Highly-scalable Image Reconstruction Using Deep Convolutional Neural Networks With Bandpass Filtering
Cheng; Joseph Y. ; et al.
U.S. patent application number 15/900330 was filed with the patent office on 2019-08-22 for highly-scalable image reconstruction using deep convolutional neural networks with bandpass filtering. The applicant listed for this patent is The Board of Trustees of the Leland Stanford Junior University. Invention is credited to Joseph Y. Cheng, John M. Pauly, Shreyas S. Vasanawala.
| Application Number | 20190257905 15/900330 |
| Document ID | / |
| Family ID | 67616780 |
| Filed Date | 2019-08-22 |



| United States Patent Application | 20190257905 |
| Kind Code | A1 |
| Cheng; Joseph Y. ; et al. | August 22, 2019 |
HIGHLY-SCALABLE IMAGE RECONSTRUCTION USING DEEP CONVOLUTIONAL NEURAL NETWORKS WITH BANDPASS FILTERING
Abstract
A method for magnetic resonance imaging (MRI) scans a field of view and acquires sub-sampled multi-channel k-space data U. An imaging model A is estimated. Sub-sampled multi-channel k-space data U is divided into sub-sampled k-space patches, each of which is processed using a deep convolutional neural network (ConvNet) to produce corresponding fully-sampled k-space patches, which are assembled to form fully-sampled k-space data V, which is transformed to image space using the imaging model adjoint A.sub.adj to produce an image domain MRI image. The processing of each k-space patch u.sub.i preferably includes applying the k-space patch u.sub.i as input to the ConvNet to infer an image space bandpass-filtered image y.sub.i, where the ConvNet comprises repeated de-noising blocks and data-consistency blocks; and estimating the fully-sampled k-space patch v.sub.i from the image space bandpass-filtered image y.sub.i using the imaging model A and a mask matrix.
| Inventors: | Cheng; Joseph Y.; (Los Altos, CA) ; Vasanawala; Shreyas S.; (Stanford, CA) ; Pauly; John M.; (Stanford, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 67616780 | ||||||||||
| Appl. No.: | 15/900330 | ||||||||||
| Filed: | February 20, 2018 |
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G01R 33/5611 20130101; G01R 33/4824 20130101; G06T 2207/10088 20130101; G01R 33/5608 20130101; G01R 33/56509 20130101; G01R 33/56545 20130101 |
| International Class: | G01R 33/56 20060101 G01R033/56; G01R 33/48 20060101 G01R033/48; G01R 33/561 20060101 G01R033/561; G01R 33/565 20060101 G01R033/565 |
Goverment Interests
STATEMENT REGARDING FEDERALLY SPONSORED RESEARCH OR DEVELOPMENT
[0001] This invention was made with Government support under contracts R01 EB019241 and R01-EB009690 awarded by the National Institutes of Health. The Government has certain rights in the invention.
Claims
1. A method for magnetic resonance imaging (MRI) comprising: (a) scanning a field of view using an MRI apparatus; (b) acquiring sub-sampled multi-channel k-space data U representative of MRI signals in the field of view; (c) estimating an imaging model A and corresponding model adjoint A.sub.adj by estimating a sensitivity profile map; (d) dividing sub-sampled multi-channel k-space data U into sub-sampled k-space patches; (e) processing the sub-sampled k-space patches using a deep convolutional neural network (ConvNet) to produce corresponding fully-sampled k-space patches; (f) assembling the fully-sampled k-space patches together with each other and with the sub-sampled multi-channel k-space data U to form a fully-sampled k-space data V, (g) transforming the fully-sampled k-space data V to image space using the model adjoint A.sub.adj operation to produce an image domain MRI image.
2. The method of claim 1 wherein processing the sub-sampled k-space patches using a deep convolutional neural network (ConvNet) to produce corresponding fully-sampled k-space patches comprises: processing each k-space patch u.sub.i of the sub-sampled k-space patches separately and independently from other patches to produce a corresponding fully-sampled k-space patch v.sub.i, thereby allowing for parallel processing.
3. The method of claim 2 wherein processing each k-space patch u.sub.i to produce a corresponding fully-sampled k-space patch v.sub.i comprises: applying the k-space patch u.sub.i as input to the ConvNet to infer an image space bandpass-filtered image y.sub.i, wherein the ConvNet comprises repeated de-noising blocks and data-consistency blocks; estimating the fully-sampled k-space patch v.sub.i from the image space bandpass-filtered image y.sub.i using the imaging model A and a mask matrix.
4. The method of claim 3 wherein each of the de-noising blocks comprises transforming k-space patch data to image space bandpass-filtered image data and passing the image space bandpass-filtered image data through multiple convolution layers to produce de-noised image space bandpass-filtered image data; wherein each of the data-consistency blocks comprises passing the de-noised image space bandpass-filtered image data through the imaging model A to produce known k-space patch data; wherein applying the k-space patch u.sub.i as input to a ConvNet to infer an image space bandpass-filtered image y.sub.i further comprises applying masks and a window function to k-space patch data, and passing k-space patch data through the adjoint model to produce image space bandpass-filtered image data.
5. The method of claim 4 wherein the multiple convolution layers are two-dimensional convolution layers, or three-dimensional convolution layers.
6. The method of claim 1 wherein the sub-sampled multi-channel k-space data U, sub-sampled k-space patches, fully-sampled k-space patches, fully-sampled k-space data V, and image domain MRI image are all two-dimensional data or are all three-dimensional data.
7. The method of claim 1 wherein estimating an imaging model A comprises including motion information and off-resonance de-phasing in the imaging model.
8. The method of claim 1 wherein estimating an imaging model A comprises including non-Cartesian sampling trajectories in the imaging model.
Description
FIELD OF THE INVENTION
[0002] The present invention relates generally to techniques for magnetic resonance imaging. More specifically, it relates to improved methods for magnetic resonance image reconstruction and artifact reduction.
