Method And System For Performing Searches For Television Content Using Reduced Text Input
Venkataraman; Sashikumar ; et al.
U.S. patent application number 16/397408 was filed with the patent office on 2019-08-15 for method and system for performing searches for television content using reduced text input. The applicant listed for this patent is Veveo, Inc.. Invention is credited to Rahul Agrawal, Murali Aravamudan, Rakesh Barve, Pranav Rajanala, Ajit Rajasekharan, Sashikumar Venkataraman.
| Application Number | 20190253762 16/397408 |
| Document ID | / |
| Family ID | 36317890 |
| Filed Date | 2019-08-15 |




| United States Patent Application | 20190253762 |
| Kind Code | A1 |
| Venkataraman; Sashikumar ; et al. | August 15, 2019 |
METHOD AND SYSTEM FOR PERFORMING SEARCHES FOR TELEVISION CONTENT USING REDUCED TEXT INPUT
Abstract
A method and system are provided for identifying a television content item desired by a television viewer from a set of television content items. Each of the television content items has one or more associated descriptors. The system receives from the television viewer a reduced text search entry directed at identifying the desired television content item. The search entry is a prefix substring of one or more words relating to the desired television content item. The system dynamically identifies a group of one or more television content items from the set of television content items having one or more descriptors matching the search entry as the television viewer enters each character of the search entry. The system then transmits the names of the one or more television content items of the identified group to be displayed on a device operated by the television viewer.
| Inventors: | Venkataraman; Sashikumar; (Andover, MA) ; Barve; Rakesh; (Bangalore, IN) ; Rajanala; Pranav; (Bangalore, IN) ; Agrawal; Rahul; (Bhopal, IN) ; Aravamudan; Murali; (Andover, MA) ; Rajasekharan; Ajit; (West Windsor, NJ) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 36317890 | ||||||||||
| Appl. No.: | 16/397408 | ||||||||||
| Filed: | April 29, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 14833710 | Aug 24, 2015 | 10277952 | ||
| 16397408 | ||||
| 13006846 | Jan 14, 2011 | 9135337 | ||
| 14833710 | ||||
| 11136261 | May 24, 2005 | 7895218 | ||
| 13006846 | ||||
| 60664879 | Mar 24, 2005 | |||
| 60626274 | Nov 9, 2004 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | H04N 21/4828 20130101; H04N 21/47 20130101; G06F 16/322 20190101; H04N 7/163 20130101; H04N 21/482 20130101; G06F 16/78 20190101; H04N 5/44543 20130101; H04N 21/42204 20130101 |
| International Class: | H04N 21/482 20060101 H04N021/482; G06F 16/31 20060101 G06F016/31; G06F 16/78 20060101 G06F016/78; H04N 5/445 20060101 H04N005/445; H04N 21/422 20060101 H04N021/422; H04N 7/16 20060101 H04N007/16 |
Claims
1. A method of incrementally identifying and selecting a content item to be presented from a relatively large set of selectable content items, the content items being associated with descriptive terms that characterize the selectable content items, the method comprising: using an ordering criteria to rank and associate subsets of content items with corresponding strings of one or more descriptor prefix strings, each descriptor prefix string being a variable length string containing a subset of the characters of the descriptive terms that characterize the selectable content items, wherein each descriptor prefix string contains less than all characters of the descriptive terms; subsequent to ranking and associating the content items with strings of one or more descriptor prefix strings, receiving incremental text input entered by a user, the incremental text input including a first descriptor prefix of a word entered by the user for incrementally identifying at least one desired content item of the relatively large set of content items, wherein the first descriptor prefix contains less than all characters of the word the user is using to incrementally identify the at least one desired content item; selecting and presenting on a display device the subset of content items that is associated with the first descriptor prefix string; subsequent to receiving the first descriptor prefix, receiving subsequent incremental text input entered by the user, the subsequent incremental text input including a second descriptor prefix of a word entered by the user for incrementally identifying the at least one desired content item and forming a string of prefixes including the first descriptor prefix and the second descriptor prefix in the order received, wherein the second descriptor prefix contains less than all characters of the word the user is using to incrementally identify the at least one desired content item; and selecting and presenting on the display device the subset of content items that is associated with the string of prefixes received.
Description
RELATED APPLICATIONS
[0001] The present application claims priority under 35 U.S.C. .sctn. 120 to U.S. patent application Ser. No. 11/136,261, filed May 24, 2005 and entitled "Method and System for Performing Searches for Television Content Using Reduced Text Input." U.S. patent application Ser. No. 11/136,261 in turn claims priority under 35 U.S.C. .sctn. 119(e) to U.S. Provisional Application No. 60/626,274. filed Nov. 9, 2004 and entitled "Television Systems and Associated Methods." U.S. patent application Ser. No. 11/136,261 also claims priority under 35 U.S.C. .sctn. 119(e) to U.S. Provisional Application No. 60/664,879, filed Mar. 24, 2005 and entitled "Method and System for Performing Searches for Television Programming Using Reduced Text Input." Each of the foregoing applications is incorporated herein by reference in its entirety.
BACKGROUND OF THE INVENTION
Field of Invention
[0002] The present invention generally relates to a method and system for performing searches for television content and, more particularly, to a method and system for performing searches with text entry by a user reduced to prefix substrings representing elements of a namespace containing a set of names composed of one or more words that are either ordered or unordered.
Description of Related Art
[0003] Search engines have become increasingly important for finding needed information on the Internet using Personal Computers (PCs). While performing searches is predominantly a PC based activity to date, searching has begun percolating to non-PC domains such as televisions and hand-held devices, as content choices for these domains proliferate. Text input continues to be the primary input technique for search engines since speech input and other input technologies have not sufficiently matured. Though progress has been made recently for PCs with full QWERTY keyboards to reduce the amount of text input needed to arrive at a desired result, the search input process is still grossly deficient and cumbersome when it comes to searching for desired information or content on a large ten-foot interface television environment or a hand-held device. In these usage scenarios, the text input is ordinarily made using keys that are typically overloaded with multiple characters. Of the various device interactions (key stroke, scroll, selection etc.) during a search process in these non-PC systems, text input remains a dominant factor in determining the usability of search. This usability criterion typically constrains text input to a single keyword (such as a name) or a few keywords to describe the item that is being searched. Rich text input such as "natural language input" is generally precluded in the non-PC systems not by the limitations of search engines, but by the difficulty of entering text.
