Aptamers For Oral Care Applications
Velasquez; Juan Esteban ; et al.
U.S. patent application number 16/059597 was filed with the patent office on 2019-02-14 for aptamers for oral care applications. The applicant listed for this patent is The Procter & Gamble Company. Invention is credited to Gregory Allen Penner, Paul Albert Sagel, Amy Violet Trejo, Juan Esteban Velasquez.
| Application Number | 20190048349 16/059597 |
| Document ID | / |
| Family ID | 63371804 |
| Filed Date | 2019-02-14 |










View All Diagrams
| United States Patent Application | 20190048349 |
| Kind Code | A1 |
| Velasquez; Juan Esteban ; et al. | February 14, 2019 |
APTAMERS FOR ORAL CARE APPLICATIONS
Abstract
An aptamer composition is disclosed which has one or more oligonucleotides that include at least one of deoxyribonucleotides, ribonucleotides, derivatives of deoxyribonucleotides, derivatives of ribonucleotides, or mixtures thereof. The aptamer composition has a binding affinity for a material that is at least one of tooth, enamel, dentin, carbonated calcium-deficient hydroxyapatite, or mixtures thereof.
| Inventors: | Velasquez; Juan Esteban; (Cincinnati, OH) ; Trejo; Amy Violet; (Oregonia, OH) ; Sagel; Paul Albert; (Maineville, OH) ; Penner; Gregory Allen; (Lond, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 63371804 | ||||||||||
| Appl. No.: | 16/059597 | ||||||||||
| Filed: | August 9, 2018 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 62542936 | Aug 9, 2017 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | A61Q 11/00 20130101; C12N 2310/321 20130101; C12N 2310/314 20130101; A61K 31/4706 20130101; A61K 8/606 20130101; A61K 47/549 20170801; A61K 31/7125 20130101; B82Y 5/00 20130101; C12N 2310/3341 20130101; C11D 1/90 20130101; A61K 9/1676 20130101; A61K 47/14 20130101; A61K 31/522 20130101; A61K 9/51 20130101; C12N 15/115 20130101; C12N 2310/3125 20130101; C12N 2310/313 20130101; A61K 47/26 20130101; C12N 2310/16 20130101; C12N 2310/315 20130101 |
| International Class: | C12N 15/115 20060101 C12N015/115; A61K 9/16 20060101 A61K009/16; A61K 31/7125 20060101 A61K031/7125; A61K 47/26 20060101 A61K047/26; A61K 9/51 20060101 A61K009/51; A61K 31/522 20060101 A61K031/522; A61K 31/4706 20060101 A61K031/4706; A61K 47/14 20060101 A61K047/14 |
Claims
1. An aptamer composition comprising an oligonucleotide that is at least one of deoxyribonucleotides, ribonucleotides, derivatives of deoxyribonucleotides, derivatives of ribonucleotides, or mixtures thereof; wherein the aptamer composition has a binding affinity for at least one of tooth, enamel, dentin, carbonated calcium-deficient hydroxyapatite, or mixtures thereof.
2. The aptamer composition of claim 1, wherein the aptamer composition has a binding affinity for tooth.
3. The aptamer composition of claim 1, comprising at least one oligonucleotide that has at least 50% nucleotide sequence identity to at least one of SEQ ID NO 1 to SEQ ID NO 234.
4. The aptamer composition of claim 1, comprising at least one oligonucleotide of SEQ ID NO 1 to SEQ ID NO 234.
5. The aptamer composition of claim 1, comprising an oligonucleotide that is at least one of SEQ ID NO 1, SEQ ID NO 9, SEQ ID NO 25, SEQ ID NO 112, SEQ ID NO 120, SEQ ID NO 136, or SEQ ID NO 223 to SEQ ID NO 234.
6. The aptamer composition of claim 1, wherein the oligonucleotide comprises one or more motifs that are at least one of SEQ ID NO 235, SEQ ID NO 236, SEQ ID NO 237, SEQ ID NO 238, SEQ ID NO 239, SEQ ID NO 240, SEQ ID NO 241, SEQ ID NO 242, SEQ ID NO 243, and SEQ ID NO 244.
7. The aptamer composition of claim 1, wherein the oligonucleotide comprises natural or non-natural nucleobases.
8. The aptamer composition of claim 7, wherein the non-natural nucleobases are at least one of hypoxanthine, xanthine, 7-methylguanine, 5,6-dihydrouracil, 5-5-methylcytosine, 5-hydroxymethylcytosine, thiouracil, 1-methylhypoxanthine, 6-methylisoquinoline-1-thione-2-yl, 3-methoxy-2-naphthyl, 5-propynyluracil-1-yl, 5-methylcytosin-1-yl, 2-aminoadenin-9-yl, 7-deaza-7-iodoadenin-9-yl, 7-deaza-7-propynyl-2-aminoadenin-9-yl, phenoxazinyl, phenoxazinyl-G-clam, or mixtures thereof.
9. The aptamer composition of claim 1, wherein the nucleosides of the oligonucleotide are linked by a chemical motif that is at least one of natural phosphate diester, chiral phosphorothionate, chiral methyl phosphonate, chiral phosphoramidate, chiral phosphate chiral triester, chiral boranophosphate, chiral phosphoroselenoate, phosphorodithioate, phosphorothionate amidate, methylenemethylimino, 3'-amide, 3' achiral phosphoramidate, 3' achiral methylene phosphonates, thioformacetal, thioethyl ether, or mixtures thereof.
10. The aptamer composition of claim 1, where the derivatives of ribonucleotides or said derivatives of deoxyribonucleotides are at least one of locked oligonucleotides, peptide oligonucleotides, glycol oligonucleotides, threose oligonucleotides, hexitol oligonucleotides, altritol oligonucleotides, butyl oligonucleotides, L-ribonucleotides, arabino oligonucleotides, 2'-fluoroarabino oligonucleotides, cyclohexene oligonucleotides, phosphorodiamidate morpholino oligonucleotides, or mixtures thereof.
11. The aptamer composition of claim 1, comprising at least one polymeric material, wherein the at least one polymeric material is covalently linked to the oligonucleotide.
12. The aptamer composition of claim 11, wherein the at least one polymeric material is polyethylene glycol.
13. The aptamer composition of claim 1, wherein the nucleotides at the 5'- and 3'-ends of the oligonucleotide are inverted.
14. The aptamer composition of claim 1, wherein at least one nucleotide of the oligonucleotide is fluorinated at the 2' position of the pentose group.
15. The aptamer composition of claim 1, wherein pyrimidine nucleotides of the oligonucleotide are fluorinated at the 2' position of the pentose group.
16. The aptamer composition of claim 1, wherein the oligonucleotide is covalently or non-covalently attached to at least one oral care active ingredient comprising whitening agents, brightening agents, anti-stain agents, anti-cavity agents, anti-erosion agents, anti-tartar agents, anti-calculus agents, anti-plaque agents, teeth remineralizing agents, anti-fracture agents, strengthening agents, abrasion resistance agents, anti-gingivitis agents, anti-microbial agents, anti-bacterial agents, anti-fungal agents, anti-yeast agents, anti-viral, anti-malodor agents, breath freshening agents, flavoring agents, cooling agents, taste enhancement agents, olfactory enhancement agents, anti-adherence agents, smoothness agents, surface modification agents, anti-tooth pain agents, anti-sensitivity agents, anti-inflammatory agents, gum protecting agents, periodontal actives, tissue regeneration agents, anti-blood coagulation agents, anti-clot stabilizer agents, salivary stimulant agents, salivary rheology modification agents, enhanced retention agents, soft/hard tissue targeted agents, tooth/soft tissue cleaning agents, antioxidants, pH modifying agents, H-2 antagonists, analgesics, natural extracts and essential oils, dyes, optical brighteners, cations, phosphates, fluoride ion sources, peptides, nutrients, enzymes, mouth and throat products, or mixtures thereof.
17. The aptamer composition of claim 16, wherein the oral care active ingredient is at least one of dyes or optical brighteners.
18. The aptamer composition of claim 16, wherein the oral care active ingredient is 4,4'-diamino-2,2'-stilbenedisulfonic acid.
19. The aptamer composition of claim 1, wherein the oligonucleotide is covalently or non-covalently attached to one or more nanomaterials.
20. A method for delivering one or more oral care active ingredients to the oral cavity comprising administering an oral care composition comprising at least one nucleic acid aptamer and one or more oral care active ingredients; wherein the at least one nucleic acid aptamer and said one or more oral care active ingredients are covalently or non-covalently attached; and wherein the at least one nucleic acid aptamer has a binding affinity for an oral cavity component.
Description
FIELD OF INVENTION
[0001] The present invention generally relates to nucleic acid aptamers that have a high binding affinity and specificity for teeth. This invention also relates to the use of such aptamers as delivery vehicles of active ingredients to the oral cavity.
BACKGROUND OF THE INVENTION
[0002] Aptamers are short single-stranded oligonucleotides, with a specific and complex three-dimensional shape, that bind to target molecules. The molecular recognition of aptamers is based on structure compatibility and intermolecular interactions, including electrostatic forces, van der Waals interactions, hydrogen bonding, and .pi.-.pi. stacking interactions of aromatic rings with the target material. The targets of aptamers include, but are not limited to, peptides, proteins, nucleotides, amino acids, antibiotics, low molecular weight organic or inorganic compounds, and even whole cells. The dissociation constant of aptamers typically varies between micromolar and picomolar levels, which is comparable to the affinity of antibodies to their antigens. Aptamers can also be designed to have high specificity, enabling the discrimination of target molecules from closely related derivatives.
[0003] Aptamers are usually designed in vitro from large libraries of random nucleic acids by Systematic Evolution of Ligands by Exponential Enrichment (SELEX). The SELEX method was first introduced in 1990 when single stranded RNAs were selected against low molecular weight dyes (Ellington, A. D., Szostak, J. W., 1990. Nature 346: 818-822). A few years later, single stranded DNA aptamers and aptamers containing chemically modified nucleotides were also described (Ellington, A. D., Szostak, J. W., 1992. Nature 355: 850-852; Green, L. S., et al., 1995. Chem. Biol. 2: 683-695). Since then, aptamers for hundreds of microscopic targets, such as cations, small molecules, proteins, cells, or tissues have been selected. A compilation of examples from the literature is included in the database at the website: http://www.aptagen.com/aptamer-index/aptamer-list.aspx. However, a need still exists for aptamers that selectively bind to surfaces in the oral cavity, including teeth.
