized 314caggtacagc tggtggagtc tggtggaggc
gtggtccagc ctgggaggtc cctgagactc 60tcctgtgcag cttctggatt ctccctcagt
ggctacgaca tgagctgggt ccgtcaggct 120ccaggcaagg gactggagtg
ggtgggactc attagttatg atggtaacac atactacgcg 180acctccgcga
aaggccgatt caccatctcc agagacaatt ccaagaacac gctgtacctg
240caaatgtcta gcctgagagc cgaggacacg gctgtgtatt actgtgctag
aagtctttat 300gctggtccta atgctggtat cggaccgttt aacatctggg
gccaaggtac cctcgtcacc 360gtctcgagcg cctccaccaa gggcccatcg
gtcttccccc tggcaccctc ctccaagagc 420acctctgggg gcacagcggc
cctgggctgc ctggtcaagg actacttccc cgaaccggtg 480acggtgtcgt
ggaactcagg cgccctgacc agcggcgtgc acaccttccc ggctgtccta
540cagtcctcag gactctactc cctcagcagc gtggtgaccg tgccctccag
cagcttgggc 600acccagacct acatctgcaa cgtgaatcac aagcccagca
acaccaaggt ggacaagaga 660gttgagccca aatcttgtga caaaactcac
acatgcccac cgtgcccagc acctgaactc 720ctggggggac cgtcagtctt
cctcttcccc ccaaaaccca aggacaccct catgatctcc 780cggacccctg
aggtcacatg cgtggtggtg gacgtgagcc acgaagaccc tgaggtcaag
840ttcaactggt acgtggacgg cgtggaggtg cataatgcca agacaaagcc
gcgggaggag 900cagtacgcca gcacgtaccg tgtggtcagc gtcctcaccg
tcctgcacca ggactggctg 960aatggcaagg agtacaagtg caaggtctcc
aacaaagccc tcccagcccc catcgagaaa 1020accatctcca aagccaaagg
gcagccccga gaaccacagg tgtacaccct gcccccatcc 1080cgggaggaga
tgaccaagaa ccaggtcagc ctgacctgcc tggtcaaagg cttctatccc
1140agcgacatcg ccgtggagtg ggagagcaat gggcagccgg agaacaacta
caagaccacg 1200cctcccgtgc tggactccga cggctccttc ttcctctaca
gcaagctcac cgtggacaag 1260agcaggtggc agcaggggaa cgtcttctca
tgctccgtga tgcatgaggc tctgcacaac 1320cactacacgc agaagagcct
ctccctgtct ccgggtaaat ga 136231533DNAOryctolagus cuniculus
315caggccagtc agaacattgt taccaactta gcc 3331621DNAOryctolagus
cuniculus 316ggtgcatcca ctctggcatc t 2131729DNAOryctolagus
cuniculus 317cagagctatg atggtttcaa tagtgctgg 2931815DNAOryctolagus
cuniculus 318ggctacgaca tgagc 1531948DNAArtificial
SequenceChemically Synthesized 319ctcattagtt atgatggtaa cacatactac
gcgacctccg cgaaaggc 4832045DNAOryctolagus cuniculus 320agtctttatg
ctggtcctaa tgctggtatc ggaccgttta acatc 45321336DNAOryctolagus
cuniculus 321gccgccgtgc tgacccagac tccatctccc gtgtctgcag ctgtgggagg
cacagtcagc 60atcagttgcc agtccagtca gaatgtttat aagaacaact acttatcctg
gtatcagcag 120aaaccagggc agcctcccaa gctcctgatc tacaaggcat
ccactctggc atctggggtc 180ccatcgcggt tcaaaggcgg tggatctggg
acagatttca ctctcaccat cagcgacgtg 240cagtgtgacg ctgctgccac
ttactactgt gcaggcggtt ataccagtag tagtgataat 300gctttcggcg
gagggaccga ggtggtggtc aaacgt
336322656DNAArtificial SequenceChemically Synthesized 322gccgccgtgc
tgacccagac tccatctccc gtgtctgcag ctgtgggagg cacagtcagc 60atcagttgcc
agtccagtca gaatgtttat aagaacaact acttatcctg gtatcagcag
120aaaccagggc agcctcccaa gctcctgatc tacaaggcat ccactctggc
atctggggtc 180ccatcgcggt tcaaaggcgg tggatctggg acagatttca
ctctcaccat cagcgacgtg 240cagtgtgacg ctgctgccac ttactactgt
gcaggcggtt ataccagtag tagtgataat 300gctttcggcg gagggaccga
ggtggtggtc aaacgtacgg tagcggcccc atctgtcttc 360atcttcccgc
catctgatga gcagttgaaa tctggaactg cctctgttgt gtgcctgctg
420aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc
cctccaatcg 480ggtaactccc aggagagtgt cacagagcag gacagcaagg
acagcaccta cagcctcagc 540agcaccctga cgctgagcaa agcagactac
gagaaacaca aagtctacgc ctgcgaagtc 600acccatcagg gcctgagctc
gcccgtcaca aagagcttca acaggggaga gtgtta 656323351DNAOryctolagus
cuniculus 323cagtcggtgg aggcgtccgg gggtcgcctg gtcacgcctg ggacacccct
gacactcacc 60tgcacagcct ctggattctc cctcagtacc tactggatga gctgggtccg
ccaggctcca 120gggaaggggc tggaatggat cggagacatt tattttagta
atgaagaaac aaactacgcg 180agctgggcga aaggccgatt taccatctcc
aaaacctcga ccacggtgga tctgaatgtc 240atcagtccga caaccgagga
cacggccacc tatttctgtg ccagaggttc tcctgatgtt 300gatattggta
tagatatgtg gggcccgggc accctcgtca ccgtctcgag c
3513241344DNAArtificial SequenceChemically Synthesized
324cagtcggtgg aggcgtccgg gggtcgcctg gtcacgcctg ggacacccct
gacactcacc 60tgcacagcct ctggattctc cctcagtacc tactggatga gctgggtccg
ccaggctcca 120gggaaggggc tggaatggat cggagacatt tattttagta
atgaagaaac aaactacgcg 180agctgggcga aaggccgatt taccatctcc
aaaacctcga ccacggtgga tctgaatgtc 240atcagtccga caaccgagga
cacggccacc tatttctgtg ccagaggttc tcctgatgtt 300gatattggta
tagatatgtg gggcccgggc accctcgtca ccgtctcgag cgcctccacc
360aagggcccat cggtcttccc cctggcaccc tcctccaaga gcacctctgg
gggcacagcg 420gccctgggct gcctggtcaa ggactacttc cccgaaccgg
tgacggtgtc gtggaactca 480ggcgccctga ccagcggcgt gcacaccttc
ccggctgtcc tacagtcctc aggactctac 540tccctcagca gcgtggtgac
cgtgccctcc agcagcttgg gcacccagac ctacatctgc 600aacgtgaatc
acaagcccag caacaccaag gtggacaaga gagttgagcc caaatcttgt
660gacaaaactc acacatgccc accgtgccca gcacctgaac tcctgggggg
accgtcagtc 720ttcctcttcc ccccaaaacc caaggacacc ctcatgatct
cccggacccc tgaggtcaca 780tgcgtggtgg tggacgtgag ccacgaagac
cctgaggtca agttcaactg gtacgtggac 840ggcgtggagg tgcataatgc
caagacaaag ccgcgggagg agcagtacgc cagcacgtac 900cgtgtggtca
gcgtcctcac cgtcctgcac caggactggc tgaatggcaa ggagtacaag
960tgcaaggtct ccaacaaagc cctcccagcc cccatcgaga aaaccatctc
caaagccaaa 1020gggcagcccc gagaaccaca ggtgtacacc ctgcccccat
cccgggagga gatgaccaag 1080aaccaggtca gcctgacctg cctggtcaaa
ggcttctatc ccagcgacat cgccgtggag 1140tgggagagca atgggcagcc
ggagaacaac tacaagacca cgcctcccgt gctggactcc 1200gacggctcct
tcttcctcta cagcaagctc accgtggaca agagcaggtg gcagcagggg
1260aacgtcttct catgctccgt gatgcatgag gctctgcaca accactacac
gcagaagagc 1320ctctccctgt ctccgggtaa atga 134432539DNAOryctolagus
cuniculus 325cagtccagtc agaatgttta taagaacaac tacttatcc
3932621DNAOryctolagus cuniculus 326aaggcatcca ctctggcatc t
2132733DNAOryctolagus cuniculus 327gcaggcggtt ataccagtag tagtgataat
gct 3332815DNAOryctolagus cuniculus 328acctactgga tgagc
1532951DNAOryctolagus cuniculus 329gacatttatt ttagtaatga agaaacaaac
tacgcgagct gggcgaaagg c 5133033DNAOryctolagus cuniculus
330ggttctcctg atgttgatat tggtatagat atg 33331336DNAArtificial
SequenceChemically Synthesized 331gacatccaga tgacccagtc tccatcctcc
ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc agtccagtca gaatgtttat
aagaacaact acttatcctg gtatcagcag 120aaaccaggga aagtccctaa
gctcctgatc tataaggcat ccactctggc atctggggtc 180ccatctcgtt
tcagtggcag tggatctggg acagatttca ctctcaccat cagcagcctg
240cagcctgaag atgttgcaac ttattactgt gcaggcggtt ataccagtag
tagtgataat 300gctttcggcg gaggaaccaa ggtggaaatc aaacgt
336332657DNAArtificial SequenceChemically Synthesized 332gacatccaga
tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc
agtccagtca gaatgtttat aagaacaact acttatcctg gtatcagcag
120aaaccaggga aagtccctaa gctcctgatc tataaggcat ccactctggc
atctggggtc 180ccatctcgtt tcagtggcag tggatctggg acagatttca
ctctcaccat cagcagcctg 240cagcctgaag atgttgcaac ttattactgt
gcaggcggtt ataccagtag tagtgataat 300gctttcggcg gaggaaccaa
ggtggaaatc aaacgtacgg tagcggcccc atctgtcttc 360atcttcccgc
catctgatga gcagttgaaa tctggaactg cctctgttgt gtgcctgctg
420aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc
cctccaatcg 480ggtaactccc aggagagtgt cacagagcag gacagcaagg
acagcaccta cagcctcagc 540agcaccctga cgctgagcaa agcagactac
gagaaacaca aagtctacgc ctgcgaagtc 600acccatcagg gcctgagctc
gcccgtcaca aagagcttca acaggggaga gtgttag 657333360DNAArtificial
SequenceChemically Synthesized 333gaggtgcagc tggtggagtc tgggggaggc
ttggtccagc ctggggggtc cctgagactc 60tcctgtgcag cctctggatt caccgtcagt
acctactgga tgagctgggt ccgtcaggct 120ccagggaagg ggctggagtg
ggtcggagac atttacttta gtaatgaaga aacaaactac 180gcgagcagcg
cgaaaggccg attcaccatc tccagagaca attccaagaa caccctgtat
240cttcaaatga acagcctgag agctgaggac actgctgtgt attactgtgc
tagaggttct 300cctgatgttg atattggtat agatatgtgg ggcccaggga
ccctcgtcac cgtctcgagc 3603341353DNAArtificial SequenceChemically
Synthesized 334gaggtgcagc tggtggagtc tgggggaggc ttggtccagc
ctggggggtc cctgagactc 60tcctgtgcag cctctggatt caccgtcagt acctactgga
tgagctgggt ccgtcaggct 120ccagggaagg ggctggagtg ggtcggagac
atttacttta gtaatgaaga aacaaactac 180gcgagcagcg cgaaaggccg
attcaccatc tccagagaca attccaagaa caccctgtat 240cttcaaatga
acagcctgag agctgaggac actgctgtgt attactgtgc tagaggttct
300cctgatgttg atattggtat agatatgtgg ggcccaggga ccctcgtcac
cgtctcgagc 360gcctccacca agggcccatc ggtcttcccc ctggcaccct
cctccaagag cacctctggg 420ggcacagcgg ccctgggctg cctggtcaag
gactacttcc ccgaaccggt gacggtgtcg 480tggaactcag gcgccctgac
cagcggcgtg cacaccttcc cggctgtcct acagtcctca 540ggactctact
ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc
600tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagag
agttgagccc 660aaatcttgtg acaaaactca cacatgccca ccgtgcccag
cacctgaact cctgggggga 720ccgtcagtct tcctcttccc cccaaaaccc
aaggacaccc tcatgatctc ccggacccct 780gaggtcacat gcgtggtggt
ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 840tacgtggacg
gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacgcc
900agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct
gaatggcaag 960gagtacaagt gcaaggtctc caacaaagcc ctcccagccc
ccatcgagaa aaccatctcc 1020aaagccaaag ggcagccccg agaaccacag
gtgtacaccc tgcccccatc ccgggaggag 1080atgaccaaga accaggtcag
cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 1140gccgtggagt
gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg
1200ctggactccg acggctcctt cttcctctac agcaagctca ccgtggacaa
gagcaggtgg 1260cagcagggga acgtcttctc atgctccgtg atgcatgagg
ctctgcacaa ccactacacg 1320cagaagagcc tctccctgtc tccgggtaaa tga
135333539DNAOryctolagus cuniculus 335cagtccagtc agaatgttta
taagaacaac tacttatcc 3933621DNAOryctolagus cuniculus 336aaggcatcca
