Therapeutic Applications Of Cpf1-based Genome Editing
Gersbach; Charles A. ; et al.
U.S. patent application number 16/318745 was filed with the patent office on 2019-05-23 for therapeutic applications of cpf1-based genome editing. The applicant listed for this patent is Duke University. Invention is credited to Charles A. Gersbach, Sarina Madhavan, Christopher Nelson.
| Application Number | 20190151476 16/318745 |
| Document ID | / |
| Family ID | 60992881 |
| Filed Date | 2019-05-23 |

| United States Patent Application | 20190151476 |
| Kind Code | A1 |
| Gersbach; Charles A. ; et al. | May 23, 2019 |
THERAPEUTIC APPLICATIONS OF CPF1-BASED GENOME EDITING
Abstract
Disclosed herein are therapeutic applications of CRISPR/Cpf1-based genome editing.
| Inventors: | Gersbach; Charles A.; (Durham, NC) ; Madhavan; Sarina; (Katy, TX) ; Nelson; Christopher; (Durham, NC) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 60992881 | ||||||||||
| Appl. No.: | 16/318745 | ||||||||||
| Filed: | July 19, 2017 | ||||||||||
| PCT Filed: | July 19, 2017 | ||||||||||
| PCT NO: | PCT/US2017/042921 | ||||||||||
| 371 Date: | January 18, 2019 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 62363888 | Jul 19, 2016 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | C12N 2320/33 20130101; C12N 15/907 20130101; A61K 48/0066 20130101; C07K 14/4708 20130101; C12N 2310/20 20170501; C12N 15/111 20130101; Y02A 50/479 20180101; A61K 48/0008 20130101; A61K 48/0075 20130101; C12N 2750/14143 20130101; A61K 48/0091 20130101; A61K 38/465 20130101; A61K 48/0058 20130101; A61P 21/00 20180101; Y02A 50/30 20180101; C12N 15/113 20130101; Y02A 50/402 20180101; C12N 9/22 20130101; A61K 31/7105 20130101; A61K 38/465 20130101; A61K 2300/00 20130101 |
| International Class: | A61K 48/00 20060101 A61K048/00; A61P 21/00 20060101 A61P021/00 |
Goverment Interests
STATEMENT OF GOVERNMENT INTEREST
[0002] This invention was made with government support under Federal Grant Nos. AR069085 and MD140071 awarded by the NIH and Army/MRMC, respectively. The U.S. Government has certain rights to this invention.
Claims
1. A Cpf1 guide RNA (gRNA) that targets a dystrophin gene and comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof.
2. A DNA targeting composition comprising a Cpf1 endonuclease and at least one Cpf1 gRNA of claim 1.
3. A DNA targeting composition comprising a first Cpf1 gRNA and a second Cpf1 gRNA, the first Cpf1 gRNA and the second Cpf1 gRNA each comprising a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise different polynucleotide sequences, and wherein the first Cpf1 gRNA and the second Cpf1 gRNA target a dystrophin gene.
4. The DNA targeting composition of claim 3, wherein the first Cpf1 gRNA comprises a polynucleotide sequence corresponding to SEQ ID NO: 54, SEQ ID NO: 55, or SEQ ID NO: 56, and the second Cpf1 gRNA comprises a polynucleotide sequence corresponding to SEQ ID NO: 62, SEQ ID NO: 63, or SEQ ID NO: 61.
5. The DNA targeting composition of claim 3 or 4, wherein the first Cpf1 gRNA and the second Cpf1 gRNA are selected from the group consisting of: (i) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 54 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 62; (ii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 55 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 63; and (iii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 56 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 61.
6. The DNA targeting composition of any one of claims 3 to 5, further comprising a Cpf1 endonuclease.
7. The DNA targeting composition of claim 2 or 6, wherein the Cpf1 endonuclease recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123).
8. The DNA targeting composition of claim 7, wherein the Cpf1 endonuclease is derived from a bacterial species selected from the group consisting of Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Bityrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens and Porphyromonas macacae.
9. The DNA targeting composition of any one of claims 6 to 8, wherein the Cpf1 endonuclease is derived from Lachnospiraceae bacterium ND2006 (LbCpf1) or from Acidaminococcus (AsCpf1).
10. The DNA targeting composition of any one of claims 6 to 9, wherein the Cpf1 endonuclease is encoded by a polynucleotide sequence comprising SEQ ID NO: 124 or SEQ ID NO: 125.
11. An isolated polynucleotide comprising the Cpf1 gRNA of claim 1 or a polynucleotide sequence encoding the DNA targeting composition of any one of claims 2 to 10.
12. A vector comprising the Cpf1 gRNA of claim 1, a polynucleotide sequence encoding the DNA targeting composition of any one of claims 2 to 10, or the isolated polynucleotide of claim 10.
13. The vector of claim 12, further comprising a polynucleotide sequence encoding a Cpf1 endonuclease.
14. A vector encoding: (a) a first Cpf1 guide RNA (gRNA), (b) a second Cpf1 gRNA, and (c) at least one Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, and wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise different polynucleotide sequences.
15. The vector of claim 14, wherein the vector is configured to form a first and a second double strand break in a first and a second intron flanking exon 51 of the human DMD gene.
16. The vector of claim 14 or 15, wherein the first Cpf1 gRNA and the second Cpf1 gRNA are selected from the group consisting of: (i) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 54 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 62; (ii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 55 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 63; and (iii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 56 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 61.
17. The vector of any one of claims 12 to 16, wherein the vector is a viral vector.
18. The vector of claim 17, wherein the vector is an Adeno-associated virus (AAV) vector.
19. The vector of any one of claims 12 to 18, wherein the vector comprises a tissue-specific promoter operably linked to the polynucleotide sequence encoding the first Cpf1 gRNA, the second Cpf1 gRNA, and/or the Cpf1 endonuclease.
20. The vector of claim 19, wherein the tissue-specific promoter is a muscle specific promoter.
21. A cell comprising the Cpf1 gRNA of claim 1, a polynucleotide sequence encoding the DNA targeting composition of any one of claims 2 to 10, the isolated polynucleotide of claim 11, or the vector of any one of claims 12 to 20.
22. A kit comprising the Cpf1 gRNA of claim 1, a polynucleotide sequence encoding the DNA targeting composition of any one of claims 2 to 10, the isolated polynucleotide of claim 11, the vector of any one of claims 12 to 20, or the cell of claim 21.
23. A composition for deleting a segment of a dystrophin gene comprising exon 51, the composition comprising: (a) a first vector comprising a polynucleotide sequence encoding a first Cpf1 guide RNA (gRNA) and a polynucleotide sequence encoding a first Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), and (b) a second vector comprising a polynucleotide sequence encoding a second Cpf1 gRNA and a polynucleotide sequence encoding a second Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise different polynucleotide sequences, and wherein the first vector and second vector are configured to form a first and a second double strand break in a first intron and a second intron flanking exon 51 of the human DMD gene, respectively, thereby deleting a segment of the dystrophin gene comprising exon 51.
24. The composition of claim 23, wherein the first Cpf1 gRNA and the second Cpf1 gRNA are selected from the group consisting of: (i) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 54 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 62; (ii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 55 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 63; and (iii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 56 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 61.
25. The composition of claim 23 or 24, wherein the first Cpf1 endonuclease and the second Cpf1 endonuclease are the same.
26. The composition of claim 23 or 24, wherein the first Cpf1 endonuclease and the second Cpf1 endonuclease are different.
27. The composition of claim 25 or 26, wherein the first Cpf1 endonuclease and/or the second Cpf1 endonuclease are CPF1 endonuclease from Lachnospiraceae bacterium ND2006 (LbCpf1) and/or from Acidaminococcus (AsCpf1).
28. The composition of any one of claims 25 to 27, wherein the first Cpf1 endonuclease and/or the second Cpf1 endonuclease are encoded by a polynucleotide sequence comprising SEQ ID NO: 124 or SEQ ID NO: 125.
29. The composition of any one of claims 23 to 28, wherein the first vector and/or the second vector is a viral vector.
30. The composition of claim 29, wherein the first vector and/or the second vector is an Adeno-associated virus (AAV) vector.
31. The composition of claim 30, wherein the AAV vector is an AAV8 vector or an AAV9 vector.
32. The composition of any one of claims 23 to 31, wherein the dystrophin gene is a human dystrophin gene.
33. The composition of any one of claims 23 to 32, for use in a medicament.
34. The composition of any one of claims 23 to 32, for use in the treatment of Duchenne Muscular Dystrophy.
35. A cell comprising the composition of any one of claims 23 to 34.
36. A modified adeno-associated viral vector for genome editing a mutant dystrophin gene in a subject comprising a first polynucleotide sequence encoding the Cpf1 gRNA of claim 1, and a second polynucleotide sequence encoding a Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123).
37. A method of correcting a mutant dystrophin gene in a cell, the method comprising administering to a cell the Cpf1 gRNA of claim 1, a polynucleotide sequence encoding the DNA targeting composition of any one of claims 2 to 10, the isolated polynucleotide of claim 11, the vector of any one of claims 12 to 20, the composition of any one of claims 23 to 34, or the modified adeno-associated viral vector of claim 36.
38. The method of claim 37, wherein correcting the mutant dystrophin gene comprises nuclease-mediated non-homologous end joining or homology-directed repair.
39. A method of genome editing a mutant dystrophin gene in a subject, the method comprising administering to the subject a genome editing composition comprising the Cpf1 gRNA of claim 1, a polynucleotide sequence encoding the DNA targeting composition of any one of claims 2 to 10, the isolated polynucleotide of claim 11, the vector of any one of claims 12 to 20, the composition of any one of claims 23 to 34, or the modified adeno-associated viral vector of claim 36.
40. The method of claim 39, wherein the genome editing composition is administered to the subject intramuscularly, intravenously, or a combination thereof.
41. The method of claim 39 or 40, wherein the genome editing comprises nuclease-mediated non-homologous end joining or homology-directed repair.
42. A method of treating a subject in need thereof having a mutant dystrophin gene, the method comprising administering to the subject the Cpf1 gRNA of claim 1, a polynucleotide sequence encoding the DNA targeting composition of any one of claims 2 to 10, the isolated polynucleotide of claim 11, the vector of any one of claims 12 to 20, the composition of any one of claims 23 to 34, or the modified adeno-associated viral vector of claim 36.
43. A method of correcting a mutant dystrophin gene in a cell, comprising administering to the cell: (a) a first vector comprising a polynucleotide sequence encoding a first Cpf1 guide RNA (gRNA) and a polynucleotide sequence encoding a first Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), and (b) a second vector comprising a polynucleotide sequence encoding a second Cpf1 gRNA and a polynucleotide sequence encoding a second Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, and the vector is configured to form a first and a second double strand break in a first and a second intron flanking exon 51 of the human dystrophin gene, respectively, thereby deleting a segment of the dystrophin gene comprising exon 51 and correcting the mutant dystrophin gene in a cell.
44. The method of claim 43, wherein the first Cpf1 gRNA and the second Cpf1 gRNA are selected from the group consisting of: a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 54 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 62; (ii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 55 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 63; and (iii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 56 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 61.
45. The method of claim 43 or 44, wherein the mutant dystrophin gene comprises a premature stop codon, disrupted reading frame, an aberrant splice acceptor site, or an aberrant splice donor site.
46. The method of claim 45, wherein the mutant dystrophin gene comprises a frameshift mutation which causes a premature stop codon and a truncated gene product.
47. The method of claim 43 or 44, wherein the mutant dystrophin gene comprises a deletion of one or more exons which disrupts the reading frame.
48. The method of any one of claims 43 to 47, wherein the correction of the mutant dystrophin gene comprises a deletion of a premature stop codon, correction of a disrupted reading frame, or modulation of splicing by disruption of a splice acceptor site or disruption of a splice donor sequence.
49. The method of claim 48, wherein the correction of the mutant dystrophin gene comprises deletion of exon 51.
50. The method of any one of claims 43 to 49, wherein the correction of the mutant dystrophin gene comprises nuclease mediated non-homologous end joining or homology-directed repair.
51. The method of any one of claims 43 to 50, wherein the cell is a myoblast cell.
52. The method of any one of claims 43 to 51, wherein the cell is from a subject suffering from Duchenne muscular dystrophy.
53. A method of treating a subject in need thereof having a mutant dystrophin gene, the method comprising administering to the subject: (a) a first vector comprising a polynucleotide sequence encoding a first Cpf1 guide RNA (gRNA) and a polynucleotide sequence encoding a first Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), and (b) a second vector comprising a polynucleotide sequence encoding a second Cpf1 gRNA and a polynucleotide sequence encoding a second Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, and the first vector and the second vector are configured to form a first and a second double strand break in a first and a second intron flanking exon 51 of the human dystrophin gene, respectively, thereby deleting a segment of the dystrophin gene comprising exon 51 and treating the subject.
54. The method of claim 53, wherein the first Cpf1 gRNA and the second Cpf1 gRNA are selected from the group consisting of: (i) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 54, and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 62; (ii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 55, and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 63; and (iii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 56, and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 61.
55. The method of claim 53 or 54, wherein the subject is suffering from Duchenne muscular dystrophy.
56. The method of any one of claims 53 to 55, wherein the first vector and second vector are administered to the subject intramuscularly, intravenously, or a combination thereof.
57. A Cpf1 guide RNA (gRNA) that targets an enhancer of the B-cell lymphoma/leukemia 11A (BCL11a) gene and comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 65-70, or a complement thereof.
58. A method of disrupting an enhancer of a B-cell lymphoma/leukemia 11A gene in a cell, the method comprising administering to the cell at least one Cpf1 gRNA of claim 57 and a Cpf1 endonuclease.
Description
CROSS REFERENCE TO RELATED APPLICATIONS
[0001] This application claims priority to U.S. Provisional Application No. 62/363,888, filed Jul. 19, 2016, which is incorporated herein by reference in its entirety.
SEQUENCE LISTING
[0003] The instant application includes a Sequence Listing which has been submitted electronically in ASCII format and is hereby incorporated by reference in its entirety. Said ASCII copy, created on Jul. 19, 2017, is named 028193-9250-WO00 Sequence Listing.txt and is 46,056 bytes in size.
TECHNICAL FIELD
[0004] The present disclosure relates to the field of gene expression alteration, genome engineering and genomic alteration of genes using Clustered Regularly Interspaced Short Palindromic Repeats from Prevotella and Francisella 1 (CRISPR/Cpf1) based systems and viral delivery systems.
BACKGROUND
[0005] RNA-guided nucleases have been adapted for genome modification in human cells including CRISPR/Cpf1 systems derived from Streptococcus pyogenes and Staphylococcus aureus. Numerous microorganisms have been shown to have DNA-editing or RNA-editing systems. Cas9 derived from S. pyogenes and S. aureus make blunt-ended double-stranded breaks (DSBs) through genomic DNA which are repaired by non-homologous end-joining (NHEJ) leaving small insertions and deletions (indels) at the repaired site or through homology directed repair in the presence of a template. These indels can be used to knockout a gene, remove a splice acceptor, or dissect genetic regulatory elements.
[0006] Hereditary genetic diseases have devastating effects on children in the United States. These diseases currently have no cure and can only be managed by attempts to alleviate the symptoms. For decades, the field of gene therapy has promised a cure to these diseases. However technical hurdles regarding the safe and efficient delivery of therapeutic genes to cells and patients have limited this approach. Duchenne muscular dystrophy (DMD) is a fatal genetic disease, clinically characterized by muscle wasting, loss of ambulation, and death typically in the third decade of life due to the loss of functional dystrophin. DMD is the result of inherited or spontaneous mutations in the dystrophin gene. Most mutations causing DMD are a result of deletions of exon(s), pushing the translational reading frame out of frame.
[0007] Dystrophin is a key component of a protein complex that is responsible for regulating muscle cell integrity and function. DMD patients typically lose the ability to physically support themselves during childhood, become progressively weaker during the teenage years, and die in their twenties. Current experimental gene therapy strategies for DMD require repeated administration of transient gene delivery vehicles or rely on permanent integration of foreign genetic material into the genomic DNA. Both of these methods have serious safety concerns. Furthermore, these strategies have been limited by an inability to deliver the large and complex dystrophin gene sequence. There remains a need for more precise and efficient gene editing tools for correcting and treating patients with mutations in the dystrophin gene.
SUMMARY
[0008] The present invention is directed to a Cpf1 guide RNA (gRNA) that targets a dystrophin gene and comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof.
[0009] The present invention is directed to a DNA targeting composition comprising a Cpf1 endonuclease and at least one Cpf1 gRNA described above.
[0010] The present invention is directed to a DNA targeting composition comprising a first Cpf1 gRNA and a second Cpf1 gRNA, the first Cpf1 gRNA and the second Cpf1 gRNA each comprising a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise different polynucleotide sequences, and wherein the first Cpf1 gRNA and the second Cpf1 gRNA target a dystrophin gene.
[0011] The present invention is directed to an isolated polynucleotide comprising the Cpf1 gRNA described above or a polynucleotide sequence encoding the DNA targeting composition described above.
[0012] The present invention is directed to a vector comprising the Cpf1 gRNA described above, a polynucleotide sequence encoding the DNA targeting composition described above, or the isolated polynucleotide described above.
[0013] The present invention is directed to a vector encoding: (a) a first Cpf1 guide RNA (gRNA), (b) a second Cpf1 gRNA, and (c) at least one Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, and wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise different polynucleotide sequences.
[0014] The present invention is directed to a cell comprising the Cpf1 gRNA described above, a polynucleotide sequence encoding the DNA targeting composition described above, the isolated polynucleotide described above, or the vector described above.
[0015] The present invention is directed to a kit comprising the Cpf1 gRNA described above, a polynucleotide sequence encoding the DNA targeting composition described above, the isolated polynucleotide described above, the vector described above, or the cell described above.
[0016] The present invention is directed to a composition for deleting a segment of a dystrophin gene comprising exon 51, the composition comprising: (a) a first vector comprising a polynucleotide sequence encoding a first Cpf1 guide RNA (gRNA) and a polynucleotide sequence encoding a first Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), and (b) a second vector comprising a polynucleotide sequence encoding a second Cpf1 gRNA and a polynucleotide sequence encoding a second Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise different polynucleotide sequences, and wherein the first vector and second vector are configured to form a first and a second double strand break in a first intron and a second intron flanking exon 51 of the human DMD gene, respectively, thereby deleting a segment of the dystrophin gene comprising exon 51.
[0017] The present invention is directed to a cell comprising the composition described above.
[0018] The present invention is directed to a modified adeno-associated viral vector for genome editing a mutant dystrophin gene in a subject comprising a first polynucleotide sequence encoding the Cpf1 gRNA described above, and a second polynucleotide sequence encoding a Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123).
[0019] The present invention is directed to a method of correcting a mutant dystrophin gene in a cell, the method comprising administering to a cell the Cpf1 gRNA described above, a polynucleotide sequence encoding the DNA targeting composition described above, the isolated polynucleotide described above, the vector described above, the composition described above, or the modified adeno-associated viral vector described above.
[0020] The present invention is directed to a method of genome editing a mutant dystrophin gene in a subject, the method comprising administering to the subject a genome editing composition comprising the Cpf1 gRNA described above, a polynucleotide sequence encoding the DNA targeting composition described above, the isolated polynucleotide described above, the vector described above, the composition described above, or the modified adeno-associated viral vector described above.
[0021] The present invention is directed to a method of treating a subject in need thereof having a mutant dystrophin gene, the method comprising administering to the subject the Cpf1 gRNA described above, a polynucleotide sequence encoding the DNA targeting composition described above, the isolated polynucleotide described above, the vector described above, the composition described above, or the modified adeno-associated viral vector described above.
[0022] The present invention is directed to a method of correcting a mutant dystrophin gene in a cell, comprising administering to the cell: (a) a first vector comprising a polynucleotide sequence encoding a first Cpf1 guide RNA (gRNA) and a polynucleotide sequence encoding a first Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), and (b) a second vector comprising a polynucleotide sequence encoding a second Cpf1 gRNA and a polynucleotide sequence encoding a second Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, and the vector is configured to form a first and a second double strand break in a first and a second intron flanking exon 51 of the human dystrophin gene, respectively, thereby deleting a segment of the dystrophin gene comprising exon 51 and correcting the mutant dystrophin gene in a cell.
[0023] The present invention is directed to a method of treating a subject in need thereof having a mutant dystrophin gene, the method comprising administering to the subject: (a) a first vector comprising a polynucleotide sequence encoding a first Cpf1 guide RNA (gRNA) and a polynucleotide sequence encoding a first Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), and (b) a second vector comprising a polynucleotide sequence encoding a second Cpf1 gRNA and a polynucleotide sequence encoding a second Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, and the first vector and the second vector are configured to form a first and a second double strand break in a first and a second intron flanking exon 51 of the human dystrophin gene, respectively, thereby deleting a segment of the dystrophin gene comprising exon 51 and treating the subject.
[0024] The present invention is directed to a Cpf1 guide RNA (gRNA) that targets an enhancer of the B-cell lymphoma/leukemia 11A (BCL11a) gene and comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 65-70, or a complement thereof.
[0025] The present invention is directed to a method of disrupting an enhancer of a B-cell lymphoma/leukemia 11A gene in a cell, the method comprising administering to the cell at least one Cpf1 gRNA described above and a Cpf1 endonuclease.
BRIEF DESCRIPTION OF THE DRAWINGS
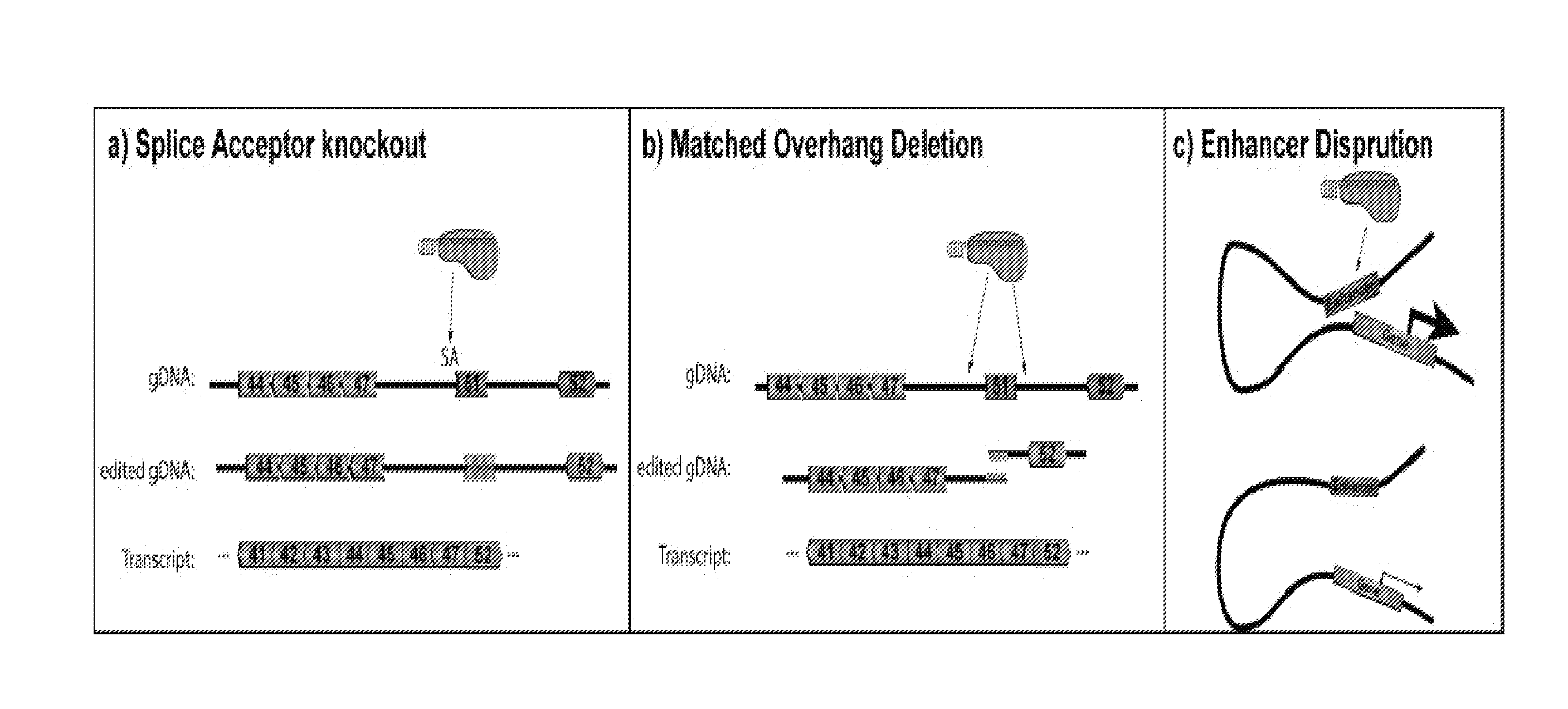
[0026] FIG. 1 is a schematic drawing showing the use of Cpf1 in three methods of treatment for genetic diseases, such as DMD and SCA/beta thalassemia, in accordance with some embodiments of the present disclosure.
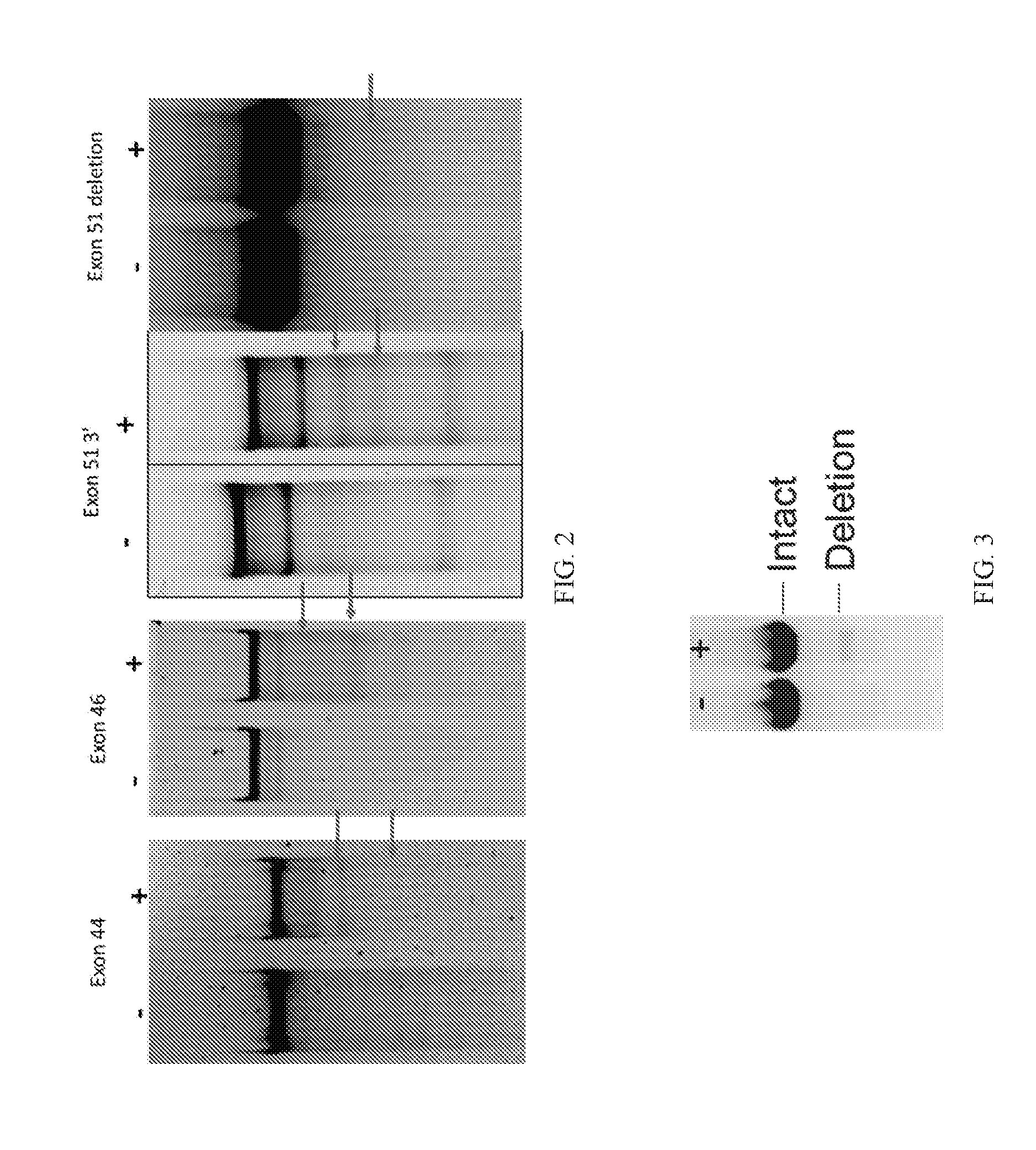
[0027] FIG. 2 shows blots showing exon 44, 46 and 51 are targeted gRNAs with detectable activity in accordance with several embodiments of the present disclosure.
