Methods for Data-Dependent Mass Spectrometry of Mixed Biomolecular Analytes
YIP; Ping F. ; et al.
U.S. patent application number 16/262385 was filed with the patent office on 2019-05-30 for methods for data-dependent mass spectrometry of mixed biomolecular analytes. This patent application is currently assigned to Thermo Finnigan LLC. The applicant listed for this patent is Thermo Finnigan LLC. Invention is credited to Oksana GVOZDYAK, James L. STEPHENSON, JR., Ping F. YIP.
| Application Number | 20190164735 16/262385 |
| Document ID | / |
| Family ID | 55629131 |
| Filed Date | 2019-05-30 |




View All Diagrams
| United States Patent Application | 20190164735 |
| Kind Code | A1 |
| YIP; Ping F. ; et al. | May 30, 2019 |
Methods for Data-Dependent Mass Spectrometry of Mixed Biomolecular Analytes
Abstract
A method for mass spectral analysis of a sample containing a plurality of intact protein molecule species comprises: (a) mass analyzing a plurality of ion species generated from a sample portion; (b) automatically recognizing, for each of at least one intact protein molecule species, a respective subset of m/z ratios corresponding to ion species generated from the each intact protein molecule species; and (c) storing or reporting to a user information relating to each subset of the m/z ratios, wherein step (b) comprises: automatically assigning a tentative charge state to each above-threshold m/z ratio; automatically adjusting the tentative charge to achieve a set of self-consistent assigned charge states; and decomposing the assigned charge states into analyte-specific clusters, each analyte-specific cluster being a one of the subsets of the m/z ratios.
| Inventors: | YIP; Ping F.; (Salem, MA) ; STEPHENSON, JR.; James L.; (Raleigh, NC) ; GVOZDYAK; Oksana; (BEDFORD, MA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assignee: | Thermo Finnigan LLC |
||||||||||
| Family ID: | 55629131 | ||||||||||
| Appl. No.: | 16/262385 | ||||||||||
| Filed: | January 30, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15067727 | Mar 11, 2016 | 10217619 | ||
| 16262385 | ||||
| 62132124 | Mar 12, 2015 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G01N 33/6848 20130101; H01J 49/0031 20130101; H01J 49/004 20130101; H01J 49/0036 20130101; G01N 33/6851 20130101 |
| International Class: | H01J 49/00 20060101 H01J049/00; G01N 33/68 20060101 G01N033/68 |
Claims
1. A method for mass spectral analysis of a sample containing a plurality of intact protein molecule species, said method including repeatedly introducing a respective portion of the sample into an ionization source of a mass spectrometer; and using the ionization source to generate, from each sample portion, a population of multi-protonated ions that comprises a plurality of ion species generated from each respective intact protein molecule species of said each portion, each ion species comprising a respective charge state, z, and mass-to-charge (m/z) ratio, the method comprising: (a) mass analyzing a plurality of ions generated from a first one of the sample portions, thereby generating a mass spectrum thereof, wherein each ion species generated from a protein is represented in the mass spectrum by a respective m/z ratio and a corresponding respective intensity; (b) automatically recognizing, for each of two or more intact protein molecule species, a respective subset of the m/z ratios corresponding to a set of ion species generated from said each intact protein molecule species and automatically determining a respective charge state, z, for each m/z ratio of each subset; and (c) storing or reporting to a user information relating to each subset of the m/z ratios, wherein the step (b) includes: (b1) automatically assigning a tentative charge state to each m/z ratio measured in step (a) that corresponds to an above-threshold intensity; (b2) automatically adjusting the assigned tentative charge states to thereby generate a set of self-consistent assigned charge states; and (b3) decomposing the assigned charge states into analyte-specific clusters of charge states, each analyte-specific cluster being a one of the subsets of the m/z ratios.
2. A method as recited in claim 1, wherein: the step (b) further includes representing each mass spectrum peak as a respective centroid.
3. A method as recited in claim 1, wherein the repeated introducing of a respective portion of the sample into an ionization source of a mass spectrometer is performed in the absence of prior chromatographic separation of the sample into chromatographic fractions.
4. A method as recited in claim 1, further comprising, after the automatic recognition step (b), the step of: determining a molecular weight of an intact protein molecule species from the m/z ratios and determined charge states of a recognized subset of the m/z ratios, wherein the step (c) further comprises storing or reporting to a user the determined molecular weight.
5. A method for mass spectral analysis as recited in claim 1, wherein the repeated introducing of a respective portion of the sample into an ionization source of a mass spectrometer comprises introducing a continuous flow of eluate discharged from a liquid chromatograph into the ionization source, the method further comprising: (d) mass analyzing a plurality of ion species that are generated from a different, second one of the sample portions; (e) automatically recognizing any additional m/z ratios detected in step (d) that were not observed during execution of step (a); (f) automatically determining if each additional m/z ratio recognized in step (e) corresponds to an intact protein molecule species for which there exists a previously recognized subset of m/z ratios; (g) automatically recognizing at least one additional subset of m/z ratios if any additional m/z ratio recognized in step (e) does not correspond to an intact protein molecule species for which there exists a previously recognized subset of m/z ratios; (h) assigning at least one additional m/z ratio to a one of the additional recognized subsets of m/z ratios; and (i) storing or reporting to a user information relating each additional subset of the m/z ratios.
6. A method for mass spectral analysis as recited in claim 1, wherein the repeated introducing of a respective portion of the sample into an ionization source of a mass spectrometer comprises repeated ionization of a respective sample portion by laser-assisted desorption and ionization.
7. A method as recited in claim 1, further comprising, after the automatic recognition step (b), the step of: determining a respective molecular weight of each of the two or more intact protein molecule species from the m/z ratios and determined charge states of the two or more recognized subsets of the m/z ratios, wherein the step (c) further comprises storing or reporting to a user the two or more determined molecular weights.
8. A method as recited in claim 7, wherein the step (c) comprises reporting the information relating to each subset of the m/z ratios and information relating to the two or more molecular weights to the user in the form of a displayed graph comprising: a horizontal axis scaled in units of m/z ratio; a vertical axis scaled in units of molecular weight; and a plurality of points plotted on the graph, each point representing a respective ion species in the mass spectrum for which an m/z value is recognized, wherein a horizontal coordinate of each plotted point represents the recognized m/z value of the respective ion species and a vertical coordinate of each plotted point represents the determined molecular weight of the respective intact protein molecule species.
9. A method as recited in claim 7, wherein the displayed graph further comprises: a set of horizontal lines, the vertical coordinate of each horizontal line corresponding to a respective determined molecular weight of a respective intact protein molecule species, wherein each horizontal line connects plotted points representing ion species generated from said respective intact protein molecule species; and a set of non-horizontal lines, wherein each non-horizontal line connects plotted points representing ion species having a same charge state.
10. A method as recited in claim 1 wherein the solution comprising the mixture of the intact protein molecule species is an extract derived from a bacterium, further comprising: determining a respective molecular weight of each of two or more of the intact protein molecule species from the m/z ratios and determined charge states of the two or more recognized subsets of the m/z ratios; and determining a bacterium species identification based on the determined two or more molecular weights of the intact protein molecule species.
11. A method as recited in claim 10, wherein the repeated introducing of a respective portion of the sample to an ionization source comprises introducing a continuous flow of the bacterium extract to the ionization source during direct infusion of the sample into the mass spectrometer.
12. A method as recited in claim 11, wherein at least one of the sample portions includes four or more unique intact protein molecule species.
13. A method as recited in claim 10, wherein the step (b) is performed in not more than one second.
14. A method as recited in claim 10, wherein the repeated introducing of a respective portion of the sample to an ionization source comprises: introducing the bacterium extract into a liquid chromatographic column; performing a partial chromatographic separation of the intact protein molecule species of the bacterium extract using the liquid chromatographic column, wherein the chromatographic column is operated such that all of the intact protein molecule species elute from the column during a time span of not greater than five minutes; and introducing a continuous flow of eluate discharged from the liquid chromatographic column to the ionization source, the continuous flow including all of the sample portions.
15. A method as recited in claim 14, wherein at least one of the sample portions includes four or more unique intact protein molecule species.
16. A method for mass spectral analysis of a sample containing a plurality of intact protein molecule species, said method including repeatedly introducing a respective portion of the sample into an ionization source of a mass spectrometer; and using the ionization source to generate, from each sample portion, a population of multi-protonated ions that comprises a plurality of ion species generated from each respective intact protein molecule species of said each portion, each ion species comprising a respective charge state, z, and mass-to-charge (m/z) ratio, the method comprising: (a) mass analyzing a plurality of ions generated from a first one of the sample portions, thereby generating a mass spectrum thereof, wherein each ion species generated from a protein is represented in the mass spectrum by a respective m/z ratio and a corresponding respective intensity; (b) automatically recognizing, for each of two or more intact protein molecule species, a respective subset of the m/z ratios corresponding to a set of ion species generated from said each intact protein molecule species and automatically determining a respective charge state, z, for each m/z ratio of each subset; (c) determining a respective molecular weight of each of the two or more intact protein molecule species from the m/z ratios and determined charge states of the two or more recognized subsets of the m/z ratios; and (d) reporting information relating to each subset of the m/z ratios and information relating to the two or more molecular weights to a user in the form of a displayed graph comprising: a horizontal axis scaled in units of m/z ratio; a vertical axis scaled in units of molecular weight; and a plurality of points plotted on the graph, each point representing a respective ion species in the mass spectrum for which an m/z value is recognized, wherein a horizontal coordinate of each plotted point represents the recognized m/z value of the respective ion species and a vertical coordinate of each plotted point represents the determined molecular weight of the respective intact protein molecule species.
17. A method as recited in claim 16, wherein the displayed graph further comprises: a set of horizontal lines, the vertical coordinate of each horizontal line corresponding to a respective determined molecular weight of a respective intact protein molecule species, wherein each horizontal line connects plotted points representing ion species generated from said respective intact protein molecule species; and a set of non-horizontal lines, wherein each non-horizontal line connects plotted points representing ion species having a same charge state.
18. A method as recited in claim 16, wherein the solution comprising the mixture of the intact protein molecule species is an extract derived from a bacterium, further comprising: determining a bacterium species identification based on the determined two or more molecular weights of the intact protein molecule species.
Description
CROSS REFERENCE TO RELATED APPLICATIONS
[0001] This application is a Continuation of and claims, under 35 U.S.C .sctn. 120, the benefit of the filing date of and right of priority to co-pending U.S. patent application Ser. No. 15/067,727, filed on Mar. 11, 2016, now US Pat. No. nn,nnn,nnn, which claims priority to and the benefit of the filing date, under 35 U.S.C. .sctn. 119(e), of US Provisional Application for Patent No. 62/132,124, filed on Mar. 12, 2015 and titled "Methods for Data-Dependent Mass Spectrometry of Mixed Biomolecular Analytes", said prior applications assigned to the assignee of the present invention and incorporated herein by reference in their entirety.
FIELD OF THE INVENTION
[0002] The present invention relates to mass spectrometry and, more particularly, relates to methods and systems for automatically discriminating between mass spectral signatures of a plurality of biopolymer molecules, such as peptides and proteins, and, based on the discriminated signatures, controlling operation of a tandem mass spectrometer and performing identification of the biopolymer molecules.
BACKGROUND OF THE INVENTION
[0003] Structural elucidation of ionized molecules of complex structure, such as proteins, is often carried out using a tandem mass spectrometer that is coupled to a liquid chromatograph. The general technique of conducting mass spectrometry (MS) analysis of ions generated from compounds separated by liquid chromatography (LC) may be referred to as "LC-MS". If the mass spectrometry analysis is conducted as tandem mass spectrometry (MS/MS), then the above-described procedure may be referred to as "LC-MS/MS". In conventional LC-MS/MS experiments a sample is initially analyzed by mass spectrometry to determine mass-to-charge ratios (m/z) corresponding to the peaks of interest. The sample is then analyzed further by performing product ion MS/MS scans on the selected peak(s). Specifically, in a first stage of analysis, frequently referred to as "MS.sup.1", a full-scan mass spectrum, comprising an initial survey scan, is obtained. This full-scan spectrum is the followed by the selection (from the results obtained) of one or more precursor ion species. The precursor ions of the selected species are subjected to ion activation (generally, a deposition of energy) followed by one or more reactions, such as fragmentation, such as may be accomplished employing a collision cell or employing another form of fragmentation cell such as those employing surface-induced dissociation, electron-transfer dissociation or photon dissociation. In a second stage, the resulting fragment (product) ions are detected for further analysis (frequently referred to as either "MS/MS" or "MS.sup.2") using either the same or a second mass analyzer. A resulting product spectrum exhibits a set of fragmentation peaks (a fragment set) which, in many instances, may be used as a means to derive structural information relating to the precursor peptide or protein or other biochemical oligomer. It should be noted that, using the fragment ions as a starting population, the process of ion selection and subsequent fragmentation may be repeated yet again, thereby yielding an "MS.sup.3" spectrum. In the general case, a mass spectrum obtained after (n-1) iterated stages of selection and fragmentation may be referred to as an "MS.sup.n" spectrum. This is a time-consuming process because the sample needs to be mass analyzed at least twice and the MS/MS data is only recorded for a limited number of components.
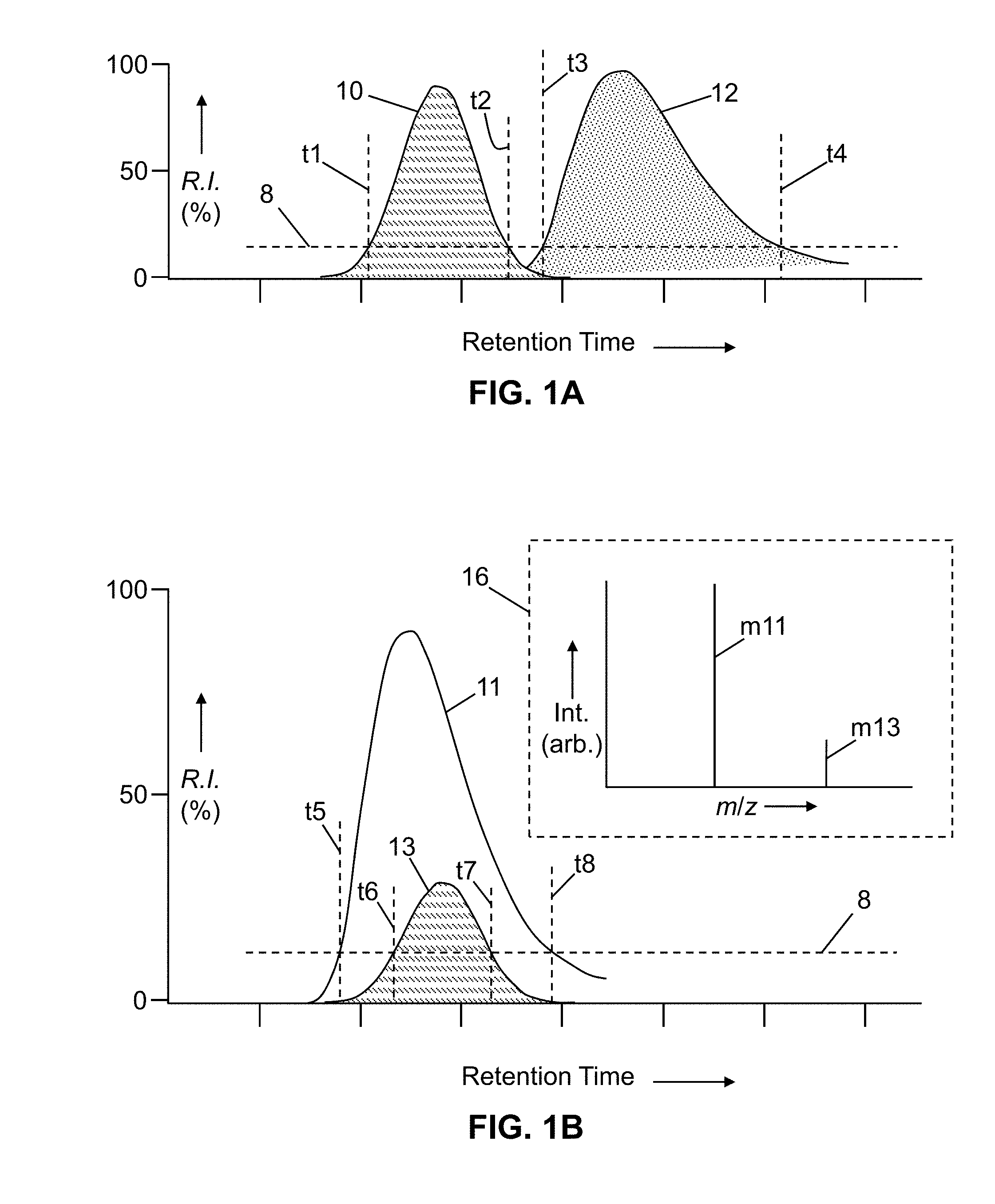
[0004] Most presently available mass spectrometers capable of tandem analysis are equipped with an automatic data-dependent function whereby, when selecting the precursor ion for MS.sup.2 analysis from the ion peaks in MS.sup.1, the ion precursors are selected in decreasing intensities. In a simple data-dependent experiment shown in FIG. 1A, a detector continuously measures total current attributable to ions entering a mass spectrometer detector. A threshold intensity level 8 of the total ion current is set below which only MS.sup.1 data is acquired. As a first component--detected as peak 10--elutes, the total ion current intensity crosses the threshold 8 at time t1. When this occurs, an on-board processor or other controller of the mass spectrometer determines the most intense ion in the MS.sup.1 spectra and immediately initiates an MS/MS scan with regard to the most intense ion. Subsequently, the leading edge of another elution peak 12 is detected. When the total ion current once again breaches the threshold intensity 8 at time t3, an MS/MS scan is initiated with regard to the most intense ion detected after time t3. Generally, the peak 12 will correspond to the elution of a different chemical component and, thus, the most abundant ion detected after time t3 will be different from the ion for which MS/MS analysis was conducted during the elution peak 10. In this way, both MS and MS/MS spectra are acquired on each component as it elutes.
[0005] The simple data dependent experiment described above works well with chromatographically resolved or partially resolved components, as are illustrated in FIG. 1A. However, in a very complex mixture there may be components whose elution peaks completely overlap, as illustrated in the graph of ion current intensity versus retention time in FIG. 1B. In this example elution peak 11 represents the ion current attributable to ion m11, and elution peak 13 represents the ion current attributable to ion m13, the masses of these ions being schematically illustrated in the mass spectrum representation in inset box 16. In the hypothetical situation shown in FIG. 1B, there is almost perfect overlap of the elution of the compounds that give rise to ions m11 and m13, with the mass spectral intensity of ion m11 always being greater than that of ion m13 during the course of the elution. Under these conditions, the simple data-dependent technique discussed above with reference to FIG. 1A will fail to ever initiate MS/MS analysis of ion m13 (and possibly other important ions), since only the most intense component (m11) will be selected for MS/MS.
[0006] The hypothetical two-ion situation illustrated in FIG. 1B is a simplified example. Most modern mass spectrometer instruments are capable of performing a series of MS/MS analyses with regard to each respective one of several abundant ions detected in an MS.sup.1 analysis. Typically, instead of choosing just a single most-abundant precursor, modern instruments will select the "top P number of the most abundant precursors" for tandem mass analysis based on the information of a preceding MS.sup.1 data acquisition, where the number P is either a constant or perhaps a variable input by a user. Nonetheless, the basic issue demonstrated by FIG. 1B remains, especially for multicomponent samples of biopolymer analytes which may give rise to tens to hundreds of mass spectral peaks in a single mass spectrum. Regardless of how such a sample is introduced into a mass spectrometer (for example, by chromatographic separation, flow injection, or capillary electrophoresis; as a chemical separate delivered from a lab-on-a-chip device, by infusion or other method), more than one analyte may be represented in a single mass spectrum from a single time point, and each such analyte may give rise to many ions, as illustrated in hypothetical mass spectrum illustrated in FIG. 1C. In FIG. 1C, solid vertical lines outlined by envelope 208 represent centroids of a first set of mass spectral peaks generated from a first analyte compound and dotted vertical lines outlined by envelope 206 represent centroids of a second set of mass spectral peaks generated from a second co-eluting analyte compound. It is evident that, even if the number, P, of most-abundant peaks to be analyzed is equal to 10, for example, than only the ions of only one of the analyte compounds will be selected for MS/MS analysis using the traditional data dependent methods described above. Information relating to the second analyte will be lost. Further, the data so obtained will comprise redundant information on the same component.
