Media Content Identification on Mobile Devices
Stojancic; Mihailo M. ; et al.
U.S. patent application number 16/441936 was filed with the patent office on 2019-12-05 for media content identification on mobile devices. The applicant listed for this patent is Gracenote, Inc.. Invention is credited to Oleksiy Bolgarov, Sunil Suresh Kulkarni, Shashank Merchant, Jose Pio Pereira, Mihailo M. Stojancic.
| Application Number | 20190373312 16/441936 |
| Document ID | / |
| Family ID | 68692637 |
| Filed Date | 2019-12-05 |











View All Diagrams
| United States Patent Application | 20190373312 |
| Kind Code | A1 |
| Stojancic; Mihailo M. ; et al. | December 5, 2019 |
Media Content Identification on Mobile Devices
Abstract
A mobile device responds in real time to media content presented on a media device, such as a television. The mobile device captures temporal fragments of audio-video content on its microphone, camera, or both and generates corresponding audio-video query fingerprints. The query fingerprints are transmitted to a search server located remotely or used with a search function on the mobile device for content search and identification. Audio features are extracted and audio signal global onset detection is used for input audio frame alignment. Additional audio feature signatures are generated from local audio frame onsets, audio frame frequency domain entropy, and maximum change in the spectral coefficients. Video frames are analyzed to find a television screen in the frames, and a detected active television quadrilateral is used to generate video fingerprints to be combined with audio fingerprints for more reliable content identification.
| Inventors: | Stojancic; Mihailo M.; (San Jose, CA) ; Kulkarni; Sunil Suresh; (Santa Cruz, CA) ; Merchant; Shashank; (Sunnyvale, CA) ; Pereira; Jose Pio; (Cupertino, CA) ; Bolgarov; Oleksiy; (San Jose, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 68692637 | ||||||||||
| Appl. No.: | 16/441936 | ||||||||||
| Filed: | June 14, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15053064 | Feb 25, 2016 | |||
| 16441936 | ||||
| 13590701 | Aug 21, 2012 | 9313359 | ||
| 15053064 | ||||
| 61601234 | Feb 21, 2012 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | H04N 21/4332 20130101; H04N 21/41407 20130101; H04N 21/439 20130101; H04N 21/4394 20130101; G10H 2210/041 20130101; H04N 21/42203 20130101; H04N 21/8456 20130101; H04N 21/4223 20130101; G10H 2250/235 20130101; G10H 2210/051 20130101; H04N 21/4307 20130101; H04N 21/8352 20130101; G10H 1/0008 20130101; H04N 1/32 20130101; G10H 2240/141 20130101; H04N 21/6581 20130101; H04N 21/84 20130101 |
| International Class: | H04N 21/439 20060101 H04N021/439; H04N 1/32 20060101 H04N001/32; H04N 21/8352 20060101 H04N021/8352; G10H 1/00 20060101 G10H001/00; H04N 21/414 20060101 H04N021/414; H04N 21/422 20060101 H04N021/422; H04N 21/4223 20060101 H04N021/4223; H04N 21/433 20060101 H04N021/433; H04N 21/84 20060101 H04N021/84; H04N 21/845 20060101 H04N021/845 |
Claims
1. A computer-implemented method comprising: obtaining, by a portable computing device, a fragment of media content using an input device of the portable computing device, wherein the fragment of media content is a representation of a sequence of media content that is presented by a playback device; generating, by the portable computing device, a query fingerprint using the fragment of media content; comparing, by the portable computing device, the query fingerprint with a set of reference fingerprints, wherein the set of reference fingerprints correspond to the sequence of media content and are stored in a memory of the portable computing device; detecting, by the portable computing device based on a result of the comparing, a change from the sequence of media content to a different sequence of media content; and in response to detecting the change, transmitting, by the portable computing device to a server device, the query fingerprint for comparison with reference fingerprints of a reference database.
2. The computer-implemented method of claim 1, wherein detecting the change comprises determining that the query fingerprint does not match any reference fingerprints of the set of reference fingerprints.
3. The computer-implemented method of claim 1, further comprising receiving, from the server device, an identity of the different sequence of media content.
4. The computer-implemented method of claim 1, further comprising receiving, from the server device, a set of reference fingerprints corresponding to the different sequence of media content.
5. The computer-implemented method of claim 1, further comprising: obtaining, by the portable computing device from the server device, the set of reference fingerprints corresponding to the sequence of media content; and storing, by the portable computing device, the set of reference fingerprints corresponding to the sequence of media content in the memory of the portable computing device.
6. The computer-implemented method of claim 1, wherein the input device comprises a microphone, wherein the fragment of media content comprises an audio fragment, and wherein the query fingerprint comprises an audio fingerprint.
7. The computer-implemented method of claim 6, further comprising resampling the audio fragment or down-mixing the audio fragment prior to generating the audio fingerprint.
8. The computer-implemented method of claim 1, wherein the input device comprises a camera, wherein the fragment of media content comprises a video fragment, and wherein the query fingerprint comprises a video fingerprint.
9. The computer-implemented method of claim 8, further comprising selecting a video frame of the video fragment, wherein generating the query fingerprint comprises generating the video fingerprint using the video frame.
10. The computer-implemented method of claim 1, wherein the playback device comprises a television.
11. A portable computing device comprising: an input device; one or more processors; and a computer-readable medium having stored therein instructions that are executable by the one or more computers to cause the portable computing device to perform functions comprising: obtaining a fragment of media content using the input device, wherein the fragment of media content is a representation of a sequence of media content that is presented by a playback device, generating a query fingerprint using the fragment of media content, comparing the query fingerprint with a set of reference fingerprints, wherein the set of reference fingerprints correspond to the sequence of media content and are stored in a memory of the portable computing device, detecting, based on a result of the comparing, a change from the sequence of media content to a different sequence of media content, and in response to detecting the change, transmitting, to a server device, the query fingerprint for comparison with reference fingerprints of a reference database.
12. The portable computing device of claim 11, wherein detecting the change comprises determining that the query fingerprint does not match any reference fingerprints of the set of reference fingerprints.
13. The portable computing device of claim 11, wherein the functions further comprise receiving, from the server device, an identity of the different sequence of media content.
14. The portable computing device of claim 11, wherein the functions further comprise receiving, from the server device, a set of reference fingerprints corresponding to the different sequence of media content.
15. The portable computing device of claim 11, wherein the input device comprises a microphone, wherein the fragment of media content comprises an audio fragment, and wherein the query fingerprint comprises an audio fingerprint.
16. The portable computing device of claim 11, wherein the input device comprises a camera, wherein the fragment of media content comprises a video fragment, and wherein the query fingerprint comprises a video fingerprint.
17. A non-transitory computer-readable medium having stored therein instructions that are executable by one or more processors to cause a portable computing device to perform functions comprising: obtaining a fragment of media content using an input device of the portable computing device, wherein the fragment of media content is a representation of a sequence of media content that is presented by a playback device; generating a query fingerprint using the fragment of media content; comparing the query fingerprint with a set of reference fingerprints, wherein the set of reference fingerprints correspond to the sequence of media content and are stored in a memory of the portable computing device; detecting, based on a result of the comparing, a change from the sequence of media content to a different sequence of media content; and in response to detecting the change, transmitting, to a server device, the query fingerprint for comparison with reference fingerprints of a reference database.
18. The non-transitory computer-readable medium of claim 17, wherein detecting the change comprises determining that the query fingerprint does not match any reference fingerprints of the set of reference fingerprints.
19. The non-transitory computer-readable medium of claim 17, wherein the input device comprises a microphone, wherein the fragment of media content comprises an audio fragment, and wherein the query fingerprint comprises an audio fingerprint.
20. The non-transitory computer-readable medium of claim 17, wherein the input device comprises a camera, wherein the fragment of media content comprises a video fragment, and wherein the query fingerprint comprises a video fingerprint.
Description
[0001] The present application is a continuation of U.S. patent application Ser. No. 15/053,064, filed Feb. 25, 2016, which is a divisional of U.S. patent application Ser. No. 13/590,701, filed Aug. 21, 2012 which claims the benefit of U.S. Provisional Patent Application No. 61/601,234 entitled "Methods and Apparatus for Synchronous Television/Media Content Identification on Mobile/Media Devices", filed on Feb. 21, 2012 which are hereby incorporated by reference in their entirety.
