Multi-modal Electronic Document Classification
LEIBOVITZ; Guy ; et al.
U.S. patent application number 16/271847 was filed with the patent office on 2020-01-16 for multi-modal electronic document classification. The applicant listed for this patent is NETAPP, INC.. Invention is credited to Adam BALI, Guy LEIBOVITZ.
| Application Number | 20200019769 16/271847 |
| Document ID | / |
| Family ID | 65495999 |
| Filed Date | 2020-01-16 |



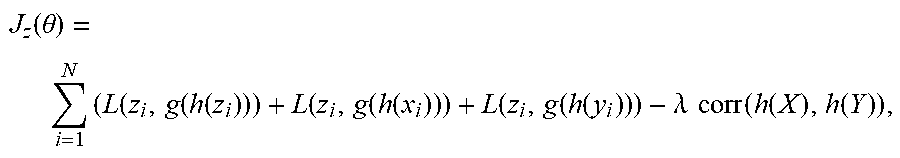
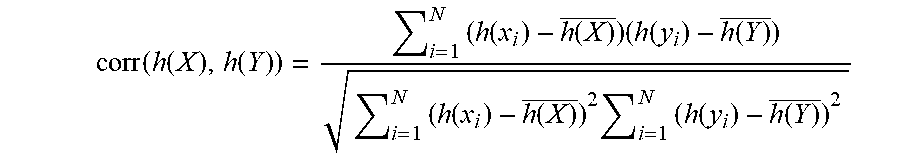
| United States Patent Application | 20200019769 |
| Kind Code | A1 |
| LEIBOVITZ; Guy ; et al. | January 16, 2020 |
MULTI-MODAL ELECTRONIC DOCUMENT CLASSIFICATION
Abstract
A method comprising operating at least one hardware processor for: receiving, as input, a plurality of electronic documents, training a machine learning classifier based, at least on part, on a training set comprising: (i) labels associated with the electronic documents, (ii) raw text from each of said plurality of electronic documents, and (iii) a rasterized version of each of said plurality of electronic documents, and applying said machine learning classifier to classify one or more new electronic documents.
| Inventors: | LEIBOVITZ; Guy; (Tel Aviv, IL) ; BALI; Adam; (Tel Aviv, IL) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 65495999 | ||||||||||
| Appl. No.: | 16/271847 | ||||||||||
| Filed: | February 10, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 16037194 | Jul 17, 2018 | 10223586 | ||
| 16271847 | ||||
| 62698168 | Jul 15, 2018 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06N 3/08 20130101; G06K 9/6271 20130101; G06K 9/6256 20130101; G06K 9/6267 20130101; G06N 3/0481 20130101; G06K 9/6289 20130101; G06N 3/0445 20130101; G06K 9/00469 20130101; G06K 9/4676 20130101; G06K 9/00442 20130101; G06K 9/00456 20130101; G06K 9/00483 20130101; G06K 9/4628 20130101; G06K 9/629 20130101; G06K 2209/01 20130101; G06N 3/0454 20130101 |
| International Class: | G06K 9/00 20060101 G06K009/00; G06N 3/08 20060101 G06N003/08; G06K 9/46 20060101 G06K009/46; G06K 9/62 20060101 G06K009/62 |
Claims
1. A method comprising: receiving, at a computer, an electronic document on which to train a machine learning classifier; applying, by the computer, a first neural network to raw text extracted from the electronic document to determine a textual data representation of the electronic document; applying, by the computer, a second neural network to a raster image extracted from the electronic document to determine a visual data representation of the electronic document; generating, by the computer, a fusion representation based on the textual data representation and the visual data representation of the electronic document; and applying, by the computer, the machine learning classifier based on the fusion representation to classify one or more new electronic documents.
2. The method of claim 1, wherein the generating is further based on a label associated with the electronic document, the label denoting a document category.
3. The method of claim 1, wherein the applying the first neural network further comprises: generating, by the computer, the textual data representation of said extracted text as a fixed length vector.
4. The method of claim 1, wherein the generating further comprises: generating, by the computer, the fusion representation based on a correlation between the textual data representation and the visual data representation, the textual data representation, and the visual data representation.
5. The method of claim 1, wherein the first neural network is different from the second neural network.
6-7. (canceled)
8. The method of claim 1, wherein the generating is based, at least in part, on a cost function which maximizes a correlation between the textual data representation and the visual data representation.
9. The method of claim 1, wherein the applying the machine learning classifier further comprises: classifying, by the computer, the one or more new electronic documents with the machine learning classifier based on one of textual content and raster image of the one or more new electronic documents.
10. A computing device comprising: a memory containing machine readable medium comprising machine executable code having stored thereon instructions for performing a method of multi-modal electronic document classification; a processor coupled to the memory, the processor configured to execute the machine executable code to cause the processor to: receive, as input, an electronic document on which to train a machine learning classifier for the multi-modal electronic document classification; apply a first neural network to raw text extracted from the electronic document to determine a textual data representation; apply a second neural network to an image extracted from the electronic document to determine a visual data representation; calculate a correlation between the textual data representation and the visual data representation; generate a fusion representation based on the correlation, the textual data representation, and the visual data representation; and (iii) apply the machine learning classifier based on the fusion representation to classify a new electronic document.
11. The computing device of claim 10, wherein the generation of the fusion representation is further based on a label denoting a document category.
12. The computing device of claim 10, wherein the processor is further configured to execute the machine executable code to cause the processor, as part of the application of the first neural network to: generate the textual data representation of the raw text as a fixed length vector.
13. The computing device of claim 10, wherein the first neural network is different from the second neural network.
14. The computing device of claim 10, wherein the first neural network is the same as the second neural network.
15-16. (canceled)
17. The computing device of claim 10, wherein the generation of the fusion representation is based, at least in part, on a cost function which maximizes the correlation between the textual data representation and the visual data representation.
18. (canceled)
19. A non-transitory machine readable medium having stored thereon instructions for performing a method comprising machine executable code which when executed by at least one machine, causes the machine to: extract raw text and an image from an electronic document on which to train a machine learning classifier; apply a first neural network to the raw text to determine a textual data representation of the electronic document; apply a second neural network to the image to determine a visual data representation of the electronic document; generate a fusion representation based on the textual data representation, the visual data representation, and a correlation between the textual data representation and the visual data representation; and apply the machine learning classifier based on the fusion representation to classify one or more new electronic documents.
