Antigen Binding Proteins
HAMBLIN; Paul Andrew ; et al.
U.S. patent application number 16/426321 was filed with the patent office on 2019-12-19 for antigen binding proteins. The applicant listed for this patent is GLAXOSMITHKLINE INTELLECTUAL PROPERTY DEVELOPMENT LIMITED. Invention is credited to Paul Andrew HAMBLIN, Alan Peter Lewis, Thomas Matthew Webb.
| Application Number | 20190382482 16/426321 |
| Document ID | / |
| Family ID | 50272641 |
| Filed Date | 2019-12-19 |




| United States Patent Application | 20190382482 |
| Kind Code | A1 |
| HAMBLIN; Paul Andrew ; et al. | December 19, 2019 |
ANTIGEN BINDING PROTEINS
Abstract
This application discloses antigen binding proteins that bind Lymphocyte Activation Gene 3 (LAG-3), and more particularly to antigen binding proteins that cause depletion of LAG-3+ activated T cells.
| Inventors: | HAMBLIN; Paul Andrew; (Stevenage, GB) ; Lewis; Alan Peter; (Stevenage, GB) ; Webb; Thomas Matthew; (Brentford, GB) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 50272641 | ||||||||||
| Appl. No.: | 16/426321 | ||||||||||
| Filed: | May 30, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 14208684 | Mar 13, 2014 | 10344088 | ||
| 16426321 | ||||
| 61789325 | Mar 15, 2013 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | A61P 37/02 20180101; A61P 29/00 20180101; C07K 2317/24 20130101; A61P 25/00 20180101; A61P 1/16 20180101; A61P 1/04 20180101; A61K 39/39558 20130101; A61P 1/00 20180101; C07K 16/2803 20130101; A61P 37/08 20180101; A61P 31/00 20180101; C07K 2317/92 20130101; C07K 2317/56 20130101; A61P 37/06 20180101; A61P 35/00 20180101; A61P 37/00 20180101; A61K 39/39541 20130101; A61P 17/06 20180101; C07K 2317/565 20130101; A61P 37/04 20180101; A61P 43/00 20180101; C07K 2317/732 20130101; A61P 19/02 20180101 |
| International Class: | C07K 16/28 20060101 C07K016/28 |
Claims
1. An isolated nucleic acid molecule which encodes an antigen binding protein which is capable of binding Lymphocyte Activating Gene 3 (LAG-3) and which comprises CDRL1 comprising SEQ ID NO: 1; CDRL2 comprising SEQ ID NO: 2; CDRL3 comprising SEQ ID NO: 3; CDRH1 comprising SEQ ID NO: 6; CDRH2 comprising SEQ ID NO: 7; and CDRH3 comprising SEQ ID NO: 8.
2. An isolated nucleic acid molecule according to claim 1, wherein the antigen binding protein encoded by the isolated nucleic acid molecule is a humanised antibody, wherein the humanised antibody comprises an IgG1 constant region.
3. An expression vector comprising a nucleic acid molecule according to claim 1.
4. An expression vector comprising a nucleic acid molecule according to claim 2.
5. A host cell comprising an expression vector according to claim 2.
6. A host cell comprising an expression vector according to claim 4.
7. A host cell comprising an expression vector according to claim 3, wherein FUT8 gene encoding alpha-1,6-fucosyltransferase has been inactivated in the host cell.
8. A host cell comprising an expression vector according to claim 4, wherein FUT8 gene encoding alpha-1,6-fucosyltransferase has been inactivated in the host cell.
9. A method of producing an antigen binding protein comprising a) culturing a host cell according to claim 5 and b) isolating the antigen binding protein.
10. A method of producing an antigen binding protein comprising a) culturing a host cell according to claim 7 and b) isolating the antigen binding protein.
11. A method of treatment of a human or animal subject comprising administering to the human or animal subject an antigen binding protein which is capable of binding Lymphocyte Activating Gene 3 (LAG-3) and which comprises CDRL1 comprising SEQ ID NO: 1; CDRL2 comprising SEQ ID NO: 2; CDRL3 comprising SEQ ID NO: 3; CDRH1 comprising SEQ ID NO: 6; CDRH2 comprising SEQ ID NO: 7; and CDRH3 comprising SEQ ID NO: 8.
12. A method of treatment according to claim 11, wherein the disease is associated with the involvement of pathogenic T cells in the human or animal subject.
13. A method of treatment according to claim 12, wherein the disease is an autoimmune disease or cancer.
14. A method of treatment according to claim 13, wherein the disease is an autoimmune disease and the autoimmune disease is selected from the group consisting of psoriasis, Crohn's disease, rheumatoid arthritis, primary biliary cirrhosis, SLE, Sjogren's syndrome, multiple sclerosis, ulcerative colitis, and autoimmune hepatitis.
15. A method of producing an antigen binding protein, comprising a) culturing a host cell according to claim 6, and b) isolating the antigen binding protein.
16. A method of producing an antigen binding protein comprising a) culturing a host cell according to claim 8, and b) isolating the antigen binding protein.
Description
[0001] This application is a divisional of U.S. application Ser. No. 14/208,684, filed on May 13, 2014, which claims benefit of U.S. Provisional Application 61/789,325, filed on Mar. 15, 2013, all of which are incorporated herein in their entirety.
FIELD OF THE INVENTION
[0002] The present invention is directed to antigen binding proteins, particularly antibodies that bind Lymphocyte Activation Gene (LAG-3) and cause depletion of activated T cells expressing LAG-3, polynucleotides encoding such antigen binding proteins, pharmaceutical compositions containing said antigen binding proteins, and to the use of said antigen binding proteins in the treatment and/or prevention of diseases associated with the involvement of pathogenic T cells.
BACKGROUND TO THE INVENTION
[0003] Lymphocyte Activation Gene-3 (LAG-3) is a negative co-stimulatory receptor that modulates T cell homeostasis, proliferation and activation (Sierro S et al; Expert Opin. Ther. Targets (2010) 15: 91-101). An immunoglobulin superfamily member, LAG-3 is a CD4-like protein which, like CD4, binds to MHC class II molecules, but with two-fold higher affinity and at a distinct site from CD4 (Huard B et al., (1997) Proc Natl Acad Sci USA 94: 5744-9). In addition to exerting very distinct functions, CD4 is a positive co-stimulatory molecule, the two receptors are also differentially regulated. CD4 is constitutively expressed on the surface of all mature CD4+ T cells, with only a small fraction residing intracellularly, whereas a large proportion of LAG-3 molecules are retained in the cell close to the microtubule-organizing centre, and only induced following antigen specific T cell activation (Woo S R et al., (2010) Eur J Immunol 40: 1768-77). The role of LAG-3 as a negative regulator of T cell responses is based on studies with LAG-3 knockout mice and use of blocking anti-LAG-3 antibodies in model in vitro and in vivo systems (Sierro S et al., Expert Opin. Ther. Targets (2010) 15: 91-101; Hannier S et al (1998), J Immunol 161: 4058-65; Macon-Lemaitre L et al (2005), Immunology 115: 170-8; Workman C J et al (2003), Eur J Immunol 33:970-9).
[0004] At the cell surface, LAG-3 is expressed as a dimer, which is required for formation of stable MHC class II binding sites (Huard B et al. (1997) Proc Natl Acad Sci USA 94: 5744-9). LAG-3, in soluble form, also occurs in serum of healthy donors and patients with tuberculosis and cancer (Lienhardt C et al. (2002), Eur J Immunol 32: 1605-13; Triebel F et al (2006). Cancer Lett 235: 147-53), and this form may correlate with the number of LAG-3+ T cells (Siawaya J et al. (2008). J of Infection 56: 340-7). The key attribute of LAG-3 as a target antigen for an enhanced lymphocyte depletion agent is its relatively selective expression profile when compared with other agents currently in the clinic, i.e. Campath (T/B cells), Amevive (most CD45R0+ T-cells) or Rituxan (B-cells). Few molecules have been identified as sustained markers of in vivoT cell activation in humans. These include LAG-3, OX40, MHC class II, CD69, CD38, ICOS and CD40L. However, apart from LAG-3 and OX40 the majority of these molecules are also constitutively expressed on human natural T regs or on other cell types. LAG-3 is expressed on a small proportion of T-cells in healthy humans (ca. 1-4%), and in a similar proportion of NK cells (Baixeras E et al. (1992), J Exp Med 176: 327-37; Huard B et al (1994), Immunogenetics 39: 213-7). Upon activation with anti-CD3 ca. 30-80% of both CD4+ and CD8+ T cells express LAG-3 within 24 to 48 h; this percentage is increased in presence of IL2, IL7 and IL12 (Sierro S et al, Expert Opin. Ther. Targets (2010) 15: 91-101; Bruniquel D et al (1998), Immunogenetics 48: 116-24). Following antigen-specific stimulation with recall antigen (i.e. CMV or Tetanus toxoid) the majority of activated T cells are LAG-3+. In addition, in humans, LAG-3 is expressed on a sub-population (1-10%) of CD4+ CD25+ FoxP3+ T regs in healthy human blood. This population appears to be functionally suppressive in vitro by cell contact and IL10 dependent mechanisms and therefore may represent a population of recently activated natural or induced T regs [Camisaschi C, Casati C, Rini F et al. (2010). LAG-3 expression defines a subset of CD4+CD25highFox3P+regulatory T cells that are expanded at tumour sites. J. Immunol 184: 6545-51). LAG-3 has been detected on other cell types of hematopoietic lineage, such as plasmacytoid dendritic cells, B-cells, and NKT-cells, but only in the mouse, and mostly following activation (Sierro S, Romero P & Speiser D; Expert Opin. Ther. Targets (2010) 15: 91-101).
[0005] Depletion of LAG-3+ T cells may be used to treat or prevent T cell driven immuno-inflammatory disorders. In auto-immune diseases where the majority of auto-reactive cells are chronically activated by self antigens at the disease site and/or re-circulate in the periphery, a short course of a depleting antigen binding protein may selectively deplete this auto-immune T cell repertoire providing long term remission. The precedence for this approach has been demonstrated with the pan-lymphocyte depleting antibody Campath, in which a single 12 mg injection reduced the rate of relapse by 74% compared to standard treatment in a multiple sclerosis trial (The CAMMS223 Trial Investigators (2008), N Engl J Med. 359:1786-801). Due to the more selective expression of LAG-3 compared with CD52, the target for Campath, the impact on the naive and resting memory T cell and natural T regs repertoire should be reduced. This is expected to lead to an improved therapeutic index, maintaining efficacy, but with reduced risk of infection and malignancy as well as onset of auto-immunity associated with Campath. Additionally, in a baboon tuberculin skin challenge model, the LAG-3 targeting chimeric antibody IMP731 mediated depletion of LAG-3+ T-cells, both in the periphery and at the skin challenge site, resulting in a reduction in the tuberculin skin challenge response (Poirier N et al. (2011), Clin Exp Immunol 164: 265-74). In a further study, a LAG-3 polyclonal antibody depleted LAG-3+ infiltrating T-cells from a rat cardiac allograft and prolonged the survival of these grafts (Haudebourg T et al. (2007), Transplantation 84: 1500-1506).
[0006] There exists a need in the art for antigen binding proteins, particularly humanised antibodies, that bind LAG-3 and cause deletion of LAG-3+ activated T cells, and which may have use in the treatment of auto-immune diseases, such as psoriasis, Crohn's disease, rheumatoid arthritis, primary biliary cirrhosis, SLE, Sjogren's syndrome, multiple sclerosis, ulcerative colitis and autoimmune hepatitis; and cancer.
SUMMARY OF THE INVENTION
[0007] The present invention is broadly directed to antigen binding proteins, such as humanised antibodies, which bind Lymphocyte Activation Gene 3 (LAG-3) and which may be able to cause depletion of LAG-3+ activated T cells. More specifically, antigen binding protein of the present invention may comprise CDRL1 of SEQ ID No. 5, wherein position 27E is proline.
[0008] Antigen binding proteins described herein may have use in the treatment or prevention of diseases associated with the involvement of pathogenic T cells, for example auto-immune diseases, such as psoriasis, Crohn's disease, rheumatoid arthritis, primary biliary cirrhosis, SLE, Sjogren's syndrome, multiple sclerosis, ulcerative colitis and autoimmune hepatitis. Accordingly, the invention is further directed to pharmaceutical compositions comprising an antigen binding protein, and optionally one or more pharmaceutically acceptable excipients and/or carriers.
BRIEF DESCRIPTION OF THE DRAWINGS
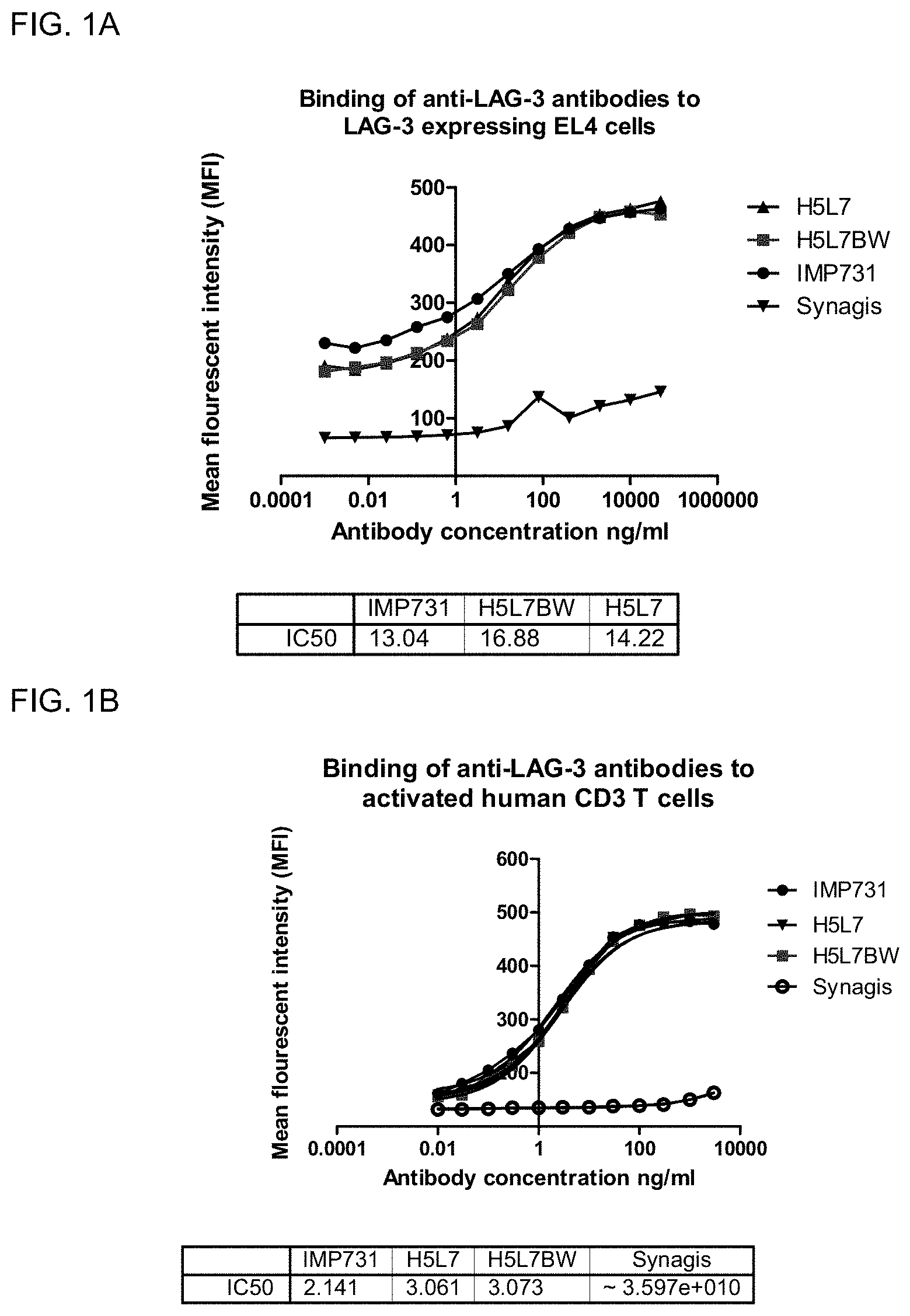
[0009] FIG. 1A shows a graph of three antibodies (H5L7BW, H5L7 and IMP731) binding to LAG-3 expressing EL4 cells as measured by FACS analysis, using Synagis, a monoclonal antibody against an unrelated target, as negative control.
[0010] FIG. 1B shows a graph of three antibodies (H5L7BW, H5L7 and IMP731) binding to activated human CD3+ T cells as measured by FACS analysis, using Synagis as negative control.
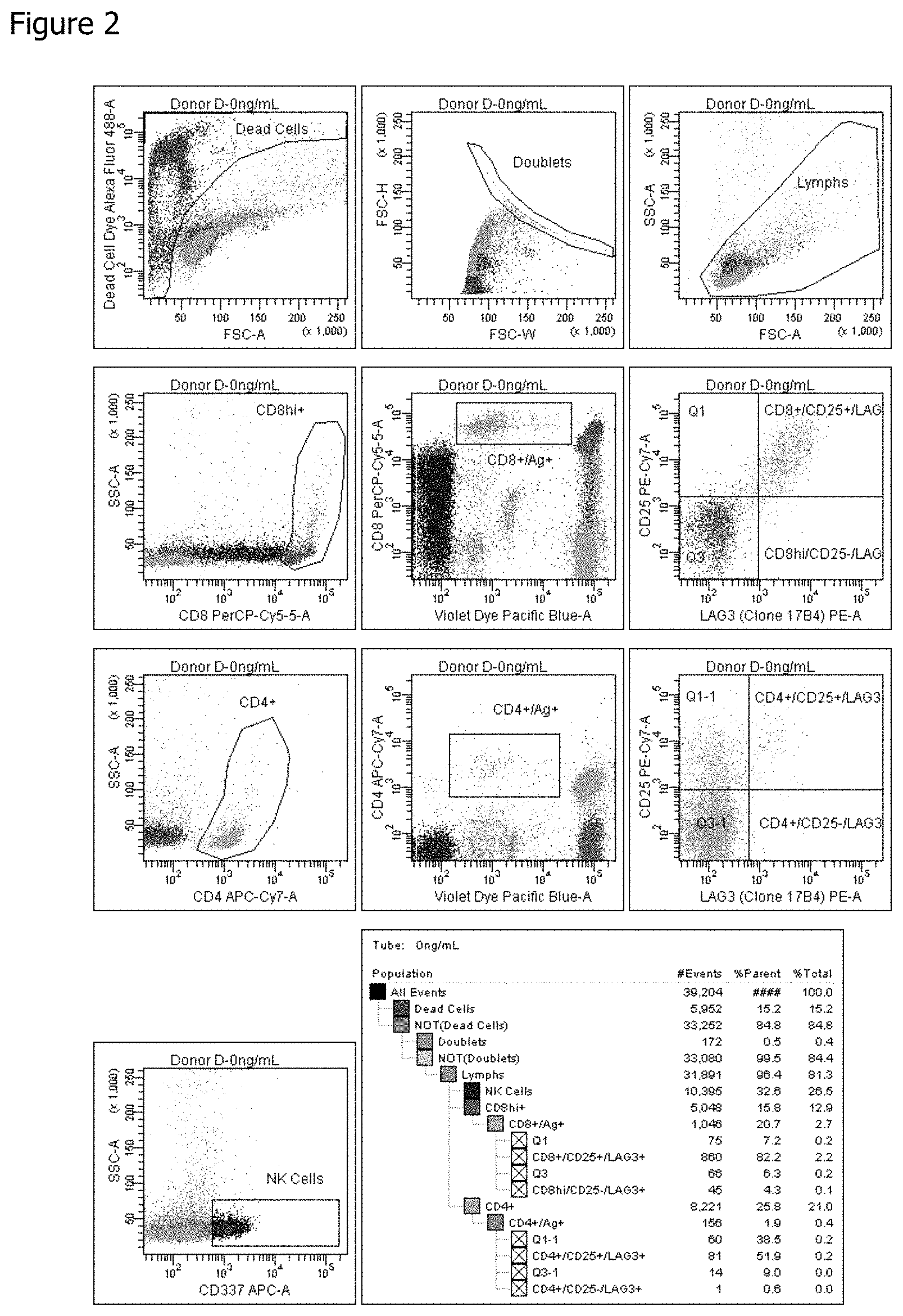
[0011] FIG. 2 shows FACS Plots illustrating the gating strategy used to identify LAG-3 positive antigen specific T cells.
[0012] FIG. 3A shows a graph of the quantification of human CD4.sup.+ LAG-3.sup.+ and CD8.sup.+ LAG-3.sup.+ T cells 24 hours after co-administration of 1.times.10.sup.7 activated human PBMCs and 5 mg/kg Control antibody, H5L7BW or MabCampath (Donor A: Control n=2; H5L7BW n=2, MabCampath n=1; Donor B: Control n=2; H5L7BW n=3, MabCampath n=2).
[0013] FIG. 3B shows a graph of the quantification of total CD4.sup.+ and CD8.sup.+ T cells (*p<0.001) 24 hours after co-administration of 1.times.10.sup.7 activated human PBMCs and 5 mg/kg Control antibody, H5L7BW or MabCampath (Donor A: Control n=2; H5L7BW n=2, MabCampath n=1; Donor B: Control n=2; H5L7BW n=3, MabCampath n=2).
[0014] FIG. 4A shows a graph of the quantification of human CD4.sup.+ LAG-3.sup.+ and CD8.sup.+LAG-3.sup.+ T cells 5 hours after co-administration of 1.times.10.sup.7 activated human PBMCs and 5 mg/kg Control antibody, H5L7BW or H5L7 (n=3 per group), which demonstrates the effect of H5L7BW and its non-ADCC enhanced variant H5L7 on activated human PBMCs co-administered intra-peritoneally and retrieved from the peritoneal cavity 5 hours post-injection.
[0015] FIG. 4B shows a graph of the quantification of total CD4.sup.+ and CD8.sup.+ T cells (*p<0.001) 5 hours after co-administration of 1.times.10.sup.7 activated human PBMCs and 5 mg/kg Control antibody, H5L7BW or H5L7 (n=3 per group), which demonstrates the effect of H5L7BW and its non-ADCC enhanced variant H5L7 on activated human PBMCs co-administered intra-peritoneally and retrieved from the peritoneal cavity 5 hours post-injection.
[0016] FIG. 5A shows a graph of the quantification of human CD4.sup.+LAG-3.sup.+ and CD8.sup.+LAG-3.sup.+T cells 5 hours after i.p. injection of 5.times.10.sup.6 (n=1 per group) or 1.times.10.sup.7 (n=4 per group) activated human PBMCs into SCID mice, where H5L7BW was administered intravenously 18 hours before administration of human activated PBMCs into the peritoneum of SCID mice.
[0017] FIG. 5B shows a graph of the quantification of total CD4.sup.+ and CD8.sup.+ T cells 5 hours after i.p. injection of 5.times.10.sup.6 (n=1 per group) or 1.times.10.sup.7 (n=4 per group) activated human PBMCs into SCID mice, where 5 mg/kg H5L7BW or control antibody was injected intravenously 18 hours before administration of activated human PBMCs. (*p<0.001, # p=0.0052)
[0018] FIG. 6A shows a graph of the quantification of human CD4.sup.+LAG-3.sup.+ and CD8.sup.+LAG-3.sup.+T cells 5 hours after i.p. injection of 1.times.10.sup.7 (n=4 per group) activated human PBMCs into SCID mice, where 5 mg/kg H5L7BW, H5L7, IMP731 or control antibody were injected intravenously 18 hours before administration of human PBMCs.
[0019] FIG. 6B shows a graph of the quantification of total CD4.sup.+ and CD8.sup.+ T cells 5 hours after i.p. injection of 1.times.10.sup.7 (n=4 per group) activated human PBMCs into SCID mice, where 5 mg/kg LAG-3 depleting antibodies or control antibody were injected intravenously 18 hours pre-injection of activated human PBMCs. (*p<0.001)
DETAILED DESCRIPTION OF THE INVENTION
[0020] The present invention is broadly directed to antigen binding proteins that bind Lymphocyte Activation Gene 3 (LAG-3), and more particularly to antigen binding proteins that may cause depletion of LAG-3+ activated T cells.
[0021] The term "antigen binding protein" as used herein refers to antibodies and fragments thereof which are capable of binding to LAG-3. Unless otherwise specified, the term "LAG-3" as used herein refers to Lymphocyte Activation Gene 3, expressed as a dimer on the surface of, for example, activated T cells, NK cells and B cells. The term "SLAG-3" as used herein refers to a soluble form of LAG-3 found, for example, in serum. Unless otherwise specified, references herein to "SLAG-3" and "LAG-3" are to human polypeptides.
[0022] In one aspect, the present invention provides antigen binding proteins that are capable of binding LAG-3 and which comprise CDRL1 of SEQ ID No. 5, wherein position 27E is proline.
[0023] In a further aspect, the present invention provides antigen binding proteins, which comprises CDRL1 of SEQ ID NO. 1.
[0024] In a further aspect, the present invention provides antigen binding proteins that in addition to comprising CDRL1 of SEQ ID NO.5, also comprise CDRL2 and/or CDRL3 from SEQ ID NO. 5, or a CDR variant thereof.
[0025] In a further aspect, the present invention provides antigen binding proteins comprising CDRL2 of SEQ ID NO. 2 and/or CDRL3 of SEQ ID NO. 3 or a CDR variant thereof.
[0026] In a further aspect, the present invention provides antigen binding proteins comprising one or more of CDRH1, CDRH2 and CDRH3, or a CDR variant thereof, from SEQ ID NO 10.
[0027] In a further aspect, the present invention provides antigen binding proteins comprising one or more CDRs, or a CDR variant thereof, selected from the group comprising CDRH1 of SEQ ID NO. 6, CDRH2 of SEQ ID NO. 7 and CDRH3 of SEQ ID NO. 8.
[0028] In a further aspect, the present invention provides antigen binding proteins comprising the following CDRs: [0029] CDRL1: SEQ ID NO. 1 [0030] CDRL2: SEQ ID NO. 2 [0031] CDRL3: SEQ ID NO. 3 [0032] CDRH1: SEQ ID NO. 6 [0033] CDRH2: SEQ ID NO. 7 [0034] CDRH3: SEQ ID NO. 8
[0035] The term "CDR" as used herein, refers to the complementarity determining region amino acid sequences of an antigen binding protein. These are the hypervariable regions of immunoglobulin heavy and light chains. There are three heavy chain and three light chain CDRs (or CDR regions) in the variable portion of an immunoglobulin.
[0036] It will be apparent to those skilled in the art that there are various numbering conventions for CDR sequences; Chothia (Chothia et al. (1989) Nature 342: 877-883), Kabat (Kabat et al., Sequences of Proteins of Immunological Interest, 4th Ed., U.S. Department of Health and Human Services, National Institutes of Health (1987)), AbM (University of Bath) and Contact (University College London). The minimum overlapping region using at least two of the Kabat, Chothia, AbM and contact methods can be determined to provide the "minimum binding unit". The minimum binding unit may be a sub-portion of a CDR. The structure and protein folding of the antibody may mean that other residues are considered part of the CDR sequence and would be understood to be so by a skilled person.
[0037] Unless otherwise stated and/or in absence of a specifically identified sequence, references herein to "CDR", "CDRL1", "CDRL2", "CDRL3", "CDRH1", "CDRH2", "CDRH3" refer to amino acid sequences numbered according to any of the known conventions identified in Table 1.
[0038] Table 1 below represents one definition using each numbering convention for each CDR or binding unit. It should be noted that some of the CDR definitions may vary depending on the individual publication used.
TABLE-US-00001 TABLE 1 Kabat Chothia AbM Contact Minimum CDR CDR CDR CDR binding unit H1 31-35/ 26-32/ 26-35/ 30-35/ 31-32 35A/35B 33/34 35A/35B 35A/35B H2 50-65 52-56 50-58 47-58 52-56 H3 95-102 95-102 95-102 93-101 95-101 L1 24-34 24-34 24-34 30-36 30-34 L2 50-56 50-56 50-56 46-55 50-55 L3 89-97 89-97 89-97 89-96 89-96
[0039] The term "CDR variant" as used herein, refers to a CDR that has been modified by at least one, for example 1, 2 or 3, amino acid substitution(s), deletion(s) or addition(s), wherein the modified antigen binding protein comprising the CDR variant substantially retains the biological characteristics of the antigen binding protein pre-modification. It will be appreciated that each CDR that can be modified may be modified alone or in combination with another CDR. In one aspect, the modification is a substitution, particularly a conservative substitution, for example as shown in Table 2.
TABLE-US-00002 TABLE 2 Side chain Members Hydrophobic Met, Ala, Val, Leu, Ile Neutral hydrophilic Cys, Ser, Thr Acidic Asp, Glu Basic Asn, Gln, His, Lys, Arg Residues that influence chain orientation Gly, Pro Aromatic Trp, Tyr, Phe
[0040] For example, in a variant CDR, the amino acid residues of the minimum binding unit may remain the same, but the flanking residues that comprise the CDR as part of the Kabat or Chothia definition(s) may be substituted with a conservative amino acid residue.
[0041] Such antigen binding proteins comprising modified CDRs or minimum binding units as described above may be referred to herein as "functional CDR variants" or "functional binding unit variants".
[0042] Antigen binding proteins of the present invention may be capable of binding sLAG-3. In one aspect, the equilibrium dissociation constant (KD) of the antigen binding protein-sLAG-3 interaction is 10 nM or less, such as 1 nM or less, for example between 1 pM and 300, 400, 500 pM or between 500 pM and 1 nM. A skilled person will appreciate that the smaller the KD numerical value, the stronger the binding. The reciprocal of KD (i.e. 1/KD) is the equilibrium association constant (KA) having units M.sup.-1. A skilled person will appreciate that the larger the KA numerical value, the stronger the binding.
[0043] In one aspect, the present invention provides antigen binding proteins that are capable of binding recombinant LAG-3 with a KD of less than 1 nM, for example between 1 pM and 300 pM, when determined by Biacore.TM. surface Plasmon resonance analysis using recombinant human, or cynomolgus macaque LAG-3 extracellular domains (ECDs) of SEQ ID NOs:51 and 52, respectively. Furthermore, antigen binging proteins of the present invention may also be capable of binding LAG-3 expressed on, for example, EL4 cells or activated human CD3+ T cells.
[0044] Antigen binding proteins of the present invention may also be capable of depleting LAG-3+ activated T cells, in particular, CD4+LAG-3+ and CD8+LAG-3+ T cells. Depletion of LAG-3+ T cells may occur by, for example, antibody dependent cell mediated cytotoxic activity (ADCC) and/or complement-dependent cytotoxic activity (CDC).
[0045] In one aspect, the present invention provides antigen binding proteins that are capable of causing greater than 40% depletion of antigen specific CD4 and/or CD8 LAG-3.sup.+ human T cells by ADCC in an in-vitro assay using primary human T cells.
[0046] In a further aspect, the present invention provides antigen binding proteins that, at a concentration of 0.1 .mu.g/mL, are capable of causing greater than 50% depletion in an in vitro ADCC assay using europium-labelled LAG-3 expressing EL4 cells as target cells and human PBMCs as effector cells, wherein the effector:target ratio is no greater than 50:1 and the assay is run for a period of 2 hours. % cell lysis is calculated based on europium release from LAG-3 expressing EL4 cells.
[0047] The interaction between the constant region of an antigen binding protein and various Fc receptors (FcR) including Fc.gamma.RI (CD64), Fc.gamma.RII (CD32) and Fc.gamma.RIII (CD16) is believed to mediate the effector functions, such as ADCC and CDC, of the antigen binding protein. Significant biological effects can be a consequence of effector functionality. Usually, the ability to mediate effector function requires binding of the antigen binding protein to an antigen and not all antigen binding proteins will mediate every effector function.
[0048] Effector function can be measured in a number of ways including for example via binding of the Fc.gamma.RIII to Natural Killer cells or via Fc.gamma.RI to monocytes/macrophages to measure for ADCC effector function. For example an antigen binding protein of the present invention can be assessed for ADCC effector function in a Natural Killer cell assay. Examples of such assays can be found in Shields et al, 2001 The Journal of Biological Chemistry, Vol. 276, p 6591-6604; Chappel et al, 1993 The Journal of Biological Chemistry, Vol 268, p 25124-25131; Lazar et al, 2006 PNAS, 103; 4005-4010.
[0049] Examples of assays to determine CDC function include that described in 1995 J Imm Meth 184:29-38.
[0050] In one aspect of the present invention, the antigen binding protein is an antibody.
[0051] The term "antibody" as used herein refers to molecules with an immunoglobulin-like domain and includes monoclonal (for example IgG, IgM, IgA, IgD or IgE), recombinant, polyclonal, chimeric, humanised, bispecific and heteroconjugate antibodies; a single variable domain (e.g., VH, VHH, VL), a domain antibody (dAb.RTM.), antigen binding fragments, immunologically effective fragments, Fab, F(ab').sub.2, Fv, disulphide linked Fv, single chain Fv, closed conformation multispecific antibody, disulphide-linked scFv, diabodies, TANDABS.TM., etc. and modified versions of any of the foregoing (for a summary of alternative "antibody" formats see Holliger and Hudson, Nature Biotechnology, 2005, Vol 23, No. 9, 1126-1136). Alternative antibody formats include alternative scaffolds in which the one or more CDRs of any molecules in accordance with the disclosure can be arranged onto a suitable non-immunoglobulin protein scaffold or skeleton, such as an affibody, a SpA scaffold, an LDL receptor class A domain, an avimer (see, e.g., U.S. Patent Application Publication Nos. 2005/0053973, 2005/0089932, 2005/0164301) or an EGF domain.
[0052] In a further aspect, the antigen binding protein is a humanised antibody.
[0053] A "humanised antibody" refers to a type of engineered antibody having its CDRs derived from a non-human donor immunoglobulin, the remaining immunoglobulin-derived parts of the molecule being derived from one (or more) human immunoglobulin(s). In addition, framework support residues may be altered to preserve binding affinity (see, e.g., Queen et al., Proc. Natl Acad Sci USA, 86:10029-10032 (1989), Hodgson et al., Bio/Technology, 9:421 (1991)). A suitable human acceptor antibody may be one selected from a conventional database, e.g., the KABAT.RTM. database, Los Alamos database, and Swiss Protein database, by homology to the nucleotide and amino acid sequences of the donor antibody. A human antibody characterized by a homology to the framework regions of the donor antibody (on an amino acid basis) may be suitable to provide a heavy chain constant region and/or a heavy chain variable framework region for insertion of the donor CDRs. A suitable acceptor antibody capable of donating light chain constant or variable framework regions may be selected in a similar manner. It should be noted that the acceptor antibody heavy and light chains are not required to originate from the same acceptor antibody. The prior art describes several ways of producing such humanised antibodies--see for example EP-A-0239400 and EP-A-054951.
[0054] In yet a further aspect, the humanised antibody has a human antibody constant region that is an IgG1, for example, the heavy chain constant region of SEQ ID No. 46.
[0055] It will be understood that the present invention further provides humanised antibodies which comprise a) a light chain sequence of SEQ ID NO. 5 or a light chain sequence with at least 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% or 99% identity to any of SEQ ID NO. 5 and b) a heavy chain sequence of SEQ ID NO. 10 or a heavy chain sequence with at least 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% or 99% identity to any of SEQ ID NO. 10.
[0056] It will be understood that the present invention further provides humanised antibodies which comprise a) a light chain sequence of SEQ ID NO. 35 or a light chain sequence with at least 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% or 99% identity to any of SEQ ID NO. 35 and b) a heavy chain sequence of SEQ ID NO. 36 or a heavy chain sequence with at least 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% or 99% identity to any of SEQ ID NO. 36.
[0057] In a further aspect, the present invention provides antigen binding proteins comprising CDRL1-L3 and CDRH1-H3 of SEQ ID NO: 35 and 36, respectively.
[0058] For nucleotide and amino acid sequences, the term "identical" or "identity" indicates the degree of identity between two nucleic acid or two amino acid sequences when optimally aligned and compared with appropriate insertions or deletions.
