Efficient Empirical Determination, Computation, And Use Of Acoustic Confusability Measures
Printz; Harry ; et al.
U.S. patent application number 16/158900 was filed with the patent office on 2019-02-14 for efficient empirical determination, computation, and use of acoustic confusability measures. The applicant listed for this patent is Promptu Systems Corporation. Invention is credited to Naren Chittar, Harry Printz.
| Application Number | 20190051294 16/158900 |
| Document ID | / |
| Family ID | 46329716 |
| Filed Date | 2019-02-14 |


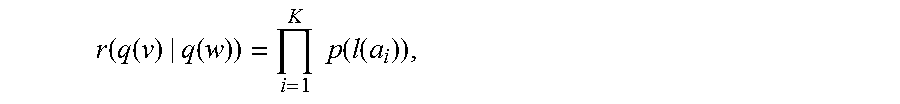
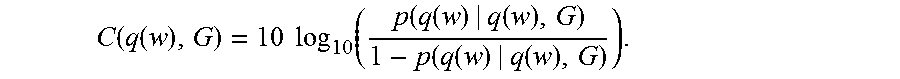
View All Diagrams
| United States Patent Application | 20190051294 |
| Kind Code | A1 |
| Printz; Harry ; et al. | February 14, 2019 |
EFFICIENT EMPIRICAL DETERMINATION, COMPUTATION, AND USE OF ACOUSTIC CONFUSABILITY MEASURES
Abstract
Efficient empirical determination, computation, and use of an acoustic confusability measure comprises: (1) an empirically derived acoustic confusability measure, comprising a means for determining the acoustic confusability between any two textual phrases in a given language, where the measure of acoustic confusability is empirically derived from examples of the application of a specific speech recognition technology, where the procedure does not require access to the internal computational models of the speech recognition technology, and does not depend upon any particular internal structure or modeling technique, and where the procedure is based upon iterative improvement from an initial estimate; (2) techniques for efficient computation of empirically derived acoustic confusability measure, comprising means for efficient application of an acoustic confusability score, allowing practical application to very large-scale problems; and (3) a method for using acoustic confusability measures to make principled choices about which specific phrases to make recognizable by a speech recognition application.
| Inventors: | Printz; Harry; (San Francisco, CA) ; Chittar; Naren; (Mountain View, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 46329716 | ||||||||||
| Appl. No.: | 16/158900 | ||||||||||
| Filed: | October 12, 2018 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15457964 | Mar 13, 2017 | 10121469 | ||
| 16158900 | ||||
| 14574314 | Dec 17, 2014 | 9626965 | ||
| 15457964 | ||||
| 11932122 | Oct 31, 2007 | 8959019 | ||
| 14574314 | ||||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G10L 15/187 20130101; G06F 16/95 20190101; G10L 15/142 20130101; G10L 15/18 20130101; G06F 16/9535 20190101; G10L 15/22 20130101; G06Q 30/02 20130101; G10L 2015/025 20130101; G10L 15/02 20130101; G10L 17/26 20130101 |
| International Class: | G10L 15/187 20060101 G10L015/187; G10L 15/14 20060101 G10L015/14 |
Claims
1. A method for generating an acoustic confusability measure, comprising: recognizing, via a speech recognition system, at least one utterance within a corpus of utterances, said corpus comprising utterances with corresponding reliable transcriptions, each reliable transcription having at least one associated reliable phoneme sequence, to yield at least one recognized word sequence, each said recognized word sequence having at least one associated recognized phoneme sequence; and generating an empirically derived acoustic confusability measure from analysis of pairs of phoneme sequences, each said pair of phoneme sequences comprising one said associated recognized phoneme sequence and one said associated reliable phoneme sequence, wherein the constituents of each said pair of phoneme sequences are associated with the same utterance within said corpus of utterances, said empirically derived acoustic confusability measure comprising a family of probability models over a phoneme alphabet.
2. The method of claim 1, wherein said family of probability models over a phoneme alphabet is a family of conditional probability models over a phoneme alphabet.
3. The method of claim 1, wherein said phoneme alphabet includes the empty phoneme.
4. A computer-implemented method, comprising: empirically deriving an acoustic confusability measure that determines acoustic confusability between at least any two textual phrases in a given language; wherein said acoustic confusability measure is empirically derived from the output of processing example utterances by a specific speech recognition application and iterating from an initial estimate of said acoustic confusability measure to improve said measure; and using said acoustic confusability measure to selectively limit which specific phrases to make recognizable by revised version of said speech recognition application.
5. A method for computing an empirically derived acoustic confusability of two phrases, comprising the steps of: determining a desired probability model family ; using to compute acoustic confusability of two arbitrary phrases v and w by: computing a raw phrase acoustic confusability measure, which is a measure of the acoustic similarity of phrases v and w; and computing a grammar-relative confusion probability measure, which is an estimate of the probability that a grammar-constrained recognizer returns the phrase v as a decoding, when a true phrase is w.
6. The method of claim 5, said step of computing a raw phrase acoustic confusability measure further comprising the steps of: given pronunciations q(v) and q(w) of phrases v and w, computing the raw pronunciation acoustic confusability by: defining decoding costs for each phoneme; constructing a lattice L=q(v).times.q(w), and labeling it with said phoneme decoding costs, depending upon the phonemes of q(v) and q(w); finding a minimum cost path A=a.sub.1, a.sub.2, . . . , a.sub.K, from a source node to a terminal node of L; computing a cost of a minimum cost path A, as a sum S of the decoding costs for each arc a.di-elect cons.A; computing a raw pronunciation acoustic confusability measure of q(v) and q(w) as the quantity exp(-S); computing said raw phrase confusability measure from the raw pronunciation acoustic confusability measure of q(v) and q(w).
7. The method of claim 6, wherein the step of computing a raw phrase acoustic confusability measure from the raw pronunciation acoustic confusability measure of q(v) and q(w) proceeds by any one of the following methods: worst case, summed; worst case, individual pronunciations; most common; average case; random; and a combination of any of the worst case, summed, worst case, individual pronunciations, most common, average case, and random methods into additional hybrid variants.
8. The method of claim 5, said step of computing a grammar-relative pronunciation confusion probability comprising the steps of: letting L(G) be a set of all phrases admissible by a grammar G, and letting Q(L(G)) be a set of all pronunciations of all such phrases; letting two pronunciations q(v), q(w).di-elect cons.Q(L(G)) be given; estimating a probability that an utterance corresponding to a pronunciation q(w) is decoded by a recognizer R.sub.G as q(v), as follows: computing a normalizer of q(w) relative to G, written Z(q(w), G), as Z(q(w),G)=.SIGMA.r(q(x)|q(w)), where the sum extends over all q(x).di-elect cons.Q(L(G)), excluding those q(x) where q(x)=q(w) with x.noteq.w, and where r(q(x)|q(w)) is a raw pronunciation acoustic confusability measure of q(x) and q(w); and setting a probability p(q(v)|q(w), G)=r(q(v)|q(w))/Z(q(w), G)
Description
CROSS REFERENCE TO RELATED APPLICATIONS
[0001] This application is a continuation of U.S. patent application Ser. No. 15/457,964, filed Mar. 13, 2017, which is a divisional of U.S. patent application Ser. No. 14/574,314, filed Dec. 17, 2014, now U.S. Pat. No. 9,626,965, issued Apr. 18, 2017, which is a divisional application of U.S. patent application Ser. No. 11/932,122, filed Oct. 31, 2007, now U.S. Pat. No. 8,959,019, issued Feb. 17, 2015, each of which are incorporated herein in their entirety by this reference thereto.
BACKGROUND OF THE INVENTION
Technical Field
[0002] The invention relates to speech recognition. More particularly, the invention relates to efficient empirical determination, computation, and use of an acoustic confusability measure.
Description of the Prior Art
[0003] In United States Patent Application Publication No. 20020032549, it is stated:
In the operation of a speech recognition system, some acoustic information is acquired, and the system determines a word or word sequence that corresponds to the acoustic information. The acoustic information is generally some representation of a speech signal, such as the variations in voltage generated by a microphone. The output of the system is the best guess that the system has of the text corresponding to the given utterance, according to its principles of operation.
[0004] The principles applied to determine the best guess are those of probability theory. Specifically, the system produces as output the most likely word or word sequence corresponding to the given acoustic signal. Here, "most likely" is determined relative to two probability models embedded in the system: an acoustic model and a language model. Thus, if A represents the acoustic information acquired by the system, and W represents a guess at the word sequence corresponding to this acoustic information, then the system's best guess W* at the true word sequence is given by the solution of the following equation:
W*=argmax.sub.WP(A|W)P(W).
[0005] Here P(A|W) is a number determined by the acoustic model for the system, and P(W) is a number determined by the language model for the system. A general discussion of the nature of acoustic models and language models can be found in "Statistical Methods for Speech Recognition," Jelinek, The MIT Press, Cambridge, Mass. 1999, the disclosure of which is incorporated herein by reference. This general approach to speech recognition is discussed in the paper by Bahl et al., "A Maximum Likelihood Approach to Continuous Speech Recognition," IEEE Transactions on Pattern Analysis and Machine Intelligence, Volume PAMI-5, pp. 179-190, March 1983, the disclosure of which is incorporated herein by reference.
[0006] The acoustic and language models play a central role in the operation of a speech recognition system: the higher the quality of each model, the more accurate the recognition system. A frequently-used measure of quality of a language model is a statistic known as the perplexity, as discussed in section 8.3 of Jelinek. For clarity, this statistic will hereafter be referred to as "lexical perplexity." It is a general operating assumption within the field that the lower the value of the lexical perplexity, on a given fixed test corpus of words, the better the quality of the language model.
[0007] However, experience shows that lexical perplexity can decrease while errors in decoding words increase. For instance, see Clarkson et al., "The Applicability of Adaptive Language Modeling for the Broadcast News Task," Proceedings of the Fifth International Conference on Spoken Language Processing, Sydney, Australia, November 1998, the disclosure of which is incorporated herein by reference. Thus, lexical perplexity is actually a poor indicator of language model effectiveness.
[0008] Nevertheless, lexical perplexity continues to be used as the objective function for the training of language models, when such models are determined by varying the values of sets of adjustable parameters. What is needed is a better statistic for measuring the quality of language models, and hence for use as the objective function during training.
[0009] United States Patent Application Publication No. 20020032549 teaches an invention that attempts to solve these problems by:
Providing two statistics that are better than lexical perplexity for determining the quality of language models. These statistics, called acoustic perplexity and the synthetic acoustic word error rate (SAWER), in turn depend upon methods for computing the acoustic confusability of words. Some methods and apparatuses disclosed herein substitute models of acoustic data in place of real acoustic data in order to determine confusability.
[0010] In a first aspect of the invention taught in United States Patent Application Publication No. 20020032549, two word pronunciations l(w) and l(x) are chosen from all pronunciations of all words in fixed vocabulary V of the speech recognition system. It is the confusability of these pronunciations that is desired. To do so, an evaluation model (also called valuation model) of l(x) is created, a synthesizer model of l(x) is created, and a matrix is determined from the evaluation and synthesizer models. Each of the evaluation and synthesizer models is preferably a hidden Markov model. The synthesizer model preferably replaces real acoustic data. Once the matrix is determined, a confusability calculation may be performed. This confusability calculation is preferably performed by reducing an infinite series of multiplications and additions to a finite matrix inversion calculation. In this manner, an exact confusability calculation may be determined for the evaluation and synthesizer models.
[0011] In additional aspects of the invention taught in United States Patent Application Publication No. 20020032549, different methods are used to determine certain numerical quantities, defined below, called synthetic likelihoods. In other aspects of the invention, (i) the confusability may be normalized and smoothed to better deal with very small probabilities and the sharpness of the distribution, and (ii) methods are disclosed that increase the speed of performing the matrix inversion and the confusability calculation. Moreover, a method for caching and reusing computations for similar words is disclosed.
[0012] Such teachings are yet limited and subject to improvement.
SUMMARY OF THE INVENTION
[0013] There are three related elements to the invention herein:
Empirically Derived Acoustic Confusability Measures
[0014] The first element comprises a means for determining the acoustic confusability of any two textual phrases in a given language. Some specific advantages of the means presented here are:
[0015] Empirically Derived. The measure of acoustic confusability is empirically derived from examples of the application of a specific speech recognition technology. Thus, the confusability scores assigned by the measure may be expected to reflect the actual performance of a deployed instance of the technology, in a particular application.
[0016] Depends Only on Recognizer Output. The procedure described herein does not require access to the internal computational models of the underlying speech recognition technology, and does not depend upon any particular internal structure or modeling technique, such as Hidden Markov Models (HMMs). Only the output of the speech recognition system, comprising the sequence of decoded phonemes, is needed.