BACKGROUND OF THE INVENTION
[0003] The ability to reconstruct magnetic resonance (MR) images from vastly undersampled acquisitions has significant clinical value. It allows the duration of the MR scan to be reduced and enables the visualization of rapid hemodynamics.
[0004] Using advanced image reconstruction algorithms, images can be reconstructed with negligible loss in image quality despite high undersampling factors (R>6). To achieve this performance, algorithms exploit the data acquisition model with the localized sensitivity profiles of high-density receiver coil arrays for parallel imaging. Additionally, image sparsity can be exploited to constrain the reconstruction problem for compressed sensing. With the use of nonlinear sparsity priors, these types of reconstruction problems are solved using an iterative algorithm. These traditional iterative algorithms, however, have considerable computational complexity for undersampled data.
[0005] To improve the image reconstruction in terms of speed and robustness, deep convolutional neural networks (ConvNets) have been proposed. There are various challenges in applying ConvNets to MRI reconstruction, however.
[0006] ConvNets are conventionally trained and applied in the image domain. With the fundamental elements of the network as simple convolutions, convolutional neural networks are simple to train and fast to apply. In contrast, MRI data acquisition differs from conventional imaging applications because the data acquisition is performed in the frequency domain, or k-space domain. Consequently, many of the known techniques for image processing with ConvNets do not directly translate to MRI image reconstruction.
[0007] Existing ConvNets do not explicitly enforce that the reconstruction solution will not deviate from the measured data. Without a data consistency step, the ConvNets may "hallucinate" new structures in the image or remove existing ones, leading to erroneous diagnosis.
[0008] On the other hand, if an attempt is made to use a data consistency step, the training and application can not be image-patch based, because if only small image patches are used, known information in the measurement domain (k-space domain) is lost. As a result, the ConvNets must be applied and trained on fixed image sizes and resolutions. Thus, to train a ConvNet to accurately reconstruct a high-resolution MR image, the specific ConvNet must be trained on MR images with equivalent or higher spatial resolutions. This limitation increases the memory footprint of the ConvNet and decreases the speed of training and inference.
[0009] In addition, existing ConvNet techniques are not easily extendable to high-dimensional MR images and multi-dimensional MR images, because the training and inference of the ConvNet can never be fully parallelized: specific steps within the ConvNet (such as transforming from k-space domain to image domain) requires the gathering of all data before proceeding to the next step of the network.
BRIEF SUMMARY OF THE INVENTION
[0010] In contrast to prior techniques, which divide imaging data into image-domain patches for training and inference, the present invention divides the imaging data into frequency-domain patches. At the same time, the techniques of the present invention leverage the use of the imaging model to ensure that the reconstructed images do not deviate from the undersampled measurement data. The invention also can naturally account for images with differing resolutions and sizes by reconstructing different frequency bands independently. The technique is able to train and apply a model for images of varying resolutions which increases the flexibility of the network and minimize the need to re-train the network for each specific case.
[0011] The techniques of the present invention train and apply ConvNets on patches of k-space domain data. In other words, a bandpass filter is used to select and isolate the reconstruction to small localized patches in the k-space domain. With contiguous patches of k-space, the ability to exploit the data acquisition model is maintained which enables a ConvNet architecture to enforce consistency with the measured data. Also, by selecting small patches of k-space domain, the input data sizes into the ConvNets are reduced which decreases the memory footprint and increases the computational speed. This smaller memory requirement enables the processing of extremely large datasets in terms of size of each dimension and/or the number of dimensions. Thus, the possible resolutions are not limited by the computation hardware or the acceptable computation duration for high-speed applications. Each k-space patch can be reconstructed independently which enables simple parallelization of the algorithm that further reduces the reconstruction times. All these features allow for this type of ConvNet to be applied and trained on high-dimensional (.gtoreq.256) and multi-dimensional (two, three, and higher dimensional) images.
[0012] In one aspect, the invention provides a method for magnetic resonance imaging (MRI) comprising: scanning a field of view using an MRI apparatus; acquiring sub-sampled multi-channel k-space data U representative of MRI signals in the field of view; estimating an imaging model A and corresponding model adjoint A.sub.adj by estimating a sensitivity profile map; dividing sub-sampled multi-channel k-space data U into sub-sampled k-space patches; processing the sub-sampled k-space patches using a deep convolutional neural network (ConvNet) to produce corresponding fully-sampled k-space patches; assembling the fully-sampled k-space patches together with each other and with the sub-sampled multi-channel k-space data U to form a fully-sampled k-space data V, and transforming the fully-sampled k-space data V to image space using the model adjoint A.sub.adj operation to produce an image domain MRI image.
[0013] The processing of the sub-sampled k-space patches to produce corresponding fully-sampled k-space patches preferably involves processing each k-space patch u.sub.i of the sub-sampled k-space patches separately and independently from other patches to produce a corresponding fully-sampled k-space patch v.sub.i, thereby allowing for parallel processing.
[0014] The processing of each k-space patch u.sub.i preferably includes applying the k-space patch u.sub.i as input to the ConvNet to infer a corresponding image space bandpass-filtered image y.sub.i, wherein the ConvNet comprises repeated de-noising blocks and data-consistency blocks; and estimating the fully-sampled k-space patch v.sub.i from the image space bandpass-filtered image y.sub.i using the imaging model A and a mask matrix.
[0015] Each of the de-noising blocks preferably includes transforming k-space patch data to image space bandpass-filtered image data, and passing the image space bandpass-filtered image data through multiple 2D or 3D convolution layers to produce de-noised image space bandpass-filtered image data.
[0016] Each of the data-consistency blocks preferably includes passing the de-noised image space bandpass-filtered image data through the imaging model A to produce known k-space patch data. Applying the k-space patch u, as input to a ConvNet to infer an image space bandpass-filtered image y.sub.i preferably includes applying masks and a window function to k-space patch data, and passing k-space patch data through the adjoint model to produce image space bandpass-filtered image data.
[0017] Preferably, the sub-sampled multi-channel k-space data U, sub-sampled k-space patches, fully-sampled k-space patches, fully-sampled k-space data V, and image domain MRI image are two-dimensional data. Alternatively, they may be three-dimensional data.
