MIC-1 Compounds and Use Thereof
Zhang; Xujia ; et al.
U.S. patent application number 16/303516 was filed with the patent office on 2019-08-15 for mic-1 compounds and use thereof. This patent application is currently assigned to Novo Nordisk A/S. The applicant listed for this patent is Novo Nordisk A/S. Invention is credited to Xiang Gao, Hongtao Guan, Kristian Tage Hansen, Lars Fogh Iversen, Sebastian Beck Joergensen, Per Noergaard, Kristian Sass-Oerum, Henning Thoegersen, Yi Wang, Xujia Zhang.
| Application Number | 20190248852 16/303516 |
| Document ID | / |
| Family ID | 59009675 |
| Filed Date | 2019-08-15 |

| United States Patent Application | 20190248852 |
| Kind Code | A1 |
| Zhang; Xujia ; et al. | August 15, 2019 |
MIC-1 Compounds and Use Thereof
Abstract
The invention relates to MIC-1 compounds. More specifically it relates to compounds comprising a MIC-1 polypeptide and an N-terminal amino acid extension, wherein said extension consists of 3 to 36 amino acid residues and where the compound has a calculated pI lower than 6.5. The compounds of the invention have MIC-1 activity. 5 The invention also relates to pharmaceutical compositions comprising such compounds and pharmaceutically acceptable excipients, as well as the medical use of the compounds.
| Inventors: | Zhang; Xujia; (Beijing, CN) ; Gao; Xiang; (Beijing, CN) ; Guan; Hongtao; (Shanghai, CN) ; Thoegersen; Henning; (Farum, DK) ; Sass-Oerum; Kristian; (Koebenhavn V, DK) ; Iversen; Lars Fogh; (Holte, DK) ; Noergaard; Per; (Humlebaek, DK) ; Joergensen; Sebastian Beck; (Virum, DK) ; Hansen; Kristian Tage; (Slangerup, DK) ; Wang; Yi; (Beijing, CN) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assignee: | Novo Nordisk A/S Bagsvaerd DK Novo Nordisk A/S Bagsvaerd DK |
||||||||||
| Family ID: | 59009675 | ||||||||||
| Appl. No.: | 16/303516 | ||||||||||
| Filed: | May 24, 2017 | ||||||||||
| PCT Filed: | May 24, 2017 | ||||||||||
| PCT NO: | PCT/EP2017/062583 | ||||||||||
| 371 Date: | November 20, 2018 |
| Current U.S. Class: | 1/1 |
| Current CPC Class: | A61P 3/04 20180101; A61K 38/00 20130101; C07K 2319/31 20130101; C07K 14/475 20130101; A61K 38/27 20130101 |
| International Class: | C07K 14/475 20060101 C07K014/475; A61P 3/04 20060101 A61P003/04 |
Foreign Application Data
| Date | Code | Application Number |
|---|---|---|
| May 24, 2016 | CN | PCT/CN2016/083104 |
| Oct 27, 2016 | CN | PCT/CN2016/103574 |
Claims
1. A MIC-1 compound comprising a MIC-1 polypeptide and an N-terminal amino acid extension, wherein said extension consists of 3 to 36 amino acid residues and where the compound has a calculated p1 lower than 6.5.
2. The compound according to claim 1, wherein the compound is a homodimer and consists of between 218-296, 224-296 or 230-296 amino acid residues.
3. The compound according to claim 1, wherein said extension is in the range of 3-36, 3-30, 3-24, 3-12, 4-36, 4-30, 4-24, 4-12, 5-36, 5-30, 5-24, 5-12, 6-36, 6-30, 6-24, 6-12, 7-36, 7-30, 7-24, 7-12, 8-36, 8-30, 8-24, 8-12, 30-36, 32-36, 30-34, or 30-32 amino acid residues in length.
4. The compound according to claim 1, wherein the extension has surplus of acidic amino acid residues (Aspartic acid and Glutamic acid) of at least 3, 4, 5 or 6 compared to the number of basic amino acid residues (Lysine, Arginine and Histidine)
5. The compound according to claim 1, wherein the extension is composed of amino acid residues selected among the group consisting of A, E, G, P, S, T, Q, and D and wherein said extension comprises at least three E and/or D amino acid residues.
6. The compound according to claim 5, wherein the extension comprises 6 Ser, 4 Pro, 4 Gly, 4 Thr, 4 Glu and 2 Ala.
7. The compound according to claim 1, wherein the extension comprises one or more of the following sequences TABLE-US-00016 (SEQ ID NO: 4) SPAGSP, (SEQ ID NO: 5) TSESAT, (SEQ ID NO: 6) TSTEPE, (SEQ ID NO: 7) SEPATS, (SEQ ID NO: 8) TSTEEG, (SEQ ID NO: 9) PESGPG, (SEQ ID NO: 10) SGSAPG, (SEQ ID NO: 11) GSETPG, (SEQ ID NO: 12) SEPATSGSETPGSPAGSPTSTEEG, (SEQ ID NO: 13) SEPATSGSETPGTSESATPESGPG, (SEQ ID NO: 14) SEPATSGSETPGTSTEPESGSAPG, (SEQ ID NO: 15) SEPATSGSETPGSPAGSPTSTEEGSPAGSP, (SEQ ID NO: 16) SEPATSGSETPGTSESATPESGPGSPAGSP, (SEQ ID NO: 17) SEPATSGSETPGTSTEPESGSAPGSPAGSP, (SEQ ID NO: 18) SEPATSGSETPGSPAGSPTSTEEGTSESAT, (SEQ ID NO: 19) SEPATSGSETPGTSESATPESGPGTSESAT, (SEQ ID NO: 20) SEPATSGSETPGTSTEPESGSAPGTSESAT, (SEQ ID NO: 21) SEPATSGSETPGSPAGSPTSTEEGTSTEPE, (SEQ ID NO: 22) SEPATSGSETPGTSESATPESGPGTSTEPE, (SEQ ID NO: 23) SEPATSGSETPGTSTEPESGSAPGTSTEPE, (SEQ ID NO: 24) SEPATSGSETPGSPAGSPTSTEEGSEPATS, (SEQ ID NO: 25) SEPATSGSETPGTSESATPESGPGSEPATS, (SEQ ID NO: 26) SEPATSGSETPGTSTEPESGSAPGSEPATS, (SEQ ID NO: 27) SEPATSGSETPGSPAGSPTSTEEGTSTEEG, (SEQ ID NO: 28) SEPATSGSETPGTSESATPESGPGTSTEEG, (SEQ ID NO: 29) SEPATSGSETPGTSTEPESGSAPGTSTEEG, (SEQ ID NO: 30) SEPATSGSETPGSPAGSPTSTEEGPESGPG, (SEQ ID NO: 31) SEPATSGSETPGTSESATPESGPGPESGPG, (SEQ ID NO: 32) SEPATSGSETPGTSTEPESGSAPGPESGPG, (SEQ ID NO: 33) SEPATSGSETPGSPAGSPTSTEEGSGSAPG, (SEQ ID NO: 34) SEPATSGSETPGTSESATPESGPGSGSAPG, (SEQ ID NO: 35) SEPATSGSETPGTSTEPESGSAPGSGSAPG, (SEQ ID NO: 36) SEPATSGSETPGSPAGSPTSTEEGGSETPG, (SEQ ID NO: 37) SEPATSGSETPGTSESATPESGPGGSETPG, (SEQ ID NO: 38) SEPATSGSETPGTSTEPESGSAPGGSETPG, (SEQ ID NO: 70) SEPATSGSETPGTSESATPESGPGTSTEPS, (SEQ ID NO: 71) SEPATSGSETPGTSESATPESGPGTSTEPSEG, (SEQ ID NO: 39) SEPATSGSETPGSPAGSPTSTEEGTSESATPESGPG, (SEQ ID NO: 40) SEPATSGSETPGSPAGSPTSTEEGSPAGSPTSTEEG, (SEQ ID NO: 41) SEPATSGSETPGSPAGSPTSTEEGTSTEPESGSAPG, (SEQ ID NO: 42) SEPATSGSETPGTSESATPESGPGSPAGSPTSTEEG, (SEQ ID NO: 43) SEPATSGSETPGTSESATPESGPGTSESATPESGPG, (SEQ ID NO: 44) SEPATSGSETPGTSESATPESGPGTSTEPESGSAPG, (SEQ ID NO: 45) SEPATSGSETPGTSESATPESGPGSEPATSGSETPG, (SEQ ID NO: 46) SEPATSGSETPGTSTEPESGSAPGSPAGSPTSTEEG, (SEQ ID NO: 47) SEPATSGSETPGTSTEPESGSAPGTSESATPESGPG, (SEQ ID NO: 48) SEPATSGSETPGTSTEPESGSAPGTSTEPESGSAPG, (SEQ ID NO: 49) SEPATSGSETPGTSTEPESGSAPGSEPATSGSETPG, (SEQ ID NO: 50) SEPATSGSETPGSEPATSGSETPGSPAGSPTSTEEG, (SEQ ID NO: 51) SEPATSGSETPGSEPATSGSETPGTSESATPESGPG, (SEQ ID NO: 52) SEPATSGSETPGSEPATSGSETPGTSTEPESGSAPG, (SEQ ID NO: 53) SEPATSGSETPGSEPATSGSETPGSEPATSGSETPG, (SEQ ID NO: 136) GGGS, (SEQ ID NO: 137) GSGS, (SEQ ID NO: 138) GGSS and (SEQ ID NO: 139) SSSG.
8. The compound according to claim 1, wherein the extension comprises one or more of the following sequences TABLE-US-00017 (SEQ ID NO: 118) GEPS, (SEQ ID NO: 119) GPSE, (SEQ ID NO: 120) GPES, (SEQ ID NO: 121) GSPE, (SEQ ID NO: 122) GSEP, (SEQ ID NO: 140) GEPSGEPSGEPSGEPSGEPS, (SEQ ID NO: 141) GPSEGPSEGPSEGPSEGPSE, (SEQ ID NO: 142) GPESGPESGPESGPESGPES, (SEQ ID NO: 143) GSPEGSPEGSPEGSPEGSPE, (SEQ ID NO: 144) GSEPGSEPGSEPGSEPGSE, (SEQ ID NO: 123) GEPQ, (SEQ ID NO: 124) GEQP, (SEQ ID NO: 125) GPEQ, (SEQ ID NO: 126) GPQE, (SEQ ID NO: 127) GQEP, (SEQ ID NO: 128) GQPE, (SEQ ID NO: 145) GEPQGEPQGEPQGEPQGEPQ, (SEQ ID NO: 146) GEQPGEQPGEQPGEQPGEQP, (SEQ ID NO: 147) GPEQGPEQGPEQGPEQGPEQ, (SEQ ID NO: 148) GPQEGPQEGPQEGPQEGPQE, (SEQ ID NO: 149) GQEPGQEPGQEPGQEPGQEP, (SEQ ID NO: 150) GQPEGQPEGQPEGQPEGQPE, (SEQ ID NO: 136) GGGS, (SEQ ID NO: 137) GSGS, (SEQ ID NO: 138) GGSS and (SEQ ID NO: 139) SSSG.
9. The compound according to claim 1, wherein the extension comprises one or more of the following sequences TABLE-US-00018 (SEQ ID NO: 129) PEDEETPEQE, (SEQ ID NO: 130) PDEGTEEETE, (SEQ ID NO: 131) PAAEEEDDPD, (SEQ ID NO: 132) AEPDEDPQSED, (SEQ ID NO: 133) AEPDEDPQSE, (SEQ ID NO: 134) AEPEEQEED, (SEQ ID NO: 135) AEPEEQEE, (SEQ ID NO: 151) AEEAEEAEEAEEAEE, (SEQ ID NO: 136) GGGS, (SEQ ID NO: 137) GSGS, (SEQ ID NO: 138) GGSS and (SEQ ID NO: 139) SSSG.
10. The compound according to claim 1, wherein the MIC-1 polypeptide displays at least 85%, 90%, 95% or 98% sequence identity to MIC-1 of SEQ ID NO:1.
11. The compound according to claim 1, wherein the MIC-1 polypeptide comprise one or more of the following substitutions N3E, P11E, H18E, R21E, A30E, A47E, R53E, A54E, M57E, M57L, H66E, R67E, L68E, K69E, A75E, A81E, P85E, M86L, Q90E, T92E, L105E and K107E compared to MIC-1 of SEQ ID NO:1.
12. The compound according to claim 1, wherein the MIC-1 polypeptide comprise a deletion of the first three residues (MIC-1-.DELTA.1-3) or a deletion of N3 (des-N3) compared to MIC-1 of SEQ ID NO:1.
13. A MIC-1 compound comprising a MIC-1 polypeptide and an N-terminal amino acid extension, wherein the compound comprises an amino acid sequence according to SEQ ID NO: 100, 104, 106, 107, 108, 109, 111, 112, 113, 114, 115, 116, 117 or 164.
14. The compound according to claim 13, wherein the compound has a solubility of 0.5, 1.0, 5.0, 10, 30 or 50 mg/ml at pH 8.0 in a Tris buffer system.
15. A method for treating a metabolic disorder, comprising administering to a subject in need thereof the compound according to claim 1, wherein the metabolic disorder is selected from the group consisting of obesity, diabetes, cardiovascular like dyslipidaemia, arteriosclerosis, steatohepatitis, and diabetic nephropathy.
Description
TECHNICAL FIELD
[0001] The present invention relates to MIC-1 compounds and their pharmaceutical use.
INCORPORATION-BY-REFERENCE OF THE SEQUENCE LISTING
[0002] The Sequence Listing, entitled "SEQUENCE LISTING", is 142,554 bytes, was created on 24 May 2017 and is incorporated herein by reference.
BACKGROUND OF INVENTION
[0003] Macrophage Inhibitory Cytokine-1 (MIC-1) was first described in 1997 (Bootcov et al, Proc. Natl. Acad. Sci. October 1997) based on experiments showing increased expression in activated macrophages. MIC-1 has subsequently been identified by others and given several additional names such as placental transforming growth factor beta (PTGF-.beta.), placental bone morphogenetic protein, growth differentiation factor-15 (GDF15), prostate derived factor (PDF), non-steroidal anti-inflammatory drug-activated gene (NAG-1) and PL74.
[0004] MIC-1 is a distant member of the TGF-beta super family, a family of peptide hormones involved in cell growth and differentiation. MIC-1 circulates as a cysteine-rich homodimer with a molecular mass of 24.5 kDa. MIC-1 was initially reported to be up-regulated in macrophages by stimuli including IL-1b, TNF-alpha, IL-2, and TGF-b. It was also shown that MIC-1 could reduce lipopolysaccharide-induced TNF-alpha production and it was based on these data proposed that MIC-1 was an anti-inflammatory cytokine.
[0005] More recently, (Johnen et al, Nat Med., November 2007) data from patients with advanced cancer showed that weight loss correlated with circulating levels of MIC-1. These data indicates that MIC-1 regulates body weight. This hypothesis was tested in mice xenografted with prostate tumor cells, where elevated MIC-1 levels were associated with loss of body weight and decreased food intake, an effect which could be reversed by administration of neutralising antibodies against MIC-1. As administration of recombinant MIC-1 to mice regulated hypothalamic neuropeptide Y and pro-opiomelanocortin it was proposed that MIC-1 regulates food intake by a central mechanism. Furthermore, transgenic mice overexpressing MIC-1 are gaining less weight and body fat both on a normal low fat diet and on a high fat diet (Macia et al, PLoS One, April 2012). Also, transgenic mice overexpressing MIC-1 fed both on a low and high fat diet, respectively, had improved glucose tolerance compared with wild type animals on a comparable diet.
[0006] Obesity is most commonly caused by excessive calorie intake alone or in conjunction with decreased energy expenditure and/or lack of physical exercise. Obesity is a well-established risk factor for metabolic diseases like diabetes, cardiovascular diseases, sleep apnea and cancer.
SUMMARY OF INVENTION
[0007] Described herein are MIC-1 compounds comprising MIC-1 polypeptides with N-terminal amino acid extensions.
[0008] In one aspect, the MIC-1 compounds of the invention have good biophysical properties. These properties include but are not limited to solubility and stability. In one aspect, the MIC-1 compounds of the invention have improved solubility. In one aspect, the MIC-1 compounds of the invention have improved chemical stability.
[0009] In one aspect, the compounds of the invention have improved biophysical stability as shown by reduced crystal forming tendency.
[0010] In one aspect, the MIC-1 compounds of the invention have retained MIC-1 receptor potency and in vivo efficacy on lowering food intake and body weight. These MIC-1 compounds can therefore be used for treatment of metabolic disorders such as obesity, diabetes, cardiovascular diseases like dyslipidaemia and arteriosclerosis and other disorders such as steatohepatitis and diabetic nephropathy.
[0011] In one aspect, the MIC-1 compounds of the invention comprises a MIC-1 polypeptide and an N-terminal amino acid extension, wherein said extension consists of 3 to 36 amino acid residues and where the compound has a calculated pI lower than 6.5.
[0012] In some embodiments of the invention the MIC-1 compound has a calculated pI that is lower than 6.1.
[0013] In some embodiments of the invention the MIC-1 compound has a calculated pI that is higher than 4.7.
[0014] In some embodiments of the invention the MIC-1 compound has a calculated pI that is higher than 4.7 and lower than 6.1.
[0015] In some embodiments of the invention the MIC-1 compound has a calculated pI is in the range of 5.8-5.2.
[0016] In some embodiments the MIC-1 compounds of the invention, as homodimers, have between 218-296, 224-296 or 230-296 amino acid residues.
[0017] In some embodiments the MIC-1 compounds of the invention comprise an N-terminal extension that is in the range of 3-35, 3-30, 3-25, 3-24, 4-36, 4-35, 4-30, 4-25, 4-24, 5-36, 5-35, 5-30, 5-25, 5-24, 6-36, 6-35, 6-30, 6-25, 6-24, 7-36, 7-35, 7-30, 7-25, 7-24, 8-36, 8-35, 8-30, 8-25, 8-24, 8-12, 30-36, 32-36, 30-34, or 30-32 amino acid residues in length.
[0018] In some embodiments the MIC-1 compounds of the invention comprise an N-terminal extension that is in the range of 30-32 amino acid residues in length.
[0019] In some embodiments the MIC-1 compounds of the invention comprise an N-terminal extension that has surplus of acidic amino acid residues (Aspartic acid and Glutamic acid) of at least 3, 4, 5 or 6 compared to the number of basic amino acid residues (Lysine, Arginine and Histidine).
[0020] In some embodiments of the invention the MIC-1 compounds comprise N-terminal extensions composed of amino acid residues selected among the group consisting of A, E, G, P, S, T, Q, and D wherein said extension comprises at least three E and/or D amino acid residues.
[0021] In some embodiments the MIC-1 compounds of the invention comprise an MIC-1 polypeptide that display at least 85%, 90%, 95% or 98% sequence identity to MIC-1 of SEQ ID NO:1.
[0022] In some embodiments the MIC-1 compounds of the invention comprise an MIC-1 polypeptide that comprises one or more of the following substitutions N3E, P11E, H18E, R21E, A30E, A47E, R53E, A54E, M57E, M57L, R67E, L68E, K69E, A75E, A81E, P85E, M86L, L105E, and K107E compared to MIC-1 of SEQ ID NO:1 and/or a deletion of the first three residues (MIC-1-.DELTA.1-3) or a deletion of N3 (des-N3) compared to MIC-1 of SEQ ID NO:1.
[0023] In a particular embodiment of the invention the MIC-1 compound comprises a MIC-1 polypeptide and an N-terminal amino acid extension with an amino acid sequence according to SEQ ID NO: 87, 90, 92, 93, 94, 97, 98, 99, 100, 101, 102, 108, 109, or 164.
[0024] In one aspect, the invention provides MIC-1 compounds having a solubility of about 0.5, 1.0, 5.0, 10, 30 or 50 mg/ml at pH 8.0 in a tris(hydroxymethyl)aminomethane (Tris) buffer system.
[0025] In one aspect, the invention provides a polynucleotide molecule encoding a MIC-1 compound of the invention.
[0026] In one aspect, the invention provides a pharmaceutical composition comprising the MIC-1 compound of the invention or a pharmaceutically acceptable salt, amide or ester thereof, and one or more pharmaceutically acceptable excipients.
[0027] In one aspect, the invention provides a MIC-1 compound of the invention for use as a medicament.
[0028] In one aspect, the invention provides a MIC-1 compound of the invention for use in the prevention and/or treatment of a metabolic disorder, wherein the metabolic disorder is obesity, type 2 diabetes, dyslipidemia, or diabetic nephropathy.
[0029] In one aspect, the invention provides a MIC-1 compound of the invention for use in the prevention and/or treatment of eating disorders, such as obesity, e.g. by decreasing food intake, reducing body weight, suppressing appetite and inducing satiety.
[0030] In one aspect, the invention provides a MIC-1 compound of the invention for use in the prevention and/or treatment of obesity.
[0031] In one aspect, the compounds of the invention are MIC-1 receptor agonists. In one aspect, the compounds of the invention inhibit food intake. In one aspect, the compounds of the invention reduce body weight.
[0032] In one aspect, the invention provides a MIC-1 compound of the invention for use in the prevention and/or treatment of a cardiovascular disease.
[0033] In one aspect, the invention provides a MIC-1 compound of the invention for use in the prevention and/or treatment of dyslipidaemia, arteriosclerosis, steatohepatitis, or diabetic nephropathy.
BRIEF DISCRIPTION OF DRAWINGS
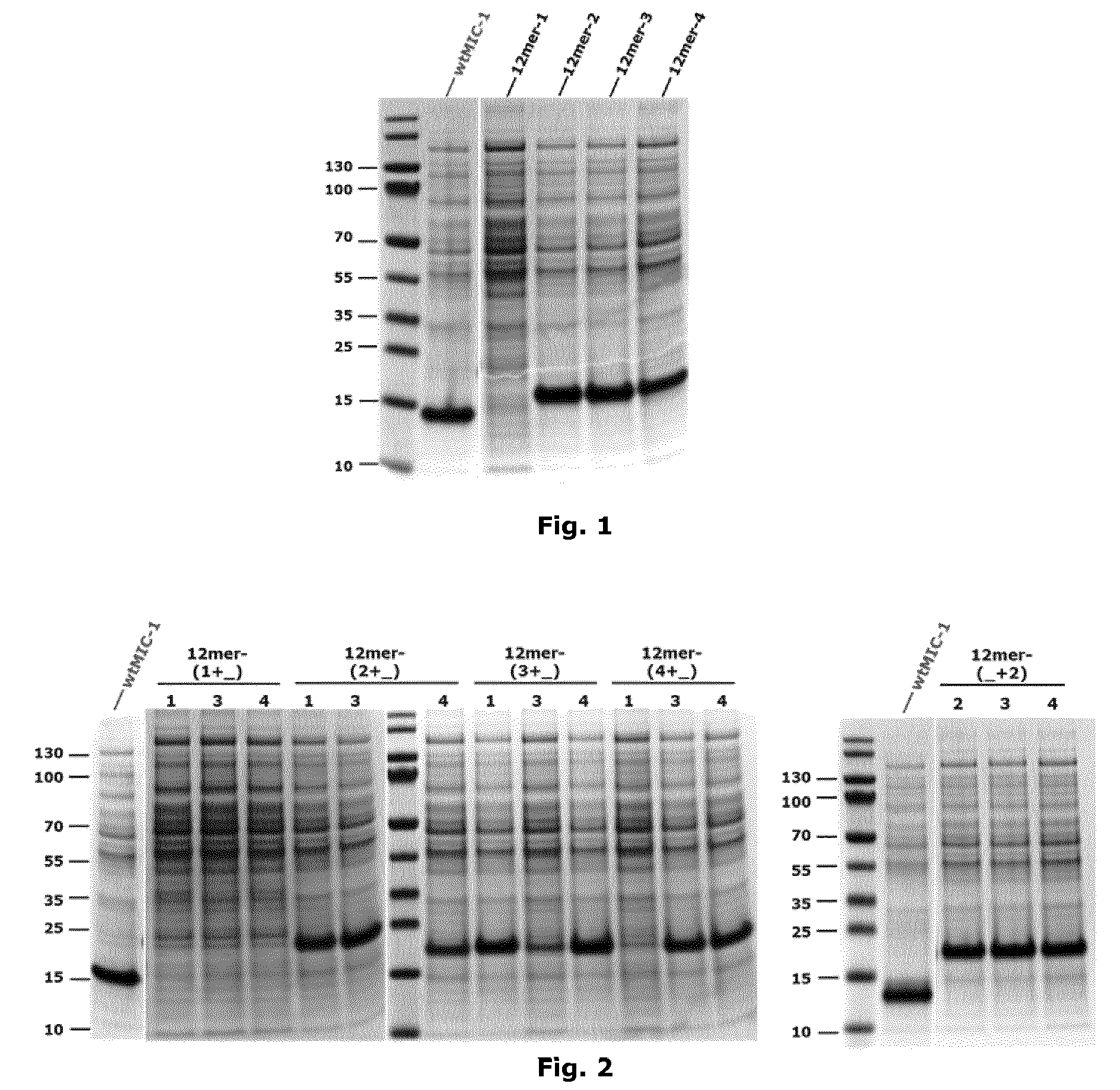
[0034] FIG. 1: The expression of MIC-1 compounds with single 12-mer building blocks. All cells were grown in TB at 37.degree. C. and proteins were induced to express by adding 0.5 mM IPTG after OD600 reached 1.0. Cells were harvested after overnight and the expression level was checked by loading the total lysate on SDS-PAGE. wtMIC-1 was loaded as the positive control.
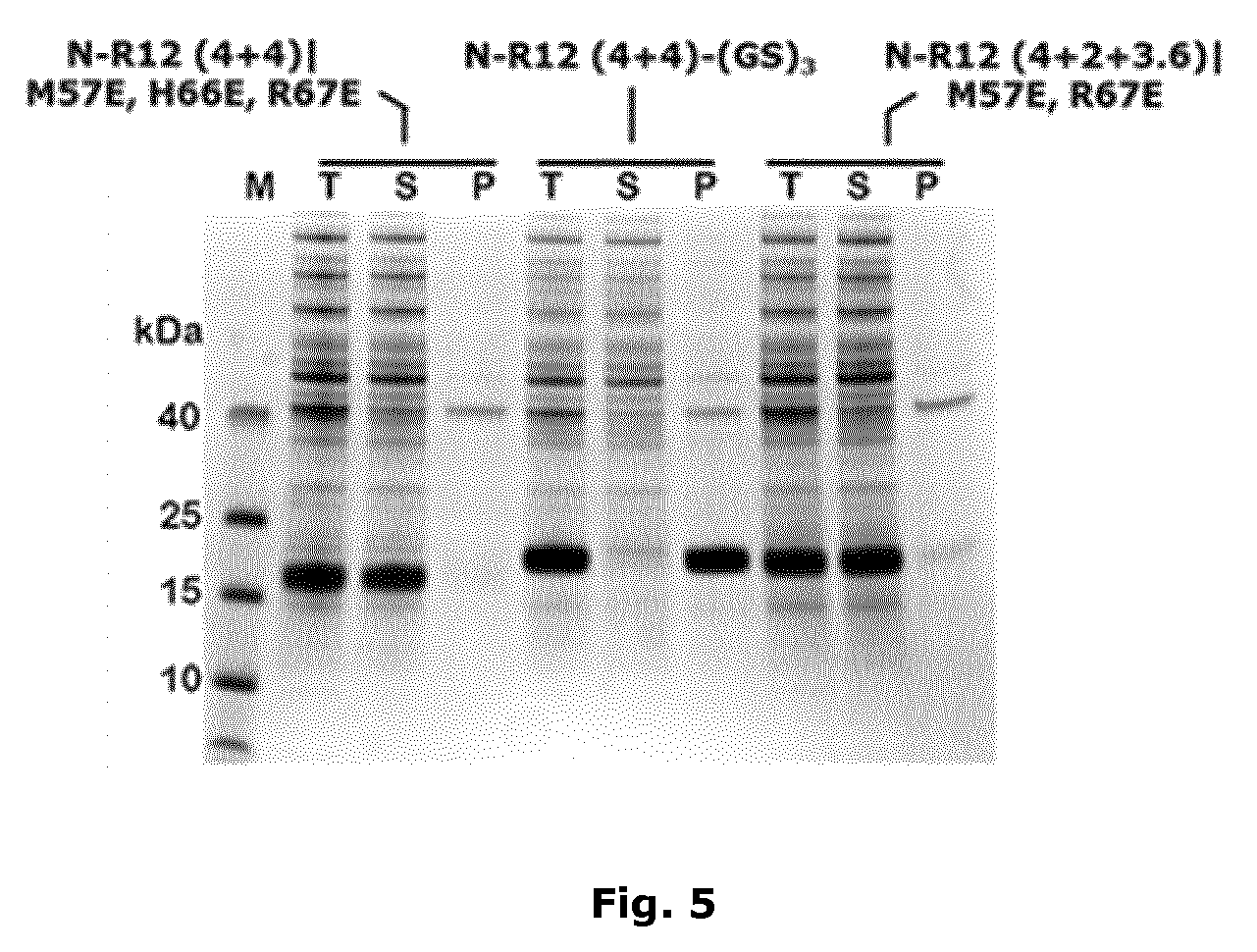
[0035] FIG. 2: The expression of MIC-1 compounds with double 12-mer building blocks. All cells were grown in TB at 37.degree. C. and proteins were induced to express by adding 0.5 mM IPTG after OD600 reached 1.0. Cells were harvested after overnight and the expression level was checked by loading the total lysate on SDS-PAGE. wtMIC-1 was loaded as the positive control.
