Methods And Systems For Improving Machine Learning Performance
Erle; Schuyler D. ; et al.
U.S. patent application number 16/125343 was filed with the patent office on 2019-08-08 for methods and systems for improving machine learning performance. This patent application is currently assigned to Idibon, Inc.. The applicant listed for this patent is Jason Brenier, Brendan D. Callahan, Michelle Casbon, Schuyler D. Erle, Stefan Krawczyk, Jessica D. Long, Robert J. Munro, Aneesh Nair, James B. Robinson, Paul A. Tepper. Invention is credited to Jason Brenier, Brendan D. Callahan, Michelle Casbon, Schuyler D. Erle, Stefan Krawczyk, Jessica D. Long, Robert J. Munro, Aneesh Nair, James B. Robinson, Paul A. Tepper.
| Application Number | 20190243886 16/125343 |
| Document ID | / |
| Family ID | 56094482 |
| Filed Date | 2019-08-08 |






| United States Patent Application | 20190243886 |
| Kind Code | A1 |
| Erle; Schuyler D. ; et al. | August 8, 2019 |
METHODS AND SYSTEMS FOR IMPROVING MACHINE LEARNING PERFORMANCE
Abstract
Systems and methods are presented for providing improved machine performance in natural language processing. In some example embodiments, an API module is presented that is configured to drive processing of a system architecture for natural language processing. Aspects of the present disclosure allow for a natural language model to classify documents while other documents are being retrieved in real time. The natural language model and the documents are configured to be stored in a stateless format, which also allows for additional functions to be performed on the documents while the natural language model is used to continue classifying other documents.
| Inventors: | Erle; Schuyler D.; (San Francisco, VA) ; Munro; Robert J.; (San Francisco, CA) ; Callahan; Brendan D.; (Philadelphia, PA) ; Brenier; Jason; (Oakland, CA) ; Tepper; Paul A.; (San Francisco, CA) ; Long; Jessica D.; (San Francisco, CA) ; Robinson; James B.; (San Francisco, CA) ; Nair; Aneesh; (Fremont, CA) ; Casbon; Michelle; (San Antonio, TX) ; Krawczyk; Stefan; (Menlo Park, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assignee: | Idibon, Inc. San Francisco CA |
||||||||||
| Family ID: | 56094482 | ||||||||||
| Appl. No.: | 16/125343 | ||||||||||
| Filed: | September 7, 2018 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 14964510 | Dec 9, 2015 | |||
| 16125343 | ||||
| 62089736 | Dec 9, 2014 | |||
| 62089742 | Dec 9, 2014 | |||
| 62089745 | Dec 9, 2014 | |||
| 62089747 | Dec 9, 2014 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06F 40/30 20200101; G06F 16/3329 20190101; G06F 40/137 20200101; G06F 40/42 20200101; G06F 16/24532 20190101; G06F 16/288 20190101; G06F 16/285 20190101; G06F 16/243 20190101; G06F 16/951 20190101; G06F 16/35 20190101; G06F 16/367 20190101; G06F 3/0482 20130101; G06N 20/00 20190101; G06Q 50/01 20130101; G06F 40/169 20200101; G06F 40/40 20200101; G06F 16/93 20190101; G06F 40/221 20200101 |
| International Class: | G06F 17/24 20060101 G06F017/24; G06F 16/332 20060101 G06F016/332; G06F 17/28 20060101 G06F017/28; G06F 16/28 20060101 G06F016/28; G06F 16/93 20060101 G06F016/93; G06F 16/35 20060101 G06F016/35; G06F 16/2453 20060101 G06F016/2453; G06F 16/951 20060101 G06F016/951; G06F 16/242 20060101 G06F016/242; G06F 17/22 20060101 G06F017/22; G06Q 50/00 20060101 G06Q050/00; G06F 17/27 20060101 G06F017/27; G06F 3/0482 20060101 G06F003/0482; G06F 16/36 20060101 G06F016/36 |
Claims
1. A method for conducting natural language processing, the method comprising: generating a natural language model by a natural language platform; storing the natural language model in a first stateless format; accessing a plurality of documents to be classified by the natural language model; storing the plurality of documents in a second stateless format; and classifying, by the natural language platform, at least one document among the plurality of documents while the at least one document is stored in the second stateless format using the natural language model while stored in the first stateless format.
2. The method of claim 1, wherein storing the natural language model in the first stateless format comprises storing the natural language model in a language agnostic format.
3. The method of claim 1, wherein storing the plurality of documents in a second stateless format comprises storing all configuration and auxiliary data used to process each document among the plurality of documents with a combination of said document and the natural language model.
4. The method of claim 1, further comprising performing an intelligent queuing operation on a subset of the documents within the plurality of documents while classifying the at least one document, wherein the subset of documents is distinct from the at least one document.
5. The method of claim 1, further comprising performing a discover topics operation to discover documents that are classified into a specified label while classifying the at least one document.
6. The method of claim 1, wherein: accessing the plurality of documents to be classified by the natural language model comprises retrieving a subset of the plurality of documents from a database; and classifying the at least one document occurs while retrieving the subset of the plurality of documents, wherein the at least one document is distinct from the subset of the plurality of documents.
7. The method of claim 1, wherein storing the natural language model in a stateless format comprises storing replicas of the natural language model each into a server among a plurality of parallelized servers.
8. A natural language processing system comprising: a plurality of server machines communicatively coupled in parallel, each of the plurality of servers comprising a memory and at least one processor, each of the plurality of servers configured to: store, in said memory of said server, a replica of a natural language model in a first stateless format; access a plurality of documents to be classified by said replica of the natural language model; store the plurality of documents in a second stateless format; and classify at least one document among the plurality of documents while the at least one document is stored in the second stateless format using said replica of the natural language model while stored in the first stateless format.
9. The system of claim 8, wherein storing the replica of the natural language model in the first stateless format comprises storing the replica natural language model in a language agnostic format.
10. The system of claim 8, wherein storing the plurality of documents in a second stateless format comprises storing all configuration and auxiliary data used to process each document among the plurality of documents with a combination of said document and the replica natural language model.
11. The system of claim 8, wherein each of the plurality of servers is further configured to perform an intelligent queuing operation on a subset of the documents within the plurality of documents while classifying the at least one document, wherein the subset of documents is distinct from the at least one document.
12. The system of claim 8, wherein each of the plurality of servers is further configured to perform a discover topics operation to discover documents that are classified into a specified label while classifying the at least one document.
13. The system of claim 8, wherein: accessing the plurality of documents to be classified by the natural language model comprises retrieving a subset of the plurality of documents from a database; and classifying the at least one document occurs while retrieving the subset of the plurality of documents, wherein the at least one document is distinct from the subset of the plurality of documents.
14. A non-transitory computer readable medium comprising instructions that, when executed by a process, cause the processor to perform operations comprising: generating a natural language model; storing the natural language model in a first stateless format; accessing a plurality of documents to be classified by the natural language model; storing the plurality of documents in a second stateless format; and classifying at least one document among the plurality of documents while the at least one document is stored in the second stateless format using the natural language model while stored in the first stateless format.
15. The computer readable medium of claim 14, wherein storing the natural language model in the first stateless format comprises storing the natural language model in a language agnostic format.
16. The computer readable medium of claim 14, wherein storing the plurality of documents in a second stateless format comprises storing all configuration and auxiliary data used to process each document among the plurality of documents with a combination of said document and the natural language model.
17. The computer readable medium of claim 14, wherein the operations further comprise performing an intelligent queuing operation on a subset of the documents within the plurality of documents while classifying the at least one document, wherein the subset of documents is distinct from the at least one document.
18. The computer readable medium of claim 14, wherein the operations further comprise performing a discover topics operation to discover documents that are classified into a specified label while classifying the at least one document.
19. The computer readable medium of claim 14, wherein: accessing the plurality of documents to be classified by the natural language model comprises retrieving a subset of the plurality of documents from a database; and classifying the at least one document occurs while retrieving the subset of the plurality of documents, wherein the at least one document is distinct from the subset of the plurality of documents.