[0028] FIG. 3 shows a blot showing 42 guide RNA pairs are screened targeting exon 51 deletion in accordance with one embodiment of the present disclosure.
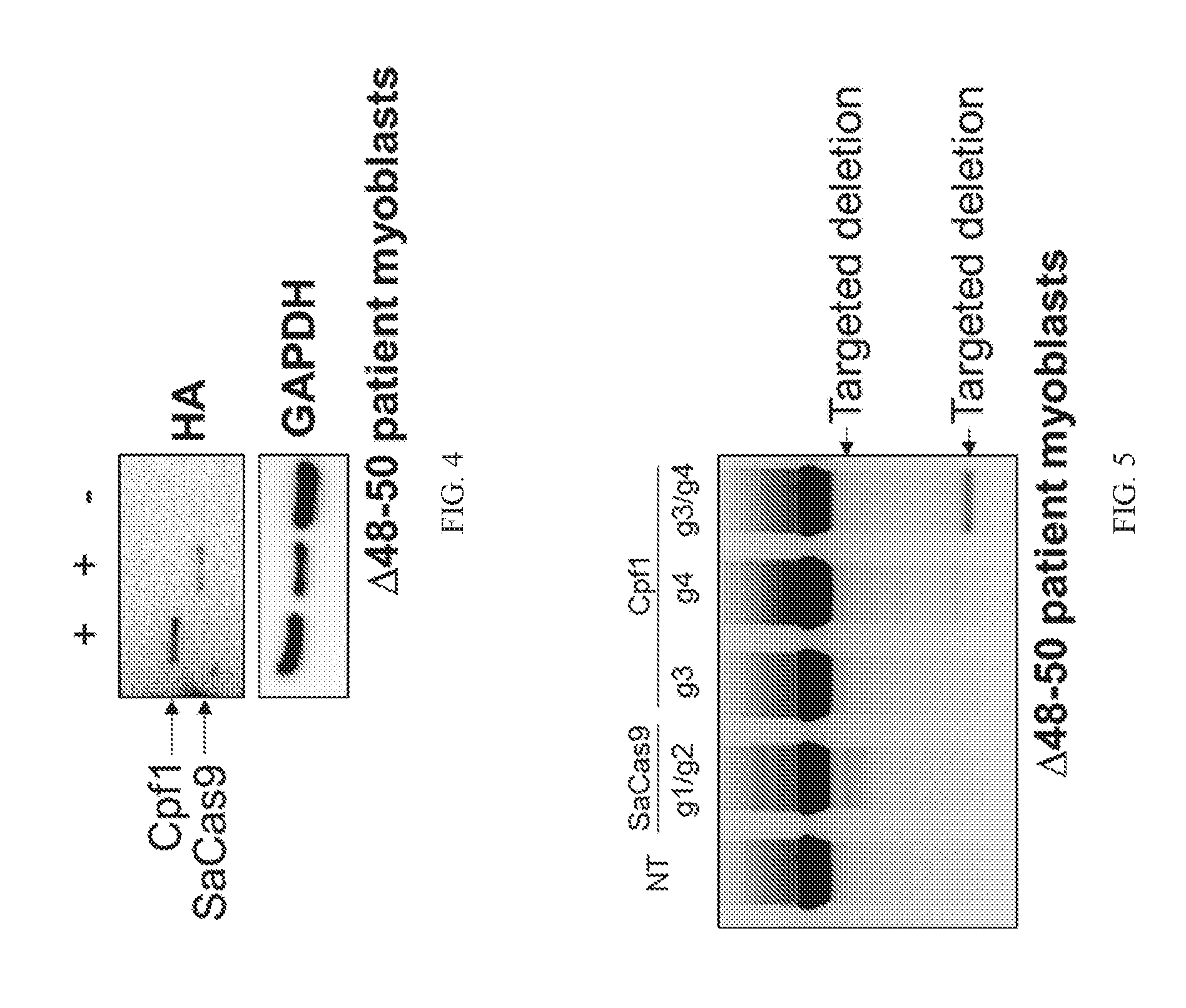
[0029] FIG. 4 shows SaCas9 and LbCpf1 are expressed in patient derived myoblasts.
[0030] FIG. 5 shows genomic deletions generated by SaCas9 or LbCpf1 in patient myoblasts.
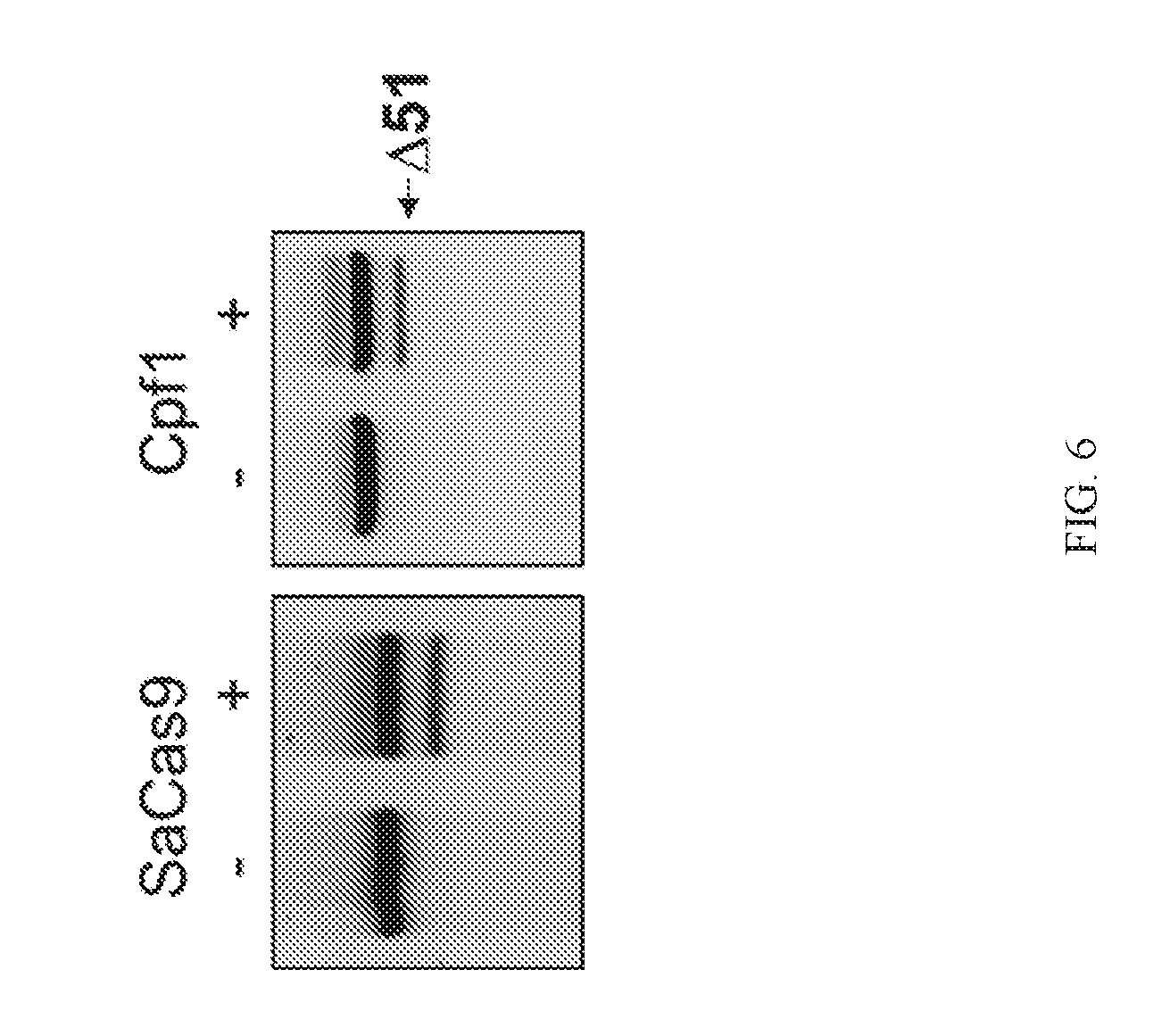
[0031] FIG. 6 shows SaCas9 or LbCpf1 targeting exon 51 remove the exon from the transcript.
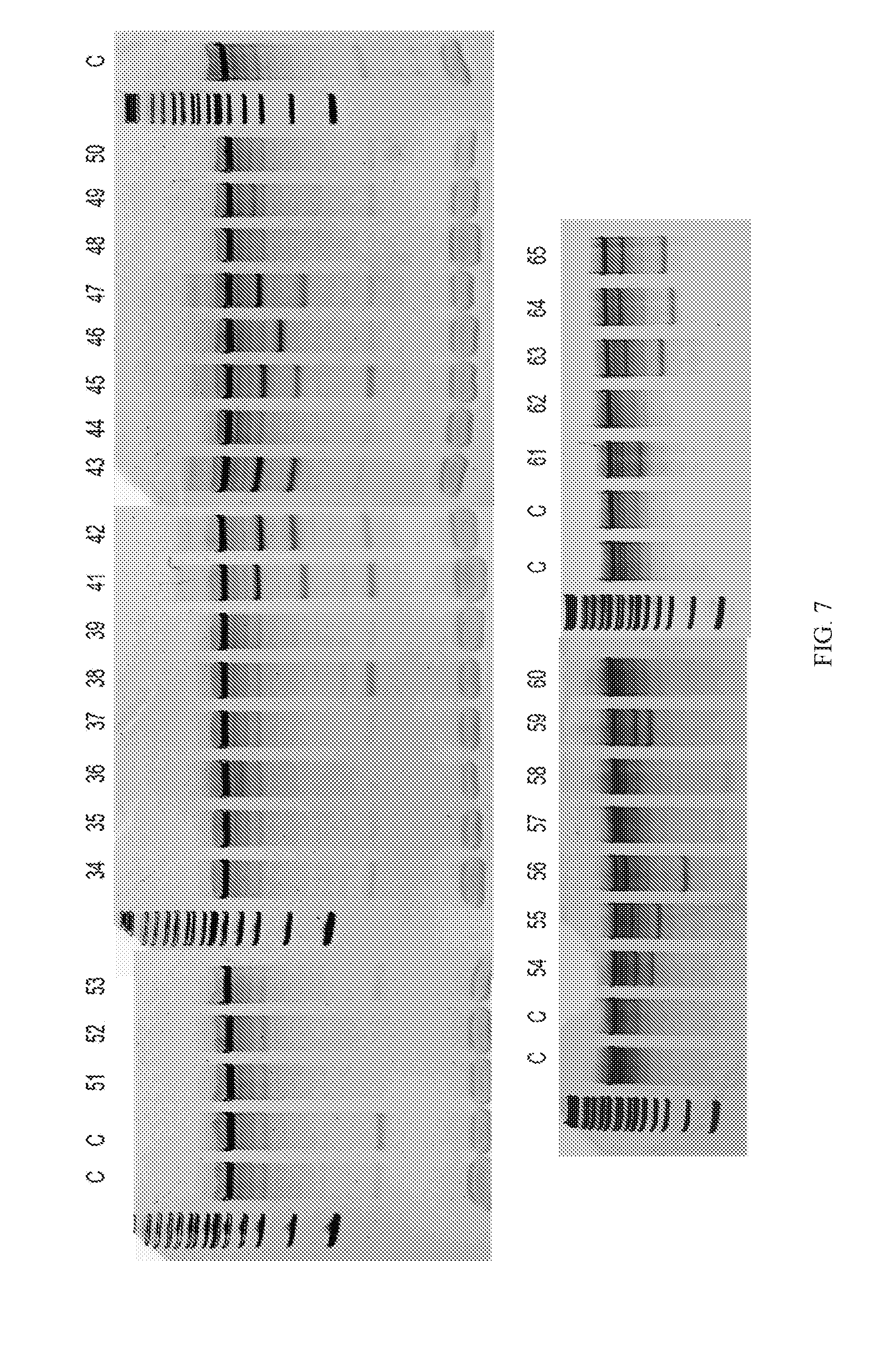
[0032] FIG. 7 illustrates a panel of Cpf1 crRNAs showing surveyor nuclease activity throughout the exon.
DETAILED DESCRIPTION
[0033] The present disclosure provides, in part, therapeutic applications of CRISPR/Cpf1-based genome editing for the treatment of diseases. Cpf1, a type V CRISPR-Cas effector endonuclease, is involved in the adaptive immunity of prokaryotes, including Acidaminococcus and Lachnospiraceae among others, and exhibits gene-editing activity in human cells through a single RNA-guided approach. The present disclosure provides methods in which the CRISPR/Cpf1-based system can be used in the treatment of genetic diseases, such as Duchenne muscular dystrophy (DMD), sickle cell anemia (SCA) and .beta.-thalassemia.
[0034] According to one aspect of the present disclosure, the first method comprises a splice acceptor knockout. Cpf1 produces a larger indel footprint making efficient disruption of splice acceptors and removal of target exons from the transcript (see FIG. 1A). As shown in FIG. 1A, Cpf1 generates a 5-base-pair staggered double-stranded break through the DNA, which may be repaired through non-homologous end joining (NHEJ) and produce a larger insertion or deletion (indel) foot print then S. pyogenes or S. aureus Cas9. This will allow for more powerful disruption of splice acceptors and removal of targeted exons as the repair may leave a larger indel footprint making knockout of genetic elements, such as splice acceptors and enhancers, more efficient. Cpf1 also has a distinct protospacer-adjacent motif (PAM) sequence that increases the diversity of genomic regions that can be targeted. Cpf1 recognizes TTTN whereas S. pyogenes Cas9 recognizes NGG and S. aureus Cas9 recognizes NNGRRT. In addition, Cpf1 does not need a tracrRNA, therefore, only crRNA is required, thus also using a small guide RNA.
[0035] Another aspect of the present disclosure provides a method comprising a matched overhang deletion. Cpf1 can encourage genetic deletions through matching overhangs to remove genetic elements (see FIG. 1B). As shown in FIG. 1B, Cpf1 generates a 5-base-pair overhang that can be matched with a second double stranded break. Multiplexed Cpf1 guide RNAs can be provided with matched overhangs to encourage seamless genetic deletions. Previous work with S. aureus Cas9 has shown .about.67% of genetic deletions are seamless with one guide RNA pair. For example, matched overhangs generated by multiplexing Cpf1 around a genetic region of interest (e.g. exon 51 in dystrophin) can encourage seamless deletions. After NHEJ, genetic deletions are made that can restore the reading frame of a mutated gene. By matching the overhangs, very precise ligations could be encouraged.
[0036] Yet another aspect of the present disclosure provides a method comprising an enhancer disruption. Cpf1 can produce a larger indel footprint making disruption of enhancers and other genetic regulatory elements more probable (see FIG. 1C). As shown in FIG. 1C, the larger indel footprint generated by Cpf1 could also be harnessed to disrupt enhancers to study enhancer function or as a potential treatment for diseases, such as SCA.
[0037] For example, the present disclosure describes the adaption of Cpf1 for the targeted genetic removal of single and multiple exons of the dystrophin gene for the treatment of Duchenne muscular dystrophy (DMD). This is accomplished by targeted mutagenesis of splice acceptors in mutational hotspots for single exon removal or by genetic deletions of single or multiple exons. Through targeted exon removal, the reading frame of dystrophin can be restored leading to improved muscle function and patient phenotype. Genetic enhancers can also be targeted as a therapeutic approach to treating disease, specifically targeting the BCL11a enhancer region or gamma globin promoter as a treatment for sickle cell anemia (SCA) or .beta.-thalassemia. The disclosed Cpf1 gRNAs can be used with the CRISPR/Cpf1-based system to target genetic regions, such as intronic regions surrounding exon 51 of the human dystrophin gene, causing genomic deletions of this region in order to restore expression of functional dystrophin in cells from DMD patients.
[0038] Also described herein are genetic constructs, compositions and methods for delivering CRISPR/Cpf1-based gene editing system and multiple gRNAs to target the dystrophin gene. The presently disclosed subject matter also provides for methods for delivering the genetic constructs (e.g., vectors) or compositions comprising thereof to skeletal muscle. The vector can be an AAV, including modified AAV vectors. The presently disclosed subject matter describes a way to deliver active forms of this class of therapeutics to skeletal muscle that is effective, efficient and facilitates successful genome modification, as well as provide a means to rewrite the human genome for therapeutic applications and target model species for basic science applications.
[0039] Section headings as used in this section and the entire disclosure herein are merely for organizational purposes and are not intended to be limiting.
1. DEFINITIONS
[0040] Unless otherwise defined, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art. In case of conflict, the present document, including definitions, will control. Preferred methods and materials are described below, although methods and materials similar or equivalent to those described herein can be used in practice or testing of the present invention. All publications, patent applications, patents and other references mentioned herein are incorporated by reference in their entirety. The materials, methods, and examples disclosed herein are illustrative only and not intended to be limiting.
[0041] The terms "comprise(s)," "include(s)," "having," "has," "can," "contain(s)," and variants thereof, as used herein, are intended to be open-ended transitional phrases, terms, or words that do not preclude the possibility of additional acts or structures. The singular forms "a," "an" and "the" include plural references unless the context clearly dictates otherwise. The present disclosure also contemplates other embodiments "comprising," "consisting of" and "consisting essentially of," the embodiments or elements presented herein, whether explicitly set forth or not.
[0042] For the recitation of numeric ranges herein, each intervening number there between with the same degree of precision is explicitly contemplated. For example, for the range of 6-9, the numbers 7 and 8 are contemplated in addition to 6 and 9, and for the range 6.0-7.0, the number 6.0, 6.1, 6.2, 6.3, 6.4, 6.5, 6.6, 6.7, 6.8, 6.9, and 7.0 are explicitly contemplated.
[0043] As used herein, the term "about" or "approximately" means within an acceptable error range for the particular value as determined by one of ordinary skill in the art, which will depend in part on how the value is measured or determined, i.e., the limitations of the measurement system. For example, "about" can mean within 3 or more than 3 standard deviations, per the practice in the art. Alternatively, "about" can mean a range of up to 20%, preferably up to 10%, more preferably up to 5%, and more preferably still up to 1% of a given value. Alternatively, particularly with respect to biological systems or processes, the term can mean within an order of magnitude, preferably within 5-fold, and more preferably within 2-fold, of a value.
[0044] "Adeno-associated virus" or "AAV" as used interchangeably herein refers to a small virus belonging to the genus Dependovirus of the Parvoviridae family that infects humans and some other primate species. AAV is not currently known to cause disease and consequently the virus causes a very mild immune response.
[0045] "Binding region" as used herein refers to the region within a nuclease target region that is recognized and bound by the nuclease.
[0046] "Cardiac muscle" or "heart muscle" as used interchangeably herein means a type of involuntary striated muscle found in the walls and histological foundation of the heart, the myocardium. Cardiac muscle is made of cardiomyocytes or myocardiocytes. Myocardiocytes show striations similar to those on skeletal muscle cells but contain only one, unique nucleus, unlike the multinucleated skeletal cells. In certain embodiments, "cardiac muscle condition" refers to a condition related to the cardiac muscle, such as cardiomyopathy, heart failure, arrhythmia, and inflammatory heart disease.
[0047] "Coding sequence" or "encoding nucleic acid" as used herein means the nucleic acids (RNA or DNA molecule) that comprise a polynucleotide sequence which encodes a protein. The coding sequence can further include initiation and termination signals operably linked to regulatory elements including a promoter and polyadenylation signal capable of directing expression in the cells of an individual or mammal to which the nucleic acid is administered. The coding sequence may be codon optimize.
[0048] "Complement" or "complementary" as used herein means a nucleic acid can mean Watson-Crick (e.g., A-T/U and C-G) or Hoogsteen base pairing between polynucleotides or polynucleotide analogs of nucleic acid molecules. "Complementarity" refers to a property shared between two nucleic acid sequences, such that when they are aligned antiparallel to each other, the polynucleotide bases at each position will be complementary.
[0049] "Correcting", "genome editing" and "restoring" as used herein refers to changing a mutant gene that encodes a truncated protein or no protein at all, such that a full-length functional or partially full-length functional protein expression is obtained. Correcting or restoring a mutant gene may include replacing the region of the gene that has the mutation or replacing the entire mutant gene with a copy of the gene that does not have the mutation with a repair mechanism such as homology-directed repair (HDR). Correcting or restoring a mutant gene may also include repairing a frameshift mutation that causes a premature stop codon, an aberrant splice acceptor site or an aberrant splice donor site, by generating a double stranded break in the gene that is then repaired using non-homologous end joining (NHEJ). NHEJ may add or delete at least one base pair during repair which may restore the proper reading frame and eliminate the premature stop codon. Correcting or restoring a mutant gene may also include disrupting an aberrant splice acceptor site or splice donor sequence. Correcting or restoring a mutant gene may also include deleting a non-essential gene segment by the simultaneous action of two nucleases on the same DNA strand in order to restore the proper reading frame by removing the DNA between the two nuclease target sites and repairing the DNA break by NHEJ.
[0050] "Cpf1 endonuclease" or "Cpf1" as used interchangeably herein refers to a single RNA-Guided endonuclease of a Class 2 CRISPR-Cas system that is a smaller and a simpler endonuclease than Cas9. The Cpf1 endonuclease targets and cleaves as a 5-nucleotide staggered cut distal to a 5'T-rich PAM.
[0051] "Donor DNA", "donor template" and "repair template" as used interchangeably herein refers to a double-stranded DNA fragment or molecule that includes at least a portion of the gene of interest. The donor DNA may encode a full-functional protein or a partially-functional protein.
[0052] "Duchenne Muscular Dystrophy" or "DMD" as used interchangeably herein refers to a recessive, fatal, X-linked disorder that results in muscle degeneration and eventual death. DMD is a common hereditary monogenic disease and occurs in 1 in 3500 males. DMD is the result of inherited or spontaneous mutations that cause nonsense or frame shift mutations in the dystrophin gene. The majority of dystrophin mutations that cause DMD are deletions of exons that disrupt the reading frame and cause premature translation termination in the dystrophin gene. DMD patients typically lose the ability to physically support themselves during childhood, become progressively weaker during the teenage years, and die in their twenties.
[0053] "Dystrophin" as used herein refers to a rod-shaped cytoplasmic protein which is a part of a protein complex that connects the cytoskeleton of a muscle fiber to the surrounding extracellular matrix through the cell membrane. Dystrophin provides structural stability to the dystroglycan complex of the cell membrane that is responsible for regulating muscle cell integrity and function. The dystrophin gene or "DMD gene" as used interchangeably herein is 2.2 megabases at locus Xp21. The primary transcription measures about 2,400 kb with the mature mRNA being about 14 kb. 79 exons code for the protein which is over 3500 amino acids.
[0054] "Exon 51" as used herein refers to the 51.sup.4 exon of the dystrophin gene. Exon 51 is frequently adjacent to frame-disrupting deletions in DMD patients and has been targeted in clinical trials for oligonucleotide-based exon skipping. A clinical trial for the exon 51 skipping compound eteplirsen recently reported a significant functional benefit across 48 weeks, with an average of 47% dystrophin positive fibers compared to baseline. Mutations in exon 51 are ideally suited for permanent correction by NHEJ-based genome editing.
[0055] "Frameshift" or "frameshift mutation" as used interchangeably herein refers to a type of gene mutation wherein the addition or deletion of one or more polynucleotides causes a shift in the reading frame of the codons in the mRNA. The shift in reading frame may lead to the alteration in the amino acid sequence at protein translation, such as a missense mutation or a premature stop codon.
[0056] "Functional" and "full-functional" as used herein describes protein that has biological activity. A "functional gene" refers to a gene transcribed to mRNA, which is translated to a functional protein.
[0057] "Genetic construct" as used herein refers to the DNA or RNA molecules that comprise a polynucleotide sequence that encodes a protein. The coding sequence includes initiation and termination signals operably linked to regulatory elements including a promoter and polyadenylation signal capable of directing expression in the cells of the individual to whom the nucleic acid molecule is administered. As used herein, the term "expressible form" refers to gene constructs that contain the necessary regulatory elements operable linked to a coding sequence that encodes a protein such that when present in the cell of the individual, the coding sequence will be expressed.
[0058] "Genetic disease" as used herein refers to a disease, partially or completely, directly or indirectly, caused by one or more abnormalities in the genome, especially a condition that is present from birth. The abnormality may be a mutation, an insertion or a deletion. The abnormality may affect the coding sequence of the gene or its regulatory sequence. The genetic disease may be, but not limited to DMD, Becker Muscular Dystrophy (BMD), hemophilia, cystic fibrosis, Huntington's chorea, familial hypercholesterolemia (LDL receptor defect), hepatoblastoma, Wilson's disease, congenital hepatic porphyria, inherited disorders of hepatic metabolism, Lesch Nyhan syndrome, sickle cell anemia, thalassaemias, such as .beta.-thalassemia, xeroderma pigmentosum, Fanconi's anemia, retinitis pigmentosa, ataxia telangiectasia, Bloom's syndrome, retinoblastoma, and Tay-Sachs disease.
[0059] "Homology-directed repair" or "HDR" as used interchangeably herein refers to a mechanism in cells to repair double strand DNA lesions when a homologous piece of DNA is present in the nucleus, mostly in G2 and S phase of the cell cycle. HDR uses a donor DNA template to guide repair and may be used to create specific sequence changes to the genome, including the targeted addition of whole genes. If a donor template is provided along with the CRISPR/Cpf1-based gene editing system, then the cellular machinery will repair the break by homologous recombination, which is enhanced several orders of magnitude in the presence of DNA cleavage. When the homologous DNA piece is absent, non-homologous end joining may take place instead.
[0060] "Genome editing" as used herein refers to changing a gene. Genome editing may include correcting or restoring a mutant gene. Genome editing may include knocking out a gene, such as a mutant gene or a normal gene. Genome editing may be used to treat disease or enhance muscle repair by changing the gene of interest.
[0061] "Identical" or "identity" as used herein in the context of two or more nucleic acids or polypeptide sequences means that the sequences have a specified percentage of residues that are the same over a specified region. The percentage may be calculated by optimally aligning the two sequences, comparing the two sequences over the specified region, determining the number of positions at which the identical residue occurs in both sequences to yield the number of matched positions, dividing the number of matched positions by the total number of positions in the specified region, and multiplying the result by 100 to yield the percentage of sequence identity. In cases where the two sequences are of different lengths or the alignment produces one or more staggered ends and the specified region of comparison includes only a single sequence, the residues of single sequence are included in the denominator but not the numerator of the calculation. When comparing DNA and RNA, thymine (T) and uracil (U) may be considered equivalent. Identity may be performed manually or by using a computer sequence algorithm such as BLAST or BLAST 2.0.
[0062] "Mutant gene" or "mutated gene" as used interchangeably herein refers to a gene that has undergone a detectable mutation. A mutant gene has undergone a change, such as the loss, gain, or exchange of genetic material, which affects the normal transmission and expression of the gene. A "disrupted gene" as used herein refers to a mutant gene that has a mutation that causes a premature stop codon. The disrupted gene product is truncated relative to a full-length undisrupted gene product.
[0063] "Non-homologous end joining (NHEJ) pathway" as used herein refers to a pathway that repairs double-strand breaks in DNA by directly ligating the break ends without the need for a homologous template. The template-independent re-ligation of DNA ends by NHEJ is a stochastic, error-prone repair process that introduces random micro-insertions and micro-deletions (indels) at the DNA breakpoint. This method may be used to intentionally disrupt, delete, or alter the reading frame of targeted gene sequences. NHEJ typically uses short homologous DNA sequences called microhomologies to guide repair. These microhomologies are often present in single-stranded overhangs on the end of double-strand breaks. When the overhangs are perfectly compatible, NHEJ usually repairs the break accurately, yet imprecise repair leading to loss of polynucleotides may also occur, but is much more common when the overhangs are not compatible.
[0064] "Normal gene" as used herein refers to a gene that has not undergone a change, such as a loss, gain, or exchange of genetic material. The normal gene undergoes normal gene transmission and gene expression.
[0065] "Nuclease mediated NHEJ" as used herein refers to NHEJ that is initiated after a nuclease, such as a Cpf1 endonuclease, cuts double stranded DNA.
[0066] "Nucleic acid" or "oligonucleotide" or "polynucleotide" as used herein means at least two polynucleotides covalently linked together. The depiction of a single strand also defines the sequence of the complementary strand. Thus, a nucleic acid also encompasses the complementary strand of a depicted single strand. Many variants of a nucleic acid may be used for the same purpose as a given nucleic acid. Thus, a nucleic acid also encompasses substantially identical nucleic acids and complements thereof. A single strand provides a probe that may hybridize to a target sequence under stringent hybridization conditions. Thus, a nucleic acid also encompasses a probe that hybridizes under stringent hybridization conditions.