[0059] The percent identity between two sequences is a function of the number of identical positions shared by the sequences (i.e., % identity=number of identical positions/total number of positions multiplied by 100), taking into account the number of gaps, and the length of each gap, which need to be introduced for optimal alignment of the two sequences. The comparison of sequences and determination of percent identity between two sequences can be accomplished using a mathematical algorithm, as described below.
[0060] Percent identity between a query nucleic acid sequence and a subject nucleic acid sequence is the "Identities" value, expressed as a percentage, which is calculated by the BLASTN algorithm when a subject nucleic acid sequence has 100% query coverage with a query nucleic acid sequence after a pair-wise BLASTN alignment is performed. Such pair-wise BLASTN alignments between a query nucleic acid sequence and a subject nucleic acid sequence are performed by using the default settings of the BLASTN algorithm available on the National Center for Biotechnology Institute's website with the filter for low complexity regions turned off. Importantly, a query nucleic acid sequence may be described by a nucleic acid sequence identified in one or more claims herein.
[0061] Percent identity between a query amino acid sequence and a subject amino acid sequence is the "Identities" value, expressed as a percentage, which is calculated by the BLASTP algorithm when a subject amino acid sequence has 100% query coverage with a query amino acid sequence after a pair-wise BLASTP alignment is performed. Such pair-wise BLASTP alignments between a query amino acid sequence and a subject amino acid sequence are performed by using the default settings of the BLASTP algorithm available on the National Center for Biotechnology Institute's website with the filter for low complexity regions turned off. Importantly, a query amino acid sequence may be described by an amino acid sequence identified in one or more claims herein.
[0062] In a further aspect, the present invention provides a humanised antibody, which comprises a) a light chain sequence with at least 90% identity to SEQ ID NO. 5, and b) a heavy chain sequence with at least 90% identity to SEQ ID NO. 10.
[0063] In a further aspect, the present invention provides a humanised antibody, which comprises a) a light chain sequence with at least 95% identity to SEQ ID NO. 5, and b) a heavy chain sequence with at least 95% identity to SEQ ID NO. 10.
[0064] In yet a further aspect, the present invention provides a humanised antibody, which comprises a) a light chain sequence with at least 97% identity to SEQ ID NO. 5, and b) a heavy chain sequence with at least 97% identity to SEQ ID NO. 10.
[0065] In yet a further aspect, the present invention provides a humanised antibody, which comprises a) a light chain sequence of SEQ ID NO. 5, and b) a heavy chain sequence of SEQ ID NO. 10.
Production
[0066] The antigen binding proteins, for example antibodies of the present invention may be produced by transfection of a host cell with an expression vector comprising the coding sequence for the antigen binding protein of the invention. An expression vector or recombinant plasmid is produced by placing these coding sequences for the antigen binding protein in operative association with conventional regulatory control sequences capable of controlling the replication and expression in, and/or secretion from, a host cell. Regulatory sequences include promoter sequences, e.g., CMV promoter, and signal sequences which can be derived from other known antibodies. Similarly, a second expression vector can be produced having a DNA sequence which encodes a complementary antigen binding protein light or heavy chain. In certain embodiments this second expression vector is identical to the first except insofar as the coding sequences and selectable markers are concerned, so to ensure as far as possible that each polypeptide chain is functionally expressed. Alternatively, the heavy and light chain coding sequences for the antigen binding protein may reside on a single vector.
[0067] A selected host cell is co-transfected by conventional techniques with both the first and second vectors (or simply transfected by a single vector) to create the transfected host cell of the invention comprising both the recombinant or synthetic light and heavy chains. The transfected cell is then cultured by conventional techniques to produce the engineered antigen binding protein of the invention. The antigen binding protein which includes the association of both the recombinant heavy chain and/or light chain is screened from culture by appropriate assay, such as ELISA or RIA. Similar conventional techniques may be employed to construct other antigen binding proteins.
[0068] Suitable vectors for the cloning and subcloning steps employed in the methods and construction of the compositions of this invention may be selected by one of skill in the art. For example, the conventional pUC series of cloning vectors may be used. One vector, pUC19, is commercially available from supply houses, such as Amersham (Buckinghamshire, United Kingdom) or Pharmacia (Uppsala, Sweden). Additionally, any vector which is capable of replicating readily, has an abundance of cloning sites and selectable genes (e.g., antibiotic resistance), and is easily manipulated may be used for cloning. Thus, the selection of the cloning vector is not a limiting factor in this invention.
[0069] The expression vectors may also be characterized by genes suitable for amplifying expression of the heterologous DNA sequences, e.g., the mammalian dihydrofolate reductase gene (DHFR). Other preferable vector sequences include a poly A signal sequence, such as from bovine growth hormone (BGH) and the betaglobin promoter sequence (betaglopro). The expression vectors useful herein may be synthesized by techniques well known to those skilled in this art. The components of such vectors, e.g. replicons, selection genes, enhancers, promoters, signal sequences and the like, may be obtained from commercial or natural sources or synthesized by known procedures for use in directing the expression and/or secretion of the product of the recombinant DNA in a selected host. Other appropriate expression vectors of which numerous types are known in the art for mammalian, bacterial, insect, yeast, and fungal expression may also be selected for this purpose.
[0070] The present invention also encompasses a cell line transfected with a recombinant plasmid containing the coding sequences of the antigen binding proteins of the present invention. Host cells useful for the cloning and other manipulations of these cloning vectors are also conventional. However, cells from various strains of E. coli may be used for replication of the cloning vectors and other steps in the construction of antigen binding proteins of this invention.
[0071] Suitable host cells or cell lines for the expression of the antigen binding proteins of the invention include mammalian cells such as NSO, Sp2/0, CHO (e.g. DG44), COS, HEK, a fibroblast cell (e.g., 3T3), and myeloma cells, for example it may be expressed in a CHO or a myeloma cell. Human cells may be used, thus enabling the molecule to be modified with human glycosylation patterns. Alternatively, other eukaryotic cell lines may be employed. The selection of suitable mammalian host cells and methods for transformation, culture, amplification, screening and product production and purification are known in the art. See, e.g., Sambrook et al., cited above.
[0072] Bacterial cells may prove useful as host cells suitable for the expression of the recombinant Fabs or other embodiments of the present invention (see, e.g., Pluckthun, A., Immunol. Rev., 130:151-188 (1992)). However, due to the tendency of proteins expressed in bacterial cells to be in an unfolded or improperly folded form or in a non-glycosylated form, any recombinant Fab produced in a bacterial cell would have to be screened for retention of antigen binding ability. If the molecule expressed by the bacterial cell was produced in a properly folded form, that bacterial cell would be a desirable host, or in alternative embodiments the molecule may express in the bacterial host and then be subsequently re-folded. For example, various strains of E. coli used for expression are well-known as host cells in the field of biotechnology. Various strains of B. subtilis, Streptomyces, other bacilli and the like may also be employed in this method.
[0073] Where desired, strains of yeast cells known to those skilled in the art are also available as host cells, as well as insect cells, e.g. Drosophila and Lepidoptera and viral expression systems. See, e.g. Miller et al., Genetic Engineering, 8:277-298, Plenum Press (1986) and references cited therein.
[0074] The general methods by which the vectors may be constructed, the transfection methods required to produce the host cells of the invention, and culture methods necessary to produce the antigen binding protein of the invention from such host cell may all be conventional techniques. Typically, the culture method of the present invention is a serum-free culture method, usually by culturing cells serum-free in suspension. Likewise, once produced, the antigen binding proteins of the invention may be purified from the cell culture contents according to standard procedures of the art, including ammonium sulfate precipitation, affinity columns, column chromatography, gel electrophoresis and the like. Such techniques are within the skill of the art and do not limit this invention. For example, preparations of altered antibodies are described in WO 99/58679 and WO 96/16990.
[0075] Yet another method of expression of the antigen binding proteins may utilize expression in a transgenic animal, such as described in U.S. Pat. No. 4,873,316. This relates to an expression system using the animals casein promoter which when transgenically incorporated into a mammal permits the female to produce the desired recombinant protein in its milk.
[0076] In a further aspect of the invention there is provided a method of producing an antibody of the invention which method comprises the step of culturing a host cell transformed or transfected with a vector encoding the light and/or heavy chain of the antibody of the invention and recovering the antibody thereby produced.
[0077] In accordance with the present invention there is provided a method of producing an anti-LAG-3 antibody of the present invention which binds to human LAG-3, which method comprises the steps of; [0078] (a) providing a first vector encoding a heavy chain of the antibody; [0079] (b) providing a second vector encoding a light chain of the antibody; [0080] (c) transforming a mammalian host cell (e.g. CHO) with said first and second vectors; [0081] (d) culturing the host cell of step (c) under conditions conducive to the secretion of the antibody from said host cell into said culture media; [0082] (e) recovering the secreted antibody of step (d).
[0083] Once expressed by the desired method, the antibody may then be examined for in vitro activity by use of an appropriate assay, such as Biacore.TM. surface Plasmon resonance analysis, to assess binding of the antibody to LAG-3. Additionally, other in vitro and in vivo assays may also be used to determine an antibody's ability to cause depletion of cells expressing LAG-3, such as activated human T cell populations.
[0084] The skilled person will appreciate that, upon production of an antigen binding protein such as an antibody, in particular depending on the cell line used and particular amino acid sequence of the antigen binding protein, post-translational modifications may occur. For example, this may include the cleavage of certain leader sequences, the addition of various sugar moieties in various glycosylation and phosphorylation patterns, deamidation, oxidation, disulfide bond scrambling, isomerisation, C-terminal lysine clipping, and N-terminal glutamine cyclisation. The present invention encompasses the use of antigen binding proteins which have been subjected to, or have undergone, one or more post-translational modifications. Thus an "antigen binding protein" or "antibody" of the invention includes an "antigen binding protein" or "antibody", respectively, as defined earlier which has undergone a post-translational modification such as described herein.
[0085] Glycosylation of antibodies at conserved positions in their constant regions is known to have a profound effect on antibody function, particularly effector functioning, see for example, Boyd et al. (1996) Mol. Immunol. 32: 1311-1318. Glycosylation variants of the antigen binding proteins of the invention wherein one or more carbohydrate moiety is added, substituted, deleted or modified are contemplated. Introduction of an asparagine-X-serine or asparagine-X-threonine motif creates a potential site for enzymatic attachment of carbohydrate moieties and may therefore be used to manipulate the glycosylation of an antibody. In Raju et al. (2001) Biochemistry 40: 8868-8876 the terminal sialyation of a TNFR-IgG immunoadhesin was increased through a process of regalactosylation and/or resialylation using beta-1,4-galactosyltransferace and/or alpha, 2,3 sialyltransferase. Increasing the terminal sialylation is believed to increase the half-life of the immunoglobulin. Antibodies, in common with most glycoproteins, are typically produced as a mixture of glycoforms. This mixture is particularly apparent when antibodies are produced in eukaryotic, particularly mammalian cells. A variety of methods have been developed to manufacture defined glycoforms, see Zhang et al. (2004) Science 303: 371: Sears et al. (2001) Science 291: 2344; Wacker et al. (2002) Science 298: 1790; Davis et al. (2002) Chem. Rev. 102: 579; Hang et al. (2001) Acc. Chem. Res 34: 727. The antibodies (for example of the IgG isotype, e.g. IgG1) as herein described may comprise a defined number (e.g. 7 or less, for example 5 or less, such as two or a single) of glycoform(s).
[0086] Deamidation is an enzymatic reaction primarily converting asparagine (N) to iso-aspartic acid and aspartic acid (D) at approximately 3:1 ratio. To a much lesser degree, deamidation can occur with glutamine residues in a similar manner. Deamidation in a CDR results in a change in charge of the molecule, but typically does not result in a change in antigen binding, nor does it impact on PK/PD.
[0087] Oxidation can occur during production and storage (i.e. in the presence of oxidizing conditions) and results in a covalent modification of a protein, induced either directly by reactive oxygen species or indirectly by reaction with secondary by-products of oxidative stress. Oxidation happens primarily with methionine residues, but occasionally can occur at tryptophan and free cysteine residues.
[0088] Disulfide bond scrambling can occur during production and basic storage conditions. Under certain circumstances, disulfide bonds can break or form incorrectly, resulting in unpaired cysteine residues (--SH). These free (unpaired) sulfhydryls (--SH) can promote shuffling.
[0089] Isomerization typically occurs during production, purification, and storage (at acidic pH) and usually occurs when aspartic acid is converted to isoaspartic acid through a chemical process.
[0090] N-terminal glutamine in the heavy chain and/or light chain is likely to form pyroglutamate (pGlu). Most pGlu formation happens in the production bioreactor, but it can be formed non-enzymatically, depending on pH and temperature of processing and storage conditions. pGlu formation is considered as one of the principal degradation pathways for recombinant mAbs.
[0091] C-terminal lysine clipping is an enzymatic reaction catalyzed by carboxypeptidases, and is commonly observed in recombinant mAbs. Variants of this process include removal of lysine from one or both heavy chains. Lysine clipping does not appear to impact bioactivity and has no effect on mAb effector function.
Effector Function Enhancement
[0092] The interaction between the constant region of an antigen binding protein and various Fc receptors (FcR) including Fc.gamma.RI (CD64), Fc.gamma.RII (CD32) and Fc.gamma.RIII (CD16) is believed to mediate the effector functions, such as ADCC and CDC, of the antigen binding protein.
[0093] The term "Effector Function" as used herein is meant to refer to one or more of Antibody dependant cell mediated cytotoxic activity (ADCC), Complement-dependant cytotoxic activity (CDC) mediated responses, Fc-mediated phagocytosis or antibody dependant cellular phagocytosis (ADCP) and antibody recycling via the FcRn receptor.
[0094] The ADCC or CDC properties of antigen binding proteins of the present invention may be enhanced in a number of ways.
[0095] Human IgG1 constant regions containing specific mutations or altered glycosylation on residue Asn297 have been shown to enhance binding to Fc receptors. In some cases these mutations have also been shown to enhance ADCC and CDC (Lazar et al. PNAS 2006, 103; 4005-4010; Shields et al. J Biol Chem 2001, 276; 6591-6604; Nechansky et al. Mol Immunol, 2007, 44; 1815-1817).
[0096] In one embodiment of the present invention, such mutations are in one or more of positions selected from 239, 332 and 330 (IgG1), or the equivalent positions in other IgG isotypes. Examples of suitable mutations are S239D and I332E and A330L. In one embodiment, the antigen binding protein of the invention herein described is mutated at positions 239 and 332, for example S239D and I332E or in a further embodiment it is mutated at three or more positions selected from 239 and 332 and 330, for example S239D and I332E and A330L. (EU index numbering).
[0097] In one embodiment of the present invention, there is provided an antigen binding protein comprising a chimaeric heavy chain constant region for example an antigen binding protein comprising a chimaeric heavy chain constant region with at least one CH2 domain from IgG3 such that the antigen binding protein has enhanced effector function, for example wherein it has enhanced ADCC or enhanced CDC, or enhanced ADCC and CDC functions. In one such embodiment, the antigen binding protein may comprise one CH2 domain from IgG3 or both CH2 domains may be from IgG3.
[0098] Also provided is a method of producing an antigen binding protein according to the invention comprising the steps of: [0099] a) culturing a recombinant host cell comprising an expression vector comprising an isolated nucleic acid as described herein wherein the expression vector comprises a nucleic acid sequence encoding an Fc domain having both IgG1 and IgG3 Fc domain amino acid residues; and [0100] b) recovering the antigen binding protein.
[0101] Such methods for the production of antigen binding proteins can be performed, for example, using the COMPLEGENT.TM. technology system available from BioWa, Inc. (Princeton, N.J.) and Kyowa Hakko Kogyo (now, Kyowa Hakko Kirin Co., Ltd.) Co., Ltd. In which a recombinant host cell comprising an expression vector in which a nucleic acid sequence encoding a chimeric Fc domain having both IgG1 and IgG3 Fc domain amino acid residues is expressed to produce an antigen binding protein having enhanced complement dependent cytotoxicity (CDC) activity that is increased relative to an otherwise identical antigen binding protein lacking such a chimeric Fc domain. Aspects of the COMPLEGENT.TM. technology system are described in WO2007011041 and US20070148165 each of which are incorporated herein by reference. In an alternative embodiment CDC activity may be increased by introducing sequence specific mutations into the Fc region of an IgG chain. Those of ordinary skill in the art will also recognize other appropriate systems.
[0102] In an alternative embodiment of the present invention, there is provided an antigen binding protein comprising a heavy chain constant region with an altered glycosylation profile such that the antigen binding protein has enhanced effector function. For example, wherein the antigen binding protein has enhanced ADCC or enhanced CDC or wherein it has both enhanced ADCC and CDC effector function. Examples of suitable methodologies to produce antigen binding proteins with an altered glycosylation profile are described in WO2003011878, WO2006014679 and EP1229125, all of which can be applied to the antigen binding proteins of the present invention.
[0103] The present invention also provides a method for the production of an antigen binding protein according to the invention comprising the steps of: [0104] a) culturing a recombinant host cell comprising an expression vector comprising the isolated nucleic acid as described herein, wherein the FUT8 gene encoding alpha-1,6-fucosyltransferase has been inactivated in the recombinant host cell; and [0105] b) recovering the antigen binding protein.
[0106] Such methods for the production of antigen binding proteins can be performed, for example, using the POTELLIGENT.TM. technology system available from BioWa, Inc. (Princeton, N.J.) in which CHOK1SV cells lacking a functional copy of the FUT8 gene produce monoclonal antibodies having enhanced antibody dependent cell mediated cytotoxicity (ADCC) activity that is increased relative to an identical monoclonal antibody produced in a cell with a functional FUT8 gene. Aspects of the POTELLIGENT.TM. technology system are described in U.S. Pat. Nos. 7,214,775, 6,946,292, WO0061739 and WO0231240 all of which are incorporated herein by reference. Those of ordinary skill in the art will also recognize other appropriate systems.
[0107] In a further aspect, the present invention provides non-fucosylated antibodies. Non-fucosylated antibodies harbour a tri-mannosyl core structure of complex-type N-glycans of Fc without fucose residue. These glycoengineered antibodies that lack core fucose residue from the Fc N-glycans may exhibit stronger ADCC than fucosylated equivalents due to enhancement of Fc.gamma.RIIIa binding capacity.
[0108] It will be apparent to those skilled in the art that such modifications may not only be used alone but may be used in combination with each other in order to further enhance effector function.
[0109] In one such embodiment of the present invention there is provided an antigen binding protein comprising a heavy chain constant region which comprises a mutated and chimaeric heavy chain constant region for example wherein an antigen binding protein comprising at least one CH2 domain from IgG3 and one CH2 domain from IgG1, wherein the IgG1 CH2 domain has one or more mutations at positions selected from 239 and 332 and 330 (for example the mutations may be selected from S239D and I332E and A330L) such that the antigen binding protein has enhanced effector function, for example wherein it has one or more of the following functions, enhanced ADCC or enhanced CDC, for example wherein it has enhanced ADCC and enhanced CDC. In one embodiment the IgG1 CH2 domain has the mutations S239D and I332E.
[0110] In an alternative embodiment of the present invention there is provided an antigen binding protein comprising a chimaeric heavy chain constant region and which has an altered glycosylation profile. In one such embodiment the heavy chain constant region comprises at least one CH2 domain from IgG3 and one CH2 domain from IgG1 and has an altered glycosylation profile such that the ratio of fucose to mannose is 0.8:3 or less, for example wherein the antigen binding protein is defucosylated so that said antigen binding protein has an enhanced effector function in comparison with an equivalent antigen binding protein with an immunoglobulin heavy chain constant region lacking said mutations and altered glycosylation profile, for example wherein it has one or more of the following functions, enhanced ADCC or enhanced CDC, for example wherein it has enhanced ADCC and enhanced CDC.
[0111] In an alternative embodiment the antigen binding protein has at least one IgG3 CH2 domain and at least one heavy chain constant domain from IgG1 wherein both IgG CH2 domains are mutated in accordance with the limitations described herein.
[0112] In one aspect of the invention there is provided a method of producing an antigen binding protein according to the invention described herein comprising the steps of: [0113] a) culturing a recombinant host cell containing an expression vector containing an isolated nucleic acid as described herein, said expression vector further comprising a Fc nucleic acid sequence encoding a chimeric Fc domain having both IgG1 and IgG3 Fc domain amino acid residues, and wherein the FUT8 gene encoding alpha-1,6-fucosyltransferase has been inactivated in the recombinant host cell; and [0114] b) recovering the antigen binding protein.
[0115] Such methods for the production of antigen binding proteins can be performed, for example, using the ACCRETAMAB.TM. technology system available from BioWa, Inc. (Princeton, N.J.) which combines the POTELLIGENT.TM. and COMPLEGENT.TM. technology systems to produce an antigen binding protein having both ADCC and CDC enhanced activity that is increased relative to an otherwise identical monoclonal antibody lacking a chimeric Fc domain and which has fucose on the oligosaccharide
[0116] In yet another embodiment of the present invention there is provided an antigen binding protein comprising a mutated and chimeric heavy chain constant region wherein said antigen binding protein has an altered glycosylation profile such that the antigen binding protein has enhanced effector function, for example wherein it has one or more of the following functions, enhanced ADCC or enhanced CDC. In one embodiment the mutations are selected from positions 239 and 332 and 330, for example the mutations are selected from S239D and I332E and A330L. In a further embodiment the heavy chain constant region comprises at least one CH2 domain from IgG3 and one Ch2 domain from IgG1. In one embodiment the heavy chain constant region has an altered glycosylation profile such that the ratio of fucose to mannose is 0.8:3 or less for example the antigen binding protein is defucosylated, so that said antigen binding protein has an enhanced effector function in comparison with an equivalent non-chimaeric antigen binding protein or with an immunoglobulin heavy chain constant region lacking said mutations and altered glycosylation profile.
Half-Life Extension
[0117] Increased half-life, or half-life extension, can be useful in in vivo applications of antigen binding proteins, especially antibodies and most especially antibody fragments of small size. Such fragments (Fvs, disulphide bonded Fvs, Fabs, scFvs, dAbs) are generally rapidly cleared from the body. Antigen binding proteins in accordance with the disclosure can be adapted or modified to provide increased serum half-life in vivo and consequently longer persistence, or residence, times of the functional activity of the antigen binding protein in the body. Suitably, such modified molecules have a decreased clearance and increased Mean Residence Time compared to the non-adapted molecule. Increased half-life can improve the pharmacokinetic and pharmacodynamic properties of a therapeutic molecule and can also be important for improved patient compliance.
[0118] The phrases, "half-life" ("t.sub.1/2") and "serum half life", refer to the time taken for the serum (or plasma) concentration of an antigen binding protein in accordance with the disclosure to reduce by 50%, in vivo, for example due to degradation of the antigen binding protein and/or clearance or sequestration of the antigen binding protein by natural mechanisms.
[0119] The antigen binding proteins of the disclosure can be stabilized in vivo and their half-life increased by binding to molecules which resist degradation and/or clearance or sequestration ("half-life extending moiety" or "half-life extending molecule"). Half-life extension strategies are reviewed, for example, in "Therapeutic Proteins: Strategies to Modulate Their Plasma Half-Lives", Edited by Roland Kontermann, Wiley-Blackwell, 2012, ISBN: 978-3-527-32849-9. Suitable half-life extension strategies include: PEGylation, polysialylation, HESylation, recombinant PEG mimetics, N-glycosylation, O-glycosylation, Fc fusion, engineered Fc, IgG binding, albumin fusion, albumin binding, albumin coupling and nanoparticles.
[0120] In one embodiment, the half-life extending moiety or molecule is a polyethylene glycol moiety or a PEG mimetic. In one embodiment, the antigen binding protein comprises (optionally consists of) a single variable domain of the disclosure linked to a polyethylene glycol moiety (optionally, wherein said moiety has a size of about 20 to about 50 kDa, optionally about 40 kDa linear or branched PEG). Reference is made to WO04081026 for more detail on PEGylation of domain antibodies and binding moieties. In one embodiment, the antagonist consists of a domain antibody monomer linked to a PEG, wherein the domain antibody monomer is a single variable domain according to the disclosure. Suitable PEG mimetics are reviewed, for example in Chapter 4, pages 63-80, "Therapeutic Proteins: Strategies to Modulate Their Plasma Half-Lives" Edited by Roland Kontermann, Wiley-Blackwell, 2012, ISBN: 978-3-527-32849-9.
[0121] The interaction between the Fc region of an antibody and various Fc receptors (Fc.gamma.R) is believed to mediate phagocytosis and half-life/clearance of an antibody or antibody fragment. The neonatal FcRn receptor is believed to be involved in both antibody clearance and the transcytosis across tissues (see Junghans (1997) Immunol. Res 16: 29-57; and Ghetie et al. (2000) Annu. Rev. Immunol. 18: 739-766). In one embodiment, the half-life extending moiety may be an Fc region from an antibody. Such an Fc region may incorporate various modifications depending on the desired property. For example, a salvage receptor binding epitope may be incorporated into the antibody to increase serum half life, see U.S. Pat. No. 5,739,277.
[0122] Human IgG1 residues determined to interact directly with human FcRn includes Ile253, Ser254, Lys288, Thr307, GIn311, Asn434 and His435. Accordingly, substitutions at any of the positions described in this section may enable increased serum half-life and/or altered effector properties of the antibodies.
[0123] Half-life extension by fusion to the Fc region is reviewed, for example, in Chapter 9, pages 157-188, "Therapeutic Proteins: Strategies to Modulate Their Plasma Half-Lives" Edited by Roland Kontermann, Wiley-Blackwell, 2012, ISBN: 978-3-527-32849-9.
[0124] Typically, a polypeptide that enhances serum half-life in vivo, i.e. a half-life extending molecule, is a polypeptide which occurs naturally in vivo and which resists degradation or removal by endogenous mechanisms which remove unwanted material from the organism (e.g., human). Typically, such molecules are naturally occurring proteins which themselves have a long half-life in vivo.
[0125] For example, a polypeptide that enhances serum half-life in vivo can be selected from proteins from the extracellular matrix, proteins found in blood, proteins found at the blood brain barrier or in neural tissue, proteins localized to the kidney, liver, muscle, lung, heart, skin or bone, stress proteins, disease-specific proteins, or proteins involved in Fc transport. Suitable polypeptides are described, for example, in WO2008/096158.
[0126] Such an approach can also be used for targeted delivery of an antigen binding protein, e.g. a single variable domain, in accordance with the disclosure to a tissue of interest. In one embodiment targeted delivery of a high affinity single variable domain in accordance with the disclosure is provided.
[0127] In one embodiment, an antigen binding protein, e.g. single variable domain, in accordance with the disclosure can be linked, i.e. conjugated or associated, to serum albumin, fragments and analogues thereof. Half-life extension by fusion to albumin is reviewed, for example in Chapter 12, pages 223-247, "Therapeutic Proteins: Strategies to Modulate Their Plasma Half-Lives" Edited by Roland Kontermann, Wiley-Blackwell, 2012, ISBN: 978-3-527-32849-9.
[0128] Examples of suitable albumin, albumin fragments or albumin variants are described, for example, in WO2005077042 and WO2003076567.
[0129] In another embodiment, a single variable domain, polypeptide or ligand in accordance with the disclosure can be linked, i.e. conjugated or associated, to transferrin, fragments and analogues thereof.
[0130] In one embodiment, half-life extension can be achieved by targeting an antigen or epitope that increases half-live in vivo. The hydrodynamic size of an antigen binding protein and its serum half-life may be increased by conjugating or associating an antigen binding protein of the disclosure to a binding domain that binds a naturally occurring molecule and increases half-live in vivo.
[0131] For example, the antigen binding protein in accordance with the invention can be conjugated or linked to an anti-serum albumin or anti-neonatal Fc receptor antibody or antibody fragment, e.g. an anti-SA or anti-neonatal Fc receptor dAb, Fab, Fab' or scFv, or to an anti-SA affibody or anti-neonatal Fc receptor Affibody or an anti-SA avimer, or an anti-SA binding domain which comprises a scaffold selected from, but not limited to, the group consisting of CTLA-4, lipocallin, SpA, an affibody, an avimer, GroEl and fibronectin (see WO2008096158 for disclosure of these binding domains). Conjugating refers to a composition comprising polypeptide, dAb or antagonist of the disclosure that is bonded (covalently or noncovalently) to a binding domain such as a binding domain that binds serum albumin.
[0132] In another embodiment, the binding domain may be a polypeptide domain such as an Albumin Binding Domain (ABD) or a small molecule which binds albumin (reviewed, for example in Chapter 14, pages 269-283 and Chapter 15, pages 285-296, "Therapeutic Proteins: Strategies to Modulate Their Plasma Half-Lives" Edited by Roland Kontermann, Wiley-Blackwell, 2012, ISBN: 978-3-527-32849-9).
[0133] In one embodiment, there is provided a fusion protein comprising an antigen binding protein in accordance with the invention and an anti-serum albumin or anti-neonatal Fc receptor antibody or antibody fragment.
[0134] The long half-life of IgG antibodies is reported to be dependent on its binding to FcRn. Therefore, substitutions that increase the binding affinity of IgG to FcRn at pH 6.0 while maintaining the pH dependence of the interaction by engineering the constant region have been extensively studied (Ghetie et al., Nature Biotech. 15: 637-640, 1997; Hinton et al., BC 279: 6213-6216, 2004; Dall'Acqua et al.,
[0135] 10 J Immunol 117: 1129-1138, 2006). Another means of modifying antigen binding proteins of the present invention involves increasing the in-vivo half life of such proteins by modification of the immunoglobulin constant domain or FcRn (Fc receptor neonate) binding domain.
[0136] In adult mammals, FcRn, also known as the neonatal Fc receptor, plays a key role in maintaining serum antibody levels by acting as a protective receptor that binds and salvages antibodies of the IgG isotype from degradation. IgG molecules are endocytosed by endothelial cells, and if they bind to FcRn, are recycled out into circulation. In contrast, IgG molecules that do not bind to FcRn enter the cells and are targeted to the lysosomal pathway where they are degraded.
[0137] The neonatal FcRn receptor is believed to be involved in both antibody clearance and the transcytosis across tissues (see Junghans R. P (1997) Immunol. Res 16. 29-57 and Ghetie et al (2000) Annu. Rev. Immunol. 18, 739-766). Human IgG1 residues determined to interact directly with human FcRn includes Ile253, Ser254, Lys288, Thr307, GIn311, Asn434 and His435. Switches at any of these positions described in this section may enable increased serum half-life and/or altered effector properties of antigen binding proteins of the invention.
[0138] Antigen binding proteins of the present invention may have amino acid modifications that increase the affinity of the constant domain or fragment thereof for FcRn. Increasing the half-life of therapeutic and diagnostic IgG's and other bioactive molecules has many benefits including reducing the amount and/or frequency of dosing of these molecules. In one embodiment there is therefore provided an antigen binding according to the invention provided herein or a fusion protein comprising all or a portion (an FcRn binding portion) of an IgG constant domain having one or more of these amino acid modifications and a non-IgG protein or non-protein molecule conjugated to such a modified IgG constant domain, wherein the presence of the modified IgG constant domain increases the in vivo half life of the antigen binding protein.
[0139] PCT Publication No. WO 00/42072 discloses a polypeptide comprising a variant Fc region with altered FcRn binding affinity, which polypeptide comprises an amino acid modification at any one or more of amino acid positions 238, 252, 253, 254, 255, 256, 265, 272, 286, 288, 303, 305, 307, 309, 311, 312, 317, 340, 356, 360, 362, 376, 378, 380, 386, 388, 400, 413, 415, 424, 433, 434, 435, 436, 439, and 447 of the Fc region, wherein the numbering of the residues in the Fc region is that of the EU index (Kabat et al).
[0140] PCT Publication No. WO 02/060919 A2 discloses a modified IgG comprising an IgG constant domain comprising one or more amino acid modifications relative to a wild-type IgG constant domain, wherein the modified IgG has an increased half-life compared to the half-life of an IgG having the wild-type IgG constant domain, and wherein the one or more amino acid modifications are at one or more of positions 251, 253, 255, 285-290, 308-314, 385-389, and 428-435.
[0141] Shields et al. (2001, J Biol Chem; 276:6591-604) used alanine scanning mutagenesis to alter residues in the Fc region of a human IgG1 antibody and then assessed the binding to human FcRn. Positions that effectively abrogated binding to FcRn when changed to alanine include 1253, S254, H435, and Y436. Other positions showed a less pronounced reduction in binding as follows: E233-G236, R255, K288, L309, S415, and H433. Several amino acid positions exhibited an improvement in FcRn binding when changed to alanine; notable among these are P238, T256, E272, V305, T307, Q311, D312, K317, D376, E380, E382, S424, and N434. Many other amino acid positions exhibited a slight improvement (D265, N286, V303, K360, Q362, and A378) or no change (S239, K246, K248, D249, M252, E258, T260, S267, H268, S269, D270, K274, N276, Y278, D280, V282, E283, H285, T289, K290, R292, E293, E294, Q295, Y296, N297, S298, R301, N315, E318, K320, K322, S324, K326, A327, P329, P331, E333, K334, T335, S337, K338, K340, Q342, R344, E345, Q345, Q347, R356, M358, T359, K360, N361, Y373, S375, S383, N384, Q386, E388, N389, N390, K392, L398, S400, D401, K414, R416, Q418, Q419, N421, V422, E430, T437, K439, S440, S442, S444, and K447) in FcRn binding.
[0142] The most pronounced effect was found for combination variants with improved binding to FcRn. At pH 6.0, the E380A/N434A variant showed over 8-fold better binding to FcRn, relative to native IgG1, compared with 2-fold for E380A and 3.5-fold for N434A. Adding T307A to this effected a 12-fold improvement in binding relative to native IgG1. In one embodiment the antigen binding protein of the invention comprises the E380A/N434A mutations and has increased binding to FcRn.
[0143] Dall'Acqua et al. (2002, J Immunol.; 169:5171-80) described random mutagenesis and screening of human IgG1 hinge-Fc fragment phage display libraries against mouse FcRn. They disclosed random mutagenesis of positions 251, 252, 254-256, 308, 309, 311, 312, 314, 385-387, 389, 428, 433, 434, and 436. The major improvements in IgG1-human FcRn complex stability occur in substituting residues located in a band across the Fc-FcRn interface (M252, S254, T256, H433, N434, and Y436) and to lesser extend substitutions of residues at the periphery like V308, L309, Q311, G385, Q386, P387, and N389. The variant with the highest affinity to human FcRn was obtained by combining the M252Y/S254T/T256E and H433K/N434F/Y436H mutations and exhibited a 57-fold increase in affinity relative to the wild-type IgG1. The in vivo behaviour of such a mutated human IgG1 exhibited a nearly 4-fold increase in serum half-life in cynomolgus monkey as compared to wild-type IgG1.
[0144] The present invention therefore provides a variant of an antigen binding protein with optimized binding to FcRn. In a preferred embodiment, the said variant of an antigen binding protein comprises at least one amino acid modification in the Fc region of said antigen binding protein, wherein said modification is selected from the group consisting of 226, 227, 228, 230, 231, 233, 234, 239, 241, 243, 246, 250, 252, 256, 259, 264, 265, 267, 269, 270, 276, 284, 285, 288, 289, 290, 291, 292, 294, 297, 298, 299, 301, 302, 303, 305, 307, 308, 309, 311, 315, 317, 320, 322, 325, 327, 330, 332, 334, 335, 338, 340, 342, 343, 345, 347, 350, 352, 354, 355, 356, 359, 360, 361, 362, 369, 370, 371, 375, 378, 380, 382, 384, 385, 386, 387, 389, 390, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401 403, 404, 408, 411, 412, 414, 415, 416, 418, 419, 420, 421, 422, 424, 426, 428, 433, 434, 438, 439, 440, 443, 444, 445, 446 and 447 of the Fc region as compared to said parent polypeptide, wherein the numbering of the amino acids in the Fc region is that of the EU index in Kabat.
[0145] In a further aspect of the invention the modifications are M252Y/S254T/T256E.