[0036] FIG. 3: a) comparison of expression levels among MIC-1 compounds initiating with 12mer-(4+2+_), -(4+4+_) and -(4+3+_). It should be noticed that the group bearing 12mer-(4+3_) and the construct indicated by the dot contain M57L in the backbone of MIC-1. b) the effects of the extended 12mers on the expression level. In addition, the lowest data point in the group of 3.6 is the MIC-1 compound containing M57L. In this figure, "1.6 latter" represents TSTEEG, "2.6" represents TSESAT, "3.6" represents TSTEPS and "4.6" represents SEPATS.
[0037] FIG. 4: SDS-PAGE of representatives bearing 12mer-(4+2+_), 12mer-(4+3+_)+M57L, 12mer-(three repeats) and 12mer-(four repeats). T: total protein, S: soluble fraction, P: cell pellet (inclusion body).
[0038] FIG. 5: Solubility of MIC-1 compounds with in-sequence mutations. In this figure, the backbone is MIC-1 del(1-3).
DETAILED DESCRIPTION
[0039] The invention relates to a MIC-1 compound comprising a MIC-1 polypeptide. In one aspect, the invention relates to a MIC-1 compound comprising a MIC-1 polypeptide and an N-terminal amino acid extension, wherein said extension consists of 3 to 200 amino acid residues and where the compound has a calculated pI lower than 6.5.
MIC-1
[0040] The term "MIC-1" as used herein means Macrophage Inhibitory Cytokine-1 (MIC-1), also known as Growth Differentiation Factor 15 (GDF-15), placental bone morphogenetic protein (PLAB) and nonsteroidal anti-inflammatory drug-activated gene (NAG-1). MIC-1 is synthesized as a 62 kDa intracellular homodimer precursor protein which subsequently is cleaved by a furin-like protease into a 24.5 kDa homodimer. The sequence of the full length wild type human MIC-1 is available from the UNIPROT database with accession no. Q99988. The 308 amino acid precursor sequence includes a signal peptide (amino acids 1-29), a propeptide (amino acids 30-196) and a MIC-1 monomer sequence (amino acids 197-308). The 112 amino acid MIC-1 monomer sequence is included herein as SEQ ID NO:1. MIC-1 monomer contains nine cysteine residues which give rise to the formation of 4 intrachain disulphide bonds and one interchain disulphide bond to create a covalently linked 24.5 kDa homodimer. A naturally occurring mutation corresponding to H6D in the MIC-1 monomer sequence (SEQ ID NO:1) has been described.
[0041] The term "MIC-1 compound", as used herein, refers to a compound comprising a MIC-1 polypeptide and an N-terminal amino acid extension. The MIC-1 compound is typically in the form of a homodimer.
[0042] The term "MIC-1 polypeptide" as used herein refers to the human MIC-1 monomer sequence of SEQ ID NO:1 or an analogue thereof. Numerical references to particular MIC-1 residues, if not stated otherwise, refer to the 112 amino acid monomer sequence (i.e., residue 1 is Alanine (A1), and residue 112 is Isoleucine (I112).
[0043] The term "MIC-1 analogue", or "analogue of MIC-1" as used herein refers to a MIC-1 polypeptide, which is an amino acid variant of the monomer MIC-1 sequence of SEQ ID NO:1. In other words, a MIC-1 analogue is a MIC-1 polypeptide in which a number of amino acid residues have been changed when compared to human MIC-1 (SEQ ID NO: 1). These changes may represent, independently, one or more amino acid substitutions, additions, and/or deletions.
[0044] MIC-1 analogues may be described by reference to the amino acid residue which is changed, the number of the amino acid residue (i.e. the corresponding position in the MIC-1 monomer sequence (SEQ ID NO:1)), and the change (e.g. the amino acid residue change to).
[0045] In one aspect, the MIC-1 analogue is a functional variant of the MIC-1 of SEQ ID NO:1. In one aspect of the invention, the MIC-1 analogues display at least 85%, 90% or 95% sequence identity to MIC-1 of SEQ ID NO:1. As an example of a method for determination of the sequence identity between two analogues the two peptides H6D MIC-1 and MIC-1 of SEQ ID NO:1 are aligned. The sequence identity of the H6D MIC-1 analogue relative to MIC-1 of SEQ ID NO:1 is given by the number of aligned identical residues minus the number of different residues divided by the total number of residues in MIC-1 of SEQ ID NO:1. Accordingly, in said example the sequence identity in percentage is (112-1)/112.times.100. In the determination of the sequence identity of a MIC-1 analogue, the N-terminal amino acid extension is not included.
[0046] In another aspect of the invention, the MIC-1 analogues comprise less than for example less than 15, 10 or 5, amino acid modifications (substitutions, deletions, additions (including insertions) and any combination thereof) relative to human MIC-1 of SEQ ID NO:1. The term "amino acid modification" used throughout this application is used in the meaning of a modification to an amino acid as compared to monomer MIC-1 (SEQ ID NO:1). This modification can be the result of a deletion of an amino acid, addition of an amino acid, substitution of one amino acid with another or a substituent covalently attached to an amino acid of the peptide.
[0047] Substitutions: In one aspect amino acids may be substituted by conservative substitution. The term "conservative substitution" as used herein denotes that one or more amino acids are replaced by another, biologically similar residue. Examples include substitution of amino acid residues with similar characteristics, e.g. small amino acids, acidic amino acids, polar amino acids, basic amino acids, hydrophobic amino acids and aromatic amino acids.
[0048] In one aspect amino acids may be substituted by non-conservative substitution. The term "non-conservative substitution" as used herein denotes that one or more amino acids are replaced by another amino acid having different characteristics. Examples include substitution of a basic amino acid residue with an acidic amino acid residue, substitution of a polar amino acid residue with an aromatic amino acid residue, etc. In one aspect, the non-conservative substitution is substitution of a coded amino acid to another coded amino acid having different characteristics. In one aspect, the MIC-1 analogues may comprise substitutions of one or more unnatural and/or non-amino acids, e.g., amino acid mimetics, into the sequence of MIC-1.
[0049] The asparagine residue in position 3 (N3) of human MIC-1 monomer sequence (SEQ ID NO:1) is chemically labile. In one aspect of the invention, the asparagine in the position corresponding to position 3 of monomer MIC-1 sequence (SEQ ID NO:1) may be substituted to Serine (N3S), Glutamic acid (N3E), Alanine (N3A), or Glutamine (N3Q). In one aspect of the invention, the asparagine in the position corresponding to position 3 of human MIC-1 monomer sequence (SEQ ID NO:1) has been substituted to Glutamic acid (N3E).
[0050] In one aspect of the invention, the arginine in the position corresponding to position 2 of human MIC-1 monomer sequence (SEQ ID NO:1) has been substituted to alanine (R2A), and the asparagine in the position corresponding to position 3 of human MIC-1 monomer sequence (SEQ ID NO:1) has been substituted to Glutamic acid (N3E).
[0051] Deletions and Truncations: In one aspect, the MIC-1 analogues of the invention may have one or more amino acid residues deleted from the amino acid sequence of MIC-1 (SEQ ID NO:1), alone or in combination with one or more insertions or substitutions.
[0052] MIC-1 analogues with amino acid deletions may be described by "des", reference to the amino acid residue which is deleted, and followed by the number of the deleted amino acid (i.e. the corresponding position in the monomer MIC-1 (SEQ ID NO:1)). In some embodiments of the invention, the asparagine in the position corresponding to position 3 of human monomer MIC-1 (SEQ ID NO:1) is deleted (MIC-1 des-N3, SEQ ID NO:2).
[0053] MIC-1 analogues with a truncation of one or more amino acid residues at the N or C terminal may be described by "MIC-1-.DELTA." and reference to the number(s) of the deleted amino acid residues (i.e. the corresponding position in the monomer MIC-1 (SEQ ID NO:1)). In some embodiments of the invention, the first three residues (A1, R2, N3) at the N terminal are deleted (MIC-1-.DELTA.1-3, SEQ ID NO:3).
[0054] Insertions: In one aspect, the MIC-1 analogues of the invention may have one or more amino acid residues inserted into the amino acid sequence of human MIC-1, alone or in combination with one or more deletions and/or substitutions.
[0055] In one aspect, the MIC-1 analogues of the invention may include insertions of one or more unnatural amino acids and/or non-amino acids into the sequence of MIC-1.
[0056] The term "protein" or "polypeptide", as e.g. used herein, refers to a compound which comprises a series of amino acids interconnected by amide (or peptide) bonds. Amino acids are molecules containing an amine group and a carboxylic acid group, and, optionally, one or more additional groups, often referred to as a side chain.
[0057] The term "amino acid" includes coded (or proteinogenic or natural) amino acids (amongst those the 20 standard amino acids), as well as non-coded (or non-proteinogenic or non-natural) amino acids. Coded amino acids are those which are naturally incorporated into proteins. The standard amino acids are those encoded by the genetic code. Non-coded amino acids are either not found in proteins, or not produced by standard cellular machinery (e.g., they may have been subject to post-translational modification). In what follows, all amino acids of the MIC-1 proteins for which the optical isomer is not stated is to be understood to mean the L-isomer (unless otherwise specified).
[0058] As is apparent from the above, amino acid residues may be identified by their full name, their one-letter code, and/or their three-letter code. These three ways are fully equivalent. For the reader's convenience, the single and three letter amino acid codes are provided below:
[0059] Glycine: G and Gly; Proline: P and Pro; Alanine: A and Ala; Valine: V and Val; Leucine: L and Leu; Isoleucine: I and Ile; Methionine: M and Met; Cysteine: C and Cys; Phenylalanine: F and Phe; Tyrosine: Y and Tyr; Tryptophan: W and Trp; Histidine: H and His; Lysine: K and Lys; Arginine: R and Arg; Glutamine: Q and Gin; Asparagine: N and Asn; Glutamic Acid: E and Glu; Aspartic Acid: D and Asp; Serine: S and Ser; and Threonine: T and Thr.
N-Terminal Amino Acid Extension
[0060] In some embodiments of the invention the MIC-1 compound comprises an N-terminal amino acid extension.
[0061] The term "N-terminal amino acid extension" as used herein, means that the N-terminal of the MIC-1 polypeptide is attached to the C-terminal of the N-terminal amino acid extension via an amide bond, preferably a peptide bond. The terms "N-terminal amino acid extension", "N-terminal extension", and "N-extension" herein means the same thing and are used interchangeably. In one embodiment, the compound of the invention comprises human MIC-1 monomer sequence (SEQ ID NO:1) with an amino acid extension attached at the N-terminal, i.e. the Alanine at positon 1 (A1) via a peptide bond.
[0062] In some embodiments of the invention, the N-terminal amino acid extension is up to 200 amino acid residues long. In a particular embodiment of the invention the N-terminal amino acid extension has from 3 to 36 amino acid residues.
[0063] In one aspect of the invention, the N-terminal amino acid extension has a surplus of acidic amino acid residues (Aspartic acid and Glutamic acid) of at least 3, 4, 5 or 6 compared to the number of basic amino acid residues (Lysine, Arginine and Histidine). A "surplus" of acidic amino acid residues means that the number of acidic residues exceeds the number of basic residues. A defined value of the surplus of acidic amino acid residues is calculated as the number of acidic residues minus the number of basic residues.
[0064] Methionine is the initial amino acid for protein expression in prokaryotic cells (e.g. bacteria, for instance, E.coli). In some embodiments of the invention, the initial Methionine is removed from the protein during the protein expression. Therefore, the initial Methionine is not included in the sequence of the N-extension of MIC-1 compound. However, a person skilled in the art knows that the start codon, coding the initial Methionine, is required for the protein translation initiation and should be incorporated right in front of the nucleotide sequence for protein expression without exception.
[0065] Meanwhile, it can be understood that those MIC-1 compounds with N-extensions having the initial Methionine also fall into the scope of the invention.
Isoelectric Point (pI)
[0066] The calculated pI of a MIC-1 compound is defined as the pH at which the net calculated charge of the compound is zero. The calculated charge of the MIC-1 compound as a function of pH is obtained using the pKa values of the amino acid residues described in Table 1 and the method described by B. Skoog and A. Wichman (Trends in Analytical Chemistry, 1986, vol. 5, pp. 82-83). The side chain pKa of cysteine (Cys) is only included in the charge calculation for cysteines with a free sulfhydryl group. As an example the calculated pI value of human wtMIC-1 is 8.8 as the homodimer.
[0067] As described herein, pI calculations on MIC-1 compounds are made on MIC-1 compounds as homodimers.
TABLE-US-00001 TABLE 1 pKa of amino acid residues used for calculating pI. The pKa values are those described in "Correlation of Electrophoretic Mobilities from Capillary Electrophoresis with Physicochemical Properties of Proteins and Peptides by Rickard E C, Strohl M M, Nielsen R G. Analytical Biochemistry 1991, vol 197, pp 197-207". N-terminus C-Terminus Side chain Asp 8.6 2.75 3.5 Asn 7.3 2.75 -- Thr 8.2 3.2 -- Ser 7.3 3.2 -- Glu 8.2 3.2 4.5 Gln 7.7 3.2 -- Pro 9 3.2 -- Gly 8.2 3.2 -- Ala 8.2 3.2 -- Val 8.2 3.2 -- Cys 7.3 2.75 10.3 Met 9.2 3.2 -- Ile 8.2 3.2 -- Leu 8.2 3.2 -- Tyr 7.7 3.2 10.3 Phe 7.7 3.2 -- Lys 7.7 3.2 10.3 His 8.2 3.2 6.2 Trp 8.2 3.2 -- Arg 8.2 3.2 12.5
[0068] In one aspect, the MIC-1 compounds of the invention have good biophysical properties. These properties include but are not limited to solubility and/or stability.
Solubility
[0069] The human wild type MIC-1 is a hydrophobic protein, with a calculated pI 8.8 based on the homodimer. Consequently, wild type MIC-1 can only be solubilized to around 0.5 mg/ml in neutral pH aqueous buffer systems. The low solubility of MIC-1 significantly hampers its formulation properties and therapeutic use, so developing a solubility-engineered MIC-1 compound is important for MIC-1 molecular engineering.
[0070] In one aspect, the compounds of the invention have improved solubility (i.e. are more soluble) relative to human MIC-1 of SEQ ID NO:1.
[0071] As described herein, solubility is measured as described in Example 4.
[0072] In certain embodiments, the MIC-1 compounds of the invention have a solubility of at least 1 mg/ml in Tris buffer at pH 8.0. In other embodiments, the compounds of the invention have a solubility of at least 5 mg/ml, at least 10 mg/ml, at least 30 mg/ml, or at least 40 mg/ml in Tris buffer at pH 8.0.
[0073] As described herein, solubility is measured on MIC-1 compounds as homodimers.
Stability
[0074] The human wild type MIC-1 sequence is a chemically instable and several residues of the amino acid sequence could be modified during storage, including deamidation on Asparagine at position 3 (N3) and oxidation of methionines M43, M57 and M86. Chemical instability of certain residues could impact pharmaceutical properties so developing chemical stable MIC-1 compounds would be another important part of making a MIC-1 therapeutic compound.
[0075] In one aspect, the compounds of the invention have improved chemical stability relative to human MIC-1 of SEQ ID NO:1.
[0076] The term "chemical stability" refers to chemical changes in the polypeptide structure leading to formation of chemical degradation products potentially having a reduced biological activity, decreased solubility, and/or increased immunogenic effect as compared to the intact polypeptide. The chemical stability can be evaluated by measuring the amount of chemical degradation products at various time-points after exposure to different environmental conditions, e.g. by SEC-HPLC, and/or RP-HPLC.
[0077] MIC-1 may be chemically instable; and several residues, of the amino acid sequence (SEQ ID NO:1) could be modified during storage, including deamidation of N3 and oxidation of the methionines M43, M57 and M86. Chemical instability of certain residues could impact pharmaceutical properties like low chemical stability for MIC-1 as a therapeutic compound.
[0078] In certain embodiments of the invention, certain residues of the MIC-1 monomer sequence (SEQ ID NO:1) is modified, e.g. by substitution to increase the chemical stability of the MIC-1 compounds. To avoid deamidation, N3 could be deleted or substituted with other amino acids, e.g. E or Q. To decrease oxidation, Methionine could be substituted with other amino acids, e.g. E or L.
Crystallisation
[0079] In one aspect, the compounds of the invention are showing reduced crystal forming tendency at pH 8.0 compared with MIC-1 of SEQ ID NO:1.
Immunogenicity
[0080] In one aspect, the compounds of the invention have low immunogenicity risk.
In Vitro Activity
[0081] In one aspect, the compounds of the invention have retained MIC-1 receptor potency relative to human MIC-1 (SEQ ID NO:1). Receptor potency and efficacy can be measured in mammalian cells transfected with human MIC-1 receptor (hGFRAL, GDNF family receptor alpha like) and its signalling co-receptor hRET51 (proto-oncogene tyrosine-protein kinase receptor Ret isoform 51). MIC-1 compounds activation of the receptor complex is measured by phosphorylation of extracellular signal-regulated kinases (ERKs) as described in Example 6.
[0082] As described herein receptor potency and efficacy is measured on MIC-1 compounds as homodimers.
In Vivo Biological Activity
[0083] In one aspect the compounds of the invention are potent in vivo, which may be determined as is known in the art in any suitable animal model.
[0084] The non-obese Sprague Dawley rat is one example of a suitable animal model, and the changes in food intake may be determined in such rats in vivo, e.g. as described in Example 7. In one aspect the compounds of the invention inhibits in vivo food intake in non-obese Sprague Dawley rats. Diet-Induced Obese (DIO) Sprague Dawley rats is another example of a suitable animal model, and the changes in food intake may be determined in such rats in vivo, In one aspect the compounds of the invention inhibits in vivo food intake and lowers body weight in DIO Sprague Dawley rats.
Production Processes
[0085] MIC-1 compounds of the present invention may be produced by means of recombinant protein technology known to persons skilled in the art. In general, nucleic acid sequences encoding the proteins of interest or functional variants thereof are modified to encode the desired MIC-1 compound. This modified sequence is then inserted into an expression vector, which is in turn transformed or transfected into the expression host cells.
[0086] The nucleic acid construct encoding the MIC-1 compound may suitably be of genomic, cDNA or synthetic origin. Amino acid sequence alterations are accomplished by modification of the genetic code by well-known techniques.
[0087] The DNA sequence encoding the MIC-1 compound is usually inserted into a recombinant vector which may be any vector, which may conveniently be subjected to recombinant DNA procedures, and the choice of vector will often depend on the host cell into which it is to be introduced. Thus, the vector may be an autonomously replicating vector, i.e. a vector, which exists as an extrachromosomal entity, the replication of which is independent of chromosomal replication, e.g. a plasmid. Alternatively, the vector may be one which, when introduced into a host cell, is integrated into the host cell genome and replicated together with the chromosome(s) into which it has been integrated.
[0088] The vector is preferably an expression vector in which the DNA sequence encoding the MIC-1 compound is operably linked to additional segments required for transcription of the DNA. The term, "operably linked" indicates that the segments are arranged so that they function in concert for their intended purposes, e.g. transcription initiates in a promoter and proceeds through the DNA sequence coding for the polypeptide until it terminates within a terminator.
[0089] Thus, expression vectors for use in expressing the MIC-1 compound will comprise a promoter capable of initiating and directing the transcription of a cloned gene or cDNA. The promoter may be any DNA sequence, which shows transcriptional activity in the host cell of choice and may be derived from genes encoding proteins either homologous or heterologous to the host cell.
[0090] Additionally, expression vectors for expression of the MIC-1 compound will also comprise a terminator sequence, a sequence recognized by a host cell to terminate transcription. The terminator sequence is operably linked to the 3' terminus of the nucleic acid sequence encoding the polypeptide. Any terminator which is functional in the host cell of choice may be used in the present invention.
[0091] Expression of the MIC-1 compound can be aimed for either intracellular expression in the cytosol of the host cell or be directed into the secretory pathway for extracellular expression into the growth medium.
[0092] Intracellular expression is the default pathway and requires an expression vector with a DNA sequence comprising a promoter followed by the DNA sequence encoding the MIC-1 compound followed by a terminator.
[0093] To direct the sequence of the MIC-1 compound into the secretory pathway of the host cells, a secretory signal sequence (also known as signal peptide or a pre sequence) is needed as an extension of the MIC-1 sequence. A DNA sequence encoding the signal peptide is joined to the 5' end of the DNA sequence encoding the MIC-1 compound in the correct reading frame. The signal peptide may be that normally associated with the protein or may be from a gene encoding another secreted protein.
[0094] The procedures used to ligate the DNA sequences coding for the MIC-1 compound, the promoter, the terminator and/or secretory signal sequence, respectively, and to insert them into suitable vectors containing the information necessary for replication, are well known to persons skilled in the art (cf., for instance, Sambrook et al., Molecular Cloning: A Laboratory Manual, Cold Spring Harbor, New York, 1989).
[0095] The host cell into which the DNA sequence encoding the MIC-1 compound is introduced may be any cell that is capable of expressing the MIC-1 compound either intracellularly or extracellularly. The MIC-1 compound may be produced by culturing a host cell containing a DNA sequence encoding the MIC-1 compound and capable of expressing the MIC-1 compound in a suitable nutrient medium under conditions permitting the expression of the MIC-1 compound. Non-limiting examples of host cells suitable for expression of MIC-1 compounds are: Escherichia coli, Saccharomyces cerevisiae, as well as human embryonic kidney (HEK), Baby Hamster Kidney (BHK) or Chinese hamster ovary (CHO) cell lines. If posttranslational modifications are needed, suitable host cells include yeast, fungi, insects and higher eukaryotic cells such as mammalian cells.
[0096] Once the MIC-1 compound has been expressed in a host organism it may be recovered and purified to the required quality by conventional techniques. Non-limiting examples of such conventional recovery and purification techniques are centrifugation, solubilization, filtration, precipitation, ion-exchange chromatography, immobilized metal affinity chromatography (IMAC), Reversed phase--High Performance Liquid Chromatography (RP-HPLC), gel-filtration and freeze drying.
[0097] Examples of recombinant expression and purification of MIC-1 proteins may be found in e.g. Cordingley et al., J. Virol. 1989, 63, pp5037-5045; Birch et al., Protein Expr Purif., 1995, 6, pp 609-618 and in WO2008/043847.
[0098] Examples of microbial expression and purification of MIC-1 proteins may be found in e.g. Chich et al, Anal. Biochem, 1995, 224, pp 245-249 and Xin et al., Protein Expr. Purif. 2002, 24, pp530-538.
[0099] Specific examples of methods of preparing a number of the compounds of the invention are included in the experimental part.
Inclusion Body and Protein Expression
[0100] MIC-1 compounds can be expressed in bacteria such as E. coli. In the context of the present invention, large scale protein production of said MIC-1 polypeptides with an N-extension could take of using Inclusion Bodies (IB) as this represent an advantageous approach to controlling process recovery, protein purity, protease degradation and general protein stability. This becomes particular important for large scale protein production. Of critical importance for the quality of IB is the balance of MIC-1 polypeptides with an N-extension solubility partly controlled by the calculated pI and IB formation.
Mode of Administration
[0101] The term "treatment" is meant to include both the prevention and minimization of the referenced disease, disorder, or condition (i.e., "treatment" refers to both prophylactic and therapeutic administration of a compound of the invention or composition comprising a compound of the invention unless otherwise indicated or clearly contradicted by context.
[0102] The route of administration may be any route which effectively transports a compound of this invention to the desired or appropriate place in the body, such as parenterally, for example, subcutaneously, intramuscularly or intraveneously. Alternatively, a compound of this invention can be administered orally, pulmonary, rectally, transdermally, buccally, sublingually, or nasally.
[0103] The amount of a compound of this invention to be administered, the determination of how frequently to administer a compound of this invention, and the election of which compound or compounds of this invention to administer, optionally together with another pharmaceutically active agent, is decided in consultation with a practitioner who is familiar with the treatment of obesity and related disorders.
Pharmaceutical Compositions
[0104] Pharmaceutical compositions comprising a compound of the invention or a pharmaceutically acceptable salt, amide, or ester thereof, and a pharmaceutically acceptable excipient may be prepared as is known in the art.
[0105] The term "excipient" broadly refers to any component other than the active therapeutic ingredient(s). The excipient may be an inert substance, an inactive substance, and/or a not medicinally active substance.
[0106] The excipient may serve various purposes, e.g. as a carrier, vehicle, diluent, tablet aid, and/or to improve administration, and/or absorption of the active substance.
[0107] The formulation of pharmaceutically active ingredients with various excipients is known in the art, see e.g. Remington: The Science and Practice of Pharmacy (e.g. 19.sup.th edition (1995), and any later editions).
Combination Treatment
[0108] The treatment with a compound according to the present invention may also be combined with one or more pharmacologically active substances, e.g., selected from antiobesity agents, appetite regulating agents, and agents for the treatment and/or prevention of complications and disorders resulting from or associated with obesity.
[0109] Pharmaceutical Indications
[0110] In one aspect, the present invention relates to a compound of the invention, for use as a medicament.
[0111] In particular embodiments, the compound of the invention may be used for the following medical treatments:
[0112] (i) Prevention and/or treatment of eating disorders, such as obesity, e.g. by decreasing food intake, reducing body weight, suppressing appetite and inducing satiety.
[0113] (ii) Prevention and/or treatment of hyperglycemia, insulin resistance and/or impaired glucose tolerance.
[0114] (iii) Prevention and/or treatment of dyslipidaemia.
[0115] In some embodiments the invention relates to a method for weight management. In some embodiments the invention relates to a method for reduction of appetite. In some embodiments the invention relates to a method for reduction of food intake.
[0116] Generally, all subjects suffering from obesity are also considered to be suffering from overweight. In some embodiments the invention relates to a method for treatment or prevention of obesity. In some embodiments the invention relates to use of the MIC-1 compounds of the invention for treatment or prevention of obesity. In some embodiments the subject suffering from obesity is human, such as an adult human or a paediatric human (including infants, children, and adolescents). Body mass index (BMI) is a measure of body fat based on height and weight. The formula for calculation is BMI=weight in kilograms/height in meters.sup.2. A human subject suffering from obesity may have a BMI of .gtoreq.30; this subject may also be referred to as obese. In some embodiments the human subject suffering from obesity may have a BMI of .gtoreq.35 or a BMI in the range of .gtoreq.30 to <40. In some embodiments the obesity is severe obesity or morbid obesity, wherein the human subject may have a BMI of .gtoreq.40.