[0067] Nucleic acids may be single stranded or double stranded, or may contain portions of both double stranded and single stranded sequence. The nucleic acid may be DNA, both genomic and cDNA, RNA, or a hybrid, where the nucleic acid may contain combinations of deoxyribo- and ribo-nucleotides, and combinations of bases including uracil, adenine, thymine, cytosine, guanine, inosine, xanthine hypoxanthine, isocytosine and isoguanine. Nucleic acids may be obtained by chemical synthesis methods or by recombinant methods.
[0068] "Operably linked" as used herein means that expression of a gene is under the control of a promoter with which it is spatially connected. A promoter may be positioned 5' (upstream) or 3' (downstream) of a gene under its control. The distance between the promoter and a gene may be approximately the same as the distance between that promoter and the gene it controls in the gene from which the promoter is derived. As is known in the art, variation in this distance may be accommodated without loss of promoter function.
[0069] "Partially-functional" as used herein describes a protein that is encoded by a mutant gene and has less biological activity than a functional protein but more than a non-functional protein.
[0070] "Premature stop codon" or "out-of-frame stop codon" as used interchangeably herein refers to nonsense mutation in a sequence of DNA, which results in a stop codon at location not normally found in the wild-type gene. A premature stop codon may cause a protein to be truncated or shorter compared to the full-length version of the protein.
[0071] "Promoter" as used herein means a synthetic or naturally-derived molecule which is capable of conferring, activating or enhancing expression of a nucleic acid in a cell. A promoter may comprise one or more specific transcriptional regulatory sequences to further enhance expression and/or to alter the spatial expression and/or temporal expression of same. A promoter may also comprise distal enhancer or repressor elements, which may be located as much as several thousand base pairs from the start site of transcription. A promoter may be derived from sources including viral, bacterial, fungal, plants, insects, and animals. A promoter may regulate the expression of a gene component constitutively, or differentially with respect to cell, the tissue or organ in which expression occurs or, with respect to the developmental stage at which expression occurs, or in response to external stimuli such as physiological stresses, pathogens, metal ions, or inducing agents. Representative examples of promoters include the bacteriophage T7 promoter, bacteriophage T3 promoter, SP6 promoter, lac operator-promoter, tac promoter, SV40 late promoter, SV40 early promoter, RSV-LTR promoter, CMV IE promoter, SV40 early promoter or SV40 late promoter, human U6 (hU6) promoter, and CMV IE promoter.
[0072] "Skeletal muscle" as used herein refers to a type of striated muscle, which is under the control of the somatic nervous system and attached to bones by bundles of collagen fibers known as tendons. Skeletal muscle is made up of individual components known as myocytes, or "muscle cells", sometimes colloquially called "muscle fibers." Myocytes are formed from the fusion of developmental myoblasts (a type of embryonic progenitor cell that gives rise to a muscle cell) in a process known as myogenesis. These long, cylindrical, multinucleated cells are also called myofibers.
[0073] "Skeletal muscle condition" as used herein refers to a condition related to the skeletal muscle, such as muscular dystrophies, aging, muscle degeneration, wound healing, and muscle weakness or atrophy.
[0074] "Subject" and "patient" as used herein interchangeably refers to any vertebrate, including, but not limited to, a mammal (e.g., cow, pig, camel, llama, horse, goat, rabbit, sheep, hamsters, guinea pig, cat, dog, rat, and mouse, a non-human primate (for example, a monkey, such as a cynomolgous or rhesus monkey, chimpanzee, etc.) and a human). In some embodiments, the subject may be a human or a non-human. The subject or patient may be undergoing other forms of treatment.
[0075] "Target gene" as used herein refers to any polynucleotide sequence encoding a known or putative gene product. The target gene may be a mutated gene involved in a genetic disease. In certain embodiments, the target gene is a human dystrophin gene or a human B-cell lymphoma/leukemia 11A gene. In certain embodiments, the target gene is a mutant human dystrophin gene.
[0076] "Target region" as used herein refers to the region of the target gene to which the CRISPR/Cpf1-based gene editing system is designed to bind and cleave.
[0077] "Transgene" as used herein refers to a gene or genetic material containing a gene sequence that has been isolated from one organism and is introduced into a different organism. This non-native segment of DNA may retain the ability to produce RNA or protein in the transgenic organism, or it may alter the normal function of the transgenic organism's genetic code. The introduction of a transgene has the potential to change the phenotype of an organism.
[0078] "Variant" used herein with respect to a nucleic acid means (i) a portion or fragment of a referenced polynucleotide sequence; (ii) the complement of a referenced polynucleotide sequence or portion thereof; (iii) a nucleic acid that is substantially identical to a referenced nucleic acid or the complement thereof; or (iv) a nucleic acid that hybridizes under stringent conditions to the referenced nucleic acid, complement thereof, or a sequences substantially identical thereto.
[0079] "Variant" with respect to a peptide or polypeptide that differs in amino acid sequence by the insertion, deletion, or conservative substitution of amino acids, but retain at least one biological activity. Variant may also mean a protein with an amino acid sequence that is substantially identical to a referenced protein with an amino acid sequence that retains at least one biological activity. A conservative substitution of an amino acid, i.e., replacing an amino acid with a different amino acid of similar properties (e.g., hydrophilicity, degree and distribution of charged regions) is recognized in the art as typically involving a minor change. These minor changes may be identified, in part, by considering the hydropathic index of amino acids, as understood in the art. Kyte et al., J. Mol. Biol. 157:105-132 (1982). The hydropathic index of an amino acid is based on a consideration of its hydrophobicity and charge. It is known in the art that amino acids of similar hydropathic indexes may be substituted and still retain protein function. In one aspect, amino acids having hydropathic indexes of .+-.2 are substituted. The hydrophilicity of amino acids may also be used to reveal substitutions that would result in proteins retaining biological function. A consideration of the hydrophilicity of amino acids in the context of a peptide permits calculation of the greatest local average hydrophilicity of that peptide. Substitutions may be performed with amino acids having hydrophilicity values within .+-.2 of each other. Both the hydrophobicity index and the hydrophilicity value of amino acids are influenced by the particular side chain of that amino acid. Consistent with that observation, amino acid substitutions that are compatible with biological function are understood to depend on the relative similarity of the amino acids, and particularly the side chains of those amino acids, as revealed by the hydrophobicity, hydrophilicity, charge, size, and other properties.
[0080] "Vector" as used herein means a nucleic acid sequence containing an origin of replication. A vector may be a viral vector, bacteriophage, bacterial artificial chromosome or yeast artificial chromosome. A vector may be a DNA or RNA vector. A vector may be a self-replicating extrachromosomal vector, and preferably, is a DNA plasmid. For example, the vector may encode a Cpf1 endonuclease and at least one Cpf1 gRNA, such as a Cpf1 gRNA comprising a polynucleotide sequence of any one of SEQ ID NOs: 36-119, or complement thereof.
[0081] Unless otherwise defined herein, scientific and technical terms used in connection with the present disclosure shall have the meanings that are commonly understood by those of ordinary skill in the art. For example, any nomenclatures used in connection with, and techniques of, cell and tissue culture, molecular biology, immunology, microbiology, genetics and protein and nucleic acid chemistry and hybridization described herein are those that are well known and commonly used in the art. The meaning and scope of the terms should be clear; in the event however of any latent ambiguity, definitions provided herein take precedent over any dictionary or extrinsic definition. Further, unless otherwise required by context, singular terms shall include pluralities and plural terms shall include the singular.
2. CRISPR SYSTEM
[0082] A presently disclosed genetic construct (e.g., a vector) encodes a CRISPR/Cpf1-based gene editing system that is specific for a dystrophin gene (e.g., human dystrophin gene). "Clustered Regularly Interspaced Short Palindromic Repeats" and "CRISPRs", as used interchangeably herein refers to loci containing multiple short direct repeats that are found in the genomes of approximately 40% of sequenced bacteria and 90% of sequenced archaea. The CRISPR system is a microbial nuclease system involved in defense against invading phages and plasmids that provides a form of acquired immunity. The CRISPR loci in microbial hosts contain a combination of CRISPR-associated (Cas) genes as well as non-coding RNA elements capable of programming the specificity of the CRISPR-mediated nucleic acid cleavage. Short segments of foreign DNA, called spacers, are incorporated into the genome between CRISPR repeats, and serve as a `memory` of past exposures.
[0083] Three classes of CRISPR systems (Types I, II and III effector systems) are known. The Type II effector system carries out targeted DNA double-strand break in four sequential steps, using a single effector enzyme, such as a Cpf1 endonuclease, to cleave dsDNA. Compared to the Type I and Type III effector systems, which require multiple distinct effectors acting as a complex, the Type II effector system may function in alternative contexts such as eukaryotic cells. Cpf1 endonuclease mediates cleavage of target DNA if a correct PAM is also present on the 5' end of the protospacer.
[0084] CRISPR/Cpf1 systems activity has three stages: adaptation, formation of crRNAs, and interference. During adaptation, Cas1 and Cas2 proteins facilitate the adaptation of small fragments of DNA into the CRISPR array. The processing of pre-cr-RNAs occurs during formation of crRNAs to produce mature crRNAs to guide the Cas protein, i.e., the Cpf1 endonuclease. During interference: the Cpf1 is bound to a crRNA to form a binary complex to identify and cleave a target DNA sequence.
[0085] In this system, the Cpf1 endonuclease is directed to genomic target sites by a synthetically reconstituted Cpf1 "guide RNA" ("Cpf1 gRNA"). The Cpf1 endonuclease leaves one strand longer than the other, creating `sticky` ends, for example 4-5 nucleotide long sticky ends, unlike Cas9 which generates blunt ends. The Cpf1 endonuclease also cleaves target DNA further away from PAM compared to Cas9.
[0086] The target gene (e.g., a dystrophin gene, e.g., human dystrophin gene) can be involved in differentiation of a cell or any other process in which activation of a gene can be desired, or can have a mutation such as a frameshift mutation or a nonsense mutation. If the target gene has a mutation that causes a premature stop codon, an aberrant splice acceptor site or an aberrant splice donor site, the CRISPR/Cpf1-based gene editing system can be designed to recognize and bind a polynucleotide sequence upstream or downstream from the premature stop codon, the aberrant splice acceptor site or the aberrant splice donor site. The CRISPR/Cpf1-based system can also be used to disrupt normal gene splicing by targeting splice acceptors and donors to induce skipping of premature stop codons or restore a disrupted reading frame. The CRISPR/Cpf1-based gene editing system may or may not mediate off-target changes to protein-coding regions of the genome.
[0087] Provided herein are CRISPR/Cpf1-based engineered systems for use in genome editing and treating genetic diseases. A unique capability of the CRISPR/Cpf1-based gene editing system is the straightforward ability to simultaneously target multiple distinct genomic loci by co-expressing a single Cpf1 endonuclease with two or more Cpf1 gRNAs. The CRISPR/Cpf1-based engineered systems can be designed to target any gene, including genes involved in a genetic disease, aging, tissue regeneration, or wound healing. The CRISPR/Cpf1-based gene editing systems can include a Cpf1 endonuclease and at least one Cpf1 gRNA. In certain embodiments, the system comprises two Cpf1 gRNAs.
[0088] a. Cpf1 Endonuclease
[0089] The CRISPR/Cpf1-based gene editing system can include a Cpf1 endonuclease. Cpf1 endonuclease is an endonuclease that cleaves nucleic acid. The Cpf1 endonuclease cleaves in a staggered fashion, creating a 5 nucleotide 5' overhang 18-23 bases away from the PAM, whereas Cas9 generates blunt ends 3 nucleotide upstream of the PAM site. The Cpf1 endonuclease can be from any bacterial or archaea species, including, but not limited to, Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GWC2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens or Porphyromonas macacae. In certain embodiments, the Cpf1 endonuclease is a Cpf1 endonuclease from Lachnospiraceae bacterium ND2006 ("LbCpf1") or from Acidaminococcus ("AsCpf1").
[0090] In some embodiments, the Cpf1 endonuclease can include a humanized AsCpf1 sequence (SEQ ID NO: 124) as follows:
TABLE-US-00001 (SEQ ID NO: 124) gacggatcgggagatctcccgatcccctatggtgcactctcagtacaatc tgctctgatgccgcatagttaagccagtatctgctccctgcttgtgtgtt ggaggtcgctgagtagtgcgcgagcaaaatttaagctacaacaaggcaag gcttgaccgacaattgcatgaagaatctgcttagggttaggcgttttgcg ctgcttcgcgatgtacgggccagatatacgcgttgacattgattattgac tagttattaatagtaatcaattacggggtcattagttcatagcccatata tggagttccgcgttacataacttacggtaaatggcccgcctggctgaccg cccaacgacccccgcccattgacgtcaataatgacgtatgttcccatagt aacgccaatagggactttccattgacgtcaatgggtggagtatttacggt aaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccc cctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagta catgaccttatgggactttcctacttggcagtacatctacgtattagtca tcgctattaccatggtgatgcggttttggcagtacatcaatgggcgtgga tagcggtttgactcacggggatttccaagtctccaccccattgacgtcaa tgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgta acaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggag gtctatataagcagagctctctggctaactagagaacccactgcttactg gcttatcgaaattaatacgactcactatagggagacccaagctggctagc gtttaaacttaagcttggtaccgccaccATGACACAGTTCGAGGGCTTTA CCAACCTGTATCAGGTGAGCAAGACACTGCGGTTTGAGCTGATCCCACAG GGCAAGACCCTGAAGCACATCCAGGAGCAGGGCTTCATCGAGGAGGACAA GGCCCGCAATGATCACTACAAGGAGCTGAAGCCCATCATCGATCGGATCT ACAAGACCTATGCCGACCAGTGCCTGCAGCTGGTGCAGCTGGATTGGGAG AACCTGAGCGCCGCCATCGACTCCTATAGAAAGGAGAAAACCGAGGAGAC AAGGAACGCCCTGATCGAGGAGCAGGCCACATATCGCAATGCCATCCACG ACTACTTCATCGGCCGGACAGACAACCTGACCGATGCCATCAATAAGAGA CACGCCGAGATCTACAAGGGCCTGTTCAAGGCCGAGCTGTTTAATGGCAA GGTGCTGAAGCAGCTGGGCACCGTGACCACAACCGAGCACGAGAACGCCC TGCTGCGGAGCTTCGACAAGTTTACAACCTACTTCTCCGGCTTTTATGAG AACAGGAAGAACGTGTTCAGCGCCGAGGATATCAGCACAGCCATCCCACA CCGCATCGTGCAGGACAACTTCCCCAAGTTTAAGGAGAATTGTCACATCT TCACACGCCTGATCACCGCCGTGCCCAGCCTGCGGGAGCACTTTGAGAAC GTGAAGAAGGCCATCGGCATCTTCGTGAGCACCTCCATCGAGGAGGTGTT TTCCTTCCCTTTTTATAACCAGCTGCTGACACAGACCCAGATCGACCTGT ATAACCAGCTGCTGGGAGGAATCTCTCGGGAGGCAGGCACCGAGAAGATC AAGGGCCTGAACGAGGTGCTGAATCTGGCCATCCAGAAGAATGATGAGAC AGCCCACATCATCGCCTCCCTGCCACACAGATTCATCCCCCTGTTTAAGC AGATCCTGTCCGATAGGAACACCCTGTCTTTCATCCTGGAGGAGTTTAAG AGCGACGAGGAAGTGATCCAGTCCTTCTGCAAGTACAAGACACTGCTGAG AAACGAGAACGTGCTGGAGACAGCCGAGGCCCTGTTTAACGAGCTGAACA GCATCGACCTGACACACATCTTCATCAGCCACAAGAAGCTGGAGACAATC AGCAGCGCCCTGTGCGACCACTGGGATACACTGAGGAATGCCCTGTATGA GCGGAGAATCTCCGAGCTGACAGGCAAGATCACCAAGTCTGCCAAGGAGA AGGTGCAGCGCAGCCTGAAGCACGAGGATATCAACCTGCAGGAGATCATC TCTGCCGCAGGCAAGGAGCTGAGCGAGGCCTTCAAGCAGAAAACCAGCGA GATCCTGTCCCACGCACACGCCGCCCTGGATCAGCCACTGCCTACAACCC TGAAGAAGCAGGAGGAGAAGGAGATCCTGAAGTCTCAGCTGGACAGCCTG CTGGGCCTGTACCACCTGCTGGACTGGTTTGCCGTGGATGAGTCCAACGA GGTGGACCCCGAGTTCTCTGCCCGGCTGACCGGCATCAAGCTGGAGATGG AGCCTTCTCTGAGCTTCTACAACAAGGCCAGAAATTATGCCACCAAGAAG CCCTACTCCGTGGAGAAGTTCAAGCTGAACTTTCAGATGCCTACACTGGC CTCTGGCTGGGACGTGAATAAGGAGAAGAACAATGGCGCCATCCTGTTTG TGAAGAACGGCCTGTACTATCTGGGCATCATGCCAAAGCAGAAGGGCAGG TATAAGGCCCTGAGCTTCGAGCCCACAGAGAAAACCAGCGAGGGCTTTGA TAAGATGTACTATGACTACTTCCCTGATGCCGCCAAGATGATCCCAAAGT GCAGCACCCAGCTGAAGGCCGTGACAGCCCACTTTCAGACCCACACAACC CCCATCCTGCTGTCCAACAATTTCATCGAGCCTCTGGAGATCACAAAGGA GATCTACGACCTGAACAATCCTGAGAAGGAGCCAAAGAAGTTTCAGACAG CCTACGCCAAGAAAACCGGCGACCAGAAGGGCTACAGAGAGGCCCTGTGC AAGTGGATCGACTTCACAAGGGATTTTCTGTCCAAGTATACCAAGACAAC CTCTATCGATCTGTCTAGCCTGCGGCCATCCTCTCAGTATAAGGACCTGG GCGAGTACTATGCCGAGCTGAATCCCCTGCTGTACCACATCAGCTTCCAG AGAATCGCCGAGAAGGAGATCATGGATGCCGTGGAGACAGGCAAGCTGTA CCTGTTCCAGATCTATAACAAGGACTTTGCCAAGGGCCACCACGGCAAGC CTAATCTGCACACACTGTATTGGACCGGCCTGTTTTCTCCAGAGAACCTG GCCAAGACAAGCATCAAGCTGAATGGCCAGGCCGAGCTGTTCTACCGCCC TAAGTCCAGGATGAAGAGGATGGCACACCGGCTGGGAGAGAAGATGCTGA ACAAGAAGCTGAAGGATCAGAAAACCCCAATCCCCGACACCCTGTACCAG GAGCTGTACGACTATGTGAATCACAGACTGTCCCACGACCTGTCTGATGA GGCCAGGGCCCTGCTGCCCAACGTGATCACCAAGGAGGTGTCTCACGAGA TCATCAAGGATAGGCGCTTTACCAGCGACAAGTTCTTTTTCCACGTGCCT ATCACACTGAACTATCAGGCCGCCAATTCCCCATCTAAGTTCAACCAGAG GGTGAATGCCTACCTGAAGGAGCACCCCGAGACACCTATCATCGGCATCG ATCGGGGCGAGAGAAACCTGATCTATATCACAGTGATCGACTCCACCGGC AAGATCCTGGAGCAGCGGAGCCTGAACACCATCCAGCAGTTTGATTACCA GAAGAAGCTGGACAACAGGGAGAAGGAGAGGGTGGCAGCAAGGCAGGCCT GGTCTGTGGTGGGCACAATCAAGGATCTGAAGCAGGGCTATCTGAGCCAG GTCATCCACGAGATCGTGGACCTGATGATCCACTACCAGGCCGTGGTGGT GCTGGAGAACCTGAATTTCGGCTTTAAGAGCAAGAGGACCGGCATCGCCG AGAAGGCCGTGTACCAGCAGTTCGAGAAGATGCTGATCGATAAGCTGAAT TGCCTGGTGCTGAAGGACTATCCAGCAGAGAAAGTGGGAGGCGTGCTGAA CCCATACCAGCTGACAGACCAGTTCACCTCCTTTGCCAAGATGGGCACCC AGTCTGGCTTCCTGTTTTACGTGCCTGCCCCATATACATCTAAGATCGAT CCCCTGACCGGCTTCGTGGACCCCTTCGTGTGGAAAACCATCAAGAATCA CGAGAGCCGCAAGCACTTCCTGGAGGGCTTCGACTTTCTGCACTACGACG TGAAAACCGGCGACTTCATCCTGCACTTTAAGATGAACAGAAATCTGTCC TTCCAGAGGGGCCTGCCCGGCTTTATGCCTGCATGGGATATCGTGTTCGA GAAGAACGAGACACAGTTTGACGCCAAGGGCACCCCTTTCATCGCCGGCA AGAGAATCGTGCCAGTGATCGAGAATCACAGATTCACCGGCAGATACCGG GACCTGTATCCTGCCAACGAGCTGATCGCCCTGCTGGAGGAGAAGGGCAT CGTGTTCAGGGATGGCTCCAACATCCTGCCAAAGCTGCTGGAGAATGACG ATTCTCACGCCATCGACACCATGGTGGCCCTGATCCGCAGCGTGCTGCAG ATGCGGAACTCCAATGCCGCCACAGGCGAGGACTATATCAACAGCCCCGT GCGCGATCTGAATGGCGTGTGCTTCGACTCCCGGTTTCAGAACCCAGAGT GGCCCATGGACGCCGATGCCAATGGCGCCTACCACATCGCCCTGAAGGGC CAGCTGCTGCTGAATCACCTGAAGGAGAGCAAGGATCTGAAGCTGCAGAA CGGCATCTCCAATCAGGACTGGCTGGCCTACATCCAGGAGCTGCGCAACA AAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGA TCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGA TTATGCATACCCATATGATGTCCCCGACTATGCCTAAGaattctgcagat atccagcacagtggcggccgctcgagtctagagggcccgtttaaacccgc tgatcagcctcgactgtgccttctagttgccagccatctgttgtttgccc ctcccccgtgccttccttgaccctggaaggtgccactcccactgtccttt cctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattct attctggggggtggggtggggcaggacagcaagggggaggattgggaaga caatagcaggcatgctggggatgcggtgggctctatggcttctgaggcgg aaagaaccagctggggctctagggggtatccccacgcgccctgtagcggc gcattaagcgcggcgggtgtggtggttacgcgcagcgtgaccgctacact tgccagcgccctagcgcccgctcctttcgctttcttcccttcctttctcg ccacgttcgccggctttccccgtcaagctctaaatcgggggctcccttta gggttccgatttagtgctttacggcacctcgaccccaaaaaacttgatta gggtgatggttcacgtagtgggccatcgccctgatagacggtttttcgcc ctttgacgttggagtccacgttctttaatagtggactatgttccaaactg gaacaacactcaaccctatctcggtctattcttttgatttataagggatt ttgccgatttcggcctattggttaaaaaatgagctgatttaacaaaaatt taacgcgaattaattctgtggaatgtgtgtcagttagggtgtggaaagtc cccaggctccccagcaggcagaagtatgcaaagcatgcatctcaattagt cagcaaccaggtgtggaaagtccccaggctccccagcaggcagaagtatg caaagcatgcatctcaattagtcagcaaccatagtcccgcccctaactcc gcccatcccgcccctaactccgcccagttccgcccattctccgccccatg gctgactaattttttttatttatgcagaggccgaggccgcctctgcctct gagctattccagaagtagtgaggaggcttttttggaggcctaggatttgc aaaaagctcccgggagcttgtatatccattttcggatctgatcaagagac aggatgaggatcgtttcgcatgattgaacaagatggattgcacgcaggtt ctccggccgcttgggtggagaggctattcggctatgactgggcacaacag
acaatcggctgctctgatgccgccgtgttccggctgtcagcgcaggggcg cccggttctttttgtcaagaccgacctgtccggtgccctgaatgaactgc aggacgaggcagcgcggctatcgtggctggccacgacgggcgttccttgc gcagctgtgctcgacgttgtcactgaagcgggaagggactggctgctatt gggcgaagtgccggggcaggatctcctgtcatctcaccttgctcctgccg agaaagtatccatcatggctgatgcaatgcggcggctgcatacgcttgat ccggctacctgcccattcgaccaccaagcgaaacatcgcatcgagcgagc acgtactcggatggaagccggtcttgtcgatcaggatgatctggacgaag agcatcaggggctcgcgccagccgaactgttcgccaggctcaaggcgcgc atgcccgacggcgaggatctcgtcgtgacccatggcgatgcctgcttgcc gaatatcatggtggaaaatggccgcttttctggattcatcgactgtggcc ggctgggtgtggcggaccgctatcaggacatagcgttggctacccgtgat attgctgaagagcttggcggcgaatgggctgaccgcttcctcgtgcttta cggtatcgccgctcccgattcgcagcgcatcgccttctatcgccttcttg acgagttcttctgagcgggactctggggttcgaaatgaccgaccaagcga cgcccaacctgccatcacgagatttcgattccaccgccgccttctatgaa aggttgggcttcggaatcgttttccgggacgccggctggatgatcctcca gcgcggggatctcatgctggagttcttcgcccaccccaacttgtttattg cagcttataatggttacaaataaagcaatagcatcacaaatttcacaaat aaagcatttttttcactgcattctagttgtggtttgtccaaactcatcaa tgtatcttatcatgtctgtataccgtcgacctctagctagagcttggcgt aatcatggtcatagctgtttcctgtgtgaaattgttatccgctcacaatt ccacacaacatacgagccggaagcataaagtgtaaagcctggggtgccta atgagtgagctaactcacattaattgcgttgcgctcactgcccgctttcc agtcgggaaacctgtcgtgccagctgcattaatgaatcggccaacgcgcg gggagaggcggtttgcgtattgggcgctcttccgcttcctcgctcactga ctcgctgcgctcggtcgttcggctgcggcgagcggtatcagctcactcaa aggcggtaatacggttatccacagaatcaggggataacgcaggaaagaac atgtgagcaaaaggccagcaaaaggccaggaaccgtaaaaaggccgcgtt gctggcgtttttccataggctccgcccccctgacgagcatcacaaaaatc gacgctcaagtcagaggtggcgaaacccgacaggactataaagataccag gcgtttccccctggaagctccctcgtgcgctctcctgttccgaccctgcc gcttaccggatacctgtccgcctttctcccttcgggaagcgtggcgcttt ctcatagctcacgctgtaggtatctcagttcggtgtaggtcgttcgctcc aagctgggctgtgtgcacgaaccccccgttcagcccgaccgctgcgcctt atccggtaactatcgtcttgagtccaacccggtaagacacgacttatcgc cactggcagcagccactggtaacaggattagcagagcgaggtatgtaggc ggtgctacagagttcttgaagtggtggcctaactacggctacactagaag aacagtatttggtatctgcgctctgctgaagccagttaccttcggaaaaa gagttggtagctcttgatccggcaaacaaaccaccgctggtagcggtttt tttgtttgcaagcagcagattacgcgcagaaaaaaaggatctcaagaaga tcctttgatcttttctacggggtctgacgctcagtggaacgaaaactcac gttaagggattttggtcatgagattatcaaaaaggatcttcacctagatc cttttaaattaaaaatgaagttttaaatcaatctaaagtatatatgagta aacttggtctgacagttaccaatgcttaatcagtgaggcacctatctcag cgatctgtctatttcgttcatccatagttgcctgactccccgtcgtgtag ataactacgatacgggagggcttaccatctggccccagtgctgcaatgat accgcgagacccacgctcaccggctccagatttatcagcaataaaccagc cagccggaagggccgagcgcagaagtggtcctgcaactttatccgcctcc atccagtctattaattgttgccgggaagctagagtaagtagttcgccagt taatagtttgcgcaacgttgttgccattgctacaggcatcgtggtgtcac gctcgtcgtttggtatggcttcattcagctccggttcccaacgatcaagg cgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcgg tcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatgg ttatggcagcactgcataattctcttactgtcatgccatccgtaagatgc ttttctgtgactggtgagtactcaaccaagtcattctgagaatagtgtat gcggcgaccgagttgctcttgcccggcgtcaatacgggataataccgcgc cacatagcagaactttaaaagtgctcatcattggaaaacgttcttcgggg cgaaaactctcaaggatcttaccgctgttgagatccagttcgatgtaacc cactcgtgcacccaactgatcttcagcatcttttactttcaccagcgttt ctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagg gcgacacggaaatgttgaatactcatactcttcctttttcaatattattg aagcatttatcagggttattgtctcatgagcggatacatatttgaatgta tttagaaaaataaacaaataggggttccgcgcacatttccccgaaaagtg ccacctgacgtc.