SUMMARY OF THE INVENTION
[0004] In this invention, we have demonstrated the use of SELEX for the selection of aptamers against teeth and the use of such aptamers for the delivery of active ingredients to the oral cavity.
[0005] In certain embodiments of the present invention, an aptamer composition is provided. The aptamer composition comprises at least one oligonucleotide which may include: deoxyribonucleotides, ribonucleotides, derivatives of deoxyribonucleotides, derivatives of ribonucleotides, or mixtures thereof; wherein said aptamer composition has a binding affinity for a material selected from the group consisting of: tooth, enamel, dentin, carbonated calcium-deficient hydroxyapatite, and mixtures thereof.
[0006] In another embodiment of the present invention, an aptamer composition is provided. The aptamer composition including at least one oligonucleotide comprising SEQ ID NO 1, SEQ ID NO 9, SEQ ID NO 25, SEQ ID NO 112, SEQ ID NO 120, SEQ ID NO 136, or SEQ ID NO 223 to SEQ ID NO 234.
[0007] In another embodiment of the present invention, an aptamer composition includes at least one oligonucleotide having one or more motifs comprising SEQ ID NO 235, SEQ ID NO 236, SEQ ID NO 237, SEQ ID NO 238, SEQ ID NO 239, SEQ ID NO 240, SEQ ID NO 241, SEQ ID NO 242, SEQ ID NO 243, or SEQ ID NO 244.
[0008] In another embodiment of the present invention, an oral care composition is provided. The oral care composition comprises at least one nucleic acid aptamer; wherein said at least one nucleic acid aptamer has a binding affinity for an oral cavity component. In another embodiment of the present invention, said oral cavity component comprises at least one of: tooth, enamel, dentin, or any other surfaces in the oral cavity. In yet another embodiment, said oral cavity component is tooth.
[0009] In another embodiment of the present invention, a method for delivering one or more oral care active ingredients to the oral cavity is provided. The method comprises administering an oral care composition comprising at least one nucleic acid aptamer and one or more oral care active ingredients; wherein said at least one nucleic acid aptamer and said one or more oral care active ingredients are covalently or non-covalently attached; and wherein said at least one nucleic acid aptamer has a binding affinity for an oral cavity component.
[0010] In another embodiment of the present invention, a method for delivering one or more oral care active ingredients to the oral cavity is provided. The method comprises administering an oral care composition comprising: at least one nucleic acid aptamer and one or more nanomaterials; wherein said at least one nucleic acid aptamer and said one or more nanomaterials are covalently or non-covalently attached; and wherein said at least one nucleic acid aptamer has a binding affinity for an oral cavity component.
BRIEF DESCRIPTION OF THE DRAWINGS
[0011] For a more complete understanding of the disclosure, reference should be made to the following detailed description and drawing FIGS.
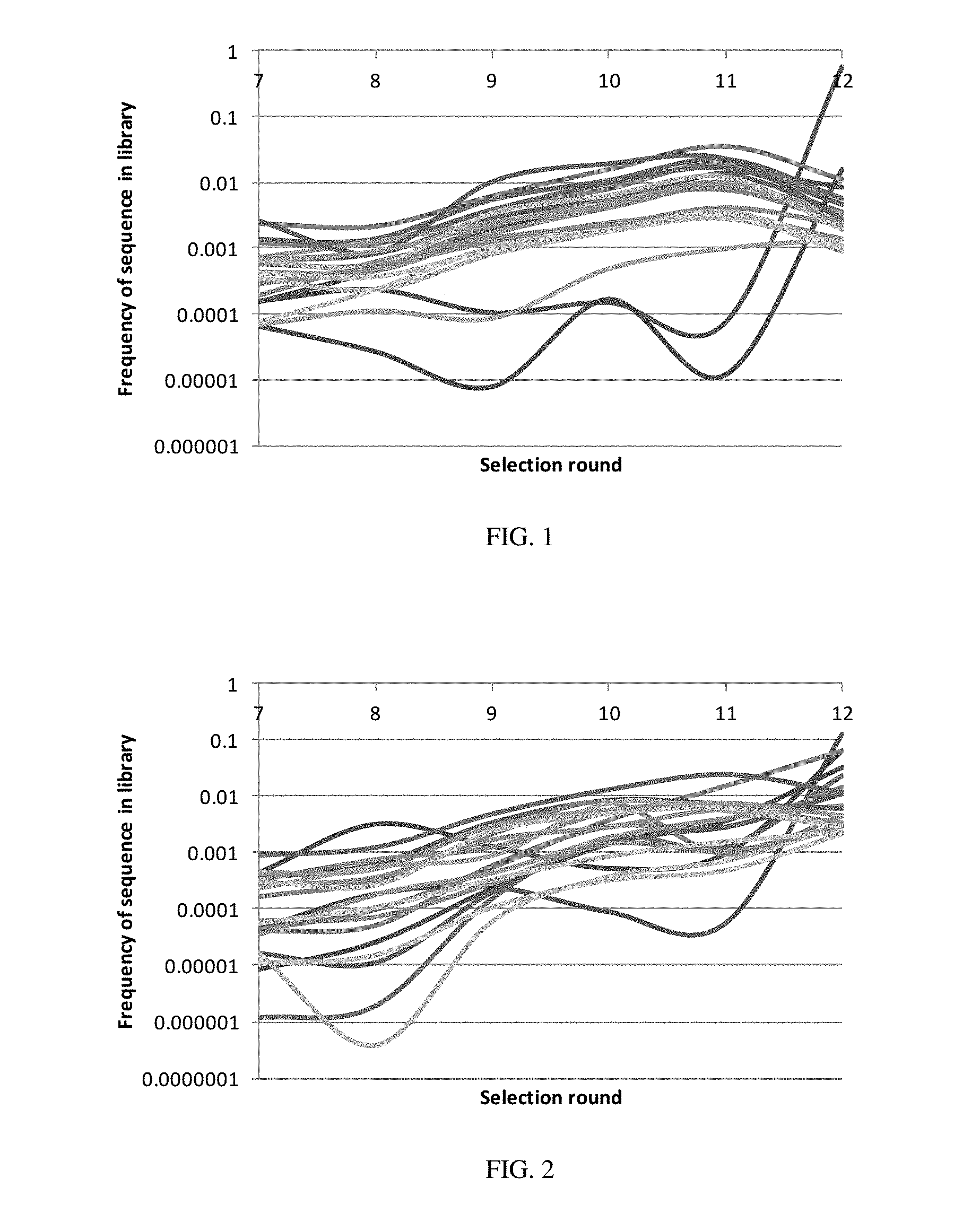
[0012] FIG. 1 illustrates the enrichment trajectories of the top twenty sequences in terms of copy number across different selection rounds for Experiment A.
[0013] FIG. 2 illustrates the enrichment trajectories of the top twenty sequences in terms of copy number across different selection rounds for Experiment B.
[0014] FIG. 3A shows a negative control.
[0015] FIG. 3B shows the binding of the aptamer identified as "OC1R-B1" to teeth.
[0016] FIG. 3C shows the binding of the aptamer identified as "OC1R-B9" to teeth.
[0017] FIG. 3D shows the binding of the aptamer identified as "OC1R-B25/OC1R-A9" to teeth.
[0018] FIG. 4 illustrates the correlation matrix ordered by clustering (Ward.D2 method) for enrichment trajectories of the top 100 sequences in terms of copy number for Experiment B.
[0019] FIG. 5 illustrates the results of the motif analysis of random region of aptamer OC1R-B1.
[0020] FIG. 6 illustrates the predicted secondary structure of aptamer OC1R-B1 and its conserved motif.
[0021] FIG. 7 illustrates the results of the motif analysis of random region of aptamer OC1R-B9.
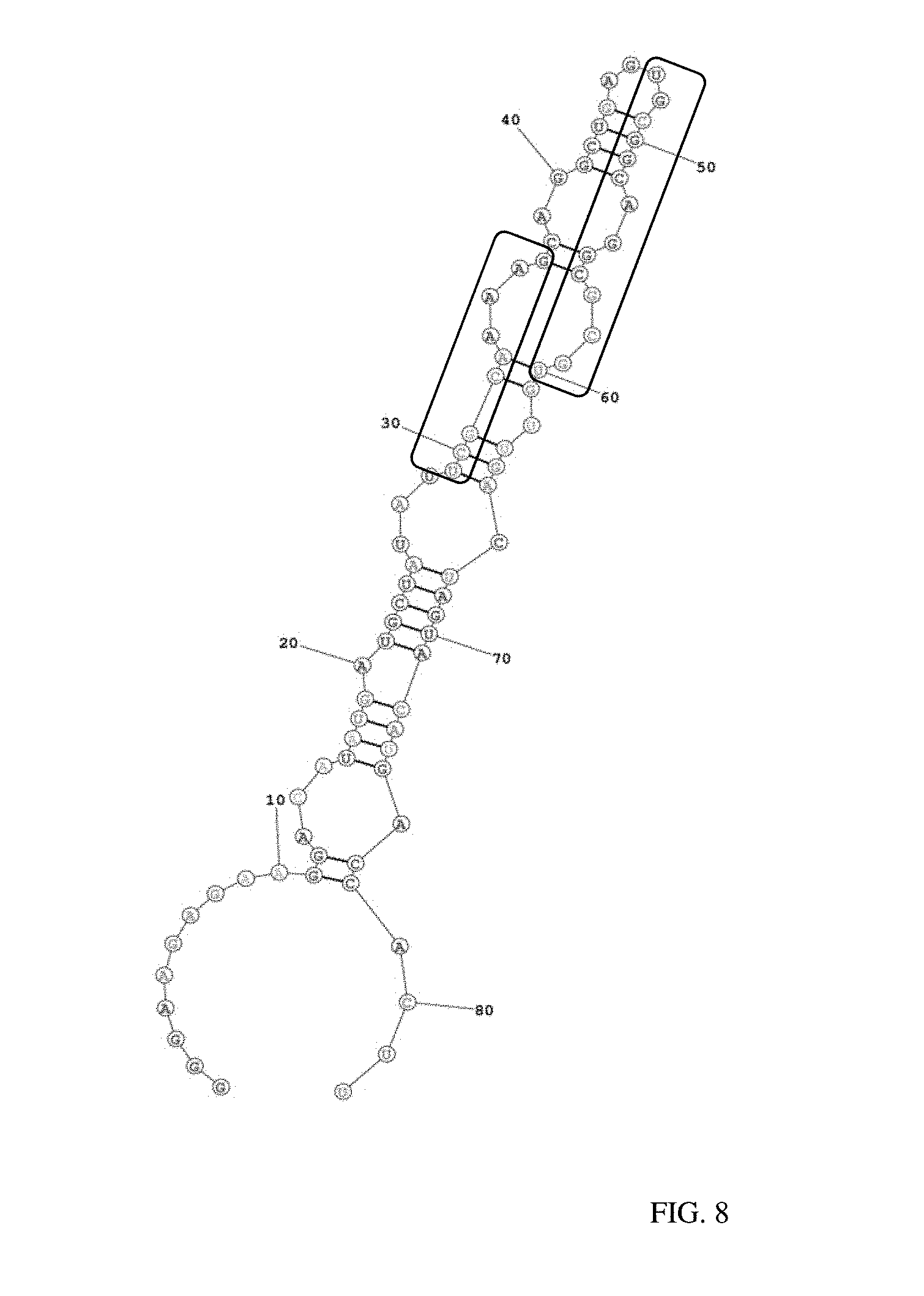
[0022] FIG. 8 illustrates the predicted secondary structure of aptamer OC1R-B9 and its conserved motifs.
