System and Method for Targeted Depletion of Nucleic Acids
Bouriakov; Venera ; et al.
U.S. patent application number 15/423850 was filed with the patent office on 2019-09-19 for system and method for targeted depletion of nucleic acids. The applicant listed for this patent is Roche Sequencing Solutions, Inc.. Invention is credited to Venera Bouriakov, Daniel Burgess.
| Application Number | 20190284602 15/423850 |
| Document ID | / |
| Family ID | 63039159 |
| Filed Date | 2019-09-19 |





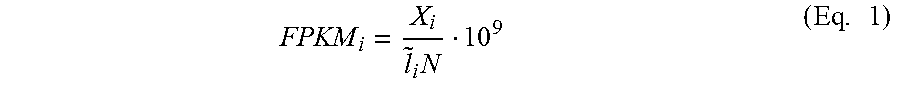


View All Diagrams
| United States Patent Application | 20190284602 |
| Kind Code | A9 |
| Bouriakov; Venera ; et al. | September 19, 2019 |
System and Method for Targeted Depletion of Nucleic Acids
Abstract
The present disclosure provides a system and method for depleting target nucleic acids from a nucleic acid sample. In one aspect, a kit according to the present disclosure includes a plurality of DNA probes. Each of the DNA probes is hybridizable to form a heteroduplex with at least one of a plurality of target RNA transcripts in a nucleic acid sample. The number of unique target RNA transcripts hybridized by the plurality of DNA probes is at least three. The kit further includes an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity, where degrades at least the RNA portion of the heteroduplex.
| Inventors: | Bouriakov; Venera; (Madison, WI) ; Burgess; Daniel; (Madison, WI) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Prior Publication: |
|
||||||||||
| Family ID: | 63039159 | ||||||||||
| Appl. No.: | 15/423850 | ||||||||||
| Filed: | February 3, 2017 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 62295307 | Feb 15, 2016 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | C12Y 301/26004 20130101; C12Q 1/6806 20130101; C12Q 2537/113 20130101; C12Q 2521/327 20130101; C12Q 2535/122 20130101; C12N 9/22 20130101; C12Q 1/6806 20130101 |
| International Class: | C12Q 1/68 20060101 C12Q001/68; C12N 9/22 20060101 C12N009/22 |
Claims
1.-11. (canceled)
12. A method for depleting target nucleic acids from a nucleic acid sample, the method comprising: hybridizing a plurality of deoxyribonucleic acid (DNA) probes with a plurality of target ribonucleic acid (RNA) transcripts in a nucleic acid sample, each of the DNA probes forming a heteroduplex with at least one of the plurality of target RNA transcripts; and treating the heteroduplex with an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity, thereby degrading at least the RNA portion of the heteroduplex, wherein the number of unique target RNA transcripts hybridized by the plurality of DNA probes is at least 3.
13. The method of claim 12, wherein the number of unique DNA probes is at least 100.
14. The method of claim 12, wherein the fraction of the total number of bases of each target RNA transcript hybridizable by the DNA probes is at least 0.5.
15. The method of claim 12, wherein the fraction of the total number of bases of each target RNA transcript hybridizable by the DNA probes is at least 0.75.
16. The method of claim 12, wherein the fraction of the total number of bases hybridizable by the DNA probes is at least 0.9.
17. The method of claim 12, wherein the number of unique target RNA transcripts hybridized by the plurality of DNA probes is at least 10.
18. The method of claim 12, wherein the number of unique target RNA transcripts hybridized by the plurality of DNA probes is at least 100.
19. The method of claim 12, wherein the DNA probes are hybridizable along the length of each of the target RNA transcripts with a regular spacing, wherein for each pair of adjacently hybridizable DNA probes, the 3' end of a first one of the pair of DNA probes is spaced apart from the 5' end of a second one of the pair of DNA probes by a nucleotide interval relative to the target RNA transcript.
20. The method of claim 19, wherein the nucleotide interval is less than about 50.
21. The method of claim 19, wherein the interval of nucleotides is less than about 10.
22. The method of claim 12, further comprising depleting the quantity of the target RNA transcripts by at least about 50%.
23. The method of claim 12, further comprising depleting the quantity of the target RNA transcripts by at least about 80%.
24.-26. (canceled)
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application is based on, claims the benefit of, and incorporates herein by reference, U.S. Provisional Patent Application Ser. No. 62/295,307 filed 15 Feb. 2016 and entitled, "System and Method for Targeted Depletion of Nucleic Acids".
STATEMENT REGARDING FEDERALLY SPONSORED RESEARCH
[0002] Not applicable.
BACKGROUND OF THE INVENTION
[0003] The disclosure relates, in general, to targeted depletion of nucleic acids and, more particularly, to a system and method for degrading selected nucleic acids polymers amongst a broader population of nucleic acids.
[0004] Whole transcriptome sequencing, also known as RNA-sequencing or RNA-seq, is a useful technique for characterizing the total gene expression of a biological sample. In this technique, RNA (either total or poly-A selected) is converted into cDNA using reverse transcriptase, followed by second-strand synthesis, addition of sequencing adapters, and high-throughput sequencing. One challenge associated with this approach is that only a very few genes (e.g., less than about ten) account for the vast majority of transcripts expressed in any particular tissue or cell type. As a result, the major portion of a given set of sequencing reads are derived from the most highly expressed genes, whereas a small portion of the sequencing reads are derived from the genes having the lowest expression levels. For example, ribosomal RNA (rRNA) can represent 90% or more of the material in a human total RNA sample. For experiments where the remaining 10% or less of the material in the sample may be relevant for a given experiment, the presence of rRNA can consume costly sequencing reagents, obscure the presence of low expression level transcripts, decrease experimental throughput, the like, or combinations thereof. The aforementioned approach to RNA-seq is therefore inefficient for studying the expression patterns and transcript structures of lowly expressed genes that may have important biological functions. Accordingly, what is needed is a new experimental approach that mitigates the detrimental effects that highly abundant transcripts can have on the efficient analysis of RNA.
SUMMARY OF THE INVENTION
[0005] The present invention overcomes the aforementioned drawbacks by providing a system and method for targeted depletion of nucleic acids.
[0006] In accordance with one embodiment of the present disclosure, a kit for depleting target nucleic acids from a nucleic acid sample includes a plurality of deoxyribonucleic acid (DNA) probes, each of the DNA probes hybridizable to form a heteroduplex with at least one of a plurality of target ribonucleic acid (RNA) transcripts in a nucleic acid sample, where the number of unique target RNA transcripts hybridized by the plurality of DNA probes is at least 3. The kit further includes an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity, where the enzyme degrades at least the RNA portion of the heteroduplex.
[0007] In one aspect, the number of unique DNA probes is at least 10.
[0008] In one aspect, the number of unique DNA probes is at least 100.
[0009] In another aspect, the fraction of the total number of bases of each target RNA transcript hybridizable by the DNA probes is at least 0.5.
[0010] In another aspect, the fraction of the total number of bases hybridizable by the DNA probes is at least 0.75.
[0011] In another aspect, the fraction of the total number of bases hybridizable by the DNA probes is at least 0.9.
[0012] In another aspect, the number of unique target RNA transcripts hybridized by the plurality of DNA probes is at least 10.
[0013] In another aspect, the number of unique target RNA transcripts hybridized by the plurality of DNA probes is at least 100.
[0014] In another aspect, the DNA probes are hybridizable along the length of each of the target RNA transcripts at a regular spacing, where for each pair of adjacently hybridizable DNA probes, the 3' end of a first one of the pair of DNA probes is spaced apart from the 5' end of a second one of the pair of DNA probes by a nucleotide interval relative to the target RNA transcript.
[0015] In another aspect, the nucleotide interval is less than about 50.
[0016] In another aspect, the nucleotide interval is less than about 10.
[0017] In accordance with another embodiment of the present disclosure, a method for depleting target nucleic acids from a nucleic acid sample includes hybridizing a plurality of deoxyribonucleic acid (DNA) probes with a plurality of target ribonucleic acid (RNA) transcripts in a nucleic acid sample, each of the DNA probes forming a heteroduplex with at least one of the plurality of target RNA transcripts. The method further includes treating the heteroduplex with an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity, thereby degrading at least the RNA portion of the heteroduplex. The number of unique target RNA transcripts hybridized by the plurality of DNA probes is at least 3.
[0018] In one aspect, the number of unique DNA probes is at least 10.
[0019] In one aspect, the number of unique DNA probes is at least 100.
[0020] In another aspect, the fraction of the total number of bases of each target RNA transcript hybridizable by the DNA probes is at least 0.5.
[0021] In another aspect, the fraction of the total number of bases hybridizable by the DNA probes is at least 0.75.
[0022] In another aspect, the fraction of the total number of bases hybridizable by the DNA probes is at least 0.9.
[0023] In another aspect, the number of unique target RNA transcripts hybridized by the plurality of DNA probes is at least 10.
[0024] In another aspect, the number of unique target RNA transcripts hybridized by the plurality of DNA probes is at least 100.
[0025] In another aspect, the DNA probes are hybridizable along the length of each of the target RNA transcripts with a regular spacing, where for each pair of adjacently hybridizable DNA probes, the 3' end of a first one of the pair of DNA probes is spaced apart from the 5' end of a second one of the pair of DNA probes by a nucleotide interval relative to the target RNA transcript.
[0026] In another aspect, the nucleotide interval is less than about 50.
[0027] In another aspect, the interval of nucleotides is less than about 10.
[0028] In another aspect, the method further includes depleting the quantity of the target RNA transcripts by at least about 50%.
[0029] In another aspect, the method further includes depleting the quantity of the target RNA transcripts by at least about 80%.
[0030] In accordance with another embodiment of the present disclosure, a method for depleting target nucleic acids from a nucleic acid sample includes selecting a plurality of target ribonucleic acid (RNA) transcripts to deplete from a nucleic acid sample, each of the target RNA transcripts derived from a corresponding deoxyribonucleic acid (DNA) having a known sequence. The method further includes synthesizing a plurality of DNA probes hybridizable to form a heteroduplex with at least one of the plurality of target RNA transcripts, hybridizing the plurality of DNA probes with the target RNA transcripts in the nucleic acid sample, each of the DNA probes forming a heteroduplex with at least one of the plurality of target RNA transcripts, and treating the heteroduplex with an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity, thereby degrading at least the RNA portion of the heteroduplex. The number of unique target RNA transcripts hybridized by the plurality of DNA probes is at least 3.
[0031] In one aspect, the method further includes designing the plurality of DNA probes to hybridize along the length of each of the target RNA transcripts with a regular spacing, wherein for each pair of adjacently hybridizable DNA probes, the 3' end of a first one of the pair of DNA probes is spaced apart from the 5' end of a second one of the pair of DNA probes by a nucleotide interval relative to the target RNA transcript.
[0032] In another aspect, the nucleotide interval is less than about 50.
[0033] The foregoing and other aspects and advantages of the invention will appear from the following description. In the description, reference is made to the accompanying drawings which form a part hereof, and in which there is shown by way of illustration a preferred embodiment of the invention. Such embodiment does not necessarily represent the full scope of the invention, however, and reference is made therefore to the claims and herein for interpreting the scope of the invention.
BRIEF DESCRIPTION OF THE DRAWINGS
[0034] FIG. 1 is a schematic illustration showing a broad overview of a system and method for targeted depletion of nucleic acids according to the present disclosure.
[0035] FIG. 2 is a schematic flow diagram illustrating an embodiment of a method for targeted depletion of target RNA transcripts from a nucleic acid sample.
[0036] FIG. 3 is a schematic illustration of various embodiments of DNA probe designs for use with a system and method for depletion of target RNA transcripts from a nucleic acid sample according to the present disclosure.
[0037] FIG. 4 is a schematic illustration of yet other embodiments of DNA probe designs for use with a system and method for depletion of target RNA transcripts from a nucleic acid sample according to the present disclosure. N is used to represent any nucleotide, and vertical lines extending between nucleotides are used to represent base pairing.
[0038] FIG. 5 is a schematic illustration detailing an embodiment of a method for depletion of target RNA transcripts from a nucleic acid sample according to the present disclosure.
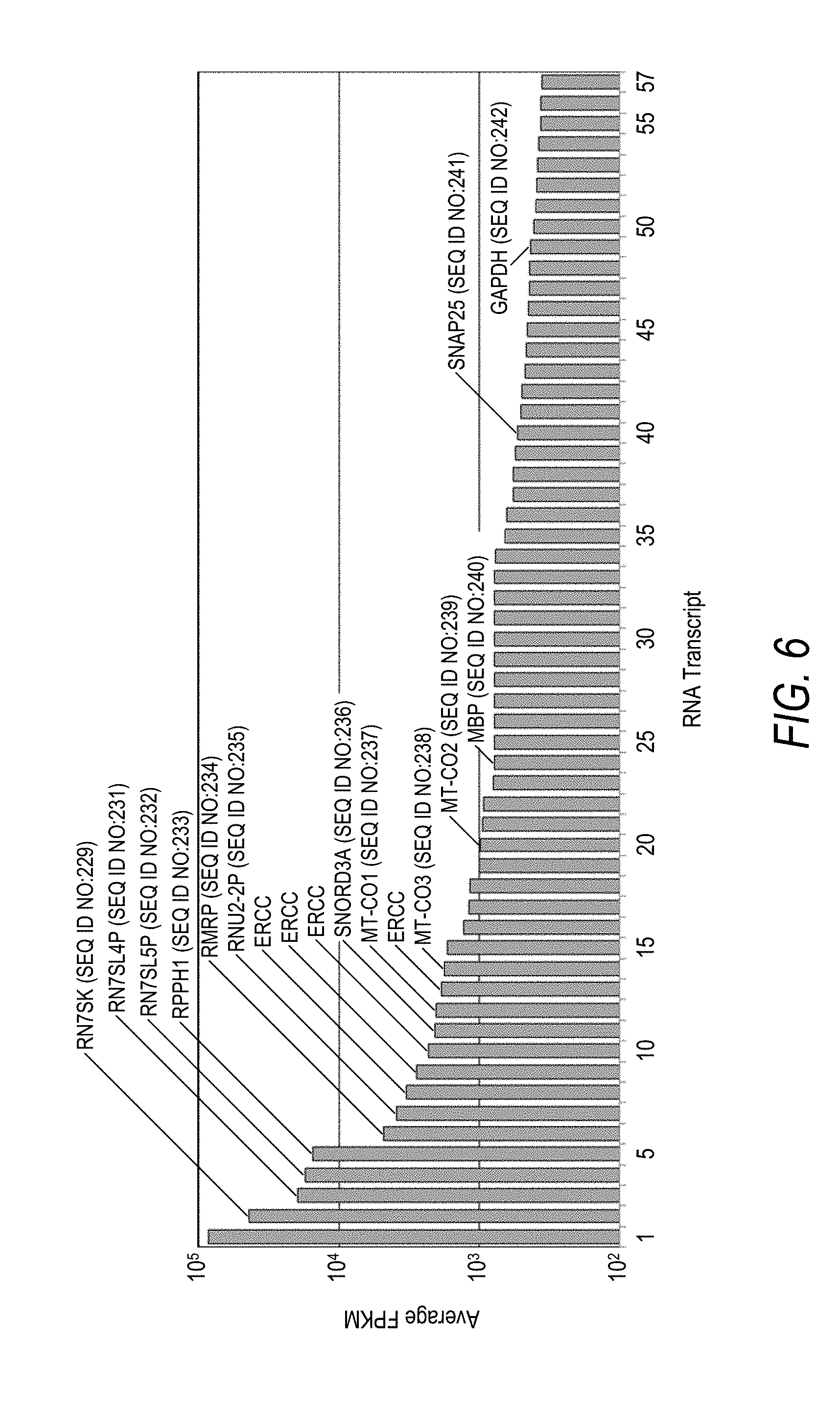
[0039] FIG. 6 is a plot of average FPKM values for the most abundant RNA transcripts from human brain total RNA as determined by sequencing. Four RNA-Seq experiments were performed with human brain total RNA. FPKM values were calculated and the most abundant transcripts were identified from each of the four experiments and plotted in order of descending average FPKM value. Data corresponding to RNA transcripts targeted for depletion in subsequent experiments are denoted along with data corresponding to ERCC spike-in controls (ERCC). Of the 57 data points shown, the 14 RNA transcripts selected for depletion were RN7SL1 (SEQ ID NO:229) (1), RN7SK (SEQ ID NO:230) (2), RN7SL4P (SEQ ID NO:231) (3), RN7SL5P (SEQ ID NO:232) (4), RPPH1 (SEQ ID NO:233) (5), RMRP (SEQ ID NO:234) (6), RNU2-2P (SEQ ID NO:235) (7), SNORD3A (SEQ ID NO:236) (11), MT-CO1 (SEQ ID NO:237) (12), MT-CO3 (SEQ ID NO:238) (14), MT-CO2 (SEQ ID NO:239) (20), MBP (SEQ ID NO:240) (24), SNAP25 (SEQ ID NO:241) (40), and GAPDH (SEQ ID NO:242) (49).
