Using Classified Text And Deep Learning Algorithms To Assess Risk And Provide Early Warning
Brestoff; Nelson E.
U.S. patent application number 16/366705 was filed with the patent office on 2019-07-18 for using classified text and deep learning algorithms to assess risk and provide early warning. The applicant listed for this patent is Nelson E. Brestoff. Invention is credited to Nelson E. Brestoff.
| Application Number | 20190220937 16/366705 |
| Document ID | / |
| Family ID | 59701475 |
| Filed Date | 2019-07-18 |

| United States Patent Application | 20190220937 |
| Kind Code | A1 |
| Brestoff; Nelson E. | July 18, 2019 |
USING CLASSIFIED TEXT AND DEEP LEARNING ALGORITHMS TO ASSESS RISK AND PROVIDE EARLY WARNING
Abstract
Deep learning is used to identify specific risks to an enterprise of a pending litigation and identify documents of interest for the litigation. The system involves mining and using existing classifications of data (e.g., from a litigation database) to train one or more deep learning algorithms, and then examining the electronically stored information with the trained algorithm, to generate a scored output that will enable enterprise personnel to review risks to the enterprise, e.g. to enable enterprise personnel to assess the nature and extent of the potential damage from the litigation, and to identify relevant documents that would be saved to prevent spoliation.
| Inventors: | Brestoff; Nelson E.; (Sequim, WA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 59701475 | ||||||||||
| Appl. No.: | 16/366705 | ||||||||||
| Filed: | March 27, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| PCT/US2017/050555 | Sep 7, 2017 | |||
| 16366705 | ||||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06K 9/6267 20130101; G06N 3/08 20130101; G06Q 10/0635 20130101; G06F 40/40 20200101; G06N 3/0481 20130101; G06N 3/0445 20130101; G06K 9/6256 20130101; G06N 20/00 20190101; G06Q 50/18 20130101 |
| International Class: | G06Q 50/18 20120101 G06Q050/18; G06K 9/62 20060101 G06K009/62; G06N 3/04 20060101 G06N003/04 |
Claims
1. A method of using classified text and deep learning algorithms to assess risk and identify relevant documents comprising: creating one or more training datasets for textual data corresponding to a specific risk classification, wherein said risk classification comprises a nature of a recently filed lawsuit; training one or more deep learning algorithms using said one or more training datasets; collecting and extracting a corpus of documents comprising electronically stored information stored by an enterprise; applying said one or more deep learning algorithms to said corpus of documents to identify and report one or more documents of interest in the said corpus of documents for an early assessment of the potential harm to the enterprise of said lawsuit; determining if said identified one or more documents of interest is a false positive or a true positive; and re-training said one or more deep learning algorithms if said identified one or more documents of interest is a false positive.
2. The method of claim 1, wherein said one or more deep learning algorithms is a framework for natural language processing of text.
3. The method of claim 1, wherein said one or more deep learning algorithms is a recurrent neural network with a multiplicity of layers and various features, including but not limited to long short-term memory or gated recurrent units.
4. The method of claim 1, wherein the one or more deep learning algorithms have been trained with different classifiers using previously classified data sourced and provided by a subject matter expert to become models for specific threats or risks of interest.
5. The method of claim 1, wherein each one of said one or more deep learning algorithms has also been trained with one or more datasets unrelated to the threats or risks of interest.
6. The method of claim 1, wherein said one or more training datasets is obtained by mining one or more litigation databases.
7. A method of using classified text and deep learning algorithms to identify risk and provide early warning comprising: creating one or more training datasets by mining one or more litigation databases for textual data corresponding to a specific threat or risk of interest; training one or more deep learning algorithms using said one or more training datasets; collecting and extracting a corpus of documents comprising electronically stored information stored by an enterprise; applying said one or more deep learning algorithms to said corpus of documents to identify and report one or more documents of interest in the said corpus of documents for an early assessment of the potential harm to the enterprise of said lawsuit; determining if said identified one or more documents of interest is a false positive or a true positive; and re-training said one or more deep learning algorithms if said identified one or more documents of interest is a false positive.
8. The method of claim 7, wherein each one of said one or more deep learning algorithms scores the data for accuracy with the deep learning model classification of the data.
9. The method of claim 8, wherein said report comprises providing the scores and related data to one or more designated users.
10. The method of claim 8, wherein the report may be limited to scores which surpass a specified threshold associated with each of said one or more deep learning algorithms.
11. The method of claim 8, wherein the report and the documents of interest are exported to an existing case management system for investigation and review and possible further action.
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] The present application is a continuation in part of PCT Application No. PCT/US2017/50555, filed, Sep. 7, 2017, which claims the benefit of U.S. Provisional Application Ser. No. 62/357,803, filed on Jul. 1, 2016, all of which are herein incorporated by reference for completeness of disclosure.
BACKGROUND OF THE INVENTION
Field of the Invention
[0002] This invention relates generally to machine learning and more specifically to training deep learning algorithms as text classifiers and using them to assess a risk that has been realized in a recently filed lawsuit and identify relevant documents to prevent spoliation.
Description of the Related Art
[0003] Law professor Louis M. Brown (1909-1996) advocated "preventive law." Indeed, he pioneered this concept. His philosophy was this: "The time to see an attorney is when you're legally healthy--certainly before the advent of litigation, and prior to the time legal trouble occurs." He likened his approach to preventive medicine. However, Prof. Brown passed away before computer hardware and software had reached the point where his concept could be implemented. There are no conferences or journals today which focus on preventive law.
[0004] In modern society, entities such as commercial businesses, not-for-profit organizations, governmental agencies, and other ongoing concerns (all hereinafter referred to collectively as "enterprises") are exposed to potential liabilities if they breach contractual, criminal, governmental, or tort obligations.
[0005] In Preventing Litigation: An Early Warning System, Etc. (Business Expert Press 2015) ("Preventing Litigation"), I presented the data showing that the average annual cost of commercial tort litigation in terms of payouts, defense attorneys' fees, and administrative expenses (collectively, "cost"), during the 10-year period from 2001 through 2010, was $160 billion. The total cost for that 10-year timeframe was $1.6 trillion. That pain is enormous.
[0006] In Preventing Litigation, I compiled the federal and state caseload for that same 10-year period, and computed the cost per case. The result was $408,000, but I concluded that the cost per case was better set at $350,000, as a minimum.
[0007] Since litigation is neither a cost of goods sold nor a cost of services provided, this result indicates a loss to the enterprise of net gains of over $1 million for only three average commercial tort litigation matters, but it was not surprising. It is common knowledge that the cost of litigation is high. On occasion, employee misbehavior, at every level, has violated the rights of another employee, severely impaired an enterprise, harmed an entire marketplace, or physically harmed enterprise employees, members of the public, or violated their rights. However, I assert that my data compilation and calculation was the first "per case" derivation of the average cost per case. I showed how much of a losing proposition it is for an enterprise to have to defend a commercial tort litigation matter, even if the client's attorneys are successful in the defense they mount.
