Secure Broker-Mediated Data Analysis and Prediction
Ceulemans; Hugo ; et al.
U.S. patent application number 15/722742 was filed with the patent office on 2019-04-04 for secure broker-mediated data analysis and prediction. This patent application is currently assigned to IMEC VZW. The applicant listed for this patent is IMEC VZW, Janssen Pharmaceutica NV, Katholieke Universiteit Leuven, KU LEUVEN R&D. Invention is credited to Adam Arany, Hugo Ceulemans, Charlotte Herzeel, Yves Jean Luc Moreau, Jaak Simm, Wilfried Verachtert, Roel Wuyts.
| Application Number | 20190102670 15/722742 |
| Document ID | / |
| Family ID | 63862100 |
| Filed Date | 2019-04-04 |





View All Diagrams
| United States Patent Application | 20190102670 |
| Kind Code | A1 |
| Ceulemans; Hugo ; et al. | April 4, 2019 |
Secure Broker-Mediated Data Analysis and Prediction
Abstract
The present disclosure relates to secure broker-mediated data analysis and prediction. One example embodiment includes a method. The method includes receiving, by a managing computing device, a plurality of datasets from client computing devices. The method also includes computing, by the managing computing device, a shared representation based on a shared function having one or more shared parameters. Further, the method includes transmitting, by the managing computing device, the shared representation and other data to the client computing devices. In addition, the method includes, based on the shared representation and the other data, the client computing devices update partial representations and individual functions with one or more individual parameters. Still further, the method includes determining, by the client computing devices, feedback values to provide to the managing computing device. Additionally, the method includes updating, by the managing computing device, the one or more shared parameters based on the feedback values.
| Inventors: | Ceulemans; Hugo; (Bertem, BE) ; Wuyts; Roel; (Boortmeerbeek, BE) ; Verachtert; Wilfried; (Keerbergen, BE) ; Simm; Jaak; (Leuven, BE) ; Arany; Adam; (Leuven, BE) ; Moreau; Yves Jean Luc; (Heverlee, BE) ; Herzeel; Charlotte; (Leuven, BE) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assignee: | IMEC VZW Leuven BE Janssen Pharmaceutica NV Beerse BE Katholieke Universiteit Leuven, KU LEUVEN R&D Leuven BE |
||||||||||
| Family ID: | 63862100 | ||||||||||
| Appl. No.: | 15/722742 | ||||||||||
| Filed: | October 2, 2017 |
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06F 21/6218 20130101; G16C 20/30 20190201; G06F 21/6245 20130101; G06N 3/084 20130101; G06N 3/04 20130101; G16H 10/60 20180101; G06N 3/0427 20130101; G16C 20/70 20190201 |
| International Class: | G06N 3/04 20060101 G06N003/04; G06N 3/08 20060101 G06N003/08 |
Claims
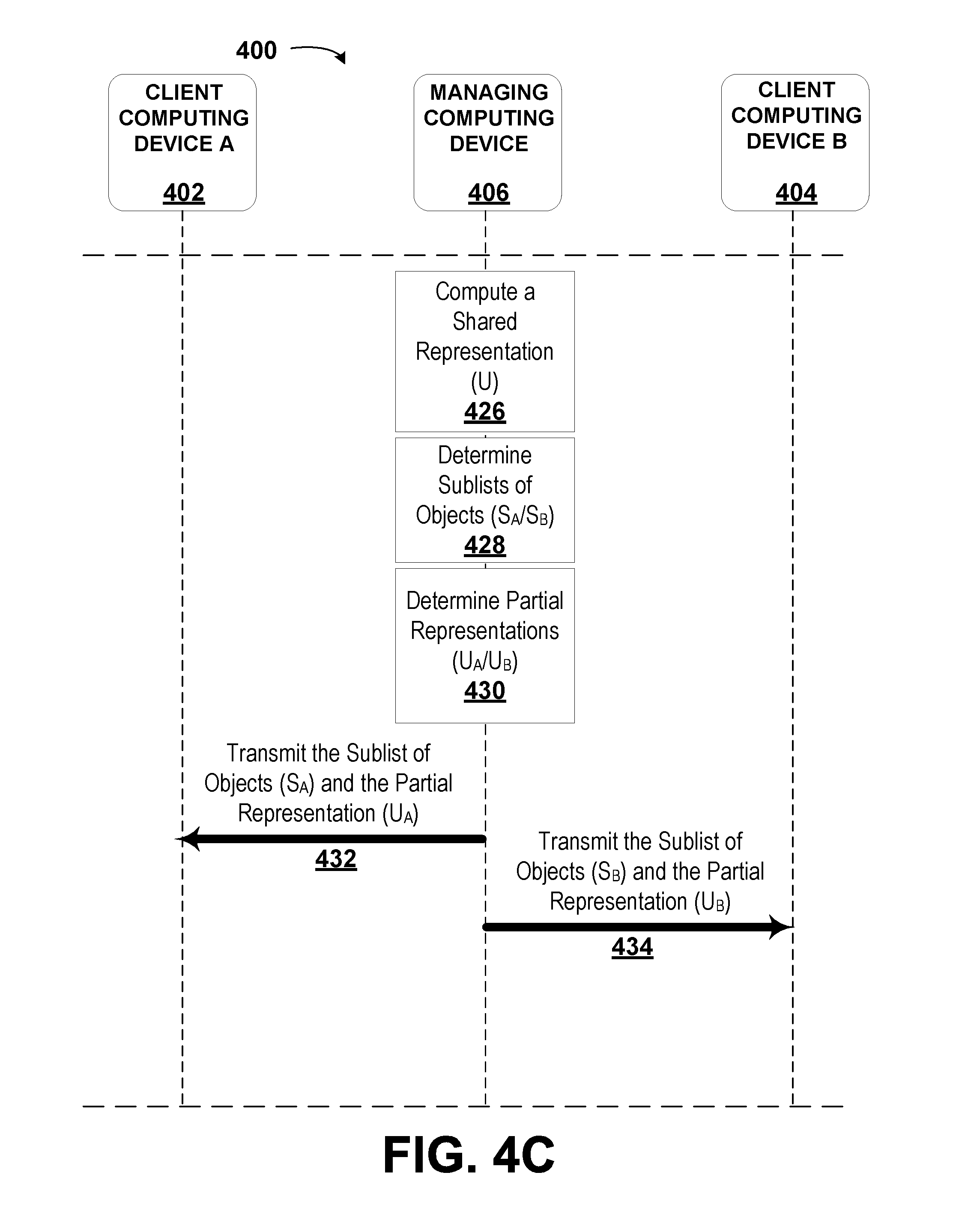
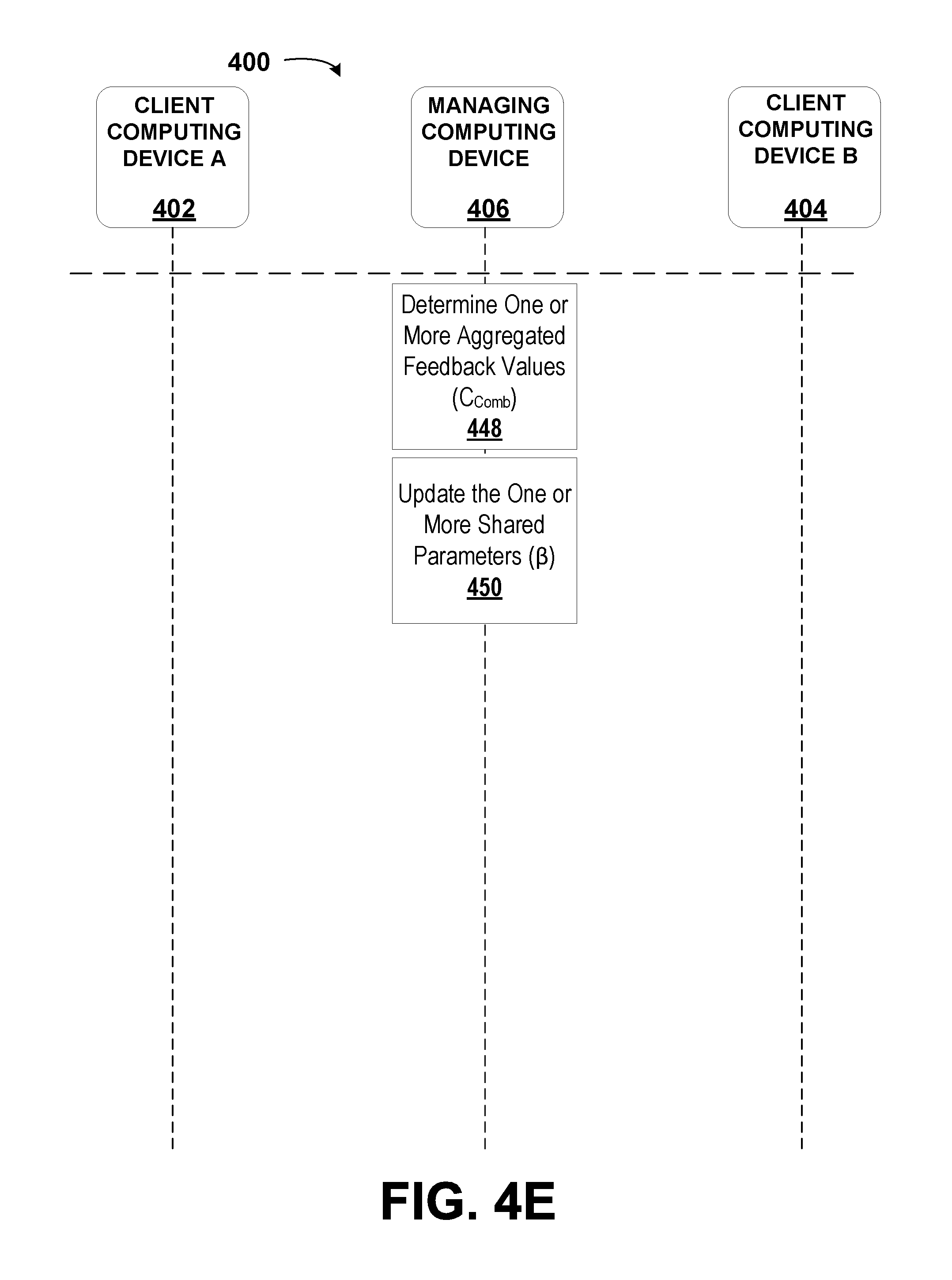
1. A method, comprising: receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, and wherein each dataset comprises objects; determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; determining, by the managing computing device, a list of unique objects from among the plurality of datasets; selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; transmitting, by the managing computing device, to each of the client computing devices: the sublist of objects for the respective dataset; and the partial representation for the respective dataset; receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset; updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; and updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values.
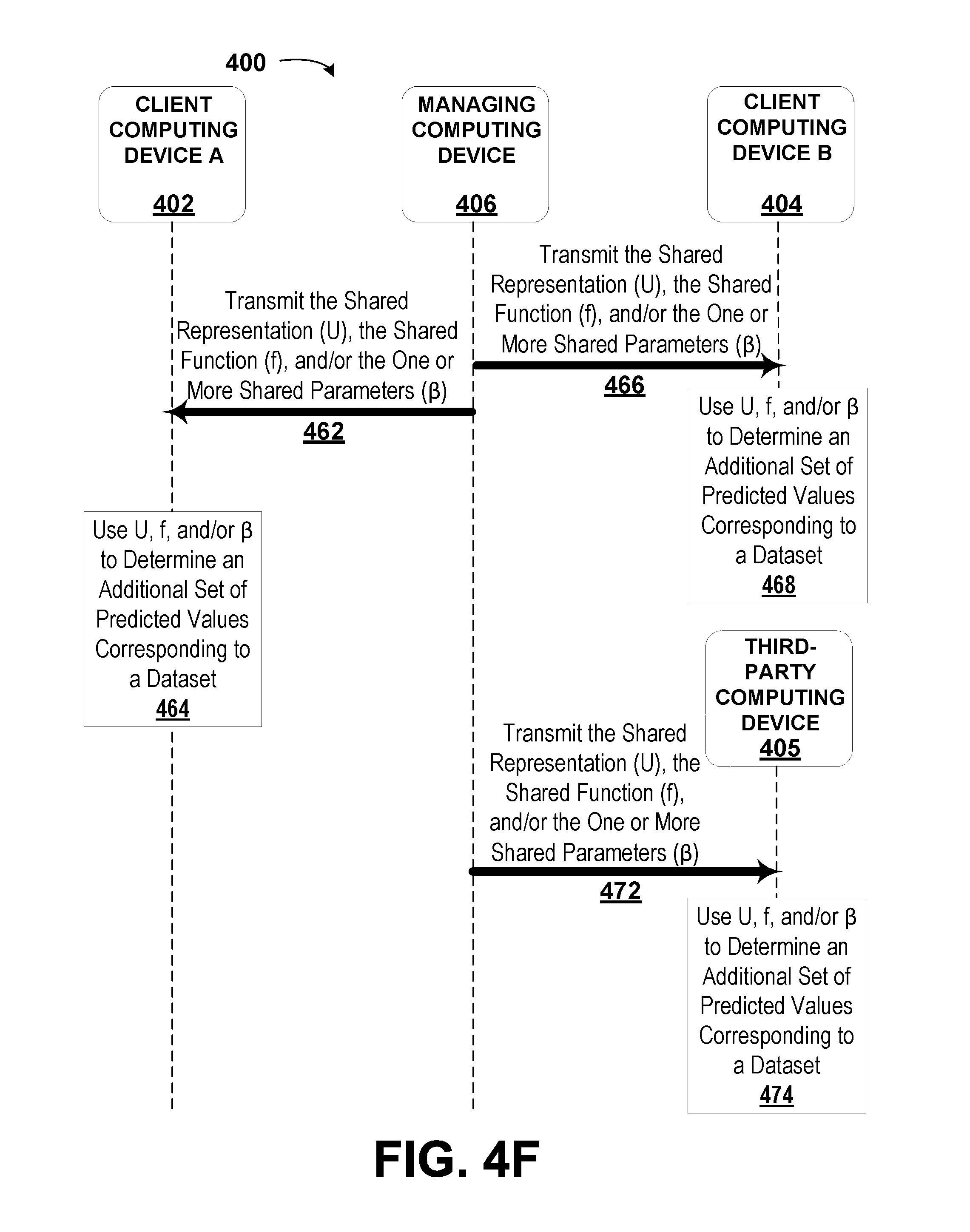
2. The method of claim 1, further comprising transmitting, by the managing computing device, the shared function and the one or more shared parameters to each of the client computing devices.
3. The method of claim 1, wherein determining, by the managing computing device, the list of unique objects from among the plurality of datasets comprises: creating, by the managing computing device, a composite list of objects that is a combination of the objects from each dataset; and removing, by the managing computing device, duplicate objects from the composite list of objects based on an intersection of the lists of identifiers for each of the plurality of datasets.
4. The method of claim 1, wherein determining the error for the respective dataset comprises: identifying, by the respective client computing device, which of the non-empty entries in the set of recorded values corresponding to the respective dataset corresponds to an object in the sublist of objects; determining, by the respective client computing device, a partial error value for each of the identified non-empty entries in the set of recorded values corresponding to the respective dataset by applying the individual loss function between each identified non-empty entry and its corresponding predicted value in the set of predicted values corresponding to the respective dataset; and combining, by the respective client computing device, the partial error values.
5. The method of claim 1, further comprising: calculating, by the managing computing device, a final shared representation of the datasets based on the list of unique objects, the shared function, and the one or more shared parameters; and transmitting, by the managing computing device, the final shared representation of the datasets to each of the client computing devices.
6. The method of claim 5, wherein the final shared representation of the datasets is usable by each of the client computing devices to determine a final set of predicted values corresponding to the respective dataset.
7. The method of claim 6, wherein determining the final set of predicted values corresponding to the respective dataset comprises: receiving, by the respective client computing device, the sublist of objects for the respective dataset; determining, by the respective client computing device, a final partial representation for the respective dataset based on the sublist of objects and the final shared representation; and determining, by the respective client computing device, the final set of predicted values corresponding to the respective dataset based on the final partial representation, the individual function, and the one or more individual parameters corresponding to the respective dataset.
8. The method of claim 1, wherein the one or more feedback values from each of the client computing devices are based on back-propagated errors.
9. The method of claim 1, wherein each of the plurality of datasets comprises an equal number of dimensions.
10. The method of claim 1, wherein each of the plurality of datasets is represented by a tensor, and wherein at least one of the plurality of datasets is represented by a sparse tensor.
11. The method of claim 1, further comprising: selecting, by the managing computing device, an additional subset of identifiers from the composite list of identifiers; determining, by the managing computing device, an additional subset of the list of unique objects corresponding to each identifier in the additional subset of identifiers; computing, by the managing computing device, a revised shared representation of the datasets based on the additional subset of the list of unique objects and the shared function having the one or more shared parameters; determining, by the managing computing device, additional sublists of objects for the respective dataset of each client computing device based on an intersection of the additional subset of identifiers with the list of identifiers for the respective dataset; determining, by the managing computing device, a revised partial respective for the respective dataset of each client computing device based on the additional sublist of objects for the respective dataset and the revised shared representation; transmitting, by the managing computing device, to each of the client computing devices: the additional sublist of objects for the respective dataset; and the revised partial representation for the respective dataset; receiving, by the managing computing device, one or more revised feedback values from at least one of the client computing devices, wherein the one or more revised feedback values are determined by the client computing devices by: determining, by the respective client computing device, a revised set of predicted values corresponding to the respective dataset, wherein the revised set of predicted values is based on the revised partial representation and the individual function with the one or more individual parameters corresponding to the respective dataset; determining, by the respective client computing device, a revised error for the respective dataset based on the individual loss function for the respective dataset, the revised set of predicted values corresponding to the respective dataset, the additional sublist of objects, and the non-empty entries in the set of recorded values corresponding to the respective dataset; updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and determining, by the respective client computing device, the one or more revised feedback values, wherein the one or more revised feedback values are used to determine a change in the revised partial representation that corresponds to an improvement in the set of predicted values; determining, by the managing computing device, based on the additional sublists of objects and the one or more revised feedback values, one or more revised aggregated feedback values; updating, by the managing computing device, the one or more shared parameters based on the one or more revised aggregated feedback values; and determining, by the managing computing device based on the one or more revised aggregated feedback values, that an aggregated error corresponding to the revised errors for all respective datasets has been minimized.
12. The method of claim 1, further comprising initializing, by the managing computing device, the shared function and the one or more shared parameters based on a related shared function used to model a similar relationship.
13. The method of claim 1, wherein determining the one or more feedback values by the client computing devices further comprises initializing, by the respective client computing device, the individual function and the one or more individual parameters corresponding to the respective dataset based on a random number generator or a pseudo-random number generator.
14. The method of claim 1, wherein each of the plurality of datasets comprises at least two dimensions, wherein a first dimension of each of the plurality of datasets comprises a plurality of chemical compounds, wherein a second dimension of each of the plurality of datasets comprises descriptors of the chemical compounds, wherein entries in each of the plurality of datasets correspond to a binary indication of whether a respective chemical compound exhibits a respective descriptor, wherein each of the sets of recorded values corresponding to each of the plurality of datasets comprises at least two dimensions, wherein a first dimension of each of the sets of recorded values comprises the plurality of chemical compounds, wherein a second dimension of each of the sets of recorded values comprises activities of the chemical compounds in a plurality of biological assays, and wherein entries in each of the sets of recorded values correspond to a binary indication of whether a respective chemical compound exhibits a respective activity.
15. The method of claim 14, further comprising: calculating, by the managing computing device, a final shared representation of the datasets based on the list of unique objects, the shared function, and the one or more shared parameters; and transmitting, by the managing computing device, the final shared representation of the datasets to each of the client computing devices, wherein the final shared representation of the datasets is usable by each of the client computing devices to determine a final set of predicted values corresponding to the respective dataset, and wherein the final set of predicted values is used by at least one of the client computing devices to identify one or more effective treatment compounds among the plurality of chemical compounds.
16. The method of claim 1, wherein each of the plurality of datasets comprises at least two dimensions, wherein a first dimension of each of the plurality of datasets comprises a plurality of patients, wherein a second dimension of each of the plurality of datasets comprises descriptors of the patients, wherein entries in each of the plurality of datasets correspond to a binary indication of whether a respective patient exhibits a respective descriptor, wherein each of the sets of recorded values corresponding to each of the plurality of datasets comprises at least two dimensions, wherein a first dimension of each of the sets of recorded values comprises the plurality of patients, wherein a second dimension of each of the sets of recorded values comprises clinical diagnoses of the patients, and wherein entries in each of the sets of recorded values correspond to a binary indication of whether a respective patient exhibits a respective clinical diagnosis.
17. The method of claim 16, further comprising: calculating, by the managing computing device, a final shared representation of the datasets based on the list of unique objects, the shared function, and the one or more shared parameters; and transmitting, by the managing computing device, the final shared representation of the datasets to each of the client computing devices, wherein the final shared representation of the datasets is usable by each of the client computing devices to determine a final set of predicted values corresponding to the respective dataset, and wherein the final set of predicted values is used by at least one of the client computing devices to diagnose at least one of the plurality of patients.
18. The method of claim 1, wherein each of the sets of predicted values corresponding to one of the plurality of datasets corresponds to a predicted value tensor, wherein the predicted value tensor is factored into a first tensor multiplied by a second tensor, and wherein the first tensor corresponds to the respective dataset multiplied by the one or more shared parameters.
19. The method of claim 18, wherein the respective dataset encodes side information about the objects of the dataset.
20. The method of claim 18, wherein the predicted value tensor is factored using a Macau factorization method.
21. A non-transitory, computer-readable medium with instructions stored thereon, wherein the instructions are executable by a processor to perform a method, comprising: receiving a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, and wherein each dataset comprises objects; determining a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; determining a list of unique objects from among the plurality of datasets; selecting a subset of identifiers from the composite list of identifiers; determining a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; computing a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; transmitting to each of the client computing devices: the sublist of objects for the respective dataset; and the partial representation for the respective dataset; receiving one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset; updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; determining based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; and updating the one or more shared parameters based on the one or more aggregated feedback values.
22. A memory with a model stored thereon, wherein the model is generated according to a method, comprising: receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, and wherein each dataset comprises objects; determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; determining, by the managing computing device, a list of unique objects from among the plurality of datasets; selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; transmitting, by the managing computing device, to each of the client computing devices: the sublist of objects for the respective dataset; and the partial representation for the respective dataset; receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset; updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values; and storing, by the managing computing device, the shared representation, the shared function, and the one or more shared parameters on the memory.
Description
BACKGROUND
[0001] Unless otherwise indicated herein, the materials described in this section are not prior art to the claims in this application and are not admitted to be prior art by inclusion in this section.
[0002] Machine learning is a branch of computer science that seeks to automate the building of an analytical model. In machine learning, algorithms are used to create models that "learn" using datasets. Once "taught", the machine-learned models may be used to make predictions about other datasets, including future datasets. Machine learning has proven useful for developing models in a variety of fields. For example, machine learning has been applied to computer vision, statistics, data analytics, bioinformatics, deoxyribose nucleic acid (DNA) sequence identification, marketing, linguistics, economics, advertising, speech recognition, gaming, etc.
[0003] Machine learning involves training the model on a set of data, usually called "training data." Training the model may include two main subclasses: supervised learning and unsupervised learning.
[0004] In supervised learning, training data may include a plurality of datasets for which the outcome is known. For example, training data in the area of image recognition may correspond to images depicting certain objects which have been labeled (e.g., by a human) as containing a specific type of object (e.g., a dog, a pencil, a car, etc.). Such training data may be referred to as "labeled training data."
[0005] In unsupervised learning, the training data may not necessarily correspond to a known value or outcome. As such, the training data may be "unlabeled." Because the outcome for each piece of training data is unknown, the machine learning algorithm may infer a function from the training data. As an example, the function may be weighted based on one or more dimensions within the training data. Further, the function may be used to make predictions about new data to which the model is applied.
[0006] Upon training a model using training data, predictions may be made using the model. The more training data that is used to train a given model, the more the model may be refined and the more accurate the model may become. A common optimization in machine learning includes obtaining the most robust and reliable model while having access to the least amount of training data.
[0007] In some cases, additional sources of training data may provide a better-trained machine-learned model. However, in some scenarios, attaining more training data may not be possible. For example, two corporations may possess respective sets of training data that could be collectively used to train a machine-learned model that is superior to a model trained on either set of training data utilized individually. However, each corporation may desire that their data remains private (e.g., each corporation does not want to reveal the private data to the other corporation).
SUMMARY
[0008] The specification and drawings disclose embodiments that relate to secure broker-mediated data analysis and prediction.
[0009] The disclosure describes a method for performing joint machine learning using multiple datasets from multiple parties without revealing private information between the multiple parties. Such a method may include multiple client computing devices that transmit respective datasets to a managing computing device. The managing computing device may then combine the datasets, perform a portion of a machine learning algorithm on the combined datasets, and then transmit a portion of the results of the machine learning algorithm back to each of the client computing devices. Each client computing device may then perform another portion of the machine learning algorithm and send its portion of the results back to the managing computing device. Based on the results received from each client computing device, the managing computing device may then perform an additional portion of the machine learning algorithm to update a corresponding machine-learned model. In some cases, the method may be carried out multiple times in an optimization-type or recursive-type manner and/or may be carried out on an on-going basis.
[0010] In a first aspect, the disclosure describes a method. The method includes receiving, by a managing computing device, a plurality of datasets. Each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices. Each dataset corresponds to a set of recorded values. Each dataset includes objects. The method also includes determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers including a combination of the lists of identifiers of each dataset of the plurality of datasets. Further, the method includes determining, by the managing computing device, a list of unique objects from among the plurality of datasets. In addition, the method includes selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers. The method additionally includes determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers. Still further, the method includes computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters. Even further, the method includes determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset. Still even further, the method includes determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation. Even yet further, the method includes transmitting, by the managing computing device, to each of the client computing devices the sublist of objects for the respective dataset and the partial representation for the respective dataset. Yet further, the method includes receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices. The one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset. The set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset. In addition, the one or more feedback values are also determined by the client computing devices by determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset. Even further, the one or more feedback values are also determined by the client computing devices by updating, by the respective client computing device, the one or more individual parameters for the respective dataset. Still further, the one or more feedback values are also determined by the client computing devices by determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values. The method also includes determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values. Yet still further, the method includes updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values.
[0011] In a second aspect, the disclosure describes a method. The method includes receiving, by a managing computing device, a plurality of datasets. Each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices. Each dataset corresponds to a set of recorded values, wherein each dataset relates a plurality of chemical compounds to a plurality of descriptors of the chemical compounds. Each dataset includes objects. The method also includes determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers including a combination of the lists of identifiers of each dataset of the plurality of datasets. Further, the method includes determining, by the managing computing device, a list of unique objects from among the plurality of datasets. In addition, the method includes selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers. Still further, the method includes determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers. Additionally, the method includes computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters. Even further, the method includes determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset. Still even further, the method includes determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation. Even yet further, the method includes transmitting, by the managing computing device, to each of the client computing devices the sublist of objects for the respective dataset and the partial representation for the respective dataset. Yet further, the method includes receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices. The one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset. The set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset. Even further, the one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset. The set of recorded values corresponding to the respective dataset relates the plurality of chemical compounds to activities of the chemical compounds in a plurality of biological assays. In addition, the one or more feedback values are determined by the client computing devices by updating, by the respective client computing device, the one or more individual parameters for the respective dataset. Still further, the one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, the one or more feedback values. The one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values. The method additionally includes determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values. Yet still further, the method includes updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values. The shared representation, the shared function, or the one or more shared parameters are usable by at least one of the plurality of client computing devices to identify one or more effective treatment compounds among the plurality of chemical compounds.
[0012] In a third aspect, the disclosure describes a method. The method includes receiving, by a managing computing device, a plurality of datasets. Each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices. Each dataset corresponds to a set of recorded values, wherein each dataset relates a plurality of patients to a plurality of descriptors of the patients. Each dataset includes objects. The method also includes determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers including a combination of the lists of identifiers of each dataset of the plurality of datasets. Further, the method includes determining, by the managing computing device, a list of unique objects from among the plurality of datasets. In addition, the method includes selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers. Still further, the method includes determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers. Additionally, the method includes computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters. Even further, the method includes determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset. Still even further, the method includes determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation. Even yet further, the method includes transmitting, by the managing computing device, to each of the client computing devices the sublist of objects for the respective dataset and the partial representation for the respective dataset. Yet further, the method includes receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices. The one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset. The set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset. Even further, the one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset. The set of recorded values corresponding to the respective dataset relates the plurality of patients to clinical diagnoses of patients. In addition, the one or more feedback values are determined by the client computing devices by updating, by the respective client computing device, the one or more individual parameters for the respective dataset. Still further, the one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, the one or more feedback values. The one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values. The method additionally includes determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values. Yet still further, the method includes updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values. The shared representation, the shared function, or the one or more shared parameters are usable by at least one of the plurality of client computing devices to diagnose one or more of the plurality of patients.
[0013] In a fourth aspect, the disclosure describes a method. The method includes receiving, by a managing computing device, a plurality of datasets. Each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices. Each dataset corresponds to a set of recorded values, wherein each dataset provides a set of book ratings for a plurality of book titles by a plurality of users. Each dataset includes objects. The method also includes determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers including a combination of the lists of identifiers of each dataset of the plurality of datasets. Further, the method includes determining, by the managing computing device, a list of unique objects from among the plurality of datasets. In addition, the method includes selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers. Still further, the method includes determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers. Additionally, the method includes computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters. Even further, the method includes determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset. Still even further, the method includes determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation. Even yet further, the method includes transmitting, by the managing computing device, to each of the client computing devices the sublist of objects for the respective dataset and the partial representation for the respective dataset. Yet further, the method includes receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices. The one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset. The set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset. Even further, the one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset. The set of recorded values corresponding to the respective dataset provides a set of movie ratings for a plurality of movie titles by the plurality of users. In addition, the one or more feedback values are determined by the client computing devices by updating, by the respective client computing device, the one or more individual parameters for the respective dataset. Still further, the one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, the one or more feedback values. The one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values. The method additionally includes determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values. Yet still further, the method includes updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values. The shared representation, the shared function, or the one or more shared parameters are usable by at least one of the plurality of client computing devices to recommend a movie to one or more of the plurality of users.
[0014] In a fifth aspect, the disclosure describes a method. The method includes transmitting, by a first client computing device to a managing computing device, a first dataset corresponding to the first client computing device. The first dataset is one of a plurality of datasets transmitted to the managing computing device by a plurality of client computing devices. Each dataset corresponds to a set of recorded values. Each dataset includes objects. The method also includes receiving, by the first client computing device, a first sublist of objects for the first dataset and a first partial representation for the first dataset. The first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers that includes a combination of the lists of identifiers of each dataset of the plurality of datasets. The first sublist of objects for the first dataset and the first partial representation for the first dataset are also determined by determining, by the managing computing device, a list of unique objects from among the plurality of datasets. Further, the first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by selecting, by the managing computing device, the subset of identifiers from the composite list of identifiers. Even further, the first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers. Still further, the first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by computing, by the managing computing device, the shared representation of the plurality of datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters. Even further, the first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by determining, by the managing computing device, the first sublist of objects for the first dataset based on an intersection of the subset of identifiers with the list of identifiers for the first dataset. Yet further, the first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by determining, by the managing computing device, the first partial representation for the first dataset based on the first sublist of objects and the shared representation. Even further, the method includes determining, by the first client computing device, a first set of predicted values corresponding to the first dataset. The first set of predicted values is based on the first partial representation and a first individual function with one or more first individual parameters corresponding to the first dataset. In addition, the method includes determining, by the first client computing device, a first error for the first dataset based on a first individual loss function for the first dataset, the first set of predicted values corresponding to the first dataset, the first sublist of objects, and non-empty entries in the set of recorded values corresponding to the first dataset. Still further, the method includes updating, by the first client computing device, the one or more first individual parameters for the first dataset. Yet further, the method includes determining, by the first client computing device, one or more feedback values. The one or more feedback values are used to determine a change in the first partial representation that corresponds to an improvement in the first set of predicted values. Yet still further, the method includes transmitting, by the first client computing device to the managing computing device, the one or more feedback values. The one or more feedback values are usable by the managing computing device along with sublists of objects from the plurality of client computing devices to determine one or more aggregated feedback values. The one or more aggregated feedback values are usable by the managing computing device to update the one or more shared parameters.
[0015] In a sixth aspect, the disclosure describes a non-transitory, computer-readable medium with instructions stored thereon. The instructions are executable by a processor to perform a method. The method includes receiving, by a managing computing device, a plurality of datasets. Each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices. Each dataset corresponds to a set of recorded values. Each dataset includes objects. The method also includes determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers including a combination of the lists of identifiers of each dataset of the plurality of datasets. Further, the method includes determining, by the managing computing device, a list of unique objects from among the plurality of datasets. In addition, the method includes selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers. The method additionally includes determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers. Still further, the method includes computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters. Even further, the method includes determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset. Still even further, the method includes determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation. Even yet further, the method includes transmitting, by the managing computing device, to each of the client computing devices the sublist of objects for the respective dataset and the partial representation for the respective dataset. Yet further, the method includes receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices. The one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset. The set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset. In addition, the one or more feedback values are also determined by the client computing devices by determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset. Even further, the one or more feedback values are also determined by the client computing devices by updating, by the respective client computing device, the one or more individual parameters for the respective dataset. Still further, the one or more feedback values are also determined by the client computing devices by determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values. The method also includes determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values. Yet still further, the method includes updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values.
[0016] In a seventh aspect, the disclosure describes a memory with a model stored thereon. The model is generated according to a method. The method includes receiving, by a managing computing device, a plurality of datasets. Each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices. Each dataset corresponds to a set of recorded values. Each dataset includes objects. The method also includes determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers including a combination of the lists of identifiers of each dataset of the plurality of datasets. Further, the method includes determining, by the managing computing device, a list of unique objects from among the plurality of datasets. In addition, the method includes selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers. The method additionally includes determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers. Still further, the method includes computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters. Even further, the method includes determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset. Still even further, the method includes determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation. Even yet further, the method includes transmitting, by the managing computing device, to each of the client computing devices the sublist of objects for the respective dataset and the partial representation for the respective dataset. Yet further, the method includes receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices. The one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset. The set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset. In addition, the one or more feedback values are also determined by the client computing devices by determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset. Even further, the one or more feedback values are also determined by the client computing devices by updating, by the respective client computing device, the one or more individual parameters for the respective dataset. Still further, the one or more feedback values are also determined by the client computing devices by determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values. The method also includes determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values. Yet still further, the method includes updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values. Yet even further, the method includes storing, by the managing computing device, the shared representation, the shared function, and the one or more shared parameters on the memory.
[0017] In an eighth aspect, the disclosure describes a method. The method includes receiving, by a managing computing device, a plurality of datasets. Each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices. Each dataset corresponds to a set of recorded values. Each dataset includes objects. The method also includes determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers including a combination of the lists of identifiers of each dataset of the plurality of datasets. Further, the method includes determining, by the managing computing device, a list of unique objects from among the plurality of datasets. In addition, the method includes selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers. The method additionally includes determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers. Still further, the method includes computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters. Even further, the method includes determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset. Still even further, the method includes determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation. Even yet further, the method includes transmitting, by the managing computing device, to each of the client computing devices the sublist of objects for the respective dataset and the partial representation for the respective dataset. Yet further, the method includes receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices. The one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset. The set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset. In addition, the one or more feedback values are also determined by the client computing devices by determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset. Even further, the one or more feedback values are also determined by the client computing devices by updating, by the respective client computing device, the one or more individual parameters for the respective dataset. Still further, the one or more feedback values are also determined by the client computing devices by determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values. The method also includes determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values. Yet still further, the method includes updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values. Yet even further, the method includes using, by a computing device, the shared representation, the shared function, or the one or more shared parameters to determine an additional set of predicted values corresponding to a dataset.
[0018] In a ninth aspect, the disclosure describes a server device. The server device has instructions stored thereon that, when executed by a processor, perform a method. The method includes receiving a plurality of datasets. Each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices. Each dataset corresponds to a set of recorded values. Each dataset includes objects. The method also includes determining a respective list of identifiers for each dataset and a composite list of identifiers that includes a combination of the lists of identifiers of each dataset of the plurality of datasets. Further, the method includes determining a list of unique objects from among the plurality of datasets. In addition, the method includes selecting a subset of identifiers from the composite list of identifiers. Still further, the method includes determining a subset of the list of unique objects corresponding to each identifier in the subset of identifiers. The method additionally includes computing a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters. Even further, the method includes determining a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset. Yet further, the method includes determining a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation. Even still further, the method includes transmitting to each of the client computing devices: the sublist of objects for the respective dataset and the partial representation for the respective dataset. Yet still further, the method includes receiving one or more feedback values from at least one of the client computing devices. The one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset. The set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset. The one or more feedback values are also determined by the client computing devices by determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset. Further, the one or more feedback values are determined by the client computing devices by updating, by the respective client computing device, the one or more individual parameters for the respective dataset. In addition, the one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, the one or more feedback values. The one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values. Even yet further, the method includes determining based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values. Still yet further, the method includes updating the one or more shared parameters based on the one or more aggregated feedback values.