[0007] To more successfully address the complexities of mass spectral analysis of co-eluting compounds, many mass spectral instruments also employ the so-called "Dynamic Exclusion" principle by which a mass-to-charge ratio is temporarily put into an exclusion list after its MS.sup.n spectrum is acquired. The excluded mass-to-charge ratio is not analyzed by MS.sup.n again until a certain time duration has elapsed after the prior MS.sup.n spectrum acquisition. This technique minimizes a chance of fragmenting the same precursor ion in several subsequent scans, and allows a mass spectrometer to collect MS.sup.n spectra on other components having less intense peaks which would otherwise not be examined. After a selected period of time the excluded ion will be removed from the list so that any other compounds with the same mass-to-charge ratio can be analyzed. This time duration during which the ion species is on the exclusion list is generally estimated based on an average or estimated chromatographic peak width. Thus, use of the Dynamic Exclusion principle allows more data to be obtained on more components in complex mixtures.
[0008] Unfortunately, existing dynamic exclusion techniques may perform poorly for analyzing mass spectra of mixtures of complex biomolecules. For example, consider once again the hypothetical situation illustrated in FIG. 1C. If the ions depicted in FIG. 1C are analyzed using the dynamic exclusion principle, then at least 10 ion species derived from a single analyte (outlined by envelope 208) will be analyzed, in decreasing order of their intensities in the illustrated MS.sup.1 spectrum, by MS.sup.n analysis prior to any peaks from the less abundant analyte (outlined by envelope 206) being considered. This sequence will occur regardless of the fact that each precursor each ions species is placed onto an exclusion list after its respective analysis. The amount of time consumed performing ten unnecessarily redundant MS.sup.n analyses may then lead to expiration of the exclusion time of the most abundant ion (or may lead to exhaustion of the time available to fully analyze a small number of most abundant ions), after which the entire sequence may of MS.sup.n analyses may be repeated.
[0009] A further complicating factor in the application of the dynamic exclusion principle to mass analysis of mixtures of complex biomolecules derives from the fact that the elution profiles of the various compounds are highly variable and difficult to predict. Different biopolymer compounds may exhibit different elution profiles as a result of complex interactions between a chromatographic stationary phase and a biopolymer with multiple molecular interaction sites. Moreover, the time profiles of various ions generated from even a single such compound may fail to correlate with the elution profile of the un-ionized compound or with the profiles of one another as a result of ionization suppression within an ionization source of a mass spectrometer.
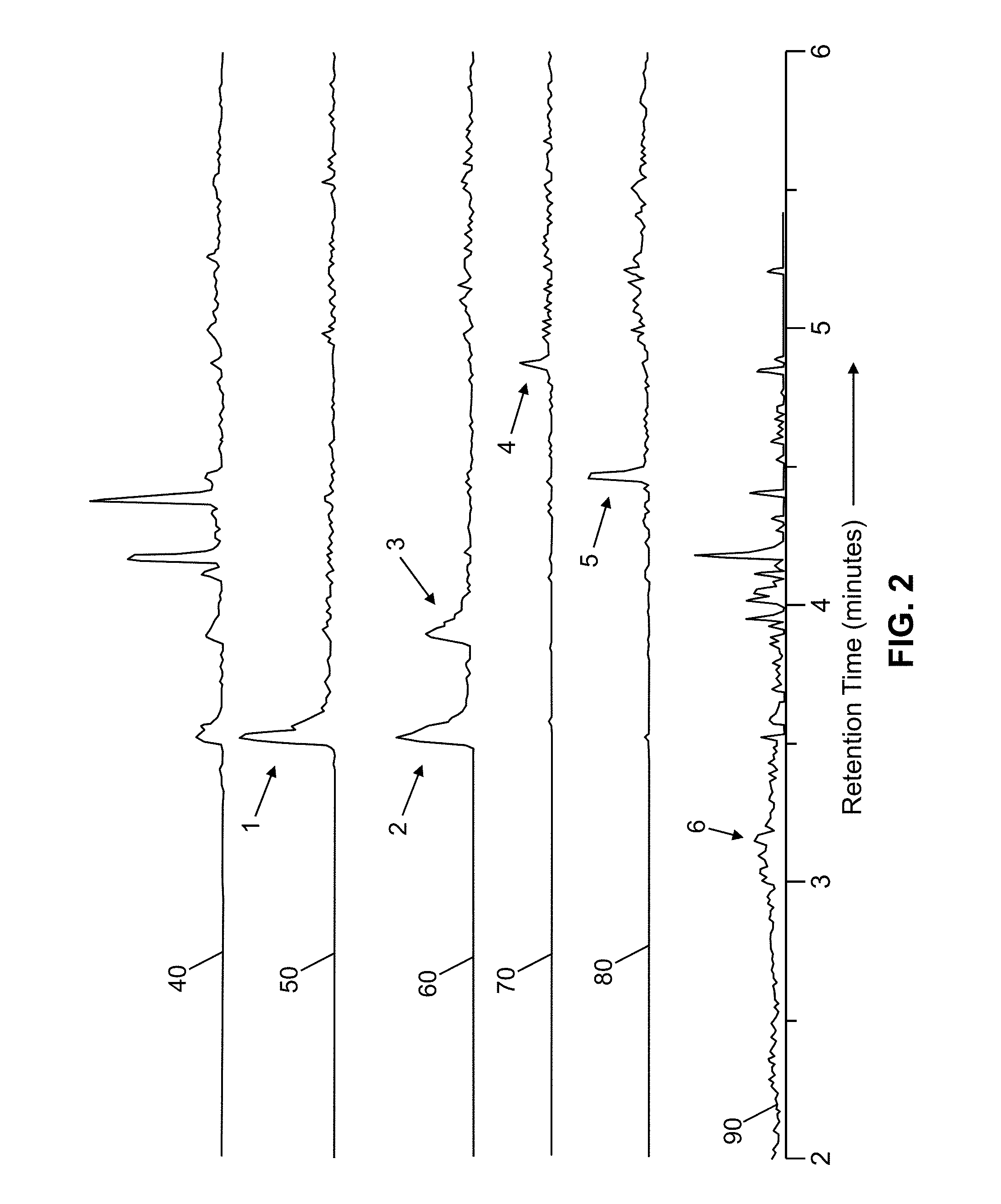
[0010] As an example of the elution profile variability that may be encountered, FIG. 2 illustrates a set of chromatograms collected from a single liquid chromatography-mass spectrometry experimental run of an E.Coli extract. Total ion current is shown in the topmost chromatogram (curve 40) and various extracted ion chromatograms, illustrating the ion current that is contributed by respective m/z-ratio ranges are shown in the lowermost five plots (curves 50, 60, 70, 80 and 90). Curve 50 represents the m/z range 660.0-660.5 Da. Similarly, curves 60, 70, 80 and 90 represent m/z ranges 700.5-701.5 Da, 1114.5-1114.5 Da, 942.5-943.5 Da and 540.5-540.5 Da. Peaks 1, 2 and 3 are examples of peaks with broad chromatographic profiles. Peaks 4 and 5 are examples of narrow profiles. Peak 6 shows an extremely broad peak. The peak widths span over an order of magnitude, therefore severely limiting the applicability of an exclusion list having a pre-defined exclusion time duration.
[0011] The existing data dependent and dynamic exclusion workflow techniques and corresponding algorithms were developed for small molecules, small peptides and other analytes which acquire a limited number of charges (for example, 1-3 charges) in the electrospray ionization process. When applied to higher-molecular-weight biopolymer analytes (most commonly, intact proteins during the course of so-called "top-down" proteomics studies) these conventional methodologies significantly under-perform due to a combination of different electrospray behavior and computational limitations. More specifically: (1) intact high mass analytes in general, and proteins in particular, develop many more charge states (up to 50 charges or more per molecule, e.g., FIG. 1C) than do small molecules during the electrospray ionization process because of a greater number of charge acquiring sites which results in much more complex MS spectra; (2) in complex mixtures such as cell lysates or their fractions, there is a wide distribution of molecular weights and copy numbers which results in a very complex overlap of charge state distribution patterns of varying intensities; (3) variability in physiochemical properties of the high-mass analytes of the same or different chemical nature results in significant variability of chromatographic peak shapes and analyte retention on the column; (4) if the mass spectra are acquired on a mass spectrometer with high resolving power such as an Orbitrap.TM. mass analyzer (a type of electrostatic trap mass analyzer) or a time-of-flight (TOF) mass analyzer, corresponding peaks further resolve into a number of isotopes in a series of clusters whose quality is often far from a theoretical binomial distribution; (5) matrix ionization effects of a variety of different proteins can greatly influence the observed intensity of multiply overlapping species so as to distort the true ratios of protein intensities found in any given standard or sample. These factors make it difficult to estimate a time for placing analyte-specific m/z values on a dynamic exclusion list. Additional levels of complexity are introduced by oxidized species of the same analyte or adducts, overlaps of isotope clusters and inability of existing software tools correctly calculate charge state for high mass species.
[0012] It is not uncommon for a single protein to generate greater than hundreds of resolved peaks (including both charge states and isotopes) per MS mass spectrum on high resolution/mass accuracy instruments. In practical terms, the above considerations imply that, in the case of intact proteins and other biopolymers, existing data dependent algorithms are being confounded and MS/MS is being performed in a redundant fashion on a number of different charge states from the same biopolymer. Also, when isotopic clusters do not match the traditional binomial distribution patterns defined by the number of carbon, hydrogen, nitrogen, oxygen, nitrogen and sulfur atoms present in a given biopolymer, or do not meet intensity threshold or signal-to-noise requirements, redundancy occurs from fragmenting multiple isotopes which belong to the same isotopic cluster. This duplication of work leads to redundancy in identification of the most abundant/ionizable proteins, while the information about other species is lost and provides very little opportunity for triggering an MS.sup.n analysis.
[0013] There is thus a need in the art of mass spectrometry of biomolecules for improved methods of analysis that can efficiently differentiate signal from noise, correctly allocate related m/z values into proper isotopic clusters, correctly determine charge states and properly organize the various charge states into distribution envelopes. Such improvements are required for success in both data acquisition and post acquisition processing workflows.
[0014] Preferably, the improved methods and algorithms should be able to work in a "real-time" environment such that automated data-dependent decisions may be made while mass spectra are being acquired. Such methods and algorithms should be able to not only extract as much information from each mass spectrum as possible, but also to direct subsequent MS.sup.n analysis in a desired way based on the information gathered in a preceding mass spectrum. The present disclosure addresses these needs.
SUMMARY
[0015] The current invention eliminates the above described limitations and enables both effective (1) non-redundant data dependent mass spectrometry analysis and (2) post-acquisition data processing for individual high mass analytes and their mixtures of different complexities. For data dependent mass spectrometry analysis, the herein-described novel "Top P Unique Analyte-Specific Clusters" workflow and associated computation replaces the previous state-of-the-art "Top P Most Abundant Precursors" logic. Each such species-correlative envelope is a set of related mass spectral lines (m/z values) which are indicated, according to the methods of the present teachings, to all be generated from a single unique molecule. Each species-correlative envelope groups together various charge states and isotopic clusters that are indicated to have been produced from a single molecule. However, the species-correlative envelope can exclude adducts if desired, which are removed prior to data analysis.
[0016] Tandem mass spectrometry (or, more-generally, MS.sup.n analysis) is performed only on selected representatives of a given species-correlative charge state distribution envelope after which data acquisition is directed to the next species-correlative charge state distribution envelope (i.e., of a different compound) that is determined in a preceding MS spectrum, and so on. Prior to MS.sup.n analysis, computed charge state distribution patterns are filtered so as to exclude oxidized (or other specified) species of the same analyte and various other unwanted adducts. In this approach, the most possible abundant information on the analytes in a sample is retrieved either on a chromatographic time scale, or in experiments in which sample is introduced into a mass spectrometer by infusion, flow injection or by means of any other sample introduction device. In all cases, data-acquisition redundancy is either totally eliminated or significantly reduced.
[0017] The "Top P Unique Analyte-Specific Clusters" workflow may include one or more of (1) correct computational assignment of charge state to each peak (centroid) in isotopic clusters found in a scan; (2) the use of information on charge state to assign isotopic clusters (either resolved or unresolved) to the appropriate charge-state envelope(s); (3) optional determination of molecular weights; and (4) the control of data-dependent acquisition in a way to allow only one (or a selected number) of MS.sup.n event(s) per each individual charge state envelope. The "Top P Unique Cluster" method can be set up to work with the most intense charge state for a given biopolymer, the median charge state between the highest charge state detected and the most intense charge state observed, or any other desired charge state. The method is therefore well-suited for use with a variety of ion activation methods including but not limited to collision-induced dissociation (CID) and electron-transfer dissociation (ETD), defined for a given molecular weight range, or in instances in which the least abundant proteins species are interrogated first. Similar methods may be employed for post-acquisition data processing, in which the same computation logic is applied to raw MS spectra for which acquisition is completed prior to execution of the novel methods. Post-acquisition data processing may further include molecular weight determination and analyte identification.
[0018] These principles of the present teachings can be applied for analytes of various molecular weights and chemical nature on high resolution tandem mass spectrometry systems including but not limited to mass spectrometer instruments that are based on or include an Orbitrap.TM. mass analyzer. Such instruments include Orbitrap Fusion.TM., Orbitrap Velos-Pro.TM., Q-Exactive.TM., and Orbitrap Elite.TM. as well as quadrupole time-of-flight (QTOF) mass spectrometers and Fourier transform ion cyclotron resonance (FT-ICR) mass spectrometers. Further, the same principles can be applied to isotopically unresolved charge state envelopes which can be seen in mass spectra obtained on high resolution mass spectrometry systems for comparatively very high mass analytes, or to unit resolution mass spectra obtained on mass analyzers such as linear ion traps or any other Paul trap configuration. In instances, instead of making charge determinations based on a distance between individually resolved lines of isotopic clusters, these are instead calculated using distances between charge states within the same charge state envelope. Again, this clustering based strategy can be applied to unit resolution data as well as to data generated by linear ion traps and triple quadrupole instrumentation.
[0019] When used in conjunction with chromatographic separation, the proposed workflow methods maximize information from each individual mass spectrum obtained during the course of a chromatographic run. The novel methods may also be employed in conjunction with mass spectral experiments in which sample is introduced by infusion or flow injection. In most experimental situations, the novel methods significantly reduce total analysis time. When applied to data already acquired, the novel "Top P Unique Analyte-Specific Clusters" workflow methods can maximize the information yield from MS spectra and can calculate the molecular weights of the analytes in real time.
[0020] The novel principles, workflows and algorithms and methods described and taught in this disclosure are applicable in all cases when several analytes are mass spectrometrically (MS) detectable within the same mass spectrum. For example, the novel teachings may be employed in cases in which two or more analytes co-elute from a chromatographic column and the co-eluting analytes are simultaneously introduced into a mass spectrometer. As a second example, the novel teachings may be employed in cases in which two or more analytes are introduced into a mass spectrometer using a flow injection methodology. In yet a third example, the novel teachings may be employed in cases in which two or more analytes are introduced into a mass spectrometer using syringe infusion. In still yet other examples, the novel teachings may be employed in cases in which analytes are introduced into a mass spectrometer after separation by a capillary electrophoresis apparatus or a lab-on-a-chip apparatus. The novel methods may be employed in conjunction with mass spectrometers employing any known ionization technique, such as, without limitation, photo-ionization, thermospray ionization, electrospray ionization (ESI), desorption electrospray ionization (DESI), paper spray ionization, atmospheric pressure chemical ionization (APCI) and matrix-assisted laser desorption ionization (MALDI).
BRIEF DESCRIPTION OF THE DRAWINGS
[0021] To further clarify the above and other advantages and features of the present disclosure, a more particular description of the disclosure will be rendered by reference to specific embodiments thereof, which are illustrated in the appended drawings. It is appreciated that these drawings depict only illustrated embodiments of the disclosure and are therefore not to be considered limiting of its scope. Accordingly, the disclosure will be described and explained with additional specificity and detail through the use of the accompanying drawings, not necessarily drawn to scale, in which:
[0022] FIG. 1A is a schematic illustration of simple intensity-threshold-based data dependent mass spectral analysis of two analytes exhibiting well-resolved chromatographic peaks;
[0023] FIG. 1B is a schematic illustration of a portion of a chromatogram with highly overlapping elution peaks, both of which are above an analytical threshold;
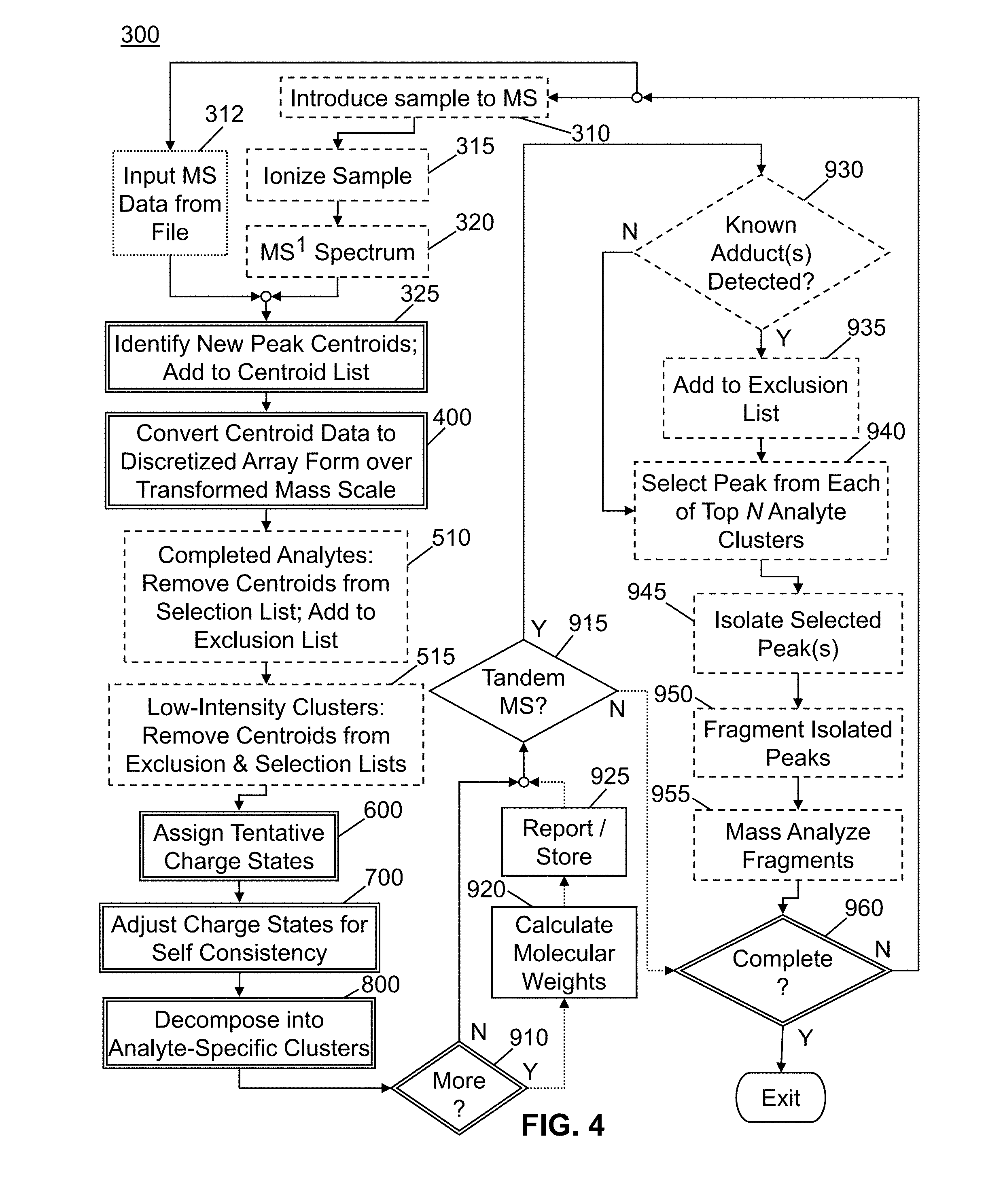
[0024] FIG. 1C is an illustration of multiple interleaved mass spectral peaks of two simultaneously eluting biopolymer analytes;
[0025] FIG. 2 is a set of chromatograms collected from a single liquid chromatography-mass spectrometry experimental run of an E. Coli extract, including a total ion current chromatogram (top curve) and also illustrating various extracted ion chromatograms (lower curves) that contribute to the total ion current, each extracted ion chromatograph representing a respective m/z ratio range;
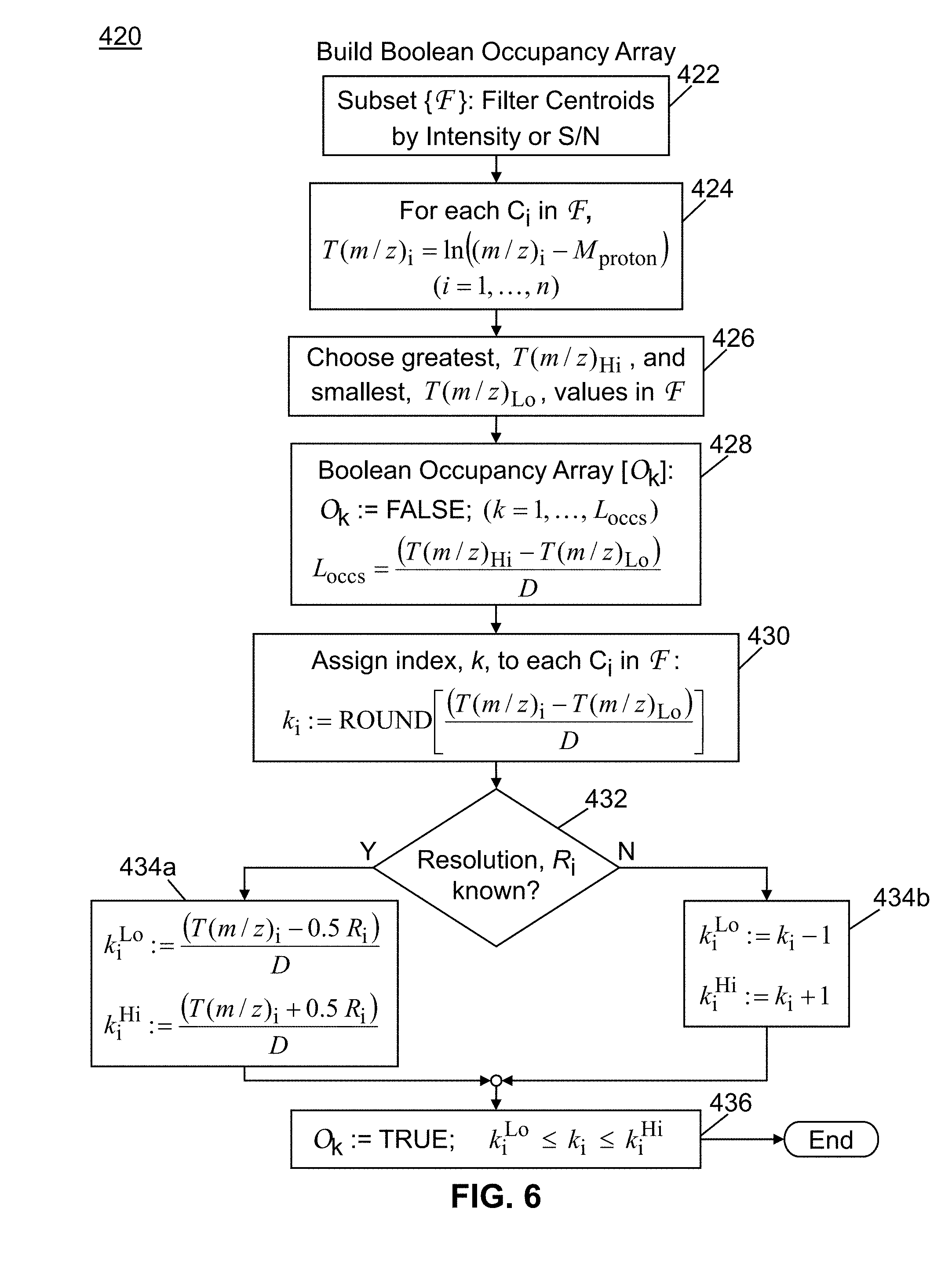
[0026] FIG. 3A is a schematic diagram of a system for generating and automatically analyzing chromatography/mass spectrometry spectra in accordance with the present teachings;
[0027] FIG. 3B is a schematic illustration of an example of a conventional triple quadrupole mass spectrometer in which MS.sup.n mass spectrometry may be performed;
[0028] FIG. 3C is a schematic illustration of a known multi-component, multi-analyzer mass spectrometer in which MS.sup.n mass spectrometry may be performed;
[0029] FIG. 4 is a flowchart of a general set of steps employed by various methods in accordance with the present teachings;
[0030] FIG. 5 is a flowchart of a method to convert experimentally measured mass spectral centroids to a transformed matrix form, in accordance with the present teachings;
[0031] FIG. 6 is a flowchart of a method in accordance with the present teachings for constructing a Boolean occupancy array within a mathematically transformed mass-to-charge space from experimentally determined mass spectral centroid data;
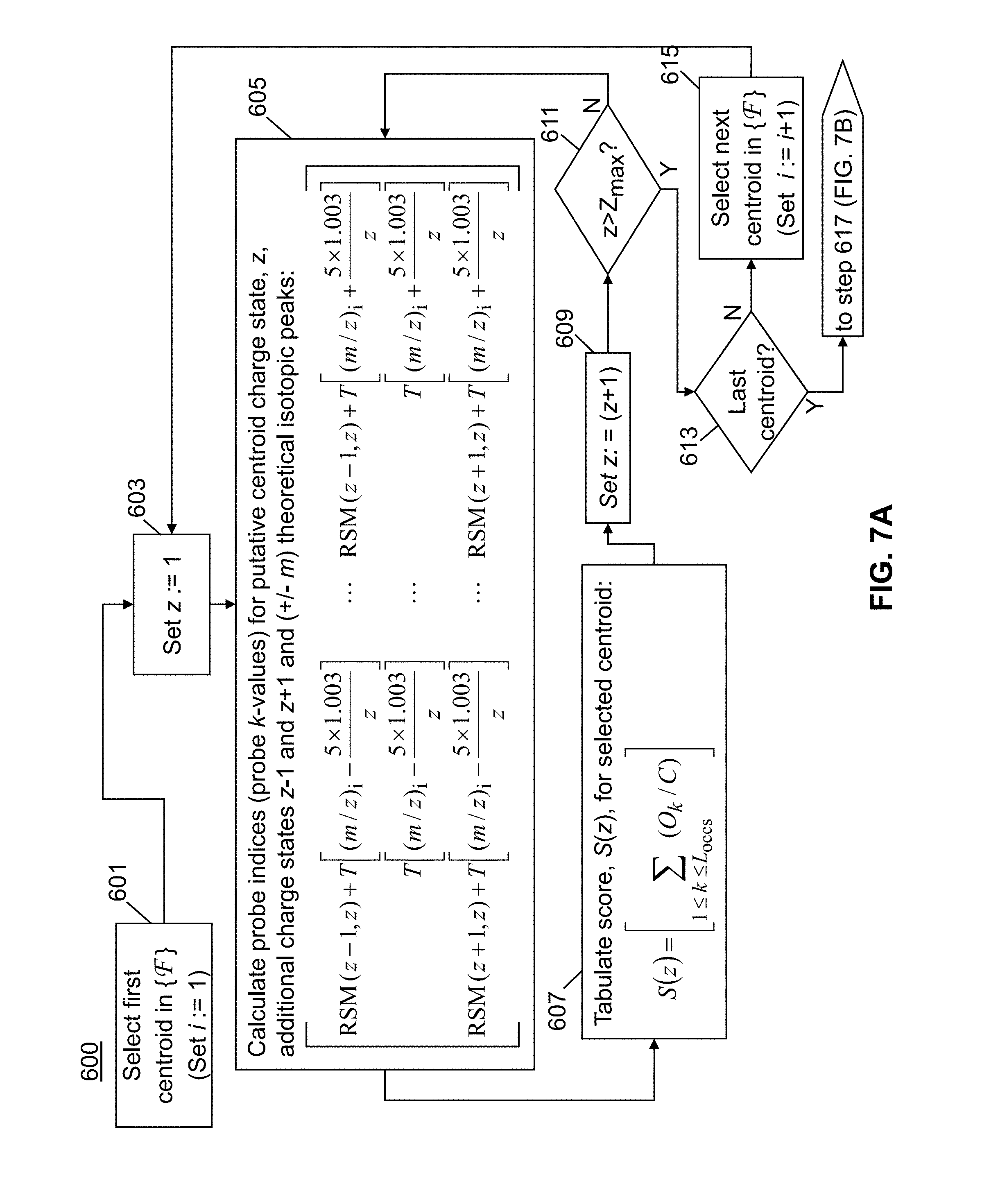
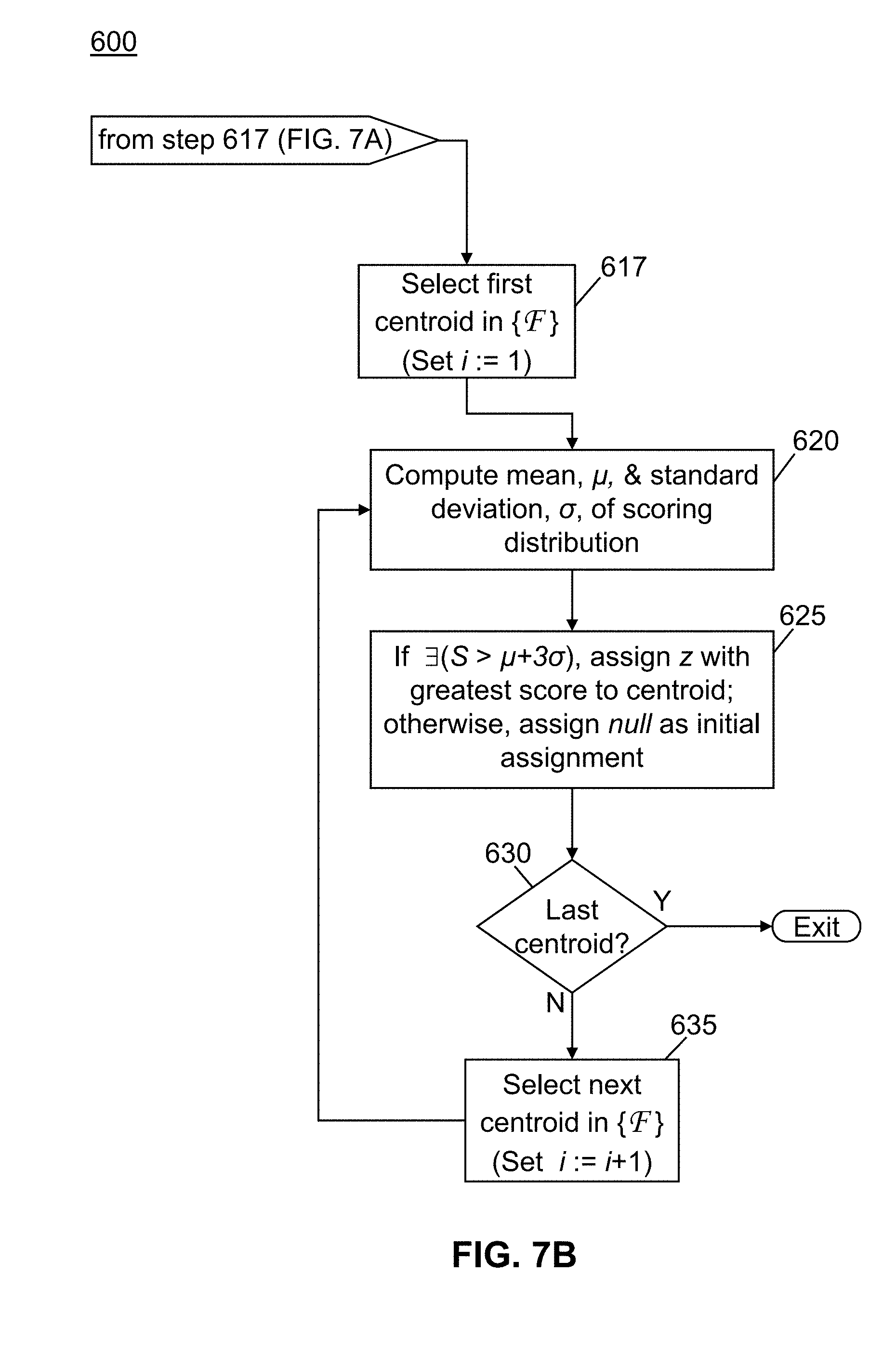
[0032] FIG. 7, comprising FIG. 7A and continuation on FIG. 7B, is a flowchart of a method in accordance with the present teachings for assigning tentative charge states for a plurality of experimentally determined mass spectral centroids;
[0033] FIG. 8 is a flowchart of a method in accordance with the present teachings for adjusting a set of previously tentatively assigned charge states such that the resulting final assigned charge states are self-consistent;
[0034] FIG. 9 is a flowchart of a method in accordance with the present teachings for decomposing a set of experimentally determined centroids having assigned charge states into analyte-specific clusters;
[0035] FIG. 10A and continuations on FIGS. 10B, 10C and 10D, is a table showing typical molecular weights, expected number of C.sup.13 atoms in the most abundant isotope (mode), expected average number of C.sup.13 atoms among all isotopes and the difference between the expected average number and the mode, as they vary with the total number of C.sup.12 atoms in a protein;
[0036] FIGS. 11A, 11B, 11C and 11D are depictions of computer screen user interfaces which may be employed in conjunction with user control of and information display from computer software that employs methods in accordance with the present teachings;
[0037] FIG. 12A is a depiction of a computer screen information display illustrating peak cluster decomposition results, as generated by computer software employing methods in accordance with the present teachings, calculated from a mass spectrum of a five-component protein mixture consisting of cytochrome-c, lysozyme, myoglobin, trypsin inhibitor, and carbonic anhydrase;
[0038] FIG. 12B is a depiction of a computer screen information display illustrating peak cluster decomposition results, as generated by computer software employing methods in accordance with the present teachings, the display illustrating an expanded portion of the decomposition results shown in FIG. 12A;
[0039] FIG. 12C is a depiction of a computer screen information display illustrating peak cluster decomposition results, as generated by computer software employing methods in accordance with the present teachings, the display illustrating an even-further expanded portion of the decomposition results shown in FIG. 12B;
[0040] FIG. 13A is a depiction of a computer screen information display illustrating peak cluster decomposition results, as generated by computer software employing methods in accordance with the present teachings, the display illustrating peak cluster decomposition results calculated from a single-stage mass spectrum of a crude extract from the bacterium E. coli directly infused into a mass spectrometer;
[0041] FIG. 13B is a depiction of a computer screen information display illustrating peak cluster decomposition results, as generated by computer software employing methods in accordance with the present teachings, the display illustrating an expanded portion of the decomposition results shown in FIG. 13A;
[0042] FIG. 13C is a depiction of the mass spectral data whose peak cluster decomposition is shown in FIGS. 13A-13B, showing peak positions and charge-state assignments as provided by a conventional mass spectral peak analysis computer program;
[0043] FIG. 13D is a depiction of the mass spectral data whose peak cluster decomposition is shown in FIGS. 13A-13B, showing charge-state assignments as provided by methods in accordance with the present teachings;