[0004] A useful usage scenario for searching in these limited input capability environments could be to find information on a keyword a user has in mind, where the keyword could be the name of a person, place, object, media entity etc. Examples of such a search could be finding the movie "Guns of Navarone" (which as further described below can be considered a three-word name instance from an ordered name space), and "John Doe" (a two-word name instance from an unordered name space). An interesting property of certain search domains is that the percentage of names in the search domain with two or more words is quite significant. For instance, in the case of searching for a person's name (e.g., John Doe) in a phone database, the search domain name size (number of words constituting a name--2 in the case of John Doe) is at least two. In the movie space, a random sampling of 150,000 English movie titles revealed that 86% of the titles have name size greater than or equal to two, even with the removal of some of the most frequently occurring "article stop words" such as "a", "an", and "the."
[0005] It would be desirable for search engines for devices (with limited input capabilities in particular) to enable user to get to desired results with reduced input representing a namespace. In particular, a search method or system able to perform one or more of the following would be desirable: [0006] (1) Captures information from one or more words making up a name, using a reduced number of characters to represent the original name. The number of results matched for the name entry is preferably limited to a given threshold, which can, e.g., be determined by the display space for rendering the results and the ease of scrolling through the results. [0007] (2) Allows users to enter words in the namespace in any order. For example, a person lookup search such as "John Doe" should be possible either as "John Doe or Doe John." In this example, "John" and "Doe" is a two-word instance of a name from an unordered namespace. [0008] (3) Facilitates learning of an efficient usage of the reduced text entry scheme intuitively and gradually. First time users should preferably be able to even enter the full string if they choose to. The system preferably provides users with cues and assistance to help learn to key in the reduced string to get to desired results. [0009] (4) Works across search domains with diverse attributes such as (a) size of the search domain (b) the language used for search, (c) the clustering characteristics of names in the search domain, (d) the interface capabilities of the device used for search, and (e) computational power, memory, and bandwidth availability of the search system.
BRIEF SUMMARY OF EMBODIMENTS OF THE INVENTION
[0010] In accordance with one or more embodiments of the invention, a method and system are provided for identifying a television content item desired by a television viewer from a set of television content items. Each of the television content items has one or more associated descriptors. The system receives from the television viewer a reduced text search entry directed at identifying the desired television content item. The search entry is a prefix substring of one or more words relating to the desired television content item. The system dynamically identifies a group of one or more television content items from the set of television content items having one or more descriptors matching the search entry as the television viewer enters each character of the search entry. The system then transmits the names of the identified group of one or more television content items to be displayed on a device operated by the television viewer.
[0011] These and other features will become readily apparent from the following detailed description wherein embodiments of the invention are shown and described by way of illustration. As will be realized, the invention is capable of other and different embodiments and its several details may be capable of modifications in various respects, all without departing from the invention. Accordingly, the drawings and description are to be regarded as illustrative in nature and not in a restrictive or limiting sense with the scope of the application being indicated in the claims.
BRIEF DESCRIPTION OF THE DRAWINGS
[0012] For a more complete understanding of various embodiments of the present invention, reference is now made to the following descriptions taken in connection with the accompanying drawings in which:
[0013] FIG. 1 illustrates a reduced text entry search system in accordance with one or more embodiments of the invention being used in different device and network configurations.
[0014] FIG. 2 illustrates configuration options of exemplary devices for performing searches in accordance with one or more embodiments of the invention.
[0015] FIG. 3 illustrates examples of a discrete structural composition of text input to a search system in accordance with one or more embodiments of the invention.
[0016] FIG. 4 illustrates a process of user starting a new search and entering text and arriving at a desired result in accordance with one or more embodiments of the invention.
[0017] FIG. 5 illustrates a preprocessing step on a search space prior to indexing it in accordance with one or more embodiments of the invention.
[0018] FIG. 6 illustrates an example of a data structure to enable dynamic search leveraging off pre-indexed substring prefixes in accordance with one or more embodiments of the invention.
[0019] FIG. 7 illustrates internal steps of search as each character is input in accordance with one or more embodiments of the invention.
[0020] FIGS. 8A and 8B illustrate interface characteristics of two search devices in accordance with one or more embodiments of the invention.
[0021] In the figures, like reference numerals refer to generally like elements.
DETAILED DESCRIPTION OF PREFERRED EMBODIMENTS
[0022] Briefly, as will be described in further detail below, in accordance with more embodiments of the invention, methods and systems are provided for identifying a television content item desired by a television viewer from a set of available television content items. Such television content items can include a wide variety of video/audio content including, but not limited to, television programs, movies, music videos, video-on-demand, or any other identifiable content that can be selected by a television viewer.
[0023] The television viewer can enter into a search device having a text input interface a reduced text search entry directed at identifying the desired television content item. The text can be one or more characters, which can be any alphanumeric character, symbol, space or character separator that can be entered by the user. Each television content item has one or more associated descriptors, particularly names in a namespace relating to the desired television content item. The descriptors specify information about the content, which can include, e.g., information on titles, cast, directors, descriptions, and key words. The names are composed of one or more words that can be either ordered or unordered. The user's search entry comprises one or more prefix substrings that represent a name or names in the namespace. A prefix substring of a word in a name captures information from the word and can be a variable length string that contains fewer than all the characters making up the word.
[0024] The system identifies a group of one or more television content items from the set of available television content items having descriptors matching the search entry. The names of the identified group of one or more television content items is then transmitted to and displayed on a device operated by the television viewer. The viewer can then select the desired content item from the group displayed, or enter further characters or edit the substring to narrow or change the results as desired.
