Fusion Of Inertial And Depth Sensors For Movement Measurements And Recognition
KEHTARNAVAZ; Nasser ; et al.
U.S. patent application number 16/453999 was filed with the patent office on 2019-10-17 for fusion of inertial and depth sensors for movement measurements and recognition. The applicant listed for this patent is THE TEXAS A&M UNIVERSITY SYSTEM. Invention is credited to Chen CHEN, Roozbeh JARARI, Nasser KEHTARNAVAZ, Kui LIU, Jian WU.
| Application Number | 20190320103 16/453999 |
| Document ID | / |
| Family ID | 57017284 |
| Filed Date | 2019-10-17 |
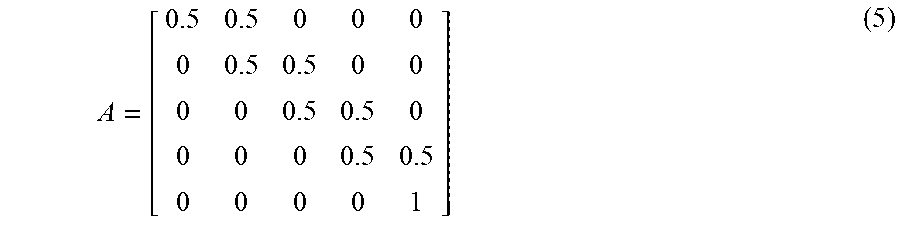
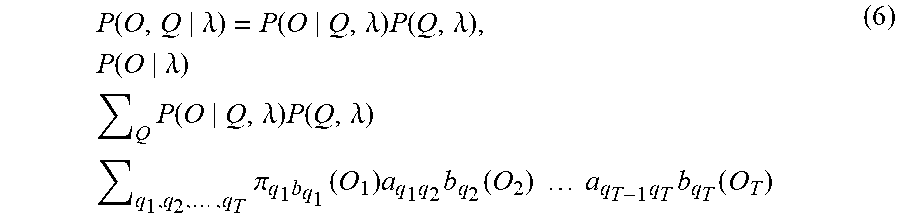
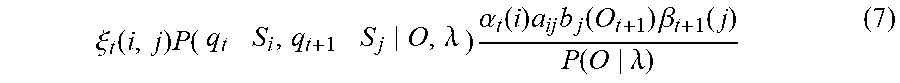
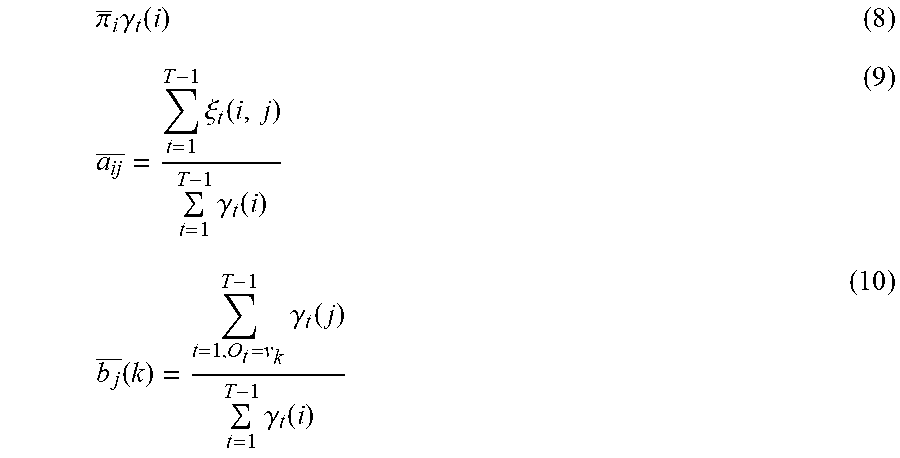
View All Diagrams
| United States Patent Application | 20190320103 |
| Kind Code | A1 |
| KEHTARNAVAZ; Nasser ; et al. | October 17, 2019 |
FUSION OF INERTIAL AND DEPTH SENSORS FOR MOVEMENT MEASUREMENTS AND RECOGNITION
Abstract
A method of recognizing movement includes measuring, by an inertial sensor, a first unit of inertia of an object. In addition, the method includes measuring a three dimensional shape of the object. Further, the method includes receiving, by a processor, a signal representative of the measured first unit of inertia from the inertial sensor and a signal representative of the measured shape from the depth sensor. Still further, the method includes determining a type of movement of the object based on the measured first unit of inertia and the measured shape utilizing a classification model.
| Inventors: | KEHTARNAVAZ; Nasser; (Plano, TX) ; JARARI; Roozbeh; (University Park, TX) ; LIU; Kui; (Dallas, TX) ; CHEN; Chen; (Richardson, TX) ; WU; Jian; (Richardson, TX) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 57017284 | ||||||||||
| Appl. No.: | 16/453999 | ||||||||||
| Filed: | June 26, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15092347 | Apr 6, 2016 | |||
| 16453999 | ||||
| 62143331 | Apr 6, 2015 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06K 9/00342 20130101; G06K 9/6297 20130101; H04N 5/232 20130101; G06K 9/00355 20130101; G06K 9/6278 20130101; G06K 9/6292 20130101 |
| International Class: | H04N 5/232 20060101 H04N005/232; G06K 9/62 20060101 G06K009/62; G06K 9/00 20060101 G06K009/00 |
Claims
1. A method of recognizing movement comprising: measuring, by an inertial sensor, a first unit of inertia of an object; measuring a three dimensional shape of the object; receiving, by a processor, a signal representative of the measured first unit of inertia from the inertial sensor and a signal representative of the measured shape from the depth sensor; determining a type of movement of the object based on the measured first unit of inertia and the measured shape utilizing a classification model.
2. The method of claim 1, wherein the determining the type of movement comprises: initializing Hidden Markov model (HMM) parameters, including an HMM probability and a transition matrix, for a plurality of HMMs, each of the plurality of HMMs corresponding to a particular type of movement; determining an observation sequence of the particular type of movement for the particular HMM being trained; calculating a probability of the observation sequence; performing a Baum Welch reestimation of the probability of the observation sequence to update the HMM; calculating a likelihood of probability for each of the plurality of trained HMMs based on the signal representative of the measured first unit of inertia and the signal representative of the measured shape; and selecting the type of movement corresponding to the trained HMM having the highest likelihood of probability.
3. The method of claim 1, wherein the determining the type of movement comprises: training a first, second, and third plurality of Hidden Markov models (HMMs), each of the first plurality of HMMs corresponding to a particular type of movement for the measured first unit of inertia, each of the second plurality of HMMs corresponding to the particular type of movement for a measured second unit of inertia, and each of the third plurality of HMMs corresponding to the particular type of movement for the measured shape; calculating a first for each of the first plurality of HMMs based on the signal representative of the measured first unit of inertia, second likelihood of probability for each of the second plurality of HMMs based on the signal representative of the measured second unit of inertia, and third likelihood of probability for each of the third plurality of HMMs based on the signal representative of the measured shape; pooling together the first, second, and third likelihood of probabilities to generate an overall probability for each of the first, second, and third pluralities of HMMs; and selecting the type of movement corresponding to the trained HMM having the highest overall probability.
4. The method of claim 1, wherein the determining the type of movement comprises: extracting a depth feature set from the signal representative of the measured shape; extracting a inertial feature set from the signal representative of the measured first unit of inertia; and fusing the depth feature and the inertial feature at a decision-level.
5. The method of claim 4, wherein the extracting the depth feature comprises: extracting a foreground containing the object from the signal representative of the measured shape utilizing a background subtraction algorithm to generate a foreground extracted depth image; generating three two dimensional projected maps corresponding to a front, view of the foreground extracted depth image; and accumulating a difference between two consecutive projected maps through an entire depth video sequence to generate a depth motion map (DMM).
6. The method of claim 4, wherein the fusing the depth feature and the inertial feature comprises: applying a sparse representation classifier (SRC) or collaborative representation classifier (CRC) to the extracted depth feature set and the extracted inertial feature set to generate a first and second basic probability assignments (BPAs) respectively; combining the first and second BPAs; and selecting the type of movement.
7. A non-transitory computer-readable medium storing instructions that when executed on a computing system cause the computing system to: receive a signal representative of a measured first unit of inertia from an inertial sensor coupled to an object and a signal representative of a measured shape of the object from a depth sensor; and determine a type of movement of the object based on the measured first unit of inertia and the measured shape utilizing a classification model.
8. The computer-readable medium of claim 7, wherein the instructions further cause the computing system to: train a plurality of Hidden Markov models (HMMs), each of the plurality of HMMs corresponding to a particular type of movement; calculate a likelihood of probability for each of the plurality of trained HMMs based on the signal representative of the measured first unit of inertia and the signal representative of the measured shape; and select the type of movement corresponding to the trained HMM having the highest likelihood of probability.