[0019] In a tenth aspect, the disclosure describes a server device. The server device has instructions stored thereon that, when executed by a processor, perform a method. The method includes transmitting, to a managing computing device, a first dataset corresponding to the server device. The first dataset is one of a plurality of datasets transmitted to the managing computing device by a plurality of server devices. Each dataset corresponds to a set of recorded values. Each dataset includes objects. The method also includes receiving a first sublist of objects for the first dataset and a first partial representation for the first dataset. The first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by the managing computing device by determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers that includes a combination of the lists of identifiers of each dataset of the plurality of datasets. The first sublist of objects for the first dataset and the first partial representation for the first dataset are also determined by the managing computing device by determining, by the managing computing device, a list of unique objects from among the plurality of datasets. Further, the first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by the managing computing device by selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers. In addition, the first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by the managing computing device by determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers. Still further, the first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by the managing computing device by computing, by the managing computing device, a shared representation of the plurality of datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters. The first sublist of objects for the first dataset and the first partial representation for the first dataset are additionally determined by the managing computing device by determining, by the managing computing device, the first sublist of objects for the first dataset based on an intersection of the subset of identifiers with the list of identifiers for the first dataset. Yet further, the first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by the managing computing device by determining, by the managing computing device, the first partial representation for the first dataset based on the first sublist of objects and the shared representation. Further, the method includes determining a first set of predicted values corresponding to the first dataset. The first set of predicted values is based on the first partial representation and a first individual function with one or more first individual parameters corresponding to the first dataset. Additionally, the method includes determining a first error for the first dataset based on a first individual loss function for the first dataset, the first set of predicted values corresponding to the first dataset, the first sublist of objects, and non-empty entries in the set of recorded values corresponding to the first dataset. Even further, the method includes updating the one or more first individual parameters for the first dataset. The method additionally includes determining one or more feedback values. The one or more feedback values are used to determine a change in the first partial representation that corresponds to an improvement in the first set of predicted values. Yet further, the method includes transmitting, to the managing computing device, the one or more feedback values. The one or more feedback values are usable by the managing computing device along with sublists of objects from the plurality of server devices to determine one or more aggregated feedback values. The one or more aggregated feedback values are usable by the managing computing device to update the one or more shared parameters.
[0020] In an eleventh aspect, the disclosure describes a system. The system includes a server device. The system also includes a plurality of client devices each communicatively coupled to the server device. The server device has instructions stored thereon that, when executed by a processor, perform a first method. The first method includes receiving a plurality of datasets. Each dataset of the plurality of datasets is received from a respective client device of the plurality of client devices. Each dataset corresponds to a set of recorded values. Each dataset includes objects. The first method also includes determining a respective list of identifiers for each dataset and a composite list of identifiers that includes a combination of the lists of identifiers of each dataset of the plurality of datasets. Additionally, the first method includes determining a list of unique objects from among the plurality of datasets. Further, the first method includes selecting a subset of identifiers from the composite list of identifiers. The first method additionally includes determining a subset of the list of unique objects corresponding to each identifier in the subset of identifiers. The first method further includes computing a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters. Still further, the first method includes determining a sublist of objects for the respective dataset of each client device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset. Yet further, the first method includes determining a partial representation for the respective dataset of each client device based on the sublist of objects for the respective dataset and the shared representation. Even further, the first method includes transmitting to each of the client devices: the sublist of objects for the respective dataset and the partial representation for the respective dataset. Each client device has instructions stored thereon that, when executed by a processor, perform a second method. The second method includes determining a set of predicted values corresponding to the respective dataset. The set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset. The second method also includes determining an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset. Further, the second method includes updating the one or more individual parameters for the respective dataset. The second method additionally includes determining one or more feedback values. The one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values. The second method further includes transmitting, to the server device, the one or more feedback values. Yet even further, the first method includes determining based on the sublists of objects and the one or more feedback values from the client devices, one or more aggregated feedback values. Still yet further, the first method includes updating the one or more shared parameters based on the one or more aggregated feedback values.
[0021] In a twelfth aspect, the disclosure describes an optimized model. The model is optimized according to a method. The method includes receiving, by a managing computing device, a plurality of datasets. Each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices. Each dataset corresponds to a set of recorded values. Each dataset includes objects. The method also includes determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers that includes a combination of the lists of identifiers of each dataset of the plurality of datasets. Further, the method includes determining, by the managing computing device, a list of unique objects from among the plurality of datasets. The method additionally includes selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers. The method further includes determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers. Additionally, the method includes computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters. Even further, the method includes determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset. Yet further, the method includes determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation. Still further, the method includes transmitting, by the managing computing device, to each of the client computing devices: the sublist of objects for the respective dataset and the partial representation for the respective dataset. Even still further, the method includes receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices. The one or more feedback values are determined by the client computing devices by determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset. The set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset. The one or more feedback values are also determined by the client computing devices by determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset. Further, the one or more feedback values are determined by the client computing devices by updating, by the respective client computing device, the one or more individual parameters for the respective dataset. The one or more feedback values are additionally determined by the client computing devices by determining, by the respective client computing device, the one or more feedback values. The one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values. Even yet further, the method includes determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices one or more aggregated feedback values. Still even further, the method includes updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values. Still yet even further, the method includes computing, by the managing computing device, an updated shared representation of the datasets based on the shared function and the one or more updated shared parameters. The updated shared representation corresponds to the optimized model.
[0022] The foregoing summary is illustrative only and is not intended to be in any way limiting. In addition to the illustrative aspects, embodiments, and features described above, further aspects, embodiments, and features will become apparent by reference to the figures and the following detailed description.
BRIEF DESCRIPTION OF THE FIGURES
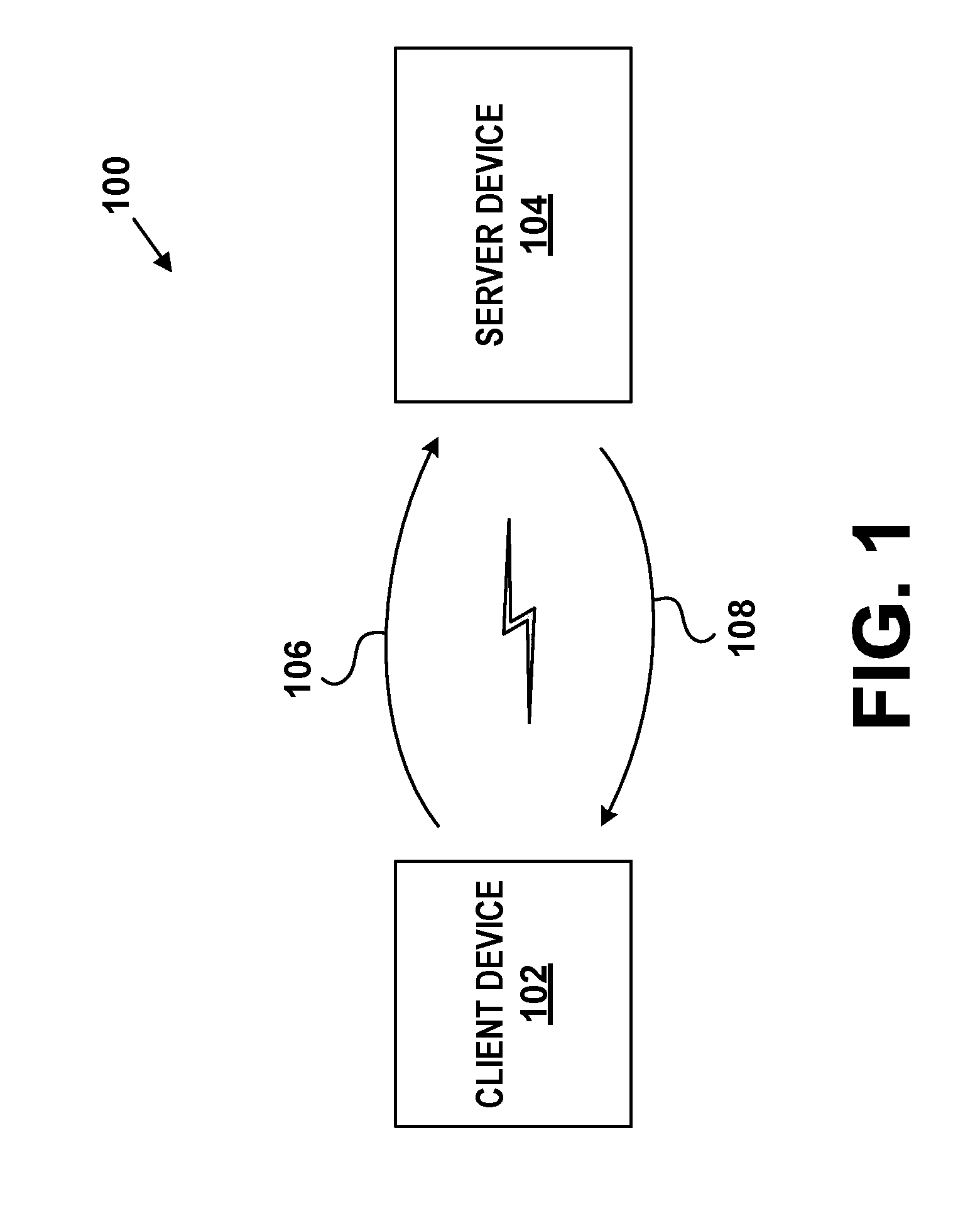
[0023] FIG. 1 is a high-level illustration of a client-server computing system, according to example embodiments.
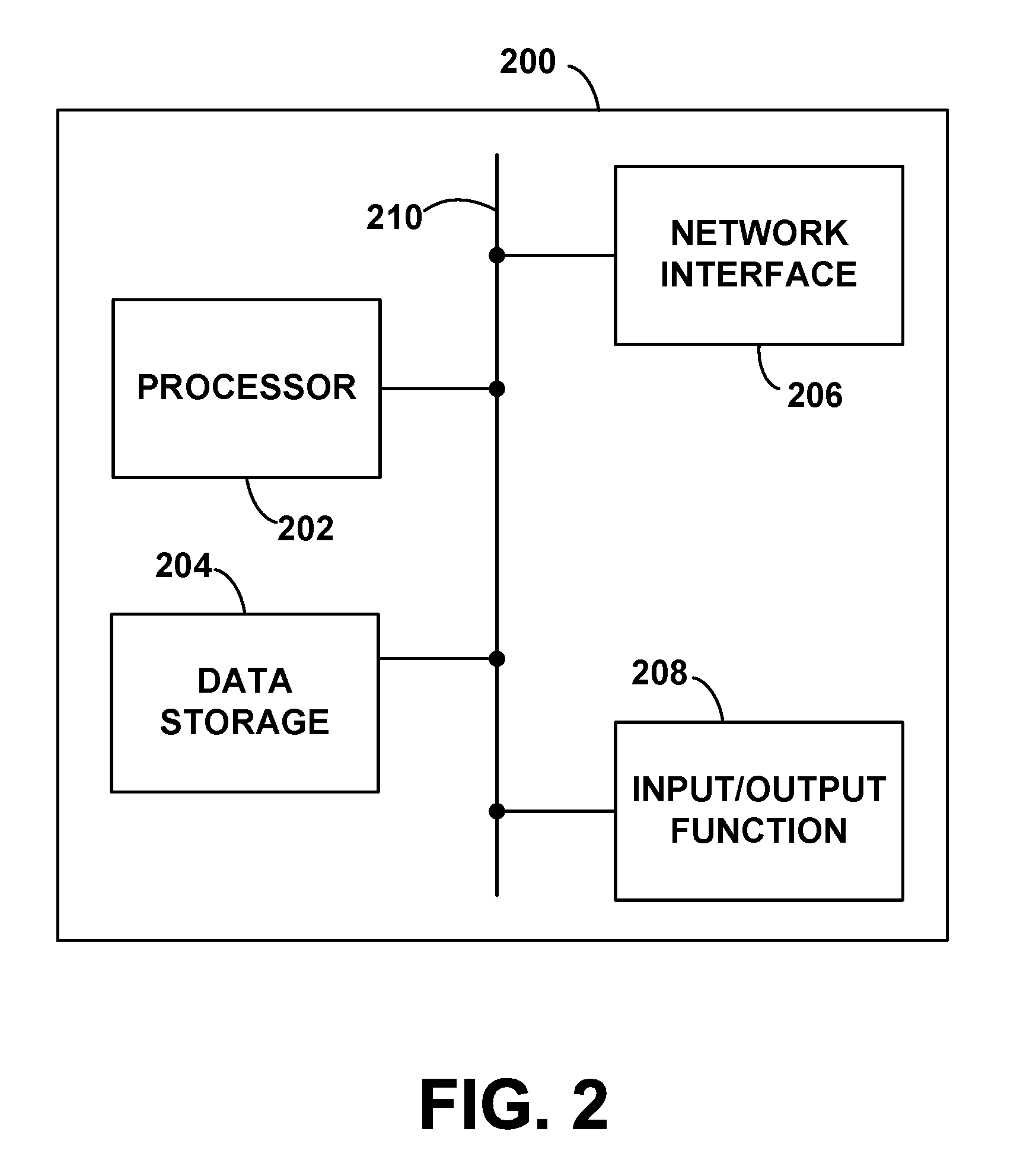
[0024] FIG. 2 is a schematic illustration of a computing device, according to example embodiments.
[0025] FIG. 3 is a schematic illustration of a networked server cluster, according to example embodiments.
[0026] FIG. 4A illustrates a schematic drawing of a network including client computing devices and a managing computing device, according to example embodiments.
[0027] FIG. 4B is a data flow diagram of a portion of a method, according to example embodiments.
[0028] FIG. 4C is a data flow diagram of a portion of a method, according to example embodiments.
[0029] FIG. 4D is a data flow diagram of a portion of a method, according to example embodiments.
[0030] FIG. 4E is a data flow diagram of a portion of a method, according to example embodiments.
[0031] FIG. 4F is a data flow diagram of a portion of a method, according to example embodiments.
[0032] FIG. 5A illustrates a dataset and a set of predicted values, according to example embodiments.
[0033] FIG. 5B illustrates a dataset and a set of predicted values, according to example embodiments.
[0034] FIG. 6A illustrates a list of identifiers for a dataset, according to example embodiments.
[0035] FIG. 6B illustrates a list of identifiers for a dataset, according to example embodiments.
[0036] FIG. 7 illustrates a composite list of identifiers, according to example embodiments.
[0037] FIG. 8 illustrates a list of unique objects, according to example embodiments.
[0038] FIG. 9 illustrates a subset of identifiers, according to example embodiments.
[0039] FIG. 10 illustrates a subset of the list of unique objects, according to example embodiments.
[0040] FIG. 11 illustrates a shared representation, according to example embodiments.
[0041] FIG. 12A illustrates a sublist of objects for a dataset, according to example embodiments.
[0042] FIG. 12B illustrates a sublist of objects for a dataset, according to example embodiments.
[0043] FIG. 13A illustrates a partial representation, according to example embodiments.
[0044] FIG. 13B illustrates a partial representation, according to example embodiments.
[0045] FIG. 14A illustrates an individual function, according to example embodiments.
[0046] FIG. 14B illustrates an individual function, according to example embodiments.
[0047] FIG. 15A illustrates a set of predicted values, according to example embodiments.
[0048] FIG. 15B illustrates a set of predicted values, according to example embodiments.
[0049] FIG. 16A illustrates a dataset and a set of recorded values, according to example embodiments.
[0050] FIG. 16B illustrates a dataset and a set of recorded values, according to example embodiments.
[0051] FIG. 16C illustrates a dataset and a set of recorded values, according to example embodiments.
[0052] FIG. 17A illustrates a matrix factorization algorithm, according to example embodiments.
[0053] FIG. 17B illustrates a matrix factorization algorithm, according to example embodiments.
[0054] FIG. 18A illustrates a dataset and a set of predicted values, according to example embodiments.
[0055] FIG. 18B illustrates a dataset and a set of predicted values, according to example embodiments.
[0056] FIG. 19A illustrates a list of identifiers for a dataset, according to example embodiments.
[0057] FIG. 19B illustrates a list of identifiers for a dataset, according to example embodiments.
[0058] FIG. 20 illustrates a composite list of identifiers, according to example embodiments.
[0059] FIG. 21 illustrates a list of unique objects, according to example embodiments.
[0060] FIG. 22 illustrates a subset of identifiers, according to example embodiments.
[0061] FIG. 23 illustrates a subset of the list of unique objects, according to example embodiments.
[0062] FIG. 24 illustrates a shared representation, according to example embodiments.
[0063] FIG. 25A illustrates a sublist of objects for a dataset, according to example embodiments.
[0064] FIG. 25B illustrates a sublist of objects for a dataset, according to example embodiments.
[0065] FIG. 26A illustrates a partial representation, according to example embodiments.
[0066] FIG. 26B illustrates a partial representation, according to example embodiments.
[0067] FIG. 27A illustrates an individual function, according to example embodiments.
[0068] FIG. 27B illustrates an individual function, according to example embodiments.
DETAILED DESCRIPTION
[0069] Example methods and systems are described herein. Any example embodiment or feature described herein is not necessarily to be construed as preferred or advantageous over other embodiments or features. The example embodiments described herein are not meant to be limiting. It will be readily understood that certain aspects of the disclosed systems and methods can be arranged and combined in a wide variety of different configurations, all of which are contemplated herein.
[0070] Furthermore, the particular arrangements shown in the figures should not be viewed as limiting. It should be understood that other embodiments might include more or less of each element shown in a given figure. In addition, some of the illustrated elements may be combined or omitted. Similarly, an example embodiment may include elements that are not illustrated in the figures.
I. Overview
[0071] Example embodiments relate to secure broker-mediated data analysis and prediction. The secure broker-mediated data analysis and prediction may be used to develop a machine learning model (e.g., an artificial neural network) using private data from multiple parties without revealing the private data of one party to another party. One example embodiment described herein relates to a method.
[0072] The method may include a managing computing device (e.g., a server) transmitting data to and receiving data from a plurality of client computing devices. The data may be transmitted to and received from the plurality of client computing devices to develop a machine learning model. For example, the managing computing device may receive multiple datasets from multiple client computing devices. Subsequently, the managing computing device may use these datasets to establish an initial version of the machine learning model (e.g., based on a function with initial parameters).
[0073] Then, the managing computing device may transmit different portions of the initial version of the machine learning model to different client computing devices. In some embodiments, the managing computing device may send the entire model to the client computing devices, as well as indications of which portion corresponds to a respective client computing device's dataset. Subsequently, the respective client computing device may extract the appropriate portion of the model from the entire model. Upon receiving/extracting a portion of the machine learning model that corresponds to the respective client computing device, each client computing device may update a local machine learning model that is stored within the respective client computing device. Then, each client computing device may use the updated local machine learning model to make a prediction (e.g., compute a set of predicted or expected values).
[0074] Upon making the prediction, the respective client computing device may compare the prediction to a set of recorded values stored within the client computing device. Based on the comparison, the client computing device may determine one or more errors with the prediction (and therefore one or more errors with the updated local machine learning model on which the prediction was based). In some embodiments, such errors may be calculated using a loss function. Based on the errors and the portion of the entire machine learning model that corresponds to the respective client computing device, the client computing device may transmit one or more feedback values to the managing computing device indicating that there is an error in a respective portion of the entire machine learning model. Similar feedback may be provided to the managing computing device by one, multiple, or all client computing devices.
[0075] Upon receiving the feedback from the client computing devices, the managing computing device may then update the entire machine learning model (e.g., including the function and the parameters) based on the feedback. In such a scenario, the entire machine learning model may be improved and/or refined. The steps outlined above of transmitting portions of the model to the client computing devices, having the client computing devices make and evaluate predictions based on the portions of the model, and then receiving feedback from the client computing devices may be repeated for multiple iterations until the entire machine learning model can no longer be improved (e.g., the predictions made by each client computing device have no error) or until the improvement between each iteration is below a threshold value of improvement (e.g., the errors in the predictions made by each client computing device do not substantially change from one iteration to the next).
[0076] Once the training of the entire machine learning model is complete (e.g., the improvement between subsequent iterations is below a threshold value), the machine learning model can be used to make predictions or recommendations. For example, the managing computing device could utilize the machine learning model to make predictions based on future events. Additionally or alternatively, once the model is trained, the entire machine learning model (or a portion thereof) may be transmitted to one or more of the client computing devices by the managing computing device. At this point, at least one of the one or more client computing devices may utilize the model to make predictions or recommendations (e.g., recommend a book to one of its users based on the machine learning model). Still further, the model could also be transmitted to one or more third parties who did not provide data used in the training of the machine learning model. Such third parties may be required to pay a fee, join a subscription service, view an advertisement, or log in with validation credentials before being able to view and/or utilize the machine learning model. Additionally, the third parties may utilize the machine learning model to make predictions or recommendations based on their own data (e.g., data other than the data provided to the managing computing device in the training of the machine learning model).
II. Example Systems
[0077] The following description and accompanying drawings will elucidate features of various example embodiments. The embodiments provided are by way of example, and are not intended to be limiting. As such, the dimensions of the drawings are not necessarily to scale.
[0078] FIG. 1 illustrates an example communication system 100 for carrying out one or more of the embodiments described herein. Communication system 100 may include computing devices. As described herein, a "computing device" may refer to either a client device, a server device (e.g., a stand-alone server computer or networked cluster of server equipment), or some other type of computational platform.
[0079] Client device 102 may be any type of device including a personal computer, laptop computer, a wearable computing device, a wireless computing device, a head-mountable computing device, a mobile telephone, or tablet computing device, etc., that is configured to transmit data 106 to and/or receive data 108 from a server device 104 in accordance with the embodiments described herein. For example, in FIG. 1, client device 102 may communicate with server device 104 via one or more wireline or wireless interfaces. In some cases, client device 102 and server device 104 may communicate with one another via a local-area network. Alternatively, client device 102 and server device 104 may each reside within a different network, and may communicate via a wide-area network, such as the Internet. In some embodiments, the client device 102 may correspond to a "client computing device." Further, in some embodiments, the communication system 100 may include multiple client devices 102. Additionally or alternatively, one or more "client computing devices" may include computing components more similar to the server device 104 than the client device 102. In other words, in some embodiments, multiple server devices 104 may communicate with one another, rather than a single server device 104 communicating with a single client device 102.
[0080] Client device 102 may include a user interface, a communication interface, a main processor, and data storage (e.g., memory). The data storage may contain instructions executable by the main processor for carrying out one or more operations relating to the data sent to, or received from, server device 104. The user interface of client device 102 may include buttons, a touchscreen, a microphone, and/or any other elements for receiving inputs, as well as a speaker, one or more displays, and/or any other elements for communicating outputs.
[0081] Server device 104 may be any entity or computing device arranged to carry out the server operations described herein. Further, server device 104 may be configured to send data 108 to and/or receive data 106 from the client device 102. In some embodiments, the server device 104 may correspond to a "managing computing device" (e.g., a "broker"). Additionally or alternatively, in some embodiments, the server device 104 may correspond to one or more "client computing devices" (e.g., a "data-supplying party").
[0082] Data 106 and data 108 may take various forms. For example, data 106 and 108 may represent packets transmitted by client device 102 or server device 104, respectively, as part of one or more communication sessions. Such a communication session may include packets transmitted on a signaling plane (e.g., session setup, management, and teardown messages), and/or packets transmitted on a media plane (e.g., text, graphics, audio, and/or video data).
[0083] Regardless of the exact architecture, the operations of client device 102, server device 104, as well as any other operation associated with the architecture of FIG. 1, can be carried out by one or more computing devices. These computing devices may be organized in a standalone fashion, in cloud-based (networked) computing environments, or in other arrangements.
[0084] FIG. 2 is a simplified block diagram exemplifying a computing device 200, illustrating some of the functional components that could be included in a computing device arranged to operate in accordance with the embodiments herein. Example computing device 200 could be a client device, a server device, or some other type of computational platform. For illustrative purposes, this specification may equate computing device 200 to a server device 104 and/or a client device 102 from time to time. Nonetheless, the description of computing device 200 could apply to any component used for the purposes described herein.
[0085] In this example, computing device 200 includes a processor 202, a data storage 204, a network interface 206, and an input/output function 208, all of which may be coupled by a system bus 210 or a similar mechanism. Processor 202 can include one or more CPUs, such as one or more general purpose processors and/or one or more dedicated processors (e.g., application specific integrated circuits (ASICs), digital signal processors (DSPs), network processors, etc.).
[0086] Data storage 204, in turn, may include volatile and/or non-volatile data storage devices and can be integrated in whole or in part with processor 202. Data storage 204 can hold program instructions, executable by processor 202, and data that may be manipulated by such program instructions to carry out the various methods, processes, or operations described herein. Alternatively, these methods, processes, or operations can be defined by hardware, firmware, and/or any combination of hardware, firmware, and software. By way of example, the data in data storage 204 may contain program instructions, perhaps stored on a non-transitory, computer-readable medium, executable by processor 202 to carry out any of the methods, processes, or operations disclosed in this specification or the accompanying drawings. The data storage 204 may include non-volatile memory (e.g., a read-only memory, ROM) and/or volatile memory (e.g., random-access memory, RAM), in various embodiments. For example, the data storage 204 may include a hard drive (e.g., hard disk), flash memory, a solid-state drive (SSD), electrically erasable programmable read-only memory (EEPROM), dynamic random-access memory (DRAM), and/or static random-access memory (SRAM). It will be understood that other types of transitory or non-transitory data storage devices are possible and contemplated within the scope of the present disclosure.
[0087] Network interface 206 may take the form of a wireline connection, such as an Ethernet, Token Ring, or T-carrier connection. Network interface 206 may also take the form of a wireless connection, such as IEEE 802.11 (WiFi), BLUETOOTH.RTM., BLUETOOTH LOW ENERGY (BLE).RTM., or a wide-area wireless connection. However, other forms of physical layer connections and other types of standard or proprietary communication protocols may be used over network interface 206. Furthermore, network interface 206 may include multiple physical interfaces.
[0088] Input/output function 208 may facilitate user interaction with example computing device 200. Input/output function 208 may comprise multiple types of input devices, such as a keyboard, a mouse, a touch screen, and so on. Similarly, input/output function 208 may comprise multiple types of output devices, such as a screen, monitor, printer, or one or more light emitting diodes (LEDs). Additionally or alternatively, example computing device 200 may support remote access from another device, via network interface 206 or via another interface (not shown), such as a universal serial bus (USB) or high-definition multimedia interface (HDMI) port.
[0089] In some embodiments, one or more computing devices may be deployed in a networked architecture. The exact physical location, connectivity, and configuration of the computing devices may be unknown and/or unimportant to client devices. Accordingly, the computing devices may be referred to as "cloud-based" devices that may be housed at various remote locations.
[0090] FIG. 3 depicts a cloud-based server cluster 304 in accordance with an example embodiment. In FIG. 3, functions of a server device, such as server device 104 (as exemplified by computing device 200) may be distributed between server devices 306, cluster data storage 308, and cluster routers 310, all of which may be connected by local cluster network 312. The number of server devices, cluster data storages, and cluster routers in server cluster 304 may depend on the computing task(s) and/or applications assigned to server cluster 304.
[0091] For example, server devices 306 can be configured to perform various computing tasks of computing device 200. Thus, computing tasks can be distributed among one or more of server devices 306. To the extent that these computing tasks can be performed in parallel, such a distribution of tasks may reduce the total time to complete these tasks and return a result. For purpose of simplicity, both server cluster 304 and individual server devices 306 may be referred to as "a server device." This nomenclature should be understood to imply that one or more distinct server devices, data storage devices, and cluster routers may be involved in server device operations.
[0092] Cluster data storage 308 may be data storage arrays that include disk array controllers configured to manage read and write access to groups of hard disk drives. The disk array controllers, alone or in conjunction with server devices 306, may also be configured to manage backup or redundant copies of the data stored in cluster data storage 308 to protect against disk drive failures or other types of failures that prevent one or more of server devices 306 from accessing units of cluster data storage 308.
[0093] Cluster routers 310 may include networking equipment configured to provide internal and external communications for the server clusters. For example, cluster routers 310 may include one or more packet-switching and/or routing devices configured to provide (i) network communications between server devices 306 and cluster data storage 308 via cluster network 312, and/or (ii) network communications between the server cluster 304 and other devices via communication link 302 to network 300.
[0094] Additionally, the configuration of cluster routers 310 can be based at least in part on the data communication requirements of server devices 306 and cluster data storage 308, the latency and throughput of the local cluster networks 312, the latency, throughput, and cost of communication link 302, and/or other factors that may contribute to the cost, speed, fault-tolerance, resiliency, efficiency and/or other design goals of the system architecture.
[0095] As a possible example, cluster data storage 308 may include any form of database, such as a structured query language (SQL) database. Various types of data structures may store the information in such a database, including but not limited to tables, arrays, lists, trees, and tuples. Furthermore, any databases in cluster data storage 308 may be monolithic or distributed across multiple physical devices.
[0096] Server devices 306 may be configured to transmit data to and receive data from cluster data storage 308. This transmission and retrieval may take the form of SQL queries or other types of database queries, and the output of such queries, respectively. Additional text, images, video, and/or audio may be included as well. Furthermore, server devices 306 may organize the received data into web page representations. Such a representation may take the form of a markup language, such as the hypertext markup language (HTML), the extensible markup language (XML), or some other standardized or proprietary format. Moreover, server devices 306 may have the capability of executing various types of computerized scripting languages, such as but not limited to Perl, Python, PHP Hypertext Preprocessor (PHP), Active Server Pages (ASP), JavaScript, and so on. Computer program code written in these languages may facilitate the provision of web pages to client devices, as well as client device interaction with the web pages.
[0097] FIG. 4A is an illustration of a computing network 401. The computing network 401 may include client computing device A 402, client computing device B 404, and a managing computing device 406 (in some embodiments, the managing computing device 406 may be additionally or alternatively referred to as a "broker"). Optionally, in some embodiments the computing network 401 may also include a third-party computing device 405. As described above, each of client computing device A 402, client computing device B 404, the third-party computing device 405 and the managing computing device 406 may be a server device (e.g., the server device 104 of FIG. 1) or a client device (e.g., the client device 102 of FIG. 1). For example, in some embodiments, all components in FIG. 4A may be server devices communicating with one another. In other embodiments, all components in FIG. 4A may be client devices communicating with one another. In still other embodiments, some component(s) may be client devices, while other component(s) are server devices (e.g., the managing computing device 406 is a server device, while client computing device A 402, client computing device B 404, and the third-party computing device 405 are client devices).
[0098] The dashed lines in FIG. 4A illustrate communicative couplings between computing components. As illustrated, client computing device A 402 may be communicatively coupled to the managing computing device 406. Similarly, client computing device B 402 may also be communicatively coupled to the managing computing device 406. Further, in embodiments including a third-party computing device 405, the dotted lines indicate potential communicative couplings between computing components (e.g., the third-party computing device 405 may be communicatively coupled to any subset of client computing A 402, client computing device B 404, and the managing computing device 406). Such communicative couplings may occur using a variety of technologies (e.g., over WiFi, over BLUETOOTH.RTM., over the public Internet, etc.).
[0099] Also as illustrated, client computing device A 402 and client computing device B 404 may be communicatively uncoupled from one another. In this way, privacy of communications between a respective client computing device and the managing computing device 406 may be preserved. In some embodiments, additional technologies to preserve privacy may be implemented (e.g., a private key/public key encryption mechanism for communications between a client computing device and the managing computing device 406).
[0100] In alternate embodiments, client computing device A 402 and client computing device B 404 may be communicatively coupled to one another. This may allow a sharing of some or all of a client computing device's data with another client computing device. In still other embodiments, there may be any number of client computing devices communicating with the managing computing device 406 (e.g., more than two client computing devices). For example, three or more client computing devices may provide data to and receive data from the managing computing device 406.
[0101] In an example embodiment, the third-party computing device 405 need not be directly involved in the determination of a machine learning model (e.g., shared representation U) as described with regard to method 400 herein. In such scenarios, third-party computing device 405 need not carry out all of the operations of method 400, as described herein. Rather, the third-party computing device 405 could be a recipient of information based on the machine learning model determined using other operations of method 400.
III. Example Processes
[0102] In various embodiments described herein, some operations are described as being performed by managing computing device(s) and/or client computing device(s). It is understood that operations performed by a single managing computing device could be spread over multiple managing computing devices (e.g., to decrease computational time). Similarly, operations performed by a single client computing device could instead be performed by a collection of computing devices that are each of a part of the single client computing device. Even further, multiple operations are described herein as being performed by a client computing device (e.g., client computing device A 402). It is also understood that any operation performed on a single client computing device could, but need not, be mirrored and performed on one or more other client computing devices (e.g., for respective datasets/sets of recorded values). Similarly, some operations are described herein as being performed by multiple client computing devices, but it is understood that in alternate embodiments, only one client computing device may perform the operation (e.g., transmitting one or more feedback values to the managing computing device may only be performed by one client computing device, in some embodiments). Even further, some client computing devices may store multiple datasets and/or multiple sets of recorded values, and therefore may perform actions corresponding to multiple computing devices disclosed herein. Still further, in some embodiments, the managing computing device may be integrated with one or more of the client computing devices (e.g., depending on the level of privacy required by the interacting parties/client computing devices).
[0103] The methods and systems described herein may be described using mathematical syntax (e.g., to represent variables in order to succinctly describe processes). It is understood that a variety of mathematical syntax, including mathematical syntax different than used herein, supplemental to used herein, or no mathematical syntax at all, may be employed when describing the methods and systems disclosed herein. Further, it is understood that the mathematical syntax employed may be based on the given machine-learning model used (e.g., syntax used to represent an artificial neural network model may be different than syntax used to represent a support vector machine model). By way of example, the following table summarizes the mathematical syntax used herein to illustrate the methods and systems of the disclosure (e.g., the mathematical syntax used in reference to FIGS. 4B-15B):
TABLE-US-00001 Variable Description of Variable U Shared Representation f Shared Function .beta. One or More Shared Parameters .beta. Weight Tensor Representing the One or More Shared Parameters X.sub.A Dataset A X.sub.B Dataset B d Number of Dimensions in a Dataset Y.sub.A Set of Recorded Values Corresponding to Dataset A Y.sub.B Set of Recorded Values Corresponding to Dataset B M.sub.A List of Identifiers for Dataset A M.sub.B List of Identifiers for Dataset B M.sub.Comb Composite List of Identifiers X.sub.Comb List of Unique Objects S Subset of Identifiers Z Subset of the List of Unique Objects S.sub.A Sublist of Objects for Dataset A S.sub.B Sublist of Objects for Dataset B U.sub.A Partial Representation for Dataset A U.sub.B Partial Representation for Dataset B .sub.A Set of Predicted Values Corresponding to Dataset A .sub.B Set of Predicted Values Corresponding to Dataset B g.sub.A Individual Function Corresponding to Dataset A g.sub.B Individual Function Corresponding to Dataset B .gamma..sub.A One or More Individual Parameters Corresponding to Dataset A .gamma..sub.B One or More Individual Parameters Corresponding to Dataset B .gamma..sub.i Weight Tensor Representing the One or More Individual Parameters E.sub.A Error for Dataset A E.sub.B Error for Dataset B L.sub.A Individual Loss Function for Dataset A L.sub.B Individual Loss Function for Dataset B W.sub.A Non-Empty Entries in the Set of Recorded Values for Dataset A W.sub.B Non-Empty Entries in the Set of Recorded Values for Dataset B C.sub.A One or More Feedback Values Corresponding to Dataset A C.sub.B One or More Feedback Values Corresponding to Dataset B C.sub.Comb One or More Aggregated Feedback Values U.sub.Final Final Shared Representation .sub.A.sub.Final Final Set of Predicted Values Corresponding to Dataset A .sub.B.sub.Final Final Set of Predicted Values Corresponding to Dataset B U.sub.Final.sub.--.sub.A Final Partial Representation for Dataset A U.sub.Final.sub.--.sub.B Final Partial Representation for Dataset B FLN Tensor Representing Values for First-Level Neurons MLN Tensor Representing the Values for Mid-Level Neurons ULN Tensor Representating Values for Upper-Level Neurons I.sub.A Individual Representation for Dataset A I.sub.B Individual Representation for Dataset B R.sub.A Individual Learning Rate Corresponding to Dataset A R.sub.B Individual Learning Rate Corresponding to Dataset B .eta. Shared Learning Rate C.sub.A Feedback Tensor Corresponding to Dataset A C.sub.B Feedback Tensor Corresponding to Dataset B C.sub.Comb Tensor Representing the One or More Aggregated Feedback Values
[0104] FIG. 4B is a data flow diagram illustrating a portion of a method 400. Additional portions of the method 400 are illustrated in FIGS. 4C-4E. The method 400 may be used to develop a shared representation (U) based on a shared function (f) and one or more shared parameters (13). The method 400 may be carried out by client computing device A 402, client computing device B 404, and the managing computing device 406 of the computing network 401 (e.g., as illustrated in FIG. 4A). As indicated with respected to FIG. 4A, in alternate embodiments, there may be any number of client computing devices communicating with the managing computing device. Additional client computing devices may serve to provide additional data with which to refine the shared representation (U).
