Ptd-smad7 Therapeutics
Wang; Xiao-Jing ; et al.
U.S. patent application number 16/584608 was filed with the patent office on 2020-01-23 for ptd-smad7 therapeutics. The applicant listed for this patent is THE REGENTS OF THE UNIVERSITY OF COLORADO, A BODY CORPORATE. Invention is credited to Yosef REFAELI, Xiao-Jing Wang, Qinghong ZHANG.
| Application Number | 20200023037 16/584608 |
| Document ID | / |
| Family ID | 51492023 |
| Filed Date | 2020-01-23 |












View All Diagrams
| United States Patent Application | 20200023037 |
| Kind Code | A1 |
| Wang; Xiao-Jing ; et al. | January 23, 2020 |
PTD-SMAD7 THERAPEUTICS
Abstract
The present technology provides methods and compositions for the treatment of inflammatory and/or tissue damage conditions. In particular, the use of Smad7 compositions delivered locally or systemically to a site of inflammation and/or tissue damage is described. Other specific embodiments concern treatment or prevention of side effects caused by radiation and/or chemotherapy, including but not limited to oral and gastric mucositis. Also provided are codon-optimized nucleic acids encoding for Smad7 fusion proteins.
| Inventors: | Wang; Xiao-Jing; (Greenwood Village, CO) ; ZHANG; Qinghong; (Englewood, CO) ; REFAELI; Yosef; (Denver, CO) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 51492023 | ||||||||||
| Appl. No.: | 16/584608 | ||||||||||
| Filed: | September 26, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 14773167 | Sep 4, 2015 | 10456448 | ||
| PCT/US2014/022052 | Mar 7, 2014 | |||
| 16584608 | ||||
| 61775252 | Mar 8, 2013 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | A61P 17/06 20180101; C07K 14/475 20130101; C12N 2740/16322 20130101; A61P 29/00 20180101; A61P 17/02 20180101; C12N 2800/22 20130101; C07K 2319/23 20130101; C07K 14/005 20130101; C07K 14/4703 20130101; C12N 7/00 20130101; A61K 38/162 20130101; A61P 37/02 20180101; A61K 38/18 20130101; A61K 48/005 20130101; C07K 2319/10 20130101; C07K 2319/20 20130101; A61K 38/00 20130101; C07K 14/4702 20130101; A61P 1/02 20180101; C12N 2740/16311 20130101 |
| International Class: | A61K 38/18 20060101 A61K038/18; C07K 14/47 20060101 C07K014/47; A61K 38/16 20060101 A61K038/16; C07K 14/005 20060101 C07K014/005; C07K 14/475 20060101 C07K014/475; C12N 7/00 20060101 C12N007/00 |
Goverment Interests
STATEMENT OF GOVERNMENT INTEREST
[0002] This invention was made with government support under grant number AR061796 awarded by the National Institutes of Health. The government has certain rights in the invention.
Claims
1-48. (canceled)
49. A protein molecule comprising a protein transduction domain and a human mothers against decapentaplegic-7 protein (Smad7) fragment comprising amino acids 259-426 of the human Smad7 protein, wherein the Smad7 fragment retains one or more biological activities of the functional full-length Smad7 protein, and with the proviso that the protein molecule lacks at least amino acids 1-203 of the human Smad7 protein.
50. The protein molecule of claim 49, wherein the human mothers against decapentaplegic-7 protein (Smad7) fragment consists of amino acids 259-426 of the human Smad7 protein.
51. The protein molecule of claim 49, wherein the protein transduction domain is Tat.
52. The protein molecule of claim 50, wherein the protein transduction domain is Tat.
53. A pharmaceutical composition comprising the protein molecule of claim 49, and one or more pharmaceutically acceptable excipients.
54. A method for treating an inflammatory condition in a subject in need thereof, comprising administering to the subject a therapeutically effective amount of the protein molecule of claim 49.
55. The method of claim 54, wherein the inflammatory condition is selected from the group consisting of radiation-induced damage, psoriasis, stomatitis, proctitis, ulcerative colitis, Crohn's disease, irritable bowel disease, and inflammatory bowel disease.
56. A method for treating a disease or disorder in a subject in need thereof, comprising administering to the subject a therapeutically effective amount of the protein of claim 49, wherein the administration of the protein results in an increase in one or more of cell proliferation or cell migration, or reducing one or more of apoptosis or DNA damage in the subject.
57. A method for treating a disease or disorder in a subject in need thereof, comprising administering to the subject a therapeutically effective amount of the protein of claim 49, wherein the disease or disorder is selected from the group consisting of promoting wound healing, treating inflammatory diseases, aberrant healing, auto-immune diseases and auto-immune disorders.
58. The method of claim 57, wherein the promoting wound healing comprises promoting wound healing of chronic wounds, acute wounds or mucositis.
59. The method of claim 58, wherein the chronic wounds are selected from the group consisting of diabetic ulcers, pressure ulcers, venous ulcers, and oral ulcers.
60. The method of claim 58, wherein the acute wounds are selected from the group consisting of trauma-induced wounds, surgical wounds, and scarring.
61. The method of claim 58, wherein the promoting healing in mucositis comprises promoting healing in radiation-induced mucositis and chemotherapy-induced mucositis.
62. The method of claim 58, wherein the mucositis is selected from the group consisting of oral mucositis and gastrointestinal mucositis.
63. The method of claim 57, wherein the aberrant healing comprises scarring and fibrosis.
64. The method claim 57, wherein the autoimmune diseases and auto-immune disorders are selected from the group consisting of psoriasis, stomatitis, proctitis, ulcerative colitis, Crohn's disease, irritable bowel disease, and inflammatory bowel disease.
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] The present application is a continuation of U.S. patent application Ser. No. 14/773,167, filed Sep. 4, 2015, which is a National Stage Application under 35 U.S.C. .sctn. 371 of International Application Serial No. PCT/US2014/022052, filed on Mar. 7, 2014, which claims the benefit of and priority to U.S. provisional patent application U.S. Ser. No. 61/775,252, filed Mar. 8, 2013, all of which are incorporated herein by reference in their entireties.
SEQUENCE LISTING
[0003] The instant application contains a Sequence Listing which has been submitted electronically in ASCII format and is hereby incorporated by reference in its entirety. Said ASCII copy, created on Apr. 29, 2014, is named 089491-0303_SL.txt and is 120,505 bytes in size.
BACKGROUND
[0004] Oral mucositis, a severe oral ulceration, is a common adverse effect of a large dose of radiation for bone marrow transplant or craniofacial radiotherapy for cancer. Severe oral mucositis could require feeding tubes, management of severe pain, and prematurely halting radiotherapy. Excessive inflammation and epithelial ablation are key features of oral mucositis.
[0005] Palifermin, a KGF (human keratinocyte growth factor) recombinant protein, is approved for preventing oral mucositis in bone-marrow transplant patients. Two Palifermin clinical trials in head and neck cancer patients showed that Palifermin reduced severe oral mucositis incidence from 67% and 69% to 51% and 54%, respectively. Other oral mucositis drugs in clinical trials or pre-clinical studies include growth factors, agents for radioprotection, anti-inflammatory agents or immune modulators.
[0006] The modest effects of Palifermin and drugs being developed in the above mentioned categories highlight the need for identification of biomarkers for novel therapies. However, the lack of routine diagnostic biopsies or discarded tissues from oral mucositis patients has hindered this effort.
[0007] Cutaneous wound healing progresses through three overlapping phases: inflammation, tissue formation, and tissue remodeling. These are dynamic processes that involve interactions among the epidermis, leukocytes, extracellular matrix (ECM), and dermal fibroblasts. In response to skin injury, blood clots, infiltrated inflammatory cells and other cell types in the wound release multiple cytokines and chemokines. These cytokines initiate fibroblast proliferation and synthesis of ECM that fill the wound deficit and lead to wound closure.
[0008] Meanwhile, keratinocytes at the wound edge begin to proliferate and migrate to cover the wound surface. Underneath the re-epithelialized epidermis, new stroma, called granulation tissue, begins to fill the wound space, which contains provisional ECM, inflammatory cells, fibroblasts, and blood vessels. Once the wound area is filled with the granulation tissue and covered by newly re-epithelialized epidermis, the process of wound closure is completed. Later on, the wound gradually returns to normal strength and texture through tissue remodeling.
[0009] Among the many molecules known to influence wound healing, transforming growth factor .beta. (TGF-.beta.) has the broadest spectrum of action, affecting all cell types that are involved in all stages of wound healing (Feng et al., Annu Rev Cell Dev Biol 21:659-693, 2005). The various functions of TGF-.beta. are mediated by a number of signaling molecules, including the Smad family members. When a ligand binds to TGF-.beta. type I and type II receptors (TGF.beta.RI and TGF-.beta.RII), TGF-.beta.RI phosphorylates Smad2 and Smad3. Phosphorylated Smad2 and Smad3 bind a co-Smad, Smad4, to form heteromeric Smad complexes and translocate into the nucleus to regulate transcription of TGF-.beta. target genes.
[0010] TGF-.beta. signaling has been reported to exert both positive and negative effects on wound healing (Wang et al., J Investig Dermatol Symp Proc 11: 112-117, 2006). For instance, Smad3 deficient mice, in which TGF-.beta. signaling is partially abrogated, exhibit accelerated wound healing (Ashcroft et al., Nat Cell Biol 1:260-266, 1999). In contrast, the introduction of exogenous Smad3 to wound sites to enhance TGF-.beta. signaling also accelerated wound healing in a rabbit dermal ulcer model (Sumiyoshi et al., J Invest Dermatol 123:229-236, 2004). Skin wounds in Smad4-deficient mice have a dramatic increase in inflammation and angiogenesis causing a delay in wound closure and formed an excessive scar (Owens et al., Am J Pathol 176:122-133, 2010). Transient adenoviral gene transfer of Smad7, an antagonist of TGF-.beta. signaling, in corneal epithelium and stroma resulted in accelerated corneal wound healing with reduced inflammation (Saika et al., Am J Pathol 166:1405-1418, 2005). Further, Smad7 gene transfer to the lens epithelium and stroma prevented injury-induced epithelial-mesenchymal transition of lens epithelial cells and suggests a potential role of Smad7 in prevention of capsular fibrosis (Saika et al., Lab Invest 84:1259-1270, 2004). However, adenoviral vector delivery of Smad7 to balloon injury in rat carotid arteries resulted in reduced vascular healing (Mallawaarachchi et al., Arterioscler Thromb Vasc Biol 25: 1383-1387, 2005). These studies suggest that the effects of TGF-.beta. signaling components, such as Smad7, on wound healing are complex and highly context-specific. Additionally, the effect of Smad7 may not always be explained by its role in TGF-.beta. signaling. For instance, Smad7 has also been shown to interact with components of the Wnt/.beta.-catenin (Han et al., Dev Cell Biol 11:301-312, 2006) and the TNF.beta./NF-.kappa.B (Hong et al., Nat Immunol 8:504-513, 2007) families.
SUMMARY
[0011] The present technology provides a nucleic acid molecule comprising a codon-optimized human Smad7 cDNA nucleotide sequence. In some embodiments, the codon-optimized human Smad7 nucleotide sequence may include one or more codons for arginine optimized for expression in one or more of bacteria or yeast, including one or more codons for serine optimized for expression in one or more of bacteria or yeast, and/or including one or more codons for histidine optimized for expression in one or more of bacteria or yeast. In some embodiments, the codon-optimized human Smad7 nucleotide sequence may include 28 serine codons, 6 histidine codons, and 9 arginine codons optimized for expression in one or more of bacteria or yeast. In some embodiments, the codon-optimized human Smad7 nucleotide sequence may be selected from the group consisting of SEQ ID NOs: 9, 21, 23, 24, 26, 28, 30, 32-34, 36, 38, 39, 87, 89, 91, 93, 96, 97, 99, and 100. In some embodiments, the codon-optimized human Smad7 nucleotide sequence may have about 65 to 75 percent homology to human Smad7 cDNA, may comprise a nucleotide sequence encoding an N-terminal fragment SMAD7, may comprise a nucleotide sequence encoding a C-terminal fragment of SMAD7, may comprise nucleotides encoding amino acids 2-258 of the human Smad7 protein, may comprise nucleotides encoding amino acids 259-426 of the human Smad7 protein, or may comprise nucleotides encoding amino acids 203-258 of the human Smad7 protein. In some embodiments, any of the foregoing may further comprise a nucleotide sequence encoding a protein transduction domain, such as Tat. In some embodiments, any of the foregoing may also further comprise a nucleotide sequence encoding one or more of an epitope tag or a purification tag, such as V5, glutathione-S-transferase, or 6-Histidine (SEQ ID NO: 40).
[0012] In some embodiments, any of the foregoing may be isolated and/or purified. In some embodiments, any one of the foregoing may also encode a polypeptide having one or more biological activities selected from the group consisting of reducing or eliminating phosphorylation of Smad2, reducing or eliminating nuclear translocation of the NF-.kappa.B p50 subunit, increasing cell proliferation, reducing apoptosis, reducing radiation-induced DNA damage, reducing inflammation, reducing angiogenesis, promoting healing in oral mucositis, promoting wound healing, and treating auto-immune disease. In some embodiments, pharmaceutical compositions comprising the nucleic acid molecules above and one or more pharmaceutically acceptable excipients are provided. In some embodiments, expression vectors comprising the nucleic acid molecules above operably linked to a promoter are provided, as are host cells comprising such expression vectors, and pharmaceutical compositions comprising such vectors and host cells with one or more pharmaceutically acceptable excipients.
[0013] In one aspect, a protein molecule comprising a human Smad7 protein having leucine at position 216 is provided. In some embodiments, the human Smad7 protein may be truncated at the C-terminal, or truncated at the N-terminal. In some embodiments, the truncated human Smad7 protein may include about 50% of the full-length Smad7 sequence, or may include about 13% of the full-length Smad7 sequence. In some embodiments, the human Smad7 protein may comprise or consist of amino acids 2-258, amino acids 203-258, or amino acids 259-426 of the human Smad7 protein. In some embodiments, the protein molecule may have one or more biological activities selected from the group consisting of reducing or eliminating phosphorylation of Smad2, reducing or eliminating nuclear translocation of the NF-.kappa.B p50 subunit, increasing cell proliferation, reducing apoptosis, reducing radiation-induced DNA damage, reducing inflammation, reducing angiogenesis, promoting healing in oral mucositis, promoting wound healing, and treating auto-immune disease. In some embodiments, any of the foregoing may further comprise a protein transduction domain, such as Tat. In some embodiments, any of the foregoing may also further comprise one or more of an epitope tag or a purification tag, such as V5, glutathione-S-transferase or 6-histidine (SEQ ID NO: 40). In some embodiments, a pharmaceutical composition comprising any of the foregoing, a protein molecule, and one or more pharmaceutically acceptable excipients is provided.
[0014] In another aspect, a method is provided for treating or preventing an inflammatory condition in a subject comprising providing to the subject a therapeutically effective amount of the pharmaceutical composition described above. In some embodiments, the inflammatory condition may be one or more of a chronic wound, skin inflammation, psoriasis, or an autoimmune disease. In some embodiments, the composition may reduce inflammation through inhibition of TGF-.beta. and NF-.kappa.B signaling.
[0015] In another aspect, a method is provided for preventing or treating a disease or disorder in a subject comprising one or more of increasing one or more of cell proliferation or cell migration, or preventing one or more of apoptosis or DNA damage in the subject comprising providing to the subject a therapeutically effective amount of the pharmaceutical composition as described above, wherein one or more of increasing one or more of cell proliferation or cell migration, or preventing one or more of apoptosis or DNA damage is useful in preventing or treating the disease or disorder. In some embodiments, the disease or disorder may include one or more of chronic wounds, acute wounds, or mucositis. In some embodiments, the chronic wounds may include one or more of diabetic ulcers, pressure ulcers, venous ulcers, or oral ulcers, the acute wounds may include one or more of trauma-induced wounds, surgical wounds, or scarring, the mucositis may include one or more of radiation-induced mucositis or chemotherapy-induced mucositis and the mucositis may include one or more of oral mucositis or gut mucositis.
[0016] It is contemplated that any method or composition described herein can be implemented with respect to any other method or composition described herein.
[0017] The use of the word "a" or "an" when used in conjunction with the term "comprising" in the claims and/or the specification may mean "one," but it is also consistent with the meaning of "one or more," "at least one," and "one or more than one." The word "about" means plus or minus 5% of the stated number.
[0018] Other objects, features and advantages of the present technology will become apparent from the following detailed description. It should be understood, however, that the detailed description and the specific examples, while indicating specific embodiments of the present technology, are given by way of illustration only, since various changes and modifications within the spirit and scope of the present technology will become apparent to those skilled in the art from this detailed description.
BRIEF DESCRIPTION OF THE DRAWINGS
[0019] The following drawings form part of the present specification and are included to further demonstrate certain embodiments of the present technology. The embodiments may be better understood by reference to one or more of these drawings in combination with the detailed description of specific embodiments presented herein.
[0020] FIGS. 1A-G provide an illustrative embodiment of data showing that K5.Smad7 mice were resistant to radiation-induced oral mucositis. FIG. 1A provides an illustrative embodiment of H&E staining in non-irradiated and irradiated (day 9 after initiation of radiation) wild-type (WT) and K5.Smad7 tongues. The vertical lines in the images of tongues from WT mice highlight the ulcer boundary and dotted lines in the images indicate the epithelial-stromal boundary (scale bar, 50 .mu.m). FIG. 1B provides a graphical representation of the quantification of sizes of tongue ulcers (mean+s.e.m); n=8 for WT mice and n=7 for K5.Smad7 mice in 8 Gy.times.3 radiation; n=5 for WT mice and n=4 for K5.Smad7 mice in 18-Gy radiation; n=5 per group for WT and K5.Smad7 mice in 22-Gy radiation. FIG. 1C provides an illustrative embodiment of human ventricular posterior of the tongue (top) and radiation-induced tongue mucositis (bottom) visualized using H&E (left) and CD45 staining (right). The solid line indicates the ulcer boundary, and dotted lines indicate the basement membrane (scale bar, 25 .mu.m). FIG. 1D provides an illustrative embodiment of immunostaining of CD45, proliferating cell nuclear antigen (PCNA), and TUNEL assay in irradiated sections adjacent to an ulcer from WT mice and in damaged areas from K5.Smad7 mice (PI, propidium iodide). Dotted lines indicate the basement membrane (scale bar, 25 .mu.m). FIGS. 1E-1G provide graphical representations of the quantification of staining in FIG. 1D (n=3 or 4 per group). Data are expressed as mean+s.e.m (FIG. 1B) or mean+s.d (FIGS. 1E-1G), and two-tail Student t-test is used to calculate P values. *P<0.05, **P<0.01, ***P<0.001, NS, no significance determined by two-tailed Student's t-test. Dotted lines in (FIG. 1A), (FIG. 1C) and (FIG. 1D) highlight the basement membrane. Scale bar: 50 .mu.m for all panels in (FIG. 1A) and (FIG. 1C), 25 .mu.m for all panels in (FIG. 1D).
[0021] FIGS. 2A-G provide an illustrative embodiment of data showing molecular alterations attenuated by Smad7. FIG. 2A provides an illustrative embodiment of immune-staining of NF-.kappa.B p50, TGF-.beta.1 and pSmad2. Irradiated tongue sections of wild-type (WT) were adjacent to ulcer and sections of K5.Smad7 were from the damaged area. Human samples were from non-irradiated oral mucosa and radiation-induced mucositis. Dotted lines delineate epithelial-stromal boundary. Scale bar, 25 .mu.m for all panels. FIG. 2B provides a graphical representation of the quantification of immunostaining of NF-.kappa.B p50 and pSmad2 shown in (FIG. 2A). FIG. 2C provides an illustrative embodiment of qRT-PCR of TGF-.beta.1 (normalized by Keratin 5, n=6 per group for day 0, n=4 for day 7 and day 9, and n=7 for day 10). FIG. 2D provides a graphical representation of the quantification of human oral keratinocyte migration (see images in FIG. 8). Scrambled, scrambled siRNA; n=3 per group. FIG. 2E provides an illustrative embodiment of a western analysis of knockdown efficiency of siSmad7-1 and siSmad7-2 for Smad7 and for Rac1, 72 hours after Smad7 knockdown. M, molecular markers. FIG. 2F provides an illustrative embodiment of western analysis of total and activated (GTP-bound) Rac1 protein. M: molecular markers. FIG. 2G provides a graphical representation of the quantification of the effect of Rac1 knockdown on Smad7-mediated keratinocyte migration (see knockdown efficiency in FIG. 9A and images in FIG. 9D). n=3 per group. Data are presented as mean+s.d. and two-tail Student's t-test was used to calculate P values for (FIG. 2B-2D) and (FIG. 2G). *P<0.05, **P<0.01, ***P<0.001. NS, no significance.
[0022] FIGS. 3A-H provide an illustrative embodiment of data showing Smad7 increased Rac1 expression by repressing individual Smad and CtBP1 binding to the SBE of the Rac1 promoter. FIG. 3A provides a graphical representation of the quantification of Rac1 mRNA in wild-type (WT) and Smad7 transgenic keratinocytes. n=4 per group. FIG. 3B provides an illustrative embodiment of western analysis of GTP-Rac1 and total Rac1 in WT and Smad7 keratinocytes. Smad7 protein levels in WT and Smad7 keratinocytes were determined by reprobing the tubulin western blot with an antibody to Smad7 (see an additional western blot and quantification in FIGS. 10A-B). FIG. 3C provides an illustrative embodiment of western analysis of Rac1 protein level after knocking down individual Smad2, Smad3 or Smad4 in human keratinocytes (see FIG. 10C-10E for Smad knockdown efficiencies). FIG. 3D provides an illustrative embodiment of a ChIP assay for Smad-2, -3, -4, and -7 binding to the -1.5 Kb SBE site of the Rac1 promoter in WT and Smad7 transgenic keratinocytes. FIG. 3E provides a graphical representation of the quantification of Rac1 luciferase reporter assay in mouse keratinocytes. Scrambled: scrambled siRNA. n=6. FIG. 3F provides a graphical representation of the quantification of the activities of Rac1 luciferase reporter containing SBE or mutant (mut) SBE in WT or Smad7 transgenic keratinocytes. n=6. FIG. 3G provides an illustrative embodiment of images of ChIP assays of CtBP1 binding to the SBE-1.5 Kb site of the Rac1 promoter in WT or K5.Smad7 keratinocytes. FIG. 3H provides a graphical representation of ChIP-qPCR quantification of CtBP1 binding to the SBE shown in FIG. 3G in WT and Smad7 transgenic keratinocytes. n=4. Data are presented as mean+s.d. and two-tail Student's t-test is used to calculate P values for FIGS. 3A, 3E, 3F and 3H. *P<0.05, **P <0.01, ***P<0.001.
[0023] FIGS. 4A-G provide an illustrative embodiment of data showing CtBP1-associated Rac1 repression contributed to inhibition of keratinocyte migration. FIG. 4A provides an illustrative embodiment of western analysis of Rac1 protein after knockdown of CtBP1 in human oral keratinocytes. FIG. 4B provides a graphical representation of the quantification of SBE-containing Rac1 luc reporter activity. n=6. FIG. 4C provides a graphical representation of the quantification of the effect of CtBP1 knockdown on human oral keratinocyte migration. n=3 per group. FIG. 4D provides an illustrative embodiment of immunostaining of CtBP1. Irradiated sections were adjacent to the ulcer (WT) or the damaged area (K5.Smad7). Dotted lines denote the basement membrane. Scale bar, 50 .mu.m for all panels. FIG. 4E provides an illustrative embodiment of immunostaining of CtBP1 in non-irradiated oral mucosa and radiation-induced oral mucositis in human specimens. Dotted lines denote the basement membrane. Scale bar, 50 .mu.m for both panels. FIG. 4F provides a graphical representation of the quantification of CtBP1 nuclear positive cells in FIGS. 4D-E. n=3 or 4 per group. FIG. 4G provides a graphical representation of the quantification of qRT-PCR for CtBP1 (normalized with Keratin K5). n=6 per group for day 0, n=4 for day 7 and day 9, and n=7 for day 10. Data are presented as mean+s.d. and two-tail Student's t-test is used to calculate P values for FIGS. 4B, 4C, 4F and 4G. *P<0.05, **P<0.01, ***P<0.001.
[0024] FIGS. 5A-G provide an illustrative embodiment of data showing oral Tat-Smad7 application prevented radiation-induced oral mucositis in mice. FIG. 5A provides a graphical representation of the quantification of oral mucositis ulcer sizes on day 9 after initiation of 8 Gy.times.3 radiation. Vehicle=saline or 50% glycerol/PBS. FIG. 5B provides an illustrative embodiment of pathological alterations on day 9 of initiation of 8 Gy.times.3 radiation. Vehicle=saline or 50% glycerol/PBS. Scale bar, 50 .mu.m for H&E panels and 25 .mu.m for remaining panels. Dotted lines delineate epithelial-stromal boundary; the solid line highlights the ulcer boundary. FIGS. 5C, 5D, 5E, 5F, and 5G provide a graphical representation of the quantification of immunostaining shown in FIG. 5B. n=3 or 4 per group. Data are presented as mean+s.e.m (FIG. 5A) or mean+s.d. (FIGS. 5C-5G) and two-tail Student's t-test is used to calculate P values. *P<0.05, **P<0.01, ***P<0.001. NS, no significance.
[0025] FIGS. 6A-G provide an illustrative embodiment of data showing Tat-Smad7 treatment on oral mucositis. FIG. 6A provides a graphical representation of the quantification of ulcer sizes measured on day 10 after initiation of 8 Gy.times.3 radiation. Glycerol=50% glycerol/PBS. FIG. 6B provides an illustrative embodiment of H&E staining of oral mucosa. Upper panels: open ulcer in Palifermin treated but not Tat-Smad7 treated mucosa. Lower panels: comparison of epithelial thickness between Palifermin treated and Tat-Smad7 treated mucosa. Dotted lines delineate the basement membrane. The vertical line highlights the ulcer boundary. Scale bar, 50 .mu.m for all panels. FIG. 6C provides an illustrative embodiment of immune-staining of Tat-Smad7 treatment in 20 Gy-induced oral mucositis after ulcers healed. V5 immunostaining visualizes Tat-Smad7 in oral epithelia (sections are away from the damaged regions). K14 immunostaining was used as counterstain. Dotted lines delineate basement membrane. Scale bar, 25 .mu.m for all panels. FIG. 6D provides an illustrative embodiment of Rac1 western analysis of Tat-Smad7 treated mouse tongues, day 10 after initiation of 8 Gy.times.3 radiation. FIG. 6E provides an illustrative embodiment of Rac1 western analysis on Tat-Smad7 treated normal human oral keratinocytes 48 hours after treatment. FIG. 6F provides an illustrative embodiment of the effect of Tat-Smad7 treatment on oral human keratinocyte migration (NOK-SI, see images in FIG. 13A). n=4 per group. FIG. 6G provides a graphical representation of the quantification of survival curves of NOK-SI keratinocytes and SCC lines (Cal27 and MSK921) with or without Tat-Smad7 treatment. n=4 per group for each radiation dose. Data are presented as mean+s.e.m (FIG. 6A) or mean+s.d. (FIGS. 6F, 6G) and two-tail Student's t-test is used to calculate P values. *P<0.05, **P<0.01, ***P<0.001. NS, no significance.
[0026] FIGS. 7A-E provide an illustrative embodiment of data showing K5. Smad7 oral mucosal tissues were resistant to radiation-induced oral mucositis. FIG. 7A provides an illustrative embodiment of Smad7 western blots: undetectable in non-irradiated wild-type (WT) tongue and barely detectable after radiation. K5.Smad7 tongues have comparable Smad7 protein levels before and after radiation. M: molecular marker. FIG. 7B provides an illustrative embodiment of Smad7 immunostaining. Note that nuclei in some irradiated epithelial cells are hypertrophic. Dotted lines delineate epithelial-stromal boundary. FIG. 7C provides a graphical representation of the quantification of reduced incidence of oral mucositis-induced morbidity in K5.Smad7 mice. Fisher's exact test is used to calculate the p value. **P=0.007. FIG. 7D provides an illustrative embodiment of immune-staining of K5.Smad7 tongue showing reduced infiltration of neutrophils (Ly-6G), macrophages (BM8) and activated T cells (CD4) compared to WT oral mucositis. Dotted lines delineate epithelial-stromal boundary. FIG. 7E provides an illustrative embodiment of immune-staining showing no significant difference in pSmad1/5/8-nuclear positive cells (light) between WT and K5.Smad7 oral mucosa before or after radiation. Keratin (K14) immunostaining (dark) highlights the epithelial compartment. Note that nuclei of irradiated epithelial cells are hypertrophic. The scale bar is 50 .mu.m for all panels.
[0027] FIGS. 8A-D provide an illustrative embodiment of data showing migration in spontaneously immortalized human oral epithelial cells (NOK-SI) was delayed by knocking down Smad7 but accelerated by knocking down TGF-.beta.1. FIGS. 8A and 8B provide an illustrative embodiment of representative images of cell migration. Pairs of dotted lines delineate the scratch wound. Quantification of cell migration and efficiency of Smad7 knockdown are presented in FIG. 2D and FIG. 2E (above). Scrambled, scrambled siRNA. FIG. 8C provides a graphical representation of the quantification of cell migration after TGF-.beta.1 knockdown from 3 separate experiments. FIG. 8D provides a graphical representation of qRT-PCR showing TGF-.beta.1 knockdown efficiency. Data are presented as mean+s.d. and two-tail Student's t-test was used to calculate P values. *P<0.05, **P<0.01. NS, no significance.
[0028] FIGS. 9A-D provide an illustrative embodiment of data showing knocking down Rac1 reduced proliferation and migration of wild-type (WT) and Smad7 transgenic keratinocytes. FIG. 9A provides an illustrative embodiment of western blot analysis for Rac1 48 hours after Rac1 siRNA (siRac1-1, siRac1-2) transfection. Control, scrambled siRNA. FIG. 9B provides a graphical representation of the percentage of BrdU labeled cells in WT and Smad7 cultured cells in BrdU incorporation assay with or without Rac1 knockdown. Data from 3 separate experiments were presented as mean+s.d. ***P<0.001. FIG. 9C provides an illustrative embodiment of representative immunofluorescence of BrdU positive cells presented in (FIG. 9B). An antibody against keratin 14 (K14, red) was used for counterstain. FIG. 9D provides an illustrative embodiment of in vitro cell migration assay for Smad7 transgenic and WT keratinocytes after Rac1 knockdown. Pairs of dotted lines delineate the scratch wound. Quantification of cell migration is presented in FIG. 2G.
[0029] FIGS. 10A-F provide an illustrative embodiment of data showing Smad7 increased Rac1 expression by repressing Smad and CtBP1 binding to the SBE of the Rac1 promoter. FIG. 10A provides an illustrative embodiment of western blot analysis for GTP-Rac1 and total Rac1 in Smad7 transgenic keratinocytes. Additional samples are shown in FIG. 3B. M, molecular marker. FIG. 10B provides a graphical representation of the quantification of GTP-Rac1, total Rac1 and Smad7 in WT and K5.Smad7 keratinocytes shown in FIG. 10A and in FIG. 3B. The protein level in WT keratinocytes of each blot was normalized as "1". Data is presented as mean+s.d. and two-tail Student's t-test was used to calculate P values. **P<0.01, ***P<0.001. FIGS. 10C and 10D provide an illustrative embodiment of western blot analysis for Smad2, Smad3, and Smad4 knockdown in NOK-SI cells. Their effects on Rac1 expression are shown in FIG. 3C. M, molecular marker. GAPDH, internal protein control by reprobing same blot. FIG. 10F provides an illustrative embodiment showing CtBP1 knockdown promotes NOK-SI cell migration. Pairs of dotted lines delineate the scratch wound. Quantification of cell migration and efficiency of CtBP1 knockdown are shown in FIG. 4A and FIG. 4C.
[0030] FIGS. 11A-G provide an illustrative embodiment of data showing the purification and characterization of Tat-Smad7 and Tat-Cre proteins. FIG. 11A shows an illustrative embodiment of a schematic representation of Tat-Smad7 protein. FIG. 11A discloses SEQ ID NOs: 49 and 101, respectively, in order of appearance. FIG. 11B provides an illustrative embodiment of a western blot of purified Tat-Smad7 protein. FIG. 11C provides an illustrative embodiment of immune-staining of Tat-Smad7 protein transduction in keratinocytes. Left and middle panels: Tat-Smad7 staining (light) using a V5 antibody, counterstained with a K14 antibody (dark). Cells showed Tat-Smad7 in the nucleus 5 min after transduction and in both nucleus and cytoplasm 12 hours after transduction. Right panels: Tat-Smad7 abrogated Smad2 phosphorylation (pSmad2, light). V5 (dark) counterstain visualizes Tat-Smad7 transduced cells. FIG. 11D provides an illustrative embodiment of immune-staining showing that V5 antibody staining detects Tat-Smad7 transduction in buccal mucosa 12 hours after Tat-Smad7 topical application. A K14 antibody was used for counterstain. Scale bar, 50 .mu.m for both panels. FIG. 11E provides an illustrative embodiment of a western blot of purified Tat-Cre protein with the same Tat and V5 tags shown in FIG. 11A. FIG. 11F provides an illustrative embodiment of an agarose gel showing activity of Tat-Cre: Tat-Cre cuts out a 1,460 bp floxed fragment from the 7,650 bp vector pLL3.7. FIG. 11G provides a graphical representation showing Tat-Smad7 protein preventive treatment reduced 20 Gy radiation-induced oral ulcers. Data are expressed as mean+s.e.m. Two-tail Student's t-test is used to calculate P values. *P<0.05, ***P<0.001.
[0031] FIGS. 12A-I provide an illustrative embodiment of data showing effects of Tat-Smad7 treatment on oral mucositis. FIG. 12A provides a graphical representation of the quantification of reduced ulcer size in Tat-Smad7 (0.8 .mu.g daily, day 6 to day 9) treated oral mucosa. Samples were harvested on day 10. n=8 per group. FIG. 12B provides an illustrative embodiment of immunostaining of molecular markers for samples from FIG. 12A. Scale bar, 50 .mu.m for the top two panels and 25 .mu.m for other panels. Propidium iodide (PI) and K14 were used as counterstain. FIGS. 12C-G provide graphical representation of the quantifications of immunostaining shown in FIG. 12C. 3-4 samples were used. FIG. 12H provides a graphical representation quantification of the Luciferase assay. Tat-Smad7 treatment increased the activity of the Rac1 promoter with SBE but not the mutant SBE in mouse keratinocytes. FIG. 12I provides an illustrative embodiment of a ChIP assay for CtBP1 binding to the SBE of mouse Rac1 promoter in Tat-Smad7 treated mouse keratinocytes. Data are expressed as mean+s.e.m (a) or mean+s.d (c-h) and two-tail Student's t-test is used to calculate P values. *P<0.05, **P<0.01, ***P<0.001. NS, no significance.
[0032] FIGS. 13A-H provide an illustrative embodiment of data showing effects of Tat-Smad7 treatment on migration of human keratinocytes and tumor cell lines. FIG. 13A provides an illustrative embodiment showing Tat-Smad7 accelerates NOK-SI cell migration. Quantification from four separate experiments is shown in FIG. 6F (above). Pairs of dotted lines delineate initial wounds. FIG. 13B provides an illustrative embodiment of immunostaining of Tat-Smad7 treatment in NOK-SI cells showing attenuated radiation-induced pSmad2 and NF-.kappa.B p50 nuclear localization. FIG. 13C provides an illustrative embodiment showing V5 staining of MSK921 cells 2 hours after Tat-Smad7 treatment. K14 staining was used as counterstain. FIG. 13D provides an illustrative embodiment of a Rac1 western analysis in MSK921 60 hours after Tat-Smad7 treatment. M, molecular marker. FIG. 13E provides a graphical representation of quantification of MSK921 cell migration from 3 separate experiments. FIG. 13F provides an illustrative embodiment showing a representative MSK921 cell migration assay treated with Tat-Smad7 and PBS. Pairs of solid lines delineate initial wounds. Dotted lines highlight the forefront of migrated cells. FIG. 13G provides a graphical representation of quantification of Cal27 cell migration from 3 separate experiments. FIG. 13H provides an illustrative embodiment showing representative images for FIG. 13G. Pairs of solid lines delineate initial wounds. Dotted lines highlight the forefront of migrated cells. Data are expressed as mean+s.d. and the two-tail Student's t-test is used to calculate P values. NS, no significance.
[0033] FIGS. 14A-B show an illustrative schematic of a summary of potential mechanisms of Smad7-mediated protection and healing of oral mucositis. FIG. 14A shows an illustrative schematic of how radiation activates NF-.kappa.B, increases TGF-.beta.1 and CtBP1. NF-.kappa.B and TGF-.beta.1 induce inflammation. TGF-.beta.1 induces apoptosis, growth arrest and activates Smad-2, -3 and -4, which recruit CtBP1 to the Rac1 promoter to repress Rac1 transcription, leading to blunted re-epithelialization. FIG. 14B shows an illustrative schematic of how Smad7 blocks NF-.kappa.B and TGF-.beta.1-induced inflammation and blocks TGF-.beta.1-induced apoptosis and growth arrest. Smad7 relieves Rac1 transcriptional repression by either preventing TGF-.beta.1-mediated Smad activation (phosphorylation) or competing with signaling Smads/CtBP1 transcriptional repression complex in binding to the Rac1 promoter. Increased Rac1 induced by Smad7 contributes to keratinocyte migration during re-epithelialization.
[0034] FIG. 15 shows an illustrative schematic of Smad 7 domains associated with protein partners, potential target effects, and potential physiological effects.
[0035] FIGS. 16A-B are graphs demonstrating the ability of truncated Smad7 proteins to accelerate wound healing in a mouse wound healing model. FIG. 16A is a graph showing the effect of C-terminally truncated (259-426aa) Tat-C-Smad7 on average percent wound healing over time relative to full-length Tat-Smad7 and control (PBS). n=3 for each group. FIG. 16B is a graph illustrating the effect of Tat-N-Smad7 (1-258aa) on average percent wound healing over time relative to full-length Tat-Smad7 and control (PBS). n=6 for each group. Data are presented as mean+s.d., and two-tail Student's t-test was used to calculate P values. *p<0.05 compared to control (PBS), # p<0.05 compared to Tat-Smad7.
[0036] FIGS. 17A-C are photographs and graphs demonstrating that Smad7 accelerates wound healing in an impaired wound-healing model. FIG. 17A is a digital photograph illustrating the gross appearance of wounds in diabetic (db/db) mice treated with PBS or Tat-Smad7 over a time period of thirteen days. FIG. 17B is a graph showing the effect of Tat-Smad7 on average percent wound healing over time relative to REGRANEX.RTM. and control (PBS). n=6 for each group. Data are presented as mean+s.d., and two-tail Student's t-test was used to calculate P values. *p<0.05 compared to control (PBS). FIG. 17C is a histological comparison of wound samples taken eight days after wounding. The vertical dotted lines in the image from the control (PBS) db/db mouse (top panel) highlight the wound boundary.
DETAILED DESCRIPTION
[0037] As further described herein, the disclosure provides Smad7 proteins and biologically active fragments and derivatives thereof, nucleic acids encoding such proteins, vectors including such nucleic acids, and cells encompassing the vectors, nucleic acids, and/or proteins all for use in formulating medicaments and for treating and/or preventing one or more diseases or disorders. Also provided are methods for making and for screening Smad7 proteins and biologically active fragments and derivatives thereof useful for treating and/or preventing one or more diseases or disorders. Also provided are methods for predicting and/or evaluating a response to treatment using one or more markers associated with exposure to Smad7. Such markers may include, but are not limited to, Rac1 for cell migration, NF-.kappa.B for inflammation, and TGF-.beta. for growth arrest and inflammation.
[0038] Smad7 treatable diseases and disorders may include those including one or more of reduced cell proliferation, reduced cell migration, increased cell death, excessive inflammation, and/or DNA damage. Smad7 treatable diseases and disorders may include those where treatment with a Smad7 protein and biologically active fragments and derivatives thereof that have one or more activities including but not limited to increasing proliferation, reducing or inhibiting cell death, reducing excessive inflammation, preventing DNA damage, and/or increasing cell migration. Such diseases and/or disorders may include but are not limited to acute (e.g., through surgery, combat, trauma) and chronic wounds (e.g., ulcers, such as diabetic, pressure, venous), scarring, fibrosis, and aberrant healing, mucositis (e.g., oral and/or gastro-intestinal), stomatitis, proctitis, autoimmune disease (e.g., psoriasis, arthritis), and cancer.
[0039] It is critical for oral mucositis prevention and treatment to overcome epithelial ablation due to massive apoptosis and blunted keratinocyte proliferation. The proliferative and anti-apoptotic effects of Smad7 are more obvious in oral mucositis than in normal oral mucosa, when TGF-.beta.1, a potent growth inhibitor and apoptosis inducer for epithelial cells, was increased.
[0040] Although not wishing to be bound by theory, it is believed that increased Rac1 activation is largely responsible for Smad7-mediated keratinocyte migration in wound closure. This finding was unexpected, given the documented role of TGF-.beta. signaling in Rho/Rac activation in cancer cells via a Smad-independent mechanism (Dernyck et al., Nature 415:577-584, 2003).
[0041] It is believed that during oral mucositis, Smad-dependent Rac1 repression overcomes Smad-independent Rac1 activation (if any) due to increased Smad signaling (evidenced by increased pSmad2) and Smad transcriptional co-repressor CtBP1. When this repression is abrogated by Smad7, it permits Rac1 activation-mediated keratinocyte migration. However, in oral cancer cells, signaling Smads are lost or inactivated, or other mechanisms independently activate Rac1. As a result, Smad7-mediated abrogation of Rac1 repression would no longer occur.
[0042] Although Rac1 activation also contributed to keratinocyte proliferation, knocking down Rac1 only partially attenuated the proliferative effect of Smad7. Therefore, Rac1's contribution to proliferation appears to be limited, and blocking TGF-.beta.1-induced growth arrest is also needed to overcome radiation-induced growth inhibitory effects.
[0043] Dampening excessive inflammation creates a microenvironment for oral mucositis healing. The antagonistic effect of Smad7 on both TGF-.beta. and NF-.kappa.B signaling makes Smad7 a more efficient anti-inflammatory molecule than other agents targeting only NF-.kappa.B. Because inflammatory cells produce cytokines that further activate TGF-.beta. and NF-.kappa.B, reduced TGF-.beta. and NF-.kappa.B signaling, found in K5.Smad7 or Tat-Smad7 treated oral mucosa after radiation, reflects the direct antagonistic effect of Smad7 on these two pathways and the consequence of reduced inflammatory cytokines from infiltrated leukocytes. However, Smad7 did not reduce NF-.kappa.B or TGF-.beta. signaling below their normal physiological conditions. This incomplete blockade of NF-.kappa.B or TGF-.beta. signaling may be beneficial to oral mucositis healing, as a complete loss of either pathway could induce excessive inflammation.
[0044] The primary obstacle to using growth factors to treat oral mucositis in cancer patients is the potential risk of promoting cancer cell growth. The majority of human oral cancers lose TGF-.beta. signaling in tumor epithelial cells. Thus, anti-Smad-associated cell proliferation and migration by Smad7 would not be effective in cancer cells. In tumors with intact TGF-.beta. signaling, activation of other oncogenic pathways could override TGF-.beta.-induced tumor suppressive effects. These two scenarios could explain why there was no observation of Smad7 increasing proliferation and migration in oral cancer cells with mutant or intact TGF-.beta. signaling components.
[0045] Additionally, TGF-.beta. signaling promotes tumor invasion mainly through Smad-independent mechanisms after loss of TGF-.beta.-induced tumor suppression. Thus, blocking TGF-.beta. signaling by Smad7 in cancer cells could abrogate TGF-.beta.-mediated tumor promotion effects, which behaves similarly to TGF-.beta. inhibitors currently being used in clinical trials for advanced cancers. Further, the potent anti-inflammatory effect of Smad7 may reduce the risk of tumor progression. Therefore, long-term Smad7 application may also be helpful in cancer treatment.
[0046] Spontaneous tumor formation in K5.Smad7 mice has not been observed. Because Smad7 is not a secreted protein, local and short-term Smad7 protein delivery in oral mucositis treatment should have few systemic effects. In bone marrow transplant patients, whose oral epithelia do not contain cancer cells, Smad7 topical application may be suitable for both prevention and treatment of oral mucositis.
[0047] Although not wishing to be bound by any theory, Smad7-mediated oral mucositis healing appears to be a result of targeting multiple pathogenic processes mediated by one or more molecules (see, e.g., FIGS. 14A-B). It is believed that one or more of these molecules (e.g., TGF-.beta., NF-.kappa.B, CtBP1, Rac1) may also be helpful as predictive and therapeutic responsive markers of oral mucositis in patients.
A. Nucleic Acids, Vectors and Host Cells
[0048] The present disclosure also provides, in another embodiment, genes encoding Smad7. In addition to the wild-type SMAD7 gene (SEQ ID NOs: 22, 88), as well as various codon-optimized versions (SEQ ID NOs: 9, 21, 23, 24, 26, 28, 30, 32-34, 36, 38, 39, 87, 89, 91, 93, 96, 97, 99, and 100), it should be clear that the present technology is not limited to the specific nucleic acids disclosed herein. As discussed below, a "Smad7 gene" may contain a variety of different bases and yet still produce a corresponding polypeptide that is functionally indistinguishable from, and in some cases structurally identical to, the human gene disclosed herein.
[0049] 1. Nucleic Acids Encoding Smad7
[0050] Nucleic acids according to the present technology may represent an entire Smad7 gene, a truncated portion, and/or a fragment of Smad7 that expresses a polypeptide with one or more activity associated with Smad7 such as but not limited to increasing proliferation, reducing or inhibiting cell death, reducing excessive inflammation, preventing DNA damage, and/or increasing cell migration, as well as treating or preventing one or more disease or disorders in which such treatment would be helpful as further discussed herein. Such activities can be assessed using one or more assays including, but not limited to, the ability to block phosphorylation of Smad2 and/or nuclear translocation of the NF-.kappa.B p50 subunit, increase cell proliferation, reduce apoptosis and/or radiation-induced DNA damage, reduce inflammation and/or angiogenesis, promote healing in oral mucositis, surgical wounds, diabetes wounds, and/or wounds associated with chronic inflammation in mice. The nucleic acid may be derived from genomic DNA, i.e., cloned directly from the genome of a particular organism. In particular embodiments, however, the nucleic acid would comprise complementary DNA (cDNA). Also provided is a cDNA plus a natural intron or an intron derived from another gene; such engineered molecules are sometime referred to as "mini-genes." At a minimum, these and other nucleic acids of the present technology may be used as molecular weight standards in, for example, gel electrophoresis.
[0051] The term "cDNA" is intended to refer to DNA prepared using messenger RNA (mRNA) as template. The advantage of using a cDNA, as opposed to genomic DNA or DNA polymerized from a genomic, non- or partially-processed RNA template, is that the cDNA primarily contains coding sequences of the corresponding protein. There may be times when the full or partial genomic sequence is preferred, such as where the non-coding regions are required for optimal expression or where non-coding regions such as introns are to be targeted in an antisense strategy.
