High-Speed Data Packet Capture and Storage with Playback Capabilities
Foo; Aaron
U.S. patent application number 16/528952 was filed with the patent office on 2019-11-21 for high-speed data packet capture and storage with playback capabilities. The applicant listed for this patent is FMAD Engineering GK. Invention is credited to Aaron Foo.
| Application Number | 20190354318 16/528952 |
| Document ID | / |
| Family ID | 67988740 |
| Filed Date | 2019-11-21 |









View All Diagrams
| United States Patent Application | 20190354318 |
| Kind Code | A1 |
| Foo; Aaron | November 21, 2019 |
High-Speed Data Packet Capture and Storage with Playback Capabilities
Abstract
An embodiment may involve receiving a chunk and a chunk index, where the chunk contains packets captured by a network interface unit and the chunk index contains timestamps of first and last packets within the chunk. The chunk may be stored in a first ring buffer of a first memory and the chunk index may be stored in an index buffer of the first memory. A processor may allocate an entry in an I/O queue of a second memory and an entry in a chunk processing queue of the first memory. The processor may read the chunk processing queue to identify and copy the chunk from the first ring buffer to a location in a second ring buffer of the second memory, the location associated with the entry in the I/O queue. The same or a different processor may instruct a controller to write the chunk to a non-volatile memory unit.
| Inventors: | Foo; Aaron; (Tokyo, JP) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 67988740 | ||||||||||
| Appl. No.: | 16/528952 | ||||||||||
| Filed: | August 1, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15609729 | May 31, 2017 | 10423358 | ||
| 16528952 | ||||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G11C 29/52 20130101; G06F 13/287 20130101; G06F 3/061 20130101; G06F 3/0604 20130101; G06F 3/0643 20130101; G06F 3/0656 20130101; G06F 16/182 20190101; G06F 3/0688 20130101; G06F 11/1068 20130101; G06F 3/067 20130101; G06F 3/0631 20130101; G06F 11/1076 20130101; G06F 11/1004 20130101; G06F 3/0659 20130101 |
| International Class: | G06F 3/06 20060101 G06F003/06; G06F 16/182 20060101 G06F016/182; G06F 13/28 20060101 G06F013/28; G06F 11/10 20060101 G06F011/10; G11C 29/52 20060101 G11C029/52 |
Claims
1. A system comprising: a plurality of non-volatile packet storage memory units; a non-volatile file system memory unit containing a file system; a network interface unit configured to arrange received packets into chunks, wherein each chunk contains a plurality of packets, and wherein the network interface unit is further configured to generate chunk indexes for each chunk, the chunk indexes respectively containing one or more timestamps or counts of packets within the associated chunks; a first processor and a first memory coupled to the network interface unit, wherein the first memory contains a first buffer; a second processor and a second memory coupled to the first processor and to the non-volatile file system memory unit, wherein the second memory contains a second buffer and an I/O queue; and a storage controller coupled to the second processor and to the plurality of non-volatile packet storage memory units, wherein the system is configured to: (i) allocate an entry in the I/O queue for a particular chunk stored in the first buffer, (ii) copy the particular chunk from the first buffer to a location in the second buffer associated with the entry in the I/O queue, (iii) write the particular chunk from the second buffer to one of the plurality of non-volatile packet storage memory units, and (iv) write a chunk index associated with the particular chunk to the file system.
2. The system of claim 1, wherein the first buffer and the second buffer are ring buffers.
3. The system of claim 1, wherein a size of each of the chunks is fixed and identical.
4. The system of claim 1, wherein each of the chunks contains an integer number of packets, and wherein unused space in any of the chunks is filled with padding bytes.
5. The system of claim 1, wherein the first processor and the first memory are part of a first non-uniform memory access (NUMA) node, and wherein the second processor and the second memory are part of a second NUMA node.
6. The system of claim 1, wherein system is also configured to, for a group of the chunks that are consecutively placed in a chunk processing queue: calculate one or more parity chunks by applying an error-correcting code to the group of the chunks; store the one or more parity chunks in a chunk parity write buffer of the second memory; and write the one or more parity chunks across one or more non-volatile parity storage memory units that are separate from the plurality of non-volatile packet storage memory units.
7. The system of claim 1, wherein the plurality of non-volatile packet storage memory units comprises a plurality of solid state drives (SSDs).
8. The system of claim 1, wherein the network interface unit comprises one or more Ethernet interfaces, each with a line speed of at least 10 gigabits per second.
9. The system of claim 1, wherein the first processor and the first memory are communicatively coupled to the network interface unit by way of a first system bus, and wherein the second processor and the second memory communicatively coupled to the non-volatile file system memory unit by way of a second system bus.
10. The system of claim 9, wherein the network interface unit includes a direct memory access (DMA) engine that writes chunks to the first memory by way of the first system bus, and wherein the network interface unit includes a back-pressure throttle that causes delay or dropping of received packets when the DMA engine detects congestion on the first system bus.
11. The system of claim 1, wherein chunks stored sequentially in the second buffer are written to the non-volatile packet storage memory units in a round-robin fashion.
12. The system of claim 1, wherein the network interface unit includes a NOP generator configured to generate synthetic null packets, wherein the NOP generator is triggered by (i) receiving a signal, (ii) no packets having been received at the network interface unit for a pre-determined amount of time, or (iii) at a fixed pre-determined time interval.
13. A computer-implemented method comprising: receiving, by a first memory and from a network interface unit, a chunk and a chunk index, wherein the chunk contains a plurality of packets that were captured by the network interface unit, and wherein the chunk index contains timestamps or a count of packets in the chunk; storing the chunk in a first buffer of the first memory and storing the chunk index in an index buffer of the first memory; allocating an entry for the chunk in an I/O queue of a second memory and an entry for the chunk in a chunk processing queue of the first memory; reading the chunk processing queue to identify the chunk; copying the chunk from the first buffer to a location in a second buffer of the second memory, wherein the location is associated with the entry that was allocated in the I/O queue; instructing a storage controller to write the chunk to one of a plurality of non-volatile packet storage memory units coupled to the storage controller; and writing the chunk index to a file system.
14. The computer-implemented method of claim 13, wherein multiple chunks are received from the network interface unit and stored in the plurality of non-volatile packet storage memory units coupled to the storage controller, and wherein a size of each of the chunks is fixed and identical.
15. The computer-implemented method of claim 13, wherein a first processor and the first memory are part of a first non-uniform memory access (NUMA) node, and wherein a second processor and the second memory are part of a second NUMA node.
16. The computer-implemented method of claim 13, wherein a group of chunks are consecutively placed in the chunk processing queue, the computer-implemented method further comprising: calculating one or more parity chunks by applying an error-correcting code to the group of chunks; storing the one or more parity chunks in a chunk parity write buffer of the second memory; and writing the one or more parity chunks across one or more non-volatile parity storage memory units that are separate from the plurality of non-volatile packet storage memory units.
17. The computer-implemented method of claim 13, wherein each of the chunks contains an integer number of packets, and wherein unused space in any of the chunks is filled with padding bytes.
18. The computer-implemented method of claim 13, wherein the network interface unit comprises one or more Ethernet interfaces, each with a line speed of at least 10 gigabits per second.
19. The computer-implemented method of claim 13, wherein a first processor and the first memory are communicatively coupled to the network interface unit by way of a first system bus, and wherein a second processor and the second memory communicatively coupled to the plurality of non-volatile packet storage memory units by way of a second system bus.
20. The computer-implemented method of claim 19, wherein the network interface unit includes a direct memory access (DMA) engine that writes chunks to the first memory by way of the first system bus, and wherein the network interface unit includes a back-pressure throttle that causes delay or dropping of received packets when the DMA engine detects congestion on the first system bus.
Description
CROSS-REFERENCE TO RELATED APPLICATION
[0001] This application is a continuation of and claims priority to U.S. patent application Ser. No. 15/609,729, filed May 31, 2017, which is hereby incorporated by reference in its entirety.
BACKGROUND
[0002] Data packet capture has become an essential tool for the securing and debugging of networks and network protocols. A computing device may capture packets on a network by configuring its network interface to receive some or all packets traversing the segment of the network to which the network interface is connected. The computing device may store captured packets, and/or display a representation of their contents in real time. As just some examples, intrusion detection systems (IDSs), intrusion prevention systems (IPSs), and packet analyzers rely on accurate data packet capture.
SUMMARY
[0003] Conventional data packet capture tools, such as Tcpdump and Wireshark, operate on general purpose computing devices (e.g., personal computers operating WINDOWS.RTM. or LINUX.RTM. operating systems). These tools provide mechanisms for capturing packets for storage or real-time display.
[0004] While processor speed, memory size, and network data rates have each grown significantly over the last 20 years, network data rate improvements have outpaced that of processor speed and memory size. As a result, it is challenging to provide reliable, low-loss data packet capture in a high speed network. For example, capturing all data packets on one of today's Ethernet links operating at a speed of 10 gigabits per second, 40 gigabits per second, or 100 gigabits per second is virtually impossible using a software-based implementation on generic computing devices. Captured packets may be dropped in the network interface as they await processing by the kernel (operating system) of a computing device, dropped in the kernel as they await processing by a packet capture application operating on the computing device, or dropped because the packet arrival rate exceeds the rate at which captured packets can be written to a file system (e.g., disk drive) of the computing device.
[0005] The embodiments herein involve a packet capture architecture that processes chunks of packets rather than individual packets. These chunks are processed in a pipelined fashion with ample buffering as they are transferred between a customized network interface, memory units, and long-term (non-volatile) packet storage. As a result of this specifically-design architecture, sustained capture rates of 100 gigabits per second can be achieved.
[0006] Accordingly, a first example embodiment may involve a plurality of non-volatile packet storage memory units and a non-volatile file system memory unit containing a file system. The first example embodiment may also involve a network interface unit based on field-programmable gate array technology, where the network interface unit is configured to arrange sequentially-received packets into chunks, where each chunk contains a plurality of packets, and where the network interface unit is further configured to generate chunk indexes for each chunk, the chunk indexes containing timestamps of first and last packets within the associated chunks as well as a count of packets in the associated chunks. The first example embodiment may also involve a first processor and a first memory coupled to the network interface unit, where the first memory contains a first ring buffer, an index buffer, and a chunk processing queue. The first example embodiment may also involve a second processor and a second memory coupled to the first processor and to the non-volatile file system memory unit, where the second memory contains a second ring buffer and an I/O queue. The first example embodiment may also involve a storage controller coupled to the second processor and to the plurality of non-volatile packet storage memory units. The network interface unit may be configured to: write chunks by way of direct memory access transfer into the capture ring buffer, and write associated chunk indexes into the index buffer. The first processor may be configured to: allocate an entry in the I/O queue and an entry in the chunk processing queue for a particular chunk stored in the first ring buffer, read the chunk processing queue to identify the particular chunk, and copy the particular chunk from the first ring buffer to a location in the second ring buffer associated with the allocated entry in the I/O queue. The second processor may be configured to instruct the storage controller to write the particular chunk to one of the plurality of non-volatile packet storage memory units. The first processor or the second processor may be further configured to write the associated chunk index to the file system.
[0007] A second example embodiment may involve receiving, by a first memory and from a network interface unit, a chunk and a chunk index, where the chunk contains a plurality of packets that were captured by the network interface unit, and where the chunk index contains timestamps of first and last packets within the chunk as well as a count of packets in the chunk. The second example embodiment may also involve storing the chunk in a first ring buffer of the first memory and storing the chunk index in an index buffer of the first memory. The second example embodiment may also involve allocating, by a first processor coupled to the first memory, an entry for the chunk in an I/O queue of a second memory and an entry for the chunk in a chunk processing queue of the first memory. The second example embodiment may also involve reading, by a first processor coupled to the first processor, to the second memory, and to a storage controller, the chunk processing queue to identify the chunk. The second example embodiment may also involve copying, by the first processor, the chunk from the first ring buffer to a location in a second ring buffer of the second memory, where the location is associated with the allocated entry in the I/O queue. The second example embodiment may also involve instructing, by the second processor, the storage controller to write the chunk to one of a plurality of non-volatile packet storage memory units coupled to the storage controller. The second example embodiment may also involve writing, by the first processor or the second processor, the chunk index to a file system.