20. The computer readable medium of claim 1, wherein storing the natural language model in a stateless format comprises storing replicas of the natural language model each into a server among a plurality of parallelized servers.
Description
CROSS REFERENCES TO RELATED APPLICATIONS
[0001] This application is a continuation of U.S. patent application Ser. No. 14/964,510, filed Dec. 9, 2015, and titled "METHODS AND SYSTEMS FOR IMPROVING MACHINE LEARNING PERFORMANCE," which claims the benefits of U.S. Provisional Application 62/089,736, filed Dec. 9, 2014, and titled, "METHODS AND SYSTEMS FOR ANNOTATING NATURAL LANGUAGE PROCESSING," U.S. Provisional Application 62/089,742, filed Dec. 9, 2014, and titled, "METHODS AND SYSTEMS FOR IMPROVING MACHINE PERFORMANCE IN NATURAL LANGUAGE PROCESSING," U.S. Provisional Application 62/089,745, filed Dec. 9, 2014, and titled, "METHODS AND SYSTEMS FOR IMPROVING FUNCTIONALITY IN NATURAL LANGUAGE PROCESSING," and U.S. Provisional Application 62/089,747, filed Dec. 9, 2014, and titled, "METHODS AND SYSTEMS FOR SUPPORTING NATURAL LANGUAGE PROCESSING," the disclosures of which are incorporated herein by reference in their entireties and for all purposes.
[0002] This application is also related to US non provisional applications (Attorney Docket No. 1402805.00006_IDB006), titled "METHODS FOR GENERATING NATURAL LANGUAGE PROCESSING SYSTEMS," (Attorney Docket No. 1402805.00007_IDB007), titled "ARCHITECTURES FOR NATURAL LANGUAGE PROCESSING," (Attorney Docket No. 1402805.00012_IDB012), titled "OPTIMIZATION TECHNIQUES FOR ARTIFICIAL INTELLIGENCE," (Attorney Docket No. 1402805.00013_IDB013), titled "GRAPHICAL SYSTEMS AND METHODS FOR HUMAN-IN-THE-LOOP MACHINE INTELLIGENCE," (Attorney Docket No. 1402805.000015_IDB015), titled "METHODS AND SYSTEMS FOR MODELING COMPLEX TAXONOMIES WITH NATURAL LANGUAGE UNDERSTANDING," (Attorney Docket No. 1402805.00016_IDB016), titled "AN INTELLIGENT SYSTEM THAT DYNAMICALLY IMPROVES ITS KNOWLEDGE AND CODE-BASE FOR NATURAL LANGUAGE UNDERSTANDING," (Attorney Docket No. 1402805.00017_IDB017), titled "METHODS AND SYSTEMS FOR LANGUAGE-AGNOSTIC MACHINE LEARNING IN NATURAL LANGUAGE PROCESSING USING FEATURE EXTRACTION," (Attorney Docket No. 1402805.00018_IDB018), titled "METHODS AND SYSTEMS FOR PROVIDING UNIVERSAL PORTABILITY IN MACHINE LEARNING," and (Attorney Docket No. 1402805.00019_IDB019), titled "TECHNIQUES FOR COMBINING HUMAN AND MACHINE LEARNING IN NATURAL LANGUAGE PROCESSING," each of which are filed concurrently herewith, and the entire contents and substance of all of which are hereby incorporated in total by reference in their entireties and for all purposes.
TECHNICAL FIELD
[0003] The subject matter disclosed herein generally relates to processing data. In some example embodiments, the present disclosures relate to systems and methods for improving machine performance in natural language processing.
BRIEF SUMMARY
[0004] In some embodiments, methods and systems for improving machine performance in natural language processing are presented. In some embodiments, a method may include: generating a natural language model by a natural language platform; storing the natural language model in a first stateless format; accessing a plurality of documents to be classified by the natural language model; storing the plurality of documents in a second stateless format; and classifying, by the natural language platform, at least one document among the plurality of documents while the at least one document is stored in the second stateless format using the natural language model while stored in the first stateless format.
[0005] In some embodiments of the method, storing the natural language model in the first stateless format comprises storing the natural language model in a language agnostic format.
[0006] In some embodiments of the method, storing the plurality of documents in a second stateless format comprises storing all configuration and auxiliary data used to process each document among the plurality of documents with a combination of said document and the natural language model.
[0007] In some embodiments, the method further comprises performing an intelligent queuing operation on a subset of the documents within the plurality of documents while classifying the at least one document, wherein the subset of documents is distinct from the at least one document.
[0008] In some embodiments, the method further comprises performing a discover topics operation to discover documents that are classified into a specified label while classifying the at least one document.
[0009] In some embodiments of the method, accessing the plurality of documents to be classified by the natural language model comprises retrieving a subset of the plurality of documents from a database; and classifying the at least one document occurs while retrieving the subset of the plurality of documents, wherein the at least one document is distinct from the subset of the plurality of documents.
[0010] In some embodiments of the method, storing the natural language model in a stateless format comprises storing replicas of the natural language model each into a server among a plurality of parallelized servers.
[0011] In some embodiments, a natural language processing system is presented and comprises: a plurality of server machines communicatively coupled in parallel, each of the plurality of servers comprising a memory and at least one processor, each of the plurality of servers configured to: store, in said memory of said server, a replica of a natural language model in a first stateless format; access a plurality of documents to be classified by said replica of the natural language model; store the plurality of documents in a second stateless format; and classify at least one document among the plurality of documents while the at least one document is stored in the second stateless format using said replica of the natural language model while stored in the first stateless format.
[0012] In some embodiments, a non-transitory computer readable medium is presented comprising instructions that, when executed by a process, cause the processor to perform operations comprising: generating a natural language model; storing the natural language model in a first stateless format; accessing a plurality of documents to be classified by the natural language model; storing the plurality of documents in a second stateless format; and classifying at least one document among the plurality of documents while the at least one document is stored in the second stateless format using the natural language model while stored in the first stateless format.
BRIEF DESCRIPTION OF THE DRAWINGS
[0013] Some embodiments are illustrated by way of example and not limitation in the figures of the accompanying drawings.
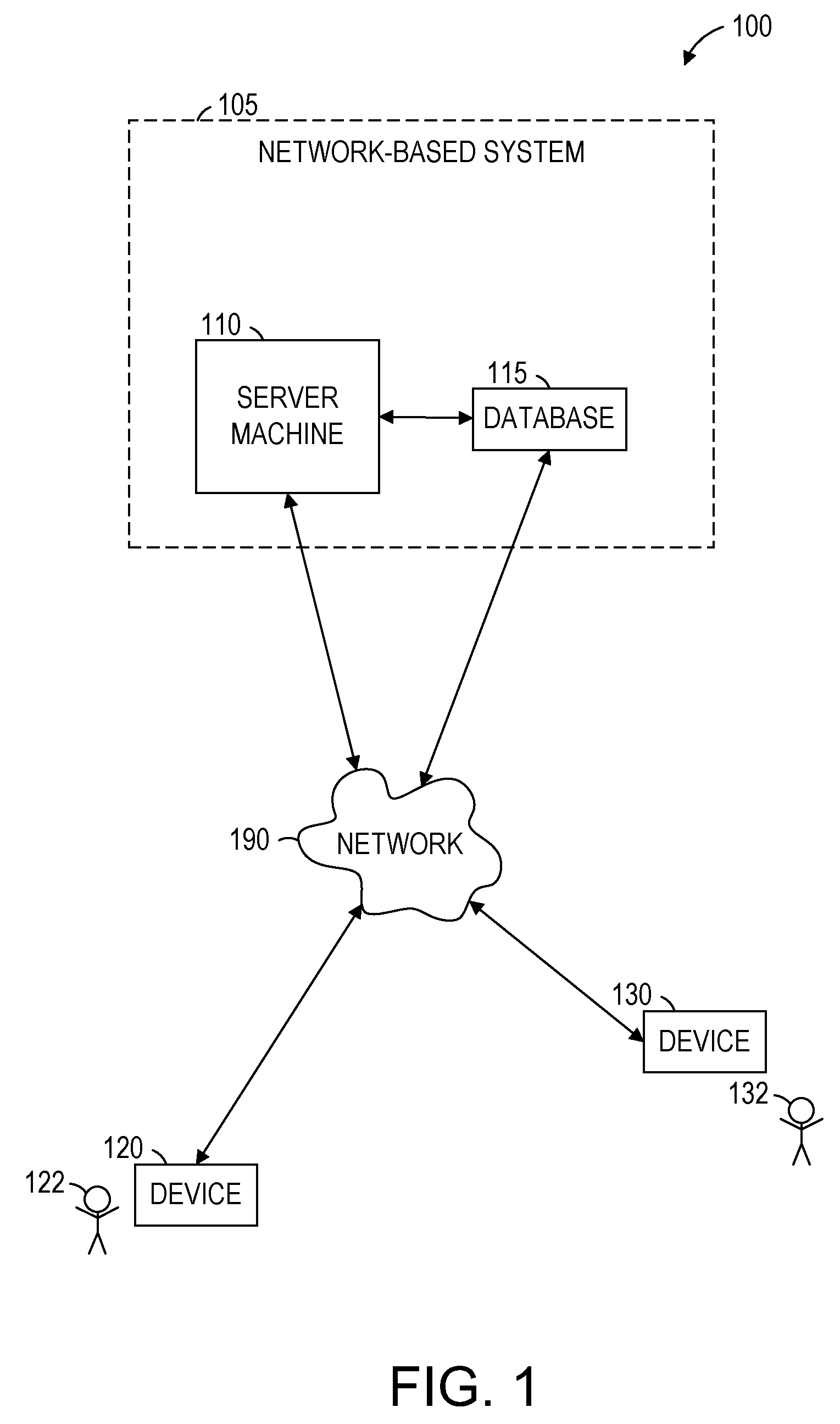
[0014] FIG. 1 is a network diagram illustrating an example network environment suitable for aspects of the present disclosure, according to some example embodiments.
