Gene-regulating Compositions And Methods For Improved Immunotherapy
BENSON; Micah ; et al.
U.S. patent application number 16/354102 was filed with the patent office on 2019-09-19 for gene-regulating compositions and methods for improved immunotherapy. The applicant listed for this patent is KSQ Therapeutics, Inc.. Invention is credited to Micah BENSON, Gregory V. KRYUKOV, Jason MERKIN, Michael SCHLABACH, Solomon Martin SHENKER, Noah TUBO.
| Application Number | 20190284553 16/354102 |
| Document ID | / |
| Family ID | 67905215 |
| Filed Date | 2019-09-19 |











View All Diagrams
| United States Patent Application | 20190284553 |
| Kind Code | A1 |
| BENSON; Micah ; et al. | September 19, 2019 |
GENE-REGULATING COMPOSITIONS AND METHODS FOR IMPROVED IMMUNOTHERAPY
Abstract
The present disclosure provides methods and compositions related to the modification of immune effector cells to increase therapeutic efficacy. In some embodiments, immune effector cells modified to reduce expression of one or more endogenous target genes, or to reduce one or more functions of an endogenous protein to enhance effector functions of the immune cells are provided. In some embodiments, immune effector cells further modified by introduction of transgenes conferring antigen specificity, such as exogenous T cell receptors (TCRs) or chimeric antigen receptors (CARs) are provided. Methods of treating a cell proliferative disorder, such as a cancer, using the modified immune effector cells described herein are also provided.
| Inventors: | BENSON; Micah; (Cambridge, MA) ; MERKIN; Jason; (Cambridge, MA) ; KRYUKOV; Gregory V.; (Cambridge, MA) ; SHENKER; Solomon Martin; (Cambridge, MA) ; SCHLABACH; Michael; (Cambridge, MA) ; TUBO; Noah; (Cambridge, MA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 67905215 | ||||||||||
| Appl. No.: | 16/354102 | ||||||||||
| Filed: | March 14, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 62643578 | Mar 15, 2018 | |||
| 62692010 | Jun 29, 2018 | |||
| 62768428 | Nov 16, 2018 | |||
| 62643587 | Mar 15, 2018 | |||
| 62692019 | Jun 29, 2018 | |||
| 62768443 | Nov 16, 2018 | |||
| 62804265 | Feb 12, 2019 | |||
| 62643597 | Mar 15, 2018 | |||
| 62692100 | Jun 29, 2018 | |||
| 62768448 | Nov 16, 2018 | |||
| 62643598 | Mar 15, 2018 | |||
| 62692110 | Jun 29, 2018 | |||
| 62768458 | Nov 16, 2018 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | C07K 14/7051 20130101; A61K 2039/505 20130101; A61K 38/00 20130101; C12N 2310/14 20130101; A61K 39/0011 20130101; C07K 2319/03 20130101; A61K 39/001106 20180801; A61K 39/001188 20180801; C12N 2510/00 20130101; C07K 14/70517 20130101; C07K 16/2863 20130101; C07K 16/2818 20130101; C12N 2310/20 20170501; A61P 35/02 20180101; A61K 39/001104 20180801; A61K 39/001191 20180801; C07K 16/32 20130101; C12N 2310/122 20130101; C07K 2317/622 20130101; A61K 2035/124 20130101; A61K 39/001112 20180801; A61P 35/00 20180101; C07K 2319/33 20130101; C12N 9/22 20130101; A61K 39/001153 20180801; A61K 2039/5158 20130101; A61K 39/39541 20130101; A61P 35/04 20180101; C07K 2319/30 20130101; C12N 15/113 20130101; A61K 2039/5156 20130101; C12N 15/1138 20130101; C12N 2800/80 20130101; C07K 16/2803 20130101; C12N 15/11 20130101; A61K 35/17 20130101; C12N 5/0636 20130101; A61K 39/39541 20130101; A61K 2300/00 20130101; A61K 39/0011 20130101; A61K 2300/00 20130101 |
| International Class: | C12N 15/11 20060101 C12N015/11; A61K 35/17 20060101 A61K035/17; A61P 35/00 20060101 A61P035/00; A61P 35/02 20060101 A61P035/02; A61P 35/04 20060101 A61P035/04; C12N 9/22 20060101 C12N009/22; C12N 15/113 20060101 C12N015/113; C12N 5/0783 20060101 C12N005/0783; C07K 16/28 20060101 C07K016/28; C07K 16/32 20060101 C07K016/32; C07K 14/725 20060101 C07K014/725; C07K 14/705 20060101 C07K014/705 |
Claims
1.-288. (canceled)
289. A modified immune effector cell comprising reduced expression or function of NR4A3, wherein the reduced expression or function of NR4A3 enhances an effector function of the modified immune effector cell.
290. The modified immune effector cell of claim 289, further comprising reduced expression or function of one or more endogenous target genes selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR.
291. The modified immune effector cell of claim 289, wherein the NR4A3 gene comprises an inactivating mutation and wherein the inactivating mutation reduces the expression or function of NR4A3.
292. The modified immune effector cell of claim 291, wherein the expression or function of the one or more endogenous target genes is reduced by at least 50%, at least 60%, at least 70%, at least 80%, or at least 90% compared to an un-modified or control immune effector cell.
293. The modified immune effector cell of claim 289, wherein the immune effector cell is a lymphocyte selected from a T cell, a natural killer (NK) cell, an NKT cell, and a tumor infiltrating lymphocyte.
294. The modified immune effector cell of claim 289, further comprising an engineered immune receptor displayed on the cell surface.
295. The modified immune effector cell of claim 294, wherein the engineered immune receptor is a chimeric antigen receptor (CAR) or an engineered T cell receptor (TCR).
296. The modified immune effector cell of claim 289, further comprising an exogenous transgene expressing an immune activating molecule.
297. The modified immune effector cell of claim 296, wherein the immune activating molecule is selected from the group consisting of a cytokine, a chemokine, a co-stimulatory molecule, an activating peptide, an antibody, or an antigen-binding fragment thereof.
298. The modified immune effector cell of claim 289, wherein the modified immune effector cells are autologous to a subject.
299. The modified immune effector cell of claim 289, wherein the modified immune effector cells are allogenic to a subject.
300. The modified immune effector cell of claim 289, wherein the effector function is selected from cell proliferation, cell viability, tumor infiltration, cytotoxicity, anti-tumor immune responses, and resistance to exhaustion.
301. The modified immune effector cell of claim 300, wherein the effector function of the modified immune cell is increased by at least 10% compared to a non-modified control immune cell.
302. The modified immune effector cell of claim 301, wherein the NR4A3 gene comprises an inactivating mutation and wherein the inactivating mutation reduces the expression or function of NR4A3.
303. A pharmaceutical composition comprising the modified immune effector cell of claim 289.
304. The composition of claim 303, wherein the modified immune effector cells are autologous to a subject.
305. The composition of claim 303, wherein the modified immune effector cells are allogenic to a subject.
306. A method of treating a disease or disorder in a subject in need thereof comprising administering an effective amount of modified immune effector cells to the subject in need thereof, wherein the modified immune effector cells comprise reduced expression or function of NR4A3, and wherein the reduced expression or function of NR4A3 enhances an effector function of the modified immune effector cell.
307. The method of claim 306, wherein the disease or disorder is a cancer selected from a leukemia, a lymphoma, or a solid tumor.
308. The method of claim 306, wherein the solid tumor is a melanoma, a pancreatic tumor, a bladder tumor, a lung tumor or metastasis, a colorectal cancer, a cervical cancer, or a head and neck cancer.
309. The method of claim 306, wherein the cancer is a PD1-inhibitor resistant or refractory cancer.
310. The method of claim 306, wherein the modified immune effector cells are autologous to the subject.
311. The method of claim 306, wherein the modified immune effector cells are allogenic to the subject.
312. The method of claim 306, wherein the disease or disorder is a solid tumor and wherein the tumor is decreased by at least 10% more compared to treatment with a non-modified control immune cell.
313. The method of claim 312, wherein the solid tumor is selected from a melanoma tumor or metastasis, a lung tumor or metastasis, or a colorectal cancer.
314. A gene-regulating system capable of reducing the expression or function of NR4A3 in a cell comprising: (i) one or more nucleic acid molecules selected from an siRNA, an shRNA, a microRNA (miR), an antagomiR, or an antisense RNA; (ii) one or more enzymatic proteins selected from a zinc finger nuclease and a transcription-activator-like effector nuclease (TALEN); or (iii) one or more guide RNAs (gRNAs) and a Cas endonuclease.
315. The gene-regulating system of claim 314, wherein the Cas endonuclease comprises: (a) a wild-type Cas protein comprising two enzymatically active domains; (b) a Cas nickase mutant comprising one enzymatically active domain; or (c) a deactivated Cas protein (dCas) associated with a heterologous protein.
316. The gene-regulating system of claim 314, wherein the Cas protein is a Cas9 protein.
317. The gene-regulating system of claim 314, comprising one or more siRNA or shRNA molecules that bind to an RNA sequence encoded by a DNA sequence in the NR4A3 gene defined by a set of genomic coordinate selected from those in Tables 6G and 6H.
318. The gene-regulating system of claim 314, comprising one or more siRNA or shRNA molecules that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 1539-1566.
319. The gene-regulating system of claim 314, comprising a plurality of siRNA or shRNA molecules.
320. The gene regulating system of claim 314, wherein the one or more gRNAs comprise a targeting domain sequence that is complementary to a target DNA sequence in the NR4A3 gene defined by a set of genomic coordinates selected from those in Table 6G and Table 6H.
321. The gRNA nucleic acid molecule of claim 314, wherein the gRNA comprises a targeting domain sequence that binds to a target DNA sequence selected from SEQ ID NOs: 1539-1566.
322. The gene regulating system of claim 314, comprising a plurality of gRNA nucleic acid molecules.
323. The gene regulating system of claim 314, wherein the one or more gRNAs comprise a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1539-1566.
324. A kit comprising the gene regulating system of claim 314.
325. A modified immune effector cell comprising the gene-regulating system of claim 314.
326. A method of producing a modified immune effector cell, comprising introducing the gene-regulating system of claim 314 into the immune effector cell.
327. A method of enhancing one or more effector functions of an immune effector cell comprising introducing a gene-regulating system of claim 314 into the immune effector cell, wherein the immune effector cell demonstrates one or more enhanced effector functions compared to an immune effector cell that has not been modified.
328. The method of claim 327, wherein the one or more effector functions are selected from cell proliferation, cell viability, cytotoxicity, tumor infiltration, increased cytokine production, anti-tumor immune responses, and resistance to exhaustion.
329. The method of claim 328, wherein the one or more effector functions are increased by at least 10% compared to a control immune effector cell.
330. A guide RNA (gRNA) nucleic acid molecule comprising a targeting domain nucleic acid sequence that is complementary to a target DNA sequence in the NR4A3 gene selected from a target DNA sequence defined by a set of genomic coordinates selected from those listed in Table 6G and Table 6H.
331. The gRNA nucleic acid molecule of claim 330, wherein the gRNA comprises a targeting domain sequence that binds to a target DNA sequence selected from SEQ ID NOs: 1539-1566.
332. The gRNA nucleic acid molecule of claim 330, wherein the gRNA comprises a targeting domain sequence encoded by a sequence selected from SEQ ID NOs: 1539-1566.
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application claims priority to U.S. Provisional Application No. 62/643,578, filed Mar. 15, 2018; U.S. Provisional Application No. 62/692,010, filed Jun. 29, 2018; U.S. Provisional Application No. 62/768,428, filed Nov. 16, 2018; U.S. Provisional Application No. 62/643,587, filed Mar. 15, 2018; U.S. Provisional Application No. 62/692,019, filed Jun. 29, 2018; U.S. Provisional Application No. 62/768,443, filed Nov. 16, 2018; U.S. Provisional Application No. 62/804,265, filed Feb. 12, 2019; U.S. Provisional Application No. 62/643,597, filed Mar. 15, 2018; U.S. Provisional Application No. 62/692,100, filed Jun. 29, 2018; U.S. Provisional Application No. 62/768,448, filed Nov. 16, 2018; U.S. Provisional Application No. 62/643,598, filed Mar. 15, 2018; U.S. Provisional Application No. 62/692,110, filed Jun. 29, 2018; and U.S. Provisional Application No. 62/768,458, filed Nov. 16, 2018, each of which is hereby incorporated by reference in its entirety.
DESCRIPTION OF THE TEXT FILE SUBMITTED ELECTRONICALLY
[0002] The contents of the text file submitted electronically herewith are incorporated herein by reference in their entirety: A computer readable format copy of the Sequence Listing (filename: KSQT_007_04US_SeqList_ST25.txt; date recorded: Mar. 14, 2019; file size 308 kilobytes).
FIELD
[0003] The disclosure relates to methods, compositions, and components for editing a target nucleic acid sequence, or modulating expression of a target nucleic acid sequence, and applications thereof in connection with immunotherapy, including use with receptor-engineered immune effector cells, in the treatment of cell proliferative diseases, inflammatory diseases, and/or infectious diseases.
BACKGROUND
[0004] Adoptive cell transfer utilizing genetically modified T cells, in particular CAR-T cells has entered clinical testing as a therapeutic for solid and hematologic malignancies. Results to date have been mixed. In hematologic malignancies (especially lymphoma, CLL and ALL), the majority of patients in several Phase 1 and 2 trials exhibited at least a partial response, with some exhibiting complete responses (Kochenderfer et al., 2012 Blood 1 19, 2709-2720). In 2017, the FDA approved two CAR-T therapies, Kymriah.TM. and Yescarta.TM., both for the treatment of hematological cancers. However, in most tumor types (including melanoma, renal cell carcinoma and colorectal cancer), fewer responses have been observed (Johnson et al., 2009 Blood 1 14, 535-546; Lamers et al., 2013 Mol. Ther. 21, 904-912; Warren et al., 1998 Cancer Gene Ther. 5, S1-S2). As such, there is considerable room for improvement with adoptive T cell therapies, as success has largely been limited to CAR-T cells approaches targeting hematological malignancies of the B cell lineage.
SUMMARY
[0005] There exists a need to improve the efficacy of adoptive transfer of modified immune cells in cancer treatment, in particular increasing the efficacy of adoptive cell therapies against solid malignancies, as reduced responses have been observed in these tumor types (melanoma, renal cell carcinoma and colorectal cancer; Yong, 2017, Imm Cell Biol., 95:356-363). In addition, even in hematological malignancies where a benefit of adoptive transfer has been observed, not all patients respond and relapses occur with a greater than desired frequency, likely as a result of diminished function of the adoptively transferred T cells.
[0006] Factors limiting the efficacy of genetically modified immune cells as cancer therapeutics include (1) cell proliferation, e.g., limited proliferation of T cells following adoptive transfer; (2) cell survival, e.g., induction of T cell apoptosis by factors in the tumor environment; and (3) cell function, e.g., inhibition of cytotoxic T cell function by inhibitory factors secreted by host immune cells and cancer cells and exhaustion of immune cells during manufacturing processes and/or after transfer.
[0007] Particular features thought to increase the anti-tumor effects of an immune cell include a cell's ability to 1) proliferate in the host following adoptive transfer; 2) infiltrate a tumor; 3) persist in the host and/or exhibit resistance to immune cell exhaustion; and 4) function in a manner capable of killing tumor cells. The present disclosure provides immune cells comprising decreased expression and/or function of one or more endogenous target genes wherein the modified immune cells demonstrate an enhancement of one or more effector functions including increased proliferation, increased infiltration into tumors, persistence of the immune cells in a subject, and/or increased resistance to immune cell exhaustion. The present disclosure also provides methods and compositions for modification of immune effector cells to elicit enhanced immune cell activity towards a tumor cell, as well as methods and compositions suitable for use in the context of adoptive immune cell transfer therapy.
[0008] In some embodiments, the present disclosure provides a modified immune effector cell comprising reduced expression and/or function of ZC3H12A nucleic acid or protein (also known as Regnase-1). The present disclosure describes and demonstrates inhibition of ZC3H12A by multiple modalities, including CRISPR/Cas systems, zinc-finger systems, and siRNA/shRNA systems. In some embodiments, the reduced expression/function of ZC3H12A is mediated by an antibody, a small molecule, or a peptide. In some embodiments, the present disclosure provides a method of killing a cancerous cell comprising exposing the cancerous cell to a ZC3H12A protein inhibitor, wherein said inhibitor is an antibody, small molecule or peptide that binds to ZC3H12A and reduces ZC3H12A function and wherein said inhibitor is in an amount effective to kill said cancerous cell. In some embodiments, the exposure is in vitro, in vivo, or ex vivo
[0009] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system capable of reducing expression and/or function of one or more endogenous target genes selected from: (a) the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS; (b) ZC3H12A; (c) MAP4K1; or (d) NR4A3. In some embodiments, the reduced expression and/or function of the one or more endogenous genes enhances an effector function of the immune effector cell.
[0010] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system capable of reducing the expression and/or function of one or more endogenous target genes selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, the reduced expression and/or function of the one or more endogenous genes enhances an effector function of the immune effector cell. In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of two or more of endogenous target genes selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, and IKZF2 and at least one of the endogenous target genes is selected from the group consisting of CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR.
[0011] In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of at least one endogenous target gene selected from the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS and at least one endogenous target gene selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR.
[0012] In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of ZC3H12A and at least one endogenous target gene selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of ZC3H12A and CBLB. In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of ZC3H12A and BCOR. In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of ZC3H12A and TNFAIP3.
[0013] In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of MAP4K1 and at least one endogenous target gene selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of MAP4K1 and CBLB. In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of MAP4K1 and BCOR. In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of MAP4K1 and TNFAPI3.
[0014] In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of NR4A3 and at least one endogenous target gene selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of NR4A3 and CBLB. In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of NR4A3 and BCOR. In some embodiments, the gene-regulating system is capable of reducing the expression and/or function of NR4A3 and TNFAPI3.
[0015] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system, wherein the gene-regulating system comprises (i) one or more nucleic acid molecules; (ii) one or more enzymatic proteins; or (iii) one or more guide nucleic acid molecules and an enzymatic protein. In some embodiments, the one or more nucleic acid molecules are selected from an siRNA, an shRNA, a microRNA (miR), an antagomiR, or an antisense RNA. In some embodiments, the gene-regulating system comprises an siRNA or an shRNA nucleic acid molecule.
[0016] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system, wherein the gene-regulating system comprises an siRNA or an shRNA nucleic acid molecule, wherein the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, the siRNA or shRNA comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, the gene-regulating system comprises an siRNA or an shRNA nucleic acid molecule, wherein the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6A and Table 6B. In some embodiments, the siRNA or shRNA comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 814-1064.
[0017] In some embodiments, the gene-regulating system comprises an siRNA or an shRNA nucleic acid molecule, wherein the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6C and Table 6D. In some embodiments, the siRNA or shRNA comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 1065-1509. In some embodiments, the gene-regulating system comprises an siRNA or an shRNA nucleic acid molecule, wherein the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6E and Table 6F. In some embodiments, the siRNA or shRNA comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 510-1538. In some embodiments, the gene-regulating system comprises an siRNA or an shRNA nucleic acid molecule, wherein the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6G and Table 6H. In some embodiments, the siRNA or shRNA comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 1539-1566.
[0018] In some embodiments, the gene-regulating system comprises a plurality of siRNA or shRNA molecules and is capable of reducing the expression and/or function of two or more endogenous target genes. In some embodiments, at least one of the endogenous target genes is selected from the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6A and Table 6B and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 814-1064 and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, at least one of the endogenous target genes is selected from the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS and at least one of the endogenous target genes is selected from the group consisting of TNFAIP3, CBLB, and BCOR.
[0019] In some embodiments, the gene-regulating system comprises a plurality of siRNA or shRNA molecules and is capable of reducing the expression and/or function of two or more endogenous target genes. In some embodiments, at least one of the endogenous target genes is ZC3H12A and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6C and Table 6D and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 1065-1509 and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, at least one of the endogenous target genes is selected from the group consisting of ZC3H12A and at least one of the endogenous target genes is selected from the group consisting of TNFAIP3, CBLB, and BCOR.
[0020] In some embodiments, the gene-regulating system comprises a plurality of siRNA or shRNA molecules and is capable of reducing the expression and/or function of two or more endogenous target genes. In some embodiments, at least one of the endogenous target genes is MAP4K1 and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6E and Table 6F and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 510-1538 and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, at least one of the endogenous target genes is MAP4K1 and at least one of the endogenous target genes is selected from the group consisting of TNFAIP3, CBLB, and BCOR.
[0021] In some embodiments, the gene-regulating system comprises a plurality of siRNA or shRNA molecules and is capable of reducing the expression and/or function of two or more endogenous target genes. In some embodiments, at least one of the endogenous target genes is NR4A3 and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6G and Table 6H and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 1539-1566 and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, at least one of the endogenous target genes is NR4A3 and at least one of the endogenous target genes is selected from the group consisting of TNFAIP3, CBLB, and BCOR.
[0022] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system, wherein the gene-regulating system comprises an enzymatic protein, and wherein the enzymatic protein has been engineered to specifically bind to a target sequence in one or more of the endogenous genes. In some embodiments, the protein is a Transcription activator-like effector nuclease (TALEN), a zinc-finger nuclease, or a meganuclease.
[0023] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system, wherein the gene-regulating system comprises a guide nucleic acid molecule and an enzymatic protein, wherein the nucleic acid molecule is a guide RNA (gRNA) molecule and the enzymatic protein is a Cas protein or Cas ortholog.
[0024] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system capable of reducing the expression and/or function of at least one endogenous target gene, wherein the gene-regulating system comprises a guide RNA (gRNA) molecule and a Cas protein or Cas ortholog, and wherein the one or more endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR, and wherein the gRNA molecule comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, the gRNA molecule comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 154-813.
[0025] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system capable of reducing the expression and/or function of at least one endogenous target gene, wherein the gene-regulating system comprises a guide RNA (gRNA) molecule and a Cas protein or Cas ortholog, and wherein the one or more endogenous target genes is selected from the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS, and wherein the gRNA molecule comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Table 6A and Table 6B. In some embodiments, the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 814-1064. In some embodiments, the gRNA molecule comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 814-1064.
[0026] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system capable of reducing the expression and/or function of at least one endogenous target gene, wherein the gene-regulating system comprises a guide RNA (gRNA) molecule and a Cas protein or Cas ortholog, and wherein the one or more endogenous target genes is ZC3H12A, and wherein the gRNA molecule comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Table 6C and Table 6D. In some embodiments, the gRNA molecule comprises a targeting domain sequence that binds to a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1065-1509. In some embodiments, the gRNA molecule comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1065-1509.
[0027] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system capable of reducing the expression and/or function of at least one endogenous target gene, wherein the gene-regulating system comprises a guide RNA (gRNA) molecule and a Cas protein or Cas ortholog, and wherein the one or more endogenous target genes is M4AP4K1, and wherein the gRNA molecule comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Tables 6E and 6F. In some embodiments, the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 510-1538. In some embodiments, the gRNA molecule comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 510-1538.
[0028] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system capable of reducing the expression and/or function of at least one endogenous target gene, wherein the gene-regulating system comprises a guide RNA (gRNA) molecule and a Cas protein or Cas ortholog, and wherein the one or more endogenous target genes is NR4A3, and wherein the gRNA molecule comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Tables 6G and 6H. In some embodiments, the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 1539-1566. In some embodiments, the gRNA molecule comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1539-1566.
[0029] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system capable of reducing the expression and/or function of at least two endogenous target genes, wherein the gene-regulating system comprises a plurality of gRNAs and a Cas protein or Cas ortholog. In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system capable of reducing the expression and/or function of at least two endogenous target genes, wherein the gene-regulating system comprises a plurality of gRNAs and a Cas protein or Cas ortholog, wherein at least one of the endogenous target genes selected from the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Table 6A and Table 6B and at least one of the plurality of gRNA molecule comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 814-1064 and at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 814-1064 and at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, at least one of the endogenous target genes selected from the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS and at least one of the endogenous target genes is selected from the group consisting of TNFAIP3, CBLB, and BCOR.
[0030] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system capable of reducing the expression and/or function of at least two endogenous target genes, wherein the gene-regulating system comprises a plurality of gRNAs and a Cas protein or Cas ortholog, wherein at least one of the endogenous target genes is ZC3H12A and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Table 6C and Table 6D and at least one of the plurality of gRNA molecule comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 1065-1509 and at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 1065-1509 and at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, at least one of the endogenous target genes is ZC3H12A and at least one of the endogenous target genes is selected from the group consisting of TNFAIP3, CBLB, and BCOR.
[0031] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system capable of reducing the expression and/or function of at least two endogenous target genes, wherein the gene-regulating system comprises a plurality of gRNAs and a Cas protein or Cas ortholog, wherein at least one of the endogenous target genes is MAP4K1 and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Table 6E and Table 6F and at least one of the plurality of gRNA molecule comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 510-1538 and at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 510-1538 and at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, at least one of the endogenous target genes is M4AP4K1 and at least one of the endogenous target genes is selected from the group consisting of TNFAIP3, CBLB, and BCOR.
[0032] In some embodiments, the present disclosure provides a modified immune effector cell comprising a gene-regulating system capable of reducing the expression and/or function of at least two endogenous target genes, wherein the gene-regulating system comprises a plurality of gRNAs and a Cas protein or Cas ortholog, wherein at least one of the endogenous target genes is NR4A3 and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Table 6G and Table 6H and at least one of the plurality of gRNA molecule comprises a targeting domain sequence that binds to a nucleic acid sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 1539-1566 and at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1539-1566 and at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 154-813. In some embodiments, at least one of the endogenous target genes is NR4A3 and at least one of the endogenous target genes is selected from the group consisting of TNFAIP3, CBLB, and BCOR.
[0033] In some embodiments, the present disclosure provides a modified immune effector cell comprising a Cas protein or Cas ortholog, wherein: (a) the Cas protein is a wild-type Cas protein comprising two enzymatically active domains, and capable of inducing double stranded DNA breaks; (b) the Cas protein is a Cas nickase mutant comprising one enzymatically active domain and capable of inducing single stranded DNA breaks; or (c) the Cas protein is a deactivated Cas protein (dCas) and is associated with a heterologous protein capable of modulating the expression of the one or more endogenous target genes. In some embodiments, the Cas protein is a Cas9 protein. In some embodiments, the heterologous protein is selected from the group consisting of MAX-interacting protein 1 (MXI1), Kruppel-associated box (KRAB) domain, methyl-CpG binding protein 2 (MECP2), and four concatenated mSin3 domains (SID4X).
[0034] In some embodiments, the gene regulating system introduces an inactivating mutation into the one or more endogenous target genes. In some embodiments, the inactivating mutation comprises a deletion, substitution, or insertion of one or more nucleotides in the genomic sequences of the two or more endogenous genes. In some embodiments, the deletion is a partial or complete deletion of the two or more endogenous target genes. In some embodiments, the inactivating mutation is a frame shift mutation. In some embodiments, the inactivating mutation reduces the expression and/or function of the two or more endogenous target genes.
[0035] In some embodiments, the gene-regulating system is introduced to the immune effector cell by transfection, transduction, electroporation, or physical disruption of the cell membrane by a microfluidics device. In some embodiments, the gene-regulating system is introduced as a polynucleotide encoding one or more components of the system, a protein, or a ribonucleoprotein (RNP) complex.
[0036] In some embodiments, the present disclosure provides a modified immune effector cell comprising reduced expression and/or function of one or more endogenous genes selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR, wherein the reduced expression and/or function of the one or more endogenous genes enhances an effector function of the immune effector cell. In some embodiments, the present disclosure provides a modified immune effector cell comprising reduced expression and/or function of one or more endogenous genes selected from: (a) the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, and IKZF2; or (b) the group consisting of CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR, wherein the reduced expression and/or function of the one or more endogenous genes enhances an effector function of the immune effector cell.
[0037] In some embodiments, the present disclosure provides a modified immune effector cell comprising reduced expression and/or function of one or more endogenous genes selected from: (a) the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS; (b) ZC3H12A; (c) MAP4K1; or (d) NR4A3, wherein the reduced expression and/or function of the one or more endogenous genes enhances an effector function of the modified immune effector cell.
[0038] In some embodiments, the present disclosure provides a modified immune effector cell comprising reduced expression and/or function of two or more target genes selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR, wherein the reduced expression and/or function of the two or more endogenous genes enhances an effector function of the modified immune effector cell. In some embodiments, the modified immune effector comprises reduced expression and/or function of CBLB and BCOR.
[0039] In some embodiments, the present disclosure provides a modified immune effector cell comprising reduced expression and/or function of two or more target genes, wherein at least one target gene is selected from the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS, and wherein at least one target gene is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR, wherein the reduced expression and/or function of the two or more endogenous genes enhances an effector function of the modified immune effector cell.
[0040] In some embodiments, the present disclosure provides a modified immune effector cell comprising reduced expression and/or function of two or more target genes, wherein at least one target gene is ZC3H12A, and wherein at least one target gene is selected from the group consisting of IKZF, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR, wherein the reduced expression and/or function of the two or more endogenous genes enhances an effector function of the modified immune effector cell. In some embodiments, the modified immune effector comprises reduced expression and/or function of ZC3H12A and CBLB. In some embodiments, the modified immune effector comprises reduced expression and/or function of ZC3H12A and BCOR. In some embodiments, the modified immune effector comprises reduced expression and/or function of ZC3H12A and TNFAIP3.
[0041] In some embodiments, the present disclosure provides a modified immune effector cell comprising reduced expression and/or function of two or more target genes, wherein at least one target gene is MAP4K1, and wherein at least one target gene is selected from the group consisting of IKZF, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR, wherein the reduced expression and/or function of the two or more endogenous genes enhances an effector function of the modified immune effector cell. In some embodiments, the modified immune effector comprises reduced expression and/or function of MAP4K1 and CBLB. In some embodiments, the modified immune effector comprises reduced expression and/or function of MAP4K1 and BCOR. In some embodiments, the modified immune effector comprises reduced expression and/or function of MAP4K1 and TNFAIP3.
[0042] In some embodiments, the present disclosure provides a modified immune effector cell comprising reduced expression and/or function of two or more target genes, wherein at least one target gene is NR4A3, and wherein at least one target gene is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR, wherein the reduced expression and/or function of the two or more endogenous genes enhances an effector function of the modified immune effector cell. In some embodiments, the modified immune effector comprises reduced expression and/or function of NR4A3 and CBLB. In some embodiments, the modified immune effector comprises reduced expression and/or function of NR4A3 and BCOR. In some embodiments, the modified immune effector comprises reduced expression and/or function of NR4A3 and TNFAIP3.
[0043] In some embodiments, the present disclosure provides a modified immune effector cell comprising an inactivating mutation in one or more endogenous genes selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, the present disclosure provides a modified immune effector cell comprising an inactivating mutation in one or more endogenous genes selected from: (a) the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, and IKZF2; or (b) the group consisting of CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR.
[0044] In some embodiments, the present disclosure provides a modified immune effector cell comprising an inactivating mutation in one or more endogenous genes selected from: (a) the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS; (b) ZC3H12A; (c) MAP4K1; or (d) NR4A3.
[0045] In some embodiments, the present disclosure provides a modified immune effector cell comprising an inactivating mutation in two or more target genes selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, the modified immune effector comprises an inactivating mutation in the CBLB and BCOR genes.
[0046] In some embodiments, the present disclosure provides a modified immune effector cell comprising an inactivating mutation in two or more target genes, wherein at least one target gene is selected from the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS, and at least one target gene is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR.
[0047] In some embodiments, the present disclosure provides a modified immune effector cell comprising an inactivating mutation in two or more target genes, wherein at least one target gene is ZC3H12A and at least one target gene is selected from the group consisting of IKZF, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, the modified immune effector comprises an inactivating mutation in the ZC3H12A and CBLB genes. In some embodiments, the modified immune effector comprises an inactivating mutation in the ZC3H12A and BCOR genes. In some embodiments, the modified immune effector comprises an inactivating mutation in the ZC3H12A and TNFAIP3 genes.
[0048] In some embodiments, the present disclosure provides a modified immune effector cell comprising an inactivating mutation in two or more target genes, wherein at least one target gene is MAP4K1 and at least one target gene is selected from the group consisting of IKZF, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD, and BCOR. In some embodiments, the modified immune effector comprises an inactivating mutation in the M4AP4K1 and CBLB genes. In some embodiments, the modified immune effector comprises an inactivating mutation in the MAP4K1 and BCOR genes. In some embodiments, the modified immune effector comprises an inactivating mutation in the MAP4K1 and TNFAIP3 genes.
[0049] In some embodiments, the present disclosure provides a modified immune effector cell comprising an inactivating mutation in two or more target genes, wherein at least one target gene is NR4A3 and at least one target gene is selected from the group consisting of IKZF, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, the modified immune effector comprises an inactivating mutation in the NR4A3 and CBLB genes. In some embodiments, the modified immune effector comprises an inactivating mutation in the NR4A3 and BCOR genes. In some embodiments, the modified immune effector comprises an inactivating mutation in the NR4A3 and TNFAIP3 genes.
[0050] In some embodiments, the inactivating mutation comprises a deletion, substitution, or insertion of one or more nucleotides in the genomic sequences of the two or more endogenous genes. In some embodiments, the deletion is a partial or complete deletion of the two or more endogenous target genes. In some embodiments, the inactivating mutation is a frame shift mutation. In some embodiments, the inactivating mutation reduces the expression and/or function of the two or more endogenous target genes.
[0051] In some embodiments, the expression of the one or more endogenous target genes is reduced by at least 50%, at least 60%, at least 70%, at least 80%, or at least 90% compared to an un-modified or control immune effector cell. In some embodiments, the function of the one or more endogenous target genes is reduced by at least 50%, at least 60%, at least 70%, at least 80%, or at least 90% compared to an un-modified or control immune effector cell.
[0052] In some embodiments, the modified immune effector cell further comprises an engineered immune receptor displayed on the cell surface. In some embodiments, the engineered immune receptor is a CAR comprising an antigen-binding domain, a transmembrane domain, and an intracellular signaling domain. In some embodiments, the engineered immune receptor is an engineered TCR. In some embodiments, the engineered immune receptor specifically binds to an antigen expressed on a target cell, wherein the antigen is a tumor-associated antigen.
[0053] In some embodiments, the modified immune effector cell further comprises an exogenous transgene expressing an immune activating molecule. In some embodiments, the immune activating molecule is selected from the group consisting of a cytokine, a chemokine, a co-stimulatory molecule, an activating peptide, an antibody, or an antigen-binding fragment thereof. In some embodiments, the antibody or binding fragment thereof specifically binds to and inhibits the function of the protein encoded by NRP1, HAVCR2, LAG3, TIGIT, CTLA4, or PDCD1.
[0054] In some embodiments, the immune effector cell is a wherein the immune effector cell is a lymphocyte selected from a T cell, a natural killer (NK) cell, an NKT cell. In some embodiments, the lymphocyte is a tumor infiltrating lymphocyte (TIL).
[0055] In some embodiments, the effector function is selected from cell proliferation, cell viability, tumor infiltration, cytotoxicity, anti-tumor immune responses, and/or resistance to exhaustion.
[0056] In some embodiments, the present disclosure provides a composition comprising the modified immune effector cells described herein. In some embodiments, the composition further comprises a pharmaceutically acceptable carrier or diluent. In some embodiments, the composition comprises at least 1.times.10.sup.4, 1.times.10.sup.5, 1.times.10.sup.6, 1.times.10.sup.7, 1.times.10.sup.8, 1.times.10.sup.9, 1.times.10.sup.10, or 1.times.10.sup.11 modified immune effector cells. In some embodiments, the composition is suitable for administration to a subject in need thereof. In some embodiments, the composition comprises autologous immune effector cells derived from the subject in need thereof. In some embodiments, the composition comprises allogeneic immune effector cells derived from a donor subject.
[0057] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression and/or function of one or more endogenous target genes in a cell selected from: (a) the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, and IKZF2; or (b) the group consisting of CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR, wherein the system comprises (i) a nucleic acid molecule; (ii) an enzymatic; or (iii) a guide nucleic acid molecule and an enzymatic protein.
[0058] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell selected from: (a) the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS; (b) ZC3H12A; (c) MAP4K1; or (d) NR4A3, wherein the system comprises (i) a nucleic acid molecule; (ii) an enzymatic; or (iii) a guide nucleic acid molecule and an enzymatic protein.
[0059] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell comprising a guide RNA (gRNA) nucleic acid molecule and a Cas endonuclease.
[0060] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell comprising a guide RNA (gRNA) nucleic acid molecule and a Cas endonuclease, wherein the one or more endogenous target genes are selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, and IKZF2 or is selected from CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR and wherein the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A and Table 5B. In some embodiments, the one or more endogenous target genes are selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, and IKZF2 and wherein the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 154-498. In some embodiments, the gRNA molecule comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 154-498.
[0061] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell comprising a guide RNA (gRNA) nucleic acid molecule and a Cas endonuclease, wherein the one or more endogenous target genes are selected from CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR and wherein the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 499-813. In some embodiments, the gRNA molecule comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 499-813.
[0062] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell comprising a guide RNA (gRNA) nucleic acid molecule and a Cas endonuclease, wherein the one or more endogenous target genes are selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS and wherein the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 6A and Table 6B. In some embodiments, the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 814-1064. In some embodiments, the gRNA molecule comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 814-1064.
[0063] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell comprising a guide RNA (gRNA) nucleic acid molecule and a Cas endonuclease, wherein the one or more endogenous target gene is ZC3H12A and wherein the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 6C and Table 6D. In some embodiments, the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 1065-1509. In some embodiments, the gRNA molecule comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1065-1509. In some embodiments, the gRNA molecule comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1065-1509.
[0064] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell comprising a guide RNA (gRNA) nucleic acid molecule and a Cas endonuclease, wherein the one or more endogenous target genes comprises M4AP4K1 and wherein the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 6E and Table 6F. In some embodiments, the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 510-1538. In some embodiments, the gRNA molecule comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 510-1538.
[0065] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell comprising a guide RNA (gRNA) nucleic acid molecule and a Cas endonuclease, wherein the one or more endogenous target genes comprises NR4A3 and wherein the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 6G and Table 6H. In some embodiments, the gRNA molecule comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 1539-1566. In some embodiments, the gRNA molecule comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1539-1566.
[0066] In some embodiments, the gene-regulating system comprises an siRNA or an shRNA nucleic acid molecule.
[0067] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell, wherein the gene-regulating system comprises an siRNA or an shRNA nucleic acid molecule and wherein the one or more endogenous target genes are selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, and IKZF2 or is selected from CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR and wherein the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, the one or more endogenous target genes are selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, and IKZF2 and wherein the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from SEQ ID NOs: 154-498. In some embodiments, the one or more endogenous target genes are selected from CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR and wherein the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from SEQ ID NOs: 499-813.
[0068] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell, wherein the gene-regulating system comprises an siRNA or an shRNA nucleic acid molecule, wherein the one or more endogenous target genes are selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS and wherein the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6A and Table 6B. In some embodiments, the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from SEQ ID NOs: 814-1064.
[0069] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell, wherein the gene-regulating system comprises an siRNA or an shRNA nucleic acid molecule, wherein the one or more endogenous target gene is ZC3H12A and wherein the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6C and Table 6D. In some embodiments, the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from SEQ ID NOs: 1065-1509.
[0070] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell, wherein the gene-regulating system comprises an siRNA or an shRNA nucleic acid molecule, wherein the one or more endogenous target genes comprises MAP4K1 and wherein the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6E and Table 6F. In some embodiments, the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from SEQ ID NOs: 510-1538.
[0071] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing expression of one or more endogenous target genes in a cell, wherein the gene-regulating system comprises an siRNA or an shRNA nucleic acid molecule, wherein the one or more endogenous target genes comprises NR4A3 and wherein the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6G and Table 6H. In some embodiments, the siRNA or shRNA molecule comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from SEQ ID NOs: 1539-1566.
[0072] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing the expression and/or function of two or more endogenous target genes in a cell, wherein at least one of the endogenous target genes is selected from: (a) the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS; (b) ZC3H12A; (c) MAP4K1; or (d) NR4A3, and wherein at least one of the endogenous target genes is selected from: (e) the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, and IKZF2; or (f) the group consisting of CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR, wherein the system comprises (i) a nucleic acid molecule; (ii) an enzymatic; or (iii) a guide nucleic acid molecule and an enzymatic protein
[0073] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing the expression and/or function of two or more endogenous target genes in a cell, wherein the system comprises a plurality of guide RNA (gRNA) nucleic acid molecules and a Cas endonuclease.
[0074] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing the expression and/or function of two or more endogenous target genes in a cell, wherein the system comprises a plurality of guide RNA (gRNA) nucleic acid molecules and a Cas endonuclease, wherein at least one of the endogenous target genes is selected from the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of gRNAs binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 6A and Table 6B, and wherein at least one of the plurality of gRNAs binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 814-1064 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 814-1064 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0075] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing the expression and/or function of two or more endogenous target genes in a cell, wherein the system comprises a plurality of guide RNA (gRNA) nucleic acid molecules and a Cas endonuclease, wherein at least one of the endogenous target genes is ZC3H12A and at least one of the endogenous target genes is selected from the group consisting of IKZF, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of gRNAs binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 6C and Table 6D, and wherein at least one of the plurality of gRNAs binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 1065-1509 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 1065-1509 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 499-524. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1065-1509 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1065-1509 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from SEQ ID NOs: 499-524.
[0076] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing the expression and/or function of two or more endogenous target genes in a cell, wherein the system comprises a plurality of guide RNA (gRNA) nucleic acid molecules and a Cas endonuclease, wherein at least one of the endogenous target genes is MAP4K1 and at least one of the endogenous target genes is selected from the group consisting of IKZF, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of gRNAs binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 6E and Table 6F, and wherein at least one of the plurality of gRNAs binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 510-1538 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 510-1538 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 499-524. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 510-1538 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 510-1538 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 499-524.
[0077] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing the expression and/or function of two or more endogenous target genes in a cell, wherein the system comprises a plurality of guide RNA (gRNA) nucleic acid molecules and a Cas endonuclease, wherein at least one of the endogenous target genes is NR4A3 and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of gRNAs binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 6G and Table 6H, and wherein at least one of the plurality of gRNAs binds to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 1539-1566 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 1539-1566 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence that binds to a target DNA sequence selected from the group consisting of SEQ ID NOs: 499-524. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1539-1566 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1539-1566 and wherein at least one of the plurality of gRNA molecules comprises a targeting domain sequence encoded by a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 499-524.
[0078] In some embodiments, the gene-regulating system comprises a Cas protein, wherein the Cas protein is: (a) a wild-type Cas protein comprising two enzymatically active domains, and capable of inducing double stranded DNA breaks; (b) a Cas nickase mutant comprising one enzymatically active domain and capable of inducing single stranded DNA breaks; (c) a deactivated Cas protein (dCas) and is associated with a heterologous protein capable of modulating the expression of the one or more endogenous target genes. In some embodiments, the heterologous protein is selected from the group consisting of MAX-interacting protein 1 (MXI1), Kruppel-associated box (KRAB) domain, and four concatenated mSin3 domains (SID4X). In some embodiments, the Cas protein is a Cas9 protein.
[0079] In some embodiments, the gene-regulating system comprises a nucleic acid molecule and wherein the nucleic acid molecule is an siRNA, an shRNA, a microRNA (miR), an antagomiR, or an antisense RNA. In some embodiments, the gene-regulating system comprises a plurality of shRNA or siRNA molecules.
[0080] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing the expression and/or function of two or more endogenous target genes in a cell, wherein the gene-regulating system comprises a plurality of shRNA or siRNA molecules, wherein at least one of the endogenous target genes is selected from the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6A and Table 6B and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 814-1064 and wherein at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0081] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing the expression and/or function of two or more endogenous target genes in a cell, wherein the gene-regulating system comprises a plurality of shRNA or siRNA molecules, wherein at least one of the endogenous target genes is ZC3H12A and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6C and Table 6D and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 1065-1509 and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 1065-1509 and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 499-524.
[0082] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing the expression and/or function of two or more endogenous target genes in a cell, wherein the gene-regulating system comprises a plurality of shRNA or siRNA molecules, wherein at least one of the endogenous target genes is MAP4K1 and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6E and Table 6F and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 510-1538 and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 510-1538 and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 499-524.
[0083] In some embodiments, the present disclosure provides a gene-regulating system capable of reducing the expression and/or function of two or more endogenous target genes in a cell, wherein the gene-regulating system comprises a plurality of shRNA or siRNA molecules, wherein at least one of the endogenous target genes is NR4A3 and at least one of the endogenous target genes is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 6G and Table 6H and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence defined by a set of genome coordinates shown in Table 5A and Table 5B. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 1539-1566 and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 1539-1566 and at least one of the plurality of siRNA or shRNA molecules comprises about 19-30 nucleotides that bind to an RNA sequence encoded by a DNA sequence selected from the group consisting of SEQ ID NOs: 499-524.
[0084] In some embodiments, the gene-regulating system comprises a protein comprising a DNA binding domain and an enzymatic domain and is selected from a zinc finger nuclease and a transcription-activator-like effector nuclease (TALEN).
[0085] In some embodiments, the present disclosure provides a gene-regulating system comprising a vector encoding one or more gRNAs and a vector encoding a Cas endonuclease protein, wherein the one or more gRNAs comprise a targeting domain sequence encoded by a nucleic acid sequence selected from: SEQ ID NOs: 814-1064, SEQ ID NOs: 1065-1509, SEQ ID NOs: 510-1538, SEQ ID NOs: 1539-1566, SEQ ID NOs: 154-498, or SEQ ID NOs: 499-813.
[0086] In some embodiments, the present disclosure provides a gene-regulating system comprising a vector encoding a plurality of gRNAs and a vector encoding a Cas endonuclease protein, wherein at least one of the plurality of gRNA comprises a targeting domain sequence encoded by a nucleic acid sequence selected from: SEQ ID NOs: 814-1064, SEQ ID NOs: 1065-1509, SEQ ID NOs: 510-1538, or SEQ ID NOs: 1539-1566, and wherein at least one of the plurality of gRNA comprises a targeting domain sequence encoded by a nucleic acid sequence selected from: SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0087] In some embodiments, the present disclosure provides a gene-regulating system comprising a vector encoding one or more gRNAs and an mRNA molecule encoding a Cas endonuclease protein, wherein the one or more gRNAs comprise a targeting domain sequence encoded by a nucleic acid sequence selected from SEQ ID NOs: 814-1064, SEQ ID NOs: 1065-1509, SEQ ID NOs: 510-1538, SEQ ID NOs: 1539-1566, SEQ ID NOs: 154-498, or SEQ ID NOs: 499-813.
[0088] In some embodiments, the present disclosure provides a gene-regulating system comprising a vector encoding a plurality of gRNAs and an mRNA molecule encoding a Cas endonuclease protein, wherein at least one of the plurality of gRNA comprises a targeting domain sequence encoded by a nucleic acid sequence selected from: SEQ ID NOs: 814-1064, SEQ ID NOs: 1065-1509, SEQ ID NOs: 510-1538, or SEQ ID NOs: 1539-1566, and wherein at least one of the plurality of gRNA comprises a targeting domain sequence encoded by a nucleic acid sequence selected from: SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0089] In some embodiments, the present disclosure provides a gene-regulating system comprising one or more gRNAs and a Cas endonuclease protein, wherein the one or more gRNAs comprise a targeting domain sequence encoded by a nucleic acid sequence selected from: SEQ ID NOs: 814-1064, SEQ ID NOs: 1065-1509, SEQ ID NOs: 510-1538, SEQ ID NOs: 1539-1566, SEQ ID NOs: 154-498, or SEQ ID NOs: 499-813, and wherein the one or more gRNAs and the Cas endonuclease protein are complexed to form a ribonucleoprotein (RNP) complex.
[0090] In some embodiments, the present disclosure provides a gene-regulating system comprising a plurality of gRNAs and a Cas endonuclease protein: wherein at least one of the plurality of gRNA comprises a targeting domain sequence encoded by a nucleic acid sequence selected from: SEQ ID NOs: 814-1064, SEQ ID NOs: 1065-1509, SEQ ID NOs: 510-1538, or SEQ ID NOs: 1539-1566, wherein at least one of the plurality of gRNA comprises a targeting domain sequence encoded by a nucleic acid sequence selected from: SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813, and wherein the one or more gRNAs and the Cas endonuclease protein are complexed to form a ribonucleoprotein (RNP) complex.
[0091] In some embodiments, the present disclosure provides a kit comprising a gene-regulating system described herein.
[0092] In some embodiments, the present disclosure provides a gRNA nucleic acid molecule comprising a targeting domain nucleic acid sequence that binds to a target sequence in an endogenous target gene selected from: (a) the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS; (b) ZC3H12A; (c) MAP4K1; (d) NR4A3; (e) IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, and IKZF2; or (f) CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR. In some embodiments, (a) the endogenous gene is selected from the group consisting of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS and the gRNA comprises a targeting domain sequence that binds to a target DNA sequence located at genomic coordinates selected from those shown in Tables 6A and 6B; (b) the endogenous gene is ZC3H12A and the gRNA comprises a targeting domain sequence that binds to a target DNA sequence located at genomic coordinates selected from those shown in Table 6C and Table 6D; (c) the endogenous gene is MAP4K1 and the gRNA comprises a targeting domain sequence that binds to a target DNA sequence located at genomic coordinates selected from those shown in Table 6E and Table 6F; (d) the endogenous gene is NR4A3 and the gRNA comprises a targeting domain sequence that binds to a target DNA sequence located at genomic coordinates selected from those shown in Table 6G and Table 6H; (e) the endogenous gene is selected from the group consisting of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, and IKZF2 and the gRNA comprises a targeting domain sequence that binds to a target DNA sequence located at genomic coordinates selected from those shown in Table 5A and Table 5B; or (f) the endogenous gene is selected from the group consisting of CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR and the gRNA comprises a targeting domain sequence that binds to a target DNA sequence located at genomic coordinates selected from those shown in Table 5A and Table 5B.
[0093] In some embodiments, the gRNA comprises a targeting domain sequence that binds to a target DNA sequence selected from SEQ ID NOs: 814-1064, SEQ ID NOs: 1065-1509, SEQ ID NOs: 510-1538, SEQ ID NOs: 1539-1566, SEQ ID NOs: 154-498, or SEQ ID NOs: 499-813. In some embodiments, the gRNA comprises a targeting domain sequence encoded by a sequence selected from SEQ ID NOs: 814-1064, SEQ ID NOs: 1065-1509, SEQ ID NOs: 510-1538, SEQ ID NOs: 1539-1566, SEQ ID NOs: 154-498, or SEQ ID NOs: 499-813. In some embodiments, the target sequence comprises a PAM sequence.
[0094] In some embodiments, the gRNA is a modular gRNA molecule. In some embodiments, the gRNA is a dual gRNA molecule. In some embodiments, the targeting domain is 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26 or more nucleotides in length. In some embodiments, the gRNA molecule comprises a modification at or near its 5' end (e.g., within 1-10, 1-5, or 1-2 nucleotides of its 5' end) and/or a modification at or near its 3' end (e.g., within 1-10, 1-5, or 1-2 nucleotides of its 3' end). In some embodiments, the modified gRNA exhibits increased stability towards nucleases when introduced into a T cell. In some embodiments, the modified gRNA exhibits a reduced innate immune response when introduced into a T cell.
[0095] In some embodiments, the present disclosure provides a polynucleotide molecule encoding a gRNA molecule described herein. In some embodiments, the present disclosure provides a composition comprising one or more gRNA molecules described herein or polynucleotides encoding the same. In some embodiments, the present disclosure provides a kit comprising one or more gRNA molecules described herein or polynucleotides encoding the same.
[0096] In some embodiments, the present disclosure provides a method of producing a modified immune effector cell comprising: (a) obtaining an immune effector cell from a subject; (b) introducing the gene-regulating system of any one of claims Error! Reference source not found.--Error! Reference source not found. into the immune effector cell; and (c) culturing the immune effector cell such that the expression and/or function of one or more endogenous target genes is reduced compared to an immune effector cell that has not been modified.
[0097] In some embodiments, the present disclosure provides a method of producing a modified immune effector cell comprising introducing a gene-regulating system described herein into the immune effector cell. In some embodiments, the methods further comprise introducing a polynucleotide sequence encoding an engineered immune receptor selected from a CAR and a TCR. In some embodiments, the gene-regulating system and/or the polynucleotide encoding the engineered immune receptor are introduced to the immune effector cell by transfection, transduction, electroporation, or physical disruption of the cell membrane by a microfluidics device. In some embodiments, the gene-regulating system is introduced as a polynucleotide sequence encoding one or more components of the system, as a protein, or as an ribonucleoprotein (RNP) complex.
[0098] In some embodiments, the present disclosure provides a method of producing a modified immune effector cell comprising: (a) expanding a population of immune effector cells in culture; and (b) introducing a gene-regulating system of any one of claims Error! Reference source not found.--Error! Reference source not found. into the population of immune effector cells. In some embodiments, the methods further comprise obtaining the population of immune effector cells from a subject. In some embodiments, the gene-regulating system is introduced to the population of immune effector cells before, during, or after expansion. In some embodiments, the expansion of the population of immune effector cells comprises a first round expansion and a second round of expansion. In some embodiments, the gene-regulating system is introduced to the population of immune effector cells before, during, or after the first round of expansion. In some embodiments, the gene-regulating system is introduced to the population of immune effector cells before, during, or after the second round of expansion. In some embodiments, the gene-regulating system is introduced to the population of immune effector cells before the first and second rounds of expansion. In some embodiments, the gene-regulating system is introduced to the population of immune effector cells after the first and second rounds of expansion. In some embodiments, the gene-regulating system is introduced to the population of immune effector cells after the first round of expansion and before the second round of expansion.
[0099] In some embodiments, the present disclosure provides a method of treating a disease or disorder in a subject in need thereof comprising administering an effective amount of a modified immune effector described herein, or composition thereof. In some embodiments, the disease or disorder is a cell proliferative disorder, an inflammatory disorder, or an infectious disease. In some embodiments, the disease or disorder is a cancer or a viral infection. In some embodiments, the cancer is selected from a leukemia, a lymphoma, or a solid tumor. In some embodiments, the solid tumor is a melanoma, a pancreatic tumor, a bladder tumor, a lung tumor or metastasis, a colorectal cancer, or a head and neck cancer. In some embodiments, the cancer is a PD1 resistant or insensitive cancer. In some embodiments, the subject has previously been treated with a PD1 inhibitor or a PDL1 inhibitor. In some embodiments, the methods further comprise administering to the subject an antibody or binding fragment thereof that specifically binds to and inhibits the function of the protein encoded by NRP1, HAVCR2, LAG3, TIGIT, CTLA4, or PDCD1. In some embodiments, the modified immune effector cells are autologous to the subject. In some embodiments, the modified immune effector cells are allogenic to the subject. In some embodiments, the subject has not undergone lymphodepletion prior to administration of the modified immune effector cells or compositions thereof. In some embodiments, the subject does not receive high-dose IL-2 treatment with or after the administration of the modified immune effector cells or compositions thereof. In some embodiments, the subject receives low-dose IL-2 treatment with or after the administration of the modified immune effector cells or compositions thereof. In some embodiments, the subject does not receive IL-2 treatment with or after the administration of the modified immune effector cells or compositions thereof.
[0100] In some embodiments, the present disclosure provides a method of killing a cancerous cell comprising exposing the cancerous cell to a modified immune effector cell described herein or a composition thereof. In some embodiments, the exposure is in vitro, in vivo, or ex vivo.
[0101] In some embodiments, the present disclosure provides a method of enhancing one or more effector functions of an immune effector cell comprising introducing a gene-regulating system described herein into the immune effector cell. In some embodiments, the present disclosure provides a method of enhancing one or more effector functions of an immune effector cell comprising introducing a gene-regulating system described herein into the immune effector cell, wherein the modified immune effector cell demonstrates one or more enhanced effector functions compared to the immune effector cell that has not been modified. In some embodiments, the one or more effector functions are selected from cell proliferation, cell viability, cytotoxicity, tumor infiltration, increased cytokine production, anti-tumor immune responses, and/or resistance to exhaustion.
BRIEF DESCRIPTION OF THE FIGURES
[0102] FIG. 1A-FIG. 1B illustrate combinations of endogenous target genes that can be modified by the methods described herein.
[0103] FIG. 2A-FIG. 2B illustrate combinations of endogenous target genes that can be modified by the methods described herein.
[0104] FIG. 3A-FIG. 3B illustrate combinations of endogenous target genes that can be modified by the methods described herein.
[0105] FIG. 4A-FIG. 4D illustrates editing of the TRAC and B2M genes using methods described herein.
[0106] FIG. 5A-FIG. 5B illustrate TIDE analysis data for editing of CBLB in primary human T cells.
[0107] FIG. 6 illustrates a western blot for CBLB protein in primary human T cells edited with a CBLB gRNA (D6551-CBLB) compared to unedited controls (D6551-WT).
[0108] FIG. 7A-FIG. 7E show tumor growth over time in a murine B16/Ova syngeneic tumor model. FIG. 7A shows tumor growth in mice treated with CBLB-edited OT1 T cells compared to unedited OT1 T cells. FIG. 7B-FIG. 7C shows tumor growth in mice treated with ZC3H12A-edited OT1 T cells compared to unedited OT1 T cells. FIG. 7D shows tumor growth in mice treated with MAP4K1-edited OT1 T cells compared to unedited OT1 T cells. FIG. 7E shows tumor growth in mice treated with NR4A3-edited OT1 T cells compared to unedited OT1 T cells.
[0109] FIG. 8A-FIG. 8B show tumor growth over time in a murine B16/Ova syngeneic tumor model in mice treated with single-edited T cells and/or in combination with anti-PD1 therapy. FIG. 8A shows tumor growth in mice treated with a combination of MAP4K1-edited OT1 T cells and anti-PD1 therapy compared to control and MAP4K1-edited OT1 cells alone.
[0110] FIG. 8B shows tumor growth in mice treated with a combination of NR4A3-edited OT1 T cells and anti-PD1 therapy compared to control and NR4A3-edited OT1 cells alone.
[0111] FIG. 9 shows tumor growth over time in a murine MC38/gp100 syngeneic tumor model in mice treated with Zc3h12a-edited PMEL T cells.
[0112] FIG. 10 shows a survival curve of mice treated with Zc3h12a-edited PMEL T cells and PD1-edited PMEL T cells in a B16F10 lung met model.
[0113] FIG. 11 shows tumor growth over time in a murine Eg7 Ova syngeneic tumor model in mice treated with Zc3h12a-edited T cells.
[0114] FIG. 12A-FIG. 12B shows tumor growth over time in a murine A375 xenograft model for mice. FIG. 12A shows tumor growth over time in a murine A375 xenograft model for mice treated with CBLB-edited NY-ESO-1-specific TCR transgenic T cells compared to unedited NY-ESO-1-specific TCR transgenic T cells. FIG. 12B shows tumor growth over time in a murine A375 xenograft model for mice treated with ZC3H12A-edited NY-ESO-1-specific TCR transgenic T cells compared to control edited T cells.
[0115] FIG. 13A-FIG. 13B shows tumor growth after treatment with single-edited CD19 CAR T cells in a subcutaneous model of Burkitt's lymphoma using Raji cells. FIG. 13A shows tumor growth after treatment with MAP4K1-edited CD19 CAR T cells compared to unedited CD19 CAR T cells. FIG. 13B shows tumor growth after treatment with NR4A3-edited CD19 CAR T cells compared to unedited CD19 CAR T cells.
[0116] FIG. 14 shows tumor growth over time in mice treated with BCOR-edited, CBLB-edited, or BCOR/CBLB dual-edited anti-CD19 CAR T cells. Tumor growth is compared to mice treated with no CAR T cells or unedited anti-CD19 CAR T cells.
[0117] FIG. 15 shows accumulation of BCOR-edited or BCOR/CBLB-edited CD19 CAR T cells in an in vitro culture system.
[0118] FIG. 16 shows IL-2 production by BCOR-edited or BCOR/CBLB-edited CD19 CAR T cells in an in vitro culture system.
[0119] FIG. 17 shows IFN.gamma. production by BCOR-edited or BCOR/CBLB-edited CD19 CAR T cells in an in vitro culture system.
[0120] FIG. 18 shows tumor growth over time in a murine B16/Ova syngeneic tumor model in mice treated with dual-edited Zc3h12a/Cblb OT1 T cells.
[0121] FIG. 19 shows tumor growth over time in a murine B16/Ova syngeneic tumor model in mice treated with Pd1/Lag3 dual-edited OT1 T cells.
[0122] FIG. 20 shows validation of Zc3h12a as target conferring anti-tumor memory and epitope spreading.
[0123] FIG. 21 shows production of IFN.gamma., IL-2, and TNF.alpha. in MAP4K1-edited PBMCs.
[0124] FIG. 22 shows mRNA expression of Icos, Il6, Il2, Ifng, and Nfkbiz in Zc3h12a-edited murine CD8 T cells.
[0125] FIG. 23 shows cell surface expression of ICOS in Zc3h12a-edited murine CD8 T cells.
[0126] FIG. 24 shows production of IL-2 and IFN.gamma. by Zc3h12a-edited murine CD8 T cells after anti-CD3/CD28 stimulation.
[0127] FIG. 25A-FIG. 25B show increased expression of IL6 in ZC3H12A-edited primary human T cells. FIG. 25A shows IL-6 protein production from ZC3H12A-edited PBMCs derived from donors. FIG. 25B shows IL6 mRNA expression in ZC3H12A-edited PBMCs.
DETAILED DESCRIPTION
[0128] The present disclosure provides methods and compositions related to the modification of immune effector cells to increase their therapeutic efficacy in the context of immunotherapy. In some embodiments, immune effector cells are modified by the methods of the present disclosure to reduce expression of one or more endogenous target genes, or to reduce one or more functions of an endogenous protein such that one or more effector functions of the immune cells are enhanced. In some embodiments, the immune effector cells are further modified by introduction of transgenes conferring antigen specificity, such as introduction of T cell receptor (TCR) or chimeric antigen receptor (CAR) expression constructs. In some embodiments, the present disclosure provides compositions and methods for modifying immune effector cells, such as compositions of gene-regulating systems. In some embodiments, the present disclosure provides methods of treating a cell proliferative disorder, such as a cancer, comprising administration of the modified immune effector cells described herein to a subject in need thereof.
I. Definitions
[0129] As used in this specification and the appended claims, the singular forms "a," "an" and "the" include plural references unless the content clearly dictates otherwise.
[0130] As used in this specification, the term "and/or" is used in this disclosure to mean either "and" or "or" unless indicated otherwise.
[0131] Throughout this specification, unless the context requires otherwise, the words "comprise", or variations such as "comprises" or "comprising", will be understood to imply the inclusion of a stated element or integer or group of elements or integers but not the exclusion of any other element or integer or group of elements or integers.
[0132] As used in this application, the terms "about" and "approximately" are used as equivalents. Any numerals used in this application with or without about/approximately are meant to cover any normal fluctuations appreciated by one of ordinary skill in the relevant art. In certain embodiments, the term "approximately" or "about" refers to a range of values that fall within 25%, 20%, 19%, 18%, 17%, 16%, 15%, 14%, 13%, 12%, 11%, 10%, 9%, 8%, 7%, 6%, 5%, 4%, 3%, 2%, 1%, or less in either direction (greater than or less than) of the stated reference value unless otherwise stated or otherwise evident from the context (except where such number would exceed 100% of a possible value).
[0133] "Decrease" or "reduce" refers to a decrease or a reduction in a particular value of at least 5%, for example, a 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99%, or 100% decrease as compared to a reference value. A decrease or reduction in a particular value may also be represented as a fold-change in the value compared to a reference value, for example, at least a 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 30, 40, 50, 60, 70, 80, 90, 100, 200, 500, 1000-fold, or more, decrease as compared to a reference value.
[0134] "Increase" refers to an increase in a particular value of at least 5%, for example, a 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99%, 100%, 200%, 300%, 400%, 500%, or more increase as compared to a reference value. An increase in a particular value may also be represented as a fold-change in the value compared to a reference value, for example, at least a 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 30, 40, 50, 60, 70, 80, 90, 100, 200, 500, 1000-fold or more, increase as compared to the level of a reference value.
[0135] The terms "peptide," "polypeptide," and "protein" are used interchangeably herein, and refer to a polymeric form of amino acids of any length, which can include coded and non-coded amino acids, chemically or biochemically modified or derivatized amino acids, and polypeptides having modified peptide backbones.
[0136] The terms "polynucleotide" and "nucleic acid," used interchangeably herein, refer to a polymeric form of nucleotides of any length, either ribonucleotides or deoxyribonucleotides. Thus, this term includes, but is not limited to, single-, double-, or multi-stranded DNA or RNA, genomic DNA, cDNA, DNA-RNA hybrids, or a polymer comprising purine and pyrimidine bases or other natural, chemically or biochemically modified, non-natural, or derivatized nucleotide bases. "Oligonucleotide" generally refers to polynucleotides of between about 5 and about 100 nucleotides of single- or double-stranded DNA. However, for the purposes of this disclosure, there is no upper limit to the length of an oligonucleotide. Oligonucleotides are also known as "oligomers" or "oligos" and may be isolated from genes, or chemically synthesized by methods known in the art. The terms "polynucleotide" and "nucleic acid" should be understood to include, as applicable to the embodiments being described, single-stranded (such as sense or antisense) and double-stranded polynucleotides.
[0137] "Fragment" refers to a portion of a polypeptide or polynucleotide molecule containing less than the entire polypeptide or polynucleotide sequence. In some embodiments, a fragment of a polypeptide or polynucleotide comprises at least 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95%, 96%, 97%, 98%, or 99% of the entire length of the reference polypeptide or polynucleotide. In some embodiments, a polypeptide or polynucleotide fragment may contain 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, or more nucleotides or amino acids.
[0138] The term "sequence identity" refers to the percentage of bases or amino acids between two polynucleotide or polypeptide sequences that are the same, and in the same relative position. As such one polynucleotide or polypeptide sequence has a certain percentage of sequence identity compared to another polynucleotide or polypeptide sequence. For sequence comparison, typically one sequence acts as a reference sequence, to which test sequences are compared. The term "reference sequence" refers to a molecule to which a test sequence is compared.
[0139] "Complementary" refers to the capacity for pairing, through base stacking and specific hydrogen bonding, between two sequences comprising naturally or non-naturally occurring bases or analogs thereof. For example, if a base at one position of a nucleic acid is capable of hydrogen bonding with a base at the corresponding position of a target, then the bases are considered to be complementary to each other at that position. Nucleic acids can comprise universal bases, or inert abasic spacers that provide no positive or negative contribution to hydrogen bonding. Base pairings may include both canonical Watson-Crick base pairing and non-Watson-Crick base pairing (e.g., Wobble base pairing and Hoogsteen base pairing). It is understood that for complementary base pairings, adenosine-type bases (A) are complementary to thymidine-type bases (T) or uracil-type bases (U), that cytosine-type bases (C) are complementary to guanosine-type bases (G), and that universal bases such as such as 3-nitropyrrole or 5-nitroindole can hybridize to and are considered complementary to any A, C, U, or T. Nichols et al., Nature, 1994; 369:492-493 and Loakes et al., Nucleic Acids Res., 1994; 22:4039-4043. Inosine (I) has also been considered in the art to be a universal base and is considered complementary to any A, C, U, or T. See Watkins and SantaLucia, Nucl. Acids Research, 2005; 33 (19): 6258-6267.
[0140] As referred to herein, a "complementary nucleic acid sequence" is a nucleic acid sequence comprising a sequence of nucleotides that enables it to non-covalently bind to another nucleic acid in a sequence-specific, antiparallel, manner (i.e., a nucleic acid specifically binds to a complementary nucleic acid) under the appropriate in vitro and/or in vivo conditions of temperature and solution ionic strength.
[0141] Methods of sequence alignment for comparison and determination of percent sequence identity and percent complementarity are well known in the art. Optimal alignment of sequences for comparison can be conducted, e.g., by the homology alignment algorithm of Needleman and Wunsch, (1970) J. Mol. Biol. 48:443, by the search for similarity method of Pearson and Lipman, (1988) Proc. Nat'l. Acad. Sci. USA 85:2444, by computerized implementations of these algorithms (GAP, BESTFIT, FASTA, and TFASTA in the Wisconsin Genetics Software Package, Genetics Computer Group, 575 Science Dr., Madison, Wis.), by manual alignment and visual inspection (see, e.g., Brent et al., (2003) Current Protocols in Molecular Biology), by use of algorithms know in the art including the BLAST and BLAST 2.0 algorithms, which are described in Altschul et al., (1977) Nuc. Acids Res. 25:3389-3402; and Altschul et al., (1990) J. Mol. Biol. 215:403-410, respectively. Software for performing BLAST analyses is publicly available through the National Center for Biotechnology Information.
[0142] Herein, the term "hybridize" refers to pairing between complementary nucleotide bases (e.g., adenine (A) forms a base pair with thymine (T) in a DNA molecule and with uracil (U) in an RNA molecule, and guanine (G) forms a base pair with cytosine (C) in both DNA and RNA molecules) to form a double-stranded nucleic acid molecule. (See, e.g., Wahl and Berger (1987) Methods Enzymol. 152:399; Kimmel, (1987) Methods Enzymol. 152:507). In addition, it is also known in the art that for hybridization between two RNA molecules (e.g., dsRNA), guanine (G) base pairs with uracil (U). For example, G/U base-pairing is partially responsible for the degeneracy (i.e., redundancy) of the genetic code in the context of tRNA anti-codon base-pairing with codons in mRNA. In the context of this disclosure, a guanine (G) of a protein-binding segment (dsRNA duplex) of a guide RNA molecule is considered complementary to a uracil (U), and vice versa. As such, when a G/U base-pair can be made at a given nucleotide position a protein-binding segment (dsRNA duplex) of a guide RNA molecule, the position is not considered to be non-complementary, but is instead considered to be complementary. It is understood in the art that the sequence of polynucleotide need not be 100% complementary to that of its target nucleic acid to be specifically hybridizable. Moreover, a polynucleotide may hybridize over one or more segments such that intervening or adjacent segments are not involved in the hybridization event (e.g., a loop structure or hairpin structure). A polynucleotide can comprise at least 70%, at least 80%, at least 90%, at least 95%, at least 99%, or 100% sequence complementarity to a target region within the target nucleic acid sequence to which they are targeted.
[0143] The term "modified" refers to a substance or compound (e.g., a cell, a polynucleotide sequence, and/or a polypeptide sequence) that has been altered or changed as compared to the corresponding unmodified substance or compound.
[0144] The term "naturally-occurring" as used herein as applied to a nucleic acid, a polypeptide, a cell, or an organism, refers to a nucleic acid, polypeptide, cell, or organism that is found in nature. For example, a polypeptide or polynucleotide sequence that is present in an organism (including viruses) that can be isolated from a source in nature and which has not been intentionally modified by a human in the laboratory is naturally occurring.
[0145] "Isolated" refers to a material that is free to varying degrees from components which normally accompany it as found in its native state.
[0146] An "expression cassette" or "expression construct" refers to a DNA polynucleotide sequence operably linked to a promoter. "Operably linked" refers to a juxtaposition wherein the components so described are in a relationship permitting them to function in their intended manner. For instance, a promoter is operably linked to a polynucleotide sequence if the promoter affects the transcription or expression of the polynucleotide sequence.
[0147] The term "recombinant vector" as used herein refers to a polynucleotide molecule capable transferring or transporting another polynucleotide inserted into the vector. The inserted polynucleotide may be an expression cassette. In some embodiments, a recombinant vector may be viral vector or a non-viral vector (e.g., a plasmid).
[0148] The term "sample" refers to a biological composition (e.g., a cell or a portion of a tissue) that is subjected to analysis and/or genetic modification. In some embodiments, a sample is a "primary sample" in that it is obtained directly from a subject; in some embodiments, a "sample" is the result of processing of a primary sample, for example to remove certain components and/or to isolate or purify certain components of interest.
[0149] The term "subject" includes animals, such as e.g. mammals. In some embodiments, the mammal is a primate. In some embodiments, the mammal is a human. In some embodiments, subjects are livestock such as cattle, sheep, goats, cows, swine, and the like; or domesticated animals such as dogs and cats. In some embodiments (e.g., particularly in research contexts) subjects are rodents (e.g., mice, rats, hamsters), rabbits, primates, or swine such as inbred pigs and the like. The terms "subject" and "patient" are used interchangeably herein.
[0150] "Administration" refers herein to introducing an agent or composition into a subject.
[0151] "Treating" as used herein refers to delivering an agent or composition to a subject to affect a physiologic outcome.
[0152] As used herein, the term "effective amount" refers to the minimum amount of an agent or composition required to result in a particular physiological effect. The effective amount of a particular agent may be represented in a variety of ways based on the nature of the agent, such as mass/volume, # of cells/volume, particles/volume, (mass of the agent)/(mass of the subject), # of cells/(mass of subject), or particles/(mass of subject). The effective amount of a particular agent may also be expressed as the half-maximal effective concentration (EC.sub.50), which refers to the concentration of an agent that results in a magnitude of a particular physiological response that is half-way between a reference level and a maximum response level.
[0153] "Population" of cells refers to any number of cells greater than 1, but is preferably at least 1.times.10.sup.3 cells, at least 1.times.10.sup.4 cells, at least 1.times.10.sup.5 cells, at least 1.times.10.sup.6 cells, at least 1.times.10.sup.7 cells, at least 1.times.10.sup.8 cells, at least 1.times.10.sup.9 cells, at least 1.times.10.sup.10 cells, at least 1.times.10.sup.11 or more cells. A population of cells may refer to an in vitro population (e.g., a population of cells in culture) or an in vivo population (e.g., a population of cells residing in a particular tissue).
[0154] General methods in molecular and cellular biochemistry can be found in such standard textbooks as Molecular Cloning: A Laboratory Manual, 3rd Ed. (Sambrook et al., HaRBor Laboratory Press 2001); Short Protocols in Molecular Biology, 4th Ed. (Ausubel et al. eds., John Wiley & Sons 1999); Protein Methods (Bollag et al., John Wiley & Sons 1996); Nonviral Vectors for Gene Therapy (Wagner et al. eds., Academic Press 1999); Viral Vectors (Kaplift & Loewy eds., Academic Press 1995); Immunology Methods Manual (I. Lefkovits ed., Academic Press 1997); and Cell and Tissue Culture: Laboratory Procedures in Biotechnology (Doyle & Griffiths, John Wiley & Sons 1998), the disclosures of which are incorporated herein by reference.
II. Modified Immune Effector Cells
[0155] In some embodiments, the present disclosure provides modified immune effector cells. Herein, the term "modified immune effector cells" encompasses immune effector cells comprising one or more genomic modifications resulting in the reduced expression and/or function of one or more endogenous target genes as well as immune effector cells comprising a gene-regulating system capable of reducing the expression and/or function of one or more endogenous target genes. Herein, an "un-modified immune effector cell" or "control immune effector cell" refers to a cell or population of cells wherein the genomes have not been modified and that does not comprise a gene-regulating system or comprises a control gene-regulating system (e.g., an empty vector control, a non-targeting gRNA, a scrambled siRNA, etc.).
[0156] The term "immune effector cell" refers to cells involved in mounting innate and adaptive immune responses, including but not limited to lymphocytes (such as T-cells (including thymocytes) and B-cells), natural killer (NK) cells, NKT cells, macrophages, monocytes, eosinophils, basophils, neutrophils, dendritic cells, and mast cells. In some embodiments, the modified immune effector cell is a T cell, such as a CD4+ T cell, a CD8+ T cell (also referred to as a cytotoxic T cell or CTL), a regulatory T cell (Treg), a Th1 cell, a Th2 cell, or a Th17 cell.
[0157] In some embodiments, the immune effector cell is a T cell that has been isolated from a tumor sample (referred to herein as "tumor infiltrating lymphocytes" or "TILs"). Without wishing to be bound by theory, it is thought that TILs possess increased specificity to tumor antigens (Radvanyi et al., 2012 Clin Canc Res 18:6758-6770) and can therefore mediate tumor antigen-specific immune response (e.g., activation, proliferation, and cytotoxic activity against the cancer cell) leading to cancer cell destruction (Brudno et al., 2018 Nat Rev Clin Onc 15:31-46)) without the introduction of an exogenous engineered receptor. Therefore, in some embodiments, TILs are isolated from a tumor in a subject, expanded ex vivo, and re-infused into a subject. In some embodiments, TILs are modified to express one or more exogenous receptors specific for an autologous tumor antigen, expanded ex vivo, and re-infused into the subject. Such embodiments can be modeled using in vivo mouse models wherein mice have been transplanted with a cancer cell line expressing a cancer antigen (e.g., CD19) and are treated with modified T cells that express an exogenous receptor that is specific for the cancer antigen (See e.g., Examples 10 and 11).
[0158] In some embodiments, the immune effector cell is an animal cell or is derived from an animal cell, including invertebrate animals and vertebrate animals (e.g., fish, amphibian, reptile, bird, or mammal). In some embodiments, the immune effector cell is a mammalian cell or is derived from a mammalian cell (e.g., a pig, a cow, a goat, a sheep, a rodent, a non-human primate, a human, etc.). In some embodiments, the immune effector cell is a rodent cell or is derived from a rodent cell (e.g., a rat or a mouse). In some embodiments, the modified immune effector cell is a human cell or is derived from a human cell.
[0159] In some embodiments, the modified immune effector cells comprise one or more modifications (e.g., insertions, deletions, or mutations of one or more nucleic acids) in the genomic DNA sequence of an endogenous target gene resulting in the reduced expression and/or function the endogenous gene. Such modifications are referred to herein as "inactivating mutations" and endogenous genes comprising an inactivating mutation are referred to as "modified endogenous target genes." In some embodiments, the inactivating mutations reduce or inhibit mRNA transcription, thereby reducing the expression level of the encoded mRNA transcript and protein. In some embodiments, the inactivating mutations reduce or inhibit mRNA translation, thereby reducing the expression level of the encoded protein. In some embodiments, the inactivating mutations encode a modified endogenous protein with reduced or altered function compared to the unmodified (i.e., wild-type) version of the endogenous protein (e.g., a dominant-negative mutant, described infra).
[0160] In some embodiments, the modified immune effector cells comprise one or more genomic modifications at a genomic location other than an endogenous target gene that result in the reduced expression and/or function of the endogenous target gene or that result in the expression of a modified version of an endogenous protein. For example, in some embodiments, a polynucleotide sequence encoding a gene regulating system is inserted into one or more locations in the genome, thereby reducing the expression and/or function of an endogenous target gene upon the expression of the gene-regulating system. In some embodiments, a polynucleotide sequence encoding a modified version of an endogenous protein is inserted at one or more locations in the genome, wherein the function of the modified version of the protein is reduced compared to the un-modified or wild-type version of the protein (e.g., a dominant-negative mutant, described infra).
