Chemical Ligation Dependent Probe Amplification (clpa)
Terbrueggen; Robert
U.S. patent application number 15/985282 was filed with the patent office on 2019-04-11 for chemical ligation dependent probe amplification (clpa). The applicant listed for this patent is DXTERITY DIAGNOSTICS INCORPORATED. Invention is credited to Robert Terbrueggen.
| Application Number | 20190106739 15/985282 |
| Document ID | / |
| Family ID | 42828614 |
| Filed Date | 2019-04-11 |









| United States Patent Application | 20190106739 |
| Kind Code | A1 |
| Terbrueggen; Robert | April 11, 2019 |
CHEMICAL LIGATION DEPENDENT PROBE AMPLIFICATION (CLPA)
Abstract
The present invention provides compositions, apparatuses and methods for detecting one or more nucleic acid targets present in a sample. Methods of the invention include utilizing two or more oligonucleotide probes that reversibly bind a target nucleic acid in close proximity to each other and possess complementary reactive ligation moieties. When such probes have bound to the target in the proper orientation, they are able to undergo a spontaneous chemical ligation reaction that yields a ligated oligonucleotide product. In one aspect, the ligation product is of variable length that correlates with a particular target. Following chemical ligation, the probes may be amplified and detected by capillary electrophoresis or microarray analysis.
| Inventors: | Terbrueggen; Robert; (Manhattan Beach, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 42828614 | ||||||||||
| Appl. No.: | 15/985282 | ||||||||||
| Filed: | May 21, 2018 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 12798108 | Mar 29, 2010 | 9976177 | ||
| 15985282 | ||||
| 61165839 | Apr 1, 2009 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | C12Q 1/6855 20130101; C12Q 1/6862 20130101; C12Q 2525/155 20130101; C12Q 1/6855 20130101; C12Q 2525/204 20130101; C12Q 2525/155 20130101; C12Q 2525/204 20130101; C12Q 2523/109 20130101; C12Q 2523/109 20130101; C12Q 2525/15 20130101; C12Q 1/6862 20130101 |
| International Class: | C12Q 1/6855 20060101 C12Q001/6855; C12Q 1/6862 20060101 C12Q001/6862 |
Claims
1. A method for detecting in a sample, comprising a plurality of sample nucleic acids of different sequence, the presence of at least one specific target nucleic acid sequence comprising a first and a second target domain, the domains located essentially adjacent to one another, comprising the steps of: a) contacting the sample nucleic acids with a plurality of different probes sets, each probe set comprising i. a first ligation probe comprising: 1) a first probe domain substantially complementary to said first target domain; and 2) a first non-complementary region being essentially non-complementary to the said target nucleic acid 3) a 5'-ligation moiety; and ii. second ligation probe comprising: 1) a second probe domain substantially complementary to said second target domain; 2) a second non-complementary region, being essentially non-complementary to the said target nucleic acid 3) a 3' ligation moiety; wherein at least one of said ligation probe comprises a variable spacer sequence; and b) ligating said first and second ligation probes in the absence of a ligase enzyme to form a ligation product; c) amplifying said ligation product; and d) detecting the presence of said ligation product.
2. A method of claim 1 wherein said target sequence is RNA and/or DNA.
3. A method of claim 1 wherein said target sequence comprises unpurified RNA
4. The method of claim 1 wherein said sample is derived from a mammalian body selected from the group consisting of blood, urine, saliva and feces.
5.-7. (canceled)
8. A method as in claim 1 wherein said step of detection is by mass spectrometry.
9. The method of claim 1 wherein said 5' ligation moiety on said first ligation probe is DAB SYL moiety and said 3' ligation moiety on said second ligation probe is 3-phophorothioate moiety.
10. A method as in claim 1 wherein said first and second ligation probes each further comprising a universal primer sequence for amplification of said ligation product.
11. The method of claim 10 wherein one of the universal primers that binds said primer sequence contains a detectable label.
12. (canceled)
13. (canceled)
14. A method for detecting in a sample, comprising a plurality of sample nucleic acids of different sequence, the presence of at least one specific target nucleic acid sequence comprising a first and a second target domain, the domains located essentially adjacent to one another, comprising the steps of: a) Contacting the sample nucleic acids with a plurality of different probes sets, each probe set comprising i) a first ligation probe comprising: 1) a first probe domain substantially complementary to said first target domain; and 2) a first non-complementary region being essentially non-complementary to the said target nucleic acid 3) a 5'-ligation moiety; and ii) second ligation probe comprising: 1) a second probe domain substantially complementary to said second target domain; 2) a second non-complementary region, being essentially non-complementary to the said target nucleic acid; and 3) a 3' ligation moiety; wherein at least one of said first and second ligation probes further comprises an anchor sequence b) capturing said ligation product on a microarray substrate comprising a capture probe substantially complementary to said anchor sequence; and c) detecting the presence of said ligated product.
15. A method as in claim 14 wherein said first and second ligation probes each further comprising a universal primer sequence for amplification of said ligation product wherein one of the universal primers that binds said primer sequence contains a detectable label wherein said detectable label is selected from the group consisting of a fluorescent label, an electrochemical label and a magnetic label.
16. A method for detecting in a sample, comprising a plurality of sample nucleic acids of different sequence, the presence of at least one specific target nucleic acid sequence comprising a first and a second target domain, and a third domain located between the first and second domains, the domains located essentially adjacent to one another, comprising the steps of: b) contacting the sample nucleic acids with a plurality of different probes sets, each probe set comprising i. a first ligation probe comprising: 1) a first probe domain substantially complementary to said first target domain; and 2) a first non-complementary region being essentially non-complementary to the said target nucleic acid 3) a 5'-ligation moiety; and ii. second ligation probe comprising: 1) a second probe domain substantially complementary to said second target domain; 2) a second non-complementary region, being essentially non-complementary to the said target nucleic acid 3) a 3' ligation moiety; iii. a third ligation probe comprising 1) a third probe domain substantially complementary to the said third target domain 2) a 3' and a 5' ligation moiety; b) ligating said first ligation probe, said second ligation probe, and said third ligation probe in the absence of a ligase enzyme to form a ligation product; c) amplifying said ligation product; and c) detecting the presence of said ligated product.
17. A method of claim 16 wherein said target sequence is RNA and/or DNA.
18. The method of claim 16 wherein said sample is derived from a mammalian body selected from the group consisting of blood, urine, saliva and feces.
19.22. (canceled)
23. A method as in claim 16 wherein said first and second ligation probes each further comprising a universal primer sequence for amplification of said ligation product.
24. The method of claim 16 wherein one of the universal primers that binds said primer sequence contains a detectable label.
25.-31. (canceled)
Description
CROSS REFERENCE TO RELATED APPLICATIONS
[0001] This application is a Continuation of U.S. patent application Ser. No. 12/798,108 filed Mar. 29, 2010, which claims priority from U.S. Provisional Application No. 61/165,839, filed Apr. 1, 2009, the disclosures of which are incorporated by this reference as though set forth fully herein.
REFERENCE TO SEQUENCE LISTING SUBMITTED ELECTRONICALLY
[0002] The sequence listing contained in the file named 068433-5002-US01_ST25", created on May 21, 2018, and having a size of 8.77 kilobytes, has been submitted electronically herewith via EFS-Web, and the contents of the txt file are hereby incorporated by reference in their entirety.
FIELD OF THE INVENTION
[0003] This invention relates to compositions and methods for detecting nucleic acids in a sample using chemical ligation.
BACKGROUND OF THE INVENTION
[0004] This invention relates to compositions, apparatus and methods for detecting one or more nucleic acid targets present in a sample. The detection of specific nucleic acids is an important tool for diagnostic medicine and molecular biology research.
[0005] Gene probe assays currently play roles in identifying infectious organisms such as bacteria and viruses, in probing the expression of normal and mutant genes and identifying genes associated with disease or injury, such as oncogenes, in typing tissue for compatibility preceding tissue transplantation, in matching tissue or blood samples for forensic medicine, for responding to emergency response situations like a nuclear incident or pandemic flu outbreak, in determining disease prognosis or causation, and for exploring homology among genes from different species.
[0006] Ideally, a gene probe assay should be sensitive, specific and easily automatable (for a review, see Nickerson, Current Opinion in Biotechnology (1993) 4:48-51.) The requirement for sensitivity (i.e. low detection limits) has been greatly alleviated by the development of the polymerase chain reaction (PCR) and other amplification technologies which allow researchers to exponentially amplify a specific nucleic acid sequence before analysis (for a review, see Abramson et al., Current Opinion in Biotechnology, (1993) 4:41-47). For example, multiplex PCR amplification of SNP loci with subsequent hybridization to oligonucleotide arrays has been shown to be an accurate and reliable method of simultaneously genotyping hundreds of SNPs (see Wang et al., Science, (1998) 280:1077; see also Schafer et al., Nature Biotechnology, (1989)16:33-39).
[0007] Specificity also remains a problem in many currently available gene probe assays. The extent of molecular complementarity between probe and target defines the specificity of the interaction. Variations in composition and concentrations of probes, targets and salts in the hybridization reaction as well as the reaction temperature, and length of the probe may all alter the specificity of the probe/target interaction.
[0008] It may be possible under some circumstances to distinguish targets with perfect complementarity from targets with mismatches, although this is generally very difficult using traditional technology, since small variations in the reaction conditions will alter the hybridization. Newer techniques with the necessary specificity for mismatch detection include probe digestion assays in which mismatches create sites for probe cleavage, and DNA ligation assays where single point mismatches prevent ligation.
[0009] A variety of enzymatic and non-enzymatic methods are available for detecting sequence variations. Examples of enzyme based methods include Invader.TM., oligonucleotide ligation assay (OLA) single base extension methods, allelic PCR, and competitive probe analysis (e.g. competitive sequencing by hybridization). Enzymatic DNA ligation reactions are well known in the art (Landegren, Bioessays (1993) 15(11):761-5; Pritchard et al., Nucleic Acids Res. (1997) 25(17):3403-7; Wu et al., Genomics, (1989) 4(4):560-9) and have been used extensively in SNP detection, enzymatic amplification reactions and DNA repair.
[0010] A number of non-enzymatic or template mediated chemical ligation methods have been developed that can be used to detect sequence variations. These include chemical ligation methods that utilize coupling reagents, such as N-cyanoimidazole, cyanogen bromide, and 1-ethyl-3-(3-dimethylaminopropyl)-carbodiimide hydrochloride. See Metelev, V. G., et al., Nucleosides & Nucleotides (1999) 18:2711; Luebke, K. J., and Dervan, P. B. J. Am. Chem. Soc. (1989) 111:8733; and Shabarova, Z. A., et al., Nucleic Acids Research (1991)19:4247, each of which is incorporated herein by reference in its entirety.
[0011] Kool (U.S. Pat. No 7,033,753), which is incorporated herein by reference in its entirety describes the use of chemical ligation and fluorescence resonance energy transfer (FRET) to detect genetic polymorphisms. The readout in this process is based on the solution phase change in fluorescent intensity.
[0012] Terbrueggen (U.S. Patent application 60/746,897) which is incorporated herein by reference in its entirety describes the use of chemical ligation methods, compositions and reagents for the detection of nucleic acids via microarray detection.
[0013] Other chemical ligation methods react a 5'-tosylate or 5'-iodo group with a 3'-phosphorothioate group, resulting in a DNA structure with a sulfur replacing one of the bridging phosphodiester oxygen atoms. See Gryanov, S. M., and Letsinger, R. L., Nucleic Acids Research (1993) 21:1403; Xu, Y. and Kool, E. T. Tetrahedron Letters (1997) 38:5595; and Xu, Y. and Kool, E. T., Nucleic Acids Research (1999) 27:875, each of which is herein incorporated by reference in its entirety.
[0014] Some of the advantages of using non-enzymatic approaches for nucleic acid target detection include lower sensitivity to non-natural DNA analog structures, ability to use RNA target sequences, lower cost and greater robustness under varied conditions. Letsinger et al (U.S. Pat. No. 5,780,613, herein incorporated by reference in its entirety) have previously described an irreversible, nonenzymatic, covalent autoligation of adjacent, template-bound oligonucleotides wherein one oligonucleotide has a 5' displaceable group and the other oligonucleotide has a 3' thiophosphoryl group.
[0015] PCT applications WO 95/15971, PCT/US96/09769, PCT/US97/09739, PCT US99/01705, WO96/40712 and WO98/20162, all of which are expressly incorporated herein by reference in their entirety, describe novel compositions comprising nucleic acids containing electron transfer moieties, including electrodes, which allow for novel detection methods of nucleic acid hybridization.
[0016] One technology that has gained increased prominence involves the use of DNA arrays (Marshall et al., Nat Biotechnol. (1998) 16(1):27-31), especially for applications involving simultaneous measurement of numerous nucleic acid targets. DNA arrays are most often used for gene expression monitoring where the relative concentration of 1 to 100,000 nucleic acids targets (mRNA) is measured simultaneously. DNA arrays are small devices in which nucleic acid anchor probes are attached to a surface in a pattern that is distinct and known at the time of manufacture (Marshall et al., Nat Biotechnol. (1998) 16(1):27-31) or can be accurately deciphered at a later time such as is the case for bead arrays (Steemers et al., Nat Biotechnol. (2000) 18(1):91-4; and Yang et al., Genome Res. (2001) 11(11):1888-98.). After a series of upstream processing steps, the sample of interest is brought into contact with the DNA array, the nucleic acid targets in the sample hybridize to anchor oligonucleotides on the surface, and the identity and often concentration of the target nucleic acids in the sample are determined.
[0017] Many of the nucleic acid detection methods in current use have characteristics and/or limitations that hinder their broad applicability. For example, in the case of DNA microarrays, prior to bringing a sample into contact with the microarray, there are usually a series of processing steps that must be performed on the sample. While these steps vary depending upon the manufacturer of the array and/or the technology that is used to read the array (fluorescence, electrochemistry, chemiluminescence, magnetoresistance, cantilever deflection, surface plasmon resonance), these processing steps usually fall into some general categories: Nucleic acid isolation and purification, enzymatic amplification, detectable label incorporation, and clean up post-amplification. Other common steps are sample concentration, amplified target fragmentation so as to reduce the average size of the nucleic acid target, and exonuclease digestion to convert PCR amplified targets to a single stranded species.
[0018] The requirement of many upstream processing steps prior to contacting the DNA array with the sample can significantly increase the time and cost of detecting a nucleic acid target(s) by these methods. It can also have significant implications on the quality of the data obtained. For instance, some amplification procedures are very sensitive to target degradation and perform poorly if the input nucleic acid material is not well preserved (Foss et al., Diagn Mol Pathol. (1994) 3(3):148-55). Technologies that can eliminate or reduce the number and/or complexity of the upstream processing steps could significantly reduce the cost and improve the quality of results obtained from a DNA array test. One method for reducing upstream processing steps involves using ligation reactions to increase signal strength and improve specificity.
[0019] There remains a need for methods and compositions for efficient and specific nucleic acid detection. Accordingly, the present invention provides methods and compositions for non-enzymatic chemical ligation reactions which provides very rapid target detection and greatly simplified processes of detecting and measuring nucleic acid targets.
SUMMARY OF THE INVENTION
[0020] Accordingly, in one aspect, the invention relates to a method comprising providing a ligation substrate comprising a target nucleic acid sequence comprising at least a first target domain and a second target domain, and a first and second ligation probe. The ligation probes may comprise a stuffer sequence of variable length and/or sequence. The first ligation probe comprises a first probe domain substantially complementary to the first target domain, and a 5'-ligation moiety. The second ligation probe comprises a second probe domain substantially complementary to the second target domain, and a 3' ligation moiety. Optionally, the first target domain and the second target domain are separated by at least one nucleotide. Optionally, at least one of the first and said second ligation probes comprises an anchor sequence and/or a label, including a label probe binding sequence. The first and second ligation probes are ligated in the absence of exogeneously added ligase enzyme to form a ligation product. The ligated product may optionally be captured on a substrate comprising a capture probe substantially complementary to said anchor sequence and detected. The ligation product may be amplified and detected by capillary electrophoresis, microarray analysis, or any other suitable method.