ctctggcatc t 2133733DNAOryctolagus cuniculus 337gcaggcggtt
ataccagtag tagtgataat gct 3333815DNAOryctolagus cuniculus
338acctactgga tgagc 1533951DNAArtificial SequenceChemically
Synthesized 339gacatttact ttagtaatga agaaacaaac tacgcgagca
gcgcgaaagg c 5134033DNAOryctolagus cuniculus 340ggttctcctg
atgttgatat tggtatagat atg 33341336DNAOryctolagus cuniculus
341gcagccgtgc tgacccagac accatcgccc gtgtctgcag ctgtgggaga
cacagtcacc 60atcaagtgcc agtccagtca gagtgtttat aagaacaact acttatcctg
gtatcagcag 120aaaccagggc agcctcccaa gctcctgatc tatgatgcat
ccaatctgcc atctggggtc 180ccatcacggt tcagcggcag tggatctggg
acacagttca ctctcaccat cagcggcgtg 240cagtgtgacg atgctgccac
ttactactgt ctaggcgatt atgatgatga tactgataat 300ggtttcggcg
gagggaccga ggtggtggtc aaacgt 336342657DNAArtificial
SequenceChemically Synthesized 342gcagccgtgc tgacccagac accatcgccc
gtgtctgcag ctgtgggaga cacagtcacc 60atcaagtgcc agtccagtca gagtgtttat
aagaacaact acttatcctg gtatcagcag 120aaaccagggc agcctcccaa
gctcctgatc tatgatgcat ccaatctgcc atctggggtc 180ccatcacggt
tcagcggcag tggatctggg acacagttca ctctcaccat cagcggcgtg
240cagtgtgacg atgctgccac ttactactgt ctaggcgatt atgatgatga
tactgataat 300ggtttcggcg gagggaccga ggtggtggtc aaacgtacgg
tagcggcccc atctgtcttc 360atcttcccgc catctgatga gcagttgaaa
tctggaactg cctctgttgt gtgcctgctg 420aataacttct atcccagaga
ggccaaagta cagtggaagg tggataacgc cctccaatcg 480ggtaactccc
aggagagtgt cacagagcag gacagcaagg acagcaccta cagcctcagc
540agcaccctga cgctgagcaa agcagactac gagaaacaca aagtctacgc
ctgcgaagtc 600acccatcagg gcctgagctc gcccgtcaca aagagcttca
acaggggaga gtgttag 657343336DNAOryctolagus cuniculus 343cagtcggtgg
aggagtccgg gggtcgcctg gtcacgcctg ggacacccct gacactcacc 60tgcacagtct
ctggaatcga cctcagtagc tatgcaatga tctgggtccg ccaggctcca
120gggaaggggc tggaatacat cggaatcatt tggagtggtg gcacctacta
cgcgacctgg 180gcgaaaggcc gattcaccat ctccaaaacc tcgaccacgg
tggatctgca aatcaccagt 240ccgacaaccg aggacgcggc cacctatttc
tgtgccgcag gtggtggtag tatttatgat 300gtttggggcc cgggcaccct
ggtcaccgtc tcgagc 3363441329DNAArtificial SequenceChemically
Synthesized 344cagtcggtgg aggagtccgg gggtcgcctg gtcacgcctg
ggacacccct gacactcacc 60tgcacagtct ctggaatcga cctcagtagc tatgcaatga
tctgggtccg ccaggctcca 120gggaaggggc tggaatacat cggaatcatt
tggagtggtg gcacctacta cgcgacctgg 180gcgaaaggcc gattcaccat
ctccaaaacc tcgaccacgg tggatctgca aatcaccagt 240ccgacaaccg
aggacgcggc cacctatttc tgtgccgcag gtggtggtag tatttatgat
300gtttggggcc cgggcaccct ggtcaccgtc tcgagcgcct ccaccaaggg
cccatcggtc 360ttccccctgg caccctcctc caagagcacc tctgggggca
cagcggccct gggctgcctg 420gtcaaggact acttccccga accggtgacg
gtgtcgtgga actcaggcgc cctgaccagc 480ggcgtgcaca ccttcccggc
tgtcctacag tcctcaggac tctactccct cagcagcgtg 540gtgaccgtgc
cctccagcag cttgggcacc cagacctaca tctgcaacgt gaatcacaag
600cccagcaaca ccaaggtgga caagagagtt gagcccaaat cttgtgacaa
aactcacaca 660tgcccaccgt gcccagcacc tgaactcctg gggggaccgt
cagtcttcct cttcccccca 720aaacccaagg acaccctcat gatctcccgg
acccctgagg tcacatgcgt ggtggtggac 780gtgagccacg aagaccctga
ggtcaagttc aactggtacg tggacggcgt ggaggtgcat 840aatgccaaga
caaagccgcg ggaggagcag tacgccagca cgtaccgtgt ggtcagcgtc
900ctcaccgtcc tgcaccagga ctggctgaat ggcaaggagt acaagtgcaa
ggtctccaac 960aaagccctcc cagcccccat cgagaaaacc atctccaaag
ccaaagggca gccccgagaa 1020ccacaggtgt acaccctgcc cccatcccgg
gaggagatga ccaagaacca ggtcagcctg 1080acctgcctgg tcaaaggctt
ctatcccagc gacatcgccg tggagtggga gagcaatggg 1140cagccggaga
acaactacaa gaccacgcct cccgtgctgg actccgacgg ctccttcttc
1200ctctacagca agctcaccgt ggacaagagc aggtggcagc aggggaacgt
cttctcatgc 1260tccgtgatgc atgaggctct gcacaaccac tacacgcaga
agagcctctc cctgtctccg 1320ggtaaatga 132934539DNAOryctolagus
cuniculus 345cagtccagtc agagtgttta taagaacaac tacttatcc
3934621DNAOryctolagus cuniculus 346gatgcatcca atctgccatc t
2134733DNAOryctolagus cuniculus 347ctaggcgatt atgatgatga tactgataat
ggt 3334815DNAOryctolagus cuniculus 348agctatgcaa tgatc
1534945DNAOryctolagus cuniculus 349atcatttgga gtggtggcac ctactacgcg
acctgggcga aaggc 4535024DNAOryctolagus cuniculus 350ggtggtggta
gtatttatga tgtt 24351336DNAOryctolagus cuniculus 351gccctggtga
tgacccagac tccatcctcc acgtctgaac cagtgggagg cacagtcacc 60atcaattgcc
aggctagtca gaatattggt aacgacctat cctggtatca gcagaaacca
120gggcagcctc ccgagctcct aatctattct acatccaaac tggcaactgg
ggtcccaaag 180cggttcagtg gcagcagatc tgggacacag ttcactctca
ccatcagcga cctggagtgt 240gacgatgctg ccacttacta ctgtctaggt
gtttatagtt atattagtga tgatggtaat 300gctttcggcg gagggaccga
ggtggtggtc aaacgt 336352657DNAArtificial SequenceChemically
Synthesized 352gccctggtga tgacccagac tccatcctcc acgtctgaac
cagtgggagg cacagtcacc 60atcaattgcc aggctagtca gaatattggt aacgacctat
cctggtatca gcagaaacca 120gggcagcctc ccgagctcct aatctattct
acatccaaac tggcaactgg ggtcccaaag 180cggttcagtg gcagcagatc
tgggacacag ttcactctca ccatcagcga cctggagtgt 240gacgatgctg
ccacttacta ctgtctaggt gtttatagtt atattagtga tgatggtaat
300gctttcggcg gagggaccga ggtggtggtc aaacgtacgg tagcggcccc
atctgtcttc 360atcttcccgc catctgatga gcagttgaaa tctggaactg
cctctgttgt gtgcctgctg 420aataacttct atcccagaga ggccaaagta
cagtggaagg tggataacgc cctccaatcg 480ggtaactccc aggagagtgt
cacagagcag gacagcaagg acagcaccta cagcctcagc 540agcaccctga
cgctgagcaa agcagactac gagaaacaca aagtctacgc ctgcgaagtc
600acccatcagg gcctgagctc gcccgtcaca aagagcttca acaggggaga gtgttag
657353360DNAOryctolagus cuniculus 353cagtcggtgg aggagttcgg
gggtcgcctg gtcacgcctg ggacacccct gacactcacc 60tgcaccgtct ctggattctc
cctcaataac tatgcaatga cctgggtccg ccaggctcca 120gggaaggggc
tggagtggat cgggatcatt ggtagtattg gtaccacata ctacgcgagc
180tgggcgaaag gccgattctt catctccaaa acctcgacca ctgtggatct
gaaaatcatt 240agtccgacaa ccgaggacac ggccacctat ttctgtgcca
gagatgctgg cgttactgtt 300gatggttatg gctactactt taacatctgg
ggcccaggca ccctcgtcac cgtctcgagc 3603541353DNAArtificial
SequenceChemically Synthesized 354cagtcggtgg aggagttcgg gggtcgcctg
gtcacgcctg ggacacccct gacactcacc 60tgcaccgtct ctggattctc cctcaataac
tatgcaatga cctgggtccg ccaggctcca 120gggaaggggc tggagtggat
cgggatcatt ggtagtattg gtaccacata ctacgcgagc 180tgggcgaaag
gccgattctt catctccaaa acctcgacca ctgtggatct gaaaatcatt
240agtccgacaa ccgaggacac ggccacctat ttctgtgcca gagatgctgg
cgttactgtt 300gatggttatg gctactactt taacatctgg ggcccaggca
ccctcgtcac cgtctcgagc 360gcctccacca agggcccatc ggtcttcccc
ctggcaccct cctccaagag cacctctggg 420ggcacagcgg ccctgggctg
cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 480tggaactcag
gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca
540ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg
cacccagacc 600tacatctgca acgtgaatca caagcccagc aacaccaagg
tggacaagag agttgagccc 660aaatcttgtg acaaaactca cacatgccca
ccgtgcccag cacctgaact cctgggggga 720ccgtcagtct tcctcttccc
cccaaaaccc aaggacaccc tcatgatctc ccggacccct 780gaggtcacat
gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg
840tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga
gcagtacgcc 900agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc
aggactggct gaatggcaag 960gagtacaagt gcaaggtctc caacaaagcc
ctcccagccc ccatcgagaa aaccatctcc 1020aaagccaaag ggcagccccg
agaaccacag gtgtacaccc tgcccccatc ccgggaggag 1080atgaccaaga
accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc
1140gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac
gcctcccgtg 1200ctggactccg acggctcctt cttcctctac agcaagctca
ccgtggacaa gagcaggtgg 1260cagcagggga acgtcttctc atgctccgtg
atgcatgagg ctctgcacaa ccactacacg 1320cagaagagcc tctccctgtc
tccgggtaaa tga 135335533DNAOryctolagus cuniculus 355caggctagtc
agaatattgg taacgaccta tcc 3335621DNAOryctolagus cuniculus
356tctacatcca aactggcaac t 2135739DNAOryctolagus cuniculus
357ctaggtgttt atagttatat tagtgatgat ggtaatgct 3935815DNAOryctolagus
cuniculus 358aactatgcaa tgacc 1535948DNAOryctolagus cuniculus
359atcattggta gtattggtac cacatactac gcgagctggg cgaaaggc
4836045DNAOryctolagus cuniculus 360gatgctggcg ttactgttga tggttatggc
tactacttta acatc 45361336DNAOryctolagus cuniculus 361gccatcgaaa
tgacccagac tccattctcc gtgtctgcag ctgtgggagg cacagtcacc 60atcaagtgcc
aggccagtca gaccattagc aactacttag cctggtatca gcagaaacca
120gggcagcctc ccaagctcct gatctatggt gcatccaatc tggaatctgg
ggtcccatcg 180cggttcaaag gcagtggatc tgggacacag ttcactctca
ccatcagcga cctggagtgt 240gacgatgctg ccacttacta ctgtcaacag
ggttatacta tcagtaatgt tgataacaat 300gttttcggcg gagggaccga
ggtggtggtc aaacgt 336362657DNAArtificial SequenceChemically
Synthesized 362gccatcgaaa tgacccagac tccattctcc gtgtctgcag
ctgtgggagg cacagtcacc 60atcaagtgcc aggccagtca gaccattagc aactacttag
cctggtatca gcagaaacca 120gggcagcctc ccaagctcct gatctatggt
gcatccaatc tggaatctgg ggtcccatcg 180cggttcaaag gcagtggatc
tgggacacag ttcactctca ccatcagcga cctggagtgt 240gacgatgctg
ccacttacta ctgtcaacag ggttatacta tcagtaatgt tgataacaat
300gttttcggcg gagggaccga ggtggtggtc aaacgtacgg tagcggcccc
atctgtcttc 360atcttcccgc catctgatga gcagttgaaa tctggaactg
cctctgttgt gtgcctgctg 420aataacttct atcccagaga ggccaaagta
cagtggaagg tggataacgc cctccaatcg 480ggtaactccc aggagagtgt
cacagagcag gacagcaagg acagcaccta cagcctcagc 540agcaccctga
cgctgagcaa agcagactac gagaaacaca aagtctacgc ctgcgaagtc
600acccatcagg gcctgagctc gcccgtcaca aagagcttca acaggggaga gtgttag
657363345DNAOryctolagus cuniculus 363cagtcgctgg aggagtccgg
gggtcgcctg gtcacgcctg ggggatccct gacactcacc 60tgcgcagcct ctggattctc
cctcactggc tacaacttgg tctgggtccg ccaggctcca 120gggaaggggc
tggagtggat cggattcatt agttatggtg ataccacata ctacgcgagc