[0008] Worse, severe misconduct causing massive financial and/or physical harm may escalate to the level where criminal charges are filed. Such charges may be filed against the enterprise and the individuals responsible for the harm. In the early 1990s, the Federal Sentencing Guidelines provided benchmarks for misconduct. The Sentencing Guidelines make room for mitigating conduct and actions that speak against the heaviest penalties. In this context, a system enabling the prevention of harm may function to avoid criminal prosecution altogether. Such a system is evidence of a specific intent to avoid harm, which is the opposite of an element any prosecutor would be forced by law to meet: a specific intent to do harm.
[0009] However, litigation can cost an enterprise in still other ways. For example, the enterprise's reputation may suffer, productivity may be reduced, as when an executive or technology employee receives a litigation hold notice and must divert his or her attention from the matters at hand; meets with in-house or outside counsel; or prepares for and then sits for a deposition or testifies in court.
[0010] These high costs and risks are sufficient motivation to find a way to identify the risks of litigation before the damage is done. If a risk can be identified and eliminated before causing damage, the risk cannot give rise to a lawsuit. No civil lawsuit is viable without a good faith allegation of the necessary element of damages.
[0011] The attorneys who are closest to the data internal to an enterprise are the attorneys employed by the enterprise. However, these in-house attorneys are blind to the data which contain indications of litigation risks.
[0012] There is no software technology or product extant today which permits enterprise employees to identify and surface examples of the risks of being sued while they are still only potential legal liabilities.
