Method For Identifying Clusters Of Fluorescence-activated Cell Sorting Data Points
Walther; Guenther ; et al.
U.S. patent application number 15/373241 was filed with the patent office on 2019-02-14 for method for identifying clusters of fluorescence-activated cell sorting data points. The applicant listed for this patent is THE BOARD OF TRUSTEES OF THE LELAND STANFORD JUNIOR UNIVERSITY. Invention is credited to Ilana Belitskaya-Levy, Leonore A. Herzenberg, Wayne Moore, Jinhui Pan, David Parks, Guenther Walther.
| Application Number | 20190050408 15/373241 |
| Document ID | / |
| Family ID | 43527961 |
| Filed Date | 2019-02-14 |











View All Diagrams
| United States Patent Application | 20190050408 |
| Kind Code | A9 |
| Walther; Guenther ; et al. | February 14, 2019 |
METHOD FOR IDENTIFYING CLUSTERS OF FLUORESCENCE-ACTIVATED CELL SORTING DATA POINTS
Abstract
A method and/or system for analyzing data using population clustering through density based merging.
| Inventors: | Walther; Guenther; (Mountain View, CA) ; Belitskaya-Levy; Ilana; (New York, NY) ; Pan; Jinhui; (Mountain View, CA) ; Herzenberg; Leonore A.; (Stanford, CA) ; Moore; Wayne; (San Francisco, CA) ; Parks; David; (San Francisco, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Prior Publication: |
|
||||||||||
| Family ID: | 43527961 | ||||||||||
| Appl. No.: | 15/373241 | ||||||||||
| Filed: | December 8, 2016 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 13886932 | May 3, 2013 | 9552416 | ||
| 15373241 | ||||
| 10832992 | Apr 26, 2004 | 8473215 | ||
| 13886932 | ||||
| 60465703 | Apr 25, 2003 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06F 16/2272 20190101; G16B 5/00 20190201; G16B 25/10 20190201; G06F 16/355 20190101; G06F 16/35 20190101; G06F 16/90 20190101; G06F 16/24564 20190101; G06F 16/55 20190101 |
| International Class: | G06F 17/30 20060101 G06F017/30; G06F 19/12 20060101 G06F019/12 |
Goverment Interests
STATEMENT OF GOVERNMENT FUNDING
[0002] This invention was made with Government support under contract HL68522 awarded by the National Institutes of Health. The Government has certain rights in this invention.
Claims
1.-5. (canceled)
6. An apparatus for creating groupings from data comprising: means for assigning each piece of data from said set of data to a point on a lattice; means for assigning weights to each lattice point based on the data near said lattice point; means for determining for each of said lattice points if each of said lattice points should be associated with one of its surrounding lattice points and if so creating a pointer from the individual lattice point to the surrounding lattice point it is associated with; and means for creating clusterings of the lattice points.
7. A set of application program interfaces embodied on a computer-readable medium for execution on a computer in conjunction with an application program that determines clusters within a set of data, comprising: a first interface that receives data; a second interface that receives parameters; and returns groupings of said data.
8. A method of clustering data items, wherein a data item is associated with one or more semi-continuous values, using an information system comprising: creating a reduction data item set, each reduction data item associated with one or more quantized values correlated with said one or more semi-continuous values; assigning each data item to a reduction data item according to an assignment rule; calculating weights for said reduction data items using one or more data items according to a weighting rule; determining for a plurality of reduction data items if it should be associated with another reduction data item according to an association rule; for at least one reduction data item, creating a directional association with at least one other reduction data item; and identifying one or more clusters of said reduction data items using one or more directional associations and/or one or more of said weights.
9. A method enabling analysis of large sets of data observation points, each point having multiple parameters comprising: performing a first automated clustering of data points using a subset of said parameters using an information system, said first clustering providing one or more data clusters; selecting a first selected cluster; successively performing subsequent automated child clusterings on selected clusters, while optionally choosing different parameters allowing for said clustering.
10. A method enabling analysis of large sets of data observation points, each point having multiple parameters using an information system comprising: displaying to a user results of an automated clustering of data points using a subset of said parameters, said first clustering indicating one or more data clusters; registering an input from said user selecting a first selected cluster from which to generate children clusters; providing an interface allowing a user to optionally choose different parameters allowing for said children clusters; and displaying a hierarchy of clustering results.
11. The method of claim 8, wherein the step of calculating weights includes linear binning in accordance with the formula: w m = i = 1 n j = 1 d max ( 0 , 1 - x i , j - y mj / .DELTA. j ) ##EQU00009##
12.-20. (canceled)
Description
CROSS REFERENCE TO RELATED APPLICATIONS
[0001] This application is a divisional of U.S. application Ser. No. 10/832,992, filed Apr. 26, 2004, which claims priority to U.S. provisional patent application No.60/465,703, filed 25 Apr. 2003, the contents of which is incorporated by reference herein in its entirety.
COPYRIGHT NOTICE
[0003] Pursuant to 37 C.F.R. 1.71(e), applicants note that a portion of this disclosure contains material that is subject to and for which is claimed copyright protection, such as, but not limited to, source code listings, screen shots, user interfaces, or user instructions, or any other aspects of this submission for which copyright protection is or may be available in any jurisdiction. The copyright owner has no objection to the facsimile reproduction by anyone of the patent document or patent disclosure, as it appears in the Patent and Trademark Office patent file or records. All other rights are reserved, and all other reproduction, distribution, creation of derivative works based on the contents, public display, and public performance of the application or any part thereof are prohibited by applicable copyright law.