CROSS REFERENCE TO RELATED APPLICATION
[0002] U.S. Pat. No. 8,229,227 filed on Jun. 18, 2008 entitled "Methods and Apparatus for Providing a Scalable Identification of Digital Video Sequences", U.S. Pat. No. 8,171,030 filed on Jun. 18, 2008 entitled "Method and Apparatus for Multi-Dimensional Content Search and Video Identification", U.S. Pat. No. 8,189,945 filed on Nov. 5, 2009 entitled "Digital Video Content Fingerprinting Based on Scale Invariant Interest Region Detection with an Array of Anisotropic Filters", U.S. Pat. No. 8,195,689 filed on May 3, 2010 entitled "Media Fingerprinting and Identification System", U.S. patent application Ser. No. 13/094,158 filed on Apr. 26, 2011 entitled "Actionable Event Detection for Enhanced Television Delivery and Ad Monitoring Based on Video/Audio Content Fingerprinting", and U.S. Provisional Patent Application Ser. No. 61/610,672 filed on Mar. 14, 2012 entitled "A Method for Efficient Data Base Formation and Search on Portable Media Devices Acting Synchronously with Television Programming", have the same assignee as the present application, are related applications and are hereby incorporated by reference in their entirety.
FIELD OF THE INVENTION
[0003] The present invention relates to identifying television or other media programming at a receiving station by using a mobile device. More particularly, the present invention addresses design of an efficient television/media identification system based on fingerprinting of captured audio and video signals in the presence of ambient noise, including speech and music interference from multiple external sources, as well as various optical and geometry distortions of the video signal.
BACKGROUND OF THE INVENTION
[0004] Recent development of audio and video content fingerprinting technologies and capable mobile devices, such as smart phones and tablets, have opened up a plethora of new possibilities in developing sophisticated real time applications associated with detected television programming events. With the ubiquity of mobile devices, especially smart mobile phones, a large proportion of the population often simultaneously watch programming content on their television while using their portable mobile device for text messaging or other Internet related activities. Due to the presence of varying levels of ambient noise and image distortions, reliably identifying content that is being played on a television set is considered a difficult capability to provide on a portable mobile device. Such capability has to be robust to potential audio and video degradation in order to accurately process and identify audio and video content.
SUMMARY OF THE INVENTION
[0005] In one or more of its several embodiments, the invention addresses problems such as those outlined in the previous section. One embodiment of the invention addresses a method for a mobile device to respond in real time to content identified on a television program display device. Audio content generated on a television (TV) display device is captured as a waveform from a microphone on the mobile device. Video content displayed on the TV display device is captured as a set of video frames from an optical image capture device on the mobile device.
[0006] Contours of a TV display screen on the TV display device are detected in one or more video frames on the mobile device, wherein the detected contours of the TV display screen are overlaid on images of the captured video content displayed on the mobile device.
[0007] Another embodiment addresses a method for audio fingerprinting by using content based audio feature extraction. Input audio samples, divided into overlapping frames, are analyzed to produce windowed audio frame samples for each overlapped frame. A fast Fourier transform (FFT) for the windowed audio frame samples is computed which FFT results are filtered by a filter bank on the spectral components to produce a set of filter bank output coefficients. A log function and a square root function of each set of filter bank output coefficients are computed to produce log and square root output coefficients. A discrete cosine transform (DCT) is applied separately to the log and square root output coefficients to produce two sets of DCT spectral components. A temporal multi-tap finite impulse response (FIR) smoothing derivative filter is applied to the two sets of DCT spectral components to produce two separate primary descriptors, wherein values in the two separate primary descriptors are sampled to produce two primary signatures.
[0008] Another embodiment addresses a method for audio content feature extraction. An onset in a time domain is detected for each audio frame of a plurality of audio frames. A frequency domain entropy is calculated for each audio frame of the plurality of audio frames to produce an entropy difference between consecutive frames. A maximum difference in the spectral output coefficients is calculated for each audio frame of the plurality of audio frames.
[0009] Another embodiment of the invention addresses a method for audio signal onset detection and audio frame time positions for alignment based on detected audio signal onsets. A multi-channel audio signal is down mixed to a mono signal and resampled to a desired sampling rate. An energy waveform of the audio signal is computed by squaring the audio waveform. A low-pass filter is applied to the energy signal and resampled to a minimum sampling period. A filtered derivative of the resulting resampled signal is computed for different filter widths. Maximum indices of the filtered derivative signal are computed for different maximum filter widths to produce time positions of maximum indices that exceed a threshold, wherein the time positions represent onset events.
[0010] Another embodiment addresses a method to enable mobile device software applications to provide a real time response to an identified segment of broadcast television media content. Audio content and video content are captured on a mobile device. On the mobile device, multi-dimensional audio and video query signatures and multi-dimensional feature signatures are generated for audio and video features identified in a temporal segment of audio and video data received on the mobile device. On the mobile device, cluster query signatures are generated based on a combination of the multi-dimensional audio and video query signatures and the multi-dimensional feature signatures. A reference multimedia clip database is searched, as initiated by the mobile device, using the multi-dimensional cluster query signature for fast reference data base traversal to find a set of signatures that are within a specified signature distance to the multi-dimensional query signature, wherein the mobile device is provided access to data related to multimedia content associated with a likely matching signature selected from the set of signatures. Based on the search results, a software application is triggered within the mobile device, which performs at least one action that is synchronized to the identified captured audio and video content.
BRIEF DESCRIPTION OF THE DRAWINGS
[0011] FIG. 1 illustrates a system for providing mobile device applications in accordance with the present invention based on analysis of audio, video, or audio and video signals acquired from a media presentation device;
[0012] FIG. 2 illustrates a media acquisition subsystem configured to acquire played television media content from a television device on a mobile device;
[0013] FIG. 3 illustrates a process for identification of audio or video content captured by a mobile device from a nearby TV set and triggering a mobile application action;
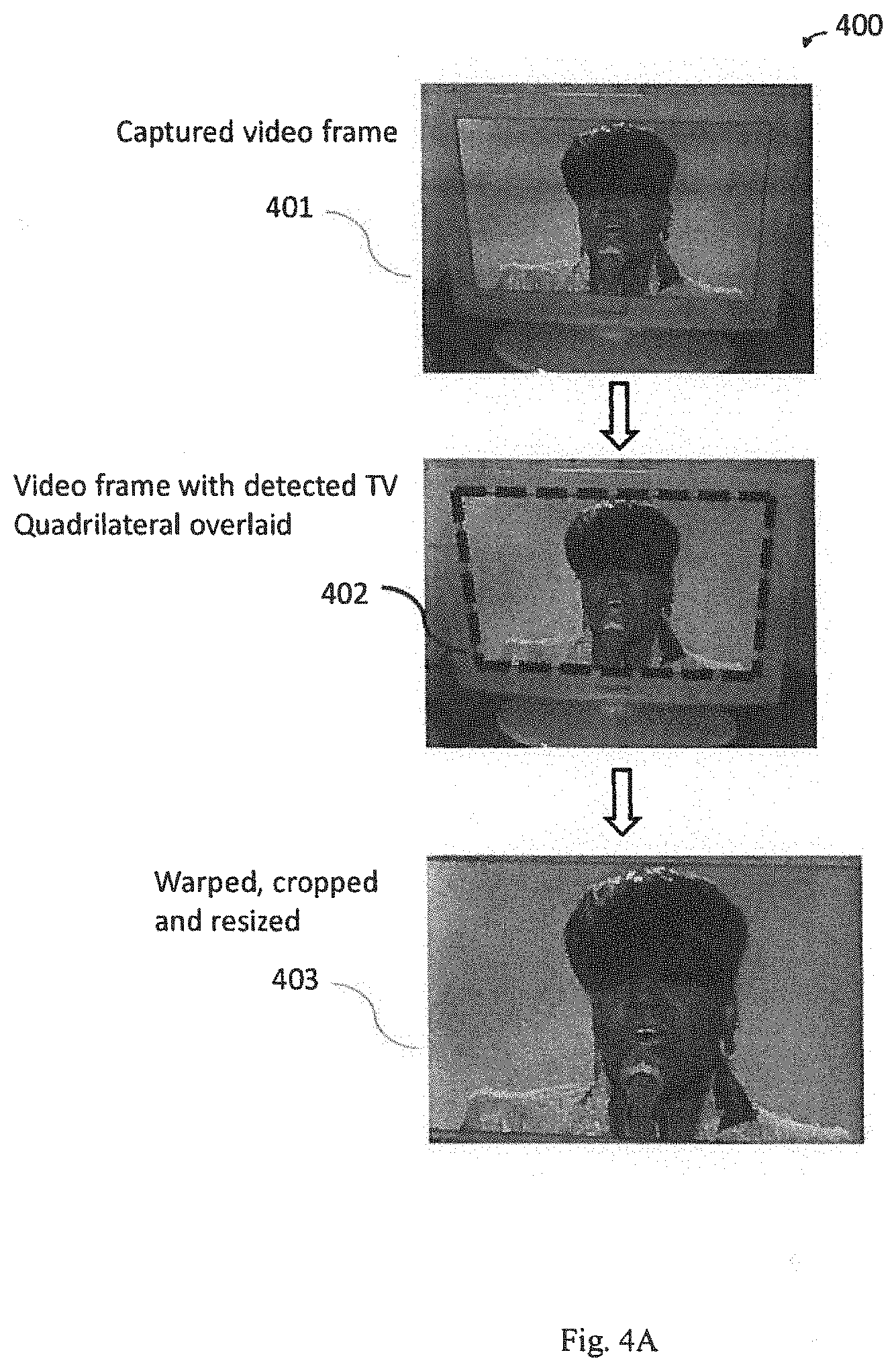
[0014] FIG. 4A illustrates a process for processing a video fragment acquired by a mobile camcorder operating on the smart phone;
[0015] FIG. 4B illustrates a process for multiple primary audio signature generation;
[0016] FIG. 5 illustrates a process for cluster signature generation;
[0017] FIG. 6 illustrates a process for audio signal onset detection in the time domain;
[0018] FIG. 7 illustrates a process for utilization of audio signal onset information;
[0019] FIG. 8 illustrates a process for onset detection in the time domain based on audio frame envelope tracking and continuous moving average tracking as an audio frame feature;
[0020] FIG. 9 illustrates a process for audio frame frequency domain entropy computation as an audio frame feature;
[0021] FIG. 10 illustrates a process to compute position of the maximum change in the audio descriptor coefficients between two consecutive audio frames, which is used as an audio frame feature;
[0022] FIG. 11A illustrates an exemplary signature data structure used in a signature database;
[0023] FIG. 11B illustrates a signature selection and database formation process;
[0024] FIG. 12 illustrates a process for fingerprinting and searching with multiple signatures and features;
[0025] FIG. 13 illustrates a process for combining audio and video data base search results to refine the search process and improve accuracy in finding a matching audio/video sequence.