[0052] As used in this application, the term "a nucleic acid encoding a Smad7" may refer to a nucleic acid molecule that has been isolated free of total cellular nucleic acid and/or may refer to a cDNA encoding a Smad7 polypeptide. As used herein, the term "isolated free of total cellular nucleic acid" means that the nucleic acid molecule is about or at least about 75% pure, 80% pure, 85% pure, 90% pure, 95% pure, 96% pure, 97% pure, 98% pure, 99% pure, or 100% pure of other cellular nucleic acid molecules as determined using standard biochemical techniques, such as but not limited to agarose gel electrophoresis. As used herein, the term "isolated free of total cellular protein" means that the protein molecule is about or at least about 75% pure, 80% pure, 85% pure, 90% pure, 95% pure, 96% pure, 97% pure, 98% pure, 99% pure, or 100% pure of other cellular nucleic acid molecules as determined using standard biochemical techniques, such as but not limited to a western blot. In certain embodiments, the present technology concerns a nucleic acid sequence essentially as set forth in, and/or including any one of SEQ ID NOs: 9, 21, 23, 24, 26, 28, 30, 32-34, 36, 38, 39, 87, 89, 91, 93, 96, 97, 99, and 100.
[0053] An isolated nucleic acid molecule may be produced using recombinant DNA technology (e.g., polymerase chain reaction (PCR) amplification, cloning) or chemical synthesis. Isolated nucleic acid molecules include natural nucleic acid molecules and homologues thereof, including, but not limited to, natural allelic variants and modified nucleic acid molecules in which nucleotides have been inserted, deleted, substituted, and/or inverted in such a manner that such modifications provide the desired effect (e.g., production of Smad7 protein in non-human expression systems).
[0054] The term "essentially as set forth in one or more nucleic acid sequence (e.g., SEQ ID NOs: 9-11, 21, 23-41" means that the nucleic acid sequence substantially corresponds to at least a portion, and in some cases the entirety, of the one or more nucleic acid sequence (e.g., SEQ ID NOs: 9, 21, 23, 24, 26, 28, 30, 32-34, 36, 38, 39, 87, 89, 91, 93, 96, 97, 99, and 100). In some embodiments, sequences that substantially correspond to at least a portion of a nucleic acid sequence, may correspond to about, or at least about 50 nucleic acids, 75 nucleic acids, 150 nucleic acids, 200 nucleic acids, 250 nucleic acids, 300 nucleic acids, 350 nucleic acids, 400 nucleic acids, 450 nucleic acids, 500 nucleic acids, 550 nucleic acids, 600 nucleic acids, 650 nucleic acids, 700 nucleic acids, 750 nucleic acids, 800 nucleic acids, 900 nucleic acids, 1000 nucleic acids, 1100 nucleic acids, 1200 nucleic acids, or 1250 nucleic acids of one or more of the sequences described herein. In some embodiments, sequences that substantially correspond to at least a portion of a nucleic acid sequence, may correspond to about a range of about 50-1250 nucleic acids, 75-1250 nucleic acids, 150-1250 nucleic acids, 200-1250 nucleic acids, 250-1250 nucleic acids, 300-1250 nucleic acids, 350-1250 nucleic acids, 400-1250 nucleic acids, 450-1250 nucleic acids, 500-1250 nucleic acids, 550-1250 nucleic acids, 600-1250 nucleic acids, 650-1250 nucleic acids, 700-1250 nucleic acids, 750-1250 nucleic acids, 800-1250 nucleic acids, 900-1250 nucleic acids, 1000-1250 nucleic acids, 1100-1250 nucleic acids, 1200-1250 nucleic acids, at least about 50-75 nucleic acids, 75-150 nucleic acids, 75-200 nucleic acids, 75-250 nucleic acids, 75-300 nucleic acids, 75-350 nucleic acids, 75-400 nucleic acids, 75-450 nucleic acids, 75-500 nucleic acids, 75-550 nucleic acids, 75-600 nucleic acids, 75-650 nucleic acids, 75-700 nucleic acids, 75-750 nucleic acids, 75-800 nucleic acids, 75-900 nucleic acids, 75-1000 nucleic acids, 75-1100 nucleic acids, 75-1200 nucleic acids, or 75-1250 nucleic acids or 1250 nucleic acids of one or more of the sequences described herein.
[0055] In some embodiments, sequences that substantially correspond to at least a portion of a nucleic acid sequence include identical sequences to that portion of the nucleic acid sequence. In some embodiments, sequences that substantially correspond to at least a portion of a nucleic acid sequence or the entirety of a nucleic acid sequence may include one or more functionally equivalent codons. The term "functionally equivalent codon" is used herein to refer to one or more codons that encode the same amino acid, such as the six codons for arginine or serine, and in some embodiments refers to codons that encode biologically equivalent amino acids, as discussed in the following pages. The term "biologically equivalent" amino acid is used herein to refer to one or more amino acids that when changed from the amino acid present in the amino acid sequence of human Smad7 wild-type protein, do not change one or more (or in some embodiments any) of the biological activities of Smad7 described herein, such as but not limited to, increasing proliferation, reducing or inhibiting cell death, reducing excessive inflammation, preventing DNA damage, and/or increasing cell migration, as well as treating or preventing one or more disease or disorders in which such treatment would be helpful as further discussed herein.
[0056] In some embodiments, allowing for the degeneracy of the genetic code, sequences that have about or at least about 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, and/or 99% of nucleotides that are identical to the nucleotides of any one of the codon-optimized nucleic acid sequences (e.g., SEQ ID NOs: 9-11, 21, 23-41) may be considered substantially corresponding nucleic acid sequences. Sequences that are essentially the same as those set forth in any one of the nucleic acid sequences (e.g., SEQ ID NOs: 9-11, 21, 23-41) also may be functionally defined as sequences that are capable of hybridizing to a nucleic acid segment containing the complement of SEQ ID NOs: 9-11, 21, 23-41 under various standard conditions.
[0057] For applications requiring high selectivity, one will typically desire to employ relatively high stringency conditions to form the hybrids. For example, relatively low salt and/or high temperature conditions, such as provided by about 0.02 M to about 0.10 M NaCl at temperatures of about 50.degree. C. to about 70.degree. C. Such high stringency conditions tolerate little, if any, mismatch between the probe or primers and the template or target strand and would be particularly suitable for isolating specific genes or for detecting specific mRNA transcripts. It is generally appreciated that conditions can be rendered more stringent by the addition of increasing amounts of formamide.
[0058] For certain applications it is appreciated that lower stringency conditions are preferred. Under these conditions, hybridization may occur even though the sequences of the hybridizing strands are not perfectly complementary, but are mismatched at one or more positions. Conditions may be rendered less stringent by increasing salt concentration and/or decreasing temperature. For example, a medium stringency condition could be provided by about 0.1 to 0.25 M NaCl at temperatures of about 37.degree. C. to about 55.degree. C., while a low stringency condition could be provided by about 0.15 M to about 0.9 M salt, at temperatures ranging from about 20.degree. C. to about 55.degree. C. Hybridization conditions can be readily manipulated depending on the desired results.
[0059] In other embodiments, hybridization may be achieved under conditions of, for example, 50 mM Tris-HCl (pH 8.3), 75 mM KCl, 3 mM MgCl.sub.2, 1.0 mM dithiothreitol, at temperatures between approximately 20.degree. C. to about 37.degree. C. Other hybridization conditions utilized could include approximately 10 mM Tris-HCl (pH 8.3), 50 mM KCl, 1.5 mM MgCl.sub.2, at temperatures ranging from approximately 40.degree. C. to about 72.degree. C.
[0060] To determine the percent homology of two amino acid sequences or of two nucleic acids, the sequences are aligned for optimal comparison purposes (e.g., gaps are introduced in the sequence of a first amino acid or nucleic acid sequence for optimal alignment with a second amino acid or nucleic acid sequence). The amino acid residues or nucleotides at corresponding amino acid positions or nucleotide positions can then be compared. When a position in the first sequence is occupied by the same amino acid residue or nucleotide as the corresponding position in the second sequence, then the molecules are identical at that position. The percent homology between the two sequences is a function of the number of identical positions shared by the sequences (% identity=# of identical positions/total # of positions (e.g., overlapping positions).times.100). In some embodiments the two sequences are the same length.
[0061] To determine percent homology between two sequences, the algorithm of Karlin and Altschul (1990) Proc. Natl. Acad. Sci. USA 87:2264-2268, modified as in Karlin and Altschul (1993) Proc. Natl. Acad. Sci. USA 90:5873-5877 can be used. Such an algorithm is incorporated into the NBLAST and XBLAST programs of Altschul et al. (1990) J. Mol Biol. 215:403-410. BLAST nucleotide searches is performed with the NBLAST program, score=100, wordlength=12 to obtain nucleotide sequences homologous to a nucleic acid molecules described or disclose herein. BLAST protein searches is performed with the XBLAST program, score=50, wordlength=3. To obtain gapped alignments for comparison purposes, Gapped BLAST may be utilized as described in Altschul et al. (1997) Nucleic Acids Res. 25:3389-3402. When utilizing BLAST and Gapped BLAST programs, the default parameters of the respective programs (for example, XBLAST and NBLAST) are used. See the website of the National Center for Biotechnology Information for further details (on the World Wide Web at ncbi.nlm.nih.gov). Proteins suitable for use in the methods described herein also includes proteins having between 1 to 15 amino acid changes, for example, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, or 15 amino acid substitutions, deletions, or additions, compared to the amino acid sequence of any protein described herein. In other embodiments, the altered amino acid sequence is at least 75% identical, for example, 77%, 80%, 82%, 85%, 88%, 90%, 92%, 95%, 97%, 98%, 99%, or 100% identical to the amino acid sequence of any protein inhibitor described herein. Such sequence-variant proteins are suitable for the methods described herein as long as the altered amino acid sequence retains sufficient biological activity to be functional in the compositions and methods described herein. In certain instances conservative amino acid substitutions are utilized. Illustrative conservative substitution among amino acids are within each of the following groups: (1) glycine, alanine, valine, leucine, and isoleucine, (2) phenylalanine, tyrosine, and tryptophan, (3) serine and threonine, (4) aspartate and glutamate, (5) glutamine and asparagine, and (6) lysine, arginine and histidine. The BLOSUM62 table is an amino acid substitution matrix derived from about 2,000 local multiple alignments of protein sequence segments, representing highly conserved regions of more than 500 groups of related proteins (Henikoff et al. (1992), Proc. Natl Acad. Sci. USA, 89:10915-10919). The BLOSUM62 substitution frequencies can be used to define conservative amino acid substitutions that, in some embodiments, are introduced into the amino acid sequences described or disclosed herein. Although it is possible to design amino acid substitutions based solely upon chemical properties (as discussed above), the language "conservative amino acid substitution" preferably refers to a substitution represented by a BLOSUM62 value of greater than -1. For example, an amino acid substitution is conservative if the substitution is characterized by a BLOSUM62 value of 0, 1, 2, or 3. According to this system, preferred conservative amino acid substitutions are characterized by a BLOSUM62 value of at least 1 (e.g., 1, 2 or 3), while more preferred conservative amino acid substitutions are characterized by a BLOSUM62 value of at least 2 (e.g., 2 or 3).
[0062] The DNA segments of the present technology include those encoding biologically functional equivalent Smad7 proteins and peptides, as described above. Such sequences may arise as a consequence of codon redundancy and amino acid functional equivalency that are known to occur naturally within nucleic acid sequences and the proteins thus encoded. Alternatively, functionally equivalent proteins or peptides may be created via the application of recombinant DNA technology, in which changes in the protein structure may be engineered, based on considerations of the properties of the amino acids being exchanged. Changes designed by man may be introduced through the application of site-directed mutagenesis techniques or may be introduced randomly and screened later for the desired function, as described elsewhere.
[0063] As described in greater detail below, the Smad7 nucleic acid sequence has been optimized for expression in alternative host organisms (e.g., non-human). Although as described above, the genetic code is degenerate, so frequently one amino acid may be coded for by two or more nucleotide codons. Thus, multiple nucleic acid sequences may encode one amino acid sequence. Although this creates identical proteins, the nucleic acids themselves are distinct, and can have distinct properties. As described herein, one aspect of the choice of codon usage can be (but is not limited to) the ability to express a protein in a non-native cells (e.g., a human protein in bacteria or yeast), or the level of expression in such cells. In order to obtain enough protein for purification, testing, and use in in vitro assays, in animal models, and eventually in clinical development, efficient protein expression in non-human systems is needed.
[0064] A series of 23 arginine amino acids in the human Smad7 protein sequence coded for by one or more of AGG (1.7% codon utilization; 9 residues), AGA (2.8% codon utilization; 2 residues), CGA (3.5% codon utilization; 4 residues), or CGG (5.4% codon utilization; 8 residues) has been identified, and it has been determined that in order to have efficient protein expression from non-human sources, such as, but not limited to, bacteria and/or yeast that one or more, and potentially all the arginine codons should be modified to CGT (20.6% codon utilization). Therefore, in some embodiments, the Smad7 codon-optimized nucleic acid sequence includes at least 1, at least 2, at least 3, at least 4, at least 5, at least 6, at least 7, at least 8, at least 9, at least 10, at least 11, at least 12, at least 13, at least 14, at least 15, at least 16, at least 17, at least 18, at least 19, at least 20, at least 21, at least 22, or 23 codons for arginine that have been changed to CGT. In some embodiments, the Smad7 codon-optimized nucleic acid sequence includes one or more or all of the arginine codons at nucleic acid sequence positions 7-9, 43-45, 169-171, 403-405, 490-492, 526-528, 526-528, 823-825, 1057-1059, 16-18, 136-138, 199-201, 598-600, 31-33, 112-114, 316-318, 772-774, 940-942, 973-975, 1135-1137, 1276-1278, 637-639, or 814-816 be changed to CGT.
[0065] A series of 33 serine residues in the human Smad7 protein sequence coded for by TCC or TCG (9%) has been identified, and it has been determined that it may be beneficial to efficient protein expression and purification from non-human sources, such as, but not limited to, bacteria and/or yeast, that one or more, and potentially all the serine codons be modified to AGC (15% codon utilization). Therefore, in some embodiments, the Smad7 codon-optimized nucleic acid sequence includes at least 1, at least 2, at least 3, at least 4, at least 5, at least 6, at least 7, at least 8, at least 9, at least 10, at least 11, at least 12, at least 13, at least 14, at least 15, at least 16, at least 17, at least 18, at least 19, at least 20, at least 21, at least 22, at least 23, at least 24, at least 25, at least 26, at least 27, at least 28, at least 29, at least 30, at least 31, at least 32 or 33 codons for serine that have been changed to (AGC). In some embodiments, the Smad7 codon-optimized nucleic acid sequence includes one or more or all of the serine codons at nucleic acid sequence positions 19-21, 46-48, 133-135, 292-294, 349-351, 451-453, 454-456, 460-462, 511-513, 514-516, 544-546, 595-597, 616-618, 634-636, 691-693, 694-696, 739-741, 745-747, 775-777, 847-849, 907-909, 919-921, 943-945, 1006-1008, 1009-1101, 1030-1032, 1054-1056, 1093-1095, 1126-1128, 1192-1194, 1237-1239, 1240-1242, 1273-1275. Of these, 23 codons (19-21, 292-294, 349-351, 451-453, 454-456, 460-462, 511-513, 514-516, 544-546, 616-618, 634-636, 691-693, 694-696, 739-741, 745-747, 775-777, 847-849, 907-909, 919-921, 1009-1101, 1030-1032, 1054-1056, 1093-1095) can be changed without introducing potential alternative open reading frames.
[0066] A series of 12 histidine residues in the human Smad7 protein sequence coded for by CAC (9.6% codon usage) has also been identified, and it has been determined that it may be beneficial to efficient protein expression and purification from non-human sources, such as but not limited to bacteria and/or yeast, that one or more, and potentially all the serine codons be modified to CAT (optionally to 12.6% usage). Therefore, in some embodiments, the Smad7 codon-optimized nucleic acid sequence includes at least 1, at least 2, at least 3, at least 4, at least 5, at least 6, at least 7, at least 8, at least 9, at least 10, at least 11, or 12 codons for histidine that have been changed to (CAT). In some embodiments, the Smad7 codon-optimized nucleic acid sequence includes one or more or all of the serine codons at nucleic acid sequence positions 142-144, 214-216, 217-219, 220-222, 226-228, 289-291, 589-591, 778-780, 1072-1074, 1147-1149. Of these, 4 codons (nucleotides 217-219, 220-222, 589-591, 778-780) can be changed without introducing potential alternative open reading frames.
[0067] In some embodiments, one or more codon-optimized nucleic acids may include one or more of at least one and any integer up to 22 of its arginine codons modified to CGT, at least one and any integer up to 28 of its serine codons (optionally that are able to be modified with introducing open reading frames) modified to AGC, or at least one and any integer up to 12 of its histidine codons (optionally that are able to be modified with introducing open reading frames) modified to CAT. In some embodiments, one or more codon-optimized nucleic acid may include at least one and any integer up to 22 of its arginine codons modified to CGT, at least one and any integer up to 28 of its serine codons (optionally that are able to be modified with introducing open reading frames) modified to AGC, and at least one and any integer up to 12 (optionally that are able to be modified with introducing open reading frames) of its histidine codons modified to CAT. In some embodiments, one or more codon-optimized nucleic acid may include 22 of its arginine codons modified to CGT, 28 of its serine codons (optionally that are able to be modified with introducing open reading frames) modified to AGC, and 12 of its histidine codons (optionally that are able to be modified with introducing open reading frames) modified to CAT. In some embodiments, one or more codon-optimized nucleic acid may also have a nucleotide substitution in the codon for Met216 (ATG), to form the codon for Leu216 (CTG).
[0068] In some embodiments, one or more codon-optimized nucleic acids may have about 65% to 75%, about 65% to 68%, about 68% to 75%, or about 68% to 71% homology to human Smad7 wild-type cDNA (SEQ ID NOs: 22, 88). In some embodiments, one or more codon-optimized nucleic acid may have about 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, or 75%, homology to human Smad7 wild-type cDNA (SEQ ID NOs: 12, 22). In some embodiments, one or more codon-optimized nucleic acid may also have a nucleotide substitution in the codon for Met216 (ATG), to form the codon for Leu216 (CTG).
[0069] A methionine codon (Met216; ATG) that has the potential for being perceived by translation machinery (e.g., such as but not limited bacteria or yeast) as an alternative open reading frame has been identified. Although not intending to be bound by theory, it is believed that the presence of the second potential open reading frame may decrease expression of the Smad7 protein. In some embodiments, one or more Smad7 nucleic acid sequences are modified at nucleotide position (646-648) to encode a human Smad7 protein where Met216 (ATG) is modified to Leu216 (CTG).
[0070] It has also been discovered that various truncated forms and fragments of Smad7 protein retain one or more of the activities of full-length human Smad7, such as, but not limited to, increasing proliferation, reducing or inhibiting cell death, reducing excessive inflammation, preventing DNA damage, and/or increasing cell migration, as well as treating or preventing one or more disease or disorders in which such treatment would be helpful as further discussed herein. Such activities can be assessed using one or more assays including, but not limited to, the ability to block phosphorylation of Smad2 and/or nuclear translocation of the NF-.kappa.B p50 subunit, increase cell proliferation, reduce apoptosis and/or radiation-induced DNA damage, reduce inflammation and/or angiogenesis, promote healing in oral mucositis, surgical wounds, diabetes wounds, and/or wounds associated with chronic inflammation in mice.
[0071] Further, in some embodiments, various truncated forms and fragments of Smad7 protein retain only a subset of the one or more of the activities of full-length human Smad7. For example, the C-terminal MH2 domain of Smad7 may primarily mediate the anti-inflammatory effect of Smad7. Smad7 peptides having this anti-inflammatory function may be sufficient and optionally an improvement for treating chronic inflammation associated conditions, such as but not limited to, oral mucositis, stomatitis, arthritis, and psoriasis, among others. The N-terminal MH1 domain may primarily mediate cell migration and/or blocking TGF-.beta.-induced growth arrest and/or fibrotic response. Smad7 peptides having this cell migration and proliferation function may be sufficient, and optionally an improvement, for enhancing healing that is not associated with excessive inflammation. Types of wounds that might benefit from this form of treatment include, but are not limited to, surgical wounds, fibrotic scarring, and diabetes wounds, defective healing and/or scarring among others.
[0072] In some embodiments, nucleic acid molecules (optionally codon-optimized nucleic acid molecules as described above and herein) encode fragments or truncated forms of Smad7 protein (optionally including Leu216). In some embodiments, these fragments and/or truncated forms of Smad7 protein retain one or more or all of the activities of full-length human Smad7 protein. In some embodiments, such truncated nucleic acid sequences encode the N-terminal portion of the Smad7 protein. In some embodiments, such truncated nucleic acid sequences encode the C-terminal portion of the Smad7 protein. In some embodiments, such truncated nucleic acid sequences (nucleotide positions 4-774) encode amino acids 2-258 of the human Smad7 protein. In some embodiments, such truncated nucleic acid sequences (nucleotide positions 775-1278) encode amino acids 259-426 of the human Smad7 protein. In some embodiments, such fragments of the nucleic acid sequences (nucleotide positions 607-774) encode amino acids 203-258 of the human Smad7 protein.
[0073] The term "truncated" as used herein in reference to nucleic acid molecules refers to a molecule that contains nucleotide sequences encoding the natural N-terminus of a corresponding protein (with or without a cleaved leader sequence), but lacks one or more nucleotides starting from the C-terminus-encoding portion of the molecule, or a molecule that contains nucleotide sequences encoding the natural C-terminus of a corresponding protein (with or without a cleaved leader sequence), but lacks one or more nucleotides starting from the N-terminus-encoding portion of the molecule. In some embodiments, molecules lacking nucleotides encoding at least about 25, at least about 50, at least about 75, at least about 100, at least about 125, at least about 150, at least about 200, at least about 250, at least about 300, or at least about 350, or at least about 400 amino acids from one or the other terminus are specifically provided. Similarly, the term "truncated" may also be used in reference to protein molecules encoded by truncated nucleic acid molecules. In some embodiments, a "truncated" molecule is biologically active, having (or encoding a polypeptide having) one or more of the Smad7 activities described herein.
[0074] The term "fragment" as used herein in reference to nucleic acid molecules refers to a molecule containing contiguous residues of a full length sequence but lacking some 5' and/or 3' sequences of the full length sequence. In some embodiments, a "fragment" includes a portion of one or more of the full length sequences described herein. In some embodiments, the "fragment" does not include sequences encoding either the N-terminal or the C-terminal, but only internal fragments. In some embodiments, a "fragment" encodes a polypeptide that is biologically active, having one or more of the Smad7 activities described herein. In some embodiments, nucleic acid fragments may encode proteins having at least about 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550, 600, 650, 700, 750, 800, 850, 900, 950, 1000, 1050, 1100, 1150 amino acids. Similarly, "fragment" may also be used in reference to protein molecules encoded by Smad7 nucleic acid fragments.
[0075] The term "N-terminal portion" as used herein in refers to a fragment of a corresponding protein that contains the protein's N-terminus but lacks all sequences C-terminal to an internal residue.
[0076] The term "C-terminal portion" as used herein in refers to a fragment of a corresponding protein that contains the protein's C-terminus but lacks all sequences N-terminal to an internal residue.
[0077] Although not intending to be bound by theory, the Smad7 protein activity is generally believed to be the result of interactions in both the cytoplasm and nucleus of a cell. For that reason among others, there existed a general belief that Smad7 protein was not a candidate for a therapeutic role. However, it was decided to pursue development of Smad7 as a protein therapeutic, and modify the Smad7 nucleic acid sequence to encode a protein transduction domain (PTD) in frame with the Smad7 nucleic acid sequence (e.g., optionally any nucleic acid sequence described herein encoding Smad7 protein, including human wild-type and codon-optimized sequences, both full-length and biologically active fragments or truncated portions). In some embodiments, the PTD is located at the 3' end of the Smad7 nucleic acid sequence, and in some embodiments the PTD is located at the 5' end of the Smad7 nucleic acid sequence. In some embodiments, there is a linker sequence encoding 1, 2, 3, 4, 5, or 6 amino acids that connects the PTD and the Smad7 nucleic acid sequence.
[0078] In some embodiments, the PTD nucleic acid sequence is a Tat nucleic acid sequence. ggccgtaaaaaacgccgtcaacgccgccgt (SEQ ID NO: 1) encoding GRKKRRQRRR (SEQ ID NO: 2), tatggccgtaaaaaacgccgtcaacgccgccgt (SEQ ID NO: 3) encoding YGRKKRRQRRR (SEQ ID NO: 4), or ggccgtaaaaaacgccgtcaa (SEQ ID NO: 5) encoding GRKKRRQ (SEQ ID NO: 6).
[0079] In some embodiments, the nucleic acid sequence further includes a nucleotide sequence encoding one or more of an epitope tag or a purification tag. In some embodiments, the epitope tag is V5. In some embodiments, the purification tag is one or more of glutathione-S-Transferase (GST) or 6-histidine (H6) (SEQ ID NO: 40).
[0080] The term "epitope tag" as used herein in reference to nucleic acid molecules refers to nucleotides encoding peptide sequences that are recognized and bound by the variable region of an antibody or fragment. In some embodiments, the epitope tag is not part of the native protein. In some embodiments, the epitope tag is removable. In some embodiments, the epitope tag is not intrinsic to the protein's native biological activity. Examples of epitope tags include, but are not limited to V5.
[0081] The term "purification tag" as used herein in reference to nucleic acid molecules refers to nucleotides encoding peptide sequences that facilitate the purification of the protein, but are generally not necessary for the protein's biological activity. In some embodiments, purification tags may be removed following protein purification. Examples of purification tags include, but are not limited to GST and H-6 (SEQ ID NO: 40).
[0082] 2. Vectors for Cloning, Gene Transfer and Expression
[0083] Within certain embodiments, expression vectors are employed to express the Smad7 polypeptide product, which can then be purified for various uses. In other embodiments, the expression vectors are used in gene therapy. Expression requires that appropriate signals be provided in the vectors, and which include various regulatory elements, such as enhancers/promoters from both viral and mammalian sources that drive expression of the genes of interest in host cells. Elements designed to optimize messenger RNA stability and translatability in host cells also are defined. The conditions for the use of a number of dominant drug selection markers for establishing permanent, stable cell clones expressing the products are also provided, as is an element that links expression of the drug selection markers to expression of the polypeptide.
[0084] Throughout this application, the term "expression construct" is meant to include any type of genetic construct containing a nucleic acid coding for a gene product in which part or all of the nucleic acid encoding sequence is capable of being transcribed. The transcript may be translated into a protein, but it need not be. In certain embodiments, expression includes both transcription of a gene and translation of mRNA into a gene product. In other embodiments, expression only includes transcription of the nucleic acid encoding a gene of interest.
[0085] The term "vector" is used to refer to a carrier nucleic acid molecule into which a nucleic acid sequence can be inserted for introduction into a cell where it can be replicated. A nucleic acid sequence can be "exogenous," which means that it is foreign to the cell into which the vector is being introduced or that the sequence is homologous to a sequence in the cell but in a position within the host cell nucleic acid in which the sequence is ordinarily not found. Vectors include plasmids, cosmids, viruses (bacteriophage, animal viruses, and plant viruses), and artificial chromosomes (e.g., YACs). One of skill in the art would be well-equipped to construct a vector through standard recombinant techniques, which are described, e.g., in Sambrook, et al., Molecular Cloning (Cold Spring Harbor Lab Press, 1989), and Ausubel, et al., Current Protocols in Molecular Biology (Wiley, 1994), both incorporated herein by reference.
[0086] The term "expression vector" refers to a vector containing a nucleic acid sequence coding for at least part of a gene product capable of being transcribed. In some cases, RNA molecules are then translated into a protein, polypeptide, or peptide. In other cases, these sequences are not translated, for example, in the production of antisense molecules or ribozymes. Expression vectors can contain a variety of "control sequences," which refer to nucleic acid sequences necessary for the transcription and possibly translation of an operably linked coding sequence in a particular host organism, including promoters and enhancers. In addition to control sequences that govern transcription and translation, vectors and expression vectors may contain nucleic acid sequences that serve other functions, such as transcription termination signals and poly-adenylation sites.
[0087] The capacity of certain viral vectors to efficiently infect or enter cells, to integrate into a host cell genome and stably express viral genes, have led to the development and application of a number of different viral vector systems. Robbins, et al., Pharmacol. Ther. 80:35-47 (1998). Viral systems are currently used as vectors for ex vivo and in vivo gene transfer. For example, adenovirus, herpes-simplex virus, lentiviruses, retrovirus and adeno-associated virus vectors are being evaluated currently for treatment of diseases such as cancer, cystic fibrosis, Gaucher disease, renal disease and arthritis. Robbins, et al., Pharmacol. Ther. 80:35-47 (1998); Imai, et al., Nephrologie 19:379-402 (1998); U.S. Pat. No. 5,670,488. The various viral vectors present specific advantages and disadvantages, depending on the particular gene-therapeutic application.
[0088] Suitable non-viral methods for nucleic acid delivery for transformation of an organelle, a cell, a tissue or an organism for use with the present technology are believed to include virtually any method by which a nucleic acid (e.g., DNA) can be introduced into an organelle, a cell, a tissue or an organism, as described herein or as would be known to one of ordinary skill in the art. Such methods include, but are not limited to, direct delivery of DNA such as by injection (U.S. Pat. Nos. 5,994,624, 5,981,274, 5,945,100, 5,780,448, 5,736,524, 5,702,932, 5,656,610, 5,589,466 and 5,580,859, each incorporated herein by reference), including microinjection (Harland and Weintraub, 1985; U.S. Pat. No. 5,789,215, incorporated herein by reference); by electroporation (U.S. Pat. No. 5,384,253, incorporated herein by reference); by calcium phosphate precipitation (Graham, et al., Virology 52:456-467 (1973); Chen, et al., Mol. Cell Biol. 7:2745-2752 (1987); Rippe, et al., Mol. Cell Biol. 10:689-695 (1990)); by using DEAE-dextran followed by polyethylene glycol (Gopal, Mol. Cell Biol. 5:1188-1190 (1985)); by direct sonic loading (Fechheimer, et al., PNAS 84:8463-8467 (1987)); by liposome mediated transfection (Nicolau, et al., Biochim. Biophys. Acta 721:185-190 (1982); Fraley, et al., PNAS 76:3348-3352 (1979); Nicolau, et al., Methods Enzymol. 149: 157-176 (1987); Wong, et al., Gene 10:87-94 (1980); Kaneda, et al., J. Biol. Chem. 264:12126-12129 (1989); Kato, et al., J. Biol. Chem. 266:3361-3364 (1991)); by microprojectile bombardment (PCT Application Nos. WO 94/09699 and 95/06128; U.S. Pat. Nos. 5,610,042; 5,322,783, 5,563,055, 5,550,318, 5,538,877 and 5,538,880, and each incorporated herein by reference); by agitation with silicon carbide fibers (Kaeppler, et al., Plant Cell Rep. 9:415-418 (1990); U.S. Pat. Nos. 5,302,523 and 5,464,765, each incorporated herein by reference); or by PEG-mediated transformation of protoplasts (Omirulleh, et al., Plant Mol. Biol. 21:415-428 (1993); U.S. Pat. Nos. 4,684,611 and 4,952,500, each incorporated herein by reference); by desiccation/inhibition-mediated DNA uptake (Potrykus, et al., Mol. Gen. Genet. 199:169-177 (1985)). Through the application of techniques such as these, organelle(s), cell(s), tissue(s) or organism(s) may be stably or transiently transformed.
[0089] 3. Expression Systems
[0090] Numerous expression systems exist that comprise at least a part or all of the compositions discussed above. Prokaryote- and/or eukaryote-based systems can be employed for use with the present technology to produce nucleic acid sequences, or their cognate polypeptides, proteins and peptides. Many such systems are commercially and widely available.
[0091] The insect cell/baculovirus system can produce a high level of protein expression of a heterologous nucleic acid segment, such as described in U.S. Pat. Nos. 5,871,986 and 4,879,236, both herein incorporated by reference, and which can be bought, for example, under the name MAXBAC.RTM. 2.0 from INVITROGEN.RTM. and BACPACK.TM. BACULOVIRUS EXPRESSION SYSTEM FROM CLONTECH.RTM..
[0092] Other examples of expression systems include STRATAGENE.RTM.'s COMPLETE CONTROL.TM. Inducible Mammalian Expression System, which involves a synthetic ecdysone-inducible receptor, or its pET Expression System, an E. coli expression system. Another example of an inducible expression system is available from INVITROGEN.RTM., which carries the T-REX.TM. (tetracycline-regulated expression) System, an inducible mammalian expression system that uses the full-length CMV promoter. INVITROGEN.RTM. also provides a yeast expression system called the Pichia methanolica Expression System, which is designed for high-level production of recombinant proteins in the methylotrophic yeast Pichia methanolica. One of skill in the art would know how to express a vector, such as an expression construct, to produce a nucleic acid sequence or its cognate polypeptide, protein, or peptide.
[0093] Primary mammalian cell cultures may be prepared in various ways. In order for the cells to be kept viable while in vitro and in contact with the expression construct, it is necessary to ensure that the cells maintain contact with the correct ratio of oxygen and carbon dioxide and nutrients but are protected from microbial contamination. Cell culture techniques are well documented.
[0094] One embodiment of the foregoing involves the use of gene transfer to immortalize cells for the production of proteins. The gene for the protein of interest may be transferred as described above into appropriate host cells followed by culture of cells under the appropriate conditions. The gene for virtually any polypeptide may be employed in this manner. The generation of recombinant expression vectors, and the elements included therein, are discussed above. Alternatively, the protein to be produced may be an endogenous protein normally synthesized by the cell in question.
[0095] Examples of useful mammalian host cell lines are Vero and HeLa cells and cell lines of Chinese hamster ovary, W138, BHK, COS-7, 293, HepG2, NIH3T3, RIN and MDCK cells. In addition, a host cell strain may be chosen that modulates the expression of the inserted sequences, or modifies and process the gene product in the manner desired. Such modifications (e.g., glycosylation) and processing (e.g., cleavage) of protein products may be important for the function of the protein. Different host cells have characteristic and specific mechanisms for the post-translational processing and modification of proteins. Appropriate cell lines or host systems can be chosen to insure the correct modification and processing of the foreign protein expressed.
[0096] A number of selection systems may be used including, but not limited to, HSV thymidine kinase, hypoxanthine-guanine phosphoribosyltransferase and adenine phosphoribosyltransferase genes, in tk-, hgprt- or aprt-cells, respectively. Also, anti-metabolite resistance can be used as the basis of selection for dhfr, that confers resistance to; gpt, that confers resistance to mycophenolic acid; neo, that confers resistance to the aminoglycoside G418; and hygro, that confers resistance to hygromycin.
[0097] As used herein, the terms "cell," "cell line," and "cell culture" may be used interchangeably. All of these terms also include their progeny, which are any and all subsequent generations. It is understood that all progeny may not be identical due to deliberate or inadvertent mutations. In the context of expressing a heterologous nucleic acid sequence, "host cell" refers to a prokaryotic or eukaryotic cell, and it includes any transformable organism that is capable of replicating a vector and/or expressing a heterologous gene encoded by a vector. A host cell can, and has been, used as a recipient for vectors. A host cell may be "transfected" or "transformed," which refers to a process by which exogenous nucleic acid is transferred or introduced into the host cell. A transformed cell includes the primary subject cell and its progeny.
[0098] Host cells may be derived from prokaryotes or eukaryotes (e.g., bacteria or yeast), depending upon whether the desired result is replication of the vector or expression of part or all of the vector-encoded nucleic acid sequences. Numerous cell lines and cultures are available for use as a host cell, and they can be obtained through the American Type Culture Collection (ATCC), which is an organization that serves as an archive for living cultures and genetic materials (atcc.org). An appropriate host can be determined by one of skill in the art based on the vector backbone and the desired result. A plasmid or cosmid, for example, can be introduced into a prokaryote host cell for replication of many vectors. Bacterial cells used as host cells for vector replication and/or expression include DH5.alpha., JM109, and KC8, as well as a number of commercially available bacterial hosts such as SURE.RTM. Competent Cells and SOLOPACK.TM. Gold Cells (STRATAGENE.RTM., La Jolla). Alternatively, bacterial cells such as E. coli LE392 could be used as host cells for phage viruses.
[0099] Examples of eukaryotic host cells for replication and/or expression of a vector include HeLa, NIH3T3, Jurkat, 293, Cos, CHO, Saos, and PC12. Many host cells from various cell types and organisms are available and would be known to one of skill in the art. Similarly, a viral vector may be used in conjunction with either a eukaryotic or prokaryotic host cell, particularly one that is permissive for replication or expression of the vector.
[0100] Some vectors may employ control sequences that allow it to be replicated and/or expressed in both prokaryotic and eukaryotic cells. One of skill in the art would further understand the conditions under which to incubate all of the above described host cells to maintain them and to permit replication of a vector. Also understood and known are techniques and conditions that would allow large-scale production of vectors, as well as production of the nucleic acids encoded by vectors and their cognate polypeptides, proteins, or peptides.
B. Smad7 Proteins and Protein Fragments
[0101] Mothers against decapentaplegic homolog 7 (Smad7) was previously identified as an antagonist of TGF-.beta. signaling by several mechanisms including: (a) blockade of TGF-.beta. receptor-mediated phosphorylation and nuclear translocation of signaling Smads; (b) increased degradation of TGF-.beta. receptors and signaling Smads through specific ubiquitin-proteasome pathways and (c) inhibition of signaling Smads for their binding to Smad binding elements (SBEs). Smad7 also antagonizes other signaling pathways, like the NF-.kappa.B pathway.
[0102] Smad7 protein is encoded by the SMAD7 gene, discussed above. Like many other TGF-.beta. family members, Smad7 is involved in cell signaling. It is a TGF-.beta. type 1 receptor antagonist. It blocks TGF-.beta.1 and activin associating with the receptor, blocking access to Smad2. It is an inhibitory Smad (I-SMAD) and is enhanced by SMURF2. Smad7 also enhances muscle differentiation.
[0103] The terms "polypeptide," "peptide," and "protein" are used interchangeably herein to refer to a polymer of amino acid residues. The terms apply to naturally occurring amino acid polymers as well as amino acid polymers in which one or more amino acid residues is a non-naturally occurring amino acid, for example, an amino acid analog. As used herein, the terms encompass amino acid chains of any length, including full length proteins, wherein the amino acid residues are linked by covalent peptide bonds.
[0104] In one embodiment, the present technology relates to Smad7 protein compositions. In addition to the entire Smad7 molecule, the present technology also relates to truncated portions and fragments of the polypeptide that retain one or more activity associated with Smad7, such as, but not limited to, increasing proliferation, reducing or inhibiting cell death, reducing excessive inflammation, preventing DNA damage, and/or increasing cell migration, as well as treating or preventing one or more disease or disorders in which such treatment would be helpful as further discussed herein. Such activities can be assessed using one or more assays including, but not limited to, the ability to block phosphorylation of Smad2 and/or nuclear translocation of the NF-.kappa.B p50 subunit, increase cell proliferation, reduce apoptosis and/or radiation-induced DNA damage, reduce inflammation and/or angiogenesis, promote healing in oral mucositis, surgical wounds, diabetes wounds, and/or wounds associated with chronic inflammation in mice.
[0105] Protein fragments may be generated by genetic engineering of translation stop sites within the coding region (discussed below). Alternatively, treatment of the Smad7 molecule with proteolytic enzymes, known as proteases, can produces a variety of N-terminal, C-terminal and internal fragments. These fragments may be purified according to known methods, such as precipitation (e.g., ammonium sulfate), HPLC, ion exchange chromatography, affinity chromatography (including immunoaffinity chromatography) or various size separations (sedimentation, gel electrophoresis, gel filtration).
[0106] As used herein, reference to an isolated protein or polypeptide in the present embodiments include full-length proteins, fusion proteins, chimeric proteins, or any fragment (truncated form, portion) or homologue of such a protein. More specifically, an isolated protein can be a protein (including a polypeptide or peptide) that has been removed from its natural milieu (i.e., that has been subject to human manipulation), and can include, but is not limited to, purified proteins, partially purified proteins, recombinantly produced proteins, proteins complexed with lipids, soluble proteins, synthetically produced proteins, and isolated proteins associated with other proteins. As such, "isolated" does not reflect the extent to which the protein has been purified. Preferably, an isolated protein is produced recombinantly.
[0107] Variants of Smad7 are also provided--these can be substitutional, insertional or deletion variants. Deletion variants lack one or more residues of the native protein that are not essential for activity, including the truncation mutants described above and herein. Substitutional variants typically contain the exchange of one amino acid for another at one or more sites within the protein, and may be designed to modulate one or more properties of the polypeptide, such as stability against proteolytic cleavage and/or translation and/or transcription (protein expression), without the loss of other functions or properties. Substitutions of this kind preferably are conservative, that is, one amino acid is replaced with one of similar shape and charge. Conservative substitutions are well known in the art and include, for example, each amino acid can be changed or substituted with a different amino acid. In making substitutional variants, the hydropathic index, hydrophilicity, charge and size are normally considered.
[0108] Specifically contemplated deletion variants of Smad7 include truncations and fragments, for example, including polypeptide molecules having N-terminal sequences, but not C-terminal sequences, having C-terminal sequences but not N-terminal sequences, or having internal sequences, but not N-terminal or c-terminal sequences. Specifically contemplated Smad7 polypeptide truncations or fragments include, but are not limited to, molecules including amino acid residues 2-258, 259-426, and 203-258 corresponding to the native human Smad7 protein sequence.
[0109] The term "truncated" as used herein in reference to protein sequences refers to a molecule that contains the natural N-terminus of a corresponding protein (with or without a cleaved leader sequence), but lacks one or more amino acids starting from the C-terminus of the molecule, or a molecule that contains the natural C-terminus of a corresponding protein (with or without a cleaved leader sequence), but lacks one or more amino acids starting from the N-terminus of the molecule. In some embodiments, molecules lacking at least about 25, at least about 50, at least about 75, at least about 100, at least about 125, at least about 150, at least about 200, at least about 250, at least about 300, or at least about 350, or at least about 400 amino acids from one or the other terminus are specifically provided. In some embodiments, a "truncated" molecule is biologically active, having one or more of the Smad7 activities described herein.
[0110] The term "fragment" as used herein in reference to polypeptide sequences refers to a molecule containing contiguous residues of a full length sequence but lacking some N-terminal and/or C-terminal residues of the full length sequence. In some embodiments, a "fragment" includes a portion of one or more of the full length sequences described herein. In some embodiments, the "fragment" does not include sequences encoding either the N-terminal or the C-terminal, but only internal fragments. In some embodiments, a "fragment" encodes a polypeptide that is biologically active, having one or more of the Smad7 activities described herein. In some embodiments, polypeptide fragments have at least about 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550, 600, 650, 700, 750, 800, 850, 900, 950, 1000, 1050, 1100, 1150 amino acids.
[0111] A specialized kind of variant is the fusion protein. This molecule generally has all or a substantial portion of the native molecule, linked at the N- or C-terminus, to all or a portion of a second polypeptide. However, in some embodiments, the fusion protein may include any one of the fragments and/or truncated (N-terminal, C-terminal) Smad7 proteins described throughout the disclosure. For example, fusions may employ leader sequences from other species to permit the recombinant expression of a protein in a heterologous host. Another useful fusion includes the addition of an optional functionally active domain, such as but not limited to an antibody epitope and/or a purification tag (e.g., V5: GKPIPNPLLGLDST (SEQ ID NO: 41); Flag: KYKDDDDK (SEQ ID NO: 42); HA: YPYDVPDYA (SEQ ID NO: 43)). Another type of fusion includes attaching a domain that can act as the target for an activating or inactivating ligand, thereby permitting control of the fusion protein's function once delivered to a subject. Such domains include, for example, steroid ligand binding (e.g., ER, PR, GR), which can be activated by small molecules, e.g., 4-hydroxyl tamoxifen or RU486 that are either uniquely able to activate those steroid ligand binding domains and/or do not exist in nature and will therefore enable full control of the Smad7 function by the presence of these small molecules.