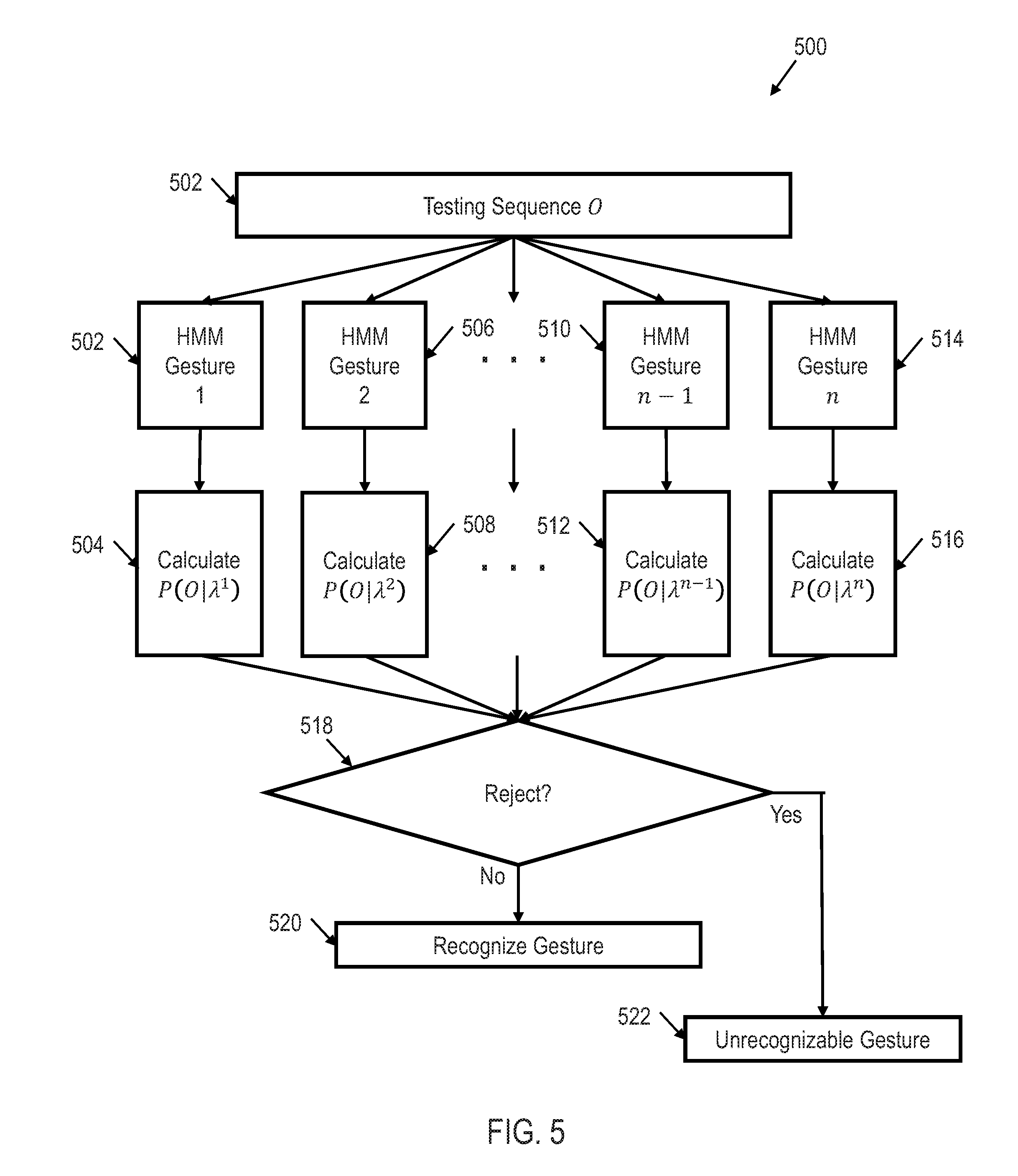
9. The computer-readable medium of claim 7, wherein the instructions further cause the computing system to: train a first, second, and third plurality of Hidden Markov models (HMMs), each of the first plurality of HMMs corresponding to a particular type of movement for the measured first unit of inertia, each of the second plurality of HMMs corresponding to the particular type of movement for a measured second unit of inertia, and each of the third plurality of HMMs corresponding to the particular type of movement for the measured shape; calculate a first for each of the first plurality of HMMs based on the signal representative of the measured first unit of inertia, second likelihood of probability for each of the second plurality of HMMs based on the signal representative of the measured second unit of inertia, and third likelihood of probability for each of the third plurality of HMMs based on the signal representative of the measured shape; pool together the first, second, and third likelihood of probabilities to generate an overall probability for each of the first, second, and third pluralities of HMMs; and select the type of movement corresponding to the trained HMM having the highest overall probability.
10. The computer-readable medium of claim 7, wherein the instructions further cause the computing system to: extract a depth feature set from the signal representative of the measured shape; extract a inertial feature set from the signal representative of the measured first unit of inertia; and fuse the depth feature and the inertial feature at a decision-level.
11. The computer-readable medium of claim 7, wherein the measured first unit of inertia comprises acceleration data of the object.
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application is a continuation of U.S. application Ser. No. 15/092,347 filed Apr. 6, 2016, and entitled "Fusion of Inertial and Depth Sensors for Body Movement Measurements and Recognition," which claims benefit of U.S. Provisional Application Ser. No. 62/143,331 filed Apr. 6, 2015, and entitled "Fusion of Inertial and Depth Sensors for Body Movement Measurements and Recognition," each which is hereby incorporated herein by reference in its entirety for all purposes.
BACKGROUND
[0002] Depth sensors or inertial body sensors have been used for measurement or recognition of human body movements spanning various applications including healthcare rehabilitation and consumer electronics entertainment applications, Each of the above two sensors has been used individually for body movement measurements and recognition. However, each sensor has limitations when operating under real world conditions.
[0003] The application of depth sensors has been steadily growing for body movement measurements and recognition. For example, depth images captured by depth sensors have been used to recognize American Sign Language (ASL). Depth sensors typically utilize one of two major matching techniques for gesture recognition including: Dynamic Time Warping (DTW) and Elastic Matching (EM). Statistical modeling techniques, such as particle filtering and Hidden Markov model (HMM), have also been utilized for gesture recognition utilizing a depth sensor alone.
[0004] Inertial body sensors have also been utilized to recognize body movement measurements and recognition. For example, the human motion capture system may utilize wireless inertial sensors. Wireless body sensors have been utilized to recognize the activity and position of upper trunk and lower extremities, A support vector machine (SVM) classifier has been used to estimate the severity of Parkinson disease symptoms. Furthermore, Kalman filtering has been used to obtain orientations and positions of body limbs. However, the use of inertial body sensors with depth sensors at the same time and together to increase system recognition robustness has not been well developed.
SUMMARY
[0005] The problems noted above are solved in large part by systems and methods for recognizing and/or measuring movements utilizing both an inertial sensor and a depth sensor. In some embodiments, a movement recognition system includes an inertial sensor, a depth sensor, and a processor. The inertial sensor is coupled to an object and configured to measure a first unit of inertia of the object. The depth sensor is configured to measure a three dimensional shape of the object using projected light patterns and a camera. The processor is configured to receive a signal representative of the measured first unit of inertia from the inertial sensor and a signal representative of the measured shape from the depth sensor and to determine a type of movement of the object based on the measured first unit of inertia and the measured shape utilizing a classification model.
[0006] Another illustrative embodiment is a method of recognizing movement of an object. The method comprises measuring, by an inertial sensor, a first unit of inertia of an object. The method also comprises measuring a three dimensional shape of the object. The method also comprises receiving, by a processor, a signal representative of the measured first unit of inertia from the inertial sensor and a signal representative of the measured shape from the depth sensor. The method also comprises determining a type of movement of the object based on the measured first unit of inertia and the measured shape utilizing classification model.
[0007] Yet another illustrative embodiment is a non-transitory computer-readable medium. The non-transitory computer-readable medium stores instructions that when executed on a computing system cause the computing system to receive a signal representative of a measured first unit of inertia from an inertial sensor coupled to an object and a signal representative of a measured shape of the object from a depth sensor and determine a type of movement of the object based on the measured first unit of inertia and the measured shape utilizing a classification model.
BRIEF DESCRIPTION OF THE DRAWINGS
[0008] For a detailed description of various examples, reference will now be made to the accompanying drawings in which:
[0009] FIG. 1 shows an illustrative block diagram of a movement recognition system utilizing an inertial sensor and a depth sensor in accordance with various embodiments;
[0010] FIG. 2 shows an illustrative block diagram of a computer in a movement recognition system utilizing an inertial sensor and a depth sensor in accordance with various embodiments;
[0011] FIG. 3 shows an illustrative block diagram of a processor of a computer in a movement recognition system utilizing an inertial sensor and a depth sensor in accordance with various embodiments:
[0012] FIG. 4 shows an illustrative flow diagram of a method for HMM training in accordance with various embodiments;
[0013] FIG. 5 shows an illustrative flow diagram of a method for HMM testing and/or movement recognition utilizing single HMM classification in accordance with various embodiments;
[0014] FIG. 6 shows an illustrative framework for HMM testing and/or movement recognition utilizing multi-HMM classification in accordance with various embodiments;
[0015] FIG. 7 shows an illustrative flow diagram of real time movement recognition utilizing a depth motion map (DMM) classification model in accordance with various embodiments; and
[0016] FIG. 8 shows an illustrative flow diagram of a method for conducting a fitness test utilizing a movement recognition system in accordance with various embodiments.
NOTATION AND NOMENCLATURE
[0017] Certain terms are used throughout the following description and claims to refer to particular system components. As one skilled in the art will appreciate, entities and/or individuals may refer to a component by different names. This document does not intend to distinguish between components that differ in name but not function. In the following discussion and in the claims, the terms "including" and "comprising" are used in an open-ended fashion, and thus should be interpreted to mean "including, but not limited to . . . ." Also, the term "couple" or "couples" is intended to mean either an indirect or direct connection. Thus, if a first device couples to a second device, that connection may be through a direct connection, or through an indirect connection via other devices and connections. The recitation "based on" is intended to mean "based at least in part on." Therefore, if X is based on Y. X may be based on Y and any number of other factors.
DETAILED DESCRIPTION
[0018] The following discussion is directed to various embodiments of the invention. Although one or more of these embodiments may be preferred, the embodiments disclosed should not be interpreted, or otherwise used, as limiting the scope of the disclosure, including the claims. In addition, one skilled in the art will understand that the following description has broad application, and the discussion of any embodiment is meant only to be exemplary of that embodiment, and not intended to intimate that the scope of the disclosure, including the claims, is limited to that embodiment.
[0019] As discussed above, both depth sensors and inertial body sensors have been utilized individually to recognize body movements. However, each of these systems has limitations. It is therefore desirable to create a general purpose fusion framework to increase the robustness of object movement recognition by utilizing the information from two or more sensors at the same time. Therefore, in accordance with the disclosed principles two sensors, one a depth sensor and one an inertial sensor, are deployed in such a way that they act in a complementary manner by compensating for erroneous data that may be generated by each sensor individually.