[0161] In some embodiments, the modified immune effector cells described herein comprise one or more modified endogenous target genes, wherein the one or more modifications result in a reduced expression and/or function of a gene product (i.e., an mRNA transcript or a protein) encoded by the endogenous target gene compared to an unmodified immune effector cell. For example, in some embodiments, a modified immune effector cell demonstrates reduced expression of an mRNA transcript and/or reduced expression of a protein. In some embodiments, the expression of the gene product in a modified immune effector cell is reduced by at least 5% compared to the expression of the gene product in an unmodified immune effector cell. In some embodiments, the expression of the gene product in a modified immune effector cell is reduced by at least 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, or more compared to the expression of the gene product in an unmodified immune effector cell. In some embodiments, the modified immune effector cells described herein demonstrate reduced expression and/or function of gene products encoded by a plurality (e.g., two or more) of endogenous target genes compared to the expression of the gene products in an unmodified immune effector cell. For example, in some embodiments, a modified immune effector cell demonstrates reduced expression and/or function of gene products from 2, 3, 4, 5, 6, 7, 8, 9, 10, or more endogenous target genes compared to the expression of the gene products in an unmodified immune effector cell.
[0162] In some embodiments, the present disclosure provides a modified immune effector cell wherein one or more endogenous target genes, or a portion thereof, are deleted (i.e., "knocked-out") such that the modified immune effector cell does not express the mRNA transcript or protein. In some embodiments, a modified immune effector cell comprises deletion of a plurality of endogenous target genes, or portions thereof. In some embodiments, a modified immune effector cell comprises deletion of 2, 3, 4, 5, 6, 7, 8, 9, 10, or more endogenous target genes.
[0163] In some embodiments, the modified immune effector cells described herein comprise one or more modified endogenous target genes, wherein the one or more modifications to the target DNA sequence result in expression of a protein with reduced or altered function (e.g., a "modified endogenous protein") compared to the function of the corresponding protein expressed in an unmodified immune effector cell (e.g., a "unmodified endogenous protein"). In some embodiments, the modified immune effector cells described herein comprise 2, 3, 4, 5, 6, 7, 8, 9, 10, or more modified endogenous target genes encoding 2, 3, 4, 5, 6, 7, 8, 9, 10, or more modified endogenous proteins. In some embodiments, the modified endogenous protein demonstrates reduced or altered binding affinity for another protein expressed by the modified immune effector cell or expressed by another cell; reduced or altered signaling capacity; reduced or altered enzymatic activity; reduced or altered DNA-binding activity; or reduced or altered ability to function as a scaffolding protein.
[0164] In some embodiments, the modified endogenous target gene comprises one or more dominant negative mutations. As used herein, a "dominant-negative mutation" refers to a substitution, deletion, or insertion of one or more nucleotides of a target gene such that the encoded protein acts antagonistically to the protein encoded by the unmodified target gene. The mutation is dominant-negative because the negative phenotype confers genic dominance over the positive phenotype of the corresponding unmodified gene. A gene comprising one or more dominant-negative mutations and the protein encoded thereby are referred to as a "dominant-negative mutants", e.g. dominant-negative genes and dominant-negative proteins. In some embodiments, the dominant negative mutant protein is encoded by an exogenous transgene inserted at one or more locations in the genome of the immune effector cell.
[0165] Various mechanisms for dominant negativity are known. Typically, the gene product of a dominant negative mutant retains some functions of the unmodified gene product but lacks one or more crucial other functions of the unmodified gene product. This causes the dominant-negative mutant to antagonize the unmodified gene product. For example, as an illustrative embodiment, a dominant-negative mutant of a transcription factor may lack a functional activation domain but retain a functional DNA binding domain. In this example, the dominant-negative transcription factor cannot activate transcription of the DNA as the unmodified transcription factor does, but the dominant-negative transcription factor can indirectly inhibit gene expression by preventing the unmodified transcription factor from binding to the transcription-factor binding site. As another illustrative embodiment, dominant-negative mutations of proteins that function as dimers are known. Dominant-negative mutants of such dimeric proteins may retain the ability to dimerize with unmodified protein but be unable to function otherwise. The dominant-negative monomers, by dimerizing with unmodified monomers to form heterodimers, prevent formation of functional homodimers of the unmodified monomers.
[0166] In some embodiments, the modified immune effector cells comprise a gene-regulating system capable of reducing the expression or function of one or more endogenous target genes. The gene-regulating system can reduce the expression and/or function of the endogenous target genes modifications by a variety of mechanisms including by modifying the genomic DNA sequence of the endogenous target gene (e.g., by insertion, deletion, or mutation of one or more nucleic acids in the genomic DNA sequence); by regulating transcription of the endogenous target gene (e.g., inhibition or repression of mRNA transcription); and/or by regulating translation of the endogenous target gene (e.g., by mRNA degradation).
[0167] In some embodiments, the modified immune effector cells described herein comprise a gene-regulating system (e.g., a nucleic acid-based gene-regulating system, a protein-based gene-regulating system, or a combination protein/nucleic acid-based gene-regulating system). In such embodiments, the gene-regulating system comprised in the modified immune effector cell is capable of modifying one or more endogenous target genes. In some embodiments, the modified immune effector cells described herein comprise a gene-regulating system comprising:
[0168] (a) one or more nucleic acid molecules capable of reducing the expression or modifying the function of a gene product encoded by one or more endogenous target genes;
[0169] (b) one or more polynucleotides encoding a nucleic acid molecule that is capable of reducing the expression or modifying the function of a gene product encoded by one or more endogenous target genes;
[0170] (c) one or more proteins capable of reducing the expression or modifying the function of a gene product encoded by one or more endogenous target genes;
[0171] (d) one or more polynucleotides encoding a protein that is capable of reducing the expression or modifying the function of a gene product encoded by one or more endogenous target genes;
[0172] (e) one or more guide RNAs (gRNAs) capable of binding to a target DNA sequence in an endogenous gene;
[0173] (f) one or more polynucleotides encoding one or more gRNAs capable of binding to a target DNA sequence in an endogenous gene;
[0174] (g) one or more site-directed modifying polypeptides capable of interacting with a gRNA and modifying a target DNA sequence in an endogenous gene;
[0175] (h) one or more polynucleotides encoding a site-directed modifying polypeptide capable of interacting with a gRNA and modifying a target DNA sequence in an endogenous gene;
[0176] (i) one or more guide DNAs (gDNAs) capable of binding to a target DNA sequence in an endogenous gene;
[0177] (j) one or more polynucleotides encoding one or more gDNAs capable of binding to a target DNA sequence in an endogenous gene;
[0178] (k) one or more site-directed modifying polypeptides capable of interacting with a gDNA and modifying a target DNA sequence in an endogenous gene;
[0179] (l) one or more polynucleotides encoding a site-directed modifying polypeptide capable of interacting with a gDNA and modifying a target DNA sequence in an endogenous gene;
[0180] (m) one or more gRNAs capable of binding to a target mRNA sequence encoded by an endogenous gene;
[0181] (n) one or more polynucleotides encoding one or more gRNAs capable of binding to a target mRNA sequence encoded by an endogenous gene;
[0182] (o) one or more site-directed modifying polypeptides capable of interacting with a gRNA and modifying a target mRNA sequence encoded by an endogenous gene;
[0183] (p) one or more polynucleotides encoding a site-directed modifying polypeptide capable of interacting with a gRNA and modifying a target mRNA sequence encoded by an endogenous gene; or
[0184] (q) any combination of the above.
[0185] In some embodiments, one or more polynucleotides encoding the gene-regulating system are inserted into the genome of the immune effector cell. In some embodiments, one or more polynucleotides encoding the gene-regulating system are expressed episomaly and are not inserted into the genome of the immune effector cell.
[0186] In some embodiments, the modified immune effector cells described herein comprise reduced expression and/or function of one or more endogenous target genes and further comprise one or more exogenous transgenes inserted at one or more genomic loci (e.g., a genetic "knock-in"). In some embodiments, the one or more exogenous transgenes encode detectable tags, safety-switch systems, chimeric switch receptors, and/or engineered antigen-specific receptors.
[0187] In some embodiments, the modified immune effector cells described herein further comprise an exogenous transgene encoding a detectable tag. Examples of detectable tags include but are not limited to, FLAG tags, poly-histidine tags (e.g. 6.times.His), SNAP tags, Halo tags, cMyc tags, glutathione-S-transferase tags, avidin, enzymes, fluorescent proteins, luminescent proteins, chemiluminescent proteins, bioluminescent proteins, and phosphorescent proteins. In some embodiments the fluorescent protein is selected from the group consisting of blue/UV proteins (such as BFP, TagBFP, mTagBFP2, Azurite, EBFP2, mKalama1, Sirius, Sapphire, and T-Sapphire); cyan proteins (such as CFP, eCFP, Cerulean, SCFP3A, mTurquoise, mTurquoise2, monomeric Midoriishi-Cyan, TagCFP, and mTFP1); green proteins (such as: GFP, eGFP, meGFP (A208K mutation), Emerald, Superfolder GFP, Monomeric Azami Green, TagGFP2, mUKG, mWasabi, Clover, and mNeonGreen); yellow proteins (such as YFP, eYFP, Citrine, Venus, SYFP2, and TagYFP); orange proteins (such as Monomeric Kusabira-Orange, mKOK, mKO2, mOrange, and mOrange2); red proteins (such as RFP, mRaspberry, mCherry, mStrawberry, mTangerine, tdTomato, TagRFP, TagRFP-T, mApple, mRuby, and mRuby2); far-red proteins (such as mPlum, HcRed-Tandem, mKate2, mNeptune, and NirFP); near-infrared proteins (such as TagRFP657, IFP1.4, and iRFP); long stokes shift proteins (such as mKeima Red, LSS-mKate1, LSS-mKate2, and mBeRFP); photoactivatible proteins (such as PA-GFP, PAmCherry 1, and PATagRFP); photoconvertible proteins (such as Kaede (green), Kaede (red), KikGR1 (green), KikGR1 (red), PS-CFP2, PS-CFP2, mEos2 (green), mEos2 (red), mEos3.2 (green), mEos3.2 (red), PSmOrange, and PSmOrange); and photoswitchable proteins (such as Dronpa). In some embodiments, the detectable tag can be selected from AmCyan, AsRed, DsRed2, DsRed Express, E2-Crimson, HcRed, ZsGreen, ZsYellow, mCherry, mStrawberry, mOrange, mBanana, mPlum, mRasberry, tdTomato, DsRed Monomer, and/or AcGFP, all of which are available from Clontech.
[0188] In some embodiments, the modified immune effector cells described herein further comprise an exogenous transgene encoding a safety-switch system. Safety-switch systems (also referred to in the art as suicide gene systems) comprise exogenous transgenes encoding for one or more proteins that enable the elimination of a modified immune effector cell after the cell has been administered to a subject. Examples of safety-switch systems are known in the art. For example, safety-switch systems include genes encoding for proteins that convert non-toxic pro-drugs into toxic compounds such as the Herpes simplex thymidine kinase (Hsv-tk) and ganciclovir (GCV) system (Hsv-tk/GCV). Hsv-tk converts non-toxic GCV into a cytotoxic compound that leads to cellular apoptosis. As such, administration of GCV to a subject that has been treated with modified immune effector cells comprising a transgene encoding the Hsv-tk protein can selectively eliminate the modified immune effector cells while sparing endogenous immune effector cells. (See e.g., Bonini et al., Science, 1997, 276(5319):1719-1724; Ciceri et al., Blood, 2007, 109(11):1828-1836; Bondanza et al., Blood 2006, 107(5):1828-1836).
[0189] Additional safety-switch systems include genes encoding for cell-surface markers, enabling elimination of modified immune effector cells by administration of a monoclonal antibody specific for the cell-surface marker via ADCC. In some embodiments, the cell-surface marker is CD20 and the modified immune effector cells can be eliminated by administration of an anti-CD20 monoclonal antibody such as Rituximab (See e.g., Introna et al., Hum Gene Ther, 2000, 11(4):611-620; Serafini et al., Hum Gene Ther, 2004, 14, 63-76; van Meerten et al., Gene Ther, 2006, 13, 789-797). Similar systems using EGF-R and Cetuximab or Panitumumab are described in International PCT Publication No. WO 2018006880. Additional safety-switch systems include transgenes encoding pro-apoptotic molecules comprising one or more binding sites for a chemical inducer of dimerization (CID), enabling elimination of modified immune effector cells by administration of a CID which induces oligomerization of the pro-apoptotic molecules and activation of the apoptosis pathway. In some embodiments, the pro-apoptotic molecule is Fas (also known as CD95) (Thomis et al., Blood, 2001, 97(5), 1249-1257). In some embodiments, the pro-apoptotic molecule is caspase-9 (Straathof et al., Blood, 2005, 105(11), 4247-4254).
[0190] In some embodiments, the modified immune effector cells described herein further comprise an exogenous transgene encoding a chimeric switch receptor. Chimeric switch receptors are engineered cell-surface receptors comprising an extracellular domain from an endogenous cell-surface receptor and a heterologous intracellular signaling domain, such that ligand recognition by the extracellular domain results in activation of a different signaling cascade than that activated by the wild type form of the cell-surface receptor. In some embodiments, the chimeric switch receptor comprises the extracellular domain of an inhibitory cell-surface receptor fused to an intracellular domain that leads to the transmission of an activating signal rather than the inhibitory signal normally transduced by the inhibitory cell-surface receptor. In particular embodiments, extracellular domains derived from cell-surface receptors known to inhibit immune effector cell activation can be fused to activating intracellular domains. Engagement of the corresponding ligand will then activate signaling cascades that increase, rather than inhibit, the activation of the immune effector cell. For example, in some embodiments, the modified immune effector cells described herein comprise a transgene encoding a PD1-CD28 switch receptor, wherein the extracellular domain of PD1 is fused to the intracellular signaling domain of CD28 (See e.g., Liu et al., Cancer Res 76:6 (2016), 1578-1590 and Moon et al., Molecular Therapy 22 (2014), S201). In some embodiments, the modified immune effector cells described herein comprise a transgene encoding the extracellular domain of CD200R and the intracellular signaling domain of CD28 (See Oda et al., Blood 130:22 (2017), 2410-2419).
[0191] In some embodiments, the modified immune effector cells described herein further comprise an engineered antigen-specific receptor recognizing a protein target expressed by a target cell, such as a tumor cell or an antigen presenting cell (APC), referred to herein as "modified receptor-engineered cells" or "modified RE-cells". The term "engineered antigen receptor" refers to a non-naturally occurring antigen-specific receptor such as a chimeric antigen receptor (CAR) or a recombinant T cell receptor (TCR). In some embodiments, the engineered antigen receptor is a CAR comprising an extracellular antigen binding domain fused via hinge and transmembrane domains to a cytoplasmic domain comprising a signaling domain. In some embodiments, the CAR extracellular domain binds to an antigen expressed by a target cell in an MHC-independent manner leading to activation and proliferation of the RE cell. In some embodiments, the extracellular domain of a CAR recognizes a tag fused to an antibody or antigen-binding fragment thereof. In such embodiments, the antigen-specificity of the CAR is dependent on the antigen-specificity of the labeled antibody, such that a single CAR construct can be used to target multiple different antigens by substituting one antibody for another (See e.g., U.S. Pat. Nos. 9,233,125 and 9,624,279; US Patent Application Publication Nos. 20150238631 and 20180104354). In some embodiments, the extracellular domain of a CAR may comprise an antigen binding fragment derived from an antibody. Antigen binding domains that are useful in the present disclosure include, for example, scFvs; antibodies; antigen binding regions of antibodies; variable regions of the heavy/light chains; and single chain antibodies.
[0192] In some embodiments, the intracellular signaling domain of a CAR may be derived from the TCR complex zeta chain (such as CD3 signaling domains), Fc.gamma.RIII, Fc.epsilon.RI, or the T-lymphocyte activation domain. In some embodiments, the intracellular signaling domain of a CAR further comprises a costimulatory domain, for example a 4-1BB, CD28, CD40, MyD88, or CD70 domain. In some embodiments, the intracellular signaling domain of a CAR comprises two costimulatory domains, for example any two of 4-1BB, CD28, CD40, MyD88, or CD70 domains. Exemplary CAR structures and intracellular signaling domains are known in the art (See e.g., WO 2009/091826; US 20130287748; WO 2015/142675; WO 2014/055657; and WO 2015/090229, incorporated herein by reference).
[0193] CARs specific for a variety of tumor antigens are known in the art, for example CD171-specific CARs (Park et al., Mol Ther (2007) 15(4):825-833), EGFRvIII-specific CARs (Morgan et al., Hum Gene Ther (2012) 23(10):1043-1053), EGF-R-specific CARs (Kobold et al., JNatl Cancer Inst (2014) 107(1):364), carbonic anhydrase K-specific CARs (Lamers et al., Biochem Soc Trans (2016) 44(3):951-959), FR-.alpha.-specific CARs (Kershaw et al., Clin Cancer Res (2006) 12(20):6106-6015), HER2-specific CARs (Ahmed et al., J Clin Oncol (2015) 33(15)1688-1696; Nakazawa et al., Mol Ther (2011) 19(12):2133-2143; Ahmed et al., Mol Ther (2009) 17(10):1779-1787; Luo et al., Cell Res (2016) 26(7):850-853; Morgan et al., Mol Ther (2010) 18(4):843-851; Grada et al., Mol Ther Nucleic Acids (2013) 9(2):32), CEA-specific CARs (Katz et al., Clin Cancer Res (2015) 21(14):3149-3159), IL13R.alpha.2-specific CARs (Brown et al., Clin Cancer Res (2015) 21(18):4062-4072), GD2-specific CARs (Louis et al., Blood (2011) 118(23):6050-6056; Caruana et al., Nat Med (2015) 21(5):524-529), ErbB2-specific CARs (Wilkie et al., J Clin Immunol (2012) 32(5):1059-1070), VEGF-R-specific CARs (Chinnasamy et al., Cancer Res (2016) 22(2):436-447), FAP-specific CARs (Wang et al., Cancer Immunol Res (2014) 2(2): 154-166), MSLN-specific CARs (Moon et al, Clin Cancer Res (2011) 17(14):4719-30), NKG2D-specific CARs (VanSeggelen et al., Mol Ther (2015) 23(10):1600-1610), CD19-specific CARs (Axicabtagene ciloleucel (Yescarta.RTM.) and Tisagenlecleucel (Kymriah.RTM.). See also, Li et al., J Hematol and Oncol (2018) 11(22), reviewing clinical trials of tumor-specific CARs.
[0194] In some embodiments, the engineered antigen receptor is an engineered TCR. Engineered TCRs comprise TCR.alpha. and/or TCR.beta. chains that have been isolated and cloned from T cell populations recognizing a particular target antigen. For example, TCR.alpha. and/or TCR.beta. genes (i.e., TRAC and TRBC) can be cloned from T cell populations isolated from individuals with particular malignancies or T cell populations that have been isolated from humanized mice immunized with specific tumor antigens or tumor cells. Engineered TCRs recognize antigen through the same mechanisms as their endogenous counterparts (e.g., by recognition of their cognate antigen presented in the context of major histocompatibility complex (MHC) proteins expressed on the surface of a target cell). This antigen engagement stimulates endogenous signal transduction pathways leading to activation and proliferation of the TCR-engineered cells.
[0195] Engineered TCRs specific for tumor antigens are known in the art, for example WT1-specific TCRs (JTCR016, Juno Therapeutics; WT1-TCRc4, described in US Patent Application Publication No. 20160083449), MART-1 specific TCRs (including the DMF4T clone, described in Morgan et al., Science 314 (2006) 126-129); the DMF5T clone, described in Johnson et al., Blood 114 (2009) 535-546); and the ID3T clone, described in van den Berg et al., Mol. Ther. 23 (2015) 1541-1550), gp100-specific TCRs (Johnson et al., Blood 114 (2009) 535-546), CEA-specific TCRs (Parkhurst et al., Mol Ther. 19 (2011) 620-626), NY-ESO and LAGE-1 specific TCRs (1G4T clone, described in Robbins et al., J Clin Oncol 26 (2011) 917-924; Robbins et al., Clin Cancer Res 21 (2015) 1019-1027; and Rapoport et al., Nature Medicine 21 (2015) 914-921), and MAGE-A3-specific TCRs (Morgan et al., J Immunother 36 (2013) 133-151) and Linette et al., Blood 122 (2013) 227-242). (See also, Debets et al., Seminars in Immunology 23 (2016) 10-21).
[0196] In some embodiments, the engineered antigen receptor is directed against a target antigen selected from a cluster of differentiation molecule, such as CD3, CD4, CD8, CD16, CD24, CD25, CD33, CD34, CD45, CD64, CD71, CD78, CD80 (also known as B7-1), CD86 (also known as B7-2), CD96, CD116, CD117, CD123, CD133, and CD138, CD371 (also known as CLL1); a tumor-associated surface antigen, such as 5T4, BCMA (also known as CD269 and TNFRSF17, UniProt# Q02223), carcinoembryonic antigen (CEA), carbonic anhydrase 9 (CAIX or MN/CAIX), CD19, CD20, CD22, CD30, CD40, disialogangliosides such as GD2, ELF2M, ductal-epithelial mucin, ephrin B2, epithelial cell adhesion molecule (EpCAM), ErbB2 (HER2/neu), FCRL5 (UniProt# Q68SN8), FKBP11 (UniProt# Q9NYL4), glioma-associated antigen, glycosphingolipids, gp36, GPRC5D (UniProt# Q9NZD1), mut hsp70-2, intestinal carboxyl esterase, IGF-I receptor, ITGA8 (UniProt# P53708), KAMP3, LAGE-la, MAGE, mesothelin, neutrophil elastase, NKG2D, Nkp30, NY-ESO-1, PAP, prostase, prostate-carcinoma tumor antigen-1 (PCTA-1), prostate specific antigen (PSA), PSMA, prostein, RAGE-1, ROR1, RU1 (SFMBT1), RU2 (DCDC2), SLAMF7 (UniProt#Q9NQ25), survivin, TAG-72, and telomerase; a major histocompatibility complex (MHC) molecule presenting a tumor-specific peptide epitope; tumor stromal antigens, such as the extra domain A (EDA) and extra domain B (EDB) of fibronectin; the A1 domain of tenascin-C (TnC A1) and fibroblast associated protein (FAP); cytokine receptors, such as epidermal growth factor receptor (EGFR), EGFR variant III (EGFRvIII), TFG.beta.-R or components thereof such as endoglin; a major histocompatibility complex (MHC) molecule; a virus-specific surface antigen such as an HIV-specific antigen (such as HIV gp120); an EBV-specific antigen, a CMV-specific antigen, a HPV-specific antigen, a Lassa virus-specific antigen, an Influenza virus-specific antigen as well as any derivate or variant of these surface antigens.
A. Effector Functions
[0197] In some embodiments, the modified immune effector cells described herein demonstrate an increase in one or more immune cell effector functions. Herein, the term "effector function" refers to functions of an immune cell related to the generation, maintenance, and/or enhancement of an immune response against a target cell or target antigen. In some embodiments, the modified immune effector cells described herein demonstrate one or more of the following characteristics compared to an unmodified immune effector cell: increased infiltration or migration in to a tumor, increased proliferation, increased or prolonged cell viability, increased resistance to inhibitory factors in the surrounding microenvironment such that the activation state of the cell is prolonged or increased, increased production of pro-inflammatory immune factors (e.g., pro-inflammatory cytokines, chemokines, and/or enzymes), increased cytotoxicity, and/or increased resistance to exhaustion.
[0198] In some embodiments, the modified immune effector cells described herein demonstrate increased infiltration into a tumor compared to an unmodified immune effector cell. In some embodiments, increased tumor infiltration by modified immune effector cells refers to an increase the number of modified immune effector cells infiltrating into a tumor during a given period of time compared to the number of unmodified immune effector cells that infiltrate into a tumor during the same period of time. In some embodiments, the modified immune effector cells demonstrate a 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2, 2.5, 3, 3.5, 4, 4.5, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100, or more fold increase in tumor filtration compared to an unmodified immune cell. Tumor infiltration can be measured by isolating one or more tumors from a subject and assessing the number of modified immune cells in the sample by flow cytometry, immunohistochemistry, and/or immunofluorescence.
[0199] In some embodiments, the modified immune effector cells described herein demonstrate an increase in cell proliferation compared to an unmodified immune effector cell. In these embodiments, the result is an increase in the number of modified immune effector cells present compared to unmodified immune effector cells after a given period of time. For example, in some embodiments, modified immune effector cells demonstrate increased rates of proliferation compared to unmodified immune effector cells, wherein the modified immune effector cells divide at a more rapid rate than unmodified immune effector cells. In some embodiments, the modified immune effector cells demonstrate a 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2, 2.5, 3, 3.5, 4, 4.5, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100, or more fold increase in the rate of proliferation compared to an unmodified immune cell. In some embodiments, modified immune effector cells demonstrate prolonged periods of proliferation compared to unmodified immune effector cells, wherein the modified immune effector cells and unmodified immune effector cells divide at similar rates, but wherein the modified immune effector cells maintain the proliferative state for a longer period of time. In some embodiments, the modified immune effector cells maintain a proliferative state for 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2, 2.5, 3, 3.5, 4, 4.5, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100, or more times longer than an unmodified immune cell.
[0200] In some embodiments, the modified immune effector cells described herein demonstrate increased or prolonged cell viability compared to an unmodified immune effector cell. In such embodiments, the result is an increase in the number of modified immune effector cells or present compared to unmodified immune effector cells after a given period of time. For example, in some embodiments, modified immune effector cells described herein remain viable and persist for 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2, 2.5, 3, 3.5, 4, 4.5, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100, or more times longer than an unmodified immune cell.
[0201] In some embodiments, the modified immune effector cells described herein demonstrate increased resistance to inhibitory factors compared to an unmodified immune effector cell. Exemplary inhibitory factors include signaling by immune checkpoint molecules (e.g., PD1, PDL1, CTLA4, LAG3, IDO) and/or inhibitory cytokines (e.g., IL-10, TGF.beta.).
[0202] In some embodiments, the modified T cells described herein demonstrate increased resistance to T cell exhaustion compared to an unmodified T cell. T cell exhaustion is a state of antigen-specific T cell dysfunction characterized by decreased effector function and leading to subsequent deletion of the antigen-specific T cells. In some embodiments, exhausted T cells lack the ability to proliferate in response to antigen, demonstrate decreased cytokine production, and/or demonstrate decreased cytotoxicity against target cells such as tumor cells. In some embodiments, exhausted T cells are identified by altered expression of cell surface markers and transcription factors, such as decreased cell surface expression of CD122 and CD127; increased expression of inhibitory cell surface markers such as PD1, LAG3, CD244, CD160, TIM3, and/or CTLA4; and/or increased expression of transcription factors such as Blimp1, NFAT, and/or BATF. In some embodiments, exhausted T cells demonstrate altered sensitivity to cytokine signaling, such as increased sensitivity to TGF.beta. signaling and/or decreased sensitivity to IL-7 and IL-15 signaling. T cell exhaustion can be determined, for example, by co-culturing the T cells with a population of target cells and measuring T cell proliferation, cytokine production, and/or lysis of the target cells. In some embodiments, the modified immune effector cells described herein are co-cultured with a population of target cells (e.g., autologous tumor cells or cell lines that have been engineered to express a target tumor antigen) and effector cell proliferation, cytokine production, and/or target cell lysis is measured. These results are then compared to the results obtained from co-culture of target cells with a control population of immune cells (such as unmodified immune effector cells or immune effector cells that have a control modification).
[0203] In some embodiments, resistance to T cell exhaustion is demonstrated by increased production of one or more cytokines (e.g., IFN.gamma., TNF.alpha., or IL-2) from the modified immune effector cells compared to the cytokine production observed from the control population of immune cells. In some embodiments, a 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5, 6, 7, 8, 9, 10, 15, 20, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100 or more fold increase in cytokine production from the modified immune effector cells compared to the cytokine production from the control population of immune cells is indicative of an increased resistance to T cell exhaustion. In some embodiments, resistance to T cell exhaustion is demonstrated by increased proliferation of the modified immune effector cells compared to the proliferation observed from the control population of immune cells. In some embodiments, a 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5, 6, 7, 8, 9, 10, 15, 20, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100 or more fold increase in proliferation of the modified immune effector cells compared to the proliferation of the control population of immune cells is indicative of an increased resistance to T cell exhaustion. In some embodiments, resistance to T cell exhaustion is demonstrated by increased target cell lysis by the modified immune effector cells compared to the target cell lysis observed by the control population of immune cells. In some embodiments, a 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5, 6, 7, 8, 9, 10, 15, 20, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100 or more fold increase in target cell lysis by the modified immune effector cells compared to the target cell lysis by the control population of immune cells is indicative of an increased resistance to T cell exhaustion.
[0204] In some embodiments, exhaustion of the modified immune effector cells compared to control populations of immune cells is measured during the in vitro or ex vivo manufacturing process. For example, in some embodiments, TILs isolated from tumor fragments are modified according to the methods described herein and then expanded in one or more rounds of expansion to produce a population of modified TILs. In such embodiments, the exhaustion of the modified TILs can be determined immediately after harvest and prior to a first round of expansion, after the first round of expansion but prior to a second round of expansion, and/or after the first and the second round of expansion. In some embodiments, exhaustion of the modified immune effector cells compared to control populations of immune cells is measured at one or more time points after transfer of the modified immune effector cells into a subject. For example, in some embodiments, the modified cells are produced according to the methods described herein and administered to a subject. Samples can then be taken from the subject at various time points after the transfer to determine exhaustion of the modified immune effector cells in vivo over time.
[0205] In some embodiments, the modified immune effector cells described herein demonstrate increased expression or production of pro-inflammatory immune factors compared to an unmodified immune effector cell. Examples of pro-inflammatory immune factors include cytolytic factors, such as granzyme B, perforin, and granulysin; and pro-inflammatory cytokines such as interferons (IFN.alpha., IFN.beta., IFN.gamma.), TNF.alpha., IL-10, IL-12, IL-2, IL-17, CXCL8, and/or IL-6.
[0206] In some embodiments, the modified immune effector cells described herein demonstrate increased cytotoxicity against a target cell compared to an unmodified immune effector cell. In some embodiments, the modified immune effector cells demonstrate a 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, or more fold increase in cytotoxicity against a target cell compared to an unmodified immune cell.
[0207] Assays for measuring immune effector function are known in the art. For example, tumor infiltration can be measured by isolating tumors from a subject and determining the total number and/or phenotype of the lymphocytes present in the tumor by flow cytometry, immunohistochemistry, and/or immunofluorescence. Cell-surface receptor expression can be determined by flow cytometry, immunohistochemistry, immunofluorescence, Western blot, and/or qPCR. Cytokine and chemokine expression and production can be measured by flow cytometry, immunohistochemistry, immunofluorescence, Western blot, ELISA, and/or qPCR. Responsiveness or sensitivity to extracellular stimuli (e.g., cytokines, inhibitory ligands, or antigen) can be measured by assaying cellular proliferation and/or activation of downstream signaling pathways (e.g., phosphorylation of downstream signaling intermediates) in response to the stimuli. Cytotoxicity can be measured by target-cell lysis assays known in the art, including in vitro or ex vivo co-culture of the modified immune effector cells with target cells and in vivo murine tumor models, such as those described throughout the Examples.
B. Regulation of Endogenous Pathways and Genes
[0208] In some embodiments, the modified immune effector cells described herein demonstrate a reduced expression or function of one or more endogenous target genes and/or comprise a gene-regulating system capable of reducing the expression and/or function of one or more endogenous target genes (described infra). In some embodiments, the one or more endogenous target genes are present in pathways related to the activation and regulation of effector cell responses. In such embodiments, the reduced expression or function of the one or more endogenous target genes enhances one or more effector functions of the immune cell.
[0209] Exemplary pathways suitable for regulation by the methods described herein are shown in Table 1. In some embodiments, the expression of an endogenous target gene in a particular pathway is reduced in the modified immune effector cells. In some embodiments, the expression of a plurality (e.g., two or more) of endogenous target genes in a particular pathway are reduced in the modified immune effector cells. For example, the expression of 2, 3, 4, 5, 6, 7, 8, 9, 10, or more endogenous target genes in a particular pathway may be reduced. In some embodiments, the expression of an endogenous target gene in one pathway and the expression of an endogenous target genes in another pathway is reduced in the modified immune effector cells. In some embodiments, the expression of a plurality of endogenous target genes in one pathway and the expression of a plurality of endogenous target genes in another pathway are reduced in the modified immune effector cells. For example, the expression of 2, 3, 4, 5, 6, 7, 8, 9, 10, or more endogenous target genes in one pathway may be reduced and the expression of 2, 3, 4, 5, 6, 7, 8, 9, 10, or more endogenous target genes in another particular pathway may be reduced.
[0210] In some embodiments, the expression of a plurality of endogenous target genes in a plurality of pathways is reduced. For example, one endogenous gene from each of a plurality of pathways (e.g., 2, 3, 4, 5, 6, 7, 8, 9, 10, or more pathways) may be reduced. In additional aspects, a plurality of endogenous genes (e.g., 2, 3, 4, 5, 6, 7, 8, 9, 10, or more genes) from each of a plurality of pathways (e.g., 2, 3, 4, 5, 6, 7, 8, 9, 10, or more pathways) may be reduced.
TABLE-US-00001 TABLE 1 Exemplary Endogenous Pathways Pathway Description Lymphocyte differentiation Signaling pathway which controls stem cell differentiation from a common lymphoid progenitor to the distinctive lymphocyte type (T cell, B cell or NK cell) NF.kappa..beta. signaling Signaling pathway that controls transcription of DNA, cytokine production and cell survival generally in response to harmful cell stimuli. TGF-.beta. signaling Signaling pathway that regulates cell growth, cell differentiation, apoptosis, cellular homeostasis and other cellular functions. T cell activation Pathway that is initiated by binding of the T cell receptor (TCR) complex to a major histocompatibility complex molecule carrying a peptide antigen and by binding of the co-stimulatory receptor CD28 to proteins in the surface of the antigen presenting cell. Activation of a TCR initiates a signaling pathway which triggers antibody production, activation of phagocytic cells and direct cell killing. T cell growth Signaling pathway that controls programmed cell death in response to either extrinsic signals or intrinsic cellular stresses Pyrimidine biosynthesis A de novo nucleotide biosynthesis pathway for components of RNA and DNA Cytokine Signaling Signaling pathways down stream of cytokine receptors, typically involve positive JAK/STAT signaling Apoptosis initiation Genes that initiate either the intrinsic or extrinsic apoptotic pathway, which drives programed cell death of the cell Transcription initiation Genes that directly bind the promoters of target genes and act as repressors or transcriptional activators of target gene transcription Ca2++ binding Ca2++ serves as a second messenger in response to stimuli and drives intracellular signaling in a number of processes, including inflammation and the immune response. In T cells, Ca2++ signaling is required for the activation of T cells in response to antigen
[0211] Exemplary endogenous target genes are shown below in Tables 2 and 3.
[0212] In some embodiments, the modified effector cells comprise reduced expression and/or function of one or more of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR (e.g., one or more endogenous target genes selected from Table 2). In some embodiments, the modified effector cells comprise reduced expression and/or function of one or more of TNFAIP3, CBLB, or BCOR.
[0213] In some embodiments, the modified immune effector cells comprise reduced expression and/or function of at least two genes selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR (e.g., at least two genes selected from Table 2). For example, in some embodiments, the modified immune effector cells comprise reduced expression and/or function of at least two genes selected from Combination Nos. 1-600, as illustrated in FIG. 1A-FIG. 1B. In some embodiments, the modified immune effector cells comprise reduced expression and/or function of BCOR and reduced expression and/or function of CBLB. While exemplary methods for modifying the expression of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and/or BCOR are described herein, the expression of these endogenous target genes may also be modified by methods known in the art. For example, inhibitory antibodies against PD1 (encoded by PDCD1), NRP1, HACR2, LAG3, TIGIT, and CTLA4 are known in the art and some are FDA approved for oncologic indications (e.g., nivolumab and pembrolizumab for PD1).
[0214] In some embodiments, the modified immune effector cells comprise reduced expression and/or function of one or more of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 (e.g., one or more endogenous target genes selected from Table 3).
[0215] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the Semaphorin 7A, (SEMA7A) gene, also known as CD108. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the SEMA7A gene.
[0216] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the RNA-binding protein 39 (RBM39) gene. The RBM39 protein is found in the nucleus, where it colocalizes with core spliceosomal proteins. Studies of a mouse protein with high sequence similarity to this protein suggest that this protein may act as a transcriptional coactivator for JUN/AP-1 and estrogen receptors. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the RBM39 gene.
[0217] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the Bcl-2-like protein 11 (BCL2L11) gene, also commonly called BIM. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the BCL2L11 gene
[0218] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the Friend leukemia integration 1 transcription factor (FLI1) gene, also known as transcription factor ERGB. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the FLI1 gene.
[0219] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the Calmodulin 2 (CALM2) gene. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the CALM2 gene.
[0220] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the Dihydroorotate dehydrogenase gene (DHODH) gene. The DHODH protein is a mitochondrial protein located on the outer surface of the inner mitochondrial membrane and catalyzes the ubiquinone-mediated oxidation of dihydroorotate to orotate in de novo pyrimidine biosynthesis. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the DHODH gene.
[0221] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the uridine monophosphate synthase (UMPS) gene, also referred to as orotate phosphoribosyl transferase or orotidine-5'-decarboxylase. The UMPS protein catalyses the formation of uridine monophosphate (UMP), an energy-carrying molecule in many important biosynthetic pathways. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the UMPS gene.
[0222] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the cysteine rich hydrophobic domain 2 (CHIC2) gene. The encoded CHIC2 protein contains a cysteine-rich hydrophobic (CHIC) motif, and is localized to vesicular structures and the plasma membrane and is associated with some cases of acute myeloid leukemia. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the CHIC2 gene.
[0223] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the Poly(rC)-binding protein 1(PCBP1) gene. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the PCBP1 gene.
[0224] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the Protein polybromo-1 (PBRM1) gene, also known as BRG1-associated factor 180 (BAF180). PBRM1 is a component of the SWI/SNF-B chromatin-remodeling complex, and is a tumor suppressor gene in many cancer subtypes. Mutations are especially prevalent in clear cell renal cell carcinoma. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the PBRM1 gene.
[0225] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the WD repeat-containing protein 6 (WDR6) gene, a member of the WD repeat protein family ubiquitously expressed in adult and fetal tissues. WD repeats are minimally conserved regions of approximately 40 amino acids typically bracketed by gly-his and trp-asp (GH-WD), which may facilitate formation of heterotrimeric or multiprotein complexes. Members of this family are involved in a variety of cellular processes, including cell cycle progression, signal transduction, apoptosis, and gene regulation. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the WDR6 gene.
[0226] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the E2F transcription factor 8 (E2F8) gene. The encoded E2F8 protein regulates progression from G1 to S phase by ensuring the nucleus divides at the proper time. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the E2F8 gene.
[0227] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the serpin family A member 3 (SERPINA3) gene. SERPINA3 encodes the Alpha 1-antichymotrypsin (.alpha.1AC, A1AC, or a1ACT) protein, which inhibits the activity of certain proteases, such as cathepsin G and chymases. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the SERPINA3 gene.
[0228] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the GNAS complex locus (GNAS) gene. It is the stimulatory G-protein alpha subunit (Gs-.alpha.), a key component of many signal transduction pathways. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the GNAS gene.
[0229] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the ZC3H12A gene. Zc3h12a, also referred to as MCPIP1 and Regnase-1, is a RNase that possesses a RNase domain just upstream of a CCCH-type zinc-finger motif. Through its nuclease activity, Zc3h12a targets and destabilizes the mRNAs of transcripts, such as IL-6, by binding a conserved stem loop structure within the 3' UTR of these genes. In T cells, Zc3h12a controls the transcript levels of a number of pro-inflammatory genes, including c-Rel, Ox40, and IL-2. In monocytes, Zc3h12a downregulates IL-6 and IL-12B mRNAs, thus mitigating inflammation. In cancer cells, Zc3h12a promotes apoptosis by inhibiting anti-apoptotic genes including Bcl2L1, Bcl2A1, RelB and Bcl3. Zc3h12a activation is transient and is subject to negative feedback mechanisms including proteasome-mediated degradation or mucosa-associated lymphoid tissue 1 (MALT1) mediated cleavage. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the ZC3H12A gene.
[0230] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the MAP4K1 gene. MAP4K1, also referred to as HPK1, is a member of the MAP4K family of mammalian Ste20-related protein kinases and is a protein serine-threonine kinase predominantly expressed in hematopoietic organs. The MAP4K1 protein comprises an N-terminal kinase domain followed by four proline-rich motifs capable of binding to proteins containing Src homology 3 domains. Upon phosphorylation by kinases such as Lck and Zap70 and in the presence of ATP, MAP4K1 possesses catalytic activity and mediates autophosphorylation as well as phosphorylation of downstream substrate proteins such as SLP-76 and MAP3K proteins. Phosphorylation of SLP-76 at Ser-376 leads to both the ubiquitination and proteosomal degradation of SLP-76 as well as increased interactions between SLP-76 and 14-3-3.tau., which negatively regulates TCR signaling. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the MAP4K1 gene.
[0231] In some embodiments, the modified effector cells described herein comprise reduced expression and/or function of the NR4A3 gene. NR4A3 is an inducible orphan receptor and member of the steroid-thyroid hormone-retinoid receptor superfamily, and is a transcriptional activator. When expression is induced by various stimuli, NR4A3 drives gene expression in a ligand-independent way by translocating from the cytoplasm to the nucleus and binding to NR4A1 response elements (NBRE) as monomers and Nur response elements (NurRE) as homodimers. NR4A3 then drives the transcription of discrete sets of genes controlling cellular survival and differentiation both within and outside the immune system. In some embodiments, the modified effector cells described herein comprise an inactivating mutation in the NR4A3 gene.
[0232] In some embodiments, the modified immune effector cells comprise reduced expression and/or function of at least two genes selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 (e.g., two or more genes selected from Table 3). For example, in some embodiments, the modified immune effector cells comprise reduced expression and/or function of at least two genes selected from Combination Nos. 1176-1681, as illustrated in FIG. 3A-FIG. 3B. In some embodiments, the modified immune effector cells comprise reduced expression and/or function of at least two genes selected from Combination Nos. 1176-1483, as illustrated in FIG. 3A. In some embodiments, the modified immune effector cells comprise reduced expression and/or function of at least two genes selected from Combination Nos. 1250-1265, as illustrated in FIG. 3B. In some embodiments, the modified immune effector cells comprise reduced expression and/or function of at least two genes selected from Combination Nos. 1266-1281, as illustrated in FIG. 3B. In some embodiments, the modified immune effector cells comprise reduced expression and/or function of at least two genes selected from Combination Nos. 1282-1297, as illustrated in FIG. 3B.
[0233] In some embodiments, the modified effector cells comprise reduced expression and/or function of one or more of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 (e.g., one or more gene selected from Table 3) and one or more of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR (e.g., one or more gene selected from Table 2). For example, the modified immune effector cells may comprise reduced expression and/or function of a combination of an endogenous target genes selected from Combination Nos. 601-1025. In some embodiments, the modified immune effector cells may comprise reduced expression and/or function of a combination of two endogenous target genes selected from Combination Nos. 601-950 (as illustrated in FIG. 2A). In some embodiments, the modified immune effector cells may comprise reduced expression and/or function of a combination of two endogenous target genes selected from Combination Nos. 951-975 (as illustrated in FIG. 2B). In some embodiments, the modified immune effector cells may comprise reduced expression and/or function of a combination of two endogenous target genes selected from Combination Nos. 976-1000 (as illustrated in FIG. 2B). In some embodiments, the modified immune effector cells may comprise reduced expression and/or function of a combination of two endogenous target genes selected from Combination Nos. 1001-1025 (as illustrated in FIG. 2B).
[0234] In some embodiments, the modified effector cells comprise reduced expression and/or function of at least one gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS and reduced expression and/or function of at least one gene selected from TNFAIP3, CBLB, or BCOR. In some embodiments, the modified effector cells comprise reduced expression and/or function of ZC3H12A and at least one gene selected from TNFAIP3, CBLB, or BCOR. In some embodiments, the modified effector cells comprise inactivating mutations in ZC3H12A and at least one gene selected from TNFAIP3, CBLB, or BCOR. In some embodiments, the modified effector cells comprise reduced expression and/or function of MAP4K1 and at least one gene selected from TNFAIP3, CBLB, or BCOR. In some embodiments, the modified effector cells comprise inactivating mutations in MAP4K1 and at least one gene selected from TNFAIP3, CBLB, or BCOR. In some embodiments, the modified effector cells comprise reduced expression and/or function of NR4A3 and at least one gene selected from TNFAIP3, CBLB, or BCOR. In some embodiments, the modified effector cells comprise inactivating mutations in NR4A3 and at least one gene selected from TNFAIP3, CBLB, or BCOR.
[0235] In some embodiments, the modified effector cells comprise reduced expression and/or function of at least one gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 and reduced expression and/or function of CBLB. In some embodiments, the modified effector cells comprise reduced expression and/or function of at least one gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS and reduced expression and/or function of CBLB. In some embodiments, the modified effector cells comprise reduced expression and/or function of ZC3H12A and CBLB. In some embodiments, the modified effector cells comprise inactivating mutations in ZC3H12A and CBLB. In some embodiments, the modified effector cells comprise reduced expression and/or function of MAP4K1 and CBLB. In some embodiments, the modified effector cells comprise inactivating mutations in MAP4K1 and CBLB. In some embodiments, the modified effector cells comprise reduced expression and/or function of NR4A3 and CBLB. In some embodiments, the modified effector cells comprise inactivating mutations in NR4A3 and CBLB.
[0236] In some embodiments, the modified immune effector cells comprise reduced expression and/or function of a gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR (e.g., one or more gene selected from Table 2) and reduced expression and/or function of two genes selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 (e.g., one or more gene selected from Table 3). For example, in some embodiments, the modified immune effector cells comprises reduced expression and/or function of a gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, and BCOR in addition to reduced expression and/or function of two endogenous target gene combinations selected from Combination Nos. 1026-1297 (as illustrated in FIG. 3A-FIG. 3B).
[0237] In some embodiments, the modified immune effector cells comprise reduced expression and/or function of a gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 (e.g., a gene selected from Table 3) and reduced expression and/or function of two genes selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR (e.g., one or more gene selected from Table 2). For example, in some embodiments, the modified immune effector cells comprise reduced expression and/or function of any one of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 in addition to reduced expression and/or function of two endogenous target gene combinations selected from Combination Nos. 1-600 illustrated in FIG. 1A-FIG. 1B. In some embodiments, the modified immune effector cells comprise reduced expression and/or function of a gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS in addition to reduced expression and/or function of two endogenous target gene combinations selected from Combination Nos. 1-600 illustrated in FIG. 1A-FIG. 1B. In some embodiments, the modified immune effector cells comprise reduced expression and/or function of ZC3H12A in addition to reduced expression and/or function of two endogenous target gene combinations selected from Combination Nos. 1-600 illustrated in FIG. 1A-FIG. 1B. In some embodiments, the modified immune effector cells comprise reduced expression and/or function of MAP4K1 in addition to reduced expression and/or function of two endogenous target gene combinations selected from Combination Nos. 1-600 illustrated in FIG. 1A-FIG. 1B. In some embodiments, the modified immune effector cells comprise reduced expression and/or function of NR4A3 in addition to reduced expression and/or function of two endogenous target gene combinations selected from Combination Nos. 1-600 illustrated in FIG. 1A-FIG. 1B.
[0238] In some embodiments, the modified immune effector cells comprise reduced expression and/or function of a plurality of genes selected from Table 2 and reduced expression and/or function of a plurality of genes selected from Table 3. In some embodiments, the modified immune effector cells comprise reduced expression and/or function of two genes selected from Table 2 and reduced expression and/or function of two genes selected from Table 3. For example, in some embodiments, the modified immune effector cells comprise reduced expression and/or function of a combination of two genes selected from Combination Nos. 1026-1297 as shown in FIG. 3A-FIG. 3B and a combination of two genes selected from Combination Nos. 1-600 as shown in FIG. 1A-FIG. 1B. In some embodiments, the modified immune effector cells may comprise reduced expression and/or function of three or more of IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and reduced expression and/or function of three or more of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3.
TABLE-US-00002 TABLE 2 Exemplary Endogenous Genes Human Murine Gene UniProt Human UniProt Murine Symbol Gene Name Ref. NCBI ID Ref. NCBI ID IKZF1 IKAROS family zinc Q13422 10320 Q03267 22778 finger 1 IKZF2 IKAROS family zinc Q9UKS7 22807 P81183 22779 finger 2 IKZF3 IKAROS family zinc Q9UKT9 22806 O08900 22780 finger 3 NFKBIA NFKB inhibitor P25963 4792 Q9Z1E3 18035 alpha BCL3 B cell P20749 602 Q9Z2F6 12051 CLL/lymphoma 3 TNIP1 TNFAIP3 interacting Q15025 10318 Q9WUU8 57783 protein 1 TNFAIP3 TNF alpha induced P21580 7128 Q60769 21929 protein 3 SMAD2 SMAD family Q15796 4087 Q919P9 17126 member 2 TGFBR1 transforming growth P36897 7046 Q64729 21812 factor beta receptor 1 TGFBR2 transforming growth P37173 7048 Q623212 21813 factor beta receptor 2 TANK TRAF family Q92844 10010 P70347 21353 member associated NFKB activator FOXP3 forkhead box P3 Q9BZS1 50943 Q99JB6 20371 CBLB Cbl proto-oncogene Q13191 868 Q3TTA7 208650 B PPP2R2D protein phosphatase 2 Q66LE6 55844 Q7ZX64 52432 regulatory subunit Bdelta NRP1 neuropilin 1 Q14786 8829 P97333 18186 HAVCR2 hepatitis A virus Q8TDQ0 84868 Q8VIM0 171285 cellular receptor 2 LAG3 lymphocyte P18627 3902 Q61790 16768 activating 3 TIGIT T cell Q495A1 201633 P86176 100043314 immunoreceptor with Ig and ITIM domains CTLA4 cytotoxic T- P16410 1493 P09793 12477 lymphocyte associated protein 4 PTPN6 protein tyrosine P29350 5777 P29351 15170 phosphatase, non- receptor type 6 BCOR BCL6 corepressor Q6W2J9 54880 Q8CGN4 71458 GATA3 GATA binding P23771 2625 P23772 14462 protein 3 PDCD1 Programmed cell Q15116 5133 Q02242 18566 death 1 protein RC3H1 Ring finger and Q5TC82 149041 Q4VGL6 381305 CCCH-type domains 1 TRAF6 TNF receptor Q9Y4K3 7186 P70196 22034 associated factor 6
TABLE-US-00003 TABLE 3 Exemplary Genes for Novel Regulation Human Murine Gene UniProt Human UniProt Murine Symbol Gene Name Ref. NCBI ID Ref. NCBI ID SEMA7A semaphorin 7A O75326 8482 Q9QUR8 20361 RBM39 RNA binding motif protein Q14498 9584 Q8VH51 170791 39 BCL2L11 BCL2 like 11 O43521 10018 O54918 12125 FLI1 Fli-1 proto-oncogene, ETS Q01543 2313 P26323 14247 transcription factor CALM2 calmodulin 2 P0P24 805 P0DP30 12314 DHODH dihydroorotate Q02127 1723 O35435 56749 dehydrogenase (quinone) UMPS uridine monophosphate P11172 7372 P13439 22247 synthetase CHIC2 cysteine rich hydrophobic Q9UKJ5 26511 Q9D9G3 74277 domain 2 PCBP1 poly(rC) binding protein 1 Q15365 5093 P60335 23983 PBRM1 polybromo 1 Q86U86 55193 Q8BSQ9 66923 WDR6 WD repeat domain 6 Q9NNW5 11180 Q99ME2 83669 E2F8 E2F transcription factor 8 A0AVK6 79733 Q58FA4 108961 SERPINA3 serpin family A member 3 P01011 12 GNAS guanine nucleotide binding Q5JWF2 2778 Q6R0H7 14683 protein, alpha stimulating ZC3H12A Endoribonuclease Q5D1E8 80149 Q5D1E7 230738 ZC3H12A MAP4K1 mitogen-activated protein Q92918 11184 P70218 26411 kinase kinase kinase kinase 1 NR4A3 Nuclear receptor subfamily Q92570 8013 Q9QZB6 18124 4 group A member 3
III. Gene-Regulating Systems
[0239] Herein, the term "gene-regulating system" refers to a protein, nucleic acid, or combination thereof that is capable of modifying an endogenous target DNA sequence when introduced into a cell, thereby regulating the expression or function of the encoded gene product. Numerous gene editing systems suitable for use in the methods of the present disclosure are known in the art including, but not limited to, shRNAs, siRNAs, zinc-finger nuclease systems, TALEN systems, and CRISPR/Cas systems.
[0240] As used herein, "regulate," when used in reference to the effect of a gene-regulating system on an endogenous target gene encompasses any change in the sequence of the endogenous target gene, any change in the epigenetic state of the endogenous target gene, and/or any change in the expression or function of the protein encoded by the endogenous target gene.
[0241] In some embodiments, the gene-regulating system may mediate a change in the sequence of the endogenous target gene, for example, by introducing one or more mutations into the endogenous target sequence, such as by insertion or deletion of one or more nucleic acids in the endogenous target sequence. Exemplary mechanisms that can mediate alterations of the endogenous target sequence include, but are not limited to, non-homologous end joining (NHEJ) (e.g., classical or alternative), microhomology-mediated end joining (MMEJ), homology-directed repair (e.g., endogenous donor template mediated), SDSA (synthesis dependent strand annealing), single strand annealing or single strand invasion.
[0242] In some embodiments, the gene-regulating system may mediate a change in the epigenetic state of the endogenous target sequence. For example, in some embodiments, the gene-regulating system may mediate covalent modifications of the endogenous target gene DNA (e.g., cytosine methylation and hydroxymethylation) or of associated histone proteins (e.g. lysine acetylation, lysine and arginine methylation, serine and threonine phosphorylation, and lysine ubiquitination and sumoylation).
[0243] In some embodiments, the gene-regulating system may mediate a change in the expression of the protein encoded by the endogenous target gene. In such embodiments, the gene-regulating system may regulate the expression of the encoded protein by modifications of the endogenous target DNA sequence, or by acting on the mRNA product encoded by the DNA sequence. In some embodiments, the gene-regulating system may result in the expression of a modified endogenous protein. In such embodiments, the modifications to the endogenous DNA sequence mediated by the gene-regulating system result in the expression of an endogenous protein demonstrating a reduced function as compared to the corresponding endogenous protein in an unmodified immune effector cell. In such embodiments, the expression level of the modified endogenous protein may be increased, decreased or may be the same, or substantially similar to, the expression level of the corresponding endogenous protein in an unmodified immune cell.
A. Nucleic Acid-Based Gene-Regulating Systems
[0244] As used herein, a nucleic acid-based gene-regulating system is a system comprising one or more nucleic acid molecules that is capable of regulating the expression of an endogenous target gene without the requirement for an exogenous protein. In some embodiments, the nucleic acid-based gene-regulating system comprises an RNA interference molecule or antisense RNA molecule that is complementary to a target nucleic acid sequence.
[0245] An "antisense RNA molecule" refers to an RNA molecule, regardless of length, that is complementary to an mRNA transcript. Antisense RNA molecules refer to single stranded RNA molecules that can be introduced to a cell, tissue, or subject and result in decreased expression of an endogenous target gene product through mechanisms that do not rely on endogenous gene silencing pathways, but rather rely on RNaseH-mediated degradation of the target mRNA transcript. In some embodiments, an antisense nucleic acid comprises a modified backbone, for example, phosphorothioate, phosphorodithioate, or others known in the art, or may comprise non-natural internucleoside linkages. In some embodiments, an antisense nucleic acid can comprise locked nucleic acids (LNA).
[0246] "RNA interference molecule" as used herein refers to an RNA polynucleotide that mediates the decreased the expression of an endogenous target gene product by degradation of a target mRNA through endogenous gene silencing pathways (e.g., Dicer and RNA-induced silencing complex (RISC)). Exemplary RNA interference agents include micro RNAs (also referred to herein as "miRNAs"), short hair-pin RNAs (shRNAs), small interfering RNAs (siRNAs), RNA aptamers, and morpholinos.
[0247] In some embodiments, the nucleic acid-based gene-regulating system comprises one or more miRNAs. miRNAs refers to naturally occurring, small non-coding RNA molecules of about 21-25 nucleotides in length. miRNAs are at least partially complementary to one or more target mRNA molecules. miRNAs can downregulate (e.g., decrease) expression of an endogenous target gene product through translational repression, cleavage of the mRNA, and/or deadenylation.
[0248] In some embodiments, the nucleic acid-based gene-regulating system comprises one or more shRNAs. shRNAs are single stranded RNA molecules of about 50-70 nucleotides in length that form stem-loop structures and result in degradation of complementary mRNA sequences. shRNAs can be cloned in plasmids or in non-replicating recombinant viral vectors to be introduced intracellularly and result in the integration of the shRNA-encoding sequence into the genome. As such, an shRNA can provide stable and consistent repression of endogenous target gene translation and expression.
[0249] In some embodiments, nucleic acid-based gene-regulating system comprises one or more siRNAs. siRNAs refer to double stranded RNA molecules typically about 21-23 nucleotides in length. The siRNA associates with a multi protein complex called the RNA-induced silencing complex (RISC), during which the "passenger" sense strand is enzymatically cleaved. The antisense "guide" strand contained in the activated RISC then guides the RISC to the corresponding mRNA because of sequence homology and the same nuclease cuts the target mRNA, resulting in specific gene silencing. Optimally, an siRNA is 18, 19, 20, 21, 22, 23 or 24 nucleotides in length and has a 2 base overhang at its 3' end. siRNAs can be introduced to an individual cell and/or culture system and result in the degradation of target mRNA sequences. siRNAs and shRNAs are further described in Fire et al., Nature, 391:19, 1998 and U.S. Pat. Nos. 7,732,417; 8,202,846; and 8,383,599.
[0250] In some embodiments, the nucleic acid-based gene-regulating system comprises one or more morpholinos. "Morpholino" as used herein refers to a modified nucleic acid oligomer wherein standard nucleic acid bases are bound to morpholine rings and are linked through phosphorodiamidate linkages. Similar to siRNA and shRNA, morpholinos bind to complementary mRNA sequences. However, morpholinos function through steric-inhibition of mRNA translation and alteration of mRNA splicing rather than targeting complementary mRNA sequences for degradation.
[0251] In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA encoded by a DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR (i.e., those listed in Table 2). In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B. Throughout this application, the referenced genomic coordinates are based on genomic annotations in the GRCh38 (also referred to as hg38) assembly of the human genome from the Genome Reference Consortium, available at the National Center for Biotechnology Information website. Tools and methods for converting genomic coordinates between one assembly and another are known in the art and can be used to convert the genomic coordinates provided herein to the corresponding coordinates in another assembly of the human genome, including conversion to an earlier assembly generated by the same institution or using the same algorithm (e.g., from GRCh38 to GRCh37), and conversion an assembly generated by a different institution or algorithm (e.g., from GRCh38 to NCBI33, generated by the International Human Genome Sequencing Consortium). Available methods and tools known in the art include, but are not limited to, NCBI Genome Remapping Service, available at the National Center for Biotechnology Information website, UCSC LiftOver, available at the UCSC Genome Brower website, and Assembly Converter, available at the Ensembl.org website.
[0252] In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, the nucleic acid-based gene-regulating system is capable of reducing the expression and/or function of CBLB, and comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 499-524. In some embodiments, the nucleic acid-based gene-regulating system is capable of reducing the expression and/or function of BCOR, and comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 708-772 or SEQ ID NOs: 708-764. In some embodiments, the nucleic acid-based gene-regulating system is capable of reducing the expression and/or function of TNFAIP3, and comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 348-396 or SEQ ID NOs: 348-386. In some embodiments, the nucleic acid-based gene-regulating system comprises an siRNA molecule or an shRNA molecule selected from those known in the art, such as the siRNA and shRNA constructs available from commercial suppliers such as Sigma Aldrich, Dharmacon, ThermoFisher, and the like.
[0253] In some embodiments, the endogenous target gene is CBLB and the nucleic acid molecule is an shRNA encoded by a nucleic acid sequence selected from SEQ ID NOs: 41-44 (See International PCT Publication No. 2018156886) or selected from SEQ ID NOs: 45-53 (See International PCT Publication No. WO 2017120998). In some embodiments, the endogenous target gene is CBLB and the nucleic acid molecule is an siRNA comprising a nucleic acid sequence selected from SEQ ID NOs: 54-63 (See International PCT Publication No. WO 2018006880) or SEQ ID NOs: 64-73 (See International PCT Publication Nos. WO 2018120998 and WO 2018137293).
[0254] In some embodiments, the endogenous target gene is TNFAIP3 and the nucleic acid molecule is an shRNA encoded by a nucleic acid sequence selected from SEQ ID NOs: 74-95 (See U.S. Pat. No. 8,324,369). In some embodiments, the endogenous target gene is TNFAIP3 and the nucleic acid molecule is an siRNA comprising a nucleic acid sequence selected from SEQ ID NOs: 96-105 (See International PCT Publication No. WO 2018006880).
[0255] In some embodiments, the endogenous target gene is CTLA4 and the nucleic acid molecule is an shRNA encoded by a nucleic acid sequence selected from SEQ ID NOs: 128-133 (See International PCT Publication No. WO 2017120996). In some embodiments, the endogenous target gene is CTLA4 and the nucleic acid molecule is an siRNA comprising a nucleic acid sequence selected from SEQ ID NOs: 134-143 (See International PCT Publication Nos. WO2017120996, WO 2017120998, WO 2018137295, and WO 2018137293) or SEQ ID NOs: 144-153 (See International PCT Publication No. WO 2018006880).
[0256] In some embodiments, the endogenous target gene is PDCD1 and the nucleic acid molecule is an shRNA encoded by a nucleic acid sequence selected from SEQ ID NOs: 106-107 (See International PCT Publication Nos. WO 2017120996). In some embodiments, the endogenous target gene is PDCD1 and the nucleic acid molecule is an siRNA comprising a nucleic acid sequence selected from SEQ ID NOs: 108-117 (See International PCT Publication Nos. WO2017120996, WO 201712998, WO 2018137295, and WO 2018137293) or SEQ ID NOs: 118-127 (See International PCT Publication No. WO 2018006880).
[0257] In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 (i.e., those listed in Table 3). In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99%, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in Table 6A-Table 6H. In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99%, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 814-1566.
[0258] In some embodiments, the nucleic acid-based gene-regulating system is capable of reducing the expression and/or function of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS. In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99%, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in one of Table 6A or Table 6B. In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99%, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 814-1064.
[0259] In some embodiments, the nucleic acid-based gene-regulating system is capable of reducing the expression and/or function of ZC3H12A. In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99%, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in one of Table 6C or Table 6D. In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99%, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 1065-1509. In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99%, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 1065-1264.
[0260] In some embodiments, the nucleic acid-based gene-regulating system is capable of reducing the expression and/or function of MAP4K1. In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99%, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in one of Table 6E or Table 6F. In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99%, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 510-1538.
[0261] In some embodiments, the nucleic acid-based gene-regulating system is capable of reducing the expression and/or function of NR4A3. In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99%, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in one of Table 6G or Table 6H. In some embodiments, the nucleic acid-based gene-regulating system comprises a nucleic acid molecule (e.g., an siRNA, an shRNA, an RNA aptamer, or a morpholino) that binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99%, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 1539-1566.
[0262] In some embodiments, the nucleic acid-based gene-regulating system comprises an siRNA molecule or an shRNA molecule selected from those known in the art, such as those available from commercial suppliers such as Sigma Aldrich, Dharmacon, ThermoFisher, and the like. Exemplary siRNA and shRNA constructs are described in Table 4A and Table 4B below. In some embodiments, the nucleic acid-based gene-regulating system comprises two or more siRNA molecules selected from those known in the art, such as the siRNA constructs described in Table 4A. In some embodiments, the nucleic acid-based gene-regulating system comprises two or more shRNA molecules selected from those known in the art, such as the shRNA constructs described in Table 4B.
TABLE-US-00004 TABLE 4A Exemplary siRNA constructs Target Gene siRNA construct SEMA7A MISSION .RTM. esiRNA human SEMA7A (esiRNA1) (SigmaAldrich Product# EHU143161) MISSION .RTM. esiRNA targeting mouse Sema7a (esiRNA1) (SigmaAldrich Product# EMU010311) human Rosetta Predictions (SigmaAldrich Product# NM_003612) murine Rosetta Predictions (SigmaAldrich Product# NM_011352) RBM39 MISSION .RTM. esiRNA human RBM39 (esiRNA1) (SigmaAldrich Product# EHU070351) human Rosetta Predictions (SigmaAldrich Product# NM_004902) human Rosetta Predictions (SigmaAldrich Product# NM_184234) human Rosetta Predictions (SigmaAldrich Product# NM_184237) human Rosetta Predictions (SigmaAldrich Product# NM_184241) human Rosetta Predictions (SigmaAldrich Product# NM_184244) BCL2L11 MISSION .RTM. esiRNA targeting mouse Bcl2l11 (esiRNA1) (SigmaAldrich Product# human Rosetta Predictions (SigmaAldrich Product# NM_006538) human Rosetta Predictions (SigmaAldrich Product# NM_138621) human Rosetta Predictions (SigmaAldrich Product# NM_138622) human Rosetta Predictions (SigmaAldrich Product# NM_138623) human Rosetta Predictions (SigmaAldrich Product# NM_138624) FLI1 MISSION .RTM. esiRNA human FLI1(esiRNA1) (SigmaAldrich Product# EHU091961) MISSION .RTM. esiRNA targeting mouse Fli1 (esiRNA1) (SigmaAldrich Product# EMU090601) human Rosetta Predictions (SigmaAldrich Product# NM_002017) murine Rosetta Predictions (SigmaAldrich Product# NM_008026) CALM2 MISSION .RTM. esiRNA human CALM2 (esiRNA1) (SigmaAldrich Product# EHU110161) MISSION .RTM. esiRNA targeting mouse Calm2 (SigmaAldrich Product# EMU176331) human Rosetta Predictions (SigmaAldrich Product# NM_001743) murine Rosetta Predictions (SigmaAldrich Product# NM_007589) DHODH MISSION .RTM. esiRNA human DHODH (esiRNA1) (SigmaAldrich Product# EHU138421) MISSION .RTM. esiRNA targeting mouse Dhodh (esiRNA1) (SigmaAldrich Product# EMU072221) human Rosetta Predictions (SigmaAldrich Product# NM_001025193) human Rosetta Predictions (SigmaAldrich Product# NM_001361) DHODH murine Rosetta Predictions (SigmaAldrich Product# NM_020046) UMPS MISSION .RTM. esiRNA human UMPS (esiRNA1) (SigmaAldrich Product# EHU093891) MISSION .RTM. esiRNA targeting mouse Umps (esiRNA1) (SigmaAldrich Product# EMU023181) human Rosetta Predictions (SigmaAldrich Product# NM_000373) murine Rosetta Predictions (SigmaAldrich Product# NM_009471) CHIC2 MISSION .RTM. esiRNA human CHIC2 (esiRNA1) (SigmaAldrich Product# EHU137501) MISSION .RTM. esiRNA targeting mouse Chic2 (esiRNA1) (SigmaAldrich Product# EMU019221 human Rosetta Predictions (SigmaAldrich Product# NM_012110) murine Rosetta Predictions (SigmaAldrich Product# NM_028850) PCBP1 MISSION .RTM. esiRNA targeting mouse Pcbpl (esiRNA1) (SigmaAldrich Product# EMU011551) human Rosetta Predictions (SigmaAldrich Product# NM_006196) murine Rosetta Predictions (SigmaAldrich Product# NM_011865) PBRM1 MISSION .RTM. esiRNA human PBRM1 (esiRNA1) (SigmaAldrich Product# EHU075001) human Rosetta Predictions (SigmaAldrich Product# NM_018165) human Rosetta Predictions (SigmaAldrich Product# NM_018313) human Rosetta Predictions (SigmaAldrich Product# NM_181042) WDR6 MISSION .RTM. esiRNA human WDR6 (esiRNA1) (SigmaAldrich Product# EHU065441) MISSION .RTM. esiRNA targeting mouse Wdr6 (esiRNA1) (SigmaAldrich Product# EMU038981) human Rosetta Predictions (SigmaAldrich Product# NM_018031) murine Rosetta Predictions (SiemaAldrich Product# NM_031392) E2F8 MISSION .RTM. esiRNA human E2F8 (esiRNA1) (SigmaAldrich Product# EHU025641) MISSION .RTM. esiRNA targeting mouse E2f8 (SigmaAldrich Product# EMU206861) human Rosetta Predictions (SigmaAldrich Product# NM_024680) murine Rosetta Predictions (SigmaAldrich Product# NM_001013368) SERPINA3 MISSION .RTM. esiRNA human SERPINA3 (esiRNA1) (SigmaAldrich Product# EHU150301) human Rosetta Predictions (SigmaAldrich Product# NM_001085) GNAS MISSION .RTM. esiRNA human GNAS (esiRNA1) (SigmaAldrich Product# EHU117321) MISSION .RTM. esiRNA targeting mouse Gnas (esiRNA1) (SigmaAldrich Product# EMU074141) human Rosetta Predictions (SigmaAldrich Product# NM_000516) human Rosetta Predictions (SigmaAldrich Product# NM_001077488) human Rosetta Predictions (SigmaAldrich Product# NM_001077489) GNAS human Rosetta Predictions (SigmaAldrich Product# NM_001077490) human Rosetta Predictions (SigmaAldrich Product# NM_016592) ZC3H12A MISSION .RTM. esiRNA targeting human ZC3H12A (esiRNA1) (SigmaAldrich# EHU009491) MISSION .RTM. esiRNA targeting mouse Zc3hl2a (esiRNA1) (SigmaAldrich# EMU048551) Rosetta Predictions human (SigmaAldrich# NM_025079) Rosetta Predictions mouse (SigmaAldrich# NM_153159) ZC3H12A Accell Mouse Zc3h12a (230738) siRNA - SMARTpool (Dharmacon# E- 052076-00-0005) MAP4K1 MISSION .RTM. esiRNA targeting human MAP4K1 (esiRNA1) (SigmaAldrich# EHU005191) MISSION .RTM. esiRNA targeting mouse Map4kl (esiRNA1) (SigmaAldrich# EMU086771) Rosetta Predictions human (SigmaAldrich# NM_001042600) Rosetta Predictions human (SigmaAldrich# NM_007181) Rosetta Predictions mouse (SigmaAldrich# NM_008279) NR4A3 MISSION .RTM. esiRNA targeting human NR4A3 (esiRNA1) (SigmaAldrich# EHU014951) Rosetta Predictions human (SigmaAldrich# NM_006981) Rosetta Predictions human (SigmaAldrich# NM_173198) Rosetta Predictions human (SigmaAldrich# NM_173199) Rosetta Predictions human (SigmaAldrich# NM_173200)
TABLE-US-00005 TABLE 4B Exemplary shRNA constructs Target Gene shRNA construct SEMA7A MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_011352) MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_003612) RBM39 MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_133242) MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_004902) BCL2L11 MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_009754) MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_138621) FLI1 MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_002017 MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_008026) CALM2 MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_007589) MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_001743) DHODH MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_020046) MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_001361) UMPS MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_009471) MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_000373) CHIC2 MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_028850) MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_012110) PCBP1 MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_011865) MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_006196) PBRM1 MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_001081251) PBRM1 MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_018165) WDR6 MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_031392) MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_018031) E2F8 MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_001013368) MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_024680) SERPINA3 MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_001085) GNAS MISSION .RTM. shRNA murine Plasmid DNA (SigmaAldrich Product# SHCLND-NM_010309) MISSION .RTM. shRNA human Plasmid DNA (SigmaAldrich Product# SHCLND-NM_000516) ZC3H12A MISSION .RTM. shRNA Plasmid DNA human (SigmaAldrich# SHCLND-NM_025079) MISSION .RTM. shRNA Plasmid DNA mouse (SigmaAldrich# SHCLND-NM_153159) MAP4K1 MISSION .RTM. shRNA Plasmid DNA human- (SigmaAldrich# SHCLND-NM_007181) MISSION .RTM. shRNA Plasmid DNA mouse (SigmaAldrich# SHCLND-NM_008279) NR4A3 MISSION .RTM. shRNA Plasmid DNA human (SigmaAldrich# SHCLND-NM_006981) MISSION .RTM. shRNA Plasmid DNA mouse (SigmaAldrich# SHCLND-NM_015743)
[0263] In some embodiments, the gene-regulating system comprises two or more nucleic acid molecules (e.g., two or more siRNAs, two or more shRNAs, two or more RNA aptamers, or two or more morpholinos), wherein at least one of the nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR (e.g., a gene selected from Table 2) and wherein at least one of the nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 (e.g., a gene selected from Table 3).
[0264] In some embodiments, at least one of the two or more nucleic acid molecules to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in Table 6A-Table 6H. In some embodiments, at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical an RNA sequence encoded by one of SEQ ID NOs: 814-1566 and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical an RNA sequence encoded by one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0265] In some embodiments, the gene-regulating system comprises two or more nucleic acid molecules, wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS. In some embodiments, at least one of the two or more nucleic acid molecules to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in Table 6A or Table 6B. In some embodiments, at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 814-1064 and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0266] In some embodiments, the gene-regulating system comprises two or more nucleic acid molecules, wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of CBLB and wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS. In some embodiments, at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 814-1064 and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 499-524.
[0267] In some embodiments, the gene-regulating system comprises two or more nucleic acid molecules, wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of ZC3H12A. In some embodiments, at least one of the two or more nucleic acid molecules to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in Table 6C or Table 6D. In some embodiments, at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 1065-1509 and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 In some embodiments, the gene-regulating system comprises two or more nucleic acid molecules, wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of the CBLB gene and wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of the ZC3H12A gene. In some embodiments, at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 1065-1509 and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 499-524. In some embodiments, at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 1065-1264 and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 499-524.
[0268] In some embodiments, the gene-regulating system comprises two or more nucleic acid molecules, wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of MAP4K1. In some embodiments, at least one of the two or more nucleic acid molecules to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in Table 6E or Table 6F. In some embodiments, at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 510-1538 and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0269] In some embodiments, the gene-regulating system comprises two or more nucleic acid molecules, wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of the CBLB gene and wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of M4AP4K1. In some embodiments, at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 510-1538 and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 499-524.
[0270] In some embodiments, the gene-regulating system comprises two or more nucleic acid molecules, wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of NR4A3. In some embodiments, at least one of the two or more nucleic acid molecules to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by a DNA sequence defined by a set of genomic coordinates shown in Table 6G or Table 6H. In some embodiments, at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 1539-1566 and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0271] In some embodiments, the gene-regulating system comprises two or more nucleic acid molecules, wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of the CBLB gene and wherein at least one of the nucleic acid molecules binds to a target RNA sequence encoded by a DNA sequence of NR4A3. In some embodiments, at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 1539-1566 and at least one of the two or more nucleic acid molecules binds to a target RNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to an RNA sequence encoded by one of SEQ ID NOs: 499-524.
B. Protein-Based Gene-Regulating Systems
[0272] In some embodiments, a protein-based gene-regulating system is a system comprising one or more proteins capable of regulating the expression of an endogenous target gene in a sequence specific manner without the requirement for a nucleic acid guide molecule. In some embodiments, the protein-based gene-regulating system comprises a protein comprising one or more zinc-finger binding domains and an enzymatic domain. In some embodiments, the protein-based gene-regulating system comprises a protein comprising a Transcription activator-like effector nuclease (TALEN) domain and an enzymatic domain. Such embodiments are referred to herein as "TALENs".
1. Zinc Finger Systems
[0273] Zinc finger-based systems comprise a fusion protein comprising two protein domains: a zinc finger DNA binding domain and an enzymatic domain. A "zinc finger DNA binding domain", "zinc finger protein", or "ZFP" is a protein, or a domain within a larger protein, that binds DNA in a sequence-specific manner through one or more zinc fingers, which are regions of amino acid sequence within the binding domain whose structure is stabilized through coordination of a zinc ion. The zinc finger domain, by binding to a target DNA sequence, directs the activity of the enzymatic domain to the vicinity of the sequence and, hence, induces modification of the endogenous target gene in the vicinity of the target sequence. A zinc finger domain can be engineered to bind to virtually any desired sequence. Accordingly, after identifying a target genetic locus containing a target DNA sequence at which cleavage or recombination is desired (e.g., a target locus in a target gene referenced in Tables 2 or 3), one or more zinc finger binding domains can be engineered to bind to one or more target DNA sequences in the target genetic locus. Expression of a fusion protein comprising a zinc finger binding domain and an enzymatic domain in a cell, effects modification in the target genetic locus.
[0274] In some embodiments, a zinc finger binding domain comprises one or more zinc fingers. Miller et al. (1985) EMBO J. 4:1609-1614; Rhodes (1993) Scientific American Febuary:56-65; U.S. Pat. No. 6,453,242. Typically, a single zinc finger domain is about 30 amino acids in length. An individual zinc finger binds to a three-nucleotide (i.e., triplet) sequence (or a four-nucleotide sequence which can overlap, by one nucleotide, with the four-nucleotide binding site of an adjacent zinc finger). Therefore the length of a sequence to which a zinc finger binding domain is engineered to bind (e.g., a target sequence) will determine the number of zinc fingers in an engineered zinc finger binding domain. For example, for ZFPs in which the finger motifs do not bind to overlapping subsites, a six-nucleotide target sequence is bound by a two-finger binding domain; a nine-nucleotide target sequence is bound by a three-finger binding domain, etc. Binding sites for individual zinc fingers (i.e., subsites) in a target site need not be contiguous, but can be separated by one or several nucleotides, depending on the length and nature of the amino acids sequences between the zinc fingers (i.e., the inter-finger linkers) in a multi-finger binding domain. In some embodiments, the DNA-binding domains of individual ZFNs comprise between three and six individual zinc finger repeats and can each recognize between 9 and 18 basepairs.
[0275] Zinc finger binding domains can be engineered to bind to a sequence of choice. See, for example, Beerli et al. (2002) Nature Biotechnol. 20:135-141; Pabo et al. (2001) Ann. Rev. Biochem. 70:313-340; Isalan et al. (2001) Nature Biotechnol. 19:656-660; Segal et al. (2001) Curr. Opin. Biotechnol. 12:632-637; Choo et al. (2000) Curr. Opin. Struct. Biol. 10:411-416. An engineered zinc finger binding domain can have a novel binding specificity, compared to a naturally-occurring zinc finger protein. Engineering methods include, but are not limited to, rational design and various types of selection.
[0276] Selection of a target DNA sequence for binding by a zinc finger domain can be accomplished, for example, according to the methods disclosed in U.S. Pat. No. 6,453,242. It will be clear to those skilled in the art that simple visual inspection of a nucleotide sequence can also be used for selection of a target DNA sequence. Accordingly, any means for target DNA sequence selection can be used in the methods described herein. A target site generally has a length of at least 9 nucleotides and, accordingly, is bound by a zinc finger binding domain comprising at least three zinc fingers. However binding of, for example, a 4-finger binding domain to a 12-nucleotide target site, a 5-finger binding domain to a 15-nucleotide target site or a 6-finger binding domain to an 18-nucleotide target site, is also possible. As will be apparent, binding of larger binding domains (e.g., 7-, 8-, 9-finger and more) to longer target sites is also possible.
[0277] In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR (e.g., a gene selected from Table 2). In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0278] In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of CBLB. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of BCOR. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 708-772 or SEQ ID NOs: 708-764. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of TNFAIP3. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 348-396 or SEQ ID NOs: 348-386.
[0279] In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected BCL2L1, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 (e.g., a gene selected from Table 3). In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in one of Table 6A-Table 6H. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1566.
[0280] In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected BCL2L1, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6A or Table 6B. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1064. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of ZC3H12A. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6C or Table 6D. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1509. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1264.