COMPACT DISC PROGRAM LISTING APPENDIX
[0004] Attached herewith is a compact disc program listing appendix illustrating example source code illustrating specific implementations of specific embodiments of the invention.
FIELD OF THE INVENTION
[0005] The present invention relates to the field of data analysis. More specifically, the invention relates to an information system and/or method for making certain determinations regarding data sets.
[0006] In some embodiments, the invention involves a data analysis strategy useful in biologic settings, such as analyzing large populations of biologic samples. In further specific embodiments, the invention involves a data analysis method useful in cell analysis methods, such as FACS. In further specific embodiments, the invention involves a data analysis method useful in analyzing market or other data sets. In further specific embodiments, the invention involves a data analysis method useful in analysis of protein and/or genetic and/or chemical and/or other research and/or industrial data.
BACKGROUND OF THE INVENTION
[0007] The discussion of any work, publications, sales, or activity anywhere in this submission, including in any documents submitted with this application, shall not be taken as an admission that any such work constitutes prior art. The discussion of any activity, work, or publication herein is not an admission that such activity, work, or publication existed or was known in any particular jurisdiction.
[0008] In many different industrial, medical, biological, business, research and/or other settings, it is desirable to make some determinations from data sets. Both the art of data analysis and it applications have developed dramatically in recent years.
[0009] However, data analysis is often hindered by the amount of data that must be handled and the questions that can be answered thereby. Thus, various proposals have been made for Probabilistic Data Clustering, such as that discussed in U.S. Pat. No. 6,460,035 and its cited art. These proposals fall short in many applications.
OTHER REFERENCES
[0010] Fukunaga, K. and Hostetler, L. D. (1975). The estimation of the gradient of a density function, with applications in pattern recognition. IEEE Trans.Info. Thy. IT-21, 32-40
[0011] Kittler, J. (1976). A locally sensitive method for cluster analysis. Pattern Recognition 8, 23-33
[0012] Koontz, W. L. G., Narenda, P. M. and Fukunaga, K. (1976). A graph-theoretic approach to nonparametric cluster analysis. IEEE Trans. Comput. C-25, 936-943
[0013] Wand, M. P. (1994). Fast computation of multivariate kernel estimators. Journal of Computational and Graphical Statistics 3, 433-445
SUMMARY
[0014] Various methods for analyzing data can be employed in specific embodiments. According to specific embodiments, of the invention is directed to cluster creation and determines one or more useful clusters, groupings, and/or populations to which the data belongs. The invention can be used in several areas including flow cytometry analysis and analysis of marketing data. The invention may also be used with in any field in which it is found helpful to cluster and/or group data.
[0015] Various embodiments of the present invention provide methods and/or systems for analysis that can be implemented on a general purpose or special purpose information handling system using a suitable programming language such as Java, C++, Cobol, C, Pascal, Fortran, PL1, LISP, assembly, etc., and any suitable data or formatting specifications, such as HTML, XML, dHTML, TIFF, JPEG, tab-delimited text, binary, etc. In the interest of clarity, not all features of an actual implementation are described in this specification. It will be understood that in the development of any such actual implementation (as in any software development project), numerous implementation-specific decisions must be made to achieve the developers' specific goals and sub goals, such as compliance with system-related and/or business-related constraints, which will vary from one implementation to another. Moreover, it will be appreciated that such a development effort might be complex and time-consuming, but would nevertheless be a routine undertaking of software engineering for those of ordinary skill having the benefit of this disclosure.
[0016] The invention and various specific aspects and embodiments will be better understood with reference to the following drawings and detailed descriptions. In some of the drawings and detailed descriptions below, the present invention is described in terms of the important independent embodiment of a system operating on a digital device or data network.
[0017] This should not be taken to limit the invention, which, using the teachings provided herein, can be applied to other situations, such as cable television networks, wireless networks, etc.
[0018] For purposes of clarity, this discussion refers to devices, methods, and concepts in terms of specific examples. However, the invention and aspects thereof may have applications to a variety of types of devices and systems. It is therefore intended that the invention not be limited except as provided in the attached claims.
[0019] It is well known in the art that logic systems and methods such as described herein can include a variety of different components and different functions in a modular fashion. Different embodiments of the invention can include different mixtures of elements and functions and may group various functions as parts of various elements. For purposes of clarity, the invention is described in terms of systems and/or methods that include many different innovative components and innovative combinations of innovative components and known components. No inference should be taken to limit the invention to combinations containing all of the innovative components listed in any illustrative embodiment in this specification. The functional aspects of the invention that are implemented on a computer, as will be understood from the teachings herein, may be implemented or accomplished using any appropriate implementation environment or programming language, such as C, C++, Cobol, Pascal, Java, Java-script, HTML, XML, dHTML, assembly or machine code programming, etc.
[0020] All references, publications, patents, and patent applications cited herein are hereby incorporated by reference in their entirety for all purposes. All documents, data, or other written or otherwise available material described or referred to herein, is herein incorporated by reference. All materials in any IDS submitted with this application are hereby incorporated by reference.
[0021] When used herein, "the invention" should be understood to indicate one or more specific embodiments of the invention. Many variations according to the invention will be understood from the teachings herein to those of skill in the art.
BRIEF DESCRIPTIONS OF THE DRAWINGS
[0022] FIG. 1 illustrates an example of a portion of one type of data set that can be analyzed according to specific embodiments of the invention.
[0023] FIG. 2 illustrates an example user interface according to specific embodiments of the invention.
[0024] FIG. 3 illustrates an example user interface according to specific embodiments of the invention.
[0025] FIG. 4 is a block diagram showing a representative example logic device in which various aspects of the present invention may be embodied.