20. (canceled)
21. The non-transitory machine readable medium of claim 19, further comprising machine executable code which when executed by the at least one machine causes the machine to: generate the textual data representation of the raw text as a fixed length vector.
22. The non-transitory machine readable medium of claim 19, wherein the first neural network is different from the second neural network.
23. (canceled)
24. The non-transitory machine readable medium of claim 19, further comprising machine executable code which when executed by the at least one machine causes the machine to: calculate the correlation between textual data representation and visual data representation.
25. (canceled)
26. The non-transitory machine readable medium of claim 19, further comprising machine executable code which when executed by the at least one machine causes the machine to: generate the fusion representation based, at least in part, on a cost function which maximizes the correlation.
27. The non-transitory machine readable medium of claim 19, further comprising machine executable code which when executed by the at least one machine causes the machine to: classify the one or more new electronic documents with the machine learning classifier based on one of textual content and raster image of the one or more new electronic documents.
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application is a continuation of U.S. patent application Ser. No. 16/037,194, filed Jul. 17, 2018, and entitled "Multi-Modal Electronic Document Classification", which claims the benefit of priority to U.S. Provisional Patent Application No. 62/698,168, filed Jul. 15, 2018, and entitled "Multi-Modal Electronic Document Classification". The contents of the above applications are all incorporated by reference as if fully set forth herein in their entirety.
BACKGROUND
[0002] The invention relates to the field of machine learning.
[0003] Multi-modal representation of data may be beneficial in several machine learning tasks, such as image captioning, visual question answering, multi-lingual data retrieval, and electronic document classification. This is because, in many instances, an amalgamation of multiple views of an input sample is likely to capture more meaningful information than a representation that accounts for only a single modality. For example, in the task of scene recognition in a video, video data generally is comprised of video frames (images) along with audio. Images and audio thus comprise two different representations of the same input sample, each with different representative features. By combining these two modalities into a common subspace, classification of abstract scenes from the video can become more accurate.
[0004] The foregoing examples of the related art and limitations related therewith are intended to be illustrative and not exclusive. Other limitations of the related art will become apparent to those of skill in the art upon a reading of the specification and a study of the figures.
SUMMARY
[0005] The following embodiments and aspects thereof are described and illustrated in conjunction with systems, tools and methods which are meant to be exemplary and illustrative, not limiting in scope.
[0006] There is provided, in accordance with an embodiment, method comprising operating at least one hardware processor for: receiving, as input, a plurality of electronic documents, training a machine learning classifier based, at least on part, on a training set comprising: (i) labels associated with the electronic documents, (ii) raw text from each of said plurality of electronic documents, and (iii) a rasterized version of each of said plurality of electronic documents, and applying said machine learning classifier to classify one or more new electronic documents.
[0007] There is also provided, in accordance with an embodiment, a system comprising at least one hardware processor; and a non-transitory computer-readable storage medium having stored thereon program instructions, the program instructions executable by the at least one hardware processor to: receive, as input, a plurality of electronic documents, train a machine learning classifier based, at least on part, on a training set comprising: (i) labels associated with the electronic documents, (ii) raw text from each of said plurality of electronic documents, and (iii) a rasterized version of each of said plurality of electronic documents, and apply said machine learning classifier to classify one or more new electronic documents.
[0008] There is further provided, in accordance with an embodiment, a computer program product comprising a non-transitory computer-readable storage medium having program instructions embodied therewith, the program instructions executable by at least one hardware processor to: receive, as input, a plurality of electronic documents, train a machine learning classifier based, at least on part, on a training set comprising: (i) labels associated with the electronic documents, (ii) raw text from each of said plurality of electronic documents, and (iii) a rasterized version of each of said plurality of electronic documents, and apply said machine learning classifier to classify one or more new electronic documents.
[0009] In some embodiments, said labels denote document categories.
[0010] In some embodiments, the method further comprises, and in the case of the system and computer program product, the instructions further comprise, with respect to each of said plurality of sample electronic documents, applying one or more neural networks (i) to said extracted text, to generate a data representation of said extracted text as a fixed length vector; and (ii) to said image, to generate a data representation of said image which corresponds to a visual layout of said sample electronic document.
[0011] In some embodiments, said one or more neural networks are selected from the group consisting of: Neural Bag-of-Words (NBOW), recurrent neural network (RNN), Recursive Neural Tensor Network (RNTN), Convolutional neural network (CNN), Dynamic Convolutional Neural Network (DCNN), Long short-term memory network (LSTM), and recursive neural network (RecNN).
[0012] In some embodiments, said one or more neural networks comprise one or more hidden layers.
[0013] In some embodiments, the method further comprises, and in the case of the system and computer program product, the instructions further comprise, calculating a correlation between (i) said data representation of said extracted text, and (ii) said data representation of said image.
[0014] In some embodiments, the method further comprises, and in the case of the system and computer program product, the instructions further comprise, generating, with respect to each of said plurality of electronic documents, a combined data representation based, at least in part, on (i) said data representation of said extracted text, (ii) said data representation of said image, and (iii) said correlation.
[0015] In some embodiments, said generating is based, at least in part, on a cost function which: (i) minimizes an error of reconstructing said extracted text from said data representation of said extracted text, and said image from said data representation of said image; (ii) minimizes an error of cross-reconstructing said extracted text from said data representation of said image and said image from said data representation of said extracted; and (iii) maximizes said correlation between said data representation of said extracted text, and said data representation of said image.
[0016] In some embodiments, said combined data representation is provided as a training input to said machine classifier.
[0017] In addition to the exemplary aspects and embodiments described above, further aspects and embodiments will become apparent by reference to the figures and by study of the following detailed description.
BRIEF DESCRIPTION OF THE FIGURES
[0018] Exemplary embodiments are illustrated in referenced figures. Dimensions of components and features shown in the figures are generally chosen for convenience and clarity of presentation and are not necessarily shown to scale. The figures are listed below.