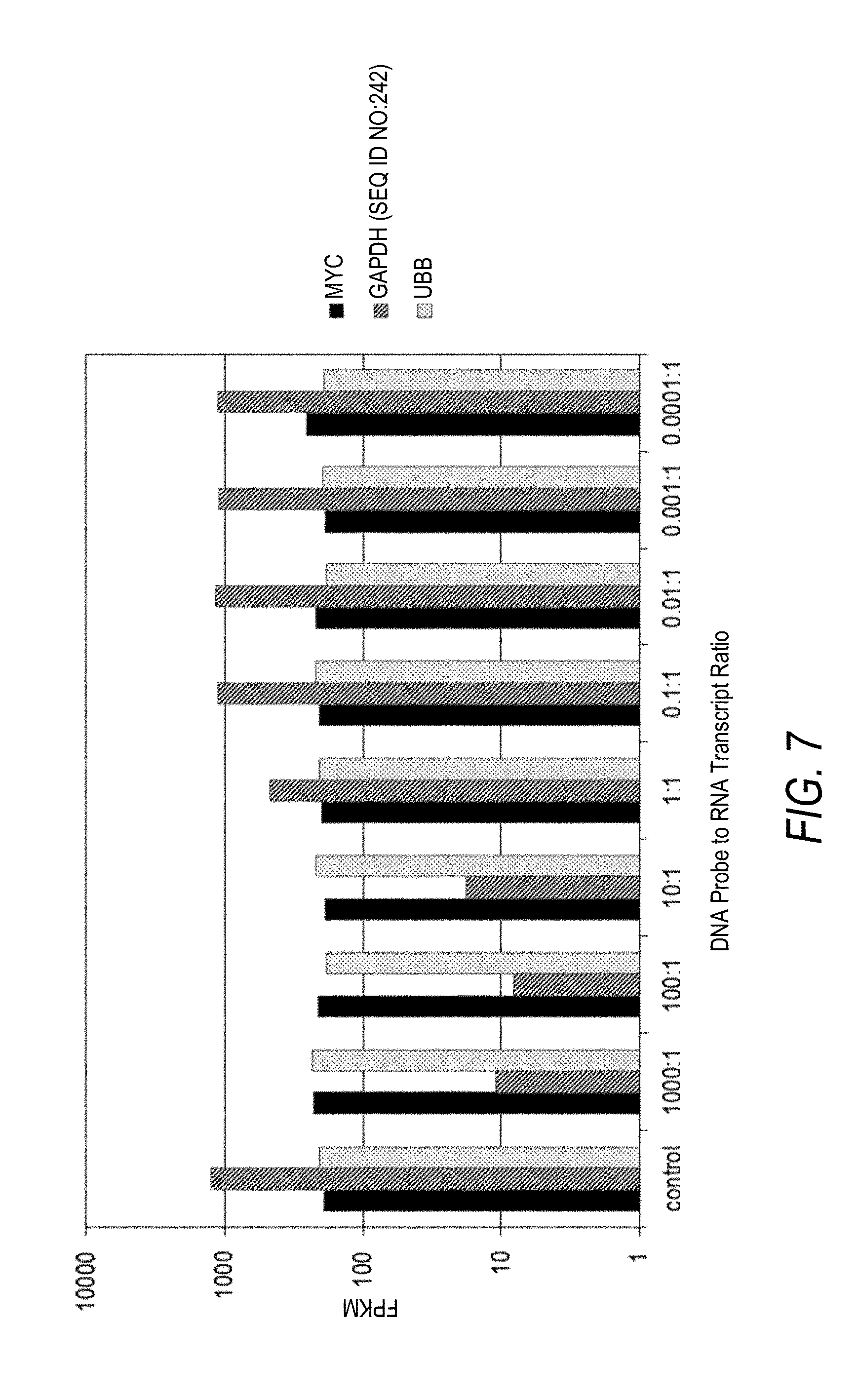
[0040] FIG. 7 is a plot of FPKM values for three unique RNA transcripts as a function of DNA probe to target RNA transcript ratio for nine separate depletion experiments. DNA probes designed for depletion of GAPDH (SEQ ID NO:242) target RNA transcripts were added to total RNA samples at a DNA probe to GAPDH (SEQ ID NO:242) target RNA transcript ratio of 1000:1, 100:1, 10:1, 1:1, 0.1:1, 0.01:1, 0.001:1, or 0.0001:1. Control data were collected for a total RNA sample with DNA probes targeting GAPDH (SEQ ID NO:242) omitted (control). The effect of DNA probe to GAPDH (SEQ ID NO:242) target RNA ratio on measured FPKM following depletion and sequencing was compared against untargeted RNA transcripts MYC and UBB.
[0041] FIG. 8 is a plot of FPKM values for thirteen unique RNA transcripts as a function of DNA probe to target RNA transcript ratio for three separate depletion experiments. DNA probes designed for depletion of GAPDH (SEQ ID NO:242) target RNA transcripts were added to total RNA samples at a DNA probe to GAPDH (SEQ ID NO:242) target RNA transcript ratio of 1:10 or 1:100. Control data were collected for a total RNA sample with DNA probes targeting GAPDH (SEQ ID NO:242) omitted (control). The effect of DNA probe to GAPDH (SEQ ID NO:242) target RNA ratio on measured FPKM following depletion and sequencing was compared against a number of untargeted RNA transcripts including a selection of the most abundant RNA transcripts as shown in FIG. 6. Untargeted RNA transcripts compared against GAPDH (SEQ ID NO:242) included UBB, RN7SL1 (SEQ ID NO:229), RN7SK (SEQ ID NO:230), RPPH1 (SEQ ID NO:233), RMRP (SEQ ID NO:234), RNU2-2P (SEQ ID NO:235), SNORD3A (SEQ ID NO:236), MT-CO1 (SEQ ID NO:237), MT-CO3 (SEQ ID NO:238), MT-CO2 (SEQ ID NO:239), MBP (SEQ ID NO:240), and SNAP25 (SEQ ID NO:241).
[0042] FIG. 9 is a plot of FPKM values for thirteen unique RNA transcripts targeted for depletion as a function of DNA probe to target RNA transcript ratio for five separate depletion experiments. DNA probes designed for depletion of thirteen unique RNA transcripts were added to total RNA samples at a DNA probe to target RNA transcript ratio of 1:1, 1:5, 1:10, or 1:100. Control data were collected for a total RNA sample with DNA probes targeting the thirteen unique RNA transcripts omitted (control). The effect of DNA probe to target RNA transcript ratio on measured FPKM following depletion and sequencing was compared against untargeted RNA transcripts including GAPDH (SEQ ID NO:242) and UBB. The thirteen unique target RNA transcripts included RN7SL1 (SEQ ID NO:229), RN7SK (SEQ ID NO:230), RN7SL4P (SEQ ID NO:231), RN7SL5P (SEQ ID NO:232), RPPH1 (SEQ ID NO:233), RMRP (SEQ ID NO:234), RNU2-2P (SEQ ID NO: 235), SNORD3A (SEQ ID NO:236), MT-CO1 (SEQ ID NO:237), MT-CO3 (SEQ ID NO:238), MT-CO2 (SEQ ID NO:239), MBP (SEQ ID NO:240), and SNAP25 (SEQ ID NO:241).
DETAILED DESCRIPTION OF THE INVENTION
[0043] As also discussed above, in various situations it may be useful to employ techniques such as RNA-seq to determine the sequences and relative abundance of transcripts in an RNA sample. In general, RNA is first converted (e.g., reverse transcribed) into complementary DNA (cDNA), and then the cDNA is converted into double-stranded DNA (dsDNA), ligated to sequencing adapters, and sequenced. The sequencing reads, usually numbering in the millions, are analyzed using standard bioinformatics methods to determine which genes and transcript variants the sequencing reads represent. However, the relative abundance of different transcripts in an RNA sample can vary considerably between different cells and different tissues, at different developmental stages, and as a consequence of disease or environmental stimuli. This can present a significant challenge when the goal of an RNA-seq experiment is to study transcripts that are present in the sample at a much lower relative abundance, because most of the sequencing reads generated in an RNA-seq experiment are derived from high-abundance transcripts (e.g., rRNA molecules) while relatively few are derived from the transcripts of interest.
[0044] One approach to compensate for imbalances in transcript abundance is simply to generate more sequencing reads in the RNA-seq experiment, so that an adequate amount of data for analysis can be obtained for lowly expressed transcripts of interest. However, increased sequencing imposes increased time and reagent requirements, thereby resulting in an inefficient and costly solution. Another approach to compensate for imbalances in transcript abundance is targeted depletion of individual high-abundance transcript such as rRNA or alpha-globin and beta-globin. Specific methods developed to exclusively deplete RNA samples prior to sequencing include: (i) hybridization of biotinylated capture probes to rRNA or alpha-globin and beta-globin, and removal of the hybridized complexes from the sample via binding to streptavidin-coated magnetic beads, (ii) poly-A RNA purification, which does not select for non-polyadenylated RNA molecules such as rRNA, and (iii) hybridization of DNA probes complementary to rRNA followed by enzymatic fragmentation of the RNA component of the DNA-RNA duplexes via RNase H treatment.
[0045] Each of the aforementioned rRNA depletion techniques are more or less effective for reducing sequencing reads derived from either rRNA or globin in RNA-seq experiments. Nonetheless, other categories of RNA molecules may still be much more highly expressed than the transcripts of interest. Accordingly, it may be useful to remove additional or alternative RNA molecules to further increase the proportion of sequencing reads derived from transcripts of interest. However, an efficient, targeted method for simultaneously depleting several (i.e., greater than two) of the most highly expressed transcripts from an RNA sample in an RNA-Seq workflow has not yet been demonstrated. Moreover, current commercial products for targeted depletion of rRNA or globin transcripts are specific for a particular source of RNA (e.g., human RNA), and consequently are not useful for treating RNA derived from other sources.
[0046] These and other challenges may be overcome with a system and method for targeted depletion of nucleic acids according to the present disclosure. In one embodiment of the present disclosure, a method is provided for depleting target nucleic acids from a nucleic acid sample. The method includes the use of a collection of DNA probes designed to selectively and specifically hybridize with multiple different target RNA transcripts in a nucleic acid sample. The resulting DNA:RNA heteroduplexes are then treated with an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity to degrade the RNA portion of the heteroduplex, thereby depleting the target RNA transcripts from the nucleic acid sample while leaving the rest of the nucleic acid sample intact. By enabling depletion of the target RNA transcripts, the untargeted RNA transcripts are enriched within the nucleic acid sample. The enriched nucleic acid sample permits more efficient downstream analysis as various reagents and other sequencing resources are not consumed or occupied by material derived from RNA transcripts of little to no experimental interest (e.g., highly expressed RNAs).
[0047] Embodiments of the present disclosure have several further advantages over known approaches for targeted depletion of RNA. In one aspect, DNA probes can be designed to target more than just one or two target RNA transcripts for depletion at a time. For example, embodiments of the present disclosure stem from the surprising discovery that DNA probes can be designed to target at least ten or more target RNA transcripts simultaneously. Further, the probes can be customized for a particular RNA sample derived from any cell or tissue as long as the nucleic acid sequences of the target RNA transcripts are known or can be determined. With respect to the DNA probes for targeted depletion, parameters such as the number, spacing, length, concentration, or combinations thereof can be tuned to achieve a specified degree of target RNA transcript depletion. For example, one or more of the aforementioned parameters can be varied according to the present disclosure in order to reduce the concentration of a target RNA transcript in a nucleic acid sample by up to 90% or greater.
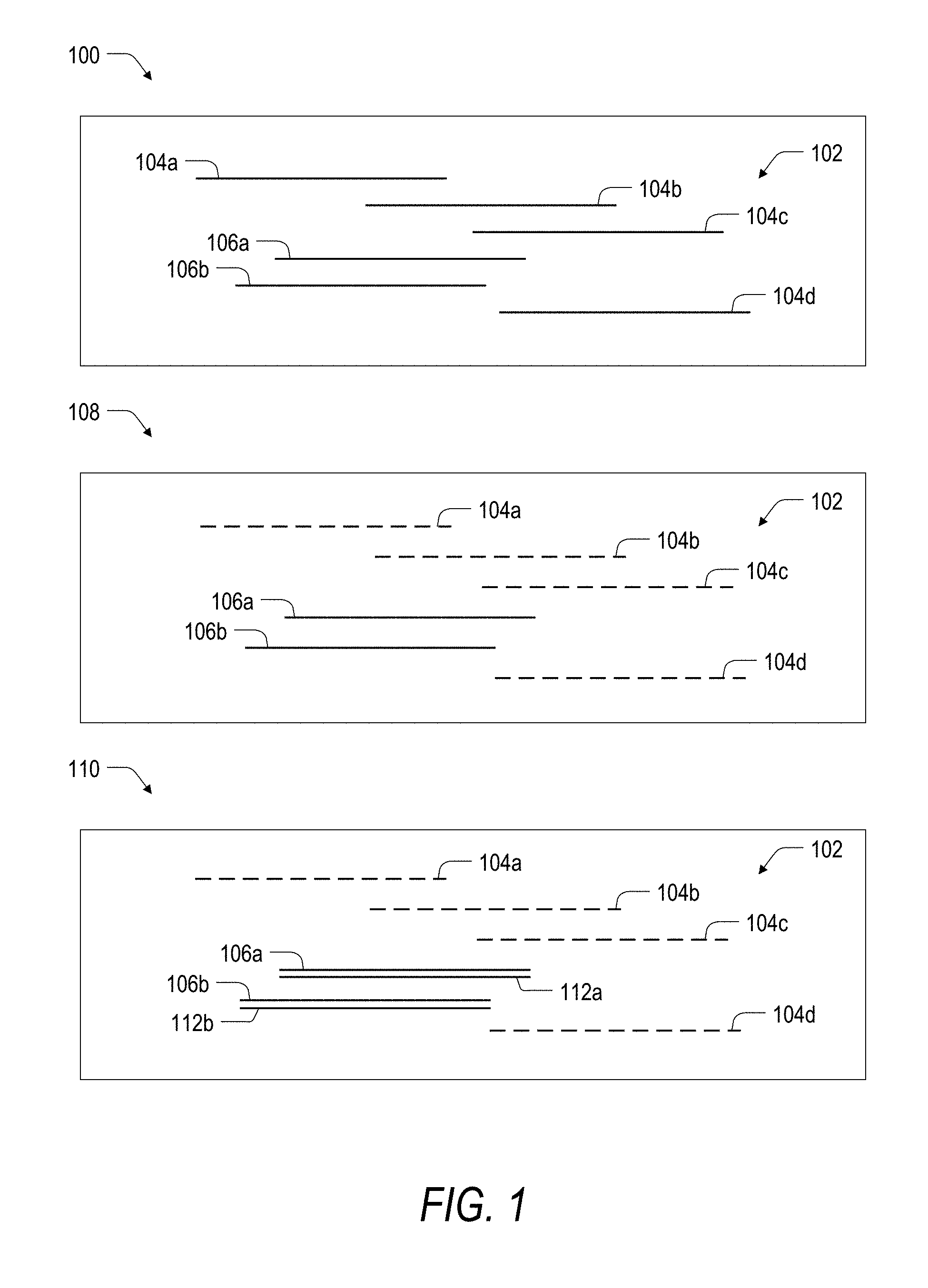
[0048] Turning now to FIG. 1, a system and method for targeted nucleic acid depletion is broadly illustrated as including three phases. In a first phase 100, a nucleic acid sample 102 is provided for depletion of target RNA transcripts. The nucleic acid sample 102 includes a plurality of unique target RNA transcripts 104a, 104b, 104c, and 104d (collectively, target RNA transcripts 104), as well as a number of unique untargeted RNA transcripts 106a and 106b (collectively, untargeted RNA transcripts 106). While the nucleic acid sample 102 in FIG. 1 is illustrated as including only a few unique RNA transcripts, it will be appreciated that the nucleic acid sample 102 or another nucleic acid sample for use with the present disclosure can include any number of unique targeted or untargeted RNA transcripts. A unique RNA transcript is defined herein as an RNA transcript having a unique nucleic acid sequence or portion thereof. That is, a first RNA transcript derived, for example, from a first DNA sequence can be said to be unique relative to a second RNA transcript derived from a second DNA sequence different from the first DNA sequence. Notably, the two or more copies of an RNA transcript identically derived from the first DNA sequence would not be considered to be unique with respect to each other. Further, if the first RNA transcript was to become degraded, fragmented, or otherwise broken down into two or more constituent parts, then each of the individual parts of the first RNA transcript would not be considered to be unique RNA transcripts relative to one another.
[0049] With continued reference to FIG. 1, the present disclosure provides for targeted depletion of the target RNA transcripts 104, while leaving the untargeted RNA transcripts 106 intact. The result is that the untargeted RNA transcripts 106 are ultimately enriched within the nucleic acid sample 102. Accordingly, in a second phase 108, each of the target RNA transcripts 104 are selectively degraded (or otherwise depleted) as indicated by the dashed lines while the untargeted RNA transcripts 106 are left intact as indicated by the solid lines. To degrade the target RNA transcripts 104, a plurality of DNA probes (not shown) are specifically hybridized to the target RNA transcripts, and the resulting DNA:RNA heteroduplexes are treated with an enzyme (not shown) having RNA-DNA hybrid ribonucleotidohydrolase activity such that the enzyme degrades the RNA portion of the heteroduplex.