[0023] FIG. 9 illustrates the results of the motif analysis of random region of aptamer OC1R-A9.
[0024] FIG. 10 illustrates the predicted secondary structure of aptamer OC1R-A9 and its conserved motif.
[0025] FIG. 11 illustrates the predicted secondary structure of aptamer OC1D-A9.
[0026] FIG. 12 illustrates the alignment of exemplary sequences with at least 90% nucleotide sequence identity that were identified during the selection process.
[0027] FIG. 13 illustrates the alignment of exemplary sequences with at least 70% nucleotide sequence identity that were identified during the selection process.
[0028] FIG. 14 illustrates the alignment of exemplary sequences with at least 50% nucleotide sequence identity that were identified during the selection process.
[0029] FIG. 15 illustrates the amount of DNA Aptamers bound to teeth.
[0030] FIG. 16 illustrates the amount of DNA Aptamers bound to teeth after every washing.
[0031] FIG. 17 illustrates the total amount of DNA aptamers bound (remaining), washed (eluted), and unrecovered (lost) from teeth.
[0032] FIG. 18A illustrates the predicted secondary structures of aptamer OC1D-B1.
[0033] FIG. 18B illustrates the predicted secondary structures of aptamer OC1D-B1.1.
[0034] FIG. 18C illustrates the predicted secondary structures of aptamer OC1D-B1.2.
[0035] FIG. 18D illustrates the predicted secondary structures of aptamer OC1D-B1.3.
[0036] FIG. 19A illustrates the predicted secondary structure of aptamer OC1D-B9.
[0037] FIG. 19B illustrates the predicted secondary structure of aptamer OC1D-B9.1.
[0038] FIG. 19C illustrates the predicted secondary structure of aptamer OC1D-B9.2.
[0039] FIG. 20A illustrates the predicted secondary structure of aptamer OC1D-A9.
[0040] FIG. 20B illustrates the predicted secondary structure of aptamer OC1D-A9.1.
[0041] FIGS. 21A-C illustrate the binding of truncated DNA aptamers to teeth.
DETAILED DESCRIPTION OF THE INVENTION
[0042] The present invention includes oral care compositions comprising one or more aptamers, wherein the aptamers are designed to bind to specific targets within the oral cavity, such as tooth surfaces or mucosal tissue. Oral care actives may be bound to the aptamers allowing the actives to be delivered to the specific oral cavity target, allowing for greater efficiency and affect.
Definitions
[0043] As used herein, the term "aptamer" refers to a single stranded oligonucleotide or a peptide that has a binding affinity for a specific target.
[0044] As used herein, the term "nucleic acid" refers to a polymer or oligomer of nucleotides. Nucleic acids are also referred as "ribonucleic acids" when the sugar moiety of the nucleotides is D-ribose and as "deoxyribonucleic acids" when the sugar moiety is 2-deoxy-D-ribose.
[0045] As used herein, the term "nucleotide" usually refers to a compound consisting of a nucleoside esterified to a monophosphate, polyphosphate, or phosphate-derivative group via the hydroxyl group of the 5-carbon of the sugar moiety. Nucleotides are also referred as "ribonucleotides" when the sugar moiety is D-ribose and as "deoxyribonucleotides" when the sugar moiety is 2-deoxy-D-ribose.
[0046] As used herein, the term "nucleoside" refers to a glycosylamine consisting of a nucleobase, such as a purine or pyrimidine, usually linked to a 5-carbon sugar (e.g. D-ribose or 2-deoxy-D-ribose) via a .beta.-glycosidic linkage. Nucleosides are also referred as "ribonucleosides" when the sugar moiety is D-ribose and as "deoxyribonucleosides" when the sugar moiety is 2-deoxy-D-ribose.
[0047] As used herein, the term "nucleobase", refers to a compound containing a nitrogen atom that has the chemical properties of a base. Non-limiting examples of nucleobases are compounds comprising pyridine, purine, or pyrimidine moieties, including, but not limited to adenine, guanine, hypoxanthine, thymine, cytosine, and uracil.
[0048] As used herein, the term "oligonucleotide" refers to an oligomer composed of nucleotides.
[0049] As used herein, the term "identical" or "sequence identity," in the context of two or more oligonucleotides, nucleic acids, or aptamers, refers to two or more sequences that are the same or have a specified percentage of nucleotides that are the same, when compared and aligned for maximum correspondence, as measured using sequence comparison algorithms or by visual inspection.
[0050] As used herein, the term "substantially homologous" or "substantially identical" in the context of two or more oligonucleotides, nucleic acids, or aptamers, generally refers to two or more sequences or subsequences that have at least 40%, 60%, 80%, 90%, 95%, 96%, 97%, 98% or 99% nucleotide identity, when compared and aligned for maximum correspondence, as measured using sequence comparison algorithms or by visual inspection.
[0051] As used herein, the term "epitope" refers to the region of a target that interacts with the aptamer. An epitope can be a contiguous stretch within the target or can be represented by multiple points that are physically proximal in a folded form of the target.
[0052] As used herein, the term "motif" refers to the sequence of contiguous, or series of contiguous, nucleotides occurring in a library of aptamers with binding affinity towards a specific target (e.g. teeth) and that exhibit a statistically significant higher probability of occurrence than would be expected compared to a library of random oligonucleotides. The motif sequence is frequently the result or driver of the aptamer selection process.
[0053] As used herein the term "binding affinity" may be calculated using the following equation: Binding Affinity=Amount of aptamer bound to one or more teeth/Total amount of aptamer incubated with one or more teeth.
[0054] By "oral care composition", as used herein, is meant a product, which in the ordinary course of usage, is not intentionally swallowed for purposes of systemic administration of therapeutic agents, but is rather retained in the oral cavity for a time sufficient to contact dental surfaces or oral tissues. Examples of oral care compositions include dentifrice, tooth gel, subgingival gel, mouth rinse, mousse, foam, mouth spray, lozenge, chewable tablet, chewing gum, tooth whitening strips, floss and floss coatings, breath freshening dissolvable strips, or denture care or adhesive product. The oral care composition may also be incorporated onto strips or films for direct application or attachment to oral surfaces.
[0055] The term "dentifrice", as used herein, includes tooth or subgingival-paste, gel, or liquid formulations unless otherwise specified. The dentifrice composition may be a single phase composition or may be a combination of two or more separate dentifrice compositions. The dentifrice composition may be in any desired form, such as deep striped, surface striped, multilayered, having a gel surrounding a paste, or any combination thereof. Each dentifrice composition in a dentifrice comprising two or more separate dentifrice compositions may be contained in a physically separated compartment of a dispenser and dispensed side-by-side.
[0056] All percentages and ratios used hereinafter are by weight of total composition, unless otherwise indicated. All percentages, ratios, and levels of ingredients referred to herein are based on the actual amount of the ingredient, and do not include solvents, fillers, or other materials with which the ingredient may be combined as a commercially available product, unless otherwise indicated.
[0057] All measurements referred to herein are made at 25.degree. C. unless otherwise specified.
[0058] As used herein, the term "oral cavity" means the part of the mouth including the teeth and gums and the cavity behind the teeth and gums that is bounded above by the hard and soft palates and below by the tongue and mucous membrane.
Aptamer Compositions
[0059] Nucleic acid aptamers are single-stranded oligonucleotides, with specific secondary and tertiary structures, that can bind to targets with high affinity and specificity. In certain embodiments of the present invention, an aptamer composition comprises at least one oligonucleotide comprising: deoxyribonucleotides, ribonucleotides, derivatives of deoxyribonucleotides, derivatives of ribonucleotides, or mixtures thereof; wherein said aptamer composition has a binding affinity for a material that is at least one of: tooth, enamel, dentin, hydroxyapatite, carbonated calcium-deficient hydroxyapatite, or mixtures thereof. In another embodiment, said aptamer composition has a binding affinity for tooth.