[0015] FIG. 2 is a diagram showing an example system architecture for performing aspects of the present disclosure, according to some example embodiments.
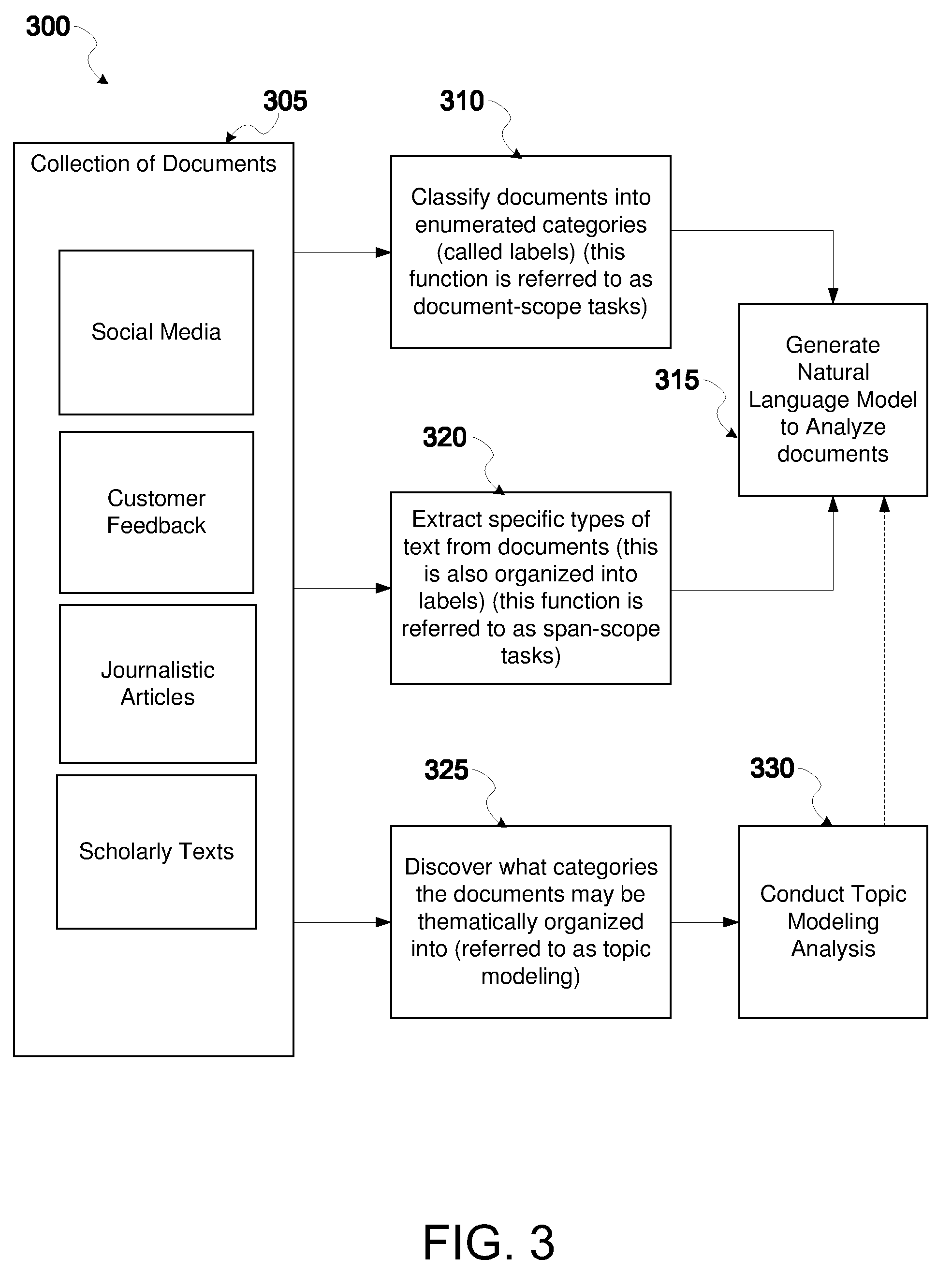
[0016] FIG. 3 is a high level diagram showing various examples of types of human communications and what the objectives may be for a natural language model to accomplish, according to some embodiments.
[0017] FIG. 4 is a diagram showing an example flowchart for how different data structures within the system architecture may be related to one another, according to some example embodiments.
[0018] FIG. 5 is a diagram describing further details of an example implementation of a stateless storage of a natural language model, according to some embodiments.
[0019] FIG. 6 is a diagram describing further details of a feature selection module that may be used to improve model training performance of the natural language platform, according to some embodiments.
[0020] FIG. 7 is a block diagram illustrating components of a machine, according to some example embodiments, able to read instructions from a machine-readable medium and perform any one or more of the methodologies discussed herein.
DETAILED DESCRIPTION
[0021] Example methods, apparatuses, and systems (e.g., machines) are presented for improving performance when performing natural language processing techniques using human annotations applied to machine learning techniques of natural language.
[0022] Aspects of the present disclosure are presented for assisting customers or users to accurately and expediently process human communications brought upon by the capabilities of the digital age. The modes of human communications brought upon by digital technologies have created a deluge of information that can be difficult for human readers to handle alone. Companies and research groups may want to determine trends in the human communications to determine what people generally care about for any particular topic, whether it be what car features are being most expressed on Twitter.RTM., what political topics are being most expressed on Facebook.RTM., what people are saying about the customer's latest product in their customer feedback page, and so forth. It may be desirable for companies to aggregate and then synthesize the thousands or even millions of human communications from the many different modes available in the digital age (e.g., Twitter.RTM., blogs, email, etc.). Processing all this information by humans alone can be overwhelming and cost-inefficient. Methods today may therefore rely on computers to apply natural language processing in order to interpret the many human communications available in order to analyze, group, and ultimately categorize the many human communications into digestible patterns of communication.
[0023] Aspects of the present disclosure include novel methods for combining natural language machine learning processing of the millions of individual human communications with human annotations of the machine results to best refine how the machines process all the data. The human annotations help the machine learning techniques resolve inevitable ambiguities in the human communications, as well as provide intelligence or meaning to communications the machine does not accurately comprehend. The human annotations can then enable computers to provide better natural language results of the human communications, which can then in turn be better refined by more human annotations as necessary. This cyclical or iterative process can converge to provide companies or users of the present disclosures with accurate summaries and analysis of the thousands or millions of human communications in the user's subject matter area.