[0117] In some embodiments the invention relates to a method for treatment or prevention of overweight, optionally in the presence of at least one weight-related comorbidity. In some embodiments the invention relates to use of the MIC-1 compounds of the invention for treatment or prevention of overweight, optionally in the presence of at least one weight-related comorbidity.
[0118] In some embodiments the subject suffering from overweight is human, such as an adult human or a paediatric human (including infants, children, and adolescents). In some embodiments a human subject suffering from overweight may have a BMI of such as a BMI of In some embodiments a human subject suffering from overweight has a BMI in the range of 25 to <30 or in the range of 27 to <30. In some embodiments the weight-related comorbidity is selected from the group consisting of hypertension, diabetes (such as type 2 diabetes), dyslipidaemia, high cholesterol, and obstructive sleep apnoea.
[0119] In some embodiments the invention relates to a method for reduction of body weight. In some embodiments the invention relates to use of the MIC-1 compounds of the invention for reduction of body weight. A human to be subjected to reduction of body weight according to the present invention may have a BMI of .gtoreq.25, such as a BMI of .gtoreq.27 or a BMI of .gtoreq.30. In some embodiments the human to be subjected to reduction of body weight according to the present invention may have a BMI of .gtoreq.35 or a BMI of .gtoreq.40. The term "reduction of body weight" may include treatment or prevention of obesity and/or overweight.
[0120] In some embodiments the invention relates to a method for treatment or prevention of cardiovascular diseases like arteriosclerosis and other disorders such as steatohepatitis, and diabetic nephropathy.
[0121] The articles "a" and "an" are used herein to refer to one or to more than one (i.e., to at least one) of the grammatical object of the article. By way of example, "a MIC-1 polypeptide" means one MIC-1 polypeptide or more than one MIC-1 polypeptide.
[0122] Particular Embodiments
[0123] The invention is further described by the following non-limiting embodiments of the invention: [0124] 1. A MIC-1 compound comprising a MIC-1 polypeptide and an N-terminal amino acid extension, wherein said extension consists of 3 to 200 amino acid residues and wherein the compound has a calculated pI lower than 6.5. [0125] 2. Compound according to embodiment 1, wherein the MIC-1 polypeptide and the amino acid extension consists of between 109-312, 112-312, 115-312, 112-148 or 115-148 amino acid residues. [0126] 3. Compound according to embodiment 1, wherein the compound is a homodimer. [0127] 4. Compound according to embodiment 1, wherein the compound as a homodimer consists of between 218-296, 224-296, 230-296, 218-310, 224-310, 230-310, 218-360, 224-360, 230-360, 218-624, 224-624, 230-296 or 230-296 amino acid residues. [0128] 5. Compound consisting of a MIC-1 polypeptide with an N-terminal amino acid extension, wherein said extension consists of 3 to 200 amino acid residues and where the compound has a calculated pI lower than 6.5. [0129] 6. Compound according to embodiments 1-5, wherein the calculated pI is lower than 6.1. [0130] 7. Compound according to embodiments 1-5, wherein the calculated pI is lower than 6.0. [0131] 8. Compound according to any one of embodiments 1-5, wherein the calculated pI is lower than 6.4, 6.3, 6.2, 6.1, 6.0, 5.9, 5.8, 5.7, 5.6, 5.5, 5.4, 5.3, or 5.2, 5.1, or 5.0, 4.9, 4.8, 4.7, 4.6, 4.5, 4.4, 4.3, 4.2, 4.1 or 4.0. [0132] 9. Compound according to any one of embodiments 1-7, wherein the calculated pI is higher than 4.7. [0133] 10. Compound according to any one of embodiments 1-7, wherein the calculated pI is higher than 4.8. [0134] 11. Compound according to any one of embodiments 1-7, wherein the calculated pI is higher than 4.9. [0135] 12. Compound according to any one of embodiments 1-7, wherein the calculated pI is higher than 5.0. [0136] 13. Compound according to any one of embodiments 1-7, wherein the calculated pI is higher than 5.1. [0137] 14. Compound according to any one of embodiments 1-5, wherein the calculated pI is in the range of 6.5-3.0, 6.5-3.5, 6.5-4.0, 6.1-3.0, 6.1-3.5, 6.1-4.0, 6.1-4.7, 6.1-4.9, 6.1-5.0, 6.1-5.1, 6.0-3.0, 6.0-3.5, 6.0-4.0, 5.9-3.0, 5.9-3.5, 5.9-4.0, 5.9-5.0, 5.9-5.1, 5.8-3.0, 5.8-3.5, 5.8-4.0, 5.8-5.1, 5.8-5.2, 5.5-3.0, 5.5-3.5, 5.5-4.0, or 5.0-4.0.
[0138] 15. Compound according to any one of embodiments 1-14, wherein the calculated pI is in the range of 5.8-5.2. [0139] 16. Compound according to any of the preceding embodiments, wherein said extension is in the range of 3-100, 3-50, 3-40, 3-30, 5-100, 5-50, 5-40, 5-30, 10-100, 10-50, 10-40, 10-30, 3-36, 3-30, 3-25, 3-24, 3-12, 4-36, 4-30, 4-24, 4-12, 5-36, 5-30, 5-24, 5-12, 6-36, 6-30, 6-24, 6-12, 7-36, 7-30, 7-24, 7-12, 8-36, 8-30, 8-24, 8-12, 30-36, 32-36, 30-34, or 30-32 amino acid residues in length. [0140] 17. Compound according to any of the preceding embodiments, wherein said extension is 3 to 36 amino acids in length. [0141] 18. Compound according to any of the preceding embodiments, wherein said extension is in the range of 30-32 amino acid residues in length. [0142] 19. Compound according to any of the preceding embodiments, wherein the extension has a surplus of acidic amino acid residues (Aspartic acid or Glutamic acid) of at least 3, 4, 5, 6, 7, 8, 9 or 10 compared to the number of basic amino acid residues (Lysine, Arginine or Histidine). [0143] 20. Compound according to any one of embodiments 1-18, wherein the extension comprise at least 15%, 20%, 25%, 30%, 40%, 50%, 60%, 70% or 75% surplus of acidic amino acid residues (Aspartic acid or Glutamic acid) compared to number of basic amino acid residues (Lysine or Arginine or Histidine). [0144] 21. Compound according to any of the preceding embodiments, wherein the extension comprise at least 15% acidic amino acid residues. [0145] 22. Compound according to embodiment 21, wherein the extension comprise at least 25% acidic amino acid residues. [0146] 23. Compound according to any of the preceding embodiments, wherein the extension is composed of amino acid residues selected among the group consisting of A, E, G, P, S, T, D, N, and Q wherein said extension comprises at least three E and/or D amino acid residues. [0147] 24. Compound according to any of the preceding embodiments, wherein the extension is composed of amino acid residues selected among the group consisting of A, E, G, P, S, T, Q and D, wherein said extension comprises at least three E and/or D amino acid residues. [0148] 25. Compound according to embodiment 23 or 24, wherein the extension comprises at least three E and at least one P. [0149] 26. Compound according to embodiment 25, wherein the extension further comprises S, G, T and A. [0150] 27. Compound according to embodiment 26, wherein the extension comprises 6 Ser, 4 Pro, 4 Gly, 4 Thr, 4 Glu and 2 Ala. [0151] 28. Compound according to embodiment 27, wherein the extension comprises two of sequences selected from the group consisting of SPAGSPTSTEEG, TSESATPESGPG, TSTEPSEGSAPG and SEPATSGSETPG. [0152] 29. Compound according to embodiment 28, wherein the extension further comprises 6-8 consecutive amino acids of SPAGSPTSTEEG, TSESATPESGPG, TSTEPSEGSAPG or SEPATSGSETPG, such as the first 6-8 amino acid residues, the last 6-8 residues or the internal 6-8 residues. [0153] 30. Compound according to any one of embodiments 23 to 29, wherein the extension starts with S. [0154] 31. Compound according to any one of embodiments 30, wherein the extension starts with SE. [0155] 32. Compound according to any one of embodiments 31, wherein the extension starts with SEP. [0156] 33. Compound according to any one of embodiments 1 to 24, wherein the extension comprises one or more of the following sequences SPAGSP (SEQ ID NO:4), TSESAT (SEQ ID NO:5), TSTEPE (SEQ ID NO:6), SEPATS (SEQ ID NO:7), TSTEEG (SEQ ID NO:8), PESGPG (SEQ ID NO:9), SGSAPG (SEQ ID NO:10), GSETPG (SEQ ID NO:11), SEPATSGSETPGSPAGSPTSTEEG (SEQ ID NO:12), SEPATSGSETPGTSESATPESGPG (SEQ ID NO:13), SEPATSGSETPGTSTEPESGSAPG (SEQ ID NO:14), SEPATSGSETPGSPAGSPTSTEEGSPAGSP (SEQ ID NO:15), SEPATSGSETPGTSESATPESGPGSPAGSP (SEQ ID NO:16), SEPATSGSETPGTSTEPESGSAPGSPAGSP (SEQ ID NO:17), SEPATSGSETPGSPAGSPTSTEEGTSESAT (SEQ ID NO:18), SEPATSGSETPGTSESATPESGPGTSESAT (SEQ ID NO:19), SEPATSGSETPGTSTEPESGSAPGTSESAT (SEQ ID NO:20), SEPATSGSETPGSPAGSPTSTEEGTSTEPE (SEQ ID NO:21), SEPATSGSETPGTSESATPESGPGTSTEPE (SEQ ID NO:22), SEPATSGSETPGTSTEPESGSAPGTSTEPE (SEQ ID NO:23), SEPATSGSETPGSPAGSPTSTEEGSEPATS (SEQ ID NO:24), SEPATSGSETPGTSESATPESGPGSEPATS (SEQ ID NO:25), SEPATSGSETPGTSTEPESGSAPGSEPATS (SEQ ID NO:26), SEPATSGSETPGSPAGSPTSTEEGTSTEEG (SEQ ID NO:27), SEPATSGSETPGTSESATPESGPGTSTEEG (SEQ ID NO:28), SEPATSGSETPGTSTEPESGSAPGTSTEEG (SEQ ID NO:29), SEPATSGSETPGSPAGSPTSTEEGPESGPG (SEQ ID NO:30), SEPATSGSETPGTSESATPESGPGPESGPG (SEQ ID NO:31), SEPATSGSETPGTSTEPESGSAPGPESGPG (SEQ ID NO:32), SEPATSGSETPGSPAGSPTSTEEGSGSAPG (SEQ ID NO:33), SEPATSGSETPGTSESATPESGPGSGSAPG (SEQ ID NO:34), SEPATSGSETPGTSTEPESGSAPGSGSAPG (SEQ ID NO:35), SEPATSGSETPGSPAGSPTSTEEGGSETPG (SEQ ID NO:36), SEPATSGSETPGTSESATPESGPGGSETPG (SEQ ID NO:37), SEPATSGSETPGTSTEPESGSAPGGSETPG (SEQ ID NO:38), SEPATSGSETPGTSESATPESGPGTSTEPS (SEQ ID NO:70), SEPATSGSETPGTSESATPESGPGTSTEPSEG (SEQ ID NO:71), SEPATSGSETPGSPAGSPTSTEEGTSESATPESGPG (SEQ ID NO:39), SEPATSGSETPGSPAGSPTSTEEGSPAGSPTSTEEG (SEQ ID NO:40), SEPATSGSETPGSPAGSPTSTEEGTSTEPESGSAPG (SEQ ID NO:41), SEPATSGSETPGTSESATPESGPGSPAGSPTSTEEG (SEQ ID NO:42), SEPATSGSETPGTSESATPESGPGTSESATPESGPG (SEQ ID NO:43), SEPATSGSETPGTSESATPESGPGTSTEPESGSAPG (SEQ ID NO:44), SEPATSGSETPGTSESATPESGPGSEPATSGSETPG (SEQ ID NO:45), SEPATSGSETPGTSTEPESGSAPGSPAGSPTSTEEG (SEQ ID NO:46), SEPATSGSETPGTSTEPESGSAPGTSESATPESGPG (SEQ ID NO:47), SEPATSGSETPGTSTEPESGSAPGTSTEPESGSAPG (SEQ ID NO:48), SEPATSGSETPGTSTEPESGSAPGSEPATSGSETPG (SEQ ID NO:49), SEPATSGSETPGSEPATSGSETPGSPAGSPTSTEEG (SEQ ID NO:50), SEPATSGSETPGSEPATSGSETPGTSESATPESGPG (SEQ ID NO:51), SEPATSGSETPGSEPATSGSETPGTSTEPESGSAPG (SEQ ID NO:52), SEPATSGSETPGSEPATSGSETPGSEPATSGSETPG (SEQ ID NO:53), GEPS (SEQ ID NO:118), GPSE (SEQ ID NO:119), GPES (SEQ ID NO:120), GSPE (SEQ ID NO:121), GSEP (SEQ ID NO:122), GEPQ (SEQ ID NO:123), GEQP (SEQ ID NO:124), GPEQ (SEQ ID NO:125), GPQE (SEQ ID NO:126), GQEP (SEQ ID NO:127) or GQPE (SEQ ID NO:128), PEDEETPEQE (SEQ ID NO:129), PDEGTEEETE (SEQ ID NO:130), PAAEEEDDPD (SEQ ID NO:131), AEPDEDPQSED (SEQ ID NO:132), AEPDEDPQSE (SEQ ID NO:133), AEPEEQEED (SEQ ID NO:134), AEPEEQEE (SEQ ID NO:135), GGGS (SEQ ID NO:136), GSGS (SEQ ID NO:137), GGSS (SEQ ID NO:138) and SSSG (SEQ ID NO:139). [0157] 34. Compound according to any one of embodiments 1 to 24, wherein the extension comprises one or more of the following sequences SPAGSP, TSESAT, TSTEPE, SEPATS, TSTEEG, PESGPG, SGSAPG, GSETPG, SEPATSGSETPGSPAGSPTSTEEG, SEPATSGSETPGTSESATPESGPG, SEPATSGSETPGTSTEPESGSAPG, SEPATSGSETPGSPAGSPTSTEEGSPAGSP, SEPATSGSETPGTSESATPESGPGSPAGSP, SEPATSGSETPGTSTEPESGSAPGSPAGSP, SEPATSGSETPGSPAGSPTSTEEGTSESAT, SEPATSGSETPGTSESATPESGPGTSESAT, SEPATSGSETPGTSTEPESGSAPGTSESAT, SEPATSGSETPGSPAGSPTSTEEGTSTEPE, SEPATSGSETPGTSESATPESGPGTSTEPE, SEPATSGSETPGTSTEPESGSAPGTSTEPE, SEPATSGSETPGSPAGSPTSTEEGSEPATS, SEPATSGSETPGTSESATPESGPGSEPATS, SEPATSGSETPGTSTEPESGSAPGSEPATS, SEPATSGSETPGSPAGSPTSTEEGTSTEEG, SEPATSGSETPGTSESATPESGPGTSTEEG, SEPATSGSETPGTSTEPESGSAPGTSTEEG, SEPATSGSETPGSPAGSPTSTEEGPESGPG, SEPATSGSETPGTSESATPESGPGPESGPG, SEPATSGSETPGTSTEPESGSAPGPESGPG, SEPATSGSETPGSPAGSPTSTEEGSGSAPG, SEPATSGSETPGTSESATPESGPGSGSAPG, SEPATSGSETPGTSTEPESGSAPGSGSAPG, SEPATSGSETPGSPAGSPTSTEEGGSETPG, SEPATSGSETPGTSESATPESGPGGSETPG, SEPATSGSETPGTSTEPESGSAPGGSETPG SEPATSGSETPGSPAGSPTSTEEGTSESATPESGPG, SEPATSGSETPGSPAGSPTSTEEGSPAGSPTSTEEG, SEPATSGSETPGSPAGSPTSTEEGTSTEPESGSAPG, SEPATSGSETPGTSESATPESGPGSPAGSPTSTEEG, SEPATSGSETPGTSESATPESGPGTSESATPESGPG, SEPATSGSETPGTSESATPESGPGTSTEPESGSAPG, SEPATSGSETPGTSESATPESGPGSEPATSGSETPG, SEPATSGSETPGTSTEPESGSAPGSPAGSPTSTEEG, SEPATSGSETPGTSTEPESGSAPGTSESATPESGPG, SEPATSGSETPGTSTEPESGSAPGTSTEPESGSAPG, SEPATSGSETPGTSTEPESGSAPGSEPATSGSETPG, SEPATSGSETPGSEPATSGSETPGSPAGSPTSTEEG, SEPATSGSETPGSEPATSGSETPGTSESATPESGPG, SEPATSGSETPGSEPATSGSETPGTSTEPESGSAPG, SEPATSGSETPGSEPATSGSETPGSEPATSGSETPG, GEPQ, GEPS, GGGS, GSGS, GGSS, and SSSG. [0158] 35. Compound according to any one of embodiments 1-24, wherein the extension comprises any combination of any 2-6 of the following sequences SPAGSP, TSESAT, TSTEPE, SEPATS, TSTEEG, PESGPG, SGSAPG, GSETPG, GEPQ, GEPS, GGGS, GSGS, GGSS, and SSSG. [0159] 36. Compound according to any one of embodiments 1-24, wherein the extension comprises one or more of the following sequences GEPS, GPSE, GPES, GSPE, GSEP, GEPQ, GEQP, GPEQ, GPQE, GQEP, GQPE, GGGS, GSGS, GGSS, and SSSG. [0160] 37. Compound according to embodiment 36, wherein the extension comprises any combination of 2-9 of the following sequences GEPS, GPSE, GPES, GSPE, GSEP, GEPQ, GEQP, GPEQ, GPQE, GQEP, GQPE, GGGS, GSGS, GGSS, and SSSG. [0161] 38. Compound according to any one of embodiments 1-24, wherein the extension comprises one or more of the following sequences GEPS, GPSE, GPES, GSPE, GSEP, GGGS, GSGS, GGSS, and SSSG. [0162] 39. Compound according to embodiment 38, wherein the extension comprises any combination of 2-9 of the following sequences GEPS, GPSE, GPES, GSPE, GSEP, GGGS, GSGS, GGSS, and SSSG. [0163] 40. Compound according to embodiment 39, wherein the extension comprises one or more of the following sequences GEPSGEPSGEPSGEPSGEPS (SEQ ID NO:140), GPSEGPSEGPSEGPSEGPSE (SEQ ID NO:141), GPESGPESGPESGPESGPES (SEQ ID NO:142), GSPEGSPEGSPEGSPEGSPE (SEQ ID NO:143), and GSEPGSEPGSEPGSEPGSEP (SEQ ID NO:144). [0164] 41. Compound according to any one of embodiments 1-24, wherein the extension comprises one or more of the following sequences GEPQ, GEQP, GPEQ, GPQE, GQEP, GQPE, GGGS, GSGS, GGSS, and SSSG. [0165] 42. Compound according to embodiment 41, wherein the extension comprises any combination of 2-9 of the following sequences GEPQ, GEQP, GPEQ, GPQE, GQEP, GQPE, GGGS, GSGS, GGSS, and SSSG. [0166] 43. Compound according to embodiment 42, wherein the extension comprises one or more of the following sequences GEPQGEPQGEPQGEPQGEPQ (SEQ ID NO:145), GEQPGEQPGEQPGEQPGEQP (SEQ ID NO:146), GPEQGPEQGPEQGPEQGPEQ(SEQ ID NO:147), GPQEGPQEGPQEGPQEGPQE (SEQ ID NO:148), GQEPGQEPGQEPGQEPGQEP (SEQ ID NO:149), and GQPEGQPEGQPEGQPEGQPE (SEQ ID NO:150). [0167] 44. Compound according to any of the embodiments 1-24 , wherein the extension comprises one or more of the following sequences PEDEETPEQE, PDEGTEEETE, PAAEEEDDPD, AEPDEDPQSED, AEPDEDPQSE, AEPEEQEED, and AEPEEQEE, GGGS, GSGS, GGSS and SSSG. [0168] 45. Compound according to any of the embodiments 1-24, wherein the extension comprises any combination of two to three of the following sequences PEDEETPEQE, PDEGTEEETE, PAAEEEDDPD, AEPDEDPQSED, AEPDEDPQSE, AEPEEQEED, AEPEEQEE and AEEAEEAEEAEEAEE. [0169] 46. Compound according to any of the embodiments 1-24, wherein the extension comprises one or more of the following sequences SEQ ID NO:54, SEQ ID NO:55, SEQ ID NO:56, SEQ ID NO:57, SEQ ID NO:58, SEQ ID NO:59, SEQ ID NO:60, SEQ ID NO:61, SEQ ID NO:62, SEQ ID NO:63, SEQ ID NO:64, SEQ ID NO:65, SEQ ID NO:66, SEQ ID NO:67, SEQ ID NO:68, SEQ ID NO:69, SEQ ID NO:70, SEQ ID NO:71, SEQ ID NO:72, SEQ ID NO:161, SEQ ID NO:162, SEQ ID NO:181, SEQ ID NO:182, SEQ ID NO:183, SEQ ID NO:184, SEQ ID NO:185, SEQ ID NO:186, SEQ ID NO:187, SEQ ID NO:188, SEQ ID NO:189, SEQ ID NO:190, SEQ ID NO:191, SEQ ID NO:192, SEQ ID NO:193, SEQ ID NO:194 and SEQ ID NO:195. [0170] 47. Compound according to any one of preceding embodiments, wherein the extension comprises 1-3 alanine amino acid residues N-terminally. [0171] 48. Compound according to any one of preceding embodiments, wherein the extension comprises 1-4 Glycine and Serine amino acid residues C-terminally. [0172] 49. Compound according to any one of preceding embodiments, wherein the extension comprises a (Gly-Ser)n or a (Ser-Gly)n sequence C-terminally, wherein n is an integer between 1-8. [0173] 50. Compound according to any one of preceding embodiments, wherein the extension comprises GGGS, GSGS, GGSS or SSSG C-terminally. [0174] 51. Compound according to any of the preceding embodiments, wherein the MIC-1 polypeptide displays at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% or 99% sequence identity to wild type MIC-1 (SEQ ID NO:1). [0175] 52. Compound according to embodiment 51, wherein the MIC-1 polypeptide displays at least 95% sequence identity to wild type MIC-1 (SEQ ID NO:1). [0176] 53. Compound according to any one of embodiments 1-51, wherein the MIC-1 polypeptide has a maximum of 10, 9, 8, 7, 6, 5, 4, 3, 2 or 1 amino acid modifications compared to MIC-1 of SEQ ID NO:1. [0177] 54. Compound according to any one of embodiments 1-53, wherein the MIC-1 polypeptide has a maximum of 7, 6, 5, 4, 3 or 2 amino acid modifications compared to MIC-1 of SEQ ID NO:1. [0178] 55. A compound comprising a MIC-1 polypeptide, wherein said compound has a calculated pI lower than 6.5. [0179] 56. Compound according to any one of the preceding embodiments wherein the MIC-1 polypeptide comprises one or more of the following substitutions P11E, H18E, R21E, A30E, M43L, M43E, A47E, R53E, A54E, M57E, M57L, H66E, R67E, L68E, K69E, A75E, A81E, P85E, M86F, M86L, Q90E, T92E, L105E, K107E compared to wild type MIC-1 (SEQ ID NO:1). [0180] 57. Compound according to any one of the preceding embodiments wherein the MIC-1 polypeptide comprises one or more of the following substitutions R2S, R2A, N3S N3E, N3A, N3T, N3P, N3G, N3V, N3H, N3Y or N3Q compared to MIC-1 of SEQ ID NO:1. [0181] 58. Compound according to any one of the preceding embodiments wherein the MIC-1 polypeptide comprises a deletion of N3 (des-N3) compared to MIC-1 of SEQ ID NO:1. [0182] 59. Compound according to any one of the preceding embodiments wherein the MIC-1 polypeptide comprises a M57E or M57L substitution compared to MIC-1 of SEQ ID NO:1. [0183] 60. Compound according to any one of the preceding embodiments wherein the MIC-1 polypeptide comprises a M86L or M86F substitution compared to MIC-1 of SEQ ID NO:1. [0184] 61. Compound according to embodiment 60 wherein the MIC-1 polypeptide further comprises a Q90E or T92E substitution compared to MIC-1 of SEQ ID NO:1. [0185] 62. Compound according to any one of the preceding embodiments wherein the MIC-1 polypeptide comprises a H66E substitution compared to MIC-1 of SEQ ID NO:1. [0186] 63. Compound according to any one of the preceding embodiments wherein the MIC-1 polypeptide comprises a R67E substitution compared to MIC-1 of SEQ ID NO:1. [0187] 64. Compound according to any one of the preceding embodiments wherein the MIC-1 polypeptide comprises a deletion of the first 3, 4, 5 or 6 residues compared to MIC-1 of SEQ ID NO:1. [0188] 65. Compound according to any one of the preceding embodiments wherein the MIC-1 polypeptide comprises a deletion of the first 3 residues compared to MIC-1 of SEQ ID NO:1. [0189] 66. Compound according to any one of embodiments 1-56, wherein the MIC-1 polypeptide has a sequence according to SEQ ID NO:154 (M43L/des-N3). [0190] 67. Compound according to any one of embodiments 1-56, wherein the MIC-1 polypeptide has a sequence according to SEQ ID NO:155 (M43L/.DELTA.1-3). [0191] 68. Compound according to any one of embodiments 1-56, wherein the MIC-1 polypeptide has a sequence according to SEQ ID NO:156 (M57E/H66E/des-N3).