[0017] Iteratively Trained. The procedure described is based upon iterative improvement from an initial estimate, and therefore may be expected to be superior to any a priori human assignment of phoneme confusion scores, or to a method that makes only a single, initial estimate of phoneme confusion scores, without iterative improvement.
Techniques for Efficient Computation of Empirically Derived Acoustic Confusability Measures
[0018] The second element comprises computational techniques for efficiently applying the acoustic confusability scoring mechanism. Previous inventions have alluded to the use of acoustic confusability measures, but notably do not discuss practical aspects of applying them. In any real-world practical scheme, it is often required to estimate the mutual acoustic confusability of tens of thousands of distinct phrases. Without efficient means of computing the measure, such computations rapidly become impractical. In this patent, we teach means for efficient application of our acoustic confusability measure, allowing practical application to very large-scale problems.
Method for Using Acoustic Confusability Measures
[0019] The third element comprises a method for using acoustic confusability measures, derived by whatever means (thus, not limited to the measure disclosed here), to make principled choices about which specific phrases to make recognizable by a speech recognition application.
BRIEF DESCRIPTION OF THE DRAWINGS
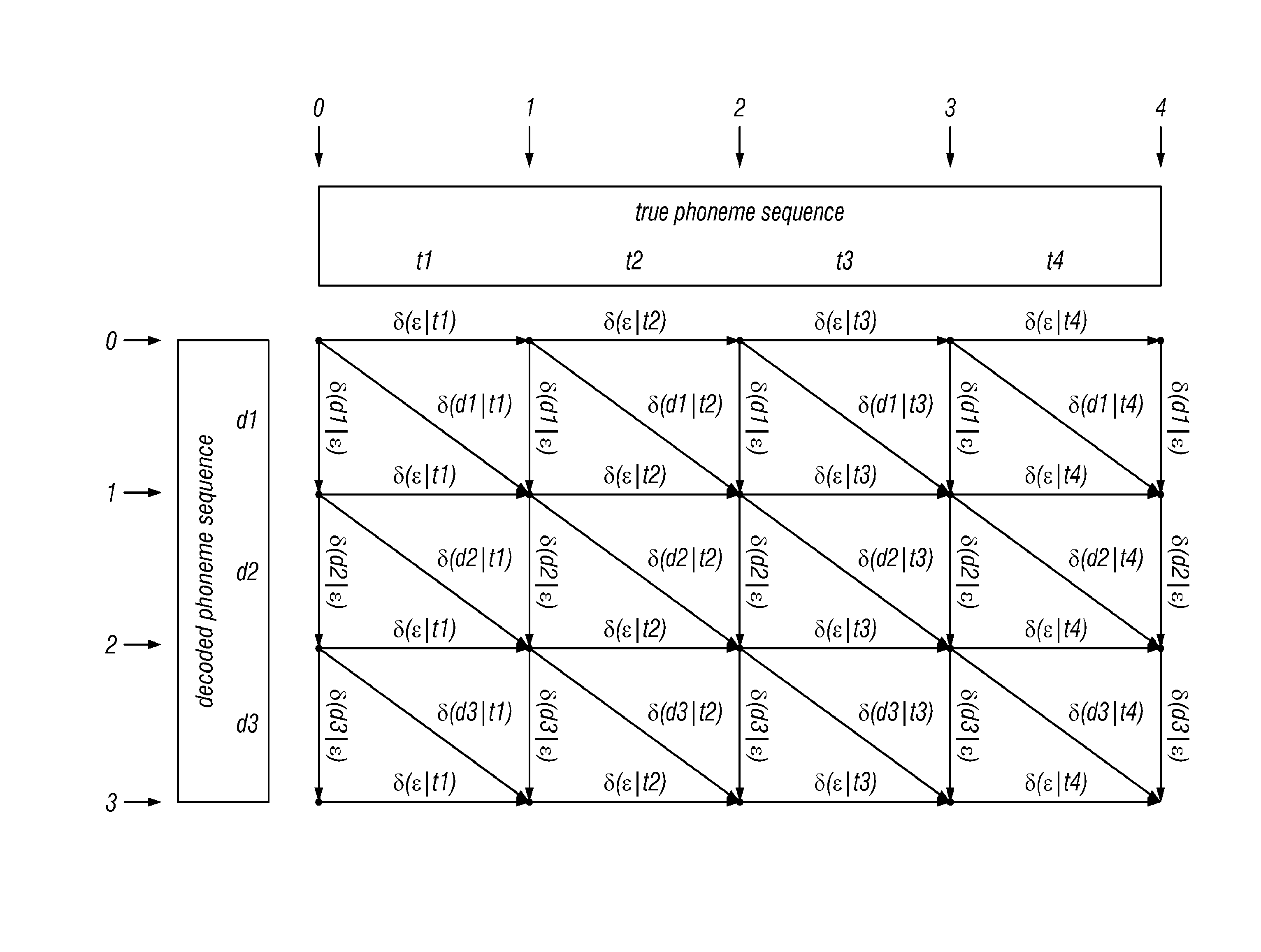
[0020] FIG. 1 shows a basic lattice according to the invention, where the numbers along the left are the row coordinates, the numbers along the top are column coordinates, and the small dots are the nodes of the lattice. The coordinates are used to identify the nodes of the lattice, in the form (row coordinate, column coordinate). Thus, the coordinates of the node in the upper-right corner are (0, 4);
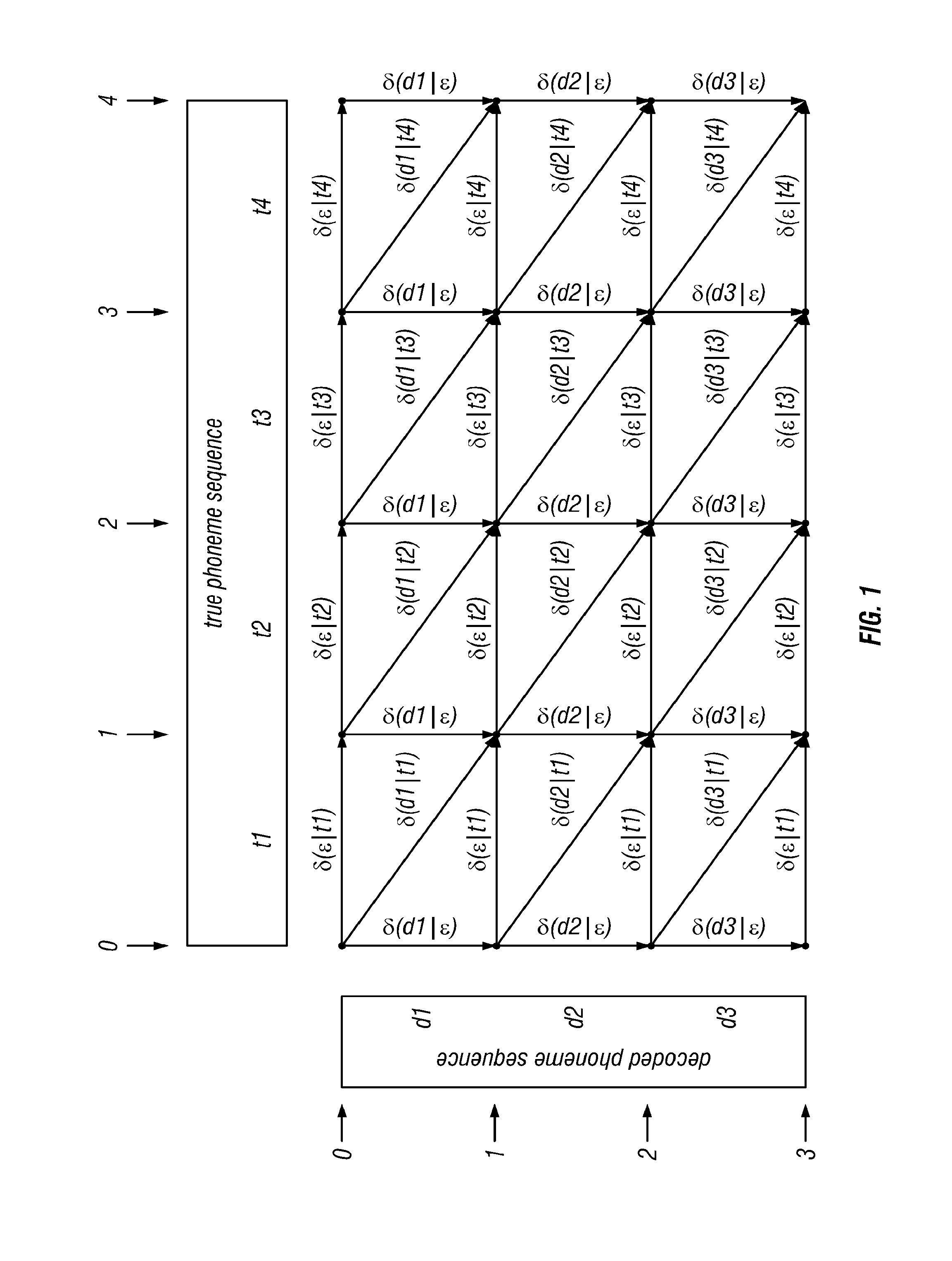
[0021] FIG. 2 shows a basic lattice with actual phonemes according to the invention, where the purely symbolic phonemes d.sub.1 etc. have been replaced by actual phonemes from the SAMPA phoneme alphabet for US English. The true phoneme sequence shown is a pronunciation of the English word "hazy," the decoded phoneme sequence is a pronunciation of the word "raise;"
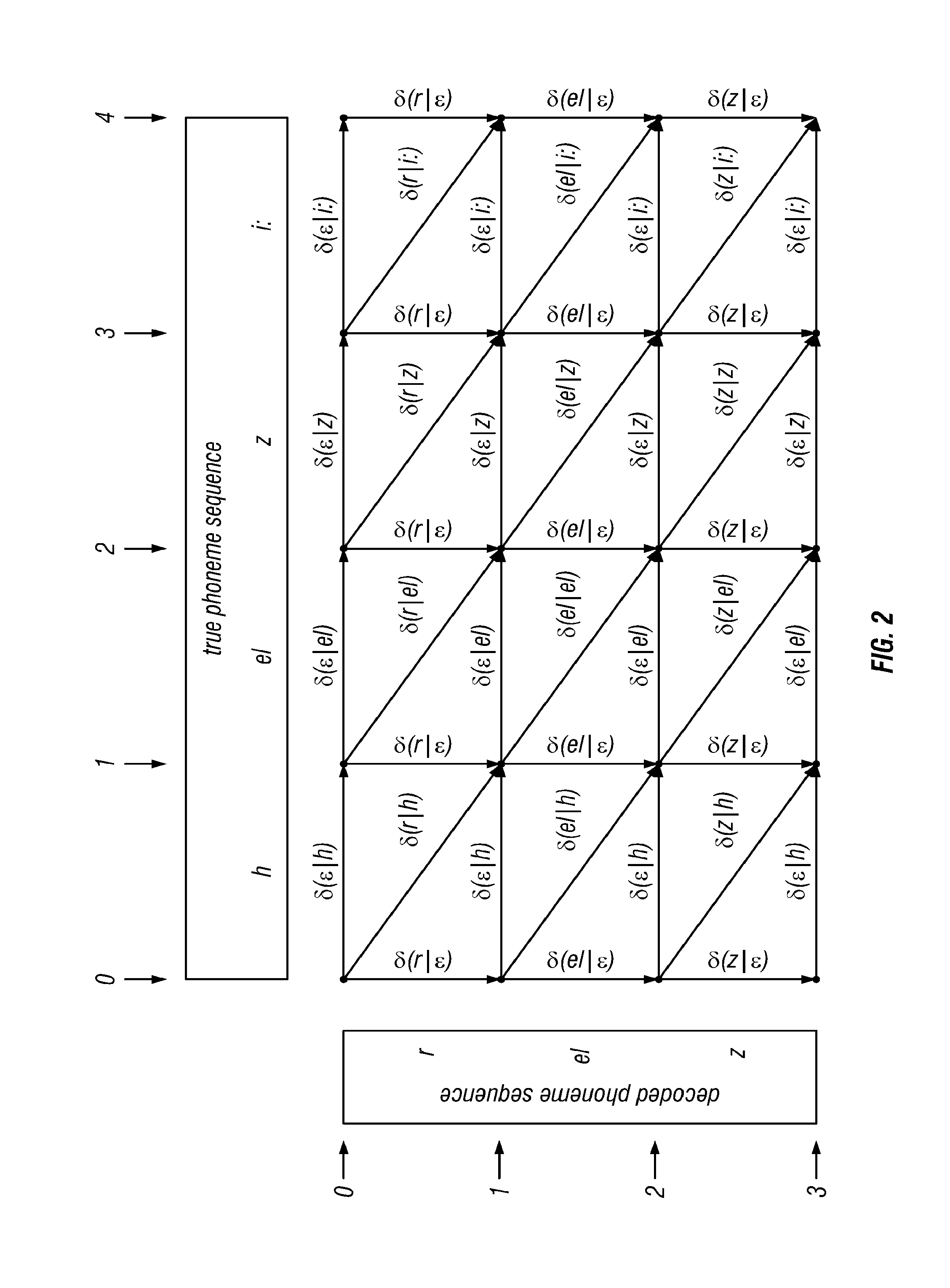
[0022] FIG. 3 shows a basic lattice with actual decoding costs according to the invention, where the symbolic decoding costs .delta.(d|t) have been replaced by the starting values proposed in the text;
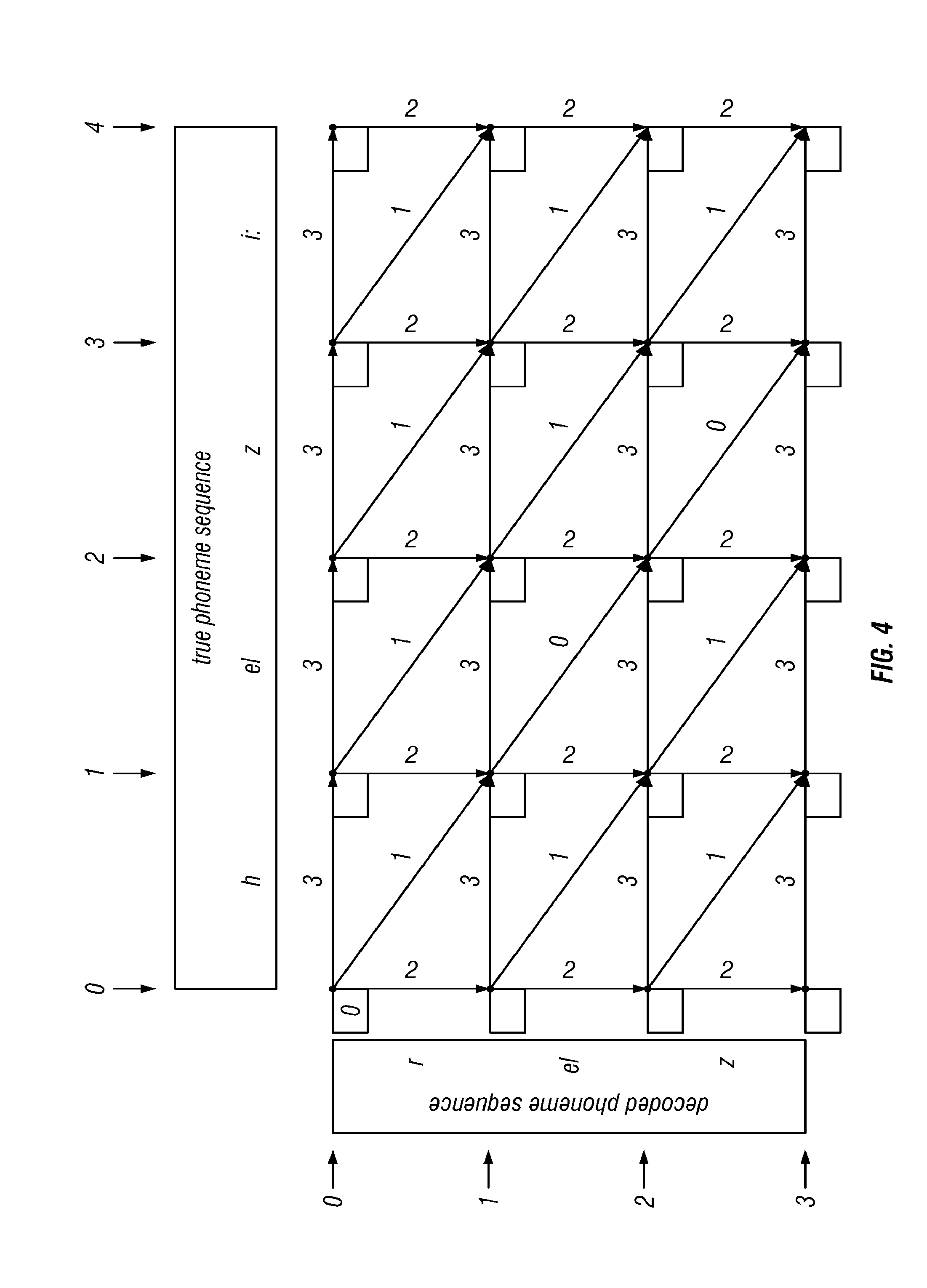
[0023] FIG. 4: Initial State of Bellman-Ford Algorithm. Each node now has a box to record the minimum-path cost from the source node, at coordinates (0, 0), to the node in question. The cost from the source node to itself is 0, so that value has been filled. In accordance with the invention;
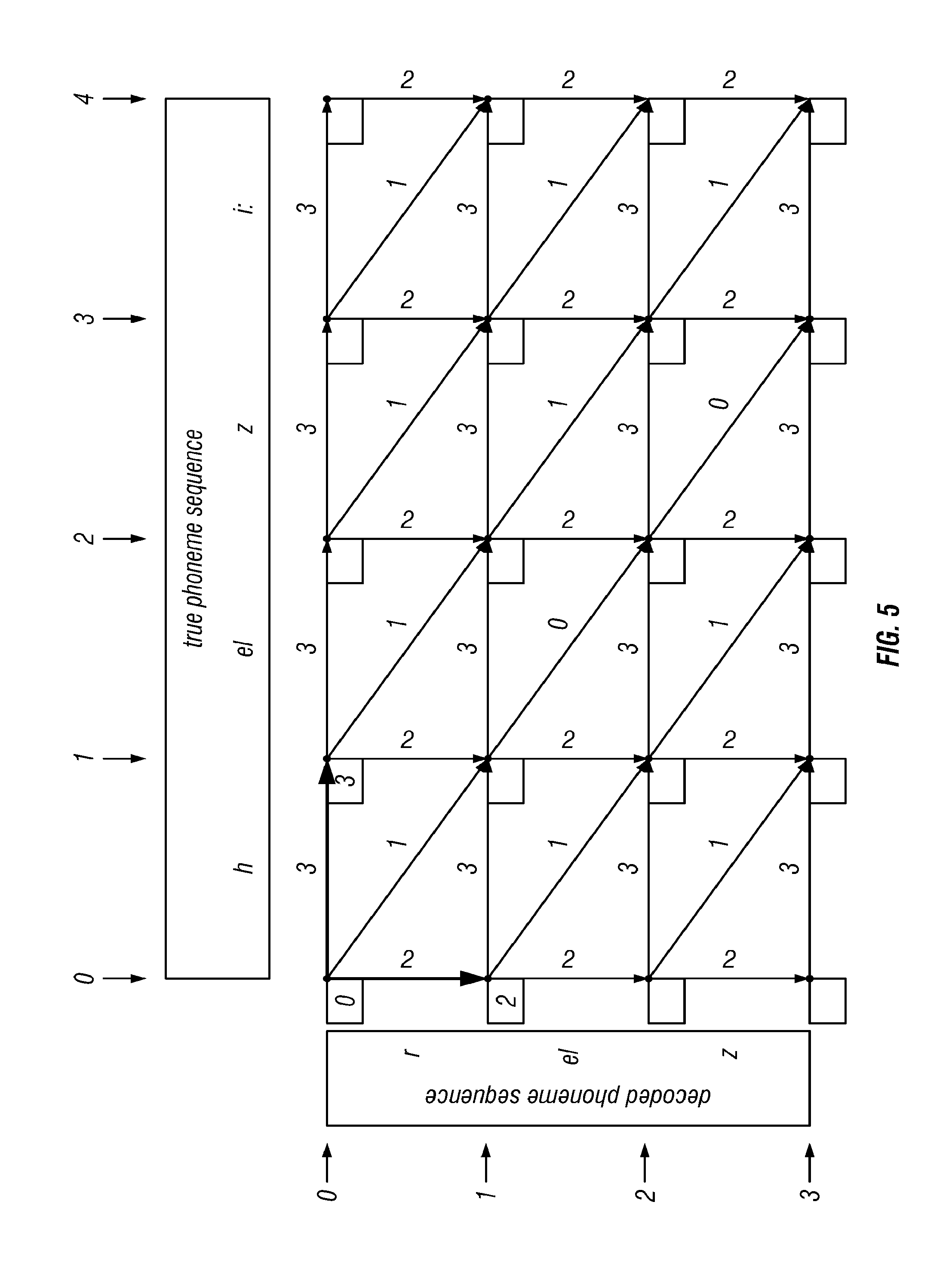
[0024] FIG. 5 shows two nodes with minimum path costs after labeling according to the invention, where the costs to reach nodes (0, 1) and (1, 0) have been determined and filled in, and the arcs of the minimum cost path in each case have been marked, by rendering them with a thicker line;
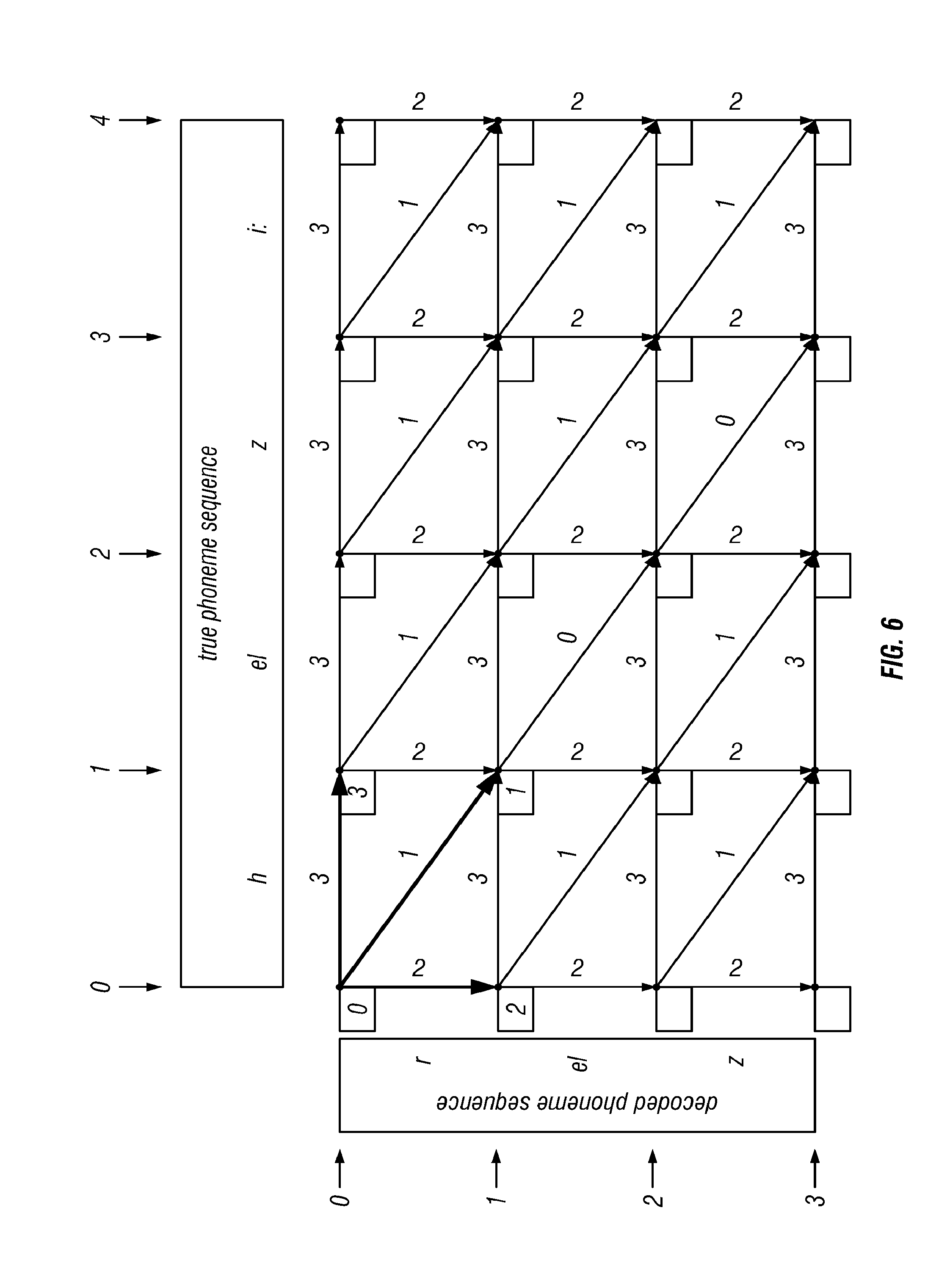
[0025] FIG. 6 shows the state of the lattice after a next step of the algorithm according to the invention, where the cost of the minimum cost path to (1, 1), and the arc followed for that path, have both been determined. This is the first non-trivial step of the algorithm. The result is determined as described in the text;
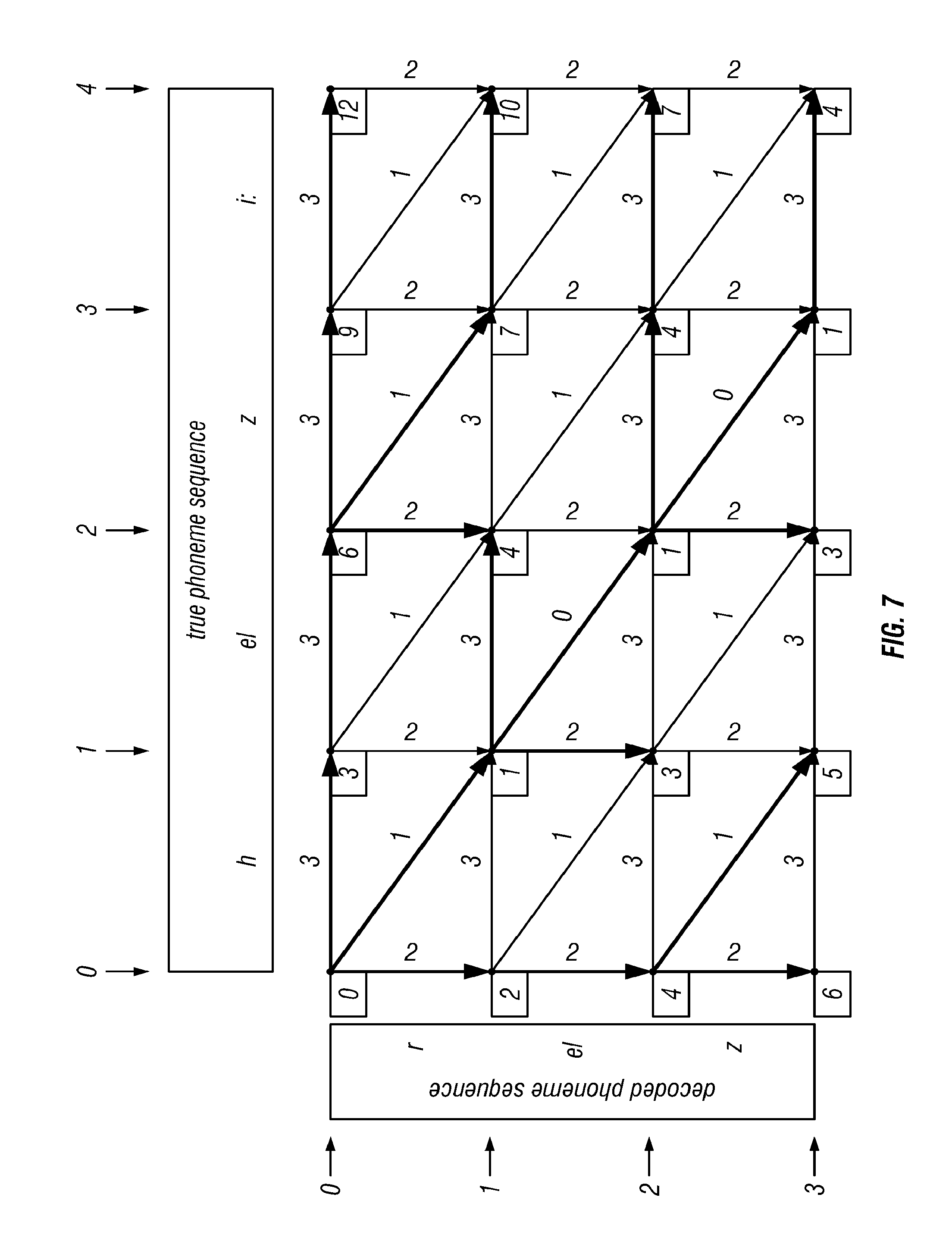
[0026] FIG. 7 shows the state of the lattice after completion of the algorithm according to the invention, where every node has been labeled with its minimum cost path, and the associated arcs have all been determined; and where some arbitrary choices, between paths of equal cost, have been made in selecting the minimum cost arcs;
[0027] FIG. 8 shows a confusatron output for typical homonyms according to the invention, comprising a small portion of the list of homonyms, generated from a grammar that comprised popular musical artist names, where the parenthesized text is the pronunciation that is shared by the two colliding phrases and, where in each case, the list of colliding phrases appears to the right, enclosed in angle brackets, with list elements separated by a # sign; and
[0028] FIG. 9 shows a confusatron output for typical dangerous words according to the invention, comprising a small portion of the list of dangerous words, where each entry is comprised of the nominal truth, and its clarity score, followed by a list (in order of decreasing confusability) of the other literals in the grammar that are likely to be confused with it and, where the items listed below the true literal are likely erroneous decodings, when the given true utterance has been spoken.
DETAILED DESCRIPTION OF THE INVENTION
[0029] There are three related elements to the presently preferred embodiment of invention disclosed herein:
Empirically Derived Acoustic Confusability Measures
[0030] The first element comprises a means for determining the acoustic confusability of any two textual phrases in a given language. Some specific advantages of the means presented here are:
[0031] Empirically Derived. The measure of acoustic confusability is empirically derived from examples of the application of a specific speech recognition technology. Thus, the confusability scores assigned by the measure may be expected to reflect the actual performance of a deployed instance of the technology, in a particular application.
[0032] Depends Only on Recognizer Output. The procedure described herein does not require access to the internal computational models of the underlying speech recognition technology, and does not depend upon any particular internal structure or modeling technique, such as Hidden Markov Models (HMMs). Only the output of the speech recognition system, comprising the sequence of decoded phonemes, is needed.
[0033] Iteratively Trained. The procedure described is based upon iterative improvement from an initial estimate, and therefore may be expected to be superior to any a priori human assignment of phoneme confusion scores, or to a method that makes only a single, initial estimate of phoneme confusion scores, without iterative improvement.
Techniques for Efficient Computation of Empirically Derived Acoustic Confusability Measures
[0034] The second element comprises computational techniques for efficiently applying the acoustic confusability scoring mechanism. Previous inventions have alluded to the use of acoustic confusability measures, but notably do not discuss practical aspects of applying such mechanisms. In any real-world practical scheme, it is often required to estimate the mutual acoustic confusability of tens of thousands of distinct phrases. Without efficient means of computing the measure, such computations rapidly become impractical. In this patent, we teach means for efficient application of our acoustic confusability score, allowing practical application to very large-scale problems.
Method for Using Acoustic Confusability Measures
[0035] The third element comprises a method for using acoustic confusability measures, derived by whatever means (thus, not limited to the measure disclosed here), to make principled choices about which specific phrases to make recognizable by a speech recognition application.
Empirically Derived Acoustic Confusability Measure
[0036] The immediately following discussion explains how to derive and compute an empirically derived acoustic confusability measure. The discussion is divided into several subsections;
In Section 1, we establish some notation and nomenclature, common to the invention as a whole. In Section 2, we explain how to empirically derive our acoustic confusability measure. In Section 3, we explain how to use the output of the preceding section to compute the acoustic confusability of any two phrases.
1. Notation and Nomenclature
[0037] We first establish some notation and nomenclature. The symbol or expression being defined appears in the left hand column; the associated text explains its meaning or interpretation. Italicized English words, in the associated text, give the nomenclature we use to refer to the symbol and the concept. [0038] u a single complete utterance, represented as an audio recording [0039] w a word sequence, phrase, or literal, represented as text. We will use these terms interchangeably. [0040] X the corpus; thus a sequence of utterances u.sub.1, u.sub.2, . . . , u.sub.C and associated transcriptions T.sub.1, T.sub.2, . . . , T.sub.C, where C is the number of utterances in the corpus. To underscore that the corpus contains audio data, we will sometimes refer to it as the audio corpus or acoustic corpus. [0041] P the recognized corpus; the result of passing the audio corpus through a given speech recognition system. [0042] .PHI. the phoneme alphabet of the human language in question. This is a finite collection of the basic sound units of the language, denoted by some textual names or symbols. For the purposes of this discussion, we will use the Speech Assessment Methods Phonetic Alphabet (SAMPA) for US English, as defined in Language Supplement, OpenSpeech.TM. Recognizer, (US English), for English in the United States (en-US), Second Edition, May 2004, page 33. Additional discussion may be found in Wikipedia. [0043] q(w) a pronunciation or baseform (there may be several) of the phrase w, represented as a sequence of phonemes .PHI..sub.1, .PHI..sub.2, . . . , .PHI..sub.Q, where Q is the number of phonemes in the pronunciation. Each .PHI..sub.i is a member of .PHI.. [0044] Q(w) the set of all pronunciations of w [0045] G a grammar, in the sense of an automatic speech recognition system; thus comprising a representation of all phrases (also referred to as word sequences or literals) that the system may recognize, nominally with some symbolic meaning attached to each phrase [0046] L(G) the language of G; thus a list of all word sequences admissible by G [0047] Q(L(G)) the set of all pronunciations of all word sequences appearing in L(G); thus a list of one or more phoneme sequences for each word sequence in L(G) [0048] R a recognizer or automatic speech recognition system; thus a computer system that accepts utterances as input and returns decodings. We will use the terms "recognizer," "automatic