[0281] In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the MAP4K1 gene. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6E or Table 6F. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 510-1538. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the NR4A3 gene. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6G or Table 6H. In some embodiments, the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1539-1566.
[0282] In some embodiments, the zinc finger system is selected from those known in the art, such as those available from commercial suppliers such as Sigma Aldrich. For example, in some embodiments, the zinc finger system is selected from those known in the art, such as those described in Table 7 below.
TABLE-US-00006 TABLE 7 Exemplary Zinc Finger Systems Target Gene Zinc Finger System SEMA7A CompoZr .RTM. Knockout ZFN plasmid human SEMA7A NM_003612 (SigmaAldrich Product# CKOZFND19082) CompoZr .RTM. Knockout ZFN plasmid murine Sema7aNM_011352.2 (SigmaAldrich Product# CKOZFND19082) RBM39 CompoZr .RTM. Knockout ZFN plasmid Human RBM39 (NM_004902) (SigmaAldrich Product# CKOZFND18044) CompoZr .RTM. Knockout ZFN plasmid Mouse Rbm39 (NM_133242.2) (SigmaAldrich Product # CKOZFND39983) BCL2L11 CompoZr .RTM. Knockout ZFN plasmid Human BCL2L11 (NM_006538) (SigmaAldrich Product # CKOZFND3909) CompoZr .RTM. Knockout ZFN plasmid Mouse Bcl2111 (NM_207680.2) (SigmaAldrich Product # CKOZFND27562) FLI1 CompoZr .RTM. Knockout ZFN Kit Human FLI1 (NM_002017) (SigmaAldrich Product# CKOZFN8731) FLI1 CompoZr .RTM. Knockout ZFN plasmid Mouse Fli1 (NM_008026.4) (SigmaAldrich Product# CKOZFND31430) CALM2 CompoZr .RTM. Knockout ZFN Kit Human CALM2 (NM_001743) (SigmaAldrich Product# CKOZFN5301) CompoZr .RTM. Knockout ZFN plasmid Mouse Calm2 (NM_007589.5) (SigmaAldrich Product# CKOZFND27915) DHODH CompoZr .RTM. Knockout ZFN plasmid Human DHODH (NM_001361) (SigmaAldrich Product # CKOZFND1982) CompoZr .RTM. Knockout ZFN plasmid Mouse Dhodh (NM_020046.3) (SigmaAldrich Product # CKOZFND29960) UMPS CompoZr .RTM. Knockout ZFN plasmid Human UMPS (NM_000373) (SigmaAldrich Product# CKOZFND1693) CompoZr .RTM. Knockout ZFN plasmid Mouse Umps (NM_009471.2) (SigmaAldrich Product# CKOZFND43931) CHIC2 CompoZr .RTM. Knockout ZFN Kit Human CHIC2 (NM_012110) (SigmaAldrich Product # CKOZFN6059) CompoZr .RTM. Knockout ZFN plasmid Mouse Chic2 (NM_028850.4) (SigmaAldrich Product# CKOZFND28691) PCBP1 CompoZr .RTM. Knockout ZFN plasmid Human PCBP1 (NM_006196) (SigmaAldrich Product# CKOZFND16392) CompoZr .RTM. Knockout ZFN plasmid Mouse Pcbp1 (NM_011865.3) (SigmaAldrich Product# CKOZFND38313) PBRM1 CompoZr .RTM. Knockout ZFN plasmid Human PBRM1 (NM_018165) (SigmaAldrich Product # CKOZFND2434) CompoZr .RTM. Knockout ZFN plasmid Mouse Pbrm1 (NM_001081251.1) (SigmaAldrich Product # CKOZFND38304) WDR6 CompoZr .RTM. Knockout ZFN plasmid Human WDR6 (NM_018031) (SigmaAldrich Product# CKOZFND22841) CompoZr .RTM. Knockout ZFN plasmid Mouse Wdr6 (NM_031392.2) (SigmaAldrich Product # CKOZFND44594) E2F8 CompoZr .RTM. Knockout ZFN plasmid Human E2F8 (NM_024680) (SigmaAldrich Product# CKOZFND7610) CompoZr .RTM. Knockout ZFN plasmid Mouse E2f8 (NM_001013368.5) (SigmaAldrich Product # CKOZFND30371) SERPINA3 CompoZr .RTM. Knockout ZFN plasmid Human SERPINA3 (NM_001085) (SigmaAldrich Product # CKOZFND1900) GNAS CompoZr .RTM. Knockout ZFN plasmid Human GNAS (NM_000516) (SigmaAldrich Product# CKOZFND1354) CompoZr .RTM. Knockout ZFN plasmid Mouse Gnas (NM_001077510.2) (SigmaAldrich Product # CKOZFND32583) ZC3H12A CompoZr .RTM. Knockout ZFN Kit, ZFN plasmid Human ZC3H12A (NM_025079) (SigmaAldrich# CKOZFND23094) CompoZr .RTM. Knockout ZFN Kit, ZFN plasmid mouse Zc3h12a (NM_153159.2) (SigmaAldrich# CKOZFND44851) MAP4K1 CompoZr .RTM. Knockout ZFN plasmid Human MAP4K1 (NM_001042600) (SigmaAldrich# CKOZFND12999) CompoZr .RTM. Knockout ZFN plasmid Mouse Map4k1 (NM_008279.2) (SigmaAldrich# CKOZFND35246) NR4A3 CompoZr .RTM. Knockout ZFN plasmid Human NR4A3 (NM_006981) (SigmaAldrich# CKOZFND2362) CompoZr .RTM. Knockout ZFN plasmid Mouse Nr4a3 (NM_015743.2) (SigmaAldrich# CKOZFND36667)
[0283] In some embodiments, the gene-regulating system comprises two or more ZFP-fusion proteins each comprising a zinc finger binding domain, wherein at least one of the zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or 100% identical to a target DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and wherein at least one of the zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3. In some embodiments, at least one of the zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in one of Tables 6A-Table 6H. In some embodiments, at least one of the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 and at least one of the zinc finger binding domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1566.
[0284] In some embodiments, the gene-regulating system comprises two or more ZFP-fusion proteins each comprising a zinc finger binding domain, wherein at least one of the zinc finger binding domains binds to a target DNA sequence a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and at least one of the zinc finger binding domains binds to a target DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS. In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90% 95%, 96%, 97%, 98%, or 99% identical, or 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90% 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6A or Table 6B. In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1064 and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0285] In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1064 and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524.
[0286] In some embodiments, the gene-regulating system comprises two or more ZFP-fusion proteins each comprising a zinc finger binding domain, wherein at least one of the zinc finger binding domains binds to a target DNA sequence a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and at least one of the zinc finger binding domains binds to a target DNA sequence of ZC3H12A. In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90% 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90% 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6C or Table 6D. In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1509 and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0287] In some embodiments, the gene-regulating system comprises two or more ZFP-fusion proteins each comprising a zinc finger binding domain, wherein at least one of the zinc finger binding domains binds to a target DNA sequence the CBLB gene and at least one of the zinc finger binding domains binds to a target DNA sequence of the ZC3H12A gene. In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1509 and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524. In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1264 and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524.
[0288] In some embodiments, the gene-regulating system comprises two or more ZFP-fusion proteins each comprising a zinc finger binding domain, wherein at least one of the zinc finger binding domains binds to a target DNA sequence a target gene selected from IKZF, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and at least one of the zinc finger binding domains binds to a target DNA sequence of the MAP4K1 gene. In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6D or Table 6E. In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 510-1538 and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0289] In some embodiments, the gene-regulating system comprises two or more ZFP-fusion proteins each comprising a zinc finger binding domain, wherein at least one of the zinc finger binding domains binds to a target DNA sequence the CBLB gene selected and at least one of the zinc finger binding domains binds to a target DNA sequence of the MAP4K1 gene. In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 510-1538 and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524.
[0290] In some embodiments, the gene-regulating system comprises two or more ZFP-fusion proteins each comprising a zinc finger binding domain, wherein at least one of the zinc finger binding domains binds to a target DNA sequence a target gene selected from IKZF, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and at least one of the zinc finger binding domains binds to a target DNA sequence of the NR4A3 gene. In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6F or Table 6G. In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1539-1566 and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0291] In some embodiments, the gene-regulating system comprises two or more ZFP-fusion proteins each comprising a zinc finger binding domain, wherein at least one of the zinc finger binding domains binds to a target DNA sequence the CBLB gene selected and at least one of the zinc finger binding domains binds to a target DNA sequence of the NR4A3 gene. In some embodiments, at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1539-1566 and at least one of the two or more zinc finger binding domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524.
[0292] The enzymatic domain portion of the zinc finger fusion proteins can be obtained from any endo- or exonuclease. Exemplary endonucleases from which an enzymatic domain can be derived include, but are not limited to, restriction endonucleases and homing endonucleases. See, for example, 2002-2003 Catalogue, New England Biolabs, Beverly, Mass.; and Belfort et al. (1997) Nucleic Acids Res. 25:3379-3388. Additional enzymes which cleave DNA are known (e.g., 51 Nuclease; mung bean nuclease; pancreatic DNaseI; micrococcal nuclease; yeast HO endonuclease; see also Linn et al. (eds.) Nucleases, Cold Spring Harbor Laboratory Press, 1993). One or more of these enzymes (or functional fragments thereof) can be used as a source of cleavage domains.
[0293] Exemplary restriction endonucleases (restriction enzymes) suitable for use as an enzymatic domain of the ZFPs described herein are present in many species and are capable of sequence-specific binding to DNA (at a recognition site), and cleaving DNA at or near the site of binding. Certain restriction enzymes (e.g., Type IIS) cleave DNA at sites removed from the recognition site and have separable binding and cleavage domains. For example, the Type IIS enzyme FokI catalyzes double-stranded cleavage of DNA, at 9 nucleotides from its recognition site on one strand and 13 nucleotides from its recognition site on the other. See, for example, U.S. Pat. Nos. 5,356,802; 5,436,150 and 5,487,994; as well as Li et al. (1992) Proc. Natl. Acad. Sci. USA 89:4275-4279; Li et al. (1993) Proc. Natl. Acad. Sci. USA 90:2764-2768; Kim et al. (1994a) Proc. Natl. Acad. Sci. USA 91:883-887; Kim et al. (1994b) J. Biol. Chem. 269:31,978-31,982. Thus, in one embodiment, fusion proteins comprise the enzymatic domain from at least one Type IIS restriction enzyme and one or more zinc finger binding domains.
[0294] An exemplary Type IIS restriction enzyme, whose cleavage domain is separable from the binding domain, is FokI. This particular enzyme is active as a dimer. Bitinaite et al. (1998) Proc. Natl. Acad. Sci. USA 95: 10,570-10,575. Thus, for targeted double-stranded DNA cleavage using zinc finger-FokI fusions, two fusion proteins, each comprising a FokI enzymatic domain, can be used to reconstitute a catalytically active cleavage domain. Alternatively, a single polypeptide molecule containing a zinc finger binding domain and two FokI enzymatic domains can also be used. Exemplary ZFPs comprising FokI enzymatic domains are described in U.S. Pat. No. 9,782,437.
2. TALEN Systems
[0295] TALEN-based systems comprise a protein comprising a TAL effector DNA binding domain and an enzymatic domain. They are made by fusing a TAL effector DNA-binding domain to a DNA cleavage domain (a nuclease which cuts DNA strands). The FokI restriction enzyme described above is an exemplary enzymatic domain suitable for use in TALEN-based gene-regulating systems.
[0296] TAL effectors are proteins that are secreted by Xanthomonas bacteria via their type III secretion system when they infect plants. The DNA binding domain contains a repeated, highly conserved, 33-34 amino acid sequence with divergent 12th and 13th amino acids. These two positions, referred to as the Repeat Variable Diresidue (RVD), are highly variable and strongly correlated with specific nucleotide recognition. Therefore, the TAL effector domains can be engineered to bind specific target DNA sequences by selecting a combination of repeat segments containing the appropriate RVDs. The nucleic acid specificity for RVD combinations is as follows: HD targets cytosine, NI targets adenenine, NG targets thymine, and NN targets guanine (though, in some embodiments, NN can also bind adenenine with lower specificity).
[0297] In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR (e.g., a gene selected from Table 2). In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the CBLB gene. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the BCOR gene, and bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 708-772 or SEQ ID NOs: 708-764. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the TNFAIP3, bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 348-396 or SEQ ID NOs: 348-386.
[0298] In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 (e.g., a gene selected from Table 3). In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in one of Tables 6A-Table 6H. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1566.
[0299] In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6A or Table 6B. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1064. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of ZC3H12A. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6C or Table 6D. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1509. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1264.
[0300] In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the MAP4K1 gene. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6E or Table 6F. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 510-1538. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the NR4A3 gene. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6G or Table 6H. In some embodiments, the TAL effector domains bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1539-1566.
[0301] In some embodiments, the gene-regulating system comprises two or more TAL effector-fusion proteins each comprising a TAL effector domain, wherein at least one of the TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and at least one of the TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3. In some embodiments, at least one of the TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in one of Tables 6A-Table 6H. In some embodiments, at least one of the TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 and at least one of the TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1566.
[0302] In some embodiments, the gene-regulating system comprises two or more TAL effector-fusion proteins each comprising a TAL effector domain, wherein at least one of the TAL effector domains binds to a target DNA sequence a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and at least one of the TAL effector domains binds to a target DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS. In some embodiments, at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6A or Table 6B. In some embodiments, at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1064 and at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0303] In some embodiments, the gene-regulating system comprises two or more TAL effector-fusion proteins each comprising a TAL effector domain, wherein at least one of the TAL effector domains binds to a target DNA sequence of CBLB and at least one of the TAL effector domains binds to a target DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS. In some embodiments, at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1064 and at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524.
[0304] In some embodiments, the gene-regulating system comprises two or more TAL effector-fusion proteins each comprising a TAL effector domain, wherein at least one of the TAL effector domains binds to a target DNA sequence a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and at least one of the TAL effector domains binds to a target DNA sequence of ZC3H12A. In some embodiments, at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more TAL effector domains binds binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6C or Table 6D. In some embodiments, at least one of the two or more TAL effector domains binds binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1509 and at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0305] In some embodiments, the gene-regulating system comprises two or more TAL effector-fusion proteins each comprising a TAL effector domain, wherein at least one of the TAL effector domains binds to a target DNA sequence the CBLB gene and at least one of the TAL effector domains binds to a target DNA sequence of the ZC3H12A gene. In some embodiments, at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1509 and at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524. In some embodiments, at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1264 and at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524.
[0306] In some embodiments, the gene-regulating system comprises two or more TAL effector-fusion proteins each comprising a TAL effector domain, wherein at least one of the TAL effector domains binds to a target DNA sequence a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and at least one of the TAL effector domains binds to a target DNA sequence of the MAP4K1 gene. In some embodiments, at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6D or Table 6E. In some embodiments, at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 510-1538 and at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0307] In some embodiments, the gene-regulating system comprises two or more TAL effector-fusion proteins each comprising a TAL effector domain, wherein at least one of the TAL effector domains binds to a target DNA sequence of the CBLB gene selected and at least one of the TAL effector domains binds to a target DNA sequence of the MAP4K1 gene. In some embodiments, at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 510-1538 and at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524.
[0308] In some embodiments, the gene-regulating system comprises two or more TAL effector-fusion proteins each comprising a TAL effector domain, wherein at least one of the TAL effector domains binds to a target DNA sequence a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and at least one of the TAL effector domains binds to a target DNA sequence of the NR4A3 gene. In some embodiments, at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6F or Table 6G. In some embodiments, at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1539-1566 and at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813.
[0309] In some embodiments, the gene-regulating system comprises two or more TAL effector-fusion proteins each comprising a TAL effector domain, wherein at least one of the TAL effector domains binds to a target DNA sequence of the CBLB gene selected and at least one of the TAL effector domains binds to a target DNA sequence of the NR4A3 gene. In some embodiments, at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1539-1566 and at least one of the two or more TAL effector domains binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524.
[0310] Methods and compositions for assembling the TAL-effector repeats are known in the art. See e.g., Cermak et al, Nucleic Acids Research, 39:12, 2011, e82. Plasmids for constructions of the TAL-effector repeats are commercially available from Addgene.
C. Combination Nucleic Acid/Protein-Based Gene-Regulating Systems
[0311] Combination gene-regulating systems comprise a site-directed modifying polypeptide and a nucleic acid guide molecule. Herein, a "site-directed modifying polypeptide" refers to a polypeptide that binds to a nucleic acid guide molecule, is targeted to a target nucleic acid sequence, (for example, an endogenous target DNA or RNA sequence) by the nucleic acid guide molecule to which it is bound, and modifies the target nucleic acid sequence (e.g., by cleavage, mutation, or methylation of the target nucleic acid sequence).
[0312] A site-directed modifying polypeptide comprises two portions, a portion that binds the nucleic acid guide and an activity portion. In some embodiments, a site-directed modifying polypeptide comprises an activity portion that exhibits site-directed enzymatic activity (e.g., DNA methylation, DNA or RNA cleavage, histone acetylation, histone methylation, etc.), wherein the site of enzymatic activity is determined by the guide nucleic acid. In some cases, a site-directed modifying polypeptide comprises an activity portion that has enzymatic activity that modifies the endogenous target nucleic acid sequence (e.g., nuclease activity, methyltransferase activity, demethylase activity, DNA repair activity, DNA damage activity, deamination activity, dismutase activity, alkylation activity, depurination activity, oxidation activity, pyrimidine dimer forming activity, integrase activity, transposase activity, recombinase activity, polymerase activity, ligase activity, helicase activity, photolyase activity or glycosylase activity). In other cases, a site-directed modifying polypeptide comprises an activity portion that has enzymatic activity that modifies a polypeptide (e.g., a histone) associated with the endogenous target nucleic acid sequence (e.g., methyltransferase activity, demethylase activity, acetyltransferase activity, deacetylase activity, kinase activity, phosphatase activity, ubiquitin ligase activity, deubiquitinating activity, adenylation activity, deadenylation activity, SUMOylating activity, deSUMOylating activity, ribosylation activity, deribosylation activity, myristoylation activity or demyristoylation activity). In some embodiments, a site-directed modifying polypeptide comprises an activity portion that modulates transcription of a target DNA sequence (e.g., to increase or decrease transcription). In some embodiments, a site-directed modifying polypeptide comprises an activity portion that modulates expression or translation of a target RNA sequence (e.g., to increase or decrease transcription).
[0313] The nucleic acid guide comprises two portions: a first portion that is complementary to, and capable of binding with, an endogenous target nucleic sequence (referred to herein as a "nucleic acid-binding segment"), and a second portion that is capable of interacting with the site-directed modifying polypeptide (referred to herein as a "protein-binding segment"). In some embodiments, the nucleic acid-binding segment and protein-binding segment of a nucleic acid guide are comprised within a single polynucleotide molecule. In some embodiments, the nucleic acid-binding segment and protein-binding segment of a nucleic acid guide are each comprised within separate polynucleotide molecules, such that the nucleic acid guide comprises two polynucleotide molecules that associate with each other to form the functional guide.
[0314] The nucleic acid guide mediates the target specificity of the combined protein/nucleic acid gene-regulating systems by specifically hybridizing with a target nucleic acid sequence. In some embodiments, the target nucleic acid sequence is an RNA sequence, such as an RNA sequence comprised within an mRNA transcript of a target gene. In some embodiments, the target nucleic acid sequence is a DNA sequence comprised within the DNA sequence of a target gene. Reference herein to a target gene encompasses the full-length DNA sequence for that particular gene which comprises a plurality of target genetic loci (i. e., portions of a particular target gene sequence (e.g., an exon or an intron)). Within each target genetic loci are shorter stretches of DNA sequences referred to herein as "target DNA sequences" that can be modified by the gene-regulating systems described herein. Further, each target genetic loci comprises a "target modification site," which refers to the precise location of the modification induced by the gene-regulating system (e.g., the location of an insertion, a deletion, or mutation, the location of a DNA break, or the location of an epigenetic modification).
[0315] The gene-regulating systems described herein may comprise a single nucleic acid guide, or may comprise a plurality of nucleic acid guides (e.g., 2, 3, 4, 5, 6, 7, 8, 9, 10, or more nucleic acid guides).
[0316] In some embodiments, the combined protein/nucleic acid gene-regulating systems comprise site-directed modifying polypeptides derived from Argonaute (Ago) proteins (e.g., T. thermophiles Ago or TtAgo). In such embodiments, the site-directed modifying polypeptide is a T. thermophiles Ago DNA endonuclease and the nucleic acid guide is a guide DNA (gDNA) (See, Swarts et al., Nature 507 (2014), 258-261). In some embodiments, the present disclosure provides a polynucleotide encoding a gDNA. In some embodiments, a gDNA-encoding nucleic acid is comprised in an expression vector, e.g., a recombinant expression vector. In some embodiments, the present disclosure provides a polynucleotide encoding a TtAgo site-directed modifying polypeptide or variant thereof. In some embodiments, the polynucleotide encoding a TtAgo site-directed modifying polypeptide is comprised in an expression vector, e.g., a recombinant expression vector.
[0317] In some embodiments, the gene editing systems described herein are CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats)/Cas (CRISPR Associated) nuclease systems. In some embodiments, the CRISPR/Cas system is a Class 2 system. Class 2 CRISPR/Cas systems are divided into three types: Type II, Type V, and Type VI systems. In some embodiments, the CRISPR/Cas system is a Class 2 Type II system, utilizing the Cas9 protein. In such embodiments, the site-directed modifying polypeptide is a Cas9 DNA endonuclease (or variant thereof) and the nucleic acid guide molecule is a guide RNA (gRNA). In some embodiments, the CRISPR/Cas system is a Class 2 Type V system, utilizing the Cas12 proteins (e.g., Cas12a (also known as Cpf1), Cas12b (also known as C2c1), Cas12c (also known as C2c3), Cas12d (also known as CasY), and Cas12e (also known as CasX)). In such embodiments, the site-directed modifying polypeptide is a Cas12 DNA endonuclease (or variant thereof) and the nucleic acid guide molecule is a gRNA. In some embodiments, the CRISPR/Cas system is a Class 2 and Type VI system, utilizing the Cas13 proteins (e.g., Cas13a (also known as C2c2), Cas13b, and Cas13c). (See, Pyzocha et al., ACS Chemical Biology, 13(2), 347-356). In such embodiments, the site-directed modifying polypeptide is a Cas13 RNA riboendonuclease and the nucleic acid guide molecule is a gRNA.
[0318] A Cas polypeptide refers to a polypeptide that can interact with a gRNA molecule and, in concert with the gRNA molecule, home or localize to a target DNA or target RNA sequence. Cas polypeptides include naturally occurring Cas proteins and engineered, altered, or otherwise modified Cas proteins that differ by one or more amino acid residues from a naturally-occurring Cas sequence.
[0319] A guide RNA (gRNA) comprises two segments, a DNA-binding segment and a protein-binding segment. In some embodiments, the protein-binding segment of a gRNA is comprised in one RNA molecule and the DNA-binding segment is comprised in another separate RNA molecule. Such embodiments are referred to herein as "double-molecule gRNAs" or "two-molecule gRNA" or "dual gRNAs." In some embodiments, the gRNA is a single RNA molecule and is referred to herein as a "single-guide RNA" or an "sgRNA." The term "guide RNA" or "gRNA" is inclusive, referring both to two-molecule guide RNAs and sgRNAs.
[0320] The protein-binding segment of a gRNA comprises, in part, two complementary stretches of nucleotides that hybridize to one another to form a double stranded RNA duplex (dsRNA duplex), which facilitates binding to the Cas protein. The nucleic acid-binding segment (or "nucleic acid-binding sequence") of a gRNA comprises a nucleotide sequence that is complementary to and capable of binding to a specific target nucleic acid sequence. The protein-binding segment of the gRNA interacts with a Cas polypeptide and the interaction of the gRNA molecule and site-directed modifying polypeptide results in Cas binding to the endogenous nucleic acid sequence and produces one or more modifications within or around the target nucleic acid sequence. The precise location of the target modification site is determined by both (i) base-pairing complementarity between the gRNA and the target nucleic acid sequence; and (ii) the location of a short motif, referred to as the protospacer adjacent motif (PAM), in the target DNA sequence (referred to as a protospacer flanking sequence (PFS) in target RNA sequences). The PAM/PFS sequence is required for Cas binding to the target nucleic acid sequence. A variety of PAM/PFS sequences are known in the art and are suitable for use with a particular Cas endonuclease (e.g., a Cas9 endonuclease)(See e.g., Nat Methods. 2013 November; 10(11): 1116-1121 and Sci Rep. 2014; 4: 5405). In some embodiments, the PAM sequence is located within 50 base pairs of the target modification site in a target DNA sequence. In some embodiments, the PAM sequence is located within 10 base pairs of the target modification site in a target DNA sequence. The DNA sequences that can be targeted by this method are limited only by the relative distance of the PAM sequence to the target modification site and the presence of a unique 20 base pair sequence to mediate sequence-specific, gRNA-mediated Cas binding. In some embodiments, the PFS sequence is located at the 3' end of the target RNA sequence. In some embodiments, the target modification site is located at the 5' terminus of the target locus. In some embodiments, the target modification site is located at the 3' end of the target locus. In some embodiments, the target modification site is located within an intron or an exon of the target locus.
[0321] In some embodiments, the present disclosure provides a polynucleotide encoding a gRNA. In some embodiments, a gRNA-encoding nucleic acid is comprised in an expression vector, e.g., a recombinant expression vector. In some embodiments, the present disclosure provides a polynucleotide encoding a site-directed modifying polypeptide. In some embodiments, the polynucleotide encoding a site-directed modifying polypeptide is comprised in an expression vector, e.g., a recombinant expression vector.
1. Cas Proteins
[0322] In some embodiments, the site-directed modifying polypeptide is a Cas protein. Cas molecules of a variety of species can be used in the methods and compositions described herein, including Cas molecules derived from S. pyogenes, S. aureus, N. meningitidis, S. thermophiles, Acidovorax avenae, Actinobacillus pleuropneumoniae, Actinobacillus succinogenes, Actinobacillus suis, Actinomyces sp., Cycliphilus denitrificans, Aminomonas paucivorans, Bacillus cereus, Bacillus smithii, Bacillus thuringiensis, Bacteroides sp., Blastopirellula marina, Bradyrhizobium sp., Brevibacillus laterospoxus, Campylobacter coli, Campylobacter jejuni, Campylobacter lari, Candidatus puniceispirillum, Clostridium cellulolyticum, Clostridium perfringens, Corynebacterium accolens, Corynebacterium diphtheria, Corynebacterium matruchotii, Dinoroseobacter shibae, Eubacterium dolichum, Gammaproteobacterium, Gluconacetobacter diazotrophicus, Haemophilus parainfluenzae, Haemophilus sputomm, Helicobacter canadensis, Helicobacter cinaedi, Helicobacter mustelae, Ilyobacter polytropus, Kingella kingae, Lactobacillus crispatus, Listeria ivanovii, Listeria monocytogenes, Listeriaceae bacterium, Methylocystis sp., Methylosinus trichosporium, Mobiluncus mulieris, Neisseria bacilliformis, Neisseria cinerea, Neisseria flavescens, Neisseria lactamica, Neisseria meningitidis, Neisseria sp., Neisseria wadsworthii, Nitrosomonas sp., Parvibaculum lavamentivorans, Pasteurella multocida, Phascolarctobacterium succinatutens, Ralstonia syzygii, Rhodopseudomonas palustris, Rhodovulum sp., Simonsiella muelleri, Sphingomonas sp., Sporolactobacillus vineae, Staphylococcus aureus, Staphylococcus lugdunensis, Streptococcus sp., Subdoligranulum sp., Tistrella mobilis, Treponema sp., or Verminephrobacter eiseniae.
[0323] In some embodiments, the Cas protein is a naturally-occurring Cas protein. In some embodiments, the Cas endonuclease is selected from the group consisting of C2C1, C2C3, Cpf1 (also referred to as Cas12a), Cas12b, Cas12c, Cas12d, Cas12e, Cas13a, Cas13b, Cas13c, Cas13d, Cas1, Cas1B, Cas2, Cas3, Cas4, Cas5, Cas6, Cas7, Cas8, Cas9 (also known as Csn1 and Csx12), Cas10, Csy1, Csy2, Csy3, Cse1, Cse2, Csc1, Csc2, Csa5, Csn2, Csm2, Csm3, Csm4, Csm5, Csm6, Cmr1, Cmr3, Cmr4, Cmr5, Cmr6, Csb1, Csb2, Csb3, Csx17, Csx14, Csx10, Csx16, CsaX, Csx3, Csx1, Csx15, Csf1, Csf2, Csf3, and Csf4.
[0324] In some embodiments, the Cas protein is an endoribonuclease such as a Cas13 protein. In some embodiments, the Cas13 protein is a Cas13a (Abudayyeh et al., Nature 550 (2017), 280-284), Cas13b (Cox et al., Science (2017) 358:6336, 1019-1027), Cas13c (Cox et al., Science (2017) 358:6336, 1019-1027), or Cas13d (Zhang et al., Cell 175 (2018), 212-223) protein.
[0325] In some embodiments, the Cas protein is a wild-type or naturally occurring Cas9 protein or a Cas9 ortholog. Wild-type Cas9 is a multi-domain enzyme that uses an HNH nuclease domain to cleave the target strand of DNA and a RuvC-like domain to cleave the non-target strand. Binding of WT Cas9 to DNA based on gRNA specificity results in double-stranded DNA breaks that can be repaired by non-homologous end joining (NHEJ) or homology-directed repair (HDR). Exemplary naturally occurring Cas9 molecules are described in Chylinski et al., RNA Biology 2013 10:5, 727-737 and additional Cas9 orthologs are described in International PCT Publication No. WO 2015/071474. Such Cas9 molecules include Cas9 molecules of a cluster 1 bacterial family, cluster 2 bacterial family, cluster 3 bacterial family, cluster 4 bacterial family, cluster 5 bacterial family, cluster 6 bacterial family, a cluster 7 bacterial family, a cluster 8 bacterial family, a cluster 9 bacterial family, a cluster 10 bacterial family, a cluster 11 bacterial family, a cluster 12 bacterial family, a cluster 13 bacterial family, a cluster 14 bacterial family, a cluster 15 bacterial family, a cluster 16 bacterial family, a cluster 17 bacterial family, a cluster 18 bacterial family, a cluster 19 bacterial family, a cluster 20 bacterial family, a cluster 21 bacterial family, a cluster 22 bacterial family, a cluster 23 bacterial family, a cluster 24 bacterial family, a cluster 25 bacterial family, a cluster 26 bacterial family, a cluster 27 bacterial family, a cluster 28 bacterial family, a cluster 29 bacterial family, a cluster 30 bacterial family, a cluster 31 bacterial family, a cluster 32 bacterial family, a cluster 33 bacterial family, a cluster 34 bacterial family, a cluster 35 bacterial family, a cluster 36 bacterial family, a cluster 37 bacterial family, a cluster 38 bacterial family, a cluster 39 bacterial family, a cluster 40 bacterial family, a cluster 41 bacterial family, a cluster 42 bacterial family, a cluster 43 bacterial family, a cluster 44 bacterial family, a cluster 45 bacterial family, a cluster 46 bacterial family, a cluster 47 bacterial family, a cluster 48 bacterial family, a cluster 49 bacterial family, a cluster 50 bacterial family, a cluster 51 bacterial family, a cluster 52 bacterial family, a cluster 53 bacterial family, a cluster 54 bacterial family, a cluster 55 bacterial family, a cluster 56 bacterial family, a cluster 57 bacterial family, a cluster 58 bacterial family, a cluster 59 bacterial family, a cluster 60 bacterial family, a cluster 61 bacterial family, a cluster 62 bacterial family, a cluster 63 bacterial family, a cluster 64 bacterial family, a cluster 65 bacterial family, a cluster 66 bacterial family, a cluster 67 bacterial family, a cluster 68 bacterial family, a cluster 69 bacterial family, a cluster 70 bacterial family, a cluster 71 bacterial family, a cluster 72 bacterial family, a cluster 73 bacterial family, a cluster 74 bacterial family, a cluster 75 bacterial family, a cluster 76 bacterial family, a cluster 77 bacterial family, or a cluster 78 bacterial family.
[0326] In some embodiments, the naturally occurring Cas9 polypeptide is selected from the group consisting of SpCas9, SpCas9-HF1, SpCas9-HF2, SpCas9-HF3, SpCas9-HF4, SaCas9, FnCpf, FnCas9, eSpCas9, and NmeCas9. In some embodiments, the Cas9 protein comprises an amino acid sequence having at least 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% sequence identity to a Cas9 amino acid sequence described in Chylinski et al., RNA Biology 2013 10:5, 727-737; Hou et al., PNAS Early Edition 2013, 1-6).
[0327] In some embodiments, the Cas polypeptide comprises one or more of the following activities:
[0328] (a) a nickase activity, i.e., the ability to cleave a single strand, e.g., the non-complementary strand or the complementary strand, of a nucleic acid molecule;
[0329] (b) a double stranded nuclease activity, i.e., the ability to cleave both strands of a double stranded nucleic acid and create a double stranded break, which in an embodiment is the presence of two nickase activities;
[0330] (c) an endonuclease activity;
[0331] (d) an exonuclease activity; and/or
[0332] (e) a helicase activity, i.e., the ability to unwind the helical structure of a double stranded nucleic acid.
[0333] In some embodiments, the Cas polypeptide is fused to heterologous proteins that recruit DNA-damage signaling proteins, exonucleases, or phosphatases to further increase the likelihood or the rate of repair of the target sequence by one repair mechanism or another. In some embodiments, a WT Cas polypeptide is co-expressed with a nucleic acid repair template to facilitate the incorporation of an exogenous nucleic acid sequence by homology-directed repair.
[0334] In some embodiments, different Cas proteins (i.e., Cas9 proteins from various species) may be advantageous to use in the various provided methods in order to capitalize on various enzymatic characteristics of the different Cas proteins (e.g., for different PAM sequence preferences; for increased or decreased enzymatic activity; for an increased or decreased level of cellular toxicity; to change the balance between NHEJ, homology-directed repair, single strand breaks, double strand breaks, etc.).
[0335] In some embodiments, the Cas protein is a Cas9 protein derived from S. pyogenes and recognizes the PAM sequence motif NGG, NAG, NGA (Mali et al, Science 2013; 339(6121): 823-826). In some embodiments, the Cas protein is a Cas9 protein derived from S. thermophiles and recognizes the PAM sequence motif NGGNG and/or NNAGAAW (W=A or T) (See, e.g., Horvath et al, Science, 2010; 327(5962): 167-170, and Deveau et al, J Bacteriol 2008; 190(4): 1390-1400). In some embodiments, the Cas protein is a Cas9 protein derived from S. mutans and recognizes the PAM sequence motif NGG and/or NAAR (R=A or G) (See, e.g., Deveau et al, J BACTERIOL 2008; 190(4): 1390-1400). In some embodiments, the Cas protein is a Cas9 protein derived from S. aureus and recognizes the PAM sequence motif NNGRR (R=A or G). In some embodiments, the Cas protein is a Cas9 protein derived from S. aureus and recognizes the PAM sequence motif N GRRT (R=A or G). In some embodiments, the Cas protein is a Cas9 protein derived from S. aureus and recognizes the PAM sequence motif N GRRV (R=A or G). In some embodiments, the Cas protein is a Cas9 protein derived from N. meningitidis and recognizes the PAM sequence motif N GATT or N GCTT (R=A or G, V=A, G or C) (See, e.g., Hou et ah, PNAS 2013, 1-6). In the aforementioned embodiments, N can be any nucleotide residue, e.g., any of A, G, C or T. In some embodiments, the Cas protein is a Cas13a protein derived from Leptotrichia shahii and recognizes the PFS sequence motif of a single 3' A, U, or C.
[0336] In some embodiments, a polynucleotide encoding a Cas protein is provided. In some embodiments, the polynucleotide encodes a Cas protein that is at least 90% identical to a Cas protein described in International PCT Publication No. WO 2015/071474 or Chylinski et al., RNA Biology 2013 10:5, 727-737. In some embodiments, the polynucleotide encodes a Cas protein that is at least 95%, 96%, 97%, 98%, or 99% identical to a Cas protein described in International PCT Publication No. WO 2015/071474 or Chylinski et al., RNA Biology 2013 10:5, 727-737. In some embodiments, the polynucleotide encodes a Cas protein that is 100% identical to a Cas protein described in International PCT Publication No. WO 2015/071474 or Chylinski et al., RNA Biology 2013 10:5, 727-737.
2. Cas Mutants
[0337] In some embodiments, the Cas polypeptides are engineered to alter one or more properties of the Cas polypeptide. For example, in some embodiments, the Cas polypeptide comprises altered enzymatic properties, e.g., altered nuclease activity, (as compared with a naturally occurring or other reference Cas molecule) or altered helicase activity. In some embodiments, an engineered Cas polypeptide can have an alteration that alters its size, e.g., a deletion of amino acid sequence that reduces its size without significant effect on another property of the Cas polypeptide. In some embodiments, an engineered Cas polypeptide comprises an alteration that affects PAM recognition. For example, an engineered Cas polypeptide can be altered to recognize a PAM sequence other than the PAM sequence recognized by the corresponding wild-type Cas protein.
[0338] Cas polypeptides with desired properties can be made in a number of ways, including alteration of a naturally occurring Cas polypeptide or parental Cas polypeptide, to provide a mutant or altered Cas polypeptide having a desired property. For example, one or more mutations can be introduced into the sequence of a parental Cas polypeptide (e.g., a naturally occurring or engineered Cas polypeptide). Such mutations and differences may comprise substitutions (e.g., conservative substitutions or substitutions of non-essential amino acids); insertions; or deletions. In some embodiments, a mutant Cas polypeptide comprises one or more mutations (e.g., at least 1, 2, 3, 4, 5, 10, 15, 20, 30, 40 or 50 mutations) relative to a parental Cas polypeptide.
[0339] In an embodiment, a mutant Cas polypeptide comprises a cleavage property that differs from a naturally occurring Cas polypeptide. In some embodiments, the Cas is a deactivated Cas (dCas) mutant. In such embodiments, the Cas polypeptide does not comprise any intrinsic enzymatic activity and is unable to mediate target nucleic acid cleavage. In such embodiments, the dCas may be fused with a heterologous protein that is capable of modifying the target nucleic acid in a non-cleavage based manner. For example, in some embodiments, a dCas protein is fused to transcription activator or transcription repressor domains (e.g., the Kruppel associated box (KRAB or SKD); the Mad mSIN3 interaction domain (SID or SID4X); the ERF repressor domain (ERD); the MAX-interacting protein 1 (MXI1); methyl-CpG binding protein 2 (MECP2); etc.). In some such cases, the dCas fusion protein is targeted by the ggRNA to a specific location (i.e., sequence) in the target nucleic acid and exerts locus-specific regulation such as blocking RNA polymerase binding to a promoter (which selectively inhibits transcription activator function), and/or modifying the local chromatin status (e.g., when a fusion sequence is used that modifies the target DNA or modifies a polypeptide associated with the target DNA). In some cases, the changes are transient (e.g., transcription repression or activation). In some cases, the changes are inheritable (e.g., when epigenetic modifications are made to the target DNA or to proteins associated with the target DNA, e.g., nucleosomal histones).
[0340] In some embodiments, the dCas is a dCas13 mutant (Konermann et al., Cell 173 (2018), 665-676). These dCas13 mutants can then be fused to enzymes that modify RNA, including adenosine deaminases (e.g., ADAR1 and ADAR2). Adenosine deaminases convert adenine to inosine, which the translational machinery treats like guanine, thereby creating a functional A.fwdarw.G change in the RNA sequence. In some embodiments, the dCas is a dCas9 mutant.
[0341] In some embodiments, the mutant Cas9 is a Cas9 nickase mutant. Cas9 nickase mutants comprise only one catalytically active domain (either the HNH domain or the RuvC domain). The Cas9 nickase mutants retain DNA binding based on gRNA specificity, but are capable of cutting only one strand of DNA resulting in a single-strand break (e.g. a "nick"). In some embodiments, two complementary Cas9 nickase mutants (e.g., one Cas9 nickase mutant with an inactivated RuvC domain, and one Cas9 nickase mutant with an inactivated HNH domain) are expressed in the same cell with two gRNAs corresponding to two respective target sequences; one target sequence on the sense DNA strand, and one on the antisense DNA strand. This dual-nickase system results in staggered double stranded breaks and can increase target specificity, as it is unlikely that two off-target nicks will be generated close enough to generate a double stranded break. In some embodiments, a Cas9 nickase mutant is co-expressed with a nucleic acid repair template to facilitate the incorporation of an exogenous nucleic acid sequence by homology-directed repair.
[0342] In some embodiments, the Cas polypeptides described herein can be engineered to alter the PAM/PFS specificity of the Cas polypeptide. In some embodiments, a mutant Cas polypeptide has a PAM/PFS specificity that is different from the PAM/PFS specificity of the parental Cas polypeptide. For example, a naturally occurring Cas protein can be modified to alter the PAM/PFS sequence that the mutant Cas polypeptide recognizes to decrease off target sites, improve specificity, or eliminate a PAM/PFS recognition requirement. In some embodiments, a Cas protein can be modified to increase the length of the PAM/PFS recognition sequence. In some embodiments, the length of the PAM recognition sequence is at least 4, 5, 6, 7, 8, 9, 10 or 15 amino acids in length. Cas polypeptides that recognize different PAM/PFS sequences and/or have reduced off-target activity can be generated using directed evolution. Exemplary methods and systems that can be used for directed evolution of Cas polypeptides are described, e.g., in Esvelt et al. Nature 2011, 472(7344): 499-503.
[0343] Exemplary Cas mutants are described in International PCT Publication No. WO 2015/161276 and Konermann et al., Cell 173 (2018), 665-676 which are incorporated herein by reference in their entireties.
3. gRNAs
[0344] The present disclosure provides guide RNAs (gRNAs) that direct a site-directed modifying polypeptide to a specific target nucleic acid sequence. A gRNA comprises a "nucleic acid-targeting domain" or "targeting domain" and protein-binding segment. The targeting domain may also be referred to as a "spacer" sequence and comprises a nucleotide sequence that is complementary to a target nucleic acid sequence. As such, the targeting domain segment of a gRNA interacts with a target nucleic acid in a sequence-specific manner via hybridization (i.e., base pairing) and determines the location within the target nucleic acid that the gRNA will bind. The targeting domain segment of a gRNA can be modified (e.g., by genetic engineering) to hybridize to a desired sequence within a target nucleic acid sequence. In some embodiments, the targeting domain sequence is between about 13 and about 22 nucleotides in length. In some embodiments, the targeting domain sequence is about 13, 14, 15, 16, 17, 18, 19, 20, 21, or 22 nucleotides in length. In some embodiments, the targeting domain sequence is about 20 nucleotides in length.
[0345] The protein-binding segment of a gRNA interacts with a site-directed modifying polypeptide (e.g. a Cas protein) to form a ribonucleoprotein (RNP) complex comprising the gRNA and the site-directed modifying polypeptide. The targeting domain segment of the gRNA then guides the bound site-directed modifying polypeptide to a specific nucleotide sequence within target nucleic acid via the above-described spacer sequence. The protein-binding segment of a gRNA comprises at least two stretches of nucleotides that are complementary to one another and which form a double stranded RNA duplex. The protein-binding segment of a gRNA may also be referred to as a "scaffold" segment or a "tracr RNA". In some embodiments, the tracr RNA sequence is between about 30 and about 180 nucleotides in length. In some embodiments, the tracr RNA sequence is between about 40 and about 90 nucleotides, about 50 and about 90 nucleotides, about 60 and about 90 nucleotides, about 65 and about 85 nucleotides, about 70 and about 80 nucleotides, about 65 and about 75 nucleotides, or about 75 and about 85 nucleotides in length. In some embodiments, the tracr RNA sequence is about 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, or about 90 nucleotides in length. In some embodiments, the tracr RNA comprises a nucleic acid sequence encoded by the DNA sequence of SEQ ID NO: 34 (See Mali et al., Science (2013) 339(6121):823-826), SEQ ID NOs: 35-36 (See PCT Publication No. WO 2016/106236), SEQ ID NOs: 37-39 (See Deltcheva et al., Nature. 2011 Mar. 31; 471(7340): 602-607), or SEQ ID NO: 40 (See Chen et al., Cell. 2013; 155(7); 1479-1491). Any of the foregoing tracr sequences are suitable for use in combination with any of the gRNA targeting domain embodiments described herein.
[0346] In some embodiments, a gRNA comprises two separate RNA molecules (i.e., a "dual gRNA"). In some embodiments, a gRNA comprises a single RNA molecule (i. e. a "single guide RNA" or "sgRNA"). Herein, use of the term "guide RNA" or "gRNA" is inclusive of both dual gRNAs and sgRNAs. A dual gRNA comprises two separate RNA molecules: a "crispr RNA" (or "crRNA") and a "tracr RNA". A crRNA molecule comprises a spacer sequence covalently linked to a "tracr mate" sequence. The tracer mate sequence comprises a stretch of nucleotides that are complementary to a corresponding sequence in the tracr RNA molecule. The crRNA molecule and tracr RNA molecule hybridize to one another via the complementarity of the tracr and tracer mate sequences.
[0347] In some embodiments, the gRNA is an sgRNA. In such embodiments, the nucleic acid-targeting sequence and the protein-binding sequence are present in a single RNA molecule by fusion of the spacer sequence to the tracr RNA sequence. In some embodiments, the sgRNA is about 50 to about 200 nucleotides in length. In some embodiments, the sgRNA is about 75 to about 150 or about 100 to about 125 nucleotides in length. In some embodiments, the sgRNA is about 100 nucleotides in length.
[0348] In some embodiments, the gRNAs of the present disclosure comprise a targeting domain sequence that is least 90%, 95%, 96%, 97%, 98%, or 99% complementary, or is 100% complementary to a target nucleic acid sequence within a target locus. In some embodiments, the target nucleic acid sequence is an RNA target sequence. In some embodiments, the target nucleic acid sequence is a DNA target sequence.
[0349] In some embodiments, the gRNAs provided herein comprise a targeting domain sequence that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR (e.g., a gene selected from Table 2). In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B. In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813. In some embodiments, the gRNAs provided herein comprise a targeting domain sequence that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the CBLB gene. In some embodiments, the nucleic acid-binding segments of the gRNA sequences bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524. Additional gRNAs suitable for targeting CBLB are described in US Patent Application Publication No. 2017/0175128.
[0350] In some embodiments, the gRNAs provided herein comprise a targeting domain sequence that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the TNFAIP3 gene. In some embodiments, the nucleic acid-binding segments of the gRNA sequences bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 348-396 or SEQ ID NOs: 348-3486. In some embodiments, the gRNAs provided herein comprise a targeting domain sequence that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the BCOR gene. In some embodiments, the nucleic acid-binding segments of the gRNA sequences bind to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 708-772 or SEQ ID NOs: 708-764.
[0351] In some embodiments, the gRNAs provided herein comprise a targeting domain sequence that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 (e.g., a gene selected from Table 3). In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Tables 6A-Table 6H. In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1566.
[0352] In some embodiments, the gRNAs provided herein comprise a targeting domain sequence that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS. In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6A or Table 6B. In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1064. In some embodiments, the gRNAs provided herein comprise a targeting domain sequence that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a sequence of ZC3H12A. In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6C or Table 6D. In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1509. In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1264.
[0353] In some embodiments, the gRNAs provided herein comprise a targeting domain sequence that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a sequence of the MAP4K1 gene. In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6E or Table 6F. In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 510-1538. In some embodiments, the gRNAs provided herein comprise a targeting domain sequence that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a sequence of the NR4A3 gene. In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 6G or Table 6H. In some embodiments, the targeting domain sequence binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1539-1566.
[0354] In some embodiments, the gene-regulating system comprises two or more gRNA molecules, wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR (e.g., a gene selected from Table 2) and wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and NR4A3 (e.g., a gene selected from Table 3).
[0355] In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in one of Tables 6A-6H. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1566. In some embodiments, at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 and at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1566.
[0356] In some embodiments, the gene-regulating system comprises two or more gRNA molecules, wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from BCL2L11, FLI1, CALM12, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in one of Table 6A or Table 6B. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1064. In some embodiments, at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 and at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1064.
[0357] In some embodiments, the gene-regulating system comprises two or more gRNA molecules, wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the CBLB and wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, and GNAS. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524 and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1064. In some embodiments, at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524 and at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 814-1064.
[0358] In some embodiments, the gene-regulating system comprises two or more gRNA molecules, wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of ZC3H12A. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in one of Table 6C or Table 6D. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1509. In some embodiments, at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 and at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1509.
[0359] In some embodiments, the gene-regulating system comprises two or more gRNA molecules, wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the CBLB gene and wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the ZC3H12A gene. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524 and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1509. In some embodiments, at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524 and at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1509. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524 and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1264. In some embodiments, at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524 and at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1065-1264.
[0360] In some embodiments, the gene-regulating system comprises two or more gRNA molecules, wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the MAP4K1 gene. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in one of Table 6E or Table 6F. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1510-1538. In some embodiments, at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 and at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1510-1538.
[0361] In some embodiments, the gene-regulating system comprises two or more gRNA molecules, wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the CBLB gene and wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the M4AP4K1 gene. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524 and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1510-1538. In some embodiments, at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524 and at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1510-1538.
[0362] In some embodiments, the gene-regulating system comprises two or more gRNA molecules, wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of a target gene selected from IKZF1, IKZF3, GATA3, BCL3, TNIP1, TNFAIP3, NFKBIA, SMAD2, TGFBR1, TGFBR2, TANK, FOXP3, RC3H1, TRAF6, IKZF2, CBLB, PPP2R2D, NRP1, HAVCR2, LAG3, TIGIT, CTLA4, PTPN6, PDCD1, or BCOR and wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the NR4A3 gene. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in Table 5A or Table 5B and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence defined by a set of genomic coordinates shown in one of Table 6G or Table 6H. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1539-1566. In some embodiments, at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 154-498 or SEQ ID NOs: 499-813 and at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1539-1566.
[0363] In some embodiments, the gene-regulating system comprises two or more gRNA molecules, wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the CBLB gene and wherein at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to a target DNA sequence of the NR4A3 gene. In some embodiments, at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524 and at least one of the gRNAs comprises a targeting domain that binds to a target DNA sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1539-1566. In some embodiments, at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 499-524 and at least one of the gRNAs comprises a targeting domain encoded by a nucleic acid sequence that is at least 90%, 95%, 96%, 97%, 98%, or 99% identical, or is 100% identical to one of SEQ ID NOs: 1539-1566.
[0364] In some embodiments, the nucleic acid-binding segments of the gRNA sequences described herein are designed to minimize off-target binding using algorithms known in the art (e.g., Cas-OFF finder) to identify target sequences that are unique to a particular target locus or target gene.
[0365] In some embodiments, the gRNAs described herein can comprise one or more modified nucleosides or nucleotides which introduce stability toward nucleases. In such embodiments, these modified gRNAs may elicit a reduced innate immune as compared to a non-modified gRNA. The term "innate immune response" includes a cellular response to exogenous nucleic acids, including single stranded nucleic acids, generally of viral or bacterial origin, which involves the induction of cytokine expression and release, particularly the interferons, and cell death.
[0366] In some embodiments, the gRNAs described herein are modified at or near the 5' end (e.g., within 1-10, 1-5, or 1-2 nucleotides of their 5' end). In some embodiments, the 5' end of a gRNA is modified by the inclusion of a eukaryotic mRNA cap structure or cap analog (e.g., a G(5')ppp(5')G cap analog, a m7G(5')ppp(5')G cap analog, or a 3'-0-Me-m7G(5')ppp(5')G anti reverse cap analog (ARCA)). In some embodiments, an in vitro transcribed gRNA is modified by treatment with a phosphatase (e.g., calf intestinal alkaline phosphatase) to remove the 5' triphosphate group. In some embodiments, a gRNA comprises a modification at or near its 3' end (e.g., within 1-10, 1-5, or 1-2 nucleotides of its 3' end). For example, in some embodiments, the 3' end of a gRNA is modified by the addition of one or more (e.g., 25-200) adenine (A) residues.
[0367] In some embodiments, modified nucleosides and modified nucleotides can be present in a gRNA, but also may be present in other gene-regulating systems, e.g., mRNA, RNAi, or siRNA-based systems. In some embodiments, modified nucleosides and nucleotides can include one or more of:
[0368] (a) alteration, e.g., replacement, of one or both of the non-linking phosphate oxygens and/or of one or more of the linking phosphate oxygens in the phosphodiester backbone linkage;
[0369] (b) alteration, e.g., replacement, of a constituent of the ribose sugar, e.g., of the 2' hydroxyl on the ribose sugar;
[0370] (c) wholesale replacement of the phosphate moiety with "dephospho" linkers;
[0371] (d) modification or replacement of a naturally occurring nucleobase;
[0372] (e) replacement or modification of the ribose-phosphate backbone;
[0373] (f) modification of the 3' end or 5' end of the oligonucleotide, e.g., removal, modification or replacement of a terminal phosphate group or conjugation of a moiety; and
[0374] (g) modification of the sugar.
[0375] In some embodiments, the modifications listed above can be combined to provide modified nucleosides and nucleotides that can have two, three, four, or more modifications. For example, in some embodiments, a modified nucleoside or nucleotide can have a modified sugar and a modified nucleobase. In some embodiments, every base of a gRNA is modified. In some embodiments, each of the phosphate groups of a gRNA molecule are replaced with phosphorothioate groups.
[0376] In some embodiments, a software tool can be used to optimize the choice of gRNA within a user's target sequence, e.g., to minimize total off-target activity across the genome. Off target activity may be other than cleavage. For example, for each possible gRNA choice using S. pyogenes Cas9, software tools can identify all potential off-target sequences (preceding either NAG or NGG PAMs) across the genome that contain up to a certain number (e.g., 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10) of mismatched base-pairs. The cleavage efficiency at each off-target sequence can be predicted, e.g., using an experimentally-derived weighting scheme. Each possible gRNA can then be ranked according to its total predicted off-target cleavage; the top-ranked gRNAs represent those that are likely to have the greatest on-target and the least off-target cleavage. Other functions, e.g., automated reagent design for gRNA vector construction, primer design for the on-target Surveyor assay, and primer design for high-throughput detection and quantification of off-target cleavage via next-generation sequencing, can also be included in the tool.
IV. Polynucleotides
[0377] In some embodiments, the present disclosure provides polynucleotides or nucleic acid molecules encoding a gene-regulating system described herein. As used herein, the terms "nucleotide" or "nucleic acid" refer to deoxyribonucleic acid (DNA), ribonucleic acid (RNA) and DNA/RNA hybrids. Polynucleotides may be single-stranded or double-stranded and either recombinant, synthetic, or isolated. Polynucleotides include, but are not limited to: pre-messenger RNA (pre-mRNA), messenger RNA (mRNA), RNA, genomic DNA (gDNA), PCR amplified DNA, complementary DNA (cDNA), synthetic DNA, or recombinant DNA. Polynucleotides refer to a polymeric form of nucleotides of at least 5, at least 10, at least 15, at least 20, at least 25, at least 30, at least 40, at least 50, at least 100, at least 200, at least 300, at least 400, at least 500, at least 1000, at least 5000, at least 10000, or at least 15000 or more nucleotides in length, either ribonucleotides or deoxyribonucleotides or a modified form of either type of nucleotide, as well as all intermediate lengths. It will be readily understood that "intermediate lengths," in this context, means any length between the quoted values, such as 6, 7, 8, 9, etc., 101, 102, 103, etc.; 151, 152, 153, etc.; 201, 202, 203, etc.
[0378] In particular embodiments, polynucleotides may be codon-optimized. As used herein, the term "codon-optimized" refers to substituting codons in a polynucleotide encoding a polypeptide in order to increase the expression, stability and/or activity of the polypeptide. Factors that influence codon optimization include, but are not limited to one or more of: (i) variation of codon biases between two or more organisms or genes or synthetically constructed bias tables, (ii) variation in the degree of codon bias within an organism, gene, or set of genes, (iii) systematic variation of codons including context, (iv) variation of codons according to their decoding tRNAs, (v) variation of codons according to GC %, either overall or in one position of the triplet, (vi) variation in degree of similarity to a reference sequence for example a naturally occurring sequence, (vii) variation in the codon frequency cutoff, (viii) structural properties of mRNAs transcribed from the DNA sequence, (ix) prior knowledge about the function of the DNA sequences upon which design of the codon substitution set is to be based, (x) systematic variation of codon sets for each amino acid, (xi) isolated removal of spurious translation initiation sites and/or (xii) elimination of fortuitous polyadenylation sites otherwise leading to truncated RNA transcripts.
[0379] The recitations "sequence identity" or, for example, comprising a "sequence 50% identical to," as used herein, refer to the extent that sequences are identical on a nucleotide-by-nucleotide basis or an amino acid-by-amino acid basis over a window of comparison. A "comparison window" refers to a conceptual segment of at least 6 contiguous positions, usually about 50 to about 100, more usually about 100 to about 150 in which a sequence is compared to a reference sequence of the same number of contiguous positions after the two sequences are optimally aligned. Thus, a "percentage of sequence identity" may be calculated by comparing two optimally aligned sequences over the window of comparison, determining the number of positions at which the identical nucleic acid base (e.g., A, T, C, G, I) or the identical amino acid residue (e.g., Ala, Pro, Ser, Thr, Gly, Val, Leu, Ile, Phe, Tyr, Trp, Lys, Arg, His, Asp, Glu, Asn, Gln, Cys and Met) occurs in both sequences to yield the number of matched positions, dividing the number of matched positions by the total number of positions in the window of comparison (i.e., the window size), and multiplying the result by 100 to yield the percentage of sequence identity.
[0380] As used herein, the terms "polynucleotide variant" and "variant" and the like refer to polynucleotides displaying substantial sequence identity with a reference polynucleotide sequence or polynucleotides that hybridize with a reference sequence under stringent conditions that are defined hereinafter. These terms include polynucleotides in which one or more nucleotides have been added or deleted, or replaced with different nucleotides compared to a reference polynucleotide. In this regard, it is well understood in the art that certain alterations inclusive of mutations, additions, deletions and substitutions can be made to a reference polynucleotide whereby the altered polynucleotide retains the biological function or activity of the reference polynucleotide.
[0381] In particular embodiments, polynucleotides or variants have at least or about 50%, 55%, 60%, 65%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% or 100% sequence identity to a reference sequence.
[0382] Moreover, it will be appreciated by those of ordinary skill in the art that, as a result of the degeneracy of the genetic code, there are many nucleotide sequences that encode a polypeptide, or fragment of variant thereof, as described herein. Some of these polynucleotides bear minimal homology to the nucleotide sequence of any native gene. Nonetheless, polynucleotides that vary due to differences in codon usage are specifically contemplated in particular embodiments, for example polynucleotides that are optimized for human and/or primate codon selection. Further, alleles of the genes comprising the polynucleotide sequences provided herein may also be used. Alleles are endogenous genes that are altered as a result of one or more mutations, such as deletions, additions and/or substitutions of nucleotides.
[0383] The polynucleotides contemplated herein, regardless of the length of the coding sequence itself, may be combined with other DNA sequences, such as promoters and/or enhancers, untranslated regions (UTRs), signal sequences, Kozak sequences, polyadenylation signals, additional restriction enzyme sites, multiple cloning sites, internal ribosomal entry sites (IRES), recombinase recognition sites (e.g., LoxP, FRT, and Att sites), termination codons, transcriptional termination signals, and polynucleotides encoding self-cleaving polypeptides, epitope tags, as disclosed elsewhere herein or as known in the art, such that their overall length may vary considerably. It is therefore contemplated that a polynucleotide fragment of almost any length may be employed in particular embodiments, with the total length preferably being limited by the ease of preparation and use in the intended recombinant DNA protocol.
[0384] Polynucleotides can be prepared, manipulated and/or expressed using any of a variety of well-established techniques known and available in the art.
Vectors
[0385] In order to express a gene-regulating system described herein in a cell, an expression cassette encoding the gene-regulating system can be inserted into appropriate vector. The term "nucleic acid vector" is used herein to refer to a nucleic acid molecule capable transferring or transporting another nucleic acid molecule. The transferred nucleic acid is generally linked to, e.g., inserted into, the vector nucleic acid molecule. A nucleic acid vector may include sequences that direct autonomous replication in a cell, or may include sequences sufficient to allow integration into host cell DNA.
[0386] The term "expression cassette" as used herein refers to genetic sequences within a vector which can express an RNA, and subsequently a protein. The nucleic acid cassette contains the gene of interest, e.g., a gene-regulating system. The nucleic acid cassette is positionally and sequentially oriented within the vector such that the nucleic acid in the cassette can be transcribed into RNA, and when necessary, translated into a protein or a polypeptide, undergo appropriate post-translational modifications required for activity in the transformed cell, and be translocated to the appropriate compartment for biological activity by targeting to appropriate intracellular compartments or secretion into extracellular compartments. Preferably, the cassette has its 3' and 5' ends adapted for ready insertion into a vector, e.g., it has restriction endonuclease sites at each end. The cassette can be removed and inserted into a plasmid or viral vector as a single unit.
[0387] In particular embodiments, vectors include, without limitation, plasmids, phagemids, cosmids, transposons, artificial chromosomes such as yeast artificial chromosome (YAC), bacterial artificial chromosome (BAC), or P1-derived artificial chromosome (PAC), bacteriophages such as lambda phage or M13 phage, and animal viruses. In particular embodiments, the coding sequences of the gene-regulating systems disclosed herein can be ligated into such vectors for the expression of the gene-regulating systems in mammalian cells.
[0388] In some embodiments, non-viral vectors are used to deliver one or more polynucleotides contemplated herein to an immune effector cell, e.g., a T cell. In some embodiments, the recombinant vector comprising a polynucleotide encoding one or more components of a gene-regulating system described herein is a plasmid. Numerous suitable plasmid expression vectors are known to those of skill in the art, and many are commercially available. The following vectors are provided by way of example; for eukaryotic host cells: pXT1, pSG5 (Stratagene), pSVK3, pBPV, pMSG, and pSVLSV40 (Pharmacia). However, any other plasmid vector may be used so long as it is compatible with the host cell. Depending on the cell type and gene-regulating system utilized, any of a number of suitable transcription and translation control elements, including constitutive and inducible promoters, transcription enhancer elements, transcription terminators, etc. may be used in the expression vector (see e.g., Bitter et al. (1987) Methods in Enzymology, 153:516-544).
[0389] In some embodiments, the recombinant vector comprising a polynucleotide encoding one or more components of a gene-regulating system described herein is a viral vector. Suitable viral vectors include, but are not limited to, viral vectors based on vaccinia virus; poliovirus; adenovirus (see, e.g., Li et al., Invest Opthalmol Vis Sci 35:2543 2549, 1994; Borras et al., Gene Ther 6:515 524, 1999; Li and Davidson, PNAS 92:7700 7704, 1995; Sakamoto et al., H Gene Ther 5:1088 1097, 1999; WO 94/12649, WO 93/03769; WO 93/19191; WO 94/28938; WO 95/11984 and WO 95/00655); adeno-associated virus (see, e.g., U.S. Pat. No. 7,078,387; Ali et al., Hum Gene Ther 9:81 86, 1998, Flannery et al., PNAS 94:6916 6921, 1997; Bennett et al., Invest Opthalmol Vis Sci 38:2857 2863, 1997; Jomary et al., Gene Ther 4:683 690, 1997, Rolling et al., Hum Gene Ther 10:641 648, 1999; Ali et al., Hum Mol Genet 5:591 594, 1996; Srivastava in WO 93/09239, Samulski et al., J. Vir. (1989) 63:3822-3828; Mendelson et al., Virol. (1988) 166:154-165; and Flotte et al., PNAS (1993) 90:10613-10617); SV40; herpes simplex virus; human immunodeficiency virus (see, e.g., Miyoshi et al., PNAS 94:10319 23, 1997; Takahashi et al., J Virol 73:7812 7816, 1999); a retroviral vector (e.g., Murine Leukemia Virus, spleen necrosis virus, and vectors derived from retroviruses such as Rous Sarcoma Virus, Harvey Sarcoma Virus, avian leukosis virus, a lentivirus, human immunodeficiency virus, myeloproliferative sarcoma virus, and mammary tumor virus); and the like. Examples of vectors are pClneo vectors (Promega) for expression in mammalian cells; pLenti4/V5-DEST.TM., pLenti6/V5-DEST.TM., and pLenti6.2/V5-GW/lacZ (Invitrogen) for lentivirus-mediated gene transfer and expression in mammalian cells.
[0390] In some embodiments, the vector is a non-integrating vector, including but not limited to, an episomal vector or a vector that is maintained extrachromosomally. As used herein, the term "episomal" refers to a vector that is able to replicate without integration into host's chromosomal DNA and without gradual loss from a dividing host cell also meaning that said vector replicates extrachromosomally or episomally. The vector is engineered to harbor the sequence coding for the origin of DNA replication or "ori" from a lymphotrophic herpes virus or a gamma herpesvirus, an adenovirus, SV40, a bovine papilloma virus, or a yeast, specifically a replication origin of a lymphotrophic herpes virus or a gamma herpesvirus corresponding to oriP of EBV. In a particular aspect, the lymphotrophic herpes virus may be Epstein Barr virus (EBV), Kaposi's sarcoma herpes virus (KSHV), Herpes virus saimiri (HS), or Marek's disease virus (MDV). Epstein Barr virus (EBV) and Kaposi's sarcoma herpes virus (KSHV) are also examples of a gamma herpesvirus.
[0391] In some embodiments, a polynucleotide is introduced into a target or host cell using a transposon vector system. In certain embodiments, the transposon vector system comprises a vector comprising transposable elements and a polynucleotide contemplated herein; and a transposase. In one embodiment, the transposon vector system is a single transposase vector system, see, e.g., WO 2008/027384. Exemplary transposases include, but are not limited to: piggyBac, Sleeping Beauty, Mos1, Tc1/mariner, Tol2, mini-Tol2, Tc3, MuA, Himar I, Frog Prince, and derivatives thereof. The piggyBac transposon and transposase are described, for example, in U.S. Pat. No. 6,962,810, which is incorporated herein by reference in its entirety. The Sleeping Beauty transposon and transposase are described, for example, in Izsvak et al., J. Mol. Biol. 302: 93-102 (2000), which is incorporated herein by reference in its entirety. The Tol2 transposon which was first isolated from the medaka fish Oryzias latipes and belongs to the hAT family of transposons is described in Kawakami et al. (2000). Mini-Tol2 is a variant of Tol2 and is described in Balciunas et al. (2006). The Tol2 and Mini-Tol2 transposons facilitate integration of a transgene into the genome of an organism when co-acting with the Tol2 transposase. The Frog Prince transposon and transposase are described, for example, in Miskey et al., Nucleic Acids Res. 31:6873-6881 (2003).
[0392] In some embodiments, a polynucleotide sequence encoding one or more components of a gene-regulating system described herein is operably linked to a control element, e.g., a transcriptional control element, such as a promoter. "Control elements" refer those non-translated regions of the vector (e.g., origin of replication, selection cassettes, promoters, enhancers, translation initiation signals (Shine Dalgamo sequence or Kozak sequence) introns, a polyadenylation sequence, 5' and 3' untranslated regions) which interact with host cellular proteins to carry out transcription and translation. Such elements may vary in their strength and specificity. The transcriptional control element may be functional in either a eukaryotic cell (e.g., a mammalian cell) or a prokaryotic cell (e.g., bacterial or archaeal cell). In some embodiments, a polynucleotide sequence encoding one or more components of a gene-regulating system described herein is operably linked to multiple control elements that allow expression of the polynucleotide in both prokaryotic and eukaryotic cells.
[0393] Depending on the cell type and gene-regulating system utilized, any of a number of suitable transcription and translation control elements, including constitutive and inducible promoters, transcription enhancer elements, transcription terminators, etc. may be used in the expression vector (see e.g., Bitter et al. (1987) Methods in Enzymology, 153:516-544). The term "promoter" as used herein refers to a recognition site of a polynucleotide (DNA or RNA) to which an RNA polymerase binds. An RNA polymerase initiates and transcribes polynucleotides operably linked to the promoter. In particular embodiments, promoters operative in mammalian cells comprise an AT-rich region located approximately 25 to 30 bases upstream from the site where transcription is initiated and/or another sequence found 70 to 80 bases upstream from the start of transcription, a CNCAAT region where N may be any nucleotide. The term "enhancer" refers to a segment of DNA which contains sequences capable of providing enhanced transcription and in some instances can function independent of their orientation relative to another control sequence. An enhancer can function cooperatively or additively with promoters and/or other enhancer elements.
[0394] In some embodiments, polynucleotides encoding one or more components of a gene-regulating system described herein are operably linked to a promoter. The term "operably linked", refers to a juxtaposition wherein the components described are in a relationship permitting them to function in their intended manner. In one embodiment, the term refers to a functional linkage between a nucleic acid expression control sequence (such as a promoter, and/or enhancer) and a second polynucleotide sequence, e.g., a polynucleotide encoding one or more components of a gene-regulating system, wherein the expression control sequence directs transcription of the nucleic acid corresponding to the second sequence.
[0395] Non-limiting examples of suitable eukaryotic promoters (promoters functional in a eukaryotic cell) include those from cytomegalovirus (CMV) immediate early, herpes simplex virus (HSV) thymidine kinase, a viral simian virus 40 (SV40) (e.g., early and late SV40), a spleen focus forming virus (SFFV) promoter, long terminal repeats (LTRs) from retrovirus (e.g., a Moloney murine leukemia virus (MoMLV) LTR promoter or a a Rous sarcoma virus (RSV) LTR), a herpes simplex virus (HSV) (thymidine kinase) promoter, H5, P7.5, and P11 promoters from vaccinia virus, an elongation factor 1-alpha (EF1.alpha.) promoter, early growth response 1 (EGR1) promoter, a ferritin H (FerH) promoter, a ferritin L (FerL) promoter, a Glyceraldehyde 3-phosphate dehydrogenase (GAPDH) promoter, a eukaryotic translation initiation factor 4A1 (EIF4A1) promoter, a heat shock 70 kDa protein 5 (HSPA5) promoter, a heat shock protein 90 kDa beta, member 1 (HSP90B1) promoter, a heat shock protein 70 kDa (HSP70) promoter, a .beta.-kinesin (.beta.-KIN) promoter, the human ROSA 26 locus (Irions et al., Nature Biotechnology 25, 1477-1482 (2007)), a Ubiquitin C (UBC) promoter, a phosphoglycerate kinase-1 (PGK) promoter, a cytomegalovirus enhancer/chicken .beta.-actin (CAG) promoter, a .beta.-actin promoter and a myeloproliferative sarcoma virus enhancer, negative control region deleted, dl587rev primer-binding site substituted (MND) promoter, and mouse metallothionein-1. Selection of the appropriate vector and promoter is well within the level of ordinary skill in the art. The expression vector may also contain a ribosome binding site for translation initiation and a transcription terminator. The expression vector may also include appropriate sequences for amplifying expression. The expression vector may also include nucleotide sequences encoding protein tags (e.g., 6.times.His tag, hemagglutinin tag, green fluorescent protein, etc.) that are fused to the site-directed modifying polypeptide, thus resulting in a chimeric polypeptide.
[0396] In some embodiments, a polynucleotide sequence encoding one or more components of a gene-regulating system described herein is operably linked to a constitutive promoter. In such embodiments, the polynucleotides encoding one or more components of a gene-regulating system described herein are constitutively and/or ubiquitously expressed in a cell.
[0397] In some embodiments, a polynucleotide sequence encoding one or more components of a gene-regulating system described herein is operably linked to an inducible promoter. In such embodiments, polynucleotides encoding one or more components of a gene-regulating system described herein are conditionally expressed. As used herein, "conditional expression" may refer to any type of conditional expression including, but not limited to, inducible expression; repressible expression; expression in cells or tissues having a particular physiological, biological, or disease state (e.g., cell type or tissue specific expression) etc. Illustrative examples of inducible promoters/systems include, but are not limited to, steroid-inducible promoters such as promoters for genes encoding glucocorticoid or estrogen receptors (inducible by treatment with the corresponding hormone), metallothionine promoter (inducible by treatment with various heavy metals), MX-1 promoter (inducible by interferon), the "GeneSwitch" mifepristone-regulatable system (Sirin et al., 2003, Gene, 323:67), the cumate inducible gene switch (WO 2002/088346), tetracycline-dependent regulatory systems, etc.
[0398] In some embodiments, the vectors described herein further comprise a transcription termination signal. Elements directing the efficient termination and polyadenylation of the heterologous nucleic acid transcripts increases heterologous gene expression. Transcription termination signals are generally found downstream of the polyadenylation signal. In particular embodiments, vectors comprise a polyadenylation sequence 3' of a polynucleotide encoding a polypeptide to be expressed. The term "polyA site" or "polyA sequence" as used herein denotes a DNA sequence which directs both the termination and polyadenylation of the nascent RNA transcript by RNA polymerase II. Polyadenylation sequences can promote mRNA stability by addition of a polyA tail to the 3' end of the coding sequence and thus, contribute to increased translational efficiency. Cleavage and polyadenylation is directed by a poly(A) sequence in the RNA. The core poly(A) sequence for mammalian pre-mRNAs has two recognition elements flanking a cleavage-polyadenylation site. Typically, an almost invariant AAUAAA hexamer lies 20-50 nucleotides upstream of a more variable element rich in U or GU residues. Cleavage of the nascent transcript occurs between these two elements and is coupled to the addition of up to 250 adenosines to the 5' cleavage product. In particular embodiments, the core poly(A) sequence is an ideal polyA sequence (e.g., AATAAA, ATTAAA, AGTAAA). In particular embodiments, the poly(A) sequence is an SV40 polyA sequence, a bovine growth hormone polyA sequence (BGHpA), a rabbit .beta.-globin polyA sequence (r.beta.gpA), variants thereof, or another suitable heterologous or endogenous polyA sequence known in the art.
[0399] In some embodiments, a vector may also comprise a sequence encoding a signal peptide (e.g., for nuclear localization, nucleolar localization, mitochondrial localization), fused to the polynucleotide encoding the one or more components of the system. For example, a vector may comprise a nuclear localization sequence (e.g., from SV40) fused to the polynucleotide encoding the one or more components of the system.
[0400] Methods of introducing polynucleotides and recombinant vectors into a host cell are known in the art, and any known method can be used to introduce components of a gene-regulating system into a cell. Suitable methods include e.g., viral or bacteriophage infection, transfection, conjugation, protoplast fusion, lipofection, electroporation, calcium phosphate precipitation, polyethyleneimine (PEI)-mediated transfection, DEAE-dextran mediated transfection, liposome-mediated transfection, particle gun technology, calcium phosphate precipitation, direct micro injection, nanoparticle-mediated nucleic acid delivery (see, e.g., Panyam et al., Adv Drug Deliv Rev. 2012 Sep. 13. pii: S0169-409X(12)00283-9), microfluidics delivery methods (See e.g., International PCT Publication No. WO 2013/059343), and the like. In some embodiments, delivery via electroporation comprises mixing the cells with the components of a gene-regulating system in a cartridge, chamber, or cuvette and applying one or more electrical impulses of defined duration and amplitude. In some embodiments, cells are mixed with components of a gene-regulating system in a vessel connected to a device (e.g., a pump) which feeds the mixture into a cartridge, chamber, or cuvette wherein one or more electrical impulses of defined duration and amplitude are applied, after which the cells are delivered to a second vessel. Illustrative examples of polynucleotide delivery systems suitable for use in particular embodiments contemplated in particular embodiments include, but are not limited to, those provided by Amaxa Biosystems, Maxcyte, Inc., BTX Molecular Delivery Systems, Neon.TM. Transfection Systems, and Copernicus Therapeutics Inc. Lipofection reagents are sold commercially (e.g., Transfectam.TM. and Lipofectin.TM.). Cationic and neutral lipids that are suitable for efficient lipofection of polynucleotides have been described in the literature. See e.g., Liu et al. (2003) Gene Therapy. 10:180-187; and Balazs et al. (2011) Journal of Drug Delivery. 2011:1-12.
[0401] In some embodiments, vectors comprising polynucleotides encoding one or more components of a gene-regulating system described herein are introduced to cells by viral delivery methods, e.g., by viral transduction. In some embodiments, vectors comprising polynucleotides encoding one or more components of a gene-regulating system described herein are introduced to cells by non-viral delivery methods. Illustrative methods of non-viral delivery of polynucleotides contemplated in particular embodiments include, but are not limited to: electroporation, sonoporation, lipofection, microinjection, biolistics, virosomes, liposomes, immunoliposomes, nanoparticles, polycation or lipid:nucleic acid conjugates, naked DNA, artificial virions, DEAE-dextran-mediated transfer, gene gun, and heat-shock.
[0402] In some embodiments, one or more components of a gene-regulating system, or polynucleotide sequence encoding one or more components of a gene-regulating system described herein are introduced to a cell in a non-viral delivery vehicle, such as a transposon, a nanoparticle (e.g., a lipid nanoparticle), a liposome, an exosome, an attenuated bacterium, or a virus-like particle. In some embodiments, the vehicle is an attenuated bacterium (e.g., naturally or artificially engineered to be invasive but attenuated to prevent pathogenesis including Listeria monocytogenes, certain Salmonella strains, Bifidobacterium longum, and modified Escherichia coli), bacteria having nutritional and tissue-specific tropism to target specific cells, and bacteria having modified surface proteins to alter target cell specificity. In some embodiments, the vehicle is a genetically modified bacteriophage (e.g., engineered phages having large packaging capacity, less immunogenicity, containing mammalian plasmid maintenance sequences and having incorporated targeting ligands). In some embodiments, the vehicle is a mammalian virus-like particle. For example, modified viral particles can be generated (e.g., by purification of the "empty" particles followed by ex vivo assembly of the virus with the desired cargo). The vehicle can also be engineered to incorporate targeting ligands to alter target tissue specificity. In some embodiments, the vehicle is a biological liposome. For example, the biological liposome is a phospholipid-based particle derived from human cells (e.g., erythrocyte ghosts, which are red blood cells broken down into spherical structures derived from the subject and wherein tissue targeting can be achieved by attachment of various tissue or cell-specific ligands), secretory exosomes, or subjectiderived membrane-bound nanovescicles (30-100 nm) of endocytic origin (e.g., can be produced from various cell types and can therefore be taken up by cells without the need for targeting ligands).
V. Methods of Producing Modified Immune Effector Cells
[0403] In some embodiments, the present disclosure provides methods for producing modified immune effector cells. In some embodiments, the methods comprise introducing a gene-regulating system into a population of immune effector cells wherein the gene-regulating system is capable of reducing expression and/or function of one or more endogenous target genes.
[0404] The components of the gene-regulating systems described herein, e.g., a nucleic acid-, protein-, or nucleic acid/protein-based system can be introduced into target cells in a variety of forms using a variety of delivery methods and formulations. In some embodiments, a polynucleotide encoding one or more components of the system is delivered by a recombinant vector (e.g., a viral vector or plasmid, described supra). In some embodiments, where the system comprises more than a single component, a vector may comprise a plurality of polynucleotides, each encoding a component of the system. In some embodiments, where the system comprises more than a single component, a plurality of vectors may be used, wherein each vector comprises a polynucleotide encoding a particular component of the system. In some embodiments, the introduction of the gene-regulating system to the cell occurs in vitro. In some embodiments, the introduction of the gene-regulating system to the cell occurs in vivo. In some embodiments, the introduction of the gene-regulating system to the cell occurs ex vivo.