[0091] In some embodiments, the Cpf1 endonuclease can include a humanized LbCpf1 sequence (SEQ ID NO: 125) as follows:
TABLE-US-00002 (SEQ ID NO: 125) gacggatcgggagatctcccgatcccctatggtgcactctcagtacaatc tgctctgatgccgcatagttaagccagtatctgctccctgcttgtgtgtt ggaggtcgctgagtagtgcgcgagcaaaatttaagctacaacaaggcaag gcttgaccgacaattgcatgaagaatctgatagggttaggcgttttgcgc tgatcgcgatgtacgggccagatatacgcgttgacattgattattgacta gttattaatagtaatcaattacggggtcattagttcatagcccatatatg gagttccgcgttacataacttacggtaaatggcccgcctggctgaccgcc caacgacccccgcccattgacgtcaataatgacgtatgttcccatagtaa cgccaatagggactttccattgacgtcaatgggtggagtatttacggtaa actgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccc tattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtaca tgaccttatgggactttcctacttggcagtacatctacgtattagtcatc gctattaccatggtgatgcggttttggcagtacatcaatgggcgtggata gcggtttgactcacggggatttccaagtctccaccccattgacgtcaatg ggagtttgttttggcaccaaaatcaacgggactttccaaatgtcgtaaca actccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtc tatataagcagagctctctggctaactagagaacccactgcttactggct tatcgaaattaatacgactcactatagggagacccaagctggctagcgtt taaacttaagcttggtaccgccaccATGAGCAAGCTGGAGAAGTTTACAA ACTGCTACTCCCTGTCTAAGACCCTGAGGTTCAAGGCCATCCCTGTGGGC AAGACCCAGGAGAACATCGACAATAAGCGGCTGCTGGTGGAGGACGAGAA GAGAGCCGAGGATTATAAGGGCGTGAAGAAGCTGCTGGATCGCTACTATC TGTCTTTTATCAACGACGTGCTGCACAGCATCAAGCTGAAGAATCTGAAC AATTACATCAGCCTGTTCCGGAAGAAAACCAGAACCGAGAAGGAGAATAA GGAGCTGGAGAACCTGGAGATCAATCTGCGGAAGGAGATCGCCAAGGCCT TCAAGGGCAACGAGGGCTACAAGTCCCTGTTTAAGAAGGATATCATCGAG ACAATCCTGCCAGAGTTCCTGGACGATAAGGACGAGATCGCCCTGGTGAA CAGCTTCAATGGCTTTACCACAGCCTTCACCGGCTTCTTTGATAACAGAG AGAATATGTTTTCCGAGGAGGCCAAGAGCACATCCATCGCCTTCAGGTGT ATCAACGAGAATCTGACCCGCTACATCTCTAATATGGACATCTTCGAGAA GGTGGACGCCATCTTTGATAAGCACGAGGTGCAGGAGATCAAGGAGAAGA TCCTGAACAGCGACTATGATGTGGAGGATTTCTTTGAGGGCGAGTTCTTT AACTTTGTGCTGACACAGGAGGGCATCGACGTGTATAACGCCATCATCGG CGGCTTCGTGACCGAGAGCGGCGAGAAGATCAAGGGCCTGAACGAGTACA TCAACCTGTATAATCAGAAAACCAAGCAGAAGCTGCCTAAGTTTAAGCCA CTGTATAAGCAGGTGCTGAGCGATCGGGAGTCTCTGAGCTTCTACGGCGA GGGCTATACATCCGATGAGGAGGTGCTGGAGGTGTTTAGAAACACCCTGA ACAAGAACAGCGAGATCTTCAGCTCCATCAAGAAGCTGGAGAAGCTGTTC AAGAATTTTGACGAGTACTCTAGCGCCGGCATCTTTGTGAAGAACGGCCC CGCCATCAGCACAATCTCCAAGGATATCTTCGGCGAGTGGAACGTGATCC GGGACAAGTGGAATGCCGAGTATGACGATATCCACCTGAAGAAGAAGGCC GTGGTGACCGAGAAGTACGAGGACGATCGGAGAAAGTCCTTCAAGAAGAT CGGCTCCTTTTCTCTGGAGCAGCTGCAGGAGTACGCCGACGCCGATCTGT CTGTGGTGGAGAAGCTGAAGGAGATCATCATCCAGAAGGTGGATGAGATC TACAAGGTGTATGGCTCCTCTGAGAAGCTGTTCGACGCCGATTTTGTGCT GGAGAAGAGCCTGAAGAAGAACGACGCCGTGGTGGCCATCATGAAGGACC TGCTGGATTCTGTGAAGAGCTTCGAGAATTACATCAAGGCCTTCTTTGGC GAGGGCAAGGAGACAAACAGGGACGAGTCCTTCTATGGCGATTTTGTGCT GGCCTACGACATCCTGCTGAAGGTGGACCACATCTACGATGCCATCCGCA ATTATGTGACCCAGAAGCCCTACTCTAAGGATAAGTTCAAGCTGTATTTT CAGAACCCTCAGTTCATGGGCGGCTGGGACAAGGATAAGGAGACAGACTA TCGGGCCACCATCCTGAGATACGGCTCCAAGTACTATCTGGCCATCATGG ATAAGAAGTACGCCAAGTGCCTGCAGAAGATCGACAAGGACGATGTGAAC GGCAATTACGAGAAGATCAAATAAGCTGCTGCCCGGCCCTAATAAGATGC TGCCAAAGGTGTTCTTTTCTAAGAAGTGGATGGCCTACTATAACCCCAGC GAGGACATCCAGAAGATCTACAAGAATGGCACATTCAAGAAGGGCGATAT GTTTAACCTGAATGACTGTCACAAGCTGATCGACTTCTTTAAGGATAGCA TCTCCCGGTATCCAAAGTGGTCCAATGCCTACGATTTCAACTTTTCTGAG ACAGAGAAGTATAAGGACATCGCCGGCTTTTACAGAGAGGTGGAGGAGCA GGGCTATAAGGTGAGCTTCGAGTCTGCCAGCAAGAAGGAGGTGGATAAGC TGGTGGAGGAGGGCAAGCTGTATATGTTCCAGATCTATAACAAGGACTTT TCCGATAAGTCTCACGGCACACCCAATCTGCACACCATGTACTTCAAGCT GCTGTTTGACGAGAACAATCACGGACAGATCAGGCTGAGCGGAGGAGCAG AGCTGTTCATGAGGCGCGCCTCCCTGAAGAAGGAGGAGCTGGTGGTGCAC CCAGCCAACTCCCCTATCGCCAACAAGAATCCAGATAATCCCAAGAAAAC CACAACCCTGTCCTACGACGTGTATAAGGATAAGAGGTTTTCTGAGGACC AGTACGAGCTGCACATCCCAATCGCCATCAATAAGTGCCCCAAGAACATC TTCAAGATCAATACAGAGGTGCGCGTGCTGCTGAAGCACGACGATAACCC CTATGTGATCGGCATCGATAGGGGCGAGCGCAATCTGCTGTATATCGTGG TGGTGGACGGCAAGGGCAACATCGTGGAGCAGTATTCCCTGAACGAGACT ATCAACAACTTCAACGGCATCAGGATCAAGACAGATTACCACTCTCTGCT GGACAAGAAGGAGAAGGAGAGGTTCGAGGCCCGCCAGAACTGGACCTCCA TCGAGAATATCAAGGAGCTGAAGGCCGGCTATATCTCTCAGGTGGTGCAC AAGATCTGCGAGCTGGTGGAGAAGTACGATGCCGTGATCGCCCTGGAGGA CCTGAACTCTGGCTTTAAGAATAGCCGCGTGAAGGTGGAGAAGCAGGTGT ATCAGAAGTTCGAGAAGATGCTGATCGATAAGCTGAACTACATGGTGGAC AAGAAGTCTAATCCTTGTGCAACAGGCGGCGCCCTGAAGGGCTATCAGAT CACCAATAAGTTCGAGAGCTTTAAGTCCATGTCTACCCAGAACGGCTTCA TCTTTTACATCCCTGCCTGGCTGACATCCAAGATCGATCCATCTACCGGC TTTGTGAACCTGCTGAAAACCAAGTATACCAGCATCGCCGATTCCAAGAA GTTCATCAGCTCCTTTGACAGGATCATGTACGTGCCCGAGGAGGATCTGT TCGAGTTTGCCCTGGACTATAAGAACTTCTCTCGCACAGACGCCGATTAC ATCAAGAAGTGGAAGCTGTACTCCTACGGCAACCGGATCAGAATCTTCCG GAATCCTAAGAAGAACAACGTGTTCGACTGGGAGGAGGTGTGCCTGACCA GCGCCTATAAGGAGCTGTTCAACAAGTACGGCATCAATTATCAGCAGGGC GATATCAGAGCCCTGCTGTGCGAGCAGTCCGACAAGGCCTTCTACTCTAG CTTTATGGCCCTGATGAGCCTGATGCTGCAGATGCGGAACAGCATCACAG GCCGCACCGACGTGGATTTTCTGATCAGCCCTGTGAAGAACTCCGACGGC ATCTTCTACGATAGCCGGAACTATGAGGCCCAGGAGAATGCCATCCTGCC AAAGAACGCCGACGCCAATGGCGCCTATAACATCGCCAGAAAGGTGCTGT GGGCCATCGGCCAGTTCAAGAAGGCCGAGGACGAGAAGCTGGATAAGGTG AAGATCGCCATCTCTAACAAGGAGTGGCTGGAGTACGCCCAGACCAGCGT GAAGCACAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGA AAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGAC GTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGaatt ctgcagatatccagcacagtggcggccgctcgagtctagagggcccgttt aaacccgctgatcagcctcgactgtgccttctagttgccagccatctgtt gtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccac tgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggt gtcattctattctggggggtggggtggggcaggacagcaagggggaggat tgggaagacaatagcaggcatgctggggatgcggtgggctctatggatct gaggcggaaagaaccagctggggctctagggggtatccccacgcgccctg tagcggcgcattaagcgcggcgggtgtggtggttacgcgcagcgtgaccg ctacacttgccagcgccctagcgcccgctcctttcgctttcttccatcat tctcgccacgttcgccggctttccccgtcaagctctaaatcgggggctcc ctttagggttccgatttagtgctttacggcacctcgaccccaaaaaactt gattagggtgatggttcacgtagtgggccatcgccctgatagacggtttt tcgccctttgacgttggagtccacgttctttaatagtggactcttgttcc aaactggaacaacactcaaccctatctcggtctattcttttgatttataa gggattttgccgatttcggcctattggttaaaaaatgagctgatttaaca aaaatttaacgcgaattaattctgtggaatgtgtgtcagttagggtgtgg aaagtccccaggctccccagcaggcagaagtatgcaaagcatgcatctca attagtcagcaaccaggtgtggaaagtccccaggctccccagcaggcaag agtatgcaaagcatgcatctcaattagtcagcaaccatagtcccgcccct aactccgcccatcccgcccctaactccgcccagttccgcccattctccgc cccatggctgactaattttttttatttatgcagaggccgaggccgcctct gcctctgagctattccagaagtagtgaggaggcttttttggaggcctagg cttttgcaaaaagctcccgggagcttgtatatccattttcggatctgatc aagagacaggatgaggatcgtttcgcatgattgaacaagatggattgcac gcaggttctccggccgcttgggtggagaggctattcggctatgactgggc acaacagacaatcggctgctctgatgccgccgtgttccggctgtcagcgc aggggcgcccggttctttttgtcaagaccgacctgtccggtgccctgaat gaactgcaggacgaggcagcgcggctatcgtggctggccacgacgggcgt tccttgcgcagctgtgctcgacgttgtcactgaagcgggaagggactggc tgctattgggcgaagtgccggggcaggatctcctgtcatctcaccttgct
cctgccgagaaagtatccatcatggctgatgcaatgcggcggctgcatac gcttgatccggctacctgcccattcgaccaccaagcgaaacatcgcatcg agcgagcacgtactcggatggaagccggtcttgtcgatcaggatgatctg gacgaagagcatcaggggctcgcgccagccgaactgttcgccaggctcaa ggcgcgcatgcccgacggcgaggatctcgtcgtgacccatggcgatgcct gcttgccgaatatcatggtggaaaatggccgcttttctggattcatcgac tgtggccggctgggtgtggcggaccgctatcaggacatagcgttggctac ccgtgatattgctgaagagcttggcggcgaatgggctgaccgcttcctcg tgctttacggtatcgccgctcccgattcgcagcgcatcgccttctatcgc cttcttgacgagttcttctgagcgggactctggggttcgaaatgaccgac caagcgacgcccaacctgccatcacgagatttcgattccaccgccgcctt ctatgaaaggttgggcttcggaatcgttttccgggacgccggctggatga tcctccagcgcggggatctcatgctggagttcttcgcccaccccaacttg tttattgcagcttataatggttacaaataaagcaatagcatcacaaattt cacaaataaagcatttttttcactgcattctagttgtggtttgtccaaca tcatcaatgtatcttatcatgtctgtataccgtcgacctctagctagagc ttggcgtaatcatggtcatagctgtttcctgtgtgaaattgttatccgct cacaattccacacaacatacgagccggaagcataaagtgtaaagcctggg gtgcctaatgagtgagctaactcacattaattgcgttgcgctcactgccc gctttccagtcgggaaacctgtcgtgccagctgcattaatgaatcggcca acgcgcggggagaggcggtttgcgtattgggcgctcttccgcttcctcgc tcactgactcgctgcgctcggtcgttcggctgcggcgagcggtatcagct cactcaaaggcggtaatacggttatccacagaatcaggggataacgcagg aaagaacatgtgagcaaaaggccagcaaaaggccaggaaccgtaaaaagg ccgcgttgctggcgtttttccataggctccgcccccctgacgagcatcac aaaaatcgacgctcaagtcagaggtggcgaaacccgacaggactataaag ataccaggcgtttccccctggaagctccctcgtgcgctctcctgttccga ccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtg gcgctttctcatagctcacgctgtaggtatctcagttcggtgtaggtcgt tcgctccaagctgggctgtgtgcacgaaccccccgttcagcccgaccgct gcgccttatccggtaactatcgtcttgagtccaacccggtaagacacgac ttatcgccactggcagcagccactggtaacaggattagcagagcgaggta tgtaggcggtgctacagagttcttgaagtggtggcctaactacggctaca ctagaagaacagtatttggtatctgcgctctgctgaagccagttaccttc ggaaaaagagttggtagctcttgatccggcaaacaaaccaccgctggtag cggtttttttgtttgcaagcagcagattacgcgcagaaaaaaaggatctc aagaagatcctttgatcttttctacggggtctgacgctcagtggaacgaa aactcacgttaagggattttggtcatgagattatcaaaaaggatcttcac ctagatccttttaaattaaaaatgaagttttaaatcaatctaaagtatat atgagtaaacttggtctgacagttaccaatgcttaatcagtgaggcacct atctcagcgatctgtctatttcgttcatccatagttgcctgactccccgt cgtgtagataactacgatacgggagggcttaccatctggccccagtgctg caatgataccgcgagacccacgctcaccggctccagatttatcagcaata aaccagccagccggaagggccgagcgcagaagtggtcctgcaactttatc cgcctccatccagtctattaattgttgccgggaagctagagtaagtagtt cgccagttaatagtttgcgcaacgttgttgccattgctacaggcatcgtg gtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaacg atcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagct ccttcggtcctccgatcgttgtcagaagtaagttggccgcagtgttatca ctcatggttatggcagcactgcataattctcttactgtcatgccatccgt aagatgcttttctgtgactggtgagtactcaaccaagtcattctgagaat agtgtatgcggcgaccgagttgctcttgcccggcgtcaatacgggataat accgcgccacatagcagaactttaaaagtgctcatcattggaaaacgttc ttcggggcgaaaactctcaaggatcttaccgctgttgagatccagttcga tgtaacccactcgtgcacccaactgatcttcagcatcttttactttcacc agcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaaggg aataagggcgacacggaaatgttgaatactcatactcttcctttttcaat attattgaagcatttatcagggttattgtctcatgagcggatacatattt gaatgtatttagaaaaataaacaaataggggttccgcgcacatttccccg aaaagtgccacctgacgtc.
[0092] A Cpf1 endonuclease can interact with one or more Cpf1 gRNAs and, in concert with the Cpf1 gRNA(s), localizes to a site which comprises a target domain, and in certain embodiments, a PAM sequence. In certain embodiments, the ability of a Cpf1 endonuclease to interact with and cleave a target nucleic acid is PAM sequence dependent. A PAM sequence is a sequence in the target nucleic acid. In certain embodiments, cleavage of the target nucleic acid occurs upstream from the PAM sequence. Cpf1 endonucleases from different bacterial species can recognize different sequence motifs (e.g., PAM sequences). In certain embodiments, a Cpf1 endonuclease recognizes a PAM of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123).
[0093] In certain embodiments, the vector encodes at least one Cpf1 endonuclease that recognizes a PAM of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123). In certain embodiments, the at least one Cpf1 endonuclease is a Cpf1 endonuclease from Lachnospiraceae bacterium ND2006 ("LbCpf1") or from Acidaminococcus ("AsCpf1"). In certain embodiments, the Cpf1 endonuclease is encoded by the polynucleotide sequence of SEQ ID NO: 124 or SEQ ID NO: 125.
[0094] A nucleic acid encoding a Cpf1 endonuclease can be a synthetic nucleic acid sequence. For example, the synthetic nucleic acid molecule can be chemically modified. The synthetic nucleic acid sequence can be codon optimized, e.g., at least one non-common codon or less-common codon has been replaced by a common codon. For example, the synthetic nucleic acid can direct the synthesis of an optimized messenger mRNA, e.g., optimized for expression in a mammalian expression system, e.g., described herein.
[0095] Additionally or alternatively, a nucleic acid encoding a Cpf1 endonuclease may comprise a nuclear localization sequence (NLS). Nuclear localization sequences are known in the art.
[0096] b. Cpf1 gRNAs
[0097] The CRISPR/Cpf1-based gene editing system includes at least one Cpf1 gRNA, e.g., one Cpf1 gRNA, two Cpf1 gRNAs, three gRNAs, etc. The gRNA provides the targeting of a CRISPR/Cpf1-based gene editing system. The Cpf1 gRNA may target any desired DNA sequence by exchanging the sequence encoding a protospacer which confers targeting specificity with the desired DNA target. The "target region", "target sequence" or "protospacer" as used interchangeably herein refers to the region of the target gene (e.g., a dystrophin gene) to which the CRISPR/Cpf1-based gene editing system targets. The target sequence or protospacer is preceded by a PAM sequence at the 5' end of the protospacer. In some embodiments, the PAM sequence may be TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123).
[0098] In some embodiments, the protospacer can be between about 17 bp to about 23 bp. In some embodiments, the Cpf1 gRNA can include a polynucleotide sequence that corresponds to the protospacer or a fragment thereof. In some embodiments, the Cpf1 gRNA can include between about 17 bp to about 23 bp of the protospacer. In some embodiments, the about 17 bp to about 23 bp of the protospacer are consecutive.
[0099] In some embodiments, the target region can include a polynucleotide sequence of any one of SEQ ID NOs: 1-35, a fragment of any one of SEQ ID NOs: 1-35, or complement thereof. In some embodiments, the Cpf1 gRNA includes a polynucleotide sequence of any one of SEQ ID NOs: 36-119, a fragment of any one of SEQ ID NOs: 36-119, or complement thereof. In some embodiments, the fragment of any one of SEQ ID NOs: 36-119 is about 17 bp to about 23 bp in length. In some embodiments, the about 17 bp to about 23 bp in the fragment are consecutive.
[0100] The CRISPR/Cpf1-based gene editing system may include at least one Cpf1 gRNA, wherein the gRNAs target different DNA sequences. The target DNA sequences may be overlapping. The number of Cpf1 gRNAs encoded by a presently disclosed genetic construct (e.g., an AAV vector) can be at least 1 Cpf1 gRNA, at least 2 different Cpf1 gRNA, at least 3 different Cpf1 gRNA at least 4 different Cpf1 gRNA, at least 5 different Cpf1 gRNA, at least 6 different Cpf1 gRNA, at least 7 different Cpf1 gRNA, at least 8 different Cpf1 gRNA, at least 9 different Cpf1 gRNA, at least 10 different Cpf1 gRNAs, at least 11 different Cpf1 gRNAs, at least 12 different Cpf1 gRNAs, at least 13 different Cpf1 gRNAs, at least 14 different Cpf1 gRNAs, at least 15 different Cpf1 gRNAs, at least 16 different Cpf1 gRNAs, at least 17 different Cpf1 gRNAs, at least 18 different Cpf1 gRNAs, at least 18 different Cpf1 gRNAs, at least 20 different Cpf1 gRNAs, at least 25 different Cpf1 gRNAs, at least 30 different Cpf1 gRNAs, at least 35 different Cpf1 gRNAs, at least 40 different Cpf1 gRNAs, at least 45 different Cpf1 gRNAs, or at least 50 different Cpf1 gRNAs. The number of Cpf1 gRNA encoded by a presently disclosed vector can be between at least 1 Cpf1 gRNA to at least 50 different Cpf1 gRNAs, at least 1 Cpf1 gRNA to at least 45 different Cpf1 gRNAs, at least 1 Cpf1 gRNA to at least 40 different Cpf1 gRNAs, at least 1 Cpf1 gRNA to at least 35 different Cpf1 gRNAs, at least 1 Cpf1 gRNA to at least 30 different Cpf1 gRNAs, at least 1 Cpf1 gRNA to at least 25 different Cpf1 gRNAs, at least 1 Cpf1 gRNA to at least 20 different Cpf1 gRNAs, at least 1 Cpf1 gRNA to at least 16 different Cpf1 gRNAs, at least 1 Cpf1 gRNA to at least 12 different Cpf1 gRNAs, at least 1 Cpf1 gRNA to at least 8 different Cpf1 gRNAs, at least 1 Cpf1 gRNA to at least 4 different Cpf1 gRNAs, at least 4 Cpf1 gRNAs to at least 50 different Cpf1 gRNAs, at least 4 different Cpf1 gRNAs to at least 45 different Cpf1 gRNAs, at least 4 different Cpf1 gRNAs to at least 40 different Cpf1 gRNAs, at least 4 different Cpf1 gRNAs to at least 35 different Cpf1 gRNAs, at least 4 different Cpf1 gRNAs to at least 30 different Cpf1 gRNAs, at least 4 different Cpf1 gRNAs to at least 25 different Cpf1 gRNAs, at least 4 different Cpf1 gRNAs to at least 20 different Cpf1 gRNAs, at least 4 different Cpf1 gRNAs to at least 16 different Cpf1 gRNAs, at least 4 different Cpf1 gRNAs to at least 12 different Cpf1 gRNAs, at least 4 different Cpf1 gRNAs to at least 8 different Cpf1 gRNAs, at least 8 different Cpf1 gRNAs to at least 50 different Cpf1 gRNAs, at least 8 different Cpf1 gRNAs to at least 45 different Cpf1 gRNAs, at least 8 different Cpf1 gRNAs to at least 40 different Cpf1 gRNAs, at least 8 different Cpf1 gRNAs to at least 35 different Cpf1 gRNAs, 8 different Cpf1 gRNAs to at least 30 different Cpf1 gRNAs, at least 8 different Cpf1 gRNAs to at least 25 different Cpf1 gRNAs, 8 different Cpf1 gRNAs to at least 20 different Cpf1 gRNAs, at least 8 different Cpf1 gRNAs to at least 16 different Cpf1 gRNAs, or 8 different Cpf1 gRNAs to at least 12 different Cpf1 gRNAs. In certain embodiments, the genetic construct (e.g., an AAV vector) encodes one Cpf1 gRNA, i.e., a first Cpf1 gRNA, and optionally a Cpf1 endonuclease. In certain embodiments, a first genetic construct (e.g., a first AAV vector) encodes one Cpf1 gRNA, i.e., a first Cpf1 gRNA, and optionally a Cpf1 endonuclease, and a second genetic construct (e.g., a second AAV vector) encodes one Cpf1 gRNA, i.e., a second Cpf1 gRNA, and optionally a Cpf1 endonuclease.
3. CRISPR/Cpf1-BASED GENE EDITING SYSTEM GENETIC CONSTRUCTS FOR GENOME EDITING OF DYSTROPHIN GENE
[0101] The present invention is directed to genetic constructs for genome editing, genomic alteration or altering gene expression of a dystrophin gene (e.g., human dystrophin gene). The genetic constructs include at least one Cpf1 gRNA that targets human dystrophin gene sequences, such as Cpf1 endonuclease-compatible targets. The disclosed gRNAs can be included in a CRISPR/Cpf1-based gene editing system, including systems that use Cpf1 endonuclease, to target regions in the dystrophin gene, such as intronic regions surrounding exons, such as exon 51, of the human dystrophin gene, splice acceptor sites, and/or exonic regions, causing genomic deletions of this region in order to restore expression of functional dystrophin in cells from DMD patients.
[0102] DMD is a severe muscle wasting disease caused by genetic mutations to the dystrophin gene. Dystrophin is a rod-shaped cytoplasmic protein which is a part of a protein complex that connects the cytoskeleton of a muscle fiber to the surrounding extracellular matrix through the cell membrane. Dystrophin provides structural stability to the dystroglycan complex of the cell membrane. The dystrophin gene is 2.2 megabases at locus Xp21. The primary transcription measures about 2,400 kb with the mature mRNA being about 14 kb. 79 exons code for the protein which is over 3500 amino acids. Normal skeleton muscle tissue contains only small amounts of dystrophin but its absence of abnormal expression leads to the development of severe and incurable symptoms. Some mutations in the dystrophin gene lead to the production of defective dystrophin and severe dystrophic phenotype in affected patients. Some mutations in the dystrophin gene lead to partially-functional dystrophin protein and a much milder dystrophic phenotype in affected patients.
[0103] DMD is the result of inherited or spontaneous mutations that cause nonsense or frame shift mutations in the dystrophin gene. Naturally occurring mutations and their consequences are relatively well understood for DMD. Mutations are typically deletions or duplications of regions of the gene that make the protein out of frame and completely dysfunctional. Removal of single exons can be applied to as many as 83% of patients by frame corrections restoring a nearly functional protein. CPF1 can target dystrophin exons and be used to knockout single exons by targeting splice acceptors or delete genetic regions to remove single or multiple exons.
[0104] It is known that in-frame deletions that occur in the exon 45-55 regions (e.g., exon 51) contained within the rod domain can produce highly functional dystrophin proteins, and many carriers are asymptomatic or display mild symptoms. Furthermore, more than 60% of patients may theoretically be treated by targeting exons in this region of the dystrophin gene (e.g., targeting an exon of dystrophin gene, such as exon 51). Efforts have been made to restore the disrupted dystrophin reading frame in DMD patients by skipping non-essential exon(s) (e.g., exon 51 skipping) during mRNA splicing to produce internally deleted but functional dystrophin proteins. The deletion of internal dystrophin exon(s) (e.g., deletion of exon 51) retains the proper reading frame but cause the less severe Becker muscular dystrophy, or BMD. The Becker muscular dystrophy, or BMD, genotype is similar to DMD in that deletions are present in the dystrophin gene. However, these deletions leave the reading frame intact. Thus an internally truncated but partially functional dystrophin protein is created. BMD has a wide array of phenotypes, but often if deletions are between exons 45-55 of dystrophin the phenotype is much milder compared to DMD. Thus changing a DMD genotype to a BMD genotype is a common strategy to correct dystrophin. There are many strategies to correct dystrophin, many of which rely on restoring the reading frame of the endogenous dystrophin. This shifts the disease genotype from DMD to Becker muscular dystrophy. Many BMD patients have intragenic deletions that maintain the translational reading frame, leading to a shorter but largely functional dystrophin protein.
[0105] In certain embodiments, modification of exon 51 (e.g., deletion or excision of exon 51 by, e.g., NHEJ) to restore reading frame ameliorates the phenotype DMD subjects, including DMD subjects with deletion mutations. In certain embodiments, exon 51 of a dystrophin gene refers to the 51.sup.st exon of the dystrophin gene. Exon 51 is frequently adjacent to frame-disrupting deletions in DMD patients and has been targeted in clinical trials for oligonucleotide-based exon skipping. A clinical trial for the exon 51 skipping compound eteplirsen reported a significant functional benefit across 48 weeks, with an average of 47% dystrophin positive fibers compared to baseline. Mutations in exon 51 are ideally suited for permanent correction by NHEJ-based genome editing.