180tgggcgaaag gccgattcac catctccaaa acctcgacca cggtgactct
gacgatcacc 240gatctgcaac cttcagacac gggcacctat ttctgtgcca
gagagactgc taatacttat 300gattatggca tctggggccc aggcaccctc
gtcaccgtct cgagc 3453641338DNAArtificial SequenceChemically
Synthesized 364cagtcgctgg aggagtccgg gggtcgcctg gtcacgcctg
ggggatccct gacactcacc 60tgcgcagcct ctggattctc cctcactggc tacaacttgg
tctgggtccg ccaggctcca 120gggaaggggc tggagtggat cggattcatt
agttatggtg ataccacata ctacgcgagc 180tgggcgaaag gccgattcac
catctccaaa acctcgacca cggtgactct gacgatcacc 240gatctgcaac
cttcagacac gggcacctat ttctgtgcca gagagactgc taatacttat
300gattatggca tctggggccc aggcaccctc gtcaccgtct cgagcgcctc
caccaagggc 360ccatcggtct tccccctggc accctcctcc aagagcacct
ctgggggcac agcggccctg 420ggctgcctgg tcaaggacta cttccccgaa
ccggtgacgg tgtcgtggaa ctcaggcgcc 480ctgaccagcg gcgtgcacac
cttcccggct gtcctacagt cctcaggact ctactccctc 540agcagcgtgg
tgaccgtgcc ctccagcagc ttgggcaccc agacctacat ctgcaacgtg
600aatcacaagc ccagcaacac caaggtggac aagagagttg agcccaaatc
ttgtgacaaa 660actcacacat gcccaccgtg cccagcacct gaactcctgg
ggggaccgtc agtcttcctc 720ttccccccaa aacccaagga caccctcatg
atctcccgga cccctgaggt cacatgcgtg 780gtggtggacg tgagccacga
agaccctgag gtcaagttca actggtacgt ggacggcgtg 840gaggtgcata
atgccaagac aaagccgcgg gaggagcagt acgccagcac gtaccgtgtg
900gtcagcgtcc tcaccgtcct gcaccaggac tggctgaatg gcaaggagta
caagtgcaag 960gtctccaaca aagccctccc agcccccatc gagaaaacca
tctccaaagc caaagggcag 1020ccccgagaac cacaggtgta caccctgccc
ccatcccggg aggagatgac caagaaccag 1080gtcagcctga cctgcctggt
caaaggcttc tatcccagcg acatcgccgt ggagtgggag 1140agcaatgggc
agccggagaa caactacaag accacgcctc ccgtgctgga ctccgacggc
1200tccttcttcc tctacagcaa gctcaccgtg gacaagagca ggtggcagca
ggggaacgtc 1260ttctcatgct ccgtgatgca tgaggctctg cacaaccact
acacgcagaa gagcctctcc 1320ctgtctccgg gtaaatga
133836533DNAOryctolagus cuniculus 365caggccagtc agaccattag
caactactta gcc 3336621DNAOryctolagus cuniculus 366ggtgcatcca
atctggaatc t 2136739DNAOryctolagus cuniculus 367caacagggtt
atactatcag taatgttgat aacaatgtt 3936815DNAOryctolagus cuniculus
368ggctacaact tggtc 1536948DNAOryctolagus cuniculus 369ttcattagtt
atggtgatac cacatactac gcgagctggg cgaaaggc 4837030DNAOryctolagus
cuniculus 370gagactgcta atacttatga ttatggcatc 30371336DNAArtificial
SequenceChemically Synthesized 371gacatccaga tgacccagtc tccttccacc
ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgtc aggctagtca gaccattagc
aactacttag cctggtatca gcagaaacca 120ggaaaagccc ctaagctcct
gatctatggt gcatccaatc tggaatctgg agtcccatca 180aggttcagcg
gcagtggatc tggaacagaa ttcactctca ccatcagcag cctgcagcct
240gatgattttg caacttacta ctgtcaacag ggttatacta tcagtaatgt
tgataacaat 300gttttcggcg gaggaaccaa ggtggaaatc aaacgt
336372657DNAArtificial SequenceChemically Synthesized 372gacatccaga
tgacccagtc tccttccacc ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgtc
aggctagtca gaccattagc aactacttag cctggtatca gcagaaacca
120ggaaaagccc ctaagctcct gatctatggt gcatccaatc tggaatctgg
agtcccatca 180aggttcagcg gcagtggatc tggaacagaa ttcactctca
ccatcagcag cctgcagcct 240gatgattttg caacttacta ctgtcaacag
ggttatacta tcagtaatgt tgataacaat 300gttttcggcg gaggaaccaa
ggtggaaatc aaacgtacgg tagcggcccc atctgtcttc 360atcttcccgc
catctgatga gcagttgaaa tctggaactg cctctgttgt gtgcctgctg
420aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc
cctccaatcg 480ggtaactccc aggagagtgt cacagagcag gacagcaagg
acagcaccta cagcctcagc 540agcaccctga cgctgagcaa agcagactac
gagaaacaca aagtctacgc ctgcgaagtc 600acccatcagg gcctgagctc
gcccgtcaca aagagcttca acaggggaga gtgttag 657373354DNAArtificial
SequenceChemically Synthesized 373gaggtgcagc tggtggagtc tgggggaggc
ttggtccagc ctggggggtc cctgagactc 60tcctgtgcag cctctggatt caccgtcagt
ggctacaact tggtctgggt ccgtcaggct 120ccagggaagg ggctggagtg
ggtcggattc attagttatg gtgataccac atactacgct 180agctctgcta
aaggccgatt caccatctcc agagacaatt ccaagaacac cctgtatctt
240caaatgaaca gcctgagagc tgaggacact gctgtgtatt actgtgctag
agagactgct 300aatacttatg attatggcat ctggggccaa gggaccctcg
tcaccgtctc gagc 3543741347DNAArtificial SequenceChemically
Synthesized 374gaggtgcagc tggtggagtc tgggggaggc ttggtccagc
ctggggggtc cctgagactc 60tcctgtgcag cctctggatt caccgtcagt ggctacaact
tggtctgggt ccgtcaggct 120ccagggaagg ggctggagtg ggtcggattc
attagttatg gtgataccac atactacgct 180agctctgcta aaggccgatt
caccatctcc agagacaatt ccaagaacac cctgtatctt 240caaatgaaca
gcctgagagc tgaggacact gctgtgtatt actgtgctag agagactgct
300aatacttatg attatggcat ctggggccaa gggaccctcg tcaccgtctc
gagcgcctcc 360accaagggcc catcggtctt ccccctggca ccctcctcca
agagcacctc tgggggcaca 420gcggccctgg gctgcctggt caaggactac
ttccccgaac cggtgacggt gtcgtggaac 480tcaggcgccc tgaccagcgg
cgtgcacacc ttcccggctg tcctacagtc ctcaggactc 540tactccctca
gcagcgtggt gaccgtgccc tccagcagct tgggcaccca gacctacatc
600tgcaacgtga atcacaagcc cagcaacacc aaggtggaca agagagttga
gcccaaatct 660tgtgacaaaa ctcacacatg cccaccgtgc ccagcacctg
aactcctggg gggaccgtca 720gtcttcctct tccccccaaa acccaaggac
accctcatga tctcccggac ccctgaggtc 780acatgcgtgg tggtggacgt
gagccacgaa gaccctgagg tcaagttcaa ctggtacgtg 840gacggcgtgg
aggtgcataa tgccaagaca aagccgcggg aggagcagta cgccagcacg
900taccgtgtgg tcagcgtcct caccgtcctg caccaggact ggctgaatgg
caaggagtac 960aagtgcaagg tctccaacaa agccctccca gcccccatcg
agaaaaccat ctccaaagcc 1020aaagggcagc cccgagaacc acaggtgtac
accctgcccc catcccggga ggagatgacc 1080aagaaccagg tcagcctgac
ctgcctggtc aaaggcttct atcccagcga catcgccgtg 1140gagtgggaga
gcaatgggca gccggagaac aactacaaga ccacgcctcc cgtgctggac
1200tccgacggct ccttcttcct ctacagcaag ctcaccgtgg acaagagcag
gtggcagcag 1260gggaacgtct tctcatgctc cgtgatgcat gaggctctgc
acaaccacta cacgcagaag 1320agcctctccc tgtctccggg taaatga
134737533DNAOryctolagus cuniculus 375caggctagtc agaccattag
caactactta gcc 3337621DNAOryctolagus cuniculus 376ggtgcatcca
atctggaatc t 2137739DNAOryctolagus cuniculus 377caacagggtt
atactatcag taatgttgat aacaatgtt 3937815DNAOryctolagus cuniculus
378ggctacaact tggtc 1537948DNAArtificial SequenceChemically
Synthesized 379ttcattagtt atggtgatac cacatactac gctagctctg ctaaaggc
4838030DNAOryctolagus cuniculus 380gagactgcta atacttatga ttatggcatc
30381336DNAOryctolagus cuniculus 381gccgccgtgc tgacccagac
tccatctccc gtgtctgcag ctgtgggagg cacagtcagc 60atcagttgcc agtccagtca
gaatgtttat aagaacaact atttatcctg gtatcagcag 120aaaccagggc
agcctcccaa gctcctgatc tacaaggctt ccactctggc atctggggtc
180ccatcgcggt tcaaaggcag tggatctggg acagatttca ctctcaccat
cagcgacgtg 240cagtgtgacg ctgctgccac ttactactgt gcaggcggtt
atagtagtag tagtgataat 300gctttcggcg gagggaccga ggtggtggtc aaacgt
336382657DNAArtificial SequenceChemically Synthesized 382gccgccgtgc
tgacccagac tccatctccc gtgtctgcag ctgtgggagg cacagtcagc 60atcagttgcc
agtccagtca gaatgtttat aagaacaact atttatcctg gtatcagcag
120aaaccagggc agcctcccaa gctcctgatc tacaaggctt ccactctggc
atctggggtc 180ccatcgcggt tcaaaggcag tggatctggg acagatttca
ctctcaccat cagcgacgtg 240cagtgtgacg ctgctgccac ttactactgt
gcaggcggtt atagtagtag tagtgataat 300gctttcggcg gagggaccga
ggtggtggtc aaacgtacgg tagcggcccc atctgtcttc 360atcttcccgc
catctgatga gcagttgaaa tctggaactg cctctgttgt gtgcctgctg
420aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc
cctccaatcg 480ggtaactccc aggagagtgt cacagagcag gacagcaagg
acagcaccta cagcctcagc 540agcaccctga cgctgagcaa agcagactac
gagaaacaca aagtctacgc ctgcgaagtc 600acccatcagg gcctgagctc
gcccgtcaca aagagcttca acaggggaga gtgttag 657383351DNAOryctolagus
cuniculus 383cagtcggtgg aggcgtccgg gggtcgtctg gtcatgcctg gaggatccct
gacactcacc 60tgcacagcct ctggattctc cctcagtacc tactggatgt cctgggtccg
ccaggctcca 120gggaaggggc tggaatggat cggagacatt tattttagta
atgaggaaac aaactacgcg 180acctgggcga aaggccgatt taccatctcc
aaaacctcga ccacggtgga tctgaatgtc 240atcagtccga caaccgagga
cacggccacc tatttctgtg caagaggttc tcctgatgtt 300gagattgcta
tagatatgtg gggccagggc accctcgtca ccgtctcgag c
3513841344DNAArtificial SequenceChemically Synthesized
384cagtcggtgg aggcgtccgg gggtcgtctg gtcatgcctg gaggatccct
gacactcacc 60tgcacagcct ctggattctc cctcagtacc tactggatgt cctgggtccg
ccaggctcca 120gggaaggggc tggaatggat cggagacatt tattttagta
atgaggaaac aaactacgcg 180acctgggcga aaggccgatt taccatctcc
aaaacctcga ccacggtgga tctgaatgtc 240atcagtccga caaccgagga
cacggccacc tatttctgtg caagaggttc tcctgatgtt 300gagattgcta
tagatatgtg gggccagggc accctcgtca ccgtctcgag cgcctccacc
360aagggcccat cggtcttccc cctggcaccc tcctccaaga gcacctctgg
gggcacagcg 420gccctgggct gcctggtcaa ggactacttc cccgaaccgg
tgacggtgtc gtggaactca 480ggcgccctga ccagcggcgt gcacaccttc
ccggctgtcc tacagtcctc aggactctac 540tccctcagca gcgtggtgac
cgtgccctcc agcagcttgg gcacccagac ctacatctgc 600aacgtgaatc
acaagcccag caacaccaag gtggacaaga gagttgagcc caaatcttgt
660gacaaaactc acacatgccc accgtgccca gcacctgaac tcctgggggg
accgtcagtc 720ttcctcttcc ccccaaaacc caaggacacc ctcatgatct
cccggacccc tgaggtcaca 780tgcgtggtgg tggacgtgag ccacgaagac
cctgaggtca agttcaactg gtacgtggac 840ggcgtggagg tgcataatgc
caagacaaag ccgcgggagg agcagtacgc cagcacgtac 900cgtgtggtca
gcgtcctcac cgtcctgcac caggactggc tgaatggcaa ggagtacaag
960tgcaaggtct ccaacaaagc cctcccagcc cccatcgaga aaaccatctc
caaagccaaa 1020gggcagcccc gagaaccaca ggtgtacacc ctgcccccat
cccgggagga gatgaccaag 1080aaccaggtca gcctgacctg cctggtcaaa
ggcttctatc ccagcgacat cgccgtggag 1140tgggagagca atgggcagcc
ggagaacaac tacaagacca cgcctcccgt gctggactcc 1200gacggctcct
tcttcctcta cagcaagctc accgtggaca agagcaggtg gcagcagggg
1260aacgtcttct catgctccgt gatgcatgag gctctgcaca accactacac