[0050] Finally, in a third phase 110, the nucleic acid sample 102 can be further prepared for sequencing or other downstream analysis. Treatment of the nucleic acid sample 102 will typically include first strand cDNA synthesis using the untargeted RNA transcripts 106 as templates. In particular, a first strand cDNA 112a can be prepared from the untargeted RNA transcript template 106a, while a first strand cDNA 112b can be prepared from the untargeted RNA transcript template 106b. In one aspect, the length (i.e., number of nucleotides) of each of the degraded target RNA transcripts 104 may be too small to be useful as templates for first strand cDNA synthesis. In another aspect, the untargeted RNA transcripts 106 may be purified away from the degraded target RNA transcripts (e.g., using a size-based separation technique) prior to first strand cDNA synthesis or other downstream treatment step.
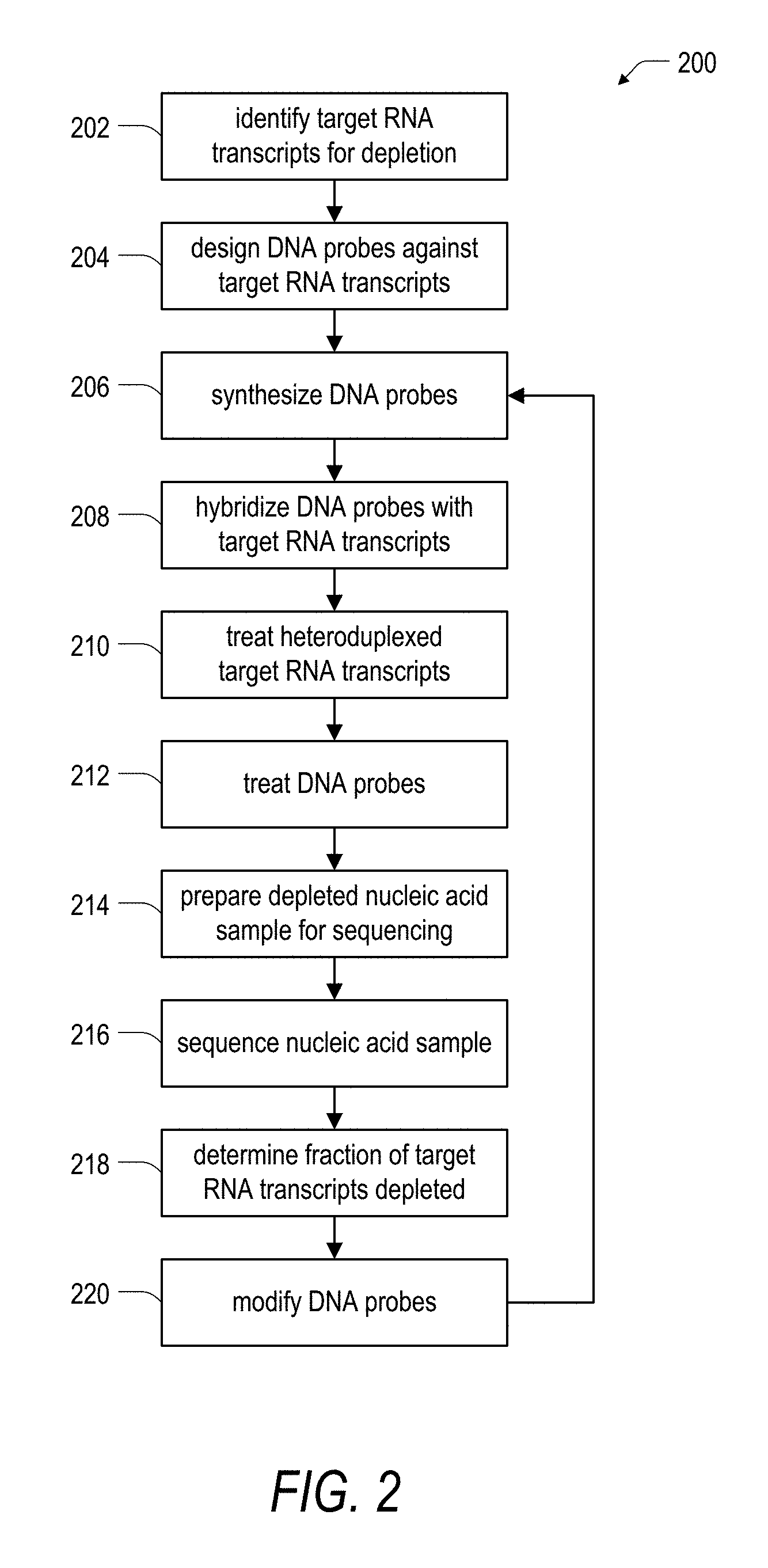
[0051] Turning now to FIG. 2, a method 200 for targeted depletion of a nucleic acids is outlined in greater detail. A step 202 of the method 200 includes identifying target RNA transcripts for depletion from a larger nucleic acid sample. The nucleic acid sample can include RNA derived from any cell, tissue, or other source of RNA. The nucleic acid sample can further include additional components (e.g., DNA, protein, lipids, salts, or the like); however, it may be useful to purify the RNA away from one or more of the additional components in the case that these additional components interfere with or otherwise reduce the efficacy of the method 200. Examples of target RNA transcripts include highly expressed or abundant RNAs, ribosomal RNAs, pseudogene transcripts, untranslated RNAs, all known RNA transcripts, any RNA transcript that is not of interest for a particular experiment, and combinations thereof. In general, any combination of RNA transcripts can be targeted for depletion within a nucleic acid sample, and the number and identity of the RNA transcripts targeted for depletion can vary depending on the nature of the experiment.
[0052] In order to identify the target RNA transcripts for depletion in the step 202, it may be useful to determine the predicted or actual coding sequences of the target RNA transcripts. As described with respect to FIG. 1, the target RNA transcripts are depleted through the use of an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity. To employ this approach, the target RNA transcripts are hybridized with complementary DNA probes while ensuring that the untargeted RNA transcripts remain as single stranded RNAs. That is, the untargeted RNA transcripts should generally not form heteroduplexes that are substrates for an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity. Therefore, in a step 204 of the method 200, it may be useful to determine the predicted or actual coding sequences of the target RNA transcripts to inform design of DNA probes against the target RNA transcripts. For a target RNA transcript where the nucleic acid sequence is known, DNA probes can be designed in any suitable manner in order to form a DNA:RNA heteroduplex with a target RNA, where the DNA:RNA heteroduplex is a substrate for an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity. For example, the DNA probes can have a variable or fixed length, can be designed to be complementary to all or a portion of the target RNA transcript, can include zero, one, or more mismatches, can include one or more chemical modifications, the like, or combinations thereof.
[0053] Following design of the DNA probes in the step 202, the method 200 can include a step 206 of synthesizing the designed DNA probes. The DNA probes can be synthesized using any known method. For example, the DNA probes can be prepared synthetically using solid phase synthesis methods such as column or array-based approaches including traditional mask-based photolithography or maskless array-based synthesis methods. One consideration for choosing a method for DNA probe synthesis relates to the fidelity of the synthesis method. Herein, DNA synthesis fidelity refers to the accuracy with which the probe designs are realized through DNA synthesis. A synthesized DNA probe that is identical to the sequence of the designed probe can be said to have been synthesized with 100% fidelity, whereas a ten nucleotide long DNA probe design that is synthesized with a total of three errors (i.e., insertions, deletions, substitutions, etc.) can be said to have been synthesized with 70% fidelity.
[0054] Factors such as the experimental conditions employed for hybridization, the characteristics of the enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity, and experimental conditions employed for enzyme treatment can place limitations on the required fidelity of the DNA probes. In some embodiments, the nature of the selected enzyme and the experimental conditions employed can necessitate a high degree of fidelity (e.g., >95%), whereas other enzymes or conditions may afford the use of synthesis techniques with a lower degree of synthesis fidelity. For example, the minimum size of the DNA:RNA heteroduplex recognized by RNase HI from Escherichia coli has been reported to be a tetramer. Accordingly, when using the E. coli RNase HI enzyme, a selected DNA synthesis method should be capable of synthesizing on average at least four consecutive nucleotides with 100% fidelity. However, the overall fidelity of a thirty nucleotide DNA probe including the aforementioned four consecutive nucleotides may be less than 100% while still potentially resulting in an effective DNA probe for use according the present disclosure.
[0055] A step 208 of the method 200 includes hybridizing the DNA probes synthesized in the step 206 with a nucleic acid sample known (or at least suspected) to include the target RNA transcripts identified in the step 202. Achieving successful hybridization of the DNA probes with the target RNA transcripts in the step 208 depends on several parameters. Examples parameters include the complexity of the nucleic acid sample (e.g., number of unique RNA transcripts, transcript abundance, transcript nucleotide length distribution, transcript quality, and the like), DNA probe characteristics (e.g., total number of unique DNA probes, probe length, probe fidelity, number of probes per transcript, and the like), and characteristics of the hybridization reaction (e.g., temperature, time, choice of buffer, and the like). In one aspect, it may be useful to vary the concentration of the DNA probes based on an estimate of the quantity of the corresponding target RNA transcript. For example, it may be useful to provide a ratio of DNA probes to the corresponding target RNA transcript of between about 10.sup.-4:1 and about 10.sup.3:1 on a molar basis. That is, if a ratio of 10:1 DNA probe to target RNA transcript is chosen, then a hybridization mixture would include 10 copies (molecules) of each DNA probe for each copy (molecule) of the corresponding target RNA transcript. Notably, conditions useful for implementation in the step 208 are generally in-line with typical DNA oligo/RNA transcript hybridization conditions known in the art.
[0056] With continued reference to FIG. 2, a step 210 of the method 200 includes treating the heteroduplexed target RNA transcripts with the ultimate goal of depleting the target RNA transcripts from the nucleic acid sample. One approach for treatment in the step 210 includes providing an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity in order to degrade at least the RNA portion of any target RNA transcripts that hybridized with DNA probes in the step 208. In one aspect, degradation can involve breaking or modification of one or more chemical bonds that make up the target RNA transcripts. In the case of E. coli RNase HI and other RNase H-like enzymes, in general, the RNA strand of a DNA-RNA hybrid is cleaved yielding a 3'-hydroxyl and a 5'-phosphate at the hydrolysis site. The extent to which each target RNA transcript is cleaved by an RNase is at least in part dependent on factors discussed with respect to the step 204 and the step 208. However, parameters such as the identity of the RNase H or other like enzyme, and the treatment conditions (e.g., time, temperature, and the like) can also have an effect on depletion of the target RNA transcripts. Further, while an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity can be used in the step 210 to treat the heteroduplexed target RNA transcripts, other treatment methods can also be used. For example, an enzyme or other non-enzymatic chemistry enabling simultaneous cleavage of both RNA and DNA strands in the heteroduplex would also function to deplete the target RNA transcripts in the step 210. Notably, an RNase or other like enzyme or chemical conversion scheme should not have a deleterious effect on untargeted RNA transcripts. For example, an RNase should generally be provided that does not degrade or otherwise deplete RNA transcripts that are not hybridized with one or more DNA probes (i.e., untargeted RNA transcripts).
[0057] In a step 212 of the method 200, it may be useful to treat the DNA probes. For example, in the case that only the target RNA transcripts are degraded or otherwise depleted in the step 210, it may be useful to further treat the DNA probes. In one aspect, treatment of the DNA probes can include digestion of the DNA probes with an enzyme possessing DNase activity. In another aspect, treatment of the DNA probes can include selective capture, isolation, or purification of the DNA probes away from the remaining RNA transcripts in the nucleic acid sample. Moreover, it will be appreciated that the step 212 and additionally (or alternatively) other steps of the method 200 can include one or more clean-up or other like purification steps in order to accommodate the use of various enzymes, buffers, or other treatment conditions throughout the method 200. Example purification steps for recovery and clean-up of a nucleic acid sample that can be employed include the use of solid phase reversible immobilization (SPRI) beads, ethanol precipitation, silica membrane-based column purification, phenol-chloroform extraction, or any other suitable method.
[0058] The method 200 can further include a step 214 of preparing a nucleic acid sample depleted of target RNA transcripts for sequencing. A variety of method exist for preparing RNA libraries for sequencing, and the method selected will vary depending on how the sample will be sequenced. One approach suitable for implementation in the step 214 includes performing first strand cDNA synthesis using an enzyme having reverse transcriptase activity with the remaining (untargeted) RNA transcripts in the nucleic acid sample as a template. Thereafter, steps such as second strand synthesis, A-tailing, adapter ligation, and library amplification can be performed as required by the selected sequencing approach. Notably, the choice of sequencing method will dictate yet other additional or alternative steps that can be included in the step 214.
[0059] In a step 216 of the method 200, the depleted nucleic acid sample can be sequenced using any sequencing method. The step 216 can provide not only the sequence of each of the untargeted RNA transcripts in the nucleic acid sample, but also statistical data such as the relative abundance of each of the untargeted RNA transcripts. The step 216 can also provide information related to the efficacy of the method 200 for depleting the target RNA transcripts in the nucleic acid sample. Accordingly, a step 218 of the method can include determining what fraction or percent of the target RNA transcripts were depleted from the nucleic acid. In some example cases, the method 200 can effectively deplete a given target RNA transcript such that no copies of the transcript are detected through analysis of the sequencing data produced in the step 216. However, in other case, the method 200 can result in insufficient depletion of a target RNA transcript as determined by the particular goals of an experimental method. In one aspect, insufficient depletion can include a determination that a reduction of target RNA transcript of less than an order of magnitude was achieved. In such a case, a step 220 of the method can include modification of one or more aspects of the DNA probes used for targeted depletion. Modification such as the number of DNA probes per transcript, the length, or spacing of the DNA probes, or modifications to other of the aforementioned parameters can be made. The method 200 can then return to the step 206 (or alternatively another one of the steps 202-218 in the method 200) to implement the modifications to the DNA probes. Importantly, modifications to reaction conditions, choice of treatments for RNA or DNA depletion, or the like can be made in order to the tailor the method 200 to achieve a desired degree of target RNA depletion.
[0060] Turning now to FIGS. 3 and 4, DNA probes can be designed in a variety of ways according to the present disclosure. Previous approaches for depletion of rRNA have relied on only a small total number of DNA probes to target only a small total number of RNA transcripts. For example, one published approach for depleting human rRNA uses a total of only two DNA probes to target hemoglobin alpha (HBA) and hemoglobin beta (HBB) mRNAs while leaving all other RNA transcripts in the treated nucleic acid sample untargeted (Wu et al., 2007. Affymetrix Technical Note. Globin reduction protocol: A method for processing whole blood RNA samples for improved array results). Further, the approach relies on two twenty-three nucleotide long DNA probes, with each probe designed to target an approximately four-hundred and twenty (420) nucleotide long RNA transcripts, thereby resulting in a DNA probe to target RNA transcript coverage ratio of about 23:420 or about 0.05:1. In contrast to the aforementioned approach, embodiments of the present disclosure relate to the use of at least two or more DNA probes per target RNA transcript. Yet other embodiments of the present disclosure provide for a relatively greater DNA probe to target RNA transcript coverage ratio as will be described herein.
[0061] As shown in FIG. 3, a first example heteroduplex 300 includes a target RNA transcript 302 hybridized with a first DNA probe 304a, a second DNA probe 304b, a third DNA probe 304c, a fourth DNA probe 304d, and a fifth DNA probe 304e (collectively, "DNA probes 304"). Each of the target RNA transcripts 302 in FIG. 3 are illustrated from left to right in the 5' to 3' direction. Base-pairing between the target RNA transcript 302 and the DNA probes 304 is schematically illustrated by short vertical lines extending between the target RNA transcript 302 and a complementary portion of the corresponding one of the DNA probes 304 hybridized thereto. In one aspect, the DNA probes 304 can have a length of from about 10 nucleotides to about 150 nucleotides. In another aspect, the DNA probes 304 can have a length of from about 20 nucleotides to about 100 nucleotides. In yet another aspect, the DNA probes 304 can have a length of from about 25 nucleotides to about 50 nucleotides. In yet another aspect, the DNA probes 304 can have a length of from about 30 nucleotides to about 40 nucleotides.
[0062] Each of the DNA probes 304 can have a different nucleotide sequence designed to have up to 100% complementary to the indicated region or section of the target RNA transcript 302. In general, DNA probes will be designed to have 100% complementarity to the sequence of a section of a target RNA transcript. However, it may be useful to include one or more degenerate bases or intentional mismatches in a DNA probe. In one aspect, the use of a degenerate base in a DNA probe design can account for the presence of observed or predicted polymorphisms. It will also be appreciated that errors can occur during synthesis of DNA probes that result in insertions, deletions, or substitutions yielding DNA probes with less than 100% complementarity to a target RNA transcript.
[0063] As shown for the heteroduplex 300, the DNA probes 304 are designed to be spaced or tiled along the entire length of the target RNA transcript 302. While the DNA probes are illustrated as being spaced along the entire length of the target RNA transcript 302, FIG. 3 further illustrates that neither is there a single DNA probe 304 that extends along the full length of the target RNA transcript 302, nor are the DNA probes 304 necessarily spaced in a continuous manner. In particular, the DNA probes 304 are spaced discontinuously along the length of the target RNA transcript 302 such that there exist one or more unpaired nucleotides (on the target RNA transcript 302) located between portions of the target RNA transcript 302 that are hybridized with the DNA probes 304. The nucleotide spacing between DNA probes (indicated at 306) can be between about one nucleotide and ten nucleotides and can be constant or variable along the length of the target RNA transcript 302. For example, the spacing of the DNA probes 304 along the target RNA transcript 302 is illustrated as being constant (i.e., there are a fixed number of unpaired target RNA transcript 302 bases between each of the hybridized DNA probes 304).