BRIEF DESCRIPTION OF THE DRAWINGS
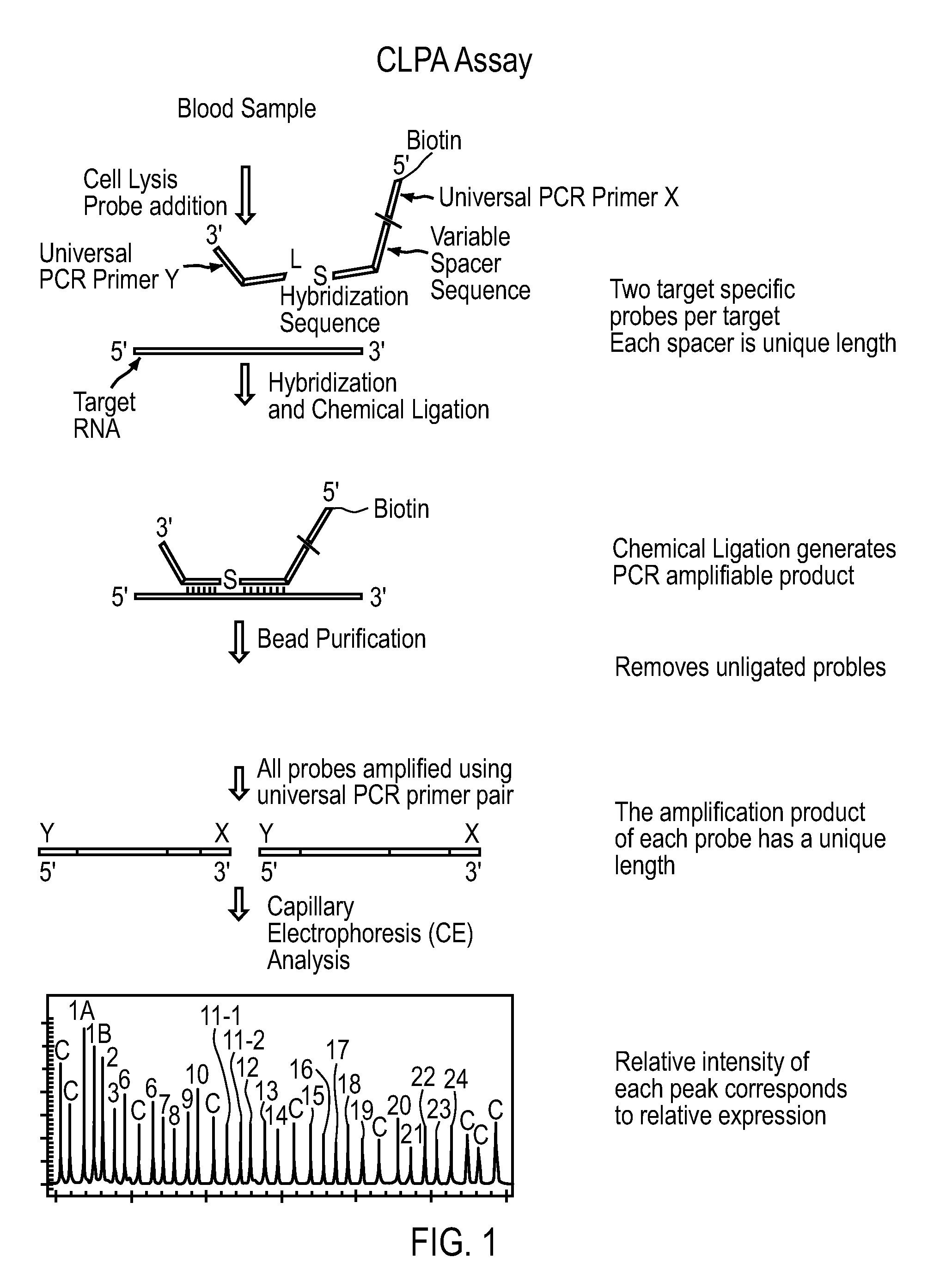
[0021] FIG. 1. Schematic representation of one embodiment of CLPA-CE assay.
[0022] FIG. 2. Schematic representation of one embodiment of CLPA-MDM assay.
[0023] FIG. 3. Schematic representation showing one embodiment of the 2-probe and the 3-probe CLPA reaction.
[0024] FIG. 4. Schematic Representation of a DNA synthesis resin that can be used to manufacture DNA with a 3'-DABSYL leaving group
[0025] FIG. 5. Schematic Representation on the process flow for one embodiment of the CLPA-CE assay
[0026] FIG. 6. Schematic chart showing probe design for CLPA assay in which is incorporated a size-variant stuffer sequence.
[0027] FIG. 7. Electrophoretic separation profile on sample analyzed by CLPA-CE.
[0028] FIG. 8. Linear relationship between target concentration and peak height in CLPA-CE analysis.
DETAILED DESCRIPTION OF THE INVENTION
[0029] The practice of the present invention may employ, unless otherwise indicated, conventional techniques and descriptions of organic chemistry, polymer technology, molecular biology (including recombinant techniques), cell biology, biochemistry, and immunology, which are within the skill of the art. Such conventional techniques include polymer array synthesis, hybridization, ligation, and detection of hybridization using a label. Specific illustrations of suitable techniques can be had by reference to the example herein below. However, other equivalent conventional procedures can also be used. Such conventional techniques and descriptions can be found in standard laboratory manuals such as Genome Analysis: A Laboratory Manual Series (Vols. I-IV), Using Antibodies: A Laboratory Manual, Cells: A Laboratory Manual, PCR Primer: A Laboratory Manual, and Molecular Cloning: A Laboratory Manual (all from Cold Spring Harbor Laboratory Press), Stryer, L. (1995) Biochemistry (4th Ed.) Freeman, New York, Gait, "Oligonucleotide Synthesis: A Practical Approach" 1984, IRL Press, London, Nelson and Cox (2000), Lehninger, Principles of Biochemistry 3rd Ed., W. H. Freeman Pub., New York, N.Y. and Berg et al. (2002) Biochemistry, 5.sup.th Ed., W. H. Freeman Pub., New York, N.Y., all of which are hereby incorporated in their entirety by reference for all purposes. Furthermore, all references cited in this application are herein incorporated in their entirety by reference for all purposes.
Overview
[0030] The invention provides compositions, apparatus and methods for the detection of one or more nucleic acid targets in a sample including DNA and RNA targets. Moreover, the sample need not be purified. Indeed, one aspect of the invention relates to analyzing impure samples including body samples such as, but not limited to, whole blood. The invention provides methods utilizing two or more oligonucleotide probes that reversibly bind a target nucleic acid in close proximity to each other and possess complementary reactive ligation moieties (it should be noted, as is further described herein, that the reactive moieties are referred to herein as "ligation moieties"). When the probes have bound the target in the proper orientation, they are able to undergo a spontaneous chemical ligation reaction that yields a ligated oligonucleotide product. Following ligation, a new product is generated that can be amplified by an enzymatic or chemical reaction. In the preferred embodiment, the chemical ligation reaction joins two probes that have PCR primer sites on them, e.g. universal PCR primers. Additionally, in one embodiment of the invention, one or both ligation probes contain a stuffer sequence, or variable spacer sequence, which is designed to have differing lengths for each probe set (i.e. each target sequence) thereby resulting in a ligation product having a target-specific length. Following ligation a defined length oligonucleotide can now be exponentially amplified by PCR. In accordance with one aspect of the invention, the probes can possess detectable labels (fluorescent labels, electrochemical labels, magnetic beads, nanoparticles, biotin) to aid in the identification, purification, quantification or detection of the ligated oligonucleotide product. The probes may also optionally include in their structure: anchoring oligonucleotide sequences designed for subsequent capture on a solid support (microarrays, microbeads, nanoparticles), molecule handles that promote the concentration or manipulation of the ligated product (magnetic particles, oligonucleotide coding sequences), and promoter sequences to facilitate subsequent secondary amplification of the ligated product via an enzyme like a DNA or RNA polymerase. The ligation reactions of the invention proceed rapidly, are specific for the target(s) of interest, and can produce multiple copies of the ligated product for each target(s), resulting in an amplification (sometimes referred to herein as "product turnover") of the detectable signal. The ligation reactions of the invention do not require the presence of exogeneously added ligases, nor additional enzymes, although some secondary reactions may rely on the use of enzymes such as polymerases, as described below. Ligation chemistries can be chosen from many of the previously described chemical moieties. Preferred chemistries are ones that can be easily incorporated into routine manufacture techniques, are stable during storage, and demonstrate a large preference for target specific ligation when incorporated into a properly designed ligation probe set. Additionally, for embodiments which involve subsequent amplification by an enzyme, ligation chemistries and probe designs (including unnatural nucleotide analogs) that result in a ligation product that can be efficiently processed by an enzyme are preferred. Amplification of the target may also include turnover of the ligation product, in which the ligation product has a lower or comparable affinity for the template or target nucleic acid than do the separate ligation probes. Thus, upon ligation of the hybridized probes, the ligation product is released from the target, freeing the target to serve as a template for a new ligation reaction.
[0031] In one embodiment, the ligation reactions of the invention include transfer reactions. In this embodiment, the probes hybridize to the target sequence, but rather than oligonucleotide probes being ligated together to form a ligation product, a nucleic acid-directed transfer of a molecular entity (including reporter molecules such as fluorophores, quenchers, etc) from one oligonucleotide probe to other occurs. This transfer reaction is analogous to a ligation reaction, however instead of joining of two or more probes, one of the probes is ligated to the transfer molecule and the other probe is the "leaving group" of the chemical reaction. We use the term "transfer" reaction so as to distinguish between the different nature of the resulting final product. Importantly, similar to the ligation reaction, the transfer reaction is facilitated by the proximal binding of the transfer probes onto a nucleic acid target, such that significant signal is detected only if the probes have hybridized to the target nucleic acid in close enough proximity to one another (e.g., at adjacent sites) for the transfer reaction to take place.
[0032] Samples
[0033] Accordingly, in one aspect the present invention provides compositions and methods for detecting the presence or absence of target sequences in samples. As will be appreciated by those in the art, the sample solution may comprise any number of things, including, but not limited to, bodily fluids (including, but not limited to, blood, urine, serum, lymph, saliva, anal and vaginal secretions, perspiration and semen, of virtually any organism, with mammalian samples being preferred and human samples being particularly preferred); environmental samples (including, but not limited to, air, agricultural, water and soil samples); plant materials; biological warfare agent samples; research samples (for example, the sample may be the product of an amplification reaction, for example general amplification of genomic DNA); purified samples, such as purified genomic DNA, RNA, proteins, etc.; raw samples (bacteria, virus, genomic DNA, etc.); as will be appreciated by those in the art, virtually any experimental manipulation may have been done on the sample. Some embodiments utilize siRNA and microRNA as target sequences (Zhang et al., J Cell Physiol. (2007) 210(2):279-89; Osada et al., Carcinogenesis. (2007) 28(1):2-12; and Mattes et al., Am J Respir Cell Mol Biol. (2007) 36(1):8-12, each of which is incorporated herein by reference in its entirety).
[0034] Some embodiments of the invention utilize nucleic acid samples from stored (e.g. frozen and/or archived) or fresh tissues. Paraffin-embedded samples are of particular use in many embodiments, as these samples can be very useful, due to the presence of additional data associated with the samples, such as diagnosis and prognosis. Fixed and paraffin-embedded tissue samples as described herein refers to storable or archival tissue samples. Most patient-derived pathological samples are routinely fixed and paraffin-embedded to allow for histological analysis and subsequent archival storage. Such samples are often not useful for traditional methods of nucleic acid detection, because such studies require a high integrity of the nucleic acid sample so that an accurate measure of nucleic acid expression can be made. Often, gene expression studies in paraffin-embedded samples are limited to qualitative monitoring by using immunohistochemical staining to monitor protein expression levels.
[0035] Methods and compositions of the present invention are useful in detection of nucleic acids from paraffin-embedded samples, because the process of fixing and embedding in paraffin often results in degradation of the samples' nucleic acids. The present invention is able to amplify and detect even degraded samples, such as those found in paraffin-embedded samples.
[0036] A number of techniques exist for the purification of nucleic acids from fixed paraffin-embedded samples as described in WO 2007/133703 the entire contents of which is herein incorporated by reference.
[0037] In a preferred embodiment, the target analytes are nucleic acids. By "nucleic acid" or "oligonucleotide" or grammatical equivalents herein means at least two nucleotides covalently linked together. A nucleic acid of the present invention will generally contain phosphodiester bonds (for example in the case of the target sequences), although in some cases, as outlined below, nucleic acid analogs are included that may have alternate backbones (particularly for use with the ligation probes), comprising, for example, phosphoramide (Beaucage et al., Tetrahedron (1993) 49(10):1925 and references therein; Letsinger, J. Org. Chem. (1970) 35:3800; Sprinzl et al., Eur. J. Biochem. (1977) 81:579; Letsinger et al., Nucl. Acids Res. (1986) 14:3487; Sawai et al, Chem. Lett. (1984) 805; Letsinger et al., J. Am. Chem. Soc. (1988) 110:4470; and Pauwels et al., Chemica Scripta (1986) 26:141), phosphorothioate (Mag et al., Nucleic Acids Res. (1991) 19:1437; and U.S. Pat. No. 5,644,048), phosphorodithioate (Briu et al., J. Am. Chem. Soc. (1989) 111:2321, O-methylphophoroamidite linkages (see Eckstein, Oligonucleotides and Analogues: A Practical Approach, Oxford University Press), and peptide nucleic acid backbones and linkages (see Egholm, J. Am. Chem. Soc. (1992)114:1895; Meier et al., Chem. Int. Ed. Engl. (1992) 31:1008; Nielsen, Nature, (1993) 365:566; Carlsson et al., Nature (1996) 380:207, all of which are incorporated herein by reference in their entirety). Other analog nucleic acids include those with bicyclic structures including locked nucleic acids, Koshkin et al., J. Am. Chem. Soc. (1998) 120:13252 3); positive backbones (Denpcy et al., Proc. Natl. Acad. Sci. USA (1995) 92:6097; non-ionic backbones (U.S. Pat. Nos. 5,386,023, 5,637,684, 5,602,240, 5,216,141 and 4,469,863; Kiedrowshi et al., Angew. Chem. Intl. Ed. English (1991) 30:423; Letsinger et al., J. Am. Chem. Soc. (1988) 110:4470; Letsinger et al., Nucleoside & Nucleotide (1994) 13:1597; Chapters 2 and 3, ASC Symposium Series 580, Ed. Y. S. Sanghui and P. Dan Cook; Mesmaeker et al., Bioorganic & Medicinal Chem. Lett. (1994) 4:395 ; Jeffs et al., J. Biomolecular NMR (1994) 34:17; Xu et al., Tetrahedron Lett. (1996) 37:743) and non-ribose backbones, including those described in U.S. Pat. Nos. 5,235,033 and 5,034,506, and Chapters 6 and 7, ASC Symposium Series 580, Ed. Y. S. Sanghui and P. Dan Cook. Nucleic acids containing one or more carbocyclic sugars are also included within the definition of nucleic acids (see Jenkins et al., Chem. Soc. Rev. (1995) pp 169-176). Several nucleic acid analogs are described in Rawls, C & E News Jun. 2, 1997 page 35. All of these references are herein expressly incorporated by reference. These modifications of the ribose-phosphate backbone may be done to facilitate the addition of labels or other moieties, to increase or decrease the stability and half-life of such molecules in physiological environments, etc.
[0038] As will be appreciated by those in the art, all of these nucleic acid analogs may find use in the present invention. In addition, mixtures of naturally occurring nucleic acids and analogs can be made; for example, at the site of a ligation moiety, an analog structure may be used. Alternatively, mixtures of different nucleic acid analogs, and mixtures of naturally occurring nucleic acids and analogs may be made.
[0039] Nucleic acid analogue may include, for example, peptide nucleic acid (PNA, WO 92/20702, incorporated herein by reference in its entirety) and Locked Nucleic Acid (LNA, Koshkin A A et al. Tetrahedron (1998) 54:3607-3630., Koshkin A A et al. J. Am. Chem. Soc. (1998) 120:13252-13253., Wahlestedt C et al. PNAS (2000) 97:5633-5638, each of which is incorporated herein by reference in its entirety). In some applications analogue backbones of this type may exhibit improved hybridization kinetics, improved thermal stability and improved sensitivity to mismatch sequences.
[0040] The nucleic acids may be single stranded or double stranded, as specified, or contain portions of both double stranded or single stranded sequences. The nucleic acid may be DNA, both genomic and cDNA, RNA or a hybrid, where the nucleic acid contains any combination of deoxyribo- and ribo-nucleotides, and any combination of bases, including naturally occurring nucleobases (uracil, adenine, thymine, cytosine, guanine) and non-naturally occurring nucleobases (inosine, xathanine hypoxathanine, isocytosine, isoguanine, 5-methylcytosine, pseudoisocytosine, 2-thiouracil and 2-thiothymine, 2-aminopurine, N9-(2-amino-6-chloropurine), N9-(2,6-diaminopurine), hypoxanthine, N9-(7-deaza-guanine), N9-(7-deaza-8-aza-guanine) and N8-(7-deaza-8-aza-adenine). 5-propynyl-uracil, 2-thio-5-propynyl-uracil) etc. As used herein, the term "nucleobase" includes both "nucleosides" and "nucleotides", and monomers of nucleic acid analogs. Thus, for example, the individual units of a peptide nucleic acid, each containing a base, are referred to herein as a nucleobase.