[0112] Another specific form of a fusion protein finding particular utility in the present technology is a fusion including a protein transduction domain (PTD), also called a cell delivery domain or cell transduction domain. Such domains have been described in the art and are generally characterized as short amphipathic or cationic peptides and peptide derivatives, often containing multiple lysine and arginine resides (Fischer, Med. Res. Rev. 27:755-795 (2007)). In some embodiments, the PTD is one or more variant of TAT protein from HIV (GRKKRRQRRR (SEQ ID NO: 2), YGRKKRRQRRR (SEQ ID NO: 4), or GRKKRRQ (SEQ ID NO: 6)) or alternatively, HSV VP 16. Alternate forms of Tat may be used. In some embodiments, a linker may be used to connect one or more PTDs and SMad7. In some embodiments, the PTD (optionally Tat) is fused or linked in frame to the N-terminal and/or C-terminal end of any one of the Smad7 full-length, fragments, and/or truncated (N-terminal, C-terminal) proteins described throughout the disclosure. Other examples of PTDs provided by the present technology are shown in Table 1.
TABLE-US-00001 TABLE 1 PROTEIN TRANSDUCTION DOMAINS SEQ ID NO: GALFLGWLGAAGSTMGAKK 44 KRKV RQIKIWFQNRRMKWKK 45 RRMKWKK 46 RRWRRWWRRWWRRWRR 47 RGGRLSYSRRRFSTSTGR 48 YGRKKRRQRRR 4 RKKRRQRRR 49 YARAAARQARA 50 RRRRRRRR 51 KKKKKKKK 52 GWTLNSAGYLLGKINLKALA 53 ALAKXIL LLILLRRRIRKQANAHSK 54 SRRHHCRSKAKRSRHH 55 NRARRNRRRVR 56 RQLRIAGRRLRGRSR 57 KLIKGRTPIKFGK 58 RRIPNRRPRR 59 KLALKLALKALKAALKLA 60 KLAKLAKKLAKLAK 61 GALFLGFLGAAGSTNGAWSQ 62 PKKKRKV KETWWETWWTEWSQPKKKR 63 KV LKKLLKKLLKKLLKKLLKKL 64 QAATATRGRSAASRPTERPR 65 APARSASRPRRPVE MGLGLHLLVLAAALQGAKS 66 KRKV AAVALLPAVLLALLAPAAA 67 NYKKPKL MANLGYWLLALFVTMWTD 68 VGLCKKRPKP LGTYTQDFNKFHTFPQTAIG 69 VGAP DPKGDPKGVTVTVTVTVTG 70 KGDPXPD PPPPPPPPPPPPPP 71 VRLPPPVRLPPPVRLPPP 72 PRPLPPPRPG 73 SVRRRPRPPYLPRPRPPPFFPP 74 RLPPRIPP TRSSRAGLQFPVGRVHRLLRK 75 GIGKFLHSAKKFGKAFVGEI 76 MNS KWKLFKKIEKVGQNIRDGII 77 KAGPAVAVVGQATQIAK ALWMTLLKKVLKAAAKAA 78 LNAVLVGANA GIGAVLKVLTTGLPALISWIK 79 RKRQQ INLKALAALAKKIL 80 GFFALIPKIISSPLPKTLLSAV 81 GSALGGSGGQE LAKWALKQGFAKLKS 82 SMAQDIISTIGDLVKWIIQTV 83 NXFTKK LLGDFFRKSKEKIGKEFKRIV 84 QRIKQRIKDFLANLVPRTES PAWRKAFRWAWRMLKKAA 85 KLKLKLKLKLKLKLKLKL 86
[0113] In particular embodiments, the present technology provides for sequence variants of Smad7 in which one or more residues have been altered. For example, in one embodiment, the methionine residue found at position 216 of the human Smad7 sequence is modified to a leucine residue (ATG to CTG).
C. Methods of Treatment
[0114] Smad7-treatable diseases and disorders may include those including one or more of reduced cell proliferation, reduced cell migration, increased cell death, excessive inflammation, and/or DNA damage. Smad7-related diseases and disorders may include those where treatment with a Smad7 protein and biologically active fragments and derivatives thereof that have one or more activities including but not limited to increasing proliferation, reducing or inhibiting cell death, reducing excessive inflammation, preventing DNA damage, and/or increasing cell migration is helpful. Such diseases and/or disorders may include but are not limited to acute (e.g., through surgery, combat, trauma) and chronic wounds (e.g., ulcers, such as diabetic, pressure, venous), scarring, fibrosis, and aberrant healing, mucositis (e.g., oral and/or gastro-intestinal), stomatitis, proctitis, autoimmune disease (e.g., psoriasis, arthritis), and cancer.
[0115] In some embodiments, one or more of the diseases and or disorders described herein may be prevented, treated, and/or ameliorated by providing to a subject in need of such treatment a therapeutically effective amount of one or more of the Smad7 proteins (e.g., full-length or biologically active truncated (e.g., N-terminal or C-terminal) or fragment thereof) described in the disclosure. In some embodiments, the one or more Smad7 proteins are fusion proteins including a PTD domain. In some embodiments, the one or more Smad7 proteins includes Leu216. In some embodiments, the Smad7 proteins make part of a pharmaceutical composition including one or more pharmaceutically acceptable excipients.
[0116] In some embodiments, one or more of the diseases and or disorders described herein may be prevented, treated, and/or ameliorated by providing to a subject in need of such treatment a therapeutically effective amount of one or more of the nucleic acid molecules encoding one or more Smad7 proteins (e.g., full-length or biologically active truncated (e.g., N-terminal or C-terminal) or fragment thereof) described in the disclosure. In some embodiments, the one or more nucleic acid molecules include codon-optimized nucleotide sequences and/or sequences that encode Leu216. In some embodiments, the one or more Smad7 nucleic acid molecules are provided to the subject in a construct including an expression vector. In some embodiments, the Smad7 nucleic acid molecules (optionally part of an expression vector) make part of a pharmaceutical composition including one or more pharmaceutically acceptable excipients.
[0117] The term "subject" or "patient" as used herein refers to persons or non-human animals in need of treatment and or prevention using one or more of the treatments described herein. In some embodiments, non-human animals include laboratory animals such as monkeys, mice, rats, and rabbits, domestic pets such as dogs and cats, and livestock such as cattle, horses, pigs, goats and sheep.
[0118] 1. Chronic Wounds
[0119] A chronic wound is a wound that does not heal in an orderly set of stages and in a predictable amount of time the way most wounds do; wounds that do not heal within three months are often considered chronic. Chronic wounds seem to be detained in one or more of the phases of wound healing. For example, chronic wounds often remain in the inflammatory stage for too long. In acute wounds, there is a precise balance between production and degradation of molecules such as collagen; in chronic wounds this balance is lost and degradation plays too large a role.
[0120] As described in more detail elsewhere herein, PTD-Smad7 has been shown to enhance wound healing in a mouse skin model and a mucosal model. Application of PTD-Smad7 was effective through a topical route, which is desirable for wound treatment. Although not intending to be bound by theory, it is believed that PTD-Smad7 may act to treat or ameliorate chronic wounds through multiple routes, which may include one or more of reducing inflammation, increasing cell proliferation (e.g., keratinocytes), increasing cell migration (e.g., keratinocytes), or reducing fibrosis (e.g., through modulation of collagen), among others.
[0121] Chronic wounds may never heal or may take years to do so. These wounds cause patients severe emotional and physical stress as well as creating a significant financial burden on patients and the whole healthcare system. Acute and chronic wounds are at opposite ends of a spectrum of wound healing types that progress toward being healed at different rates. The vast majority of chronic wounds can be classified into three categories: venous ulcers, diabetic, and pressure ulcers. A small number of wounds that do not fall into these categories may be due to causes such as radiation poisoning or ischemia.
[0122] Venous and Arterial Ulcers.
[0123] Venous ulcers, which usually occur in the legs, account for about 70% to 90% of chronic wounds and mostly affect the elderly. They are thought to be due to venous hypertension caused by improper function of valves that exist in the veins to prevent blood from flowing backward. Ischemia results from the dysfunction and, combined with reperfusion injury, causes the tissue damage that leads to the wounds.
[0124] Diabetic Ulcers.
[0125] Another major cause of chronic wounds, diabetes, is increasing in prevalence. Diabetics have a 15% higher risk for amputation than the general population due to chronic ulcers. Diabetes causes neuropathy, which inhibits nociception and the perception of pain. Thus patients may not initially notice small wounds to legs and feet, and may therefore fail to prevent infection or repeated injury. Further, diabetes causes immune compromise and damage to small blood vessels, preventing adequate oxygenation of tissue, which can cause chronic wounds. Pressure also plays a role in the formation of diabetic ulcers.
[0126] Pressure Ulcers.
[0127] Another leading type of chronic wounds is pressure ulcers, which usually occur in people with conditions such as paralysis that inhibit movement of body parts that are commonly subjected to pressure such as the heels, shoulder blades, and sacrum. Pressure ulcers are caused by ischemia that occurs when pressure on the tissue is greater than the pressure in capillaries, and thus restricts blood flow into the area. Muscle tissue, which needs more oxygen and nutrients than skin does, shows the worst effects from prolonged pressure. As in other chronic ulcers, reperfusion injury damages tissue.
[0128] Chronic wounds may affect only the epidermis and dermis, or they may affect tissues all the way to the fascia. They may be formed originally by the same things that cause acute wounds, such as surgery or accidental trauma, or they may form as the result of systemic infection, vascular, immune, or nerve insufficiency, or comorbidities such as neoplasias or metabolic disorders. Although not intending to be bound by theory, the reason a wound becomes chronic is that the body's ability to deal with the damage is overwhelmed by factors such as repeated trauma, continued pressure, ischemia, or illness. Some of the major factors that lead to chronic wounds include, but are not limited to, ischemia, reperfusion injury, and bacterial colonization.
[0129] Ischemia.
[0130] Ischemia is an important factor in the formation and persistence of wounds, especially when it occurs repetitively (as it usually does) or when combined with a patient's old age. Ischemia causes tissue to become inflamed and cells to release factors that attract neutrophils such as interleukins, chemokines, leukotrienes, and complement factors.
[0131] While they fight pathogens, neutrophils also release inflammatory cytokines and enzymes that damage cells. One of their important functions is to produce Reactive Oxygen Species (ROS) to kill bacteria, for which they use an enzyme called myeloperoxidase. The enzymes and ROS produced by neutrophils and other leukocytes damage cells and prevent cell proliferation and wound closure by damaging DNA, lipids, proteins, the ECM, and cytokines that speed healing. Neutrophils remain in chronic wounds for longer than they do in acute wounds, and contribute to the fact that chronic wounds have higher levels of inflammatory cytokines and ROS. Because wound fluid from chronic wounds has an excess of proteases and ROS, the fluid itself can inhibit healing by inhibiting cell growth and breaking down growth factors and proteins in the ECM.
[0132] Bacterial Colonization.
[0133] Since more oxygen in the wound environment allows white blood cells to produce ROS to kill bacteria, patients with inadequate tissue oxygenation, for example, those who suffered hypothermia during surgery, are at higher risk for infection. The host's immune response to the presence of bacteria prolongs inflammation, delays healing, and damages tissue. Infection can lead not only to chronic wounds but also to gangrene, loss of the infected limb, and death of the patient.
[0134] Like ischemia, bacterial colonization and infection damage tissue by causing a greater number of neutrophils to enter the wound site. In patients with chronic wounds, bacteria with resistance to antibiotics may have time to develop. In addition, patients carrying drug resistant bacterial strains, such as methicillin-resistant Staphylococcus aureus (MRSA), have more chronic wounds.
[0135] Growth Factors Andproteolytic Enzymes.
[0136] Chronic wounds also differ in makeup from acute wounds in that their levels of proteolytic enzymes such as elastase and matrix metalloproteinases (MMPs) are higher, while their concentrations of growth factors such as Platelet-derived growth factor and Keratinocyte Growth Factor are lower.
[0137] Since growth factors (GFs) are imperative in timely wound healing, inadequate GF levels may be an important factor in chronic wound formation. In chronic wounds, the formation and release of growth factors may be prevented, the factors may be sequestered and unable to perform their metabolic roles, or degraded in excess by cellular or bacterial proteases.
[0138] Chronic wounds such as diabetic and venous ulcers are also caused by a failure of fibroblasts to produce adequate ECM proteins and by keratinocytes to epithelialize the wound. Fibroblast gene expression is different in chronic wounds than in acute wounds.
[0139] Although all wounds require a certain level of elastase and proteases for proper healing, too high a concentration is damaging. Leukocytes in the wound area release elastase, which increases inflammation, destroys tissue, proteoglycans, and collagen, and damages growth factors, fibronectin, and factors that inhibit proteases. The activity of elastase is increased by human serum albumin, which is the most abundant protein found in chronic wounds. However, chronic wounds with inadequate albumin are especially unlikely to heal, so regulating the wound's levels of that protein may in the future prove helpful in healing chronic wounds.
[0140] Excess matrix metalloproteinases, which are released by leukocytes, may also cause wounds to become chronic. MMPs break down ECM molecules, growth factors, and protease inhibitors, and thus increase degradation while reducing construction, throwing the delicate compromise between production and degradation out of balance.
[0141] Oral Ulcers.
[0142] A mouth ulcer (also termed an oral ulcer, or a mucosal ulcer) is an ulcer that occurs on the mucous membrane of the oral cavity. More plainly, a mouth ulcer is a sore or open lesion in the mouth. Mouth ulcers are very common, occurring in association with many diseases and by many different mechanisms, but usually there is no serious underlying cause. The two most common causes of oral ulceration are local trauma (e.g., rubbing from a sharp edge on a filling) and aphthous stomatitis ("canker sores"), a condition characterized by recurrent formation of oral ulcers for largely unknown reasons. Some consider ulcers on the lips or on the skin around the mouth to be included under the general term oral ulceration (e.g., an ulcer left by rupture of a blister caused by herpes labialis, i.e., a cold sore). Mouth ulcers often cause pain and discomfort, and may alter the person's choice of food while healing occurs (e.g., avoiding acidic or spicy foods and beverages). They may occur singly or multiple ulcers may occur at the same time (a "crop" of ulcers). Once formed, the ulcer may be maintained by inflammation and/or secondary infection. Rarely, a mouth ulcer that does not heal for many weeks may be a sign of oral cancer. Other causes include burns, chemical injury, or infection.
[0143] A mucosal ulcer is an ulcer which specifically occurs on a mucous membrane. An ulcer is a tissue defect which has penetrated the epithelial-connective tissue border, with its base at a deep level in the submucosa, or even within muscle or periosteum. An ulcer is a deeper breech of the epithelium than an erosion or an excoriation, and involves damage to both epithelium and lamina propria. An erosion is a superficial breach of the epithelium, with little damage to the underlying lamina propria. A mucosal erosion is an erosion which specifically occurs on a mucous membrane. Only the superficial epithelial cells of the epidermis or of the mucosa are lost, and the lesion can reach the depth of the basement membrane. Erosions heal without scar formation. Excoriation is a term sometimes used to describe a breach of the epithelium which is deeper than an erosion but shallower than an ulcer. This type of lesion is tangential to the rete pegs and shows punctiform (small pinhead spots) bleeding, caused by exposed capillary loops.
[0144] 2. Acute Wounds/Trauma
[0145] Physical trauma is a serious and body-altering physical injury, such as the removal of a limb. Blunt force trauma, a type of physical trauma caused by impact or other force applied from or with a blunt object, whereas penetrating trauma is a type of physical trauma in which the skin or tissues are pierced by an object. Trauma can also be described as both unplanned, such as an accident, or planned, in the case of surgery. Both can be characterized by mild to severe tissue damage, blood loss and/or shock, and both may lead to subsequent infection, including sepsis. The present technology provides for treatment of trauma, including both pre-treatment (in the case of a medical procedure) and treatment after trauma injury has occurred.
[0146] As described in more detail elsewhere herein (and briefly mentioned above), PTD-Smad7 has been shown to enhance wound healing in a mouse skin model and a mucosal model. Application of PTD-Smad7 was effective through a topical route, which is desirable for wound treatment. Although not intending to be bound by theory, it is believed that PTD-Smad7 may act to treat or ameliorate wounds through multiple routes, which may include one or more of reducing inflammation, increasing cell proliferation (e.g., keratinocytes), increasing cell migration (e.g., keratinocytes), or reducing fibrosis (e.g., through modulation of collagen), among others. As described briefly below, reduced inflammation could significantly contribute to accelerated wound healing, optionally through reduced angiogenesis and collagen production and/or reduced leukocyte infiltration leading to reduction of cytokines and chemokines normally released by leukocytes, which are angiogenic and fibrogenic. Temporal treatment with Smad7 may allow early stage angiogenesis and collagen production required for wound repair, while preventing prolonged angiogenesis and collagen production. These changes could potentially accelerate wound stromal remodeling and prevent excessive scarring due to unresolved inflammation or collagen overproduction. For surgical procedures (as well as everyday injuries), particularly where the potential for scarring is an issue, treatment with Smad7 may be beneficial.
[0147] Surgery.
[0148] Surgery uses operative manual and instrumental techniques on a patient to investigate and/or treat a pathological condition such as disease or injury, to help improve bodily function or appearance, or sometimes for some other reason. The present technology can address trauma resulting from surgeries, as defined further below.
[0149] As a general rule, a procedure is considered surgical when it involves cutting of a patient's tissues or closure of a previously sustained wound. Other procedures that do not necessarily fall under this rubric, such as angioplasty or endoscopy, may be considered surgery if they involve common surgical procedure or settings, such as use of a sterile environment, anesthesia, antiseptic conditions, typical surgical instruments, and suturing or stapling. All forms of surgery are considered invasive procedures; so-called noninvasive surgery usually refers to an excision that does not penetrate the structure being addressed (e.g., laser ablation of the cornea) or to a radiosurgical procedure (e.g., irradiation of a tumor). Surgery can last from minutes to hours.
[0150] Surgical procedures are commonly categorized by urgency, type of procedure, body system involved, degree of invasiveness, and special instrumentation. Elective surgery is done to correct a non-life-threatening condition, and is carried out at the patient's request, subject to the surgeon's and the surgical facility's availability. Emergency surgery is surgery which must be done quickly to save life, limb, or functional capacity. Exploratory surgery is performed to aid or confirm a diagnosis. Therapeutic surgery treats a previously diagnosed condition.
[0151] Amputation involves cutting off a body part, usually a limb or digit. Replantation involves reattaching a severed body part. Reconstructive surgery involves reconstruction of an injured, mutilated, or deformed part of the body. Cosmetic surgery is done to improve the appearance of an otherwise normal structure. Excision is the cutting out of an organ, tissue, or other body part from the patient. Transplant surgery is the replacement of an organ or body part by insertion of another from different human (or animal) into the patient. Removing an organ or body part from a live human or animal for use in transplant is also a type of surgery.
[0152] When surgery is performed on one organ system or structure, it may be classified by the organ, organ system or tissue involved. Examples include cardiac surgery (performed on the heart), gastrointestinal surgery (performed within the digestive tract and its accessory organs), and orthopedic surgery (performed on bones and/or muscles).
[0153] Minimally invasive surgery involves smaller outer incision(s) to insert miniaturized instruments within a body cavity or structure, as in laparoscopic surgery or angioplasty. By contrast, an open surgical procedure requires a large incision to access the area of interest. Laser surgery involves use of a laser for cutting tissue instead of a scalpel or similar surgical instruments. Microsurgery involves the use of an operating microscope for the surgeon to see small structures. Robotic surgery makes use of a surgical robot, such as Da Vinci or Zeus surgical systems, to control the instrumentation under the direction of the surgeon.
[0154] 3. Autoimmune/Inflammatory Disease
[0155] The present technology contemplates the treatment of a variety of autoimmune and/or inflammatory disease states such as spondyloarthropathy, ankylosing spondylitis, psoriatic arthritis, reactive arthritis, enteropathic arthritis, ulcerative colitis, Crohn's disease, irritable bowel disease, inflammatory bowel disease, rheumatoid arthritis, juvenile rheumatoid arthritis, familial Mediterranean fever, amyotrophic lateral sclerosis, Sjogren's syndrome, early arthritis, viral arthritis, multiple sclerosis, or psoriasis. The diagnosis and treatment of these diseases are well documented in the literature.
[0156] In general, autoimmune diseases are associated with an overactive immune response of a body against substances and tissues normally present in the body, and not normally the focus of an immune response. There are more than 80 types of autoimmune diseases, some of which have similar symptoms, and they may arise from a similar underlying cause. The classic sign of an autoimmune disease is inflammation, which as disclosed herein is amenable to treatment with Smad7 (optionally PTD-Smad7) compositions.
[0157] 4. Chemotherapy, Radiotherapy and Cytokine Therapy Toxicity
[0158] Various forms of cancer therapy, including chemotherapy, radiation, and cytokines, are associated with toxicity, sometimes severe, in the cancer patient. The present technology seeks to reduce this toxicity using the pharmaceutical compositions of the present technology, thereby reducing or alleviating discomfort on the part of the patient, as well as permitting higher doses of the therapy.
[0159] As described at length throughout this disclosure, it has been found that PTD-Smad7 acts to heal as well as to prevent oral mucositis in a mouse model. PTD-Smad7 was shown to be more effective than palifermin, the existing approved drug for preventing oral mucositis, in direct comparisons.
[0160] Oral cancer, the 6.sup.th most common cancer worldwide, is a subtype of head and neck cancer, and includes any cancerous tissue growth located in the oral cavity. It may arise as a primary lesion originating in any of the oral tissues, by metastasis from a distant site of origin, or by extension from a neighboring anatomic structure, such as the nasal cavity or the oral cancers may originate in any of the tissues of the mouth, and may be of varied histologic types: teratoma, adenocarcinoma derived from a major or minor salivary gland, lymphoma from tonsillar or other lymphoid tissue, or melanoma from the pigment-producing cells of the oral mucosa. There are several types of oral cancers, but around 90% are squamous cell carcinomas, originating in the tissues that line the mouth and lips. Oral or mouth cancer most commonly involves the tongue. It may also occur on the floor of the mouth, cheek lining, gingiva (gums), lips, or palate (roof of the mouth). Most oral cancers look very similar under the microscope and are called squamous cell carcinoma. These are malignant and tend to spread rapidly.
[0161] Over 80% of oral cancer patients are treated with radiation therapy and at least 75% of these individuals will develop oral mucositis. Oral mucositis is a chronic oral ulceration. This disease frequently occurs in radiation-treated patients of all cancer types, including but not limited to patients who are radiation-treated for organ transplants (to eliminate rejection of the transplants), and patients undergoing routine chemotherapy. Severe oral mucositis is extremely painful and impairs food/liquid intake, hence is often the most severe complication of cancer therapy. Oral mucositis is a major factor in determining the maximum dose possible of radiation and chemotherapy to the head and neck region; it can significantly complicate cancer treatment, extend hospitalization, decrease quality of life and increase costs.
[0162] Currently, there is no established therapy to effectively treat severe oral mucositis. To date, palifermin (KEPIVANCE.RTM.), a recombinant protein of human keratinocyte growth factor (KGF), is the only FDA approved drug for intravenous (i.v.) injections for severe oral mucositis in bone-marrow transplant patients, and its use in cancer patients remains to be determined. It is also used for prevention of oral mucositis. Hence, this drug is available for only 4% of the at-risk population. It also suffers from the need for medical service providers due to the i.v. administration route. Other potential therapies include topical rinses, such as viscous 2% lidocaine rinses, or baking soda and saline solutions, or a cocktail solution, for instance BAX (lidocaine, diphenhyramine, sorbitol and MYLANTA.RTM.). Other investigative or mucoprotective adjuvant therapies include, but are not limited to, beta carotene, tocopherol, laser irradiation, prophylactic brushing the oral mucosa with silver-nitrate, misoprostol, leucovorin, systemic KGF, pentoxifylline, allopurinol mouthwash, systemic sucralfate, chlorhexidine gluconate, and cryotherapy.
[0163] Chemotherapy- and radiation-induced gut mucositis is an inflammatory condition that arises as a result of the acute death of rapidly dividing intestinal epithelial cells. Most chemotherapeutic drugs used for treatment of solid tumors, alone, in a combination of drugs, or with radiation, will result in the death of a large number of intestinal epithelial cells. The clinical manifestations of the ensuing mucositis include digestive symptoms such as nausea and vomiting, serious diarrhea, acute weight loss and wasting. This is fast becoming one of the limiting factors for administering chemotherapy for many cancer patients. The ability of Tat-Smad7 to protect intestinal epithelial cells from either chemotherapeutic agents, radiation, or a combinations of those, will significantly decrease the undesirable side effects of cancer therapies, and enable more aggressive ways to treat the disease with existing tools.
[0164] Bone marrow failure syndromes are a set of conditions that develop when the hematopoietic stem cell compartment is compromised and fails to give rise to normal cell types. Bone marrow failure occurs as a result of inherited genetic abnormalities, exposure to a noxious substance, such as toxins, chemicals or viruses. Although the nature and identity of environmental factors that can lead to the development of acquired bone marrow failure is still not completely understood, a few factors have been linked to the development of acquired bone marrow failure among military personnel including exposure to mustard gas, ionizing radiation, and infectious agents such as visceral leishmaniasis or African trypanosomiasis. The best approach for management of bone marrow failure syndromes is still the transplantation of hematopoietic stem cells (HSCs), unless a sufficient number of the remaining resident bone marrow HSCs can be spared from these stresses and encouraged to repopulate the hematopoietic compartment. The modulation of Smad 7, as described here, should enable for the deliberate protection of the remaining resident HSCs in patients that exhibit clinical signs consistent with bone marrow failure.
[0165] 5. Cancer
[0166] TGF-.beta. and NF-.kappa.B activations are known to promote cancer invasion and metastasis. Currently, TGF-.beta. inhibitors are in clinical trials for treating metastatic cancer and NF-.kappa.B inhibitors are used in cancer prevention. The demonstrated effect of Smad7 on blocking both TGF-.beta. and NF-.kappa.B signaling present the possibility that it is an even stronger anti-cancer/anti-metastasis agent than other inhibitors that inhibit only one of these two pathways. Smad7 has been shown to prevent angiogenesis and fibrogenesis, and may therefore be particularly useful in situations where the tumor needs to develop a blood supply and/or stroma.
[0167] The cancer may be selected from the group consisting of brain, lung, liver, spleen, kidney, lymph node, small intestine, pancreas, blood cells, colon, stomach, breast, endometrium, prostate, testicle, cervix, uterus, ovary, skin, head & neck, esophagus, bone marrow and blood cancer. The cancers may be metastatic or primary, recurrent or multi-drug resistant. In some embodiments, the cancer is a solid tumor (organ tumor). Solid tumors refer to a mass of cells that grow in organ systems and can occur anywhere in the body. Two types of solid tumors include epithelial tumors (carcinomas) that occur in the epithelial tissue inside or outside an organ, and sarcomas (connective tissue tumors) that occur in connective tissue such as, but not limited to, muscles, tendons, fat, nerves and other connective tissues that support, surround, or connect structures and organs in the body. In some embodiments the cancer is a liquid tumor or cancer of the blood, bone marrow, or lymph nodes. These tumors include, but are not limited to, leukemia, lymphoma, and myeloma.
[0168] 6. Scarring, Fibrosis, and Aberrant Healing
[0169] In addition to accelerated re-epithelialization (e.g., through increasing cell proliferation and/or increasing cell migration), Smad7 effects on wound stroma include one or more of reducing inflammation, angiogenesis, or collagen production, among others. Although not intending to be bound by theory these effects may be mediated through reduction of NF-.kappa.B signaling (evidenced by reduced p50), and blocking TGF-.beta. signaling (evidenced by reduced pSmad2). As a result, reduced inflammation could significantly contribute to accelerated wound healing, optionally through reduced angiogenesis and collagen production and/or reduced leukocyte infiltration leading to reduction of cytokines and chemokines normally released by leukocytes, which are angiogenic and fibrogenic. Temporal treatment with Smad7 may allow early stage angiogenesis and collagen production required for wound repair, while preventing prolonged angiogenesis and collagen production. These changes could potentially accelerate wound stromal remodeling and prevent excessive scarring due to unresolved inflammation or collagen overproduction.
[0170] 7. Stomatitis
[0171] Stomatitis is an inflammation of the mucous lining of any of the structures in the mouth, which may involve the cheeks, gums, tongue, lips, throat, and roof or floor of the mouth. The inflammation can be caused by conditions in the mouth itself, such as poor oral hygiene, dietary protein deficiency, poorly fitted dentures, or from mouth burns from hot food or drinks, toxic plants, or by conditions that affect the entire body, such as medications, allergic reactions, radiation therapy, or infections. Severe iron deficiency anemia can lead to stomatitis. Iron is necessary for the upregulation of transcriptional elements for cell replication and repair. Lack of iron can cause the genetic downregulation of these elements, leading to ineffective repair and regeneration of epithelial cells, especially in the mouth and lips. This condition is also prevalent in people who have a deficiency in vitamin B2 (Riboflavin), B3 (Niacin), B6 (Pyridoxine), B9 (folic acid) or B12 (cobalamine). When it also involves an inflammation of the gingiva (gums), it is called gingivostomatitis. It may also be seen in ariboflavinosis (riboflavin deficiency) or neutropenia.
[0172] Irritation and fissuring in the corners of the lips is termed angular stomatitis or angular cheilitis. In children, angular stomatitis is a frequent cause is repeated lip-licking and in adults it may be a sign of underlying iron deficiency anemia, or vitamin B deficiencies (e.g., B2-riboflavin, B9-folate or B12-cobalamin), which in turn may be evidence of poor diets or malnutrition (e.g., celiac disease). Also, angular cheilitis can be caused by a patient's jaws at rest being "overclosed" due to edentulousness or tooth wear, causing the jaws to come to rest closer together than if the complete/unaffected dentition were present. This causes skin folds around the angle of the mouth which are kept moist by saliva which in turn favours infection; mostly by Candida albicans or similar species. Treatment usually involves the administration of topical nystatin or similar antifungal agents. Another treatment can be to correct the jaw relationship with dental treatment (e.g., dentures or occlusal adjustment).
[0173] Migratory stomatitis is a condition in which extensive areas in the oral cavity mucosa are affected by annular atrophic red lesions that are surrounded by a thin white rim. This is a relatively uncommon form of the geographic tongue condition, that, as opposed to migratory stomatitis, is confined to the dorsal and lateral aspects of the tongue mucosa only.
[0174] 8. Proctitis
[0175] Proctitis is inflammation of the lining of the rectum, the lower end of the large intestine leading to the anus. With proctitis, inflammation of the rectal lining-called the rectal mucosa--is uncomfortable and sometimes painful. The condition may lead to bleeding or mucous discharge from the rectum, among other symptoms. Some causes of proctitis include, but are not limited to: sexually transmitted diseases (STDs), such as those that can be transmitted during anal sex (e.g., gonorrhea, chlamydia, syphilis, and herpes); non-STD infections from, for example, food borne bacteria (e.g., Salmonella and Shigella); anorectal trauma from, for example, anal sex or the insertion of objects or substances into the rectum (e.g., chemicals from enemas); ulcerative colitis and Crohn's disease or other inflammatory bowel diseases, may cause ulcers (e.g., sores) in the inner lining of the colon and rectum; radiation therapy, particularly of the pelvic area (e.g., rectal, ovarian, or prostate cancer) which may lead to rectal bleeding; antibiotics which lead to a loss of commensal bacteria allowing harmful bacteria (e.g., Clostridium difficile) to cause disease.
[0176] 9. Formulations and Routes of Administration
[0177] Where clinical applications are contemplated, it will be necessary to prepare pharmaceutical compositions--proteins, expression vectors, virus stocks, proteins and drugs--in a form appropriate for the intended application. Generally, this will entail preparing compositions that are essentially free of pyrogens, as well as other impurities that could be harmful to humans or animals.
[0178] PTD-Smad7 (and truncated variants) were purified extensively prior to use in animal models. PTD-Smad7 (and truncated versions) were prepared for topical and trans-mucosal application using a mixture of glycerol and PBS.
[0179] One will generally desire to employ appropriate salts and buffers to render delivery vectors stable and allow for uptake by target cells. Buffers also will be employed when recombinant cells are introduced into a patient. Aqueous compositions of the present technology comprise an effective amount of the vector to cells, dissolved or dispersed in a pharmaceutically acceptable carrier or aqueous medium. Such compositions also are referred to as inocula. The phrase "pharmaceutically or pharmacologically acceptable" refer to molecular entities and compositions that do not produce adverse, allergic, or other untoward reactions when administered to an animal or a human. As used herein, "pharmaceutically acceptable carrier" includes any and all solvents, dispersion media, coatings, antibacterial and antifungal agents, isotonic and absorption delaying agents and the like. The use of such media and agents for pharmaceutically active substances is well known in the art. Except insofar as any conventional media or agent is incompatible with the vectors or cells of the present technology, its use in therapeutic compositions is contemplated. Supplementary active ingredients also can be incorporated into the compositions.
[0180] The active compositions of the present technology may include classic pharmaceutical preparations. Administration of these compositions according to the present technology will be via any common route so long as the target tissue is available via that route. Such routes of administration may include oral parenteral (including intravenous, intramuscular, subcutaneous, intradermal, intra-articular, intra-synovial, intrathecal, intra-arterial, intracardiac, subcutaneous, intraorbital, intracapsular, intraspinal, intrastemal, and transdermal), nasal, buccal, urethral, rectal, vaginal, mucosal, dermal, or topical (including dermal, buccal, and sublingual). Alternatively, administration may be by orthotopic, intradermal, subcutaneous, intramuscular, intraperitoneal or intravenous injection. Such compositions would normally be administered as pharmaceutically acceptable compositions, described supra. Of particular interest is direct intratumoral administration, perfusion of a tumor, or administration local or regional to a tumor, for example, in the local or regional vasculature or lymphatic system, or in a resected tumor bed. Administration can also be via nasal spray, surgical implant, internal surgical paint, infusion pump, or via catheter, stent, balloon or other delivery device. The most useful and/or beneficial mode of administration can vary, especially depending upon the condition of the recipient and the disorder being treated.
[0181] Solutions of the active compounds as free base or pharmacologically acceptable salts can be prepared in water suitably mixed with a surfactant, such as hydroxypropylcellulose. Dispersions can also be prepared in glycerol, liquid polyethylene glycols, and mixtures thereof and in oils. Under ordinary conditions of storage and use, these preparations contain a preservative to prevent the growth of microorganisms.
[0182] The pharmaceutical forms suitable for injectable use include sterile aqueous solutions or dispersions and sterile powders for the extemporaneous preparation of sterile injectable solutions or dispersions. In all cases, the form must be sterile and must be fluid to the extent that easy syringability exists. It must be stable under the conditions of manufacture and storage and must be preserved against the contaminating action of microorganisms, such as bacteria and fungi. The carrier can be a solvent or dispersion medium containing, for example, water, ethanol, polyol (e.g., glycerol, propylene glycol, and liquid polyethylene glycol, and the like), suitable mixtures thereof, and vegetable oils. The proper fluidity can be maintained, for example, by the use of a coating, such as lecithin, by the maintenance of the required particle size in the case of dispersion and by the use of surfactants. The prevention of the action of microorganisms can be brought about by various antibacterial an antifungal agents, for example, parabens, chlorobutanol, phenol, sorbic acid, thimerosal, and the like. In many cases, it will be preferable to include isotonic agents, for example, sugars or sodium chloride. Prolonged absorption of the injectable compositions can be brought about by the use in the compositions of agents delaying absorption, for example, aluminum monostearate and gelatin.
[0183] Sterile injectable solutions are prepared by incorporating the active compounds in the required amount in the appropriate solvent with various of the other ingredients enumerated above, as required, followed by filtered sterilization. Generally, dispersions are prepared by incorporating the various sterilized active ingredients into a sterile vehicle which contains the basic dispersion medium and the required other ingredients from those enumerated above. In the case of sterile powders for the preparation of sterile injectable solutions, the preferred methods of preparation are vacuum-drying and freeze-drying techniques which yield a powder of the active ingredient plus any additional desired ingredient from a previously sterile-filtered solution thereof.
[0184] As used herein, "pharmaceutically acceptable carrier" includes any and all solvents, dispersion media, coatings, antibacterial and antifungal agents, isotonic and absorption delaying agents and the like. The use of such media and agents for pharmaceutical active substances is well known in the art. Except insofar as any conventional media or agent is incompatible with the active ingredient, its use in the therapeutic compositions is contemplated. Supplementary active ingredients can also be incorporated into the compositions.
[0185] The compositions of the present technology may be formulated in a neutral or salt form. Pharmaceutically-acceptable salts include the acid addition salts (formed with the free amino groups of the protein) and which are formed with inorganic acids such as, for example, hydrochloric or phosphoric acids, or such organic acids as acetic, oxalic, tartaric, mandelic, and the like. Salts formed with the free carboxyl groups can also be derived from inorganic bases such as, for example, sodium, potassium, ammonium, calcium, or ferric hydroxides, and such organic bases as isopropylamine, trimethylamine, histidine, procaine and the like.
[0186] The formulations are easily administered in a variety of dosage forms. Some variation in dosage will necessarily occur depending on the condition of the subject being treated. The person responsible for administration will, in any event, determine the appropriate dose for the individual subject. Moreover, for human administration, preparations should meet sterility, pyrogenicity, general safety and purity standards as required by FDA Office of Biologics standards.
[0187] For oral administration the polypeptides of the present technology may be incorporated with excipients and used in the form of non-ingestible mouthwashes and dentifrices. It is anticipated that virtually any pill or capsule type known to one of skill in the art including, e.g., coated, and time delay, slow release, etc., may be used with the present technology. A mouthwash may be prepared incorporating the active ingredient in the required amount in an appropriate solvent, such as a sodium borate solution (Dobell's Solution). Alternatively, the active ingredient may be incorporated into an antiseptic wash containing sodium borate, glycerin and potassium bicarbonate. The active ingredient may also be dispersed in dentifrices, including: gels, pastes, creams, powders and slurries. The active ingredient may be added in a therapeutically effective amount to a paste dentifrice that may include water, binders, abrasives, flavoring agents, foaming agents, and humectants.
[0188] Pharmaceutical compositions suitable for oral dosage may take various forms, such as tablets, capsules, caplets, and wafers (including rapidly dissolving or effervescing), each containing a predetermined amount of the active agent. The compositions may also be in the form of a powder or granules, a solution or suspension in an aqueous or non-aqueous liquid, and as a liquid emulsion (oil-in-water and water-in-oil). The active agents may also be delivered as a bolus, electuary, or paste. It is generally understood that methods of preparations of the above dosage forms are generally known in the art, and any such method would be suitable for the preparation of the respective dosage forms for use in delivery of the compositions.
[0189] In one embodiment, an active agent compound may be administered orally in combination with a pharmaceutically acceptable vehicle such as an inert diluent or an edible carrier. Oral compositions may be enclosed in hard or soft shell gelatin capsules, may be compressed into tablets or may be incorporated directly with the food of the patient's diet. The percentage of the composition and preparations may be varied; however, the amount of substance in such therapeutically useful compositions is preferably such that an effective dosage level will be obtained.
[0190] Hard capsules containing the active agent compounds may be made using a physiologically degradable composition, such as gelatin. Such hard capsules comprise the compound, and may further comprise additional ingredients including, for example, an inert solid diluent such as calcium carbonate, calcium phosphate, or kaolin. Soft gelatin capsules containing the compound may be made using a physiologically degradable composition, such as gelatin. Such soft capsules comprise the compound, which may be mixed with water or an oil medium such as peanut oil, liquid paraffin, or olive oil.
[0191] Sublingual tablets are designed to dissolve very rapidly. Examples of such compositions include ergotamine tartrate, isosorbide dinitrate, and isoproterenol HCL. The compositions of these tablets contain, in addition to the drug, various soluble excipients, such as lactose, powdered sucrose, dextrose, and mannitol. The solid dosage forms of the present technology may optionally be coated, and examples of suitable coating materials include, but are not limited to, cellulose polymers (such as cellulose acetate phthalate, hydroxypropyl cellulose, hydroxypropyl methylcellulose, hydroxypropyl methylcellulose phthalate, and hydroxypropyl methylcellulose acetate succinate), polyvinyl acetate phthalate, acrylic acid polymers and copolymers, and methacrylic resins (such as those commercially available under the trade name EUDRAGIT.RTM.), zein, shellac, and polysaccharides.
[0192] Powdered and granular compositions of a pharmaceutical preparation may be prepared using known methods. Such compositions may be administered directly to a patient or used in the preparation of further dosage forms, such as to form tablets, fill capsules, or prepare an aqueous or oily suspension or solution by addition of an aqueous or oily vehicle thereto. Each of these compositions may further comprise one or more additives, such as dispersing or wetting agents, suspending agents, and preservatives. Additional excipients (e.g., fillers, sweeteners, flavoring, or coloring agents) may also be included in these compositions.
[0193] Liquid compositions of pharmaceutical compositions which are suitable for oral administration may be prepared, packaged, and sold either in liquid form or in the form of a dry product intended for reconstitution with water or another suitable vehicle prior to use.
[0194] A tablet containing one or more active agent compounds described herein may be manufactured by any standard process readily known to one of skill in the art, such as, for example, by compression or molding, optionally with one or more adjuvant or accessory ingredient. The tablets may optionally be coated or scored and may be formulated so as to provide slow or controlled release of the active agents.
[0195] Solid dosage forms may be formulated so as to provide a delayed release of the active agents, such as by application of a coating. Delayed release coatings are known in the art, and dosage forms containing such may be prepared by any known suitable method. Such methods generally include that, after preparation of the solid dosage form (e.g., a tablet or caplet), a delayed release coating composition is applied. Application can be by methods, such as airless spraying, fluidized bed coating, use of a coating pan, or the like. Materials for use as a delayed release coating can be polymeric in nature, such as cellulosic material (e.g., cellulose butyrate phthalate, hydroxypropyl methylcellulose phthalate, and carboxymethyl ethylcellulose), and polymers and copolymers of acrylic acid, methacrylic acid, and esters thereof.
[0196] Solid dosage forms according to the present technology may also be sustained release (i.e., releasing the active agents over a prolonged period of time), and may or may not also be delayed release. Sustained release compositions are known in the art and are generally prepared by dispersing a drug within a matrix of a gradually degradable or hydrolyzable material, such as an insoluble plastic, a hydrophilic polymer, or a fatty compound. Alternatively, a solid dosage form may be coated with such a material.