[0064] Although one example of DNA probe design is shown for the target RNA transcript 302, yet other DNA probes designs are possible according to the present disclosure. For example, a heteroduplex 308 including the same target RNA transcript 302 from the heteroduplex 300, a first DNA probe 310a, a second DNA probe 310b, and a third DNA probe 310c (collectively, "DNA probes 310") is illustrated as having a relatively greater nucleotide spacing between DNA probes (indicated at 312) as compared with the heteroduplex 300. The DNA probes 310 can be about the same length as the DNA probes 304 with at least one difference being that the spacing 312 is much greater than the spacing 306. For example, the DNA probes 310 can be designed to have a spacing 312 of between about eleven nucleotides and about one hundred nucleotides or more. Notably, the DNA probes 310 are still distributed across the entire length of the target RNA transcript 302, with the first DNA probe 310a and the third DNA probe 310c positioned at opposing ends of the target RNA transcript 302, and the second DNA probe 310b positioned at an intermediate point between the first DNA probe 310a and the third DNA probe 310c. In one aspect, it may not be necessary to design probes for complete coverage of a given target RNA transcript as shown for the heteroduplex 308, as the use of a relatively fewer number of DNA probes with increased spacing between each of the probes may be sufficient to deplete the target RNA transcript. For example, it may be useful to generate degraded target RNA transcript fragments (i.e., following hybridization and treatment with an RNase enzyme) that are less than about 50 nucleotides. Thereafter, a size-based separation step can be used to recover untargeted RNA transcripts that have an average nucleotide length that is greater than the average nucleotide length of the RNA fragments resulting from the degraded target RNA transcript.
[0065] In comparison to the heteroduplex 308, a heteroduplex 314 illustrates yet another DNA probe design approach that includes the target RNA transcript 302, a first DNA probe 316a, a second DNA probe 316b, and a third DNA probe 316c (collectively, "DNA probes 316"). For the heteroduplex 314, the DNA probes 316 are each positioned at the 3' end of the target RNA transcript 302 with a spacing 318 between each of the probes comparable to the spacing 306. In contrast to the DNA probe design for either of the heteroduplex 300 and the heteroduplex 308, none of the DNA probes 316 are designed to hybridize to the 5' end of the RNA transcript 302. In a related example, a heteroduplex 320 includes the target RNA transcript 302, a first DNA probe 322a, a second DNA probe 322b, and a third DNA probe 322c (collectively, "DNA probes 322). The DNA probes 322 are each positioned at the 5' end of the target RNA transcript 302 with a spacing 324 between each of the probes comparable to the spacing 306 or the spacing 318. In contrast to both the heteroduplex 314 and either of the heteroduplex 300 and the heteroduplex 308, none of the DNA probes 322 are designed to hybridize to the 3' end of the RNA transcript 302. Finally, a third example of DNA probe design characterized at least in part by incomplete target RNA transcript coverage includes a heteroduplex 326. The DNA probe design for hybridizing the target RNA transcript 302 in the heteroduplex 326 omits DNA probe coverage at the 5' and 3' termini of the target RNA transcript 302, but does include a first DNA probe 328a, a second DNA probe 328b, and a third DNA probe 328c (collectively, "DNA probes 328"), where the DNA probes 328 are each designed to hybridize to a portion at an intermediate point between the 5' and 3' ends of the target RNA transcript 302. A spacing 330 of the DNA probes 328 can be relative small, similar to the spacing 306, for example.
[0066] For a variety of reasons, it can be useful to omit DNA probes for hybridization to either of the 5' end of an RNA transcript, the 3' end of an RNA transcript, or a combination thereof. In one aspect, the use of fewer DNA probes can provide for a simpler overall design, thereby reducing off-target effects (e.g., undesirable probe hybridization with untargeted RNA transcripts), decreasing manufacturing costs, and the like. Moreover, the use of DNA probes that hybridize to only a portion of a given RNA transcript can provide sufficiently degraded target RNA transcript depending on the overall length or complexity of the target RNA transcript. In another aspect, depending on the downstream analysis or sequencing methods employed, degrading either the interior portion or one or both ends of a given target RNA transcript can be sufficient to effectively prevent downstream conversion to cDNA or amplification of the RNA. Yet other factors can also motivate a probe design including incomplete target RNA transcript coverage.
[0067] With continued reference to FIG. 3, two further examples of DNA probe design for targeted depletion include the use of closely spaced or overlapping DNA probes. In a first example, a heteroduplex 332 includes the target RNA transcript 302, a first DNA probe 334a, a second DNA probe 334b, a third DNA probe 334c, a fourth DNA probe 334d, a fifth DNA probe 334e, and a sixth DNA probe 334f (collectively, "DNA probes 334"), where the DNA probes 334 are designed to hybridize along the length of the target RNA transcript 302 with a spacing 336 of between zero and about two nucleotides. In the present example of the heteroduplex 332, there is the possibility for every nucleotide in the target RNA transcript to be hybridized by one (and only one) of the DNA probes (as the DNA probes do not overlap). However, there are still multiple DNA probes used to provide the illustrated coverage of the target RNA transcript 302 in the heteroduplex 332, as opposed to the use of a single continuous DNA probe.
[0068] In a second example of closely spaced or overlapping DNA probe sequences, a heteroduplex 338 includes the target RNA transcript 302, a first DNA probe 340a, a second DNA probe 340b, a third DNA probe 340c, a fourth DNA probe 340d, a fifth DNA probe 340e, a sixth DNA probe 340f, a seventh DNA probe 340g, and an eighth DNA probe 340h (collectively, "DNA probes 334"), where the DNA probes 340 are designed to hybridize along the length of the target RNA transcript 302 with an overlap 342 of at least one nucleotide. The overlap 342 results from a probe design where the 3' end of one DNA probe has the potential to hybridize to the same portion of a target RNA transcript as 5' end of another DNA probe. For example, the 3' end of the first DNA probe 340a is designed to be capable of hybridizing to the same portion of the target RNA transcript 302 as the 5' end of the second DNA probe 340b. Notably, each of the 3' end of the first DNA probe 340a and the 5' end of the second DNA probe 340b can simultaneously hybridize to the same portion of the target RNA transcript 302. However, it can still be useful to select a probe design including overlapping DNA probes. In one aspect, the DNA probes can hybridize sequentially to an individual target RNA transcript during a treatment step. In another aspect, the DNA probes can hybridize simultaneously to different copies of the same target RNA transcript. Yet other design considerations can additionally or alternatively suggest the use of overlapping DNA probes for hybridization to a target RNA transcript.
[0069] With reference to FIG. 4, and as described with reference to FIG. 3, DNA probes can be designed in a variety of ways. In one aspect, it can be generally useful to design two or more probes for hybridization to the same target RNA transcript. However, the characteristics of the probe design can vary greatly. In one aspect, a heteroduplex 400 includes a target RNA transcript 402, a first DNA probe 404a, a second DNA probe 404b, and a third DNA probe 404c (collectively, "DNA probes 404"). Each of the DNA probes 404 have an each length of twenty nucleotides. Moreover, each of the DNA probes 404 is designed to hybridize with a uniform spacing along the length of the target RNA transcript 402. As illustrated for the heteroduplex 400, a spacing 406a between adjacent ends of the first DNA probe 404a and the second DNA probe 404b is equal to the spacing 406b between adjacent ends of the second DNA probe 404b and the third DNA probe 404c. While the spacing 406a and the spacing 406b are illustrated as five nucleotides, it will be appreciated that a larger or smaller nucleotide spacing can be used. In another aspect, additional or alternative probes designs, including variable DNA probe lengths and inter-DNA probe spacing, can be used. For example, the heteroduplex 408 includes the target RNA transcript 402 and three alternative DNA probes designed for hybridization thereto. In one aspect, a first DNA probe 410a has a length of twenty-five nucleotides, a second DNA probe 410b has a length of fifteen nucleotides, and a third DNA probe 410c has a length of twenty nucleotides (collectively, "DNA probes 410"). The DNA probes 410 have a variable length design as compared to the DNA probes 404. However, akin to the spacing 406 for the heteroduplex 400, a five nucleotide spacing 412a between adjacent ends of the first DNA probe 410a and the second DNA probe 410b is equal to a spacing 412b between adjacent ends of the second DNA probe 410b and the third DNA probe 410c. Accordingly, in some DNA probes designs, the DNA probe length can be varied while maintaining a uniform spacing between adjacent DNA probes.
[0070] In yet another example of DNA probe design, a heteroduplex 414 includes the target RNA transcript 402, a first DNA probe 416a, a second DNA probe 416b, and a third DNA probe 416c (collectively, "DNA probes 416"). By way of comparison to either of the heteroduplex 400 and the heteroduplex 408, the DNA probes 416 in the heteroduplex 414 are each twenty nucleotides in length with a variable spacing between each of the adjacent probes. In one aspect, a spacing 418a is seven nucleotides, whereas a spacing 418b is only three nucleotides. The spacing for a given probe design can therefore vary between pairs of adjacent probes without necessarily varying the length of each of the DNA probes. However, as shown for a heteroduplex 420 in FIG. 4, in some embodiments, each of the DNA probe length and the spacing between adjacent DNA probes can vary simultaneously. In the illustrated example of the heteroduplex 420, the target RNA transcript 402 is capable of hybridization to the DNA probes 416 as well as a first DNA probe 422a and a second DNA probe 422b (collectively, "DNA probes 422"). In one aspect, the first DNA probe 422a has a length of ten nucleotides and is designed in part to be capable of hybridization to the same portion of the target RNA transcript 420 as the first DNA probe 416a with an overlap 424a of four nucleotides. Further, the 5' end of the DNA probe 422b exhibits an overlap 424c of four nucleotides with the adjacent DNA probe 416b, while the 3' end of the DNA probe 422b exhibits an overlap 424d of four nucleotides with the adjacent DNA probe 416c.
[0071] As discussed with respect to the heteroduplex 338 in FIG. 3, the DNA probe 416a and the DNA probe 422a will not necessarily be able to hybridize simultaneously to the target RNA transcript 402. Similarly, the DNA probe 422b and either of the DNA probe 416b and the DNA probe 416c will not necessarily be able to hybridize simultaneously to the target RNA transcript 402. Still, it can be useful to provide a design including overlapping DNA probe sequences as illustrated for the heteroduplex 420 in FIG. 4. However, both ends of a given DNA probe need not include overlapping sequence with an adjacently hybridizable DNA probe. For example, in contrast to the overlap 424a exhibited at the 5' end of the DNA probe 422a, the 3' end of the DNA probe 422a is spaced apart from the 5' end of the DNA probe 416b with a spacing 424b of one nucleotide. It will also be appreciated that further combinations of DNA probe length and spacing are also encompassed by embodiments of the present disclosure.
[0072] Referring now to FIG. 5, an overview of a method for depleting target nucleic acids from a nucleic acid sample according to the present disclosure includes a combining a plurality of DNA probes 502 with a nucleic acid sample including a plurality of target RNA transcripts 504 and a plurality of non-target (or untargeted) RNA transcripts 506. While FIG. 5 shows only a single target RNA transcript 504 an untargeted RNA transcript 506 for simplicity, a nucleic acid sample will include at least three unique target RNA transcripts. In another aspect, a nucleic acid sample will include at least ten unique target RNA transcripts. In yet another aspect, a nucleic acid sample will include at least one hundred unique target RNA transcripts.
[0073] The DNA probes 502 are each hybridizable with a corresponding one of the target RNA transcripts 504 to form one or more DNA-RNA heteroduplexes 508. By contrast, the untargeted RNA transcripts 506 are preferably not hybridized by any of the DNA probes 502. Depending on the design of the DNA probes 502 for depleting the target RNA transcripts 504, the nucleotide length 510 of the DNA probes 502 and the spacing 512 between adjacently hybridized DNA probes 502 can vary. In one aspect, the DNA probes 502 are hybridizable along the length of each of the target RNA transcripts 504 with a regular spacing 512, where for each pair of adjacently hybridizable DNA probes 502, the 3' end of a first one of the pair of DNA probes 502 is spaced apart from the 5' end of a second one of the pair of DNA probes 502 by a nucleotide interval relative to the target RNA transcript 504 that is less than about fifty nucleotides. In another example, the interval between adjacently hybridizable DNA probes 502 is less than about ten nucleotides. In yet another example, the interval between adjacently hybridizable DNA probes 502 is less than about five nucleotides.
[0074] The number of different DNA probes 502 designed to hybridize with each unique one of the target RNA transcripts 504 can additionally (or alternatively) be variable. In FIG. 5, for example, at least three different DNA probes 502 are hybridizable to the target RNA transcript 504. In other embodiments, the number of unique DNA probes 502 hybridizable to a unique target RNA transcript 504 is at least ten. In a further aspect, the fraction of the total number of bases of each target RNA transcript 504 hybridizable by the DNA probes 502 is at least 0.5. That is, the fraction of the number of nucleotides in the target RNA transcript that are capable of base pairing with a DNA probe designed to hybridize to the target RNA transcript is at least 0.5. In another aspect, the fraction of the total number of bases of the target RNA transcript 504 hybridizable by the DNA probes 502 is at least 0.75. In yet another aspect, the fraction of the total number of bases of the target RNA transcript 504 hybridizable by the DNA probes 502 is at least 0.9.
[0075] The heteroduplexes 508 can be treated in order to deplete the nucleic acid sample of the target RNA transcripts 504. In the present example shown in FIG. 5, the heteroduplexes 508 are treated with an enzyme 514 having RNA-DNA hybrid ribonucleotidohydrolase activity. One example of an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity is RNase H (EC 3.1.26.4), although any enzyme possessing RNA-DNA hybrid ribonucleotidohydrolase activity can be used. In a first step, an unbound one of the enzymes 514a identifies a portion of the heteroduplex 508 including one of the DNA probes 502 hybridized to a portion of the corresponding target RNA transcript 504 to become a bound enzyme 514b. The bound enzymes 514b then interacts with the heteroduplex 508 to at least partially degrade a portion of the target RNA transcript 504. Upon disassociation, the bound enzyme 514b becomes a newly unbound enzyme 514c, revealing that the target RNA transcript 504 portion of the heteroduplex 508 now includes a nick or cut-site 516 that subdivides the target RNA transcript 504 into two separate target RNA fragments 518. In particular, the enzymes 514 preferably cut or otherwise degrade the target RNA transcript 504 at two or more locations, thereby generating a plurality of cut-sites 516. Upon disassociation of the DNA probes 502 from the treated target RNA transcript 504 (e.g., through heating, enzymatic digestion of the DNA fragments, or another like dissociation process), the nucleic acid sample will include a plurality of target RNA fragments 518 resulting from the (now depleted) target RNA transcripts 504, along with intact untargeted RNA transcripts 506. The untargeted RNA transcripts 506 can then be purified away from the target RNA fragments 518 and DNA probes 502 to enable downstream sequencing or other like analysis.
[0076] With respect to downstream analysis of the nucleic acid sample, it can be useful to determine the extent to which one or more of the target RNA transcripts 504 were depleted. One method for measuring depletion includes quantifying the number of fragments per kilobase of transcript per million mapped reads (FPKM) for each of the target RNA transcripts following sequencing of the depleted nucleic acid sample (Equation 1).
FPKM i = X i l ~ i N 10 9 ( Eq . 1 ) ##EQU00001##
In Equation 1, FPKM.sub.i is the FPKM of a given RNA transcript (or fragment thereof) i, X.sub.i is the counts observed for the transcript i, {tilde over (l)}.sub.i is the effective length of the RNA transcript i (computed as 1 plus the actual length less the mean of the fragment length distribution learned from the aligned read for the sequencing experiment), and N is the number of fragments sequenced. The FPKM for a target RNA transcript from an untreated (control) sample (i.e., a sample where the target RNA transcript was purposely not depleted) is compared with the FPKM for the same target RNA transcript from a treated sample (i.e., a sample where the target RNA transcript was purposely depleted as illustrated in FIG. 5). The ratio of the FPKM for the target RNA transcript from the treated sample to the FPKM for the target RNA transcript from the untreated (control) sample can be used to determine a percent depletion (Equation 2). Notably, the FPKM of a given RNA transcript in the treated sample should be less than or equal to the FPKM of the same transcript in the treated sample when using Equation 2.
% depletion = ( 1 - FPKM i , treated FPKM i , untreated ) 100 % ( Eq . 2 ) ##EQU00002##
[0077] In one aspect, a method according to the present disclosure can be employed to deplete the quantity of each of the target RNA transcript by at least about 50% (i.e., 50% depletion as determined with Equation 2). In another aspect, a method according to the present disclosure can be employed to deplete the quantity of each of the target RNA transcript by at least about 80%. In yet another aspect, a method according to the present disclosure can be employed to deplete the quantity of each of the target RNA transcript by at least about 90%. In still another aspect, a method according to the present disclosure can be employed to deplete the quantity of each of the target RNA transcript by at least an order of magnitude as compared with an untreated (control) sample.