DESCRIPTION OF SPECIFIC EMBODIMENTS
1. DEFINITIONS
[0026] A "lattice" as used herein shall be understood to be a mathematically relationship relating to one or many dimensional analysis and representing a rules-based ordering of values used as a reference framework for performing analysis of various data-sets. Data analysis according to the present invention can be perform using reference values whether or not those values are described or describable as a lattice. For ease of illustration, a lattice herein may be drawn and discussed as comprising a two-dimensional, regular, finite and linear lattice. However, the present invention can be used with any system for determining coordinates in a data space, including lattices in three-dimensions, and higher dimensions, as well as non-linear regular lattices including logarithmic lattices, sinusoidal based lattices, etc., and rules-based lattices.
[0027] A "lattice point" as used herein shall be understood to indicate a data reduction point or region in any data space in which a lattice is defined. Thus a lattice point can have one, two, three, sixteen or any number of coordinates as appropriate for a dataspace.
[0028] Placement of a lattice point can be accomplished a number of ways, including a geometric center in the number of coordinates of the dataspace, at predefined interstitial points on the lattice in a data space, etc.
2. DESCRIPTION OF GENERAL METHOD
[0029] According to specific embodiments of the invention, a method of the invention can be understood within the art of data analysis, particularly statistical analysis and set analysis. The following description of general methods is presented in a particular order to facilitate understanding and it will be understood in the art that according to specific embodiments of the invention various steps can be performed in different orders and can be organized and/or atomized in different ways. A familiarity with the field of data set analysis and the reference mentioned herein will aid in understanding the invention.
Data Set
[0030] According to specific embodiments of the invention, a data set of observations is analyzed to determine meaningful clusters. For purposes of understand the invention, consider a large data set of n observations, where n can be very large, such as n>>10.sup.6. FIG. 1 illustrates an example of a portion of one type of data set that can be analyzed according to specific embodiments of the invention. In a variety of different fields, each observation of interest will have associated with it a number of parameters where each parameter (or dimension) can represent some observed or calculated or predicted parameter relative to observation and/or sample x.sub.i. For example, in FACS, a number of dimensions may be a light intensity measured for a particular cell and/or group and/or sample of cells, in market analysis each dimension may be a measure of different characteristics and/or predictions and/or observations related to a market participant x.sub.i. In genetic analysis, parameters can be different states that a specific DNA/RNA location can represent. In protein analysis, each observation could be an amino acid and each parameter an angle or folding configuration or other state of the amino acid in a protein.
The Cluster Model
[0031] According to specific embodiments of the invention and as will be generally understood in the art, it is assumed that the observations can be clustered in at least two groups or clusters, with one of the at least two being a background state or cluster representing observations that are due to noise, etc. According to specific embodiments of the invention, the invention uses a method that can be employed on an information system to automatically determine a number of clusters that are useful and to assign data points and/or divide the data space to correspond to those clusters. The invention employs novel methods to do so even in large data set environments.
Data Reduction
[0032] Lattice/Grid
[0033] According to specific embodiments of the invention, a lattice or grid is determined in the data space according to a lattice rule. In generally terms, the lattice can be understood as simply a regular and normalized lattice in the number of dimensions and with normalization set to take account of a set of data points of interest. In a particular embodiment, the lattice has the same number of intervals in all directions. In this case, a lattice with M intervals in each direction will define Md lattice points.
[0034] Weighting
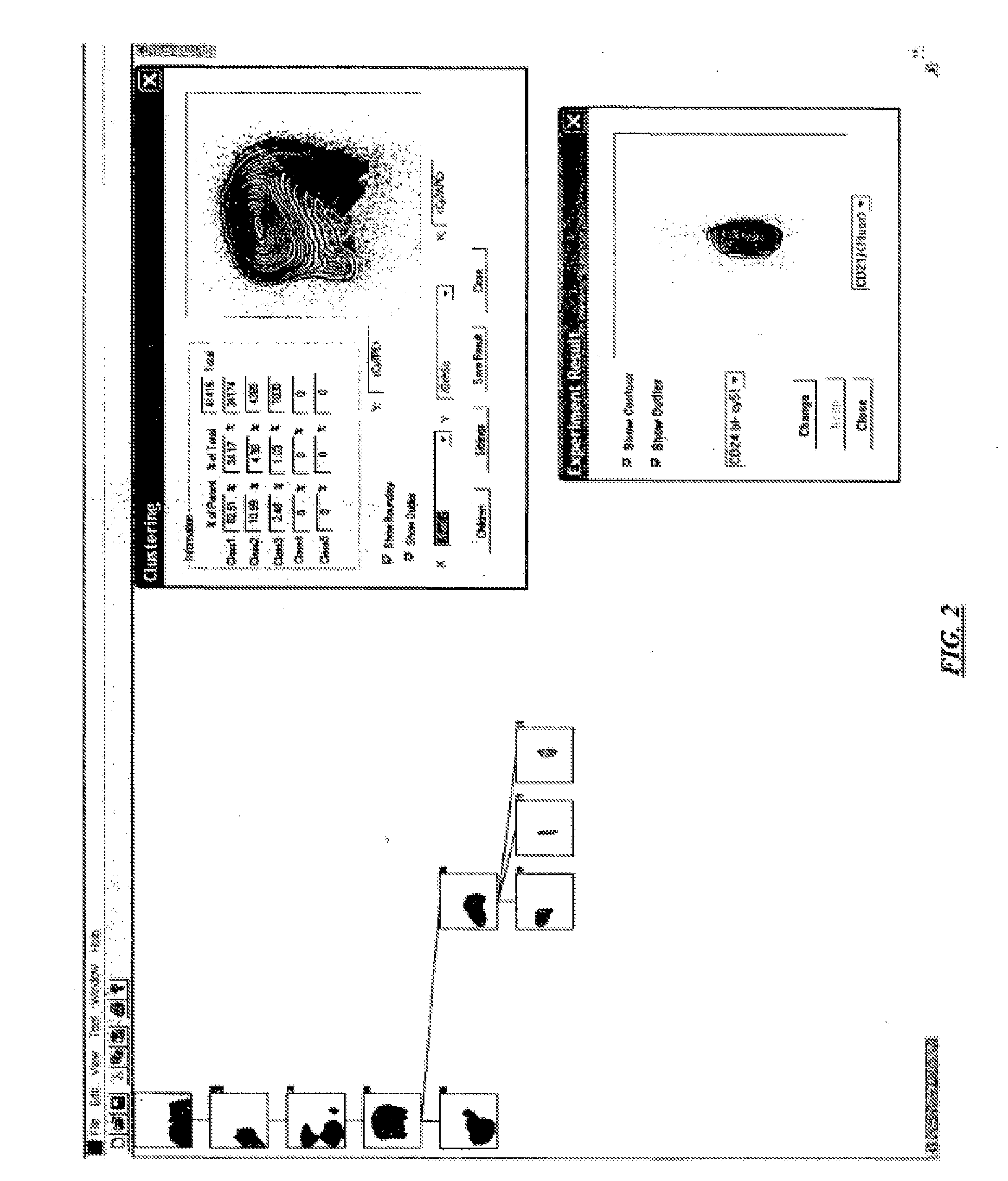
[0035] According to specific embodiments of the invention, each lattice point is assigned a weight that is based on one or more of the observed data points. Weights can be assigned in a number of fashions, but can be understood as the average of all the values in the data set near that point. The region of average for determining weights may be reduced.
[0036] Density Estimate