[0013] Thus, there is a need for a system capable of identifying an enterprise's own internal risks, including but not limited to the risk of litigation, and providing early warning to appropriate personnel.
BRIEF SUMMARY OF THE INVENTION
[0014] This invention comprises a computer-enabled software system using deep learning to assess specific risks of a litigation by evaluating electronically stored information ("ESI"). ESIs may be emails and any attachments thereto, a collection of call center notes, a set of warranty claims, other internal company documents, or transcriptions of voice mail messages. One or more embodiments of the invention relies on existing classifications of litigation data to train one or more deep learning algorithms, and then to examine ESIs with them, to identify relevant data and assess risk of a newly filed lawsuit. A computer-based examination of ESIs could be near real-time, e.g., overnight. After all, the purpose of an early warning system is to enable the enterprise to be proactive instead of reactive, and as soon as possible.
BRIEF DESCRIPTION OF THE DRAWINGS
[0015] The above and other aspects, features and advantages of the invention will be more apparent from the following more particular description thereof, presented in conjunction with the following drawings wherein:
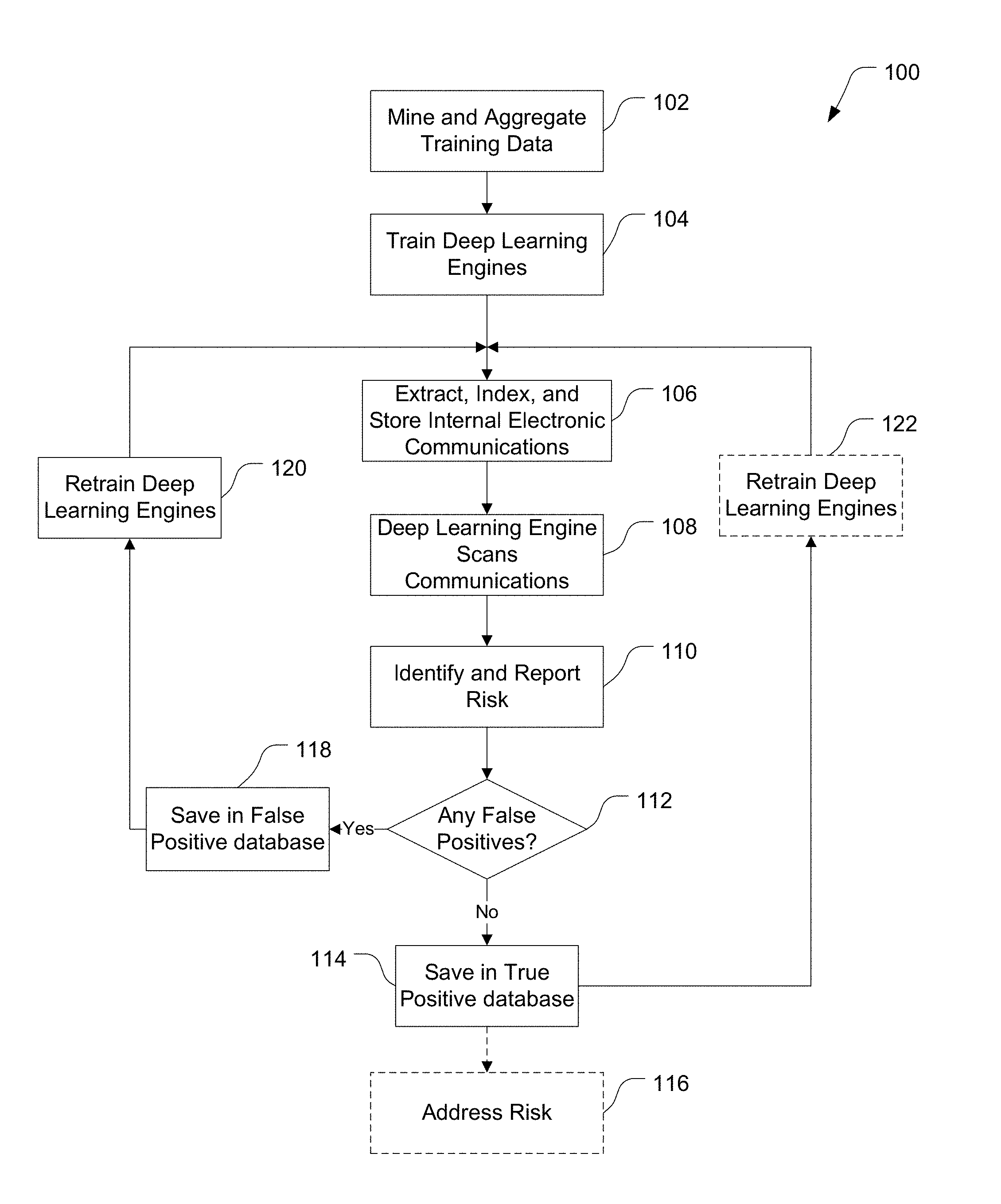
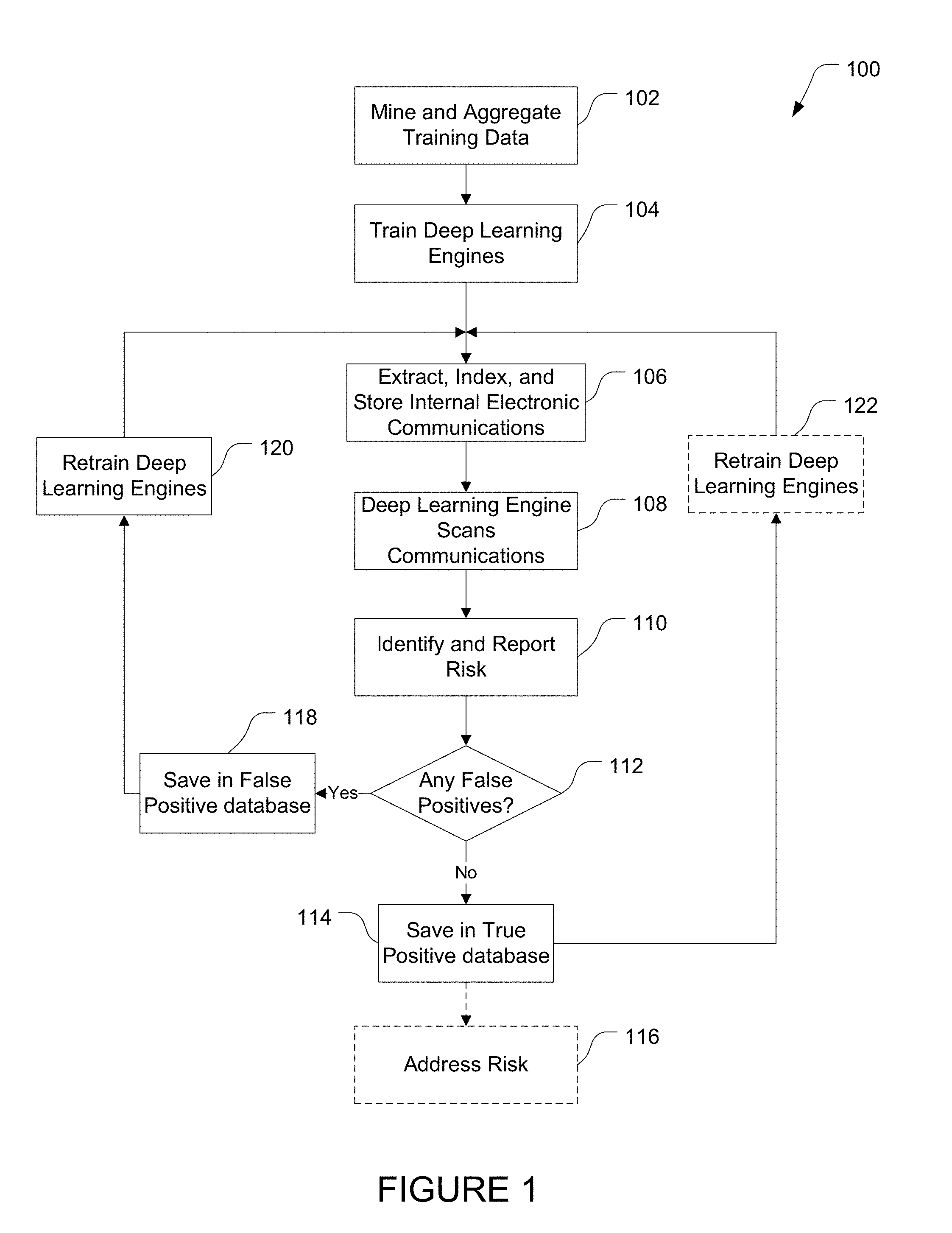
[0016] FIG. 1 is a flow chart illustration of the process for using classified text and deep learning algorithms to identify risk and provide early warning in accordance with one or more embodiments of the present invention.
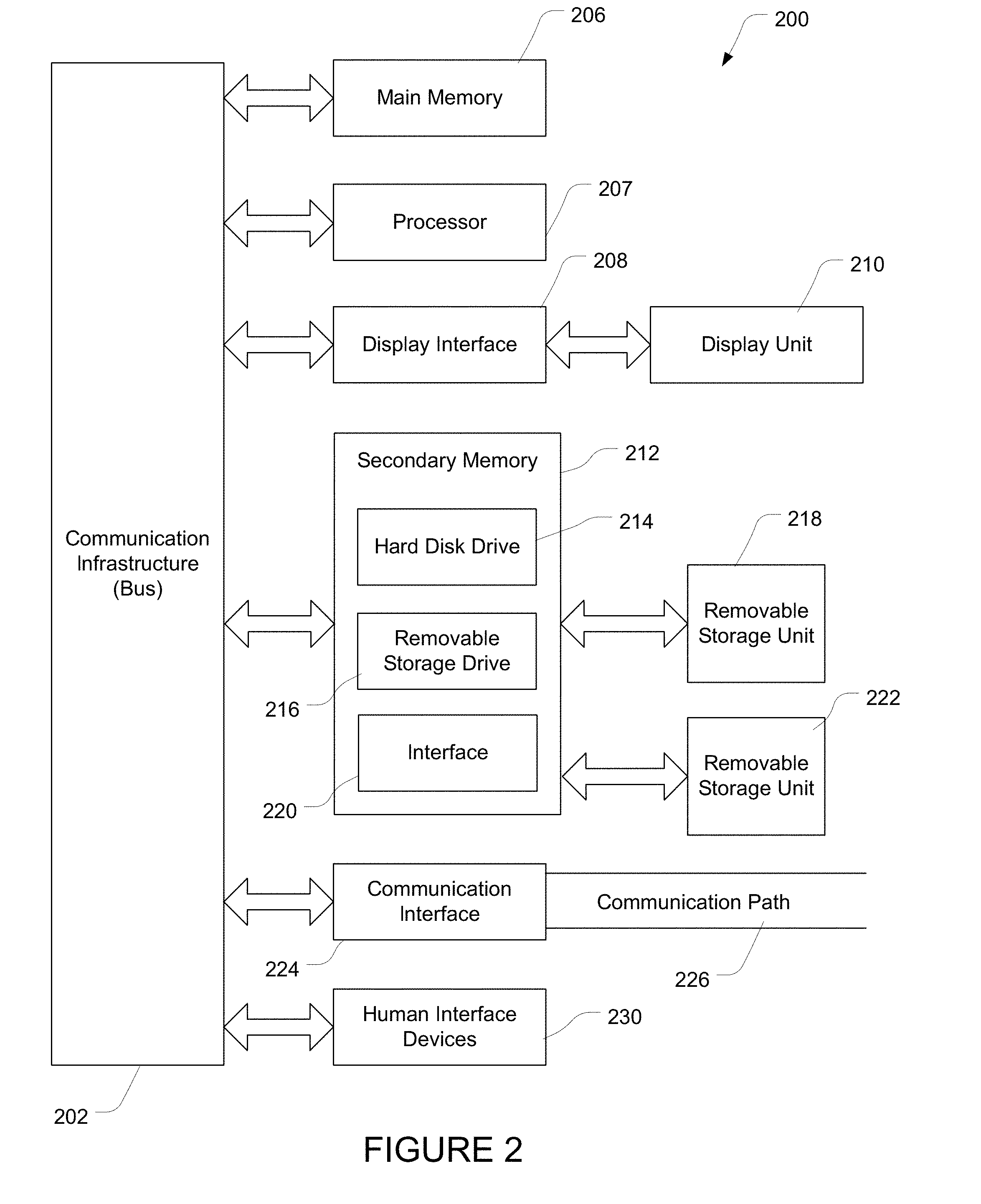
[0017] FIG. 2 illustrates a general-purpose computer and peripherals that when programmed as described herein may operate as a specially programmed computer capable of implementing one or more methods, apparatus and/or systems of the present invention.