[0018] In the imaging model A estimation, non-Cartesian sampling trajectories, motion information, and/or off-resonance de-phasing may be included in the imaging model.
[0019] The techniques of the present invention perform rapid and robust image reconstruction for magnetic resonance imaging scans that are prospectively subsampled. Subsampling reduces the acquisition time for each scan, reducing the total MRI exam duration. The techniques of the invention are especially useful for situations where the reconstruction is memory limited, as in the case of multi-dimensional imaging (three or more dimensions) that may include volumetric spatial dimensions, cardiac motion, respiratory motion, contrast-enhancement, velocity, diffusion, and echo dimensions. This invention can be applied for the scaling and enlargement of images for display in high-resolution displays and for prints. This invention enables the flexibility to use a single trained network for the enlargement of images to different sizes and spatiotemporal resolutions. Further, these techniques can be applied to other imaging applications where the measurement is performed in the image frequency domain.
BRIEF DESCRIPTION OF THE SEVERAL VIEWS OF THE DRAWINGS
[0020] FIG. 1 is a schematic diagram illustrating an overview of a method for processing sub-sampled MRI data, according to an embodiment of the invention.
[0021] FIG. 2 is a schematic diagram illustrating an MRI imaging model, according to an embodiment of the invention.
[0022] FIG. 3 shows a grid of MRI imaging data in various steps of processing, for with different subsampling factors (R), according to an embodiment of the invention.
[0023] FIG. 4 shows a grid of MRI imaging data for different subsampling factors (R), contrasting output images of conventional compressed sensing reconstructions with output images according to an embodiment of the invention.
[0024] FIG. 5 is a flowchart illustrating the steps of a method for MRI imaging, according to an embodiment of the invention.
DETAILED DESCRIPTION OF THE INVENTION
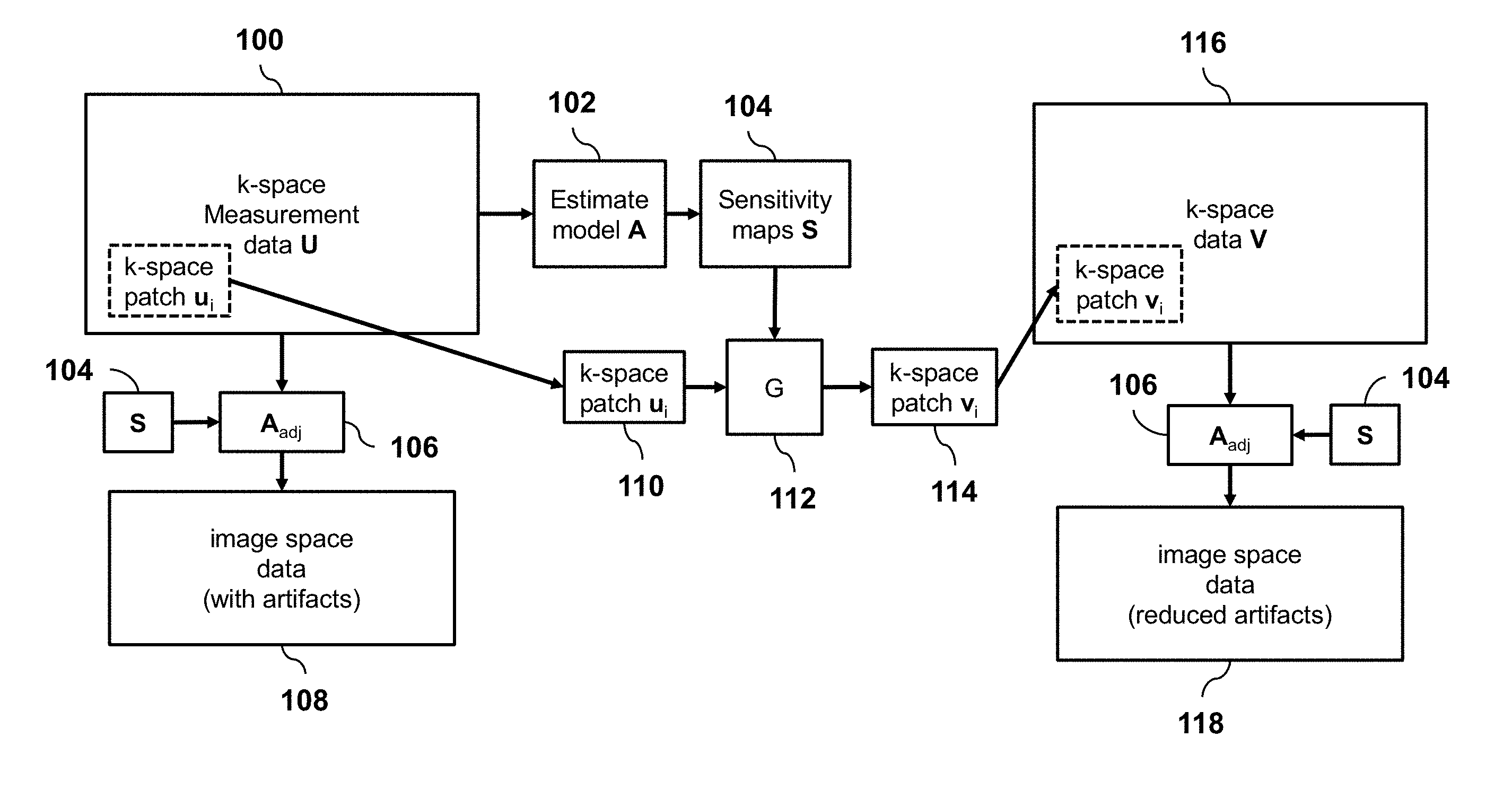
[0025] According to an embodiment of the invention, training and inference will all be performed on localized patches of k-space. FIG. 1 provides an overview of the method of processing subsampled multi-channel measurement data 100 in the k-space domain. The imaging model A is first estimated 102 by extracting the sensitivity maps 104 of the imaging sensors specific for the input data. This model can be directly applied with the model adjoint A.sub.adj operation 106 to yield a simple image reconstruction 108 with image artifacts from data subsampling. For the reconstruction, a k-space patch 110 of the input data is inserted into a convolution neural network G 112 which also uses the imaging model in the form of sensitivity maps. The output of G is a fully sampled k-space patch 114 for that k-space region. This patch is then inserted into the final k-space output 116. Two example patches are shown in blue and green with the corresponding images overlaid. By applying this network for all k-space patches, the full k-space data 116 is reconstructed. The final artifact-free image 118 is obtained by application of the model adjoint A.sub.adj operation 106 to the final k-space output 116.