[0197] Compositions for parenteral administration include aqueous and non-aqueous sterile injection solutions, which may further contain additional agents, such as antioxidants, buffers, bacteriostats, and solutes, which render the compositions isotonic with the blood of the intended recipient. The compositions may include aqueous and non-aqueous sterile suspensions, which contain suspending agents and thickening agents. Such compositions for parenteral administration may be presented in unit-dose or multi-dose containers, such as, for example, sealed ampoules and vials, and may be stores in a freeze-dried (lyophilized) condition requiring only the addition of the sterile liquid carrier, for example, water (for injection), immediately prior to use. Extemporaneous injection solutions and suspensions may be prepared from sterile powders, granules, and tablets of the kind previously described.
[0198] Compositions for rectal delivery include rectal suppositories, creams, ointments, and liquids. Suppositories may be presented as the active agents in combination with a carrier generally known in the art, such as polyethylene glycol. Such dosage forms may be designed to disintegrate rapidly or over an extended period of time, and the time to complete disintegration can range from a short time, such as about 10 minutes, to an extended period of time, such as about 6 hours.
[0199] Topical compositions may be in any form suitable and readily known in the art for delivery of active agents to the body surface, including dermally, buccally, and sublingually. Typical examples of topical compositions include ointments, creams, gels, pastes, and solutions. Compositions for administration in the mouth include lozenges.
[0200] In accordance with these embodiments, oral (topical, mucosal, and/or dermal) delivery materials can also include creams, salves, ointments, patches, liposomes, nanoparticles, microparticles, timed-release formulations and other materials known in the art for delivery to the oral cavity, mucosa, and/or to the skin of a subject for treatment and/or prevention of a condition disclosed herein. Certain embodiments concern the use of a biodegradable oral (topical, mucosal, and/or dermal) patch delivery system or gelatinous material. These compositions can be a liquid formulation or a pharmaceutically acceptable delivery system treated with a formulation of these compositions, and may also include activator/inducers.
[0201] The compositions for use in the methods of the present technology may also be administered transdermally, wherein the active agents are incorporated into a laminated structure (generally referred to as a "patch") that is adapted to remain in intimate contact with the epidermis of the recipient for a prolonged period of time. Typically, such patches are available as single layer "drug-in-adhesive" patches or as multi-layer patches where the active agents are contained in a layer separate from the adhesive layer. Both types of patches also generally contain a backing layer and a liner that is removed prior to attachment to the recipient's skin. Transdermal drug delivery patches may also be comprised of a reservoir underlying the backing layer that is separated from the skin of the recipient by a semi-permeable membrane and adhesive layer. Transdermal drug delivery may occur through passive diffusion, electrotransport, or iontophoresis.
[0202] In certain embodiments, a patch contemplated herein may be a slowly dissolving or a time-released patch. In accordance with these embodiments, a slowly dissolving patch can be an alginate patch. In certain examples, a patch may contain a detectible indicator dye or agent such as a fluorescent agent. In other embodiments, a tag (e.g., detectible tag such as a biotin or fluorescently tagged agent) can be associated with a treatment molecule in order to detect the molecule after delivery to the subject. In certain embodiments, one or more oral delivery patches or other treatment contemplated herein may be administered to a subject three times daily, twice daily, once a day, every other day, weekly, and the like, depending on the need of the subject as assessed by a health professional. Patches contemplated herein may be oral-biodegradable patches or patches for exterior use that may or may not degrade. Patches contemplated herein may be 1 mm, 2 mm, 3 mm, 4 mm to 5 mm in size or more depending on need. In addition, skin patches are contemplated herein for use for example in a subject suffering from psoriasis. In treating psoriasis and chronic wounds, Smad7 can be delivered topically using vehicles such as glycerol, carboxymethycellulose. It can also use transdermal system (e.g., commercially available from 3M) for delivery. Subcutaneous injection into the lesion (in normal saline or PBS) can also be used.
[0203] In some embodiments, compositions may include short-term, rapid-onset, rapid-offset, controlled release, sustained release, delayed release, and pulsatile release compositions, providing the compositions achieve administration of a compound as described herein. See Remington's Pharmaceutical Sciences (18th ed.; Mack Publishing Company, Eaton, Pa., 1990), herein incorporated by reference in its entirety.
[0204] In certain embodiments, the compounds and compositions disclosed herein can be delivered via a medical device. Such delivery can generally be via any insertable or implantable medical device, including, but not limited to stents, catheters, balloon catheters, shunts, or coils. In one embodiment, the present technology provides medical devices, such as stents, the surface of which is coated with a compound or composition as described herein. The medical device of this technology can be used, for example, in any application for treating, preventing, or otherwise affecting the course of a disease or condition, such as those disclosed herein.
[0205] It is contemplated that any molecular biology, cellular biology or biochemical technique known in the art may be used to generate and/or test treatments provided herein. In addition, protein chemistry techniques are contemplated to assess utility of treatments in model systems developed herein (e.g., mouse model system).
[0206] 10. Combination Therapies
[0207] It is common in many fields of medicine to treat a disease with multiple therapeutic modalities, often called "combination therapies." Many of the diseases described herein (e.g., inflammatory disease and cancer) are no exception. In some embodiments, to treat inflammatory disorders using the methods and compositions of the present technology, one would contact a target cell, organ or subject with a Smad7 protein, expression construct or activator and at least one other therapy. These therapies would be provided in a combined amount effective to achieve a reduction in one or more disease parameter. This process may involve contacting the cells/subjects with the both agents/therapies at the same time, e.g., using a single composition or pharmacological formulation that includes both agents, or by contacting the cell/subject with two distinct compositions or formulations, at the same time, wherein one composition includes the Smad7 agent and the other includes the other agent.
[0208] Alternatively, the Smad7 agent may precede or follow the other treatment by intervals ranging from minutes to weeks. One would generally ensure that a significant period of time did not expire between the time of each delivery, such that the therapies would still be able to exert an advantageously combined effect on the cell/subject. In such instances, it is contemplated that one would contact the cell with both modalities within about 12-24 hours of each other, within about 6-12 hours of each other, or with a delay time of only about 12 hours. In some situations, it may be desirable to extend the time period for treatment significantly; however, where several days (2, 3, 4, 5, 6 or 7) to several weeks (1, 2, 3, 4, 5, 6, 7 or 8) lapse between the respective administrations.
[0209] It also is conceivable that more than one administration of either the Smad7 agent or the other therapy will be desired. Various combinations may be employed, where the Smad7 agent is "A," and the other therapy is "B," as exemplified below:
[0210] A/B/A B/A/B B/B/A A/A/B B/A/A A/B/B B/B/B/A B/B/A/B
[0211] A/A/B/B A/B/A/B A/B/B/A B/B/A/A B/A/B/A B/A/A/B B/B/B/A
[0212] A/A/A/B B/A/A/A A/B/A/A A/A/B/A A/B/B/B B/A/B/B B/B/A/B
[0213] Other combinations are provided. Other agents suitable for use in a combined therapy against an inflammatory disorder include steroids, glucocorticoids, non-steriodal anti-inflammatory drugs (NSAIDS; including COX-1 and COX-2 inhibitors), aspirin, ibuprofen, and naproxen. Analgesics are commonly associated with anti-inflammatory drugs but which have no anti-inflammatory effects. An example is paracetamol, called acetaminophen in the U.S. and sold under the brand name of Tylenol. As opposed to NSAIDS, which reduce pain and inflammation by inhibiting COX enzymes, paracetamol has recently been shown to block the reuptake of endocannabinoids, which only reduces pain, likely explaining why it has minimal effect on inflammation. A particular agent for combination use is an anti-TGF-.beta. antibody.
[0214] The skilled artisan is directed to Remington's Pharmaceutical Sciences, 15th Edition, chapter 33, in particular, pages 624-652, 1990. Some variation in dosage will necessarily occur depending on the condition of the subject being treated. The person responsible for administration will, in any event, determine the appropriate dose for the individual subject. Moreover, for human administration, preparations should meet sterility, pyrogenicity, general safety and purity standards as required by FDA Office of Biologics standards.
[0215] It also should be pointed out that any of the foregoing therapies may prove useful by themselves in treating inflammation.
[0216] As discussed above, the present technology has particular relevance to the treatment of DNA damage and/or inflammation resulting from certain anti-cancer therapies, and for the treatment of cancer. Thus, in particular, the present technology may be applied as a combination with cancer therapies. This process may involve contacting the cells, organ, or patient with the agents/therapies at the same time, including by contacting the cells, organ or patient with a single composition or pharmacological formulation that includes both agents, or with two distinct compositions or formulations at the same time, wherein one composition includes the Smad7 agent and the other includes the other agent. Alternatively, analogous to the chart set forth above, the compositions can be delivered at different times, including repeated doses of one or both agents.
[0217] Agents or factors suitable for use in a combined therapy include any chemical compound or treatment method that induces DNA damage when applied to a cell. Such agents and factors include radiation and waves that induce DNA damage such as, irradiation, microwaves, electronic emissions, and the like. A variety of chemical compounds, also described as "chemotherapeutic" or "genotoxic agents," are intended to be of use in the combined treatment methods disclosed herein. In treating cancer according to the present technology, one would contact the tumor cells with an agent in addition to the expression construct. This may be achieved by irradiating the localized tumor site; alternatively, the tumor cells may be contacted with the agent by administering to the subject a therapeutically effective amount of a pharmaceutical composition.
[0218] Various classes of chemotherapeutic agents are provided for use with in combination with peptides of the present technology. For example, selective estrogen receptor antagonists ("SERMs"), such as Tamoxifen, 4-hydroxy Tamoxifen (Afimoxfene), Falsodex, Raloxifene, Bazedoxifene, Clomifene, Femarelle, Lasofoxifene, Ormeloxifene, and Toremifene.
[0219] Chemotherapeutic agents contemplated to be of use, include, e.g., camptothecin, actinomycin-D, mitomycin C. The present technology also encompasses the use of a combination of one or more DNA damaging agents, whether radiation-based or actual compounds, such as the use of X-rays with cisplatin or the use of cisplatin with etoposide. The agent may be prepared and used as a combined therapeutic composition, or kit, by combining it with a MUC1 peptide, as described above.
[0220] Heat shock protein 90 is a regulatory protein found in many eukaryotic cells. HSP90 inhibitors have been shown to be useful in the treatment of cancer. Such inhibitors include Geldanamycin, 17-(Allylamino)-17-demethoxygeldanamycin, PU-H71 and Rifabutin.
[0221] Agents that directly cross-link DNA or form adducts are also envisaged. Agents such as cisplatin, and other DNA alkylating agents may be used. Cisplatin has been widely used to treat cancer, with efficacious doses used in clinical applications of 20 mg/m.sup.2 for 5 days every three weeks for a total of three courses. Cisplatin is not absorbed orally and must therefore be delivered via injection intravenously, subcutaneously, intratumorally or intraperitoneally.
[0222] Agents that damage DNA also include compounds that interfere with DNA replication, mitosis and chromosomal segregation. Such chemotherapeutic compounds include adriamycin, also known as doxorubicin, etoposide, verapamil, podophyllotoxin, and the like. Widely used in a clinical setting for the treatment of neoplasms, these compounds are administered through bolus injections intravenously at doses ranging from 25-75 mg/m.sup.2 at 21 day intervals for doxorubicin, to 35-50 mg/m.sup.2 for etoposide intravenously or double the intravenous dose orally. Microtubule inhibitors, such as taxanes, also are contemplated. These molecules are diterpenes produced by the plants of the genus Taxus, and include paclitaxel and docetaxel.
[0223] Epidermal growth factor receptor inhibitors, such as Iressa, mTOR, the mammalian target of rapamycin, also known as FK506-binding protein 12-rapamycin associated protein 1 (FRAP1) is a serine/threonine protein kinase that regulates cell growth, cell proliferation, cell motility, cell survival, protein synthesis, and transcription. Rapamycin and analogs thereof ("rapalogs") are therefore provided for use in combination cancer therapy in accordance with the present technology.
[0224] Another possible combination therapy with the peptides claimed herein is TNF-.alpha. (tumor necrosis factor-alpha), a cytokine involved in systemic inflammation and a member of a group of cytokines that stimulate the acute phase reaction. The primary role of TNF is in the regulation of immune cells. TNF is also able to induce apoptotic cell death, to induce inflammation, and to inhibit tumorigenesis and viral replication.
[0225] Agents that disrupt the synthesis and fidelity of nucleic acid precursors and subunits also lead to DNA damage. As such a number of nucleic acid precursors have been developed. Particularly useful are agents that have undergone extensive testing and are readily available. As such, agents such as 5-fluorouracil (5-FU), are preferentially used by neoplastic tissue, making this agent particularly useful for targeting to neoplastic cells. Although quite toxic, 5-FU, is applicable in a wide range of carriers, including topical, however intravenous administration with doses ranging from 3 to 15 mg/kg/day being commonly used.
[0226] Other factors that cause DNA damage and have been used extensively include what are commonly known as .gamma.-rays, x-rays, and/or the directed delivery of radioisotopes to tumor cells. Other forms of DNA damaging factors are also contemplated such as microwaves and UV-irradiation. It is most likely that all of these factors effect a broad range of damage DNA, on the precursors of DNA, the replication and repair of DNA, and the assembly and maintenance of chromosomes. Dosage ranges for x-rays range from daily doses of 50 to 200 roentgens for prolonged periods of time (3 to 4 weeks), to single doses of 2000 to 6000 roentgens. Dosage ranges for radioisotopes vary widely, and depend on the half-life of the isotope, the strength and type of radiation emitted, and the uptake by the neoplastic cells.
[0227] The skilled artisan is directed to Remington's Pharmaceutical Sciences, 15th Edition, chapter 33, in particular pages 624-652. Some variation in dosage will necessarily occur depending on the condition of the subject being treated. The person responsible for administration will, in any event, determine the appropriate dose for the individual subject. Moreover, for human administration, preparations should meet sterility, pyrogenicity, general safety and purity standards as required by FDA Office of Biologics standards.
[0228] In addition to combining Smad7 therapies with chemo- and radiotherapies, it also is contemplated that combination with immunotherapy, hormone therapy, toxin therapy and surgery. In particular, one may employ targeted therapies such as AVASTIN.RTM., ERBITUX.RTM., GLEEVEC.RTM., HERCEPTIN.RTM., and RITUXAN.RTM..
[0229] In other embodiments, to assess the roles and mechanisms of Smad7 within the context of oral mucositis, "gene-switch" transgenic mouse models were developed to allow control of the level and duration of Smad7 transgene expression specifically in oral epithelia. In accordance with these embodiments, these models may be used to test other genes or downstream molecules for their effects on oral epithelia and oral mucosa. Thus, these models can be used for, but are not limited to, further analysis of oral wound healing biology and testing therapeutic approaches to oral wound healing. Molecular Smad7 targets identified in these studies can provide additional therapeutic targets for subjects suffering from oral mucositis. Models and resources developed herein can provide unique tools for analytical studies to identify biomarkers and therapeutic targets related to Smad7 overexpression and control, for example, downstream molecules turned on or bound by Smad7 can be identified as additional therapeutic targets for example, to treat oral mucositis, psoriasis and other conditions aggravated by TGF-.beta. activities and NF-.kappa.B activities.
D. Kits
[0230] In certain embodiments, a kit provided herein may include compositions discussed above for treating a subject having a condition provided herein, such as but not limited to oral mucositis, psoriasis, or wound healing. The kits can include one or more containers containing the therapeutic Smad7 compositions of the present technology. Any of the kits will generally include at least one vial, test tube, flask, bottle, syringe or other container, into which compositions may be preferably and/or suitably aliquoted. Kits herein may also include a kit for assessing biological targets that contribute to a condition provided herein.
E. Methods of Predicting or Evaluating Responses
[0231] Also provided are methods for predicting and/or evaluating a response to treatment with Smad7 using by assessing the level of expression of one or more markers associated with exposure to Smad7. Such markers may include, but are not limited to, Rac1 for cell migration, NF-.kappa.B for inflammation, and TGF-.beta. for growth arrest and inflammation. As is discussed in the Examples, methods for detection of and/or changes in the levels of one or more markers associated with Smad7 activity are provided and/or known in the art. In some embodiments, the level of expression of one or more of the Smad7 markers in a subject may be assessed, and based on the level detected, a decision may be made to treat (or to continue or discontinue treatment) with Smad7, or to employ an alternate treatment.
[0232] The term "detection of" as used herein refers to the ability to measure the presence or absence of a marker at some repeatable and controlled level. Typically, detection is performed over background values, which may include the noise (or detection limits) inherent in the testing system. As such, there is typically a "lower limit" of detection associated with an assay, and in order to be detected, a change may need to be above a certain cut-off level, for example. Determination of such limits is well-known in the art.
[0233] In some embodiments, detection is performed as compared to controls, which may include, but are not limited to, a comparison with data from normal subjects and/or comparable normal tissue (in the same or different subjects) absent the disease or disorder present in the subject (or the specific tissue of the subject tested). In some embodiments, the comparison may be between levels detected at a variety of time intervals (and/or locations) in a patient. In some embodiments, the detection needs to be statistically significant as compared to background or control levels; the ability to assess significance is well-known in the art, and exemplified in the Examples.
[0234] The term "changes in the levels" as used herein refers to a detectable change from a control or background level, and or a previously detected level. In some embodiments, the change is an increase as compared to another level, and in some embodiments the change is a decrease as compared to another level. In some embodiments, the detectable change (increase or decrease) is statistically significant. In some embodiments, such changes can be assessed quantitatively as at least about a 5%, 10%, 25%, 50%, 100%, 200%, 500% or greater change, and/or about a 5-10%, 10-25%, 10-50%, 25-50%, 50-75%, 50-100%, 100-150%, 100-200%, 200-300%, 300-500%, or 500-1000% change.
F. Method of Screening for Additional Biologically Active Fragments
[0235] In another aspect, methods of screening for additional biologically active fragments (including, but not limited to truncations) of Smad7 are contemplated. In some embodiments, biological activity may be assessed using one of the methods described herein, including those described below in Examples 5 and 8. Some of the biological activities that can be assessed include, but are not limited to, increasing cell proliferation, reducing or inhibiting cell death, reducing excessive inflammation, preventing DNA damage, and/or increasing cell migration, as well as animal models treating or preventing one or more disease or disorders in which such treatment would be helpful as further discussed herein. Such activities can be assessed using one or more assays including, but not limited to, the ability to block phosphorylation of Smad2 and/or nuclear translocation of the NF-.kappa.B p50 subunit, increase cell proliferation, reduce apoptosis and/or radiation-induced DNA damage, reduce inflammation and/or angiogenesis, promote healing in oral mucositis, surgical wounds, diabetes wounds, and/or wounds associated with chronic inflammation in mice and other laboratory models. Some specific examples include, but are not limited to, immunofluorescence (IF), immunohistochemistry (IHC), and TUNEL assay for apoptosis.
[0236] In some embodiments, biologically active fragments are those that are selected to include one or more or all of the activities described herein. In some embodiments, biologically active fragments selected to include only or primarily 1, only or primarily 2, only or primarily 3, only or primarily 4, or only or primarily 5 of the activities described herein. In some embodiments, biologically active fragments selected to exclude only or primarily 1, only or primarily 2, only or primarily 3, only or primarily 4, or only or primarily 5 of the activities described herein. In some embodiments, the biologically active fragments are selected to include or to exclude a specific subset of the activities described herein. For instance, increased proliferation and migration may be sufficient for treating diabetic wounds, whereas anti-inflammation is needed in chronic inflammatory wounds. Reduced apoptosis and DNA damage activities are needed for treating oral mucositis but not for treating surgical wounds
[0237] The term "primarily includes" as used herein refers to fragments in which although some level of other biological activity may remain, that activity is reduced as compared with full-length fragments, whereas the activity that is considered "primary" remains at about the same or an increased level as that observed in the full-length native protein. Similarly, the term "primarily excludes" as used herein refers to fragments in which although some level of a particular biological activity may remain, the level of that particular activity is reduced (optionally significantly and/or statistically significantly reduced) as compared with full-length fragments, whereas one or more other biological activities remains at about the same or increased level as that observed in the full-length native protein.
[0238] In some embodiments involving selection of biologically active fragments, the methods include assessing changes in the level of expression of one or more biological activities, including increases and decreases of one or more activities in a selected fragment are assessed as changes in reference to the activities observed in the full-length protein. In some embodiments, one or more biological activities are being selected to remain the same as that observed in the full-length fragments while other activities may be increased or decreased or even eliminated (e.g., such fragments would lack one or more of the activities discussed). In some embodiments, the change is an increase as compared to another level, and in some embodiments the change is a decrease as compared to another level. In some embodiments, the detectable change (increase or decrease) is statistically significant. In some embodiments, such changes can be assessed quantitatively as at least about a 5%, 10%, 25%, 50%, 100%, 200%, 500% or greater change, and/or about a 5-10%, 10-25%, 10-50%, 25-50%, 50-75%, 50-100%, 100-150%, 100-200%, 200-300%, 300-500%, or 500-1000% change. In some embodiments, an activity that "remains the same" can still be observed to have some change from the activity of the full-length protein, but such change might be limited to, for example, about a 1%, 2%, 5%, 10%, or 20% change or less.
[0239] In a non-limiting example, fragments of interest may include those that primarily mediate the anti-inflammatory effect of Smad7. Smad7 peptides having this anti-inflammatory function may be sufficient and optionally an improvement for treating chronic inflammation associated conditions, such as but not limited to, oral mucositis, stomatitis and psoriasis, among others. In another non-limiting example, fragments of interest may include those that primarily mediate cell migration and/or blocking TGF-.beta.-induced growth arrest and/or fibrotic response. Smad7 peptides having this cell migration and proliferation function may be sufficient, and optionally an improvement, for enhancing healing that is not associated with excessive inflammation. Types of wounds that might benefit from this form of treatment include, but are not limited to, surgical wounds, fibrotic scarring, and diabetes wounds, defective healing and/or scarring among others.
G. Methods of Producing Smad7 Protein
[0240] In another aspect, methods for producing Smad7 protein, including any of the Smad7 variants, fragments, truncations, fusion proteins (e.g., PTD-Smad7) described herein are contemplated. The inventors have discovered methods of producing Smad7 protein at levels and purity sufficient for research, development, or commercialization that include nucleic acid codon optimization. As a result, methods for producing Smad7 including the use of one or more of the codon-optimized Smad7 nucleic acid molecules described herein (e.g., within the Examples) are expressly contemplated.
EXAMPLES
[0241] The following examples are included to illustrate various embodiments. It should be appreciated by those of skill in the art that the techniques disclosed in the examples that follow represent techniques discovered to function well in the practice of the claimed methods, compositions and apparatus. However, those of skill in the art should, in light of the present disclosure, appreciate that many changes may be made in the specific embodiments which are disclosed and still obtain a like or similar result without departing from the spirit and scope of the present technology.
Example 1: K5.Smad7 Mice are Resistant to Oral Mucositis
[0242] A transgenic mouse model expressing a human Smad7 protein in keratinocytes (K5.Smad7) was generated as previously described (Han et al., Dev. Cell, 11:301-312, 2006). Transgene expression in oral epithelia was confirmed (FIGS. 7A-B). The mice were bred into in the C57BL/6 background, and 8-10 weeks old male and female transgenic mice and wild-type littermates were used in studies. These mice showed improved healing of excisional skin wounds (Han et al., Am. J. Pathol., 179:1768-1779, 2011) and radiation-induced oral mucositis.
[0243] K5.Smad7 mice and wild-type littermates were exposed to cranial radiation to determine the biological equivalent dose (BED) required to induce oral mucositis in mice. It was determined that 8 Gy.times.3 (BED=43.2), a regimen relevant to hypo-fractionated radiotherapy in clinic, was the minimal dose needed to induce oral mucositis (FIGS. 1A-B). To evaluate the potency of Smad7 effects, they also tested single doses of cranial radiation and found that oral mucositis severity correlated with BED values between 18 Gy (BED=50.4) and 22 Gy (BED=70.4) (FIGS. 1A-B, FIG. 7C). By day 9 after initiation of radiation, wild-type mice developed oral ulcers (FIGS. 1A-B).
[0244] K5.Smad7 oral mucosa prior to irradiation had morphology similar to wild-type mice, but exhibited resistance to radiation-induced oral mucositis (FIGS. 1A-B). Histological analyses revealed that wild-type mice developed oral mucositis (FIG. 1A) similar to that in humans (FIG. 1C). The First Affiliated Hospital of Kunming Medical University, China provided de-identified archived human tissue paraffin sections and approved the study as an exempt for human subjects. Oral mucositis lesions were from the tongue, buccal or oropharyngeal mucosa adjacent to recurrent oral cancers that had undergone radiotherapy. Non-irradiated oral mucosa sections were from surgically removed sleep apnea oral tissues and a tongue biopsy adjacent to a cyst (mucocele).
[0245] K5.Smad7 oral epithelia typically showed radiation dose-dependent damage, i.e., thinning epithelium and flattened tongue papillae after 8 Gy.times.3 radiation, and more damaged (hypo- or hypertrophic) epithelial cells after 18 Gy and 22 Gy radiation (FIG. 1A). Consistent with increased leukocyte infiltration in human oral mucositis lesions (FIG. 1C), lesions in wild-type mice harbored numerous infiltrated leukocytes (FIGS. 1D-E) consisting of neutrophils, macrophages, and lymphocytes (FIG. 7D); all were substantially reduced in K5.Smad7 oral mucosa (FIGS. 1D-E and 7D).
[0246] Because it is difficult to capture human oral mucositis pathology at the acute phase, a mouse model was utilized to assess proliferation and apoptosis when ulcers are just formed. Similar to previous reports, proliferative cells were sparse in irradiated wild-type oral epithelium, but were seen more in irradiated K5.Smad7 oral epithelium (FIGS. 1D and 1F). Conversely, apoptotic cells were significantly reduced in irradiated K5.Smad7 oral mucosa compared to wild-type mice (FIGS. 1D and 1G).
[0247] As expected, cells with nuclear NF-.kappa.B p50 subunit were significantly increased in oral mucositis compared to non-irradiated wild-type oral mucosa (FIGS. 2A-B). Interestingly, TGF-.beta.1, an immune suppressant in internal organ, but pro-inflammatory in oral mucosa, together with its activated signaling mediator, phosphorylated (p) Smad2, were also increased in oral mucositis compared to non-irradiated oral mucosa in wild-type mice (FIGS. 2A-B). Similar changes were also detected in human oral mucositis lesions (FIGS. 2A-B).
[0248] Irradiated K5.Smad7 oral epithelia significantly reduced cells positive for nuclear NF-.kappa.B p50 and pSmad2, even though they still had abundant TGF-.beta.1 protein (FIGS. 2A-B). TGF-.beta.1 mRNA in irradiated wild-type oral mucosa was significantly increased on day 9 and day 10 (FIG. 2C). TGF-.beta.1 mRNA level in K5.Smad7 mucosa was similar to wild-type mucosa at earlier time points, but was back to normal by day 10 (FIG. 2C). Although not wishing to be bound by any theory, these data suggest that TGF-.beta.1 transcription is not inhibited by Smad7, but its more rapid decline in K5.Smad7 mucosa could be a consequence of accelerated healing.
[0249] Phospho-Smad1/5/8, markers for activated BMP signaling, were not affected by Smad7 before and after radiation (FIG. 7E). This result is consistent with the ability of Smad7 to preferentially inhibit TGF-.beta. signaling.
Example 2: Rac1 Contributes to Smad7-Mediated Keratinocyte Migration
[0250] To determine if Smad7 contributes to healing in human oral keratinocytes, Smad7 was knocked down in spontaneously immortalized human oral keratinocytes (NOK-SI) Smad7 knockdown blunted keratinocyte migration after wounding (FIG. 2D and FIG. 8A). Conversely, knocking down TGF-.beta.1 accelerated keratinocyte migration (FIGS. 8B-8D), consistent with accelerated wound healing seen in mice null for TGF-.beta.1 or Smad3.
[0251] To search for molecular mechanisms associated with Smad7-mediated keratinocyte migration, Rac1, a protein indispensable for oral wound healing was examined. Rac1 was reduced after Smad7 knockdown (FIG. 2E). It was expected that TGF-.beta.1 overexpression in oral mucositis would activate Rac1 through a Smad-independent mechanism. However, although total Rac1 protein increased by 2-fold after irradiation, activated Rac1 protein did not change considerably in wild-type tongues (FIG. 2F).
[0252] In K5.Smad7 oral mucosa, both total and activated Rac1 were significantly increased by 4-fold and 8-fold, respectively, compared to wild-type oral mucosa (FIG. 2F). To determine the functional significance of Smad7-induced Rac1 activation, Rac1 was knocked down in primary keratinocytes isolated from wild-type and Smad7 transgenic neonatal skin, and assays for cell proliferation and migration were performed. Rac1 knockdown showed modestly reduced proliferation in wild-type and Smad7 keratinocytes (FIGS. 9A-9C), but almost completely abrogated Smad7-induced migration (FIG. 2G and FIG. 9D), suggesting that increased Rac1 contributes to Smad7-mediated cell migration.
[0253] It was observed that increased Rac1 mRNA levels in Smad7 transgenic keratinocytes correlated with total and active Rac1 protein levels (FIGS. 3A-B and FIGS. 10A-B), suggesting that increased Rac1 activation in Smad7 keratinocytes is, at least in part, a consequence of increased Rac1 transcripts. Further, Rac1 protein increased by .about.3-fold (FIG. 3C) after knockdown of individual Smads in NOK-SI cells (FIGS. 10C-10E). These data suggest that normal Smad signaling represses Rac1 transcription.
[0254] Among the two putative Smad binding elements (SBEs) in the mouse Rac1 promoter (-2.1 Kb and -1.5 Kb upstream of the coding sequence), which are in similar regions of the human Rac1 promoter, chromatin immunoprecipitation (ChIP) identified Smad-2, -3, -4, and -7 binding to the -1.5 Kb site (FIG. 3D), but not the -2.1 Kb site in wild-type keratinocytes; binding of Smad-2, -3 and -4 was significantly reduced in Smad7 transgenic keratinocytes (FIG. 3D).
[0255] Luciferase reporter assays using a SBE-containing Rac1-Luc construct show that knockdown of Smad7 in wild-type keratinocytes significantly reduced luciferase activity (FIG. 3E). Conversely, Smad7 transgenic cells had increased luciferase activity compared to wild-type cells, and mutating the SBE attenuated this increase (FIG. 3F). Thus, Smad7 binding to SBE appears necessary to expel signaling Smads to abrogate Rac1 repression.
[0256] Among known Smad transcriptional co-repressors, it was found that CtBP1 bound to the Rac1 promoter SBE-1.5 Kb site in wild-type keratinocytes (FIG. 3G), and Smad7 transgene expression significantly reduced CtBP1 binding to the SBE (FIGS. 3G-H). When CtBP1 was knocked down in NOK-SI cells, Rac1 protein and Rac1-Luc activity were increased compared to keratinocytes transfected with scrambled siRNA (FIGS. 4A-B), suggesting that CtBP1 binding to SBE-1.5 Kb represses Rac1 expression. Further, knocking down CtBP1 in NOK-SI cells increased their migration (FIG. 4C and FIG. 10F).
[0257] Upon examination of CtBP1 protein in radiation-induced oral mucositis, it was found that CtBP1 is barely detectable in non-irradiated mouse and human oral mucosa (FIGS. 4D-4F); however, CtBP1 positive cells were significantly increased in irradiated oral mucosa of wild-type and K5.Smad7 mice as well as in human oral mucositis (FIGS. 4D-4F). Additionally, CtBP1 mRNA in irradiated wild-type oral mucosa was significantly increased on day 9 and day 10 (FIG. 4G). CtBP1 mRNA level in K5.Smad7 mucosa was similar to wild-type mucosa at earlier time points, but declined to normal by day 10 (FIG. 4G). These results indicate that Smad7 does not reduce CtBP1 mRNA but instead inhibits CtBP1 binding to the Rac1 promoter by repelling the Smad/CtBP1 complex from the SBE binding site; further, more rapid CtBP1 reduction in K5.Smad7 mucosa serves as a marker of healing.
Example 3: Tat-Smad7 Alleviates Radiation-Induced Oral Mucositis
[0258] Smad7 transgene's ability to block multiple pathological processes of oral mucositis prompted us to explore if localized Smad7 delivery can be used to prevent and treat oral mucositis. Because Smad7 is a nuclear protein, local Smad7 delivery needs to allow Smad7 to rapidly enter into cells before saliva washes off the protein. Thus, a recombinant human Smad7 with an N-terminal Tat-tag allowing proteins to rapidly permeate the cell membrane and enter the nucleus was produced. A V5 epitope was added to the C-terminal end of the Tat-Smad7 protein to track Tat-Smad7 cell penetration (FIGS. 11A-11D).
[0259] Using its ability to block Smad2 phosphorylation, Tat-Smad7 bioactivity was tested (FIG. 11C). Tat-Cre recombinant protein with the same tags as a control (FIGS. 11E-F) was produced, and cloned into the pET101-Topo protein expression vector (Invitrogen) that contains a sequence encoding C-terminal 6.lamda.His (SEQ ID NO: 40). Tat-Cre was transformed into BL-21 STAR.TM. E. coli (Invitrogen) to produce Tat-Cre protein and was purified with Ni-NTA column.
[0260] The purity and size of both proteins was verified using SDS-PAGE electrophoresis. To evaluate transduction and activity of Tat-Smad7 protein in vitro, Tat-Smad7 was added to primary mouse keratinocytes. Slides were fixed in cold methanol for 5 minutes and stained for V5 and pSmad2. Tat-Cre activity was verified by digesting a 1,460 bp floxed fragment from the 7,650 bp vector pLL3.7 (Addgene). For in vivo treatments, 30 L 50% glycerol/PBS as a vehicle control and Tat-Cre as a non-irrelevant protein control were used. Tat-Smad7 or Tat-Cre (in 30 .mu.L 50% glycerol/PBS, doses and regimens are specified in each figure) was topically applied to mouse oral cavity and mice were restricted from oral intake for 1 hour.
[0261] For oral mucositis prevention, both Tat-Smad7 and Tat-Cre (in 50% glycerol/PBS) were topically applied to the oral cavity of 8-10 week old C3H females (Jackson Laboratory) or C57BL/6 mice daily, starting 24 hours prior to radiation through day 8 after initiation of radiation. Treated tissues were examined on day 9. Mouse tongues were harvested, fixed in 10% formalin, embedded in paraffin, and cut into 5 .mu.m sections. Histological changes were analyzed and ulcers were measured using H&E stained slides. An additional group received Palifermin treatment with a clinical regimen, i.e., 6.25 mg kg.sup.-1 (i.p.) daily for 3 days prior to irradiation, and daily for 3 days 24 hours after the last dose of radiation.
[0262] Tat-Cre showed no effect compared to vehicle controls (FIGS. 5A-B). Tat-Smad7 treatments showed preventive effects on ulcer formation similar to Palifermin (FIG. 5A). The dose-dependent effect of Tat-Smad7 was more obvious when used on animals given a 20 Gy (BED=60) single dose of radiation that induced larger oral ulcers than fractionated radiation (FIG. 11G). Microscopically, both Palifermin and Tat-Smad7 treated oral mucosa prevented open ulceration in the majority of cases (FIG. 5B). Palifermin-treated mucosa exhibited more keratinocyte down-growth but also more damaged keratinocytes (condensed or charcoal-like nuclei, swelled mono- or multi-nucleated cells and shattered nuclear fragments in conified layers) than Tat-Smad7-treated mucosa (FIG. 5B). Immunostaining revealed that Palifermin increased proliferation more significantly than Tat-Smad7. Tat-Smad7 reduced apoptosis, leukocyte infiltration, nuclear pSmad2 and NF-.kappa.B p50, but Palifermin did not (FIGS. 5B-5G).
[0263] To test whether Tat-Smad7 can be used to treat existing oral mucositis, mice were exposed to fractionated (8 Gy.times.3) cranial radiation and Tat-Smad7 (topically) or Palifermin (6.25 mg kg.sup.-1, i.p.) was applied daily from day 6 after initiation of radiation (when mucosal damage was obvious) till day 9. Treated tissues were examined on day 10. Although beginning post-radiation administration of Palifermin at earlier time points than the current protocol reduced oral mucositis in mice, Palifermin administration with the current protocol did not accelerate ulcer closure (FIG. 6A), regardless of its hyperproliferative effect on the entire oral mucosa (FIG. 6B). This is not surprising, as Palifermin is approved to prevent but not treat oral mucositis.
[0264] Tat-Smad7 treated oral mucositis reduced ulcer sizes and pathological alterations after both fractionated and single dose radiation (FIGS. 6A-B and FIGS. 12A-12G). Away from ulcers, Tat-Smad7 treated oral mucosa exhibited less hyperplasia and more differentiated epithelia than Palifermin-treated oral mucosa (FIG. 6B). With a 20 Gy single dose radiation that caused slower healing than fractionated radiation, the effect of Tat-Smad7 on recovery after wound closure was more obvious. When vehicle treated ulcer was just re-epithelialized, Tat-Smad7 treated mucosa had almost recovered to normal morphology (FIG. 6C).
[0265] Consistent with observations in K5.Smad7 mice, Tat-Smad7 increased Rac1 promoter activity and reduced CtBP1 binding to the SBE of the mouse Rac1 promoter (FIGS. 12G and 12I), and increased Rac1 protein in mouse oral mucositis and human oral keratinocytes (FIGS. 6D-E).
[0266] Tat-Smad7-treated human oral keratinocytes after wound scratch had accelerated wound closure (FIG. 6F and FIG. 13A). Further, irradiated human oral keratinocytes increased nuclear pSmad2 and NF-.kappa.B p50, which were attenuated by Tat-Smad7 treatment (FIG. 13B). In contrast, although Tat-Smad7 penetrated oral cancer cells efficiently (FIG. 13C), it did not further elevate Rac1 protein level that is already abundant in cancer cells (FIG. 13D). This result could account for faster migration of cancer cells than normal keratinocytes (FIG. 6F and FIGS. 13A, 13E-13H), and the lack of an effect of Tat-Smad7 on migration in two oral cancer cell lines: MSK921 which does not contain genetic loss of TGF-.beta. signaling components; and Cal27 which has a mutated Smad4 (FIGS. 13E-13H).
[0267] Colony assays show that survival of human oral keratinocytes was slightly increased by Tat-Smad7 treatment with or without radiation (FIG. 6G). Consistent with the notion that reduced survival after irradiation is more prominent in cancer cells than in normal cells, SCC cells showed substantial reductions in cell survival after radiation. Treatment with Tat-Smad7 did not affect survival in SCC cells with or without radiation (FIG. 6G).
Example 4: Design of a Cell-Penetrating Smad7 Protein
[0268] It was hypothesized that in order to be effective as a therapeutic, SMAD7 needed to be able to penetrate cells efficiently. In order to achieve this, the Smad7 sequence was modified to include a protein transduction domain.
[0269] The Tat sequence from HIV was selected to test with Smad7 as a protein transduction domain. The nucleotide and protein sequences of Tat that were used in fusion proteins with Smad7 and Smad7 fragments are derived from Cardarelli et al., Traffic Apr 9(4):528-39 (2008). The Tat nucleotide and amino acid sequences are provided below:
TABLE-US-00002 (SEQ ID NO: 1) ggccgtaaaaaacgccgtcaacgccgccgt (SEQ ID NO: 2) G R K K R R Q R R R
[0270] Fusion proteins were prepared having Tat directly linked in frame to human Smad7 complementary DNA (cDNA) either at the 5' or 3' ends of Smad7 as shown below:
TABLE-US-00003 (SEQ ID NO: 7) 5' Tat: Ggccgtaaaaaacgccgtcaacgccgccgt -Smad7 (SEQ ID NO: 8) 3' Tat: Smad7-Ggccgtaaaaaacgccgtcaacgccgccgt
[0271] The 5' Tat-Smad7 construct included a 3' V5 tag sequence, and was cloned into the pGEX-6p-1 protein expression vector (New England Biolabs) to make a GST-Tat-Smad7 fusion protein. Tat-Smad7 gene was transformed into BL-21 Star Escherichia coli (Invitrogen) to produce Tat-Smad7 protein. The protein was purified by glutathione column purification and elution, using enzymatic cleavage from the Glutathione S Transferase (GST) fusion (Precision enzyme, GE Life Sciences).
[0272] While creating a PTD-Smad7 fusion protein, a V5 tag at the 3' end was included to monitor Tat-Smad7 penetration into cells by immunostaining using a V5 antibody. This epitope tag can be deleted for use in the clinic (e.g., by re-cloning the sequence in the absence of the V5 tag), if appropriate.
[0273] A PTD-Smad7 fusion protein (Tat-Smad7-V5-6H) ("6H" disclosed as SEQ ID NO: 40) was also created having a 6-Histidine (6-H) tag (SEQ ID NO: 40) for protein purification, and is shown below. Tat-Smad7-V5-6H ("6H" disclosed as SEQ ID NO: 40) has the following nucleotide sequence: 1-53 include the 5' sequence of pET-TOPO; 54-1365 include Tat-Smad7; 1366-1497 include 3' pET-TOPO containing the V5 epitope and 6.times.His tag (SEQ ID NO: 40) (V5 includes 1393-1434, His tag includes 1444-1461, and the Stop includes 1462-1464).
[0274] Tat-human Smad7, codon-optimized for protein production, cloned to pET101/D-Topo vector is shown below:
TABLE-US-00004 ttcccctctagaaataattttgtttaactttaagaaggaattcaggagcccttcaccatg M cgtaaaaaacgccgtcaacgccgccgtggtttccgtacgaaacgctcggccctggtccgt R K K R R Q R R R G F R T K R S A L V R cgcctgtggcgctcccgtgctccgggtggtgaagatgaagaagaaggtgctggcggcggt R L W R S R A P G G E D E E E G A G G G ggcggtggcggtgaactgcgtggcgagggtgcaaccgatagtcgtgcacacggtgcaggc G G G G E L R G E G A T D S R A H G A G ggtggcggtccgggtcgtgctggttgctgtctgggtaaagctgtgcgcggcgcgaaaggt G G G P G R A G C C L G K A V R G A K G catcaccatccgcacccgccggcagcaggtgcaggtgcagctggcggtgcggaagccgat H H H P H P P A A G A G A A G G A E A D ctgaaagccctgacccatagtgtcctgaaaaaactgaaagaacgtcagctggagctgctg L K A L T H S V L K K L K E R Q L E L L ctgcaagcagtagaatcccgtggcggtacccgtacggcttgtctgctgctgccgggtcgt L Q A V E S R G G T R T A C L L L P G R ctggattgccgtctgggtccgggtgcaccggctggtgcgcagccggcacaaccgccgagc L D C R L G P G A P A G A Q P A Q P P S tcttacagcctgccgctgctgctgtgtaaagtgtttcgttggccggacctgcgccacagt S Y S L P L L L C K V F R W P D L R H S tccgaagttaaacgcctgtgctgttgcgagagctatggcaaaattaacccggaactggtt S E V K R L C C C E S Y G K I N P E L V tgttgcaatccgcaccatctgtctcgtctgtgtgaactggagagcccgccgccgccgtat C C N P H H L S R L C E L E S P P P P Y tctcgttacccgatggatttcctgaaaccgactgcagattgcccggacgcagtcccgtca S R Y P M D F L K P T A D C P D A V P S tcggctgagaccggcggcaccaactatctggcaccgggcggtctgagtgattcccagctg S A E T G G T N Y L A P G G L S D S Q L ctgctggaaccgggcgaccgttcacattggtgtgtggttgcctattgggaagagaaaacg L L E P G D R S H W C V V A Y W E E K T cgtgtcggtcgcctgtactgcgtacaggaaccgtcgctggatatcttttatgacctgccg R V G R L Y C V Q E P S L D I F Y D L P cagggcaatggtttctgtctgggccaactgaactcagataataaatcgcagctggtgcaa Q G N G F C L G Q L N S D N K S Q L V Q aaagttcgctcaaaaattggctgcggtatccagctgacccgtgaagttgacggtgtctgg K V R S K I G C G I Q L T R E V D G V W gtatataaccgcagctcttacccgatttttatcaaaagtgccaccctggataatccggac V Y N R S S Y P I F I K S A T L D N P D tcccgtacgctgctggtccacaaagtatttccgggcttctcaatcaaagcgttcgattac S R T L L V H K V F P G F S I K A F D Y gagaaagcctactcgctgcagcgcccgaacgaccatgaattcatgcagcaaccgtggacg E K A Y S L Q R P N D H E F M Q Q P W T ggttttactgtgcagatctctttcgttaaaggctggggtcaatgctacacccgtcagttt G F T V Q I S F V K G W G Q C Y T R Q F atctcgtcctgtccgtgctggctggaagtgattttcaatagccgcaagggcgagctcaat I S S C P C W L E V I F N S R K G E L N tcgaagcttgaaggtaagcctatccctaaccctctcctcggtctcgattctacgcgtacc S K L E G K P I P N P L L G L D S T R T ggtcatcatcaccatcaccattgagtttgatccggctgctaacaaagcccgaaagga (SEQ ID NO: 9) G H H H H H H - (SEQ ID NO: 10)
[0275] A comparison of the protein sequence of Tat-Smad7-v5 and Smad7 is provided below. The first amino acid of Smad7 in Tat-Smad7 is not M (unlike Smad7), because Tat-Smad7 is designed to be in-frame with Tat and/or GST to form a GST fusion protein. Tat-Smad7 is then cleaved from the GST fusion protein after purification. Upper case nucleotides identify the V5 tag. Underlined italics indicate amino acids from the optional pET101-Topo backbone vector.
[0276] Below a Tat-Smad7-v5 and Smad7 comparison is presented:
TABLE-US-00005 Tat-Smad7-V5 1 gsgrkkrrqrrrgfrtkrsalvrrlwrsrapggedeeegagggggggelr human Smad7 1 ------------mfrtkrsalvrrlwrsrapggedeeegagggggggelr Tat-Smad7-V5 51 gegatdsrahgaggggpgragcclgkavrgakghhhphppaagagaagga human Smad7 39 gegatdsrahgaggggpgragcclgkavrgakghhhphppaagagaagga Tat-Smad7-V5 101 eadlkalthsvlkklkerqlelllqavesrggtrtaclllpgrldcrlgp human Smad7 89 eadlkalthsvlkklkerqlelllqavesrggtrtaclllpgrldcrlgp Tat-Smad7-V5 151 gapagaqpaqppssyslplllckvfrwpdlrhssevkrlcccesygkinp human Smad7 139 gapagaqpaqppssyslplllckvfrwpdlrhssevkrlcccesygkinp Tat-Smad7-V5 201 elvccnphhlsrlcelesppppysrypmdflkptadcpdavpssaetggt human Smad7 189 elvccnphhlsrlcelesppppysrypmdflkptadcpdavpssaetggt Tat-Smad7-V5 251 nylapgglsdsqlllepgdrshwcvvayweektrvgrlycvqepsldify human Smad7 239 nylapgglsdsqlllepgdrshwcvvayweektrvgrlycvqepsldify Tat-Smad7-V5 301 dlpqgngfclgqlnsdnksqlvqkvrskigcgiqltrevdgvwvynrssy human Smad7 289 dlpqgngfclgqlnsdnksqlvqkvrskigcgiqltrevdgvwvynrssy Tat-Smad7-V5 351 pifiksatldnpdsrtllvhkvfpgfsikafdyekayslqrpndhefmqq human Smad7 339 pifiksatldnpdsrtllvhkvfpgfsikafdyekayslqrpndhefmqq Tat-Smad7-V5 401 pwtgftvgisfvkgwgqcytrqfisscpcwlevifnsrkgelnskleGKP human Smad7 389 pwtgftvqisfvkgwgqcytrqfisscpcwlevifnsr------------ Tat-Smad7-V5 451 IPNPLLGLDST (SEQ ID NO: 11) human Smad7 427 ----------- (SEQ ID NO: 12)