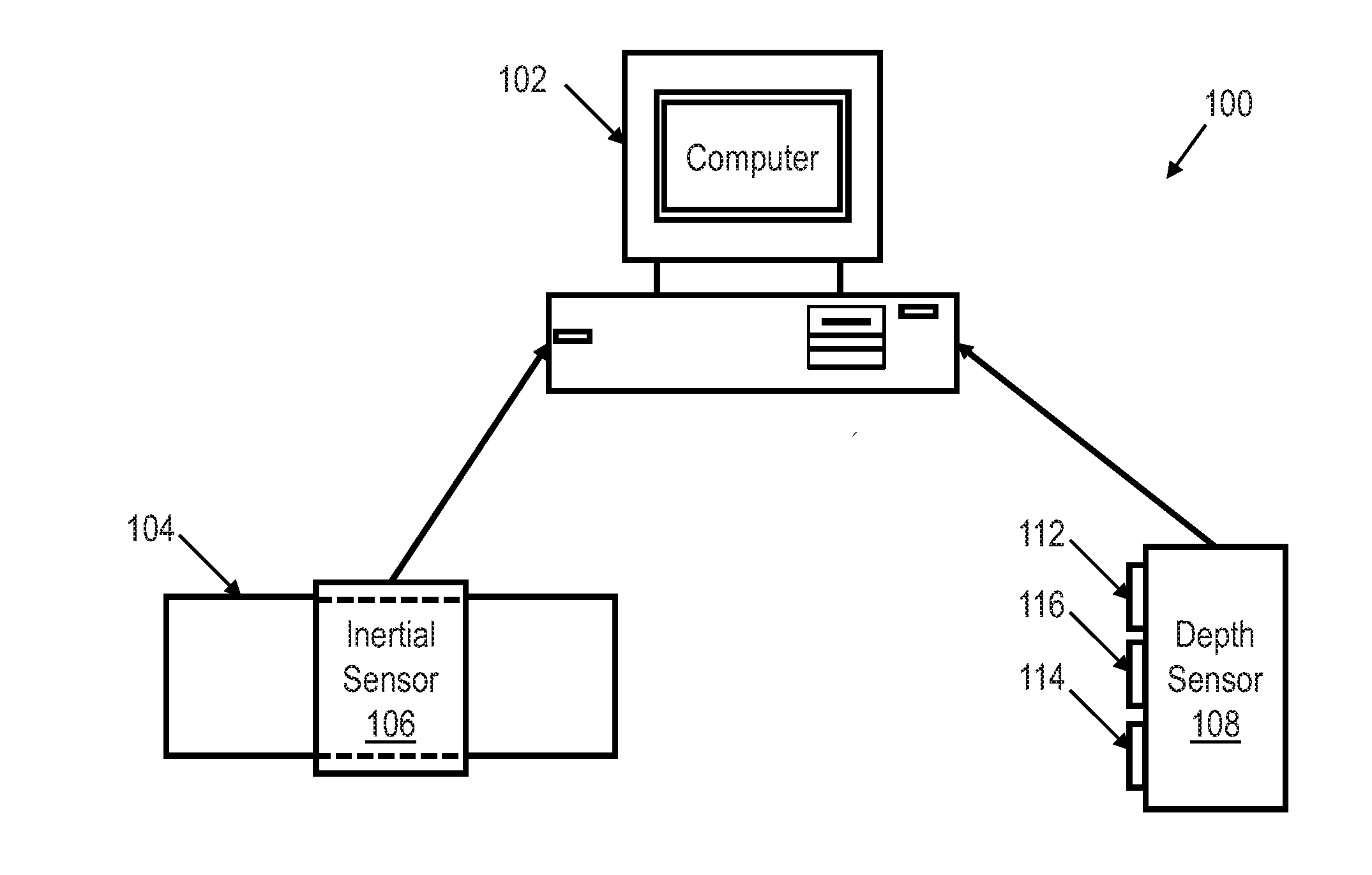
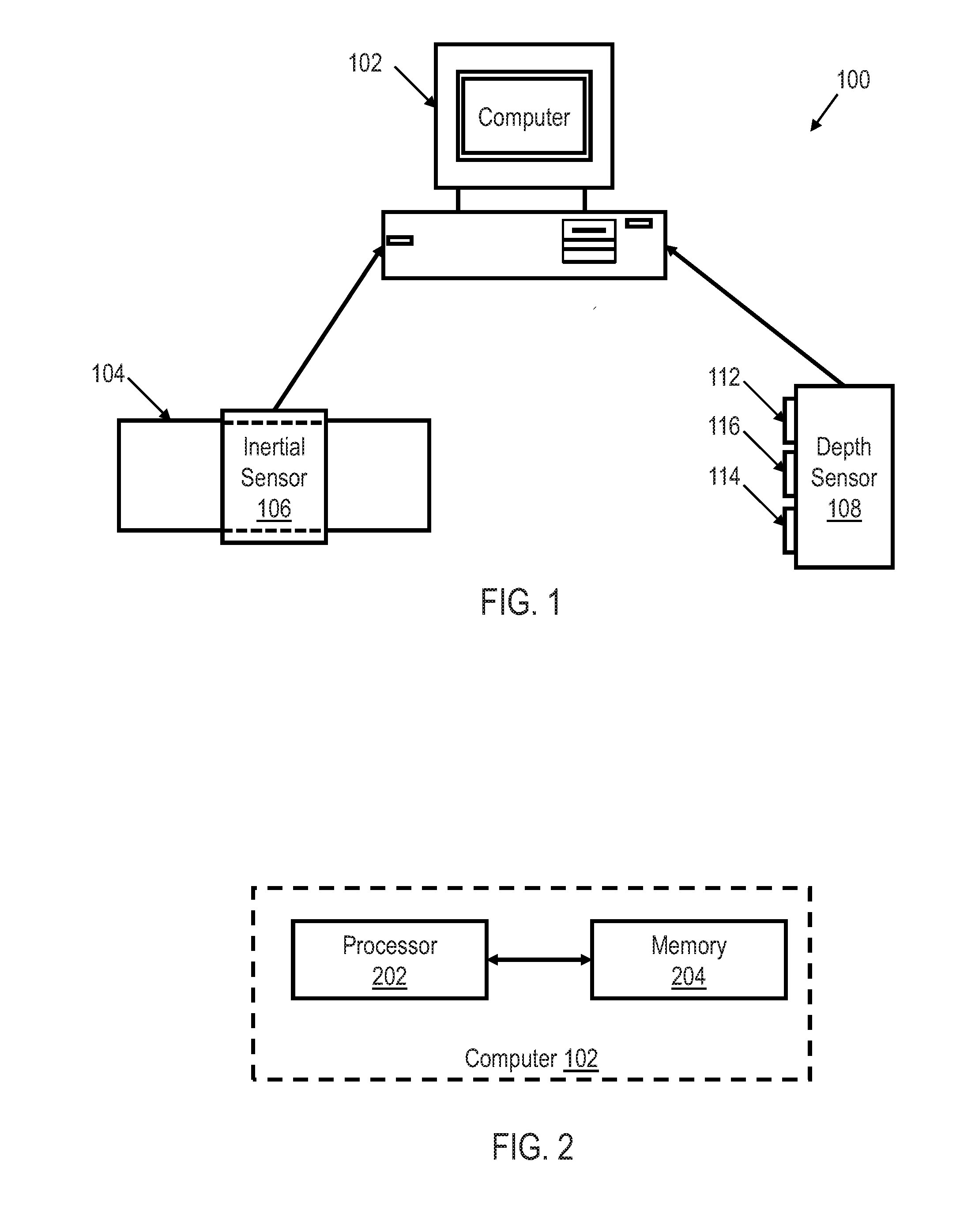
[0020] FIG. 1 shows an illustrative block diagram of a movement recognition system 100 utilizing an inertial sensor 106 and a depth sensor 108 in accordance with various embodiments. The movement recognition system 100 may include computer system 102, inertial sensor 106, and depth sensor 108. Computer system 102 may include computer hardware that may execute instructions stored in computer system 102 or stored in another computer system and/or memory connected to computer system 102. While shown as a desktop computer, computer system 102 may be any electronic device having some amount of computing power. Among other things, servers, portable computers, personal digital assistants (PDAs), and mobile phones may be configured to carry out aspects of the disclosed embodiments. In some embodiments, computing system 102 may include several computers and components that are interconnected via communication links, using one or more computer networks or direct connections.
[0021] Inertial sensor 106 may be any type of inertial sensor that may measure information corresponding to an object's inertial movement, sometimes referred to as a unit of inertia (i.e., specific force, acceleration, angular rate, pitch, roll, yaw, and/or magnetic field). Thus, inertial sensor 106 may be an accelerometer, a gyroscope, a magnetometer, or any combination thereof. For example, inertial sensor 106 may include both an accelerometer and a gyroscope. In an alternative example, inertial sensor 106 may include only an accelerometer. In some embodiments, inertial sensor 106 is a micro-electro-mechanical system (MEMS). In an embodiment, the inertial sensor 106 includes a 9-axis MEMS sensor which captures 3-axis acceleration, 3-axis angular velocity, and 3-axis magnetic strength data.
[0022] Inertial sensor 106 may be coupled to an object 104 to measure the object 104's inertial movement. For example, inertial sensor 106 may be coupled to object 104 to measure object 104's acceleration and angular rate. Object 104 may be any type of object including animate objects such as a human wrist or any other human body part. For example, inertial sensor 106 may be coupled to the wrist of a human such that the inertial sensor 106 measures inertial movement of the human's wrist.
[0023] The inertial sensor 106 may be wirelessly and/or wireline coupled to computer system 102. For example, inertial sensor 106 may be configured to communicate data to computer system 102 through a network based on the IEEE 802.15.4e standard, a wireless local area network ("WLAN"), such as network based on the IEEE 802.11 standard, and/or a wireless personal area network ("WPAN") (e.g., a BLUETOOTH network), Thus, inertial sensor 106 may communicate a signal and/or signals to computer system 102 representative of the inertial measurements of object 104.
[0024] Depth sensor 108 may be configured to measure a three dimensional shape of object 104 utilizing projected light patterns and a camera. Therefore, depth sensor 108 may include an infrared (IR) emitter 112, a camera (in some embodiments, a color camera) 116, and an IR depth sensor 114. Thus, depth sensor 108 may capture a series of depth images of object 104 as object 104 changes position. In some embodiments, to measure the three dimensional shape of object 104, depth sensor 108 may capture more than thirty frames per second of object 104. In some embodiments, the depth sensor 108 may be a MICROSOFT KINNECT.
[0025] The depth sensor 106 may be wirelessly and/or wireline coupled to computer system 102. For example, depth sensor 108 may be configured to communicate data to computer system 102 through a network based on the IEEE 802.15.4e standard, a wireless local area network ("WLAN"), such as network based on the IEEE 802.11 standard, and/or a wireless personal area network ("WPAN") (e.g., a BLUETOOTH network). Thus, depth sensor 108 may communicate a signal and/or signals to computer system 102 representative of the measured shape of object 104.
[0026] FIG. 2 shows an illustrative block diagram of computer system 102 of movement recognition system 100 in accordance with various embodiments. The computer system 102 includes one or more processors 202 that may be configured to receive the signals representative of the inertial measurements of object 104 from inertial sensor 106 and the signals representative of the measured shape of object 104 from depth sensor 108. Processor 202 may be coupled to system memory 204 via an input/output interface. Processor 202 may include a central processing unit (CPU), a semiconductor-based microprocessor, a graphics processing unit (CPU), and/or other hardware devices suitable for retrieval and execution of instructions that may be stored in memory 204 or other memory.
[0027] Processor 202 may include a single processor, multiple processors, a single computer, a network of computers, or any other type of processing device. For example, processor 202 may include multiple cores on a chip, multiple cores across multiple chips, multiple cores across multiple devices, or combinations thereof, Processor 202 may include at least one integrated circuit (IC), other control logic, other electronic circuits, or combinations thereof that include a number of electronic components. Processor 202 may perform operations such as graphics, signal processing, encryption, input/output (I/O) interfacing with peripheral devices, floating point arithmetic, string processing, etc.