[0041] In one aspect, ligation probes of the invention are any polymeric species that is capable of interacting with a nucleic acid target(s) in a sequence specific manner and possess chemical moieties allowing the probes to undergo a spontaneous chemical ligation reaction with another polymeric species possessing complementary chemical moieties. In one embodiment, the oligonucleotide probes can be DNA, RNA, PNA, LNA, modified versions of the aforementioned and/or any hybrids of the same (e.g. DNA/RNA hybrids, DNA/LNA hybrids, DNA/PNA hybrids). In a preferred embodiment, the oligonucleotide probes are DNA or RNA oligonucleotides.
[0042] Nucleic acid samples (e.g. target sequences) that do not exist in a single-stranded state in the region of the target sequence(s) are generally rendered single-stranded in such region(s) prior to detection or hybridization. Generally, nucleic acid samples can be rendered single-stranded in the region of the target sequence using heat denaturation. For polynucleotides obtained via amplification, methods suitable for generating single-stranded amplification products are preferred. Non-limiting examples of amplification processes suitable for generating single-stranded amplification product polynucleotides include, but are not limited to, T7 RNA polymerase run-off transcription, RCA, Asymmetric PCR (Bachmann et al., Nucleic Acid Res. (1990) 18:1309), and Asynchronous PCR (WO 01/94638). Commonly known methods for rendering regions of double-stranded polynucleotides single stranded, such as the use of PNA openers (U.S. Pat. No. 6,265,166), may also be used to generate single-stranded target sequences on a polynucleotide.
[0043] In one aspect, the invention provides methods of detecting target sequences. By "target sequence" or "target nucleic acid" or grammatical equivalents herein means a nucleic acid sequence on a single strand of nucleic acid. The target sequence may be a portion of a gene, a regulatory sequence, genomic DNA, cDNA, RNA including mRNA, MicroRNA and rRNA, or others. As is outlined herein, the target sequence may be a target sequence from a sample, or a secondary target such as a product of an amplification reaction, etc. It may be any length, with the understanding that longer sequences are more specific. As will be appreciated by those in the art, the complementary target sequence may take many forms. For example, it may be contained within a larger nucleic acid sequence, i.e. all or part of a gene or mRNA, a restriction fragment of a plasmid or genomic DNA, among others.
[0044] In some embodiments, the target sequence is comprised of different types of target domain. For example, a first target domain of the sample target sequence may hybridize to a first ligation probe, and a second target domain in the target sequence may hybridize to a second ligation probe. Other target domains may hybridize to a capture probe on a substrate such as an array, or a label probe, etc..
[0045] The target domains may be adjacent or separated as indicated, as is more fully described below. In some cases, when detection is based on ligation and the application requires amplification of signal, the ligation probes may utilize linkers and be separated by one or more nucleobases of the target sequence to confer hybridization instability on the ligated product. In other applications, for example in single nucleotide polymorphism (SNP) detection, or in transfer reactions, the ligation probes may hybridize to adjacent nucleobases of the target sequence. Unless specified, the terms "first" and "second" are not meant to confer an orientation of the sequences with respect to the 5'-3' orientation of the target sequence. For example, assuming a 5'-3' orientation of the complementary target sequence, the first target domain may be located either 5' to the second domain, or 3' to the second domain. For ease of reference and not to be limiting, these domains are sometimes referred to as "upstream" and "downstream", with the normal convention being the target sequence being displayed in a 5' to 3' orientation
[0046] The probes are designed such that when the probes bind to a part of the target polynucleotide in close spatial proximity, a chemical ligation reaction occurs between the probes. In general, the probes comprise chemically reactive moieties (herein generally referred to as "ligation moieties") and bind to the target polynucleotide in a particular orientation, such that the chemically reactive moieties come into close spatial proximity, thus resulting in a spontaneous ligation reaction.
[0047] Probe Components
[0048] In one embodiment, the invention provides sets of ligation probes, usually a first and a second ligation probe, although as is described herein some embodiments utilize more than two. In addition, as noted herein, in some cases a transfer reaction is done rather than ligation; "ligation probes" includes "transfer probes". Each ligation probe comprises a nucleic acid portion, sometimes referred to herein as a "probe domain" that is substantially complementary to one of the target domains. Probes of the present invention are designed to be complementary to a target sequence such that hybridization of the target sequence and the probes of the present invention occurs. As outlined herein, this complementarity need not be perfect; there may be any number of base pair mismatches which will interfere with hybridization between the target sequence and the probes of the present invention. However, if the number of mutations is so great that no hybridization can occur under even the least stringent of hybridization conditions, the sequence is not a complementary sequence. Thus, by "substantially complementary" herein is meant that the probes are sufficiently complementary to the target sequences to hybridize under normal reaction conditions. "Identical" sequences are those that over the length of the shorter sequence of nucleobases, perfect complementarity exists.
[0049] In one aspect of the invention, the length of the probe is designed to vary with the length of the target sequence, the specificity required, the reaction (e.g. ligation or transfer) and the hybridization and wash conditions. Generally, in this aspect ligation probes range from about 5 to about 150 nucleobases, with from about 15 to about 100 being preferred and from about 25 to about 75 being especially preferred. In general, these lengths apply equally to ligation and transfer probes.
[0050] In another embodiment of the invention, referred to herein as "CLPA-CE" which is described more fully below, probe length is designed to vary for each target of interest thereby generating ligation products that can be identified and analyzed based on length variance.
[0051] A variety of hybridization conditions may be used in the present invention, including high, moderate and low stringency conditions; see for example Maniatis et al., Molecular Cloning: A Laboratory Manual, 2d Edition, 1989, and Ausubel, et al, Short Protocols in Molecular Biology, herein incorporated by reference. The hybridization conditions may also vary when a non-ionic backbone, e.g. PNA is used, as is known in the art.
Ligation Moieties
[0052] In addition to ligation domains, the ligation probes of the invention have ligation moieties. Accordingly, in one aspect, the invention relates to methods of chemical ligation that include the binding of at least a first and a second ligation probe to the target nucleic acid to form a "ligation substrate" under conditions such that the ligation moieties of the first and second ligation probes are able to spontaneously react, ligating the probes together, in the absence of exogenous ligase; that is, no exogenous ligase is added to the reaction. In the case of the transfer reaction, this may be referred to as either a "ligation substrate" or a "transfer substrate". By "ligation substrate" herein is meant a substrate for chemical ligation comprising at least one target nucleic acid sequence and two or more ligation probes. Similarly, included within the definition of "ligation substrate" is a "transfer substrate", comprising at least one target nucleic acid sequence and two or more transfer probes.
[0053] In some embodiments of the invention, for example when additional specificity is desired, more than two ligation probes can be used. In this embodiment, the "middle" ligation probe(s) can also be adjacent or separated by one or more nucleobases of the target sequence. In a preferred embodiment, the ligation reaction does not require the presence of a ligase enzyme and occurs spontaneously between the bound probes in the absence of any addition (e.g. exogeneous) ligase.
[0054] Oligonucleotide probes of the invention are designed to be specific for the polynucleotide target. These probes bind to the target in close spatial proximity to each other and are oriented in such a manner that the chemically reactive moieties are in close spatial proximity. In one aspect, two or more probes are designed to bind near adjacent sites on a target polynucleotide. In a preferred embodiment, two probes bind to the target such that the ligation moiety at the 5' end of one oligonucleotide probe is able to interact with the ligation moiety at the 3' end of the other probe.
[0055] Chemical ligation can, under appropriate conditions, occur spontaneously without the addition of any additional activating reagents or stimuli. Alternatively, "activating" agents or external stimuli can be used to promote the chemical ligation reaction. Examples of activating agents include, without limitation, carbodiimide, cyanogen bromide (BrCN), imidazole, 1-methylimidazole/carbodiimide/cystamine, N-cyanoimidazole, dithiothreitol (DTT), tris(2-carboxyethyl)phosphine (TCEP) and other reducing agents as well as external stimuli like ultraviolet light, heat and/or pressure changes.
[0056] As is outlined herein, the ligation moieties of the invention may take a variety of configurations, depending on a number of factors. Most of the chemistries depicted herein are used in phosphoramidite reactions that generally progress in a 3' to 5' direction. That is, the resin contains chemistry allowing attachment of phosphoramidites at the 5' end of the molecule. However, as is known in the art, phosphoramidites can be used to progress in the 5' to 3' direction; thus, the invention includes moieties with opposite orientation to those outlined herein.
[0057] Each set of ligation probes (or transfer probes) contains a set of a first ligation moiety and a second ligation moiety. The identification of these ligation moiety pairs depends on the chemistry of the ligation to be used. In addition, as described herein, linkers (including but not limited to destabilization linkers) may be present between the probe domain and the ligation moiety of one or both ligation probes. In general, for ease of discussion, the description herein may use the terms "upstream" and "downstream" ligation probes, although this is not meant to be limiting.
[0058] Halo Leaving Group Chemistry
[0059] In one embodiment of the invention, the chemistry is based on 5' halogen leaving group technology such as is generally described in Gryanov, S. M., and Letsinger, R. L., (1993) Nucleic Acids Research, 21:1403; Xu, Y. and Kool, E. T. (1997) Tetrahedron Letters, 38:5595; Xu, Y. and Kool, E. T., (1999) Nucleic Acids Research, 27:875; Arar et al., (1995), BioConj. Chem., 6:573; Kool, E. T. et. al, (2001) Nature Biotechnol 19:148; Kool, E. T. et. al., (1995) Nucleic Acids Res, 23 (17):3547; Letsinger et al., U.S. Pat. No. 5,476,930; Shouten et al., U.S. Pat. No. 6,955,901; Andersen et al., U.S. Pat. No. 7,153,658, all of which are expressly incorporated by reference herein. In this embodiment, the first ligation probe includes at its 5' end a nucleoside having a 5' leaving group, and the second ligation probe includes at its 3' end a nucleoside having 3' nucleophilic group such as a 3' thiophosphoryl. The 5' leaving group can include many common leaving groups know to those skilled in the art including, for example the halo-species (I, Br, Cl) and groups such as those described by Abe and Kool, J. Am. Chem. Soc. (2004) 126:13980-13986, which is incorporated herein by reference in its entirety. In a more preferred embodiment of this aspect of the invention, the first ligation probe has a 5' leaving group attached through a flexible linker and a downstream oligonucleotide which has a 3' thiophosphoryl group. This configuration leads to a significant increase in the rate of reaction and results in multiple copies of ligated product being produced for every target.
[0060] The "upstream" oligonucleotide, defined in relation to the 5' to 3' direction of the polynucleotide template as the oligonucleotide that binds on the "upstream" side (i.e., the left, or 5' side) of the template includes, as its 5' end, a 5'-leaving group. Any leaving group capable of participating in an S.sub.N2 reaction involving sulfur, selenium, or tellurium as the nucleophile can be utilized. The leaving group is an atom or group attached to carbon such that on nucleophilic attack of the carbon atom by the nucleophile (sulfur, selenium or tellurium) of the modified phosphoryl group, the leaving group leaves as an anion. Suitable leaving groups include, but are not limited to a halide, such as iodide, bromide or chloride, a tosylate, benzenesulfonate or p-nitrophenylester, as well as RSO.sub.3 where R is phenyl or phenyl substituted with one to five atoms or groups comprising F, Cl, Br, I, alkyl (C1 to C6), nitro, cyano, sulfonyl and carbonyl, or R is alkyl with one to six carbons. The leaving group is preferably an iodide, and the nucleoside at the 5' end of the upstream oligonucleotide is, in the case of DNA, a 5'-deoxy-5'-iodo-2'-deoxynucleoside. Examples of suitable 5'-deoxy-5'-iodo-2'-deoxynucleosides include, but are not limited to, 5'-deoxy-5'-iodothymidine (5'-I-T), 5'-deoxy-5'-iodo-2'-deoxycytidine (5'-I-dC), 5'-deoxy-5'-iodo-2'-deoxyadenosine (5'-I-dA), 5'-deoxy-5'-iodo-3-deaza-2'-deoxyadenosine (5'-I-3-deaza-dA), 5'-deoxy-5'-iodo-2'-deoxyguanosine (5'-I-dG) and 5'-deoxy-5'-iodo-3-deaza-2'-deoxyguanosine (5'-I-3-deaza-dG), and the phosphoroamidite derivatives thereof (see FIG. 2). In the case of RNA oligonucleotides, analogous examples of suitable 5'-deoxy-5'-iodonucleosides include, but are not limited to, 5'-deoxy-5'-iodouracil (5'-I-U), 5'-deoxy-5'-iodocytidine (5'-I-C), 5'-deoxy-5'-iodoadenosine (5'-I-A), 5'-deoxy-5'-iodo-3-deazaadenosine (5'-I-3-deaza-A), 5'-deoxy-5'-iodoguanosine (5'-I-G) and 5'-deoxy-5'-iodo-3-deazaguanosine (5'-I-3-deaza-G), and the phosphoroamidite derivatives thereofIn a preferred embodiment, an upstream ligation probe contains 2'-deoxyribonucleotides except that the modified nucleotide on the 5' end, which comprises the 5' leaving group, is a ribonucleotide. This embodiment of the upstream nucleotide is advantageous because the bond between the penultimate 2'-deoxyribonucleotide and the terminal 5' ribonucleotide is susceptible to cleavage using base. This allows for potential reuse of an oligonucleotide probe that is, for example, bound to a solid support, as described in more detail below. In reference to the CLPA assay, which is described more fully below, the 5' leaving group of the "upstream" probe is most preferably DAB SYL.
[0061] The "downstream" oligonucleotide, which binds to the polynucleotide template "downstream" of, i.e., 3' to, the upstream oligonucleotide, includes, as its 3' end, a nucleoside having linked to its 3' hydroxyl a phosphorothioate group (i.e., a "3'-phosphorothioate group"), a phosphoroselenoate group (i.e., a "3'-phosphoroselenoate group), or a phosphorotelluroate group (i.e., a "3'-phosphorotelluroate group"). The chemistries used for autoligation are thus sulfur-mediated, selenium-mediated, or tellurium mediated. Self-ligation yields a ligation product containing a 5' bridging phosphorothioester (--O--P(O)(O.sup.-)-S-), phosphoroselenoester (--O--P(O)(O.sup.-)-Se-) or phosphorotelluroester (--O--P(O)(O.sup.-)-Te-), as dictated by the group comprising the 3' end of the downstream oligonucleotide. This non-natural, achiral bridging diester is positioned between two adjacent nucleotides and takes the place of a naturally occurring 5' bridging phosphodiester. Surprisingly, the selenium-mediated ligation is 3 to 4 times faster than the sulfur-mediated ligation, and the selenium-containing ligation product was very stable, despite the lower bond strength of the Se--P bond. Further, the bridging phosphoroselenoester, as well as the bridging phosphorotelluroester, are expected to be cleavable selectively by silver or mercuric ions under very mild conditions (see Mag et al., Nucleic Acids Res. (1991) 19:1437 1441).
[0062] In one embodiment, a downstream oligonucleotide contains 2'-deoxyribonucleotides except that the modified nucleotide on the 3' end, which comprises the 3' phosphorothioate, phosphoroselenoate, or phosphorotelluroate, is a ribonucleotide. This embodiment of the upstream nucleotide is advantageous because the bond between the penultimate 2'-deoxyribonucleotide and the terminal ribonucleotide is susceptible to cleavage using base, allowing for potential reuse of an oligonucleotide probe that is, for example, bound to a solid support. In reference to the CLPA assay, as described more fully below, the "downstream" probe most preferably includes at its 3' end 3'-phosphorothioate.
[0063] It should be noted that the "upstream" and "downstream" oligonucleotides can, optionally, constitute the two ends of a single oligonucleotide, in which event ligation yields a circular ligation product. The binding regions on the 5' and 3' ends of the linear precursor oligonucleotide must be linked by a number of intervening nucleotides sufficient to allow binding of the 5' and 3' binding regions to the polynucleotide target.