[0060] In another embodiment, an aptamer composition includes at least one oligonucleotide comprising oligonucleotides with at least 50% nucleotide sequence identity to sequences that are at least one of SEQ ID NO 1 to SEQ ID NO 234. In another embodiment, an aptamer composition includes at least one oligonucleotide comprising oligonucleotides with at least 70% nucleotide sequence identity to sequences including SEQ ID NO 1 to SEQ ID NO 234. In yet another embodiment, an aptamer composition comprises at least one oligonucleotide having at least 90% nucleotide sequence identity to at least one of SEQ ID NO 1 to SEQ ID NO 234. In another embodiment, an aptamer composition comprises at least one oligonucleotide having at least 20 contiguous nucleotides from at least one of SEQ ID NO 1 to SEQ ID NO 222. In another embodiment, an aptamer composition comprises at least one oligonucleotide having at least 40 contiguous nucleotides from at least one of SEQ ID NO 1 to SEQ ID NO 222. In another embodiment, an aptamer composition comprises at least one oligonucleotide having at least 60 contiguous nucleotides from at least one of SEQ ID NO 1 to SEQ ID NO 222. In another embodiment, an aptamer composition comprises at least one oligonucleotide having at least 70 contiguous nucleotides from at least one of SEQ ID NO 1 to SEQ ID NO 222. In another embodiment, an aptamer composition comprises at least one oligonucleotide having at least 80 contiguous nucleotides from at least one of SEQ ID NO 1 to SEQ ID NO 222.
[0061] In another embodiment, an aptamer composition comprises at least one oligonucleotide comprising SEQ ID NO 1, SEQ ID NO 9, SEQ ID NO 25, SEQ ID NO 112, SEQ ID NO 120, SEQ ID NO 136, or SEQ ID NO 223 to SEQ ID NO 234. In another embodiment, an aptamer composition comprises at least one oligonucleotide having at least 50% nucleotide sequence identity to at least one of SEQ ID NO 1, SEQ ID NO 9, SEQ ID NO 25, SEQ ID NO 112, SEQ ID NO 120, SEQ ID NO 136, or SEQ ID NO 223 to SEQ ID NO 234. In another embodiment, an aptamer composition comprises at least one oligonucleotide having at least 70% nucleotide sequence identity to at least one of SEQ ID NO 1, SEQ ID NO 9, SEQ ID NO 25, SEQ ID NO 112, SEQ ID NO 120, SEQ ID NO 136, or SEQ ID NO 223 to SEQ ID NO 234. In another embodiment, an aptamer composition comprises at least one oligonucleotide having at least 90% nucleotide sequence identity to at least one of SEQ ID NO 1, SEQ ID NO 9, SEQ ID NO 25, SEQ ID NO 112, SEQ ID NO 120, SEQ ID NO 136, or SEQ ID NO 223 to SEQ ID NO 234. Non-limiting examples of oligonucleotides with at least 90% nucleotide sequence identity to SEQ ID NO 1 are SEQ ID NO 49, SEQ ID NO 69, and SEQ ID NO 75. A non-limiting example of an oligonucleotide with at least 50% nucleotide sequence identity to SEQ ID NO 9 is SEQ ID NO 14.
[0062] In another embodiment, an oligonucleotide comprises at least one or more motifs of SEQ ID NO 235, SEQ ID NO 236, SEQ ID NO 237, SEQ ID NO 238, SEQ ID NO 239, SEQ ID NO 240, SEQ ID NO 241, SEQ ID NO 242, SEQ ID NO 243, or SEQ ID NO 244. In another embodiment, an aptamer composition comprises at least one oligonucleotide having at least 70% nucleotide sequence identity to at least one of SEQ ID NO 235, SEQ ID NO 236, SEQ ID NO 237, SEQ ID NO 238, SEQ ID NO 239, SEQ ID NO 240, SEQ ID NO 241, SEQ ID NO 242, SEQ ID NO 243, or SEQ ID NO 244. In another embodiment, an aptamer composition comprises at least one oligonucleotide having at least 80% nucleotide sequence identity to at least one of SEQ ID NO 235, SEQ ID NO 236, SEQ ID NO 237, SEQ ID NO 238, SEQ ID NO 239, SEQ ID NO 240, SEQ ID NO 241, SEQ ID NO 242, SEQ ID NO 243, or SEQ ID NO 244. In another embodiment, an aptamer composition comprises at least one oligonucleotide having at least 90% nucleotide sequence identity to at least one of SEQ ID NO 235, SEQ ID NO 236, SEQ ID NO 237, SEQ ID NO 238, SEQ ID NO 239, SEQ ID NO 240, SEQ ID NO 241, SEQ ID NO 242, SEQ ID NO 243, or SEQ ID NO 244.
[0063] In another embodiment, the fluorinated pyrimidine nucleotides of SEQ ID NO 1 to SEQ ID NO 111 and SEQ ID NO 223 to 228 are substituted by the corresponding natural non-fluorinated pyrimidine nucleotides.
[0064] Chemical modifications can introduce new features into the aptamers such as different molecular interactions with the target, improved binding capabilities, enhanced stability of oligonucleotide conformations, or increased resistance to nucleases. In certain embodiments, an oligonucleotide of an aptamer composition comprises natural or non-natural nucleobases. Natural nucleobases are adenine, cytosine, guanine, thymine, and uracil. Non-limiting examples of non-natural nucleobases are hypoxanthine, xanthine, 7-methylguanine, 5,6-dihydrouracil, 5-5-methylcytosine, 5-hydroxymethylcytosine, thiouracil, 1-methylhypoxanthine, 6-methylisoquinoline-1-thione-2-yl, 3-methoxy-2-naphthyl, 5-propynyluracil-1-yl, 5-methylcytosin-1-yl, 2-aminoadenin-9-yl, 7-deaza-7-iodoadenin-9-yl, 7-deaza-7-propynyl-2-aminoadenin-9-yl, phenoxazinyl, phenoxazinyl-G-clam, bromouracil, 5-iodouracil, and mixtures thereof.
[0065] Modifications of the phosphate backbone of the oligonucleotides can also increase the resistance against nuclease digestion. In certain embodiments, the nucleosides of oligonucleotides are linked by a chemical motif that is at least one of: natural phosphate diester, chiral phosphorothionate, chiral methyl phosphonate, chiral phosphoramidate, chiral phosphate chiral triester, chiral boranophosphate, chiral phosphoroselenoate, phosphorodithioate, phosphorothionate amidate, methylenemethylimino, 3'-amide, 3' achiral phosphoramidate, 3' achiral methylene phosphonates, thioformacetal, thioethyl ether, fluorophosphate, or mixtures thereof. In another embodiment, the nucleosides of oligonucleotides may be linked by natural phosphate diesters.
[0066] In another embodiment, the sugar moiety of the nucleosides of oligonucleotides may be at least one of: ribose, deoxyribose, 2'-fluoro deoxyribose, 2'-O-methyl ribose, 2'-O-(3-amino)propyl ribose, 2'-O-(2-methoxy)ethyl ribose, 2'-O-2-(N,N-dimethylaminooxy)ethyl ribose, 2'-O-2-[2-(N,N-dimethylamino)ethyloxy]ethyl ribose, 2'-O--N,N-dimethylacetamidyl ribose, N-morpholinophosphordiamidate, .alpha.-deoxyribofuranosyl, other pentoses, hexoses, or mixtures thereof.
[0067] In another embodiment, said derivatives of ribonucleotides or derivatives of deoxyribonucleotides may be at least one of: locked oligonucleotides, peptide oligonucleotides, glycol oligonucleotides, threose oligonucleotides, hexitol oligonucleotides, altritol oligonucleotides, butyl oligonucleotides, L-ribonucleotides, arabino oligonucleotides, 2'-fluoroarabino oligonucleotides, cyclohexene oligonucleotides, phosphorodiamidate morpholino oligonucleotides, or mixtures thereof.
[0068] In another embodiment, the nucleotides at the 5'- and 3'-ends of an oligonucleotide are inverted. In another embodiment, at least one nucleotide of an oligonucleotide is fluorinated at the 2' position of the pentose group. In another embodiment, the pyrimidine nucleotides of an oligonucleotide are fluorinated at the 2' position of the pentose group. In another embodiment, the aptamer composition further comprises at least one polymeric material, wherein the polymeric material may be covalently linked to an oligonucleotide; wherein the polymeric material may be polyethylene glycol.
[0069] In another embodiment, an oligonucleotide may be between about 10 and about 200 nucleotides in length. In another embodiment, an oligonucleotide may be less than about 100 nucleotides in length. In yet another embodiment, an oligonucleotide may be less than about 50 nucleotides in length.
[0070] In another embodiment, an oligonucleotide may be covalently or non-covalently attached to one or more oral care active ingredients. Suitable oral care active ingredients include any material that is generally considered as safe for use in the oral cavity and that provides changes to the overall health of the oral cavity; and specifically, to the condition of the oral surfaces that such oral care active ingredients interact with. Examples of oral conditions these actives address include, but are not limited to, appearance and structural changes to teeth, whitening, stain prevention and removal, stain bleaching, plaque prevention and removal, tartar prevention and removal, cavity prevention and treatment, inflamed and/or bleeding gums, mucosal wounds, lesions, ulcers, aphthous ulcers, cold sores, and tooth abscesses.
[0071] In another embodiment, said one or more oral care active ingredients are selected from the group comprising: whitening agents, brightening agents, anti-stain agents, anti-cavity agents, anti-erosion agents, anti-tartar agents, anti-calculus agents, anti-plaque agents, teeth remineralizing agents, anti-fracture agents, strengthening agents, abrasion resistance agents, anti-gingivitis agents, anti-microbial agents, anti-bacterial agents, anti-fungal agents, anti-yeast agents, anti-viral, anti-malodor agents, breath freshening agents, flavoring agents, cooling agents, taste enhancement agents, olfactory enhancement agents, anti-adherence agents, smoothness agents, surface modification agents, anti-tooth pain agents, anti-sensitivity agents, anti-inflammatory agents, gum protecting agents, periodontal actives, tissue regeneration agents, anti-blood coagulation agents, anti-clot stabilizer agents, salivary stimulant agents, salivary rheology modification agents, enhanced retention agents, soft/hard tissue targeted agents, tooth/soft tissue cleaning agents, antioxidants, pH modifying agents, H-2 antagonists, analgesics, natural extracts and essential oils, dyes, optical brighteners, cations, phosphates, fluoride ion sources, peptides, nutrients, enzymes, mouth and throat products, and mixtures thereof. Non-limiting specific examples of oral care active ingredients are listed in Section IV.