[0146] Additionally, various publications describe methods for obtaining physiologically active molecules whose half-lives are modified either by introducing an FcRn-binding polypeptide into the molecules (WO 97/43316; U.S. Pat. Nos. 5,869,046; 5,747,035; WO 96/32478; WO 91/14438) or by fusing the molecules with antibodies whose FcRn-binding affinities are preserved but affinities for other Fc receptors have been greatly reduced (WO 99/43713) or fusing with FcRn binding domains of antibodies (WO 00/09560; U.S. Pat. No. 4,703,039).
[0147] Although substitutions in the constant region are able to significantly improve the functions of therapeutic IgG antibodies, substitutions in the strictly conserved constant region have the risk of immunogenicity in human (Presta, supra, 2008; De Groot and Martin, Clin Immunol 131: 189-201, 2009) and substitution in the highly diverse variable region sequence might be less immunogenic. Reports concerned with the variable region include engineering the CDR residues to improve binding affinity to the antigen (Rothe et al., Expert Opin Bioi Ther 6: 177-187, 2006; Bostrom et al., Methods Mol Bioi 525: 353-376, 2009; Thie et al., Methods Mol Bioi 525: 309-322, 2009) and engineering the CDR and framework residues to improve stability (Worn and Pluckthun, J Mol Bioi 305: 989-1010, 2001; Ewert et al., Methods 34: 184-199, 2004) and decrease immunogenicity risk (De Groot and Martin, supra, 2009; Jones et al., Methods Mol Bio 525: 405-423, xiv, 2009). As reported, improved affinity to the antigen can be achieved by affinity maturation using the phage or ribosome display of a randomized library.
[0148] Improved stability can be rationally obtained from sequence- and structure-based rational design. Decreased immunogenicity risk (deimmunization) can be accomplished by various humanization methodologies and the removal of T-cell epitopes, which can be predicted using in silico technologies or determined by in vitro assays. Additionally, variable regions have been engineered to lower pI. A longer half life was observed for these antibodies as compared to wild type antibodies despite comparable FcRn binding. Engineering or selecting antibodies with pH dependent antigen binding to modify antibody and/or antigen half life e.g., IgG2 antibody half life, can be shortened if antigen-mediated clearance mechanisms normally degrade the antibody when bound to the antigen. Similarly, the antigen:antibody complex can impact the half-life of the antigen, either extending half-life by protecting the antigen from the typical degradation processes, or shortening the half-life via antibody-mediated degradation. One embodiment relates to antibodies with higher affinity for antigen at pH 7.4 as compared to endosomal pH (i.e., pH 5.5-6.0) such that the KD ratio at pH5.5/pH 7.4 or at pH 6.0/pH 7.4 is 2 or more. For example, to enhance the pharmacokinetic (PK) and pharmacodynamic (PD) properties of the antibody, it is possible to engineer pH-sensitive binding to the antibody by introducing histidines into CDR residues.
Pharmaceutical Compositions
[0149] The antigen binding proteins of the present invention will normally, but not necessarily, be formulated into pharmaceutical compositions prior to administration to a patient. Accordingly, in another aspect of the invention there is provided a pharmaceutical composition comprising an antigen binding protein and optionally one or more pharmaceutically acceptable excipients and/or carriers.
[0150] Methods for the preparation of such pharmaceutical compositions are well known to those skilled in the art (e.g. Remington's Pharmaceutical Sciences, 16th edition (1980) Mack Publishing Co and Pharmaceutical Biotechnology; Plenum publishing corporation; Volumes 2, 5 and 9).
[0151] The antigen binding proteins of the present invention may be formulated for administration in any convenient way. Pharmaceutical compositions may, for example, be administered by injection or continuous infusion (examples include, but are not limited to, intravenous, intraperitoneal, intradermal, subcutaneous, intramuscular and intraportal). In one embodiment, the composition is suitable for subcutaneous injection.
[0152] Pharmaceutical compositions may be suitable for topical administration (which includes, but is not limited to, epicutaneous, inhaled, intranasal or ocular administration) or enteral administration (which includes, but is not limited to, oral or rectal administration).
[0153] Pharmaceutical compositions may comprise between 0.0001 mg/kg to 10 mg/kg of antigen binding protein, for example between 0.1 mg/kg and 5 mg/kg of antigen binding protein. Alternatively, the composition may comprise between 1.0 mg/kg and 3.0 mg/kg.
[0154] Pharmaceutical compositions may comprise, in addition to an antigen binding protein of the present invention, one or more other therapeutic agents.
Methods of Use
[0155] The antigen binding proteins described herein may have use in therapy. Antigen binding proteins of the present invention that bind Lymphocyte Activation Gene 3 (LAG-3) and cause depletion of LAG-3+ activated T cells may have use in the treatment or prevention of diseases associated with the involvement of pathogenic T cells, such as auto-immune diseases and cancer.
[0156] Examples of disease states in which the antigen binding proteins have potentially beneficial effects include psoriasis, Crohn's disease, rheumatoid arthritis, primary biliary cirrhosis, SLE, Sjogren's syndrome, multiple sclerosis, ulcerative colitis and autoimmune hepatitis.
[0157] The antigen binding proteins of the present invention may also have use in the treatment of cancer.
[0158] It will be appreciated by those skilled in the art that references herein to "treatment" or "therapy" may, depending on the condition, extend to prophylaxis in addition to the treatment of an established condition.
[0159] There is thus provided as a further aspect of the invention an antigen binding protein of the present invention for use in therapy.
[0160] There is also therefore provided an antigen binding protein of the present invention for use in the treatment of psoriasis, Crohn's disease, rheumatoid arthritis, primary biliary cirrhosis, SLE, Sjogren's syndrome, multiple sclerosis, ulcerative colitis or autoimmune hepatitis.
[0161] In a further embodiment, there is provided an antigen binding protein of the present invention for use in the treatment of psoriasis.
[0162] There is further provided the use of an antigen binding protein of the present invention in the manufacture of a medicament for the treatment of psoriasis, Crohn's disease, rheumatoid arthritis, primary biliary cirrhosis, SLE, Sjogren's syndrome, multiple sclerosis, ulcerative colitis or autoimmune hepatitis.
[0163] In a further embodiment, there is provided the use of an antigen binding protein of the present invention in the manufacture of a medicament for the treatment of psoriasis.
[0164] There is further provided a method of treatment of psoriasis, Crohn's disease, rheumatoid arthritis, primary biliary cirrhosis, SLE, Sjogren's syndrome, multiple sclerosis, ulcerative colitis or autoimmune hepatitis, which method comprises administering to a human subject in need thereof, a therapeutically effective amount of an antigen binding protein of the present invention.
[0165] In a further embodiment, there is provided a method of treatment of psoriasis, which method comprises administering to a human subject in need thereof, a therapeutically effective amount of an antigen binding protein of the present invention.
[0166] The phrase "therapeutically effective amount" as used herein is an amount of an antigen binding protein of the present invention required to ameliorate or reduce one or more symptoms of, or to prevent or cure, the disease.
Examples
[0167] The following Examples illustrate but do not limit the invention.
Example 1: Biacore.TM. SPR Analysis of Purified Anti-LAG-3 Humanised Antibodies
[0168] Anti-LAG-3 humanised antibodies were expressed in HEK 293 6E cells and purified by affinity chromatography as follows:
[0169] 100 ml Scale HEK 293 6E Expression
[0170] Expression plasmids encoding heavy and light chains of the humanised antibodies identified in Table 3 were transiently co-transfected into HEK 293 6E cells and expressed at 100 ml scale to produce antibody.
[0171] Purification of Humanised Antibodies
[0172] The expressed antibody molecules were purified by affinity chromatography. Protein A sepharose beads (GE Healthcare Cat No 17-5280-04), were added to the cell culture supernatants and mixed at room temperature for 30-60 minutes. The protein A sepharose beads were then centrifuged and washed in PBS. The mixture was then added into a 10 ml disposable column (Pierce Cat No: 29924) and the PBS allowed to drain. The column was washed 3 times with 10 ml PBS before elution of the antibody with IgG Elution buffer (Pierce Cat No: 21009). The antibody eluted was immediately neutralized using 1M Trizma.RTM. hydrochloride buffer (T2819) and was then buffer exchanged into PBS with a Vivaspin 6 mwco 5000 column (Cat. No.: FDP-875-105D). The yield was determined by measurement of absorbance at 280 nm. The level of aggregated protein in the purified sample was determined by size exclusion chromatography.
[0173] Binding Kinetics
[0174] The binding kinetics of the purified antibodies for sLAG-3 were assessed by SPR using a Biacore.TM. 3000. A goat anti-human kappa antibody (Southern Biotech, Catalogue No. 2060-01) was immobilised on a CM5 chip by primary amine coupling. Humanised anti-LAG3 antibodies were captured on this surface and the LAG3-Ig molecule IMP321 (Chrystelle Brignone, Caroline Grygar, Manon Marcu, Knut Schakel, Frederic Triebel, The Journal of Immunology, 2007, 179: 4202-4211) used as the analyte at 64 nM with a buffer injection (i.e. 0 nM) used to double reference the binding curves. Regeneration was with 10 mM Glycine, pH1.5. The run was carried out on the Biacore.TM. 3000, using HBS-EP as running buffer and at 25.degree. C. Sensorgrams were normalised for binding at maximal association and off-rates compared against IMP731 by visual inspection of the sensorgram profiles.
[0175] The results show that the purified humanised anti-LAG-3 antibodies can be categorised into 3 groups; group 1 with humanised variants that appear to be better at binding to IMP321 than the chimeric IMP731, group 2 with variants that appear to bind in a very similar manner to IMP731 and group 3 with variants that demonstrate worse binding than IMP731.
[0176] 10 humanised variants fall within group 1 and demonstrate improved off-rates when compared to IMP731 by visual inspection of the Biacore.TM. sensorgrams. All of these molecules contained the L7 light chain, which contains a glycine to proline substitution at position 27e in light chain CDR1. This data indicates that proline at position 27e improves the off-rate for IMP321 of the humanised anti-LAG-3 antibodies when paired with numerous humanised heavy chains.
[0177] Of the remaining antibodies tested, 4 molecules fall within group 2 and had similar off-rates to the chimeric IMP731 antibody, while 4 other molecules fall within group 3 and exhibit worse off-rates than IMP731. Table 3 provides an approximate ranking of those molecules in comparison to IMP731. H5L7 exhibits the best off-rate in this experiment.
TABLE-US-00003 TABLE 3 Comparison of off-rates with IMP731 Humanised Off-rate comparison Rank order of Variant with IMP731 off-rates H5L7 better 1 H1L7 better 2 J7L7 better 3 H4L7 better 4 J11L7 better 5 H2L7 better 6 J13L7 better 7 H7L7 better 8 J0L7 better 9 H0L7 better 10 H1L1 same H5L1 same J7L1 same J11L1 same J13L1 worse H7L1 worse J0L1 worse H0L1 worse
Example 2: Binding Analysis of Wild Type Fucosylated and Afucosylated Humanised Anti-LAG-3 Antibodies for Binding to Recombinant Human LAG-3-his Using the Biacore.TM. T100
[0178] Afucosylated antibody H5L7BW was generated by expression of plasmids encoding H5L7 in the BioWa Potelligent.RTM. (FUT8 knock-out CHO) cell line. Afucosylated antibodies produced using Potelligent.RTM. technology have been shown to exhibit increased antibody dependent cell-mediated cytotoxicity (ADCC) compared to equivalent highly-fucosylated conventional antibodies through increased affinity to Fc.gamma.RIIIa (CD16).
[0179] Wild type fucosylated and afucosylated antibodies were compared for their ability to bind to recombinant human LAG-3 ECD with a C-terminal His6 (SEQ ID NO:51) using the Biacore.TM. T100 (GE Healthcare.TM.). Protein A was immobilised on a CM5 chip by primary amine coupling. This surface was then used to capture the humanised antibodies. Recombinant human LAG-3 ECD-His6 was then passed over the captured antibodies at 32, 8, 2, 0.5 and 0.125 nM and regeneration was carried out using 50 mM NaOH. The binding curves were double referenced with buffer injection (i.e. 0 nM) and the data was fitted to the T100 analysis software using the 1:1 model. The run was carried out at 25.degree. C., using HBS-EP as the running buffer.
[0180] In order to investigate the statistical significance of this kinetic data, this experiment was repeated 3 times with the same batch of the four antibodies and the chimeric control. KD, ka and kd parameters were each log (base 10) transformed prior to separate statistical analyses. For each parameter, a mixed model analysis of variance (`Anova`) was performed on transformed data, including terms for Run (random block effect) and Antibody.
[0181] From the Anova, geometric means were predicted for each antibody, along with statistically plausible ranges (95% confidence intervals) for each mean. Planned comparisons of antibodies were performed within the Anova. Comparisons are presented as ratios of the two antibodies compared, again with 95% confidence intervals and p values. The ratios may also be interpreted as a fold change, e.g. a ratio of 0.1 corresponds to a 90% decrease.
[0182] Geometric means were derived for each of the humanised antibodies and the chimeric control IMP731 for the binding affinity (KD), shown in Table 4. The mean KD for H5L7 was 0.2075 nM, a significant decrease of 92% (i.e. 10 fold decrease) with p<0.0001 when compared with IMP731. IMP731 exhibited a mean KD of 2.76 nM. Afucosylated H5L7BW exhibits equivalent binding as fucosylated H5L7, with a geometric KD of 0.2179 nM, with no significant difference (p=0.1790).
[0183] The improvement in affinity observed for H5L7 in comparison to IMP731 is predominantly driven by differences in the off-rates of the antibodies for LAG-3-ECD-His6, shown in Table 5. There is an approximate 85% decrease (i.e. almost 10 fold decrease) in kd for H5L7 in comparison IMP731 which is highly statistically significant. There is no significant difference between afucosylated H5L7BW and H5L7 (p=0.4408).
TABLE-US-00004 TABLE 4 Statistical evaluation for the KD of fucosylated and afucosylated anti-LAG-3 variants binding to recombinant human LAG-3-His Geometric Means for KD (nM) Geometric Lower Upper Antibody Batch No mean 95% CI 95% CI H5L7 GRITS42382 2.08E-10 1.89E-10 2.28E-10 H5L7BW GRITS42760 2.18E-10 1.98E-10 2.40E-10 IMP731 020909 2.76E-09 2.51E-09 3.04E-09 Comparisons of KD Lower Upper KD comparison Ratio 95% CI 95% CI P value H5L7BW-H5L7 1.0502 0.97268 1.13389 0.179 H5L7-IMP731 0.07736 0.0715 0.0837 <.0001
TABLE-US-00005 TABLE 5 Statistical evaluation for the kd of fucosylated and afucosylated anti-LAG-3 variants binding to recombinant human LAG-3-His Geometric Means for kd (1/s) Geometric Lower Upper Antibody Batch No mean 95% CI 95% CI H5L7 GRITS42382 3.95E-03 3.16E-03 4.94E-03 H5L7BW GRITS42760 4.41E-03 3.53E-03 5.51E-03 IMP731 020909 2.75E-02 2.20E-02 3.44E-02 Comparisons of kd Lower Upper KD comparison Ratio 95% CI 95% CI P value H5L7BW-H5L7 1.11715 0.81531 1.53073 0.4408 H5L7-IMP731 0.15478 0.11157 0.21471 <.0001
Example 3: Evaluation of the LAG-3-his Binding Epitope of Anti-LAG-3 Humanised Variants in Comparison with Chimeric Antibody IMP731 Using the ProteOn.TM.
[0184] An epitope binning experiment was performed with H5L7 to evaluate whether the LAG-3 epitope within which IMP731 binds was conserved upon humanisation. Furthermore, the binding epitope of fucosylated and afucosylated humanised variants was also compared.
[0185] Epitope binding was evaluated using the ProteOn.TM. XPR36 (BioRad.TM.) biosensor machine, by assessing whether anti-LAG-3 antibodies were able to simultaneously bind to LAG-3-His in complex with antibody captured on the ProteOn.TM. chip surface. IMP731 and non-competitive murine antibody 1764 were utilised as controls in this assay.
[0186] The antibodies to be tested were biotinylated using Ez-Link-sulfo-NHS biotinylation kit. Each biotinylated antibody was captured on a separate flow cell on a neutravidin NLC chip using a vertical injection. After antibody capture, the surface was blocked with biocytin at 2.5 mg/ml. Using the co-inject facility inherent to the ProteOn run software, LAG-3 ECD-His6 was injected over the coupled antibodies at 100 nM, followed by the un-biotinylated antibodies at 100 nM with both injections being horizontal so that the LAG-3-His and the antibodies cross all 6 neutravidin captured antibodies. The assay was run at 25.degree. C. and in HBS-EP on the ProteOn XPR36 Protein Interaction Array System.
[0187] Data analysis was carried out using report points taken after the LAG-3-His injection and report points taken after the un-biotinylated antibody analyte injection. The overall response was calculated by subtracting the response seen with the antibody binding from the response seen with LAG-3 ECD-His6 binding. A positive resonance unit (RU) value meant that antibody analyte injection had bound to LAG-3 ECD-His6 complexed with the biotinylated antibody on the neutravidin capture surface, indicative of binding at non-competitive epitopes. No response or a negative response meant that antibody analyte injection had not bound to LAG-3 ECD-His6 complexed with the biotinylated antibody on the neutravidin capture surface, indicating antibodies bind at competitive epitopes.
[0188] Anti-LAG-3 humanised variants (fucosylated and afucosylated) are unable to bind to human LAG-3 ECD-His6 in complex with IMP731, indicative that the epitope for LAG-3 ECD-His6 is shared and thus conserved. Murine antibody 17134 is able to bind to human LAG-3 ECD-His6 in complex with IMP731 substantiating that this antibody is non-competitive for LAG-3 ECD-His6 binding with IMP731. Conversely, the humanised antibodies are able to bind to human LAG-3 ECD-His6 in complex with 1764.
[0189] The results confirm that there has been no alteration in epitope between the chimeric IMP731 and the humanised variant of IMP731 tested in this experiment. The experiment also shows that there is no difference between fucosylated and afucosylated antibodies for binding.
Example 4: Binding Analysis of Anti-LAG-3 Humanised Antibodies to Recombinant Cynomolgus Macaque and Baboon LAG-3 ECD-His6 Using the Biacore.TM. T100
[0190] The binding cross reactivity of anti-LAG-3 humanised antibodies for both cynomolgus macaque (cyno) and baboon recombinant LAG-3 ECD-His6 (SEQ ID NOs 52 and 53, respectively) was assessed using the Biacore.TM. T100 (GE Healthcare.TM.).
[0191] Protein A was immobilised on a CM5 chip by primary amine coupling. This surface was then used to capture the humanised antibodies. In-house generated recombinant cynomolgus macaque and baboon LAG-3 ECD-His6 were then passed over the captured antibodies and regeneration was carried out using 50 mM NaOH. LAG-3 ECD-His6 was passed over at 16, 4, 1, 0.25 and 0.0625 nM. The binding curves were double referenced with buffer injection (i.e. 0 nM) and the data was fitted to the T100 analysis software using the 1:1 model. The run was carried out at 37.degree. C. using HBS-EP as the running buffer.
[0192] H5L7, H5L7BW and IMP731 bind with comparable affinity to both cynomolgus macaque and baboon recombinant LAG-3 ECD-His6. Data was generated from separate experiments, however chimeric antibody IMP731 was utilised as a control between experiments.
[0193] This data indicates that both non-human primate recombinant LAG-3 orthologues bind to the H5L7 derived antibodies with a 10 fold improvement in affinity in comparison with human recombinant LAG-3 ECD-His6 (SEQ ID NO: 51) (H5L7: human LAG-3 0.208 nM, cyno LAG-3 0.017 nM and baboon LAG-3 0.022 nM; H5L7BW human LAG-3 0.218 nM, cyno LAG-3 0.021 nM and baboon LAG-3 0.024 nM). Whilst both non-human primate recombinant LAG-3 orthologues bind to IMP731 derived antibodies with an improvement in affinity of approximately 100 fold in comparison with human recombinant LAG-3 ECD-His6 (SEQ ID NO: 51) (IMP731: human LAG-3 2.76 nM, cyno LAG-3 0.021 nM and baboon LAG-3 0.019 nM).
Example 5: Binding Profiles of H5L7BW, H5L7 and IMP731 to Human LAG-3 Expressing EL4 Cells, and Human Primary Activated CD3+ T Cells
[0194] Human LAG-3 expressing EL4 cells were incubated with either IMP731, H5L7WT or H5L7BW Alexa647-conjugated antibodies at varying concentrations of up to 50 .mu.g/ml for 30 minutes at room temperature. Cells were washed with FACS buffer (PBS+0.5% BSA) to remove unbound antibody.
[0195] CD3.sup.+ T cells were prepared from PBMCs by negative selection using Untouched Human T cell Dynal beads. CD3.sup.+ T cells were activated by incubation with immobilised anti-CD3 and anti-CD28 and soluble recombinant human IL-12 for 3 days at 37.degree. C. Activated cells were incubated with Alexa 647-conjugated antibodies of varying concentrations up to 3 .mu.g/ml for 30 minutes at room temperature. Cells were washed with FACS buffer (PBS+0.5% BSA).
[0196] EL4 cells and CD3.sup.+ T cells were analysed by FACS using a Beckman Coulter FC 500 flow cytometer. FACS raw data were analysed using CXP Analysis software (Beckman Coulter). The data was initially plotted on a forward-scatter versus side-scatter plot and the population of cells of interest were gated. This gated population was then plotted as a histogram displaying fluorescence intensity and the mean fluorescence intensity (MFI) calculated. MFI values were then plotted in GraphPad Prism 5 software to generate dose response curves.
[0197] Binding profiles of H5L7BW, H5L7 and IMP731 to human LAG-3 expressing EL4 cells, and human primary activated CD3+ T cells are shown in FIG. 1A and FIG. 1B. The three antibodies exhibited similar binding characteristics to human LAG-3 expressing EL4 cells (FIG. 1A) and activated human CD3+ T cells (FIG. 1B).
Example 6: Assessment of the Depleting Activity of H5L7BW and H5L7 by Antibody Dependent Cellular Cytotoxicity (ADCC) in Primary Human T Cells
[0198] The donors used in these experiments were screened for re-call responses to the CD4 antigens present in Revaxis, (Diptheria, Tetanus and Poliomyelitis) and to either a CMVpp65 peptide pool or to a CD8 peptide pool, which contained peptide epitopes to CMV, EBV and Influenza. The antigen used to perform initial studies was the CMVpp65 peptide pool. However, due to the limited number of donors that demonstrated a re-call response to this antigen, Revaxis and the CD8 peptide pool were the antigens used to generate the majority of the potency data for the anti-LAG3 antibodies.
[0199] Peripheral blood was collected from healthy human volunteers on day 0 (25 mL) and day 5 (75 mL) of the experiment and was used to prepare mononuclear cells by ficollplaque density gradient centrifugation. The PBMCs prepared on day 0 were labeled using the CellTrace.TM. Violet Cell Proliferation Kit, in accordance with the manufacturer's instructions, after which they were washed, seeded in 24-well flat bottomed tissue culture plates at a density of 2.times.106/mL in medium and stimulated with antigen (Revaxis and the CD8 peptide pool were used at a dilution of 1 in 1000; the CMVpp65 peptide was used at a dilution of 1 in 100). The PBMCs were incubated for 5 days at 37.degree. C. in a 5% CO2 humidified incubator.
[0200] Autologous donor NK cells were purified from the PBMCs prepared on day 5 of the experiment by negative selection using kits from either Invitrogen or Miltenyi Biotec in accordance with the specific instructions of each manufacturer. The purified NK cells were counted and diluted to a density of 1.3.times.10.sup.6/mL in medium.
[0201] The cells that had been stimulated with antigen for 5 days were washed, counted and diluted to a density of 2.times.10.sup.6/viable cells/mL in medium.
[0202] Autologous donor NK cells (80 .mu.L) and antigen activated cells (100 .mu.L) were pipetted into round-bottomed 5 mL polystyrene FACS tubes with test antibody or medium (20 .mu.L). The final concentrations of the anti LAG-3 antibodies tested ranged from 1000 to 0.015 ng/mL. The samples were incubated for 18 h at 37.degree. C. in a 5% CO2 humidified incubator. After 18 h the ADCC assay samples were analysed for the presence of antigen specific LAG-3 positive T cells using flow cytometry. Briefly, the samples were washed in FACS buffer, blocked with human IgG (3 .mu.g/tube), and incubated with mouse anti-human CD4, CD8, CD337, CD25 and LAG-3 fluorochrome conjugated antibodies for 30 minutes in the dark at room temperature. After a further wash step in PBS the cells were incubated in the presence of a fixable green dead cell for 30 minutes in the dark at room temperature. The samples were finally washed with PBS, fixed and analysed by flow cytometry using a 60 second acquisition time at a flow rate of 1 .mu.L per second.
[0203] All sample data were acquired using the BD FACSCanto II Flow Cytometer with FACS Diva software version 6.1.3 (BD BioSciences). The gating strategy used is shown in FIG. 2. The Live/Dead fixable green dead cell stain was used as a dead cell exclusion marker and appropriate isotype and FMO-1 controls were used to define negative populations. Briefly dead cells were omitted from the analysis using a plot of forward scatter (FSC-A) against fluorescence in FL1 (Green dead cell stain). Doublets were then excluded from the analysis by using a plot of FSC-W against FSC-H. Viable single lymphocytes were subsequently identified and gated using a plot of forward scatter (FSC-A) against side scatter (SSC-A). CD4 antigen specific T cells were identified from this gated population of cells using plots of CD4 fluorescence against SSC-A and Violet Dye fluorescence against CD4 fluorescence respectively. Antigen specific CD4 T cells were identified by a reduction of Violet Dye fluorescence. A further plot of CD25 fluorescence against LAG-3 fluorescence was drawn to confirm the activation state of this population of cells and that they expressed LAG-3. Similar plots were drawn to identify antigen specific CD8 T cells.
[0204] The percentages of antigen specific CD4 and CD8 T cells present in each sample (as a percentage of the viable lymphocyte population) were recorded. Nonlinear variable slope curve-fits of these data were plotted and EC50 values were generated using GraphPad Prism software (v5.03).
[0205] To calculate the maximum level of depletion observed in an assay, at the highest concentration of antibody tested, the following formula was used: (1-(% Antigen specific T cells remaining after antibody treatment)/(% Antigen specific T cells remaining in the absence of antibody))*100.
[0206] Potency data for the depletion of LAG3 positive antigen specific CD8 and CD4 T cells by H5L7BW and H5L7 was generated using the in vitro assay system detailed above. H5L7BW induced depletion of LAG3 positive antigen specific CD4 and CD8 T cells by ADCC in six of the seven donors studied for disappearance of the respective cell types. The potency of H5L7BW in antigen specific CD4 T cells, as quantified by EC50 values, ranged from 14 .mu.g/mL to 3.4 ng/mL with maximum levels of depletion ranging from 44 to 78%. The potency of this antibody in antigen specific LAG-3 positive CD8 T cells ranged from 122 .mu.g/mL to 17.5 ng/mL, with maximum levels of depletion ranging from 39 to 87%. H5L7 mediated low levels of depletion, or was inactive, in the donors studied.
Example 7: Assessment of the Depleting Activity of H5L7BW and H5L7 in an In-Vivo Human PBMC/Mouse SCID Xenograft Model
[0207] This assay describes the use of a human PBMC/mouse SCID xenograft model to assess in vivo depletion efficacy of the monoclonal, fully humanised, afucosylated LAG-3 depleting antibody H5L7BW on activated human T cells. Healthy volunteer peripheral blood mononuclear cells (PBMCs) were isolated and stimulated overnight (anti-CD3, IL-12) to induce LAG-3 expression prior to injection into the peritoneum of immuno-compromised SCID mice. LAG-3 depleting or control antibodies were either co-administered into the peritoneum or injected intravenously.
[0208] Depletion of LAG-3 positive cells was assessed by flow cytometry in peritoneal lavage samples 5 or 24 hours after cell injection.
[0209] Mice were injected with activated huPBMCs (4.times.10.sup.6-2.times.10.sup.7 cells in 0.4 ml of PBS) by the intraperitoneal route. Depending on the particular study route, LAG-3 antibodies or huIgG1 BioWa controls were either co-administered i.p. with the huPBMCs or mice were pre-treated intravenously 18 h prior to huPBMC injection. 5 or 24 hours post-cell injection, mice were euthanized, a peritoneal lavage was performed and the cellular content of the lavage buffer analysed by flow cytometry. Briefly, peritoneal lavage involved 3.times.5 ml washes of the intact peritoneal cavity using cold PBS containing 3 mM EDTA.
[0210] All sample data were acquired using the BD FACSCanto II Flow Cytometer with FACS Diva software version 6.1.3 (BD BioSciences). Approximately 1.times.10.sup.6 cells (where possible) were added per FACS tube, the cell suspensions centrifuged at 1500 rpm for 10 minutes, and the pellet then re-suspended in 3 ml PBS. The supernatants were then carefully decanted and the cell pellets re-suspended in 100 .mu.l cold FACS wash buffer. 15 .mu.l FcR Blocking Reagent was then added per tube and the cells incubated for 10 minutes at room temperature. 5 .mu.l of each staining antibody (10 .mu.l of 1:100 pre-diluted anti-LAG-3 blocking/detection antibody 1764-PE) or isotype control were then added respectively and incubated for 20 minutes at room temperature protected from light. The cells were subsequently washed by addition of 4 ml FACS buffer per tube and centrifugation at 1500 rpm for 5 minutes after which the supernatant was carefully decanted. This washing step was repeated. Finally the cells were re-suspended in 300 .mu.l FACS buffer and analysed by flow cytometry. In addition to LAG-3 detection by use of the fluorescently labeled LAG-3 blocking antibody 1764-PE, the following T cell and activation markers were used for T cell phenotyping: CD45, CD4, CD8, and CD25. Percentages of CD4 and CD8 T cells were expressed as percentage of CD45 positive cells. LAG-3 positive T cell populations were expressed as percentages of their parent populations CD4 and CD8.
[0211] FACS Diva software version 6.1.3 was used to generate batch analyses of individual cell counts/events and cell population percentages. Data were analysed with SAS version 9.2.2 software using a generalized linear model for binomial data. This analysis directly models the cell count as a proportion of the parent population. In this way, the size of the parent population is taken into account during the analysis. Means were calculated for proportions of target cell type for each treatment, along with 95% confidence intervals. These were expressed as percentages.
[0212] Planned comparisons of treatments versus Control were made using odds ratios. This expresses the odds of having a target cell type in one treatment as a ratio to the odds of having the target cell type on control treatment. An odds ratio <1 would indicate a reduced odds of having the cell type in the treatment of interest compared to the control. An odds ratio <1 would indicate a reduced odds of having the cell type in the treatment of interest compared to the control.
[0213] All experiments were performed using PBMCs from individual healthy blood donors and due to the large blood volumes required per experiment, no donor was used more than once. LAG-3 expression levels after overnight stimulation varied greatly between donors (ranging from 2-73% cell surface expression) but these differences in expression levels had no effect on the highly significant depletion efficacy of the tested antibodies.
[0214] The human PBMC/mouse SCID in vivo model was successfully used to show depletion of activated human, LAG-3 expressing T cells in the peritoneum of immunocompromised SCID mice. Depending on donor, route of administration and time point of analysis, between 84.22-99.71% of LAG-3 positive human CD4 T cells and between 84.64-99.62% of LAG-3 positive human CD8 T cells were depleted. As shown in FIG. 3A and FIG. 3B, co-administration of 5 mg/kg H5L7BW to activated human PBMCs in the peritoneum of SCID mice led to highly significant depletion of LAG-3 positive CD4 and CD8 positive T cells 24 hours after injection compared to Control IgG injected animals.
[0215] FIG. 4A and FIG. 4B highlight the comparison between 5 mg/kg H5L7BW and H5L7 5 hours after co-i.p. administration to activated human PBMCs as described before. Both antibodies induced highly significant depletion of LAG-3 positive CD4 and CD8 T cells (FIG. 4A).
[0216] As shown in FIG. 5A and FIG. 5B, administration of 5 mg/kg H5L7BW via the intra-venous route resulted in a highly statistically significant depletion of LAG-3 positive T cells after 5 hours, similar to what was observed in the experiments with i.p. co-administered LAG-3 depletion antibodies (FIG. 5A). The comparison between i.v. administered H5L7BW, H5L7 and IMP731 (all at 5 mg/kg) 5 hours after i.p. administration of activated human PBMCs revealed very similar depletion efficacies between the 3 molecules compared to control treated animals (FIG. 6A and FIG. 6B). Each of the 3 tested LAG-3 depleting antibodies caused highly significant reduction in the number of LAG-3 positive CD4 and CD8 T cells (FIG. 6A) with H5L7BW demonstrating greater depletion capacity compared to H5L7 or IMP731.