[0064] Compositions provided by the invention include a 5'-deoxy-5-'iodo-2'-deoxynucleoside, for example a 5'-deoxy-5'-iodothymidine (5'-I-T), 5'-deoxy-5'-iodo-2'-deoxycytidine (5'-I-dC), 5'-deoxy-5'-iodo-2'-deoxyadenosine (5'-I-dA), 5'-deoxy-5'-iodo-3-deaza-2'-deoxyadenosine (5'-I-3-deaza-dA), 5'-deoxy-5'-iodo-2'-deoxyguanosine (5'-I-dG) and 5'-deoxy-5'-iodo-3-deaza-2'-deoxyguanosine (5'-I-3-deaza-dG), and the phosphoroamidite derivatives thereof, as well as an oligonucleotide comprising, as its 5' end, a 5'-deoxy-5'-iodo-2'-deoxynucleoside of the invention. Compositions provided by the invention further include a 5'-deoxy-5'-iodonucleoside such as 5'-deoxy-5'-iodouracil (5'-I-U), 5'-deoxy-5'-iodocytidine (5'-I-C), 5'-deoxy-5'-iodoadenosine (5'-1-A), 5'-deoxy-5'-iodo-3-deazaadenosine (5'-I-3-deaza-A), 5'-deoxy-5'-iodoguanosine (5'-I-G) and 5'-deoxy-5'-iodo-3-deazaguanosine (5'-I-3-deaza-G), and the phosphoroamidite derivatives thereof, as well as an oligonucleotide comprising, as its 5' end, a 5'-deoxy-5'-iodonucleoside of the invention. Also included in the invention is a nucleoside comprising a 3'-phosphoroselenoate group or a 3'-phosphorotelluroate group, and an oligonucleotide comprising as its 3' end a nucleoside comprising a 3'-phosphoroselenoate group or a 3'-phosphorotelluroate group. Oligonucleotides containing either or both of these classes of modified nucleosides are also included in the invention, as are methods of making the various nucleosides and oligonucleotides. Oligonucleotides that are modified at either or both of the 5' or 3' ends in accordance with the invention optionally, but need not, include a detectable label, preferably a radiolabel, a fluorescence energy donor or acceptor group, an excimer label, or any combination thereof.
[0065] In addition, in some cases, substituent groups may also be protecting groups (sometimes referred to herein as "PG"). Suitable protecting groups will depend on the atom to be protected and the conditions to which the moiety will be exposed. A wide variety of protecting groups are known; for example, DMT is frequently used as a protecting group in phosphoramidite chemistry (as depicted in the figures; however, DMT may be replaced by other protecting groups in these embodiments. A wide variety of protecting groups are suitable; see for example, Greene's Protective Groups in Organic Synthesis, herein incorporated by reference for protecting groups and associated chemistry.
[0066] By "alkyl group" or grammatical equivalents herein is meant a straight or branched chain alkyl group, with straight chain alkyl groups being preferred. If branched, it may be branched at one or more positions, and unless specified, at any position. The alkyl group may range from about 1 to about 30 carbon atoms (C1-C30), with a preferred embodiment utilizing from about 1 to about 20 carbon atoms (C1-C20), with about C1 through about C12 to about C15 being preferred, and C1 to C5 being particularly preferred, although in some embodiments the alkyl group may be much larger. Also included within the definition of an alkyl group are cycloalkyl groups such as C5 and C6 rings, and heterocyclic rings with nitrogen, oxygen, sulfur or phosphorus. Alkyl also includes heteroalkyl, with heteroatoms of sulfur, oxygen, nitrogen, and silicone being preferred. Alkyl includes substituted alkyl groups. By "substituted alkyl group" herein is meant an alkyl group further comprising one or more substitution moieties "R", as defined above.
[0067] By "amino groups" or grammatical equivalents herein is meant NH.sub.2, --NHR and --NR.sub.2 groups, with R being as defined herein. In some embodiments, for example in the case of the peptide ligation reactions, primary and secondary amines find particular use, with primary amines generally showing faster reaction rates.
[0068] By "nitro group" herein is meant an --NO.sub.2 group.
[0069] By "sulfur containing moieties" herein is meant compounds containing sulfur atoms, including but not limited to, thia-, thio- and sulfo-compounds, thiols (--SH and --SR), and sulfides (--RSR--). A particular type of sulfur containing moiety is a thioester (--(CO)--S--), usually found as a substituted thioester (--(CO)--SR). By "phosphorus containing moieties" herein is meant compounds containing phosphorus, including, but not limited to, phosphines and phosphates. By "silicon containing moieties" herein is meant compounds containing silicon.
[0070] By "ether" herein is meant an --O--R group. Preferred ethers include alkoxy groups, with --O--(CH.sub.2).sub.2 CH.sub.3 and --O--(CH.sub.2).sub.4 CH.sub.3 being preferred.
[0071] By "ester" herein is meant a --COOR group.
[0072] By "halogen" herein is meant bromine, iodine, chlorine, or fluorine. Preferred substituted alkyls are partially or fully halogenated alkyls such as CF.sub.3, etc.
[0073] By "aldehyde" herein is meant --RCOH groups.
[0074] By "alcohol" herein is meant --OH groups, and alkyl alcohols --ROH.
[0075] By "amido" herein is meant --RCONH-- or RCONR-- groups.
[0076] By "ethylene glycol" herein is meant a --(O--CH.sub.2--CH.sub.2).sub.n-- group, although each carbon atom of the ethylene group may also be singly or doubly substituted, i.e. --(--CR.sub.2--CR.sub.2).sub.n--, with R as described above. Ethylene glycol derivatives with other heteroatoms in place of oxygen (i.e. --(N--CH.sub.2--CH.sub.2).sub.n-- or --(S--CH.sub.2--CH.sub.2).sub.n--, or with substitution groups) are also preferred.
[0077] Additionally, in some embodiments, the R group may be a functional group, including quenchers, destabilization moieties and fluorophores (as defined below). Fluorophores of particular use in this embodiment include, but are not limited to Fluorescein and its derivatizes, TAMRA (Tetramethyl-6-carboxyrhodamine), Alexa dyes, and Cyanine dyes (e.g. Cy3 and Cy5).
[0078] Quencher moieties or molecules are known in the art, and are generally aromatic, multiring compounds that can deactivate the excited state of another molecule. Fluorophore-quencher pairs are well known in the art. Suitable quencher moieties include, but are not limited to Dabcyl (Dimethylamini(azobenzene) sulfonyl) Dabcyl (Dimethylamino(azobenzene)carbonyl), Eclipse Quenchers (Glen Research Catalog) and blackhole Quenchers (BHQ-1, BHQ-2 and BHQ-3) from Biosearch Technologies.
[0079] Suitable destabilization moieties are discussed below and include, but are not limited to molecule entities that result in a decrease in the overall binding energy of an oligonucleotide to its target site. Potential examples include, but are not limited to alkyl chains, charged complexes, and ring structures.
[0080] Nucleophile Ligation Moieties
[0081] In this embodiment, the other ligation probe comprises a ligation moiety comprising a nucleophile such as an amine. Ligation moieties comprising both a thiol and an amine find particular use in certain reactions. In general, the nucleophile ligation moieites can include a wide variety of potential amino, thiol compounds as long as the nucleophile ligation moiety contains a thiol group that is proximal to a primary or secondary amino and the relative positioning is such that at least a 5 or 6 member ring transition state can be achieve during the S to N acyl shift.
[0082] Accordingly, nucleophile ligation molecules that comprise 1, 2 or 1, 3 amine thiol groups find particular use. Primary amines find use in some embodiments when reaction time is important, as the reaction time is generally faster for primary than secondary amines, although secondary amines find use in acyl transferase reactions that contribute to destabilization as discussed below. The carbons between the amino and thiol groups can be substituted with non-hydrogen R groups, although generally only one non-hydrogen R group per carbon is utilized. Additionally, adjacent R groups (depicted as R' and R'' in Figure *CC) may be joined together to form cyclic structures, including substituted and unsubstituted cycloalkyl and aryl groups, including heterocycloalkyl and heteroaryl and the substituted and unsubstituted derivatives thereof. In the case where a 1,2 amino thiol group is used and adjacent R groups are attached, it is generally preferred that the adjacent R groups form cycloalkyl groups (including heterocycloalkyl and substituted derivatives thereof) rather than aryl groups.
[0083] In this embodiment, for the generation of the 4 sigma bond contraction of the chain for destabilization, the replacement ligation moiety relies on an acyl transferase reaction.
[0084] Linkers
[0085] In many embodiments, linkers (sometimes shown herein as "L" or "-(linker).sub.n--), (where n is zero or one) may optionally be included at a variety of positions within the ligation probe(s). Suitable linkers include alkyl and aryl groups, including heteroalkyl and heteroaryl, and substituted derivatives of these. In some instances, for example when Native Peptide Ligation reactions are done, the linkers may be amino acid based and/or contain amide linkages. As described herein, some linkers allow the ligation probes to be separated by one or more nucleobases, forming abasic sites within the ligation product, which serve as destabilization moieties, as described below.
[0086] Destabilization Moieties
[0087] In accordance with one aspect of the invention, it is desirable to produce multiple copies of ligated product for each target molecule without the aid of an enzyme. One way to achieve this goal involves the ligated product disassociating from the target following the chemical ligation reaction to allow a new probe set to bind to the target. To increase ligation product turnover, probe designs, instrumentation, and chemical ligation reaction chemistries that increase product disassociation from the target molecule are desirable.
[0088] Previous work has shown one way to achieve product disassociation and increase product turnover is to "heat cycle" the reaction mixture. Heat cycling is the process of varying the temperature of a reaction so as to facilitate a desired outcome. Most often heat cycling takes the form of briefly raising the temperature of the reaction mixture so that the reaction temperature is above the melting temperature of the ligated product for a brief period of time causing the product to disassociate from the target. Upon cooling, a new set of probes is able to bind the target, and undergo another ligation reaction. This heat cycling procedure has been practiced extensively for enzymatic reactions like PCR.
[0089] While heat cycling is one way to achieve product turnover, it is possible to design probes such that there is significant product turnover without heat cycling. Probe designs and ligation chemistries that help to lower the melting temperature of the ligated product increase product turnover by decreasing product inhibition of the reaction cycle.
[0090] Accordingly, in one aspect, the probes are designed to include elements (e.g. destabilization moieties), which, upon ligation of the probes, serve to destabilize the hybridization of the ligation product to the target sequence. As a result, the ligated substrate disassociates after ligation, resulting in a turnover of the ligation product, e.g. the ligation product comprising the two ligation probes dehybridizes from the target sequence, freeing the target sequence for hybridization to another probe set.
[0091] In addition, increasing the concentration of the free (e.g. unhybridized) ligation probes can also help drive the equilibrium towards release of the ligation product (or transfer product) from the target sequence. Accordingly, some embodiments of the invention use concentrations of probes that are 1,000,000 fold higher than that of the target while in other embodiments the probes are 10,000 to 100 fold higher than that of the target. As will be appreciated by those skilled in the art, increasing the concentration of free probes can be used by itself or with any embodiment outlined herein to achieve product turnover (e.g. amplification). While increasing the probe concentration can result in increased product turnover, it can also lead to significant off target reactions such as probe hydrolysis and non-target mediated ligation.
[0092] In one aspect, probe elements include structures which lower the melting temperature of the ligated product. In some embodiments, probe elements are designed to hybridize to non-adjacent target nucleobases, e.g. there is a "gap" between the two hybridized but unligated probes. In general, this is done by using one or two linkers between the probe domain and the ligation moiety. That is, there may be a linker between the first probe domain and the first ligation moiety, one between the second probe domain and the second ligation moiety, or both. In some embodiments, the gap comprises a single nucleobase, although more can also be utilized as desired. As will be appreciated by those skilled in the art, there may be a tradeoff between reaction kinetics and length of the linkers; if the length of the linker(s) are so long that contact resulting in ligation is kinetically disfavored, shorter linkers may be desired. However, in some cases, when kinetics are not important, the length of the gap and the resulting linkers may be longer, to allow spanning gaps of 1 to 10 nucleobases. Generally, in this embodiment, what is important is that the length of the linker(s) roughly corresponds to the number of nucleobases in the gap.
[0093] In another aspect of this embodiment of the invention, the formation of abasic sites in a ligation product as compared to the target sequence serves to destabilize the duplex. For example, Abe and Kool (J. Am. Chem. Soc. (2004) 126:13980-13986) compared the turnover when two different 8-mer oligonucleotide probes (Bu42 and DT40) were ligated with the same 7-mer probe (Thio 4). When Thio4 is ligated with DT40, a continuous 15-mer oligonucleotide probe with a nearly native DNA structure is formed that should be perfectly matched with the DNA target. However, when Thio4 is ligated with Bu42, a 15-mer oligonucleotide probe is formed, but when the probe is bound to the target, it has an abasic site in the middle that is spanned by an alkane linker. Comparison of the melting temperature (Tm) of these two probes when bound to the target shows approximately a 12.degree. C. difference in melting temperature (58.5 for Bu42 versus 70.7.degree. C. for DT40). This 12.degree. C. difference in melting temperature led to roughly a 10-fold increase in product turnover (91.6- Bu42 versus 8.2 DT40) at 25.degree. C. when the probe sets (10,000-fold excess, 10 .mu.M conc) were present in large excess compared to the target (1 nM). Similarly, Dose et al (Dose 2006) showed how a 4.degree. C. decrease in Tm for two identical sequences, chemically ligated PNA probes (53.degree. C. versus 57.degree. C.) results in approximately a 4-fold increase in product turnover.
[0094] Recent work has demonstrated the use of chemical ligation based Quenched Auto-Ligation (QUAL) probes to monitor RNA expression and detect single base mismatches inside bacterial and human cells (WO 2004/0101011 herein incorporated by reference).
[0095] In one embodiment, destabilization moieties are based on the removal of stabilization moieties. That is, if a ligation probe contains a moiety that stabilizes its hybridization to the target, upon ligation and release of the stabilization moiety, there is a drop in the stability of the ligation product. Accordingly, one general scheme for reducing product inhibition is to develop probes that release a molecular entity like a minor groove binding molecule during the course of the initial chemical ligation reaction or following a secondary reaction post ligation. Depending on the oligonucleotide sequence, minor groove binders like the dihydropyrroloindole tripeptide (DPI.sub.3) described by Kutyavin (Kutyavin 1997 and Kutyavin 2000) can increase the Tm of a duplex nucleic acid by up to 40.degree. C. when conjugated to the end of an oligonucleotide probe. In contrast, the unattached version of the DPI.sub.3 only increases the Tm of the same duplex by 2.degree. C. or so. Thus, minor groove binders can be used to produce probe sets with enhanced binding strengths, however if the minor groove binder is released during the course of the reaction, the binding enhancement is loss and the ligated product will display a decreased Tm relative to probes in which the minor groove binder is still attached.
[0096] Suitable minor groove binding molecules include, but are not limited to, dihydropyrroloindole tripeptide (DPI.sub.3), distamycin A, and pyrrole-imidazole polyamides (Gottesfeld, J. M., et al., J. Mol. Biol. (2001) 309:615-629.
[0097] In addition to minor groove binding molecules tethered intercalators and related molecules can also significantly increase the melting temperature of oligonucleotide duplexes, and this stabilization is significantly less in the untethered state. (Dogan, et al., J. Am. Chem Soc. (2004) 126:4762-4763 and Narayanan, et al., Nucleic Acids Research, (2004) 32:2901-2911).
[0098] Similarly, as will be appreciated by those in the art, probes with attached oligonucleotide fragments (DNA, PNA, LNA, etc) capable of triple helix formation, can serve as stabilization moieties that upon release, results in a decrease of stabilization of the ligation product to the target sequence (Pooga, M, et al., Biomolecular Engineering (2001) 17:183-192.
[0099] Another general scheme for decreasing product inhibition by lowering the binding strength of the ligated product is to incorporate abasic sites at the point of ligation. This approach has been previously demonstrated by Abe (J. Am. Chem. Soc. (2004) 126:13980-13986), however it is also possible to design secondary probe rearrangements to further amplify the decrease in Tm via straining the alignment between the ligated probes and the target. For example, Dose et al. (Org. Letters (2005) 7:20 4365-4368) showed how a rearrangement post-ligation that changed the spacing between PNA bases from the ideal 12 sigma bonds to 13 resulted in a lowering of the Tm by 4.degree. C. Larger rearrangements and secondary reactions that interfere with the binding of the product to the target or result in the loss of oligonucleotide bases can further decrease the Tm.