[0025] The descriptors can include a preferably partial subset of pre-indexed prefix substring combinations. The prefix substrings entered by a user are input to an algorithm that can dynamically generate results leveraging off the pre-indexed prefix substring combinations. The size of the pre-indexed prefix substring combinations can be based on some balance between computational power, memory availability, and optionally bandwidth constraints of the system in which reduced text entry search is deployed.
[0026] The variable prefix substring search algorithm can allow multiple names to be entered, preferably without regard to the order. The results list for search is preferably dynamically culled by the text input of each character. The results are preferably ordered based on a relevance function that can be a domain specific combination of, e.g., popularity, temporal relevance, location relevance, personal preferences, and the number of words in the input search string.
[0027] One or more embodiments of the present invention also includes a system for intuitively informing and educating the user of the smallest or generally smallest substring for yielding a particular result, thereby empowering the user with a user-friendly search method particularly on platforms with limited text entry capabilities. The flexibility of entering prefix substrings of variable sizes to get to the desired result makes the reduced text entry scheme intuitive and easy to use.
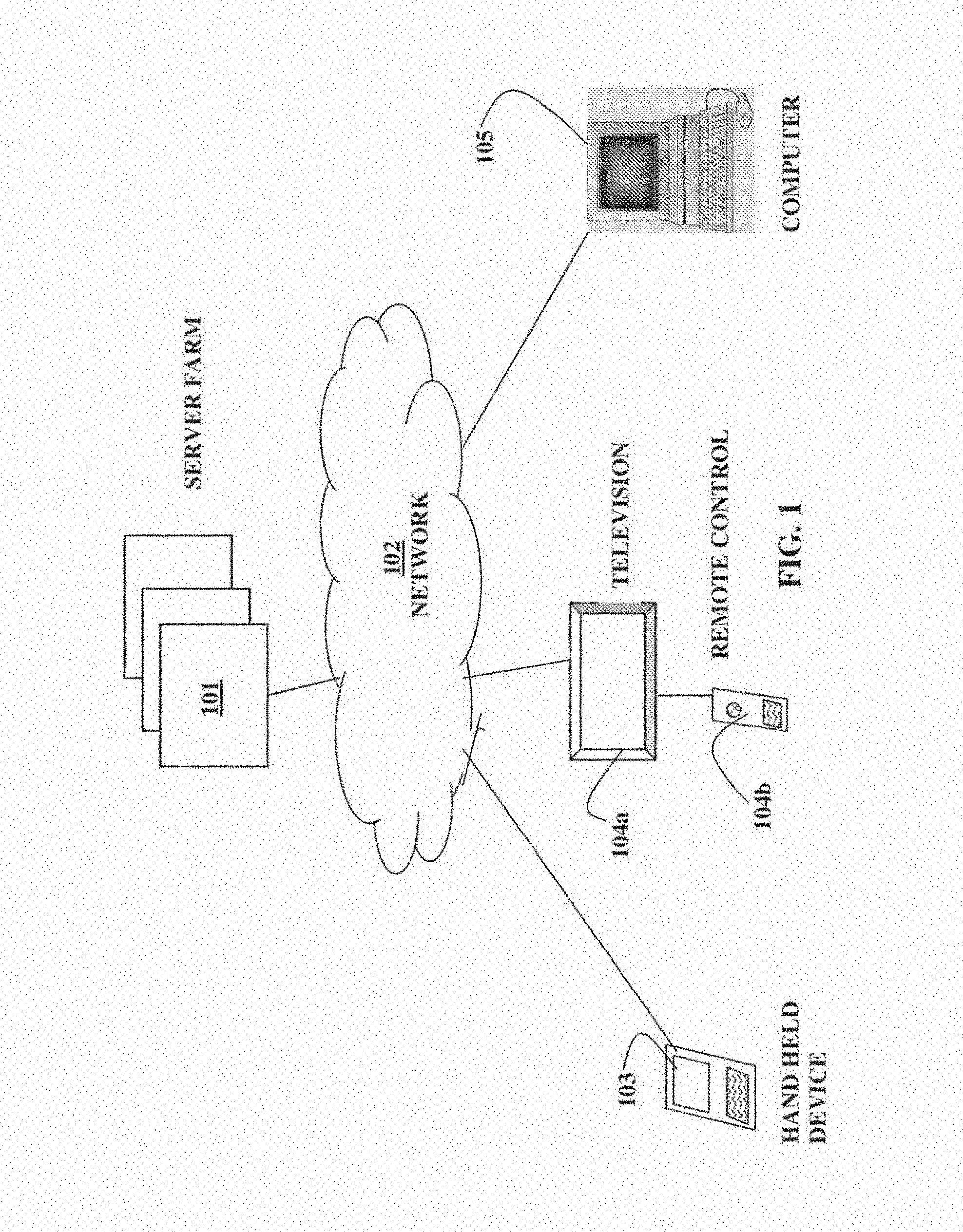
[0028] FIG. 1 illustrates an overall system for performing searches with reduced text entry using a wide range of devices in accordance with one or more embodiments of the invention. A server farm 101 can serve as the source of search data and relevance updates with a network 102 functioning as the distribution framework. The distribution framework could be a combination of wired and wireless connections. Examples of possible networks include cable television networks, satellite television networks, and IP-based television networks. The search devices could have a wide range of interface capabilities such as a hand-held device 103 (e.g., a phone or PDA) with limited display size and overloaded or small QWERTY or other keypad, a television 104a coupled with a remote control device 104b having an overloaded or small QWERTY or other keypad, and a Personal Computer (PC) 105 with a full QWERTY or other keyboard and a computer display.
[0029] FIG. 2 illustrates multiple exemplary configurations for search devices in accordance with one or more embodiments of the invention. In one configuration, a search device (e.g., PC 105) can have a display 201, a processor 202, volatile memory 203, text input interface 204 (which can be on-device or through a wireless remote control 104b), remote connectivity 205 to the server 101 through the network 102, and a persistent storage 206. A device configuration for a device such as the hand-held device 103 might not include local persistent storage 206. In this case, the device 103 could have remote connectivity 205 to submit the query to the server 101 and retrieve results from it. Another configuration of the device 103 may not have remote connectivity 205. In this case, the search database may be locally resident on a local persistent storage 206. The persistent storage 206 may be, e.g., a removable storage element too such as SD, SmartMedia, CompactFlash card etc. In a configuration of the device with remote connectivity 205 and persistent storage 206 for search (e.g., television 104a), the device may use the remote connectivity for search relevance data update or for the case where the search database is distributed on the local storage 206 and on the server 101. In one or more exemplary embodiments of the invention, a television 104a may have a set-top box with a one-way link to a satellite network. In this configuration, all search data including relevance updates may be downloaded to the device through a satellite link to perform local searching.