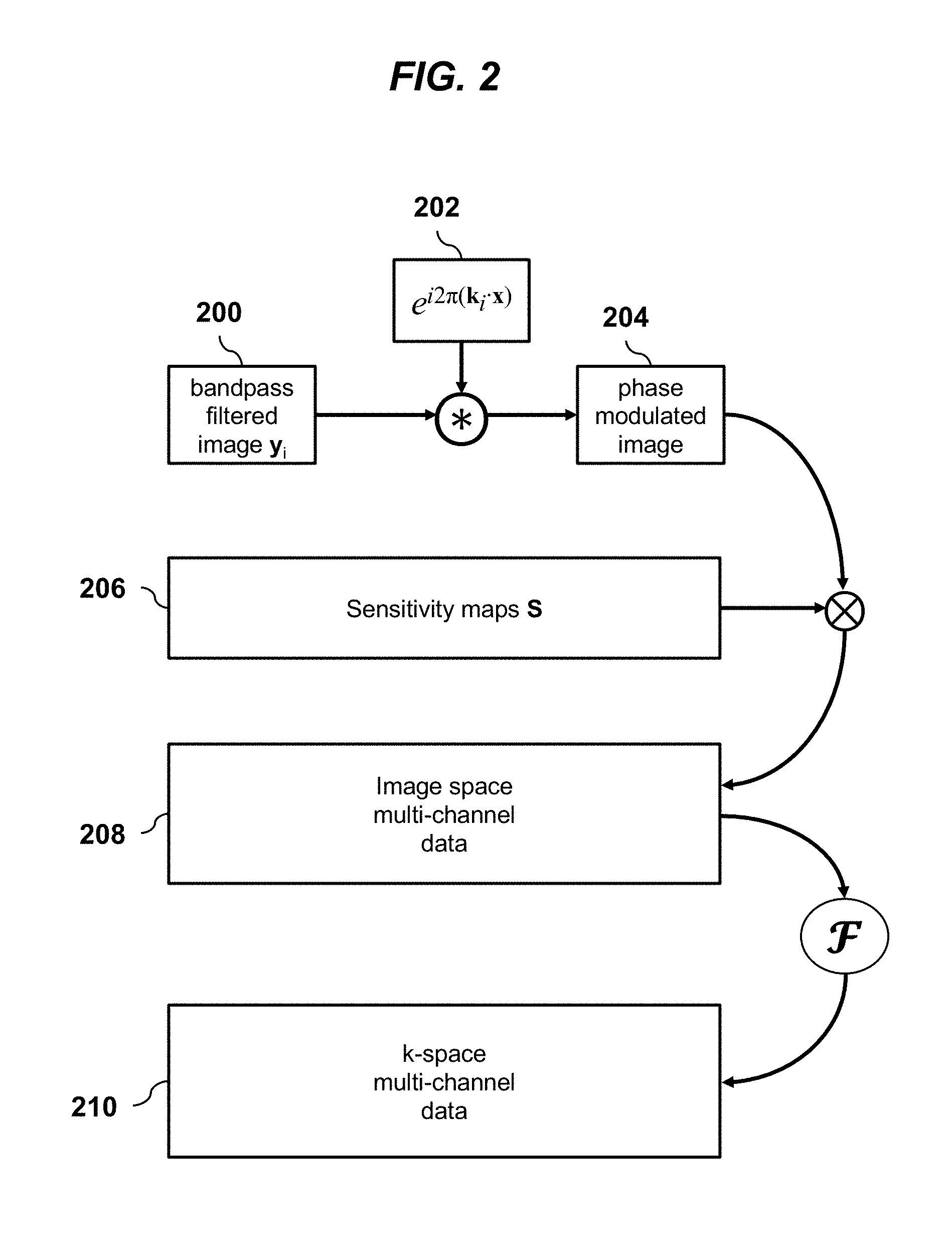
[0026] The reconstruction relies upon the estimation and application of imaging acquisition model A. FIG. 2 provides an overview of the imaging model A. Bandpass-filtered image-space data y.sub.i 200 is passed through the imaging model for MRI where a windowing function centered at k.sub.i was applied in frequency space. First, a phase modulation e.sup.i2.pi.k.sup.i.sup.x 202 is applied to the bandpass-filtered image-space data y.sub.i 200 through a point-wise multiplication (*). The resulting image 204 is then multiplied by the sensitivity maps 206 to yield multi-channel data 208. In this example, six channels are shown, and these channels were derived after a singular-value-decomposition-based compression. A Fourier transform operator I is then applied to transform the image-space data into the frequency domain (or k-space) data 210.
[0027] For each localized k-space patch, the goal of reconstruction is to solve the following inverse problem:
u.sub.i=M.sub.iA(e.sup.i2.pi.k.sup.i.sup.x*y.sub.i) (1)
where u.sub.i is a selected k-space patch with its center pixel at k-space location k.sub.i, M.sub.i is a mask matrix, and y.sub.i is image-space data that is bandpass-filtered at frequency k.sub.i corresponding to the k-space patch u.sub.i. The imaging model A transforms the desired image-space data y.sub.i to the k-space (measurement) domain using sensitivity profile maps S and a Fourier transform I. Sensitivity maps S are independent of the k-space patch location and can be estimated using conventional algorithms, such as ESPIRiT. Since S is set to have the same image dimensions as the k-space patch, S is faster to compute and have a smaller memory requirement in this bandpass formulation.