[0028] Memory 204 may be any electronic, magnetic, optical, or other physical storage device that contains or stores executable instructions. Thus, memory 204 may be, for example, Random Access Memory (RAM), Read Only Memory (ROM), an Electrically Erasable Programmable Read-Only Memory (EEPROM), a storage drive, a Compact Disc Read Only Memory (CD-ROM), and the like. The computer may also include a network interface coupled to the input/output interface.
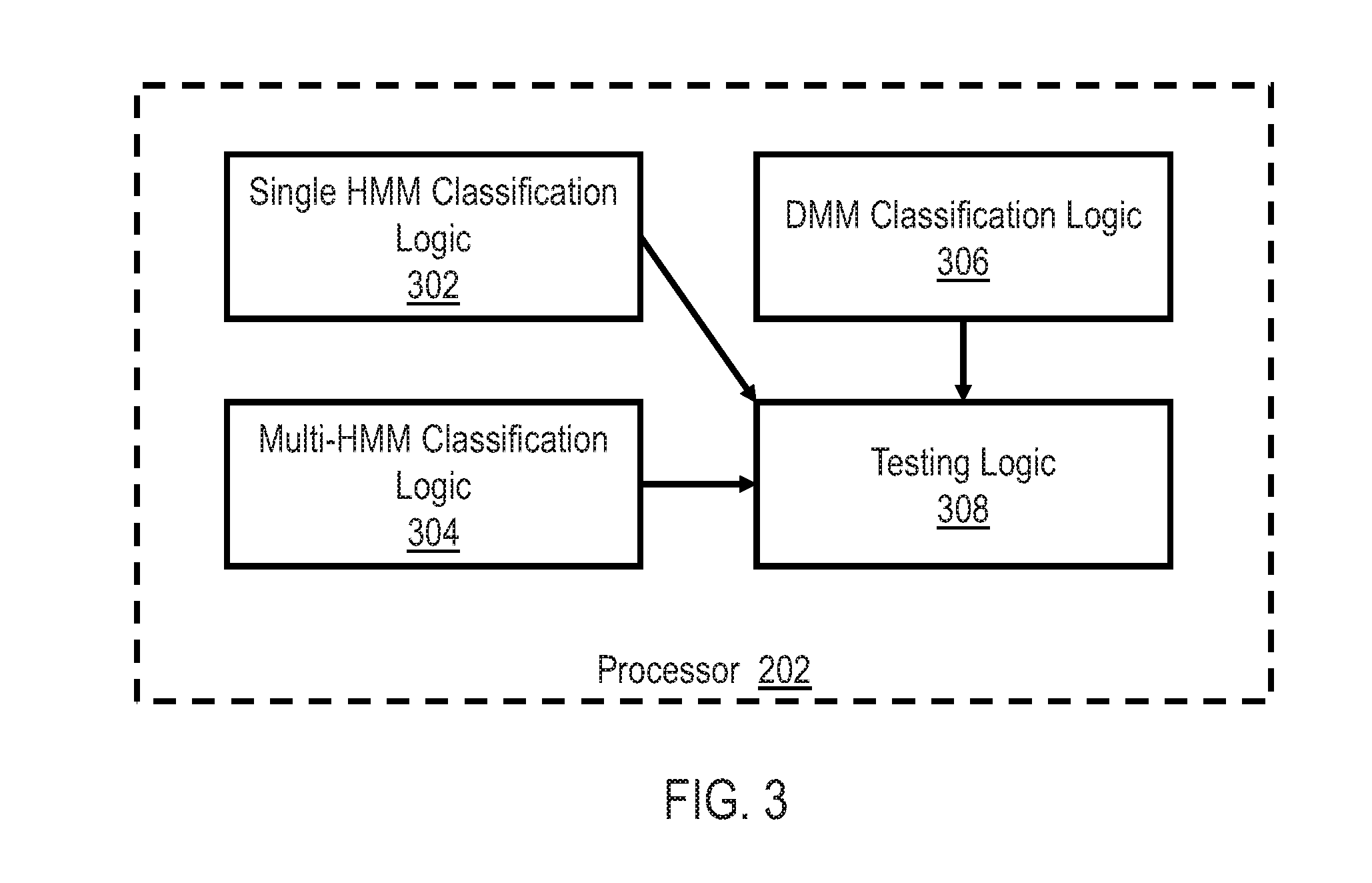
[0029] FIG. 3 shows an illustrative block diagram of processor 202 in accordance with various embodiments. Processor 202 may include single HMM classification logic 302, multi-HMM classification logic 304, .COPYRGT.MM classification logic 306, and testing logic 308. In an embodiment, single HMM classification logic 302 receives the signals representative of the inertial measurements of object 104 from inertial sensor 106 and the signals representative of the measured shape of object 104 from depth sensor 108. Because the sampling rates of the signals from the inertial sensor 106 and the depth sensor 108 may be different (e.g., the inertial sensor 106 may have a sampling rate of 200 Hz while the depth sensor 108 may have a sampling rate of 30 Hz), the data from the inertial sensor 106 and/or depth sensor 108 may be down-sampled by single HMM classification logic 302 such that the sampling frequencies match. Furthermore, to reduce jitter in the two signals, a moving average window may be utilized.
[0030] Single HMM classification logic 302 may be configured to determine a type of movement of object 104 (i.e., classify a movement) utilizing the signals from both the inertial sensor 106 and the depth sensor 108 by utilizing a HMM classifier. For example, single HMM classification logic 302 may be configured to determine a type of hand gesture (e.g., waving, hammering, punching, circle movement, etc.) utilizing the signals from both the inertial sensor 106 and the depth sensor 108 by utilizing a HMM classifier.
[0031] The HMM classifier model characterizes a state transfer probability distribution A and observation (the received signals from the inertial sensor 106 and the depth sensor 108) probability distribution B. Given an initial state matrix .pi., an HMM is described by the triplet .lamda.={.pi., A, B}. If a random sequence of signals O={O.sub.1, O.sub.2, . . . , O.sub.T} is observed; V={v.sub.1, v.sub.2, . . . , v.sub.T} denotes all possible outcomes, S={S.sub.1, S.sub.2, . . . , S.sub.T} denotes all HMM states, and q.sub.t denotes the state at time t, where T indicates the number of time samples. The HMM probabilities are:
.pi.={p.sub.i=P(Q.sub.1=S.sub.i)},1.ltoreq.i.ltoreq.M (1)
A=={a.sub.ij=P(q.sub.t=S.sub.j|q.sub.t-1=S.sub.i)},1.ltoreq.i,j.ltoreq.M (2)
B={b.sub.j(k)=P(O.sub.t=v.sub.k|q.sub.t=S.sub.j)},1.ltoreq.j.ltoreq.M,1.- ltoreq.k.ltoreq.T (3)
where:
.SIGMA..sub.i-1.sup.M=1,.SIGMA..sub.j=1.sup.Ma.sub.ij=1, and .SIGMA..sub.k=1.sup.Tb.sub.j(k)=1 (4)
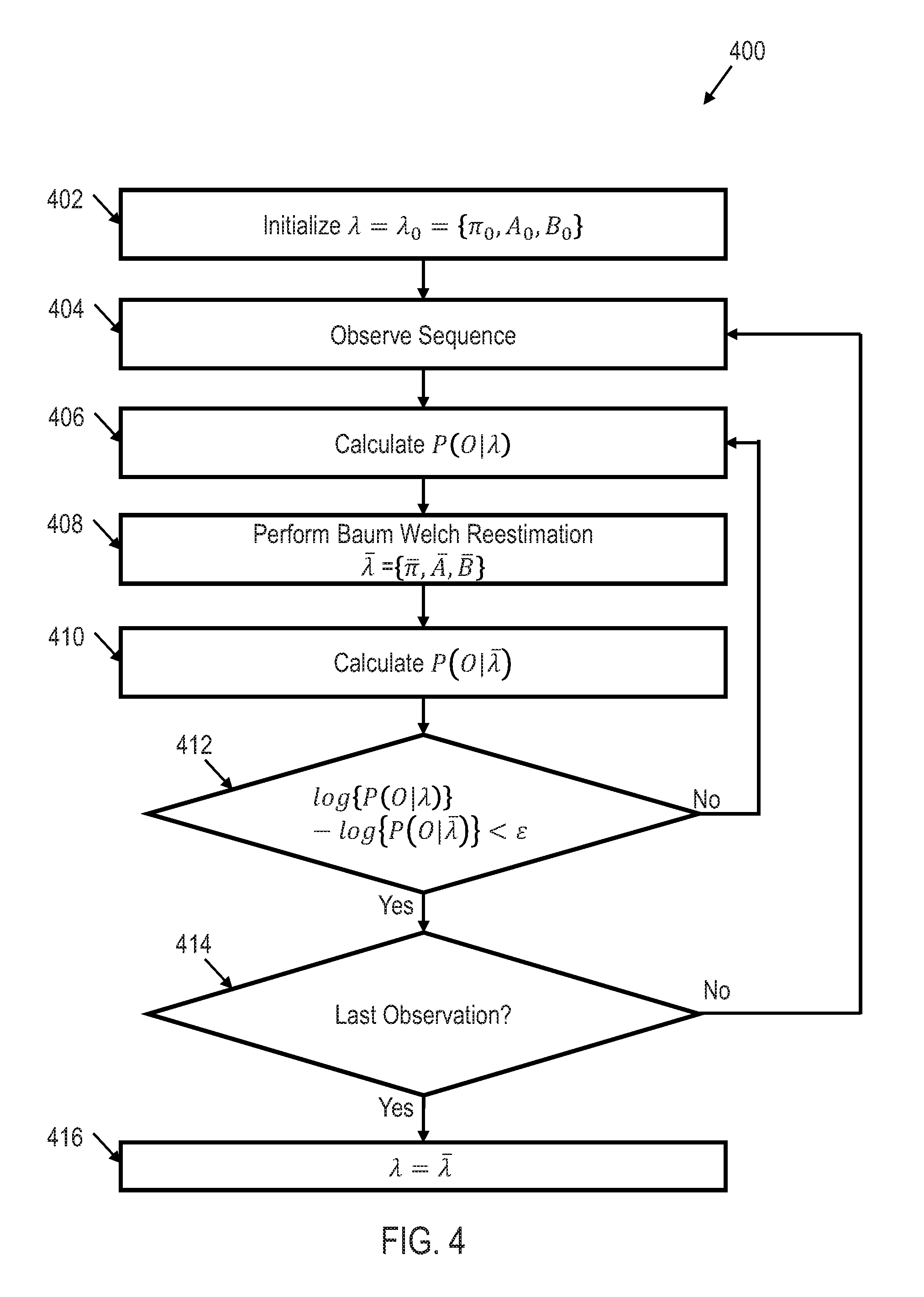
[0032] Single HMM classification logic 302 may train the HMM so as to recognize particular types of movement for the object 104. For example, single HMM classification logic 302 may train a plurality of HMMs to each be able to recognize a single type of movement (e.g., each HMM is trained to recognize one of multiple gestures made by object 104). FIG. 4 shows an illustrative flow diagram of a method 400 for HMM training that may be performed by single HMM classification logic 302 in accordance with various embodiments. Though depicted sequentially as a matter of convenience, at least some of the actions shown can be performed in a different order and/or performed in parallel. Additionally, some embodiments may perform only some of the actions shown.