[0072] In another embodiment, an oligonucleotide is non-covalently attached to one or more oral care active ingredients, via molecular interactions. Examples of molecular interactions are electrostatic forces, van der Waals interactions, hydrogen bonding, and .pi.-.pi. stacking interactions of aromatic rings.
[0073] In another embodiment, an oligonucleotide may be covalently attached to said one or more oral care active ingredients using one or more linkers or spacers. Non-limiting examples of linkers are chemically labile linkers, enzyme-labile linkers, and non-cleavable linkers. Examples of chemically labile linkers are acid-cleavable linkers and disulfide linkers. Acid-cleavable linkers take advantage of low pH to trigger hydrolysis of an acid-cleavable bond, such as a hydrazone bond, to release the active ingredient or payload. Disulfide linkers can release the active ingredients under reducing environments. Examples of enzyme-labile linkers are peptide linkers that can be cleaved in the present of proteases and .beta.-glucuronide linkers that are cleaved by glucuronidases releasing the payload. Non-cleavable linkers can also release the active ingredient if the aptamer is degraded by nucleases.
[0074] In another embodiment, an oligonucleotide may be covalently or non-covalently attached to one or more nanomaterials. In another embodiment, an oligonucleotide and one or more oral care active ingredients may be covalently or non-covalently attached to one or more nanomaterials. In another embodiment, one or more oral care active ingredients are carried by one or more nanomaterials. Non-limiting examples of nanomaterials are gold nanoparticles, nano-scale iron oxides, carbon nanomaterials (such as single-walled carbon nanotubes and graphene oxide), mesoporous silica nanoparticles, quantum dots, liposomes, poly (lactide-co-glycolic acids) nanoparticles, polymeric micelles, dendrimers, serum albumin nanoparticles, and DNA-based nanomaterials. These nanomaterials can serve as carriers for large volumes of oral care active ingredients, while the aptamers can facilitate the delivery of the nanomaterials with the actives to the expected target.
[0075] Nanomaterials can have a variety of shapes or morphologies. Non-limiting examples of shapes or morphologies are spheres, rectangles, polygons, disks, toroids, cones, pyramids, rods/cylinders, and fibers. In the context of the present invention, nanomaterials may have at least one spatial dimension that is less than about 100 .mu.m and more preferably less than about 10 .mu.m. Nanomaterials comprise materials in solid phase, semi-solid phase, or liquid phase.
[0076] Aptamers can also be peptides that bind to targets with high affinity and specificity. These peptide aptamers can be part of a scaffold protein. Peptide aptamers can be isolated from combinatorial libraries and improved by directed mutation or rounds of variable region mutagenesis and selection. In certain embodiments of the present invention, an aptamer composition may comprise at least one peptide or protein; wherein the aptamer composition has a binding affinity for a material selected from the group consisting of: tooth, enamel, dentin, hydroxyapatite, carbonated calcium-deficient hydroxyapatite, and mixtures thereof.
Methods of Designing Aptamer Compositions
[0077] The method of designing nucleic acid aptamers known as Systematic Evolution of Ligands by Exponential Enrichment (SELEX) has been broadly studied and improved for the selection of aptamers against small molecules and proteins (WO 91/19813). In brief, in the conventional version of SELEX, the process starts with the synthesis of a large library of oligonucleotides consisting of randomly generated sequences of fixed length flanked by constant 5'- and 3'-ends that serve as primers. The oligonucleotides in the library are then exposed to the target ligand and those that do not bind the target are removed. The bound sequences are eluted and amplified by PCR to prepare for subsequent rounds of selection in which the stringency of the elution conditions is usually increased to identify the tightest-binding oligonucleotides. In addition to conventional SELEX, there are improved versions such as capillary electrophoresis-SELEX, magnetic bead-based SELEX, cell-SELEX, automated SELEX, complex-target SELEX, among others. A review of aptamer screening methods is found in "Kim, Y. S. and M. B. Gu (2014). Advances in Aptamer Screening and Small Molecule Aptasensors. Adv. Biochem. Eng./Biotechnol. 140 (Biosensors based on Aptamers and Enzymes): 29-67" and "Stoltenburg, R., et al. (2007). SELEX-A (r)evolutionary method to generate high-affinity nucleic acid ligands. Biomol. Eng. 24(4): 381-403," the contents of which are incorporated herein by reference. Although the SELEX method has been broadly applied, it is neither predictive nor standardized for every target. Instead, a method must be developed for each particular target in order for the method to lead to viable aptamers.
[0078] Despite the large number of selected aptamers, SELEX has not been routinely applied for the selection of aptamers with binding affinities towards macroscopic materials and surfaces. For the successful selection of aptamers with high binding affinity and specificity against macroscopic materials, the epitope should be present in sufficient amount and purity to minimize the enrichment of unspecifically binding oligonucleotides and to increase the specificity of the selection. Also, the presence of positively charged groups (e.g. primary amino groups), the presence of hydrogen bond donors and acceptors, and planarity (aromatic compounds) facilitate the selection of aptamers. In contrast, negatively charged molecules (e.g. containing phosphate groups) make the selection process more difficult. Unexpectedly, in spite of the detrimental chemical features of teeth that make aptamer selection challenging, the inventors have found that SELEX can be used for the design of aptamers with high binding affinity and specificity for teeth.
Selection Library
[0079] In SELEX, the initial candidate library is generally a mixture of chemically synthesized DNA oligonucleotides, each comprising a long variable region of n nucleotides flanked, at the 3' and 5' ends, by conserved regions or primer recognition regions for all the candidates of the library. These primer recognition regions allow the central variable region to be manipulated during SELEX, in particular by means of PCR.
[0080] The length of the variable region determines the diversity of the library, which is equal to 4.sup.n since each position can be occupied by one of four nucleotides A, T, G or C. For long variable regions, huge library complexities arise. For instance, when n=50, the theoretical diversity is 4.sup.50 or 10.sup.30, which is an inaccessible value in practice as it corresponds to more than 10.sup.5 tons of material for a library wherein each sequence is represented once. The experimental limit is around 10.sup.15 different sequences, which is that of a library wherein all candidates having a variable region of 25 nucleotides are represented. If one chooses to manipulate a library comprising a 30-nucleotide variable region whose theoretical diversity is about 10.sup.18, only 1/1000 of the possibilities will thus be explored. In practice, that is generally sufficient to obtain aptamers having the desired properties. Additionally, since the polymerases used are unreliable and introduce errors at a rate on the order of 10.sup.-4, they contribute to significantly enrich the diversity of the sequence pool throughout the SELEX process: one candidate in 100 will be modified in each amplification cycle for a library with a random region of 100 nucleotides in length, thus leading to the appearance of 10.sup.13 new candidates for the overall library.
[0081] In certain embodiments of the present invention, the starting mixture of oligonucleotides may comprise more than about 10.sup.6 different oligonucleotides or from between about 10.sup.13 to about 10.sup.15 different oligonucleotides. In another embodiment of the present invention, the length of the variable region may be between about 10 and about 100 nucleotides. In another embodiment, the length of the variable region may be between about 20 and about 60 nucleotides. In yet another embodiment, the length of the variable region is about 40 nucleotides. Random regions shorter than 10 nucleotides may be used, but may be constrained in their ability to form secondary or tertiary structures and in their ability to bind to target molecules. Random regions longer than 100 nucleotides may also be used but may present difficulties in terms of cost of synthesis. The randomness of the variable region is not a constraint of the present invention. For instance, if previous knowledge exists regarding oligonucleotides that bind to a given target, libraries spiked with such sequences may work as well or better than completely random ones.
[0082] In the design of primer recognition sequences care should be taken to minimize potential annealing among sequences, fold back regions within sequences, or annealing of the same sequence itself. In certain embodiments of the present invention, the length of primer recognition sequences may be between about 10 and about 40 nucleotides. In another embodiment, the length of primer recognition sequences may be between about 12 and about 30 nucleotides. In yet another embodiment, the length of primer recognition sequences may be between about 18 and about 26 nucleotides, i.e., about 18, 19, 20, 21, 22, 23, 24, 25 or 26 nucleotides. The length and sequence of the primer recognition sequences determine their annealing temperature. In certain embodiments, the primer recognition sequences of oligonucleotides may have an annealing temperature between about 60.degree. C. and about 72.degree. C.
[0083] Aptamers can be ribonucleotides (RNA), deoxynucleotides (DNA), or their derivatives. When aptamers are ribonucleotides, the first SELEX step may consist in transcribing the initial mixture of chemically synthesized DNA oligonucleotides via the primer recognition sequence at the 5' end. After selection, the candidates are converted back into DNA by reverse transcription before being amplified. RNA and DNA aptamers having comparable characteristics have been selected against the same target and reported in the art. Additionally, both types of aptamers can be competitive inhibitors of one another, suggesting potential overlapping of interaction sites.
[0084] New functionalities, such as hydrophobicity or photoreactivity, can be incorporated into the oligonucleotides by modifications of the nucleobases before or after selection. Modifications at the C-5 position of pyrimidines or at the C-8 or N-7 positions of purines are especially common and compatible with certain enzymes used during the amplification step in SELEX. In certain embodiments of the present invention, said oligonucleotides comprise natural or non-natural nucleobases. Natural nucleobases are adenine, cytosine, guanine, thymine, and uracil. Non-limiting examples of non-natural nucleobases are hypoxanthine, xanthine, 7-methylguanine, 5,6-dihydrouracil, 5-5-methylcytosine, 5-hydroxymethylcytosine, thiouracil, 1-methylhypoxanthine, 6-methylisoquinoline-1-thione-2-yl, 3-methoxy-2-naphthyl, 5-propynyluracil-1-yl, 5-methylcytosin-1-yl, 2-aminoadenin-9-yl, 7-deaza-7-iodoadenin-9-yl, 7-deaza-7-propynyl-2-aminoadenin-9-yl, phenoxazinyl, phenoxazinyl-G-clam, 5-bromouracil, 5-iodouracil, and mixtures thereof. Some non-natural nucleobases, such as 5-bromouracil or 5-iodouracil, can be used to generate photo-cross-linkable aptamers, which can be activated by UV light to form a covalent link with the target.