gcagaagagc 1320ctctccctgt ctccgggtaa atga 134438539DNAOryctolagus
cuniculus 385cagtccagtc agaatgttta taagaacaac tatttatcc
3938621DNAOryctolagus cuniculus 386aaggcttcca ctctggcatc t
2138733DNAOryctolagus cuniculus 387gcaggcggtt atagtagtag tagtgataat
gct 3338815DNAOryctolagus cuniculus 388acctactgga tgtcc
1538951DNAOryctolagus cuniculus 389gacatttatt ttagtaatga ggaaacaaac
tacgcgacct gggcgaaagg c 5139033DNAOryctolagus cuniculus
390ggttctcctg atgttgagat tgctatagat atg 33391336DNAArtificial
SequenceChemically Synthesized 391gacatccaga tgacccagtc tccatcctcc
ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc agtccagtca gaatgtttat
aagaacaact acttatcctg gtatcagcag 120aaaccaggga aagtccctaa
gctcctgatc tataaggcat ccactctggc atctggggtc 180ccatctcgtt
tcagtggcag tggatctggg acagatttca ctctcaccat cagcagcctg
240cagcctgaag atgttgcaac ttattactgt gcaggcggtt ataccagtag
tagtgataat 300gctttcggcg gaggaaccaa ggtggaaatc aaacgt
336392657DNAArtificial SequenceChemically Synthesized 392gacatccaga
tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc
agtccagtca gaatgtttat aagaacaact acttatcctg gtatcagcag
120aaaccaggga aagtccctaa gctcctgatc tataaggcat ccactctggc
atctggggtc 180ccatctcgtt tcagtggcag tggatctggg acagatttca
ctctcaccat cagcagcctg 240cagcctgaag atgttgcaac ttattactgt
gcaggcggtt ataccagtag tagtgataat 300gctttcggcg gaggaaccaa
ggtggaaatc aaacgtacgg tagcggcccc atctgtcttc 360atcttcccgc
catctgatga gcagttgaaa tctggaactg cctctgttgt gtgcctgctg
420aataacttct atcccagaga ggccaaagta cagtggaagg tggataacgc
cctccaatcg 480ggtaactccc aggagagtgt cacagagcag gacagcaagg
acagcaccta cagcctcagc 540agcaccctga cgctgagcaa agcagactac
gagaaacaca aagtctacgc ctgcgaagtc 600acccatcagg gcctgagctc
gcccgtcaca aagagcttca acaggggaga gtgttag 657393360DNAArtificial
SequenceChemically Synthesized 393gaggtgcagc tggtggagtc tgggggaggc
ttggtccagc ctggggggtc cctgagactc 60tcctgtgcag cctctggatt caccgtcagt
acctactgga tgagctgggt ccgtcaggct 120ccagggaagg ggctggagtg
ggtcggagac atttacttta gtaatgaaga aacaaactac 180gcgaccagcg
cgaaaggccg attcaccatc tccagagaca attccaagaa caccctgtat
240cttcaaatga acagcctgag agctgaggac actgctgtgt attactgtgc
tagaggttct 300cctgatgttg agattgctat agatatgtgg ggccaaggga
ccctcgtcac cgtctcgagc 3603941353DNAArtificial SequenceChemically
Synthesized 394gaggtgcagc tggtggagtc tgggggaggc ttggtccagc
ctggggggtc cctgagactc 60tcctgtgcag cctctggatt caccgtcagt acctactgga
tgagctgggt ccgtcaggct 120ccagggaagg ggctggagtg ggtcggagac
atttacttta gtaatgaaga aacaaactac 180gcgaccagcg cgaaaggccg
attcaccatc tccagagaca attccaagaa caccctgtat 240cttcaaatga
acagcctgag agctgaggac actgctgtgt attactgtgc tagaggttct
300cctgatgttg agattgctat agatatgtgg ggccaaggga ccctcgtcac
cgtctcgagc 360gcctccacca agggcccatc ggtcttcccc ctggcaccct
cctccaagag cacctctggg 420ggcacagcgg ccctgggctg cctggtcaag
gactacttcc ccgaaccggt gacggtgtcg 480tggaactcag gcgccctgac
cagcggcgtg cacaccttcc cggctgtcct acagtcctca 540ggactctact
ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc
600tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagag
agttgagccc 660aaatcttgtg acaaaactca cacatgccca ccgtgcccag
cacctgaact cctgggggga 720ccgtcagtct tcctcttccc cccaaaaccc
aaggacaccc tcatgatctc ccggacccct 780gaggtcacat gcgtggtggt
ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 840tacgtggacg
gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacgcc
900agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct
gaatggcaag 960gagtacaagt gcaaggtctc caacaaagcc ctcccagccc
ccatcgagaa aaccatctcc 1020aaagccaaag ggcagccccg agaaccacag
gtgtacaccc tgcccccatc ccgggaggag 1080atgaccaaga accaggtcag
cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 1140gccgtggagt
gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg
1200ctggactccg acggctcctt cttcctctac agcaagctca ccgtggacaa
gagcaggtgg 1260cagcagggga acgtcttctc atgctccgtg atgcatgagg
ctctgcacaa ccactacacg 1320cagaagagcc tctccctgtc tccgggtaaa tga
135339539DNAOryctolagus cuniculus 395cagtccagtc agaatgttta
taagaacaac tacttatcc 3939621DNAOryctolagus cuniculus 396aaggcatcca
ctctggcatc t 2139733DNAOryctolagus cuniculus 397gcaggcggtt
ataccagtag tagtgataat gct 3339815DNAOryctolagus cuniculus
398acctactgga tgagc 1539951DNAArtificial SequenceChemically
Synthesized 399gacatttact ttagtaatga agaaacaaac tacgcgacca
gcgcgaaagg c 5140033DNAArtificial SequenceChemically Synthesized
400ggttctcctg atgttgagat tgctatagat atg 33401217PRTArtificial
SequenceChemically Synthesized 401Asp Ile Gln Met Thr Gln Ser Pro
Ser Thr Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys
Gln Ala Ser Gln Ser Ile Tyr Ser Asn 20 25 30Leu Ala Trp Tyr Gln Gln
Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Asp Ala Ser Thr
Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly Ser Gly
Thr Glu Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro65 70 75 80Asp Asp
Phe Ala Thr Tyr Tyr Cys Gln Gln Gly Phe Thr Val Ser Asp 85 90 95Ile
Asp Asn Ala Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr 100 105
110Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
115 120 125Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
Tyr Pro 130 135 140Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
Leu Gln Ser Gly145 150 155 160Asn Ser Gln Glu Ser Val Thr Glu Gln
Asp Ser Lys Asp Ser Thr Tyr 165 170 175Ser Leu Ser Ser Thr Leu Thr
Leu Ser Lys Ala Asp Tyr Glu Lys His 180 185 190Lys Val Tyr Ala Cys
Glu Val Thr His Gln Gly Leu Ser Ser Pro Val 195 200 205Thr Lys Ser
Phe Asn Arg Gly Glu Cys 210 215402451PRTArtificial
SequenceChemically Synthesized 402Glu Val Gln Leu Val Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala
Ala Ser Gly Phe Thr Val Ser Asn Tyr 20 25 30Ala Val Gly Trp Val Arg
Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40 45Gly Ile Ile Gly Arg
Asn Gly Asn Thr Trp Tyr Ala Ser Ser Ala Arg 50 55 60Gly Arg Phe Thr
Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu65 70 75 80Gln Met
Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg
Gly Tyr Gly Arg Ser Val Ala Tyr Tyr Val Phe Asn Ile Trp Gly 100 105
110Pro Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
Thr Ala 130 135 140Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
Pro Val Thr Val145 150 155 160Ser Trp Asn Ser Gly Ala Leu Thr Ser
Gly Val His Thr Phe Pro Ala 165
170 175Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
Val 180 185 190Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn
Val Asn His 195 200 205Lys Pro Ser Asn Thr Lys Val Asp Ala Arg Val
Glu Pro Lys Ser Cys 210 215 220Asp Lys Thr His Thr Cys Pro Pro Cys
Pro Ala Pro Glu Leu Leu Gly225 230 235 240Gly Pro Ser Val Phe Leu
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met 245 250 255Ile Ser Arg Thr
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His 260 265 270Glu Asp
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val 275 280
285His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Ala Ser Thr Tyr
290 295 300Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
Asn Gly305 310 315 320Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
Leu Pro Ala Pro Ile 325 330 335Glu Lys Thr Ile Ser Lys Ala Lys Gly
Gln Pro Arg Glu Pro Gln Val 340 345 350Tyr Thr Leu Pro Pro Ser Arg
Glu Glu Met Thr Lys Asn Gln Val Ser 355 360 365Leu Thr Cys Leu Val
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu 370 375 380Trp Glu Ser
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro385 390 395
400Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
405 410 415Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
Val Met 420 425 430His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
Leu Ser Leu Ser 435 440 445Pro Gly Lys 450403654DNAArtificial
SequenceChemically Synthesized 403gacatccaga tgacccagtc tccttccacc
ctgtctgcat ctgtaggaga cagagtcacc 60atcacttgcc aggccagtca gagcatttac
agcaatcttg cctggtatca gcagaaacca 120ggaaaagccc ctaagctcct
gatctatgat gcatccactc tggaatctgg agtcccatca 180aggttcagcg
gcagtggatc tgggacagag tacactctca ccatcagcag cctgcagcct
240gatgattttg caacttacta ctgccaacag ggttttactg ttagtgatat
tgataatgct 300ttcggcggag gaaccaaggt ggaaatcaaa cgtacggtag
cggccccatc tgtcttcatc 360ttcccgccat ctgatgagca gttgaaatct
ggaactgcct ctgttgtgtg cctgctgaat 420aacttctatc ccagagaggc
caaagtacag tggaaggtgg ataacgccct ccaatcgggt 480aactcccagg
agagtgtcac agagcaggac agcaaggaca gcacctacag cctcagcagc
540accctgacgc tgagcaaagc agactacgag aaacacaaag tctacgcctg
cgaagtcacc 600catcagggcc tgagctcgcc cgtcacaaag agcttcaaca
ggggagagtg ttag 6544041356DNAArtificial SequenceChemically
Synthesized 404gaggtgcagc tggtggagtc tgggggaggc ttggtccagc
ctggggggtc cctgagactc 60tcctgtgcag cctctggatt caccgtcagt aactatgcag
tgggctgggt ccgtcaggct 120ccagggaagg ggctggagtg ggtcggaatc
attggtcgta atggtaacac atggtacgcg 180agctctgcaa gaggccgatt
caccatctcc agagacaatt ccaagaacac cctgtatctt 240caaatgaaca
gcctgagagc tgaggacact gctgtgtatt actgtgctag aggatatggc
300cgtagtgttg cttactacgt ctttaacatc tggggcccag ggaccctcgt
caccgtctcg 360agcgcctcca ccaagggccc atcggtcttc cccctggcac
cctcctccaa gagcacctct 420gggggcacag cggccctggg ctgcctggtc
aaggactact tccccgaacc ggtgacggtg 480tcgtggaact caggcgccct
gaccagcggc gtgcacacct tcccggctgt cctacagtcc 540tcaggactct
actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag
600acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggacgc
gagagttgag 660cccaaatctt gtgacaaaac tcacacatgc ccaccgtgcc
cagcacctga actcctgggg 720ggaccgtcag tcttcctctt ccccccaaaa