[0105] In some embodiments, the method 400 illustrated in FIGS. 4B-4E may correspond to instructions stored on a non-transitory, computer-readable medium (e.g., similar to the data storage 204 illustrated in FIG. 2). The instructions may be executable by a processor to perform the operations of the method 400. Additionally or alternatively, the method 400 may be used to produce a model. The model may be stored on a memory (e.g., similar to the data storage 204 illustrated in FIG. 2). Such a memory with a model stored thereon may be sold or licensed to a party (e.g., an individual or a corporation) corresponding to client computing device A 402, a party (e.g., an individual or a corporation) corresponding to client computing device B 404, or a third party (e.g., an individual or a corporation) that is unrelated to either of the client computing devices or the managing computing device 406. Similarly, the model itself (e.g., the arrangement of data corresponding to the model) may be distributed to one or more third parties without an associated memory.
[0106] According to an example embodiment, the operations of the method 400 will be enumerated with reference to FIGS. 4B-4E. However, additional details for the operations of the example embodiment shown and described in FIGS. 4B-4E are provided below with reference to FIGS. 5A-15B. The dashed horizontal lines in FIGS. 4B-4E illustrate a continuation of the method 400 onto the next figure or from the previous figure.
[0107] At operation 412, the method 400 may include client computing device A 402 transmitting dataset A (X.sub.A) to the managing computing device 406. Dataset A (X.sub.A) may correspond to a set of recorded values (Y.sub.A). Further, dataset A (X.sub.A) may include objects. In alternate embodiments, client computing device A 402 may also transmit the corresponding set of recorded values (Y.sub.A) to the managing computing device 406 (e.g., in addition to dataset A (X.sub.A)).
[0108] At operation 414, the method 400 may include client computing device B 404 transmitting dataset B (X.sub.B) to the managing computing device 406. Dataset B (X.sub.B) may correspond to a set of recorded values (Y.sub.B). Further, dataset B (X.sub.B) may include objects. In alternate embodiments, client computing device B 404 may also transmit the corresponding set of recorded values (Y.sub.B) to the managing computing device 406 (e.g., in addition to dataset B (X.sub.B)).
[0109] At operation 416, the method 400 may include the managing computing device 406 determining a list of identifiers for dataset A (M.sub.A) and a list of identifiers for dataset B (M.sub.B).
[0110] At operation 418, the method 400 may include the managing computing device 406 determining a composite list of identifiers (M.sub.Comb, e.g., representing the "combined" list of identifiers). The composite list of identifiers may include a combination of the lists of identifiers for dataset A (M.sub.A) and dataset B (M.sub.B).
[0111] At operation 420, the method 400 may include the managing computing device 406 determining a list of unique objects (X.sub.Comb, e.g., representing the "combined" list of objects from the datasets) from dataset A (X.sub.A) and dataset B (X.sub.B).
[0112] At operation 422, the method 400 may include the managing computing device 406 selecting a subset of identifiers (S) from the composite list of identifiers (M.sub.Comb).
[0113] At operation 424, the method 400 may include the managing computing device 406 determining a subset of the list of unique objects (Z) corresponding to each identifier in the subset of identifiers (S).
[0114] FIG. 4C is a data flow diagram illustrating a portion of a method 400. Additional operations of the method 400 are illustrated in FIG. 4C.
[0115] At operation 426, the method 400 may include the managing computing device 406 computing a shared representation (U) of the datasets (X.sub.A/X.sub.B) based on the subset (Z) of the list of unique objects (X.sub.Comb) and a shared function (f) having one or more shared parameters (.beta.).
[0116] At operation 428, the method 400 may include the managing computing device 406 determining a sublist of objects (S.sub.A/S.sub.B) for the respective dataset (X.sub.A/X.sub.B) of each client computing device. The sublist of objects (S.sub.A/S.sub.B) may be based on an intersection of the subset of identifiers (S) with the list of identifiers (M.sub.A/M.sub.B) for the respective dataset (X.sub.A/X.sub.B).
[0117] At operation 430, the method 400 may include the managing computing device 406 determining a partial representation (U.sub.A/U.sub.B) for the respective dataset (X.sub.A/X.sub.B) of each client computing device based on the sublist of objects (S.sub.A/S.sub.B) for the respective dataset (X.sub.A/X.sub.B) and the shared representation (U).
[0118] At operation 432, the method 400 may include the managing computing device 406 transmitting the sublist of objects (S.sub.A) for dataset A (X.sub.A) and the partial representation (U.sub.A) for dataset A (X.sub.A) to client computing device A 402.
[0119] At operation 434, the method 400 may include the managing computing device 406 transmitting the sublist of objects (S.sub.B) for dataset B (X.sub.B) and the partial representation (U.sub.B) for dataset B (X.sub.B) to client computing device B 404. It is understood that, in some embodiments, operation 434 may also happen before or substantially simultaneous with operation 432.
[0120] In alternate embodiments, instead of operations 428, 430, 432, and 434, the managing computing device 406 may transmit: the shared representation (U), the subset of identifiers (S), and the list of identifiers (M.sub.A) for dataset A (X.sub.A) to client computing device A 402; and the shared representation (U), the subset of identifiers (S), and the list of identifiers (M.sub.B) for dataset B (X.sub.B) to client computing device B 404. Then, each respective client computing device may determine, for itself, the corresponding sublist of objects (S.sub.A/S.sub.B) for its respective dataset (X.sub.A/X.sub.B). The sublist of objects (S.sub.A) for dataset A (X.sub.A) may be based on an intersection of the subset of identifiers (S) with the list of identifiers (M.sub.A) for dataset A (X.sub.A). The sublist of objects (S.sub.B) for dataset B (X.sub.B) may be based on an intersection of the subset of identifiers (S.sub.B) with the list of identifiers (M.sub.B) for dataset B (X.sub.B). Further, each respective client computing device may determine, for itself, the partial representation (U.sub.A/U.sub.B) for its respective dataset (X.sub.A/X.sub.B). The partial representation (U.sub.A) for dataset A (X.sub.A) may be based on the sublist of objects (S.sub.A) and the shared representation (U). The partial representation (U.sub.B) for dataset B (X.sub.B) may be based on the sublist of objects (S.sub.B) and the shared representation (U).
[0121] FIG. 4D is a data flow diagram illustrating a portion of a method 400. Additional operations of the method 400 are illustrated in FIG. 4D.
[0122] At operation 436A, the method 400 may include client computing device A 402 determining a set of predicted values ( .sub.A) that corresponds to dataset A (X.sub.A). The set of predicted values may be based on the partial representation (U.sub.A) and an individual function (g.sub.A) with one or more individual parameters (.gamma..sub.A) corresponding to dataset A (X.sub.A).
[0123] At operation 436B, the method 400 may include client computing device B 404 determining a set of predicted values ( .sub.B) that corresponds to dataset B (X.sub.B). The set of predicted values may be based on the partial representation (U.sub.B) and an individual function (g.sub.B) with one or more individual parameters (.gamma..sub.B) corresponding to dataset B (X.sub.B).
[0124] At operation 438A, the method 400 may include client computing device A 402 determining an error (E.sub.A) for dataset A (X.sub.A). The error (E.sub.A) may be based on an individual loss function (L.sub.A) for dataset A (X.sub.A), the set of predicted values (V.sub.A) that corresponds to dataset A (X.sub.A), the sublist of objects (S.sub.A), and non-empty entries (W.sub.A) in the set of recorded values (Y.sub.A) corresponding to dataset A (X.sub.A).
[0125] At operation 438B, the method 400 may include client computing device B 404 determining an error (E.sub.B) for dataset B (X.sub.B). The error (E.sub.B) may be based on an individual loss function (L.sub.B) for dataset B (X.sub.B), the set of predicted values ( .sub.B) that corresponds to dataset B (X.sub.B), the sublist of objects (S.sub.B), and non-empty entries (W.sub.B) in the set of recorded values (Y.sub.B) corresponding to dataset B (X.sub.B).
[0126] At operation 440A, the method 400 may include client computing device A 402 updating the one or more individual parameters (.gamma..sub.A) for dataset A (X.sub.A).
[0127] At operation 440B, the method 400 may include client computing device B 404 updating the one or more individual parameters (.gamma..sub.B) for dataset B (X.sub.B).
[0128] At operation 442A, the method 400 may include client computing device A 402 determining one or more feedback values (C.sub.A). The one or more feedback values (C.sub.A) may be used to determine a change in the partial representation (U.sub.A) that corresponds to an improvement in the set of predicted values ( .sub.A).
[0129] At operation 442B, the method 400 may include client computing device B 404 determining one or more feedback values (C.sub.B). The one or more feedback values (C.sub.B) may be used to determine a change in the partial representation (U.sub.B) that corresponds to an improvement in the set of predicted values ( .sub.B).
[0130] At operation 444, the method 400 may include client computing device A 402 transmitting the one or more feedback values (C.sub.A) to the managing computing device 406.
[0131] At operation 446, the method 400 may include client computing device B 404 transmitting the one or more feedback values (C.sub.B) to the managing computing device 406. In some embodiments, operation 444 may occur after or substantially simultaneous with operation 446.
[0132] In some embodiments (e.g., embodiments including more than two datasets and/or more than two client computing devices), only a subset of the client computing devices may transmit one or more feedback values (e.g., C.sub.A/C.sub.B) to the managing computing device 406. In such embodiments, the managing computing device 406 may update the one or more shared parameters (.beta.) based only on the one or more feedback values provided, rather than all possible sets of one or more feedback values from all client computing devices. Alternatively, in embodiments where only a subset of the client computing devices transmit one or more feedback values to the managing computing device 406, the managing computing device 406 may transmit a request to those client computing devices that did not provide one or more feedback values for one or more feedback values from the respective client computing device.
[0133] FIG. 4E is a data flow diagram illustrating a portion of a method 400. Additional operations of the method 400 are illustrated in FIG. 4E.
[0134] At operation 448, the method 400 may include the managing computing device 406 determining one or more aggregated feedback values (C.sub.Comb). The one or more aggregated feedback values (C.sub.Comb) may be based on the sublists of objects (S.sub.A/S.sub.B) corresponding to dataset A (X.sub.A) and dataset B (X.sub.B), respectively, and the one or more feedback values (C.sub.A/C.sub.B) from client computing device A 402 and client computing device B 404, respectively.
[0135] At operation 450, the method 500 may include the managing computing device 406 updating the one or more shared parameters (.beta.) based on the one or more aggregated feedback values (C.sub.Comb). In some embodiments (e.g., embodiments where the one or more aggregated feedback values (C.sub.Comb) correspond to back-propagated errors), the one or more shared parameters (.beta.) may be updated according to a gradient descent method.
[0136] In some embodiments, the method illustrated in FIGS. 4B-4E may include additional operations. Such additional operations may occur before, after, or concurrently with operations illustrated in FIGS. 4B-4E. Further, the following additional operations may occur in various orders and combinations in various embodiments.
[0137] For example, as illustrated in FIG. 4F, in some alternate embodiments, at operation 462 and operation 466, the method 400 may optionally include the managing computing device 406 transmitting the shared representation (U), the shared function (f) and/or the one or more shared parameters (.beta.) to each of the client computing devices. Alternatively, in some embodiments, the method may include the managing computing device 406 transmitting the shared function (f) and/or the one or more shared parameters (.beta.) to a subset of the client computing devices. Such a subset may be chosen by the managing computing device 406 based on whether the respective client computing device paid a fee (e.g., for a machine-learned model subscription service), entered access credentials (e.g., a username and password), or is a member of a given group (e.g., a group with administrative privileges). Also as illustrated in FIG. 4F, at operation 464, the method 400 may optionally include client computing device A 402 using the shared representation (U), the shared function (f), and/or the one or more shared parameters (.beta.) to determine an additional set of predicted values corresponding to a dataset (e.g., dataset A (X.sub.A) or an alternate dataset). Similarly, at operation 468, the method 400 may optionally include client computing device B 404 using the shared representation (U), the shared function (f), and/or the one or more shared parameters (.beta.) to determine an additional set of predicted values corresponding to a dataset (e.g., dataset B (X.sub.B) or an alternate dataset).
[0138] Optionally (e.g., in embodiments that include the third-party computing device 405), as illustrated in FIG. 4F, at operation 472, the method 400 may also include the managing computing device 406 transmitting the shared representation (U), the shared function (f), and/or the one or more shared parameters (.beta.) to the third-party computing device 405. Similarly, at operation 474 the method 400 may further include the third-party computing device 405 using the shared representation (U), the shared function (f), and/or the one or more shared parameters (.beta.) to determine an additional set of predicted values corresponding to a dataset. In still other embodiments, the third-party computing device 405 may receive the shared representation (U), the shared function (f), and/or the one or more shared parameters (.beta.) from one or more of the client computing devices (e.g., client computing device A 402 and/or client computing device B 404), rather than from the managing computing device 406.
[0139] In yet other embodiments, the method may include the managing computing device 406 transmitting only a portion of the shared function (f) and/or only a portion of the one or more shared parameters (.beta.) to the client computing devices 402/404 and/or the third-party computing device 405. The portions received by the client computing devices 402/404 or the third-party computing device 405 may be different. For example, each client computing device may only receive the portion of the one or more shared parameters (.beta.) that correspond to the portion of the shared representation (U) that was developed according to the dataset (X.sub.A/X.sub.B) supplied by the client computing device.
[0140] Additionally or alternatively, the method may include the managing computing device 406 computing a final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B). Such a final shared representation (U.sub.Final) may be based on the list of unique objects (X.sub.Comb), the shared function (f), and the one or more shared parameters (.beta.). Further, the method may include the managing computing device 406 transmitting the final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) to client computing device A 402 and/or client computing device B 404. The shared representation (U.sub.Final) may be usable by each client computing device (or a subset of the client computing devices) to determine a final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) corresponding to the respective dataset (X.sub.A/X.sub.B) of the client computing device. Determining the final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) may include the respective client computing device determining a final partial representation (U.sub.Final.sub._.sub.A/U.sub.Final.sub._.sub.B) for the respective dataset (X.sub.A/X.sub.B) based on the list of identifiers (M.sub.A/M.sub.B) for the respective dataset (X.sub.A/X.sub.B). Determining the final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) may also include the respective client computing device determining the final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) corresponding to the respective dataset (X.sub.A/X.sub.B) based on the final partial representation (U.sub.Final.sub._.sub.A/U.sub.Final.sub._.sub.B), the individual function (g.sub.A/g.sub.B), and the one or more individual parameters (Y.sub.A/Y.sub.B) corresponding to the respective dataset (X.sub.A/X.sub.B). In some embodiments, the final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) may be displayed by at least one of the client computing devices. In some embodiments, the final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) may be used by at least one of the client computing devices to provide one or more predictions about objects in the dataset (X.sub.A/X.sub.B) corresponding to the respective client computing device.
[0141] In some embodiments, multiple operations may be repeated one or more times to further refine the machine-learned model. For example, operations 422, 424, 426, 428, 430, 432, 434, 436A, 436B, 438A, 438B, 440A, 440B, 442A, 442B, 444, 446, 448, and 450 may be repeated one or more times to refine the machine-learned model. When these operations are repeated, they may be repeated such that each determining/selecting operation includes determining/selecting additional subsets of data (e.g., possibly different from the selections in the previous iteration).
[0142] In some embodiments, the method may also include the managing computing device 406 removing ("purging") the list of unique objects (X.sub.Comb), the shared representation (U), the lists of identifiers (M.sub.A/M.sub.B) for each dataset (X.sub.A/X.sub.B), and the composite list of identifiers (M.sub.Comb) from a memory (e.g., a data storage 204 as illustrated in FIG. 2) of the managing computing device 406. In some embodiments, removing the above data from the managing computing device 406 may include removing the data from a corresponding cloud storage device and/or from multiple servers used to store the data of the managing computing device. The removal of such data may prevent the managing computing device from having access to the data for an unspecified amount of time after the machine-learned model has been developed.
[0143] FIG. 5A is an illustration of dataset A (X.sub.A) and a corresponding set of recorded values (Y.sub.A) (e.g., as described with respect to FIGS. 4B-4E). Dataset A (X.sub.A) and the corresponding set of recorded values (Y.sub.A) may correspond to client computing device A 402. In some embodiments, dataset A (X.sub.A) may be stored in a primary memory storage (e.g., an internal hard drive) of client computing device A 402 and the corresponding set of recorded values (Y.sub.A) may be stored in a secondary memory storage (e.g., an external hard drive) of client computing device A 402.
[0144] As illustrated, dataset A (X.sub.A) includes four objects in a first dimension (e.g., "Timmy," "Johnny," "Sally," and "Sue"). These objects may correspond to user profiles of an online book-rating and movie-rating platform (e.g., including a database) run by client computing device A 402 or associated with client computing device A 402, for example. Such user profiles may be identified by their profile name, their user identification (ID) number, a hash code, a social security number, or an internet protocol (IP) address associated with a user profile. Other methods of identifying user profiles are also possible.
[0145] In a second dimension of dataset A (X.sub.A), there may be seven features corresponding to each of the four objects (e.g., "Book Title 1," "Book Title 2," "Book Title 3," "Book Title 4," "Book Title 5," "Book Title 6," and "Book Title 7"). Such features may alternatively be identified by their 10-digit or 13-digit international standard book number (ISBN), for example, or by a corresponding unified resource locator (URL) from the book-rating and movie-rating platform.
[0146] The entries corresponding to each pair of (object, feature) may correspond to a rating value (e.g., ranging from 0-100). For example, user "Sally" may have rated "Book Title 4" with a rating of "17." These entries may be scaled such that they all have the same range (e.g., some of the ratings may have originally be issued between 0-10 and then scaled to ensure they ranged from 0-100 and were normalized to the other rating values).
[0147] In alternate embodiments, other types of objects and/or features may be used within dataset A (X.sub.A). Further, in other embodiments, other numbers of objects and/or features may be used. In addition, in some embodiments, other types of data entries may be used. Additionally or alternatively, in some embodiments, there may be greater than two dimensions (d) for dataset A (X.sub.A).
[0148] As illustrated, the corresponding set of recorded values (Y.sub.A) includes the same four objects in a first dimension (e.g., "Timmy," "Johnny," "Sally," and "Sue") as the four objects in dataset A (X.sub.A). As with above, these objects may correspond to user profiles of an online book-rating and movie-rating platform run by client computing device A 402 or associated with client computing device A 402, for example. Again, such user profiles may be identified by their profile name, their user ID number, a hash code, a social security number, or an IP address associated with a user profile. Other methods of identifying user profiles are also possible.
[0149] In a second dimension of the corresponding set of recorded values (Y.sub.A), there may be five features corresponding to each of the four objects (e.g., "Movie Title 1," "Movie Title 2," "Movie Title 3," "Movie Title 4," and "Movie Title 5"). Such features may alternatively be identified by their barcode or a corresponding URL from the book-rating and movie-rating platform.
[0150] The entries corresponding to each pair of (object, feature) in the corresponding set of recorded values (Y.sub.A) may correspond to a rating value (e.g., ranging from 0-100). For example, object "Johnny" may have rated feature "Movie Title 2" with a value of "18." These entries may be scaled such that they all have the same range (e.g., some of the ratings may have originally be issued between 0-10 and then scaled to ensure they ranged from 0-100 and were normalized to the other rating values).
[0151] In alternate embodiments, other types of objects and/or features may be used within the corresponding set of recorded values (Y.sub.A). Further, in other embodiments, other numbers of objects and/or features may be used. In addition, in some embodiments, other types of data entries may be used. Additionally or alternatively, in some embodiments, there may be greater than two dimensions (d) for the corresponding set of recorded values (Y.sub.A). The number of dimensions (d) in the corresponding set of recorded values (Y.sub.A) may be the same as the number of dimensions (d) in dataset A (X.sub.A). Alternate embodiments of datasets and corresponding sets of recorded values are illustrated and described further with reference to FIGS. 16A-16C.
[0152] FIG. 5B is an illustration of dataset B (X.sub.B) and a corresponding set of recorded values (Y.sub.B) (e.g., as described with respect to FIGS. 4B-4E). Dataset B (X.sub.B) and the corresponding set of recorded values (Y.sub.B) may correspond to client computing device B 404. Dataset B (X.sub.B) and the corresponding set of recorded values (Y.sub.B) may correspond to a separate book-rating and movie-rating platform (e.g., including a database) from the book-rating and movie-rating platform of dataset A (X.sub.A) and its corresponding set of recorded values (Y.sub.A). As illustrated in FIG. 5B, the objects in dataset B (X.sub.B) might not be the same as the objects in dataset A (X.sub.A). In some embodiments, as illustrated, there may be some overlap in objects between dataset B (X.sub.B) and dataset A (X.sub.A). In still other embodiments, the objects in the datasets (X.sub.A/X.sub.B) may be entirely the same. In even further embodiments, the objects in the datasets (X.sub.A/X.sub.B) may be entirely disjoint. Also as illustrated, the number of objects in dataset B (X.sub.B) might not be the same as the number of objects in dataset A (X.sub.A).
[0153] As illustrated, the number of features in additional dimensions of dataset B (X.sub.B) and the corresponding set of recorded values (Y.sub.B) may be the same as the number of features in additional dimensions of dataset A (X.sub.A) and its corresponding set of recorded values (Y.sub.A). As illustrated, there are seven features in the additional dimension of dataset B (X.sub.B) (e.g., "Book Title 1," "Book Title 2," "Book Title 3," "Book Title 4," "Book Title 5," "Book Title 6," and "Book Title 7"). As shown, these features are the same as the features of dataset A (X.sub.A) illustrated in FIG. 5A.
[0154] Still further, the number of features the corresponding set of recorded values (Y.sub.B) may be different than the number of features in the corresponding set of recorded values (Y.sub.A). As illustrated, there are nine features in the additional dimension of the corresponding set of recorded values (Y.sub.B) (e.g., "Movie Title 1," "Movie Title 3," "Movie Title 4," "Movie Title 5," "Movie Title 6," "Movie Title 7," "Movie Title 8," "Movie Title 9," and "Movie Title 10"). As shown, some of these features are the same as the features of the corresponding set of recorded values (Y.sub.A) illustrated in FIG. 5A. In alternate embodiments, all or none of the features will overlap with features of corresponding sets of recorded values.
[0155] Additionally, in some embodiments, the numbers of dimensions (d) in dataset B (X.sub.B) and corresponding set of recorded values (Y.sub.B) of FIG. 5B, might not be same as the number of dimensions (d) in dataset A (X.sub.A) and corresponding set of recorded values (Y.sub.A) of FIG. 5A. In some embodiments, each of the plurality of datasets (e.g., X.sub.A/X.sub.B) may include an equal number of dimensions (d). In various embodiments, the number of dimensions (d) may be two, three, four, five, six, seven, eight, nine, ten, sixteen, thirty-two, sixty-four, one-hundred and twenty-eight, two-hundred and fifty-six, five-hundred and twelve, or one-thousand and twenty-four. Other numbers of dimensions (d) are also possible. In some embodiments, each of the plurality of datasets may be represented by a tensor. Further, in some embodiments, at least one of the plurality of datasets may be represented by a sparse tensor. In various embodiments, a tensor may be a "sparse" tensor if the tensor's sparsity is greater than 50%, greater than 60%, greater than 70%, greater than 75%, greater than 80%, greater than 90%, greater than 95%, greater than 98%, greater than 99%, greater than 99.9%, greater than 99.99%, greater than 99.999%, or greater than 99.9999%. In the embodiment illustrated in FIGS. 5A/5B, both of the datasets (X.sub.A/X.sub.B) are represented by tensors (e.g., two-dimensional tensors, i.e., "matrices").
[0156] Additionally or alternatively, in some embodiments, at least one of the corresponding sets of recorded values may be represented by a tensor. In addition, in some embodiments, at least one of the corresponding sets of recorded values may be represented by a sparse tensor. In the embodiment illustrated in FIGS. 5A/5B, both of the corresponding sets of recorded values (Y.sub.A/Y.sub.B) are represented by tensors (e.g., two-dimensional tensors, i.e., "matrices").
[0157] In some embodiments, there may be more than two pairs of datasets and corresponding sets of recorded values. Additional pairs of datasets and sets of recorded values may be transmitted by and/or stored within client computing device A 402 or client computing device B 404. Additionally or alternatively, additional pairs of datasets and sets of recorded values may be transmitted by and/or stored within additional client computing devices (e.g., client computing devices not illustrated in FIG. 4A). Additionally or alternatively, in some embodiments, some or all of the datasets (e.g., X.sub.A/X.sub.B) may be stored and/or transmitted on separate client computing devices from their corresponding sets of recorded values (e.g., Y.sub.A/Y.sub.B). If two separate client computing devices store and/or transmit a dataset (e.g., X.sub.A) and the corresponding set of recorded values (Y.sub.A), the separate client computing devices may be controlled and/or owned by a single client (e.g., a corporation). Alternatively, the separate client computing devices may be controlled and/or owned by separate clients. Still further, in embodiments where the separate client computing devices are controlled and/or owned by separate clients, the separate clients may not communicate with one another (e.g., for privacy reasons), leaving the managing computing device 406 to ultimately associate dataset A (X.sub.A) with the corresponding set of recorded values (Y.sub.A) upon receiving both individually. This may be done using metadata (e.g., tags) attached to dataset A (X.sub.A) and the corresponding set of recorded values (Y.sub.A) by each of the separate client computing devices such that the managing computing device 406 can identify that dataset A (X.sub.A) corresponds to the set of recorded values (Y.sub.A).
[0158] In various embodiments, the data represented by the datasets and the corresponding sets of recorded values may vary. For example, the method 400 may be used in a variety of applications, each application potentially corresponding to a different set of data stored within the datasets and different corresponding sets of recorded values. This is described and illustrated further with reference to FIGS. 16A-16C.
[0159] FIGS. 6A and 6B illustrate operation 416 of the method 400 illustrated in FIGS. 4B-4E. As described with reference to FIG. 4B, at operation 416, the method 400 may include the managing computing device determining a list of identifiers (M.sub.A) for dataset A (X.sub.A) and a list of identifiers (M.sub.B) for dataset B (X.sub.B). As illustrated in FIG. 6A, the objects of the dataset (X.sub.A) are being converted to a list of identifiers (M.sub.A) for dataset (X.sub.A). The list of identifiers (M.sub.A) may correspond to unique IDs (e.g., strings, hash codes, or integers) assigned by the managing computing device 406 to each object in the dataset (X.sub.A). The unique IDs in the list of identifiers (M.sub.A) may be generated such that the objects in dataset A (X.sub.A) may be meaningfully compared to the objects in dataset B (X.sub.B). Hence, as illustrated in FIG. 6B, the objects of dataset B (X.sub.B) are being converted to a list of identifiers (M.sub.B) for dataset B (X.sub.B). The list of identifiers (M.sub.B) may also correspond to unique IDs (e.g., strings, hash codes, or integers) assigned by the managing computing device 406 to each object in dataset B (X.sub.B). As illustrated, in some embodiments, those objects that are the same in both dataset A (X.sub.A) and dataset B (X.sub.B) may be assigned the same identifier (e.g., "Timmy" is assigned "User00" and "Johnny" is assigned "User01" in both lists of identifiers M.sub.A/M.sub.B).
[0160] Determining, by the managing computing device 406, a respective list of identifiers for each dataset (X.sub.A/X.sub.B) may include various operations in various embodiments. In some embodiments, the lists of identifiers (M.sub.A/M.sub.B) may be provided to the managing computing device 406 by the respective client computing devices (computing device A 402/computing device B 404). In other embodiments, the managing computing device 406 may define the unique IDs based on an algorithm of the managing computing device 406. In still other embodiments, determining, by the managing computing device, the lists of identifiers (M.sub.A/M.sub.B) may include receiving commercially available identifiers for the objects (e.g., ISBNs for books or social security numbers for patients). Such commercially available identifiers for the objects may be provided to the managing computing device 406 by a third party (e.g., a domain name registrar may provide corresponding IP addresses for objects corresponding to domain names). Regardless of the technique used to define the unique IDs in the lists of identifiers (M.sub.A/M.sub.B), the unique IDs may be defined such that each unique ID is defined according to a common syntax, thereby enabling a creation of a composite list of identifiers (M.sub.Comb).
[0161] FIG. 7 illustrates operation 418 of the method 400 illustrated in FIGS. 4B-4E. As described with reference to FIG. 4B, at operation 418, the method 400 may include the managing computing device 406 determining a composite list of identifiers (M.sub.Comb). As illustrated in FIG. 7, the list of identifiers (M.sub.A) for dataset A (X.sub.A) and the list of identifiers (M.sub.B) for dataset B (M.sub.B) may be combined (e.g., concatenated) to form a list of all identifiers. This list of all identifiers may have repeated (i.e., "redundant") identifiers (e.g., "User00" and "User01" in the example embodiment of FIG. 7) removed. Upon removing the redundant identifiers, a composite list of identifiers (M.sub.Comb) may remain. The composite list of identifiers (M.sub.Comb) may include all non-repeated identifiers corresponding to all datasets (X.sub.A/X.sub.B) received by the managing computing device 406.
[0162] FIG. 8 illustrates operation 420 of the method 400 illustrated in FIGS. 4B-4E. As described with reference to FIG. 4B, at operation 420, the method 400 may include the managing computing device 406 determining a list of unique objects (X.sub.Comb) from dataset A (X.sub.A) and dataset B (X.sub.B). As illustrated in FIG. 8, determining a list of unique objects (X.sub.Comb) may include combining data from all datasets into a single list (e.g., a single tensor). The data may be combined based on the composite list of identifiers (M.sub.Comb). For example, "User00" may have been an object in both dataset A (X.sub.A) and dataset B (X.sub.B). Hence, as illustrated in FIG. 8, the data from dataset A (X.sub.A) and dataset B (X.sub.B) is combined into data for a single object ("User00") in the list of unique objects (X.sub.Comb). In some embodiments, if different scales were used (e.g., if dataset A (X.sub.A) has ratings ranging from 0 to 10 and dataset B (X.sub.B) has ratings scaling from 0 to 100), the values of the objects in each dataset may be normalized before inputting them into the list of unique objects (X.sub.Comb).
[0163] In some embodiments, two or more datasets may include the same object (e.g., "Timmy" in FIG. 8 was in dataset A (X.sub.A) and dataset B (X.sub.B)), but have conflicting data for the same feature of the same object. For example, if "Timmy" had provided "Book Title 5" with a rating of "84" in dataset A (X.sub.A), but with a rating of "60" in dataset B (X.sub.B), this would give rise to a conflict. In some embodiments, such a conflict may be resolved by assigning identifiers in such a way that only those objects having the exact same data for the same features (e.g., the same data for all of the features of the object or the same data for those features of the object where a given object has data at all) will be assigned a common identifier. Using the example in this paragraph, the "Timmy" object in dataset A (X.sub.A) and the "Timmy" object in dataset B (X.sub.B) may could be assigned different identifiers if they do not share the same data for every feature (e.g., the "Timmy" object from dataset A (X.sub.A) may be assigned identifier "User00" while the "Timmy" object from dataset B (X.sub.B) may be assigned the identifier "User05"). Using such a technique, adverse effects on machine-learned models, as described herein, due to conflicts may be prevented.
[0164] In some embodiments, operation 420 may be performed before operation 418. For example, the objects from dataset A (X.sub.A) and the objects from dataset B (X.sub.B), and any other dataset in embodiments having greater than two datasets, may be combined prior to creating a composite list of identifiers (M.sub.Comb). Once combined, repeated (i.e., "duplicate") objects in the combined set of objects may be removed, thereby forming the list of unique objects (X.sub.Comb). The repeated objects may be removed based on an intersection of the lists of identifiers (M.sub.A/M.sub.B) for each of the plurality of datasets (X.sub.A/X.sub.B). Then, based on the list of unique objects, the composite list of identifiers (M.sub.Comb) may be generated.
[0165] FIG. 9 illustrates operation 422 of the method 400 illustrated in FIGS. 4B-4E. As described with reference to FIG. 4B, at operation 422, the method 400 may include the managing computing device 406 selecting a subset of identifiers (S) from the composite list of identifiers (M.sub.Comb). The subset of identifiers (S) may be selected using various methods. For example, the subset of identifiers (S) may be selected randomly (e.g., using a random number generator, such as a hardware random number generator) or pseudo-randomly (e.g., using a pseudo-random number generator with a seed value). In some embodiments, the subset of identifiers (S) may be selected based on a Mersenne Twister pseudo-random number generator. Additionally or alternatively, each identifier in the subset of identifiers (S) may be selected according to an algorithm known only to the managing computing device 406. In other embodiments, each identifier in the subset of identifiers (S) may be selected according to a publicly available algorithm (e.g., an algorithm that is published by the managing computing device 406 and transmitted to one or more of the plurality of client computing devices 402/404).
[0166] FIG. 10 illustrates operation 424 of the method 400 illustrated in FIGS. 4B-4E. As described with reference to FIG. 4B, at operation 424, the method 400 may include the managing computing device 406 determining a subset (Z) of the list of unique objects (X.sub.Comb) corresponding to each identifier in the subset of identifiers (S). Determining the subset (Z) may include the managing computing device 406 retrieving the list of unique objects (X.sub.Comb), and then creating a new list of objects based on the list of unique objects (X.sub.Comb). The managing computing device 406 may then remove from the new list of objects the objects whose corresponding identifiers are not contained within the subset of identifiers (S), thereby creating the subset (Z) of the list of unique objects (X.sub.Comb). Alternatively, determining the subset (Z) may include the managing computing device 406 retrieving the subset of identifiers (S). Then, based on the subset of identifiers (S), the managing computing device 406 may assemble a new list by adding an object from the list of unique objects (X.sub.Comb) that corresponds to an identifier in the subset of identifiers (S) for each identifier in the subset of identifiers (S).
[0167] FIG. 11 illustrates operation 426 of the method 400 illustrated in FIGS. 4B-4E. As described with reference to FIG. 4C, at operation 426, the method 400 may include the managing computing device 406 computing a shared representation (U) of the datasets (X.sub.A/X.sub.B) based on the subset (Z) of the list of unique objects (X.sub.Comb) and a shared function (f) having one or more shared parameters (13). In some embodiments (e.g., embodiments where the machine learning model is an artificial neural network), the one or more shared parameters (.beta.) may correspond to a shared parameter tensor (e.g., shared parameter matrix), such as a weight tensor (.beta.).
[0168] FIGS. 11, 13A, 13B, 14A, and 14B (and consequently operations 426, 430, 436A, and 436B of the method 400) are illustrated using, as an example, an artificial neural network model of machine learning (e.g., the shared function (f) may include an artificial neural network having rectified linear unit (ReLU) non-linearity and dropout). It is understood that this model is provided by way of example only, and is not meant to preclude other machine learning models (or even non-machine learning models, e.g., based on statistical approaches) from the scope of the disclosure. Other machine learning models, including supervised learning models, unsupervised learning models, and semi-supervised learning models (e.g., discriminant analysis), may be used in conjunction with the method 400. For example, decision tree learning, association rule learning, deep learning, inductive logic programming, support vector machines, relevance vector machines, clustering, Bayesian networks, reinforcement learning, representation learning, similarity and metric learning, sparse dictionary learning, genetic algorithms, rule-based machine learning, learning classifier systems, deep belief networks, recurrent neural networks, or various combinations of the aforementioned techniques are all implicitly contemplated herein. An alternate type of machine learning for use with the method 400 that is based on matrix factorization is explicitly shown and described with reference to FIGS. 17A and 17B.
[0169] As illustrated in FIG. 11, in the example case of an artificial neural network, computing the shared representation (U) of the datasets (X.sub.A/X.sub.B) may include correlating each of the features of the objects in the list of unique objects (X.sub.Comb) to a first-level neuron 1102. After correlating each of the features to a respective first-level neuron 1102, the first-level neurons 1102 may be connected to mid-level neurons 1104 (i.e., intermediate neurons). Only one first-level neuron 1102 and one mid-level neuron 1104 are labeled in FIG. 11 to prevent clutter of the figure. The dashed lines in FIG. 11 are meant to illustrate the possibility that additional neuron layers (e.g., hidden neuron layers) may be present between the first-level neuron 1102 layer and the mid-level neuron 1104 layer.