speech recognition system," "speech recognition system" and "recognition system" interchangeably; they mean the same thing. [0049] R.sub.G a recognizer that is constrained to return only decodings that correspond to phrases in the grammar G [0050] D a decoding; the output of a speech recognition system when presented with an utterance. To exhibit the particular input utterance associated to the decoding, we write D(u). For our purposes, a decoding consists of a pair f, s, where f is the decoded frame sequence (defined below), and s is the associated confidence score. (Note: we may sometimes use D to denote the length of a phoneme sequence, this will be clear from context.) [0051] s a confidence score; a number, determined by the recognition system, that expresses the likelihood that the decoding returned by the recognizer is correct. By assumptions lies in the interval [0, 1]; if not this can be arranged via a suitable scaling operation. Written s(u) to exhibit the associated utterance u. [0052] T a transcription or true transcription; regular text in the human language in question. To exhibit the particular utterance associated to the transcription, we write T(u). (Note: we may sometimes use T to denote the length of a phoneme sequence, this will be clear from context.) [0053] f a frame of decoded speech; thus the recognizer's output for a short segment of speech, nominally a phoneme in (D. Written f(u) to exhibit the associated utterance u. [0054] f=f.sub.1 f.sub.2 . . . f.sub.F a decoded frame sequence; the sequence of frames associated to a particular decoding, where F is the number of frames in the sequence. Written f(u) or f.sub.1(u)f.sub.2(u) . . . f.sub.F(u) to exhibit the associated utterance u. [0055] d=d.sub.1 d.sub.2 . . . d.sub.N a decoded phoneme sequence; the sequence of phonemes, where N is the number of phonemes in the sequence, derived from a particular decoded frame sequence, by the operations of phoneme mapping and coalescing, explained below. Written d.sub.1(u) d.sub.2(u) . . . d.sub.N(u) to exhibit the associated utterance u. [0056] t=t.sub.1 t.sub.2 . . . t.sub.Q a true phoneme sequence; the sequence of phonemes, where Q is the number of phonemes in the sequence, derived from a true transcription T, by a means that is explained below. Also known as a pronunciation of T. Written t(u) or t.sub.1(u) t.sub.2(u) . . . t.sub.Q(u) to exhibit the associated utterance u. Compare with the decoded phoneme sequence, as defined above, and note that for one and the same utterance u, the decoded phoneme sequence and true phoneme sequence may and typically will differ, and may even contain different numbers of phonemes. [0057] c(d|t) the integer-valued count of the phoneme pair d|t, derived as explained below. [0058] .delta.(d|t) the decoding cost of decoding phoneme t as phoneme d. If neither d nor t is the empty phoneme (defined below), this is also referred to as the substitution cost of substituting d for t. [0059] .delta..sub.(i)(d|t) the decoding cost of decoding phoneme t as phoneme d, at iteration i of the method. The index i is a so-called "dummy index"; the same quantity may also be denoted using the dummy index m as .delta..sub.(m)(d|t) to refer to the decoding cost at iteration m of the method. [0060] .epsilon. the empty phoneme, sometimes called epsilon [0061] .PHI.+.epsilon. the augmented phoneme alphabet; the set .PHI. augmented with the empty phoneme. Thus, .PHI..orgate.{.epsilon.}. Sometimes written .PHI.'. [0062] .delta.(d|.epsilon.) the insertion cost of inserting phoneme d into a decoding. [0063] .delta.(.epsilon.|t) the deletion cost of deleting phoneme t from a decoding. [0064] p(d|t) the probability of decoding a true phoneme t as the phoneme d. [0065] p.sub.(i)(d|t) the probability of decoding a true phoneme t as the phoneme d, at iteration i of the method. The index i is a so-called "dummy index"; the same quantity may also be denoted using the dummy index m. [0066] .PI.={p(d|t)} a family of conditional probability models, where each p(|t) comprises a probability model, for each t in .PHI.+.epsilon., over the space .OMEGA.=.PHI.+.epsilon.. [0067] .PI..sub.(i)={p.sub.(i)(d|t)} a family of conditional probability models, at iteration i of the method. The index i is a so-called "dummy index"; the same quantity may also be denoted using the dummy index m. [0068] L a lattice; formally a directed acyclic graph comprising a set of nodes N and a set of arcs or edges E.OR right.N.times.N. [0069] a an arc of L; formally an ordered pair of nodes t, h.di-elect cons.E. If a=t, h, we say that a is an arc from t to h, and refer to t as the tail, and h as the head, of arc a. [0070] A=a.sub.1, a.sub.2, . . . , a.sub.K a path (of length K) in L; formally a sequence of arcs a.sub.1, a.sub.2, . . . , a.sub.K of L, with the property that the head of arc a is the tail of arc a.sub.i+1, for each i=1, . . . , K-1. [0071] 1(a) the label of arc a; comprising the phoneme pair x|y, with x, y.di-elect cons..PHI.', that is associated with the given arc in L
2. Method for Constructing an Empirically Derived Acoustic Confusability Measure
[0072] We first present an outline of the method, then present a detailed explanation of how to apply the method.