[0030] FIG. 3 illustrates an exemplary structure of a reduced text entry query for search in accordance with one or more embodiments of the invention. Each query can be composed of one or more words preferably delimited by a separator such as, e.g., a space character or a symbol. Adjacent words of the query may constitute an ordered name, e.g., "Guns of Navarone" or an unordered name, e.g., "John Doe" as illustrated in example 303. Individual words can also be part of a set of ordered or unordered names such as "Malkovich" or "Casablanca," though the ordering attribute is irrelevant in this case. A set of names that is either ordered or unordered constitutes a namespace. An example of an unordered namespace is a phone book with names of people. An example of an ordered namespace is a database of movie titles.
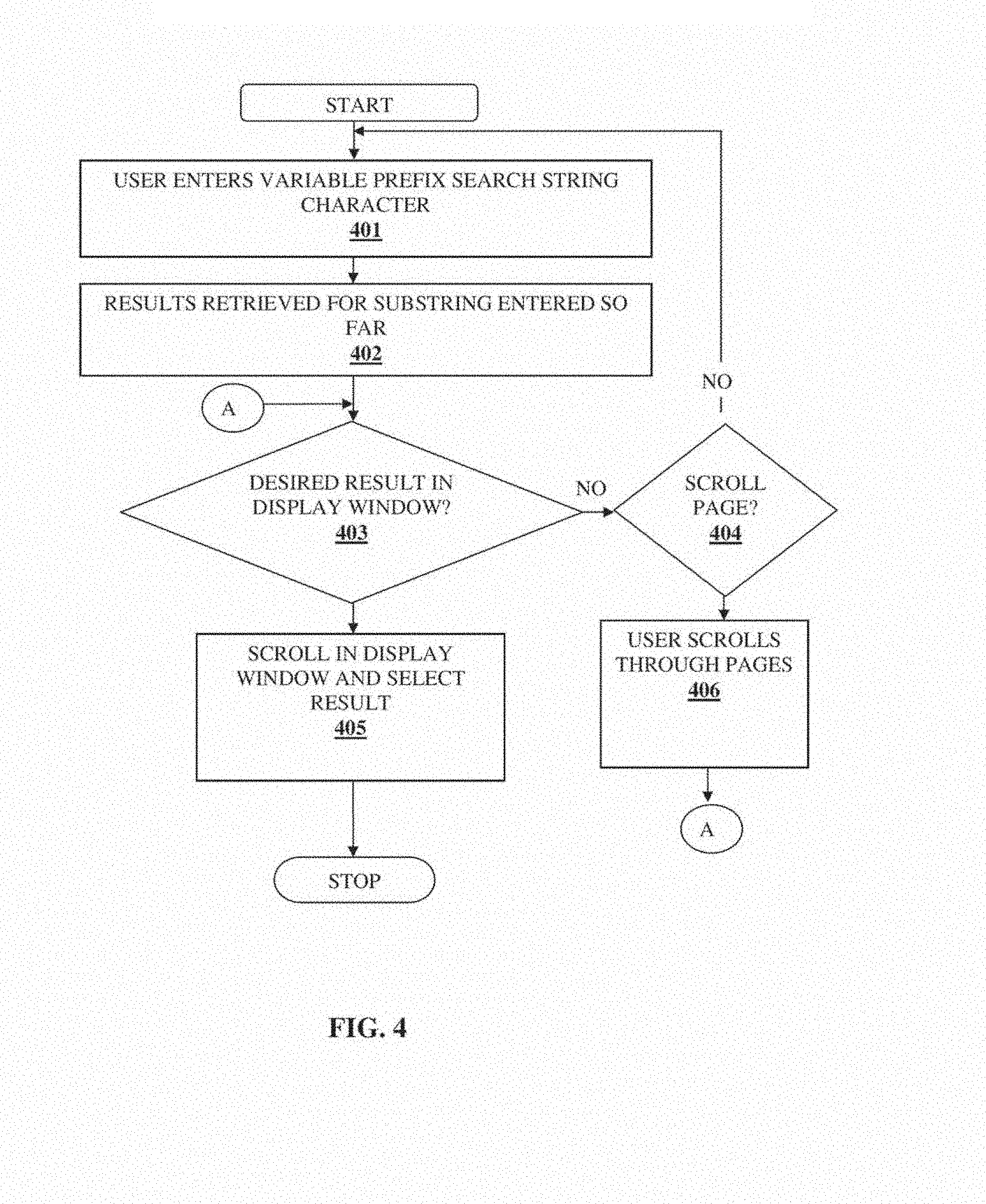
[0031] FIG. 4 illustrates an exemplary process of user starting a new search, entering characters and arriving at the desired result in accordance with one or more embodiments of the invention. A user enters one or more search string characters at 401, which could be a variable size prefix of the intended query (e.g., to represent `Brad Pitt`, the user can enter B P, BR P, B PI etc.). Results are then preferably dynamically retrieved for the cumulative substring of characters entered up to that point at 402 and displayed. The user determines at 403 as to whether the desired result is shown in a display window. If the result is displayed in the display window, the user can scroll to the desired result within the display window and select the desired result at 405. If the desired result is the first entry in the display window 405, it can be selected by default obviating the need to scroll through the display window.
[0032] The ordering of results in the display window is preferably governed by a relevance function that is a domain specific combination of, e.g., popularity, temporal and location relevance. For example when a user is searching for a restaurant using a phone or Personal Digital Assistant (PDA) with GPS capabilities, then the listings could be ordered in descending order of the most popular restaurants in that area. If the user entered NBA, then the system could list the games in order of temporal relevance such as those in progress or are scheduled to begin in the near future are listed first.