[0106] The presently disclosed vectors can generate deletions in the dystrophin gene, e.g., the human dystrophin gene. In certain embodiments, the vector is configured to form two double stand breaks (a first double strand break and a second double strand break) in two introns (a first intron and a second intron) flanking a target position of the dystrophin gene, thereby deleting a segment of the dystrophin gene comprising the dystrophin target position. A "dystrophin target position" can be a dystrophin exonic target position or a dystrophin intra-exonic target position, as described herein. Deletion of the dystrophin exonic target position can optimize the dystrophin sequence of a subject suffering from Duchenne muscular dystrophy, e.g., it can increase the function or activity of the encoded dystrophin protein, or results in an improvement in the disease state of the subject. In certain embodiments, excision of the dystrophin exonic target position restores reading frame. The dystrophin exonic target position can comprise one or more exons of the dystrophin gene. In certain embodiments, the dystrophin target position comprises exon 51 of the dystrophin gene (e.g., human dystrophin gene).
[0107] A presently disclosed genetic construct (e.g., a vector) can mediate highly efficient gene editing at exon 51 of a dystrophin gene (e.g., the human dystrophin gene). A presently disclosed genetic construct (e.g., a vector) can restore dystrophin protein expression in cells from DMD patients. Exon 51 is frequently adjacent to frame-disrupting deletions in DMD. Elimination of exon 51 from the dystrophin transcript by exon skipping can be used to treat approximately 15% of all DMD patients. This class of dystrophin mutations is ideally suited for permanent correction by NHEJ-based genome editing and HDR. The genetic constructs (e.g., vectors) described herein have been developed for targeted modification of exon 51 in the human dystrophin gene. A presently disclosed genetic construct (e.g., a vector) is transfected into human DMD cells and mediates efficient gene modification and conversion to the correct reading frame. Protein restoration is concomitant with frame restoration and detected in a bulk population of CRISPR/Cpf1-based gene editing system-treated cells.
[0108] Single or multiplexed gRNAs can be designed to restore the dystrophin reading frame by targeting the mutational hotspot at exon 51 or and introducing either intraexonic small insertions and deletions, or excision of exon 51. Following treatment with a presently disclosed vector, dystrophin expression can be restored in Duchenne patient muscle cells in vitro. Human dystrophin was detected in vivo following transplantation of genetically corrected patient cells into immunodeficient mice. Significantly, the unique multiplex gene editing capabilities of the CRISPR/Cpf1-based gene editing system enable efficiently generating large deletions of this mutational hotspot region that can correct up to 62% of patient mutations by universal or patient-specific gene editing approaches. In some embodiments, candidate gRNAs are evaluated and chosen based on off-target activity, on-target activity as measured by surveyor, and distance from the exon.
[0109] The Cpf1 gRNA may target a region of the dystrophin gene (DMD). In certain embodiments, the Cpf1 gRNA can target at least one of exons, introns, the promoter region, the enhancer region, splice acceptor sites, and/or the transcribed region of the dystrophin gene. In some embodiments, the target region comprises a polynucleotide sequence of at least one of SEQ ID NOs: 1-28. In certain embodiments, the Cpf1 gRNA targets intron 50 of the human dystrophin gene. In certain embodiments, the Cpf1 gRNA targets intron 51 of the human dystrophin gene. In certain embodiments, the Cpf1 gRNA targets exon 51 of the human dystrophin gene. The Cpf1 gRNA may include a polynucleotide sequence of any one of SEQ ID NO: 36-64, 71-119, a fragment of any one of SEQ ID NOs: 36-64, 71-119, or a complement thereof.
4. CRISPR/Cpf1-BASED GENE EDITING SYSTEM GENETIC CONSTRUCTS FOR GENOME EDITING OF B-CELL LYMPHOMA/LEUKEMIA 11A (BCL11a) GENE
[0110] Sickle cell anemia (SCA) is caused by a point mutation in the .beta.-globin gene, and .beta.-thalassemia is caused by other mutations leading to loss of .beta.-globin expression. BCL11a is a transcriptional repressor that silences embryonic and fetal globin genes. Complete loss of BCL11a is embryonically lethal; however, disrupting the erythroid-specific enhancer region of BCL11a may reduce the abundance of the transcriptional repressor and increase fetal globin levels improving phenotype of the disease. Similarly, a particular mutation to the .gamma.-globin (HBG1/2) promoter leads to loss of transcriptional repression and hereditary persistence of fetal hemoglobin (HPFH). The larger indel footprint generated by Cpf1 can efficiently disrupt the enhancer region of BCL11a or repression regions of HBG1/2. In some embodiments, the Cpf1 gRNAs is designed to disrupt the enhancer region of BCL11a, increase fetal globin levels, and improve phenotype of SCA. In some embodiments, the enhancer region comprises a polynucleotide sequence of at least one of SEQ ID NOs: 29-35. In some embodiments, the Cpf1 gRNA comprises a polynucleotide sequence of any one of SEQ ID NOs: 65-70, a fragment of any one of SEQ ID NOs: 65-70, or a complement thereof.
5. DNA TARGETING COMPOSITIONS
[0111] The present invention is also directed to DNA targeting compositions that comprise such genetic constructs. The DNA targeting compositions include at least one Cpf1 gRNA (e.g., one Cpf1 gRNA, two Cpf1 gRNAs, three gRNAs, etc.) that targets a dystrophin gene (e.g., human dystrophin gene), as described above. The at least one Cpf1 gRNA can bind and recognize a target region. The target regions can be chosen immediately upstream of possible out-of-frame stop codons such that insertions or deletions during the repair process restore the dystrophin reading frame by frame conversion. Target regions can also be splice acceptor sites or splice donor sites, such that insertions or deletions during the repair process disrupt splicing and restore the dystrophin reading frame by splice site disruption and exon exclusion. Target regions can also be aberrant stop codons such that insertions or deletions during the repair process restore the dystrophin reading frame by eliminating or disrupting the stop codon.
[0112] In certain embodiments, the presently disclosed DNA targeting composition includes a first Cpf1 gRNA and a second Cpf1 gRNA, wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise a polynucleotide sequence set forth in SEQ ID NOs: 36-119, or a complement thereof. In some embodiments the polynucleotide sequence comprises at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof. In some embodiments the polynucleotide sequence comprises at least one of SEQ ID NOs: 65-70, or a complement thereof. In certain embodiments, the first Cpf1 gRNA and the second Cpf1 gRNA comprise polynucleotide sequences.
[0113] In certain embodiments, the first Cpf1 gRNA and the second Cpf1 gRNA are selected from the group consisting of: (i) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 54, and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 62; (ii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 55, and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 63; and (iii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 56, and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 61.
[0114] In certain embodiments, the DNA targeting composition may further include at least one Cpf1 endonuclease that recognizes a PAM of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123). In some embodiments, the DNA targeting composition includes a Cpf1 endonuclease encoded by a polynucleotide sequence set forth in SEQ ID NO: 124 or SEQ ID NO: 125. In certain embodiments, the vector is configured to form a first and a second double strand break in a first and a second intron flanking exon 51 of the human dystrophin gene, respectively, thereby deleting a segment of the dystrophin gene comprising exon 51.
[0115] The deletion efficiency of the presently disclosed vectors can be related to the deletion size, i.e., the size of the segment deleted by the vectors. In certain embodiments, the length or size of specific deletions is determined by the distance between the PAM sequences in the gene being targeted (e.g., a dystrophin gene). In certain embodiments, a specific deletion of a segment of the dystrophin gene, which is defined in terms of its length and a sequence it comprises (e.g., exon 51), is the result of breaks made adjacent to specific PAM sequences within the target gene (e.g., a dystrophin gene).
[0116] In certain embodiments, the deletion size is about 50 to about 2,000 base pairs (bp), e.g., about 50 to about 1999 bp, about 50 to about 1900 bp, about 50 to about 1800 bp, about 50 to about 1700 bp, about 50 to about 1650 bp, about 50 to about 1600 bp, about 50 to about 1500 bp, about 50 to about 1400 bp, about 50 to about 1300 bp, about 50 to about 1200 bp, about 50 to about 1150 bp, about 50 to about 1100 bp, about 50 to about 1000 bp, about 50 to about 900 bp, about 50 to about 850 bp, about 50 to about 800 bp, about 50 to about 750 bp, about 50 to about 700 bp, about 50 to about 600 bp, about 50 to about 500 bp, about 50 to about 400 bp, about 50 to about 350 bp, about 50 to about 300 bp, about 50 to about 250 bp, about 50 to about 200 bp, about 50 to about 150 bp, about 50 to about 100 bp, about 100 to about 1999 bp, about 100 to about 1900 bp, about 100 to about 1800 bp, about 100 to about 1700 bp, about 100 to about 1650 bp, about 100 to about 1600 bp, about 100 to about 1500 bp, about 100 to about 1400 bp, about 100 to about 1300 bp, about 100 to about 1200 bp, about 100 to about 1150 bp, about 100 to about 1100 bp, about 100 to about 1000 bp, about 100 to about 900 bp, about 100 to about 850 bp, about 100 to about 800 bp, about 100 to about 750 bp, about 100 to about 700 bp, about 100 to about 600 bp, about 100 to about 1000 bp, about 100 to about 400 bp, about 100 to about 350 bp, about 100 to about 300 bp, about 100 to about 250 bp, about 100 to about 200 bp, about 100 to about 150 bp, about 200 to about 1999 bp, about 200 to about 1900 bp, about 200 to about 1800 bp, about 200 to about 1700 bp, about 200 to about 1650 bp, about 200 to about 1600 bp, about 200 to about 1500 bp, about 200 to about 1400 bp, about 200 to about 1300 bp, about 200 to about 1200 bp, about 200 to about 1150 bp, about 200 to about 1100 bp, about 200 to about 1000 bp, about 200 to about 900 bp, about 200 to about 850 bp, about 200 to about 800 bp, about 200 to about 750 bp, about 200 to about 700 bp, about 200 to about 600 bp, about 200 to about 2000 bp, about 200 to about 400 bp, about 200 to about 350 bp, about 200 to about 300 bp, about 200 to about 250 bp, about 300 to about 1999 bp, about 300 to about 1900 bp, about 300 to about 1800 bp, about 300 to about 1700 bp, about 300 to about 1650 bp, about 300 to about 1600 bp, about 300 to about 1500 bp, about 300 to about 1400 bp, about 300 to about 1300 bp, about 300 to about 1200 bp, about 300 to about 1150 bp, about 300 to about 1100 bp, about 300 to about 1000 bp, about 300 to about 900 bp, about 300 to about 850 bp, about 300 to about 800 bp, about 300 to about 750 bp, about 300 to about 700 bp, about 300 to about 600 bp, about 300 to about 3000 bp, about 300 to about 400 bp, or about 300 to about 350 bp. In certain embodiments, the deletion size can be about 118 base pairs, about 233 base pairs, about 326 base pairs, about 766 base pairs, about 805 base pairs, or about 1611 base pairs.
6. COMPOSITIONS FOR GENOME EDITING IN MUSCLE
[0117] The present invention is directed to genetic constructs (e.g., vectors) or a composition thereof for genome editing a target gene in skeletal muscle or cardiac muscle of a subject. The composition includes a modified AAV vector and a polynucleotide sequence encoding a CRISPR/Cpf1-based gene editing system, e.g., a Cpf1 gRNA and a Cpf1 endonuclease. The composition delivers active forms of CRISPR/Cpf1-based gene editing systems to skeletal muscle or cardiac muscle. The presently disclosed genetic constructs (e.g., vectors) can be used in correcting or reducing the effects of mutations in the dystrophin gene involved in genetic diseases and/or other skeletal or cardiac muscle conditions, e.g., DMD. The composition may further comprise a donor DNA or a transgene. These compositions may be used in genome editing, genome engineering, and correcting or reducing the effects of mutations in genes involved in genetic diseases and/or other skeletal or cardiac muscle conditions.
[0118] a. CRISPR/Cpf1-Based Gene Editing System for Targeting Dystrophin
[0119] A CRISPR/Cpf1-based gene editing system specific for dystrophin gene are disclosed herein. The CRISPR/Cpf1-based gene editing system may include Cpf1 endonuclease and at least one Cpf1 gRNA to target the dystrophin gene. The CRISPR/Cpf1-based gene editing system may bind and recognize a target region. The target regions may be chosen immediately upstream of possible out-of-frame stop codons such that insertions or deletions during the repair process restore the dystrophin reading frame by frame conversion. Target regions may also be splice acceptor sites or splice donor sites, such that insertions or deletions during the repair process disrupt splicing and restore the dystrophin reading frame by splice site disruption and exon exclusion. Target regions may also be aberrant stop codons such that insertions or deletions during the repair process restore the dystrophin reading frame by eliminating or disrupting the stop codon.
[0120] The Cpf1 gRNA may target a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1-35, or a complement thereof. For example, the disclosed CRISPR/Cpf1-based gene editing systems were engineered to mediate highly efficient gene editing at exon 51 of the dystrophin gene. These CRISPR/Cpf1-based gene editing systems restored dystrophin protein expression in cells from DMD patients.
[0121] b. Adeno-Associated Virus Vectors
[0122] The composition may also include a viral delivery system. In certain embodiments, the vector is an adeno-associated virus (AAV) vector. The AAV vector is a small virus belonging to the genus Dependovirus of the Parvoviridae family that infects humans and some other primate species. AAV vectors may be used to deliver CRISPR/Cpf1-based gene editing systems using various construct configurations. For example, AAV vectors may deliver Cpf1 endonucleases and Cpf1 gRNA expression cassettes on separate vectors or on the same vector. Alternatively, both the Cpf1 endonucleases and up to two gRNA expression cassettes may be combined in a single AAV vector within the 4.7 kb packaging limit.
[0123] In certain embodiments, the AAV vector is a modified AAV vector. The modified AAV vector may have enhanced cardiac and skeletal muscle tissue tropism. The modified AAV vector may be capable of delivering and expressing the CRISPR/Cpf1-based gene editing system in the cell of a mammal. For example, the modified AAV vector may be an AAV-SASTG vector (Piacentino et al. (2012) Human Gene Therapy 23:635-646). The modified AAV vector may deliver nucleases to skeletal and cardiac muscle in vivo. The modified AAV vector may be based on one or more of several capsid types, including AAV1, AAV2, AAV5, AAV6, AAV8, and AAV9. The modified AAV vector may be based on AAV2 pseudotype with alternative muscle-tropic AAV capsids, such as AAV2/1, AAV2/6, AAV2/7, AAV2/8, AAV2/9, AAV2.5 and AAV/SASTG vectors that efficiently transduce skeletal muscle or cardiac muscle by systemic and local delivery (Seto et al. Current Gene Therapy (2012) 12:139-151). The modified AAV vector may be AAV2i8G9 (Shen et al. J. Biol. Chem. (2013) 288:28814-28823).
7. METHODS OF GENOME EDITING IN MUSCLE
[0124] The present disclosure is directed to a method of genome editing in a skeletal muscle or cardiac muscle of a subject. The method comprises administering to the skeletal muscle or cardiac muscle of the subject the composition for genome editing in skeletal muscle or cardiac muscle, as described above. The genome editing may include correcting a mutant gene or inserting a transgene. Correcting the mutant gene may include deleting, rearranging, or replacing the mutant gene. Correcting the mutant gene may include nuclease-mediated NHEJ or HDR.
8. METHODS OF CORRECTING A MUTANT GENE AND TREATING A SUBJECT
[0125] The presently disclosed subject matter provides for methods of correcting a mutant gene (e.g., a mutant dystrophin gene, e.g., a mutant human dystrophin gene) in a cell and treating a subject suffering from a genetic disease, such as DMD. The method can include administering to a cell or a subject a presently disclosed genetic construct (e.g., a vector) or a composition comprising thereof as described above. The method can comprises administering to the skeletal muscle or cardiac muscle of the subject the presently disclosed genetic construct (e.g., a vector) or a composition comprising thereof for genome editing in skeletal muscle or cardiac muscle, as described above. Use of presently disclosed genetic construct (e.g., a vector) or a composition comprising thereof to deliver the CRISPR/Cpf1-based gene editing system to the skeletal muscle or cardiac muscle may restore the expression of a full-functional or partially-functional protein with a repair template or donor DNA, which can replace the entire gene or the region containing the mutation. The CRISPR/Cpf1-based gene editing system may be used to introduce site-specific double strand breaks at targeted genomic loci. Site-specific double-strand breaks are created when the CRISPR/Cpf1-based gene editing system binds to a target DNA sequences, thereby permitting cleavage of the target DNA. This DNA cleavage may stimulate the natural DNA-repair machinery, leading to one of two possible repair pathways: homology-directed repair (HDR) or the non-homologous end joining (NHEJ) pathway.
[0126] The present disclosure is directed to genome editing with a CRISPR/Cpf1-based gene editing system without a repair template, which can efficiently correct the reading frame and restore the expression of a functional protein involved in a genetic disease. The disclosed CRISPR/Cpf1-based gene editing systems may involve using homology-directed repair or nuclease-mediated non-homologous end joining (NHEJ)-based correction approaches, which enable efficient correction in proliferation-limited primary cell lines that may not be amenable to homologous recombination or selection-based gene correction. This strategy integrates the rapid and robust assembly of active CRISPR/Cpf1-based gene editing systems with an efficient gene editing method for the treatment of genetic diseases caused by mutations in nonessential coding regions that cause frameshifts, premature stop codons, aberrant splice donor sites or aberrant splice acceptor sites.
[0127] a. Nuclease Mediated Non-Homologous End Joining
[0128] Restoration of protein expression from an endogenous mutated gene may be through template-free NHEJ-mediated DNA repair. In contrast to a transient method targeting the target gene RNA, the correction of the target gene reading frame in the genome by a transiently expressed CRISPR/Cpf1-based gene editing system may lead to permanently restored target gene expression by each modified cell and all of its progeny. In certain embodiments, NHEJ is a nuclease mediated NHEJ, which in certain embodiments, refers to NHEJ that is initiated a Cpf1 endonuclease, cuts double stranded DNA. The method comprises administering a presently disclosed genetic construct (e.g., a vector) or a composition comprising thereof to the skeletal muscle or cardiac muscle of the subject for genome editing in skeletal muscle or cardiac muscle.
[0129] Nuclease mediated NHEJ gene correction may correct the mutated target gene and offers several potential advantages over the HDR pathway. For example, NHEJ does not require a donor template, which may cause nonspecific insertional mutagenesis. In contrast to HDR, NHEJ operates efficiently in all stages of the cell cycle and therefore may be effectively exploited in both cycling and post-mitotic cells, such as muscle fibers. This provides a robust, permanent gene restoration alternative to oligonucleotide-based exon skipping or pharmacologic forced read-through of stop codons and could theoretically require as few as one drug treatment. NHEJ-based gene correction using a CRISPR/Cpf1-based gene editing system, as well as other engineered nucleases including meganucleases and zinc finger nucleases, may be combined with other existing ex vivo and in vivo platforms for cell- and gene-based therapies, in addition to the plasmid electroporation approach described here. For example, delivery of a CRISPR/Cpf1-based gene editing system by mRNA-based gene transfer or as purified cell permeable proteins could enable a DNA-free genome editing approach that would circumvent any possibility of insertional mutagenesis.
[0130] b. Homology-Directed Repair
[0131] Restoration of protein expression from an endogenous mutated gene may involve homology-directed repair. The method as described above further includes administrating a donor template to the cell. The donor template may include a polynucleotide sequence encoding a full-functional protein or a partially-functional protein. For example, the donor template may include a miniaturized dystrophin construct, termed minidystrophin ("minidys"), a full-functional dystrophin construct for restoring a mutant dystrophin gene, or a fragment of the dystrophin gene that after homology-directed repair leads to restoration of the mutant dystrophin gene.
[0132] c. Methods of Correcting a Mutant Gene and Treating a Subject Using CRISPR/Cpf1-Based Gene Editing System
[0133] The present disclosure is also directed to genome editing with the CRISPR/Cpf1-based gene editing system to restore the expression of a full-functional or partially-functional protein with a repair template or donor DNA, which can replace the entire gene or the region containing the mutation. The CRISPR/Cpf1-based gene editing system may be used to introduce site-specific double strand breaks at targeted genomic loci. Site-specific double-strand breaks are created when the CRISPR/Cpf1-based gene editing system binds to a target DNA sequences using the gRNA, thereby permitting cleavage of the target DNA. The CRISPR/Cpf1-based gene editing system has the advantage of advanced genome editing due to their high rate of successful and efficient genetic modification. This DNA cleavage may stimulate the natural DNA-repair machinery, leading to one of two possible repair pathways: homology-directed repair (HDR) or the non-homologous end joining (NHEJ) pathway. For example, a CRISPR/Cpf1-based gene editing system directed towards the dystrophin gene may include a Cpf1 gRNA having a nucleic acid sequence of any one of SEQ ID NOs: 36-64, 71-119, or complement thereof.
[0134] The present disclosure is directed to genome editing with CRISPR/Cpf1-based gene editing system without a repair template, which can efficiently correct the reading frame and restore the expression of a functional protein involved in a genetic disease. The disclosed CRISPR/Cpf1-based gene editing system and methods may involve using homology-directed repair or nuclease-mediated non-homologous end joining (NHEJ)-based correction approaches, which enable efficient correction in proliferation-limited primary cell lines that may not be amenable to homologous recombination or selection-based gene correction. This strategy integrates the rapid and robust assembly of active CRISPR/Cpf1-based gene editing system with an efficient gene editing method for the treatment of genetic diseases caused by mutations in nonessential coding regions that cause frameshifts, premature stop codons, aberrant splice donor sites or aberrant splice acceptor sites.
[0135] The present disclosure provides methods of correcting a mutant gene in a cell and treating a subject suffering from a genetic disease, such as DMD. The method may include administering to a cell or subject a CRISPR/Cpf1-based gene editing system, a polynucleotide or vector encoding said CRISPR/Cpf1-based gene editing system, or composition of said CRISPR/Cpf1-based gene editing system as described above. The method may include administering a CRISPR/Cpf1-based gene editing system, such as administering a Cpf1 endonuclease, a polynucleotide sequence encoding said Cpf1 endonuclease, and/or at least one Cpf1 gRNA, wherein the gRNAs target different DNA sequences. The target DNA sequences may be overlapping. The number of gRNA administered to the cell may be at least 1 gRNA, at least 2 different gRNA, at least 3 different gRNA at least 4 different gRNA, at least 5 different gRNA, at least 6 different gRNA, at least 7 different gRNA, at least 8 different gRNA, at least 9 different gRNA, at least 10 different gRNA, at least 15 different gRNA, at least 20 different gRNA, at least 30 different gRNA, or at least 50 different gRNA, as described above. The gRNA may include a nucleic acid sequence of at least one of SEQ ID NOs: 36-64, 71-119, or complement thereof. The method may involve homology-directed repair or non-homologous end joining.
9. METHODS OF TREATING DISEASE
[0136] The present disclosure is directed to a method of treating a subject in need thereof. The method comprises administering to a tissue of a subject the presently disclosed genetic construct (e.g., a vector) or a composition comprising thereof, as described above. In certain embodiments, the method may comprises administering to the skeletal muscle or cardiac muscle of the subject the presently disclosed genetic construct (e.g., a vector) or composition comprising thereof, as described above. In certain embodiments, the method may comprises administering to a vein of the subject the presently disclosed genetic construct (e.g., a vector) or composition comprising thereof, as described above. In certain embodiments, the subject is suffering from a skeletal muscle or cardiac muscle condition causing degeneration or weakness or a genetic disease. For example, the subject may be suffering from Duchenne muscular dystrophy, as described above.
[0137] a. Duchenne Muscular Dystrophy
[0138] The method, as described above, may be used for correcting the dystrophin gene and recovering full-functional or partially-functional protein expression of said mutated dystrophin gene. In some aspects and embodiments the disclosure provides a method for reducing the effects (e.g., clinical symptoms/indications) of DMD in a patient. In some aspects and embodiments the disclosure provides a method for treating DMD in a patient. In some aspects and embodiments the disclosure provides a method for preventing DMD in a patient. In some aspects and embodiments the disclosure provides a method for preventing further progression of DMD in a patient.
10. CONSTRUCTS AND PLASMIDS
[0139] The compositions, as described above, may comprise genetic constructs that encodes the CRISPR/Cpf1-based gene editing system, as disclosed herein. The genetic construct, such as a plasmid, may comprise a nucleic acid that encodes the CRISPR/Cpf1-based gene editing system, such as the Cpf1 endonuclease and/or at least one of the Cpf1 gRNAs. The compositions, as described above, may comprise genetic constructs that encodes the modified AAV vector and a nucleic acid sequence that encodes the CRISPR/Cpf1-based gene editing system, as disclosed herein. The genetic construct, such as a plasmid, may comprise a nucleic acid that encodes the CRISPR/Cpf1-based gene editing system. The compositions, as described above, may comprise genetic constructs that encodes the modified lentiviral vector, as disclosed herein.
[0140] In some embodiments, the genetic construct may comprise a promoter that operably linked to the polynucleotide sequence encoding the at least one Cpf1 gRNA and/or a Cpf1 endonuclease. In some embodiments, the promoter is operably linked to the polynucleotide sequence encoding a first Cpf1 gRNA, a second Cpf1 gRNA, and/or a Cpf1 endonuclease. The genetic construct may be present in the cell as a functioning extrachromosomal molecule. The genetic construct may be a linear minichromosome including centromere, telomeres or plasmids or cosmids.
[0141] The genetic construct may also be part of a genome of a recombinant viral vector, including recombinant lentivirus, recombinant adenovirus, and recombinant adenovirus associated virus. The genetic construct may be part of the genetic material in attenuated live microorganisms or recombinant microbial vectors which live in cells. The genetic constructs may comprise regulatory elements for gene expression of the coding sequences of the nucleic acid. The regulatory elements may be a promoter, an enhancer, an initiation codon, a stop codon, or a polyadenylation signal.
[0142] In certain embodiments, the genetic construct is a vector. The vector can be an Adeno-associated virus (AAV) vector, which encode at least one Cpf1 endonuclease and at least one Cpf1 gRNA; the vector is capable of expressing the at least one Cpf1 endonuclease and the at least one Cpf1 gRNA, in the cell of a mammal. The vector can be a plasmid. The vectors can be used for in vivo gene therapy. The vector may be recombinant. The vector may comprise heterologous nucleic acid encoding the CRISPR/Cpf1-based gene editing system. The vector may be a plasmid. The vector may be useful for transfecting cells with nucleic acid encoding the CRISPR/Cpf1-based gene editing system, which the transformed host cell is cultured and maintained under conditions wherein expression of the CRISPR/Cpf1-based gene editing system takes place.
[0143] Coding sequences may be optimized for stability and high levels of expression. In some instances, codons are selected to reduce secondary structure formation of the RNA such as that formed due to intramolecular bonding.
[0144] The vector may comprise heterologous nucleic acid encoding the CRISPR/Cpf1-based gene editing system and may further comprise an initiation codon, which may be upstream of the CRISPR/Cpf1-based gene editing system coding sequence, and a stop codon, which may be downstream of the CRISPR/Cpf1-based gene editing system coding sequence. The initiation and termination codon may be in frame with the CRISPR/Cpf1-based gene editing system coding sequence. The vector may also comprise a promoter that is operably linked to the CRISPR/Cpf1-based gene editing system coding sequence. The promoter that is operably linked to the CRISPR/Cpf1-based gene editing system coding sequence may be a promoter from simian virus 40 (SV40), a mouse mammary tumor virus (MMTV) promoter, a human immunodeficiency virus (HIV) promoter such as the bovine immunodeficiency virus (BIV) long terminal repeat (LTR) promoter, a Moloney virus promoter, an avian leukosis virus (ALV) promoter, a cytomegalovirus (CMV) promoter such as the CMV immediate early promoter, Epstein Barr virus (EBV) promoter, a U6 promoter, such as the human U6 promoter, or a Rous sarcoma virus (RSV) promoter. The promoter may also be a promoter from a human gene such as human ubiquitin C (hUbC), human actin, human myosin, human hemoglobin, human muscle creatine, or human metalothionein. The promoter may also be a tissue specific promoter, such as a muscle or skin specific promoter, natural or synthetic. Examples of such promoters are described in US Patent Application Publication Nos. US20040175727 and US20040192593, the contents of which are incorporated herein in their entirety. Examples of muscle-specific promoters include a Spc5-12 promoter (described in US Patent Application Publication No. US 20040192593, which is incorporated by reference herein in its entirety; Hakim et al. Mol. Ther. Methods Clin. Dev. (2014) 1:14002: and Lai et al. Hum Mol Genet. (2014) 23(12): 3189-3199), a MHCK7 promoter (described in Salva et al., Mol. Ther. (2007) 15:320-329), a CK8 promoter (described in Park et al. PLoS ONE (2015) 10(4): e0124914), and a CK8e promoter (described in Muir et al., Mol. Ther. Methods Clin. Dev. (2014) 1:14025). In some embodiments, the expression of the gRNA and/or Cpf1 endonuclease is driven by tRNAs.