[0192] 69. Compound according to any one of embodiments 1-56, wherein the MIC-1 polypeptide has a sequence according to SEQ ID NO:157 (M57L/.DELTA.1-3). [0193] 70. Compound according to any one of embodiments 1-56, wherein the MIC-1 polypeptide has a sequence according to SEQ ID NO:158 (M57L/des-N3). [0194] 71. Compound according to any one of embodiments 1-56, wherein the MIC-1 polypeptide has a according to SEQ ID NO:159 (M86L/.DELTA.1-3). [0195] 72. Compound according to any one of embodiments 1-56, wherein the MIC-1 polypeptide has a sequence according to SEQ ID NO:160 (M86L/des-N3). [0196] 73. Compound according to any one of embodiments 1-56, wherein the MIC-1 polypeptide has a sequence according to SEQ ID NO:222 (M57L, M86L/des-N3). [0197] 74. Compound according to any one of embodiments 1-55, wherein the MIC-1 polypeptide has a sequence according to SEQ ID NO:1. [0198] 75. A MIC-1 compound comprising a MIC-1 polypeptide and an N-terminal amino acid extension, wherein the compound comprises an amino acid sequence according to SEQ ID NO: 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117 or 164. [0199] 76. A MIC-1 compound comprising a MIC-1 polypeptide and an N-terminal amino acid extension, wherein the compound comprises an amino acid sequence according to SEQ ID NO: 100, 104, 106, 107, 108, 109, 111, 112, 113, 114, 115, 116, 117 or 164. [0200] 77. Compound according to any one of the preceding embodiments, showing improved solubility compared with MIC-1 of SEQ ID NO:1. [0201] 78. Compound according to any one of the preceding embodiments, showing improved solubility compared with MIC-1 of SEQ ID NO:1 at pH 8.0 in a Tris buffer system. [0202] 79. Compound according to any one of embodiments 1-78, wherein the compound has more than a 2-fold, 5-fold, 10-fold, 50-fold up to 100-fold improvement in solubility compared with MIC-1 of SEQ ID NO:1 at pH 8.0 in a Tris buffer system. [0203] 80. Compound according to any one of embodiments 1-79, wherein the compound has a solubility of 0.5, 1.0, 5.0, 10, 30 or 50 mg/ml at pH 8.0 in a Tris buffer system. [0204] 81. Compound according to embodiment 80, wherein the compound has a solubility of 30 mg/ml at pH 8.0 in a Tris buffer system. [0205] 82. Compound according to any one of the preceding embodiments wherein the MIC-1 compound is showing reduced crystal forming tendency at pH 8.0 compared with MIC-1 of SEQ ID NO:1. [0206] 83. Compound according to embodiment 82, wherein the crystal forming tendency is measured at pH 8.0 in a Tris buffer system. [0207] 84. Compound according to any of the preceding embodiments, wherein the compound has low immunogenicity risk. [0208] 85. Compound according to any of the preceding embodiments, wherein the compound has improved in vivo efficacy on lowering food intake and/or lowering body weight compared with MIC-1 of SEQ ID NO:1. [0209] 86. A compound according to any one of embodiments 1-85 for use as a medicament. [0210] 87. A compound according to any one of embodiments 1-85 for use in the prevention and/or treatment of a metabolic disorder. [0211] 88. A compound according to embodiment 87 for use in the prevention and/or treatment of a metabolic disorder, wherein the metabolic disorder is obesity, type 2 diabetes, dyslipidemia, or diabetic nephropathy. [0212] 89. A compound according to any one of embodiments 1-85 for use in the prevention and/or treatment of eating disorders, such as obesity. [0213] 90. A compound according to embodiment 89 for use in the prevention and/or treatment of obesity by decreasing food intake, reducing body weight, suppressing appetite and/or inducing satiety. [0214] 91. A compound according to any one of embodiments 1-85 for use in the prevention and/or treatment of a cardiovascular disease. [0215] 92. A compound according to embodiment 91 for use in the prevention and/or treatment of dyslipidaemia, arteriosclerosis, steatohepatitis, or diabetic nephropathy. [0216] 93. A pharmaceutical composition comprising a compound according to any one of embodiments 1-85 or a pharmaceutically acceptable salt, amide or ester thereof, and one or more pharmaceutically acceptable excipients. [0217] 94. The use of a compound according to any one of embodiments 1-85 in the manufacture of a medicament for the prevention and/or treatment of a metabolic disorder, wherein the metabolic disorder is obesity, type 2 diabetes, dyslipidemia, or diabetic nephropathy. [0218] 95. The use of a compound according to any one of embodiments 1-85 in the manufacture of a medicament for the prevention and/or treatment of eating disorders. [0219] 96. The use of a compound according to any one of embodiments 1-85 in the manufacture of a medicament for the prevention and/or treatment of obesity. [0220] 97. The use of a compound according to any one of embodiments 1-85 in the manufacture of a medicament for the prevention and/or treatment of obesity by decreasing food intake, reducing body weight, suppressing appetite and/or inducing satiety. [0221] 98. The use of a compound according to any one of embodiments 1-85 in the manufacture of a medicament for the prevention and/or treatment of a cardiovascular disease. [0222] 99. The use of a compound according to any one of embodiments 1-85 in the manufacture of a medicament for the prevention and/or treatment of dyslipidaemia, arteriosclerosis, steatohepatitis, or diabetic nephropathy. [0223] 100. A method of treating and/or preventing a metabolic disorder by administering a pharmaceutically active amount of a compound according to any one of embodiments 1-85, wherein the metabolic disorder is obesity, type 2 diabetes, dyslipidemia, or diabetic nephropathy. [0224] 101. A method of treating and/or preventing eating disorders by administering a pharmaceutically active amount of a compound according to any one of embodiments 1-85. [0225] 102. A method of treating and/or preventing obesity by administering a pharmaceutically active amount of a compound according to any one of embodiments 1-85. [0226] 103. A method of treating and/or preventing obesity by decreasing food intake, reducing body weight, suppressing appetite and/or inducing satiety by administering a pharmaceutically active amount of a compound according to any one of embodiments 1-85. [0227] 104. A method of treating and/or preventing a cardiovascular disease by administering a pharmaceutically active amount of a compound according to any one of embodiments 1-85. [0228] 105. A method of treating and/or preventing dyslipidaemia, arteriosclerosis, steatohepatitis, or diabetic nephropathy by administering a pharmaceutically active amount of a compound according to any one of embodiments 1-85. [0229] 106. A polynucleotide molecule encoding a compound according to any one of embodiments 1-85.
EXAMPLES
List of Abbreviations
[0230] "Main peak" refers to the peak in a purification chromatogram which has the highest UV intensity in milliabsorbance units and which contains the fusion protein.
[0231] HPLC is High performance liquid chromatography.
[0232] SDS-PAGE is Sodium dodecyl sulfate Polyacrylamide gel electrophoresis.
[0233] IMAC is immobilized metal affinity chromatography.
[0234] SEC is size exclusion chromatography.
[0235] MS is mass spectrometry.
[0236] In this description, Greek letters may be represented by their symbol or the corresponding written name, for example: .alpha.=alpha; .beta.=beta; .epsilon.=epsilon; .gamma.=gamma; .omega.=omega; .DELTA.=delta; etc. Also, the Greek letter of .mu. may be represented by "u", e.g. in .mu.l=ul, or in .mu.M=uM.
Design of MIC-1 Compounds
[0237] In an aspect of the invention, MIC-1 compounds were designed to have increased solubility. In an aspect of the invention, this was achieved by adding an N-terminal "acidic" extension to the MIC-1 polypeptide. In an aspect of the invention, solubility were enhanced and stability improved by modification of the amino acid sequence of the MIC-1 polypeptide. For example extensions were added to the N terminal of a MIC-1 polypeptide, and/or modification was done within the amino acid sequence of the MIC-1 polypeptide (in-sequence mutation).
[0238] N-Extension Design:
[0239] In the design of the N-terminal amino acid_extension, F, I, L, M, V, W and Y were excluded, since they could contribute to protein aggregation. H, K, and R were also excluded, since they could cause undesired binding on cell membrane. A, E, G, P, S, T, D, N, and Q are preferred for the N-extension sequence. E and D are particularly preferred since they increase the solubility by decreasing pI value of the compound. Particularly, for some N-extensions, one or two additional Alanine(s) were added at the very N-terminal to increase the initial Methionine removing efficiency when MIC-1 compounds were expressed in E.coli.
[0240] Various N-terminal amino acid_extensions were designed based on the above principles. Some N-extensions comprise sequences originating from human proteins (humanized sequences); some comprise artificially designed sequence(s) (e.g. GS, SG, AEE, AES, GEPQ (SEQ ID NO:123), GEPS (SEQ ID NO:118)); some comprise several repeats of the humanized sequences or artificial sequences; some comprise a combination of the above. Several 6-residue sequences (6-mers) were designed. N-extensions could comprise one or more of a 6-mers, part of a 6-mers (e.g., 1-5 residues of a 6-mers), or a combination of the above. The amino acid residues of the artificial sequences (including 6-mers) and the humanized sequences could be arranged in any order.
[0241] Some representative 6-mers and combinations of 6-mers are listed in Table 2:
TABLE-US-00002 TABLE 2 6-mers and combinations of 6-mers 6-mers: 6-mer-1: SPAGSP (SEQ ID NO: 4) 6-mer-2: TSESAT (SEQ ID NO: 5) 6-mer-3: TSTEPE (SEQ ID NO: 6) 6-mer-4: SEPATS (SEQ ID NO: 7) 6-mer-5: TSTEEG (SEQ ID NO: 8) 6-mer-6: PESGPG (SEQ ID NO: 9) 6-mer-7: SGSAPG (SEQ ID NO: 10) 6-mer-8: GSETPG (SEQ ID NO: 11) Combinations: SEPATSGSETPGSPAGSPTSTEEG (SEQ ID NO: 12) SEPATSGSETPGTSESATPESGPG (SEQ ID NO: 13) SEPATSGSETPGTSTEPESGSAPG (SEQ ID NO: 14) SEPATSGSETPGSPAGSPTSTEEGSPAGSP (SEQ ID NO: 15) SEPATSGSETPGTSESATPESGPGSPAGSP (SEQ ID NO: 16) SEPATSGSETPGTSTEPESGSAPGSPAGSP (SEQ ID NO: 17) SEPATSGSETPGSPAGSPTSTEEGTSESAT (SEQ ID NO: 18) SEPATSGSETPGTSESATPESGPGTSESAT (SEQ ID NO: 19) SEPATSGSETPGTSTEPESGSAPGTSESAT (SEQ ID NO: 20) SEPATSGSETPGSPAGSPTSTEEGTSTEPE (SEQ ID NO: 21) SEPATSGSETPGTSESATPESGPGTSTEPE (SEQ ID NO: 22) SEPATSGSETPGTSTEPESGSAPGTSTEPE (SEQ ID NO: 23) SEPATSGSETPGSPAGSPTSTEEGSEPATS (SEQ ID NO: 24) SEPATSGSETPGTSESATPESGPGSEPATS (SEQ ID NO: 25) SEPATSGSETPGTSTEPESGSAPGSEPATS (SEQ ID NO: 26) SEPATSGSETPGSPAGSPTSTEEGTSTEEG (SEQ ID NO: 27) SEPATSGSETPGTSESATPESGPGTSTEEG (SEQ ID NO: 28) SEPATSGSETPGTSTEPESGSAPGTSTEEG (SEQ ID NO: 29) SEPATSGSETPGSPAGSPTSTEEGPESGPG (SEQ ID NO: 30) SEPATSGSETPGTSESATPESGPGPESGPG (SEQ ID NO: 31) SEPATSGSETPGTSTEPESGSAPGPESGPG (SEQ ID NO: 32) SEPATSGSETPGSPAGSPTSTEEGSGSAPG (SEQ ID NO: 33) SEPATSGSETPGTSESATPESGPGSGSAPG (SEQ ID NO: 34) SEPATSGSETPGTSTEPESGSAPGSGSAPG (SEQ ID NO: 35) SEPATSGSETPGSPAGSPTSTEEGGSETPG (SEQ ID NO: 36) SEPATSGSETPGTSESATPESGPGGSETPG (SEQ ID NO: 37) SEPATSGSETPGTSTEPESGSAPGGSETPG (SEQ ID NO: 38) SEPATSGSETPGSPAGSPTSTEEGTSESATPESGPG (SEQ ID NO: 39) SEPATSGSETPGSPAGSPTSTEEGSPAGSPTSTEEG (SEQ ID NO: 40) SEPATSGSETPGSPAGSPTSTEEGTSTEPESGSAPG (SEQ ID NO: 41) SEPATSGSETPGTSESATPESGPGSPAGSPTSTEEG (SEQ ID NO: 42) SEPATSGSETPGTSESATPESGPGTSESATPESGPG (SEQ ID NO: 43) SEPATSGSETPGTSESATPESGPGTSTEPESGSAPG (SEQ ID NO: 44) SEPATSGSETPGTSESATPESGPGSEPATSGSETPG (SEQ ID NO: 45) SEPATSGSETPGTSTEPESGSAPGSPAGSPTSTEEG (SEQ ID NO: 46) SEPATSGSETPGTSTEPESGSAPGTSESATPESGPG (SEQ ID NO: 47) SEPATSGSETPGTSTEPESGSAPGTSTEPESGSAPG (SEQ ID NO: 48) SEPATSGSETPGTSTEPESGSAPGSEPATSGSETPG (SEQ ID NO: 49) SEPATSGSETPGSEPATSGSETPGSPAGSPTSTEEG (SEQ ID NO: 50) SEPATSGSETPGSEPATSGSETPGTSESATPESGPG (SEQ ID NO: 51) SEPATSGSETPGSEPATSGSETPGTSTEPESGSAPG (SEQ ID NO: 52) SEPATSGSETPGSEPATSGSETPGSEPATSGSETPG (SEQ ID NO: 53)
TABLE-US-00003 TABLE 3 Examples of N-extensions Residue SEQ ID NO number Sequence of N-extension SEQ ID NO: 54 6 AEEAES SEQ ID NO: 55 3 AES SEQ ID NO: 56 9 (AEE).sub.2AES SEQ ID NO: 57 20 (GEPS).sub.5 SEQ ID NO: 58 24 SPAGSPTSTEEGTSESATPESGPG SEQ ID NO: 59 21 (AEE).sub.6AES SEQ ID NO: 60 18 (AEE).sub.5AES SEQ ID NO: 61 12 (AEE).sub.3AES SEQ ID NO: 62 26 AASPAGSPTSTEEGTSESATPESGPG SEQ ID NO: 63 24 TSESATPESGPGTSESATPESGPG SEQ ID NO: 64 26 AASPAGSPTSTEEGTSESATPESGPG SEQ ID NO: 65 22 AAPEDEETPEQEGSGSGSGSGS SEQ ID NO: 66 12 AAPEDEETPEQE SEQ ID NO: 67 22 AAPDEGTEEETEGSGSGSGSGS SEQ ID NO: 68 24 SEPATSGSETPGSEPATSGSETPG SEQ ID NO: 69 25 A(GPEQGQEP).sub.3 SEQ ID NO: 70 30 SEPATSGSETPGTSESATPESGPGTS TEPS SEQ ID NO: 71 32 SEPATSGSETPGTSESATPESGPGTS TEPSEG SEQ ID NO: 72 24 (GEPS).sub.6 SEQ ID NO: 161 36 (GEPS).sub.9 SEQ ID NO: 162 36 (GPEQ).sub.9 SEQ ID NO: 163 25 AGPEQGQEPGEPQGQEPQPGEPEGQ
[0242] In-Sequence Mutations:
[0243] Certain internal residues of MIC-1 (SEQ ID NO:1) were modified, e.g. by substitution. For example, to increase the solubility of MIC-1 compounds, a hydrophobic residue of MIC-1 could be substituted with a hydrophilic residue, preferably by with an acidic residue; a positive charged residue could be substituted with an acidic residue, etc. To decrease oxidation, methionine could be substituted with other amino acids, e.g. E, F or L.
[0244] In-sequence mutations for increasing solubility include but are not limited to: P11E, H18E, R21E, A30E, A47E, R53E, A54E, M57E, R67E, L68E, K69E, A75E, A81E, P85E, L105E and K107E.
[0245] In-sequence mutations for decreasing oxidation include but are not limited to: M43L, M57E, M57L, M86F and M86L.
[0246] In-sequence mutations for increasing chemical stability include but are not limited to R2S, R2A, N3S N3E, N3A, N3T, N3P, N3G, N3V, N3H, N3Y and N3Q.
pI Calculation of MIC-1 Compounds
[0247] The calculated pI of a MIC-1 compound is defined as the pH at which the net calculated charge of the compound is zero. The calculated charge of the MIC-1 compound as a function of pH is obtained using the pKa values of the amino acid residues described in Table 1 and the method described by B. Skoog and A. Wichman (Trends in Analytical Chemistry, 1986, vol. 5, pp. 82-83). The side chain pKa of cysteine (Cys) is only included in the charge calculation for cysteines with a free sulfhydryl group. As an example the calculated pI value of human wtMIC-1 is 8.8 as the homodimer.
[0248] Herein, and throughout this document, pI calculations on MIC-1 compounds, if not stated otherwise, are made on MIC-1 compounds as homodimers.
TABLE-US-00004 TABLE 4 Calculated pI value of MIC-1 compounds comprising N-extension and MIC-1 (SEQ ID NO: 1)/MIC-1 analogues MIC-1-.DELTA.1-3 MIC-1 (SEQ MIC-1 -.DELTA.1-3 MIC-1-.DELTA.1-3 MIC-1-.DELTA.1-3 (M57E, H66E ID NO: 1) MIC-1-des-N3 MIC-1-.DELTA.1-3 (M57E) (M57E, H66E) (M57E, R67E) and R67E) Any combinations 6.1 6.1 5.8 5.5 5.0 5.0 4.7 of four of 6mers 1-8 Any combinations 5.8 5.8 5.5 5.2 4.8 4.8 4.6 of five 6mers 1-8 (GEPQ*).sub.5 or (GEPS*).sub.5 5.8 5.8 5.5 5.2 4.8 4.8 4.6 (GEPQ*)6 5.5 5.5 5.2 5.2 4.7 4.7 4.5 Humanized sequences 4.5~5.5 4.5~5.5 4.2~5.3 4.2~5.2 4.2~5.1 4.2~5.1 4.2~5.0 in examples *The amino acid residues of "GEPQ" or "GEPS" may be arranged in any order
Materials and Methods
General Methods of Preparation
Example-1: Expression and Fermentation of the MIC-1 Compounds
[0249] The cDNA of MIC-1 compound was sub-cloned into a pET11b derived vector. Overexpression of MIC-1 compounds as inclusion bodies was induced in E. coli by 0.5 mM isopropyl .beta.-d-thiogalactoside (IPTG) when the cell density reached an OD600 of 1.0. After continuous growth in TB for 20 h at 37.degree. C., the cells were harvested and samples for both LC/MS and UPLC were prepared to confirm the molecular weight.
[0250] Fermentation was carried out on fed-batch process in chemical defined medium as supplement. Fermentation yield largely depended on different compounds, which varied from 1 g/L to 8 g/L from compound to compound.
Example-2: Purification and Refolding:
[0251] The MIC-1 compounds were further purified as follows:
[0252] Slurry (20% w/v) of E. coli in 10 mM Tris buffer pH 8.0 was sonicated (3 seconds on/off intervals on ice for 5 minutes) and the MIC-1 compounds was pelleted by centrifugation (10,000.times.g, for 30 minutes). The inclusion bodies were re-solubilised by 8 M urea in 20 mM Tris pH 8.0, and debris removed by centrifugation (10,000.times.g, for 30 minutes). The MIC-1 compounds in the resulting supernatant was collected and diluted into the refolding buffer (50 mM Tris, pH 8.5 and 10% DMF or 10% DMSO) to the final concentration of 0.1 mg/ml. The refolding process lasted for 48 hours in the cold room. The resulting solution was filtered by 0.4 .mu.m filter and loaded onto Hydrophobic Interaction column or anion exchange chromatography (50 mM Tris pH 8.0, 0-500 mM NaCl) using Q Sepharose Fast Flow resin (GE Healthcare), as generally described in Protein Purification. Principles and Practice Series: Springer Advanced Texts in Chemistry Scopes, Robert K. 3rd ed., 1994 (Chapter 6 and Chapter 8). In some instances, further purification was done by size exclusion chromatography using a HiLoad 26/60 Superdex pg 75 column (GE Healthcare) operated with 50 mM Tris pH 8.0 and 200 mM NaCl. For storage, the MIC-1 compounds was transferred to DPBS, and stored frozen.
TABLE-US-00005 TABLE 5 Synthesized MIC-1 compounds or MIC-1 analogues and their maximal solubility at pH8 in Tris buffer tested according to Example 4 Max. Calculated solubility SEQ ID NO Structure pI (mg/ml) SEQ ID NO: 1 MIC-1 (SEQ ID NO: 1) 8.8 0.3 SEQ ID NO: 73 MIC-1(R2A, N3E) 6.8 0.9 SEQ ID NO: 74 MIC-1(R2A, N3E, A54E) 6.4 1.0 SEQ ID NO: 75 MIC-1(R2A, N3E, A81E) 6.4 N.D.* SEQ ID NO: 76 MIC-1(R2A, N3E, H18E) 6.2 1.7 SEQ ID NO: 77 MIC-1(R2A, N3E, K69E) 6.1 2.2 SEQ ID NO: 78 MIC-1(R2A, N3E, K107E) 6.1 1.9 SEQ ID NO: 79 MIC-1(R2A, N3E, L68E) 6.4 3.9 SEQ ID NO: 80 MIC-1(R2A, N3E, A47E) 6.4 1.0 SEQ ID NO: 81 MIC-1(R2A, N3E, L105E) 6.4 N.D. SEQ ID NO: 82 MIC-1(R2A, N3E, M57E) 6.4 1.7 SEQ ID NO: 83 MIC-1(R2A, N3E, P85E) 6.4 N.D. SEQ ID NO: 84 MIC-1(R2A, N3E, P11E) 6.4 1.6 SEQ ID NO: 85 MIC-1(R2A, N3E, R21E) 6.1 1.8 SEQ ID NO: 86 MIC-1(R2A, N3E, R53E) 6.1 1.9 SEQ ID NO: 87 MIC-1(R2A, N3E, R67E) 6.1 1.8 SEQ ID NO: 88 MIC-1(R2A, N3E, A30E) 6.4 1.5 SEQ ID NO: 89 AEEAES-MIC-1-.DELTA.1-3 6.1 N.D. SEQ ID NO: 90 AES-MIC-1-.DELTA.1-3 6.8 0.9 SEQ ID NO: 91 (AEE).sub.2AES-MIC-1-.DELTA.1-3 5.5 N.D. SEQ ID NO: 92 (GEPS).sub.5-MIC-1(SEQ ID NO: 1) 5.8 35.1 SEQ ID NO: 93 SPAGSPTSTEEGTSESATPESGPG- 6.1 44.5 MIC-1(SEQ ID NO: 1) SEQ ID NO: 94 (AEE).sub.6AES-MIC-1(SEQ ID NO: 1) 4.5 39.0 SEQ ID NO: 95 (AEE).sub.5AES-MIC-1-.DELTA.1-3 4.6 35.0 SEQ ID NO: 96 (AEE).sub.3AES-MIC-1-.DELTA.1-3 5.0 36.0 SEQ ID NO: 97 AASPAGSPTSTEEGTSESATPESG 6.1 N.D. PG-MIC-1(SEQ ID NO: 1) SEQ ID NO: 98 TSESATPESGPGTSESATPESGPG- 5.5 N.D. MIC-1(R2A, N3E) SEQ ID NO: 99 AASPAGSPTSTEEGTSESATPESG 5.8 N.D. PG-MIC-1-.DELTA.1-3 SEQ ID NO: 100 AAPEDEETPEQEGSGSGSGSGS- 5.2 35.7 MIC-1-.DELTA.1-3 SEQ ID NO: 101 AAPEDEETPEQE-MIC-1-.DELTA.1-3 5.2 N.D. SEQ ID NO: 102 AAPDEGTEEETEGSGSGSGSGS- 5.2 N.D. MIC-1-.DELTA.1-3 SEQ ID NO: 103 SEPATSGSETPGTSTEPSEGSAPG- 5.8 N.D. MIC-1-.DELTA.1-3 SEQ ID NO: 104 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3 5.8 35.4 SEQ ID NO: 105 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1- 5.5 37.1 3(M57E) SEQ ID NO: 106 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1- 5.8 32.5 3(M57L) SEQ ID NO: 107 A(GPEQGQEP).sub.3-MIC-1-.DELTA.1-3 5.2 32.2 SEQ ID NO: 108 SEPATSGSETPGTSESATPESGPG 5.5 40.0 TSTEPS-MIC-1-.DELTA.1-3 SEQ ID NO: 109 SEPATSGSETPG TSESATPESGPG 5.2 40.0 TSTEPSEG-MIC-1-.DELTA.1-3 SEQ ID NO: 110 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1- 5.8 N.D. 3(M86L) SEQ ID NO: 111 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1- 5.8 31.1 3(M57L, M86L) SEQ ID NO: 112 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1- 5.0 N.D. 3(M57E, H66E) SEQ ID NO: 113 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1- 5.0 N.D. 3(M57E, R67E) SEQ ID NO: 114 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1- 5.0 N.D. 3(M57E, R67E, M86L) SEQ ID NO: 115 SEPATSGSETPG 5.5 N.D. TSESATPESGPGTSTEPSG-MIC- 1-.DELTA.1-3(M57L, M86L) SEQ ID NO: 116 (GEPS).sub.6-MIC-1-.DELTA.-3 5.2 N.D. SEQ ID NO: 117 (SEPATSGSETPG).sub.2-MIC-1-des- 6.1 N.D. N3 *N.D.: Not determined
Example-3: pH-Dependent Solubility of MIC-1 Compounds of the Invention
[0253] The purpose of this experiment was to screen for the MIC-1 compounds with improved solubility, and determine the optimal pH window for formulation.
[0254] MIC-1 compounds were dissolved in a mixture of water and ethanol (60% water and 40% ethanol) with a concentration range between 3 mg/ml to 10 mg/ml. The solvent was evaporated with SpeedVac (Concentrator Plus, Eppendorf) for 6 hours to obtain pellet of said MIC-1 compound.
[0255] Below buffers were used for this pH-dependent solubility curve assay: acetate buffer (pH 3 to pH 6); Tris buffer (pH 7 to pH 9); CAPS buffer (pH 10 to pH 11).
[0256] Buffers were added into each well of the 96-well plate together with MIC-1 compounds. The amount used may not be exactly the same but all targeting a theoretical concentration within 12-18 mg/ml. The concentration of MIC-1 compounds in the supernatant was determined by UPLC (Table 6). Based on the results, solubility of the MIC-1 compounds of the invention was significantly improved between pH 6-9 compared with wtMIC-1. The optimal pH window of the MIC-1 compounds falls into the pH range that is preferred for formulation, e.g. pH 6.5-8.5.
TABLE-US-00006 TABLE 6 pH-dependent solubility test of MIC-1 analogues (mg/ml) SEQ ID pH NO Structure 3.0 4.0 5.0 6.0 7.0 8.0 9.0 10.0 11.0 SEQ ID MIC-1 (SEQ 12.8 2.0 0.2 0.3 0.2 0.3 0.6 3.6 13.9 NO: 1 ID NO: 1) SEQ ID MIC- 13.3 1.3 0.4 0.6 0.5 1.0 1.5 3.6 15.5 NO: 74 1(R2A, N3E, A54E) SEQ ID MIC- 14.5 3.4 0.4 0.4 0.9 1.7 3.0 14.3 13.6 NO: 76 1(R2A, N3E, H18E) SEQ ID MIC- 13.6 1.4 1.4 1.7 3.2 3.9 3.9 4.0 12.1 NO: 79 1(R2A, N3E, L68E) SEQ ID MIC- 13.4 2.5 0.5 0.6 0.9 1.0 1.0 2.9 10.8 NO: 80 1(R2A, N3E, A47E) SEQ ID MIC- 14.9 1.6 0.5 0.5 1.4 1.8 1.7 2.5 12.9 NO: 85 1(R2A, N3E, R21E) SEQ ID MIC- 13.9 1.7 0.8 0.8 1.4 1.5 2.1 2.4 13.7 NO: 88 1(R2A, N3E, A30E) SEQ ID AES-MIC-1- 12.5 2.3 0.6 0.7 1.2 0.9 1.0 3.6 8.9 NO: 90 .DELTA.1-3 SEQ ID SPAGSPTST 12.9 1.5 1.2 1.4 5.1 12.8 13.0 13.0 13.5 NO: 93 EEGTSESAT PESGPG- MIC-1(SEQ ID NO: 1) SEQ ID (AEE).sub.6AES- 7.3 0.2 2.9 9.5 11.6 15.3 15.1 15.0 14.8 NO: 94 MIC-1-.DELTA.1-3 SEQ ID (AEE).sub.5AES- 11.9 0.3 1.6 5.7 9.4 15.8 15.7 14.9 15.0 NO: 95 MIC-1-.DELTA.1-3 SEQ ID AAPEDEETP 11.2 3.2 2.1 5.1 8.3 15.0 15.3 15.0 15.6 NO: 100 EQEGSGSG SGSGS- MIC-1-.DELTA.1-3 SEQ ID (SEPATSGS 12.2 0.7 0.3 1.0 4.6 16.4 16.9 16.0 16.2 NO: 104 ETPG).sub.2- MIC-1-.DELTA.1-3 SEQ ID (SEPATSGS 7.2 1.2 0.8 3.8 11.5 15.6 15.2 14.9 16.2 NO: 105 ETPG).sub.2- MIC-1-.DELTA.1- 3(M57E) SEQ ID (SEPATSGS 10.1 0.2 0.3 1.6 4.3 15.6 16.1 16.1 16.8 NO: 106 ETPG).sub.2- MIC-1-.DELTA.1- 3(M57L)
Example 4: Maximal Solubility of MIC-1 Compounds at pH 8
[0257] In order to test the maximal solubility, the MIC-1 compounds were dissolved in a mixture of water and ethanol (60% water and 40% ethanol) with a concentration range between 3 mg/ml to 10 mg/ml. Then the solution (150 .mu.L each well) was aliquot into a 96-well plate (Corning). The solvent was evaporated with SpeedVac (Concentrator Plus, Eppendorf) for 6 hours to obtain pellet of the MIC-1 compound. Tris buffer (pH 8.0, without excipients) was added into each well of the 96-well plate. The amount of buffer added to the well was less than the amount needed for solving the whole pellet in the well, so that maximal concentration was achieved. The plate was shaken on a plate shaker at 800 rpm (MixMate, Eppendorf) for 2 hours. The pellet was spun down at 3600 g for 5 min. The supernatants were transferred to a 96-deep-well plate and diluted 20 times with 40% ethanol. Then all of the samples were subject to UPLC (Acquity, Waters), plate reader (Infinite M200 pro, Tecan) and UV spectrometer (NanoDrop 8000, Thermo Scientific) to determine the concentration (Table 7)
[0258] Based on the results, solubility of the MIC-1 compounds of the invention was significantly improved at pH 8.0. Especially, the MIC-1 compounds with N-extensions achieved solubility of more than 30 mg/ml at pH 8.0.