[0044] FIG. 14A is a depiction of a mass spectrum of an intact antibody having varying degrees of glycosylation (main plot) also showing (inset) an expanded portion of the spectrum illustrating the different glycoforms of the antibody;
[0045] FIG. 14B is a depiction of a computer screen information display illustrating peak cluster decomposition results, as generated by computer software employing methods in accordance with the present teachings, calculated from the mass spectral data shown in FIG. 14A, showing the calculated molecular weights of the four decomposed glycoforms of the antibody ranging from 148378 Da to 148763 Da;
[0046] FIG. 15A is a depiction of an MS.sup.2 spectrum of the protein carbonic anhydrase II, generated by collision-induced dissociation of the +26 charge state of the protein occurring at m/z=807.00 Da, showing peak assignments as determined by a conventional mass spectral analysis method;
[0047] FIG. 15B is a depiction of a computer screen information display illustrating peak cluster decomposition results, as generated by computer software employing methods in accordance with the present teachings, calculated from the MS.sup.2 mass spectral data shown in FIG. 15A;
[0048] FIG. 15C is a depiction of a second MS.sup.2 spectrum of the protein carbonic anhydrase II, generated by collision-induced dissociation of the +21 charge state of the protein at m/z=1001.00 Da, showing peak assignments as determined by a conventional mass spectral analysis method;
[0049] FIG. 15D is a depiction of a computer screen information display illustrating peak cluster decomposition results, as generated by computer software employing methods in accordance with the present teachings, calculated from the MS.sup.2 mass spectral data shown in FIG. 15C;
[0050] FIG. 16 is a table of the accuracy of molecular weights, as calculated in accordance with the presently taught methods, of five standard proteins;
[0051] FIG. 17 is a portion of a plot of calculated molecular weights, as calculated in accordance with the presently taught methods, from a mass analysis of a mixture of five standard proteins including isotopic variants;
[0052] FIG. 18A is a plot of a first portion of calculated molecular weights, as calculated in accordance with the presently taught methods, of mass analyzed proteins from a lysate of the bacterium E. Coli after treatment of the lysate with a proton transfer reagent;
[0053] FIG. 18B is a plot of a second portion of the calculated molecular weights of the sample of FIG. 18A;
[0054] FIG. 19 is a table of molecular weights of proteins that are diagnostic for distinguishing between closely related bacterial species, as determined by mass spectrometric analyses used in conjunction with methods in accordance with the present teachings;
[0055] FIG. 20 is a table of the accuracy of identifications of various yeast species, using mass spectrometric analyses in conjunction with methods in accordance with the present teachings;
[0056] FIGS. 21A and 21B are a table illustrating a comparison between theoretical and observed protein fragment ion masses obtained during long gradient LCMS analysis of an extract of the yeast Candida albicans; and
[0057] FIG. 22 is a table of times required for calculating the mass spectrometry deconvolution results that are shown in various of the accompanying figures.
DETAILED DESCRIPTION
[0058] The present disclosure describes various improved and novel methods for data-dependent mass spectrometry of biopolymer molecules as well as novel methods for analyzing and interpreting mass spectra of biopolymer molecules. The following description is presented to enable any person skilled in the art to make and use the invention, and is provided in the context of a particular application and its requirements. Various modifications to the described embodiments will be readily apparent to those skilled in the art and the generic principles herein may be applied to other embodiments. Thus, the present invention is not intended to be limited to the embodiments and examples shown but is to be accorded the widest possible scope in accordance with the features and principles shown and described.
1. Mass Spectrometer Hardware Examples
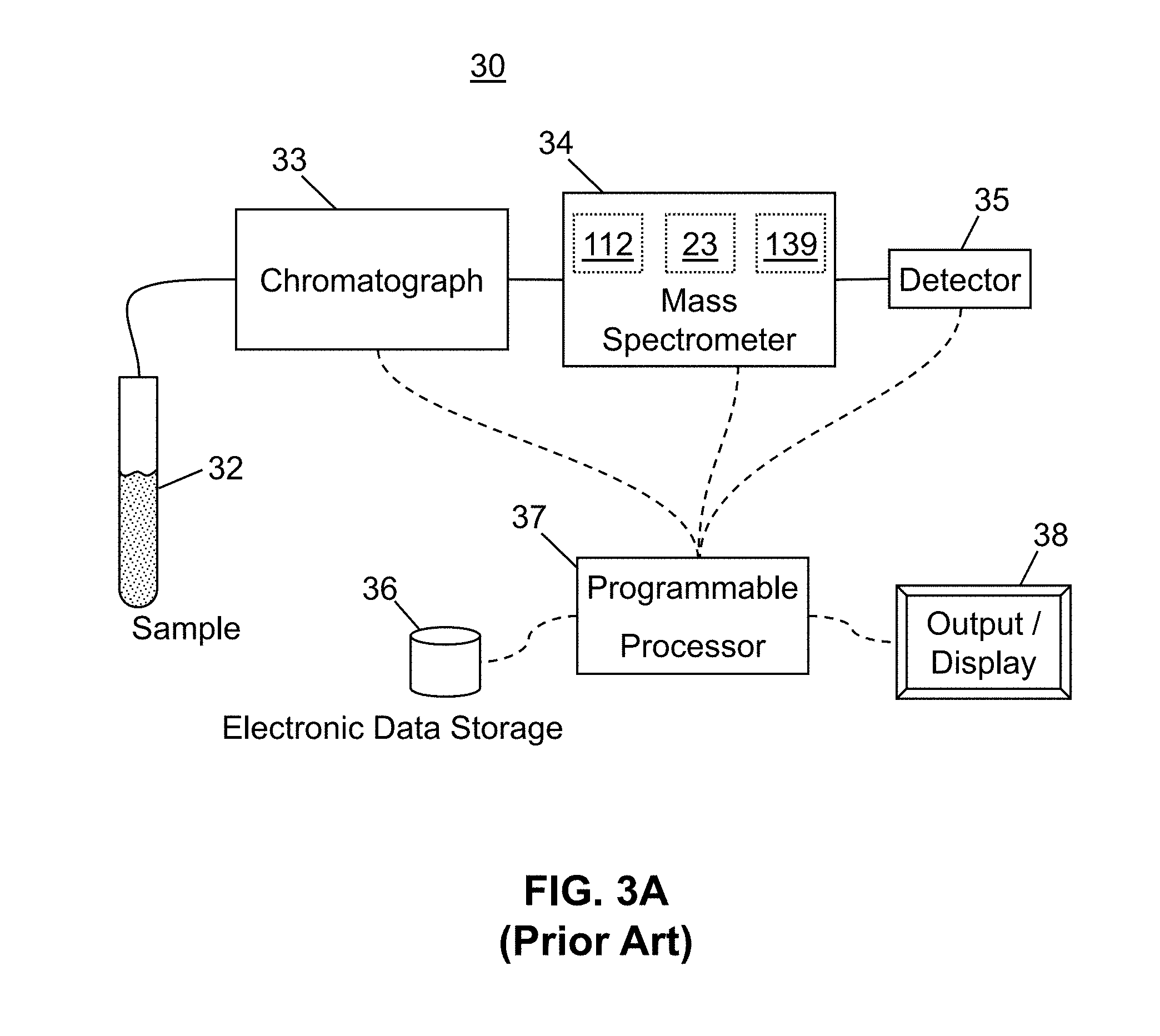
[0059] FIG. 3A is a schematic example of a general system 30 for generating and automatically analyzing chromatography/mass spectrometry spectra as may be employed in conjunction with the methods of the present teachings. A chromatograph 33, such as a liquid chromatograph, high-performance liquid chromatograph or ultra high performance liquid chromatograph receives a sample 32 of an analyte mixture and at least partially separates the analyte mixture into individual chemical components, in accordance with well-known chromatographic principles. The resulting at least partially separated chemical components are transferred to a mass spectrometer 34 at different respective times for mass analysis. As each chemical component is received by the mass spectrometer, it is ionized by an ionization source 112 of the mass spectrometer. The ionization source may produce a plurality of ions comprising a plurality of ion species (i.e., a plurality of precursor ion species) comprising differing charges or masses from each chemical component. Thus, a plurality of ion species of differing respective mass-to-charge ratios may be produced for each chemical component, each such component eluting from the chromatograph at its own characteristic time. These various ion species are analyzed--generally by spatial or temporal separation--by a mass analyzer 139 of the mass spectrometer and detected by a detector 35. As a result of this process, the ion species may be appropriately identified according to their various mass-to-charge (m/z) ratios. As illustrated in FIG. 3A, the mass spectrometer comprises a reaction cell 23 to fragment or cause other reactions of the precursor ions, thereby generating a plurality of product ions comprising a plurality of product ion species.
[0060] Still referring to FIG. 3A, a programmable processor 37 is electronically coupled to the detector of the mass spectrometer and receives the data produced by the detector during chromatographic/mass spectrometric analysis of the sample(s). The programmable processor may comprise a separate stand-alone computer or may simply comprise a circuit board or any other programmable logic device operated by either firmware or software. Optionally, the programmable processor may also be electronically coupled to the chromatograph and/or the mass spectrometer in order to transmit electronic control signals to one or the other of these instruments so as to control their operation. The nature of such control signals may possibly be determined in response to the data transmitted from the detector to the programmable processor or to the analysis of that data as performed by a method in accordance with the present teachings. The programmable processor may also be electronically coupled to a display or other output 38, for direct output of data or data analysis results to a user, or to electronic data storage 36. The programmable processor shown in FIG. 3A is generally operable to: receive a precursor ion chromatography/mass spectrometry spectrum and a product ion chromatography/mass spectrometry spectrum from the chromatography/mass spectrometry apparatus and to automatically perform the various instrument control, data analysis, data retrieval and data storage operations in accordance with the various methods discussed below.
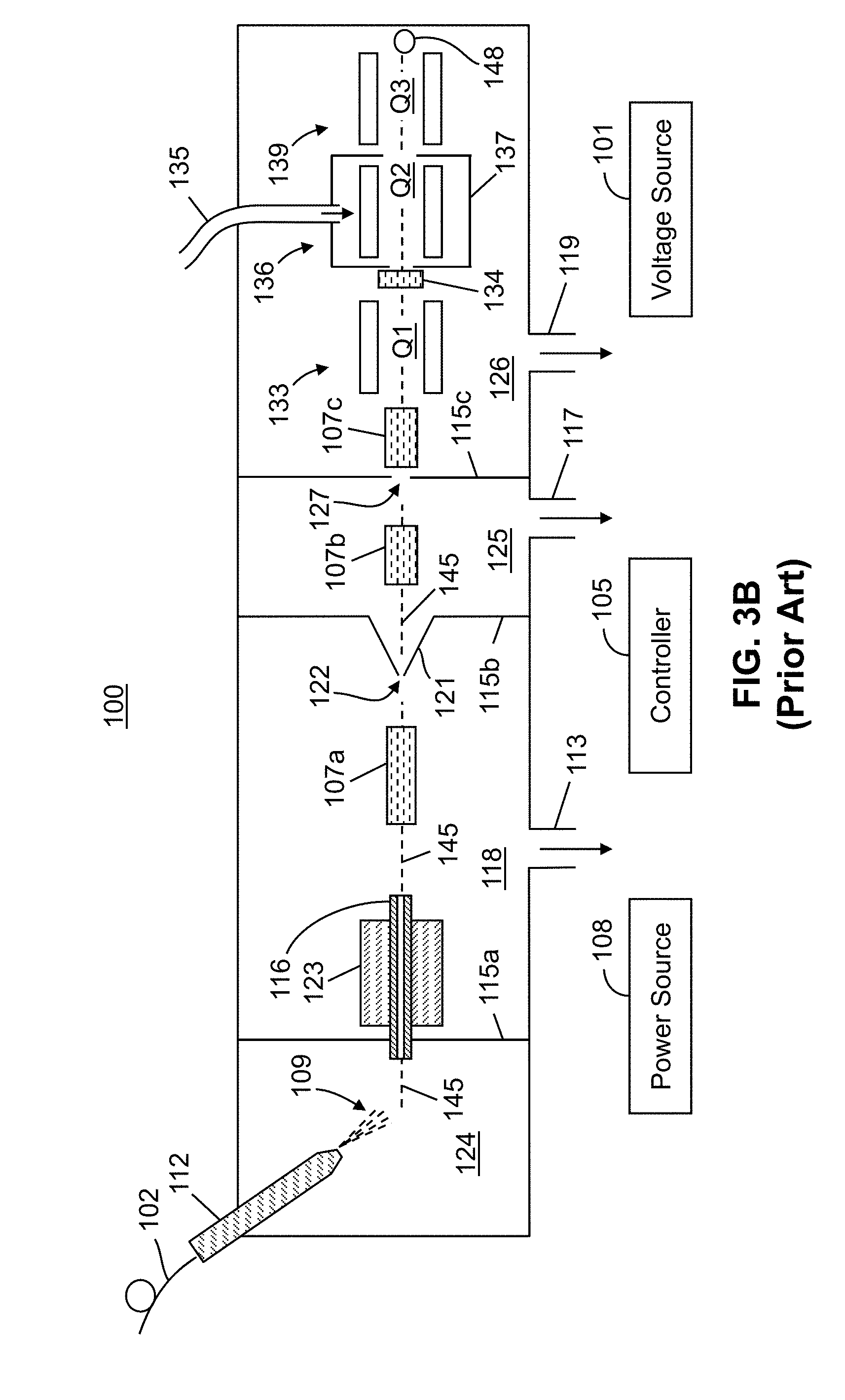
[0061] FIG. 3B is a schematic illustration of an example of a conventional triple quadrupole mass spectrometer system, shown generally at 100, generally capable of performing MS.sup.1 or MS.sup.2 analysis. Referring to FIG. 3B, an ion source 112 housed in an ionization chamber 124 is connected to receive a liquid or gaseous sample from an associated apparatus such as for instance a liquid chromatograph or syringe pump through a capillary 102. As but one example, an atmospheric pressure electrospray source is illustrated. However, any ion source may be employed, such as a heated electrospray ionization (H-ESI) source, an atmospheric pressure chemical ionization (APCI) source, an atmospheric pressure matrix assisted laser desorption (MALDI) source, a photoionization source, a desorption ionization (DESI) source, a paper spray ion source or a source employing any other ionization technique or a combination of the above techniques. The ion source 112 forms charged particles 109 (either ions or charged droplets that may be desolvated so as to release ions) representative of the sample. The charged particles 109 are subsequently transported from the ion source 112 to the mass analyzer 139 in high-vacuum chamber 126 through intermediate-vacuum chambers 118 and 125 of successively lower pressure in the direction of ion travel. In particular, the droplets or ions are entrained in a background gas and may be transported from the ion source 112 through an ion transfer tube 116 that passes through a first partition element or wall 115a into an intermediate-vacuum chamber 118 which is maintained at a lower pressure than the pressure of the ionization chamber 124 but at a higher pressure than the pressure of the high-vacuum chamber 126. The ion transfer tube 116 may be physically coupled to a heating element or block 123 that provides heat to the gas and entrained particles in the ion transfer tube so as to aid in desolvation of charged droplets so as to thereby release free ions.
[0062] Due to the differences in pressure between the ionization chamber 124 and the intermediate-vacuum chamber 118 (FIG. 3B), gases and entrained ions are caused to flow through ion transfer tube 116 into the intermediate-vacuum chamber 118. A second partition element or wall 115b separates the intermediate-vacuum chamber 118 from a second intermediate-pressure region 125, likewise a third partition element or wall 115c separates the second intermediate pressure region 125 from the high-vacuum chamber 126. A first ion optical assembly 107a provides an electric field that guides and focuses the ion stream leaving ion transfer tube 116 through an aperture 122 in the second partition element or wall 115b that may be an aperture of a skimmer 121. A second ion optical assembly 107b may be provided so as to transfer or guide ions to an aperture 127 in the third partition element or wall 115c and, similarly, another ion optical assembly 107c may be provided in the high vacuum chamber 126 containing a mass analyzer 139. The ion optical assemblies or lenses 107a-107c may comprise transfer elements, such as, for instance a multipole ion guide and/or one or more ion lenses, so as to direct the ions through aperture 122 and into the mass analyzer 139. The mass analyzer 139 comprises one or more detectors 148 whose output can be displayed as a mass spectrum. Vacuum ports 113, 117 and 119 may be used for evacuation of the various vacuum chambers.
[0063] The mass spectrometer system 100 (as well as other such systems illustrated herein) is in electronic communication with a controller 105 which includes hardware and/or software logic for performing data analysis and control functions. Such controller may be implemented in any suitable form, such as one or a combination of specialized or general purpose processors, field-programmable gate arrays, and application-specific circuitry. In operation, the controller effects desired functions of the mass spectrometer system (e.g., analytical scans, isolation, and dissociation) by adjusting voltages (for instance, RF, DC and AC voltages) applied to the various electrodes of ion optical assemblies 107a-107c and quadrupoles or mass analyzers 133, 136 and 139, and also receives and processes signals from detector 148. The controller 105 may be additionally configured to store and run data-dependent methods in which output actions are selected and executed in real time based on the application of input criteria to the acquired mass spectral data. The data-dependent methods, as well as the other control and data analysis functions, will typically be encoded in software or firmware instructions executed by controller. A power source 108 supplies an RF voltage to electrodes of the devices and a voltage source 101 is configured to supply DC voltages to predetermined devices.
[0064] As illustrated in FIG. 3B, the conventional mass spectrometer system 100 is a triple-quadrupole system comprising a first quadrupole device 133, a second quadrupole device 136 and a third quadrupole device 139, the last of which is a mass analyzer comprising one or more ion detectors 148. The first, second and third quadrupole devices may be denoted as, using common terminology, as Q1, Q2 and Q3, respectively. A lens stack 134 disposed at the ion entrance to the second quadrupole device 136 may be used to provide a first voltage point along the ions' path. The lens stack 134 may be used in conjunction with ion optical elements along the path after stack 134 to impart additional kinetic energy to the ions. The additional kinetic energy is utilized in order to effect collisions between ions and neutral gas molecules within the second quadrupole device 136 thereby generating product ions. If collisions are desired, the voltage of all ion optical elements (not shown) after lens stack 134 are lowered (assuming positively charged ions) relative to lens stack 134 so as to provide a potential energy difference which imparts the necessary kinetic energy.
[0065] Conventional triple-quadrupole systems, such as the system 100 depicted in FIG. 3B, may generally only be operated so as to provide one stage of ion fragmentation (thereby, in such operation, performing an MS.sup.2-type experiment). Under special operation, they can be configured to perform, at most, one additional stage of ion fragmentation in the vicinity of an aperture 122 of a skimmer 121. This type of operation requires proper configuration of the electrical potential applied to the skimmer and to an electrode upstream from the skimmer. Although this approach can yield a form MS.sup.3 operation, it does not allow for initial selection of a precursor ion but, instead, causes fragmentation of all ion species as they cross the skimmer interface.
[0066] Other types of mass spectrometer systems can provide capability to perform general MS.sup.n experiments and the flexibility to adapt such experiments to particular samples or conditions. FIG. 3C schematically illustrates one such system, which is marketed and sold under the Thermo Scientific.TM. Orbitrap Fusion.TM. mass spectrometer name by Thermo Fisher Scientific of Waltham, Mass. USA. The system 200 illustrated in FIG. 3C is a composite system comprising multiple mass analyzers including: (a) a dual-pressure linear ion trap analyzer 240 and (b) an Orbitrap.TM. mass analyzer (a type of electrostatic trap analyzer) 260. A key performance characteristic of this instrument is its high duty cycle, which is realized by efficient scan scheduling, so that master scans are acquired with one analyzer while data-dependent MS.sup.n scans are acquired with the other analyzer. In addition to the two mass analyzers, the system 200 further includes a quadrupole mass filter 233 which may be employed for precursor ion selection, a C-trap ion trap 250 which is operational to route ions into the Orbitrap.TM. mass analyzer and an ion-routing multipole ion guide 209 which may be configured to either store ions or fragment ions by collision-induced dissociation (CID) and is capable of routing ions in the direction of either the C-trap ion trap 250 or the dual-pressure linear ion trap analyzer 240.
[0067] The dual-pressure linear ion trap analyzer 240 comprises a high-pressure cell portion 240a and a low-pressure cell portion 240b. The high-pressure cell portion 240a may be infused with either an inert gas for purposes of enabling ion fragmentation by collision-induced dissociation or with a reagent gas for purposes of enabling ion fragmentation by electron transfer dissociation (ETD). The low-pressure cell portion 240b is maintained under high vacuum and includes ion detectors 241 for operation as a linear ion trap mass analyzer. Thus, the system 200 provides ion fragmentation capability in either the multipole ion guide 209 or in the high-pressure cell portion 240a of the dual-pressure linear ion trap analyzer 240. The system may be operated so as to perform multiple successive stages of ion fragmentation--that is, (n-1) stages of fragmentation for MS.sup.n analysis--of ions derived from an initially introduced batch of ions by shuttling the ions or the derived ions between the multipole ion guide 209 and the high-pressure cell portion.
[0068] In operation of the system 200, ions introduced from ion source 112 are efficiently guided and focused into an evacuated chamber by stacked ring ion guide 202. A bent active beam guide 207 causes ions to change their trajectory whereas neutral molecules follow a straight-line trajectory which enables them to be vented by the vacuum system (not illustrated). The ions then pass into the quadrupole mass filter which may be operated, in known fashion, such that only ions comprising a certain pre-determined ink range or ranges pass through in the direction of the C-trap 250. From the C-trap, ions may be directed into the Orbitrap mass analyzer for high-accuracy mass analysis or may be caused to pass into the multipole ion guide 209 or the ion trap analyzer 240 for either fragmentation, mass analysis or both. After fragmentation, product ions may be routed back to the C-trap 250 for subsequent injection into the Orbitrap mass analyzer for high-accuracy mass analysis.
[0069] Invention embodiments in accordance with the present teachings may be used in conjunction with operation of any of the above-described mass spectrometer systems as well as others that are not specifically shown. For example, the invention described herein has been successfully run in conjunction with operation of a Q-Exactive.TM. mass spectrometer system, which lacks the dual-pressure linear ion trap analyzer 240 and associated detectors 241 shown in FIG. 3C and instead includes a higher-energy collisional dissociation cell (HCD cell) in the general position to the right-hand-side (as illustrated in FIG. 3C) of the C-trap 250. Thus, the a Q-Exactive.TM. mass spectrometer system essentially combines precursor-ion selection by a high-performance quadrupole mass filter with high-resolution mass analysis and detection by an Orbitrap.TM. mass analyzer. During operation, the HCD cell is used for fragmentation or storage of ions for subsequent analysis by the Orbitrap analyzer.
2. Computational Methods
[0070] As biological samples are generally very complex, a single MS spectrum can easily contain hundreds to even thousands of peaks which belong to different analytes--all interwoven over a given m/z range in which the ion signals of very different intensities overlap and suppress one other. The resulting computational challenge is to trace each peak back to a certain analyte(s). The elimination of "noise" and determination of correct charge assignments are the first step in tackling this challenge. Once the charge of a peak is determined, then one can further use known relationships between the charge states in a charge state envelope to group analyte related charge states. This information can be further used to determine molecular weight of analyte(s) in a process which is best described as mathematical decomposition (also referred to, in the art, as mathematical deconvolution).
[0071] Obviously, the computations are much more challenging in real time during an automatic top-down data dependent analysis since this should occur very fast, especially when chromatographic separation is involved. To succeed, one needs to have a data acquisition strategy that anticipates multiple mass spectral lines for each ion species and an optimized real time data analysis strategy as is described below. As a general rule, the mathematical deconvolution process should not be any slower than the mass spectrometric instrumental time for a typical tandem mass spectrometry (i.e, MS/MS or MS.sup.2) experiment or run. Typically, this requires that the deconvolution process should be accomplished in less than one second of time. In the following, the inventors describe an algorithm that achieves the required analyses of complex samples within such time constraints, running as application software. Alternatively, the algorithm could be encoded into a hardware processor coupled to a mass spectrometer instrument so as to run even faster.
2.1. Key Features of Self Consistent Map Charge Assignment Algorithm
2.1.1. Use of Centroids Exclusively