[0405] In particular embodiments, the introduction of the gene-regulating system to the cell occurs in vitro or ex vivo. In some embodiments, the immune effector cells are modified in vitro or ex vivo without further manipulation in culture. For example, in some embodiments, the methods of producing a modified immune effector cell described herein comprise introduction of a gene-regulating system in vitro or ex vivo without additional activation and/or expansion steps. In some embodiments, the immune effector cells are modified and are further manipulated in vitro or ex vivo. For example, in some embodiments, the immune effector cells are activated and/or expanded in vitro or ex vivo prior to introduction of a gene-regulating system. In some embodiments, a gene-regulating system is introduced to the immune effector cells and are then activated and/or expanded in vitro or ex vivo. In some embodiments, successfully modified cells can be sorted and/or isolated (e.g., by flow cytometry) from unsuccessfully modified cells to produce a purified population of modified immune effector cells. These successfully modified cells can then be further propagated to increase the number of the modified cells and/or cryopreserved for future use.
[0406] In some embodiments, the present disclosure provides methods for producing modified immune effector cells comprising obtaining a population of immune effector cells. The population of immune effector cells may be cultured in vitro under various culture conditions necessary to support growth, for example, at an appropriate temperature (e.g., 37.degree. C.) and atmosphere (e.g., air plus 5% CO.sub.2) and in an appropriate culture medium. Culture medium may be liquid or semi-solid, e.g. containing agar, methylcellulose, etc. Illustrative examples of cell culture media include Minimal Essential Media (MEM), Iscove's modified DMEM, RPMI 1640Clicks, AIM-V, F-12, X-Vivo 15, X-Vivo 20, and Optimizer, with added amino acids, sodium pyruvate, and vitamins, either serum-free or supplemented with an appropriate amount of serum (or plasma) or a defined set of hormones, and/or an amount of cytokine(s) sufficient for the growth and expansion of the immune effector cells.
[0407] Culture media may be supplemented with one or more factors necessary for proliferation and viability including, but not limited to, growth factors such as serum (e.g., fetal bovine or human serum at about 5%-10%), interleukin-2 (IL-2), insulin, IFN-.gamma., IL-4, IL-7, IL-21, GM-CSF, IL-10, IL-12, IL-15, TGF.beta., and TNF-.alpha.. Illustrative examples of other additives for T cell expansion include, but are not limited to, surfactant, piasmanate, pH buffers such as HEPES, and reducing agents such as N-acetyl-cysteine and 2-mercaptoethanol, or any other additives suitable for the growth of cells known to the skilled artisan such as L-glutamine, a thiol, particularly 2-mercaptoethanol, and/or antibiotics, e.g. penicillin and streptomycin. Typically, antibiotics are included only in experimental cultures, not in cultures of cells that are to be infused into a subject.
[0408] In some embodiments, the population of immune effector cells is obtained from a sample derived from a subject. In some embodiments, a population of immune effector cells is obtained is obtained from a first subject and the population of modified immune effector cells produced by the methods described herein is administered to a second, different subject. In some embodiments, a population of immune effector cells is obtained from a subject and the population of modified immune effector cells produced by the methods described herein is administered to the same subject. In some embodiments, the sample is a tissue sample, a fluid sample, a cell sample, a protein sample, or a DNA or RNA sample. In some embodiments, a tissue sample may be derived from any tissue type including, but not limited to skin, hair (including roots), bone marrow, bone, muscle, salivary gland, esophagus, stomach, small intestine (e.g., tissue from the duodenum, jejunum, or ileum), large intestine, liver, gallbladder, pancreas, lung, kidney, bladder, uterus, ovary, vagina, placenta, testes, thyroid, adrenal gland, cardiac tissue, thymus, spleen, lymph node, spinal cord, brain, eye, ear, tongue, cartilage, white adipose tissue, or brown adipose tissue. In some embodiments, a tissue sample may be derived from a cancerous, pre-cancerous, or non-cancerous tumor. In some embodiments, a fluid sample comprises buccal swabs, blood, plasma, oral mucous, vaginal mucous, peripheral blood, cord blood, saliva, semen, urine, ascites fluid, pleural fluid, spinal fluid, pulmonary lavage, tears, sweat, semen, seminal fluid, seminal plasma, prostatic fluid, pre-ejaculatory fluid (Cowper's fluid), excreta, cerebrospinal fluid, lymph, cell culture media comprising one or more populations of cells, buffered solutions comprising one or more populations of cells, and the like.
[0409] In some embodiments, the sample is processed to enrich or isolate a population of immune effector cells from the remainder of the sample. In certain embodiments, the sample is a peripheral blood sample which is then subject to leukapheresis to separate the red blood cells and platelets and to isolate lymphocytes. In some embodiments, the sample is a leukopak from which immune effector cells can be isolated or enriched. In some embodiments, the sample is a tumor sample that is further processed to isolate lymphocytes present in the tumor (i.e., by fragmentation and enzymatic digestion of the tumor to obtain a cell suspension of tumor infiltrating lymphocytes).
[0410] In some embodiments, a method for manufacturing modified immune effector cells contemplated herein comprises activation and/or expansion of a population of immune effector cells, as described, for example, in U.S. Pat. Nos. 6,352,694; 6,534,055; 6,905,680; 6,692,964; 5,858,358; 6,887,466; 6,905,681; 7,144,575; 7,067,318; 7,172,869; 7,232,566; 7,175,843; 5,883,223; 6,905,874; 6,797,514; 6,867,041; and U.S. Patent Application Publication No. 20060121005.
[0411] In various embodiments, a method for manufacturing modified immune effector cells contemplated herein comprises activating a population of cells comprising immune effector cells. In particular embodiments, the immune effector cells are T cells. T cell activation can be accomplished by providing a primary stimulation signal (e.g., through the T cell TCR/CD3 complex or via stimulation of the CD2 surface protein) and by providing a secondary co-stimulation signal through an accessory molecule.
[0412] In some embodiments, the TCR/CD3 complex may be stimulated by contacting the T cell with a suitable CD3 binding agent, e.g., a CD3 ligand or an anti-CD3 monoclonal antibody. Illustrative examples of CD3 antibodies include, but are not limited to, OKT3, G19-4, BC3, CRIS-7 and 64.1. In some embodiments, a CD2 binding agent may be used to provide a primary stimulation signal to the T cells. Illustrative examples of CD2 binding agents include, but are not limited to, CD2 ligands and anti-CD2 antibodies, e.g., the T11.3 antibody in combination with the T11.1 or T11.2 antibody (Meuer, S. C. et al. (1984) Cell 36:897-906) and the 9.6 antibody (which recognizes the same epitope as TI 1.1) in combination with the 9-1 antibody (Yang, S. Y. et al. (1986) J. Immunol. 137:1097-1100).
[0413] In addition to the stimulatory signal provided through the TCR/CD3 complex or CD2, induction of T cell responses typically requires a second, costimulatory signal provided by a ligand that specifically binds a costimulatory molecule on a T cell, thereby providing a costimulatory signal which, in addition to the primary signal provided by, for instance, binding of a TCR/CD3 complex, mediates a desired T cell response. Suitable costimulatory ligands include, but are not limited to, CD7, B7-1 (CD80), B7-2 (CD86), 4-1BBL, OX40L, inducible costimulatory ligand (ICOS-L), intercellular adhesion molecule (ICAM), CD30L, CD40, CD70, CD83, HLA-G, MICA, MICB, HVEM, lymphotoxin beta receptor, ILT3, ILT4, an agonist or antibody that binds Tol1 ligand receptor, and a ligand that specifically binds with B7-H3.
[0414] In some embodiments, a costimulatory ligand comprises an antibody or antigen binding fragment thereof that specifically binds to a costimulatory molecule present on a T cell, including but not limited to, CD27, CD28, 4-1BB, OX40, CD30, CD40, ICOS, lymphocyte function-associated antigen-1 (LFA-1), CD7, LIGHT, NKG2C, B7-H3, and a ligand that specifically binds with CD83. In particular embodiments, a CD28 binding agent can be used to provide a costimulatory signal. Illustrative examples of CD28 binding agents include but are not limited to: natural CD28 ligands, e.g., a natural ligand for CD28 (e.g., a member of the B7 family of proteins, such as B7-1 (CD80) and B7-2 (CD86); and anti-CD28 monoclonal antibody or fragment thereof capable of crosslinking the CD28 molecule, e.g., monoclonal antibodies 9.3, B-T3, XR-CD28, KOLT-2, 15E8, 248.23.2, and EX5.3D10.
[0415] In certain embodiments, binding agents that provide stimulatory and costimulatory signals are localized on the surface of a cell. This can be accomplished by transfecting or transducing a cell with a nucleic acid encoding the binding agent in a form suitable for its expression on the cell surface or alternatively by coupling a binding agent to the cell surface. In some embodiments, the costimulatory signal is provided by a costimulatory ligand presented on an antigen presenting cell, such as an artificial APC (aAPC). Artificial APCs can be made by engineering K562, U937, 721.221, T2, or C1R cells to stably express and/or secrete of a variety of costimulatory molecules and cytokines to support ex vivo growth and long-term expansion of genetically modified T cells. In a particular embodiment, K32 or U32 aAPCs are used to direct the display of one or more antibody-based stimulatory molecules on the aAPC cell surface. Populations of T cells can be expanded by aAPCs expressing a variety of costimulatory molecules including, but not limited to, CD137L (4-1BBL), CD134L (OX40L), and/or CD80 or CD86. Exemplary aAPCs are provided in WO 03/057171 and US2003/0147869, incorporated by reference in their entireties.
[0416] In some embodiments, binding agents that provide activating and costimulatory signals are localized a solid surface (e.g., a bead or a plate). In some embodiments, the binding agents that provide activating and costimulatory signals are both provided in a soluble form (provided in solution).
[0417] In some embodiments, the population of immune effector cells is expanded in culture in one or more expansion phases. "Expansion" refers to culturing the population of immune effector cells for a pre-determined period of time in order to increase the number of immune effector cells. Expansion of immune effector cells may comprise addition of one or more of the activating factors described above and/or addition of one or more growth factors such as a cytokine (e.g., IL-2, IL-15, IL-21, and/or IL-7) to enhance or promote cell proliferation and/or survival. In some embodiments, combinations of IL-2, IL-15, and/or IL-21 can be added to the cultures during the one or more expansion phases. In some embodiments, the amount of IL-2 added during the one or more expansion phases is less than 6000 U/mL. In some embodiments, the amount of IL-2 added during the one or more expansion phases is about 5500 U/mL, about 5000 U/mL, about 4500 U/mL, about 4000 U/mL, about 3500 U/mL, about 3000 U/mL, about 2500 U/mL, about 2000 U/mL, about 1500 U/mL, about 1000 U/mL, or about 500 U/mL. In some embodiments, the amount of IL-2 added during the one or more expansion phases is between about 500 U/mL and about 5500 U/mL. In some embodiments, the population of immune effector cells may be co-cultured with feeder cells during the expansion process.
[0418] In some embodiments, the population of immune effector cells is expanded for a pre-determined period of time, wherein the pre-determined period of time is less than about 30 days. In some embodiments, the pre-determined period of time is less than 30 days, less than 25 days, less than 20 days, less than 18 days, less than 15 days, or less than 10 days. In some embodiments, the pre-determined period of time is less than 4 weeks, less than 3 weeks, less than 2 weeks, or less than 1 week. In some embodiments, the pre-determined period of time is about 7 days, 8 days, 9 days, 10 days, 11 days, 12 days, 13 days, 14 days, 15 days, 16 days, 17 days, 18 days, 19 days, 20 days, or 21 days. In some embodiments, the pre-determined period of time is about 5 days to about 25 days, about 10 to about 28 days, about 10 to about 25 days, about 10 to about 21 days, about 10 to about 20 days, about 10 to about 19 days, about 11 to about 28 days, about 11 to about 25 days, about 11 to about 21 days, about 11 to about 20 days, about 11 to about 19 days, about 12 to about 28 days, about 12 to about 25 days, about 12 to about 21 days, about 12 to about 20 days, about 12 to about 19 days, about 15 to about 28 days, about 15 to about 25 days, about 15 to about 21 days, about 15 to about 20 days, or about 15 to about 19 days. In some embodiments, the pre-determined period of time is about 5 days to about 10 days, about 10 days to about 15 days, about 15 days to about 20 days, or about 20 days to about 25 days.
[0419] In some embodiments, the population of immune effector cells is expanded until the number of cells reaches a pre-determined threshold. For example, in some embodiments, the population of immune effector cells is expanded until the culture comprises at least 5.times.10.sup.6, 1.times.10.sup.7, 5.times.10.sup.7, 1.times.10.sup.8, 5.times.10.sup.8, 1.times.10.sup.9, 5.times.10.sup.9, 1.times.10.sup.10, 5.times.10.sup.10, 1.times.10.sup.11, 5.times.10.sup.11, 1.times.10.sup.12 5.times.10.sup.12, 1.times.10.sup.13, or at least 5.times.10.sup.13 total cells. In some embodiments, the population of immune effector cells is expanded until the culture comprises between about 1.times.10.sup.9 total cells and about 1.times.10.sup.11 total cells.
[0420] In some embodiments, the methods provided herein comprise at least two expansion phases. For example, in some embodiments, the population of immune effector cells can be expanded after isolation from a sample, allowed to rest, and then expanded again. In some embodiments, the immune effector cells can be expanded in one set of expansion conditions followed by a second round of expansion in a second, different, set of expansion conditions. Methods for ex vivo expansion of immune cells are known in the art, for example, as described in US Patent Application Publication Nos. 2018-0207201, 20180282694 and 20170152478 and U.S. Pat. Nos. 8,383,099 and 8,034,334, herein incorporated by reference.
[0421] At any point during the activation and/or expansion processes, the gene-regulating systems described herein can be introduced to the immune effector cells to produce a population of modified immune effector cells. In some embodiments, the gene-regulating system is introduced to the population of immune effector cells immediately after enrichment from a sample. In some embodiments, the gene-regulating system is introduced to the population of immune effector cells before, during, or after the one or more expansion process. In some embodiments, the gene-regulating system is introduced to the population of immune effector cells immediately after enrichment from a sample or harvest from a subject, and prior to any expansion rounds. In some embodiments, the gene-regulating system is introduced to the population of immune effector cells after a first round of expansion and prior to a second round of expansion. In some embodiments, the gene-regulating system is introduced to the population of immune effector cells after a first and a second round of expansion.
[0422] In some embodiments, the present disclosure provides methods of manufacturing populations of modified immune effector cells comprising obtaining a population of immune effector cells, introducing a gene-regulating system described herein to the population of immune effector cells, and expanding the population of immune effector cells in one or more round of expansion. In some aspects of this embodiment, the population of immune effector cells is expanded in a first round of expansion prior to the introduction of the gene-regulating system and is expanded in a second round of expansion after the introduction of the gene-regulating system. In some aspects of this embodiment, the population of immune effector cells is expanded in a first round of expansion and a second round of expansion prior to the introduction of the gene-regulating system. In some aspects of this embodiment, the gene-regulating system is introduced to the population of immune effector cells prior to the first and second rounds of expansion.
[0423] In some embodiments, the methods described herein comprise removal of a tumor from a subject and processing of the tumor sample to obtain a population of tumor infiltrating lymphocytes (e.g., by fragmentation and enzymatic digestion of the tumor to obtain a cell suspension) introducing a gene-regulating system described herein to the population of immune effector cells, and expanding the population of immune effector cells in one or more round of expansion. In some aspects of this embodiment, the population of tumor infiltrating lymphocytes is expanded in a first round of expansion prior to the introduction of the gene-regulating system and is expanded in a second round of expansion after the introduction of the gene-regulating system. In some aspects of this embodiment, the population of tumor infiltrating lymphocytes is expanded in a first round of expansion and a second round of expansion prior to the introduction of the gene-regulating system. In some aspects of this embodiment, the gene-regulating system is introduced to the population of tumor infiltrating lymphocytes prior to the first and second rounds of expansion.
[0424] In some embodiments, the modified immune effector cells produced by the methods described herein may be used immediately. In some embodiments, the manufacturing methods contemplated herein may further comprise cryopreservation of modified immune cells for storage and/or preparation for use in a subject. As used herein, "cryopreserving," refers to the preservation of cells by cooling to sub-zero temperatures, such as (typically) 77 K or -196.degree. C. (the boiling point of liquid nitrogen). In some embodiments, a method of storing modified immune effector cells comprises cryopreserving the immune effector cells such that the cells remain viable upon thawing. When needed, the cryopreserved modified immune effector cells can be thawed, grown and expanded for more such cells. Cryoprotective agents are often used at sub-zero temperatures to prevent the cells being preserved from damage due to freezing at low temperatures or warming to room temperature. Cryopreservative agents and optimal cooling rates can protect against cell injury. Cryoprotective agents which can be used include but are not limited to dimethyl sulfoxide (DMSO) (Lovelock and Bishop, Nature, 1959; 183: 1394-1395; Ashwood-Smith, Nature, 1961; 190: 1204-1205), glycerol, polyvinylpyrrolidine (Rinfret, Ann. N Y. Acad. Sci., 1960; 85: 576), and polyethylene glycol (Sloviter and Ravdin, Nature, 1962; 196: 48). In some embodiments, the cells are frozen in 10% dimethylsulfoxide (DMSO), 50% serum, 40% buffered medium, or some other such solution as is commonly used in the art to preserve cells at such freezing temperatures, and thawed in a manner as commonly known in the art for thawing frozen cultured cells.
A. Producing Modified Immune Effector Cells Using CRISPR/Cas Systems
[0425] In some embodiments, a method of producing a modified immune effector cell involves contacting a target DNA sequence with a complex comprising a gRNA and a Cas polypeptide. As discussed above, a gRNA and Cas polypeptide form a complex, wherein the DNA-binding domain of the gRNA targets the complex to a target DNA sequence and wherein the Cas protein (or heterologous protein fused to an enzymatically inactive Cas protein) modifies target DNA sequence. In some embodiments, this complex is formed intracellularly after introduction of the gRNA and Cas protein (or polynucleotides encoding the gRNA and Cas proteins) to a cell. In some embodiments, the nucleic acid encoding the Cas protein is a DNA nucleic acid and is introduced to the cell by transduction. In some embodiments, the Cas9 and gRNA components of a CRISPR/Cas gene editing system are encoded by a single polynucleotide molecule. In some embodiments, the polynucleotide encoding the Cas protein and gRNA component are comprised in a viral vector and introduced to the cell by viral transduction. In some embodiments, the Cas9 and gRNA components of a CRISPR/Cas gene editing system are encoded by different polynucleotide molecules. In some embodiments, the polynucleotide encoding the Cas protein is comprised in a first viral vector and the polynucleotide encoding the gRNA is comprised in a second viral vector. In some aspects of this embodiment, the first viral vector is introduced to a cell prior to the second viral vector. In some aspects of this embodiment, the second viral vector is introduced to a cell prior to the first viral vector. In such embodiments, integration of the vectors results in sustained expression of the Cas9 and gRNA components. However, sustained expression of Cas9 may lead to increased off-target mutations and cutting in some cell types. Therefore, in some embodiments, an mRNA nucleic acid sequence encoding the Cas protein may be introduced to the population of cells by transfection. In such embodiments, the expression of Cas9 will decrease over time, and may reduce the number of off target mutations or cutting sites. In some embodiments, the gRNA and Cas protein are introduced separately by electroporation.
[0426] In some embodiments, this complex is formed in a cell-free system by mixing the gRNA molecules and Cas proteins together and incubating for a period of time sufficient to allow complex formation. This pre-formed complex, comprising the gRNA and Cas protein and referred to herein as a CRISPR-ribonucleoprotein (CRISPR-RNP) can then be introduced to a cell in order to modify a target DNA sequence. In some embodiments, the CRISPR-RNP is introduced to the cell by electroporation.
[0427] In any of the above described embodiments for producing a modified immune effector cell using the CRISPR/Cas system, the system may comprise one or more gRNAs targeting a single endogenous target gene, for example to produce a single-edited modified immune effector cell. Alternatively, in any of the above described embodiments for producing a modified immune effect cell using the CRISPR/Cas system, the system may comprise two or more gRNAs targeting two or more endogenous target genes, for example to produce a dual-edited modified immune effector cell.
B. Producing Modified Immune Effector Cells Using shRNA Systems
[0428] In some embodiments, a method of producing a modified immune effector cell introducing into the cell one or more DNA polynucleotides encoding one or more shRNA molecules with sequence complementary to the mRNA transcript of a target gene. The immune effector cell can be modified to produce the shRNA by introducing specific DNA sequences into the cell nucleus via a small gene cassette. Both retroviruses and lentiviruses can be used to introduce shRNA-encoding DNAs into immune effector cells. The introduced DNA can either become part of the cell's own DNA or persist in the nucleus, and instructs the cell machinery to produce shRNAs. shRNAs may be processed by Dicer or AGO2-mediated slicer activity inside the cell to induce RNAi mediated gene knockdown.
VI. Compositions and Kits
[0429] The term "composition" as used herein refers to a formulation of a gene-regulating system or a modified immune effector cell described herein that is capable of being administered or delivered to a subject or cell. Typically, formulations include all physiologically acceptable compositions including derivatives and/or prodrugs, solvates, stereoisomers, racemates, or tautomers thereof with any physiologically acceptable carriers, diluents, and/or excipients. A "therapeutic composition" or "pharmaceutical composition" (used interchangeably herein) is a composition of a gene-regulating system or a modified immune effector cell capable of being administered to a subject for the treatment of a particular disease or disorder or contacted with a cell for modification of one or more endogenous target genes.
[0430] The phrase "pharmaceutically acceptable" is employed herein to refer to those compounds, materials, compositions, and/or dosage forms which are, within the scope of sound medical judgment, suitable for use in contact with the tissues of human beings and animals without excessive toxicity, irritation, allergic response, or other problem or complication, commensurate with a reasonable benefit/risk ratio.
[0431] As used herein "pharmaceutically acceptable carrier, diluent or excipient" includes without limitation any adjuvant, carrier, excipient, glidant, sweetening agent, diluent, preservative, dye/colorant, flavor enhancer, surfactant, wetting agent, dispersing agent, suspending agent, stabilizer, isotonic agent, solvent, surfactant, and/or emulsifier which has been approved by the United States Food and Drug Administration as being acceptable for use in humans and/or domestic animals. Exemplary pharmaceutically acceptable carriers include, but are not limited to, to sugars, such as lactose, glucose and sucrose; starches, such as corn starch and potato starch; cellulose, and its derivatives, such as sodium carboxymethyl cellulose, ethyl cellulose and cellulose acetate; tragacanth; malt; gelatin; talc; cocoa butter, waxes, animal and vegetable fats, paraffins, silicones, bentonites, silicic acid, zinc oxide; oils, such as peanut oil, cottonseed oil, safflower oil, sesame oil, olive oil, corn oil and soybean oil; glycols, such as propylene glycol; polyols, such as glycerin, sorbitol, mannitol and polyethylene glycol; esters, such as ethyl oleate and ethyl laurate; agar; buffering agents, such as magnesium hydroxide and aluminum hydroxide; alginic acid; pyrogen-free water; isotonic saline; Ringer's solution; ethyl alcohol; phosphate buffer solutions; and any other compatible substances employed in pharmaceutical formulations. Except insofar as any conventional media and/or agent is incompatible with the agents of the present disclosure, its use in therapeutic compositions is contemplated. Supplementary active ingredients also can be incorporated into the compositions.
[0432] "Pharmaceutically acceptable salt" includes both acid and base addition salts. Pharmaceutically-acceptable salts include the acid addition salts (formed with the free amino groups of the protein) and which are formed with inorganic acids such as, for example, hydrochloric acid, hydrobromic acid, sulfuric acid, nitric acid, phosphoric acid and the like, and organic acids such as, but not limited to, acetic acid, 2,2-dichloroacetic acid, adipic acid, alginic acid, ascorbic acid, aspartic acid, benzenesulfonic acid, benzoic acid, 4-acetamidobenzoic acid, camphoric acid, camphor-10-sulfonic acid, capric acid, caproic acid, caprylic acid, carbonic acid, cinnamic acid, citric acid, cyclamic acid, dodecylsulfuric acid, ethane-1,2-disulfonic acid, ethanesulfonic acid, 2-hydroxyethanesulfonic acid, formic acid, fumaric acid, galactaric acid, gentisic acid, glucoheptonic acid, gluconic acid, glucuronic acid, glutamic acid, glutaric acid, 2-oxo-glutaric acid, glycerophosphoric acid, glycolic acid, hippuric acid, isobutyric acid, lactic acid, lactobionic acid, lauric acid, maleic acid, malic acid, malonic acid, mandelic acid, methanesulfonic acid, mucic acid, naphthalene-1,5-disulfonic acid, naphthalene-2-sulfonic acid, 1-hydroxy-2-naphthoic acid, nicotinic acid, oleic acid, orotic acid, oxalic acid, palmitic acid, pamoic acid, propionic acid, pyroglutamic acid, pyruvic acid, salicylic acid, 4-aminosalicylic acid, sebacic acid, stearic acid, succinic acid, tartaric acid, thiocyanic acid, ptoluenesulfonic acid, trifluoroacetic acid, undecylenic acid, and the like. Salts formed with the free carboxyl groups can also be derived from inorganic bases such as, for example, sodium, potassium, lithium, ammonium, calcium, magnesium, iron, zinc, copper, manganese, aluminum salts and the like. Salts derived from organic bases include, but are not limited to, salts of primary, secondary, and tertiary amines, substituted amines including naturally occurring substituted amines, cyclic amines and basic ion exchange resins, such as ammonia, isopropylamine, trimethylamine, diethylamine, triethylamine, tripropylamine, diethanolamine, ethanolamine, deanol, 2-dimethylaminoethanol, 2-diethylaminoethanol, dicyclohexylamine, lysine, arginine, histidine, caffeine, procaine, hydrabamine, choline, betaine, benethamine, benzathine, ethylenediamine, glucosamine, methylglucamine, theobromine, triethanolamine, tromethamine, purines, piperazine, piperidine, N-ethylpiperidine, polyamine resins and the like. Particularly preferred organic bases are isopropylamine, diethylamine, ethanolamine, trimethylamine, dicyclohexylamine, choline and caffeine.
[0433] Wetting agents, emulsifiers and lubricants, such as sodium lauryl sulfate and magnesium stearate, as well as coloring agents, release agents, coating agents, sweetening, flavoring and perfuming agents, preservatives and antioxidants can also be present in the compositions.
[0434] Examples of pharmaceutically-acceptable antioxidants include: (1) water soluble antioxidants, such as ascorbic acid, cysteine hydrochloride, sodium bisulfate, sodium metabisulfite, sodium sulfite and the like; (2) oil-soluble antioxidants, such as ascorbyl palmitate, butylated hydroxyanisole (BHA), butylated hydroxytoluene (BHT), lecithin, propyl gallate, alpha-tocopherol, and the like; and (3) metal chelating agents, such as citric acid, ethylenediamine tetraacetic acid (EDTA), sorbitol, tartaric acid, phosphoric acid, and the like.
[0435] Further guidance regarding formulations that are suitable for various types of administration can be found in Remington's Pharmaceutical Sciences, Mace Publishing Company, Philadelphia, Pa., 17th ed. (1985). For a brief review of methods for drug delivery, see, Langer, Science 249:1527-1533 (1990).
[0436] In some embodiments, the present disclosure provides kits for carrying out a method described herein. In some embodiments, a kit can include:
[0437] (a) one or more nucleic acid molecules capable of reducing the expression or modifying the function of a gene product encoded by one or more endogenous target genes;
[0438] (b) one or more polynucleotides encoding a nucleic acid molecule that is capable of reducing the expression or modifying the function of a gene product encoded by one or more endogenous target genes;
[0439] (c) one or more proteins capable of reducing the expression or modifying the function of a gene product encoded by one or more endogenous target genes;
[0440] (d) one or more polynucleotides encoding a modifying protein that is capable of reducing the expression or modifying the function of a gene product encoded by one or more endogenous target genes;
[0441] (e) one or more gRNAs capable of binding to a target DNA sequence in an endogenous gene;
[0442] (f) one or more polynucleotides encoding one or more gRNAs capable of binding to a target DNA sequence in an endogenous gene;
[0443] (g) one or more site-directed modifying polypeptides capable of interacting with a gRNA and modifying a target DNA sequence in an endogenous gene;
[0444] (h) one or more polynucleotides encoding a site-directed modifying polypeptide capable of interacting with a gRNA and modifying a target DNA sequence in an endogenous gene;
[0445] (i) one or more guide DNAs (gDNAs) capable of binding to a target DNA sequence in an endogenous gene;
[0446] (j) one or more polynucleotides encoding one or more gDNAs capable of binding to a target DNA sequence in an endogenous gene;
[0447] (k) one or more site-directed modifying polypeptides capable of interacting with a gDNA and modifying a target DNA sequence in an endogenous gene;
[0448] (l) one or more polynucleotides encoding a site-directed modifying polypeptide capable of interacting with a gDNA and modifying a target DNA sequence in an endogenous gene;
[0449] (m) one or more gRNAs capable of binding to a target mRNA sequence encoded by an endogenous gene;
[0450] (n) one or more polynucleotides encoding one or more gRNAs capable of binding to a target mRNA sequence encoded by an endogenous gene;
[0451] (o) one or more site-directed modifying polypeptides capable of interacting with a gRNA and modifying a target mRNA sequence encoded by an endogenous gene;
[0452] (p) one or more polynucleotides encoding a site-directed modifying polypeptide capable of interacting with a gRNA and modifying a target mRNA sequence encoded by an endogenous gene;
[0453] (q) a modified immune effector cell described herein; or
[0454] (r) any combination of the above.
[0455] In some embodiments, the kits described herein further comprise one or more immune checkpoint inhibitors. Several immune checkpoint inhibitors are known in the art and have received FDA approval for the treatment of one or more cancers. For example, FDA-approved PD-L1 inhibitors include Atezolizumab (Tecentriq.RTM., Genentech), Avelumab (Bavencio.RTM., Pfizer), and Durvalumab (Imfinzi.RTM., AstraZeneca); FDA-approved PD-1 inhibitors include Pembrolizumab (Keytruda.RTM., Merck) and Nivolumab (Opdivo.RTM., Bristol-Myers Squibb); and FDA-approved CTLA4 inhibitors include Ipilimumab (Yervoy.RTM., Bristol-Myers Squibb). Additional inhibitory immune checkpoint molecules that may be the target of future therapeutics include A2AR, B7-H3, B7-H4, BTLA, IDO, LAG3 (e.g., BMS-986016, under development by BSM), KIR (e.g., Lirilumab, under development by BSM), TIM3, TIGIT, and VISTA.
[0456] In some embodiments, the kits described herein comprise one or more components of a gene-regulating system (or one or more polynucleotides encoding the one or more components) and one or more immune checkpoint inhibitors known in the art (e.g., a PD1 inhibitor, a CTLA4 inhibitor, a PDL1 inhibitor, etc.). In some embodiments, the kits described herein comprise one or more components of a gene-regulating system (or one or more polynucleotides encoding the one or more components) and an anti-PD1 antibody (e.g., Pembrolizumab or Nivolumab). In some embodiments, the kits described herein comprise a modified immune effector cell described herein (or population thereof) and one or more immune checkpoint inhibitors known in the art (e.g., a PD1 inhibitor, a CTLA4 inhibitor, a PDL1 inhibitor, etc.). In some embodiments, the kits described herein comprise a modified immune effector cell described herein (or population thereof) and an anti-PD1 antibody (e.g., Pembrolizumab or Nivolumab).
[0457] In some embodiments, the kit comprises one or more components of a gene-regulating system (or one or more polynucleotides encoding the one or more components) and a reagent for reconstituting and/or diluting the components. In some embodiments, a kit comprising one or more components of a gene-regulating system (or one or more polynucleotides encoding the one or more components) and further comprises one or more additional reagents, where such additional reagents can be selected from: a buffer for introducing the gene-regulating system into a cell; a wash buffer; a control reagent; a control expression vector or RNA polynucleotide; a reagent for in vitro production of the gene-regulating system from DNA, and the like. Components of a kit can be in separate containers or can be combined in a single container.
[0458] In addition to above-mentioned components, in some embodiments a kit further comprises instructions for using the components of the kit to practice the methods of the present disclosure. The instructions for practicing the methods are generally recorded on a suitable recording medium. For example, the instructions may be printed on a substrate, such as paper or plastic, etc. As such, the instructions may be present in the kits as a package insert or in the labeling of the container of the kit or components thereof (i.e., associated with the packaging or sub-packaging). In other embodiments, the instructions are present as an electronic storage data file present on a suitable computer readable storage medium, e.g. CD-ROM, diskette, flash drive, etc. In yet other embodiments, the actual instructions are not present in the kit, but means for obtaining the instructions from a remote source, e.g. via the internet, are provided. An example of this embodiment is a kit that includes a web address where the instructions can be viewed and/or from which the instructions can be downloaded. As with the instructions, this means for obtaining the instructions is recorded on a suitable substrate.
VII. Therapeutic Methods and Applications
[0459] In some embodiments, the modified immune effector cells and gene-regulating systems described herein may be used in a variety of therapeutic applications. For example, in some embodiments the modified immune effector cells and/or gene-regulating systems described herein may be administered to a subject for purposes such as gene therapy, e.g. to treat a disease, for use as an antiviral, for use as an anti-pathogenic, for use as an anti-cancer therapeutic, or for biological research.
[0460] In some embodiments, the subject may be a neonate, a juvenile, or an adult. Of particular interest are mammalian subjects. Mammalian species that may be treated with the present methods include canines and felines; equines; bovines; ovines; etc. and primates, particularly humans. Animal models, particularly small mammals (e.g. mice, rats, guinea pigs, hamsters, rabbits, etc.) may be used for experimental investigations.
[0461] Administration of the modified immune effector cells described herein, populations thereof, and compositions thereof can occur by injection, irrigation, inhalation, consumption, electro-osmosis, hemodialysis, iontophoresis, and other methods known in the art. In some embodiments, administration route is local or systemic. In some embodiments administration route is intraarterial, intracranial, intradermal, intraduodenal, intrammamary, intrameningeal, intraperitoneal, intrathecal, intratumoral, intravenous, intravitreal, ophthalmic, parenteral, spinal, subcutaneous, ureteral, urethral, vaginal, or intrauterine.
[0462] In some embodiments, the administration route is by infusion (e.g., continuous or bolus). Examples of methods for local administration, that is, delivery to the site of injury or disease, include through an Ommaya reservoir, e.g. for intrathecal delivery (See e.g., U.S. Pat. Nos. 5,222,982 and 5,385,582, incorporated herein by reference); by bolus injection, e.g. by a syringe, e.g. into a joint; by continuous infusion, e.g. by cannulation, such as with convection (See e.g., US Patent Application Publication No. 2007-0254842, incorporated herein by reference); or by implanting a device upon which the cells have been reversibly affixed (see e.g. US Patent Application Publication Nos. 2008-0081064 and 2009-0196903, incorporated herein by reference). In some embodiments, the administration route is by topical administration or direct injection. In some embodiments, the modified immune effector cells described herein may be provided to the subject alone or with a suitable substrate or matrix, e.g. to support their growth and/or organization in the tissue to which they are being transplanted.
[0463] In some embodiments, at least 1.times.10.sup.3 cells are administered to a subject. In some embodiments, at least 5.times.10.sup.3 cells, 1.times.10.sup.4 cells, 5.times.10.sup.4 cells, 1.times.10.sup.5 cells, 5.times.10.sup.5 cells, 1.times.10.sup.6, 2.times.10.sup.6, 3.times.10.sup.6, 4.times.10.sup.6, 5.times.10.sup.6, 1.times.10.sup.7, 1.times.10.sup.8, 5.times.10.sup.8, 1.times.10.sup.9, 5.times.10.sup.9, 1.times.10.sup.10, 5.times.10.sup.10, 1.times.10.sup.11, 5.times.10.sup.11, 1.times.10.sup.12, 5.times.10.sup.12, or more cells are administered to a subject. In some embodiments, between about 1.times.10.sup.7 and about 1.times.10.sup.12 cells are administered to a subject. In some embodiments, between about 1.times.10.sup.8 and about 1.times.10.sup.12 cells are administered to a subject. In some embodiments, between about 1.times.10.sup.9 and about 1.times.10.sup.12 cells are administered to a subject. In some embodiments, between about 1.times.10.sup.10 and about 1.times.10.sup.12 cells are administered to a subject. In some embodiments, between about 1.times.10.sup.11 and about 1.times.10.sup.12 cells are administered to a subject. In some embodiments, between about 1.times.10.sup.7 and about 1.times.10.sup.11 cells are administered to a subject. In some embodiments, between about 1.times.10.sup.7 and about 1.times.10.sup.10 cells are administered to a subject. In some embodiments, between about 1.times.10.sup.7 and about 1.times.10.sup.9 cells are administered to a subject. In some embodiments, between about 1.times.10.sup.7 and about 1.times.10.sup.8 cells are administered to a subject. The number of administrations of treatment to a subject may vary. In some embodiments, introducing the modified immune effector cells into the subject may be a one-time event. In some embodiments, such treatment may require an on-going series of repeated treatments. In some embodiments, multiple administrations of the modified immune effector cells may be required before an effect is observed. The exact protocols depend upon the disease or condition, the stage of the disease and parameters of the individual subject being treated.
[0464] In some embodiments, the gene-regulating systems described herein are employed to modify cellular DNA or RNA in vivo, such as for gene therapy or for biological research. In such embodiments, a gene-regulating system may be administered directly to the subject, such as by the methods described supra. In some embodiments, the gene-regulating systems described herein are employed for the ex vivo or in vitro modification of a population of immune effector cells. In such embodiments, the gene-regulating systems described herein are administered to a sample comprising immune effector cells.
[0465] In some embodiments, the modified immune effector cells described herein are administered to a subject. In some embodiments, the modified immune effector cells described herein administered to a subject are autologous immune effector cells. The term "autologous" in this context refers to cells that have been derived from the same subject to which they are administered. For example, immune effector cells may be obtained from a subject, modified ex vivo according to the methods described herein, and then administered to the same subject in order to treat a disease. In such embodiments, the cells administered to the subject are autologous immune effector cells. In some embodiments, the modified immune effector cells, or compositions thereof, administered to a subject are allogenic immune effector cells. The term "allogenic" in this context refers to cells that have been derived from one subject and are administered to another subject. For example, immune effector cells may be obtained from a first subject, modified ex vivo according to the methods described herein and then administered to a second subject in order to treat a disease. In such embodiments, the cells administered to the subject are allogenic immune effector cells.
[0466] In some embodiments, the modified immune effector cells described herein are administered to a subject in order to treat a disease. In some embodiments, treatment comprises delivering an effective amount of a population of cells (e.g., a population of modified immune effector cells) or composition thereof to a subject in need thereof. In some embodiments, treating refers to the treatment of a disease in a mammal, e.g., in a human, including (a) inhibiting the disease, i.e., arresting disease development or preventing disease progression;
[0467] (b) relieving the disease, i.e., causing regression of the disease state or relieving one or more symptoms of the disease; and (c) curing the disease, i.e., remission of one or more disease symptoms. In some embodiments, treatment may refer to a short-term (e.g., temporary and/or acute) and/or a long-term (e.g., sustained) reduction in one or more disease symptoms. In some embodiments, treatment results in an improvement or remediation of the symptoms of the disease. The improvement is an observable or measurable improvement, or may be an improvement in the general feeling of well-being of the subject.
[0468] The effective amount of a modified immune effector cell administered to a particular subject will depend on a variety of factors, several of which will differ from patient to patient including the disorder being treated and the severity of the disorder; activity of the specific agent(s) employed; the age, body weight, general health, sex and diet of the patient; the timing of administration, route of administration; the duration of the treatment; drugs used in combination; the judgment of the prescribing physician; and like factors known in the medical arts.
[0469] In some embodiments, the effective amount of a modified immune effector cell may be the number of cells required to result in at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, or more fold decrease in tumor mass or volume, decrease in the number of tumor cells, or decrease in the number of metastases. In some embodiments, the effective amount of a modified immune effector cell may be the number of cells required to achieve an increase in life expectancy, an increase in progression-free or disease-free survival, or amelioration of various physiological symptoms associated with the disease being treated. In some embodiments, an effective amount of modified immune effector cells will be at least 1.times.10.sup.3 cells, for example 5.times.10.sup.3 cells, 1.times.10.sup.4 cells, 5.times.10.sup.4 cells, 1.times.10.sup.5 cells, 5.times.10.sup.5 cells, 1.times.10.sup.6, 2.times.10.sup.6, 3.times.10.sup.6, 4.times.10.sup.6, 5.times.10.sup.6, 1.times.10.sup.7, 1.times.10.sup.8, 5.times.10.sup.8, 1.times.10.sup.9, 5.times.10.sup.9, 1.times.10.sup.10, 5.times.10.sup.10, 1.times.10.sup.11, 5.times.10.sup.11, 1.times.10.sup.12, 5.times.10.sup.12, or more cells.
[0470] In some embodiments, the modified immune effector cells and gene-regulating systems described herein may be used in the treatment of a cell-proliferative disorder, such as a cancer. Cancers that may be treated using the compositions and methods disclosed herein include cancers of the blood and solid tumors. For example, cancers that may be treated using the compositions and methods disclosed herein include, but are not limited to, adenoma, carcinoma, sarcoma, leukemia or lymphoma. In some embodiments, the cancer is chronic lymphocytic leukemia (CLL), B cell acute lymphocytic leukemia (B-ALL), acute lymphoblastic leukemia (ALL), acute myeloid leukemia (AML), non-Hodgkin's lymphoma (NHL), diffuse large cell lymphoma (DLCL), diffuse large B cell lymphoma (DLBCL), Hodgkin's lymphoma, multiple myeloma, renal cell carcinoma (RCC), neuroblastoma, colorectal cancer, bladder cancer, breast cancer, colorectal cancer, ovarian cancer, melanoma, sarcoma, prostate cancer, lung cancer, esophageal cancer, hepatocellular carcinoma, pancreatic cancer, astrocytoma, mesothelioma, head and neck cancer, and medulloblastoma, and liver cancer. In some embodiments, the cancer is selected from a melanoma, head and neck cancer, bladder cancer, lung cancer, cervical cancer, pancreatic cancer, breast cancer, and colorectal cancer. In some embodiments, the cancer is insensitive, or resistant, to treatment with a PD1 inhibitor. In some embodiments, the cancer is insensitive, or resistant to treatment with a PD1 inhibitor and is selected from a melanoma, head and neck cancer, bladder cancer, lung cancer, cervical cancer, pancreatic cancer, breast cancer, and colorectal cancer.
[0471] As described above, several immune checkpoint inhibitors are currently approved for use in a variety of oncologic indications (e.g., CTLA4 inhibitors, PD1 inhibitors, PDL1 inhibitors, etc.). In some embodiments, administration of a modified immune effector cell comprising reduced expression and/or function of an endogenous target gene described herein results in an enhanced therapeutic effect (e.g., a more significant reduction in tumor growth, an increase in tumor infiltration by lymphocytes, an increase in the length of progression free survival, etc.) than is observed after treatment with an immune checkpoint inhibitor.
[0472] Further, some oncologic indications are non-responsive (i.e., are insensitive) to treatment with immune checkpoint inhibitors. Further still, some oncologic indications that are initially responsive (i.e., sensitive) to treatment with immune checkpoint inhibitors develop an inhibitor-resistant phenotype during the course of treatment. Therefore, in some embodiments, the modified immune effector cells described herein, or compositions thereof, are administered to treat a cancer that is resistant (or partially resistant) or insensitive (or partially insensitive) to treatment with one or more immune checkpoint inhibitors. In some embodiments, administration of the modified immune effector cells or compositions thereof to a subject suffering from a cancer that is resistant (or partially resistant) or insensitive (or partially insensitive) to treatment with one or more immune checkpoint inhibitors results in treatment of the cancer (e.g., reduction in tumor growth, an increase in the length of progression free survival, etc.). In some embodiments, the cancer is resistant (or partially resistant) or insensitive (or partially insensitive) to treatment with a PD1 inhibitor.
[0473] In some embodiments, the modified immune effector cells or compositions thereof are administered in combination with an immune checkpoint inhibitor. In some embodiments, administration of the modified immune effector cells in combination with the immune checkpoint inhibitor results in an enhanced therapeutic effect in a cancer that is resistant, refractory, or insensitive to treatment by an immune checkpoint inhibitor than is observed by treatment with either the modified immune effector cells or the immune checkpoint inhibitor alone. In some embodiments, administration of the modified immune effector cells in combination with the immune checkpoint inhibitor results in an enhanced therapeutic effect in a cancer that is partially resistant, partially refractory, or partially insensitive to treatment by an immune checkpoint inhibitor than is observed by treatment with either the modified immune effector cells or the immune checkpoint inhibitor alone. In some embodiments, the cancer is resistant (or partially resistant), refractory (or partially refractory), or insensitive (or partially insensitive) to treatment with a PD1 inhibitor.
[0474] In some embodiments, administration of a modified immune effector cell described herein or composition thereof in combination with an anti-PD1 antibody results in an enhanced therapeutic effect in a cancer that is resistant or insensitive to treatment by the anti-PD1 antibody alone. In some embodiments, administration of a modified immune effector cell described herein or composition thereof in combination with an anti-PD1 antibody results in an enhanced therapeutic effect in a cancer that is partially resistant or partially insensitive to treatment by the anti-PD1 antibody alone.
[0475] Cancers that demonstrate resistance or sensitivity to immune checkpoint inhibition are known in the art and can be tested in a variety of in vivo and in vitro models. For example, some melanomas are sensitive to treatment with an immune checkpoint inhibitor such as an anti-PD1 antibody and can be modeled in an in vivo B16-Ova tumor model (See Examples 6, 7, 16, and 19). Further, some colorectal cancers are known to be resistant to treatment with an immune checkpoint inhibitor such as an anti-PD1 antibody and can be modeled in a PMEL/MC38-gp100 model (See Examples 8 and 17). Further still, some lymphomas are known to be insensitive to treatment with an immune checkpoint inhibitor such as an anti-PD1 antibody and can be modeled in a various models by adoptive transfer or subcutaneous administration of lymphoma cell lines, such as Raji cells (See Examples 12, 14, 15, 21, and 22).
[0476] In some embodiments, the modified immune effector cells and gene-regulating systems described herein may be used in the treatment of a viral infection. In some embodiments, the virus is selected from one of adenoviruses, herpesviruses (including, for example, herpes simplex virus and Epstein Barr virus, and herpes zoster virus), poxviruses, papovaviruses, hepatitis viruses, (including, for example, hepatitis B virus and hepatitis C virus), papilloma viruses, orthomyxoviruses (including, for example, influenza A, influenza B, and influenza C), paramyxoviruses, coronaviruses, picornaviruses, reoviruses, togaviruses, flaviviruses, bunyaviridae, rhabdoviruses, rotavirus, respiratory syncitial virus, human immunodeficiency virus, or retroviruses.
INCORPORATION BY REFERENCE
[0477] All references, articles, publications, patents, patent publications, and patent applications cited herein are incorporated by reference in their entireties for all purposes. However, mention of any reference, article, publication, patent, patent publication, and patent application cited herein is not, and should not be taken as, an acknowledgment or any form of suggestion that they constitute valid prior art or form part of the common general knowledge in any country in the world.
EXAMPLES
Example 1: Materials and Methods
[0478] The experiments described herein utilize the CRISPR/Cas9 system to modulate expression of one or more endogenous target genes in different T cell populations.
I. Materials
[0479] gRNAs:
[0480] Unless otherwise indicated, all experiments use single-molecule gRNAs (sgRNAs). Dual gRNA molecules were used as indicated and were formed by duplexing 200 .mu.M tracrRNA (IDT Cat#1072534) with 200 .mu.M of target-specific crRNA (IDT) in nuclease free duplex buffer (IDT Cat#11-01-03-01) for 5 min at 95.degree. C., to form 100 .mu.M of tracrRNA:crRNA duplex, where the tracrRNA and crRNA are present at a 1:1 ratio. Targeting sequences of the gRNAs used in the following experiments are provided in Table 10 below.
TABLE-US-00007 TABLE 10 Experiment gRNA targeting-domain encoding sequences SEQ Target Gene Guide ID Sequence ID Pdcd1-murine Nm.Pdcd1 CGGAGGATCTTATGCTGAAC 778 Lag3-murine Nm.Lag3 GCCAAGTGGACTCCTCCTGG 602 Cblb-murine Nm.Cblb CCTTATCTTCAGTCACATGC 502 CBLB-human Nm.CBLB TAAACTTACCTGAAACAGCC 521 BCOR-human Nm.BCOR GTGCAGACTGGAGAATACAG 715 Zc3h12a-murine Nm.Zc3h12a TTCCCTCCTCTGCCAGCCAT 1505 ZC3H12A-human Nh.ZC3H12A_1 GGAGTGGAAGCGCTTCATCG 1434 Nr4a3-murine Nm.Nr4a3 GGCAGCGTTGTCGCCGCACA 1544 Map4k1-murine Nm.Map4k1 TTGCCGGCACGCCAACATCG 1515 OR1A2-human Nh.OR1A2_1 AGATGATGTCAACCAAGGAG 1574 Olfr421-mouse Nm.Olfr421_1 GGAAGAAGTACATCTGCAAG 1574
[0481] Cas9:
[0482] Cas9 was expressed in target cells by introduction of either Cas9 mRNA or a Cas9 protein. Unless otherwise indicated, Cas9-encoding mRNA comprising a nuclear localization sequence (Cas9-NLS mRNA) derived from S. pyogenes (Trilink L-7206) or Cas9 protein derived from S. pyogenes (IDT Cat#1074182) was used in the following experiments.
[0483] RNPs:
[0484] Human gRNA-Cas9 ribonucleoproteins (RNPs) were formed by combining 1.2 .mu.L of 100 .mu.M tracrRNA:crRNA duplex with 1 .mu.L of 20 .mu.M Cas9 protein and 0.8 .mu.L of PBS. Mixtures were incubated at RT for 20 minutes to form the RNP complexes. Murine RNPs were formed by combining 1 Volume of 44 .mu.M tracrRNA:crRNA duplex with 1 Volume of 36 .mu.M Cas9. Mixtures were incubated at RT for 20 minutes to form the RNP complexes.
[0485] Mice:
[0486] Wild type CD8.sup.+ T cells were derived from C57BL/6J mice (The Jackson Laboratory, Bar Harbor Me.). Ovalbumin (Ova)-specific CD8.sup.+ T cells were derived from OT1 mice (C57BL/6-Tg(TcraTcrb) 1100Mjb/J; Jackson Laboratory). OT1 mice comprise a transgenic TCR that recognizes residues 257-264 of the ovalbumin (Ova) protein. gp100-specific CD8+ T cells were derived from PMEL mice (B6.Cg-Thy1<a>/CyTg(TcraTcrb) 8Rest/J; The Jackson Laboratory, Bar Harbor Me. Cat #005023). Mice constitutively expressing the Cas9 protein were obtain from Jackson labs (B6J.129(Cg)-Gt(ROSA)26Sortm1.1(CAG-cas9*,-EGFP)Fezh/J; The Jackson Laboratory, Bar Harbor Me. Strain #026179), TCR-transgenic mice constitutively expressing Cas9 were obtained by breeding of OT1 and PMEL mice with Cas9 mice.
[0487] CAR Expression Constructs:
[0488] CARs specific for human CD19, Her2/Erbb2, and EGFR proteins were generated. Briefly, the 22 amino acid signal peptide of the human granulocyte-macrophage colony stimulating factor receptor subunit alpha (GMSCF-Rt) was fused to an antigen-specific scFv domain specifically binding to one of CD19, Her2/Erbb2, or EGFR. The human CD8t stalk was used as a transmembrane domain. The intracellular signaling domains of the CD35 chain were fused to the cytoplasmic end of the CD8t stalk. For anti-CD19 CARs, the scFv was derived from the anti-human CD19 clone FMC63. To create a CAR specific for human HER2/ERBB2, the anti-human HER2 scFv derived from trastuzumab was used. Similarly, to generate a CAR specific for EGFR, the anti-EGFR scFv derived from cetuximab was used. A summary of exemplary CAR constructs is shown below and amino acid sequences of the full length CAR constructs are provided in SEQ ID NOs: 26, 28, and 30, and nucleic acid sequences of the full length CAR constructs are provided in SEQ ID NOs: 27, 29, and 31.
TABLE-US-00008 TABLE 11 Exemplary CAR constructs Ag- Intra - Trans- AA NA binding cellular membrane SEQ SEQ CAR Ref ID Target domain Domain Domain ID ID KSQCAR017 human Cetuximab CD3 CD8a 26 27 EGFR H225 zeta hinge scFv KSQCAR1909 human FMC63 CD3 CD8a 28 28 CD19 scFv zeta hinge KSQCAR010 human Herceptin CD3 CD8a 30 31 HER2 scFv zeta hinge
[0489] Engineered TCRs Expression Constructs:
[0490] Recombinant TCRs specific for NY-ESO1, MART-1, and WT-1 were generated. Paired TCR-.alpha.:TCR-.beta. variable region protein sequences encoding the 1G4 TCR specific for the NY-ESO-1 peptide SLLMWITQC (SEQ ID NO: 2), the DMF4 and DMF5 TCRs specific for the MART-1 peptide AAGIGILTV (SEQ ID NO: 3), and the DLT and high-affinity DLT TCRs specific for the WT-1 peptide, each presented by HLA-A*02:01, were identified from the literature (Robbins et al, Journal of Immunology 2008 180:6116-6131). TCRt chains were composed of V and J gene segments and CDR3.alpha. sequences and TCR.beta. chains were composed of V, D, and J gene segment and CDR3-.beta. sequences. The native TRAC (SEQ ID NO: 22) and TRBC (SEQ ID NOs: 24) protein sequences were fused to the C-terminal ends of the a and 3 chain variable regions, respectively, to produce 1G4-TCR .alpha./.beta.chains (SEQ ID NOs: 11 and 12, respectively), 95:LY 1G4-TCR .alpha./.beta.chains (SEQ ID NOs: 14 and 13, respectively), DLT-TCR .alpha./.beta.chains (SEQ ID NOs: 5 and 4, respectively), high-affinity DLT-TCR .alpha./.beta.chains (SEQ ID NOs: 8 and 7, respectively), DMF4-TCR .alpha./.beta.chains (SEQ ID NOs: 17 and 16, respectively), and DMF5-TCR .alpha./.beta.chains (SEQ ID NOs: 20 and 19, respectively).
[0491] Codon-optimized DNA sequences encoding the engineered TCR.alpha. and TCR.beta. chain proteins were generated where the P2A sequence (SEQ ID NO: 1) was inserted between the DNA sequences encoding the TCR.beta. and the TCR.alpha. chain, such that expression of both TCR chains was driven off of a single promoter in a stoichiometric fashion. The expression cassettes encoding the engineered TCR chains therefore comprised the following format: TCR.beta.-P2A-TCR.alpha.. Final protein sequences for each TCR construct are provided in SEQ ID NO: 12 (1G4), SEQ ID NO: 15 (95:LY 1G4), SEQ ID NO: 6 (DLT), SEQ ID NO: 9 (high-affinity DLT), SEQ ID NO: 18 (DMF4), and SEQ ID NO: 21 (DMF5).
[0492] Lentiviral Expression of CAR and TCR Constructs:
[0493] The CAR and engineered TCR expression constructs described above were then inserted into a plasmid comprising an SFFV promoter driving expression of the engineered receptor, a T2A sequence, and a puromycin resistance cassette. Unless otherwise indicated, these plasmids further comprised a human or a murine (depending on the species the T cells were derived from) U6 promoter driving expression of one or more sgRNAs. Lentivirus constructs comprising an engineered TCR expression construct may further comprise an sgRNA targeting the endogenous TRAC gene, which encodes the constant region of the a chain of the T cell receptor. Lentiviruses encoding the engineered receptors described above were generated as follows. Briefly, 289.times.10.sup.6 of LentiX-293T cells were plated out in a 5-layer CellSTACK 24 hours prior to transfection. Serum-free OptiMEM and TransIT-293 were combined and incubated for 5 minutes before combining helper plasmids (58 .mu.g VSVG and 115 .mu.g PAX2-Gag-Pol) with 231 .mu.g of an engineered receptor- and sgRNA-expressing plasmid described above. After 20 minutes, this mixture was added to the LentiX-293T cells with fresh media. Media was replaced 18 hours after transfection and viral supernatants were collected 48 hours post-transfection. Supernatants were treated with Benzonase.RTM. nuclease and passed through a 0.45 .mu.m filter to isolate the viral particles. Virus particles were then concentrated by Tangential Flow Filtration (TFF), aliquoted, tittered, and stored at -80.degree. C.
[0494] Retroviral sgRNA Expression Constructs and Production:
[0495] sgRNA sequences were inserted into a plasmid downstream of a murine U6 promoter. Human CD2 was inserted under the UbiC promoter downstream of the sgRNA as a selectable marker. When rescue experiments were conducted, plasmids included the above elements as well as a codon optimized, gRNA-resistant cDNA encoding wild-type murine Zc3h12a. Retroviruses were generated as follows. Phoenix-GP cells (ATCC.RTM. CRL-3215.TM.) were used as producer cells. When 80% confluent, producer cells were transfected with pCL-Eco Retrovirus Packaging Vector and the plasmid encoding the sgRNA and surface selection marker described above using TransIT.RTM.-293 Transfection Reagent (Mirusbio, Catalog #2706). 18 hours after transfection, media was changed for complete T cell media (RPMI+10% heat inactivated FBS, 20 mM HEPES, 100 U/mL Penicillin, 100 .mu.g/mL Streptomycin, 50 .mu.M Beta-Mercaptoethanol). Viral supernatants were harvested every 12 hours for a total of 3 harvests, spun and frozen at -80.degree. C.
II. Methods
[0496] Human T Cell Isolation and Activation:
[0497] Total human PBMCs were isolated from fresh leukopacks by Ficoll gradient centrifugation. CD8+ T-cells were then purified from total PBMCs using a CD8+ T-cell isolation kit (Stemcell Technologies Cat #17953). For T cell activation, CD8+ T cells were plated at 2.times.106 cells/mL in X-VIVO 15 T Cell Expansion Medium (Lonza, Cat#04-418Q) in a T175 flask, with 6.25 .mu.L/mL of ImmunoCult T-cell activators (anti-CD3/CD28/CD2, StemCell Technologies, Vancouver BC, Canada) and 10 ng/mL human IL2. T-cells were activated for 18 hours prior to transduction with lentiviral constructs.
[0498] Human TIL Isolation and Activation:
[0499] Tumor infiltrating lymphocytes can also be modified by the methods described herein. In such cases, tumors are surgically resected from human patients and diced with scalpel blades into 1 mm3 pieces, with a single piece of tumor placed into each well of a 24 plate. 2 mL of complete TIL media (RPMI+10% heat inactivated human male AB serum, 1 mM pyruvate, 20 .mu.g/mL gentamycin, 1.times. glutamax) supplemented with 6000 U/mL of recombinant human IL-2 is added to each well of isolated TILs. 1 mL of media is removed from the well and replaced with fresh media and IL-2 up to 3 times a week as needed. As wells reach confluence, they are split 1:1 in new media+IL-2. After 4-5 weeks of culture, the cells are harvested for rapid expansion.
[0500] TIL Rapid Expansion:
[0501] TILs are rapidly expanded by activating 500,000 TILs with 26.times.106 allogeneic, irradiated (5000cGy) PBMC feeder cells in 20 mL TIL media+20 mL of Aim-V media (Invitrogen)+30 ng/mL OKT3 mAb. 48 hours later (Day 2), 6000 U/mL IL-2 is added to the cultures. On day 5, 20 mL of media is removed, and 20 mL fresh media (+30 ng/ml OKT3) is added. On Day 7, cells are counted, and reseeded at 60.times.106 cells/L in G-Rex6M well plates (Wilson Wolf, Cat#80660M) or G-Rex100M (Wilson Wolf, Cat#81100S), depending on the number of cells available. 6000 U/mL fresh IL-2 is added on Day 9 and 3000 U/mL fresh IL-2 is added on Day 12. TILs are harvested on Day 14. Expanded cells are then slow-frozen in Cryostor CS-10 (Stemcell Technologies Cat #07930) using Coolcell Freezing containers (Corning) and stored long term in liquid nitrogen.
[0502] Murine T Cell Isolation and Activation:
[0503] Spleens from WT or transgenic mice were harvested and reduced to a single cell suspension using the GentleMACS system, according to the manufacturer's recommendations. Purified CD8.sup.+ T cells were obtained using the EasySep Mouse CD8.sup.+ T Cell Isolation Kit (StemCell Catalog #19853). CD8 T-cells were cultured at 1.times.106 cells/mL in complete T cell media (RPMI+10% heat inactivated FBS, 20 mM HEPES, 100 U/mL Penicillin, 100 .mu.g/mL Streptomycin, 50 .mu.M Beta-Mercaptoethanol) supplemented with 2 ng/mL of Recombinant Mouse IL-2 (Biolegend Catalog #575406) and activated with anti-CD3/anti-CD28 beads (Dynabeads.TM. Mouse T-Activator CD3/CD28 for T-Cell Expansion and Activation Cat #11456D).
[0504] Lentiviral Transduction of Human T Cells:
[0505] T-cells activated 18 hours prior were seeded at 5.times.10.sup.6 cells per well in a 6 well plate, in 1.5 mL volume of X-VIVO 15 media, 10 ng/mL human IL-2 and 12.5 .mu.L Immunocult Human CD3/CD28/CD2 T-cell Activator. Lentivirus expressing the engineered receptors was added at an MOI capable of infecting 80% of all cells. 25 .mu.L of Retronectin (1 mg/mL) was added to each well. XVIVO-15 media was added to a final volume of 2.0 mL per well. Unless otherwise indicated, lentiviruses also expressed the sgRNAs. Plates were spun at 600.times.g for 1.5 hours at room temperature. After 18 hours (Day 2), cells were washed and seeded at 1.times.10.sup.6 cells/mL in X-VIVO 15, 10 ng/mL IL2+ T-cell activators.
[0506] Retroviral Transduction of Murine T Cells:
[0507] Where indicated, gRNAs were introduced into Cas9 transgenic T cells by Retroviral transduction. Murine T-cells activated 24 hours prior were seeded at 3.times.10.sup.6 cells per well in a 6 well plate coated with 5 .mu.g/mL RetroNectin (Takara Clontech Catalog # T100B), in 2 mL Retrovirus supernatant with 5 .mu.g/mL protamine sulfate and 2 ng/mL of Recombinant Mouse IL-2. Retroviruses express the gRNAs and a surface selection marker (hCD2 or CD90.1). Plates were spun at 600.times.g for 1.5 hours at room temperature. After 18 hours (Day 2), cells were washed and seeded at 1.times.10.sup.6 cells/mL in complete T cell media supplemented with 2 ng/mL of Recombinant Mouse IL-2. 24 hours after infection, cells were washed and cultured in complete T cell media supplemented with IL-2. After 24 hours, activation beads were removed and infected cells were purified using EasySep Human CD2 Positive Selection Kit (StemCell Catalog #18657) or EasySep Mouse CD90.1 Positive Selection Kit (StemCell Catalog #18958). Edited murine CD8 T were cultured at 1.times.10.sup.6 cells/mL in complete T cell media supplemented with IL-2 for an additional 1-4 days.
[0508] Electroporation of Human T Cells:
[0509] 3 days after T cell activation, T cells were harvested and resuspended in nucleofection buffer (18% supplement 1, 82% P3 buffer from the Amaxa P3 primary cell 4D-Nuclefector X kit S) at a concentration of 100.times.10.sup.6 cells/mL. 1.5 .mu.L of sgRNA/Cas9 RNP complexes (containing 120 pmol of crRNA:tracrRNA duplex and 20 pmol of Cas9 nuclease) and 2.1 .mu.L (100 pmol) of electroporation enhancer were added per 20 .mu.L of cell solution. 25 .mu.L of the cell/RNP/enhancer mixture was then added to each electroporation well. Cells were electroporated using the Lonza electroporator with the "EO-115" program. After electroporation, 80 .mu.L of warm X-VIVO 15 media was added to each well and cells were pooled into a culture flask at a density of 2.times.10.sup.6 cells/mL in X-VIVO 15 media containing IL-2 (10 ng/mL). On Day 4, cells were washed, counted, and seeded at densities of 50-100.times.10.sup.6 cells/L in X-VIVO 15 media containing IL-2 (10 ng/mL) in G-Rex6M well plates or G-Rex100M, depending on the number of cells available. On Days 6 and 8, 10 ng/mL of fresh recombinant human IL-2 was added to the cultures.
[0510] Electroporation of Mouse T Cells:
[0511] Murine T-cells activated 48 hours prior were harvested, activation beads were removed and cells were washed and resuspended in Neon nucleofection buffer T. Up to 2.times.10.sup.6 cells resuspended in 9 uL Buffer T and 20.times.10.sup.6 cells resuspended in 90 uL Buffer T can be electroporated using Neon.TM. 10-.mu.L tip and Neon.TM. 100-.mu.L tip respectively. gRNA/Cas9 RNP complexes or ZFN mRNAs (1 .mu.L per 10 .mu.L tip or 10 .mu.L per 100 .mu.L Tip) and 10.8 .mu.M electroporation enhancer (2 .mu.L per 10 .mu.L Tip or 20 .mu.L per 100 .mu.L Tip) were added to the cells. T-cells mixed with gRNA/Cas9 RNP complexes or ZFN mRNAs were pipeted into the Neon.TM. tips and electroporated using the Neon Transfection System (1700 V/20 ms/1 pulses). Immediately after electroporation, cells were transferred into a culture flask at a density of 1.6.times.10.sup.6 cells/mL in warm complete T cell media supplemented with 2 ng/mL of Recombinant Mouse IL-2. Edited murine CD8 T cells were further cultured at 1.times.10.sup.6 cells/mL in complete T cell media supplemented with IL-2 for an additional 1-4 days.
[0512] Purification and Characterization of Engineered T Cells:
[0513] 10 days after T cell activation, cells were removed from the culture flasks, and edited, engineered receptor-expressing CD8.sup.+ T cells were purified. Expression of the engineered receptor can be determined by antibody staining, e.g., antibodies for V1312 for DMF4 TCR or V.beta.13/13.1 for NY-ESO-1 or 1G4). Further determination of editing of target genes can be assessed by FACS analysis of surface proteins (e.g., CD3), western blot of the target protein, and/or TIDE/NGS analysis of the genomic cut-site. Purified cells can then be slow-frozen in Cryostor CS-10 (Stemcell Technologies Cat #07930) using Coolcell Freezing containers (Corning), and stored long term in liquid nitrogen for future use.
Example 2: Characterization of Edited, Receptor-Engineered T Cells
[0514] Experiments were performed in which edited receptor-expressing cells were purified based on cell surface expression of CD3. Prior to engineering, CD8+ T cells express CD3 molecules on the cell surface as part of a complex that includes the TCR .alpha./.beta. chains (FIG. 4A). The T cells were transduced with a lentivirus expressing a CAR, a guide RNA targeting the TRAC gene, and a guide RNA targeting the B2M gene, which was used to assess the editing of non-TCR genes as a proxy for target gene editing. Following lentiviral transduction and Cas9 mRNA electroporation, successfully transduced and edited T cells demonstrate a loss of surface CD3 expression due to editing of the TRAC gene and a loss of HLA-ABC expression due to the editing of the B2M gene (FIG. 4B). CD3-expressing cells were removed from the bulk population (FIG. 4B) using the EasySep human CD3-positive selection kit (StemCell Tech Cat#18051). Cells were then subjected to two rounds of negative magnetic selection for CD3. This process yielded highly purified CD3-negative T cells expressing (FIG. 4C). Staining with a recombinant CD19-Fc reagent (which binds CD19 CAR) demonstrated that edited cells show surface expression of the CD19 CAR, whereas unedited cells do not (FIG. 4D). Similar experiments were performed with CD45 and B2M targeting sgRNAs. Cas9 editing activity in T cells was confirmed by assessing CD45 and B2M expression by flow cytometry was assessed 96 hours later, and efficient Cas9 function is indicated by a loss of CD45 expression on the surface of the T cells as determined by FACS. Co-electroporation with Cas9 mRNA and Cas9 RNPs led to substantial editing at the CD45 and B2M loci, with 66.3% of the cells exhibiting dual editing.
[0515] Target editing was performed as described in the above examples and the editing of a single exemplary gene, CBLB, was confirmed using both the Tracking of Indels by Decomposition (TIDE) analysis method and western blot analysis. TIDE quantifies editing efficacy and identifies the predominant types of insertions and deletions (indels) in the DNA of a targeted cell pool.
[0516] Genomic DNA (gDNA) was isolated from edited T cells using the Qiagen Blood and Cell Culture DNA Mini Kit (Cat #: 13323) following the vendor recommended protocol and quantified. Following gDNA isolation, PCR was performed to amplify the region of edited DNA using locus-specific PCR primers (F: 5'-CCACCTCCAGTTGTTGCATT-3' (SEQ ID NO: 32); R: 5'-TGCTGCTTCAAAGGGAGGTA-3' (SEQ ID NO: 33). The resulting PCR products were run on a 1% agarose gel, extracted, and purified using the QIAquick Gel Extraction Kit (Cat#: 28706). Extracted products were sequenced by Sanger sequencing and Sanger sequencing chromatogram sequence files were analyzed by TIDE. In CBLB-edited T cells edited by methods using either gRNA/Cas9 RNP complexes or Cas9 mRNA introduced with gRNA expressing lentivirus (in each case, the CBLB gRNA used is SEQ ID NO: 288), the resulting TIDE analysis confirmed editing of the CBLB target gene. In addition to TIDE, depletion of CBLB protein levels were confirmed by western blot using an anti-CBLB antibody (SCT Cat #9498). The data is provided in FIGS. 5A and 5B and FIG. 6.
[0517] Another method by which editing of a gene is assessed is by next generation sequencing. For this method, genomic DNA (gDNA) was isolated from edited T cells using the Qiagen Blood and Cell Culture DNA Mini Kit (Cat#: 13323) following the vendor recommended protocol and quantified. Following gDNA isolation, PCR was performed to amplify the region of edited genomic DNA using locus-specific PCR primers containing overhangs required for the addition of Illumina Next Generation sequencing adapters. The resulting PCR product was run on a 1% agarose gel to ensure specific and adequate amplification of the genomic locus occurred before PCR cleanup was conducted according to the vendor recommended protocol using the Monarch PCR & DNA Cleanup Kit (Cat#: T1030S). Purified PCR product was then quantified, and a second PCR was performed to anneal the Illumina sequencing adapters and sample specific indexing sequences required for multiplexing. Following this, the PCR product was run on a 1% agarose gel to assess size before being purified using AMPure XP beads (produced internally). Purified PCR product was then quantified via qPCR using the Kapa Illumina Library Quantification Kit (Cat#: KK4923) and Kapa Illumina Library Quantification DNA Standards (Cat#: KK4903). Quantified product was then loaded on the Illumina NextSeq 500 system using the Illumina NextSeq 500/550 Mid Output Reagent Cartridge v2 (Cat#: FC-404-2003). Analysis of produced sequencing data was performed to assess insertions and deletions (indels) at the anticipated cut site in the DNA of the edited T cell pool.
Example 3: Identification of Adoptive T Cell Transfer Therapy Targets Through an OT1/B16-Ova CRISPR/Cas9 Functional Genomic Screen
[0518] Experiments were performed to identify targets that regulate accumulation of T cells in tumors. A pooled CRISPR screen was performed in which a pool of sgRNAs, each of which target a single gene, were introduced into a population of tumor-specific T cells such that each cell in the population comprised a single sgRNA targeting a single gene. To determine the effect of a particular gene on the accumulation of T cells in tumor samples, the frequency of each sgRNA in the population of T cells was determined at the beginning of the experiment and compared to the frequency of the same sgRNA at a later time-point in the experiment. The frequency of sgRNAs targeting genes that positively regulate T cell accumulation in tumor samples (e.g., genes that positively-regulate T cell proliferation, viability, and/or tumor infiltration) is expected to increase over time, while the frequency of sgRNAs targeting genes that negatively regulate T cell accumulation in tumor samples (e.g., genes that negatively-regulate T cell proliferation, viability, and/or tumor infiltration) is expected to decrease over time.
[0519] Pooled CRISPR screens were performed with CD8.sup.+ T cells derived from Cas9 expressing OT1 mice according to methods described in Example 1. The pooled sgRNA library was introduced to purified OTI CD8.sup.+ T cells cultured in vitro to generate a population of edited CD8.sup.+ T cells. After in vitro engineering, the edited OT1 CD8.sup.+ T cells were intravenously (iv) administered to B16/Ova tumor-bearing, C56BL/6 mice. After in vivo expansion, organs were harvested and CD45+ cells were enriched. Genomic DNA from the isolated CD45+ cells was isolated using Qiagen DNA extraction kits. The sgRNA library was then amplified by PCR and sequenced using Illumina next-generation sequencing (NGS).
[0520] The distribution and/or frequency of each sgRNA in samples harvested from tumor-bearing mice was analyzed and compared to the distribution and/or frequency of each sgRNA in the initial T cell population. Statistical analyses were performed for each individual sgRNA to identify guides that were significantly enriched in T cell populations harvested from tumor bearing mice and to assign an enrichment score to each of the guides. Enrichment scores for individual sgRNA targeting the same gene were aggregated to identify target genes that had a consistent and reproducible effect on T cell accumulation across multiple sgRNAs and across multiple OT1 donor mice. The results of these experiments are shown below in Table 12. Percentiles in Table 12 were calculated using the following equation: percentile score=1-(gene enrichment rank/total number of genes screened).
TABLE-US-00009 TABLE 12 Target Gene Percentile Scores Target Name Percentile Score IKZF1 0.995 NFKBIA 0.986 GATA3 0.993 BCL3 0.698 IKZF3 0.995 SMAD2 0.978 TGFBR1 0.991 TGFBR2 0.987 TNIP1 0.991 TNFAIP3 0.998 IKZF2 0.622 TANK 0.83 PTPN6 0.782 BCOR 0.720 CBLB 0.999 NRP1 0.826 HAVCR2 0.86 LAG3 0.82 BCL2L11 0.9928 CHIC2 0.997 FLI1 0.999 PCBP1 0.997 PBRM1 0.944 WDR6 0.953 E2F8 0.867 SERPINA3 0.822 SEMA7A 0.78 DHODH 0.990 UMPS 0.989 ZC3H12A 0.999 MAP4K1 0.842 NR4A3 0.997
Example 4: Identification of Adoptive T Cell Transfer Therapy Targets Through In Vitro CAR-T and CRISPR/Cas9 Functional Genomic Screens
[0521] Experiments were performed to identify targets that regulate accumulation of CAR-T cells tumor samples. A pooled, genome-wide CRISPR screen was performed in which a pool of sgRNAs, each of which target a single gene, was introduced into a population of tumor-specific human CAR-T cells, such that each cell in the population comprised a single sgRNA targeting a single gene. To determine the effect of a particular gene in CAR-T cell accumulation in tumor samples, the frequency of each sgRNA in the population of CAR-T cells was determined at the beginning of the experiment and compared to the frequency of the same sgRNA at a later time-point in the experiment. The frequency of sgRNAs targeting genes that positively regulate CAR-T cell accumulation in tumor samples (e.g., genes that positively-regulate T cell proliferation, viability, and/or tumor infiltration) is expected to increase over time, while the frequency of sgRNAs targeting genes that negatively regulate CAR-T cell accumulation in tumor samples (e.g., genes that negatively-regulate T cell proliferation, viability, and/or tumor infiltration) is expected to decrease over time.
[0522] In vitro screens were performed using CAR-T cells specific for human CD19. Pooled sgRNA libraries were introduced to the CD19 CARTs as described above and cells were electroporated with Cas9 mRNA as described in Example 1 to generate a population of Cas9-edited CD19 CARTs. The edited CD19 CARTs were then co-cultured with an adherent colorectal carcinoma (CRC) cell line engineered to express CD19 or a Burkitt's lymphoma cell line expressing endogenous CD19. CARTs were harvested at various time points throughout the co-culture period and cell pellets were frozen down. Genomic DNA (gDNA) was isolated from these cell pellets using Qiagen DNA extraction kits and sequenced using Illumina next-generation sequencing.
[0523] The distribution and/or frequency of each sgRNA in the aliquots taken from the CART/tumor cell co-culture was analyzed and compared to the distribution and/or frequency of each sgRNA in the initial edited CAR-T cell population. Statistical analyses were performed for each individual sgRNA to identify sgRNAs that were significantly enriched in CAR-T cell populations after tumor cell co-culture and to assign an enrichment score to each of the guides. Enrichment scores for individual sgRNA that target the same gene were aggregated to identify target genes that have a consistent and reproducible effect on CAR-T cell accumulation in tumor samples across multiple sgRNAs and CAR-T cell population. Targets were ranked and called for further investigation based on percentile. The results of these experiments are shown below in Table 13. Percentiles in Table 13 were calculated using the following equation:
percentile score=1-(gene enrichment rank/total number of genes screened).
TABLE-US-00010 TABLE 13 Target Gene Percentile Scores Target Name Percentile Score IKZF1 0.999 IKZF3 0.962 TGFBR1 0.778 TNIP1 0.64 TNFAIP3 0.791 FOXP3 0.866 IKZF2 0.907 TANK 0.93 PTPN6 0.707 BCOR 0.999 CBLB 0.989 BCL2L11 0.93 CHIC2 0.71 WDR6 0.962 E2F8 0.971 DHODH 0.763
Example 5: Identification of Adoptive T Cell Transfer Therapy Targets Through an In Vivo CAR-T/Tumor CRISPR/Cas9 Functional Genomic Screen
[0524] Experiments were performed to identify targets that regulate CAR-T cell accumulation in the presence of tumors. A pooled CRISPR screen was performed in which a pool of sgRNAs, each of which target a single gene, was introduced into a population of tumor-specific human CAR-T cells such that each cell in the population comprised a single sgRNA targeting a single gene. To determine the effect of a particular gene in CAR-T cell accumulation in tumor samples, the frequency of each sgRNA in the population of CAR-T cells was determined at the beginning of the experiment and compared to the frequency of the same sgRNA at a later time-point in the experiment. The frequency of sgRNAs targeting genes that positively regulate CAR-T cell accumulation in tumor samples (e.g., genes that positively-regulate T cell proliferation, viability, and/or tumor infiltration) is expected to increase over time, while the frequency of sgRNAs targeting genes that negatively regulate CAR-T cell accumulation in tumor samples (e.g., genes that negatively regulate T cell proliferation, viability, and/or tumor infiltration) is expected to decrease over time.
[0525] In vivo screens performed in two separate subcutaneous xenograft models: a Burkitt lymphoma model and a colorectal cancer (CRC) model. For the Burkitt model, 1.times.10.sup.6 Burkitt lymphoma tumor cells in Matrigel were subcutaneously injected into the right flank of 6-8 week old NOD/SCID gamma (NSG) mice. Mice were monitored, randomized, and enrolled into the study 13 days post-inoculation, when tumors reached approximately 200 mm.sup.3 in volume. For the CRC model, CRC cells were engineered to express CD19, and 5.times.10.sup.6 tumor cells in Matrigel were subcutaneously injected into the right flank of 6-8 week old NSG mice. Mice were monitored, randomized, and enrolled into the study 12 days post-inoculation when tumors reached approximately 200 mm.sup.3 in volume. Cas9-engineered CD19 CAR-T cells were administered iv via the tail vein at 3.times.10.sup.6 and 10.times.10.sup.6/mouse (3M and 10M). Tumors were collected 8 to 10 days post-CAR-T injection and frozen in liquid nitrogen. These tissues were later dissociated and processed for genomic DNA extraction.