[0100] The present invention provides methods and compositions for a ligation reaction that results in a chain contraction of up to 4 sigma bonds during the rearrangement, which should have a significant effect on the Tm post-rearrangement compared to the 1 base expansion using the chemistry described by Dose. This chemistry is based on the acyl transfer auxiliary that has been described previously (Offer et al., J Am Chem Soc. (2002) 124(17):4642-6). Following completion of the chain contraction, a free-thiol is generated that is capable of undergoing another reaction either with a separate molecule or with itself. For example, this thiol could react with an internal thioester to severely kink the oligonucleotide and thus further decrease the ligation product's ability to bind to the target.
[0101] Thus, in this embodiment, ligation reactions that release functional groups that will undergo a second reaction with the ligation product can reduce stabilization of the hybrid of the ligation product and the target sequence.
[0102] Additional Functionalities of Ligation Probes
[0103] In addition to the target domains, ligation moieties, and optional linkers, one or more of the ligation probes of the invention can have additional functionalities, including, but not limited to, promoter and primer sequences (or complements thereof, depending on the assay), labels including label probe binding sequences and anchor sequences. Additional functionalities including variable spacer sequences (also referred to as stuffer sequences) are described hereinbelow with reference to the CLPA assay.
[0104] In one aspect of the invention, the upstream oligonucleotide probe can have a promoter site or primer binding site for a subsequent enzymatic amplification reaction. In one embodiment, the upstream probe contains the promoter sequence for a RNA polymerase, e.g. T7, SP6 or T3. In another embodiment, both the upstream and down stream oligonucleotides contain primer binding sequences. Promoter and primer binding sequences are designed so as to not interact with the nucleic acid targets to any appreciable extent. In a preferred embodiment, when detecting multiple targets simultaneously, all of the oligonucleotide probe sets in the reaction are designed to contain identical promoter or primer pair binding sites such that following ligation and purification, if appropriate, all of the ligated products can be amplified simultaneously using the same enzyme and/or same primers.
[0105] In one embodiment, one or more of the ligation probes comprise a promoter sequence. In embodiments that employ a promoter sequence, the promoter sequence or its complement will be of sufficient length to permit an appropriate polymerase to interact with it. Detailed descriptions of sequences that are sufficiently long for polymerase interaction can be found in, among other places, Sambrook and Russell. In certain embodiments, amplification methods comprise at least one cycle of amplification, for example, but not limited to, the sequential procedures of: interaction of a polymerase with a promoter; synthesizing a strand of nucleotides in a template-dependent manner using a polymerase; and denaturing the newly-formed nucleic acid duplex to separate the strands.
[0106] In another embodiment, one or both of the ligation probes comprise a primer sequence. As outlined below, the ligation products of the present invention may be used in additional reactions such as enzymatic amplification reactions. In one embodiment, the ligation probes include primer sequences designed to allow an additional level of amplification. As used herein, the term "primer" refers to nucleotide sequence, whether occurring naturally as in a purified restriction digest or produced synthetically, which is capable of acting as a point of initiation of nucleic acid sequence synthesis when placed under conditions in which synthesis of a primer extension product which is complementary to a nucleic acid strand is induced, i.e. in the presence of different nucleotide triphosphates and a polymerase in an appropriate buffer ("buffer" includes pH, ionic strength, cofactors etc.) and at a suitable temperature. One or more of the nucleotides of the primer can be modified, for instance by addition of a methyl group, a biotin or digoxigenin moiety, a fluorescent tag or by using radioactive nucleotides. A primer sequence need not reflect the exact sequence of the template. For example, a non-complementary nucleotide fragment may be attached to the 5' end of the primer, with the remainder of the primer sequence being substantially complementary to the target strand.
[0107] By using several priming sequences and primers, a first ligation product can serve as the template for additional ligation products. These primer sequences may serve as priming sites for PCR reactions, which can be used to amplify the ligation products. In addition to PCR reactions, other methods of amplification can utilize the priming sequences, including but not limited to ligase chain reactions, InvaderTM, positional amplification by nick translation (NICK), primer extension/nick translation, and other methods known in the art. As used herein, "amplification" refers to an increase in the number of copies of a particular nucleic acid. Copies of a particular nucleic acid made in vitro in an amplification reaction are called "amplicons" or "amplification products".
[0108] Amplification may also occur through a second ligation reaction, in which the primer sites serve as hybridization sites for a new set of ligation probes which may or may not comprise sequences that are identical to the first set of ligation probes that produced the original ligation products. The target sequence is thus exponentially amplified through amplification of ligation products in subsequent cycles of amplification.
[0109] In another embodiment of this aspect of the invention, the primer sequences are used for nested ligation reactions. In such nested ligation reactions, a first ligation reaction is accomplished using methods described herein such that the ligation product can be captured, for example by using biotinylated primers to the desired strand and capture on beads (particularly magnetic beads) coated with streptavidin. After the ligation products are captured, a second ligation reaction is accomplished by hybridization of ligation probes to primer sequences within a section of the ligation product which is spatially removed from (i.e., downstream from) the end of the ligation product which is attached to the capture bead, probe, etc. At least one of the primer sequences for the secondary ligation reaction will be located within the region of the ligation product complementary to the ligation probe which is not the ligation probe that included the anchor or capture sequence. The ligation products from this second ligation reaction will thus necessarily only result from those sequences successfully formed from the first chemical ligation, thus removing any "false positives" from the amplification reaction. In another embodiment, the primer sequences used in the secondary reaction may be primer sites for other types of amplification reactions, such as PCR.
[0110] In one embodiment, one or more of the ligation probes comprise an anchor sequence. By "anchor sequence" herein is meant a component of a ligation probe that allows the attachment of a ligation product to a support for the purposes of detection. Suitable means for detection include a support having attached thereto an appropriate capture moiety. Generally, such an attachment will occur via hybridization of the anchor sequence with a capture probe, which is substantially complementary to the anchor sequence.
[0111] In one embodiment of this aspect of the invention, the upstream oligonucleotide is designed to have an additional nucleotide segment that does not bind to the target of interest, but is to be used to subsequently capture the ligated product on a suitable solid support or device of some sort. In a preferred embodiment of this aspect of the invention, the downstream oligonucleotide has a detectable label attached to it, such that following ligation, the resulting product will contain a capture sequence for a solid support at its 3' end and a detectable label at its 5' end, and only ligated products will contain both the capture sequence and the label.
[0112] In another aspect of the invention pertaining to multiplex target detection, each upstream probe of a probe set may be designed to have a unique sequence at is 3' end that corresponds to a different position on a DNA array. Each downstream probe of a probe set may optionally contain a detectable label that is identical to the other down stream probes, but a unique target binding sequence that corresponds to its respective targets. Following hybridization with the DNA array, only ligated probes that have both an address sequence (upstream probe) and a label (downstream probe) will be observable.
[0113] In another aspect of the invention, the detectable label can be attached to the upstream probe and the capture sequence can be a part of the downstream probe, such that the ligated products will have the detectable label more towards the 3' end and the capture sequence towards the 5' end of the ligated product. The exact configuration is best determined via consideration of the ease of synthesis as well as the characteristics of the devices to be used to subsequently detect the ligated reaction product.
[0114] The anchor sequence may have both nucleic and non-nucleic acid portions. Thus, for example, flexible linkers such as alkyl groups, including polyethylene glycol linkers, may be used to provide space between the nucleic acid portion of the anchor sequence and the support surface. This may be particularly useful when the ligation products are large.
[0115] In addition, in some cases, sets of anchor sequences that correspond to the capture probes of "universal arrays" can be used. As is known in the art, arrays can be made with synthetic generic sequences as capture probes, that are designed to non-complementary to the target sequences of the sample being analyzed but to complementary to the array binding sequences of the ligation probe sets. These "universal arrays" can be used for multiple types of samples and diagnostics tests because same array binding sequences of the probes can be reused/paired with different target recognition sequences.
[0116] In one embodiment, one or more of the ligation probes comprise a label. By "label" or "labeled" herein is meant that a compound has at least one element, isotope or chemical compound attached to enable the detection of the compound, e.g. renders a ligation probe or ligation or transfer product detectable using known detection methods, e.g., electronic, spectroscopic, photochemical, or electrochemiluminescent methods.. In general, labels fall into three classes: a) isotopic labels, which may be radioactive or heavy isotopes; b) magnetic, electrical, thermal; and c) colored or luminescent dyes; although labels include enzymes and particles such as magnetic particles as well. The dyes may be chromophores or phosphors but are preferably fluorescent dyes, which due to their strong signals provide a good signal-to-noise ratio. Suitable dyes for use in the invention include, but are not limited to, fluorescent lanthanide complexes, including those of Europium and Terbium, fluorescein, fluorescein isothiocyanate, carboxyfluorescein (FAM), dichlorotriazinylamine fluorescein, rhodamine, tetramethylrhodamine, umbelliferone, eosin, erythrosin, coumarin, methyl-coumarins, pyrene, Malacite green, Cy3, Cy5, stilbene, Lucifer Yellow, Cascade Blue.TM., Texas Red, alexa dyes, dansyl chloride, phycoerythin, green fluorescent protein and its wavelength shifted variants, bodipy, and others known in the art such as those described in Haugland, Molecular Probes Handbook, (Eugene, Oreg.) 6th Edition; The Synthegen catalog (Houston, Tex.), Lakowicz, Principles of Fluorescence Spectroscopy, 2nd Ed., Plenum Press New York (1999), and others described in the 6th Edition of the Molecular Probes Handbook by Richard P. Haugland, herein expressly incorporated by reference. Additional labels include nanocrystals or Q-dots as described in U.S. Ser. No. 09/315,584, herein expressly incorporated by reference.
[0117] In a preferred embodiment, the label is a secondary label that part of a binding partner pair. For example, the label may be a hapten or antigen, which will bind its binding partner. In a preferred embodiment, the binding partner can be attached to a solid support to allow separation of extended and non-extended primers. For example, suitable binding partner pairs include, but are not limited to: antigens (such as proteins (including peptides)) and antibodies (including fragments thereof (FAbs, etc.)); proteins and small molecules, including biotin/streptavidin; enzymes and substrates or inhibitors; other protein--protein interacting pairs; receptor-ligands; and carbohydrates and their binding partners. Nucleic acid--nucleic acid binding protein pairs are also useful. In general, the smaller of the pair is attached to the NTP for incorporation into the primer. Preferred binding partner pairs include, but are not limited to, biotin (or imino-biotin) and streptavidin, digeoxinin and Abs, and Prolinx.TM. reagents.
In a preferred embodiment, the binding partner pair comprises biotin or imino-biotin and streptavidin. Imino-biotin is particularly preferred as imino-biotin disassociates from streptavidin in pH 4.0 buffer while biotin requires harsh denaturants (e.g. 6 M guanidinium HCl, pH 1.5 or 90% formamide at 95.degree. C.).
[0118] In a preferred embodiment, the binding partner pair comprises a primary detection label (for example, attached to a ligation probe) and an antibody that will specifically bind to the primary detection label. By "specifically bind" herein is meant that the partners bind with specificity sufficient to differentiate between the pair and other components or contaminants of the system. The binding should be sufficient to remain bound under the conditions of the assay, including wash steps to remove non-specific binding. In some embodiments, the dissociation constants of the pair will be less than about 10.sup.-4 to 10.sup.-6 M.sup.-1, with less than about 10.sup.-5 to 10.sup.-9 M.sup.-1 being preferred and 10.sup.-9 M.sup.-1 being particularly preferred.
[0119] In a preferred embodiment, the secondary label is a chemically modifiable moiety. In this embodiment, labels comprising reactive functional groups are incorporated into the nucleic acid. The functional group can then be subsequently labeled with a primary label. Suitable functional groups include, but are not limited to, amino groups, carboxy groups, maleimide groups, oxo groups and thiol groups, with amino groups and thiol groups being particularly preferred. For example, primary labels containing amino groups can be attached to secondary labels comprising amino groups, for example using linkers as are known in the art; for example, homo-or hetero-bifunctional linkers as are well known (see 1994 Pierce Chemical Company catalog, technical section on cross-linkers, pages 155 200, incorporated herein by reference).
[0120] In this embodiment, the label may also be a label probe binding sequence or complement thereof. By "label probe" herein is meant a nucleic acid that is substantially complementary to the binding sequence and is labeled, generally directly.
Synthetic Methods
[0121] The compositions of the invention are generally made using known synthetic techniques. In general, methodologies based on standard phosphoramidite chemistries find particular use in one aspect of the present invention, although as is appreciated by those skilled in the art, a wide variety of nucleic acid synthetic reactions are known.
[0122] Methods of making probes having halo leaving groups is known in the art; see for example Abe et al., Proc Natl Acad Sci USA (2006)103(2):263-8; Silverman et al., Nucleic Acids Res. (2005) 33(15):4978-86; Cuppolletti et al., Bioconjug Chem. (2005) 16(3):528-34; Sando et al., J Am Chem Soc. (2004) 4;126(4):1081-7; Sando et al., Nucleic Acids Res Suppl. (2002) 2:121-2; Sando et al., J Am Chem Soc. (2002) 124(10):2096-7; Xu et al., Nat Biotechnol. (2001) 19(2):148-52; Xu et al., Nucleic Acids Res. (1998) 26(13):3159-64; Moran et al., Proc Natl Acad Sci USA (1997) 94(20):10506-11; Kool, U.S. Pat. No. 7,033,753; Kool, U.S. Pat. No. 6,670,193; Kool, U.S. Pat. No. 6,479,650; Kool, U.S. Pat. No. 6,218,108; Kool, U.S. Pat. No. 6,140,480; Kool, U.S. Pat. No. 6,077,668; Kool, U.S. Pat. No. 5,808,036; Kool, U.S. Pat. No. 5,714,320; Kool, U.S. Pat. No. 5,683,874; Kool, U.S. Pat. No. 5,674,683; and Kool, U.S. Pat. No. 5,514,546, each of which is incorporated herein by reference in its entirety.
[0123] Additional components such as labels, primer sequences, promoter sequences, etc. are generally incorporated as is known in the art. The spacing of the addition of fluorophores and quenchers is well known as well.
Secondary Reactions
[0124] Prior to detecting the ligation or transfer reaction product, there may be additional amplification reactions. Secondary amplification reactions can be used to increase the signal for detection of the target sequence; e.g. by increasing the number of ligated products produced per copy of target. In one embodiment, any number of standard amplification reactions can be performed on the ligation product, including, but not limited to, strand displacement amplification (SDA), nucleic acid sequence based amplification (NASBA), ligation amplification and the polymerase chain reaction (PCR); including a number of variations of PCR, including "quantitative competitive PCR" or "QC-PCR", "arbitrarily primed PCR" or "AP-PCR", "immuno-PCR", "Alu-PCR", "PCR single strand conformational polymorphism" or "PCR-SSCP", "reverse transcriptase PCR" or "RT-PCR", "biotin capture PCR", "vectorette PCR". "panhandle PCR", and "PCR select cDNA subtraction", among others. In one embodiment, the amplification technique is not PCR. According to certain embodiments, one may use ligation techniques such as gap-filling ligation, including, without limitation, gap-filling OLA and LCR, bridging oligonucleotide ligation, FEN-LCR, and correction ligation. Descriptions of these techniques can be found, among other places, in U.S. Pat. No. 5,185,243, published European Patent Applications EP 320308 and EP 439182, published PCT Patent Application WO 90/01069, published PCT Patent Application WO 02/02823, and U.S. patent application Ser. No. 09/898,323.
[0125] In addition to standard enzymatic amplification reactions, it is possible to design probe schemes where the ligated product that is initially produced can itself be the target of a secondary chemical ligation reaction.
[0126] Furthermore, "preamplification reactions" can be done on starting sample nucleic acids to generate more target sequences for the chemical reaction ligation. For example, whole genome amplification can be done.
Assays
[0127] As will be appreciated by those skilled in the art, assays utilizing methods and compositions of the invention can take on a wide variety of configurations, depending on the desired application, and can include in situ assays (similar to FISH), solution based assays (e.g. transfer/removal of fluorophores and/or quenchers), and heterogeneous assays (e.g. utilizing solid supports for manipulation, removal and/or detection, such as the use of high density arrays). In addition, assays can include additional reactions, such as pre-amplification of target sequences and secondary amplification reactions after ligation has occurred, as is outlined herein.
[0128] Assays pertaining to this aspect of the invention, as described herein, may rely on increases in a signal, e.g. the generation of fluorescence or chemiluminescence. However, as will be appreciated by those in the art, assays that rely on decreases in such signals are also possible.
[0129] In one embodiment, assay reactions are performed "in situ" (also referred to in various assay formats as "in vitro" and/or "ex vivo" depending on the sample), similar to FISH reactions. Since no exogeneous enzymes need be added, reagents can be added to cells (living, electroporated, fixed, etc.) such as histological samples for the determination of the presence of target sequences, particularly those associated with disease states or other pathologies.