[0072] Standard mass spectral charge assignment algorithms (e.g., Senko et al., 1995) use full profile data of the lines in a mass spectrum. By contrast, the novel approach which is employed in the present methods uses centroids. The key advantage of using centroids over line profiles is data reduction. Typically the number of profile data points is about an order of magnitude larger than that of the centroids. Any algorithm that uses centroids will gain a significant advantage in computational efficiency over that standard assignment method. For applications that demand real-time charge assignment, it is preferable to design an algorithm that only requires centroid data. The main disadvantage to using centroids is imprecision of the m/z values. Factors such as mass accuracy, resolution and peak picking efficiency all tend to compromise the quality of the centroid data. But these concerns can be mostly mitigated by factoring in the m/z imprecision into the algorithm which employs centroid data.
2.1.2. Intensity is Binary
[0073] Another key departure from most existing algorithms is the encoding of intensities as binary (or Boolean) variables (true/false or present/absent) according to the present methods. The present methods only take into consideration whether a centroid intensity is above a threshold or not. If the intensity value meets a user-settable criterion based on signal intensity or signal-to-noise ratio or both, then that intensity value assumes a Boolean "True" value, otherwise a value of "False" is assigned, regardless of the actual numerical value of the intensity. Again the encoding of a numerical value as a simple binary value results in a significant data reduction. In many programming languages, a double-precision value uses eight bytes of memory storage whereas a binary (or Boolean) value uses just a single byte. Also, comparing Booleans is intrinsically much faster than comparing double-precision variables. A well known disadvantage of using a Boolean value is the loss of information. However, if one has an abundance of data points to work with--for example, thousands of centroids in a typical high resolution spectrum, the loss of intensity information is more than compensated for by the sheer number of Boolean variables. Accordingly, the inventors' approach and, consequentially, the algorithms taught herein, exploit this data abundance to achieve both efficiency and accuracy.
[0074] Nonetheless, additional accuracy without significant computational speed loss can be realized by using, in alternative embodiments, approximate intensity values rather than just a Boolean true/false variable. For example, one can envision the situation where only peaks of similar heights are compared to each other. One can easily accommodate the added information by discretizing the intensity values into a small number of low-resolution bins (e.g., "low", "medium", "high" and "very high"). Such binning can achieve a good balance of having "height information" without sacrificing the computational simplicity of a very simplified representation of intensities. As a further example, given an observed centroid of interest and a putative charge state, Z, if a neighboring centroid (either a neighbor that is putatively part of an isotopic cluster or charge state distribution with the given centroid) has a very reduced intensity, say 10.times. smaller than the given centroid, one should not count this neighbor towards the score for that putative charge state Z. Excluding vastly smaller neighbors can improve the robustness of the charge assignment against random noise interference.
[0075] In order to achieve computational efficiency comparable to that using Boolean variables alone while nonetheless incorporating intensity information, one approach is to encode the intensity as a byte, which is the same size as the Boolean variable. One can easily achieve this by using the logarithm of the intensity (instead of raw intensity) in the calculations together with a suitable logarithm base. One can further cast the logarithm of intensity as an integer. If the logarithm base is chosen appropriately, the log(intensity) values will all fall comfortably within the range of values 0-255, which may be represented as a byte. In addition, the rounding error in transforming a double-precision variable to an integer may be minimized by careful choice of logarithm base. The inventors have found that using a logarithm base of 1.1 works very well. Thus each log level differs by only 10% from its two nearest log levels. Stated differently, the loss of precision from transforming the raw intensity to single-byte form is only 10%. Since most experimental precision in intensity exceeds 10%, and the difference we are interested in is more than 10.times., the precision of 10% is sufficient.
[0076] To further minimize any performance degradation that might be incurred from byte arithmetic (instead of Boolean arithmetic), the calculations may that are employed to separate or group centroids only need to compute ratios of intensities, instead of the byte-valued intensities themselves. The ratios can be computed extremely efficiently because: 1) instead of using a floating point division, the logarithm of a ratio is simply the difference of logarithms, which in this case, translates to just a subtraction of two bytes, and 2) to recover the exact ratio from the difference in log values, one only needs to perform an exponentiation of the difference in logarithms. Since such calculations will only encounter the exponential of a limited and predefined set of numbers (i.e. all possible integral differences between 2 bytes (-255 to +255), the exponentials can be pre-computed and stored as a look-up array. Thus by using a byte representation of the log intensities and a pre-computed exponential lookup array, computational efficiency will not be compromised.
2.1.3. Mass-to-Charge Values are Transformed and Assembled into Low-Resolution Bins and Relative Charge State Intervals are Pre-Computed Once and Cached for Efficiency
[0077] Another innovation of the approach taught in the present disclosure is in transformation of m/z values of mass spectral lines from their normal linear scale in Daltons into a more natural dimensionless logarithmic representation. As may be seen from the detailed discussion following, this transformation greatly simplifies the computation of m/z values for any peaks that belong to the same protein, for example, but represent potentially different charge states. This transformation involves no compromise in precision. When performing calculations with the transformed variables, one can take advantage of cached relative m/z values to improve the computational efficiency.
2.1.4. Simple Counting-Based Scoring and Statistical Selection Criterion
[0078] Combining the encoding of centroid intensities as Boolean values, and the transformation of m/z values, the present approach encodes the whole content of any mass spectrum in question into a single Boolean-valued array. The scoring of charge states reduces to just a simple counting of yes or no (true or false) of the Boolean variables at transformed m/z positions appropriate to the charge states being queried. Again, this approach bypasses computationally expensive operations involving double-precision variables. Once the scores are compiled for a range of potential charge states, the optimal value can easily be picked out by a simple statistical procedure. Using a statistical criterion is more rigorous and reliable than using an arbitrary score cutoff or just picking the highest scoring charge state.
2.1.5. Iterative Process to Achieve Optimality and Defined by Complete Self Consistency of Charge Assignment
[0079] The final key feature of the present novel approach is the use of an appropriate optimality condition that leads the charge-assignment towards a solution. The optimal condition is simply defined to be most consistent assignment of charges of all centroids of the spectra. Underlying this condition is the reasoning that the charge state assigned to each centroid should be consistent with those assigned to other centroids in the spectrum. The present algorithm implements an iterative procedure to generate the charge state assignments as guided by the above optimality condition. This procedure conforms to accepted norms of an optimization procedure. That is, an appropriate optimality condition is first defined and then an algorithm is designed to meet this condition and, finally, one can then judge the effectiveness of the algorithm by how well it satisfies the optimality condition. Most existing approaches lack this logical framework, and their theoretical merits are therefore difficult to assess objectively.
2.2. Details of Decomposition Algorithm
[0080] The inventors have developed methods that, inter alia, are capable of assigning self-consistent charge states to mass spectral lines and decomposing complex mass spectra comprising overlapping information pertaining to several analytes into multiple sets of lines, wherein each set of lines corresponds to a respective analyte. FIG. 4 is an overview flowchart of a general set of steps in accordance with the present teachings for accomplishing these results. Several operations listed in FIG. 4 are illustrated in greater detail in other flow diagrams of the accompanying set of drawings.
2.2.1. High-Level Methods
[0081] As shown, FIG. 4 depicts at least two general execution or workflow pathways. According to a first general execution pathway or workflow--here termed "File-Deconvolution Workflow" only for purposes of reference--the methods of the present teachings are employed for the purposes of analyzing and possibly interpreting previously collected and stored mass spectral data. According to a second general execution pathway or workflow--here termed "Data-Dependent-Acquisition Workflow" only for purposes of reference--the methods of the present teachings are employed in a "real-time" or "online" fashion at the time that mass spectral data is being acquired and at least some aspects of the course of data acquisition are determined or controlled based on the results of computations or algorithms in accordance with the invention. Some steps illustrated in FIG. 4 are common to both of the above-defined execution pathways and are denoted in FIG. 4 by boxes defined by double lines. Other steps are exclusive to the Data-Dependent-Acquisition Workflow pathway and are denoted by boxes defined by dashed lines. At least one step--step 312--is exclusive to the File-Deconvolution Workflow pathway and is denoted by a box defined by a dotted line. Finally, steps 920 and 925, which are depicted by boxes with single solid lines, are optional with regard to the Data-Dependent-Acquisition Workflow but will generally be performed in conjunction with the File-Deconvolution Workflow. The File-Deconvolution Workflow will typically follow the general pathway indicated by dotted arrows at the lower portion of FIG. 4.
[0082] Still with reference to FIG. 4, the File-Deconvolution Workflow commences at step 312, in which previously acquired and stored mass spectral data in the form of at least one mass spectrum is input from an electronic storage device and made available for use in subsequent analysis. The mass spectrum may be an MS.sup.1 spectrum, an MS.sup.2 spectrum or, generally, any form of MS.sup.n spectrum. By contrast, the Data-Dependent-Acquisition Workflow begins at step 310 in which a sample is introduced into a mass spectrometer and is subsequently ionized in step 315. The sample introduction may be from a chromatograph, by means of injection or by other means. An MS.sup.1 spectrum of the ions is generated in step 320. It is assumed that steps similar to steps 310, 315 and 320 would have been formed in the generation of the data that is input in the alternative pathway that includes step 312.
[0083] In step 325, new peak centroids (i.e., centroids not previously identified during the experiment in question or in a prior MS.sup.1 spectrum of the input data); are identified and added to a list of centroids. In the next step 400, the m/z values of the centroids are transformed and the intensity data is converted to a Boolean-valued data array in which bins are assigned over the transformed m/z scale. The step 400 comprises a first substep 420 of constructing and populating a Boolean occupancy array and a second substep 460 of constructing and populating a relative separation matrix (see FIG. 5). The details of these substeps are described in greater detail in a subsequent section of this disclosure.
[0084] In step 510, which only applies to the Data-Dependent-Acquisition Workflow, centroids of analytes for which MS.sup.n analysis has been completed are removed from a "selection list" and added to an "exclusion list". The selection list includes one or more mass-to-charge (m/z) values or value ranges which are to be analyzed or which are being analyzed by the mass spectrometer by tandem mass analysis (MS/MS analysis) or possibly by MS.sup.n analysis, each such m/z value or range corresponding to a chemical component of the sample as identified by the methods of the present teachings. The exclusion list includes one or more mass-to-charge (m/z) values or value ranges which are to be excluded from future analysis either for the duration of an experiment or for a temporary time period during the experiment. The temporary time period, if employed, may be determined according to methods of the present teachings, as described in a subsequent portion of this disclosure. Alternatively for direct infusion or flow injection analysis, the one or more mass-to-charge values or value ranges which are to be excluded from future analysis can be performed on signal rank basis. Centroids depicting low-intensity mass spectral lines are removed from the exclusion and selection lists in step 515. The removed m/z values or ranges may be later added to the selection list if the corresponding mass spectral signal intensities subsequently increase during an experimental run.
[0085] In step 600 tentative charge states assignments are made as outlined in FIG. 7 and further discussed below with reference to that figure. Then, in step 700, the tentatively assigned charge states are adjusted and final charge state assignments are made using requirements for self-consistency. The details of this process are outlined in FIG. 8 and further discussed below with reference to that figure. Once the final charge state assignments have been made, the experimentally observed centroids are decomposed into analyte-specific clusters in step 800 using information derived from the spacing of isotopic clusters. The details of step 800 are illustrated in FIG. 9 and described further with reference to that figure.
[0086] The execution of the method 300 may branch at step 910 along one of two possible execution paths indicated by solid-line arrows and dotted-line arrows, respectively. If real-time tandem mass spectrometry is being controlled by the results of the prior data analysis, then the method execution may follow the "N" branch (denoted by solid lines) from step 910 directly to step 915, thereby skipping steps 920 and 925. Alternatively, if more data analysis operations are to be conducted upon MS.sup.1 data measured in step 320 or if data was previously input in step 312, then the "Y" branch of step 910 is followed whereafter molecular weights may be calculated or analyte species identified (step 920) and the results of the calculations may be reported or stored (step 925). As determined at step 915, if tandem mass spectrometry is to be performed, as will generally be true if the Data-Dependent-Acquisition Workflow execution path is being followed, then the method branches along the "Y" branch to step 930. Otherwise, execution proceeds, along the "N" branch to step 960.
[0087] Considering, now, the "online" execution path illustrated on the right-hand side of FIG. 4, a determination is made in step 930 if centroids attributable to known adducts are present in the considered set of centroids. If so (the "Y" branch of step 930) then the centroids corresponding to adduct species or to otherwise-modified species (for instance, species generated from loss of a neutral molecule) are added to the exclusion list in step 935. Otherwise, step 935 is bypassed. Step 940 is the commencement of top-down analysis in which a representative peak is selected for fragmentation from each of top P analyte-specific clusters determined in step 800. The following steps 945, 950 and 955 are conventional steps of, respectively, isolating ions of the m/z ratios corresponding to the selected centroids, fragmenting the isolated ions and performing a mass analysis (MS.sup.2) of the product ions.
[0088] Execution of the method 300 may end after step 960, if either the mass spectral experimentation or the data analysis is complete. Otherwise, execution passes back to either step 310 at which the next portion of sample is introduced to the mass spectrometer or to step 312 at which the next portion of mass spectral data is input.
2.2.2. Building a Boolean-Valued Occupancy Array
[0089] FIG. 6 shows the details of the step 420 of building an occupancy array, [O.sub.k]. The values of the array are Boolean variables and the indices of the array correspond to the discretized transformed mass/charge values. The step 420 takes, as input, a collection of centroids, C.sub.i (1.ltoreq.i.ltoreq.L) where L is an observed number of mass spectral lines. Each C.sub.i is characterized by its mass/charge (m/z).sub.i, its intensity I.sub.i, its signal-to-noise ratio (S/N).sub.i and its resolution R.sub.i. Next, a filtering of the centroids is performed (step 422) by collecting the subset {} of centroids which pass a user settable criterion of intensity and signal to noise thresholds. Next, in step 424, a mass/charge transformation is performed on each C.sub.i in {} by taking the natural log of the mass/charge value minus that of the mass of a proton, M.sub.proton as in Eq. 1.
T(m/z).sub.i=ln((m/z).sub.i-M.sub.proton) Eq. (1)
[0090] After this transformation, each centroid, C.sub.i in the subset {} is characterized by T(m/z).sub.i, I.sub.i, (S/N).sub.i and R.sub.i. The greatest, T(m/z).sub.High, and the smallest, T(m/z).sub.low, values of the T(m/z) values from subset {} are noted in step 426. This information is then used to create the array [O.sub.k] of values, where each element of the array is a Boolean-valued "occupancy" which maintains a record of whether or not a "signal" is deemed to occur at the respective transformed mass-to-charge value, T(m/z).sub.k, associated with the array element. Upon creation, each element, O.sub.k, of the array is initialized to the Boolean value "FALSE". The number of discrete elements in the array, or "length" of the array [O.sub.k] is denoted as L.sub.occs, which is determined as
L occs = ( T ( m / z ) high - T ( m / z ) low ) D Eq . ( 2 ) ##EQU00001##
where D is the width of each bin in the array and is D=MA/10.sup.6, where MA, typically 10, denotes a user settable parameter of the mass accuracy of the spectrum of interest.
[0091] After creation and initialization, the array [O.sub.k] must be populated (performed in step 436) with meaningful values. The elements of the occupancy array [O.sub.k] are indexed by the variable, k(1.ltoreq.k.ltoreq.L.sub.occs) whereas the elements of the filtered centroid subset {} are indexed by the variable, i. The latter indices are converted into corresponding k-values in step 430, in which, for each centroid, C.sub.i, in the subset {}, the corresponding index, k.sub.i, is determined as follows:
k i = ( T ( m / z ) i - T ( m / z ) low ) D Eq . ( 3 ) ##EQU00002##
and is rounded to the nearest integer (the rounding operation is indicated by the operator "ROUND[ ]" in FIG. 6. If the resolution, R.sub.i, of the centroid C.sub.i is available (some spectra such as those collected in the centroid mode, may not have this defined), then the "Y" branch of the decision step 432 is followed, in which the additional indices k.sub.i.sup.Lo and k.sub.i.sup.Hi are calculated in step 434a as follows
k i Lo = ( T ( m / z ) i - 0.5 ( R i ) ) D Eq . ( 4 a ) k i Hi = ( T ( m / z ) i + 0.5 ( R i ) ) D Eq . ( 4 b ) ##EQU00003##
with values rounded to the nearest integer. For mass spectrometer instruments that include Fourier-Transform based mass analyzer, such as instrument systems employing an Orbitrap.TM. electrostatic trap mass analyzer, the instrument acquisition software automatically calculates the centroid resolution values, R.sub.i, and, thus, these values become attributes of the centroids. These, along with other attributes, are captured in the raw file that the instrument generates during the measurement procedure and, thus, the calculation algorithms in accordance with the present teachings may simply input these values from the file. For ion-trap-type instruments, the centroid information is not as complete in the raw file and, in such situations, the user can enter an appropriate resolution value. In cases in which R.sub.i is not available, these indices are instead set to k.sub.i-1 and k.sub.i+1, respectively, in step 434b. Finally, in step 436, array values are all set to the Boolean value "TRUE" for indices ranging from k.sub.i.sup.Lo to k.sub.i.sup.Hi, namely
O.sub.k:=TRUE;k.sub.i.sup.Lo.ltoreq.k.ltoreq.k.sub.i.sup.Hi Eq. (5)
2.2.3. Building a Relative Separation Matrix (RSM)