Example 5: Additional Assays for PTD-Smad7 Protein Activity
[0277] Immunofluorescence (IF), immunohistochemistry (IHC), and TUNEL assay for apoptosis.
[0278] IF and IHC were performed as previously described (Han, G., Li, F., Ten Dijke, P. & Wang, X. J. Temporal smad7 transgene induction in mouse epidermis accelerates skin wound healing. Am J Pathol 179, 1768-1779 (2011)). Primary antibodies used were guinea pig antibody to K14 (1:400, Fitzgerald, 20R-CP200), rat antibody to CD4 (1:20, BD Bioscience, 550278), Ly-6G (1:20, BD Bioscience, 550291), BM8 (antibody to F4/80, 1:20, Invitrogen, MF48000), FITC-labeled antibody to BrdU (BD Bioscience, 347583), rat antibody to CD45 (1:50, BD Bioscience, 550539) for mouse samples, mouse antibody to CD45 (1:50, Abcam, Ab781) for human samples, chicken antibody to TGF-.beta.1 (1:50, R&D, AF-101-NA), rabbit antibody to CtBP1 (1:100, Millipore, 07-306), rabbit antibody to NF-.kappa.B p50 (1:200, Santa Cruz Biotechnology, SC-7178), rabbit antibody to PCNA (1:200, Santa Cruz Biotechnology, SC-7907), rabbit antibody to pSmad2 (1:100, Cell Signaling Technology, 3101), and mouse antibody to V5 (1:500, Invitrogen, 460705). For IF, secondary antibodies to different species IgG were Alexa Fluor.RTM. 594 (red) or 488 (green) conjugated (1:200 for all, Invitrogen). For IHC, secondary biotinylated antibodies to different species IgG (1:300, Vector Labs) were used and were developed using Vectastain ABC kit (Vector Labs). A Terminal deoxynucleotidyl transferase uridine nick end-labeling (TUNEL, G3250) kit (Promega) was used on formalin fixed tissue sections to detect apoptotic cells. BrdU labeling was performed in vivo by i.p. injection of 0.125 mg g.sup.-1 BrdU 1 hour prior to euthanization. PCNA or BrdU were quantified as cells mm.sup.-1 epithelial length including all epithelial cells, TUNEL or CD45-positive cells as cells mm.sup.- epithelial length including all epithelial layers and stroma above the muscle layer, nuclear pSmad2 or NF-.kappa.B p50 positive cells as the number of positive cells/existing total remaining epithelial cells (i.e., excluding sloughed epithelial cells induced by irradiation). Consecutive fields of slides were used to count BrdU-labeled cells using MetaMorph software.
[0279] Cell Culture.
[0280] Smad7 transgenic and wild-type primary keratinocytes were prepared from neonatal mouse skin as previously described (Han, G., Li, F., Ten Dijke, P. & Wang, X. J. Temporal smad7 transgene induction in mouse epidermis accelerates skin wound healing. Am J Pathol 179, 1768-1779 (2011)), and cultured in PCT medium (CELLnTEC). Spontaneously immortalized normal oral keratinocytes (NOK-SI) derived from gingival tissues of healthy volunteers were cultured and maintained in defined keratinocyte medium (Castilho, R. M., et al. Rac1 is required for epithelial stem cell function during dermal and oral mucosal wound healing but not for tissue homeostasis in mice. PloS one 5, e10503 (2010)). Oral cancer cells Cal27 (ATCC) and MSK921 were cultured (D. Raben's lab, fingerprinted by University of Colorado Cancer Center Tissue Culture Core) in Dulbecco Modified Eagle Medium supplemented with 10% fetal bovine serum (GIBCO.RTM.; Invitrogen). To assess the effect of Tat-Smad7 in irradiated cells, the above human cell lines were cultured in chamber slides (BD Bioscience, 354108), irradiated with 3 Gy, and Tat-Smad7 (1 .mu.g mL.sup.-1) was added to the culture medium immediately after irradiation. Cells were fixed in 100% cold methanol 4 hours after Tat-Smad7 treatment for immunostaining of pSmad2, NF-.kappa.B p50 and V5.
[0281] Transfection with siRNA.
[0282] When cultured keratinocytes reached 70% confluency, 100 nM of target siRNA or scrambled siRNA (Dharmacon) was transfected using LIPOFECTAMINE.RTM. 2000 (Invitrogen). Cells were harvested 48-72 hours after transfection and subjected to western analyses to determine knockdown efficiency. For migration assays, siRNA was transfected when cells were plated. Target siRNAs included in this study are: mouse siRac1-1 (Invitrogen, MSS237708) and siRac1-2 (IDT, MMC.RNAI.N009007.12.3); human siSmad2 (Dharmacon, L-003561-00-0005), siSmad3 (Invitrogen, HSS106252), and siSmad4 (Invitrogen, HSS118066); human siCtBP1-1 and siCtBP1-2; human siSmad7-1 and siSmad7-2; human TGF-.beta.1 (Dharmacon, J-012562-08-0005); mouse siSmad7.
[0283] In Vitro Keratinocyte Proliferation Assay.
[0284] In vitro keratinocyte proliferation was determined by BrdU incorporation in wild-type and Smad7 transgenic keratinocytes. Cells at 70% confluency were transfected with Rac1 siRNAs, and changed to regular culture medium 24 hours later. An in situ cell proliferation kit (Roche Applied Science) was used to perform in vitro BrdU labeling and detection, and MetaMorph software was used to count BrdU-labeled cells.
[0285] In Vitro Cell Migration Assays.
[0286] When cells reached 100% confluency, the cells were treated with mitomycin C (Sigma) at 10 .mu.g mL.sup.-1 for 2 hours to inhibit cell proliferation and a scratch wound was introduced with a Fisherbrand pipet tip. Cell migration was photographed daily. Migration assays were performed when cells reached confluency after 24 to 36 hours of siRNA transfection, and Image-J software was used to document cell migration as the wound area occupied with migrating cells. For Tat-Smad7 treatment, cells were exposed to Tat-Smad7 protein at 1 .mu.g mL.sup.-1 or vehicle control (PBS) in medium after wound scratch, and medium was changed every other day with freshly added Tat-Smad7 until migrating cells fully covered the scratched wound.
[0287] Cell Survival Assay.
[0288] Cell survival assays were performed as previously described (Munshi, A., Hobbs, M. & Meyn, R. E. Clonogenic cell survival assay. Methods in molecular medicine 110, 21-28 (2005)), with slight modifications. Briefly, cells were plated in 12-well plates at 500 cells well.sup.-1 for non-irradiated wells, and increased up to 1,500 cells well.sup.-1 along with increased radiation doses. Cells were irradiated 24 hours after they were plated. Tat-Smad7 was added at 1 .mu.g mL.sup.-1 or the same volume of PBS used to dissolve Tat-Smad7 (control) to culture medium of irradiated and non-irradiated cells. The medium was changed every other day with freshly added Tat-Smad7 or PBS for 10 to 14 days. Colonies were fixed in methanol, stained in 0.5% crystal violet solution (containing 25% methanol), counted and the average from 4 wells in each experiment was calculated. Two to three separate experiments were performed for each cell line. The relative surviving fraction was calculated as previously described, i.e., the absolute surviving fraction (colony numbers/total plated cells) under each radiation dose divided by the absolute surviving fraction of non-irradiated cells.
[0289] Western Analysis.
[0290] Protein extraction and western analyses were performed as previously described (Li, A. G., Lu, S. L., Zhang, M. X., Deng, C. & Wang, X. J. Smad3 knockout mice exhibit a resistance to skin chemical carcinogenesis. Cancer Res 64, 7836-7845 (2004)). The antibodies used in this study included rabbit antibody to Smad7 (1:500), rabbit antibodies to Smad2 (1:300, Zymed, 51-1300) and Smad4 (1:300, Epitomics, 1676-1), rabbit antibody to Smad3 (1:300, Cell Signaling Technology, 9513), mouse antibody to Rac1 (1:500, BD Biosciences, 610651), rabbit antibody to CtBP1 (1:500, Millipore, 07-306), mouse antibody to tubulin (1:3000, Sigma, T5168), mouse antibody to GAPDH (1:5000, Abcam, Ab8245) and goat antibody to actin (1:1000, Santa Cruz Biotechnology, SC1616). Gray-scale images were obtained using the ODYSSEY.RTM. v.1.2 software (LI-COR Biosciences).
[0291] Rac1 Activation Assay.
[0292] Active GTP-bound Rac1 was examined using a BIOCHEM.TM. Kit for Rac1 activation (Cytoskeleton Inc, BK035). Wild-type and Smad7 transgenic keratinocytes were cultured in 15 cm diameter tissue culture plates and prepared protein lysates using the provided lysis buffer. To assay Rac1 activity, 1 mg of cell lysate was used. To examine total Rac1 and Smad7 proteins, 50 .mu.g of lysate was used. To measure GTP-bound Rac1 in mouse tongues, half of the tongue was ground to a powder in liquid nitrogen and lysed with lysis buffer to extract protein, GTP-bound Rac1 was assayed in 2 mg of protein lysate per sample and 50 .mu.g of protein lysate was loaded for total Rac1 protein western blot.
[0293] Chip Assays.
[0294] ChIP assays were performed using the ChIP-IT express kit (Active Motive, 53009) as previously described (Hoot, K. E., et al. HGF upregulation contributes to angiogenesis in mice with keratinocyte-specific Smad2 deletion. J Clin Invest 120, 3606-3616 (2010); Hoot, K. E., et al. Keratinocyte-specific Smad2 ablation results in increased epithelial-mesenchymal transition during skin cancer formation and progression. Owens, et al., J. Clin. Invest 118, 2722-2732 (2008). Smad4-dependent desmoglein-4 expression contributes to hair follicle integrity. Owens, et al., Dev. Biol. 322:156-166 (2008). DNA-protein complex was isolated from primary mouse keratinocytes. For ChIP, 6.3 .mu.g sheared chromatin was incubated with protein-G magnetic beads and 2 .mu.g each of rabbit antibodies to Smad2 (Cell Signaling Technology, 3122), Smad3 (Cell Signaling Technology, 9523), Smad4 (Cell Signaling Technology, 9515), Smad7 antibody (Santa Cruz Biotechnology, SC-11392), CtBP1 (Millipore) or a negative control rabbit IgG (Santa Cruz Biotechnology, SC-2027). Eluted DNA from the protein-DNA complex was used for PCR analyses, and CtBP1 binding to the Rac1 promoter was compared in wild-type and Smad7 transgenic keratinocytes by ChIP band intensities on gel images or by quantitative PCR using Power SYBR Green Master Mix (Applied Biosystems). Primers used to amplify the Rac1 SBE-1.5 Kb promoter regions:
TABLE-US-00006 (SEQ ID NO: 13) 5'-TGGAATTCCTGGTCTGGTTT-3' (sense) (SEQ ID NO: 14) 5'-GCCAAGCTGCTCTTCCAGTA-3' (antisense) (SEQ ID NO: 15) 5'-TCTCAGGGGGCCAAAGGTGTT-3' (sense) (SEQ ID NO: 16) 5'-TCCCAGCACCTGAATCACATGG-3' (antisense)
[0295] Rac1 Promoter Luciferase Reporter Construct, Site-Directed Mutagenesis and Luciferase Assay.
[0296] The 883 bp fragment of -1671 bp to -789 bp of the Rac1 promoter, encompassing the SBE-1.5 Kb site, was amplified from wild-type mouse DNA using 5' XhoI and 3' HindIII tagged primers, and this Rac1 promoter fragment was cloned into pGL4.26 vector (Promega) to make the Rac1 promoter-pGL4.26 luciferase reporter (Rac1-Luc) construct. For site-directed mutagenesis, the SBE sequence 5'-TGTCTGTGCT-3' (SEQ ID NO: 17) was mutated to 5'-TGATAGAGCT-3' (SEQ ID NO: 18). Rac1-Luc and pGL4.74 (1:20) were co-transfected with Smad7 siRNA, CtBP1 siRNA or scrambled siRNA using Lipofectamine 2000 (Invitrogen) to primary mouse keratinocytes, or primary mouse keratinocytes with Tat-Smad7 treatment (1 .mu.g mL.sup.-1). Cell lysates were collected and luciferase assays were performed 48 hours after transfection or Tat-Smad7 treatment, using the DUAL-LUCIFERASE.RTM. Reporter Assay kit (Promega) following manufacturer's instructions. Rac1-luciferase activity was measured with the Glomax machine (Promega) and expressed by the ratio of firefly activity to Renilla activity. Primers used for amplification of Rac1 promoter sequence were:
TABLE-US-00007 (SEQ ID NO: 19) 5'-ATCCTCGAG-TATCCTCCAGGTCTGGG-3' (SEQ ID NO: 20) 5'-GCCAAGCTT-AGCGTCCAGCGTTAACCTG-3'
[0297] Statistical Analysis.
[0298] Statistical differences in molecular analyses and oral mucositis ulcer size were analyzed using the Student's t-test and all data was presented by mean+s.d. except ulcer size, which was presented by mean+s.e.m. Oral mucositis incidences were analyzed by Fisher's exact test.
Example 6: Codon Optimization for Smad7 Protein Production in E. coli or Yeast
[0299] Although many mammalian proteins can be produced in bacteria without nucleotide sequence modification, the analysis indicated that the Smad7 nucleotide sequence would need to be modified to allow protein expression in bacteria.
[0300] Analysis of Smad7 cDNA mammalian codon use revealed nine arginine amino acids coded for by the following nucleotides: 7-9, 43-45, 169-171, 403-405, 490-492, 526-528, 526-528, 823-825, 1057-1059 are a rare codon (AGG, codon utilization 1.7%). Since these codons are rare codons in bacteria, it is expected that they could halt or reduce protein translation and/or production in bacteria. The amino acids coded for by rare arginine codons are indicated by bold capitals below in the illustrated human Smad7 protein, including arginines at positions 3, 15, 57, 135, 164, 169, 176, 275, and 353. Additionally, the following arginine codons also have low frequency usages. CGA (3.5% codon utilization): nucleotides 16-18, 136-138, 199-201, 598-600, which code for arginine at positions 6, 46, 67, 200; CGG (5.4% codon utilization): nucleotides 31-33, 112-114, 316-318, 772-774, 940-942, 973-975, 1135-1137, 1276-1278, which code for arginine at positions 11, 38, 106, 258, 314, 325, 379, 426; AGA (2.8% codon utilization): nucleotides 637-639, 814-816, which code for arginine at positions 213, 272. These arginine residues are highlighted in bold upper case R below and they are changed to CGC in at least one of the codon-optimized nucleic acid sequences (20.6% codon utilization):
TABLE-US-00008 (SEQ ID NO: 12) 1 mfRtkRsalv RrlwRsrapg gedeeegagg gggggelRge gatdsRahga 51 ggggpgRagc clgkavrgak ghhhphppaa gagaaggaea dlkalthsvl 101 kklkeRqlel llqavesrgg trtaclllpg rldcRlgpga pagaqpaqpp 151 ssyslplllc kvfRwpdlRh ssevkRlccc esygkinpel vccnphhlsR 201 lcelespppp ysRypmdflk ptadcpdavp ssaetggtny lapgglsdsq 251 lllepgdRsh wcvvayweek tRvgRlycvq epsldifydl pqgngfclgq 301 lnsdnksqlv qkvRskigcg iqltRevdgv wvynrssypi fiksatldnp 351 dsRtllvhkv fpgfsikafd yekayslqRp ndhefmqqpw tgftvqisfy 401 kgwgqcytrq fisscpcwle vifnsR
[0301] Based on this analysis, it was decided to optimize the Smad7 nucleotide sequence to codons that were believed to allow increased Tat-Smad7 protein production in E. coli or yeast. Provided below is the optimized nucleic acid codon sequence made by Genscript. Briefly, the sequence has the following composition: nucleotides 1-6 include the restriction recognition site for BamHI; nucleotides 7-36 include the Tat sequence; nucleotides 37-1314 include codon-optimized human Smad7 cDNA; nucleotides 1342-1383 include the V5 epitope; nucleotides 1384-1386 are the stop codon; and nucleotides 1387-1392 including the restriction recognition site for SalI. In this sequence, ATG is removed to be used with GST. The entire designed sequence was converted to E. coli codons based on "Codon-Usage Database." The initial optimized Smad7 sequence (SEQ ID NO: 23) is shown below:
TABLE-US-00009 (SEQ ID NO: 23) 1 ggatccggcc gtaaaaaacg ccgtcaacgc cgccgtggtt tccgtacgaa acgctcggcc 61 ctggtccgtc gcctgtggcg ctcccgtgct ccgggtggtg aagatgaaga agaaggtgct 121 ggcggcggtg gcggtggcgg tgaactgcgt ggcgagggtg caaccgatag tcgtgcacac 181 ggtgcaggcg gtggcggtcc gggtcgtgct ggttgctgtc tgggtaaagc tgtgcgcggc 241 gcgaaaggtc atcaccatcc gcacccgccg gcagcaggtg caggtgcagc tggcggtgcg 301 gaagccgatc tgaaagccct gacccatagt gtcctgaaaa aactgaaaga acgtcagctg 361 gagctgctgc tgcaagcagt agaatcccgt ggcggtaccc gtacggcttg tctgctgctg 421 ccgggtcgtc tggattgccg tctgggtccg ggtgcaccgg ctggtgcgca gccggcacaa 481 ccgccgagct cttacagcct gccgctgctg ctgtgtaaag tgtttcgttg gccggacctg 541 cgccacagtt ccgaagttaa acgcctgtgc tgttgcgaga gctatggcaa aattaacccg 601 gaactggttt gttgcaatcc gcaccatctg tctcgtctgt gtgaactgga gagcccgccg 661 ccgccgtatt ctcgttaccc gatggatttc ctgaaaccga ctgcagattg cccggacgca 721 gtcccgtcat cggctgagac cggcggcacc aactatctgg caccgggcgg tctgagtgat 781 tcccagctgc tgctggaacc gggcgaccgt tcacattggt gtgtggttgc ctattgggaa 841 gagaaaacgc gtgtcggtcg cctgtactgc gtacaggaac cgtcgctgga tatcttttat 901 gacctgccgc agggcaatgg tttctgtctg ggccaactga actcagataa taaatcgcag 961 ctggtgcaaa aagttcgctc aaaaattggc tgcggtatcc agctgacccg tgaagttgac 1021 ggtgtctggg tatataaccg cagctcttac ccgattttta tcaaaagtgc caccctggat 1081 aatccggact cccgtacgct gctggtccac aaagtatttc cgggcttctc aatcaaagcg 1141 ttcgattacg agaaagccta ctcgctgcag cgcccgaacg accatgaatt catgcagcaa 1201 ccgtggacgg gttttactgt gcagatctct ttcgttaaag gctggggtca atgctacacc 1261 cgtcagttta tctcgtcctg tccgtgctgg ctggaagtga ttttcaatag ccgcaagggc 1321 gagctcaatt cgaagcttga aggtaagcct atccctaacc ctctcctcgg tctcgattct 1381 acgtgagtcg ac
[0302] A nucleotide sequence comparison between Tat-Smad7-V5 (SEQ ID NO: 23) and human Smad7 (SEQ ID NO: 22) cDNA is provided below. Human Smad7 and codon-optimized Tat-Smad7-V5 share 68% codon homology. Human Smad7 and codon-optimized Tat-Smad7 share 71% codon homology. Human Smad7 and codon-optimized Smad7 share 73% codon homology.
TABLE-US-00010 Alignment: Global DNA alignment against reference molecule Parameters: Scoring matrix: Linear (Mismatch 2, OpenGap 4, ExtGap 1) Reference molecule: human Smad7 mRNA, Region 1-1281 Number of sequences to align: 2 Settings: Similarity significance value cutoff: >= 90% Summary of Percent Matches: Reference: human Smad7 mRNA 1-1281 (1281 bps) -- Sequence 2: Tat-Smad7-V5 1-1392 (1392 bps) 68% human Smad7 1 --atg----------------------------------ttcaggaccaaacgatctgcg Tat-Smad7-V5 1 ggatccggccgtaaaaaacgccgtcaacgccgccgtggtttccgtacgaaacgctcggcc human Smad7 25 ctcgtccggcgtctctggaggagccgtgcgcccggcggcgaagacgaggaagagggcgca Tat-Smad7-V5 61 ctggtccgtcgcctgtggcgctcccgtgctccgggtggtgaagatgaagaaaaaggtgct human Smad7 85 gggggaggtggaggaggaggcgagctgcggggagaaggggcgacggacagccgagcgcat Tat-Smad7-V5 121 ggcggcggtggcggtggcggtgaactgcgtggcgagggtgcaaccgatagtcgtgcacac human Smad7 145 ggggccggtggcggcggcccgggcagggctggatgctgcctgggcaaggcaatgcgaggt Tat-Smad7-V5 181 ggtgcaggcggtggcggtccgggtcgtgctggttgctgtctgggtaaagctgtgcgcggc human Smad7 205 gccaaaggtcaccaccatccccacccgccagccgcgggcgccggcgcggccgggggcgcc Tat-Smad7-V5 241 gcgaaaggtcatcaccatccgcacccgccggcagcaggtgcaggtgcagctggcggtgcg human Smad7 265 gaggcggatctgaaggcgctcacgcactcggtgctcaagaaactgaaggagcggcagcta Tat-Smad7-V5 301 gaagccgatctgaaagccctgacccatagtgtcctgaaaaaactgaaagaacgtcagctg human Smad7 325 gagctgctgctccaggccgtggagtcccgcggcgggacgcgcaccgcgtgcctcctgctg Tat-Smad7-V5 361 gagctgctgctgcaagcagtagaatcccgtggcggtacccgtacggcttgtctgctgctg human Smad7 385 cccggccgcctggactgcaggctaggcccgggggcgcccgccggcgcgcagcctgcgcag Tat-Smad7-V5 421 ccgggtcgtctggattgccgtctgggtccgggtgcaccggctggtgcgcagccggcacaa human Smad7 445 ccgccctcgtcctactcgctccccctcctgctgtgcaaagtgttcaggtggccggatctc Tat-Smad7-V5 481 ccgccgagctcttacagcctgccgctgctgctgtgtaaagtgtttcgttggccggaccta human Smad7 505 aggcattcctcggaagtcaagaggctgtgttgctgtgaatcttacgggaagatcaacccc Tat-Smad7-V5 541 cgccacagttccgaagttaaacgcctgtgctgttgcgagagctatggcaaaattaacccg human Smad7 565 gagctggtgtgctgcaacccccatcaccttagccgactctgcgaactagagtctcccccc Tat-Smad7-V5 601 gaactggtttgttgcaatccgcaccatctgtctcgtctgtgtgaactggagagcccgcca human Smad7 625 cctccttactccagatacccgatggattttctcaaaccaactgcagactgtccagatgct Tat-Smad7-V5 661 ccgccgtattctcgttacccgatggatttcctgaaaccgactgcagattgcccggacgca human Smad7 685 gtgccttcctccgctgaaacagggggaacgaattatctggcccctgggggactttcagat Tat-Smad7-V5 721 gtcccgtcatcggctgagaccggcggcaccaactatctggcaccgggcggtctgagtgat human Smad7 745 tcccaacttcttctggagcctggggatcggtcacactggtgcgtggtggcatactgggag Tat-Smad7-V5 781 tcccagctgctgctggaaccgggcgaccgttcacattggtgtgtggttgcctattgggaa human Smad7 805 gagaagacgagagtggggaggctctactgtgtccaggagccctctctggatatcttctat Tat-Smad7-V5 841 gagaaaacgcgtgtcggtcgcctgtactgcgtacaggaaccgtcgctggatatcttttat human Smad7 865 gatctacctcaggggaatggcttttgcctcggacagctcaattcggacaacaagagtcag Tat-Smad7-V5 901 gacctgccgcagggcaatggtttctgtctgggccaactgaactcagataataaatcgcag human Smad7 925 ctggtgcagaaggtgcggagcaaaatcggctgcggcatccagctgacgcgggaggtggat Tat-Smad7-V5 961 ctggtgcaaaaagttcgctcaaaaattggctgcggtatccagctgacccgtgaagttgac human Smad7 985 ggtgtgtgggtgtacaaccgcagcagttaccccatcttcatcaagtccgccacactggac Tat-Smad7-V5 1021 ggtgtctgggtatataaccgcagctattacccgatttttatcaaaagtgccaccctggat human Smad7 1045 aacccggactccaggacgctgttggtacacaaggtgttccccggtttctccatcaaggct Tat-Smad7-V5 1081 aatccggactcccgtacgctgctggtccacaaagtatttccgggcttctcaatcaaagcg human Smad7 1105 ttcgactacgagaaggcgtacagcctgcagcggcccaatgaccacgagtttatgcagcag Tat-Smad7-V5 1141 ttcgattacgagaaagcctactcgctgcagcgcccgaacgaccatgaattcatgcagcaa human Smad7 1165 ccgtggacgggctttaccgtgcagatcagctttgtgaagggctggggtcagtgctacacc Tat-Smad7-V5 1201 ccgtggacgggttttactgtgcagatctctttcgttaaaggctggggtcaatgctacacc human Smad7 1225 cgccagttcatcagcagctgcccgtgctggctagaggtcatcttcaacagccggtag--- Tat-Smad7-V5 1261 cgtcagtttatctcgtcctgtccgtgctggctagaagtgattttcaatagccgcaagaac human Smad7 1282 ------------------------------------------------------------ Tat-Smad7-V5 1321 gagctcaattcgaagcttgaaggtaagcctatccctaaccctctcctcggtctcgattct human Smad7 1282 ------------ Tat-Smad7-V5 1381 acgtgagtcgac
[0303] In this optimization, Met216, which may form an alternative open reading frame, was not altered as it was desired to preserve the amino acid sequence of Smad7, if possible. In future codon optimizations, Met216 will be mutated to Leu216 to improve protein production without impacting function in vitro and in vivo.
Example 7: Production of Truncated Smad7 Proteins
[0304] It is believed that Smad7 has several activities in vivo including, but not limited to, one or more of enhancing cell proliferation, enhancing cell migration, reducing DNA damage, reducing cell apoptosis, and decreasing inflammation. Smad7's effects on these processes are due to one or more of blocking TGF-.beta. signaling, blocking NF-.kappa.B signaling, blocking CtBP1 activity, and/or increasing Rac1 expression and/or activity. It is believed that a smaller functional domain of Ptd-Smad7 may be sufficient to deliver a therapeutic effect (see, e.g., FIG. 15). In addition, the resulting shorter protein sequence is expected to enhance protein production. Additionally, it is believed that different truncated Tat-Smad7 proteins that contain partial Smad7 sequences may be useful for different treatments.
[0305] For example, it is believed that the C-terminal MH2 domain of Smad7 (about half length of Smad7 protein, e.g., 208-426aa) may primarily mediate the anti-inflammatory effect of Smad7 (Hong et al., Nat Immunology, 8, 504-513, 2007). Smad7 peptides having this anti-inflammatory function may be sufficient and optionally an improvement for treating chronic inflammation associated conditions, such as but not limited to, oral mucositis, stomatitis and psoriasis, among others.
[0306] The N-terminal MH1 domain plus the linker region of Smad7 (about half of the protein, e.g., 2-208aa) is known to activate MAPK and binds to Smurf, a ubiquitin E3 ligase to degrade TGF-.beta. receptor (Aragon, et al., Structure 20:1726-1736 (2012)). It is believed that it may primarily mediate cell migration and/or blocking TGF-.beta.-induced growth arrest and/or fibrotic response. Smad7 peptides having this cell migration and proliferation function may be sufficient, and optionally an improvement, for enhancing healing that is not associated with excessive inflammation. Types of wounds that might benefit from this form of treatment include, but are not limited to, surgical wounds, fibrotic scarring, and diabetes wounds, defective healing and/or scarring among others.
[0307] Truncated Smad7 N-terminal and C-terminal PTD-fusion proteins were designed. One example of a Tat-Smad7-C-terminal codon-optimized nucleotide and protein sequence is provided below. In the nucleic acid sequence, nucleotides 1-6 include the restriction recognition site for BamHI; nucleotides 7-36 include the Tat PTD sequence; nucleotides 37-810 include codon-optimized for the C terminal amino acids 258 to 426 of human Smad7; nucleotides 568-609 include the V5 epitope sequence; nucleotides 610-612 include the stop sequence; and nucleotides 613-618 include the restriction recognition site for SalI:
TABLE-US-00011 ggatccggccgtaaaaaacgccgtcaacgccgccgttcacattggtgtgtggttgcctat G S G R K K R R Q R R R S H W C V V A Y tgggaagagaaaacgcgtgtcggtcgcctgtactgcgtacaggaaccgtcgctggatatc W E E K T R V G R L Y C V Q E P S L D I ttttatgacctgccgcagggcaatggtttctgtctgggccaactgaactcagataataaa F Y D L P Q G N G F C L G Q L N S D N K tcgcagctggtgcaaaaagttcgctcaaaaattggctgcggtatccagctgacccgtgaa S Q L V Q K V R S K I G C G I Q L T R E gttgacggtgtctgggtatataaccgcagctcttacccgatttttatcaaaagtgccacc V D G V W V Y N R S S Y P I F I K S A T ctggataatccggactcccgtacgctgctggtccacaaagtatttccgggcttctcaatc L D N P D S R T L L V H K V F P G F S I aaagcgttcgattacgagaaagcctactcgctgcagcgcccgaacgaccatgaattcatg K A F D Y E K A Y S L Q R P N D H E F M cagcaaccgtggacgggttttactgtgcagatctctttcgttaaaggctggggtcaatgc Q Q P W T G F T V Q I S F V K G W G Q C tacacccgtcagtttatctcgtcctgtccgtgctggctggaagtgattttcaatagccgc Y T R Q F I S S C P C W L E V I F N S R aagggcgagctcaattcgaagcttgaaggtaagcctatccctaaccctctcctcggtctc K G E L N S K L E G K P I P N P L L G L gattctacgtgagtcgac (SEQ ID NO: 24) D S T - (SEQ ID NO: 25)
[0308] In the nucleic acid sequence, nucleotides 1-6 include the restriction recognition site for BamHI; nucleotides 7-36 include the Tat PTD sequence; nucleotides 37-810 include codon-optimized for the N terminal amino acids 1-258 of human Smad7; nucleotides 811-852 include the V5 epitope sequence (corresponding amino acid sequence in bold); nucleotides 853-855 include the stop sequence; and nucleotides 856-861 include the restriction recognition site for SalI. ATG is removed to allow for fusion with GST:
TABLE-US-00012 ggatccggccgtaaaaaacgccgtcaacgccgccgtggtttccgtacgaaacgctcggcc G S G R K K R R Q R R R G F R T K R S A ctggtccgtcgcctgtggcgctcccgtgctccgggtggtgaagatgaagaagaaggtgct L V R R L W R S R A P G G E D E E E G A ggcggcggtggcggtggcggtgaactgcgtggcgagggtgcaaccgatagtcgtgcacac G G G G G G G E L R G E G A T D S R A H ggtgcaggcggtggcggtccgggtcgtgctggttgctgtctgggtaaagctgtgcgcggc G A G G G G P G R A G C C L G K A V R G gcgaaaggtcatcaccatccgcacccgccggcagcaggtgcaggtgcagctggcggtgcg A K G H H H P H P P A A G A G A A G G A gaagccgatctgaaagccctgacccatagtgtcctgaaaaaactgaaagaacgtcagctg E A D L K A L T H S V L K K L K E R Q L gagctgctgctgcaagcagtagaatcccgtggcggtacccgtacggcttgtctgctgctg E L L L Q A V E S R G G T R T A C L L L ccgggtcgtctggattgccgtctgggtccgggtgcaccggctggtgcgcagccggcacaa P G R L D C R L G P G A P A G A Q P A Q ccgccgagctcttacagcctgccgctgctgctgtgtaaagtgtttcgttggccggacctg P P S S Y S L P L L L C K V F R W P D L cgccacagttccgaagttaaacgcctgtgctgttgcgagagctatggcaaaattaacccg R H S S E V K R L C C C E S Y G K I N P gaactggtttgttgcaatccgcaccatctgtctcgtctgtgtgaactggagagcccgccg E L V C C N P H H L S R L C E L E S P P ccgccgtattctcgttacccgatggatttcctgaaaccgactgcagattgcccggacgca P P Y S R Y P M D F L K P T A D C P D A gtcccgtcatcggctgagaccggcggcaccaactatctggcaccgggcggtctgagtgat V P S S A E T G G T N Y L A P G G L S D tcccagctgctgctggaaccgggcgaccgtggtaagcctatccctaaccctctcctcggt S Q L L L E P G D R G K P I P N P L L G ctcgattctacgtgagtcgac (SEQ ID NO: 26) L D S T - (SEQ ID NO: 27)
Example 8: Testing of Truncated Smad7 Proteins
[0309] Activity of truncated Smad7 proteins is tested using the in vitro and in vivo assays used to test full-length Smad7 described above, among other assays. Such assays include, but are not limited to, the ability to block phosphorylation of Smad2 and/or nuclear translocation of the NF-.kappa.B p50 subunit, increase cell proliferation, reduce apoptosis and/or radiation-induced DNA damage, reduce inflammation and/or angiogenesis, promote healing in oral mucositis, surgical wounds, diabetes wounds, and/or wounds associated with chronic inflammation in mice.
[0310] In a wound healing assay, 6-mm punch biopsies were performed in wild-type mice followed by daily topical application of C-terminal or N-terminal Tat-Smad7. By measuring gross wound closure, both truncated Smad7 proteins described above (e.g., Tat-Smad7 C-terminal and N-terminal protein) were found to have promoted wound healing similar to full length Tat-Smad7.
Example 9: Truncated Smad7 Proteins Accelerate Wound Healing
[0311] The ability of truncated Smad7 proteins to accelerate wound healing was examined in wild-type mice. FIG. 16A demonstrates the effect of C-terminally truncated (259-426aa) Tat-C-Smad7 on a mouse wound healing model. Wild-type C57BL/6 mice were anaesthetized, dorsally wounded by a 6-mm dermal punch biopsy, and treated every other day with the topical application of PBS (control, 3 mice, 4 wounds/mouse), full-length Tat-Smad7 (0.4 .mu.g/10 .mu.L PBS/wound, 3 mice, 4 wounds/mouse) or Tat-C-Smad7 (0.4 .mu.g/10 .mu.L/wound PBS, 3 mice, 4 wounds/mouse, total of 12 wounds were treated). Wound area was photographed with Canon digital camera and measured by imaging analysis using the Image J software with a 6-mm circle inside of the photo for normalization at 1, 2, 4 and 5 days after wounding, and the average percent wound area remaining was calculated for each treatment group. The ability of Tat-C-Smad7 to accelerate wound healing was similar to that of full-length Smad7 (FIG. 16A).
[0312] FIG. 16B illustrates the effect of N-terminally truncated (1-258aa) Tat-N-Smad7 on wound healing. Wild-type C57BL/6 mice were anaesthetized, dorsally wounded by a 6-mm dermal punch biopsy, and treated every other day with the topical application of PBS (control, 6 mice, 4 wounds/mouse), full-length Tat-Smad7 (0.4 .mu.g/10 .mu.L PBS, 6 mice, 4 wounds/mouse), or Tat-N-Smad7 (0.4 .mu.g/10 .mu.L PBS, 6 mice, 4 wounds/mouse). Wound area was measured by imaging analysis using the Image J software with a 6-mm circle inside of the photo for normalization at 1, 2, and 4 days after wounding, and the average percent wound area remaining was calculated for each treatment group. There was a significant difference in the rate of wound healing between the control and Tat-Smad7-treated mice after two days, with the latter healing faster (FIG. 16B, p<0.05). Although Tat-N-Smad7 was tested as a negative control, it unexpectedly promoted significantly accelerated wound healing relative to control mice after just one day, and significantly accelerated wound healing relative to full-length Tat-Smad7-treated mice after two days (FIG. 16B, p<0.05). Tat-Cre had no effect on wound closure relative to control treatment (data not shown).
[0313] These results demonstrate that both full-length Tat-Smad7 and truncated Tat-Smad7 proteins (Tat-C-Smad7 and Tat-N-Smad7) promote wound healing. Moreover, these results demonstrate that certain truncated Tat-Smad7 proteins are more effective in accelerating wound healing than full-length Tat-Smad7.
[0314] Accordingly, compositions comprising truncated Tat-Smad7 proteins are useful in treating wounds and in accelerating wound healing.
Example 10: Smad7 Accelerates Wound Healing in an Impaired Wound-Healing Model
[0315] Diabetic (db/db) mice were dorsally wounded by a 6-mm dermal punch biopsy as described above in Example 9, and treated every other day with the topical application of PBS (control, 6 mice, 4 wounds/mouse), full-length Tat-Smad7 (0.4 .mu.g/10 .mu.L PBS, 6 mice, 4 wounds/mouse), or REGRANEX.RTM. cream (smear with cotton swab, 6 mice 4 wounds/mouse) to the wounds before day 8 when the wounds were not completely covered by scabs. After day 10, the treatments were topically applied to the gap between the scab and wound periphery to avoid the barrier of the hard scab and the unwounded stratum corneum. REGRANEX.RTM., which contains a recombinant human platelet-derived growth factor (PDGF), is approved for topical administration to diabetic ulcers.
[0316] Wound closure was visually assessed at 1, 2, 4, 6, 8, 9, 10, 11, 12, and 13 days after wounding (FIG. 17A). At each time point, the wounds were photographed with Canon digital camera. After 8 days, there was a marked visual improvement in the wound closure in Tat-Smad7-treated mice compared to controls (FIG. 17A).
[0317] Wound size was measured by using the Image J software with a 6-mm circle inside of the photo for normalization at 1, 2, 3, 4, 7, 9, and 11 days after wounding, and the average percent wound area remaining was calculated for each treatment group. The ability of Tat-Smad7 to accelerate wound healing was similar to that of REGRANEX.RTM. (FIG. 17B). On day 7, image analysis results indicated that wound closure was significantly accelerated in Tat-Smad7-treated mice relative to controls (FIG. 17B, p<0.05). These results were similar to those achieved with REGRANEX.RTM..
[0318] Formalin fixed paraffin dorsal wound sections (1 mm) from day 8 wound samples were stained using hematoxylin and eosin (H&E). Histological comparison of day 8 wound samples revealed complete re-epithelialization and an accelerated wound closure in Smad7-treated db/db mice relative to controls (FIG. 17C).
[0319] Collectively, these results demonstrate that Tat-Smad7 is useful for accelerating wound closure in poorly healing diabetic wounds, and provides an alternative to treatment with REGRANEX.RTM..
Example 11: Additional Codon Optimization for Smad7 Protein Production
[0320] Smad7 nucleic acid molecules are designed with additional nucleotide changes selected to increase protein production. For example, the utilization of codons encoding the amino acids Ser and His will be manipulated. In codon-optimized human Smad7 in examples above, the Ser codon (TCC or TCG) has an amino acid frequency of approximately 9% of codon utilization. It is believed that changing the codon of Ser to AGC will increase Smad7 protein production, at least partly because it can optionally increase codon usage to 15%. There are 33 Ser amino acids in Smad7 protein (nucleotides at positions 19-21, 46-48, 133-135, 292-294, 349-351, 451-453, 454-456, 460-462, 511-513, 514-516, 544-546, 595-597, 616-618, 634-636, 691-693, 694-696, 739-741, 745-747, 775-777, 847-849, 907-909, 919-921, 943-945, 1006-1008, 1009-1101, 1030-1032, 1054-1056, 1093-1095, 1126-1128, 1192-1194, 1237-1239, 1240-1242, 1273-1275; with a corresponding serine amino acid position of 7, 16, 45, 98, 117, 151, 152, 154, 171, 172, 182, 199, 206, 212, 231, 232, 247, 249, 259, 283, 303, 307, 315, 336, 337, 344, 352, 365, 376, 398, 413, 414, 425). Of these, 23 (nucleotides 19-21, 292-294, 349-351, 451-453, 454-456, 460-462, 511-513, 514-516, 544-546, 616-618, 634-636, 691-693, 694-696, 739-741, 745-747, 775-777, 847-849, 907-909, 919-921, 1009-1101, 1030-1032, 1054-1056, 1093-1095; corresponding serine amino acid position of 7, 98, 117, 151, 152, 154, 171, 172, 182, 206, 212, 231, 232, 247, 249, 259, 283, 303, 307, 337, 344, 352, 365) can be changed without introducing potential alternative open reading frames.
[0321] Similarly, in codon-optimized human Smad7 in the examples above, the His codon (CAC) has 9.6% of codon usage. It is believed that changing the His codon to CAT (optionally to 12.6% usage) will increase Smad7 protein production. There are 12 His (nucleotides 142-144, 214-216, 217-219, 220-222, 226-228, 289-291, 589-591, 778-780, 1072-1074, 1147-1149; corresponding to histidine amino acids at position 48, 72, 73, 74, 76, 97, 170, 196, 197, 260, 358, 383) in Smad7 protein. Of these, 4 (nucleotides 217-219. 220-222, 589-591, 778-780, histidine residues 73, 76, 197, 260) can be changed without introducing potential alternative open reading frames.
[0322] In addition, wild-type human Smad7 includes a Met amino acid as amino acid 216 (Met216). This may be perceived as an alternative open reading frame by bacterial machinery, for example, and decrease protein production. It is believed that changing Met216 to Leu216 (ATG to CTG), the amino acid that has the biochemical property the closest to Met and thus not expected to change 3D structure of the protein, will increase protein production.
[0323] The comparison between original codon-optimized Tat-Smad7-V5 and further changes is provided below. Top strand: Tat-Smad7-V5 (SEQ ID NO: 23); bottom strand: after optimized Ser, His and M216 .mu.L mutation (SEQ ID NO: 30).
TABLE-US-00013 Alignment: Local DNA homologies. Parameters: Both strands. Method: FastScan - Max Score Mol 1 20120323113102B12-854366-164160-1-PGEX-5.seq (1-1463) Mol 2 TatSmad7 Ser-His optim Number of sequences to align: 2 Settings: Similarity significance value cutoff: >=60% Homology Block: Percent Matches 94 Score 1227 Length 1392 201203231131 30 ggatccggccgtaaaaaacgccgtcaacgccgccgtggtttccgtacgaaacgctcggcc TatSmad7 Ser 1 ......................................................agc... 201203231131 90 ctggtccgtcgcctgtggcgctcccgtgctccgggtggtgaagatgaagaagaaggtgct TatSmad7 Ser 61 .....................ag..................................... 201203231131 150 ggcggcggtggcggtggcggtgaactgcgtggcgagggtgcaaccgatagtcgtgcacac TatSmad7 Ser 121 ..................................................c........t 201203231131 210 ggtgcaggcggtggcggtccgggtcgtgctggttgctgtctgggtaaagctgtgcgcggc TatSmad7 Ser 181 ............................................................ 201203231131 270 gcgaaaggtcatcaccatccgcacccgccggcagcaggtgcaggtgcagctggcggtgcg TatSmad7 Ser 241 ..............t........t.................................... 201203231131 330 gaagccgatctgaaagccctgacccatagtgtcctgaaaaaaccgaaagaacgtcagctg TatSmad7 Ser 301 .............................c.............................. 201203231131 390 gagctgctgctgcaagcagtagaatcccgtggcggtacccgtacggcttgtctgctgctg TatSmad7 Ser 361 ........................ag.................................. 201203231131 450 ccgggtcgtctggattgccgtctgggtccgggtgcaccggctggtgcgcagccggcacaa TatSmad7 Ser 421 ............................................................ 201203231131 510 ccgccgagctcttacagcctgccgctgctgctgtgtaaagtgtttcgttggccggacctg TatSmad7 Ser 481 .........agc................................................ 201203231131 570 cgccacagttccgaagttaaacgcctgtgctgttgcgagagctatggcaaaattaacccg TatSmad7 Ser 541 .....t..cag................................................. 201203231131 630 gaactggtttgttgcaatccgcaccatctgtctcgtctgtgtgaactggagagcccgccg TatSmad7 Ser 601 .......................t......agc........................... 201203231131 690 ccgccgtattctcgttacccgatggatttcctgaaaccgactgcagattgcccggacgca TatSmad7 Ser 661 .........agc.........c...................................... 201203231131 750 gtcccgtcatcggctgagaccggcggcaccaactatctggcaccgggcggtctgagtgat TatSmad7 Ser 721 ......agcagc............................................c... 201203231131 810 tcccagctgctgctggaaccgggcgaccgttcacattggtgtgtggttgcctattgggaa TatSmad7 Ser 781 ag............................agc........................... 201203231131 870 gagaaaacgcgtgtcggtcgcctgtactgcgtacaggaaccgtcgctggatatcttttat TatSmad7 Ser 841 ..........................................agc............... 201203231131 930 gacctgccgcagggcaatggtttctgtctgggccaactgaactcagataataaatcgcag TatSmad7 Ser 901 ..........................................agc.........agc... 201203231131 990 ctggtgcaaaaagttcgctcaaaaattggctgcggtatccagctgacccgtgaagttgac TatSmad7 Ser 961 ..................agc....................................... 201203231131 1050 ggtgtctgggtatataaccgcagctcttacccgatttttatcaaaagtgccaccctggat TatSmad7 Ser 1021 ........................agc....................c............ 201203231131 1110 aatccggactcccgtacgctgctggtccacaaagtatttccgggcttctcaatcaaagcg TatSmad7 Ser 1081 .........ag..................t..................agc......... 201203231131 1170 ttcgattacgagaaagcctactcgctgcagcgcccgaacgaccatgaattcatgcagcaa TatSmad7 Ser 1141 .....................agc.................................... 201203231131 1230 ccgtggacgggttttactgtgcagatctctttcattaaaggctggggtcaatgctacacc TatSmad7 Ser 1201 ...........................agc.............................. 201203231131 1290 cgtcagtttatctcgtcctgtccgtgctggctggaagtgattttcaatagccgcaagggc TatSmad7 Ser 1261 ............agcag........................................... 201203231131 1350 gagctcaattcgaagcttgaaggtaagcctatccctaaccctctcctcggtctcgattct TatSmad7 Ser 1321 .........agc.............................................agc 201203231131 1410 acgtgagtcgac TatSmad7 Ser 1381 ............
[0324] Nucleic acid sequences and their corresponding amino acid sequences that would include all these changes are provided below. The amino acid sequence includes the V5 epitope indicated in bold, and the pET101-Topo backbone indicated by italics and underlining. The Tat-Smad7.sup.M216L fully-optimized full length nucleotide and protein sequence is shown below:
TABLE-US-00014 ggatccggccgtaaaaaacgccgtcaacgccgccgtggtttccgtacgaaacgcagcgcc G S G R K K R R Q R R R G F R T K R S A ctggtccgtcgcctgtggcgcagccgtgctccgggtggtgaagatgaagaagaaggtgct L V R R L W R S R A P G G E D E E E G A ggcggcggtggcggtggcggtgaactgcgtggcgagggtgcaaccgatagccgtgcacat G G G G G G G E L R G E G A T D S R A H ggtgcaggcggtggcggtccgggtcgtgctggttgctgtctgggtaaagctgtgcgcggc G A G G G G P G R A G C C L G K A V R G gcgaaaggtcatcatcatccgcatccgccggcagcaggtgcaggtgcagctggcggtgcg A K G H H H P H P P A A G A G A A G G A gaagccgatctgaaagccctgacccatagcgtcctgaaaaaactgaaagaacgtcagctg E A D L K A L T H S V L K K L K E R Q L gagctgctgctgcaagcagtagaaagccgtggcggtacccgtacggcttgtctgctgctg E L L L Q A V E S R G G T R T A C L L L ccgggtcgtctggattgccgtctgggtccgggtgcaccggctggtgcgcagccggcacaa P G R L D C R L G P G A P A G A Q P A Q ccgccgagcagctacagcctgccgctgctgctgtgtaaagtgttcgttggccggacctg P P S S Y S L P L L L C K V F R W P D L cgccatagcagcgaagttaaacgcctgtgctgttgcgagagctatggcaaaattaacccg R H S S E V K R L C C C E S Y G K I N P gaactggtttgttgcaatccgcatcatctgagccgtctgtgtgaactggagagcccgccg E L V C C N P H H L S R L C E L E S P P ccgccgtatagccgttacccgctggatttcctgaaaccgactgcagattgcccggacgca P P Y S R Y P L D F L K P T A D C P D A gtcccgagcagcgctgagaccggcggcaccaactatctggcaccgggcggtctgagcgat V P S S A E T G G T N Y L A P G G L S D agccagctgctgctggaaccgggcgaccgtagccattggtgtgtggttgcctattgggaa S Q L L L E P G D R S H W C V V A Y W E gagaaaacgcgtgtcggtcgcctgtactgcgtacaggaaccgagcctggatatcttttat E K T R V G R L Y C V Q E P S L D I F Y gacctgccgcagggcaatggtttctgtctgggccaactgaacagcgataataaaagccag D L P Q G N G F C L G Q L N S D N K S Q ctggtgcaaaaagttcgcagcaaaattggctgcggtatccagctgacccgtgaagttgac L V Q K V R S K I G C G I Q L T R E V D ggtgtctgggtatataaccgcagcagctacccgatttttatcaaaagcgccaccctggat G V W V Y N R S S Y P I F I K S A T L D aatccggacagccgtacgctgctggtccataaagtatttccgggcttcagcatcaaagcg N P D S R T L L V H K V F P G F S I K A ttcgattacgagaaagcctacagcctgcagcgcccgaacgaccatgaattcatgcagcaa F D Y E K A Y S L Q R P N D H E F M Q Q ccgtggacgggttttactgtgcagatcagcttcgttaaaggctggggtcaatgctacacc P W T G F T V Q I S F V K G W G Q C Y T cgtcagtttatcagcagctgtccgtgctggctggaagtgattttcaatagccgcaagggc R Q F I S S C P C W L E V I F N S R K G gagctcaatagcaagcttgaaggtaagcctatccctaaccctctcctcggtctcgatagc E L N S K L E G K P I P N P L L G L D S acgtgagtcgac (SEQ ID NO: 30) T - (SEQ ID NO: 31)
[0325] The optimized nucleotide and amino acid sequences will also be used to make a variety of N-terminal and C-terminal Tat-Smad7 fragments. Representative examples are provided below.
[0326] The Tat-N-Smad7-V5 most optimized nucleotide and amino acid sequences are provided. The protein sequence includes the V5 epitope, which is indicated by bold capital letters.
TABLE-US-00015 ggatccggccgtaaaaaacgccgtcaacgccgccgtggtttccgtacgaaacgcagcgcc G S G R K K R R Q R R R G F R T K R S A ctggtccgtcgcctgtggcgcagccgtgctccgggtggtgaagatgaagaagaaggtgct L V R R L W R S R A P G G E D E E E G A ggcggcggtggcggtggcggtgaactgcgtggcgagggtgcaaccgatagccgtgcacat G G G G G G G E L R G E G A T D S R A H ggtgcaggcggtggcggtccgggtcgtgctggttgctgtctgggtaaagctgtgcgcggc G A G G G G P G R A G C C L G K A V R G gcgaaaggtcatcatcatccgcatccgccggcagcaggtgcaggtgcagctggcggtgcg A K G H H H P H P P A A G A G A A G G A gaagccgatctgaaagccctgacccatagcgtcctgaaaaaactgaaagaacgtcagctg E A D L K A L T H S V L K K L K E R Q L gagctgctgctgcaagcagtagaaagccgtggcggtacccgtacggcttgtctgctgctg E L L L Q A V E S R G G T R T A C L L L ccgggtcgtctggattgccgtctgggtccgggtgcaccggctggtgcgcagccggcacaa P G R L D C R L G P G A P A G A Q P A Q ccgccgagcagctacagcctgccgctgctgctgtgtaaagtgtttcgttggccggacctg P P S S Y S L P L L L C K V F R W P D L cgccatagcagcgaagttaaacgcctgtgctgttgcgagagctatggcaaaattaacccg R H S S E V K R L C C C E S Y G K I N P gaactggtttgttgcaatccgcatcatctgagccgtctgtgtgaactggagagcccgccg E L V C C N P H H L S R L C E L E S P P ccgccgtatagccgttacccgatggatttcctgaaaccgactgcagattgcccggacgca P P Y S R Y P M D F L K P T A D C P D A gtcccgagcagcgctgagaccggcggcaccaactatctggcaccgggcggtctgagcgat V P S S A E T G G T N Y L A P G G L S D agccagctgctgctggaaccgggcgaccgtggtaagcctatccctaaccctctcctcggt S Q L L L E P G D R G K P I P N P L L G ctcgattctacgtgagtcgac (SEQ ID NO: 32) L D S T - (SEQ ID NO: 27)
[0327] Tat-C-Smad7-V5 most optimized nucleotide and amino acid sequences are provided. The protein sequence includes the V5 epitope (indicated by bold capital letters), and the pET101-Topo backbone (indicated by underlined italics).
TABLE-US-00016 ggatccggccgtaaaaaacgccgtcaacgccgccgttcacattggtgtgtggttgcctat G S G R K K R R Q R R R S H W C V V A Y tgggaagagaaaacgcgtgtcggtcgcctgtactgcgtacaggaaccgagcctggatatc W E E K T R V G R L Y C V Q E P S L D I ttttatgacctgccgcagggcaatggtttctgtctgggccaactgaacagcgataataaa F Y D L P Q G N G F C L G Q L N S D N K agccagctggtgcaaaaagttcgcagcaaaattggctgcggtatccagctgacccgtgaa S Q L V Q K V R S K I G C G I Q L T R E gttgacggtgtctgggtatataaccgcagcagctacccgatttttatcaaaagcgccacc V D G V W V Y N R S S Y P I F I K S A T ctggataatccggacagccgtacgctgctggtccataaagtatttccgggcttcagcatc L D N P D S R T L L V H K V F P G F S I aaagcgttcgattacgagaaagcctacagcctgcagcgcccgaacgaccatgaattcatg K A F D Y E K A Y S L Q R P N D H E F M cagcaaccgtggacgggttttactgtgcagatcagcttcgttaaaggctggggtcaatgc Q Q P W T G F T V Q I S F V K G W G Q C tacacccgtcagtttatcagcagctgtccgtgctggctggaagtgattttcaatagccgc Y T R Q F I S S C P C W L E V I F N S R aagggcgagctcaatagcaagcttgaaggtaagcctatccctaaccctctcctcggtctc K G E L N S K L E G K P I P N P L L G L gatagcacgtgagtcgac (SEQ ID NO: 34) D S T - (SEQ ID NO: 25)
[0328] The comparisons before and after the above optimizations are provided below. C-terminal optimization (top strand) (alignment discloses SEQ ID NOs: 34 and 24, respectively, in order of appearance):
TABLE-US-00017 Alignment: Local DNA homologies. Parameters: Both strands. Method: PastScan - Max Score Mol 1 Tat-C-Smad7-ser-his optimized (1-618) Mol 2 Tat-C-termal Smad7-VS (1-618) Number of sequences to align: 2 Settings: Similarity significance value cutoff: >=60% Homology Block: Percent Matches 93 Score 541 Length 618 Tat-C-Smad7- 1 ggatccggccgtaaaaaacgccgtcaacgccgccgttcacattggtgtgtggttgcctat Tat-C-termal 1 ............................................................ Tat-C-Smad7- 61 tgggaagagaaaacgcgtgtcggtcgcctgtactgcgtacaggaaccgagcctggatatc Tat-C-termal 61 ................................................tcg......... Tat-C-Smad7- 121 ttttatgacctgccgcagggcaatggtttctgtctgggccaactgaacagcgataataaa Tat-C-termal 121 ................................................tca......... Tat-C-Smad7- 181 agccagctggtgcaaaaagttcgcagcaaaattggctgcggtatccagctgacccgtgaa Tat-C-termal 181 tcg.....................tca................................. Tat-C-Smad7- 241 gttgacggtgtctgggtatataaccgcagcagctacccgatttttatcaaaagcgccacc Tat-C-termal 241 ..............................tct....................t...... Tat-C-Smad7- 301 ctggataatccggacagccgtacgctgctggtccataaagtatttccgggcttcagcatc Tat-C-termal 301 ...............tc..................c..................tca... Tat-C-Smad7- 361 aaagcgttcgattacgagaaagcctacagcctgcagcgcccgaacgaccatgaattcatg Tat-C-termal 361 ...........................tcg.............................. Tat-C-Smad7- 421 cagcaaccgtggacgggttttactgtgcagatcagcttcgttaaaggctggggtcaatgc Tat-C-termal 421 .................................tct........................ Tat-C-Smad7- 481 tacacccgtcagtttatcagcagctgtccgcactgactagaagtgattttcaatagccgc Tat-C-termal 481 ..................tcgtc..................................... Tat-C-Smad7- 541 aagggcgagctcaatagcaagcttgaaggtaagcctatccctaaccctctcctcggtctc Tat-C-termal 541 ...............tcg.......................................... Tat-C-Smad7- 601 gatagcacgtgagtcgac Tat-C-termal 601 ...tct............
N-terminal optimization (top strand) (alignment discloses SEQ ID NOs: 32 and 26, respectively, in order of appearance):
TABLE-US-00018 Alignment: Local DNA homologies. Parameters: Both strands. Method: FastScan - Max Score Mol 1 Tat-N-Smad7-V5-Ser-His optimized (1-861) Mol 2 Tat-N-Smad7-V5 (1-861) Number of sequences to align: 2 Settings: Similarity significance value cutoff: >=60% Homology Block: Percent Matches 95 Score 781 Length 861 Tat-N-Smad7- 1 ggatccggccgtaaaaaacgccgtcaacgccgccgtggtttccgtacgaaacgcagcgcc Tat-N-Smad7- 1 ......................................................tcg... Tat-N-Smad7- 61 ctggtccgtcgcctgtggcgcagccgtgctccgggtggtgaagatgaagaagaaggtgct Tat-N-Smad7- 61 .....................tc..................................... Tat-N-Smad7- 121 ggcggcggtggcggtggcggtgaactgcgtggcgagggtgcaaccgatagccgtgcacat Tat-N-Smad7- 121 ..................................................t........c Tat-N-Smad7- 181 ggtgcaggcggtggcggtccgggtcgtgctggttgctgtctgggtaaagctgtgcgcggc Tat-N-Smad7- 181 ............................................................ Tat-N-Smad7- 241 gcgaaaggtcatcatcatccgcatccgccggcagcaggtgcaggtgcagctggcggtgcg Tat-N-Smad7- 241 ..............c........c.................................... Tat-N-Smad7- 301 gaagccgatctgaaagccctgacccatagcgtcctgaaaaaactgaaagaacgtcagctg Tat-N-Smad7- 301 .............................t.............................. Tat-N-Smad7- 361 gagctgctgctgcaagcagtagaaagccgtggcggtacccgtacggcttgtctgctgctg Tat-N-Smad7- 361 ........................tc.................................. Tat-N-Smad7- 421 ccgggtcgtctggattgccgtctgggtccgggtgcaccggctggtgcgcagccggcacaa Tat-N-Smad7- 421 ............................................................ Tat-N-Smad7- 481 ccgccgagcagctacagcctgccgctgctgctgtgtaaagtgtttcgttggccggacctg Tat-N-Smad7- 481 .........tct................................................ Tat-N-Smad7- 541 cgccatagcagcgaagttaaacgcctgtgctgttgcgagagctatggcaaaattaacccg Tat-N-Smad7- 541 .....c.ttc.................................................. Tat-N-Smad7- 601 gaactggtttgttgcaatccgcatcatctgagccgtctgtgtgaactggagagcccgccg Tat-N-Smad7- 601 .......................c......tct........................... Tat-N-Smad7- 661 ccgccgtatagccgttacccgatggatttcctgaaaccgactgcagattgcccggacgca Tat-N-Smad7- 661 .........tct................................................ Tat-N-Smad7- 721 gtcccgagcagcgctgagaccggcggcaccaactatctggcaccgggcggtctgagcgat Tat-N-Smad7- 721 ......tcatcg............................................t... Tat-N-Smad7- 781 agccagctgctgctggaaccgggcgaccgtggtaagcctatccctaaccctctcctcggt Tat-N-Smad7- 781 tc.......................................................... Tat-N-Smad7- 841 ctcgattctacgtgagtcgac Tat-N-Smad7- 841 .....................