[0028] After the imaging model A transforms the data to the k-space domain, matrix M.sub.i is applied to mask out the missing points (due to subsampling) from the k-space patch u.sub.i. When selecting the k-space patch u.sub.i with its center pixel at k-space location k.sub.i, a phase is induced. To remove the impact of this phase when solving the inverse problem, the phase is modeled separately as e.sup.i2.pi.kx where x is the corresponding spatial location of each pixel in y.sub.i. This phase is applied through an element-wise multiplication, denoted as *.
[0029] The inverse problem of Eq. 1 can be solved to estimate the image space bandpass-filtered image data y.sub.i using any standard algorithm for inverse problems with a least squares formulation with a regularization function R (y.sub.i) and regularization parameter .lamda. to help constrain the problem:
y ^ i = arg min y i W [ M i A ( e i 2 .pi. k i x * y i ) - u i ] 2 2 + .lamda. R ( y i ) . ( 2 ) ##EQU00001##
In Eq. 2, we introduce a windowing function W to avoid Gibbs ringing artifacts. The model A includes sensitivity maps S that can be considered as a element-wise multiplication in the image domain or a convolution in the k-space domain. This window function also accounts for the wrapping effect of the k-space convolution when applying S in the image domain. Alternatively, the imaging acquisition model A can be applied in the k-space domain as convolutions. These k-space approaches include GRAPPA and SPIRiT. However, these approaches reconstruct y.sub.i as a multi-channel image and increases the number of channels for the regularization function R(.). In the corresponding deep neural network formulation of these approaches, the increase in number of channels will also increase the number of channels as the initial input to the neural network.
[0030] Though Eqs. 1 and 2 are set up to solve for y.sub.i which is a bandpass-filtered version of the final image, the final goal is to estimate the missing data points v.sub.i that were not originally measured. After estimating for y.sub.i, the missing points can be estimated using the modified forward imaging model as
v.sub.i=M.sub.i.sup.cA(e.sup.i2.pi.kx*y.sub.i) (3)
where M.sub.i.sup.c masks out the measured points and leaves the points that were not originally measured.
[0031] Incorporating a strong prior in the form of a regularization function has been demonstrated to enable high image quality despite high subsampling factors. In compressed sensing, the sparsity of the image in a sparsifying transform domain, such as spatial Wavelets or finite differences, can be exploited to enable undersampling factors of over 8 times Nyquist rates. Even though the problem formulation is similar to applying Wavelet transforms, directly enforcing sparsity in that domain may not be the optimal solution and the regularization parameter for each k-space location must be tuned.
[0032] To avoid the problems above with existing approaches, instead of solving Eq. 1 using a standard algorithm, the techniques of the present invention apply developments in deep convolutional neural networks (ConvNets). A key insight is that the ConvNets can be trained to rapidly solve the many small inverse problems in a feed-forward fashion. Based on the input k-space patch, the ConvNet is sufficiently flexible to adapt to solve the corresponding inverse problem, as outlined above with reference to FIG. 1. The ConvNet can be considered to learn a better de-noising operation for each specific bandpass-filtered image for a stronger image prior. After the different frequency bands are reconstructed, the different k-space patches 114 are gathered to form the final image 116. The technique allows for flexibility in choosing the patch sizes and the amount of overlap between each patch.
[0033] In our experiments, we used 64.times.64 overlapping k-space patches. To avoid artifacts from the windowing function and from edge effects, the center 44.times.44 of the output is inserted into the final k-space image 116. In the areas of overlap, outputs are averaged for the final solution.
[0034] The reconstruction pipeline is summarized in Algorithm 1.
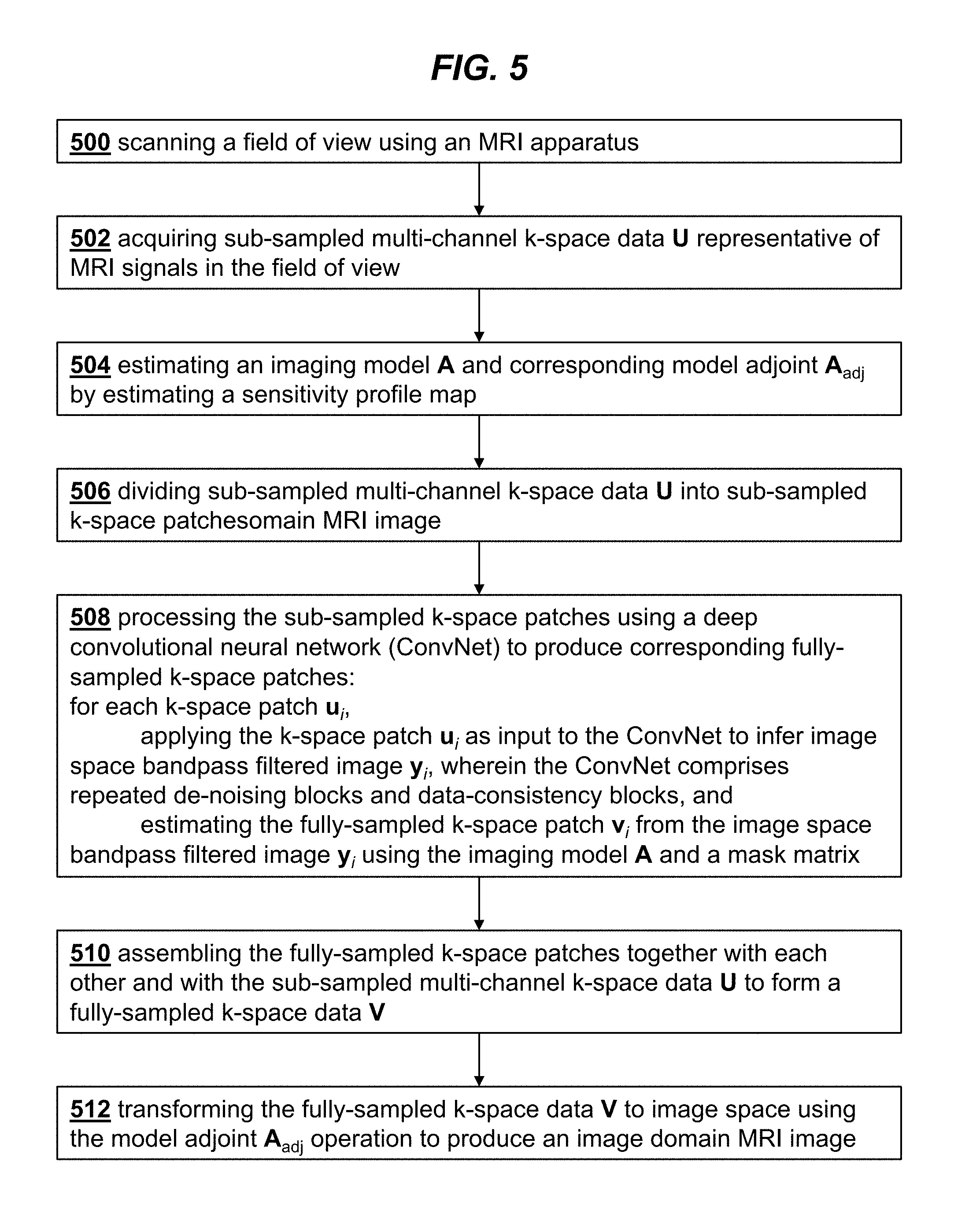