[0092] As shown in FIG. 5, step 460 is the step of constructing a relative separation matrix and is the second sub-step of the general step 400. The creation of a relative separation matrix is motivated by observation that, given two centroids C.sub.1 and C.sub.2, then, if they belong to the same protein isotopic peak but differ just in charge states, then their mass/charge values are related as
|z.sub.1|.times.((m/z).sub.1-M.sub.proton)=|z.sub.2|.times.((m/z).sub.2-- M.sub.proton) Eq. (6)
in which z.sub.1 and z.sub.2 are the charge state of the centroids C.sub.1 and C.sub.2 respectively, and M.sub.proton is the mass of a proton. The charge state values, z.sub.1 and z.sub.2, will generally be either all positive or all negative depending on the mode of ionization used in the mass spectrometer instrument conducting the analyses. Performing the transformation as described in Eq. (1) yields the relationship that
T(m/z).sub.1=T(m/z).sub.2+ln|z.sub.2/z.sub.1| Eq. (7)
[0093] The important property of Eq. (7) is that the transformed T(m/z).sub.i values at different charge states are related by an additive factor that is independent of the transformed values. Thus one can pre-compute and cache the quantities ln(z.sub.2/z.sub.1) as a matrix that can be reused in subsequent calculations by simple look-ups by pre-computing the RSM. The absolute values of the charge states will generally range between unity and some maximum value, |Z.sub.max| or, more specifically, 1.ltoreq.z.sub.1, z.sub.2.ltoreq.|Z.sub.max|. The last step is to discretize the ln|z.sub.2/z.sub.1| matrix by dividing by D as in Eq. (4):
RSM z 1 , z 2 = ln z 2 / z 1 D Eq . ( 8 ) ##EQU00004##
[0094] The limits of the matrix, determined by Z.sub.max, may be set by a user anticipating the maximum and minimum charge states that will be encountered in a set of spectra. Alternatively, Z.sub.max may be a pre-determined or pre-calculated value. Typically, the absolute values of the charge states range from 1 to 50 for a top down experiment. So in such a case, RSM will be a 50.times.50 anti-symmetric matrix.
2.2.4. Building a Scoring Distribution for Each Centroid and Using it to Assign Tentative Charge States
[0095] Before a self-consistent set of charge assignments may be determined by iteration (in step 700, FIG. 8), a reasonable initial set of tentative charge assignments must be formulated. The step 600, the details of which are shown in FIGS. 7A and 7B, generates this initial set of by assigning a likely charge state to various of the centroids of subset {}. Steps 601-615 consider each such centroid, in turn, and, for each considered centroid, step through various putative values of putative charge state, z, from a minimum charge state value, Z.sub.min up to a maximum charge state value, Z.sub.max. For example, putative charge states from z=1 through z=50 might be considered for each centroid. For each combination of a centroid, C.sub.i (as selected in step 601 or step 615) and a putative charge state z.sub.i, (as set in either step 603 of 609), a set of "probe indices" k.sub.p(C.sub.i,z.sub.i) is calculated in step 605. The probe indices are a set of k-values that reference bins of the occupancy array, [O.sub.k], for purposes of testing for "TRUE" values at each of these indices. The k.sub.p(C.sub.i,z.sub.i) matrix includes a first row having the indices corresponding to the discretized T(m/z).sub.i values of the (+/-m) theoretical isotopic peaks of the selected centroid C.sub.i. For example, if m=5, the probe indices corresponding to the (+/-5) theoretical isotopic peaks are the transformed values of:
( m / z ) i - ( 5 ) ( 1.003 ) z , ( m / z ) i - ( 4 ) ( 1.003 ) z , , ( m / z ) i + ( 5 ) ( 1.003 ) z ##EQU00005##
The k.sub.p(C.sub.i,z.sub.i) matrix also includes two additional rows, the elements of which are calculated by generating, for each of the 2m probe indices in the row described above, an additional probe index corresponding to expected location of the z-1 peak and another additional probe index corresponding to the expected location of the z+1 peaks. Specifically, the indices [k.sub.p(C.sub.i,z.sub.i)+RSM(z.sub.i-1, z.sub.i)] and [k.sub.p(C.sub.i,z.sub.i)+RSM(z.sub.i+1, z.sub.i)] are generated, where RSM is the pre-computed and cached relative separation matrix described above. Note that the k.sub.i index of the centroid C.sub.i, itself, is excluded from the probe indices matrix because, at this stage of execution of the algorithm, it is given that the occupancy array contains a value of "TRUE" at such index. Similarly, one can also increase the probe matrix in include more charge states of (z-m, z-m+1, . . . , z+m-1, z+m) instead of just (z-1, z, z+1) as described above.
[0096] In step 607, a score value is calculated for each tested z value and each centroid C.sub.i. The set of scores is used to generate a scoring distribution for each z value. Each score S(z) is calculated by summing, for each possible value of z.sub.i, the experimentally-derived occupancy values. Specifically, the score for each value of z is determined by
S(z)=.SIGMA.O.sub.k/C Eq. (9)
where the sum is over k of k.sub.p(C.sub.i,z.sub.i) such that (1.ltoreq.k.ltoreq.L.sub.OCCS) and C is just the number of such k's. In other words, the score at z is just the fraction of k.sub.p(C.sub.i,z.sub.i) indices that are "occupied" by a measured above-threshold mass spectral signal (i.e., a value of "TRUE") as coded in occupancy array constructed in step 420 (FIG. 5). Thus, the calculation in step 605 is a form of streamlined approximate "inner product" calculation, with the greatest possible score of any single calculation being unity. The score distribution is formed by summing the scores for each value of z from the lowest to the highest user settable limits. Using our example of 1 and 50 as the low and high limits, we will end up with a distribution of 50 scores for each centroid. Decision step 611 determines, for each centroid, if the maximum value of z has been considered. If not then execution returns to step 605 for calculation of probe indices with a new value of z (as set in step 609). Otherwise, execution branches to decision step 613 which determines if the last centroid in the subset {} has been considered. If not, then execution proceeds to step 615 in which the next centroid is selected and then to step 603 in which the z-value is reset to its initial state. Otherwise, execution proceeds to step 617 (FIG. 7B) at which the process of formulating tentative charge assignments is begun.
[0097] Steps 617-635 shown in FIG. 7B illustrate the process of making tentative charge assignments using the scoring distributions previously generated in multiple iterations of step 607 (FIG. 7A). In step 617, the first centroid is selected; later the choice of centroid being considered is updated in step 635. After either of these two steps, the mean, .mu., and standard deviation, .sigma., of the respective scoring distribution is computed in step 620. Thus, repeated iteration of steps 620-635 causes these statistical measures to be computed for the scoring distribution associated with each centroid. In step 625, if there are any scores larger than mean .mu.+3.sigma., then the z-value with the largest score is assigned to the centroid as the initial charge-state assignment. If there are no scores larger than .mu.+3.sigma., then a null value as provided as the initial assignment for the centroid in question.
2.2.5. Achieving Optimality of Completely Self Consistent Charge Assignment by Iteration
[0098] After the tentative charge-state assignments have been made in step 600, execution of the method 300 (FIG. 4) proceeds to step 700 in which the tentative charge state assignments are adjusted. Details of the step 700 are shown in FIG. 8. The optimal condition is simply defined to be most consistent assignment of charges of all centroids of the spectra. Underlying this condition is the reasoning that the charge state assigned to each centroid should be consistent with those assigned to other centroids in the spectrum.
[0099] The details of the step 700 shown in FIG. 8 implement an iterative procedure to generate the charge state assignments as guided by the above optimality condition. Each centroid with a non-null assignment (as assigned in step 625 of FIG. 7B) is considered, in turn. Each of these may be associated with a set of probe indices as indicated in step 605 of FIG. 7A. This process is repeated for all centroids with a non-null assignment, and a new charge state distribution is determined at each probe index. Specifically, in step 702, the first or next centroid having a non-null tentatively assigned charge state, z.sub.t, is selected. In step 704, the probe indices for the centroid in question are generated, as previously described with respect to step 605 of FIG. 7A, if necessary. Then, in step 706, a charge state is calculated at each of the probe indices corresponding to the centroid in question, assuming that the charge state of the selected centroid is z.sub.t. For each probe index, a record is kept of how many times each charge state is calculated for that probe index. Before beginning each loop through steps 702-710, these records are cleared (re-set zero) in step 701. Thereafter, during each loop, each time that a charge state is calculated for a probe index in step 706, the number of times that the charge state has been so calculated at that probe index is incremented. If, at step 710, there are additional centroids with a non-null assignment, then execution returns to step 702 and the next such centroid is selected.
[0100] After the last centroid has been considered, execution branches to step 712. In step 712, the number of occurrences of each charge state (as calculated in step 706) are tabulated at each probe index, thereby generating a charge state distribution for each probe index. Using the new charge-state distributions, a "charge assignment by majority" (CAM) is obtained in step 714 by adjusting tentative charge state at each probe index so at to equal the charge state with the highest number of tabulated at the respective index. The set of all such CAM charge assignments forms an array of values--the charge assignment by majority array.
[0101] The charge assignments are considered to be inconsistent if, at step 716, the values of the CAM array differ from the charge-state values used in the generation of the CAM array. By contrast, a completely self consistent charge assignment is defined as the assignment of charge at each index such that it is in complete concordance with that from the CAM array resulting from it. Thus, at step 716, the adjusted tentative charge states are compared to their prior values. If there has been a change that is greater than a certain tolerable limit, then the charge assignments are not self-consistent. In this case, the "N" branch of step 716 is followed and execution returns to step 701 whereby a new set of calculations are performed so as to achieve self consistency. Thus, a set of repetitions of the CAM array determination are performed by using the charges from each CAM to generate a subsequent CAM. Optimality is achieved when convergence is achieved--that is, the CAM generates the same CAM.
[0102] In practice, one might not achieve exact convergence by this procedure. However, the inventors' experience shows that, after a few iterations, the incidence of non-concordance becomes negligibly small and thus one can stop the iteration at a very good charge-state assignment. Accordingly, in step 716, convergence is considered to be operationally achieved when the difference in successive CAM arrays is within a certain tolerable limit (i.e., within a certain tolerance). In this case, execution branches to step 718 at which the final self-consistent charge state and each centroid is set to be equal to the tentative charge state at which the operational convergence occurred.
2.3. Determination of Analyte-Specific Clusters
[0103] The clustering approach starts with the clustering criterion defined by Eq. (10), in which the number of C.sup.13 non-monoisotopic peaks, .DELTA.N.sup.C13, that are reasonably expected to occur within a restricted m/z range is given by
Number of C 13 Peaks = [ ( z 1 ( m / z ) 1 ) - ( z 2 ( m / z ) 2 ) ] - ( z 1 - z 2 ) M proton M C 13 Eq . ( 10 ) ##EQU00006##
in which z.sub.1 and z.sub.2 are the charge states assigned to mass spectral lines, (m/z).sub.i and (m/z).sub.2 are the experimentally measured mass to charge values, M.sub.C13 is the mass difference between the isotopes of carbon, C.sup.13 and C.sup.12, and M.sub.proton is the mass of a proton. The error (.delta.) or standard deviation associated with the calculation is computed from a user-supplied value of accuracy, a, which is defined in ppm (e.g., see FIG. 11B), as well as the resolutions R.sub.1 and R.sub.2 of the centroids under consideration as described in Eq. (11)
.delta. = 1 M C 13 { ( .alpha. 2 + 1 / 2 R 1 2 ) ( z 1 ( m / z ) 1 ) 2 + ( .alpha. 2 + 1 / 2 R 2 2 ) ( z 2 ( m / z ) 2 ) 2 } Eq . ( 11 ) ##EQU00007##
To determine if any two centroids (peaks) belong to the same analyte-specific cluster (associated with a particular bio-molecule such as a protein), the theoretical .DELTA.N.sup.C13 value is calculated using Eq. (10). If the calculated .DELTA.N.sup.C13 value is an integer within the measurement error, as computed as in Eq. (11), then the two centroids are considered to belong to the same analyte-specific cluster, provided that the number of C.sup.13 peaks does not exceed a user defined limit (typically 10 to 15). Of course, one skilled in the art can easily use a multitude of other similar statistical tests such as the z-test, or t-test to determine whether the two peaks differ by an integral number of C.sup.13, given the uncertainties of their m/z's as encoded in .alpha. and the resolution R's.
[0104] The step 800 of decomposing the mass spectral lines into analyte-specific clusters shown in FIG. 9 makes use of the above reasoning. The step 800 considers centroids for which charge assignments have been made, as previously described. Step 805 begins with the charge-assigned centroid that has the greatest experimentally-observed intensity. The so-selected centroid is then uses as a "seed" for the first cluster. Then, proceeding in order of decreasing intensity (steps 810 through 830), a check is made to determine if the next centroid in the list clusters with the seed centroid of this cluster. This check is performed by first calculating .DELTA.N.sup.C13 and its error, .delta., using Eq. 10 and Eq. 11, respectively (step 815). If it is noted, in the decision step 820, that the presently-calculated value of .DELTA.N.sup.C13 is an integer, within the calculated error, then execution follows along the "Y" branch to step 825 in which the centroid under consideration is grouped together with the seed centroid as belonging to a single cluster. If not, then the "N" branch is followed such that, in step 830, if there are remaining non-seed centroids, execution returns to step 810 in which the next-intense non-seed centroid is selected for cluster checking. If, at step 830, the list of non-seed centroids is exhausted (that is, there are no remaining non-seed centroids having intensities less than the presently considered centroid) but there are remaining non-clustered centroids (determined in step 835), then execution returns to step 805 in which a new cluster is started with using the most-intense non-seed centroid as the new seed. Subsequent iterations check against all cluster seeds created and create new clusters if the new centroid does not cluster with any preceding clusters.
[0105] Finally, in step 840, a simple heuristic is employed to determine if any cluster created by the clustering algorithm is "healthy". In our initial implementation, we use the simple rule that a "healthy" cluster must have at least four distinct charge states or at least N (user settable, but defaulting to 15) member centroids. We filter out clusters that are not "healthy" according to these criteria. After the removal of "unhealthy" clusters, the remaining are the final analyte-specific clusters, each representing a different bio-polymer or other high-mass compound.
2.4. Protein Molecular Weight Calculations
[0106] One of the more common ways of calculating the mono-isotopic molecular weight, M.sub.mono, of a protein from an experimental high-resolution spectrum is to use the so-called "Averagine" method (Senko, M. W, Beu, S. C. and McLafferty, F. W., 1995, Determination of monoisotopic masses and ion populations for large biomolecules from resolved isotopic distributions. J. Am. Soc. Mass Spectrom., 6: 229-233), which itself is an extension of an earlier method for low-resolution data (Zubarev, R. A. and Bonddarenko, P. V., 1991, An a-priori relationship between the average and monoisotopic masses of peptides and oligonucleotides. Rapid Commun. Mass Spectrom., 5: 276-277). Briefly, the Averagine method first models an experimental isotopic cluster by a hypothetical model molecule--the "Averagine" molecule. By optimizing the fit between the experimental and the theoretical isotopic distribution, one can arrive at an estimate of the mono-isotopic mass desired.
[0107] The Averagine technique is used within various mass spectrometry peak decomposition and analysis algorithms that are commercially available from Thermo Fisher Scientific of Waltham Mass. USA. Although the Averagine method has been highly successful, the present inventors are motivated to develop a different approach based on the following considerations: (1) Calculation speed. Averagine fitting may be time consuming, a not insignificant consideration for real-time applications, such as those described herein in which decisions are automatically made, in real time, regarding which of several observed ions to fragment. It should be noted, however, that, in situations where a large number of spectral fits are not required, calculation speed may not pose any concern; and (2) Mass accuracy. For a larger molecular weight protein whose signature appears in a crowded spectrum, the corresponding isotopic cluster tends to be noisy and incomplete (missing isotopes--especially the edges, missing charge states etc). The use of an Averagine fit may not be appropriate in such instances.
[0108] The present inventors therefore here teach an approach that promises to produce a robust estimate of the mono-isotopic mass that is very easy to calculate and more resistant to noise and artifacts. The main goal is robustness and precision, accepting the compromise that the estimate might be biased. In short, the estimate might not be the "true" mono-isotopic mass (but nonetheless very close to it), but it should be robust/stable in face of experimental imperfections. The error should deviate from the true mono-isotopic mass by either 0 or +/-1 dalton (1 Da) precisely, after taking mass accuracy into consideration. The inventors here point out that robustness, in many cases, is more important than accuracy. For example, if one were to build a molecular weight database based on experimental data, the ability to produce the same answer both while building the database and while testing the database by new data is generally desired, even if the estimates are potentially off by 1 Da from the true molecular weight but nonetheless are identical from experiment to experiment.
[0109] The approach starts with three simple observations: (1) the isotopic patterns for most proteins are due to the C.sup.12/C.sup.13 binomial distribution and all the other isotopes are of too low an abundance to warrant consideration; (2) the mode (i.e., the peak having the greatest intensity) of a binomial distribution is a very robust feature of the binomial distribution compared to either the average, the standard deviation, or the exact boundaries of the distribution, and (3) for the binomial distribution, the mode is located less than 1 Da to the left of the average (see Table 1 in FIGS. 10A, 10B, 10C, and 10D). This means that the mode is a very usable replacement for the average, which itself is more difficult to estimate for more noisy data. For example, a distribution truncated at the edges will give rise to an unreliable average estimate while the mode, unless the distribution is highly distorted, is very stable against such truncations.
[0110] The starting point for the calculation is defined by M, the observed mode of an isotopic cluster. Zubarev's approach to calculate the first approximation of the monoisotopic mass is then employed where:
M.sub.1=M.times.0.999316 Eq. (12)
[0111] The second approximation of the monoisotopic mass is then defined by:
M.sub.2=M-n.times.1.003 Eq. (13)
where n is the smallest integer such that M.sub.2.gtoreq.M.sub.1. Finally, in the calculation of the monoisotopic mass, M.sub.mono, if there is an experimental peak of the cluster which is within 1 Dalton greater than M.sub.2 then:
M.sub.mono=M.sub.2+1.003 Eq. (14a)
otherwise,
M.sub.mono=M.sub.2 Eq. (14b)