[0024] In addition, aspects of the present disclosure may construct machine learning models based on this iterative process that can be specifically tailored to a user's unique needs or subject matter area. For example, the words important to categorizing communications in biotechnology may be different than the words important to categorizing communications in the automobile industry. The biotechnology user may desire to tailor the machine learning model to better understand articles related to biotechnology, while the automobile industry user may desire to tailor the machine learning model to better understand customer feedback emails. As another example, the language, grammar, and idioms used in social media may vary drastically from communications in professional writings, e.g., legal or medical journals. A user focusing on Twitter.RTM. communications may desire to tailor the machine learning model to better determine when tweets of adolescent teens convey positive sentiment or negative sentiment, while a user focusing on legal documents may desire to tailor the machine learning model to better understand whether a legal decision is favorable or unfavorable. As another example, answers to poll questions or customer surveys can be determined without polling or conducting any survey, based on analyzing public communications, e.g., tweets, Disqus.TM. comments and so forth. The machine learning model can be trained through the iterative process utilizing human annotations described herein to more easily determine what actual public sentiment may that might otherwise be determined through polling or surveys.
[0025] Once tuned to a user's specific needs through the iterative process described, aspects of the present disclosure allow for these tailored machine learning models to be applied to any number of present and future human communications. In some cases, the machine learning models can act as a filter of sorts, to discern and parse out what communications are relevant to the user before humans or even other machine language techniques process and analyze the data further.
[0026] In some example embodiments, a comprehensive system for producing these catered natural language models is presented. The comprehensive system may include an application program interface (API) to perform much of the functionality described herein. The API may be configured to improve performance in generating the natural language models by specially integrating specific functions and modules designed to reduce memory usage and reduce processing time while still providing accurate results. The comprehensive system may also include a series of background modules configured to provide certain functionality for the API to help achieve these performance benchmarks. The comprehensive system may also include a user interface to allow users to supplement the machine learning techniques with human annotations, as each user may have different focuses for processing data, each with specific vocabulary and language nuances more catered to the user's purposes.
[0027] In addition, the present disclosures describe how performance when utilizing the natural language models is improved through a novel design of storing the natural language model and the documents to be classified by the natural language model in a stateless format. This allows for a number of performance improvements, such as performing classification predictions while still ingesting the documents, and querying the current results for particular information while the model continues to process new documents.
[0028] Examples merely demonstrate possible variations. Unless explicitly stated otherwise, components and functions are optional and may be combined or subdivided, and operations may vary in sequence or be combined or subdivided. In the following description, for purposes of explanation, numerous specific details are set forth to provide a thorough understanding of example embodiments. It will be evident to one skilled in the art, however, that the present subject matter may be practiced without these specific details.
[0029] Referring to FIG. 1, a network diagram illustrating an example network environment 100 suitable for performing aspects of the present disclosure is shown, according to some example embodiments. The example network environment 100 includes a server machine 110, a database 115, a first device 120 for a first user 122, and a second device 130 for a second user 132, all communicatively coupled to each other via a network 190. The server machine 110 may form all or part of a network-based system 105 (e.g., a cloud-based server system configured to provide one or more services to the first and second devices 120 and 130). The server machine 110, the first device 120, and the second device 130 may each be implemented in a computer system, in whole or in part, as described below with respect to FIG. 7. The network-based system 105 may be an example of a natural language platform configured to generate natural language models as described herein. The server machine 110 and the database 115 may be components of the natural language platform configured to perform these functions. While the server machine 110 is represented as just a single machine and the database 115 where is represented as just a single database, in some embodiments, multiple server machines and multiple databases communicatively coupled in parallel or in serial may be utilized, and embodiments are not so limited.
[0030] Also shown in FIG. 1 are a first user 122 and a second user 132. One or both of the first and second users 122 and 132 may be a human user, a machine user (e.g., a computer configured by a software program to interact with the first device 120), or any suitable combination thereof (e.g., a human assisted by a machine or a machine supervised by a human). The first user 122 may be associated with the first device 120 and may be a user of the first device 120. For example, the first device 120 may be a desktop computer, a vehicle computer, a tablet computer, a navigational device, a portable media device, a smartphone, or a wearable device (e.g., a smart watch or smart glasses) belonging to the first user 122. Likewise, the second user 132 may be associated with the second device 130. As an example, the second device 130 may be a desktop computer, a vehicle computer, a tablet computer, a navigational device, a portable media device, a, smartphone, or a wearable device (e.g., a smart watch or smart glasses) belonging to the second user 132. The first user 122 and a second user 132 may be examples of users or customers interfacing with the network-based system 105 to utilize a natural language model according to their specific needs. In other cases, the users 122 and 132 may be examples of annotators who are supplying annotations to documents to be used for training purposes when developing a natural language model. In other cases, the users 122 and 132 may be examples of analysts who are providing inputs to the natural language platform to more efficiently train the natural language model. The users 122 and 132 may interface with the network-based system 105 through the devices 120 and 130, respectively.
[0031] Any of the machines, databases 115, or first or second devices 120 or 130 shown in FIG. 1 may be implemented in a general-purpose computer modified (e.g., configured or programmed) by software (e.g., one or more software modules) to be a special-purpose computer to perform one or more of the functions described herein for that machine, database 115, or first or second device 120 or 130. For example, a computer system able to implement any one or more of the methodologies described herein is discussed below with respect to FIG. 7. As used herein, a "database" may refer to a data storage resource and may store data structured as a text file, a table, a spreadsheet, a relational database (e.g., an object-relational database), a triple store, a hierarchical data store, any other suitable means for organizing and storing data or any suitable combination thereof. Moreover, any two or more of the machines, databases, or devices illustrated in FIG. 1 may be combined into a single machine, and the functions described herein for any single machine, database, or device may be subdivided among multiple machines, databases, or devices.
[0032] The network 190 may be any network that enables communication between or among machines, databases 115, and devices (e.g., the server machine 110 and the first device 120). Accordingly, the network 190 may be a wired network, a wireless network (e.g., a mobile or cellular network), or any suitable combination thereof. The network 190 may include one or more portions that constitute a private network, a public network (e.g., the Internet), or any suitable combination thereof. Accordingly, the network 190 may include, for example, one or more portions that incorporate a local area network (LAN), a wide area network (WAN), the Internet, a mobile telephone network (e.g., a cellular network), a wired telephone network (e.g., a plain old telephone system (POTS) network), a wireless data network (e.g., WiFi network or WiMax network), or any suitable combination thereof. Any one or more portions of the network 190 may communicate information via a transmission medium. As used herein, "transmission medium" may refer to any intangible (e.g., transitory) medium that is capable of communicating (e.g., transmitting) instructions for execution by a machine (e.g., by one or more processors of such a machine), and can include digital or analog communication signals or other intangible media to facilitate communication of such software.
[0033] Referring to FIG. 2, a diagram 200 is presented showing an example system architecture for performing aspects of the present disclosure, according to some example embodiments. The example system architecture according to diagram 200 represents various data structures and their interrelationships that may comprise a natural language platform, such as the natural language platform 170, or the network-based system 105. These various data structures may be implemented through a combination of hardware and software, the details of which may be apparent to those with skill in the art based on the descriptions of the various data structures described herein. For example, an API module 205 includes one or more API processors, where multiple API processors may be connected in parallel. In some example embodiments, the repeating boxes in the diagram 200 represent identical servers or machines, to signify that the system architecture in diagram 200 may be scalable to an arbitrary degree. The API module 205 may represent a point of contact for multiple other modules, includes a database module 210, a cache module 215, background processes module 220, applications module 225, and even an interface for users 235 in some example embodiments. The API module 205 may be configured to receive or access data from database module 210. The data may include digital forms of thousands or millions of human communications. The cache module 215 may store in more accessible memory various information from the database module 210 or from users 235 or other subscribers. Because the database module 210 and cache module 215 show accessibility through API module 205, the API module 205 can also support authentication and authorization of the data in these modules. The background module 220 may be configured to perform a number of background processes for aiding natural language processing functionality. Various examples of the background processes include a model training module, a cross validation module, an intelligent queuing module, a model prediction module, a topic modeling module, an annotation aggregation module, an annotation validation module, and a feature extraction module. These various modules are described in more detail below as well as in non-provisional applications (Attorney Docket Nos. 1402805.00006_IDB006, 1402805.00007_IDB007, 1402805.00012_IDB012, 1402805.00013_IDB013, 1402805.00016_IDB016, 1402805.00017_IDB017, and 1402805.00019_IDB019), each of which again are incorporated by reference in their entireties. The API module 205 may also be configured to support display and functionality of one or more applications in applications module 225.