[0329] In addition, other codon-optimized nucleic acids will also be assessed for their ability to produce Smad7 protein in one or more expression systems. Provided below is another example of such a sequence.
[0330] Tat-Smad7.sup.M7216L-V5 optimized by Optimizer program:
TABLE-US-00019 ggatccggtcgtaaaaaacgtcgtcagcgtcgtcgtggtttccgtaccaaacgttctgcg G S G R K K R R Q R R R G F R T K R S A ctggttcgtcgtctgtggcgttctcgtgcgccgggtggtgaagacgaagaagaaggtgcg L V R R L W R S R A P G G E D E E E G A ggtggtggtggtggtggtggtgaactgcgtggtgaaggtgcgaccgactctcgtgcgcac G G G G G G G E L R G E G A T D S R A H ggtgcgggtggtggtggtccgggtcgtgcgggttgctgcctgggtaaagcggttcgtggt G A G G G G P G R A G C C L G K A V R G gcgaaaggtcaccaccacccgcacccgccggcggcgggtgcgggtgcggcgggtggtgcg A K G H H H P H P P A A G A G A A G G A gaagcggacctgaaagcgctgacccactctgttctgaaaaaactgaaagaacgtcagctg E A D L K A L T H S V L K K L K E R Q L gaactgctgctgcaggcggttgaatctcgtggtggtacccgtaccgcgtgcctgctgctg E L L L Q A V E S R G G T R T A C L L L ccgggtcgtctggactgccgtctgggtccgggtgcgccggcgggtgcgcagccggcgcag P G R L D C R L G P G A P A G A Q P A Q ccgccgtcttcttactctctgccgctgctgctgtgcaaagttttccgttggccggacctg P P S S Y S L P L L L C K V F R W P D L cgtcactcttctgaagttaaacgtctgtgctgctgcgaatcttacggtaaaatcaacccg R H S S E V K R L C C C E S Y G K I N P gaactggtttgctgcaacccgcaccacctgtctcgtctgtgcgaactggaatctccgccg E L V C C N P H H L S R L C E L E S P P ccgccgtactctcgttacccgctggacttcctgaaaccgaccgcggactgcccggacgcg P P Y S R Y P L D F L K P T A D C P D A gttccgtcttctgcggaaaccggtggtaccaactacctggcgccgggtggtctgtctgac V P S S A E T G G T N Y L A P G G L S D tctcagctgctgctggaaccgggtgaccgttctcactggtgcgttgttgcgtactgggaa S Q L L L E P G D R S H W C V V A Y W E gaaaaaacccgtgttggtcgtctgtactgcgttcaggaaccgtctctggacatcttctac E K T R V G R L Y C V Q E P S L D I F Y gacctgccgcagggtaacggtttctgcctgggtcagctgaactctgacaacaaatctcag D L P Q G N G F C L G Q L N S D N K S Q ctggttcagaaagttcgttctaaaatcggttgcggtatccagctgacccgtgaagttgac L V Q K V R S K I G C G I Q L T R E V D ggtgtttgggtttacaaccgttcttcttacccgatcttcatcaaatctgcgaccctggac G V W V Y N R S S Y P I F I K S A T L D aacccggactctcgtaccctgctggttcacaaagttttcccgggtttctctatcaaagcg N P D S R T L L V H K V F P G F S I K A ttcgactacgaaaaagcgtactctctgcagcgtccgaacgaccacgaattcatgcagcag F D Y E K A Y S L Q R P N D H E F M Q Q ccgtggaccggtttcaccgttcagatctctttcgttaaaggttggggtcagtgctacacc P W T G F T V Q I S F V K G W G Q C Y T cgtcagttcatctcttcttgcccgtgctggctggaagttatcttcaactctcgtggtaaa R Q F I S S C P C W L E V I F N S R G K ccgatcccgaacccgctgctgggtctggactctacctgagtcgac (SEQ ID NO: 36) P I P N P L L G L D S T - - (SEQ ID NO: 37)
[0331] Nucleotide Sequence:
1-6: BamHI; 7-36: Tat; 37-1314: codon-optimized human Smad7; 1315-1356: V5; 137-1359: stop; 1360-1365 SalI ATG is removed to be used with GST; 682 ATG to CTG (M216 to L)
TABLE-US-00020 (SEQ ID NO: 36) 1 ggatccggtc gtaaaaaacg tcgtcagcgt cgtcgtggtt tccgtaccaa acgttctgcg 61 ctggttcgtc gtctgtggcg ttctcgtgcg ccgggtggtg aagacgaaga agaaggtgcg 121 ggtggtggtg gtggtggtgg tgaactgcgt ggtgaaggtg cgaccgactc tcgtgcgcac 181 ggtgcgggtg gtggtggtcc gggtcgtgcg ggttgctgcc tgggtaaagc ggttcgtggt 241 gcgaaaggtc accaccaccc gcacccgccg gcggcgggtg cgggtgcggc gggtggtgcg 301 gaagcggacc tgaaagcgct gacccactct gttctgaaaa aactgaaaga acgtcagctg 361 gaactgctgc tgcaggcggt tgaatctcgt ggtggtaccc gtaccgcgtg cctgctgctg 421 ccgggtcgtc tggactgccg tctgggtccg ggtgcgccgg cgggtgcgca gccggcgcag 481 ccgccgtctt cttactctct gccgctgctg ctgtgcaaag ttttccgttg gccggacctg 541 cgtcactctt ctgaagttaa acgtctgtgc tgctgcgaat cttacggtaa aatcaacccg 601 gaactggttt gctgcaaccc gcaccacctg tctcgtctgt gcgaactgga atctccgccg 661 ccgccgtact ctcgttaccc gctggacttc ctgaaaccga ccgcggactg cccggacgcg 721 gttccgtctt ctgcggaaac cggtggtacc aactacctgg cgccgggtgg tctgtctgac 781 tctcagctgc tgctggaacc gggtgaccgt tctcactggt gcgttgttgc gtactgggaa 841 gaaaaaaccc gtgttggtcg tctgtactgc gttcaggaac cgtctctgga catcttctac 901 gacctgccgc agggtaacgg tttctgcctg ggtcagctga actctgacaa caaatctcag 961 ctggttcaga aagttcgttc taaaatcggt tgcggtatcc agctgacccg tgaagttgac 1021 ggtgtttggg tttacaaccg ttcttcttac ccgatcttca tcaaatctgc gaccctggac 1081 aacccggact ctcgtaccct gctggttcac aaagttttcc cgggtttctc tatcaaagcg 1141 ttcgactacg aaaaagcgta ctctctgcag cgtccgaacg accacgaatt catgcagcag 1201 ccgtggaccg gtttcaccgt tcagatctct ttcgttaaag gttggggtca gtgctacacc 1261 cgtcagttca tctcttcttg cccgtgctgg ctggaagtta tcttcaactc tcgtggtaaa 1321 ccgatcccga acccgctgct gggtctggac tctacctgag tcgac
[0332] Sequence comparison with Tat-Smad7.sup.M7216L-V5 described in Example 4 (alignment discloses SEQ ID NOs: 36 and 30, respectively, in order of appearance):
TABLE-US-00021 Alignment: Global DNA alignment against reference molecule Parameters: Scoring matrix: Linear (Mismatch 2, OpenGap 4, ExtGap 1) Reference molecule: Tat-Smad7-216L-V5-optimizer, Region 1-1365 Number of sequences to align: 2 Settings: Similarity significance value cutoff: >=60% Summary of Percent Matches: Reference: Tat-Smad7-216L-V5-optimizer 1-1365 (1365 bps) -- Sequence 2: TatSmad7 Ser-His optimized-682 mutant 1-1392 (1392 bps) 79% Tat-Smad7-21 1 ggatccggtcgtaaaaaacgtcgtcagcgtcgtcgtggtttccgtaccaaacgttctgcg TatSmad7 Ser 1 ggatccggccgtaaaaaacgccgtcaacgccgccgtggtttccgtacgaaacgcagcgcc Tat-Smad7-21 61 ctggttcgtcgtctgtggcgttctcgtgcgccgggtggtgaagacgaagaagaaggtgcg TatSmad7 Ser 61 ctggtccgtcgcctgtggcgcagccgtgctccgggtggtgaagatgaagaagaaggtgct Tat-Smad7-21 121 ggtggtggtggtggtggtggtgaactgcgtggtgaaggtgcgaccgactctcgtgcgcac TatSmad7 Ser 121 ggcggcggtggcggtggcggtgaactgcgtggcgagggtgcaaccgatagccgtgcacat Tat-Smad7-21 181 ggtgcgggtggtggtggtccgggtcgtgcgggttgctgcctgggtaaagcggttcgtggt TatSmad7 Ser 181 ggtgcaggcggtggcggtccgggtcgtgctggttgctgtctgggtaaagctgtgcgcggc Tat-Smad7-21 241 gcgaaaggtcaccaccacccgcacccgccggcggcgggtgcgggtgcggcgggtggtgcg TatSmad7 Ser 241 gcgaaaggtcatcatcatccgcatccgccggcagcaggtgcaggtgcagctggcggtgcg Tat-Smad7-21 301 gaagcggacctgaaagcgctgacccactctgttctgaaaaaactgaaagaacgtcagctg TatSmad7 Ser 301 gaagccgatctgaaagccctgacccatagcgtcctgaaaaaactgaaagaacgtcagctg Tat-Smad7-21 361 gaactgctgctgcaggcggttgaatctcgtggtggtacccgtaccgcgtgcctgctgctg TatSmad7 Ser 361 gagctgctgctgcaagcagtagaaagccgtggcggtacccgtacggcttgtctgctgctg Tat-Smad7-21 421 ccgggtcgtctggactgccgtctgggtccgggtgcgccggcgggtgcgcagccggcgcag TatSmad7 Ser 421 ccgggtcgtctggattgccgtctgggtccgggtgcaccggctggtgcgcagccggcacaa Tat-Smad7-21 481 ccgccgtcttcttactctctgccgctgctgctgtgcaaagttttccgttggccggacctg TatSmad7 Ser 481 ccgccgagcagctacagcctgccgctgctgctgtgtaaagtgtttcgttggccggacctg Tat-Smad7-21 541 cgtcactcttctgaagttaaacgtctgtgctgctgcgaatcttacggtaaaatcaacccg TatSmad7 Ser 541 cgccatagcagcgaagttaaacgcctgtgctgttgcgagagctatggcaaaattaacccg Tat-Smad7-21 601 gaactggtttgctgcaacccgcaccacctgtctcgtctgtgcgaactggaatctccgccg TatSmad7 Ser 601 gaactggtttgttgcaatccgcatcatctgagccgtctgtgtgaactggagagcccgccg Tat-Smad7-21 661 ccgccgtactctcgttacccgctggacttcctgaaaccgaccgcggactgcccggacgcg TatSmad7 Ser 661 ccgccgtatagccgttacccgctggatttcctgaaaccgactgcagattgcccggacgca Tat-Smad7-21 721 gttccgtcttctgcggaaaccggtggtaccaactacctggcgccgggtggtctgtctgac TatSmad7 Ser 721 gtcccgagcagcgctgagaccggcggcaccaactatctggcaccgggcggtctgagcgat Tat-Smad7-21 781 tctcagctgctgctggaaccgggtgaccgttctcactggtgcgttgttgcgtactgggaa TatSmad7 Ser 781 agccagctgctgctggaaccgggcgaccgtagccattggtgtgtggttgcctattgggaa Tat-Smad7-21 841 gaaaaaacccgtgttggtcgtctgtactgcgttcaggaaccgtctctggacatcttctac TatSmad7 Ser 841 gagaaaacgcgtgtcggtcgcctgtactgcgtacaggaaccgagcctggatatcttttat Tat-Smad7-21 901 gacctgccgcagggtaacggtttctgcctgggtcagctgaactctgacaacaaatctcag TatSmad7 Ser 901 gacctgccgcagggcaatggtttctgtctgggccaactgaacagcgataataaaagccag Tat-Smad7-21 961 ctggttcagaaagttcgttctaaaatcggttgcggtatccagctgacccgtgaagttgac TatSmad7 Ser 961 ctggtgcaaaaagttcgcagcaaaattggctgcggtatccagctgacccgtgaagttgac Tat-Smad7-21 1021 ggtgtttgggtttacaaccgttcttcttacccgatcttcatcaaatctgcgaccctggac TatSmad7 Ser 1021 ggtgtctgggtatataaccgcagcagctacccgatttttatcaaaagcgccaccctggat Tat-Smad7-21 1081 aacccggactctcgtaccctgctggttcacaaagttttcccgggtttctctatcaaagcg TatSmad7 Ser 1081 aatccggacagccgtacgctgctggtccataaagtatttccgggcttcagcatcaaagcg Tat-Smad7-21 1141 ttcgactacgaaaaagcgtactctctgcagcgtccgaacgaccacgaattcatgcagcag TatSmad7 Ser 1141 ttcgattacgagaaagcctacagcctgcagcgcccgaacgaccatgaattcatgcagcaa Tat-Smad7-21 1201 ccgtggaccggtttcaccgttcagatctctttcgttaaaggttggggtcagtgctacacc TatSmad7 Ser 1201 ccgtggacgggttttaccgtgcagatcagcttcgttaaaggctggggtcaatgctacacc Tat-Smad7-21 1261 cgtcagttcatctcttcttgcccgtgctggctggaagttatcttcaactctcgt------ TatSmad7 Ser 1261 cgtcagtttatcagcagctgtccgtgctggctggaagtgattttcaatagccgcaagggc Tat-Smad7-21 1315 ---------------------ggtaaaccgatcccgaacccgctgctgggtctggactct TatSmad7 Ser 1321 gagctcaatagcaagcttgaaggtaagcctatccctaaccctctcctcggtctcgatagc Tat-Smad7-21 1354 acctgagtcgac TatSmad7 Ser 1381 acgtgagtcgac
[0333] Protein production using the sequences below is carried out by transfecting mammalian expression vectors (e.g., pCMV-6-Entry) into HEK293 or CHO cells.
[0334] Optimized GST-Tat-Smad7-myc-flag nucleotide sequence, cloned in pCMV6-Entry plasmid:
TABLE-US-00022 (SEQ ID NO: 87) 1 gacgttgtat acgactccta tagggcggcc gggaattcgt cgactggatc cggtaccgag 61 gagatctgcc gccgcgatcg ccatgtcccc cattctgggc tactggaaga ttaagggcct 121 ggtgcagcct actagactgc tgctggaata cctggaggaa aaatatgaag agcatctgta 181 tgaaagagac gagggggata aatggaggaa caagaaattc gaactgggac tggagtttcc 241 taatctgcca tactatattg acggcgatgt gaagctgact cagtctatgg ctatcattag 301 atacatcgca gacaaacaca acatgctggg cgggtgtcct aaggaaaggg cagagattag 361 tatgctggag ggagccgtgc tggatattag atacggcgtc tcacgcatcg cctatagcaa 421 agacttcgaa accctgaagg tggattttct gagcaaactg cctgaaatgc tgaagatgtt 481 cgaggacaga ctgtgccaca aaacctacct gaatggcgac catgtcacac acccagattt 541 tatgctgtac gacgccctgg atgtggtcct gtatatggac cccatgtgtc tggatgcttt 601 ccctaagctg gtgtgcttta agaaaaggat cgaggcaatt ccccagatcg ataagtacct 661 gaaaagctcc aagtatatcg cttggcctct ccagggctgg caggcaacat tcggaggcgg 721 ggaccatccc cctaaaagcg acctggaggt gctgtttcag ggaccactgg gcagcggccg 781 gaagaagcgg cggcagaggc gccgaagtag gttccgcact aagcggtcag cactggtgcg 841 gagactgtgg cgatctcggg ctcctggagg agaggacgag gaagagggag caggcggcgg 901 cggaggagga ggagaactgc gcggggaggg agctacagat agccgagccc acggagctgg 961 aggaggagga ccagggcgag ccggatgctg tctgggcaaa gcagtgagag gcgccaaggg 1021 gcaccatcac ccccatccac ccgccgctgg cgcaggagca gccggcggag ctgaggcaga 1081 cctgaaagcc ctgactcaca gtgtgctgaa gaaactgaag gaaagacagc tggagctgct 1141 gctccaggca gtcgaatcac gcggaggcac ccgaacagct tgtctgctgc tgcccggccg 1201 gctggactgc cggctgggac ccggcgcccc tgctggggca cagccagccc agcctccatc 1261 tagttatagc ctgcccctgc tgctgtgtaa ggtgttccga tggcctgatc tgcggcattc 1321 aagcgaagtc aaaaggctgt gctgttgcga gtcctacggc aagattaacc cagaactggt 1381 gtgttgcaat ccccatcacc tgtctcgact gtgtgaactg gagtcccccc ctccacccta 1441 ctctaggtat cctatggact ttctgaagcc aaccgctgac tgcccagatg cagtgccctc 1501 ctctgccgag actgggggaa ccaactacct ggctcctggc ggactgagcg actcccagct 1561 gctgctggaa ccaggggatc gcagccactg gtgtgtggtc gcctactggg aagagaagac 1621 aagagtggga aggctgtatt gcgtccagga gccttccctg gacatcttct acgatctgcc 1681 acaggggaat ggattttgtc tgggccagct gaactctgac aataagagtc agctggtgca 1741 gaaagtccgg agcaagattg gctgcggcat ccagctgacc agggaggtgg acggcgtgtg 1801 ggtctacaac cgcagttcat atccaatctt catcaagagc gccactctgg acaatcccga 1861 ttcccgcacc ctgctggtgc ataaggtctt ccccggcttc agcatcaagg ccttcgacta 1921 cgagaaggct tatagtctcc agcggcccaa cgatcacgag ttcatgcagc agccttggac 1981 aggcttcact gtgcagatca gcttcgtcaa gggatggggc cagtgctaca caaggcagtt 2041 catctcaagc tgtccctgtt ggctggaagt cattttcaat agtaggacgc gtacqcqqcc 2101 gctcgagcag aaactcatct cagaagagga tctggcagca aatgatatcc tggattacaa 2161 ggatgacgac gataaggttt aa
[0335] The entire sequence (up to the NotI site) is codon optimized for mammalian expression, using the OPTIMUMGENE.TM. program from GenScript.
[0336] 1790-1792: changes GAT to GAC, (kept Asp) to avoid alternative ORF (highlight)
[0337] 1-82: cloning sites+kozac sequence in pCMV6-Entry
[0338] 83-777: GST+ precision enzyme sites; 776-805: Tat;
[0339] 806-2086: full length human Smad7
[0340] 2087-2107: MluI, NotI, XhoI
[0341] 2108-2182: myc-flag from pCMV6-Entry
[0342] Bold underline: unique NotI site
[0343] The above nucleotide sequence is 79% homologous to native human Smad7.
TABLE-US-00023 Mol 1 human Smad7 mRNA (1-3103) Mol 2 optimized GST-Tat-Smad7-myc-flag (1-2182) Number of sequences to align: 2 Settings: Sort results list by Score human Smad7 500 tcaccaccatccccacccgccagccgcgggcgccggcgcggccgggggcg optimized GS 1027 .....c......--.......----..t.....a..a..a.....c.a. human Smad7 550 ccgaggcggatctgaaggcgctcacgcactcggtgctcaagaaactgaag optimized GS 1071 .t.....a..c.....a..c..g..t...agt.....g............ human Smad7 600 gagcggcagctggagctgctgctccaggccgtggagtcccgcggcgggac optimized GS 1121 ..aa.a.......................a..c..a..a.....a..c. human Smad7 650 gcgcaccgcgtgcctcctgctgcccggccgcctggactgcaggctgggcc optimized GS 1171 c..a..a..t..t..g..............g.........c.......a. human Smad7 700 cgggggcgcccgccggcgcgcagcctgcgcagccgccctcgtcctactcg optimized GS 1221 .c..c..c..t..t..g..a.....a..c.....t..a..tagt..tagc human Smad7 750 ctccccctcctgctgtgcaaagtgttcaggtggccggatctcaggcattc optimized GS 1271 ..g.....g........t..g......c.a.....t.....gc....... human Smad7 800 ctcggaagtcaagaggctgtgttgctgtgaatcttacgggaagatcaacc optimized GS 1321 aagc........a........c..t..c..g..c.....c.....t.... human Smad7 850 ccgagctggtgtgctgcaacccccatcaccttagccgactctgcgaacta optimized GS 1371 .a..a........t.....t...........gtct.....g..t.....g human Smad7 900 gagtctcccccccctccttactccagatacccgatggattttctcaaacc optimized GS 1421 .....c.....t..a..c.....t..g..t..t.....c.....g..g.. human Smad7 950 aactgcagactgtccagatgctgtgccttcctccgctgaaacagggggaa optimized GS 1471 ...c.t.....c........a.....c.....t..c..g..t....... human Smad7 1000 cgaattatctggcccctggggggctttcagattcccaacttcttctggag optimized GS 1521 .c.c.c.....t.....c..a..gagc..c.....g..g..g.....a human Smad7 1050 cctggggatcggtcacactggtgcgtggtggcatactgggaggagaagac optimized GS 1571 ..a........cagc........t.....c.c........a........ human Smad7 1100 gagagtggggaggctctactgtgtccaggagccctctctggatatcttct optimized GS 1621 a........a.....g..t..c...........t..c.....c....... human Smad7 1150 atgatctacctcaggggaatggcttttgcctcggacagctcaattcggac optimized GS 1671 .c.....g..a...........a.....t..g..c.....g..c..t... human Smad7 1200 aacaagagtcagctggtgcagaaggtgcggagcaaaatcggctgcggcat optimized GS 1721 ..t....................a..c........g..t........... human Smad7 1250 ccagctgacgcgggaggtggatggtgtgtgggtgtacaaccgcagcagtt optimized GS 1771 .........ca..........c.c........c...........ttca. human Smad7 1300 accccatcttcatcaagtccgccacactggacaacccggactccaggacg optimized GS 1821 .t..a............ag......t........t..c..t...c.c..c human Smad7 1350 ctgttggtacacaaggtgttccccggtttctccatcaaggctttcgacta optimized GS 1871 ...c....g..t.....c........c...ag.........c........ human Smad7 1400 cgagaaggcgtacagcctgcagcggcccaatgaccacgagtttatgcagc optimized GS 1921 .........t..t..t..c...........c.t........c....... human Smad7 1450 agccgtggacgggctttaccgtgcagatcagctttgtgaagggctggggt optimized GS 1971 ....t.....a.....c.t..............c.c.....a.....c human Smad7 1500 cagtgctacacccgccagttcatcagcagctgcccgtgctggctagaggt optimized GS 2021 ...........aa.g.........tca.....t..c..t.....g..a.. human Smad7 1550 catcttcaa (SEQ ID NO: 88) optimized GS 2071 ...t..... (SEQ ID NO: 89)
[0344] Optimized GST-Tat-Smad7-myc-flag protein sequence from the above nucleotide sequence:
TABLE-US-00024 (SEQ ID NO: 90) 1 mspilgywki kglvqptrll leyleekyee hlyerdegdk wrnkkfelgl efpnlpyyid 61 gdvkltqsma iiryiadkhn mlggcpkera eismlegavl dirygvsria yskdfetlkv 121 dflsklpeml kmfedrlchk tylngdhvth pdfmlydald vvlymdpmcl dafpklvcfk 181 krieaipqid kylksskyia wplqgwqatf gggdhppksd levlfqgplg sgrkkrrqrr 241 rsrfrtkrsa lvrrlwrsra pggedeeega gggggggelr gegatdsrah gaggggpgra 301 gcclgkavrg akghhhphpp aagagaagga eadlkalths vlkklkerql elllqavesr 361 ggtrtaclll pgrldcrlgp gapagagpaq ppssyslpll lckvfrwpdl rhssevkrlc 421 ccesygkinp elvccnphhl srlcelespp ppysrypmdf lkptadcpda vpssaetggt 481 nylapgglsd sqlllepgdr shwcvvaywe ektrvgrlyc vqepsldify dlpqgngfcl 541 gqlnsdnksq lvqkvrskig cgiqltrevd gvwvynrssy pifiksatld npdsrtllvh 601 kvfpgfsika fdyekayslq rpndhefmqq pwtgftvqis fvkgwgqcyt rqfisscpcw 661 levifnsrtr trpleqklis eedlaandil dykddddkv 1-229: GST+precision sites 232-668 Tat-Smad7 671-699: restriction sites+myc-Flag
[0345] Optimized GST-Tat-N-Smad7-myc-flag nucleotide sequence, cloned in pCMV6-Entry plasmid:
TABLE-US-00025 (SEQ ID NO: 91) 1 gaattcgtcg actggatccg gtaccgagga gatctgccgc cgcgatcgcc atgtccccca 61 ttctgggcta ctggaagatt aagggcctgg tgcagcctac tagactgctg ctggaatacc 121 tggaggaaaa atatgaagag catctgtatg aaagagacga gggggataaa tggaggaaca 181 agaaattcga actgggactg gagtttccta atctgccata ctatattgac ggcgatgtga 241 agctgactca gtctatggct atcattagat acatcgcaga caaacacaac atgctgggcg 301 ggtgtcctaa ggaaagggca gagattagta tgctggaggg agccgtgctg gatattagat 361 acggcgtctc acgcatcgcc tatagcaaag acttcgaaac cctgaaggtg gattttctga 421 gcaaactgcc tgaaatgctg aagatgttcg aggacagact gtgccacaaa acctacctga 481 atggcgacca tgtcacacac ccagatttta tgctgtacga cgccctggat gtggtcctgt 541 atatggaccc catgtgtctg gatgctttcc ctaagctggt gtgctttaag aaaaggatcg 601 aggcaattcc ccagatcgat aagtacctga aaagctccaa gtatatcgct tggcctctcc 661 agggctggca ggcaacattc ggaggcgggg accatccccc taaaagcgac ctggaggtgc 721 tgtttcaggg accactgggc agcggccgga agaagcggcg gcagaggcgc cgaagtaggt 781 tccgcactaa gcggtcagca ctggtgcgga gactgtggcg atctcgggct cctggaggag 841 aggacgagga agagggagca ggcggcggcg gaggaggagg agaactgcgc ggggagggag 901 ctacagatag ccgagcccac ggagctggag gaggaggacc agggcgagcc ggatgctgtc 961 tgggcaaagc agtgagaggc gccaaggggc accatcaccc ccatccaccc gccgctggcg 1021 caggagcagc cggcggagct gaggcagacc tgaaagccct gactcacagt gtgctgaaga 1081 aactgaagga aagacagctg gagctgctgc tccaggcagt cgaatcacgc ggaggcaccc 1141 gaacagcttg tctgctgctg cccggccggc tggactgccg gctgggaccc ggcgcccctg 1201 ctggggcaca gccagcccag cctccatcta gttatagcct gcccctgctg ctgtgtaagg 1261 tgttccgatg gcctgatctg cggcattcaa gcgaagtcaa aaggctgtgc tgttgcgagt 1321 cctacggcaa gattaaccca gaactggtgt gttgcaatcc ccatcacctg tctcgactgt 1381 gtgaactgga gtccccccct ccaccctact ctaggtatcc tatggacttt ctgaagccaa 1441 ccgctgactg cccagatgca gtgccctcct ctgccgagac tgggggaacc aactacctgg 1501 ctcctggcgg actgagcgac tcccagctgc tgctggaacc aggggatcgg cqqccqctcg 1561 agcagaaact catctcagaa gaggatctgg cagcaaatga tatcctggat tacaaggatg 1621 acgacgataa ggtttaa
[0346] The entire sequence (up to the NotI site) is codon optimized for mammalian expression, using the OPTIMUMGENE.TM. program from GenScript.
[0347] 1-50: cloning sites+kozac sequence in pCMV6-Entry
[0348] 51-743: GST+ precision enzyme sites
[0349] 744-773-: Tat
[0350] 774-1549-: human Smad7 encoding N-terminal 1-258aa
[0351] 1550-1563: NotI, XhoI, Bold underline: unique NotI site
[0352] 1564-1637: myc-flag from pCMV6-Entry
[0353] Optimized GST-Tat-N-Smad7-myc-flag protein sequence from the above nucleotide sequence:
TABLE-US-00026 (SEQ ID NO: 92) 1 mspilgywki kglvqptrll leyleekyee hlyerdegdk wrnkkfelgl efpnlpyyid 61 gdvkltqsma iiryiadkhn mlggcpkera eismlegavl dirygvsria yskdfetlkv 121 dflsklpeml kmfedrlchk tylngdhvth pdfmlydald vvlymdpmcl dafpklvcfk 181 krieaipqid kylksskyia wplqgwqatf gggdhppksd levlfqgplg sgrkkrrqrr 241 rsrfrtkrsa lvrrlwrsra pggedeeega gggggggelr gegatdsrah gaggggpgra 301 gcclgkavrg akghhhphpp aagagaagga eadlkalths vlkklkerql elllqavesr 361 ggtrtaclll pgrldcrlgp gapagaqpaq ppssyslpll lckvfrwpdl rhssevkrlc 421 ccesygkinp elvccnphhl srlcelespp ppysrypmdf lkptadcpda vpssaetggt 481 nylapgglsd sqlllepgdr rpleqklise edlaandild ykddddkv 1-241: GST-Tat 244-500: N-Smad7 2-258 501-528: restriction sites+myc-Flag
[0354] Optimized GST-Tat-C-Smad7-myc-flag nucleotide sequence, cloned in pCMV6-Entry plasmid:
TABLE-US-00027 (SEQ ID NO: 93) 1 gaattcgtcg actggatccg gtaccgagga gatctgccgc cgcgatcgcc atgtccccca 61 ttctgggcta ctggaagatt aagggcctgg tgcagcctac tagactgctg ctggaatacc 121 tggaggaaaa atatgaagag catctgtatg aaagagacga gggggataaa tggaggaaca 181 agaaattcga actgggactg gagtttccta atctgccata ctatattgac ggcgatgtga 241 agctgactca gtctatggct atcattagat acatcgcaga caaacacaac atgctgggcg 301 ggtgtcctaa ggaaagggca gagattagta tgctggaggg agccgtgctg gatattagat 361 acggcgtctc acgcatcgcc tatagcaaag acttcgaaac cctgaaggtg gattttctga 421 gcaaactgcc tgaaatgctg aagatgttcg aggacagact gtgccacaaa acctacctga 481 atggcgacca tgtcacacac ccagatttta tgctgtacga cgccctggat gtggtcctgt 541 atatggaccc catgtgtctg gatgctttcc ctaagctggt gtgctttaag aaaaggatcg 601 aggcaattcc ccagatcgat aagtacctga aaagctccaa gtatatcgct tggcctctcc 661 agggctggca ggcaacattc ggaggcgggg accatccccc taaaagcgac ctggaggtgc 721 tgtttcaggg accactgggc agcggccgga agaagcggcg gcagaggcgc agccactggt 781 gtgtggtcgc ctactgggaa gagaagacaa gagtgggaag gctgtattgc gtccaggagc 841 cttccctgga catcttctac gatctgccac aggggaatgg attttgtctg ggccagctga 901 actctgacaa taagagtcag ctggtgcaga aagtccggag caagattggc tgcggcatcc 961 agctgaccag ggaggtggac ggcgtgtggg tctacaaccg cagttcatat ccaatcttca 1021 tcaagagcgc cactctggac aatcccgatt cccgcaccct gctggtgcat aaggtcttcc 1081 ccggcttcag catcaaggcc ttcgactacg agaaggctta tagtctccag cggcccaacg 1141 atcacgagtt catgcagcag ccttggacag gcttcactgt gcagatcagc ttcgtcaagg 1201 gatggggcca gtgctacaca aggcagttca tctcaagctg tccctgttgg ctggaagtca 1261 ttttcaatag taggacgcgt acgcggccgc tcgagcagaa actcatctca gaagaggatc 1321 tggcagcaaa tgatatcctg gattacaagg atgacgacga taaggtttaa
[0355] The entire sequence (up to the NotI site) is codon optimized for mammalian expression, using the OPTIMUMGENE.TM. program from GenScript.
[0356] 1-50: cloning sites+kozac sequence in pCMV6-Entry
[0357] 51-743: GST+ precision enzyme sites
[0358] 744-773: Tat
[0359] 774-1274: c-terminal Smad7
[0360] 1275: Mlu
[0361] 1283: NotI
[0362] 1275-1370: mluI, NotI, XhoI, myc+flag
[0363] Optimized GST-Tat-C-Smad7-myc-flag protein sequence from the above nucleotide sequence:
TABLE-US-00028 (SEQ ID NO: 94) 1 mspilgywki kglvqptrll leyleekyee hlyerdegdk wrnkkfelgl efpnlpyyid 61 gdvkltqsma iiryiadkhn mlggcpkera eismlegavl dirygvsria yskdfetlkv 121 dflsklpeml kmfedrlchk tylngdhvth pdfmlydald vvlymdpmcl dafpklvcfk 181 krieaipqid kylksskyia wplqgwqatf gggdhppksd levlfqgplg sgrkkrrqrr 241 rshwcvvayw eektrvgrly cvqepsldif ydlpqgngfc lgqlnsdnks qlvqkvrski 301 gcgiqltrev dgvwvynrss ypifiksatl dnpdsrtllv hkvfpgfsik afdyekaysl 361 qrpndhefmq qpwtgftvqi sfvkgwgqcy trqfisscpc wlevifnsrt rtrpleqkli 421 seedlaandi ldykddddkv 1-241: GST+precision+Tat 242-409: c-Smad7 (259-426aa) 410-440: Mlu+Not+myc+flag: restriction sites+myc-Flag
[0364] Based on the Smad7 structure, it is anticipated that the linker (203-258aa), which contains the PY domain (203-217aa), will have therapeutic effects by blocking TGF-.beta.-induced inflammation or growth inhibition (FIG. 15).
[0365] The amino acid sequence for the Tat-Smad7-linker peptide (203-258aa) is:
TABLE-US-00029 (SEQ ID NO: 95) GRKKRRQRRR-ELESPPPPYSRYPMDFLKPTADCPDAVPSSAETGGTNYL APGGLSDSQLLLEPGDR 1-10: Tat
[0366] The codon optimized nucleotide sequence for the above peptide in bacterial production is:
TABLE-US-00030 (SEQ ID NO: 96) 1 ggccgtaaaa aacgccgtca acgccgccgt gaactggaga gcccgccgcc gccgtatagc 61 cgttacccga tggatttcct gaaaccgact gcagattgcc cggacgcagt cccgagcagc 121 gctgagaccg gcggcaccaa ctatctggca ccgggcggtc tgagcgatag ccagctgctg 181 ctggaaccgg gcgaccgtgg taagcctatc cctaaccctc tcctcggtct cgattctacg 241 tgagtcgac 1-30: Tat 31-198: Smad7 linker 199-249: V5
[0367] The codon optimized nucleotide sequence for the above peptide in mammalian cell production is:
TABLE-US-00031 (SEQ ID NO: 97) 1 ggccggaaga agcggcggca gaggcgccga gaactggagt ccccccctcc accctactct 61 aggtatccta tggactttct gaagccaacc gctgactgcc cagatgcagt gccctcctct 121 gccgagactg ggggaaccaa ctacctggct cctggcggac tgagcgactc ccagctgctg 181 ctggaaccag gggatcggcg gccgctcgag cagaaactca tctcagaaga ggatctggca 241 gcaaatgata tcctggatta caaggatgac gacgataagg tttaa 1-30: mammalian codon optimized Tat 31-198: Smad7 linker 199-285: NotI, Myc tag, Flag tag
[0368] The amino acid sequence for the Tat-Smad7-PY peptide (203-217aa) is:
TABLE-US-00032 (SEQ ID NO: 98) GRKKRRQRRR-ELESPPPPYSRYPMD 1-10: Tat
[0369] The codon optimized nucleotide sequence for the above peptide in bacterial production is:
TABLE-US-00033 (SEQ ID NO: 99) 1 ggccgtaaaa aacgccgtca acgccgccgt gaactggaga gcccgccgcc gccgtatagc 61 cgttacccga tggatggtaa gcctatccct aaccctctcc tcggtctcga ttctacgtga 121 gtcgac 1-30: Tat 31-75: Smad7-PY 76-126: V5
[0370] The codon optimized nucleotide sequence for the above peptide in mammalian cell production is:
TABLE-US-00034 (SEQ ID NO: 100) 1 ggccggaaga agcggcggca gaggcgccga gaactggagt ccccccctcc accctactct 61 aggtatccta tggaccggcc gctcgagcag aaactcatct cagaagagga tctggcagca 121 aatgatatcc tggattacaa ggatgacgac gataaggttt aa 1-30: mammalian codon optimized Tat 31-75: Smad7 PY 76-162: NotI, Myc tag, Flag tag
[0371] The foregoing discussion of the present technology has been presented for purposes of illustration and description. The foregoing is not intended to limit the present technology to the form or forms disclosed herein. Although the description of the present technology has included description of one or more embodiments and certain variations and modifications, other variations and modifications are within the scope of the present technology, e.g., as may be within the skill and knowledge of those in the art, after understanding the present disclosure. It is intended to obtain rights which include alternative embodiments to the extent permitted, including alternate, interchangeable and/or equivalent structures, functions, ranges or steps to those claimed, whether or not such alternate, interchangeable and/or equivalent structures, functions, ranges or steps are disclosed herein, and without intending to publicly dedicate any patentable subject matter.
Sequence CWU 1
1
101130DNAHuman immunodeficiency virusCDS(1)..(30) 1ggc cgt aaa aaa
cgc cgt caa cgc cgc cgt 30Gly Arg Lys Lys Arg Arg Gln Arg Arg Arg1
5 10210PRTHuman immunodeficiency virus 2Gly Arg Lys Lys Arg Arg Gln
Arg Arg Arg1 5 10333DNAHuman immunodeficiency virus 3tatggccgta
aaaaacgccg tcaacgccgc cgt 33411PRTHuman immunodeficiency virus 4Tyr
Gly Arg Lys Lys Arg Arg Gln Arg Arg Arg1 5 10521DNAHuman
immunodeficiency virus 5ggccgtaaaa aacgccgtca a 2167PRTHuman
immunodeficiency virus 6Gly Arg Lys Lys Arg Arg Gln1 5730DNAHuman
immunodeficiency virus 7ggccgtaaaa aacgccgtca acgccgccgt
30830DNAHuman immunodeficiency virus 8ggccgtaaaa aacgccgtca
acgccgccgt 3091497DNAArtificial SequenceDescription of Artificial
Sequence Synthetic polynucleotideCDS(58)..(1461) 9ttcccctcta
gaaataattt tgtttaactt taagaaggaa ttcaggagcc cttcacc 57atg cgt aaa
aaa cgc cgt caa cgc cgc cgt ggt ttc cgt acg aaa cgc 105Met Arg Lys
Lys Arg Arg Gln Arg Arg Arg Gly Phe Arg Thr Lys Arg1 5 10 15tcg gcc
ctg gtc cgt cgc ctg tgg cgc tcc cgt gct ccg ggt ggt gaa 153Ser Ala
Leu Val Arg Arg Leu Trp Arg Ser Arg Ala Pro Gly Gly Glu 20 25 30gat
gaa gaa gaa ggt gct ggc ggc ggt ggc ggt ggc ggt gaa ctg cgt 201Asp
Glu Glu Glu Gly Ala Gly Gly Gly Gly Gly Gly Gly Glu Leu Arg 35 40
45ggc gag ggt gca acc gat agt cgt gca cac ggt gca ggc ggt ggc ggt
249Gly Glu Gly Ala Thr Asp Ser Arg Ala His Gly Ala Gly Gly Gly Gly
50 55 60ccg ggt cgt gct ggt tgc tgt ctg ggt aaa gct gtg cgc ggc gcg
aaa 297Pro Gly Arg Ala Gly Cys Cys Leu Gly Lys Ala Val Arg Gly Ala
Lys65 70 75 80ggt cat cac cat ccg cac ccg ccg gca gca ggt gca ggt
gca gct ggc 345Gly His His His Pro His Pro Pro Ala Ala Gly Ala Gly
Ala Ala Gly 85 90 95ggt gcg gaa gcc gat ctg aaa gcc ctg acc cat agt
gtc ctg aaa aaa 393Gly Ala Glu Ala Asp Leu Lys Ala Leu Thr His Ser
Val Leu Lys Lys 100 105 110ctg aaa gaa cgt cag ctg gag ctg ctg ctg
caa gca gta gaa tcc cgt 441Leu Lys Glu Arg Gln Leu Glu Leu Leu Leu
Gln Ala Val Glu Ser Arg 115 120 125ggc ggt acc cgt acg gct tgt ctg
ctg ctg ccg ggt cgt ctg gat tgc 489Gly Gly Thr Arg Thr Ala Cys Leu
Leu Leu Pro Gly Arg Leu Asp Cys 130 135 140cgt ctg ggt ccg ggt gca
ccg gct ggt gcg cag ccg gca caa ccg ccg 537Arg Leu Gly Pro Gly Ala
Pro Ala Gly Ala Gln Pro Ala Gln Pro Pro145 150 155 160agc tct tac
agc ctg ccg ctg ctg ctg tgt aaa gtg ttt cgt tgg ccg 585Ser Ser Tyr
Ser Leu Pro Leu Leu Leu Cys Lys Val Phe Arg Trp Pro 165 170 175gac
ctg cgc cac agt tcc gaa gtt aaa cgc ctg tgc tgt tgc gag agc 633Asp
Leu Arg His Ser Ser Glu Val Lys Arg Leu Cys Cys Cys Glu Ser 180 185
190tat ggc aaa att aac ccg gaa ctg gtt tgt tgc aat ccg cac cat ctg
681Tyr Gly Lys Ile Asn Pro Glu Leu Val Cys Cys Asn Pro His His Leu
195 200 205tct cgt ctg tgt gaa ctg gag agc ccg ccg ccg ccg tat tct
cgt tac 729Ser Arg Leu Cys Glu Leu Glu Ser Pro Pro Pro Pro Tyr Ser
Arg Tyr 210 215 220ccg atg gat ttc ctg aaa ccg act gca gat tgc ccg
gac gca gtc ccg 777Pro Met Asp Phe Leu Lys Pro Thr Ala Asp Cys Pro
Asp Ala Val Pro225 230 235 240tca tcg gct gag acc ggc ggc acc aac
tat ctg gca ccg ggc ggt ctg 825Ser Ser Ala Glu Thr Gly Gly Thr Asn
Tyr Leu Ala Pro Gly Gly Leu 245 250 255agt gat tcc cag ctg ctg ctg
gaa ccg ggc gac cgt tca cat tgg tgt 873Ser Asp Ser Gln Leu Leu Leu
Glu Pro Gly Asp Arg Ser His Trp Cys 260 265 270gtg gtt gcc tat tgg
gaa gag aaa acg cgt gtc ggt cgc ctg tac tgc 921Val Val Ala Tyr Trp
Glu Glu Lys Thr Arg Val Gly Arg Leu Tyr Cys 275 280 285gta cag gaa
ccg tcg ctg gat atc ttt tat gac ctg ccg cag ggc aat 969Val Gln Glu
Pro Ser Leu Asp Ile Phe Tyr Asp Leu Pro Gln Gly Asn 290 295 300ggt
ttc tgt ctg ggc caa ctg aac tca gat aat aaa tcg cag ctg gtg 1017Gly
Phe Cys Leu Gly Gln Leu Asn Ser Asp Asn Lys Ser Gln Leu Val305 310
315 320caa aaa gtt cgc tca aaa att ggc tgc ggt atc cag ctg acc cgt
gaa 1065Gln Lys Val Arg Ser Lys Ile Gly Cys Gly Ile Gln Leu Thr Arg
Glu 325 330 335gtt gac ggt gtc tgg gta tat aac cgc agc tct tac ccg
att ttt atc 1113Val Asp Gly Val Trp Val Tyr Asn Arg Ser Ser Tyr Pro
Ile Phe Ile 340 345 350aaa agt gcc acc ctg gat aat ccg gac tcc cgt
acg ctg ctg gtc cac 1161Lys Ser Ala Thr Leu Asp Asn Pro Asp Ser Arg
Thr Leu Leu Val His 355 360 365aaa gta ttt ccg ggc ttc tca atc aaa
gcg ttc gat tac gag aaa gcc 1209Lys Val Phe Pro Gly Phe Ser Ile Lys
Ala Phe Asp Tyr Glu Lys Ala 370 375 380tac tcg ctg cag cgc ccg aac
gac cat gaa ttc atg cag caa ccg tgg 1257Tyr Ser Leu Gln Arg Pro Asn
Asp His Glu Phe Met Gln Gln Pro Trp385 390 395 400acg ggt ttt act
gtg cag atc tct ttc gtt aaa ggc tgg ggt caa tgc 1305Thr Gly Phe Thr
Val Gln Ile Ser Phe Val Lys Gly Trp Gly Gln Cys 405 410 415tac acc
cgt cag ttt atc tcg tcc tgt ccg tgc tgg ctg gaa gtg att 1353Tyr Thr
Arg Gln Phe Ile Ser Ser Cys Pro Cys Trp Leu Glu Val Ile 420 425
430ttc aat agc cgc aag ggc gag ctc aat tcg aag ctt gaa ggt aag cct
1401Phe Asn Ser Arg Lys Gly Glu Leu Asn Ser Lys Leu Glu Gly Lys Pro
435 440 445atc cct aac cct ctc ctc ggt ctc gat tct acg cgt acc ggt
cat cat 1449Ile Pro Asn Pro Leu Leu Gly Leu Asp Ser Thr Arg Thr Gly
His His 450 455 460cac cat cac cat tgagtttgat ccggctgcta acaaagcccg
aaagga 1497His His His His46510468PRTArtificial SequenceDescription
of Artificial Sequence Synthetic polypeptide 10Met Arg Lys Lys Arg
Arg Gln Arg Arg Arg Gly Phe Arg Thr Lys Arg1 5 10 15Ser Ala Leu Val
Arg Arg Leu Trp Arg Ser Arg Ala Pro Gly Gly Glu 20 25 30Asp Glu Glu
Glu Gly Ala Gly Gly Gly Gly Gly Gly Gly Glu Leu Arg 35 40 45Gly Glu
Gly Ala Thr Asp Ser Arg Ala His Gly Ala Gly Gly Gly Gly 50 55 60Pro
Gly Arg Ala Gly Cys Cys Leu Gly Lys Ala Val Arg Gly Ala Lys65 70 75
80Gly His His His Pro His Pro Pro Ala Ala Gly Ala Gly Ala Ala Gly
85 90 95Gly Ala Glu Ala Asp Leu Lys Ala Leu Thr His Ser Val Leu Lys
Lys 100 105 110Leu Lys Glu Arg Gln Leu Glu Leu Leu Leu Gln Ala Val
Glu Ser Arg 115 120 125Gly Gly Thr Arg Thr Ala Cys Leu Leu Leu Pro
Gly Arg Leu Asp Cys 130 135 140Arg Leu Gly Pro Gly Ala Pro Ala Gly
Ala Gln Pro Ala Gln Pro Pro145 150 155 160Ser Ser Tyr Ser Leu Pro
Leu Leu Leu Cys Lys Val Phe Arg Trp Pro 165 170 175Asp Leu Arg His
Ser Ser Glu Val Lys Arg Leu Cys Cys Cys Glu Ser 180 185 190Tyr Gly
Lys Ile Asn Pro Glu Leu Val Cys Cys Asn Pro His His Leu 195 200
205Ser Arg Leu Cys Glu Leu Glu Ser Pro Pro Pro Pro Tyr Ser Arg Tyr
210 215 220Pro Met Asp Phe Leu Lys Pro Thr Ala Asp Cys Pro Asp Ala
Val Pro225 230 235 240Ser Ser Ala Glu Thr Gly Gly Thr Asn Tyr Leu
Ala Pro Gly Gly Leu 245 250 255Ser Asp Ser Gln Leu Leu Leu Glu Pro
Gly Asp Arg Ser His Trp Cys 260 265 270Val Val Ala Tyr Trp Glu Glu
Lys Thr Arg Val Gly Arg Leu Tyr Cys 275 280 285Val Gln Glu Pro Ser
Leu Asp Ile Phe Tyr Asp Leu Pro Gln Gly Asn 290 295 300Gly Phe Cys
Leu Gly Gln Leu Asn Ser Asp Asn Lys Ser Gln Leu Val305 310 315
320Gln Lys Val Arg Ser Lys Ile Gly Cys Gly Ile Gln Leu Thr Arg Glu
325 330 335Val Asp Gly Val Trp Val Tyr Asn Arg Ser Ser Tyr Pro Ile
Phe Ile 340 345 350Lys Ser Ala Thr Leu Asp Asn Pro Asp Ser Arg Thr
Leu Leu Val His 355 360 365Lys Val Phe Pro Gly Phe Ser Ile Lys Ala
Phe Asp Tyr Glu Lys Ala 370 375 380Tyr Ser Leu Gln Arg Pro Asn Asp
His Glu Phe Met Gln Gln Pro Trp385 390 395 400Thr Gly Phe Thr Val
Gln Ile Ser Phe Val Lys Gly Trp Gly Gln Cys 405 410 415Tyr Thr Arg
Gln Phe Ile Ser Ser Cys Pro Cys Trp Leu Glu Val Ile 420 425 430Phe
Asn Ser Arg Lys Gly Glu Leu Asn Ser Lys Leu Glu Gly Lys Pro 435 440
445Ile Pro Asn Pro Leu Leu Gly Leu Asp Ser Thr Arg Thr Gly His His
450 455 460His His His His46511461PRTArtificial SequenceDescription
of Artificial Sequence Synthetic polypeptide 11Gly Ser Gly Arg Lys
Lys Arg Arg Gln Arg Arg Arg Gly Phe Arg Thr1 5 10 15Lys Arg Ser Ala
Leu Val Arg Arg Leu Trp Arg Ser Arg Ala Pro Gly 20 25 30Gly Glu Asp
Glu Glu Glu Gly Ala Gly Gly Gly Gly Gly Gly Gly Glu 35 40 45Leu Arg
Gly Glu Gly Ala Thr Asp Ser Arg Ala His Gly Ala Gly Gly 50 55 60Gly
Gly Pro Gly Arg Ala Gly Cys Cys Leu Gly Lys Ala Val Arg Gly65 70 75
80Ala Lys Gly His His His Pro His Pro Pro Ala Ala Gly Ala Gly Ala
85 90 95Ala Gly Gly Ala Glu Ala Asp Leu Lys Ala Leu Thr His Ser Val
Leu 100 105 110Lys Lys Leu Lys Glu Arg Gln Leu Glu Leu Leu Leu Gln
Ala Val Glu 115 120 125Ser Arg Gly Gly Thr Arg Thr Ala Cys Leu Leu
Leu Pro Gly Arg Leu 130 135 140Asp Cys Arg Leu Gly Pro Gly Ala Pro
Ala Gly Ala Gln Pro Ala Gln145 150 155 160Pro Pro Ser Ser Tyr Ser
Leu Pro Leu Leu Leu Cys Lys Val Phe Arg 165 170 175Trp Pro Asp Leu
Arg His Ser Ser Glu Val Lys Arg Leu Cys Cys Cys 180 185 190Glu Ser
Tyr Gly Lys Ile Asn Pro Glu Leu Val Cys Cys Asn Pro His 195 200
205His Leu Ser Arg Leu Cys Glu Leu Glu Ser Pro Pro Pro Pro Tyr Ser
210 215 220Arg Tyr Pro Met Asp Phe Leu Lys Pro Thr Ala Asp Cys Pro
Asp Ala225 230 235 240Val Pro Ser Ser Ala Glu Thr Gly Gly Thr Asn
Tyr Leu Ala Pro Gly 245 250 255Gly Leu Ser Asp Ser Gln Leu Leu Leu
Glu Pro Gly Asp Arg Ser His 260 265 270Trp Cys Val Val Ala Tyr Trp
Glu Glu Lys Thr Arg Val Gly Arg Leu 275 280 285Tyr Cys Val Gln Glu
Pro Ser Leu Asp Ile Phe Tyr Asp Leu Pro Gln 290 295 300Gly Asn Gly
Phe Cys Leu Gly Gln Leu Asn Ser Asp Asn Lys Ser Gln305 310 315
320Leu Val Gln Lys Val Arg Ser Lys Ile Gly Cys Gly Ile Gln Leu Thr
325 330 335Arg Glu Val Asp Gly Val Trp Val Tyr Asn Arg Ser Ser Tyr
Pro Ile 340 345 350Phe Ile Lys Ser Ala Thr Leu Asp Asn Pro Asp Ser
Arg Thr Leu Leu 355 360 365Val His Lys Val Phe Pro Gly Phe Ser Ile
Lys Ala Phe Asp Tyr Glu 370 375 380Lys Ala Tyr Ser Leu Gln Arg Pro
Asn Asp His Glu Phe Met Gln Gln385 390 395 400Pro Trp Thr Gly Phe
Thr Val Gln Ile Ser Phe Val Lys Gly Trp Gly 405 410 415Gln Cys Tyr
Thr Arg Gln Phe Ile Ser Ser Cys Pro Cys Trp Leu Glu 420 425 430Val
Ile Phe Asn Ser Arg Lys Gly Glu Leu Asn Ser Lys Leu Glu Gly 435 440
445Lys Pro Ile Pro Asn Pro Leu Leu Gly Leu Asp Ser Thr 450 455
46012426PRTHomo sapiens 12Met Phe Arg Thr Lys Arg Ser Ala Leu Val
Arg Arg Leu Trp Arg Ser1 5 10 15Arg Ala Pro Gly Gly Glu Asp Glu Glu
Glu Gly Ala Gly Gly Gly Gly 20 25 30Gly Gly Gly Glu Leu Arg Gly Glu
Gly Ala Thr Asp Ser Arg Ala His 35 40 45Gly Ala Gly Gly Gly Gly Pro
Gly Arg Ala Gly Cys Cys Leu Gly Lys 50 55 60Ala Val Arg Gly Ala Lys
Gly His His His Pro His Pro Pro Ala Ala65 70 75 80Gly Ala Gly Ala
Ala Gly Gly Ala Glu Ala Asp Leu Lys Ala Leu Thr 85 90 95His Ser Val
Leu Lys Lys Leu Lys Glu Arg Gln Leu Glu Leu Leu Leu 100 105 110Gln
Ala Val Glu Ser Arg Gly Gly Thr Arg Thr Ala Cys Leu Leu Leu 115 120
125Pro Gly Arg Leu Asp Cys Arg Leu Gly Pro Gly Ala Pro Ala Gly Ala
130 135 140Gln Pro Ala Gln Pro Pro Ser Ser Tyr Ser Leu Pro Leu Leu
Leu Cys145 150 155 160Lys Val Phe Arg Trp Pro Asp Leu Arg His Ser
Ser Glu Val Lys Arg 165 170 175Leu Cys Cys Cys Glu Ser Tyr Gly Lys
Ile Asn Pro Glu Leu Val Cys 180 185 190Cys Asn Pro His His Leu Ser
Arg Leu Cys Glu Leu Glu Ser Pro Pro 195 200 205Pro Pro Tyr Ser Arg
Tyr Pro Met Asp Phe Leu Lys Pro Thr Ala Asp 210 215 220Cys Pro Asp
Ala Val Pro Ser Ser Ala Glu Thr Gly Gly Thr Asn Tyr225 230 235
240Leu Ala Pro Gly Gly Leu Ser Asp Ser Gln Leu Leu Leu Glu Pro Gly
245 250 255Asp Arg Ser His Trp Cys Val Val Ala Tyr Trp Glu Glu Lys
Thr Arg 260 265 270Val Gly Arg Leu Tyr Cys Val Gln Glu Pro Ser Leu
Asp Ile Phe Tyr 275 280 285Asp Leu Pro Gln Gly Asn Gly Phe Cys Leu
Gly Gln Leu Asn Ser Asp 290 295 300Asn Lys Ser Gln Leu Val Gln Lys
Val Arg Ser Lys Ile Gly Cys Gly305 310 315 320Ile Gln Leu Thr Arg
Glu Val Asp Gly Val Trp Val Tyr Asn Arg Ser 325 330 335Ser Tyr Pro
Ile Phe Ile Lys Ser Ala Thr Leu Asp Asn Pro Asp Ser 340 345 350Arg
Thr Leu Leu Val His Lys Val Phe Pro Gly Phe Ser Ile Lys Ala 355 360
365Phe Asp Tyr Glu Lys Ala Tyr Ser Leu Gln Arg Pro Asn Asp His Glu
370 375 380Phe Met Gln Gln Pro Trp Thr Gly Phe Thr Val Gln Ile Ser
Phe Val385 390 395 400Lys Gly Trp Gly Gln Cys Tyr Thr Arg Gln Phe
Ile Ser Ser Cys Pro 405 410 415Cys Trp Leu Glu Val Ile Phe Asn Ser
Arg 420 4251320DNAArtificial SequenceDescription of Artificial
Sequence Synthetic primer 13tggaattcct ggtctggttt
201420DNAArtificial SequenceDescription of Artificial Sequence
Synthetic primer 14gccaagctgc tcttccagta 201521DNAArtificial
SequenceDescription of Artificial Sequence Synthetic primer
15tctcaggggg ccaaaggtgt t 211622DNAArtificial SequenceDescription
of Artificial Sequence Synthetic primer 16tcccagcacc tgaatcacat gg
221710DNAUnknownDescription of Unknown Smad binding element
oligonucleotide 17tgtctgtgct 101810DNAArtificial
SequenceDescription of Artificial Sequence Synthetic
oligonucleotide 18tgatagagct 101926DNAArtificial
SequenceDescription of Artificial Sequence Synthetic primer
19atcctcgagt atcctccagg tctggg 262028DNAArtificial
SequenceDescription of Artificial Sequence Synthetic primer
20gccaagctta gcgtccagcg ttaacctg 28211392DNAArtificial
SequenceDescription of
Artificial Sequence Synthetic polynucleotide 21ggatccggcc
gtaaaaaacg ccgtcaacgc cgccgtggtt tccgtacgaa acgctcggcc 60ctggtccgtc
gcctgtggcg ctcccgtgct ccgggtggtg aagatgaaga agaaggtgct
120ggcggcggtg gcggtggcgg tgaactgcgt ggcgagggtg caaccgatag
tcgtgcacac 180ggtgcaggcg gtggcggtcc gggtcgtgct ggttgctgtc
tgggtaaagc tgtgcgcggc 240gcgaaaggtc atcaccatcc gcacccgccg
gcagcaggtg caggtgcagc tggcggtgcg 300gaagccgatc tgaaagccct
gacccatagt gtcctgaaaa aactgaaaga acgtcagctg 360gagctgctgc
tgcaagcagt agaatcccgt ggcggtaccc gtacggcttg tctgctgctg
420ccgggtcgtc tggattgccg tctgggtccg ggtgcaccgg ctggtgcgca
gccggcacaa 480ccgccgagct cttacagcct gccgctgctg ctgtgtaaag
tgtttcgttg gccggacctg 540cgccacagtt ccgaagttaa acgcctgtgc
tgttgcgaga gctatggcaa aattaacccg 600gaactggttt gttgcaatcc
gcaccatctg tctcgtctgt gtgaactgga gagcccgccg 660ccgccgtatt
ctcgttaccc gatggatttc ctgaaaccga ctgcagattg cccggacgca
720gtcccgtcat cggctgagac cggcggcacc aactatctgg caccgggcgg
tctgagtgat 780tcccagctgc tgctggaacc gggcgaccgt tcacattggt
gtgtggttgc ctattgggaa 840gagaaaacgc gtgtcggtcg cctgtactgc
gtacaggaac cgtcgctgga tatcttttat 900gacctgccgc agggcaatgg
tttctgtctg ggccaactga actcagataa taaatcgcag 960ctggtgcaaa
aagttcgctc aaaaattggc tgcggtatcc agctgacccg tgaagttgac
1020ggtgtctggg tatataaccg cagctcttac ccgattttta tcaaaagtgc
caccctggat 1080ggtgtctggg tatataaccg cagctcttac ccgattttta
tcaaaagtgc caccctggat 1140aatccggact cccgtacgct gctggtccac
aaagtatttc cgggcttctc aatcaaagcg 1200ccgtggacgg gttttactgt
gcagatctct ttcgttaaag gctggggtca atgctacacc 1260cgtcagttta
tctcgtcctg tccgtgctgg ctggaagtga ttttcaatag ccgcaagggc
1320gagctcaatt cgaagcttga aggtaagcct atccctaacc ctctcctcgg
tctcgattct 1380acgtgagtcg ac 1392221281DNAHomo sapiens 22atgttcagga
ccaaacgatc tgcgctcgtc cggcgtctct ggaggagccg tgcgcccggc 60ggcgaggacg
aggaggaggg cgcaggggga ggtggaggag gaggcgagct gcggggagaa
120ggggcgacgg acagccgagc gcatggggcc ggtggcggcg gcccgggcag
ggctggatgc 180tgcctgggca aggcggtgcg aggtgccaaa ggtcaccacc
atccccaccc gccagccgcg 240ggcgccggcg cggccggggg cgccgaggcg
gatctgaagg cgctcacgca ctcggtgctc 300aagaaactga aggagcggca
gctggagctg ctgctccagg ccgtggagtc ccgcggcggg 360acgcgcaccg
cgtgcctcct gctgcccggc cgcctggact gcaggctggg cccgggggcg
420cccgccggcg cgcagcctgc gcagccgccc tcgtcctact cgctccccct
cctgctgtgc 480aaagtgttca ggtggccgga tctcaggcat tcctcggaag
tcaagaggct gtgttgctgt 540gaatcttacg ggaagatcaa ccccgagctg
gtgtgctgca acccccatca ccttagccga 600ctctgcgaac tagagtctcc
cccccctcct tactccagat acccgatgga ttttctcaaa 660ccaactgcag
actgtccaga tgctgtgcct tcctccgctg aaacaggggg aacgaattat
720ctggcccctg gggggctttc agattcccaa cttcttctgg agcctgggga
tcggtcacac 780tggtgcgtgg tggcatactg ggaggagaag acgagagtgg
ggaggctcta ctgtgtccag 840gagccctctc tggatatctt ctatgatcta
cctcagggga atggcttttg cctcggacag 900ctcaattcgg acaacaagag
tcagctggtg cagaaggtgc ggagcaaaat cggctgcggc 960atccagctga
cgcgggaggt ggatggtgtg tgggtgtaca accgcagcag ttaccccatc
1020ttcatcaagt ccgccacact ggacaacccg gactccagga cgctgttggt
acacaaggtg 1080ttccccggtt tctccatcaa ggctttcgac tacgagaagg
cgtacagcct gcagcggccc 1140aatgaccacg agtttatgca gcagccgtgg
acgggcttta ccgtgcagat cagctttgtg 1200aagggctggg gtcagtgcta
cacccgccag ttcatcagca gctgcccgtg ctggctagag 1260gtcatcttca
acagccggta g 1281231392DNAArtificial SequenceDescription of
Artificial Sequence Synthetic polynucleotide 23ggatccggcc
gtaaaaaacg ccgtcaacgc cgccgtggtt tccgtacgaa acgctcggcc 60ctggtccgtc
gcctgtggcg ctcccgtgct ccgggtggtg aagatgaaga agaaggtgct
120ggcggcggtg gcggtggcgg tgaactgcgt ggcgagggtg caaccgatag
tcgtgcacac 180ggtgcaggcg gtggcggtcc gggtcgtgct ggttgctgtc
tgggtaaagc tgtgcgcggc 240gcgaaaggtc atcaccatcc gcacccgccg
gcagcaggtg caggtgcagc tggcggtgcg 300gaagccgatc tgaaagccct
gacccatagt gtcctgaaaa aactgaaaga acgtcagctg 360gagctgctgc
tgcaagcagt agaatcccgt ggcggtaccc gtacggcttg tctgctgctg
420ccgggtcgtc tggattgccg tctgggtccg ggtgcaccgg ctggtgcgca
gccggcacaa 480ccgccgagct cttacagcct gccgctgctg ctgtgtaaag
tgtttcgttg gccggacctg 540cgccacagtt ccgaagttaa acgcctgtgc
tgttgcgaga gctatggcaa aattaacccg 600gaactggttt gttgcaatcc
gcaccatctg tctcgtctgt gtgaactgga gagcccgccg 660ccgccgtatt
ctcgttaccc gatggatttc ctgaaaccga ctgcagattg cccggacgca
720gtcccgtcat cggctgagac cggcggcacc aactatctgg caccgggcgg
tctgagtgat 780tcccagctgc tgctggaacc gggcgaccgt tcacattggt
gtgtggttgc ctattgggaa 840gagaaaacgc gtgtcggtcg cctgtactgc
gtacaggaac cgtcgctgga tatcttttat 900gacctgccgc agggcaatgg
tttctgtctg ggccaactga actcagataa taaatcgcag 960ctggtgcaaa
aagttcgctc aaaaattggc tgcggtatcc agctgacccg tgaagttgac
1020ggtgtctggg tatataaccg cagctcttac ccgattttta tcaaaagtgc
caccctggat 1080aatccggact cccgtacgct gctggtccac aaagtatttc
cgggcttctc aatcaaagcg 1140ttcgattacg agaaagccta ctcgctgcag
cgcccgaacg accatgaatt catgcagcaa 1200ccgtggacgg gttttactgt
gcagatctct ttcgttaaag gctggggtca atgctacacc 1260cgtcagttta
tctcgtcctg tccgtgctgg ctggaagtga ttttcaatag ccgcaagggc
1320gagctcaatt cgaagcttga aggtaagcct atccctaacc ctctcctcgg
tctcgattct 1380acgtgagtcg ac 139224618DNAArtificial
SequenceDescription of Artificial Sequence Synthetic
polynucleotideCDS(1)..(609) 24gga tcc ggc cgt aaa aaa cgc cgt caa
cgc cgc cgt tca cat tgg tgt 48Gly Ser Gly Arg Lys Lys Arg Arg Gln
Arg Arg Arg Ser His Trp Cys1 5 10 15gtg gtt gcc tat tgg gaa gag aaa
acg cgt gtc ggt cgc ctg tac tgc 96Val Val Ala Tyr Trp Glu Glu Lys
Thr Arg Val Gly Arg Leu Tyr Cys 20 25 30gta cag gaa ccg tcg ctg gat
atc ttt tat gac ctg ccg cag ggc aat 144Val Gln Glu Pro Ser Leu Asp
Ile Phe Tyr Asp Leu Pro Gln Gly Asn 35 40 45ggt ttc tgt ctg ggc caa
ctg aac tca gat aat aaa tcg cag ctg gtg 192Gly Phe Cys Leu Gly Gln
Leu Asn Ser Asp Asn Lys Ser Gln Leu Val 50 55 60caa aaa gtt cgc tca
aaa att ggc tgc ggt atc cag ctg acc cgt gaa 240Gln Lys Val Arg Ser
Lys Ile Gly Cys Gly Ile Gln Leu Thr Arg Glu65 70 75 80gtt gac ggt
gtc tgg gta tat aac cgc agc tct tac ccg att ttt atc 288Val Asp Gly
Val Trp Val Tyr Asn Arg Ser Ser Tyr Pro Ile Phe Ile 85 90 95aaa agt
gcc acc ctg gat aat ccg gac tcc cgt acg ctg ctg gtc cac 336Lys Ser
Ala Thr Leu Asp Asn Pro Asp Ser Arg Thr Leu Leu Val His 100 105
110aaa gta ttt ccg ggc ttc tca atc aaa gcg ttc gat tac gag aaa gcc
384Lys Val Phe Pro Gly Phe Ser Ile Lys Ala Phe Asp Tyr Glu Lys Ala
115 120 125tac tcg ctg cag cgc ccg aac gac cat gaa ttc atg cag caa
ccg tgg 432Tyr Ser Leu Gln Arg Pro Asn Asp His Glu Phe Met Gln Gln
Pro Trp 130 135 140acg ggt ttt act gtg cag atc tct ttc gtt aaa ggc
tgg ggt caa tgc 480Thr Gly Phe Thr Val Gln Ile Ser Phe Val Lys Gly
Trp Gly Gln Cys145 150 155 160tac acc cgt cag ttt atc tcg tcc tgt
ccg tgc tgg ctg gaa gtg att 528Tyr Thr Arg Gln Phe Ile Ser Ser Cys
Pro Cys Trp Leu Glu Val Ile 165 170 175ttc aat agc cgc aag ggc gag
ctc aat tcg aag ctt gaa ggt aag cct 576Phe Asn Ser Arg Lys Gly Glu
Leu Asn Ser Lys Leu Glu Gly Lys Pro 180 185 190atc cct aac cct ctc
ctc ggt ctc gat tct acg tgagtcgac 618Ile Pro Asn Pro Leu Leu Gly
Leu Asp Ser Thr 195 20025203PRTArtificial SequenceDescription of
Artificial Sequence Synthetic polypeptide 25Gly Ser Gly Arg Lys Lys
Arg Arg Gln Arg Arg Arg Ser His Trp Cys1 5 10 15Val Val Ala Tyr Trp
Glu Glu Lys Thr Arg Val Gly Arg Leu Tyr Cys 20 25 30Val Gln Glu Pro
Ser Leu Asp Ile Phe Tyr Asp Leu Pro Gln Gly Asn 35 40 45Gly Phe Cys
Leu Gly Gln Leu Asn Ser Asp Asn Lys Ser Gln Leu Val 50 55 60Gln Lys
Val Arg Ser Lys Ile Gly Cys Gly Ile Gln Leu Thr Arg Glu65 70 75
80Val Asp Gly Val Trp Val Tyr Asn Arg Ser Ser Tyr Pro Ile Phe Ile
85 90 95Lys Ser Ala Thr Leu Asp Asn Pro Asp Ser Arg Thr Leu Leu Val
His 100 105 110Lys Val Phe Pro Gly Phe Ser Ile Lys Ala Phe Asp Tyr
Glu Lys Ala 115 120 125Tyr Ser Leu Gln Arg Pro Asn Asp His Glu Phe
Met Gln Gln Pro Trp 130 135 140Thr Gly Phe Thr Val Gln Ile Ser Phe
Val Lys Gly Trp Gly Gln Cys145 150 155 160Tyr Thr Arg Gln Phe Ile
Ser Ser Cys Pro Cys Trp Leu Glu Val Ile 165 170 175Phe Asn Ser Arg
Lys Gly Glu Leu Asn Ser Lys Leu Glu Gly Lys Pro 180 185 190Ile Pro
Asn Pro Leu Leu Gly Leu Asp Ser Thr 195 20026861DNAArtificial
SequenceDescription of Artificial Sequence Synthetic
polynucleotideCDS(1)..(852) 26gga tcc ggc cgt aaa aaa cgc cgt caa
cgc cgc cgt ggt ttc cgt acg 48Gly Ser Gly Arg Lys Lys Arg Arg Gln
Arg Arg Arg Gly Phe Arg Thr1 5 10 15aaa cgc tcg gcc ctg gtc cgt cgc
ctg tgg cgc tcc cgt gct ccg ggt 96Lys Arg Ser Ala Leu Val Arg Arg
Leu Trp Arg Ser Arg Ala Pro Gly 20 25 30ggt gaa gat gaa gaa gaa ggt
gct ggc ggc ggt ggc ggt ggc ggt gaa 144Gly Glu Asp Glu Glu Glu Gly
Ala Gly Gly Gly Gly Gly Gly Gly Glu 35 40 45ctg cgt ggc gag ggt gca
acc gat agt cgt gca cac ggt gca ggc ggt 192Leu Arg Gly Glu Gly Ala
Thr Asp Ser Arg Ala His Gly Ala Gly Gly 50 55 60ggc ggt ccg ggt cgt
gct ggt tgc tgt ctg ggt aaa gct gtg cgc ggc 240Gly Gly Pro Gly Arg
Ala Gly Cys Cys Leu Gly Lys Ala Val Arg Gly65 70 75 80gcg aaa ggt
cat cac cat ccg cac ccg ccg gca gca ggt gca ggt gca 288Ala Lys Gly
His His His Pro His Pro Pro Ala Ala Gly Ala Gly Ala 85 90 95gct ggc
ggt gcg gaa gcc gat ctg aaa gcc ctg acc cat agt gtc ctg 336Ala Gly
Gly Ala Glu Ala Asp Leu Lys Ala Leu Thr His Ser Val Leu 100 105
110aaa aaa ctg aaa gaa cgt cag ctg gag ctg ctg ctg caa gca gta gaa
384Lys Lys Leu Lys Glu Arg Gln Leu Glu Leu Leu Leu Gln Ala Val Glu
115 120 125tcc cgt ggc ggt acc cgt acg gct tgt ctg ctg ctg ccg ggt
cgt ctg 432Ser Arg Gly Gly Thr Arg Thr Ala Cys Leu Leu Leu Pro Gly
Arg Leu 130 135 140gat tgc cgt ctg ggt ccg ggt gca ccg gct ggt gcg
cag ccg gca caa 480Asp Cys Arg Leu Gly Pro Gly Ala Pro Ala Gly Ala
Gln Pro Ala Gln145 150 155 160ccg ccg agc tct tac agc ctg ccg ctg
ctg ctg tgt aaa gtg ttt cgt 528Pro Pro Ser Ser Tyr Ser Leu Pro Leu
Leu Leu Cys Lys Val Phe Arg 165 170 175tgg ccg gac ctg cgc cac agt
tcc gaa gtt aaa cgc ctg tgc tgt tgc 576Trp Pro Asp Leu Arg His Ser
Ser Glu Val Lys Arg Leu Cys Cys Cys 180 185 190gag agc tat ggc aaa
att aac ccg gaa ctg gtt tgt tgc aat ccg cac 624Glu Ser Tyr Gly Lys
Ile Asn Pro Glu Leu Val Cys Cys Asn Pro His 195 200 205cat ctg tct
cgt ctg tgt gaa ctg gag agc ccg ccg ccg ccg tat tct 672His Leu Ser
Arg Leu Cys Glu Leu Glu Ser Pro Pro Pro Pro Tyr Ser 210 215 220cgt
tac ccg atg gat ttc ctg aaa ccg act gca gat tgc ccg gac gca 720Arg
Tyr Pro Met Asp Phe Leu Lys Pro Thr Ala Asp Cys Pro Asp Ala225 230
235 240gtc ccg tca tcg gct gag acc ggc ggc acc aac tat ctg gca ccg
ggc 768Val Pro Ser Ser Ala Glu Thr Gly Gly Thr Asn Tyr Leu Ala Pro
Gly 245 250 255ggt ctg agt gat tcc cag ctg ctg ctg gaa ccg ggc gac
cgt ggt aag 816Gly Leu Ser Asp Ser Gln Leu Leu Leu Glu Pro Gly Asp
Arg Gly Lys 260 265 270cct atc cct aac cct ctc ctc ggt ctc gat tct
acg tgagtcgac 861Pro Ile Pro Asn Pro Leu Leu Gly Leu Asp Ser Thr
275 28027284PRTArtificial SequenceDescription of Artificial
Sequence Synthetic polypeptide 27Gly Ser Gly Arg Lys Lys Arg Arg
Gln Arg Arg Arg Gly Phe Arg Thr1 5 10 15Lys Arg Ser Ala Leu Val Arg
Arg Leu Trp Arg Ser Arg Ala Pro Gly 20 25 30Gly Glu Asp Glu Glu Glu
Gly Ala Gly Gly Gly Gly Gly Gly Gly Glu 35 40 45Leu Arg Gly Glu Gly
Ala Thr Asp Ser Arg Ala His Gly Ala Gly Gly 50 55 60Gly Gly Pro Gly
Arg Ala Gly Cys Cys Leu Gly Lys Ala Val Arg Gly65 70 75 80Ala Lys
Gly His His His Pro His Pro Pro Ala Ala Gly Ala Gly Ala 85 90 95Ala
Gly Gly Ala Glu Ala Asp Leu Lys Ala Leu Thr His Ser Val Leu 100 105
110Lys Lys Leu Lys Glu Arg Gln Leu Glu Leu Leu Leu Gln Ala Val Glu
115 120 125Ser Arg Gly Gly Thr Arg Thr Ala Cys Leu Leu Leu Pro Gly
Arg Leu 130 135 140Asp Cys Arg Leu Gly Pro Gly Ala Pro Ala Gly Ala