TABLE-US-00007 TABLE 7 Max solubility test of MIC-1 compounds at pH 8.0 Solubility SEQ IN NO Structure (mg/ml) SEQ ID NO: 96 (AEE).sub.3AES-MIC-1-.DELTA.1-3 36.0 SEQ ID NO: 95 (AEE).sub.5AES-MIC-1-.DELTA.1-3 35.0 SEQ ID NO: 94 (AEE).sub.6AES-MIC-1(SEQ ID NO: 1) 39.0 SEQ ID NO: 93 SPAGSPTSTEEGTSESATPESGPG-MIC-1 44.5 SEQ ID NO: 92 (GEPS).sub.5-MIC-1(SEQ ID NO: 1) 35.1 SEQ ID NO: 100 AAPEDEETPEQEGSGSGSGSGS-MIC-1-.DELTA.1-3 35.7 SEQ ID NO: 79 MIC-1(R2A, N3E, L68E) 3.9 SEQ ID NO: 85 MIC-1(R2A, N3E, R21E) 1.8 SEQ ID NO: 88 MIC-1(R2A, N3E, A30E) 1.5 SEQ ID NO: 74 MIC-1(R2A, N3E, A54E) 1.0 SEQ ID NO: 76 MIC-1(R2A, N3E, H18E) 1.7 SEQ ID NO: 77 MIC-1(R2A, N3E, K69E) 2.2 SEQ ID NO: 80 MIC-1(R2A, N3E, A47E) 1.0 SEQ ID NO: 90 AES-MIC-1-.DELTA.1-3 0.9 SEQ ID NO: 78 MIC-1(R2A, N3E, K107E) 1.9 SEQ ID NO: 82 MIC-1(R2A, N3E, M57E) 1.7 SEQ ID NO: 84 MIC-1(R2A, N3E, P11E) 1.6 SEQ ID NO: 86 MIC-1(R2A, N3E, R53E) 1.9 SEQ ID NO: 87 MIC-1(R2A, N3E, R67E) 1.8 SEQ ID NO: 104 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3 35.4 SEQ ID NO: 105 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3(M57E) 37.1 SEQ ID NO: 106 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3(M57L) 32.5 SEQ ID NO: 107 A(GPEQGQEP).sub.3-MIC-1-.DELTA.1-3 32.2 SEQ ID NO: 108 SEPATSGSETPGTSESATPESGPGTSTEPS-MIC-1- 40.0 .DELTA.1-3 SEQ ID NO: 109 SEPATSGSETPGTSESATPESGPG TSTEPSEG-MIC- 40.0 1-.DELTA.1-3 SEQ ID NO: 111 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3(M57L, M86L) 31.1 SEQ ID NO: 73 MIC-1(R2A, N3E) 0.9 SEQ ID NO: 164 SEPATSGSETPGTSESATPESGPGTSTEPSEG-MIC- 40.0 1-des-N3 (M57L, M86L) SEQ ID NO: 1 MIC-1(SEQ ID NO: 1) 0.3
General Methods of in Vitro Activity Screening
Example 5: Establishment of BHK21-hGFRAL-IRES-hRET Cell Line
[0259] The purpose of this example was to establish a cell based in vitro assay for testing MIC-1 activity. Mammalian cells were transfected and stably expressed full length MIC-1 receptor (hGFRAL) and its full signaling co-receptor hRET51.
[0260] Plasmids expressing full length hGFRAL and full length hRET51 were constructed by inserting synthesized DNA nucleotides encoding full length hGFRAL and full length hRET51 into mammalian expression vector pEL. IRES (internal ribosome entry site) is a commonly used linker between two DNA sequences, so that the two DNA sequences can be simultaneously translated into mRNA. pEL vector backbone was provided by Taihegene CRO company.
[0261] Two millions of BHK21 cells were seeded in a 10 cm petri dish and cultured for overnight in culture medium (DMEM+10% FBS+1% PS). Cells were transfected with pEL-hGFRAL-IRES-hRET plasmids. Transfected cells were split into new 10 cm dishes at different densities and grew in selection medium (DMEM+10% FBS+1% PS+1 mg/ml G418) for more than 2 weeks to get single clones. The single clones were transferred to 6 well plates and cultured to 100% confluence. mRNA expression of hGFRAL and hRET was measured by qPCR. Successfully transfected clones were picked up and tested for MIC-1 binding (FIG. 15 and Table 13).
Example 6: MIC-1 Cell-Based in Vitro Activity Assay
[0262] wtMIC-1 and MIC-1 compounds induced both phosphorylation of ERK1/2 in BHK21-hGFRAL-IRES-hRET stable cells (Table 8). It can be concluded from the results that the ternary complex of MIC-1, GFRAL and RET phosphorylates RET protein tyrosine kinase to induce in vivo activities of MIC-1 through signal pathways comprising ERK/MAPK pathway by phosphorylation of ERK1/2.
[0263] Results from screening MIC-1 compounds using BHK21-hGFRAL-IRES-hRET is shown in Table 8. MIC-1 compounds with N-extensions only or MIC-1 analogues with in-sequence mutations only achieved in vitro activity equal to or even higher than wtMIC-1. Also, combination of N-extension and in-sequence mutations can also achieve similar activity.
TABLE-US-00008 TABLE 8 In vitro activity of MIC-1 compounds pERK EC50 Emax SEQ IN NO Structure (nM) (0/0) SEQ ID NO: 1 MIC-1(SEQ ID NO: 1) 0.3 100% SEQ ID NO: 73 MIC-1(R2A, N3E) 0.3 100% SEQ ID NO: 74 MIC-1(R2A, N3E, A54E) 0.3 100% SEQ ID NO: 75 MIC-1(R2A, N3E, A81E) 0.3 100% SEQ ID NO: 76 MIC-1(R2A, N3E, H18E) 0.5 100% SEQ ID NO: 77 MIC-1(R2A, N3E, K69E) 0.5 100% SEQ ID NO: 78 MIC-1(R2A, N3E, K107E) 0.3 100% SEQ ID NO: 79 MIC-1(R2A, N3E, L68E) 0.8 100% SEQ ID NO: 80 MIC-1(R2A, N3E, A47E) 0.4 100% SEQ ID NO: 81 MIC-1(R2A, N3E, L105E) 0.7 100% SEQ ID NO: 82 MIC-1(R2A, N3E, M57E) 0.3 70% SEQ ID NO: 83 MIC-1(R2A, N3E, P85E) 0.6 100% SEQ ID NO: 84 MIC-1(R2A, N3E, P11E) 0.4 100% SEQ ID NO: 85 MIC-1(R2A, N3E, R21E) 0.6 100% SEQ ID NO: 86 MIC-1(R2A, N3E, R53E) 0.4 100% SEQ ID NO: 87 MIC-1(R2A, N3E, R67E) 0.5 100% SEQ ID NO: 88 MIC-1(R2A, N3E, A30E) 0.7 100% SEQ ID NO: 89 AEEAES-MIC-1-.DELTA.1-3 0.3 100% SEQ ID NO: 90 AES-MIC-1-.DELTA.1-3 0.3 100% SEQ ID NO: 91 (AEE).sub.2AES-MIC-1-.DELTA.1-3 0.4 100% SEQ ID NO: 92 (GEPS).sub.5-MIC-1(SEQ ID NO: 1) 0.5 100% SEQ ID NO: 93 SPAGSPTSTEEGTSESATPESGPG-MIC- 0.4 100% 1(SEQ ID NO: 1) SEQ ID NO: 94 (AEE).sub.6AES-MIC-1 0.8 100% SEQ ID NO: 95 (AEE).sub.5AES-MIC-1-.DELTA.1-3 0.5 100% SEQ ID NO: 96 (AEE).sub.3AES-MIC-1-.DELTA.1-3 0.5 100% SEQ ID NO: 97 AASPAGSPTSTEEGTSESATPESGPG-MIC- 0.4 100% 1(SEQ ID NO: 1) SEQ ID NO: 98 TSESATPESGPGTSESATPESGPG-MIC- 0.3 100% 1(R2A, N3E) SEQ ID NO: 99 AASPAGSPTSTEEGTSESATPESGPG-MIC-1- 0.7 100% .DELTA.1-3 SEQ ID NO: 100 AAPEDEETPEQEGSGSGSGSGS-MIC-1-.DELTA.1-3 0.5 100% SEQ ID NO: 101 AAPEDEETPEQE-MIC-1-.DELTA.1-3 0.5 100% SEQ ID NO: 102 AAPDEGTEEETEGSGSGSGSGS-MIC-1-.DELTA.1-3 0.5 100% SEQ ID NO: 103 SEPATSGSETPGTSTEPESGSAPG-MIC-1- 0.7 100% .DELTA.1-3 SEQ ID NO: 104 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3 0.4 100% SEQ ID NO: 105 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3(M57E) 0.6 60% SEQ ID NO: 106 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3(M57L) 0.6 100% SEQ ID NO: 107 A(GPEQGQEP).sub.3-MIC-1-.DELTA.1-3 0.8 100% SEQ ID NO: 108 SEPATSGSETPGTSESATPESGPGTSTEPS- 0.4 100% MIC-1-.DELTA.1-3 SEQ ID NO: 109 SEPATSGSETPGTSESATPESGPG 0.4 100% TSTEPSEG-MIC-1-.DELTA.1-3 SEQ ID NO: 110 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3(M86L) 0.4 100% SEQ ID NO: 111 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3(M57L, 0.4 100% M86L)
[0264] Increasing solubility of MIC-1 may also be achieved by N-terminal fusion of MIC-1 polypeptides with Human Serum Albumin (HSA). It is known that HSA fusion could increase the solubility of MIC-1. Two such HSA-MIC-1 fusion proteins were tested for in vitro activity (Table 9).
TABLE-US-00009 TABLE 9 pERK EC50 of HSA-MIC-1 conjugates pERK Calcu- EC50 lated HSA-MIC-1 fusion protein (nM) pI HSA-GGSSSGS(SEQ ID NO: 152)-MIC-1 3.6 6.2 (SEQ ID NO: 1) HSA-PTPTPTPTPTPTPTPTPTPTPTPTPTPTPTP 4.5 6.2 (SEQ ID NO: 153)-MIC-1(SEQ ID NO: 1)
[0265] A significant loss of potency was observed, thus demonstrating that these MIC-1 fusion proteins with high solubility did not retain receptor potency.
[0266] In Vivo Efficacy
Example 7: Effect of MIC-1 Compounds on Food Intake in Lean Sprague Dawley Rats
[0267] The in vivo efficacy of MIC-1 compounds of the invention was measured in 9-11 weeks old lean male Sprague Dawley rats. Animals were injected once daily with a dose of 8 nmol/kg body weight (4 nmol/kg for two HSA-MIC-1 fusion proteins) 1-2 hrs before the onset of the dark period. Compounds were administrate subcutaneously (1-4 ml/kg) in appropriate buffered solution. Changes in food intake were measured by automatic food monitoring systems (BioDAQ system and HM2 system for rat). In the BioDAQ system animals were single housed; and in the HM2 system animals were in group housed with up to 3 animals per cage. Each compound was tested in n=4-8 animals. Animals were acclimatized for at least 7 days prior to the experiment. Collected data are expressed as daily food intake (24 hour food intake) measured from the onset of each daily 12 hour dark phase to the next day dark phase. Daily changes in food intake in response to administrated compound were calculated by subtracting the average daily food intake of the vehicle group from the average daily food intake of the treatment group. Changes were considered significant if p<0.1 using a two-tailed student's t-test ( ). Results are expressed as the "maximum reduction" in food intake compared with vehicle (percentage) recorded during the study period. Data are also expressed as the "accumulated reduction" in food intake which as the sum of significant (p<0.1) daily reductions in food intake (percentage) during the study period.
TABLE-US-00010 TABLE 10 Effect of daily doses (8 nmol/kg) of MIC-1 compounds on food intake in lean SD rats. Maximum Efficacy Accumulated SEQ ID NO NNC (%) Efficacy (%) SEQ ID NO: 1 MIC-1(SEQ ID NO: 1) 68 361 SEQ ID NO: 77 MIC-1(R2A, N3E, K69E) 46 247 SEQ ID NO: 82 MIC-1(R2A, N3E, M57E) 72 395 SEQ ID NO: 92 (GEPS).sub.5-MIC-1(SEQ ID NO: 1) 84 469 SEQ ID NO: 97 AASPAGSPTSTEEGTSESATPESGPG- 90 456 MIC-1(SEQ ID NO: 1) SEQ ID NO: 98 TSESATPESGPGTSESATPESGPG-MIC- 90 503 1(R2A, N3E) SEQ ID NO: 100 AAPEDEETPEQEGSGSGSGSGS-MIC-1- 84 446 .DELTA.1-3 SEQ ID NO: 101 AAPEDEETPEQE-MIC-1-.DELTA.1-3 75 408 SEQ ID NO: 102 AAPDEGTEEETEGSGSGSGSGS-MIC-1- 82 423 .DELTA.1-3 SEQ ID NO: 103 SEPATSGSETPGTSTEPESGSAPG-MIC-1- 82 452 .DELTA.1-3 SEQ ID NO: 104 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3 93 509 SEQ ID NO: 105 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3(M57E) 97 532 SEQ ID NO: 106 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3(M57L) 99 532 SEQ ID NO: 107 A(GPEQGQEP).sub.3-MIC-1-.DELTA.1-3 81 395 SEQ ID NO: 108 SEPATSGSETPGTSESATPESGPGTSTEPS- 80 448 MIC-1-.DELTA.1-3 SEQ ID NO: 165 A(GPEQGQEPGEPQGQEPQPGEPEGQ)- 78 382 MIC-1-.DELTA.1-3 SEQ ID NO: 109 SEPATSGSETPGTSESATPESGPGTSTEPS 82 445 EG-MIC-1-.DELTA.1-3 SEQ ID NO: 110 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3 (M86L) 70 398 SEQ ID NO: 111 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3 85 462 (M57L/M86L) SEQ ID NO: 112 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3 80 369 (M57E/H66E) SEQ ID NO: 113 (SEPATSGSETPG).sub.2-MIC-1-.DELTA.1-3 67 266 (M57E/R67E) N/A HSA-GGSSSGS(SEQ ID NO: 152)-MIC- 28 72 1(SEQ ID NO: 1)* N/A HSA- 23 23 PTPTPTPTPTPTPTPTPTPTPTPTPTPTPTP (SEQ ID NO: 153)-MIC-1(SEQ ID NO: 1)* Note: *means the dose of administration is 4 nmol/kg body weight.
[0268] The inventors surprisingly found that these MIC-1 compounds not only increased the solubility molecules but also resulted in efficacy equal to or even better than wtMIC-1 (Table 10). For instance compounds according to SEQ ID NO:105 and SEQ ID NO:106 had a maximum and accumulated in vivo efficacy which was 40-50% greater than wtMIC-1 with subcutaneous dosing. The increase in efficacy was furthermore associated with an increase in solubility as compounds according to SEQ ID NO:92, SEQ ID NO:104, SEQ ID NO:105 and SEQ ID NO:106 all had elevated solubility and a significant greater in vivo efficacy compared with wtMIC-1. This correlation seems not to be explained by changes in the in vitro Emax as all compounds in table 10, except compound according to SEQ ID NO:105, had an Emax comparable with wtMIC-1. In fact, compound SEQ ID NO:105 had a lower Emax than wtMIC-1 and was still more efficacious than wtMIC-1 in vivo. Also, the in vitro potencies were comparable between compounds as none of the compounds had an EC50 which differed from wtMIC-1. Thus, the association between increased in vivo efficacies and increased solubility is surprising and cannot be simply be explained by changes in increased receptor activation in vitro.
Example 8: MIC-1 Expression and Initial Met Removal Efficiency of Different 12-mer Blocks
[0269] In the human body, N-Formyl-Methionine is recognized by the immune system as foreign material, or as an alarm signal released by damaged cells, and stimulates the body to fight against potential infection (Pathologic Basis of Veterinary Disease5: Pathologic Basis of Veterinary Disease, By James F. Zachary, M. Donald McGavin). In addition, Methionine is an instable residue that could be easily oxidized. Therefore, the N-Met cleavage efficiency is very important to MIC-1 expression.
[0270] There are 4 different types of 12mers, and all of them are comprised of 3 Ser, 2 Pro, 2 Gly, 2 Thr, 2 Glu and 1 Ala. However, the 12 residues in each repeat are arranged in different ways.
[0271] Little is known about the effects of different 12mers on the expression level and the N-Met cleavage efficiency. Thus, systematically investigation of MIC-1 compounds initiating with single and double 12mers respectively is quite necessary.
[0272] The cDNA of MIC-1 compound was sub-cloned into a pET11b derived vector. Overexpression of MIC-1 compounds as inclusion bodies or soluble protein was induced in E. coli by 0.5mM isopropyl .beta.-d-thiogalactoside (IPTG) when the cell density reached an OD600 of 1.0. After continuous growth in TB for 20 h at 37.degree. C., the cells were harvested and sonicated in buffer A (20 mM Tris, pH 8.0). The resulting mixture was centrifugated at 10,000 g for 20 min and analysed by LC/MS and SDS-PAGE to confirm the molecular weight.
[0273] Fermentation was carried out on fed-batch process in chemical defined medium as supplement. Fermentation yield largely depended on different compounds, which varied from 1 g/L to 8 g/L from compound to compound.
[0274] Compounds designed for the single-12mer test and the result are shown in Table 11 and FIG. 1.
TABLE-US-00011 TABLE 11 Initial Met removal efficiency of single 12-mer building blocks N-Met cleavage N- MIC-1 efficiency extension N-aa sequence Backbone (%) 12mer-1 SPAGSPTSTEEG MIC-1 N/A (SEQ ID NO: 166) del(1-3) 12mer-2 TSESATPESGPG 0 (SEQ ID NO: 167) 12mer-3 TSTEPSEGSAPG 0 (SEQ ID NO: 168) 12mer-4 SEPATSGSETPG 100 (SEQ ID NO: 169) N/A: means MIC-1 with the N-extension did not express in E.coli.
[0275] Compounds bearing double 12mers are listed in Table 12, and the results are shown as well (see Table 12 and FIG. 2).
TABLE-US-00012 TABLE 12 Initial Met removal efficiency of double 12-mers building blocks N-Met cleavage SEQ ID N- N-aa sequence efficiency NO extension backbone MIC-1 (%) N/A 12 mer- SPAGSPTSTEEG- MIC-1 N/A (1 + 1) SPAGSPTSTEEG del (SEQ ID NO: 170) (1-3) N/A 12 mer- SPAGSPTSTEEG- N/A (1 + 3) TSTEPSEGSAPG (SEQ ID NO: 171) N/A 12 mer- SPAGSPTSTEEG- N/A (1 + 4) SEPATSGSETPG (SEQ ID NO: 172) N/A 12 mer- TSESATPESGPG- 58.1 (2 + 1) SPAGSPTSTEEG (SEQ ID NO: 173) N/A 12 mer- TSESATPESGPG- 30.0 (2 + 2) TSESATPESGPG (SEQ ID NO: 174) N/A 12 mer- TSESATPESGPG- 58.5 (2 + 3) TSTEPSEGSAPG (SEQ ID NO: 175) N/A 12 mer- TSESATPESGPG- 64.5 (2 + 4) SEPATSGSETPG (SEQ ID NO: 176) N/A 12 mer- TSTEPSEGSAPG- 10.0 (3 + 1) SPAGSPTSTEEG (SEQ ID NO: 177) N/A 12 mer- TSTEPSEGSAPG- 1.0 (3 + 2) TSESATPESGPG (SEQ ID NO: 178) N/A 12 mer- TSTEPESGSAPG- 26.4 (3 + 3) TSTEPESGSAPG (SEQ ID NO: 179) N/A 12 mer- TSTEPSEGSAPG- 10.5 (3 + 4) SEPATSGSETPG (SEQ ID NO: 180) N/A 12 mer- SEPATSGSETPG- N/A (4 + 1) SPAGSPTSTEEG (SEQ ID NO: 12) SEQ ID 12 mer- SEPATSGSETPG- 100 NO: 182 (4 + 2) TSESATPESGPG (SEQ ID NO: 13) SEQ ID 12 mer- SEPATSGSETPG- 100 NO: 103 (4 + 3) TSTEPSEGSAPG (SEQ ID NO: 14) SEQ ID 12 mer- SEPATSGSETPG- 100 NO: 104 (4 + 4) SEPATSGSETPG (SEQ ID NO: 181) N/A: means MIC-1 compound with the N-extension did not express in E.coli.
[0276] In conclusion, N-extensions starting with the 12mer-1 block could not be expressed in E. coli. For the other 12mer blocks, protein expression was achieved but only 12mer-4 as the initial sequence resulted in complete methionine cleavage. In addition, the N-met cleavage efficiency of 12mer-2 series is better than that of 12mer-3 series.
Example 9: Expression Level and Inclusion Body Ratio of MIC-1 Peptide Compound with 2* or 2.5*12mer N-Extension
[0277] (1) Expression of MIC-1 Compound with 2.5*12mer N-Extension
[0278] See Example 8 for protein production method. The results are shown in Table 13, FIG. 3 and FIG. 4.
TABLE-US-00013 TABLE 13 Constructs and protein production for 2.5* 12 mer test UPLC UPLC SEQ ID N- N-aa MIC-1 Shaker Flask Fermenter NO extension sequence backbone (g/L/100D) (g/L/100D) SEQ ID 12 mer- SEPATSGSETPG MIC-1 N/A NO: 200 (4 + 2 + 1.6 TSESATPESGPG del(1-3) latter) TSTEEG (SEQ ID NO: 28) SEQ ID 12 mer- SEPATSGSETPG 0.197 NO: 201 (4 + 2 + 2.6) TSESATPESGPG TSESAT (SEQ ID NO: 19) SEQ ID 12 mer- SEPATSGSETPG 0.206 NO: 202 (4 + 2 + 2.6 TSESATPESGPG inter) ESATPE (SEQ ID NO: 183) SEQ ID 12 mer- SEPATSGSETPG 0.367 0.374 NO: 108 (4 + 2 + 3.6) TSESATPESGPG TSTEPS (SEQ ID NO: 70) SEQ ID 12 mer- SEPATSGSETPG 0.243 NO: 203 (4 + 2 + 3.6 TSESATPESGPG inter) STEPSE (SEQ ID NO: 184) SEQ ID 12 mer- SEPATSGSETPG 0.273 0.162 NO: 109 (4 + 2 + 3.8) TSESATPESGPG TSTEPSEG (SEQ ID NO: 71) SEQ ID 12 mer- SEPATSGSETPG 0.373 NO: 204 (4 + 2 + 4.6) TSESATPESGPG SEPATS (SEQ ID NO: 25) SEQ ID 12 mer- SEPATSGSETPG MIC-1 del (1- 0.195 NO: 205 (4 + 3 + 1.6 TSTEPSEGSAPG 3), M57L latter) TSTEEG (SEQ ID NO: 185) SEQ ID 12 mer- SEPATSGSETPG 0.234 NO: 206 (4 + 3 + 2.6) TSTEPSEGSAPG TSESAT (SEQ ID NO: 186) SEQ ID 12 mer- SEPATSGSETPG 0.367 NO: 207 (4 + 3 + 3.6) TSTEPSEGSAPG TSTEPS (SEQ ID NO: 187) SEQ ID 12 mer- SEPATSGSETPG 0.324 NO: 208 (4 + 3 + 4.6) TSTEPSEGSAPG SEPATS (SEQ ID NO: 188) SEQ ID 12 mer- SEPATSGSETPG MIC-1 del (1- 0.148 NO: 209 (4 + 4 + 1.6 SEPATSGSETPG 3), M57L latter) TSTEEG(SEQ ID NO: 189) SEQ ID 12 mer- SEPATSGSETPG MIC-1 0.361 NO: 210 (4 + 4 + 2.6) SEPATSGSETPG del(1-3) TSESAT (SEQ ID NO: 190) SEQ ID 12 mer- SEPATSGSETPG N/A NO: 211 c4 + 4 + 2.6 SEPATSGSETPG inter) ESATPE (SEQ ID NO: 191) SEQ ID 12 mer- SEPATSGSETPG MIC-1 del (1- 0.262 NO: 212 (4 + 4 + 3.6) SEPATSGSETPG 3), M57L TSTEPS (SEQ ID NO: 192) SEQ ID 12 mer- SEPATSGSETPG MIC-1 N/A NO: 213 (4 + 4 + 3.6 SEPATSGSETPG del(1-3) inter2) STEPSE (SEQ ID NO: 193) SEQ ID 12 mer- SEPATSGSETPG NO: 214 (4 + 4 + 4.6) SEPATSGSETPG 0.330 SEPATS (SEQ ID NO: 194) Notes: ".6" means the first 6 aa of 12 mers, "latter" means the last 6 aa of 12 mers, "inter" means the internal 6 aa from 12 mers.
[0279] Although the extended 12mer (6aa) locate 24aa away from the N-terminal, the expression levels of MIC-1 compound vary a lot among different groups. It is clear that the fragment from 12mer-1 is not suitable for expression, which is consistent with previous results. The average expression levels of 12mer-(4+_+3.6) and -(4+_+4.6) are relatively higher than others. [0280] (2) Inclusion Body Ratio of MIC-1 Compound with 2* or 2.5*12mer N-Extension
[0281] For large scale protein production, inclusion body is usually considered as a good choice mainly due to its better up-scaling properties, which mainly include: high expression level, simple recovery step and high purity, protease-resistant and good process stability.
[0282] MIC-1 compounds could be expressed either inclusion body or soluble form, which is mainly dependent on compounds' pI and extension length. The results are shown in Table 14 and FIG. 4.