[0019] FIGS. 1A-1B illustrate a raster image of a document and raw text extracted therefrom;
[0020] FIGS. 2A-2C schematically illustrate a process for the creation of a fusion representation of an electronic document, according to an embodiment; and
[0021] FIGS. 3A-3D illustrate various multi-modal classification models, according to an embodiment; and
[0022] FIG. 4 is a flowchart of the functional steps in a method for training a multi modal classifier, according to an embodiment.
DETAILED DESCRIPTION
[0023] Disclosed herein are a method, system, and computer program product for training a machine learning classifier to classify electronic documents based on a multi-modal training model. In some embodiments, the training model is based on at least two modalities: the raw textual content of the electronic documents, and the visual structure of the electronic documents (which may, in turn, include at least one of text styling and non-textual graphics such as illustrations and photos).
[0024] As used herein, the term "electronic document" refers broadly to any document containing mainly text and stored in a computer-readable format. Electronic document formats may include, among others, Portable Document Format (PDF), Digital Visual Interface (DVI), PostScript, word processing file formats, such as docx, doc, and Rich Text Format (RTF), and/or XML Paper Specification (XPS).
[0025] Document classification is a known task in the field of information retrieval and machine learning, and it plays an important role in a variety of applications. Embodiments of the present invention may contribute to enterprise content management, by ensuring that enterprise documents are stored in a logical, organized way that makes it easy to retrieve the information quickly and efficiently. An automatic document classification tool according to some embodiments can thus realize a significant reduction in manual entry costs, and improve the speed and turnaround time for document processing. Such tools may be especially useful for publishers, financial institutions, insurance companies, and/or any industry that deals with large amounts of content.
[0026] In some embodiments, the present invention may be configured for automatic document classification based, at least in part, on content-based assignment of one or more predefined categories (classes) to documents. By classifying the content of a document, it may be assigned one or more predefined classes or categories, thus making it easier to manage and sort.
[0027] Typically, multi-class machine learning classifiers are trained on a training set of documents, where each document belongs to one of a certain number of distinct classes (e.g., invoices, scientific papers, resumes, letters). The training set may be labeled with the correct classes (e.g., for supervised learning), or may not be labeled (e.g., in the case of unsupervised learning). Following a training stage, the classifier may be able to predict the most probable class for each document in a test set of documents. Although document classification may be based on textual content alone, for some types of documents, the task of classification can be significantly enhanced by also generating features from the visual structure of the document. This is based on the idea that documents in the same category often also share similar layout and structure features.
[0028] Accordingly, in some embodiments, the present invention provides for training a multi-modal machine learning classifier on a training set comprising a plurality of electronic documents, each represented by (i) its textual content (i.e., raw text), and (ii) a raster image thereof. In some cases, an electronic document in the training set may only include one representation of the two. In such cases, a preprocessing stage may be necessary to generate the second representation from the first. For example, a raster image of a document may be created using a suitable application, or raw text may be extracted from a raster image using, e.g., optical character recognition (OCR). FIG. 1, in panel A, illustrates an exemplary raster image of an electronic document. In panel B, raw text has been extracted from the raster image using, e.g., OCR. In some cases, the preprocessing stage may further include scanning hard copies of documents to generate a raster image, from which raw text may then be extracted using OCR.
[0029] In some embodiments, following a multi-modal training stage, a trained classifier of the present invention may be configured for classifying electronic documents based on a multi-modal input comprising both representations of the documents. In other embodiments, the trained classifier may be configured for classifying electronic documents based on only a single modality input (e.g., textual content or raster image alone), with improved classification accuracy as compared to a classifier which has been trained solely based on a single modality.
[0030] In some embodiments, the present invention may employ one or more types of neural networks to further generate data representations of the multi-modal inputs. For example, raw input text from an electronic document may be processed so as to generate a data representation of the text as a fixed-length vector. Similarly, images of the electronic document (e.g., thumbnails or raster images) may be processed to extract image features.
[0031] In some embodiments, the neural network models employed by the present invention to generate textual data representations may be selected from the group consisting of Neural Bag-of-Words (NBOW); recurrent neural network (RNN), Recursive Neural Tensor Network (RNTN); Dynamic Convolutional Neural Network (DCNN); Long short-term memory network (LSTM); and recursive neural network (RecNN). See, e.g., Pengfei Liu et al., "Recurrent Neural Network for Text Classification with Multi-Task Learning", Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16). Convolutional neural network (CNN) may be used, e.g., to extract image features which represent the physical visual structure of a document.
[0032] In some embodiments, the present invention may further be configured for employing a common representation learning (CRL) framework, for learning a common representation of the two views of data (i.e., textual and visual). CRL is associated with multi-view data that can be represented in multiple forms. The learned common representation can then be used to train a model to reconstruct all the views of the data from each input. CRL of multi-view data can be categorized into two main categories: canonical-based approaches and autoencoder-based methods. Canonical Correlation Analysis (CCA)-based approaches comprise learning a joint representation by maximizing correlation of the views when projected to the common subspace. Autoencoder (AE) methods learn a common representation by minimizing the error of reconstructing the two views. AE-based approaches use deep neural networks that try to optimize two objective functions. The first objective is to find a compressed hidden representation of data in a low-dimensional vector space. The other objective is to reconstruct the original data from the compressed low-dimensional subspace. Multi-modal autoencoders (MAE) are two-channeled models which specifically perform two types of reconstructions. The first is the self-reconstruction of view from itself, and the other is the cross-reconstruction where each view is reconstructed from the other. These reconstruction objectives provide MAE the ability to adapt towards transfer learning tasks as well. In the context of CRL, each of these approaches has its own advantages and disadvantages. For example, though CCA based approaches outperform AE based approaches for the task of transfer learning, they are not as scalable as the latter.
[0033] Accordingly, in some embodiments, the present invention may combine elements of both CCA and AE. In some embodiments, given data representations of both textual and visual structure data representations of an electronic document, the present invention may be configured for training a neural network to maximize reconstruction and cross-reconstruction abilities of both input sources, based, at least in part, on an autoencoder framework. The present invention may then provide for extracting a correlation between the two representations using, e.g., a DCCA (deep CCA) paradigm, in order to create a fusion representation which may optimally summarize both the textual content and the visual structure data contained in the input electronic document. In some embodiments, the fusion representation of the present model may further be applied as a direct input in an electronic document classification model.