[0145] Each of the polynucleotide sequences encoding the Cpf1 gRNA and/or Cpf1 endonuclease may each be operably linked to a promoter. The promoters that are operably linked to the Cpf1 gRNA and/or Cpf1 endonuclease may be the same promoter. The promoters that are operably linked to the Cpf1 gRNA and/or Cpf1 endonuclease may be different promoters. The promoter may be a constitutive promoter, an inducible promoter, a repressible promoter, or a regulatable promoter.
[0146] The vector may also comprise a polyadenylation signal, which may be downstream of the CRISPR/Cpf1-based gene editing system. The polyadenylation signal may be a SV40 polyadenylation signal, LTR polyadenylation signal, bovine growth hormone (bGH) polyadenylation signal, human growth hormone (hGH) polyadenylation signal, or human .beta.-globin polyadenylation signal. The SV40 polyadenylation signal may be a polyadenylation signal from a pCEP4 vector (Invitrogen, San Diego, Calif.).
[0147] The vector may also comprise an enhancer upstream of the CRISPR/Cpf1-based gene editing system, i.e., the Cpf1 endonuclease coding sequence, Cpf1 gRNAs, or the CRISPR/Cpf1-based gene editing system. The enhancer may be necessary for DNA expression. The enhancer may be human actin, human myosin, human hemoglobin, human muscle creatine or a viral enhancer such as one from CMV, HA, RSV or EBV. Polynucleotide function enhancers are described in U.S. Pat. Nos. 5,593,972, 5,962,428, and WO94/016737, the contents of each are fully incorporated by reference. The vector may also comprise a mammalian origin of replication in order to maintain the vector extrachromosomally and produce multiple copies of the vector in a cell. The vector may also comprise a regulatory sequence, which may be well suited for gene expression in a mammalian or human cell into which the vector is administered. The vector may also comprise a reporter gene, such as green fluorescent protein ("GFP") and/or a selectable marker, such as hygromycin ("Hygro").
[0148] The vector may be expression vectors or systems to produce protein by routine techniques and readily available starting materials including Sambrook et al., Molecular Cloning and Laboratory Manual, Second Ed., Cold Spring Harbor (1989), which is incorporated fully by reference. In some embodiments the vector may comprise the nucleic acid sequence encoding the CRISPR/Cpf1-based gene editing system, including the nucleic acid sequence encoding the Cpf1 endonuclease and the nucleic acid sequence encoding the at least one Cpf1 gRNA comprising the nucleic acid sequence of at least one of SEQ ID NOs: 36-119, or complement thereof.
11. PHARMACEUTICAL COMPOSITIONS
[0149] The presently disclosed subject matter provides for compositions comprising the above-described genetic constructs. The pharmaceutical compositions according to the present invention can be formulated according to the mode of administration to be used. In cases where pharmaceutical compositions are injectable pharmaceutical compositions, they are sterile, pyrogen free and particulate free. An isotonic formulation is preferably used. Generally, additives for isotonicity may include sodium chloride, dextrose, mannitol, sorbitol and lactose. In some cases, isotonic solutions such as phosphate buffered saline are preferred. Stabilizers include gelatin and albumin. In some embodiments, a vasoconstriction agent is added to the formulation.
[0150] The composition may further comprise a pharmaceutically acceptable excipient. The pharmaceutically acceptable excipient may be functional molecules as vehicles, adjuvants, carriers, or diluents. The pharmaceutically acceptable excipient may be a transfection facilitating agent, which may include surface active agents, such as immune-stimulating complexes (ISCOMS), Freunds incomplete adjuvant, LPS analog including monophosphoryl lipid A, muramyl peptides, quinone analogs, vesicles such as squalene and squalene, hyaluronic acid, lipids, liposomes, calcium ions, viral proteins, polyanions, polycations, or nanoparticles, or other known transfection facilitating agents.
[0151] The transfection facilitating agent is a polyanion, polycation, including poly-L-glutamate (LGS), or lipid. The transfection facilitating agent is poly-L-glutamate, and more preferably, the poly-L-glutamate is present in the composition for genome editing in skeletal muscle or cardiac muscle at a concentration less than 6 mg/ml. The transfection facilitating agent may also include surface active agents such as immune-stimulating complexes (ISCOMS), Freunds incomplete adjuvant, LPS analog including monophosphoryl lipid A, muramyl peptides, quinone analogs and vesicles such as squalene and squalene, and hyaluronic acid may also be used administered in conjunction with the genetic construct. In some embodiments, the DNA vector encoding the composition may also include a transfection facilitating agent such as lipids, liposomes, including lecithin liposomes or other liposomes known in the art, as a DNA-liposome mixture (see for example International Patent Publication No. WO9324640), calcium ions, viral proteins, polyanions, polycations, or nanoparticles, or other known transfection facilitating agents. Preferably, the transfection facilitating agent is a polyanion, polycation, including poly-L-glutamate (LGS), or lipid.
12. METHODS OF DELIVERY
[0152] Provided herein is a method for delivering the presently disclosed genetic construct (e.g., a vector) or a composition thereof to a cell. The delivery of the compositions may be the transfection or electroporation of the composition as a nucleic acid molecule that is expressed in the cell and delivered to the surface of the cell. The nucleic acid molecules may be electroporated using BioRad Gene Pulser Xcell or Amaxa Nucleofector IIb devices. Several different buffers may be used, including BioRad electroporation solution, Sigma phosphate-buffered saline product #D8537 (PBS), Invitrogen OptiMEM I (OM), or Amaxa Nucleofector solution V (N. V.). Transfections may include a transfection reagent, such as Lipofectamine 2000.
[0153] Upon delivery of the presently disclosed genetic construct or composition to the tissue, and thereupon the vector into the cells of the mammal, the transfected cells will express the Cpf1 gRNA(s) and the Cpf1 endonuclease. The genetic construct or composition may be administered to a mammal to alter gene expression or to re-engineer or alter the genome. For example, the genetic construct or composition may be administered to a mammal to correct the dystrophin gene in a mammal. The mammal may be human, non-human primate, cow, pig, sheep, goat, antelope, bison, water buffalo, bovids, deer, hedgehogs, elephants, llama, alpaca, mice, rats, or chicken, and preferably human, cow, pig, or chicken.
[0154] The genetic construct (e.g., a vector) encoding the Cpf1 gRNA(s) and the Cpf1 endonuclease can be delivered to the mammal by DNA injection (also referred to as DNA vaccination) with and without in vivo electroporation, liposome mediated, nanoparticle facilitated, and/or recombinant vectors. The recombinant vector can be delivered by any viral mode. The viral mode can be recombinant lentivirus, recombinant adenovirus, and/or recombinant adeno-associated virus.
[0155] A presently disclosed genetic construct (e.g., a vector) or a composition comprising thereof can be introduced into a cell to genetically correct a dystrophin gene (e.g., human dystrophin gene). In certain embodiments, a presently disclosed genetic construct (e.g., a vector) or a composition comprising thereof is introduced into a myoblast cell from a DMD patient. In certain embodiments, the genetic construct (e.g., a vector) or a composition comprising thereof is introduced into a fibroblast cell from a DMD patient, and the genetically corrected fibroblast cell can be treated with MyoD to induce differentiation into myoblasts, which can be implanted into subjects, such as the damaged muscles of a subject to verify that the corrected dystrophin protein is functional and/or to treat the subject. The modified cells can also be stem cells, such as induced pluripotent stem cells, bone marrow-derived progenitors, skeletal muscle progenitors, human skeletal myoblasts from DMD patients, CD 133.sup.+ cells, mesoangioblasts, and MyoD- or Pax7-transduced cells, or other myogenic progenitor cells. For example, the CRISPR/Cpf1-based gene editing system may cause neuronal or myogenic differentiation of an induced pluripotent stem cell.
13. ROUTES OF ADMINISTRATION
[0156] The presently disclosed genetic constructs (e.g., vectors) or a composition comprising thereof may be administered to a subject by different routes including orally, parenterally, sublingually, transdermally, rectally, transmucosally, topically, via inhalation, via buccal administration, intrapleurally, intravenous, intraarterial, intraperitoneal, subcutaneous, intramuscular, intranasal intrathecal, and intraarticular or combinations thereof. In certain embodiments, the presently disclosed genetic construct (e.g., a vector) or a composition is administered to a subject (e.g., a subject suffering from DMD) intramuscularly, intravenously or a combination thereof. For veterinary use, the presently disclosed genetic constructs (e.g., vectors) or compositions may be administered as a suitably acceptable formulation in accordance with normal veterinary practice. The veterinarian may readily determine the dosing regimen and route of administration that is most appropriate for a particular animal. The compositions may be administered by traditional syringes, needleless injection devices, "microprojectile bombardment gone guns", or other physical methods such as electroporation ("EP"), "hydrodynamic method", or ultrasound.
[0157] The presently disclosed genetic construct (e.g., a vector) or a composition may be delivered to the mammal by several technologies including DNA injection (also referred to as DNA vaccination) with and without in vivo electroporation, liposome mediated, nanoparticle facilitated, recombinant vectors such as recombinant lentivirus, recombinant adenovirus, and recombinant adenovirus associated virus. The composition may be injected into the skeletal muscle or cardiac muscle. For example, the composition may be injected into the tibialis anterior muscle or tail.
[0158] In some embodiments, the presently disclosed genetic construct (e.g., a vector) or a composition thereof is administered by 1) tail vein injections (systemic) into adult mice; 2) intramuscular injections, for example, local injection into a muscle such as the TA or gastrocnemius in adult mice; 3) intraperitoneal injections into P2 mice; or 4) facial vein injection (systemic) into P2 mice.
14. CELL TYPES
[0159] Any of these delivery methods and/or routes of administration can be utilized with a myriad of cell types, for example, those cell types currently under investigation for cell-based therapies of DMD, including, but not limited to, immortalized myoblast cells, such as wild-type and DMD patient derived lines, for example .DELTA.48-50 DMD, DMD 6594 (de148-50), DMD 8036 (del48-50), C25C14 and DMD-7796 cell lines, primal DMD dermal fibroblasts, induced pluripotent stem cells, bone marrow-derived progenitors, skeletal muscle progenitors, human skeletal myoblasts from DMD patients, CD 133.sup.+ cells, mesoangioblasts, cardiomyocytes, hepatocytes, chondrocytes, mesenchymal progenitor cells, hematopoetic stem cells, smooth muscle cells, and MyoD- or Pax7-transduced cells, or other myogenic progenitor cells. Immortalization of human myogenic cells can be used for clonal derivation of genetically corrected myogenic cells. Cells can be modified ex vivo to isolate and expand clonal populations of immortalized DMD myoblasts that include a genetically corrected dystrophin gene and are free of other nuclease-introduced mutations in protein coding regions of the genome. Alternatively, transient in vivo delivery of CRISPR/Cpf1-based systems by non-viral or non-integrating viral gene transfer, or by direct delivery of purified proteins and gRNAs containing cell-penetrating motifs may enable highly specific correction in situ with minimal or no risk of exogenous DNA integration.
15. KITS
[0160] Provided herein is a kit, which may be used to correct a mutated dystrophin gene. The kit comprises at least one Cpf1 gRNA for correcting a mutated dystrophin gene and instructions for using the CRISPR/Cpf1-based gene editing system. Also provided herein is a kit, which may be used for genome editing of a dystrophin gene in skeletal muscle or cardiac muscle. The kit comprises genetic constructs (e.g., vectors) or a composition comprising thereof for genome editing in skeletal muscle or cardiac muscle, as described above, and instructions for using said composition.
[0161] Instructions included in kits may be affixed to packaging material or may be included as a package insert. While the instructions are typically written or printed materials they are not limited to such. Any medium capable of storing such instructions and communicating them to an end user is contemplated by this disclosure. Such media include, but are not limited to, electronic storage media (e.g., magnetic discs, tapes, cartridges, chips), optical media (e.g., CD ROM), and the like. As used herein, the term "instructions" may include the address of an internet site that provides the instructions.
[0162] The genetic constructs (e.g., vectors) or a composition comprising thereof for correcting a mutated dystrophin or genome editing of a dystrophin gene in skeletal muscle or cardiac muscle may include a modified AAV vector that includes a Cpf1 gRNA(s) and a Cpf1 endonuclease, as described above, that specifically binds and cleaves a region of the dystrophin gene. The CRISPR/Cpf1-based gene editing system, as described above, may be included in the kit to specifically bind and target a particular region in the mutated dystrophin gene. The kit may further include donor DNA, a different gRNA, or a transgene, as described above.
[0163] The kit can also optionally include one or more components, such as reagents required to use the disclosed compositions or to facilitate quality control evaluations, such as standards, buffers, diluents, salts, enzymes, enzyme co-factors, substrates, detection reagents, and the like. Other components, such as buffers and solutions for the isolation and/or treatment of the cells, also can be included in the kit. The kit can additionally include one or more other controls. One or more of the components of the kit can be lyophilized, in which case the kit can further comprise reagents suitable for the reconstitution of the lyophilized components.
16. EXAMPLES
[0164] It will be readily apparent to those skilled in the art that other suitable modifications and adaptations of the methods of the present disclosure described herein are readily applicable and appreciable, and may be made using suitable equivalents without departing from the scope of the present disclosure or the aspects and embodiments disclosed herein. Having now described the present disclosure in detail, the same will be more clearly understood by reference to the following examples, which are merely intended only to illustrate some aspects and embodiments of the disclosure, and should not be viewed as limiting to the scope of the disclosure. The disclosures of all journal references, U.S. patents, and publications referred to herein are hereby incorporated by reference in their entireties.
[0165] The present invention has multiple aspects, illustrated by the following non-limiting examples.
Example 1
Guide RNA Design and Material Preparation
[0166] Cpf1 from Acidaminococcus was obtained from the Addgene non-profit plasmid repository (pY010 (pcDNA3.1-hAsCpf1; "the AsCPF1 plasmid") from Feng Zhang (Addgene plasmid #69982)). The AsCPF1 plasmid was transformed into chemically competent E. coli and amplified, after which the sequence was verified. Cpf1 guide RNAs (also known as Cpf1 crRNAs) were designed with the University of California Santa Cruz Genome Browser program to target splice sites on prevalent exon mutations in dystrophin and the BCL11a enhancer, ordered as oligomers from Integrated DNA Technologies (IDT), prepared with PCR, and column purified as previously described (Zetsche et al., Cell 163(3):759-71 (2015)).
[0167] Guide RNA validation. Transfections were performed with Lipofectamine 2000 in 24-well plates of HEK293 cells (ATCC) following manufacturer's recommendations. Each well received 400 ng of AsCPF1 plasmid and 100 ng U6::sgRNA PCR products. After 72 hours, cells were isolated and genomic DNA was purified with a DNeasy column (QIAGEN). Surveyor nuclease digestion (IDT) and deletion PCR was performed with primers flanking the genomic region of interest as previously described (Ousterout et al., Nature Communications 6:6244 (2015); Guschin et al., Methods Mol. Biol. 649:247-256 (2010)). Digested PCR products were electrophoresed in TBE gels (Invitrogen) for 30 min at 200V, stained with ethidium bromide (EtBr), and imaged on a Gel Doc.TM. (Biorad). Deletion PCR products were electrophoresed in 1% agarose gels for 30 min at 120V, stained with EtBr, and imaged on a Gel Doc.TM. (Biorad).
Example 2
Dystrophin Splice-Acceptor Guide RNA
[0168] 15 guide RNAs targeting the top-ranking highly-mutated dystrophin exons were designed by targeting the cut region as close to the splice acceptor as possible permitted by the presence of an available PAM (Table 1). If possible, multiple guide RNAs were targeted to the same splice acceptor. Candidate guide RNAs were screened in vitro. Guide RNAs that showed immediate positive results include those targeting exon 44, exon 46, and exon 51 (FIGS. 2A-2C). Surveyor nuclease digestion was detected in guide RNAs targeting exon 44 splice acceptor (FIG. 2A), exon 46 splice acceptor (FIG. 2B), and the 3' end of exon 51 (FIG. 2C). FIG. 2D shows that genetic deletions can be created with a guide RNA targeting the splice acceptor of exon 51 and the 3' end of exon 51 implying activity of the exon 51 targeted guide RNA.
[0169] Table 1 shows the design of guide RNAs targeting dystrophin exons. The PAM sequence (TTTN) is underlined. Sense guide-RNAs have TTTN on 5' end. Guide RNAs on the antisense strand have NAAA PAMs on the 3' end.
TABLE-US-00003 TABLE 1 SEQ ID Target Target Sequence Guide RNA NO: Exon TTTGCAAAAACCCAAAATATTTTAGCT CAAAAACCCAAAATATTTTAGCT 36 Exon (SEQ ID NO: 1) 51 TTTGCCTTTTTGGTATCTTACAGGAAC CCTTTTTGGTATCTTACAGGAAC 37 Exon (SEQ ID NO: 2) 45 TCCAGGATGGCATTGGGCAGCGGCAAA CCGCTGCCCAATGCCATCCTGGA 38 Exon (SEQ ID NO: 3) 45 TTTATTTTTCCTTTTATTCTAGTTGAA TTTTTCCTTTTATTCTAGTTGAA 39 Exon (SEQ ID NO: 4) 53 TTTCTTGATCCATATGCTTTTACCTGC TTGATCCATATGCTTTTACCTGC 40 Exon (SEQ ID NO: 5) 44 AGGCGATTTGACAGATCTGTTGAGAAA TCAACAGATCTGTCAAATCGCCT 41 Exon (SEQ ID NO: 6) 44 TTTATTCTTCTTTCTCCAGGCTAGAAG TTCTTCTTTCTCCAGGCTAGAAG 42 Exon (SEQ ID NO: 7) 46 TTCTTTCTCCAGGCTAGAAGAACAAAA GTTCTTCTAGCCTGGAGAAAGAA 43 Exon (SEQ ID NO: 8) 46 TACAGGCAACAATGCAGGATTTGGAAC CAAATCCTGCATTGTTGCCTGTA 44 Exon (SEQ ID NO: 9) 52 TTTTCTGTTAAAGAGGAAGTTAGAAGA CTGTTAAAGAGGAAGTTAGAAG 45 Exon (SEQ ID NO: 10) A 50 TTTTAAAATTTTTATATTACAGAATAT AAAATTTTTATATTACAGAATAT 46 Exon (SEQ ID NO: 11) 43 AGAATATAAAAGATAGTCTACAA TTGTAGACTATCTTTTATATTCT 47 Exon CAAA (SEQ ID NO: 12) 43 TTTATTTTGCATTTTAGATGAAAGAGA TTTTGCATTTTAGATGAAAGAGA 48 Exon 2 (SEQ ID NO: 13) TTTTAGATGAAAGAGAAGATGTTCAAA AACATCTTCTCTTTCATCTAAAA 49 Exon 2 (SEQ ID NO: 14) GATGAAAGAGAAGATGTTCAAAAGAA TTTTGAACATCTTCTCTTTCATC 50 Exon 2 A (SEQ ID NO: 15)
Example 3
Matched Overhang Deletions of Exon 51
[0170] To determine if guide RNAs with matched overhang sequences encourage seamless deletions, 6 guide RNAs were designed within intron 50 and 7 guide RNAs were designed within intron 51 (Table 2) to generate matched overhang deletions. 42 unique gRNA pairs (6.times.7) were tested and screened for deletion activity, i.e., targeting exon 51 deletions. Included within this set were three overhang-matched pairs (see Table 2). 7 pairs were validated for activity. FIG. 3 is a representative image showing a smaller band indicating the deletion of exon 51. These results show for the first time Cpf1-targeted splice-acceptor disruption and deletion of exon 51 of the dystrophin gene.
TABLE-US-00004 TABLE 2 CPF1 guide RNAs targeting regions flanking exon 51 SEQ ID TARGET SEQUENCE Guide RNA NO: TARGET TTTGCAAAAACCCAAAATATTTTAGCT CAAAAACCCAAAATATTTTAGCT 51 Intron 50 (SEQ ID NO: 16) TTTAGCTTGTGTTTCTAATTTTTCTTT GCTTGTGTTTCTAATTTTTCTTT 52 Intron 50 (SEQ ID NO: 17) TTTGACTTATTGTTATTGAAATTGGCT ACTTATTGTTATTGAAATTGGCT 53 Intron 50 (SEQ ID NO: 18) TTTCTACCATGTATTGCTAAACAAAGT TACCATGTATTGCTAAACAAAGT 54 Intron 50 Matched (SEQ ID NO: 19) pair 1 TTTAGTATCAATTCACACCAGCAAGTT GTATCAATTCACACCAGCAAGTT 55 Intron 50 Matched (SEQ ID NO: 20) pair 2 ATAATCGCCACTTTACAGAGGAGTAAA CTCCTCTGTAAAGTGGCGATTAT 56 Intron 50 Matched (SEQ ID NO: 21) pair 3 TTTCTTTAAAATGAAGATTTTCCACCA TTTAAAATGAAGATTTTCCACCA 57 Intron 51 (SEQ ID NO: 22) TTTAAAATGAAGATTTTCCACCAATCA AAATGAAGATTTTCCACCAATCA 58 Intron 51 (SEQ ID NO: 23) TTTTCCACCAATCACTTTACTCTCCTA CCACCAATCACTTTACTCTCCTA 59 Intron 51 (SEQ ID NO: 24) TTTCCCACCAGTTCTTAGGCAACTGTT CCACCAGTTCTTAGGCAACTGTT 60 Intron 51 (SEQ ID NO: 25) ATAATCAAGGATATAAATTAATGCAAA CATTAATTTATATCCTTGATTAT 61 Intron 51 Matched (SEQ ID NO: 26) pair 3 TTTTGTTGTTGTTGTTAAGGTCAAAGT GTTGTTGTTGTTAAGGTCAAAGT 62 Intron 51 Matched (SEQ ID NO: 27) pair 1 TTTAAAATTACCCTAGATCTTAAAGTT AAATTACCCTAGATCTTAAAGTT 63 Intron 51 Matched (SEQ ID NO: 28) pair 2
Example 4
Targeted Deletion of Exon 51 in Patient Derived Myoblasts
[0171] Patient derived myoblasts with an exon 48-50 deletion (.DELTA.48-50) were cultured in skeletal muscle growth media. Electroporations were conducted according to standard lab procedure. Cells were cultured for 3 days and evaluated for protein expression (FIG. 4) and genomic deletion generated by SaCas9 (Cas9 from Staphylococcus aureus) or LbCpf1 (CPF1 from Lachnospiraceae bacterium ND2006) in patient myoblasts (FIG. 5). FIG. 4 shows a western blot for the HA-tagged SaCas9 and LbCpf1 show expression in extracted protein 72 hours after plasmid transfection. FIG. 5 shows PCR across the targeted genomic region shows a smaller band in bulk-treated myoblasts with SaCas9 gRNAs or Cpf1 crRNAs consistent with removal of exon 51 and portions of the surrounding introns.
[0172] Myoblasts were then differentiated and evaluated for dystrophin transcript expression and deletion of exon 51 (FIG. 6). FIG. 6 shows that differentiated myoblasts expressed a dystrophin transcript with an absent exon 51 as indicated by the smaller bands produced by RT-PCR, thus indicating that SaCas9 or LbCpf1 targeting of exon 51 removed exon 51 exon from the transcript.
[0173] A large panel of Cpf1 crRNAs were evaluated in HEK293 cells (FIG. 7; see Table 3 for Cpf1 crRNA sequences). All of the Cpf1 crRNAs targeting exon 51 or surrounding introns used are listed in Table 3. As shown in FIG. 7, HEK293 cells treated for 3 days with a panel of crRNAs showed variable activity by the Surveyor.RTM. nuclease assay. Cpf1 crRNAs #38, 41, 42, 43, 45, 46, 47, 49, 54, 55, 56, 59, 63, 64, and 65 showed the highest activity indicated by shorted bands.
TABLE-US-00005 TABLE 3 crRNA sequences # crRNA Sequence SEQ ID NO: 12 TTCCATTCTAATGGGTGGCTGTT 71 13 CTCCTCTGTAAAGTGGCGAT 72 14 TTCCATTCTAATGGGTGGCT 73 15 GTATCAATTCACACCAGCAA 74 16 TACCATGTATTGCTAAACAA 75 17 ACTTATTGTTATTGAAATTG 76 18 GCTTGTGTTTCTAATTTTTC 77 19 CAAAAACCCAAAATATTTTA 78 20 TTTAAAATGAAGATTTTCCA 79 21 AAATGAAGATTTTCCACCAA 80 22 CCACCAATCACTTTACTCTC 81 23 CCACCAGTTCTTAGGCAACT 82 24 CATTAATTTATATCCTTGAT 83 25 AGTTATAGCTCTCTTTCAAT 84 26 ATGTATAACAATTCCAACAT 85 27 AAATTACCCTAGATCTTAAA 86 28 GTTGTTGTTGTTAAGGTCAA 87 34 GCTTGTGTTTCTAATTTTTC 88 35 TAATTTTTCTTTTTCTTCTT 89 36 GCAAAAAGGAAAAAAGAAGA 90 37 GGGTTTTTGCAAAAAGGAAA 91 38 AGCTCCTACTCAGACTGTTA 92 39 TGCAAAAACCCAAAATATTT 93 40 TGTCACCAGAGTAACAGTCT 94 41 CTTAGTAACCACAGGTTGTG 95 42 TAGTTTGGAGATGGCAGTTT 96 43 GAGATGGCAGTTTCCTTAGT 97 44 CTTGATGTTGGAGGTACCTG 98 45 ATGTTGGAGGTACCTGCTCT 99 46 TAACTTGATCAAGCAGAGAA 100 47 TCTGCTTGATCAAGTTATAA 101 48 TAAAATCACAGAGGGTGATG 102 49 ATATCCTCAAGGTCACCCAC 103 50 ATGATCATCTCGTTGATATC 104 51 TCATACCTTCTGCTTGATGA 105 52 TCATTTTTTCTCATACCTTC 106 53 TGCCAACTTTTATCATTTTT 107 54 AATCAGAAAGAAGATCTTAT 108 55 ATTTCCCTAGGGTCCAGCTT 109 56 GCTCAAATTGTTACTCTTCA 110 57 AGCTCCTACTCAGACTGTTA 111 58 ATTCTAGTACTATGCATCTT 112 59 ACTTAAGTTACTTGTCCAGG 113 60 CCAAGGTCCCAGAGTTCCTA 114 61 TTTCCCTGGCAAGGTCTGAA 115 62 GCTCATTCTCATGCCTGGAC 116 63 TTTAGCAATACATGGTAGAA 117 64 AGCCAAACTCTTATTCATGA 118 65 TAACAATGTGGATACTTTGT 119
Example 5
BCL11a Enhancer Targeting
[0174] Potential candidate for increasing fetal globin levels in sickle cell anemia (SCA) were designed. Guide RNAs for Cpf1 were designed to target the BCL11a enhancer region (Table 3) in order to generate potential candidate for increasing fetal globin levels in sickle cell anemia (SCA). These reagents were designed to disrupt the BCL11a enhancer. These reagents will be tested in cell models of SCA.
TABLE-US-00006 TABLE 4 guide RNAs targeting the human BCL11a enhancer region SEQ ID Target Sequence Guide RNA NO CACGCCCCCACCCTAATCAGAGGCCAAA GCCTCTGATTAGGGTGGGGGCGTG 64 (SEQ ID NO: 29) CCAAACCCTTCCTGGAGCCTGTGATAAA TCACAGGCTCCAGGAAGGGTTTGG 65 (SEQ ID NO: 30) CCTTCCGAAAGAGGCCCCCCTGGGCAAA CCCAGGGGGGCCTCTTTCGGAAGG 66 (SEQ ID NO: 31) TCTCCATCACCAAGAGAGCCTTCCGAAA GGAAGGCTCTCTTGGTGATGGAGA 67 (SEQ ID NO: 32) TGTTAGCTTGCACTAGACTAGCTTCAAA AAGCTAGTCTAGTGCAAGCTAACA 68 (SEQ ID NO: 33) TTTTCTGGCCTATGTTATTACCTGTATG CTGGCCTATGTTATTACCTGTATG 69 (SEQ ID NO: 34) TTTCTGGCCTATGTTATTACCTGTATGG TGGCCTATGTTATTACCTGTATGG 70 (SEQ ID NO: 35)
[0175] It is understood that the foregoing detailed description and accompanying examples are merely illustrative and are not to be taken as limitations upon the scope of the invention, which is defined solely by the appended claims and their equivalents.
[0176] Various changes and modifications to the disclosed embodiments will be apparent to those skilled in the art. Such changes and modifications, including without limitation those relating to the chemical structures, substituents, derivatives, intermediates, syntheses, compositions, formulations, or methods of use of the invention, may be made without departing from the spirit and scope thereof.