[0018] FIG. 3 is a bar graph illustration of email score frequencies above 0.80 for 400 training documents.
[0019] FIG. 4 is a bar graph illustration of email score frequencies after training to find employment discrimination risks.
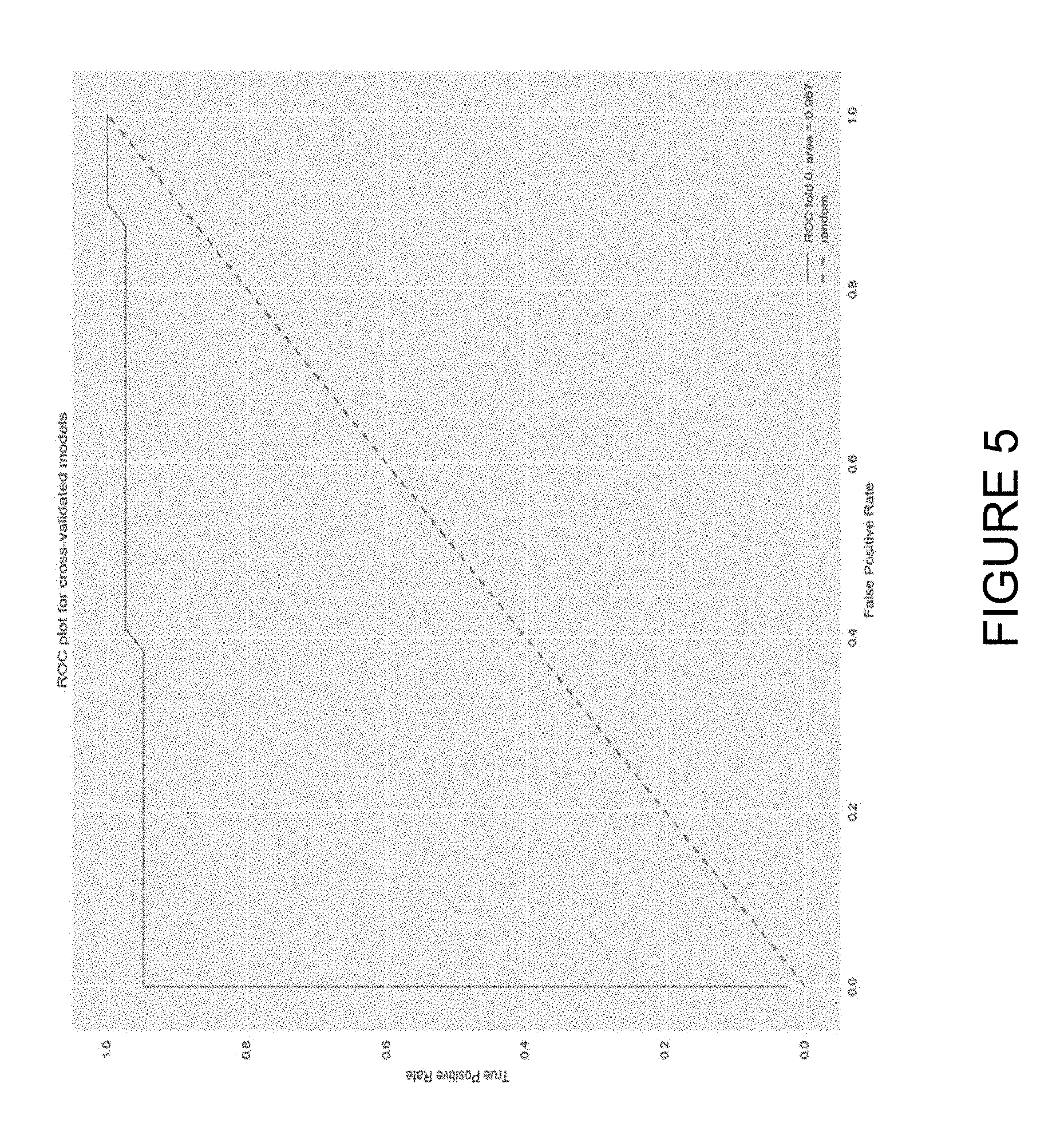
[0020] FIG. 5 is a graph of Receiver Operating Characteristic (ROC) and related Area Under the Curve (AUC).
DETAILED DESCRIPTION
[0021] The present invention comprising using classified text and deep learning algorithms to identify risk and provide early warning will now be described. In the following exemplary description numerous specific details are set forth in order to provide a more thorough understanding of embodiments of the invention. It will be apparent, however, to an artisan of ordinary skill that the present invention may be practiced without incorporating all aspects of the specific details described herein. Furthermore, although steps or processes are set forth in an exemplary order to provide an understanding of one or more systems and methods, the exemplary order is not meant to be limiting. One of ordinary skill in the art would recognize that one or more steps or processes may be performed simultaneously or in multiple process flows without departing from the spirit or the scope of the invention. In other instances, specific features, quantities, or measurements well known to those of ordinary skill in the art have not been described in detail so as not to obscure the invention. It should be noted that although examples of the invention are set forth herein, the claims, and the full scope of any equivalents, are what define the metes and bounds of the invention.
[0022] For a better understanding of the disclosed embodiment, its operating advantages, and the specified object attained by its uses, reference should be made to the accompanying drawings and descriptive matter in which there are illustrated exemplary disclosed embodiments. The disclosed embodiments are not intended to be limited to the specific forms set forth herein. It is understood that various omissions and substitutions of equivalents are contemplated as circumstances may suggest or render expedient, but these are intended to cover the application or implementation.
[0023] The term "first", "second" and the like, herein do not denote any order, quantity or importance, but rather are used to distinguish one element from another, and the terms "a" and "an" herein do not denote a limitation of quantity, but rather denote the presence of at least one of the referenced item. The terms "email" and "Email" both refer to an email and any attachment.
[0024] The term "algorithm" refers to a "deep learning algorithm," "deep learning neural network," or a "deep learning model," all of which here refer to a form of text classification.
[0025] One or more embodiments of the present invention will now be described with references to FIGS. 1-5.
[0026] FIG. 1 is a flow chart illustration of the process 100 for using classified text and deep learning algorithms to identify risk and provide early warning. As illustrated, the process 100 begins at block 102 with mining of data for training one or more deep learning algorithms. In the typical instance, subject matter experts identify one or more datasets with classifications of risk or threats having a sufficient number of textual documents. These classifications (or categories or labels) of risk are more typically from sources outside of the enterprise. The system data-mines such classified datasets to extract a sufficient number of documents within a specific category to train one or more deep learning algorithms.
[0027] In the context of litigation risk, for example, a subject matter expert would note that the federal court litigation database known as the Public Access to Court Electronic Records (PACER) is based on well over one hundred case types, to which PACER assigns Nature of Suit (NOS) codes. When a federal court lawsuit is initiated, the person filing it must complete and file a form called a Civil Cover Sheet, which instructs the person responsible for filing the lawsuit to review a list of NOS codes and choose one and only one code which best describes the lawsuit, even if there is more than one theory of recovery.