cccaaggaca ccctcatgat ctcccggacc 780cctgaggtca catgcgtggt
ggtggacgtg agccacgaag accctgaggt caagttcaac 840tggtacgtgg
acggcgtgga ggtgcataat gccaagacaa agccgcggga ggagcagtac
900gccagcacgt accgtgtggt cagcgtcctc accgtcctgc accaggactg
gctgaatggc 960aaggagtaca agtgcaaggt ctccaacaaa gccctcccag
cccccatcga gaaaaccatc 1020tccaaagcca aagggcagcc ccgagaacca
caggtgtaca ccctgccccc atcccgggag 1080gagatgacca agaaccaggt
cagcctgacc tgcctggtca aaggcttcta tcccagcgac 1140atcgccgtgg
agtgggagag caatgggcag ccggagaaca actacaagac cacgcctccc
1200gtgctggact ccgacggctc cttcttcctc tacagcaagc tcaccgtgga
caagagcagg 1260tggcagcagg ggaacgtctt ctcatgctcc gtgatgcatg
aggctctgca caaccactac 1320acgcagaaga gcctctccct gtctccgggt aaatga
1356405217PRTArtificial SequenceChemically Synthesized 405Asp Ile
Gln Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly1 5 10 15Asp
Arg Val Thr Ile Thr Cys Gln Ala Ser Gln Ser Ile Tyr Ser Asn 20 25
30Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45Tyr Asp Ala Ser Thr Leu Glu Ser Gly Val Pro Ser Arg Phe Ser
Gly 50 55 60Ser Gly Ser Gly Thr Glu Tyr Thr Leu Thr Ile Ser Ser Leu
Gln Pro65 70 75 80Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Gly Phe
Thr Val Ser Asp 85 90 95Ile Asp Asn Ala Phe Gly Gly Gly Thr Lys Val
Glu Ile Lys Arg Thr 100 105 110Val Ala Ala Pro Ser Val Phe Ile Phe
Pro Pro Ser Asp Glu Gln Leu 115 120 125Lys Ser Gly Thr Ala Ser Val
Val Cys Leu Leu Asn Asn Phe Tyr Pro 130 135 140Arg Glu Ala Lys Val
Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly145 150 155 160Asn Ser
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr 165 170
175Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
180 185 190Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
Pro Val 195 200 205Thr Lys Ser Phe Asn Arg Gly Glu Cys 210
215406228PRTArtificial SequenceChemically Synthesized 406Glu Val
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Val Ser Asn Tyr 20 25
30Ala Val Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45Gly Ile Ile Gly Arg Asn Gly Asn Thr Trp Tyr Ala Ser Ser Ala
Arg 50 55 60Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
Tyr Leu65 70 75 80Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val
Tyr Tyr Cys Ala 85 90 95Arg Gly Tyr Gly Arg Ser Val Ala Tyr Tyr Val
Phe Asn Ile Trp Gly 100 105 110Pro Gly Thr Leu Val Thr Val Ser Ser
Ala Ser Thr Lys Gly Pro Ser 115 120 125Val Phe Pro Leu Ala Pro Ser
Ser Lys Ser Thr Ser Gly Gly Thr Ala 130 135 140Ala Leu Gly Cys Leu
Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val145 150 155 160Ser Trp
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala 165 170
175Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
180 185 190Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
Asn His 195 200 205Lys Pro Ser Asn Thr Lys Val Asp Ala Arg Val Glu
Pro Lys Ser Cys 210 215 220Asp Lys Thr His225407217PRTArtificial
SequenceChemically Synthesized 407Asp Ile Gln Met Thr Gln Ser Pro
Ser Thr Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys
Gln Ala Ser Gln Ser Ile Tyr Ser Asn 20 25 30Leu Ala Trp Tyr Gln Gln
Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45Tyr Asp Ala Ser Thr
Leu Glu Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60Ser Gly Ser Gly
Thr Glu Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro65 70 75 80Asp Asp
Phe Ala Thr Tyr Tyr Cys Gln Gln Gly Phe Thr Val Ser Asp 85 90 95Ile
Asp Asn Ala Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg Thr 100 105
110Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
115 120 125Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
Tyr Pro 130 135 140Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
Leu Gln Ser Gly145 150 155 160Asn Ser Gln Glu Ser Val Thr Glu Gln
Asp Ser Lys Asp Ser Thr Tyr 165 170 175Ser Leu Ser Ser Thr Leu Thr
Leu Ser Lys Ala Asp Tyr Glu Lys His 180 185 190Lys Val Tyr Ala Cys
Glu Val Thr His Gln Gly Leu Ser Ser Pro Val 195 200 205Thr Lys Ser
Phe Asn Arg Gly Glu Cys 210 215408228PRTArtificial
SequenceChemically Synthesized 408Glu Val Gln Leu Val Glu Ser Gly
Gly Gly Leu Val Gln Pro Gly Gly1 5 10 15Ser Leu Arg Leu Ser Cys Ala
Ala Ser Gly Phe Thr Val Ser Asn Tyr 20 25 30Ala Val Gly Trp Val Arg
Gln Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40 45Gly Ile Ile Gly Arg
Asn Gly Asn Thr Trp Tyr Ala Ser Ser Ala Arg 50 55 60Gly Arg Phe Thr
Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu65 70 75 80Gln Met
Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg
Gly Tyr Gly Arg Ser Val Ala Tyr Tyr Val Phe Asn Ile Trp Gly 100 105
110Pro Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
115 120 125Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
Thr Ala 130 135 140Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
Pro Val Thr Val145 150 155 160Ser Trp Asn Ser Gly Ala Leu Thr Ser
Gly Val His Thr Phe Pro Ala 165 170 175Val Leu Gln Ser Ser Gly Leu
Tyr Ser Leu Ser Ser Val Val Thr Val 180 185 190Pro Ser Ser Ser Leu
Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His 195 200 205Lys Pro Ser
Asn Thr Lys Val Asp Ala Arg Val Glu Pro Lys Ser Cys 210 215 220Asp
Lys Thr His225409654DNAArtificial SequenceChemically Synthesized
409gacatccaga tgacccagtc tccttccacc ctgtctgcat ctgtaggaga
cagagtcacc 60atcacttgcc aggccagtca gagcatttac agcaatcttg cctggtatca
gcagaaacca 120ggaaaagccc ctaagctcct gatctatgat gcatccactc
tggaatctgg agtcccatca 180aggttcagcg gcagtggatc tgggacagag
tacactctca ccatcagcag cctgcagcct 240gatgattttg caacttacta
ctgccaacag ggttttactg ttagtgatat tgataatgct 300ttcggcggag
gaaccaaggt ggaaatcaaa cgtacggtag cggccccatc tgtcttcatc
360ttcccgccat ctgatgagca gttgaaatct ggaactgcct ctgttgtgtg
cctgctgaat 420aacttctatc ccagagaggc caaagtacag tggaaggtgg
ataacgccct ccaatcgggt 480aactcccagg agagtgtcac agagcaggac
agcaaggaca gcacctacag cctcagcagc 540accctgacgc tgagcaaagc
agactacgag aaacacaaag tctacgcctg cgaagtcacc 600catcagggcc
tgagctcgcc cgtcacaaag agcttcaaca ggggagagtg ttag
654410687DNAArtificial SequenceChemically Synthesized 410gaggtgcagc
tggtggagtc tgggggaggc ttggtccagc ctggggggtc cctgagactc 60tcctgtgcag
cctctggatt caccgtcagt aactatgcag tgggctgggt ccgtcaggct
120ccagggaagg ggctggagtg ggtcggaatc attggtcgta atggtaacac
atggtacgcg 180agctctgcaa gaggccgatt caccatctcc agagacaatt
ccaagaacac cctgtatctt 240caaatgaaca gcctgagagc tgaggacact
gctgtgtatt actgtgctag aggatatggc 300cgtagtgttg cttactacgt
ctttaacatc tggggcccag ggaccctcgt caccgtctcg 360agcgcctcca
ccaagggccc atcggtcttc cccctggcac cctcctccaa gagcacctct
420gggggcacag cggccctggg ctgcctggtc aaggactact tccccgaacc
ggtgacggtg 480tcgtggaact caggcgccct gaccagcggc gtgcacacct
tcccggctgt cctacagtcc 540tcaggactct actccctcag cagcgtggtg
accgtgccct ccagcagctt gggcacccag 600acctacatct gcaacgtgaa
tcacaagccc agcaacacca aggtggacgc gagagttgag 660cccaaatctt
gtgacaaaac tcactag 687411120PRTHomo sapiens 411Ser Ser Ser His Pro
Ile Phe His Arg Gly Glu Phe Ser Val Cys Asp1 5 10 15Ser Val Ser Val
Trp Val Gly Asp Lys Thr Thr Ala Thr Asp Ile Lys 20 25 30Gly Lys Glu
Val Met Val Leu Gly Glu Val Asn Ile Asn Asn Ser Val 35 40 45Phe Lys
Gln Tyr Phe Phe Glu Thr Lys Cys Arg Asp Pro Asn Pro Val 50 55 60Asp
Ser Gly Cys Arg Gly Ile Asp Ser Lys His Trp Asn Ser Tyr Cys65 70 75
80Thr Thr Thr His Thr Phe Val Lys Ala Leu Thr Met Asp Gly Lys Gln
85 90 95Ala Ala Trp Arg Phe Ile Arg Ile Asp Thr Ala Cys Val Cys Val
Leu 100 105 110Ser Arg Lys Ala Val Arg Arg Ala 115 120412105PRTHomo
sapiens 412Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
Gln Leu1 5 10 15Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
Phe Tyr Pro 20 25 30Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala
Leu Gln Ser Gly 35 40 45Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser
Lys Asp Ser Thr Tyr 50 55 60Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys
Ala Asp Tyr Glu Lys His65 70 75 80Lys Val Tyr Ala Cys Glu Val Thr
His Gln Gly Leu Ser Ser Pro Val 85 90 95Thr Lys Ser Phe Asn Arg Gly
Glu Cys 100 105413330PRTHomo sapiens 413Ala Ser Thr Lys Gly Pro Ser
Val Phe Pro Leu Ala Pro Ser Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser 35 40 45Gly Val His Thr
Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr65 70 75 80Tyr
Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys 85 90
95Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
Pro Pro 115 120 125Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
Glu Val Thr Cys 130 135 140Val Val Val Asp Val Ser His Glu Asp Pro
Glu Val Lys Phe Asn Trp145 150 155 160Tyr Val Asp Gly Val Glu Val
His Asn Ala Lys Thr Lys Pro Arg Glu 165 170 175Glu Gln Tyr Ala Ser
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu 180 185 190His Gln Asp
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn 195 200 205Lys
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly 210 215
220Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu
Glu225 230 235 240Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
Lys Gly Phe Tyr 245 250 255Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
Asn Gly Gln Pro Glu Asn 260 265 270Asn Tyr Lys Thr Thr Pro Pro Val
Leu Asp Ser Asp Gly Ser Phe Phe 275 280 285Leu Tyr Ser Lys Leu Thr
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn 290 295 300Val Phe Ser Cys
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr305 310 315 320Gln
Lys Ser Leu Ser Leu Ser Pro Gly Lys 325 330
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012