[0033] In block 402, the parameters discussed in equations (1)-(4) are initialized such that .lamda.=.lamda..sub.0={.pi..sub.0, A.sub.0, B.sub.0}. Matrix A controls the transitions in the HMM. To initialize matrix A, all of the nonadjacent probabilities in the matrix are zeroed out, thus, limiting the state transitions to the sequence of adjacent states representing the type of movement being trained. In other words, state transitions are constrained to occur from left-to-right and between two adjacent states. Hence, the initial transition matrix A is:
A = [ 0.5 0.5 0 0 0 0 0.5 0.5 0 0 0 0 0.5 0.5 0 0 0 0 0.5 0.5 0 0 0 0 1 ] ( 5 ) ##EQU00001##
[0034] In block 404, an observation sequence of the particular type of movement being trained is determined. In block 406, the probability of the observation sequence is calculated. If, the observation sequence is O={O.sub.1, O.sub.2, . . . , O.sub.T} of the particular type of movement being trained and Q={q.sub.1, q.sub.2, . . . , q.sub.T} is the corresponding state sequence, then the probability of the observation sequence calculated in block 406 is (O|Q, .lamda.) .PI..sub.t=1.sup.TP(O.sub.t|q.sub.t, .lamda.).
[0035] In block 408, a Baum Welch reestimation of the probability sequence is performed to update the HMM being trained. According to the Baum Welch algorithm, the probability P(O|.lamda.).pi..sub.q.sub.1a.sub.q.sub.1.sub.q.sub.2a.sub.q.sub.2.sub.q.- sub.3a.sub.q.sub.3.sub.q.sub.4 . . . a.sub.q.sub.T-1.sub.q.sub.T is calculated to update A. Because
P ( O , Q .lamda. ) = P ( O Q , .lamda. ) P ( Q , .lamda. ) , P ( O .lamda. ) Q P ( O Q , .lamda. ) P ( Q , .lamda. ) q 1 , q 2 , , q T .pi. q 1 b q 1 ( O 1 ) a q 1 q 2 b q 2 ( O 2 ) a q T - 1 q T b q T ( O T ) ( 6 ) ##EQU00002##
[0036] To update the current model .lamda.={.pi., A, B}, the updated model is .lamda.={.pi., , B} and is calculated in block 410. To estimate .lamda.={.pi., , B}, the probability of the joint event that O.sub.1, O.sub.7, . . . , O.sub.7, is observed is .alpha..sub.T(i). Thus, .alpha..sub.T(i)=P(O.sub.1, O.sub.2, . . . , O.sub.T, q.sub.T=S.sub.i|.lamda.). Similarly, .beta..sub.T(i)=P(O.sub.t+1, O.sub.t+2, . . . , O.sub.T, q.sub.T=S.sub.i|.lamda.). The probability of being in state S.sub.i at time t and state S.sub.j at time t+1 is thus given by
.xi. t ( i , j ) P ( q t S i , q t + 1 S j O , .lamda. ) .alpha. t ( i ) a ij b j ( O t + 1 ) .beta. t + 1 ( j ) P ( O .lamda. ) ( 7 ) ##EQU00003##
[0037] if .gamma..sub.t(i) is the probability of being in state S.sub.i at time t, then
[0038] .gamma..sub.t(i) .SIGMA..sub.j=1.sup.N.xi..sub.t(i,j), .lamda.{.pi., ,B} where
.pi. _ i .gamma. t ( i ) ( 8 ) a ij _ = t = 1 T - 1 .xi. t ( i , j ) t = 1 T - 1 .gamma. t ( i ) ( 9 ) b j _ ( k ) = t = 1 , O t = v k T - 1 .gamma. t ( j ) t = 1 T - 1 .gamma. t ( i ) ( 10 ) ##EQU00004##
[0039] Because there is a very small threshold value (e.g., .epsilon.=10.sup.-6) the training may be terminated when log {P(O|.lamda.)}-log {P(O|.lamda.)}<.epsilon.. Therefore, in block 412, a determination is made of whether log {P(O|.lamda.)}log{P(O|.lamda.)}<.epsilon.. If log{P(O|.lamda.)}-log {P(O|.lamda.)} is not less than .epsilon., then the method 400 continues in block 406 with calculating MIA). However, if log {P(O|.lamda.)}-log {P(O|.lamda.)} is less than .epsilon., then the method 400 continues in block 414 with determining whether any additional observations are needed to train the HMM for the particular type of movement. If it is determined that this is not the last observation, then the method 400 continues in 404 with observing an additional sequence of the particular type of movement being trained. However, if it is determined that this is the last observation, then the training of the HMM is complete and .lamda.=.lamda..
[0040] Once each of the HMMs are trained for their respective particular type of movement, single HMM classification logic 302 may make a determination of the type of movement of object 104. FIG. 5 shows an illustrative flow diagram of a method 500 for HMM testing and/or movement recognition that may be performed by single HMM classification logic 302 in accordance with various embodiments. Though depicted sequentially as a matter of convenience, at least some of the actions shown can be performed in a different order and/or performed in parallel. Additionally, some embodiments may perform only some of the actions shown.
[0041] The method 500 begins in block 502 with receiving, by the single HMM classification logic 502, a testing sequence and/or an observation sequence O. In other words, the single HMM classification logic 502 receives the signals generated by the inertial sensor 106 and the depth sensor 108 due to the movement of object 104. For each of the trained HMMs 502, 506, 510, 514 (e.g., a trained HMM for gesture 1, a trained HMM for gesture 2, etc.), the likelihood of probability 1)(01.1) is calculated in blocks 504, 508, 512, 516 resulting in n likelihood of probabilities where ii is the number of types of movement that are trained.
[0042] In block 518, a determination is made as to whether all of the calculated likelihood of probabilities should be rejected. For example, a high confidence interval (e.g., 95%) may be applied to the n calculated likelihood of probabilities. If .mu. represents the mean and .sigma. represents the variance of the n calculated likelihood of probabilities, then to meet the 95% confidence interval, at least one of the n likelihood of probabilities must be larger than
.mu. + 1.96 .sigma. n . ##EQU00005##
While a confidence interval of 95% is shown in this example, other confidence intervals may be utilized in a similar manner. If none of the n calculated likelihood of probabilities meet the selected confidence interval, the sequence is rejected and the type of movement is unrecognizable in block 522. However, if any of the n calculated likelihood of probabilities meets the selected confidence interval, the type of movement corresponding to the trained HMM 502, 506, 510, 514 having the highest likelihood of probability is selected as the type of movement.
[0043] Returning to FIG. 3, processor 202 may also include multi-HMM classification logic 304, In an embodiment, like single HMM classification logic 302, multi-HMM classification logic 304 receives the signals representative of the inertial measurements of object 104 from inertial sensor 106 and the signals representative of the measured shape of object 104 from depth sensor 108. In alternative embodiments, only multi-HMM classification logic 304 receives the signals representative of the inertial measurements of object 104 from inertial sensor 106 and the signals representative of the measured shape of object 104 from depth sensor 108. Because the sampling rates of the signals from the inertial sensor 106 and the depth sensor 108 may be different (e.g., the inertial sensor 106 may have a sampling rate of 200 Hz while the depth sensor 108 may have a sampling rate of 30 Hz), the data from the inertial sensor 106 and/or depth sensor 108 may be down-sampled by multi-HMM classification logic 304 such that the sampling frequencies match. Furthermore, to reduce jitter in the two signals, a moving average window may be utilized.
[0044] Multi-HMM classification logic 304 may be configured to determine a type of movement of object 104 (i.e., classify a movement) utilizing the signals from both the inertial sensor 106 and the depth sensor 108 by utilizing multiple HMM classifiers. Thus, multi-HMM classification logic 302 may be configured to determine a type of hand gesture (e.g., waving, hammering, punching, circle, etc.) utilizing the signals from both the inertial sensor 106 and the depth sensor 108 by utilizing multiple HMM classifiers.
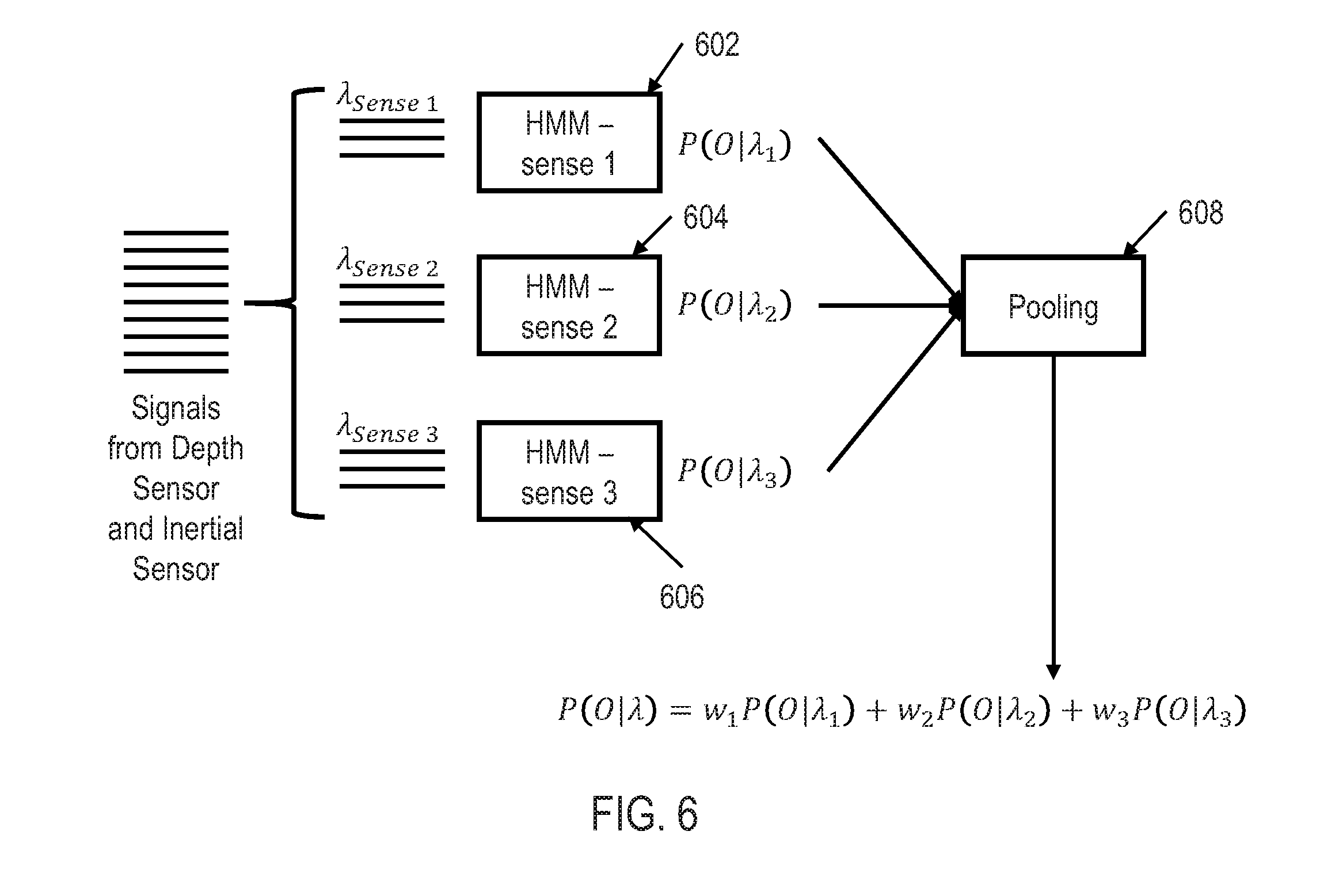
[0045] FIG. 6 shows an illustrative framework for HMM testing and/or movement recognition utilizing multi-HMM classification logic 304 in accordance with various embodiments. Though depicted sequentially as a matter of convenience, at least some of the actions shown can be performed in a different order and/or performed in parallel. Additionally, some embodiments may perform only some of the actions shown.