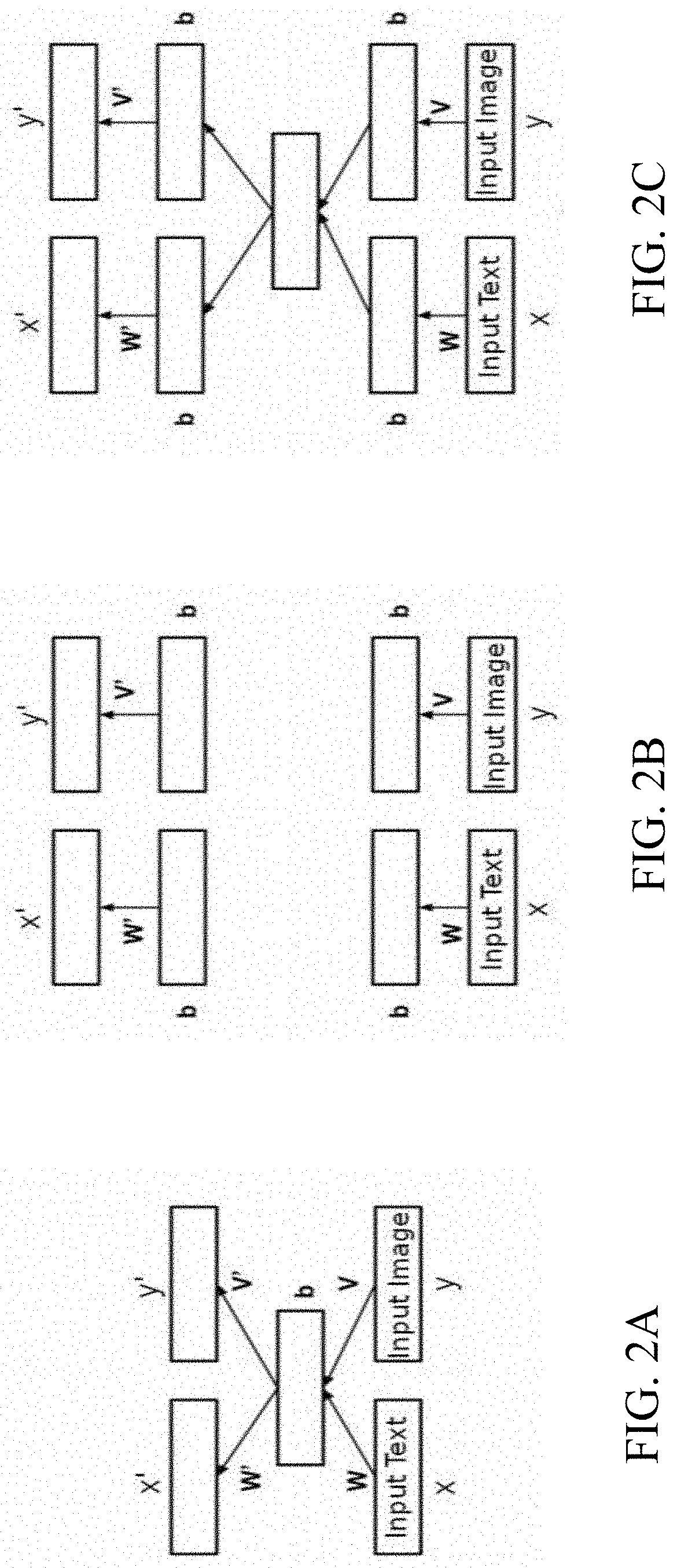
[0034] In some embodiments, A Correlation Neural Networks (CorrNet) may be trained on maximizing a reconstruction ability with respect to each representation, as well as maximizing the correlation between the two representations, thus producing a fusion representation of the document, which may be then used for enhanced classification purposes. In addition, in some embodiments, once the CorrNet classification model has been trained on both representations, an enhanced classification prediction may then be achieved using only a single input source. In other words, the multi-modal trained classification model may allow for textual content to be sufficient on its own as an input, to generate improved classification accuracy, as compared to a model which has been trained solely based on textual input.
[0035] FIG. 2 schematically illustrates a process for the creation of a fusion representation of an electronic document, according to an embodiment. In some embodiments, given a space
z=(x,y),
where x and y are a raw text and image inputs, respectively, of a sample electronic document, a correlational neural model of the present invention may be configured, at a step A, to create a compressed multi-modal representation as follows:
h(z)=f(Wx+Vy+b),
where W, V are projection matrices, and b is a bias vector.
[0036] An output layer of the model may then aim to generate z', which is a reconstruction of z, from the hidden representations of x, y as follows:
z'=g([W'h(z),V'h(z)]+b'),
where W, V' are reconstruction matrices and b' is a bias vector.
[0037] In some embodiments, the present invention may thus be configured for training a correlational neural network to classify samples comprising both textual (x.sub.i) and visual (y.sub.i) content, based on a cost function which, with respect to each sample in the given training set (x.sub.i,y.sub.i), attempts to: [0038] Minimize the self-reconstruction error (L.sub.1), which is equal to the errors in reconstructing x.sub.i from x.sub.i and y.sub.i from y.sub.i; [0039] minimize the cross-reconstruction errors (L.sub.2, L.sub.3), which are equal to the errors in reconstructing x.sub.i from y.sub.i and y.sub.i from x.sub.i; and [0040] maximize the correlation (L.sub.4) between the representations of both views.
[0041] In some embodiments, using a regularization hyper-parameter .lamda. for scaling the offset of the correlation, the cost function employed by the present model may be defined as:
J z ( .theta. ) = i = 1 N ( L ( z i , g ( h ( z i ) ) ) + L ( z i , g ( h ( x i ) ) ) + L ( z i , g ( h ( y i ) ) ) - .lamda. corr ( h ( X ) , h ( Y ) ) , ##EQU00001##
where (i) L(z.sub.i,g(h(z.sub.i)) is the self-reconstruction error L.sub.1; (ii) L(z.sub.i,g(h(x.sub.i)) and L(z.sub.i,g(h(y.sub.i)) are the cross-reconstruction errors L.sub.2, L.sub.3; and (iii) .lamda. corr(h(X), h(Y)) is the correlation L.sub.4. In some embodiments, the correlation L.sub.4 between the two representations of the views may be computed as:
corr ( h ( X ) , h ( Y ) ) = i = 1 N ( h ( x i ) - h ( X ) _ ) ( h ( y i ) - h ( Y ) _ ) i = 1 N ( h ( x i ) - h ( X ) _ ) 2 i = 1 N ( h ( y i ) - h ( Y ) _ ) 2 ##EQU00002##
[0042] The above process can be further repeated to obtain a deeper neural architecture, with hidden layers added to both the encoding and the decoding phases, e.g., as shown at B and C in FIG. 2. Once the correlational neural model has been trained on the training set, the correlational representation achieved in the middle layer of the network can then be utilized for the classification task.