[0078] In some embodiments, the methods described herein and illustrated at least in FIG. 5 can be at least partially facilitated through the use of a kit according to the present disclosure. One example of a kit for depleting target nucleic acids from a nucleic acid sample includes a plurality of DNA probes. Each of the DNA probes is hybridizable to form a heteroduplex with at least one of a plurality of target RNA transcripts in a nucleic acid sample. The DNA probes can be custom designed based on the known or suspected sequences of RNA transcripts included in the nucleic acid sample. In one aspect, the DNA probes can be designed to hybridize or target at least three unique target RNA transcripts. However, the number of unique target RNA transcripts hybridized by the DNA probes can be at least ten or more. For example, in some embodiments, a kit can include a plurality of DNA probes for hybridizing to, and ultimately depleting, at least one hundred unique target RNA transcripts. The kit can further include an enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity. In one particular embodiment, a kit for depleting target nucleic acids from a nucleic acid sample includes a plurality of DNA probes for hybridization to the top ten most highly expressed genes in a nucleic acid sample. In one aspect, the number of DNA probes designed to target each unique RNA transcript for each of the top ten most highly expressed genes is at least three. In another aspect, the kit can include RNase H or another enzyme having RNA-DNA hybrid ribonucleotidohydrolase activity. In yet another aspect, the kit can include any additional materials useful for processing the nucleic acid sample including, but not limited to buffers, DNA polymerase, reverse transcriptase, RNase A, DNase I, nuclease-free water, sequencing adapters, primers for amplification or sequencing, the like, and combinations thereof.
EXAMPLES
[0079] For Identification of depletion targets, four RNA-Seq experiments were performed using 100 ng human brain total RNA (AMBION). Sequencing libraries (cDNA) were constructed using the KAPA Stranded RNA-Seq Kits with RiboErase (KAPA BIOSYSTEMS) according to manufacturer instructions. The cDNA libraries were sequenced using a HiSeq 2500 System sequencing instrument (ILLUMINA) with 2.times.100 bp reads. The raw sequencing reads were randomly down-sampled to a total of 3 million reads and the data were analyzed using standard bioinformatics methods. FPKM were calculated and the top 50 highest expressing transcripts were identified from each of the four experiments. The data from the top 50 transcripts identified in all four experiments, were combined and the average FPKM values were calculated (FIG. 6).
[0080] The top ten highest expressing transcripts, were initially targeted for depletion. Since three of these top ten transcripts were very similar in sequence and could be targeted by several of the same depletion oligos (i.e., DNA probes), an additional three gene transcripts were targeted for depletion. The coding DNA (cDNA) sequences of each of the fourteen targeted genes (i.e., gene transcripts) targeted for depletion in descending order of average FPKM values were: RN7SL1 (NR_002715.1) (SEQ ID NO:229), RN7SK (NR_001445.2) (SEQ ID NO:230), RN7SL4P (NG_002425.3) (SEQ ID NO:231), RN7SL5P (NG_002426.2) (SEQ ID NO:232), RPPH1 (HG505981.1) (SEQ ID NO:233), RMRP (NR_003051.3) (SEQ ID NO:234), RNU2-2P (NG_044735.1) (SEQ ID NO:235), SNORD3A (HG508764.1) (SEQ ID NO:236), MT-CO1 (ENST00000361624) (SEQ ID NO:237), MT-CO3 (ENST00000362079) (SEQ ID NO:238), MT-CO2 (ENST00000361739) (SEQ ID NO:239), MBP (NM_001025081.1) (SEQ ID NO:240), SNAP25 (NM_130811.2) (SEQ ID NO:241), and GAPDH (NM_001289745.1) (SEQ ID NO:242). The fourteen genes targeted for depletion in the various examples, including expression abundance rank (most abundant=1), average FPKM value, and RNA transcript length in nucleotides (nt), are listed in Table 1.
TABLE-US-00001 TABLE 1 RNA Average transcript Target # Gene ID Rank FPKM length (nt) 1 RN7SL1 (SEQ ID NO: 229) 1 86128 299 2 RN7SK (SEQ ID NO: 230) 2 44167 332 3 RN7SL4P (SEQ ID NO: 231) 3 19646 295 4 RN7SL5P (SEQ ID NO: 232) 4 17515 321 5 RPPH1 (SEQ ID NO: 233) 5 15597 333 6 RMRP (SEQ ID NO: 234) 6 4834 277 7 RNU2-2P (SEQ ID NO: 235) 7 3879 191 8 SNORD3A (SEQ ID NO: 236) 8 2086 699 9 MT-CO1 (SEQ ID NO: 237) 9 2066 1542 10 MT-CO3 (SEQ ID NO: 238) 10 1776 784 11 MT-CO2 (SEQ ID NO: 239) 16 988 684 12 MBP (SEQ ID NO: 240) 18 790 2254 13 SNAP25 (SEQ ID NO: 241) 33 531 2069 14 GAPDH (SEQ ID NO: 242) 40 439 1490
[0081] For design of the DNA probes for targeted depletion, the sequences of the targeted transcripts were retrieved from the National Center for Biotechnology Information (NCBI) and Ensembl (release 83) databases. DNA probes were designed as DNA sequences of uniform length (35 nucleotides in length for all genes except GAPDH (SEQ ID NO:242) for which the oligos were 38 nucleotides in length), complementary to the sequences of the targeted RNA transcripts. Further, the DNA probes for depletion of GAPDH (SEQ ID NO:242) included a 3' inverted dT chemical modification, whereas DNA probes for depletion of the other target RNA transcripts were not modified. The spacing between the 3' end of one depletion oligo and the 5' end of the adjacent depletion oligo was varied, for example, from about two nucleotides (GAPDH (SEQ ID NO:242)) to about ten nucleotides (MBP (SEQ ID NO:240)), but was generally uniform for DNA probes designed for depletion of a unique target RNA transcript (Table 2):
TABLE-US-00002 TABLE 2 No. probe typical DNA length spacing coverage Gene ID probes (nt) (nt) (%) RN7SL1 (SEQ ID NO: 229) 7 35 5 81.9 RN7SK (SEQ ID NO: 230) 7 35 5 73.8 RN7SL4P (SEQ ID NO: 231) 7 35 5 83.1 RN7SL5P (SEQ ID NO: 232) 7 35 5 76.3 RPPH1 (SEQ ID NO: 233) 8 35 5 84.1 RMRP (SEQ ID NO:234) 6 35 5 75.8 RNU2-2P (SEQ ID NO: 235) 4 35 5 73.3 SNORD3A (SEQ ID NO: 236) 16 35 5 80.1 MT-CO1 (SEQ ID NO: 237) 34 35 10 77.2 MT-CO3 (SEQ ID NO: 238) 17 35 10 75.9 MT-CO2 (SEQ ID NO: 239) 15 35 10 76.8 MBP (SEQ ID NO: 240) 50 35 10 76.1 SNAP25 (SEQ ID NO: 241) 25 35 10 42.3 GAPDH (SEQ ID NO: 242) 37 38 2 92.9
[0082] In general, the starting approach for the DNA probe designs in Table 2 was to maintain consistent DNA probe length and DNA probe spacing. However, based on factors such as the sequence and length of a particular target RNA transcript, the actual spacing between DNA probes was varied for several of the DNA probe designs including those DNA probes targeting SNAP25 (SEQ ID NO:241), RN7SK (SEQ ID NO:230), and RNU2-2P (SEQ ID NO:235). Sequences for the DNA probes described in Table 2 were as follows: GAPDH probes (SEQ ID NOs:1-37); MBP probes (SEQ ID NOs:38-87); MT-CO1 probes (SEQ ID NOs:88-121); MT-CO2 probes (SEQ ID NOs:122-136); MT-CO3 probes (SEQ ID NOs:137-153); RMRP probes (SEQ ID NOs:154-159); RN7SL1 probes (SEQ ID NOs:160-168); RN7SL5P probes (SEQ ID NOs:160-168); RN7SL4P probes (SEQ ID NOs:160-168); RN7SK probes (SEQ ID NOs:169-175); RNU2-2P probes (SEQ ID NOs:176-179); RPPH1 probes (SEQ ID NOs:180-187); SNAP25 probes (SEQ ID NOs:188-212); and SNORD3A probes (SEQ ID NOs:213-228).
[0083] The indicated percent coverage for each set of DNA probes was determined by summing the DNA probe length for each of the DNA probes targeting a given RNA transcript and dividing by the RNA transcript length (Equation 3).
% coverage = i ( probe length ) i RNA transcript length 100 % ( Eq . 3 ) ##EQU00003##
where i represents the number of different DNA probes designed to hybridize to a unique target RNA transcript.
[0084] Targeted depletion of rRNA in conjunction with a single additional target RNA transcript was first demonstrated for a human total RNA sample. In general, the experiment followed the protocol outlined in the KAPA Stranded RNA-Seq Kit with RiboErase (HMR) (KR1151-v3.15; KAPA BIOSYSTEMS), with changes to the protocol noted as follows: Human Cervical Adenocarcinoma (HeLa-S3) Total RNA at a concentration of 1 mg/mL (AMBION) was selected as the nucleic acid sample for targeted depletion. Thirty-seven DNA probes were designed against glyceraldehyde-3-phosphate dehydrogenase (GAPDH) using transcript variant 3 of GAPDH (NM_001289745.1) (SEQ ID NO:242) as a reference (Table 2). The DNA probes were resuspended in nuclease free water to a concentration of 10 uM and a dilution series was made to achieve a range of molar ratios between 0.0001:1 and 1000:1 DNA probe to target RNA transcript (DNA:RNA ratio) for an input of 10 .mu.g total RNA (Table 3; n. a.=not applicable).
TABLE-US-00003 TABLE 3 sample DNA:RNA ratio 0 n.a. 1 1000:1 2 100:1 3 10:1 4 1:1 5 0.1:1 6 0.01:1 7 0.001:1 8 0.0001:1
[0085] Depletion of GAPDH (SEQ ID NO:242) target RNA transcript with RNase H treatment was carried out in the presence of a GAPDH (SEQ ID NO:242) depletion oligos at the ratios indicated in Table 3. GAPDH (SEQ ID NO:242) depletion oligos were added at the same time as a RiboErase probes. Stranded RNA library preparation was carried out according to the KAPA Stranded RNA-Seq Kit with RiboErase (HMR) protocol. PCR amplification was carried out as described in Table 4.
TABLE-US-00004 TABLE 4 Step Temp (.degree. C.) Time (m:s) Cycles Initial Denaturation 98 0:45 1 Denaturation 98 0:15 10 Annealing* 60 0:30 Extension 72 0:30 Final Extension 72 5:00 1 Hold 4 n.a. 1
[0086] The resulting amplified libraries were prepared using MiSeq V2 Reagent Kit (ILLUMINA) and sequenced on a MiSeq desktop sequencer (ILLUMINA). FPKM values were determined for each of the target RNA transcripts from the resulting sequencing data (Table 5; FIG. 7). FPKM values for MYC (X00364.2) and UBB (NM_018955.3) were used as internal controls for each sequenced nucleic acid sample.
TABLE-US-00005 TABLE 5 GAPDH (SEQ ID MYC NO: 242) UBB Depletion sample DNA:RNA ratio (FPKM) (FPKM) (FPKM) (%) 0 n.a. 189.5 1273.7 207.9 n.a. 1 1000:1 229.0 11.0 232.5 99.1 2 100:1 212.1 8.2 183.2 99.4 3 10:1 187.7 17.9 220.4 98.6 4 1:1 196.7 478.0 207.2 62.5 5 0.1:1 206.0 1121.1 217.7 12.0 6 0.01:1 217.3 1163.5 183.0 8.7 7 0.001:1 187.7 1099.5 193.9 13.7 8 0.0001:1 254.0 1121.8 190.3 11.9
[0087] As seen from the results in Table 5 and FIG. 7, GAPDH (SEQ ID NO:242) transcripts were effectively depleted from the nucleic acid samples in a probe concentration dependent manner. Further, depletion of GAPDH (SEQ ID NO:242) had no observable depletion effect on any of the measured untargeted RNA transcripts including those listed in Table 1 (FIG. 8). In one aspect, each of the three largest DNA probe to RNA ratio (i.e., 1000:1, 100:1, and 10:1) were effective for reducing the calculated FPKM for GAPDH (SEQ ID NO:242) by at least an order of magnitude relative to the undepleted control sample, with the 100:1 ratio exhibiting the greatest overall reduction in FPKM for GAPDH (SEQ ID NO:242). In another aspect, a trend of decreasing depletion with decreasing DNA probe to RNA ratio was observed, with a notable reduction in depletion from sample 3 to sample 4, and from sample 4 to sample 5. Accordingly, it can be useful to tune the concentration of DNA probes used to target a particular RNA transcript in order to effectively deplete the target RNA transcript from a nucleic acid sample.
[0088] In a next experiment, selective depletion of at least ten of the most highly expressed transcripts from Human Brain Reference RNA (AMBION) was demonstrated. DNA probes were designed against fourteen target RNA transcripts (Tables 1 and 2), and a number of probe combinations were prepared as 5 .mu.M or 10 .mu.M stock solutions (Table 6). RNase H treatment, stranded RNA library preparation, PCR amplification, and sequencing were performed as described above for GAPDH (SEQ ID NO:242) depletion. In addition, rRNA was simultaneously targeted for depletion in all RNA samples.
TABLE-US-00006 TABLE 6 Concentration Sample ID DNA probes (.mu.M) A GAPDH (SEQ ID NO: 242) 10 B MBP (SEQ ID NO: 240) 10 C MT-CO1 (SEQ ID NO: 237), MT-CO2 (SEQ ID NO: 239), MT- 10 CO3 (SEQ ID NO: 238) D RN7SL1 (SEQ ID NO: 229), RN7SK (SEQ ID NO: 230), 10 RN7SL4P (SEQ ID NO: 231), RN7SL5P (SEQ ID NO: 232), RPPHI (SEQ ID NO: 233), RMRP (SEQ ID NO: 234), RNU2-2P (SEQ ID NO: 235) E SNORD3A (SEQ ID NO: 236), SNAP25 (SEQ ID NO: 241) 10 F MBP (SEQ ID NO: 240), MT-CO1 (SEQ ID NO: 237), MT-CO2 5 (SEQ ID NO: 239), MT-CO3 (SEQ ID NO: 238), RN7SL1 (SEQ ID NO: 229), RN7SK (SEQ ID NO: 230), RN7SL4P (SEQ ID NO: 231), RN7SL5P (SEQ ID NO: 232), RPPHI (SEQ ID NO: 233), RMRP (SEQ ID NO: 234), RNU2-2P (SEQ ID NO: 235), SNORD3A (SEQ ID NO: 236), SNAP25 (SEQ ID NO: 241)
[0089] With Reference to Table 7 and FIG. 9, the results for DNA probe combination targeting the most highly expressed RNA transcripts illustrates that at least ten RNA transcripts can be effectively depleted from a nucleic acid sample by RNase H mediated degradation of target RNA transcripts. Notably, Table 7 summarizes data collected from seven separate experiments in the left-most column under the heading "Gene(s) Depleted". For example, one experiment (control) omitted probes for targeted depletion, another experiment included probes targeted for depletion of GAPDH (SEQ ID NO:242) only, another experiment included probes targeted for depletion of SNORD3A (SEQ ID NO:236) and SNAP25 (SEQ ID NO:241), and yet another experiment (top 10) included probes targeted for depletion of greater than ten of the most highly expressed RNA transcripts. It will be appreciated that this "top 10" experiment excluded probes targeting GAPDH (SEQ ID NO:242) for depletion.