Sequences
TABLE-US-00006 [0217] TABLE 6 Sequence Summary Sequence Identifier (SEQ ID No.) Amino Poly- acid nucleotide Sequence Sequence Sequence H5L7, CDRL1 (Kabat defined) 1 57 H5L7, CDRL2 (Kabat defined) 2 58 H5L7, CDRL3 (Kabat defined) 3 59 H5L7, VL 4 60 H5L7, light chain humanized construct 5 61 H5L7, CDRH1 (Kabat defined) 6 62 H5L7, CDRH2 (Kabat defined) 7 63 H5L7, CDRH3 (Kabat defined) 8 64 H5L7, VH 9 65 H5L7, heavy chain humanised construct 10 66 H1L7, light chain humanised construct 11 67 H1L7, heavy chain humanised construct 12 68 J7L7, light chain humanised construct 13 69 J7L7, heavy chain humanised construct 14 70 H4L7, light chain humanised construct 15 71 H4L7, heavy chain humanised construct 16 72 J11L7, light chain humanised construct 17 73 J11L7, heavy chain humanised construct 18 74 H2L7, light chain humanised construct 19 75 H2L7, heavy chain humanised construct 20 76 J13L7, light chain humanised construct 21 77 J13L7, heavy chain humanised construct 22 78 H7L7, light chain humanised construct 23 79 H7L7, heavy chain humanised construct 24 80 J0L7, light chain humanised construct 25 81 J0L7, heavy chain humanised construct 26 82 H0L7, light chain humanised construct 27 83 H0L7, heavy chain humanised construct 28 84 H1L1, light chain humanised construct 29 85 H1L1, heavy chain humanised construct 30 86 H5L1, light chain humanised construct 31 87 H5L1, heavy chain humanised construct 32 88 J7L1, light chain humanised construct 33 89 J7L1, heavy chain humanised construct 34 90 J11L1, light chain humanised construct 35 91 J11L1, heavy chain humanised construct 36 92 J13L1, light chain humanised construct 37 93 J13L1, heavy chain humanised construct 38 94 H7L1, light chain humanised construct 39 95 H7L1, heavy chain humanised construct 40 96 J0L1, light chain humanised construct 41 97 J0L1, heavy chain humanised construct 42 98 H0L1, light chain humanised construct 43 99 H0L1, heavy chain humanised construct 44 100 Human kappa chain constant region 45 101 Human IgG1 constant region 46 102 IMP731, VH 47 103 IMP731, VL 48 104 IMP731, heavy chain sequence 49 105 IMP731, light chain sequence 50 106 Recombinant human LAG-3-ECD-His6 51 107 Recombinant cynomolgus macaque 52 108 LAG-3 ECD-His6 Recombinant baboon LAG-3 ECD-His6 53 109 Leader sequence used for humanised 54 110 variant heavy and light chain constructs IMP731 Leader sequence 55 111 Leader sequence used for soluble 56 112 LAG-3 constructs
TABLE-US-00007 SEQ ID NO. 1 KSSQSLLNPSNQKNYLA SEQ ID NO. 2 FASTRDS SEQ ID NO. 3 LQHFGTPPT SEQ ID NO. 4 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNPSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKR SEQ ID NO. 5 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNPSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 6 AYGVN SEQ ID NO. 7 MIWDDGSTDYDSALKS SEQ ID NO. 8 EGDVAFDY SEQ ID NO. 9 QVQLQESGPGLVKPSETLSLTCTVSGFSLTAYGVNWIRQPPGKGLEWIGMIWDDGSTDYDSALKSRVTISVDTS KNQFSLKLSSVTAADTAVYYCAREGDVAFDYWGQGTLVTVSS SEQ ID NO. 10 QVQLQESGPGLVKPSETLSLTCTVSGFSLTAYGVNWIRQPPGKGLEWIGMIWDDGSTDYDSALKSRVTISVDTS KNQFSLKLSSVTAADTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 11 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNPSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 12 QVQLQESGPGLVKPSETLSLTCTVSGFSLTAYGVNWIRQPPGKGLEWIGMIWDDGSTDYNSALKSRVTISVDTS KNQFSLKLSSVTAADTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 13 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNPSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 14 QVQLVQSGAEVKKPGSSVKVSCKASGESLTAYGVNWVRQAPGQGLEWMGMIWDDGSTDYNSALKSRVTITADKS TSTAYMELSSLRSEDTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 15 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNPSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 16 QVQLQESGPGLVKPSETLSLTCTVSGFSLTAYGVNWIRQPPGKGLEWLGMIWDDGSTDYNSALKSRLTISKDNS KNQVSLKLSSVTAADTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 17 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNPSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 18 QVQLVQSGAEVKKPGSSVKVSCKASGESLTAYGVNWVRQAPGQGLEWMGMIWDDGSTDYDSALKSRVTITADKS TSTAYMELSSLRSEDTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 19 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNPSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 20 QVQLQESGPGLVKPSETLSLTCTVSGFSLTAYGVNWIRQPPGKGLEWIGMIWDDGSTDYNSALKSRVTISKDNS KNQVSLKLSSVTAADTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 21 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNPSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 22 QVQLVQSGAEVKKPGSSVKVSCKASGGTESAYGVNWVRQAPGQGLEWMGMIWDDGSTDYDSALKSRVTITADKS TSTAYMELSSLRSEDTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 23 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNPSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 24
QVQLQESGPGLVKPSETLSLTCTVSGGSISAYGVNWIRQPPGKGLEWIGMIWDDGSTDYDSALKSRVTISVDTS KNQFSLKLSSVTAADTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 25 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNPSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 26 QVQLVQSGAEVKKPGSSVKVSCKASGGTESAYGVNWVRQAPGQGLEWMGMIWDDGSTDYNSALKSRVTITADKS TSTAYMELSSLRSEDTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 27 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNPSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 28 QVQLQESGPGLVKPSETLSLTCTVSGGSISAYGVNWIRQPPGKGLEWIGMIWDDGSTDYNSALKSRVTISVDTS KNQFSLKLSSVTAADTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 29 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNGSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 30 QVQLQESGPGLVKPSETLSLTCTVSGFSLTAYGVNWIRQPPGKGLEWIGMIWDDGSTDYNSALKSRVTISVDTS KNQFSLKLSSVTAADTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 31 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNGSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 32 QVQLQESGPGLVKPSETLSLTCTVSGFSLTAYGVNWIRQPPGKGLEWIGMIWDDGSTDYDSALKSRVTISVDTS KNQFSLKLSSVTAADTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 33 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNGSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 34 QVQLVQSGAEVKKPGSSVKVSCKASGFSLTAYGVNWVRQAPGQGLEWMGMIWDDGSTDYNSALKSRVTITADKS TSTAYMELSSLRSEDTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 35 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNGSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 36 QVQLVQSGAEVKKPGSSVKVSCKASGFSLTAYGVNWVRQAPGQGLEWMGMIWDDGSTDYDSALKSRVTITADKS TSTAYMELSSLRSEDTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 37 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNGSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 38 QVQLVQSGAEVKKPGSSVKVSCKASGGTFSAYGVNWVRQAPGQGLEWMGMIWDDGSTDYDSALKSRVTITADKS TSTAYMELSSLRSEDTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 39 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNGSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 40 QVQLQESGPGLVKPSETLSLTCTVSGGSISAYGVNWIRQPPGKGLEWIGMIWDDGSTDYDSALKSRVTISVDTS KNQFSLKLSSVTAADTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN
STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 41 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNGSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 42 QVQLVQSGAEVKKPGSSVKVSCKASGGTFSAYGVNWVRQAPGQGLEWMGMIWDDGSTDYNSALKSRVTITADKS TSTAYMELSSLRSEDTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 43 DIQMTQSPSSLSASVGDRVTITCKSSQSLLNGSNQKNYLAWYQQKPGKAPKLLVYFASTRDSGVPSRFSGSGSG TDFTLTISSLQPEDFATYYCLQHFGTPPTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 44 QVQLQESGPGLVKPSETLSLTCTVSGGSISAYGVNWIRQPPGKGLEWIGMIWDDGSTDYNSALKSRVTISVDTS KNQFSLKLSSVTAADTAVYYCAREGDVAFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 45 TVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLS KADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 46 ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSS SLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVD VSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKA KGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVD KSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK SEQ ID NO. 47 QVQLKESGPGLVAPSQSLSITCTVSGFSLTAYGVNWVRQPPGKGLEWLGMIWDDGSTDYNSALKSRLSISKDNS KSQVFLKMNSLQTDDTARYYCAREGDVAFDYWGQGTTLTVSS SEQ ID NO. 48 DIVMTQSPSSLAVSVGQKVTMSCKSSQSLLNGSNQKNYLAWYQQKPGQSPKLLVYFASTRDSGVPDRFIGSGSG TDFTLTISSVQAEDLADYFCLQHFGTPPTFGGGTKLEIKR SEQ ID NO. 49 (Note different leader sequence used for chimeric antibodies) QVQLKESGPGLVAPSQSLSITCTVSGFSLTAYGVNWVRQPPGKGLEWLGMIWDDGSTDYNSALKSRLSISKDNS KSQVFLKMNSLQTDDTARYYCAREGDVAFDYWGQGTTLTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDY FPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKT HTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKG FYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP GK SEQ ID NO. 50 DIVMTQSPSSLAVSVGQKVTMSCKSSQSLLNGSNQKNYLAWYQQKPGQSPKLLVYFASTRDSGVPDRFIGSGSG TDFTLTISSVQAEDLADYFCLQHFGTPPTFGGGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPR EAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC SEQ ID NO. 51 LQPGAEVPVVWAQEGAPAQLPCSPTIPLQDLSLLRRAGVTWQHQPDSGPPAAAPGHPLAPGPHPAAPSSWGPRP RRYTVLSVGPGGLRSGRLPLQPRVQLDERGRQRGDFSLWLRPARRADAGEYRAAVHLRDRALSCRLRLRLGQAS MTASPPGSLRASDWVILNCSFSRPDRPASVHWFRNRGQGRVPVRESPHHHLAESFLFLPQVSPMDSGPWGCILT YRDGFNVSIMYNLTVLGLEPPTPLTVYAGAGSRVGLPCRLPAGVGTRSFLTAKWTPPGGGPDLLVTGDNGDFTL RLEDVSQAQAGTYTCHIHLQEQQLNATVTLAIITVTPKSFGSPGSLGKLLCEVTPVSGQERFVWSSLDTPSQRS FSGPWLEAQEAQLLSQPWQCQLYQGERLLGAAVYFTELSSPHHHHHH SEQ ID NO. 52 PQPGAEISVVWAQEGAPAQLPCSPTIPLQDLSLLRRAGVTWQHQPDSGPPAPAPGHPPAPGHRPAAPYSWGPRP RRYTVLSVGPGGLRSGRLPLQPRVQLDERGRQRGDFSLWLRPARRADAGEYRATVHLRDRALSCRLRLRVGQAS MTASPPGSLRTSDWVILNCSFSRPDRPASVHWFRSRGQGRVPVQGSPHHHLAESFLFLPHVGPMDSGLWGCILT YRDGFNVSIMYNLTVLGLEPATPLTVYAGAGSRVELPCRLPPAVGTQSFLTAKWAPPGGGPDLLVAGDNGDFTL RLEDVSQAQAGTYICHIRLQGQQLNATVTLAIITVTPKSFGSPGSLGKLLCEVTPASGQEHFVWSPLNTPSQRS FSGPWLEAQEAQLLSQPWQCQLHQGERLLGAAVYFTELSSPHHHHHH SEQ ID NO. 53 PQPGAEISVVWAQEGAPAQLPCSPTIPLQDLSLLRRAGVTWQHQPDSGPPAPAPGHPPAPGHRPAAPYSWGPRP RRYTVLSVGPGGLRSGRLPLQPRVQLDERGRQRGDFSLWLRPARRADAGEYRATVHLRDRALSCRLRLRVGQAS MTASPPGSLRTSDWVILNCSFSRPDRPASVHWFRSRGQGQVPVQESPHHHLAESFLFLPHVGPMDSGLWGCILT YRDGFNVSIMYNLTVLGLEPTTPLTVYAGAGSRVELPCRLPPAVGTQSFLTAKWAPPGGGPDLLVVGDNGNFTL RLEDVSQAQAGTYICHIRLQGQQLNATVTLAIITVTPKSFGSPGSLGKLLCEVTPASGQERFVWSPLNTPSQRS FSGPWLEAQEAQLLSQPWQCQLHQGERLLGAAVYFTELSSPHHHHHH SEQ ID NO. 54 MGWSCIILFLVATATGVHS SEQ ID NO. 55 MESQTQVLMFLLLWVSGACA SEQ ID NO. 56 MPLLLLLPLL WAGALA SEQ ID NO. 57 AAGAGCAGCCAGAGCCTGCTGAACCCCAGCAACCAGAAGAACTACCTGGCC SEQ ID NO. 58 TTCGCCTCTACCAGGGATTCC SEQ ID NO. 59 CTGCAGCACTTCGGCACCCCTCCCACT SEQ ID NO. 60 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACCCCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGT SEQ ID NO. 61 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACCCCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 62 GCCTACGGCGTCAAC SEQ ID NO. 63
ATGATCTGGGACGACGGCAGCACCGACTACGACAGCGCCCTGAAGAGC SEQ ID NO. 64 GAGGGCGACGTGGCCTTCGATTAC SEQ ID NO. 65 CAGGTGCAGCTCCAGGAGAGCGGCCCCGGCCTGGTGAAGCCTAGCGAGACCCTGAGCCTGACCTGCACCGTGAG CGGCTTCTCCCTGACCGCCTACGGCGTCAACTGGATCAGGCAGCCCCCCGGCAAAGGCCTGGAGTGGATTGGGA TGATCTGGGACGACGGCAGCACCGACTACGACAGCGCCCTGAAGAGCAGGGTGACCATCAGCGTGGACACCAGC AAGAACCAGTTCAGCCTGAAGCTGAGCAGCGTGACTGCCGCCGACACCGCCGTCTATTACTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGC SEQ ID NO. 66 CAGGTGCAGCTCCAGGAGAGCGGCCCCGGCCTGGTGAAGCCTAGCGAGACCCTGAGCCTGACCTGCACCGTGAG CGGCTTCTCCCTGACCGCCTACGGCGTCAACTGGATCAGGCAGCCCCCCGGCAAAGGCCTGGAGTGGATTGGGA TGATCTGGGACGACGGCAGCACCGACTACGACAGCGCCCTGAAGAGCAGGGTGACCATCAGCGTGGACACCAGC AAGAACCAGTTCAGCCTGAAGCTGAGCAGCGTGACTGCCGCCGACACCGCCGTCTATTACTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 67 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACCCCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 68 CAGGTGCAGCTCCAGGAGAGCGGCCCCGGCCTGGTGAAGCCTAGCGAGACCCTGAGCCTGACCTGCACCGTGAG CGGCTTCTCCCTGACCGCCTACGGCGTCAACTGGATCAGGCAGCCCCCCGGCAAAGGCCTGGAGTGGATTGGGA TGATCTGGGACGACGGCAGCACCGACTACAACAGCGCCCTGAAGAGCAGGGTGACCATCAGCGTGGACACCAGC AAGAACCAGTTCAGCCTGAAGCTGAGCAGCGTGACTGCCGCCGACACCGCCGTCTATTACTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 69 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACCCCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 70 CAGGTGCAGCTCGTGCAGAGCGGGGCCGAAGTCAAGAAACCCGGCAGCTCCGTGAAGGTGAGCTGCAAGGCCAG CGGCTTCTCTCTCACTGCCTACGGCGTGAACTGGGTGAGGCAGGCTCCCGGCCAGGGCCTGGAGTGGATGGGCA TGATCTGGGACGACGGCAGCACCGACTACAACAGCGCCCTGAAGAGCAGGGTGACCATCACCGCCGACAAGAGC ACCAGCACCGCCTACATGGAACTGAGCAGCCTGAGGAGCGAGGACACCGCCGTGTACTATTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 71 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACCCCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC
CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 72 CAGGTGCAGCTCCAGGAGAGCGGCCCCGGCCTGGTGAAGCCTAGCGAGACCCTGAGCCTGACCTGCACCGTGAG CGGCTTCTCCCTGACCGCCTACGGCGTCAACTGGATCAGGCAGCCCCCCGGCAAAGGCCTGGAGTGGCTGGGGA TGATCTGGGACGACGGCAGCACCGACTACAACAGCGCCCTGAAGAGCAGGCTGACCATCAGCAAGGACAACAGC AAGAACCAGGTGAGCCTGAAGCTGAGCAGCGTGACTGCCGCCGACACCGCCGTCTATTACTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 73 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACCCCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 74 CAGGTGCAGCTCGTGCAGAGCGGGGCCGAAGTCAAGAAACCCGGCAGCTCCGTGAAGGTGAGCTGCAAGGCCAG CGGCTTCTCTCTCACTGCCTACGGCGTGAACTGGGTGAGGCAGGCTCCCGGCCAGGGCCTGGAGTGGATGGGCA TGATCTGGGACGACGGCAGCACCGACTACGACAGCGCCCTGAAGAGCAGGGTGACCATCACCGCCGACAAGAGC ACCAGCACCGCCTACATGGAACTGAGCAGCCTGAGGAGCGAGGACACCGCCGTGTACTATTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 75 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACCCCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 76 CAGGTGCAGCTCCAGGAGAGCGGCCCCGGCCTGGTGAAGCCTAGCGAGACCCTGAGCCTGACCTGCACCGTGAG CGGCTTCTCCCTGACCGCCTACGGCGTCAACTGGATCAGGCAGCCCCCCGGCAAAGGCCTGGAGTGGATTGGGA TGATCTGGGACGACGGCAGCACCGACTACAACAGCGCCCTGAAGAGCAGGGTGACCATCAGCAAGGACAACAGC AAGAACCAGGTGAGCCTGAAGCTGAGCAGCGTGACTGCCGCCGACACCGCCGTCTATTACTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 77 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACCCCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC
CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 78 CAGGTGCAGCTCGTGCAGAGCGGGGCCGAAGTCAAGAAACCCGGCAGCTCCGTGAAGGTGAGCTGCAAGGCCAG CGGCGGCACCTTCAGCGCCTACGGCGTGAACTGGGTGAGGCAGGCTCCCGGCCAGGGCCTGGAGTGGATGGGCA TGATCTGGGACGACGGCAGCACCGACTACGACAGCGCCCTGAAGAGCAGGGTGACCATCACCGCCGACAAGAGC ACCAGCACCGCCTACATGGAACTGAGCAGCCTGAGGAGCGAGGACACCGCCGTGTACTATTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 79 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACCCCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 80 CAGGTGCAGCTCCAGGAGAGCGGCCCCGGCCTGGTGAAGCCTAGCGAGACCCTGAGCCTGACCTGCACCGTGAG CGGCGGCTCCATCAGCGCCTACGGCGTCAACTGGATCAGGCAGCCCCCCGGCAAAGGCCTGGAGTGGATTGGGA TGATCTGGGACGACGGCAGCACCGACTACGACAGCGCCCTGAAGAGCAGGGTGACCATCAGCGTGGACACCAGC AAGAACCAGTTCAGCCTGAAGCTGAGCAGCGTGACTGCCGCCGACACCGCCGTCTATTACTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 81 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACCCCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 82 CAGGTGCAGCTCGTGCAGAGCGGGGCCGAAGTCAAGAAACCCGGCAGCTCCGTGAAGGTGAGCTGCAAGGCCAG CGGCGGCACCTTCAGCGCCTACGGCGTGAACTGGGTGAGGCAGGCTCCCGGCCAGGGCCTGGAGTGGATGGGCA TGATCTGGGACGACGGCAGCACCGACTACAACAGCGCCCTGAAGAGCAGGGTGACCATCACCGCCGACAAGAGC ACCAGCACCGCCTACATGGAACTGAGCAGCCTGAGGAGCGAGGACACCGCCGTGTACTATTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 83 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG
CAGCCAGAGCCTGCTGAACCCCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 84 CAGGTGCAGCTCCAGGAGAGCGGCCCCGGCCTGGTGAAGCCTAGCGAGACCCTGAGCCTGACCTGCACCGTGAG CGGCGGCTCCATCAGCGCCTACGGCGTCAACTGGATCAGGCAGCCCCCCGGCAAAGGCCTGGAGTGGATTGGGA TGATCTGGGACGACGGCAGCACCGACTACAACAGCGCCCTGAAGAGCAGGGTGACCATCAGCGTGGACACCAGC AAGAACCAGTTCAGCCTGAAGCTGAGCAGCGTGACTGCCGCCGACACCGCCGTCTATTACTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 85 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACGGCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 86 CAGGTGCAGCTCCAGGAGAGCGGCCCCGGCCTGGTGAAGCCTAGCGAGACCCTGAGCCTGACCTGCACCGTGAG CGGCTTCTCCCTGACCGCCTACGGCGTCAACTGGATCAGGCAGCCCCCCGGCAAAGGCCTGGAGTGGATTGGGA TGATCTGGGACGACGGCAGCACCGACTACAACAGCGCCCTGAAGAGCAGGGTGACCATCAGCGTGGACACCAGC AAGAACCAGTTCAGCCTGAAGCTGAGCAGCGTGACTGCCGCCGACACCGCCGTCTATTACTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 87 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACGGCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 88 CAGGTGCAGCTCCAGGAGAGCGGCCCCGGCCTGGTGAAGCCTAGCGAGACCCTGAGCCTGACCTGCACCGTGAG CGGCTTCTCCCTGACCGCCTACGGCGTCAACTGGATCAGGCAGCCCCCCGGCAAAGGCCTGGAGTGGATTGGGA TGATCTGGGACGACGGCAGCACCGACTACGACAGCGCCCTGAAGAGCAGGGTGACCATCAGCGTGGACACCAGC AAGAACCAGTTCAGCCTGAAGCTGAGCAGCGTGACTGCCGCCGACACCGCCGTCTATTACTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 89 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG
CAGCCAGAGCCTGCTGAACGGCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 90 CAGGTGCAGCTCGTGCAGAGCGGGGCCGAAGTCAAGAAACCCGGCAGCTCCGTGAAGGTGAGCTGCAAGGCCAG CGGCTTCTCTCTCACTGCCTACGGCGTGAACTGGGTGAGGCAGGCTCCCGGCCAGGGCCTGGAGTGGATGGGCA TGATCTGGGACGACGGCAGCACCGACTACAACAGCGCCCTGAAGAGCAGGGTGACCATCACCGCCGACAAGAGC ACCAGCACCGCCTACATGGAACTGAGCAGCCTGAGGAGCGAGGACACCGCCGTGTACTATTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 91 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACGGCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 92 CAGGTGCAGCTCGTGCAGAGCGGGGCCGAAGTCAAGAAACCCGGCAGCTCCGTGAAGGTGAGCTGCAAGGCCAG CGGCTTCTCTCTCACTGCCTACGGCGTGAACTGGGTGAGGCAGGCTCCCGGCCAGGGCCTGGAGTGGATGGGCA TGATCTGGGACGACGGCAGCACCGACTACGACAGCGCCCTGAAGAGCAGGGTGACCATCACCGCCGACAAGAGC ACCAGCACCGCCTACATGGAACTGAGCAGCCTGAGGAGCGAGGACACCGCCGTGTACTATTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 93 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACGGCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 94 CAGGTGCAGCTCGTGCAGAGCGGGGCCGAAGTCAAGAAACCCGGCAGCTCCGTGAAGGTGAGCTGCAAGGCCAG CGGCGGCACCTTCAGCGCCTACGGCGTGAACTGGGTGAGGCAGGCTCCCGGCCAGGGCCTGGAGTGGATGGGCA TGATCTGGGACGACGGCAGCACCGACTACGACAGCGCCCTGAAGAGCAGGGTGACCATCACCGCCGACAAGAGC ACCAGCACCGCCTACATGGAACTGAGCAGCCTGAGGAGCGAGGACACCGCCGTGTACTATTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 95 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG
CAGCCAGAGCCTGCTGAACGGCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 96 CAGGTGCAGCTCCAGGAGAGCGGCCCCGGCCTGGTGAAGCCTAGCGAGACCCTGAGCCTGACCTGCACCGTGAG CGGCGGCTCCATCAGCGCCTACGGCGTCAACTGGATCAGGCAGCCCCCCGGCAAAGGCCTGGAGTGGATTGGGA TGATCTGGGACGACGGCAGCACCGACTACGACAGCGCCCTGAAGAGCAGGGTGACCATCAGCGTGGACACCAGC AAGAACCAGTTCAGCCTGAAGCTGAGCAGCGTGACTGCCGCCGACACCGCCGTCTATTACTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 97 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACGGCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 98 CAGGTGCAGCTCGTGCAGAGCGGGGCCGAAGTCAAGAAACCCGGCAGCTCCGTGAAGGTGAGCTGCAAGGCCAG CGGCGGCACCTTCAGCGCCTACGGCGTGAACTGGGTGAGGCAGGCTCCCGGCCAGGGCCTGGAGTGGATGGGCA TGATCTGGGACGACGGCAGCACCGACTACAACAGCGCCCTGAAGAGCAGGGTGACCATCACCGCCGACAAGAGC ACCAGCACCGCCTACATGGAACTGAGCAGCCTGAGGAGCGAGGACACCGCCGTGTACTATTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 99 GACATCCAGATGACCCAGAGCCCCTCTAGCCTCAGCGCCAGCGTGGGCGACAGGGTGACCATCACCTGCAAGAG CAGCCAGAGCCTGCTGAACGGCAGCAACCAGAAGAACTACCTGGCCTGGTACCAGCAGAAACCCGGCAAGGCCC CCAAGCTGCTGGTCTACTTCGCCTCTACCAGGGATTCCGGCGTCCCCAGCAGGTTCAGCGGCAGCGGCAGCGGC ACCGACTTCACACTGACCATCAGCAGCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCTGCAGCACTTCGG CACCCCTCCCACTTTTGGCCAGGGCACCAAGCTGGAGATTAAGCGTACGGTGGCCGCCCCCAGCGTGTTCATCT TCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGTGTGTCTGCTGAACAACTTCTACCCCCGG GAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCAACAGCCAGGAGAGCGTGACCGAGCAGGA CAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGCAAGGCCGACTACGAGAAGCACAAGGTGT ACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAAGAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 100 CAGGTGCAGCTCCAGGAGAGCGGCCCCGGCCTGGTGAAGCCTAGCGAGACCCTGAGCCTGACCTGCACCGTGAG CGGCGGCTCCATCAGCGCCTACGGCGTCAACTGGATCAGGCAGCCCCCCGGCAAAGGCCTGGAGTGGATTGGGA TGATCTGGGACGACGGCAGCACCGACTACAACAGCGCCCTGAAGAGCAGGGTGACCATCAGCGTGGACACCAGC AAGAACCAGTTCAGCCTGAAGCTGAGCAGCGTGACTGCCGCCGACACCGCCGTCTATTACTGCGCCAGGGAGGG CGACGTGGCCTTCGATTACTGGGGCCAGGGCACACTAGTGACCGTGTCCAGCGCCAGCACCAAGGGCCCCAGCG TGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCTGGGCTGCCTGGTGAAGGACTAC TTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCGTGCACACCTTCCCCGCCGTGCT GCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACA TCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGAGCCCAAGAGCTGTGACAAGACC CACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGTTCCTGTTCCCCCCCAAGCCTAA GGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGATGTGAGCCACGAGGACCCTGAGG TGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAAGCCCAGGGAGGAGCAGTACAAC AGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGAACGGCAAGGAGTACAAGTGTAA GGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCCAAGGGCCAGCCCAGAGAGCCCC AGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTGAAGGGC TTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGAACAACTACAAGACCACCCCCCC TGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAGAGCAGATGGCAGCAGGGCA ACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGAGCCTGAGCCTGTCCCCT GGCAAG SEQ ID NO. 101
ACGGTGGCCGCCCCCAGCGTGTTCATCTTCCCCCCCAGCGATGAGCAGCTGAAGAGCGGCACCGCCAGCGTGGT GTGTCTGCTGAACAACTTCTACCCCCGGGAGGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGAGCGGCA ACAGCCAGGAGAGCGTGACCGAGCAGGACAGCAAGGACTCCACCTACAGCCTGAGCAGCACCCTGACCCTGAGC AAGGCCGACTACGAGAAGCACAAGGTGTACGCCTGTGAGGTGACCCACCAGGGCCTGTCCAGCCCCGTGACCAA GAGCTTCAACCGGGGCGAGTGC SEQ ID NO. 102 GCCAGCACCAAGGGCCCCAGCGTGTTCCCCCTGGCCCCCAGCAGCAAGAGCACCAGCGGCGGCACAGCCGCCCT GGGCTGCCTGGTGAAGGACTACTTCCCCGAACCGGTGACCGTGTCCTGGAACAGCGGAGCCCTGACCAGCGGCG TGCACACCTTCCCCGCCGTGCTGCAGAGCAGCGGCCTGTACAGCCTGAGCAGCGTGGTGACCGTGCCCAGCAGC AGCCTGGGCACCCAGACCTACATCTGTAACGTGAACCACAAGCCCAGCAACACCAAGGTGGACAAGAAGGTGGA GCCCAAGAGCTGTGACAAGACCCACACCTGCCCCCCCTGCCCTGCCCCCGAGCTGCTGGGAGGCCCCAGCGTGT TCCTGTTCCCCCCCAAGCCTAAGGACACCCTGATGATCAGCAGAACCCCCGAGGTGACCTGTGTGGTGGTGGAT GTGAGCCACGAGGACCCTGAGGTGAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCACAATGCCAAGACCAA GCCCAGGGAGGAGCAGTACAACAGCACCTACCGGGTGGTGTCCGTGCTGACCGTGCTGCACCAGGATTGGCTGA ACGGCAAGGAGTACAAGTGTAAGGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAGAAAACCATCAGCAAGGCC AAGGGCCAGCCCAGAGAGCCCCAGGTGTACACCCTGCCCCCTAGCAGAGATGAGCTGACCAAGAACCAGGTGTC CCTGACCTGCCTGGTGAAGGGCTTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAACGGCCAGCCCGAGA ACAACTACAAGACCACCCCCCCTGTGCTGGACAGCGATGGCAGCTTCTTCCTGTACAGCAAGCTGACCGTGGAC AAGAGCAGATGGCAGCAGGGCAACGTGTTCAGCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCA GAAGAGCCTGAGCCTGTCCCCTGGCAAG SEQ ID NO. 103 CAGGTGCAGCTGAAGGAGTCAGGTCCTGGCCTGGTGGCGCCCTCACAGAGCCTGTCCATCACATGCACCGTCTC AGGGTTCTCATTAACCGCCTATGGTGTAAACTGGGTTCGCCAGCCTCCAGGAAAGGGTCTGGAGTGGCTGGGAA TGATATGGGATGATGGAAGCACAGACTATAATTCAGCTCTCAAATCCAGACTGAGCATCAGTAAGGACAACTCC AAGAGCCAAGTTTTCTTAAAAATGAACAGTCTGCAAACTGATGACACAGCCAGGTACTACTGTGCCAGAGAAGG GGACGTAGCCTTTGACTACTGGGGCCAAGGCACCACTCTCACAGTCTCCTCA SEQ ID NO. 104 GACATTGTGATGACACAGTCTCCCTCCTCCCTGGCTGTGTCAGTAGGACAGAAGGTCACTATGAGCTGCAAGTC CAGTCAGAGCCTTTTAAATGGTAGCAATCAAAAGAACTACTTGGCCTGGTACCAGCAGAAACCAGGACAGTCTC CTAAACTTCTGGTATACTTTGCATCCACTAGGGATTCTGGGGTCCCTGATCGCTTCATAGGCAGTGGATCTGGG ACAGATTTCACTCTTACCATCAGCAGTGTGCAGGCTGAAGACCTGGCAGATTACTTCTGTCTGCAACATTTTGG CACTCCTCCGACGTTCGGTGGAGGCACCAAACTGGAAATCAAACGG SEQ ID NO. 105 CAGGTGCAGCTGAAGGAGTCAGGTCCTGGCCTGGTGGCGCCCTCACAGAGCCTGTCCATCACATGCACCGTCTC AGGGTTCTCATTAACCGCCTATGGTGTAAACTGGGTTCGCCAGCCTCCAGGAAAGGGTCTGGAGTGGCTGGGAA TGATATGGGATGATGGAAGCACAGACTATAATTCAGCTCTCAAATCCAGACTGAGCATCAGTAAGGACAACTCC AAGAGCCAAGTTTTCTTAAAAATGAACAGTCTGCAAACTGATGACACAGCCAGGTACTACTGTGCCAGAGAAGG GGACGTAGCCTTTGACTACTGGGGCCAAGGCACCACTCTCACAGTCTCCTCAGCTAGCACCAAGGGCCCATCGG TCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTAC TTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCT ACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCTACA TCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACT CACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAA GGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGG TCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAAC AGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAA GGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCAC AGGTGTACACCCTGCCCCCATCCCGGGATGAGCTGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGC TTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCC CGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGA ACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCG GGTAAA SEQ ID NO. 106 GACATTGTGATGACACAGTCTCCCTCCTCCCTGGCTGTGTCAGTAGGACAGAAGGTCACTATGAGCTGCAAGTC CAGTCAGAGCCTTTTAAATGGTAGCAATCAAAAGAACTACTTGGCCTGGTACCAGCAGAAACCAGGACAGTCTC CTAAACTTCTGGTATACTTTGCATCCACTAGGGATTCTGGGGTCCCTGATCGCTTCATAGGCAGTGGATCTGGG ACAGATTTCACTCTTACCATCAGCAGTGTGCAGGCTGAAGACCTGGCAGATTACTTCTGTCTGCAACATTTTGG CACTCCTCCGACGTTCGGTGGAGGCACCAAACTGGAAATCAAACGGACCGTGGCTGCACCATCTGTCTTCATCT TCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGA GAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGA CAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCT ACGCCTGCGAAGTCACCCATCAGGGCCTGAGTTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGT SEQ ID NO. 107 CTCCAGCCAGGGGCTGAGGTCCCGGTGGTGTGGGCCCAGGAGGGGGCTCCTGCCCAGCTCCCCTGCAGCCCCAC AATCCCCCTCCAGGATCTCAGCCTTCTGCGAAGAGCAGGGGTCACTTGGCAGCATCAGCCAGACAGTGGCCCGC CCGCTGCCGCCCCCGGCCATCCCCTGGCCCCCGGCCCTCACCCGGCGGCGCCCTCCTCCTGGGGGCCCAGGCCC CGCCGCTACACGGTGCTGAGCGTGGGTCCCGGAGGCCTGCGCAGCGGGAGGCTGCCCCTGCAGCCCCGCGTCCA GCTGGATGAGCGCGGCCGGCAGCGCGGGGACTTCTCGCTATGGCTGCGCCCAGCCCGGCGCGCGGACGCCGGCG AGTACCGCGCCGCGGTGCACCTCAGGGACCGCGCCCTCTCCTGCCGCCTCCGTCTGCGCCTGGGCCAGGCCTCG ATGACTGCCAGCCCCCCAGGATCTCTCAGAGCCTCCGACTGGGTCATTTTGAACTGCTCCTTCAGCCGCCCTGA CCGCCCAGCCTCTGTGCATTGGTTCCGGAACCGGGGCCAGGGCCGAGTCCCTGTCCGGGAGTCCCCCCATCACC ACTTAGCGGAAAGCTTCCTCTTCCTGCCCCAAGTCAGCCCCATGGACTCTGGGCCCTGGGGCTGCATCCTCACC TACAGAGATGGCTTCAACGTCTCCATCATGTATAACCTCACTGTTCTGGGTCTGGAGCCCCCAACTCCCTTGAC AGTGTACGCTGGAGCAGGTTCCAGGGTGGGGCTGCCCTGCCGCCTGCCTGCTGGTGTGGGGACCCGGTCTTTCC TCACTGCCAAGTGGACTCCTCCTGGGGGAGGCCCTGACCTCCTGGTGACTGGAGACAATGGCGACTTTACCCTT CGACTAGAGGATGTGAGCCAGGCCCAGGCTGGGACCTACACCTGCCATATCCATCTGCAGGAACAGCAGCTCAA TGCCACTGTCACATTGGCAATCATCACAGTGACTCCCAAATCCTTTGGGTCACCTGGATCCCTGGGGAAGCTGC TTTGTGAGGTGACTCCAGTATCTGGACAAGAACGCTTTGTGTGGAGCTCTCTGGACACCCCATCCCAGAGGAGT TTCTCAGGACCTTGGCTGGAGGCACAGGAGGCCCAGCTCCTTTCCCAGCCTTGGCAATGCCAGCTGTACCAGGG GGAGAGGCTTCTTGGAGCAGCAGTGTACTTCACAGAGCTGTCTAGCCCACACCACCATCATCACCAT SEQ ID NO. 108 CCCCAGCCAGGGGCTGAGATCTCGGTGGTGTGGGCCCAGGAGGGGGCTCCTGCCCAGCTCCCCTGCAGCCCCAC AATCCCCCTCCAGGATCTCAGCCTTCTGCGAAGAGCAGGGGTCACTTGGCAGCATCAACCAGACAGTGGCCCGC CCGCTCCCGCCCCCGGCCACCCCCCGGCCCCCGGCCATCGCCCGGCGGCGCCCTACTCTTGGGGGCCCAGGCCC CGCCGCTACACAGTGCTGAGCGTGGGTCCTGGAGGCCTGCGCAGCGGGAGGCTGCCCCTGCAGCCCCGCGTCCA GCTGGATGAGCGCGGCCGGCAGCGCGGGGACTTCTCGCTGTGGCTGCGCCCAGCCCGGCGCGCGGACGCCGGCG AGTACCGCGCCACGGTGCACCTCAGGGACCGCGCCCTCTCCTGCCGCCTTCGTCTGCGCGTGGGCCAGGCCTCG ATGACTGCCAGCCCCCCAGGGTCTCTCAGGACCTCTGACTGGGTCATTTTGAACTGCTCCTTCAGCCGCCCTGA CCGCCCAGCCTCTGTGCATTGGTTCCGGAGCCGTGGCCAGGGCCGAGTCCCTGTCCAGGGGTCCCCCCATCACC ACTTAGCGGAAAGCTTCCTCTTCCTGCCCCATGTCGGCCCCATGGACTCTGGGCTCTGGGGCTGCATCCTCACC TACAGAGATGGCTTCAATGTCTCCATCATGTATAACCTCACTGTTCTGGGTCTGGAGCCCGCAACTCCCTTGAC
AGTGTACGCTGGAGCAGGTTCCAGGGTGGAGCTGCCCTGCCGCCTGCCTCCTGCTGTGGGGACCCAGTCTTTCC TTACTGCCAAGTGGGCTCCTCCTGGGGGAGGCCCTGACCTCCTGGTGGCTGGAGACAATGGCGACTTTACCCTT CGACTAGAGGATGTAAGCCAGGCCCAGGCTGGGACCTACATCTGCCATATCCGTCTACAGGGACAGCAGCTCAA TGCCACTGTCACATTGGCAATCATCACAGTGACTCCCAAATCCTTTGGGTCACCTGGCTCCCTGGGGAAGCTGC TTTGTGAGGTGACTCCAGCATCTGGACAAGAACACTTTGTGTGGAGCCCCCTGAACACCCCATCCCAGAGGAGT TTCTCAGGACCATGGCTGGAGGCCCAGGAAGCCCAGCTCCTTTCCCAGCCTTGGCAATGCCAGCTGCACCAGGG GGAGAGGCTTCTTGGAGCAGCAGTATACTTCACAGAACTGTCTAGCCCACACCACCATCATCACCAT SEQ ID NO. 109 CCCCAGCCAGGGGCTGAGATCTCGGTGGTGTGGGCCCAGGAGGGGGCTCCTGCCCAGCTCCCCTGCAGCCCCAC AATCCCCCTCCAGGATCTCAGCCTTCTGCGAAGAGCAGGGGTCACTTGGCAGCATCAACCAGACAGTGGCCCGC CCGCTCCCGCCCCCGGCCACCCCCCGGCCCCCGGCCATCGCCCGGCGGCGCCCTACTCTTGGGGGCCCAGGCCC CGCCGCTACACAGTGCTGAGCGTGGGTCCTGGAGGCCTGCGCAGCGGGAGGCTGCCCCTGCAGCCCCGCGTCCA GCTGGATGAGCGCGGCCGGCAGCGCGGGGACTTCTCGCTGTGGCTGCGCCCAGCCCGGCGCGCGGACGCCGGCG AGTACCGCGCCACGGTGCACCTCAGGGACCGCGCCCTCTCCTGCCGCCTTCGTCTGCGCGTGGGCCAGGCCTCG ATGACTGCCAGCCCCCCAGGGTCTCTCAGGACCTCTGACTGGGTCATTTTGAACTGCTCCTTCAGCCGCCCTGA CCGCCCAGCCTCTGTGCATTGGTTCCGGAGCCGTGGCCAGGGCCAAGTCCCTGTCCAGGAGTCCCCCCATCACC ACTTAGCGGAAAGCTTCCTCTTCCTGCCCCATGTCGGCCCCATGGACTCTGGGCTCTGGGGCTGCATCCTCACC TACAGAGATGGCTTCAATGTCTCCATCATGTATAACCTCACTGTTCTGGGTCTGGAGCCCACAACTCCCTTGAC AGTGTACGCTGGAGCAGGTTCCAGGGTGGAGCTGCCCTGCCGCCTGCCTCCTGCTGTGGGGACCCAGTCTTTCC TTACTGCCAAGTGGGCTCCTCCTGGGGGAGGCCCTGACCTCCTGGTGGTTGGAGACAATGGCAACTTTACCCTT CGACTAGAGGATGTAAGCCAGGCCCAGGCTGGGACCTACATCTGCCATATCCGTCTACAGGGACAGCAGCTCAA TGCCACTGTCACATTGGCAATCATCACAGTGACTCCCAAATCCTTTGGGTCACCTGGCTCCCTGGGGAAGCTGC TTTGTGAGGTGACTCCAGCATCTGGACAAGAACGCTTTGTGTGGAGCCCCCTGAACACCCCATCCCAGAGGAGT TTCTCAGGACCGTGGCTGGAGGCCCAGGAAGCCCAGCTCCTTTCCCAGCCTTGGCAATGCCAGCTGCACCAGGG GGAGAGGCTTCTTGGAGCAGCAGTATACTTCACAGAACTGTCTAGCCCACACCACCATCATCACCAT SEQ ID NO. 110 ATGGGCTGGAGCTGCATCATCCTGTTCCTGGTGGCCACCGCTACCGGAGTGCACAGC SEQ ID NO. 111 ATGGAATCACAGACCCAGGTCCTCATGTTTCTTCTGCTCTGGGTATCTGGTGCCTGTGCA SEQ ID NO. 112 ATGCCGCTGC TGCTACTGCT GCCCCTGCTG TGGGCAGGGG CGCTAGCT
Sequence CWU 1
1
112117PRTArtificial SequenceH5L7, CDRL1 (Kabat defined) 1Lys Ser
Ser Gln Ser Leu Leu Asn Pro Ser Asn Gln Lys Asn Tyr Leu1 5 10
15Ala27PRTMurine 2Phe Ala Ser Thr Arg Asp Ser1 539PRTMurine 3Leu
Gln His Phe Gly Thr Pro Pro Thr1 54114PRTArtificial SequenceH5L7,
VL 4Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val
Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu
Asn Pro 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe Ala Ser Thr Arg
Asp Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr
Asp Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln Pro Glu Asp Phe
Ala Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr Pro Pro Thr Phe
Gly Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg5220PRTArtificial
SequenceH5L7, light chain humanised construct 5Asp Ile Gln Met Thr
Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr
Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asn Pro 20 25 30Ser Asn Gln
Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys 35 40 45Ala Pro
Lys Leu Leu Val Tyr Phe Ala Ser Thr Arg Asp Ser Gly Val 50 55 60Pro
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr65 70 75
80Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln
85 90 95His Phe Gly Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu
Ile 100 105 110Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro
Pro Ser Asp 115 120 125Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val
Cys Leu Leu Asn Asn 130 135 140Phe Tyr Pro Arg Glu Ala Lys Val Gln
Trp Lys Val Asp Asn Ala Leu145 150 155 160Gln Ser Gly Asn Ser Gln
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp 165 170 175Ser Thr Tyr Ser
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr 180 185 190Glu Lys
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser 195 200
205Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys 210 215
22065PRTMurine 6Ala Tyr Gly Val Asn1 5716PRTArtificial
SequenceH5L7, CDRH2 (Kabat defined) 7Met Ile Trp Asp Asp Gly Ser
Thr Asp Tyr Asp Ser Ala Leu Lys Ser1 5 10 1588PRTMurine 8Glu Gly
Asp Val Ala Phe Asp Tyr1 59116PRTArtificial SequenceH5L7, VH 9Gln
Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu1 5 10
15Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Ala Tyr
20 25 30Gly Val Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
Ile 35 40 45Gly Met Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asp Ser Ala
Leu Lys 50 55 60Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln
Phe Ser Leu65 70 75 80Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala
Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr Trp
Gly Gln Gly Thr Leu Val 100 105 110Thr Val Ser Ser
11510446PRTArtificial SequenceH5L7, heavy chain humanised construct
10Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu1
5 10 15Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Ala
Tyr 20 25 30Gly Val Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
Trp Ile 35 40 45Gly Met Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asp Ser
Ala Leu Lys 50 55 60Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn
Gln Phe Ser Leu65 70 75 80Lys Leu Ser Ser Val Thr Ala Ala Asp Thr
Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr
Trp Gly Gln Gly Thr Leu Val 100 105 110Thr Val Ser Ser Ala Ser Thr
Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120 125Pro Ser Ser Lys Ser
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu 130 135 140Val Lys Asp
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly145 150 155
160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys Val Glu Pro Lys Ser
Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro Cys Pro Ala Pro Glu
Leu Leu Gly Gly Pro Ser Val Phe225 230 235 240Leu Phe Pro Pro Lys
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro 245 250 255Glu Val Thr
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val 260 265 270Lys
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr 275 280
285Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
Lys Cys305 310 315 320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
Glu Lys Thr Ile Ser 325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro
Gln Val Tyr Thr Leu Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys
Asn Gln Val Ser Leu Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp385 390 395
400Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
Leu His 420 425 430Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
Gly Lys 435 440 44511220PRTArtificial SequenceH1L7, light chain
humanised construct 11Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser
Gln Ser Leu Leu Asn Pro 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp
Tyr Gln Gln Lys Pro Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe
Ala Ser Thr Arg Asp Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser
Gly Ser Gly Thr Asp Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln
Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr
Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120
125Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
Ala Leu145 150 155 160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu
Gln Asp Ser Lys Asp 165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu
Thr Leu Ser Lys Ala Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala
Cys Glu Val Thr His Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys
Ser Phe Asn Arg Gly Glu Cys 210 215 22012446PRTArtificial
SequenceH1L7, heavy chain humanised construct 12Gln Val Gln Leu Gln
Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu1 5 10 15Thr Leu Ser Leu
Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Ala Tyr 20 25 30Gly Val Asn
Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile 35 40 45Gly Met
Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asn Ser Ala Leu Lys 50 55 60Ser
Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu65 70 75
80Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu
Val 100 105 110Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
Pro Leu Ala 115 120 125Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
Ala Leu Gly Cys Leu 130 135 140Val Lys Asp Tyr Phe Pro Glu Pro Val
Thr Val Ser Trp Asn Ser Gly145 150 155 160Ala Leu Thr Ser Gly Val
His Thr Phe Pro Ala Val Leu Gln Ser Ser 165 170 175Gly Leu Tyr Ser
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu 180 185 190Gly Thr
Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr 195 200
205Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
Val Phe225 230 235 240Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
Ile Ser Arg Thr Pro 245 250 255Glu Val Thr Cys Val Val Val Asp Val
Ser His Glu Asp Pro Glu Val 260 265 270Lys Phe Asn Trp Tyr Val Asp
Gly Val Glu Val His Asn Ala Lys Thr 275 280 285Lys Pro Arg Glu Glu
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val 290 295 300Leu Thr Val
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys305 310 315
320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu Asn Asn Tyr Lys Thr
Thr Pro Pro Val Leu Asp Ser Asp385 390 395 400Gly Ser Phe Phe Leu
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp 405 410 415Gln Gln Gly
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His 420 425 430Asn
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 435 440
44513220PRTArtificial SequenceJ7L7, light chain humanised construct
13Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1
5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asn
Pro 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe Ala Ser Thr Arg Asp
Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala
Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr Pro Pro Thr Phe Gly
Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg Thr Val Ala Ala Pro
Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120 125Glu Gln Leu Lys Ser
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn 130 135 140Phe Tyr Pro
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu145 150 155
160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala
Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His
Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys Ser Phe Asn Arg Gly
Glu Cys 210 215 22014446PRTArtificial SequenceJ7L7, heavy chain
humanised construct 14Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val
Lys Lys Pro Gly Ser1 5 10 15Ser Val Lys Val Ser Cys Lys Ala Ser Gly
Phe Ser Leu Thr Ala Tyr 20 25 30Gly Val Asn Trp Val Arg Gln Ala Pro
Gly Gln Gly Leu Glu Trp Met 35 40 45Gly Met Ile Trp Asp Asp Gly Ser
Thr Asp Tyr Asn Ser Ala Leu Lys 50 55 60Ser Arg Val Thr Ile Thr Ala
Asp Lys Ser Thr Ser Thr Ala Tyr Met65 70 75 80Glu Leu Ser Ser Leu
Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp
Val Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val 100 105 110Thr Val
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120
125Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn
Ser Gly145 150 155 160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
Val Leu Gln Ser Ser 165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val
Thr Val Pro Ser Ser Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys
Asn Val Asn His Lys Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys
Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe225 230 235
240Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
Glu Val 260 265 270Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
Asn Ala Lys Thr 275 280 285Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
Tyr Arg Val Val Ser Val 290 295 300Leu Thr Val Leu His Gln Asp Trp
Leu Asn Gly Lys Glu Tyr Lys Cys305 310 315 320Lys Val Ser Asn Lys
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser 325 330 335Lys Ala Lys
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro 340 345 350Ser
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val 355 360
365Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
Ser Asp385 390 395 400Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
Asp Lys Ser Arg Trp 405 410 415Gln Gln Gly Asn Val Phe Ser Cys Ser
Val Met His Glu Ala Leu His 420 425 430Asn His Tyr Thr Gln Lys Ser
Leu Ser Leu Ser Pro Gly Lys 435 440 44515220PRTArtificial
SequenceH4L7, light chain humanised construct 15Asp Ile Gln Met Thr
Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr
Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asn Pro 20 25 30Ser Asn Gln
Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys 35 40 45Ala Pro
Lys Leu Leu Val Tyr Phe Ala Ser Thr Arg Asp Ser Gly Val 50 55 60Pro
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr65 70 75
80Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu
Gln
85 90 95His Phe Gly Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu
Ile 100 105 110Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro
Pro Ser Asp 115 120 125Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val
Cys Leu Leu Asn Asn 130 135 140Phe Tyr Pro Arg Glu Ala Lys Val Gln
Trp Lys Val Asp Asn Ala Leu145 150 155 160Gln Ser Gly Asn Ser Gln
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp 165 170 175Ser Thr Tyr Ser
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr 180 185 190Glu Lys
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser 195 200
205Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys 210 215
22016446PRTArtificial SequenceH4L7, heavy chain humanised construct
16Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu1
5 10 15Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Ala
Tyr 20 25 30Gly Val Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
Trp Leu 35 40 45Gly Met Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asn Ser
Ala Leu Lys 50 55 60Ser Arg Leu Thr Ile Ser Lys Asp Asn Ser Lys Asn
Gln Val Ser Leu65 70 75 80Lys Leu Ser Ser Val Thr Ala Ala Asp Thr
Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr
Trp Gly Gln Gly Thr Leu Val 100 105 110Thr Val Ser Ser Ala Ser Thr
Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120 125Pro Ser Ser Lys Ser
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu 130 135 140Val Lys Asp
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly145 150 155
160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys Val Glu Pro Lys Ser
Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro Cys Pro Ala Pro Glu
Leu Leu Gly Gly Pro Ser Val Phe225 230 235 240Leu Phe Pro Pro Lys
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro 245 250 255Glu Val Thr
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val 260 265 270Lys
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr 275 280
285Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
Lys Cys305 310 315 320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
Glu Lys Thr Ile Ser 325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro
Gln Val Tyr Thr Leu Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys
Asn Gln Val Ser Leu Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp385 390 395
400Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
Leu His 420 425 430Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
Gly Lys 435 440 44517220PRTArtificial SequenceJ11L7, light chain
humanised construct 17Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser
Gln Ser Leu Leu Asn Pro 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp
Tyr Gln Gln Lys Pro Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe
Ala Ser Thr Arg Asp Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser
Gly Ser Gly Thr Asp Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln
Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr
Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120
125Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
Ala Leu145 150 155 160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu
Gln Asp Ser Lys Asp 165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu
Thr Leu Ser Lys Ala Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala
Cys Glu Val Thr His Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys
Ser Phe Asn Arg Gly Glu Cys 210 215 22018446PRTArtificial
SequenceJ11L7, heavy chain humanised construct 18Gln Val Gln Leu
Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser1 5 10 15Ser Val Lys
Val Ser Cys Lys Ala Ser Gly Phe Ser Leu Thr Ala Tyr 20 25 30Gly Val
Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met 35 40 45Gly
Met Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asp Ser Ala Leu Lys 50 55
60Ser Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr Met65
70 75 80Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
Ala 85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr Trp Gly Gln Gly Thr
Leu Val 100 105 110Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
Phe Pro Leu Ala 115 120 125Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
Ala Ala Leu Gly Cys Leu 130 135 140Val Lys Asp Tyr Phe Pro Glu Pro
Val Thr Val Ser Trp Asn Ser Gly145 150 155 160Ala Leu Thr Ser Gly
Val His Thr Phe Pro Ala Val Leu Gln Ser Ser 165 170 175Gly Leu Tyr
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu 180 185 190Gly
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr 195 200
205Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
Val Phe225 230 235 240Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
Ile Ser Arg Thr Pro 245 250 255Glu Val Thr Cys Val Val Val Asp Val
Ser His Glu Asp Pro Glu Val 260 265 270Lys Phe Asn Trp Tyr Val Asp
Gly Val Glu Val His Asn Ala Lys Thr 275 280 285Lys Pro Arg Glu Glu
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val 290 295 300Leu Thr Val
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys305 310 315
320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu Asn Asn Tyr Lys Thr
Thr Pro Pro Val Leu Asp Ser Asp385 390 395 400Gly Ser Phe Phe Leu
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp 405 410 415Gln Gln Gly
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His 420 425 430Asn
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 435 440
44519220PRTArtificial SequenceH2L7, light chain humanised construct
19Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1
5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asn
Pro 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe Ala Ser Thr Arg Asp
Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala
Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr Pro Pro Thr Phe Gly
Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg Thr Val Ala Ala Pro
Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120 125Glu Gln Leu Lys Ser
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn 130 135 140Phe Tyr Pro
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu145 150 155
160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala
Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His
Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys Ser Phe Asn Arg Gly
Glu Cys 210 215 22020446PRTArtificial SequenceH2L7, heavy chain
humanised construct 20Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu
Val Lys Pro Ser Glu1 5 10 15Thr Leu Ser Leu Thr Cys Thr Val Ser Gly
Phe Ser Leu Thr Ala Tyr 20 25 30Gly Val Asn Trp Ile Arg Gln Pro Pro
Gly Lys Gly Leu Glu Trp Ile 35 40 45Gly Met Ile Trp Asp Asp Gly Ser
Thr Asp Tyr Asn Ser Ala Leu Lys 50 55 60Ser Arg Val Thr Ile Ser Lys
Asp Asn Ser Lys Asn Gln Val Ser Leu65 70 75 80Lys Leu Ser Ser Val
Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp
Val Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val 100 105 110Thr Val
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120
125Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn
Ser Gly145 150 155 160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
Val Leu Gln Ser Ser 165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val
Thr Val Pro Ser Ser Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys
Asn Val Asn His Lys Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys
Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe225 230 235
240Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
Glu Val 260 265 270Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
Asn Ala Lys Thr 275 280 285Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
Tyr Arg Val Val Ser Val 290 295 300Leu Thr Val Leu His Gln Asp Trp
Leu Asn Gly Lys Glu Tyr Lys Cys305 310 315 320Lys Val Ser Asn Lys
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser 325 330 335Lys Ala Lys
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro 340 345 350Ser
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val 355 360
365Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
Ser Asp385 390 395 400Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
Asp Lys Ser Arg Trp 405 410 415Gln Gln Gly Asn Val Phe Ser Cys Ser
Val Met His Glu Ala Leu His 420 425 430Asn His Tyr Thr Gln Lys Ser
Leu Ser Leu Ser Pro Gly Lys 435 440 44521220PRTArtificial
SequenceJ13L7, light chain humanised construct 21Asp Ile Gln Met
Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val
Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asn Pro 20 25 30Ser Asn
Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys 35 40 45Ala
Pro Lys Leu Leu Val Tyr Phe Ala Ser Thr Arg Asp Ser Gly Val 50 55
60Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr65
70 75 80Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu
Gln 85 90 95His Phe Gly Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu
Glu Ile 100 105 110Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe
Pro Pro Ser Asp 115 120 125Glu Gln Leu Lys Ser Gly Thr Ala Ser Val
Val Cys Leu Leu Asn Asn 130 135 140Phe Tyr Pro Arg Glu Ala Lys Val
Gln Trp Lys Val Asp Asn Ala Leu145 150 155 160Gln Ser Gly Asn Ser
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp 165 170 175Ser Thr Tyr
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr 180 185 190Glu
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser 195 200
205Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys 210 215
22022446PRTArtificial SequenceJ13L7, heavy chain humanised
construct 22Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro
Gly Ser1 5 10 15Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe
Ser Ala Tyr 20 25 30Gly Val Asn Trp Val Arg Gln Ala Pro Gly Gln Gly
Leu Glu Trp Met 35 40 45Gly Met Ile Trp Asp Asp Gly Ser Thr Asp Tyr
Asp Ser Ala Leu Lys 50 55 60Ser Arg Val Thr Ile Thr Ala Asp Lys Ser
Thr Ser Thr Ala Tyr Met65 70 75 80Glu Leu Ser Ser Leu Arg Ser Glu
Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp Val Ala Phe
Asp Tyr Trp Gly Gln Gly Thr Leu Val 100 105 110Thr Val Ser Ser Ala
Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120 125Pro Ser Ser
Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu 130 135 140Val
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly145 150
155 160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
Ser 165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
Ser Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
Lys Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys Val Glu Pro Lys
Ser Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro Cys Pro Ala Pro
Glu Leu Leu Gly Gly Pro Ser Val Phe225 230 235 240Leu Phe Pro Pro
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro 245 250 255Glu Val
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val 260 265
270Lys Phe Asn Trp Tyr
Val Asp Gly Val Glu Val His Asn Ala Lys Thr 275 280 285Lys Pro Arg
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val 290 295 300Leu
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys305 310
315 320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
Ser 325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
Leu Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
Leu Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro Ser Asp Ile Ala
Val Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu Asn Asn Tyr Lys
Thr Thr Pro Pro Val Leu Asp Ser Asp385 390 395 400Gly Ser Phe Phe
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp 405 410 415Gln Gln
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His 420 425
430Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 435 440
44523220PRTArtificial SequenceH7L7, light chain humanised construct
23Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1
5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asn
Pro 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe Ala Ser Thr Arg Asp
Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala
Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr Pro Pro Thr Phe Gly
Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg Thr Val Ala Ala Pro
Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120 125Glu Gln Leu Lys Ser
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn 130 135 140Phe Tyr Pro
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu145 150 155
160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala
Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His
Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys Ser Phe Asn Arg Gly
Glu Cys 210 215 22024446PRTArtificial SequenceH7L7, heavy chain
humanised construct 24Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu
Val Lys Pro Ser Glu1 5 10 15Thr Leu Ser Leu Thr Cys Thr Val Ser Gly
Gly Ser Ile Ser Ala Tyr 20 25 30Gly Val Asn Trp Ile Arg Gln Pro Pro
Gly Lys Gly Leu Glu Trp Ile 35 40 45Gly Met Ile Trp Asp Asp Gly Ser
Thr Asp Tyr Asp Ser Ala Leu Lys 50 55 60Ser Arg Val Thr Ile Ser Val
Asp Thr Ser Lys Asn Gln Phe Ser Leu65 70 75 80Lys Leu Ser Ser Val
Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp
Val Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val 100 105 110Thr Val
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120
125Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn
Ser Gly145 150 155 160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
Val Leu Gln Ser Ser 165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val
Thr Val Pro Ser Ser Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys
Asn Val Asn His Lys Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys
Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe225 230 235
240Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
Glu Val 260 265 270Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
Asn Ala Lys Thr 275 280 285Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
Tyr Arg Val Val Ser Val 290 295 300Leu Thr Val Leu His Gln Asp Trp
Leu Asn Gly Lys Glu Tyr Lys Cys305 310 315 320Lys Val Ser Asn Lys
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser 325 330 335Lys Ala Lys
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro 340 345 350Ser
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val 355 360
365Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
Ser Asp385 390 395 400Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
Asp Lys Ser Arg Trp 405 410 415Gln Gln Gly Asn Val Phe Ser Cys Ser
Val Met His Glu Ala Leu His 420 425 430Asn His Tyr Thr Gln Lys Ser
Leu Ser Leu Ser Pro Gly Lys 435 440 44525220PRTArtificial
SequenceJ0L7, light chain humanised construct 25Asp Ile Gln Met Thr
Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr
Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asn Pro 20 25 30Ser Asn Gln
Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys 35 40 45Ala Pro
Lys Leu Leu Val Tyr Phe Ala Ser Thr Arg Asp Ser Gly Val 50 55 60Pro
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr65 70 75
80Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln
85 90 95His Phe Gly Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu
Ile 100 105 110Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro
Pro Ser Asp 115 120 125Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val
Cys Leu Leu Asn Asn 130 135 140Phe Tyr Pro Arg Glu Ala Lys Val Gln
Trp Lys Val Asp Asn Ala Leu145 150 155 160Gln Ser Gly Asn Ser Gln
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp 165 170 175Ser Thr Tyr Ser
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr 180 185 190Glu Lys
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser 195 200
205Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys 210 215
22026446PRTArtificial SequenceJ0L7, heavy chain humanised construct
26Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser1
5 10 15Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ala
Tyr 20 25 30Gly Val Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu
Trp Met 35 40 45Gly Met Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asn Ser
Ala Leu Lys 50 55 60Ser Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser
Thr Ala Tyr Met65 70 75 80Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr
Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr
Trp Gly Gln Gly Thr Leu Val 100 105 110Thr Val Ser Ser Ala Ser Thr
Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120 125Pro Ser Ser Lys Ser
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu 130 135 140Val Lys Asp
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly145 150 155
160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys Val Glu Pro Lys Ser
Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro Cys Pro Ala Pro Glu
Leu Leu Gly Gly Pro Ser Val Phe225 230 235 240Leu Phe Pro Pro Lys
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro 245 250 255Glu Val Thr
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val 260 265 270Lys
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr 275 280
285Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
Lys Cys305 310 315 320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
Glu Lys Thr Ile Ser 325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro
Gln Val Tyr Thr Leu Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys
Asn Gln Val Ser Leu Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp385 390 395
400Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
Leu His 420 425 430Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
Gly Lys 435 440 44527220PRTArtificial SequenceH0L7, light chain
humanised construct 27Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser
Gln Ser Leu Leu Asn Pro 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp
Tyr Gln Gln Lys Pro Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe
Ala Ser Thr Arg Asp Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser
Gly Ser Gly Thr Asp Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln
Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr
Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120
125Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
Ala Leu145 150 155 160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu
Gln Asp Ser Lys Asp 165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu
Thr Leu Ser Lys Ala Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala
Cys Glu Val Thr His Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys
Ser Phe Asn Arg Gly Glu Cys 210 215 22028446PRTArtificial
SequenceH0L7, heavy chain humanised construct 28Gln Val Gln Leu Gln
Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu1 5 10 15Thr Leu Ser Leu
Thr Cys Thr Val Ser Gly Gly Ser Ile Ser Ala Tyr 20 25 30Gly Val Asn
Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Ile 35 40 45Gly Met
Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asn Ser Ala Leu Lys 50 55 60Ser
Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser Leu65 70 75
80Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu
Val 100 105 110Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
Pro Leu Ala 115 120 125Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
Ala Leu Gly Cys Leu 130 135 140Val Lys Asp Tyr Phe Pro Glu Pro Val
Thr Val Ser Trp Asn Ser Gly145 150 155 160Ala Leu Thr Ser Gly Val
His Thr Phe Pro Ala Val Leu Gln Ser Ser 165 170 175Gly Leu Tyr Ser
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu 180 185 190Gly Thr
Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr 195 200
205Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
Val Phe225 230 235 240Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
Ile Ser Arg Thr Pro 245 250 255Glu Val Thr Cys Val Val Val Asp Val
Ser His Glu Asp Pro Glu Val 260 265 270Lys Phe Asn Trp Tyr Val Asp
Gly Val Glu Val His Asn Ala Lys Thr 275 280 285Lys Pro Arg Glu Glu
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val 290 295 300Leu Thr Val
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys305 310 315
320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu Asn Asn Tyr Lys Thr
Thr Pro Pro Val Leu Asp Ser Asp385 390 395 400Gly Ser Phe Phe Leu
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp 405 410 415Gln Gln Gly
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His 420 425 430Asn
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 435 440
44529220PRTArtificial SequenceH1L1, light chain humanised construct
29Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1
5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asn
Gly 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe Ala Ser Thr Arg Asp
Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala
Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr Pro Pro Thr Phe Gly
Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg Thr Val Ala Ala Pro
Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120 125Glu Gln Leu Lys Ser
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn 130 135 140Phe Tyr Pro