[0028] To create a set of training documents for a particular federal court litigation risk, a user of this invention would use PACER's Application Programming Interface (API) to obtain hundreds if not thousands of text documents from previous lawsuits which have been filed in a specific NOS category. Such a user would then compile a large number of training documents which describe the facts (not the law) which prompted the lawsuit to be filed in the first place.
[0029] In this illustrative example, PACER would be a generic source of classified text outside of the enterprise, which is as training data. A ready (but not the only) source of training data is a lawsuit complaint in a specific case-type category, as identified by its NOS category name or number.
[0030] NOS categories are not difficult to understand. One of them, for example, is the category of Civil Rights-Employment which, in other words, means illegal discrimination against employees, whether it is for age, race, sex, or some other subclass of illegal discrimination. In addition, and among over one hundred categories, there are codes for breach of contract, fraud and product liability case-types.
[0031] There may be other sources of training data, i.e. internal enterprise sources of specific litigation--case-type training data. Some examples are: textual data from the previous litigation history of an enterprise; text in warranty claims; and data from the confirmation by a user that a specific system output document (e.g., email) has been scored by the algorithm in a way indicating that it should be saved and used for re-training the algorithm.
[0032] Using litigation case-type data, a complaint is usually (but not always) identified as the first document in a litigation docket, i.e. Document Number 1. In order to train a deep learning algorithm, the focus is on the factual allegations in these complaints. These factual allegations may be stated in a section of a complaint entitled "Background Facts" or the like.
[0033] Many sections of a complaint are unnecessary and consist of legalistic statements that can be deleted for the purpose of training the algorithm. For example, the sections that pertain to jurisdiction, venue, the identification of the parties, the legal theories for recovery, and the prayer for damages are unnecessary. By deleting unnecessary text, the amount of training data is reduced, and the training data will contain less "noise" for analysis by the deep learning algorithm.
[0034] In some cases, the plaintiff in a case may be represented by an attorney. In that case, the fact section is based on information provided by the attorney's client and by the information stemming from the attorney's research. Because attorneys typically present facts in a logical way, so as to be both understood and persuasive, we assume that such facts have been vetted. For this reason, complaints written by counsel are a prime source of training data.
[0035] However, additional facts may be developed after the complaint is filed and during the discovery of electronically stored information, e.g., by way of production of documents, responses to written interrogatories, or by testimony given during depositions and the like. Although such facts are generally not placed in the public record, certain key facts are put into the public record (e.g. in PACER) as part of motions for summary judgment.
[0036] The data mining needed to create a strong deep learning algorithm aims at surfacing a large number of factual allegations within a specific risk case-type.
[0037] In one or more embodiments, the system's primary, but not only, source of training data consists of the facts alleged in previously filed complaints filed in a specific category of lawsuit.
[0038] Such litigation data is positive training data, and typically contains no emails. The risks the system of the present invention would seek to surface test data that would be "related" to the aggregation of these positive facts. The degree of the relation is reported by an accuracy score ranging from 0.50 to a maximum of 1.0. The training data also includes negative training data, such as text concerning some unrelated topic, e.g., the Holy Roman Empire. (Negative, unrelated training data may be obtained from Wikipedia, for example.) The system uses negative training data to better score test data as either related or unrelated to a specific case-type.
[0039] The training data is crucial for a deep learning engine to be able to produce an accuracy score for the text in the test data, which typically consists primarily of emails. The algorithm can produce an accuracy score by comparing an email, as encoded, to the vector space described by the positive training data related to the risk, and to the negative training data, which is unrelated.
[0040] The process of aggregating this training material and providing it to a deep learning engine involves creating a "vector" for each word in the block in relation to the two or three words before and after it. Accordingly, each word vector has its own context, and that context is meaningful in connection with the type of case (and the type of risk) for which the deep learning algorithm is being trained. Transforming the text used in a specific classification (or, for litigation, specific category or type of case) into numerical vectors may be accomplished via various methods such as Word2vec by Tomas Mikolov at Google, "GloVe: Global Vectors for Word Representation" by Jeffrey Pennington, et al., etc.
[0041] However, to make the matter clear, although the deep learning algorithm will encode the text in the above-described manner, i.e. words within the context of other words, the factual allegations are not provided to the algorithm word by word, sentence by sentence, or paragraph by paragraph. Instead, the whole block of factual allegations is presented for ingestion as a document.
[0042] One object of amassing a sufficient number (hundreds if not thousands) of training documents is to train a deep learning algorithm so that it functions well, and so is considered "strong." Consequently, at step 104, category-specific training documents are passed to, and ingested by, one or more deep learning algorithms best suited to handle natural language processing (NLP). The algorithm more commonly used in the context of NLP and text analysis, is known to practitioners in the art as a recurrent neural networks (RNN).
[0043] Such deep learning RNNs use hidden computational "nodes" and various "gates," and require manipulation known in the art as "tuning." After the process of "tuning", the algorithm will be evaluated to assess the degree to which it accurately identifies the textual test data it has never before encountered with the "vector space" it has been trained to recognize. As one example, practitioners construct a Receiver Operating Characteristic (ROC) graph and calculate the Area Under the Curve (AUC) score. An ROC graph measures true positives (on the y-axis) versus false positives (on the x-axis). Because the maximum AUC score is one (1.0), an ROC-AUC score in the mid-nineties, e.g., 0.95, indicates that there are far more true positives than false positives. In experiments, described below, the RNNs of the present invention have achieved scores above 0.967.
[0044] When an algorithm is trained to "understand" a particular type of case, it may be thought of as a "filter." Typically, the system will consist of more than one filter. The system passes the enterprise data through each filter. The reason is clear: A deep learning algorithm trained to identify "breach of contract" risks, which we now call a filter, may find no risk in the test data, but an "employment discrimination" filter may find one or more high-scoring emails in the same data.
[0045] Once the Deep Learning Engine is trained, at step 106 the system indexes and also extracts text from each Email and in any attachment. Those of skill in the art will appreciate that other implementations are contemplated. For example, it may be necessary or desirable to only extract the subject line and the unstructured text in the message field. In addition, the indexed data may be stored for a specific period of time in a database, a period which the Enterprise may designate in accordance with its data destruction policies.
[0046] In one or more embodiments, the system at step 106 may operate in a non-real-time mode by extracting existing internal email data, e.g. from the previous day's Email, and then stores the data in a database. In other embodiments, the system at step 106 may operate in real-time to intercept, index, store and extract text from internal Email data.
[0047] After indexing, extracting text, and storing the internal Email data in a database, the system passes that data to each of the category-specific algorithms at step 108, which are also referred to herein as "filters." Each filter scores the data for each Email for accuracy in comparison to how each filter was trained.
[0048] Once each Email is scored for accuracy in relation to the risks or threats by one of the filters, the score and text are output at step 110. The Emails related to a particular risk may be reported as an "early warning" alert to specific employees, for example. These employees may be a pre-determined list of in-house attorneys, paralegals or other employees in the legal department.
[0049] In addition, an enterprise may configure the system to send its "early warning" alert to a list of devices owned by the enterprise where the communication of the output may be encrypted using appropriate security measures.