Gln Pro Ala Gln145 150 155 160Pro Pro Ser Ser Tyr Ser Leu Pro Leu
Leu Leu Cys Lys Val Phe Arg 165 170 175Trp Pro Asp Leu Arg His Ser
Ser Glu Val Lys Arg Leu Cys Cys Cys 180 185 190Glu Ser Tyr Gly Lys
Ile Asn Pro Glu Leu Val Cys Cys Asn Pro His 195 200 205His Leu Ser
Arg Leu Cys Glu Leu Glu Ser Pro Pro Pro Pro Tyr Ser 210 215 220Arg
Tyr Pro Met Asp Phe Leu Lys Pro Thr Ala Asp Cys Pro Asp Ala225 230
235 240Val Pro Ser Ser Ala Glu Thr Gly Gly Thr Asn Tyr Leu Ala Pro
Gly 245 250 255Gly Leu Ser Asp Ser Gln Leu Leu Leu Glu Pro Gly Asp
Arg Gly Lys 260 265 270Pro Ile Pro Asn Pro Leu Leu Gly Leu Asp Ser
Thr 275 280281442DNAArtificial SequenceDescription of Artificial
Sequence Synthetic polynucleotide 28ggatccggcc gtaaaaaacg
ccgtcaacgc cgccgtggtt tccgtacgaa acgctcggcc 60ctggtccgtc gcctgtggcg
ctcccgtgct ccgggtggtg aagatgaaga agaaggtgct 120ggcggcggtg
gcggtggcgg tgaactgcgt aagatgaaga agaaggtgct ggcggcggtg
180gcggtggcgg tgaactgcgt ggcgagggtg caaccgatag tcgtgcacac
ggtgcaggcg 240gtggcggtcc gggtcgtgct ggttgctgtc tgggtaaagc
tgtgcgcggc gcgaaaggtc 300atcaccatcc gcacccgccg gcagcaggtg
caggtgcagc tggcggtgcg gaagccgatc 360tgaaagccct gacccatagt
gtcctgaaaa aactgaaaga acgtcagctg gagctgctgc 420tgcaagcagt
agaatcccgt ggcggtaccc gtacggcttg tctgctgctg ccgggtcgtc
480tggattgccg tctgggtccg ggtgcaccgg ctggtgcgca gccggcacaa
ccgccgagct 540cttacagcct gccgctgctg ctgtgtaaag tgtttcgttg
gccggacctg cgccacagtt 600ccgaagttaa acgcctgtgc tgttgcgaga
gctatggcaa aattaacccg gaactggttt 660gttgcaatcc gcaccatctg
tctcgtctgt gtgaactgga gagcccgccg ccgccgtatt 720ctcgttaccc
gatggatttc ctgaaaccga ctgcagattg cccggacgca gtcccgtcat
780cggctgagac cggcggcacc aactatctgg caccgggcgg tctgagtgat
tcccagctgc 840tgctggaacc gggcgaccgt tcacattggt gtgtggttgc
ctattgggaa gagaaaacgc 900gtgtcggtcg cctgtactgc gtacaggaac
cgtcgctgga tatcttttat gacctgccgc 960agggcaatgg tttctgtctg
ggccaactga actcagataa taaatcgcag ctggtgcaaa 1020aagttcgctc
aaaaattggc tgcggtatcc agctgacccg tgaagttgac ggtgtctggg
1080tatataaccg cagctcttac ccgattttta tcaaaagtgc caccctggat
aatccggact 1140cccgtacgct gctggtccac aaagtatttc cgggcttctc
aatcaaagcg ttcgattacg 1200agaaagccta ctcgctgcag cgcccgaacg
accatgaatt catgcagcaa ccgtggacgg 1260gttttactgt gcagatctct
ttcgttaaag gctggggtca atgctacacc cgtcagttta 1320tctcgtcctg
tccgtgctgg ctggaagtga ttttcaatag ccgcaagggc gagctcaatt
1380cgaagcttga aggtaagcct atccctaacc ctctcctcgg tctcgattct
acgtgagtcg 1440ac 14422966DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 29agcagctttc
agtcagtagc agccagcagc cagagcagca gccagtagca gcagcagcag 60agcagc
66301392DNAArtificial SequenceDescription of Artificial Sequence
Synthetic polynucleotideCDS(1)..(1383) 30gga tcc ggc cgt aaa aaa
cgc cgt caa cgc cgc cgt ggt ttc cgt acg 48Gly Ser Gly Arg Lys Lys
Arg Arg Gln Arg Arg Arg Gly Phe Arg Thr1 5 10 15aaa cgc agc gcc ctg
gtc cgt cgc ctg tgg cgc agc cgt gct ccg ggt 96Lys Arg Ser Ala Leu
Val Arg Arg Leu Trp Arg Ser Arg Ala Pro Gly 20 25 30ggt gaa gat gaa
gaa gaa ggt gct ggc ggc ggt ggc ggt ggc ggt gaa 144Gly Glu Asp Glu
Glu Glu Gly Ala Gly Gly Gly Gly Gly Gly Gly Glu 35 40 45ctg cgt ggc
gag ggt gca acc gat agc cgt gca cat ggt gca ggc ggt 192Leu Arg Gly
Glu Gly Ala Thr Asp Ser Arg Ala His Gly Ala Gly Gly 50 55 60ggc ggt
ccg ggt cgt gct ggt tgc tgt ctg ggt aaa gct gtg cgc ggc 240Gly Gly
Pro Gly Arg Ala Gly Cys Cys Leu Gly Lys Ala Val Arg Gly65
70 75 80gcg aaa ggt cat cat cat ccg cat ccg ccg gca gca ggt gca ggt
gca 288Ala Lys Gly His His His Pro His Pro Pro Ala Ala Gly Ala Gly
Ala 85 90 95gct ggc ggt gcg gaa gcc gat ctg aaa gcc ctg acc cat agc
gtc ctg 336Ala Gly Gly Ala Glu Ala Asp Leu Lys Ala Leu Thr His Ser
Val Leu 100 105 110aaa aaa ctg aaa gaa cgt cag ctg gag ctg ctg ctg
caa gca gta gaa 384Lys Lys Leu Lys Glu Arg Gln Leu Glu Leu Leu Leu
Gln Ala Val Glu 115 120 125agc cgt ggc ggt acc cgt acg gct tgt ctg
ctg ctg ccg ggt cgt ctg 432Ser Arg Gly Gly Thr Arg Thr Ala Cys Leu
Leu Leu Pro Gly Arg Leu 130 135 140gat tgc cgt ctg ggt ccg ggt gca
ccg gct ggt gcg cag ccg gca caa 480Asp Cys Arg Leu Gly Pro Gly Ala
Pro Ala Gly Ala Gln Pro Ala Gln145 150 155 160ccg ccg agc agc tac
agc ctg ccg ctg ctg ctg tgt aaa gtg ttt cgt 528Pro Pro Ser Ser Tyr
Ser Leu Pro Leu Leu Leu Cys Lys Val Phe Arg 165 170 175tgg ccg gac
ctg cgc cat agc agc gaa gtt aaa cgc ctg tgc tgt tgc 576Trp Pro Asp
Leu Arg His Ser Ser Glu Val Lys Arg Leu Cys Cys Cys 180 185 190gag
agc tat ggc aaa att aac ccg gaa ctg gtt tgt tgc aat ccg cat 624Glu
Ser Tyr Gly Lys Ile Asn Pro Glu Leu Val Cys Cys Asn Pro His 195 200
205cat ctg agc cgt ctg tgt gaa ctg gag agc ccg ccg ccg ccg tat agc
672His Leu Ser Arg Leu Cys Glu Leu Glu Ser Pro Pro Pro Pro Tyr Ser
210 215 220cgt tac ccg ctg gat ttc ctg aaa ccg act gca gat tgc ccg
gac gca 720Arg Tyr Pro Leu Asp Phe Leu Lys Pro Thr Ala Asp Cys Pro
Asp Ala225 230 235 240gtc ccg agc agc gct gag acc ggc ggc acc aac
tat ctg gca ccg ggc 768Val Pro Ser Ser Ala Glu Thr Gly Gly Thr Asn
Tyr Leu Ala Pro Gly 245 250 255ggt ctg agc gat agc cag ctg ctg ctg
gaa ccg ggc gac cgt agc cat 816Gly Leu Ser Asp Ser Gln Leu Leu Leu
Glu Pro Gly Asp Arg Ser His 260 265 270tgg tgt gtg gtt gcc tat tgg
gaa gag aaa acg cgt gtc ggt cgc ctg 864Trp Cys Val Val Ala Tyr Trp
Glu Glu Lys Thr Arg Val Gly Arg Leu 275 280 285tac tgc gta cag gaa
ccg agc ctg gat atc ttt tat gac ctg ccg cag 912Tyr Cys Val Gln Glu
Pro Ser Leu Asp Ile Phe Tyr Asp Leu Pro Gln 290 295 300ggc aat ggt
ttc tgt ctg ggc caa ctg aac agc gat aat aaa agc cag 960Gly Asn Gly
Phe Cys Leu Gly Gln Leu Asn Ser Asp Asn Lys Ser Gln305 310 315
320ctg gtg caa aaa gtt cgc agc aaa att ggc tgc ggt atc cag ctg acc
1008Leu Val Gln Lys Val Arg Ser Lys Ile Gly Cys Gly Ile Gln Leu Thr
325 330 335cgt gaa gtt gac ggt gtc tgg gta tat aac cgc agc agc tac
ccg att 1056Arg Glu Val Asp Gly Val Trp Val Tyr Asn Arg Ser Ser Tyr
Pro Ile 340 345 350ttt atc aaa agc gcc acc ctg gat aat ccg gac agc
cgt acg ctg ctg 1104Phe Ile Lys Ser Ala Thr Leu Asp Asn Pro Asp Ser
Arg Thr Leu Leu 355 360 365gtc cat aaa gta ttt ccg ggc ttc agc atc
aaa gcg ttc gat tac gag 1152Val His Lys Val Phe Pro Gly Phe Ser Ile
Lys Ala Phe Asp Tyr Glu 370 375 380aaa gcc tac agc ctg cag cgc ccg
aac gac cat gaa ttc atg cag caa 1200Lys Ala Tyr Ser Leu Gln Arg Pro
Asn Asp His Glu Phe Met Gln Gln385 390 395 400ccg tgg acg ggt ttt
act gtg cag atc agc ttc gtt aaa ggc tgg ggt 1248Pro Trp Thr Gly Phe
Thr Val Gln Ile Ser Phe Val Lys Gly Trp Gly 405 410 415caa tgc tac
acc cgt cag ttt atc agc agc tgt ccg tgc tgg ctg gaa 1296Gln Cys Tyr
Thr Arg Gln Phe Ile Ser Ser Cys Pro Cys Trp Leu Glu 420 425 430gtg
att ttc aat agc cgc aag ggc gag ctc aat agc aag ctt gaa ggt 1344Val
Ile Phe Asn Ser Arg Lys Gly Glu Leu Asn Ser Lys Leu Glu Gly 435 440
445aag cct atc cct aac cct ctc ctc ggt ctc gat agc acg tgagtcgac
1392Lys Pro Ile Pro Asn Pro Leu Leu Gly Leu Asp Ser Thr 450 455
46031461PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 31Gly Ser Gly Arg Lys Lys Arg Arg Gln Arg Arg
Arg Gly Phe Arg Thr1 5 10 15Lys Arg Ser Ala Leu Val Arg Arg Leu Trp
Arg Ser Arg Ala Pro Gly 20 25 30Gly Glu Asp Glu Glu Glu Gly Ala Gly
Gly Gly Gly Gly Gly Gly Glu 35 40 45Leu Arg Gly Glu Gly Ala Thr Asp
Ser Arg Ala His Gly Ala Gly Gly 50 55 60Gly Gly Pro Gly Arg Ala Gly
Cys Cys Leu Gly Lys Ala Val Arg Gly65 70 75 80Ala Lys Gly His His
His Pro His Pro Pro Ala Ala Gly Ala Gly Ala 85 90 95Ala Gly Gly Ala
Glu Ala Asp Leu Lys Ala Leu Thr His Ser Val Leu 100 105 110Lys Lys
Leu Lys Glu Arg Gln Leu Glu Leu Leu Leu Gln Ala Val Glu 115 120
125Ser Arg Gly Gly Thr Arg Thr Ala Cys Leu Leu Leu Pro Gly Arg Leu
130 135 140Asp Cys Arg Leu Gly Pro Gly Ala Pro Ala Gly Ala Gln Pro
Ala Gln145 150 155 160Pro Pro Ser Ser Tyr Ser Leu Pro Leu Leu Leu
Cys Lys Val Phe Arg 165 170 175Trp Pro Asp Leu Arg His Ser Ser Glu
Val Lys Arg Leu Cys Cys Cys 180 185 190Glu Ser Tyr Gly Lys Ile Asn
Pro Glu Leu Val Cys Cys Asn Pro His 195 200 205His Leu Ser Arg Leu
Cys Glu Leu Glu Ser Pro Pro Pro Pro Tyr Ser 210 215 220Arg Tyr Pro
Leu Asp Phe Leu Lys Pro Thr Ala Asp Cys Pro Asp Ala225 230 235
240Val Pro Ser Ser Ala Glu Thr Gly Gly Thr Asn Tyr Leu Ala Pro Gly
245 250 255Gly Leu Ser Asp Ser Gln Leu Leu Leu Glu Pro Gly Asp Arg
Ser His 260 265 270Trp Cys Val Val Ala Tyr Trp Glu Glu Lys Thr Arg
Val Gly Arg Leu 275 280 285Tyr Cys Val Gln Glu Pro Ser Leu Asp Ile
Phe Tyr Asp Leu Pro Gln 290 295 300Gly Asn Gly Phe Cys Leu Gly Gln
Leu Asn Ser Asp Asn Lys Ser Gln305 310 315 320Leu Val Gln Lys Val
Arg Ser Lys Ile Gly Cys Gly Ile Gln Leu Thr 325 330 335Arg Glu Val
Asp Gly Val Trp Val Tyr Asn Arg Ser Ser Tyr Pro Ile 340 345 350Phe
Ile Lys Ser Ala Thr Leu Asp Asn Pro Asp Ser Arg Thr Leu Leu 355 360
365Val His Lys Val Phe Pro Gly Phe Ser Ile Lys Ala Phe Asp Tyr Glu
370 375 380Lys Ala Tyr Ser Leu Gln Arg Pro Asn Asp His Glu Phe Met
Gln Gln385 390 395 400Pro Trp Thr Gly Phe Thr Val Gln Ile Ser Phe
Val Lys Gly Trp Gly 405 410 415Gln Cys Tyr Thr Arg Gln Phe Ile Ser
Ser Cys Pro Cys Trp Leu Glu 420 425 430Val Ile Phe Asn Ser Arg Lys
Gly Glu Leu Asn Ser Lys Leu Glu Gly 435 440 445Lys Pro Ile Pro Asn
Pro Leu Leu Gly Leu Asp Ser Thr 450 455 46032861DNAArtificial
SequenceDescription of Artificial Sequence Synthetic
polynucleotideCDS(1)..(852) 32gga tcc ggc cgt aaa aaa cgc cgt caa
cgc cgc cgt ggt ttc cgt acg 48Gly Ser Gly Arg Lys Lys Arg Arg Gln
Arg Arg Arg Gly Phe Arg Thr1 5 10 15aaa cgc agc gcc ctg gtc cgt cgc
ctg tgg cgc agc cgt gct ccg ggt 96Lys Arg Ser Ala Leu Val Arg Arg
Leu Trp Arg Ser Arg Ala Pro Gly 20 25 30ggt gaa gat gaa gaa gaa ggt
gct ggc ggc ggt ggc ggt ggc ggt gaa 144Gly Glu Asp Glu Glu Glu Gly
Ala Gly Gly Gly Gly Gly Gly Gly Glu 35 40 45ctg cgt ggc gag ggt gca
acc gat agc cgt gca cat ggt gca ggc ggt 192Leu Arg Gly Glu Gly Ala
Thr Asp Ser Arg Ala His Gly Ala Gly Gly 50 55 60ggc ggt ccg ggt cgt
gct ggt tgc tgt ctg ggt aaa gct gtg cgc ggc 240Gly Gly Pro Gly Arg
Ala Gly Cys Cys Leu Gly Lys Ala Val Arg Gly65 70 75 80gcg aaa ggt
cat cat cat ccg cat ccg ccg gca gca ggt gca ggt gca 288Ala Lys Gly
His His His Pro His Pro Pro Ala Ala Gly Ala Gly Ala 85 90 95gct ggc
ggt gcg gaa gcc gat ctg aaa gcc ctg acc cat agc gtc ctg 336Ala Gly
Gly Ala Glu Ala Asp Leu Lys Ala Leu Thr His Ser Val Leu 100 105
110aaa aaa ctg aaa gaa cgt cag ctg gag ctg ctg ctg caa gca gta gaa
384Lys Lys Leu Lys Glu Arg Gln Leu Glu Leu Leu Leu Gln Ala Val Glu
115 120 125agc cgt ggc ggt acc cgt acg gct tgt ctg ctg ctg ccg ggt
cgt ctg 432Ser Arg Gly Gly Thr Arg Thr Ala Cys Leu Leu Leu Pro Gly
Arg Leu 130 135 140gat tgc cgt ctg ggt ccg ggt gca ccg gct ggt gcg
cag ccg gca caa 480Asp Cys Arg Leu Gly Pro Gly Ala Pro Ala Gly Ala
Gln Pro Ala Gln145 150 155 160ccg ccg agc agc tac agc ctg ccg ctg
ctg ctg tgt aaa gtg ttt cgt 528Pro Pro Ser Ser Tyr Ser Leu Pro Leu
Leu Leu Cys Lys Val Phe Arg 165 170 175tgg ccg gac ctg cgc cat agc
agc gaa gtt aaa cgc ctg tgc tgt tgc 576Trp Pro Asp Leu Arg His Ser
Ser Glu Val Lys Arg Leu Cys Cys Cys 180 185 190gag agc tat ggc aaa
att aac ccg gaa ctg gtt tgt tgc aat ccg cat 624Glu Ser Tyr Gly Lys
Ile Asn Pro Glu Leu Val Cys Cys Asn Pro His 195 200 205cat ctg agc
cgt ctg tgt gaa ctg gag agc ccg ccg ccg ccg tat agc 672His Leu Ser
Arg Leu Cys Glu Leu Glu Ser Pro Pro Pro Pro Tyr Ser 210 215 220cgt
tac ccg atg gat ttc ctg aaa ccg act gca gat tgc ccg gac gca 720Arg
Tyr Pro Met Asp Phe Leu Lys Pro Thr Ala Asp Cys Pro Asp Ala225 230
235 240gtc ccg agc agc gct gag acc ggc ggc acc aac tat ctg gca ccg
ggc 768Val Pro Ser Ser Ala Glu Thr Gly Gly Thr Asn Tyr Leu Ala Pro
Gly 245 250 255ggt ctg agc gat agc cag ctg ctg ctg gaa ccg ggc gac
cgt ggt aag 816Gly Leu Ser Asp Ser Gln Leu Leu Leu Glu Pro Gly Asp
Arg Gly Lys 260 265 270cct atc cct aac cct ctc ctc ggt ctc gat tct
acg tgagtcgac 861Pro Ile Pro Asn Pro Leu Leu Gly Leu Asp Ser Thr
275 28033558DNAArtificial SequenceDescription of Artificial
Sequence Synthetic polynucleotide 33ggatccggcc gtaaaaaacg
ccgtcaacgc cgccgttcac attggtgtgt ggttgcctat 60tgggaagaga aaacgcgtgt
cggtcgcctg tactgcgtac aggaaccgag cctggatatc 120ttttatgacc
tgccgcaggg caatggtttc tgtctgggcc aactgaacag cgataataaa
180agccagctgg tgcaaaaagt tcgcagcaaa attggctgcg gtatccagct
gacccgtgaa 240gttgacggtg tctgggtata taaccgcagc agctacccga
tttttatcaa aagcgccacc 300ctggataatc cggacagccg tacgctgctg
gtccataaag tatttccggg cttcagcatc 360aaagcgttcg attacgagaa
agcctacagc ctgcagcgcc cgaacgacca tgaattcatg 420cagcaaccgt
ggacgggttt tactgtgcag atcagcttcg ttaaaggctg gggtcaatgc
480aagggcgagc tcaatagcaa gcttgaaggt aagcctatcc ctaaccctct
cctcggtctc 540gatagcacgt gagtcgac 55834618DNAArtificial
SequenceDescription of Artificial Sequence Synthetic
polynucleotideCDS(1)..(609) 34gga tcc ggc cgt aaa aaa cgc cgt caa
cgc cgc cgt tca cat tgg tgt 48Gly Ser Gly Arg Lys Lys Arg Arg Gln
Arg Arg Arg Ser His Trp Cys1 5 10 15gtg gtt gcc tat tgg gaa gag aaa
acg cgt gtc ggt cgc ctg tac tgc 96Val Val Ala Tyr Trp Glu Glu Lys
Thr Arg Val Gly Arg Leu Tyr Cys 20 25 30gta cag gaa ccg agc ctg gat
atc ttt tat gac ctg ccg cag ggc aat 144Val Gln Glu Pro Ser Leu Asp
Ile Phe Tyr Asp Leu Pro Gln Gly Asn 35 40 45ggt ttc tgt ctg ggc caa
ctg aac agc gat aat aaa agc cag ctg gtg 192Gly Phe Cys Leu Gly Gln
Leu Asn Ser Asp Asn Lys Ser Gln Leu Val 50 55 60caa aaa gtt cgc agc
aaa att ggc tgc ggt atc cag ctg acc cgt gaa 240Gln Lys Val Arg Ser
Lys Ile Gly Cys Gly Ile Gln Leu Thr Arg Glu65 70 75 80gtt gac ggt
gtc tgg gta tat aac cgc agc agc tac ccg att ttt atc 288Val Asp Gly
Val Trp Val Tyr Asn Arg Ser Ser Tyr Pro Ile Phe Ile 85 90 95aaa agc
gcc acc ctg gat aat ccg gac agc cgt acg ctg ctg gtc cat 336Lys Ser
Ala Thr Leu Asp Asn Pro Asp Ser Arg Thr Leu Leu Val His 100 105
110aaa gta ttt ccg ggc ttc agc atc aaa gcg ttc gat tac gag aaa gcc
384Lys Val Phe Pro Gly Phe Ser Ile Lys Ala Phe Asp Tyr Glu Lys Ala
115 120 125tac agc ctg cag cgc ccg aac gac cat gaa ttc atg cag caa
ccg tgg 432Tyr Ser Leu Gln Arg Pro Asn Asp His Glu Phe Met Gln Gln
Pro Trp 130 135 140acg ggt ttt act gtg cag atc agc ttc gtt aaa ggc
tgg ggt caa tgc 480Thr Gly Phe Thr Val Gln Ile Ser Phe Val Lys Gly
Trp Gly Gln Cys145 150 155 160tac acc cgt cag ttt atc agc agc tgt
ccg tgc tgg ctg gaa gtg att 528Tyr Thr Arg Gln Phe Ile Ser Ser Cys
Pro Cys Trp Leu Glu Val Ile 165 170 175ttc aat agc cgc aag ggc gag
ctc aat agc aag ctt gaa ggt aag cct 576Phe Asn Ser Arg Lys Gly Glu
Leu Asn Ser Lys Leu Glu Gly Lys Pro 180 185 190atc cct aac cct ctc
ctc ggt ctc gat agc acg tgagtcgac 618Ile Pro Asn Pro Leu Leu Gly
Leu Asp Ser Thr 195 2003539DNAArtificial SequenceDescription of
Artificial Sequence Synthetic oligonucleotide 35tcgtcatcgt
catctttcct catcgtcttc gtctcgtct 39361365DNAArtificial
SequenceDescription of Artificial Sequence Synthetic
polynucleotideCDS(1)..(1356) 36gga tcc ggt cgt aaa aaa cgt cgt cag
cgt cgt cgt ggt ttc cgt acc 48Gly Ser Gly Arg Lys Lys Arg Arg Gln
Arg Arg Arg Gly Phe Arg Thr1 5 10 15aaa cgt tct gcg ctg gtt cgt cgt
ctg tgg cgt tct cgt gcg ccg ggt 96Lys Arg Ser Ala Leu Val Arg Arg
Leu Trp Arg Ser Arg Ala Pro Gly 20 25 30ggt gaa gac gaa gaa gaa ggt
gcg ggt ggt ggt ggt ggt ggt ggt gaa 144Gly Glu Asp Glu Glu Glu Gly
Ala Gly Gly Gly Gly Gly Gly Gly Glu 35 40 45ctg cgt ggt gaa ggt gcg
acc gac tct cgt gcg cac ggt gcg ggt ggt 192Leu Arg Gly Glu Gly Ala
Thr Asp Ser Arg Ala His Gly Ala Gly Gly 50 55 60ggt ggt ccg ggt cgt
gcg ggt tgc tgc ctg ggt aaa gcg gtt cgt ggt 240Gly Gly Pro Gly Arg
Ala Gly Cys Cys Leu Gly Lys Ala Val Arg Gly65 70 75 80gcg aaa ggt
cac cac cac ccg cac ccg ccg gcg gcg ggt gcg ggt gcg 288Ala Lys Gly
His His His Pro His Pro Pro Ala Ala Gly Ala Gly Ala 85 90 95gcg ggt
ggt gcg gaa gcg gac ctg aaa gcg ctg acc cac tct gtt ctg 336Ala Gly
Gly Ala Glu Ala Asp Leu Lys Ala Leu Thr His Ser Val Leu 100 105
110aaa aaa ctg aaa gaa cgt cag ctg gaa ctg ctg ctg cag gcg gtt gaa
384Lys Lys Leu Lys Glu Arg Gln Leu Glu Leu Leu Leu Gln Ala Val Glu
115 120 125tct cgt ggt ggt acc cgt acc gcg tgc ctg ctg ctg ccg ggt
cgt ctg 432Ser Arg Gly Gly Thr Arg Thr Ala Cys Leu Leu Leu Pro Gly
Arg Leu 130 135 140gac tgc cgt ctg ggt ccg ggt gcg ccg gcg ggt gcg
cag ccg gcg cag 480Asp Cys Arg Leu Gly Pro Gly Ala Pro Ala Gly Ala
Gln Pro Ala Gln145 150 155 160ccg ccg tct tct tac tct ctg ccg ctg
ctg ctg tgc aaa gtt ttc cgt 528Pro Pro Ser Ser Tyr Ser Leu Pro Leu
Leu Leu Cys Lys Val Phe Arg 165 170 175tgg ccg gac ctg cgt cac tct
tct gaa gtt aaa cgt ctg tgc tgc tgc 576Trp Pro Asp Leu Arg His Ser
Ser Glu Val Lys Arg Leu Cys Cys Cys 180 185 190gaa tct tac ggt aaa
atc aac ccg gaa ctg gtt tgc tgc aac ccg cac 624Glu Ser Tyr Gly Lys
Ile Asn Pro Glu Leu Val Cys Cys Asn Pro His 195 200 205cac ctg tct
cgt ctg tgc gaa ctg gaa tct ccg ccg ccg ccg tac tct 672His Leu Ser
Arg Leu Cys Glu Leu Glu Ser Pro Pro Pro Pro Tyr Ser 210 215 220cgt
tac ccg ctg gac ttc ctg aaa ccg acc gcg gac tgc ccg gac gcg 720Arg
Tyr Pro Leu Asp Phe Leu Lys Pro Thr Ala Asp Cys Pro Asp Ala225 230
235 240gtt ccg tct tct gcg gaa acc ggt ggt acc aac tac ctg gcg ccg
ggt 768Val Pro Ser Ser Ala Glu Thr Gly Gly Thr Asn Tyr Leu Ala Pro
Gly 245
250 255ggt ctg tct gac tct cag ctg ctg ctg gaa ccg ggt gac cgt tct
cac 816Gly Leu Ser Asp Ser Gln Leu Leu Leu Glu Pro Gly Asp Arg Ser
His 260 265 270tgg tgc gtt gtt gcg tac tgg gaa gaa aaa acc cgt gtt
ggt cgt ctg 864Trp Cys Val Val Ala Tyr Trp Glu Glu Lys Thr Arg Val
Gly Arg Leu 275 280 285tac tgc gtt cag gaa ccg tct ctg gac atc ttc
tac gac ctg ccg cag 912Tyr Cys Val Gln Glu Pro Ser Leu Asp Ile Phe
Tyr Asp Leu Pro Gln 290 295 300ggt aac ggt ttc tgc ctg ggt cag ctg
aac tct gac aac aaa tct cag 960Gly Asn Gly Phe Cys Leu Gly Gln Leu
Asn Ser Asp Asn Lys Ser Gln305 310 315 320ctg gtt cag aaa gtt cgt
tct aaa atc ggt tgc ggt atc cag ctg acc 1008Leu Val Gln Lys Val Arg
Ser Lys Ile Gly Cys Gly Ile Gln Leu Thr 325 330 335cgt gaa gtt gac
ggt gtt tgg gtt tac aac cgt tct tct tac ccg atc 1056Arg Glu Val Asp
Gly Val Trp Val Tyr Asn Arg Ser Ser Tyr Pro Ile 340 345 350ttc atc
aaa tct gcg acc ctg gac aac ccg gac tct cgt acc ctg ctg 1104Phe Ile
Lys Ser Ala Thr Leu Asp Asn Pro Asp Ser Arg Thr Leu Leu 355 360
365gtt cac aaa gtt ttc ccg ggt ttc tct atc aaa gcg ttc gac tac gaa
1152Val His Lys Val Phe Pro Gly Phe Ser Ile Lys Ala Phe Asp Tyr Glu
370 375 380aaa gcg tac tct ctg cag cgt ccg aac gac cac gaa ttc atg
cag cag 1200Lys Ala Tyr Ser Leu Gln Arg Pro Asn Asp His Glu Phe Met
Gln Gln385 390 395 400ccg tgg acc ggt ttc acc gtt cag atc tct ttc
gtt aaa ggt tgg ggt 1248Pro Trp Thr Gly Phe Thr Val Gln Ile Ser Phe
Val Lys Gly Trp Gly 405 410 415cag tgc tac acc cgt cag ttc atc tct
tct tgc ccg tgc tgg ctg gaa 1296Gln Cys Tyr Thr Arg Gln Phe Ile Ser
Ser Cys Pro Cys Trp Leu Glu 420 425 430gtt atc ttc aac tct cgt ggt
aaa ccg atc ccg aac ccg ctg ctg ggt 1344Val Ile Phe Asn Ser Arg Gly
Lys Pro Ile Pro Asn Pro Leu Leu Gly 435 440 445ctg gac tct acc
tgagtcgac 1365Leu Asp Ser Thr 45037452PRTArtificial
SequenceDescription of Artificial Sequence Synthetic polypeptide
37Gly Ser Gly Arg Lys Lys Arg Arg Gln Arg Arg Arg Gly Phe Arg Thr1
5 10 15Lys Arg Ser Ala Leu Val Arg Arg Leu Trp Arg Ser Arg Ala Pro
Gly 20 25 30Gly Glu Asp Glu Glu Glu Gly Ala Gly Gly Gly Gly Gly Gly
Gly Glu 35 40 45Leu Arg Gly Glu Gly Ala Thr Asp Ser Arg Ala His Gly
Ala Gly Gly 50 55 60Gly Gly Pro Gly Arg Ala Gly Cys Cys Leu Gly Lys
Ala Val Arg Gly65 70 75 80Ala Lys Gly His His His Pro His Pro Pro
Ala Ala Gly Ala Gly Ala 85 90 95Ala Gly Gly Ala Glu Ala Asp Leu Lys
Ala Leu Thr His Ser Val Leu 100 105 110Lys Lys Leu Lys Glu Arg Gln
Leu Glu Leu Leu Leu Gln Ala Val Glu 115 120 125Ser Arg Gly Gly Thr
Arg Thr Ala Cys Leu Leu Leu Pro Gly Arg Leu 130 135 140Asp Cys Arg
Leu Gly Pro Gly Ala Pro Ala Gly Ala Gln Pro Ala Gln145 150 155
160Pro Pro Ser Ser Tyr Ser Leu Pro Leu Leu Leu Cys Lys Val Phe Arg
165 170 175Trp Pro Asp Leu Arg His Ser Ser Glu Val Lys Arg Leu Cys
Cys Cys 180 185 190Glu Ser Tyr Gly Lys Ile Asn Pro Glu Leu Val Cys
Cys Asn Pro His 195 200 205His Leu Ser Arg Leu Cys Glu Leu Glu Ser
Pro Pro Pro Pro Tyr Ser 210 215 220Arg Tyr Pro Leu Asp Phe Leu Lys
Pro Thr Ala Asp Cys Pro Asp Ala225 230 235 240Val Pro Ser Ser Ala
Glu Thr Gly Gly Thr Asn Tyr Leu Ala Pro Gly 245 250 255Gly Leu Ser
Asp Ser Gln Leu Leu Leu Glu Pro Gly Asp Arg Ser His 260 265 270Trp
Cys Val Val Ala Tyr Trp Glu Glu Lys Thr Arg Val Gly Arg Leu 275 280
285Tyr Cys Val Gln Glu Pro Ser Leu Asp Ile Phe Tyr Asp Leu Pro Gln
290 295 300Gly Asn Gly Phe Cys Leu Gly Gln Leu Asn Ser Asp Asn Lys
Ser Gln305 310 315 320Leu Val Gln Lys Val Arg Ser Lys Ile Gly Cys
Gly Ile Gln Leu Thr 325 330 335Arg Glu Val Asp Gly Val Trp Val Tyr
Asn Arg Ser Ser Tyr Pro Ile 340 345 350Phe Ile Lys Ser Ala Thr Leu
Asp Asn Pro Asp Ser Arg Thr Leu Leu 355 360 365Val His Lys Val Phe
Pro Gly Phe Ser Ile Lys Ala Phe Asp Tyr Glu 370 375 380Lys Ala Tyr
Ser Leu Gln Arg Pro Asn Asp His Glu Phe Met Gln Gln385 390 395
400Pro Trp Thr Gly Phe Thr Val Gln Ile Ser Phe Val Lys Gly Trp Gly
405 410 415Gln Cys Tyr Thr Arg Gln Phe Ile Ser Ser Cys Pro Cys Trp
Leu Glu 420 425 430Val Ile Phe Asn Ser Arg Gly Lys Pro Ile Pro Asn
Pro Leu Leu Gly 435 440 445Leu Asp Ser Thr 450381365DNAArtificial
SequenceDescription of Artificial Sequence Synthetic polynucleotide
38ggatccggtc gtaaaaaacg tcgtcagcgt cgtcgtggtt tccgtaccaa acgttctgcg
60ctggttcgtc gtctgtggcg ttctcgtgcg ccgggtggtg aagacgaaga agaaggtgcg
120ggtggtggtg gtggtggtgg tgaactgcgt ggtgaaggtg cgaccgactc
tcgtgcgcac 180ggtgcgggtg gtggtggtcc gggtcgtgcg ggttgctgcc
tgggtaaagc ggttcgtggt 240gcgaaaggtc accaccaccc gcacccgccg
gcggcgggtg cgggtgcggc gggtggtgcg 300gaagcggacc tgaaagcgct
gacccactct gttctgaaaa aactgaaaga acgtcagctg 360gaactgctgc
tgcaggcggt tgaatctcgt ggtggtaccc gtaccgcgtg cctgctgctg
420ccgggtcgtc tggactgccg tctgggtccg ggtgcgccgg cgggtgcgca
gccggcgcag 480ccgccgtctt cttactctct gccgctgctg ctgtgcaaag
ttttccgttg gccggacctg 540cgtcactctt ctgaagttaa acgtctgtgc
tgctgcgaat cttacggtaa aatcaacccg 600gaactggttt gctgcaaccc
gcaccacctg tctcgtctgt gcgaactgga atctccgccg 660ccgccgtact
ctcgttaccc gctggacttc ctgaaaccga ccgcggactg cccggacgcg
720gttccgtctt ctgcggaaac cggtggtacc aactacctgg cgccgggtgg
tctgtctgac 780tctcagctgc tgctggaacc gggtgaccgt tctcactggt
gcgttgttgc gtactgggaa 840gaaaaaaccc gtgttggtcg tctgtactgc
gttcaggaac cgtctctgga catcttctac 900gacctgccgc agggtaacgg
tttctgcctg ggtcagctga actctgacaa caaatctcag 960ctggttcaga
aagttcgttc taaaatcggt tgcggtatcc agctgacccg tgaagttgac
1020ggtgtttggg tttacaaccg ttcttcttac ccgatcttca tcaaatctgc
gaccctggac 1080aacccggact ctcgtaccct gctggttcac aaagttttcc
cgggtttctc tatcaaagcg 1140ttcgactacg aaaaagcgta ctctctgcag
cgtccgaacg accacgaatt catgcagcag 1200ccgtggaccg gtttcaccgt
tcagatctct ttcgttaaag gttggggtca gtgctacacc 1260cgtcagttca
tctcttcttg cccgtgctgg ctggaagtta tcttcaactc tcgtggtaaa
1320ccgatcccga acccgctgct gggtctggac tctacctgag tcgac
1365391392DNAArtificial SequenceDescription of Artificial Sequence
Synthetic polynucleotide 39ggatccggcc gtaaaaaacg ccgtcaacgc
cgccgtggtt tccgtacgaa acgcagcgcc 60ctggtccgtc gcctgtggcg cagccgtgct
ccgggtggtg aagatgaaga agaaggtgct 120ggcggcggtg gcggtggcgg
tgaactgcgt ggcgagggtg caaccgatag ccgtgcacat 180ggtgcaggcg
gtggcggtcc gggtcgtgct ggttgctgtc tgggtaaagc tgtgcgcggc
240gcgaaaggtc atcatcatcc gcatccgccg gcagcaggtg caggtgcagc
tggcggtgcg 300gaagccgatc tgaaagccct gacccatagc gtcctgaaaa
aactgaaaga acgtcagctg 360gagctgctgc tgcaagcagt agaaagccgt
ggcggtaccc gtacggcttg tctgctgctg 420ccgggtcgtc tggattgccg
tctgggtccg ggtgcaccgg ctggtgcgca gccggcacaa 480ccgccgagca
gctacagcct gccgctgctg ctgtgtaaag tgtttcgttg gccggacctg
540cgccatagca gcgaagttaa acgcctgtgc tgttgcgaga gctatggcaa
aattaacccg 600gaactggttt gttgcaatcc gcatcatctg agccgtctgt
gtgaactgga gagcccgccg 660ccgccgtata gccgttaccc gctggatttc
ctgaaaccga ctgcagattg cccggacgca 720gtcccgagca gcgctgagac
cggcggcacc aactatctgg caccgggcgg tctgagcgat 780agccagctgc
tgctggaacc gggcgaccgt agccattggt gtgtggttgc ctattgggaa
840gagaaaacgc gtgtcggtcg cctgtactgc gtacaggaac cgagcctgga
tatcttttat 900gacctgccgc agggcaatgg tttctgtctg ggccaactga
acagcgataa taaaagccag 960ctggtgcaaa aagttcgcag caaaattggc
tgcggtatcc agctgacccg tgaagttgac 1020ggtgtctggg tatataaccg
cagcagctac ccgattttta tcaaaagcgc caccctggat 1080aatccggaca
gccgtacgct gctggtccat aaagtatttc cgggcttcag catcaaagcg
1140ttcgattacg agaaagccta cagcctgcag cgcccgaacg accatgaatt
catgcagcaa 1200ccgtggacgg gttttactgt gcagatcagc ttcgttaaag
gctggggtca atgctacacc 1260cgtcagttta tcagcagctg tccgtgctgg
ctggaagtga ttttcaatag ccgcaagggc 1320gagctcaata gcaagcttga
aggtaagcct atccctaacc ctctcctcgg tctcgatagc 1380acgtgagtcg ac
1392406PRTArtificial SequenceDescription of Artificial Sequence
Synthetic 6xHis tag 40His His His His His His1 54114PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 41Gly
Lys Pro Ile Pro Asn Pro Leu Leu Gly Leu Asp Ser Thr1 5
10428PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 42Lys Tyr Lys Asp Asp Asp Asp Lys1
5439PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 43Tyr Pro Tyr Asp Val Pro Asp Tyr Ala1
54423PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 44Gly Ala Leu Phe Leu Gly Trp Leu Gly Ala Ala Gly
Ser Thr Met Gly1 5 10 15Ala Lys Lys Lys Arg Lys Val
204516PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 45Arg Gln Ile Lys Ile Trp Phe Gln Asn Arg Arg Met
Lys Trp Lys Lys1 5 10 15467PRTArtificial SequenceDescription of
Artificial Sequence Synthetic peptide 46Arg Arg Met Lys Trp Lys
Lys1 54716PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 47Arg Arg Trp Arg Arg Trp Trp Arg Arg Trp Trp Arg
Arg Trp Arg Arg1 5 10 154818PRTArtificial SequenceDescription of
Artificial Sequence Synthetic peptide 48Arg Gly Gly Arg Leu Ser Tyr
Ser Arg Arg Arg Phe Ser Thr Ser Thr1 5 10 15Gly Arg499PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 49Arg
Lys Lys Arg Arg Gln Arg Arg Arg1 55011PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 50Tyr
Ala Arg Ala Ala Ala Arg Gln Ala Arg Ala1 5 10518PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 51Arg
Arg Arg Arg Arg Arg Arg Arg1 5528PRTArtificial SequenceDescription
of Artificial Sequence Synthetic peptide 52Lys Lys Lys Lys Lys Lys
Lys Lys1 55327PRTArtificial SequenceDescription of Artificial
Sequence Synthetic peptideMOD_RES(25)..(25)Any amino acid 53Gly Trp
Thr Leu Asn Ser Ala Gly Tyr Leu Leu Gly Lys Ile Asn Leu1 5 10 15Lys
Ala Leu Ala Ala Leu Ala Lys Xaa Ile Leu 20 255418PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 54Leu
Leu Ile Leu Leu Arg Arg Arg Ile Arg Lys Gln Ala Asn Ala His1 5 10
15Ser Lys5516PRTArtificial SequenceDescription of Artificial
Sequence Synthetic peptide 55Ser Arg Arg His His Cys Arg Ser Lys
Ala Lys Arg Ser Arg His His1 5 10 155611PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 56Asn
Arg Ala Arg Arg Asn Arg Arg Arg Val Arg1 5 105715PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 57Arg
Gln Leu Arg Ile Ala Gly Arg Arg Leu Arg Gly Arg Ser Arg1 5 10
155813PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 58Lys Leu Ile Lys Gly Arg Thr Pro Ile Lys Phe Gly
Lys1 5 105910PRTArtificial SequenceDescription of Artificial
Sequence Synthetic peptide 59Arg Arg Ile Pro Asn Arg Arg Pro Arg
Arg1 5 106018PRTArtificial SequenceDescription of Artificial
Sequence Synthetic peptide 60Lys Leu Ala Leu Lys Leu Ala Leu Lys
Ala Leu Lys Ala Ala Leu Lys1 5 10 15Leu Ala6114PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 61Lys
Leu Ala Lys Leu Ala Lys Lys Leu Ala Lys Leu Ala Lys1 5
106227PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 62Gly Ala Leu Phe Leu Gly Phe Leu Gly Ala Ala Gly
Ser Thr Asn Gly1 5 10 15Ala Trp Ser Gln Pro Lys Lys Lys Arg Lys Val
20 256321PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 63Lys Glu Thr Trp Trp Glu Thr Trp Trp Thr Glu Trp
Ser Gln Pro Lys1 5 10 15Lys Lys Arg Lys Val 206420PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 64Leu
Lys Lys Leu Leu Lys Lys Leu Leu Lys Lys Leu Leu Lys Lys Leu1 5 10
15Leu Lys Lys Leu 206534PRTArtificial SequenceDescription of
Artificial Sequence Synthetic polypeptide 65Gln Ala Ala Thr Ala Thr
Arg Gly Arg Ser Ala Ala Ser Arg Pro Thr1 5 10 15Glu Arg Pro Arg Ala
Pro Ala Arg Ser Ala Ser Arg Pro Arg Arg Pro 20 25 30Val
Glu6623PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 66Met Gly Leu Gly Leu His Leu Leu Val Leu Ala Ala
Ala Leu Gln Gly1 5 10 15Ala Lys Ser Lys Arg Lys Val
206726PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 67Ala Ala Val Ala Leu Leu Pro Ala Val Leu Leu Ala
Leu Leu Ala Pro1 5 10 15Ala Ala Ala Asn Tyr Lys Lys Pro Lys Leu 20
256828PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 68Met Ala Asn Leu Gly Tyr Trp Leu Leu Ala Leu Phe
Val Thr Met Trp1 5 10 15Thr Asp Val Gly Leu Cys Lys Lys Arg Pro Lys
Pro 20 256924PRTArtificial SequenceDescription of Artificial
Sequence Synthetic peptide 69Leu Gly Thr Tyr Thr Gln Asp Phe Asn
Lys Phe His Thr Phe Pro Gln1 5 10 15Thr Ala Ile Gly Val Gly Ala Pro
207026PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptideMOD_RES(24)..(24)Any amino acid 70Asp Pro Lys Gly
Asp Pro Lys Gly Val Thr Val Thr Val Thr Val Thr1 5 10 15Val Thr Gly
Lys Gly Asp Pro Xaa Pro Asp 20 257114PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 71Pro
Pro Pro Pro Pro Pro Pro Pro Pro Pro Pro Pro Pro Pro1 5
107218PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 72Val Arg Leu Pro Pro Pro Val Arg Leu Pro Pro Pro
Val Arg Leu Pro1 5 10 15Pro Pro7310PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 73Pro
Arg Pro Leu Pro Pro Pro Arg Pro Gly1 5 107430PRTArtificial
SequenceDescription of Artificial Sequence Synthetic polypeptide
74Ser Val Arg Arg Arg Pro Arg Pro Pro Tyr Leu Pro Arg Pro Arg Pro1
5 10 15Pro Pro Phe Phe Pro Pro Arg Leu Pro Pro Arg Ile Pro Pro 20
25 307521PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 75Thr Arg Ser Ser Arg Ala Gly Leu Gln Phe Pro Val
Gly Arg Val His1 5 10 15Arg Leu Leu Arg Lys 207623PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 76Gly
Ile Gly Lys Phe Leu His Ser Ala Lys Lys Phe Gly Lys Ala Phe1 5 10
15Val Gly Glu Ile Met Asn Ser 207737PRTArtificial
SequenceDescription of Artificial Sequence Synthetic polypeptide
77Lys Trp Lys Leu Phe Lys Lys Ile Glu Lys Val Gly Gln Asn Ile Arg1
5 10 15Asp Gly Ile Ile Lys Ala Gly Pro Ala Val Ala Val Val Gly Gln
Ala 20 25 30Thr Gln Ile Ala Lys 357828PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 78Ala
Leu Trp Met Thr Leu Leu Lys Lys Val Leu Lys Ala Ala Ala Lys1 5 10
15Ala Ala Leu Asn Ala Val Leu Val Gly Ala Asn Ala 20
257926PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 79Gly Ile Gly Ala Val Leu Lys Val Leu Thr Thr Gly
Leu Pro Ala
Leu1 5 10 15Ile Ser Trp Ile Lys Arg Lys Arg Gln Gln 20
258014PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 80Ile Asn Leu Lys Ala Leu Ala Ala Leu Ala Lys Lys
Ile Leu1 5 108133PRTArtificial SequenceDescription of Artificial
Sequence Synthetic polypeptide 81Gly Phe Phe Ala Leu Ile Pro Lys
Ile Ile Ser Ser Pro Leu Pro Lys1 5 10 15Thr Leu Leu Ser Ala Val Gly
Ser Ala Leu Gly Gly Ser Gly Gly Gln 20 25 30Glu8215PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 82Leu
Ala Lys Trp Ala Leu Lys Gln Gly Phe Ala Lys Leu Lys Ser1 5 10
158327PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptideMOD_RES(23)..(23)Any amino acid 83Ser Met Ala Gln
Asp Ile Ile Ser Thr Ile Gly Asp Leu Val Lys Trp1 5 10 15Ile Ile Gln
Thr Val Asn Xaa Phe Thr Lys Lys 20 258441PRTArtificial
SequenceDescription of Artificial Sequence Synthetic polypeptide
84Leu Leu Gly Asp Phe Phe Arg Lys Ser Lys Glu Lys Ile Gly Lys Glu1
5 10 15Phe Lys Arg Ile Val Gln Arg Ile Lys Gln Arg Ile Lys Asp Phe
Leu 20 25 30Ala Asn Leu Val Pro Arg Thr Glu Ser 35
408518PRTArtificial SequenceDescription of Artificial Sequence
Synthetic peptide 85Pro Ala Trp Arg Lys Ala Phe Arg Trp Ala Trp Arg
Met Leu Lys Lys1 5 10 15Ala Ala8618PRTArtificial
SequenceDescription of Artificial Sequence Synthetic peptide 86Lys
Leu Lys Leu Lys Leu Lys Leu Lys Leu Lys Leu Lys Leu Lys Leu1 5 10
15Lys Leu872182DNAArtificial SequenceDescription of Artificial
Sequence Synthetic polynucleotide 87gacgttgtat acgactccta
tagggcggcc gggaattcgt cgactggatc cggtaccgag 60gagatctgcc gccgcgatcg
ccatgtcccc cattctgggc tactggaaga ttaagggcct 120ggtgcagcct
actagactgc tgctggaata cctggaggaa aaatatgaag agcatctgta
180tgaaagagac gagggggata aatggaggaa caagaaattc gaactgggac
tggagtttcc 240taatctgcca tactatattg acggcgatgt gaagctgact
cagtctatgg ctatcattag 300atacatcgca gacaaacaca acatgctggg
cgggtgtcct aaggaaaggg cagagattag 360tatgctggag ggagccgtgc
tggatattag atacggcgtc tcacgcatcg cctatagcaa 420agacttcgaa
accctgaagg tggattttct gagcaaactg cctgaaatgc tgaagatgtt
480cgaggacaga ctgtgccaca aaacctacct gaatggcgac catgtcacac
acccagattt 540tatgctgtac gacgccctgg atgtggtcct gtatatggac
cccatgtgtc tggatgcttt 600ccctaagctg gtgtgcttta agaaaaggat
cgaggcaatt ccccagatcg ataagtacct 660gaaaagctcc aagtatatcg
cttggcctct ccagggctgg caggcaacat tcggaggcgg 720ggaccatccc
cctaaaagcg acctggaggt gctgtttcag ggaccactgg gcagcggccg
780gaagaagcgg cggcagaggc gccgaagtag gttccgcact aagcggtcag
cactggtgcg 840gagactgtgg cgatctcggg ctcctggagg agaggacgag
gaagagggag caggcggcgg 900cggaggagga ggagaactgc gcggggaggg
agctacagat agccgagccc acggagctgg 960aggaggagga ccagggcgag
ccggatgctg tctgggcaaa gcagtgagag gcgccaaggg 1020gcaccatcac
ccccatccac ccgccgctgg cgcaggagca gccggcggag ctgaggcaga
1080cctgaaagcc ctgactcaca gtgtgctgaa gaaactgaag gaaagacagc
tggagctgct 1140gctccaggca gtcgaatcac gcggaggcac ccgaacagct
tgtctgctgc tgcccggccg 1200gctggactgc cggctgggac ccggcgcccc
tgctggggca cagccagccc agcctccatc 1260tagttatagc ctgcccctgc
tgctgtgtaa ggtgttccga tggcctgatc tgcggcattc 1320aagcgaagtc
aaaaggctgt gctgttgcga gtcctacggc aagattaacc cagaactggt
1380gtgttgcaat ccccatcacc tgtctcgact gtgtgaactg gagtcccccc
ctccacccta 1440ctctaggtat cctatggact ttctgaagcc aaccgctgac
tgcccagatg cagtgccctc 1500ctctgccgag actgggggaa ccaactacct
ggctcctggc ggactgagcg actcccagct 1560gctgctggaa ccaggggatc
gcagccactg gtgtgtggtc gcctactggg aagagaagac 1620aagagtggga
aggctgtatt gcgtccagga gccttccctg gacatcttct acgatctgcc
1680acaggggaat ggattttgtc tgggccagct gaactctgac aataagagtc
agctggtgca 1740gaaagtccgg agcaagattg gctgcggcat ccagctgacc
agggaggtgg acggcgtgtg 1800ggtctacaac cgcagttcat atccaatctt
catcaagagc gccactctgg acaatcccga 1860ttcccgcacc ctgctggtgc
ataaggtctt ccccggcttc agcatcaagg ccttcgacta 1920cgagaaggct
tatagtctcc agcggcccaa cgatcacgag ttcatgcagc agccttggac
1980aggcttcact gtgcagatca gcttcgtcaa gggatggggc cagtgctaca
caaggcagtt 2040catctcaagc tgtccctgtt ggctggaagt cattttcaat
agtaggacgc gtacgcggcc 2100gctcgagcag aaactcatct cagaagagga
tctggcagca aatgatatcc tggattacaa 2160ggatgacgac gataaggttt aa
2182881059DNAHomo sapiens 88tcaccaccat ccccacccgc cagccgcggg
cgccggcgcg gccgggggcg ccgaggcgga 60tctgaaggcg ctcacgcact cggtgctcaa
gaaactgaag gagcggcagc tggagctgct 120gctccaggcc gtggagtccc
gcggcgggac gcgcaccgcg tgcctcctgc tgcccggccg 180cctggactgc
aggctgggcc cgggggcgcc cgccggcgcg cagcctgcgc agccgccctc
240gtcctactcg ctccccctcc tgctgtgcaa agtgttcagg tggccggatc
tcaggcattc 300ctcggaagtc aagaggctgt gttgctgtga atcttacggg
aagatcaacc ccgagctggt 360gtgctgcaac ccccatcacc ttagccgact
ctgcgaacta gagtctcccc cccctcctta 420ctccagatac ccgatggatt
ttctcaaacc aactgcagac tgtccagatg ctgtgccttc 480ctccgctgaa
acagggggaa cgaattatct ggcccctggg gggctttcag attcccaact
540tcttctggag cctggggatc ggtcacactg gtgcgtggtg gcatactggg
aggagaagac 600gagagtgggg aggctctact gtgtccagga gccctctctg
gatatcttct atgatctacc 660tcaggggaat ggcttttgcc tcggacagct
caattcggac aacaagagtc agctggtgca 720gaaggtgcgg agcaaaatcg
gctgcggcat ccagctgacg cgggaggtgg atggtgtgtg 780ggtgtacaac
cgcagcagtt accccatctt catcaagtcc gccacactgg acaacccgga
840ctccaggacg ctgttggtac acaaggtgtt ccccggtttc tccatcaagg
ctttcgacta 900cgagaaggcg tacagcctgc agcggcccaa tgaccacgag
tttatgcagc agccgtggac 960gggctttacc gtgcagatca gctttgtgaa
gggctggggt cagtgctaca cccgccagtt 1020catcagcagc tgcccgtgct
ggctagaggt catcttcaa 1059891053DNAArtificial SequenceDescription of
Artificial Sequence Synthetic polynucleotide 89tcacccccat
ccacccgccg ctggcgcagg agcagccggc ggagctgagg cagacctgaa 60agccctgact
cacagtgtgc tgaagaaact gaaggaaaga cagctggagc tgctgctcca
120ggcagtcgaa tcacgcggag gcacccgaac agcttgtctg ctgctgcccg
gccggctgga 180ctgccggctg ggacccggcg cccctgctgg ggcacagcca
gcccagcctc catctagtta 240tagcctgccc ctgctgctgt gtaaggtgtt
ccgatggcct gatctgcggc attcaagcga 300agtcaaaagg ctgtgctgtt
gcgagtccta cggcaagatt aacccagaac tggtgtgttg 360caatccccat
cacctgtctc gactgtgtga actggagtcc ccccctccac cctactctag
420gtatcctatg gactttctga agccaaccgc tgactgccca gatgcagtgc
cctcctctgc 480cgagactggg ggaaccaact acctggctcc tggcggactg
agcgactccc agctgctgct 540ggaaccaggg gatcgcagcc actggtgtgt
ggtcgcctac tgggaagaga agacaagagt 600gggaaggctg tattgcgtcc
aggagccttc cctggacatc ttctacgatc tgccacaggg 660gaatggattt
tgtctgggcc agctgaactc tgacaataag agtcagctgg tgcagaaagt
720ccggagcaag attggctgcg gcatccagct gaccagggag gtggacggcg
tgtgggtcta 780caaccgcagt tcatatccaa tcttcatcaa gagcgccact
ctggacaatc ccgattcccg 840caccctgctg gtgcataagg tcttccccgg
cttcagcatc aaggccttcg actacgagaa 900ggcttatagt ctccagcggc
ccaacgatca cgagttcatg cagcagcctt ggacaggctt 960cactgtgcag
atcagcttcg tcaagggatg gggccagtgc tacacaaggc agttcatctc
1020aagctgtccc tgttggctgg aagtcatttt caa 105390699PRTArtificial
SequenceDescription of Artificial Sequence Synthetic polypeptide
90Met Ser Pro Ile Leu Gly Tyr Trp Lys Ile Lys Gly Leu Val Gln Pro1
5 10 15Thr Arg Leu Leu Leu Glu Tyr Leu Glu Glu Lys Tyr Glu Glu His
Leu 20 25 30Tyr Glu Arg Asp Glu Gly Asp Lys Trp Arg Asn Lys Lys Phe
Glu Leu 35 40 45Gly Leu Glu Phe Pro Asn Leu Pro Tyr Tyr Ile Asp Gly
Asp Val Lys 50 55 60Leu Thr Gln Ser Met Ala Ile Ile Arg Tyr Ile Ala
Asp Lys His Asn65 70 75 80Met Leu Gly Gly Cys Pro Lys Glu Arg Ala
Glu Ile Ser Met Leu Glu 85 90 95Gly Ala Val Leu Asp Ile Arg Tyr Gly
Val Ser Arg Ile Ala Tyr Ser 100 105 110Lys Asp Phe Glu Thr Leu Lys
Val Asp Phe Leu Ser Lys Leu Pro Glu 115 120 125Met Leu Lys Met Phe
Glu Asp Arg Leu Cys His Lys Thr Tyr Leu Asn 130 135 140Gly Asp His
Val Thr His Pro Asp Phe Met Leu Tyr Asp Ala Leu Asp145 150 155
160Val Val Leu Tyr Met Asp Pro Met Cys Leu Asp Ala Phe Pro Lys Leu
165 170 175Val Cys Phe Lys Lys Arg Ile Glu Ala Ile Pro Gln Ile Asp
Lys Tyr 180 185 190Leu Lys Ser Ser Lys Tyr Ile Ala Trp Pro Leu Gln
Gly Trp Gln Ala 195 200 205Thr Phe Gly Gly Gly Asp His Pro Pro Lys
Ser Asp Leu Glu Val Leu 210 215 220Phe Gln Gly Pro Leu Gly Ser Gly
Arg Lys Lys Arg Arg Gln Arg Arg225 230 235 240Arg Ser Arg Phe Arg
Thr Lys Arg Ser Ala Leu Val Arg Arg Leu Trp 245 250 255Arg Ser Arg
Ala Pro Gly Gly Glu Asp Glu Glu Glu Gly Ala Gly Gly 260 265 270Gly
Gly Gly Gly Gly Glu Leu Arg Gly Glu Gly Ala Thr Asp Ser Arg 275 280
285Ala His Gly Ala Gly Gly Gly Gly Pro Gly Arg Ala Gly Cys Cys Leu
290 295 300Gly Lys Ala Val Arg Gly Ala Lys Gly His His His Pro His
Pro Pro305 310 315 320Ala Ala Gly Ala Gly Ala Ala Gly Gly Ala Glu
Ala Asp Leu Lys Ala 325 330 335Leu Thr His Ser Val Leu Lys Lys Leu
Lys Glu Arg Gln Leu Glu Leu 340 345 350Leu Leu Gln Ala Val Glu Ser
Arg Gly Gly Thr Arg Thr Ala Cys Leu 355 360 365Leu Leu Pro Gly Arg
Leu Asp Cys Arg Leu Gly Pro Gly Ala Pro Ala 370 375 380Gly Ala Gln
Pro Ala Gln Pro Pro Ser Ser Tyr Ser Leu Pro Leu Leu385 390 395
400Leu Cys Lys Val Phe Arg Trp Pro Asp Leu Arg His Ser Ser Glu Val
405 410 415Lys Arg Leu Cys Cys Cys Glu Ser Tyr Gly Lys Ile Asn Pro
Glu Leu 420 425 430Val Cys Cys Asn Pro His His Leu Ser Arg Leu Cys
Glu Leu Glu Ser 435 440 445Pro Pro Pro Pro Tyr Ser Arg Tyr Pro Met
Asp Phe Leu Lys Pro Thr 450 455 460Ala Asp Cys Pro Asp Ala Val Pro
Ser Ser Ala Glu Thr Gly Gly Thr465 470 475 480Asn Tyr Leu Ala Pro
Gly Gly Leu Ser Asp Ser Gln Leu Leu Leu Glu 485 490 495Pro Gly Asp
Arg Ser His Trp Cys Val Val Ala Tyr Trp Glu Glu Lys 500 505 510Thr
Arg Val Gly Arg Leu Tyr Cys Val Gln Glu Pro Ser Leu Asp Ile 515 520
525Phe Tyr Asp Leu Pro Gln Gly Asn Gly Phe Cys Leu Gly Gln Leu Asn
530 535 540Ser Asp Asn Lys Ser Gln Leu Val Gln Lys Val Arg Ser Lys
Ile Gly545 550 555 560Cys Gly Ile Gln Leu Thr Arg Glu Val Asp Gly
Val Trp Val Tyr Asn 565 570 575Arg Ser Ser Tyr Pro Ile Phe Ile Lys
Ser Ala Thr Leu Asp Asn Pro 580 585 590Asp Ser Arg Thr Leu Leu Val
His Lys Val Phe Pro Gly Phe Ser Ile 595 600 605Lys Ala Phe Asp Tyr
Glu Lys Ala Tyr Ser Leu Gln Arg Pro Asn Asp 610 615 620His Glu Phe
Met Gln Gln Pro Trp Thr Gly Phe Thr Val Gln Ile Ser625 630 635
640Phe Val Lys Gly Trp Gly Gln Cys Tyr Thr Arg Gln Phe Ile Ser Ser
645 650 655Cys Pro Cys Trp Leu Glu Val Ile Phe Asn Ser Arg Thr Arg
Thr Arg 660 665 670Pro Leu Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu
Ala Ala Asn Asp 675 680 685Ile Leu Asp Tyr Lys Asp Asp Asp Asp Lys
Val 690 695911637DNAArtificial SequenceDescription of Artificial
Sequence Synthetic polynucleotide 91gaattcgtcg actggatccg
gtaccgagga gatctgccgc cgcgatcgcc atgtccccca 60ttctgggcta ctggaagatt
aagggcctgg tgcagcctac tagactgctg ctggaatacc 120tggaggaaaa
atatgaagag catctgtatg aaagagacga gggggataaa tggaggaaca
180agaaattcga actgggactg gagtttccta atctgccata ctatattgac
ggcgatgtga 240agctgactca gtctatggct atcattagat acatcgcaga
caaacacaac atgctgggcg 300ggtgtcctaa ggaaagggca gagattagta
tgctggaggg agccgtgctg gatattagat 360acggcgtctc acgcatcgcc
tatagcaaag acttcgaaac cctgaaggtg gattttctga 420gcaaactgcc
tgaaatgctg aagatgttcg aggacagact gtgccacaaa acctacctga
480atggcgacca tgtcacacac ccagatttta tgctgtacga cgccctggat
gtggtcctgt 540atatggaccc catgtgtctg gatgctttcc ctaagctggt
gtgctttaag aaaaggatcg 600aggcaattcc ccagatcgat aagtacctga
aaagctccaa gtatatcgct tggcctctcc 660agggctggca ggcaacattc
ggaggcgggg accatccccc taaaagcgac ctggaggtgc 720tgtttcaggg
accactgggc agcggccgga agaagcggcg gcagaggcgc cgaagtaggt
780tccgcactaa gcggtcagca ctggtgcgga gactgtggcg atctcgggct
cctggaggag 840aggacgagga agagggagca ggcggcggcg gaggaggagg
agaactgcgc ggggagggag 900ctacagatag ccgagcccac ggagctggag
gaggaggacc agggcgagcc ggatgctgtc 960tgggcaaagc agtgagaggc
gccaaggggc accatcaccc ccatccaccc gccgctggcg 1020caggagcagc
cggcggagct gaggcagacc tgaaagccct gactcacagt gtgctgaaga
1080aactgaagga aagacagctg gagctgctgc tccaggcagt cgaatcacgc
ggaggcaccc 1140gaacagcttg tctgctgctg cccggccggc tggactgccg
gctgggaccc ggcgcccctg 1200ctggggcaca gccagcccag cctccatcta
gttatagcct gcccctgctg ctgtgtaagg 1260tgttccgatg gcctgatctg
cggcattcaa gcgaagtcaa aaggctgtgc tgttgcgagt 1320cctacggcaa
gattaaccca gaactggtgt gttgcaatcc ccatcacctg tctcgactgt
1380gtgaactgga gtccccccct ccaccctact ctaggtatcc tatggacttt
ctgaagccaa 1440ccgctgactg cccagatgca gtgccctcct ctgccgagac
tgggggaacc aactacctgg 1500ctcctggcgg actgagcgac tcccagctgc
tgctggaacc aggggatcgg cggccgctcg 1560agcagaaact catctcagaa
gaggatctgg cagcaaatga tatcctggat tacaaggatg 1620acgacgataa ggtttaa
163792528PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 92Met Ser Pro Ile Leu Gly Tyr Trp Lys Ile Lys
Gly Leu Val Gln Pro1 5 10 15Thr Arg Leu Leu Leu Glu Tyr Leu Glu Glu
Lys Tyr Glu Glu His Leu 20 25 30Tyr Glu Arg Asp Glu Gly Asp Lys Trp
Arg Asn Lys Lys Phe Glu Leu 35 40 45Gly Leu Glu Phe Pro Asn Leu Pro
Tyr Tyr Ile Asp Gly Asp Val Lys 50 55 60Leu Thr Gln Ser Met Ala Ile
Ile Arg Tyr Ile Ala Asp Lys His Asn65 70 75 80Met Leu Gly Gly Cys
Pro Lys Glu Arg Ala Glu Ile Ser Met Leu Glu 85 90 95Gly Ala Val Leu
Asp Ile Arg Tyr Gly Val Ser Arg Ile Ala Tyr Ser 100 105 110Lys Asp
Phe Glu Thr Leu Lys Val Asp Phe Leu Ser Lys Leu Pro Glu 115 120
125Met Leu Lys Met Phe Glu Asp Arg Leu Cys His Lys Thr Tyr Leu Asn
130 135 140Gly Asp His Val Thr His Pro Asp Phe Met Leu Tyr Asp Ala
Leu Asp145 150 155 160Val Val Leu Tyr Met Asp Pro Met Cys Leu Asp
Ala Phe Pro Lys Leu 165 170 175Val Cys Phe Lys Lys Arg Ile Glu Ala
Ile Pro Gln Ile Asp Lys Tyr 180 185 190Leu Lys Ser Ser Lys Tyr Ile
Ala Trp Pro Leu Gln Gly Trp Gln Ala 195 200 205Thr Phe Gly Gly Gly
Asp His Pro Pro Lys Ser Asp Leu Glu Val Leu 210 215 220Phe Gln Gly
Pro Leu Gly Ser Gly Arg Lys Lys Arg Arg Gln Arg Arg225 230 235
240Arg Ser Arg Phe Arg Thr Lys Arg Ser Ala Leu Val Arg Arg Leu Trp
245 250 255Arg Ser Arg Ala Pro Gly Gly Glu Asp Glu Glu Glu Gly Ala
Gly Gly 260 265 270Gly Gly Gly Gly Gly Glu Leu Arg Gly Glu Gly Ala
Thr Asp Ser Arg 275 280 285Ala His Gly Ala Gly Gly Gly Gly Pro Gly
Arg Ala Gly Cys Cys Leu 290 295 300Gly Lys Ala Val Arg Gly Ala Lys
Gly His His His Pro His Pro Pro305 310 315 320Ala Ala Gly Ala Gly
Ala Ala Gly Gly Ala Glu Ala Asp Leu Lys Ala 325 330 335Leu Thr His
Ser Val Leu Lys Lys Leu Lys Glu Arg Gln Leu Glu Leu 340 345 350Leu
Leu Gln Ala Val Glu Ser Arg Gly Gly Thr Arg Thr Ala Cys Leu 355 360
365Leu Leu Pro Gly Arg Leu Asp Cys Arg Leu Gly Pro Gly Ala Pro Ala
370 375 380Gly Ala Gln Pro Ala Gln Pro Pro Ser Ser Tyr Ser Leu Pro
Leu Leu385 390 395 400Leu Cys Lys Val Phe Arg Trp Pro Asp Leu Arg
His Ser Ser Glu Val 405 410 415Lys Arg Leu Cys Cys Cys Glu Ser Tyr
Gly Lys Ile Asn Pro Glu Leu 420 425 430Val Cys Cys Asn Pro His His
Leu Ser Arg Leu Cys Glu Leu
Glu Ser 435 440 445Pro Pro Pro Pro Tyr Ser Arg Tyr Pro Met Asp Phe
Leu Lys Pro Thr 450 455 460Ala Asp Cys Pro Asp Ala Val Pro Ser Ser
Ala Glu Thr Gly Gly Thr465 470 475 480Asn Tyr Leu Ala Pro Gly Gly
Leu Ser Asp Ser Gln Leu Leu Leu Glu 485 490 495Pro Gly Asp Arg Arg
Pro Leu Glu Gln Lys Leu Ile Ser Glu Glu Asp 500 505 510Leu Ala Ala
Asn Asp Ile Leu Asp Tyr Lys Asp Asp Asp Asp Lys Val 515 520
525931370DNAArtificial SequenceDescription of Artificial Sequence
Synthetic polynucleotide 93gaattcgtcg actggatccg gtaccgagga
gatctgccgc cgcgatcgcc atgtccccca 60ttctgggcta ctggaagatt aagggcctgg
tgcagcctac tagactgctg ctggaatacc 120tggaggaaaa atatgaagag
catctgtatg aaagagacga gggggataaa tggaggaaca 180agaaattcga
actgggactg gagtttccta atctgccata ctatattgac ggcgatgtga
240agctgactca gtctatggct atcattagat acatcgcaga caaacacaac
atgctgggcg 300ggtgtcctaa ggaaagggca gagattagta tgctggaggg
agccgtgctg gatattagat 360acggcgtctc acgcatcgcc tatagcaaag
acttcgaaac cctgaaggtg gattttctga 420gcaaactgcc tgaaatgctg
aagatgttcg aggacagact gtgccacaaa acctacctga 480atggcgacca
tgtcacacac ccagatttta tgctgtacga cgccctggat gtggtcctgt
540atatggaccc catgtgtctg gatgctttcc ctaagctggt gtgctttaag
aaaaggatcg 600aggcaattcc ccagatcgat aagtacctga aaagctccaa
gtatatcgct tggcctctcc 660agggctggca ggcaacattc ggaggcgggg
accatccccc taaaagcgac ctggaggtgc 720tgtttcaggg accactgggc
agcggccgga agaagcggcg gcagaggcgc agccactggt 780gtgtggtcgc
ctactgggaa gagaagacaa gagtgggaag gctgtattgc gtccaggagc
840cttccctgga catcttctac gatctgccac aggggaatgg attttgtctg
ggccagctga 900actctgacaa taagagtcag ctggtgcaga aagtccggag
caagattggc tgcggcatcc 960agctgaccag ggaggtggac ggcgtgtggg
tctacaaccg cagttcatat ccaatcttca 1020tcaagagcgc cactctggac
aatcccgatt cccgcaccct gctggtgcat aaggtcttcc 1080ccggcttcag
catcaaggcc ttcgactacg agaaggctta tagtctccag cggcccaacg
1140atcacgagtt catgcagcag ccttggacag gcttcactgt gcagatcagc
ttcgtcaagg 1200gatggggcca gtgctacaca aggcagttca tctcaagctg
tccctgttgg ctggaagtca 1260ttttcaatag taggacgcgt acgcggccgc
tcgagcagaa actcatctca gaagaggatc 1320tggcagcaaa tgatatcctg
gattacaagg atgacgacga taaggtttaa 137094440PRTArtificial
SequenceDescription of Artificial Sequence Synthetic polypeptide
94Met Ser Pro Ile Leu Gly Tyr Trp Lys Ile Lys Gly Leu Val Gln Pro1
5 10 15Thr Arg Leu Leu Leu Glu Tyr Leu Glu Glu Lys Tyr Glu Glu His
Leu 20 25 30Tyr Glu Arg Asp Glu Gly Asp Lys Trp Arg Asn Lys Lys Phe
Glu Leu 35 40 45Gly Leu Glu Phe Pro Asn Leu Pro Tyr Tyr Ile Asp Gly
Asp Val Lys 50 55 60Leu Thr Gln Ser Met Ala Ile Ile Arg Tyr Ile Ala
Asp Lys His Asn65 70 75 80Met Leu Gly Gly Cys Pro Lys Glu Arg Ala
Glu Ile Ser Met Leu Glu 85 90 95Gly Ala Val Leu Asp Ile Arg Tyr Gly
Val Ser Arg Ile Ala Tyr Ser 100 105 110Lys Asp Phe Glu Thr Leu Lys
Val Asp Phe Leu Ser Lys Leu Pro Glu 115 120 125Met Leu Lys Met Phe
Glu Asp Arg Leu Cys His Lys Thr Tyr Leu Asn 130 135 140Gly Asp His
Val Thr His Pro Asp Phe Met Leu Tyr Asp Ala Leu Asp145 150 155
160Val Val Leu Tyr Met Asp Pro Met Cys Leu Asp Ala Phe Pro Lys Leu
165 170 175Val Cys Phe Lys Lys Arg Ile Glu Ala Ile Pro Gln Ile Asp
Lys Tyr 180 185 190Leu Lys Ser Ser Lys Tyr Ile Ala Trp Pro Leu Gln
Gly Trp Gln Ala 195 200 205Thr Phe Gly Gly Gly Asp His Pro Pro Lys
Ser Asp Leu Glu Val Leu 210 215 220Phe Gln Gly Pro Leu Gly Ser Gly
Arg Lys Lys Arg Arg Gln Arg Arg225 230 235 240Arg Ser His Trp Cys
Val Val Ala Tyr Trp Glu Glu Lys Thr Arg Val 245 250 255Gly Arg Leu
Tyr Cys Val Gln Glu Pro Ser Leu Asp Ile Phe Tyr Asp 260 265 270Leu
Pro Gln Gly Asn Gly Phe Cys Leu Gly Gln Leu Asn Ser Asp Asn 275 280
285Lys Ser Gln Leu Val Gln Lys Val Arg Ser Lys Ile Gly Cys Gly Ile
290 295 300Gln Leu Thr Arg Glu Val Asp Gly Val Trp Val Tyr Asn Arg
Ser Ser305 310 315 320Tyr Pro Ile Phe Ile Lys Ser Ala Thr Leu Asp
Asn Pro Asp Ser Arg 325 330 335Thr Leu Leu Val His Lys Val Phe Pro
Gly Phe Ser Ile Lys Ala Phe 340 345 350Asp Tyr Glu Lys Ala Tyr Ser
Leu Gln Arg Pro Asn Asp His Glu Phe 355 360 365Met Gln Gln Pro Trp
Thr Gly Phe Thr Val Gln Ile Ser Phe Val Lys 370 375 380Gly Trp Gly
Gln Cys Tyr Thr Arg Gln Phe Ile Ser Ser Cys Pro Cys385 390 395
400Trp Leu Glu Val Ile Phe Asn Ser Arg Thr Arg Thr Arg Pro Leu Glu
405 410 415Gln Lys Leu Ile Ser Glu Glu Asp Leu Ala Ala Asn Asp Ile
Leu Asp 420 425 430Tyr Lys Asp Asp Asp Asp Lys Val 435
4409566PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 95Gly Arg Lys Lys Arg Arg Gln Arg Arg Arg Glu
Leu Glu Ser Pro Pro1 5 10 15Pro Pro Tyr Ser Arg Tyr Pro Met Asp Phe
Leu Lys Pro Thr Ala Asp 20 25 30Cys Pro Asp Ala Val Pro Ser Ser Ala
Glu Thr Gly Gly Thr Asn Tyr 35 40 45Leu Ala Pro Gly Gly Leu Ser Asp
Ser Gln Leu Leu Leu Glu Pro Gly 50 55 60Asp Arg6596249DNAArtificial
SequenceDescription of Artificial Sequence Synthetic polynucleotide
96ggccgtaaaa aacgccgtca acgccgccgt gaactggaga gcccgccgcc gccgtatagc
60cgttacccga tggatttcct gaaaccgact gcagattgcc cggacgcagt cccgagcagc
120gctgagaccg gcggcaccaa ctatctggca ccgggcggtc tgagcgatag
ccagctgctg 180ctggaaccgg gcgaccgtgg taagcctatc cctaaccctc
tcctcggtct cgattctacg 240tgagtcgac 24997285DNAArtificial
SequenceDescription of Artificial Sequence Synthetic polynucleotide
97ggccggaaga agcggcggca gaggcgccga gaactggagt ccccccctcc accctactct
60aggtatccta tggactttct gaagccaacc gctgactgcc cagatgcagt gccctcctct
120gccgagactg ggggaaccaa ctacctggct cctggcggac tgagcgactc
ccagctgctg 180ctggaaccag gggatcggcg gccgctcgag cagaaactca
tctcagaaga ggatctggca 240gcaaatgata tcctggatta caaggatgac
gacgataagg tttaa 2859825PRTArtificial SequenceDescription of
Artificial Sequence Synthetic peptide 98Gly Arg Lys Lys Arg Arg Gln
Arg Arg Arg Glu Leu Glu Ser Pro Pro1 5 10 15Pro Pro Tyr Ser Arg Tyr
Pro Met Asp 20 2599126DNAArtificial SequenceDescription of
Artificial Sequence Synthetic polynucleotide 99ggccgtaaaa
aacgccgtca acgccgccgt gaactggaga gcccgccgcc gccgtatagc 60cgttacccga
tggatggtaa gcctatccct aaccctctcc tcggtctcga ttctacgtga 120gtcgac
126100162DNAArtificial SequenceDescription of Artificial Sequence
Synthetic polynucleotide 100ggccggaaga agcggcggca gaggcgccga
gaactggagt ccccccctcc accctactct 60aggtatccta tggaccggcc gctcgagcag
aaactcatct cagaagagga tctggcagca 120aatgatatcc tggattacaa
ggatgacgac gataaggttt aa 16210113PRTArtificial SequenceDescription
of Artificial Sequence Synthetic peptide 101Gly Leu Pro Ile Pro Asn
Pro Leu Leu Gly Leu Asp Ser1 5 10
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012
D00013