[0037] With the lattice points defined and each point having a set of weighted parameter values associated with it, the invention according to specific embodiments, next determines an estimated density surface that allows lattice points to be compared.
[0038] Determining Pointers/Paths Between Lattice Points
[0039] Using the lattice points, weights, and surface, the invention next traces out one or more paths between the lattice points. This analysis can be performed by beginning at any lattice point and making a directional connection to one of the surrounding lattice points following a rule based on the density surface, for example, a rule that seeks to follow the steepest path between points. Lattice points that do not have a surrounding point that meets the rule are terminal lattice points and are either associated with a new cluster or with a default background cluster. One or more methods can be used to split paths that converge on a false maximum.
[0040] According to specific embodiments of the invention, at the end of the analysis, each lattice point will have associated with it one or more directional pointers in one or more paths, with the paths defining one or more meaningful clusters.
[0041] In further specific embodiments, a lattice point either has one directed pointer emanating from it or not. The pointer from a first l ttice point to a second lattice point represents an association between the first lattice point and the second lattice point. The lattice points may be scanned in any direction or manner to determine whether each of the particular lattice points possesses a pointer to any of the other neighboring lattice points. In specific embodiments, the determination of whether there is a pointer and to which lattice point the pointer points to is as follows and can be performed for every lattice point or for some subset of lattice points.
Example of Determining Existence of Direction of a Pointer
[0042] For a given lattice point, the value of the density estimate at that given lattice point may be compared to the value of the density estimate of all of the neighboring lattice points. If the former is smaller than the maximum of the latter, a pointer from the given lattice point is established to the neighboring lattice point where the maximum is attained. If the former is larger than the maximum of the later, then no pointer is created and that lattice point can be understood as representing a local maximum. After doing this at each lattice point, the result is one or more pointer chains, each consisting of a sequence of pointers that consecutively connect a number of lattice points. Several chains may end in the same lattice point.
[0043] According to specific embodiments of the invention, an example method can be described as choosing a lattice point and traversing the sequence of pointers emanating from that lattice point to a peak lattice point. If the density estimate of the last lattice point is above a certain threshold (such as the 65th percentile of all density estimates on the lattice), then this lattice point is labeled as the root of a cluster; if not, then all lattice points along the chain are labeled as background noise. Then the algorithm proceeds to the next chain. If the last lattice point of that chain was already traversed before, i.e. it is also a member of an earlier chain, then the chain is merged with the earlier chain, i.e. it points to the same root, or is assigned to background noise. Otherwise, this chain is dealt with as the first chain, resulting in a new root of a cluster or in an assignment to background noise. After the algorithm has dealt with all chains, each lattice point is assigned via a sequence of pointers to either a root of a cluster, or to background noise. Next, the algorithm determines whether some roots need to be merged.
[0044] Merging
[0045] If the distance of two roots is below a threshold (such as 3 lattice points), then they will be merged by giving them the same identifier. Two roots will also be merged if there is a path of consecutive lattice points along which the values of the density estimates (described in the previous paragraph) do not fall more than a certain amount below the minimum values of the two roots. For instance the minimum chosen may be 5% of the square root of the minimum value of the two roots. After each pair of roots has been considered, the algorithm iterates the procedure on the new roots until no more changes are made.
[0046] Thus, each resulting root represents a cluster. The cluster membership of each data point can be determined as follows. First one may find the nearest lattice point and then follow the chain of pointers to a root, which represents the cluster, or to a label assigning it to background noise. A list is established, which notes for each lattice point the pertaining cluster number, or notes that it is background noise.
[0047] For each cluster, all pertaining data points can be retrieved as follows: Going through the above list delivers all lattice points pertaining to that cluster, and the data points pertaining to each lattice point can be accessed e.g. via a Voronoi diagram.