[0050] When a scored Email is reported to a designated enterprise employee, that employee may be enabled to review the Email in one or more of several modes, e.g., the scored text in a spreadsheet format and/or a bar graph distribution. Using the spreadsheet format, after reviewing a row of score and Email text, a user may call that Email to the fore and review it in its native state. This feature is possible because the Emails were indexed when they were copied into the system.
[0051] At step 112, when a determination is made, e.g. by a reviewer such as an attorney or paralegal, that a specific Email is, at least provisionally, a false positive (and that further investigation is not warranted), the process proceeds to step 118 where the email is stored in a False Positive database. A user interface, e.g. graphical, may be provided for the reviewer to perform the necessary designations, for example. Those of skill in the art would appreciate that the system could be configured to perform this determination step automatically, with the reviewer having a veto or override capability, for example.
[0052] However, if at step 112 a determination is made that an identified Email is a true positive, a copy of that Email may be placed in a True Positive database at step 114. When a designated number of Emails have been saved for either purpose, the positive or negative training data may be updated. In this way, the generic training data may be augmented with company-specific training data. With this additional training data, the deep learning algorithms may be re-trained in steps 120 and/or 122 to amplify the positive or negative vector spaces for each filter, and to better reflect the enterprise's experience and culture.
[0053] Email marked as true positive and placed in True Positive database at step 114 may be exported via an API to the enterprise's existing litigation or investigation case management system at step 116, if any, from which the risk may be optionally addressed. The algorithm's positive output may be limited to scores which surpass a user-specified threshold, for example.
[0054] The system of the invention we have now described has two additional advantages. The first advantage is confidentiality. If the enterprise directs its legal department to install the system and have its attorneys direct and control its operation, including any involvement by the IT department, then the attorneys using the system may invoke the attorney work-product doctrine. Then, when the system provides an output to a designated list of attorneys or other legal department personnel, such as paralegals, the enterprise may again invoke the attorney-work product doctrine when someone in the legal department decides which emails to investigate. Similarly, the work-product doctrine should apply when legal department personnel use an API to access and use whatever case or investigation management platform the enterprise uses.
[0055] In addition, when an investigation appears to warrant further action of a proactive, preventive nature, the enterprise attorneys may advise a control group executive in order to invoke the attorney-client privilege.
[0056] Thus, by installing and operating the system in the manner described above, the invention provides confidentiality to the sensitive information that is being brought to light.
[0057] The second advantage arises whenever a regulatory investigation becomes problematic. Should a governmental entity file criminal charges against the enterprise and or any of its personnel, the prosecuting authorities will have to present evidence of a specific intent to do harm. But by installing and operating the system of this invention in good faith, the enterprise and anyone so charged will have countervailing evidence of a specific intent to avoid harm.
[0058] To summarize: Once the deep learning algorithm is trained, the system has three major subsystems, enterprise data, the deep learning algorithms or filter(s), and the output data. Taken together, the system operates to identify a potentially adverse risk to the enterprise and provide early warning to a user. In the exemplary embodiments provided herein, the potentially adverse risk is the risk of a specific type of litigation but could just as well be other types of risk, including the risk of physical harm to the enterprise's customers by the enterprise's products.
[0059] FIG. 2 diagrams a general-purpose computer and peripherals 200, when programmed as described herein, may operate as a specially programmed computer capable of implementing one or more methods, apparatus and/or systems of the solution described in this disclosure. Processor 207 may be coupled to bi-directional communication infrastructure 202 such as communication infrastructure system bus 202. Communication infrastructure 202 may generally be a system bus that provides an interface to the other components in the general-purpose computer system such as processor 207, main memory 206, display interface 208, secondary memory 212 and/or communication interface 224.
[0060] Main memory 206 may provide a computer readable medium for accessing and executed stored data and applications. Display interface 208 may communicate with display unit 210 that may be utilized to display outputs to the user of the specially-programmed computer system. Display unit 210 may comprise one or more monitors that may visually depict aspects of the computer program to the user. Main memory 206 and display interface 208 may be coupled to communication infrastructure 202, which may serve as the interface point to secondary memory 212 and communication interface 224. Secondary memory 212 may provide additional memory resources beyond main memory 206, and may generally function as a storage location for computer programs to be executed by processor 207. Either fixed or removable computer-readable media may serve as Secondary memory 212. Secondary memory 212 may comprise, for example, hard disk 214 and removable storage drive 216 that may have an associated removable storage unit 218. There may be multiple sources of secondary memory 212 and systems implementing the solutions described in this disclosure may be configured as needed to support the data storage requirements of the user and the methods described herein. Secondary memory 212 may also comprise interface 220 that serves as an interface point to additional storage such as removable storage unit 222. Numerous types of data storage devices may serve as repositories for data utilized by the specially programmed computer system. For example, magnetic, optical or magnetic-optical storage systems, or any other available mass storage technology that provides a repository for digital information may be used.
[0061] Communication interface 224 may be coupled to communication infrastructure 202 and may serve as a conduit for data destined for or received from communication path 226. A network interface card (NIC) is an example of the type of device that once coupled to communication infrastructure 202 may provide a mechanism for transporting data to communication path 226. Computer networks such Local Area Networks (LAN), Wide Area Networks (WAN), Wireless networks, optical networks, distributed networks, the Internet or any combination thereof are some examples of the type of communication paths that may be utilized by the specially program computer system. Communication path 226 may comprise any type of telecommunication network or interconnection fabric that can transport data to and from communication interface 224.
[0062] To facilitate user interaction with the specially programmed computer system, one or more human interface devices (HID) 230 may be provided. Some examples of HIDs that enable users to input commands or data to the specially programmed computer may comprise a keyboard, mouse, touch screen devices, microphones or other audio interface devices, motion sensors or the like, as well as any other device able to accept any kind of human input and in turn communicate that input to processor 207 to trigger one or more responses from the specially programmed computer are within the scope of the system disclosed herein.
[0063] While FIG. 2 depicts a physical device, the scope of the system may also encompass a virtual device, virtual machine or simulator embodied in one or more computer programs executing on a computer or computer system and acting or providing a computer system environment compatible with the methods and processes of this disclosure. In one or more embodiments, the system may also encompass a cloud computing system or any other system where shared resources, such as hardware, applications, data, or any other resource are made available on demand over the Internet or any other network. In one or more embodiments, the system may also encompass parallel systems, multi-processor systems, multi-core processors, and/or any combination thereof. Where a virtual machine, process, device or otherwise performs substantially similarly to that of a physical computer system, such a virtual platform will also fall within the scope of disclosure provided herein, notwithstanding the description herein of a physical system such as that in FIG. 2.
Experimental Results
[0064] Embodiments of the present invention were validated using training data for the employment discrimination case-type, two similar (but different) deep learning algorithm providers, and a portion of Ken Lay's Enron email corpus. The system found one (1) risky email out of 7,665 emails.
[0065] The system as described herein requires multiple types of factual information. For example, the factual information may include but is not limited to a compilation of factual allegations previously presented as pre-litigation demands; a compilation of factual allegations previously presented as part of filed lawsuits; factual details extracted from hypothetical examples of potential legal liability as identified and preserved by authorized personnel; factual details extracted from learned treatises; factual details from employee complaints; and factual details from customer complaints.