TABLE-US-00007 TABLE 7 GAPDH RN7SL1 RN7SK RN7SL4P Gene(s) oligo:RNA (SEQ ID (SEQ ID (SEQ ID (SEQ ID Depleted (.mu.M/.mu.g) NO: 242) UBB NO: 229) NO: 230) NO: 231) control n.a. 351 195 23617 18584 8501 GAPDH (SEQ ID 2.2 n.d. 205 29986 22250 11275 NO: 242) 0.22 n.d. 199 23594 19637 10092 MBP (SEQ ID 2.2 424 200 36394 12220 12526 NO: 240) 0.22 423 226 35892 16831 13122 MT-CO* (SEQ ID 2.2 447 205 41377 16529 11071 NOs: 237-239) 0.22 466 223 85049 26014 14547 RN7S* (SEQ ID 22 575 311 78 22 25 NOs: 229-232), 2.2 551 241 161 45 57 RPPH1 (SEQ ID 0.22 604 274 288 43 152 NO: 233), RMRP (SEQ ID NO: 234), RNU2-2P (SEQ ID NO: 235) SNORD3A (SEQ ID 2.2 497 236 81060 26787 13724 NO: 236), 0.22 643 336 135996 38730 25145 SNAP25 (SEQ ID NO: 241) top 10 11 519 269 68 24 23 1.1 542 259 96 16 27 0.11 576 247 120 31 44 0.011 670 288 1017 143 541 RN7SL5P RPPH1 RMRP RNU2-2P SNORD3A Gene(s) oligo:RNA (SEQ ID (SEQ ID (SEQ ID (SEQ ID (SEQ ID Depleted (.mu.M/.mu.g) NO: 232) NO: 233) NO: 234) NO: 235) NO: 236) control n.a. 9917 2838 860 518 474 GAPDH (SEQ ID 2.2 11998 4640 1447 1254 870 NO: 242) 0.22 11434 3553 1097 830 814 MBP (SEQ ID 2.2 13254 5286 2103 1859 1143 NO: 240) 0.22 13631 5161 1957 1897 1449 MT-CO* (SEQ ID 2.2 12481 5530 1740 1874 1268 NOs: 237-239) 0.22 18333 8358 2328 2976 4191 RN7S* (SEQ ID 22 18 n.d. 5 n.d. 5655 NOs: 229-232), 2.2 31 4 n.d. 6 5222 RPPH1 (SEQ ID 0.22 51 31 11 133 4514 NO: 233), RMRP (SEQ ID NO: 234), RNU2-2P (SEQ ID NO: 235) SNORD3A (SEQ ID 2.2 16853 8194 2266 3353 n.d. NO: 236), 0.22 29599 14568 3013 1903 25 SNAP25 (SEQ ID NO: 241) top 10 11 14 4 13 n.d. n.d. 1.1 17 2 5 n.d. n.d. 0.11 21 10 9 18 5 0.011 261 195 20 383 26 MT-CO1 MT-CO3 MT-CO2 MBP SNAP25 Gene(s) oligo:RNA (SEQ ID (SEQ ID (SEQ ID (SEQ ID (SEQ ID Depleted (.mu.M/.mu.g) NO: 237) NO: 238) NO: 239) NO: 240) NO: 241) control n.a. 17287 10665 10247 1971 423 GAPDH (SEQ ID 2.2 13154 8730 7376 1888 451 NO: 242) 0.22 15855 10244 9257 1862 445 MBP (SEQ ID 2.2 12541 7632 6414 71 466 NO: 240) 0.22 12128 8074 7027 73 463 MT-CO* (SEQ ID 2.2 98 137 102 1989 469 NOs: 237-239) 0.22 52 83 56 2109 441 RN7S* (SEQ ID 22 11043 6293 5971 2333 492 NOs: 229-232), 2.2 10962 6297 5814 2249 479 RPPH1 (SEQ ID 0.22 10817 6560 5589 2190 495 NO: 233), RMRP (SEQ ID NO: 234), RNU2-2P (SEQ ID NO: 235) SNORD3A (SEQ ID 2.2 9487 5952 5027 1948 35 NO: 236), 0.22 8593 5256 4585 3016 72 SNAP25 (SEQ ID NO: 241) top 10 11 30 95 42 73 25 1.1 37 66 42 58 25 0.11 44 79 26 58 24 0.011 79 105 62 78 83
[0090] The thirteen target RNA transcripts selected for depletion in the data illustrated in the last row of Table 7 (top 10) and in FIG. 9 included RN7SL1 (SEQ ID NO:229), RN7SK (SEQ ID NO:230), RN7SL4P (SEQ ID NO:231), RN7SL5P (SEQ ID NO:232), RPPH1 (SEQ ID NO:233), RMRP (SEQ ID NO:234), RUN2-2P (SEQ ID NO: 235), SNORD3A (SEQ ID NO:236), MT-CO1 (SEQ ID NO:237), MT-CO3 (SEQ ID NO:238), MT-CO2, MBP (SEQ ID NO:240), and SNAP25 (SEQ ID NO:241). Notably, GAPDH (SEQ ID NO:242) was not targeted for depletion. Each of the target RNA transcripts were depleted for each of the DNA probe to target RNA transcript ratios tested as compared with the undepleted control sample where no DNA probes were used. In one aspect, the DNA probe to target RNA transcript ratio resulting in the greatest reduction in FPKM varied for each of the target RNA transcripts. For example, a ratio of 1:1 resulted in the greatest reduction for target RNA transcripts including RN7SL1 (SEQ ID NO:229) and MT-CO1 (SEQ ID NO:237), a ratio of 1:5 resulted in the greatest reduction for target RNA transcripts including RN7SK (SEQ ID NO:230) and RPPH1 (SEQ ID NO:233), and a ratio of 1:10 resulted in the greatest reduction for target RNA transcripts including MT-CO2 (SEQ ID NO:239) and SNAP25 (SEQ ID NO:241). Accordingly, as an alternative to selecting a fixed DNA probe ratio for each target RNA transcript, it can be useful to select a different DNA probe ratio for each unique target RNA transcript. Note that is Table 7, under the heading, "Gene(s) Depleted", MT-CO* includes target RNA transcripts MT-CO1 (SEQ ID NO:237), MT-CO2 (SEQ ID NO:239), and MT-CO3 (SEQ ID NO:238). Similarly, RN7S* includes target RNA transcripts RN7SL1 (SEQ ID NO:229), RN7SL4P (SEQ ID NO:231), RN7SL5P (SEQ ID NO:232), and RN7SK (SEQ ID NO:230).
[0091] With continued reference to FIG. 9 and Table 7, depletion of the target RNA transcripts was not observed to have a deleterious effect on untargeted RNA transcripts including GAPDH (SEQ ID NO:242) and UBB. By contrast, the observation was made that the average FPKM for GAPDH (SEQ ID NO:242) and UBB generally increased for depleted samples relative to the control sample. In one aspect, an increase in FPKM for untargeted RNA transcripts might be anticipated as the total number of reads for the selected sequencing method is generally a fixed number. By depleting target RNA transcripts, fewer sequencing reads are consumed by the target RNA transcripts, thereby making a greater number or sequencing reads available for consumption by untargeted RNA transcripts. Therefore, embodiments of the present disclosure anticipate methods of increasing the detectability of low abundance RNA transcripts through targeted depletion of comparatively high abundance transcripts, medium abundance transcripts, or a combination thereof.
[0092] Another outcome of depleting highly expressed transcripts was an increase in the efficiency of RNA-seq experiments and the sensitivity for detecting more lowly expressed transcripts in an RNA sample. To measure the effect of depleting highly expressed transcripts on the detection of lowly expressed transcripts by sequencing, the above data (FIG. 9, Table 7) was analyzed in order to identify changes in the rank order (from high to low, according to FPKM quantification) for the thirteen targeted RNA transcripts listed in the last row (top 10) of Table 7 with and without depletion. Notably, GAPDH (SEQ ID NO:242) was not targeted for depletion in this experiment. However, the RNA transcript RN7SL2 (NR_027260.1) (SEQ ID NO:243), which was determined to have greater than 99% sequence identity with RN7SL1 (SEQ ID NO:229), was additionally targeted for depletion, thereby bringing the total number of targeted RNA transcripts to fourteen.
[0093] With reference to Table 8, the observation was made that the rank order (FPKM, high to low) of genes whose RNA transcripts were targeted for depletion decreased significantly with depletion as compared to the control experiment without depletion.
TABLE-US-00008 TABLE 8 undepleted depleted Gene Rank FPKM Rank FPKM Depletion (%) RN7SL2 (SEQ ID NO: 243) 1 25,166 189 129 99.49 RN7SL1 (SEQ ID NO: 229) 2 23,617 506 68 99.71 RN7SK (SEQ ID NO: 230) 3 18,584 2,200 24 99.87 MT-CO1 (SEQ ID NO: 237) 4 17,287 1,600 30 99.82 MT-CO3 (SEQ ID NO: 238) 8 10,665 308 95 99.11 MT-CO2 (SEQ ID NO: 239) 10 10,247 1,002 42 99.59 RN7SL5P (SEQ ID NO: 232) 11 9,917 4,240 14 99.86 RN7SL4P (SEQ ID NO: 231) 12 8,501 2,367 23 99.73 RPPH1 (SEQ ID NO: 233) 20 2,838 n.a. <5 >99 MBP (SEQ ID NO: 240) 22 1,971 461 73 96.30 RMRP (SEQ ID NO: 234) 28 860 4,615 13 98.47 RNU2-2P (SEQ ID NO: 235) 35 518 n.a. <5 >99 SNORD3A (SEQ ID NO: 236) 36 474 n.a. <5 >99 SNAP25 (SEQ ID NO: 241) 38 423 2,105 25 94.03
[0094] The concept that the depletion of highly expressed transcripts facilitates detection of more lowly expressed transcripts in an RNA-seq experiment was supported by the observation that the control experiment (no depletion) had 8,521 unique transcripts that were ranked with values greater than 5 FPKM, with the average transcript detected at 48.26 FPKM. By comparison, the experimental data (with depletion of the fourteen target genes) had 9,561 unique transcripts that were ranked with values greater than 5 FPKM, with the average transcript detected at 27.41 FPKM. Accordingly, depletion of the fourteen target RNA transcripts enabled the detection of 1,040 additional genes with at least 5 FPKM that would not have been otherwise detected, which corresponded to an increase in the number of unique RNA transcripts detected of 12%. A selection of genes from the list of 1,040 genes that were otherwise undetectable without depletion (within the detection threshold of the experiment), and which are known to be involved in human disease, are listed in Table 9.
TABLE-US-00009 TABLE 9 Gene Phenotype (MIM Number) COX15 Cardioencephalomyopathy, Fatal Infantile (603646) RARS2 Pontocerebellar Hypoplasia, Type 6 (611524) CA4 Retinitis Pigmentosa 17 (114760) AASS Hyperlysinemia, Type I (605113) DNASE1 Systemic Lupus Erythematosus, Susceptibility To (125505) MUTYH Familial Adenomatous Polyposis 2 (604933) DOCK8 Hyper-IgE Recurrent Infection Syndrome, Recessive (611432) ATR Seckel Syndrome 1 (601215) GLE1 Lethal Congenital Contracture Syndrome 1 (603371) KIF22 Spondyloepimetaphyseal Dysplasia with Joint Laxity, Type 2 (603213) MCM9 Ovarian Dysgenesis 4 (610098) RECQL4 Rothmund-Thomson Syndrome (603780) MMP14 Winchester Syndrome (600754) CLN8 Ceroid Lipofuscinosis, Neuronal, 8 (607837) KDM6A Kabuki Syndrome 2 (300128) CDK6 Microcephaly 12, Primary, Autosomal Recessive (603368) CTSC Papillon-Lefevre Syndrome (602365) FBXL4 Mito DNA Depletion Synd 13 (Encephalomyopathic Type) (605654) TPMT Thiopurine S-Methyltransferase Deficiency (187680)
[0095] With reference to Table 9, the phenotype of each of the listed genes along with the associated Mendelian Inheritance in Man (MIM) number was determined using the Online Mendelian Inheritance in Man (OMIM) database. In one aspect, many genes involved in human disease or phenotypic variation when mutated are expressed at low levels. Thus, the data illustrated that embodiments of the present disclosure can be used to increase the sensitivity of experiments or tests that depend on the relative abundances of transcripts in RNA samples.
[0096] The schematic flow charts shown in the Figures are generally set forth as logical flow chart diagrams. As such, the depicted order and labeled steps are indicative of one embodiment of the presented method. Other steps and methods may be conceived that are equivalent in function, logic, or effect to one or more steps, or portions thereof, of the illustrated method. Additionally, the format and symbols employed in the Figures are provided to explain the logical steps of the method and are understood not to limit the scope of the method. Although various arrow types and line types may be employed, they are understood not to limit the scope of the corresponding method. Indeed, some arrows or other connectors may be used to indicate only the logical flow of the method. For instance, an arrow may indicate a waiting or monitoring period of unspecified duration between enumerated steps of the depicted method. Additionally, the order in which a particular method occurs may or may not strictly adhere to the order of the corresponding steps shown.
[0097] The present invention is presented in several varying embodiments in the following description with reference to the Figures, in which like numbers represent the same or similar elements. Reference throughout this specification to "one embodiment," "an embodiment," or similar language means that a particular feature, structure, or characteristic described in connection with the embodiment is included in at least one embodiment of the present invention. Thus, appearances of the phrases "in one embodiment," "in an embodiment," and similar language throughout this specification may, but do not necessarily, all refer to the same embodiment.
[0098] The described features, structures, or characteristics of the invention may be combined in any suitable manner in one or more embodiments. In the following description, numerous specific details are recited to provide a thorough understanding of embodiments of the system. One skilled in the relevant art will recognize, however, that the system and method may both be practiced without one or more of the specific details, or with other methods, components, materials, and so forth. In other instances, well-known structures, materials, or operations are not shown or described in detail to avoid obscuring aspects of the invention. Accordingly, the foregoing description is meant to be exemplary, and does not limit the scope of present inventive concepts.
[0099] Each reference identified in the present application is herein incorporated by reference in its entirety.