[0033] If the desired result is not in the display window at step 403, the user can decide whether or not to scroll through pages of results not currently displayed in the window at 404. If the user decides to scroll through the pages, he or she can scroll down the display window linearly or page by page at 406 to reveal more results. If user does not want to scroll through pages, he or she can enter additional characters at 401 to narrow the results.
[0034] In the scenario where user does not reach the result due to misspelling or due to the case of a word whose uniqueness (e.g., Tom Brown, Todd Brown) is embedded in the suffix of a word in the query (as opposed to the prefix). the user would have to either go back to the first word and enter more characters or erase one or more of the typed characters and re-enter characters to reach the desired result. The dynamic update of results for each character entry enables the user to recover from an error during the text entry process itself, in contrast to discovering that no results match after typing the entire text.
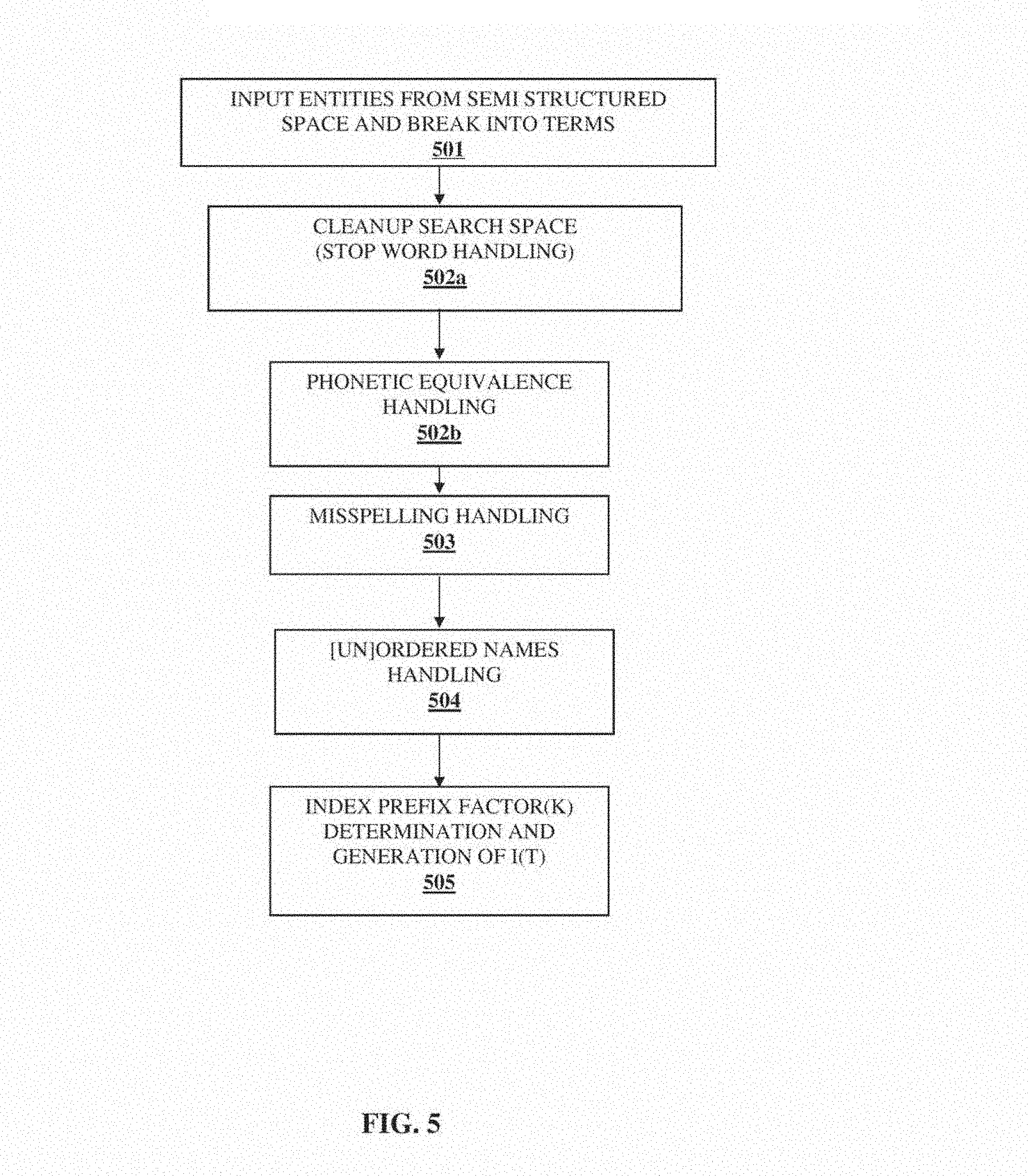
[0035] FIG. 5 illustrates various steps in a pre-processing phase in accordance with one or more embodiments of the invention. As illustrated in FIG. 3, the input to this phase can be a semi-structured space of any size composed of entities or descriptors (e.g., titles, cast, directors, description, key words) with their metadata values. This semi-structured search space can have a wide range of sizes, e.g., from the size of a PDA phone book to a large subspace obtained by a focused web crawl followed by relevant text processing to derive entities. In scenarios where the search space size is large, it can be possible to organize the space into smaller sub-spaces based on a categorization scheme. The first step 501 is the breakup of entities into terms (e.g., Tom Hanks, Secret Discoveries in Ancient China). A term is a set of ordered or unordered words. In accordance with one or more embodiments of the invention, multiple permutations of the words in the entity may be considered as candidate terms (e.g., Secret Discoveries of Ancient China, Discoveries of Ancient China, Ancient China, China). This allows searching a given entity using variable prefixes of any of the candidate terms. The second step is the cleanup of the entity space at 502a. The cleanup phase involves finding the locations of stop words such as "a", "an", "the". In the next step at 502b, entity names can be duplicated for phonetic equivalence handling (e.g., Jeff and Geoff). The duplication may be either implemented by actually creating multiple variants in data, or tagging for future algorithmic equivalence determination. A misspelling handling step 503 can address typical misspellings committed while entering text. An unordered names handling step 504 can first identify all the ordered and unordered names in a namespace, and then duplicate the unordered names (e.g., John Doe, Doe John). Duplication can involve either data duplication or tagging for algorithmic determination. The steps 501 through 504 determine a set of candidate terms T for each entity. A record is any particular prefix string of a term in T. For example, for the term "guns of navarone", "g o navarone" and "gu of navarone" are two of the many possible records. The set of all possible records of the terms in T is denoted by P(T), and searching for the given item could potentially be accomplished by using any of the prefix in this set.