[0043] Accordingly, in some embodiments, the classification model of the present invention may be configured for unsupervised training, solely based on document data points consisting of textual content and visual content, absent any training labels. In other embodiments, a variation of the classification model described above may comprise at least a partially-labelled training set. In such embodiments, the classification model may incorporate the classification ability of the generated representation directly in the loss function, and create additional fully connected layers on top of the representation inside the correlational model, ending with a softmax activation layer to categorize each representation to its corresponding predicted class.
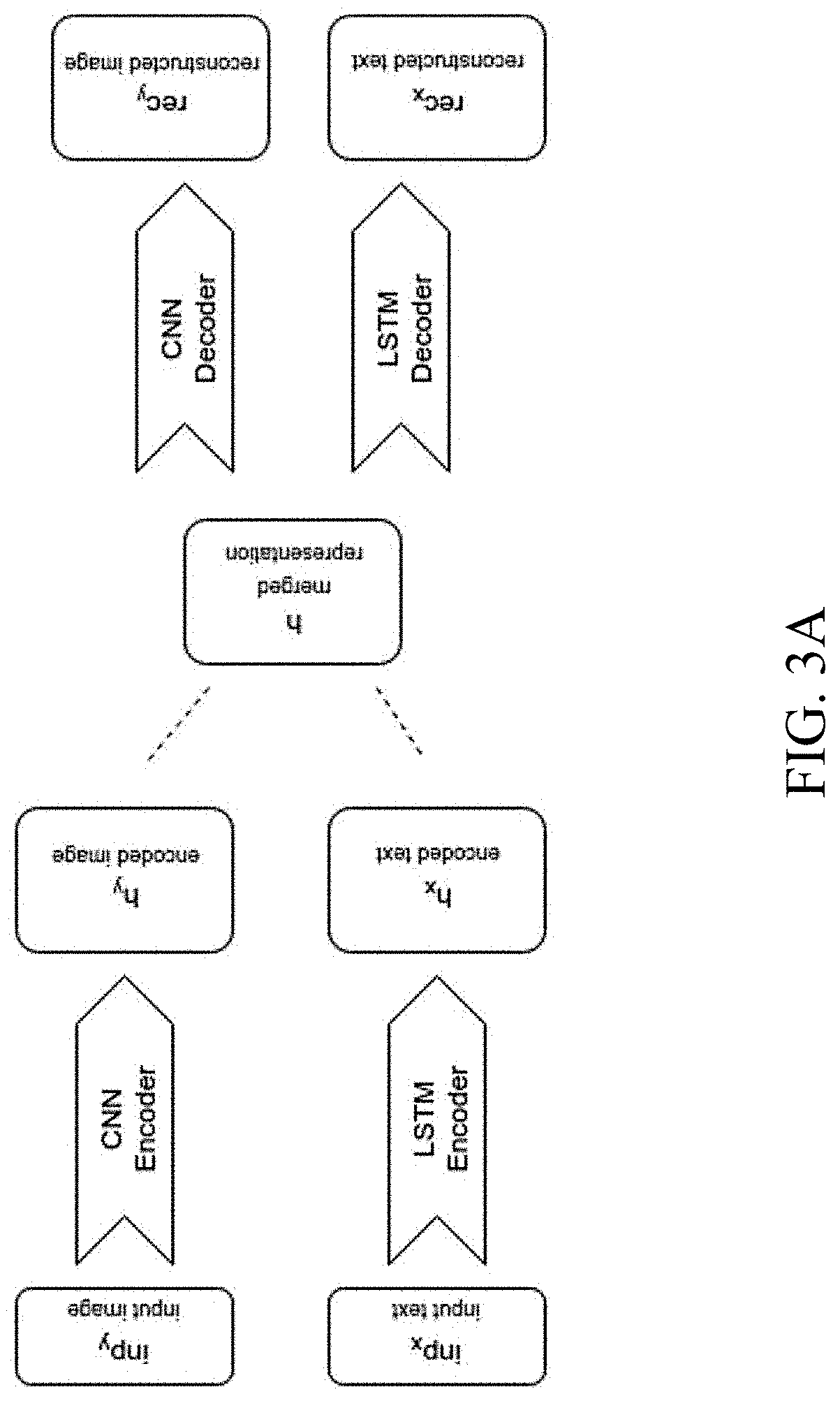
[0044] In some embodiments, the present invention comprises one or more types of AE neural networks, wherein each type of AE may be best suited for a different type of representation encoding/decoding task. For example, a CNN may be used for creating representations of visual structure input, and an RNN or LSTM may be used for textual inputs.
[0045] FIG. 3A schematically illustrates a `branch` classification model according to an embodiment, which comprises two types of encoders: a LSTM for textual input (x), and a CNN for visual structure input (y). As can be seen, both inputs are encoded into fixed-sized vector representations, which are then fused into a single mutual representation (e.g., a `merged` layer in the middle), from which the model is able to decode both visual and text inputs separately.