[0048] Assigning Observed Points to Lattice Points
[0049] With the lattice points each assigned to a cluster or to background noise, the observations are assigned to clusters by relating each observation to a lattice point and then using the cluster assignment of the lattice point. This is accomplished by an assignment rule. One assignment rule that can be used according to specific embodiments of the invention is to assign each data point to the nearest (in Euclidean metric) lattice point, as described below.
3. EXAMPLE USER INTERFACE
[0050] The algorithm may be executed through a web-page and web-server. An exemplary display will appear as shown in FIG. 2 or FIG. 3. An alternative embodiment may be the use of the present algorithm with a command line interface instead of a GUI interface.
Example Execution Environment
[0051] The preferred embodiment is for the present invention to be executed by a computer as software stored in a storage medium. The present invention may be executed as an application resident on the hard disk of a PC computer with an Intel Pentium or other microprocessor and displayed with a monitor. The processing device may also be a multiprocessor. The computer may be connected to a mouse or any other equivalent manipulation device. The computer may also be connected to a view screen or any other equivalent display device.
4. EXAMPLE DETAILED DESCRIPTION
[0052] The present invention can also be described using terms and mathematically notation that are generally familiar in the fields of statistical analysis. It would be a straightforward endeavor using the description provided below to configure and/or program an information processing system to perform in accordance with this mathematically description.
Data Set
[0053] Consider a data set of n observations x.sub.1, . . . , x.sub.n, where n can be very large, such as n>>10.sup.6 for example for FACS analysis or large scale population and/or market analysis. Each observation x.sub.i has d dimensions, where each dimension can represent some observed or calculated or predicted parameter relative to observation and/or sample x.sub.i. For example, in FACS, a number of dimensions may be a light intensity measured for a particular cell and/or group and/or sample of cells, in market analysis each dimension may be a measure of different characteristics and/or predictions and/or observations related to a market participant x.sub.i. In some FACS applications, for example, d.about.10. Thus, in specific embodiments, each x.sub.i can be understood to denote an ordered set of values, representing the dimensions 1 to d, e.g., x.sub.i={d.sub.1, d.sub.2, d.sub.3 . . . d.sub.d}. or, using notation that will allow individual dimensions to be indicated for specific observations x.sub.i={x.sub.i,1, x.sub.i,2, x.sub.i,3 . . . , x.sub.i,d}.
[0054] In specific implementations, an implementation of the invention (e.g., a software implementation) according to specific embodiments uses d=2 and can, for example examine 2-dimensional projections and/or two-dimensional samples of higher-dimensional data. A method according to specific embodiments of the invention can further successively and/or selectively and/or interactively use various sets of 2 or more dimensions to perform clustering and can further select and/or combine results for different 2 or more dimensional analysis. The detailed interface example shows one example of an interactive two-dimensional analysis system allowing for successive analyses.
[0055] According to further specific embodiments of the invention, in selecting a cluster for further analysis, the invention may use extrinsic information either to enhance an interactive selecting or to perform an automatic selection of a cluster for further analysis. This intrinsic information can include information in a database, knowledge base or any other externally supplied information.
[0056] Furthermore, in the present discussion, assume that one or more dimensions/coordinates of observations x; are continuous for some given decimal precision.
[0057] For example, for FACS data, each observation x.sub.i could represents one cell and/or sample measured and each parameter and/or coordinate and/or dimensional value represents a measured characteristic of the cell. In many typical FACS systems, one or more parameters of an observed cell x.sub.i will represent a florescence color detected for a cell. As a further example, for marketing data, each observation x.sub.i can represent a market participant with each coordinate representing a certain characteristic and/or prediction and/or observation of the market participant such as income, confidence, buying characteristics, market power, etc.
The Cluster Model
[0058] According to specific embodiments of the invention and as will be generally understood in the art, it is assumed that the observations x.sub.i, . . . , x.sub.n are drawn from (or generated by) a density
f ( x ) = k = 1 K a .kappa. g .kappa. ( x ) , a .kappa. > 0 , .kappa. a .kappa. = 1. ( 1 ) ##EQU00001##
where represent g.sub.k represent one of a number of clusters/components 1 through K and .alpha..sub.k represents a percentage coefficient value that each cluster contributes to the total set of observed data. Thus, k represents a cluster index. In the art, it is sometimes said that the densities g.sub.k(x) are the component densities that represent the populations (or clusters).
[0059] Furthermore, according to specific embodiments of the invention from experience in the case of example FACS data, assume for the component densities g.sub.k that all level sets L(t)={x .di-elect cons.R.sup.d:g.sub..kappa.(x).gtoreq.t}, t.gtoreq.0, are path connected, that is for every t.gtoreq.0 and every x, y .di-elect cons. L(t) there exists a continuous function
p:[0,1]R.sup.d such that p(0)=x, p(1)=y and p(u) .di-elect cons.L(t) for all u .di-elect cons.[0,1].
[0060] Thus, according to the example model shown in Eq. (1), each observation x.sub.i arises from one of the components/clusters g.sub.k, k=1, . . . ,K, where g.sub.1 is a cluster that is understood or assigned to model `background noise` (e.g., g.sub.1 is understood as the source of all observations x.sub.i that are not related to, or grouped by any of the clusters g.sub.2, . . . ,g.sub.k).
[0061] An aspect of an example clustering procedure is to determine, based on x.sub.1, . . . ,x.sub.n, a value for K (e.g., how many components/clusters there are) and to determine a rule that assigns each observation x.sub.i and or each region of the relevant data space (to provide assignment for future observations not yet available) to one of the components/clusters g.sub.k.