Sequence CWU 1
1
243138DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 1ctggttgagc acagggtact ttattgatgg tacatgac
38238DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 2ggtgcggctc cctaggcccc tcccctcttc aaggggtc
38338DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 3catggcaact gtgaggaggg gagattcagt gtggtggg
38438DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 4actgagtgtg gcagggactc cccagcagtg agggtctc
38538DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 5tcttcctctt gtgctcttgc tggggctggt ggtccagg
38638DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 6tcttactcct tggaggccat gtgggccatg aggtccac
38738DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 7ccctgttgct gtagccaaat tcgttgtcat accaggaa
38838DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 8gagcttgaca aagtggtcgt tgagggcaat gccagccc
38938DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 9gcgtcaaagg tggaggagtg ggtgtcgctg ttgaagtc
381038DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 10aggagaccac ctggtgctca gtgtagccca ggatgccc
381138DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 11gagggggccc tccgacgcct gcttcaccac cttcttga
381238DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 12tcatcatatt tggcaggttt ttctagacgg caggtcag
381338DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 13ccaccactga cacgttggca gtggggacac ggaaggcc
381438DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 14gccagtgagc ttcccgttca gctcagggat gaccttgc
381538DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 15acagccttgg cagcgccagt agaggcaggg atgatgtt
381638DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 16ggagagcccc gcggccatca cgccacagtt tcccggag
381738DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 17gccatccaca gtcttctggg tggcagtgat ggcatgga
381838DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 18gtggtcatga gtccttccac gataccaaag ttgtcatg
381938DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 19tgaccttggc caggggtgct aagcagttgg tggtgcag
382038DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 20ggcattgctg atgatcttga ggctgttgtc atacttct
382138DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 21tggttcacac ccatgacgaa catgggggca tcagcaga
382238DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 22gggcagagat gatgaccctt ttggctcccc cctgcaaa
382338DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 23agccccagcc ttctccatgg tggtgaagac gccagtgg
382438DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 24tccacgacgt actcagcgcc agcatcgccc cacttgat
382538DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 25tggagggatc tcgctcctgg aagatggtga tgggattt
382638DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 26attgatgaca agcttcccgt tctcagcctt gacggtgc
382738DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 27tggaatttgc catgggtgga atcatattgg aacatgta
382838DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 28ccatgtagtt gaggtcaatg aaggggtcat tgatggca
382938DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 29aatatccact ttaccagagt taaaagcagc cctggtga
383038DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 30aggcgcccaa tacgaccaaa tccgttgact ccgacctt
383138DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 31ccttccccat ggtgtctgag cgatgtggct cggcccgc
383238DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 32cggcgcgaac acatccggcc tgcgcccgcc cctgccgc
383338DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 33tcaggccgtc cctagcctcc cgggtttctc tccgcccg
383438DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 34ttcacctggc gacgcaaaag aagatgcggc tgactgtc
383538DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 35acaggaggag cagagagcga agcgggaggc tgcgggct
383638DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 36atttatagaa accgggggcg cggcggcagg cggtgact
383738DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 37gaccccgcct cccgccaggc tcagccagtc ccagccca
383835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 38ggtctggagc tcgtcggact cagagggcct gtctt
353935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 39cacaatgttc ttgaagaagt ggactacggg gtttt
354035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 40cagtcctctc ccctttccct gcgacggggg tggtg
354135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 41tcctggtctc tggccttcgg ccccccagct aaatc
354235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 42cttgtgagcc gatttatagt cggacgctct gcctc
354335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 43aaaaattttg gaaagcgtgc cctgggcatc gactc
354435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 44tctagccatg ggtgatccag agcgactatc tcttc
354535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 45taagaagctg aggacaggat tccggaacca ggtgg
354635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 46taggtaacag gggcaagtgg gattaaagtt ttaag
354735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 47gtgcacaact ccgcaggcat taggggaggg gtcat
354835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 48ttggccggaa attgccggta ggctgccgtg gcctg
354935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 49catcacatcc aggctctcgg aggtggctgc actgt
355035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 50gggacagttt taaccgtttt ctgttttcat gttct
355135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 51ctgggggcac attgcggggg aaggaacgtg atctt
355235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 52tggagggacg tctgtgcacc tggccccctg aagac
355335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 53ccgcagccac ggcgaaaaga aagtccaagg gtgga
355435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 54cagctgtgtg cctccatggc agtgaccagc aaaag
355535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 55ggatgtcaac agtcctctct gccgcccacg tcctc
355635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 56tttaggaggt gagagaagga caggaaaaaa aaaca
355735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 57gccactcctt gactgtctaa tcctgttagg aaaaa
355835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 58tgcccagccc gcatgtcaca taccaaaagc tccca
355935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 59gaggtggccc cctctctgtg ctgccccacg ttgga
356035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 60caggtacttg gatccgtgcc tctgggaggg tctct
356135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 61acgcgaattc agctaattgg ggtgtgtggg cagcc
356235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 62gccattgccc agcccacgtt tgcctccttt tcctc
356335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 63atctccatca ccaaatctcc aggaagaccc tgttt
356435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 64ccaccatgca gggcaacggt gacgtccaga ggcca
356535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 65ggctgtggtt tggaaacgag gttgttcata gaggc
356635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 66ccttctgctc tgagtgcgca agtcttcctg gactc
356735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 67tatgggcgac tggcgcggct gcgaggctgt ctaga
356835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 68cactgtgcac tgccgctgcc agcacgcccg gtcac
356935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 69gaagtgaatg agccggttat cttctcaggg agggt
357035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 70caggtgcacg cctgtgccta ctcgctacca cgcgt
357135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 71tgggaggaag ccatgcctgg catggtccat ggtac
357235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 72ggggccgtct gctcagcccg tgtgtctcgg tgagt
357335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 73gtgttaagaa ggatatggtc agaagagctc tttgt
357435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 74gggtcagtag gttagggagg gaggcgcgaa aggag
357535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 75tctttggaag gcctatcaat cacaggtgcg ctaaa
357635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 76tactcctcat ctccgtcctc ggggagggtg atgcc
357735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 77gaattagaat tggattaaga agacgcgttt tggca
357835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 78gctatatatt aatagacatg gtattaagcc cacac
357935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 79gtttgtgtct ggagttttgt tctttgtaac tctct
358035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 80acctcagctc agcgacgcag agtgcttctg ctgaa
358135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 81cagcacgtgc tgtgtgggtg cggccacgta tggat
358235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 82aaagaagcgc ccgatggagt caaggatgcc cgtgt
358335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 83ttcaatattc aggaacagtg tacactttcc gttca
358435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 84gggtaccttg ccagagcccc gcttgggcgc acccc
358535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 85gctgcgggca tgagagggca gagggctccg gcccg
358635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 86tgccgggtgg tgtgagtcct tgtacatgtt gcaca
358735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 87ccggccgtgt gacttctggg gcagggagcc gtagt
358835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 88aatgtctttg tggtttgtag agaatagtca acggt
358935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 89taaggagaag atggttaggt ctacggaggc tccag
359035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 90gatgaaattg atggccccta agatagagga gacac
359135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 91ttggtattgg gttatggcag ggggttttat attga
359235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 92aagtaggact gctgtgatta ggacggatca gacga
359335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 93tagtagtata gtgatgccag cagctaggac tggga
359435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 94tcctccggcg gggtcgaaga aggtggtgtt gaggt
359535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 95gtgaccgaaa aatcagaata ggtgttggta tagaa
359635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 96ggagattatt ccgaagcctg gtaggataag aatat
359735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 97gtatccaaat ggttcttttt ttccggagta gtaag
359835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 98aaaccctagg aagccaattg atatcatagc tcaga
359935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 99gcctaggact ccagctcatg cgccgaataa taggt
3510035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 100gtctacgtct attcctactg taaatatatg gtgtg
3510135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 101ggggatagcg atgattatgg tagcggaggt gaaat
3510235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 102gcttccgtgg agtgtggcga gtcagctaaa tactt
3510335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 103gatgaatcct agggctcaga gcactgcagc agatc
3510435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 104gtttgctaat acaatgccag tcaggccacc tacgg
3510535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 105ggctacaacg tagtacgtgt cgtgtagtac gatgt
3510635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 106tatgatggca aatacagctc ctattgatag gacat
3510735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 107tagggtgtag cctgagaata ggggaaatca gtgaa
3510835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 108gccgatgaat atgatagtga aatggatttt ggcgt
3510935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 109tccggatagg ccgagaaagt gttgtgggaa gaaag
3511035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 110gcctggctgg cccagctcgg ctcgaataag gaggc
3511135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 111tcatgtggtg tatgcatcgg ggtagtccga gtaac
3511235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 112tactgctgtt agagaaatga atgagcctac agatg
3511335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 113tcgcttcgaa gcgaaggctt ctcaaatcat gaaaa
3511435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 114tagtcactcc aggtttatgg agggttcttc tacta
3511535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 115gtatacgggt tcttcgaatg tgtggtaggg tgggg
3511635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 116ggctgtgacg ataacgttgt agatgtggtc gttac
3511735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 117gattatgatg ggtattacta tgaagaagat tatta
3511835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 118gggggcaccg attattaggg gaactagtca gttgc
3511935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 119taagagtcag aagcttatgt tgtttatgcg gggaa
3512035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 120ggcctccact atagcagatg cgagcaggag tagga
3512135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 121gttccctgct aagggagggt agactgttca acctg
3512235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 122aggggaagta gcgtcttgta gacctacttg cgctg
3512335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 123aatgggggct tcaatcggga gtactactcg attgt
3512435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 124gacagctcat gagtgcaaga cgtcttgtga tgtaa
3512535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 125gtttagacgt ccgggaattg catctgtttt taagc
3512635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 126ttgaccgtag tatacccccg gtcgtgtagc ggtga
3512735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 127gacgatgggc atgaaactgt ggtttgctcc acaga
3512835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 128aaatacgggc cctatttcaa agatttttag gggaa
3512935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 129gattatgagg gcgtgatcat gaaaggtgat aagct
3513035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 130tgttaggaaa agggcataca ggactaggaa gcaga
3513135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 131ttcctgagcg tctgagatgt tagtattagt tagtt
3513235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 132gaggactagg atgatggcgg gcaggatagt tcaga
3513335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 133gacctcgtct gttatgtaaa ggatgcgtag ggatg
3513435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 134gtaccattgg tggccaattg atttgatggt aaggg
3513535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 135ggagttgaag attagtccgc cgtagtcggt gtact
3513635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 136gagtcgcagg tcgcctggtt ctaggaataa tgggg
3513735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 137tgggctgggt tttactatat gataggcatg tgatt
3513835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 138actatggtga gctcaggtga ttgatactcc tgatg
3513935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 139aataagcagt gcttgaatta tttggtttcg gttgt
3514035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 140ctctgaggct tgtaggaggg taaaatagag accca
3514135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 141tgagccgtag atgccgtcgg aaatggtgaa gggag
3514235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 142aataatgacg tgaagtccgt ggaagcctgt ggcta
3514335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 143aaatattagt tggcggatga agcagatagt gagga
3514435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 144tcaggcggcg gcttcgaagc caaagtgatg tttgg
3514535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 145ggagacatac agaaatagtc aaaccacatc tacaa
3514635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 146gccggaggtc attaggaggg ctgagagggc ccctg
3514735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 147tagtatgagg agcgttatgg agtggaagtg aaatc
3514835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 148atcgcgccat cattggtata tggttagtgt gttgg
3514935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 149gacaggtggt gtgtggtggc cttggtatgt gcttt
3515035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 150ttctgaggta ataaatagga ttatcccgta tcgaa
3515135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 151gctggagtgg taaaaggctc agaaaaatcc tgcga
3515235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 152gcctgttggg ggccagtgcc ctcctaattg ggggg
3515335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 153ggatgtgttt aggagtggga cttctagggg attta
3515435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 154ctcagtgtgt agcctaggat acaggccttc agcac
3515535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 155cggggacttt cccctaggcg gaaaggggag gaaca
3515635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 156gtctacgtgc gtatgcacgt ggcactctct gcccg
3515735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 157atacgcttct tggcggactt tggagtggga agcgg
3515835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 158agctgacgga tgacgccccc gcgccacgcc gctca
3515935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 159ggttggtgcg cggacacgca ctgcctgcgt aacta
3516035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 160atcctccagc ctcagcctcc cgagtagctg ggact
3516135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 161atcctcccac ctcagcctcc cgagtagctg ggact
3516235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 162ggcatagcgc actacagccc agaactcctg gactc
3516335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 163gtcaccatat tgatgccgaa cttagtgcgg acacc
3516435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 164cccctcctta ggcaacctgg tggtcccccg ctccc
3516535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 165ggagttttga cctgctccgt ttccgacctg ggccg
3516635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 166ggagttttga cctgctctgt ttccgacctg ggccg
3516735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 167gtggctattc acaggcgcga tcccactact gatca
3516835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 168agagacgggg tctcgctatg ttgcccaggc tggag
3516935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 169atggggtgac agatgtcgca gccagatcgc cctca
3517035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 170gcctagccag ccagatcagc cgaatcaacc ctggc
3517135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 171ggggatggtc gtcctcttcg accgagcgcg cagct
3517235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 172tactcgtata cccttgaccg aagaccggtc ctcct
3517335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 173cttgagagct tgtttggagg ttctagcagg ggagc
3517435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 174cttggaagct tgactaccct acgttctcct acaaa
3517535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 175gactgccaca tgcagcgcct catttggatg tgtct
3517635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 176gatactacac ttgatcttag ccaaaaggcc gagaa
3517735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 177gtcctcggat agaggacgta tcagatatta aactg
3517835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 178cggagcaagc tcctattcca tctcctattt ccaaa
3517935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 179gtgcaccgtt cctggaagta ctgcaatacc aggtc
3518035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 180gcactcagct cgtggcccca ctgatgagct tccct
3518135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 181tcagaccttc ccaagggaca tgggagtgga gtgac
3518235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 182ctcagggaga gccctgttag ggccgcctct ggccc
3518335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 183cgcgcggagc cccgttctct gggaactcac ctccc