[0130] In addition, "in vitro" assays can be done where target sequences are extracted from samples. Samples can be processed (e.g. for paraffin embedded samples, the sample can be prepared), the reagents added and the reaction allowed to proceed, with detection following as is done in the art.
[0131] In one embodiment, ligated products are detected using solid supports. For example, the ligated products are attached to beads, using either anchor probe/capture probe hybridization or other binding techniques, such as the use of a binding partner pair (e.g. biotin and streptavidin). In one embodiment, a transfer reaction results in a biotin moiety being transferred from the first ligation probe to a second ligation probe comprising a label. Beads comprising streptavidin are contacted with the sample, and the beads are examined for the presence of the label, for example using FACS technologies.
[0132] In other embodiments, ligated products are detected using heterogeneous assays. That is, the reaction is done in solution and the product is added to a solid support, such as an array or beads. Generally, one ligation probe comprises an anchor sequence or a binding pair partner (e.g. biotin, haptens, etc.) and the other comprises a label (e.g. a fluorophore, a label probe binding sequence, etc.). The ligated product is added to the solid support, and the support optionally washed. In this embodiment, only the ligated product will be captured and be labeled.
[0133] In another aspect of the invention, one of oligonucleotide probes has an attached magnetic bead or some other label (biotin) that allows for easy manipulation of the ligated product. The magnetic bead or label can be attached to either the upstream or the downstream probe using any number of configurations as outlined herein.
[0134] As described herein, secondary reactions can also be done, where additional functional moieties (e.g. anchor sequences, primers, labels, etc.) are added. Similarly, secondary amplification reactions can be done as described herein.
[0135] Detection systems are known in the art, and include optical assays (including fluorescence and chemiluminescent assays), enzymatic assays, radiolabelling, surface plasmon resonance, magnetoresistance, cantilever deflection, surface plasmon resonance, etc. In some embodiments, the ligated product can be used in additional assay technologies, for example, as described in 2006/0068378, hereby incorporated by reference, the ligated product can serve as a linker between light scattering particles such as colloids, resulting in a color change in the presence of the ligated product.
[0136] In some embodiments, the detection system can be included within the sample collection tube; for example, blood collection devices can have assays incorporated into the tubes or device to allow detection of pathogens or diseases.
Solid Supports
[0137] As outlined above, the assays can be run in a variety of ways. In assays that utilize detection on solid supports, there are a variety of solid supports, including arrays, that find use in the invention.
[0138] In some embodiments, solid supports such as beads find use in the present invention. For example, binding partner pairs (one on the ligated product and one on the bead) can be used as outlined above to remove non-ligated reactants. In this embodiment, magnetic beads are particularly preferred.
[0139] In some embodiments of the invention, capture probes are attached to solid supports for detection. For example, capture probes can be attached to beads for subsequent analysis using any suitable technique, e.g. FACS. Similarly, bead arrays as described below may be used.
[0140] In one embodiment, the present invention provides arrays, each array location comprising at a minimum a covalently attached nucleic acid probe, generally referred to as a "capture probe". By "array" herein is meant a plurality of nucleic acid probes in an array format; the size of the array will depend on the composition and end use of the array. Arrays containing from about 2 different capture ligands to many thousands can be made. Generally, for electrode-based assays, the array will comprise from two to as many as 100,000 or more, depending on the size of the electrodes, as well as the end use of the array. Preferred ranges are from about 2 to about 10,000, with from about 5 to about 1000 being preferred, and from about 10 to about 100 being particularly preferred. In some embodiments, the compositions of the invention may not be in array format; that is, for some embodiments, compositions comprising a single capture probe may be made as well. In addition, in some arrays, multiple substrates may be used, either of different or identical compositions. Thus, for example, large arrays may comprise a plurality of smaller substrates. Nucleic acid arrays are known in the art, and can be classified in a number of ways; both ordered arrays (e.g. the ability to resolve chemistries at discrete sites), and random arrays (e.g. bead arrays) are included. Ordered arrays include, but are not limited to, those made using photolithography techniques (e.g. Affymetrix GeneChip.RTM.), spotting techniques (Synteni and others), printing techniques (Hewlett Packard and Rosetta), electrode arrays, three dimensional "gel pad" arrays and liquid arrays.
[0141] In a preferred embodiment, the arrays are present on a substrate. By "substrate" or "solid support" or other grammatical equivalents herein is meant any material that can be modified to contain discrete individual sites appropriate for the attachment or association of nucleic acids. The substrate can comprise a wide variety of materials, as will be appreciated by those skilled in the art, including, but not limited to glass, plastics, polymers, metals, metalloids, ceramics, and organics. When the solid support is a bead, a wide variety of substrates are possible, including but not limited to magnetic materials, glass, silicon, dextrans, and plastics.
Hardware
[0142] Microfluidics
[0143] In another aspect of the invention, a fluidic device similar to those described by Liu (2006) is used to automate the methodology described in this invention. See for example U.S. Pat. No. 6,942,771, herein incorporated by reference for components including but not limited to cartridges, devices, pumps, wells, reaction chambers, and detection chambers. The fluidic device may also include zones for capture of magnetic particles, separation filters and resins, including membranes for cell separation (i.e.Leukotrap.TM. from Pall). The device may include detection chambers for in-cartridge imaging of fluorescence signal generated during Real-Time PCR amplification (i.e. SYBR green, Taqman, Molecular Beacons), as well as capillary electrophoresis channels for on-device separation and detection of reactions products (amplicons and ligation products). In a preferred embodiment, the capillary electrophoresis channel can be molded in a plastic substrate and filled with a sieving polymer matrix (POP-7.TM. from Applied Biosystems). Channels containing non-sieving matrix can also be used with properly designed probe sets.
[0144] In a preferred embodiment, the devices of the invention comprise liquid handling components, including components for loading and unloading fluids at each station or sets of stations. The liquid handling systems can include robotic systems comprising any number of components. In addition, any or all of the steps outlined herein may be automated; thus, for example, the systems may be completely or partially automated.
[0145] As will be appreciated by those in the art, there are a wide variety of components which can be used, including, but not limited to, one or more robotic arms; plate handlers for the positioning of microplates; holders with cartridges and/or caps; automated lid or cap handlers to remove and replace lids for wells on non-cross contamination plates; tip assemblies for sample distribution with disposable tips; washable tip assemblies for sample distribution; 96 well loading blocks; cooled reagent racks; microtitler plate pipette positions (optionally cooled); stacking towers for plates and tips; and computer systems.
[0146] Fully robotic or microfluidic systems include automated liquid-, particle-, cell- and organism-handling including high throughput pipetting to perform all steps of screening applications. This includes liquid, particle, cell, and organism manipulations such as aspiration, dispensing, mixing, diluting, washing, accurate volumetric transfers; retrieving, and discarding of pipet tips; and repetitive pipetting of identical volumes for multiple deliveries from a single sample aspiration. These manipulations are cross-contamination-free liquid, particle, cell, and organism transfers. This instrument performs automated replication of microplate samples to filters, membranes, and/or daughter plates, high-density transfers, full-plate serial dilutions, and high capacity operation.
[0147] In a preferred embodiment, chemically derivatized particles, plates, cartridges, tubes, magnetic particles, or other solid phase matrix with specificity to the assay components are used. The binding surfaces of microplates, tubes or any solid phase matrices include non-polar surfaces, highly polar surfaces, modified dextran coating to promote covalent binding, antibody coating, affinity media to bind fusion proteins or peptides, surface-fixed proteins such as recombinant protein A or G, nucleotide resins or coatings, and other affinity matrix are useful in this invention.
[0148] In a preferred embodiment, platforms for multi-well plates, multi-tubes, holders, cartridges, minitubes, deep-well plates, microfuge tubes, cryovials, square well plates, filters, chips, optic fibers, beads, and other solid-phase matrices or platform with various volumes are accommodated on an upgradable modular platform for additional capacity. This modular platform includes a variable speed orbital shaker, and multi-position work decks for source samples, sample and reagent dilution, assay plates, sample and reagent reservoirs, pipette tips, and an active wash station.
[0149] In a preferred embodiment, thermocycler and thermoregulating systems are used for stabilizing the temperature of heat exchangers such as controlled blocks or platforms to provide accurate temperature control of incubating samples from 0 .degree. C. to 100 .degree. C.; this is in addition to or in place of the station thermocontrollers.
[0150] In a preferred embodiment, interchangeable pipet heads (single or multi-channel) with single or multiple magnetic probes, affinity probes, or pipetters robotically manipulate the liquid, particles, cells, and organisms. Multi-well or multi-tube magnetic separators or platforms manipulate liquid, particles, cells, and organisms in single or multiple sample formats.
[0151] In some embodiments, the instrumentation will include a detector, which can be a wide variety of different detectors, depending on the labels and assay. In a preferred embodiment, useful detectors include a microscope(s) with multiple channels of fluorescence; plate readers to provide fluorescent, electrochemical and/or electrical impedance analyzers, ultraviolet and visible spectrophotometric detection with single and dual wavelength endpoint and kinetics capability, fluroescence resonance energy transfer (FRET), luminescence, quenching, two-photon excitation, and intensity redistribution; CCD cameras to capture and transform data and images into quantifiable formats; capillary electrophoresis systems, mass spectrometers and a computer workstation.
[0152] These instruments can fit in a sterile laminar flow or fume hood, or are enclosed, self-contained systems, for cell culture growth and transformation in multi-well plates or tubes and for hazardous operations. The living cells may be grown under controlled growth conditions, with controls for temperature, humidity, and gas for time series of the live cell assays. Automated transformation of cells and automated colony pickers may facilitate rapid screening of desired cells.
[0153] Flow cytometry or capillary electrophoresis formats can be used for individual capture of magnetic and other beads, particles, cells, and organisms.
[0154] The flexible hardware and software allow instrument adaptability for multiple applications. The software program modules allow creation, modification, and running of methods. The system diagnostic modules allow instrument alignment, correct connections, and motor operations. The customized tools, labware, and liquid, particle, cell and organism transfer patterns allow different applications to be performed. The database allows method and parameter storage. Robotic and computer interfaces allow communication between instruments.
[0155] In a preferred embodiment, the robotic apparatus includes a central processing unit which communicates with a memory and a set of input/output devices (e.g., keyboard, mouse, monitor, printer, etc.) through a bus. Again, as outlined below, this may be in addition to or in place of the CPU for the multiplexing devices of the invention. The general interaction between a central processing unit, a memory, input/output devices, and a bus is known in the art. Thus, a variety of different procedures, depending on the experiments to be run, are stored in the CPU memory.
[0156] These robotic fluid handling systems can utilize any number of different reagents, including buffers, reagents, samples, washes, assay components such as label probes, etc.
Kits
[0157] In another aspect of the invention, a kit for the routine detection of a predetermined set of nucleic acid targets is produced that utilizes probes, techniques, methods, and a chemical ligation reaction as described herein as part of the detection process. The kit can comprise probes, target sequences, instructions, buffers, and/or other assay components.
Chemical Ligation Dependent Probe Amplification (CLPA)
[0158] In another embodiment, the invention relates to chemical ligation dependent probe amplification (CLPA) technology. CLPA is based on the chemical ligation of target specific oligonucleotide probes to form a ligation product. This ligation product subsequently serves as a template for an enzymatic amplification reaction to produce amplicons which are subsequently analyzed using any suitable means. CLPA can be used for a variety of purposes including but not limited to analysis of complex gene signature patterns. Unlike other techniques such as DASL (Bibikova, M., et al., American Journal of Pathology, (2004), 165:5, 1799-1807) and MLPA (Schouten, U.S. Pat. No. 6,955,901) which utilize an enzymatic ligation reaction, CLPA uses a chemical ligation reaction.
[0159] In one embodiment, the CLPA assay comprises the use of oligonucleotide probe pairs that incorporate reactive moieties that can self-ligate when properly positioned on a target sequence. In a preferred embodiment, a 3'-phosphorothioate moiety on one probe reacts with a 5'-DABSYL leaving group on the other probe (See Scheme 1 and FIG. 6).
##STR00001##
[0160] The 5'-DABSYL group reacts about four times faster than other moieties, e.g. iodine, and also simplifies purification of the probes during synthesis.
[0161] CLPA has several distinct advantages over other sequence-based hybridization techniques. First, CLPA can be applied directly to RNA analysis without the need to make a DNA copy beforehand. Second, CLPA is relatively insensitive to sample contaminants and can be applied directly to impure samples including body samples such as blood, urine, saliva and feces. Third, CLPA involves fewer steps than other known methods, thereby reducing the time required to gain a result. Moreover, CLPA probes can be stored dry, and properly designed systems will spontaneously react to join two or more oligonucleotides in the presence of a complementary target sequence. Chemical ligation reactions show excellent sequence selectivity and can be used to discriminate single nucleotide polymorphisms.
[0162] Significantly, unlike enzymatic ligation methods, CLPA shows nearly identical reactivity on DNA and RNA targets which, as described more fully below, renders CLPA more efficient that other known systems, and expands the scope of applications to which CLPA can be utilized.
[0163] Advantageously, the CLPA assay reduces the number of steps required to achieve a result, which provides the potential to achieve results in significantly shorter time periods. For example, the general process flow for a standard reverse transcriptase (RT)- multiplex ligase-dependent probe ligation (MLPA) involves the following steps:
[0164] 1. Isolate total RNA.
[0165] 2. Use Reverse Transcriptase to make cDNA copy.
[0166] 3. Hybridize MLPA probe sets to the cDNA target overnight.
[0167] 4. Add DNA Ligase to join target-bound probes.
[0168] 5. Amplify ligated probes, e.g. PCR amplification using Taq polymerase and fluorescently labeled PCR primers.
[0169] 6. Analyze the sample, for example, by CE.
[0170] Unlike standard RT-MLPA, CLPA enables analysis to be carried out directly on cell and blood lysates and on RNA targets. Thus, unlike a RT-MLPA, CLPA avoids the necessity of having to isolate the RNA, and then perform reverse transcription to make a cDNA copy prior to ligation. This shortens the time for achieving a result and provides a means to achieve faster analysis.
[0171] A further advantage of CLPA is that incorporation of a capture moiety on one probe enables a rapid and specific method for purification of the resulting ligation product from the crude sample free of all impurities and non-target nucleic acid materials, as described below for a biotin-labeled probe. This capability is particularly advantageous in applications where the target nucleic acid is found in the presence of a large excess of non-target nucleic acid, such as in detection of infectious agents (bacteria, fungi, viruses). In this case, the presence of large amounts of host nucleic acid requires use of a high-capacity extraction method, which in turn can result in inefficient amplification of the target nucleic acid due to large amounts of non-target nucleic acid and/or carry-over of inhibitory contaminants.
[0172] In another embodiment of this aspect of the invention, faster reaction times are further facilitated by driving the hybridization reaction with higher probe concentrations. Thus, for example, input probe sets may be incorporated in the CLPA reaction at relatively high concentrations, for example, approximately 100-fold higher than those typically used in an MLPA reaction. Elevating the probe concentration significantly reduces the time required for the hybridization step, typically from overnight to between about 15 minutes to about 1 hour.
[0173] When higher probe concentrations are used it is generally preferred to incorporate a purification step prior to amplification, especially for high multiplex analysis (e.g. greater than about 5 targets). In one embodiment of this aspect of this invention, a solid support based capture methodology can be employed including membrane capture, magnetic bead capture and/or particle capture. In a preferred embodiment, a biotin/streptavidin magnetic bead purification protocol is employed after ligation and prior to enzymatic amplification. In some instances, the magnetic particles can be directly added to the amplification master mix without interfering with the subsequent amplification reaction. In other instances, it is preferable to release the captured oligonucleotide from the beads and the released oligonucleotide solution is subsequently amplified without the capture particle or surface being present.
[0174] In a preferred embodiment, CLPA involves hybridization of a set of probes to a nucleic acid target sequences such that the probes can undergo self-ligation without addition of a ligase. After a ligation product is produced, amplification is generally preferred to facilitate detection and analysis of the product. For this purpose, probes are preferably designed to incorporate PCR primers such as, e.g. universal PCR primers. In a preferred embodiment, the universal primers are not added until after the ligation portion of the reaction is complete, and the primers are added after surface capture purification along with the polymerase, often as part of a PCR master mix.