[0034] In some example embodiments, the users 235 may access the API module 205, in some cases enabling the users 235 to create their own applications using the system architecture of diagram 200. The users 235 may be other examples of the users 120 or 130, and may also include project managers and analysts. Project managers may utilize the natural language platform to direct the overall construction of one or more natural language models. Analysts may utilize the natural language platform to provide expert analysis and annotations to more efficiently train a natural language model. Also, annotators 230 may have access to applications already created in applications module 225.
[0035] In some embodiments, the system architecture according to diagram 200 may be scalable and reproducible at various client sites. Thus, the database modules 210 and the cache module 215 may be implemented specifically for each client, such that each client does not share memory capacity with another client to ensure better privacy.
[0036] In some embodiments, the API module 205 may be implemented in a plurality of servers communicatively coupled in parallel, for example in a cloud environment. Load balancing may be performed across the plurality of servers to automatically distribute processing and memory use within the API module 205. In addition, each of the plurality of servers may be configured to store an identical copy of a natural language model in a corresponding memory that provides quick access, such as in RAM. This form of storing the natural language models may be referred to as a "blob." In some example embodiments, this is handled with agent-based operationalized training that are deployed on AWS instances. In some example embodiments, the horizontal scalability supported by some example embodiments of the API module 205 assist in this process. In this way, each of the servers may quickly access their respective natural language models stored in such memory. In addition, the natural language models may be stored in memory as a stateless data structure that is language agnostic. This allows the API module 205 overall to utilize the natural language model in real-time and generally dramatically improves the performance of making predictions with the natural language model by dramatically reducing latency. In addition, this configuration allows for an arbitrary degree of scalability, further augmenting the versatility of this design architecture. Additional details about the universal portability of the natural language models are described in application (Attorney Docket No. 1402805.00018_IDB018), which again is incorporated herein by reference.
[0037] In some embodiments, API module 205 is configured to produce a document in a stateless form using a natural language model according to the following example transformation process:
[0038] 1. The document text is partitioned into a sequence of tokens and plurality of associated tags, each token representing a character sequence, morpheme, or word from the original text. More details about the tokenization process are described in application (Attorney Docket No. 1402805.00016_IDB016), which is incorporated herein by reference.
[0039] 2. The document text, tokens, tags, document metadata and auxiliary data are used by a feature extracting algorithm as described in application (Attorney Docket No. 1402805.00017_IDB017), which is incorporated herein by reference. The feature extracting algorithm is configured to use the set of feature types and associated configuration parameters stored with the natural language model. Similarly, any auxiliary data needed by a feature type (for example, to designate documents longer or shorter than a median document length) are stored within the natural language model.
[0040] 3. A machine learning prediction is generated by combining the stored probabilities for each feature extracted in step 2.
[0041] 4. A rule-based prediction is generated by applying rules and associated weights stored in the natural language model to the document text, if any.
[0042] The predictions generated in step 2 and step 3 are combined according to the ratio of the number of extracted features to the number of matching rules.
[0043] In some embodiments, all configuration and auxiliary data used in steps 1-4 is either contained in the natural language model "blob" or provided with each document as needed to process it (for example, the document text), thereby providing stateless document processing.
[0044] These steps are illustrated in the flowchart 500 of FIG. 5. Blocks 505, 510, 515, and 520 correspond to the general descriptions of steps 1-4 described above.
[0045] In some embodiments, the feature types supported by the feature extracting algorithm applied in step 2 are configured to perform the same transformations regardless of the language or languages used to write the document. In these embodiments, feature extraction is performed only with respect to the tokens and each token's associated tags, thereby allowing the same training and prediction process to be performed equally effectively across any languages supported by the tokenizer. Such embodiments are considered language-agnostic since the same feature extracting, model training, and document processing algorithms may be used to create natural language models which understand an arbitrary number of written languages, without requiring special programming.
[0046] The process described above provides an example for configuring each document intended for classification to be stored in a stateless format. This process, combined with processes for generating and storing the natural language model into a stateless "blob," allows for the natural language platform to not need to be configured into a particular state before beginning classification of the documents using the natural language model. Further examples processes for storing a natural language model in a stateless "blob" format are described in application (Attorney Docket No. 1402805.00018_IDB018), again incorporated herein by reference.
[0047] In contrast, conventional methods do not generate natural language models stored in a stateless format. Conventional methods therefore tend to require that documents be ingested and pre-processed before being allowed to perform any classification or even declare the action of classifying the documents, because the natural language platform needs to reach a certain state in order to utilize the natural language model. As a result, large wait times must occur where a user or client cannot even begin to utilize the model until all of the pre-selected number of documents is processed. No documents can then be processed in a near real-time fashion due to the model and the documents requiring a particular state before processing, unlike the methods described herein due to the stateless nature of the natural language model and the documents to be processed.
[0048] In some embodiments, a user or client of the natural language model may be apportioned a dedicated environment in memory for utilizing their particular natural language model. In essence, memory of each server in the cloud environment may be partitioned for each client, allowing use of their respective natural language models while still achieving fast performance such as real-time capabilities.
[0049] In some embodiments, the feature extraction module may also be stored in memory of each of the parallelized servers of the API module 205. The feature extraction module may also be stored as a stateless and language agnostic data structure within each memory. This configuration may allow for a high degree of flexibility and versatility when extracting features from text. Additional details about the feature extraction aspects are discussed in application (Attorney Docket No. 1402805.00017_IDB017), which again is incorporated herein by reference.
[0050] In some embodiments, the stateless, language-agnostic models generated by the model training process such as in background module 220 are configured to limit the number of features stored in the model, for example, to at most 100,000 features per label. In these embodiments, the model training process includes a feature selection algorithm that is configured to efficiently select which features in documents extracted by the feature extraction module should be used by the natural language model when making predictions. For example, the feature selection algorithm may order features according to the amount of information entropy each feature provides, by counting the number of times each feature occurs in documents annotated for each label relative to other documents where the feature appears. If fewer features can be selected while still achieving comparable predictive performance, then natural language models may be stored more efficiently, allowing for more efficient use of memory. Limiting the number of features stored in a model reduces the size and memory requirement in order to use the model, thereby enabling use of the models in more resource-constrained environments, or allowing a larger number of models to remain resident in memory of each of the parallelized servers for the API module 205.
[0051] Example flowchart 600 of FIG. 6 exemplifies this process for performing feature selection through steps 605, 610, 615, 620, and 625. Steps 615 and 620 may repeat for feature to determine if said feature should remain and be stored with the label in the natural language model. The ordering of which features to examine may be based on the order of the features by information entropy in step 610 and consistent with the description above. Once it is determined that the predictive performance is sufficiently compromised due to the exclusion of the next feature, then the remaining list of features may be stored as the total list of features associated with said label. Other examples for performing feature selection are described in application (Attorney Docket No. 1402805.0006_IDB006), again incorporated herein by reference.
[0052] Referring to FIG. 3, a high level diagram 300 is presented showing various examples of types of human communications and what the objectives may be for a natural language model to accomplish. Here, various sources of data, sometimes referred to as a collection of documents 305, may be obtained and stored in, for example database 115, client data store 155, or database modules 210, and may represent different types of human communications, all capable of being analyzed by a natural language model. Examples of the types of documents 305 include, but are not limited to, posts in social media, emails or other writings for customer feedback, pieces of or whole journalistic articles, commands spoken or written to electronic devices, transcribed call center recordings; electronic (instant) messages; corporate communications (e.g., SEC 10-k, 10-q); confidential documents and communications stored on internal collaboration systems (e.g., SharePoint, Notes), and pieces of or whole scholarly texts.