[0170] Connecting the first-level neurons 1102 to the mid-level neurons 1104 may include using the first-level neurons 1102 as inputs to the mid-level neurons 1104. Using the first-level neurons 1102 as inputs to the mid-level neurons 1104 may include multiplying a value of each first-level neuron 1102 by one or more shared parameters (13) (i.e., one or more "weights"). These one or more shared parameters (.beta.) may be stored as a tensor (e.g., a "weight matrix" in two-dimensional examples). For example, in FIG. 11, Mid-Level Neuron 1 may have a value corresponding to the value of the "Book Title 1" first-level neuron multiplied by a first entry (e.g., "weight") in a weight tensor (e.g., a matrix representing the one or more shared parameters ((3)), plus the value of the "Book Title 2" first-level neuron multiplied by a second entry in the weight tensor, plus the value of the "Book Title 3" first-level neuron multiplied by a third entry in the weight tensor, etc. This process may be repeated for each object in the subset (Z) of the list of unique objects (X.sub.Comb) to arrive at the complete shared representation (U). Represented mathematically, this definition of the complete shared representation (U) may correspond to:
U:=f(Z;.beta.).fwdarw.FLN.times..beta.=MLN
where FLN is a tensor (e.g., matrix) representing the input values for each of the first-level neurons 1102 for each object in the subset (Z) of the list of unique objects (X.sub.Comb), .beta. is a weight tensor representing the one or more shared parameters (.beta.) that define the shared function (f) (e.g., that define how values of the mid-level neurons 1104 depend upon values of the first-level neurons 1102), and MLN is a tensor (e.g., matrix) representing the output values for each of the mid-level neurons 1104. As shown above, the shared representation (U) may be defined by the shared function (f) and the objects in the subset (Z) (e.g., U:=f(Z; .beta.)). As illustrated, the shared function (f) may correspond to one or more first layers of an artificial neural network model.
[0171] In the example of FIG. 11, FLN may be a 4.times.7 matrix (7 values for each of 4 objects in the subset (Z)), {dot over (.beta.)} may be a 7.times.4 matrix (showing how the 4 mid-level neurons 1104 each depend on the 7 first-level neurons 1102), and MLN may be a 4.times.4 matrix (4 values for each of 4 objects in the subset (Z)). FLN may be a sparse matrix, as not every object ("user") has provided a value ("rating") for each feature ("book title") in the datasets (X.sub.A/X.sub.B) received by the managing computing device 406. In other words, because the datasets (X.sub.A/X.sub.B) provided by the client computing devices 402/404 may not be complete, FLN may also be incomplete (e.g., have entries with no values). Consequently, based on the matrix multiplication above, for example, MLN may also be a sparse matrix.
[0172] In some embodiments, prior to computing the shared representation (U), the shared function (f) and the one or more shared parameters (.beta.) (e.g., stored within a "weight" tensor in artificial neural network embodiments) may be initialized by the managing computing device 406. For example, the shared function (f) and the one or more shared parameters (.beta.) may be initialized based on a related shared function used to model a similar relationship (e.g., if the shared function (f) is being used to model a relationship between risk factors of a given insured individual and a given premium for providing life insurance to that individual, the shared function (f) and the one or more shared parameters (.beta.) may be set based on a previous model developed to model a relationship between risk factors of a given insured individual and a given premium for providing health insurance to that individual). Initializing the shared function (f) and the one or more shared parameters (.beta.) based on a related shared function may include setting the shared function (f) and the one or more shared parameters (.beta.) equal to the related shared function and the one or more shared parameters for the related shared function. Alternatively, initializing the shared function (f) and the one or more shared parameters (.beta.) based on a related shared function may include scaling and/or normalizing the related shared function and the one or more shared parameters for the related shared function, and then using the scaled and/or normalized values as initial values for the shared function (f) and the one or more shared parameters (.beta.).
[0173] In alternate embodiments, the managing computing device 406 initializing the shared function (f) or the one or more shared parameters (.beta.) may include the managing computing device 406 receiving initial values for the one or more shared parameters (.beta.) from one of the client computing devices (e.g., computing device A 402 or computing device B 404). The managing computing device 406 may initialize the shared function (f) and the one or more shared parameters (.beta.) based on the initial values received. The initial values for the one or more shared parameters (.beta.) may be determined by the respective client computing device (e.g., client computing device A 402 or client computing device B 404) based upon one or more public models (e.g., publicly available machine-learned models).
[0174] In still other embodiments, the managing computing device 406 may initialize the shared function (f) and the one or more shared parameters (.beta.) based on a random number generator or a pseudo-random number generator (e.g., a Mersenne Twister pseudo-random number generator). For example, the managing computing device 406 may select random values for each of the one or more shared parameters (.beta.) within a corresponding weight tensor of an artificial neural network. In yet other embodiments, the managing computing device 406 may initialize the shared function (f) and the one or more shared parameters (.beta.) such that the one or more shared parameters are each at the midpoint of all possible values for the one or more shared parameters (.beta.). For example, if the one or more shared parameters (.beta.) represent a weight tensor (and each parameter of the one or more shared parameters (.beta.) represents a weight), all values of the one or more shared parameters (.beta.) may be initialized to 0.5 (midpoint between 0.0 and 1.0) by the managing computing device 406.
[0175] FIGS. 12A and 12B are illustrations of operation 428 of method 400. As described with reference to FIG. 4C, at operation 428, the method 400 may include client computing device A 402 determining a sublist of objects (S.sub.A) for dataset A (X.sub.A). The sublist of objects (S.sub.A) may be based on an intersection of the subset of identifiers (S) and the list of identifiers (M.sub.A) for dataset A (X.sub.A). Similarly, at operation 428, the method 400 may include client computing device B 404 determining a sublist of objects (S.sub.B) for dataset B (X.sub.B). The sublist of objects (S.sub.B) may be based on an intersection of the subset of identifiers (S) and the list of identifiers (M.sub.B) for dataset B (X.sub.B).
[0176] FIGS. 13A and 13B illustrate operation 430 of the method 400 illustrated in FIGS. 4B-4E, respectively. As described with reference to FIG. 4C, at operation 430, the method 400 may include the managing computing device 406 determining a partial representation (U.sub.A) for dataset A (X.sub.A). The partial representation (U.sub.A) may be based on the sublist of objects (S.sub.A) and the shared representation (U). Similarly as described with reference to FIG. 4C, at operation 430, the method 400 may include the managing computing device 406 determining a partial representation (U.sub.B) for dataset B (X.sub.B). The partial representation (U.sub.B) may be based on the sublist of objects (S.sub.B) and the shared representation (U). In FIGS. 13A and 13B, only one of the mid-level neurons 1104 and one of the first-level neurons 1102 are labeled, in order to avoid cluttering the figures.
[0177] In FIG. 13A, only those components of the shared representation (U) that correspond to the sublist of objects (S.sub.A) may be included in the partial representation (U.sub.A). For example, the partial representation (U.sub.A) may not include data based on calculations done with respect to objects that are not included in the sublist of objects (S.sub.A). Returning to the matrix above where FLN.times..beta.=MLN, if the fourth row of FLN corresponds to "User04" (an object that is not present in the sublist of objects (S.sub.A)), then the corresponding fourth row of MLN may not be present in the partial representation (U.sub.A), because "User04" is not included in the sublist of objects (S.sub.A). Hence, while the one or more shared parameters (.beta.) may be applied to each of the objects within the subset (Z) of the list of unique objects (X.sub.Comb), only the values of the partial representation (U.sub.A) corresponding to those objects that are included in a respective sublist of objects (S.sub.A) may be included in the respective partial representation (U.sub.A). In some embodiments (e.g., artificial neural network embodiments), as described above, this may correspond to only certain rows of MLN being present in the partial representation (U.sub.A).
[0178] Similarly in FIG. 13B, only those components of the shared representation (U) that correspond to the sublist of objects (S.sub.B) may be included in the partial representation (U.sub.B). For example, the partial representation (U.sub.B) may not include data based on calculations done with respect to objects that are not included in the sublist of objects (S.sub.B). Returning to the matrix above where FLN.times..beta.=MLN, if the third row of FLN corresponds to "User03" (an object that is not present in the sublist of objects (S.sub.B)), then the corresponding third row of MLN may not be present in the partial representation (U.sub.B), because "User03" is not included in the sublist of objects (S.sub.B). Hence, while the one or more shared parameters (.beta.) may be applied to each of the objects within the subset (Z) of the list of unique objects (X.sub.Comb), only the values of the partial representation (U.sub.B) corresponding to those objects that are included in a respective sublist of objects (S.sub.B) may be included in the respective partial representation (U.sub.B). In some embodiments (e.g., artificial neural network embodiments), as described above, this may correspond to only certain rows of MLN being present in the partial representation (U.sub.B).
[0179] In some embodiments, as described with reference to FIG. 4C, after determining the sublists of objects (S.sub.A/S.sub.B) and the partial representations (U.sub.A/U.sub.B) for the datasets (X.sub.A/X.sub.B), the managing computing device 406 (e.g., at operations 432 and 434 of method 400) may transmit the sublists of objects (S.sub.A/S.sub.B) and the partial representations (U.sub.A/U.sub.B) for the respective datasets (X.sub.A/X.sub.B) to the respective client computing devices (client computing device A 402/client computing device B 404).
[0180] FIGS. 14A and 14B illustrate portions of operations 436A and 436B of the method 400 illustrated in FIGS. 4B-4E, respectively. As described with reference to FIG. 4D, at operation 436A, the method 400 may include client computing device A 402 determining a set of predicted values ( .sub.A) that corresponds to dataset A (X.sub.A). The set of predicted values may be based on the partial representation (U.sub.A) and an individual function (g.sub.A) with one or more individual parameters (Y.sub.A) corresponding to dataset A (X.sub.A). Similarly as described with reference to FIG. 4D, at operation 436B, the method 400 may include client computing device B 404 determining a set of predicted values (Y.sub.B) that corresponds to dataset B (X.sub.B). The set of predicted values may be based on the partial representation (U.sub.B) and an individual function (g.sub.B) with one or more individual parameters (.gamma..sub.B) corresponding to dataset B (X.sub.B).
[0181] In example embodiments employing an artificial neural network model, the sets of predicted values ( .sub.A/ .sub.B) may correspond to a set of output values for each upper-level neuron 1402 for each object in the respective sublist of objects (S.sub.A/S.sub.B), as illustrated in FIGS. 14A and 14B. Using the example datasets (X.sub.A/X.sub.B) and corresponding sets of recorded values (Y.sub.A/Y.sub.B) illustrated in FIGS. 5A and 5B, the sets of predicted values ( .sub.A/ .sub.B) may correspond to ratings of "Movie Title 1," "Movie Title 2," "Movie Title 3," "Movie Title 4," and "Movie Title 5." Also as illustrated, these sets of predicted values ( .sub.A/ .sub.B) may be determined based on the values of the mid-level neurons 1104 (which themselves are based on the first-level neurons 1102 multiplied by the one or more shared parameter) multiplied by the respective one or more individual parameters (.gamma..sub.A/.gamma..sub.B) corresponding to the dataset (X.sub.A/X.sub.B). These individual parameters may be stored in a weight tensor (e.g., weight matrix) (.gamma..sub.A/.gamma..sub.B), for example. In alternate embodiments, where a different machine learning model is used (e.g., other than an artificial neural network), the one or more individual parameters (.gamma..sub.A/.gamma..sub.B) may correspond to other parameters of the machine learning model (e.g., parameters other than a weight tensor). As in FIGS. 11, 13A, and 13B, the dashed lines illustrate that, in some embodiments, there may be additional hidden layers (e.g., one, two, three, four, five, six, seven, eight, nine, ten, fifteen, sixteen, twenty, thirty-two, or sixty-four hidden layers) between the layers of the artificial neural network illustrated.
[0182] In FIGS. 14A and 14B, only a portion of the respective figure represents the individual function (g.sub.A/g.sub.B). The portion representing the individual function (g.sub.A/g.sub.B) is the mid-level neurons 1104 connected to the upper-level neurons 1402. The connections between the mid-level neurons 1104 and the first-level neurons 1102, as well as the first-level neurons 1102 themselves, are illustrated only to provide context for the respective individual functions (g.sub.A/g.sub.B). For example, the respective individual functions (g.sub.A/g.sub.B) each only act on the partial representation (U.sub.A/U.sub.B) rather than the entire shared representation (U). As with above, only a single first-level neuron 1102, a single mid-level neuron 1104, and a single upper-level neuron 1402 are labeled to avoid cluttering the figures.
[0183] The variables, as described below, that use subscript `i`, are intended to reference the corresponding dataset. For example, the subscript `i` may be replaced with an `A` when referring to any variable corresponding to dataset A (X.sub.A) and may be replaced with a `B` when referring to any variable corresponding to dataset B (X.sub.B). Hence, the individual function (g.sub.i) corresponding to a given dataset may be replaced with variable names (g.sub.i.fwdarw.g.sub.A/g.sub.B), where appropriate. Similar replacement may be used for the partial representation for a given dataset (U.sub.i.fwdarw.U.sub.A/U.sub.B) and the individual parameter for a given dataset (.gamma..sub.i.fwdarw..gamma..sub.A/.gamma..sub.B).
[0184] As described above, the shared representation (U) may be defined by the shared function (f) and the objects in the subset (Z) (e.g., U:=f(Z; .beta.)). Further, the shared function (f) may correspond to one or more layers of an artificial neural network model, as illustrated in FIGS. 11, 13A, and 13B. Similar to the definition of the shared representation (U), an individual representation (I.sub.A/I.sub.B) may be generated for each dataset (X.sub.A/X.sub.B) by each client computing device (client computing device A 402/client computing device B), respectively. The individual representation (I.sub.A/I.sub.B) may be defined analogously to the shared representation (U). Represented mathematically, this definition of the individual representation (I.sub.i), based on the individual function corresponding to a given dataset (g.sub.i), the partial representation for a given dataset (U.sub.i), and the one or more individual parameters for a given dataset (.gamma..sub.i), may correspond to:
I.sub.i:=g.sub.i(U.sub.i;.gamma..sub.i).fwdarw.MLN.times..gamma..sub.i=U- LN
where MLN is a tensor (e.g., matrix) representing the input values for each of the mid-level neurons 1104 taken from the respective partial representation for a given dataset (U.sub.i), .gamma..sub.i is a weight tensor representing the one or more individual parameters for a given dataset (.gamma..sub.i) that define the individual function for a given dataset (g.sub.i) (e.g., that define how values of the upper-level neurons 1402 depend upon values of the mid-level neurons 1104), and ULN is a tensor (e.g., matrix) representing the output values for each of the upper-level neurons 1402. As shown above, the individual representations (I.sub.i) may be defined by the individual functions for a given dataset (g.sub.i) and the partial representation (U.sub.i) (e.g., I:=g.sub.i(U.sub.i; .gamma..sub.i)). As illustrated, each individual function (g.sub.i) may correspond to at least a portion of one or more second layers of an artificial neural network model. At least one of the one or more first layers that correspond to the shared function (f) described above may be an input layer to at least one of the one or more second layers that correspond to the individual function (g.sub.i).
[0185] In the example of FIG. 14A, MLN may be a 3.times.4 matrix (4 mid-level neuron 1104 values for each of 3 objects in the sublist of objects (S.sub.A)), {dot over (.gamma.)}.sub.A may be a 4.times.5 matrix (showing how the 5 upper-level neurons 1402 each depend on the 4 mid-level neurons 1104), and ULN may be a 3.times.5 matrix (5 upper-level neuron 1402 values for each of 3 objects in the sublist of objects (S.sub.A)). ULN may be a sparse matrix, as not every object ("user") has provided a value ("rating") for each feature ("book title") in the dataset (X.sub.A) received by the managing computing device 406. In other words, because the dataset (X.sub.A) provided by client computing device A 402 may not be complete, FLN, as described above, may be incomplete/sparse (e.g., have entries with no values). Consequently, based on the two layers of matrix multiplication described above, for example, ULN may also be a sparse matrix.
[0186] In the example of FIG. 14B, MLN may also be a 3.times.4 matrix (4 mid-level neuron 1104 values for each of 3 objects in the sublist of objects (S.sub.B)), .gamma..sub.B may be a 4.times.9 matrix (showing how the 9 upper-level neurons 1402 each depend on the 4 mid-level neurons 1104), and ULN may be a 3.times.9 matrix (9 upper-level neuron 1402 values for each of 3 objects in the sublist of objects (S.sub.B)). ULN may be a sparse matrix, as not every object ("user") has provided a value ("rating") for each feature ("book title") in the dataset (X.sub.B) received by the managing computing device 406. In other words, because the dataset (X.sub.B) provided by client computing device B 404 may not be complete, FLN, as described above, may be incomplete/sparse (e.g., have entries with no values). Consequently, based on the two layers of matrix multiplication described above, for example, ULN may also be a sparse matrix.
[0187] In some embodiments, prior to computing an individual representation (I), the individual function (g.sub.i) and the one or more individual parameters (.gamma..sub.i) (e.g., stored within a "weight" tensor in artificial neural network embodiments) may be initialized by the respective client computing device. The respective client computing devices may initialize the individual function (g.sub.i) and the one or more individual parameters (.gamma..sub.i) corresponding to the respective dataset (X.sub.A/X.sub.B) based on a random number generator or a pseudo-random number generator (e.g., a Mersenne Twister pseudo-random number generator).
[0188] FIGS. 15A and 15B illustrate portions of operations 438A and 438B of the method 400 illustrated in FIGS. 4B-4E, respectively. As described with reference to FIG. 4D, at operation 438A, the method 400 may include client computing device A 402 determining an error (E.sub.A) for dataset A (X.sub.A). The error (E.sub.A) may be based on an individual loss function (L.sub.A) for dataset A (X.sub.A), the set of predicted values (V.sub.A) that corresponds to dataset A (X.sub.A), the sublist of objects (S.sub.A), and non-empty entries (W.sub.A) in the set of recorded values (Y.sub.A) corresponding to dataset A (X.sub.A). Similarly as described with reference to FIG. 4D, at operation 438B, the method 400 may include client computing device B 402 determining an error (E.sub.B) for dataset B (X.sub.B). The error (E.sub.B) may be based on an individual loss function (L.sub.B) for dataset B (X.sub.B), the set of predicted values (Y.sub.B) that corresponds to dataset B (X.sub.B), the sublist of objects (S.sub.B), and non-empty entries (W.sub.B) in the set of recorded values (Y.sub.B) corresponding to dataset B (X.sub.B).
[0189] To generate the data represented in FIGS. 15A and 15B, the set of predicted values 1504 ( .sub.A/ .sub.B) are compared to the set of recorded values 1502 (Y.sub.A/Y.sub.B) corresponding to each dataset (X.sub.A/X.sub.B). Using the example datasets (X.sub.A/X.sub.B) and corresponding sets of recorded values 1502 (Y.sub.A/Y.sub.B) illustrated in FIGS. 5A and 5B, the sets of predicted values 1504 ( .sub.A/Y.sub.B) correspond to estimated movie ratings, and the sets of recorded values 1502 (Y.sub.A/Y.sub.B) correspond to actual movie ratings. In FIG. 15A, the set of recorded values 1502 (Y.sub.A) for "User00" (e.g., a first row of a matrix corresponding to the set of recorded values 1502 (Y.sub.A)) is compared with the set of predicted values 1504 ( .sub.A) for "User00" (e.g., a first row of a matrix corresponding to the set of predicted values 1504 ( .sub.A)). In FIG. 15B, the set of recorded values 1502 (Y.sub.B) for "User04" (e.g., a third row of a matrix corresponding to the set of recorded values 1502 (Y.sub.B)) is compared with the set of predicted values 1504 ( .sub.B) for "User04" (e.g., a third row of a matrix corresponding to the set of predicted values 1504 ( .sub.B)).
[0190] For both datasets, the set of recorded values 1502 (Y.sub.A/Y.sub.B) and the set of predicted values 1504 ( .sub.A/ .sub.B) are illustrated in FIGS. 15A and 15B by way of example. Similar plots may be made for the sets of recorded values 1502 (Y.sub.A/Y.sub.B) and the sets of predicted values 1504 ( .sub.A/ .sub.B) for other objects in the respective sublists of objects (S.sub.A/S.sub.B). For example, "User01" and "User03" from the sublist of objects (S.sub.A) corresponding to dataset A (X.sub.A) could also be plotted. There are some features (e.g., "movie titles" using the example datasets (X.sub.A/X.sub.B) and the example sets of recorded values (Y.sub.A/Y.sub.B) from FIGS. 5A and 5B) for which there are no corresponding recorded values 1502 (e.g., "Movie Title 2" for "User00"). Hence, for these features, there is no corresponding recorded value 1502 (e.g., "Actual Movie Rating" (Y.sub.A/Y.sub.B)) illustrated in FIGS. 15A and 15B.
[0191] The sets of predicted values 1504 ( .sub.A/ .sub.B), similar to the sets of recorded values 1502 (Y.sub.A/Y.sub.B) may be stored as a tensor (e.g., a matrix). The sets of predicted values 1504 ( .sub.A/ .sub.B) may then be compared to the sets of recorded values 1502 (Y.sub.A/Y.sub.B) to compute an error for the respective dataset (X.sub.A/X.sub.B). The error (E.sub.A/E.sub.B) may be calculated according to an individual loss function (L.sub.A/L.sub.B). For example, the error (E.sub.A/E.sub.B) corresponding to each dataset (X.sub.A/X.sub.B) may be the sum of the individual loss function (L.sub.A/L.sub.B) evaluated at each non-zero entry (W.sub.A/W.sub.B) in a tensor representing the set of recorded values 1502 (Y.sub.A/Y.sub.B). As illustrated in FIG. 15A, the individual loss function (L.sub.A/L.sub.B) evaluated for a given entry may be based on the difference 1506 between the predicted value 1504 for that entry and the recorded value 1502 for that entry. Only one difference 1506 is labeled in each of FIGS. 15A and 15B to avoid cluttering the figures. Mathematically, the error (E.sub.A) corresponding to dataset A (X.sub.A) may be represented by:
E.sub.A=.SIGMA..sub.W.sub.A.sup.L.sup.A( .sub.A,W.sub.AY.sub.A,W.sub.A)
[0192] The above equation represents that the error (E.sub.A) corresponding to dataset A (X.sub.A) equals the sum of the individual loss function (L.sub.A), evaluated between the entry in the set of predicted values ( .sub.A) and the entry in the set of recorded values (Y.sub.A), for each non-empty entry (W.sub.A) of each object in the sublist of objects (S.sub.A) corresponding to the set of recorded values (Y.sub.A) for dataset A (X.sub.A). The addend in the above sum may be referred to as a "partial error value." The mathematical representation for dataset B (X.sub.B) is analogous with the mathematical representation for dataset A (X.sub.A), mutatis mutandis.
[0193] In some embodiments, the individual loss functions (L.sub.A/L.sub.B) may include at least one of: a quadratic loss function, a logarithmic loss function, a hinge loss function, a quantile loss function, or a loss function associated with the Cox proportional hazard model. Further, in some embodiments, different client computing devices may use the same individual loss functions (e.g., the individual loss function used by each client computing device may be prescribed by the managing computing device 406), referred to as a "shared loss function." For example both client computing device A 402 and client computing device B 404 may use a quadratic loss function for respective individual loss functions (L.sub.A/L.sub.B) (e.g., L.sub.A(j,k)=(j-k).sup.2). In alternate embodiments, the individual loss functions (L.sub.A/L.sub.B) corresponding to different datasets (X.sub.A/X.sub.B) may be different. However, in such embodiments, certain results generated (e.g., errors (E.sub.A/E.sub.B)) by a dataset's (X.sub.A/X.sub.B) respective client computing device may be normalized prior to or after transmission to the managing computing device 406, such that the results can be meaningfully compared against one another even though different individual loss functions (L.sub.A/L.sub.B) were used. In some such embodiments, information about the particular individual loss function (L.sub.A/L.sub.B) used by a client computing device and/or about a corresponding set of recorded values (Y.sub.A/Y.sub.B) may be transmitted to the managing computing device 406. The information about the particular individual loss function (L.sub.A/L.sub.B) used and/or about the corresponding set of recorded values (Y.sub.A/Y.sub.B) may be used by the managing computing device 406 to perform a normalization.
[0194] In some embodiments, as illustrated and described with reference to FIG. 4D, the method 400 may also include updating one or more individual parameters (.gamma..sub.A/.gamma..sub.B). For example, at operation 440A, the method 400 may include client computing device A 402 updating the one or more individual parameters (.gamma..sub.A) for dataset A (X.sub.A). Similarly, at operation 440B, the method 400 may include client computing device B 404 updating the one or more individual parameters (.gamma..sub.B) for dataset B (X.sub.B). Updating the one or more individual parameters (.gamma..sub.A/.gamma..sub.B) may include performing gradient descent with respect to the calculated respective error (E.sub.A/E.sub.B). Additionally or alternatively (e.g., when the machine learning model being employed is an artificial neural network), updating the one or more individual parameters (.gamma..sub.A/.gamma..sub.B) may include back-propagating the respective errors (E.sub.A/E.sub.B) based on weight tensors (e.g., weight matrix) (.gamma..sub.A/.gamma..sub.B). Based on the back-propagated errors (E.sub.A/E.sub.B), the respective one or more individual parameters (.gamma..sub.A/.gamma..sub.B) may be updated, which could result in an improvement to the respective sets of predicted values ( .sub.A/ .sub.B).
[0195] The amount by which the respective one or more individual parameters (.gamma..sub.A/.gamma..sub.B) are updated may correspond to a respective individual learning rate (R.sub.A/R.sub.B). The individual learning rates (R.sub.A/R.sub.B) may be determined by each of the client computing devices independently, in some embodiments. In other embodiments, the individual learning rates (R.sub.A/R.sub.B) may be determined by the managing computing device 406 and then transmitted to the client computing devices, individually. Alternatively, the individual learning rates (R.sub.A/R.sub.B) may be inherent in a gradient descent method used by each respective client computing device. In some embodiments, either or both of the individual learning rates (R.sub.A/R.sub.B) may include at least one of: an exponentially decayed learning rate, a harmonically decayed learning rate, a step-wise exponentially decayed learning rate, or an adaptive learning rate.
[0196] In some embodiments, as illustrated and described with reference to FIG. 4D, the method 400 may also include determining one or more feedback values (C.sub.A/C.sub.B). For example, at operation 442A, the method 400 may include client computing device A 402 determining one or more feedback values (C.sub.A). The one or more feedback values (C.sub.A) may be used to determine a change in the partial representation (U.sub.A) that corresponds to an improvement in the set of predicted values ( .sub.A). Similarly, at operation 442B, the method 400 may include client computing device B 404 determining one or more feedback values (C.sub.B). The one or more feedback values (C.sub.B) may be used to determine a change in the partial representation (U.sub.B) that corresponds to an improvement in the set of predicted values ( .sub.B). The one or more feedback values (C.sub.A/C.sub.B) may correspond to back-propagated errors (E.sub.A/E.sub.B) (e.g., based on weight tensors (.gamma..sub.A/.gamma..sub.B)).
[0197] In some embodiments, determining one or more feedback values (C.sub.A/C.sub.B) may correspond to performing, by the respective client computing device (client computing device A 402/client computing device B 404), a gradient descent method. Additionally or alternatively, when determining a change in the respective partial representation (U.sub.A/U.sub.B) that corresponds to an improvement in the respective sets of predicted values ( .sub.A/ .sub.B), the respective sets of predicted values may correspond to a threshold improvement value. The threshold improvement value may be based on a shared learning rate (.eta.). In some embodiments, the shared learning rate (.eta.) may be determined by the managing computing device 406 and transmitted by the managing computing device 406 to each of the client computing devices. Additionally or alternatively, in some embodiments, the shared learning rate (.eta.) may be defined by the gradient descent method used by the client computing devices. For example, the client computing devices may each use the same gradient descent method (e.g., a shared gradient descent method prescribed by the managing computing device 406) that has an associated shared learning rate (.eta.). Further, the shared learning rate (.eta.) may include at least one of: an exponentially decayed learning rate, a harmonically decayed learning rate, or a step-wise exponentially decayed learning rate. In other embodiments, the shared learning rate (.eta.) may include an adaptive learning rate.
[0198] In some embodiments, when determining a change in the respective partial representation (U.sub.A/U.sub.B) that corresponds to an improvement in the respective sets of predicted values ( .sub.A/ .sub.B), improvement in the set of predicted values ( .sub.A/ .sub.B) corresponds to a threshold improvement value defined by an individual learning rate (R.sub.A/R.sub.B) that is determined by each of the client computing devices independently. In some embodiments, the individual learning rate (R.sub.A/R.sub.B) may include at least one of: an exponentially decayed learning rate, a harmonically decayed learning rate, or a step-wise exponentially decayed learning rate.
[0199] In some embodiments, the one or more feedback values (C.sub.A/C.sub.B) may be organized into respective feedback tensors (C.sub.A/C.sub.B). Each feedback tensor (C.sub.A/C.sub.B) may have a dimensionality that is equal to a dimensionality of the respective partial representation (U.sub.A/U.sub.B). For example, using the example datasets (X.sub.A/X.sub.B) and sets of recorded values (Y.sub.A/Y.sub.B) illustrated in FIGS. 5A and 5B, corresponding feedback tensors (C.sub.A/C.sub.B) developed using the method 400 may be a two-dimensional feedback tensors (i.e., feedback matrices).
[0200] In some embodiments, as illustrated and described with reference to FIG. 4D, the method 400 may also include (e.g., at operation 444) client computing device A 402 transmitting the one or more feedback values (C.sub.A) to the managing computing device 406. Additionally or alternatively, the method 400 may include (e.g., at operation 446) client computing device B 404 transmitting the one or more feedback values (C.sub.B) to the managing computing device 406. In some embodiments, client computing device B 406 may transmit the one or more feedback values (C.sub.B) to the managing computing device 406 prior to or simultaneous with client computing device A 404 transmitting the one or more feedback values (C.sub.A) to the managing computing device 406. Alternatively, in some embodiments, only one of the client computing devices (e.g., client computing device A 402), rather than both, may transmit one or more feedback values (e.g., C.sub.A) to the managing computing device 406.
[0201] In some embodiments, as illustrated and described with reference to FIG. 4E, the method 400 may also include (e.g., at operation 448) the managing computing device 406 determining one or more aggregated feedback values (C.sub.Comb). The one or more aggregated feedback values (C.sub.Comb) may be based on the sublists of objects (S.sub.A/S.sub.B) corresponding to dataset A (X.sub.A) and dataset B (X.sub.B), respectively, and the one or more feedback values (C.sub.A/C.sub.B) from client computing device A 402 and client computing device B 404, respectively. In some embodiments, determining the one or more aggregated feedback values (C.sub.Comb) may include the managing computing device 406 defining, based on the sublists of objects (S.sub.A/S.sub.B) and the one or more feedback values (C.sub.A/C.sub.B) from the client computing devices, a tensor (C.sub.Comb) representing the one or more aggregated feedback values (C.sub.Comb). Further, determining the one or more aggregated feedback values (C.sub.Comb) may also include the managing computing device 406 summing, based on the sublists of objects (S.sub.A/S.sub.B), those feedback values of the one or more feedback values (C.sub.A/C.sub.B) from the client computing devices that correspond to objects in the sublists of objects (S.sub.A/S.sub.B) that have shared identifiers into a shared entry of the tensor (C.sub.Comb) representing the one or more aggregated feedback values (C.sub.Comb).
[0202] In some embodiments, the one or more aggregated feedback values (C.sub.Comb) may be organized into an aggregated feedback tensor (C.sub.Comb). The aggregated feedback tensor (C.sub.Comb) may have a dimensionality that is equal to a dimensionality of the shared representation (U). For example, using the example datasets (X.sub.A/X.sub.B) and sets of recorded values (Y.sub.A/Y.sub.B) illustrated in FIGS. 5A and 5B, corresponding aggregated feedback tensors (C.sub.Comb) developed using the method 400 may be a two-dimensional aggregated feedback tensor (i.e., a feedback matrix).
[0203] In some embodiments, as illustrated and described with reference to FIG. 4E, the method 400 may also include (e.g., at operation 450) the managing computing device 406 updating the one or more shared parameters (.beta.) based on the one or more aggregated feedback values (C.sub.Comb). In some embodiments, updating the one or more shared parameters (.beta.) based on the more aggregated feedback values (C.sub.Comb) may include evaluating a sum of partial derivatives, where each of the partial derivatives are partial derivatives of the error (E.sub.A/E.sub.B) for a respective dataset (X.sub.A/X.sub.B) with respect to the one or more shared parameters (.beta.). Such a sum may be represented mathematically as:
i .differential. E i .differential. .beta. = C Comb ( .differential. U .differential. .beta. ) ##EQU00001##
where `i` in the above sum is an index corresponding to a respective dataset (e.g., dataset A (X.sub.A)).
[0204] Additionally or alternatively, in some embodiments, updating the one or more shared parameters (.beta.) based on the more aggregated feedback values (C.sub.Comb) may include evaluating a sum of products of first partial derivatives and second partial derivatives, where each of the first partial derivatives are partial derivatives of the error (E.sub.A/E.sub.B) for a respective dataset (X.sub.A/X.sub.B) with respect to the respective partial representation (U.sub.A/U.sub.B), and where each of the second partial derivatives are partial derivatives of the respective partial representation (U.sub.A/U.sub.B) with respect to the one or more shared parameters (.beta.). Such a sum may be represented mathematically as:
i .differential. E i .differential. U i ( .differential. U i .differential. .beta. ) = C Comb ( .differential. U .differential. .beta. ) ##EQU00002##
where `i` in the above sum is an index corresponding to a respective dataset (e.g., dataset A (X.sub.A)).
[0205] FIGS. 16A-16C illustrate combinations of datasets and sets of recorded values, analogous to dataset A (X.sub.A) and the set of recorded values (Y.sub.A) illustrated in FIG. 5A and dataset B (X.sub.B) and the set of recorded values (Y.sub.B) illustrated in FIG. 5B. The combinations of datasets and sets of recorded values are provided as additional examples of datasets and sets of recorded values. The types of representation, data, features, dimensions, and values (e.g., for various entries in the datasets and/or the sets of recorded values) are provided as examples, and are not meant to be limiting. In various embodiments contemplated herein, various alternative data structures, types of data, amounts of data, and/or representations of data may be used for datasets and sets of recorded values.
[0206] Illustrated in FIG. 16A is a dataset 1602 (X.sub.Binary) and a corresponding set of recorded values 1604 (Y.sub.Binary). The dataset 1602 (X.sub.Binary) includes binary values for each relationship between an object and a feature (e.g., corresponding to insurance data). In FIG. 16A, the black entries in dataset 1602 (X.sub.Binary) may correspond to entries for which the object exhibits the given feature. For example, object "Jordan" may exhibit "fewer than 3 accidents," "a restricted license," and be "insured for accidents." The corresponding set of recorded values 1604 (Y.sub.Binary) illustrated in FIG. 16A may include binary data, textual data (e.g., classification data), and numeric data corresponding to various features. For example, object "Jason" may exhibit an "age" value of "22" (numeric data), a "gender" of "M" (textual data), a "state of residence" of "KY" (textual data), an "income (in thousands)" of "42" (numeric data), a "number of children" of "2" (numeric data), and be "married" (binary data).
[0207] In some embodiments of both datasets and sets of recorded values, data for values of various entries may be purely binary data, purely textual data (e.g., classification data), or purely numeric data, for example. In alternate embodiments of both datasets and sets of recorded values, data for values of various entries may be a combination of binary data, textual data (e.g., classification data), and numeric data. In still other embodiments, data may be in the form of sound recordings (e.g., used to develop a machine learning model that can be used to perform voice recognition) or images (e.g., used to develop a machine learning model that can be used to perform object recognition).
[0208] In some embodiments (e.g., embodiments that are not illustrated), datasets and corresponding sets of recorded values may have greater than two dimensions. In such example embodiments, the datasets and the corresponding sets of recorded values may correspond to n-dimensional tensors (e.g., rather than two-dimensional tensors, i.e., matrices).
[0209] Illustrated in FIG. 16B is a dataset 1612 (X.sub.Drug Discovery) and a corresponding set of recorded values 1614 (Y.sub.Drug Discovery). The dataset 1612 (X.sub.Drug Discovery) and the set of recorded values 1614 (Y.sub.Drug Discovery) may correspond to data related to pharmaceutical discovery (e.g., arising from a clinical trial). For example, the data in the dataset 1612 (X.sub.Drug Discovery) and the corresponding set of recorded values 1614 (Y.sub.Drug Discovery) may have been generated by a pharmaceutical corporation during the course of testing a variety of candidate pharmaceutical compounds using a variety of assays. As illustrated, the dataset 1612 (X.sub.Drug Discovery) may relate a series of compounds to a series of chemical fingerprints and/or additional descriptors. The values of the entries of the dataset 1612 (X.sub.Drug Discovery) may be binary. For example, object "compound B" exhibits "chemistry fingerprint 2" as well as "additional descriptor 3." In alternate embodiments, the values of the entries of the dataset 1612 (X.sub.Drug Discovery) could be any combination of binary data, textual data (e.g., classification data), and numeric data. Also as illustrated, the corresponding set of recorded values 1614 (Y.sub.Drug Discovery) may relate a series of compounds to a series of assay activities and concentrations for half-maximum activity (half-max). Some of the values of the entries of the set of recorded values 1614 (Y.sub.Drug Discovery) may be binary, while other values of the entries may be numeric data. For example, object "compound C" exhibits "activity in assay 1," "activity in assay 6," a "concentration for half-max assay 5" of 0.2 (e.g., 0.2 Molar), and a "concentration for half-max assay 9" of 0.8 (e.g., 0.8 Molar). In alternate embodiments, the values of the entries of the corresponding set of recorded values 1614 (Y.sub.Drug Discovery) could be any combination of binary data, textual data (e.g., classification data), and numeric data.