Example Data Reduction
[0062] Example Lattice/Grid Use
[0063] Again, typically x.sub.i can represent very large sets of data, include sets where the number of observations x.sub.i are much greater than 10.sup.6. Thus, to reduce the data set both to allow for easier computation and to provide other inferences, a data reduction technique using a lattice is used as described in detail below.
[0064] According to specific embodiments of the invention, a lattice L is constructed and/or assumed and/or defined in R.sup.d space consisting of M.sup.d points, where M is generally a positive integer, and for example for FACS applications can be such as 64 or 128. In general terms, such a lattice can be understood as simply a regular and normalized lattice in d dimensions where the normalization is set to take account of all or some subset of the observed data. Stated more formally, set .DELTA..sub.j=max.sub.ix.sub.ij-min;x.sub.ij)/(M-1), j=1, . . . ,d, in other words, set the size of a d-dimensional unit area or volume to be .DELTA..sub.j. Define the jth coordinate of lattice points y(ml, . . . ,md) to be y.sub.mj=min.sub.ix.sub.ij+(m.sub.j-1).DELTA..sub.j, m.sub.j=1, . . . ,M. Then the lattice L is defined as L={y.sub.(ml, . . . ,md):(m.sub.1, . . . ,m.sub.d).di-elect cons.{1, . . . ,M}.sup.d}.
Example Weighting Assignment
[0065] Next, each lattice point y.sub.m is assigned a weight w.sub.m that, for example, is derived in part from one or more of the observed data points x.sub.i in the data space. One weight assignment example according to specific embodiments of the present invention is to use a linear binning technique such as:
w m = i = 1 n j = 1 d max ( 0 , 1 - x i , j - y mj / .DELTA. j ) . ##EQU00002##
While this particular example formally uses all of the observations x; in calculating each weighting faction, in fact points more than 111 away are largely not included in the weight for a particular ym. Various other weighting functions, including functions that eliminate outlying points, etc., can be used to assign weights according to specific embodiments of the invention. Examples of such methods that can be employed according to specific embodiments of the invention are as described in Fan, hanging and Marron, James S. "Fast implementations of nonparametric curve estimators". Journal of Computational and Graphical Statistics. 1994, Vol. 3, 35-56.
Computing the Density Estimate
[0066] According to specific embodiments of the invention, at each lattice point y.sub.m a calculation is performed allowing the contours of the y.sub.m lattice points based on weights to be analyzed. One method for doing this is to compute an estimate of a density surface {circumflex over (f)}(y.sub.m). According to specific embodiments of the invention, this can be performed as follows. Denote the Gaussian kernel by .phi.(b)=1/ {square root over (2)}.pi.exp(-b.sup.2/2). Then the estimated density at y.sub.m can be computed by:
f ^ ( y m ) = 1 / n l 1 = - Z 1 Z 1 l d = - Z d Z d .omega. m - 1 j = 1 d .phi. ( l j .DELTA. j / h j ) / h j , ##EQU00003##
where
1=(l.sub.1, . . . , l.sub.d), Z.sub.j=min(.left brkt-bot.4h.sub.j/.DELTA..sub.j.right brkt-bot.l,M-1), and h.sub.j=SD({x.sub.i,j, i=1, . . . ,n})n.sup.-1/(d+4))
where SD denotes standard deviation. The sum in the previous display can be computed quickly with the Fast Fourier Transform (FFT) in a well-known way, for example as discussed in Wand (1994), but it can also be computed directly using the above formula without the FFT. Note that while this expression has been written for clarity in terms of the observations x.sub.ij, it could equivalently be written in terms of y.sub.m and the weights.
Clustering By Associating Pointers Between Lattice Points
[0067] According to specific embodiments of the invention, clusters are determined in the lattice space defined by lattice points y.sub.m using a correlation between the lattice points, such as the density surface. In order to make associations between the lattice points, considering each lattice point y.sub.m in turn, according to specific embodiments, the invention computes
.sigma. ^ m 2 = 1 n ( n - 1 ) l 1 = - Z 1 Z 1 l d = - Z 1 Z d w m - 1 j = 1 d .phi. 2 ( l j .DELTA. j / h j ) / h j 2 - 1 n - 1 f ^ ( y m ) 2 , ##EQU00004##
[0068] which can be generally understood as an estimate of the standard deviation of the density estimate. The sum can be computed with the FFT as above. Define the index set
S={m .di-elect cons.{1, . . . M}.sup.d:{circumflex over (f)}(y.sub.m)>4.3* {square root over ({circumflex over (.sigma.)}.sub.m.sup.2)}}.
[0069] According to specific embodiments of the invention, association pointers are used to determine clusters. These pointers can be understood as pointing from a lattice point to a neighboring lattice point. In specific embodiments, these pointers are established or removed by successively executing a series of evaluations, such as described below.