D00013

D00014

D00015

D00016

D00017

D00018

D00019

D00020

D00021

D00022

D00023

D00024

D00025

D00026

D00027

D00028

D00029

D00030

D00031

D00032

D00033

D00034

D00035

D00036

D00037

D00038

D00039

D00040

D00041

D00042

D00043

D00044

D00045

D00046

D00047

D00048

D00049

D00050

D00051

D00052

D00053
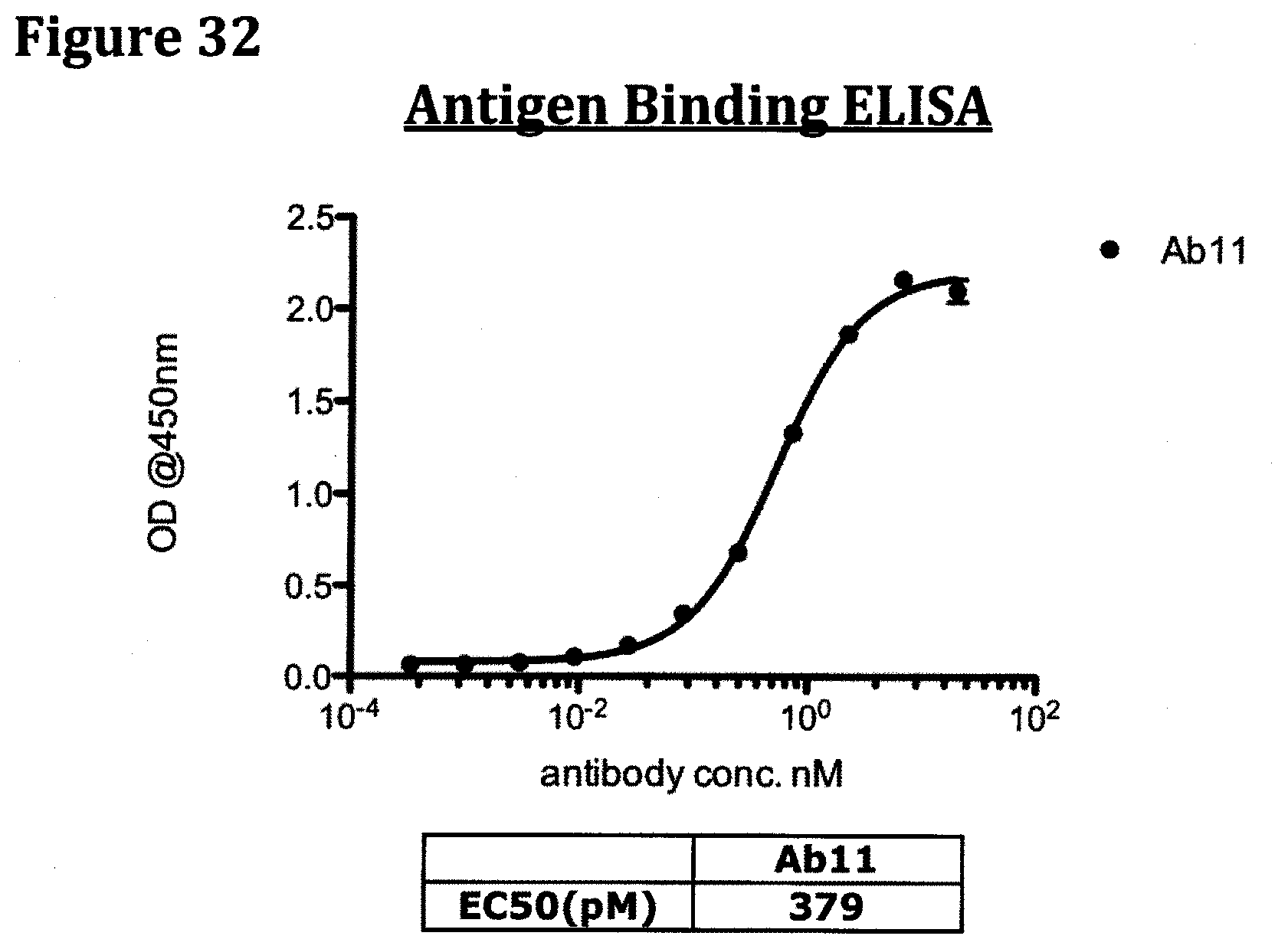
D00054

D00055

D00056

D00057

D00058

D00059

D00060
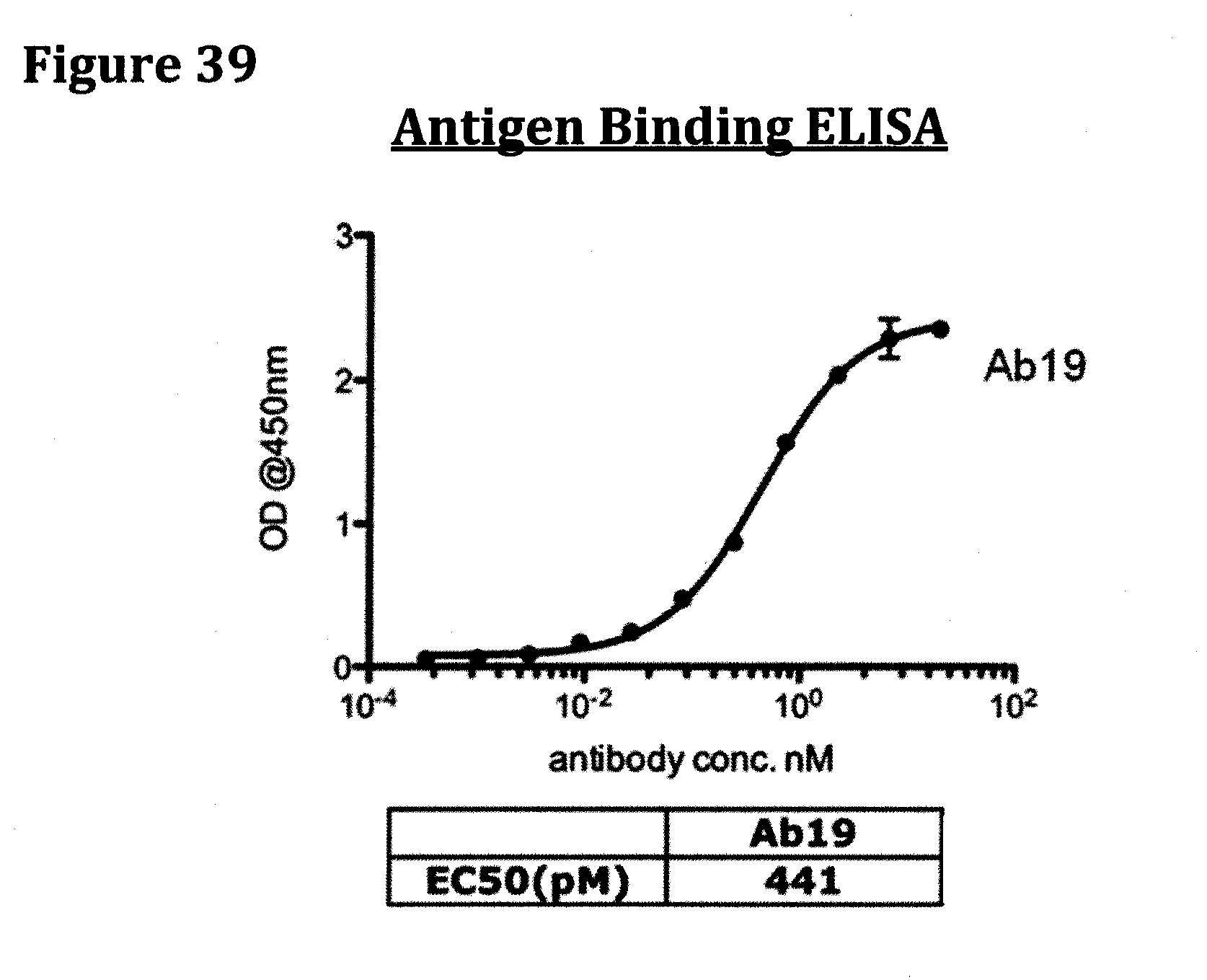
D00061

D00062
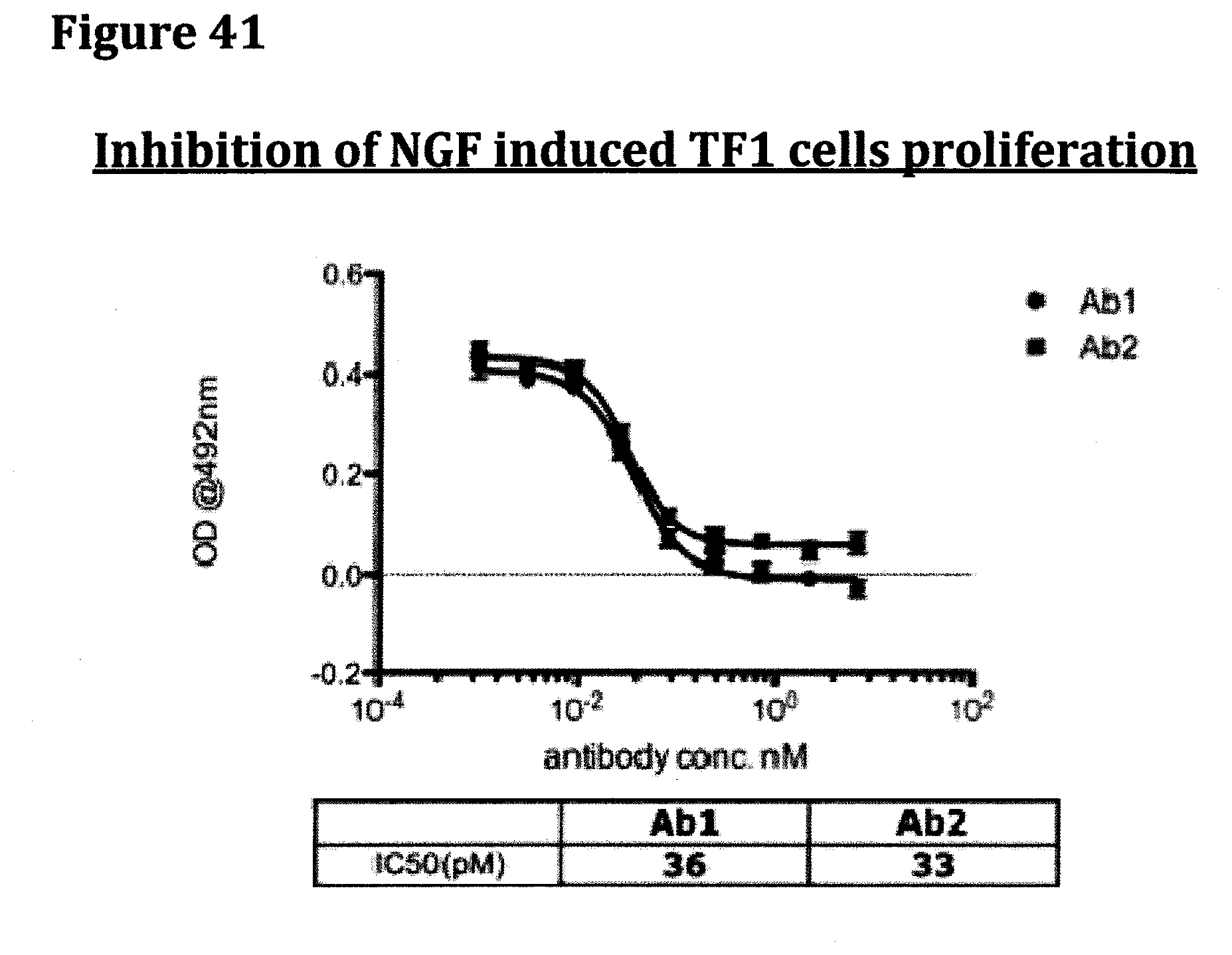
D00063

D00064

D00065

D00066
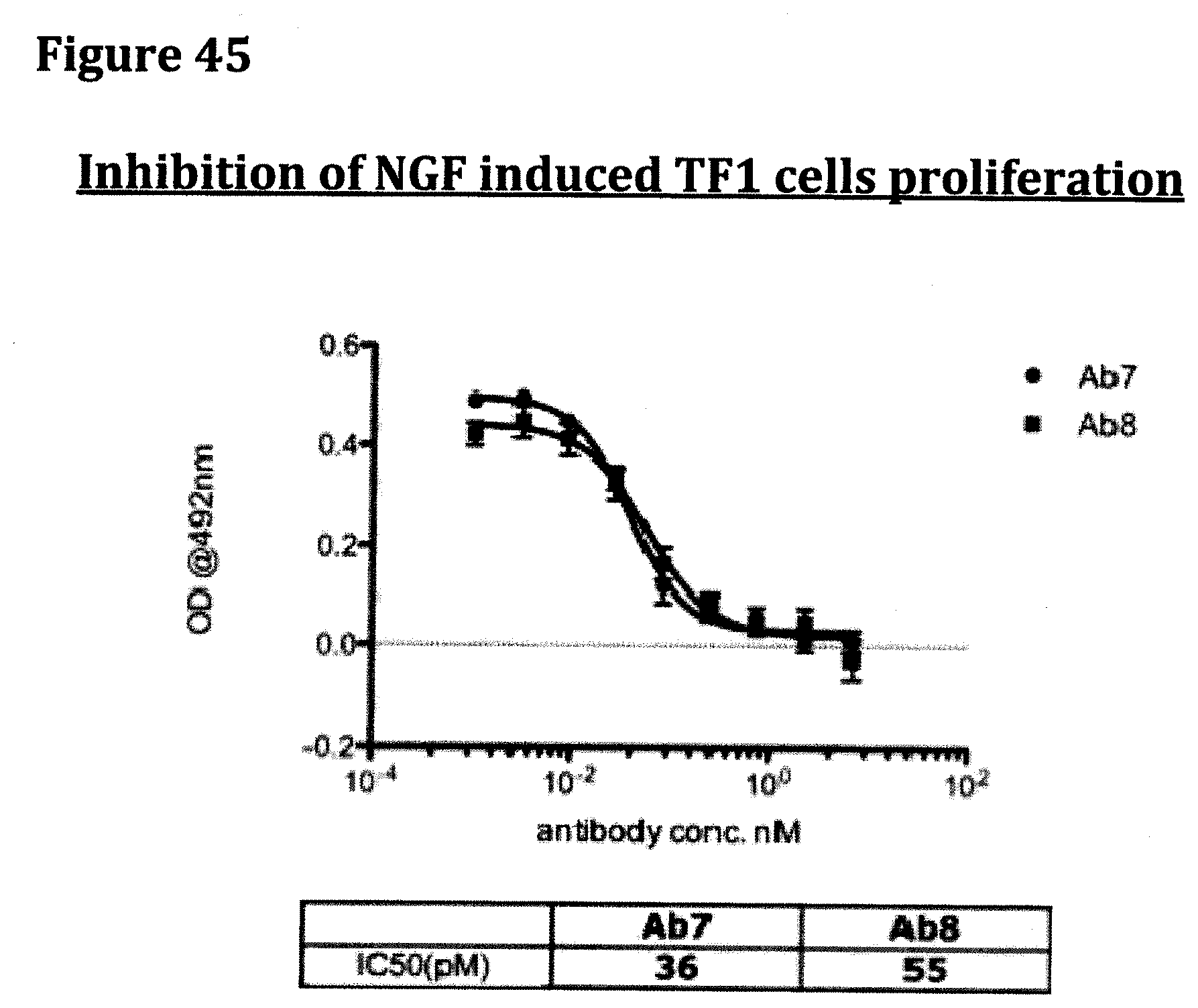
D00067
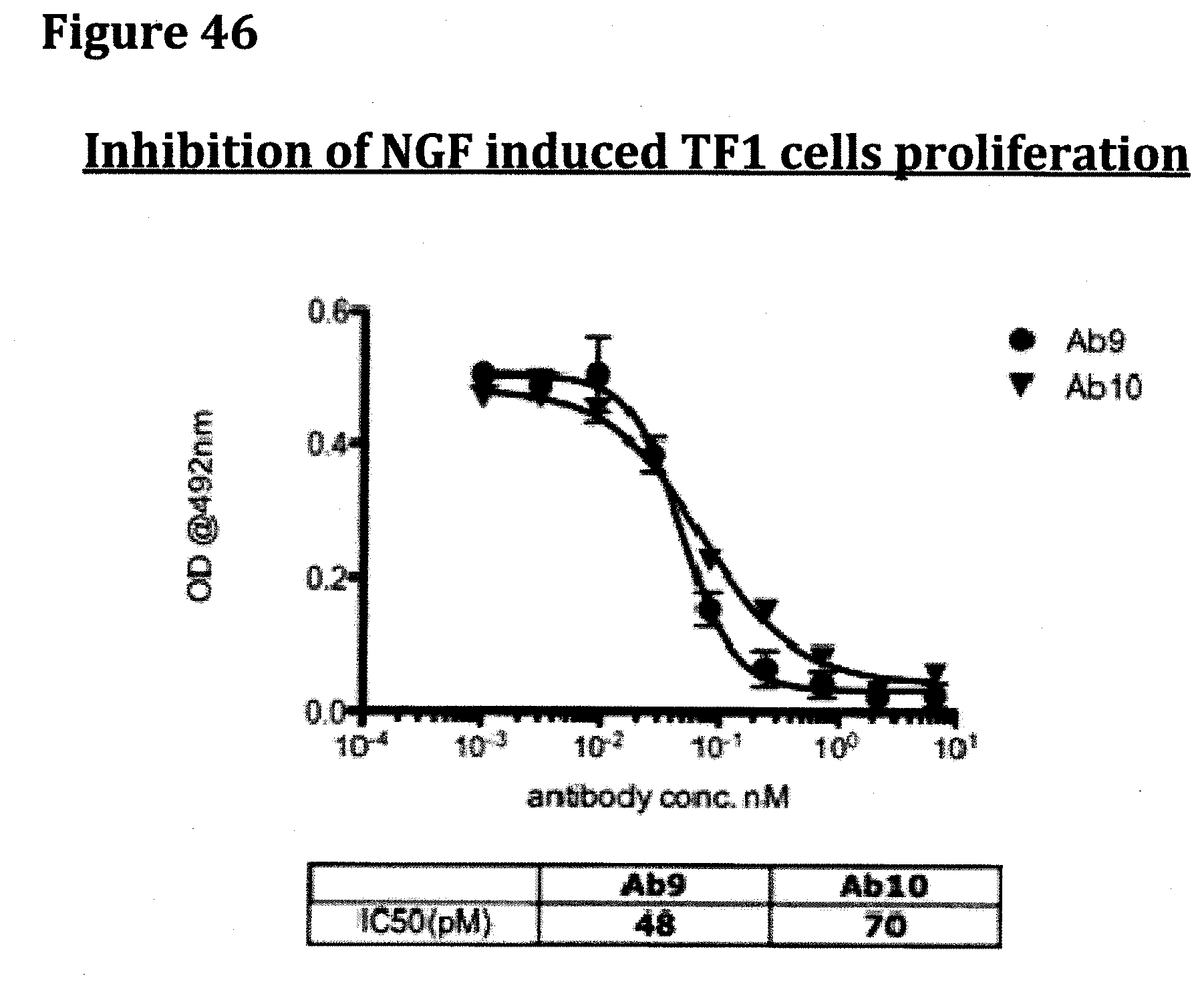
D00068