[0035] A method for magnetic resonance imaging (MRI) using this reconstruction technique is shown in the flowchart of FIG. 5. In step 500 a field of view is scanned using an MRI apparatus. Sub-sampled multi-channel k-space data U representative of MRI signals in the field of view is acquired in step 502. In step 504 an imaging model A is estimated by estimating a sensitivity profile map. The corresponding model adjoint A.sub.adj obtained from A. In step 506 the sub-sampled multi-channel k-space data U is divided into sub-sampled k-space patches. Step 508 performs the processing of the sub-sampled k-space patches using a deep convolutional neural network (ConvNet) to produce corresponding fully-sampled k-space patches. The fully-sampled k-space patches are assembled together to form a fully-sampled
TABLE-US-00001 Algorithm 1 Reconstruction pipeline Input: Set of k-space patches u.sub.i of full k-space image U with corresponding k-space location k.sub.i for the center pixel of each patch. U is subsampled (has missing points). Output: Reconstructed k-space image V 1: Estimate model A 2: V .rarw. U {Initialize V with known measurements} 3: for all u.sub.i at k.sub.i do 4: y.sub.i .rarw. G(u.sub.i, k.sub.i, A) {Inference using ConvNet G(.)} 5: v.sub.i .rarw. M.sub.i.sup.cA (e.sup.i2.pi.kx * y.sub.i) {Estimate missing data points} 6: Insert v.sub.i into V 7: end for
k-space data V in step 510, and in step 512 the fully-sampled k-space data V is transformed to image space using the model adjoint A.sub.adj operation to produce an image domain MRI image.
[0036] The processing of the sub-sampled k-space patches in 508 processes each k-space patch u.sub.i of the sub-sampled k-space patches separately and independently from other patches to produce a corresponding fully-sampled k-space patch v.sub.i, thereby allowing for parallel processing. Each k-space patch u.sub.i is applied as input to the ConvNet to infer an image space bandpass-filtered image y.sub.i. The fully-sampled k-space patch v.sub.i is estimated from the image space bandpass-filtered image y.sub.i using the imaging model A and a mask matrix.
[0037] According to embodiments of the present invention, the inverse problem of Eq. 2 is solved with a convolutional neural network (ConvNet), denoted as G(.) in Algorithm 1 and FIG. 1. Any ConvNet architecture can be used for this purpose, but to demonstrate the ability to incorporate the imaging model in an easy to understand fashion, the architecture illustrated here is based on the unrolled optimization with deep priors. For simplicity, the architecture used to demonstrate solving the inverse problem is based on projection onto convex sets (POCS). In this framework, two different blocks are repeated: 1) de-noising block and 2) data-consistency block.
[0038] The de-noising block is composed of 2D convolution layers. The real and imaginary components of the complex data are treated as two separate channels. The input is a bandpass-filtered image of dimensions N.times.N.times.2. The input is passed through an initial convolution layer with 3.times.3 kernels that expands the data to 128 feature maps. The data is then passed through 5 layers of repeated 3.times.3 convolution layers with the same number of 128 feature maps. A final 3.times.3 convolution layer combines the 128 feature maps back to the 2 feature maps of real and imaginary components. Additionally, the initial input is added back to the output of the convolution layers. After each of the convolution layer except the last one, the data is passed through a batch normalization layer (BN) and a Rectified Linear Unit layer (ReLU). No normalization or activation layer is applied at the last layer to ensure that the sign (positive or negative) of the data is perserved. The input data for k-space patch u.sub.i to the k-th de-noising block R.sub.k is denoted as y.sub.i.sup.k. The output of the de-noising block is denoted as y.sub.i.sup.k+:
y.sub.i.sup.k+=R.sub.k(y.sub.i.sup.k). (4)
[0039] The data-consistency block enforces consistency with the measured data points. This block is important to ensure that the final reconstructed image agrees with the measured data points to minimize the chance of hallucination. More specifically, the data y.sub.i.sup.k+ after the k-th de-noising block is passed through the forward model to transform the data into the measurement (k-space) domain:
u.sub.i.sup.k=A(e.sup.i2.pi.k.sup.i.sup.x*y.sub.i.sup.k+1). (5)
The known measured points u.sub.i are inserted into the correct k-space locations, and then multiplied by the window function W:
u.sub.i.sup.k+1=W(M.sub.i.sup.cu.sub.i.sup.k+M.sub.iu.sub.i) (6)
The data is then passed through the adjoint model to transform the data back to the image domain:
y.sub.i.sup.k+1=e.sup.-i2.pi.k.sup.i.sup.xA.sub.adju.sub.i.sup.k+1. (7)
Here, A.sub.adj denotes the adjoint to A.