[0085] In another embodiment, the nucleosides of said oligonucleotides are linked by a chemical motif selected from the group comprising: natural phosphate diester, chiral phosphorothionate, chiral methyl phosphonate, chiral phosphoramidate, chiral phosphate chiral triester, chiral boranophosphate, chiral phosphoroselenoate, phosphorodithioate, phosphorothionate amidate, methylenemethylimino, 3'-amide, 3' achiral phosphoramidate, 3' achiral methylene phosphonates, thioformacetal, thioethyl ether, fluorophosphate, and mixtures thereof. In yet another embodiment, the nucleosides of said oligonucleotides are linked by natural phosphate diesters.
[0086] In another embodiment, the sugar moiety of the nucleosides of said oligonucleotides may be selected from the group comprising: ribose, deoxyribose, 2'-fluoro deoxyribose, 2'-O-methyl ribose, 2'-O-(3-amino)propyl ribose, 2'-O-(2-methoxy)ethyl ribose, 2'-O-2-(N,N-dimethylaminooxy)ethyl ribose, 2'-O-2-[2-(N,N-dimethylamino)ethyloxy]ethyl ribose, 2'-O--N,N-dimethylacetamidyl ribose, N-morpholinophosphordiamidate, .alpha.-deoxyribofuranosyl, other pentoses, hexoses, and mixtures thereof.
[0087] In another embodiment, said derivatives of ribonucleotides or said derivatives of deoxyribonucleotides are selected from the group comprising: locked oligonucleotides, peptide oligonucleotides, glycol oligonucleotides, threose oligonucleotides, hexitol oligonucleotides, altritol oligonucleotides, butyl oligonucleotides, L-ribonucleotides, arabino oligonucleotides, 2'-fluoroarabino oligonucleotides, cyclohexene oligonucleotides, phosphorodiamidate morpholino oligonucleotides, and mixtures thereof.
[0088] When using modified nucleotides during the SELEX process, they should be compatible with the enzymes used during the amplification step. Non-limiting examples of modifications that are compatible with commercial enzymes include modifications at the 2' position of the sugar in RNA libraries. The ribose 2'-OH group of pyrimidine nucleotides can be replaced with 2'-amino, 2'-fluoro, 2'-methyl, or 2'-O-methyl, which protect the RNA from degradation by nucleases. Additional modifications in the phosphate linker, such as phosphorothionate and boranophosphate, are also compatible with the polymerases and confer resistance to nucleases.
[0089] In certain embodiments of the present invention, at least one nucleotide of said oligonucleotides is fluorinated at the 2' position of the pentose group. In another embodiment, the pyrimidine nucleotides of said oligonucleotides are at least partially fluorinated at the 2' position of the pentose group. In yet another embodiment, all the pyrimidine nucleotides of said oligonucleotides are fluorinated at the 2' position of the pentose group. In another embodiment, at least one nucleotide of said oligonucleotides is aminated at the 2' position of the pentose group.
[0090] Another approach, recently described as two-dimensional SELEX, simultaneously applies in vitro oligonucleotide selection and dynamic combinatorial chemistry (DCC), e.g., a reversible reaction between certain groups of the oligonucleotide (amine groups) and a library of aldehyde compounds. The reaction produces imine oligonucleotides which are selected on the same principles as for conventional SELEX. It was thus possible to identify for a target hairpin RNA modified aptamers that differ from natural aptamers.
[0091] A very different approach relates to the use of optical isomers. Natural oligonucleotides are D-isomers. L-analogs are resistant to nucleases but cannot be synthesized by polymerases. According to the laws of optical isomerism, an L-series aptamer can form with its target (T) a complex having the same characteristics as the complex formed by the D-series isomer and the enantiomer (T') of the target (T). Consequently, if compound T' can be chemically synthesized, it can be used to perform the selection of a natural aptamer (D). Once identified, this aptamer can be chemically synthesized in an L-series. This L-aptamer is a ligand of the natural target (T).
Selection Step
[0092] Single stranded oligonucleotides can fold to generate secondary and tertiary structures, resembling the formation of base pairs. The initial sequence library is thus a library of three-dimensional shapes, each corresponding to a distribution of units that can trigger electrostatic interactions, create hydrogen bonds, etc. Selection becomes a question of identifying in the library the shape suited to the target, i.e., the shape allowing the greatest number of interactions and the formation of the most stable aptamer-target complex. For small targets (dyes, antibiotics, etc.) the aptamers identified are characterized by equilibrium dissociation constants in the micromolar range, whereas for protein targets K.sub.d values below 10.sup.-9 M are not rare.
[0093] Selection in each round occurs by means of physical separation of oligonucleotides associated with the target from free oligonucleotides. Multiple techniques may be applied (chromatography, filter retention, electrophoresis, etc.). The selection conditions are adjusted (relative concentration of target/candidates, ion concentration, temperature, washing, etc.) so that a target-binding competition occurs between the oligonucleotides. Generally, stringency is increased as the rounds proceed in order to promote the capture of oligonucleotides with the highest affinity. In addition, counter-selections or negative selections are carried out to eliminate oligonucleotides that recognize the support or unwanted targets (e.g., filter, beads, etc.).
[0094] The SELEX process for the selection of target-specific aptamers is characterized by repetition of five main steps: binding of oligonucleotides to the target, partition or removal of oligonucleotides with low binding affinity, elution of oligonucleotides with high binding affinity, amplification or replication of oligonucleotides with high binding affinity, and conditioning or preparation of the oligonucleotides for the next cycle. This selection process is designed to identify the oligonucleotides with the greatest affinity and specificity for the target material.
[0095] In certain embodiments of the present invention, a method of designing an aptamer composition comprises the step of contacting: a) a mixture of oligonucleotides, b) a selection buffer, and c) a target material selected from the group consisting of: tooth, enamel, dentin, hydroxyapatite, carbonated calcium-deficient hydroxyapatite, and mixtures thereof. In another embodiment, said target material is tooth. In another embodiment, said tooth is at least partially coated with saliva before said contacting step. In another embodiment of the present invention, said mixture of oligonucleotides comprises oligonucleotides selected from the group consisting of deoxyribonucleotides, ribonucleotides, derivatives of deoxyribonucleotides, derivatives of ribonucleotides, and mixtures thereof.
[0096] SELEX cycles are usually repeated several times until oligonucleotides with high binding affinity are identified. The number of cycles depends on multiple variables, including target features and concentration, design of the starting random oligonucleotide library, selection conditions, ratio of target binding sites to oligonucleotides, and the efficiency of the partitioning step. In certain embodiments, said contacting step is performed at least 5 times. In another embodiment, said contacting step is performed between 6 and 15 times. In another embodiment, said method further comprises the step of removing the oligonucleotides that do not bind said target material during said contacting step.
[0097] Oligonucleotides are oligo-anions, each unit having a charge and hydrogen-bond donor/acceptor sites at a particular pH. Thus, the pH and ionic strength of the selection buffer are important and should represent the conditions of the intended aptamer application. In certain embodiments of the present invention, the pH of said selection buffer is between about 2 and about 9. In another embodiment, the pH of said selection buffer is between about 6 and about 8. In yet another embodiment, the pH of said selection buffer is between about 2 and about 5. Selection buffers with low pH can be important if the aptamers are expected to have good binding affinities in acidic environments.
[0098] Cations can facilitate the proper folding of the oligonucleotides and provide benefits in the oral cavity. In certain embodiments of the present invention, said selection buffer comprises cations. Non-limiting examples of cations are Ca.sup.2+, Sn.sup.2+, Sn.sup.4+, Zn.sup.2+, Al.sup.3+, Cu.sup.2+, Fe.sup.2+, and Fe.sup.3+. In yet another embodiment, said selection buffer comprises divalent cations selected from the group comprising Sn.sup.2+ and Ca.sup.2+.
[0099] In order for the aptamers to maintain their structures and function during their application, the in vitro selection process can be carried out under conditions similar to those for which they are being developed. In certain embodiments of the present invention, said selection buffer comprises a solution or suspension of an oral care composition selected from the group comprising dentifrices, dentifrices, toothpowders, mouthwashes, mouthrinses, flosses, brushes, strips, sprays, patches, paint on, dissolvables, edibles, lozenges, gums, chewables, soluble fibers, insoluble fibers, putties, waxes, denture adhesives, denture cleansers, and mixtures thereof. In another embodiment of the present invention, said selection buffer comprises a solution of a dentifrice. In another embodiment of the present invention, said selection buffer comprises a solution of saliva.
[0100] In certain embodiments of the present invention, said selection buffer comprises at least one surfactant. In another embodiment, said at least one surfactant is selected from the group comprising sodium lauryl sulfate, betaines, chlorhexidine, sarcosinates, pluronics and triclosan. In another embodiment, said at least one surfactant is sodium lauryl sulfate. In another embodiment, said selection buffer comprises at least one abrasive material selected from the group comprising aluminum hydroxide, calcium carbonate, calcium hydrogen phosphates, calcium pyrophosphate, calcium pyrophosphate (beta phase), silicates, aluminosilicates, hydroxyapatite, and mixtures thereof. In yet another embodiment, said selection buffer comprises: a) at least one surfactant; b) at least one abrasive material selected from the group comprising aluminum hydroxide, calcium carbonate, calcium hydrogen phosphates, calcium pyrophosphate, calcium pyrophosphate (beta phase), silicates, aluminosilicates, hydroxyapatite, and mixtures thereof; c) at least one phosphate salt; and d) at least one fluoride salt.