[0008] A third example embodiment may involve obtaining a packet filter specification, where the packet filter specification contains representations of a time period and a protocol. The third example embodiment may also involve applying the packet filter specification to a plurality of chunk indexes stored in a file system. The plurality of chunk indexes may be respectively associated with chunks of captured packets stored in a plurality of non-volatile packet storage memory units separate from the file system. The plurality of chunk indexes may include representations of respective capture timestamps and protocols for the captured packets within the chunks. Application of the packet filter specification may identify a subset of chunk indexes from the plurality of chunk indexes that contain packets matching the packet filter specification. The third example embodiment may involve, for the subset of chunk indexes, retrieving the associated chunks from the plurality of non-volatile packet storage memory units. The third example embodiment may involve applying the packet filter specification to the associated chunks. Application of the packet filter specification may identify a subset of the packets that match the packet filter specification. The third example embodiment may involve writing the subset of packets to the file system.
[0009] In a fourth example embodiment, an article of manufacture may include a non-transitory computer-readable medium, having stored thereon program instructions that, upon execution by a computing system, cause the computing system to perform operations in accordance with the first, second, and/or third example embodiment.
[0010] In a fifth example embodiment, a computing system may include at least one processor, as well as memory and program instructions. The program instructions may be stored in the memory, and upon execution by the at least one processor, cause the computing system to perform operations in accordance with the first, second, and/or third example embodiment.
[0011] In a sixth example embodiment, a system may include various means for carrying out each of the operations of the first, second, and/or third example embodiment.
[0012] These as well as other embodiments, aspects, advantages, and alternatives will become apparent to those of ordinary skill in the art by reading the following detailed description, with reference where appropriate to the accompanying drawings. Further, this summary and other descriptions and figures provided herein are intended to illustrate embodiments by way of example only and, as such, that numerous variations are possible. For instance, structural elements and process steps can be rearranged, combined, distributed, eliminated, or otherwise changed, while remaining within the scope of the embodiments as claimed.
BRIEF DESCRIPTION OF THE DRAWINGS
[0013] FIG. 1 illustrates a schematic drawing of a computing device, in accordance with example embodiments.
[0014] FIG. 2 illustrates packet processing in a kernel space and a user space that support packet capture, in accordance with example embodiments.
[0015] FIG. 3A depicts an arrangement of data in a packet capture file, in accordance with example embodiments.
[0016] FIG. 3B depicts a packet capture file header, in accordance with example embodiments.
[0017] FIG. 3C depicts a per-packet header in a packet capture file, in accordance with example embodiments.
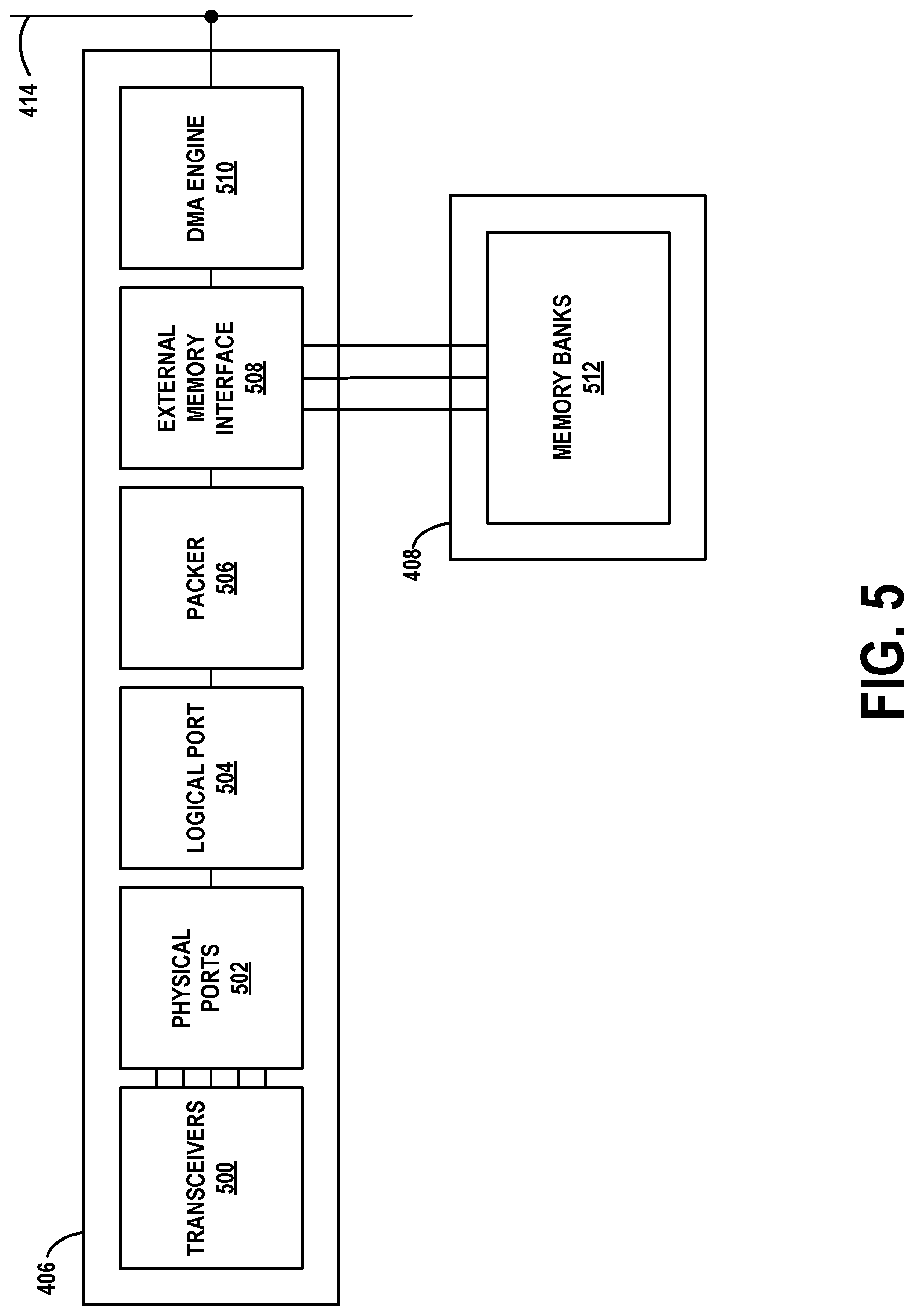
[0018] FIG. 4 depicts a schematic drawing of a computing device arranged for high-speed packet capture, in accordance with example embodiments.
[0019] FIG. 5 depicts a network interface unit arranged for high-speed packet capture, in accordance with example embodiments.
[0020] FIG. 6A depicts components of physical ports on the network interface unit, in accordance with example embodiments.
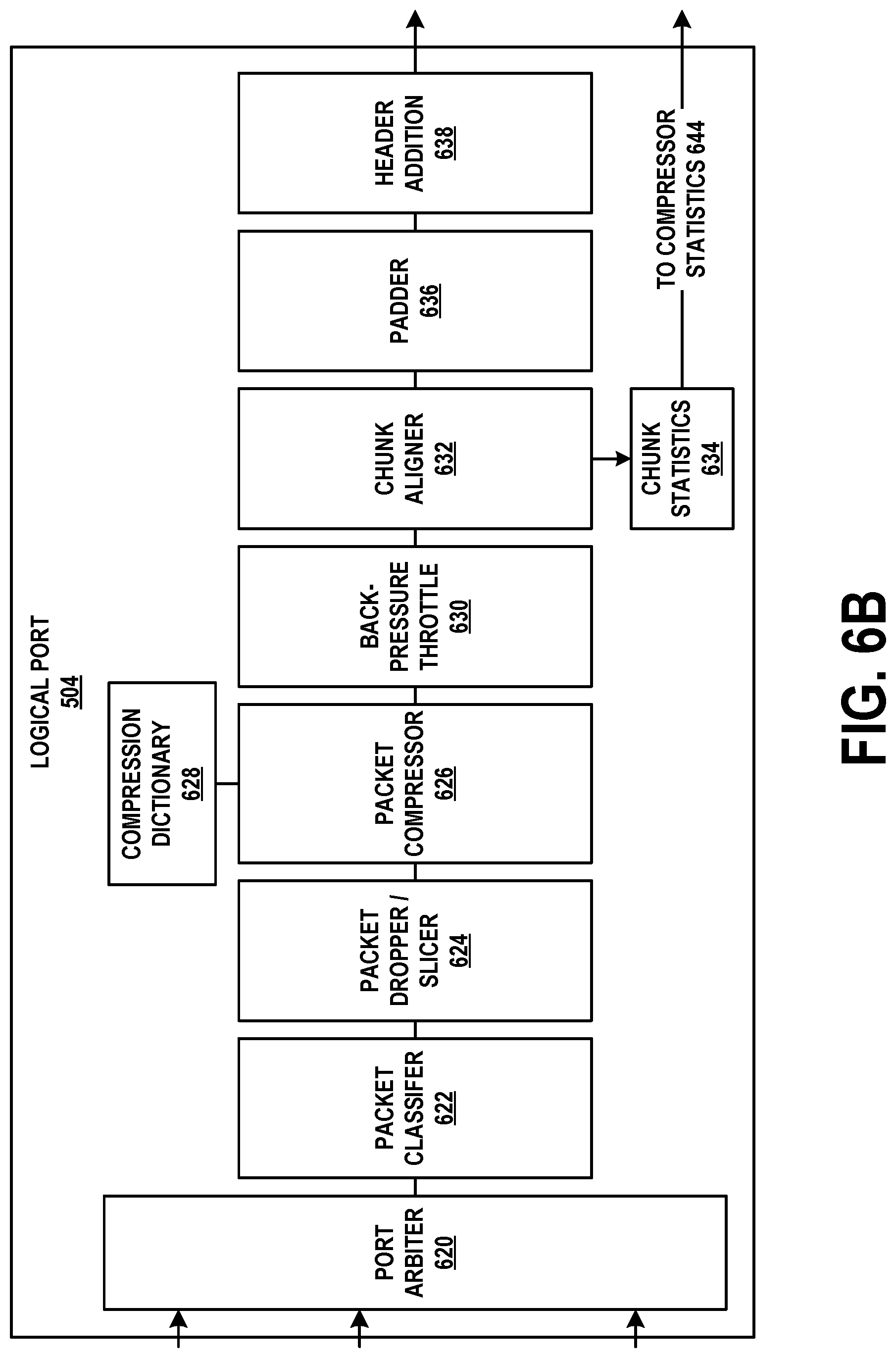
[0021] FIG. 6B depicts a logical port on the network interface unit, in accordance with example embodiments.