[0036] At step 505, the number of variable prefix strings I(T) that will be pre-computed and stored in the index is determined. In many situations, it is not practical to pre-compute and store all the possible prefixes for all the terms due to expensive memory requirements. One or more embodiments of the present invention accordingly use a flexible method to store only a subset of P(T) based on different parameters such as available memory, computational power, and in some usage scenarios--bandwidth.
[0037] While computing I(T), there are a number of terms that are meant to recall entity names. Denote any such term `T` of length N>=1 as [0038] T=W.sub.1_W.sub.2_W.sub.3_ . . . W.sub.N where W.sub.i denotes the i.sup.th word and `_` denotes a space (which is an example of a word delimiter)
[0039] For any integer `k`, let W.sup.k denote the k-character prefix of word W. If k is greater than length of word W, W.sup.k=W. Let W(K) denote the set of words W.sup.k for 1<=k<=K, where K denotes the upper bound of the size of the prefix. For example, for the word "guns", W(2) consists of prefixes "g" and "gu". For any term T, its corresponding indexed set of I(T,K,C) of bounded multi-word prefix strings can be defined as follows
I(T,K,C)={X.sub.1_X.sub.2_X.sub.3_X.sub.4_X.sub.5_ . . . X.sub.C_W.sub.C+1 . . . W.sub.N}
Where X.sub.i.di-elect cons.W.sub.i(K) and W.sub.i is the i.sup.th word in the term T, and where C denotes the number of words for which prefixes are pre-computed. In a preferred embodiment of the invention, the set I(T,K,C) (also denoted by I(T)) is the set of strings pre-computed on account of term T and tunable parameters K and C. The set I(T) represents the pre-computed records corresponding to the terms in T and is usually a proper subset of P(T). The computation method indexes only the set I(T) as a part of the pre-computation, though the user could input any string in P(T) (which possibly may not belong to I(T)) to efficiently retrieve the term T. This is done by performing some appropriate computation at runtime during the search process leveraging of the set I(T).
[0040] The special case of I(T, .infin., .infin.) (i.e., K=.infin. and C=.infin.) is the scenario where each record is pre-computed for all the terms in T. In this case I(T)=P(T). It may be impractical to implement this case since the memory requirements would be high even for search spaces of modest size. The case K=0 and C=0, is the scenario where no records are pre-computed, and the search for any term is done dynamically by lookup of all possible terms matching the prefix query. In such a scenario, the runtime costs could be high due to a complete lookup during the search process especially for small prefixes that match with a large number of terms. A practical implementation would choose a value of K and C that is a balance between available memory, computational power and in some usage scenarios bandwidth. For example, a practical implementation may choose K=2 and C=1. In this case for a term "guns of navarone", the pre-computed prefix strings (or records) would be "g_ of navarone, gu_ of navarone" in addition, to the term "guns of navarone" itself. Though I(T) would in most practical implementations be a proper subset of P(T), the system would dynamically match terms that are not in I(T) (such as gun o nav) leveraging off the set I(T). It may be noted that such queries that are not in I(T) contain at least K initial characters of the first word thereby reducing the potential number of matching terms significantly. These terms may then be collected and analyzed for the matching of the remaining words in the term.