[0046] As shown in FIG. 6, all of the signals from the inertial sensor 106 and depth sensor 108 are received by the multi-HMM classification logic 304, However, the inertial sensor 106 and depth sensor 108 may provide different types of data (e.g., the inertial sensor 106 may provide acceleration data of object 104 while the depth sensor provides shape (and/or depth) data of object 104). Furthermore, inertial sensor 106 may itself provide multiple types of data (e.g., acceleration data and angular rate data). Therefore, each type of data may be fed into its own HMM classifier 602-606, each classifier generating its own likelihood of probability. First, each HMM classifier 602-606 may be trained for that specific type of data in a similar manner as shown in FIG. 4. Thus, HMM classifier 602 may be trained to recognize different types of movements for one specific type of data (e.g., acceleration). Similarly, HMM classifier 604 may be trained to recognize the same types of movements as HMM classifier 602, only for a different type of data (e.g., angular rate) than HMM classifier 602 while HMM classifier 606 may be trained to recognize the same types of movements as HMM classifiers 602 and 604, but only utilizing a different type of data (e.g., depth data), Thus, in this example, a plurality of HMMs is trained to recognize a specific type of movement (e.g., hand gesture) utilizing only acceleration data, while two other pluralities of HMMs are trained to recognize the same types of movement utilizing angular rate data and depth data respectively.
[0047] Similar to the single HMM classification logic 302, multi-HMM classification logic 304 may calculate the likelihood of probabilities for each of the HMM classifiers 602-606. In block 608, the likelihood of probabilities from each of the HMM classifiers 602-606 for each of the specific types of movement trained then may be multiplied by a weight and pooled together by adding the individually weighted likelihood of probabilities into an overall probability of all of the input signals as:
P(O|.lamda.)=w.sub.1P(O|.lamda..sub.1)+w.sub.2P(O|.lamda..sub.3)+w.sub.3- P(O|.lamda..sub.3) (11)
[0048] In the example shown in FIG. 6, three HMM classifiers are utilized which may be denoted as .lamda..sub.sense(1)0={.pi..sub.sense(1)0, A.sub.sense(1)0, B.sub.(sense (1)0}, .lamda..sub.sense(2)0={.pi..sub.sense(2)0, A.sub.sense(2)0, B.sub.(sense (2)0}, .lamda..sub.sense(3)0={.pi..sub.sense(3)0, A.sub.sense(3)0, B.sub.(sense (3)0} representing each of the senses sensed by the inertial sensor 106 and depth sensor 108. The parameters of these models are then estimated according to the Baum-Welch algorithm as discussed above. During movement recognition, the overall likelihood of probability for a specific type of movement P(O|.lamda.) is computed based on the three likelihood of probabilities P(O|.lamda..sub.1), P(O|.lamda..sub.2), P(O|.lamda..sub.3), The type of movement with the maximum average of the three weighted likelihood of probabilities w.sub.1P(O|.lamda..sub.1), w.sub.2P(O|.lamda..sub.2), w.sub.3P(O|.lamda..sub.3) then may be selected as the type of movement of the object 104. One advantage of utilizing the multi-HMM classification logic 304 over the single HMM classification logic 302 is that the differences between the probability of likelihoods is diminished and/or the discriminatory power is increased.
[0049] Returning to FIG. 3, processor 202 may also include DMM classification logic 306. In an embodiment, like single HMM classification logic 302 and multi-HMM classification logic 304, DMM classification logic 306 receives the signals representative of the inertial measurements of object 104 from inertial sensor 106 and the signals representative of the measured shape of object 104 from depth sensor 108. In alternative embodiments, only DMM classification logic 306 receives the signals representative of the inertial measurements of object 104 from inertial sensor 106 and the signals representative of the measured shape of object 104 from depth sensor 108. Because the sampling rates of the signals from the inertial sensor 106 and the depth sensor 108 may be different (e.g., the inertial sensor 106 may have a sampling rate of 200 Hz while the depth sensor 108 may have a sampling rate of 30 Hz), the data from the inertial sensor 106 and/or depth sensor 108 may be down-sampled by DMM classification logic 306 such that the sampling frequencies match. Furthermore, to reduce jitter in the two signals, a moving average window may be utilized.
[0050] DMM classification logic 306 may be configured to determine a type of movement of object 104 (i.e., classify a movement) utilizing the signals from both the inertial sensor 106 and the depth sensor 108. Thus, DMM classification logic 306 may be configured to determine a type of hand gesture (e.g., waving, hammering, punching, circle, etc.) utilizing the signals from both the inertial sensor 106 and the depth sensor 108.
[0051] More particularly, DMM classification logic 306 may utilize both feature-level and decision-level fusion of the signals from the inertial sensor 106 and the depth sensor 108 to recognize (classify) the type of movement of object 104. First, a depth feature may be extracted from the signal representative of the measured shape by DMM classification logic 306. Before performing depth image projections, the foreground that contains the moving object is extracted. Any dynamic background subtraction algorithms may be utilized to extract the foreground including background modeling techniques or spatio-temporal filtering to extract the spatio-temporal interest points corresponding to an action of object 104. To make this task computationally efficient, the mean depth value .mu. for each M.sub.0.times.N.sub.0 depth image may be computed and the foreground region may be selected according to:
d a , b = { d a , b , if d a , b - .mu. .ltoreq. 0 , otherwise ( 12 ) ##EQU00006##
where d.sub.a,b (a=1, 2, . . . , M.sub.0, b=1, 2, . . . , N.sub.0) is the depth value (indicating the distance between the depth sensor 108 and the object 104) of the pixel in the ath row and hth column of the depth image, .epsilon. is a threshold for the depth value with a unit of mm. Based on the Berkeley multi-modal human database (MHAD), the foreground may be extracted by setting .epsilon..di-elect cons.[800,900]. In alternative embodiments, other settings may be utilized to extract the foreground. For example, if object 104 is a human body, the position of the joints of the human's skeleton may determine the depth range for foreground extraction.
[0052] Each foreground extracted depth image then may be used to generate three 2D projected maps corresponding to the front, side, and top views of the shape detected by the depth sensor 108, denoted by map, where v.di-elect cons.(f,s,t), For a point (x, y, z) in the depth image with z denoting the depth value in a right-handed coordinate system, the pixel values in the three projected maps (map.sub.f, map.sub.s, rnap.sub.t) are indicated by z, x, and y, respectively. For each projection view, the absolute difference between two consecutive projected maps may be accumulated through an entire depth video sequence forming a DMM. Specifically, for each projected map, the motion energy is calculated as the absolute difference between two consecutive maps. For a depth video sequence with N frames, the depth motion map DMM.sub.v is obtained by stacking the motion energy across an entire depth video sequence as follows:
DMM.sub.v=.SIGMA..sub.q=1.sup.N-1|map.sub.v.sup.q+1 map.sub.v.sup.q| (13)
where q represents the frame index, and map.sub.v.sup.q the projected map of the qth frame for the projection view v. In some embodiments, to keep the computational cost low, only the DMM generated from the front view, i.e. DMM.sub.f, is used as the depth feature; however, in alternative embodiments additional and/or different DMMs may be utilized. A bounding box may be set to extract the non-zero region as the region of interest (ROI) in each DMM.sub.f. The ROI extracted DMM.sub.f is denoted as DMA.sub.f'. Since DMM.sub.f' of different video sequences may have different sizes, bicubic interpolation may be used to resize all DMM.sub.f' to a fixed size in order to reduce the intra-class variations.
[0053] Next, an inertial feature may be extracted from the signal representative of the measured unit of inertia by COMM classification logic 306. Each inertia sensor 106 sequence (e.g., accelerometer sequence) may be partitioned into N.sub.S temporal windows. Statistical measures, including mean, variance, standard deviation, and root mean square, may be computationally efficient and useful for capturing structural patterns in motion data. Therefore, these four measures may be computed along each direction in each temporal window. In alternative embodiments, only some of these measures may be computed. For each inertial sensor 106, concatenating all measures from N.sub.s windows results in a column feature vector of dimensionality 4.times.3.times.N.sub.s.
[0054] DMM classification logic 306 then may perform feature-level fusion of the data from the inertial sensor 106 and the depth sensor 108. If U={u.sub.l}.sub.l=1.sup.n in .sup.d.sup.1 (d.sub.1-dimensional feature space) and V={v.sub.t}.sub.l=1.sup.n in .sup.d.sup.2 (d.sub.2-dimensional feature space), they represent the feature sets generated, respectively, from the depth sensor 108 and the inertial sensor 106 for n training action samples. Column vectors u.sub.l and v.sub.l may be normalized to have the unit length. Then, the fused feature set may be represented by F={f.sub.l}.sub.l=1.sup.n in .sup.d.sup.1.sup.+d.sup.2 with each column vector being f.sub.l=[u.sub.1.sup.T,v.sub.l.sup.T].sup.T. The fused feature set then may be fed into a classifier such as a sparse representation classifier (SRC), a collaborative representation classifier (CRC), and/or and HMM classifier for classification of the type of movement.