[0210] Illustrated in FIG. 16C is a dataset 1622 (X.sub.Treatment) and a corresponding set of recorded values 1624 (Y.sub.Treatment). The dataset 1622 (X.sub.Treatment) and the set of recorded values 1624 (Y.sub.Treatment) may correspond to data related to patient diagnosis and care (e.g., arising from doctor's records). For example, the data in the dataset 1622 (X.sub.Treatment) and the corresponding set of recorded values 1624 (Y.sub.Treatment) may have been generated by a doctor during the course of diagnosing and treating a patient. As illustrated, the dataset 1622 (X.sub.Treatment) may relate a series of patients to a series of patient descriptors. The values of the entries of the dataset 1622 (X.sub.Treatment) may be a combination of binary data, textual data (e.g., classification data), and numeric data. For example, object "patient A" exhibits "generic marker 1" as well as "family history of disease 2," has a value for "gender" corresponding "F," and has a value for "age" corresponding to "22" and a value of weight corresponding to "107." In alternate embodiments, the values of the entries of the dataset 1622 (X.sub.Treatment) could be any combination of binary data, textual data (e.g., classification data), and numeric data. Also as illustrated, the corresponding set of recorded values 1624 (Y.sub.Treatment) may relate a series of patients to a series of clinical diagnoses. The values of the entries of the set of recorded values 1624 (Y.sub.Treatment) may be binary. For example, object "patient C" exhibits "clinical diagnosis 3," "clinical diagnosis 4," and "clinical diagnosis 6." In alternate embodiments, the values of the entries of the corresponding set of recorded values 1624 (Y.sub.Treatment) could be any combination of binary data, textual data (e.g., classification data), and numeric data.
[0211] In some embodiments, all objects within a given dimension of a dataset or a corresponding set of recorded values may be the same (e.g., all objects within a first dimension of a dataset may be of designated type "user"). As illustrated in FIGS. 5A and 5B, the datasets (X.sub.A/X.sub.B) and the corresponding sets of recorded values (Y.sub.A/Y.sub.B) may each contain objects of the same type in each of their dimensions. For example, in a first dimension of dataset A (X.sub.A), the objects may be designated type "user," in a second dimension of dataset A (X.sub.A), the objects may be designated type "book," in a first dimension of set of recorded values A (Y.sub.A), the objects may be of type "user," and in a second dimension of set of recorded values A (Y.sub.A), the objects may be of type "movie." This may be analogous to dataset B (X.sub.B) and corresponding set of recorded values B (Y.sub.B) (i.e., in a first dimension of dataset B (X.sub.B), the objects may be designated type "user," in a second dimension of dataset B (X.sub.B), the objects may be designated type "book," in a first dimension of set of recorded values B (Y.sub.B), the objects may be of type "user," and in a second dimension of set of recorded values B (Y.sub.B), the objects may be of type "movie"). In alternate embodiments, this may not be the case. For example, a first dataset may have a first dimension with object type "user" and a second dimension with object type "book," whereas a second dataset (e.g., from a different client computing device) may have a first dimension with object type "user" and a second dimension with object type "movie."
[0212] Dimensions from different datasets containing different object types may still be used by the managing computing device 406 to develop a shared representation and to update the one or more shared parameters (.beta.). In some embodiments, using different object types to develop a shared representation may include normalizing (e.g., by the managing computing device 406 or a respective client computing device) values corresponding to the different object types, such that those values can be meaningfully compared with one another.
[0213] The method described above, and various embodiments both explicitly and implicitly contemplated herein, may be used in a wide variety of applications. One example application includes a pharmaceutical discovery method. For example, in one embodiment, a first dimension of each of the plurality of datasets (X.sub.A/X.sub.B) transmitted to a managing computing device may include a plurality of chemical compounds and a second dimension of each of the plurality of datasets (X.sub.A/X.sub.B) may include descriptors of the chemical compounds (e.g., chemistry-derived fingerprints or descriptors identified via transcriptomics or image screening). In such an embodiment, entries in each of the plurality of datasets (X.sub.A/X.sub.B) may correspond to a binary indication of whether a respective chemical compound exhibits a respective descriptor. Further, in such an embodiment, a first dimension of each of the sets of recorded values (Y.sub.A/Y.sub.B) respectively corresponding to the plurality of datasets (X.sub.A/X.sub.B) may include the plurality of chemical compounds and a second dimension of each of the sets of recorded values (Y.sub.A/Y.sub.B) may include activities of the chemical compounds in a plurality of biological assays (e.g., concentration of a given product of a chemical reaction produced per unit time, fluorescence level, cellular reproduction rate, coloration of solution, pH of solution, or cellular death rate). In such an embodiment, entries in each of the sets of recorded values (Y.sub.A/Y.sub.B) may correspond to a binary indication of whether a respective chemical compound exhibits a respective activity.
[0214] The pharmaceutical discovery method may include the managing computing device 406 calculating a final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) based on the list of unique objects (X.sub.Comb), the shared function (f), and the one or more shared parameters (.beta.). The pharmaceutical discovery method may also include the managing computing device 406 transmitting the final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) to each of the client computing devices. The final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) may be usable by each of the client computing devices to determine a final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) corresponding to the respective dataset (X.sub.A/X.sub.B). Further, the final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) may be used by at least one of the client computing devices to identify one or more effective treatment compounds among the plurality of chemical compounds.
[0215] An additional example application includes a pharmaceutical diagnostic method. For example, in one embodiment, a first dimension of each of the plurality of datasets (X.sub.A/X.sub.B) transmitted to a managing computing device may include a plurality of patients and a second dimension of each of the plurality of datasets (X.sub.A/X.sub.B) may include descriptors of the patients (e.g., genomic-based descriptors, patient demographics, patient age, patient height, patient weight, or patient gender). In such an embodiment, entries in each of the plurality of datasets (X.sub.A/X.sub.B) may correspond to a binary indication of whether a respective patient exhibits a respective descriptor. Further, in such an embodiment, a first dimension of each of the sets of recorded values (Y.sub.A/Y.sub.B) respectively corresponding to the plurality of datasets (X.sub.A/X.sub.B) may include the plurality of patients and a second dimension of each of the sets of recorded values (Y.sub.A/Y.sub.B) may include clinical diagnoses of the patients (e.g., cancer diagnosis, heart disease diagnosis, broken bone diagnosis, skin infection diagnosis, psychological diagnosis, genetic disorder diagnosis, or torn ligament diagnosis). In such an embodiment, entries in each of the sets of recorded values (Y.sub.A/Y.sub.B) may correspond to a binary indication of whether a respective patient exhibits a respective clinical diagnosis.
[0216] The pharmaceutical diagnostic method may include the managing computing device 406 calculating a final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) based on the list of unique objects (X.sub.Comb), the shared function (f), and the one or more shared parameters (j3). The pharmaceutical diagnostic method may also include the managing computing device 406 transmitting the final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) to each of the client computing devices. The final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) may be usable by each of the client computing devices to determine a final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) corresponding to the respective dataset (X.sub.A/X.sub.B). Further, the final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) may be used by at least one of the client computing devices to diagnose at least one of the plurality of patients.
[0217] A further example application includes a media (e.g., book, movie, music, etc.) recommendation method. For example, in one embodiment, a first dimension of each of the plurality of datasets (X.sub.A/X.sub.B) transmitted to a managing computing device may include a plurality of users and a second dimension of each of the plurality of datasets (X.sub.A/X.sub.B) may include a plurality of book titles. In such an embodiment, entries in each of the plurality of datasets (X.sub.A/X.sub.B) may correspond to a rating of a respective book title by a respective user. Further, in such an embodiment, a first dimension of each of the sets of recorded values (Y.sub.A/Y.sub.B) respectively corresponding to the plurality of datasets (X.sub.A/X.sub.B) may include the plurality of users and a second dimension of each of the sets of recorded values (Y.sub.A/Y.sub.B) may include a plurality of movie titles. In such an embodiment, entries in each of the sets of recorded values (Y.sub.A/Y.sub.B) may correspond to a rating of a respective movie title by a respective user.
[0218] The media recommendation method may include the managing computing device 406 calculating a final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) based on the list of unique objects (X.sub.Comb), the shared function (f), and the one or more shared parameters (.beta.). The media recommendation method may also include the managing computing device 406 transmitting the final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) to each of the client computing devices. The final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) may be usable by each of the client computing devices to determine a final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) corresponding to the respective dataset (X.sub.A/X.sub.B). Further, the final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) may be used by at least one of the client computing devices to recommend at least one of the plurality of movie titles to at least one of the plurality of users.
[0219] Another example application includes an insurance policy determination method. For example, in one embodiment, a first dimension of each of the plurality of datasets (X.sub.A/X.sub.B) transmitted to a managing computing device may include a plurality of insurance policies and a second dimension of each of the plurality of datasets (X.sub.A/X.sub.B) may include a plurality of deductible amounts. In such an embodiment, entries in each of the plurality of datasets (X.sub.A/X.sub.B) may correspond to a binary indication of whether a respective insurance policy has a respective deductible amount. Further, in such an embodiment, a first dimension of each of the sets of recorded values (Y.sub.A/Y.sub.B) respectively corresponding to the plurality of datasets (X.sub.A/X.sub.B) may include the plurality of insurance policies and a second dimension of each of the sets of recorded values (Y.sub.A/Y.sub.B) may include a plurality of insurance premiums. In such an embodiment, entries in each of the sets of recorded values (Y.sub.A/Y.sub.B) may correspond to a binary indication of whether a respective insurance policy has a respective insurance premium.
[0220] The media recommendation method may include the managing computing device 406 calculating a final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) based on the list of unique objects (X.sub.Comb), the shared function (f), and the one or more shared parameters (.beta.). The media recommendation method may also include the managing computing device 406 transmitting the final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) to each of the client computing devices. The final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) may be usable by each of the client computing devices to determine a final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) corresponding to the respective dataset (X.sub.A/X.sub.B). Further, the final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) may be used by at least one of the client computing devices to recommend an insurance premium based on a prospective deductible amount.
[0221] Yet another example application includes an automotive fuel-efficiency-prediction method. For example, in one embodiment, a first dimension of each of the plurality of datasets (X.sub.A/X.sub.B) transmitted to a managing computing device may include a plurality of automobiles (e.g., identified by vehicle identification number (VIN) or serial number) and a second dimension of each of the plurality of datasets (X.sub.A/X.sub.B) may include a plurality of automobile parts. In such an embodiment, entries in each of the plurality of datasets (X.sub.A/X.sub.B) may correspond to a binary indication of whether a respective automobile has a respective automobile part equipped. Further, in such an embodiment, a first dimension of each of the sets of recorded values (Y.sub.A/Y.sub.B) respectively corresponding to the plurality of datasets (X.sub.A/X.sub.B) may include the plurality of automobiles and a second dimension of each of the sets of recorded values (Y.sub.A/Y.sub.B) may include a plurality of average fuel efficiencies. In such an embodiment, entries in each of the sets of recorded values (Y.sub.A/Y.sub.B) may correspond to a binary indication of whether a respective automobile has a respective average fuel efficiency.
[0222] The media recommendation method may include the managing computing device 406 calculating a final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) based on the list of unique objects (X.sub.Comb), the shared function (f), and the one or more shared parameters (.beta.). The media recommendation method may also include the managing computing device 406 transmitting the final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) to each of the client computing devices. The final shared representation (U.sub.Final) of the datasets (X.sub.A/X.sub.B) may be usable by each of the client computing devices to determine a final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) corresponding to the respective dataset (X.sub.A/X.sub.B). Further, the final set of predicted values ( .sub.A.sub.Final/ .sub.B.sub.Final) may be used by at least one of the client computing devices to predict an average fuel efficiency of an automobile model based on a set of equipped automobile parts.
[0223] In addition to those embodiments enumerated above, several other applications will be apparent. For example, various sets of datasets (X.sub.A/X.sub.B) and corresponding sets of recorded values (Y.sub.A/Y.sub.B) may be used to generate various machine-learned models, which could be used to perform various tasks (e.g., make recommendations and/or predictions). In various embodiments, such machine-learned models may be used to: make an attorney recommendation for a potential client based on various factors (e.g., competency of the attorney, specialty of the attorney, nature of client issue, timeline, cost, location of the client, location of the attorney, etc.), make a physician recommendation for a patient based on various factors (e.g., competency of the physician, specialty of the physician, nature of patient issue, timeline, cost, insurance, location of the physician, location of the patient, etc.), make a route recommendation or selection for navigation (e.g., for an autonomous vehicle) based on various factors (e.g., traffic data, automobile type, real-time weather data, construction data, etc.), make an air travel reservation and/or recommendation based on various factors (e.g., historical airline price data, weather data, calendar data, passenger preferences, airplane specifications, airport location, etc.), make a recommendation of a vacation destination based on various factors (e.g., prior travel locations of a traveler, traveler preferences, price data, weather data, calendar information for multiple travelers, ratings from prior travelers for a given destination, etc.), provide translations of text or speech from one language to another based on various factors (e.g., input accent detected, rate of speech, punctuation used, context of text, etc.), perform object recognition on one or more images in an image database based on various factors (e.g., size of the image and/or object, shape of the image and/or object, color(s) of the image and/or object, texture(s) of the image and/or object, saturation of the image and/or object, hue of the image and/or object, location of the object within the image, etc.), recommend an insurance premium, deductible, and/or coverage amount for automotive insurance, home insurance, life insurance, health insurance, dental insurance, boat insurance, malpractice insurance, and/or long term disability insurance based on various factors (e.g., age of the insured, health of the insured, gender of the insured, marital status of the insured, insurance premium amount, insurance deductible amount, insurance coverage amount, credit history, other demographic information about the insured, etc.), recommend an interest rate for home, automotive, and/or boat loan based on various factors (e.g., age of the home/automobile/boat, credit score of the borrower, down payment amount, repayment term, resale value of the home/automobile/boat, reliability statistics about homes/automobiles/boats, etc.), recommend a lender for an home, automotive, and/or boat loan based on various factors (e.g., credit score of the borrower, amount of the loan, repayment term of the loan, down payment amount on the loan, etc.), calculate a credit score for a creditor based on various factors (e.g., creditor age, creditor gender, creditor repayment history, creditor credit card ownership data, creditor average interest rate, amount creditor is in debt, etc.), grant or deny biometric access for a requester based on various factors (e.g., object recognition in a set of biometric images, fingerprint data, retinal data, requester height, requester gender, requester age, requester eye color, requester hair color, requester race, etc.), recommend a restaurant to a patron based on various factors (e.g., prior restaurants visited by the patron, cuisine preference data, weather data, calendar data, real-time restaurant wait-time data, ratings from prior patrons of various restaurants, restaurant location data, patron location data, etc.), or predict the outcome of a sporting event based on various data (e.g., record of prior sports contests involving the participants, current betting statistics for the sporting event, betting statistics for prior sporting events, weather data, location of the sporting event data, etc.), recommending a menu-item selection for a restaurant patron based on various factors (e.g., patron preferences, ratings of previous patrons, cuisine type data, alternative options on the menu, price, spice-level data, preparation-time data, etc.), determine viability and success of one or more genetic modifications to an organism with regards to curing a disease and/or palliate symptoms based on various factors (e.g., locus of genetic modification, probability of occurrence of genetic modification, complexity of the genome of the organism, side-effects of the genetic modification, number of mutations/splices required to create genetic modification, gender of organism with genetic modification, symptoms of organism with genetic modification, age of organism with genetic modification, etc.), determine how to allocate funding in a smart city according to various factors (e.g., amount of funds, traffic data, ages of buildings/infrastructure, population density data, hospital data, power supply demand data, criminal statistics, etc.), recommend an investment strategy based on various factors (e.g., investor income data, investor risk aversion data, stock market data, etc.), and/or recommend preventative maintenance be performed (e.g., on an automobile, boat, industrial machine, factory equipment, airplane, infrastructure, etc.) based on various factors (e.g., age of the object, money invested into the object, statistical data regarding similar objects, year when the object was built, object use data, weather data, last preventative maintenance performed, cost of maintenance, etc.).
[0224] Any of the "various factors" provided as examples above could be components of datasets (e.g., one or more dimensions of a dataset). Similarly, corresponding "outcomes" (e.g., the recommended attorney or recommended physician) could be components of sets of predicted values ( .sub.A/ .sub.B) (e.g., one or more dimension of a set of predicted values) and/or sets of recorded values (Y.sub.A/Y.sub.B) (e.g., one or more dimension of a set of recorded values).
[0225] FIGS. 17A and 17B illustrate a matrix factorization algorithm (e.g., using a Macau factorization method), according to example embodiments. The matrix factorization method, similar to the methods described above, may be used to generate a machine-learned model while still preserving privacy of individual party's data. The matrix factorization algorithm may be performed using similar operations to those described with reference to FIGS. 4B-4E, for example. The matrix factorization algorithm illustrated is provided as an example of one embodiment of a myriad of embodiments contemplated herein that do not necessarily incorporate an artificial neural network model. In alternate embodiments, however, performing the matrix factorization illustrated in FIGS. 17A and 17B may include developing an artificial neural network model, in tandem with factoring the matrices. Similarly, in still other embodiments, other machine learning models/methods may be used in conjunction with the illustrated matrix factorization.
[0226] As illustrated in FIG. 17A, the recorded value tensor Y may be factored into matrices and V. In other words, Y may be equal to .times.V. The recorded value tensor Y may contain the set of recorded values corresponding to a respective dataset. For example, the recorded value tensor Y.sub.A may correspond to dataset A (X.sub.A). In such embodiments, a tensor (X.sub.A) representing dataset A (X.sub.A) may be multiplied by a shared parameter tensor (.beta.) (e.g., a one-dimensional shared parameter tensor, called a shared parameter vector) corresponding to one or more shared parameters (.beta.) in order to form one of the factored matrices ( .sub.A) relating to dataset A (X.sub.A). In other words, .sub.A may be equal to X.sub.A.times..beta.. In this way, the shared parameter tensor (.beta.) can be used to encode side information about objects in dataset A (X.sub.A). For example, in embodiments where dataset A (X.sub.A) represents ratings for a plurality of movies, the shared parameter tensor (.beta.) may represent information describing genres (e.g., horror, comedy, romance, etc.) of the plurality of movies. Such side information can improve the machine learning model generated (e.g., by assuming a viewer who gives a first movie in the "horror" genre a high rating may be more likely to give a second movie in the "horror" genre a high rating than a user who gave the first movie in the "horror" genre a low rating). In some embodiments (e.g., embodiments where the recorded value tensor Y.sub.A has three or more dimensions), there may be multiple corresponding tensors (e.g., a number of matrices corresponding to the rank of the recorded value tensor Y.sub.A) multiplied together to result in the recorded value tensor Y.sub.A.
[0227] Similar to the embodiments described above (with reference to FIGS. 4B-15B), the tensor ( .sub.A) may correspond to a partial representation (U.sub.A) that is part of a shared representation (U). The shared representation (U) may be based on all of the datasets transmitted and received by a managing computing device 1706, as illustrated in FIG. 17B. For example, the managing computing device 1706 may originally receive dataset A (X.sub.A) from client computing device A 1702 and dataset B (X.sub.B) from client computing B 1704. Upon receiving dataset A (X.sub.A) and dataset B (X.sub.B) the managing computing device 1706 may then create a list of unique objects (X.sub.Comb) (e.g., using a process similar to that described above with respect to FIGS. 4B-4E).
[0228] Upon creating the list of unique objects (X.sub.Comb), the managing computing device may determine a shared representation (U) based on one or more shared parameters (.beta.). In some embodiments, the one or more shared parameters may be randomly instantiated, prior to updating. This may happen according to the equation X.sub.Comb.times..beta.= , as illustrated in FIG. 17B. The shared representation (U) may then be transmitted to each of the client computing devices 1702/1704 by the managing computing device 1706. Then, each client computing device may determine which portion of the shared representation (U) corresponds to the dataset corresponding to the respective client computing device (e.g., based on a subset of identifiers (S) and a list of identifiers (M.sub.A/M.sub.B) for a respective dataset corresponding to the respective client computing device). This determined portion may represent the respective partial representation (U.sub.A/U.sub.B).
[0229] In some embodiments, a method may then be employed to update/refine the one or more shared parameters (.beta.). The method may include client computing device A 1702 using the determined partial representation (U.sub.A) to calculate a set of predicted values ({circumflex over (Y)}.sub.A). The set of predicted values may be calculated by .sub.A.sup.o.times.V.sub.A.sup.o={circumflex over (Y)}.sub.A.sup.o (where `o` denotes that this is the initial iteration). In some embodiments, the original value for the other factored tensor (V.sub.A.sup.o) may be instantiated randomly. Upon calculating a set of predicted values ({circumflex over (Y)}.sub.A.sup.o) (e.g., referred to as a predicted value tensor), the partial representation tensor ( .sub.A.sup.o) and the other factored tensor (V.sub.A.sup.o) may be updated (e.g., to a second iteration, indicated by `1` rather than `o`) by factoring the set of predicted values ({circumflex over (Y)}.sub.A.sup.o). Using the updated partial representation tensor ( .sub.A.sup.1, the shared parameter tensor (.beta.) may then be updated by solving X.sub.A.times..beta.= .sub.A.sup.1 for .beta. (or, in some embodiments, at least solving for the regions of the shared parameter tensor .beta. that correspond to non-zero entries in the tensor (X.sub.A) representing dataset A (X.sub.A)). After updating the shared parameter tensor (.beta.), the partial representation tensor ( .sub.A.sup.1) may then be transmitted to the managing computing device 1706. The above-described operations of updating the partial representation tensor and the shared parameter tensor, and the transmission of the partial representation tensor to the managing computing device 1706, may be performed by multiple client computing devices (e.g., both client computing device A 1702 and client computing device B 1704) for their respective datasets (e.g., dataset A (X.sub.A) and dataset B (X.sub.B)).
[0230] Upon receiving the updated partial representation matrices ( .sub.A.sup.1/ .sub.B.sup.1), the managing computing device may recombine them into a shared representation tensor ( .sub.1). Using the shared representation tensor, a shared parameter tensor (.beta.) may be updated using the list of unique objects (X.sub.Comb) by solving the following equation: X.sub.Comb.times..beta.= .sub.1, as illustrated in FIG. 17B.
[0231] Thereafter, the updated shared representation tensor ( .sup.1) may then be transmitted to each of the client computing devices 1702/1704 by the managing computing device 1706. Then, each client computing device may determine which portion of the updated shared representation tensor ( .sup.1) corresponds to the dataset corresponding to the respective client computing device (e.g., based on a subset of identifiers (S) and a list of identifiers (M.sub.A/M.sub.B) for a respective dataset corresponding to the respective client computing device). This determined portion may represent the respective partial representation (U.sub.A/U.sub.B). Based on this partial representation (U.sub.A/U.sub.B), an second iteration of a set of predicted values ({circumflex over (Y)}.sub.A.sup.1) may be calculated, a second partial representation tensor ( .sub.A.sup.1) and the other factored tensor (V.sub.A.sup.1) may be updated (e.g., to a third iteration) by factoring the second iteration of the set of predicted values ({circumflex over (Y)}.sub.A.sup.1) (e.g., using Macau factorization), and the shared parameter tensor ({dot over (.beta.)}) may be updated by solving X.sub.A.times..beta.= .sub.A.sup.2 for .beta.. The steps of the previous paragraphs may be repeated until the shared parameter tensor (.beta.) stop improving after an iteration or stop improving at least a threshold amount per iteration.
[0232] FIGS. 18A-27B illustrate an alternative embodiment of the method 400 illustrated in FIGS. 4B-4F. For example, FIGS. 18A-27B may be respectively analogous to FIGS. 5A-14B. However, as illustrated in FIGS. 18A and 18B, dataset A (X.sub.A), the set of recorded values (Y.sub.A) corresponding to dataset A (X.sub.A), dataset B (X.sub.B), and the set of recorded values (Y.sub.B) corresponding to dataset B (X.sub.B) may include different data than is included in the example embodiments of FIGS. 5A-14B.
[0233] As illustrated in FIG. 18A, dataset A (X.sub.A) may include four objects in a first dimension (e.g., "Book Title 1," "Book Title 2," "Book Title 3," and "Book Title 4"). These objects may correspond to books that are stocked and/or sold from a bookseller (e.g., an online bookseller or a bookstore). Such a bookseller may correspond to client computing device A 402, for example. In a second dimension of dataset A (X.sub.A), there may be five features corresponding to each of the four objects (e.g., "Genre," "Author," "ISBN," "Language," and "Publication Year"). The entries corresponding to each pair of (object, feature) may correspond to a value of a given feature for a given object. For example, object "Book Title 1" may have a value for feature "ISBN" of "56415." While values corresponding to "ISBN" are illustrated using 5 digits, other numbers of digits may be used in example embodiments (e.g., 10 digits, 13 digits, 20 digits, etc.). Further, in some embodiments, ISBN may be a binary number or a hexadecimal number (e.g., rather than a decimal number).
[0234] Further, as illustrated in FIG. 18A, the corresponding set of recorded values (Y.sub.A) includes the same four objects in a first dimension (e.g., "Book Title 1," "Book Title 2," "Book Title 3," and "Book Title 4") as the four objects in dataset A (X.sub.A). The set of recorded values (Y.sub.A) may also correspond to the bookseller that corresponds to dataset A (X.sub.A). In a second dimension of the corresponding set of recorded values (Y.sub.A), there may be five features corresponding to each of the four objects (e.g., "Timmy," "Johnny," "Sally," "Sue," and "Mark"). The entries corresponding to each pair of (object, feature) in the corresponding set of recorded values (Y.sub.A) may correspond to a rating value (e.g., ranging from 0-100). For example, feature "Johnny" may have rated object "Book Title 2" with a value of "18."
[0235] Similarly, as illustrated in FIG. 18B, dataset B (X.sub.B) may include three objects in a first dimension (e.g., "Book Title 2," "Book Title 5," and "Book Title 6"). These objects may correspond to books that are stocked and/or sold from a bookseller (e.g., an online bookseller or a bookstore that is different from the online bookseller or bookstore corresponding to dataset A (X.sub.A)). Such a bookseller may correspond to client computing device B 404, for example. In a second dimension of dataset B (X.sub.B), there may be five features corresponding to each of the three objects (e.g., "Genre," "Author," "ISBN," "Language," and "Publication Year"). As illustrated, the features of dataset B (X.sub.B) may be the same as the features of dataset A (X.sub.A). The entries corresponding to each pair of (object, feature) may correspond to a value of a given feature for a given object. For example, object "Book Title 5," may have a value for feature "Language" of "English."
[0236] Further, as illustrated in FIG. 18B, the corresponding set of recorded values (Y.sub.B) includes the same three objects in a first dimension (e.g., "Book Title 2," "Book Title 5," and "Book Title 6") as the three objects in dataset B (X.sub.B). The set of recorded values (Y.sub.B) may also correspond to the bookseller that corresponds to dataset B (X.sub.B). In a second dimension of the corresponding set of recorded values (Y.sub.B), there may be three features corresponding to each of the three objects (e.g., "Bob," "Margarette," and "Bram"). The entries corresponding to each pair of (object, feature) in the corresponding set of recorded values (Y.sub.B) may correspond to a rating value (e.g., ranging from 0-100). For example, feature "Bram" may have rated object "Book Title 6" with a value of "74."
[0237] As illustrated in FIGS. 19A-23, ISBNs may be used by the managing computing device 406 as identifiers for each of the objects in dataset A (X.sub.A) and dataset B (X.sub.B).
[0238] Propagating through the operations of the method 400 illustrated in FIGS. 4B-4E (e.g., as illustrated in FIGS. 19A-27B), sets of predicted values (Y.sub.A/Y.sub.B) can be determined for a respective partial representation (U.sub.A/U.sub.B) by each client computing device, as illustrated in FIGS. 27A and 27B. Using the sets of predicted values ( .sub.A/ .sub.B) and the corresponding sets of recorded values (Y.sub.A/Y.sub.B), the client computing devices may determine errors (E.sub.A/E.sub.B) (e.g., based on individual loss functions (L.sub.A/L.sub.B)). Based on these errors, the client computing devices may determine and transmit respective feedback values (C.sub.A/C.sub.B) to the managing computing device 406. Using the respective feedback values (C.sub.A/C.sub.B), the managing computing device 406 may update the shared representation (U).
[0239] If the shared representation (U) and/or the one or more shared parameters (.beta.) are distributed to the client computing devices, the client computing devices may use the shared representation (U) and/or the one or more shared parameters (.beta.) to make future predictions. For example, if a bookseller corresponding to client computing device A 402 and dataset A (X.sub.A) offers a new book for sale, that bookseller may predict the ratings that pre-existing customers will give to the new book (e.g., based on the new book's values corresponding to the features of "Genre," "Author," "ISBN," "Language," and/or "Publication Year").
[0240] In another example embodiment, the objects within the datasets (X.sub.A/X.sub.B) may be chemical compounds (e.g., in FIGS. 18A and 18B, "Book Title 1," "Book Title 2," etc. may be replaced with "Chemical Compound 1," "Chemical Compound 2," etc.). In such embodiments, the identifiers used for the chemical compounds may be a chemical fingerprint (e.g., analogously to ISBNs as illustrated in FIGS. 19A-23). Further, in such embodiments, features of the corresponding sets of recorded values (Y.sub.A/Y.sub.B) may correspond to cellular targets (e.g., cancer cells, gametes, etc.), rather than users (e.g., "Timmy," "Johnny," etc. may be replaced with "Cancer Cells," "Gametes," etc.). Still further in such embodiments, features of the datasets (X.sub.A/X.sub.B) such as "Genre" and "Author" may be replaced with features regarding chemical side information (e.g., such as certain functional groups that may be comprise a portion of a chemical compound, such as a hydroxyl group).
IV. Conclusion
[0241] The present disclosure is not to be limited in terms of the particular embodiments described in this application, which are intended as illustrations of various aspects. Many modifications and variations can be made without departing from its scope, as will be apparent to those skilled in the art. Functionally equivalent methods and apparatuses within the scope of the disclosure, in addition to those described herein, will be apparent to those skilled in the art from the foregoing descriptions. Such modifications and variations are intended to fall within the scope of the appended claims.
[0242] The above detailed description describes various features and operations of the disclosed systems, devices, and methods with reference to the accompanying figures. The example embodiments described herein and in the figures are not meant to be limiting. Other embodiments can be utilized, and other changes can be made, without departing from the scope of the subject matter presented herein. It will be readily understood that the aspects of the present disclosure, as generally described herein, and illustrated in the figures, can be arranged, substituted, combined, separated, and designed in a wide variety of different configurations.
[0243] With respect to any or all of the message flow diagrams, scenarios, and flow charts in the figures and as discussed herein, each step, block, operation, and/or communication can represent a processing of information and/or a transmission of information in accordance with example embodiments. Alternative embodiments are included within the scope of these example embodiments. In these alternative embodiments, for example, operations described as steps, blocks, transmissions, communications, requests, responses, and/or messages can be executed out of order from that shown or discussed, including substantially concurrently or in reverse order, depending on the functionality involved. Further, more or fewer blocks and/or operations can be used with any of the message flow diagrams, scenarios, and flow charts discussed herein, and these message flow diagrams, scenarios, and flow charts can be combined with one another, in part or in whole.
[0244] A step, block, or operation that represents a processing of information can correspond to circuitry that can be configured to perform the specific logical functions of a herein-described method or technique. Alternatively or additionally, a step or block that represents a processing of information can correspond to a module, a segment, or a portion of program code (including related data). The program code can include one or more instructions executable by a processor for implementing specific logical operations or actions in the method or technique. The program code and/or related data can be stored on any type of computer-readable medium such as a storage device including RAM, a disk drive, a solid state drive, or another storage medium.
[0245] The computer-readable medium can also include non-transitory computer-readable media such as computer-readable media that store data for short periods of time like register memory and processor cache. The computer-readable media can further include non-transitory computer-readable media that store program code and/or data for longer periods of time. Thus, the computer-readable media may include secondary or persistent long term storage, like ROM, optical or magnetic disks, solid state drives, compact-disc read only memory (CD-ROM), for example. The computer-readable media can also be any other volatile or non-volatile storage systems. A computer-readable medium can be considered a computer-readable storage medium, for example, or a tangible storage device.
[0246] Moreover, a step, block, or operation that represents one or more information transmissions can correspond to information transmissions between software and/or hardware modules in the same physical device. However, other information transmissions can be between software modules and/or hardware modules in different physical devices.
[0247] The particular arrangements shown in the figures should not be viewed as limiting. It should be understood that other embodiments can include more or less of each element shown in a given figure. Further, some of the illustrated elements can be combined or omitted. Yet further, an example embodiment can include elements that are not illustrated in the figures.
[0248] While various aspects and embodiments have been disclosed herein, other aspects and embodiments will be apparent to those skilled in the art. The various aspects and embodiments disclosed herein are for purpose of illustration and are not intended to be limiting, with the true scope being indicated by the following claims.
[0249] Embodiments of the present disclosure may thus relate to one of the enumerated example embodiments (EEEs) listed below.
[0250] EEE 1 is a method, comprising: [0251] receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, and wherein each dataset comprises objects; [0252] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0253] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0254] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0255] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0256] computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0257] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0258] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0259] transmitting, by the managing computing device, to each of the client computing devices: [0260] the sublist of objects for the respective dataset; and [0261] the partial representation for the respective dataset; [0262] receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0263] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0264] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset; [0265] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0266] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0267] determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; and [0268] updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values.
[0269] EEE 2 is the method of EEE 1, further comprising transmitting, by the managing computing device, the shared function and the one or more shared parameters to each of the client computing devices.
[0270] EEE 3 is the method of EEEs 1 or 2, wherein each identifier of the subset of identifiers is selected randomly or pseudo-randomly.
[0271] EEE 4 is the method of EEE 3, wherein each identifier of the subset of identifiers is selected based on a Mersenne Twister pseudo-random number generator.
[0272] EEE 5 is the method of EEEs 1 or 2, wherein each identifier of the subset of identifiers is selected according to an algorithm known only to the managing computing device.
[0273] EEE 6 is the method of EEEs 1 or 2, wherein each identifier of the subset of identifiers is selected according to a publicly available algorithm.
[0274] EEE 7 is the method of any of EEEs 1-6, wherein determining, by the managing computing device, the list of unique objects from among the plurality of datasets comprises: [0275] creating, by the managing computing device, a composite list of objects that is a combination of the objects from each dataset; and [0276] removing, by the managing computing device, duplicate objects from the composite list of objects based on an intersection of the lists of identifiers for each of the plurality of datasets.
[0277] EEE 8 is the method of any of EEEs 1-7, wherein the individual loss function comprises at least one of: a quadratic loss function, a logarithmic loss function, a hinge loss function, or a quantile loss function.
[0278] EEE 9 is the method of any of EEEs 1-8, wherein determining the error for the respective dataset comprises: [0279] identifying, by the respective client computing device, which of the non-empty entries in the set of recorded values corresponding to the respective dataset corresponds to an object in the sublist of objects; [0280] determining, by the respective client computing device, a partial error value for each of the identified non-empty entries in the set of recorded values corresponding to the respective dataset by applying the individual loss function between each identified non-empty entry and its corresponding predicted value in the set of predicted values corresponding to the respective dataset; and [0281] combining, by the respective client computing device, the partial error values.
[0282] EEE 10 is the method of any of EEEs 1-9, further comprising: [0283] calculating, by the managing computing device, a final shared representation of the datasets based on the list of unique objects, the shared function, and the one or more shared parameters; and [0284] transmitting, by the managing computing device, the final shared representation of the datasets to each of the client computing devices.
[0285] EEE 11 is the method of EEE 10, wherein the final shared representation of the datasets is usable by each of the client computing devices to determine a final set of predicted values corresponding to the respective dataset.
[0286] EEE 12 is the method of EEE 11, wherein determining the final set of predicted values corresponding to the respective dataset comprises: [0287] receiving, by the respective client computing device, the sublist of objects for the respective dataset; [0288] determining, by the respective client computing device, a final partial representation for the respective dataset based on the sublist of objects and the final shared representation; and [0289] determining, by the respective client computing device, the final set of predicted values corresponding to the respective dataset based on the final partial representation, the individual function, and the one or more individual parameters corresponding to the respective dataset.