[0053] In some embodiments, at block 310, it may be desired to classify any of the documents 305 into a number of enumerated categories or topics, consistent with some of the descriptions mentioned above. This may be referred to as performing a document-scope task. For example, a user 130 in telecommunications may supply thousands of customer service emails related to services provided by a telecommunications company. The user 130 may desire to have a natural language model generated that classifies the emails into predetermined categories, such as negative sentiment about their Internet service, positive sentiment about their Internet service, negative sentiment about their cable service, and positive sentiment about their cable service. As previously mentioned, these various categories for which a natural language model may classify the emails into, e.g. "negative" sentiment about "Internet service," "positive" sentiment about "Internet service," "negative" sentiment about "cable service," etc., may be referred to as "labels." Based on these objectives, at block 315, a natural language model may be generated that is tailored to automatically classify these types of emails into these types of labels.
[0054] As another example, in some embodiments, at block 320, it may be desired to extract specific subsets of text from documents, consistent with some of the descriptions mentioned above. This may be another example of performing a span-scope task, in reference to the fact that this function focuses on a subset within each document (as previously mentioned, referred to herein as a "span"). For example, a user 130 may desire to identify all instances of a keyword, key phrase, or general subject matter within a novel. As another example, a company may want to extract phrases that correspond to products or product features (e.g., "iPhone 5" or "battery life"). Certainly, this span scope task may be applied to multiple novels or other documents. Here too, based on this objective, at block 315, a natural language model may be generated that is tailored to perform this function for a specified number of documents.
[0055] As another example, in some embodiments, at block 325, it may be desired to discover what categories the documents may be thematically or topically organized into in the first place, consistent with descriptions above about topic modeling. In some cases, the user 130 may utilize the natural language platform only to perform topic modeling and to discover what topics are most discussed in a specified collection of documents 305. To this end, the natural language platform may be configured to conduct topic modeling analysis at block 330. Topic modeling is discussed in more detail below, as well as in applications (Attorney Docket Nos. 1402805.00012_IDB012, 1402805.00013_IDB013, 1402805.00016_IDB016, 1402805.00017_IDB017, and 1402805.00019_IDB019), each of which again are incorporated herein by reference in their entireties. In some cases, it may be desired to then generate a natural language model that categorizes the documents 305 into these newfound topics. Thus, after performing the topic modeling analysis 230, in some embodiments, the natural language model may also be generated at block 315.
[0056] Referring to FIG. 4, a diagram 400 is presented showing an example flowchart for how different data structures within the system architecture may be related to one another, according to some example embodiments. Here, the collections data structure 410 represents a set of documents 435 that in some cases may generally be homogenous. A document 435 represents a human communication expressed in a single discrete package, such as a single tweet, a webpage, a chapter of a book, a command to a device, or a journal article, or any part thereof. Each collection 410 may have one or more tasks 430 associated with it. A task 430 may be thought of as a classification scheme. For example, a collection 410 of tweets may be classified by its sentiment, e.g. a positive sentiment or a negative sentiment, where each classification constitutes a task 430 about a collection 410. A label 445 refers to a specific prediction about a specific classification. For example, a label 445 may be the "positive sentiment" of a human communication, or the "negative sentiment" of a human communication. In some cases, labels 445 can be applied to merely portions of documents 435, such as paragraphs in an article or particular names or places mentioned in a document 435. For example, a label 445 may be a "positive opinion" expressed about a product mentioned in a human communication, or a "negative opinion" expressed about a product mentioned in a human communication. In some example embodiments, a task may be a sub-task of another task, allowing for a hierarchy or complex network of tasks. For example, if a task has a label of "positive opinion," there might be sub-tasks for types of "positives opinions," like "intention to purchase the product," "positive review," "recommendation to friend," and so on, and there may be subtasks that capture other relevant information, such as "positive features."
[0057] Annotations 440 refer to classifications imputed onto a collection 410 or a document 435, often times by human input but may also be added by programmatic means, such as interpolating from available metadata (e.g., customer value, geographic location, etc.), generated by a pre-existing natural language model, or generated by a topic modeling process. As an example, an annotation 440 applies a label 445 manually to a document 435. In other cases, annotations 440 are provided by users 235 from pre-existing data. In other cases, annotations 440 may be derived from human critiques of one or more documents 435, where the computer determines what annotation 440 should be placed on a document 435 (or collection 410) based on the human critique. In other cases, with enough data in a language model, annotations 440 of a collection 410 can be derived from one or more patterns of pre-existing annotations found in the collection 410 or a similar collection 410.
[0058] In some example embodiments, features 450 refer to a library or collection of certain key words or groups of words that may be used to determine whether a task 430 should be associated with a collection 410 or document 435. Thus, each task 430 has associated with it one or more features 450 that help define the task 430. In some example embodiments, features 450 can also include a length of words or other linguistic descriptions about the language structure of a document 435, in order to define the task 430. For example, classifying a document 435 as being a legal document may be based on determining if the document 435 contains a threshold number of words with particularly long lengths, words belonging to a pre-defined dictionary of legal-terms, or words that are related through syntactic structures and semantic relationships. In some example embodiments, features 450 are defined by code, while in other cases features 450 are discovered by statistical methods. In some example embodiments, features 450 are treated independently, while in other cases features 450 are networked combinations of simpler features that are used in combination utilizing techniques like "deep-learning." In some example embodiments, combinations of the methods described herein may be used to define the features 450, and embodiments are not so limited. One or more processors may be used to identify in a document 435 the words found in features data structure 450 to determine what task should be associated with the document 435.
[0059] In some example embodiments, a work unit's data structure 455 specifies when humans should be tasked to further examine a document 425. Thus, human annotations may be applied to a document 435 after one or more work units 455 is applied to the document 435. The work units 455 may specify how many human annotators should examine the document 435 and in what order of documents should document 435 be examined. In some example embodiments, work units 455 may also determine what annotations should be reviewed in a particular document 435 and what the optimal user interface should be for review.
[0060] In some example embodiments, the data structures 405, 415, 420 and 425 represent data groupings related to user authentication and user access to data in system architecture. For example, the subscribers block 405 may represent users and associated identification information about the users. The subscribers 405 may have associated API keys 415, which may represent one or more authentication data structures used to authenticate subscribers and provide access to the collections 410. Groups 420 may represent a grouping of subscribers based on one or more common traits, such as subscribers 405 belonging to the same company. Individual users 425 capable of accessing the collections 410 may also result from one or more groups 420. In addition, in some cases, each group 420, user 425, or subscriber 405 may have associated with it a more personalized or customized set of collections 510, documents 435, annotations 440, tasks, 430, features 450, and labels 445, based on the specific needs of the customer.
[0061] In some example embodiments, an API module is presented that is configured to drive processing of the system architecture described in FIGS. 1 and 2. An example of the API module is API module 205. In addition, the API module 205 may also enable users 235 to access many of the functionality provided by the system architecture, as well as support data storage for any and all human communications to be analyzed by the users 235 via, e.g., database module 210 and cache module 215. In some example embodiments, the API module 205 is also configured to handle an arbitrary amount of customers or users 235 and data at any given time, as well as satisfactorily perform the functions the users 235 want. The API module 205 may also support the display and functionality of any applications in application module 225, and may connect to any and all background support systems module 220. In some example embodiments, the API module 205 also provides authentication services to verify and authenticate users 235.
[0062] Aspects of the present disclosure allow for the API module 205 to process tasks from an arbitrary number of users simultaneously. In addition, the arbitrary number of users may also access the natural language process techniques in an arbitrary number of languages, provided the system architecture of the present disclosures have been implemented to support the desired languages. In some cases, the arbitrary number of users may also access an arbitrary number of queries and human communications per use. The techniques described herein can therefore refer to techniques for improving the scalability of natural language processing. The following are a number of improvements toward these ends, according to some example embodiments.