[0026] FIG. 14 illustrates system architecture for mobile audio/video synchronous 2-screen applications;
[0027] FIG. 15 illustrates television audio/video capture on a mobile/media device;
[0028] FIG. 16 illustrates a flowchart of captured audio/video content identification, and as a result triggering a mobile/media device application action;
[0029] FIG. 17 illustrates automatic switching between remote search (external search server), and local search (mobile/media device);
[0030] FIG. 18 illustrates a mobile/media device local search levels;
[0031] FIG. 19 illustrates the remote/local query architecture with a miss counter; and
[0032] FIG. 20 illustrates the mobile/media device local query architecture with a miss counter.
DETAILED DESCRIPTION
[0033] The present invention will now be described more fully with reference to the accompanying drawings, in which several embodiments of the invention are shown. This invention may, however, be embodied in various forms and should not be construed as being limited to the embodiments set forth herein. Rather, these embodiments are provided so that this disclosure will be thorough and complete, and will fully convey the scope of the invention to those skilled in the art.
[0034] It will be appreciated that the present disclosure may be embodied as methods, systems, or computer program products. Accordingly, the present inventive concepts disclosed herein may take the form of a hardware embodiment, a software embodiment or an embodiment combining software and hardware aspects. Furthermore, the present inventive concepts disclosed herein may take the form of a computer program product on a computer-readable non-transitory storage medium having computer-usable program code embodied in the storage medium. Any suitable computer readable non-transitory medium may be utilized including hard disks, CD-ROMs, optical storage devices, flash memories, or magnetic storage devices.
[0035] Computer program code or software programs that are operated upon or for carrying out operations according to the teachings of the invention may be written in a high level programming language such as C, C++, JAVA.RTM., Smalltalk, JavaScript.RTM., Visual Basic.RTM., TSQL, Perl, use of .NET.TM. Framework, Visual Studio.RTM. or in various other programming languages. Software programs may also be written directly in a native assembler language for a target processor. A native assembler program uses instruction mnemonic representations of machine level binary instructions. Program code or computer readable medium as used herein refers to code whose format is understandable by a processor. Software embodiments of the disclosure do not depend upon their implementation with a particular programming language.
[0036] The methods described in connection with the embodiments disclosed herein may be embodied directly in hardware, in a software module that stores non-transitory signals executed by a processor, or in a combination of the two. A software module may reside in RAM memory, flash memory, ROM memory, EPROM memory, EEPROM memory, registers, hard disk, a removable disk, a CD-ROM, or any other form of non-transitory storage medium known in the art. A computer-readable non-transitory storage medium may be coupled to the processor through local connections such that the processor can read information from, and write information to, the storage medium or through network connections such that the processor can download information from or upload information to the storage medium. In the alternative, the storage medium may be integral to the processor.
[0037] FIG. 1 illustrates a system 100 for providing mobile device applications in accordance with the present invention based on analysis of audio, video, or audio and video signals acquired from a media presentation device. The input of audio, video, or audio and video signals hereinafter is referred to as media content. One embodiment addresses a method to identify media content, by acquiring media content on a mobile device from a media presentation device, appropriately processing the media content, fingerprinting the media content, and searching fingerprint databases to identify the media content. The system 100 includes a media presentation device 104, such as a television set, a desktop, laptop, or tablet computer, a digital video disc (DVD) player, or a smartphone device configured to display television programming or play audio media such as wireless received radio signals, compact discs (CDs), or the like. The media presentation device, such as a television set, may be connected to a remote media broadcast system 105 for receiving television programming content. Also, the media presentation device 104 may or may not be connected to the Internet 106. The system 100 also includes a remote content identification system 108 and a mobile device 110 connected over the Internet 106 to the remote content identification system 108. Connections 112, 114, and 116 may be wired or cabled connections, wireless connections, or a combination of wire cable and wireless connections. For example, the mobile device 110 may connect wirelessly to the Internet 106 through a wireless router or over 3G or 4G networks while the remote content identification system 108 may be wire or cable attached through a modem to the Internet 106. The mobile device 110 may be configured to acquire audio signals from the media presentation device 104 by use of a microphone. The mobile device 110 may also be configured to acquire images or a video from the media presentation device 104 by use of a charge coupled device (CCD) image sensor and a camera lens assembly included in the mobile device 110.
[0038] Illustrated system 100 supports applications on the mobile device 110 that operate in real time and in accordance with television or other media programming content that is being presented on a media presentation device 104 and received by the mobile device 110.
[0039] The mobile device 110 is configured to acquire a temporal fragment of media content, including audio content, video content, or both, that are playing on the media presentation device 104, using the mobile device's microphone, camera, or both, and generates query fingerprints of the temporal fragment of the acquired media content. A chunk of the query fingerprints, which is a set of the query fingerprints corresponding to a time segment of the query audio signal, or a digest of the chunk of the query fingerprints are transmitted as a search query to the remote content identification system 108, also referred to as a remote search server 108, for content identification. A digest of the query fingerprints is a summarization of the fingerprints generated for the acquired media content. If the search query is found in a reference database of the search server 108, the search server 108 responds with a title and timing information of the identified media content, along with related metadata, and sends the title, the timing information, and the related metadata to the mobile device 110. The original chunk of query reference fingerprints or the digest of the query fingerprints is stored on the mobile device 110 for further use in querying a mobile device database located on the mobile device 110 and tracking of media content. The mobile device 110 may be configured to continuously listen, observe, or listen and observe the media programming content. If a change in the media programming content is detected, the mobile device 110 generates one or more new queries that are sent to the remote search server 108 for content identification. If the new query is found in the reference database of the remote search server 108, the search server 108 responds with a title and timing of the media content associated with the new query, along with related metadata, and sends the identified information to the mobile device 110. The original new chunk of reference fingerprints are stored on the mobile device 110 for further use in querying and tracking operations locally on the mobile device 110. This process continues as long as the mobile device 110 is listening, or observing, or both to the media programming content. The mobile device 110 may be equipped with an actionable program event detection system, which generates an action signal upon detection of a particular audio, or video, or audio and video fragment stored in the reference fingerprint database. A software application running on the mobile device 110 can then perform actions based on local search results, presenting to the user a variety of additional information on the same mobile device 110 in real time while the remote media programming is still playing the associated media content.