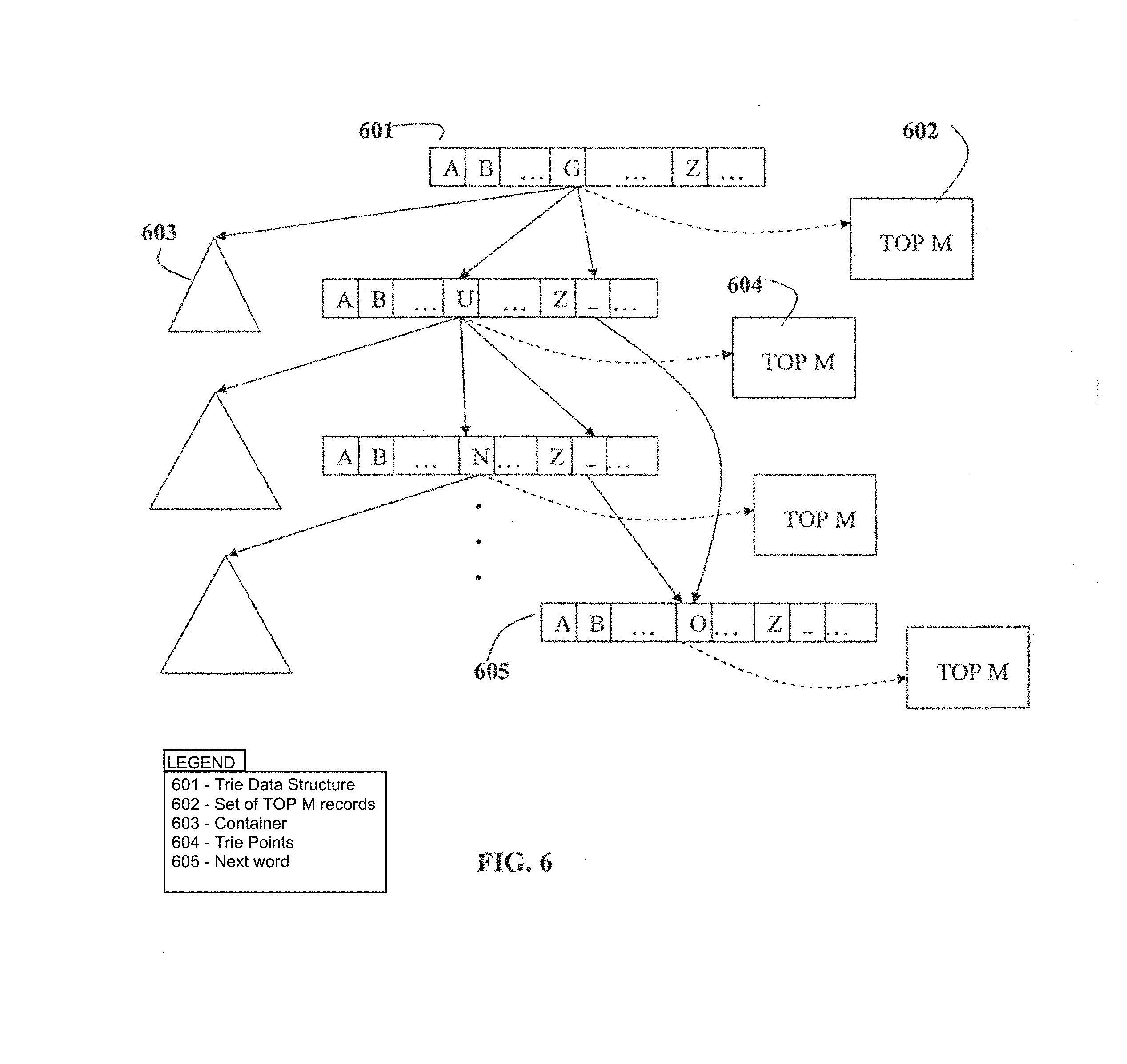
[0041] FIG. 6 illustrates a data structure that enables searching using variable prefix strings. This exemplary illustration shows the case of K=2 and C=1 (although subsequent words in the term are not illustrated). The illustration uses a trie data structure 601 to index the prefix strings. Each character in the trie 604 points to a set of top M 602 records that contains the most popular terms that begin with the prefix corresponding to the path from the root to that character. The ordering could be governed, e.g., by popularity, temporal relevance, location relevance, and personal preference. Single word terms may be selectively given a boost in the ordering in order for it to be discovered quickly since it cannot leverage off the "K" factor or "C" factor. The TOP M records corresponding to every node in the trie may be placed in memory that enables quick access to them. The value of M may be determined by factors such as the display size of the devices from which search would be done and the available memory capacity of the server or client system where the search metadata is stored. Each character in the trie also points to a container 603 that holds all records following the TOP M. For the term "guns of navarone", two new prefix strings in addition to the previous term, are created for the case K=2, "g_ of navarone" and "gu_ of navarone". The prefix strings "g_" and "gu_" both point to node starting the next word "o" 605.
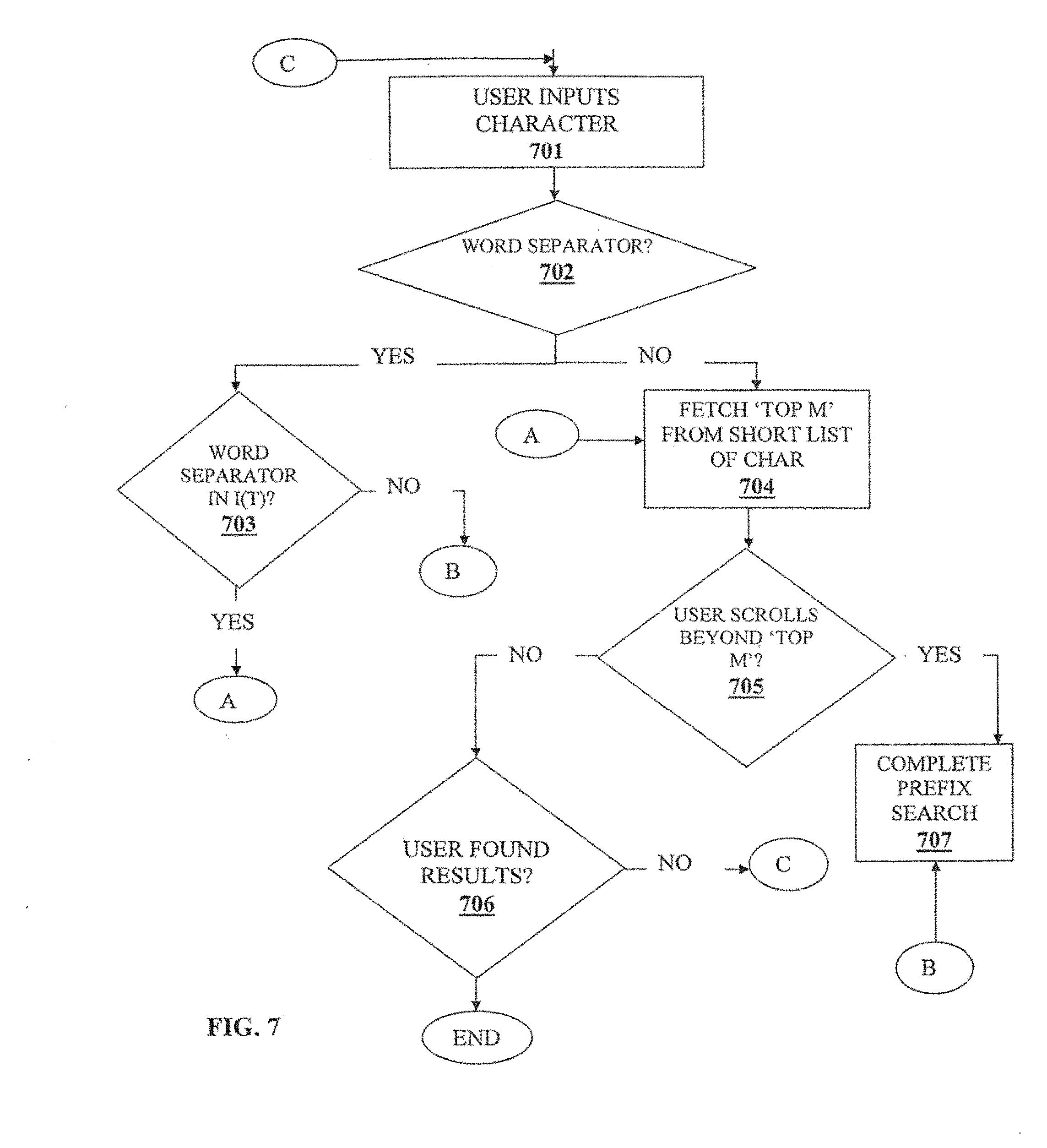
[0042] FIG. 7 illustrates a process of finding results using the variable prefix string scheme in accordance with one or more embodiments of the invention. When user inputs a character of a prefix string at 701, the system examines if it is a word separator at 702. If it is not a word separator, the system fetches the top M records at 704 for that character. If it is a word separator, system examines if the prefix with the word separator is in I(T) at 703. If it is in I(T), the system accesses the top M records for that node in the trie at 704. If the word separator is not in I(T), the system does a complete search at 707 for the records beginning with that prefix string. Also, after step 704, if user scrolls through the results list beyond top M results at 705, the system would perform a complete search at 707. If the user does not scroll beyond the top M results, and the user does not arrive at the result at 706, he can go back and enter another character at 701. So by having just a proper subset I(T) of the prefix strings precomputed, the system can leverage off the precomputed strings. For example, if user entered "gun_o" for the case K=2, C=1, the system would perform a complete search under strings beginning with gun and generate dynamically the top records that have the second word starting with `o`. Accordingly, the dynamic search process rides on top of the information provided by the precomputed prefix strings.