[0063] In some example embodiments, the speed of retrieval of documents from the API module 205 across a network connection, e.g., the Internet, is improved. For example, for a single request of documents by a user 235, multiple documents can be retrieved. For example, two different network protocol standards are combined to retrieve multiple documents using a streaming fetch mechanism, based on a single request.
[0064] In some embodiments, a natural language model may be generated for each language as specified by the user or client. Each model tailored to a particular language may be trained using annotations compiled in the particular language. Each model tailored to a specific language may be stored on different servers. This is facilitated by the fact that the models are natively stored as stateless data structures that are language agnostic, and because the feature extraction module is also language agnostic. For example, the features of documents extracted by the feature extraction module may be extracted one time and may be available for use in all languages of the natural language model. Only some features may be used for a given language, while other features may be used for another given language. For example, the feature extraction module may identify 100 features of a collection of documents, and a Spanish implemented natural language model may utilize just 10 of the features while an English implemented natural language model may utilize 50 of the features. It is possible that some of the features used in the Spanish implemented model may also be used in the English implemented model, and the remaining features not used in either model may be utilized in other language-specific models.
[0065] In some embodiments, an intelligent queuing process such as included in background support system module 220 may be used to create language-specific models from a document set containing documents written in a plurality of languages. For example, the intelligent queuing module may recognize that the features extracted from a first subset of documents written in a first language never co-occur with features extracted from a second subset of documents written in a second language. In some embodiments, the intelligent queuing process may select one or more documents for annotation from each of the subset of documents, thereby creating a natural language model for each language represented amongst the annotated documents. Additional details about the intelligent queuing process are described in more details in application (Attorney Docket No. 1402805.00012), again incorporated herein by reference.
[0066] In some example embodiments, a streaming fetch of a corpus, e.g., a collection of words from a collection of documents, via JSON combined with a multipart/mixed HTTP protocol can allow for improved document retrieval. In some example embodiments, this method can be much faster for traffic across the network, and hence faster for users 235, than a highly parallelized approach, since costs for overhead from a single request is processed only once per batch. During this document retrieval process, particular transforms using the tokenizer and feature extraction modules may be performed on the documents by the API module 205 that reduces some processes during the model training phase.
[0067] In some embodiments, the API module 205 may process the document according to one or more existing natural language models during the document retrieval, thereby eliminating the overhead of processing each document individually in the topic modeling and intelligent queuing processes. Processing the document while other documents are being retrieved may be made possible because of the stateless nature of the natural language model and the documents. Because all of the inputs needed to classify documents are stored in a stateless format, the natural language platform may be configured to simultaneously retrieve documents while processing other documents. Furthermore, due to processing documents during document retrieval, additional functions that the client may opt for may be made possible. For example, this allows for the intelligent queuing process and the discover topics functionality to occur while processing the documents. Further detailed descriptions of intelligent queuing are described in application (Attorney Docket No. 1402805.00012_IDB012), and further descriptions of the discover topics functionality are discussed in application (Attorney Docket No. 1402805.00015_IDB015), both of which again are incorporated herein by reference. In contrast, conventionally, an API module may simply retrieve documents from the database module 210 without being able to perform any additional processing at the same time.
[0068] In some example embodiments, another issue to be resolved or improved includes efficiently loading and retrieving request information. This request information can include information about the credentials of the user 235, authentication information, and various metadata about the collection of documents the user 235 intends to retrieve. The API module 205 retrieves this request information from memory, for example a database module 210. However, if the request information is repetitive across multiple requests from a user 235, the operations for loading and retrieving said request information can be cumbersome and may slow down process time.
[0069] In some example embodiments, this request information may be synchronized across multiple servers, e.g., via a cache module 215, referred to as cache synchronization. In some embodiments, cache synchronization includes methods for notifying the multiple servers about any changes in the request information. In addition, each individual server may be configured to independently determine whether said server has the latest request information, and if not, obtain an update of the latest request information.
[0070] In some example embodiments, another issue to be resolved or improved includes efficiently keeping track of a search cursor when a user 235 makes requests to retrieve a specified number of documents. A user 235 may ask for the first 1000 documents in a collection of documents, for example. The user 235 may then ask for the next 1000 documents, i.e., documents #1001-2000. The search cursor helps keep track of what indexed document the user 235 has left off at. For higher indexed documents, some methods determine where the search cursor should be by counting from the beginning of the index for each request. This can be more inefficient the more documents there are that need to be searched. The time taken to perform this operation by some methods scales linearly (order N) with the number of documents in the database or system.
[0071] In some embodiments, performance may be improved for performing topic modeling through providing a random or pseudorandom tag for each document in the database module 210, according to some embodiments. In some cases, a client or user may opt to perform a truncated topic modeling session by limiting the amount of time an API module 205 may take to conduct topic modeling using the topic modeling module. For example, the user may opt to learn what topics may be generated or discovered in a collection of documents after only 10 minutes of processing. To do this, a limited number of documents are retrieved, sufficient to be processed and grouped into topics within only 10 minutes. If there are many more documents available than may be processed, then to obtain a closely representative set of documents of the entire collection when performing the truncated topic modeling, a random subset of documents should be retrieved. Conventional retrievals, such as retrieving documents consecutively starting from a particular index, are not likely to achieve this random sampling of subject matter. Rather, according to some embodiments, each document may be applied a random or pseudorandom tag or index. The retrieval of the documents may then be based on an ordering of the documents by this random or pseudorandom tag. In some embodiments, retrieval may start at a random or pseudorandom value as well. In this way, the documents may be retrieved in a random order to achieve a more representative sampling of the entire set of documents.
[0072] Referring to FIG. 7, the block diagram illustrates components of a machine 700, according to some example embodiments, able to read instructions 724 from a machine-readable medium 722 (e.g., a non-transitory machine-readable medium, a machine-readable storage medium, a computer-readable storage medium, or any suitable combination thereof) and perform any one or more of the methodologies discussed herein, in whole or in part. Specifically, FIG. 7 shows the machine 700 in the example form of a computer system (e.g., a computer) within which the instructions 724 (e.g., software, a program, an application, an applet, an app, or other executable code) for causing the machine 700 to perform any one or more of the methodologies discussed herein may be executed, in whole or in part.
[0073] In alternative embodiments, the machine 700 operates as a standalone device or may be connected (e.g., networked) to other machines. In a networked deployment, the machine 700 may operate in the capacity of a server machine 110 or a client machine in a server-client network environment, or as a peer machine in a distributed (e.g., peer-to-peer) network environment. The machine 700 may include hardware, software, or combinations thereof, and may, as example, be a server computer, a client computer, a personal computer (PC), a tablet computer, a laptop computer, a netbook, a cellular telephone, a smartphone, a set-top box (STB), a personal digital assistant (PDA), a web appliance, a network router, a network switch, a network bridge, or any machine capable of executing the instructions 724, sequentially or otherwise, that specify actions to be taken by that machine. Further, while only a single machine 700 is illustrated, the term "machine" shall also be taken to include any collection of machines that individually or jointly execute the instructions 724 to perform all or part of any one or more of the methodologies discussed herein.
[0074] The machine 700 includes a processor 702 (e.g., a central processing unit (CPU), a graphics processing unit (GPU), a digital signal processor (DSP), an application specific integrated circuit (ASIC), a radio-frequency integrated circuit (RFIC), or any suitable combination thereof), a main memory 704, and a static memory 706, which are configured to communicate with each other via a bus 708. The processor 702 may contain microcircuits that are configurable, temporarily or permanently, by some or all of the instructions 724 such that the processor 702 is configurable to perform any one or more of the methodologies described herein, in whole or in part. For example, a set of one or more microcircuits of the processor 702 may be configurable to execute one or more modules (e.g., software modules) described herein.