[0526] The distribution and/or frequency of each sgRNA in the genomic DNA samples taken at study end was analyzed and compared to the distribution and/or frequency of each sgRNA in the initial edited-CAR-T cell population. Statistical analyses were performed for each individual sgRNA to identify sgRNAs were are significantly enriched in genomic DNA samples taken at study end and to assign an enrichment score to each of the guides. Enrichment scores for individual sgRNA that target the same gene were aggregated to identify target genes that have a consistent and reproducible effect on CAR-T cell abundance across multiple sgRNAs and CAR-T cell populations. Targets were ranked and called for further investigation based on percentile. The results of these experiments are shown below in Table 14. Percentiles in Table 14 were calculated using the following equation: percentile score=1-(gene enrichment rank/total number of genes screened).
TABLE-US-00011 TABLE 14 Target Gene Percentile Scores Target Name Percentile Score NFKBIA 0.95 SMAD2 0.816 FOXP3 0.92 IKZF2 0.895 TANK 0.923 PTPN6 0.979 CBLB 0.958 PPP2R2D 0.926 NRP1 0.795 HAVCR2 0.992 LAG3 0.97 TIGIT 0.916 CTLA4 0.884 BCL2L11 0.776 RBM39 0.94 E2F8 0.968 CALM2 0.902 SERPINA3 0.907 SEMA7A 0.918
Example 6: Validation of Single-Edited Adoptively Transferred T Cells in a Murine OT1/B16-Ova Syngeneic Tumor Model
[0527] Targets with percentile scores of 0.6 or greater in Examples 3-5 were selected for further evaluation in a single-guide format to determine whether editing a target gene in tumor-specific T cells conferred an increase in anti-tumor efficacy in a murine OT1/B16-Ova subcutaneous tumor model. Evaluation of exemplary targets is described herein, however these methods can be used to evaluate any of the potential targets described above.
[0528] Anti-tumor efficacy of single-edited T cells was evaluated in mice using the B16-Ova subcutaneous syngeneic tumor model, which is sensitive to treatment with anti-PD1 antibodies. Briefly, 6-8 week old female C57BL/6J mice from Jackson labs were injected subcutaneously with 0.5.times.10.sup.6 B16-Ova tumor cells. When tumors reached a volume of approximately 100 mm.sup.3 mice were randomized into groups of 10 and injected intravenously with edited mouse OT1 CD8+ T cells via tail vein. Prior to injection, the OT1 T cells were edited by electroporation with gRNA/Cas9 RNP complexes comprising (i) a control gRNA; (ii) a single Map4k1-targeting gRNA, (iii) a single Zc3h12a-targeting gRNA; (iv) a single Cblb-targeting gRNA; (v) a single Nr4a3-targeting gRNA or; (vi) a single PD1-targeting gRNA. To generate a population of tumor-specific CD8.sup.+ T cells with edited target genes, spleens from female OT1 mice were harvested and CD8 T cells were isolated and edited as described in Example 1. The edited OT1 CD8.sup.+ T cells were then administered intravenously to B16-Ova tumor-bearing C56BL/6 mice. Body weight and tumor volume were measured at least twice per week. Tumor volume was calculated as mean and standard error of the mean for each treatment group. The percentage tumor growth inhibition (TGI) was calculated using mean tumor volumes (TV) according to the following formulas:
% TGI=(TV-Target.sub.final-TV-Target.sub.initial)/(TV-Control.sub.final-- TV-Controlt.sub.initial),
[0529] where TV=mean tumor volume, final for Cblb TGI=Day 18 post-T cell transfer, final for Zc3h12a, Nr4a3, and Map4k1=Day 14 post-T cell transfer, and initial=Day 0 (i.e., day of T cell transfer).
[0530] Results of Cblb-edited T cells are shown in FIG. 7A. These data demonstrate that editing of the Cblb gene in T cells leads to anti-tumor efficacy with a TGI of 85% at day 18. Results of Zc3h12a-edited T cells are shown in FIG. 7B. These data demonstrate that editing of the Zc3h12a gene in T cells enhances anti-tumor efficacy of the T cells with a TGI of 106% at day 14. Data from an additional experiment with Zc3h12a-edited cells are shown in FIG. 7C. Results of Map4k1-edited T cells are shown in FIG. 7D. These data demonstrate that editing of the Map4k1 gene in T cells enhances anti-tumor efficacy of the T cells with a TGI of 72% at day 14. Results of Nr4a3-edited T cells are shown in FIG. 7E. These data demonstrate that editing of the Nr4a3 gene in T cells enhances anti-tumor efficacy of the T cells with a TGI of 56% at day 14.
Example 7: Validation of Single-Edited Adoptively Transferred T Cells in a Murine OT1/B16-Ova Syngeneic Tumor Model in Combination with Anti-Pd1 Therapy
[0531] Further experiments were performed to assess the effect of Map4k1-edited cells in combination with anti-PD1 therapy. 6-8 week old female C57BL/6J mice from Jackson labs were injected subcutaneously with 0.5.times.10.sup.6 B16-Ova tumor cells. When tumors reached a volume of approximately 100 mm.sup.3 mice were randomized into groups of 10 and injected intravenously with edited mouse OT1 CD8+ T cells via tail vein. Prior to injection these cells were edited with either a control guide or a single guide editing for the Map4k1 gene. The editing efficiency of the gRNA/Cas9 complex targeting Map4k1 gene was determined to be 82% using the NGS method. At the time of T cell transfer, designated cohorts were also initiated treatment with 2.5 mg/kg of anti-mouse PD1 antibody (clone RMP1-14, BioXcell), injected 3.times. week for the duration of the study. Body weight and tumor volume was measured at least twice per week. Tumor volume was calculated as mean and standard error of the mean for each treatment group. The percentage tumor growth inhibition (TGI) was calculated using the mean tumor volume from the Map4k1 group on day 14-day 1/mean tumor volume from control treated group on day 14-day 1 where day 1 is the day of edited mouse OT1 CD8+ T cell transfer. Results of this experiment are shown in FIG. 8A.
[0532] A similar experiment was conducted using Nr4a3-edited cells. The editing efficiency of the gRNA/Cas9 complex targeting the Nr4a3 gene was determined to be 28% using the NGS method. The percentage tumor growth inhibition (TGI) was calculated using the mean tumor volume from the Nr4a3 group on day 14-day 1/mean tumor volume from control treated group on day 14-day 1 where day 1 is the day of edited mouse OT1 CD8+ T cell transfer. Results of this experiment are shown in FIG. 8B.
[0533] Similar experiments are performed to assess the effect of Zc3h12a-edited cells in combination with anti-PD1 therapy on anti-tumor efficacy.
Example 8: Validation of Single-Edited Adoptively Transferred T Cells in a Murine PMEL and MC38/gp100 Syngeneic Tumor Model
[0534] Targets with percentile scores of 0.6 or greater in Examples 3-5 were selected for further evaluation in a single-guide format to determine whether editing a target gene in tumor-specific T cells conferred an increase in anti-tumor efficacy in a murine MC38gp100 subcutaneous syngeneic tumor model of colorectal cancer (which is insensitive to treatment with anti-PD1 antibodies). Evaluation of exemplary targets is described herein, however these methods can be used to evaluate any of the potential targets described above.
[0535] Briefly, 6-8 week old female C57BL/6J mice from Jackson labs were injected subcutaneously with 1.times.10.sup.6 MC38gp100 tumor cells. Prior to injection, the T cells were edited by electroporation with gRNA/Cas9 RNP complexes comprising (i) a control gRNA or (ii) a single Zc3h12a-targeting gRNA. When tumors reached a volume of approximately 100 mm.sup.3 mice were randomized into groups of 10 and injected intravenously with Zc3h12a-edited mouse PMEL CD8.sup.+ T cells via tail vein. Body weight and tumor volume was measured at least twice per week. Tumor volume was calculated as mean and standard error of the mean for each treatment group.
[0536] Results of Zc3h12a-edited T cells are shown in FIG. 9. These data demonstrate that editing of the Zc3h12a gene in T cells enhances anti-tumor efficacy of the T cells with a TGI of 77% at day 20. Similar experiments are performed to assess the effect of Nr4a3-edited cells and Map4k1-edited cells on anti-tumor efficacy in a PMEL/MC38 syngeneic tumor model.
Example 9: Validation of Single-Edited Adoptively Transferred T Cells in a Murine B16-F10 Syngeneic Tumor Model
[0537] Additional experiments are performed to assess the effect of editing Zc3h12a in the aggressive metastatic B16-F10 syngeneic tumor model with disease manifesting as lung metastasis.
[0538] Briefly, 6-8 week old female C57BL/6J mice from Jackson labs are injected intravenously with 0.5.times.10.sup.6 B16-F10 tumor cells. Mice are weighed and assigned to treatment groups using a randomization procedure prior to inoculation. At D3 post tumor inoculation, mice are injected intravenously with murine PMEL CD8+ T cells via tail vein. Prior to injection, these cells were edited by electroporation with gRNA/Cas9 RNP complexes comprising (i) a control gRNA; (ii) a single gRNA targeting the PD-1 gene; or (iii) a single gRNA targeting the Zc3h12a gene. Body weight is monitored at least twice per week. At Day 15 post tumor inoculation (Day 12 post edited PMEL transfer), mice lungs are perfused and fixed with 10% para-formaldehyde. After overnight fixation, lungs are transferred to 70% EtOH for further preservation. Anti-tumor efficacy can be evaluated by visually assessing the B16-F10 tumor burden which can be seen as black colonies of cancer cells on the lungs.
[0539] Survival is graphed as percent (FIG. 10). As shown in FIG. 10A, Zc3h12a-edited PMEL T cells were able to convey increased survival in comparison to control and PD1-edited PMEL T cells in a B16F10 lung met model. Similar experiments are performed to assess the effects of Nr4a3-edited and Map4k1-edited cells in a B16-F10 syngeneic tumor model.
Example 10: Validation of Single-Edited Adoptively Transferred T Cells in a Murine OT1/EG7-Ova Subcutaneous Syngeneic Tumor Model
[0540] Anti-tumor efficacy of Zc3h12a was further evaluated in mice using the Eg7-Ova subcutaneous syngeneic tumor model. 6-8 week old female C57BL/6J mice from Jackson labs were injected subcutaneously with 1.times.10.sup.6 Eg7-Ova tumor cells. When tumors reached a volume of approximately 100 mm.sup.3 mice were randomized into groups of 10 and injected intravenously with edited mouse OT1 CD8+ T cells via tail vein. Prior to injection these cells were edited with either a control guide or a single guide editing for the Zc3h12a gene. Body weight and tumor volume was measured at least twice per week. Tumor volume was calculated as mean and standard error of the mean for each treatment group.
[0541] The percentage tumor growth inhibition (TGI) was calculated using mean tumor volumes (TV) according to the following formulas:
% TGI=(TV-Target.sub.final-TV-Target.sub.initial)/(TV-Control.sub.final-- TV-Controlt.sub.initial),
[0542] where TV=mean tumor volume, final TGI=Day 14 post-T cell transfer, and initial=Day 0 (i.e., day of T cell transfer).
[0543] These data demonstrate that editing of the Zc3h12a in T cells enhances anti-tumor efficacy of the T cells with a TGI of 88% as shown in in FIG. 11. Similar experiments are performed to assess the effect of Nr4a3-edited cells and Map4k1-edited cells on anti-tumor efficacy in a OT1/EG7OVA subcutaneous syngeneic tumor model.
Example 11: Validation of Single-Edited Adoptively Transferred T Cells in the A375 Xenograft Tumor Model
[0544] Targets with percentile scores of 0.6 or greater in Examples 3-5 were selected for further evaluation in a single-guide format to determine whether editing a target gene in tumor-specific T cells conferred an increase in anti-tumor efficacy in the A375 xenograft tumor model. Evaluation of exemplary targets is described herein, however these methods can be used to evaluate any of the potential targets described above.
[0545] Briefly, 6-12 week old NSG mice from Jackson labs were injected subcutaneously with 5.times.10.sup.6 A375 cells. When tumors reached a volume of approximately 200 mm.sup.3, mice were randomized into groups of 8 and injected intravenously with 18.87.times.10.sup.6 for CBLB-edited NY-ESO-1-specific TCR transgenic T cells or 5.77.times.10.sup.6 ZC3H12A-edited NY-ESO-1-specific TCR transgenic T cells via tail vein. Body weight and tumor volume was measured at least twice per week. Tumor volume was calculated as mean and standard error of the mean for each treatment group and efficacy was evaluated as a decrease in mean tumor volume and an increase in survival compared to control edited cells. The percentage tumor growth inhibition (TGI) was calculated using the mean tumor volume from the ZC3H12A group on day 19-day 0/mean tumor volume from control treated group on day 19-day 0 where day 0 is the day of human TCR transgenic T cell transfer.
[0546] Results of these experiments are shown in FIG. 12. These data demonstrate that editing of the CBLB (FIG. 12A) and ZC3H12A (FIG. 12B) gene in T cells leads to anti-tumor efficacy in an A375 xenograft model. Similar experiments are performed to assess the efficacy of MAP4K1-edited T cells and NR4A3-edited T cells in the A375 xenograft model.
Example 12: Validation of Single-Edited Adoptively Transferred CD19 CAR-T Cells in a Raji Xenograft Model
[0547] The anti-tumor efficacy of editing MAP4K1 and NR4A3 in 1.sup.st generation CD19 CAR-T cells was evaluated in mice using the Raji subcutaneous cell derived xenograft tumor model. Raji cells are a human lymphoma cell line that are known to be insensitive to treatment with anti-PD1 antibodies.
[0548] Briefly, 6-8 week old female NSG mice from Jackson labs were injected subcutaneously with 3.times.10.sup.6 Raji tumor cells. When tumors reached a volume of approximately 200 mm.sup.3 mice were randomized into groups of 5 and injected intravenously with edited human CD19 CART cells via tail vein. Prior to injection the adoptively transferred cells were edited with either a control guide or a guide editing for MAP4K1 or NR4A3. Using the NGS method, the editing efficiency of the gRNA/Cas9 complex targeting the MAP4K1 gene and NR4A3 were determined to be 83% and 71%, respectively. Body weight and tumor volume was measured at least twice per week. Tumor volume was calculated as mean and standard error of the mean for each treatment group. The results demonstrate that editing of MAP4K1 and NR4A3 in an adoptive T cell transfer model leads to increased efficacy, with a 65% TGI for MAP4K1 (FIG. 13A) and 81% TGI for NR4A3 (FIG. 13B). Similar experiments will be performed to assess the anti-tumor efficacy of ZC3H12A-edited 1st generation CD19 CAR-T cells (human) in the Raji cell-derived xenograft subcutaneous tumor model.
Example 13: Screen for Dual-Edit Combinations
[0549] A double sgRNA library was constructed in a retroviral backbone. The library consisted of two U6 promoters (one human and one mouse), each driving expression of a single guide RNA (guide+tracr, sgRNA). The guides were cloned as pools to provide random pairings between guides, such that every sgRNA would be paired with every other sgRNA. The final double guide library was transfected into Phoenix-Eco 293T cells to generate murine ecotropic retrovirus. TCR transgenic OT1 cells expressing Cas9 were infected with the sgRNA-expressing virus to edit the two loci targeted by each of the sgRNAs. The edited transgenic T-cells were then transferred into mice bearing >400 mm.sup.3 B16-Ova tumors allografts. After two weeks, the tumors were excised and the tumor-infiltrating T-cells were purified by digesting the tumors and enriching for CD45+ cells present in the tumors. Genomic DNA was extracted from CD45+ cells using a Qiagen QUIAamp DNA blood kit and the retroviral inserts were recovered by PCR using primers corresponding to the retroviral backbone sequences. The resulting PCR product were then sequenced to identify the sgRNAs present in the tumors two weeks after transfer. The representation of guide pairs in the final isolated cell populations was compared to the initial plasmid population and the population of infected transgenic T-cells before injection into the mouse. The frequency of sgRNA pairs that improved T-cells fitness and/or tumor infiltration were expected to increase over time, while combinations that impaired fitness were expected to decrease over time. Table 15 below shows the median fold change of sgRNA frequency in the final cell population compared to the sgRNA frequency in the initial cell population transferred in vivo.
TABLE-US-00012 TABLE 15 sgRNA frequency in Combination Screen GeneA GeneB Avg(Tmedian.Ifoldch.all) CBLB CBLB 0.17 CBLB CTLA4 0.21 CBLB LAG3 0.08 CBLB Olfr1389 0.03 CBLB Olfr453 0.04 CBLB TGFBR1 0.15 CBLB TGFBR2 0.75 CBLB TIGIT 0.31 CBLB ZAP70 0 Havcr2 Havcr2 0.02 Havcr2 LAG3 0.01 Havcr2 Olfr1389 0 Havcr2 Olfr453 0.01 Havcr2 PDCD1 0.02 LAG3 Olfr1389 0 LAG3 Olfr453 0.02 LAG3 PDCD1 0.02 Olfr1389 Olfr1389 0.01 Olfr1389 Olfr453 0 Olfr1389 PDCD1 0.02 Olfr453 Olfr453 0.01 Olfr453 PDCD1 0.01 PDCD1 CTLA4 0.59 PDCD1 LAG3 0.02 PDCD1 PDCD1 0.02 PDCD1 TGFBR1 0.02 PDCD1 TGFBR2 0.07 PDCD1 TIGIT 0.02 PDCD1 ZAP70 0 TGFBR1 CTLA4 0.01 TGFBR1 LAG3 0 TGFBR1 TGFBR1 0.06 TGFBR1 TGFBR2 0.07 TGFBR1 TIGIT 0.03 TGFBR1 ZAP70 0 CBLB ZC3H12A 8.9 Havcr2 ZC3H12A 2.1 Olfr1389 ZC3H12A 0.78 Olfr453 ZC3H12A 1.58 PDCD1 ZC3H12A 1.33 TGFBR1 ZC3H12A 3.33 Tigit ZC3H12A 2.53 ZAP70 ZC3H12A 0.01 ZC3H12A CTLA4 0.61 ZC3H12A LAG3 0.73 ZC3H12A ZAP70 0.01 ZC3H12A ZC3H12A 1.14
Example 14: Validation of Dual-Edited CD19 CAR-T Cells in Raji Xenograft Model
[0550] Targets were further evaluated in combination studies to determine combinations of edited genes that increased anti-tumor efficacy of T cells in xenograft tumor models. Evaluation of exemplary targets is described herein, however these methods can be used to evaluate any of the potential targets described above
[0551] As an example of a combination effect for anti-tumor efficacy of editing, CBLB and BCOR were edited, either independently or together, in 1.sup.st generation CD19 CAR-T cells and evaluated in mice using the Raji subcutaneous cell derived xenograft tumor model. Raji cells are a lymphoma cell line that are known to be insensitive to treatment with anti-PD1 antibodies. 6-8 week old female NSG mice from Jackson labs were injected subcutaneously with 3.times.10.sup.6 Raji tumor cells. When tumors reached a volume of approximately 200 mm.sup.3 mice were randomized into groups of 5 and injected intravenously with edited human CD19 CART cells via tail vein. Prior to injection, the adoptively transferred cells were edited by electroporation with gRNA/Cas9 RNP complexes comprising (i) a control gRNA; (ii) single gRNA targeting CBLB; (iii) a single gRNA targeting BCOR; or (iv) 2 gRNAs targeting CBLB and BCOR. Body weight and tumor volume were measured at least twice per week. Tumor volume was calculated as mean and standard error of the mean for each treatment group. As shown in FIG. 14, when compared to a control guide, adoptive transfer of BCOR/CBLB dual-edited human CD19 CART cells, with target genes edited either alone or together as indicated, resulted in an anti-tumor response in the subcutaneous Burkitt's Lymphoma Raji mouse model. The anti-tumor efficacy was greater when both targets were edited in combination as compared to either target alone or as compared to a control guide. Similar experiments are performed to assess the efficacy of ZC3H12A/CBLB dual-edited T cells, MAP4K1/CBLB dual-edited T cells, and NR4A3/CBLB dual-edited T cells in the CD19 CAR-T Raji cell xenograft model.
Example 15: Double-Editing of BCOR and CBLB in CAR-Ts Leads to Enhanced Accumulation and Cytokine Production in the Presence of Tumor
[0552] 1.sup.st generation CD19 CAR-Ts were generated from human CD8 T cells, and a negative control gene, BCOR, CBLB, or both BCOR and CBLB were edited by electroporation using guide RNAs complexed to Cas9 in an RNP format. CD19 CAR-Ts were co-cultured with Raji Burkitt's Lymphoma cells in vitro at a 1:0, 0.3:1, 1:1, 3:1 and 10:1 ratio. After 24 hours, total cell counts of CAR-T cells were determined, and supernatants saved for cytokine analyses. As shown in FIG. 15, BCOR and BCOR+CBLB-edited CARTs demonstrated 30% greater accumulation compared to either control or CBLB-edited CARTs, demonstrating that editing of the BCOR confers an enhanced ability of the CAR-T cells to accumulate in the presence of a tumor. Further, CBLB and CBLB+BCOR-edited CARTs produced 10-fold or more IL-2 (FIG. 16) and IFN.gamma. (FIG. 17) compared to either control-edited CARTs, demonstrating that editing of CBLB resulted in enhanced CAR-T cell production of cytokines known to increase overall T cell fitness and functional ability. The increased production of IL-2 by CD8 T cells is surprising as these cells typically do not produce IL-2. These data demonstrate that, in some instances, production of CAR-T cells with enhanced effector functions requires editing of multiple genes. For example, in this example, the production of CAR-T cells that demonstrated both enhanced accumulation in the presence of a tumor and enhanced production of IL-2 and IFN.gamma. cytokines required editing of both BCOR and CBLB genes.
Example 16: Validation of Dual-Edited, Adoptively Transferred T Cells in A Murine OT1/B16-Ova Syngeneic Tumor Model
[0553] Targets were further evaluated in combination studies to determine combinations of edited genes that increased anti-tumor efficacy of T cells in a murine OT1/B16-Ova subcutaneous syngeneic tumor model. Evaluation of exemplary targets is described herein, however these methods can be used to evaluate any of the potential targets described above.
[0554] Anti-tumor efficacy of Zc3h12a/Cblb dual-edited T cells was evaluated in mice using the B16Ova subcutaneous syngeneic tumor model. Briefly, 6-8 week old female C57BL/6J mice from Jackson labs were injected subcutaneously with 0.5.times.10.sup.6 B16Ova tumor cells. When tumors in the entire cohort of mice reached an average volume of approximately 378.3 mm.sup.3, the mice were randomized into groups and injected intravenously with edited murine OT1 CD8+ T cells via tail vein. Prior to injection, these cells were edited by electroporation with gRNA/Cas9 RNP complexes comprising (i) a control gRNA; (ii) a single gRNA targeting the Cblb gene; (iii) a single gRNA targeting the Zc3h12a gene; or (iv) 2 gRNAs targeting the Cblb and Zc3h12a genes. Editing efficiency of the gRNA/Cas9 complex targeting the Cblb and Zc3h12a genes was determined to be 82% and 80% respectively, assessed using the NGS method. Body weight and tumor volume were measured at least twice per week. Tumor volume was calculated as mean and standard error of the mean for each treatment group. The percentage tumor growth inhibition (TGI) was calculated using the mean tumor volume according to the following formula:
% TGI=(TV-Target.sub.final-TV-Target.sub.initial)/(TV-Control.sub.final-- TV-Controlt.sub.initial)*100,
[0555] where TV=mean tumor volume, final=Day 7 post-T cell transfer, and initial=Day 0 (i.e., day of T cell transfer).
[0556] As shown in FIG. 18, transfer of Zc3h12a/Cblb dual-edited T cells resulted in an enhanced TGI compared to transfer of Cblb single-edited T cells or Zc3h12a single-edited T cells or Cblb single-edited T cells (Zc3h12a/Cblb TGI=107% compared to 46% and 99% for Cblb and Zc3h12a single edits, respectively).
[0557] Similar experiments are performed to assess the efficacy of Map4k1/Cblb dual-edited T cells and Nr4a3/Cblb dual-edited T cells in the OT1/B16 Ova syngeneic tumor model.
Example 17: Validation of Dual-Edited, Adoptively Transferred T Cells in a Murine PMEL/MC38-gp100 Tumor Model
[0558] Anti-tumor efficacy of Zc3h12a/Cblb dual-edited T cells, Map4k1/Cblb dual-edited T cells, and Nr4a3/Cblb dual-edited T cells is evaluated in mice using the MC38gp100 subcutaneous syngeneic tumor model. Briefly, 6-8 week old female C57BL/6J mice from Jackson labs are injected subcutaneously with 1.times.10.sup.6 MC38gp100 tumor cells. When tumors reach a volume of approximately 100 mm.sup.3, mice are randomized into groups of 10 and injected intravenously with edited murine PMEL CD8+ T cells via tail vein. Prior to injection, T cells are edited by electroporation with gRNA/Cas9 RNP complexes comprising (i) a control gRNA; (ii) a single gRNA targeting the PD1 gene; (iii) a single gRNA targeting the Zc3h12a gene; (iv) a single gRNA targeting the Cblb gene; (v) a single gRNA targeting the Map4k1 gene; (vi) a single gRNA targeting the Nr4a3 gene; (vii) 2 gRNAs targeting both the Zc3h12a and Cblb genes; (viii) 2 gRNAs targeting both the Nr4a3 and Cblb genes; or (ix) 2 gRNAs targeting both the Map4k1 and Cblb genes. Body weight and tumor volume are measured at least twice per week. Tumor volume is calculated as mean and standard error of the mean for each treatment group. The percentage TGI is calculated using the mean tumor volume according to the following formula:
(TV-Target.sub.final-TV-Target.sub.initial)/(TV-Control.sub.final-TV-Con- trolt.sub.Initial),
[0559] where TV=mean tumor volume, final=Day 21 post-T cell transfer, and initial=Day 0 (i.e., day of T cell transfer)
[0560] These experiments are expected to show enhanced TGI after transfer of Zc3h12a/Cblb, Map4k1/Cblb, or Nr4a3/Cblb dual-edited T cells compared to transfer of PD1 single-edited T cells, Zc3h12a single-edited T cells, Map4k1 single-edited T cells, or Nr4a3 single-edited T cells.
Example 18: Validation of Dual-Edited, Adoptively Transferred T Cells in a Murine B16-F10 Syngeneic Tumor Model
[0561] Anti-tumor efficacy of Zc3h12a/Cblb dual-edited T cells is evaluated in mice using the aggressive metastatic B16-F10 syngeneic tumor model with disease manifesting as lung metastasis. Briefly, 6-8 week old female C57BL/6J mice from Jackson labs are injected intravenously with 0.5.times.10.sup.6 B16-F10 tumor cells. Mice are weighed and assigned to treatment groups using a randomization procedure prior to inoculation. At Day 3 post tumor inoculation, mice are injected intravenously with edited murine PMEL CD8+ T cells via tail vein. Prior to injection these cells are edited by electroporation with gRNA/Cas9 RNP complexes comprising (i) a control gRNA; (ii) a single gRNA targeting the Zc3h12a gene; (iii) a single gRNA targeting the Cblb gene; (iv) a single gRNA targeting the Map4k1 gene; (v) a single gRNA targeting the Nr4a3 gene; (vi) 2 gRNAs targeting each of the Map4k1 and Cblb genes; (vii) 2 gRNAs targeting each of the Nr4a3 and Cblb genes or; (viii) 2 gRNAs targeting each of the Zc3h12a and Cblb genes. Editing efficiency of the gRNA/Cas9 complex targeting the aforementioned genes is assessed using the NGS method. Body weight will be monitored at least twice per week. At Day 15 post tumor inoculation (Day 12 post edited PMEL transfer), mice lungs are perfused and fixed with 10% para-formaldehyde. After overnight fixation, lungs are transferred to 70% EtOH for further preservation. Tumor efficacy is evaluated by visually assessing the B16-F10 tumor burden which will be seen as black colonies of cancer cells on the lungs.
[0562] These experiments are expected to show increased anti-tumor efficacy of dual-edited cells compared to controls and single-edited cells.
Example 19: Efficacy of PD1/Lag3 Dual-Edited Transgenic T Cells in a B16-Ova Murine Tumor Model
[0563] Anti-tumor efficacy of PD-1/Lag3 dual-edited T cells was evaluated in mice using the B16Ova subcutaneous syngeneic tumor model. 6-8 week old female C57BL/6J mice from Jackson labs were injected subcutaneously with 0.5.times.10.sup.6 B16Ova tumor cells. When tumors in the entire cohort of mice reached an average volume of approximately 485 mm.sup.3, the mice were randomized into groups of 10 and injected intravenously with edited mouse OT1 CD8+ T cells via tail vein. Prior to injection these cells were edited by electroporation with gRNA/Cas9 RNP complexes comprising (1) a non-targeting control gRNA; (2) a single gRNA targeting the PD1 gene; (3) a single gRNA targeting the Lag3 gene; (4) 2 gRNAs, one targeting each of the PD1 and Lag3 genes. Body weight and tumor volume were measured at least twice per week. Tumor volume was calculated as mean and standard error of the mean for each treatment group. The percentage tumor growth inhibition (TGI) was calculated using the following formula:
% TGI=(PD1/Lag3 TV.sub.final)-PD1/Lag3 TV.sub.initial)/(Control TV.sub.final-Control TV.sub.initial),
[0564] where TV=mean tumor volume, final=Day 10 and initial=day of edited mouse OT1 CD8+ T cell transfer.
[0565] The data in FIG. 19 show adoptive transfer of PD1 single-edited T cells resulted in a TGI of 70% and adoptive transfer of Lag3 single-edited T cells resulted in a TGI of 36%. Surprisingly, combination edits of PD1 and Lag3 did not result in enhanced tumor growth inhibition and demonstrated a TGI of 38%.
Example 20: Validation of Targets for Adoptive T Cell Transfer of Tumor Infiltrating Lymphocytes
[0566] Anti-tumor efficacy of Zc3h12, Map4k1, and Nr4a3/Cblb single and dual-edited tumor infiltrating lymphocytes (TILs) are evaluated in mice using the B16Ova subcutaneous syngeneic tumor model. Two mice cohorts are used in this experiment: a donor cohort of CD45.1 Pep Boy mice (B6.SJL-Ptprc.sup.aPepc.sup.b/BoyJ) and a recipient cohort of CD45.2 C57BL/6J mice (Jackson labs), each comprised of 6-8 week old female mice.
[0567] To generate TILs, donor CD45.1 Pep Boy mice (B6.SJL-Ptprc.sup.aPepc.sup.b/BoyJ) are injected subcutaneously with 0.5.times.10.sup.6 B16-Ova cells. On Day 14 post-tumor cell inoculation, tumors are harvested to generate edited CD45.1 Tumor Infiltrating Lymphocytes (TILs) to infuse into the second cohort of mice. B16-OVA tumors (200-600 mm.sup.3) are harvested, diced, and reduced to a single cell suspension using the GentleMACS system and mouse Tumor Dissociation Kit (Miltenyi Biotech Catalog #130-096-730), according to the manufacturer's recommendations. Tumor suspension are filtered over 70 .mu.m cell strainers and TILs are enriched using CD4/CD8 (TIL) Microbeads (Miltenyi Biotech Catalog #130-116-480). Isolated TILs are cultured in 6 well plates at 1.5.times.10.sup.6 cells/mL in complete mTIL media (RPMI+10% heat inactivated FBS, 20 mM HEPES, 100 U/mL Penicillin, 100 .mu.g/mL Streptomycin, 50 .mu.M Beta-Mercaptoethanol, 1.times. Glutamx) supplemented with 3000 U/mL of recombinant human IL-2 (Peprotech Catalog #200-02). On Day 3 cells are harvested, washed and resuspended in nucleofection buffer T and electroporated with gRNA/Cas9 RNPs using the Neon Transfection System as described in Example 1. After electroporation, TILs are cultured in 6 well plates at 1.5.times.10.sup.6 cells/mL in complete mTIL media supplemented with 3000 U/mL of recombinant human IL-2. On Day 5 and 7, cells are resuspended in fresh complete mTIL media supplemented with 3000 U/mL of recombinant human IL-2 and plated in flasks at a density of 1.times.10.sup.6 cells/mL. On Day 8, cells are harvested counted and resuspended in PBS for injection in vivo and pellets were prepared for gene expression analysis by qRT-PCR.
[0568] These TIL cells are edited by electroporation of gRNA/Cas9 complexes comprising (1) a non-targeting control gRNA; (2) a single gRNA targeting the Zc3h12a gene; (3) a single gRNA targeting the Map4k1 gene; (4) a single gRNA targeting the Nr4a3 gene; (5) a single gRNA targeting Cblb; (6) 2 gRNAs targeting the Zc3h12a gene and Cblb gene; (7) 2 gRNAs targeting the Map4k1 gene and Cblb gene; or (8) 2 gRNAs targeting the Nr4a3 gene and Cblb gene.
[0569] Recipient CD45.2 C57BL/6J mice are injected subcutaneously with 0.5.times.10.sup.6 B16-Ova tumor cells. When tumors reached a volume of approximately 100 mm.sup.3, mice are randomized into groups of 10 and injected intravenously with edited CD45.1 TILs via tail vein. Optionally, mice can be injected intraperitoneal with cyclophosphamide (200 mg/kg) to induce lymphodepletion prior to T cell transfer and the edited-TILs can be administered intravenously in combination with intraperitoneal treatment with recombinant human IL-2 (720,000 IU/Kg) twice daily for up to a maximum of 4 days.
[0570] Body weight and tumor volume are measured at least twice per week. Tumor volume is calculated as mean and standard error of the mean for each treatment group and the % TGI is calculated according to the following formula:
% TGI=(TV-target.sub.final)-TV-target.sub.initial)/(TV-Control.sub.final- -TV-Control.sub.initial),
[0571] where TV=mean tumor volume, final=Day 17 and initial=day of edited TIL transfer.
[0572] These results are expected to show that compared to a control guide, adoptive transfer of single-edited or dual-edited mouse TILs results in an enhanced anti-tumor response in the B16Ova subcutaneous mouse model compared to treatment with control-edited cells.
Example 21: Validation of Targets for Engineered T Cell Therapy
[0573] Experiments will be performed to validate the effects of editing BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and/or NR4A3 on the anti-tumor efficacy of CAR T cells and T cells engineered to express an artificial TCR. The engineered T cells described in Table 17 are edited as described in Example 1 to reduce expression of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and/or NR4A3. These edited T cells are then evaluated in subcutaneous murine xenograft models using the indicated cell type. For example, T cells engineered with a CD19-specific CAR or artificial TCR can be evaluated as described above in Example 12 in a Raji cell model or any of the other cell lines shown in Table 16, T cells engineered with a MART1-specific CAR or artificial TCR can be evaluated in a SKMEL5, WM2664, or IGR1 cell model, etc.
TABLE-US-00013 TABLE 16 Engineered Receptor Specificity and Target Cell Lines Receptor Specificity Target Cell Line CD19 Raji, Daudi, Jeko, NALM-6, NALM-16, RAMOS, JeKo1 BCMA Multiple Myeloma cell lines NCI-H929, U266-B1, and RPMI-8226 NYESO A375 MARTI SKMEL5, WM2664, IGR1 HER2+ BT474
[0574] Briefly, 6-8 week old female NSG mice from Jackson labs are injected subcutaneously with 3.times.10.sup.6 target cells. When tumors reached a volume of approximately 200 mm.sup.3, mice are randomized into groups of 5 and injected intravenously with the edited engineered T cells via tail vein. Prior to injection the adoptively transferred cells are edited with either a control guide or a guide editing for BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and/or NR4A3. Body weight and tumor volume are measured at least twice per week. Tumor volume is calculated as mean and standard error of the mean for each treatment group. The results of these experiments are expected to show enhanced anti-tumor efficacy of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and/or NR4A3-edited engineered T cells or as compared to a control guide, measured by survival and or reduction in tumor size.
Example 22: Validation of Target Editing on Receptor-Engineered T Function
[0575] Experiments will be performed to validate the effects of editing BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and/or NR4A3 on engineered T cell cytokine production. Briefly, the engineered T cells described in Table 16 above are generated from human CD8 T cells, and one or more of BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and/or NR4A3 are edited by electroporation using guide RNAs complexed to Cas9 in an RNP format. CAR-Ts are co-cultured with the corresponding cell line indicated in Table 18 in vitro at a 1:0, 0.3:1, 1:1, 3:1 and 10:1 ratio. After 24 hours, total cell counts of engineered T cells are determined, and supernatants saved for cytokine analyses. The results of these experiments are expected to show enhanced accumulation of and increased levels of cytokine production from edited CAR T cells compared to control edited cells.
Example 23: Manufacturing of Dual-Edited Tumor Infiltrating Lymphocytes
[0576] Edited TILs are manufactured following established protocols used previously in FDA-approved clinical trials for the isolation and expansion of TIL's. Following removal of tumor tissue, the tumor is both fragmented into 2 mm.sup.3 pieces and mechanically/enzymatically homogenized and cultured in 6,000 IU/mL recombinant human IL-2 for up to 6 weeks or until the cell numbers reach or exceed 1.times.10.sup.8; this is defined as the pre-rapid expansion phase (pre-REP) of TIL manufacturing. Upon completion of the pre-REP stage TILs are electroporated with gRNA/Cas9 RNP complexes targeting BCL2L11, FLI1, CALM2, DHODH, UMPS, RBM39, SEMA7A, CHIC2, PCBP1, PBRM1, WDR6, E2F8, SERPINA3, GNAS, ZC3H12A, MAP4K1, and/or NR4A3 genes under cGMP conditions. Cells may be also electroporated prior to or during the pre-REP process. Following electroporation, 50.times.10.sup.6 cells are transferred into a 1 L G-Rex.TM. culture flask with a 1:100 ratio of TIL:irradiated feeder cells for approximately 2 weeks. This portion of manufacturing is defined as the rapid expansion phase (REP). After the REP phase, TIL's are harvested, washed, and suspended in a solution for immediate infusion into the patient.
Example 24: Phase I Studies of Edited Immune Effector Cells
[0577] Phase 1, open-label, single-center studies will be performed, in which metastatic melanoma patients who are relapsed or refractory to anti PD-1 therapy will be treated with the modified cells described herein. Patients will receive a single infusion of cells and will remain on study until they experience progressive disease or therapy intolerance. Radiological PD will be determined by a local radiologist before discontinuation of study participation.
[0578] Study Objectives:
[0579] The primary objectives of the study are (1) to determine the maximum tolerated dose (MTD), dose limiting toxicities (DLTs), and dose of cell compositions (and the associated concomitant medications required) recommended for future studies for patients with advanced solid tumors; and (2) to observe patients for any evidence of anti-cancer activity of the transferred edited cells. The secondary objectives of the study are: (1) to determine the pharmacokinetics of the cellular compositions; (2) to assess of on-target activity of the cellular compositions, as determined by changes in pharmacodynamic biomarkers in biologic samples; and (3) to assess of proliferation of the modified cells, as determined by engineered TIL persistence post treatment. The exploratory objectives of the study are (1) to correlate any underlying genetic mutation(s) with clinical response.
[0580] Study End-Points:
[0581] The primary endpoints of this study are: Incidence and severity of adverse events (AEs), graded according the National Cancer Institute Common Terminology Criteria for Adverse Events (NCI CTCAE), version 4.3; Clinical laboratory abnormalities; Changes in 12-lead electrocardiogram (ECG) parameters; Objective response rate (ORR), per RECIST v1.1; CNS response (ORR and progression free survival [PFS], per RECIST v1.1, in patients who have active brain metastases). The secondary endpoints of this study are: Patient-reported symptoms and health-related quality of life (HRQoL) scores; Time to response; Duration of response; Disease control rate (the percentage of patients with best response of complete response [CR], PR, or SD), per RECIST v1.1; Time on treatment; Immunophenotyping; Persistence, trafficking and function of genetically engineered TIL; Pharmacodynamic biomarker in pre and post-dose samples. The exploratory endpoints of this study are: Assessment of cancer-associated mutations and/or genetic alterations utilizing FoundationOne.RTM. Cancer Gene Panel, or comparable alternative, in pre-dose tumor biopsy and/or peripheral blood.
[0582] Treatment Regimen:
[0583] A summary of the treatment regimen is as follows:
[0584] (a) Day -7 & -6: cyclophosphamide 60 mg/kg, i.v.
[0585] (b) Days -5 to -1: fludarabine 25 mg/m.sup.2, i.v.
[0586] (c) Day 1: Cell infusion
[0587] (d) Day 1-Day 15: IL-2 (125,000 IU/kg/day) up to a maximum of 14 administrations
[0588] The first dose of cells administered will not exceed a total dose of 1.times.10.sup.9 cells. Should the patient experience dose limiting toxicity (DLT), two additional patients will be treated at this dose level. If the first patient completes the DLT monitoring period (21 days) without experiencing a DLT, subsequent patients will be treated at doses not to exceed 1.times.10.sup.11 TILs.
[0589] Concomitant Treatment:
[0590] Palliation and supportive care are permitted during the study for management of symptoms and underlying medical conditions that may develop during the study.
[0591] Efficacy Evaluation:
[0592] Tumor response will be determined per RECIST v1.1 by the local radiologist and/or investigator. Tumor assessment will be performed every 6 weeks until disease progression and will continue for patients who have discontinued due to reasons other than disease progression, until disease progression, or to the start of another anticancer therapy. Survival will also be followed for up to 3 years after the last patient enrolled into the study.
[0593] Safety Evaluation:
[0594] Safety assessments will include physical and laboratory examinations, vital signs, and ECGs. Adverse events will be graded according to the NCI CTCAE v4.03. Adverse event incidence rates, as well as the frequency of occurrence of overall toxicity, categorized by toxicity grades (severity), will be described for each cohort of the study. Listings of laboratory test results will also be generated, and descriptive statistics summarizing the changes in laboratory tests over time will be presented.
[0595] Molecular Genetic Evaluations:
[0596] The mutation status of genes implicated in tumor biology will be determined through molecular analysis of tumor tissue and plasma samples. Results of these tests will be provided to the investigator and the sponsor immediately after analysis, per the testing procedure. Molecular analysis methods include, but are not limited to, direct sequencing and/or digital polymerase chain reaction (PCR).
[0597] Patient-Reported Symptoms and Quality of Life Evaluations:
[0598] Patient-reported symptoms and HRQoL will be collected by administering the validated European Organisation for Research and Treatment of Cancer (EORTC) Quality of Life Questionnaire (QLQ)-C30 (v.3.0), which has been studied extensively in global clinical studies. The EORTC QLQ-C30 will be scored for 5 functional scales (physical, role, cognitive, emotional, and social functioning); 3 symptom scales (fatigue, pain, and nausea/vomiting); and a global health status/QoL scale. Six single-item scales also are included (dyspnea, insomnia, appetite loss, constipation, diarrhea, and financial difficulties).
[0599] Study Assessments:
[0600] Assessment parameters for these studies include radiological imaging of the tumor prior to dose administration and on Day 1 of every odd number cycle thereafter, blood sample collection for PK analysis (Day 1, 2, 3, weekly.times.4, monthly.times.6) and pharmacodynamics analysis, and cytokine panel analysis (Day 1, 2, 3, weekly.times.4, monthly.times.6).
Example 25: Validation of Zc3h12a as Target Conferring Anti-Tumor Memory and Epitope Spreading
[0601] Anti-tumor memory and epitope spreading driven by Zc3h12a inhibition or deletion in T cells was evaluated in mice using the B16-Ova subcutaneous syngeneic tumor model. 6-8 week old female C57BL/6J mice from Jackson labs were injected subcutaneously with 0.5.times.10.sup.6 B16-Ova tumor cells. When tumors reached a volume of approximately 100 mm.sup.3, mice were randomized into groups of 10 and injected intravenously with edited mouse OT1 CD8+ T cells via tail vein. Prior to injection, these cells were edited by electroporation with gRNA/Cas9 RNP complexes comprising (i) a control gRNA; or (ii) a single gRNA targeting the Zc3h12a gene. Body weight and tumor volume were measured at least twice per week. Tumor volume was calculated as mean and standard error of the mean for each treatment group.
[0602] As shown in FIG. 20, 9 of the 10 mice receiving Zc3h12a-edited T cells were evaluable and rejected the tumors completely by 55 days after the transfer of OT1 CD8+ T cells (or 65 days after the initial B16-Ova tumor inoculation). These mice were deemed to be Complete Responders (CRs). Four of the CR mice were re-challenged with a second B16-Ova inoculation, with another four CR mice challenged with a B16F10 inoculation. B16-Ova is a derivative of B16F10 engineered to contain the Ova antigen against which OT1 cells are specific for. In addition, ten naive mice were inoculated with B16-Ova, and another ten naive mice were inoculated with B16F10 tumor cells. Following these inoculations, B16-Ova CR mice were found to also reject both B16-Ova re-challenge and B16F10 challenge. The B16-Ova rejection demonstrates a Zc3h12a-driven anti-tumor memory response. The B16F10 rejection demonstrates that Zc3h12a-edited T cells instruct other T cells within the host to mount a productive anti-tumor response against non-Ova tumor antigens through a phenomenon known as "epitope spreading." Epitope spreading, which is also known as determinant spreading, is when T cells not involved in the initial immune response are activated against epitopes linked in a tissue-specific manner to the initial response progressively contribute to an immune response.
Example 26: Editing of MAP4K1 in Naive Human T Cells Enhances Cytokine Production
[0603] Primary human T cells were isolated from thawed donor PBMCs and cultured overnight in Immunocult+10 ng/mL IL-2. The next day, T cells were electroporated with an RNP for a single guide control gene or MAP4K1. After four days in culture (Immunocult+10 ng/mL IL-2) to ensure gene editing, cells were cultured for 24 hr in Immunocult+CD3/28/2 activation. Supernatants were collected 24 hrs after activation and secreted cytokine levels were measured by the mesoscale discovery (MSD) platform. As shown in FIG. 21, MAP4K1-edited T cells demonstrated increased production of IFN.gamma., IL-2, and TNF.alpha.. Similar experiments can be performed to assess cytokine production of ZC3H12a-edited and NR4A3-edited PBMCs.
Example 27: Expression of T Cell Activation Markers in Zc3h12a-Edited Murine CD8 T Cells
[0604] Spleens from female OT1 or pMEL mice were harvested and CD8 T cells were isolated as described in Example 1. CD8 T cells were electroporated with RNPs comprising a Cas9 protein and sgRNAs targeting either Zc3h12a or a control gene were according to methods described in Example 1. Across multiple guides, Zc3h12a-editing efficiency was measured to be 36-69%.
[0605] Expression of Ifng, Gzma, and Icos was measured by RNA-seq. RNA extraction and sequencing (RNA-seq) from pellets of 3 million edited cells was performed by Wuxi NextCode. Gene expression levels are quantified as TPMs (Li et al., in Bioinformatics: The Impact of Accurate Quantification on Proteomic and Genetic Analysis and Research (2014)) using Salmon (version 0.11.2, Patro et al., Nat. Methods (2017) and Gencode mouse gene annotation (version M15). R package limma.sup.3 (version 3.38.0, Ritchie et al., Nucleic Acids Res. (2015)) was used to analyze the differentially expressed genes (DEGs). When multiple guides were used to inhibit a target, the analysis incorporated the impact of each guide and only genes affected by all guides were considered significantly differentially expressed.
[0606] These experiments revealed that Zc3h12a-edited mouse OT-1 or PMEL cells demonstrated significantly increased expression of Ifng (144.5-fold in OT-1; 119.2-fold in PMEL relative to control sgRNA) and Gzma mRNA (7.2-fold in OT-1 and 3.1 fold in pMEL compared to control sgRNA). In Zc3h12a-edited cells, mRNA expression of Icos, a known ZC3H12A substrate, was also upregulated 11-fold and 9.1 fold in OT-1 and PMEL cells, respectively. Together these data demonstrate that Zc3h12a-edited mouse OT-1 or PMEL cells demonstrate increased expression of the T cell activation markers Ifng, Gzma, and Icos as measured by mRNA expression.
Example 28: ICOS Expression by Zc3h12a siRNA Modified Murine T Cells
[0607] Zc3h12a mRNA targeting siRNAs were used to demonstrate the effects of modifying expression of the Zc3h12a by additional mechanisms of inhibition. Control (catalog #: K-005000-G1-02) or Zc3h12a-targeting (catalog #: E-052076-00-0005) Self-delivering Accell siRNAs were prepared according to the manufacturer's instructions. Purified murine CD8 T-cells were activated with anti-CD3/anti-CD28 beads (Dynabeads.TM. Mouse T-Activator CD3/CD28 for T-Cell Expansion and Activation Cat #11456D) in siRNA delivery media (Dharmacon Catalog # B-005000-500) containing 2.5% heat inactivated FBS supplemented with 10 ng/mL of recombinant murine IL-2 (Biolegend Catalog #575406) and Self-delivering Accell siRNAs at a final concentration of 1 .mu.M. After 72 hours, activation beads were removed and cells were assessed for surface ICOS expression by flow cytometry or gene expression analysis by qRT-PCR.
[0608] For qRT-PCR analysis, RNA was purified from T-cells using a Qiagen RNeasy miniprep kit (catalog #: 74104) and cDNA was prepared using SuperScript IV VILO (catalog #: 11755-050, Life Technologies)) according to the manufacturer's instructions. Listed below are the taqman probes (Life Technologies) used for detection of mouse or human transcripts. GAPDH was used as the control gene and relative expression was quantified using the delta-delta Ct method. Treatment of cells with Zc3h12a-specific siRNAs resulted in a 30% reduction in Zc3h12a mRNA levels compared to controls.
TABLE-US-00014 Gene Mouse Assay ID Human Assay ID GAPDH Mm99999915_gl Hs02786624_gl IL6 Mm00446190-ml Hs00174131_ml ICOS Mm00497600_ml N/A GZMA Mm013044562-ml N/A IFNG Mm0l168134_ml Hs00989291_ml
[0609] For ICOS surface expression, murine CD8 cells were stained with fluorescently labeled anti-ICOS antibodies (Biolegend cat#: 313524) at a 1:100 dilution according to the manufacturer's instructions. The relative amount of cell surface ICOS expression was measured by calculating the mean fluorescence intensity of the cells stained with the fluorescent anti-ICOS antibody, using FlowJo v10.1 software (Treestar). Consistent with sgRNA-mediated inhibition of Zc3h12a, ICOS levels were 1.8-fold higher in cells treated with Zc3h12a-targeting siRNA.
Example 29: Expression of T Cell Activation Markers in Murine T Cells Edited with Zc3h12a Zinc Fingers
[0610] ZFN-mediated editing of the Zc3h12a gene was performed to demonstrate the effects of modifying expression of the Zc3h12a by additional mechanisms of inhibition.
[0611] Engineered zinc finger nuclease (ZFN) domains were generated by Sigma Aldrich in plasmid pairs (CSTZFN-1KT COMPOZR.RTM. Custom Zinc Finger Nuclease (ZFN) R-3257609). The domains were customized to recognize positions Chr4:125122398-125122394 and Chr4:125121087-125121084 of mouse Zc3h12a gene and positions Chr6:42538446-42538447 of the control mouse gene Olfr455. Plasmids were prepared using the commercial NEB Monarch Miniprep system (Cat# T1010) following manufacturer's protocol. The DNA template was linearized using 10 .mu.g total input and purified using the NEB Monarch PCR and DNA Cleanup kit (Cat# T1030). An in vitro transcription reaction to generate 5'-capped RNA transcripts was performed using 6 .mu.g of purified DNA template and the Promega T7 RiboMAX Large Scale RNA Production System (P1300 and P1712) following the manufacture's conditions. Transcripts were purified using Qiagen RNeasy Mini purification kit (Cat#74104). The integrity and concentration of each ZFN domain transcript were confirmed using the Agilent 4200 TapeStation system. Purified transcripts were polyadenylated using the NEB E. coli Poly(A) Polymerase (M0276) using 10 units per reaction. The addition of polyadenylated tails were confirmed by a size shift using the Agilent 4200 TapeStation system. Each mature ZFN domain mRNA transcript was combined with its corresponding pair and 10 .mu.g of each pair mixed with 5 million mouse CD8 T cells and electroporated according to the methods described above for murine T cell electroporation.
[0612] Two loci in Zc3h12a were targeted by 3 ZFN each and editing efficiency was measured by NGS. To follow the effects of ZFN-mediated ZC3H12A inactivation, mRNA levels of the ZC3H12A substrates Il6 and Icos, as well as the T-cell activation marker Ifng, were assessed by by qRT-PCR. All 3 ZFNs targeting locus Chr4:125121088-125121085 resulted in increased expression of Icos (range 1.2-2-fold), Il6 (range 2.3-62.8-fold) and Ifng (2.9-12.8) mRNA compared to a control ZFN target Olfr455, confirming that ZFN-mediated editing of Zc3h12a induces similar effects on T-cells as CRISPR-mediated inhibition.
Example 30: Expression of T Cell Activation Markers in Zc3h12a-Edited Murine TILs
[0613] Mouse CD8 TILs were isolated and edited with Zc3h12a-targeting gRNA/Cas9 RNPs as described in Example 1. Zc3h12a-specific sgRNAs lead to 86% inhibition of Zc3h12a. FACS analysis confirmed that inhibition of Zc3h12a with sgRNA led to a 2.7-fold increase in ICOS expression on the cell surface. RNA-seq analysis confirmed a significant 2.7-fold increase in Icos mRNA (p=1.6.times.10.sup.-71) as well as significant increases in the mRNA of Ifng (9.3-fold relative to control sgRNA, p=0) and Gzma (1.2 fold relative to control sgRNA, p=6.3.times.10.sup.-6), confirming Zc3h12a editing in mouse TILs activates T-cells.
Example 31: Inactivation of Zc3h12a Activity by CRISPR-Mediated Editing of Zc3h12a in Mouse CD8 T Cells
[0614] The effect of genetic inactivation of Zc3h12a on the function and inflammatory phenotype of mouse CD8 T cells was assessed. Mouse OT-I CD8 T cells were activated and infected with one of 3 different retroviral supernatants using the methods described in Example 30. Retroviruses encoded either 1) an sgRNA targeting an olfactory receptor gene (negative control), 2) an sgRNA targeting Zc3h12a (Zc3h12a-edited condition), or 3) an sgRNA targeting Zc3h12a along with gene encoding the protein product of Zc3h12a (Zc3h12a edited, WT ZC3H12A rescue condition). Post selection transduction rates were greater than 91% in all cases, and next generation sequencing confirmed that genome editing rates were greater than 80% in all cases.
[0615] CD8 T cells were then stimulated for 6 hours stimulation with PMA and Ionomycin to induce inflammatory transcript expression, and quantitative RT-PCR was performed to assess mRNA levels. Transcript expression levels were evaluated relative to expression of the housekeeping gene Gapdh. Editing of the Zc3h12a locus led to a dramatic increase in the levels of Icos, Il6, Il2, Ifng, and Nfkbiz transcripts when compared to negative control cells edited at the Olf421 locus (FIG. 22). Expression of ZC3H12A protein by lentiviral co-delivery of a codon optimized Zc3h12a gene into endogenous Zc3h12a edited cells led to a reduction of inflammatory mRNA levels (FIG. 22), demonstrating dependence of the observed phenotype on the absence of functional ZC3H12A protein.
[0616] To determine if the ZC3H12A-dependent transcriptional changes observed translated to changes on the cell surface, cells were stained with fluorescent anti-ICOS antibodies and cell surface ICOS levels were determined using flow cytometry. Editing of the Zc3h12a locus led to an increase in cell surface Icos expression that was reversed by overexpression of retrovirally derived ZC3H12A (FIG. 23).
[0617] The effects of genetic inactivation of the Zc3h12a gene on cytokine secretion by CD8 T cells were also measured. Cells were seeded into wells containing media containing either IL-2 alone, or IL-2 and anti-CD3/CD28 dynabeads, for 48 hours. Cell supernatants were harvested and the levels of secreted IFN.gamma. and IL-6 were measured using the mesoscale discovery MSD platform. Upon stimulation, Zc3h12a edited CD8 T cells produced greater quantities of IL-6 and IFN.gamma. than Olf421-edited cells. Furthermore, Zc3h12a-edited cells also produced significant quantities of IFN.gamma. in the absence of exogenous anti-CD3/CD28 stimulation compared to Olf421 edited cells (FIG. 24).
Example 32: Inactivation of Zc3h12a by CRISPR-Mediated Editing of the Zc3h12a Gene in Primary Human T Cells
[0618] To determine the effects of inactivation of ZC3H12A on primary human T cells, the production of IL6 mRNA transcript and IL-6 protein by genome-edited human T cells was evaluated. Briefly, primary human T cells were isolated from peripheral blood mononuclear cells (PBMC) and genome-edited using RNPs targeting either the ZC3H12A or OR1A2 loci, following the methods as outline in Example 1. Editing efficiencies ranged from 30-72%, as determined by next generation sequencing.
[0619] Cells were seeded at equal concentrations and cultured in culture medium containing anti-CD3/CD2/CD28 tetramer reagent (Stemcell Technologies). After 24 hours, cell supernatants was harvested and IL-6 levels were determined using the Mesoscale discovery V-plex human proinflammatory panel 1. Across multiple donors, T cells edited at the ZC3H12A locus secreted more IL-6 into the culture medium than those edited at the OR1A2 locus over the 24 hour period (FIG. 25A). Significantly increased production of IL-6 mRNA (12.3-fold and 5.9-fold in donors 3835 and 6915, respectively) was also observed after 24 hour anti-CD3/CD28 stimulation (FIG. 25B).
Example 33: Zc3h12a-Tiling Screen and Validation Assays
[0620] A CRISPR-Cas9 tiling screen was performed to determine candidate inhibitor target locations within a target locus spanning the ZC3H12A gene. Primary human CD8+ T cells were isolated as described in Example 1 and transduced with a lentiviral library expressing sgRNAs designed to target genomic positions across the full length of the ZC3H12A gene. Two days after transduction with the lentiviral library, the transduced CD8+ T cells were electroporated with Cas9 mRNA and cultured for an additional 10 days. After 10 days of culture subsequent to electroporation with Cas9 mRNA, the screen performed as described below. Additional assays were performed to validate gRNAs identified in the tiling screen. 437 distinct ZC3H12A-targeting gRNAs were assayed according to the following parameters.
Tiling Screen
[0621] Proliferation Read-Out:
[0622] Cells in the first arm were harvested on Day 10 after Cas9 mRNA electroporation. DNA was extracted and amplicons spanning the recognition sites for the various sgRNAs in the library were amplified by PCR and sequenced by next-generation sequencing (NGS). Enrichment or depletion of each of the sgRNAs was determined by the log ratio of final counts divided by reference counts.
Additional Assays for Guide Validation
[0623] Additional assays were developed to further characterize the efficacy and on-target activity of gRNAs identified in the tiling screen described above. Cells were isolated and electroporated with Cas9:gRNA RNPs containing ZC3H12A-specific gRNAs identified in tiling screens. Cells were cultured for approximately 10 days at which point the following assays were performed.
[0624] DNA Editing Assay:
[0625] A DNA editing assay was developed to compare the ability of individual guides to direct editing of their respective target at the DNA level. After electroporation with Cas9:gRNA RNPs, cells were cultured for approximately 10 days, at which point pellets were harvested and DNA was extracted. Amplicons spanning the genomic target loci for the various sgRNAs were amplified by PCR using guide-specific primer sets and sequenced by NGS. Sequencing reads were aligned to the predicted guide cut site, and the percentage of reads displaying an edited DNA sequence was determined. Outcomes were evaluated based on two criteria: 1) the overall percentage of off target editing and 2) the identity of the off-target edited genes. Optimal guides were identified those having the lowest level percent off-target editing and/or most benign off target edited genes profile. For example, gene editing in intragenic regions was viewed as a benign effect while editing in known oncogenes or tumor suppressors was viewed as an undesirable off target profile
[0626] Western Blot Assay:
[0627] A Western Blot assay was used to compare the ability of individual guides to reduce protein expression of their respective targets. P After electroporation with Cas9:gRNA RNPs, cells were cultured for approximately 10 days, cell pellets were then harvested, and lysed in RIPA buffer with protease and phosphatase inhibitors. Extracted protein was quantified by Bradford assay, and 1 .mu.g was loaded onto an automated Western Blotting instrument (Wes Separation Module by Protein Simple) using the machine's standard 12-230 kD Wes Separation Module protocol. Commercially available target specific primary antibodies were employed, followed by incubation with HRP-conjugated secondary antibodies. The signal detected per target guide was normalized to the respective signal seen in the negative control guide sample.
[0628] Tiling and Validation Results:
[0629] 200 ZC3H12A-targeting gRNAs (SEQ ID NOs: 1065-1264) were identified as optimal guides based on the assays described above. Similar experiments were performed for BCOR and TNFAIP3, with 57 BCOR gRNAs (SEQ ID NOs: 708-764) and 39 TNFAIP3 gRNAs (SEQ ID NOs: 348-386) identified as potential optimal guides.