[0070] Step 1:
[0071] For all lattice points y.sub.m where m .di-elect cons. S.sub.1, in turn:
[0072] Consider all the neighboring lattice points p.sub.1, . . . ,p.sub.nm which are defined as the set of all lattice points contained in a d-dimensional rectangular volume. Let p .di-elect cons. {p.sub.1, . . . , p.sub.nm}such that {circumflex over (f)}(p)=max.sub.k.infin.l, . . . , nm{circumflex over (f)}(p.sub.k), splitting ties in an arbitrary manner. Then step 1 establishes an association pointer from y.sub.m top provided the following two conditions hold:
{circumflex over (f)}(p)>{circumflex over (f)}(y.sub.m); and
.differential. .differential. e f ^ ( y m ) > .lamda. m , where e = ( p - y m ) / p - y m , ##EQU00005##
denotes Euclidean norm, and
.differential. .differential. e f ^ ( y m ) = .sigma. = 1 d e .differential. .differential. y m e f ^ ( y m ) , ##EQU00006##
which indicates a gradient of the density estimate,
.differential. .differential. y m e f ^ ( y m ) = 1 / n l 1 = - Z 1 Z 1 l d = - Z d Z d w m - 1 - l .alpha. .DELTA. a h a 2 j = 1 d .phi. ( l j .DELTA. j / h j ) / h j ##EQU00007## .lamda. m = q ( 0.95 1 / .kappa. ) ^ m 2 ##EQU00007.2## .kappa. = # S .SIGMA. mes w m n ( 2 .pi. ) d / 2 j = 1 d h j mes w m f ^ ( y m ) ##EQU00007.3## ^ m 2 = 1 n - 1 ( a , b = 1 d e a e b [ A - .differential. .differential. y m a f ^ ( y m ) .differential. .differential. y m b f ^ ( y m ) ] ) ##EQU00007.4## A = 1 / n l 1 = - Z 1 Z 1 l d = - Z d Z d w m - 1 l a l b .DELTA. a .DELTA. b h a 2 h b 2 .PHI. = 1 .delta. .phi. 2 ( l j .DELTA. j / h j ) / h j 2 ##EQU00007.5##
(A is an estimate of
.differential. .differential. y m e f ( y m ) .differential. .differential. y m b f ( y m ) . ) ##EQU00008##
q(x) denotes the 100xth percentile of the standard normal distribution. All the sums can be computed with the FFT as above.
[0073] Step 2:
[0074] From each lattice point y.sub.m, m .di-elect cons. S, a pointer is established that points to a state representing the background noise.
[0075] Step 3:
[0076] For all lattice points Y.sub.m, m S, in turn:
[0077] If a pointer originates at y.sub.m then it will point to a different lattice point, which itself may have a pointer originating from it. A succession of pointers is followed until one arrives at a lattice point y.sub.z is reached that either (a) does not have any pointer originating from it, or (b) has a pointer originating from it that points to a state representing a cluster or background noise.
[0078] In case (a), all the pointers visited in the succession will be removed and new pointers originating from each lattice point visited in the succession will be established to the background noise state, provided that: {circumflex over (f)}(y.sub.z)<q(0.95.sup.1/x) {square root over ({circumflex over (.sigma.)}.sub.z.sup.2)}. Otherwise, only the pointer originating from y.sub.z (if any) will be removed, and a new pointer will be established that originates from y.sub.z and points to a newly cluster state. In case (b) above, no pointers are removed or established.
[0079] Step 4:
[0080] Let {y.sub.m(1), . . . y.sub.m(k)} be the set of all lattice points which have a pointer originating from them to a dummy state representing a cluster, enumerated such that [0081] {circumflex over (f)}(y.sub.m(l)).gtoreq. . . . .gtoreq.{circumflex over (f)}(y.sub.m(k)), and for i=l, . . . k do: [0082] Set A={m(i)}. Iterate the following loop until no more indices are added to A: (Begin loop) [0083] For each index .alpha..di-elect cons.A in turn, add all the indices p to A that satisfy: [0084] y.sub.p is a neighbor or y.sub.a as defined in step 1, and [0085] no pointer originates from y.sub.p, and
[0085] {circumflex over (f)}(y.sub.p)+{circumflex over (.sigma.)}.sub.p.gtoreq.{circumflex over (f)}(y.sub.m(i))+{circumflex over (.sigma.)}.sub.m(i)
[0086] (End loop)
[0087] Denote by B the set of indices of lattice points from which a pointer originates to a cluster state and that also have some yP' p E as neighbor. If B is not empty, then do the following: [0088] Define q by {circumflex over (f)} (y.sup.q)=max.sub.reB{circumflex over (f)}(y.sub.r), breaking ties arbitrarily. [0089] Establish a pointer from each y.sub.p, p .di-elect cons.A\{m(i)}, to y.sub.q For each r.di-elect cons.B,r.noteq.q: remove the pointer from y.sub.r to the state representing a cluster, and establish a new pointer from y.sub.r to y.sub.q (End loop over i)
[0090] Step 5:
[0091] Repeat step 4 until there are no more additions or deletions of pointers to cluster state.
[0092] Step 6:
[0093] From each lattice point that does not have pointer originating from it, establish a pointer pointing to the background noise state.
Lattice Point Results
[0094] With the above described procedure, according to specific embodiments of the invention, every lattice point has a pointer originating from it. Following the succession of pointers leads to a state outside of the lattice point space which either represents a background noise or a cluster. All lattice points that are linked pertain to the same cluster or to background noise.
Assigning Observed Points to Lattice Points
[0095] With the lattice points each assigned to a cluster or to background noise,
Observations x.sub.i are assigned to clusters by relating each observation to a lattice point and then using the cluster assignment of the lattice point. This is accomplished by an assignment rule. In specific embodiments, each observation x.sub.i is assigned to the lattice point y.sub.m that is closest to x.sub.i in Euclidean norm. Then x.sub.i is assigned to the same cluster to which its associated lattice point ym is assigned. Likewise, all observations assigned to a certain cluster can be found as follows: Find all lattice points y.sub.m that the algorithm assigns to the given cluster, then find all observations x.sub.i that are assigned to these lattice points.
5. EXAMPLE INTERFACE
[0096] FIG. 2 illustrates an example user interface according to specific embodiments of the invention. FIG. 3 illustrates an example user interface according to specific embodiments of the invention. From the left is illustrated a tree that shows parent-children relationships of clustering results.