D00069

D00070

D00071

D00072
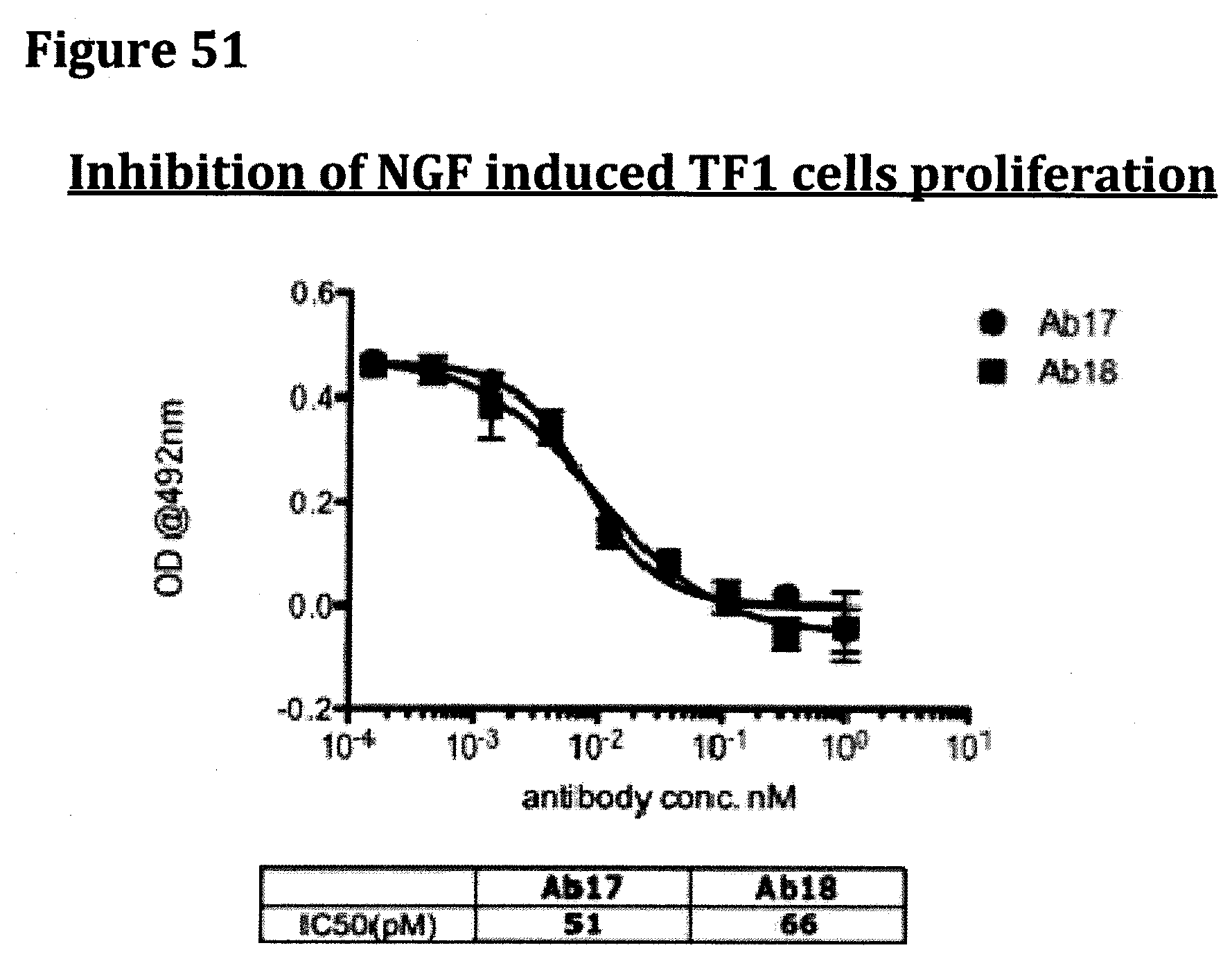
D00073

D00074

D00075

D00076
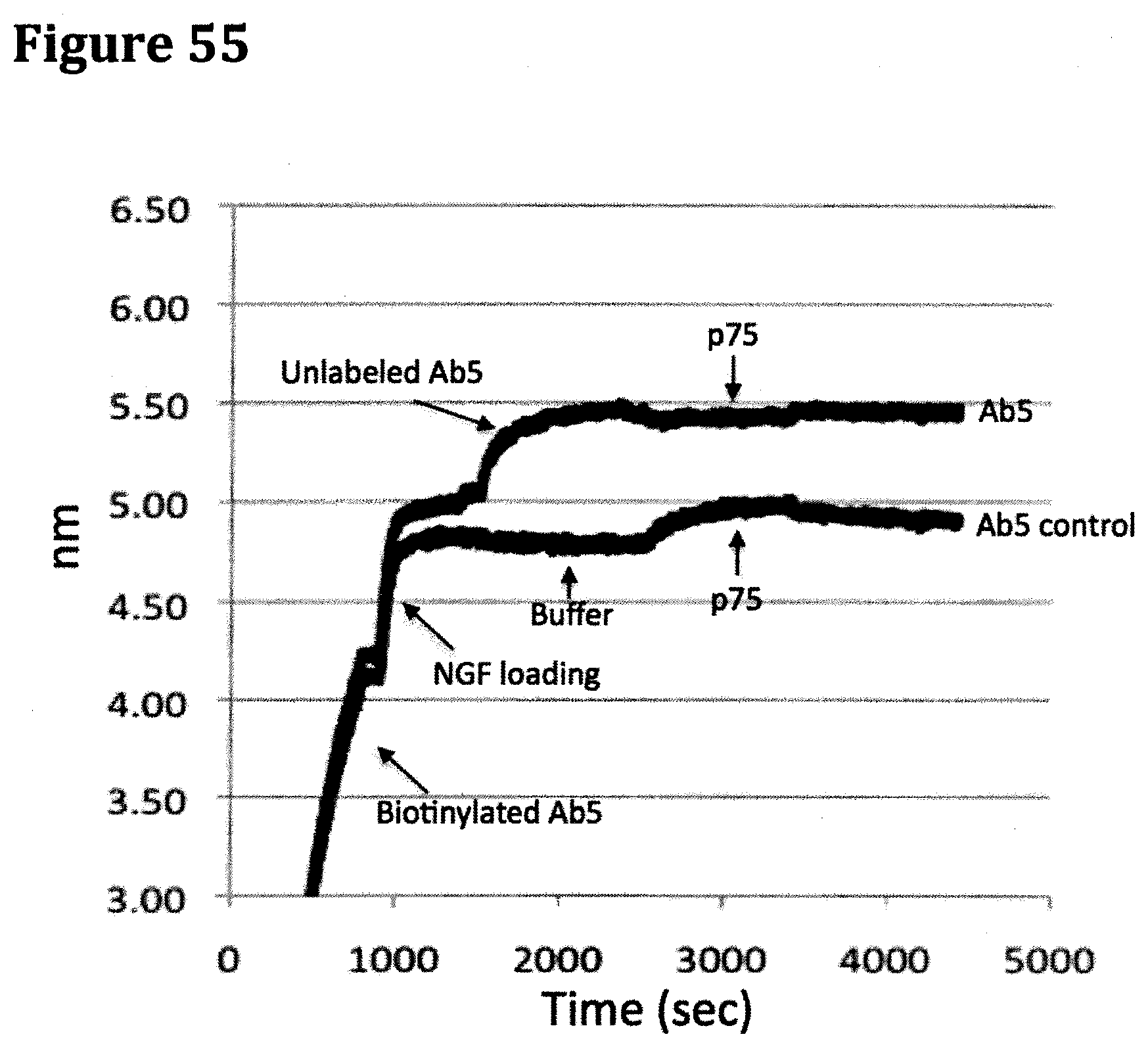
D00077

D00078

D00079

D00080
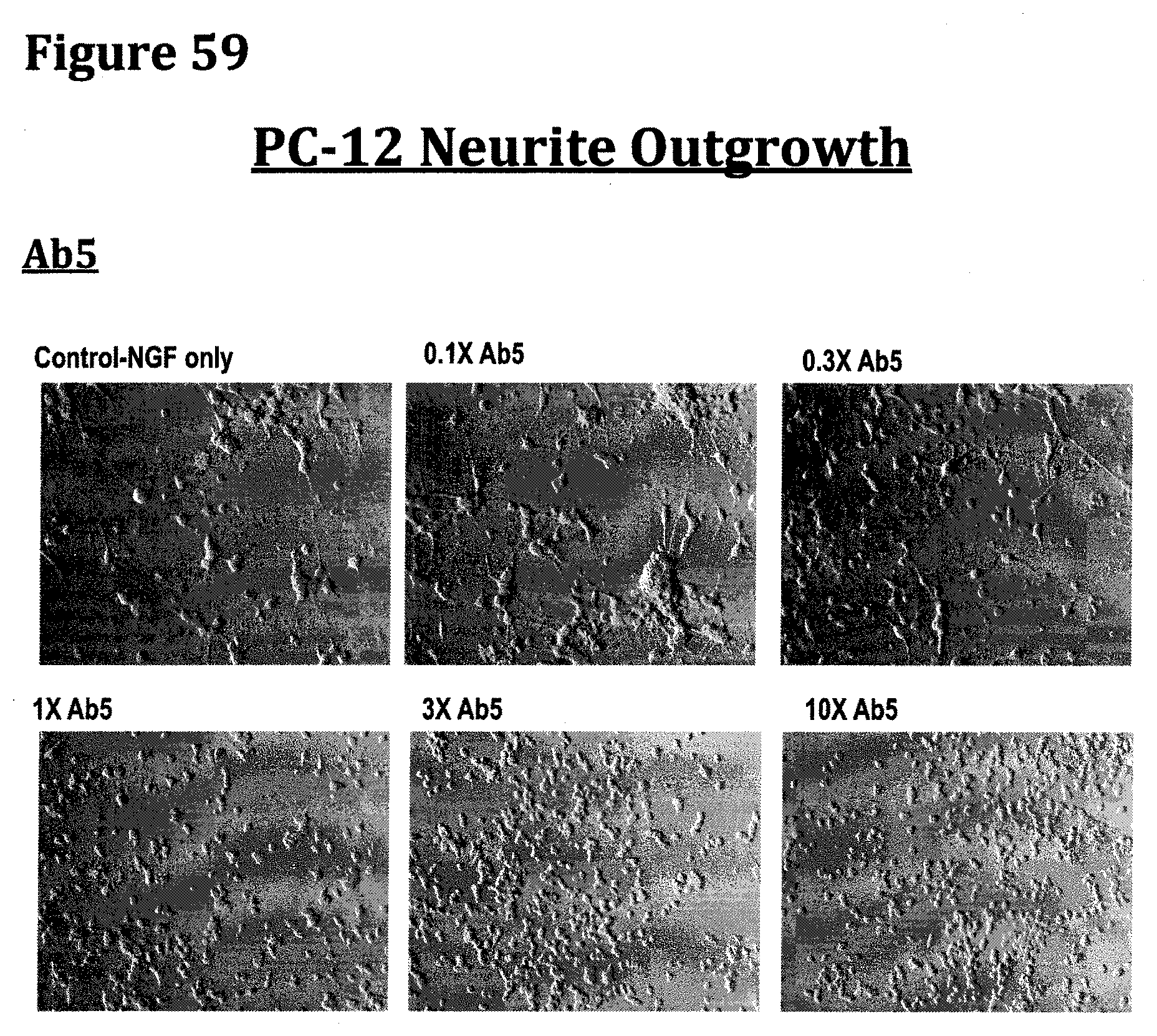
D00081

D00082

D00083

D00084

D00085

D00086

D00087

D00088