[0066] First, text data from prior court cases (and other sources) pertaining to employment discrimination lawsuits were extracted as an example of many case-types. Second, the text data was used to train two deep learning algorithms in two ways, with documents that were related to prior employment discrimination lawsuits, and with documents that were clearly not related to an employment discrimination risk. There were no emails in the training data.
[0067] Next, as trained, the deep learning algorithms were presented with test data consisting of a portion of the Enron email subset for Ken Lay, the former Chairman and CEO of Enron. The test data consisted of only these emails.
[0068] Before the experiments, the PACER database was reviewed for statistics about Enron. For the five-year period 1997-2001, the chances of finding a workplace discrimination case against an Enron company was only about one percent (1%). During that five-year timeframe, an Enron company was named in litigation 1,339 times, and was named in an employment discrimination case only 13 times. Accordingly, there was no expectation of a significant result because it is unlikely that employees with a discrimination complaint would reach out to Ken Lay. Ken Lay was, after all, the Chairman and CEO of Enron, not a manager and not the director of Human Resources.
[0069] Next, PACER was data-mined to extract certain text portions of documents filed in the employment discrimination category to create a set of training documents in this silo.
[0070] The first experiment was with a deep learning algorithm provided by MetaMind, which was later acquired by Salesforce. The amount of training data was increased in baby steps. The first experiment used only 50 training documents, but provided immediate results, which was surprising and unexpected, in part because Ken Lay was the Chairman and CEO of Enron, not the director of the Human Resources department.
[0071] As configured for the experiment, the system reported the results in two formats. The first format is an Excel spreadsheet. There, in the first row, in Column A, the system shows the scores which indicate the accuracy of the Email text compared to the case-type for which the algorithm was trained. In Column B, the system shows a portion of the Email text associated with the score. Twenty-two (22) emails were found which scored at 0.90 or above for accuracy out of 6,352 emails, and two of them expressed a risk of employment discrimination, with one being a "forward" of the other.
[0072] The second format is a bar graph of the data scored by the algorithm, illustrated in FIG. 3. The bar graph is a distribution which provides context for the highest scoring emails. On the x-axis, the bar graph shows the scores for the emails. The highest possible score is 1.0 and is on the far right. On the y-axis, the graph shows the number of emails which received any particular score. The distribution bar graph only shows the scores ranging from 0.80 to 1.00.
[0073] In reviewing the top-scoring 22 emails, i.e. the ones which scored 0.90 or above, the data showed that most of them were false positives, but two emails (as noted above) stood out. Scoring at 0.94, both of them presented a discrimination risk, but it was the same risk, because one email was a "forward" of the initial version. The subject of that email was "[M]y unfair treatment at Enron--Please HELP."
[0074] After further training, to 400 documents, the number of false positives was reduced. The deep learning algorithm scored only four (4) emails at 0.86 or higher.
[0075] In the resulting spreadsheet, lines 3 and 4 scored at the 0.86 and 0.88 levels respectively. Those emails include the phrase "my unfair treatment at Enron." Upon further review, the first paragraph of the email in the spreadsheet began: "Dear Mr. Lay, [M]y employment with Enron is to be terminated, the reason given by HR, for not meeting performance standards. However, I firmly believe that this is not the real reason, the real one being for defying the wishes of my manager . . . , who, I believe was acting in a discriminatory way towards me . . . " (Boldface and italics added.)
[0076] As the number of our training documents increased, it became evident that the deep learning algorithm was becoming more accurate. In addition, the inclusion of a negative dataset (and vector space), e.g. pertaining to the Holy Roman Empire and calendar entries, also reduced the number of false positives in the results.
[0077] Further experiments with a list of sex and race terms demonstrated that they added little to the strength of the algorithm if anything. This may be because the lists lacked any context and were as insufficient as any list of key words.
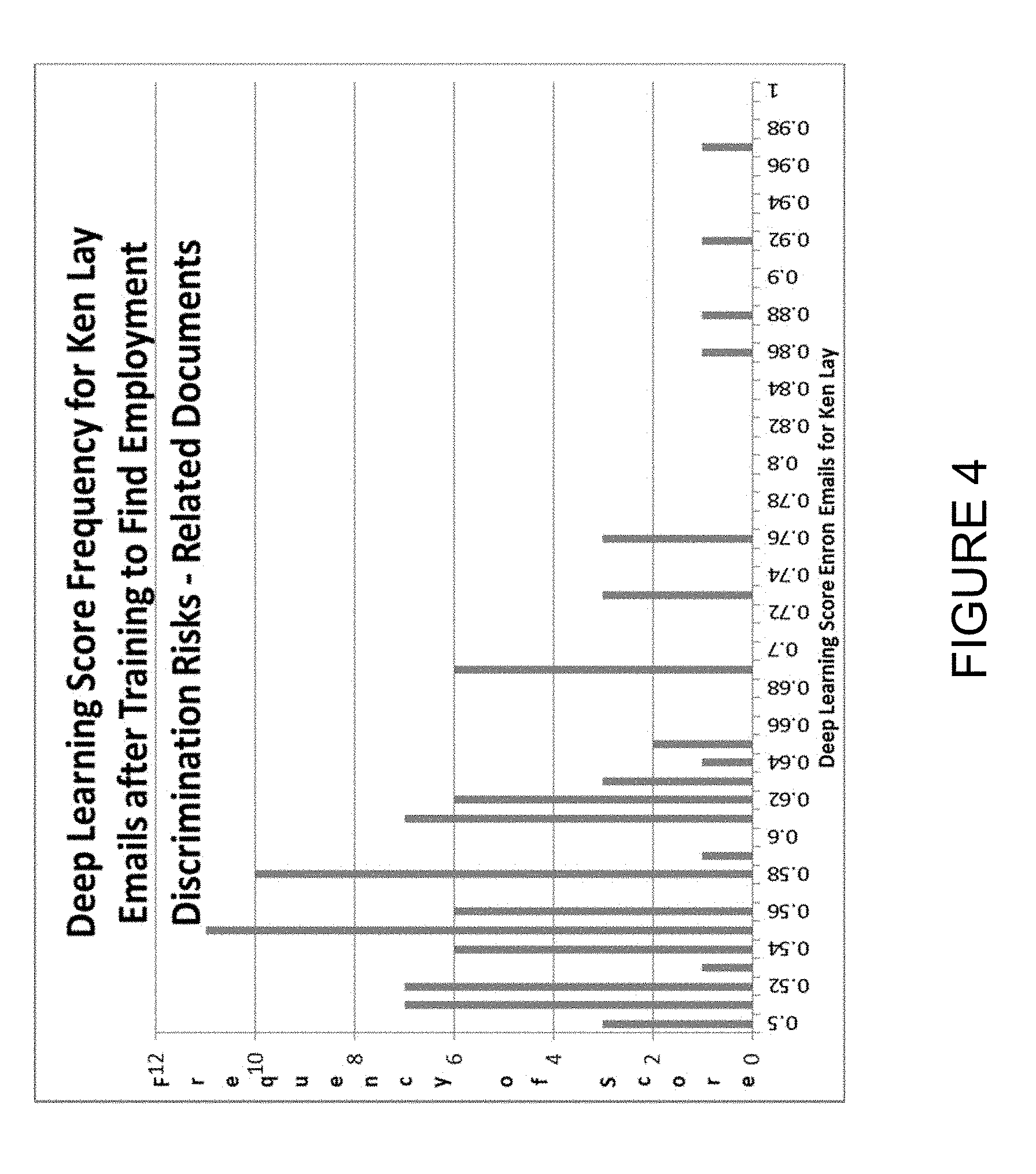
[0078] In the experiment pertaining to the spreadsheet where four high-scoring Emails were identified, about 400 training documents were used. As previously mentioned, only four emails scored at or above 0.80 for accuracy with respect to the training data. Two emails scored above 0.90 for accuracy, while the other two scored 0.88 and 0.86. In a subsequent experiment using 7,665 Ken Lay emails, the distribution bar graph for this experiment is illustrated in FIG. 4. The y-axis runs from 0 to only 12, indicating that the deep learning algorithm was now much more focused.