D00014

D00015

D00016

D00017

D00018

D00019

D00020

D00021

D00022

D00023

D00024

D00025

D00026

D00027

D00028

D00029

D00030

D00031

D00032
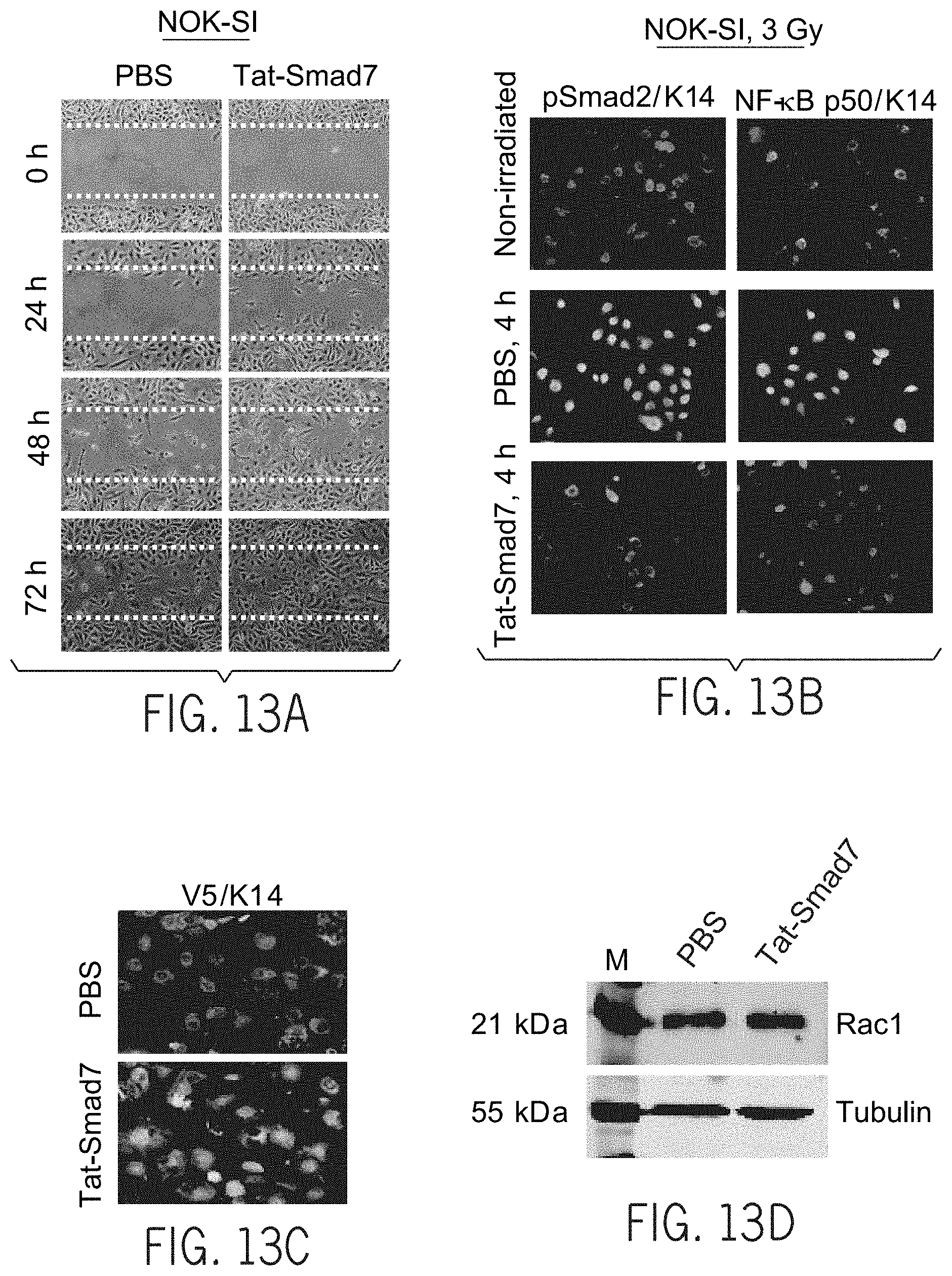
D00033

D00034

D00035

D00036

D00037

D00038

S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.