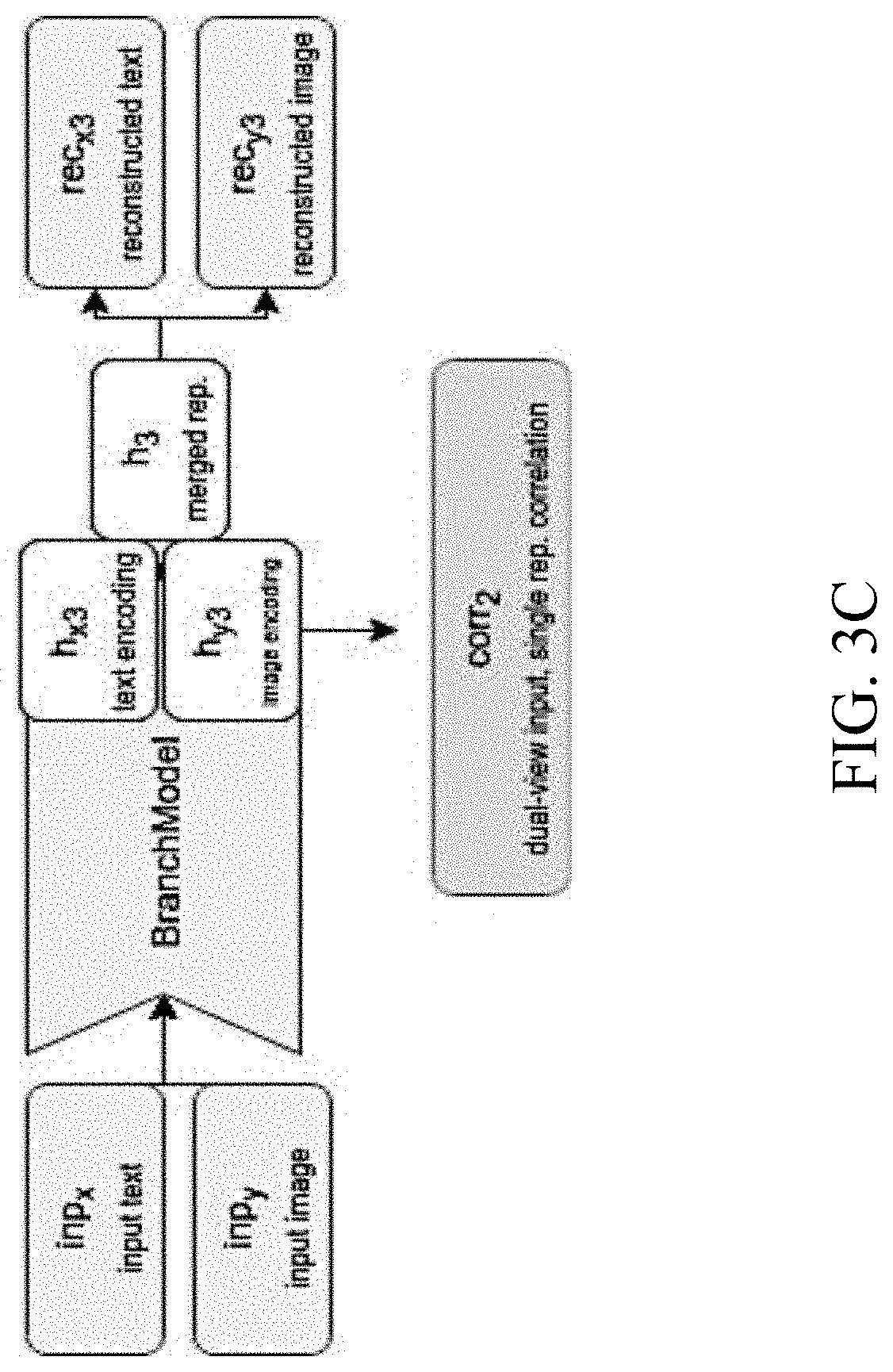
[0046] FIGS. 3B-3C schematically illustrate a CorrNet classification model according to an embodiment of the present invention. The CorrNet model comprises calls to the `branch` model described above with respect to FIG. 3A, in order to calculate the loss functions following the reconstruction processes described above. The loss functions consider the difference between the original inputs and the reconstructed outputs, offset by the correlations calculated in the process. In other words, the model is penalized for either creating a reconstruction too different from the original input, or obtaining a reconstruction using uncorrelated representations between the two views. During training, for each input type, the CorrNet model reconstructs all the relevant views from either dual-view or single-view contained in the input, and evaluates the loss functions accordingly. In some embodiments, the correlation between the two representations of a sample can be computed at different layers of representations, by calling the `branch` model. Specifically, the term L.sub.4 noted above may be expanded into the sum of the following two calculated types of correlations: [0047] Correlation of the mutual representation between the two embeddings achieved when training the model on two separate single-view inputs; and [0048] correlation of the single-view representation achieved before merging, when training the model on a dual-view input.
[0049] In some embodiments, during training, the loss functions described above is assigned weights, to direct the learning process towards the goals in a balanced manner.