TABLE-US-00015 TABLE 5A Human Genome Coordinates Target Coordinates Target Coordinates Target Coordinates IKZF1 chr7: 50387344-50387363 TNFAIP3 chr6: 137879270-137879289 HAVCR2 chr5: 157106863-157106882 IKZF1 chr7: 50400471-50400490 TNFAIP3 chr6: 137878846-137878865 HAVCR2 chr5: 157088943-157088962 IKZF1 chr7: 50327652-50327671 TNFAIP3 chr6: 137876140-137876159 HAVCR2 chr5: 157106706-157106725 IKZF1 chr7: 50400507-50400526 TNFAIP3 chr6: 137878571-137878590 HAVCR2 chr5: 157106886-157106905 IKZF1 chr7: 50376576-50376595 TNFAIP3 chr6: 137878573-137878592 HAVCR2 chr5: 157106767-157106786 IKZF1 chr7: 50400314-50400333 TNFAIP3 chr6: 137878653-137878672 HAVCR2 chr5: 157106825-157106844 IKZF1 chr7: 50327681-50327700 TNFAIP3 chr6: 137878827-137878846 HAVCR2 chr5: 157106718-157106737 IKZF1 chr7: 50391851-50391870 TNFAIP3 chr6: 137878726-137878745 HAVCR2 chr5: 157104727-157104746 IKZF1 chr7: 50368009-50368028 TNFAIP3 chr6: 137871457-137871476 HAVCR2 chr5: 157087278-157087297 IKZF1 chr7: 50382569-50382588 TNFAIP3 chr6: 137876104-137876123 LAG3 chr12: 6774679-6774698 IKZF1 chr7: 50376631-50376650 TNFAIP3 chr6: 137878762-137878781 LAG3 chr12: 6773300-6773319 IKZF1 chr7: 50400366-50400385 TNFAIP3 chr6: 137876083-137876102 LAG3 chr12: 6773939-6773958 IKZF1 chr7: 50391772-50391791 TNFAIP3 chr6: 137871402-137871421 LAG3 chr12: 6775340-6775359 IKZF1 chr7: 50399915-50399934 TNFAIP3 chr6: 137871501-137871520 LAG3 chr12: 6773781-6773800 IKZF1 chr7: 50400414-50400433 TNFAIP3 chr6: 137874861-137874880 LAG3 chr12: 6773221-6773240 IKZF1 chr7: 50368040-50368059 TNFAIP3 chr6: 137871362-137871381 LAG3 chr12: 6773335-6773354 IKZF1 chr7: 50382550-50382569 TNFAIP3 chr6: 137871249-137871268 LAG3 chr12: 6774608-6774627 IKZF1 chr7: 50387353-50387372 TNFAIP3 chr6: 137874972-137874991 LAG3 chr12: 6775514-6775533 NFKBIA chr14: 35404635-35404654 TNFAIP3 chr6: 137878495-137878514 LAG3 chr12: 6773804-6773823 NFKBIA chr14: 35402653-35402672 TNFAIP3 chr6: 137874842-137874861 LAG3 chr12: 6773283-6773302 NFKBIA chr14: 35402494-35402513 TNFAIP3 chr6: 137876139-137876158 LAG3 chr12: 6774798-6774817 NFKBIA chr14: 35404445-35404464 TNFAIP3 chr6: 137871437-137871456 TIGIT chr3: 114307905-114307924 NFKBIA chr14: 35403152-35403171 TANK chr2: 161232836-161232855 TIGIT chr3: 114295774-114295793 NFKBIA chr14: 35403258-35403277 TANK chr2: 161179709-161179728 TIGIT chr3: 114295717-114295736 NFKBIA chr14: 35404463-35404482 TANK chr2: 161224725-161224744 TIGIT chr3: 114295630-114295649 NFKBIA chr14: 35403202-35403221 TANK chr2: 161204665-161204684 TIGIT chr3: 114295615-114295634 NFKBIA chr14: 35404411-35404430 TANK chr2: 161161386-161161405 TIGIT chr3: 114295821-114295840 NFKBIA chr14: 35402666-35402685 TANK chr2: 161231124-161231143 TIGIT chr3: 114295767-114295786 NFKBIA chr14: 35403330-35403349 TANK chr2: 161179740-161179759 TIGIT chr3: 114299648-114299667 NFKBIA chr14: 35403695-35403714 TANK chr2: 161232788-161232807 TIGIT chr3: 114295577-114295596 BCL3 chr19: 44757097-44757116 TANK chr2: 161232777-161232796 TIGIT chr3: 114295650-114295669 BCL3 chr19: 44757336-44757355 TANK chr2: 161223970-161223989 TIGIT chr3: 114294023-114294042 BCL3 chr19: 44756280-44756299 TANK chr2: 161203501-161203520 TIGIT chr3: 114299682-114299701 BCL3 chr19: 44748932-44748951 TANK chr2: 161203590-161203609 CTLA4 chr2: 203872820-203872839 BCL3 chr19: 44756229-44756248 TANK chr2: 161204749-161204768 CTLA4 chr2: 203871417-203871436 BCL3 chr19: 44751352-44751371 TANK chr2: 161179691-161179710 CTLA4 chr2: 203870885-203870904 BCL3 chr19: 44756315-44756334 TANK chr2: 161161378-161161397 CTLA4 chr2: 203867944-203867963 BCL3 chr19: 44757028-44757047 FOXP3 chrX: 49258389-49258408 CTLA4 chr2: 203871421-203871440 BCL3 chr19: 44748876-44748895 FOXP3 chrX: 49255792-49255811 CTLA4 chr2: 203872759-203872778 BCL3 chr19: 44758720-44758739 FOXP3 chrX: 49253120-49253139 CTLA4 chr2: 203867944-203867963 BCL3 chr19: 44756334-44756353 FOXP3 chrX: 49251742-49251761 CTLA4 chr2: 203870640-203870659 BCL3 chr19: 44751300-44751319 FOXP3 chrX: 49256916-49256935 CTLA4 chr2: 203870767-203870786 BCL3 chr19: 44758258-44758277 FOXP3 chrX: 49254054-49254073 CTLA4 chr2: 203868001-203868020 IKZF3 chr17: 39765927-39765946 FOXP3 chrX: 49258314-49258333 CTLA4 chr2: 203870606-203870625 IKZF3 chr17: 39766306-39766325 FOXP3 chrX: 49251666-49251685 CTLA4 chr2: 203872716-203872735 IKZF3 chr17: 39788315-39788334 FOXP3 chrX: 49257496-49257515 PTPN6 chr12: 6955147-6955166 IKZF3 chr17: 39832082-39832101 FOXP3 chrX: 49258351-49258370 PTPN6 chr12: 6956188-6956207 IKZF3 chr17: 39766366-39766385 IKZF2 chr2: 213057056-213057075 PTPN6 chr12: 6952101-6952120 IKZF3 chr17: 39766410-39766429 IKZF2 chr2: 213056895-213056914 PTPN6 chr12: 6954832-6954851 IKZF3 chr17: 39765981-39766000 IKZF2 chr2: 213007992-213008011 PTPN6 chr12: 6951504-6951523 IKZF3 chr17: 39766262-39766281 IKZF2 chr2: 213022029-213022048 PTPN6 chr12: 6951637-6951656 IKZF3 chr17: 39766122-39766141 IKZF2 chr2: 213148620-213148639 PTPN6 chr12: 6952004-6952023 IKZF3 chr17: 39777926-39777945 IKZF2 chr2: 213049845-213049864 PTPN6 chr12: 6954960-6954979 IKZF3 chr17: 39777960-39777979 IKZF2 chr2: 213049749-213049768 PTPN6 chr12: 6945764-6945783 IKZF3 chr17: 39791548-39791567 IKZF2 chr2: 213013838-213013857 PTPN6 chr12: 6952156-6952175 IKZF3 chr17: 39791554-39791573 IKZF2 chr2: 213147704-213147723 PTPN6 chr12: 6951688-6951707 IKZF3 chr17: 39788306-39788325 IKZF2 chr2: 213007950-213007969 PTPN6 chr12: 6952055-6952074 IKZF3 chr17: 39777690-39777709 IKZF2 chr2: 213049803-213049822 PTPN6 chr12: 6952004-6952023 SMAD2 chr18: 47869428-47869447 IKZF2 chr2: 213022103-213022122 PTPN6 chr12: 6954869-6954888 SMAD2 chr18: 47896710-47896729 IKZF2 chr2: 213013910-213013929 BCOR chrX: 40074116-40074135 SMAD2 chr18: 47869333-47869352 IKZF2 chr2: 213056913-213056932 BCOR chrX: 40073790-40073809 SMAD2 chr18: 47869252-47869271 IKZF2 chr2: 213147790-213147809 BCOR chrX: 40077875-40077894 SMAD2 chr18: 47869371-47869390 IKZF2 chr2: 213049707-213049726 BCOR chrX: 40052324-40052343 SMAD2 chr18: 47870547-47870566 GATA3 chr10: 8064032-8064051 BCOR chrX: 40073729-40073748 SMAD2 chr18: 47896523-47896542 GATA3 chr10: 8064079-8064098 BCOR chrX: 40054273-40054292 SMAD2 chr18: 47845647-47845666 GATA3 chr10: 8073748-8073767 BCOR chrX: 40073193-40073212 SMAD2 chr18: 47896640-47896659 GATA3 chr10: 8058824-8058843 BCOR chrX: 40074630-40074649 TGFBR1 chr9: 99128854-99128873 GATA3 chr10: 8058443-8058462 BCOR chrX: 40062797-40062816 TGFBR1 chr9: 99137867-99137886 GATA3 chr10: 8069573-8069592 BCOR chrX: 40072605-40072624 TGFBR1 chr9: 99128995-99129014 GATA3 chr10: 8069532-8069551 BCOR chrX: 40073675-40073694 TGFBR1 chr9: 99132565-99132584 GATA3 chr10: 8055748-8055767 BCOR chrX: 40073080-40073099 TGFBR1 chr9: 99137897-99137916 GATA3 chr10: 8058395-8058414 BCOR chrX: 40074432-40074451 TGFBR1 chr9: 99137998-99138017 GATA3 chr10: 8058737-8058756 BCOR chrX: 40074150-40074169 TGFBR1 chr9: 99137939-99137958 GATA3 chr10: 8058349-8058368 BCOR chrX: 40073363-40073382 TGFBR1 chr9: 99132706-99132725 GATA3 chr10: 8058824-8058843 BCOR chrX: 40064581-40064600 TGFBR1 chr9: 99128942-99128961 RC3H1 chr1: 173946812-173946831 BCOR chrX: 40062765-40062784 TGFBR1 chr9: 99129014-99129033 RC3H1 chr1: 173992926-173992945 BCOR chrX: 40072562-40072581 TGFBR2 chr3: 30650327-30650346 RC3H1 chr1: 173980872-173980891 BCOR chrX: 40072987-40073006 TGFBR2 chr3: 30650394-30650413 RC3H1 chr1: 173982779-173982798 BCOR chrX: 40075168-40075187 TGFBR2 chr3: 30671914-30671933 RC3H1 chr1: 173980941-173980960 BCOR chrX: 40073376-40073395 TGFBR2 chr3: 30671753-30671772 RC3H1 chr1: 173992844-173992863 BCOR chrX: 40073489-40073508 TGFBR2 chr3: 30672089-30672108 RC3H1 chr1: 173992895-173992914 BCOR chrX: 40072671-40072690 TGFBR2 chr3: 30623239-30623258 RC3H1 chr1: 173992882-173992901 BCOR chrX: 40073707-40073726 TGFBR2 chr3: 30650357-30650376 RC3H1 chr1: 173961717-173961736 BCOR chrX: 40072455-40072474 TGFBR2 chr3: 30672412-30672431 RC3H1 chr1: 173984495-173984514 BCOR chrX: 40073856-40073875 TGFBR2 chr3: 30671782-30671801 RC3H1 chr1: 173980811-173980830 BCOR chrX: 40073454-40073473 TGFBR2 chr3: 30644886-30644905 RC3H1 chr1: 173964926-173964945 BCOR chrX: 40073223-40073242 TGFBR2 chr3: 30671709-30671728 RC3H1 chr1: 173982894-173982913 BCOR chrX: 40057164-40057183 TGFBR2 chr3: 30671765-30671784 TRAF6 chr11: 36501306-36501325 BCOR chrX: 40063694-40063713 TGFBR2 chr3: 30623229-30623248 TRAF6 chr11: 36490635-36490654 BCOR chrX: 40073114-40073133 TGFBR2 chr3: 30671933-30671952 TRAF6 chr11: 36498527-36498546 BCOR chrX: 40063765-40063784 TGFBR2 chr3: 30644834-30644853 TRAF6 chr11: 36492548-36492567 BCOR chrX: 40074230-40074249 TNIP1 chr5: 151039096-151039115 TRAF6 chr11: 36501355-36501374 BCOR chrX: 40063788-40063807 TNIP1 chr5: 151039165-151039184 TRAF6 chr11: 36501423-36501442 BCOR chrX: 40073550-40073569 TNIP1 chr5: 151033531-151033550 TRAF6 chr11: 36501487-36501506 BCOR chrX: 40072510-40072529 TNIP1 chr5: 151052229-151052248 TRAF6 chr11: 36490112-36490131 BCOR chrX: 40074371-40074390 TNIP1 chr5: 151056754-151056773 TRAF6 chr11: 36498546-36498565 BCOR chrX: 40062953-40062972 TNIP1 chr5: 151063682-151063701 TRAF6 chr11: 36490590-36490609 BCOR chrX: 40071047-40071066 TNIP1 chr5: 151033527-151033546 TRAF6 chr11: 36501262-36501281 BCOR chrX: 40073673-40073692 TNIP1 chr5: 151056795-151056814 TRAF6 chr11: 36497165-36497184 BCOR chrX: 40074756-40074775 TNIP1 chr5: 151033778-151033797 CBLB chr3: 105853475-105853494 BCOR chrX: 40074952-40074971 TNIP1 chr5: 151045881-151045900 CBLB chr3: 105853600-105853619 BCOR chrX: 40063752-40063771 TNIP1 chr5: 151063608-151063627 CBLB chr3: 105720111-105720130 BCOR chrX: 40062753-40062772 TNIP1 chr5: 151035692-151035711 CBLB chr3: 105867412-105867431 BCOR chrX: 40073052-40073071 TNIP1 chr5: 151056834-151056853 CBLB chr3: 105867529-105867548 BCOR chrX: 40075122-40075141 TNIP1 chr5: 151064993-151065012 CBLB chr3: 105720160-105720179 BCOR chrX: 40063806-40063825 TNIP1 chr5: 151033749-151033768 CBLB chr3: 105853421-105853440 BCOR chrX: 40074193-40074212 TNFAIP3 chr6: 137878782-137878801 CBLB chr3: 105751453-105751472 BCOR chrX: 40074839-40074858 TNFAIP3 chr6: 137874872-137874891 CBLB chr3: 105693541-105693560 BCOR chrX: 40074647-40074666 TNFAIP3 chr6: 137878447-137878466 CBLB chr3: 105867449-105867468 BCOR chrX: 40070980-40070999 TNFAIP3 chr6: 137878901-137878920 CBLB chr3: 105853514-105853533 BCOR chrX: 40074386-40074405 TNFAIP3 chr6: 137880092-137880111 PPP2R2D chr10: 131940160-131940179 BCOR chrX: 40072494-40072513 TNFAIP3 chr6: 137878710-137878729 PPP2R2D chr10: 131934499-131934518 BCOR chrX: 40074087-40074106 TNFAIP3 chr6: 137877173-137877192 PPP2R2D chr10: 131947775-131947794 BCOR chrX: 40057291-40057310 TNFAIP3 chr6: 137878510-137878529 PPP2R2D chr10: 131945305-131945324 BCOR chrX: 40073603-40073622 TNFAIP3 chr6: 137879002-137879021 PPP2R2D chr10: 131911562-131911581 BCOR chrX: 40074157-40074176 TNFAIP3 chr6: 137871467-137871486 PPP2R2D chr10: 131944056-131944075 BCOR chrX: 40075017-40075036 TNFAIP3 chr6: 137879001-137879020 PPP2R2D chr10: 131945382-131945401 BCOR chrX: 40074903-40074922 TNFAIP3 chr6: 137875731-137875750 PPP2R2D chr10: 131947633-131947652 BCOR chrX: 40074949-40074968 TNFAIP3 chr6: 137875820-137875839 PPP2R2D chr10: 131901284-131901303 BCOR chrX: 40053888-40053907 TNFAIP3 chr6: 137880133-137880152 PPP2R2D chr10: 131911594-131911613 BCOR chrX: 40074785-40074804 TNFAIP3 chr6: 137878796-137878815 NRP1 chr10: 33254103-33254122 BCOR chrX: 40077894-40077913 TNFAIP3 chr6: 137877195-137877214 NRP1 chr10: 33263822-33263841 BCOR chrX:
40076456-40076475 TNFAIP3 chr6: 137880103-137880122 NRP1 chr10: 33263660-33263679 BCOR chrX: 40062904-40062923 TNFAIP3 chr6: 137875750-137875769 NRP1 chr10: 33256447-33256466 PDCD1 chr2: 241852282-241852301 TNFAIP3 chr6: 137878979-137878998 NRP1 chr10: 33263677-33263696 PDCD1 chr2: 241852278-241852297 TNFAIP3 chr6: 137880119-137880138 NRP1 chr10: 33263699-33263718 PDCD1 chr2: 241852879-241852898 TNFAIP3 chr6: 137878741-137878760 NRP1 chr10: 33256400-33256419 PDCD1 chr2: 241852752-241852771 TNFAIP3 chr6: 137878795-137878814 NRP1 chr10: 33254025-33254044 PDCD1 chr2: 241852618-241852637 TNFAIP3 chr6: 137878817-137878836 NRP1 chr10: 33330718-33330737 PDCD1 chr2: 241852729-241852748 TNFAIP3 chr6: 137878974-137878993 NRP1 chr10: 33254069-33254088 PDCD1 chr2: 241852687-241852706 TNFAIP3 chr6: 137874868-137874887 NRP1 chr10: 33256432-33256451 PDCD1 chr2: 241852796-241852815 TNFAIP3 chr6: 137876091-137876110 HAVCR2 chr5: 157106936-157106955 PDCD1 chr2: 241852933-241852952 TNFAIP3 chr6: 137877199-137877218 HAVCR2 chr5: 157095368-157095387 PDCD1 chr2: 241852831-241852850 HAVCR2 chr5: 157106898-157106917 PDCD1 chr2: 241851189-241851208
TABLE-US-00016 TABLE 5B Murine Genome Coordinates Target Coordinates Target Coordinates Target Coordinates Ikzf1 chr11: 11754053-11754072 Gata3 chr2: 9874375-9874394 Lag3 chr6: 124908392-124908411 Ikzf1 chr11: 11707883-11707902 Gata3 chr2: 9858592-9858611 Lag3 chr6: 124909391-124909410 Ikzf1 chr11: 11754068-11754087 Gata3 chr2: 9877463-9877482 Lag3 chr6: 124909410-124909429 Ikzf1 chr11: 11754134-11754153 Gata3 chr2: 9877514-9877533 Tigit chr16: 43662107-43662126 Ikzf1 chr11: 11754153-11754172 Gata3 chr2: 9858607-9858626 Tigit chr16: 43662060-43662079 Ikzf1 chr11: 11754103-11754122 Gata3 chr2: 9877338-9877357 Tigit chr16: 43661976-43661995 Ikzf1 chr11: 11754015-11754034 Gata3 chr2: 9863114-9863133 Tigit chr16: 43662254-43662273 Ikzf1 chr11: 11754119-11754138 Gata3 chr2: 9858626-9858645 Tigit chr16: 43661994-43662013 Nfkbia chr12: 55491236-55491255 Rc3h1 chr1: 160930251-160930270 Tigit chr16: 43662156-43662175 Nfkbia chr12: 55491172-55491191 Rc3h1 chr1: 160930280-160930299 Tigit chr16: 43662277-43662296 Nfkbia chr12: 55491206-55491225 Rc3h1 chr1: 160930154-160930173 Tigit chr16: 43662012-43662031 Nfkbia chr12: 55490633-55490652 Rc3h1 chr1: 160942614-160942633 Tigit chr16: 43664036-43664055 Nfkbia chr12: 55491112-55491131 Rc3h1 chr1: 160930266-160930285 Tigit chr16: 43664057-43664076 Nfkbia chr12: 55490800-55490819 Rc3h1 chr1: 160930185-160930204 Tigit chr16: 43649030-43649049 Nfkbia chr12: 55490821-55490840 Rc3h1 chr1: 160938126-160938145 Tigit chr16: 43662129-43662148 Nfkbia chr12: 55490526-55490545 Rc3h1 chr1: 160930198-160930217 Tigit chr16: 43662059-43662078 Nfkbia chr12: 55491657-55491676 Traf6 chr2: 101688485-101688504 Tigit chr16: 43662148-43662167 Nfkbia chr12: 55491177-55491196 Traf6 chr2: 101691455-101691474 Tigit chr16: 43664021-43664040 Nfkbia chr12: 55491675-55491694 Traf6 chr2: 101688575-101688594 Ctla4 chr1: 60914621-60914640 Nfkbia chr12: 55490773-55490792 Traf6 chr2: 101684742-101684761 Ctla4 chr1: 60909166-60909185 Nfkbia chr12: 55490809-55490828 Traf6 chr2: 101688539-101688558 Ctla4 chr1: 60914725-60914744 Nfkbia chr12: 55491735-55491754 Traf6 chr2: 101691482-101691501 Ctla4 chr1: 60909219-60909238 Nfkbia chr12: 55490571-55490590 Traf6 chr2: 101688558-101688577 Ctla4 chr1: 60914673-60914692 Nfkbia chr12: 55490588-55490607 Traf6 chr2: 101684510-101684529 Ctla4 chr1: 60912501-60912520 Nfkbia chr12: 55491715-55491734 Cblb chr16: 52152499-52152518 Ctla4 chr1: 60912446-60912465 Nfkbia chr12: 55492316-55492335 Cblb chr16: 52139574-52139593 Ctla4 chr1: 60912725-60912744 Nfkbia chr12: 55491207-55491226 Cblb chr16: 52139603-52139622 Ctla4 chr1: 60912516-60912535 Bcl3 chr3: 19809245-19809264 Cblb chr16: 52112122-52112141 Ctla4 chr1: 60912664-60912683 Bcl3 chr3: 19811059-19811078 Cblb chr16: 52112134-52112153 Ctla4 chr1: 60912477-60912496 Bcl3 chr3: 19809632-19809651 Cblb chr16: 52152535-52152554 Ctla4 chr1: 60912618-60912637 Bcl3 chr3: 19809634-19809653 Cblb chr16: 52142891-52142910 Ctla4 chr1: 60912682-60912701 Bcl3 chr3: 19809551-19809570 Cblb chr16: 52135797-52135816 Ctla4 chr1: 60912697-60912716 Bcl3 chr3: 19809516-19809535 Cblb chr16: 52131105-52131124 Ctla4 chr1: 60912605-60912624 Bcl3 chr3: 19812411-19812430 Cblb chr16: 52112169-52112188 Ctla4 chr1: 60912433-60912452 Bcl3 chr3: 19811610-19811629 Cblb chr16: 52204542-52204561 Ctla4 chr1: 60909202-60909221 Ikzf3 chr11: 98516898-98516917 Cblb chr16: 52131058-52131077 Ctla4 chr1: 60909165-60909184 Ikzf3 chr11: 98467268-98467287 Cblb chr16: 52135876-52135895 Ctla4 chr1: 60914619-60914638 Ikzf3 chr11: 98467464-98467483 Cblb chr16: 52135763-52135782 Ctla4 chr1: 60909244-60909263 Ikzf3 chr11: 98467325-98467344 Cblb chr16: 52139509-52139528 Ptpn6 chr6: 124727399-124727418 Ikzf3 chr11: 98467181-98467200 Ppp2r2d chr7: 138876553-138876572 Ptpn6 chr6: 124732470-124732489 Ikzf3 chr11: 98477038-98477057 Ppp2r2d chr7: 138882200-138882219 Ptpn6 chr6: 124732484-124732503 Ikzf3 chr11: 98466977-98466996 Ppp2r2d chr7: 138876565-138876584 Ptpn6 chr6: 124727385-124727404 Ikzf3 chr11: 98467103-98467122 Ppp2r2d chr7: 138882451-138882470 Ptpn6 chr6: 124721816-124721835 Tgfbr1 chr4: 47396418-47396437 Ppp2r2d chr7: 138882404-138882423 Ptpn6 chr6: 124725324-124725343 Tgfbr1 chr4: 47396363-47396382 Ppp2r2d chr7: 138869675-138869694 Ptpn6 chr6: 124732430-124732449 Tgfbr1 chr4: 47393272-47393291 Ppp2r2d chr7: 138876686-138876705 Ptpn6 chr6: 124732454-124732473 Tgfbr1 chr4: 47393468-47393487 Ppp2r2d chr7: 138874130-138874149 Ptpn6 chr6: 124732329-124732348 Tgfbr1 chr4: 47393456-47393475 Nrp1 chr8: 128363358-128363377 Ptpn6 chr6: 124725334-124725353 Tgfbr1 chr4: 47396564-47396583 Nrp1 chr8: 128363296-128363315 Ptpn6 chr6: 124732349-124732368 Tgfbr1 chr4: 47393315-47393334 Nrp1 chr8: 128359628-128359647 Ptpn6 chr6: 124732309-124732328 Tgfbr1 chr4: 47396434-47396453 Nrp1 chr8: 128476138-128476157 Ptpn6 chr6: 124727402-124727421 Tgfbr1 chr4: 47393288-47393307 Nrp1 chr8: 128363272-128363291 Ptpn6 chr6: 124732435-124732454 Tgfbr1 chr4: 47396512-47396531 Nrp1 chr8: 128359612-128359631 Pdcd1 chr1: 94041239-94041258 Tgfbr1 chr4: 47402873-47402892 Nrp1 chr8: 128363336-128363355 Pdcd1 chr1: 94041292-94041311 Tgfbr1 chr4: 47396539-47396558 Nrp1 chr8: 128363210-128363229 Pdcd1 chr1: 94041357-94041376 Tgfbr1 chr4: 47393266-47393285 Nrp1 chr8: 128425932-128425951 Pdcd1 chr1: 94041207-94041226 Tgfbr1 chr4: 47396394-47396413 Nrp1 chr8: 128497936-128497955 Pdcd1 chr1: 94041223-94041242 Tgfbr1 chr4: 47393462-47393481 Nrp1 chr8: 128468551-128468570 Pdcd1 chr1: 94041394-94041413 Tgfbr2 chr9: 116129944-116129963 Nrp1 chr8: 128363251-128363270 Pdcd1 chr1: 94041165-94041184 Tgfbr2 chr9: 116129900-116129919 Nrp1 chr8: 128460693-128460712 Pdcd1 chr1: 94041179-94041198 Tgfbr2 chr9: 116129928-116129947 Havcr2 chr11: 46456439-46456458 Pdcd1 chr1: 94041468-94041487 Tgfbr2 chr9: 116131548-116131567 Havcr2 chr11: 46469515-46469534 Pdcd1 chr1: 94041331-94041350 Tgfbr2 chr9: 116131562-116131581 Havcr2 chr11: 46466864-46466883 Pdcd1 chr1: 94041421-94041440 Tgfbr2 chr9: 116131610-116131629 Havcr2 chr11: 46479374-46479393 Pdcd1 chr1: 94041165-94041184 Tgfbr2 chr9: 116131588-116131607 Havcr2 chr11: 46456495-46456514 Pdcd1 chr1: 94041421-94041440 Tgfbr2 chr9: 116131529-116131548 Havcr2 chr11: 46479356-46479375 Pdcd1 chr1: 94041331-94041350 Tgfbr2 chr9: 116110272-116110291 Havcr2 chr11: 46455033-46455052 Pdcd1 chr1: 94041468-94041487 Tgfbr2 chr9: 116109969-116109988 Havcr2 chr11: 46469534-46469553 Pdcd1 chr1: 94041239-94041258 Tgfbr2 chr9: 116129901-116129920 Havcr2 chr11: 46456242-46456261 Pdcd1 chr1: 94041292-94041311 Tgfbr2 chr9: 116129988-116130007 Havcr2 chr11: 46479302-46479321 Pdcd1 chr1: 94041357-94041376 Tgfbr2 chr9: 116110004-116110023 Havcr2 chr11: 46456496-46456515 Pdcd1 chr1: 94041207-94041226 Tnip1 chr11: 54939673-54939692 Havcr2 chr11: 46456355-46456374 Pdcd1 chr1: 94041223-94041242 Tnip1 chr11: 54930778-54930797 Havcr2 chr11: 46469521-46469540 Pdcd1 chr1: 94041394-94041413 Tnip1 chr11: 54934036-54934055 Havcr2 chr11: 46459111-46459130 Pdcd1 chr1: 94041179-94041198 Tnip1 chr11: 54934071-54934090 Havcr2 chr11: 46456301-46456320 Pdcd1 chr1: 94041412-94041431 Tnip1 chr11: 54930799-54930818 Lag3 chr6: 124908571-124908590 Pdcd1 chr1: 94041268-94041287 Tnip1 chr11: 54930820-54930839 Lag3 chr6: 124909259-124909278 Pdcd1 chr1: 94041309-94041328 Tnip1 chr11: 54933977-54933996 Lag3 chr6: 124909424-124909443 Pdcd1 chr1: 94041469-94041488 Tnip1 chr11: 54929117-54929136 Lag3 chr6: 124908491-124908510 Pdcd1 chr1: 94041189-94041208 Tnfaip3 chr10: 19011464-19011483 Lag3 chr6: 124909299-124909318 Pdcd1 chr1: 94041331-94041350 Tnfaip3 chr10: 19008246-19008265 Lag3 chr6: 124909474-124909493 Pdcd1 chr1: 94041239-94041258 Tnfaip3 chr10: 19008332-19008351 Lag3 chr6: 124909286-124909305 Pdcd1 chr1: 94041292-94041311 Tnfaip3 chr10: 19006919-19006938 Lag3 chr6: 124908450-124908469 Tnfaip3 chr10: 19008294-19008313 Lag3 chr6: 124908529-124908548 Tnfaip3 chr10: 19008234-19008253 Lag3 chr6: 124909272-124909291 Tnfaip3 chr10: 19002796-19002815 Lag3 chr6: 124909399-124909418 Tnfaip3 chr10: 19006981-19007000 Lag3 chr6: 124909228-124909247
TABLE-US-00017 TABLE 6A Human Genome Coordinates Target Coordinates Target Coordinates Target Coordinates BCL2L11 chr2: 111123809-111123828 PBRM1 chr3: 52554752-52554771 CALM2 chr2: 47167608-47167627 BCL2L11 chr2: 111142346-111142365 PBRM1 chr3: 52603635-52603654 CALM2 chr2: 47162389-47162408 BCL2L11 chr2: 111150125-111150144 PBRM1 chr3: 52634703-52634722 CALM2 chr2: 47162623-47162642 BCL2L11 chr2: 111164161-111164180 PBRM1 chr3: 52662232-52662251 CALM2 chr2: 47161766-47161785 BCL2L11 chr2: 111123880-111123899 PBRM1 chr3: 52609796-52609815 CALM2 chr2: 47161806-47161825 BCL2L11 chr2: 111142303-111142322 PBRM1 chr3: 52554720-52554739 CALM2 chr2: 47162544-47162563 BCL2L11 chr2: 111128637-111128656 PBRM1 chr3: 52668623-52668642 CALM2 chr2: 47167482-47167501 BCL2L11 chr2: 111124067-111124086 PBRM1 chr3: 52679663-52679682 CALM2 chr2: 47162606-47162625 BCL2L11 chr2: 111150032-111150051 PBRM1 chr3: 52617272-52617291 CALM2 chr2: 47162351-47162370 BCL2L11 chr2: 111153772-111153791 PBRM1 chr3: 52678502-52678521 CALM2 chr2: 47162279-47162298 BCL2L11 chr2: 111124106-111124125 PBRM1 chr3: 52558272-52558291 CALM2 chr2: 47172416-47172435 BCL2L11 chr2: 111123866-111123885 PBRM1 chr3: 52668512-52668531 SERPINA3 chr14: 94614673-94614692 BCL2L11 chr2: 111130128-111130147 PBRM1 chr3: 52643284-52643303 SERPINA3 chr14: 94619278-94619297 BCL2L11 chr2: 111123761-111123780 PBRM1 chr3: 52558266-52558285 SERPINA3 chr14: 94614582-94614601 BCL2L11 chr2: 111150081-111150100 PBRM1 chr3: 52634800-52634819 SERPINA3 chr14: 94619423-94619442 BCL2L11 chr2: 111123790-111123809 PBRM1 chr3: 52603596-52603615 SERPINA3 chr14: 94614528-94614547 BCL2L11 chr2: 111153779-111153798 PBRM1 chr3: 52643330-52643349 SERPINA3 chr14: 94614599-94614618 BCL2L11 chr2: 111124008-111124027 PBRM1 chr3: 52651751-52651770 SERPINA3 chr14: 94614744-94614763 BCL2L11 chr2: 111123848-111123867 WDR6 chr3: 49008972-49008991 SERPINA3 chr14: 94614944-94614963 BCL2L11 chr2: 111123849-111123868 WDR6 chr3: 49011963-49011982 SERPINA3 chr14: 94614885-94614904 CHIC2 chr4: 54064267-54064286 WDR6 chr3: 49011741-49011760 SERPINA3 chr14: 94614692-94614711 CHIC2 chr4: 54049066-54049085 WDR6 chr3: 49014895-49014914 SEMA7A chr15: 74417586-74417605 CHIC2 chr4: 54048982-54049001 WDR6 chr3: 49012228-49012247 SEMA7A chr15: 74416690-74416709 CHIC2 chr4: 54064276-54064295 WDR6 chr3: 49007462-49007481 SEMA7A chr15: 74417405-74417424 CHIC2 chr4: 54014101-54014120 WDR6 chr3: 49012620-49012639 SEMA7A chr15: 74416640-74416659 CHIC2 chr4: 54013870-54013889 WDR6 chr3: 49012948-49012967 SEMA7A chr15: 74415947-74415966 CHIC2 chr4: 54049029-54049048 RBM39 chr20: 35729298-35729317 SEMA7A chr15: 74411646-74411665 CHIC2 chr4: 54049258-54049277 RBM39 chr20: 35738973-35738992 SEMA7A chr15: 74417429-74417448 CHIC2 chr4: 54064203-54064222 RBM39 chr20: 35725067-35725086 SEMA7A chr15: 74414850-74414869 CHIC2 chr4: 54064222-54064241 RBM39 chr20: 35714187-35714206 SEMA7A chr15: 74417393-74417412 CHIC2 chr4: 54014065-54014084 RBM39 chr20: 35716784-35716803 DHODH chr16: 72014466-72014485 CHIC2 chr4: 54064183-54064202 RBM39 chr20: 35739528-35739547 DHODH chr16: 72008782-72008801 FLI1 chr11: 128772938-128772957 RBM39 chr20: 35734223-35734242 DHODH chr16: 72012120-72012139 FLI1 chr11: 128810556-128810575 RBM39 chr20: 35735042-35735061 DHODH chr16: 72012061-72012080 FLI1 chr11: 128768268-128768287 RBM39 chr20: 35724711-35724730 DHODH chr16: 72022430-72022449 FLI1 chr11: 128772807-128772826 RBM39 chr20: 35729482-35729501 DHODH chr16: 72014503-72014522 FLI1 chr11: 128807189-128807208 RBM39 chr20: 35731997-35732016 DHODH chr16: 72014529-72014548 FLI1 chr11: 128768230-128768249 RBM39 chr20: 35731969-35731988 DHODH chr16: 72012094-72012113 FLI1 chr11: 128807207-128807226 RBM39 chr20: 35740826-35740845 DHODH chr16: 72012147-72012166 FLI1 chr11: 128810519-128810538 RBM39 chr20: 35716771-35716790 DHODH chr16: 72017036-72017055 FLI1 chr11: 128810490-128810509 RBM39 chr20: 35707976-35707995 DHODH chr16: 72008781-72008800 FLI1 chr11: 128810665-128810684 RBM39 chr20: 35734220-35734239 DHODH chr16: 72012216-72012235 FLI1 chr11: 128772978-128772997 RBM39 chr20: 35707942-35707961 DHODH chr16: 72014491-72014510 FLI1 chr11: 128772894-128772913 RBM39 chr20: 35729478-35729497 DHODH chr16: 72008781-72008800 PCBP1 chr2: 70087872-70087891 RBM39 chr20: 35740555-35740574 DHODH chr16: 72014548-72014567 PCBP1 chr2: 70087909-70087928 RBM39 chr20: 35736543-35736562 UMPS chr3: 124738139-124738158 PCBP1 chr2: 70087790-70087809 RBM39 chr20: 35739531-35739550 UMPS chr3: 124730574-124730593 PCBP1 chr2: 70087821-70087840 RBM39 chr20: 35732003-35732022 UMPS chr3: 124737663-124737682 PCBP1 chr2: 70087998-70088017 RBM39 chr20: 35714241-35714260 UMPS chr3: 124737918-124737937 PCBP1 chr2: 70088588-70088607 RBM39 chr20: 35736551-35736570 UMPS chr3: 124735177-124735196 PCBP1 chr2: 70088106-70088125 E2F8 chr11: 19234923-19234942 GNAS chr20: 58895661-58895680 PCBP1 chr2: 70087940-70087959 E2F8 chr11: 19234390-19234409 GNAS chr20: 58903685-58903704 PCBP1 chr2: 70088307-70088326 E2F8 chr11: 19237345-19237364 GNAS chr20: 58905460-58905479 PCBP1 chr2: 70088200-70088219 E2F8 chr11: 19235005-19235024 GNAS chr20: 58840352-58840371 PCBP1 chr2: 70088063-70088082 E2F8 chr11: 19225425-19225444 GNAS chr20: 58840096-58840115 PCBP1 chr2: 70087845-70087864 E2F8 chr11: 19237329-19237348 GNAS chr20: 58840253-58840272 E2F8 chr11: 19234967-19234986 GNAS chr20: 58891819-58891838 E2F8 chr11: 19234422-19234441 GNAS chr20: 58891756-58891775 E2F8 chr11: 19237906-19237925 GNAS chr20: 58891768-58891787 E2F8 chr11: 19237980-19237999 GNAS chr20: 58840195-58840214 E2F8 chr11: 19232290-19232309 GNAS chr20: 58891728-58891747 E2F8 chr11: 19229509-19229528 GNAS chr20: 58840198-58840217
TABLE-US-00018 TABLE 6B Murine Genome Coordinates Target Coordinates Target Coordinates Target Coordinates Bcl2l11 chr2: 128128713-128128732 Fli1 chr9: 32461444-32461463 Wdr6 chr9: 108578530-108578549 Bcl2l11 chr2: 128147115-128147134 Fli1 chr9: 32461386-32461405 Wdr6 chr9: 108576565-108576584 Bcl2l11 chr2: 128128731-128128750 Fli1 chr9: 32461401-32461420 Wdr6 chr9: 108578514-108578533 Bcl2l11 chr2: 128147173-128147192 Fli1 chr9: 32465687-32465706 Wdr6 chr9: 108578497-108578516 Bcl2l11 chr2: 128128648-128128667 Fli1 chr9: 32461420-32461439 Wdr6 chr9: 108576511-108576530 Bcl2l11 chr2: 128128660-128128679 Fli1 chr9: 32424186-32424205 Dhodh chr8: 109596082-109596101 Bcl2l11 chr2: 128147091-128147110 Fli1 chr9: 32461239-32461258 Dhodh chr8: 109601459-109601478 Bcl2l11 chr2: 128128682-128128701 Fli1 chr9: 32424232-32424251 Dhodh chr8: 109603453-109603472 Bcl2l11 chr2: 128128640-128128659 Pcbp1 chr6: 86525508-86525527 Dhodh chr8: 109603306-109603325 Bcl2l11 chr2: 128147141-128147160 Pcbp1 chr6: 86524927-86524946 Dhodh chr8: 109603364-109603383 Bcl2l11 chr2: 128158269-128158288 Pcbp1 chr6: 86525842-86525861 Dhodh chr8: 109603351-109603370 Bcl2l11 chr2: 128158233-128158252 Pcbp1 chr6: 86525525-86525544 Dhodh chr8: 109596173-109596192 Bcl2l11 chr2: 128147129-128147148 Pcbp1 chr6: 86525608-86525627 Dhodh chr8: 109601503-109601522 Bcl2l11 chr2: 128128753-128128772 Pcbp1 chr6: 86525731-86525750 Gnas chr2: 174334196-174334215 Bcl2l11 chr2: 128158301-128158320 Pcbp1 chr6: 86525676-86525695 Gnas chr2: 174345476-174345495 Bcl2l11 chr2: 128147086-128147105 Pcbp1 chr6: 86525148-86525167 Gnas chr2: 174346023-174346042 Bcl2l11 chr2: 128128730-128128749 Pbrm1 14: 31040494-31040513 Gnas chr2: 174341872-174341891 Bcl2l11 chr2: 128128992-128129011 Pbrm1 14: 31038941-31038960 Gnas chr2: 174345749-174345768 Chic2 chr5: 75027179-75027198 Pbrm1 14: 31061547-31061566 Gnas chr2: 174345419-174345438 Chic2 chr5: 75044295-75044314 Pbrm1 14: 31036055-31036074 Gnas chr2: 174334251-174334270 Chic2 chr5: 75044192-75044211 Pbrm1 14: 31067548-31067567 Gnas chr2: 174345768-174345787 Chic2 chr5: 75011480-75011499 Pbrm1 14: 31027510-31027529 Chic2 chr5: 75044214-75044233 Pbrm1 14: 31067943-31067962 Chic2 chr5: 75011437-75011456 Pbrm1 14: 31030854-31030873 Chic2 chr5: 75027108-75027127 Chic2 chr5: 75044244-75044263
TABLE-US-00019 TABLE 6C Human Genome Coordinates Target Coordinates Target Coordinates Target Coordinates ZC3H12A Chr1: 37480274_37480293 ZC3H12A Chr1: 37482857_37482876 ZC3H12A Chr1: 37483381_37483400 ZC3H12A Chr1: 37482967_37482986 ZC3H12A Chr1: 37475578_37475597 ZC3H12A Chr1: 37482899_37482918 ZC3H12A Chr1: 37482922_37482941 ZC3H12A Chr1: 37480329_37480348 ZC3H12A Chr1: 37480373_37480392 ZC3H12A Chr1: 37480273_37480292 ZC3H12A Chr1: 37480288_37480307 ZC3H12A Chr1: 37481847_37481866 ZC3H12A Chr1: 37482886_37482905 ZC3H12A Chr1: 37481600_37481619 ZC3H12A Chr1: 37483330_37483349 ZC3H12A Chr1: 37483185_37483204 ZC3H12A Chr1: 37483212_37483231 ZC3H12A Chr1: 37483065_37483084 ZC3H12A Chr1: 37475817_37475836 ZC3H12A Chr1: 37483337_37483356 ZC3H12A Chr1: 37482499_37482518 ZC3H12A Chr1: 37483033_37483052 ZC3H12A Chr1: 37475542_37475561 ZC3H12A Chr1: 37483105_37483124 ZC3H12A Chr1: 37480408_37480427 ZC3H12A Chr1: 37483197_37483216 ZC3H12A Chr1: 37475631_37475650 ZC3H12A Chr1: 37483026_37483045 ZC3H12A Chr1: 37482730_37482749 ZC3H12A Chr1: 37483530_37483549 ZC3H12A Chr1: 37483463_37483482 ZC3H12A Chr1: 37475599_37475618 ZC3H12A Chr1: 37483407_37483426 ZC3H12A Chr1: 37480362_37480381 ZC3H12A Chr1: 37483262_37483281 ZC3H12A Chr1: 37483308_37483327 ZC3H12A Chr1: 37482962_37482981 ZC3H12A Chr1: 37482790_37482809 ZC3H12A Chr1: 37482853_37482872 ZC3H12A Chr1: 37475775_37475794 ZC3H12A Chr1: 37482719_37482738 ZC3H12A Chr1: 37482934_37482953 ZC3H12A Chr1: 37475509_37475528 ZC3H12A Chr1: 37482860_37482879 ZC3H12A Chr1: 37475591_37475610 ZC3H12A Chr1: 37475722_37475741 ZC3H12A Chr1: 37483443_37483462 ZC3H12A Chr1: 37475826_37475845 ZC3H12A Chr1: 37475818_37475837 ZC3H12A Chr1: 37483558_37483577 ZC3H12A Chr1: 37475865_37475884 ZC3H12A Chr1: 37482966_37482985 ZC3H12A Chr1: 37481599_37481618 ZC3H12A Chr1: 37481784_37481803 ZC3H12A Chr1: 37480388_37480407 ZC3H12A Chr1: 37475845_37475864 ZC3H12A Chr1: 37480322_37480341 ZC3H12A Chr1: 37483142_37483161 ZC3H12A Chr1: 37475730_37475749 ZC3H12A Chr1: 37475664_37475683 ZC3H12A Chr1: 37482448_37482467 ZC3H12A Chr1: 37482524_37482543 ZC3H12A Chr1: 37475757_37475776 ZC3H12A Chr1: 37483049_37483068 ZC3H12A Chr1: 37482849_37482868 ZC3H12A Chr1: 37483385_37483404 ZC3H12A Chr1: 37482905_37482924 ZC3H12A Chr1: 37475529_37475548 ZC3H12A Chr1: 37482933_37482952 ZC3H12A Chr1: 37482733_37482752 ZC3H12A Chr1: 37475664_37475683 ZC3H12A Chr1: 37475866_37475885 ZC3H12A Chr1: 37480423_37480442 ZC3H12A Chr1: 37482972_37482991 ZC3H12A Chr1: 37475843_37475862 ZC3H12A Chr1: 37482456_37482475 ZC3H12A Chr1: 37483321_37483340 ZC3H12A Chr1: 37475797_37475816 ZC3H12A Chr1: 37483551_37483570 ZC3H12A Chr1: 37482984_37483003 ZC3H12A Chr1: 37475642_37475661 ZC3H12A Chr1: 37481767_37481786 ZC3H12A Chr1: 37475807_37475826 ZC3H12A Chr1: 37483270_37483289 ZC3H12A Chr1: 37475715_37475734 ZC3H12A Chr1: 37483213_37483232 ZC3H12A Chr1: 37483024_37483043 ZC3H12A Chr1: 37483377_37483396 ZC3H12A Chr1: 37482427_37482446 ZC3H12A Chr1: 37483201_37483220 ZC3H12A Chr1: 37475593_37475612 ZC3H12A Chr1: 37483104_37483123 ZC3H12A Chr1: 37482447_37482466 ZC3H12A Chr1: 37475875_37475894 ZC3H12A Chr1: 37482879_37482898 ZC3H12A Chr1: 37483253_37483272 ZC3H12A Chr1: 37475534_37475553 ZC3H12A Chr1: 37483409_37483428 ZC3H12A Chr1: 37483429_37483448 ZC3H12A Chr1: 37482764_37482783 ZC3H12A Chr1: 37482752_37482771 ZC3H12A Chr1: 37483195_37483214 ZC3H12A Chr1: 37475869_37475888 ZC3H12A Chr1: 37480391_37480410 ZC3H12A Chr1: 37481648_37481667 ZC3H12A Chr1: 37483437_37483456 ZC3H12A Chr1: 37475694_37475713 ZC3H12A Chr1: 37483424_37483443 ZC3H12A Chr1: 37475598_37475617 ZC3H12A Chr1: 37482458_37482477 ZC3H12A Chr1: 37475580_37475599 ZC3H12A Chr1: 37482438_37482457 ZC3H12A Chr1: 37475774_37475793 ZC3H12A Chr1: 37482980_37482999 ZC3H12A Chr1: 37483257_37483276 ZC3H12A Chr1: 37475574_37475593 ZC3H12A Chr1: 37480408_37480427 ZC3H12A Chr1: 37483263_37483282 ZC3H12A Chr1: 37475803_37475822 ZC3H12A Chr1: 37483405_37483424 ZC3H12A Chr1: 37482545_37482564 ZC3H12A Chr1: 37481605_37481624 ZC3H12A Chr1: 37475740_37475759 ZC3H12A Chr1: 37483015_37483034 ZC3H12A Chr1: 37482437_37482456 ZC3H12A Chr1: 37480387_37480406 ZC3H12A Chr1: 37481595_37481614 ZC3H12A Chr1: 37482825_37482844 ZC3H12A Chr1: 37483507_37483526 ZC3H12A Chr1: 37482923_37482942 ZC3H12A Chr1: 37483595_37483614 ZC3H12A Chr1: 37483110_37483129 ZC3H12A Chr1: 37483143_37483162 ZC3H12A Chr1: 37483510_37483529 ZC3H12A Chr1: 37483325_37483344 ZC3H12A Chr1: 37482348_37482367 ZC3H12A Chr1: 37483283_37483302 ZC3H12A Chr1: 37481692_37481711 ZC3H12A Chr1: 37483018_37483037 ZC3H12A Chr1: 37482446_37482465 ZC3H12A Chr1: 37475826_37475845 ZC3H12A Chr1: 37482612_37482631 ZC3H12A Chr1: 37475700_37475719 ZC3H12A Chr1: 37483098_37483117 ZC3H12A Chr1: 37475613_37475632 ZC3H12A Chr1: 37475721_37475740 ZC3H12A Chr1: 37481758_37481777 ZC3H12A Chr1: 37475563_37475582 ZC3H12A Chr1: 37475628_37475647 ZC3H12A Chr1: 37480320_37480339 ZC3H12A Chr1: 37475535_37475554 ZC3H12A Chr1: 37482848_37482867 ZC3H12A Chr1: 37483380_37483399 ZC3H12A Chr1: 37482843_37482862 ZC3H12A Chr1: 37483134_37483153 ZC3H12A Chr1: 37483011_37483030 ZC3H12A Chr1: 37480424_37480443 ZC3H12A Chr1: 37475543_37475562 ZC3H12A Chr1: 37483509_37483528 ZC3H12A Chr1: 37482606_37482625 ZC3H12A Chr1: 37482799_37482818 ZC3H12A Chr1: 37483509_37483528 ZC3H12A Chr1: 37483098_37483117 ZC3H12A Chr1: 37483296_37483315 ZC3H12A Chr1: 37482768_37482787 ZC3H12A Chr1: 37483508_37483527 ZC3H12A Chr1: 37483332_37483351 ZC3H12A Chr1: 37475804_37475823 ZC3H12A Chr1: 37483559_37483578 ZC3H12A Chr1: 37483600_37483619 ZC3H12A Chr1: 37475808_37475827 ZC3H12A Chr1: 37483256_37483275 ZC3H12A Chr1: 37482410_37482429 ZC3H12A Chr1: 37475859_37475878 ZC3H12A Chr1: 37475936_37475955 ZC3H12A Chr1: 37481718_37481737 ZC3H12A Chr1: 37482973_37482992 ZC3H12A Chr1: 37475607_37475626 ZC3H12A Chr1: 37483395_37483414 ZC3H12A Chr1: 37475634_37475653 ZC3H12A Chr1: 37475809_37475828 ZC3H12A Chr1: 37482428_37482447 ZC3H12A Chr1: 37475854_37475873 ZC3H12A Chr1: 37483186_37483205 ZC3H12A Chr1: 37475562_37475581 ZC3H12A Chr1: 37480334_37480353 ZC3H12A Chr1: 37481747_37481766 ZC3H12A Chr1: 37483500_37483519 ZC3H12A Chr1: 37480414_37480433 ZC3H12A Chr1: 37482734_37482753 ZC3H12A Chr1: 37475827_37475846 ZC3H12A Chr1: 37480316_37480335 ZC3H12A Chr1: 37483278_37483297 ZC3H12A Chr1: 37483586_37483605 ZC3H12A Chr1: 37482971_37482990 ZC3H12A Chr1: 37482332_37482351 ZC3H12A Chr1: 37483089_37483108 ZC3H12A Chr1: 37482781_37482800 ZC3H12A Chr1: 37483109_37483128 ZC3H12A Chr1: 37483419_37483438 ZC3H12A Chr1: 37483173_37483192 ZC3H12A Chr1: 37475633_37475652 ZC3H12A Chr1: 37480285_37480304 ZC3H12A Chr1: 37482391_37482410 ZC3H12A Chr1: 37482591_37482610 ZC3H12A Chr1: 37483256_37483275 ZC3H12A Chr1: 37482392_37482411 ZC3H12A Chr1: 37483271_37483290 ZC3H12A Chr1: 37483420_37483439 ZC3H12A Chr1: 37482936_37482955 ZC3H12A Chr1: 37483603_37483622 ZC3H12A Chr1: 37475691_37475710 ZC3H12A Chr1: 37483408_37483427 ZC3H12A Chr1: 37482504_37482523 ZC3H12A Chr1: 37483419_37483438 ZC3H12A Chr1: 37481779_37481798 ZC3H12A Chr1: 37483252_37483271 ZC3H12A Chr1: 37475918_37475937 ZC3H12A Chr1: 37483206_37483225 ZC3H12A Chr1: 37483119_37483138 ZC3H12A Chr1: 37475589_37475608 ZC3H12A Chr1: 37482561_37482580 ZC3H12A Chr1: 37482343_37482362 ZC3H12A Chr1: 37482362_37482381 ZC3H12A Chr1: 37481745_37481764 ZC3H12A Chr1: 37483144_37483163 ZC3H12A Chr1: 37482566_37482585 ZC3H12A Chr1: 37475802_37475821 ZC3H12A Chr1: 37483213_37483232 ZC3H12A Chr1: 37482963_37482982 ZC3H12A Chr1: 37483494_37483513 ZC3H12A Chr1: 37482981_37483000 ZC3H12A Chr1: 37483420_37483439 ZC3H12A Chr1: 37483371_37483390 ZC3H12A Chr1: 37482789_37482808 ZC3H12A Chr1: 37483139_37483158 ZC3H12A Chr1: 37482552_37482571 ZC3H12A Chr1: 37483159_37483178 ZC3H12A Chr1: 37483619_37483638 ZC3H12A Chr1: 37475491_37475510 ZC3H12A Chr1: 37482349_37482368 ZC3H12A Chr1: 37481764_37481783 ZC3H12A Chr1: 37482479_37482498 ZC3H12A Chr1: 37483602_37483621 ZC3H12A Chr1: 37475650_37475669 ZC3H12A Chr1: 37483140_37483159 ZC3H12A Chr1: 37481596_37481615 ZC3H12A Chr1: 37483405_37483424 ZC3H12A Chr1: 37483313_37483332 ZC3H12A Chr1: 37482537_37482556 ZC3H12A Chr1: 37483037_37483056 ZC3H12A Chr1: 37483458_37483477 ZC3H12A Chr1: 37482370_37482389 ZC3H12A Chr1: 37483211_37483230 ZC3H12A Chr1: 37483320_37483339 ZC3H12A Chr1: 37475546_37475565 ZC3H12A Chr1: 37475537_37475556 ZC3H12A Chr1: 37483204_37483223 ZC3H12A Chr1: 37482598_37482617 ZC3H12A Chr1: 37475756_37475775 ZC3H12A Chr1: 37475792_37475811 ZC3H12A Chr1: 37483146_37483165 ZC3H12A Chr1: 37482403_37482422 ZC3H12A Chr1: 37483475_37483494 ZC3H12A Chr1: 37475812_37475831 ZC3H12A Chr1: 37482455_37482474 ZC3H12A Chr1: 37475577_37475596 ZC3H12A Chr1: 37483400_37483419 ZC3H12A Chr1: 37480311_37480330 ZC3H12A Chr1: 37475787_37475806 ZC3H12A Chr1: 37475703_37475722 ZC3H12A Chr1: 37482586_37482605 ZC3H12A Chr1: 37483574_37483593 ZC3H12A Chr1: 37483418_37483437 ZC3H12A Chr1: 37483099_37483118 ZC3H12A Chr1: 37480284_37480303 ZC3H12A Chr1: 37480284_37480303 ZC3H12A Chr1: 37483342_37483361 ZC3H12A Chr1: 37482369_37482388 ZC3H12A Chr1: 37482800_37482819 ZC3H12A Chr1: 37481823_37481842 ZC3H12A Chr1: 37483384_37483403 ZC3H12A Chr1: 37475721_37475740 ZC3H12A Chr1: 37482777_37482796 ZC3H12A Chr1: 37483425_37483444 ZC3H12A Chr1: 37482715_37482734 ZC3H12A Chr1: 37482412_37482431 ZC3H12A Chr1: 37482582_37482601 ZC3H12A Chr1: 37480281_37480300 ZC3H12A Chr1: 37483604_37483623 ZC3H12A Chr1: 37483153_37483172 ZC3H12A Chr1: 37482491_37482510 ZC3H12A Chr1: 37483438_37483457 ZC3H12A Chr1: 37482935_37482954 ZC3H12A Chr1: 37483497_37483516 ZC3H12A Chr1: 37482445_37482464 ZC3H12A Chr1: 37483378_37483397 ZC3H12A Chr1: 37475899_37475918 ZC3H12A Chr1: 37483331_37483350 ZC3H12A Chr1: 37482952_37482971 ZC3H12A Chr1: 37475889_37475908 ZC3H12A Chr1: 37483111_37483130 ZC3H12A Chr1: 37483399_37483418 ZC3H12A Chr1: 37482375_37482394 ZC3H12A Chr1: 37482847_37482866 ZC3H12A Chr1: 37483309_37483328 ZC3H12A Chr1: 37475741_37475760 ZC3H12A Chr1: 37483249_37483268 ZC3H12A Chr1: 37483200_37483219 ZC3H12A Chr1: 37482900_37482919 ZC3H12A Chr1: 37481754_37481773 ZC3H12A Chr1: 37481641_37481660 ZC3H12A Chr1: 37482442_37482461 ZC3H12A Chr1: 37475684_37475703 ZC3H12A Chr1: 37481656_37481675 ZC3H12A Chr1: 37481644_37481663 ZC3H12A Chr1: 37482519_37482538 ZC3H12A Chr1: 37483036_37483055 ZC3H12A Chr1: 37482464_37482483 ZC3H12A Chr1: 37482475_37482494 ZC3H12A Chr1: 37483474_37483493 ZC3H12A Chr1: 37482994_37483013 ZC3H12A Chr1: 37482613_37482632 ZC3H12A Chr1: 37483004_37483023 ZC3H12A Chr1: 37483437_37483456 ZC3H12A Chr1: 37482939_37482958 ZC3H12A Chr1: 37481846_37481865 ZC3H12A Chr1: 37482736_37482755 ZC3H12A Chr1: 37475541_37475560 ZC3H12A Chr1: 37483205_37483224 ZC3H12A Chr1: 37482538_37482557 ZC3H12A Chr1: 37481763_37481782 ZC3H12A Chr1: 37483406_37483425 ZC3H12A Chr1: 37483515_37483534 ZC3H12A Chr1: 37483231_37483250 ZC3H12A Chr1: 37480336_37480355 ZC3H12A Chr1: 37475874_37475893 ZC3H12A Chr1: 37482953_37482972 ZC3H12A Chr1: 37481716_37481735 ZC3H12A Chr1: 37483145_37483164 ZC3H12A Chr1: 37482407_37482426 ZC3H12A Chr1: 37480335_37480354 ZC3H12A Chr1: 37482587_37482606 ZC3H12A Chr1: 37475808_37475827 ZC3H12A Chr1: 37481659_37481678 ZC3H12A Chr1: 37475482_37475501 ZC3H12A Chr1: 37481620_37481639 ZC3H12A Chr1: 37475809_37475828 ZC3H12A Chr1: 37475844_37475863 ZC3H12A Chr1: 37475592_37475611 ZC3H12A Chr1: 37482565_37482584 ZC3H12A Chr1: 37480415_37480434 ZC3H12A Chr1: 37483156_37483175 ZC3H12A Chr1: 37482491_37482510 ZC3H12A Chr1: 37481709_37481728 ZC3H12A Chr1: 37480329_37480348 ZC3H12A Chr1: 37483379_37483398 ZC3H12A Chr1: 37483366_37483385 ZC3H12A Chr1: 37475573_37475592 ZC3H12A Chr1: 37481654_37481673 ZC3H12A Chr1: 37475627_37475646 ZC3H12A Chr1: 37483198_37483217 ZC3H12A Chr1: 37482567_37482586 ZC3H12A Chr1: 37482447_37482466 ZC3H12A Chr1: 37483557_37483576 ZC3H12A Chr1: 37481614_37481633 ZC3H12A Chr1: 37481758_37481777 ZC3H12A Chr1: 37482892_37482911 ZC3H12A
Chr1: 37482562_37482581 ZC3H12A Chr1: 37483560_37483579 ZC3H12A Chr1: 37483334_37483353 ZC3H12A Chr1: 37475868_37475887 ZC3H12A Chr1: 37475869_37475888 ZC3H12A Chr1: 37481708_37481727 ZC3H12A Chr1: 37482557_37482576 ZC3H12A Chr1: 37481655_37481674 ZC3H12A Chr1: 37483063_37483082 ZC3H12A Chr1: 37483511_37483530 ZC3H12A Chr1: 37481645_37481664 ZC3H12A Chr1: 37482998_37483017 ZC3H12A Chr1: 37475615_37475634 ZC3H12A Chr1: 37483016_37483035 ZC3H12A Chr1: 37482942_37482961 ZC3H12A Chr1: 37483333_37483352 ZC3H12A Chr1: 37475838_37475857 ZC3H12A Chr1: 37475508_37475527 ZC3H12A Chr1: 37482840_37482859 ZC3H12A Chr1: 37482850_37482869 ZC3H12A Chr1: 37482371_37482390 ZC3H12A Chr1: 37483545_37483564 ZC3H12A Chr1: 37475510_37475529 ZC3H12A Chr1: 37483119_37483138 ZC3H12A Chr1: 37482830_37482849 ZC3H12A Chr1: 37483510_37483529 ZC3H12A Chr1: 37482798_37482817 ZC3H12A Chr1: 37482444_37482463 ZC3H12A Chr1: 37483064_37483083 ZC3H12A Chr1: 37475859_37475878 ZC3H12A Chr1: 37482571_37482590 ZC3H12A Chr1: 37483149_37483168 ZC3H12A Chr1: 37483401_37483420 ZC3H12A Chr1: 37482553_37482572 ZC3H12A Chr1: 37483449_37483468 ZC3H12A Chr1: 37482851_37482870 ZC3H12A Chr1: 37483543_37483562 ZC3H12A Chr1: 37483264_37483283 ZC3H12A Chr1: 37475524_37475543 ZC3H12A Chr1: 37483542_37483561 ZC3H12A Chr1: 37475508_37475527 ZC3H12A Chr1: 37475601_37475620 ZC3H12A Chr1: 37482575_37482594 ZC3H12A Chr1: 37480415_37480434 ZC3H12A Chr1: 37475815_37475834 ZC3H12A Chr1: 37475855_37475874 ZC3H12A Chr1: 37482918_37482937 ZC3H12A Chr1: 37482801_37482820 ZC3H12A Chr1: 37482572_37482591 ZC3H12A Chr1: 37482474_37482493 ZC3H12A Chr1: 37475544_37475563 Zc3h12a chr1: 125122335-125122354 ZC3H12A Chr1: 37483232_37483251 ZC3H12A Chr1: 37483010_37483029 Zc3h12a chr1: 125121083-125121102 ZC3H12A Chr1: 37475732_37475751 ZC3H12A Chr1: 37483077_37483096 Zc3h12a chr1: 125120961-125120980 ZC3H12A Chr1: 37481602_37481621 ZC3H12A Chr1: 37482404_37482423 Zc3h12a chr1: 125122390-125122409 ZC3H12A Chr1: 37480289_37480308 ZC3H12A Chr1: 37475692_37475711 Zc3h12a chr1: 125120373-125120392 ZC3H12A Chr1: 37483165_37483184 ZC3H12A Chr1: 37483596_37483615 Zc3h12a chr1: 125122250-125122269 ZC3H12A Chr1: 37483248_37483267 ZC3H12A Chr1: 37483372_37483391 Zc3h12a chr1: 125122375-125122394 ZC3H12A Chr1: 37483078_37483097 ZC3H12A Chr1: 37481596_37481615 Zc3h12a chr1: 125120975-125120994 ZC3H12A Chr1: 37483017_37483036 ZC3H12A Chr1: 37480370_37480389 ZC3H12A Chr1: 37483174_37483193 ZC3H12A Chr1: 37480377_37480396
TABLE-US-00020 TABLE 6D Murine Genome Coordinates Target Coordinates Zc3h12a chr1: 125122335-125122354 Zc3h12a chr1: 125121083-125121102 Zc3h12a chr1: 125120961-125120980 Zc3h12a chr1: 125122390-125122409 Zc3h12a chr1: 125120373-125120392 Zc3h12a chr1: 125122250-125122269 Zc3h12a chr1: 125122375-125122394 Zc3h12a chr1: 125120975-125120994
TABLE-US-00021 TABLE 6E Human Genome Coordinates Target Coordinates MAP4K1 chr19: 38617794-38617813 MAP4K1 chr19: 38612617-38612636 MAP4K1 chr19: 38599957-38599976 MAP4K1 chr19: 38617616-38617635 MAP4K1 chr19: 38607904-38607923 MAP4K1 chr19: 38613865-38613884 MAP4K1 chr19: 38607916-38607935 MAP4K1 chr19: 38617828-38617847 MAP4K1 chr19: 38616225-38616244 MAP4K1 chr19: 38610007-38610026 MAP4K1 chr19: 38599964-38599983 MAP4K1 chr19: 38612614-38612633 MAP4K1 chr19: 38617365-38617384
TABLE-US-00022 TABLE 6F Murine Genome Coordinates Target Coordinates Map4k1 chr7: 28983466-28983485 Map4k1 chr7: 28983244-28983263 Map4k1 chr7: 28983478-28983497 Map4k1 chr7: 28983003-28983022 Map4k1 chr7: 28983420-28983439 Map4k1 chr7: 28983436-28983455 Map4k1 chr7: 28983405-28983424 Map4k1 chr7: 28983214-28983233 Map4k1 chr7: 28984113-28984132 Map4k1 chr7: 28984134-28984153 Map4k1 chr7: 28983019-28983038 Map4k1 chr7: 28986802-28986821 Map4k1 chr7: 28983446-28983465 Map4k1 chr7: 28983220-28983239 Map4k1 chr7: 28983466-28983485 Map4k1 chr7: 28983478-28983497
TABLE-US-00023 TABLE 6G Human Genome Coordinates Target Coordinates NR4A3 chr9: 99826780-99826799 NR4A3 chr9: 99828951-99828970 NR4A3 chr9: 99828105-99828124 NR4A3 chr9: 99826768-99826787 NR4A3 chr9: 99828319-99828338 NR4A3 chr9: 99832766-99832785 NR4A3 chr9: 99828263-99828282 NR4A3 chr9: 99828909-99828928 NR4A3 chr9: 99828489-99828508 NR4A3 chr9: 99828437-99828456 NR4A3 chr9: 99828669-99828688 NR4A3 chr9: 99832703-99832722
TABLE-US-00024 TABLE 6H Murine Genome Coordinates Target Coordinates Nr4a3 chr4: 48051580-48051599 Nr4a3 chr4: 48052171-48052190 Nr4a3 chr4: 48055944-48055963 Nr4a3 chr4: 48056028-48056047 Nr4a3 chr4: 48051515-48051534 Nr4a3 chr4: 48052131-48052150 Nr4a3 chr4: 48051303-48051322 Nr4a3 chr4: 48052115-48052134 Nr4a3 chr4: 48051287-48051306 Nr4a3 chr4: 48051580-48051599 Nr4a3 chr4: 48052171-48052190 Nr4a3 chr4: 48051348-48051367 Nr4a3 chr4: 48051255-48051274 Nr4a3 chr4: 48051366-48051385 Nr4a3 chr4: 48056024-48056043 Nr4a3 chr4: 48055983-48056002
Sequence CWU 1
1
1575122PRTArtificial SequenceP2A linker sequence 1Gly Ser Gly Ala
Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val1 5 10 15Glu Glu Asn
Pro Gly Pro 2028PRTHuman 2Ser Leu Leu Met Trp Ile Thr Gln1
539PRTHuman 3Ala Ala Gly Ile Gly Ile Leu Thr Val1 54310PRTHuman
4Met Ser Asn Gln Val Leu Cys Cys Val Val Leu Cys Phe Leu Gly Ala1 5
10 15Asn Thr Val Asp Gly Gly Ile Thr Gln Ser Pro Lys Tyr Leu Phe
Arg 20 25 30Lys Glu Gly Gln Asn Val Thr Leu Ser Cys Glu Gln Asn Leu
Asn His 35 40 45Asp Ala Met Tyr Trp Tyr Arg Gln Asp Pro Gly Gln Gly
Leu Arg Leu 50 55 60Ile Tyr Tyr Ser Gln Ile Val Asn Asp Phe Gln Lys
Gly Asp Ile Ala65 70 75 80Glu Gly Tyr Ser Val Ser Arg Glu Lys Lys
Glu Ser Phe Pro Leu Thr 85 90 95Val Thr Ser Ala Gln Lys Asn Pro Thr
Ala Phe Tyr Leu Cys Ala Ser 100 105 110Ser Pro Gly Ala Leu Tyr Glu
Gln Tyr Phe Gly Pro Gly Thr Arg Leu 115 120 125Thr Val Thr Glu Asp
Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val 130 135 140Phe Glu Pro
Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu145 150 155
160Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp
165 170 175Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp
Pro Gln 180 185 190Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg
Tyr Cys Leu Ser 195 200 205Ser Arg Leu Arg Val Ser Ala Thr Phe Trp
Gln Asn Pro Arg Asn His 210 215 220Phe Arg Cys Gln Val Gln Phe Tyr
Gly Leu Ser Glu Asn Asp Glu Trp225 230 235 240Thr Gln Asp Arg Ala
Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala 245 250 255Trp Gly Arg
Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly 260 265 270Val
Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr 275 280
285Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys
290 295 300Arg Lys Asp Ser Arg Gly305 3105270PRTHuman 5Met Thr Ser
Ile Arg Ala Val Phe Ile Phe Leu Trp Leu Gln Leu Asp1 5 10 15Leu Val
Asn Gly Glu Asn Val Glu Gln His Pro Ser Thr Leu Ser Val 20 25 30Gln
Glu Gly Asp Ser Ala Val Ile Lys Cys Thr Tyr Ser Asp Ser Ala 35 40
45Ser Asn Tyr Phe Pro Trp Tyr Lys Gln Glu Leu Gly Lys Arg Pro Gln
50 55 60Leu Ile Ile Asp Ile Arg Ser Asn Val Gly Glu Lys Lys Asp Gln
Arg65 70 75 80Ile Ala Val Thr Leu Asn Lys Thr Ala Lys His Phe Ser
Leu His Ile 85 90 95Thr Glu Thr Gln Pro Glu Asp Ser Ala Val Tyr Phe
Cys Ala Ala Thr 100 105 110Glu Asp Tyr Gln Leu Ile Trp Gly Ala Gly
Thr Lys Leu Ile Ile Lys 115 120 125Pro Asp Ile Gln Asn Pro Asp Pro
Ala Val Tyr Gln Leu Arg Asp Ser 130 135 140Lys Ser Ser Asp Lys Ser
Val Cys Leu Phe Thr Asp Phe Asp Ser Gln145 150 155 160Thr Asn Val
Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys 165 170 175Cys
Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val 180 185
190Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn
195 200 205Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser
Ser Cys 210 215 220Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp
Thr Asn Leu Asn225 230 235 240Phe Gln Asn Leu Ser Val Ile Gly Phe
Arg Ile Leu Leu Leu Lys Val 245 250 255Ala Gly Phe Asn Leu Leu Met
Thr Leu Arg Leu Trp Ser Ser 260 265 2706602PRTArtificial
SequenceDLT TCR 6Met Ser Asn Gln Val Leu Cys Cys Val Val Leu Cys
Phe Leu Gly Ala1 5 10 15Asn Thr Val Asp Gly Gly Ile Thr Gln Ser Pro
Lys Tyr Leu Phe Arg 20 25 30Lys Glu Gly Gln Asn Val Thr Leu Ser Cys
Glu Gln Asn Leu Asn His 35 40 45Asp Ala Met Tyr Trp Tyr Arg Gln Asp
Pro Gly Gln Gly Leu Arg Leu 50 55 60Ile Tyr Tyr Ser Gln Ile Val Asn
Asp Phe Gln Lys Gly Asp Ile Ala65 70 75 80Glu Gly Tyr Ser Val Ser
Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr 85 90 95Val Thr Ser Ala Gln
Lys Asn Pro Thr Ala Phe Tyr Leu Cys Ala Ser 100 105 110Ser Pro Gly
Ala Leu Tyr Glu Gln Tyr Phe Gly Pro Gly Thr Arg Leu 115 120 125Thr
Val Thr Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val 130 135
140Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
Leu145 150 155 160Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val
Glu Leu Ser Trp 165 170 175Trp Val Asn Gly Lys Glu Val His Ser Gly
Val Cys Thr Asp Pro Gln 180 185 190Pro Leu Lys Glu Gln Pro Ala Leu
Asn Asp Ser Arg Tyr Cys Leu Ser 195 200 205Ser Arg Leu Arg Val Ser
Ala Thr Phe Trp Gln Asn Pro Arg Asn His 210 215 220Phe Arg Cys Gln
Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp225 230 235 240Thr
Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala 245 250
255Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly
260 265 270Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys
Ala Thr 275 280 285Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met
Ala Met Val Lys 290 295 300Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala
Thr Asn Phe Ser Leu Leu305 310 315 320Lys Gln Ala Gly Asp Val Glu
Glu Asn Pro Gly Pro Met Thr Ser Ile 325 330 335Arg Ala Val Phe Ile
Phe Leu Trp Leu Gln Leu Asp Leu Val Asn Gly 340 345 350Glu Asn Val
Glu Gln His Pro Ser Thr Leu Ser Val Gln Glu Gly Asp 355 360 365Ser
Ala Val Ile Lys Cys Thr Tyr Ser Asp Ser Ala Ser Asn Tyr Phe 370 375
380Pro Trp Tyr Lys Gln Glu Leu Gly Lys Arg Pro Gln Leu Ile Ile
Asp385 390 395 400Ile Arg Ser Asn Val Gly Glu Lys Lys Asp Gln Arg
Ile Ala Val Thr 405 410 415Leu Asn Lys Thr Ala Lys His Phe Ser Leu
His Ile Thr Glu Thr Gln 420 425 430Pro Glu Asp Ser Ala Val Tyr Phe
Cys Ala Ala Thr Glu Asp Tyr Gln 435 440 445Leu Ile Trp Gly Ala Gly
Thr Lys Leu Ile Ile Lys Pro Asp Ile Gln 450 455 460Asn Pro Asp Pro
Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp465 470 475 480Lys
Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr Asn Val Ser 485 490
495Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys Val Leu Asp
500 505 510Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala Trp
Ser Asn 515 520 525Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn
Ser Ile Ile Pro 530 535 540Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser
Ser Cys Asp Val Lys Leu545 550 555 560Val Glu Lys Ser Phe Glu Thr
Asp Thr Asn Leu Asn Phe Gln Asn Leu 565 570 575Ser Val Ile Gly Phe
Arg Ile Leu Leu Leu Lys Val Ala Gly Phe Asn 580 585 590Leu Leu Met
Thr Leu Arg Leu Trp Ser Ser 595 6007310PRTHomo sapiens 7Met Ser Asn
Gln Val Leu Cys Cys Val Val Leu Cys Phe Leu Gly Ala1 5 10 15Asn Thr
Val Asp Gly Gly Ile Thr Gln Ser Pro Lys Tyr Leu Phe Arg 20 25 30Lys
Glu Gly Gln Asn Val Thr Leu Ser Cys Glu Gln Asn Leu Asn His 35 40
45Asp Ala Met Tyr Trp Tyr Arg Gln Asp Pro Gly Gln Gly Leu Arg Leu
50 55 60Ile Tyr Tyr Ser Gln Ile Val Asn Asp Phe Gln Lys Gly Asp Ile
Ala65 70 75 80Glu Gly Tyr Ser Val Ser Arg Glu Lys Lys Glu Ser Phe
Pro Leu Thr 85 90 95Val Thr Ser Ala Gln Lys Asn Pro Thr Ala Phe Tyr
Leu Cys Ala Ser 100 105 110Ser Pro Gly Ala Leu Tyr Glu Gln Tyr Phe
Gly Pro Gly Thr Arg Leu 115 120 125Thr Val Thr Glu Asp Leu Lys Asn
Val Phe Pro Pro Glu Val Ala Val 130 135 140Phe Glu Pro Ser Glu Ala
Glu Ile Ser His Thr Gln Lys Ala Thr Leu145 150 155 160Val Cys Leu
Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp 165 170 175Trp
Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln 180 185
190Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser
195 200 205Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg
Asn His 210 215 220Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu
Asn Asp Glu Trp225 230 235 240Thr Gln Asp Arg Ala Lys Pro Val Thr
Gln Ile Val Ser Ala Glu Ala 245 250 255Trp Gly Arg Ala Asp Cys Gly
Phe Thr Ser Glu Ser Tyr Gln Gln Gly 260 265 270Val Leu Ser Ala Thr
Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr 275 280 285Leu Tyr Ala
Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys 290 295 300Arg
Lys Asp Ser Arg Gly305 3108270PRTHomo sapiens 8Met Thr Ser Ile Arg
Ala Val Phe Ile Phe Leu Trp Leu Gln Leu Asp1 5 10 15Leu Val Asn Gly
Glu Asn Val Glu Gln His Pro Ser Thr Leu Ser Val 20 25 30Gln Glu Gly
Asp Ser Ala Val Ile Lys Cys Thr Tyr Ser Asp Ser Ala 35 40 45Ser Asn
Tyr Phe Pro Trp Tyr Lys Gln Glu Leu Gly Lys Arg Pro Gln 50 55 60Leu
Ile Ile Asp Ile Arg Ser Asn Val Gly Glu Lys Lys Asp Gln Arg65 70 75
80Ile Ala Val Thr Leu Asn Lys Thr Ala Lys His Phe Ser Leu His Ile
85 90 95Thr Glu Thr Gln Pro Glu Asp Ser Ala Val Tyr Phe Cys Ala Ala
Thr 100 105 110Glu Asp Leu Thr Leu Ile Trp Gly Ala Gly Thr Lys Leu
Ile Ile Lys 115 120 125Pro Asp Ile Gln Asn Pro Asp Pro Ala Val Tyr
Gln Leu Arg Asp Ser 130 135 140Lys Ser Ser Asp Lys Ser Val Cys Leu
Phe Thr Asp Phe Asp Ser Gln145 150 155 160Thr Asn Val Ser Gln Ser
Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys 165 170 175Cys Val Leu Asp
Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val 180 185 190Ala Trp
Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn 195 200
205Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys
210 215 220Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn
Leu Asn225 230 235 240Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile
Leu Leu Leu Lys Val 245 250 255Ala Gly Phe Asn Leu Leu Met Thr Leu
Arg Leu Trp Ser Ser 260 265 2709602PRTArtificial SequenceHigh
affinity DLT TCR 9Met Ser Asn Gln Val Leu Cys Cys Val Val Leu Cys
Phe Leu Gly Ala1 5 10 15Asn Thr Val Asp Gly Gly Ile Thr Gln Ser Pro
Lys Tyr Leu Phe Arg 20 25 30Lys Glu Gly Gln Asn Val Thr Leu Ser Cys
Glu Gln Asn Leu Asn His 35 40 45Asp Ala Met Tyr Trp Tyr Arg Gln Asp
Pro Gly Gln Gly Leu Arg Leu 50 55 60Ile Tyr Tyr Ser Gln Ile Val Asn
Asp Phe Gln Lys Gly Asp Ile Ala65 70 75 80Glu Gly Tyr Ser Val Ser
Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr 85 90 95Val Thr Ser Ala Gln
Lys Asn Pro Thr Ala Phe Tyr Leu Cys Ala Ser 100 105 110Ser Pro Gly
Ala Leu Tyr Glu Gln Tyr Phe Gly Pro Gly Thr Arg Leu 115 120 125Thr
Val Thr Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val 130 135
140Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
Leu145 150 155 160Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val
Glu Leu Ser Trp 165 170 175Trp Val Asn Gly Lys Glu Val His Ser Gly
Val Cys Thr Asp Pro Gln 180 185 190Pro Leu Lys Glu Gln Pro Ala Leu
Asn Asp Ser Arg Tyr Cys Leu Ser 195 200 205Ser Arg Leu Arg Val Ser
Ala Thr Phe Trp Gln Asn Pro Arg Asn His 210 215 220Phe Arg Cys Gln
Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp225 230 235 240Thr
Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala 245 250
255Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly
260 265 270Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys
Ala Thr 275 280 285Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met
Ala Met Val Lys 290 295 300Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala
Thr Asn Phe Ser Leu Leu305 310 315 320Lys Gln Ala Gly Asp Val Glu
Glu Asn Pro Gly Pro Met Thr Ser Ile 325 330 335Arg Ala Val Phe Ile
Phe Leu Trp Leu Gln Leu Asp Leu Val Asn Gly 340 345 350Glu Asn Val
Glu Gln His Pro Ser Thr Leu Ser Val Gln Glu Gly Asp 355 360 365Ser
Ala Val Ile Lys Cys Thr Tyr Ser Asp Ser Ala Ser Asn Tyr Phe 370 375
380Pro Trp Tyr Lys Gln Glu Leu Gly Lys Arg Pro Gln Leu Ile Ile
Asp385 390 395 400Ile Arg Ser Asn Val Gly Glu Lys Lys Asp Gln Arg
Ile Ala Val Thr 405 410 415Leu Asn Lys Thr Ala Lys His Phe Ser Leu
His Ile Thr Glu Thr Gln 420 425 430Pro Glu Asp Ser Ala Val Tyr Phe
Cys Ala Ala Thr Glu Asp Leu Thr 435 440 445Leu Ile Trp Gly Ala Gly
Thr Lys Leu Ile Ile Lys Pro Asp Ile Gln 450 455 460Asn Pro Asp Pro
Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp465 470 475 480Lys
Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr Asn Val Ser 485 490
495Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys Val Leu Asp
500 505 510Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala Trp
Ser Asn 515 520 525Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn
Ser Ile Ile Pro 530 535 540Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser
Ser Cys Asp Val Lys Leu545 550 555 560Val Glu Lys Ser Phe Glu Thr
Asp Thr Asn Leu Asn Phe Gln Asn Leu 565 570 575Ser Val Ile Gly Phe
Arg Ile Leu Leu Leu Lys Val Ala Gly Phe Asn 580 585 590Leu Leu Met
Thr Leu Arg Leu Trp Ser Ser 595 60010311PRTHuman 10Met Ser Ile Gly
Leu Leu Cys Cys Ala Ala Leu Ser Leu Leu Trp Ala1 5 10 15Gly Pro Val
Asn Ala Gly Val Thr Gln Thr Pro Lys Phe Gln Val Leu 20 25 30Lys Thr
Gly Gln Ser Met Thr Leu Gln Cys Ala Gln Asp Met Asn His 35 40
45Glu Tyr Met Ser Trp Tyr Arg Gln Asp Pro Gly Met Gly Leu Arg Leu
50 55 60Ile His Tyr Ser Val Gly Ala Gly Ile Thr Asp Gln Gly Glu Val
Pro65 70 75 80Asn Gly Tyr Asn Val Ser Arg Ser Thr Thr Glu Asp Phe
Pro Leu Arg 85 90 95Leu Leu Ser Ala Ala Pro Ser Gln Thr Ser Val Tyr
Phe Cys Ala Ser 100 105 110Ser Tyr Val Gly Asn Thr Gly Glu Leu Phe
Phe Gly Glu Gly Ser Arg 115 120 125Leu Thr Val Leu Glu Asp Leu Lys
Asn Val Phe Pro Pro Glu Val Ala 130 135 140Val Phe Glu Pro Ser Glu
Ala Glu Ile Ser His Thr Gln Lys Ala Thr145 150 155 160Leu Val Cys
Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser 165 170 175Trp
Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro 180 185
190Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro
Arg Asn 210 215 220His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser
Glu Asn Asp Glu225 230 235 240Trp Thr Gln Asp Arg Ala Lys Pro Val
Thr Gln Ile Val Ser Ala Glu 245 250 255Ala Trp Gly Arg Ala Asp Cys
Gly Phe Thr Ser Glu Ser Tyr Gln Gln 260 265 270Gly Val Leu Ser Ala
Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala 275 280 285Thr Leu Tyr
Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val 290 295 300Lys
Arg Lys Asp Ser Arg Gly305 31011274PRTHuman 11Met Glu Thr Leu Leu
Gly Leu Leu Ile Leu Trp Leu Gln Leu Gln Trp1 5 10 15Val Ser Ser Lys
Gln Glu Val Thr Gln Ile Pro Ala Ala Leu Ser Val 20 25 30Pro Glu Gly
Glu Asn Leu Val Leu Asn Cys Ser Phe Thr Asp Ser Ala 35 40 45Ile Tyr
Asn Leu Gln Trp Phe Arg Gln Asp Pro Gly Lys Gly Leu Thr 50 55 60Ser
Leu Leu Leu Ile Gln Ser Ser Gln Arg Glu Gln Thr Ser Gly Arg65 70 75
80Leu Asn Ala Ser Leu Asp Lys Ser Ser Gly Arg Ser Thr Leu Tyr Ile
85 90 95Ala Ala Ser Gln Pro Gly Asp Ser Ala Thr Tyr Leu Cys Ala Val
Arg 100 105 110Pro Thr Ser Gly Gly Ser Tyr Ile Pro Thr Phe Gly Arg
Gly Thr Ser 115 120 125Leu Ile Val His Pro Tyr Ile Gln Asn Pro Asp
Pro Ala Val Tyr Gln 130 135 140Leu Arg Asp Ser Lys Ser Ser Asp Lys
Ser Val Cys Leu Phe Thr Asp145 150 155 160Phe Asp Ser Gln Thr Asn
Val Ser Gln Ser Lys Asp Ser Asp Val Tyr 165 170 175Ile Thr Asp Lys
Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser 180 185 190Asn Ser
Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn 195 200
205Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro
210 215 220Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu
Thr Asp225 230 235 240Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile
Gly Phe Arg Ile Leu 245 250 255Leu Leu Lys Val Ala Gly Phe Asn Leu
Leu Met Thr Leu Arg Leu Trp 260 265 270Ser Ser12607PRTArtificial
SequenceIG4 TCR 12Met Ser Ile Gly Leu Leu Cys Cys Ala Ala Leu Ser
Leu Leu Trp Ala1 5 10 15Gly Pro Val Asn Ala Gly Val Thr Gln Thr Pro
Lys Phe Gln Val Leu 20 25 30Lys Thr Gly Gln Ser Met Thr Leu Gln Cys
Ala Gln Asp Met Asn His 35 40 45Glu Tyr Met Ser Trp Tyr Arg Gln Asp
Pro Gly Met Gly Leu Arg Leu 50 55 60Ile His Tyr Ser Val Gly Ala Gly
Ile Thr Asp Gln Gly Glu Val Pro65 70 75 80Asn Gly Tyr Asn Val Ser
Arg Ser Thr Thr Glu Asp Phe Pro Leu Arg 85 90 95Leu Leu Ser Ala Ala
Pro Ser Gln Thr Ser Val Tyr Phe Cys Ala Ser 100 105 110Ser Tyr Val
Gly Asn Thr Gly Glu Leu Phe Phe Gly Glu Gly Ser Arg 115 120 125Leu
Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala 130 135
140Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala
Thr145 150 155 160Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His
Val Glu Leu Ser 165 170 175Trp Trp Val Asn Gly Lys Glu Val His Ser
Gly Val Cys Thr Asp Pro 180 185 190Gln Pro Leu Lys Glu Gln Pro Ala
Leu Asn Asp Ser Arg Tyr Cys Leu 195 200 205Ser Ser Arg Leu Arg Val
Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn 210 215 220His Phe Arg Cys
Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu225 230 235 240Trp
Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu 245 250
255Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln
260 265 270Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly
Lys Ala 275 280 285Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu
Met Ala Met Val 290 295 300Lys Arg Lys Asp Ser Arg Gly Gly Ser Gly
Ala Thr Asn Phe Ser Leu305 310 315 320Leu Lys Gln Ala Gly Asp Val
Glu Glu Asn Pro Gly Pro Met Glu Thr 325 330 335Leu Leu Gly Leu Leu
Ile Leu Trp Leu Gln Leu Gln Trp Val Ser Ser 340 345 350Lys Gln Glu
Val Thr Gln Ile Pro Ala Ala Leu Ser Val Pro Glu Gly 355 360 365Glu
Asn Leu Val Leu Asn Cys Ser Phe Thr Asp Ser Ala Ile Tyr Asn 370 375
380Leu Gln Trp Phe Arg Gln Asp Pro Gly Lys Gly Leu Thr Ser Leu
Leu385 390 395 400Leu Ile Gln Ser Ser Gln Arg Glu Gln Thr Ser Gly
Arg Leu Asn Ala 405 410 415Ser Leu Asp Lys Ser Ser Gly Arg Ser Thr
Leu Tyr Ile Ala Ala Ser 420 425 430Gln Pro Gly Asp Ser Ala Thr Tyr
Leu Cys Ala Val Arg Pro Thr Ser 435 440 445Gly Gly Ser Tyr Ile Pro
Thr Phe Gly Arg Gly Thr Ser Leu Ile Val 450 455 460His Pro Tyr Ile
Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp465 470 475 480Ser
Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser 485 490
495Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp
500 505 510Lys Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn
Ser Ala 515 520 525Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala
Asn Ala Phe Asn 530 535 540Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe
Pro Ser Pro Glu Ser Ser545 550 555 560Cys Asp Val Lys Leu Val Glu
Lys Ser Phe Glu Thr Asp Thr Asn Leu 565 570 575Asn Phe Gln Asn Leu
Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys 580 585 590Val Ala Gly
Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser 595 600
60513311PRTArtificial Sequence95L TCRb 13Met Ser Ile Gly Leu Leu
Cys Cys Ala Ala Leu Ser Leu Leu Trp Ala1 5 10 15Gly Pro Val Asn Ala
Gly Val Thr Gln Thr Pro Lys Phe Gln Val Leu 20 25 30Lys Thr Gly Gln
Ser Met Thr Leu Gln Cys Ala Gln Asp Met Asn His 35 40 45Glu Tyr Met
Ser Trp Tyr Arg Gln Asp Pro Gly Met Gly Leu Arg Leu 50 55 60Ile His
Tyr Ser Val Gly Ala Gly Ile Thr Asp Gln Gly Glu Val Pro65 70 75
80Asn Gly Tyr Asn Val Ser Arg Ser Thr Thr Glu Asp Phe Pro Leu Arg
85 90 95Leu Leu Ser Ala Ala Pro Ser Gln Thr Ser Val Tyr Phe Cys Ala
Ser 100 105 110Ser Tyr Val Gly Asn Thr Gly Glu Leu Phe Phe Gly Glu
Gly Ser Arg 115 120 125Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe
Pro Pro Glu Val Ala 130 135 140Val Phe Glu Pro Ser Glu Ala Glu Ile
Ser His Thr Gln Lys Ala Thr145 150 155 160Leu Val Cys Leu Ala Thr
Gly Phe Tyr Pro Asp His Val Glu Leu Ser 165 170 175Trp Trp Val Asn
Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro 180 185 190Gln Pro
Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu 195 200
205Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn
Asp Glu225 230 235 240Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln
Ile Val Ser Ala Glu 245 250 255Ala Trp Gly Arg Ala Asp Cys Gly Phe
Thr Ser Glu Ser Tyr Gln Gln 260 265 270Gly Val Leu Ser Ala Thr Ile
Leu Tyr Glu Ile Leu Leu Gly Lys Ala 275 280 285Thr Leu Tyr Ala Val
Leu Val Ser Ala Leu Val Leu Met Ala Met Val 290 295 300Lys Arg Lys
Asp Ser Arg Gly305 31014274PRTArtificial Sequence95L TCRa 14Met Glu
Thr Leu Leu Gly Leu Leu Ile Leu Trp Leu Gln Leu Gln Trp1 5 10 15Val
Ser Ser Lys Gln Glu Val Thr Gln Ile Pro Ala Ala Leu Ser Val 20 25
30Pro Glu Gly Glu Asn Leu Val Leu Asn Cys Ser Phe Thr Asp Ser Ala
35 40 45Ile Tyr Asn Leu Gln Trp Phe Arg Gln Asp Pro Gly Lys Gly Leu
Thr 50 55 60Ser Leu Leu Leu Ile Gln Ser Ser Gln Arg Glu Gln Thr Ser
Gly Arg65 70 75 80Leu Asn Ala Ser Leu Asp Lys Ser Ser Gly Arg Ser
Thr Leu Tyr Ile 85 90 95Ala Ala Ser Gln Pro Gly Asp Ser Ala Thr Tyr
Leu Cys Ala Val Arg 100 105 110Pro Leu Tyr Gly Gly Ser Tyr Ile Pro
Thr Phe Gly Arg Gly Thr Ser 115 120 125Leu Ile Val His Pro Tyr Ile
Gln Asn Pro Asp Pro Ala Val Tyr Gln 130 135 140Leu Arg Asp Ser Lys
Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp145 150 155 160Phe Asp
Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr 165 170
175Ile Thr Asp Lys Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser
180 185 190Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys
Ala Asn 195 200 205Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe
Phe Pro Ser Pro 210 215 220Glu Ser Ser Cys Asp Val Lys Leu Val Glu
Lys Ser Phe Glu Thr Asp225 230 235 240Thr Asn Leu Asn Phe Gln Asn
Leu Ser Val Ile Gly Phe Arg Ile Leu 245 250 255Leu Leu Lys Val Ala
Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp 260 265 270Ser
Ser15607PRTArtificial Sequence95L IG4 TCR 15Met Ser Ile Gly Leu Leu
Cys Cys Ala Ala Leu Ser Leu Leu Trp Ala1 5 10 15Gly Pro Val Asn Ala
Gly Val Thr Gln Thr Pro Lys Phe Gln Val Leu 20 25 30Lys Thr Gly Gln
Ser Met Thr Leu Gln Cys Ala Gln Asp Met Asn His 35 40 45Glu Tyr Met
Ser Trp Tyr Arg Gln Asp Pro Gly Met Gly Leu Arg Leu 50 55 60Ile His
Tyr Ser Val Gly Ala Gly Ile Thr Asp Gln Gly Glu Val Pro65 70 75
80Asn Gly Tyr Asn Val Ser Arg Ser Thr Thr Glu Asp Phe Pro Leu Arg
85 90 95Leu Leu Ser Ala Ala Pro Ser Gln Thr Ser Val Tyr Phe Cys Ala
Ser 100 105 110Ser Tyr Val Gly Asn Thr Gly Glu Leu Phe Phe Gly Glu
Gly Ser Arg 115 120 125Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe
Pro Pro Glu Val Ala 130 135 140Val Phe Glu Pro Ser Glu Ala Glu Ile
Ser His Thr Gln Lys Ala Thr145 150 155 160Leu Val Cys Leu Ala Thr
Gly Phe Tyr Pro Asp His Val Glu Leu Ser 165 170 175Trp Trp Val Asn
Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro 180 185 190Gln Pro
Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu 195 200
205Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn
Asp Glu225 230 235 240Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln
Ile Val Ser Ala Glu 245 250 255Ala Trp Gly Arg Ala Asp Cys Gly Phe
Thr Ser Glu Ser Tyr Gln Gln 260 265 270Gly Val Leu Ser Ala Thr Ile
Leu Tyr Glu Ile Leu Leu Gly Lys Ala 275 280 285Thr Leu Tyr Ala Val
Leu Val Ser Ala Leu Val Leu Met Ala Met Val 290 295 300Lys Arg Lys
Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu305 310 315
320Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Glu Thr
325 330 335Leu Leu Gly Leu Leu Ile Leu Trp Leu Gln Leu Gln Trp Val
Ser Ser 340 345 350Lys Gln Glu Val Thr Gln Ile Pro Ala Ala Leu Ser
Val Pro Glu Gly 355 360 365Glu Asn Leu Val Leu Asn Cys Ser Phe Thr
Asp Ser Ala Ile Tyr Asn 370 375 380Leu Gln Trp Phe Arg Gln Asp Pro
Gly Lys Gly Leu Thr Ser Leu Leu385 390 395 400Leu Ile Gln Ser Ser
Gln Arg Glu Gln Thr Ser Gly Arg Leu Asn Ala 405 410 415Ser Leu Asp
Lys Ser Ser Gly Arg Ser Thr Leu Tyr Ile Ala Ala Ser 420 425 430Gln
Pro Gly Asp Ser Ala Thr Tyr Leu Cys Ala Val Arg Pro Leu Tyr 435 440
445Gly Gly Ser Tyr Ile Pro Thr Phe Gly Arg Gly Thr Ser Leu Ile Val
450 455 460His Pro Tyr Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu
Arg Asp465 470 475 480Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe
Thr Asp Phe Asp Ser 485 490 495Gln Thr Asn Val Ser Gln Ser Lys Asp
Ser Asp Val Tyr Ile Thr Asp 500 505 510Lys Cys Val Leu Asp Met Arg
Ser Met Asp Phe Lys Ser Asn Ser Ala 515 520 525Val Ala Trp Ser Asn
Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn 530 535 540Asn Ser Ile
Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser545 550 555
560Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu
565 570 575Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu
Leu Lys 580 585 590Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu
Trp Ser Ser 595 600 60516311PRTHomo sapiens 16Met Gly Thr Arg Leu
Phe Phe Tyr Val Ala Leu Cys Leu Leu Trp Thr1 5 10 15Gly His Met Asp
Ala Gly Ile Thr Gln Ser Pro Arg His Lys Val Thr 20 25 30Glu Thr Gly
Thr Pro Val Thr Leu Arg Cys His Gln Thr Glu Asn His 35 40 45Arg Tyr
Met Tyr Trp Tyr Arg Gln Asp Pro Gly His Gly Leu Arg Leu 50 55 60Ile
His Tyr Ser Tyr Gly Val Lys Asp Thr Asp Lys Gly Glu Val Ser65 70 75
80Asp Gly Tyr Ser Val Ser Arg Ser Lys Thr Glu Asp Phe Leu Leu Thr
85 90 95Leu Glu Ser Ala Thr Ser Ser Gln Thr Ser Val Tyr Phe Cys Ala
Ile 100 105 110Ser Glu Val Gly Val Gly Gln Pro Gln His Phe Gly Asp
Gly
Thr Arg 115 120 125Leu Ser Ile Leu Glu Asp Leu Lys Asn Val Phe Pro
Pro Glu Val Ala 130 135 140Val Phe Glu Pro Ser Glu Ala Glu Ile Ser
His Thr Gln Lys Ala Thr145 150 155 160Leu Val Cys Leu Ala Thr Gly
Phe Tyr Pro Asp His Val Glu Leu Ser 165 170 175Trp Trp Val Asn Gly
Lys Glu Val His Ser Gly Val Cys Thr Asp Pro 180 185 190Gln Pro Leu
Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu 195 200 205Ser
Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn 210 215
220His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp
Glu225 230 235 240Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile
Val Ser Ala Glu 245 250 255Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr
Ser Glu Ser Tyr Gln Gln 260 265 270Gly Val Leu Ser Ala Thr Ile Leu
Tyr Glu Ile Leu Leu Gly Lys Ala 275 280 285Thr Leu Tyr Ala Val Leu
Val Ser Ala Leu Val Leu Met Ala Met Val 290 295 300Lys Arg Lys Asp
Ser Arg Gly305 31017268PRTHomo sapiens 17Met Leu Leu Glu His Leu
Leu Ile Ile Leu Trp Met Gln Leu Thr Trp1 5 10 15Val Ser Gly Gln Gln
Leu Asn Gln Ser Pro Gln Ser Met Phe Ile Gln 20 25 30Glu Gly Glu Asp
Val Ser Met Asn Cys Thr Ser Ser Ser Ile Phe Asn 35 40 45Thr Trp Leu
Trp Tyr Lys Gln Glu Pro Gly Glu Gly Pro Val Leu Leu 50 55 60Ile Ala
Leu Tyr Lys Ala Gly Glu Leu Thr Ser Asn Gly Arg Leu Thr65 70 75
80Ala Gln Phe Gly Ile Thr Arg Lys Asp Ser Phe Leu Asn Ile Ser Ala
85 90 95Ser Ile Pro Ser Asp Val Gly Ile Tyr Phe Cys Ala Gly Gly Thr
Gly 100 105 110Asn Gln Phe Tyr Phe Gly Thr Gly Thr Ser Leu Thr Val
Ile Pro Asn 115 120 125Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu
Arg Asp Ser Lys Ser 130 135 140Ser Asp Lys Ser Val Cys Leu Phe Thr
Asp Phe Asp Ser Gln Thr Asn145 150 155 160Val Ser Gln Ser Lys Asp
Ser Asp Val Tyr Ile Thr Asp Lys Cys Val 165 170 175Leu Asp Met Arg
Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala Trp 180 185 190Ser Asn
Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser Ile 195 200
205Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp Val
210 215 220Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn
Phe Gln225 230 235 240Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu
Leu Lys Val Ala Gly 245 250 255Phe Asn Leu Leu Met Thr Leu Arg Leu
Trp Ser Ser 260 26518601PRTArtificial SequenceDMF4 TCR 18Met Gly
Thr Arg Leu Phe Phe Tyr Val Ala Leu Cys Leu Leu Trp Thr1 5 10 15Gly
His Met Asp Ala Gly Ile Thr Gln Ser Pro Arg His Lys Val Thr 20 25
30Glu Thr Gly Thr Pro Val Thr Leu Arg Cys His Gln Thr Glu Asn His
35 40 45Arg Tyr Met Tyr Trp Tyr Arg Gln Asp Pro Gly His Gly Leu Arg
Leu 50 55 60Ile His Tyr Ser Tyr Gly Val Lys Asp Thr Asp Lys Gly Glu
Val Ser65 70 75 80Asp Gly Tyr Ser Val Ser Arg Ser Lys Thr Glu Asp
Phe Leu Leu Thr 85 90 95Leu Glu Ser Ala Thr Ser Ser Gln Thr Ser Val
Tyr Phe Cys Ala Ile 100 105 110Ser Glu Val Gly Val Gly Gln Pro Gln
His Phe Gly Asp Gly Thr Arg 115 120 125Leu Ser Ile Leu Glu Asp Leu
Lys Asn Val Phe Pro Pro Glu Val Ala 130 135 140Val Phe Glu Pro Ser
Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr145 150 155 160Leu Val
Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser 165 170
175Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro
180 185 190Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr
Cys Leu 195 200 205Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln
Asn Pro Arg Asn 210 215 220His Phe Arg Cys Gln Val Gln Phe Tyr Gly
Leu Ser Glu Asn Asp Glu225 230 235 240Trp Thr Gln Asp Arg Ala Lys
Pro Val Thr Gln Ile Val Ser Ala Glu 245 250 255Ala Trp Gly Arg Ala
Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln 260 265 270Gly Val Leu
Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala 275 280 285Thr
Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val 290 295
300Lys Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser
Leu305 310 315 320Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly
Pro Met Leu Leu 325 330 335Glu His Leu Leu Ile Ile Leu Trp Met Gln
Leu Thr Trp Val Ser Gly 340 345 350Gln Gln Leu Asn Gln Ser Pro Gln
Ser Met Phe Ile Gln Glu Gly Glu 355 360 365Asp Val Ser Met Asn Cys
Thr Ser Ser Ser Ile Phe Asn Thr Trp Leu 370 375 380Trp Tyr Lys Gln
Glu Pro Gly Glu Gly Pro Val Leu Leu Ile Ala Leu385 390 395 400Tyr
Lys Ala Gly Glu Leu Thr Ser Asn Gly Arg Leu Thr Ala Gln Phe 405 410
415Gly Ile Thr Arg Lys Asp Ser Phe Leu Asn Ile Ser Ala Ser Ile Pro
420 425 430Ser Asp Val Gly Ile Tyr Phe Cys Ala Gly Gly Thr Gly Asn
Gln Phe 435 440 445Tyr Phe Gly Thr Gly Thr Ser Leu Thr Val Ile Pro
Asn Ile Gln Asn 450 455 460Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp
Ser Lys Ser Ser Asp Lys465 470 475 480Ser Val Cys Leu Phe Thr Asp
Phe Asp Ser Gln Thr Asn Val Ser Gln 485 490 495Ser Lys Asp Ser Asp
Val Tyr Ile Thr Asp Lys Cys Val Leu Asp Met 500 505 510Arg Ser Met
Asp Phe Lys Ser Asn Ser Ala Val Ala Trp Ser Asn Lys 515 520 525Ser
Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser Ile Ile Pro Glu 530 535
540Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp Val Lys Leu
Val545 550 555 560Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe
Gln Asn Leu Ser 565 570 575Val Ile Gly Phe Arg Ile Leu Leu Leu Lys
Val Ala Gly Phe Asn Leu 580 585 590Leu Met Thr Leu Arg Leu Trp Ser
Ser 595 60019310PRTHomo sapiens 19Met Arg Ile Arg Leu Leu Cys Cys
Val Ala Phe Ser Leu Leu Trp Ala1 5 10 15Gly Pro Val Ile Ala Gly Ile
Thr Gln Ala Pro Thr Ser Gln Ile Leu 20 25 30Ala Ala Gly Arg Arg Met
Thr Leu Arg Cys Thr Gln Asp Met Arg His 35 40 45Asn Ala Met Tyr Trp
Tyr Arg Gln Asp Leu Gly Leu Gly Leu Arg Leu 50 55 60Ile His Tyr Ser
Asn Thr Ala Gly Thr Thr Gly Lys Gly Glu Val Pro65 70 75 80Asp Gly
Tyr Ser Val Ser Arg Ala Asn Thr Asp Asp Phe Pro Leu Thr 85 90 95Leu
Ala Ser Ala Val Pro Ser Gln Thr Ser Val Tyr Phe Cys Ala Ser 100 105
110Ser Leu Ser Phe Gly Thr Glu Ala Phe Phe Gly Gln Gly Thr Arg Leu
115 120 125Thr Val Val Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val
Ala Val 130 135 140Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln
Lys Ala Thr Leu145 150 155 160Val Cys Leu Ala Thr Gly Phe Tyr Pro
Asp His Val Glu Leu Ser Trp 165 170 175Trp Val Asn Gly Lys Glu Val
His Ser Gly Val Cys Thr Asp Pro Gln 180 185 190Pro Leu Lys Glu Gln
Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser 195 200 205Ser Arg Leu
Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His 210 215 220Phe
Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp225 230
235 240Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
Ala 245 250 255Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr
Gln Gln Gly 260 265 270Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu
Leu Gly Lys Ala Thr 275 280 285Leu Tyr Ala Val Leu Val Ser Ala Leu
Val Leu Met Ala Met Val Lys 290 295 300Arg Lys Asp Ser Arg Gly305
31020272PRTHomo sapiens 20Met Lys Ser Leu Arg Val Leu Leu Val Ile
Leu Trp Leu Gln Leu Ser1 5 10 15Trp Val Trp Ser Gln Gln Lys Glu Val
Glu Gln Asn Ser Gly Pro Leu 20 25 30Ser Val Pro Glu Gly Ala Ile Ala
Ser Leu Asn Cys Thr Tyr Ser Asp 35 40 45Arg Gly Ser Gln Ser Phe Phe
Trp Tyr Arg Gln Tyr Ser Gly Lys Ser 50 55 60Pro Glu Leu Ile Met Phe
Ile Tyr Ser Asn Gly Asp Lys Glu Asp Gly65 70 75 80Arg Phe Thr Ala
Gln Leu Asn Lys Ala Ser Gln Tyr Val Ser Leu Leu 85 90 95Ile Arg Asp
Ser Gln Pro Ser Asp Ser Ala Thr Tyr Leu Cys Ala Val 100 105 110Asn
Phe Gly Gly Gly Lys Leu Ile Phe Gly Gln Gly Thr Glu Leu Ser 115 120
125Val Lys Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg
130 135 140Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp
Phe Asp145 150 155 160Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser
Asp Val Tyr Ile Thr 165 170 175Asp Lys Cys Val Leu Asp Met Arg Ser
Met Asp Phe Lys Ser Asn Ser 180 185 190Ala Val Ala Trp Ser Asn Lys
Ser Asp Phe Ala Cys Ala Asn Ala Phe 195 200 205Asn Asn Ser Ile Ile
Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser 210 215 220Ser Cys Asp
Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn225 230 235
240Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu
245 250 255Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp
Ser Ser 260 265 27021604PRTArtificial SequenceDMF5 TCR 21Met Arg
Ile Arg Leu Leu Cys Cys Val Ala Phe Ser Leu Leu Trp Ala1 5 10 15Gly
Pro Val Ile Ala Gly Ile Thr Gln Ala Pro Thr Ser Gln Ile Leu 20 25
30Ala Ala Gly Arg Arg Met Thr Leu Arg Cys Thr Gln Asp Met Arg His
35 40 45Asn Ala Met Tyr Trp Tyr Arg Gln Asp Leu Gly Leu Gly Leu Arg
Leu 50 55 60Ile His Tyr Ser Asn Thr Ala Gly Thr Thr Gly Lys Gly Glu
Val Pro65 70 75 80Asp Gly Tyr Ser Val Ser Arg Ala Asn Thr Asp Asp
Phe Pro Leu Thr 85 90 95Leu Ala Ser Ala Val Pro Ser Gln Thr Ser Val
Tyr Phe Cys Ala Ser 100 105 110Ser Leu Ser Phe Gly Thr Glu Ala Phe
Phe Gly Gln Gly Thr Arg Leu 115 120 125Thr Val Val Glu Asp Leu Lys
Asn Val Phe Pro Pro Glu Val Ala Val 130 135 140Phe Glu Pro Ser Glu
Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu145 150 155 160Val Cys
Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp 165 170
175Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln
180 185 190Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys
Leu Ser 195 200 205Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn
Pro Arg Asn His 210 215 220Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu
Ser Glu Asn Asp Glu Trp225 230 235 240Thr Gln Asp Arg Ala Lys Pro
Val Thr Gln Ile Val Ser Ala Glu Ala 245 250 255Trp Gly Arg Ala Asp
Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly 260 265 270Val Leu Ser
Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr 275 280 285Leu
Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys 290 295
300Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu
Leu305 310 315 320Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro
Met Lys Ser Leu 325 330 335Arg Val Leu Leu Val Ile Leu Trp Leu Gln
Leu Ser Trp Val Trp Ser 340 345 350Gln Gln Lys Glu Val Glu Gln Asn
Ser Gly Pro Leu Ser Val Pro Glu 355 360 365Gly Ala Ile Ala Ser Leu
Asn Cys Thr Tyr Ser Asp Arg Gly Ser Gln 370 375 380Ser Phe Phe Trp
Tyr Arg Gln Tyr Ser Gly Lys Ser Pro Glu Leu Ile385 390 395 400Met
Phe Ile Tyr Ser Asn Gly Asp Lys Glu Asp Gly Arg Phe Thr Ala 405 410
415Gln Leu Asn Lys Ala Ser Gln Tyr Val Ser Leu Leu Ile Arg Asp Ser
420 425 430Gln Pro Ser Asp Ser Ala Thr Tyr Leu Cys Ala Val Asn Phe
Gly Gly 435 440 445Gly Lys Leu Ile Phe Gly Gln Gly Thr Glu Leu Ser
Val Lys Pro Asn 450 455 460Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln
Leu Arg Asp Ser Lys Ser465 470 475 480Ser Asp Lys Ser Val Cys Leu
Phe Thr Asp Phe Asp Ser Gln Thr Asn 485 490 495Val Ser Gln Ser Lys
Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys Val 500 505 510Leu Asp Met
Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala Trp 515 520 525Ser
Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser Ile 530 535
540Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp
Val545 550 555 560Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn
Leu Asn Phe Gln 565 570 575Asn Leu Ser Val Ile Gly Phe Arg Ile Leu
Leu Leu Lys Val Ala Gly 580 585 590Phe Asn Leu Leu Met Thr Leu Arg
Leu Trp Ser Ser 595 60022142PRTHuman 22Pro Asn Ile Gln Asn Pro Asp
Pro Ala Val Tyr Gln Leu Arg Asp Ser1 5 10 15Lys Ser Ser Asp Lys Ser
Val Cys Leu Phe Thr Asp Phe Asp Ser Gln 20 25 30Thr Asn Val Ser Gln
Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys 35 40 45Thr Val Leu Asp
Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val 50 55 60Ala Trp Ser
Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn65 70 75 80Ser
Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys 85 90
95Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn
100 105 110Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu
Lys Val 115 120 125Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp
Ser Ser 130 135 14023142PRTArtificial Sequencecys modified TRAC
23Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser1
5 10 15Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser
Gln 20 25 30Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr
Asp Lys 35 40 45Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn
Ser Ala Val 50 55 60Ala Trp Ser Asn Lys Ser
Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn65 70 75 80Ser Ile Ile Pro
Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys 85 90 95Asp Val Lys
Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn 100 105 110Phe
Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val 115 120
125Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser 130 135
14024178PRTHuman 24Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val
Phe Glu Pro Ser1 5 10 15Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
Leu Val Cys Leu Ala 20 25 30Thr Gly Phe Tyr Pro Asp His Val Glu Leu
Ser Trp Trp Val Asn Gly 35 40 45Lys Glu Val His Ser Gly Val Ser Thr
Asp Pro Gln Pro Leu Lys Glu 50 55 60Gln Pro Ala Leu Asn Asp Ser Arg
Tyr Cys Leu Ser Ser Arg Leu Arg65 70 75 80Val Ser Ala Thr Phe Trp
Gln Asn Pro Arg Asn His Phe Arg Cys Gln 85 90 95Val Gln Phe Tyr Gly
Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg 100 105 110Ala Lys Pro
Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala 115 120 125Asp
Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu Ser Ala 130 135
140Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala
Val145 150 155 160Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys
Arg Lys Asp Ser 165 170 175Arg Gly25178PRTArtificial Sequencecys
modified TRBC 25Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe
Glu Pro Ser1 5 10 15Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu
Val Cys Leu Ala 20 25 30Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser
Trp Trp Val Asn Gly 35 40 45Lys Glu Val His Ser Gly Val Cys Thr Asp
Pro Gln Pro Leu Lys Glu 50 55 60Gln Pro Ala Leu Asn Asp Ser Arg Tyr
Cys Leu Ser Ser Arg Leu Arg65 70 75 80Val Ser Ala Thr Phe Trp Gln
Asn Pro Arg Asn His Phe Arg Cys Gln 85 90 95Val Gln Phe Tyr Gly Leu
Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg 100 105 110Ala Lys Pro Val
Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala 115 120 125Asp Cys
Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu Ser Ala 130 135
140Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala
Val145 150 155 160Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys
Arg Lys Asp Ser 165 170 175Arg Gly26444PRTArtificial SequenceKSQ
CAR017 26Met Leu Leu Leu Val Thr Ser Leu Leu Leu Cys Glu Leu Pro
His Pro1 5 10 15Ala Phe Leu Leu Ile Pro Asp Ile Leu Leu Thr Gln Ser
Pro Val Ile 20 25 30Leu Ser Val Ser Pro Gly Glu Arg Val Ser Phe Ser
Cys Arg Ala Ser 35 40 45Gln Ser Ile Gly Thr Asn Ile His Trp Tyr Gln
Gln Arg Thr Asn Gly 50 55 60Ser Pro Arg Leu Leu Ile Lys Tyr Ala Ser
Glu Ser Ile Ser Gly Ile65 70 75 80Pro Ser Arg Phe Ser Gly Ser Gly
Ser Gly Thr Asp Phe Thr Leu Ser 85 90 95Ile Asn Ser Val Glu Ser Glu
Asp Ile Ala Asp Tyr Tyr Cys Gln Gln 100 105 110Asn Asn Asn Trp Pro
Thr Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu 115 120 125Lys Gly Gly
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser 130 135 140Gln
Val Gln Leu Lys Gln Ser Gly Pro Gly Leu Val Gln Pro Ser Gln145 150
155 160Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn
Tyr 165 170 175Gly Val His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu
Glu Trp Leu 180 185 190Gly Val Ile Trp Ser Gly Gly Asn Thr Asp Tyr
Asn Thr Pro Phe Thr 195 200 205Ser Arg Leu Ser Ile Asn Lys Asp Asn
Ser Lys Ser Gln Val Phe Phe 210 215 220Lys Met Asn Ser Leu Gln Ser
Asn Asp Thr Ala Ile Tyr Tyr Cys Ala225 230 235 240Arg Ala Leu Thr
Tyr Tyr Asp Tyr Glu Phe Ala Tyr Trp Gly Gln Gly 245 250 255Thr Leu
Val Thr Val Ser Ala Thr Thr Thr Pro Ala Pro Arg Pro Pro 260 265
270Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu
275 280 285Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly
Leu Asp 290 295 300Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala
Gly Thr Cys Gly305 310 315 320Val Leu Leu Leu Ser Leu Val Ile Thr
Leu Tyr Cys Arg Val Lys Phe 325 330 335Ser Arg Ser Ala Asp Ala Pro
Ala Tyr Gln Gln Gly Gln Asn Gln Leu 340 345 350Tyr Asn Glu Leu Asn
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp 355 360 365Lys Arg Arg
Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys 370 375 380Asn
Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala385 390
395 400Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly
Lys 405 410 415Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr
Lys Asp Thr 420 425 430Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro
Arg 435 440271328DNAArtificial SequenceKSQ CAR017 27atgctcctcc
tggttactag cttgcttttg tgcgaactgc cgcatcctgc cttccttctc 60atcccagata
tacttctgac acaatctccg gtaatacttt ccgtctcacc gggggagcga
120gtgtcatttt catgccgggc gagtcaatcc atcgggacga atattcactg
gtatcagcaa 180aggactaacg gctcaccacg ccttctcatc aagtatgcca
gtgagtccat aagtggcatt 240ccctctagat tctcaggatc aggcagtggc
acggacttca cattgtcaat taatagcgta 300gaaagtgagg acatagcaga
ttattattgc caacaaaaca ataactggcc taccacattc 360ggtgcaggca
ccaagcttga gttgaagggg ggtggtggtt ctggaggcgg tgggagcggt
420ggtggtgggt cacaagtgca gcttaagcaa agcggaccag gtctggtcca
acctagccag 480tcactgtcaa tcacatgtac ggtatccggc tttagtctga
caaattatgg cgtccactgg 540gtaaggcaat cccctggaaa gggcctcgag
tggttggggg tgatttggag cggaggaaac 600accgactata ataccccttt
cacctccaga ctgtccataa acaaggacaa ctctaaaagt 660caggtattct
tcaaaatgaa cagtctgcaa agtaatgaca cagcgatata ttattgcgcg
720agagccctta catactacga ttacgagttc gcttattggg gacaaggaac
gttggtgacg 780gtgtctgcca caaccactcc tgctcccagg ccaccaacac
cggcgcctac catagcgtca 840cagccgctta gtctcaggcc ggaagcgtgt
cgccccgcag ccggtggggc ggtccacaca 900cgcgggctgg atttcgcatg
cgatatatac atctgggcac cccttgccgg gacctgcggt 960gttttgctct
tgtctctcgt aatcacgctg tactgtcggg ttaagttttc aagatctgcg
1020gatgccccgg cataccaaca agggcagaat cagttgtaca acgaactgaa
cttgggcaga 1080cgcgaggagt atgatgtctt ggacaagagg cgggggcgcg
acccggaaat gggtggcaaa 1140ccacggcgca agaacccaca agaggggctt
tacaacgaat tgcagaaaga caagatggcc 1200gaggcataca gcgagattgg
catgaaagga gagaggagga ggggaaaggg gcatgatggc 1260ctttatcagg
gcctttctac tgccaccaag gacacatacg acgcactgca catgcaggca 1320ttgccacc
132828446PRTArtificial SequenceKSQ CAR1909 28Met Leu Leu Leu Val
Thr Ser Leu Leu Leu Cys Glu Leu Pro His Pro1 5 10 15Ala Phe Leu Leu
Ile Pro Asp Ile Gln Met Thr Gln Thr Thr Ser Ser 20 25 30Leu Ser Ala
Ser Leu Gly Asp Arg Val Thr Ile Ser Cys Arg Ala Ser 35 40 45Gln Asp
Ile Ser Lys Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Asp Gly 50 55 60Thr
Val Lys Leu Leu Ile Tyr His Thr Ser Arg Leu His Ser Gly Val65 70 75
80Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr
85 90 95Ile Ser Asn Leu Glu Gln Glu Asp Ile Ala Thr Tyr Phe Cys Gln
Gln 100 105 110Gly Asn Thr Leu Pro Tyr Thr Phe Gly Gly Gly Thr Lys
Leu Glu Ile 115 120 125Thr Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
Gly Gly Gly Gly Ser 130 135 140Glu Val Lys Leu Gln Glu Ser Gly Pro
Gly Leu Val Ala Pro Ser Gln145 150 155 160Ser Leu Ser Val Thr Cys
Thr Val Ser Gly Val Ser Leu Pro Asp Tyr 165 170 175Gly Val Ser Trp
Ile Arg Gln Pro Pro Arg Lys Gly Leu Glu Trp Leu 180 185 190Gly Val
Ile Trp Gly Ser Glu Thr Thr Tyr Tyr Asn Ser Ala Leu Lys 195 200
205Ser Arg Leu Thr Ile Ile Lys Asp Asn Ser Lys Ser Gln Val Phe Leu
210 215 220Lys Met Asn Ser Leu Gln Thr Asp Asp Thr Ala Ile Tyr Tyr
Cys Ala225 230 235 240Lys His Tyr Tyr Tyr Gly Gly Ser Tyr Ala Met
Asp Tyr Trp Gly Gln 245 250 255Gly Thr Ser Val Thr Val Ser Ser Thr
Thr Thr Pro Ala Pro Arg Pro 260 265 270Pro Thr Pro Ala Pro Thr Ile
Ala Ser Gln Pro Leu Ser Leu Arg Pro 275 280 285Glu Ala Cys Arg Pro
Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu 290 295 300Asp Phe Ala
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys305 310 315
320Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Leu Arg Val
325 330 335Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly
Gln Asn 340 345 350Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu
Glu Tyr Asp Val 355 360 365Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
Met Gly Gly Lys Pro Arg 370 375 380Arg Lys Asn Pro Gln Glu Gly Leu
Tyr Asn Glu Leu Gln Lys Asp Lys385 390 395 400Met Ala Glu Ala Tyr
Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg 405 410 415Gly Lys Gly
His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys 420 425 430Asp
Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg 435 440
445291338DNAArtificial SequenceKSQ CAR1909 29atgctccttc ttgtgacgtc
actcctgctt tgtgagctgc cgcacccggc ctttctgctc 60atacccgaca tacaaatgac
acagacgaca agttcccttt ccgcctcctt gggcgaccga 120gtgacaatca
gttgccgagc ttcccaggac atatctaaat atttgaattg gtatcagcaa
180aagccagatg gtacggttaa acttcttatc taccacacct ccaggctcca
ttctggggtt 240ccgagccgat tctctggatc tggctcaggg accgattatt
ctttgactat ttccaatttg 300gagcaggaag acatcgcaac ctatttctgc
caacaaggaa atacgctgcc atacaccttc 360ggcgggggca ccaaactcga
gattactggg ggtgggggga gtggaggagg gggttccggt 420ggaggtgggt
cagaagtcaa gctgcaagag agtgggcccg ggttggttgc tcctagccaa
480tccttgagtg taacatgcac cgttagcgga gtttcacttc ctgactacgg
tgttagctgg 540ataagacagc ccccgaggaa gggtctggaa tggctggggg
tcatttgggg cagtgagacg 600acatattaca acagtgcctt gaaatccagg
cttacgatca taaaagacaa tagtaaaagc 660caagtgttcc tcaagatgaa
ctctcttcag accgacgaca cagccatcta ctattgcgca 720aaacattatt
attatggagg tagttacgct atggactatt ggggccaggg gacttcagtg
780acggtgagta gtaccacgac tccggcaccg agaccaccaa caccagcccc
aacaattgcc 840tcacagccct tgagccttag acccgaggcc tgtaggcccg
ccgcaggagg ggcagttcat 900acgcgaggat tggactttgc atgtgacatc
tatatctggg cgccacttgc gggaacttgc 960ggtgtccttt tgctctcatt
ggtcattacc ctctattgtt tgagagtaaa attttcccgc 1020tccgctgatg
cgcctgcata ccagcaaggt cagaaccaac tctacaatga gcttaacctc
1080ggtagaagag aggaatatga cgtcttggat aagaggagag gccgagaccc
agaaatgggg 1140ggaaagccgc gccgcaagaa tccacaagaa ggtctttaca
atgaactgca gaaggacaaa 1200atggccgaag cgtatagcga gataggaatg
aaaggcgaac ggagacgggg caaggggcat 1260gacgggcttt accaaggact
tagcacagcg acgaaggata catacgacgc actgcatatg 1320caagcgctgc caccgcgc
133830496PRTArtificial SequenceKSQ CAR010 30Met Asp Phe Gln Val Gln
Ile Phe Ser Phe Leu Leu Ile Ser Ala Ser1 5 10 15Val Ile Met Ser Arg
Gly Ala Thr Gly Gly Ala Thr Thr Thr Thr Cys 20 25 30Ala Gly Gly Thr
Gly Cys Ala Gly Ala Thr Thr Thr Thr Cys Ala Gly 35 40 45Cys Thr Thr
Cys Cys Thr Gly Cys Thr Ala Ala Thr Cys Ala Gly Thr 50 55 60Gly Cys
Cys Thr Cys Ala Asp Ile Gln Met Thr Gln Ser Pro Ser Ser65 70 75
80Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser
85 90 95Gln Asp Val Asn Thr Ala Val Ala Trp Tyr Gln Gln Lys Pro Gly
Lys 100 105 110Ala Pro Lys Leu Leu Ile Tyr Ser Ala Ser Phe Leu Tyr
Ser Gly Val 115 120 125Pro Ser Arg Phe Ser Gly Ser Arg Ser Gly Thr
Asp Phe Thr Leu Thr 130 135 140Ile Ser Ser Leu Gln Pro Glu Asp Phe
Ala Thr Tyr Tyr Cys Gln Gln145 150 155 160His Tyr Thr Thr Pro Pro
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile 165 170 175Lys Arg Thr Gly
Ser Thr Ser Gly Ser Gly Lys Pro Gly Ser Gly Glu 180 185 190Gly Ser
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro 195 200
205Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys
210 215 220Asp Thr Tyr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly
Leu Glu225 230 235 240Trp Val Ala Arg Ile Tyr Pro Thr Asn Gly Tyr
Thr Arg Tyr Ala Asp 245 250 255Ser Val Lys Gly Arg Phe Thr Ile Ser
Ala Asp Thr Ser Lys Asn Thr 260 265 270Ala Tyr Leu Gln Met Asn Ser
Leu Arg Ala Glu Asp Thr Ala Val Tyr 275 280 285Tyr Cys Ser Arg Trp
Gly Gly Asp Gly Phe Tyr Ala Met Asp Val Trp 290 295 300Gly Gln Gly
Thr Leu Val Thr Val Ser Ser Thr Thr Thr Pro Ala Pro305 310 315
320Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu
325 330 335Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His
Thr Arg 340 345 350Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala
Pro Leu Ala Gly 355 360 365Thr Cys Gly Val Leu Leu Leu Ser Leu Val
Ile Thr Leu Tyr Cys Leu 370 375 380Arg Val Lys Phe Ser Arg Ser Ala
Asp Ala Pro Ala Tyr Gln Gln Gly385 390 395 400Gln Asn Gln Leu Tyr
Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr 405 410 415Asp Val Leu
Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys 420 425 430Pro
Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys 435 440
445Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
450 455 460Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser
Thr Ala465 470 475 480Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln
Ala Leu Pro Pro Arg 485 490 495311488DNAArtificial SequenceKSQ
CAR010 31atggactttc aggtgcagat cttctcattc ctccttatca gtgcgagtgt
aattatgtca 60agaggtgcta caggcggtgc taccacgacg acatgcgcag ggggtaccgg
ttgtgcagga 120gcgaccacga ctacctgcgc aggttgtacc acctgttgta
ctggatgtac tgctgcgaca 180tgtgcgggga cgggttgttg cacttgtgcg
gacatacaaa tgacgcaaag cccgtccagc 240ctgtctgcat cagttgggga
tagagtgacg attacatgta gagcaagcca ggatgttaac 300accgccgtag
cgtggtacca acaaaaacca ggtaaagccc cgaagctgct catatactcc
360gccagctttc tgtattcagg cgttcccagt cggttcagcg gcagcagatc
agggacggat 420tttacgctca ctatctcttc ccttcagcct gaagattttg
ctacctatta ttgtcagcag 480cattacacga ctcccccaac ttttggtcag
gggactaaag ttgaaatcaa acgaacgggc 540tccacctcag gtagcggtaa
gccaggcagc ggagaagggt ctgaagtcca gttggttgag 600agtggaggcg
gtcttgtgca acccggtggc agcttgcgac tgagctgtgc agcgtctggc
660ttcaacataa aagatactta tattcattgg gtaagacagg ctcctggtaa
agggctggaa 720tgggtggcac gaatatatcc gactaacggt tataccagat
acgccgattc tgttaagggc 780aggttcacaa taagcgccga cacaagtaag
aatacggcgt atctgcagat gaattcactt 840cgagctgaag acacagcggt
atactactgc tccaggtggg gtggggatgg tttttatgcg 900atggacgttt
ggggtcaagg aacactggta actgttagtt ctaccacgac acctgctcct
960aggcccccca caccggcacc tacgatcgct tcccagccgc
ttagcctccg cccggaggca 1020tgccggcccg ctgcgggggg agcggtacat
actcgcgggt tggacttcgc ttgcgacatc 1080tacatttggg caccactggc
aggcacatgt ggcgttctgt tgcttagtct ggttattaca 1140ctgtattgcc
tgcgagttaa attctcccgc agcgctgatg cgcccgccta tcagcaaggt
1200caaaaccagc tgtataatga gcttaatttg ggacgccgag aagagtatga
cgtccttgac 1260aagaggcgcg ggcgcgatcc ggagatgggt ggtaaaccgc
gccggaaaaa cccccaggaa 1320ggcctttaca atgagctcca aaaagataaa
atggcagagg catactctga aataggaatg 1380aagggcgaga gacgccgggg
taagggacac gatggccttt atcaagggct tagtacagcc 1440acgaaggata
cgtatgacgc tctgcacatg caggctcttc ccccgaga 14883220DNAArtificial
SequencePrimer 32ccacctccag ttgttgcatt 203320DNAArtificial
SequencePrimer 33tgctgcttca aagggaggta 203483DNAArtificial
SequencetracrRNA 34gttttagagc tagaaatagc aagttaaaat aaggctagtc
cgttatcaac ttgaaaaagt 60ggcaccgagt cggtgctttt ttt
833565DNAArtificial SequencetracrRNA 35gggcttcatg ccgaaatcaa
caccctgtca ttttatggca gggtgttttc gttatttaat 60ttttt
653639DNAArtificial SequencetracrRNA 36aaatcaacac cctgtcattt
tatggcaggg tgttttttt 3937170DNAArtificial SequencetracrRNA
37gtattaagta ttgttttatg gctgataaat ttctttgaat ttctccttga ttatttgtta
60taaaagttat aaaataatct tgttggaacc attcaaaaca gcatagcaag ttaaaataag
120gctagtccgt tatcaacttg aaaaagtggc accgagtcgg tgcttttttt
1703889DNAArtificial SequencetracrRNA 38gttggaacca ttcaaaacag
catagcaagt taaaataagg ctagtccgtt atcaacttga 60aaaagtggca ccgagtcggt
gcttttttt 893976DNAArtificial SequencetracrRNA 39aaaacagcat
agcaagttaa aataaggcta gtccgttatc aacttgaaaa agtggcaccg 60agtcggtgct
tttttt 764093DNAArtificial SequencetracrRNA 40gtttaagagc tatgctggaa
acagcatagc aagtttaaat aaggctagtc cgttatcaac 60ttgaaaaagt ggcaccgagt
cggtgctttt ttt 9341141DNAArtificial SequenceCBLB shRNA 41gaaggctcga
gaaggtatat tgctgttgac agtgagcgat cagtgagaat gagtacttta 60tagtgaagcc
acagatgtat aaagtactca ttctcactga gtgcctactg cctcggactt
120caaggggcta gaattcgagc a 14142141DNAArtificial SequenceCBLB shRNA
42gaaggctcga gaaggtatat tgctgttgac agtgagcgaa ggtgaaaatg tcaaaactaa
60tagtgaagcc acagatgtat tagttttgac attttcacct gtgcctactg cctcggactt
120caaggggcta gaattcgagc a 14143141DNAArtificial SequenceCBLB shRNA
43gaaggctcga gaaggtatat tgctgttgac agtgagcgcc cagaaattca ccacagaaaa
60tagtgaagcc acagatgtat tttctgtggt gaatttctgg ttgcctactg cctcggactt
120caaggggcta gaattcgagc a 14144141DNAArtificial SequenceCBLB shRNA
44gaaggctcga gaaggtatat tgctgttgac agtgagcgac cagaactgta gacaccaaaa
60tagtgaagcc acagatgtat tttggtgtct acagttctgg ctgcctactg cctcggactt
120caaggggcta gaattcgagc a 1414521DNAArtificial SequenceCBLB shRNA
45gtcaattcca gggagataac t 214621DNAArtificial SequenceCBLB shRNA
46gcctggaagc aatggctcta a 214721DNAArtificial SequenceCBLB shRNA
47gcaccaaacc cggaagctat a 214821DNAArtificial SequenceCBLB shRNA
48gttgcactcg attgggacag t 214921DNAArtificial SequenceCBLB shRNA
49ggattatgtg aacctacacc t 215021DNAArtificial SequenceCBLB shRNA
50ggaatcacag cgagttcaaa t 215121DNAArtificial SequenceCBLB shRNA
51gcaaggcata gtctcattga a 215221DNAArtificial SequenceCBLB shRNA
52ggtgaagaga gccttagaga t 215321DNAArtificial SequenceCBLB shRNA
53gtgaagagag ccttagagat a 215423RNAArtificial SequenceCBLB siRNA
54aggagcuaag gucuuuucca aug 235523RNAArtificial SequenceCBLB siRNA
55augucgaugc aaaaauugca aaa 235623RNAArtificial SequenceCBLB siRNA
56gucacaugcu ggcagaaauc aaa 235723RNAArtificial SequenceCBLB siRNA
57uccagguuac auggcauuuc uca 235823RNAArtificial SequenceCBLB siRNA
58uugaacuuug aaccugugaa aug 235923RNAArtificial SequenceCBLB siRNA
59uccacaucaa cagcuaaauc auu 236023RNAArtificial SequenceCBLB siRNA
60augcuggcag aaaucaaagc aau 236123RNAArtificial SequenceCBLB siRNA
61ugcagagaau gacaaagaug uca 236223RNAArtificial SequenceCBLB siRNA
62ggcagaacuc accagucaca uca 236323RNAArtificial SequenceCBLB siRNA
63ucgguccugu gauaaugguc acu 236423RNAArtificial SequenceCBLB siRNA
64aggagcuaag gucuuuucca aug 236523RNAArtificial SequenceCBLB siRNA
65augucgaugc aaaaauugca aaa 236623RNAArtificial SequenceCBLB siRNA
66gucacaugcu ggcagaaauc aaa 236723RNAArtificial SequenceCBLB siRNA
67uccagguuac auggcauuuc uca 236823RNAArtificial SequenceCBLB siRNA
68uugaacuuug aaccugugaa aug 236923RNAArtificial SequenceCBLB siRNA
69uccacaucaa cagcuaaauc auu 237023RNAArtificial SequenceCBLB siRNA
70augcuggcag aaaucaaagc aau 237123RNAArtificial SequenceCBLB siRNA
71ugcagagaau gacaaagaug uca 237223RNAArtificial SequenceCBLB siRNA
72ggcagaacuc accagucaca uca 237323RNAArtificial SequenceCBLB siRNA
73ucgguccugu gauaaugguc acu 237419DNAArtificial SequenceTNFAIP3
shRNA 74agacacacgc aactttaaa 197519DNAArtificial SequenceTNFAIP3
shRNA 75cagacacacg caactttaa 197619DNAArtificial SequenceTNFAIP3
shRNA 76acacacgcaa ctttaaatt 197719DNAArtificial SequenceTNFAIP3
shRNA 77acgaatgctt tcagttcaa 197819DNAArtificial SequenceTNFAIP3
shRNA 78atactcggaa ctggaatga 197919DNAArtificial SequenceTNFAIP3
shRNA 79gaagcttgtg gcgctgaaa 198021DNAArtificial SequenceTNFAIP3
shRNA 80aaagccggct gcgtgtattt t 218121DNAArtificial SequenceTNFAIP3
shRNA 81aaagggagct ctagtccttt t 218221DNAArtificial SequenceTNFAIP3
shRNA 82aagggagctc tagtcctttt t 218321DNAArtificial SequenceTNFAIP3
shRNA 83aagccctcat cgacagaaac a 218421DNAArtificial SequenceTNFAIP3
shRNA 84aaacgaacgg tgacggcaat t 218521DNAArtificial SequenceTNFAIP3
shRNA 85aaacagacac acgcaacttt a 218621DNAArtificial SequenceTNFAIP3
shRNA 86aacagacaca cgcaacttta a 218721DNAArtificial SequenceTNFAIP3
shRNA 87aatgtgcagc acaacggatt t 218821DNAArtificial SequenceTNFAIP3
shRNA 88aaaagccggc tgcgtgtatt t 218921DNAArtificial SequenceTNFAIP3
shRNA 89aaactcaacc agctgccttt t 219020DNAArtificial SequenceTNFAIP3
shRNA 90aaactcaacc agctgccttt 209121DNAArtificial SequenceTNFAIP3
shRNA 91aagtccttcc tcaggctttg t 219221DNAArtificial SequenceTNFAIP3
shRNA 92aaagccagaa gaaactcaac t 219321DNAArtificial SequenceTNFAIP3
shRNA 93aatccgagct gttccacttg t 219421DNAArtificial SequenceTNFAIP3
shRNA 94aaggctggga ccatggcaca a 219521DNAArtificial SequenceTNFAIP3
shRNA 95aatgccgcaa agttggatga a 219623RNAArtificial SequenceTNFAIP3
siRNA 96uccucaguuu cgggagauca ucc 239723RNAArtificial
SequenceTNFAIP3 siRNA 97gagucucuca aaucucagga auu
239823RNAArtificial SequenceTNFAIP3 siRNA 98agcucuaguc cuuuuugugu
aau 239923RNAArtificial SequenceTNFAIP3 siRNA 99cacuggaaau
guucagaacu ugc 2310023RNAArtificial SequenceTNFAIP3 siRNA
100augaugaaug ggacaaucuu auc 2310123RNAArtificial SequenceTNFAIP3
siRNA 101cacacugugu uucaucgagu aca 2310223RNAArtificial
SequenceTNFAIP3 siRNA 102gcagaaccau ccauggacug uga
2310323RNAArtificial SequenceTNFAIP3 siRNA 103aaagaugugg ccuuuuguga
ugg 2310423RNAArtificial SequenceTNFAIP3 siRNA 104uucagaacuu
gccaguuuug ucc 2310523RNAArtificial SequenceTNFAIP3 siRNA
105augagacugg caauggucac agg 2310621DNAArtificial SequencePDCD1
shRNA 106ggccaggatg gttcttagac t 2110721DNAArtificial SequencePDCD1
shRNA 107ggatttccag tggcgagaga a 2110823RNAArtificial SequencePDCD1
siRNA 108gccuguguuc ucuguggacu aug 2310923RNAArtificial
SequencePDCD1 siRNA 109ggugcugcua gucugggucc ugg
2311023RNAArtificial SequencePDCD1 siRNA 110gacagagaga agggcagaag
ugc 2311123RNAArtificial SequencePDCD1 siRNA 111cagcuucucc
aacacaucgg aga 2311223RNAArtificial SequencePDCD1 siRNA
112ccgugucaca caacugccca acg 2311323RNAArtificial SequencePDCD1
siRNA 113uaugccacca uugucuuucc uag 2311423RNAArtificial
SequencePDCD1 siRNA 114ugcuaaacug guaccgcaug agc
2311523RNAArtificial SequencePDCD1 siRNA 115gugacagaga gaagggcaga
agu 2311623RNAArtificial SequencePDCD1 siRNA 116cugaggaugg
acacugcucu ugg 2311723RNAArtificial SequencePDCD1 siRNA
117aucggagagc uucgugcuaa acu 2311823RNAArtificial SequencePDCD1
siRNA 118gccuguguuc ucuguggacu aug 2311923RNAArtificial
SequencePDCD1 siRNA 119ggugcugcua gucugggucc ugg
2312023RNAArtificial SequencePDCD1 siRNA 120gacagagaga agggcagaag
ugc 2312123RNAArtificial SequencePDCD1 siRNA 121cagcuucucc
aacacaucgg aga 2312223RNAArtificial SequencePDCD1 siRNA
122ccgugucaca caacugccca acg 2312323RNAArtificial SequencePDCD1
siRNA 123uaugccacca uugucuuucc uag 2312423RNAArtificial
SequencePDCD1 siRNA 124ugcuaaacug guaccgcaug agc
2312523RNAArtificial SequencePDCD1 siRNA 125gugacagaga gaagggcaga
agu 2312623RNAArtificial SequencePDCD1 siRNA 126cugaggaugg
acacugcucu ugg 2312723RNAArtificial SequencePDCD1 siRNA
127aucggagagc uucgugcuaa acu 2312821DNAArtificial SequenceCTLA4
shRNA 128ggcaacggaa cccagattta t 2112921DNAArtificial SequenceCTLA4
shRNA 129ggaacccaaa ttacgtgtac t 2113021DNAArtificial SequenceCTLA4
shRNA 130gaacccaaat tacgtgtact a 2113121DNAArtificial SequenceCTLA4
shRNA 131gggagaagac tatattgtac a 2113221DNAArtificial SequenceCTLA4
shRNA 132gacgtttata gccgaaatga t 2113321DNAArtificial SequenceCTLA4
shRNA 133gacactaata caccaggtag a 2113423RNAArtificial SequenceCTLA4
siRNA 134accucacuau ccaaggacug agg 2313523RNAArtificial
SequenceCTLA4 siRNA 135augaguugac cuuccuagau gau
2313623RNAArtificial SequenceCTLA4 siRNA 136ggggaaugag uugaccuucc
uag 2313723RNAArtificial SequenceCTLA4 siRNA 137cucuggaucc
uugcagcagu uag 2313823RNAArtificial SequenceCTLA4 siRNA
138cuccucugga uccuugcagc agu 2313923RNAArtificial SequenceCTLA4
siRNA 139uuugugugug aguaugcauc ucc 2314023RNAArtificial
SequenceCTLA4 siRNA 140caccuccagu ggaaaucaag uga
2314123RNAArtificial SequenceCTLA4 siRNA 141cacgggacuc uacaucugca
agg 2314223RNAArtificial SequenceCTLA4 siRNA 142uucugacuuc
cuccucugga ucc 2314323RNAArtificial SequenceCTLA4 siRNA
143aagucugugc ggcaaccuac aug 2314423RNAArtificial SequenceCTLA4
siRNA 144accucacuau ccaaggacug agg 2314523RNAArtificial
SequenceCTLA4 siRNA 145augaguugac cuuccuagau gau
2314623RNAArtificial SequenceCTLA4 siRNA 146ggggaaugag uugaccuucc
uag 2314723RNAArtificial SequenceCTLA4 siRNA 147cucuggaucc
uugcagcagu uag 2314823RNAArtificial SequenceCTLA4 siRNA
148cuccucugga uccuugcagc agu 2314923RNAArtificial SequenceCTLA4
siRNA 149uuugugugug aguaugcauc ucc 2315023RNAArtificial
SequenceCTLA4 siRNA 150caccuccagu ggaaaucaag uga
2315123RNAArtificial SequenceCTLA4 siRNA 151cacgggacuc uacaucugca
agg 2315223RNAArtificial SequenceCTLA4 siRNA 152uucugacuuc
cuccucugga ucc 2315323RNAArtificial SequenceCTLA4 siRNA
153aagucugugc ggcaaccuac aug 2315420DNAMurine 154gccgcaggag
gttgcctttc 2015520DNAMurine 155tccaagagtg atcgaggcat
2015620DNAMurine 156agtgcagctt gatgtgccgc 2015720DNAMurine
157cggtgagggc gtccctccgg 2015820DNAMurine 158ggccacctga ggacgcactc
2015920DNAMurine 159gttgcaaaga tggcatttga 2016020DNAMurine
160cctttccagt gcaaccagtg 2016120DNAMurine 161caactatgcc tgccgccgga
2016220DNAHuman 162gttggtaaac ctcacaaatg 2016320DNAHuman
163cgtgatccag gaagagcacc 2016420DNAHuman 164tctggagtat cgcttacagg
2016520DNAHuman 165ggaagccgtg gcagcccatg 2016620DNAHuman
166gcgtgcctgt gaaatgaatg 2016720DNAHuman 167cgcgtgcggg gcgatgtggt
2016820DNAHuman 168tgagcccatg ccgatccccg 2016920DNAHuman
169ctcttaccaa gaaatttctg 2017020DNAHuman 170catatggggc tgatgacttt
2017120DNAHuman 171ggggcctcat tcacccagaa 2017220DNAHuman
172gcctcgggag agaaaatgaa 2017320DNAHuman 173cgcgcagcag gtcgtaggcg
2017420DNAHuman 174tctctgatcc tatcttgcac 2017520DNAHuman
175ggacaggccc ttgtcccctg 2017620DNAHuman 176ccgcgtggtc agcaccagcg
2017720DNAHuman 177aagatttggg aattattgca
2017820DNAHuman 178cttccagtgc aatcagtgcg 2017920DNAHuman
179cctcacaaat gtggatattg 2018020DNAMurine 180cctcgaaagt ctcggagctc
2018120DNAMurine 181ctgcgtcaag actgctacac 2018220DNAMurine
182tgctcacagg caagatgtag 2018320DNAMurine 183ccggacagcc ctccaccttg
2018420DNAMurine 184agacctacca ttgtagttgg 2018520DNAMurine
185ccaagtgctc cacgatggcc 2018620DNAMurine 186agcctctatc cacggctacc
2018720DNAMurine 187gccccaggta agctggtagg 2018820DNAMurine
188gcaagcagcg cacctgctgc 2018920DNAMurine 189tcaagactgc tacactggcc
2019020DNAMurine 190gcaggttgtt ctggaagttg 2019120DNAMurine
191gggtgctgat gtcaacgctc 2019220DNAMurine 192ccacgatggc caggtagccg
2019320DNAMurine 193tggtcagcgg cttctcttcg 2019420DNAMurine
194aatgtggggc tgatgtcaac 2019520DNAMurine 195atttcaacaa gagcgaaacc
2019620DNAMurine 196cacctgacca atgacttcca 2019720DNAMurine
197gccctggaag cagcagctca 2019820DNAMurine 198gctcacaggc aagatgtaga
2019920DNAHuman 199cgtccgcgcc atgttccagg 2020020DNAHuman
200tggtttcagg agccctgtaa 2020120DNAHuman 201acccggatac agcagcagct
2020220DNAHuman 202ttccagggct ccgagccgcg 2020320DNAHuman
203ctgaaggcta ccaactacaa 2020420DNAHuman 204gggtatttcc tcgaaagtct
2020520DNAHuman 205gagccgcagg aggtgccgcg 2020620DNAHuman
206ctgagtcagg actcccacgc 2020720DNAHuman 207cacttacgag tccccgtcct
2020820DNAHuman 208ctcaaattcc ttttggtttc 2020920DNAHuman
209ggttggtgat cacagccaag 2021020DNAHuman 210gcaggttgtt ctggaagttg
2021120DNAMurine 211cacaggtcat tgatatctta 2021220DNAMurine
212catggtgcaa ctcctgctgc 2021320DNAMurine 213gtgaacgctc agatgtattc
2021420DNAMurine 214atacatctga gcgttcacgt 2021520DNAMurine
215gtgcgcagcg gggctgacag 2021620DNAMurine 216tcacaatgac acacctctca
2021720DNAMurine 217tagacgtcca taacaacctg 2021820DNAMurine
218acgatccagg gccatggggc 2021920DNAHuman 219gctggaccgc catggccaga
2022020DNAHuman 220gttcactgcc acgtgcaggg 2022120DNAHuman
221gctggtcaac ctcttccagc 2022220DNAHuman 222acaaggcccg cagcgccgcg
2022320DNAHuman 223caggcctctc catattgctg 2022420DNAHuman
224gccacccgtg cagatgagga 2022520DNAHuman 225tcgacatcta caacaaccta
2022620DNAHuman 226atgtggtgat cacagccagg 2022720DNAHuman
227gcgcttgcgg agcggcagcg 2022820DNAHuman 228acaggtcatc gacatcctga
2022920DNAHuman 229gaccgagcct cacctgccgt 2023020DNAHuman
230ataccccatg atgtgcccca 2023120DNAHuman 231gtgaacgcgc aaatgtactc
2023220DNAMurine 232ttttctatct catgaggttt 2023320DNAMurine
233aggcatccca ttgcgggcct 2023420DNAMurine 234tcggcccgag taagtgctat
2023520DNAMurine 235gcgatcctcg tggttgctgt 2023620DNAMurine
236ttctttgttg atcactttga 2023720DNAMurine 237ttcttccaaa ccagcaagtg
2023820DNAMurine 238gacagatgct cacttcaaca 2023920DNAMurine
239tgatgttcac catccacatg 2024020DNAHuman 240catagtccag gaagaggacg
2024120DNAHuman 241gataactgga accatctccg 2024220DNAHuman
242caagcagaga agttcccttg 2024320DNAHuman 243aaagacctga tgttacctgc
2024420DNAHuman 244ttcggcgcca agatagctga 2024520DNAHuman
245gctcatacag acccgcatga 2024620DNAHuman 246agtgatcaac aaggaagggg
2024720DNAHuman 247acccgggctg agatgtcaaa 2024820DNAHuman
248tgtgattctg gcgttcttca 2024920DNAHuman 249ggtcagtgaa gccgacacca
2025020DNAHuman 250cttgcagtct tatgccgaga 2025120DNAHuman
251atgccccaca ctgattacac 2025220DNAHuman 252attccagtgt aatcagtgtg
2025320DNAHuman 253aagttccctt gaggagcaca 2025420DNAHuman
254ggacagatta gcaagcaatg 2025520DNAHuman 255cttcccaaca ggtctcttga
2025620DNAHuman 256agcagtctct tcacaactgg 2025720DNAHuman
257tcacagtcat catgaactca 2025820DNAHuman 258caactctctg atagtggtaa
2025920DNAHuman 259aatcggcaat atataacatg 2026020DNAHuman
260agcacttgct ctgaaatttg 2026120DNAHuman 261ctaaatgtgt taccatacca
2026220DNAHuman 262attattgaat ccatacctgg 2026320DNAHuman
263agaatgggca ggaagaaaag 2026420DNAMurine 264aaggtcggtt tggagaagtt
2026520DNAMurine 265attgttcttt gaacaagcag 2026620DNAMurine
266tggccttggt cctgtggagc 2026720DNAMurine 267acaacatcag ggtctggatc
2026820DNAMurine 268atttatgata tgacaacatc 2026920DNAMurine
269tttatagcag cagacaacaa 2027020DNAMurine 270gcaatgcaga cgaagcagac
2027120DNAMurine 271agtttggcga ggcaaatggc 2027220DNAMurine
272gagctggcag ctgtcattgc 2027320DNAMurine 273tctgataaat ctctgcctct
2027420DNAMurine 274gaatagatac actgttactg 2027520DNAMurine
275gttacgccat gaaaatatcc 2027620DNAMurine 276gtcagctggc cttggtcctg
2027720DNAMurine 277aatgctttct tgtaacacaa 2027820DNAMurine
278gatatgacaa catcagggtc 2027920DNAHuman 279tggcagaaac actgtaacgc
2028020DNAHuman 280attgttctct gaacaagcaa 2028120DNAHuman
281catacaaacg gcctatctcg 2028220DNAHuman 282gagatgcaga cgaagcacac
2028320DNAHuman 283attgtgttac aagaaagcat 2028420DNAHuman
284agaacgttcg tggttccgtg 2028520DNAHuman 285gtttggagag gaaagtggcg
2028620DNAHuman 286atttatgata tgacaacgtc 2028720DNAHuman
287gttgtgtata actttgtctg 2028820DNAHuman 288gtgcaccctc ttcaaaaact