[0040] For example, a movie that started at 9 PM is being watched on a television set 104. A user enables an application on a mobile device 110, such as a smartphone, that configures the smartphone 110 to acquire a fragment of media content, which may include a fragment of audio content, a fragment of video content, or fragments of both audio and video content. For example, a fragment may be five seconds of background music from a scene in the movie. A fragment may also be a snapshot of a character in the movie or may be a short narrative given by a leading character in the movie. If a video fragment is acquired by a mobile camcorder or camera operating on the smartphone 110, video frames of the fragment are initially analyzed to find the TV screen in the frames. In an exemplary case, the screen location step may be done by running edge detection on selected frames, which may also include running contour detection on the selected frames, combined with contour thresholding and selection, and searching for an initial quadrilateral of appropriate dimensions. A detected quadrilateral is further refined by tracking motion from frame to frame of pixel formations inside and in the immediate neighborhood of the quadrilateral. Also, brightness and color of the detected quadrilateral can be checked against the rest of a frame's content to further increase confidence that the TV screen area is correctly delineated. The user may be informed that a TV screen is detected by displaying an outline of a TV screen quadrilateral on the smart phone display. If no TV screen is found, then the lack of acquiring a TV screen may be communicated to the user by appropriately changing the appearance of virtual guidelines on the smartphone display, by making them flash, changing their color, and the like, for example. In the case of a detected TV screen, the frame area corresponding to the detected quadrilateral is cropped and warped to an upright rectangle and used for video fingerprint generation of the TV programming content captured from the TV set. Also, if the smart phone is held close to the TV, the video captured on the smartphone may be filled with content from the TV screen and a TV screen detection process would not be used. In such a case, the original captured frames are processed as holding TV programming content.
[0041] The application generates query fingerprints for the acquired fragment of media content as described in U.S. Pat. Nos. 8,229,227, 8,171,030, 8,189,945, and 8,195,689, and U.S. patent application Ser. No. 13/094,158 which are incorporated by reference in their entirety. The application transmits the query fingerprints as a search query to a remote search server 108 which searches for the transmitted content in a reference database of the remote search server 108. If media content associated with the query fingerprints is discovered, the remote search server 108 retrieves related content, such as a title of the media content, timing information and identifies other related information which the user may have previously requested and forwards the related content and associated information to the user's smartphone 110 for presentation to the user. At this point, the television programming is tracked in real time and preprogrammed events are identified, such as a change in television program, or onset of a selected type of commercial, or entrance of a particular character, with sub-second resolution and to trigger a notification action to alert the user.
[0042] By using such a content identification system, it is possible to configure a real-time media content analysis software application, to run on the mobile device itself. FIG. 2 illustrates a media acquisition subsystem 200 configured to acquire played television media content from a television device 204 on a mobile device 206. The television device 204 is configured to play a television program that generates sounds and speech from speakers in synchronism with images and video from a display device, such as a liquid crystal display (LCD) or light emitting diode (LED) display. The mobile device 206 is configured with a microphone 208 to acquire the sounds and speech and transform the sounds and speech to audio signals. The mobile device 206 is also configured with a camera device 210 that acquires the images and video, and transforms the images and video to a sequence of pixels or frames of pixels. The mobile device 206 is configured with a central processing unit (CPU) system 212 that acquires the audio and pixel data for analysis.
[0043] A technical concern in enabling mobile applications to operate in real time with, for example, television content played on a nearby television device is to be able to accurately identify the media content acquired directly from the TV set by the mobile device's microphone, camera, or both. Such acquisition operates in a dynamic environment of the mobile devices which tends to degrade the quality of the content being acquired. For example, the quality of an audio signal may be degraded by sources including lossy encoding of the source audio, fidelity limitations of the speaker system, equalization, multi-path interference using a multi-speaker system, fidelity limitations of the microphone on the mobile device, automatic gain adjustments or equalization on the speaker and/or microphone, and the encoding of the audio on the mobile device. With such degradations in the audio content, content identification based on the audio signal captured from a nearby TV set is a challenging problem. Even more severe signal degradation situations may arise with respect to the image and video pixel data acquired from a nearby TV set. The sources of degradation are numerous, including the encoding of the source video, fidelity limitations of a display device, such as a the television screen, automatic brightness and contrast adjustments on the display device, the fidelity limitations of the video camera on the mobile device, automatic brightness and contrast adjustments of the video camera on the mobile device, environmental lighting conditions, the viewing angle of the camera and any perspective distortion ensuing, and the encoding of the video on the mobile device.
[0044] FIG. 3 illustrates a process 300 for identification of audio or video content captured by a mobile device from a nearby TV set and triggering a mobile application action. At step 304, a television program is selected to be played on a TV set. At step 306, a fragment of audio and video signals are acquired on the mobile device. The audio and video signals are passed to the associated step in the mobile application for processing the audio and video signals as an audio waveform and video frames, respectively. At step 308, the audio waveform is framed. At step 310, the framed audio waveform is fingerprinted with an audio fingerprinting system. At step 312, one or more active regions are determined in the video frames and a set of frames are selected for further processing. At step 314, active TV regions in the selected video frames are fingerprinted with a video fingerprinting system. This fingerprinting may occur entirely locally on the mobile device, entirely remotely on a remote server, or partially locally and remotely. If performed entirely remotely, the audio waveform and the video frames are transmitted to the remote server. Alternatively, some partial fingerprint processing may be done locally and then the remainder of the fingerprint processing may be done remotely. In this alternative embodiment, video frame selection on the video frames is performed locally on the mobile device and then only the selected video frames are transmitted to the remote server for fingerprint processing. For audio, the audio waveform may be re-sampled to a lower sampling rate and down mixed to one channel, before generating the fingerprints. Compression of the video frame and the audio samples may be used to reduce transmission costs.
[0045] At step 320, the audio fingerprints and video fingerprints are combined and a selected set of fingerprints are used as query fingerprints. Having both audio fingerprints and video fingerprints representing the TV programming content increases the reliability of TV content identification under severe audio and video signal degradations due to the surrounding ambient conditions. The resulting audio and video query fingerprints are transmitted to a search server. A search function may be either local, residing on the mobile device or remote, accessed for example through the Internet cloud. At step 322, the search server responds with a message that details where the audio and video content were found in the search database, and if found, the title of the content, the matching times, and related metadata, like an image representing the program, details about actors, or the like. If a match is not found at step 322, the process 300 returns to step 306 to select another fragment of media content for processing.
[0046] At step 324, the mobile application receives the match data and may be configured to trigger actions that are based on this data. Such actions may include displaying the identity of the content to the user, retrieving related information based on the identity of the content, allowing the user to register that piece of content with a registration server online, display an interactive ad based on the content and perhaps knowledge about the user, or may enable a variety of other real time applications based on detected audio and video content.
[0047] One embodiment of the invention addresses a method for improving the accuracy and speed of audio fingerprinting by using content based audio feature extraction and signature generation. Audio features, representing the audio content, are extracted by using a mel-frequency cepstrum coefficients (MFCC) algorithmic structure with an additional temporal multi-tap filtering of the output coefficients, and subsequent generation of compact, bit-wise representation of these features.
[0048] In another embodiment, an adapted MFCC algorithm makes use of central frequencies of filters in a filter bank that are adjusted according to a robust measure of a central or mean frequency of the input audio, such as the dominant frequency or spectral centroid. If this adapted MFCC algorithm is used for fingerprinting of both query and reference audio signals, the reference and query audio fingerprint comparisons can be made more robust to pitch changes in the query audio signal.
[0049] In general, implementation of an MFCC algorithm facilitates parametric spectral representation of audio signals, which allows for generation of multidimensional audio descriptors with a plurality of dimensions independent of the number of filter bands. Quantization of multidimensional audio descriptor coefficients, where each coefficient represents a descriptor dimension, secures precise bit-wise multidimensional audio signature generation for efficient database formation and search. These bit-wise multidimensional audio signatures can be efficiently deployed as primary audio content signatures in various application environments.
[0050] Input audio samples are divided into short, overlapping frames, and subsequently windowed with a particular windowing function to prevent artifacts in the output of an applied fast Fourier transform (FFT) due to the finite extent of time samples. The amount of the consecutive audio frame overlap is determined in accordance with the desired frequency in time with which audio descriptors are generated. Next, the FFT is computed for each overlapped, windowed, audio frame, and then the resulting high-resolution frequency spectrum is used as an input to a filter bank.