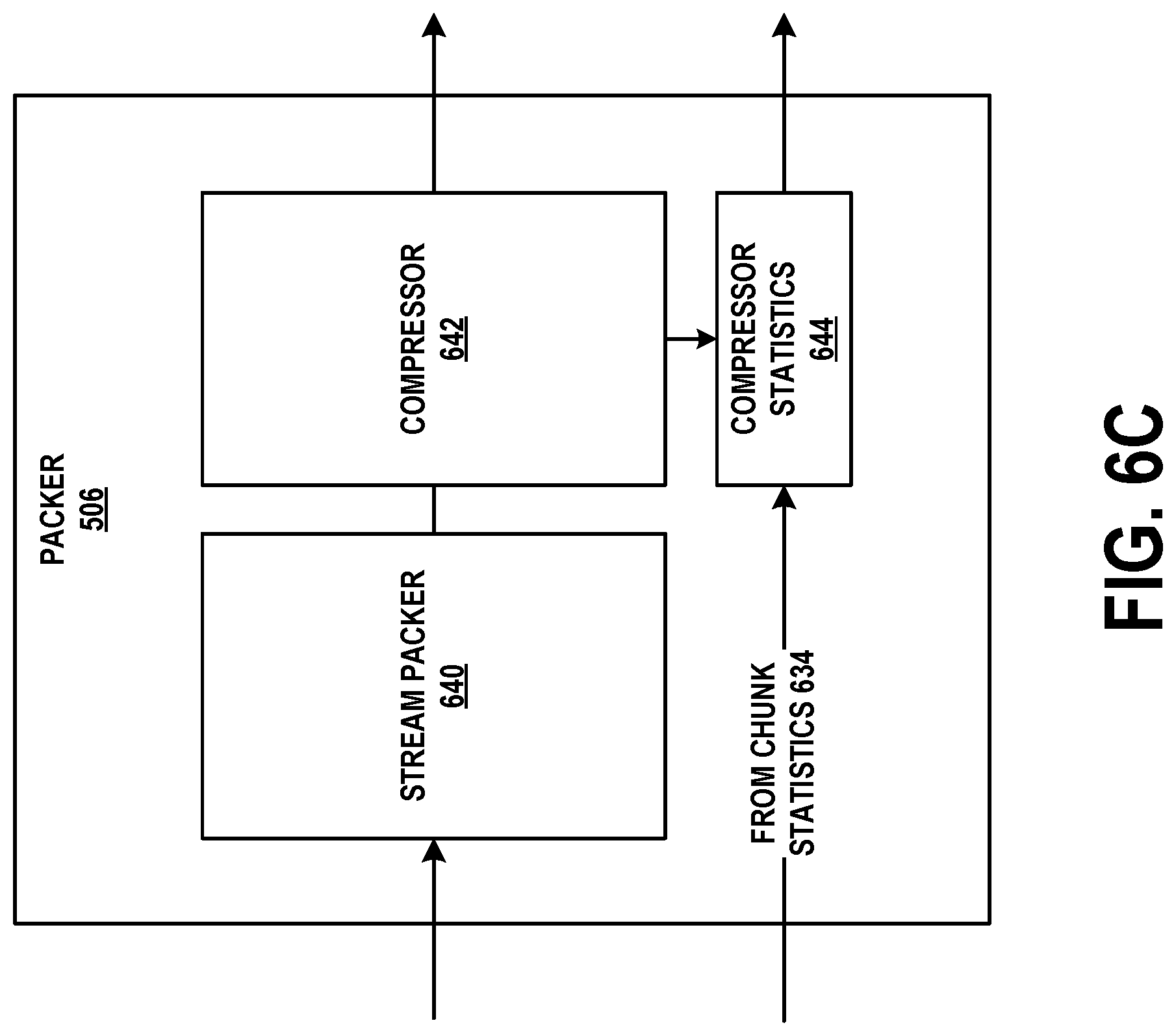
[0022] FIG. 6C depicts a packer module on the network interface unit, in accordance with example embodiments.
[0023] FIG. 6D depicts an external memory interface module on the network interface unit, in accordance with example embodiments.
[0024] FIG. 6E depicts a direct memory access engine module on the network interface unit, in accordance with example embodiments.
[0025] FIG. 7 depicts a host processor and memory arrangement, in accordance with example embodiments.
[0026] FIG. 8A depicts data structures in a memory module, in accordance with example embodiments.
[0027] FIG. 8B depicts data structures in a memory module as well as connectivity between the memory module and long-term packet storage, in accordance with example embodiments.
[0028] FIG. 8C depicts relationships between the data structures of FIGS. 8A and 8B, in accordance with example embodiments.
[0029] FIG. 8D is a flow chart, in accordance with example embodiments.
[0030] FIG. 9 is another flow chart, in accordance with example embodiments.
DETAILED DESCRIPTION
[0031] Example methods, devices, and systems are described herein. It should be understood that the words "example" and "exemplary" are used herein to mean "serving as an example, instance, or illustration." Any embodiment or feature described herein as being an "example" or "exemplary" is not necessarily to be construed as preferred or advantageous over other embodiments or features unless stated as such. Thus, other embodiments can be utilized and other changes can be made without departing from the scope of the subject matter presented herein.
[0032] Accordingly, the example embodiments described herein are not meant to be limiting. It will be readily understood that the aspects of the present disclosure, as generally described herein, and illustrated in the figures, can be arranged, substituted, combined, separated, and designed in a wide variety of different configurations. For example, the separation of features into "client" and "server" components may occur in a number of ways.
[0033] Further, unless context suggests otherwise, the features illustrated in each of the figures may be used in combination with one another. Thus, the figures should be generally viewed as component aspects of one or more overall embodiments, with the understanding that not all illustrated features are necessary for each embodiment.
[0034] Additionally, any enumeration of elements, blocks, or steps in this specification or the claims is for purposes of clarity. Thus, such enumeration should not be interpreted to require or imply that these elements, blocks, or steps adhere to a particular arrangement or are carried out in a particular order.
I. EXAMPLE COMPUTING DEVICE AND PACKET CAPTURE THEREON
[0035] As noted above, packet capture on conventional computing devices is limited due to these devices not being optimized for processing a high sustained rate of incoming packets. This section reviews these devices for purposes of comparison, focusing on their bottlenecks. This section also introduces a popular file format for storing captured packets.
[0036] A. Example Computing Device
[0037] FIG. 1 is a simplified block diagram exemplifying a computing device 100, illustrating some of the components that could be included in such a computing device. Computing device 100 could be a client device (e.g., a device actively operated by a user), a server device (e.g., a device that provides computational services to client devices), or some other type of computational platform.
[0038] In this example, computing device 100 includes processor 102, memory 104, network interface 106, and an input/output unit 108, all of which may be coupled by system bus 110 or a similar mechanism. In some embodiments, computing device 100 may include other components and/or peripheral devices (e.g., detachable storage, printers, and so on).
[0039] Processor 102 may represent one or more of any type of computer processing unit, such as a central processing unit (CPU), a co-processor (e.g., a mathematics, graphics, or encryption co-processor), a digital signal processor (DSP), a network processor, and/or a form of integrated circuit or controller that performs processor operations. In some cases, processor 102 may be a single-core processor, and in other cases, processor 102 may be a multi-core processor with multiple independent processing units. Processor 102 may also include register memory for temporarily storing instructions being executed and related data, as well as cache memory for temporarily storing recently-used instructions and data.
[0040] Memory 104 may be any form of computer-usable memory, including but not limited to register memory and cache memory (which may be incorporated into processor 102), as well as random access memory (RAM), read-only memory (ROM), and non-volatile memory (e.g., flash memory, hard disk drives (HDDs), solid state drives (SSDs), compact discs (CDs), digital video discs (DVDs), and/or tape storage). Other types of memory may be used. In some embodiments, memory 104 may include remote memory, such as Internet Small Computer Systems Interface (iSCSI).
[0041] Memory 104 may store program instructions and/or data on which program instructions may operate. As shown in FIG. 1, memory may include firmware 104A, kernel 104B, and/or applications 104C. Firmware 104A may be program code used to boot or otherwise initiate some or all of computing device 100. Kernel 104B may be an operating system, including modules for memory management, scheduling and management of processes, input/output, and communication. Kernel 104B may also include device drivers that allow the operating system to communicate with the hardware modules (e.g., memory units, networking interfaces, ports, and busses), of computing device 100. Applications 104C may be one or more user-space software programs, such as web browsers or email clients, as well as any software libraries used by these programs. Each of firmware 104A, kernel 104B, and applications 104C may store associated data (not shown) in memory 104.
[0042] Network interface 106 may include one or more wireline interfaces, such as Ethernet (e.g., Fast Ethernet, Gigabit Ethernet, and so on). Network interface 106 may also support communication over non-Ethernet media, such as coaxial cables or power lines, or over wide-area media, such as Synchronous Optical Networking (SONET) or digital subscriber line (DSL) technologies. Network interface 106 may further include one or more wireless interfaces, such as IEEE 802.11 (Wifi), BLUETOOTH.RTM., global positioning system (GPS), or a wide-area wireless interface. However, other forms of physical layer interfaces and other types of standard or proprietary communication protocols may be used over network interface(s) 106. As an example, some embodiments of computing device 100 may include Ethernet, BLUETOOTH.RTM., and Wifi interfaces.
[0043] Input/output unit 108 may facilitate user and peripheral device interaction with computing device 100. Input/output unit 108 may include one or more types of input devices, such as a keyboard, a mouse, a touch screen, and so on. Similarly, input/output unit 108 may include one or more types of output devices, such as a screen, monitor, printer, and/or one or more light emitting diodes (LEDs). Additionally or alternatively, computing device 100 may communicate with other devices using a universal serial bus (USB) or high-definition multimedia interface (HDMI) port interface, for example.
[0044] Computing device 100 may be used for packet capture. In particular, modifications to kernel 104B and applications 104C may facilitate such capture. Computing device 100 may receive packets by way of network interface 106, optionally filter these packets in kernel 104B, and then provide the filtered packets to a packet capture application. The latter may be one of applications 104C. In some cases, the filtering may take place in the packet capture application itself. Regardless, the packet capture application may obtain a series of packets for storage and/or display.
[0045] B. Example Protocol Stack
[0046] FIG. 2 depicts a protocol stack of a general purpose computer, such as computing device 100. Captured packets may traverse at least part of protocol stack 200.
[0047] Protocol stack 200 is divided into two general sections--kernel space and user space. Kernel-space modules carry out operating system functions while user-space modules are end-user applications or services that may be designed to execute on computing devices that support a specific type of kernel. Thus, user-space modules may rely on memory management, communication, and input/output services provided by the kernel. Kernel space in FIG. 2 may refer to part of kernel 104B in FIG. 1, while user space in FIG. 2 may refer to part of applications 104C in FIG. 1.
[0048] In full generality, protocol stack 200 may include more or fewer software modules. Particularly, the kernel space may contain additional kernel-space software modules to carry out operating system operations, and the user space may include additional user-space software modules to carry out application operations.
[0049] Wifi driver module 202 may be a kernel-space software module that operates and/or controls one or more physical Wifi hardware components. In some embodiments, Wifi driver module 202 provides a software interface to Wifi hardware, enabling kernel 104B of computing device 100 to access Wifi hardware functions without needing to know precise control mechanisms of the Wifi hardware being used. When data packets are transmitted or received by way of Wifi hardware, these packets may pass through Wifi driver module 202.
[0050] Similarly, Ethernet driver module 204 is a kernel-space software module that operates and/or controls one or more physical Ethernet hardware components. In some embodiments, Ethernet driver module 204 provides a software interface to Ethernet hardware, enabling kernel 104B of computing device 100 to access Ethernet hardware functions without needing to know precise control mechanisms of the Ethernet hardware being used. When data packets are transmitted or received by way of Ethernet hardware, these packets may pass through Ethernet driver module 204.
[0051] Protocol stack 200 may also include other driver modules not shown in FIG. 2. For instance, BLUETOOTH.RTM., cellular, and/or GPS driver modules may be incorporated into protocol stack 200. Further, either or both of Wifi driver module 202 and Ethernet driver module 204 may be omitted.
[0052] Low-level networking module 206 routes inbound and outbound data packets between driver software modules and network layer software modules (e.g., IPv6 module 210 and IPv4 module 212). Thus, low-level networking module 206 may serve as a software bus or switching mechanism, and may possibly provide application programming interfaces between driver software modules and network layer software modules. For instance, low-level networking module 206 may include one or more queues in which inbound data packets are placed so that they can be routed to one of IPv6 module 210 and IPv4 module 212, and one or more queues in which outbound data packets can be placed so that they can be routed to one of Wifi driver module 202 and Ethernet driver module 204. In some embodiments, low-level networking module 206 might not be present as a separate kernel-space software module, and its functionality may instead be incorporated into driver modules and/or network layer (e.g., IPv6 and/or IPv4) software modules.