3518435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 184gaagggcggg gtccacggca tctcctgccc agtct
3518535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 185ctggccgtga gtctgttcca agctccggca aagga
3518635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 186tgcggggtac ctcacctcag ccattgaact cactt
3518735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 187gcggaggaga gtagtctgaa ttgggttatg aggtc
3518835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 188cgcctgacct ccccgaggtt tcgtcttcaa tgcaa
3518935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 189ctgatggcca tctgctcccg ttcgtccact acacg
3519035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 190tcattgccca tatccagggc catgtgacgg aggtt
3519135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 191gttttgttgg aatcagcctt ctccatgatc ctgtc
3519235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 192gggcacactt aaccacttcc cagcatcttt gttgc
3519335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 193gacaacattc acaatggggg tggactgatg tgtgt
3519435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 194aagagaccaa gagagaacaa aagacacaaa gtatt
3519535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 195actcaagacc tcaaggagtt agagccacca aatga
3519635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 196cgggcctctg caggttgcaa ctgtggtgga gccgc
3519735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 197gtggaatgtc acagttttac aagaacaata ctgtg
3519835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 198aagacggcac attttgagag attcagagcc tgaca
3519935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 199tgtaattcca cattgtctaa tcatgaaatc ataaa
3520035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 200tgttgtctca tcagtatgct actgtcatgg aaagt
3520135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 201caatactgag catgctttgt tgttgttctg ttgtt
3520235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 202gacaggaaaa aagtgacact actgcacttt tgctg
3520335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 203aatttcagcc aaacatatat tttgctggaa atgat
3520435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 204ctctccaaaa catagccatc aaaagcagca aacaa
3520535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 205tggttagtaa gagtcagcct tataaaattt acatc
3520635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 206aggaggaatt taatattaca tgctataatg atatt
3520735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 207ttttaataat tttaaactag ctacaaaatg tcaat
3520835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 208tcattgcgca tgtctgcgtc ttcggccatg gtagc
3520935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 209cgggtgcttt ccagcgactc atcagccaac tggtc
3521035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 210aacataacca aagtcctgat accagcatct ttact
3521135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 211cacacacaaa gcccgcagaa ttttcctagg tccgt
3521235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 212tcctgattat tgccccaggc ttttttgtaa gcatc
3521335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 213agtaacacac tatagaaatg atccctgaaa gtata
3521435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 214cagcatcccc cgcctcgcgc caagactaaa attaa
3521535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 215atgggagaaa acgcaaaaag agacaatagg aggtg
3521635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 216gagtggcggg cgggaaacgg cgacaaaaga gggag
3521735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 217cagacagaac aagagacccg gagaccccgt ctggg
3521835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 218aggagccgag atcgcgccac tgcaatccag ccggg
3521935DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 219aggcgggaga ctcgcttgag cccgggaggc agatg
3522035DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 220ggcgtgtgcg cctttaagcc ccggctactc gggag
3522135DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 221cgtggttttc ggtgctctac acgttcagag aaact
3522235DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 222gccggcttca cgctcaggag aaaacgctac ctctc
3522335DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 223tcaatggctg acggcagttg cagccaagca acgcc
3522435DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 224ctctccctct cactccccaa tacggagaga agaac
3522535DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 225cattgagcca tcaagaagga aaaaccactc agacc
3522635DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 226cagcccagaa acgccccgga gtttacgagc tagtc
3522735DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 227aggcgaaaac ctttctcgcg acatgccaag cagga
3522835DNAArtificial SequenceDNA probe sequence for depletion of
target RNA 228caccccgaga aaacccaaga gccgtcaccg ctgaa
35229299DNAHomo sapiens 229gccgggcgcg gtggcgcgtg cctgtagtcc
cagctactcg ggaggctgag gctggaggat 60cgcttgagtc caggagttct gggctgtagt
gcgctatgcc gatcgggtgt ccgcactaag 120ttcggcatca atatggtgac
ctcccgggag cgggggacca ccaggttgcc taaggagggg 180tgaaccggcc
caggtcggaa acggagcagg tcaaaactcc cgtgctgatc agtagtggga
240tcgcgcctgt gaatagccac tgcactccag cctgggcaac atagcgagac cccgtctct
299230332DNAHomo sapiens 230ggatgtgagg gcgatctggc tgcgacatct
gtcaccccat tgatcgccag ggttgattcg 60gctgatctgg ctggctaggc gggtgtcccc
ttcctccctc accgctccat gtgcgtccct 120cccgaagctg cgcgctcggt
cgaagaggac gaccatcccc gatagaggag gaccggtctt 180cggtcaaggg
tatacgagta gctgcgctcc cctgctagaa cctccaaaca agctctcaag
240gtccatttgt aggagaacgt agggtagtca agcttccaag actccagaca
catccaaatg 300aggcgctgca tgtggcagtc tgcctttctt tt 332231295DNAHomo
sapiens 231gccgggcaca gtggcgcgtg cctgtagtcc cagctactcg ggaggctgag
gtgggaggat 60cgcttgagcc caggagttct gggctgtagt gcgctatgcc gatcgggtgt
ccgcactaag 120ttcggcatca atatggtgac ctcccgggag cgggggacca
ccaggttgcc taaggagggg 180tgaaccggcc caggtcggaa acagagcagg
tcaaaactcc cgtgctgatc aggagacaga 240gtttgtgagc agacaactgg
tctgaccaaa atttatgagg tgggaatttc ctctt 295232321DNAHomo sapiens
232gccgggcgcg gtggcgcgtg cctgtggtcc cagctactcg ggaggctgag
gctggaggat 60cgcttgagtc caggagttct gggctgtagt gcgctatgcc gatcgggtgt
ccgcactaag 120ttcggcatca atatggtgac ctcccgggag cgggggacca
ccaggttgcc taaggagggg 180tgaaccggcc caggtcggaa acggagcagg
tcaaaactcc cgtgctgatc agtagaagtc 240tgtaatgcta ctggtgtccc
ctaattttct tatagccaca gttcctttcg cctgagctca 300ttacagagac
aaatatccat t 321233333DNAHomo sapiens 233ggcggaggga agctcatcag
tggggccacg agctgagtgc gtcctgtcac tccactccca 60tgtcccttgg gaaggtctga
gactagggcc agaggcggcc ctaacagggc tctccctgag 120cttcggggag
gtgagttccc agagaacggg gctccgcgcg aggtcagact gggcaggaga
180tgccgtggac cccgcccttc ggggaggggc ccggcggatg cctcctttgc
cggagcttgg 240aacagactca cggccagcga agtgagttca atggctgagg
tgaggtaccc cgcaggggac 300ctcataaccc aattcagact actctcctcc gcc
333234277DNAHomo sapiens 234ggttcgtgct gaaggcctgt atcctaggct
acacactgag gactctgttc ctcccctttc 60cgcctagggg aaagtccccg gacctcgggc
agagagtgcc acgtgcatac gcacgtagac 120attccccgct tcccactcca
aagtccgcca agaagcgtat cccgctgagc ggcgtggcgc 180gggggcgtca
tccgtcagct ccctctagtt acgcaggcag tgcgtgtccg cgcaccaacc
240acacggggct cattctcagc gcggctgtaa aaaaaaa 277235191DNAHomo
sapiens 235atcgcttctc ggccttttgg ctaagatcaa gtgtagtatc tgttcttatc
agtttaatat 60ctgatacgtc ctctatccga ggacaatata ttaaatggat ttttggaaat
aggagatgga 120ataggagctt gctccgtcca ctccacgcat cgacctggta
ttgcagtact tccaggaacg 180gtgcactctc c 191236699DNAHomo sapiens
236aagactatac tttcagggat catttctata gtgtgttact agagaagttt
ctctgaacgt 60gtagagcacc gaaaaccacg aggaagagag gtagcgtttt ctcctgagcg
tgaagccggc 120tttctggcgt tgcttggctg caactgccgt cagccattga
tgatcgttct tctctccgta 180ttggggagtg agagggagag aacgcggtct
gagtggtttt tccttcttga tggctcaatg 240acagagacta gctcgtaaac
tccggggcgt ttctgggctg ttcgctcctg cttggcatgt 300cgcgagaaag
gttttcgcct cctgtttcag cggtgacggc tcttgggttt tctcggggtg
360gctttttaat tttagtcttg gcgcgaggcg ggggatgctg tgtggcacct
cctattgtct 420ctttttgcgt tttctcccat tctcgctccc tcttttgtcg
ccgtttcccg cccgccactc 480ccacccccag acggggtctc cgggtctctt
gttctgtctg ccggccccgg ctggattgca 540gtggcgcgat ctcggctcct
agcaacatct gcctcccggg ctcaagcgag tctcccgcct 600aagccctccc
gagtagccgg ggcttaaagg cgcacacgcc actccaggct tttttttttt
660tttttttttt ttttttggca gaaacggggt gtcagcatg 6992371542DNAHomo
sapiens 237atgttcgccg accgttgact attctctaca aaccacaaag acattggaac
actataccta 60ttattcggcg catgagctgg agtcctaggc acagctctaa gcctccttat
tcgagccgag 120ctgggccagc caggcaacct tctaggtaac gaccacatct
acaacgttat cgtcacagcc 180catgcatttg taataatctt cttcatagta
atacccatca taatcggagg ctttggcaac 240tgactagttc ccctaataat
cggtgccccc gatatggcgt ttccccgcat aaacaacata 300agcttctgac
tcttacctcc ctctctccta ctcctgctcg catctgctat agtggaggcc
360ggagcaggaa caggttgaac agtctaccct cccttagcag ggaactactc
ccaccctgga 420gcctccgtag acctaaccat cttctcctta cacctagcag
gtgtctcctc tatcttaggg 480gccatcaatt tcatcacaac aattatcaat
ataaaacccc ctgccataac ccaataccaa 540acgcccctct tcgtctgatc
cgtcctaatc acagcagtcc tacttctcct atctctccca 600gtcctagctg
ctggcatcac tatactacta acagaccgca acctcaacac caccttcttc
660gaccccgccg gaggaggaga ccccattcta taccaacacc tattctgatt
tttcggtcac 720cctgaagttt atattcttat cctaccaggc ttcggaataa
tctcccatat tgtaacttac 780tactccggaa aaaaagaacc atttggatac
ataggtatgg tctgagctat gatatcaatt 840ggcttcctag ggtttatcgt
gtgagcacac catatattta cagtaggaat agacgtagac 900acacgagcat
atttcacctc cgctaccata atcatcgcta tccccaccgg cgtcaaagta
960tttagctgac tcgccacact ccacggaagc aatatgaaat gatctgctgc
agtgctctga 1020gccctaggat tcatctttct tttcaccgta ggtggcctga
ctggcattgt attagcaaac 1080tcatcactag acatcgtact acacgacacg
tactacgttg tagcccactt ccactatgtc 1140ctatcaatag gagctgtatt
tgccatcata ggaggcttca ttcactgatt tcccctattc 1200tcaggctaca
ccctagacca aacctacgcc aaaatccatt tcactatcat attcatcggc
1260gtaaatctaa ctttcttccc acaacacttt ctcggcctat ccggaatgcc
ccgacgttac 1320tcggactacc ccgatgcata caccacatga aacatcctat
catctgtagg ctcattcatt 1380tctctaacag cagtaatatt aataattttc
atgatttgag aagccttcgc ttcgaagcga 1440aaagtcctaa tagtagaaga
accctccata aacctggagt gactatatgg atgcccccca 1500ccctaccaca
cattcgaaga acccgtatac ataaaatcta ga 1542238784DNAHomo sapiens
238atgacccacc aatcacatgc ctatcatata gtaaaaccca gcccatgacc
cctaacaggg 60gccctctcag ccctcctaat gacctccggc ctagccatgt gatttcactt
ccactccata 120acgctcctca tactaggcct actaaccaac acactaacca
tataccaatg atggcgcgat 180gtaacacgag aaagcacata ccaaggccac
cacacaccac ctgtccaaaa aggccttcga 240tacgggataa tcctatttat
tacctcagaa gtttttttct tcgcaggatt tttctgagcc 300ttttaccact
ccagcctagc ccctaccccc caattaggag ggcactggcc cccaacaggc
360atcaccccgc taaatcccct agaagtccca ctcctaaaca catccgtatt
actcgcatca 420ggagtatcaa tcacctgagc tcaccatagt ctaatagaaa
acaaccgaaa ccaaataatt 480caagcactgc ttattacaat tttactgggt
ctctatttta ccctcctaca agcctcagag 540tacttcgagt ctcccttcac
catttccgac ggcatctacg gctcaacatt ttttgtagcc 600acaggcttcc
acggacttca cgtcattatt ggctcaactt tcctcactat ctgcttcatc
660cgccaactaa tatttcactt tacatccaaa catcactttg gcttcgaagc
cgccgcctga 720tactggcatt ttgtagatgt ggtttgacta tttctgtatg
tctccatcta ttgatgaggg 780tctt 784239684DNAHomo sapiens
239atggcacatg cagcgcaagt aggtctacaa gacgctactt cccctatcat
agaagagctt 60atcacctttc atgatcacgc cctcataatc attttcctta tctgcttcct
agtcctgtat 120gcccttttcc taacactcac aacaaaacta actaatacta
acatctcaga cgctcaggaa 180atagaaaccg tctgaactat cctgcccgcc
atcatcctag tcctcatcgc cctcccatcc 240ctacgcatcc tttacataac
agacgaggtc aacgatccct cccttaccat caaatcaatt 300ggccaccaat
ggtactgaac ctacgagtac accgactacg gcggactaat cttcaactcc
360tacatacttc ccccattatt cctagaacca ggcgacctgc gactccttga
cgttgacaat 420cgagtagtac tcccgattga agcccccatt cgtataataa
ttacatcaca agacgtcttg 480cactcatgag ctgtccccac attaggctta
aaaacagatg caattcccgg acgtctaaac 540caaaccactt tcaccgctac
acgaccgggg gtatactacg gtcaatgctc tgaaatctgt 600ggagcaaacc
acagtttcat gcccatcgtc ctagaattaa ttcccctaaa aatctttgaa
660atagggcccg tatttaccct atag 6842402300DNAHomo sapiens
240ggacaacacc ttcaaagaca ggccctctga gtccgacgag ctccagacca
tccaagaaga 60cagtgcagcc acctccgaga gcctggatgt gatggcgtca cagaagagac
cctcccagag 120gcacggatcc aagtacctgg ccacagcaag taccatggac
catgccaggc atggcttcct 180cccaaggcac agagacacgg gcatccttga
ctccatcggg cgcttctttg gcggtgacag 240gggtgcgccc aagcggggct
ctggcaaggt accctggcta aagccgggcc ggagccctct 300gccctctcat
gcccgcagcc agcctgggct gtgcaacatg tacaaggact cacaccaccc
360ggcaagaact gctcactacg gctccctgcc ccagaagtca cacggccgga
cccaagatga 420aaaccccgta gtccacttct tcaagaacat tgtgacgcct
cgcacaccac ccccgtcgca 480gggaaagggg agaggactgt ccctgagcag
atttagctgg ggggccgaag gccagagacc 540aggatttggc tacggaggca
gagcgtccga ctataaatcg gctcacaagg gattcaaggg 600agtcgatgcc
cagggcacgc tttccaaaat ttttaagctg ggaggaagag atagtcgctc
660tggatcaccc atggctagac gctgaaaacc cacctggttc cggaatcctg
tcctcagctt 720cttaatataa ctgccttaaa actttaatcc cacttgcccc
tgttacctaa ttagagcaga 780tgacccctcc cctaatgcct gcggagttgt
gcacgtagta gggtcaggcc acggcagcct 840accggcaatt tccggccaac
agttaaatga gaacatgaaa acagaaaacg gttaaaactg 900tccctttctg
tgtgaagatc acgttccttc ccccgcaatg tgcccccaga cgcacgtggg
960tcttcagggg gccaggtgca cagacgtccc tccacgttca cccctccacc
cttggacttt 1020cttttcgccg tggctgcggc acccttgcgc ttttgctggt
cactgccatg gaggcacaca 1080gctgcagaga cagagaggac gtgggcggca
gagaggactg ttgacatcca agcttccttt 1140gttttttttt cctgtccttc
tctcacctcc taaagtagac ttcatttttc ctaacaggat 1200tagacagtca
aggagtggct tactacatgt gggagctttt ggtatgtgac atgcgggctg
1260ggcagctgtt agagtccaac gtggggcagc acagagaggg ggccacctcc
ccaggccgtg 1320gctgcccaca caccccaatt agctgaattc gcgtgtggca
gagggaggaa aaggaggcaa 1380acgtgggctg ggcaatggcc tcacatagga
aacagggtct tcctggagat ttggtgatgg 1440agatgtcaag caggtggcct
ctggacgtca ccgttgccct gcatggtggc cccagagcag 1500cctctatgaa
caacctcgtt tccaaaccac agcccacagc cggagagtcc aggaagactt
1560gcgcactcag agcagaaggg taggagtcct ctagacagcc tcgcagccgc
gccagtcgcc 1620catagacact ggctgtgacc gggcgtgctg gcagcggcag
tgcacagtgg ccagcactaa 1680ccctccctga gaagataacc ggctcattca
cttcctccca gaagacgcgt ggtagcgagt 1740aggcacaggc gtgcacctgc
tcccgaatta ctcaccgaga cacacgggct gagcagacgg 1800ccccgtggat
ggagacaaag agctcttctg accatatcct tcttaacacc cgctggcatc
1860tcctttcgcg cctccctccc taacctactg acccaccttt tgattttagc
gcacctgtga 1920ttgataggcc ttccaaagag tcccacgctg gcatcaccct
ccccgaggac ggagatgagg 1980agtagtcagc gtgatgccaa aacgcgtctt
cttaatccaa ttctaattct gaatgtttcg 2040tgtgggctta ataccatgtc
tattaatata tagcctcgat gatgagagag ttacaaagaa 2100caaaactcca
gacacaaacc tccaaatttt tcagcagaag cactctgcgt cgctgagctg
2160aggtcggctc tgcgatccat acgtggccgc acccacacag cacgtgctgt
gacgatggct 2220gaacggaaag tgtacactgt tcctgaatat tgaaataaaa
caataaactt ttaatggtaa 2280aaaaaaaaaa aaaaaaaaaa 23002412069DNAHomo
sapiens 241catctttgat gagggcagag ctcacgttgc attgaagacg aaacctcggg
gaggtcaggc 60gctgtctttc cttccctccc tgctcggcgg ctccaccaca gttgcaacct
gcagaggccc 120ggagaacaca accctcccga gaagcccagg tccagagcca
aacccgtcac tgacccccca 180gcccaggcgc ccagccactc cccaccgcta
ccatggccga agacgcagac atgcgcaatg 240agctggagga gatgcagcga
agggctgacc agttggctga tgagtcgctg gaaagcaccc 300gtcgtatgct
gcaactggtt gaagagagta aagatgctgg tatcaggact ttggttatgt
360tggatgaaca aggagaacaa ctggaacgca ttgaggaagg gatggaccaa
atcaataagg 420acatgaaaga agcagaaaag aatttgacgg acctaggaaa
attctgcggg ctttgtgtgt 480gtccctgtaa caagcttaaa tcaagtgatg
cttacaaaaa agcctggggc aataatcagg 540acggagtggt ggccagccag
cctgctcgtg tagtggacga acgggagcag atggccatca 600gtggcggctt
catccgcagg gtaacaaatg atgcccgaga aaatgaaatg gatgaaaacc
660tagagcaggt gagcggcatc atcgggaacc tccgtcacat ggccctggat
atgggcaatg 720agatcgatac acagaatcgc cagatcgaca ggatcatgga
gaaggctgat tccaacaaaa 780ccagaattga tgaggccaac caacgtgcaa
caaagatgct gggaagtggt taagtgtgcc 840cacccgtgtt ctcctccaaa
tgctgtcggg caagatagct ccttcatgct tttctcatgg 900tattatctag
taggtctgca cacataacac acatcagtcc acccccattg tgaatgttgt
960cctgtgtcat ctgtcagctt cccaacaata ctttgtgtct tttgttctct
cttggtctct 1020ttctttccaa aggttgtaca tagtggtcat ttggtggctc
taactccttg aggtcttgag 1080tttcattttt cattttctct cctcggtggc
atttgctgaa taacaacaat ttaggaatgc 1140tcaatgtgct gttgattctt
tcaatccaca gtattgttct tgtaaaactg tgacattcca 1200cagagttact
gccacggtcc tttgagtgtc aggctctgaa tctctcaaaa tgtgccgtct
1260ttggttcctc atggctgtta tctgtcttta tgatttcatg attagacaat
gtggaattac 1320ataacaggca ttgcactaaa agtgatgtga tttatgcatt
tatgcatgag aactaaatag 1380atttttagat tcctacttaa acaaaaactt
tccatgacag tagcatactg atgagacaac 1440acacacacac acaaaacaac
agcaacaaca acagaacaac aacaaagcat gctcagtatt 1500gagacactgt
caagattaag ttataccagc aaaagtgcag tagtgtcact tttttcctgt
1560caatatatag agacttctaa atcataatca tcctttttta aaaaaaagaa
ttttaaaaaa 1620gatggatttg acacactcac catttaatca tttccagcaa
aatatatgtt tggctgaaat 1680tatgtcaaat ggatgtaata tagggtttgt
ttgctgcttt tgatggctat gttttggaga 1740gagcaatctt gctgtgaaac
agtgtggatg taaattttat aaggctgact cttactaacc 1800accatttccc
ctgtggtttg ttatcagtac aattctttgt tgcttaatct agagctatgc
1860acaccaaatt gctgagatgt ttagtagctg ataaagaaac cttttaaaaa
aataatataa 1920atgaatgaaa tataaactgt gagataaata tcattatagc
atgtaatatt aaattcctcc 1980tgtctcctct gtcagtttgt gaagtgattg
acattttgta gctagtttaa aattattaaa 2040aattatagac tccaaaaaaa
aaaaaaaaa 20692421513DNAHomo sapiens 242gcctcaagac cttgggctgg
gactggctga gcctggcggg aggcggggtc cgagtcaccg 60cctgccgccg cgcccccggt
ttctataaat tgagcccgca gcctcccgct tcgctctctg 120ctcctcctgt
tcgacagtca gccgcatctt cttttgcgtc gccaggtgaa gacgggcgga
180gagaaacccg ggaggctagg gacggcctga aggcggcagg ggcgggcgca
ggccggatgt 240gttcgcgccg ctgcgggccg agccacatcg ctcagacacc
atggggaagg tgaaggtcgg 300agtcaacgga tttggtcgta ttgggcgcct
ggtcaccagg gctgctttta actctggtaa 360agtggatatt gttgccatca
atgacccctt cattgacctc aactacatgg tttacatgtt 420ccaatatgat
tccacccatg gcaaattcca tggcaccgtc aaggctgaga acgggaagct
480tgtcatcaat ggaaatccca tcaccatctt ccaggagcga gatccctcca
aaatcaagtg 540gggcgatgct ggcgctgagt acgtcgtgga gtccactggc
gtcttcacca ccatggagaa 600ggctggggct catttgcagg ggggagccaa
aagggtcatc atctctgccc cctctgctga 660tgcccccatg ttcgtcatgg
gtgtgaacca tgagaagtat gacaacagcc tcaagatcat 720cagcaatgcc
tcctgcacca ccaactgctt agcacccctg gccaaggtca tccatgacaa
780ctttggtatc gtggaaggac tcatgaccac agtccatgcc atcactgcca
cccagaagac 840tgtggatggc ccctccggga aactgtggcg tgatggccgc
ggggctctcc agaacatcat 900ccctgcctct actggcgctg ccaaggctgt
gggcaaggtc atccctgagc tgaacgggaa 960gctcactggc atggccttcc
gtgtccccac tgccaacgtg tcagtggtgg acctgacctg 1020ccgtctagaa
aaacctgcca aatatgatga catcaagaag gtggtgaagc aggcgtcgga
1080gggccccctc aagggcatcc tgggctacac tgagcaccag gtggtctcct
ctgacttcaa 1140cagcgacacc cactcctcca cctttgacgc tggggctggc
attgccctca acgaccactt 1200tgtcaagctc atttcctggt atgacaacga
atttggctac agcaacaggg tggtggacct 1260catggcccac atggcctcca
aggagtaaga cccctggacc accagcccca gcaagagcac 1320aagaggaaga
gagagaccct cactgctggg gagtccctgc cacactcagt cccccaccac
1380actgaatctc ccctcctcac agttgccatg tagacccctt gaagagggga
ggggcctagg 1440gagccgcacc ttgtcatgta ccatcaataa agtaccctgt
gctcaaccag ttaaaaaaaa 1500aaaaaaaaaa aaa 1513243299DNAHomo sapiens
243gccgggcgcg gtggcgcgtg cctgtagtcc cagctactcg ggaggctgag
gtgggaggat 60cgcttgagcc caggagttct gggctgtagt gcgctatgcc gatcgggtgt
ccgcactaag 120ttcggcatca atatggtgac ctcccgggag cgggggacca
ccaggttgcc taaggagggg 180tgaaccggcc caggtcggaa acggagcagg
tcaaaactcc cgtgctgatc agtagtggga 240tcgcgcctgt gaatagccac
tgcactccag cctgagcaac atagcgagac cccgtctct 299
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.