[0051] The filter bank may suitably be an MFCC filter bank with logarithmic spacing of center frequencies, or in a presently preferred embodiment, it can be adjusted according to a robust measure of the central or mean frequency of the input audio, such as the dominant frequency or spectral centroid.
[0052] For the case of an adjusted center frequency filter bank, a central frequency estimate from the spectral magnitude of the current audio frame is made. For example, with known default center frequencies of the MFCC filter bank filters, one of the filters in the filter bank is determined whose center frequency is closest to a central-frequency measure previously established. A multiplier factor is generated to scale this filter's center frequency to the central-frequency measure, and the other filters center frequencies are multiplied by this factor. The MFCC coefficients which are the amplitudes of the resulting spectrum are then computed in accordance with the adjusted filter bank.
[0053] In both cases, an advantageous logarithm of the output from each filter of the filter bank is computed to handle a wider range of volume levels. Alternatively or in addition to the logarithm computation, an advantageous square root (sqrt) of the output from each filter of the filter bank is computed to handle higher levels of noise. Then, a discrete cosine transform (DCT) is applied on the resulting signal to convert the log and/or the sqrt outputs from the filter bank to a new set of values and frequencies. Next, an advantageous multi-tap smoothing derivative finite impulse response (FIR) filter is applied in temporal domain on multiple audio descriptors which are outputs of the DCT stage of the computation computed in regular temporal intervals defined by the chosen amount of audio frame overlap. The multi-tap smoothing derivative FIR filter is applied in temporal domain separately on each audio descriptor coefficient, the DCT coefficient, to produce new, filtered DCT coefficients, representing a final multidimensional audio descriptor output.
[0054] FIG. 4A illustrates a process 400 for processing a video fragment, such as the frame captured in step 401, acquired by a mobile camcorder operating on the smart phone 110. A smartphone software application may be utilized to provide a fingerprinting and search function. Video frame 401 of the fragment is initially analyzed to identify a TV screen in the frame. In an exemplary case, the TV screen identification may be done by running edge detection on selected frames, by running corner detection on selected frames, and searching for an initial quadrilateral of appropriate dimensions as illustrated in step 402. A detected quadrilateral is further refined by tracking motion from frame to frame of pixel formations inside and in the immediate neighborhood of the quadrilateral. Also, brightness and color of the detected quadrilateral can be checked against the rest of a frame's content to further increase confidence that the TV screen area is correctly delineated. The frame area, corresponding to the detected quadrilateral, describing the TV screen active area is cropped and warped to an upright rectangle in step 403 and used for video fingerprint generation of the TV programming content captured from the TV set. The smartphone application generates query fingerprints for the acquired fragment of media content and transmits the query fingerprints to a search function. For example, a search query may be sent to a local search function operating on the mobile device or to a remote search server. The search function, either locally or remotely, searches for the query content in a reference database of the local mobile device and or an extensive reference database of the remote search server.
[0055] FIG. 4B illustrates an exemplary and advantageous process 404 for multiple primary audio signature generation that targets mobile audio distortions. At step 405, captured audio samples are received for processing. At step 406, input audio is down-sampled to mono audio and resampled to 14 kHz. At step 408, the mono audio is partitioned into overlapping frames of size 4096 samples and a frame position increment is specified as 256 samples, for example, resulting in a frame overlap of 3840 samples. At step 410, a Hamming window is applied on each input frame of samples to reduce artifacts in FFT computation due to the finite length of the input signal. At step 412, an FFT magnitude of windowed samples is generated, producing a 2048-point spectrum per frame, the spectrogram.
[0056] At step 414, the exemplary process 404 continues on to primary signature A and signature B generation steps. Using the spectrogram, MFCC coefficients are generated and processed in steps 420-426 for the two distinct signatures A and B. At step 420, for signature A, a filter bank is applied on K frequency bands, such as K=24, producing K output coefficients divided into m linearly spaced bands across 200-1100 Hz, such as m=8, and n logarithmically spaced bands across 1100-6.4 kHz, such as n=16. Also, at step 420, a log.sub.10 magnitude on the filter bank outputs is computed. At step 422, a discrete cosine transform (DCT) is computed on the filter bank outputs to produce descriptor coefficients. At step 424, for signature B, a filter bank is applied on the same number K of frequency bands, producing K output coefficients logarithmically spaced across 200-2 kHz. Also, at step 424, a square root (sqrt) function is applied on the filter bank outputs to produce final filter bank outputs.
[0057] At step 426, a DCT is computed on the final filter bank outputs to produce descriptor coefficients. Next, at steps 428 and 430, final descriptors A and B are derived by applying in temporal domain a 9-tap finite impulse response (FIR) smoothing derivative filter to each dimension of 9 consecutive descriptors computed in regular intervals, for example in intervals of 256 audio samples. This filter is applied separately on the coefficients of the set of A descriptors and on the set of B descriptors. The input to each filter consists of the current value of the descriptor coefficient, which is also referred to as a dimension, and the corresponding coefficients, also referred to as dimensions, from descriptors for the previous 8 audio frames. A set of 9 FIR filter coefficients {h.sub.0, h.sub.1, h.sub.2, h.sub.3, h.sub.4, h.sub.5, h.sub.6, h.sub.7, h.sub.8} are designed to produce a smoothing derivative filter response for each descriptor coefficient or dimension. The filter coefficients are anti-symmetric, generated in the (-1, 1) interval.
[0058] At step 432, the descriptor coefficients are quantized to either 0 or 1 based on the coefficient sign. If the descriptor coefficient is greater than 0 a value of 1 is assigned to it, and if the descriptor coefficient is less than 0 a value of zero is assigned to it. The quantized values for each descriptor coefficient are concatenated together to produce a 24-bit signature. Signatures are then selected by choosing only signatures with at least k zeros and k ones, wherein k is a predetermined value. Signatures with fewer zeros or ones are suppressed. At step 434, filtered primary signatures A and B are output to the signature selection and database formation process 1123, as shown in FIG. 11B.
[0059] FIG. 5 illustrates a process 500 for generation of audio cluster signatures, also known as traversal hash signatures. A number of lower coefficients of primary descriptors are extracted and then combined with additional bits from a set of independently detected audio content features to form the audio cluster signatures. At steps 504, primary signatures A and B are received as inputs to the process 500. At step 506, the lower 16 coefficients are extracted from both the primary signatures A and B producing two 16-bit signatures that are subsets of signatures A and B. At step 508, an additional 4 bits are produced for each subset of signatures A and B from selected additional audio features, as described in more detail below. The additional 4 audio feature signature bits are concatenated to their respective signatures A and B, resulting in two 20-bit cluster signatures. At step 510, a bit is added to both cluster signatures A and B; a 0 for cluster signature A and a 1 for cluster signature B. At step 512, two 21-bit cluster signatures are sent to signature selection and database formation process 1123 of FIG. 11B, with the exemplary data structure and signature format shown in FIG. 11A. The 21-bit cluster signature is used as an address for reference database partitioning into clusters of signatures. The 21-bit cluster signature address facilitates a fast access of content in the reference database during a content query and identification process. Selection of 16-bits from the primary signature, the four audio feature signature bits from generated audio features, and the formation of a 21-bit cluster signature as shown in the process 500 is exemplary. Other reasonable numbers of bits could be selected that in combination are less than the number of signature bits generated for the video frame 403, for example, such as the exemplary 24-bit primary signatures A and B generated at step 432 of FIG. 4B. It is noted that the exemplary 24-bit primary signatures A and B may be expanded by concatenating a number of feature bits resulting in 32-bit primary signatures, as described in more detail below. It is also noted that an alternative process may generate primary signatures A and B having for example 64-bits. In any of these cases, having 21-bit cluster signatures that are used as addresses facilitates a fast access of content in the reference database during a content query and identification process.
[0060] It is noted that in a controlled experimental environment, audio frames extracted from an audio signal are aligned to a multiple of frame step size, typically 256 or 512 samples, with a regular interval. However, in a real life dynamic environment, a starting point of the audio frames in the reference and query are generally randomly positioned with reference to each other. Hence, it would be advantageous if audio frames between the reference and the query signal are aligned based on some intrinsic audio signal features.