[0053] IPv6 module 210 operates the Internet Protocol version 6 (IPv6). IPv6 is a version of the Internet Protocol that features an expanded address space, device auto-configuration, a simplified header, integrated security and mobility support, and improved multicast capabilities. IPv6 module 210 encapsulates outbound data packets received from higher-layer modules (including those of TCP module 214 and UDP module 216) in an IPv6 header. Conversely, IPv6 module 210 also decapsulates inbound IPv6 data packets received from low-level networking module 206. Although it is not shown in FIG. 2, IPv6 module 210 may be associated with an ICMPv6 module that provides support for error and informational messages related to IPv6, as well as multicasting and address resolution.
[0054] IPv4 module 212 operates the Internet Protocol version 4 (IPv4). IPv4 is a version of the Internet Protocol that features a smaller address space than IPv6. Similar to IPv6 module 210, IPv4 module 212 encapsulates outbound data packets received from high-layer modules (including those of TCP module 214, and UDP module 216) in an IPv4 header. Conversely, IPv4 module 212 also decapsulates inbound data packets received from low-level networking module 206. Although it is not shown in FIG. 2, IPv4 module 212 may be associated with an ICMPv4 module that provides support for simple error reporting, diagnostics, and limited configuration for devices, as well as messages that report when a destination is unreachable, a packet has been redirected from one router to another, or a packet was discarded due to experiencing too many forwarding hops.
[0055] As used herein, the terms "Internet Protocol" and "IP" may refer to either or both of IPv6 and IPv4.
[0056] TCP module 214 operates the Transport Control Protocol (TCP). TCP is a reliable, end-to-end protocol that operates on the transport layer of a networking protocol stack. TCP is connection-oriented, in the sense that TCP connections are explicitly established and torn down. TCP includes mechanisms in which it can detect likely packet loss between a sender and recipient, and resend potentially lost packets. TCP is also a modified sliding window protocol, in that only a limited amount of data may be transmitted by the sender before the sender receives an acknowledgement for at least some of this data from the recipient, and the sender may operate a congestion control mechanism to avoid flooding an intermediate network with an excessive amount of data.
[0057] UDP module 216 operates the User Datagram Protocol (UDP). UDP is a connectionless, unreliable transport-layer protocol. Unlike TCP, UDP maintains little state regarding a UDP session, and does not guarantee delivery of application data contained in UDP packets.
[0058] High-level networking module 218 routes inbound and outbound data packets between (i) user-space software modules and (ii) network-layer or transport-layer software modules (e.g., TCP module 214 and UDP module 216). Thus, high-level networking module 218 may serve as a software bus or switching mechanism, and may possibly provide application programming interfaces between user-space software modules and transport layer software modules. For instance, high-level networking module 218 may include one or more queues in which inbound data packets are placed so that they can be routed to a user-space software module, and one or more queues in which outbound data packets can be placed so that they can be routed to one of TCP module 214 and UDP module 216. In some embodiments, high-level networking module 218 may be implemented as a TCP/IP socket interface, which provides well-defined function calls that user-space software modules can use to transmit and receive data.
[0059] As noted above, user-space programs, such as application 220 and application 222 may operate in the user space of computing device 100. These applications may be, for example, email applications, social networking applications, messaging applications, gaming applications, or some other type of application. Through interfaces into the kernel space (e.g., high-level networking module 218 and/or other interfaces), these applications may be able to carry out input and output operations.
[0060] The modules of FIG. 2 described so far represent software used for incoming (received) and outgoing (transmitted) packet-based communication. Examples of incoming and outgoing packet processing follows.
[0061] When the Ethernet hardware receives a packet addressed for computing device 100, it may queue the packet in a hardware buffer and send an interrupt to Ethernet driver module 204. In response to the interrupt, Ethernet driver module 204 may read the packet out of the hardware buffer, validate the packet (e.g., perform a checksum operation), determine the higher-layer protocol to which the packet should be delivered (e.g., IPv6 module 210 or IPv4 module 212), strip off the Ethernet header and trailer bytes, and pass the packet to low-level networking module 206 with an indication of the higher-layer protocol.
[0062] Low-level networking module 206 may place the packet in a queue for the determined higher-layer protocol. Assuming for the moment that this protocol is IPv4, low-level networking module 206 may place the packet in a queue, from which it is read by IPv4 module 212.
[0063] IPv4 module 212 may read the packet from the queue, validate the packet (e.g., perform a checksum operation and verify that the packet has not been forwarded more than a pre-determined number of times), combine it with other packets if the packet is a fragment, determine the higher-layer protocol to which the packet should be delivered (e.g., TCP module 214 or UDP module 216), strip off the IPv4 header bytes, and pass the packet to the determined higher-layer protocol. Assuming for the moment that this protocol is TCP, IPv4 module 212 may provide the packet to TCP module 214. In some cases, this may involve placing the packet in the queue, or IPv4 module 212 may provide TCP module 214 with a memory address at which the packet can be accessed.
[0064] TCP module 214 may read the packet from the queue, validate the packet, perform any necessary TCP congestion control and/or sliding window operations, determine the application "socket" to which the packet should be delivered, strip off the TCP header bytes, and pass the payload of the packet to the high-level networking module 218 along with an indication of the determined application. At this point, the "packet" does not contain any headers, and in most cases is just a block of application data.
[0065] High-level networking module 218 may include queues associated with the socket communication application programming interface. Each "socket" may represent a communication session and may be associated with one or more applications. Incoming data queued for a socket may eventually be read by the appropriate application. Assuming for the moment that the application data from the packet is for application 220, high-level networking module 218 may hold the application data in a queue for a socket of application 220.
[0066] Application 220 may read the application data from the socket and then process this data. At this point, the incoming packet processing has ended.
[0067] Outgoing packet processing may begin when an application, such as application 220, writes application data to a socket. The socket may be, for instance, a TCP or UDP socket. Assuming that the application data is for a TCP socket, application 220 may provide the application data to high-level networking module 218, which in turn may queue the application data for TCP module 214.
[0068] TCP module 214 may read the application data from the queue, determine the content of a TCP header for the application data, and encapsulate the application data within the TCP header to form a packet. Values of fields in the TCP header may be determined by the status of the associated TCP session as well as content of the application data. TCP module 214 may then provide the packet to either IPv6 module 210 or IPv4 module 212. This determination may be made based on the type of socket from which the application data was read. Assuming for the moment that the socket type indicates IPv4, TCP module 214 may provide the packet to IPv4 module 212. In some cases, this may involve placing the packet in a queue, or TCP module 214 may provide IPv4 module 212 with a memory address at which the packet can be accessed.
[0069] IPv4 module 212 may determine the content of an IPv4 header for the packet, and encapsulate the packet within the IPv4 header. Values of fields in the IPv4 header may be determined by the socket from which the application data was read as well as content of the application data. IPv4 module 212 may then look up the destination of the packet (e.g., its destination IP address) in a forwarding table to determine the outbound hardware interface. Assuming for the moment that this interface is Ethernet hardware, IPv4 module 212 may provide the packet to low-level networking module 206 with an indication that the packet should be queued for Ethernet driver module 204.
[0070] Low-level networking module 206 may receive the packet and place it in a queue for Ethernet driver module 204. Alternatively, IPv4 module 212 may provide the packet directly to Ethernet driver module 204.
[0071] Regardless, Ethernet driver module may encapsulate the packet in an Ethernet header and trailer, and then provide the packet to the Ethernet hardware. The Ethernet hardware may transmit the packet.
[0072] In some environments, the term "frame" is used to refer to framed data (i.e., application data with at least some header or trailer bytes appended to it) at the data-link layer, the term "packet" is used to refer to framed data at the network (IP) layer, and the term "segment" is used to refer to framed data at the transport (TCP or UDP) layer. For sake of simplicity, the nomenclature "packet" is used to represent framed application data regardless of layer.
[0073] C. Packet Capture
[0074] Given protocol stack 200 and the operations performed by each of its modules, it is desirable for a packet capture architecture to be able to intercept and capture copies of both incoming (received) and outgoing (transmitted) packets. Packet capture module 208 exists in kernel space to facilitate this functionality.
[0075] One or more of Wifi driver module 202, Ethernet driver module 204, and low-level networking module 206 may have an interface to packet capture module 208. This interface allows these modules to provide, to packet capture module 208, copies of packets transmitted and received by computing device 100. For instance, Wifi driver module 202 and Ethernet driver module 204 may provide copies of all packets they receive (including Wifi and Ethernet headers) to packet capture module 208, even if those packets are not ultimately addressed to computing device 100. Furthermore, Wifi driver module 202 and Ethernet driver module 204 may provide copies of all packets they transmit. This allows packets generated by computing device 100 to be captured as well.
[0076] Regarding the capture of received packets, network interface hardware components, such Wifi and/or Ethernet hardware, normally will discard any incoming packets without a destination Wifi or Ethernet address that matches an address used by computing device 100. Thus, Wifi driver module 202 and Ethernet driver module 204 might only receive incoming packets with a Wifi or Ethernet destination address that matches an address used by computing device 100, as well as any incoming packets with a multicast or broadcast Wifi or Ethernet destination address. However, the Wifi and/or Ethernet hardware may be placed in "promiscuous mode" so that these components do not discard any incoming packets. Instead, incoming packets that normally would be discarded by the hardware are provided to Wifi driver module 202 and Ethernet driver module 204. These modules provide copies of the packets to packet capture module 208.
[0077] In some embodiments, Wifi driver module 202 and Ethernet driver module 204 may provide incoming packets to low-level networking module 206, and low-level networking module 206 may provide copies of these packets to packet capture module 208. In the outgoing direction, low-level networking module 206 may also provide copies of packets to packet capture module 208. In order to provide Wifi and Ethernet header and trailer information in these outgoing packets, low-level networking module 206 may perform Wifi and Ethernet encapsulation of the packets prior to providing them to packet capture module 208. Low-level networking module 206 may also provide copies of these encapsulated packets to Wifi driver module 202 and/or Ethernet driver module 204 which in turn may refrain from adding any further encapsulation, and may instead provide the packets as received to their respective hardware interfaces.
[0078] Packet capture module 208 may operate in accordance with packet capture application 224 to capture packets. Particularly, packet capture application 224 may provide a user interface through which one or more packet filter expressions may be entered. The user interface may include a graphical user interface, a command line, or a file.
[0079] The packet filter expressions may specify the packets that are to be delivered to packet capture application 224. For example, the packet filter expression "host 10.0.0.2 and tcp" may capture all TCP packets to and from the computing device with the IP address 10.0.0.2. As additional examples, the packet filter expression "port 67 or port 68" may capture all Dynamic Host Configuration Protocol (DHCP) traffic, while the packet filter expression "not broadcast and not multicast" may capture only unicast traffic.
[0080] Packet filter expressions may include, as shown above, logical conjunctions such as "and", "or", and "not." With these conjunctions, complex packet filters can be defined. Nonetheless, the packet filter expressions shown above are for purpose of example, and different packet filtering syntaxes may be used. For instance, some filters may include a bitstring and an offset, and may match any packet that includes the bitstring at the offset number of bytes into the packet.
[0081] After obtaining a packet filter expression, packet capture application 224 may provide a representation of this expression to packet capture module 208. Packet capture application 224 and packet capture module 208 may communicate, for example, using raw sockets. Raw sockets are a special type of socket that allows communication of packets and commands between an application and a kernel module without protocol (e.g., IPv4, IPv6, TCP, or UDP) processing. Other types of sockets and APIs, however, may be used for packet capture instead of raw sockets.