[0175] The CLPA probes possess reactive moieties positioned such that when the CLPA probes are bound to the nucleic acid target, the reactive moieties are in close spatial orientation and able to undergo a ligation reaction without the addition of enzyme. In a preferred embodiment, the chemical ligation moieties are chosen so as to yield a ligated reaction product that can be efficiently amplified by the amplification enzyme which is often a DNA polymerase. Without being bound by theory, chemical ligation chemistries and probe set designs that produce reaction products that more closely resemble substrates that are known as being able to be amplified by DNA and RNA polymerases are more likely to yield efficient probe sets that can be used in the CLPA assay. Especially preferred reaction chemistries are chemical moieties that yield reaction products that closely resemble native DNA such as illustrated in Scheme 1 involving a reaction between a 3'-phosphorothioate and a 5' DABSYL leaving group. In another preferred embodiment, probes sets comprise a 3'-diphosphorothioate (Miller, G. P. et al, Bioorganic and Medicinal Chemistry, (2008) 16:56-64) and a 5'-DABSYL leaving group.
[0176] The CLPA probes also incorporate a stuffer sequence (also referred to herein as a variable spacer sequence) to adjust the length of the ligation product. As described further below, length variation provides a convenient means to facilitate analysis of ligation product(s). The stuffer can be located on either probe, though for convenience it is generally incorporated on the S probe (3'-phosphorothioate probe).
[0177] In one embodiment of this aspect of the invention, CLPA-CE, the stuffer sequence is varied in length in order to produce one or more variable length ligation products which provide the basis for detection and identification of specific target sequences based on length variation. In a preferred embodiment, variable length ligation products are analyzed by capillary electrophoresis (CE). Generally stuffer sequences are included such that the length of different ligation products varies in a range of at least 1 base pair to about 10 base pairs; preferably from 1 base pair to 4 base pairs. In a preferred embodiment, the length of the different ligation products vary from approximately 80 bp to about 400 bp; preferably in a range of about 100 bp to about 300 bp; more preferably in a range of about 100 bp to about 200 bp
[0178] In another embodiment, CLPA probes may also contain other optional element(s) to facilitate analysis and detection of a ligated product. For example, it is preferred that one of the probes for use in an embodiment herein referred to as CLPA-MDM incorporate an array binding sequence to bind to an appropriate capture sequence on a microarray platform. For CLPA-MDM, the different CLPA reaction products are not separated by size differences but by the differences in the array binding sequence. In this embodiment, the sequence of the array binding sequence is varied so that each CLPA probe will bind to a unique site on a DNA microarray. The length of the array binding sequence in CLPA-MDM usually varies from 15 to 150 bases, more specifically from 20 to 80 bases, and most specifically from 25 to 50 bases. In some embodiments, CLPA probes preferably also include other elements to facilitate purification and/or analysis including but not limited to labels such as fluorescent labels and hapten moieties such as, for example, biotin for purifying or detecting ligation product(s). For example, probes and/or ligation product(s) that incorporate biotin can be purified on any suitable avidin/streptavidin platform including beads. While biotin/avidin capture systems are preferred, other hapten systems (e.g. Digoxigenin (DIG) labeling) can be used, as can hybridization/oligonucleotide capture. Hybridization/oligonucleotide capture is a preferred method when it it desirable to release the capture product from the beads at a later stage. In addition to magnetic beads, anti-hapten labeled supports (filter paper, porous filters, surface capture) can be used.
[0179] CLPA probe-labeling can be on either probe, either at the end or internally. Preferably biotin is incorporated at the 5' end on the phosphorothioate (S-probe).
[0180] CLPA probes are generally incorporated in a reaction at a concentration of 250 nanomolar (nM) to 0.01 pM (picomolar) for each probe. Generally, the concentration is between about 1 nM to about 1 pM. Factors to consider when choosing probe concentration include the particular assay and the target being analyzed. The S-or phosphorothioate or Nucleophile probe and L- or leaving group or DABSYL containing probes are incorporated at a concentration that equals or exceeds the concentration of the target. Total concentration of S- and L-probes can reach as high as 10 micromolar (uM). As a non-limiting example, 1 nM for each S and L probe.times.250 CLPA probe pairs would equal 500 nm (1 nm per probe.times.2 probes per pair.times.250 targets) at 10 nM for each probe would mean a total concentration of 5 uM.
[0181] The target concentration usually ranges from about 10 micrograms of total RNA to about 10 nanograms, but it can be a little as a single copy of a gene.
[0182] In a preferred embodiment of CLPA technology, a CLPA probe set consists of 2 oligonucleotide probes with complementary reactive groups (FIGS. 1 and 2). In another embodiment, the CLPA probe set may consist of 3 or more probes that bind adjacent to each other on a target. In a preferred embodiment of the 3-probe CLPA reaction, the outer probes are designed to contain the enzymatic amplification primer binding sites, and the inner probe is designed to span the region of the target between the other probes. In a more preferred embodiment, the outer probes have non-complementary reactive groups such that they are unable to react with each other in the absence of the internal (middle) probe (FIG. 3). In some instances, both outer probes may have similar reactive moieties except that one group is at the 5' end of one probe and the 3'-end of the other probe, and the L-probe chemistries may also be similar to each other except for positioning on the probe. As is known to one who is skilled in the art, different chemical reagents and processes may be needed to manufacture the probes for the 3-probe CLPA reaction compared to the probes for the 2-probe CLPA system.
[0183] In a preferred embodiment of the 3-probe CLPA system, one outer probe contains a 3' phosphorothioate (3' S-probe), the other outer probe contains a 5'-phosphorothioate (5'-S-probe) and the center probe contains both a 3'- and a 5'-DABSYL leaving group. The manufacture of a 5'-DABSYL leaving group probes has been reported previously (Sando et al, J. Am. Chem. Soc., (2002), 124(10) 2096-2097). We recently developed a new DNA synthesis reagent that allows for the routine incorporation of a 3'-DABSYL leaving group (FIG. 4).
CLPA-CE
[0184] In one embodiment, CLPA ligation product(s) are detected by size differentiation capillary electrophoresis (CE) on a sieving matrix, or by slab gel electophoresis. A schematic representation for CLPA-CE is provided in FIG. 1. In this example, analysis is performed directly on a blood sample following cell lysis by any appropriate means including chemically, mechanically or osmotically, and addition of appropriately designed probes. In a preferred embodiment, chemical lysis of the cells is used. FIG. 6 provides a general schematic representation of the design of a probe set for CLPA-CE analysis. In this example the S probe is designed to include a universal PCR primer for subsequent amplification of ligation product(s); a stuffer sequence which is designed with a length that correlates with a specific target; and a target binding sequence. Likewise, the L-probe includes a target binding sequence and universal primer. The probes are usually labeled with a flurophore (FAM, Cy3, Cy5, etc), however they can also be detected without fluorescence labeling. The labeling is done by using a fluorescently labeled PCR primer.
[0185] In this example of CLPA-CE probes, the S probe also includes a biotin moiety at the 5' end to facilitate purification and removal of unligated probe. Following amplification of ligated product(s), each having a unique length, the reaction mixture is separated by CE, or other suitable size separation technique. The peak height or intensity of each product is a reflection of target sequence expression, i.e. level of target in the sample. (FIG. 1 and FIG. 7).
CLPA-MDM
[0186] In another embodiment of this aspect of the invention, CLPA ligation products are analyzed/detected by microarray analysis (CLPA-MDM). A schematic representation of CLPA-MDM is provided in FIG. 2. CLPA-MDM differs from CLPA-CE in at least the following respects. First, the probe sets differ in design. For example, a general representation of a CLPA- MDM probe set is depicted in FIG. 2. As with CLPA-CE probes, CLPA-MDM probe sets can include universal primers for amplification of ligation product(s). They also include target specific sequences, as well as ligation moieties for enzyme-independent ligation. Additionally, CLPA-MDM probes also may include a stuffer sequence, however the purpose of this stuffer sequence is to adjust the size of the CLPA-MDM to the same length in an effort to standardize enzymatic amplification efficiency. Normalization of amplicon size is not a requirement but a preferred embodiment. A second difference between the design of CLPA-CE and CLPA-MDM probe sets is that the latter include a unique array binding sequence for use with an appropriate microarray platform.
[0187] In respect of the CLPA-MDM aspect of the invention, a microarray binding site (ABS sequence) is incorporated into the probe designs for use with a "universal" microarray platform for the detection. Similar to the CLPA-CE system, probes are preferably labeled with a fluorophore, for example by using a fluorescently labeled PCR primer. Alternatively, for example, a sandwich assay labeling technique can be used for the final read-out. Sandwich assays involve designing the probes with a common (generic) label binding site (LBS) in place or in addition to the stuffer sequence and using a secondary probe that will bind to this site during the array hybridization step. This methodology is particularly useful when it is desirable to label the arrays with a chemiluminescent system like a horse radish peroxidase (HRP) labeled oligonucleotide, or with an electrochemical detection system. Generally, planar microarrays are employed (e.g. microarrays spotted on glass slides or circuit board) for the read-out. However, bead microarrays such as those available from Luminex and Illumina can also be used (e.g. Luminex xMAP/xtag).
EXAMPLE 1
Quantitative Multiplex Detection of 5 Targets
[0188] Multiplex CLPA reactions were performed using five (5) DNA target mimics (corresponding to portions of the MOAP1 (SEQ ID NO:5), PCNA (SEQ ID NO:9), DDB2 (SEQ ID NO:12), BBC3 (SEQ ID NO:16) and BAX (SEQ ID NO:19) genes) combined in one reaction in the presence of their respective CLPA probes (Table 1) (S and L probes at 1 nM each). The target mimics were pooled in different concentration as shown in Table 2. The target mimics, S probes and L probes were incubated in PCR buffer (1.times. PCR buffer is 1.5 mM MgCL2, 50 mM KCl, 10 mM Tris-HCl pH8.3) for 1 hour at 50 C. A 1 ul aliquot of each reaction mixture was used as template for PCR amplification using Dynamo SYBR green PCR mix in the presence of Universal Primers (SEQ ID NOS 1 and 2, 300 nM). The samples were PCR cycled for 27 cycles (95 C 15 min followed by 27 cycles of 95 C (10 s), 60 C (24 s), 72 C (10 s). After PCR amplification, the samples were denatured and injected into an ABI 3130 DNA sequencer (capillary electrophoresis instrument). The CE trace from the ABI for the 3 samples as well as a plot of the peak versus target mimic concentration of PCNA is shown in FIG. 7 and a plot of the linear response of the signal of PCNA as a function on input concentration is shown in FIG. 8.
TABLE-US-00001 TABLE 1 Probe and target sequence information. SEQ Amplicon ID Name Sequence Detail Size 1 Forward PCR Primer FAM-GGGTTCCCTAAGGGTTGGA 2 Reverse PCR Primer GTGCCAGCAAGATCCAATCTAGA 3 MOAP1-L LTACATCCTTCCTAGTCAATTACACTCTAGATTGGA 47 TCTTGCTGGCAC 4 MOAP1-S 5'-Biotin- 41 GGGTTCCCTAAGGGTTGGATAGGTAAAT GGCAGTGTAGAACS Ligated MOAP1 Amplicon 88 5 MOAP1-Target GTGTAATTGACTAGGAAGGATGTAGTTCTACACTG mimic CCATTTACCTA 6 MOAP1-RNA Target GUGUAAUUGACUAGGAAGGAUGUAGUUCUACAC mimic UGCCAUUUACCUA 7 PCNA-L LTGGTTTGGTGCTTCAAATACTCTCTAGATTGGATC 45 TTGCTGGCAC 8 PCNA-S Biotin- 63 GGGTTCCCTAAGGGTTGGATCGAGTCTACAGATCC CCAACTTTCATAGTCTGAAACTTTCTCCS Ligated PCNA Amplicon 108 9 PCNA-Target Mimic AGTATTTGAAGCACCAAACCAGGAGAAAGTTTCA GACTATGA 10 DDB2-L LTAGCAGACACATCCAGGCTCTAGATTGGATCTTG 51 CTGGCAC 11 DDB2-S Biotin- 49 GGGTTCCCTAAGGGTTGGATCGAGTCTACTCCAAC TTTGACCACCATTCGGCTACS Ligated DDB2 Amplicon 96 12 DDB2-Target Mimic GCCTGGATGTGTCTGCTAGTAGCCGAATGGTGGTC A 13 DDB2-RNA Target GCCUGGAUGUGUCUGCUAGUAGCCGAAUGGUGG Mimic UCA 14 BBC3-L LTCCGAGATTTCCCCCTCTAGATTGGATCTTGCTGG 38 CAC 15 BBC3-S Biotin- 37 GGGTTCCCTAAGGGTTGGATCCCAGACTCCTCCCT CTS Ligated BBC3 Amplicon 75 16 BBC3-Target Mimic GGG GGA AAT CTC GGA AGA GGG AGG AGT CTG GG 17 BAX-L LTCACGGTCTGCCACGCTCTAGATTGGATCTTGCTG 39 GCAC 18 BAX-S Biotin-GGGTTCCCTAAGGGTTGGA TGA GTC TAC 53 ATGA TC CT TCCCGCCACAAAGATGGS Ligated BAX Amplicon 92 19 BAX-Target Mimic CGTGGCAGACCGTGACCATCTTTGTGGCGGGA 20 3-phosphorothioate Biotin- 51 GAPDH GGGTTCCCTAAGGGTTGGACGGACGCCTGCTTCAC CACCTTCTTGATGTCAS 21 Middle 2L probe LTCATATTTGGCAGGTTTTTCTAGACGGCAGGTL 32 GAPDH 22 5'-phosphorothioate SCAGGTCCACCACTGACACGTTGGCAGTTCTAGAT 50 GAPDH TGGATCTTGCTGGCAC Ligated 3-probe amplicon 133 24 GAPDH Target ACT GCC AAC GTG TCA GTG GTG GAC CTG ACC Mimic TGC CGT CTA GAA AAA CCT GCC AAA TAT GAT GAC ATC AAG AAG GTG GTG AAG CAG GCG TC 25 GAPDH 3-L LTTTTCTAGACGGCAGGTCAGGTCCACCAGATGAT CGACGAGACACTCTCGCCATCTAGATTGGATCTTG CTGGCAC 26 GAPDH 3-S GGGTTCCCTAAGGGTTGGACGGACCAACTCCTCGC CATATCATCTGTACACCTTCTTGATGTCATCATATT TGGCAGGTS 27 GAPDH-3-FAM/BHQ-1 (FAM)ccaactcctcgccatatcatctgtacaccttc Taqman Probe ttg(BHQ-1) 28 GAPDH 4-L LTGCTGATGATCTTGAGGCTGTTGTCATACTGATG ATCGACGAGACACTCTCGCCATCTAGATTGGATCT TGCTGGCAC 29 GAPDH-4-S GGGTTCCCTAAGGGTTGGACGATGGAGTTGATGCT GACGGAAGTCATAGTAAGCAGTTGGTGGTGCAGG AGGCATS 30 GAPDH-4-QUASAR (Quasar 670)tgctgacggaagtcatagtaagca 670/BHQ-2 Taqman gttggt(BHQ-2) Probe 31 PCNA 2-L LTCCTTGAGTGCCTCCAACACCTTCTTGAGGATGAT CGACGAGACACTCTCGCCATCTAGATTGGATCTTG CTGGCAC 32 PCNA 2-S GGGTTCCCTAAGGGTTGGACGGTACAACAAGACCC AGCTGACGACTCTTAATATCCCAGCAGGCCTCGTT GATGAGGS 33 PCNA 2-Cal Fluor (CAL Red 610)ctgacgactcttaatatcccagc Orange 560/BHQ-1 aggcctcgtt(BHQ-2) 34 DDB2-2-L LTTAGTTCCAAGATAACCTTGGTTCCAGGCTGATG ATCGACGAGACACTCTCGCCATCTAGATTGGATCT TGCTGGCAC 35 DDB2-2-S BiotinGGGTTCCCTAAGGGTTGGACGTTAGACGCCA ATAGGAGTTTCACTGGTGGCTACCACCCACTGAGA GGAGAAAAGTCATS 36 DDB2-2-(CAL Fluor (Cal Orange 560)cgccaataggagtttcact Orange 560/BHQ-1 ggtggctacca(BHQ-2) L = DABSYL ligation moiety S = phosphorothiate moiety
TABLE-US-00002 TABLE 2 Sample Concentrations Sample Target Mimic Concentrations 1 All Target mimics at 10 pM final Concentration 2 MOAP1, DDB2 and BBC3 at 10 pM, PCNA at 5 pM and BAX at 2 pM 3 MOAP1, DDB2 and BBC3 at 10 pM, PCNA at 1 pM and BAX at 0.5 pM
EXAMPLE 2
CLPA Reactions Using MOAP1 and DDB2 DNA and RNA Target Mimics
[0189] Reactions were prepared in duplicate as presented in Table 3 using DNA or RNA target mimics for the MOAP1 and DDB2 genes and CLPA probes sets designed to target the sequences. The probe numbers refer to the SEQ ID NOs in Table 1. The reagents were added in the concentrations and volumes shown in Table 4. The respective S-probe, L-probe and target mimic were heated to 50.degree. C. for 60 minutes in a 0.2 mL PCR tube, after which 2.5 .mu.l of the CLPA reaction was used as template in a real-time PCR reaction with 40 amplification cycles. Real-time PCR data was averaged for the duplicate samples and is presented in Table 3 (Ct value column). Minimal differences in Ct value between RNA and DNA target mimics were observed indicating similar probe ligation efficiency on RNA and DNA substrates.