[0061] In another embodiment, audio signal onset detection in the time domain is used for audio frame alignment. Audio signal onset detection is an audio analysis technique that can be used to improve a fingerprinting system by aligning an audio signal fingerprinting window to an onset event. Onset events can also be used for feature signature or cluster signature bit generation, as well as for combining pairs of signatures based on distinct onset event times. If the same onsets are found on both the reference and the query audio signals, audio frames will be aligned to the same audio content on both the reference and the query signals. If a gap between detected onsets is larger than a frame step size, then additional audio frames can be generated with a regular interval relative to the onset. Also, by using audio frames when onsets are found, the number of audio signatures generated can be reduced.
[0062] FIG. 6 illustrates a process 600 for audio signal onset detection in the time domain. The process 600 is used to improve the audio fingerprinting and identification system, such as the system 100 of FIG. 1, by aligning audio signal fingerprinting windows to pronounced events intrinsic to the audio signal. The process 600 is a temporal process for onset detection that is precise and computationally efficient. At step 604, a multi-channel audio waveform is received and then down mixed to a mono signal, and resampled to a desired sampling rate. At step 606, an energy waveform of the audio signal is computed by squaring the resampled audio waveform. At step 608, a low-pass filter is applied to the energy waveform signal and resampled, for example to approximately 1 ms. At step 610, a filtered derivative of the resampled filtered energy waveform signal is computed for a multitude of derivative filter widths, to produce filtered derivative signals. Next, at step 612, maximum values of the filtered derivative signal are computed for a multitude of maximum filter widths. At step 614, maximum values that exceed a heuristic threshold are collected. At step 616, time positions of maximum values that exceed the threshold are output as a set of onsets for the current segment of audio signal.
[0063] The filtered derivatives of the low passed energy audio signal computed at step 610 represent a type of 1-D blob detector over the received audio waveform. By varying the derivative filter width at step 610 and the maximum filter width at step 612, audio signal onsets at different points in time are obtained.
[0064] FIG. 7 illustrates a process 700 for utilization of audio signal onset information. At step 704, a multichannel audio signal is received. In step 706, the multichannel audio signal is down mixed to a mono signal which is then resampled as needed. For example, the received audio signal may generally be sampled with 48 KHz or 44 KHz and the mono signal may be resampled to 14 KHz, however, the necessity of down sampling may be determined in a particular implementation. At step 708, output onset parameters are computed describing the time position of onset events and onset magnitudes. At step 710, an onset position is used to align an audio signal fingerprinting window to a selected onset event. At step 712, for each audio frame, the time distance to the previous onset, and separately to the next onset are computed. The combined time distance to the previous onset and to the next onset is termed an "onset-offset" value. At step 714, the onset-offset value is quantized to a k-bit value to be used as an independent feature signature in the search and correlation process for audio content identification. In step 716, the onset-offset value is quantized to an m-bit value to be used as additional bits concatenated to the cluster signatures. At step 718, the output from steps 710, 714, and 716 are collected and passed to signature A and signature B selection and database formation process 1123 of FIG. 11B.
[0065] Three exemplary embodiments for audio content feature extraction and feature signature generation are described next. A method for time domain audio frame onset detection is described with regard to FIG. 8, a method for frequency domain entropy computation for each audio frame is described with regard to FIG. 9, and a method for extraction of maximum difference in the output descriptor coefficients is described with regard to FIG. 10. The feature signatures, as described above, are used either independently during the correlation stage of the audio search and identification, or selected bits from the feature signatures are combined and concatenated with either primary or cluster signatures or both signatures to improve the uniqueness of primary and cluster signatures.
[0066] FIG. 8 illustrates an exemplary process 800 for onset detection in the time domain based on audio frame envelope tracking and continuous moving average tracking. The array of onsets computed with this process for each audio frame can be used as an audio frame feature to be associated with the audio frame primary or cluster signature. At step 804, each audio frame received for processing is divided into 16 segments of 256 samples. At step 806, an audio signal envelope detector is used to trace an audio signal envelope. The envelope detector algorithm includes variable attack and release times that can be independently adjusted according to a desired sensitivity to audio signal content changes. For each audio frame, a value of the envelope is recorded at the end of each 256 sample segment. At step 808, a moving average with an exponential decay is computed continuously over the same audio frame. At step 810, at the end of each 256 sample segment, the envelope value determined at step 806 is compared to the moving average value determined at step 808, and a difference vector is generated at step 810. At step 812, the difference vector L.sub.2 norm is computed. At step 814, the difference vector elements are normalized to the difference vector L.sub.2 norm. At step 816, a maximum difference vector element is determined and normalized. At step 818, the normalized maximum difference vector element from step 816 is quantized to a 4 bit value and its position within the audio frame is recorded. At step 820, the normalized maximum difference vector element and its position are delivered as audio feature signatures to the signature selection and database formation process 1123 of FIG. 11B, with the exemplary signature data structure 1100 as shown in FIG. 11A.
[0067] FIG. 9 illustrates a process 900 for an exemplary audio frame frequency domain entropy computation as an audio frame feature to be associated with the audio frame primary and cluster signatures. At step 904, audio frames are received for processing. At step 906, an FFT is computed for an array of N received audio frames. At step 908, a spectral magnitude of the FFT output from step 906 is used to compute an entropy function for spectral magnitude samples. An exemplary entropy function 908 may be computed as follows. If M(f) is the magnitude of the spectrum for frequency position fin a particular audio frame, then M.sub.s(f) is M(f) divided by the sum: sum(M(f)), computed for the audio frame. The spectral entropy is computed as a sum: sum{log.sub.2[M.sub.s(f)]*M.sub.s(f)}, where the summation is taken over the range of frequencies in the audio frame. At step 910, a first temporal derivative of the entropy is computed for each two consecutive audio frames. This temporal derivative computation corresponds to computing a sign of an entropy change between two consecutive frames. At step 912, signs of the most recent N samples of the entropy difference values from step 910 are concatenated to form an N-bit entropy sign difference history feature vector. At step 914, the N bit history feature vector is delivered as a feature signature to the signature selection and database formation process 1123 of FIG. 11B, with the exemplary signature data structure 1100 as shown in FIG. 11A.
[0068] FIG. 10 illustrates a process 1000 to compute an exemplary position of the maximum difference in the audio descriptor coefficients between two consecutive audio frames, to be associated with the audio frame primary or cluster signature as an audio frame feature. At step 1004, audio descriptors from step 436 of FIG. 4B for two consecutive audio frames are received for processing. At step 1006 and for each audio frame, a differential descriptor vector is computed. At step 1008, the largest magnitude difference in the upper X dimensions, such as the upper 12 dimensions as determined experimentally or by heuristic, of the descriptor is determined. At step 1010, a 4 bit value is determined as representing a position of the maximum difference within the X dimension differential descriptor vector. At step 1012, the positional index value is delivered as a feature signature to the signature selection and database formation process 1123 of FIG. 11B, with the exemplary signature data structure 1100 as shown in FIG. 11A.
[0069] FIG. 11A illustrates an exemplary audio-video signature data structure 1100. Block 1104 represents a primary signature A, such as an exemplary 24-bit value, which is concatenated with a feature aspect 1106, such as an exemplary 8-bit value, associated with the primary signature A. In a similar manner, block 1108 represents a primary signature B, such as an exemplary 24-bit value, which is concatenated with a feature aspect 1110, such as an exemplary 8-bit value, associated with the primary signature B. Blocks 1112 and 1122 represent p-bit additional features used during the correlation process of audio content search and identification to further differentiate matching results, where p may be an exemplary sixteen bit value. Also, feature bits may be added to the primary signature to increase the signature length. A similar data structure is formed for the cluster signature A, blocks 1114 and 1116, and cluster signature B, blocks 1118 and 1120.
[0070] As an example, additional q-bits in the cluster signatures may be formed as a mixture of selected bits from an onset feature, selected bits from an entropy feature, and selected bits from a maximum change in the descriptor coefficients feature. Block 1114 represents a cluster signature A, such as an exemplary 16-bit value, which is concatenated with a q-bit feature aspect block 1116 associated with the cluster signature A, where q may be an exemplary 5-bit value. In a similar manner, block 1118 represents a cluster signature B which is concatenated with a q-bit feature aspect block 1120 associated with the cluster signature B. Features, primary signatures, and cluster signatures are packed into the signature data structure as shown in FIG. 11A, and subsequently used for media search and identification, as described in more detail below.