[0082] In some embodiments, packet capture module 208 may compile the representation of the packet filter expression into bytecode or another format. Packet capture module 208 may then execute this bytecode for each packet it receives to determine whether the packet matches the specified filter. If the packet does not match the filter, the packet may be discarded. If the packet does match the filter, packet capture module 208 may provide the packet the packet capture application 224. Thus, packet capture application 224 may provide the packet filter expression to packet capture module 208 at the beginning of a packet capture session, and may receive a stream of packets matching this filter.
[0083] D. Packet Capture Formats
[0084] Packet capture application may store the received packets in one of several possible formats. One such format is the PCAP (packet capture) format, illustrated in FIG. 3A. File 300 represents a series of N+1 captured packets in the PCAP format, stored in order of the time they were captured. PCAP header 302 is a data structure defined in FIG. 3B. Each of the N+1 captured packets may be preceded by a per-packet header, as well as all protocol header and payload bytes. An example per-packet header 303 is shown in FIG. 3C.
[0085] File 300 may be a binary file that can be stored within short-term storage (e.g., main memory) or long-term storage (e.g., a disk drive) of computing device 100. In some cases, representations of the captured packets displayed in real time on computing device 100 as packet capture occurs. Thus, later-captured packets may be added to file 300 while earlier-captured packets are read from file 300 for display. In other embodiments, file 300 may be written to long-term storage for later processing.
[0086] As noted above, FIG. 3B illustrates the contents of PCAP header 302. There may be one instance of PCAP header 302 disposed at the beginning file 300.
[0087] Magic number 304 may be a pre-defined marker of the beginning of a file with PCAP header 302, and serves to indicate the byte-ordering of the computing device that performed the capture. For instance, magic number 304 may be defined to always have the hexadecimal value of 0xa1b2c3d4 in the native byte ordering of the capturing device. If the device that reads file 300 finds magic number 304 to have this value, then the byte-ordering of this device and the capturing device is the same. If the device that reads file 300 finds magic number 304 to have a value of 0xd4c3b2a1, then this device may have to swap the byte-ordering of the fields that follow magic number 304.
[0088] Major version 306 and minor version 308 may define the version of the PCAP format used in file 300. In most instances, major version 306 is 2 and minor version 308 is 4, which indicates that the version number is 2.4.
[0089] Time zone offset 310 may specify the difference, in seconds, between the local time zone of the capturing device and Coordinated Universal Time (UTC). In some cases, the capturing device will set this field to 0 regardless of its local time zone.
[0090] Timestamp accuracy 312 may specify the accuracy of any time stamps in file 300. In practice, this field is often set to 0.
[0091] Capture length 314 may specify the maximum packet size, in bytes, that can be captured. In some embodiments, this value is set to 65536, but can be set to be smaller if the user is not interested in large-payload packets, for instance. If a packet larger than what is specified in this field is captured, it may be truncated to conform to the maximum packet size.
[0092] Datalink protocol 316 may specify the type of datalink interface on which the capture took place. For instance, this field may have a value of 1 for Ethernet, 105 for Wifi, and so on.
[0093] FIG. 3C illustrates the contents of per-packet header 303. As shown in FIG. 3A, there may be one instance of per-packet header 303 for each packet represented in file 300. Each instance of per-packet header 303 may precede its associated packet.
[0094] Timestamp seconds 320 and timestamp microseconds 322 may represent the time at which the associated packet was captured. As noted above, this may be the local time of the capturing device or UTC time.
[0095] Captured packet length 324 may specify the number of bytes of packet data actually captured and saved in file 300. Original packet length 326 may specify the number of bytes in the packet as the packet appeared on the network on which it was captured.
[0096] In general, captured packet length 324 is expected to be less than or equal to original packet length 326. For example, if capture length 314 is 1000 bytes and a packet is 500 bytes, then captured packet length 324 and original packet length 326 may both be 500. However, if the packet is 1500 bytes, then captured packet length 324 may be 1000 while original packet length 326 may be 1500.
[0097] While the traditional system described in the context of FIGS. 1 and 2 may perform well in limited scenarios, it might not support high-speed packet capture in a robust fashion. For instance, modern Ethernet interface hardware support data rates of 10 gigabits per second, 40 gigabits per second, and 100 gigabits per second. Since traditional systems perform packet capture and filtering in software, the maximum speed of these systems is typically limited by the speed of processor 102. If the hardware interfaces are receiving packets at line speed, processor 102 may be unable to process incoming packets quickly enough. Furthermore, processor 102 may be performing other tasks in parallel, such as various operating system tasks and tasks related to other application.
[0098] To that point, the number of processor cycles per packet may be insufficient even for fast processors. For example a 3.0 gigahertz multiprocessor with 16 cores only has about 322 cycles per packet when processing 64 byte packets at 100 gigabits per second. In more detail, the processor operates at an aggregate speed of 48,000,000,000 cycles/per second. The interface's 100 gigabits per second provides a maximum of 12,500,000,000 bytes per second. Assuming the worst case scenario of the smallest possible Ethernet packets (64 bytes each with a 12 byte inter-packet gap and an 8-byte preamble), there are about 148,809,523 packets per second arriving. Thus, the processor can use at most 322.56 cycles per packet. This is insufficient for sustained processing.
[0099] As a result, some packets may be dropped before they can be filtered or before they can be written to a file. Particularly, packets may be dropped if (i) the network interface hardware buffer fills up at a rate that is faster than its associated driver module can remove packets from it, (ii) any queue associated with packet capture module 208 fills up at a rate that is faster than packet capture module 208 can perform packet filtering operations, or (iii) any queue associated with packet capture application 224 fills up at a rate that is faster than packet capture application 224 can write the associate packets to a file system or display representations of these packets. Notably, writing to a file system on an HDD or SSD may involve significant overhead that slows the system's sustainable packet capture rate.
[0100] This creates problems for applications that rely on accurate and complete packet capture. For instance, if packet capture application 224 is a network protocol analysis tool, missing packets may make debugging a network protocol to be difficult if not impossible. Further, if packet capture application 224 is an intrusion detection system, missing packets may effectively render this system unable to detect network attacks in a robust and timely fashion.
[0101] The next section describes the capture-direction procedures for an example high-speed packet capture system. This description follows the path of captured packets from the time they are received on a network interface until they are stored in non-volatile memory (e.g., an SSD without a traditional file system). The subsequent section describes how stored packets are read from non-volatile memory for further processing and/or display.
II. EXAMPLE IMPROVED HIGH-SPEED PACKET CAPTURE SYSTEM--CAPTURE DIRECTION
[0102] FIG. 4 depicts an example computing device 400 customized for high-speed packet capture. In some embodiments, computing device 400 may include different components and/or its components may be arranged in a different fashion.
[0103] Host processors and dedicated system memory 402 may include one or more processors, each of which may be coupled to or associated with a dedicated unit of memory (e.g., several gigabytes of RAM). For instance, each processor and its associated unit of memory may be a non-uniform memory access (NUMA) node capable of accessing its own memory and memory in other NUMA nodes, as well as that of long-term packet storage 404A and host operating system storage 404B. A particular arrangement of NUMA nodes is depicted in the embodiment of FIG. 7.
[0104] Notably, host processors and dedicated system memory 402 may have connections to system bus 414 and system bus 416. System busses 414 and 416 may each be a peripheral component interconnect express (PCIe) bus, for example. In FIG. 4, system bus 414 communicatively couples host processors and dedicated system memory 402 to FPGA-based network interface 406, management network interface 410, and input/output unit 412. Similarly, system bus 416 communicatively couples host processors and dedicated system memory 402 to long-term packet storage 404A and host operating system storage 404B. Nonetheless, other arrangement are possible, including one in which all of these components are connected by way of one system bus.
[0105] Long-term packet storage 404A may include non-volatile storage, such as one or more SSDs. Notably, long-term packet storage 404A may store captured packets in chunks thereof.
[0106] Host operating system storage 404B may also include non-volatile storage, such as one or more solid state drives. Unlike long-term packet storage 404A, host operating system storage 404B may store the operating system and file system used by the processors of host processors and dedicated system memory 402.
[0107] FPGA-based network interface 406 may be a custom hardware module that can house one or more 100 megabit per second, 1 gigabit per second, 10 gigabit per second, 25 gigabit per second, 40 gigabit per second, or 100 gigabit per second transceivers. FPGA-based network interface 406 may receive packets by way of these interfaces, and then capture and process these packets for storage. As suggested by its name, FPGA-based network interface 406 may be based on a field-programmable gate array or other digital hardware logic (i.e., an actual FPGA might not be used in all embodiments). Although Ethernet is used as the interface type for packet capture in the examples provided herein, other interface types may be possible.
[0108] Temporary packet storage memory 408 may include one or more units of RAM configured to hold packets captured by FPGA-based network interface 406 until these packets can eventually be written to a memory in host processors and dedicated system memory 402. FPGA-based network interface 406 may connect to temporary packet storage memory 408 by way of one or more memory controllers.
[0109] Network management interface 410 may be one or more network interfaces used for connectivity and data transfer. For instance, while FPGA-based network interface 406 may house one or more high-speed Ethernet interfaces from which packets are captured, network management interface 410 may house one or more network interfaces that can be used for remote access, remote configuration, and transfer of files containing captured packets. For instance, a user may be able to log on to computing device 400 by way of network management interface 410, and remotely start or stop a packet capture session.
[0110] Input/output unit 412 may be similar to input/output unit 108, in that it may facilitate user and peripheral device interaction with computing device 400. Thus, input/output unit 412 may include one or more types of input devices and one or more types of output devices.
[0111] In some embodiments, computing device 400 may include other components, peripheral devices, and/or connectivity. Accordingly, the illustration of FIG. 4 is intended to be for purpose of example and not limiting.
[0112] A. Example FPGA-Based Network Interface
[0113] FIG. 5 depicts a more detailed view of FPGA-based network interface 406 and temporary packet storage memory 408. Particularly, FPGA-based network interface 406 includes transceivers module 500, physical ports module 502, logical port module 504, packer module 506, external memory interface module 508, and direct memory access (DMA) engine module 510. Temporary packet storage memory 408 may include memory banks 512, and may be coupled to external memory interface module 508 by one or more memory controllers. DMA engine module 510 may be coupled to system bus 414, and may control the writing of packets (e.g., in the form of chunks of one or more packets) to this bus. In FIG. 5, captured packets generally flow from left to right, with possible temporary storage in temporary packet storage memory 408.
[0114] FIG. 6A depicts connectivity between transceivers module 500, physical ports module 502, and logical port module 504, as well as components of physical ports module 502.
[0115] Each transceiver 600 of transceivers module 500 may contain both a transmitter and a receiver that are combined and share common circuitry or a single housing. As noted previously, transceivers 600 may be 10 gigabit per second, 40 gigabit per second, or 100 gigabit per second Ethernet transceivers, for example. Each of transceiver 600 may also be coupled to a port 602 of physical ports 502. This coupling may include a unit that performs Ethernet medium access control (MAC), forward error correction (FEC), and physical coding sublayer (PCS) functions (not shown).
[0116] Each port 602 may include delimiter 604, cycle aligner 606, expander 608, reclocker 610, NOP generator 612, and first-in-first-out (FIFO) buffer 614 components. In some embodiments, ports 602 may include more or fewer components, and each port may be uniquely numbered (e.g., from 0 to n). Regardless, the flow of packets (and processing thereof) is generally from left to right.
[0117] Delimiter 604 may identify the beginning and end bits of an incoming Ethernet packet by detecting Ethernet preamble and epilogue delimiter bits. This sequence may be represented in hexadecimal as 0xFB 0x55 0x55 0x55 0x55 0x55 0x55 0xD5 (least-significant bit first ordering is used). The bit received immediately after this sequence may be the first of the Ethernet packet. Delimiter 604 may also record a nanosecond timestamp of when the first byte of each packet was received from a high accuracy clock source. This timestamp may be adjusted for propagation delay by a fixed offset.