[0043] FIGS. 8A and 8B illustrates two exemplary search devices in accordance with one or more further embodiments of the invention. In FIG. 8A, a television 801 is controlled by a remote control device 809 over a wireless connection 807. The device 809 has a keypad 810. a navigation interface 811, a `next word` button 808a, and a `previous` button 808b. A preferred interface layout for performing searches is illustrated on the television screen with a permanent text entry focus (which has only one text entry) and decoupled tab focus. This enables user to enter text at any time without having to explicitly switch focus to the text window 803. A results window 806 is displayed with a scroll control 805. The results window 806 can be navigated using the navigation interface 811 on the remote 809. As a user types in "JE SE" at 802, the results window content 804 is dynamically culled to show the results. The remote control 809 has a prominent and easily accessible `next word` button 808a, that facilitates entry of a space character to delimit words. The `next word` interface facilitates easy entry of multiple prefix strings. Additionally the remote also has the "previous word" button 808b to facilitate easy traversal to the end of the previous words. This can be used in the remote scenario where the user did not enter sufficient characters for the first `m` prefixes of a term and has to go back to add more characters if the desired result is not reached.
[0044] The second device illustrated in FIG. 8B is a hand-held device (e.g., a phone) 812 that has a built-in keypad 816 and navigation interface 815. The display window 813 on this device is likely to be much smaller and hence hold fewer results in a results area 817. Scrolling may be cumbersome on these devices. Aggregation of words can be used wherever applicable to reduce bucket sizes and hence scrolling.
[0045] In accordance with one or more embodiments of the invention, the system provides visual cues to users to assist in educating the user on what would be a generally optimal prefix string entry. In the illustrated examples, the visual cues are in the form of underlined prefixes beneath each result 804, 818. The user may over time learn to enter a generally optimal prefix string input due to the visual cues. The optimal prefix string that can display a term within the display space of a device without scrolling can be determined in advance by the system taking into account the number of lines in the display and the relevance factor of the term.
[0046] In accordance with one or more embodiments of the invention, entity and term space complexity is considered in designing a search/disambiguating mechanism and operations, in addition to device characteristics themselves. In some cases, in order to apply one or more embodiments of this invention to a given entity/term space, it is useful to appropriately partition the space and have multiple distinct computing engines to serve requests. For example a movie search space could be broken down into smaller search spaces by categorizing them into genres. Similarly a phone book search space can be broken down by categorizing it into cities, and towns. The average size of the hash bucket would set a lower bound on the prefix size. Furthermore, the number of characters to be entered may have to be increased to keep the hash collision count within the tolerable limit of scrolling. For example, in a study done on the movie space, a random sampling of 150,000 English movie titles revealed that 99% of the search space can be covered by 6 characters with hash collisions below 10, while approximately 50% of the search space was covered by a 4 character scheme with a hash collision size below 10. It is interesting to note while the search space was only 150,000 items, it took 6 characters or 300 million buckets to contain the collisions within 10. A study of a restaurant namespace in Westchester, N.Y. with a listing of 1,500 restaurants showed that 98-99% of the restaurants were listed within a display list of top 5 restaurants with the entry of 4 characters, where 2 characters were taken from the first word and two from the next. A study of phonebook namespace for Connecticut State Govt. with 29,500 employees expanded to 58,000 to accommodate for unordered namespace revealed that for a bucket size of 10 and with 4 characters (first word 2 characters and 2 characters from the second word), 62% were listed in the top 10 names. When the number of characters entered increased to 6, 96.5% were listed within the top 10 names.
[0047] Methods of identifying content from reduced text input in accordance with various embodiments of the invention are preferably implemented in software, and accordingly one of the preferred implementations is as a set of instructions (program code) in a code module resident in the random access memory of a computer. Until required by the computer, the set of instructions may be stored in another computer memory, e.g., in a hard disk drive, or in a removable memory such as an optical disk (for eventual use in a CD ROM) or floppy disk (for eventual use in a floppy disk drive), or downloaded via the Internet or some other computer network. In addition, although the various methods described are conveniently implemented in a general purpose computer selectively activated or reconfigured by software, one of ordinary skill in the art would also recognize that such methods may be carried out in hardware, in firmware, or in more specialized apparatus constructed to perform the specified method steps.
[0048] Having described preferred embodiments of the present invention, it should be apparent that modifications can be made without departing from the spirit and scope of the invention.
[0049] Method claims set forth below having steps that are numbered or designated by letters should not be considered to be necessarily limited to the particular order in which the steps are recited.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.