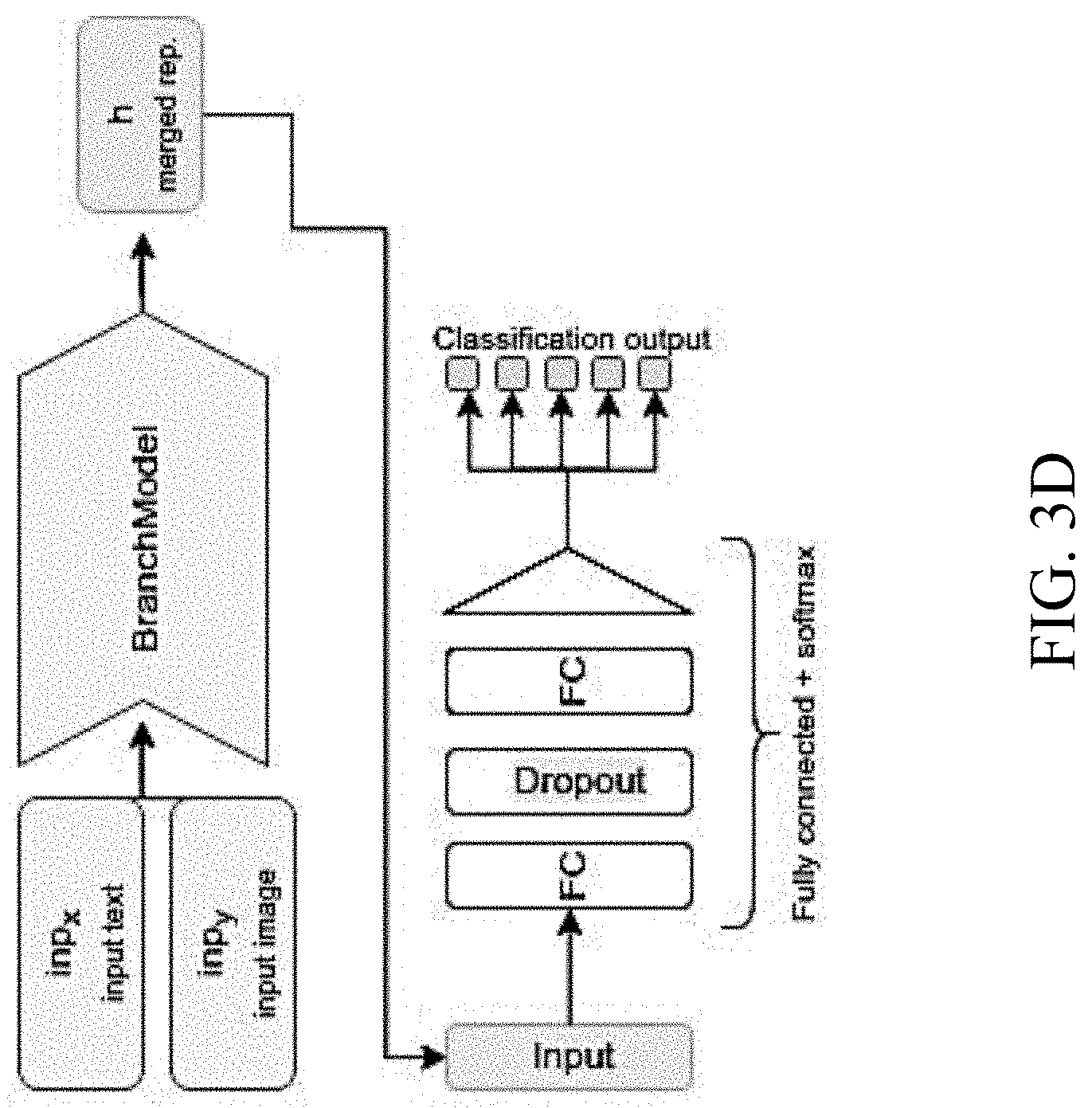
[0050] Finally, FIG. 3D schematically illustrates yet another variation of the classification model, according to an embodiment, where the middle layer achieved in the `branch` model described above is used as direct input for the classification model.
[0051] FIG. 4 is a flowchart of the functional steps in a method for training a multi modal classifier, according to an embodiment. At 402, a sample electronic document is used as input with respect to a correlational neural model of the present invention. At 404, raw text and a raster image of the sample document are extracted. At 406, textual and visual data representations of the raw text and the image are generated. At 408, a common fusion representation is generated base on the textual data representation, the visual data representation, and the correlation therebetween. Finally, at 410, the fusion representation is used a direct input in a document classifier.
Experimental Results
[0052] The present correlational neural model was tested on a training set of labeled sample electronic documents from open and private sources, including over 500 documents from the following different categories (the numbers in parenthesis represent the number of samples from each category):
[0053] Resumes (227);
[0054] invoices (154);
[0055] quarterly financial reports (50);
[0056] non-disclosure agreements (47); and
[0057] scientific papers (47).
[0058] For each sample, the raw text was extracted to be used as textual input, and a raster image was generated to be used as visual input. For experimental purposes, the data was randomly split into training and testing sets by a ratio of 2 to 1, respectively. All models were trained solely on the train set (containing two-thirds of the data), and their predictive abilities were tested on the previously unseen test set.
[0059] For the purpose of examining the proposed classification method, the following models were employed: [0060] Branch-Model: Dual auto-encoder part of the network, as illustrated with respect to FIG. 3A. This model encodes the multi-modal view of each electronic document into a fixed-size embedding vector. [0061] Correlational Network: This model runs multiple sessions of the branch model described above, each time with the relevant input containing one or more of the views, to calculate the relevant loss functions as well as the correlations between the relevant views. [0062] Classification model: This model receives as input the embedding vectors from the correlational network, and returns a predicted class of an input electronic document.
[0063] For comparison purposes, two reference single-modal models were employed, each with respect to one of the modalities used in the present multi-modal model (i.e., either text or image). Each of the single-modality models was based on the corresponding part in the CorrNet architecture, and comprises the same number of layers with the same values of hyper-parameters and activation layers. This was done to ensure the isolation the effect of the architecture and the definition of the loss functions from other factors.
[0064] Additionally, the correlational model was tested with respect to its ability to learn a dual-view correlated mapping of both modalities (text and image) given just a single modality as input, as follows: [0065] Self-reconstruction: Ability to reconstruct a single view, given the same view as input. [0066] Cross-reconstruction: Ability to reconstruct a single view, given the other view as input (i.e., image from text and vice-versa).
[0067] For the task of document classification, accuracy was tested with respect to the following classification tasks: [0068] Single-view classification: Classification accuracy given a single original view as input (either text or image). [0069] Single-view, cross-reconstructed classification: Classification accuracy given a single reconstructed view as input (either text reconstructed from original image or vice versa). [0070] Multi-modal classification: Classification accuracy given both input modalities (text and image). [0071] Multi-modal, cross-reconstructed-views classification: Classification accuracy given multi-modal reconstructions of the original input (each modality reconstructed by the model separately, and the concatenation of both reconstructed views given as input). [0072] Multi-modal, semi-reconstructed views classification: Classification accuracy given multi-modal semi-reconstructed input (a concatenation of the original text with the reconstruction of the image from the text, and vice versa).
[0073] Table 1 below provides test results for each of the above-referenced classification tasks, where: [0074] Precision (also called positive predictive value) refers to the number of correct positive results divided by the number of all positive results returned; [0075] Recall (also known as sensitivity) refers to the number of correct positive results divided by the number of all relevant samples; and [0076] F1 score refers to overall accuracy, based on the harmonic average of both the precision and the recall scores.