TABLE-US-00014 TABLE 14 MIC-1 compound's solubility in cell cytosol and their pI values Sequences of MIC-1 Inclusion pI SEQ ID NO N-extension N-extension backbone body ratio* values SEQ ID NO: 12 mer-(4 + 4) SEPATSGSETPG MIC-1 100% 5.8 104 SEPATSGSETPG del(1-3) (SEQ ID NO: 181) SEQ ID NO: 12 mer-(4 + 2 + 3.6) SEPATSGSETPG 100% 5.5 108 TSESATPESGPG TSTEPS (SEQ ID NO: 70) SEQ ID NO: 12 mer-(4 + 2 + 3.8) SEPATSGSETPG 90% 5.2 109 TSESATPESGPG TSTEPSEG (SEQ ID NO: 71) SEQ ID NO: 12 mer-(4 + 2)- SEPATSGSETPG 90% 5.2 215 GPEQGPEQ TSESATPESGPG GPEQGPEQ (SEQ ID NO: 195) SEQ ID NO: 12 mer-(4 + 2)- SEPATSGSETPG 95% 5.2 216 GEPSGEPS TSESATPESGPG GEPSGEPS (SEQ ID NO: 196) SEQ ID NO: 12 mer-(4 + 4) SEPATSGSETPG 70% 5.0 112 M57E, H66E SEPATSGSETPG (SEQ ID NO: 181) SEQ ID NO: 12 mer-(4 + 4) SEPATSGSETPG 70% 5.0 113 M57E, R67E SEPATSGSETPG (SEQ ID NO: 181) SEQ ID NO: 12 mer-(three SEPATSGSETPG MIC-1-des- 85% 5.4 217 repeats) TSESATPESGPG N3 TSTEPSEGSAPG (SEQ ID NO: 197) SEQ ID NO: 12 mer-(four SEPATSGSETPG MIC-1-des- 30% 5.1 218 repeats) TSESATPESGPG N3 TSTEPSEGSAPG TSTEPSEGSAPG (SEQ ID NO: 198) SEQ ID NO: 12 mer-(five SPAGSPTSTEEG MIC-1 0% 4.8 219 repeats) TSESATPESGPG TSTEPSEGSAPG SPAGSPTSTEEG TSTEPSEGSAPG (SEQ ID NO: 199) SEQ ID NO: 12 mer-(4 + 4) SEPATSGSETPG MIC-1 0% 4.7 220 M57E, H66E, R67E SEPATSGSETPG del(1-3) (SEQ ID NO: 181) SEQ ID NO: 12 mer-(4 + 2 + 3.6) SEPATSGSETPG 0% 4.7 221 M57E, R67E TSESATPESGPG TSTEPS (SEQ ID NO: 70) Note: *The number here is estimated by SDS-PAGE.
[0283] The solubility of MIC-1 compounds with in-sequence mutations are shown in Table 15 and Fig.5 (the backbone is MIC-1 del(1-3)).
TABLE-US-00015 TABLE 15 Solubility of MIC-1 compound with in-sequence mutations Solublity in N-extension In-sequence M cell SEPATSGSETPG M57E IBs SEPATSGSETPG M57E/H66E Partially (12 mer-(4 + 4)) soluble (SEQ ID NO: 181) M57E/H66E/R67E Fully soluble SEPATSGSETPG M57E N.D. TSESATPESGPG- M57E/H66E Fully soluble TSTEPS M57E/H66E/R67E Fully soluble (12 mer-(4 + 2 + 3.6)) (SEQ ID NO: 70)
[0284] MIC-1 compounds initiating with 12mer-(4+2+_), -(4+4+_) and -(4+3+_) were investigated with their ability to express inclusion body. It was shown that the inclusion body ratio is >90% when pI>5.1. In addition, MIC-1 compounds with in-sequence mutations M57E/H66E mainly expressed soluble fractions.
Sequence CWU 1
1
2221112PRTHomo Sapiens 1Ala Arg Asn Gly Asp His Cys Pro Leu Gly Pro
Gly Arg Cys Cys Arg1 5 10 15Leu His Thr Val Arg Ala Ser Leu Glu Asp
Leu Gly Trp Ala Asp Trp 20 25 30Val Leu Ser Pro Arg Glu Val Gln Val
Thr Met Cys Ile Gly Ala Cys 35 40 45Pro Ser Gln Phe Arg Ala Ala Asn
Met His Ala Gln Ile Lys Thr Ser 50 55 60Leu His Arg Leu Lys Pro Asp
Thr Val Pro Ala Pro Cys Cys Val Pro65 70 75 80Ala Ser Tyr Asn Pro
Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val 85 90 95Ser Leu Gln Thr
Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 100 105
1102111PRTArtificial SequenceMIC-1 des-N3 2Ala Arg Gly Asp His Cys
Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu1 5 10 15His Thr Val Arg Ala
Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val 20 25 30Leu Ser Pro Arg
Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys Pro 35 40 45Ser Gln Phe
Arg Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser Leu 50 55 60His Arg
Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala65 70 75
80Ser Tyr Asn Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val Ser
85 90 95Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile
100 105 1103109PRTArtificial SequenceMIC-1-Del (1-3) 3Gly Asp His
Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu His Thr1 5 10 15Val Arg
Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val Leu Ser 20 25 30Pro
Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys Pro Ser Gln 35 40
45Phe Arg Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser Leu His Arg
50 55 60Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala Ser
Tyr65 70 75 80Asn Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val
Ser Leu Gln 85 90 95Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys
Ile 100 10546PRTArtificial SequenceN-terminal extension 4Ser Pro
Ala Gly Ser Pro1 556PRTArtificial SequenceN-terminal extension 5Thr
Ser Glu Ser Ala Thr1 566PRTArtificial SequenceN-terminal extension
6Thr Ser Thr Glu Pro Glu1 576PRTArtificial SequenceN-terminal
extension 7Ser Glu Pro Ala Thr Ser1 586PRTArtificial
SequenceN-terminal extension 8Thr Ser Thr Glu Glu Gly1
596PRTArtificial SequenceN-terminal extension 9Pro Glu Ser Gly Pro
Gly1 5106PRTArtificial SequenceN-terminal extension 10Ser Gly Ser
Ala Pro Gly1 5116PRTArtificial SequenceN-terminal extension 11Gly
Ser Glu Thr Pro Gly1 51224PRTArtificial SequenceN-terminal
extension 12Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro
Ala Gly1 5 10 15Ser Pro Thr Ser Thr Glu Glu Gly 201324PRTArtificial
SequenceN-terminal extension 13Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
201424PRTArtificial SequenceN-terminal extension 14Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Glu Ser
Gly Ser Ala Pro Gly 201530PRTArtificial SequenceN-terminal
extension 15Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro
Ala Gly1 5 10 15Ser Pro Thr Ser Thr Glu Glu Gly Ser Pro Ala Gly Ser
Pro 20 25 301630PRTArtificial SequenceN-terminal extension 16Ser
Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10
15Ala Thr Pro Glu Ser Gly Pro Gly Ser Pro Ala Gly Ser Pro 20 25
301730PRTArtificial SequenceN-terminal extension 17Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Glu Ser
Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro 20 25
301830PRTArtificial SequenceN-terminal extension 18Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly1 5 10 15Ser Pro Thr
Ser Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr 20 25
301930PRTArtificial SequenceN-terminal extension 19Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro
Glu Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr 20 25
302030PRTArtificial SequenceN-terminal extension 20Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Glu Ser
Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr 20 25
302130PRTArtificial SequenceN-terminal extension 21Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly1 5 10 15Ser Pro Thr
Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Glu 20 25
302230PRTArtificial SequenceN-terminal extension 22Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro
Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Glu 20 25
302330PRTArtificial SequenceN-terminal extension 23Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Glu Ser
Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Glu 20 25
302430PRTArtificial SequenceN-terminal extension 24Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly1 5 10 15Ser Pro Thr
Ser Thr Glu Glu Gly Ser Glu Pro Ala Thr Ser 20 25
302530PRTArtificial SequenceN-terminal extension 25Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro
Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser 20 25
302630PRTArtificial SequenceN-terminal extension 26Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Glu Ser
Gly Ser Ala Pro Gly Ser Glu Pro Ala Thr Ser 20 25
302730PRTArtificial SequenceN-terminal extension 27Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly1 5 10 15Ser Pro Thr
Ser Thr Glu Glu Gly Thr Ser Thr Glu Glu Gly 20 25
302830PRTArtificial SequenceN-terminal extension 28Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro
Glu Ser Gly Pro Gly Thr Ser Thr Glu Glu Gly 20 25
302930PRTArtificial SequenceN-terminal extension 29Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Glu Ser
Gly Ser Ala Pro Gly Thr Ser Thr Glu Glu Gly 20 25
303030PRTArtificial SequenceN-terminal extension 30Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly1 5 10 15Ser Pro Thr
Ser Thr Glu Glu Gly Pro Glu Ser Gly Pro Gly 20 25
303130PRTArtificial SequenceN-terminal extension 31Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro
Glu Ser Gly Pro Gly Pro Glu Ser Gly Pro Gly 20 25
303230PRTArtificial SequenceN-terminal extension 32Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Glu Ser
Gly Ser Ala Pro Gly Pro Glu Ser Gly Pro Gly 20 25
303330PRTArtificial SequenceN-terminal extension 33Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly1 5 10 15Ser Pro Thr
Ser Thr Glu Glu Gly Ser Gly Ser Ala Pro Gly 20 25
303430PRTArtificial SequenceN-terminal extension 34Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro
Glu Ser Gly Pro Gly Ser Gly Ser Ala Pro Gly 20 25
303530PRTArtificial SequenceN-terminal extension 35Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Glu Ser
Gly Ser Ala Pro Gly Ser Gly Ser Ala Pro Gly 20 25
303630PRTArtificial SequenceN-terminal extension 36Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly1 5 10 15Ser Pro Thr
Ser Thr Glu Glu Gly Gly Ser Glu Thr Pro Gly 20 25
303730PRTArtificial SequenceN-terminal extension 37Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro
Glu Ser Gly Pro Gly Gly Ser Glu Thr Pro Gly 20 25
303830PRTArtificial SequenceN-terminal extension 38Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Glu Ser
Gly Ser Ala Pro Gly Gly Ser Glu Thr Pro Gly 20 25
303936PRTArtificial SequenceN-terminal extension 39Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly1 5 10 15Ser Pro Thr
Ser Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro Glu 20 25 30Ser Gly
Pro Gly 354036PRTArtificial SequenceN-terminal extension 40Ser Glu
Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly1 5 10 15Ser
Pro Thr Ser Thr Glu Glu Gly Ser Pro Ala Gly Ser Pro Thr Ser 20 25
30Thr Glu Glu Gly 354136PRTArtificial SequenceN-terminal extension
41Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly1
5 10 15Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Glu Ser
Gly 20 25 30Ser Ala Pro Gly 354236PRTArtificial SequenceN-terminal
extension 42Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser
Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly Ser Pro Ala Gly Ser
Pro Thr Ser 20 25 30Thr Glu Glu Gly 354336PRTArtificial
SequenceN-terminal extension 43Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
Thr Ser Glu Ser Ala Thr Pro Glu 20 25 30Ser Gly Pro Gly
354436PRTArtificial SequenceN-terminal extension 44Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro
Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Glu Ser Gly 20 25 30Ser Ala
Pro Gly 354536PRTArtificial SequenceN-terminal extension 45Ser Glu
Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala
Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser 20 25
30Glu Thr Pro Gly 354636PRTArtificial SequenceN-terminal extension
46Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1
5 10 15Pro Glu Ser Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr
Ser 20 25 30Thr Glu Glu Gly 354736PRTArtificial SequenceN-terminal
extension 47Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser
Thr Glu1 5 10 15Pro Glu Ser Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala
Thr Pro Glu 20 25 30Ser Gly Pro Gly 354836PRTArtificial
SequenceN-terminal extension 48Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Glu Ser Gly Ser Ala Pro Gly
Thr Ser Thr Glu Pro Glu Ser Gly 20 25 30Ser Ala Pro Gly
354936PRTArtificial SequenceN-terminal extension 49Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Glu Ser
Gly Ser Ala Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser 20 25 30Glu Thr
Pro Gly 355036PRTArtificial SequenceN-terminal extension 50Ser Glu
Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr
Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser 20 25
30Thr Glu Glu Gly 355136PRTArtificial SequenceN-terminal extension
51Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala1
5 10 15Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro
Glu 20 25 30Ser Gly Pro Gly 355236PRTArtificial SequenceN-terminal
extension 52Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu
Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu Pro
Glu Ser Gly 20 25 30Ser Ala Pro Gly 355336PRTArtificial
SequenceN-terminal extension 53Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly
Ser Glu Pro Ala Thr Ser Gly Ser 20 25 30Glu Thr Pro Gly
35546PRTArtificial SequenceN-terminal extension 54Ala Glu Glu Ala
Glu Ser1 5554PRTArtificial SequenceN-terminal extension 55Ala Glu
Ser Met1569PRTArtificial SequenceN-terminal extension 56Ala Glu Glu
Ala Glu Glu Ala Glu Ser1 55720PRTArtificial SequenceN-terminal
extension 57Gly Glu Pro Ser Gly Glu Pro Ser Gly Glu Pro Ser Gly Glu
Pro Ser1 5 10 15Gly Glu Pro Ser 205824PRTArtificial
SequenceN-terminal extension 58Ser Pro Ala Gly Ser Pro Thr Ser Thr
Glu Glu Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
205921PRTArtificial SequenceN-terminal extension 59Ala Glu Glu Ala
Glu Glu Ala Glu Glu Ala Glu Glu Ala Glu Glu Ala1 5 10 15Glu Glu Ala
Glu Ser 206018PRTArtificial SequenceN-terminal extension 60Ala Glu
Glu Ala Glu Glu Ala Glu Glu Ala Glu Glu Ala Glu Glu Ala1 5 10 15Glu
Ser6112PRTArtificial SequenceN-terminal extension 61Ala Glu Glu Ala
Glu Glu Ala Glu Glu Ala Glu Ser1 5 106226PRTArtificial
SequenceN-terminal extension 62Ala Ala Ser Pro Ala Gly Ser Pro Thr
Ser Thr Glu Glu Gly Thr Ser1 5 10 15Glu Ser Ala Thr Pro Glu Ser Gly
Pro Gly 20 256324PRTArtificial SequenceN-terminal extension 63Thr
Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Glu Ser1 5 10
15Ala Thr Pro Glu Ser Gly Pro Gly 206426PRTArtificial
SequenceN-terminal extension 64Ala Ala Ser Pro Ala Gly Ser Pro Thr
Ser Thr Glu Glu Gly Thr Ser1 5 10 15Glu Ser Ala Thr Pro Glu Ser Gly
Pro Gly 20 256522PRTArtificial SequenceN-terminal extension 65Ala
Ala Pro Glu Asp Glu Glu Thr Pro Glu Gln Glu Gly Ser Gly Ser1 5 10
15Gly Ser Gly Ser Gly Ser 206612PRTArtificial SequenceN-terminal
extension 66Ala Ala Pro Glu Asp Glu Glu Thr Pro Glu Gln Glu1 5
106722PRTArtificial SequenceN-terminal extension 67Ala Ala Pro Asp
Glu Gly Thr Glu Glu Glu Thr Glu Gly Ser Gly Ser1 5 10 15Gly Ser Gly
Ser Gly Ser 206824PRTArtificial SequenceN-terminal extension 68Ser
Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala1 5
10 15Thr Ser Gly Ser Glu Thr Pro Gly 206925PRTArtificial
SequenceN-terminal extension 69Ala Gly Pro Glu Gln Gly Gln Glu Pro
Gly Pro Glu Gln Gly Gln Glu1 5 10 15Pro Gly Pro Glu Gln Gly Gln Glu
Pro 20 257030PRTArtificial SequenceN-terminal extension 70Ser Glu
Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala
Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser 20 25
307132PRTArtificial SequenceN-terminal extension 71Ser Glu Pro Ala
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro
Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly 20 25
307224PRTArtificial SequenceN-terminal extension 72Gly Glu Pro Ser
Gly Glu Pro Ser Gly Glu Pro Ser Gly Glu Pro Ser1 5 10 15Gly Glu Pro
Ser Gly Glu Pro Ser 2073112PRTArtificial SequenceMIC-1 polypeptide
73Ala Ala Glu Gly Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg1
5 10 15Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp
Trp 20 25 30Val Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly
Ala Cys 35 40 45Pro Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile
Lys Thr Ser 50 55 60Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro
Cys Cys Val Pro65 70 75 80Ala Ser Tyr Asn Pro Met Val Leu Ile Gln
Lys Thr Asp Thr Gly Val 85 90 95Ser Leu Gln Thr Tyr Asp Asp Leu Leu
Ala Lys Asp Cys His Cys Ile 100 105 11074112PRTArtificial
SequenceMIC-1 polypeptide 74Ala Ala Glu Gly Asp His Cys Pro Leu Gly
Pro Gly Arg Cys Cys Arg1 5 10 15Leu His Thr Val Arg Ala Ser Leu Glu
Asp Leu Gly Trp Ala Asp Trp 20 25 30Val Leu Ser Pro Arg Glu Val Gln
Val Thr Met Cys Ile Gly Ala Cys 35 40 45Pro Ser Gln Phe Arg Glu Ala
Asn Met His Ala Gln Ile Lys Thr Ser 50 55 60Leu His Arg Leu Lys Pro
Asp Thr Val Pro Ala Pro Cys Cys Val Pro65 70 75 80Ala Ser Tyr Asn
Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val 85 90 95Ser Leu Gln
Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 100 105
11075112PRTArtificial SequenceMIC-1 polypeptide 75Ala Ala Glu Gly
Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg1 5 10 15Leu His Thr
Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp 20 25 30Val Leu
Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys 35 40 45Pro
Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser 50 55
60Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro65
70 75 80Glu Ser Tyr Asn Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly
Val 85 90 95Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His
Cys Ile 100 105 11076112PRTArtificial SequenceMIC-1 polypeptide
76Ala Ala Glu Gly Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg1
5 10 15Leu Glu Thr Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp
Trp 20 25 30Val Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly
Ala Cys 35 40 45Pro Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile
Lys Thr Ser 50 55 60Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro
Cys Cys Val Pro65 70 75 80Ala Ser Tyr Asn Pro Met Val Leu Ile Gln
Lys Thr Asp Thr Gly Val 85 90 95Ser Leu Gln Thr Tyr Asp Asp Leu Leu
Ala Lys Asp Cys His Cys Ile 100 105 11077112PRTArtificial
SequenceMIC-1 polypeptide 77Ala Ala Glu Gly Asp His Cys Pro Leu Gly
Pro Gly Arg Cys Cys Arg1 5 10 15Leu His Thr Val Arg Ala Ser Leu Glu
Asp Leu Gly Trp Ala Asp Trp 20 25 30Val Leu Ser Pro Arg Glu Val Gln
Val Thr Met Cys Ile Gly Ala Cys 35 40 45Pro Ser Gln Phe Arg Ala Ala
Asn Met His Ala Gln Ile Lys Thr Ser 50 55 60Leu His Arg Leu Glu Pro
Asp Thr Val Pro Ala Pro Cys Cys Val Pro65 70 75 80Ala Ser Tyr Asn
Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val 85 90 95Ser Leu Gln
Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 100 105
11078112PRTArtificial SequenceMIC-1 polypeptide 78Ala Ala Glu Gly
Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg1 5 10 15Leu His Thr
Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp 20 25 30Val Leu
Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys 35 40 45Pro
Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser 50 55
60Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro65
70 75 80Ala Ser Tyr Asn Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly
Val 85 90 95Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala Glu Asp Cys His
Cys Ile 100 105 11079112PRTArtificial SequenceMIC-1 polypeptide
79Ala Ala Glu Gly Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg1
5 10 15Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp
Trp 20 25 30Val Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly
Ala Cys 35 40 45Pro Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile
Lys Thr Ser 50 55 60Leu His Arg Glu Lys Pro Asp Thr Val Pro Ala Pro
Cys Cys Val Pro65 70 75 80Ala Ser Tyr Asn Pro Met Val Leu Ile Gln
Lys Thr Asp Thr Gly Val 85 90 95Ser Leu Gln Thr Tyr Asp Asp Leu Leu
Ala Lys Asp Cys His Cys Ile 100 105 11080112PRTArtificial
SequenceMIC-1 polypeptide 80Ala Ala Glu Gly Asp His Cys Pro Leu Gly
Pro Gly Arg Cys Cys Arg1 5 10 15Leu His Thr Val Arg Ala Ser Leu Glu
Asp Leu Gly Trp Ala Asp Trp 20 25 30Val Leu Ser Pro Arg Glu Val Gln
Val Thr Met Cys Ile Gly Glu Cys 35 40 45Pro Ser Gln Phe Arg Ala Ala
Asn Met His Ala Gln Ile Lys Thr Ser 50 55 60Leu His Arg Leu Lys Pro
Asp Thr Val Pro Ala Pro Cys Cys Val Pro65 70 75 80Ala Ser Tyr Asn
Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val 85 90 95Ser Leu Gln
Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 100 105
11081112PRTArtificial SequenceMIC-1 polypeptide 81Ala Ala Glu Gly
Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg1 5 10 15Leu His Thr
Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp 20 25 30Val Leu
Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys 35 40 45Pro
Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser 50 55
60Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro65
70 75 80Ala Ser Tyr Asn Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly
Val 85 90 95Ser Leu Gln Thr Tyr Asp Asp Leu Glu Ala Lys Asp Cys His
Cys Ile 100 105 11082112PRTArtificial SequenceMIC-1 polypeptide
82Ala Ala Glu Gly Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg1
5 10 15Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp
Trp 20 25 30Val Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly
Ala Cys 35 40 45Pro Ser Gln Phe Arg Ala Ala Asn Glu His Ala Gln Ile
Lys Thr Ser 50 55 60Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro
Cys Cys Val Pro65 70 75 80Ala Ser Tyr Asn Pro Met Val Leu Ile Gln
Lys Thr Asp Thr Gly Val 85 90 95Ser Leu Gln Thr Tyr Asp Asp Leu Leu
Ala Lys Asp Cys His Cys Ile 100 105 11083112PRTArtificial
SequenceMIC-1 polypeptide 83Ala Ala Glu Gly Asp His Cys Pro Leu Gly
Pro Gly Arg Cys Cys Arg1 5 10 15Leu His Thr Val Arg Ala Ser Leu Glu
Asp Leu Gly Trp Ala Asp Trp 20 25 30Val Leu Ser Pro Arg Glu Val Gln
Val Thr Met Cys Ile Gly Ala Cys 35 40 45Pro Ser Gln Phe Arg Ala Ala
Asn Met His Ala Gln Ile Lys Thr Ser 50 55 60Leu His Arg Leu Lys Pro
Asp Thr Val Pro Ala Pro Cys Cys Val Pro65 70 75 80Ala Ser Tyr Asn
Glu Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val 85 90 95Ser Leu Gln
Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 100 105
11084112PRTArtificial SequenceMIC-1 polypeptide 84Ala Ala Glu Gly
Asp His Cys Pro Leu Gly Glu Gly Arg Cys Cys Arg1 5 10 15Leu His Thr
Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp 20 25 30Val Leu
Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys 35 40 45Pro
Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser 50 55
60Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro65
70 75 80Ala Ser Tyr Asn Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly
Val 85 90 95Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His
Cys Ile 100 105 11085112PRTArtificial SequenceMIC-1 polypeptide
85Ala Ala Glu Gly Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg1
5 10 15Leu His Thr Val Glu Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp
Trp 20 25 30Val Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly
Ala Cys 35 40 45Pro Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile
Lys Thr Ser 50 55 60Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro
Cys Cys Val Pro65 70 75 80Ala Ser Tyr Asn Pro Met Val Leu Ile Gln
Lys Thr Asp Thr Gly Val 85 90 95Ser Leu Gln Thr Tyr Asp Asp Leu Leu
Ala Lys Asp Cys His Cys Ile 100 105 11086112PRTArtificial
SequenceMIC-1 polypeptide 86Ala Ala Glu Gly Asp His Cys Pro Leu Gly
Pro Gly Arg Cys Cys Arg1 5 10 15Leu His Thr Val Arg Ala Ser Leu Glu
Asp Leu Gly Trp Ala Asp Trp 20 25 30Val Leu Ser Pro Arg Glu Val Gln
Val Thr Met Cys Ile Gly Ala Cys 35 40 45Pro Ser Gln Phe Glu Ala Ala
Asn Met His Ala Gln Ile Lys Thr Ser 50 55 60Leu His Arg Leu Lys Pro
Asp Thr Val Pro Ala Pro Cys Cys Val Pro65 70 75 80Ala Ser Tyr Asn
Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val 85 90 95Ser Leu Gln
Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 100 105
11087112PRTArtificial SequenceMIC-1 polypeptide 87Ala Ala Glu Gly
Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg1 5 10 15Leu His Thr
Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp 20 25 30Val Leu
Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys 35 40 45Pro
Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser 50 55
60Leu His Glu Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro65
70 75 80Ala Ser Tyr Asn Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly
Val 85 90 95Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His
Cys Ile 100 105 11088112PRTArtificial SequenceMIC-1 polypeptide
88Ala Ala Glu Gly Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg1
5 10 15Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Glu Asp
Trp 20 25 30Val Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly
Ala Cys 35 40 45Pro Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile
Lys Thr Ser 50 55 60Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro
Cys Cys Val Pro65 70 75 80Ala Ser Tyr Asn Pro Met Val Leu Ile Gln
Lys Thr Asp Thr Gly Val 85 90 95Ser Leu Gln Thr Tyr Asp Asp Leu Leu
Ala Lys Asp Cys His Cys Ile 100 105 11089115PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 89Ala Glu Glu
Ala Glu Ser Gly Asp His Cys Pro Leu Gly Pro Gly Arg1 5 10 15Cys Cys
Arg Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu Gly Trp 20 25 30Ala
Asp Trp Val Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile 35 40
45Gly Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile
50 55 60Lys Thr Ser Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro
Cys65 70 75 80Cys Val Pro Ala Ser Tyr Asn Pro Met Val Leu Ile Gln
Lys Thr Asp 85 90 95Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp Leu Leu
Ala Lys Asp Cys 100 105 110His Cys Ile 11590112PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 90Ala Glu Ser
Gly Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg1 5 10 15Leu His
Thr Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp 20 25 30Val
Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys 35 40
45Pro Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser
50 55 60Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val
Pro65 70 75 80Ala Ser Tyr Asn Pro Met Val Leu Ile Gln Lys Thr Asp
Thr Gly Val 85 90 95Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys Asp
Cys His Cys Ile 100 105 11091118PRTArtificial SequenceMIC-1
polypeptide plus N-terminal extension 91Ala Glu Glu Ala Glu Glu Ala
Glu Ser Gly Asp His Cys Pro Leu Gly1 5 10 15Pro Gly Arg Cys Cys Arg
Leu His Thr Val Arg Ala Ser Leu Glu Asp 20 25 30Leu Gly Trp Ala Asp