[0112] This method of calculating the mono-isotopic mass has been incorporated in the results illustrated herein. The inventors' results show that the predictions compare very favorably to those predicted by the Averagine method. For large proteins, testing on standard proteins indicates that the mono-isotopic mass estimate is stable. In addition, a cluster molecular weight is also calculated for closely related peaks or proteoforms. We term the result of such a calculation as the "Cluster Molecular Weight". After all the proteoforms have been discovered in a batch, a cluster analysis of all the proteoforms is performed using the more discriminatory error function:
Error=min|w.sub.1-w.sub.2-N.times.1.003| Eq. (15)
over -3.ltoreq.N.ltoreq.3. If Error<0.5 (w.sub.1+w.sub.2).times.10 ppm, then w.sub.1 and w.sub.2 should be considered equivalent. Each proteoform will then be mapped into clusters of equivalent proteoforms represented by a consensus monoisotopic mass. This mass is termed and stored as "consensus MW".
2.5. Program Input and Output
[0113] FIG. 11A shows the starting page (i.e., a visual display screen capture) of a post-data-acquisition version of a computer program that employs the data dependent methods described herein. On the left hand side of the display illustrated in FIG. 11A, the "Raw File" box serves as the input line for the mass spectrometry data file to be processed. The "Batch Mode" check box can be enabled, thereby allowing a user to process multiple data files, while the "Auto Scan Increment" check box is used to enable processing of consecutive spectra. Results from the post-data-acquisition version of the program can be plotted in a display by the user enabling the "Plot Deconv" check box. The minimum and maximum spectrum (scan) number to process is set by the "Scan buttons" which directly default to the file length (in scans) or which can be set by the user.
[0114] Output can be controlled as seen in the lower left hand side of FIG. 11A, by causing results to be output to a peak list and by the user specifying the output as either MS1 or MS2 type data (in csv file format). The "Mass Tol" parameter governs how tightly the mono-isotopic masses found by are clustered across different scans (each "scan" essentially being a measurement of a respective mass spectrum at a respective time). For each scan, the deconvolution algorithm produces a list of mono-isotopic masses corresponding to the deconvoluted proteins it has discovered. But each scan is processed independently. As a result, a protein may appear over many scans, and the algorithm will calculate its mono-isotopic mass for each scan independently. In such a case, there might be scan-to-scan differences in the calculated isotopic mass, even for the same protein. The main factor contributing to the variation in mass is data quality. For example, for less abundant proteins, the isotopic clusters tend to be poorly defined and variable from scan to scan, leading to variation in the determined mono-isotopic mass. For most cases, the differences in mass for the same protein are all multiples of the 1.003 Dalton, with the multiples less than 3.times.. Sometimes, especially for larger proteins (30KD), that multiple could be as large as 10.times.. The mass tolerance (Mass Tol) parameter limits how much such variation is considered to be acceptable and defaults to 3; however this parameter can be set by the user.
[0115] Output can also be produced in a .puf file format for input into the ProSight.TM. PC protein identification program. Details of the spectral decomposition results (also referred to herein as "deconvolution" results) can also be stored in a .csv file format for further data analysis. The deconvolution summary in the "Results" tab lists the data file(s) and scan(s) analyzed to produce the report. Moving down the tab are the total number of centroids detected along with the number filtered as part of the program. The percentage of peaks successfully receiving charge-state assignments is found in the "Zscape" box along with a comparison to results (indicated by "XT" on the results tab illustrated in FIG. 11A) as calculated by one of the leading existing deconvolution programs (known as Extract) currently used by those skilled in the state-of-the-art. The "both assigned" and "concordance" boxes measure the agreement between the two programs. Moving to the bottom of the "Results" tab, the percentage of cluster assigned and the total number of unique proteins deconvoluted are shown. An expanded view of this tab is shown in FIG. 11D.
[0116] Two of the tabs located on the right hand side of the display shown in FIG. 11A provide for choosing the assignment and clustering parameters associated with the deconvolution process. In FIG. 11B, the "Assignment Parameters" tab includes the mass accuracy in parts per million (ppm), the minimum peak intensity threshold, the minimum signal-to-noise ratio (s/n) needed, and the lowest and highest charge state expected for the deconvolution process. These parameters are further divided into two columns one each for MS.sup.1 and MS.sup.2 analysis.
[0117] The "Clustering Parameters" tab shown in FIG. 11C is also divided into two columns relating to MS.sup.1 and MS.sup.2 analysis respectively. Provision is made for user input of the minimum number of contiguous charge states and isotopes for the clustering convergence calculation described above. The "Sufficient Contiguous Charge States", "Sufficient Contiguous Isotopes" and "Mass Separation" parameter input displays are also present on this input tab.
2.6. Examples
[0118] FIG. 12A shows the deconvolution result from a five component protein mixture consisting of cytochrome c, lysozyme, myoglobin, trypsin inhibitor, and carbonic anhydrase. A top display panel 1203 of the display shows the acquired data from the mass spectrometry represented as centroids. A centrally located main display panel 1201 illustrates each peak as a respective symbol. The horizontally disposed mass-to-charge (m/z) scale 1207 for both the top panel 1203 and central panel 1201 is shown below the central panel. The computer display may also include (not specifically shown in FIG. 12A) the settings for mass accuracy (expressed in ppm), the peaks/isotope cluster setting, the minimum intensity threshold and signal-to-noise settings, and the minimum and maximum charge states associated with the calculation. The panel 1205 on the left hand side of the display shows the calculated molecular weight(s), in daltons, of protein molecules. The molecular weight (MW) scale of the side panel 1205 is oriented vertically on the display, which is perpendicular to the horizontally oriented m/z scale 1207 that pertains to detected ions. Each horizontal line in the central panel 1201 indicates the detection of a protein in this example with the dotted contour lines corresponding to the ionic charge states, which are displayed as a direct result of the transformation calculation discussed previously. In FIG. 12B is shown a display pertaining to the same data set in which the molecular weight (MW) scale is greatly expanded with respect to the view shown in FIG. 12A. The expanded view of FIG. 12B illustrates well-resolved isotopes for a single protein charge state (lowermost portion of left hand panel 1205) as well as potential adduct or impurity peaks (two present in the display). The most intense of these three molecules is that of trypsin inhibitor protein. A further-expanded view in FIG. 12C shows the exact detail of the trypsin inhibitor protein at the isotopic level. The symbol size used to represent the individual isotopes is scaled according to the intensity of each isotope peak.
[0119] FIG. 13A shows the data and deconvolution results of a crude extract from the bacterium E. coli. This sample was directly infused into the mass spectrometer using only a single stage of mass spectrometry. The calculated results, obtained using methods in accordance with the present teachings, indicate the presence of 58 unique discernable proteins in this sample. Many of the proteins in this example have overlapping charge states which are easily clustered using the aforementioned algorithm. FIG. 13B illustrates another display corresponding to the same data set showing an expanded view of the m/z scale in the vicinity of m/z=700 Dale (as well as an expanded view of the MW scale in Daltons) showing three distinct charge states depicted by differently patterned centroids in the top panel 1203. The centroids 1301 in the top panel 1203 of the display correspond to a +22 isotopically resolved charge state of a protein of mass 15,305.76 Da. In this case, this is the only charge state distribution present in the displayed window (note that there are other charge states for this protein over all m/z space), yet the algorithm correctly identifies the cluster even though the centroid bars 1303 and 1305 occur within 1 Da of the charge state in question. Many currently available deconvolution programs cannot correctly assign charge state to independent distributions (two different proteins) within a 3 Da window. Also, the centroid bars 1305 represent the +23 charge state of a protein from E. coli of mass 16,017.57 Da. Note that the +23 charge state of this protein directly overlaps with the centroid bars 1303 of a separate +22 charge state protein of mass 15327.47 Da. Typical deconvolution programs are unable to correctly assign peaks in spectra having this kind of closely spaced or overlapping charge states as can be seen by comparison to FIG. 13C, which shows the same mass spectrum acquired and processed using a program employing a conventional algorithm. The conventional approach is unable to make any charge state assignments in this region of the spectrum, as is indicated by the "question marks" over the peaks of interest in the figure. FIG. 13D has the correctly labeled charge states of the original profile data as assigned by our algorithm employing the novel methods taught herein for the two overlapping charge states described above.
[0120] The program employing methods in accordance with the present teachings can also determine charge states for those peaks that do not contain individually resolved isotopes. In another example, illustrated in FIG. 14A, the mass spectrum of an intact antibody is shown with varying degrees of glycosylation. An example of the different glycoforms of the antibody are displayed in the inset of FIG. 14A. FIG. 14B illustrates the deconvoluted molecular weights of the four deconvoluted glycoforms ranging from 148378 Da to 148763 Da.
[0121] The methods in accordance with the present teachings also have utility for deconvoluting tandem mass spectrometry data. In another example, as illustrated in FIGS. 15A and 15B, two charge states from the protein carbonic anhydrase II were selected for collisional activated dissociation. In FIGS. 15A and 15B are shown the MS/MS spectrum and corresponding deconvolution of the +36 charge state of carbonic anhydrase II at m/z 807.00. Here 64% of the centroids were correctly identified compared to only 9% using the conventional algorithm. Exactly 50% of the centroids were clustered even in the event where many MS/MS fragments do not produce multiple charge states of the same fragment. The total number of fragment ions identified correctly was 35. FIGS. 15C and 15D show the MS/MS fragmentation and deconvolution of the +21 charge state of carbonic anhydrase II at m/z 1001. Here 74% of the centroids were clustered and 78% of the charge states were assigned correctly. A total of 49 fragments ions were identified using the program.
[0122] The inventors have investigated the performance of the deconvolution portions of the present teachings for the analyses of proteins in biologically-derived samples. To assess the accuracy and precision of results calculated using methods in accordance with the present teachings, repeated mass spectral analyses were performed of a sample consisting of an equimolar mixture of the five compounds: Ribonuclease A, Myoglobin, Trypsin Inhibitor, Carbonic Anhydrase and Enolase. For each of the listed protein compounds, except for Enolase, ten random individual scans were selected for performing the molecular weight calulations, each individual scan selected from a random data file. In the case of Enolase, only five such random scans were selected due to the nature of experiments from which the data was derived.
[0123] For each selected scan, an average molecular weight, a statistical modal value molecular weight and a monoisotopic molecular weight were derived from the observed (i.e., calculated) results, where the statistical average and statistical mode were taken over all isotopic variants. A mean value and a sigma (standard deviation, .sigma.) value of the average, modal and monoisotopic molecular weights were then calculated across the set of selected files chosen for each compound. These latter values are tabulated and compared with theoretical values in Table 2 of FIG. 16. The columns labeled "PPM Error" relate to the deviations of the means of the observed average, modal and monoisotopic values from theoretical values (also shown). The upper and lower values tabulated in each cell of the first "PPM error" column pertain to the errors in the average and mode molecular weights, respectively. There is no monoisotopic calculation for Enolase, since resolved isotopes were not observed. The somewhat larger error in the monoisotopic calculation for carbonic anhydrase is due to the fact that not all the charge states of this protein can be resolved to the isotopic level. Nonetheless, the derived accuracy and precision is considered to be acceptable for protein identifications as well as for use in data-dependent ion selection and fragmentation.
[0124] FIG. 17 is a portion of a plot of molecular weights (including isotopic variants), calculated using the presently taught methods, from a mass analysis of a mixture of five standard proteins including isotopic variants. The measured intensity of the most intense centroid (at 16951 Da) in the isotopic cluster spanning a range from about 16943-16960 Da is 1535928 (in arbitrary units). By contrast, the most intense centroid (at 16881 Da) in the isotopic cluster spanning the approximate range from about 16874-16888 Da is 22484. Centroids of even less intensity in other isotopic clusters are also resolved by the deconvolution methods. FIGS. 18A-18B show calculated molecular weights of selected proteins from an E. Coli lysate, after reaction with a proton transfer reagent. The intensity of the most intense centroid, at 9190 Da, shown in FIG. 18A is 26874 (in arbitrary units); the intensity of the most intense centroid, as 14722 Da, shown in FIG. 18B is 183. From such results, the inventors conclude that the presently taught methods can provide useful measurements over a signal intensity range (roughly corresponding to an analyte abundance range of at least two orders of magnitude.
[0125] FIG. 19 is a table (Table 3) of molecular weights of proteins that are diagnostic for distinguishing between closely related bacterial species using deconvolution methods in accordance with the present teachings. The tabulated results shown in Table 3 were obtained in a study to evaluate the ability of the presently taught methods to correctly differentiate very closely related species that other approaches (including MALDI) cannot successfully differentiate. Table 3 lists only those molecular weights that are unique to each of the microorganisms listed. In order to generated the tabulated molecular weight values listed in Table 3, observed values were grouped into 5 Da "bins" under the restriction that an observed molecular weight of each listed protein must appear in a bin in at least fifty percent of replicate samples in order to be considered as a "marker" for that protein. The rounding of molecular weight values associated with the binning procedure is the reason why last digit of each tabulated mass value is either a "2" or a "7".
[0126] FIG. 20 is a table (Table 4) of the accuracy of identifications of various yeast species, all from the genus Candida, using mass spectrometric analyses for which multiple overlapping mass spectral lines are deconvoluted and grouped in accordance with methods in accordance with the present teachings.
2.7. Directing Data Dependent Acquisition to Avoid Redundant Measurements
[0127] In the traditional approach to setting up a dynamic exclusion list, m/z values are placed on the list for a specified time period, which approximates the average peak width of a given compound/type of compound. When using such an approach with small molecules or peptides (i.e. tryptic peptides which typically have the same physiochemical properties), it works well to increase the dynamic range associated with the compound identification process. On the contrary, intact proteins (as are measured in top-down proteomics studies) widely vary in sizes, amino acid compositions, physiochemical properties, and 3-D structures. This variability typically leads to many more sites on the protein (than would be the case for smaller-molecule analytes) interacting with the stationary phase of a chromatographic column. The result is that some peaks may be only a few seconds wide while others can persist on the order of minutes. A typical example of the variability that can be expected is illustrated in FIG. 2, showing the varying peak profiles obtained from a single chromatographic run. Therefore, the standard approach to dynamic exclusion is not an ideal fit for top-down analysis. To rectify this problem, the present methods employ a signal intensity ranking system to determine for how long the charge states associated with a given protein should be placed on the dynamic exclusion list. In this new approach, the seed centroid of each cluster is put on the exclusion list. When a new seed centroid is proposed in subsequent MS.sup.1 scan, a check is first made to determine if the new centroid clusters with any of the seed centroids presently on the selection list in step 510. If so, a check is made to determine if the intensity of the new centroid has fallen below a threshold (as a fraction of the intensity of the original seed centroid). Only when the intensity does fall below the threshold, will the original seed centroid be taken off of the exclusion list (step 515).
[0128] Alternatively, all charge states from a given protein can be placed on the exclusion list, thus eliminating selecting different charge states from the same protein for tandem MS analysis. While these charge states are on the dynamic exclusion list, the signal intensity of the peaks comprising the list are monitored until they are below a defined minimum intensity or there is an increase in signal from one of the charge states at a defined mass difference (ppm), indicating the presence of two components of differing mass and charge but the same m/z value. It was mentioned above that, for the purpose of making data-dependent mass isolation and fragmentation decisions in "real-time", a deconvolution algorithm on which such decisions are based should be able to perform the calculation procedure in roughly the same amount of time required for a mass spectrometer to perform a tandem mass analysis (i.e., a full MS/MS analysis). Typically, this requires the calculations to be performed in less than one second. To assess the calculation speed of the presently-taught methods, the inventors have made a set of repeated executions of the calculations used to generate the results that are displayed in various of the accompanying drawings. FIG. 22 is a table (Table 6) of the times required for five different executions of each calculation. The timings shown in Table 6 indicate that the calculation speed is sufficient for use in real-time data dependent acquisition.
[0129] The discussion included in this application is intended to serve as a basic description. Although the present invention has been described in accordance with the various embodiments shown and described, one of ordinary skill in the art will readily recognize that there could be variations to the embodiments without departing from the scope of the present invention as defined in the claims. The reader should be aware that the specific discussion may not explicitly describe all embodiments possible; many alternatives are implicit. For instance, although the methods of the present teachings have been described using examples based on protein analyses, the methods taught herein are also applicable to many other biomolecules, especially various oligomer molecules such as a variety of oils as well as RNA or DNA oligonucleotides and telomeres. Accordingly, many modifications may be made by one of ordinary skill in the art without departing from the scope of the invention and neither the description nor the terminology is intended to limit the scope of the invention. Any patents, patent publications or technical publications or technical documents mentioned within this disclosure are hereby incorporated by reference herein. If any statements in the mentioned documents should conflict with statements made in this application, then the present application will control.
* * * * *
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012
D00013
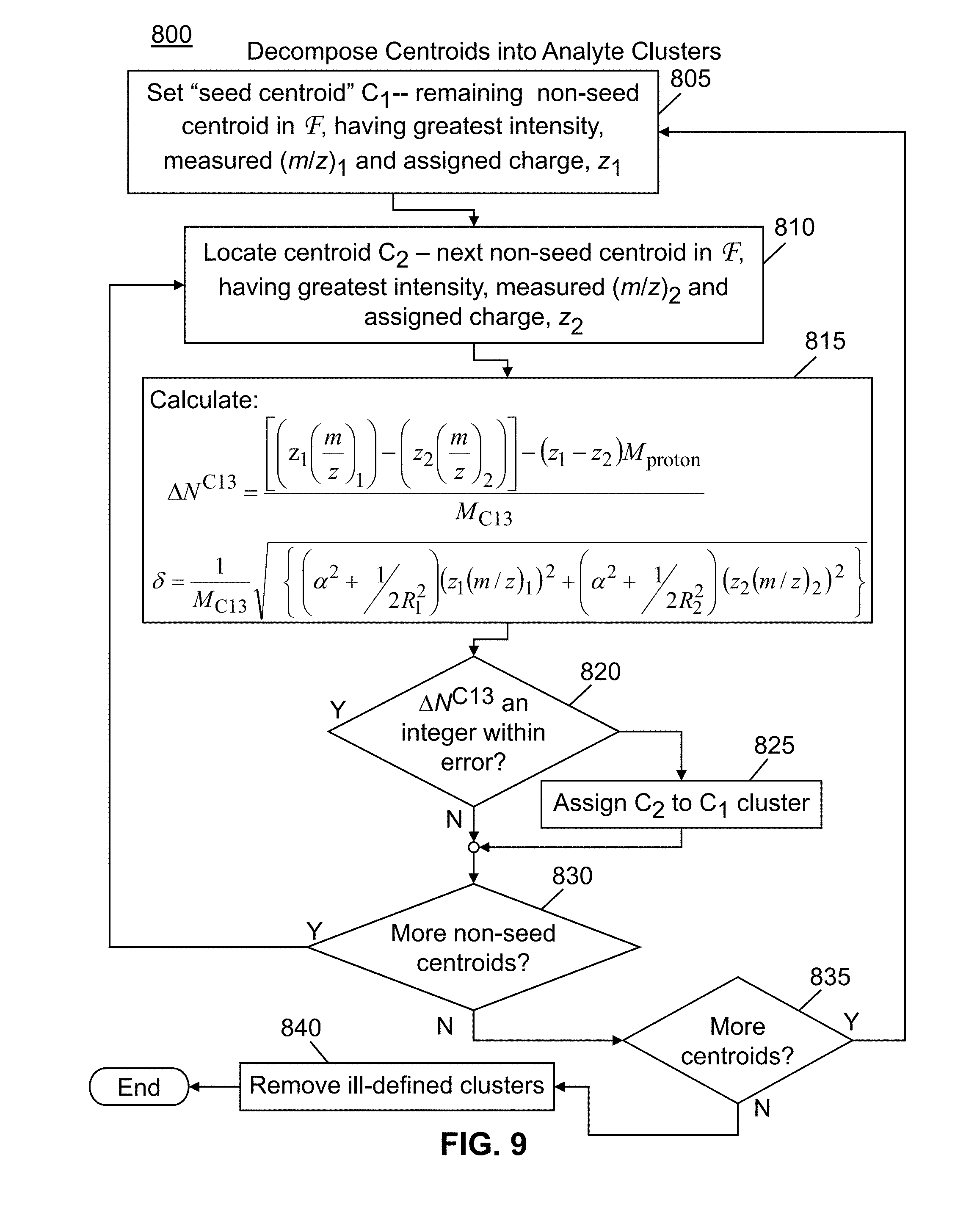
D00014