Outline of Method
[0073] The method comprises two basic steps. The first step is corpus processing, in which the original corpus is passed through the automatic speech recognition system of interest. This step is non-iterative; that is, the corpus is processed just once by the recognition system. The second step is development of a family of phoneme confusability models. This step is iterative; that is, it involves repeated passes over the corpus, at each step delivering an improved family of confusability models.
Corpus Processing
[0074] We assume that we have at our disposal some large and representative set of utterances, in some given human language, with associated reliable transcriptions. We refer to this as the corpus. By an utterance we mean a sound recording, represented in some suitable computer-readable form. By transcription we mean a conventional textual representation of the utterance; by reliable we mean that the transcription may be regarded as accurate. We refer to these transcriptions as the truth, or the true transcriptions.
[0075] In this step, we pass the utterances through an automatic speech recognition system, one utterance at a time. For each utterance, the recognition system generates a decoding, in a form called a decoded frame sequence, and a confidence score. As defined above, a frame is a brief audio segment of the input utterance.
[0076] The decoded frame sequence comprises the recognizer's best guess, for each frame of the utterance, of the phoneme being enunciated, in that audio frame. As defined above, a phoneme is one of a finite number of basic sound units of a human language.
[0077] This decoded frame sequence is then transformed, by a process that we describe below, into a much shorter decoded phoneme sequence. The confidence score is a measure, determined by the recognition system, of the likelihood that the given decoding is correct.
[0078] We then inspect the true transcription of the input utterance, and by a process that we describe below, transform the true transcription (which is just regular text, in the language of interest) into a true phoneme sequence.
[0079] Thus for each utterance we have confidence score, and a pair of phoneme sequences: the decoded phoneme sequence, and the true phoneme sequence. We refer to this entire collection as the recognized corpus, and denote it as P.
[0080] The recognized corpus constitutes the output of the corpus processing step.
Iterative Development of Probability Model Family
[0081] From the preceding step, we have at our disposal the recognized corpus P, comprising a large number of pairs of phoneme sequences.
[0082] In this step, we iteratively develop a sequence of probability model families. That is, we repeatedly pass through the recognized corpus, analyzing each pair of phoneme sequences to collect information regarding the confusability of any two phonemes. At the end of each pass, we use the information just collected to generate an improved family of probability models. We repeat the procedure until there is no further change in the family of probability models, or the change becomes negligible.
[0083] It is important to understand that this step as a whole comprises repeated iterations. In the detailed discussion below, we describe a single iteration, and the criterion for declaring the step as a whole complete.
[0084] The output of this step is a family of probability models, which estimates the acoustic confusability of any two members of the augmented phoneme alphabet (V. From these estimates, by another method that we explain, we may then derive the acoustic confusability measure that we seek.
DETAILED DESCRIPTION OF THE METHOD
[0085] We now provide detailed descriptions of the steps outlined above.
Corpus Processing
[0086] Let X={<u.sub.1, T.sub.1>, . . . , <u.sub.C, T.sub.C>} be the corpus, comprising C pairs of utterances and transcriptions. For each <u, T> pair in X:
[0087] 1. Recognize.
[0088] Apply the recognizer R (or for a grammar-based system, the recognizer R.sub.G, where G is a grammar that admits every transcription in the corpus, plus possibly other phrases that are desired to be recognized) to the utterance u, yielding as output a decoded frame sequence f and a confidence score s.
[0089] 2. Optionally Map Phonemes.
[0090] This step is optional. Let f=f.sub.1 f.sub.2 . . . f.sub.F be the decoded frame sequence. Apply a phoneme map m to each element of the decoded frame sequence, yielding a new decoded frame sequence f'=f'.sub.1 f'.sub.2 . . . f'.sub.F, where each f'.sub.j=m(f.sub.i).
[0091] The purpose of the phoneme map m is to reduce the effective size of the phoneme alphabet, by collapsing minor variants within the phoneme alphabet into a single phoneme. An example would be the mapping of the "p closure" phoneme, often denoted pcl, to the regular p phoneme. Another example would be splitting phoneme pairs, known as diphones, into separate phonemes. This operation can simplify the calculation, and avoids the problem of too finely subdividing the available statistical evidence, which can lead to unreliable estimates of phoneme confusability.
[0092] However, this operation may be skipped, or in what amounts to the same thing, the map m may be the identity map on the phoneme alphabet.
[0093] Note: it will be obvious to one skilled in the art, that by suitable modification the map m may function to expand rather than to reduce the phoneme alphabet, for instance by including left and/or right phonetic context in the output phoneme. This modification is also claimed as part of this invention.
[0094] 3. Coalesce.
[0095] Let f'=f'.sub.1 f'.sub.2 . . . f'.sub.F, be the decoded frame sequence, optionally after the application of Step 2. We now perform the operation of coalescing identical sequential phonemes in the decoded frame sequence, to obtain the decoded phoneme sequence. This is done by replacing each subsequence of identical contiguous phonemes that appear in f' by a single phoneme of the same type.
[0096] Thus if
f'=r r r r eI eI z z z z
[0097] is the decoded frame sequence, comprising 10 frames, the result of coalescing f' is the decoded phoneme sequence
d=r eI z.
[0098] Here and above, r, eI and z are all members of the phoneme alphabet .PHI.. This phoneme sequence corresponds to the regular English language word "raise." Note that d has three elements, respectively d.sub.1=r, d.sub.2=eI, and d.sub.3=z.
[0099] We denote the coalescing operation by the letter g, and write d=g(f') for the action described above.
[0100] 4. Generate Pronunciation of T.
[0101] Let T be the transcription of u. By lookup in the dictionary of the recognition system, or by use of the system's automatic pronunciation generation system, generate a pronunciation t for T, also written t=q(T). Thus if T is the regular English word "hazy," then one possibility is
t=h eI z i:
[0102] As above, h, eI, z, and i: are all members of the phoneme alphabet .PHI.. Note that t has four elements, respectively t.sub.1=h, t.sub.2=eI, t.sub.3=z, and t.sub.4=i:.
[0103] It should be noted that there may be more than one valid pronunciation for a transcription T. There are a number of ways of dealing with this:
[0104] (a) Decode the utterance u with a grammar-based recognizer R.sub.G, where the grammar G restricts the recognizer to emit only the transcription T(u). This is known as a "forced alignment," and is the preferred embodiment of the invention.
[0105] (b) Pick the most popular pronunciation, if this is known.
[0106] (c) Pick a pronunciation at random.
[0107] (d) Use all of the pronunciations, by enlarging the corpus to contain as many repetitions of u as there are pronunciations of T(u), and pairing each distinct pronunciation with a separate instance of u.
[0108] (e) Pick the pronunciation that is closest, in the sense of string edit distance, to the decoded phoneme sequence d.
[0109] By applying these steps sequentially to each element of the corpus X, we obtain the recognized corpus P={<ul, d(ul), t(ul), s(ul)>, . . . , <uC, d(uC), t(uC), s(uC)>}, or more succinctly P={<ul, dl, tl, sl>, . . . , <uC, dC, tC, sC>}.
Iterative Development of Probability Model Family
[0110] We now give the algorithm for the iterative development of the required probability model family, .PI.={p(d|t)}.
[0111] 1. Begin with the recognized corpus P.
[0112] 2. Establish a termination condition T. This condition typically depends on one or more of: the number of iterations executed, the closeness of match between the previous and current probability family models, respectively .PI..sub.(m-1) and .PI..sub.(m), or some other consideration. To exhibit this dependency explicitly, we write .tau.(m, .PI..sub.(m-1), .PI..sub.(m).
[0113] 3. Define the family of decoding costs {.delta..sub.(0)(x|y)|x, y in .PHI.'} as follows
.delta..sub.(0)(x|.epsilon.)=2 for each x in .PHI. .delta..sub.(0)(.epsilon.|x)=3 for each x in .PHI. .delta..sub.(0)(x|x)=0 for each x in .PHI.' .delta..sub.(0)(x|y)=1 for each x, y in .PHI., with x.noteq.y. Note: these settings are exemplary, and not a defining characteristic of the algorithm. Practice has shown that the algorithm is not very sensitive to these values, so long as .delta..sub.0(x|x)=0, and the other quantities are greater than 0.
[0114] 4. Set the iteration count m to 0.
[0115] 5. For each x, y in .PHI.', set the phoneme pair count c(x|y) to 0.
[0116] 6. For each entry <u, d, t, s> in P, perform the following (these steps are explained in greater detail below): [0117] a. Construct the lattice L=d.times.t. [0118] b. Populate the lattice arcs with values drawn from the current family of decoding costs, {.delta..sub.(m)(x|y)}. [0119] c. Apply the Bellman-Ford dynamic programming algorithm, or Dijkstra's minimum cost path first algorithm, to find the shortest path through this lattice, from the upper-left (source) node to the lower-right (terminal) node. The minimum cost path comprises a sequence of arcs A=a.sub.1, a.sub.2, . . . , a.sub.K, in the lattice L, where the tail of arc a.sub.1 is the source node, the head of arc a.sub.K, is the terminal node, and the head of arc a.sub.i is the tail of arc a.sub.i+1, for each i=1, . . . , K-1. [0120] d. Traverse the minimum cost path determined in step c. Each arc of the path is labeled with some pair x|y, where x and y are drawn from .PHI.'. For each x|y arc that is traversed, increment the phoneme pair count c(x|y) by 1.
[0121] 7. For each y in .PHI.', compute c(y)=.SIGMA.c(x|y), where the sum runs over all x in .PHI.'.
[0122] 8. Estimate the family of probability models .PI..sub.(m)={p.sub.(m)(x|y)}. For each fixed y in .PHI.', this is done by one of the following two formulae: [0123] a. If c(x|y) is non-zero for every x in .PHI.', then set p.sub.(m)(x|y)=c(x|y)/c(y), for each x in .PHI.'. [0124] b. If c(x|y) is zero for any x in .PHI.', apply any desired zero-count probability estimator, also known as a smoothing estimator, to estimate p.sub.(m)(x|y). A typical method is Laplace's law of succession, which is p.sub.(m)(x|y)=(c(x|y)+1)/(c(y)+|.PHI.'|), for each x in .PHI.'.
[0125] 9. If m>0, test the termination condition .tau.(m, .PI..sub.(m-1), .PI..sub.(m)). If the condition is satisfied, return .PI..sub.(m) as the desired probability model family .PI.={p(d|t)} and stop.
[0126] 10. If the condition is not satisfied, define a new family of decoding costs {.delta..sub.(m+1)(x|y)|x, y in .PHI.'} by .delta..sub.(m+1)(x|y)=-log p.sub.(m)(x|y). (The logarithm may be taken to any base greater than 1.)
[0127] Note that each p.sub.(m)(x|y) satisfies 0<p.sub.(m)(x|y)<1, and so each .delta..sub.(m+1)(x|y)>0.
[0128] 11. Increment the iteration counter m and return to step 5 above.