Trp Val Leu Ser Pro Arg Glu Val Gln Val Thr 35 40 45Met Cys Ile Gly
Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn Met His 50 55 60Ala Gln Ile
Lys Thr Ser Leu His Arg Leu Lys Pro Asp Thr Val Pro65 70 75 80Ala
Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro Met Val Leu Ile Gln 85 90
95Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala
100 105 110Lys Asp Cys His Cys Ile 11592132PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 92Gly Glu Pro
Ser Gly Glu Pro Ser Gly Glu Pro Ser Gly Glu Pro Ser1 5 10 15Gly Glu
Pro Ser Ala Arg Asn Gly Asp His Cys Pro Leu Gly Pro Gly 20 25 30Arg
Cys Cys Arg Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu Gly 35 40
45Trp Ala Asp
Trp Val Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys 50 55 60Ile Gly
Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln65 70 75
80Ile Lys Thr Ser Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro
85 90 95Cys Cys Val Pro Ala Ser Tyr Asn Pro Met Val Leu Ile Gln Lys
Thr 100 105 110Asp Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp Leu Leu
Ala Lys Asp 115 120 125Cys His Cys Ile 13093136PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 93Ser Pro Ala
Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser1 5 10 15Ala Thr
Pro Glu Ser Gly Pro Gly Ala Arg Asn Gly Asp His Cys Pro 20 25 30Leu
Gly Pro Gly Arg Cys Cys Arg Leu His Thr Val Arg Ala Ser Leu 35 40
45Glu Asp Leu Gly Trp Ala Asp Trp Val Leu Ser Pro Arg Glu Val Gln
50 55 60Val Thr Met Cys Ile Gly Ala Cys Pro Ser Gln Phe Arg Ala Ala
Asn65 70 75 80Met His Ala Gln Ile Lys Thr Ser Leu His Arg Leu Lys
Pro Asp Thr 85 90 95Val Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr Asn
Pro Met Val Leu 100 105 110Ile Gln Lys Thr Asp Thr Gly Val Ser Leu
Gln Thr Tyr Asp Asp Leu 115 120 125Leu Ala Lys Asp Cys His Cys Ile
130 13594130PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 94Ala Glu Glu Ala Glu Glu Ala Glu Glu Ala Glu Glu Ala Glu
Glu Ala1 5 10 15Glu Glu Ala Glu Ser Gly Asp His Cys Pro Leu Gly Pro
Gly Arg Cys 20 25 30Cys Arg Leu His Thr Val Arg Ala Ser Leu Glu Asp
Leu Gly Trp Ala 35 40 45Asp Trp Val Leu Ser Pro Arg Glu Val Gln Val
Thr Met Cys Ile Gly 50 55 60Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn
Met His Ala Gln Ile Lys65 70 75 80Thr Ser Leu His Arg Leu Lys Pro
Asp Thr Val Pro Ala Pro Cys Cys 85 90 95Val Pro Ala Ser Tyr Asn Pro
Met Val Leu Ile Gln Lys Thr Asp Thr 100 105 110Gly Val Ser Leu Gln
Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His 115 120 125Cys Ile
13095127PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 95Ala Glu Glu Ala Glu Glu Ala Glu Glu Ala Glu Glu Ala Glu
Glu Ala1 5 10 15Glu Ser Gly Asp His Cys Pro Leu Gly Pro Gly Arg Cys
Cys Arg Leu 20 25 30His Thr Val Arg Ala Ser Leu Glu Asp Leu Gly Trp
Ala Asp Trp Val 35 40 45Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys
Ile Gly Ala Cys Pro 50 55 60Ser Gln Phe Arg Ala Ala Asn Met His Ala
Gln Ile Lys Thr Ser Leu65 70 75 80His Arg Leu Lys Pro Asp Thr Val
Pro Ala Pro Cys Cys Val Pro Ala 85 90 95Ser Tyr Asn Pro Met Val Leu
Ile Gln Lys Thr Asp Thr Gly Val Ser 100 105 110Leu Gln Thr Tyr Asp
Asp Leu Leu Ala Lys Asp Cys His Cys Ile 115 120
12596121PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 96Ala Glu Glu Ala Glu Glu Ala Glu Glu Ala Glu Ser Gly Asp
His Cys1 5 10 15Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu His Thr Val
Arg Ala Ser 20 25 30Leu Glu Asp Leu Gly Trp Ala Asp Trp Val Leu Ser
Pro Arg Glu Val 35 40 45Gln Val Thr Met Cys Ile Gly Ala Cys Pro Ser
Gln Phe Arg Ala Ala 50 55 60Asn Met His Ala Gln Ile Lys Thr Ser Leu
His Arg Leu Lys Pro Asp65 70 75 80Thr Val Pro Ala Pro Cys Cys Val
Pro Ala Ser Tyr Asn Pro Met Val 85 90 95Leu Ile Gln Lys Thr Asp Thr
Gly Val Ser Leu Gln Thr Tyr Asp Asp 100 105 110Leu Leu Ala Lys Asp
Cys His Cys Ile 115 12097138PRTArtificial SequenceMIC-1 polypeptide
plus N-terminal extension 97Ala Ala Ser Pro Ala Gly Ser Pro Thr Ser
Thr Glu Glu Gly Thr Ser1 5 10 15Glu Ser Ala Thr Pro Glu Ser Gly Pro
Gly Ala Arg Asn Gly Asp His 20 25 30Cys Pro Leu Gly Pro Gly Arg Cys
Cys Arg Leu His Thr Val Arg Ala 35 40 45Ser Leu Glu Asp Leu Gly Trp
Ala Asp Trp Val Leu Ser Pro Arg Glu 50 55 60Val Gln Val Thr Met Cys
Ile Gly Ala Cys Pro Ser Gln Phe Arg Ala65 70 75 80Ala Asn Met His
Ala Gln Ile Lys Thr Ser Leu His Arg Leu Lys Pro 85 90 95Asp Thr Val
Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro Met 100 105 110Val
Leu Ile Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr Asp 115 120
125Asp Leu Leu Ala Lys Asp Cys His Cys Ile 130
13598136PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 98Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser
Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly Ala Ala Glu Gly Asp
His Cys Pro 20 25 30Leu Gly Pro Gly Arg Cys Cys Arg Leu His Thr Val
Arg Ala Ser Leu 35 40 45Glu Asp Leu Gly Trp Ala Asp Trp Val Leu Ser
Pro Arg Glu Val Gln 50 55 60Val Thr Met Cys Ile Gly Ala Cys Pro Ser
Gln Phe Arg Ala Ala Asn65 70 75 80Met His Ala Gln Ile Lys Thr Ser
Leu His Arg Leu Lys Pro Asp Thr 85 90 95Val Pro Ala Pro Cys Cys Val
Pro Ala Ser Tyr Asn Pro Met Val Leu 100 105 110Ile Gln Lys Thr Asp
Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp Leu 115 120 125Leu Ala Lys
Asp Cys His Cys Ile 130 13599135PRTArtificial SequenceMIC-1
polypeptide plus N-terminal extension 99Ala Ala Ser Pro Ala Gly Ser
Pro Thr Ser Thr Glu Glu Gly Thr Ser1 5 10 15Glu Ser Ala Thr Pro Glu
Ser Gly Pro Gly Gly Asp His Cys Pro Leu 20 25 30Gly Pro Gly Arg Cys
Cys Arg Leu His Thr Val Arg Ala Ser Leu Glu 35 40 45Asp Leu Gly Trp
Ala Asp Trp Val Leu Ser Pro Arg Glu Val Gln Val 50 55 60Thr Met Cys
Ile Gly Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn Met65 70 75 80His
Ala Gln Ile Lys Thr Ser Leu His Arg Leu Lys Pro Asp Thr Val 85 90
95Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro Met Val Leu Ile
100 105 110Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp
Leu Leu 115 120 125Ala Lys Asp Cys His Cys Ile 130
135100131PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 100Ala Ala Pro Glu Asp Glu Glu Thr Pro Glu Gln Glu Gly
Ser Gly Ser1 5 10 15Gly Ser Gly Ser Gly Ser Gly Asp His Cys Pro Leu
Gly Pro Gly Arg 20 25 30Cys Cys Arg Leu His Thr Val Arg Ala Ser Leu
Glu Asp Leu Gly Trp 35 40 45Ala Asp Trp Val Leu Ser Pro Arg Glu Val
Gln Val Thr Met Cys Ile 50 55 60Gly Ala Cys Pro Ser Gln Phe Arg Ala
Ala Asn Met His Ala Gln Ile65 70 75 80Lys Thr Ser Leu His Arg Leu
Lys Pro Asp Thr Val Pro Ala Pro Cys 85 90 95Cys Val Pro Ala Ser Tyr
Asn Pro Met Val Leu Ile Gln Lys Thr Asp 100 105 110Thr Gly Val Ser
Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys 115 120 125His Cys
Ile 130101121PRTArtificial SequenceMIC-1 polypeptide plus
N-terminal extension 101Ala Ala Pro Glu Asp Glu Glu Thr Pro Glu Gln
Glu Gly Asp His Cys1 5 10 15Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu
His Thr Val Arg Ala Ser 20 25 30Leu Glu Asp Leu Gly Trp Ala Asp Trp
Val Leu Ser Pro Arg Glu Val 35 40 45Gln Val Thr Met Cys Ile Gly Ala
Cys Pro Ser Gln Phe Arg Ala Ala 50 55 60Asn Met His Ala Gln Ile Lys
Thr Ser Leu His Arg Leu Lys Pro Asp65 70 75 80Thr Val Pro Ala Pro
Cys Cys Val Pro Ala Ser Tyr Asn Pro Met Val 85 90 95Leu Ile Gln Lys
Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp 100 105 110Leu Leu
Ala Lys Asp Cys His Cys Ile 115 120102131PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 102Ala Ala Pro
Asp Glu Gly Thr Glu Glu Glu Thr Glu Gly Ser Gly Ser1 5 10 15Gly Ser
Gly Ser Gly Ser Gly Asp His Cys Pro Leu Gly Pro Gly Arg 20 25 30Cys
Cys Arg Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu Gly Trp 35 40
45Ala Asp Trp Val Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile
50 55 60Gly Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln
Ile65 70 75 80Lys Thr Ser Leu His Arg Leu Lys Pro Asp Thr Val Pro
Ala Pro Cys 85 90 95Cys Val Pro Ala Ser Tyr Asn Pro Met Val Leu Ile
Gln Lys Thr Asp 100 105 110Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp
Leu Leu Ala Lys Asp Cys 115 120 125His Cys Ile
130103133PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 103Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr
Ser Thr Glu1 5 10 15Pro Ser Glu Gly Ser Ala Pro Gly Gly Asp His Cys
Pro Leu Gly Pro 20 25 30Gly Arg Cys Cys Arg Leu His Thr Val Arg Ala
Ser Leu Glu Asp Leu 35 40 45Gly Trp Ala Asp Trp Val Leu Ser Pro Arg
Glu Val Gln Val Thr Met 50 55 60Cys Ile Gly Ala Cys Pro Ser Gln Phe
Arg Ala Ala Asn Met His Ala65 70 75 80Gln Ile Lys Thr Ser Leu His
Arg Leu Lys Pro Asp Thr Val Pro Ala 85 90 95Pro Cys Cys Val Pro Ala
Ser Tyr Asn Pro Met Val Leu Ile Gln Lys 100 105 110Thr Asp Thr Gly
Val Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys 115 120 125Asp Cys
His Cys Ile 130104133PRTArtificial SequenceMIC-1 polypeptide plus
N-terminal extension 104Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly Gly Asp
His Cys Pro Leu Gly Pro 20 25 30Gly Arg Cys Cys Arg Leu His Thr Val
Arg Ala Ser Leu Glu Asp Leu 35 40 45Gly Trp Ala Asp Trp Val Leu Ser
Pro Arg Glu Val Gln Val Thr Met 50 55 60Cys Ile Gly Ala Cys Pro Ser
Gln Phe Arg Ala Ala Asn Met His Ala65 70 75 80Gln Ile Lys Thr Ser
Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala 85 90 95Pro Cys Cys Val
Pro Ala Ser Tyr Asn Pro Met Val Leu Ile Gln Lys 100 105 110Thr Asp
Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys 115 120
125Asp Cys His Cys Ile 130105133PRTArtificial SequenceMIC-1
polypeptide plus N-terminal extension 105Ser Glu Pro Ala Thr Ser
Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu
Thr Pro Gly Gly Asp His Cys Pro Leu Gly Pro 20 25 30Gly Arg Cys Cys
Arg Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu 35 40 45Gly Trp Ala
Asp Trp Val Leu Ser Pro Arg Glu Val Gln Val Thr Met 50 55 60Cys Ile
Gly Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn Glu His Ala65 70 75
80Gln Ile Lys Thr Ser Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala
85 90 95Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro Met Val Leu Ile Gln
Lys 100 105 110Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp Leu
Leu Ala Lys 115 120 125Asp Cys His Cys Ile 130106133PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 106Ser Glu Pro
Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser
Gly Ser Glu Thr Pro Gly Gly Asp His Cys Pro Leu Gly Pro 20 25 30Gly
Arg Cys Cys Arg Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu 35 40
45Gly Trp Ala Asp Trp Val Leu Ser Pro Arg Glu Val Gln Val Thr Met
50 55 60Cys Ile Gly Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn Leu His
Ala65 70 75 80Gln Ile Lys Thr Ser Leu His Arg Leu Lys Pro Asp Thr
Val Pro Ala 85 90 95Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro Met Val
Leu Ile Gln Lys 100 105 110Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr
Asp Asp Leu Leu Ala Lys 115 120 125Asp Cys His Cys Ile
130107134PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 107Ala Gly Pro Glu Gln Gly Gln Glu Pro Gly Pro Glu Gln
Gly Gln Glu1 5 10 15Pro Gly Pro Glu Gln Gly Gln Glu Pro Gly Asp His
Cys Pro Leu Gly 20 25 30Pro Gly Arg Cys Cys Arg Leu His Thr Val Arg
Ala Ser Leu Glu Asp 35 40 45Leu Gly Trp Ala Asp Trp Val Leu Ser Pro
Arg Glu Val Gln Val Thr 50 55 60Met Cys Ile Gly Ala Cys Pro Ser Gln
Phe Arg Ala Ala Asn Met His65 70 75 80Ala Gln Ile Lys Thr Ser Leu
His Arg Leu Lys Pro Asp Thr Val Pro 85 90 95Ala Pro Cys Cys Val Pro
Ala Ser Tyr Asn Pro Met Val Leu Ile Gln 100 105 110Lys Thr Asp Thr
Gly Val Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala 115 120 125Lys Asp
Cys His Cys Ile 130108139PRTArtificial SequenceMIC-1 polypeptide
plus N-terminal extension 108Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
Thr Ser Thr Glu Pro Ser Gly Asp 20 25 30His Cys Pro Leu Gly Pro Gly
Arg Cys Cys Arg Leu His Thr Val Arg 35 40 45Ala Ser Leu Glu Asp Leu
Gly Trp Ala Asp Trp Val Leu Ser Pro Arg 50 55 60Glu Val Gln Val Thr
Met Cys Ile Gly Ala Cys Pro Ser Gln Phe Arg65 70 75 80Ala Ala Asn
Met His Ala Gln Ile Lys Thr Ser Leu His Arg Leu Lys 85 90 95Pro Asp
Thr Val Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro 100 105
110Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr
115 120 125Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 130
135109141PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 109Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr
Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu
Pro Ser Glu Gly 20 25 30Gly Asp His Cys Pro Leu Gly Pro Gly Arg Cys
Cys Arg Leu His Thr 35 40 45Val Arg Ala Ser Leu Glu Asp Leu Gly Trp
Ala Asp Trp Val Leu Ser 50 55 60Pro Arg Glu Val Gln Val Thr Met Cys
Ile Gly Ala Cys Pro Ser Gln65 70 75 80Phe Arg Ala Ala Asn Met His
Ala Gln Ile Lys Thr Ser Leu His Arg 85 90 95Leu Lys Pro Asp Thr Val
Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr 100 105 110Asn Pro Met Val
Leu Ile Gln Lys Thr
Asp Thr Gly Val Ser Leu Gln 115 120 125Thr Tyr Asp Asp Leu Leu Ala
Lys Asp Cys His Cys Ile 130 135 140110133PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 110Ser Glu Pro
Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser
Gly Ser Glu Thr Pro Gly Gly Asp His Cys Pro Leu Gly Pro 20 25 30Gly
Arg Cys Cys Arg Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu 35 40
45Gly Trp Ala Asp Trp Val Leu Ser Pro Arg Glu Val Gln Val Thr Met
50 55 60Cys Ile Gly Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn Met His
Ala65 70 75 80Gln Ile Lys Thr Ser Leu His Arg Leu Lys Pro Asp Thr
Val Pro Ala 85 90 95Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro Leu Val
Leu Ile Gln Lys 100 105 110Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr
Asp Asp Leu Leu Ala Lys 115 120 125Asp Cys His Cys Ile
130111133PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 111Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser
Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly Gly Asp His Cys
Pro Leu Gly Pro 20 25 30Gly Arg Cys Cys Arg Leu His Thr Val Arg Ala
Ser Leu Glu Asp Leu 35 40 45Gly Trp Ala Asp Trp Val Leu Ser Pro Arg
Glu Val Gln Val Thr Met 50 55 60Cys Ile Gly Ala Cys Pro Ser Gln Phe
Arg Ala Ala Asn Leu His Ala65 70 75 80Gln Ile Lys Thr Ser Leu His
Arg Leu Lys Pro Asp Thr Val Pro Ala 85 90 95Pro Cys Cys Val Pro Ala
Ser Tyr Asn Pro Leu Val Leu Ile Gln Lys 100 105 110Thr Asp Thr Gly
Val Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys 115 120 125Asp Cys
His Cys Ile 130112133PRTArtificial SequenceMIC-1 polypeptide plus
N-terminal extension 112Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly Gly Asp
His Cys Pro Leu Gly Pro 20 25 30Gly Arg Cys Cys Arg Leu His Thr Val
Arg Ala Ser Leu Glu Asp Leu 35 40 45Gly Trp Ala Asp Trp Val Leu Ser
Pro Arg Glu Val Gln Val Thr Met 50 55 60Cys Ile Gly Ala Cys Pro Ser
Gln Phe Arg Ala Ala Asn Glu His Ala65 70 75 80Gln Ile Lys Thr Ser
Leu Glu Arg Leu Lys Pro Asp Thr Val Pro Ala 85 90 95Pro Cys Cys Val
Pro Ala Ser Tyr Asn Pro Met Val Leu Ile Gln Lys 100 105 110Thr Asp
Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys 115 120
125Asp Cys His Cys Ile 130113133PRTArtificial SequenceMIC-1
polypeptide plus N-terminal extension 113Ser Glu Pro Ala Thr Ser
Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu
Thr Pro Gly Gly Asp His Cys Pro Leu Gly Pro 20 25 30Gly Arg Cys Cys
Arg Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu 35 40 45Gly Trp Ala
Asp Trp Val Leu Ser Pro Arg Glu Val Gln Val Thr Met 50 55 60Cys Ile
Gly Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn Glu His Ala65 70 75
80Gln Ile Lys Thr Ser Leu His Glu Leu Lys Pro Asp Thr Val Pro Ala
85 90 95Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro Met Val Leu Ile Gln
Lys 100 105 110Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp Leu
Leu Ala Lys 115 120 125Asp Cys His Cys Ile 130114133PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 114Ser Glu Pro
Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser
Gly Ser Glu Thr Pro Gly Gly Asp His Cys Pro Leu Gly Pro 20 25 30Gly
Arg Cys Cys Arg Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu 35 40
45Gly Trp Ala Asp Trp Val Leu Ser Pro Arg Glu Val Gln Val Thr Met
50 55 60Cys Ile Gly Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn Glu His
Ala65 70 75 80Gln Ile Lys Thr Ser Leu His Glu Leu Lys Pro Asp Thr
Val Pro Ala 85 90 95Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro Leu Val
Leu Ile Gln Lys 100 105 110Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr
Asp Asp Leu Leu Ala Lys 115 120 125Asp Cys His Cys Ile
130115140PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 115Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr
Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu
Pro Ser Gly Gly 20 25 30Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys
Arg Leu His Thr Val 35 40 45Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala
Asp Trp Val Leu Ser Pro 50 55 60Arg Glu Val Gln Val Thr Met Cys Ile
Gly Ala Cys Pro Ser Gln Phe65 70 75 80Arg Ala Ala Asn Leu His Ala
Gln Ile Lys Thr Ser Leu His Arg Leu 85 90 95Lys Pro Asp Thr Val Pro
Ala Pro Cys Cys Val Pro Ala Ser Tyr Asn 100 105 110Pro Leu Val Leu
Ile Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr 115 120 125Tyr Asp
Asp Leu Leu Ala Lys Asp Cys His Cys Ile 130 135
140116133PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 116Gly Glu Pro Ser Gly Glu Pro Ser Gly Glu Pro Ser Gly
Glu Pro Ser1 5 10 15Gly Glu Pro Ser Gly Glu Pro Ser Gly Asp His Cys
Pro Leu Gly Pro 20 25 30Gly Arg Cys Cys Arg Leu His Thr Val Arg Ala
Ser Leu Glu Asp Leu 35 40 45Gly Trp Ala Asp Trp Val Leu Ser Pro Arg
Glu Val Gln Val Thr Met 50 55 60Cys Ile Gly Ala Cys Pro Ser Gln Phe
Arg Ala Ala Asn Met His Ala65 70 75 80Gln Ile Lys Thr Ser Leu His
Arg Leu Lys Pro Asp Thr Val Pro Ala 85 90 95Pro Cys Cys Val Pro Ala
Ser Tyr Asn Pro Met Val Leu Ile Gln Lys 100 105 110Thr Asp Thr Gly
Val Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys 115 120 125Asp Cys
His Cys Ile 130117135PRTArtificial SequenceMIC-1 polypeptide plus
N-terminal extension 117Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly Ala Arg
Gly Asp His Cys Pro Leu 20 25 30Gly Pro Gly Arg Cys Cys Arg Leu His
Thr Val Arg Ala Ser Leu Glu 35 40 45Asp Leu Gly Trp Ala Asp Trp Val
Leu Ser Pro Arg Glu Val Gln Val 50 55 60Thr Met Cys Ile Gly Ala Cys
Pro Ser Gln Phe Arg Ala Ala Asn Met65 70 75 80His Ala Gln Ile Lys
Thr Ser Leu His Arg Leu Lys Pro Asp Thr Val 85 90 95Pro Ala Pro Cys
Cys Val Pro Ala Ser Tyr Asn Pro Met Val Leu Ile 100 105 110Gln Lys
Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp Leu Leu 115 120
125Ala Lys Asp Cys His Cys Ile 130 1351184PRTArtificial
SequenceN-terminal extension 118Gly Glu Pro Ser11194PRTArtificial
SequenceN-terminal extension 119Gly Pro Ser Glu11204PRTArtificial
SequenceN-terminal extension 120Gly Pro Glu Ser11214PRTArtificial
SequenceN-terminal extension 121Gly Ser Pro Glu11224PRTArtificial
SequenceN-terminal extension 122Gly Ser Glu Pro11234PRTArtificial
SequenceN-terminal extension 123Gly Glu Pro Gln11244PRTArtificial
SequenceN-terminal extension 124Gly Glu Gln Pro11254PRTArtificial
SequenceN-terminal extension 125Gly Pro Glu Gln11264PRTArtificial
SequenceN-terminal extension 126Gly Pro Gln Glu11274PRTArtificial
SequenceN-terminal extension 127Gly Gln Glu Pro11284PRTArtificial
SequenceN-terminal extension 128Gly Gln Pro Glu112910PRTArtificial
SequenceN-terminal extension 129Pro Glu Asp Glu Glu Thr Pro Glu Gln
Glu1 5 1013010PRTArtificial SequenceN-terminal extension 130Pro Asp
Glu Gly Thr Glu Glu Glu Thr Glu1 5 1013110PRTArtificial
SequenceN-terminal extension 131Pro Ala Ala Glu Glu Glu Asp Asp Pro
Asp1 5 1013211PRTArtificial SequenceN-terminal extension 132Ala Glu
Pro Asp Glu Asp Pro Gln Ser Glu Asp1 5 1013310PRTArtificial
SequenceN-terminal extension 133Ala Glu Pro Asp Glu Asp Pro Gln Ser
Glu1 5 101349PRTArtificial SequenceN-terminal extension 134Ala Glu
Pro Glu Glu Gln Glu Glu Asp1 51358PRTArtificial SequenceN-terminal
extension 135Ala Glu Pro Glu Glu Gln Glu Glu1 51364PRTArtificial
SequenceN-terminal extension 136Gly Gly Gly Ser11374PRTArtificial
SequenceN-terminal extension 137Gly Ser Gly Ser11384PRTArtificial
SequenceN-terminal extension 138Gly Gly Ser Ser11394PRTArtificial
SequenceN-terminal extension 139Ser Ser Ser Gly114020PRTArtificial
SequenceN-terminal extension 140Gly Glu Pro Ser Gly Glu Pro Ser Gly
Glu Pro Ser Gly Glu Pro Ser1 5 10 15Gly Glu Pro Ser
2014120PRTArtificial SequenceN-terminal extension 141Gly Pro Ser
Glu Gly Pro Ser Glu Gly Pro Ser Glu Gly Pro Ser Glu1 5 10 15Gly Pro
Ser Glu 2014220PRTArtificial SequenceN-terminal extension 142Gly
Pro Glu Ser Gly Pro Glu Ser Gly Pro Glu Ser Gly Pro Glu Ser1 5 10
15Gly Pro Glu Ser 2014320PRTArtificial SequenceN-terminal extension
143Gly Ser Pro Glu Gly Ser Pro Glu Gly Ser Pro Glu Gly Ser Pro Glu1
5 10 15Gly Ser Pro Glu 2014420PRTArtificial SequenceN-terminal
extension 144Gly Ser Glu Pro Gly Ser Glu Pro Gly Ser Glu Pro Gly
Ser Glu Pro1 5 10 15Gly Ser Glu Pro 2014520PRTArtificial
SequenceN-terminal extension 145Gly Glu Pro Gln Gly Glu Pro Gln Gly
Glu Pro Gln Gly Glu Pro Gln1 5 10 15Gly Glu Pro Gln
2014620PRTArtificial SequenceN-terminal extension 146Gly Glu Gln
Pro Gly Glu Gln Pro Gly Glu Gln Pro Gly Glu Gln Pro1 5 10 15Gly Glu
Gln Pro 2014720PRTArtificial SequenceN-terminal extension 147Gly
Pro Glu Gln Gly Pro Glu Gln Gly Pro Glu Gln Gly Pro Glu Gln1 5 10
15Gly Pro Glu Gln 2014820PRTArtificial SequenceN-terminal extension
148Gly Pro Gln Glu Gly Pro Gln Glu Gly Pro Gln Glu Gly Pro Gln Glu1
5 10 15Gly Pro Gln Glu 2014920PRTArtificial SequenceN-terminal
extension 149Gly Gln Glu Pro Gly Gln Glu Pro Gly Gln Glu Pro Gly
Gln Glu Pro1 5 10 15Gly Gln Glu Pro 2015020PRTArtificial
SequenceN-terminal extension 150Gly Gln Pro Glu Gly Gln Pro Glu Gly
Gln Pro Glu Gly Gln Pro Glu1 5 10 15Gly Gln Pro Glu
2015115PRTArtificial SequenceN-terminal extension 151Ala Glu Glu
Ala Glu Glu Ala Glu Glu Ala Glu Glu Ala Glu Glu1 5 10
151527PRTArtificial SequenceLinker 152Gly Gly Ser Ser Ser Gly Ser1
515331PRTArtificial SequenceLinker 153Pro Thr Pro Thr Pro Thr Pro
Thr Pro Thr Pro Thr Pro Thr Pro Thr1 5 10 15Pro Thr Pro Thr Pro Thr
Pro Thr Pro Thr Pro Thr Pro Thr Pro 20 25 30154111PRTArtificial
SequenceMIC-1 polypeptide 154Ala Arg Gly Asp His Cys Pro Leu Gly
Pro Gly Arg Cys Cys Arg Leu1 5 10 15His Thr Val Arg Ala Ser Leu Glu
Asp Leu Gly Trp Ala Asp Trp Val 20 25 30Leu Ser Pro Arg Glu Val Gln
Val Thr Leu Cys Ile Gly Ala Cys Pro 35 40 45Ser Gln Phe Arg Ala Ala
Asn Met His Ala Gln Ile Lys Thr Ser Leu 50 55 60His Arg Leu Lys Pro
Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala65 70 75 80Ser Tyr Asn
Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val Ser 85 90 95Leu Gln
Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 100 105
110155109PRTArtificial SequenceMIC-1 polypeptide 155Gly Asp His Cys
Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu His Thr1 5 10 15Val Arg Ala
Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val Leu Ser 20 25 30Pro Arg
Glu Val Gln Val Thr Leu Cys Ile Gly Ala Cys Pro Ser Gln 35 40 45Phe
Arg Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser Leu His Arg 50 55
60Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr65
70 75 80Asn Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val Ser Leu
Gln 85 90 95Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 100
105156111PRTArtificial SequenceMIC-1 polypeptide 156Ala Arg Gly Asp
His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu1 5 10 15His Thr Val
Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val 20 25 30Leu Ser
Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys Pro 35 40 45Ser
Gln Phe Arg Ala Ala Asn Glu His Ala Gln Ile Lys Thr Ser Leu 50 55
60Glu Arg Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala65
70 75 80Ser Tyr Asn Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val
Ser 85 90 95Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys
Ile 100 105 110157109PRTArtificial SequenceMIC-1 polypeptide 157Gly
Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu His Thr1 5 10
15Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val Leu Ser
20 25 30Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys Pro Ser
Gln 35 40 45Phe Arg Ala Ala Asn Leu His Ala Gln Ile Lys Thr Ser Leu
His Arg 50 55 60Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro
Ala Ser Tyr65 70 75 80Asn Pro Met Val Leu Ile Gln Lys Thr Asp Thr
Gly Val Ser Leu Gln 85 90 95Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys
His Cys Ile 100 105158111PRTArtificial SequenceMIC-1 polypeptide
158Ala Arg Gly Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu1
5 10 15His Thr Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp
Val 20 25 30Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala
Cys Pro 35 40 45Ser Gln Phe Arg Ala Ala Asn Leu His Ala Gln Ile Lys
Thr Ser Leu 50 55 60His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro Cys
Cys Val Pro Ala65 70 75 80Ser Tyr Asn Pro Met Val Leu Ile Gln Lys
Thr Asp Thr Gly Val Ser 85 90 95Leu Gln Thr Tyr Asp Asp Leu Leu Ala
Lys Asp Cys His Cys Ile 100 105 110159109PRTArtificial
SequenceMIC-1 polypeptide 159Gly Asp His Cys Pro Leu Gly Pro Gly
Arg Cys Cys Arg Leu His Thr1 5 10 15Val Arg Ala Ser Leu Glu Asp Leu
Gly Trp Ala Asp Trp Val Leu Ser 20 25 30Pro Arg Glu Val Gln Val Thr
Met Cys Ile Gly Ala Cys Pro Ser Gln
35 40 45Phe Arg Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser Leu His
Arg 50 55 60Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala
Ser Tyr65 70 75 80Asn Pro Leu Val Leu Ile Gln Lys Thr Asp Thr Gly
Val Ser Leu Gln 85 90 95Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His