[0097] In the upper right window is illustrated detailed information regarding three identified clusters (Class1, Class2, and Class3) at a particular iteration of the cluster selection. The details shown in this example interface include, for each cluster/class, the % of the selected parent cluster that is in this identified cluster (e.g., 82.51 for Class1), the % of the total population that is in this identified cluster (e.g.,34.17 for Class1), and the total number of observations in that class (e.g.,34174). In this example, the total number of observations being analyzed in these displayed clusters is as indicated in the figure. (e.g., 41416).
[0098] According to specific embodiments of the invention, an interface such as that shown can also include labels indicating X and Y parameters, option inputs to show boundaries and/or contours and/or outliers, and inputs to save results.
[0099] From this window, clustering of other regions can be performed by selecting children to indicate a sub region or siblings to indicate a different clustering to be performed from the parent and further inputting the desired clustering parameters using the drop down X and Y inputs shown. FIG. 3, for example, shows a three children clusters identified from class 2 of FIG. 1.
[0100] According to specific embodiments of the invention, the right-bottom window is a window to allow a user to try different clustering parameters. The results in this window are not kept until a user chooses to do this by clicking the "keep" button.
[0101] Thus, according to specific embodiments of the invention, the invention automatically finds clusterings for a user that they must find manually otherwise. The interface provides a clear and hierarchical display to indicate the clusterings results.
6. EMBODIMENT IN A PROGRAMMED INFORMATION ANNLIANCE
[0102] FIG. 4 is a block diagram showing a representative example logic device in which various aspects of the present invention may be embodied. As will be understood from the teachings provided herein, the invention can be implemented in hardware and/or software. In some embodiments, different aspects of the invention can be implemented in either client-side logic or server-side logic. Moreover, the invention or components thereof may be embodied in a fixed media program component containing logic instructions and/or data that when loaded into an appropriately configured computing device cause that device to perform according to the invention. A fixed media containing logic instructions may be delivered to a viewer on a fixed media for physically loading into a viewer's computer or a fixed media containing logic instructions may reside on a remote server that a viewer accesses through a communication medium in order to download a program component.
[0103] FIG. 4 shows an information appliance or digital device 700 that may be understood as a logical apparatus that can perform logical operations regarding image display and/or analysis as described herein. Such a device can be embodied as a general purpose computer system or workstation running logical instructions to perform according to specific embodiments of the present invention. Such a device can also be custom and/or specialized laboratory or scientific hardware that integrates logic processing into a machine for performing various sample handling operations. In general, the logic processing components of a device according to specific embodiments of the present invention is able to read instructions from media 717 and/or network port 719, which can optionally be connected to server 720 having fixed media 722. Apparatus 700 can thereafter use those instructions to direct actions or perform analysis as understood in the art and described herein. One type of logical apparatus that may embody the invention is a computer system as illustrated in 700, containing CPU 707, optional input devices 709 and 711, storage media (such as disk drives) 715 and optional monitor 705. Fixed media 717, or fixed media 722 over port 719, may be used to program such a system and may represent a disk-type optical or magnetic media, magnetic tape, solid state dynamic or static memory, etc.. The invention may also be embodied in whole or in part as software recorded on this fixed media. Communication port 719 may also be used to initially receive instructions that are used to program such a system and may represent any type of communication connection.
[0104] FIG. 4 shows additional components that can be part of a diagnostic system in some embodiments. These components include a microscope or viewer or detector 750, sampling handling 755, light source 760 and filters 765, and a CCD camera or capture device 780 for capturing digital images for analysis as described herein for luminance detection. It will be understood to those of skill in the art that these additional components can be components of a single system that includes logic analysis and/or control. These devices also may be essentially stand-alone devices that are in digital communication with an information appliance such as 700 via a network, bus, wireless communication, etc., as will be understood in the art. It will be understood that components of such a system can have any convenient physical configuration and/or appear and can all be combined into a single integrated system. Thus, the individual components shown in FIG. 4 represent just one example system.
[0105] The invention also may be embodied in whole or in part within the circuitry of an application specific integrated circuit (ASIC) or a programmable logic device (PLD). In such a case, the invention may be embodied in a computer understandable descriptor language, which may be used to create an ASIC, or PLD that operates as herein described.
7. OTHER EMBODIMENTS
[0106] The invention has now been described with reference to specific embodiments. Other embodiments will be apparent to those of skill in the art. In particular, a viewer digital information appliance has generally been illustrated as a personal computer. However, the digital computing device is meant to be any information appliance suitable for performing the logic methods of the invention, and could include such devices as a digitally enabled laboratory systems or equipment, digitally enabled television, cell phone, personal digital assistant, etc. Modification within the spirit of the invention will be apparent to those skilled in the art. In addition, various different actions can be used to effect interactions with a system according to specific embodiments of the present invention. For example, a voice command may be spoken by an operator, a key may be depressed by an operator, a button on a client-side scientific device may be depressed by an operator, or selection using any pointing device may be effected by the user.
[0107] It is understood that the examples and embodiments described herein are for illustrative purposes and that various modifications or changes in light thereof will be suggested by the teachings herein to persons skilled in the art and are to be included withinthe spirit and purview of this application and scope of the claims.
[0108] All publications, patents, and patent applications cited herein or filed with this application, including any references filed as part of an Information Disclosure Statement, are incorporated by reference in their entirety.
* * * * *
D00000
D00001
D00002
D00003
D00004

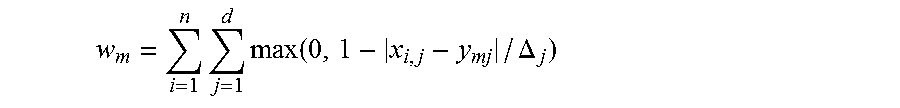
P00001

XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.