[0101] Negative selection or counter-selection steps can minimize the enrichment of oligonucleotides that bind to undesired targets or undesired epitopes within a target. For oral care applications, binding of aptamers to teeth staining materials may not be desirable. In certain embodiments of the present invention, said method of designing an aptamer composition further comprises the step of contacting: a) a mixture of oligonucleotides, b) a selection buffer, and c) one or more teeth staining materials. In another embodiment, said one or more teeth staining materials comprise one or more natural or synthetic dyes or pigments selected from the group comprising flavonoids, carotenoids, caramels, tannins, other chromogens, and mixtures thereof. In yet another embodiment, said one or more teeth staining materials are selected from the group comprising wine, coffee, tea, carbonated sodas, and mixtures thereof. During the negative selection or counter-selection, the teeth staining materials can be either unbound or immobilized to a support. Methods for negative selection or counter-selection of aptamers against unbound targets have been published in WO201735666, the content of which is incorporated herein by reference.
[0102] In certain embodiments of the present invention, the method of designing an aptamer composition may comprise the steps of: a) synthesizing a mixture of oligonucleotides; b) contacting: i. said mixture of oligonucleotides, ii. a selection buffer, and iii. a target material selected from the group consisting of: tooth, enamel, dentin, hydroxyapatite, carbonated calcium-deficient hydroxyapatite, and mixtures thereof, to produce a target suspension; c) removing the liquid phase from said target suspension to produce a target-oligonucleotide mixture; d) contacting said target-oligonucleotide mixture with a washing buffer and removing the liquid phase to produce a target-aptamer mixture; and e) contacting said target-aptamer mixture with an elution buffer and recovering the liquid phase to produce an aptamer mixture. In another embodiment, said steps are performed repetitively at least 5 times. In another embodiment, said steps are performed between 6 and 15 times.
[0103] In another embodiment, a method of designing an aptamer composition comprising the steps of: a) synthesizing a random mixture of deoxyribonucleotides comprising oligonucleotides consisting of: i. a T7 promoter sequence at the 5'-end, ii. a variable 40-nucleotide sequence in the middle, and iii. a conserved reverse primer recognition sequence at the 3' end; b) transcribing said random mixture of deoxyribonucleotides using pyrimidine nucleotides fluorinated at the 2' position of the pentose group and natural purine nucleotides and a mutant T7 polymerase to produce a mixture of fluorinated ribonucleotides; c) contacting: i. said mixture of fluorinated ribonucleotides, ii. a selection buffer, and iii. a tooth, wherein said tooth is at least partially coated with saliva, to produce a target suspension; d) removing the liquid phase from said target suspension to produce a tooth-oligonucleotide mixture; e) contacting said tooth-oligonucleotide mixture with a washing buffer and removing the liquid phase to produce a tooth-aptamer mixture; f) contacting said tooth-aptamer mixture with an elution buffer and recovering the liquid phase to produce an RNA aptamer mixture; g) reserve transcribing and amplifying said RNA aptamer mixture to produce a DNA copy of said RNA aptamer mixture; and h) sequencing said DNA copy of said RNA aptamer mixture.
Post-Selection Modification
[0104] To enhance stability of the aptamers, chemical modifications can be introduced in the aptamer after the selection process. For instance, the 2'-OH groups of the ribose moieties can be replaced by 2'-fluoro, 2'-amino, or 2'-O-methyl groups. Furthermore, the 3'- and 5'-ends of the aptamers can be capped with different groups, such as streptavidin-biotin, inverted thymidine, amine, phosphate, polyethylene-glycol, cholesterol, fatty acids, proteins, enzymes, fluorophores, among others, making the oligonucleotides resistant to exonucleases or providing some additional benefits. Other modifications are described in previous sections of the present disclosure.
[0105] Unlike backbone modifications which can cause aptamer-target interaction properties to be lost, it is possible to conjugate various groups at one of the 3'- or 5'-ends of the oligonucleotide in order to convert it into a delivery vehicle, tool, probe, or sensor without disrupting its characteristics. This versatility constitutes a significant advantage of aptamers, in particular for their application in the current invention. In certain embodiments of the present invention, one or more oral care active ingredients are covalently attached to the 3'-end of an oligonucleotide. In another embodiment, one or more oral care active ingredients are covalently attached to the 5'-end of an oligonucleotide. In yet another embodiment, one or more oral care active ingredients are covalently attached to random positions of an oligonucleotide.
[0106] Incorporation of modifications to aptamers can be performed using enzymatic or chemical methods. Non-limiting examples of enzymes used for modification of aptamers are terminal deoxynucleotidyl transferases (TdT), T4 RNA ligases, T4 polynucleotide kinases (PNK), DNA polymerases, RNA polymerases, and other enzymes known by those skilled in the art. TdTs are template-independent polymerases that can add modified deoxynucleotides to the 3' terminus of deoxyribonucleotides. T4 RNA ligases can be used to label ribonucleotides at the 3'-end by using appropriately modified nucleoside 3',5'-bisphosphates. PNK can be used to phosphorylate the 5'-end of synthetic oligonucleotides, enabling other chemical transformations (see below). DNA and RNA polymerases are commonly used for the random incorporation of modified nucleotides throughout the sequence, provided such nucleotides are compatible with the enzymes.
[0107] Non-limiting examples of chemical methods used for modification of aptamers are periodate oxidation of ribonucleotides, EDC activation of 5'-phosphate, random chemical labeling methods, and other chemical methods known by those skilled in the art, incorporated herein as embodiments of the current invention.
[0108] During periodate oxidation, meta- and ortho-perdionates cleave the C--C bonds between vicinal diols of 3'-ribonucleotides, creating two aldehyde moieties that enable the conjugation of labels or active ingredients at the 3'-end of RNA aptamers. The resulting aldehydes can be easily reacted with hydrazide- or primary amine-containing molecules. When amines are used, the produced Schiff bases can be reduced to more stable secondary amines with sodium cyanoborohydride (NaBH.sub.4).
[0109] When EDC activation of 5'-phosphate is used, the 5'-phosphate of oligonucleotides is frequently activated with EDC (1-Ethyl-3-[3-dimethylaminopropyl]carbodiimide hydrochloride) and imidazole to produce a reactive imidazolide intermediate, followed by reaction with a primary amine to generate aptamers modified at the 5'end. Because the 5' phosphate group is required for the reaction, synthetic oligonucleotides can be first treated with a kinase (e.g. PNK).
[0110] Random chemical labeling can be performed with different methods. Because they allow labeling at random sites along the aptamer, a higher degree of modification can be achieved compared to end-labeling methods. However, since the nucleobases are modified, binding of the aptamers to their target can be disrupted. The most common random chemical modification methods involve the use of photoreactive reagents, such as phenylazide-based reagents. When the phenylazide group is exposed to UV light, it forms a labile nitrene that reacts with double bonds and C--H and N--H sites of the aptamers.
[0111] Additional information about methods for modification of aptamers is summarized in "Hermanson G. T. (2008). Bioconjugate Techniques. 2nd Edition. pp. 969-1002, Academic Press, San Diego.", the content of which is incorporated herein by reference.
[0112] After selection, in addition to chemical modifications, sequence truncations can be performed to remove regions that are not essential for binding or for folding into the structure. Moreover, aptamers can be linked together to provide different features or better affinity. Thus, any truncations or combinations of the aptamers described herein are incorporated as part of the current invention.
Application of Aptamer Compositions in Oral Care Products
[0113] The aptamers of the current invention can be used in oral care compositions to provide one or more benefits. In certain embodiments of the present invention, an oral care composition comprises at least one nucleic acid aptamer; wherein said at least one nucleic acid aptamer has a binding affinity for an oral cavity component. In another embodiment, an oral care composition comprises at least one nucleic acid aptamer; wherein said at least one nucleic acid aptamer has a binding affinity for an oral cavity component selected from the group comprising: tooth, enamel, dentin, and any other surfaces in the oral cavity. In another embodiment, an oral care composition comprises at least one nucleic acid aptamer; wherein said at least one nucleic acid aptamer has a binding affinity for tooth.
[0114] The oral care compositions of the present invention can be in different forms. Non-limiting examples of said forms are: dentifrices (including dentifrices and toothpowders), mouthwashes, mouthrinses, flosses, brushes, strips, sprays, patches, paint on, dissolvables, edibles, lozenges, gums, chewables, soluble fibers, insoluble fibers, putties, waxes, denture adhesives, denture cleansers, liquids, pastes, Newtonian or non-Newtonian fluids, gels, and sols.
[0115] The oral acre compositions of the present invention may include one or more of the following:
[0116] Rheology modifiers suitable for use in the present invention include organic and inorganic rheology modifiers, and mixtures thereof. Inorganic rheology modifiers include hectorite and derivatives, hydrated silicas, ternary and quaternary magnesium silicate derivatives, bentonite and mixtures thereof. Preferred inorganic rheology modifiers are hectorite and derivatives, hydrated silicas and mixtures thereof. Organic rheology modifiers include xanthan gum, carrageenan and derivatives, gellan gum, hydroxypropyl methyl cellulose, sclerotium gum and derivatives, pullulan, rhamsan gum, welan gum, konjac, curdlan, carbomer, algin, alginic acid, alginates and derivatives, hydroxyethyl cellulose and derivatives, hydroxypropyl cellulose and derivatives, starch phosphate derivatives, guar gum and derivatives, starch and derivatives, co-polymers of maleic acid anhydride with alkenes and derivatives, cellulose gum and derivatives, ethylene glycol/propylene glycol co-polymers, poloxamers and derivatives, polyacrylates and derivatives, methyl cellulose and derivatives, ethyl cellulose and derivatives, agar and derivatives, gum arabic and derivatives, pectin and derivatives, chitosan and derivatives, resinous polyethylene glycols such as PEG-XM where X is >=1, karaya gum, locust bean gum, natto gum, co-polymers of vinyl pyrollidone with alkenes, tragacanth gum, polyacrylamides, chitin derivatives, gelatin, betaglucan, dextrin, dextran, cyclodextrin, methacrylates, microcrystalline cellulose, polyquatemiums, furcellaren gum, ghatti gum, psyllium gum, quince gum, tamarind gum, larch gum, tara gum, and mixtures thereof. Preferred are xanthan gum, carrageenan and derivatives, gellan gum, hydroxypropyl methyl cellulose, sclerotium gum and derivatives, pullulan, rhamsan gum, welan gum, konjac, curdlan, carbomer, algin, alginic acid, alginates and derivatives, hydroxyethyl cellulose and derivatives, hydroxypropyl cellulose and derivatives, starch phosphate derivatives, guar gum and derivatives, starch and derivatives, co-polymers of maleic acid anhydride with alkenes and derivatives, cellulose gum and derivatives, ethylene glycol/propylene glycol co-polymers, poloxamers and derivatives and mixtures thereof.