Cys Ile 100 105160111PRTArtificial SequenceMIC-1 polypeptide 160Ala
Arg Gly Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu1 5 10
15His Thr Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val
20 25 30Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys
Pro 35 40 45Ser Gln Phe Arg Ala Ala Asn Met His Ala Gln Ile Lys Thr
Ser Leu 50 55 60His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys
Val Pro Ala65 70 75 80Ser Tyr Asn Pro Leu Val Leu Ile Gln Lys Thr
Asp Thr Gly Val Ser 85 90 95Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys
Asp Cys His Cys Ile 100 105 11016136PRTArtificial
SequenceN-terminal extension 161Gly Glu Pro Ser Gly Glu Pro Ser Gly
Glu Pro Ser Gly Glu Pro Ser1 5 10 15Gly Glu Pro Ser Gly Glu Pro Ser
Gly Glu Pro Ser Gly Glu Pro Ser 20 25 30Gly Glu Pro Ser
3516236PRTArtificial SequenceN-terminal extension 162Gly Glu Pro
Gln Gly Glu Pro Gln Gly Glu Pro Gln Gly Glu Pro Gln1 5 10 15Gly Glu
Pro Gln Gly Glu Pro Gln Gly Glu Pro Gln Gly Glu Pro Gln 20 25 30Gly
Glu Pro Gln 3516325PRTArtificial SequenceN-terminal extension
163Ala Gly Pro Glu Gln Gly Gln Glu Pro Gly Glu Pro Gln Gly Gln Glu1
5 10 15Pro Gln Pro Gly Glu Pro Glu Gly Gln 20 25164143PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 164Ser Glu Pro
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr
Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly 20 25 30Ala
Arg Gly Asp His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu 35 40
45His Thr Val Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val
50 55 60Leu Ser Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys
Pro65 70 75 80Ser Gln Phe Arg Ala Ala Asn Leu His Ala Gln Ile Lys
Thr Ser Leu 85 90 95His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro Cys
Cys Val Pro Ala 100 105 110Ser Tyr Asn Pro Leu Val Leu Ile Gln Lys
Thr Asp Thr Gly Val Ser 115 120 125Leu Gln Thr Tyr Asp Asp Leu Leu
Ala Lys Asp Cys His Cys Ile 130 135 140165134PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 165Ala Gly Pro
Glu Gln Gly Gln Glu Pro Gly Glu Pro Gln Gly Gln Glu1 5 10 15Pro Gln
Pro Gly Glu Pro Glu Gly Gln Gly Asp His Cys Pro Leu Gly 20 25 30Pro
Gly Arg Cys Cys Arg Leu His Thr Val Arg Ala Ser Leu Glu Asp 35 40
45Leu Gly Trp Ala Asp Trp Val Leu Ser Pro Arg Glu Val Gln Val Thr
50 55 60Met Cys Ile Gly Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn Met
His65 70 75 80Ala Gln Ile Lys Thr Ser Leu His Arg Leu Lys Pro Asp
Thr Val Pro 85 90 95Ala Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro Met
Val Leu Ile Gln 100 105 110Lys Thr Asp Thr Gly Val Ser Leu Gln Thr
Tyr Asp Asp Leu Leu Ala 115 120 125Lys Asp Cys His Cys Ile
13016612PRTArtificial SequenceN-terminal extension 166Ser Pro Ala
Gly Ser Pro Thr Ser Thr Glu Glu Gly1 5 1016712PRTArtificial
SequenceN-terminal extension 167Thr Ser Glu Ser Ala Thr Pro Glu Ser
Gly Pro Gly1 5 1016812PRTArtificial SequenceN-terminal extension
168Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly1 5
1016912PRTArtificial SequenceN-terminal extension 169Ser Glu Pro
Ala Thr Ser Gly Ser Glu Thr Pro Gly1 5 1017024PRTArtificial
SequenceN-terminal extension 170Ser Pro Ala Gly Ser Pro Thr Ser Thr
Glu Glu Gly Ser Pro Ala Gly1 5 10 15Ser Pro Thr Ser Thr Glu Glu Gly
2017124PRTArtificial SequenceN-terminal extension 171Ser Pro Ala
Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu1 5 10 15Pro Ser
Glu Gly Ser Ala Pro Gly 2017224PRTArtificial SequenceN-terminal
extension 172Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Ser
Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly
2017324PRTArtificial SequenceN-teminal extension 173Thr Ser Glu Ser
Ala Thr Pro Glu Ser Gly Pro Gly Ser Pro Ala Gly1 5 10 15Ser Pro Thr
Ser Thr Glu Glu Gly 2017424PRTArtificial SequenceN-external
extension 174Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr
Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
2017524PRTArtificial SequenceN-terminal extension 175Thr Ser Glu
Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu1 5 10 15Pro Ser
Glu Gly Ser Ala Pro Gly 2017624PRTArtificial SequenceN-terminal
extension 176Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser
Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly
2017724PRTArtificial SequenceN-terminal extension 177Thr Ser Thr
Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly1 5 10 15Ser Pro
Thr Ser Thr Glu Glu Gly 2017824PRTArtificial SequenceN-terminal
extension 178Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr
Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
2017924PRTArtificial SequenceN-terminal extension 179Thr Ser Thr
Glu Pro Glu Ser Gly Ser Ala Pro Gly Thr Ser Thr Glu1 5 10 15Pro Glu
Ser Gly Ser Ala Pro Gly 2018024PRTArtificial SequenceN-terminal
extension 180Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser
Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly
2018124PRTArtificial SequenceN-terminal extension 181Ser Glu Pro
Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser
Gly Ser Glu Thr Pro Gly 20182133PRTArtificial SequenceMIC-1
polypeptide plus N-terminal extension 182Ser Glu Pro Ala Thr Ser
Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser
Gly Pro Gly Gly Asp His Cys Pro Leu Gly Pro 20 25 30Gly Arg Cys Cys
Arg Leu His Thr Val Arg Ala Ser Leu Glu Asp Leu 35 40 45Gly Trp Ala
Asp Trp Val Leu Ser Pro Arg Glu Val Gln Val Thr Met 50 55 60Cys Ile
Gly Ala Cys Pro Ser Gln Phe Arg Ala Ala Asn Met His Ala65 70 75
80Gln Ile Lys Thr Ser Leu His Arg Leu Lys Pro Asp Thr Val Pro Ala
85 90 95Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro Met Val Leu Ile Gln
Lys 100 105 110Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr Asp Asp Leu
Leu Ala Lys 115 120 125Asp Cys His Cys Ile 13018330PRTArtificial
SequenceN-terminal extension 183Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
Glu Ser Ala Thr Pro Glu 20 25 3018430PRTArtificial
SequenceN-terminal extension 184Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
Ser Thr Glu Pro Ser Glu 20 25 3018530PRTArtificial
SequenceN-terminal extension 185Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Ser Glu Gly Ser Ala Pro Gly
Thr Ser Thr Glu Glu Gly 20 25 3018630PRTArtificial
SequenceN-terminal extension 186Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Ser Glu Gly Ser Ala Pro Gly
Thr Ser Glu Ser Ala Thr 20 25 3018730PRTArtificial
SequenceN-terminal extension 187Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Ser Glu Gly Ser Ala Pro Gly
Thr Ser Thr Glu Pro Ser 20 25 3018830PRTArtificial
SequenceN-terminal extension 188Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Ser Glu Gly Ser Ala Pro Gly
Ser Glu Pro Ala Thr Ser 20 25 3018930PRTArtificial
SequenceN-terminal extension 189Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly
Thr Ser Thr Glu Glu Gly 20 25 3019030PRTArtificial
SequenceN-terminal extension 190Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly
Thr Ser Glu Ser Ala Thr 20 25 3019130PRTArtificial
SequenceN-terminal extension 191Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly
Glu Ser Ala Thr Pro Glu 20 25 3019230PRTArtificial
SequenceN-terminal extension 192Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly
Thr Ser Thr Glu Pro Ser 20 25 3019330PRTArtificial
SequenceN-terminal extension 193Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly
Ser Thr Glu Pro Ser Glu 20 25 3019430PRTArtificial
SequenceN-terminal extension 194Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly
Ser Glu Pro Ala Thr Ser 20 25 3019532PRTArtificial
SequenceN-terminal extension 195Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
Gly Pro Glu Gln Gly Pro Glu Gln 20 25 3019632PRTArtificial
SequenceN-terminal extension 196Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
Gly Glu Pro Ser Gly Glu Pro Ser 20 25 3019736PRTArtificial
SequenceN-terminal extension 197Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
Thr Ser Thr Glu Pro Ser Glu Gly 20 25 30Ser Ala Pro Gly
3519848PRTArtificial SequenceN-terminal extension 198Ser Glu Pro
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr
Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly 20 25 30Ser
Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly 35 40
4519960PRTArtificial SequenceN-terminal extension 199Ser Pro Ala
Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser1 5 10 15Ala Thr
Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly 20 25 30Ser
Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly 35 40
45Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly 50 55
60200139PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 200Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr
Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu
Glu Gly Gly Asp 20 25 30His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg
Leu His Thr Val Arg 35 40 45Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp
Trp Val Leu Ser Pro Arg 50 55 60Glu Val Gln Val Thr Met Cys Ile Gly
Ala Cys Pro Ser Gln Phe Arg65 70 75 80Ala Ala Asn Met His Ala Gln
Ile Lys Thr Ser Leu His Arg Leu Lys 85 90 95Pro Asp Thr Val Pro Ala
Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro 100 105 110Met Val Leu Ile
Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr 115 120 125Asp Asp
Leu Leu Ala Lys Asp Cys His Cys Ile 130 135201139PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 201Ser Glu Pro
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr
Pro Glu Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Gly Asp 20 25 30His
Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu His Thr Val Arg 35 40
45Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val Leu Ser Pro Arg
50 55 60Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys Pro Ser Gln Phe
Arg65 70 75 80Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser Leu His
Arg Leu Lys 85 90 95Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala
Ser Tyr Asn Pro 100 105 110Met Val Leu Ile Gln Lys Thr Asp Thr Gly
Val Ser Leu Gln Thr Tyr 115 120 125Asp Asp Leu Leu Ala Lys Asp Cys
His Cys Ile 130 135202139PRTArtificial SequenceMIC-1 polypeptide
plus N-terminal extension 202Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
Glu Ser Ala Thr Pro Glu Gly Asp 20 25 30His Cys Pro Leu Gly Pro Gly
Arg Cys Cys Arg Leu His Thr Val Arg 35 40 45Ala Ser Leu Glu Asp Leu
Gly Trp Ala Asp Trp Val Leu Ser Pro Arg 50 55 60Glu Val Gln Val Thr
Met Cys Ile Gly Ala Cys Pro Ser Gln Phe Arg65 70 75 80Ala Ala Asn
Met His Ala Gln Ile Lys Thr Ser Leu His Arg Leu Lys 85 90 95Pro Asp
Thr Val Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro 100 105
110Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr
115 120 125Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 130
135203139PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 203Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr
Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly Ser Thr Glu Pro
Ser Glu Gly Asp 20 25 30His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg
Leu His Thr Val Arg 35 40 45Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp
Trp Val Leu Ser Pro Arg 50 55 60Glu Val Gln Val Thr Met Cys Ile Gly
Ala Cys Pro Ser Gln Phe Arg65 70 75 80Ala Ala Asn Met His Ala Gln
Ile Lys Thr Ser Leu His Arg Leu Lys 85 90 95Pro Asp Thr Val Pro Ala
Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro 100 105 110Met Val Leu Ile
Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr 115 120
125Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 130
135204139PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 204Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr
Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala
Thr Ser Gly Asp 20 25 30His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg
Leu His Thr Val Arg 35 40 45Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp
Trp Val Leu Ser Pro Arg 50 55 60Glu Val Gln Val Thr Met Cys Ile Gly
Ala Cys Pro Ser Gln Phe Arg65 70 75 80Ala Ala Asn Met His Ala Gln
Ile Lys Thr Ser Leu His Arg Leu Lys 85 90 95Pro Asp Thr Val Pro Ala
Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro 100 105 110Met Val Leu Ile
Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr 115 120 125Asp Asp
Leu Leu Ala Lys Asp Cys His Cys Ile 130 135205139PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 205Ser Glu Pro
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Ser
Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu Glu Gly Gly Asp 20 25 30His
Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu His Thr Val Arg 35 40
45Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val Leu Ser Pro Arg
50 55 60Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys Pro Ser Gln Phe
Arg65 70 75 80Ala Ala Asn Leu His Ala Gln Ile Lys Thr Ser Leu His
Arg Leu Lys 85 90 95Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala
Ser Tyr Asn Pro 100 105 110Met Val Leu Ile Gln Lys Thr Asp Thr Gly
Val Ser Leu Gln Thr Tyr 115 120 125Asp Asp Leu Leu Ala Lys Asp Cys
His Cys Ile 130 135206139PRTArtificial SequenceMIC-1 polypeptide
plus N-terminal extension 206Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Ser Glu Gly Ser Ala Pro Gly
Thr Ser Glu Ser Ala Thr Gly Asp 20 25 30His Cys Pro Leu Gly Pro Gly
Arg Cys Cys Arg Leu His Thr Val Arg 35 40 45Ala Ser Leu Glu Asp Leu
Gly Trp Ala Asp Trp Val Leu Ser Pro Arg 50 55 60Glu Val Gln Val Thr
Met Cys Ile Gly Ala Cys Pro Ser Gln Phe Arg65 70 75 80Ala Ala Asn
Leu His Ala Gln Ile Lys Thr Ser Leu His Arg Leu Lys 85 90 95Pro Asp
Thr Val Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro 100 105
110Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr
115 120 125Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 130
135207139PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 207Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr
Ser Thr Glu1 5 10 15Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu
Pro Ser Gly Asp 20 25 30His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg
Leu His Thr Val Arg 35 40 45Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp
Trp Val Leu Ser Pro Arg 50 55 60Glu Val Gln Val Thr Met Cys Ile Gly
Ala Cys Pro Ser Gln Phe Arg65 70 75 80Ala Ala Asn Leu His Ala Gln
Ile Lys Thr Ser Leu His Arg Leu Lys 85 90 95Pro Asp Thr Val Pro Ala
Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro 100 105 110Met Val Leu Ile
Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr 115 120 125Asp Asp
Leu Leu Ala Lys Asp Cys His Cys Ile 130 135208139PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 208Ser Glu Pro
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu1 5 10 15Pro Ser
Glu Gly Ser Ala Pro Gly Ser Glu Pro Ala Thr Ser Gly Asp 20 25 30His
Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu His Thr Val Arg 35 40
45Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val Leu Ser Pro Arg
50 55 60Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys Pro Ser Gln Phe
Arg65 70 75 80Ala Ala Asn Leu His Ala Gln Ile Lys Thr Ser Leu His
Arg Leu Lys 85 90 95Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala
Ser Tyr Asn Pro 100 105 110Met Val Leu Ile Gln Lys Thr Asp Thr Gly
Val Ser Leu Gln Thr Tyr 115 120 125Asp Asp Leu Leu Ala Lys Asp Cys
His Cys Ile 130 135209139PRTArtificial SequenceMIC-1 polypeptide
plus N-terminal extension 209Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly
Thr Ser Thr Glu Glu Gly Gly Asp 20 25 30His Cys Pro Leu Gly Pro Gly
Arg Cys Cys Arg Leu His Thr Val Arg 35 40 45Ala Ser Leu Glu Asp Leu
Gly Trp Ala Asp Trp Val Leu Ser Pro Arg 50 55 60Glu Val Gln Val Thr
Met Cys Ile Gly Ala Cys Pro Ser Gln Phe Arg65 70 75 80Ala Ala Asn
Leu His Ala Gln Ile Lys Thr Ser Leu His Arg Leu Lys 85 90 95Pro Asp
Thr Val Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro 100 105
110Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr
115 120 125Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 130
135210139PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 210Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser
Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser
Ala Thr Gly Asp 20 25 30His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg
Leu His Thr Val Arg 35 40 45Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp
Trp Val Leu Ser Pro Arg 50 55 60Glu Val Gln Val Thr Met Cys Ile Gly
Ala Cys Pro Ser Gln Phe Arg65 70 75 80Ala Ala Asn Met His Ala Gln
Ile Lys Thr Ser Leu His Arg Leu Lys 85 90 95Pro Asp Thr Val Pro Ala
Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro 100 105 110Met Val Leu Ile
Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr 115 120 125Asp Asp
Leu Leu Ala Lys Asp Cys His Cys Ile 130 135211139PRTArtificial
SequenceMIC-1 polypeptide plus N-termnal extension 211Ser Glu Pro
Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser
Gly Ser Glu Thr Pro Gly Glu Ser Ala Thr Pro Glu Gly Asp 20 25 30His
Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu His Thr Val Arg 35 40
45Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val Leu Ser Pro Arg
50 55 60Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys Pro Ser Gln Phe
Arg65 70 75 80Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser Leu His
Arg Leu Lys 85 90 95Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala
Ser Tyr Asn Pro 100 105 110Met Val Leu Ile Gln Lys Thr Asp Thr Gly
Val Ser Leu Gln Thr Tyr 115 120 125Asp Asp Leu Leu Ala Lys Asp Cys
His Cys Ile 130 135212139PRTArtificial SequenceMIC-1 polypeptide
plus N-terminal extension 212Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly
Thr Ser Thr Glu Pro Ser Gly Asp 20 25 30His Cys Pro Leu Gly Pro Gly
Arg Cys Cys Arg Leu His Thr Val Arg 35 40 45Ala Ser Leu Glu Asp Leu
Gly Trp Ala Asp Trp Val Leu Ser Pro Arg 50 55 60Glu Val Gln Val Thr
Met Cys Ile Gly Ala Cys Pro Ser Gln Phe Arg65 70 75 80Ala Ala Asn
Leu His Ala Gln Ile Lys Thr Ser Leu His Arg Leu Lys 85 90 95Pro Asp
Thr Val Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro 100 105
110Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr
115 120 125Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 130
135213139PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 213Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser
Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly Ser Thr Glu Pro
Ser Glu Gly Asp 20 25 30His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg
Leu His Thr Val Arg 35 40 45Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp
Trp Val Leu Ser Pro Arg 50 55 60Glu Val Gln Val Thr Met Cys Ile Gly
Ala Cys Pro Ser Gln Phe Arg65 70 75 80Ala Ala Asn Met His Ala Gln
Ile Lys Thr Ser Leu His Arg Leu Lys 85 90 95Pro Asp Thr Val Pro Ala
Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro 100 105 110Met Val Leu Ile
Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr 115 120 125Asp Asp
Leu Leu Ala Lys Asp Cys His Cys Ile 130 135214139PRTArtificial
SequenceMIC-1 polypeptide plus N-terminal extension 214Ser Glu Pro
Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala1 5 10 15Thr Ser
Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala Thr Ser Gly Asp 20 25 30His
Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu His Thr Val Arg 35 40
45Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val Leu Ser Pro Arg
50 55 60Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys Pro Ser Gln Phe
Arg65 70 75 80Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser Leu His
Arg Leu Lys 85 90 95Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala
Ser Tyr Asn Pro 100 105 110Met Val Leu Ile Gln Lys Thr Asp Thr Gly
Val Ser Leu Gln Thr Tyr 115 120 125Asp Asp Leu Leu Ala Lys Asp Cys
His Cys Ile 130 135215141PRTArtificial SequenceMIC-1 polypeptide
plus N-terminal extension 215Ser Glu Pro Ala Thr Ser Gly Ser Glu
Thr Pro Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly
Gly Pro Glu Gln Gly Pro Glu Gln 20 25 30Gly Asp His Cys Pro Leu Gly
Pro Gly Arg Cys Cys Arg Leu His Thr 35 40 45Val Arg Ala Ser Leu Glu
Asp Leu Gly Trp Ala Asp Trp Val Leu Ser 50 55 60Pro Arg Glu Val Gln
Val Thr Met Cys Ile Gly Ala Cys Pro Ser Gln65 70 75 80Phe Arg Ala
Ala Asn Met His Ala Gln Ile Lys Thr Ser Leu His Arg 85 90 95Leu Lys
Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr 100 105
110Asn Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val Ser Leu Gln
115 120 125Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 130
135 140216141PRTArtificial SequenceMIC-1 polypeptide plus
N-terminal extension 216Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly Gly Glu
Pro Ser Gly Glu Pro Ser 20 25 30Gly Asp His Cys Pro Leu Gly Pro Gly
Arg Cys Cys Arg Leu His Thr 35 40 45Val Arg Ala Ser Leu Glu Asp Leu
Gly Trp Ala Asp Trp Val Leu Ser 50 55 60Pro Arg Glu Val Gln Val Thr
Met Cys Ile Gly Ala Cys Pro Ser Gln65 70 75 80Phe Arg Ala Ala Asn
Met His Ala Gln Ile Lys Thr Ser Leu His Arg 85 90 95Leu Lys Pro Asp
Thr Val Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr 100 105 110Asn Pro
Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val Ser Leu Gln 115 120
125Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 130 135
140217147PRTArtificial SequenceMIC-1 polypeptide plus N-terminal
extension 217Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr
Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu
Pro Ser Glu Gly 20 25 30Ser Ala Pro Gly Ala Arg Gly Asp His Cys Pro
Leu Gly Pro Gly Arg 35 40 45Cys Cys Arg Leu His Thr Val Arg Ala Ser
Leu Glu Asp Leu Gly Trp 50 55 60Ala Asp Trp Val Leu Ser Pro Arg Glu
Val Gln Val Thr Met Cys Ile65 70 75 80Gly Ala Cys Pro Ser Gln Phe
Arg Ala Ala Asn Met His Ala Gln Ile 85 90 95Lys Thr Ser Leu His Arg
Leu Lys Pro Asp Thr Val Pro Ala Pro Cys 100 105 110Cys Val Pro Ala
Ser Tyr Asn Pro Met Val Leu Ile Gln Lys Thr Asp 115 120 125Thr Gly
Val Ser Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys 130 135
140His Cys Ile145218159PRTArtificial SequenceMIC-1 polypeptide plus
N-terminal extension 218Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser
Thr Glu Pro Ser Glu Gly 20 25 30Ser Ala Pro Gly Thr Ser Thr Glu Pro
Ser Glu Gly Ser Ala Pro Gly 35 40 45Ala Arg Gly Asp His Cys Pro Leu
Gly Pro Gly Arg Cys Cys Arg Leu 50 55 60His Thr Val Arg Ala Ser Leu
Glu Asp Leu Gly Trp Ala Asp Trp Val65 70 75 80Leu Ser Pro Arg Glu
Val Gln Val Thr Met Cys Ile Gly Ala Cys Pro 85 90 95Ser Gln Phe Arg
Ala Ala Asn Met His Ala Gln Ile Lys Thr Ser Leu 100 105 110His Arg
Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala 115 120
125Ser Tyr Asn Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val Ser
130 135 140Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys
Ile145 150 155219172PRTArtificial SequenceMIC-1 polypeptide plus
N-terminal extension 219Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu
Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser
Thr Glu Pro Ser Glu Gly 20 25 30Ser Ala Pro Gly Ser Pro Ala Gly Ser
Pro Thr Ser Thr Glu Glu Gly 35 40 45Thr Ser Thr Glu Pro Ser Glu Gly
Ser Ala Pro Gly Ala Arg Asn Gly 50 55 60Asp His Cys Pro Leu Gly Pro
Gly Arg Cys Cys Arg Leu His Thr Val65 70 75 80Arg Ala Ser Leu Glu
Asp Leu Gly Trp Ala Asp Trp Val Leu Ser Pro 85 90 95Arg Glu Val Gln
Val Thr Met Cys Ile Gly Ala Cys Pro Ser Gln Phe 100 105 110Arg Ala
Ala Asn Met His Ala Gln Ile Lys Thr Ser Leu His Arg Leu 115 120
125Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr Asn
130 135 140Pro Met Val Leu Ile Gln Lys Thr Asp Thr Gly Val Ser Leu
Gln Thr145 150 155 160Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys
Ile 165 170220133PRTArtificial SequenceMIC-1 polypeptide plus
N-terminal extension 220Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
Gly Ser Glu Pro Ala1 5 10 15Thr Ser Gly Ser Glu Thr Pro Gly Gly Asp
His Cys Pro Leu
Gly Pro 20 25 30Gly Arg Cys Cys Arg Leu His Thr Val Arg Ala Ser Leu
Glu Asp Leu 35 40 45Gly Trp Ala Asp Trp Val Leu Ser Pro Arg Glu Val
Gln Val Thr Met 50 55 60Cys Ile Gly Ala Cys Pro Ser Gln Phe Arg Ala
Ala Asn Glu His Ala65 70 75 80Gln Ile Lys Thr Ser Leu Glu Glu Leu
Lys Pro Asp Thr Val Pro Ala 85 90 95Pro Cys Cys Val Pro Ala Ser Tyr
Asn Pro Met Val Leu Ile Gln Lys 100 105 110Thr Asp Thr Gly Val Ser
Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys 115 120 125Asp Cys His Cys
Ile 130221139PRTArtificial SequenceMIC-1 polypeptide plus
N-terminal extension 221Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
Gly Thr Ser Glu Ser1 5 10 15Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser
Thr Glu Pro Ser Gly Asp 20 25 30His Cys Pro Leu Gly Pro Gly Arg Cys
Cys Arg Leu His Thr Val Arg 35 40 45Ala Ser Leu Glu Asp Leu Gly Trp
Ala Asp Trp Val Leu Ser Pro Arg 50 55 60Glu Val Gln Val Thr Met Cys
Ile Gly Ala Cys Pro Ser Gln Phe Arg65 70 75 80Ala Ala Asn Glu His
Ala Gln Ile Lys Thr Ser Leu His Glu Leu Lys 85 90 95Pro Asp Thr Val
Pro Ala Pro Cys Cys Val Pro Ala Ser Tyr Asn Pro 100 105 110Met Val
Leu Ile Gln Lys Thr Asp Thr Gly Val Ser Leu Gln Thr Tyr 115 120
125Asp Asp Leu Leu Ala Lys Asp Cys His Cys Ile 130
135222111PRTArtificial SequenceMIC-1 polypeptide 222Ala Arg Gly Asp
His Cys Pro Leu Gly Pro Gly Arg Cys Cys Arg Leu1 5 10 15His Thr Val
Arg Ala Ser Leu Glu Asp Leu Gly Trp Ala Asp Trp Val 20 25 30Leu Ser
Pro Arg Glu Val Gln Val Thr Met Cys Ile Gly Ala Cys Pro 35 40 45Ser
Gln Phe Arg Ala Ala Asn Leu His Ala Gln Ile Lys Thr Ser Leu 50 55
60His Arg Leu Lys Pro Asp Thr Val Pro Ala Pro Cys Cys Val Pro Ala65
70 75 80Ser Tyr Asn Pro Leu Val Leu Ile Gln Lys Thr Asp Thr Gly Val
Ser 85 90 95Leu Gln Thr Tyr Asp Asp Leu Leu Ala Lys Asp Cys His Cys
Ile 100 105 110
D00001
D00002
D00003
S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.