TABLE-US-00001 [0076] TABLE 1 Test Results Method Precision Recall F1 Score Single view - Text 0.89 0.88 0.88 Single view - Image 0.75 0.75 0.74 Single view - Reconstructed Text 0.70 0.70 0.69 Single view - Reconstructed Image 0.83 0.83 0.82 Multi-Modal View - Text + Image 0.91 0.90 0.89 Multi-Modal View - Reconstructed 0.86 0.85 0.85 Text, Reconstructed Image Multi-Modal View - Reconstructed 0.72 0.72 0.72 Text, Image Multi-Modal View - Text, 0.91 0.91 0.90 Reconstructed Image Reference Model - Text Only 0.88 0.88 0.87 Reference Model - Image 0.74 0.70 0.71
[0077] The values given in table 1 suggest that the multi-modal model of the present invention is capable of generating a representation useful for a classification that outperforms classifications based on representations generated by similar approaches. Given two inputs, even if one of the inputs is a reconstruction, a fruitful representation can be achieved. Accordingly, the present model allows for effective document classification, by utilizing the multi-view correlation to maximize the abundant information prevailing not just in the textual content but also in the visual structure. Once the CorrNet architecture is trained on existing dual-view inputs, a single view is sufficient to obtain an amplified representation ready for classification.
[0078] The present invention may be a system, a method, and/or a computer program product. The computer program product may include a computer readable storage medium (or media) having computer readable program instructions thereon for causing a processor to carry out aspects of the present invention.
[0079] The computer readable storage medium can be a tangible device that can retain and store instructions for use by an instruction execution device. The computer readable storage medium may be, for example, but is not limited to, an electronic storage device, a magnetic storage device, an optical storage device, an electromagnetic storage device, a semiconductor storage device, or any suitable combination of the foregoing. A non-exhaustive list of more specific examples of the computer readable storage medium includes the following: a portable computer diskette, a hard disk, a random access memory (RAM), a read-only memory (ROM), an erasable programmable read-only memory (EPROM or Flash memory), a static random access memory (SRAM), a portable compact disc read-only memory (CD-ROM), a digital versatile disk (DVD), a memory stick, a floppy disk, a mechanically encoded device having instructions recorded thereon, and any suitable combination of the foregoing. A computer readable storage medium, as used herein, is not to be construed as being transitory signals per se, such as radio waves or other freely propagating electromagnetic waves, electromagnetic waves propagating through a waveguide or other transmission media (e.g., light pulses passing through a fiber-optic cable), or electrical signals transmitted through a wire. Rather, the computer readable storage medium is a non-transient (i.e., not-volatile) medium.
[0080] Computer readable program instructions described herein can be downloaded to respective computing/processing devices from a computer readable storage medium or to an external computer or external storage device via a network, for example, the Internet, a local area network, a wide area network and/or a wireless network. The network may comprise copper transmission cables, optical transmission fibers, wireless transmission, routers, firewalls, switches, gateway computers and/or edge servers. A network adapter card or network interface in each computing/processing device receives computer readable program instructions from the network and forwards the computer readable program instructions for storage in a computer readable storage medium within the respective computing/processing device.
[0081] Computer readable program instructions for carrying out operations of the present invention may be assembler instructions, instruction-set-architecture (ISA) instructions, machine instructions, machine dependent instructions, microcode, firmware instructions, state-setting data, or either source code or object code written in any combination of one or more programming languages, including an object oriented programming language such as Java, Smalltalk, C++ or the like, and conventional procedural programming languages, such as the "C" programming language or similar programming languages. The computer readable program instructions may execute entirely on the user's computer, partly on the user's computer, as a stand-alone software package, partly on the user's computer and partly on a remote computer or entirely on the remote computer or server. In the latter scenario, the remote computer may be connected to the user's computer through any type of network, including a local area network (LAN) or a wide area network (WAN), or the connection may be made to an external computer (for example, through the Internet using an Internet Service Provider). In some embodiments, electronic circuitry including, for example, programmable logic circuitry, field-programmable gate arrays (FPGA), or programmable logic arrays (PLA) may execute the computer readable program instructions by utilizing state information of the computer readable program instructions to personalize the electronic circuitry, in order to perform aspects of the present invention.
[0082] Aspects of the present invention are described herein with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems), and computer program products according to embodiments of the invention. It will be understood that each block of the flowchart illustrations and/or block diagrams, and combinations of blocks in the flowchart illustrations and/or block diagrams, can be implemented by computer readable program instructions.
[0083] These computer readable program instructions may be provided to a processor of a general-purpose computer, special purpose computer, or other programmable data processing apparatus to produce a machine, such that the instructions, which execute via the processor of the computer or other programmable data processing apparatus, create means for implementing the functions/acts specified in the flowchart and/or block diagram block or blocks. These computer readable program instructions may also be stored in a computer readable storage medium that can direct a computer, a programmable data processing apparatus, and/or other devices to function in a particular manner, such that the computer readable storage medium having instructions stored therein comprises an article of manufacture including instructions which implement aspects of the function/act specified in the flowchart and/or block diagram block or blocks.
[0084] The computer readable program instructions may also be loaded onto a computer, other programmable data processing apparatus, or other device to cause a series of operational steps to be performed on the computer, other programmable apparatus or other device to produce a computer implemented process, such that the instructions which execute on the computer, other programmable apparatus, or other device implement the functions/acts specified in the flowchart and/or block diagram block or blocks.
[0085] The flowchart and block diagrams in the Figures illustrate the architecture, functionality, and operation of possible implementations of systems, methods, and computer program products according to various embodiments of the present invention. In this regard, each block in the flowchart or block diagrams may represent a module, segment, or portion of instructions, which comprises one or more executable instructions for implementing the specified logical function(s). In some alternative implementations, the functions noted in the block may occur out of the order noted in the figures. For example, two blocks shown in succession may, in fact, be executed substantially concurrently, or the blocks may sometimes be executed in the reverse order, depending upon the functionality involved. It will also be noted that each block of the block diagrams and/or flowchart illustration, and combinations of blocks in the block diagrams and/or flowchart illustration, can be implemented by special purpose hardware-based systems that perform the specified functions or acts or carry out combinations of special purpose hardware and computer instructions.
[0086] The descriptions of the various embodiments of the present invention have been presented for purposes of illustration, but are not intended to be exhaustive or limited to the embodiments disclosed. Many modifications and variations will be apparent to those of ordinary skill in the art without departing from the scope and spirit of the described embodiments. The terminology used herein was chosen to best explain the principles of the embodiments, the practical application or technical improvement over technologies found in the marketplace, or to enable others of ordinary skill in the art to understand the embodiments disclosed herein.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.