We now provide the additional discussion promised above, to explain the operations in Step 6 above.
[0129] Step 6a: Consider the entry <u, d, t, s> of P, with decoded phoneme sequence d=d.sub.1 d.sub.2 . . . d.sub.N, containing N phonemes, and true phoneme sequence t=t.sub.1 t.sub.2 . . . t.sub.Q, containing Q phonemes. Construct a rectangular lattice of dimension (N+1) rows by (Q+1) columns, and with an arc from a node (i, j) to each of nodes (i+1, j), (i, j+1) and (i+1, j+1), when present in the lattice. (Note: "node (i, j)" refers to the node in row i, column j of the lattice.) The phrase "when present in the lattice" means that arcs are created only for nodes with coordinates that actually lie within the lattice. Thus, for a node in the rightmost column, with coordinates (i, Q), only the arc Q).fwdarw.(i+1, Q) is created.)
[0130] Step 6b: Label
each arc (i, j).fwdarw.(i, j+1) with the cost .delta..sub.(m)(.epsilon.|t.sub.j) each arc (i, j).fwdarw.(i+1, j) with the cost .delta..sub.(m)(d.sub.i|.epsilon.) each arc (i, j).fwdarw.(i+1, j+1) with the cost .delta..sub.(m)(d.sub.i|t.sub.j).
[0131] An example of such a lattice appears, in various versions, in FIGS. 1, 2, and 3 below. FIG. 1 exhibits the lattice labeled with symbols, for the case where N=3 and Q=4, with symbolic expressions for decoding costs. FIG. 2 shows the lattice for the particular case d=r eI z and t=h eI z i:, again with symbolic expressions for decoding costs. FIG. 3 shows the same lattice, with the actual decoding costs for iteration 0 filled in.
[0132] Step 6c: The Bellman-Ford dynamic programming algorithm is a well-known method for finding the shortest path through a directed graphic with no negative cycles. We apply it here to find the shortest path from the source node, which we define as node (0, 0), to the terminal node, which we define as node (N, Q).
[0133] FIGS. 4, 5, 6, and 7 below demonstrate the application of the Bellman-Ford algorithm to the example of FIG. 3.
[0134] FIG. 4 shows the initial state of the algorithm, with the source node labeled with the minimum cost for reaching that node from the source node, which of course is 0.
[0135] FIG. 5 shows the state of the algorithm after labeling nodes (0, 1) and (1, 0) with the minimum cost for reaching those nodes from the source node. The arcs traversed to yield the minimum cost has also been exhibited, by thickening the line of the arc.
[0136] Because there is only a single arc incident on each of these nodes, the minimum costs are respectively 0+3=3 and 0+2=2. In each case, this quantity is determined as (minimum cost to reach the immediately preceding node)+(cost of traversing the arc from the immediately preceding node).
[0137] FIG. 6 shows the state of the algorithm after labeling node (1, 1). The computation here is less trivial, and we review it in detail. Node (1, 1) has three immediate predecessors, respectively (0, 0), (0, 1) and (1, 0). Each node has been labeled with its minimum cost, and so we may compute the minimum cost to (1, 1). This of course is the minimum among the three possible paths to (1, 1), which are:
from (0, 0), via arc (0, 0).fwdarw.(1, 1), with total cost 0+1=1 from (0, 1), via arc (0, 1).fwdarw.(1, 1), with total cost 3+2=5 from (1, 0), via arc (1, 0).fwdarw.(1, 1), with total cost 2+3=5.
[0138] It is evident that the path from (0, 0) is the minimum cost path, and this is indicated in FIG. 6.
[0139] By repeated application of this process, the minimum cost path from the source node to each node of the lattice may be determined. FIG. 7 shows the final result.
[0140] Because the arc costs are guaranteed to be non-negative, it is evident to one skilled in the art that the same computation may be performed, at possibly lower computational cost, using Dijkstra's shortest path first algorithm. The improvement follows from the fact that only the minimum cost path from the source node to the terminal node is required, and so the algorithm may be halted as soon as this has been determined.
[0141] The output of this step is a sequence of arcs A=a.sub.1, a.sub.2, . . . , a.sub.x, in the lattice L, known to comprise the minimum cost path from the source node to the terminal node. We write l(a) for the phoneme pair x|y that labels the arc a.
[0142] Step 6d: For each arc a.sub.i in the minimum cost path A, labeled with phoneme pair x|y=l(a.sub.i), increment the counter c(x|y) by 1.
[0143] This completes the description of the method to construct an empirically derived acoustic confusability measure. The means of using the result of this algorithm to compute the acoustic confusability of two arbitrary phrases is described below.
N-Best Variant of the Method
[0144] An important variant of the just-described method to construct an empirically derived acoustic confusability measure, which can improve the accuracy of the resulting measure, is as follows.
[0145] It is well known to those skilled in the art that the output of a recognizer R (or R.sub.G, for a grammar-based recognition system), may comprise not a single decoding D, comprising a pair f, s, but a so-called "N-best list," comprising a ranked series of alternate decodings, written f.sub.1, s.sub.1, f.sub.2, s.sub.2, . . . , f.sub.B, s.sub.B. In this section we explain a variant of the basic method described above, called the "N-Best Variant," which makes use of this additional information. The N-best variant involves changes to both the corpus processing step, and the iterative development of probability model family step, as follows.
N-Best Variant Corpus Processing
[0146] In the N-best variant of corpus processing, for each utterance u, each entry f.sub.i(u), s.sub.i(u) in the N-best list is treated as a separate decoding. All other actions, taken for a decoding of u, are then performed as before. The result is a larger recognized corpus P'.
N-Best Variant Iterative Development of Probability Model Family
[0147] In the N-best variant of iterative development of probability model family, there are two changes. First, the input is the larger recognized corpus, P', developed as described immediately above. Second, in step 6d, as described above, when processing a given entry <u, d, t, s> of P', each count c(x|y) is incremented by the value s, which is the confidence score of the given entry, rather than by 1.
[0148] The rest of the algorithm is unchanged.
3. Method to Compute the Empirically Derived Acoustic Confusability of Two Phrases
[0149] In the preceding sections we described how to determine the desired probability model family .PI.={p(d|t)}. In this section we explain how to use .PI. to compute the acoustic confusability of two arbitrary phrases w and v.
[0150] Specifically, we give algorithms for computing two quantities, both relating to acoustic confusability. The first is the raw phrase acoustic confusability r(v|w). This is a measure of the acoustic similarity of phrases v and w. The second is the grammar-relative confusion probability p(v|w, G). This is an estimate of the probability that a grammar-constrained recognizer R.sub.G returns the phrase v as the decoding, when the true phrase was w. Note that no reference is made to any specific pronunciation, in either quantity.
[0151] In both cases, we must come to grips with the fact that the phrases v and w may have multiple acceptable pronunciations. There are a variety of ways of dealing with this, all of which are claimed as part of this patent.
[0152] In the process of computing these quantities, we also give expressions that depend upon specific pronunciations (and from which the pronunciation-free expressions are derived). These expressions have independent utility, and also are claimed as part of this patent.
Computation of Raw Pronunciation Acoustic Confusability r(q(v)|q(w)) and Raw Phrase Acoustic Confusability r(v|w)
[0153] We first assume that pronunciations q(w).di-elect cons.Q(w) and q(v).di-elect cons.Q(v) are given, and explain the computation of the raw pronunciation acoustic confusability, r(q(v)|q(w)). Then we explain methods to determine the raw phrase acoustic confusability r(v|w).
Computation of Raw Pronunciation Acoustic Confusability
[0154] Let the probability model family .PI.={p(d|t)} and the pronunciations q(w) and q(v) be given. Proceed as follows to compute the raw pronunciation acoustic confusability r(q(v)|q(w)):
[0155] 1. Define the decoding costs .delta.(d|t)=log p(d|t) for each d, t.di-elect cons..PHI.'.
[0156] 2. Construct the lattice L=q(v).times.q(w), and label it with phoneme decoding costs .delta.(d|t), depending upon the phonemes of q(v) and q(w). This means performing the actions of Steps 6a and 6b, as described above, "Iterative Development of Probability Model Family," with the phoneme sequences q(v) and q(w) in place of d and t respectively.
[0157] 3. Perform the actions of Step 6c above to find the minimum cost path A=a.sub.1, a.sub.2, . . . , a.sub.K, from the source node to the terminal node of L.
[0158] 4. Compute S, the cost of the minimum cost path A, as the sum of the decoding costs .delta.(l(a)) for each arc a.di-elect cons.A. (Recall that l(a) is the phoneme pair x|y that labels a.) Thus,
S = i = 1 K .delta. ( l ( a i ) ) . ##EQU00001##
[0159] 5. Compute r(q(v)|q(w))=exp(-S); this is the raw pronunciation acoustic confusability of q(v) and q(w). Here the exponential is computed to the same base as that used for the logarithm, in preceding steps.
[0160] Note that equivalently
r ( q ( v ) | q ( w ) ) = i = 1 K p ( l ( a i ) ) , ##EQU00002##
and indeed this quantity may be computed directly from the lattice L, by suitable modification of the steps given above.
[0161] We have described here one method of computing a measure of the acoustic confusability r(q(v)|q(w)) of two pronunciations, q(w) and q(v). In what follows we describe methods of manipulating this measure to obtain other useful expressions. It is to be noted that while the expressions developed below assume the existence of some automatic means of quantitatively expressing the confusability of two pronunciations, they do not depend on the exact formulation presented here, and stand as independent inventions.
Computation of Raw Phrase Acoustic Confusability
[0162] We begin by defining r(v|q(w))=.SIGMA.r(q(v)|q(w)), where the sum proceeds over all q(v).di-elect cons.Q(v). This accepts any pronunciation q(v) as a decoding of v. The raw phrase acoustic confusability r(v|w), with no reference to pronunciations, may then be determined by any of the following means:
[0163] 1. Worst Case, Summed.
[0164] Find q(w).di-elect cons.Q(w) that minimizes r(w|q(w)); call this q.dagger.(w). Thus q.dagger.(w) is the pronunciation of w that is least likely to be correctly decoded. Set r(v|w)=r(v|q.dagger.(w)). This is the preferred implementation.
[0165] 2. Worst Case, Individual Pronunciations.
[0166] For v.noteq.w, set r(v|w)=max {r(q(v)|q(w))}, where the maximum is taken over all q(v).di-elect cons.Q(v) and q(w).di-elect cons.Q(w). For v=w, set r(w|w)=min {r(q(w)|q(w))}, where the minimum is taken over all q(w).di-elect cons.Q(w). Since higher values of r(q(v)|q(w)) imply greater confusability, this assigns to r(v|w) the raw pronunciation confusability of the two most confusable pronunciations of v and w respectively. This is the preferred method.
[0167] 3. Most Common.
[0168] Assume the two most common pronunciations of v and w are known, respectively q*(v) and q*(w). Set r(v|w)=r(q*(v)|q*(w)).
[0169] 4. Average Case.
[0170] Assume that a probability distribution on Q(w) is known, reflecting the empirical distribution, within the general population, of various pronunciations q(w) of w. Set r(v|w)=.SIGMA.p(q(w))r(v|q(w)), where the sum proceeds over all q(w).di-elect cons.Q(w).
[0171] 5. Random.
[0172] Randomly select q(v).di-elect cons.Q(v) and q(w).di-elect cons.Q(w), and set r(v|w)=r(q(v)|q(w)).
[0173] Those skilled in the art will observe ways to combine these methods into additional hybrid variants, for instance by randomly selecting q(v), but using the most common pronunciation q*(w), and setting r(v|w)=r(q(v)|q*(w)).
Computation of Grammar-Relative Pronunciation Confusion Probability p(q(v)|q(w), G) and Grammar-Relative Phrase Confusion Probability p(v|w, G)
[0174] Suppose that a recognizer is constrained to recognize phrases within a grammar G. We proceed to define expressions that estimate the grammar-relative pronunciation confusion probability p(q(v)|q(w), G), and the grammar-relative phrase confusion probability p(v|w, G).
[0175] In what follows we write L(G) for the set of all phrases admissible by the grammar G, and Q(L(G)) for the set of all pronunciations of all such phrases. By assumption L(G) and Q(L(G)) are both finite.
Computation of Grammar-Relative Pronunciation Confusion Probability p(q(v)|q(w), G)
[0176] Let two pronunciations q(v), q(w).di-elect cons.Q(L(G)) be given; exact homonyms, that is q(v)=q(w), are to be excluded. We estimate p(q(v)|q(w), G), the probability that an utterance corresponding to the pronunciation q(w) is decoded by the recognizer R.sub.G as q(v), as follows.