[0071] As presented above, primary and cluster audio signatures are formed as a mixture of bits, representing dimensions of the associated signatures, selected from the MFCC filtered output, and additional audio features bits. Both combined K-dimension primary signature and combined M-dimension cluster signature are generated for each audio feature identified in a set of reference multimedia clips. Similarly, exemplary L-dimension video primary signatures and N-dimension video cluster signatures, as well as x, y, and scale feature signatures, are formed as described in U.S. Pat. No. 8,189,945 titled "Digital Video Content Fingerprinting Based on Scale Invariant Interest Region Detection with an Array of Anisotropic Filters" and U.S. Pat. No. 8,195,689 titled "Media Fingerprinting and Identification System" which are hereby incorporated by reference in their entirety.
[0072] An exemplary first audio and video fingerprinting process would include multiple video signatures generated on an active TV area as shown in the processed video frame in step 403 of FIG. 4A, onset detection for audio fingerprint alignment, such as the onset detection process 600 of FIG. 6, multiple primary audio signatures generated in process 404 of FIG. 4B, multiple audio cluster signatures generated in process 500 of FIG. 5, and feature signatures generated in processes 800 of FIG. 8, 900 of FIGS. 9, and 1000 of FIG. 10. The signatures in steps 432, 510, 818, 912, and 1010, are advantageously combined in the signature selection and data base formation process 1123 of FIG. 11B. It is noted that the feature signatures from steps 818, 912, and 1010 may be suitably combined by concatenation or by another combinational method to generate a combined feature signature.
[0073] In another exemplary case, a second audio and video fingerprinting process would include onset detection for audio fingerprint alignment 600, multiple primary audio signatures generated in process 404, multiple audio cluster signatures generated in process 500, and feature signatures generated in process 700. The signatures in steps 434, 512, 714, and 716 would be combined in the signature selection and database formation process 1123 of FIG. 11B.
[0074] It is noted that multiple exemplary combinations of signatures generated, as illustrated in FIGS. 4A, 4B, 5, 6, 7, 8, 9, and 10, selection, and data base formation processes may be used. An experimental analysis may be used together with application requirements to select or adapt the signature generation process most appropriate for a given situation.
[0075] Each K(L)-dimension signature and a link to a corresponding reference multimedia clip are stored at a location in a reference signature database residing either on the remote server or in storage on the local mobile device. Each location is addressable by the M(N)-dimension cluster signature, also described as a traversal hash signature. A K(L)-dimension query signature and an M(N)-dimension query cluster signature are generated for a query multimedia clip. The reference signature database is searched using the query cluster signature to find similar signatures that are within a specified signature distance, wherein the similar reference multimedia clips are aggregated in a candidate list of closely matching signatures that correspond to similar reference multimedia clips. Additional feature signatures may also be used for media query and reference signature correlation to strengthen the scoring process and reduce false positive media identification.
[0076] FIG. 11B illustrates a signature selection and database formation process 1123. In step 1124, the primary, cluster, and feature signatures are received. In step 1126, primary signatures A and primary signature B are selected based on multiple criteria related to a particular application requirement. In step 1128, feature signatures are selected to form associated feature signatures. For example, the selection may be dependent on general computational requirements and the database size limitation. In step 1130 cluster signatures A and B are selected based on the reference signature data base size, the required query response time, and the required query precision and recall. In step 1132, the set of primary, cluster, and feature signatures from steps 1126, 1128, and 1130 are combined and then used to form an audio signature database in step 1134 with the exemplary signature data structure 1100 shown in FIG. 11A.
[0077] FIG. 12 illustrates a process 1200 for fingerprinting and search with multiple signatures and features. For example, multiple signatures and features may be derived from TV program video content. In the process 1200 of FIG. 12, it is assumed that the reference database has been formed in advance by use of a fingerprinting process, such as incorporated in the database formation process 1123 of FIG. 11B. At step 1204, a query audio signal, or a query video signal, or combined audio and video query signals are submitted for fingerprinting. At step 1206, primary, cluster and feature query signatures are generated. At step 1208, query signatures are generated for a chunk of query content, usually 5-10 seconds worth of query fingerprints, and subsequently used for content identification. At step 1214, a cluster search is performed to determine a reference signature cluster closest to the query cluster signature. At step 1216, a similarity search is conducted with the query primary signature on the primary signatures belonging to the identified cluster. Search result scores are generated at step 1216 and matching candidates from the reference content are identified. At step 1210, query feature signatures are compared to the reference feature signatures for all candidates belonging to the identified cluster, and at step 1212, a feature score is generated. At step 1220, primary and feature signature scores are combined for all candidate matches. At step 1222, the resulting score is compared against a threshold T. If a matching reference audio score is above the threshold T, the process 1200 proceeds to step 1226 where notification is presented of a successful search result. At step 1228, a software application which can perform actions that are synchronized to the video content are triggered. If all candidate matching scores are below the threshold T, the process 1200 proceeds to step 1224 where notification is presented of a not found result. The threshold T, used for signature and feature comparison score evaluation, may be heuristically generated or generated based on a training process on an extensive training database.
[0078] FIG. 13 illustrates a process 1300 for combining audio and video data base search results as generated in the process 1200 to refine the search process and improve accuracy in finding a matching audio and video sequence.
[0079] The audio and video database search results, such as a set of scores for candidate matching audio and matching video sequences, are combined and further analyzed in the steps of process 1300 of FIG. 13. At step 1302, audio and video scores are received for a combined analysis. At step 1304, search result scores and computed confidence levels for both audio and video search results are analyzed on multiple reported, in other words identified, top candidate audio and video titles. At step 1306, a combined audio and video score is generated. In step 1308, the combined audio and video score is tested against a threshold T1. If the combined score is below the threshold T1, an audio and video sequence not found result is reported at step 1310. If the combined score is greater than the threshold T1, an audio and video sequence found result is reported at step 1312.
[0080] One aspect of the invention presents a method to identify multimedia content which includes audio, video, or both audio and video content, by capturing the audio and/or video data from the mobile device, appropriately processing the audio and/or video content, fingerprinting the audio and/or video data, and searching fingerprint databases to identify the video content. The system architecture of such a system is shown in FIG. 14, which shows a television device, a remote content identification system, and a mobile device, all potentially connected over a network, and with the mobile device potentially capturing audio and video from the television device. A mobile device may include a smartphone, a tablet, a laptop computer, or other such portable device. The presented method enables applications on a mobile/media device to act synchronously to television/media programming content that is being presented on a nearby located television/media device. A mobile/media device listens to the television/media content, captures some temporal fragment of the audio and/or video content on their mobile/media device using the device's microphone and/or camera, and generates query fingerprints of the temporal fragment of the audio/video content. A chunk of the query fingerprints, or a digest of the query fingerprints are transmitted to a search server for content identification. If the query is found in the search server reference database, the search server responds with the title and timing of the media content, along with related metadata, and sends down to the mobile/media device a chunk of reference fingerprints for further local querying and television/media content tracking.
[0081] The mobile/media device continuously listens to the television/media programming, generates fingerprints, and tracks the content by using locally stored mobile/media device reference data base of fingerprints. If a change of the television/media programming content is detected, the mobile/media device generated queries are sent again to the remote search server for content identification. If the query is found in the search server reference database, the search server responds again with the title and timing of the media content, along with related metadata, and sends down to the media device a new chunk of reference fingerprints for further querying and tracking. This process continues as long as the mobile/media device is listening to the television/media programming.
[0082] The method presented seamlessly and automatically switches between remote search on an external search server, and local search on a "micro search server" on the mobile/media device.
[0083] The mobile/media device may be equipped with an actionable program event detection system, which generates action data upon detection of a particular audio and/or video fragment stored in the reference fingerprint database. A software application running on the mobile/media device can then perform actions based on the local search results, presenting to the user a variety of additional information on the same media device synchronously with the remote television/media programming.
[0084] The process for capturing the audio and video data using the mobile/media device's microphone and camera is illustrated in FIG. 15.
[0085] Audio and/or video signals are captured on the mobile device. They are passed to the application as an audio waveform and/or video frames, respectively. Next, the audio waveform is fingerprinted with an audio fingerprinting system, and the video frames are fingerprinted with a video fingerprinting system. This fingerprinting may occur entirely locally on the mobile device, entirely remotely on a remote server, or partially locally and remotely. If performed entirely remotely, the audio waveform and the video frames are transmitted to the remote server. Alternatively, some partial processing may be done locally and then the remainder of the fingerprint processing remotely. For instance, a video frame selection process may be performed on the video frames locally and then the local device transmits only the selected video frames to the remote server. For audio, the audio waveform may be resampled to a lower sampling rate and down mix to one channel, before transmission. Compression of the video frame and the audio samples may also be used to reduce transmission costs.