[0290] EEE 13 is the method of EEEs 11 or 12, wherein the final set of predicted values is: [0291] displayed by at least one of the client computing devices; or [0292] used by at least one of the client computing devices to provide one or more predictions about objects in the dataset corresponding to the respective client computing device.
[0293] EEE 14 is the method of any of EEEs 1-13, wherein the one or more feedback values from each of the client computing devices are based on back-propagated errors.
[0294] EEE 15 is the method of any of EEEs 1-14, [0295] wherein the shared function corresponds to one or more first layers of an artificial neural network model, [0296] wherein each individual function corresponds to at least a portion of one or more second layers of the artificial neural network model, and [0297] wherein at least one of the one or more first layers is an input layer to at least one of the one or more second layers.
[0298] EEE 16 is the method of EEE 15, wherein the one or more shared parameters each corresponds to one or more weights in a weight tensor of the shared representation.
[0299] EEE 17 is the method of EEEs 15 or 16, wherein the one or more individual parameters each corresponds to one or more weights in a weight tensor of the individual function for the respective dataset.
[0300] EEE 18 is the method of any of EEEs 1-17, wherein each of the plurality of datasets comprises an equal number of dimensions.
[0301] EEE 19 is the method of EEE 18, wherein the number of dimensions is two, three, four, five, six, seven, eight, nine, ten, sixteen, thirty-two, sixty-four, one-hundred and twenty-eight, two-hundred and fifty-six, five-hundred and twelve, or one-thousand and twenty-four.
[0302] EEE 20 is the method of any of EEEs 1-19, [0303] wherein each of the plurality of datasets is represented by a tensor, and [0304] wherein at least one of the plurality of datasets is represented by a sparse tensor.
[0305] EEE 21 is the method of any of EEEs 1-20, wherein the shared function comprises an artificial neural network having rectified linear unit (ReLU) non-linearity and dropout.
[0306] EEE 22 is the method of any of EEEs 1-21, wherein determining, by the respective client computing device, the one or more feedback values corresponds to performing, by the respective client computing device, a gradient descent method.
[0307] EEE 23 is the method of any of EEEs 1-22, wherein the improvement in the set of predicted values corresponds to a threshold improvement value based on a shared learning rate.
[0308] EEE 24 is the method of EEE 23, further comprising: [0309] determining, by the managing computing device, the shared learning rate for the client computing devices; and [0310] transmitting, by the managing computing device, the shared learning rate to each of the client computing devices.
[0311] EEE 25 is the method of EEE 23, [0312] wherein determining, by the respective client computing device, the one or more feedback values corresponds to performing, by the respective client computing device, a gradient descent method, and [0313] wherein the shared learning rate is defined by the gradient descent method.
[0314] EEE 26 is the method of any of EEEs 23-25, wherein the shared learning rate comprises at least one of: an exponentially decayed learning rate, a harmonically decayed learning rate, or a step-wise exponentially decayed learning rate.
[0315] EEE 27 is the method of any of EEEs 1-22, wherein improvement in the set of predicted values corresponds to a threshold improvement value defined by an individual learning rate that is determined by each of the client computing devices independently.
[0316] EEE 28 is the method of EEE 27, wherein the individual learning rate comprises at least one of: an exponentially decayed learning rate, a harmonically decayed learning rate, or a step-wise exponentially decayed learning rate.
[0317] EEE 29 is the method of any of EEEs 1-28, further comprising: [0318] selecting, by the managing computing device, an additional subset of identifiers from the composite list of identifiers; [0319] determining, by the managing computing device, an additional subset of the list of unique objects corresponding to each identifier in the additional subset of identifiers; [0320] computing, by the managing computing device, a revised shared representation of the datasets based on the additional subset of the list of unique objects and the shared function having the one or more shared parameters; [0321] determining, by the managing computing device, additional sublists of objects for the respective dataset of each client computing device based on an intersection of the additional subset of identifiers with the list of identifiers for the respective dataset; [0322] determining, by the managing computing device, a revised partial respective for the respective dataset of each client computing device based on the additional sublist of objects for the respective dataset and the revised shared representation; [0323] transmitting, by the managing computing device, to each of the client computing devices: [0324] the additional sublist of objects for the respective dataset; and [0325] the revised partial representation for the respective dataset; [0326] receiving, by the managing computing device, one or more revised feedback values from at least one of the client computing devices, wherein the one or more revised feedback values are determined by the client computing devices by: [0327] determining, by the respective client computing device, a revised set of predicted values corresponding to the respective dataset, wherein the revised set of predicted values is based on the revised partial representation and the individual function with the one or more individual parameters corresponding to the respective dataset; [0328] determining, by the respective client computing device, a revised error for the respective dataset based on the individual loss function for the respective dataset, the revised set of predicted values corresponding to the respective dataset, the additional sublist of objects, and the non-empty entries in the set of recorded values corresponding to the respective dataset; [0329] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0330] determining, by the respective client computing device, the one or more revised feedback values, wherein the one or more revised feedback values are used to determine a change in the revised partial representation that corresponds to an improvement in the set of predicted values; [0331] determining, by the managing computing device, based on the additional sublists of objects and the one or more revised feedback values, one or more revised aggregated feedback values; [0332] updating, by the managing computing device, the one or more shared parameters based on the one or more revised aggregated feedback values; and [0333] determining, by the managing computing device based on the one or more revised aggregated feedback values, that an aggregated error corresponding to the revised errors for all respective datasets has been minimized.
[0334] EEE 30 is the method of any of EEEs 1-29, [0335] wherein the one or more feedback values from the client computing devices are organized into feedback tensors, and [0336] wherein each respective feedback tensor has a dimensionality that is equal to a dimensionality of the respective partial representation.
[0337] EEE 31 is the method of any of EEEs 1-30, [0338] wherein the one or more aggregated feedback values are organized into an aggregated feedback tensor, and [0339] wherein the aggregated feedback tensor has a dimensionality that is equal to a dimensionality of the shared representation.
[0340] EEE 32 is the method of any of EEEs 1-31, further comprising initializing, by the managing computing device, the shared function and the one or more shared parameters based on a related shared function used to model a similar relationship.
[0341] EEE 33 is the method of any of EEEs 1-31, further comprising: [0342] receiving, by the managing computing device, initial values for the one or more shared parameters from a first client computing device of the plurality of client computing devices; and [0343] initializing, by the managing computing device, the shared function and the one or more shared parameters based on the initial values for the one or more shared parameters.
[0344] EEE 34 is the method of EEE 33, wherein the initial values for the one or more shared parameters are determined by the first client computing device based upon one or more public models.
[0345] EEE 35 is the method of any of EEEs 1-31, further comprising initializing, by the managing computing device, the shared function and the one or more shared parameters based on at least one of: a random number generator or a pseudo-random number generator.
[0346] EEE 36 is the method of any of EEEs 1-35, wherein determining the one or more feedback values by the client computing devices further comprises initializing, by the respective client computing device, the individual function and the one or more individual parameters corresponding to the respective data set based on a random number generator or a pseudo-random number generator.
[0347] EEE 37 is the method of any of EEEs 1-36, wherein determining, based on the sublists of objects and the one or more feedback values from the client computing devices, the one or more aggregated feedback values comprises: [0348] defining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, a tensor representing the one or more aggregated feedback values; and [0349] summing, by the managing computing device based on the sublists of objects, those feedback values of the one or more feedback values from the client computing devices that correspond to objects in the sublists of objects that have shared identifiers into a shared entry of the tensor representing the one or more aggregated feedback values.
[0350] EEE 38 is the method of any of EEEs 1-37, [0351] wherein updating the one or more shared parameters based on the one or more aggregated feedback values comprises evaluating a sum of partial derivatives, and [0352] wherein each of the partial derivatives are partial derivatives of the error for a respective dataset with respect to the one or more shared parameters.
[0353] EEE 39 is the method of any of EEEs 1-37, [0354] wherein updating the one or more shared parameters based on the one or more aggregated feedback values comprises evaluating a sum of products of first partial derivatives and second partial derivatives, [0355] wherein the first partial derivatives are partial derivatives of the error for a respective dataset with respect to the respective partial representation, and [0356] wherein the second partial derivatives are partial derivatives of the respective partial representation with respect to the one or more shared parameters.
[0357] EEE 40 is the method of any of EEEs 1-39, further comprising removing, by the managing computing device, the list of unique objects, the shared representation, the lists of identifiers of each dataset of the plurality of datasets, and the composite list of identifiers from a memory of the managing computing device.
[0358] EEE 41 is the method of any of EEEs 1-40, [0359] wherein each of the plurality of datasets comprises at least two dimensions, [0360] wherein a first dimension of each of the plurality of datasets comprises a plurality of chemical compounds, [0361] wherein a second dimension of each of the plurality of datasets comprises descriptors of the chemical compounds, [0362] wherein entries in each of the plurality of datasets correspond to a binary indication of whether a respective chemical compound exhibits a respective descriptor, [0363] wherein each of the sets of recorded values corresponding to each of the plurality of datasets comprises at least two dimensions, [0364] wherein a first dimension of each of the sets of recorded values comprises the plurality of chemical compounds, [0365] wherein a second dimension of each of the sets of recorded values comprises activities of the chemical compounds in a plurality of biological assays, and [0366] wherein entries in each of the sets of recorded values correspond to a binary indication of whether a respective chemical compound exhibits a respective activity.
[0367] EEE 42 is the method of EEE 41, further comprising: [0368] calculating, by the managing computing device, a final shared representation of the datasets based on the list of unique objects, the shared function, and the one or more shared parameters; and [0369] transmitting, by the managing computing device, the final shared representation of the datasets to each of the client computing devices, [0370] wherein the final shared representation of the datasets is usable by each of the client computing devices to determine a final set of predicted values corresponding to the respective dataset, and [0371] wherein the final set of predicted values is used by at least one of the client computing devices to identify one or more effective treatment compounds among the plurality of chemical compounds.
[0372] EEE 43 is the method of any of EEEs 1-40, [0373] wherein each of the plurality of datasets comprises at least two dimensions, [0374] wherein a first dimension of each of the plurality of datasets comprises a plurality of patients, [0375] wherein a second dimension of each of the plurality of datasets comprises descriptors of the patients, [0376] wherein entries in each of the plurality of datasets correspond to a binary indication of whether a respective patient exhibits a respective descriptor, [0377] wherein each of the sets of recorded values corresponding to each of the plurality of datasets comprises at least two dimensions, [0378] wherein a first dimension of each of the sets of recorded values comprises the plurality of patients, [0379] wherein a second dimension of each of the sets of recorded values comprises clinical diagnoses of the patients, and [0380] wherein entries in each of the sets of recorded values correspond to a binary indication of whether a respective patient exhibits a respective clinical diagnosis.
[0381] EEE 44 is the method of EEE 43, further comprising: [0382] calculating, by the managing computing device, a final shared representation of the datasets based on the list of unique objects, the shared function, and the one or more shared parameters; and [0383] transmitting, by the managing computing device, the final shared representation of the datasets to each of the client computing devices, [0384] wherein the final shared representation of the datasets is usable by each of the client computing devices to determine a final set of predicted values corresponding to the respective dataset, and [0385] wherein the final set of predicted values is used by at least one of the client computing devices to diagnose at least one of the plurality of patients.
[0386] EEE 45 is the method of any of EEEs 1-40, [0387] wherein each of the plurality of datasets comprises at least two dimensions, [0388] wherein a first dimension of each of the plurality of datasets comprises a plurality of users, [0389] wherein a second dimension of each of the plurality of datasets comprises a plurality of book titles, [0390] wherein entries in each of the plurality of datasets correspond to a rating of a respective book title by a respective user, [0391] wherein each of the sets of recorded values corresponding to each of the plurality of datasets comprises at least two dimensions, [0392] wherein a first dimension of each of the sets of recorded values comprises the plurality of users, [0393] wherein a second dimension of each of the sets of recorded values comprises a plurality of movie titles, and [0394] wherein entries in each of the sets of recorded values correspond to a rating of a respective movie title by a respective user.
[0395] EEE 46 is the method of EEE 45, further comprising: [0396] calculating, by the managing computing device, a final shared representation of the datasets based on the list of unique objects, the shared function, and the one or more shared parameters; and [0397] transmitting, by the managing computing device, the final shared representation of the datasets to each of the client computing devices, [0398] wherein the final shared representation of the datasets is usable by each of the client computing devices to determine a final set of predicted values corresponding to the respective dataset, and [0399] wherein the final set of predicted values is used by at least one of the client computing devices to recommend at least one of the plurality of movie titles to at least one of the plurality of users.
[0400] EEE 47 is the method of any of EEEs 1-40, [0401] wherein each of the plurality of datasets comprises at least two dimensions, [0402] wherein a first dimension of each of the plurality of datasets comprises a plurality of insurance policies, [0403] wherein a second dimension of each of the plurality of datasets comprises a plurality of deductible amounts, [0404] wherein entries in each of the plurality of datasets correspond to a binary indication of whether a respective insurance policy has a respective deductible amount, [0405] wherein each of the sets of recorded values corresponding to each of the plurality of datasets comprises at least two dimensions, [0406] wherein a first dimension of each of the sets of recorded values comprises the plurality of insurance policies, [0407] wherein a second dimension of each of the sets of recorded values comprises a plurality of insurance premiums, and [0408] wherein entries in each of the sets of recorded values correspond to a binary indication of whether a respective insurance policy has a respective insurance premium.
[0409] EEE 48 is the method of EEE 47, further comprising: [0410] calculating, by the managing computing device, a final shared representation of the datasets based on the list of unique objects, the shared function, and the one or more shared parameters; and [0411] transmitting, by the managing computing device, the final shared representation of the datasets to each of the client computing devices, [0412] wherein the final shared representation of the datasets is usable by each of the client computing devices to determine a final set of predicted values corresponding to the respective dataset, and [0413] wherein the final set of predicted values is used by at least one of the client computing devices to recommend an insurance premium based on a prospective deductible amount.
[0414] EEE 49 is the method of any of EEEs 1-40, [0415] wherein each of the plurality of datasets comprises at least two dimensions, [0416] wherein a first dimension of each of the plurality of datasets comprises a plurality of automobiles, [0417] wherein a second dimension of each of the plurality of datasets comprises a plurality of automobile parts, [0418] wherein entries in each of the plurality of datasets correspond to a binary indication of whether a respective automobile has a respective automobile part equipped, [0419] wherein each of the sets of recorded values corresponding to each of the plurality of datasets comprises at least two dimensions, [0420] wherein a first dimension of each of the sets of recorded values comprises the plurality of automobiles, [0421] wherein a second dimension of each of the sets of recorded values comprises a plurality of average fuel efficiencies, and [0422] wherein entries in each of the sets of recorded values correspond to a binary indication of whether a respective automobile has a respective average fuel efficiency.
[0423] EEE 50 is the method of EEE 49, further comprising: [0424] calculating, by the managing computing device, a final shared representation of the datasets based on the list of unique objects, the shared function, and the one or more shared parameters; and [0425] transmitting, by the managing computing device, the final shared representation of the datasets to each of the client computing devices, [0426] wherein the final shared representation of the datasets is usable by each of the client computing devices to determine a final set of predicted values corresponding to the respective dataset, and [0427] wherein the final set of predicted values is used by at least one of the client computing devices to predict an average fuel efficiency of an automobile model based on a set of equipped automobile parts.
[0428] EEE 51 is the method of any of EEEs 1-50, [0429] wherein the respective dataset of a respective client computing device is stored in a primary memory storage, and [0430] wherein the set of recorded values corresponding to the respective dataset are stored in a secondary memory storage.
[0431] EEE 52 is the method of any of EEEs 1-14, 18-20, or 22-51, [0432] wherein each of the sets of predicted values corresponding to one of the plurality of datasets corresponds to a predicted value tensor, [0433] wherein the predicted value tensor is factored into a first tensor multiplied by a second tensor, and [0434] wherein the first tensor corresponds to the respective dataset multiplied by the one or more shared parameters.
[0435] EEE 53 is the method of EEE 52, wherein the respective dataset encodes side information about the objects of the dataset.
[0436] EEE 54 is the method of EEEs 52 or 53, wherein the predicted value tensor is factored using a Macau factorization method.
[0437] EEE 55 is the method of any of EEEs 1-54, wherein the individual loss function of each respective client computing device comprises a shared loss function.
[0438] EEE 56 is the method of any of EEEs 1-54, wherein a first individual loss function of the individual loss functions is different from a second individual loss function of the individual loss functions.
[0439] EEE 57 is a method, comprising: [0440] receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, wherein each dataset relates a plurality of chemical compounds to a plurality of descriptors of the chemical compounds, and wherein each dataset comprises objects; [0441] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0442] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0443] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0444] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0445] computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0446] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0447] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0448] transmitting, by the managing computing device, to each of the client computing devices: [0449] the sublist of objects for the respective dataset; and [0450] the partial representation for the respective dataset; [0451] receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0452] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0453] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset, wherein the set of recorded values corresponding to the respective dataset relates the plurality of chemical compounds to activities of the chemical compounds in a plurality of biological assays; [0454] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0455] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0456] determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; and [0457] updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values, [0458] wherein the shared representation, the shared function, or the one or more shared parameters are usable by at least one of the plurality of client computing devices to identify one or more effective treatment compounds among the plurality of chemical compounds.
[0459] EEE 58 is the method of EEE 57, wherein the plurality of descriptors comprises chemistry-derived fingerprints or descriptors identified via transcriptomics or image screening.
[0460] EEE 59 is a method, comprising: [0461] receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, wherein each dataset relates a plurality of patients to a plurality of descriptors of the patients, and wherein each dataset comprises objects; [0462] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0463] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0464] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0465] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0466] computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0467] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0468] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0469] transmitting, by the managing computing device, to each of the client computing devices: [0470] the sublist of objects for the respective dataset; and [0471] the partial representation for the respective dataset; [0472] receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0473] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0474] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset, wherein the set of recorded values corresponding to the respective dataset relates the plurality of patients to clinical diagnoses of patients; [0475] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0476] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0477] determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; and [0478] updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values, [0479] wherein the shared representation, the shared function, or the one or more shared parameters are usable by at least one of the plurality of client computing devices to diagnose one or more of the plurality of patients.
[0480] EEE 60 is the method of EEE 59, wherein the plurality of descriptors of the patients comprises genomic-based descriptors, patient demographics, patient age, patient height, patient weight, or patient gender.
[0481] EEE 61 is a method, comprising: [0482] receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, wherein each dataset provides a set of book ratings for a plurality of book titles by a plurality of users, and wherein each dataset comprises objects; [0483] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0484] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0485] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0486] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0487] computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0488] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0489] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0490] transmitting, by the managing computing device, to each of the client computing devices: [0491] the sublist of objects for the respective dataset; and [0492] the partial representation for the respective dataset; [0493] receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0494] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0495] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset, wherein the set of recorded values corresponding to the respective dataset provides a set of movie ratings for a plurality of movie titles by the plurality of users; [0496] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0497] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0498] determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; and [0499] updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values, [0500] wherein the shared representation, the shared function, or the one or more shared parameters are usable by at least one of the plurality of client computing devices to recommend a movie to one or more of the plurality of users.
[0501] EEE 62 is the method of EEE 61, wherein the book ratings comprise at least one of: binary ratings, classification ratings, or numerical ratings.
[0502] EEE 63 is the method of EEEs 61 or 62, wherein the movie ratings comprise at least one of: binary ratings, classification ratings, or numerical ratings.
[0503] EEE 64 is a method, comprising: [0504] transmitting, by a first client computing device to a managing computing device, a first dataset corresponding to the first client computing device, [0505] wherein the first dataset is one of a plurality of datasets transmitted to the managing computing device by a plurality of client computing devices, [0506] wherein each dataset corresponds to a set of recorded values, and [0507] wherein each dataset comprises objects; [0508] receiving, by the first client computing device, a first sublist of objects for the first dataset and a first partial representation for the first dataset, [0509] wherein the first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by the managing computing device by: [0510] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0511] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0512] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0513] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0514] computing, by the managing computing device, a shared representation of the plurality of datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0515] determining, by the managing computing device, the first sublist of objects for the first dataset based on an intersection of the subset of identifiers with the list of identifiers for the first dataset; and [0516] determining, by the managing computing device, the first partial representation for the first dataset based on the first sublist of objects and the shared representation; [0517] determining, by the first client computing device, a first set of predicted values corresponding to the first dataset, wherein the first set of predicted values is based on the first partial representation and a first individual function with one or more first individual parameters corresponding to the first dataset; [0518] determining, by the first client computing device, a first error for the first dataset based on a first individual loss function for the first dataset, the first set of predicted values corresponding to the first dataset, the first sublist of objects, and non-empty entries in the set of recorded values corresponding to the first dataset; [0519] updating, by the first client computing device, the one or more first individual parameters for the first dataset; [0520] determining, by the first client computing device, one or more feedback values, wherein the one or more feedback values are used to determine a change in the first partial representation that corresponds to an improvement in the first set of predicted values; and [0521] transmitting, by the first client computing device to the managing computing device, the one or more feedback values, [0522] wherein the one or more feedback values are usable by the managing computing device along with sublists of objects from the plurality of client computing devices to determine one or more aggregated feedback values, and [0523] wherein the one or more aggregated feedback values are usable by the managing computing device to update the one or more shared parameters.
[0524] EEE 65 is a non-transitory, computer-readable medium with instructions stored thereon, wherein the instructions are executable by a processor to perform a method, comprising: [0525] receiving a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, and wherein each dataset comprises objects; [0526] determining a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0527] determining a list of unique objects from among the plurality of datasets; [0528] selecting a subset of identifiers from the composite list of identifiers; [0529] determining a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0530] computing a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0531] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0532] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0533] transmitting to each of the client computing devices: [0534] the sublist of objects for the respective dataset; and [0535] the partial representation for the respective dataset; [0536] receiving one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0537] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0538] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset; [0539] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0540] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0541] determining based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; and [0542] updating the one or more shared parameters based on the one or more aggregated feedback values.
[0543] EEE 66 is a memory with a model stored thereon, wherein the model is generated according to a method, comprising: [0544] receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, and wherein each dataset comprises objects; [0545] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0546] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0547] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0548] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0549] computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0550] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0551] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0552] transmitting, by the managing computing device, to each of the client computing devices: [0553] the sublist of objects for the respective dataset; and [0554] the partial representation for the respective dataset; [0555] receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0556] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0557] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset; [0558] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0559] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0560] determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; [0561] updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values; and [0562] storing, by the managing computing device, the shared representation, the shared function, and the one or more shared parameters on the memory.
[0563] EEE 67 is a method, comprising: [0564] receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, and wherein each dataset comprises objects; [0565] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0566] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0567] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0568] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0569] computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0570] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0571] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0572] transmitting, by the managing computing device, to each of the client computing devices: [0573] the sublist of objects for the respective dataset; and [0574] the partial representation for the respective dataset; [0575] receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0576] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0577] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset; [0578] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0579] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0580] determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; [0581] updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values; and [0582] using, by a computing device, the shared representation, the shared function, or the one or more shared parameters to determine an additional set of predicted values corresponding to a dataset.
[0583] EEE 68 is a server device, wherein the server device has instructions stored thereon that, when executed by a processor, perform a method, the method comprising: [0584] receiving a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, and wherein each dataset comprises objects; [0585] determining a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0586] determining a list of unique objects from among the plurality of datasets; [0587] selecting a subset of identifiers from the composite list of identifiers; [0588] determining a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0589] computing a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0590] determining a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0591] determining a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0592] transmitting to each of the client computing devices: [0593] the sublist of objects for the respective dataset; and [0594] the partial representation for the respective dataset; [0595] receiving one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0596] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0597] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset; [0598] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0599] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0600] determining based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; and [0601] updating the one or more shared parameters based on the one or more aggregated feedback values.
[0602] EEE 69 is a server device, wherein the server device has instructions stored thereon that, when executed by a processor, perform a method, the method comprising: [0603] transmitting, to a managing computing device, a first dataset corresponding to the server device, [0604] wherein the first dataset is one of a plurality of datasets transmitted to the managing computing device by a plurality of server devices, [0605] wherein each dataset corresponds to a set of recorded values, and [0606] wherein each dataset comprises objects; [0607] receiving a first sublist of objects for the first dataset and a first partial representation for the first dataset, [0608] wherein the first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by the managing computing device by: [0609] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0610] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0611] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0612] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0613] computing, by the managing computing device, a shared representation of the plurality of datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0614] determining, by the managing computing device, the first sublist of objects for the first dataset based on an intersection of the subset of identifiers with the list of identifiers for the first dataset; and [0615] determining, by the managing computing device, the first partial representation for the first dataset based on the first sublist of objects and the shared representation; [0616] determining a first set of predicted values corresponding to the first dataset, wherein the first set of predicted values is based on the first partial representation and a first individual function with one or more first individual parameters corresponding to the first dataset; [0617] determining a first error for the first dataset based on a first individual loss function for the first dataset, the first set of predicted values corresponding to the first dataset, the first sublist of objects, and non-empty entries in the set of recorded values corresponding to the first dataset; [0618] updating the one or more first individual parameters for the first dataset; [0619] determining one or more feedback values, wherein the one or more feedback values are used to determine a change in the first partial representation that corresponds to an improvement in the first set of predicted values; and [0620] transmitting, to the managing computing device, the one or more feedback values, [0621] wherein the one or more feedback values are usable by the managing computing device along with sublists of objects from the plurality of server devices to determine one or more aggregated feedback values, and [0622] wherein the one or more aggregated feedback values are usable by the managing computing device to update the one or more shared parameters.
[0623] EEE 70 is a system, comprising: [0624] a server device; and [0625] a plurality of client devices each communicatively coupled to the server device, [0626] wherein the server device has instructions stored thereon that, when executed by a processor, perform a first method, the first method comprising: [0627] receiving a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client device of the plurality of client devices, wherein each dataset corresponds to a set of recorded values, and wherein each dataset comprises objects; [0628] determining a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0629] determining a list of unique objects from among the plurality of datasets; [0630] selecting a subset of identifiers from the composite list of identifiers; [0631] determining a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0632] computing a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0633] determining a sublist of objects for the respective dataset of each client device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0634] determining a partial representation for the respective dataset of each client device based on the sublist of objects for the respective dataset and the shared representation; [0635] transmitting to each of the client devices: [0636] the sublist of objects for the respective dataset; and [0637] the partial representation for the respective dataset, [0638] wherein each client device has instructions stored thereon that, when executed by a processor, perform a second method, the second method comprising: [0639] determining a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0640] determining an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset; [0641] updating the one or more individual parameters for the respective dataset; [0642] determining one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; and [0643] transmitting, to the server device, the one or more feedback values, and wherein the first method further comprises: [0644] determining based on the sublists of objects and the one or more feedback values from the client devices, one or more aggregated feedback values; and [0645] updating the one or more shared parameters based on the one or more aggregated feedback values.
[0646] EEE 71 is an optimized model, wherein the model is optimized according to a method, the method comprising: [0647] receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, and wherein each dataset comprises objects; [0648] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0649] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0650] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0651] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0652] computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0653] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0654] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0655] transmitting, by the managing computing device, to each of the client computing devices: [0656] the sublist of objects for the respective dataset; and [0657] the partial representation for the respective dataset; [0658] receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0659] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0660] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset; [0661] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0662] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0663] determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; [0664] updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values; and [0665] computing, by the managing computing device, an updated shared representation of the datasets based on the shared function and the one or more updated shared parameters, [0666] wherein the updated shared representation corresponds to the optimized model.
[0667] EEE 72 is a computer-implemented method, comprising: [0668] receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, and wherein each dataset comprises objects; [0669] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0670] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0671] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0672] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0673] computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0674] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0675] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0676] transmitting, by the managing computing device, to each of the client computing devices: [0677] the sublist of objects for the respective dataset; and [0678] the partial representation for the respective dataset; [0679] receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0680] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0681] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset; [0682] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0683] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0684] determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; and [0685] updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values.
[0686] EEE 73 is a computer-implemented method, comprising: [0687] receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, wherein each dataset relates a plurality of chemical compounds to a plurality of descriptors of the chemical compounds, and wherein each dataset comprises objects; [0688] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0689] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0690] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0691] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0692] computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0693] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0694] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0695] transmitting, by the managing computing device, to each of the client computing devices: [0696] the sublist of objects for the respective dataset; and [0697] the partial representation for the respective dataset; [0698] receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0699] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0700] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset, wherein the set of recorded values corresponding to the respective dataset relates the plurality of chemical compounds to activities of the chemical compounds in a plurality of biological assays; [0701] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0702] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0703] determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; and [0704] updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values, [0705] wherein the shared representation, the shared function, or the one or more shared parameters are usable by at least one of the plurality of client computing devices to identify one or more effective treatment compounds among the plurality of chemical compounds.
[0706] EEE 74 is a computer-implemented method, comprising: [0707] receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, wherein each dataset relates a plurality of patients to a plurality of descriptors of the patients, and wherein each dataset comprises objects; [0708] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0709] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0710] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0711] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0712] computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0713] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0714] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0715] transmitting, by the managing computing device, to each of the client computing devices: [0716] the sublist of objects for the respective dataset; and [0717] the partial representation for the respective dataset; [0718] receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0719] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0720] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset, wherein the set of recorded values corresponding to the respective dataset relates the plurality of patients to clinical diagnoses of patients; [0721] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0722] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0723] determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; and [0724] updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values, [0725] wherein the shared representation, the shared function, or the one or more shared parameters are usable by at least one of the plurality of client computing devices to diagnose one or more of the plurality of patients.
[0726] EEE 75 is a computer-implemented method, comprising: [0727] receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, wherein each dataset provides a set of book ratings for a plurality of book titles by a plurality of users, and wherein each dataset comprises objects; [0728] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0729] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0730] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0731] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0732] computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0733] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0734] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0735] transmitting, by the managing computing device, to each of the client computing devices: [0736] the sublist of objects for the respective dataset; and [0737] the partial representation for the respective dataset; [0738] receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0739] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0740] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset, wherein the set of recorded values corresponding to the respective dataset provides a set of movie ratings for a plurality of movie titles by the plurality of users; [0741] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0742] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0743] determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; and [0744] updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values, [0745] wherein the shared representation, the shared function, or the one or more shared parameters are usable by at least one of the plurality of client computing devices to recommend a movie to one or more of the plurality of users.
[0746] EEE 76 is a computer-implemented method, comprising: [0747] transmitting, by a first client computing device to a managing computing device, a first dataset corresponding to the first client computing device, [0748] wherein the first dataset is one of a plurality of datasets transmitted to the managing computing device by a plurality of client computing devices, [0749] wherein each dataset corresponds to a set of recorded values, and [0750] wherein each dataset comprises objects; [0751] receiving, by the first client computing device, a first sublist of objects for the first dataset and a first partial representation for the first dataset, [0752] wherein the first sublist of objects for the first dataset and the first partial representation for the first dataset are determined by the managing computing device by: [0753] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0754] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0755] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0756] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0757] computing, by the managing computing device, a shared representation of the plurality of datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0758] determining, by the managing computing device, the first sublist of objects for the first dataset based on an intersection of the subset of identifiers with the list of identifiers for the first dataset; and [0759] determining, by the managing computing device, the first partial representation for the first dataset based on the first sublist of objects and the shared representation; [0760] determining, by the first client computing device, a first set of predicted values corresponding to the first dataset, wherein the first set of predicted values is based on the first partial representation and a first individual function with one or more first individual parameters corresponding to the first dataset; [0761] determining, by the first client computing device, a first error for the first dataset based on a first individual loss function for the first dataset, the first set of predicted values corresponding to the first dataset, the first sublist of objects, and non-empty entries in the set of recorded values corresponding to the first dataset; [0762] updating, by the first client computing device, the one or more first individual parameters for the first dataset; [0763] determining, by the first client computing device, one or more feedback values, wherein the one or more feedback values are used to determine a change in the first partial representation that corresponds to an improvement in the first set of predicted values; and [0764] transmitting, by the first client computing device to the managing computing device, the one or more feedback values, [0765] wherein the one or more feedback values are usable by the managing computing device along with sublists of objects from the plurality of client computing devices to determine one or more aggregated feedback values, and [0766] wherein the one or more aggregated feedback values are usable by the managing computing device to update the one or more shared parameters.