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu145 150 155
160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala
Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His
Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys Ser Phe Asn Arg Gly
Glu Cys 210 215 22030446PRTArtificial SequenceH1L1, heavy chain
humanised construct 30Gln
Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu1 5 10
15Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Ala Tyr
20 25 30Gly Val Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
Ile 35 40 45Gly Met Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asn Ser Ala
Leu Lys 50 55 60Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln
Phe Ser Leu65 70 75 80Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala
Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr Trp
Gly Gln Gly Thr Leu Val 100 105 110Thr Val Ser Ser Ala Ser Thr Lys
Gly Pro Ser Val Phe Pro Leu Ala 115 120 125Pro Ser Ser Lys Ser Thr
Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu 130 135 140Val Lys Asp Tyr
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly145 150 155 160Ala
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser 165 170
175Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu
180 185 190Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser
Asn Thr 195 200 205Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp
Lys Thr His Thr 210 215 220Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu
Gly Gly Pro Ser Val Phe225 230 235 240Leu Phe Pro Pro Lys Pro Lys
Asp Thr Leu Met Ile Ser Arg Thr Pro 245 250 255Glu Val Thr Cys Val
Val Val Asp Val Ser His Glu Asp Pro Glu Val 260 265 270Lys Phe Asn
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr 275 280 285Lys
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val 290 295
300Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
Cys305 310 315 320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
Lys Thr Ile Ser 325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln
Val Tyr Thr Leu Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys Asn
Gln Val Ser Leu Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro Ser
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu Asn
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp385 390 395 400Gly
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp 405 410
415Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 44531220PRTArtificial SequenceH5L1, light chain humanised
construct 31Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu
Leu Asn Gly 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln
Lys Pro Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe Ala Ser Thr
Arg Asp Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly
Thr Asp Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln Pro Glu Asp
Phe Ala Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr Pro Pro Thr
Phe Gly Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg Thr Val Ala
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120 125Glu Gln Leu
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn 130 135 140Phe
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu145 150
155 160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
Asp 165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys
Ala Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr
His Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys Ser Phe Asn Arg
Gly Glu Cys 210 215 22032446PRTArtificial SequenceH5L1, heavy chain
humanised construct 32Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu
Val Lys Pro Ser Glu1 5 10 15Thr Leu Ser Leu Thr Cys Thr Val Ser Gly
Phe Ser Leu Thr Ala Tyr 20 25 30Gly Val Asn Trp Ile Arg Gln Pro Pro
Gly Lys Gly Leu Glu Trp Ile 35 40 45Gly Met Ile Trp Asp Asp Gly Ser
Thr Asp Tyr Asp Ser Ala Leu Lys 50 55 60Ser Arg Val Thr Ile Ser Val
Asp Thr Ser Lys Asn Gln Phe Ser Leu65 70 75 80Lys Leu Ser Ser Val
Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp
Val Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val 100 105 110Thr Val
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120
125Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn
Ser Gly145 150 155 160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
Val Leu Gln Ser Ser 165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val
Thr Val Pro Ser Ser Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys
Asn Val Asn His Lys Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys
Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe225 230 235
240Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
Glu Val 260 265 270Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
Asn Ala Lys Thr 275 280 285Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
Tyr Arg Val Val Ser Val 290 295 300Leu Thr Val Leu His Gln Asp Trp
Leu Asn Gly Lys Glu Tyr Lys Cys305 310 315 320Lys Val Ser Asn Lys
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser 325 330 335Lys Ala Lys
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro 340 345 350Ser
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val 355 360
365Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
Ser Asp385 390 395 400Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
Asp Lys Ser Arg Trp 405 410 415Gln Gln Gly Asn Val Phe Ser Cys Ser
Val Met His Glu Ala Leu His 420 425 430Asn His Tyr Thr Gln Lys Ser
Leu Ser Leu Ser Pro Gly Lys 435 440 44533220PRTArtificial
SequenceJ7L1, light chain humanised construct 33Asp Ile Gln Met Thr
Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr
Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asn Gly 20 25 30Ser Asn Gln
Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys 35 40 45Ala Pro
Lys Leu Leu Val Tyr Phe Ala Ser Thr Arg Asp Ser Gly Val 50 55 60Pro
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr65 70 75
80Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln
85 90 95His Phe Gly Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu
Ile 100 105 110Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro
Pro Ser Asp 115 120 125Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val
Cys Leu Leu Asn Asn 130 135 140Phe Tyr Pro Arg Glu Ala Lys Val Gln
Trp Lys Val Asp Asn Ala Leu145 150 155 160Gln Ser Gly Asn Ser Gln
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp 165 170 175Ser Thr Tyr Ser
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr 180 185 190Glu Lys
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser 195 200
205Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys 210 215
22034446PRTArtificial SequenceJ7L1, heavy chain humanised construct
34Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser1
5 10 15Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Ser Leu Thr Ala
Tyr 20 25 30Gly Val Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu
Trp Met 35 40 45Gly Met Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asn Ser
Ala Leu Lys 50 55 60Ser Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser
Thr Ala Tyr Met65 70 75 80Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr
Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr
Trp Gly Gln Gly Thr Leu Val 100 105 110Thr Val Ser Ser Ala Ser Thr
Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120 125Pro Ser Ser Lys Ser
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu 130 135 140Val Lys Asp
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly145 150 155
160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys Val Glu Pro Lys Ser
Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro Cys Pro Ala Pro Glu
Leu Leu Gly Gly Pro Ser Val Phe225 230 235 240Leu Phe Pro Pro Lys
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro 245 250 255Glu Val Thr
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val 260 265 270Lys
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr 275 280
285Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
Lys Cys305 310 315 320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
Glu Lys Thr Ile Ser 325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro
Gln Val Tyr Thr Leu Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys
Asn Gln Val Ser Leu Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp385 390 395
400Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
Leu His 420 425 430Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
Gly Lys 435 440 44535220PRTArtificial SequenceJ11L1, light chain
humanised construct 35Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser
Gln Ser Leu Leu Asn Gly 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp
Tyr Gln Gln Lys Pro Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe
Ala Ser Thr Arg Asp Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser
Gly Ser Gly Thr Asp Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln
Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr
Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120
125Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
Ala Leu145 150 155 160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu
Gln Asp Ser Lys Asp 165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu
Thr Leu Ser Lys Ala Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala
Cys Glu Val Thr His Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys
Ser Phe Asn Arg Gly Glu Cys 210 215 22036446PRTArtificial
SequenceJ11L1, heavy chain humanised construct 36Gln Val Gln Leu
Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser1 5 10 15Ser Val Lys
Val Ser Cys Lys Ala Ser Gly Phe Ser Leu Thr Ala Tyr 20 25 30Gly Val
Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met 35 40 45Gly
Met Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asp Ser Ala Leu Lys 50 55
60Ser Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr Met65
70 75 80Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
Ala 85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr Trp Gly Gln Gly Thr
Leu Val 100 105 110Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
Phe Pro Leu Ala 115 120 125Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr
Ala Ala Leu Gly Cys Leu 130 135 140Val Lys Asp Tyr Phe Pro Glu Pro
Val Thr Val Ser Trp Asn Ser Gly145 150 155 160Ala Leu Thr Ser Gly
Val His Thr Phe Pro Ala Val Leu Gln Ser Ser 165 170 175Gly Leu Tyr
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu 180 185 190Gly
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr 195 200
205Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
Val Phe225 230 235 240Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
Ile Ser Arg Thr Pro 245 250 255Glu Val Thr Cys Val Val Val Asp Val
Ser His Glu Asp Pro Glu Val 260 265 270Lys Phe Asn Trp Tyr Val Asp
Gly Val Glu Val His Asn Ala Lys Thr 275 280 285Lys Pro Arg Glu Glu
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val 290 295 300Leu Thr Val
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys305 310 315
320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu Asn Asn Tyr Lys Thr
Thr Pro Pro Val Leu Asp Ser Asp385 390 395 400Gly Ser Phe Phe Leu
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp 405 410
415Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
420 425 430Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 44537220PRTArtificial SequenceJ13L1, light chain humanised
construct 37Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu
Leu Asn Gly 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln
Lys Pro Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe Ala Ser Thr
Arg Asp Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly
Thr Asp Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln Pro Glu Asp
Phe Ala Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr Pro Pro Thr
Phe Gly Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg Thr Val Ala
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120 125Glu Gln Leu
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn 130 135 140Phe
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu145 150
155 160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
Asp 165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys
Ala Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr
His Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys Ser Phe Asn Arg
Gly Glu Cys 210 215 22038446PRTArtificial SequenceJ13L1, heavy
chain humanised construct 38Gln Val Gln Leu Val Gln Ser Gly Ala Glu
Val Lys Lys Pro Gly Ser1 5 10 15Ser Val Lys Val Ser Cys Lys Ala Ser
Gly Gly Thr Phe Ser Ala Tyr 20 25 30Gly Val Asn Trp Val Arg Gln Ala
Pro Gly Gln Gly Leu Glu Trp Met 35 40 45Gly Met Ile Trp Asp Asp Gly
Ser Thr Asp Tyr Asp Ser Ala Leu Lys 50 55 60Ser Arg Val Thr Ile Thr
Ala Asp Lys Ser Thr Ser Thr Ala Tyr Met65 70 75 80Glu Leu Ser Ser
Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly
Asp Val Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val 100 105 110Thr
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120
125Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn
Ser Gly145 150 155 160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
Val Leu Gln Ser Ser 165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val
Thr Val Pro Ser Ser Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys
Asn Val Asn His Lys Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys
Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe225 230 235
240Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
245 250 255Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
Glu Val 260 265 270Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
Asn Ala Lys Thr 275 280 285Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr
Tyr Arg Val Val Ser Val 290 295 300Leu Thr Val Leu His Gln Asp Trp
Leu Asn Gly Lys Glu Tyr Lys Cys305 310 315 320Lys Val Ser Asn Lys
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser 325 330 335Lys Ala Lys
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro 340 345 350Ser
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val 355 360
365Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
370 375 380Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
Ser Asp385 390 395 400Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
Asp Lys Ser Arg Trp 405 410 415Gln Gln Gly Asn Val Phe Ser Cys Ser
Val Met His Glu Ala Leu His 420 425 430Asn His Tyr Thr Gln Lys Ser
Leu Ser Leu Ser Pro Gly Lys 435 440 44539220PRTArtificial
SequenceH7L1, light chain humanised construct 39Asp Ile Gln Met Thr
Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr
Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asn Gly 20 25 30Ser Asn Gln
Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys 35 40 45Ala Pro
Lys Leu Leu Val Tyr Phe Ala Ser Thr Arg Asp Ser Gly Val 50 55 60Pro
Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr65 70 75
80Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln
85 90 95His Phe Gly Thr Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu
Ile 100 105 110Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro
Pro Ser Asp 115 120 125Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val
Cys Leu Leu Asn Asn 130 135 140Phe Tyr Pro Arg Glu Ala Lys Val Gln
Trp Lys Val Asp Asn Ala Leu145 150 155 160Gln Ser Gly Asn Ser Gln
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp 165 170 175Ser Thr Tyr Ser
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr 180 185 190Glu Lys
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser 195 200
205Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys 210 215
22040446PRTArtificial SequenceH7L1, heavy chain humanised construct
40Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu1
5 10 15Thr Leu Ser Leu Thr Cys Thr Val Ser Gly Gly Ser Ile Ser Ala
Tyr 20 25 30Gly Val Asn Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu
Trp Ile 35 40 45Gly Met Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asp Ser
Ala Leu Lys 50 55 60Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn
Gln Phe Ser Leu65 70 75 80Lys Leu Ser Ser Val Thr Ala Ala Asp Thr
Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr
Trp Gly Gln Gly Thr Leu Val 100 105 110Thr Val Ser Ser Ala Ser Thr
Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120 125Pro Ser Ser Lys Ser
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu 130 135 140Val Lys Asp
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly145 150 155
160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys Val Glu Pro Lys Ser
Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro Cys Pro Ala Pro Glu
Leu Leu Gly Gly Pro Ser Val Phe225 230 235 240Leu Phe Pro Pro Lys
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro 245 250 255Glu Val Thr
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val 260 265 270Lys
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr 275 280
285Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
Lys Cys305 310 315 320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
Glu Lys Thr Ile Ser 325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro
Gln Val Tyr Thr Leu Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys
Asn Gln Val Ser Leu Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp385 390 395
400Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
Leu His 420 425 430Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
Gly Lys 435 440 44541220PRTArtificial SequenceJ0L1, light chain
humanised construct 41Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu
Ser Ala Ser Val Gly1 5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser
Gln Ser Leu Leu Asn Gly 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp
Tyr Gln Gln Lys Pro Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe
Ala Ser Thr Arg Asp Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser
Gly Ser Gly Thr Asp Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln
Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr
Pro Pro Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120
125Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn
Ala Leu145 150 155 160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu
Gln Asp Ser Lys Asp 165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu
Thr Leu Ser Lys Ala Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala
Cys Glu Val Thr His Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys
Ser Phe Asn Arg Gly Glu Cys 210 215 22042446PRTArtificial
SequenceJ0L1, heavy chain humanised construct 42Gln Val Gln Leu Val
Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser1 5 10 15Ser Val Lys Val
Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ala Tyr 20 25 30Gly Val Asn
Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met 35 40 45Gly Met
Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asn Ser Ala Leu Lys 50 55 60Ser
Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr Met65 70 75
80Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu
Val 100 105 110Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
Pro Leu Ala 115 120 125Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
Ala Leu Gly Cys Leu 130 135 140Val Lys Asp Tyr Phe Pro Glu Pro Val
Thr Val Ser Trp Asn Ser Gly145 150 155 160Ala Leu Thr Ser Gly Val
His Thr Phe Pro Ala Val Leu Gln Ser Ser 165 170 175Gly Leu Tyr Ser
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu 180 185 190Gly Thr
Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr 195 200
205Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr
210 215 220Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
Val Phe225 230 235 240Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
Ile Ser Arg Thr Pro 245 250 255Glu Val Thr Cys Val Val Val Asp Val
Ser His Glu Asp Pro Glu Val 260 265 270Lys Phe Asn Trp Tyr Val Asp
Gly Val Glu Val His Asn Ala Lys Thr 275 280 285Lys Pro Arg Glu Glu
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val 290 295 300Leu Thr Val
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys305 310 315
320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu Asn Asn Tyr Lys Thr
Thr Pro Pro Val Leu Asp Ser Asp385 390 395 400Gly Ser Phe Phe Leu
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp 405 410 415Gln Gln Gly
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His 420 425 430Asn
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys 435 440
44543220PRTArtificial SequenceH0L1, light chain humanised construct
43Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly1
5 10 15Asp Arg Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asn
Gly 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro
Gly Lys 35 40 45Ala Pro Lys Leu Leu Val Tyr Phe Ala Ser Thr Arg Asp
Ser Gly Val 50 55 60Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
Phe Thr Leu Thr65 70 75 80Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala
Thr Tyr Tyr Cys Leu Gln 85 90 95His Phe Gly Thr Pro Pro Thr Phe Gly
Gln Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg Thr Val Ala Ala Pro
Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120 125Glu Gln Leu Lys Ser
Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn 130 135 140Phe Tyr Pro
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu145 150 155
160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala
Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His
Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys Ser Phe Asn Arg Gly
Glu Cys 210 215 22044446PRTArtificial SequenceH0L1, heavy chain
humanised construct 44Gln Val Gln Leu Gln Glu Ser Gly Pro Gly Leu
Val Lys Pro Ser Glu1 5 10 15Thr Leu Ser Leu Thr Cys Thr Val Ser Gly
Gly Ser Ile Ser Ala Tyr 20 25 30Gly Val Asn Trp Ile Arg Gln Pro Pro
Gly Lys Gly Leu Glu Trp Ile 35 40 45Gly Met Ile Trp Asp Asp Gly Ser
Thr Asp Tyr Asn Ser Ala Leu Lys 50 55 60Ser Arg Val Thr Ile Ser Val
Asp Thr Ser Lys Asn Gln Phe Ser Leu65 70 75 80Lys Leu Ser Ser Val
Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp
Val Ala Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val 100 105 110Thr Val
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120
125Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu
130 135 140Val Lys Asp
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly145 150 155
160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys Val Glu Pro Lys Ser
Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro Cys Pro Ala Pro Glu
Leu Leu Gly Gly Pro Ser Val Phe225 230 235 240Leu Phe Pro Pro Lys
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro 245 250 255Glu Val Thr
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val 260 265 270Lys
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr 275 280
285Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
Lys Cys305 310 315 320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
Glu Lys Thr Ile Ser 325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro
Gln Val Tyr Thr Leu Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys
Asn Gln Val Ser Leu Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp385 390 395
400Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
Leu His 420 425 430Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
Gly Lys 435 440 44545106PRTHomo Sapien 45Thr Val Ala Ala Pro Ser
Val Phe Ile Phe Pro Pro Ser Asp Glu Gln1 5 10 15Leu Lys Ser Gly Thr
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr 20 25 30Pro Arg Glu Ala
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser 35 40 45Gly Asn Ser
Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr 50 55 60Tyr Ser
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys65 70 75
80His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
85 90 95Val Thr Lys Ser Phe Asn Arg Gly Glu Cys 100 10546330PRTHomo
Sapien 46Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser
Ser Lys1 5 10 15Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
Lys Asp Tyr 20 25 30Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly
Ala Leu Thr Ser 35 40 45Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
Ser Gly Leu Tyr Ser 50 55 60Leu Ser Ser Val Val Thr Val Pro Ser Ser
Ser Leu Gly Thr Gln Thr65 70 75 80Tyr Ile Cys Asn Val Asn His Lys
Pro Ser Asn Thr Lys Val Asp Lys 85 90 95Lys Val Glu Pro Lys Ser Cys
Asp Lys Thr His Thr Cys Pro Pro Cys 100 105 110Pro Ala Pro Glu Leu
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro 115 120 125Lys Pro Lys
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys 130 135 140Val
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp145 150
155 160Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
Glu 165 170 175Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
Thr Val Leu 180 185 190His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
Cys Lys Val Ser Asn 195 200 205Lys Ala Leu Pro Ala Pro Ile Glu Lys
Thr Ile Ser Lys Ala Lys Gly 210 215 220Gln Pro Arg Glu Pro Gln Val
Tyr Thr Leu Pro Pro Ser Arg Asp Glu225 230 235 240Leu Thr Lys Asn
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr 245 250 255Pro Ser
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn 260 265
270Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
Gly Asn 290 295 300Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
Asn His Tyr Thr305 310 315 320Gln Lys Ser Leu Ser Leu Ser Pro Gly
Lys 325 33047116PRTMurine 47Gln Val Gln Leu Lys Glu Ser Gly Pro Gly
Leu Val Ala Pro Ser Gln1 5 10 15Ser Leu Ser Ile Thr Cys Thr Val Ser
Gly Phe Ser Leu Thr Ala Tyr 20 25 30Gly Val Asn Trp Val Arg Gln Pro
Pro Gly Lys Gly Leu Glu Trp Leu 35 40 45Gly Met Ile Trp Asp Asp Gly
Ser Thr Asp Tyr Asn Ser Ala Leu Lys 50 55 60Ser Arg Leu Ser Ile Ser
Lys Asp Asn Ser Lys Ser Gln Val Phe Leu65 70 75 80Lys Met Asn Ser
Leu Gln Thr Asp Asp Thr Ala Arg Tyr Tyr Cys Ala 85 90 95Arg Glu Gly
Asp Val Ala Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu 100 105 110Thr
Val Ser Ser 11548114PRTMurine 48Asp Ile Val Met Thr Gln Ser Pro Ser
Ser Leu Ala Val Ser Val Gly1 5 10 15Gln Lys Val Thr Met Ser Cys Lys
Ser Ser Gln Ser Leu Leu Asn Gly 20 25 30Ser Asn Gln Lys Asn Tyr Leu
Ala Trp Tyr Gln Gln Lys Pro Gly Gln 35 40 45Ser Pro Lys Leu Leu Val
Tyr Phe Ala Ser Thr Arg Asp Ser Gly Val 50 55 60Pro Asp Arg Phe Ile
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr65 70 75 80Ile Ser Ser
Val Gln Ala Glu Asp Leu Ala Asp Tyr Phe Cys Leu Gln 85 90 95His Phe
Gly Thr Pro Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile 100 105
110Lys Arg49446PRTArtificial SequenceIMP731, heavy chain sequence
49Gln Val Gln Leu Lys Glu Ser Gly Pro Gly Leu Val Ala Pro Ser Gln1
5 10 15Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Ala
Tyr 20 25 30Gly Val Asn Trp Val Arg Gln Pro Pro Gly Lys Gly Leu Glu
Trp Leu 35 40 45Gly Met Ile Trp Asp Asp Gly Ser Thr Asp Tyr Asn Ser
Ala Leu Lys 50 55 60Ser Arg Leu Ser Ile Ser Lys Asp Asn Ser Lys Ser
Gln Val Phe Leu65 70 75 80Lys Met Asn Ser Leu Gln Thr Asp Asp Thr
Ala Arg Tyr Tyr Cys Ala 85 90 95Arg Glu Gly Asp Val Ala Phe Asp Tyr
Trp Gly Gln Gly Thr Thr Leu 100 105 110Thr Val Ser Ser Ala Ser Thr
Lys Gly Pro Ser Val Phe Pro Leu Ala 115 120 125Pro Ser Ser Lys Ser
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu 130 135 140Val Lys Asp
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly145 150 155
160Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser
165 170 175Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
Ser Leu 180 185 190Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys
Pro Ser Asn Thr 195 200 205Lys Val Asp Lys Lys Val Glu Pro Lys Ser
Cys Asp Lys Thr His Thr 210 215 220Cys Pro Pro Cys Pro Ala Pro Glu
Leu Leu Gly Gly Pro Ser Val Phe225 230 235 240Leu Phe Pro Pro Lys
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro 245 250 255Glu Val Thr
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val 260 265 270Lys
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr 275 280
285Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
290 295 300Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
Lys Cys305 310 315 320Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
Glu Lys Thr Ile Ser 325 330 335Lys Ala Lys Gly Gln Pro Arg Glu Pro
Gln Val Tyr Thr Leu Pro Pro 340 345 350Ser Arg Asp Glu Leu Thr Lys
Asn Gln Val Ser Leu Thr Cys Leu Val 355 360 365Lys Gly Phe Tyr Pro
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly 370 375 380Gln Pro Glu
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp385 390 395
400Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
405 410 415Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
Leu His 420 425 430Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
Gly Lys 435 440 44550220PRTArtificial SequenceIMP731, light chain
sequence 50Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Ala Val Ser
Val Gly1 5 10 15Gln Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu
Leu Asn Gly 20 25 30Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln
Lys Pro Gly Gln 35 40 45Ser Pro Lys Leu Leu Val Tyr Phe Ala Ser Thr
Arg Asp Ser Gly Val 50 55 60Pro Asp Arg Phe Ile Gly Ser Gly Ser Gly
Thr Asp Phe Thr Leu Thr65 70 75 80Ile Ser Ser Val Gln Ala Glu Asp
Leu Ala Asp Tyr Phe Cys Leu Gln 85 90 95His Phe Gly Thr Pro Pro Thr
Phe Gly Gly Gly Thr Lys Leu Glu Ile 100 105 110Lys Arg Thr Val Ala
Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp 115 120 125Glu Gln Leu
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn 130 135 140Phe
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu145 150
155 160Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys
Asp 165 170 175Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys
Ala Asp Tyr 180 185 190Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr
His Gln Gly Leu Ser 195 200 205Ser Pro Val Thr Lys Ser Phe Asn Arg
Gly Glu Cys 210 215 22051417PRTArtificial SequenceRecombinant human
LAG-3-ECD-His6 51Leu Gln Pro Gly Ala Glu Val Pro Val Val Trp Ala
Gln Glu Gly Ala1 5 10 15Pro Ala Gln Leu Pro Cys Ser Pro Thr Ile Pro
Leu Gln Asp Leu Ser 20 25 30Leu Leu Arg Arg Ala Gly Val Thr Trp Gln
His Gln Pro Asp Ser Gly 35 40 45Pro Pro Ala Ala Ala Pro Gly His Pro
Leu Ala Pro Gly Pro His Pro 50 55 60Ala Ala Pro Ser Ser Trp Gly Pro
Arg Pro Arg Arg Tyr Thr Val Leu65 70 75 80Ser Val Gly Pro Gly Gly
Leu Arg Ser Gly Arg Leu Pro Leu Gln Pro 85 90 95Arg Val Gln Leu Asp
Glu Arg Gly Arg Gln Arg Gly Asp Phe Ser Leu 100 105 110Trp Leu Arg
Pro Ala Arg Arg Ala Asp Ala Gly Glu Tyr Arg Ala Ala 115 120 125Val
His Leu Arg Asp Arg Ala Leu Ser Cys Arg Leu Arg Leu Arg Leu 130 135
140Gly Gln Ala Ser Met Thr Ala Ser Pro Pro Gly Ser Leu Arg Ala