[0177] For reasons of completeness, various aspects of the invention are set out in the following numbered clause:
[0178] Clause 1. A Cpf1 guide RNA (gRNA) that targets a dystrophin gene and comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof.
[0179] Clause 2. A DNA targeting composition comprising a Cpf1 endonuclease and at least one Cpf1 gRNA of clause 1.
[0180] Clause 3. A DNA targeting composition comprising a first Cpf1 gRNA and a second Cpf1 gRNA, the first Cpf1 gRNA and the second Cpf1 gRNA each comprising a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise different polynucleotide sequences, and wherein the first Cpf1 gRNA and the second Cpf1 gRNA target a dystrophin gene.
[0181] Clause 4. The DNA targeting composition of clause 3, wherein the first Cpf1 gRNA comprises a polynucleotide sequence corresponding to SEQ ID NO: 54, SEQ ID NO: 55, or SEQ ID NO: 56, and the second Cpf1 gRNA comprises a polynucleotide sequence corresponding to SEQ ID NO: 62, SEQ ID NO: 63, or SEQ ID NO: 61.
[0182] Clause 5. The DNA targeting composition of clause 3 or 4, wherein the first Cpf1 gRNA and the second Cpf1 gRNA are selected from the group consisting of: (i) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 54 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 62; (ii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 55 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 63; and (iii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 56 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 61.
[0183] Clause 6. The DNA targeting composition of any one of clauses 3 to 5, further comprising a Cpf1 endonuclease.
[0184] Clause 7. The DNA targeting composition of clause 2 or 6, wherein the Cpf1 endonuclease recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123).
[0185] Clause 8. The DNA targeting composition of clause 7, wherein the Cpf1 endonuclease is derived from a bacterial species selected from the group consisting of Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens and Porphyromonas macacae.
[0186] Clause 9. The DNA targeting composition of any one of clauses 6 to 8, wherein the Cpf1 endonuclease is derived from Lachnospiraceae bacterium ND2006 (LbCpf1) or from Acidaminococcus (AsCpf1).
[0187] Clause 10. The DNA targeting composition of any one of clauses 6 to 9, wherein the Cpf1 endonuclease is encoded by a polynucleotide sequence comprising SEQ ID NO: 124 or SEQ ID NO: 125.
[0188] Clause 11. An isolated polynucleotide comprising the Cpf1 gRNA of clause 1 or a polynucleotide sequence encoding the DNA targeting composition of any one of clauses 2 to 10.
[0189] Clause 12. A vector comprising the Cpf1 gRNA of clause 1, a polynucleotide sequence encoding the DNA targeting composition of any one of clauses 2 to 10, or the isolated polynucleotide of clause 10.
[0190] Clause 13. The vector of clause 12, further comprising a polynucleotide sequence encoding a Cpf1 endonuclease.
[0191] Clause 14. A vector encoding: (a) a first Cpf1 guide RNA (gRNA), (b) a second Cpf1 gRNA, and (c) at least one Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, and wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise different polynucleotide sequences.
[0192] Clause 15. The vector of clause 14, wherein the vector is configured to form a first and a second double strand break in a first and a second intron flanking exon 51 of the human DMD gene.
[0193] Clause 16. The vector of clause 14 or 15, wherein the first Cpf1 gRNA and the second Cpf1 gRNA are selected from the group consisting of: (i) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 54 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 62; (ii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 55 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 63; and (iii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 56 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 61.
[0194] Clause 17. The vector of any one of clauses 12 to 16, wherein the vector is a viral vector.
[0195] Clause 18. The vector of clause 17, wherein the vector is an Adeno-associated virus (AAV) vector.
[0196] Clause 19. The vector of any one of clauses 12 to 18, wherein the vector comprises a tissue-specific promoter operably linked to the polynucleotide sequence encoding the first Cpf1 gRNA, the second Cpf1 gRNA, and/or the Cpf1 endonuclease.
[0197] Clause 20. The vector of clause 19, wherein the tissue-specific promoter is a muscle specific promoter.
[0198] Clause 21. A cell comprising the Cpf1 gRNA of clause 1, a polynucleotide sequence encoding the DNA targeting composition of any one of clauses 2 to 10, the isolated polynucleotide of clause 11, or the vector of any one of clauses 12 to 20.
[0199] Clause 22. A kit comprising the Cpf1 gRNA of clause 1, a polynucleotide sequence encoding the DNA targeting composition of any one of clauses 2 to 10, the isolated polynucleotide of clause 11, the vector of any one of clauses 12 to 20, or the cell of clause 21.
[0200] Clause 23. A composition for deleting a segment of a dystrophin gene comprising exon 51, the composition comprising: (a) a first vector comprising a polynucleotide sequence encoding a first Cpf1 guide RNA (gRNA) and a polynucleotide sequence encoding a first Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), and (b) a second vector comprising a polynucleotide sequence encoding a second Cpf1 gRNA and a polynucleotide sequence encoding a second Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprise different polynucleotide sequences, and wherein the first vector and second vector are configured to form a first and a second double strand break in a first intron and a second intron flanking exon 51 of the human DMD gene, respectively, thereby deleting a segment of the dystrophin gene comprising exon 51.
[0201] Clause 24. The composition of clause 23, wherein the first Cpf1 gRNA and the second Cpf1 gRNA are selected from the group consisting of: (i) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 54 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 62; (ii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 55 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 63; and (iii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 56 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 61.
[0202] Clause 25. The composition of clause 23 or 24, wherein the first Cpf1 endonuclease and the second Cpf1 endonuclease are the same.
[0203] Clause 26. The composition of clause 23 or 24, wherein the first Cpf1 endonuclease and the second Cpf1 endonuclease are different.
[0204] Clause 27. The composition of clause 25 or 26, wherein the first Cpf1 endonuclease and/or the second Cpf1 endonuclease are CPF1 endonuclease from Lachnospiraceae bacterium ND2006 (LbCpf1) and/or from Acidaminococcus (AsCpf1).
[0205] Clause 28. The composition of any one of clauses 25 to 27, wherein the first Cpf1 endonuclease and/or the second Cpf1 endonuclease are encoded by a polynucleotide sequence comprising SEQ ID NO: 124 or SEQ ID NO: 125.
[0206] Clause 29. The composition of any one of clauses 23 to 28, wherein the first vector and/or the second vector is a viral vector.
[0207] Clause 30. The composition of clause 29, wherein the first vector and/or the second vector is an Adeno-associated virus (AAV) vector.
[0208] Clause 31. The composition of clause 30, wherein the AAV vector is an AAV8 vector or an AAV9 vector.
[0209] Clause 32. The composition of any one of clauses 23 to 31, wherein the dystrophin gene is a human dystrophin gene.
[0210] Clause 33. The composition of any one of clauses 23 to 32, for use in a medicament.
[0211] Clause 34. The composition of any one of clauses 23 to 32, for use in the treatment of Duchenne Muscular Dystrophy.
[0212] Clause 35. A cell comprising the composition of any one of clauses 23 to 34.
[0213] Clause 36. A modified adeno-associated viral vector for genome editing a mutant dystrophin gene in a subject comprising a first polynucleotide sequence encoding the Cpf1 gRNA of clause 1, and a second polynucleotide sequence encoding a Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123).
[0214] Clause 37. A method of correcting a mutant dystrophin gene in a cell, the method comprising administering to a cell the Cpf1 gRNA of clause 1, a polynucleotide sequence encoding the DNA targeting composition of any one of clauses 2 to 10, the isolated polynucleotide of clause 11, the vector of any one of clauses 12 to 20, the composition of any one of clauses 23 to 34, or the modified adeno-associated viral vector of clause 36.
[0215] Clause 38. The method of clause 37, wherein correcting the mutant dystrophin gene comprises nuclease-mediated non-homologous end joining or homology-directed repair.
[0216] Clause 39. A method of genome editing a mutant dystrophin gene in a subject, the method comprising administering to the subject a genome editing composition comprising the Cpf1 gRNA of clause 1, a polynucleotide sequence encoding the DNA targeting composition of any one of clauses 2 to 10, the isolated polynucleotide of clause 11, the vector of any one of clauses 12 to 20, the composition of any one of clauses 23 to 34, or the modified adeno-associated viral vector of clause 36.
[0217] Clause 40. The method of clause 39, wherein the genome editing composition is administered to the subject intramuscularly, intravenously, or a combination thereof.
[0218] Clause 41. The method of clause 39 or 40, wherein the genome editing comprises nuclease-mediated non-homologous end joining or homology-directed repair.
[0219] Clause 42. A method of treating a subject in need thereof having a mutant dystrophin gene, the method comprising administering to the subject the Cpf1 gRNA of clause 1, a polynucleotide sequence encoding the DNA targeting composition of any one of clauses 2 to 10, the isolated polynucleotide of clause 11, the vector of any one of clauses 12 to 20, the composition of any one of clauses 23 to 34, or the modified adeno-associated viral vector of clause 36.
[0220] Clause 43. A method of correcting a mutant dystrophin gene in a cell, comprising administering to the cell: (a) a first vector comprising a polynucleotide sequence encoding a first Cpf1 guide RNA (gRNA) and a polynucleotide sequence encoding a first Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), and (b) a second vector comprising a polynucleotide sequence encoding a second Cpf1 gRNA and a polynucleotide sequence encoding a second Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, and the vector is configured to form a first and a second double strand break in a first and a second intron flanking exon 51 of the human dystrophin gene, respectively, thereby deleting a segment of the dystrophin gene comprising exon 51 and correcting the mutant dystrophin gene in a cell.
[0221] Clause 44. The method of clause 43, wherein the first Cpf1 gRNA and the second Cpf1 gRNA are selected from the group consisting of: (i) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 54 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 62; (ii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 55 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 63; and (iii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 56 and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 61.
[0222] Clause 45. The method of clause 43 or 44, wherein the mutant dystrophin gene comprises a premature stop codon, disrupted reading frame, an aberrant splice acceptor site, or an aberrant splice donor site.
[0223] Clause 46. The method of clause 45, wherein the mutant dystrophin gene comprises a frameshift mutation which causes a premature stop codon and a truncated gene product.
[0224] Clause 47. The method of clause 43 or 44, wherein the mutant dystrophin gene comprises a deletion of one or more exons which disrupts the reading frame.
[0225] Clause 48. The method of any one of clauses 43 to 47, wherein the correction of the mutant dystrophin gene comprises a deletion of a premature stop codon, correction of a disrupted reading frame, or modulation of splicing by disruption of a splice acceptor site or disruption of a splice donor sequence.
[0226] Clause 49. The method of clause 48, wherein the correction of the mutant dystrophin gene comprises deletion of exon 51.
[0227] Clause 50. The method of any one of clauses 43 to 49, wherein the correction of the mutant dystrophin gene comprises nuclease mediated non-homologous end joining or homology-directed repair.
[0228] Clause 51. The method of any one of clauses 43 to 50, wherein the cell is a myoblast cell.
[0229] Clause 52. The method of any one of clauses 43 to 51, wherein the cell is from a subject suffering from Duchenne muscular dystrophy.
[0230] Clause 53. A method of treating a subject in need thereof having a mutant dystrophin gene, the method comprising administering to the subject: (a) a first vector comprising a polynucleotide sequence encoding a first Cpf1 guide RNA (gRNA) and a polynucleotide sequence encoding a first Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), and (b) a second vector comprising a polynucleotide sequence encoding a second Cpf1 gRNA and a polynucleotide sequence encoding a second Cpf1 endonuclease that recognizes a Protospacer Adjacent Motif (PAM) of TTTA (SEQ ID NO: 120), TTTG (SEQ ID NO: 121), TTTC (SEQ ID NO: 122), or TTTT (SEQ ID NO: 123), wherein the first Cpf1 gRNA and the second Cpf1 gRNA comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 36-64, 71-119, or a complement thereof, and the first vector and the second vector are configured to form a first and a second double strand break in a first and a second intron flanking exon 51 of the human dystrophin gene, respectively, thereby deleting a segment of the dystrophin gene comprising exon 51 and treating the subject.
[0231] Clause 54. The method of clause 53, wherein the first Cpf1 gRNA and the second Cpf1 gRNA are selected from the group consisting of: (i) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 54, and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 62; (ii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 55, and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 63; and (iii) a first Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: Clause 56, and a second Cpf1 gRNA comprising a polynucleotide sequence set forth in SEQ ID NO: 61.
[0232] Clause 55. The method of clause 53 or 54, wherein the subject is suffering from Duchenne muscular dystrophy.
[0233] Clause 56. The method of any one of clauses 53 to 55, wherein the first vector and second vector are administered to the subject intramuscularly, intravenously, or a combination thereof.
[0234] Clause 57. A Cpf1 guide RNA (gRNA) that targets an enhancer of the B-cell lymphoma/leukemia 11A (BCL11a) gene and comprises a polynucleotide sequence corresponding to at least one of SEQ ID NOs: 65-70, or a complement thereof.
[0235] Clause 58. A method of disrupting an enhancer of a B-cell lymphoma/leukemia 11A gene in a cell, the method comprising administering to the cell at least one Cpf1 gRNA of clause 57 and a Cpf1 endonuclease.
Sequence CWU 1
1
125127DNAHomo sapiens 1tttgcaaaaa cccaaaatat tttagct 27227DNAHomo
sapiens 2tttgcctttt tggtatctta caggaac 27327DNAHomo sapiens
3tccaggatgg cattgggcag cggcaaa 27427DNAHomo sapiens 4tttatttttc
cttttattct agttgaa 27527DNAHomo sapiens 5tttcttgatc catatgcttt
tacctgc 27627DNAHomo sapiens 6aggcgatttg acagatctgt tgagaaa
27727DNAHomo sapiens 7tttattcttc tttctccagg ctagaag 27827DNAHomo
sapiens 8ttctttctcc aggctagaag aacaaaa 27927DNAHomo sapiens
9tacaggcaac aatgcaggat ttggaac 271027DNAHomo sapiens 10ttttctgtta
aagaggaagt tagaaga 271127DNAHomo sapiens 11ttttaaaatt tttatattac
agaatat 271227DNAHomo sapiens 12agaatataaa agatagtcta caacaaa
271327DNAHomo sapiens 13tttattttgc attttagatg aaagaga 271427DNAHomo
sapiens 14ttttagatga aagagaagat gttcaaa 271527DNAHomo sapiens
15gatgaaagag aagatgttca aaagaaa 271627DNAHomo sapiens 16tttgcaaaaa
cccaaaatat tttagct 271727DNAHomo sapiens 17tttagcttgt gtttctaatt
tttcttt 271827DNAHomo sapiens 18tttgacttat tgttattgaa attggct
271927DNAHomo sapiens 19tttctaccat gtattgctaa acaaagt 272027DNAHomo
sapiens 20tttagtatca attcacacca gcaagtt 272127DNAHomo sapiens
21ataatcgcca ctttacagag gagtaaa 272227DNAHomo sapiens 22tttctttaaa
atgaagattt tccacca 272327DNAHomo sapiens 23tttaaaatga agattttcca
ccaatca 272427DNAHomo sapiens 24ttttccacca atcactttac tctccta
272527DNAHomo sapiens 25tttcccacca gttcttaggc aactgtt 272627DNAHomo
sapiens 26ataatcaagg atataaatta atgcaaa 272727DNAHomo sapiens
27ttttgttgtt gttgttaagg tcaaagt 272827DNAHomo sapiens 28tttaaaatta
ccctagatct taaagtt 272928DNAHomo sapiens 29cacgccccca ccctaatcag
aggccaaa 283028DNAHomo sapiens 30ccaaaccctt cctggagcct gtgataaa
283128DNAHomo sapiens 31ccttccgaaa gaggcccccc tgggcaaa
283228DNAHomo sapiens 32tctccatcac caagagagcc ttccgaaa
283328DNAHomo sapiens 33tgttagcttg cactagacta gcttcaaa
283428DNAHomo sapiens 34ttttctggcc tatgttatta cctgtatg
283528DNAHomo sapiens 35tttctggcct atgttattac ctgtatgg
283623DNAArtificial SequenceSynthetic 36caaaaaccca aaatatttta gct
233723DNAArtificial SequenceSynthetic 37cctttttggt atcttacagg aac
233823DNAArtificial SequenceSynthetic 38ccgctgccca atgccatcct gga
233923DNAArtificial SequenceSynthetic 39tttttccttt tattctagtt gaa
234023DNAArtificial SequenceSynthetic 40ttgatccata tgcttttacc tgc
234123DNAArtificial SequenceSynthetic 41tcaacagatc tgtcaaatcg cct
234223DNAArtificial SequenceSynthetic 42ttcttctttc tccaggctag aag
234323DNAArtificial SequenceSynthetic 43gttcttctag cctggagaaa gaa
234423DNAArtificial SequenceSynthetic 44caaatcctgc attgttgcct gta
234523DNAArtificial SequenceSynthetic 45ctgttaaaga ggaagttaga aga
234623DNAArtificial SequenceSynthetic 46aaaattttta tattacagaa tat
234723DNAArtificial SequenceSynthetic 47ttgtagacta tcttttatat tct
234823DNAArtificial SequenceSynthetic 48ttttgcattt tagatgaaag aga
234923DNAArtificial SequenceSynthetic 49aacatcttct ctttcatcta aaa
235023DNAArtificial SequenceSynthetic 50ttttgaacat cttctctttc atc
235123DNAArtificial SequenceSynthetic 51caaaaaccca aaatatttta gct
235223DNAArtificial SequenceSynthetic 52gcttgtgttt ctaatttttc ttt
235323DNAArtificial SequenceSynthetic 53acttattgtt attgaaattg gct
235423DNAArtificial SequenceSynthetic 54taccatgtat tgctaaacaa agt
235523DNAArtificial SequenceSynthetic 55gtatcaattc acaccagcaa gtt
235623DNAArtificial SequenceSynthetic 56ctcctctgta aagtggcgat tat
235723DNAArtificial SequenceSynthetic 57tttaaaatga agattttcca cca
235823DNAArtificial SequenceSynthetic 58aaatgaagat tttccaccaa tca
235923DNAArtificial SequenceSynthetic 59ccaccaatca ctttactctc cta
236023DNAArtificial SequenceSynthetic 60ccaccagttc ttaggcaact gtt
236123DNAArtificial SequenceSynthetic 61cattaattta tatccttgat tat
236223DNAArtificial SequenceSynthetic 62gttgttgttg ttaaggtcaa agt
236323DNAArtificial SequenceSynthetic 63aaattaccct agatcttaaa gtt
236424DNAArtificial SequenceSynthetic 64gcctctgatt agggtggggg cgtg
246524DNAArtificial SequenceSynthetic 65tcacaggctc caggaagggt ttgg
246624DNAArtificial SequenceSynthetic 66cccagggggg cctctttcgg aagg
246724DNAArtificial SequenceSynthetic 67ggaaggctct cttggtgatg gaga
246824DNAArtificial SequenceSynthetic 68aagctagtct agtgcaagct aaca
246924DNAArtificial SequenceSynthetic 69ctggcctatg ttattacctg tatg
247024DNAArtificial SequenceSynthetic 70tggcctatgt tattacctgt atgg
247123DNAArtificial SequenceSynthetic 71ttccattcta atgggtggct gtt
237220DNAArtificial SequenceSynthetic 72ctcctctgta aagtggcgat
207320DNAArtificial SequenceSynthetic 73ttccattcta atgggtggct
207420DNAArtificial SequenceSynthetic 74gtatcaattc acaccagcaa
207520DNAArtificial SequenceSynthetic 75taccatgtat tgctaaacaa
207620DNAArtificial SequenceSynthetic 76acttattgtt attgaaattg
207720DNAArtificial SequenceSynthetic 77gcttgtgttt ctaatttttc
207820DNAArtificial SequenceSynthetic 78caaaaaccca aaatatttta
207920DNAArtificial SequenceSynthetic 79tttaaaatga agattttcca
208020DNAArtificial SequenceSynthetic 80aaatgaagat tttccaccaa
208120DNAArtificial SequenceSynthetic 81ccaccaatca ctttactctc
208220DNAArtificial SequenceSynthetic 82ccaccagttc ttaggcaact
208320DNAArtificial SequenceSynthetic 83cattaattta tatccttgat
208420DNAArtificial SequenceSynthetic 84agttatagct ctctttcaat
208520DNAArtificial SequenceSynthetic 85atgtataaca attccaacat
208620DNAArtificial SequenceSynthetic 86aaattaccct agatcttaaa
208720DNAArtificial SequenceSynthetic 87gttgttgttg ttaaggtcaa
208820DNAArtificial SequenceSynthetic 88gcttgtgttt ctaatttttc
208920DNAArtificial SequenceSynthetic 89taatttttct ttttcttctt
209020DNAArtificial SequenceSynthetic 90gcaaaaagga aaaaagaaga
209120DNAArtificial SequenceSynthetic 91gggtttttgc aaaaaggaaa
209220DNAArtificial SequenceSynthetic 92agctcctact cagactgtta
209320DNAArtificial SequenceSynthetic 93tgcaaaaacc caaaatattt
209420DNAArtificial SequenceSynthetic 94tgtcaccaga gtaacagtct
209520DNAArtificial SequenceSynthetic 95cttagtaacc acaggttgtg
209620DNAArtificial SequenceSynthetic 96tagtttggag atggcagttt
209720DNAArtificial SequenceSynthetic 97gagatggcag tttccttagt
209820DNAArtificial SequenceSynthetic 98cttgatgttg gaggtacctg
209920DNAArtificial SequenceSynthetic 99atgttggagg tacctgctct
2010020DNAArtificial SequenceSynthetic 100taacttgatc aagcagagaa
2010120DNAArtificial SequenceSynthetic 101tctgcttgat caagttataa
2010220DNAArtificial SequenceSynthetic 102taaaatcaca gagggtgatg
2010320DNAArtificial SequenceSynthetic 103atatcctcaa ggtcacccac
2010420DNAArtificial SequenceSynthetic 104atgatcatct cgttgatatc
2010520DNAArtificial SequenceSynthetic 105tcataccttc tgcttgatga
2010620DNAArtificial SequenceSynthetic 106tcattttttc tcataccttc
2010720DNAArtificial SequenceSynthetic 107tgccaacttt tatcattttt
2010820DNAArtificial SequenceSynthetic 108aatcagaaag aagatcttat
2010920DNAArtificial SequenceSynthetic 109atttccctag ggtccagctt
2011020DNAArtificial SequenceSynthetic 110gctcaaattg ttactcttca
2011120DNAArtificial SequenceSynthetic 111agctcctact cagactgtta
2011220DNAArtificial SequenceSynthetic 112attctagtac tatgcatctt
2011320DNAArtificial SequenceSynthetic 113acttaagtta cttgtccagg
2011420DNAArtificial SequenceSynthetic 114ccaaggtccc agagttccta
2011520DNAArtificial SequenceSynthetic 115tttccctggc aaggtctgaa
2011620DNAArtificial SequenceSynthetic 116gctcattctc atgcctggac