[0767] EEE 77 is a computer-implemented method, comprising: [0768] receiving, by a managing computing device, a plurality of datasets, wherein each dataset of the plurality of datasets is received from a respective client computing device of a plurality of client computing devices, wherein each dataset corresponds to a set of recorded values, and wherein each dataset comprises objects; [0769] determining, by the managing computing device, a respective list of identifiers for each dataset and a composite list of identifiers comprising a combination of the lists of identifiers of each dataset of the plurality of datasets; [0770] determining, by the managing computing device, a list of unique objects from among the plurality of datasets; [0771] selecting, by the managing computing device, a subset of identifiers from the composite list of identifiers; [0772] determining, by the managing computing device, a subset of the list of unique objects corresponding to each identifier in the subset of identifiers; [0773] computing, by the managing computing device, a shared representation of the datasets based on the subset of the list of unique objects and a shared function having one or more shared parameters; [0774] determining, by the managing computing device, a sublist of objects for the respective dataset of each client computing device based on an intersection of the subset of identifiers with the list of identifiers for the respective dataset; [0775] determining, by the managing computing device, a partial representation for the respective dataset of each client computing device based on the sublist of objects for the respective dataset and the shared representation; [0776] transmitting, by the managing computing device, to each of the client computing devices: [0777] the sublist of objects for the respective dataset; and [0778] the partial representation for the respective dataset; [0779] receiving, by the managing computing device, one or more feedback values from at least one of the client computing devices, wherein the one or more feedback values are determined by the client computing devices by: [0780] determining, by the respective client computing device, a set of predicted values corresponding to the respective dataset, wherein the set of predicted values is based on the partial representation and an individual function with one or more individual parameters corresponding to the respective dataset; [0781] determining, by