Ser145 150 155 160Asp Trp Val Ile Leu Asn Cys Ser Phe Ser Arg Pro
Asp Arg Pro Ala 165 170 175Ser Val His Trp Phe Arg Asn Arg Gly Gln
Gly Arg Val Pro Val Arg 180 185 190Glu Ser Pro His His His Leu Ala
Glu Ser Phe Leu Phe Leu Pro Gln 195 200 205Val Ser Pro Met Asp Ser
Gly Pro Trp Gly Cys Ile Leu Thr Tyr Arg 210 215 220Asp Gly Phe Asn
Val Ser Ile Met Tyr Asn Leu Thr Val Leu Gly Leu225 230 235 240Glu
Pro Pro Thr Pro Leu Thr Val Tyr Ala Gly Ala Gly Ser Arg Val 245 250
255Gly Leu Pro Cys Arg Leu Pro Ala Gly Val Gly Thr Arg Ser Phe Leu
260 265 270Thr Ala Lys Trp Thr Pro Pro Gly Gly Gly Pro Asp Leu Leu
Val Thr 275 280 285Gly Asp Asn Gly Asp Phe Thr Leu Arg Leu Glu Asp
Val Ser Gln Ala 290 295 300Gln Ala Gly Thr Tyr Thr Cys His Ile His
Leu Gln Glu Gln Gln Leu305 310 315 320Asn Ala Thr Val Thr Leu Ala
Ile Ile Thr Val Thr Pro Lys Ser Phe 325 330 335Gly Ser Pro Gly Ser
Leu Gly Lys Leu Leu Cys Glu Val Thr Pro Val 340 345 350Ser Gly Gln
Glu Arg Phe Val Trp Ser Ser Leu Asp Thr Pro Ser Gln 355 360 365Arg
Ser Phe Ser Gly Pro Trp Leu Glu Ala Gln Glu Ala Gln Leu Leu 370 375
380Ser Gln Pro Trp Gln Cys Gln Leu Tyr Gln Gly Glu Arg Leu Leu
Gly385 390 395 400Ala Ala Val Tyr Phe Thr Glu Leu Ser Ser Pro His
His His His His 405 410 415His52417PRTArtificial
SequenceRecombinant cynomolgus macaque LAG-3 ECD-His6 52Pro Gln Pro
Gly Ala Glu Ile Ser Val Val Trp Ala Gln Glu Gly Ala1 5 10 15Pro Ala
Gln Leu Pro Cys Ser Pro Thr Ile Pro Leu Gln Asp Leu Ser 20 25 30Leu
Leu Arg Arg Ala Gly Val Thr Trp Gln His Gln Pro Asp Ser Gly 35 40
45Pro Pro Ala Pro Ala Pro Gly His Pro Pro Ala Pro Gly His Arg Pro
50 55 60Ala Ala Pro Tyr Ser Trp Gly Pro Arg Pro Arg Arg Tyr Thr Val
Leu65 70 75 80Ser Val Gly Pro Gly Gly Leu Arg Ser Gly Arg Leu Pro
Leu Gln Pro 85 90 95Arg Val Gln Leu Asp Glu Arg Gly Arg Gln Arg Gly
Asp Phe Ser Leu 100 105 110Trp Leu Arg Pro Ala Arg Arg Ala Asp Ala
Gly Glu Tyr Arg Ala Thr 115 120 125Val His Leu Arg Asp Arg Ala Leu
Ser Cys Arg Leu Arg Leu Arg Val 130 135 140Gly Gln Ala Ser Met Thr
Ala Ser Pro Pro Gly Ser Leu Arg Thr Ser145 150 155 160Asp Trp Val
Ile Leu Asn Cys Ser Phe Ser Arg Pro Asp Arg Pro Ala 165 170 175Ser
Val His Trp Phe Arg Ser Arg Gly Gln Gly Arg Val Pro Val Gln 180 185
190Gly Ser Pro His His His Leu Ala Glu Ser Phe Leu Phe Leu Pro His
195 200 205Val Gly Pro Met Asp Ser Gly Leu Trp Gly Cys Ile Leu Thr
Tyr Arg 210 215 220Asp Gly Phe Asn Val Ser Ile Met Tyr Asn Leu Thr
Val Leu Gly Leu225 230 235 240Glu Pro Ala Thr Pro Leu Thr Val Tyr
Ala Gly Ala Gly Ser Arg Val 245 250 255Glu Leu Pro Cys Arg Leu Pro
Pro Ala Val Gly Thr Gln Ser Phe Leu 260 265 270Thr Ala Lys Trp Ala
Pro Pro Gly Gly Gly Pro Asp Leu Leu Val Ala 275 280 285Gly Asp Asn
Gly Asp Phe Thr Leu Arg Leu Glu Asp Val Ser Gln Ala 290 295 300Gln
Ala Gly Thr Tyr Ile Cys His Ile Arg Leu Gln Gly Gln Gln Leu305 310
315 320Asn Ala Thr Val Thr Leu Ala Ile Ile Thr Val Thr Pro Lys Ser
Phe 325 330 335Gly Ser Pro Gly Ser Leu Gly Lys Leu Leu Cys Glu Val
Thr Pro Ala 340 345 350Ser Gly Gln Glu His Phe Val Trp Ser Pro Leu
Asn Thr Pro Ser Gln 355 360 365Arg Ser Phe Ser Gly Pro Trp Leu
Glu
Ala Gln Glu Ala Gln Leu Leu 370 375 380Ser Gln Pro Trp Gln Cys Gln
Leu His Gln Gly Glu Arg Leu Leu Gly385 390 395 400Ala Ala Val Tyr
Phe Thr Glu Leu Ser Ser Pro His His His His His 405 410
415His53417PRTArtificial SequenceRecombinant baboon LAG-3 ECD-His6
53Pro Gln Pro Gly Ala Glu Ile Ser Val Val Trp Ala Gln Glu Gly Ala1
5 10 15Pro Ala Gln Leu Pro Cys Ser Pro Thr Ile Pro Leu Gln Asp Leu
Ser 20 25 30Leu Leu Arg Arg Ala Gly Val Thr Trp Gln His Gln Pro Asp
Ser Gly 35 40 45Pro Pro Ala Pro Ala Pro Gly His Pro Pro Ala Pro Gly
His Arg Pro 50 55 60Ala Ala Pro Tyr Ser Trp Gly Pro Arg Pro Arg Arg
Tyr Thr Val Leu65 70 75 80Ser Val Gly Pro Gly Gly Leu Arg Ser Gly
Arg Leu Pro Leu Gln Pro 85 90 95Arg Val Gln Leu Asp Glu Arg Gly Arg
Gln Arg Gly Asp Phe Ser Leu 100 105 110Trp Leu Arg Pro Ala Arg Arg
Ala Asp Ala Gly Glu Tyr Arg Ala Thr 115 120 125Val His Leu Arg Asp
Arg Ala Leu Ser Cys Arg Leu Arg Leu Arg Val 130 135 140Gly Gln Ala
Ser Met Thr Ala Ser Pro Pro Gly Ser Leu Arg Thr Ser145 150 155
160Asp Trp Val Ile Leu Asn Cys Ser Phe Ser Arg Pro Asp Arg Pro Ala
165 170 175Ser Val His Trp Phe Arg Ser Arg Gly Gln Gly Gln Val Pro
Val Gln 180 185 190Glu Ser Pro His His His Leu Ala Glu Ser Phe Leu
Phe Leu Pro His 195 200 205Val Gly Pro Met Asp Ser Gly Leu Trp Gly
Cys Ile Leu Thr Tyr Arg 210 215 220Asp Gly Phe Asn Val Ser Ile Met
Tyr Asn Leu Thr Val Leu Gly Leu225 230 235 240Glu Pro Thr Thr Pro
Leu Thr Val Tyr Ala Gly Ala Gly Ser Arg Val 245 250 255Glu Leu Pro
Cys Arg Leu Pro Pro Ala Val Gly Thr Gln Ser Phe Leu 260 265 270Thr
Ala Lys Trp Ala Pro Pro Gly Gly Gly Pro Asp Leu Leu Val Val 275 280
285Gly Asp Asn Gly Asn Phe Thr Leu Arg Leu Glu Asp Val Ser Gln Ala
290 295 300Gln Ala Gly Thr Tyr Ile Cys His Ile Arg Leu Gln Gly Gln
Gln Leu305 310 315 320Asn Ala Thr Val Thr Leu Ala Ile Ile Thr Val
Thr Pro Lys Ser Phe 325 330 335Gly Ser Pro Gly Ser Leu Gly Lys Leu
Leu Cys Glu Val Thr Pro Ala 340 345 350Ser Gly Gln Glu Arg Phe Val
Trp Ser Pro Leu Asn Thr Pro Ser Gln 355 360 365Arg Ser Phe Ser Gly
Pro Trp Leu Glu Ala Gln Glu Ala Gln Leu Leu 370 375 380Ser Gln Pro
Trp Gln Cys Gln Leu His Gln Gly Glu Arg Leu Leu Gly385 390 395
400Ala Ala Val Tyr Phe Thr Glu Leu Ser Ser Pro His His His His His
405 410 415His5419PRTMurine 54Met Gly Trp Ser Cys Ile Ile Leu Phe
Leu Val Ala Thr Ala Thr Gly1 5 10 15Val His Ser5520PRTMurine 55Met
Glu Ser Gln Thr Gln Val Leu Met Phe Leu Leu Leu Trp Val Ser1 5 10
15Gly Ala Cys Ala 205616PRTHomo Sapien 56Met Pro Leu Leu Leu Leu
Leu Pro Leu Leu Trp Ala Gly Ala Leu Ala1 5 10 155751DNAArtificial
SequenceH5L7, CDRL1 (Kabat defined) 57aagagcagcc agagcctgct
gaaccccagc aaccagaaga actacctggc c 515821DNAMurine 58ttcgcctcta
ccagggattc c 215927DNAMurine 59ctgcagcact tcggcacccc tcccact
2760342DNAArtificial SequenceH5L7, VL 60gacatccaga tgacccagag
cccctctagc ctcagcgcca gcgtgggcga cagggtgacc 60atcacctgca agagcagcca
gagcctgctg aaccccagca accagaagaa ctacctggcc 120tggtaccagc
agaaacccgg caaggccccc aagctgctgg tctacttcgc ctctaccagg
180gattccggcg tccccagcag gttcagcggc agcggcagcg gcaccgactt
cacactgacc 240atcagcagcc tgcagcccga ggacttcgcc acctactact
gcctgcagca cttcggcacc 300cctcccactt ttggccaggg caccaagctg
gagattaagc gt 34261660DNAArtificial SequenceH5L7, light chain
humanised construct 61gacatccaga tgacccagag cccctctagc ctcagcgcca
gcgtgggcga cagggtgacc 60atcacctgca agagcagcca gagcctgctg aaccccagca
accagaagaa ctacctggcc 120tggtaccagc agaaacccgg caaggccccc
aagctgctgg tctacttcgc ctctaccagg 180gattccggcg tccccagcag
gttcagcggc agcggcagcg gcaccgactt cacactgacc 240atcagcagcc
tgcagcccga ggacttcgcc acctactact gcctgcagca cttcggcacc
300cctcccactt ttggccaggg caccaagctg gagattaagc gtacggtggc
cgcccccagc 360gtgttcatct tcccccccag cgatgagcag ctgaagagcg
gcaccgccag cgtggtgtgt 420ctgctgaaca acttctaccc ccgggaggcc
aaggtgcagt ggaaggtgga caatgccctg 480cagagcggca acagccagga
gagcgtgacc gagcaggaca gcaaggactc cacctacagc 540ctgagcagca
ccctgaccct gagcaaggcc gactacgaga agcacaaggt gtacgcctgt
600gaggtgaccc accagggcct gtccagcccc gtgaccaaga gcttcaaccg
gggcgagtgc 6606215DNAMurine 62gcctacggcg tcaac 156348DNAArtificial
SequenceH5L7, CDRH2 (Kabat defined) 63atgatctggg acgacggcag
caccgactac gacagcgccc tgaagagc 486424DNAMurine 64gagggcgacg
tggccttcga ttac 2465348DNAArtificial SequenceH5L7, VH 65caggtgcagc
tccaggagag cggccccggc ctggtgaagc ctagcgagac cctgagcctg 60acctgcaccg
tgagcggctt ctccctgacc gcctacggcg tcaactggat caggcagccc
120cccggcaaag gcctggagtg gattgggatg atctgggacg acggcagcac
cgactacgac 180agcgccctga agagcagggt gaccatcagc gtggacacca
gcaagaacca gttcagcctg 240aagctgagca gcgtgactgc cgccgacacc
gccgtctatt actgcgccag ggagggcgac 300gtggccttcg attactgggg
ccagggcaca ctagtgaccg tgtccagc 348661338DNAArtificial SequenceH5L7,
heavy chain humanised construct 66caggtgcagc tccaggagag cggccccggc
ctggtgaagc ctagcgagac cctgagcctg 60acctgcaccg tgagcggctt ctccctgacc
gcctacggcg tcaactggat caggcagccc 120cccggcaaag gcctggagtg
gattgggatg atctgggacg acggcagcac cgactacgac 180agcgccctga
agagcagggt gaccatcagc gtggacacca gcaagaacca gttcagcctg
240aagctgagca gcgtgactgc cgccgacacc gccgtctatt actgcgccag
ggagggcgac 300gtggccttcg attactgggg ccagggcaca ctagtgaccg
tgtccagcgc cagcaccaag 360ggccccagcg tgttccccct ggcccccagc
agcaagagca ccagcggcgg cacagccgcc 420ctgggctgcc tggtgaagga
ctacttcccc gaaccggtga ccgtgtcctg gaacagcgga 480gccctgacca
gcggcgtgca caccttcccc gccgtgctgc agagcagcgg cctgtacagc
540ctgagcagcg tggtgaccgt gcccagcagc agcctgggca cccagaccta
catctgtaac 600gtgaaccaca agcccagcaa caccaaggtg gacaagaagg
tggagcccaa gagctgtgac 660aagacccaca cctgcccccc ctgccctgcc
cccgagctgc tgggaggccc cagcgtgttc 720ctgttccccc ccaagcctaa
ggacaccctg atgatcagca gaacccccga ggtgacctgt 780gtggtggtgg
atgtgagcca cgaggaccct gaggtgaagt tcaactggta cgtggacggc
840gtggaggtgc acaatgccaa gaccaagccc agggaggagc agtacaacag
cacctaccgg 900gtggtgtccg tgctgaccgt gctgcaccag gattggctga
acggcaagga gtacaagtgt 960aaggtgtcca acaaggccct gcctgcccct
atcgagaaaa ccatcagcaa ggccaagggc 1020cagcccagag agccccaggt
gtacaccctg ccccctagca gagatgagct gaccaagaac 1080caggtgtccc
tgacctgcct ggtgaagggc ttctacccca gcgacatcgc cgtggagtgg
1140gagagcaacg gccagcccga gaacaactac aagaccaccc cccctgtgct
ggacagcgat 1200ggcagcttct tcctgtacag caagctgacc gtggacaaga
gcagatggca gcagggcaac 1260gtgttcagct gctccgtgat gcacgaggcc
ctgcacaatc actacaccca gaagagcctg 1320agcctgtccc ctggcaag
133867660DNAArtificial SequenceH1L7, light chain humanised
construct 67gacatccaga tgacccagag cccctctagc ctcagcgcca gcgtgggcga
cagggtgacc 60atcacctgca agagcagcca gagcctgctg aaccccagca accagaagaa
ctacctggcc 120tggtaccagc agaaacccgg caaggccccc aagctgctgg
tctacttcgc ctctaccagg 180gattccggcg tccccagcag gttcagcggc
agcggcagcg gcaccgactt cacactgacc 240atcagcagcc tgcagcccga
ggacttcgcc acctactact gcctgcagca cttcggcacc 300cctcccactt
ttggccaggg caccaagctg gagattaagc gtacggtggc cgcccccagc
360gtgttcatct tcccccccag cgatgagcag ctgaagagcg gcaccgccag
cgtggtgtgt 420ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt
ggaaggtgga caatgccctg 480cagagcggca acagccagga gagcgtgacc
gagcaggaca gcaaggactc cacctacagc 540ctgagcagca ccctgaccct
gagcaaggcc gactacgaga agcacaaggt gtacgcctgt 600gaggtgaccc
accagggcct gtccagcccc gtgaccaaga gcttcaaccg gggcgagtgc
660681338DNAArtificial SequenceH1L7, heavy chain humanised
construct 68caggtgcagc tccaggagag cggccccggc ctggtgaagc ctagcgagac
cctgagcctg 60acctgcaccg tgagcggctt ctccctgacc gcctacggcg tcaactggat
caggcagccc 120cccggcaaag gcctggagtg gattgggatg atctgggacg
acggcagcac cgactacaac 180agcgccctga agagcagggt gaccatcagc
gtggacacca gcaagaacca gttcagcctg 240aagctgagca gcgtgactgc
cgccgacacc gccgtctatt actgcgccag ggagggcgac 300gtggccttcg
attactgggg ccagggcaca ctagtgaccg tgtccagcgc cagcaccaag
360ggccccagcg tgttccccct ggcccccagc agcaagagca ccagcggcgg
cacagccgcc 420ctgggctgcc tggtgaagga ctacttcccc gaaccggtga
ccgtgtcctg gaacagcgga 480gccctgacca gcggcgtgca caccttcccc
gccgtgctgc agagcagcgg cctgtacagc 540ctgagcagcg tggtgaccgt
gcccagcagc agcctgggca cccagaccta catctgtaac 600gtgaaccaca
agcccagcaa caccaaggtg gacaagaagg tggagcccaa gagctgtgac
660aagacccaca cctgcccccc ctgccctgcc cccgagctgc tgggaggccc
cagcgtgttc 720ctgttccccc ccaagcctaa ggacaccctg atgatcagca
gaacccccga ggtgacctgt 780gtggtggtgg atgtgagcca cgaggaccct
gaggtgaagt tcaactggta cgtggacggc 840gtggaggtgc acaatgccaa
gaccaagccc agggaggagc agtacaacag cacctaccgg 900gtggtgtccg
tgctgaccgt gctgcaccag gattggctga acggcaagga gtacaagtgt
960aaggtgtcca acaaggccct gcctgcccct atcgagaaaa ccatcagcaa
ggccaagggc 1020cagcccagag agccccaggt gtacaccctg ccccctagca
gagatgagct gaccaagaac 1080caggtgtccc tgacctgcct ggtgaagggc
ttctacccca gcgacatcgc cgtggagtgg 1140gagagcaacg gccagcccga
gaacaactac aagaccaccc cccctgtgct ggacagcgat 1200ggcagcttct
tcctgtacag caagctgacc gtggacaaga gcagatggca gcagggcaac
1260gtgttcagct gctccgtgat gcacgaggcc ctgcacaatc actacaccca
gaagagcctg 1320agcctgtccc ctggcaag 133869660DNAArtificial
SequenceJ7L7, light chain humanised construct 69gacatccaga
tgacccagag cccctctagc ctcagcgcca gcgtgggcga cagggtgacc 60atcacctgca
agagcagcca gagcctgctg aaccccagca accagaagaa ctacctggcc
120tggtaccagc agaaacccgg caaggccccc aagctgctgg tctacttcgc
ctctaccagg 180gattccggcg tccccagcag gttcagcggc agcggcagcg
gcaccgactt cacactgacc 240atcagcagcc tgcagcccga ggacttcgcc
acctactact gcctgcagca cttcggcacc 300cctcccactt ttggccaggg
caccaagctg gagattaagc gtacggtggc cgcccccagc 360gtgttcatct
tcccccccag cgatgagcag ctgaagagcg gcaccgccag cgtggtgtgt
420ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt ggaaggtgga
caatgccctg 480cagagcggca acagccagga gagcgtgacc gagcaggaca
gcaaggactc cacctacagc 540ctgagcagca ccctgaccct gagcaaggcc
gactacgaga agcacaaggt gtacgcctgt 600gaggtgaccc accagggcct
gtccagcccc gtgaccaaga gcttcaaccg gggcgagtgc 660701338DNAArtificial
SequenceJ7L7, heavy chain humanised construct 70caggtgcagc
tcgtgcagag cggggccgaa gtcaagaaac ccggcagctc cgtgaaggtg 60agctgcaagg
ccagcggctt ctctctcact gcctacggcg tgaactgggt gaggcaggct
120cccggccagg gcctggagtg gatgggcatg atctgggacg acggcagcac
cgactacaac 180agcgccctga agagcagggt gaccatcacc gccgacaaga
gcaccagcac cgcctacatg 240gaactgagca gcctgaggag cgaggacacc
gccgtgtact attgcgccag ggagggcgac 300gtggccttcg attactgggg
ccagggcaca ctagtgaccg tgtccagcgc cagcaccaag 360ggccccagcg
tgttccccct ggcccccagc agcaagagca ccagcggcgg cacagccgcc
420ctgggctgcc tggtgaagga ctacttcccc gaaccggtga ccgtgtcctg
gaacagcgga 480gccctgacca gcggcgtgca caccttcccc gccgtgctgc
agagcagcgg cctgtacagc 540ctgagcagcg tggtgaccgt gcccagcagc
agcctgggca cccagaccta catctgtaac 600gtgaaccaca agcccagcaa
caccaaggtg gacaagaagg tggagcccaa gagctgtgac 660aagacccaca
cctgcccccc ctgccctgcc cccgagctgc tgggaggccc cagcgtgttc
720ctgttccccc ccaagcctaa ggacaccctg atgatcagca gaacccccga
ggtgacctgt 780gtggtggtgg atgtgagcca cgaggaccct gaggtgaagt
tcaactggta cgtggacggc 840gtggaggtgc acaatgccaa gaccaagccc
agggaggagc agtacaacag cacctaccgg 900gtggtgtccg tgctgaccgt
gctgcaccag gattggctga acggcaagga gtacaagtgt 960aaggtgtcca
acaaggccct gcctgcccct atcgagaaaa ccatcagcaa ggccaagggc
1020cagcccagag agccccaggt gtacaccctg ccccctagca gagatgagct
gaccaagaac 1080caggtgtccc tgacctgcct ggtgaagggc ttctacccca
gcgacatcgc cgtggagtgg 1140gagagcaacg gccagcccga gaacaactac
aagaccaccc cccctgtgct ggacagcgat 1200ggcagcttct tcctgtacag
caagctgacc gtggacaaga gcagatggca gcagggcaac 1260gtgttcagct
gctccgtgat gcacgaggcc ctgcacaatc actacaccca gaagagcctg
1320agcctgtccc ctggcaag 133871660DNAArtificial SequenceH4L7, light
chain humanised construct 71gacatccaga tgacccagag cccctctagc
ctcagcgcca gcgtgggcga cagggtgacc 60atcacctgca agagcagcca gagcctgctg
aaccccagca accagaagaa ctacctggcc 120tggtaccagc agaaacccgg
caaggccccc aagctgctgg tctacttcgc ctctaccagg 180gattccggcg
tccccagcag gttcagcggc agcggcagcg gcaccgactt cacactgacc
240atcagcagcc tgcagcccga ggacttcgcc acctactact gcctgcagca
cttcggcacc 300cctcccactt ttggccaggg caccaagctg gagattaagc
gtacggtggc cgcccccagc 360gtgttcatct tcccccccag cgatgagcag
ctgaagagcg gcaccgccag cgtggtgtgt 420ctgctgaaca acttctaccc
ccgggaggcc aaggtgcagt ggaaggtgga caatgccctg 480cagagcggca
acagccagga gagcgtgacc gagcaggaca gcaaggactc cacctacagc
540ctgagcagca ccctgaccct gagcaaggcc gactacgaga agcacaaggt
gtacgcctgt 600gaggtgaccc accagggcct gtccagcccc gtgaccaaga
gcttcaaccg gggcgagtgc 660721338DNAArtificial SequenceH4L7, heavy
chain humanised construct 72caggtgcagc tccaggagag cggccccggc
ctggtgaagc ctagcgagac cctgagcctg 60acctgcaccg tgagcggctt ctccctgacc
gcctacggcg tcaactggat caggcagccc 120cccggcaaag gcctggagtg
gctggggatg atctgggacg acggcagcac cgactacaac 180agcgccctga
agagcaggct gaccatcagc aaggacaaca gcaagaacca ggtgagcctg
240aagctgagca gcgtgactgc cgccgacacc gccgtctatt actgcgccag
ggagggcgac 300gtggccttcg attactgggg ccagggcaca ctagtgaccg
tgtccagcgc cagcaccaag 360ggccccagcg tgttccccct ggcccccagc
agcaagagca ccagcggcgg cacagccgcc 420ctgggctgcc tggtgaagga
ctacttcccc gaaccggtga ccgtgtcctg gaacagcgga 480gccctgacca
gcggcgtgca caccttcccc gccgtgctgc agagcagcgg cctgtacagc
540ctgagcagcg tggtgaccgt gcccagcagc agcctgggca cccagaccta
catctgtaac 600gtgaaccaca agcccagcaa caccaaggtg gacaagaagg
tggagcccaa gagctgtgac 660aagacccaca cctgcccccc ctgccctgcc
cccgagctgc tgggaggccc cagcgtgttc 720ctgttccccc ccaagcctaa
ggacaccctg atgatcagca gaacccccga ggtgacctgt 780gtggtggtgg
atgtgagcca cgaggaccct gaggtgaagt tcaactggta cgtggacggc
840gtggaggtgc acaatgccaa gaccaagccc agggaggagc agtacaacag
cacctaccgg 900gtggtgtccg tgctgaccgt gctgcaccag gattggctga
acggcaagga gtacaagtgt 960aaggtgtcca acaaggccct gcctgcccct
atcgagaaaa ccatcagcaa ggccaagggc 1020cagcccagag agccccaggt
gtacaccctg ccccctagca gagatgagct gaccaagaac 1080caggtgtccc
tgacctgcct ggtgaagggc ttctacccca gcgacatcgc cgtggagtgg
1140gagagcaacg gccagcccga gaacaactac aagaccaccc cccctgtgct
ggacagcgat 1200ggcagcttct tcctgtacag caagctgacc gtggacaaga
gcagatggca gcagggcaac 1260gtgttcagct gctccgtgat gcacgaggcc
ctgcacaatc actacaccca gaagagcctg 1320agcctgtccc ctggcaag
133873660DNAArtificial SequenceJ11L7, light chain humanised
construct 73gacatccaga tgacccagag cccctctagc ctcagcgcca gcgtgggcga
cagggtgacc 60atcacctgca agagcagcca gagcctgctg aaccccagca accagaagaa
ctacctggcc 120tggtaccagc agaaacccgg caaggccccc aagctgctgg
tctacttcgc ctctaccagg 180gattccggcg tccccagcag gttcagcggc
agcggcagcg gcaccgactt cacactgacc 240atcagcagcc tgcagcccga
ggacttcgcc acctactact gcctgcagca cttcggcacc 300cctcccactt
ttggccaggg caccaagctg gagattaagc gtacggtggc cgcccccagc
360gtgttcatct tcccccccag cgatgagcag ctgaagagcg gcaccgccag
cgtggtgtgt 420ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt
ggaaggtgga caatgccctg 480cagagcggca acagccagga gagcgtgacc
gagcaggaca gcaaggactc cacctacagc 540ctgagcagca ccctgaccct
gagcaaggcc gactacgaga agcacaaggt gtacgcctgt 600gaggtgaccc
accagggcct gtccagcccc gtgaccaaga gcttcaaccg gggcgagtgc
660741338DNAArtificial SequenceJ11L7, heavy chain humanised
construct 74caggtgcagc tcgtgcagag cggggccgaa gtcaagaaac ccggcagctc
cgtgaaggtg 60agctgcaagg ccagcggctt ctctctcact gcctacggcg tgaactgggt
gaggcaggct 120cccggccagg gcctggagtg gatgggcatg atctgggacg
acggcagcac cgactacgac 180agcgccctga agagcagggt gaccatcacc
gccgacaaga gcaccagcac cgcctacatg 240gaactgagca gcctgaggag
cgaggacacc gccgtgtact attgcgccag ggagggcgac 300gtggccttcg
attactgggg ccagggcaca ctagtgaccg tgtccagcgc cagcaccaag
360ggccccagcg tgttccccct ggcccccagc agcaagagca ccagcggcgg
cacagccgcc 420ctgggctgcc tggtgaagga ctacttcccc gaaccggtga
ccgtgtcctg gaacagcgga 480gccctgacca gcggcgtgca caccttcccc
gccgtgctgc agagcagcgg cctgtacagc 540ctgagcagcg tggtgaccgt
gcccagcagc agcctgggca cccagaccta catctgtaac 600gtgaaccaca
agcccagcaa caccaaggtg gacaagaagg tggagcccaa gagctgtgac
660aagacccaca cctgcccccc ctgccctgcc cccgagctgc tgggaggccc
cagcgtgttc 720ctgttccccc ccaagcctaa ggacaccctg atgatcagca
gaacccccga ggtgacctgt 780gtggtggtgg atgtgagcca cgaggaccct
gaggtgaagt tcaactggta cgtggacggc 840gtggaggtgc acaatgccaa
gaccaagccc agggaggagc agtacaacag cacctaccgg 900gtggtgtccg
tgctgaccgt gctgcaccag gattggctga acggcaagga gtacaagtgt
960aaggtgtcca acaaggccct gcctgcccct atcgagaaaa ccatcagcaa
ggccaagggc 1020cagcccagag agccccaggt gtacaccctg ccccctagca
gagatgagct gaccaagaac
1080caggtgtccc tgacctgcct ggtgaagggc ttctacccca gcgacatcgc
cgtggagtgg 1140gagagcaacg gccagcccga gaacaactac aagaccaccc
cccctgtgct ggacagcgat 1200ggcagcttct tcctgtacag caagctgacc
gtggacaaga gcagatggca gcagggcaac 1260gtgttcagct gctccgtgat
gcacgaggcc ctgcacaatc actacaccca gaagagcctg 1320agcctgtccc ctggcaag
133875660DNAArtificial SequenceH2L7, light chain humanised
construct 75gacatccaga tgacccagag cccctctagc ctcagcgcca gcgtgggcga
cagggtgacc 60atcacctgca agagcagcca gagcctgctg aaccccagca accagaagaa
ctacctggcc 120tggtaccagc agaaacccgg caaggccccc aagctgctgg
tctacttcgc ctctaccagg 180gattccggcg tccccagcag gttcagcggc
agcggcagcg gcaccgactt cacactgacc 240atcagcagcc tgcagcccga
ggacttcgcc acctactact gcctgcagca cttcggcacc 300cctcccactt
ttggccaggg caccaagctg gagattaagc gtacggtggc cgcccccagc
360gtgttcatct tcccccccag cgatgagcag ctgaagagcg gcaccgccag
cgtggtgtgt 420ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt
ggaaggtgga caatgccctg 480cagagcggca acagccagga gagcgtgacc
gagcaggaca gcaaggactc cacctacagc 540ctgagcagca ccctgaccct
gagcaaggcc gactacgaga agcacaaggt gtacgcctgt 600gaggtgaccc
accagggcct gtccagcccc gtgaccaaga gcttcaaccg gggcgagtgc
660761338DNAArtificial SequenceH2L7, heavy chain humanised
construct 76caggtgcagc tccaggagag cggccccggc ctggtgaagc ctagcgagac
cctgagcctg 60acctgcaccg tgagcggctt ctccctgacc gcctacggcg tcaactggat
caggcagccc 120cccggcaaag gcctggagtg gattgggatg atctgggacg
acggcagcac cgactacaac 180agcgccctga agagcagggt gaccatcagc
aaggacaaca gcaagaacca ggtgagcctg 240aagctgagca gcgtgactgc
cgccgacacc gccgtctatt actgcgccag ggagggcgac 300gtggccttcg
attactgggg ccagggcaca ctagtgaccg tgtccagcgc cagcaccaag
360ggccccagcg tgttccccct ggcccccagc agcaagagca ccagcggcgg
cacagccgcc 420ctgggctgcc tggtgaagga ctacttcccc gaaccggtga
ccgtgtcctg gaacagcgga 480gccctgacca gcggcgtgca caccttcccc
gccgtgctgc agagcagcgg cctgtacagc 540ctgagcagcg tggtgaccgt
gcccagcagc agcctgggca cccagaccta catctgtaac 600gtgaaccaca
agcccagcaa caccaaggtg gacaagaagg tggagcccaa gagctgtgac
660aagacccaca cctgcccccc ctgccctgcc cccgagctgc tgggaggccc
cagcgtgttc 720ctgttccccc ccaagcctaa ggacaccctg atgatcagca
gaacccccga ggtgacctgt 780gtggtggtgg atgtgagcca cgaggaccct
gaggtgaagt tcaactggta cgtggacggc 840gtggaggtgc acaatgccaa
gaccaagccc agggaggagc agtacaacag cacctaccgg 900gtggtgtccg
tgctgaccgt gctgcaccag gattggctga acggcaagga gtacaagtgt
960aaggtgtcca acaaggccct gcctgcccct atcgagaaaa ccatcagcaa
ggccaagggc 1020cagcccagag agccccaggt gtacaccctg ccccctagca
gagatgagct gaccaagaac 1080caggtgtccc tgacctgcct ggtgaagggc
ttctacccca gcgacatcgc cgtggagtgg 1140gagagcaacg gccagcccga
gaacaactac aagaccaccc cccctgtgct ggacagcgat 1200ggcagcttct
tcctgtacag caagctgacc gtggacaaga gcagatggca gcagggcaac
1260gtgttcagct gctccgtgat gcacgaggcc ctgcacaatc actacaccca
gaagagcctg 1320agcctgtccc ctggcaag 133877660DNAArtificial
SequenceJ13L7, light chain humanised construct 77gacatccaga
tgacccagag cccctctagc ctcagcgcca gcgtgggcga cagggtgacc 60atcacctgca
agagcagcca gagcctgctg aaccccagca accagaagaa ctacctggcc
120tggtaccagc agaaacccgg caaggccccc aagctgctgg tctacttcgc
ctctaccagg 180gattccggcg tccccagcag gttcagcggc agcggcagcg
gcaccgactt cacactgacc 240atcagcagcc tgcagcccga ggacttcgcc
acctactact gcctgcagca cttcggcacc 300cctcccactt ttggccaggg
caccaagctg gagattaagc gtacggtggc cgcccccagc 360gtgttcatct
tcccccccag cgatgagcag ctgaagagcg gcaccgccag cgtggtgtgt
420ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt ggaaggtgga
caatgccctg 480cagagcggca acagccagga gagcgtgacc gagcaggaca
gcaaggactc cacctacagc 540ctgagcagca ccctgaccct gagcaaggcc
gactacgaga agcacaaggt gtacgcctgt 600gaggtgaccc accagggcct
gtccagcccc gtgaccaaga gcttcaaccg gggcgagtgc 660781338DNAArtificial
SequenceJ13L7, heavy chain humanised construct 78caggtgcagc
tcgtgcagag cggggccgaa gtcaagaaac ccggcagctc cgtgaaggtg 60agctgcaagg
ccagcggcgg caccttcagc gcctacggcg tgaactgggt gaggcaggct
120cccggccagg gcctggagtg gatgggcatg atctgggacg acggcagcac
cgactacgac 180agcgccctga agagcagggt gaccatcacc gccgacaaga
gcaccagcac cgcctacatg 240gaactgagca gcctgaggag cgaggacacc
gccgtgtact attgcgccag ggagggcgac 300gtggccttcg attactgggg
ccagggcaca ctagtgaccg tgtccagcgc cagcaccaag 360ggccccagcg
tgttccccct ggcccccagc agcaagagca ccagcggcgg cacagccgcc
420ctgggctgcc tggtgaagga ctacttcccc gaaccggtga ccgtgtcctg
gaacagcgga 480gccctgacca gcggcgtgca caccttcccc gccgtgctgc
agagcagcgg cctgtacagc 540ctgagcagcg tggtgaccgt gcccagcagc
agcctgggca cccagaccta catctgtaac 600gtgaaccaca agcccagcaa
caccaaggtg gacaagaagg tggagcccaa gagctgtgac 660aagacccaca
cctgcccccc ctgccctgcc cccgagctgc tgggaggccc cagcgtgttc
720ctgttccccc ccaagcctaa ggacaccctg atgatcagca gaacccccga
ggtgacctgt 780gtggtggtgg atgtgagcca cgaggaccct gaggtgaagt
tcaactggta cgtggacggc 840gtggaggtgc acaatgccaa gaccaagccc
agggaggagc agtacaacag cacctaccgg 900gtggtgtccg tgctgaccgt
gctgcaccag gattggctga acggcaagga gtacaagtgt 960aaggtgtcca
acaaggccct gcctgcccct atcgagaaaa ccatcagcaa ggccaagggc
1020cagcccagag agccccaggt gtacaccctg ccccctagca gagatgagct
gaccaagaac 1080caggtgtccc tgacctgcct ggtgaagggc ttctacccca
gcgacatcgc cgtggagtgg 1140gagagcaacg gccagcccga gaacaactac
aagaccaccc cccctgtgct ggacagcgat 1200ggcagcttct tcctgtacag
caagctgacc gtggacaaga gcagatggca gcagggcaac 1260gtgttcagct
gctccgtgat gcacgaggcc ctgcacaatc actacaccca gaagagcctg
1320agcctgtccc ctggcaag 133879660DNAArtificial SequenceH7L7, light
chain humanised construct 79gacatccaga tgacccagag cccctctagc
ctcagcgcca gcgtgggcga cagggtgacc 60atcacctgca agagcagcca gagcctgctg
aaccccagca accagaagaa ctacctggcc 120tggtaccagc agaaacccgg
caaggccccc aagctgctgg tctacttcgc ctctaccagg 180gattccggcg
tccccagcag gttcagcggc agcggcagcg gcaccgactt cacactgacc
240atcagcagcc tgcagcccga ggacttcgcc acctactact gcctgcagca
cttcggcacc 300cctcccactt ttggccaggg caccaagctg gagattaagc
gtacggtggc cgcccccagc 360gtgttcatct tcccccccag cgatgagcag
ctgaagagcg gcaccgccag cgtggtgtgt 420ctgctgaaca acttctaccc
ccgggaggcc aaggtgcagt ggaaggtgga caatgccctg 480cagagcggca
acagccagga gagcgtgacc gagcaggaca gcaaggactc cacctacagc
540ctgagcagca ccctgaccct gagcaaggcc gactacgaga agcacaaggt
gtacgcctgt 600gaggtgaccc accagggcct gtccagcccc gtgaccaaga
gcttcaaccg gggcgagtgc 660801338DNAArtificial SequenceH7L7, heavy
chain humanised construct 80caggtgcagc tccaggagag cggccccggc
ctggtgaagc ctagcgagac cctgagcctg 60acctgcaccg tgagcggcgg ctccatcagc
gcctacggcg tcaactggat caggcagccc 120cccggcaaag gcctggagtg
gattgggatg atctgggacg acggcagcac cgactacgac 180agcgccctga
agagcagggt gaccatcagc gtggacacca gcaagaacca gttcagcctg
240aagctgagca gcgtgactgc cgccgacacc gccgtctatt actgcgccag
ggagggcgac 300gtggccttcg attactgggg ccagggcaca ctagtgaccg
tgtccagcgc cagcaccaag 360ggccccagcg tgttccccct ggcccccagc
agcaagagca ccagcggcgg cacagccgcc 420ctgggctgcc tggtgaagga
ctacttcccc gaaccggtga ccgtgtcctg gaacagcgga 480gccctgacca
gcggcgtgca caccttcccc gccgtgctgc agagcagcgg cctgtacagc
540ctgagcagcg tggtgaccgt gcccagcagc agcctgggca cccagaccta
catctgtaac 600gtgaaccaca agcccagcaa caccaaggtg gacaagaagg
tggagcccaa gagctgtgac 660aagacccaca cctgcccccc ctgccctgcc
cccgagctgc tgggaggccc cagcgtgttc 720ctgttccccc ccaagcctaa
ggacaccctg atgatcagca gaacccccga ggtgacctgt 780gtggtggtgg
atgtgagcca cgaggaccct gaggtgaagt tcaactggta cgtggacggc
840gtggaggtgc acaatgccaa gaccaagccc agggaggagc agtacaacag
cacctaccgg 900gtggtgtccg tgctgaccgt gctgcaccag gattggctga
acggcaagga gtacaagtgt 960aaggtgtcca acaaggccct gcctgcccct
atcgagaaaa ccatcagcaa ggccaagggc 1020cagcccagag agccccaggt
gtacaccctg ccccctagca gagatgagct gaccaagaac 1080caggtgtccc
tgacctgcct ggtgaagggc ttctacccca gcgacatcgc cgtggagtgg
1140gagagcaacg gccagcccga gaacaactac aagaccaccc cccctgtgct
ggacagcgat 1200ggcagcttct tcctgtacag caagctgacc gtggacaaga
gcagatggca gcagggcaac 1260gtgttcagct gctccgtgat gcacgaggcc
ctgcacaatc actacaccca gaagagcctg 1320agcctgtccc ctggcaag
133881660DNAArtificial SequenceJ0L7, light chain humanised
construct 81gacatccaga tgacccagag cccctctagc ctcagcgcca gcgtgggcga
cagggtgacc 60atcacctgca agagcagcca gagcctgctg aaccccagca accagaagaa
ctacctggcc 120tggtaccagc agaaacccgg caaggccccc aagctgctgg
tctacttcgc ctctaccagg 180gattccggcg tccccagcag gttcagcggc
agcggcagcg gcaccgactt cacactgacc 240atcagcagcc tgcagcccga
ggacttcgcc acctactact gcctgcagca cttcggcacc 300cctcccactt
ttggccaggg caccaagctg gagattaagc gtacggtggc cgcccccagc
360gtgttcatct tcccccccag cgatgagcag ctgaagagcg gcaccgccag
cgtggtgtgt 420ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt
ggaaggtgga caatgccctg 480cagagcggca acagccagga gagcgtgacc
gagcaggaca gcaaggactc cacctacagc 540ctgagcagca ccctgaccct
gagcaaggcc gactacgaga agcacaaggt gtacgcctgt 600gaggtgaccc
accagggcct gtccagcccc gtgaccaaga gcttcaaccg gggcgagtgc
660821338DNAArtificial SequenceJ0L7, heavy chain humanised
construct 82caggtgcagc tcgtgcagag cggggccgaa gtcaagaaac ccggcagctc
cgtgaaggtg 60agctgcaagg ccagcggcgg caccttcagc gcctacggcg tgaactgggt
gaggcaggct 120cccggccagg gcctggagtg gatgggcatg atctgggacg
acggcagcac cgactacaac 180agcgccctga agagcagggt gaccatcacc
gccgacaaga gcaccagcac cgcctacatg 240gaactgagca gcctgaggag
cgaggacacc gccgtgtact attgcgccag ggagggcgac 300gtggccttcg
attactgggg ccagggcaca ctagtgaccg tgtccagcgc cagcaccaag
360ggccccagcg tgttccccct ggcccccagc agcaagagca ccagcggcgg
cacagccgcc 420ctgggctgcc tggtgaagga ctacttcccc gaaccggtga
ccgtgtcctg gaacagcgga 480gccctgacca gcggcgtgca caccttcccc
gccgtgctgc agagcagcgg cctgtacagc 540ctgagcagcg tggtgaccgt
gcccagcagc agcctgggca cccagaccta catctgtaac 600gtgaaccaca
agcccagcaa caccaaggtg gacaagaagg tggagcccaa gagctgtgac
660aagacccaca cctgcccccc ctgccctgcc cccgagctgc tgggaggccc
cagcgtgttc 720ctgttccccc ccaagcctaa ggacaccctg atgatcagca
gaacccccga ggtgacctgt 780gtggtggtgg atgtgagcca cgaggaccct
gaggtgaagt tcaactggta cgtggacggc 840gtggaggtgc acaatgccaa
gaccaagccc agggaggagc agtacaacag cacctaccgg 900gtggtgtccg
tgctgaccgt gctgcaccag gattggctga acggcaagga gtacaagtgt
960aaggtgtcca acaaggccct gcctgcccct atcgagaaaa ccatcagcaa
ggccaagggc 1020cagcccagag agccccaggt gtacaccctg ccccctagca
gagatgagct gaccaagaac 1080caggtgtccc tgacctgcct ggtgaagggc
ttctacccca gcgacatcgc cgtggagtgg 1140gagagcaacg gccagcccga
gaacaactac aagaccaccc cccctgtgct ggacagcgat 1200ggcagcttct
tcctgtacag caagctgacc gtggacaaga gcagatggca gcagggcaac
1260gtgttcagct gctccgtgat gcacgaggcc ctgcacaatc actacaccca
gaagagcctg 1320agcctgtccc ctggcaag 133883660DNAArtificial
SequenceH0L7, light chain humanised construct 83gacatccaga
tgacccagag cccctctagc ctcagcgcca gcgtgggcga cagggtgacc 60atcacctgca
agagcagcca gagcctgctg aaccccagca accagaagaa ctacctggcc
120tggtaccagc agaaacccgg caaggccccc aagctgctgg tctacttcgc
ctctaccagg 180gattccggcg tccccagcag gttcagcggc agcggcagcg
gcaccgactt cacactgacc 240atcagcagcc tgcagcccga ggacttcgcc
acctactact gcctgcagca cttcggcacc 300cctcccactt ttggccaggg
caccaagctg gagattaagc gtacggtggc cgcccccagc 360gtgttcatct
tcccccccag cgatgagcag ctgaagagcg gcaccgccag cgtggtgtgt
420ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt ggaaggtgga
caatgccctg 480cagagcggca acagccagga gagcgtgacc gagcaggaca
gcaaggactc cacctacagc 540ctgagcagca ccctgaccct gagcaaggcc
gactacgaga agcacaaggt gtacgcctgt 600gaggtgaccc accagggcct
gtccagcccc gtgaccaaga gcttcaaccg gggcgagtgc 660841338DNAArtificial
SequenceH0L7, heavy chain humanised construct 84caggtgcagc
tccaggagag cggccccggc ctggtgaagc ctagcgagac cctgagcctg 60acctgcaccg
tgagcggcgg ctccatcagc gcctacggcg tcaactggat caggcagccc
120cccggcaaag gcctggagtg gattgggatg atctgggacg acggcagcac
cgactacaac 180agcgccctga agagcagggt gaccatcagc gtggacacca
gcaagaacca gttcagcctg 240aagctgagca gcgtgactgc cgccgacacc
gccgtctatt actgcgccag ggagggcgac 300gtggccttcg attactgggg
ccagggcaca ctagtgaccg tgtccagcgc cagcaccaag 360ggccccagcg
tgttccccct ggcccccagc agcaagagca ccagcggcgg cacagccgcc
420ctgggctgcc tggtgaagga ctacttcccc gaaccggtga ccgtgtcctg