[0177] 1. Compute the normalizer of q(w) relative to G, written Z(q(w), G), as Z(q(w),G)=.SIGMA.r(q(x)|q(w)), where the sum extends over all q(x).di-elect cons.Q(L(G)), excluding exact homonyms (that is, cases where q(x)=q(w), for x.noteq.w).
[0178] 2. Set p(q(v)|q(w), G)=r(q(v)|q(w))/Z(q(w), G).
Note: by virtue of the definition of the normalizer, this is in fact a probability distribution over Q(L(G)). Computation of Grammar-Relative Phrase Confusion Probability p(v|w, G)
[0179] Let two phrases v, w.di-elect cons.L(G) be given. We estimate p(v|w, G), the probability that an utterance corresponding to any pronunciation of w is decoded by the recognizer R.sub.G as any pronunciation of v, as follows.
[0180] As above we must deal with the fact that there are in general multiple pronunciations of each phrase. We proceed in a similar manner, and begin by defining p(v|q(w),G)=.SIGMA.p(q(v)|q(w),G), where the sum is taken over all q(v).di-elect cons.Q(v). We may then proceed by one of the following methods:
[0181] 1. Worst Case, Summed.
[0182] Find q(w).di-elect cons.Q(w) that minimizes p(w|q(w), G); call this q.dagger.(w). Thus q.dagger.(w) is the pronunciation of w that is least likely to be correctly decoded. Set p(v|w, G)=p(v|q.dagger.(w), G). This is the preferred implementation.
[0183] 2. Worst Case, Individual Pronunciations.
[0184] For v.noteq.w, set p'(v|w, G)=max {p(q(v)|q(w), G)}, where the maximum is taken over all q(v).di-elect cons.Q(v) and q(w).di-elect cons.Q(w). For v=w, set p'(w|w, G)={p(q(w)|q(w), G)}, where the minimum is taken over all q(w).di-elect cons.Q(w). Renormalize the set of numbers {p'(x|w, G)} to obtain a new probability distribution p(x|w, G).
[0185] 3. Most Common.
[0186] Assume the most common pronunciation of w is known, denoted q*(w). Set p(v|w, G)=p(v|q*(w), G).
[0187] 4. Average Case.
[0188] Assume the empirical distribution p(q(w)) over Q(w) is known. Set p(v|w, G)=.SIGMA.p(q(w))p(v|q(w),G), where the sum is taken over all q(w).di-elect cons.Q(w).
[0189] 5. Random.
[0190] For any given v, w.di-elect cons.L(G), randomly select q(v) and q(w) from Q(v) and Q(w) respectively, and set p'(v|w, G)=p(q(v)|q(w), G). Renormalize the set of numbers {p'(x|w, G)} to obtain a new probability distribution p(x|w, G).
4. Techniques for Efficient Computation of Empirically Derived Acoustic Confusability Measures
[0191] In applying measures of acoustic confusability, it is typically necessary to compute a very large number of grammar-relative pronunciation confusion probabilities, p(q(v)|q(w), G), which ultimately depend upon the quantities r(q(v)|q(w)) and Z(q(w), G). We now explain three methods for improving the efficiency of these computations.
Partial Lattice Reuse
[0192] For a fixed q(w) in Q(L(G)), it is typically necessary to compute a large number of raw pronunciation confusability values r(q(v)|q(w)), as q(v) takes on each or many values of Q(L(G)). In principle for each q(v) this requires the construction, labeling and minimum-cost-path computation for the lattice L=q(v).times.q(w), and this is prohibitively expensive.
[0193] This computation can be conducted more efficiently by exploiting the following observation. Consider two pronunciations q(v.sub.1)=d.sub.11, d.sub.12, . . . , d.sub.1Q1 and q(v.sub.2)=d.sub.21, d.sub.22, . . . , d.sub.2Q2. Suppose that they share a common prefix; that is, for some M.ltoreq.Q.sub.1, Q.sub.2 we have d.sub.1j=d.sub.2j for j=1, . . . , M. Then the first M rows of the labeled and minimum-cost-path-marked lattice L.sub.1=q(v.sub.1).times.q(w) can be reused in the construction, labeling and minimum-cost-path computation for lattice L.sub.2=q(v.sub.2).times.q(w).
[0194] The reuse process consists of retaining the first (M+1) rows of nodes of the L.sub.1 lattice, and their associated arcs, labels and minimum-cost-path computation results, and then extending this to the L.sub.2 lattice, by adjoining nodes, and associated arcs and labels, corresponding to the remaining Q2-M phonemes of q(v.sub.2). Thereafter, the computation of the required minimum-cost-path costs and arcs proceeds only over the newly-added Q2-M bottom rows of L.sub.2.
[0195] For instance, continuing the exemplary lattice illustrated earlier, suppose q(w)=h eI z i:, and take q(v.sub.1)=r eI z (a pronunciation of "raise") and q(v.sub.2)=r eI t (a pronunciation of "rate"). Then to transform L.sub.1=q(v.sub.1).times.q(w) into L.sub.2=q(v.sub.2).times.q(w) we first remove all the bottom row of nodes (those with row index of 3), and all arcs incident upon them. These all correspond to the phoneme "z" in q(v.sub.1). (However, we retain all other nodes, and all labels, values and computational results that mark them.) Then we adjoin a new bottom row of nodes, and associated arcs, all corresponding to the phoneme "t" in q(v.sub.2).
[0196] Note that it is possible, for example if q(v.sub.2)=r eI (a pronunciation of "ray"), that no additional nodes need be added, to transform L.sub.1 into L.sub.2. Likewise, if for example q(v.sub.2)=r eI z @ r (a pronunciation of "razor"), it is possible that no nodes need to be removed.
[0197] This procedure may be codified as follows:
[0198] 1. Fix q(w) in Q(L(G)). Construct an initial "empty" lattice L.sub.0, consisting of only the very top row of nodes and arcs, corresponding to q(w).
[0199] 2. Sort Q(L(G)) lexicographically by phoneme, yielding an enumeration q(v.sub.1), q(v.sub.2), . . . . .
[0200] 3. Set the iteration counter i=1.
[0201] 4. Find the length M of the longest common prefix of q(v.sub.i-1)=d.sub.i-1 1, d.sub.i-1 2, . . . , d.sub.i-1 Qi-1 and q(v.sub.1)=d.sub.i 1, d.sub.i 2, . . . , d.sub.i Qi. This is the largest integer M such that d.sub.i-1 j=d.sub.i j for j=1, . . . , M.
[0202] 5. Construct lattice L.sub.i from L.sub.i-1 as follows: [0203] a. Remove the bottom Q.sub.i-1-M rows of nodes (and associated arcs, costs and labels) from L.sub.i-1, corresponding to phonemes d.sub.i-1 M+1, d.sub.i-1 Qi-1 of q(v.sub.i-1), forming interim lattice L*. [0204] b. Adjoin Q.sub.i-M rows of nodes (and associated arcs, labeled with costs) to the bottom of L*, corresponding to phonemes d.sub.i M+1, . . . , d.sub.i Qi of q(v.sub.i), forming lattice L.sub.i=q(v.sub.i).times.q(w).
[0205] 6. Execute the Bellman-Ford or Dijkstra's shortest path first algorithm on the newly-added portion of L.sub.i. Compute the value of r(q(v.sub.i)|q(w)) and record the result.
[0206] 7. Increment the iteration counter i. If additional entries of Q(L(G)) remain, go to step 4. Otherwise stop.
[0207] It will be obvious to one skilled in the art that this same technique may be applied, with appropriate modifications to operate on the columns rather than the rows of the lattice in question, by keeping q(v) fixed, and operating over an enumeration q(w.sub.1), q(w.sub.2), . . . of Q(L(G)) to compute a sequence of values r(q(v)|q(w.sub.1)), r(q(v)|q(w.sub.2)), . . . ,
Pruning
[0208] One application of acoustic confusability measures is to find phrases within a grammar, vocabulary or phrase list that are likely to be confused. That is, we seek pairs of pronunciations q(v), q(w), both drawn from Q(L(G)), with v.noteq.w, such that r(q(v)|q(w)), and hence ultimately p(q(v)|q(w), G), is large.
[0209] In principle, this involves the computation of r(q(v)|q(w)) for some |Q(L(G))|.sup.2 distinct pronunciation pairs. Because it is not uncommon for Q(L(G)) to contain as many as 100,000 members, this would entail on the order of 10 billion acoustic confusability computations. Because of the complexity of the computation, this is a daunting task for even a very fast computer.
[0210] However, it is possible to simplify this computation, as follows. If it can be established, with a small computational effort, that r(q(v)|q(w))<<r(q(w)|q(w)), then the expensive exact computation of r(q(v)|q(w)) need not be attempted. In this case we declare q(v) "not confusable" with q(w), and take r(q(v)|q(w))=0 in any further computations.
[0211] We refer to such a strategy as "pruning." We now describe two complementary methods of pruning, respectively the method of Pronunciation Lengths, and the method of Pronunciation Sequences.
Pronunciation Lengths
[0212] Consider pronunciations q(v)=d.sub.1, d.sub.2, . . . , d.sub.D and q(w)=t.sub.1, t.sub.2, . . . , t.sub.T. Suppose for a moment that D>>T; in other words that q(v) contains many more phonemes than q(w). Then the minimum cost path through the lattice L=q(v).times.q(w) necessarily traverses many edges labeled with insertion costs .delta.(x|.epsilon.), for some x in the phoneme sequence q(v). This entails a lower bound on the minimum cost path through L, which in turn entails an upper bound on r(q(v)|q(w)).
[0213] We now explain the method in detail. Let q(v)=d.sub.1, d.sub.2, . . . , d.sub.D and q(w)=t.sub.1, t.sub.2, . . . t.sub.T, and let a threshold .THETA. be given. (The value of .THETA. may be a fixed number, a function of r(q(w)|q(w)), or determined in some other way.) We proceed to compute an upper bound r.dagger.(q(v)|q(w)) on r(q(v)|q(w)).
[0214] Let us write .delta..sub.i=.delta.(d.sub.i|E) for each phoneme d.sub.i of q(v), where i=1, . . . , D. Sort these costs in increasing order, obtaining a sequence .delta..sub.i.sub.1.ltoreq..delta..sub.i.sub.2.ltoreq. . . . .ltoreq..delta..sub.i.sub.D.
[0215] Now, because D is the number of phonemes in q(v), even if the T phonemes of q(w) are exactly matched in the minimum cost path through the lattice, that path must still traverse at least I=D-T arcs labeled with the insertion cost of some phoneme d of q(v). In other words, the cost S of the minimum cost path through the lattice is bounded below by the sum of the I smallest insertion costs listed above, S.dagger.=.delta..sub.i.sub.1+.delta..sub.i.sub.2+ . . . +.delta..sub.i.sub.T. Because S.gtoreq.S.dagger., and by definition r(q(v)|q(w))=exp(-S), if we take r.dagger.(q(v)|q(w))=exp(-S.dagger.) we have r(q(v)|q(w)).ltoreq.r.dagger.(q(v)|q(w)) as desired.
[0216] Note: the computation of the exponential can be avoided if we take B=log .THETA., and equivalently check that -B.ltoreq.S.dagger..
[0217] A similar bound may be developed for the case T>>D. For this case we consider the phoneme deletion costs .delta..sub.i=.delta.(.epsilon.|t.sub.i) for each phoneme t.sub.i of q(w), where i=1, . . . , T. As before, we sort these costs, obtaining the sequence .delta..sub.i.sub.1.ltoreq..delta..sub.i.sub.2.ltoreq. . . . .ltoreq..delta..sub.i.sub.T. Letting E=T-D, we form the sum S.dagger.=.delta..sub.i.sub.1+.delta..sub.i.sub.2+ . . . +.delta..sub.i.sub.E, and proceed as before.
Pronunciation Sequences
[0218] The preceding method of Pronunciation Lengths required either D>>T or T>>D, where these are the lengths of the respective pronunciation sequences. We now describe a method that may be applied, under suitable conditions, when D.apprxeq.T.
[0219] For each .PHI. in .PHI., define .delta..sub.sd.sup.min(.PHI.)=min {.delta.(x|.PHI.)|x.di-elect cons..PHI.'}, and define .delta..sub.si.sup.min(.PHI.)=min {.delta.(.PHI.|x)|x.di-elect cons..PHI.'}. Thus .delta..sub.sd.sup.min(.PHI.) is the minimum of all costs to delete .PHI. or substitute any other phoneme for .PHI., and likewise .delta..sub.si.sup.min(.PHI.) is the minimum of all costs to insert .PHI. or substitute .PHI. for any other phoneme. Note that these values are independent of any particular q(v) and q(w), and may be computed once for all time
[0220] To apply the method, as above let q(v)=d.sub.1, d.sub.2, . . . , d.sub.D and q(w)=t.sub.1, t.sub.2, . . . , t.sub.T, and let a threshold .THETA. be given.