[0055] SRC may classify measured movements of object 104 into a type of movement. The idea is to represent a test sample according to a small number of atoms sparsely chosen out of an over-complete dictionary formed by all available training samples. Considering C distinct classes and a matrix X={x.sub.i}.sub.i=1.sup.n .sup.d.times.n formed by n dimensional training samples arranged column-wise to form the over-complete dictionary. For a test sample y .sup.d, y may be expressed as a sparse representation in terms of matrix X as follows:
y=X.alpha. (14)
where .alpha. is a n.times.1 vector of coefficients corresponding to all training samples from the C classes. .alpha. cannot directly be solved for because equation (14) is typically underdetermined. However, a solution can be obtained by solving the following l.sub.1-regularized minimization problem:
.alpha. ^ = arg min .alpha. y = X .alpha. 2 2 + .lamda. .alpha. 1 ( 15 ) ##EQU00007##
here .lamda. is a regularization parameter which balances the influence of the residual and the sparsity term. According to the class labels of the training samples, {circumflex over (.alpha.)} can be partitioned into C subsets {circumflex over (.alpha.)}=[{circumflex over (.alpha.)}.sub.1, {circumflex over (.alpha.)}.sub.2, . . . , {circumflex over (.alpha.)}.sub.C] with {circumflex over (.alpha.)}.sub.j (j.di-elect cons.1, 2, . . . , C) denoting the subset of the coefficients associated with the training samples from the jth class (i.e. X.sub.j). After coefficient partitioning, a class-specific representation {tilde over (y)}.sub.j, may be computed as follows:
{tilde over (y)}.sub.j=X.sub.j{circumflex over (.alpha.)}.sup.j (16)
[0056] The class label of y can be identified by comparing the closeness between y and {tilde over (y)}.sub.j via:
class ( y ) = arg min j .di-elect cons. { 1 , 2 , , C } r j ( y ) ( 17 ) ##EQU00008##
where r.sub.j(y)=.parallel.y-{tilde over (y)}.parallel..sub.2 indicates the residual error. Thus the SRC Algorithm may be expressed as:
TABLE-US-00001 Input: Training samples {x.sub.i}.sub.i=1.sup.n .sup.d x n, class label .omega..sub.i (used for class partitioning), test sample y .sup.d,.lamda.,C (number of classes) Calculate {circumflex over (.alpha.)} via l.sub.1-minimization of equation (15) for all j .di-elect cons. {1,2,...,C} do Partition X.sub.j.alpha..sub.j Calculate r.sub.j(y) = ||y - {tilde over (y)}||.sub.2 = ||y - X.sub.j{circumflex over (.alpha.)}.sub.j||.sub.2 end for Decide class(y) via equation (17) Output: class(y)
[0057] CRC may also classify measured movements of object 104 into a type of movement. CRC is the collaborative representation (i.e., the use of all the training samples as a dictionary, but not the l.sub.1-norm sparsity constraint) to improve classification accuracy of a measured movement. The l.sub.2-regularization generates comparable results but with significantly lower computational complexity. The CRC swaps the l.sub.1 penalty in equation (15) with an l.sub.2 penalty, i.e.
.alpha. ^ = arg min .alpha. y = X .alpha. 2 2 + .theta. .alpha. 2 2 ( 18 ) ##EQU00009##
[0058] The l.sub.2-regularized minimization of equation (18) is in the form of the Tikhonov regularization, thus, leading to the following closed form solution:
{circumflex over (.alpha.)}=(X.sup.TX+.theta.1).sup.-1X.sup.Ty (19)
where I .sup.n.times.n denotes an identity matrix. The general form of the Tikhonov regularization involves a Tikhonov regularization matrix .GAMMA.. As a result, equation (18) can be expressed as:
.alpha. ^ = arg min .alpha. y = X .alpha. 2 2 + .theta. .GAMMA. .alpha. 2 2 ( 20 ) ##EQU00010##
[0059] The term .GAMMA. allows the imposition of prior knowledge on the solution, where the training samples that are most dissimilar from a test sample are given less weight than the training samples that are most similar. Specifically, the following diagonal matrix .GAMMA. .sup.n.times.n is considered:
.GAMMA. = [ y - x 1 2 0 0 y - x n 2 ] ( 21 ) ##EQU00011##
[0060] The coefficient vector d then may be calculated as follows:
{circumflex over (.alpha.)}=(X.sup.TX+.theta..GAMMA..sup.T.GAMMA.).sup.-1X.sup.Ty (22)
[0061] DMM classification logic 306 may also perform decision-level fusion of the data from the inertial sensor 106 and the depth sensor 108. For C action classes and a test sample y, the frame of discernment is given by .THETA.={H.sub.1, H.sub.2, . . . , H.sub.C}, where H.sub.j: class(y)=j,j.di-elect cons.{1, 2, . . . , C}. The classification decision of the classifiers SRC or CRC is based on the residual error with respect to class j, r.sub.j(y) using equation (17). Each class-specific representation {tilde over (y)}.sub.j and its corresponding class label j constitute a distinct item of evidence regarding the class membership of y. If y is close to {tilde over (y)}.sub.j according to the Euclidean distance, for small r.sub.j(y), it is most likely that H.sub.j is true. If r.sub.j(y) is large, the class of {tilde over (y)}.sub.1 will provide little or no information about the class of y. This may be represented by a basic probability assignment (BPA) over .THETA. defined as follows:
m(H.sub.j|{tilde over (y)}.sub.j)=.beta..PHI..sub.j(r.sub.j(y)) (23)
m(.THETA.|{tilde over (y)}.sub.j)=1- . . . .PHI..sub.j(r.sub.j(y)) (24)
m(D|{tilde over (y)}.sub.j)=0,.A-inverted.D 2.sup..THETA.\{.THETA.,H.sub.j} (25)
where .beta. is a parameter such that 0<.beta.<1, and .PHI..sub.j is a decreasing function satisfying these two conditions:
.PHI..sub.j(0)=0 (26)
lim.sub.r(y.sub.j.sub.).fwdarw..infin..PHI..sub.j(rd(y))=0 (27)
[0062] However, as there may exist many decreasing functions satisfying the two conditions listed in equations (26) and (27), the following .PHI..sub.j may be chosen:
.PHI..sub.j(r.sub.j(y))=e.sup.-.GAMMA..sup.j.sup.r.sup.j.sup.(y).sup.2 (28)
with .PHI..sub.j being a positive parameter associated with class j. To gain computational efficiency, .gamma..sub.j may be set to 1 which makes .PHI..sub.i a Gaussian function:
.PHI..sub.j(r.sub.j(y))=e.sup.-r.sup.j.sup.(y).sup.2 (29)
[0063] Since there are C class specific representations {tilde over (y)}.sub.js, the final belief regarding the class label of y may be obtained by combining the C BPAs using the Dempster's rule of combination. The resulting global BPA, m.sub.g is:
m g ( H j ) = 1 K 0 ( 1 - { 1 - .beta. .phi. j ( r j ( y ) ) } ) p .noteq. j { 1 - .beta. .phi. j ( r j ( y ) ) } , p .di-elect cons. { 1 , , C } ( 30 ) m g ( .THETA. ) = 1 K 0 j = 1 C { 1 - .beta. .phi. j ( r j ( y ) ) } ( 31 ) ##EQU00012##
where K.sub.0 is a normalization factor:
K.sub.0=.SIGMA..sub.j=1.sup.C.PI..sub.p.noteq.j{1-.beta..PHI..sub.j(r.su- b.j(y))}+(1-C).ANG..sub.j=1.sup.C{1-.beta..PHI..sub.j(r.sub.j(y))} (32)
[0064] To effectuate the decision-level fusion, SRC or CRC is first applied to the depth feature set U and inertial feature set V, respectively. Therefore, two corresponding global BPAs, m.sub.g,1 and m.sub.g, 2, are generated. The combined BPA from m.sub.q, 1 and m.sub.g, 2 then may be obtained via the Dempster-Shafer Theory. The class label of a new test sample is determined by which corresponds to the maximum value of Bel(H.sub.j), (i.e. max(Bel(H.sub.j))).
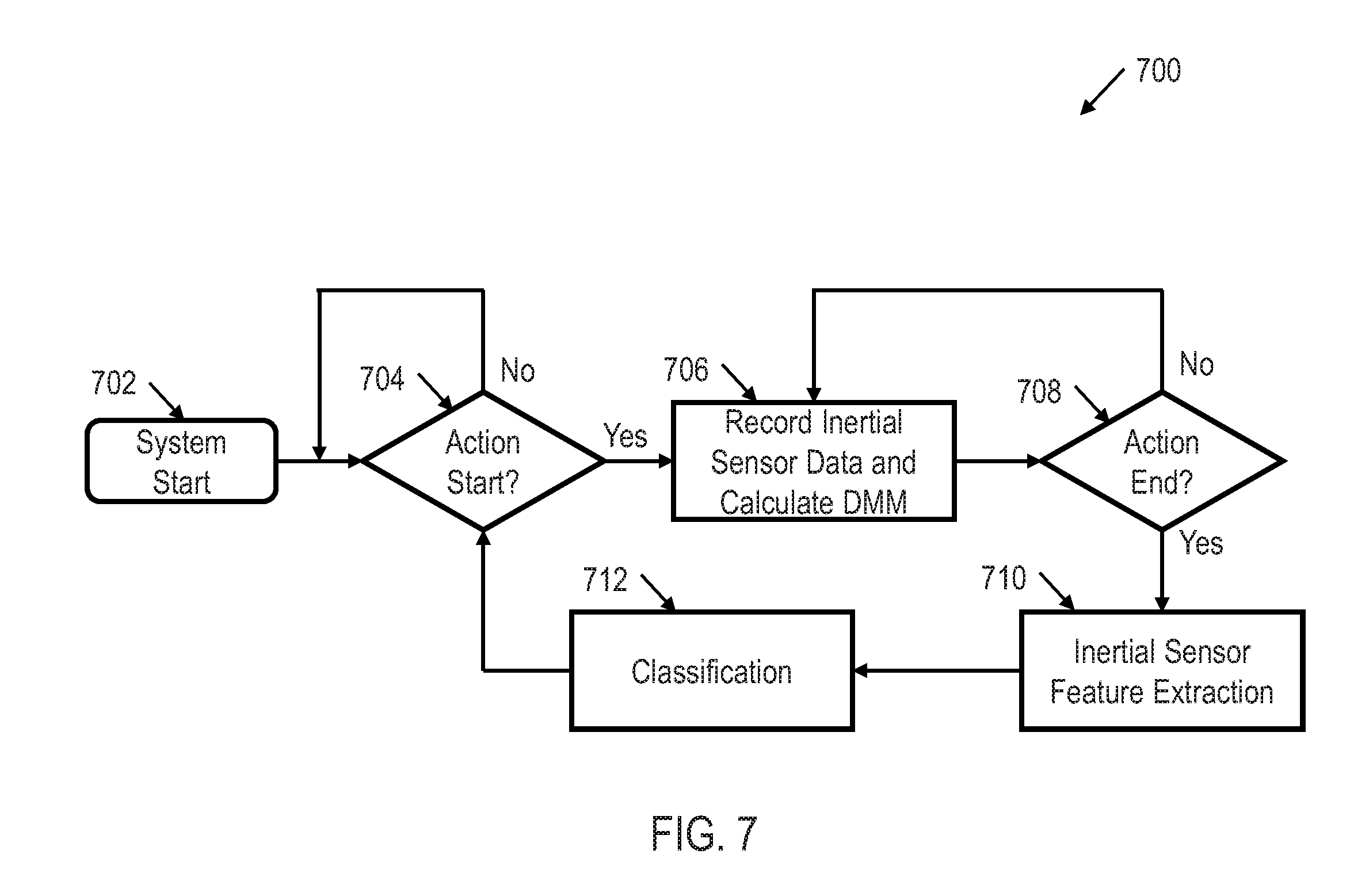
[0065] FIG. 7 shows an illustrative flow diagram of a real time movement recognition method 700 utilizing DMM classification logic 306 in accordance with various embodiments. Though depicted sequentially as a matter of convenience, at least some of the actions shown can be performed in a different order and/or performed in parallel. Additionally, some embodiments may perform only some of the actions shown.