[0118] Cycle aligner 606 may align arrange incoming packets so that there is a maximum of one packet per bus cycle (i.e., larger packets may require multiple cycles). As an example, 100 gigabit Ethernet may use four 128-bit busses from the MAC interface. These busses may be referred to as lanes 0, 1, 2, and 3. In some cases, there may be two packets (more precisely, parts of two packets) output from the MAC interface in a single bus cycle. For instance, lanes 0-2 may contain bits from packet n, while lane 3 contains bits from packet n+1. Cycle aligner 606 arranges these bits across two cycles. In a first cycle, lanes 0-2 contain bits from packet n, while lane 3 is null. In a second cycle, lanes 0-2 are null, while lane 3 contains bits from packet n+1.
[0119] Expander 608 aggregates and packs the bits aligned by cycle aligner 606 into a wider bus (e.g., a 2048-bit bus). Expander 608 does this so that the first bit of each packet begins in the same lane. Having a fixed location for the beginning of each packet makes downstream processing less complicated. In some embodiments, expander 608 may place each packet across sixteen 128-bit lanes, such that the first bit of the packet is disposed at the first bit-location of lane 0.
[0120] Reclocker 610 may adjust the timing of packet processing from that of transceiver 600 to that of port 602. In the case of 100 gigabit Ethernet, the reclocking is from 322 megahertz (Ethernet speed) to 250 megahertz (port speed). In the case of 10 gigabit Ethernet, the reclocking is from 156 megahertz (Ethernet speed) to 250 megahertz (port speed).
[0121] NOP generator 612 may generate bursts of single cycle full width packets, with a payload of 0x00 bytes (e.g., 240-byte synthetic null packets with a 16 byte header for a transfer size of 256 bytes) that can be used to flush the capture pipeline of FPGA-based network interface 406 all the way to long-term packet storage 404A. NOP generator 612 may be triggered to do so either by inactivity (e.g., no packets being received for a pre-determined amount of time) or by way of an explicit request through software (such an interface not shown in FIG. 6A).
[0122] FIFO buffer 614 may hold a number of received packets in a queue until these packets can be read from port 602 by logical port module 504.
[0123] FIG. 6B illustrates the components of logical port module 504. These components are presented for purpose of example. More or fewer components may be present in such a logical port module. Similar to the previous drawings, the flow of packets (and processing thereof) is generally from left to right.
[0124] Port arbiter 620 is connected to FIFO buffer 614 for each of ports 602. On each clock cycle, port arbiter 620 retrieves one or more packets from each of ports 602--more precisely, from the respective instances of FIFO buffer 614. If more than one of ports 602 has a packet ready in this fashion, port arbiter retrieves these packets in a pre-defined order (e.g., from the lowest port number to the highest port number).
[0125] Packet classifier 622 classifies each incoming packet based on pre-defined rules. The classifications may include two designations, drop and slice (explained below). The rules may include bit-wise logical "and" and "compare" operations on the first 64, 128, 256, or 512 bytes of the packet, for example. A total of 16-512 rules may be supported, and these rules may be software programmable. A packet may match multiple rules. As an example, if a packet matches one or more of the rules, it may be classified for slicing, but if the packet does not match any rules, it may be classified for dropping.
[0126] Packet dropper/slicer 624 may either drop or slice a packet based on the packet's classification. A dropped packet is effectively deleted and is no longer processed. A sliced packet is reduced in size--for instance, any bytes beyond the first 64, 128, 256, or 512 bytes of the packet may be removed. Doing so makes storage of packets more efficient when full packet payloads are not of interest.
[0127] Packet compressor 626 is an optional component that may compress a packet's header (e.g., Ethernet, IP, TCP, UDP headers) and/or payload, and replace that with the compressed version. When this occurs, packet compressor 626 may also set a flag bit in one of the packet's capture headers indicating that compression has been performed. In some embodiments, packet compressor 626 may use compression dictionary 628. The latter may contain a list of common byte strings that are represented by shorter, unique encodings in compressed packets.
[0128] Back-pressure throttle 630 may apply back-pressure from downstream modules and/or components when those modules and/or components are unable to keep up with the incoming flow of packets. For instance, back-pressure may be applied when system bus 414 is temporarily congested and cannot transmit data at the requested rate. This back-pressure may be a signal from back-pressure throttle 630 to port arbiter 620 or one or more of FIFO buffers 614 to skip processing of incoming packets for one or more clock cycles. In the rare case where a packet is dropped, back-pressure throttle 630 may maintain counts of total dropped packets and counts per dropped packet for each back-pressure signal. These back-pressure signals are respectively received from DMA engine 510 (due to congestion on bus 414), chunk aligner 632, and padder 636.
[0129] Chunk aligner 632 aligns a set of captured packets so that they can be packed into a chunk. Each chunk is 128 kilobytes to 32 megabytes in size, and holds such a set of captured packets such that no packet crosses a chunk boundary, and the first packet of a chunk begins at an offset of 0 within the chunk. Chunk aligner 632 may determine the amount of padding needed so that the last packet in a chunk fills any remaining space in that chunk.
[0130] Chunk statistics 634 collates statistics for the data within a chunk. These statistics include timestamps of the first and last packets within the chunk, the total number of packets within the chunk (possibly including separate counts of the total number of TCP packets and total number of UDP packets in the chunk), the total number of bytes within the chunk (not including padding), the total number of compressed bytes within the chunk, the number of packets classified to be dropped by packet classifier 622, and various other internal performance metrics. These statistics are passed on to compressor statistics 644 (see FIG. 6C).
[0131] Padder 636 adds the number of padding bytes specified by chunk aligner 632 to the last packet of a chunk. The padding bytes may be all 0's, and this padding may be applied after the last byte of the received packets.
[0132] Header addition 638 appends a custom header at the beginning of each packet. The contents of the custom header may be similar or the same as that of the PCAP per-packet header 303. In alternative embodiments, the header may be 16 bytes in length and may consist of one or more of the following fields: a NOP field that may be set when the packet contains NOP data from NOP generator 612, a frame check sequence (FCS) fail flag that may be set when the FCS the packet's Ethernet header indicates a corrupted packet, a pad flag that may be set when the chunk contains padding from padder 636, a timestamp field that may contain the time (in nanoseconds and sourced from delimiter 604) of when the packet was captured, a packet capture size field that may indicate the number of bytes of the packet that were actually captured, a packet wire size field that may indicate the actual size of the packet prior to capture, and a portID field that may identify the physical port on which the packet was received. Other fields are possible, and more or less fields may be present. The packet capture size may be less than the packet wire size when packet dropper/slicer 624 and/or compressor 626 is configured to reduce the size of captured packets.
[0133] FIG. 6C illustrates the components of packer 506. These components are presented for purpose of example. More or fewer components may be present in such a logical port module. Similar to the previous drawings, the flow of packets (and processing thereof) is generally from left to right.
[0134] Stream packer 640 may receive packets from header addition 638. Stream packer 640 may arrange these packets into a packed byte stream that may be 512, 1024, 2048, or 4096 bits wide, for example, based on bus width. For instance, suppose that the bus is 2048 bits (256 bytes) wide. Data enters stream packer 640 at a rate of at most one packet per cycle. Suppose that an 80-byte packet n arrives during cycle 0, an 80-byte packet n+1 arrives during cycle 1, and a 128-byte packet n+2 arrives during cycle 2. This sequence leaves at least half of the 2048-bit bus unused during each cycle.
[0135] Stream packer 640 arranges these packets so that the full bus is used, if possible, during each cycle. Thus, the first output cycle of stream packer 640 would include all of packet n, all of packet n+1, and the first 96 bytes of packet n+2, for a grand total of 2048 bits. The second output cycle of stream packer 640 would include the remaining 32 bytes of packet n+2, followed by any further packets. Stream packer 640 forms packets into chunks that are 128 kilobytes to 32 megabytes in size. Thus, each chunk may include multiple packets, perhaps hundreds or thousands of packets.
[0136] Compressor 642 may compress the packed byte stream from stream packer 640. These compression operations are optional and may be omitted if compressor 642 is unable to compress packets into chunks at the incoming data rate. Instead, compressor 642 can, when it is overloaded, write the packets in a pass-through mode in order to maintain line-speed performance.
[0137] In some embodiments, a general compression scheme, such as Lempel-Ziv-Welch (LZW) may be used. While this scheme can increase the effective number of packets stored in long-term packet storage by a factor of 2 or 3, it may be too slow for line rate compression for data incoming from high-speed interfaces (e.g., 40 gigabits per second or 100 gigabits per second). A trigger for pass-thru mode may be when the input queue becomes full (or beyond a high water mark), then chunks bypass the compressor until the input queue reaches a low water mark.
[0138] Compressor statistics 644 receives information from chunk statistics 634 and provides further information from compressor 642. This information may include the compressed payload size and a cyclic redundancy check (CRC) per chunk.
[0139] FIG. 6D illustrates the components of external memory interface 508. These components are presented for purpose of example. More or fewer components may be present in such a memory interface. Similar to the previous drawings, the flow of packets (and processing thereof) is generally from left to right (with a detour through memory banks 512).
[0140] External memory interface 508 may serve to buffer incoming chunks in memory banks 512. Doing so helps avoid congestion on system bus 414 that might otherwise cause these chunks to be dropped. System bus 414 may be too busy to transfer chunks due to usage by host processors and dedicated system memory 402, input/output unit 412, or other peripherals. This congestion may last anywhere from 10 microseconds to several milliseconds or longer.
[0141] External memory interface 508 may operate at the full-duplex line speed of the interface(s) through which packets are being captured. For example, if a 100 gigabit per second Ethernet interface is being used to capture packets, reading and writing between external memory interface 508 and memory banks 512 may take place at up to 200 gigabits per second (e.g., 100 gigabits per second reading and 100 gigabits per second writing).
[0142] Memory write module 650 may receive chunks from compressor 642 and write these chunks to memory banks 512, by way of memory controllers 652A, 652B, and 652C. Chunks may be written to memory in discrete blocks, the size of which may be based on the bus width between memory controllers 652A, 652B, and 652C and external memory 654A, 654B, and 654C. For each of these blocks, memory write module 650 may calculate a CRC, and store the respective CRCs with the blocks. In some embodiments, memory write module 650 may write these blocks across external memory 654A, 654B, and 654C in a round robin fashion, or in some other way that roughly balances the load on each of external memory 654A, 654B, and 654C.
[0143] Memory read module 656 may retrieve, by way of memory controllers 652A, 652B, and 652C, the blocks from memory banks 512, and reassemble these blocks into chunks. In doing so, memory read module 656 may re-calculate the CRC of each block and compare it to the block's stored CRC to determine whether the block has been corrupted during storage.
[0144] Although three memory controllers and three external memories are shown in FIG. 6D, more or fewer memory controllers and external memories may be used. Each memory controller may synchronize its refresh cycle so all external memory refresh cycles occur at the same time. This may improve memory throughput when multiple separate memory banks are used in unison.
[0145] FIG. 6E illustrates the components of DMA engine 510. These components are presented for purpose of example. More or fewer components may be present in a DMA engine. Similar to the previous drawings, the flow of packets (and processing thereof) is generally from left to right.
[0146] Chunk FIFO 660 is a buffer that receives chunks from memory read module 656 and temporarily stores these chunks for further processing by DMA engine 510. Similarly, statistics FIFO 662 is another buffer that receives statistics from various units of FPGA-based network interface 406 for a particular chunk. These statistics may include, but are not limited to, data from chunk statistics 634 and compressor statistics 644. This data may include, for example, first and last timestamps of packets within a chunk, a number of packets within a chunk, the compressed size of a chunk, and various FIFO levels and/or hardware performance metrics at the present clock cycle. Chunk FIFO 660 and Statistics FIFO 662 operate independently, although in practice (and by design) data in chunk FIFO 660 and statistics FIFO 662 usually refer to the same chunk.