[0086] The resulting audio and video fingerprints are transmitted to a search server. This search server may be either local or remote. The search server responds with a message that details where the audio and video content were found in the search database, and if found, the title of the content, the matching times, and related metadata, like an image representing the program, details about actors, etc.
[0087] The mobile application receives this data and can trigger actions that are based on this data. This may include displaying the identity of the content to the user, retrieving related information based on the identity of the content, allowing the user to "check-in" to that piece of content with a registration server online, display an interactive ad based on the content and perhaps knowledge about the user, or a variety of other video-content-synchronous applications. The above process is described in the flow chart of FIG. 16.
[0088] Integrated Remote-Local Search System
[0089] The architecture of the integrated remote-local search system, the local search system, and the mobile/media client device interface are described next.
[0090] Automatic content recognition seamlessly and automatically switches between remote search on an external search server, and local search on a micro search server on the client media device, as presented in FIG. 17.
[0091] The client mobile/media device library is accessed through a set of application interfaces (API's). For example:
[0092] 1. initWithServer: The application initializes the content identification library, and sets it up for the application use.
[0093] 2. recordAndldentify: When the application needs to identify the content being watched on the television, it will call the library to record and identify the ambient audio content.
[0094] 3. dealloc: The application calls for de-initialization when it no longer needs to use the library
[0095] The primary function of interest is the "recordAndidentify" which performs the identification of the content. There are three main sub-functions inside this function: audio capture, audio fingerprint and query reference data base.
[0096] Captured audio samples are fed to the fingerprinting system, which computes a set of signatures. These signatures are used in the query to the search system. The query function implements the seamless and automatic routing of the signatures to either the local or remote search system. The remainder of the text focuses on this query function.
[0097] There are four potential levels of search through which query can progress as shown in FIG. 18. Each level represents a progressively larger portion of the reference fingerprint database. The levels are:
[0098] Query Tracking: The reference search range is limited to the portion adjacent to the previous successful search match and just slightly larger in time span than the query length. This is the fastest possible search option.
[0099] Query -/+1 minute: The reference search range is limited to the time span around the previous successful search match, plus or minus N seconds (with the default being N=60 seconds).
[0100] Query local full database: The reference search range is the entire locally accessible set of signatures that have been downloaded to the mobile/media device (client).
[0101] Query remote: The query is re-directed to the remote server. This is the slowest search option due primarily to network delays.
[0102] FIG. 19 shows a more detailed flowchart for the remote-local query architecture. Here, a query is first sent to the local search. If not found in local search, then an internal counter of the search misses is incremented. If this counter is greater than the threshold T1, then the query is sent to remote search. Otherwise, a not found is generated. If a match is found at either the local search or remote search stage, then the counter is reset. If a match is generated at remote server, then a chunk of reference signatures corresponding to a range around the match point (time stamp) are downloaded by the mobile/media device and the match is returned.
[0103] FIG. 20 shows a flowchart for the local query method. Here, a query is first sent to the query tracking stage and, if not found, to the query "minute" stage. These two stages (1 and 2) are both fast in search speed. If not found at these two stages, then an internal counter of the search misses is incremented. If this counter is greater than the threshold T2, then the query is sent to the "query full local database" stage (3). Otherwise, a not found is generated. If a match is found at any of the stages, then the counter is reset, and the match is returned.
[0104] Signature Cache and Downloading of Signatures
[0105] A signature cache is a part of the mobile/media device local memory allocated tor signature storing. The signature cache can hold one chunk of signature data corresponding to any length of time. The client mobile/media device can be configured to download any length of signature data. As an example, two minutes worth of signature data is downloaded at a time by the client mobile/media device. When a new set of signatures is downloaded, the contents of the signature cache are overwritten.
[0106] Local Search Parameters
[0107] In addition to the download-related parameters, there are three parameters that can be set:
[0108] 1. Threshold T1: controls the number of consecutive misses (NOT FOUND's) at the local search level that occur before progressing to a slower remote query. To always proceed to the next level, T1 should be set to 0.
[0109] 2. Threshold T2: controls the number of consecutive misses (NOT FOUND's) at the local tracking/"one-minute" level that occur before progressing to a slower full local database query. To always proceed to the next level, T2 should be set to 0.
[0110] 3. Local search back-off time window: Controls the size N (seconds) of the time window that is searched in stage 2 of local search.
[0111] Remote Server Query Back-off
[0112] Querying with audio content that is not in either the local or remote servers will result in NOT FOUND at both the local and remote stages. Once the miss threshold T1 has been reached and before a match is found, queries will be sent to the remote server. This increases the load on the remote server without getting any of the caching benefits of the local search.
[0113] To resolve this case another counter (T3) is introduced at the "Return Not Found" block in FIG. 20 that keeps track of NOT FOUND count to the remote server. After T3 consecutive NOT FOUND to the remote server, the next T4 queries to the remote server are suppressed. After these T4 queries, a single query is sent to the remote server. If this is also NOT FOUND, then again the next T4 queries are suppressed, and the process repeats. If a query is found at any stage, then the appropriate counters are reset.
[0114] Asynchronous Capture and Query
[0115] The recordAndldentify function performs capture audio and query to the local and remote server. To allow for simultaneous capture and querying, as well as continuous capture and continuous querying, the following functions are introduced:
[0116] 1. startAudioCapture: This function starts the capture of audio in the background. Audio samples saved to a circular buffer.
[0117] 2. stopAudioCapture: This function stops the capture of audio.
[0118] 3. queryWithDuration: This function queries to the (local and remote) search servers with the specified duration. For instance, if the duration is 7 seconds, the audio samples in the buffer corresponding to the previous 7 seconds of content are fingerprinted and queried. It is required to have started audio capture before calling this function.
[0119] Manual and Automatic Signature Management
[0120] For automatic switching between the local and remote search server, signature cache holds one set of signatures that is automatically managed. That is, the downloading and cache management are performed automatically based on the search responses. There is another category of signature caches, a set of manually managed signature caches. The number of signature slots is specified when instantiating the system. In addition, functions are provided that allow for explicit downloading of signatures to a particular slot, flushing the contents of a slot, and returning a list of the current manually managed signature cache.
[0121] Additional Functions
[0122] 1. initWithServerAndNumSlots: This function initializes the content identification library, and sets it up for the application use. The number of signature cache slots (<=1 024) is specified. This is an alternative to the default initialization function described earlier.
[0123] 2. downloadSigsToCache: This function downloads signatures specified by the asset id to the specified signature cache slot. The content I asset id needs to currently exist on the remote server. The contents, if any, of the specified signature cache slot are overwritten.
[0124] 3. flushSigsFromCache: This function removes signatures from the specified signature cache slot.
[0125] 4. getListOfCacheContents: This function returns a list of the asset id, slot index, starting signature timestamp, ending signature timestamp, and number of signatures for each nonempty signature cache slot. The return value is a string that is formatted as xml.
[0126] Pre-fetching Signatures for Automatic Cache Management
[0127] For the signature cache that is automatically managed, if a match is found from the remote server, signatures are downloaded for next specified chunk of time. As long as the same content is being queried, the local search will match with the signatures in this automatically managed cache. After reaching the end of this signature cache, the local search will return NOT FOUND, the query will eventually hit the remote server and again the signatures will be downloaded for the next specified chunk of time.
[0128] However, before the end of the signature cache is reach (for instance, K seconds before the end), the next chunk of signatures may be downloaded in advance (pre-fetched). Thus, local search querying can continue uninterrupted.
[0129] Specifying Download Chunk Size
[0130] The size of the chunk of signatures to download is programmable, specified by the function setSigDownloadChunkSize. This function specifies (in seconds) the size of the chunk of signature data to be downloaded at one time.
[0131] Disabling Local Search
[0132] Local search is enabled by default. However, it can be enabled or disabled by enableLocalSearch. This function specifies whether local search is enabled or disabled (taking a Boolean as input).
[0133] Minimal Locking During Download
[0134] The local search database is locked during signature download. However, a function may only lock the local search database when copying downloaded signature contents into the database.
[0135] It is understood that other embodiments of the present invention will become readily apparent to those skilled in the art from the following detailed description, wherein various embodiments of the invention are shown and described by way of the illustrations. As will be realized, the invention is capable of other and different embodiments and its several details are capable of modification in various other respects, all without departing from the present invention. Accordingly, the drawings and detailed description are to be regarded as illustrative in nature and not as restrictive.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012

D00013

D00014

D00015

D00016

D00017

D00018

D00019

D00020

D00021

D00022

XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.