[0066] The method 700 begins in block 702 with starting the system. In block 704 a decision is made as to whether action and/or movement of the object 104 has begun. If not, the method 700 continues determining whether action and/or movement of the object 104 has begun until it does begin. If action and/or movement of the object 104 has begun, then the method 700 continues in block 706 with recording inertial sensor data and calculating the DMM as discussed above. The method 700 continues in block 708 with determining whether the action and/or movement of the object 104 has ended. If not, the method 700 continues in block 706 with further recording inertial sensor data and calculating the DMM as discussed above. However, if the action and/or movement of the object 104 has ended in block 708, then the method 700 continues in block 710 with extracting the inertial feature set from the signal representative of the measured first unit of inertia. In block 712, the method 712 continues with classifying and/or determining the type of movement of the object 104. The method continues in block 704 with determining whether another action and/or movement of the object 104 has begun. In this way, DMM classification logic 306 continually and in real time performs movement recognition.
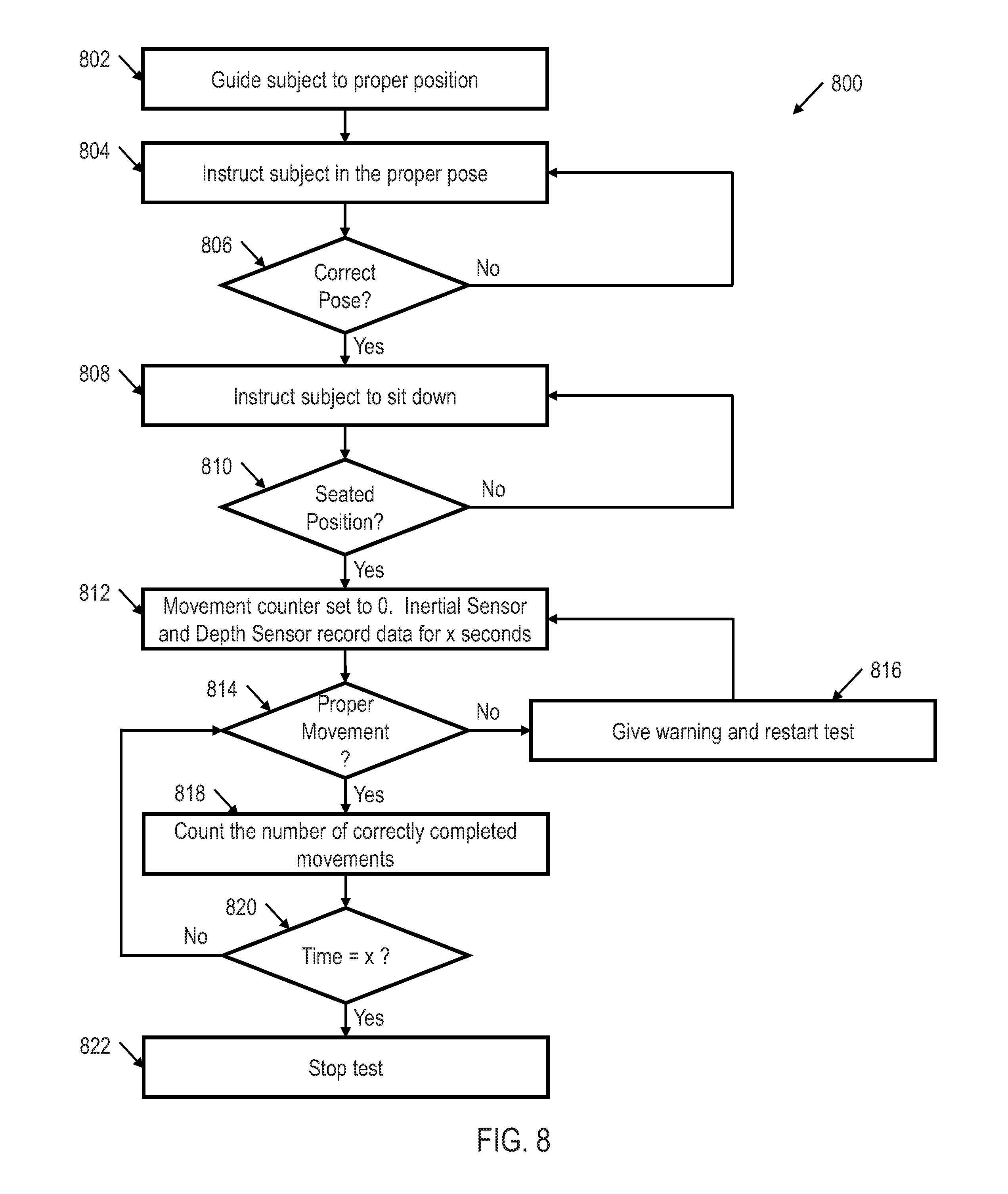
[0067] Returning to FIG. 3, processor 202 may also include testing logic 308. Testing logic may be configured to test and/or evaluate tests, utilizing the classifications and/or types of movements determined by single HMM classification logic 302, multi-HMM classification logic 304, and/or DMM classification logic 306. For example, FIG. 8 shows an illustrative flow diagram of a fitness test method 800 utilizing movement recognition system 100 that may be evaluated by testing logic 308 in accordance with various embodiments. Though depicted sequentially as a matter of convenience, at least some of the actions shown can be performed in a different order and/or performed in parallel. Additionally, some embodiments may perform only some of the actions shown.
[0068] The method 800 begins in block 802 with instructing and/or guiding a subject to position an object in a proper position. For example, the object may be a human, and the instructions provided to the human may be to properly position the human in the correct position to perform a fitness test. Similarly, in block 804, the method 800 continues with instructing the subject to pose the object in a proper position. Continuing the previous example, the subject may need to pose properly to perform the test. In block 804 a determination is made as to whether the object is posed properly. If the object is not posed properly, the method 800 continues in block 804 with again instructing the subject to pose the object in a proper position. However, if the subject is posed properly, then the method continues in block 808 with instructing the subject to sit down. In block 810, the method continues with determining whether the subject is in a seated position. If the subject is not in a seated position, the method 800 continues in block 808 with again instructing the subject to sit down. However, if the subject is in the seated position, then the method 800 continues in block 812 with setting the movement counter to 0 and causing the inertial sensor and depth sensor to record data for x seconds (e.g., for thirty seconds).
[0069] In block 814, utilizing the results from single HMM classification logic 302, multi-HMM classification logic 304, and/or DMM classification logic 306, the method 800 continues with determining whether the subject is performing the correct type of movements and/or movement classifications. This may be accomplished by comparing the classified movement type performed by the subject with a predefined intended movement type. If the subject is not performing the correct type of movements and/or movement classifications, then the method 800 continues in block 816 with giving a warning to the subject and restarting the test. The method then continues back in block 812 with setting the movement counter to 0. However, if in block 814 a determination is made that the subject is performing the correct type of movements and/or movement classifications, then the method 800 continues in block 818 with counting the number of correctly completed movements. In block 820, the method 800 continues with determining whether x seconds have been completed. If not, then the method continues in block 814 with determining whether the subject is properly completing the correct type of movements and/or movement classifications. However, if in block 820 a determination is made that x seconds have been completed, then the test stops in block 822. Method 800 is just one of many tests and/or applications that may be performed utilizing testing logic 308 and the movement recognition of single HMM classification logic 302, multi-HMM classification logic 304 and/or COMM classification logic 306.
[0070] The above discussion is meant to be illustrative of the principles and various embodiments of the present invention. Numerous variations and modifications will become apparent to those skilled in the art once the above disclosure is fully appreciated. It is intended that the following claims be interpreted to embrace all such variations and modifications.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007

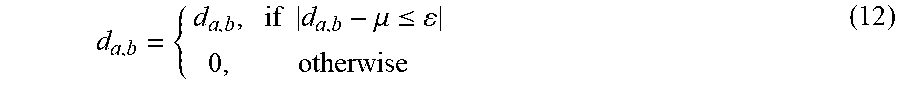
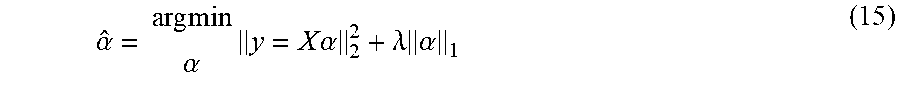




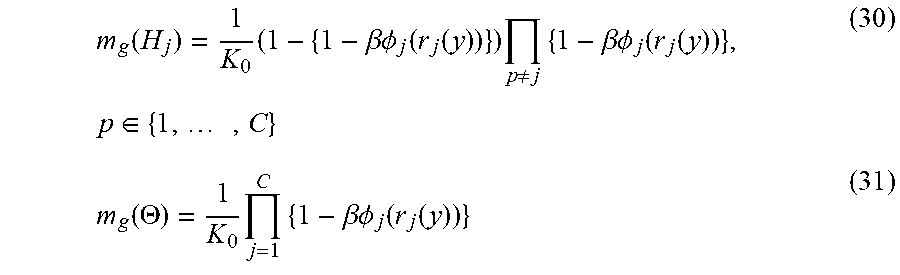
P00001
P00002
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.