the respective client computing device, an error for the respective dataset based on an individual loss function for the respective dataset, the set of predicted values corresponding to the respective dataset, the sublist of objects, and non-empty entries in the set of recorded values corresponding to the respective dataset; [0782] updating, by the respective client computing device, the one or more individual parameters for the respective dataset; and [0783] determining, by the respective client computing device, the one or more feedback values, wherein the one or more feedback values are used to determine a change in the partial representation that corresponds to an improvement in the set of predicted values; [0784] determining, by the managing computing device, based on the sublists of objects and the one or more feedback values from the client computing devices, one or more aggregated feedback values; [0785] updating, by the managing computing device, the one or more shared parameters based on the one or more aggregated feedback values; and [0786] using, by a computing device, the shared representation, the shared function, or the one or more shared parameters to determine an additional set of predicted values corresponding to a dataset.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012
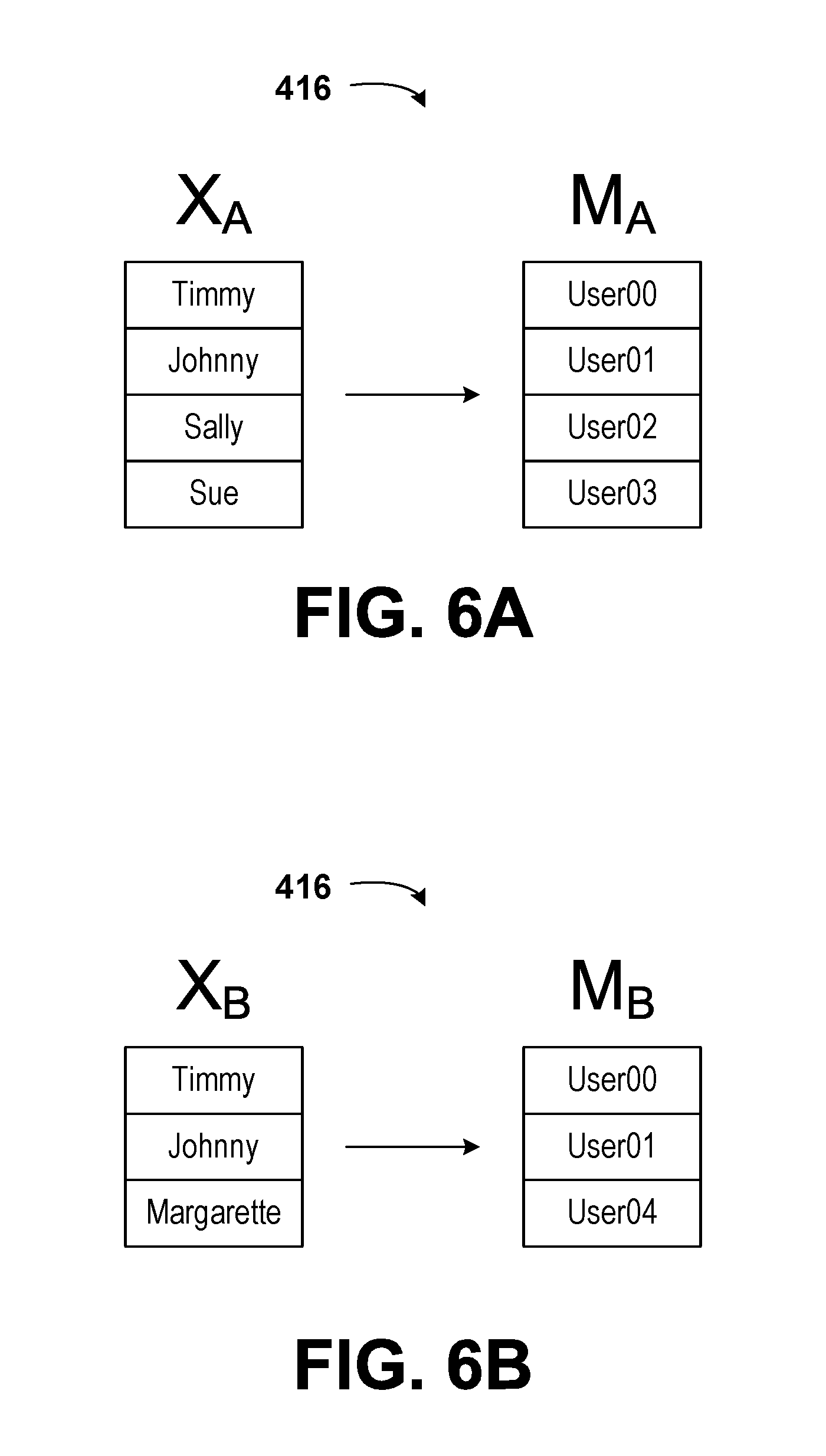
D00013

D00014
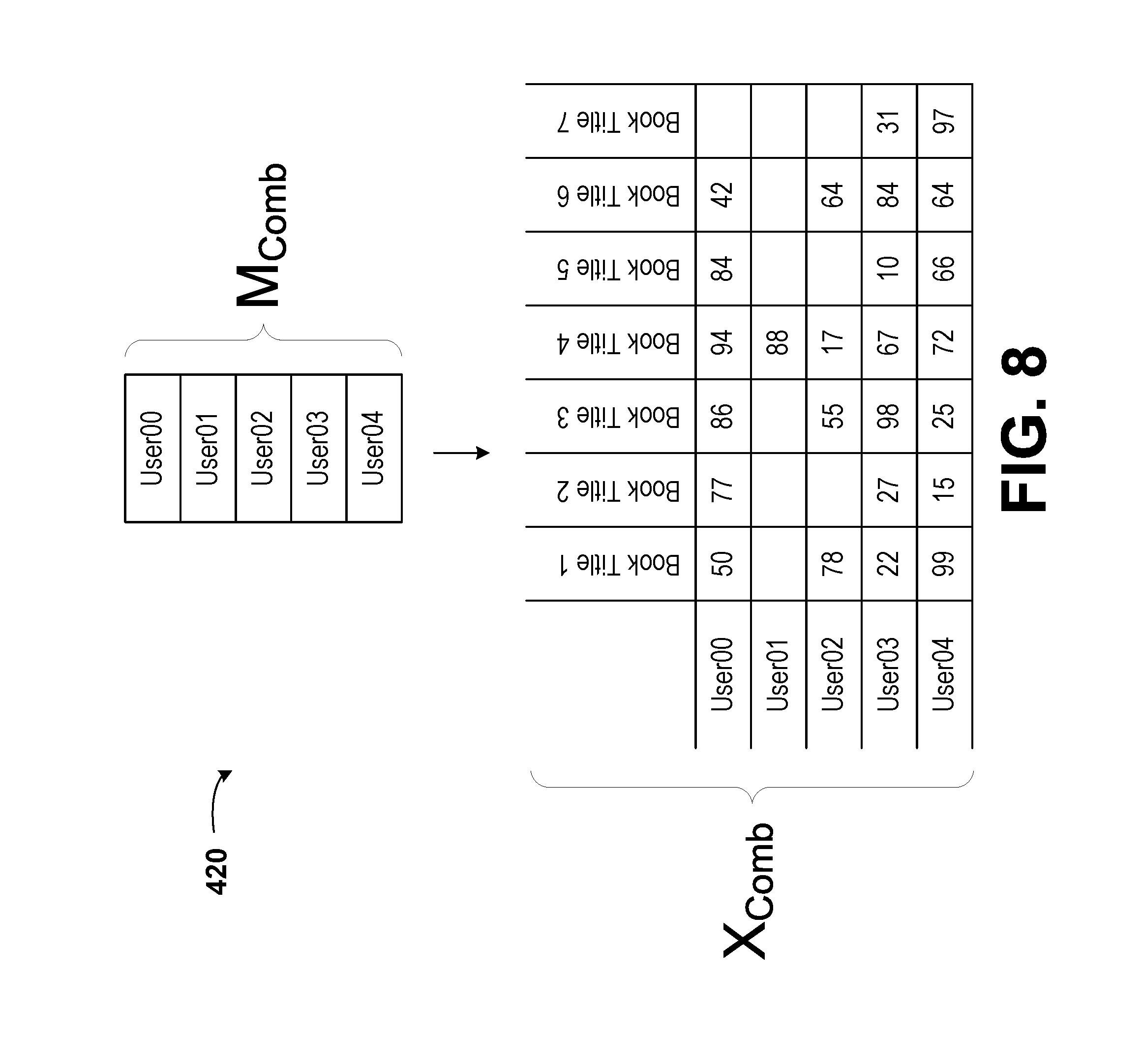
D00015
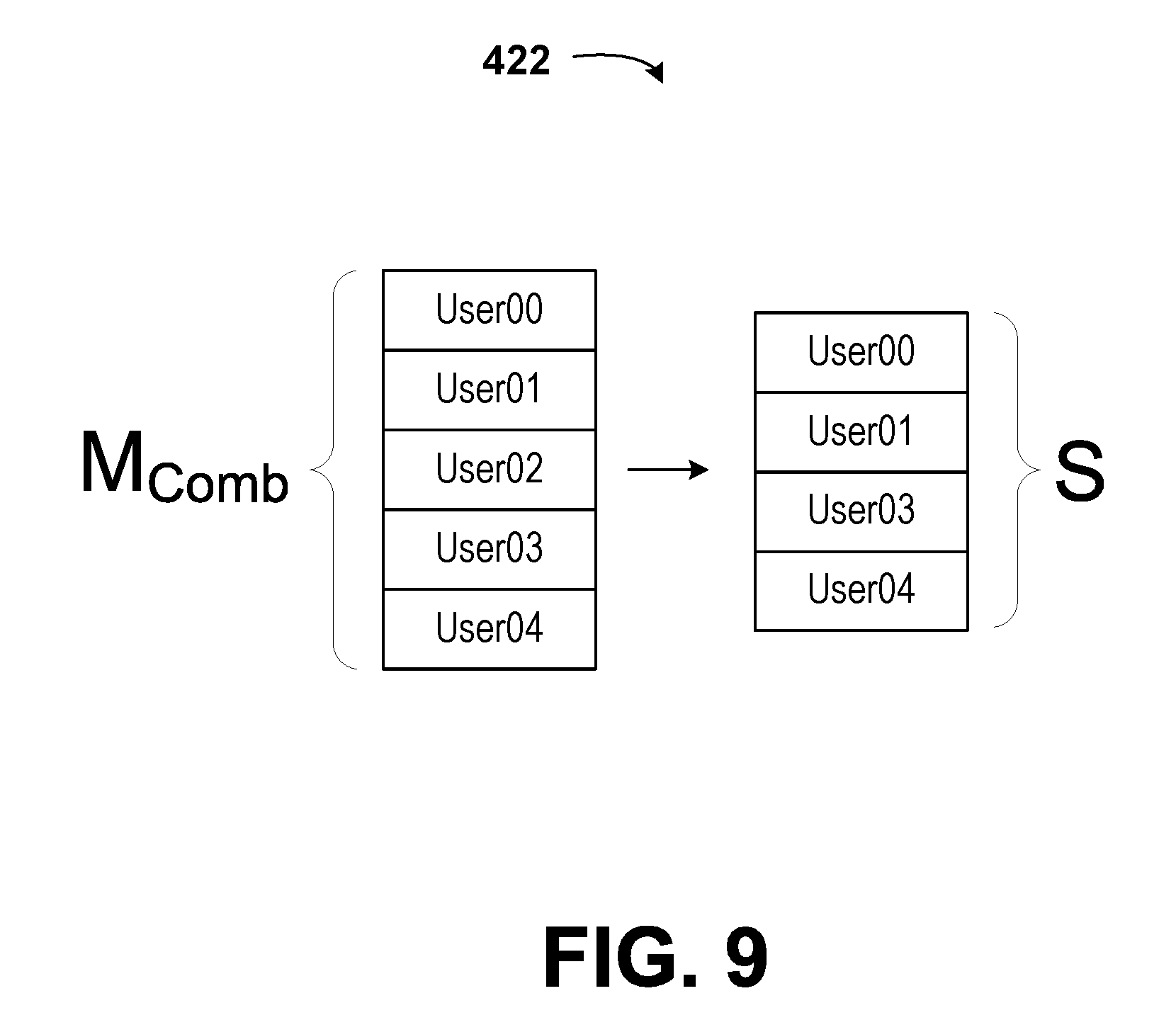
D00016
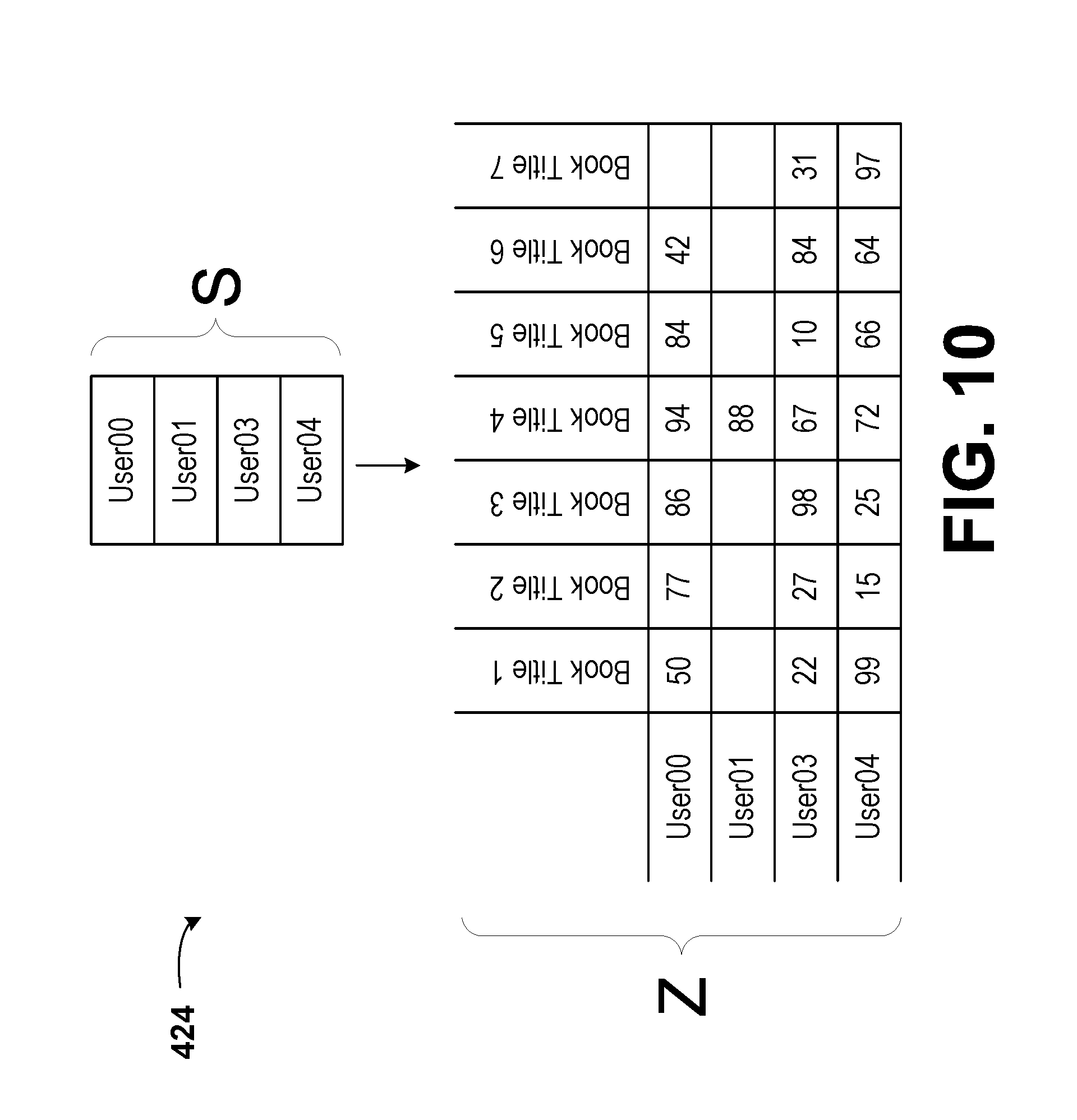
D00017
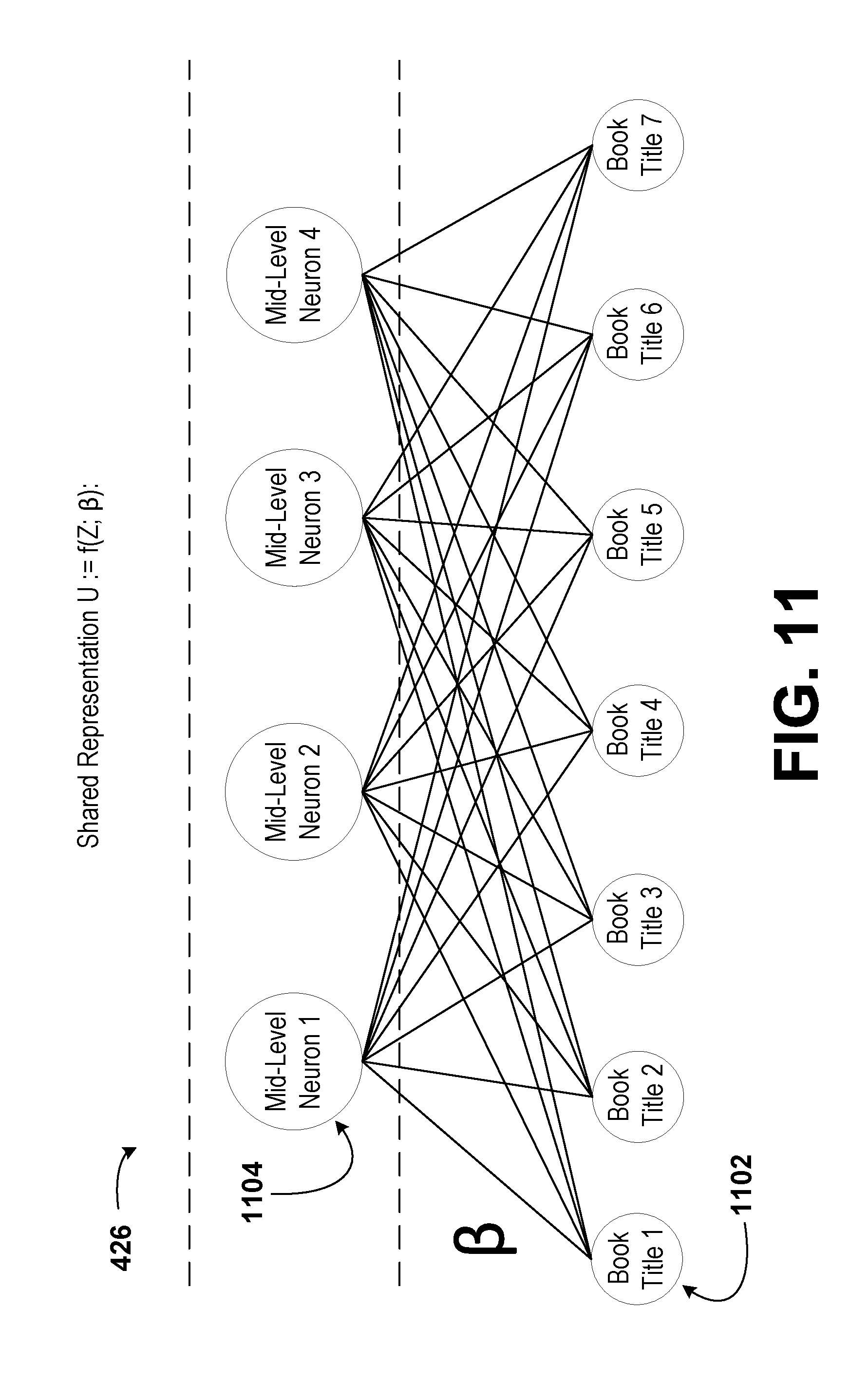
D00018

D00019

D00020
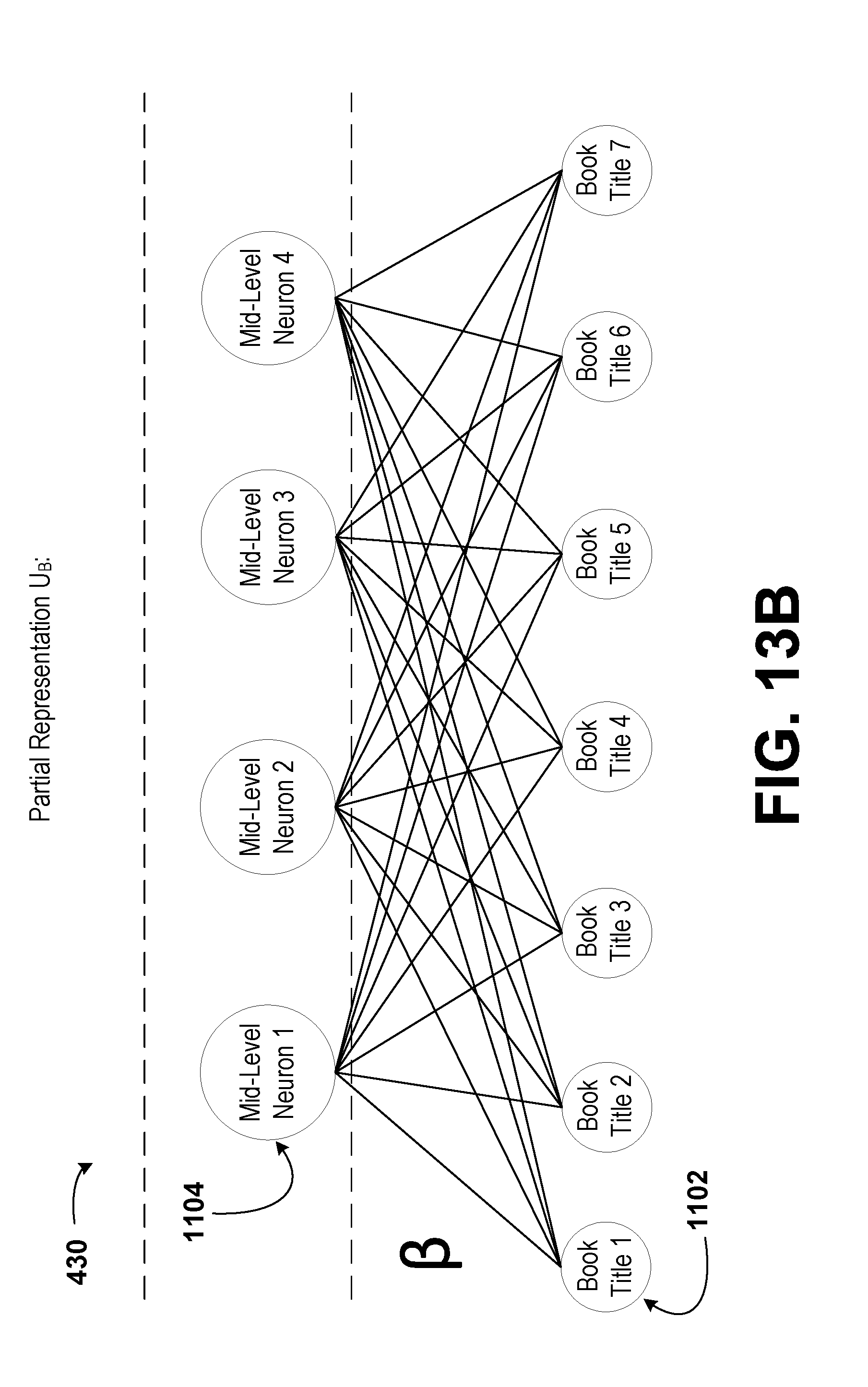
D00021
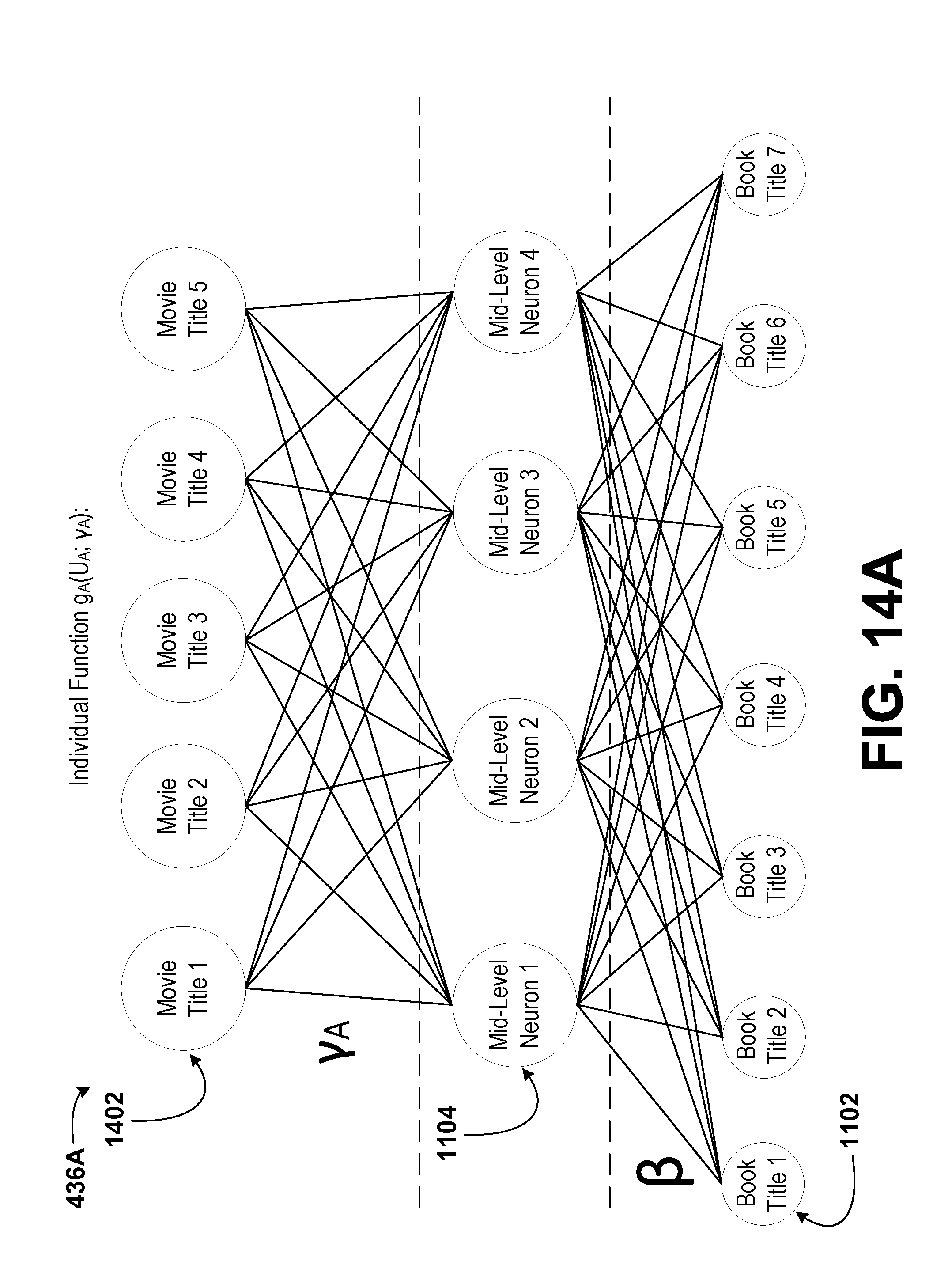
D00022
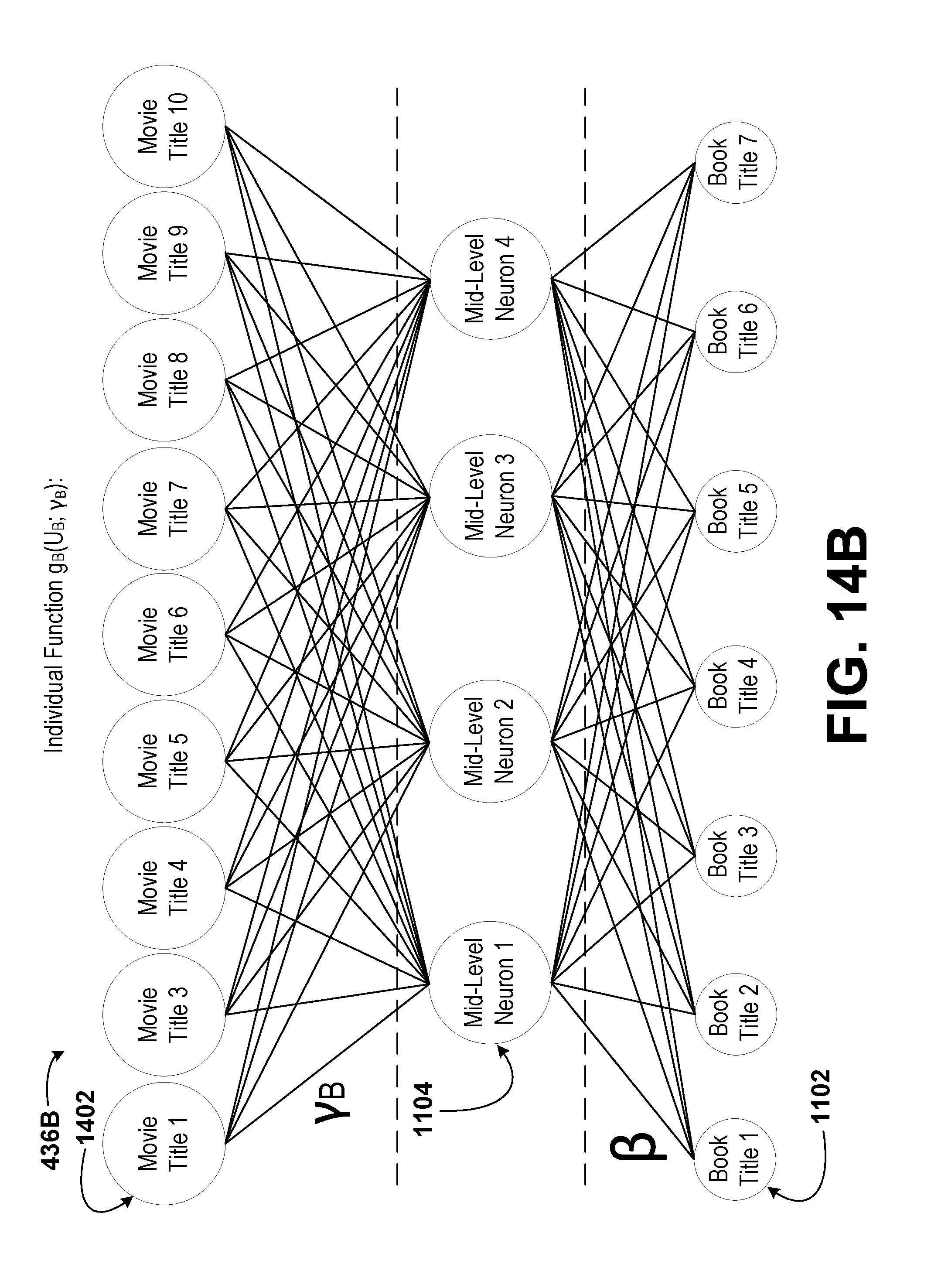
D00023

D00024

D00025

D00026
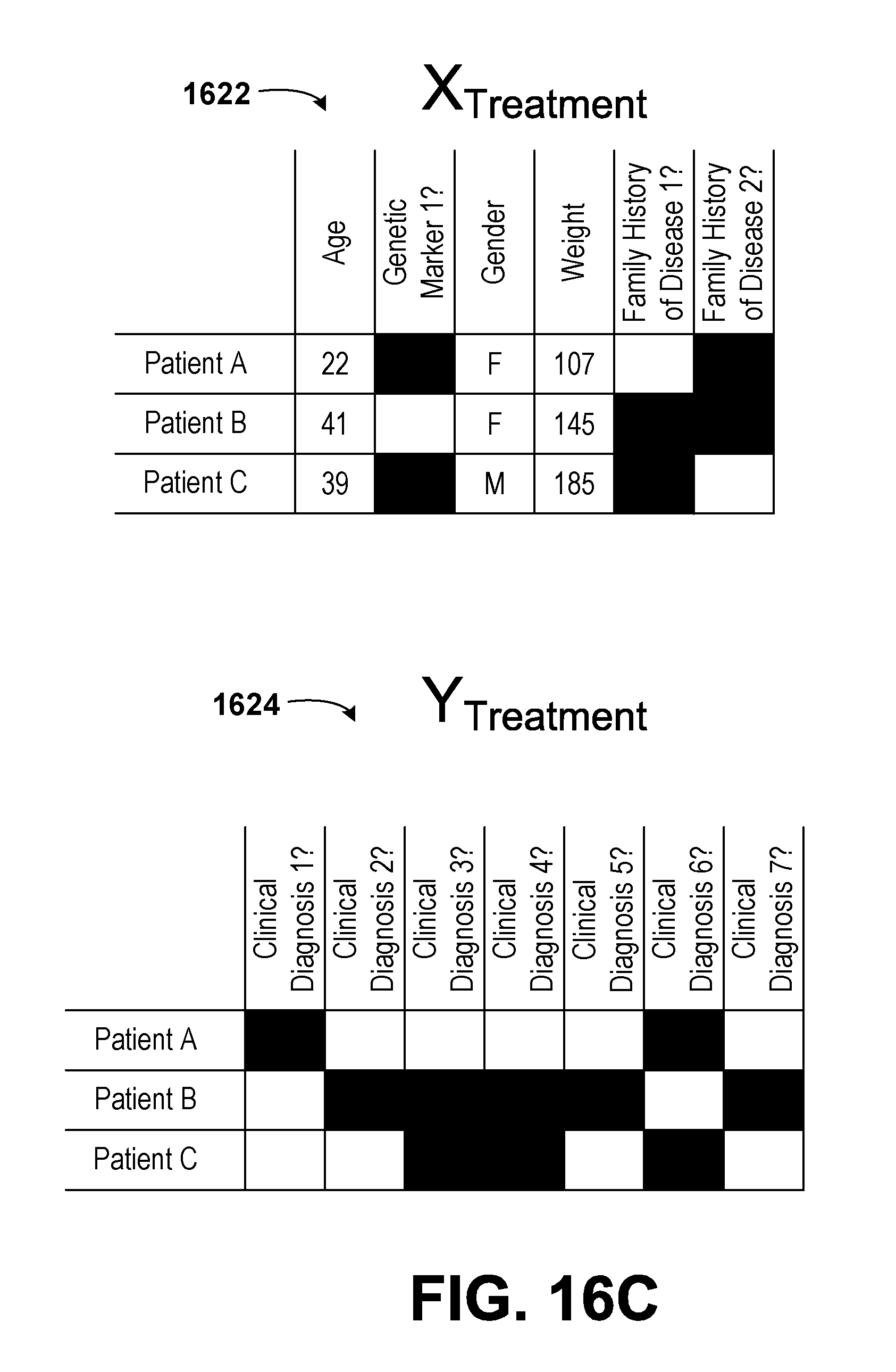
D00027

D00028
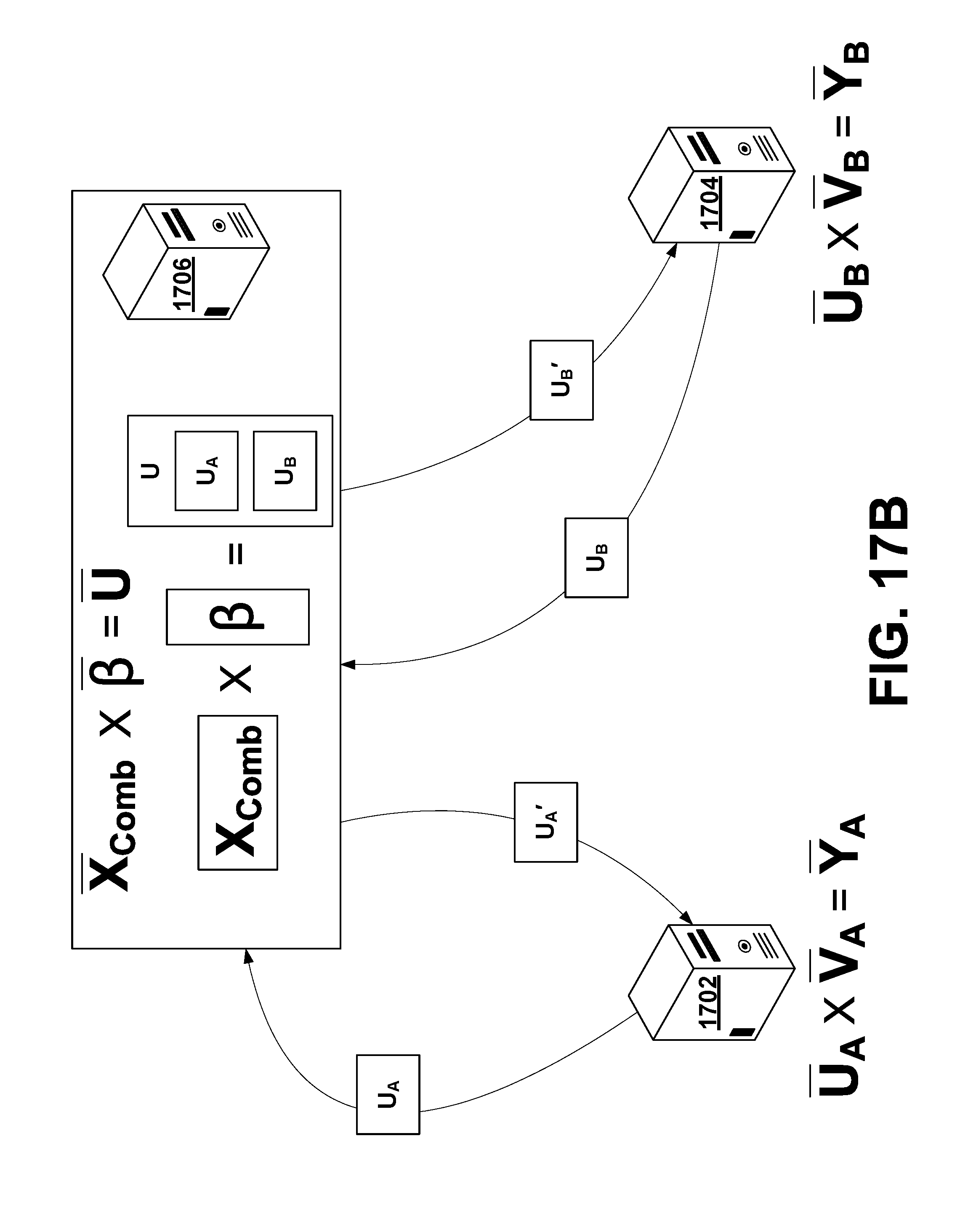
D00029
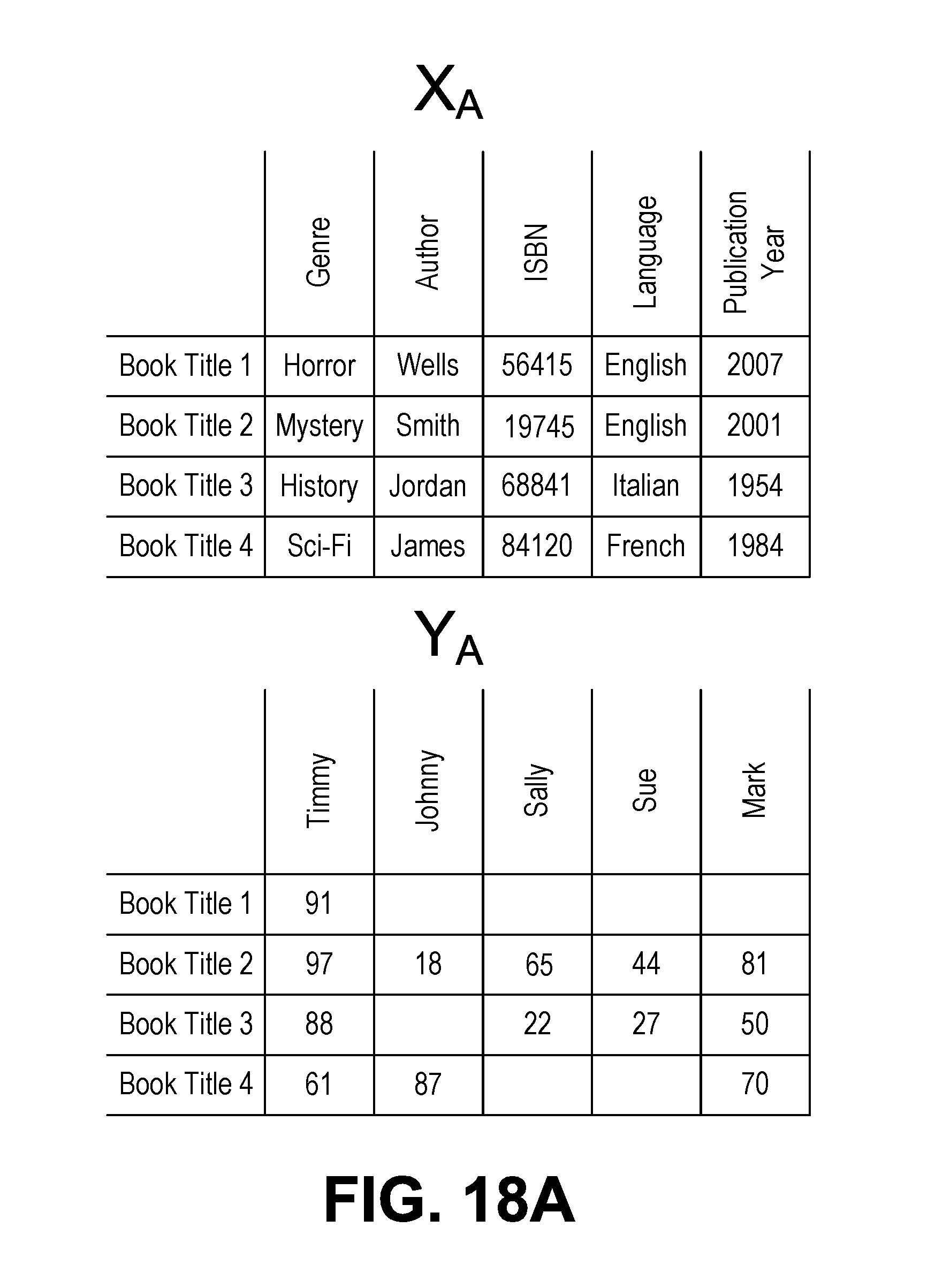
D00030
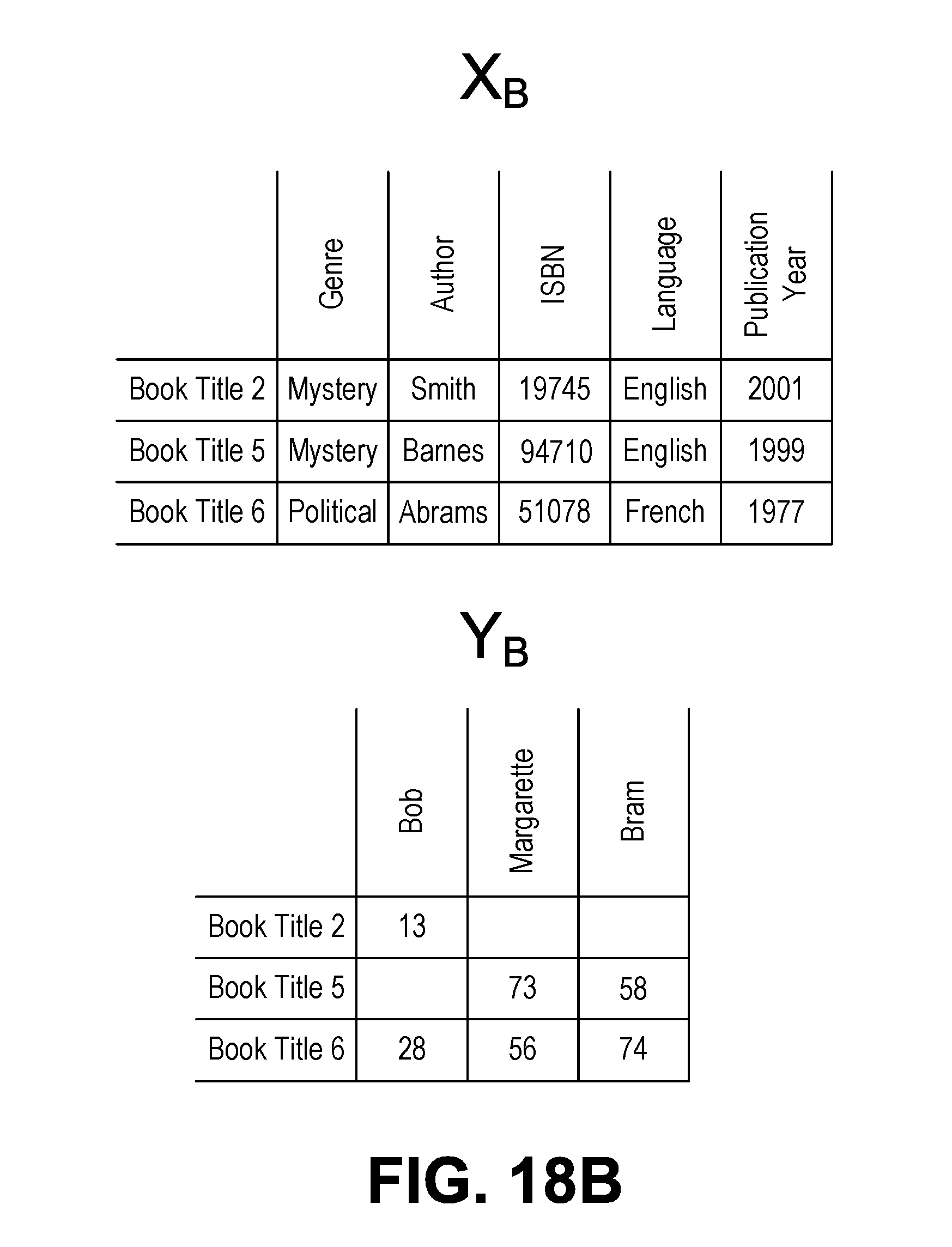
D00031
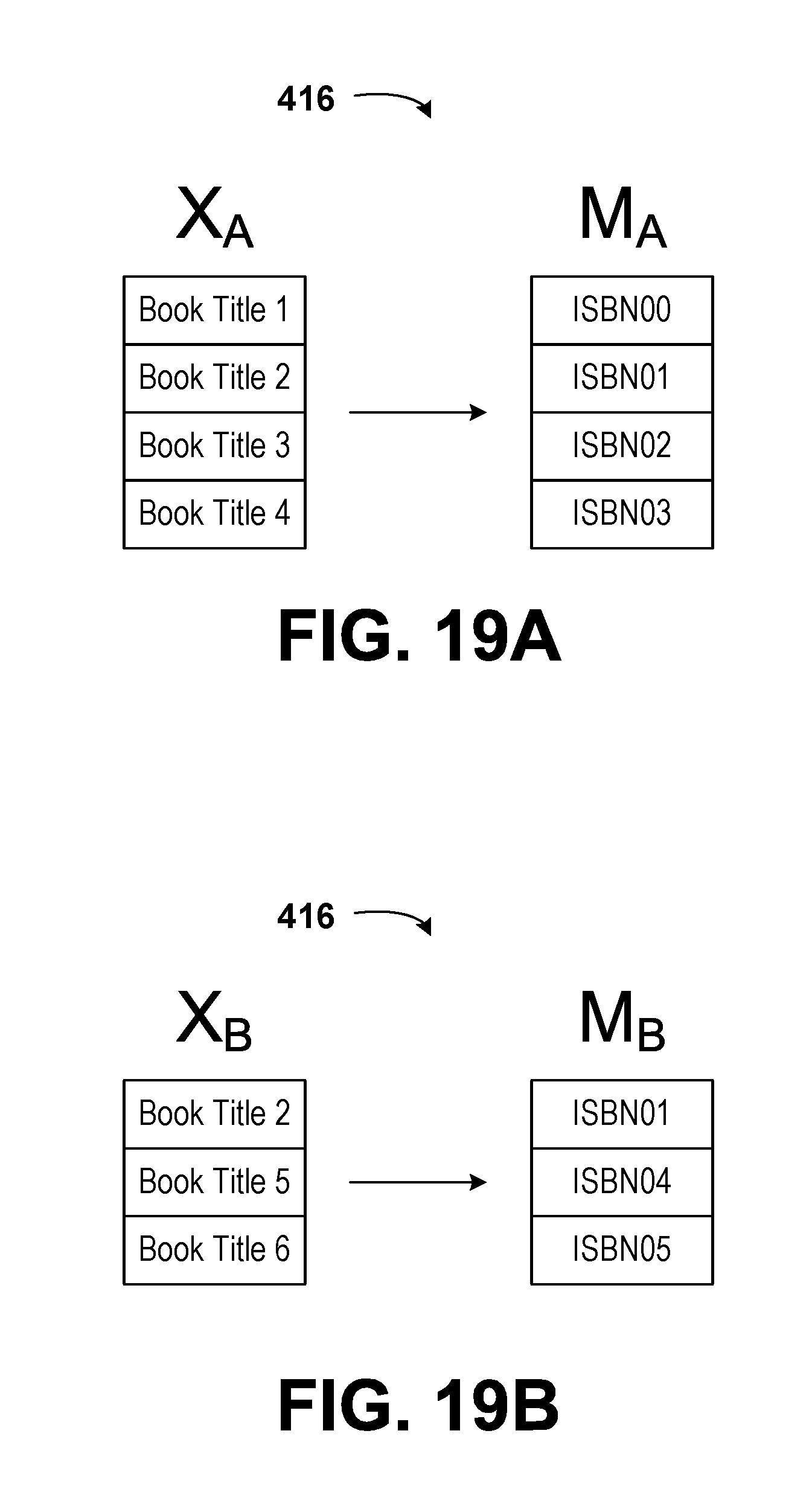
D00032

D00033
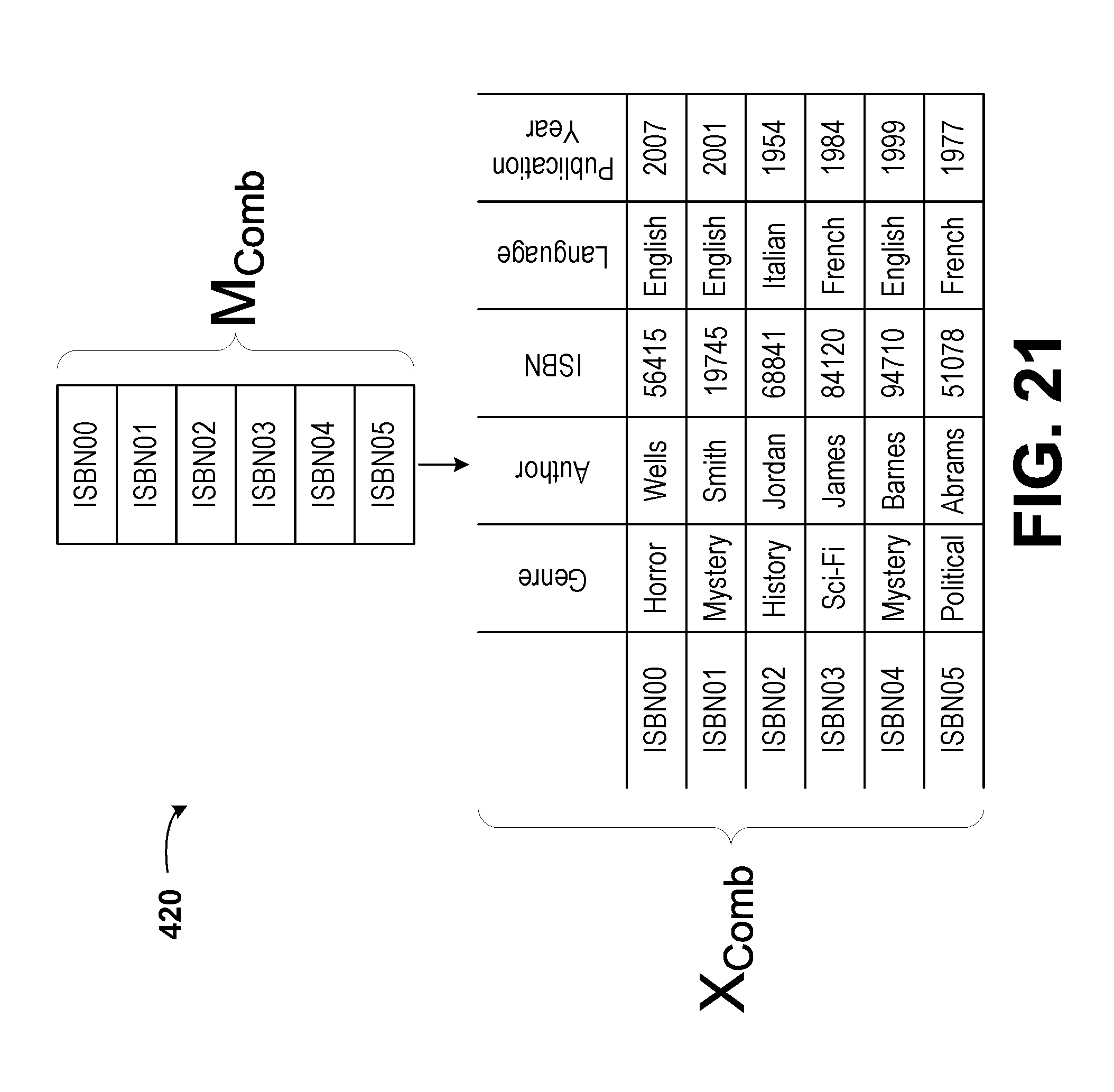
D00034
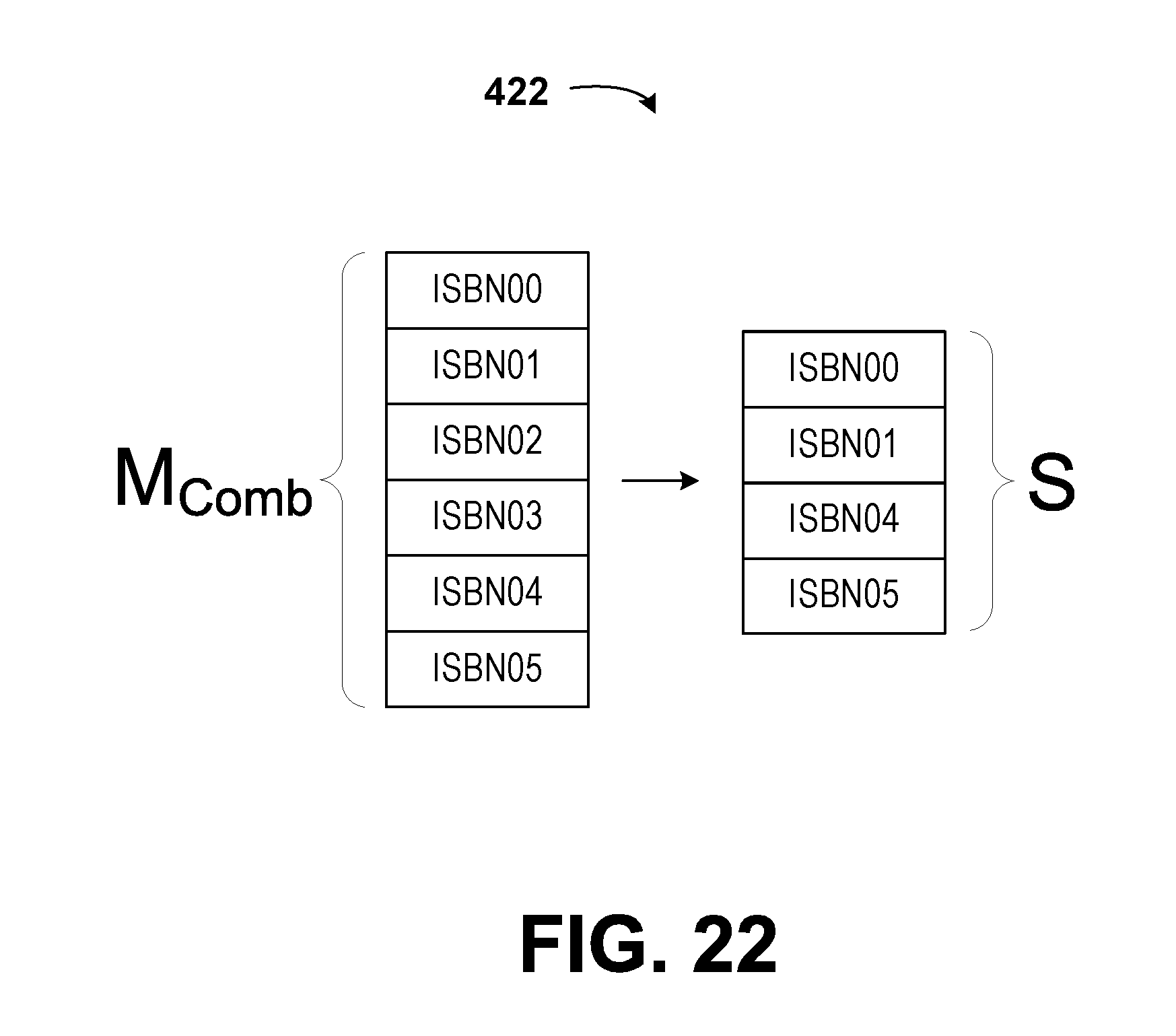
D00035
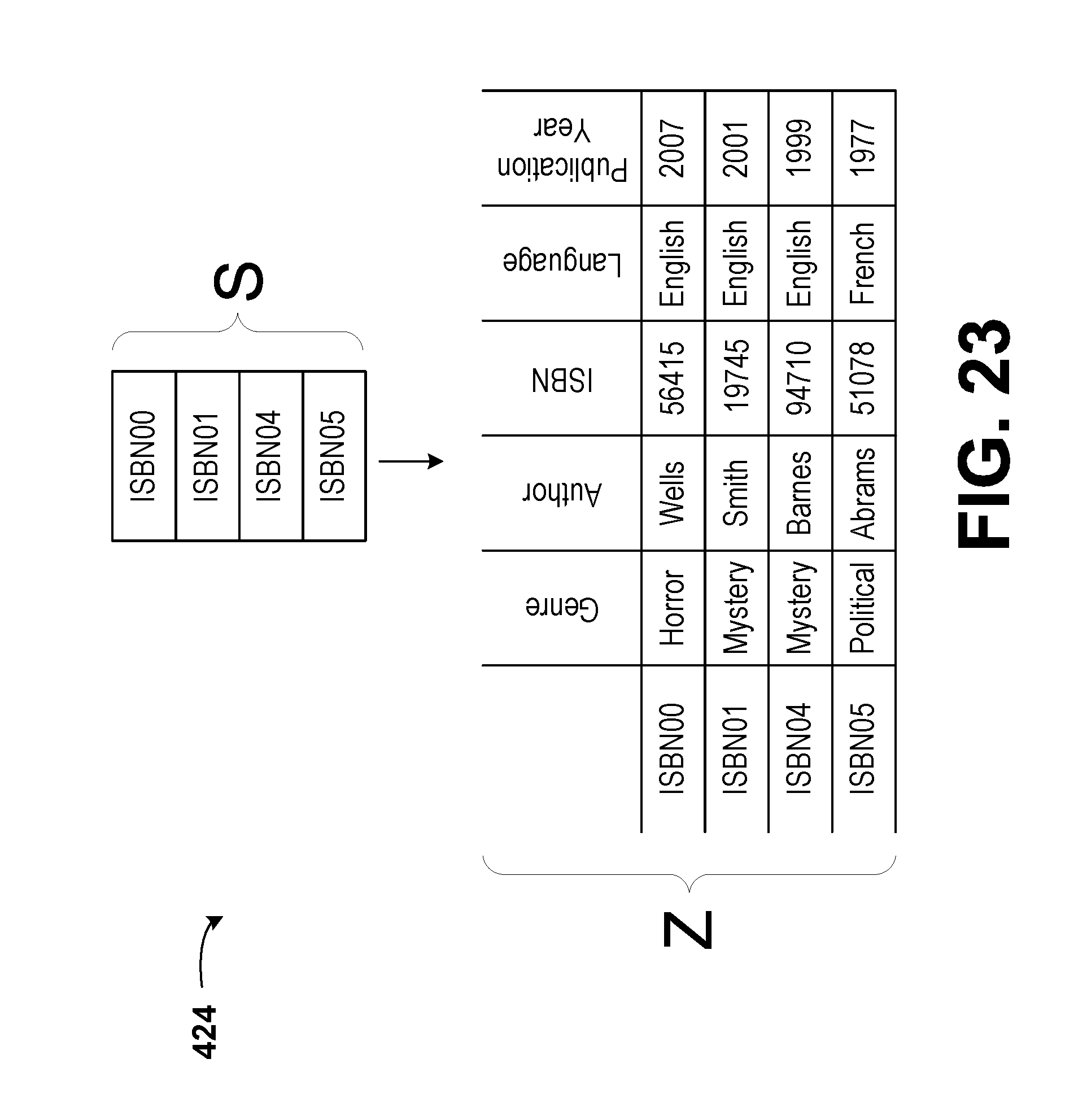
D00036
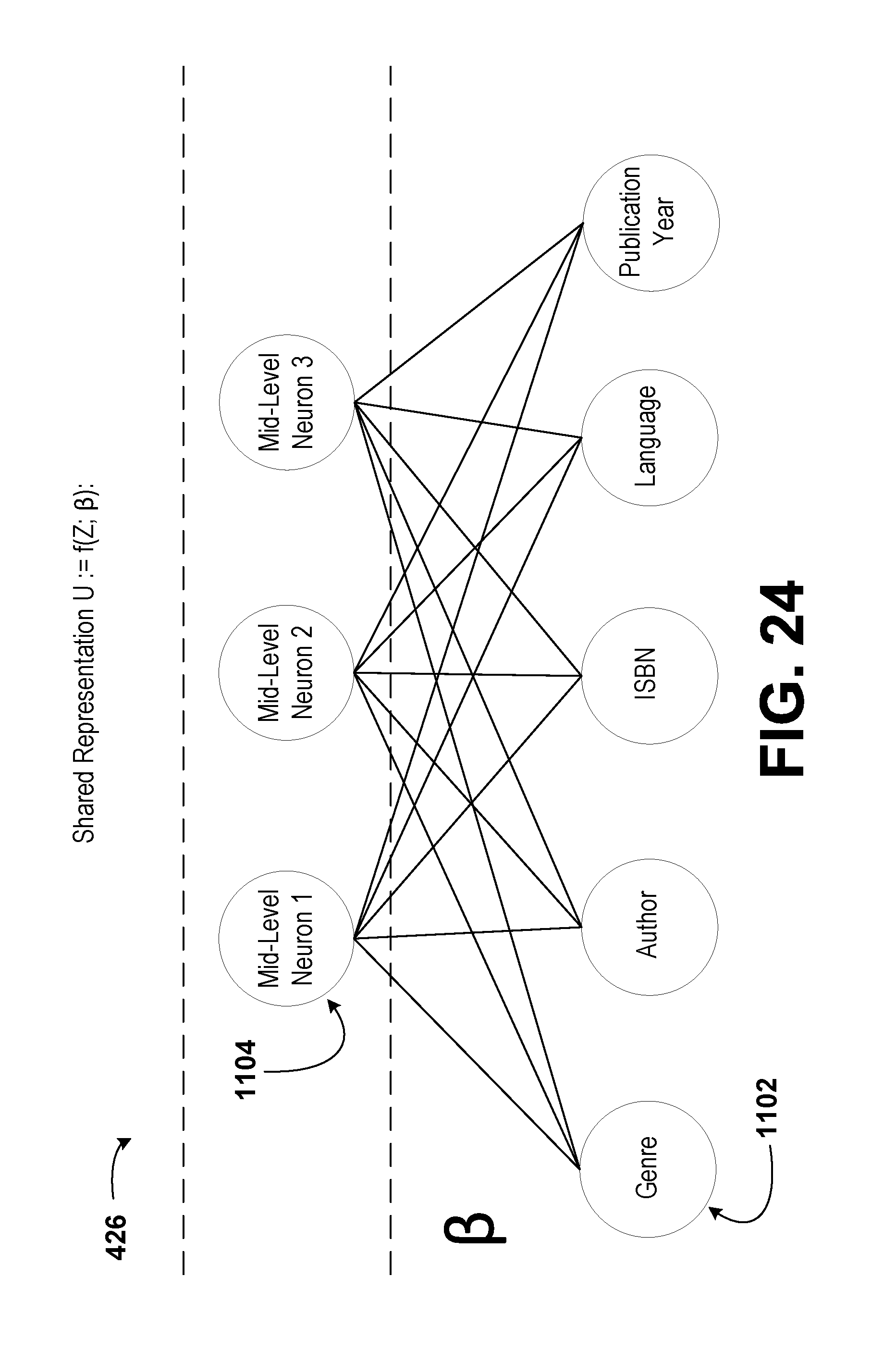
D00037
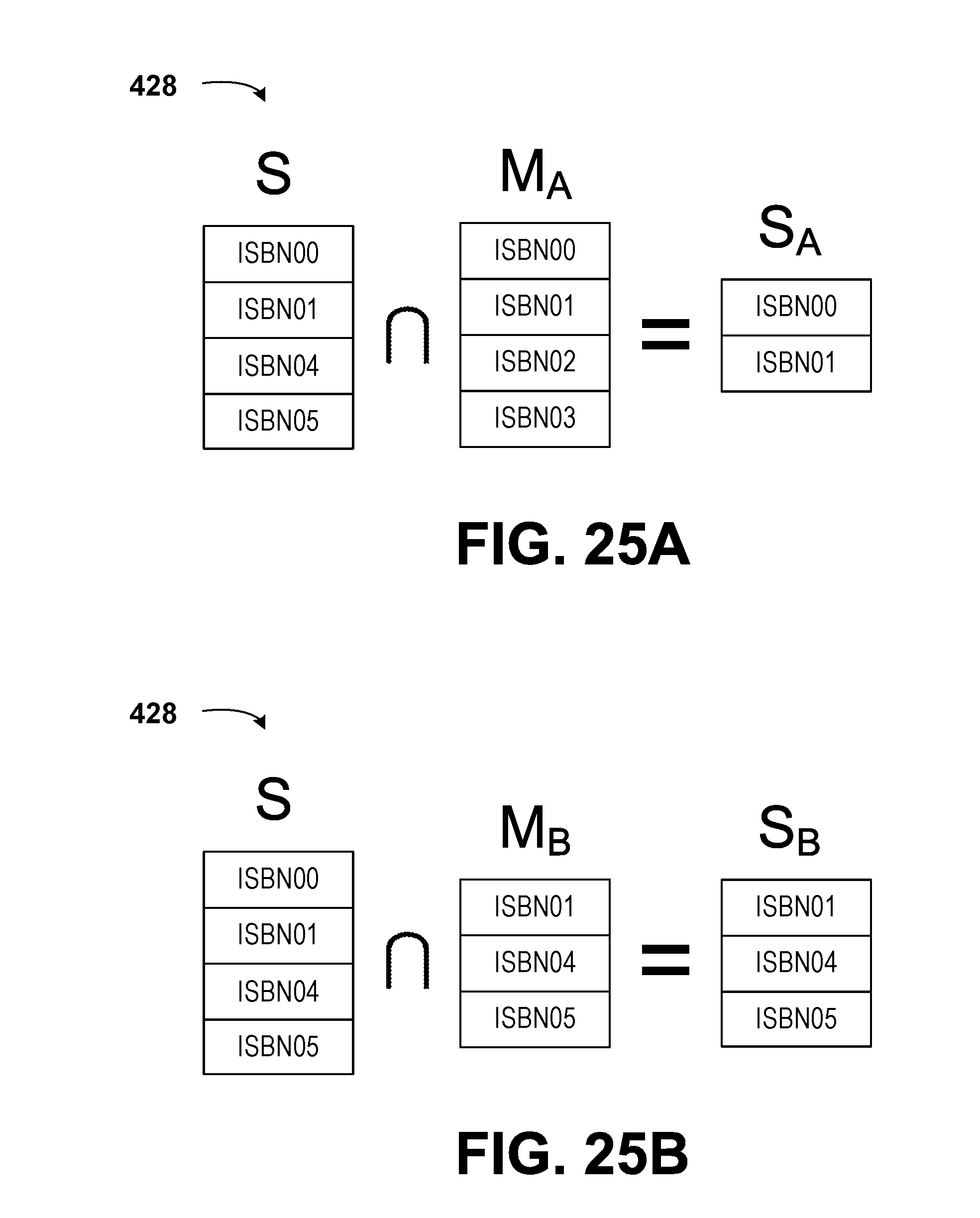
D00038
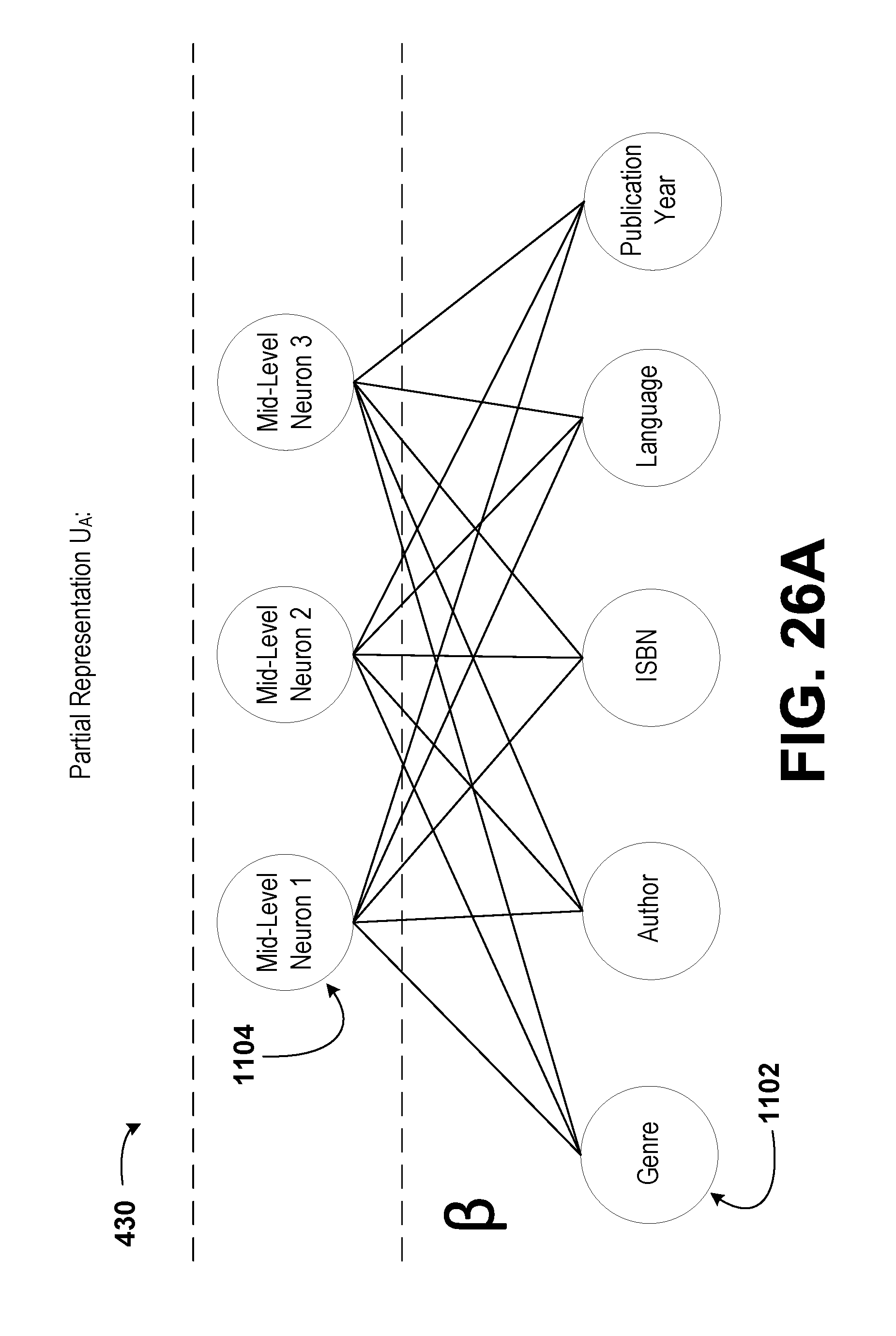
D00039

D00040

D00041
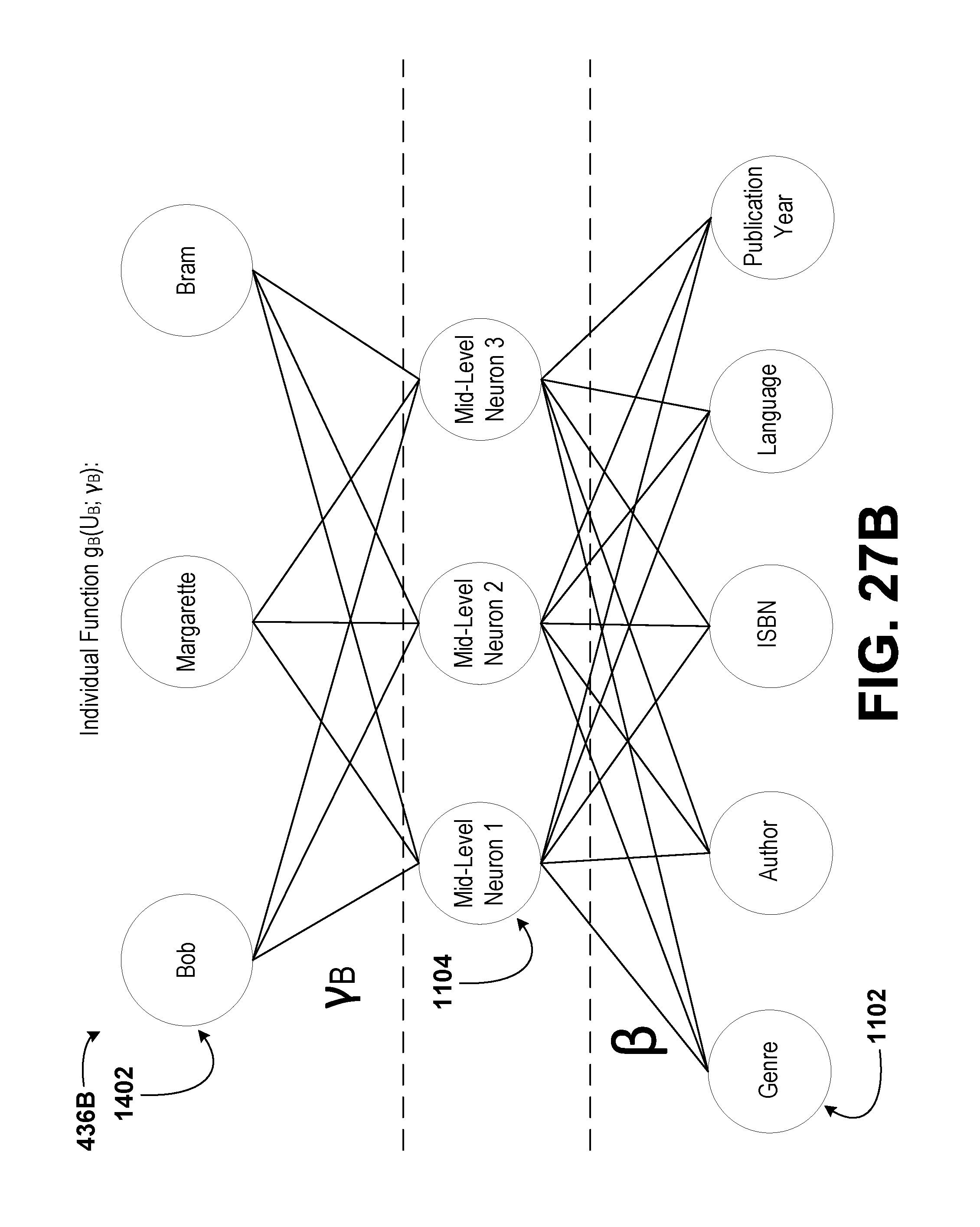

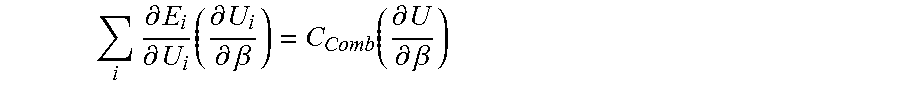
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.