[0040] The two blocks, de-noising and data-consistency, are repeated. The weights in the convolution layers in the de-noising block can be kept constant for each repeated block or varied. In our experiments, we repeat the two blocks for 8 iterations and allow the weights to vary for each block to allow for more flexibility in the network.
[0041] We now turn to discussing issues of computational implementation.
[0042] To solve the inverse problem of Eq. 1, iterative algorithms are typically used. During each iteration, element-wise multiplication and addition are performed. Additionally, the inverse and forward multi-dimensional Fourier transform is performed. Despite advanced algorithmic developments, this Fourier transform is still the most computationally expensive operation. For the conventional approach of reconstructing the entire 2D image at once, each 2D Fourier transform requires O (N.sub.zN.sub.y log(N.sub.yN.sub.z)) operations for an image of dimensions N.sub.y.times. N.sub.z.
[0043] According to the techniques of the present invention, the inverse problem is only applied for localized patches of k-space; thus, all operations including the Fourier transform are performed with smaller image dimensions. Thus, this patch-based approach significantly reduces the amount of computation. For example, given an initial image dimensions of N.sub.y=256 and N.sub.z=256, we aim to perform the reconstruction as solving the inverse problem for patches of dimensions 64.times.64. In such a formulation, we effectively reduce the computation for the Fourier transform by over 21 fold.
[0044] In embodiments of the present invention, we can further accelerate the reconstruction procedure in two ways. First, the reconstruction of each individual k-space patch can be performed independently. This property enables the ability to parallelize the reconstruction process. Therefore, the entire reconstruction can be performed in the time in takes to reconstruct a single patch which further leverages the benefit of applying the Fourier transform operator on smaller image dimensions. Second, conventional iterative approaches to solve Eq. 1 requires an unknown number of iterations for convergence and the need to empirically tune the regularization parameter for each type of scan. In the deep learning approach of the present invention, on the other hand, the number of iterations is fixed, and the network is trained to converge to an adequate solution in the given number of iterations. Further, the need to empirically tune the regularization parameter and step sizes are eliminated as these parameters are effectively learned through the given training examples.
[0045] For purposes of illustration, we now provide examples of training and reconstruction using real data.
[0046] Volumetric abdominal images were acquired using gadolinium-contrast-enhanced MRI with a 3T scanner (GE 750 Scanner) and a 32-channel cardiac coil array. Free-breathing T1-weighted scans were collected from 301 pediatric patients using a 1-2 minute RF-spoiled gradient-recalled-echo sequence with pseudo-random Cartesian view-ordering and intrinsic navigation. For the Cartesian sampling trajectory, data were fully sampled in the k.sub.x direction (spatial frequency in x) and were subsampled in the k.sub.y and k.sub.z directions (spatial frequency in y and z). The raw imaging data was first compressed from the 32 channels to 6 virtual channels using a singular-value-decomposition-based compression scheme. The datasets were modestly subsampled with a reduction factor of 1 to 2, and the datasets were first reconstructed using parallel imaging with ESPIRiT and compressed sensing with spatial wavelets. Using the motion measured with the intrinsic navigation, respiratory motion was suppressed by weighting each data point according to the degree of motion corruption. This initial reconstruction was performed using the Berkeley Advanced Reconstruction Toolbox (BART).
[0047] For training, all volumetric data were first transformed into the hybrid (x, k.sub.y, k.sub.z)-space. Each separate x-slice was considered as a separate data sample. The dataset was divided by patient: 229 patients for training (44006 slices), 14 patients for validation (2688 slices), and 58 patients for testing (11135 slices). Thirty six different sampling masks were generated using variable density poisson disc sampling with reduction factors ranging from 2 to 9 with a fully sampled calibration region of 10.times.10 in the center of the frequency space. During training, data was augmented by applying a randomly selected sampling mask and randomly flipping the data in y and in z. Sensitivity maps for the data acquisition model were estimated using ESPIRiT. For training, the Adam optimizer was used with .beta..sub.1=0.9, .beta..sub.2=0.999 and a learning rate of 0.001.