D00015

D00016
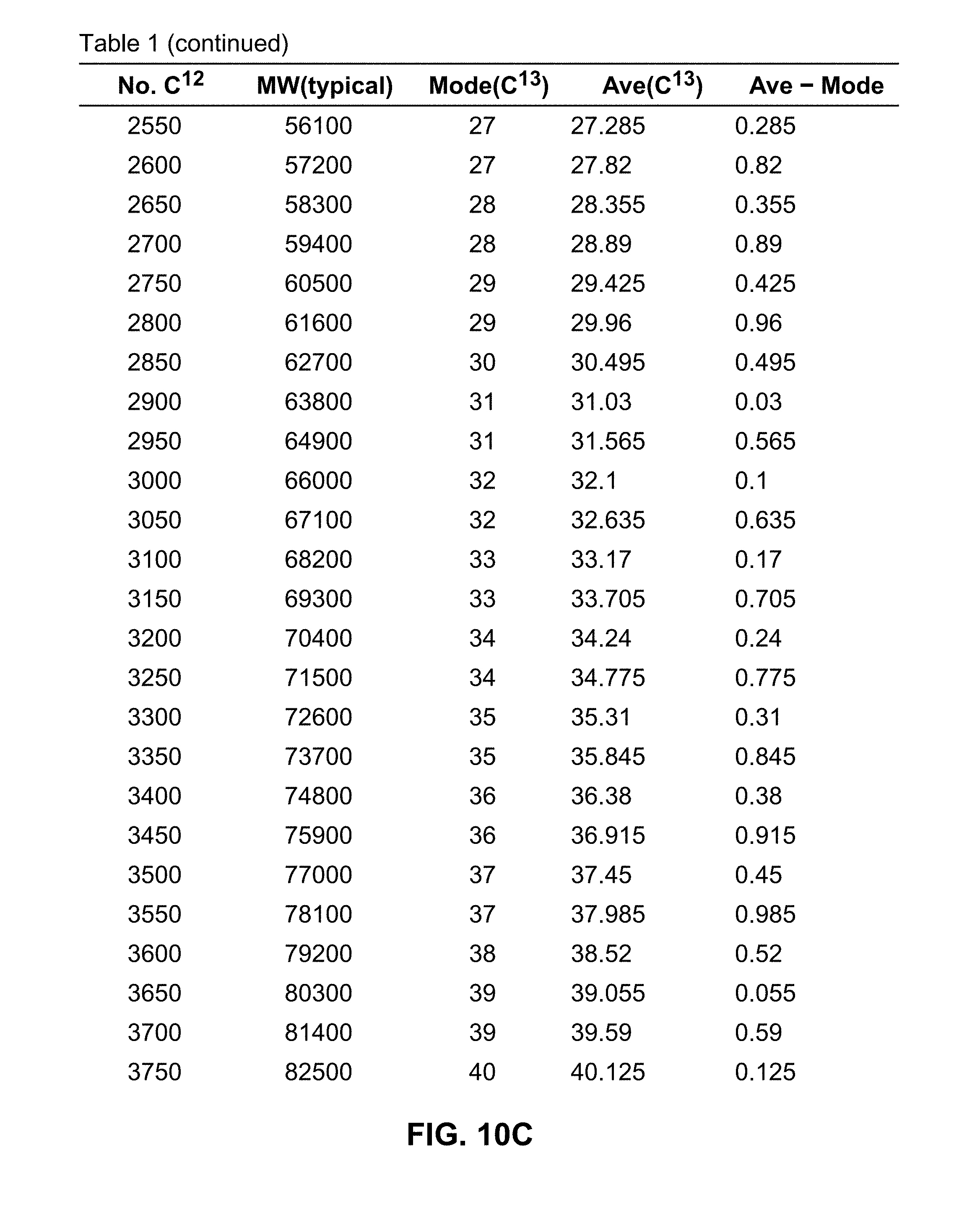
D00017

D00018

D00019
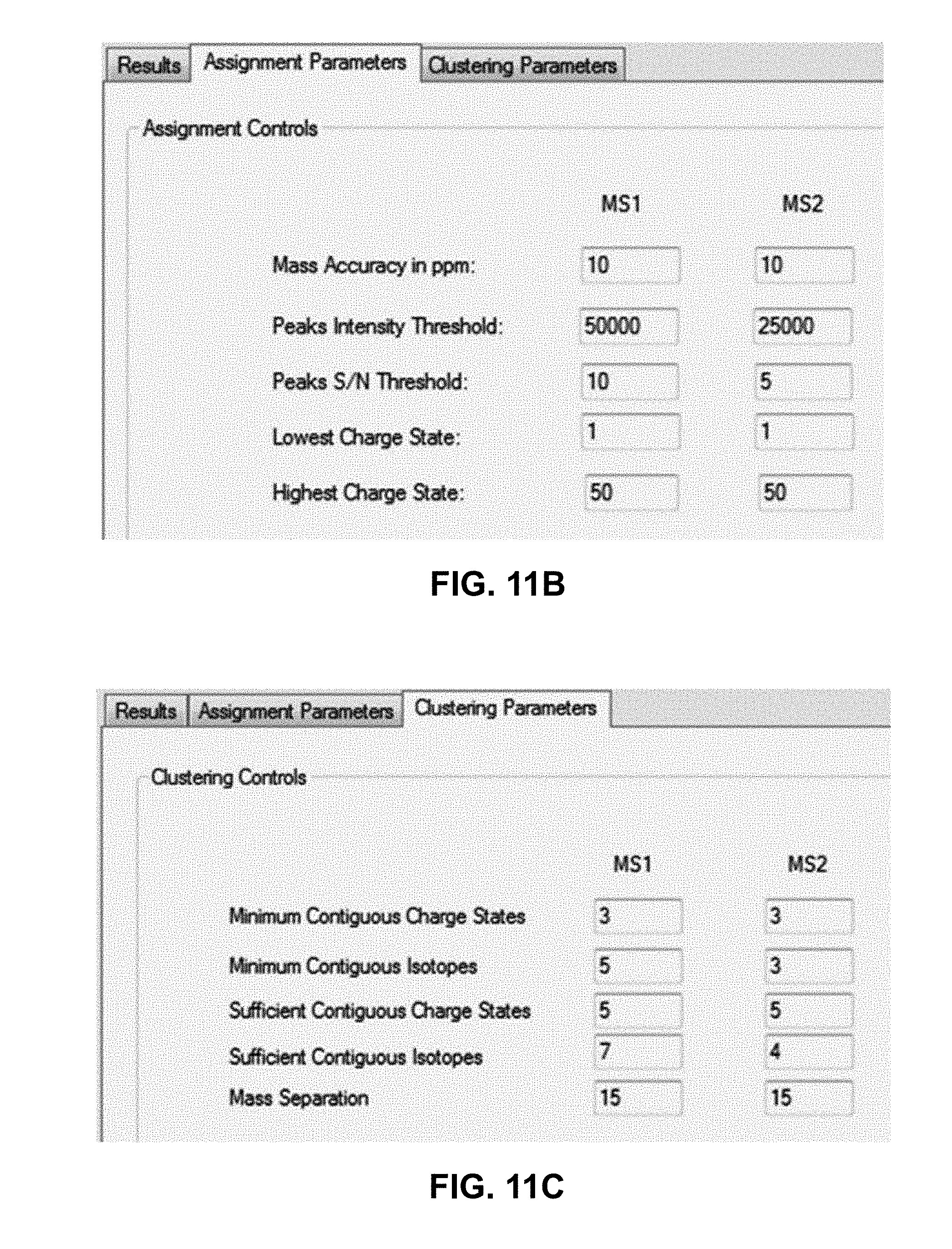
D00020

D00021

D00022
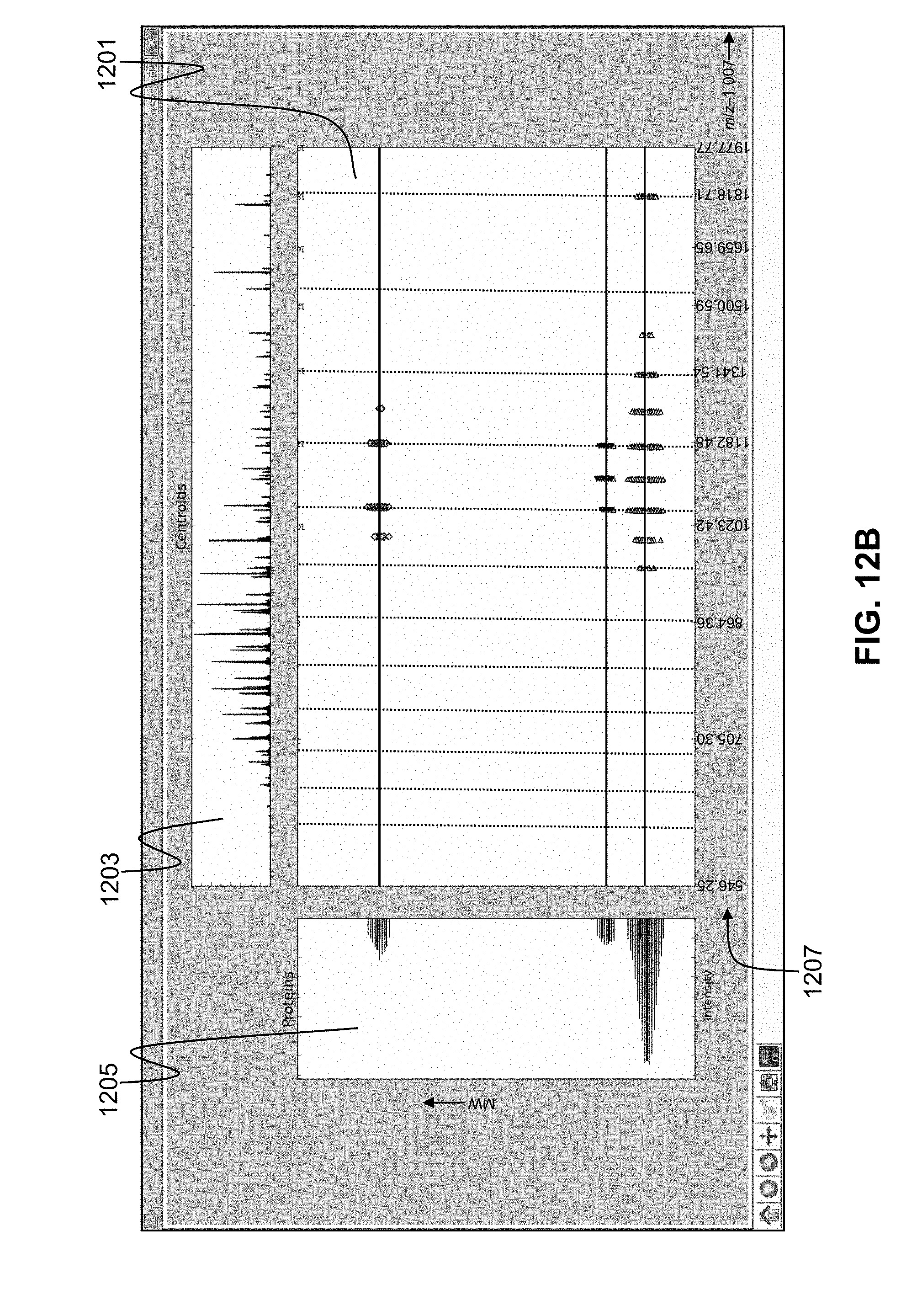
D00023
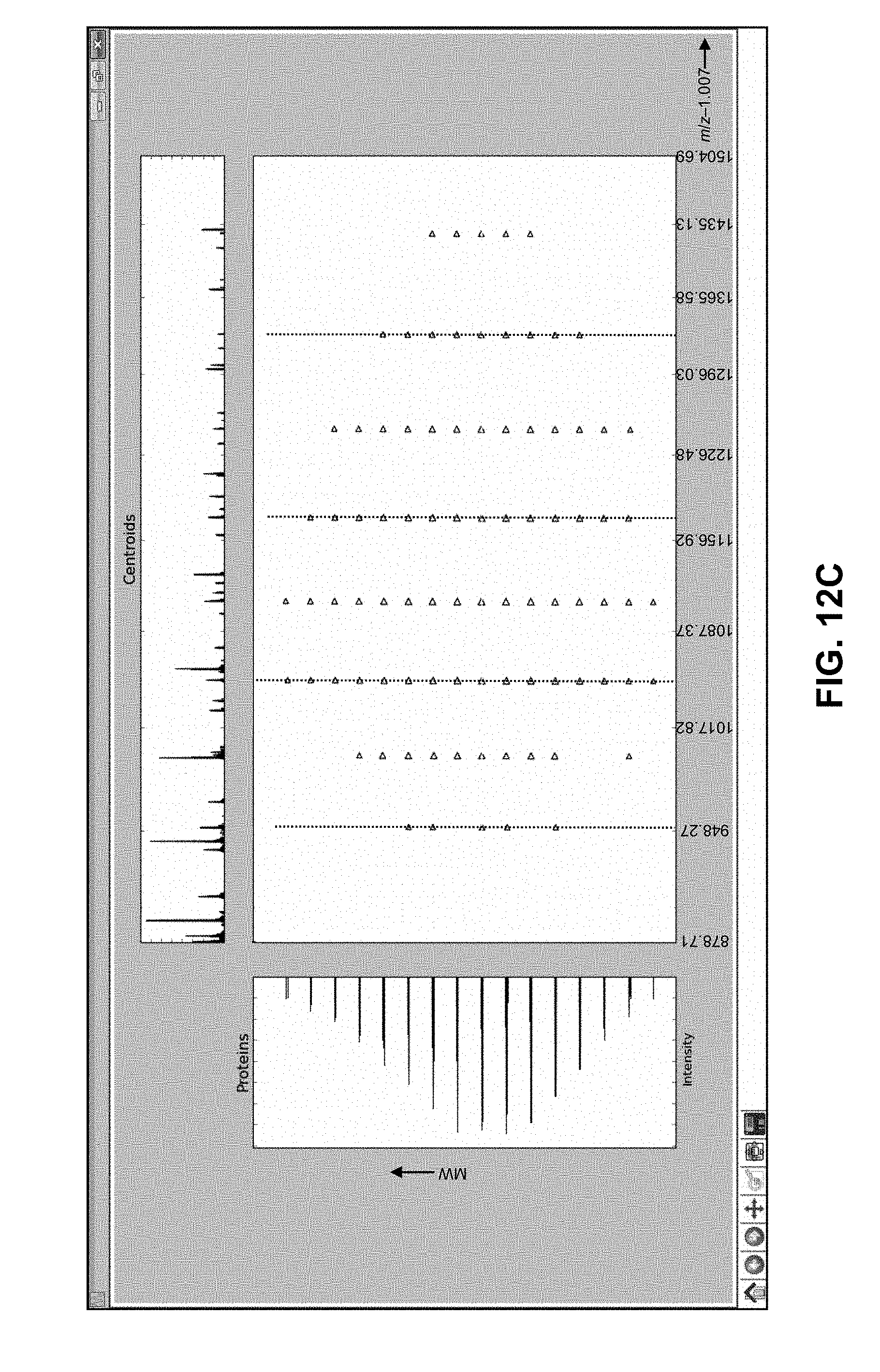
D00024