D00089
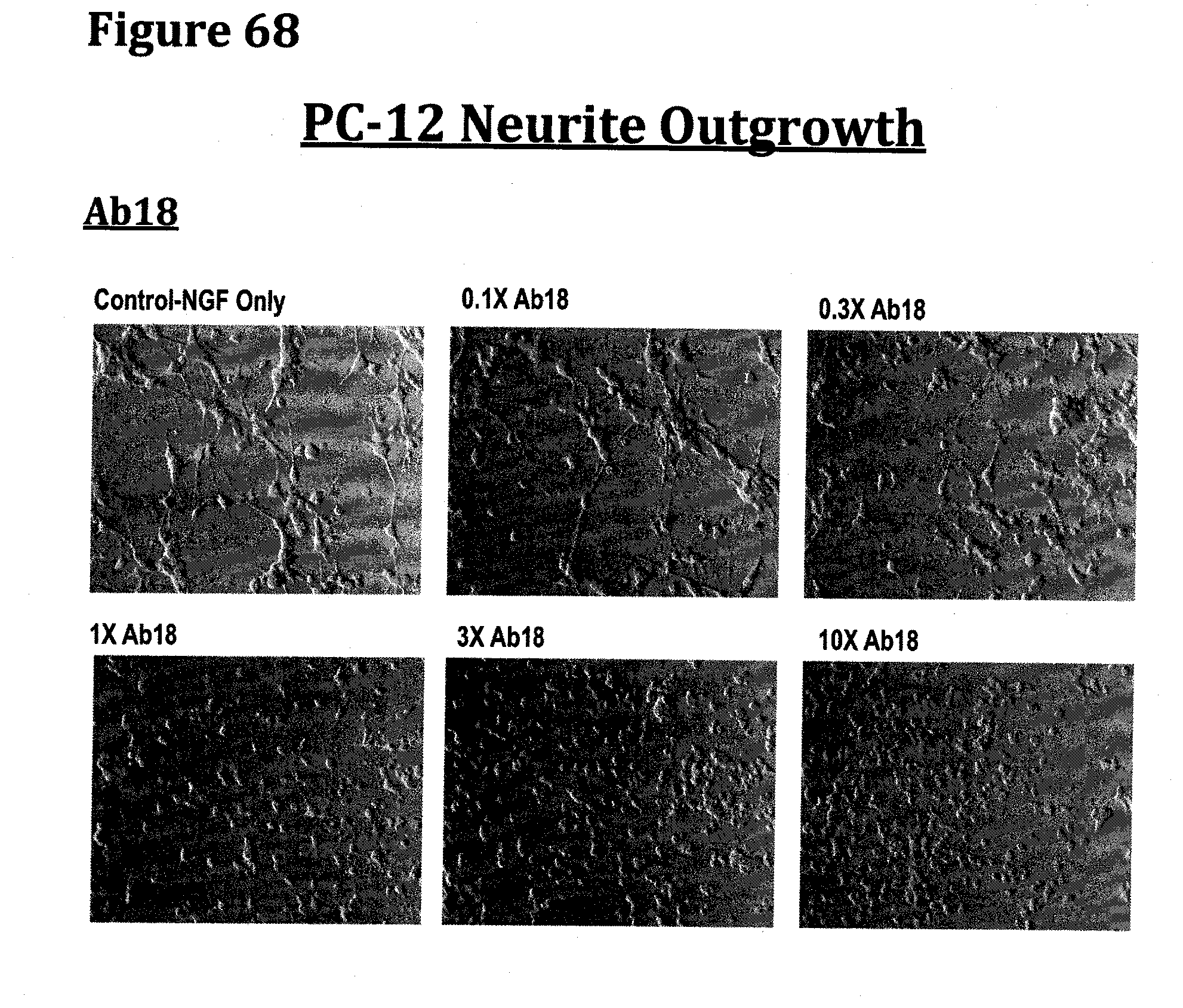
D00090

D00091
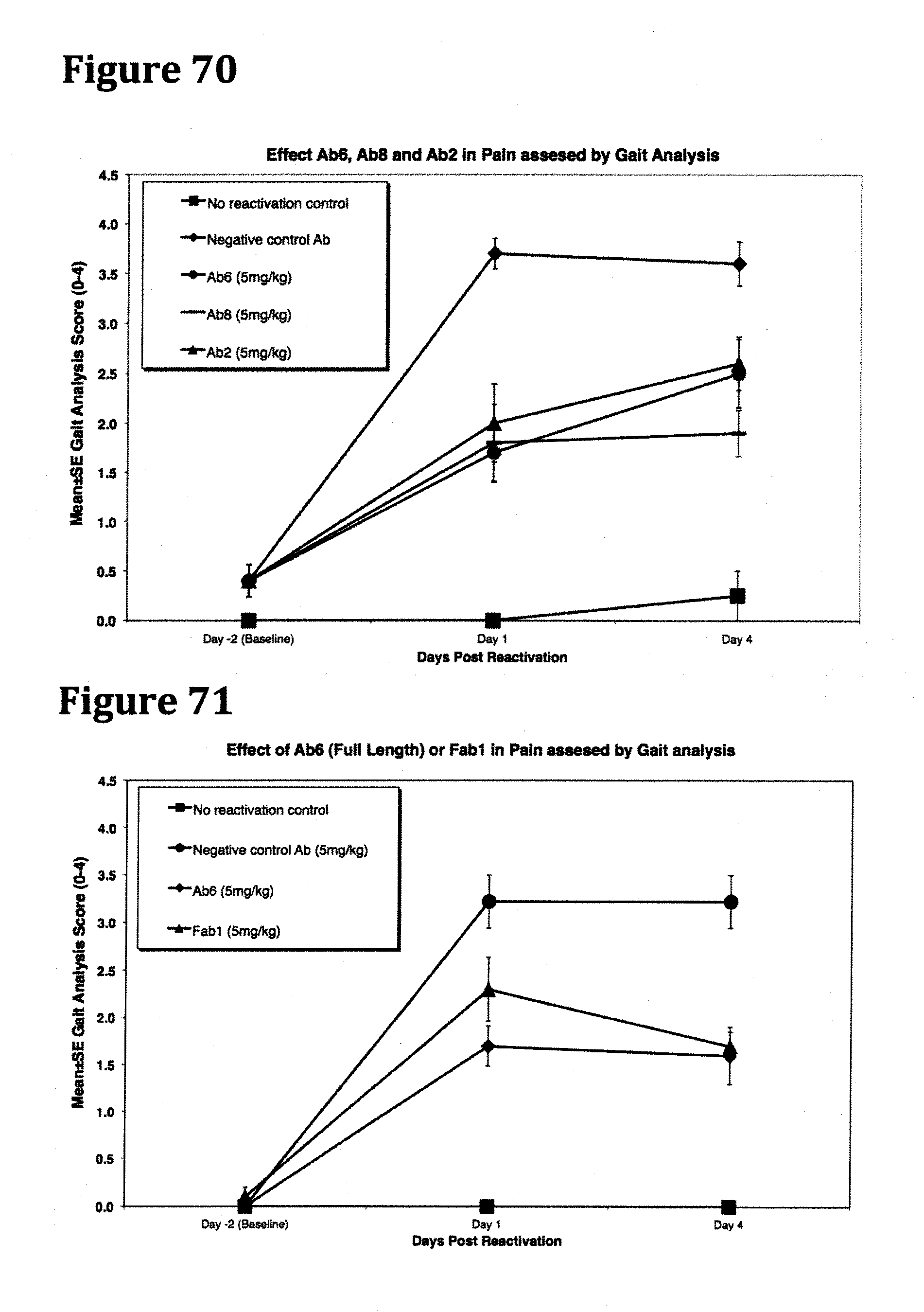
D00092
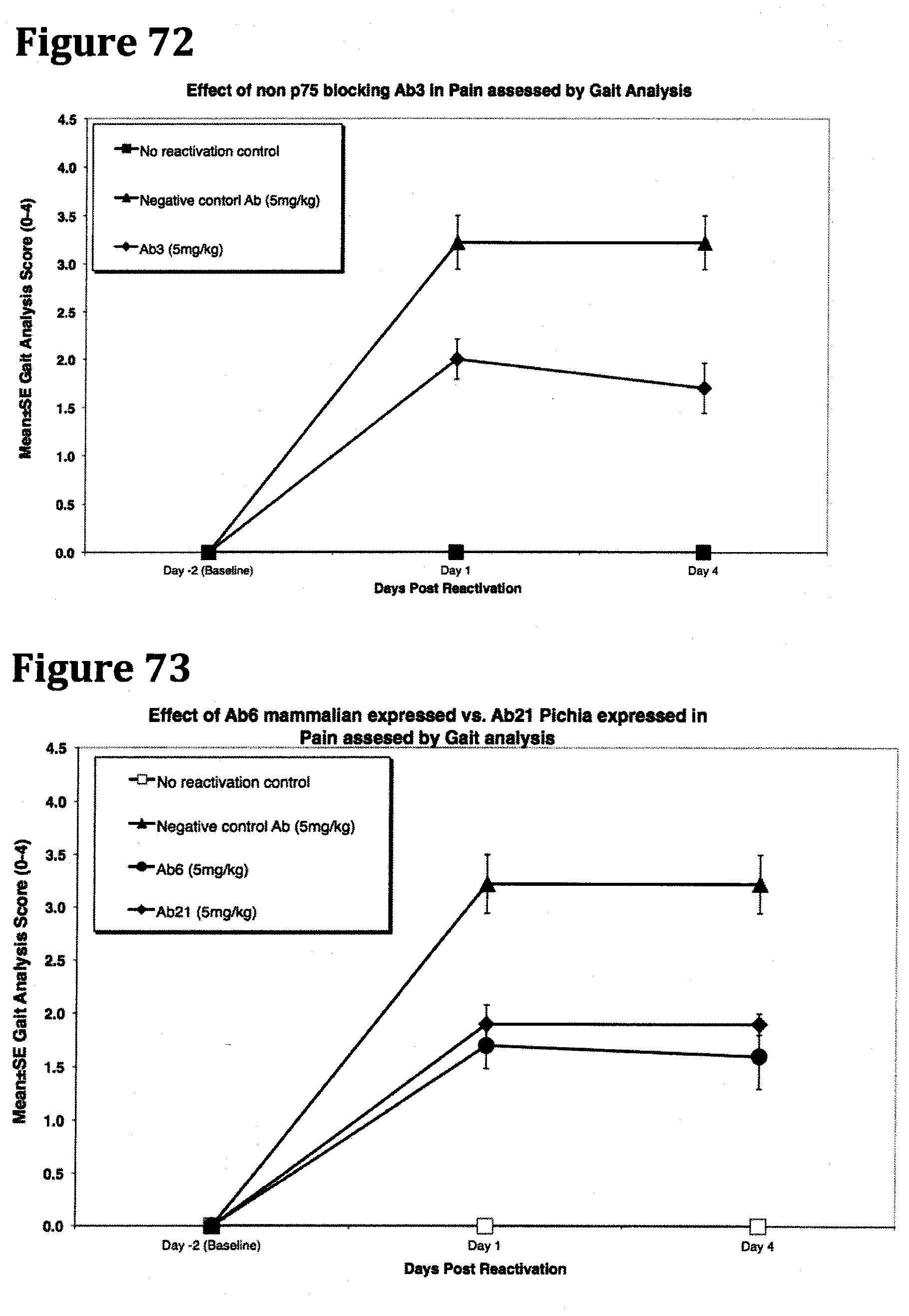
D00093

D00094

D00095

D00096
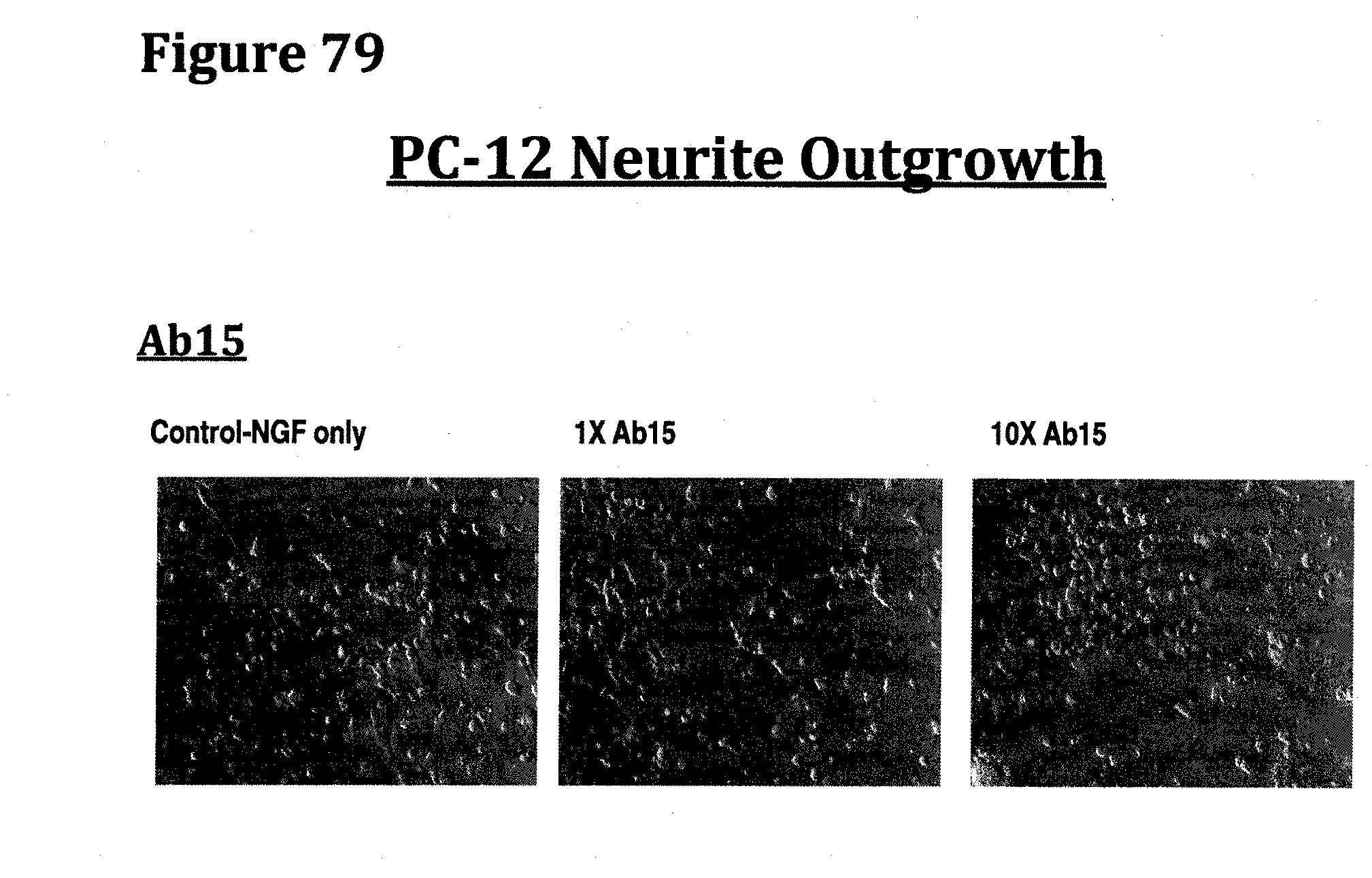
S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.