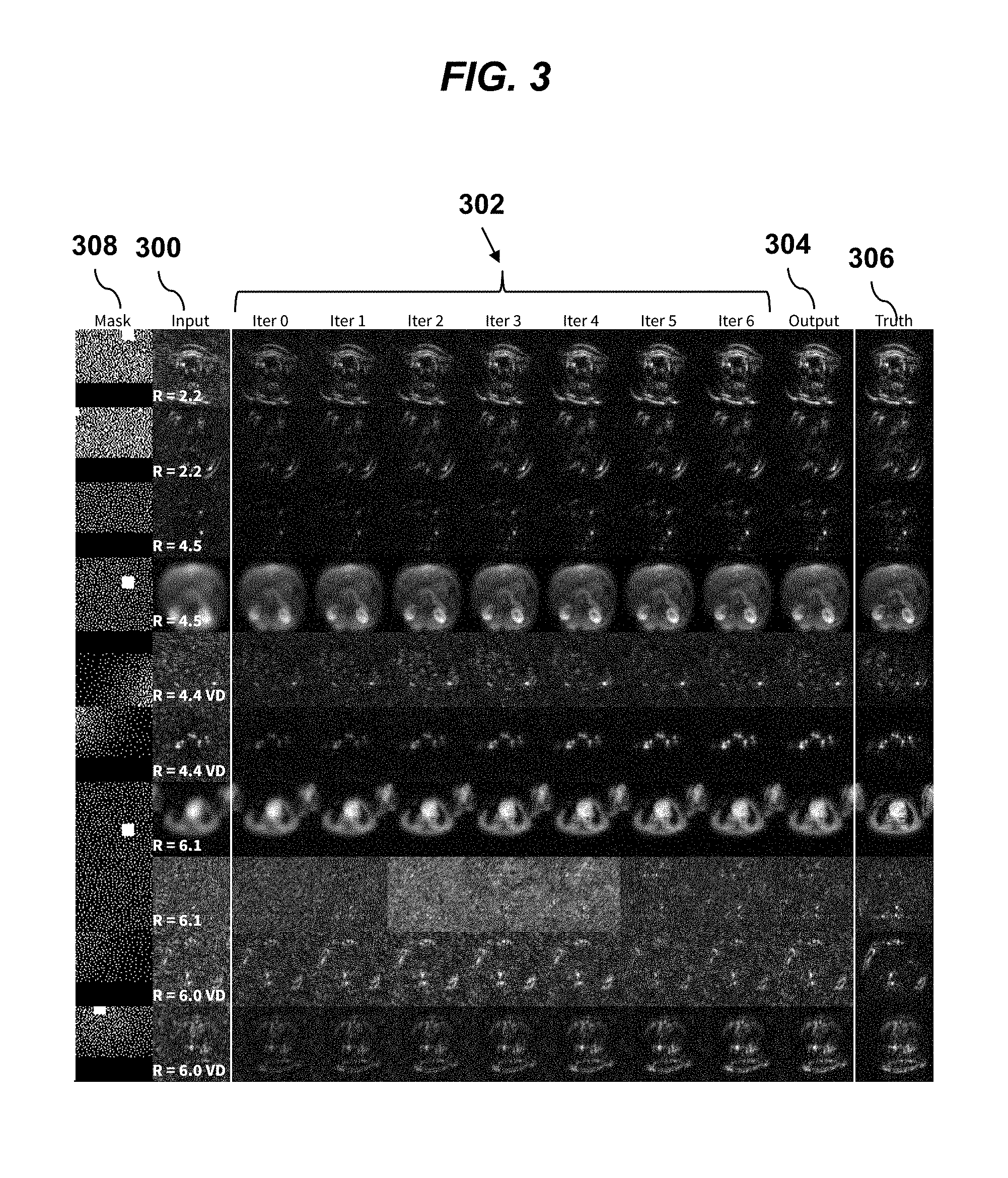
[0048] The image grid of FIG. 3 shows example outputs from the ConvNet for a random selection of data samples and frequency bands. Pseudo-random sampling masks (column 308) were generated for each input data sample (column 300) with different subsampling factors (R). If variable-density subsampling was used, the reported subsampling factor is annotated with "VD." Column 300 corresponds to the input to the network. The seven columns 302 ("Iter 0" to "Iter 6") correspond to the image at subsequent stages of an 8-stage ConvNet. The final stage is shown in column 304 as the network output. The ground truth is displayed in the final column 306. Generally, the network output 304 is comparable to the ground truth 306. For higher subsampling factors (R>5), residual artifacts remain. Further, if the data has a higher noise level, residual noise remains.
[0049] The final results of reconstruction using techniques of the present invention are compared with state-of-the-art compressed sensing with parallel imaging in the image grid of FIG. 4. Example results were randomly selected from a test set for different subsampling factors R. These examples are selected from the examples shown in FIG. 3. The original images in column 406 are subsampled with the sampling mask shown and the subsampling factor (R). The inpute subsampled image is shown in the first column 400. The output of the bandpass ConvNet technique of the present invention is shown in column 402 and the output of state-of-the-art compressed sensing reconstructions are displayed in column 404. Peak to signal noise ratio (PSNR), normalized root mean square error (NRMSE) normalized by the image norm, and structural similarity index (SSIM) are annotated below each image over the different image (.times.2). The bandpass ConvNet technique of the present invention yielded comparable image quality to the state-of-the-art compressed sensing reconstruction but with a significant reduction in computation and memory footprint.
[0050] The embodiments describe above are intended as concrete examples to illustrate the general principles of the invention as applied to specific implementations. Those skilled in the art will readily appreciate based on the teachings of the present application that many alternatives and variations of embodiments are possible.
[0051] The techniques of the present invention may be implemented on any standard MRI apparatus, suitable modified to reconstruct images in accordance with the techniques described here.
[0052] Different loss functions can be used for training to improve image accuracy and sharpness. These loss functions include structural similarity index metric (SSIM), l.sub.2 norm, l2 norm, and combinations of the different functions. Furthermore, the network can be trained using an adversarial network in a generative adversarial network structure.
[0053] Embodiments of the invention allows for flexibility in using different neural network structures that are used to reconstruct each frequency band. These neural network structure can include residual networks (ResNets), U-Nets, autoencoder, recurrent neural networks, and fully connected networks.
[0054] Embodiments of the invention can be modified to apply different and/or independent networks for each frequency band. For instance, one network can be trained and applied for frequency bands at lower spatial frequencies, and a different network can be trained and applied for frequency bands at higher spatial frequencies.
[0055] Additional information (such as the patch location, subsampling factor, anatomy) can be incorporated as additional inputs to the convolutional neural network.
[0056] Embodiments of the invention also allows for flexibility in modifying the imaging model used. The imaging model may include off-resonance information, signal decay model, k-space symmetry with homodyne filtering, and arbitrary sampling trajectories (radial, spiral, hybrid encoding, etc.).
[0057] Embodiments of the invention can be extended to multi-dimensional space that may include volumetric space, cardiac-motion dimension, respiratory-motion dimension, contrast-enhancement dimension, time dimension, diffusion direction, velocity, and echo dimension.
[0058] Embodiments of the invention can be used in conjunction with conventional image reconstruction methods. The results of the network can be used to initialize iterative reconstruction techniques. The results of the network can be applied for specific areas of the measurement domain: such as the center of k-space for improved data calibration for methods like parallel imaging.
[0059] Embodiments of the invention can be used to parallelize detection and correction of corrupt measurement values on a patch-by-patch basis.
[0060] The results from embodiments of the invention can also be passed through another deep neural network to further improve reconstruction accuracy.
* * * * *
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.