2011720DNAArtificial SequenceSynthetic 117tttagcaata catggtagaa
2011820DNAArtificial SequenceSynthetic 118agccaaactc ttattcatga
2011920DNAArtificial SequenceSynthetic 119taacaatgtg gatactttgt
201204DNAArtificial SequenceSynthetic 120ttta 41214DNAArtificial
SequenceSynthetic 121tttg 41224DNAArtificial SequenceSynthetic
122tttc 41234DNAArtificial SequenceSynthetic 123tttt
41249464DNAArtificial SequenceSynthetic AsCpf1 124gacggatcgg
gagatctccc gatcccctat ggtgcactct cagtacaatc tgctctgatg 60ccgcatagtt
aagccagtat ctgctccctg cttgtgtgtt ggaggtcgct gagtagtgcg
120cgagcaaaat ttaagctaca acaaggcaag gcttgaccga caattgcatg
aagaatctgc 180ttagggttag gcgttttgcg ctgcttcgcg atgtacgggc
cagatatacg cgttgacatt 240gattattgac tagttattaa tagtaatcaa
ttacggggtc attagttcat agcccatata 300tggagttccg cgttacataa
cttacggtaa atggcccgcc tggctgaccg cccaacgacc 360cccgcccatt
gacgtcaata atgacgtatg ttcccatagt aacgccaata gggactttcc
420attgacgtca atgggtggag tatttacggt aaactgccca cttggcagta
catcaagtgt 480atcatatgcc aagtacgccc cctattgacg tcaatgacgg
taaatggccc gcctggcatt 540atgcccagta catgacctta tgggactttc
ctacttggca gtacatctac gtattagtca 600tcgctattac catggtgatg
cggttttggc agtacatcaa tgggcgtgga tagcggtttg 660actcacgggg
atttccaagt ctccacccca ttgacgtcaa tgggagtttg ttttggcacc
720aaaatcaacg ggactttcca aaatgtcgta acaactccgc cccattgacg
caaatgggcg 780gtaggcgtgt acggtgggag gtctatataa gcagagctct
ctggctaact agagaaccca 840ctgcttactg gcttatcgaa attaatacga
ctcactatag ggagacccaa gctggctagc 900gtttaaactt aagcttggta
ccgccaccat gacacagttc gagggcttta ccaacctgta 960tcaggtgagc
aagacactgc ggtttgagct gatcccacag ggcaagaccc tgaagcacat
1020ccaggagcag ggcttcatcg aggaggacaa ggcccgcaat gatcactaca
aggagctgaa 1080gcccatcatc gatcggatct acaagaccta tgccgaccag
tgcctgcagc tggtgcagct 1140ggattgggag aacctgagcg ccgccatcga
ctcctataga aaggagaaaa ccgaggagac 1200aaggaacgcc ctgatcgagg
agcaggccac atatcgcaat gccatccacg actacttcat 1260cggccggaca
gacaacctga ccgatgccat caataagaga cacgccgaga tctacaaggg
1320cctgttcaag gccgagctgt ttaatggcaa ggtgctgaag cagctgggca
ccgtgaccac 1380aaccgagcac gagaacgccc tgctgcggag cttcgacaag
tttacaacct acttctccgg 1440cttttatgag aacaggaaga acgtgttcag
cgccgaggat atcagcacag ccatcccaca 1500ccgcatcgtg caggacaact
tccccaagtt taaggagaat tgtcacatct tcacacgcct 1560gatcaccgcc
gtgcccagcc tgcgggagca ctttgagaac gtgaagaagg ccatcggcat
1620cttcgtgagc acctccatcg aggaggtgtt ttccttccct ttttataacc
agctgctgac 1680acagacccag atcgacctgt ataaccagct gctgggagga
atctctcggg aggcaggcac 1740cgagaagatc aagggcctga acgaggtgct
gaatctggcc atccagaaga atgatgagac 1800agcccacatc atcgcctccc
tgccacacag attcatcccc ctgtttaagc agatcctgtc 1860cgataggaac
accctgtctt tcatcctgga ggagtttaag agcgacgagg aagtgatcca
1920gtccttctgc aagtacaaga cactgctgag aaacgagaac gtgctggaga
cagccgaggc 1980cctgtttaac gagctgaaca gcatcgacct gacacacatc
ttcatcagcc acaagaagct 2040ggagacaatc agcagcgccc tgtgcgacca
ctgggataca ctgaggaatg ccctgtatga 2100gcggagaatc tccgagctga
caggcaagat caccaagtct gccaaggaga aggtgcagcg 2160cagcctgaag
cacgaggata tcaacctgca ggagatcatc tctgccgcag gcaaggagct
2220gagcgaggcc ttcaagcaga aaaccagcga gatcctgtcc cacgcacacg
ccgccctgga 2280tcagccactg cctacaaccc tgaagaagca ggaggagaag
gagatcctga agtctcagct 2340ggacagcctg ctgggcctgt accacctgct
ggactggttt gccgtggatg agtccaacga 2400ggtggacccc gagttctctg
cccggctgac cggcatcaag ctggagatgg agccttctct 2460gagcttctac
aacaaggcca gaaattatgc caccaagaag ccctactccg tggagaagtt
2520caagctgaac tttcagatgc ctacactggc ctctggctgg gacgtgaata
aggagaagaa 2580caatggcgcc atcctgtttg tgaagaacgg cctgtactat
ctgggcatca tgccaaagca 2640gaagggcagg tataaggccc tgagcttcga
gcccacagag aaaaccagcg agggctttga 2700taagatgtac tatgactact
tccctgatgc cgccaagatg atcccaaagt gcagcaccca 2760gctgaaggcc
gtgacagccc actttcagac ccacacaacc cccatcctgc tgtccaacaa
2820tttcatcgag cctctggaga tcacaaagga gatctacgac ctgaacaatc
ctgagaagga 2880gccaaagaag tttcagacag cctacgccaa gaaaaccggc
gaccagaagg gctacagaga 2940ggccctgtgc aagtggatcg acttcacaag
ggattttctg tccaagtata ccaagacaac 3000ctctatcgat ctgtctagcc
tgcggccatc ctctcagtat aaggacctgg gcgagtacta 3060tgccgagctg
aatcccctgc tgtaccacat cagcttccag agaatcgccg agaaggagat
3120catggatgcc gtggagacag gcaagctgta cctgttccag atctataaca
aggactttgc 3180caagggccac cacggcaagc ctaatctgca cacactgtat
tggaccggcc tgttttctcc 3240agagaacctg gccaagacaa gcatcaagct
gaatggccag gccgagctgt tctaccgccc 3300taagtccagg atgaagagga
tggcacaccg gctgggagag aagatgctga acaagaagct 3360gaaggatcag
aaaaccccaa tccccgacac cctgtaccag gagctgtacg actatgtgaa
3420tcacagactg tcccacgacc tgtctgatga ggccagggcc ctgctgccca
acgtgatcac 3480caaggaggtg tctcacgaga tcatcaagga taggcgcttt
accagcgaca agttcttttt 3540ccacgtgcct atcacactga actatcaggc
cgccaattcc ccatctaagt tcaaccagag 3600ggtgaatgcc tacctgaagg
agcaccccga gacacctatc atcggcatcg atcggggcga 3660gagaaacctg
atctatatca cagtgatcga ctccaccggc aagatcctgg agcagcggag
3720cctgaacacc atccagcagt ttgattacca gaagaagctg gacaacaggg
agaaggagag 3780ggtggcagca aggcaggcct ggtctgtggt gggcacaatc
aaggatctga agcagggcta 3840tctgagccag gtcatccacg agatcgtgga
cctgatgatc cactaccagg ccgtggtggt 3900gctggagaac ctgaatttcg
gctttaagag caagaggacc ggcatcgccg agaaggccgt 3960gtaccagcag
ttcgagaaga tgctgatcga taagctgaat tgcctggtgc tgaaggacta
4020tccagcagag aaagtgggag gcgtgctgaa cccataccag ctgacagacc
agttcacctc 4080ctttgccaag atgggcaccc agtctggctt cctgttttac
gtgcctgccc catatacatc
4140taagatcgat cccctgaccg gcttcgtgga ccccttcgtg tggaaaacca
tcaagaatca 4200cgagagccgc aagcacttcc tggagggctt cgactttctg
cactacgacg tgaaaaccgg 4260cgacttcatc ctgcacttta agatgaacag
aaatctgtcc ttccagaggg gcctgcccgg 4320ctttatgcct gcatgggata
tcgtgttcga gaagaacgag acacagtttg acgccaaggg 4380cacccctttc
atcgccggca agagaatcgt gccagtgatc gagaatcaca gattcaccgg
4440cagataccgg gacctgtatc ctgccaacga gctgatcgcc ctgctggagg
agaagggcat 4500cgtgttcagg gatggctcca acatcctgcc aaagctgctg
gagaatgacg attctcacgc 4560catcgacacc atggtggccc tgatccgcag
cgtgctgcag atgcggaact ccaatgccgc 4620cacaggcgag gactatatca
acagccccgt gcgcgatctg aatggcgtgt gcttcgactc 4680ccggtttcag
aacccagagt ggcccatgga cgccgatgcc aatggcgcct accacatcgc
4740cctgaagggc cagctgctgc tgaatcacct gaaggagagc aaggatctga
agctgcagaa 4800cggcatctcc aatcaggact ggctggccta catccaggag
ctgcgcaaca aaaggccggc 4860ggccacgaaa aaggccggcc aggcaaaaaa
gaaaaaggga tcctacccat acgatgttcc 4920agattacgct tatccctacg
acgtgcctga ttatgcatac ccatatgatg tccccgacta 4980tgcctaagaa
ttctgcagat atccagcaca gtggcggccg ctcgagtcta gagggcccgt
5040ttaaacccgc tgatcagcct cgactgtgcc ttctagttgc cagccatctg
ttgtttgccc 5100ctcccccgtg ccttccttga ccctggaagg tgccactccc
actgtccttt cctaataaaa 5160tgaggaaatt gcatcgcatt gtctgagtag
gtgtcattct attctggggg gtggggtggg 5220gcaggacagc aagggggagg
attgggaaga caatagcagg catgctgggg atgcggtggg 5280ctctatggct
tctgaggcgg aaagaaccag ctggggctct agggggtatc cccacgcgcc
5340ctgtagcggc gcattaagcg cggcgggtgt ggtggttacg cgcagcgtga
ccgctacact 5400tgccagcgcc ctagcgcccg ctcctttcgc tttcttccct
tcctttctcg ccacgttcgc 5460cggctttccc cgtcaagctc taaatcgggg
gctcccttta gggttccgat ttagtgcttt 5520acggcacctc gaccccaaaa
aacttgatta gggtgatggt tcacgtagtg ggccatcgcc 5580ctgatagacg
gtttttcgcc ctttgacgtt ggagtccacg ttctttaata gtggactctt
5640gttccaaact ggaacaacac tcaaccctat ctcggtctat tcttttgatt
tataagggat 5700tttgccgatt tcggcctatt ggttaaaaaa tgagctgatt
taacaaaaat ttaacgcgaa 5760ttaattctgt ggaatgtgtg tcagttaggg
tgtggaaagt ccccaggctc cccagcaggc 5820agaagtatgc aaagcatgca
tctcaattag tcagcaacca ggtgtggaaa gtccccaggc 5880tccccagcag
gcagaagtat gcaaagcatg catctcaatt agtcagcaac catagtcccg
5940cccctaactc cgcccatccc gcccctaact ccgcccagtt ccgcccattc
tccgccccat 6000ggctgactaa ttttttttat ttatgcagag gccgaggccg
cctctgcctc tgagctattc 6060cagaagtagt gaggaggctt ttttggaggc
ctaggctttt gcaaaaagct cccgggagct 6120tgtatatcca ttttcggatc
tgatcaagag acaggatgag gatcgtttcg catgattgaa 6180caagatggat
tgcacgcagg ttctccggcc gcttgggtgg agaggctatt cggctatgac
6240tgggcacaac agacaatcgg ctgctctgat gccgccgtgt tccggctgtc
agcgcagggg 6300cgcccggttc tttttgtcaa gaccgacctg tccggtgccc
tgaatgaact gcaggacgag 6360gcagcgcggc tatcgtggct ggccacgacg
ggcgttcctt gcgcagctgt gctcgacgtt 6420gtcactgaag cgggaaggga
ctggctgcta ttgggcgaag tgccggggca ggatctcctg 6480tcatctcacc
ttgctcctgc cgagaaagta tccatcatgg ctgatgcaat gcggcggctg
6540catacgcttg atccggctac ctgcccattc gaccaccaag cgaaacatcg
catcgagcga 6600gcacgtactc ggatggaagc cggtcttgtc gatcaggatg
atctggacga agagcatcag 6660gggctcgcgc cagccgaact gttcgccagg
ctcaaggcgc gcatgcccga cggcgaggat 6720ctcgtcgtga cccatggcga
tgcctgcttg ccgaatatca tggtggaaaa tggccgcttt 6780tctggattca
tcgactgtgg ccggctgggt gtggcggacc gctatcagga catagcgttg
6840gctacccgtg atattgctga agagcttggc ggcgaatggg ctgaccgctt
cctcgtgctt 6900tacggtatcg ccgctcccga ttcgcagcgc atcgccttct
atcgccttct tgacgagttc 6960ttctgagcgg gactctgggg ttcgaaatga
ccgaccaagc gacgcccaac ctgccatcac 7020gagatttcga ttccaccgcc
gccttctatg aaaggttggg cttcggaatc gttttccggg 7080acgccggctg
gatgatcctc cagcgcgggg atctcatgct ggagttcttc gcccacccca
7140acttgtttat tgcagcttat aatggttaca aataaagcaa tagcatcaca
aatttcacaa 7200ataaagcatt tttttcactg cattctagtt gtggtttgtc
caaactcatc aatgtatctt 7260atcatgtctg tataccgtcg acctctagct
agagcttggc gtaatcatgg tcatagctgt 7320ttcctgtgtg aaattgttat
ccgctcacaa ttccacacaa catacgagcc ggaagcataa 7380agtgtaaagc
ctggggtgcc taatgagtga gctaactcac attaattgcg ttgcgctcac
7440tgcccgcttt ccagtcggga aacctgtcgt gccagctgca ttaatgaatc
ggccaacgcg 7500cggggagagg cggtttgcgt attgggcgct cttccgcttc
ctcgctcact gactcgctgc 7560gctcggtcgt tcggctgcgg cgagcggtat
cagctcactc aaaggcggta atacggttat 7620ccacagaatc aggggataac
gcaggaaaga acatgtgagc aaaaggccag caaaaggcca 7680ggaaccgtaa
aaaggccgcg ttgctggcgt ttttccatag gctccgcccc cctgacgagc
7740atcacaaaaa tcgacgctca agtcagaggt ggcgaaaccc gacaggacta
taaagatacc 7800aggcgtttcc ccctggaagc tccctcgtgc gctctcctgt
tccgaccctg ccgcttaccg 7860gatacctgtc cgcctttctc ccttcgggaa
gcgtggcgct ttctcatagc tcacgctgta 7920ggtatctcag ttcggtgtag
gtcgttcgct ccaagctggg ctgtgtgcac gaaccccccg 7980ttcagcccga
ccgctgcgcc ttatccggta actatcgtct tgagtccaac ccggtaagac
8040acgacttatc gccactggca gcagccactg gtaacaggat tagcagagcg
aggtatgtag 8100gcggtgctac agagttcttg aagtggtggc ctaactacgg
ctacactaga agaacagtat 8160ttggtatctg cgctctgctg aagccagtta
ccttcggaaa aagagttggt agctcttgat 8220ccggcaaaca aaccaccgct
ggtagcggtt tttttgtttg caagcagcag attacgcgca 8280gaaaaaaagg
atctcaagaa gatcctttga tcttttctac ggggtctgac gctcagtgga
8340acgaaaactc acgttaaggg attttggtca tgagattatc aaaaaggatc
ttcacctaga 8400tccttttaaa ttaaaaatga agttttaaat caatctaaag
tatatatgag taaacttggt 8460ctgacagtta ccaatgctta atcagtgagg
cacctatctc agcgatctgt ctatttcgtt 8520catccatagt tgcctgactc
cccgtcgtgt agataactac gatacgggag ggcttaccat 8580ctggccccag
tgctgcaatg ataccgcgag acccacgctc accggctcca gatttatcag
8640caataaacca gccagccgga agggccgagc gcagaagtgg tcctgcaact
ttatccgcct 8700ccatccagtc tattaattgt tgccgggaag ctagagtaag
tagttcgcca gttaatagtt 8760tgcgcaacgt tgttgccatt gctacaggca
tcgtggtgtc acgctcgtcg tttggtatgg 8820cttcattcag ctccggttcc
caacgatcaa ggcgagttac atgatccccc atgttgtgca 8880aaaaagcggt
tagctccttc ggtcctccga tcgttgtcag aagtaagttg gccgcagtgt
8940tatcactcat ggttatggca gcactgcata attctcttac tgtcatgcca
tccgtaagat 9000gcttttctgt gactggtgag tactcaacca agtcattctg
agaatagtgt atgcggcgac 9060cgagttgctc ttgcccggcg tcaatacggg
ataataccgc gccacatagc agaactttaa 9120aagtgctcat cattggaaaa
cgttcttcgg ggcgaaaact ctcaaggatc ttaccgctgt 9180tgagatccag
ttcgatgtaa cccactcgtg cacccaactg atcttcagca tcttttactt
9240tcaccagcgt ttctgggtga gcaaaaacag gaaggcaaaa tgccgcaaaa
aagggaataa 9300gggcgacacg gaaatgttga atactcatac tcttcctttt
tcaatattat tgaagcattt 9360atcagggtta ttgtctcatg agcggataca
tatttgaatg tatttagaaa aataaacaaa 9420taggggttcc gcgcacattt
ccccgaaaag tgccacctga cgtc 94641259227DNAArtificial
SequenceSynthetic LbCpf1 125gacggatcgg gagatctccc gatcccctat
ggtgcactct cagtacaatc tgctctgatg 60ccgcatagtt aagccagtat ctgctccctg
cttgtgtgtt ggaggtcgct gagtagtgcg 120cgagcaaaat ttaagctaca
acaaggcaag gcttgaccga caattgcatg aagaatctgc 180ttagggttag
gcgttttgcg ctgcttcgcg atgtacgggc cagatatacg cgttgacatt
240gattattgac tagttattaa tagtaatcaa ttacggggtc attagttcat
agcccatata 300tggagttccg cgttacataa cttacggtaa atggcccgcc
tggctgaccg cccaacgacc 360cccgcccatt gacgtcaata atgacgtatg
ttcccatagt aacgccaata gggactttcc 420attgacgtca atgggtggag
tatttacggt aaactgccca cttggcagta catcaagtgt 480atcatatgcc
aagtacgccc cctattgacg tcaatgacgg taaatggccc gcctggcatt
540atgcccagta catgacctta tgggactttc ctacttggca gtacatctac
gtattagtca 600tcgctattac catggtgatg cggttttggc agtacatcaa
tgggcgtgga tagcggtttg 660actcacgggg atttccaagt ctccacccca
ttgacgtcaa tgggagtttg ttttggcacc 720aaaatcaacg ggactttcca
aaatgtcgta acaactccgc cccattgacg caaatgggcg 780gtaggcgtgt
acggtgggag gtctatataa gcagagctct ctggctaact agagaaccca
840ctgcttactg gcttatcgaa attaatacga ctcactatag ggagacccaa
gctggctagc 900gtttaaactt aagcttggta ccgccaccat gagcaagctg
gagaagttta caaactgcta 960ctccctgtct aagaccctga ggttcaaggc
catccctgtg ggcaagaccc aggagaacat 1020cgacaataag cggctgctgg
tggaggacga gaagagagcc gaggattata agggcgtgaa 1080gaagctgctg
gatcgctact atctgtcttt tatcaacgac gtgctgcaca gcatcaagct
1140gaagaatctg aacaattaca tcagcctgtt ccggaagaaa accagaaccg
agaaggagaa 1200taaggagctg gagaacctgg agatcaatct gcggaaggag
atcgccaagg ccttcaaggg 1260caacgagggc tacaagtccc tgtttaagaa
ggatatcatc gagacaatcc tgccagagtt 1320cctggacgat aaggacgaga
tcgccctggt gaacagcttc aatggcttta ccacagcctt 1380caccggcttc
tttgataaca gagagaatat gttttccgag gaggccaaga gcacatccat
1440cgccttcagg tgtatcaacg agaatctgac ccgctacatc tctaatatgg
acatcttcga 1500gaaggtggac gccatctttg ataagcacga ggtgcaggag
atcaaggaga agatcctgaa 1560cagcgactat gatgtggagg atttctttga
gggcgagttc tttaactttg tgctgacaca 1620ggagggcatc gacgtgtata
acgccatcat cggcggcttc gtgaccgaga gcggcgagaa 1680gatcaagggc
ctgaacgagt acatcaacct gtataatcag aaaaccaagc agaagctgcc
1740taagtttaag ccactgtata agcaggtgct gagcgatcgg gagtctctga
gcttctacgg 1800cgagggctat acatccgatg aggaggtgct ggaggtgttt
agaaacaccc tgaacaagaa 1860cagcgagatc ttcagctcca tcaagaagct
ggagaagctg ttcaagaatt ttgacgagta 1920ctctagcgcc ggcatctttg
tgaagaacgg ccccgccatc agcacaatct ccaaggatat 1980cttcggcgag
tggaacgtga tccgggacaa gtggaatgcc gagtatgacg atatccacct
2040gaagaagaag gccgtggtga ccgagaagta cgaggacgat cggagaaagt
ccttcaagaa 2100gatcggctcc ttttctctgg agcagctgca ggagtacgcc
gacgccgatc tgtctgtggt 2160ggagaagctg aaggagatca tcatccagaa
ggtggatgag atctacaagg tgtatggctc 2220ctctgagaag ctgttcgacg
ccgattttgt gctggagaag agcctgaaga agaacgacgc 2280cgtggtggcc
atcatgaagg acctgctgga ttctgtgaag agcttcgaga attacatcaa
2340ggccttcttt ggcgagggca aggagacaaa cagggacgag tccttctatg
gcgattttgt 2400gctggcctac gacatcctgc tgaaggtgga ccacatctac
gatgccatcc gcaattatgt 2460gacccagaag ccctactcta aggataagtt
caagctgtat tttcagaacc ctcagttcat 2520gggcggctgg gacaaggata
aggagacaga ctatcgggcc accatcctga gatacggctc 2580caagtactat
ctggccatca tggataagaa gtacgccaag tgcctgcaga agatcgacaa
2640ggacgatgtg aacggcaatt acgagaagat caactataag ctgctgcccg
gccctaataa 2700gatgctgcca aaggtgttct tttctaagaa gtggatggcc
tactataacc ccagcgagga 2760catccagaag atctacaaga atggcacatt
caagaagggc gatatgttta acctgaatga 2820ctgtcacaag ctgatcgact
tctttaagga tagcatctcc cggtatccaa agtggtccaa 2880tgcctacgat
ttcaactttt ctgagacaga gaagtataag gacatcgccg gcttttacag
2940agaggtggag gagcagggct ataaggtgag cttcgagtct gccagcaaga
aggaggtgga 3000taagctggtg gaggagggca agctgtatat gttccagatc
tataacaagg acttttccga 3060taagtctcac ggcacaccca atctgcacac
catgtacttc aagctgctgt ttgacgagaa 3120caatcacgga cagatcaggc
tgagcggagg agcagagctg ttcatgaggc gcgcctccct 3180gaagaaggag
gagctggtgg tgcacccagc caactcccct atcgccaaca agaatccaga
3240taatcccaag aaaaccacaa ccctgtccta cgacgtgtat aaggataaga
ggttttctga 3300ggaccagtac gagctgcaca tcccaatcgc catcaataag
tgccccaaga acatcttcaa 3360gatcaataca gaggtgcgcg tgctgctgaa
gcacgacgat aacccctatg tgatcggcat 3420cgataggggc gagcgcaatc
tgctgtatat cgtggtggtg gacggcaagg gcaacatcgt 3480ggagcagtat
tccctgaacg agatcatcaa caacttcaac ggcatcagga tcaagacaga
3540ttaccactct ctgctggaca agaaggagaa ggagaggttc gaggcccgcc
agaactggac 3600ctccatcgag aatatcaagg agctgaaggc cggctatatc
tctcaggtgg tgcacaagat 3660ctgcgagctg gtggagaagt acgatgccgt
gatcgccctg gaggacctga actctggctt 3720taagaatagc cgcgtgaagg
tggagaagca ggtgtatcag aagttcgaga agatgctgat 3780cgataagctg
aactacatgg tggacaagaa gtctaatcct tgtgcaacag gcggcgccct
3840gaagggctat cagatcacca ataagttcga gagctttaag tccatgtcta
cccagaacgg 3900cttcatcttt tacatccctg cctggctgac atccaagatc
gatccatcta ccggctttgt 3960gaacctgctg aaaaccaagt ataccagcat
cgccgattcc aagaagttca tcagctcctt 4020tgacaggatc atgtacgtgc
ccgaggagga tctgttcgag tttgccctgg actataagaa 4080cttctctcgc
acagacgccg attacatcaa gaagtggaag ctgtactcct acggcaaccg
4140gatcagaatc ttccggaatc ctaagaagaa caacgtgttc gactgggagg
aggtgtgcct 4200gaccagcgcc tataaggagc tgttcaacaa gtacggcatc
aattatcagc agggcgatat 4260cagagccctg ctgtgcgagc agtccgacaa
ggccttctac tctagcttta tggccctgat 4320gagcctgatg ctgcagatgc
ggaacagcat cacaggccgc accgacgtgg attttctgat 4380cagccctgtg
aagaactccg acggcatctt ctacgatagc cggaactatg aggcccagga
4440gaatgccatc ctgccaaaga acgccgacgc caatggcgcc tataacatcg
ccagaaaggt 4500gctgtgggcc atcggccagt tcaagaaggc cgaggacgag
aagctggata aggtgaagat 4560cgccatctct aacaaggagt ggctggagta
cgcccagacc agcgtgaagc acaaaaggcc 4620ggcggccacg aaaaaggccg
gccaggcaaa aaagaaaaag ggatcctacc catacgatgt 4680tccagattac
gcttatccct acgacgtgcc tgattatgca tacccatatg atgtccccga
4740ctatgcctaa gaattctgca gatatccagc acagtggcgg ccgctcgagt
ctagagggcc 4800cgtttaaacc cgctgatcag cctcgactgt gccttctagt
tgccagccat ctgttgtttg 4860cccctccccc gtgccttcct tgaccctgga
aggtgccact cccactgtcc tttcctaata 4920aaatgaggaa attgcatcgc
attgtctgag taggtgtcat tctattctgg ggggtggggt 4980ggggcaggac
agcaaggggg aggattggga agacaatagc aggcatgctg gggatgcggt
5040gggctctatg gcttctgagg cggaaagaac cagctggggc tctagggggt
atccccacgc 5100gccctgtagc ggcgcattaa gcgcggcggg tgtggtggtt
acgcgcagcg tgaccgctac 5160acttgccagc gccctagcgc ccgctccttt
cgctttcttc ccttcctttc tcgccacgtt 5220cgccggcttt ccccgtcaag
ctctaaatcg ggggctccct ttagggttcc gatttagtgc 5280tttacggcac
ctcgacccca aaaaacttga ttagggtgat ggttcacgta gtgggccatc
5340gccctgatag acggtttttc gccctttgac gttggagtcc acgttcttta
atagtggact 5400cttgttccaa actggaacaa cactcaaccc tatctcggtc
tattcttttg atttataagg 5460gattttgccg atttcggcct attggttaaa
aaatgagctg atttaacaaa aatttaacgc 5520gaattaattc tgtggaatgt
gtgtcagtta gggtgtggaa agtccccagg ctccccagca 5580ggcagaagta
tgcaaagcat gcatctcaat tagtcagcaa ccaggtgtgg aaagtcccca
5640ggctccccag caggcagaag tatgcaaagc atgcatctca attagtcagc
aaccatagtc 5700ccgcccctaa ctccgcccat cccgccccta actccgccca
gttccgccca ttctccgccc 5760catggctgac taattttttt tatttatgca
gaggccgagg ccgcctctgc ctctgagcta 5820ttccagaagt agtgaggagg
cttttttgga ggcctaggct tttgcaaaaa gctcccggga 5880gcttgtatat
ccattttcgg atctgatcaa gagacaggat gaggatcgtt tcgcatgatt
5940gaacaagatg gattgcacgc aggttctccg gccgcttggg tggagaggct
attcggctat 6000gactgggcac aacagacaat cggctgctct gatgccgccg
tgttccggct gtcagcgcag 6060gggcgcccgg ttctttttgt caagaccgac
ctgtccggtg ccctgaatga actgcaggac 6120gaggcagcgc ggctatcgtg
gctggccacg acgggcgttc cttgcgcagc tgtgctcgac 6180gttgtcactg
aagcgggaag ggactggctg ctattgggcg aagtgccggg gcaggatctc
6240ctgtcatctc accttgctcc tgccgagaaa gtatccatca tggctgatgc
aatgcggcgg 6300ctgcatacgc ttgatccggc tacctgccca ttcgaccacc
aagcgaaaca tcgcatcgag 6360cgagcacgta ctcggatgga agccggtctt
gtcgatcagg atgatctgga cgaagagcat 6420caggggctcg cgccagccga
actgttcgcc aggctcaagg cgcgcatgcc cgacggcgag 6480gatctcgtcg
tgacccatgg cgatgcctgc ttgccgaata tcatggtgga aaatggccgc
6540ttttctggat tcatcgactg tggccggctg ggtgtggcgg accgctatca
ggacatagcg 6600ttggctaccc gtgatattgc tgaagagctt ggcggcgaat
gggctgaccg cttcctcgtg 6660ctttacggta tcgccgctcc cgattcgcag
cgcatcgcct tctatcgcct tcttgacgag 6720ttcttctgag cgggactctg
gggttcgaaa tgaccgacca agcgacgccc aacctgccat 6780cacgagattt
cgattccacc gccgccttct atgaaaggtt gggcttcgga atcgttttcc
6840gggacgccgg ctggatgatc ctccagcgcg gggatctcat gctggagttc
ttcgcccacc 6900ccaacttgtt tattgcagct tataatggtt acaaataaag
caatagcatc acaaatttca 6960caaataaagc atttttttca ctgcattcta
gttgtggttt gtccaaactc atcaatgtat 7020cttatcatgt ctgtataccg
tcgacctcta gctagagctt ggcgtaatca tggtcatagc 7080tgtttcctgt
gtgaaattgt tatccgctca caattccaca caacatacga gccggaagca
7140taaagtgtaa agcctggggt gcctaatgag tgagctaact cacattaatt
gcgttgcgct 7200cactgcccgc tttccagtcg ggaaacctgt cgtgccagct
gcattaatga atcggccaac 7260gcgcggggag aggcggtttg cgtattgggc
gctcttccgc ttcctcgctc actgactcgc 7320tgcgctcggt cgttcggctg
cggcgagcgg tatcagctca ctcaaaggcg gtaatacggt 7380tatccacaga
atcaggggat aacgcaggaa agaacatgtg agcaaaaggc cagcaaaagg
7440ccaggaaccg taaaaaggcc gcgttgctgg cgtttttcca taggctccgc
ccccctgacg 7500agcatcacaa aaatcgacgc tcaagtcaga ggtggcgaaa
cccgacagga ctataaagat 7560accaggcgtt tccccctgga agctccctcg
tgcgctctcc tgttccgacc ctgccgctta 7620ccggatacct gtccgccttt
ctcccttcgg gaagcgtggc gctttctcat agctcacgct 7680gtaggtatct
cagttcggtg taggtcgttc gctccaagct gggctgtgtg cacgaacccc
7740ccgttcagcc cgaccgctgc gccttatccg gtaactatcg tcttgagtcc
aacccggtaa 7800gacacgactt atcgccactg gcagcagcca ctggtaacag
gattagcaga gcgaggtatg 7860taggcggtgc tacagagttc ttgaagtggt
ggcctaacta cggctacact agaagaacag 7920tatttggtat ctgcgctctg
ctgaagccag ttaccttcgg aaaaagagtt ggtagctctt 7980gatccggcaa
acaaaccacc gctggtagcg gtttttttgt ttgcaagcag cagattacgc
8040gcagaaaaaa aggatctcaa gaagatcctt tgatcttttc tacggggtct
gacgctcagt 8100ggaacgaaaa ctcacgttaa gggattttgg tcatgagatt
atcaaaaagg atcttcacct 8160agatcctttt aaattaaaaa tgaagtttta
aatcaatcta aagtatatat gagtaaactt 8220ggtctgacag ttaccaatgc
ttaatcagtg aggcacctat ctcagcgatc tgtctatttc 8280gttcatccat
agttgcctga ctccccgtcg tgtagataac tacgatacgg gagggcttac
8340catctggccc cagtgctgca atgataccgc gagacccacg ctcaccggct
ccagatttat 8400cagcaataaa ccagccagcc ggaagggccg agcgcagaag
tggtcctgca actttatccg 8460cctccatcca gtctattaat tgttgccggg
aagctagagt aagtagttcg ccagttaata 8520gtttgcgcaa cgttgttgcc
attgctacag gcatcgtggt gtcacgctcg tcgtttggta 8580tggcttcatt
cagctccggt tcccaacgat caaggcgagt tacatgatcc cccatgttgt
8640gcaaaaaagc ggttagctcc ttcggtcctc cgatcgttgt cagaagtaag
ttggccgcag 8700tgttatcact catggttatg gcagcactgc ataattctct
tactgtcatg ccatccgtaa 8760gatgcttttc tgtgactggt gagtactcaa
ccaagtcatt ctgagaatag tgtatgcggc 8820gaccgagttg ctcttgcccg
gcgtcaatac gggataatac cgcgccacat agcagaactt 8880taaaagtgct
catcattgga aaacgttctt cggggcgaaa actctcaagg atcttaccgc
8940tgttgagatc cagttcgatg taacccactc gtgcacccaa ctgatcttca
gcatctttta 9000ctttcaccag cgtttctggg tgagcaaaaa caggaaggca
aaatgccgca aaaaagggaa 9060taagggcgac acggaaatgt tgaatactca
tactcttcct ttttcaatat tattgaagca 9120tttatcaggg ttattgtctc
atgagcggat acatatttga atgtatttag aaaaataaac 9180aaataggggt
tccgcgcaca tttccccgaa aagtgccacc tgacgtc 9227
D00000
D00001
D00002
D00003
D00004
D00005
S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.