TABLE-US-00003 TABLE 3 CLPA Probe Sets. L-Probe S-Probe Target Mimic (1 nM) (1 nM) (10 pM) Ct Sample Identifier SEQ ID NO SEQ ID NO SEQ ID NO value 1 MOAP-1 3 4 5 19.5 DNA 2 MOAP-1 3 4 6 20 RNA 3 DDB2 10 11 12 21 DNA 4 DDB2 10 11 13 21 RNA
TABLE-US-00004 TABLE 4 Reagent table-Example 1 1X PCR Buffer Buffer* 12.5 ul S-Probe (1 nM) & L-Probe (1 nM) 2.5 ul each Target Mimic (100 pM) 2.5 ul Water 5.0 ul Heat at 50 C. for 1 hour *1X PCR buffer is 1.5 mM MgCL2, 50 mM KCl, 10 mM Tris-HCl pH 8.3
EXAMPLE 3
Direct Analysis of DDB2 RNA Transcripts in Lysis Buffer and Lysed Blood
[0190] DDB2 messenger RNA (mRNA) was prepared using a in-vitro transcription kit from Ambion and a cDNA vector plasmid from Origene (SC122547). The concentration of mRNA was determined using PicoGreen RNA assay kit from invitrogen. The DDB2 probe sets (Table 5) were tested with different concentrations of DDB2 mRNA transcript spiked into either water or whole blood. The reactions mixture components are listed in Table 5. Samples 1-4 consisted of DDB2 transcript at 10 ng, 1 ng, 0.1 ng and 0.01 ng in water, and samples 5-8 consisted of the same concentration range spiked into whole blood. Similar reactions protocols were followed with the exception of adding Proteinase K to the blood samples so as to reduce protein coagulation. The procedure is as follows: The reagents were added in the concentrations and volumes in Table 5. The S-probes, mRNA transcript, Guanidine hydrochloride lysis buffer and either water (samples 1-4) or whole blood (samples 5-8) were heated to 80.degree. C. for 5 minutes and then they were moved to a 55.degree. C. heat block. The L-probe, wash buffer, streptavidin beads and proteinase K were added, and the reaction was incubated at 55.degree. C. for 60 minutes. The samples were removed from the heat block and the magnetic beads were captured using a dynal MPC 96S magnetic capture plate. The supernatant was removed and the beads were washed 3 times with wash buffer. DyNamo SYBR green PCR master mix (25 ul, 1.times.) and universal primers (SEQ ID NOS 1 and 2, 300 nM) were added to the beads and samples were heat cycled using a Stratagene MX4000 realtime PCR instrument for 30 cycles (95.degree. C. for 15 minutes, 30 cycles 95.degree. C. (10 s), 60.degree. C(24 s), 72.degree. C(10 s)). The Ct values were recorded and the amplified samples were injected into an Agilent Bioanalyzer 2100 so as to verify the length of the amplicons. All amplicons showed the correct size (.about.96 bp) and the performance was comparable for the blood and water samples demonstrating the ability to directly analyze RNA in lysed blood. The results are summarizes in Table 7 below.
TABLE-US-00005 TABLE 5 CLPA Probe Sets. Sample Identifier L-Probe (1 nM) S-Probe (1 nM) RNA Transcript 1-8 DDB2 SEQ ID NO: SEQ ID NO: Origene Plasmid 10 11 SC122547
TABLE-US-00006 TABLE 6 DDB2 reaction mixture. Samples 1-4 5-8 GuHCL Lysis Buffer (2X) 12.5 .mu.l 12.5 .mu.l S-Probe (5 nM) 1 .mu.l 1 .mu.l RNA Transcript (10 ng/ul to 1 .mu.l 1 .mu.l 0.01 ng/ul) Whole Blood 0 .mu.l 12.5 .mu.l Water 12.5 ul 0 .mu.l Heat 80.degree. C. for 5 min, chill on ice Wash Buffer 20 .mu.l 15 .mu.l L-Probe (5 nM) 1 .mu.l 1 .mu.l Dynal M-270 Beads 2 .mu.l 2 .mu.l Proteinase K (10 mg/ml) 0 .mu.l 5 .mu.l Total 50 .mu.l 50 .mu.l Incubate 55.degree. C. for 60 min. a) GuHCL lysis buffer (1X) is 3M GUHCL, 20 mM EDTA, 5 mM DTT, 1.5% Triton, 30 mM Tris pH 7.2). b) Wash Buffer is 100 mM Tris (pH 7.4), 0.01% Triton.
TABLE-US-00007 TABLE 7 Summary results of water versus blood Assay DDB2 Conc Ct value Sample 1 10 ng 13.5 Water 2 1 ng 17 Water 3 0.1 ng 20.2 Water 4 0.01 ng 24 Water 5 10 ng 13.5 Blood 6 1 ng 16 Blood 7 0.1 ng 19.2 Blood 8 0.01 ng 23.5 Blood
EXAMPLE 4
3-probe CLPA-CE assay
[0191] Reactions were prepared in duplicate as presented in Table 8 using DNA target mimic probe SEQ ID NO 23 and the 3-probe CLPA probe set (SEQ ID NOS 20, 21 and 22). The probe numbers refer to the SEQ ID NOS in Table 1. The reagents were added in the concentrations and volumes in Table 9. The S-probes, L-probe and target mimics were heated to 50.degree. C. for 60 minutes in a 0.2 mL PCR tube, after which 2.5 .mu.l of the CLPA reaction was used as template in a Dynamo SYBR green PCR reaction with 25 amplification cycles. Real-time PCR data was averaged for the duplicate samples and is presented in Table 8 (Ct value column). A 1 .mu.l sample of each reaction was then analyzed via Agilent Bioanalyzer 2100 to determine the size of the reaction product.
TABLE-US-00008 TABLE 8 CLPA Probe Sets. 3'-S 2L- 5'-S Target probe Probe Probe Mimic Ampli- Sam- Identi- SEQ SEQ SEQ SEQ con Ct ples fier ID NO ID NO ID NO ID NO size value 1&2 GAPDH 20 21 22 23 About 16.3 135 bp 3&4 Negative 20 21 22 23 None No ob- CT served Probes at 1 nM concentration; target mimic at 10 pM concentration.
TABLE-US-00009 TABLE 9 Reagent table-Example 1 1X PCR Buffer Buffer* 12.5 .mu.l 3 and 5' S-Probe (10 nM) & 2L-Probe (10 nM) 2.5 .mu.l each Target Mimic (1 nM) 2.5 .mu.l Water 2.5 .mu.l Heat at 50 C. for 1 hour *1X PCR buffer is 1.5 mM MgCL2, 50 mM KCl, 10 mM Tris-HCl pH 8.3
EXAMPLE 5
Multiplex Real-Time CLPA Detection of mRNA
[0192] In a 0.2 ml PCR tube was added 4 sets of CLPA reagents that were engineered to possess unique binding sites for different color dual labeled probes. The reactions were prepared as indicated in Table 10 and Table 11. The CLPA probes sets and dual labeled probes correspond to SEQ ID NOS 25 through 36 in Table 1. The S and run-off transcript mRNA (GAPDH, PCNA and DDB2) were added to 2.times. lysis buffer (GuHCL lysis buffer (1.times.) is 3M GUHCL, 20 mM EDTA, 5 mM DTT, 1.5% Triton, 30 mM Tris pH 7.2) and heated to 80.degree. C. for 5 min. The samples were cooled on ice and streptavidin coated magnetic beads (DYNAL M-270) and L-probe were added. The samples were heated at 50.degree. C. for 1 hour. The magnetic beads were captured on a DYNAL MPC plate and washed twice with wash buffer. The beads were recaptured and dynamo PCR 1.times. mastermix was added with the 4 different dual labeled probes and universal PCR primers (25 ul total volume). The samples were heat cycled using a Stratagene MX4000 realtime PCR instrument for 30 cycles (95.degree. C. for 15 minutes, 30 cycles 95.degree. C. (10 s), 60.degree. C. (24 s), 72.degree. C. (10 s)) with proper filters for monitoring the fluorescence in the FAM, Cal Fluor orange 560, Cal Fluor Red 610, and Quasar 670 channels. The Ct values observed for each channel were recorded and are indicated in Table 10.
TABLE-US-00010 TABLE 10 Multiplex reagents used in Example 5. S Probes L Probes (25 pM) (25 pM) Ct(FAM)- Ct(560)- Ct(610)- Ct(670)- Samples SEQ ID NOs SEQ ID NOs Targets GAPDH3 DDB2 PCNA GAPDH4 1 & 2 26, 29, 25, 28, 250 ng yeast tRNA; 25.5 24.5 24.8 25.8 32, 35 31, 34 40 pg GAPDH(Origene SC118869), 40 pg PCNA (SC118528), 40 pg DDB2 (SC122547) mRNA 3 & 4 26, 29, 25, 28, 250 ng yeast tRNA No Ct No Ct No Ct No Ct 32, 35 31, 34 (negative) 5 & 6 26, 29, 25, 28, 250 ng yeast tRNA; 22.1 24.5 22.1 22.2 32, 35 31, 34 40 pg GAPDH(Origene SC118869), 40 pg PCNA (SC118528), 40 pg DDB2 (SC122547) mRNA 7 & 8 26, 29, 25, 28, 250 ng yeast tRNA No Ct No Ct No Ct No Ct 32, 35 31, 34 (negative)
TABLE-US-00011 TABLE 11 Additional reagents used in Example 5. GuHCL Lysis Buffer (2X) 12.5 .mu.l S-Probes (0.25 nM Stock of each) 5 .mu.l mRNAs (250 ng tRNA +/- mRNAs) 5 .mu.l Water 2.5 .mu.l Heat 80.degree. C. for 5 min, chill on ice Water 18 .mu.l L-Probes (0.25 nm stock of each) 5 .mu.l Beads 2 .mu.l Total 50 .mu.l Incubate 50.degree. C. 1 Hour
Sequence CWU 1
1
35119DNAArtificial SequenceDescription of Artificial primer
sequence synthetic 1gggttcccta agggttgga 19223DNAArtificial
SequenceDescription of Artificial primer sequence synthetic
2gtgccagcaa gatccaatct aga 23347DNAArtificial SequenceDescription
of Artificial probe sequence synthetic 3tacatccttc ctagtcaatt
acactctaga ttggatcttg ctggcac 47441DNAArtificial
SequenceDescription of Artificial sequence syntheticprobe
4gggttcccta agggttggat aggtaaatgg cagtgtagaa c 41546DNAArtificial
SequenceDescription of Artificial sequence syntheticoligonucleotide
5gtgtaattga ctaggaagga tgtagttcta cactgccatt taccta
46646RNAArtificial SequenceDescription of Artificial sequence
synthetic oligonucleotide 6guguaauuga cuaggaagga uguaguucua
cacugccauu uaccua 46745DNAArtificial SequenceDescription of
Artificial sequence syntheticprobe 7tggtttggtg cttcaaatac
tctctagatt ggatcttgct ggcac 45863DNAArtificial SequenceDescription
of Artificial sequence synthetic probe 8gggttcccta agggttggat
cgagtctaca gatccccaac tttcatagtc tgaaactttc 60tcc
63942DNAArtificial SequenceDescription of Artificial Sequence
syntheticoligonucleotide 9agtatttgaa gcaccaaacc aggagaaagt
ttcagactat ga 421041DNAArtificial SequenceDescription of Artificial
Sequence syntheticprobe 10tagcagacac atccaggctc tagattggat
cttgctggca c 411155DNAArtificial SequenceDescription of Artificial
Sequence synthetic probe 11gggttcccta agggttggat cgagtctact
ccaactttga ccaccattcg gctac 551236DNAArtificial SequenceDescription
of Artificial Sequence syntheticoligonucleotide 12gcctggatgt
gtctgctagt agccgaatgg tggtca 361336RNAArtificial
SequenceDescription of Artificial Sequence synthetic
oligonucleotide 13gccuggaugu gucugcuagu agccgaaugg ugguca
361438DNAArtificial SequenceDescription of Artificial probe
sequence synthetic 14tccgagattt ccccctctag attggatctt gctggcac
381537DNAArtificial SequenceDescription of Artificial probe
sequence synthetic 15gggttcccta agggttggat cccagactcc tccctct
371632DNAArtificial SequenceDescription of Artificial
oligonucleotide sequence synthetic 16gggggaaatc tcggaagagg
gaggagtctg gg 321739DNAArtificial SequenceDescription of Artificial
probe sequence synthetic 17tcacggtctg ccacgctcta gattggatct
tgctggcac 391853DNAArtificial SequenceDescription of Artificial
probe sequence synthetic 18gggttcccta agggttggat gagtctacat
gatccttccc gccacaaaga tgg 531932DNAArtificial SequenceDescription
of Artificial Sequence syntheticoligonucleotide 19cgtggcagac
cgtgaccatc tttgtggcgg ga 322051DNAArtificial SequenceDescription of
Artificial Sequence synthetic probe 20gggttcccta agggttggac
ggacgcctgc ttcaccacct tcttgatgtc a 512132DNAArtificial
SequenceDescription of Artificial Sequence synthetic probe
21tcatatttgg caggtttttc tagacggcag gt 322250DNAArtificial
SequenceDescription of Artificial Sequence synthetic probe
22caggtccacc actgacacgt tggcagttct agattggatc ttgctggcac
502389DNAArtificial SequenceDescription of Artificial sequence
synthetic oligonucleotide 23actgccaacg tgtcagtggt ggacctgacc
tgccgtctag aaaaacctgc caaatatgat 60gacatcaaga aggtggtgaa gcaggcgtc
892476DNAArtificial SequenceDescription of Artificial sequence
syntheticprobe 24ttttctagac ggcaggtcag gtccaccaga tgatcgacga
gacactctcg ccatctagat 60tggatcttgc tggcac 762579DNAArtificial
SequenceDescription of Artificial sequence synthetic probe
25gggttcccta agggttggac ggaccaactc ctcgccatat catctgtaca ccttcttgat
60gtcatcatat ttggcaggt 792635DNAArtificial SequenceDescription of
Artificial sequence syntheticprobe 26ccaactcctc gccatatcat
ctgtacacct tcttg 352778DNAArtificial SequenceDescription of
Artificial sequence synthetic probe 27tgctgatgat cttgaggctg
ttgtcatact gatgatcgac gagacactct cgccatctag 60attggatctt gctggcac
782875DNAArtificial SequenceDescription of Artificial Sequence
synthetic probe 28gggttcccta agggttggac gatggagttg atgctgacgg
aagtcatagt aagcagttgg 60tggtgcagga ggcat 752930DNAArtificial
SequenceDescription of Artificial Sequence syntheticprobe
29tgctgacgga agtcatagta agcagttggt 303077DNAArtificial
SequenceDescription of Artificial Sequence syntheticprobe
30tccttgagtg cctccaacac cttcttgagg atgatcgacg agacactctc gccatctaga
60ttggatcttg ctggcac 773177DNAArtificial SequenceDescription of
Artificial Sequence synthetic probe 31gggttcccta agggttggac
ggtacaacaa gacccagctg acgactctta atatcccagc 60aggcctcgtt gatgagg
773233DNAArtificial SequenceDescription of Artificial Sequence
syntheticprobe 32ctgacgactc ttaatatccc agcaggcctc gtt
333378DNAArtificial SequenceDescription of Artificial Sequence
syntheticprobe 33ttagttccaa gataaccttg gttccaggct gatgatcgac
gagacactct cgccatctag 60attggatctt gctggcac 783479DNAArtificial
SequenceDescription of Artificial Sequence syntheticprobe
34gggttcccta agggttggac gttagacgcc aataggagtt tcactggtgg ctaccaccca
60ctgagaggag aaaagtcat 793530DNAArtificial SequenceDescription of
Artificial Sequence syntheticprobe 35cgccaatagg agtttcactg
gtggctacca 30
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.