[0079] The experiments also showed that a deep learning algorithm, however well trained, will nevertheless generate an alert that a reviewer would reject for follow up. For example, the Email scoring at 0.97 was from an Enron employee in India. In part, it read: "Subsequently, I was forced upon a cheque of severance amount on 27 Aug. 2001 which I received under protest and the notice of such protest was served by me on firm in the interest of justice. I submit such a termination is illegal, bad in law and void ab-initio and accordingly when such an action was not corrected by firm, I [was] constrained to approach the Court of law." (Boldface and italics added.)
[0080] Thus, while that Email recounts a discrimination risk, the risk appears to have already become a lawsuit. A reviewing attorney might well consider this high-scoring email to be a false positive, especially if he or she determines that a lawsuit has already been filed.
[0081] A second experiment used Indico Data Systems, Inc. ("Indico") Deep Learning Algorithm to validate the previous training with MetaMind. Indico was provided with the same training data used with MetaMind and with the same test data.
[0082] The results showed that the same risky Email found using MetaMind that had text in the subject line stating, "unfair treatment at Enron," which 0.86 and 0.88 with MetaMind, was flagged Indico's model, and the same Email scored 0.89, which is comparable.
[0083] Indico also used about 75 held-out documents in order to provide a graph of a curve showing a Receiver Operating Characteristic, illustrated in FIG. 5, which included a related indicator called the Area Under the Curve (AUC). These statistics put "true positives" on the y-axis and "false positives" on the x-axis. On both axes, the maximum score is 1.0. A strong algorithm will score high and to the left, which is what we saw.
[0084] Also since the maximum score for each axis is 1.0, the area under the ROC curve is also 1.0. According to the second provider, Indico, the AUC score was 0.967 (see the AUC score in the lower right hand corner), which means that the algorithm, as trained, is strong.
[0085] In these experiments, the early warning system, having been trained (as an example) to detect an employment discrimination risk, found one (1) email out of 7,665 emails which signaled just such a risk. Thus, the inventive concept of the system has been tested using a specific litigation category, the same training data, two different algorithms, and Enron test data, and has functioned in accordance with the inventive concept. The system, as trained, had found a needle in a haystack.
[0086] Furthermore, the early warning system would function for an authorized enterprise employee in an unobtrusive way. Enterprise personnel need not be involved in data-mining to train the Deep Learning system, and the algorithm itself would scan internal emails and would run in the background. The system would not require anyone's attention until the system had a reportable result, at a threshold the legal department could set.
[0087] At that point, the system would output an alert to a privileged list of in-house personnel, likely in-house counsel or employees under their direction and control, and they would be able to see a spreadsheet with a score in column A, the related text in column B, along with a bar chart for context, and then would be enabled to call forward the Emails of interest.
[0088] The experiments discussed above employed deep learning algorithms which are described in the academic literature as Recursive Neural Tensor Networks or as Recurrent Neural Networks (RNNs) with either Long Short-Term Memory (LSTM) or Gated Recurrent Units (GRUs). Those of skill in the arts will appreciate that use of other algorithms, including those which are now open-sourced, are contemplated.
Risk Assessment and Identification of Relevant Data for a Pending Lawsuit.
[0089] In one or more embodiments of the present invention, the context changes to a time when a lawsuit complaint has been filed and served and has come to the attention of an enterprise defendant, whether commercial or governmental. Now the enterprise must engage in a host of e-Discovery processes. One of the earliest of these processes is Early Case Assessment. The purpose is to assess the significance of the lawsuit.
[0090] Prior to doing so, however, the enterprise must understand the lawsuit's nature and which of its personnel (employees or otherwise) might possess documents, e.g., emails, attachments and other, stand-alone documents such as memoranda or reports, that are potentially relevant to the lawsuit's allegations. As such, they may be custodians of potentially relevant evidence which must be preserved for further analysis. For such personnel, the enterprise must provide such custodians with "litigation hold notices." Such notices are designed to avoid spoliation of documents that may be potentially relevant to the matter as well as to enable the enterprise to collect and aggregate the potentially relevant documents. Eventually, such collections will enable the enterprise to comply with future requests by the opposing party for the discovery of electronically stored information (ESI).
[0091] In a standard discovery workflow, the aggregation of potentially relevant documents provides the enterprise with a corpus that may be examined for an early warning of whether the complaint poses a serious or insignificant threat of high costs or other damages, e.g. to brand or personal reputations in addition to defense attorney fees, a large settlement or verdict, and, in the worst case, future adverse actions by regulators or the filing of criminal charges by prosecutors. This early examination process is called Early Case Assessment (ECA).
[0092] ECA is a post-litigation process that would use embodiments of the present invention, especially if a deep learning model has already been built for the particular litigation risk described by the complaint.
[0093] Accordingly, instead of focusing on the set of yesterday's emails in order to find a risk, e.g., of a specific type of litigation, the post-litigation variation would focus each model on the corpus of ESI collected from the custodians of the potentially relevant ESI.
[0094] In addition, if the enterprise has had previous experience with a specific "nature of suit," the feedback loop may be different. Before a risk-specific model addresses the newly-collected corpus of ESI, the model may be re-trained on the documents that were tagged in previous collections as positive for that specific type of litigation.
[0095] And, after the system scores the newly assembled corpus of ESI, the documents assessed by users as True and False Positives may be used to re-train the model yet again.
[0096] In one or more embodiments, after the model is trained, the system is employed to score the documents in the corpus of ESI.
[0097] The system then identifies documents from that corpus of ESI which are related to the nature of the lawsuit. The identified documents may be flagged to users in the legal department for ECA purposes, for example. The users may then tag, save and assess the True Positives for case management purposes.
[0098] And both True Positives and False Positives may be saved and used for company-specific retraining of the model when a new lawsuit of the same case-type is filed against the enterprise in the future.
[0099] While the invention herein disclosed has been described by means of specific embodiments and applications thereof, numerous modifications and variations could be made thereto by those skilled in the art without departing from the scope of the invention set forth in the claims.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.