gaacagcgga 480gccctgacca gcggcgtgca caccttcccc gccgtgctgc
agagcagcgg cctgtacagc 540ctgagcagcg tggtgaccgt gcccagcagc
agcctgggca cccagaccta catctgtaac 600gtgaaccaca agcccagcaa
caccaaggtg gacaagaagg tggagcccaa gagctgtgac 660aagacccaca
cctgcccccc ctgccctgcc cccgagctgc tgggaggccc cagcgtgttc
720ctgttccccc ccaagcctaa ggacaccctg atgatcagca gaacccccga
ggtgacctgt 780gtggtggtgg atgtgagcca cgaggaccct gaggtgaagt
tcaactggta cgtggacggc 840gtggaggtgc acaatgccaa gaccaagccc
agggaggagc agtacaacag cacctaccgg 900gtggtgtccg tgctgaccgt
gctgcaccag gattggctga acggcaagga gtacaagtgt 960aaggtgtcca
acaaggccct gcctgcccct atcgagaaaa ccatcagcaa ggccaagggc
1020cagcccagag agccccaggt gtacaccctg ccccctagca gagatgagct
gaccaagaac 1080caggtgtccc tgacctgcct ggtgaagggc ttctacccca
gcgacatcgc cgtggagtgg 1140gagagcaacg gccagcccga gaacaactac
aagaccaccc cccctgtgct ggacagcgat 1200ggcagcttct tcctgtacag
caagctgacc gtggacaaga gcagatggca gcagggcaac 1260gtgttcagct
gctccgtgat gcacgaggcc ctgcacaatc actacaccca gaagagcctg
1320agcctgtccc ctggcaag 133885660DNAArtificial SequenceH1L1, light
chain humanised construct 85gacatccaga tgacccagag cccctctagc
ctcagcgcca gcgtgggcga cagggtgacc 60atcacctgca agagcagcca gagcctgctg
aacggcagca accagaagaa ctacctggcc 120tggtaccagc agaaacccgg
caaggccccc aagctgctgg tctacttcgc ctctaccagg 180gattccggcg
tccccagcag gttcagcggc agcggcagcg gcaccgactt cacactgacc
240atcagcagcc tgcagcccga ggacttcgcc acctactact gcctgcagca
cttcggcacc 300cctcccactt ttggccaggg caccaagctg gagattaagc
gtacggtggc cgcccccagc 360gtgttcatct tcccccccag cgatgagcag
ctgaagagcg gcaccgccag cgtggtgtgt 420ctgctgaaca acttctaccc
ccgggaggcc aaggtgcagt ggaaggtgga caatgccctg 480cagagcggca
acagccagga gagcgtgacc gagcaggaca gcaaggactc cacctacagc
540ctgagcagca ccctgaccct gagcaaggcc gactacgaga agcacaaggt
gtacgcctgt 600gaggtgaccc accagggcct gtccagcccc gtgaccaaga
gcttcaaccg gggcgagtgc 660861338DNAArtificial SequenceH1L1, heavy
chain humanised construct 86caggtgcagc tccaggagag cggccccggc
ctggtgaagc ctagcgagac cctgagcctg 60acctgcaccg tgagcggctt ctccctgacc
gcctacggcg tcaactggat caggcagccc 120cccggcaaag gcctggagtg
gattgggatg atctgggacg acggcagcac cgactacaac 180agcgccctga
agagcagggt gaccatcagc gtggacacca gcaagaacca gttcagcctg
240aagctgagca gcgtgactgc cgccgacacc gccgtctatt actgcgccag
ggagggcgac 300gtggccttcg attactgggg ccagggcaca ctagtgaccg
tgtccagcgc cagcaccaag 360ggccccagcg tgttccccct ggcccccagc
agcaagagca ccagcggcgg cacagccgcc 420ctgggctgcc tggtgaagga
ctacttcccc gaaccggtga ccgtgtcctg gaacagcgga 480gccctgacca
gcggcgtgca caccttcccc gccgtgctgc agagcagcgg cctgtacagc
540ctgagcagcg tggtgaccgt gcccagcagc agcctgggca cccagaccta
catctgtaac 600gtgaaccaca agcccagcaa caccaaggtg gacaagaagg
tggagcccaa gagctgtgac 660aagacccaca cctgcccccc ctgccctgcc
cccgagctgc tgggaggccc cagcgtgttc 720ctgttccccc ccaagcctaa
ggacaccctg atgatcagca gaacccccga ggtgacctgt 780gtggtggtgg
atgtgagcca cgaggaccct gaggtgaagt tcaactggta cgtggacggc
840gtggaggtgc acaatgccaa gaccaagccc agggaggagc agtacaacag
cacctaccgg 900gtggtgtccg tgctgaccgt gctgcaccag gattggctga
acggcaagga gtacaagtgt 960aaggtgtcca acaaggccct gcctgcccct
atcgagaaaa ccatcagcaa ggccaagggc 1020cagcccagag agccccaggt
gtacaccctg ccccctagca gagatgagct gaccaagaac 1080caggtgtccc
tgacctgcct ggtgaagggc ttctacccca gcgacatcgc cgtggagtgg
1140gagagcaacg gccagcccga gaacaactac aagaccaccc cccctgtgct
ggacagcgat 1200ggcagcttct tcctgtacag caagctgacc gtggacaaga
gcagatggca gcagggcaac 1260gtgttcagct gctccgtgat gcacgaggcc
ctgcacaatc actacaccca gaagagcctg 1320agcctgtccc ctggcaag
133887660DNAArtificial SequenceH5L1, light chain humanised
construct 87gacatccaga tgacccagag cccctctagc ctcagcgcca gcgtgggcga
cagggtgacc 60atcacctgca agagcagcca gagcctgctg aacggcagca accagaagaa
ctacctggcc 120tggtaccagc agaaacccgg caaggccccc aagctgctgg
tctacttcgc ctctaccagg 180gattccggcg tccccagcag gttcagcggc
agcggcagcg gcaccgactt cacactgacc 240atcagcagcc tgcagcccga
ggacttcgcc acctactact gcctgcagca cttcggcacc 300cctcccactt
ttggccaggg caccaagctg gagattaagc gtacggtggc cgcccccagc
360gtgttcatct tcccccccag cgatgagcag ctgaagagcg gcaccgccag
cgtggtgtgt 420ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt
ggaaggtgga caatgccctg 480cagagcggca acagccagga gagcgtgacc
gagcaggaca gcaaggactc cacctacagc 540ctgagcagca ccctgaccct
gagcaaggcc gactacgaga agcacaaggt gtacgcctgt 600gaggtgaccc
accagggcct gtccagcccc gtgaccaaga gcttcaaccg gggcgagtgc
660881338DNAArtificial SequenceH5L1, heavy chain humanised
construct 88caggtgcagc tccaggagag cggccccggc ctggtgaagc ctagcgagac
cctgagcctg 60acctgcaccg tgagcggctt ctccctgacc gcctacggcg tcaactggat
caggcagccc 120cccggcaaag gcctggagtg gattgggatg atctgggacg
acggcagcac cgactacgac 180agcgccctga agagcagggt gaccatcagc
gtggacacca gcaagaacca gttcagcctg 240aagctgagca gcgtgactgc
cgccgacacc gccgtctatt actgcgccag ggagggcgac 300gtggccttcg
attactgggg ccagggcaca ctagtgaccg tgtccagcgc cagcaccaag
360ggccccagcg tgttccccct ggcccccagc agcaagagca ccagcggcgg
cacagccgcc 420ctgggctgcc tggtgaagga ctacttcccc gaaccggtga
ccgtgtcctg gaacagcgga 480gccctgacca gcggcgtgca caccttcccc
gccgtgctgc agagcagcgg cctgtacagc 540ctgagcagcg tggtgaccgt
gcccagcagc agcctgggca cccagaccta catctgtaac 600gtgaaccaca
agcccagcaa caccaaggtg gacaagaagg tggagcccaa gagctgtgac
660aagacccaca cctgcccccc ctgccctgcc cccgagctgc tgggaggccc
cagcgtgttc 720ctgttccccc ccaagcctaa ggacaccctg atgatcagca
gaacccccga ggtgacctgt 780gtggtggtgg atgtgagcca cgaggaccct
gaggtgaagt tcaactggta cgtggacggc 840gtggaggtgc acaatgccaa
gaccaagccc agggaggagc agtacaacag cacctaccgg 900gtggtgtccg
tgctgaccgt gctgcaccag gattggctga acggcaagga gtacaagtgt
960aaggtgtcca acaaggccct gcctgcccct atcgagaaaa ccatcagcaa
ggccaagggc
1020cagcccagag agccccaggt gtacaccctg ccccctagca gagatgagct
gaccaagaac 1080caggtgtccc tgacctgcct ggtgaagggc ttctacccca
gcgacatcgc cgtggagtgg 1140gagagcaacg gccagcccga gaacaactac
aagaccaccc cccctgtgct ggacagcgat 1200ggcagcttct tcctgtacag
caagctgacc gtggacaaga gcagatggca gcagggcaac 1260gtgttcagct
gctccgtgat gcacgaggcc ctgcacaatc actacaccca gaagagcctg
1320agcctgtccc ctggcaag 133889660DNAArtificial SequenceJ7L1, light
chain humanised construct 89gacatccaga tgacccagag cccctctagc
ctcagcgcca gcgtgggcga cagggtgacc 60atcacctgca agagcagcca gagcctgctg
aacggcagca accagaagaa ctacctggcc 120tggtaccagc agaaacccgg
caaggccccc aagctgctgg tctacttcgc ctctaccagg 180gattccggcg
tccccagcag gttcagcggc agcggcagcg gcaccgactt cacactgacc
240atcagcagcc tgcagcccga ggacttcgcc acctactact gcctgcagca
cttcggcacc 300cctcccactt ttggccaggg caccaagctg gagattaagc
gtacggtggc cgcccccagc 360gtgttcatct tcccccccag cgatgagcag
ctgaagagcg gcaccgccag cgtggtgtgt 420ctgctgaaca acttctaccc
ccgggaggcc aaggtgcagt ggaaggtgga caatgccctg 480cagagcggca
acagccagga gagcgtgacc gagcaggaca gcaaggactc cacctacagc
540ctgagcagca ccctgaccct gagcaaggcc gactacgaga agcacaaggt
gtacgcctgt 600gaggtgaccc accagggcct gtccagcccc gtgaccaaga
gcttcaaccg gggcgagtgc 660901338DNAArtificial SequenceJ7L1, heavy
chain humanised construct 90caggtgcagc tcgtgcagag cggggccgaa
gtcaagaaac ccggcagctc cgtgaaggtg 60agctgcaagg ccagcggctt ctctctcact
gcctacggcg tgaactgggt gaggcaggct 120cccggccagg gcctggagtg
gatgggcatg atctgggacg acggcagcac cgactacaac 180agcgccctga
agagcagggt gaccatcacc gccgacaaga gcaccagcac cgcctacatg
240gaactgagca gcctgaggag cgaggacacc gccgtgtact attgcgccag
ggagggcgac 300gtggccttcg attactgggg ccagggcaca ctagtgaccg
tgtccagcgc cagcaccaag 360ggccccagcg tgttccccct ggcccccagc
agcaagagca ccagcggcgg cacagccgcc 420ctgggctgcc tggtgaagga
ctacttcccc gaaccggtga ccgtgtcctg gaacagcgga 480gccctgacca
gcggcgtgca caccttcccc gccgtgctgc agagcagcgg cctgtacagc
540ctgagcagcg tggtgaccgt gcccagcagc agcctgggca cccagaccta
catctgtaac 600gtgaaccaca agcccagcaa caccaaggtg gacaagaagg
tggagcccaa gagctgtgac 660aagacccaca cctgcccccc ctgccctgcc
cccgagctgc tgggaggccc cagcgtgttc 720ctgttccccc ccaagcctaa
ggacaccctg atgatcagca gaacccccga ggtgacctgt 780gtggtggtgg
atgtgagcca cgaggaccct gaggtgaagt tcaactggta cgtggacggc
840gtggaggtgc acaatgccaa gaccaagccc agggaggagc agtacaacag
cacctaccgg 900gtggtgtccg tgctgaccgt gctgcaccag gattggctga
acggcaagga gtacaagtgt 960aaggtgtcca acaaggccct gcctgcccct
atcgagaaaa ccatcagcaa ggccaagggc 1020cagcccagag agccccaggt
gtacaccctg ccccctagca gagatgagct gaccaagaac 1080caggtgtccc
tgacctgcct ggtgaagggc ttctacccca gcgacatcgc cgtggagtgg
1140gagagcaacg gccagcccga gaacaactac aagaccaccc cccctgtgct
ggacagcgat 1200ggcagcttct tcctgtacag caagctgacc gtggacaaga
gcagatggca gcagggcaac 1260gtgttcagct gctccgtgat gcacgaggcc
ctgcacaatc actacaccca gaagagcctg 1320agcctgtccc ctggcaag
133891660DNAArtificial SequenceJ11L1, light chain humanised
construct 91gacatccaga tgacccagag cccctctagc ctcagcgcca gcgtgggcga
cagggtgacc 60atcacctgca agagcagcca gagcctgctg aacggcagca accagaagaa
ctacctggcc 120tggtaccagc agaaacccgg caaggccccc aagctgctgg
tctacttcgc ctctaccagg 180gattccggcg tccccagcag gttcagcggc
agcggcagcg gcaccgactt cacactgacc 240atcagcagcc tgcagcccga
ggacttcgcc acctactact gcctgcagca cttcggcacc 300cctcccactt
ttggccaggg caccaagctg gagattaagc gtacggtggc cgcccccagc
360gtgttcatct tcccccccag cgatgagcag ctgaagagcg gcaccgccag
cgtggtgtgt 420ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt
ggaaggtgga caatgccctg 480cagagcggca acagccagga gagcgtgacc
gagcaggaca gcaaggactc cacctacagc 540ctgagcagca ccctgaccct
gagcaaggcc gactacgaga agcacaaggt gtacgcctgt 600gaggtgaccc
accagggcct gtccagcccc gtgaccaaga gcttcaaccg gggcgagtgc
660921338DNAArtificial SequenceJ11L1, heavy chain humanised
construct 92caggtgcagc tcgtgcagag cggggccgaa gtcaagaaac ccggcagctc
cgtgaaggtg 60agctgcaagg ccagcggctt ctctctcact gcctacggcg tgaactgggt
gaggcaggct 120cccggccagg gcctggagtg gatgggcatg atctgggacg
acggcagcac cgactacgac 180agcgccctga agagcagggt gaccatcacc
gccgacaaga gcaccagcac cgcctacatg 240gaactgagca gcctgaggag
cgaggacacc gccgtgtact attgcgccag ggagggcgac 300gtggccttcg
attactgggg ccagggcaca ctagtgaccg tgtccagcgc cagcaccaag
360ggccccagcg tgttccccct ggcccccagc agcaagagca ccagcggcgg
cacagccgcc 420ctgggctgcc tggtgaagga ctacttcccc gaaccggtga
ccgtgtcctg gaacagcgga 480gccctgacca gcggcgtgca caccttcccc
gccgtgctgc agagcagcgg cctgtacagc 540ctgagcagcg tggtgaccgt
gcccagcagc agcctgggca cccagaccta catctgtaac 600gtgaaccaca
agcccagcaa caccaaggtg gacaagaagg tggagcccaa gagctgtgac
660aagacccaca cctgcccccc ctgccctgcc cccgagctgc tgggaggccc
cagcgtgttc 720ctgttccccc ccaagcctaa ggacaccctg atgatcagca
gaacccccga ggtgacctgt 780gtggtggtgg atgtgagcca cgaggaccct
gaggtgaagt tcaactggta cgtggacggc 840gtggaggtgc acaatgccaa
gaccaagccc agggaggagc agtacaacag cacctaccgg 900gtggtgtccg
tgctgaccgt gctgcaccag gattggctga acggcaagga gtacaagtgt
960aaggtgtcca acaaggccct gcctgcccct atcgagaaaa ccatcagcaa
ggccaagggc 1020cagcccagag agccccaggt gtacaccctg ccccctagca
gagatgagct gaccaagaac 1080caggtgtccc tgacctgcct ggtgaagggc
ttctacccca gcgacatcgc cgtggagtgg 1140gagagcaacg gccagcccga
gaacaactac aagaccaccc cccctgtgct ggacagcgat 1200ggcagcttct
tcctgtacag caagctgacc gtggacaaga gcagatggca gcagggcaac
1260gtgttcagct gctccgtgat gcacgaggcc ctgcacaatc actacaccca
gaagagcctg 1320agcctgtccc ctggcaag 133893660DNAArtificial
SequenceJ13L1, light chain humanised construct 93gacatccaga
tgacccagag cccctctagc ctcagcgcca gcgtgggcga cagggtgacc 60atcacctgca
agagcagcca gagcctgctg aacggcagca accagaagaa ctacctggcc
120tggtaccagc agaaacccgg caaggccccc aagctgctgg tctacttcgc
ctctaccagg 180gattccggcg tccccagcag gttcagcggc agcggcagcg
gcaccgactt cacactgacc 240atcagcagcc tgcagcccga ggacttcgcc
acctactact gcctgcagca cttcggcacc 300cctcccactt ttggccaggg
caccaagctg gagattaagc gtacggtggc cgcccccagc 360gtgttcatct
tcccccccag cgatgagcag ctgaagagcg gcaccgccag cgtggtgtgt
420ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt ggaaggtgga
caatgccctg 480cagagcggca acagccagga gagcgtgacc gagcaggaca
gcaaggactc cacctacagc 540ctgagcagca ccctgaccct gagcaaggcc
gactacgaga agcacaaggt gtacgcctgt 600gaggtgaccc accagggcct
gtccagcccc gtgaccaaga gcttcaaccg gggcgagtgc 660941338DNAArtificial
SequenceJ13L1, heavy chain humanised construct 94caggtgcagc
tcgtgcagag cggggccgaa gtcaagaaac ccggcagctc cgtgaaggtg 60agctgcaagg
ccagcggcgg caccttcagc gcctacggcg tgaactgggt gaggcaggct
120cccggccagg gcctggagtg gatgggcatg atctgggacg acggcagcac
cgactacgac 180agcgccctga agagcagggt gaccatcacc gccgacaaga
gcaccagcac cgcctacatg 240gaactgagca gcctgaggag cgaggacacc
gccgtgtact attgcgccag ggagggcgac 300gtggccttcg attactgggg
ccagggcaca ctagtgaccg tgtccagcgc cagcaccaag 360ggccccagcg
tgttccccct ggcccccagc agcaagagca ccagcggcgg cacagccgcc
420ctgggctgcc tggtgaagga ctacttcccc gaaccggtga ccgtgtcctg
gaacagcgga 480gccctgacca gcggcgtgca caccttcccc gccgtgctgc
agagcagcgg cctgtacagc 540ctgagcagcg tggtgaccgt gcccagcagc
agcctgggca cccagaccta catctgtaac 600gtgaaccaca agcccagcaa
caccaaggtg gacaagaagg tggagcccaa gagctgtgac 660aagacccaca
cctgcccccc ctgccctgcc cccgagctgc tgggaggccc cagcgtgttc
720ctgttccccc ccaagcctaa ggacaccctg atgatcagca gaacccccga
ggtgacctgt 780gtggtggtgg atgtgagcca cgaggaccct gaggtgaagt
tcaactggta cgtggacggc 840gtggaggtgc acaatgccaa gaccaagccc
agggaggagc agtacaacag cacctaccgg 900gtggtgtccg tgctgaccgt
gctgcaccag gattggctga acggcaagga gtacaagtgt 960aaggtgtcca
acaaggccct gcctgcccct atcgagaaaa ccatcagcaa ggccaagggc
1020cagcccagag agccccaggt gtacaccctg ccccctagca gagatgagct
gaccaagaac 1080caggtgtccc tgacctgcct ggtgaagggc ttctacccca
gcgacatcgc cgtggagtgg 1140gagagcaacg gccagcccga gaacaactac
aagaccaccc cccctgtgct ggacagcgat 1200ggcagcttct tcctgtacag
caagctgacc gtggacaaga gcagatggca gcagggcaac 1260gtgttcagct
gctccgtgat gcacgaggcc ctgcacaatc actacaccca gaagagcctg
1320agcctgtccc ctggcaag 133895660DNAArtificial SequenceH7L1, light
chain humanised construct 95gacatccaga tgacccagag cccctctagc
ctcagcgcca gcgtgggcga cagggtgacc 60atcacctgca agagcagcca gagcctgctg
aacggcagca accagaagaa ctacctggcc 120tggtaccagc agaaacccgg
caaggccccc aagctgctgg tctacttcgc ctctaccagg 180gattccggcg
tccccagcag gttcagcggc agcggcagcg gcaccgactt cacactgacc
240atcagcagcc tgcagcccga ggacttcgcc acctactact gcctgcagca
cttcggcacc 300cctcccactt ttggccaggg caccaagctg gagattaagc
gtacggtggc cgcccccagc 360gtgttcatct tcccccccag cgatgagcag
ctgaagagcg gcaccgccag cgtggtgtgt 420ctgctgaaca acttctaccc
ccgggaggcc aaggtgcagt ggaaggtgga caatgccctg 480cagagcggca
acagccagga gagcgtgacc gagcaggaca gcaaggactc cacctacagc
540ctgagcagca ccctgaccct gagcaaggcc gactacgaga agcacaaggt
gtacgcctgt 600gaggtgaccc accagggcct gtccagcccc gtgaccaaga
gcttcaaccg gggcgagtgc 660961338DNAArtificial SequenceH7L1, heavy
chain humanised construct 96caggtgcagc tccaggagag cggccccggc
ctggtgaagc ctagcgagac cctgagcctg 60acctgcaccg tgagcggcgg ctccatcagc
gcctacggcg tcaactggat caggcagccc 120cccggcaaag gcctggagtg
gattgggatg atctgggacg acggcagcac cgactacgac 180agcgccctga
agagcagggt gaccatcagc gtggacacca gcaagaacca gttcagcctg
240aagctgagca gcgtgactgc cgccgacacc gccgtctatt actgcgccag
ggagggcgac 300gtggccttcg attactgggg ccagggcaca ctagtgaccg
tgtccagcgc cagcaccaag 360ggccccagcg tgttccccct ggcccccagc
agcaagagca ccagcggcgg cacagccgcc 420ctgggctgcc tggtgaagga
ctacttcccc gaaccggtga ccgtgtcctg gaacagcgga 480gccctgacca
gcggcgtgca caccttcccc gccgtgctgc agagcagcgg cctgtacagc
540ctgagcagcg tggtgaccgt gcccagcagc agcctgggca cccagaccta
catctgtaac 600gtgaaccaca agcccagcaa caccaaggtg gacaagaagg
tggagcccaa gagctgtgac 660aagacccaca cctgcccccc ctgccctgcc
cccgagctgc tgggaggccc cagcgtgttc 720ctgttccccc ccaagcctaa
ggacaccctg atgatcagca gaacccccga ggtgacctgt 780gtggtggtgg
atgtgagcca cgaggaccct gaggtgaagt tcaactggta cgtggacggc
840gtggaggtgc acaatgccaa gaccaagccc agggaggagc agtacaacag
cacctaccgg 900gtggtgtccg tgctgaccgt gctgcaccag gattggctga
acggcaagga gtacaagtgt 960aaggtgtcca acaaggccct gcctgcccct
atcgagaaaa ccatcagcaa ggccaagggc 1020cagcccagag agccccaggt
gtacaccctg ccccctagca gagatgagct gaccaagaac 1080caggtgtccc
tgacctgcct ggtgaagggc ttctacccca gcgacatcgc cgtggagtgg
1140gagagcaacg gccagcccga gaacaactac aagaccaccc cccctgtgct
ggacagcgat 1200ggcagcttct tcctgtacag caagctgacc gtggacaaga
gcagatggca gcagggcaac 1260gtgttcagct gctccgtgat gcacgaggcc
ctgcacaatc actacaccca gaagagcctg 1320agcctgtccc ctggcaag
133897660DNAArtificial SequenceJ0L1, light chain humanised
construct 97gacatccaga tgacccagag cccctctagc ctcagcgcca gcgtgggcga
cagggtgacc 60atcacctgca agagcagcca gagcctgctg aacggcagca accagaagaa
ctacctggcc 120tggtaccagc agaaacccgg caaggccccc aagctgctgg
tctacttcgc ctctaccagg 180gattccggcg tccccagcag gttcagcggc
agcggcagcg gcaccgactt cacactgacc 240atcagcagcc tgcagcccga
ggacttcgcc acctactact gcctgcagca cttcggcacc 300cctcccactt
ttggccaggg caccaagctg gagattaagc gtacggtggc cgcccccagc
360gtgttcatct tcccccccag cgatgagcag ctgaagagcg gcaccgccag
cgtggtgtgt 420ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt
ggaaggtgga caatgccctg 480cagagcggca acagccagga gagcgtgacc
gagcaggaca gcaaggactc cacctacagc 540ctgagcagca ccctgaccct
gagcaaggcc gactacgaga agcacaaggt gtacgcctgt 600gaggtgaccc
accagggcct gtccagcccc gtgaccaaga gcttcaaccg gggcgagtgc
660981338DNAArtificial SequenceJ0L1, heavy chain humanised
construct 98caggtgcagc tcgtgcagag cggggccgaa gtcaagaaac ccggcagctc
cgtgaaggtg 60agctgcaagg ccagcggcgg caccttcagc gcctacggcg tgaactgggt
gaggcaggct 120cccggccagg gcctggagtg gatgggcatg atctgggacg
acggcagcac cgactacaac 180agcgccctga agagcagggt gaccatcacc
gccgacaaga gcaccagcac cgcctacatg 240gaactgagca gcctgaggag
cgaggacacc gccgtgtact attgcgccag ggagggcgac 300gtggccttcg
attactgggg ccagggcaca ctagtgaccg tgtccagcgc cagcaccaag
360ggccccagcg tgttccccct ggcccccagc agcaagagca ccagcggcgg
cacagccgcc 420ctgggctgcc tggtgaagga ctacttcccc gaaccggtga
ccgtgtcctg gaacagcgga 480gccctgacca gcggcgtgca caccttcccc
gccgtgctgc agagcagcgg cctgtacagc 540ctgagcagcg tggtgaccgt
gcccagcagc agcctgggca cccagaccta catctgtaac 600gtgaaccaca
agcccagcaa caccaaggtg gacaagaagg tggagcccaa gagctgtgac
660aagacccaca cctgcccccc ctgccctgcc cccgagctgc tgggaggccc
cagcgtgttc 720ctgttccccc ccaagcctaa ggacaccctg atgatcagca
gaacccccga ggtgacctgt 780gtggtggtgg atgtgagcca cgaggaccct
gaggtgaagt tcaactggta cgtggacggc 840gtggaggtgc acaatgccaa
gaccaagccc agggaggagc agtacaacag cacctaccgg 900gtggtgtccg
tgctgaccgt gctgcaccag gattggctga acggcaagga gtacaagtgt
960aaggtgtcca acaaggccct gcctgcccct atcgagaaaa ccatcagcaa
ggccaagggc 1020cagcccagag agccccaggt gtacaccctg ccccctagca
gagatgagct gaccaagaac 1080caggtgtccc tgacctgcct ggtgaagggc
ttctacccca gcgacatcgc cgtggagtgg 1140gagagcaacg gccagcccga
gaacaactac aagaccaccc cccctgtgct ggacagcgat 1200ggcagcttct
tcctgtacag caagctgacc gtggacaaga gcagatggca gcagggcaac
1260gtgttcagct gctccgtgat gcacgaggcc ctgcacaatc actacaccca
gaagagcctg 1320agcctgtccc ctggcaag 133899660DNAArtificial
SequenceH0L1, light chain humanised construct 99gacatccaga
tgacccagag cccctctagc ctcagcgcca gcgtgggcga cagggtgacc 60atcacctgca
agagcagcca gagcctgctg aacggcagca accagaagaa ctacctggcc
120tggtaccagc agaaacccgg caaggccccc aagctgctgg tctacttcgc
ctctaccagg 180gattccggcg tccccagcag gttcagcggc agcggcagcg
gcaccgactt cacactgacc 240atcagcagcc tgcagcccga ggacttcgcc
acctactact gcctgcagca cttcggcacc 300cctcccactt ttggccaggg
caccaagctg gagattaagc gtacggtggc cgcccccagc 360gtgttcatct
tcccccccag cgatgagcag ctgaagagcg gcaccgccag cgtggtgtgt
420ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt ggaaggtgga
caatgccctg 480cagagcggca acagccagga gagcgtgacc gagcaggaca
gcaaggactc cacctacagc 540ctgagcagca ccctgaccct gagcaaggcc
gactacgaga agcacaaggt gtacgcctgt 600gaggtgaccc accagggcct
gtccagcccc gtgaccaaga gcttcaaccg gggcgagtgc 6601001338DNAArtificial
SequenceH0L1, heavy chain humanised construct 100caggtgcagc
tccaggagag cggccccggc ctggtgaagc ctagcgagac cctgagcctg 60acctgcaccg
tgagcggcgg ctccatcagc gcctacggcg tcaactggat caggcagccc
120cccggcaaag gcctggagtg gattgggatg atctgggacg acggcagcac
cgactacaac 180agcgccctga agagcagggt gaccatcagc gtggacacca
gcaagaacca gttcagcctg 240aagctgagca gcgtgactgc cgccgacacc
gccgtctatt actgcgccag ggagggcgac 300gtggccttcg attactgggg
ccagggcaca ctagtgaccg tgtccagcgc cagcaccaag 360ggccccagcg
tgttccccct ggcccccagc agcaagagca ccagcggcgg cacagccgcc
420ctgggctgcc tggtgaagga ctacttcccc gaaccggtga ccgtgtcctg
gaacagcgga 480gccctgacca gcggcgtgca caccttcccc gccgtgctgc
agagcagcgg cctgtacagc 540ctgagcagcg tggtgaccgt gcccagcagc
agcctgggca cccagaccta catctgtaac 600gtgaaccaca agcccagcaa
caccaaggtg gacaagaagg tggagcccaa gagctgtgac 660aagacccaca
cctgcccccc ctgccctgcc cccgagctgc tgggaggccc cagcgtgttc
720ctgttccccc ccaagcctaa ggacaccctg atgatcagca gaacccccga
ggtgacctgt 780gtggtggtgg atgtgagcca cgaggaccct gaggtgaagt
tcaactggta cgtggacggc 840gtggaggtgc acaatgccaa gaccaagccc
agggaggagc agtacaacag cacctaccgg 900gtggtgtccg tgctgaccgt
gctgcaccag gattggctga acggcaagga gtacaagtgt 960aaggtgtcca
acaaggccct gcctgcccct atcgagaaaa ccatcagcaa ggccaagggc
1020cagcccagag agccccaggt gtacaccctg ccccctagca gagatgagct
gaccaagaac 1080caggtgtccc tgacctgcct ggtgaagggc ttctacccca
gcgacatcgc cgtggagtgg 1140gagagcaacg gccagcccga gaacaactac
aagaccaccc cccctgtgct ggacagcgat 1200ggcagcttct tcctgtacag
caagctgacc gtggacaaga gcagatggca gcagggcaac 1260gtgttcagct
gctccgtgat gcacgaggcc ctgcacaatc actacaccca gaagagcctg
1320agcctgtccc ctggcaag 1338101318DNAHomo Sapien 101acggtggccg
cccccagcgt gttcatcttc ccccccagcg atgagcagct gaagagcggc 60accgccagcg
tggtgtgtct gctgaacaac ttctaccccc gggaggccaa ggtgcagtgg
120aaggtggaca atgccctgca gagcggcaac agccaggaga gcgtgaccga
gcaggacagc 180aaggactcca cctacagcct gagcagcacc ctgaccctga
gcaaggccga ctacgagaag 240cacaaggtgt acgcctgtga ggtgacccac
cagggcctgt ccagccccgt gaccaagagc 300ttcaaccggg gcgagtgc
318102990DNAHomo Sapien 102gccagcacca agggccccag cgtgttcccc
ctggccccca gcagcaagag caccagcggc 60ggcacagccg ccctgggctg cctggtgaag
gactacttcc ccgaaccggt gaccgtgtcc 120tggaacagcg gagccctgac
cagcggcgtg cacaccttcc ccgccgtgct gcagagcagc 180ggcctgtaca
gcctgagcag cgtggtgacc gtgcccagca gcagcctggg cacccagacc
240tacatctgta acgtgaacca caagcccagc aacaccaagg tggacaagaa
ggtggagccc 300aagagctgtg acaagaccca cacctgcccc ccctgccctg
cccccgagct gctgggaggc 360cccagcgtgt tcctgttccc ccccaagcct
aaggacaccc tgatgatcag cagaaccccc 420gaggtgacct gtgtggtggt
ggatgtgagc cacgaggacc ctgaggtgaa gttcaactgg 480tacgtggacg
gcgtggaggt gcacaatgcc aagaccaagc ccagggagga gcagtacaac
540agcacctacc gggtggtgtc cgtgctgacc gtgctgcacc aggattggct
gaacggcaag 600gagtacaagt gtaaggtgtc caacaaggcc ctgcctgccc
ctatcgagaa aaccatcagc 660aaggccaagg gccagcccag agagccccag
gtgtacaccc tgccccctag cagagatgag 720ctgaccaaga accaggtgtc
cctgacctgc ctggtgaagg gcttctaccc cagcgacatc 780gccgtggagt
gggagagcaa cggccagccc gagaacaact acaagaccac cccccctgtg
840ctggacagcg atggcagctt cttcctgtac agcaagctga ccgtggacaa
gagcagatgg 900cagcagggca acgtgttcag ctgctccgtg atgcacgagg
ccctgcacaa tcactacacc 960cagaagagcc tgagcctgtc ccctggcaag
990103348DNAMurine 103caggtgcagc tgaaggagtc aggtcctggc ctggtggcgc
cctcacagag cctgtccatc 60acatgcaccg tctcagggtt ctcattaacc gcctatggtg
taaactgggt tcgccagcct 120ccaggaaagg gtctggagtg gctgggaatg
atatgggatg atggaagcac agactataat 180tcagctctca aatccagact
gagcatcagt aaggacaact ccaagagcca agttttctta 240aaaatgaaca
gtctgcaaac tgatgacaca gccaggtact actgtgccag agaaggggac
300gtagcctttg actactgggg ccaaggcacc actctcacag tctcctca
348104342DNAMurine 104gacattgtga tgacacagtc tccctcctcc ctggctgtgt
cagtaggaca gaaggtcact 60atgagctgca agtccagtca gagcctttta aatggtagca
atcaaaagaa ctacttggcc 120tggtaccagc agaaaccagg acagtctcct
aaacttctgg tatactttgc atccactagg 180gattctgggg tccctgatcg
cttcataggc agtggatctg ggacagattt cactcttacc 240atcagcagtg
tgcaggctga agacctggca gattacttct gtctgcaaca ttttggcact
300cctccgacgt tcggtggagg caccaaactg gaaatcaaac gg
3421051338DNAArtificial SequenceIMP731, heavy chain sequence
105caggtgcagc tgaaggagtc aggtcctggc ctggtggcgc cctcacagag
cctgtccatc 60acatgcaccg tctcagggtt ctcattaacc gcctatggtg taaactgggt
tcgccagcct 120ccaggaaagg gtctggagtg gctgggaatg atatgggatg
atggaagcac agactataat 180tcagctctca aatccagact gagcatcagt
aaggacaact ccaagagcca agttttctta 240aaaatgaaca gtctgcaaac
tgatgacaca gccaggtact actgtgccag agaaggggac 300gtagcctttg
actactgggg ccaaggcacc actctcacag tctcctcagc tagcaccaag
360ggcccatcgg tcttccccct ggcaccctcc tccaagagca cctctggggg
cacagcggcc 420ctgggctgcc tggtcaagga ctacttcccc gaaccggtga
cggtgtcgtg gaactcaggc 480gccctgacca gcggcgtgca caccttcccg
gctgtcctac agtcctcagg actctactcc 540ctcagcagcg tggtgaccgt
gccctccagc agcttgggca cccagaccta catctgcaac 600gtgaatcaca
agcccagcaa caccaaggtg gacaagaaag ttgagcccaa atcttgtgac
660aaaactcaca catgcccacc gtgcccagca cctgaactcc tggggggacc
gtcagtcttc 720ctcttccccc caaaacccaa ggacaccctc atgatctccc
ggacccctga ggtcacatgc 780gtggtggtgg acgtgagcca cgaagaccct
gaggtcaagt tcaactggta cgtggacggc 840gtggaggtgc ataatgccaa
gacaaagccg cgggaggagc agtacaacag cacgtaccgt 900gtggtcagcg
tcctcaccgt cctgcaccag gactggctga atggcaagga gtacaagtgc
960aaggtctcca acaaagccct cccagccccc atcgagaaaa ccatctccaa
agccaaaggg 1020cagccccgag aaccacaggt gtacaccctg cccccatccc
gggatgagct gaccaagaac 1080caggtcagcc tgacctgcct ggtcaaaggc
ttctatccca gcgacatcgc cgtggagtgg 1140gagagcaatg ggcagccgga
gaacaactac aagaccacgc ctcccgtgct ggactccgac 1200ggctccttct
tcctctacag caagctcacc gtggacaaga gcaggtggca gcaggggaac
1260gtcttctcat gctccgtgat gcatgaggct ctgcacaacc actacacgca
gaagagcctc 1320tccctgtctc cgggtaaa 1338106660DNAArtificial
SequenceIMP731, light chain sequence 106gacattgtga tgacacagtc
tccctcctcc ctggctgtgt cagtaggaca gaaggtcact 60atgagctgca agtccagtca
gagcctttta aatggtagca atcaaaagaa ctacttggcc 120tggtaccagc
agaaaccagg acagtctcct aaacttctgg tatactttgc atccactagg
180gattctgggg tccctgatcg cttcataggc agtggatctg ggacagattt
cactcttacc 240atcagcagtg tgcaggctga agacctggca gattacttct
gtctgcaaca ttttggcact 300cctccgacgt tcggtggagg caccaaactg
gaaatcaaac ggaccgtggc tgcaccatct 360gtcttcatct tcccgccatc
tgatgagcag ttgaaatctg gaactgcctc tgttgtgtgc 420ctgctgaata
acttctatcc cagagaggcc aaagtacagt ggaaggtgga taacgccctc
480caatcgggta actcccagga gagtgtcaca gagcaggaca gcaaggacag
cacctacagc 540ctcagcagca ccctgacgct gagcaaagca gactacgaga
aacacaaagt ctacgcctgc 600gaagtcaccc atcagggcct gagttcgccc
gtcacaaaga gcttcaacag gggagagtgt 6601071251DNAArtificial
SequenceRecombinant human LAG-3-ECD-His6 107ctccagccag gggctgaggt
cccggtggtg tgggcccagg agggggctcc tgcccagctc 60ccctgcagcc ccacaatccc
cctccaggat ctcagccttc tgcgaagagc aggggtcact 120tggcagcatc
agccagacag tggcccgccc gctgccgccc ccggccatcc cctggccccc
180ggccctcacc cggcggcgcc ctcctcctgg gggcccaggc cccgccgcta
cacggtgctg 240agcgtgggtc ccggaggcct gcgcagcggg aggctgcccc
tgcagccccg cgtccagctg 300gatgagcgcg gccggcagcg cggggacttc
tcgctatggc tgcgcccagc ccggcgcgcg 360gacgccggcg agtaccgcgc
cgcggtgcac ctcagggacc gcgccctctc ctgccgcctc 420cgtctgcgcc
tgggccaggc ctcgatgact gccagccccc caggatctct cagagcctcc
480gactgggtca ttttgaactg ctccttcagc cgccctgacc gcccagcctc
tgtgcattgg 540ttccggaacc ggggccaggg ccgagtccct gtccgggagt
ccccccatca ccacttagcg 600gaaagcttcc tcttcctgcc ccaagtcagc
cccatggact ctgggccctg gggctgcatc 660ctcacctaca gagatggctt
caacgtctcc atcatgtata acctcactgt tctgggtctg 720gagcccccaa
ctcccttgac agtgtacgct ggagcaggtt ccagggtggg gctgccctgc
780cgcctgcctg ctggtgtggg gacccggtct ttcctcactg ccaagtggac
tcctcctggg 840ggaggccctg acctcctggt gactggagac aatggcgact
ttacccttcg actagaggat 900gtgagccagg cccaggctgg gacctacacc
tgccatatcc atctgcagga acagcagctc 960aatgccactg tcacattggc
aatcatcaca gtgactccca aatcctttgg gtcacctgga 1020tccctgggga
agctgctttg tgaggtgact ccagtatctg gacaagaacg ctttgtgtgg
1080agctctctgg acaccccatc ccagaggagt ttctcaggac cttggctgga
ggcacaggag 1140gcccagctcc tttcccagcc ttggcaatgc cagctgtacc
agggggagag gcttcttgga 1200gcagcagtgt acttcacaga gctgtctagc
ccacaccacc atcatcacca t 12511081251DNAArtificial
SequenceRecombinant cynomolgus macaque LAG-3 ECD-His6 108ccccagccag
gggctgagat ctcggtggtg tgggcccagg agggggctcc tgcccagctc 60ccctgcagcc
ccacaatccc cctccaggat ctcagccttc tgcgaagagc aggggtcact
120tggcagcatc aaccagacag tggcccgccc gctcccgccc ccggccaccc
cccggccccc 180ggccatcgcc cggcggcgcc ctactcttgg gggcccaggc
cccgccgcta cacagtgctg 240agcgtgggtc ctggaggcct gcgcagcggg
aggctgcccc tgcagccccg cgtccagctg 300gatgagcgcg gccggcagcg
cggggacttc tcgctgtggc tgcgcccagc ccggcgcgcg 360gacgccggcg
agtaccgcgc cacggtgcac ctcagggacc gcgccctctc ctgccgcctt
420cgtctgcgcg tgggccaggc ctcgatgact gccagccccc cagggtctct
caggacctct 480gactgggtca ttttgaactg ctccttcagc cgccctgacc
gcccagcctc tgtgcattgg 540ttccggagcc gtggccaggg ccgagtccct
gtccaggggt ccccccatca ccacttagcg 600gaaagcttcc tcttcctgcc
ccatgtcggc cccatggact ctgggctctg gggctgcatc 660ctcacctaca
gagatggctt caatgtctcc atcatgtata acctcactgt tctgggtctg
720gagcccgcaa ctcccttgac agtgtacgct ggagcaggtt ccagggtgga
gctgccctgc 780cgcctgcctc ctgctgtggg gacccagtct ttccttactg
ccaagtgggc tcctcctggg 840ggaggccctg acctcctggt ggctggagac
aatggcgact ttacccttcg actagaggat 900gtaagccagg cccaggctgg
gacctacatc tgccatatcc gtctacaggg acagcagctc 960aatgccactg
tcacattggc aatcatcaca gtgactccca aatcctttgg gtcacctggc
1020tccctgggga agctgctttg tgaggtgact ccagcatctg gacaagaaca
ctttgtgtgg 1080agccccctga acaccccatc ccagaggagt ttctcaggac
catggctgga ggcccaggaa 1140gcccagctcc tttcccagcc ttggcaatgc
cagctgcacc agggggagag gcttcttgga 1200gcagcagtat acttcacaga
actgtctagc ccacaccacc atcatcacca t 12511091251DNAArtificial
SequenceRecombinant baboon LAG-3 ECD-His6 109ccccagccag gggctgagat
ctcggtggtg tgggcccagg agggggctcc tgcccagctc 60ccctgcagcc ccacaatccc
cctccaggat ctcagccttc tgcgaagagc aggggtcact 120tggcagcatc
aaccagacag tggcccgccc gctcccgccc ccggccaccc cccggccccc
180ggccatcgcc cggcggcgcc ctactcttgg gggcccaggc cccgccgcta
cacagtgctg 240agcgtgggtc ctggaggcct gcgcagcggg aggctgcccc
tgcagccccg cgtccagctg 300gatgagcgcg gccggcagcg cggggacttc
tcgctgtggc tgcgcccagc ccggcgcgcg 360gacgccggcg agtaccgcgc
cacggtgcac ctcagggacc gcgccctctc ctgccgcctt 420cgtctgcgcg
tgggccaggc ctcgatgact gccagccccc cagggtctct caggacctct
480gactgggtca ttttgaactg ctccttcagc cgccctgacc gcccagcctc
tgtgcattgg 540ttccggagcc gtggccaggg ccaagtccct gtccaggagt
ccccccatca ccacttagcg 600gaaagcttcc tcttcctgcc ccatgtcggc
cccatggact ctgggctctg gggctgcatc 660ctcacctaca gagatggctt
caatgtctcc atcatgtata acctcactgt tctgggtctg 720gagcccacaa
ctcccttgac agtgtacgct ggagcaggtt ccagggtgga gctgccctgc
780cgcctgcctc ctgctgtggg gacccagtct ttccttactg ccaagtgggc
tcctcctggg 840ggaggccctg acctcctggt ggttggagac aatggcaact
ttacccttcg actagaggat 900gtaagccagg cccaggctgg gacctacatc
tgccatatcc gtctacaggg acagcagctc 960aatgccactg tcacattggc
aatcatcaca gtgactccca aatcctttgg gtcacctggc 1020tccctgggga
agctgctttg tgaggtgact ccagcatctg gacaagaacg ctttgtgtgg
1080agccccctga acaccccatc ccagaggagt ttctcaggac cgtggctgga
ggcccaggaa 1140gcccagctcc tttcccagcc ttggcaatgc cagctgcacc
agggggagag gcttcttgga 1200gcagcagtat acttcacaga actgtctagc
ccacaccacc atcatcacca t 125111057DNAMurine 110atgggctgga gctgcatcat
cctgttcctg gtggccaccg ctaccggagt gcacagc 5711160DNAMurine
111atggaatcac agacccaggt cctcatgttt cttctgctct gggtatctgg
tgcctgtgca 6011248DNAHomo Sapien 112atgccgctgc tgctactgct
gcccctgctg tgggcagggg cgctagct 48
D00001
D00002
D00003
D00004
D00005
D00006
S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.