[0147] Data from both chunk FIFO 660 and statistics FIFO 662 are read by DMA arbiter 664. DMA arbiter 664 multiplexes this data from both FIFOs, as well as status updates from capture ring 800 (see FIG. 8A). These status updates indicate the next memory location in capture ring 800 that is available for chunk storage. DMA arbiter 664 assigns the highest priority to processing status updates from capture ring 800, the second highest priority to output from statistics FIFO 662, and the lowest priority to chunks from chunk FIFO 660.
[0148] System bus 414 may consist of multiple independent busses 414A, 414B, and 414C. Although three busses are shown in FIG. 6E, more or fewer busses may be used. DMA output 666 schedules data from chunk FIFO 660 and statistics FIFO 662 to be written by way of PCIe interfaces 668A, 668B, and 668C to busses 414A, 414B, and 414C, respectively. For instance, DMA output 666 may multiplex and write this data as maximum sized bus packets (e.g., 256 bytes) to busses 414A, 414B, and 414C according to a fair round-robin scheduler.
[0149] A DMA performance monitor (not shown) may be incorporated into either DMA arbiter 664 or DMA output 666. For instance, if busses 414A, 414B, and 414C are PCIe busses, this module may monitor their performance by determining the number of minimum credits, maximum credits, occupancies, stall durations and so on for each bus. This includes the allocation of PCIe credits on each bus (for flow control on these busses) and the allocation of DMA credits for flow control related to capture ring buffer 800 of a NUMA node (see FIG. 8A, below).
[0150] The latter mechanism may be based on a credit token system. For instance, one token may equate to a 256-byte write operation (a maximum sized PCIe write operation) to capture ring buffer 800. DMA arbiter 664 maintains a number of DMA credits. This is initialized to be the number of entries in capture ring buffer 800. Every time a full sized PCIe write operation is occurs, the DMA credit count is decremented. If the total number of DMA credits is zero, then back pressure is signaled which eventually leads to back pressure throttle 630 dropping packets. Also, when DMA credit is zero, no PCIe write operations are issued. Software operating on one of the NUMA nodes adds DMA credits after a chunk has been processed and removed from capture ring buffer 800, essentially freeing that memory area so the hardware can write a new chunk into it.
[0151] B. Example Host Processor and Dedicated Memory Architecture
[0152] FIG. 7 depicts host processors and dedicated memory 402, which provides the connectivity between FPGA-based network interface 406 and long-term packet storage 404A. Particularly, host processors and dedicated memory 402 may include processor 700, memory 702, processor 704, and memory 706. Both processor 700 and processor 704 may represent multiple (e.g., 2, 4, or 8) individual processors.
[0153] FPGA-based network interface 406 connects by way of system bus 414 to processor 700. Processor 700 and memory 702 may be components of a first NUMA node. Similarly, processor 704 and memory 706 may be components of a second NUMA node which may be connected to the first NUMA node by way of a quick path interconnect (QPI) interface, or some other type of processor interconnect.
[0154] The second NUMA node may also be connected, by way of system bus 416, to storage controller 708. Like system bus 414, system bus 416 may include multiple independent busses. This decoupling of the NUMA node communications further improves packet capture performance by separating the throughput and latency characteristics of writes from FPGA-based network interface 406 to memory 702 and writes from memory 706 to long-term packet storage 404A.
[0155] Storage controller 708 may be a host bus adapter (HBA) controller, for example. Storage controller 708 may provide the second NUMA node with access to long-term packet storage 404A. Long-term packet storage 404A may include an array of n solid state drives, or some other form of non-volatile storage. In some embodiments, multiple storage controllers may be used to support a packet storage rate of 100 gigabits per second. The first and/or second NUMA node may further be connected to host operating system storage 404B.
[0156] In summary, chunks of packets are written directly from FPGA-based network interface 406 to memory 702. Processor 700 reads these chunks from memory 702, and applies some additional processing such as generating CRCs and/or calculating chunk statistics. Processor 700 then writes the chunks to memory 706. Processor 700 and/or processor 704 run input/output schedulers which instruct storage controller 708 to write, from memory 706, the chunks to a specified location on one of the units of storage in long-term packet storage 404A. Storage controller 708 responsively performs these writes. This sequence of operations is further illustrated in FIGS. 8A-8D.
[0157] FIG. 8A illustrates example data structures for packet storage and management in memory 702. Capture ring buffer 800 holds chunks transferred by DMA output 666, and operates as a conventional ring buffer. Capture ring buffer may be 4 gigabytes in size in some embodiments, but can be of any size (e.g., 1, 2, 8, 16 gigabytes, etc.).
[0158] The ring buffers herein, such as capture ring buffer 800, are usually implemented as fixed sized arrays of b entries, with pointers referring to the current head and tail locations. A producer writes a new entry to the current location of the tail, while a consumer removes the oldest entry from the head. These head and tail pointers are incremented modulo b for each read and write, so that the buffer logically wraps around on itself.
[0159] Chunk index buffer 802 may store information from statistics FIFO 662 (which ultimately originated at chunk statistics 634 and compressor statistics 644 among other possible sources) for each chunk in capture ring buffer 800. Thus, this information may include timestamps of the first and last packets within the chunk, the total number of packets within the chunk, the total number of bytes within the chunk (not including padding), the total number of compressed bytes within the chunk, and so on.
[0160] Capture ring DMA status 804A, 804B, and 804C memory locations respectively associated with busses 414A, 414B, and 414C. Their contents can be used to control write access to capture ring buffer 800, as described below.
[0161] Chunk processing queue 806 contains references to chunks in capture ring buffer 800 that are ready for writing to memory 706. Use of this structure is also described below.
[0162] FIG. 8B illustrates example data structures for packet storage and management in memory 706, as well as their relation to storage controller 708 and long-term packet storage 404A. Capture write buffer 810 temporarily stores chunks transferred from capture ring buffer 800. These chunks are then distributed across n units of non-volatile storage (SSD0-SSDn). In order to do so, each chunk is queued for writing to one of these units. This information is stored in I/O queue 814. For each of then units of non-volatile storage, I/O queue 814 contains a list of entries. These entries are populated to spread consecutive chunks over the available units. While only 3 units (SSDs) are shown in FIG. 8B for purpose of convenience, more units may be used. Chunk parity write buffer 812 queues redundancy data related to chunks.
[0163] For instance, SSD0 entry 0 in SSD0 write buffer 816 may refer to the first chunk (chunk 0) in capture write buffer 810, SSD1 entry 0 in SSD1 write buffer 818 may refer to the second chunk (chunk 1) in capture write buffer 810, and SSD2 entry 0 in SSD2 write buffer 820 may refer to the third chunk (chunk 2) in capture write buffer 810. Similarly, SSD0 entry 1 in SSD0 write buffer 816 may refer to the fourth chunk (chunk 3) in capture write buffer 810, SSD1 entry 1 in SSD1 write buffer 818 may refer to the fifth chunk (chunk 4) in capture write buffer 810, and SSD2 entry 1 in SSD2 write buffer 820 may refer to the sixth chunk (chunk 5) in capture write buffer 810. More entries per SSD may be used. According to this mapping of chunks to SSDs, for a system with d SSDs, chunk c maps to SSD s entry e, where s=c mod d and e=.left brkt-bot.s/d.right brkt-bot. or the FIFO producer index of SSD0 write buffer 816/SSD1 write buffer 818/SSD2 write buffer 820.
[0164] The processing of chunks and related data may take place according to the following description. DMA output 666 may write chunks from chunk FIFO 660 to respective locations in capture ring buffer 800, while data from statistics FIFO 662 may be written to respective locations in chunk index buffer 802. DMA output 666 may also broadcast updates to capture ring DMA status 804A, 804B, and 804C by way of busses 414A, 414B, and 414C. The data written may be pointers to the next available location in capture ring buffer 800. Thus, the contents of capture ring DMA status 804A, 804B, and 804C might not take on the same value when at least one of busses 414A, 414B, and 414C is operating more slowly than the others (e.g., it is congested or stalled). This mechanism also serves to allow multiple simultaneous writes to capture ring buffer 800 and chunk index buffer 802 without using memory locking.
[0165] Processor 700 may repeatedly read capture ring DMA status 804A, 804B, and 804C for the location of the oldest transferred chunk. The oldest transferred chunk may be the chunk in the location of capture ring buffer 800 pointed to by the "lowest" of any of capture ring DMA status 804A, 804B, and 804C, taking into account the fact that these values wrap around from the end to the beginning of the ring buffer as they advance. This maintains the completion of all writes into capture ring buffer 800 for a specific chunk, regardless of any splitting or re-ordering by DMA output 666 or system busses 414A, 414B, or 414C due to system congestion and stalling.
[0166] Once this chunk is identified, processor 700 may allocate an entry in I/O queue 814 (e.g., SSD0 entry 1, SSD1 entry0, etc.) according to the mapping of chunks to SSDs described above. Further, processor 700 may allocate a new location in which to store the chunk on the selected SSD. Processor 700 may also place, into chunk processing queue 806, the memory location of the chunk, the memory location of the associated chunk index, and an indication of the entry in I/O queue 814.
[0167] For every set of j consecutive chunks processed in this manner (where j is anywhere from 2 to 100), r parity chunks (where r is anywhere from 1 to 5) may be generated for purposes of redundancy. For instance, when a non-overlapping set of j consecutive chunks have been processed for representation in chunk processing queue 806, one of processor 700 or processor 704 may calculate one or more Reed-Solomon codes (or other error-correcting codes) based on these chunks. These codes form the parity chunks, and may be stored in one or more parity SSDs (not shown). The parity SSDs may be written to in a fashion similar to that of FIG. 8B and described below. This redundancy procedure is akin to that of RAIDS or RAID6, but supports a higher level of recovery. In principle the system can recover from the failure of a greater number of SSDs.
[0168] Chunk parity write buffer 812 is where parity data is stored and queued for write operations to parity SSDs. This process is similar to that of writing chunks to SSDs, except the parity data is handled by the processor and is not used with capture ring buffer 800 or capture write buffer 810.
[0169] Regardless, processor 700, processor 704, or both may perform the following set of operations in order to transfer chunks in capture ring buffer 800 of memory 702 to capture write buffer 810 in memory 704. In some cases, multiple processors may operate in parallel on different chunks.
[0170] First, a processor reads the head of chunk processing queue 806 to obtain the location of the next chunk in capture ring buffer 800, its associated index in chunk index buffer 802, and its target entry in I/O queue 814. Based on the target entry, the processor writes this chunk to the specified memory location in capture write buffer 810.
[0171] Then, from the target entry in I/O queue 814, the processor determines the SSD and the location therein at which the chunk is to be stored. The processor issues a command instructing storage controller 708 to write the chunk from its memory location in capture write buffer 810 to this location in the designated SSD. For instance, if the chunk is referred to by SSD0 entry 1 of SSD0 write buffer 816, the chunk is written to SSD0.
[0172] Then, a CRC is calculated over the entire chunk. This CRC enables the integrity of the chunk's data in non-volatile memory to be validated at any time in the future. The value of the CRC, the location of the chunk as stored on the designated SSD, as well as the entry related to the chunk in chunk index buffer 802, are written to host operating system storage 404B. Notably, this allows the chunk to be found through a simple lookup in host operating system storage 404B rather than having to search the SSDs for the chunk. Since entries in chunk index buffer 802 are much smaller than their associated chunks, this makes finding a particular chunk an inexpensive procedure. Other chunk statistics may also be written to host operating system storage 404B.
[0173] When storage controller 708 completes writing the chunk (as well as possibly other chunks that are queued for writing) to an SSD, it writes an indication of such to an I/O queue completion buffer (not shown) associated with I/O queue 814. One of processor 700 or 704 may monitor the I/O queue completion buffer to determine when the write completes. After write completion is detected, the processor may update the entry related to the chunk in host operating system storage 404B to indicate that the chunk has been committed to storage.