[0075] The machine 700 may further include a video display 710 (e.g., a plasma display panel (PDP), a light emitting diode (LED) display, a liquid crystal display (LCD), a projector, a cathode ray tube (CRT), or any other display capable of displaying graphics or video). The machine 700 may also include an alphanumeric input device 712 (e.g., a keyboard or keypad), a cursor control device 714 (e.g., a mouse, a touchpad, a trackball, a joystick, a motion sensor, an eye tracking device, or other pointing instrument), a storage unit 716, a signal generation device 718 (e.g., a sound card, an amplifier, a speaker, a headphone jack, or any suitable combination thereof), and a network interface device 720.
[0076] The storage unit 716 includes the machine-readable medium 722 (e.g., a tangible and non-transitory machine-readable storage medium) on which are stored the instructions 724 embodying any one or more of the methodologies or functions described herein, including, for example, any of the descriptions of FIGS. 1-6. The instructions 724 may also reside, completely or at least partially, within the main memory 704, within the processor 702 (e.g., within the processor's cache memory), or both, before or during execution thereof by the machine 700. The instructions 724 may also reside in the static memory 706.
[0077] Accordingly, the main memory 704 and the processor 702 may be considered machine-readable media 722 (e.g., tangible and non-transitory machine-readable media). The instructions 724 may be transmitted or received over a network 726 via the network interface device 720. For example, the network interface device 720 may communicate the instructions 724 using any one or more transfer protocols (e.g., HTTP). The machine 700 may also represent example means for performing any of the functions described herein, including the processes described in FIGS. 1-6.
[0078] In some example embodiments, the machine 700 may be a portable computing device, such as a smart phone or tablet computer, and have one or more additional input components (e.g., sensors or gauges) (not shown). Examples of such input components include an image input component (e.g., one or more cameras), an audio input component (e.g., a microphone), a direction input component (e.g., a compass), a location input component (e.g., a GPS receiver), an orientation component (e.g., a gyroscope), a motion detection component (e.g., one or more accelerometers), an altitude detection component (e.g., an altimeter), and a gas detection component (e.g., a gas sensor). Inputs harvested by any one or more of these input components may be accessible and available for use by any of the modules described herein.
[0079] As used herein, the term "memory" refers to a machine-readable medium 722 able to store data temporarily or permanently and may be taken to include, but not be limited to, random-access memory (RAM), read-only memory (ROM), buffer memory, flash memory, and cache memory. While the machine-readable medium 722 is shown in an example embodiment to be a single medium, the term "machine-readable medium" should be taken to include a single medium or multiple media (e.g., a centralized or distributed database 115, or associated caches and servers) able to store instructions 724. The term "machine-readable medium" shall also be taken to include any medium, or combination of multiple media, that is capable of storing the instructions 724 for execution by the machine 700, such that the instructions 724, when executed by one or more processors of the machine 700 (e.g., processor 702), cause the machine 700 to perform any one or more of the methodologies described herein, in whole or in part. Accordingly, a "machine-readable medium" refers to a single storage apparatus or device 120 or 130, as well as cloud-based storage systems or storage networks that include multiple storage apparatus or devices 120 or 130. The term "machine-readable medium" shall accordingly be taken to include, but not be limited to, one or more tangible (e.g., non-transitory) data repositories in the form of a solid-state memory, an optical medium, a magnetic medium, or any suitable combination thereof.
[0080] Furthermore, the machine-readable medium 722 is non-transitory in that it does not embody a propagating signal. However, labeling the tangible machine-readable medium 722 as "non-transitory" should not be construed to mean that the medium is incapable of movement; the medium should be considered as being transportable from one physical location to another. Additionally, since the machine-readable medium 722 is tangible, the medium may be considered to be a machine-readable device.
[0081] Throughout this specification, plural instances may implement components, operations, or structures described as a single instance. Although individual operations of one or more methods are illustrated and described as separate operations, one or more of the individual operations may be performed concurrently, and nothing requires that the operations be performed in the order illustrated. Structures and functionality presented as separate components in example configurations may be implemented as a combined structure or component. Similarly, structures and functionality presented as a single component may be implemented as separate components. These and other variations, modifications, additions, and improvements fall within the scope of the subject matter herein.
[0082] Certain embodiments are described herein as including logic or a number of components, modules, or mechanisms. Modules may constitute software modules (e.g., code stored or otherwise embodied on a machine-readable medium 722 or in a transmission medium), hardware modules, or any suitable combination thereof. A "hardware module" is a tangible (e.g., non-transitory) unit capable of performing certain operations and may be configured or arranged in a certain physical manner. In various example embodiments, one or more computer systems (e.g., a standalone computer system, a client computer system, or a server computer system) or one or more hardware modules of a computer system (e.g., a processor 702 or a group of processors 702) may be configured by software (e.g., an application or application portion) as a hardware module that operates to perform certain operations as described herein.
[0083] In some embodiments, a hardware module may be implemented mechanically, electronically, or any suitable combination thereof. For example, a hardware module may include dedicated circuitry or logic that is permanently configured to perform certain operations. For example, a hardware module may be a special-purpose processor, such as a field programmable gate array (FPGA) or an ASIC. A hardware module may also include programmable logic or circuitry that is temporarily configured by software to perform certain operations. For example, a hardware module may include software encompassed within a general-purpose processor 702 or other programmable processor 702. It will be appreciated that the decision to implement a hardware module mechanically, in dedicated and permanently configured circuitry, or in temporarily configured circuitry (e.g., configured by software) may be driven by cost and time considerations.
[0084] Hardware modules can provide information to, and receive information from, other hardware modules. Accordingly, the described hardware modules may be regarded as being communicatively coupled. Where multiple hardware modules exist contemporaneously, communications may be achieved through signal transmission (e.g., over appropriate circuits and buses 708) between or among two or more of the hardware modules. In embodiments in which multiple hardware modules are configured or instantiated at different times, communications between such hardware modules may be achieved, for example, through the storage and retrieval of information in memory structures to which the multiple hardware modules have access. For example, one hardware module may perform an operation and store the output of that operation in a memory device to which it is communicatively coupled. A further hardware module may then, at a later time, access the memory device to retrieve and process the stored output. Hardware modules may also initiate communications with input or output devices, and can operate on a resource (e.g., a collection of information).
[0085] The various operations of example methods described herein may be performed, at least partially, by one or more processors 702 that are temporarily configured (e.g., by software) or permanently configured to perform the relevant operations. Whether temporarily or permanently configured, such processors 702 may constitute processor-implemented modules that operate to perform one or more operations or functions described herein. As used herein, "processor-implemented module" refers to a hardware module implemented using one or more processors 702.
[0086] Similarly, the methods described herein may be at least partially processor-implemented, a processor 702 being an example of hardware. For example, at least some of the operations of a method may be performed by one or more processors 702 or processor-implemented modules. As used herein, "processor-implemented module" refers to a hardware module in which the hardware includes one or more processors 702. Moreover, the one or more processors 702 may also operate to support performance of the relevant operations in a "cloud computing" environment or as a "software as a service" (SaaS). For example, at least some of the operations may be performed by a group of computers (as examples of machines 700 including processors 702), with these operations being accessible via a network 726 (e.g., the Internet) and via one or more appropriate interfaces (e.g., an API).
[0087] The performance of certain operations may be distributed among the one or more processors 702, not only residing within a single machine 700, but deployed across a number of machines 700. In some example embodiments, the one or more processors 702 or processor-implemented modules may be located in a single geographic location (e.g., within a home environment, an office environment, or a server farm). In other example embodiments, the one or more processors 702 or processor-implemented modules may be distributed across a number of geographic locations.
[0088] Unless specifically stated otherwise, discussions herein using words such as "processing," "computing," "calculating," "determining," "presenting," "displaying," or the like may refer to actions or processes of a machine 700 (e.g., a computer) that manipulates or transforms data represented as physical (e.g., electronic, magnetic, or optical) quantities within one or more memories (e.g., volatile memory, non-volatile memory, or any suitable combination thereof), registers, or other machine components that receive, store, transmit, or display information. Furthermore, unless specifically stated otherwise, the terms "a" or "an" are herein used, as is common in patent documents, to include one or more than one instance. Finally, as used herein, the conjunction "or" refers to a non-exclusive "or," unless specifically stated otherwise.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.