D00025

D00026
D00027

D00028

D00029

D00030
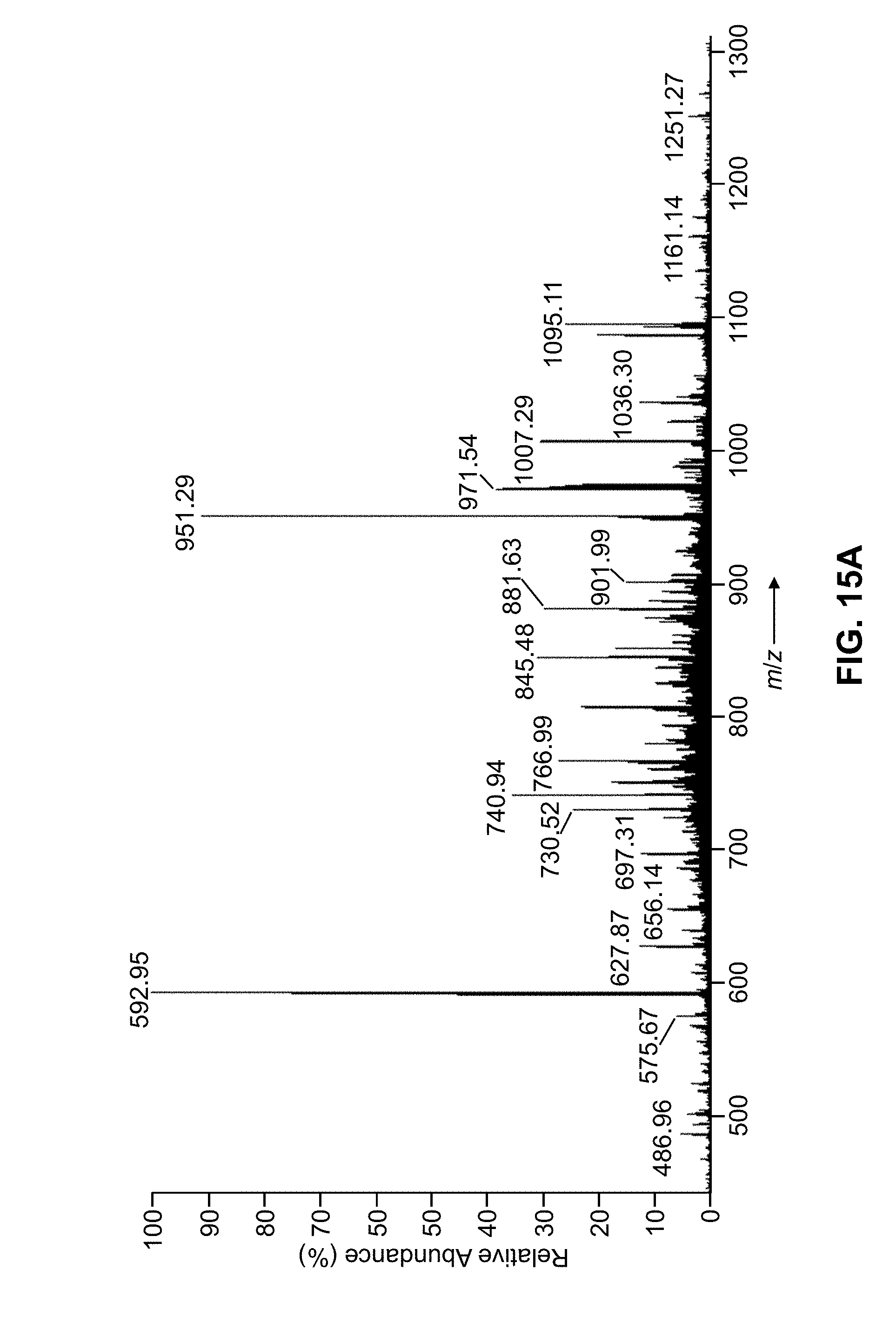
D00031

D00032

D00033

D00034
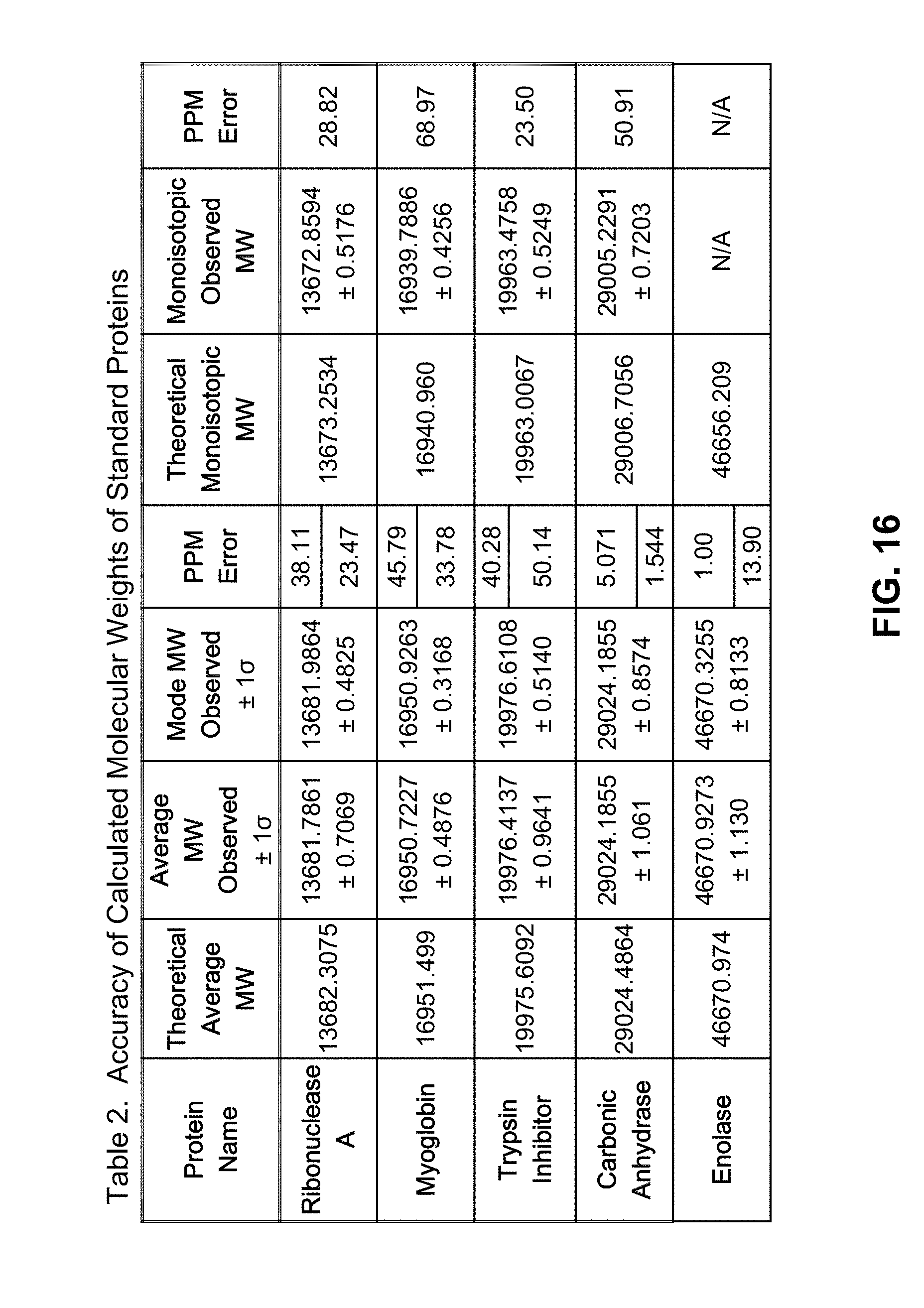
D00035
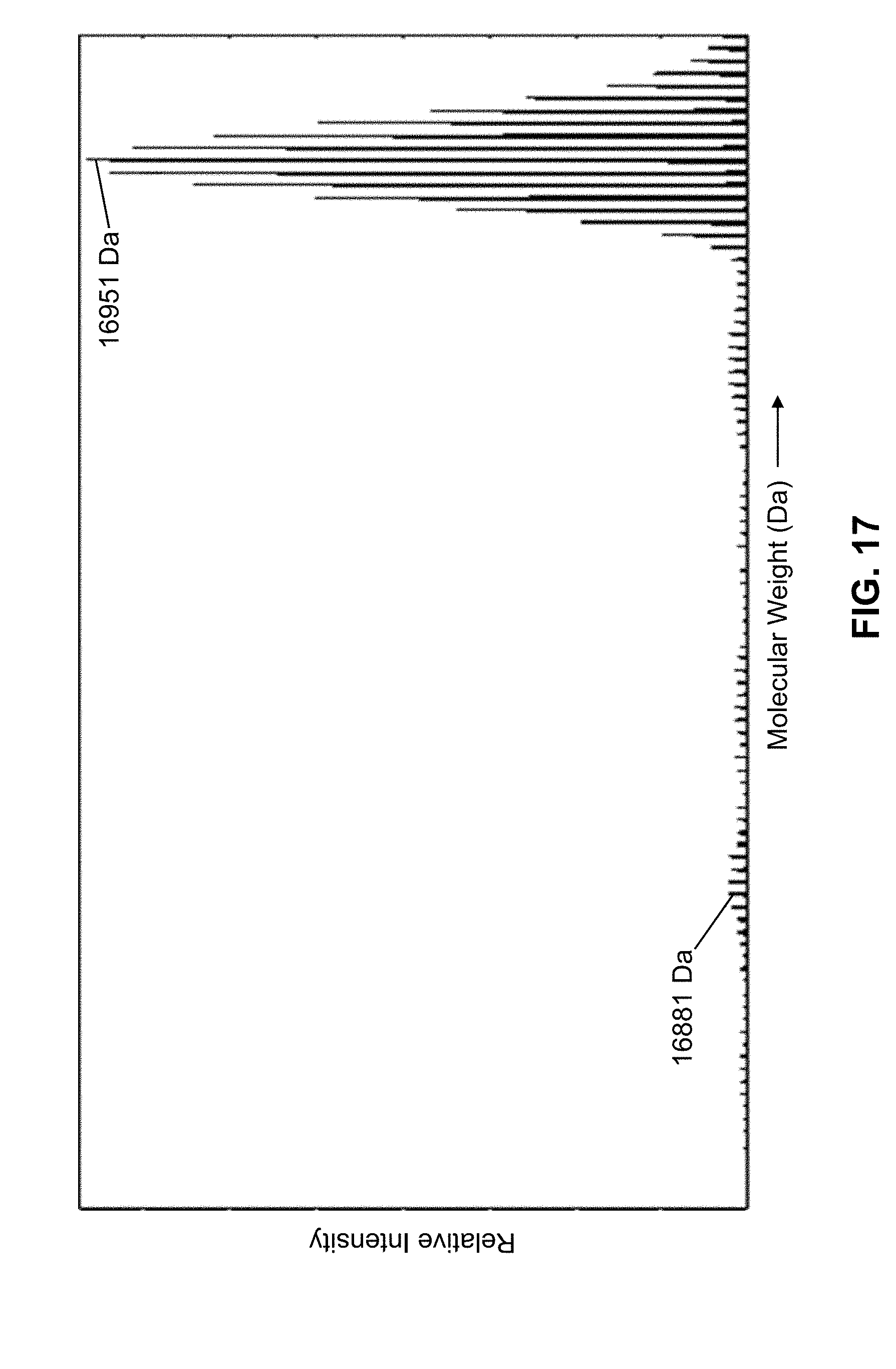
D00036
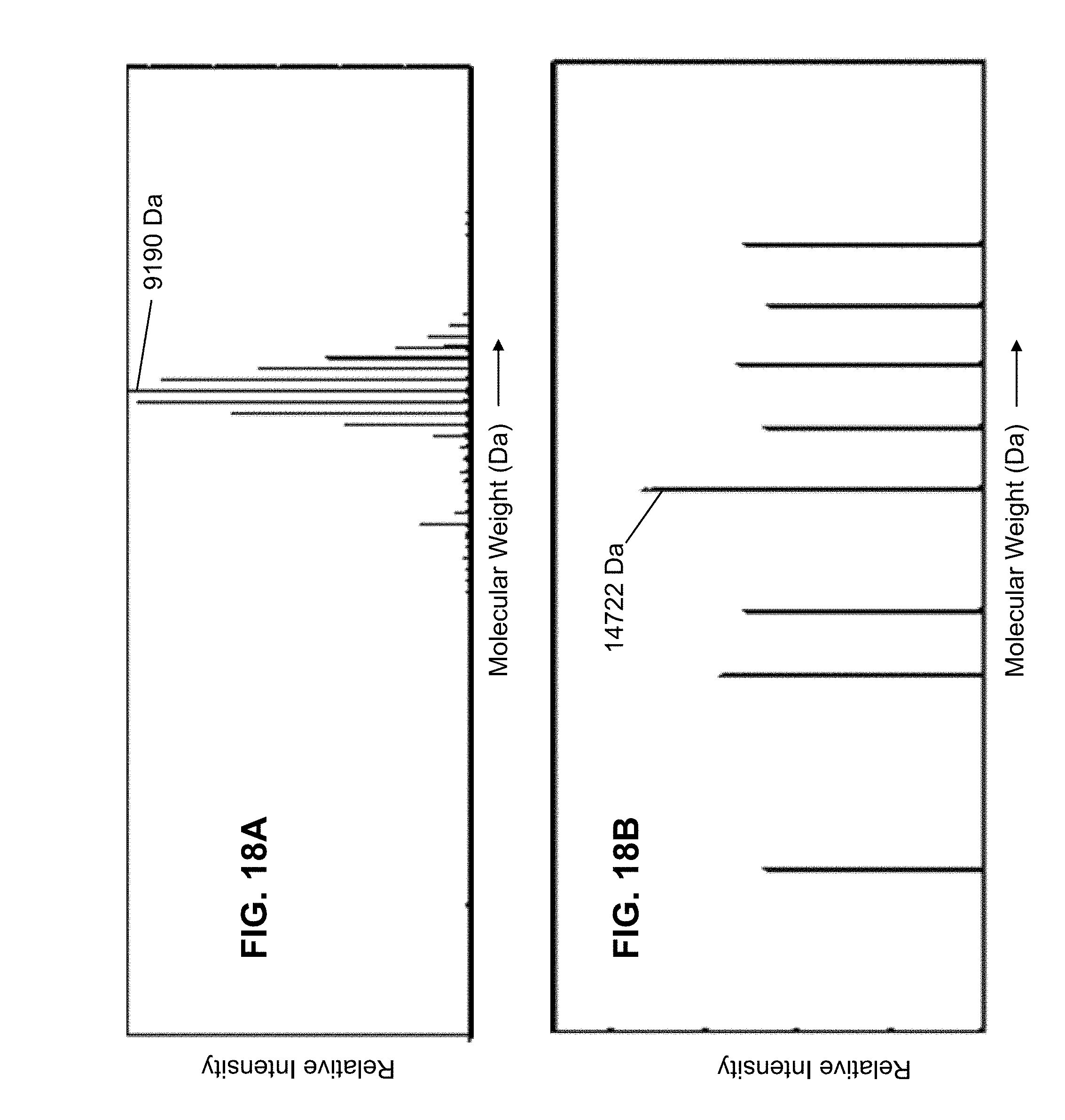
D00037
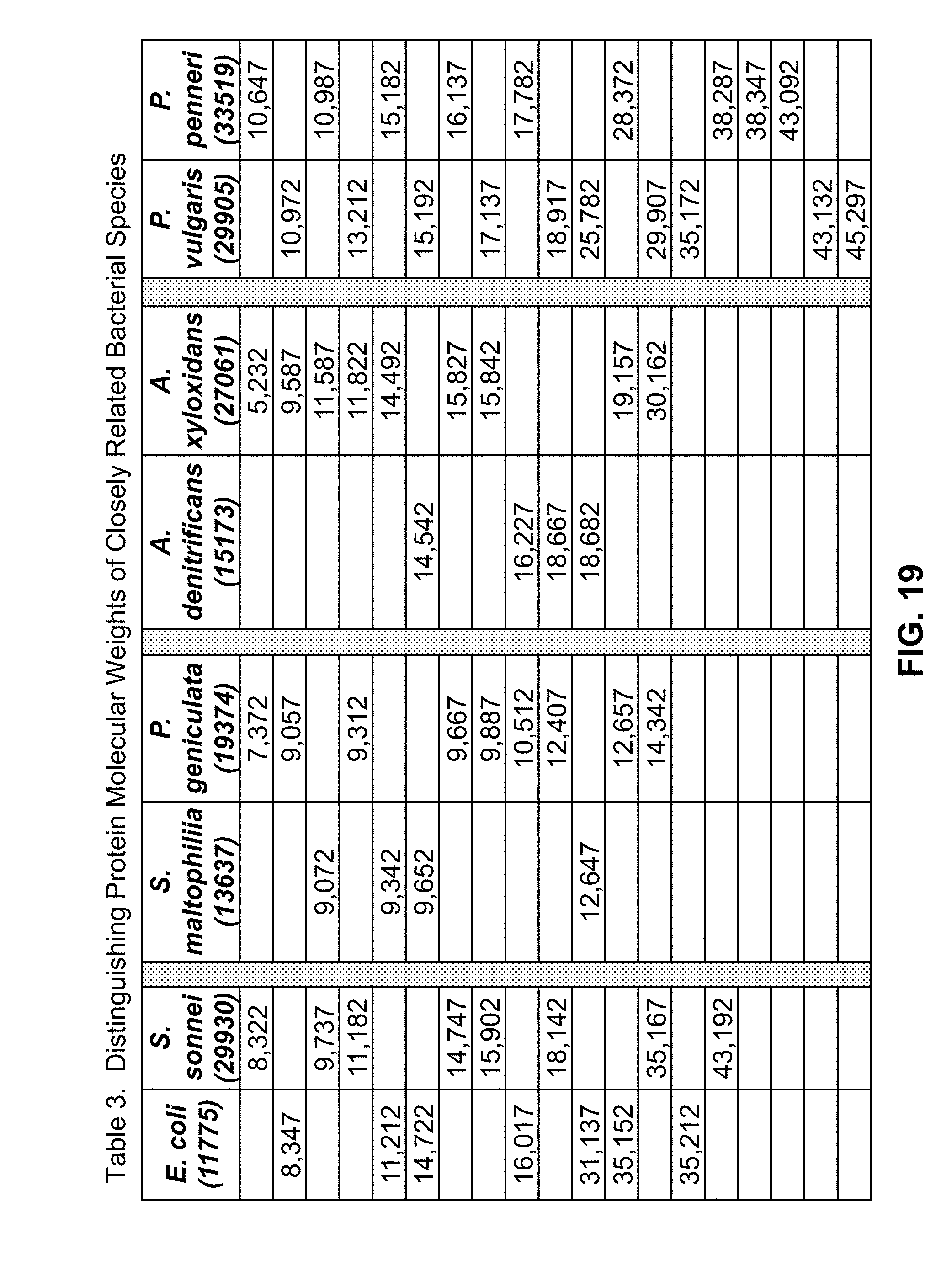
D00038

D00039

D00040
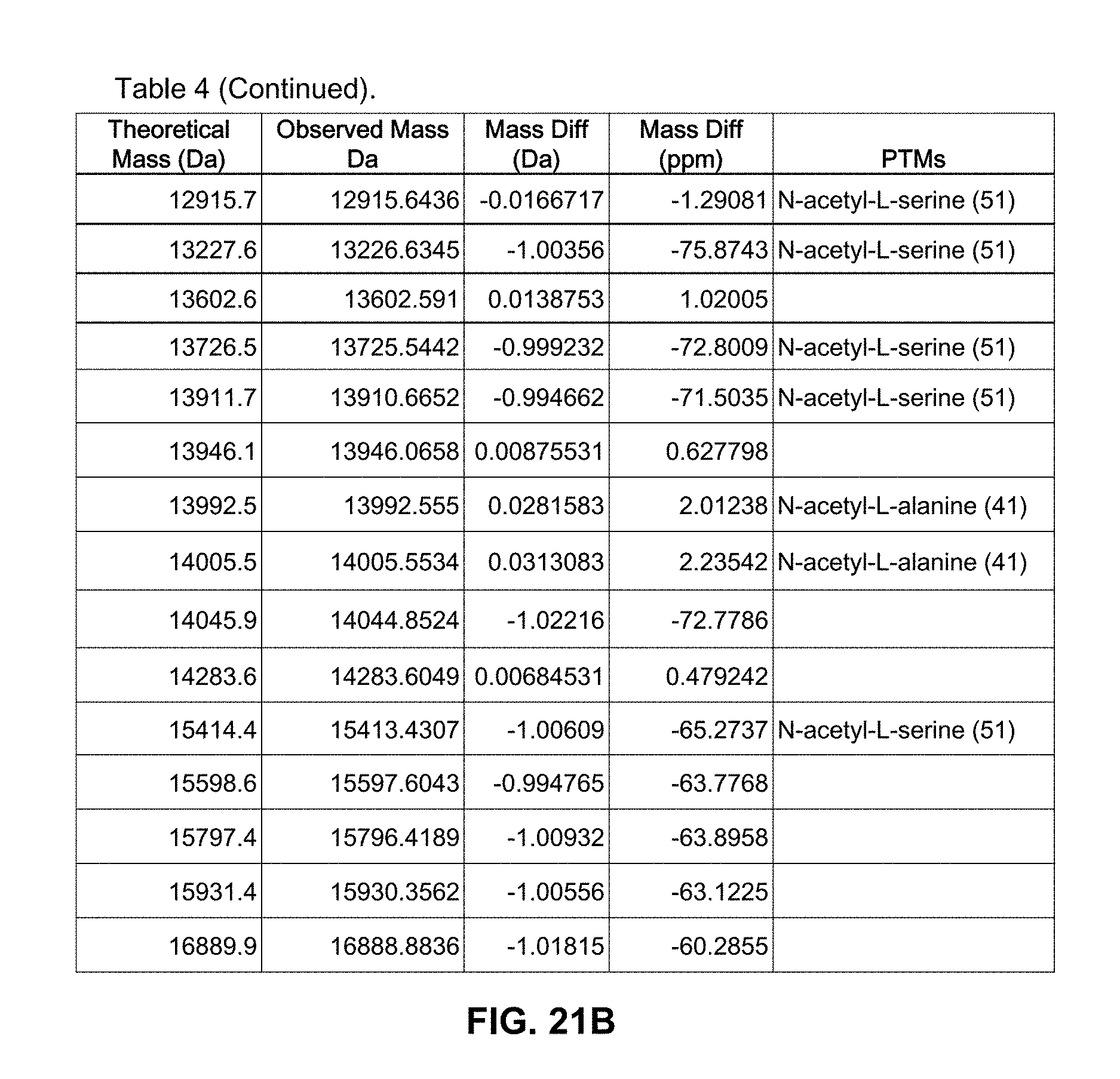
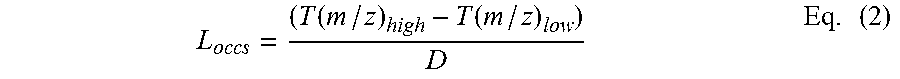
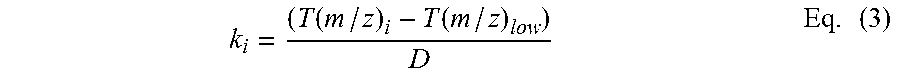


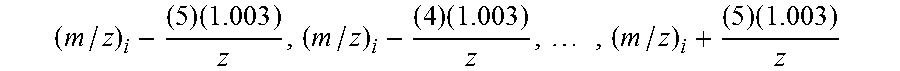
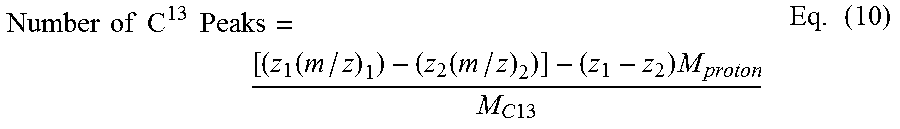

P00001

XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.