[0174] FIG. 8C depicts relationships between the data structures of FIGS. 8A and 8B. In particular, FIG. 8C includes example chunk 822 and example chunk index 824. Chunk 822 contains T+1 captured packets, ordered from least-recently captured (packet 0) to most-recently captured (packet T). Chunk index 824 is associated with chunk 822, and contains (among other information) a timestamp representing when packet 0 was captured, a timestamp representing when packet T was captured, and the number of packets in chunk 822 (T+1).
[0175] As described above, chunk 822 and chunk index 824 may be transferred by way of DMA to capture ring buffer 800 and capture index buffer 802, respectively. Any transfer or copying of data may be represented with a solid line in FIG. 8C. On the other hand, relationships between data may be represented with dotted lines.
[0176] An entry 826 is added to chunk processing queue 806. This entry refers to the locations of both chunk 822 in capture ring buffer 800 and chunk index 824 in capture index buffer 802, as well as a location in I/O queue 814 that is entry y in the queue for SSDx. A processor copies chunk 822 from capture ring buffer 800 to a location in capture write buffer 810 that is associated with entry y in the queue for SSDx. As part of processing the write queue for SSDx, the processor also instructs a storage controller to write chunk 822 to SSDx. The format used to store chunks in long-term storage, such as an SSD, may vary from the PCAP format described in reference to FIG. 3.
[0177] The processor further copies chunk index 824 and the CRC and SSD storage location of chunk 822 to host operating system storage 404B. As steps of this procedure complete, locations in capture ring buffer 800, capture index buffer 802, and capture write buffer 810 used for temporarily storing chunk 822 and chunk index 824 may be freed for other uses.
[0178] This arrangement provides for high-speed capture and storage of data packets. Particularly, sustained rates of 100 gigabytes per second can be supported. The end to end storage system described herein does so by operating on chunks rather than individual packets, carefully aligning chunks as well as packets within chunks for ease of processing, pipelining chunk processing so that multiple chunks can be processed in parallel, copying each chunk only once (from memory 702 to memory 706), writing chunks sequentially across an array of SSDs (or other storage units) to increase sequential write performance over writing sequentially to the same SSD, and prioritizing chunk writing operations over other operations.
[0179] Notably, when writing to a particular SSD, each chunk is written to a sequentially increasing location. This limits SSD stalls due to internal garbage collection and wear-leveling logic.
[0180] C. Example Packet Capture Operations
[0181] FIG. 8D is a flow chart illustrating an example embodiment. The process illustrated by FIG. 8D may be carried out by one or more processors and memories coupled to a network interface and storage controller. The storage controller may, in turn, be coupled to long-term packet storage. The network interface may receive packets and arrange these packets into chunks.
[0182] The embodiments of FIG. 8D may be simplified by the removal of any one or more of the features shown therein. Further, these embodiments may be combined with features, aspects, and/or implementations of any of the previous figures or otherwise described herein.
[0183] Block 830 may involve receiving, by a first memory and from a network interface, a chunk of packets and a chunk index. The chunk may contain a plurality of packets that were captured by the network interface, and the chunk index may contain timestamps of the first and last packets within the chunk as well as a count of packets in the chunk. The network interface unit may include one or more Ethernet interfaces, each with a line speed of at least 10 gigabits per second.
[0184] The count of packets in the associated chunk indexes may include counts of TCP packets in the associated chunks and/or counts of UDP packets in the associated chunks. In a more general case, the counts of packets in the associated chunk indexes may include a plurality of independent counters relating to user programmable packet classifiers in the associated chunks.
[0185] In some embodiments, the size of each of the chunks is fixed and identical. Each of the chunks may contain an integer number of packets, and unused space in any of the chunks may be filled with padding bytes.
[0186] Block 832 may involve storing the chunk in a first ring buffer of the first memory and storing the chunk index in an index buffer of the first memory.
[0187] Block 834 may involve allocating, by a first processor coupled to the first memory, an entry for the chunk in an I/O queue of a second memory and an entry for the chunk in a chunk processing queue of the first memory.
[0188] Block 836 may involve reading, by the first processor, the chunk processing queue to identify the chunk.
[0189] Block 838 may involve copying, by the first processor, the chunk from the first ring buffer to a location in a second ring buffer of the second memory. The location may be associated with the allocated entry in the I/O queue.
[0190] Block 840 may involve instructing, by a second processor coupled to the first processor, to the second memory, and to a storage controller, the storage controller to write the chunk to one of a plurality of non-volatile packet storage memory units coupled to the storage controller. The first processor and the first memory may be part of a first NUMA node, and the second processor and the second memory may be part of a second NUMA node. The plurality of non-volatile packet storage memory units may include a plurality of SSDs.
[0191] In some embodiments, the first processor and the first memory are communicatively coupled to the network interface unit by way of a first system bus, and the second processor and the second memory communicatively coupled to the plurality of non-volatile packet storage memory units by way of a second system bus. The network interface unit may include a DMA engine that writes chunks to the first memory by way of the first system bus. The network interface unit may also include a back-pressure throttle that causes delay or dropping of received packets when the DMA engine detects congestion on the first system bus.
[0192] Block 842 may involve writing, by the first processor or the second processor, the chunk index to a file system that is separate from the plurality of non-volatile packet storage memory units.
[0193] In some embodiments, the first processor or the second processor may also be configured to, for a group of the chunks that are consecutively placed in the chunk processing queue: calculate one or more parity chunks by applying an error-correcting code to the group of chunks, store the one or more parity chunks in a chunk parity write buffer of the second memory, and write the one or more parity chunks across one or more non-volatile parity storage memory units that are separate from the plurality of non-volatile packet storage memory units.
III. EXAMPLE IMPROVED HIGH-SPEED PACKET CAPTURE SYSTEM--READ DIRECTION
[0194] In addition to storing chunks of packets, computing device 400 may also be able to retrieve specific packets from particular stored chunks of packets. These retrieved packets may then be converted into a format, such as the PCAP format, that is compatible with available packet analysis tools.
[0195] For instance, a number of chunks of packets may be stored in long-term packet storage 404A and associated chunk indexes may be stored in host operating system storage 404B. A filter expression may be received. For instance, the filter expression may be provided by a user or read from a file. The filter expression may specify a time period.
[0196] Either one of processors 700 or 704 may look up matches to this filter in the chunk indexes stored in host operating system storage 404B. For instance, if the filter specifies a particular time period (e.g., defined by a starting timestamp and an ending timestamp), the matched chunk indexes will be those associated with chunks that contain packets captured within the particular time period. A binary search over the ordered timestamps in the chunk index may be used to locate specific chunks.
[0197] Each matched chunk index contains a reference to a storage location, in long-term packet storage 404A, of its associated chunk. Based on these locations, the processor can instruct storage controller 708 to retrieve these chunks. A CRC calculation may be run against each chunk and compared to the CRC calculation in the associated chunk index. If these values do not match, the chunk may be discarded and full chunk data may be re-calculated using the error correcting parity information.
[0198] After the CRC is validated, the chunks may be decompressed (if compression had been applied), and individual packets within the chunks that match the filter may be identified. These packets may be extracted from the chunks and stored in a format that is supported by packet analysis tools (e.g., the PCAP format).
[0199] FIG. 9 is a flow chart illustrating an example embodiment. The process illustrated by FIG. 9 may be carried out by one or more processors and memories coupled to a network interface and storage controller. The storage controller may, in turn, be coupled to long-term packet storage. The network interface may receive packets and arrange these packets into chunks.
[0200] The embodiments of FIG. 9 may be simplified by the removal of any one or more of the features shown therein. Further, these embodiments may be combined with features, aspects, and/or implementations of any of the previous figures or otherwise described herein.
[0201] Block 900 may involve obtaining a packet filter specification, wherein the packet filter specification contains representations of a time period and a protocol.
[0202] Block 902 may involve applying the packet filter specification to a plurality of chunk indexes stored in a file system. The plurality of chunk indexes may be respectively associated with chunks of captured packets stored in a plurality of non-volatile packet storage memory units separate from the file system. The plurality of chunk indexes may include representations of respective capture timestamps and protocols for the captured packets within the chunks. Application of the packet filter specification may identify a subset of chunk indexes from the plurality of chunk indexes that contain packets matching the packet filter specification.
[0203] Block 904 may involve, for the subset of chunk indexes, retrieving the associated chunks from the plurality of non-volatile packet storage memory units.
[0204] Block 906 may involve applying the packet filter specification to each packet within the associated chunks. Application of the packet filter specification may identify a subset of the packets that match the packet filter specification.
[0205] Block 908 may involve writing the subset of packets to the file system. This file system may be local or remote.
IV. CONCLUSION
[0206] The present disclosure is not to be limited in terms of the particular embodiments described in this application, which are intended as illustrations of various aspects. Many modifications and variations can be made without departing from its scope, as will be apparent to those skilled in the art. Functionally equivalent methods and apparatuses within the scope of the disclosure, in addition to those described herein, will be apparent to those skilled in the art from the foregoing descriptions. Such modifications and variations are intended to fall within the scope of the appended claims.
[0207] The above detailed description describes various features and operations of the disclosed systems, devices, and methods with reference to the accompanying figures. The example embodiments described herein and in the figures are not meant to be limiting. Other embodiments can be utilized, and other changes can be made, without departing from the scope of the subject matter presented herein. It will be readily understood that the aspects of the present disclosure, as generally described herein, and illustrated in the figures, can be arranged, substituted, combined, separated, and designed in a wide variety of different configurations.
[0208] With respect to any or all of the message flow diagrams, scenarios, and flow charts in the figures and as discussed herein, each step, block, and/or communication can represent a processing of information and/or a transmission of information in accordance with example embodiments. Alternative embodiments are included within the scope of these example embodiments. In these alternative embodiments, for example, operations described as steps, blocks, transmissions, communications, requests, responses, and/or messages can be executed out of order from that shown or discussed, including substantially concurrently or in reverse order, depending on the functionality involved. Further, more or fewer blocks and/or operations can be used with any of the ladder diagrams, scenarios, and flow charts discussed herein, and these ladder diagrams, scenarios, and flow charts can be combined with one another, in part or in whole.
[0209] A step or block that represents a processing of information can correspond to circuitry that can be configured to perform the specific logical functions of a herein-described method or technique. Alternatively or additionally, a step or block that represents a processing of information can correspond to a module, a segment, or a portion of program code (including related data). The program code can include one or more instructions executable by a processor for implementing specific logical operations or actions in the method or technique. The program code and/or related data can be stored on any type of computer readable medium such as a storage device including RAM, a disk drive, or another storage medium.
[0210] The computer readable medium can also include non-transitory computer readable media such as computer readable media that store data for short periods of time like register memory and processor cache. The computer readable media can further include non-transitory computer readable media that store program code and/or data for longer periods of time. Thus, the computer readable media may include secondary or persistent long term storage, like ROM, optical or magnetic disks, compact-disc read only memory (CD-ROM), for example. The computer readable media can also be any other volatile or non-volatile storage systems. A computer readable medium can be considered a computer readable storage medium, for example, or a tangible storage device.
[0211] Moreover, a step or block that represents one or more information transmissions can correspond to information transmissions between software and/or hardware modules in the same physical device. However, other information transmissions can be between software modules and/or hardware modules in different physical devices.
[0212] The particular arrangements shown in the figures should not be viewed as limiting. It should be understood that other embodiments can include more or less of each element shown in a given figure. Further, some of the illustrated elements can be combined or omitted. Yet further, an example embodiment can include elements that are not illustrated in the figures.
[0213] While various aspects and embodiments have been disclosed herein, other aspects and embodiments will be apparent to those skilled in the art. The various aspects and embodiments disclosed herein are for purpose of illustration and are not intended to be limiting, with the true scope being indicated by the following claims.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012

D00013

D00014

D00015

D00016

XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.