2028920DNAMurine 289gaccccaagc tcacctacca 2029020DNAMurine
290ttctcccaag tgtgtcatga 2029120DNAMurine 291ttccagagtg aagccgtggt
2029220DNAMurine 292acggccacgc agacttcatg 2029320DNAMurine
293ttcatgcggc ttctcacaga 2029420DNAMurine 294ggacttctgg ttgtcgcaag
2029520DNAMurine 295catgagcaac tgcagcatca 2029620DNAMurine
296ccagaggccc ccttaccaca 2029720DNAMurine 297caacaacagg tcgggactgc
2029820DNAMurine 298cagcttggcc ttgtagacct 2029920DNAMurine
299catgacacac ttgggagaag 2030020DNAMurine 300gttcttgtcg ttcttcctcc
2030120DNAMurine 301gctggacacg ctggtgggga 2030220DNAHuman
302ccagaataaa gtcatggtag 2030320DNAHuman 303cacatgaaga aagtctcacc
2030420DNAHuman 304ttgagctgga caccctggtg 2030520DNAHuman
305gcttctgctg ccggttaacg 2030620DNAHuman 306gaacatactc cagttcctga
2030720DNAHuman 307gggcagtcct attacagctg 2030820DNAHuman
308ttctccaaag tgcattatga 2030920DNAHuman 309tggatgacct ggctaacagt
2031020DNAHuman 310cctgggaaac cggcaagacg 2031120DNAHuman
311gaagccacag gaagtctgtg 2031220DNAHuman 312acagatatgg caactcccag
2031320DNAHuman 313gcagaagctg agttcaacct 2031420DNAHuman
314tcatctgccc cagctgtaat 2031520DNAHuman 315ggggaaaggt cgctttgctg
2031620DNAHuman 316gcaggatttc tggttgtcac 2031720DNAMurine
317ccagctcctc tgccttctgc 2031820DNAMurine 318cagccagatc ccgctgttcc
2031920DNAMurine 319ggccctcgag ttcaacaggt 2032020DNAMurine
320gtgaagagct ggctgtggtc 2032120DNAMurine 321ggccaagctg gacaagggcc
2032220DNAMurine 322ccaggagaat gaagccctga 2032320DNAMurine
323tgctggcctc acctgcagga 2032420DNAMurine 324ccagagggtg ctggcaagaa
2032520DNAHuman 325gatccagcgg ctcaacaagg 2032620DNAHuman
326ccaaaaggtc aagtacctgc 2032720DNAHuman 327acttaacctt cctctctgga
2032820DNAHuman 328gcagcttcgg aaggagaacg 2032920DNAHuman
329cacgcgcctc acctgcagaa 2033020DNAHuman 330gaaggcagag gagctagtga
2033120DNAHuman 331cctcacttaa ccttcctctc 2033220DNAHuman
332tgtgcacctt ggatgccagt 2033320DNAHuman 333ctcaggagag cgttaccatg
2033420DNAHuman 334cgagaagaag gtgaagatgc 2033520DNAHuman
335tatacctgtg agctcagcca 2033620DNAHuman 336ccaggtgaag atcttcgagg
2033720DNAHuman 337cttcacccac ctgggccgca 2033820DNAHuman
338gccgggaatt ctccttcact 2033920DNAHuman 339cccgcagaga tgttctgggt
2034020DNAMurine 340aaaagagcaa gccttaccat 2034120DNAMurine
341tgctgcagag ggccttcctc 2034220DNAMurine 342ctccttctgt cctcaggtga
2034320DNAMurine 343tacagatatc ccatcgtcct 2034420DNAMurine
344tgcagcttgt cagtacatgt 2034520DNAMurine 345tctccttaag ggtgctgcag
2034620DNAMurine 346agtgatcaca agcaggggcc 2034720DNAMurine
347cactttcaaa ggagcaaaat 2034820DNAHuman 348ctcctcaggg ttccacgcca
2034920DNAHuman 349gccccacatg tactgagaag 2035020DNAHuman
350cttaccaaaa gaaatcaatc 2035120DNAHuman 351acactgaatg tgcagcacaa
2035220DNAHuman 352aagtcagtcc cacagcgtcc 2035320DNAHuman
353actccaagcc gggccctgag 2035420DNAHuman 354gctcttaaaa gagtacttaa
2035520DNAHuman 355atggcaggaa aacagcgagc 2035620DNAHuman
356gaagtgccaa gcctgcctcc 2035720DNAHuman 357gacaccagtt gagtttcttc
2035820DNAHuman 358gaggcaggct tggcacttcc 2035920DNAHuman
359tcgggccatg ggtgtgtctg 2036020DNAHuman 360tcacctgaaa tgacaatgat
2036120DNAHuman 361ccgcattccc tccccaggca 2036220DNAHuman
362ggccccccag tggactcctc 2036320DNAHuman 363gtgatagaaa tccccgtcca
2036420DNAHuman 364ttctggaacc tggacgctgt 2036520DNAHuman
365agttgtactg aagtccactt 2036620DNAHuman 366cacacaaggc acttggatcc
2036720DNAHuman 367agaacaccat tccgtgcctg 2036820DNAHuman
368catggcgctc ggggcctctc 2036920DNAHuman 369gccccccagt ggactcctca
2037020DNAHuman 370gctgtcggtg gggccgaatg 2037120DNAHuman
371caagtgcctt gtgtggtctg 2037220DNAHuman 372gccacttctc agtacatgtg
2037320DNAHuman 373tacagatacc ccattgttct 2037420DNAHuman
374tagaaatccc cgtccaaggc 2037520DNAHuman 375aaagccggct gcgtgtattt
2037620DNAHuman 376tggtctcact gaacagaaaa 2037720DNAHuman
377tggtgaccct gaaggacagt 2037820DNAHuman 378agagaaagct
ggggcacgga
2037920DNAHuman 379cgtgccccag ctttctctca 2038020DNAHuman
380tatgccatga gtgctcagag 2038120DNAHuman 381agggctgggt gctgtcggtg
2038220DNAHuman 382ccatgccagg gagcccctca 2038320DNAHuman
383gagtttcttc tggctttcca 2038420DNAHuman 384gctgtcatag ccgagaacaa
2038520DNAHuman 385gggagaagcc tatgagccct 2038620DNAHuman
386ggggtatctg tagcattcct 2038720DNAHuman 387tggatgatct cccgaaactg
2038820DNAHuman 388cttgtggcgc tgaaaacgaa 2038920DNAHuman
389actgagaagt ggcatgcatg 2039020DNAHuman 390tgaacatttc cagtgtgtat
2039120DNAHuman 391ttgctcaaat acaaagcctg 2039220DNAHuman
392tgagagactc cagttgccag 2039320DNAHuman 393gcatgagtac aagaaatggc
2039420DNAHuman 394gaggcaattg ccgtcacctg 2039520DNAHuman
395ctgtccttca gggtcaccaa 2039620DNAHuman 396cagaaacatc caggccaccc
2039720DNAHuman 397gtattcagct taaaaaattc 2039820DNAHuman
398atccatgcat gcctgccgga 2039920DNAHuman 399aatataccag acactgcaac
2040020DNAHuman 400tgtcttgcag ataacaatta 2040120DNAHuman
401ttgggtgtgt attccaaccg 2040220DNAHuman 402tttagaaagt gattcaaaag
2040320DNAHuman 403agtaaaagaa ttacagcaaa 2040420DNAHuman
404actacagcaa gggaaacagc 2040520DNAHuman 405ttgctttcta tactacagca
2040620DNAHuman 406gcagtccttt gctccatgaa 2040720DNAHuman
407gcagagaata cgtgaacaac 2040820DNAHuman 408taacatgaac ataccttgag
2040920DNAHuman 409cctgaaatca ctttatcttg 2041020DNAHuman
410ataaagcgta tgaagccttc 2041120DNAHuman 411gtattccaac cgcggtaaga
2041220DNAHuman 412ccgggccccc agcaggtctg 2041320DNAHuman
413cctacttagg cactgccagg 2041420DNAHuman 414gcttacccag cggatgagcg
2041520DNAHuman 415cttctctgga gcctccagga 2041620DNAHuman
416tccactgacc tgtccttcct 2041720DNAHuman 417acccaggcat catccgacaa
2041820DNAHuman 418catggggttc aaggaagaag 2041920DNAHuman
419aaaccatcct gccacctgga 2042020DNAHuman 420tcatggctgg gctctccagg
2042120DNAHuman 421cagggccgag atcttcgagg 2042220DNAHuman
422agagtgatga agagtgtgac 2042320DNAHuman 423tcacatttca gtttaccatt
2042420DNAHuman 424gctgatgcag tctcatatga 2042520DNAHuman
425tgacattctg gagatagttg 2042620DNAHuman 426cactttgact atggaaacag
2042720DNAHuman 427aagctccaca ctggttacag 2042820DNAHuman
428tagctacgcc tgtagaagaa 2042920DNAHuman 429gctgtcatag agaagctcac
2043020DNAHuman 430ttactgcttg tcatgtgact 2043120DNAHuman
431aatcacctac cttggagctg 2043220DNAHuman 432gtaactttat gtgtctcaga
2043320DNAHuman 433cctcacaagt gcaactactg 2043420DNAHuman
434tccttacaat cttccatagg 2043520DNAHuman 435ggaggaatcc ggcttccgaa
2043620DNAHuman 436acaatgagct ttcacccgaa 2043720DNAHuman
437acttaccaga atgggtcctg 2043820DNAHuman 438gccatctcgc cgccacagtg
2043920DNAHuman 439gggctctatc acaaaatgaa 2044020DNAHuman
440cccctgacta tgaagaagga 2044120DNAHuman 441acctgtgctg gaccgggcct
2044220DNAHuman 442gtagacggag aggggccccg 2044320DNAHuman
443aagcttgtag tagagcccac 2044420DNAHuman 444ctggaggagg aatgccaatg
2044520DNAHuman 445cagccactcc tacatggacg 2044620DNAHuman
446gaaggggctg agattccagg 2044720DNAHuman 447ggagctgtac tcgggcacgt
2044820DNAHuman 448gctttgccgc cgtccagcca 2044920DNAHuman
449aggcccggtc cagcacaggt 2045020DNAMurine 450gaggtggcgc ttacctgtgc
2045120DNAMurine 451gctagacatc ttccggtttc 2045220DNAMurine
452ggaagctcag tatccgctga 2045320DNAMurine 453tgtctgggtg ctgaccgttg
2045420DNAMurine 454aaggcatcca gacccgaaac 2045520DNAMurine
455caaggtggac tcaccgtggt 2045620DNAMurine 456agcccacagg cattgcagac
2045720DNAMurine 457cccctgacta tgaagaaaga 2045820DNAHuman
458agtccatatg gaacccacgg 2045920DNAHuman 459agtctgagtg caaattgggc
2046020DNAHuman 460tacgaattgc accggaccag 2046120DNAHuman
461ttagaggctt gaggaaaccg 2046220DNAHuman 462ttagaaccta tgaagctctg
2046320DNAHuman 463cctgaataaa ctccaccgca 2046420DNAHuman
464aattcgaaag cccatcagtt 2046520DNAHuman 465tggccacaac ccaaactgat
2046620DNAHuman 466cagcatactc tgaggtacga 2046720DNAHuman
467ttacctctag cactgctgag 2046820DNAHuman 468tatgcagtcc attattgaca
2046920DNAHuman 469gtaacacagc ttattccgcg 2047020DNAHuman
470actttcccta gcaatgcagg 2047120DNAMurine 471caaatgggca agccttacgg
2047220DNAMurine 472ctcaatgtcc gtattgatag 2047320DNAMurine
473agtctgagtg caaattgggc 2047420DNAMurine 474ccagatagtg caaattgcta
2047520DNAMurine 475tgatagtggt ctggtcaaat 2047620DNAMurine
476aattcgaaag cccatcagtt 2047720DNAMurine 477gcccattact ttgtgtagtg
2047820DNAMurine 478tggccacagc ccaaactgat 2047920DNAHuman
479gcattcatac ttgctttcca 2048020DNAHuman 480ttagatgcag aggaatcact
2048120DNAHuman 481atggtgaaat gtccaaatga 2048220DNAHuman
482ttggttgcca tgaaaaggta 2048320DNAHuman 483tcatttatgg aggagatcca
2048420DNAHuman 484tgttacagcg ctacaggagc 2048520DNAHuman
485ctaaactgtg aaaacagctg 2048620DNAHuman 486aggcgtattg taccctggaa
2048720DNAHuman 487acgtgagatt ctttctctga 2048820DNAHuman
488ccagtcacac atgagaatgt 2048920DNAHuman 489gaagcagtgc aaacgccatg
2049020DNAHuman 490acattctgaa ggattgtcca 2049120DNAMurine
491agttgacaat gaaatactgc 2049220DNAMurine 492aatatcatct gtgaatactg
2049320DNAMurine 493taaaggctgt ttgcaaaaga 2049420DNAMurine
494tgcaaacacc atgtggccac 2049520DNAMurine 495gcgagagatt ctttccctga
2049620DNAMurine 496atcctcatca gagaacaggt 2049720DNAMurine
497acggtaaagt gcccaaataa 2049820DNAMurine 498ttaaactgtg agaacagctg
2049920DNAMurine 499tctttgttgc aggagtctga 2050020DNAMurine
500caggggcttg ttatgaggta 2050120DNAMurine 501ctgattgatg gtagcaggga
2050220DNAMurine 502ccttatcttc agtcacatgc 2050320DNAMurine
503tcacatgctg gcagaaatca 2050420DNAMurine 504ttctgtcgct gtgagataaa
2050520DNAMurine 505acaaggcagt acctgccacg 2050620DNAMurine
506tgtgactcac ccgggataca 2050720DNAMurine 507gaggtccatc agatcagctc
2050820DNAMurine 508atctccctgg aactggccat 2050920DNAMurine
509tgcaaaaatt gcaaaactca 2051020DNAMurine 510tgcacagaac tattgtacca
2051120DNAMurine 511cagattagtg cttaccttcc 2051220DNAMurine
512attccgtaaa atagagcccc 2051320DNAMurine 513ctgcactcgg ctgggacaat
2051420DNAHuman 514ccttatgaaa aagtcaaaac 2051520DNAHuman
515aaaatatcaa gtatatatgg 2051620DNAHuman 516tctagcatcg gcatgccaaa
2051720DNAHuman 517ttggaagctc atggacaaag 2051820DNAHuman
518gatttcctcc tcgaccacca 2051920DNAHuman 519cttcatctct tggatcaaag
2052020DNAHuman 520aatgtatgaa gaacagtcac 2052120DNAHuman
521taaacttacc tgaaacagcc 2052220DNAHuman 522aagaatatga tgttcctccc
2052320DNAHuman 523agcaagctgc cgcagatcgc 2052420DNAHuman
524agtactcatt ctcactgagt 2052520DNAMurine 525gatgaccaga gactatctgt
2052620DNAMurine 526cctaaacagt gccattatga 2052720DNAMurine
527ctatctgtcg gtgaaggtct 2052820DNAMurine 528gaatatatac aagttattgg
2052920DNAMurine 529tggggtgcca ggctgtgtgg 2053020DNAMurine
530catgtttcct tgcagaataa 2053120DNAMurine 531aagttcgagt gctgctggaa
2053220DNAMurine 532catcaagcca gctaatatgg 2053320DNAHuman
533aaatgagcag cattctgttg 2053420DNAHuman 534cttcttgcaa caggagacaa
2053520DNAHuman 535tggaacggtt cggataggta 2053620DNAHuman
536catcaagcct gctaacatgg 2053720DNAHuman 537ggcgtggaga ggagagctcg
2053820DNAHuman 538atgatcacta tttactgaaa 2053920DNAHuman
539tcgtctacag cagtagcaaa 2054020DNAHuman 540cagagactac ctgtcggtga
2054120DNAHuman 541gtgcttctcg caggtcaagg 2054220DNAHuman
542tggcggctca gcatgatctg 2054320DNAMurine 543caacccacat ttcgatttgg
2054420DNAMurine 544agccattcac acttctcact 2054520DNAMurine
545ccggctgtca cttaccgctg 2054620DNAMurine 546tttgtttcac agtcgttcga
2054720DNAMurine 547tggtaagaat gagggtaacc 2054820DNAMurine
548gctgcggaaa gcgcccgcca 2054920DNAMurine 549gttgatcatg attctctggt
2055020DNAMurine 550ttgttgcaga caaatgtggc 2055120DNAMurine
551ctatgaccgg ctggagatct 2055220DNAMurine 552cacatgtccg gctctcatgt
2055320DNAMurine 553gaggtgtcat cattcagggt 2055420DNAMurine
554ccagggtacc tcacatctcc 2055520DNAMurine 555aaacctgtat cctgggaaac
2055620DNAHuman 556agaccagttg gtgctatact 2055720DNAHuman
557agtggagtga taaagtcccc 2055820DNAHuman 558gaccggctag aaatctggga
2055920DNAHuman 559cctcacattg ggcgttactg 2056020DNAHuman
560ggatgttctg tcgctacgac 2056120DNAHuman 561cctgactcaa atcctccagg
2056220DNAHuman 562agagaatgcc cgatgaggat 2056320DNAHuman
563tacctgtatc cactctcggt 2056420DNAHuman 564tgtcctccaa atcgaagtga
2056520DNAHuman 565cattctcagg gtagttcagg 2056620DNAHuman
566tactgtggac agaaaacacc 2056720DNAMurine 567gccctttagc tggtatctgc
2056820DNAMurine 568atcagaactg ctatccacat 2056920DNAMurine
569catggcagag acacagacac 2057020DNAMurine 570cgaggagaac gtatatgaag
2057120DNAMurine 571aatgtgactc tggatgacca 2057220DNAMurine
572ggaaaatatc tacaccatcg 2057320DNAMurine 573gtagtagttg cagcagcagc
2057420DNAMurine 574ttggagtggg agtctctgct 2057520DNAMurine
575tccttacttt atagggtcat 2057620DNAMurine 576caacttgcct ccaggagggt
2057720DNAMurine 577atgtgactct ggatgaccat 2057820DNAMurine
578ggggcaaggg attctgtcct 2057920DNAMurine 579actgctatcc
acattggagt
2058020DNAMurine 580aaccatttct ctccgtggtt 2058120DNAMurine
581agtgtaactg cagggcagat 2058220DNAHuman 582agaagtggaa tacagagcgg
2058320DNAHuman 583atcagaatag gcatctacat 2058420DNAHuman
584ggtgtagaag cagggcagat 2058520DNAHuman 585aacctcgtgc ccgtctgctg
2058620DNAHuman 586aagagaagat acagaattta 2058720DNAHuman
587atgtgactct agcagacagt 2058820DNAHuman 588tctacacccc agccgcccca
2058920DNAHuman 589acatccagat actggctaaa 2059020DNAHuman
590tgtgtttgaa tgtggcaacg 2059120DNAHuman 591agtcacattc tctatggtca
2059220DNAHuman 592agtcggtgca ggggtgacct 2059320DNAHuman
593tggccaaaga gatgaggctg 2059420DNAMurine 594actcctgggg gcaaatgaca
2059520DNAMurine 595tgaagccatc tctgtaggtg 2059620DNAMurine
596ggctgaagga gcagttcaaa 2059720DNAMurine 597tgccactctt tccagccacg
2059820DNAMurine 598aagtcagccc cctggactct 2059920DNAMurine
599acagtgattg ctagtccctc 2060020DNAMurine 600agccccaggt cccagagtcc
2060120DNAMurine 601ctgtgggtct ggcacaggct 2060220DNAMurine
602gccaagtgga ctcctcctgg 2060320DNAMurine 603gtaggtgagg acacagcccc
2060420DNAMurine 604tgcacagaga ctgggcggtc 2060520DNAMurine
605acgtacaacc tcaaggttct 2060620DNAMurine 606gctcaatgcc actgtcacgt
2060720DNAMurine 607agtctctgtg cactggttcc 2060820DNAMurine
608tgggcggtca ggacggctga 2060920DNAHuman 609gttccggaac caatgcacag
2061020DNAHuman 610tgcgaagagc aggggtcact 2061120DNAHuman
611gcggtccctg aggtgcaccg 2061220DNAHuman 612tccccacacc agcaggcagg
2061320DNAHuman 613ccgctacacg gtgctgagcg 2061420DNAHuman
614ccggtggtgt gggcccagga 2061520DNAHuman 615gtttggggtg catacctgtc
2061620DNAHuman 616aggctctgag agatcctggg 2061720DNAHuman
617gctcaatgcc actgtcacat 2061820DNAHuman 618gtcccggagg cctgcgcagc
2061920DNAHuman 619gcagaaggct gagatcctgg 2062020DNAHuman
620taggtgagga tgcagcccca 2062120DNAMurine 621ttcagtgatc gggtggtccc
2062220DNAMurine 622gtctctgaca atgaatgaca 2062320DNAMurine
623ctgagctttc ttggaccttc 2062420DNAMurine 624aacatctctg cagaggaagg
2062520DNAMurine 625caaggggaga atattcctga 2062620DNAMurine
626cactataaat ggccagaagc 2062720DNAMurine 627caggcacgat agatacaaag
2062820DNAMurine 628gtatcctggt gggatttaca 2062920DNAMurine
629aggcagcctg tatcagcccc 2063020DNAMurine 630gctgctcctg gtctgggtcc
2063120DNAMurine 631tctctaggct tctgtagctc 2063220DNAMurine
632ctgaagcgac atgccacccc 2063320DNAMurine 633tctctgacaa tgaatgacac
2063420DNAMurine 634ccatttatag tgttgacctg 2063520DNAMurine
635tgccttcctc gctacaggta 2063620DNAHuman 636ttccacagaa tggattctga
2063720DNAHuman 637gctgaccgtg aacgatacag 2063820DNAHuman
638cccatccttc aaggatcgag 2063920DNAHuman 639caccacggca caagtgaccc
2064020DNAHuman 640atgtcacctc tcctccacca 2064120DNAHuman
641agtgtacgtc ccatcagggt 2064220DNAHuman 642gttcacggtc agcgactgga
2064320DNAHuman 643gcagatgacc accagcgtcg 2064420DNAHuman
644aacatttctg cagagaaagg 2064520DNAHuman 645ctgctgctcc cagttgacct
2064620DNAHuman 646aggccacatc tgcttcctgt 2064720DNAHuman
647ggtggtcgcg ttgactagaa 2064820DNAMurine 648aagaagtcct cttacaacag
2064920DNAMurine 649tccaagacaa gccatggctg 2065020DNAMurine
650tgctccttct tcttcataaa 2065120DNAMurine 651acaaaaggcc aagtcctaga
2065220DNAMurine 652tgaaattgct tttcacattc 2065320DNAMurine
653cacacaacac tgatgaggtc 2065420DNAMurine 654gtggtgttgg ctagcagcca
2065520DNAMurine 655cccatgccca caaagtatgg 2065620DNAMurine
656aggtccgggt gactgtgctg 2065720DNAMurine 657aggactgaga gctgttgaca
2065820DNAMurine 658tgaatattca catggaaagc 2065920DNAMurine
659attaaaggta ccactgcaga 2066020DNAMurine 660cacgggactg tacctctgca
2066120DNAMurine 661acatgagttc caccttgcag 2066220DNAMurine
662ctagattacc ccttctgcag 2066320DNAMurine 663gacccaacct tcagtggtgt
2066420DNAMurine 664ctcaactgca gctgccttct 2066520DNAMurine
665ccaagacaag ccatggctgg 2066620DNAMurine 666aaaagaagtc ctcttacaac
2066720DNAMurine 667gatgaaaaga agagtgagca 2066820DNAHuman
668atggactctc ttcttcataa 2066920DNAHuman 669tccttgcagc agttagttcg
2067020DNAHuman 670ccgccatact acctgggcat 2067120DNAHuman
671ctgaaatcca aggcaagcca 2067220DNAHuman 672accccgaact aactgctgca
2067320DNAHuman 673ttttcacatt ctggctctgt 2067420DNAHuman
674tggcttgcct tggatttcag 2067520DNAHuman 675tgcatactca cacacaaagc
2067620DNAHuman 676cctagatgat tccatctgca 2067720DNAHuman
677aaacaggaga gtgcagggcc 2067820DNAHuman 678ctgctggcca gtaccacagc
2067920DNAHuman 679aagaagccct cttacaacag 2068020DNAMurine
680cgtcatgact accagagagg 2068120DNAMurine 681atgatcaggt gactcatatt
2068220DNAMurine 682gcctcgcagg gtggatgatc 2068320DNAMurine
683ccggcctttc tccacctctc 2068420DNAMurine 684ccagtacaag tttatttacg
2068520DNAMurine 685gtgcccacct cgggccagta 2068620DNAMurine
686cttctatgac ctgtacggag 2068720DNAMurine 687tattcggatc cagaactcag
2068820DNAMurine 688tgggtactta aggtggatga 2068920DNAMurine
689atgtgtccca tactggcccg 2069020DNAMurine 690tggtgccatc tcggtcctgc
2069120DNAMurine 691gtggggtccg agcagttcag 2069220DNAMurine
692catcgtcatg actaccagag 2069320DNAMurine 693ggggacttct atgacctgta
2069420DNAHuman 694ccagggtgga cgctacacag 2069520DNAHuman
695cattgatgta gtcggacccg 2069620DNAHuman 696ggtgtcctgc aggaccgcga
2069720DNAHuman 697gcaggcagag acgctgctgc 2069820DNAHuman
698gcccccagga tggtgaggta 2069920DNAHuman 699gatgcagaga ccctgctcaa
2070020DNAHuman 700ctgagttctg gatccgaata 2070120DNAHuman
701gatgtgggtg accctgagcg 2070220DNAHuman 702aacttaagga cacctgcaag
2070320DNAHuman 703gctccgatcc cactagtgag 2070420DNAHuman
704cggcccagtc gcaagaacca 2070520DNAHuman 705gtttgcgact ctgacagagc
2070620DNAHuman 706tattcggatc cagaactcag 2070720DNAHuman
707tcacgcacaa gaaacgtcca 2070820DNAHuman 708agccagtgcc cgggcatgcc
2070920DNAHuman 709tcttcgttag gacttggccc 2071020DNAHuman
710cagctggatg aacagcgaga 2071120DNAHuman 711gaaaattgca gcgaaatatg
2071220DNAHuman 712actgggcgat accacagcag 2071320DNAHuman
713agtggcactt gggacttcta 2071420DNAHuman 714tcttggtagg tcacaaactc
2071520DNAHuman 715gtgcagactg gagaatacag 2071620DNAHuman
716tgatccctca ggagtccagg 2071720DNAHuman 717gatggccctg ctgtaacttt
2071820DNAHuman 718aacgttagtg atgacagcat 2071920DNAHuman
719ccatgagaga gcccgttacg 2072020DNAHuman 720ggataggcgt gggaatcaac
2072120DNAHuman 721tatcccaagg ctccggaagg 2072220DNAHuman
722tgggtaaggg aggtaactcc 2072320DNAHuman 723tttccaacac tatactcgcc
2072420DNAHuman 724acgtagtatt cccctgtcag 2072520DNAHuman
725actgcccaca caaaatggtt 2072620DNAHuman 726gctttaggtt cttgtcggtg
2072720DNAHuman 727tgcaaaggtg gatgcgagca 2072820DNAHuman
728taactcctgg ggtagggaat 2072920DNAHuman 729ggctttggcg cccttgctgc
2073020DNAHuman 730ggtaccaaca aagagaacct 2073120DNAHuman
731gagttcatca tgcccgcgca 2073220DNAHuman 732tttgccagct tagatggctt
2073320DNAHuman 733tagatagcac aaccatttcc 2073420DNAHuman
734agtttcaaag caaacgagaa 2073520DNAHuman 735ctgccctatg ggcttcccac
2073620DNAHuman 736gtcaactgta gtgcccagga 2073720DNAHuman
737tcagtgatgt tagtcccctg 2073820DNAHuman 738ctaaagagga gaaaccagag
2073920DNAHuman 739cagcagatgg caaacctggc 2074020DNAHuman
740cagggcaact gaaggagagg 2074120DNAHuman 741acgatgggag cagcaggtgt
2074220DNAHuman 742cccacgtgct gaataacgga 2074320DNAHuman
743taccaaagat ggagctgatg 2074420DNAHuman 744caggccactg gtgaccgcct
2074520DNAHuman 745ctgctgtttg gcaggcggcc 2074620DNAHuman
746gccgactggg aaaggttgaa 2074720DNAHuman 747gctgtcatca ctaacgtttc
2074820DNAHuman 748tccatgtaag gattgaccca 2074920DNAHuman
749accgaataca cccgagacag 2075020DNAHuman 750acctggccgg caaagcagga
2075120DNAHuman 751tactacgtgg agaatgccga 2075220DNAHuman
752gaaaaccgat tccggagggt 2075320DNAHuman 753gcactgagca tggaccgcac
2075420DNAHuman 754gttctctaag gtgcagcaag 2075520DNAHuman
755agttagcagc gagttccccg 2075620DNAHuman 756cagaagcgct gggcttggac
2075720DNAHuman 757cagcggctgg gccaagctgt 2075820DNAHuman
758actttcgttc tgttctgcaa 2075920DNAHuman 759cgccttggca gagggaaccc
2076020DNAHuman 760gatgaggctg aatcaaatga 2076120DNAHuman
761gcggttcaag acagaaaaga 2076220DNAHuman 762tcttgttctc taagcagtac
2076320DNAHuman 763ggtgccatct gcattggcat 2076420DNAHuman
764tggcaagtat cccaaggctc 2076520DNAHuman 765gctgccacaa gcactctagg
2076620DNAHuman 766atagcactga agccatttgg 2076720DNAHuman
767gaatacaccc gagacagtgg 2076820DNAHuman 768tccaagtatc tgtggctcag
2076920DNAHuman 769tcaatggtgc tagttatctg 2077020DNAHuman
770gtgaacgttc ccatacaggg 2077120DNAHuman 771gaatcccttg aaccacaacg
2077220DNAHuman 772gctgtgtgca gacgaagaag 2077320DNAMurine
773gacacacggc gcaatgacag 2077420DNAMurine 774cagctgtatg atctggaagc
2077520DNAMurine 775cagcaaccag actgaaaaac 2077620DNAMurine
776gcagggagat ggccccacag 2077720DNAMurine 777acagtggcat ctacctctgt
2077820DNAMurine 778cggaggatct tatgctgaac 2077920DNAMurine
779gagccctgga gcagagctcg 2078020DNAMurine 780gcaaaaatcg
aggagagccc
2078120DNAMurine 781gccaggctgg gtagaaggtg 2078220DNAMurine
782gctcaaacca ttacagaagg 2078320DNAMurine 783ggacaagctg caggtgaagg
2078420DNAMurine 784gagccctgga gcagagctcg 2078520DNAMurine
785ggacaagctg caggtgaagg 2078620DNAMurine 786gctcaaacca ttacagaagg
2078720DNAMurine 787gccaggctgg gtagaaggtg 2078820DNAMurine
788gacacacggc gcaatgacag 2078920DNAMurine 789cagctgtatg atctggaagc
2079020DNAMurine 790cagcaaccag actgaaaaac 2079120DNAMurine
791gcagggagat ggccccacag 2079220DNAMurine 792acagtggcat ctacctctgt
2079320DNAMurine 793cggaggatct tatgctgaac 2079420DNAMurine
794gcaaaaatcg aggagagccc 2079520DNAMurine 795cgaccagttg gacaagctgc
2079620DNAMurine 796catgtggaag tcatgcctgt 2079720DNAMurine
797agcgggcatc ctggacgggt 2079820DNAMurine 798ccaggctggg tagaaggtga
2079920DNAMurine 799gcaccccaag gcaaaaatcg 2080020DNAMurine
800gctcaaacca ttacagaagg 2080120DNAMurine 801gacacacggc gcaatgacag
2080220DNAMurine 802cagctgtatg atctggaagc 2080320DNAHuman
803cggccagttc caaaccctgg 2080420DNAHuman 804cagttccaaa ccctggtggt
2080520DNAHuman 805ctgcagcttc tccaacacat 2080620DNAHuman
806cgtgtcacac aactgcccaa 2080720DNAHuman 807agagctcagg gtgacaggtg
2080820DNAHuman 808gcgtgacttc cacatgagcg 2080920DNAHuman
809cagcggcacc tacctctgtg 2081020DNAHuman 810gctgcggtcc tcggggaagg
2081120DNAHuman 811gcagggctgg ggagaaggtg 2081220DNAHuman
812catgagcccc agcaaccaga 2081320DNAHuman 813gccctgtgtc cctgagcaga
2081420DNAMurine 814taggggcccc aggcctgagc 2081520DNAMurine
815aagatctgcg cccggagata 2081620DNAMurine 816gttctgtctg tagggaggta
2081720DNAMurine 817caacgaaact tacacaagga 2081820DNAMurine
818cactcagaac ttacatcaga 2081920DNAMurine 819tctgagtgtg acagagaagg
2082020DNAMurine 820ttcctcctga gactgtcgta 2082120DNAMurine
821gacaattgca gcctgctgag 2082220DNAMurine 822acttacatca gaaggttgct
2082320DNAMurine 823gcacaggagc tgcggcggat 2082420DNAMurine
824gttgtaagat aaccatttga 2082520DNAMurine 825gtttgcaaat gattaccgcg
2082620DNAMurine 826tcctgtgcaa tccgtatctc 2082720DNAMurine
827tcgccgtcgg gattaccttg 2082820DNAMurine 828tcttccgtct ggtatggaga
2082920DNAMurine 829ttccatacga cagtctcagg 2083020DNAMurine
830ttctgtctgt agggaggtag 2083120DNAMurine 831caaccactat ctcagtgcaa
2083220DNAHuman 832agctggggag gcctctccgc 2083320DNAHuman
833ccactgaact tccctatgaa 2083420DNAHuman 834ttaacgctta ctatgcaagg
2083520DNAHuman 835aaccattcgt gggtggtctt 2083620DNAHuman
836aggcaatcac ggaggtgaag 2083720DNAHuman 837tggcttgcag atgactccgc
2083820DNAHuman 838aaagatcacc tatatcctct 2083920DNAHuman
839gttgatttgt cacaactcat 2084020DNAHuman 840gttctgatgc agcttccatg
2084120DNAHuman 841ttttccagtt agagaaatag 2084220DNAHuman
842tagtggttga aggcctggca 2084320DNAHuman 843ttgccttcag gattaccttg
2084420DNAHuman 844acagtctcac tctgtcaccc 2084520DNAHuman
845cactcagaac ttacatcaga 2084620DNAHuman 846cttgggcgat ccatatctct
2084720DNAHuman 847aggtagacaa ttgcagcctg 2084820DNAHuman
848acttcctcta tttctctaac 2084920DNAHuman 849actggaggat cgagacagca
2085020DNAHuman 850tccctacaga cagagccaca 2085120DNAHuman
851ttgtggctct gtctgtaggg 2085220DNAMurine 852gctgttaact ctgttgatgc
2085320DNAMurine 853ggctcgccgg ctcgggatgg 2085420DNAMurine
854ccggagccgc ggaccaccac 2085520DNAMurine 855cgattgagaa gttattagaa
2085620DNAMurine 856gctcaagtac tcgcccgacc 2085720DNAMurine
857tccccgcagg actcaccttg 2085820DNAMurine 858ctgtgctgct gctgcacgtt
2085920DNAMurine 859ggacgaggag cgggccctgg 2086020DNAHuman
860cgaaatctat gaggaagagg 2086120DNAHuman 861actgttaact ctgttgatgc
2086220DNAHuman 862gcacattagg ttgcagtatg 2086320DNAHuman
863ggatttcgac gaaatctatg 2086420DNAHuman 864tctcaatcga tcttcgtgtc
2086520DNAHuman 865tgcattggag actgagcaaa 2086620DNAHuman
866gccaacgtac attaacagga 2086720DNAHuman 867gaattccctt cttcattaac
2086820DNAHuman 868ccggacccgg tggtcgtccg 2086920DNAHuman
869gcagctgctc aagtactcgc 2087020DNAHuman 870aaacaatagg ttataccaca
2087120DNAHuman 871cggtgacgtg accggagccg 2087220DNAMurine
872ccactgcaga ccccacactg 2087320DNAMurine 873tataaaggaa tacggattga
2087420DNAMurine 874gtggctggag tgggctataa 2087520DNAMurine
875cggagagtca ttgtgcctgc 2087620DNAMurine 876cacaggagca cgttcgacag
2087720DNAMurine 877aatgacggac cctgatgagg 2087820DNAMurine
878catggtactt actttccctg 2087920DNAMurine 879ccaacgccag ctgtatcacc
2088020DNAHuman 880cagcacttcc gtgttgtaga 2088120DNAHuman
881caaaatgacg gaccccgatg 2088220DNAHuman 882tggttctcga attacctgcg
2088320DNAHuman 883tgtgaggcaa tggctggagt 2088420DNAHuman
884gatcgtttgt gcccctccaa 2088520DNAHuman 885tcgttggtgg tcatgttggg
2088620DNAHuman 886tcagtaagaa tacagagcaa 2088720DNAHuman
887ccagctgtat cacctgggag 2088820DNAHuman 888tgtcggagag cagctccagg
2088920DNAHuman 889aacattatga ccaaagtgca 2089020DNAHuman
890ggcggcactt actttccctg 2089120DNAHuman 891actgtgtaaa atgaacaagg
2089220DNAMurine 892atcccccgcc acctggacct 2089320DNAMurine
893ggaaggcagg tcactattac 2089420DNAMurine 894ctgatgcacg gaaaggaagt
2089520DNAMurine 895cctgggcccc ggtgctctcg 2089620DNAMurine
896accagccgaa gtgtgaccgg 2089720DNAMurine 897gtcagcgtga tgatcctctc
2089820DNAMurine 898ctccagcttg tcgatgatca 2089920DNAMurine
899tcccgtcccg ccgtgcatca 2090020DNAHuman 900tggcgcgcgg atcaacatct
2090120DNAHuman 901gagagaatca tcactctgac 2090220DNAHuman
902tccgtgcata agaagccgaa 2090320DNAHuman 903aagcatcatt gggaagaaag
2090420DNAHuman 904ctccatgacc aacagtaccg 2090520DNAHuman
905atttggaatg gtgagttcat 2090620DNAHuman 906agagatccgc gagagtacgg
2090720DNAHuman 907gaaagcctta aagatggcat 2090820DNAHuman
908cagctcccca gtcatctgcg 2090920DNAHuman 909acacactcgg tgacagactg
2091020DNAHuman 910aatcagggag ccgcactggg 2091120DNAHuman
911gtcggttaag aggatccgcg 2091220DNAMurine 912ccaaaacata caatgagcct
2091320DNAMurine 913agactattat gcaataatta 2091420DNAMurine
914aagactttgc gatctattta 2091520DNAMurine 915gagcacatca cttaccactt
2091620DNAMurine 916gtaccaagac atagattcta 2091720DNAMurine
917cctctgtgag ctgttcatta 2091820DNAMurine 918aacgggcaag aaggatgaac
2091920DNAMurine 919gaaaccactt cataatagtc 2092020DNAHuman
920cacacctggc ggaagatggt 2092120DNAHuman 921tggagagatt cttctttcac
2092220DNAHuman 922ggagttgtcg gaataaccaa 2092320DNAHuman
923caaatcccag agtttgcaag 2092420DNAHuman 924tcaggcaact cagatctaga
2092520DNAHuman 925ttacccggtg gtgggatgcc 2092620DNAHuman
926tcaaccagac tattatgaag 2092720DNAHuman 927cccttccagc agtgtcagcg
2092820DNAHuman 928gccaggcact ataatgagga 2092920DNAHuman
929tcattagggc accaaagcga 2093020DNAHuman 930ttgagcatcc ccattggtgt
2093120DNAHuman 931ttgcattgtt aaaaagaagc 2093220DNAHuman
932aggctgcctt tactgtgtga 2093320DNAHuman 933tgctgattga gcatccccat
2093420DNAHuman 934ccagctgcac gctatgaaga 2093520DNAHuman
935aaaacatttg cataatgatg 2093620DNAHuman 936ggataggact ccatccaact
2093720DNAHuman 937atctcaagac cattgcccag 2093820DNAMurine
938gctcatactc ctcccggtta 2093920DNAMurine 939aggcgagggg cctgatttac
2094020DNAMurine 940gttacgggtc tggagtgtgt 2094120DNAMurine
941tgttggggac aggctgctgg 2094220DNAMurine 942tctggactct cttcaccatt
2094320DNAHuman 943gagaatcact tgaacctggg 2094420DNAHuman
944gcaggatgca ccctactaca 2094520DNAHuman 945cattaggctc tggccgtacc
2094620DNAHuman 946ccgtgagggc caccatctcg 2094720DNAHuman
947agcgttcgta tctggaaggt 2094820DNAHuman 948ataagctccg aggttgcccg
2094920DNAHuman 949gctggcagtg actgatacag 2095020DNAHuman
950acaaagatgg ccttgccaga 2095120DNAHuman 951aagaagtaaa ctacctcaca
2095220DNAHuman 952gctacgttct tcatggccgt 2095320DNAHuman
953aagaattcga ccaagggatt 2095420DNAHuman 954ttaatggcaa gacttgcaga
2095520DNAHuman 955tgaaagtatc cagctgatga 2095620DNAHuman
956ggcgagatgt gtgacagagg 2095720DNAHuman 957agatgtagag ctttccaagg
2095820DNAHuman 958tagatcttct tacatggaag 2095920DNAHuman
959ctttctaggt tcgagatgtg 2096020DNAHuman 960caacccaatc tttcctcgga
2096120DNAHuman 961gtagaagcaa agagaggcga 2096220DNAHuman
962ttcgatctcg acttcttgag 2096320DNAHuman 963gcttgaggct ccttacaaga
2096420DNAHuman 964ctgatgatgg acagtgaaac 2096520DNAHuman
965cataataaca aacaaagcta 2096620DNAHuman 966aggagatgta gagctttcca
2096720DNAHuman 967ttggtcagat aatatgatta 2096820DNAHuman
968gaggcaaccc aatctttcct 2096920DNAHuman 969aggtgaattc atgggagtag
2097020DNAHuman 970tacttactat gaagcattta 2097120DNAHuman
971cagggcgaga tgtgtgacag 2097220DNAHuman 972agcgaagtag aagcaaagag
2097320DNAHuman 973agtgatgaac tggaaaggac 2097420DNAHuman
974atgaagcatt tagggatctt 2097520DNAHuman 975cttggcacct tgaagagcat
2097620DNAHuman 976tttaattggg gaggaccatg 2097720DNAHuman
977gtcattattc acagcagggt 2097820DNAHuman 978cgtcctagag agtttacata
2097920DNAHuman 979ctgcagggtg aagtttacaa 2098020DNAHuman
980tgacatctgc cttgacgaag 2098120DNAHuman
981aaaacaggta cacttggcac 2098220DNAHuman 982acttctaggc ttactatctg
2098320DNAHuman 983cgcaacagag atcagaaaag 2098420DNAHuman
984aaggctctca gggagagccg 2098520DNAHuman 985gttcatgtta cagaggaaag
2098620DNAHuman 986gcaagcatgc tcgaggacag 2098720DNAHuman
987tgcttgaagt tggacagcaa 2098820DNAHuman 988cactaaacca tttcaggtaa
2098920DNAHuman 989ctatttgaca aagatggtga 2099020DNAHuman
990aagaagttga tgaaatgatc 2099120DNAHuman 991cgccatgtga tgacaaacct
2099220DNAHuman 992gtcctgtaac tctgcttctg 2099320DNAHuman
993tcagcagttc aagaccagcc 2099420DNAHuman 994tgatggaact ataacaacaa
2099520DNAHuman 995ccatcattgt cagaaattca 2099620DNAHuman
996gacgtacctt atcaaacaca 2099720DNAHuman 997ctttgcacaa caaccctgca
2099820DNAHuman 998aaggcggtgg agatgctcag 2099920DNAHuman
999aggtgatgca aactcatcat 20100020DNAHuman 1000cggattagcc tccgccaacg
20100120DNAHuman 1001tgctcccaga gaccctgaag 20100220DNAHuman
1002tgacgaggag aatctgaccc 20100320DNAHuman 1003gctgaaagcg
aagtccacgt 20100420DNAHuman 1004aggcctcaag ttcaacctca
20100520DNAHuman 1005agctgagtcc tgaaagtcag 20100620DNAHuman
1006tctgctggac aggttcacgg 20100720DNAHuman 1007ccccagagac
aggaaggcca 20100820DNAHuman 1008cctaccttca aacagaacca
20100920DNAHuman 1009atggtggctt tgatgaactg 20101020DNAHuman
1010attgtattcc tgcttccgga 20101120DNAHuman 1011gatctactac
ttcttccgag 20101220DNAHuman 1012gttcactgtc agtctccaag
20101320DNAHuman 1013tagacctcac acaggtccag 20101420DNAHuman
1014ggaatacacc tcgtcccctg 20101520DNAHuman 1015actcaagcct
tcccaacccg 20101620DNAHuman 1016aatacaatgg gaagatccct
20101720DNAMurine 1017gtgtccagtc ccaacactgc 20101820DNAMurine
1018agcggtggaa cacaggctac 20101920DNAMurine 1019aatccagtag
ggattgctgc 20102020DNAMurine 1020ttaataacag cttggtcctc
20102120DNAMurine 1021aagtgtgact ccccagcctc 20102220DNAMurine
1022gggtttcctt cctgaggctg 20102320DNAMurine 1023ggggaagaat
aagacttcgg 20102420DNAMurine 1024gggtttatgt gcaccaggta
20102520DNAHuman 1025ttcccaggaa gtgagagttc 20102620DNAHuman
1026cactcgcggg actcactttc 20102720DNAHuman 1027atagaaacgc
tcatctcccg 20102820DNAHuman 1028ggatgctgtg atcatcctgg
20102920DNAHuman 1029cctcaccagc caggataagg 20103020DNAHuman
1030aatccagtag gaattgctgc 20103120DNAHuman 1031tgacaagcat
ggggaagccg 20103220DNAHuman 1032tctcttcgcc tcctacctga
20103320DNAHuman 1033acctgatgcc gactctgcag 20103420DNAHuman
1034cagtcacggg ctttcagtgg 20103520DNAHuman 1035cactcgcggg
actcacttgc 20103620DNAHuman 1036ccgtggaagg agccccaggg
20103720DNAHuman 1037cataaattcc gaaatccagt 20103820DNAHuman
1038cactcgcggg actcactttc 20103920DNAHuman 1039gtggacggac
tttataagat 20104020DNAHuman 1040gatgaaggag ttgataactc
20104120DNAHuman 1041cccatctaca tcgatctgcg 20104220DNAHuman
1042gttgaggttc ttcagaagga 20104320DNAHuman 1043gcacccaaag
aactcagctt 20104420DNAHuman 1044gaacagataa ctgtagccaa
20104520DNAMurine 1045cactttcctt tctcaggtgc 20104620DNAMurine
1046cagctacaac atggtcattc 20104720DNAMurine 1047cccgggccaa
gtacttcatt 20104820DNAMurine 1048gaatgtagtc cactctgaac
20104920DNAMurine 1049gaccgtacca tcctcaggag 20105020DNAMurine
1050gtggtgtagc gagcgaactc 20105120DNAMurine 1051tgaagcactg
gatccacttg 20105220DNAMurine 1052tgaggatcct gcatgttaat
20105320DNAHuman 1053cattaaaccc attaacatgc 20105420DNAHuman
1054gggcaccagg ttgctcatgg 20105520DNAHuman 1055actgggcaca
gtcaatcagc 20105620DNAHuman 1056ggaatctgac cacgagcacg
20105720DNAHuman 1057tgcctaagag gatggatcgg 20105820DNAHuman
1058cgcccgtgcc cagcagcgcg 20105920DNAHuman 1059gaaggacaag
caggtctacc 20106020DNAHuman 1060ggaccagcgc aacgaggaga
20106120DNAHuman 1061cgaggagaag gcgcagcgtg 20106220DNAHuman
1062ggagagccag aggagcgcgg 20106320DNAHuman 1063actgttcccg
aggcagccca 20106420DNAHuman 1064gcaggagagc cagaggagcg
20106520DNAHuman 1065gtcctctccc tcccagccat 20106620DNAHuman
1066tccccagggt cccgccaaga 20106720DNAHuman 1067agtgagcagt
gcagcctgga 20106820DNAHuman 1068tgtcctctcc ctcccagcca
20106920DNAHuman 1069ctggactggg atgaaggtga 20107020DNAHuman
1070ggggtgggcc cggctcacca 20107120DNAHuman 1071caccaccccg
cgggactaga 20107220DNAHuman 1072ctgctgccac tgcccccgct
20107320DNAHuman 1073cggcccgacg tgcccatcac 20107420DNAHuman
1074cactgccccc gctaggtgcg 20107520DNAHuman 1075atacacgctg
gcctgctcct 20107620DNAHuman 1076caaacactgt gatgtctgtg
20107720DNAHuman 1077gcgggaccct ggggatgcct 20107820DNAHuman
1078gcgggagcgc cagacctcac 20107920DNAHuman 1079aggacaggct
tctctccaca 20108020DNAHuman 1080gcagacacca acacggtgct
20108120DNAHuman 1081ccaccacccc gcgggactag 20108220DNAHuman
1082atccccaggg tcccgccaag 20108320DNAHuman 1083cctggaggaa
ggagcagcct 20108420DNAHuman 1084agagccagat gtcggaactt
20108520DNAHuman 1085atgacccact gggccggcac 20108620DNAHuman
1086gcagctttgg gcccacagac 20108720DNAHuman 1087actctctgtt
agcagagagc 20108820DNAHuman 1088ccaggaagga aatgcaccta
20108920DNAHuman 1089aggcaccact cacctgtgat 20109020DNAHuman
1090ctgggcccgt gccggcccag 20109120DNAHuman 1091cagccagctg
ctgggggtcc 20109220DNAHuman 1092tccactcctg ccgctcgcct
20109320DNAHuman 1093cgtccaggca gacaccaaca 20109420DNAHuman
1094cccacccaca tcagtccttc 20109520DNAHuman 1095gccagctctt
gacccggcct 20109620DNAHuman 1096ctgccctcct tttcctcttc
20109720DNAHuman 1097ccagccccac catgagtctg 20109820DNAHuman
1098gccgattctt ccacccagag 20109920DNAHuman 1099ctcccagaag
aggaaaagga 20110020DNAHuman 1100gtggggcagg gcaggcagcc
20110120DNAHuman 1101gggtcaagag ctggccgctg 20110220DNAHuman
1102atgccccctg atgacccact 20110320DNAHuman 1103agccttctct
gcctttggcc 20110420DNAHuman 1104ctctgccttt ggccgggcca
20110520DNAHuman 1105ggaacccagc ctgccctccc 20110620DNAHuman
1106ggcaggagcc tcgcacctag 20110720DNAHuman 1107tcccagacca
gcacatcctg 20110820DNAHuman 1108gtgagcagtg cagcctggat
20110920DNAHuman 1109gagccagatg tcggaacttt 20111020DNAHuman
1110ggccgatggc aagccttgct 20111120DNAHuman 1111aggagcctcg
cacctagcgg 20111220DNAHuman 1112aggtccccaa gaggaaaaca
20111320DNAHuman 1113cgctgaggag gcctcggccc 20111420DNAHuman
1114gaggacagcc acagccgtca 20111520DNAHuman 1115cagccccacc
atgagtctgt 20111620DNAHuman 1116accccccaga gccccaagca
20111720DNAHuman 1117gaggcaccac tcacctgtga 20111820DNAHuman
1118ccaagaggaa aacagggcac 20111920DNAHuman 1119gtacgtctcc
caggattgcc 20112020DNAHuman 1120cacagcctcc accaggtgcg
20112120DNAHuman 1121gatctcggca gccagctgct 20112220DNAHuman
1122cagccttctc tgcctttggc 20112320DNAHuman 1123cagaagtgac
acttacctca 20112420DNAHuman 1124gctggccgct gaggaggcct
20112520DNAHuman 1125cagctccctc tagtcccgcg 20112620DNAHuman
1126cggggtgggc ccggctcacc 20112720DNAHuman 1127gacacatacc
gtgacctcca 20112820DNAHuman 1128caggaaggaa atgcacctat
20112920DNAHuman 1129agtggccagc acccatggcc 20113020DNAHuman
1130ctctcctatt cttcccagca 20113120DNAHuman 1131gcccgagtcc
aggcaatcct 20113220DNAHuman 1132caccttcatc tgcagttcca
20113320DNAHuman 1133ggcacaggca gacaggtgag 20113420DNAHuman
1134agcacccatg gcccggccaa 20113520DNAHuman 1135ccacaggcag
cttactcact 20113620DNAHuman 1136ttcctgtgct ccaaagtgag
20113720DNAHuman 1137accgcagcct tctctgcctt 20113820DNAHuman
1138gggagccaat gcccgagtcc 20113920DNAHuman 1139ttcccagcaa
ggcttgccat 20114020DNAHuman 1140agccagatgt cggaactttg
20114120DNAHuman 1141tacacgggct acagtcccta 20114220DNAHuman
1142tctgtgttag accctcttgg 20114320DNAHuman 1143aagctgcccc
cagcgctctg 20114420DNAHuman 1144ctttgggggg ttcgaggagg
20114520DNAHuman 1145gggccgatgg caagccttgc 20114620DNAHuman
1146cacaggcagc ttactcactg 20114720DNAHuman 1147cccagaccag
cacatcctgc 20114820DNAHuman 1148aggctgggtt ccataccata
20114920DNAHuman 1149ggacttctaa ttgctgagaa 20115020DNAHuman
1150ctcaaattcc cacagactca 20115120DNAHuman 1151aaaacagggc
acaggcagac 20115220DNAHuman 1152ccagatgtcg gaactttggg
20115320DNAHuman 1153ctccctctag tcccgcgggg 20115420DNAHuman
1154agcccccagt gcagagccca 20115520DNAHuman 1155cctggacgcc
cagcttctgc 20115620DNAHuman 1156caggggctgg caggagcccg
20115720DNAHuman 1157ccttgttccc atggctggga 20115820DNAHuman
1158ctcatctgcc acagagcgct 20115920DNAHuman 1159ggcagacacc
aacacggtgc 20116020DNAHuman 1160tccctcttga ttcctcttcc
20116120DNAHuman 1161ccctcccagc catgggaaca 20116220DNAHuman
1162gcgtaagaag ccactcactt 20116320DNAHuman 1163tgtgtttccc
ccgcacctgg 20116420DNAHuman 1164ctgagaccag tggtcatcga
20116520DNAHuman 1165gggcagcgac ctgagaccag 20116620DNAHuman
1166agcaattaga agtccctgca 20116720DNAHuman 1167tgggtgagct
ggtgaaacac 20116820DNAHuman 1168ctgttagcag agagctggac
20116920DNAHuman 1169cccctgatga cccactgggc 20117020DNAHuman
1170gttcacacca tcacgacgcg
20117120DNAHuman 1171tgtccaggct gggcccgtgc 20117220DNAHuman
1172acacagacct atgccccatc 20117320DNAHuman 1173ggctgcctgc
cctgccccac 20117420DNAHuman 1174ccataggtgc atttccttcc
20117520DNAHuman 1175caggctgggt tccataccat 20117620DNAHuman
1176gccccatcac agcctccacc 20117720DNAHuman 1177tgccctcctt
ttcctcttct 20117820DNAHuman 1178gccagatgtc ggaactttgg
20117920DNAHuman 1179caggcagaca ggtgagagga 20118020DNAHuman
1180ccaggagtct gagctatgag 20118120DNAHuman 1181gctccaggtt
gggagcctta 20118220DNAHuman 1182ctcacctgtg atgggcacgt
20118320DNAHuman 1183agctggccta cgagtctgac 20118420DNAHuman
1184gtgggtgggg gcagtgggta 20118520DNAHuman 1185catctgcagt
tccagggccg 20118620DNAHuman 1186gatgacccac tgggccggca
20118720DNAHuman 1187tgacctccaa ggcgagcggc 20118820DNAHuman
1188ggatctcggc agccagctgc 20118920DNAHuman 1189tccttttcct
cttctgggag 20119020DNAHuman 1190cacgacgcgt gggtggcaag
20119120DNAHuman 1191ttcacaccat cacgacgcgt 20119220DNAHuman
1192gcaggagcct cgcacctagc 20119320DNAHuman 1193cacccctaag
gctcccaacc 20119420DNAHuman 1194ttgtccttgc ttggggctct
20119520DNAHuman 1195caggacaggc ttctctccac 20119620DNAHuman
1196cacctggtgg aggctgtgat 20119720DNAHuman 1197cgtctgtggg
agccagtctg 20119820DNAHuman 1198ccccccaaag ttccgacatc
20119920DNAHuman 1199aggcagcctg gccaaggagc 20120020DNAHuman
1200tctgcctttg gccgggccat 20120120DNAHuman 1201ggacaggctt
ctctccacag 20120220DNAHuman 1202acgtgcccat cacaggtgag
20120320DNAHuman 1203agagagtgag cagtgcagcc 20120420DNAHuman
1204cgcaggaagt tgtccaggct 20120520DNAHuman 1205ggctgggagc
tcagatccat 20120620DNAHuman 1206cagctcaccc agcaccgtgt
20120720DNAHuman 1207ccagcacatc ctgcgggaac 20120820DNAHuman
1208gacctccttg ttcccatggc 20120920DNAHuman 1209ggggttcgag
gaggaggccc 20121020DNAHuman 1210cagagaaggc tgcggtggct
20121120DNAHuman 1211gggagtgagt ccagcgtctg 20121220DNAHuman
1212caggagcctc gcacctagcg 20121320DNAHuman 1213ggaggaggcc
ctggtgagcc 20121420DNAHuman 1214caagcaagga caaaaatggc
20121520DNAHuman 1215cgtcagggca ccccaaggcc 20121620DNAHuman
1216gctggcagtg aactggtttc 20121720DNAHuman 1217acctccttgt
tcccatggct 20121820DNAHuman 1218tcccgcagga tgtgctggtc
20121920DNAHuman 1219agggactgta gcccgtgtaa 20122020DNAHuman
1220ccagtactct cgaggtggaa 20122120DNAHuman 1221aattcccaca
gactcatggt 20122220DNAHuman 1222cccaccccga gccccttaca
20122320DNAHuman 1223gtgcatttcc ttcctggaag 20122420DNAHuman
1224tcagcggcca gctcttgacc 20122520DNAHuman 1225ggcccggcca
aaggcagaga 20122620DNAHuman 1226acagagcgct gggggcagct
20122720DNAHuman 1227tcttgattcc tcttccagga 20122820DNAHuman
1228gcaaggacaa aaatggccgg 20122920DNAHuman 1229cagggcaggc
agcctggcca 20123020DNAHuman 1230atctcggcag ccagctgctg
20123120DNAHuman 1231cccgcaggat gtgctggtct 20123220DNAHuman
1232ggctccaggt tgggagcctt 20123320DNAHuman 1233caacacggtg
ctgggtgagc 20123420DNAHuman 1234gcagccgtgt ccctatggta
20123520DNAHuman 1235tgtccttgct tggggctctg 20123620DNAHuman
1236tcatggtggg gctggcttcc 20123720DNAHuman 1237gaagctgggc
tattcatcca 20123820DNAHuman 1238gaccctcttg gcgggaccct
20123920DNAHuman 1239ggaaaggcag ggggcgcggg 20124020DNAHuman
1240aggtctgtgt tagaccctct 20124120DNAHuman 1241ctcagctccc
tctagtcccg 20124220DNAHuman 1242tagggactgt agcccgtgta
20124320DNAHuman 1243agggggcata aacctgcaga 20124420DNAHuman
1244ctcccaggat tgcctggact 20124520DNAHuman 1245gggatgaagg
tgaaggccgc 20124620DNAHuman 1246tgcagagccc aggggctggc
20124720DNAHuman 1247gaatcggcac ttgatcccat 20124820DNAHuman
1248ccgaggctgc tccttcctcc 20124920DNAHuman 1249ccagcttctg
caggacgctg 20125020DNAHuman 1250gggccggcac gggcccagcc
20125120DNAHuman 1251tgaggtctgg cgctcccgct 20125220DNAHuman
1252ttggggtgcc ctgacggctg 20125320DNAHuman 1253actagaggga
gctgagggca 20125420DNAHuman 1254ccagttcccg caggatgtgc
20125520DNAHuman 1255tatgccccct gatgacccac 20125620DNAHuman
1256gtgagaggag agcattggca 20125720DNAHuman 1257agcttactca
ctggggtgct 20125820DNAHuman 1258atcacagcct ccaccaggtg
20125920DNAHuman 1259actgaagtgg ccagcaccca 20126020DNAHuman
1260gccggcccag tgggtcatca 20126120DNAHuman 1261cctgcagaag
ctgggcgtcc 20126220DNAHuman 1262gcaccgtgtt ggtgtctgcc
20126320DNAHuman 1263ggccctggaa ctgcagatga 20126420DNAHuman
1264gtccttgctt ggggctctgg 20126520DNAHuman 1265ctccctggag
agccagatgt 20126620DNAHuman 1266aaattcccac agactcatgg
20126720DNAHuman 1267tcatctgcca cagagcgctg 20126820DNAHuman
1268agtcggcagg gacactgaag 20126920DNAHuman 1269actctcgagg
tggaaaggca 20127020DNAHuman 1270cccagtgagt aagctgcctg
20127120DNAHuman 1271agagggtgca aagaactctc 20127220DNAHuman
1272cacgatcccg tcagactcgt 20127320DNAHuman 1273tctgcactgg
gggctcctga 20127420DNAHuman 1274cagggggcat aaacctgcag
20127520DNAHuman 1275tgaggacagc cacagccgtc 20127620DNAHuman
1276gtttcccccg cacctggtgg 20127720DNAHuman 1277ttaggggtgc
caccaccccg 20127820DNAHuman 1278actggggtgc tgggacttgt
20127920DNAHuman 1279ctcactcccg tacgtctccc 20128020DNAHuman
1280aggggctggc aggagcccgt 20128120DNAHuman 1281tccttgttcc
catggctggg 20128220DNAHuman 1282gccaaaggca gagaaggctg
20128320DNAHuman 1283cacgggctcc tgccagcccc 20128420DNAHuman
1284ccacagcgtc ctgcagaagc 20128520DNAHuman 1285acgggctcct
gccagcccct 20128620DNAHuman 1286atgggagcaa cgtggccatg
20128720DNAHuman 1287cccaaggccg ggtcaagagc 20128820DNAHuman
1288aattgctgag aaggggccga 20128920DNAHuman 1289gggcaggagt
gaggagggcc 20129020DNAHuman 1290ggcgggaccc tggggatgcc
20129120DNAHuman 1291ggggctggca ggagcccgtg 20129220DNAHuman
1292ttccgacatc tggctctcca 20129320DNAHuman 1293gtgctgccct
tgccagccac 20129420DNAHuman 1294actcctgccg ctcgccttgg
20129520DNAHuman 1295gtggacttct tccggaagct 20129620DNAHuman
1296ccagtgcaga gcccaggggc 20129720DNAHuman 1297ggggcagtgg
cagcagcttt 20129820DNAHuman 1298gggactgtag cccgtgtaag
20129920DNAHuman 1299ccacagactc atggtggggc 20130020DNAHuman
1300aacacgggac agccaccgag 20130120DNAHuman 1301gcaaagaact
ctctggaggt 20130220DNAHuman 1302tgggcccgtg ccggcccagt
20130320DNAHuman 1303ctcctgccgg ggcatcctgc 20130420DNAHuman
1304aggcagacag gtgagaggaa 20130520DNAHuman 1305aggcaatcct
gggagacgta 20130620DNAHuman 1306tcagaccagt actctcgagg
20130720DNAHuman 1307aacatacttg tcattgacga 20130820DNAHuman
1308ggcagcttgg ccgctctggg 20130920DNAHuman 1309gagttctttg
caccctctgc 20131020DNAHuman 1310gccacaggca gcttactcac
20131120DNAHuman 1311aggctgcctg ccctgcccca 20131220DNAHuman
1312ccggcccagt gggtcatcag 20131320DNAHuman 1313ctctcgaggt
ggaaaggcag 20131420DNAHuman 1314gattgcctgg actcgggcat
20131520DNAHuman 1315tccttgcttg gggctctggg 20131620DNAHuman
1316gcagagaagg ctgcggtggc 20131720DNAHuman 1317accgtgacct
ccaaggcgag 20131820DNAHuman 1318caggacgctg tggatctccg
20131920DNAHuman 1319aggaagcagc cgtgtcccta 20132020DNAHuman
1320acgcaggaag ttgtccaggc 20132120DNAHuman 1321gaggtcccca
agaggaaaac 20132220DNAHuman 1322cccccagctt cttcccatcc
20132320DNAHuman 1323attcccacag actcatggtg 20132420DNAHuman
1324tccaaggcga gcggcaggag 20132520DNAHuman 1325gctgggagct
cagatccata 20132620DNAHuman 1326tgggggccca ggcatcccca
20132720DNAHuman 1327gggtgcaaag aactctctgg 20132820DNAHuman
1328gcgggactag agggagctga 20132920DNAHuman 1329actggagaag
aagaagatcc 20133020DNAHuman 1330ccagctcttg acccggcctt
20133120DNAHuman 1331gaactttggg gggttcgagg 20133220DNAHuman
1332gaaaccagtt cactgccagc 20133320DNAHuman 1333acagccgtca
gggcacccca 20133420DNAHuman 1334ccaccccgag ccccttacac
20133520DNAHuman 1335tctcggcagc cagctgctgg 20133620DNAHuman
1336agagagctgg actgggatga 20133720DNAHuman 1337cctttccacc
tcgagagtac 20133820DNAHuman 1338aagctggcct acgagtctga
20133920DNAHuman 1339gtctgtggga gccagtctgt 20134020DNAHuman
1340agacctatgc cccatcaggc 20134120DNAHuman 1341tgggaagaag
ctgggggccc 20134220DNAHuman 1342ctgtggagag aagcctgtcc
20134320DNAHuman 1343gggacttcta attgctgaga 20134420DNAHuman
1344ggactcgggc attggctccc 20134520DNAHuman 1345catctgccac
agagcgctgg 20134620DNAHuman 1346cttctgggag tggaggctcc
20134720DNAHuman 1347gcccccagtg cagagcccag 20134820DNAHuman
1348tttgtccttg cttggggctc 20134920DNAHuman 1349gtggggctgg
cttccaggac 20135020DNAHuman 1350tcaagagctg gccgctgagg
20135120DNAHuman 1351cctctagtcc cgcggggtgg 20135220DNAHuman
1352gctcatctgc cacagagcgc 20135320DNAHuman 1353catgagtctg
tgggaatttg 20135420DNAHuman 1354tgcgaggctc ctgcctgatg
20135520DNAHuman 1355ggagtgagtc cagcgtctgt 20135620DNAHuman
1356tgcaaagaac tctctggagg 20135720DNAHuman 1357cacagcgtcc
tgcagaagct 20135820DNAHuman 1358cagcttactc actggggtgc
20135920DNAHuman 1359actgatgtgg gtgggggcag 20136020DNAHuman
1360gcaggatgtg ctggtctggg 20136120DNAHuman 1361tcacagtgtt
tgtgccatcc 20136220DNAHuman 1362gtttgtgcca tcctggagga
20136320DNAHuman 1363tcctgaagga ctgatgtggg 20136420DNAHuman
1364tgttagcaga gagctggact 20136520DNAHuman 1365cagtgtttgt
gccatcctgg 20136620DNAHuman 1366agtctgtcag ggcctctggg
20136720DNAHuman 1367tctcgaggtg gaaaggcagg 20136820DNAHuman
1368agactggctc ccacagacgc 20136920DNAHuman 1369agccactcac
tttggagcac 20137020DNAHuman 1370tcccaggatt gcctggactc
20137120DNAHuman 1371cctggaactg cagatgaagg 20137220DNAHuman
1372ggggcgcttc ccacagctcc 20137320DNAHuman 1373cagcccctgg
gctctgcact 20137420DNAHuman 1374gcgcgggtgg gtagtcggca
20137520DNAHuman 1375gccccaagca aggacaaaaa 20137620DNAHuman
1376agcctggatg ggaagaagct 20137720DNAHuman 1377cagctcttga
cccggccttg 20137820DNAHuman 1378taggggtgcc accaccccgc
20137920DNAHuman 1379tccactccca gaagaggaaa 20138020DNAHuman
1380ggaagcgctt catcgaggag 20138120DNAHuman 1381gcatcctgct
ggcagtgaac 20138220DNAHuman 1382tggatgaata gcccagcttc
20138320DNAHuman 1383acacgggaca gccaccgagc 20138420DNAHuman
1384gggctcctga aggactgatg 20138520DNAHuman 1385cagcctggat
gggaagaagc 20138620DNAHuman 1386ttttcctctt ctgggagtgg
20138720DNAHuman 1387ctccaggttg ggagccttag 20138820DNAHuman
1388gggagctgag ggcaggggtc 20138920DNAHuman 1389agatgaaggt
ggacttcttc 20139020DNAHuman 1390tttggccggg ccatgggtgc
20139120DNAHuman 1391ctcgcaccta gcgggggcag 20139220DNAHuman
1392cccgtgtaag gggctcgggg 20139320DNAHuman 1393tgccggccca
gtgggtcatc 20139420DNAHuman 1394aaaggcagag aaggctgcgg
20139520DNAHuman 1395aggagcccgt ggggcagggc 20139620DNAHuman
1396taaggggctc ggggtgggcc 20139720DNAHuman 1397acaccatcac
gacgcgtggg 20139820DNAHuman 1398ctggcaggag cccgtggggc
20139920DNAHuman 1399ccggccttgg ggtgccctga 20140020DNAHuman
1400ctgtgttaga ccctcttggc 20140120DNAHuman 1401gtgatgggca
cgtcgggccg 20140220DNAHuman 1402gcccctgggc tctgcactgg
20140320DNAHuman 1403ctgggtgagc tggtgaaaca 20140420DNAHuman
1404ggctgctcct tcctccagga 20140520DNAHuman 1405acagcctcca
ccaggtgcgg 20140620DNAHuman 1406tgcccgagtc caggcaatcc
20140720DNAHuman 1407aggtggaaag gcagggggcg 20140820DNAHuman
1408cgacagattc attgtgaagc 20140920DNAHuman 1409gcggggtggt
ggcaccccta 20141020DNAHuman 1410ggcaatcctg ggagacgtac
20141120DNAHuman 1411gccgctcgcc ttggaggtca 20141220DNAHuman
1412tcactgccag caggatgccc 20141320DNAHuman 1413cctgaaggac
tgatgtgggt 20141420DNAHuman 1414gtgcgaggct cctgcctgat
20141520DNAHuman 1415gcacctggtg gaggctgtga 20141620DNAHuman
1416tcacagcctc caccaggtgc 20141720DNAHuman 1417gccgctctgg
gtggaagaat 20141820DNAHuman 1418gactagaggg agctgagggc
20141920DNAHuman 1419tcagctccct ctagtcccgc 20142020DNAHuman
1420ggagcctcca ctcccagaag 20142120DNAHuman 1421agaccctctt
ggcgggaccc 20142220DNAHuman 1422ccaccttcat ctgcagttcc
20142320DNAHuman 1423gggagtggag gctccaggtt 20142420DNAHuman
1424cagtgaactg gtttctggag 20142520DNAHuman 1425tcacctgtga
tgggcacgtc 20142620DNAHuman 1426tgccagcagg atgccccggc
20142720DNAHuman 1427accctcttgg cgggaccctg 20142820DNAHuman
1428tgggggcagc ttggccgctc 20142920DNAHuman 1429aggaggaggc
cctggtgagc 20143020DNAHuman 1430ctggaggtgg gagccatgca
20143120DNAHuman 1431tctggaggtg ggagccatgc 20143220DNAHuman
1432cctggatggg aagaagctgg 20143320DNAHuman 1433ccagcccctg
ggctctgcac 20143420DNAHuman 1434ggagtggaag cgcttcatcg
20143520DNAHuman 1435tgtagcccgt gtaaggggct 20143620DNAHuman
1436ggagtgagga gggccgggga 20143720DNAHuman 1437gaggtcacgg
tatgtgtcgt 20143820DNAHuman 1438ctagagggag ctgagggcag
20143920DNAHuman 1439tggtgtgttt cccccgcacc 20144020DNAHuman
1440ctgatgtggg tgggggcagt 20144120DNAHuman 1441agggccgggg
agggcaggct 20144220DNAHuman 1442tgagctatga gtggcccctg
20144320DNAHuman 1443tcttacgcag gaagttgtcc 20144420DNAHuman
1444gttccgacat ctggctctcc 20144520DNAHuman 1445agggggcgcg
ggtgggtagt 20144620DNAHuman 1446cgctggcctg ctccttggcc
20144720DNAHuman 1447gaaaggcagg gggcgcgggt 20144820DNAHuman
1448tagcccgtgt aaggggctcg 20144920DNAHuman 1449ctgagggcag
gggtccggtg 20145020DNAHuman 1450acacagctta gtatacacgc
20145120DNAHuman 1451ccgtcagggc accccaaggc 20145220DNAHuman
1452ggcaggggtc cggtgaggtc 20145320DNAHuman 1453ggacttgtag
gagaggatct 20145420DNAHuman 1454tcccagccat gggaacaagg
20145520DNAHuman 1455gacttctaat tgctgagaag 20145620DNAHuman
1456ggctcctgaa ggactgatgt 20145720DNAHuman 1457tggcaggagc
ccgtggggca 20145820DNAHuman 1458agacaggtga gaggaagggc
20145920DNAHuman 1459tcggaacttt ggggggttcg 20146020DNAHuman
1460gcctggatgg gaagaagctg 20146120DNAHuman 1461tgaaggactg
atgtgggtgg 20146220DNAHuman 1462ctgggggccc aggcatcccc
20146320DNAHuman 1463gagcccccag tgcagagccc 20146420DNAHuman
1464ggcgcgggtg ggtagtcggc 20146520DNAHuman 1465ccgtgtaagg
ggctcggggt 20146620DNAHuman 1466gtcgtgatgg tgtgaacacc
20146720DNAHuman 1467acgacgcgtg ggtggcaagc 20146820DNAHuman
1468gggggcagtg gcagcagctt 20146920DNAHuman 1469agcgtgtata
ctaagctgtg 20147020DNAHuman 1470gctcctgcct gatggggcat
20147120DNAHuman 1471gtctgtcagg gcctctggga 20147220DNAHuman
1472gtagcccgtg taaggggctc 20147320DNAHuman 1473agcccctggg
ctctgcactg 20147420DNAHuman 1474gtgaactggt ttctggagcg
20147520DNAHuman 1475ctacgagtct gacgggatcg 20147620DNAHuman
1476agtgaactgg tttctggagc 20147720DNAHuman 1477acgcgtgggt
ggcaagcggg 20147820DNAHuman 1478cgcgggacta gagggagctg
20147920DNAHuman 1479ggcaggagtg aggagggccg 20148020DNAHuman
1480aagtgagtgg cttcttacgc 20148120DNAHuman 1481ctgaaggact
gatgtgggtg 20148220DNAHuman 1482ttgccaccca cgcgtcgtga
20148320DNAHuman 1483agggcaggag tgaggagggc 20148420DNAHuman
1484tcttcttctc cagttcccgc 20148520DNAHuman 1485aggagtgagg
agggccgggg 20148620DNAHuman 1486actcccagaa gaggaaaagg
20148720DNAHuman 1487tgaggagggc cggggagggc 20148820DNAHuman
1488acctggtgga ggctgtgatg 20148920DNAHuman 1489cagggccgag
gcctcctcag 20149020DNAHuman 1490tactctcgag gtggaaaggc
20149120DNAHuman 1491ttggggctct ggggggtgag 20149220DNAHuman
1492gctcctggac ccccagcagc 20149320DNAHuman 1493ggggggtgag
aggagagcat 20149420DNAHuman 1494cggcccagtg ggtcatcagg
20149520DNAHuman 1495aggaagggca ggagtgagga 20149620DNAHuman
1496gagggccggg gagggcaggc 20149720DNAHuman 1497tgctgggggt
ccaggagctg 20149820DNAHuman 1498gctgggggtc caggagctgt
20149920DNAHuman 1499tgagaggaag ggcaggagtg 20150020DNAHuman
1500tgggagtgga ggctccaggt 20150120DNAHuman 1501gaggaagggc
aggagtgagg 20150220DNAMurine 1502gctggctgtg aactggtttc
20150320DNAMurine 1503ctagttcccg aaggatgtgc 20150420DNAMurine
1504attggagacc accactccgt 20150520DNAMurine 1505ttccctcctc
tgccagccat 20150620DNAMurine 1506cgaaggaagt tgtccaggct
20150720DNAMurine 1507atacctgtga taggcacatc 20150820DNAMurine
1508gacttccttg ttcccatggc 20150920DNAMurine 1509ggccttcgaa
tccgacggag 20151020DNAMurine 1510atcaccagag gtaactgcca
20151120DNAMurine 1511ggctttgaag atggtgaaga 20151220DNAMurine
1512atgggctaag acatcaccag 20151320DNAMurine 1513ctatgatcta
ctgcaacgac 20151420DNAMurine 1514ttctcatgct gaaaacttgc
20151520DNAMurine 1515ttgccggcac gccaacatcg 20151620DNAMurine
1516gagaatctcc ttctgaaggg 20151720DNAMurine 1517ggctcgcgac
aaggtgtcta 20151820DNAMurine 1518ctgtggagct ggttctctcc
20151920DNAMurine 1519tctaaccttg gtagatgtcc 20152020DNAMurine
1520cgactgggtg gtggaactta 20152120DNAMurine 1521cttcttctct
gaatgcaggt 20152220DNAMurine 1522gccaacatcg tggcttacca
20152320DNAMurine 1523cgacaaggtg tctaaggacc 20152420DNAMurine
1524atcaccagag gtaactgcca 20152520DNAMurine 1525atgggctaag
acatcaccag 20152620DNAHuman 1526atggggaagt ctttaaggtg
20152720DNAHuman 1527gggtgcacat caaagagcgg 20152820DNAHuman
1528tacacccacg tagtccggct 20152920DNAHuman 1529cctttgcaag
gctcgagaca 20153020DNAHuman 1530gttgcttcct gaagggtgac
20153120DNAHuman 1531ctgggcgcca ctcaccagta 20153220DNAHuman
1532agggtgacag gtatgagcct 20153320DNAHuman 1533tatgacctgc
tacagcggct 20153420DNAHuman 1534gatctgcatg gaattctgtg
20153520DNAHuman 1535gctgggatac cagttgatgc 20153620DNAHuman
1536ctttcctagc cggactacgt 20153720DNAHuman 1537agagggtgca
catcaaagag 20153820DNAHuman 1538cccatggtag gccacgatgt
20153920DNAMurine 1539tggacggctg ctgttgctgg 20154020DNAMurine
1540ccttgcagcc ctcgcaggtg 20154120DNAMurine 1541aaatgcaaaa
tatgtttgcc 20154220DNAMurine 1542gaagtgtctc agtgtcggga
20154320DNAMurine 1543atggaagagg gtcgcgagca 20154420DNAMurine
1544ggcagcgttg tcgccgcaca 20154520DNAMurine 1545ttccgagcca
taagtctgcg 20154620DNAMurine 1546gaaggcacat gtgccgtgtg
20154720DNAMurine 1547tgcgtggcgt
aagtggaccc 20154820DNAMurine 1548tggacggctg ctgttgctgg
20154920DNAMurine 1549ccttgcagcc ctcgcaggtg 20155020DNAMurine
1550catggtcagc ttggtgtagt 20155120DNAMurine 1551gctatactgg
gcttgcacgc 20155220DNAMurine 1552ccccgtgcta ccgaggtcca
20155320DNAMurine 1553ttcagaagtg tctcagtgtc 20155420DNAMurine
1554ttcggcgtct cttgtccact 20155520DNAHuman 1555tcaatcagat
ttggaaatgt 20155620DNAHuman 1556ctacggcgtg cgaacctgcg
20155720DNAHuman 1557atacagctcg gaatacacca 20155820DNAHuman
1558ctgattgagt catgcatgta 20155920DNAHuman 1559tggtgatggt
gatggtagct 20156020DNAHuman 1560gaaatcgaca gtactgacat
20156120DNAHuman 1561cctgcgtgta ccaaatgcag 20156220DNAHuman
1562gggcacgtgt gccgtgtgcg 20156320DNAHuman 1563ataacgcccc
cgcctgcggg 20156420DNAHuman 1564ggactgcttg aagtacatgg
20156520DNAHuman 1565ccacctcggc tacgacccga 20156620DNAHuman
1566aaatgcaaaa tatgtttgcc 20156725RNAArtificial SequenceZc3h12a
siRNA 1567ccuggacaac uuccuucgua agaaa 25156819RNAArtificial
SequenceZc3h12a siRNA 1568gugucccuau ggaaggaaa
19156919RNAArtificial SequenceZc3h12a siRNA 1569caacuuccuu
cguaagaaa 19157021DNAArtificial SequenceZc3h12a shRNA
1570agcgaggcca cacagatatt a 21157121DNAArtificial SequenceZc3h12a
shRNA 1571gctatgatga ccgcttcatt g 21157221DNAArtificial
SequenceZc3h12a shRNA 1572tggtctgagc cgtacccatt a
21157321DNAArtificial SequenceZc3h12a shRNA 1573ctgtgtacag
aggcgagatt t 21157420DNAHomo sapiens 1574agatgatgtc aaccaaggag
20157520DNAMus musculus 1575ggaagaagta catctgcaag 20
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012
D00013

D00014

D00015

D00016

D00017

D00018
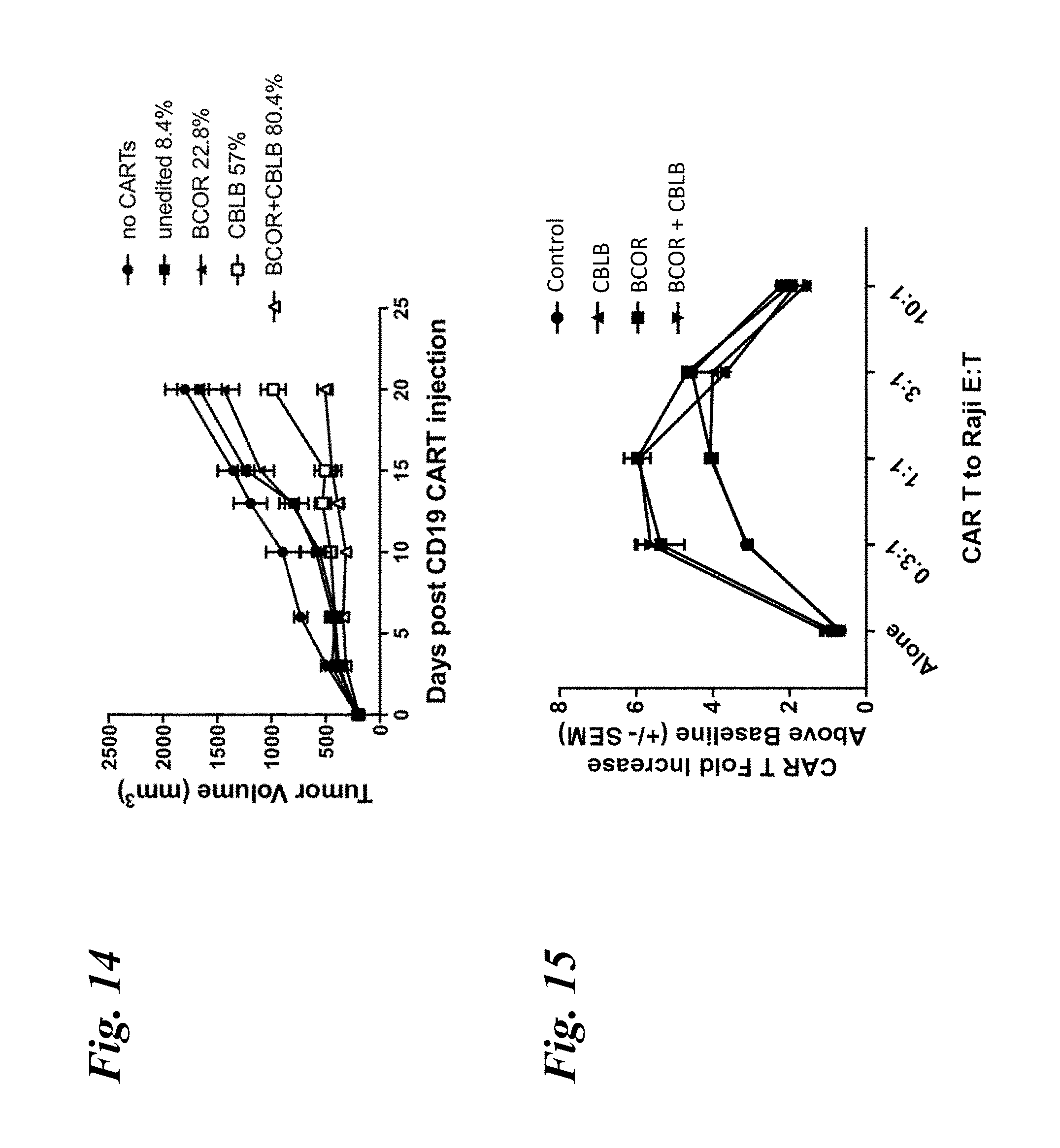
D00019
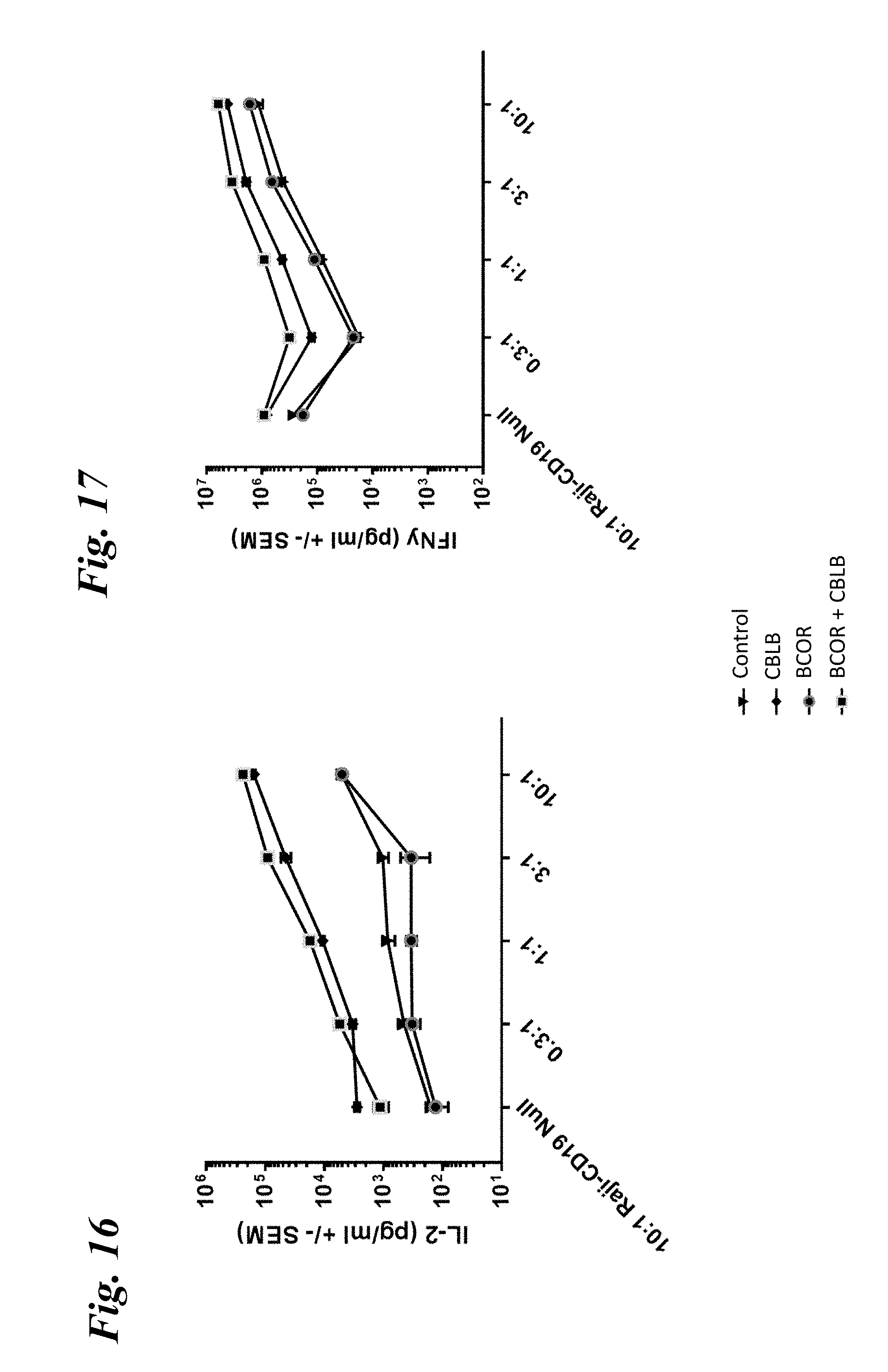
D00020

D00021
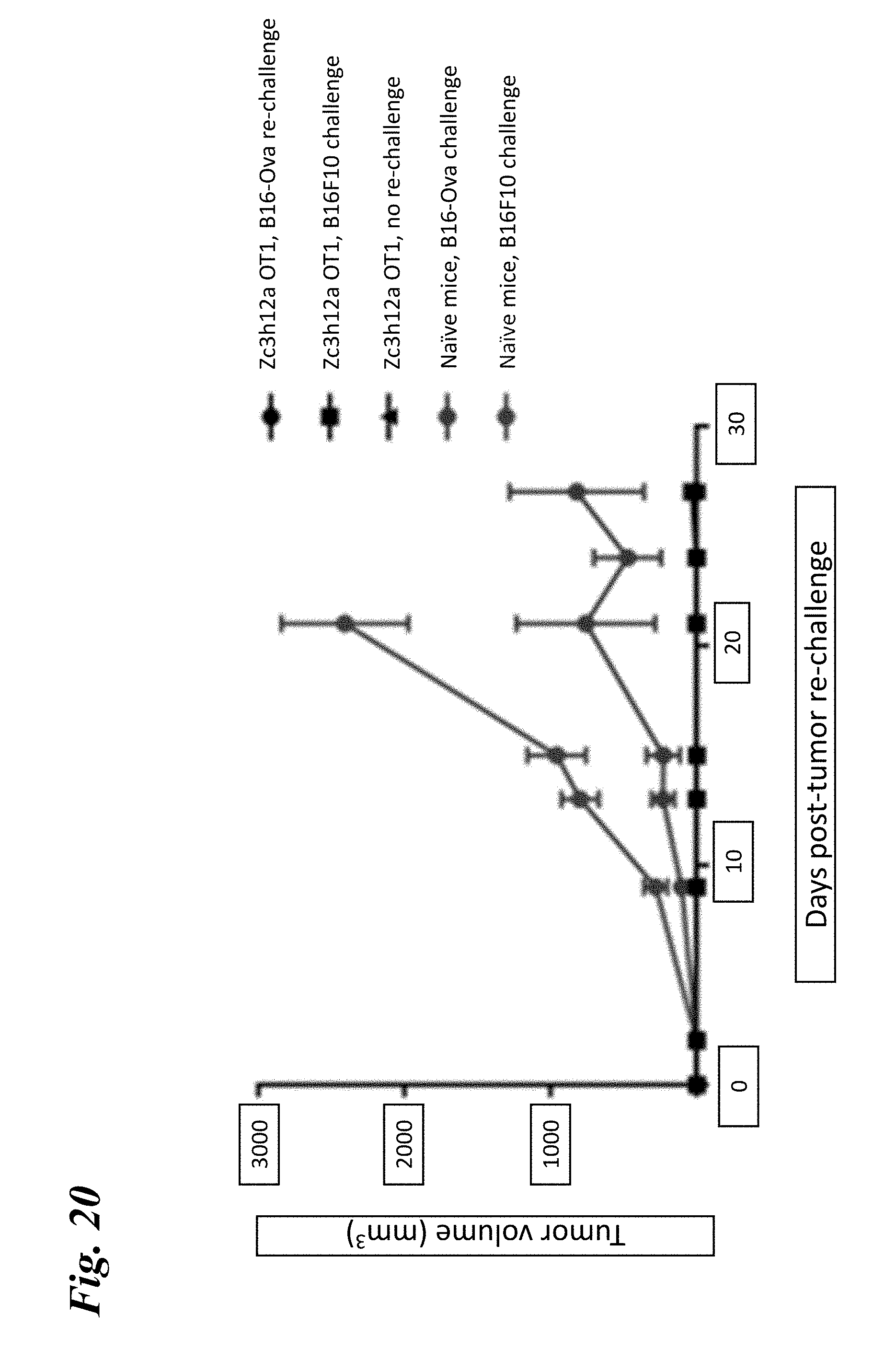
D00022
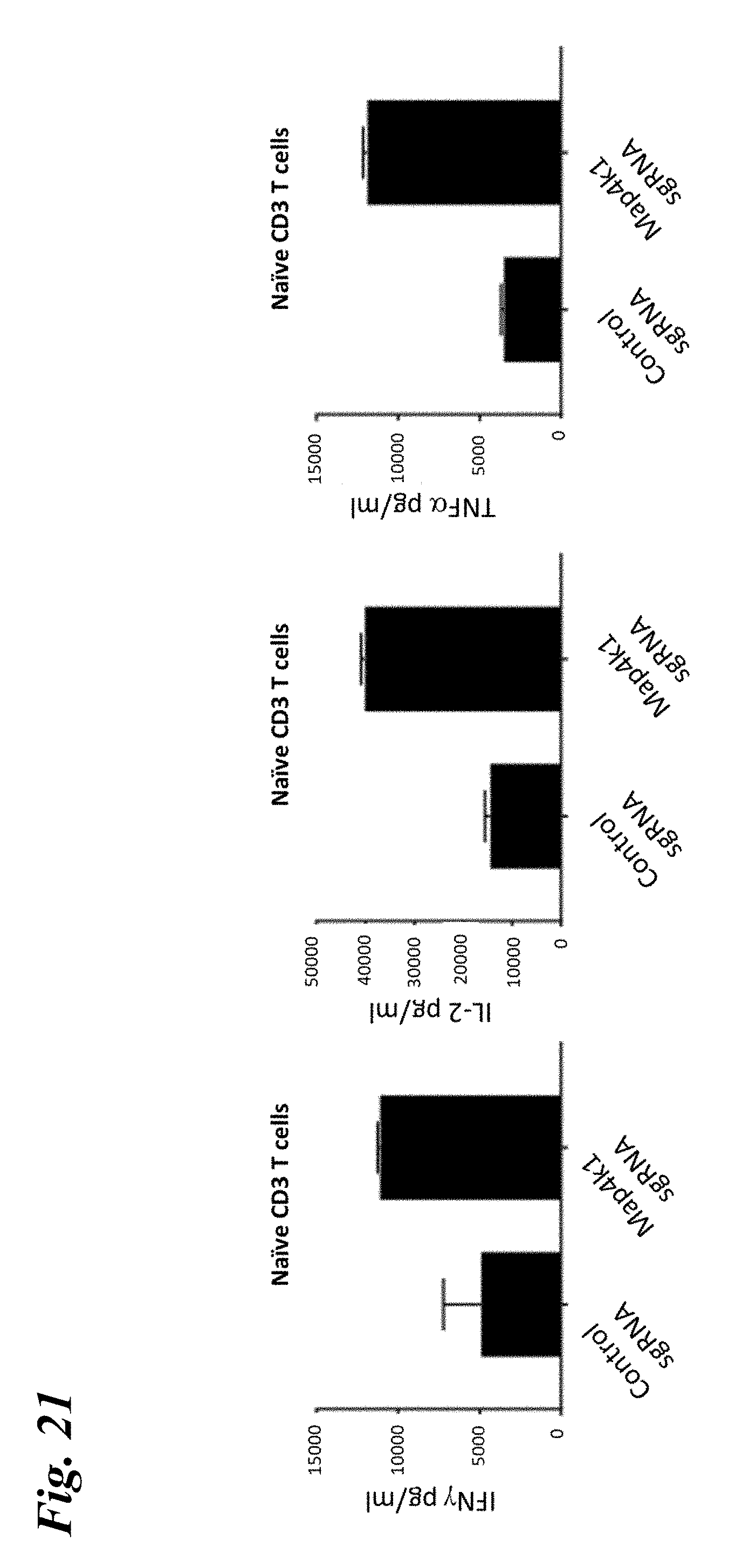
D00023
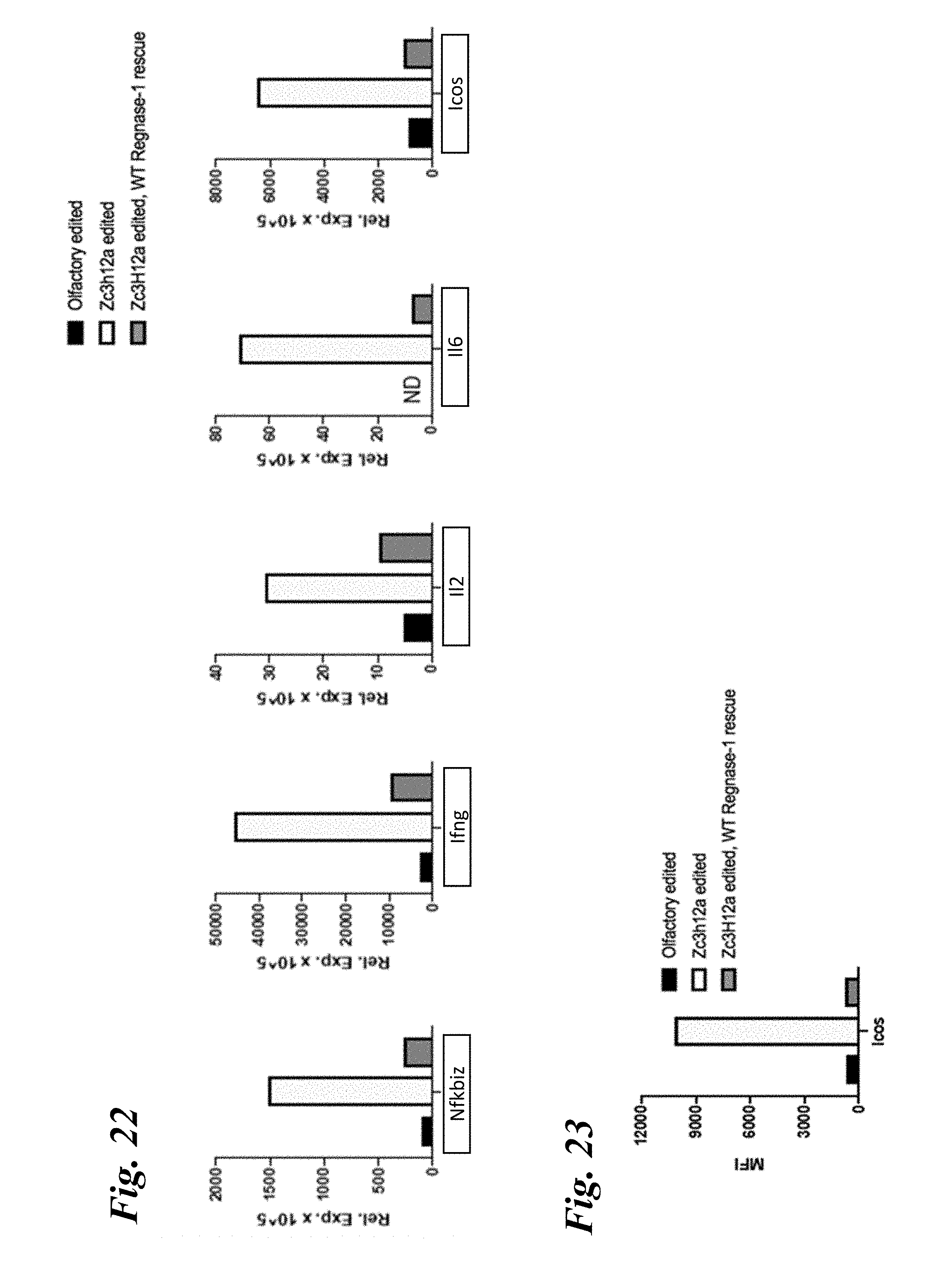
D00024
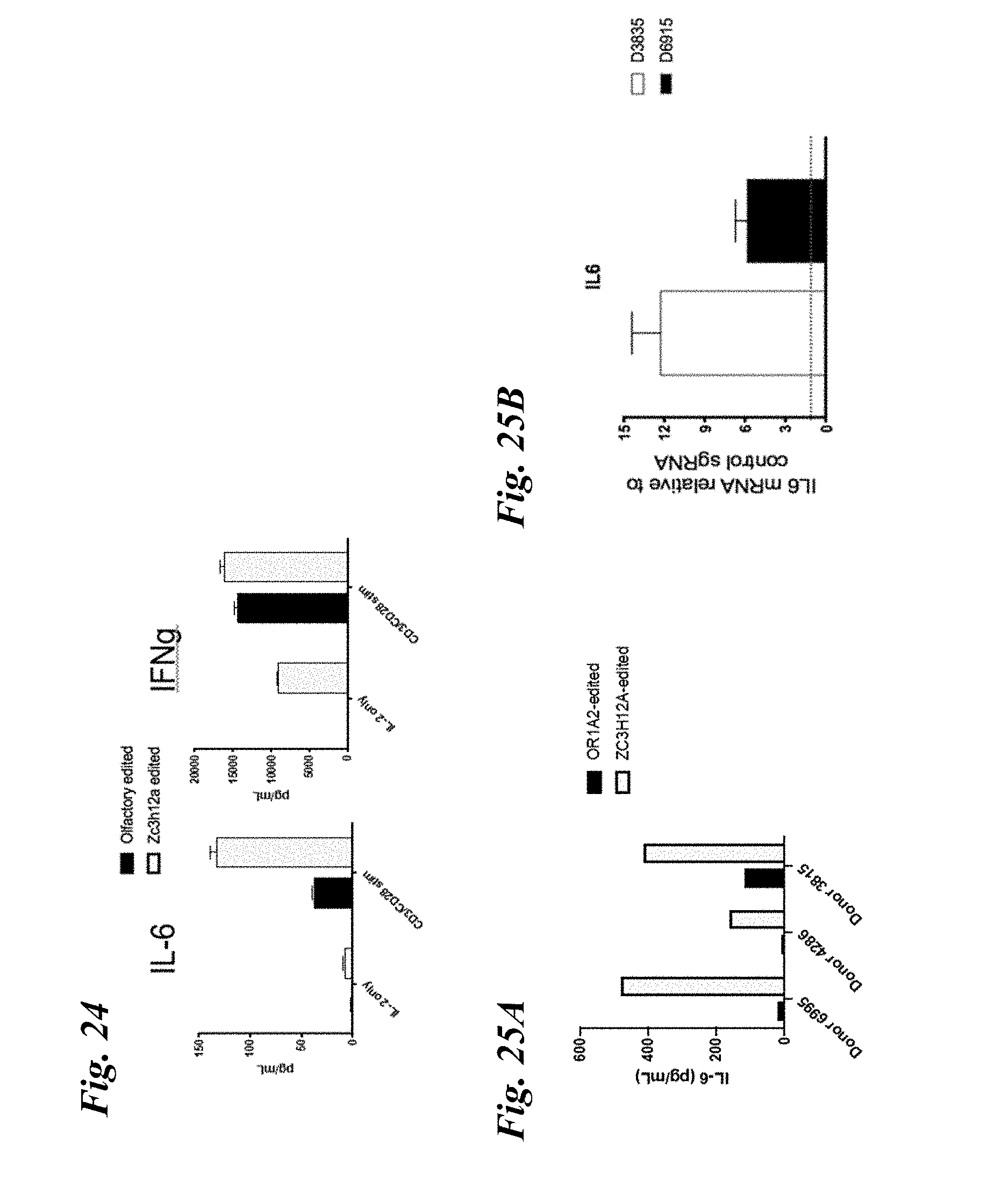
S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.