[0221] For each .PHI. in .PHI., define w#(.PHI.) and v#(.PHI.) to be the number of times the phoneme .PHI. appears in q(w) and q(v) respectively. Let n(.PHI.)=w#(.PHI.)-v#(.PHI.).
[0222] Now form the sequence W\V=.PHI..sub.1, .PHI..sub.2, . . . , where for each .PHI. in .PHI. with n(.PHI.)>0, we insert n(.PHI.) copies of .PHI. into the sequence. Note that a given .PHI. may occur multiple times in W\V, and observe that for each instance of .PHI. in W\V, the minimum cost path through the lattice L=q(v).times.q(w) must traverse a substitution or deletion arc for .PHI..
[0223] Now compute S.dagger.=.SIGMA..delta..sub.sd.sup.min(.PHI.), where the sum runs over the entries of W\V. It follows that S, the cost of the true minimal cost path through L, is bounded below by S\. Hence we may define r.dagger.(q(v)|q(w))=exp(-S.dagger.) and proceed as before.
[0224] A similar method applies with the sequence V\W, where we insert n(.PHI.)=v#(.PHI.)-w#(O) copies of .PHI. in the sequence, for n(.PHI.)>0. (Note the interchange of v and w here.) We compute S.dagger.=.SIGMA..delta..sub.si.sup.min(.PHI.), where the sum runs over the entries of V\W, and proceed as above.
Incremental Computation of Confusability in a Sequence of Grammars
[0225] Suppose have two grammars, G and G', such that L(G) and L(G') differ from one another by a relatively small number of phrases, and hence so that Q(L(G)) and Q(L(G')) differ by only a small number of pronunciations. Let us write Q and Q' for these two pronunciation lists, respectively.
[0226] Suppose further that we have already computed a full set of grammar-relative pronunciation confusion probabilities, p(q(v)|q(w), G), for the grammar G. Then we may efficiently compute a revised set p(q(v)|q(w), G'), as follows.
[0227] First observe that the value of a raw pronunciation confusion measure, r(q(v)|q(w)), is independent of any particular grammar. While Q' may contain some pronunciations not in Q, for which new values r(q(v)|q(w)) must be computed, most will already be known. We may therefore proceed as follows.
[0228] 1. Compute any r(q(v)|q(w)), for q(v), q(w) in Q', not already known.
[0229] 2. Let A=Q' \ Q, that is, newly added pronunciations. Let B=Q\Q', that is, discarded pronunciations.
[0230] 3. Observe now that the normalizer Z(q(w),G')=.SIGMA.r(q(x)|q(w)), where the sum extends over q(x) in Q', excluding exact homonyms, may be reexpressed as Z(q(w),G')=Z(q(w),G)+.SIGMA..sub.q(x).di-elect cons.Ar(q(x)|q(w))-.SIGMA..sub.q(x)Br(q(x)|q(w)). Moreover, the old normalizer Z(q(w), G') is available as the quotient r(q(w)|q(w))/p(q(w)|q(w), G). Thus the new normalizer Z(q(w), G') may be computed incrementally, at the cost of computing the two small sums.
[0231] 4. Finally, p(q(v)|q(w), G') may be obtained as r(q(v)|q(w))/Z(q(w),G') as above.
5. Methods for Using Acoustic Confusability Measures
[0232] We now present two of the primary applications of an acoustic confusability measure.
[0233] The first of these, the "Confusatron," is a computer program that takes as input an arbitrary grammar G, with a finite language L(G), and finds phrases in L(G) that are likely to be frequent sources of error, for the speech recognition system. The second is a method, called maximum utility grammar augmentation, for deciding in a principled way whether or not to add a particular phrase to a grammar.
[0234] While our discussion presumes the existence of a raw pronunciation confusability measure r(q(v)|q(w)), and/or grammar-relative pronunciation confusion probabilities p(q(v)|q(w), G), the methods presented in this section are independent of the particular measures and probabilities developed in this patent, and stand as independent inventions.
The Confusatron
[0235] We now explain a computer program, which we refer to as the "Confusatron," which automatically analyzes a given grammar G to find so-called "dangerous words." These are actually elements of L(G) with pronunciations that are easily confusable, by a given automatic speech recognition technology.
[0236] The value of the Confusatron is in its ability to guide a speech recognition system designer to decide what phrases are recognized with high accuracy within a given application, and which are not. If a phrase identified as likely to be poorly recognized may be discarded and replaced by another less confusable one, in the design phase, the system is less error-prone, and easier to use. If a phrase is likely to be troublesome, but must nevertheless be included in the system, the designer is at least forewarned, and may attempt to take some mitigating action.
[0237] We begin with a description of the Confusatron's function, and its basic mode of operation. We then describe variations; all are claimed as part of the patent.
[0238] The Confusatron generates a printed report, comprising two parts.
[0239] The first part, an example of which is exhibited in FIG. 8, lists exact homonyms. These are distinct entries v, w in L(G), with v.noteq.w, for which q(v)=q(w), for some q(v).di-elect cons.Q(v) and q(w).di-elect cons.Q(w). That is, these are distinct literals with identical pronunciations. Thus no speech recognizer, no matter what its performance, is able to distinguish between v and w, when the utterance presented for recognition contains no additional context, and the utterance presented for recognition matches the given pronunciation. We say that the literals v and w "collide" on the pronunciation q(v)=q(w). Generating this homonym list does not require an acoustic confusability measure, just a complete catalog of the pronunciation set, Q(L(G)).
[0240] However, it is the second part that is really useful. Here the Confusatron automatically identifies words with distinct pronunciations that are nevertheless likely to be confused. This is the "dangerous word" list, an example of which is exhibited in FIG. 9.
[0241] The Confusatron operates as follows. Let G be a grammar, with finite language L(G), and finite pronunciation set Q(L(G)). Let {p(q(v)|q(w), G)} be a family of grammar-relative pronunciation confusability models, either derived from an underlying raw pronunciation confusion measure r(q(v)|q(w)) as described above, or defined by independent means.
[0242] It is useful at this point to introduce the quantity C(q(w), G), called the "clarity" of q(w) in G. This is a statistic of our invention, which is defined by the formula
C ( q ( w ) , G ) = 10 log 10 ( p ( q ( w ) | q ( w ) , G ) 1 - p ( q ( w ) | q ( w ) , G ) ) . ##EQU00003##
[0243] The unit of this statistic, defined as above, is called a "deciclar," where "clar" is pronounced to rhyme with "car." This turns out to be a convenient expression, and unit, in which to measure the predicted recognizability of a given pronunciation q(w), within a given grammar G. Note that the clarity is defined with reference to a particular grammar. If the grammar is clear from context, we do not mention it or denote it in symbols.
[0244] Note that the higher the value of p(q(w)|q(w), G), which is the estimated probability that q(w) is recognized as itself, when enunciated by a competent speaker, the larger the value of C(q(w), G). Thus high clarity pronunciations are likely to be correctly decoded, whereas lower clarity pronunciations are less likely to be correctly decoded. This forms the basic operating principle of the Confusatron, which we now state in detail.
[0245] 1. By plotting a histogram of clarity scores of correctly recognized and incorrectly recognized pronunciations, determine a clarity threshold F. Words with pronunciations with clarity below .GAMMA. are flagged as dangerous. Note: this step presumably need be performed only once, for a given speech recognition technology and acoustic confusability measure.
[0246] 2. Let a grammar G be given. From G, by well-known techniques, enumerate its language L(G). From L(G), by use of the functionality of the automatic speech recognition system, or by other well-known means such as dictionary lookup, enumerate the pronunciation set Q(L(G)).
[0247] 3. For each w in L(G): [0248] a. Compute the clarity C(q(w), G) of each q(w) in Q(w). (For this computation, presumably any and all of the previously described speedup techniques may be applied to reduce the execution time of this step.) [0249] b. Set the clarity of w, written C(w, G) to the minimum of C(q(w), G), over all q(w) in Q(w). If C(w, G)<.GAMMA., declare w to be dangerous, and emit w and its clarity. [0250] c. In conjunction with the clarity computations of step 3a, identify and record the phrases v for which p(v|q(w), G) attains its highest values. Emit those phrases. [0251] d. In conjunction with the clarity computations of step 3a, identify and record any exact homonyms of q(w), and emit them separately.
[0252] Several important variations of the basic Confusatron algorithm are now noted.
Results for Pronunciations
[0253] First, rather than aggregating and presenting clarity results C(q(w), G) over all q(w) in Q(w), it is sometimes preferable to report them for individual pronunciations q(w). This can be useful if it is desirable to identify particular troublesome pronunciations.
Semantic Fusion
[0254] Second, there is often some semantic label attached to distinct phrases v and w in a grammar, such that they are known to have the same meaning. If they also have similar pronunciations (say, they differ by the presence of some small word, such as "a"), it is possible that the value of p(q(v)|q(w), G) is high. This may nominally cause q(w) to have low clarity, and thereby lead to flagging w as dangerous, when in fact the pronunciations q(v) that are confusable with q(w) have same underlying meaning to the speech recognition application.
[0255] It is straightforward to analyze the grammar's semantic labels, when they are present, and accumulate the probability mass of each p(q(v)|q(w), G) into p(q(w)|q(w), G), in those cases when v and w have the same meaning. This process is known as "semantic fusion," and it is a valuable improvement on the basic Confusatron, which is also claimed in this patent.
Dangerous Word Detection Only
[0256] Suppose our task is only to decide if a given pronunciation q(w) is dangerous or not, that is if C(q(w), G)<.GAMMA.. By straightforward algebra, this can be turned into an equivalent comparison p(q(w)|q(w),G)<10.sup.(.GAMMA./10)/(1+10.sup.(.GAMMA./10)). Let us write .PSI. for this transformed threshold 10.sup.(.GAMMA./10)/(1+10.sup.(.GAMMA./10)).
[0257] Recall that p(q(w)|q(w), G)=r(q(w)|q(w))/Z(q(w), G), and that the denominator is a monotonically growing quantity, as the defining sum proceeds over all q(v) in Q(L(G)), excluding homonyms of q(w). Now by definition p(q(w)|q(w), G)<.PSI. if r(q(w)|q(w))/Z(q(w), G)<.PSI., that is if Z(q(w), G)>r(q(w)|q(w))/.PSI..
[0258] Thus, we can proceed by first computing r(q(w)|q(w)), then accumulating Z(q(w), G), which is defined as Z(q(w), G)=.SIGMA.r(q(x)|q(w)), where the sum runs over all non-homonyms of q(w) in Q(L(G)), and stopping as soon as the sum exceeds r(q(w)|q(w))/.PSI.. If we arrange to accumulate into the sum the quantities r(q(x)|q(w)) that we expect to be large, say by concentrating on pronunciations of length close to that of q(w), then for dangerous words we may hope to terminate the accumulation of Z(q(w), G) without proceeding all the way through Q(L(G)).
Maximum Utility Grammar Augmentation
[0259] Suppose we are given a predetermined utility U(w) for recognizing a phrase w in a speech recognition application, a prior probability p(w) of the phrase. Then we may define the value of the phrase, within a grammar G, as V(w, G)=p(w) p(w|w, G) U(w). We may then further define the value of a grammar as the value of all its recognizable phrases; that is, V(G)=.SIGMA.V(w,G), where the sum extends over all win L(G).
[0260] Consider now some phrase w that is not in L(G); we are trying to decide whether to add it to G or not. On the one hand, presumably adding the phrase has some value, in terms of enabling new functionality for a given speech recognition application, such as permitting the search, by voice, for a given artist or title in a content catalog.
[0261] On the other hand, adding the phrase might also have some negative impact, if it has pronunciations that are close to those of phrases already in the grammar: adding the new phrase could induce misrecognition of the acoustically close, already-present phrases.
[0262] Let us write G+w for the grammar G with w added to it. Then a principled way to decide whether or not to add a given phrase w is to compute the gain in value .DELTA.V(w), defined as .DELTA.V(w)=V(G+w)-V(G).
[0263] Moreover, given a list of phrases w.sub.1, w.sub.2, . . . , under consideration for addition to G, this method can be used to rank their importance, by considering each .DELTA.V(w.sub.i), and adding the phrases in a greedy manner. By recomputing the value gains at each stage, and stopping when the value gain is no longer positive, a designer can be assured of not inducing any loss in value, by adding too many new phrases.
[0264] Although the invention is described herein with reference to the preferred embodiment, one skilled in the art will readily appreciate that other applications may be substituted for those set forth herein without departing from the spirit and scope of the present invention. Accordingly, the invention should only be limited by the Claims included below.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
P00001
P00002
P00003
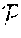
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.