[0117] In certain embodiments amounts of rheology modifiers may range from about 0.1% to about 15% or from about 0.5% to about 3% by weight of the total composition, such as dentifrice.
[0118] In addition to the above components, a sweetener, a flavor, a preservative, an effective ingredient, abrasives, fluoride ion sources, chelating agents, antimicrobials, silicone oils and other adjuvants such as preservatives and coloring agents, etc. may be added as required.
[0119] As the sweetener, saccharin sodium, sucrose, maltose, lactose, stevioside, neohesperidildigydrochalcone, glycyrrhizin, perillartine, p-methoxycinnamic aldehyde and the like may be used, in an amount of 0.05 to 5% by weight of the total composition. Essential oils such as spearmint oil, peppermint oil, salvia oil, eucalptus oil, lemon oil, lime oil, wintergreen oil and cinnamon oil, other spices and fruit flavors as well as isolated and synthetic flavoring materials such as 1-menthol, carvone, anethole, eugenol and the like can be used as flavors. The flavor may be blended in an amount of 0.1 to 5% by weight of the total composition. Ethyl paraoxy benzonate, butyl paraoxy benzoate, etc. may be used as the preservative. The sweetener may be added with the abrasive. The flavor and the preservative may be added when preparing the liquid of the slightly swollen rheology modifier or mixed with rheology modifier after mixing with the humectant. Enzymes such as dextranase, lytic enzyme, lysozyme, amylase and antiplasmin agents such as EPSILON-aminocaproic acid and tranexamic acid, fluorine compounds such as sodium monofluorophosphate sodium fluoride and stannous fluoride, chlorhexidine salts, quaternary ammonium salts, aluminum chlorohydroxyl allantoin, glycyrrhetinic acid, chlorophyll, sodium chloride and phosphoric compounds may be used as the effective ingredient. Moreover, silica gel, aluminum silica gel, organic acids and their salts may be blended as desired. An organic effective ingredient with low viscosity may be added when preparing the liquid of the slightly swollen rheology modifier.
[0120] The oral care compositions of the present invention may comprise greater than about 0.1% by weight of a surfactant or mixture of surfactants. Surfactant levels cited herein are on a 100% active basis, even though common raw materials such as sodium lauryl sulphate may be supplied as aqueous solutions of lower activity.
[0121] Suitable surfactant levels are from about 0.1% to about 15%, from about 0.25% to about 10%, or from about 0.5% to about 5% by weight of the total composition. Suitable surfactants for use herein include anionic, amphoteric, non-ionic, zwitterionic and cationic surfactants, though anionic, amphoteric, non-ionic and zwitterionic surfactants (and mixtures thereof) are preferred.
[0122] Useful anionic surfactants herein include the water-soluble salts of alkyl sulphates and alkyl ether sulphates having from 10 to 18 carbon atoms in the alkyl radical and the water-soluble salts of sulphonated monoglycerides of fatty acids having from 10 to 18 carbon atoms. Sodium lauryl sulphate and sodium coconut monoglyceride sulphonates are examples of anionic surfactants o this type.
[0123] Suitable cationic surfactants useful in the present invention can be broadly defined as derivatives of aliphatic quaternary ammonium compounds having one long alkyl chain containing from about 8 to 18 carbon atoms such as lauryl trimethylammonium chloride; cetyl pyridinium chloride; benzalkonium chloride; cetyl trimethylammonium bromide; di-isobutylphenoxyethyl-dimethylbenzylammonium chloride; coconut alkyltrimethyl-ammonium nitrite; cetyl pyridinium fluoride; etc. Certain cationic surfactants can also act as germicides in the compositions disclosed herein.
[0124] Suitable nonionic surfactants that can be used in the compositions of the present invention can be broadly defined as compounds produced by the condensation of alkylene oxide groups (hydrophilic in nature) with an organic hydrophobic compound which may be aliphatic and/or aromatic in nature. Examples of suitable nonionic surfactants include the poloxamers; sorbitan derivatives, such as sorbitan di-isostearate; ethylene oxide condensates of hydrogenated castor oil, such as PEG-30 hydrogenated castor oil; ethylene oxide condensates of aliphatic alcohols or alkyl phenols; products derived from the condensation of ethylene oxide with the reaction product of propylene oxide and ethylene diamine; long chain tertiary amine oxides; long chain tertiary phosphine oxides; long chain dialkyl sulphoxides and mixtures of such materials. These materials are useful for stabilising foams without contributing to excess viscosity build for the oral care composition.
[0125] Zwitterionic surfactants can be broadly described as derivatives of aliphatic quaternary ammonium, phosphonium, and sulphonium compounds, in which the aliphatic radicals can be straight chain or branched, and wherein one of the aliphatic substituents contains from about 8 to 18 carbon atoms and one contains an anionic water-solubilising group, e.g., carboxy, sulphonate, sulphate, phosphate or phosphonate.
[0126] The oral care compositions of the present invention may comprise greater than about 50% liquid carrier materials. Water may comprise from about 20% to about 70% or from about 30% to about 50% by weight of the total composition. These amounts of water include the free water which is added plus that which is introduced with other materials such as with sorbitol and with surfactant solutions.
[0127] Generally, the liquid carrier may further include one or more humectants. Suitable humectants include glycerin, sorbitol, and other edible polyhydric alcohols, such as low molecular weight polyethylene glycols at levels of from about 15% to about 50%. To provide the best balance of foaming properties and resistance to drying out, the ratio of total water to total humectant may be from about 0.65:1 to about 1.5:1, or from about 0.85:1 to about 1.3:1.
[0128] The viscosities of the oral care compositions herein may be affected by the viscosity of Newtonian liquids present in the composition. These may be either pure liquids such as glycerin or water, or a solution of a solute in a solvent such as a sorbitol solution in water. The level of contribution of the Newtonian liquid to the viscosity of the non-Newtonian oral care composition will depend upon the level at which the Newtonian liquid is incorporated. Water may be present in a significant amount in an oral care composition, and has a Newtonian viscosity of approximately 1 mPas at 25 deg. C. Humectants such as glycerin and sorbitol solutions typically have a significantly higher Newtonian viscosity than water. As a result, the total level of humectant, the ratio of water to humectant, and the choice of humectants, helps to determine the high shear rate viscosity of the oral care compositions.
[0129] Common humectants such as sorbitol, glycerin, polyethyleneglycols, propylene glycols and mixtures thereof may be used, but the specific levels and ratios used will differ depending on the choice of humectant. Sorbitol may be used, but due to its relatively high Newtonian viscosity, in certain embodiments cannot be incorporated at levels above 45% by weight of the composition, as it contributes significantly to the high shear rate viscosity of the oral care composition. Conversely, propylene glycol may be employed at higher levels as it has a lower Newtonian viscosity than sorbitol, and hence does not contribute as much to the high shear rate viscosity of the oral care composition. Glycerin has an intermediate Newtonian viscosity in between that of sorbitol and polyethylene glycol.
[0130] Ethanol may also be present in the oral care compositions. These amounts may range from about 0.5 to about 5%, or from about 1.5 to about 3.5% by weight of the total composition. Ethanol can be a useful solvent and can also serve to enhance the impact of a flavour, though in this latter respect only low levels are usually employed. Non-ethanolic solvents such as propylene glycol may also be employed. Also useful herein are low molecular weight polyethylene glycols.
[0131] The oral care compositions of the present invention may comprise a dental abrasive, such as those used in dentifrices. Abrasives serve to polish the teeth, remove surface deposits, or both. The abrasive material contemplated for use herein can be any material which does not excessively abrade dentine. Suitable abrasives include insoluble phosphate polishing agents, such as, for example, dicalcium phosphate, tricalcium phosphate, calcium pyrophosphate, beta-phase calcium pyrophosphate, dicalcium phosphate dihydrate, anhydrous calcium phosphate, insoluble sodium metaphosphate, and the like. Also suitable are chalk-type abrasives such as calcium and magnesium carbonates, silicas including xerogels, hydrogels, aerogels and precipitates, alumina and hydrates thereof such as alpha alumina trihydrate, aluminosilicates such as calcined aluminium silicate and aluminium silicate, magnesium and zirconium silicates such as magnesium trisilicate and thermosetting polymerised resins such as particulate condensation products of urea and formaldehyde, polymethylmethacrylate, powdered polyethylene and others such as disclosed in U.S. Pat. No. 3,070,510. Mixtures of abrasives can also be used. The abrasive polishing materials generally have an average particle size of from about 0.1 to about 30 .mu.m, or from about 1 to about 15 .mu.m.
[0132] Silica dental abrasives of various types offer exceptional dental cleaning and polishing performance without unduly abrading tooth enamel or dentin. The silica abrasive can be precipitated silica or silica gels such as the silica xerogels described in U.S. Pat. No. 3,538,230, U.S. Pat. No. 3,862,307. Silicas may be used that have an oil absorption from 30 g per 100 g to 100 g per 100 g of silica. It has been found that silicas with low oil absorption levels are less structuring, and therefore do not build the viscosity of the oral care composition to the same degree as those silicas that are more highly structuring, and therefore have higher oil absorption levels. As used herein, oil absorption is measured by measuring the maximum amount of linseed oil the silica can absorb at 25 deg. C.
[0133] Suitable abrasive levels may be from about 0% to about 20% by weight of the total composition, in certain embodiments less than 10%, such as from 1% to 10%. In certain embodiments abrasive levels from 3% to 5% by weight of the total composition can be used.
[0134] For anticaries protection, a source of fluoride ion will normally be present in the oral care composition. Fluoride sources include sodium fluoride, potassium fluoride, calcium fluoride, stannous fluoride, stannous monofluorophosphate and sodium monofluoro-phosphate. Suitable levels provide from 25 to 2500 ppm of available fluoride ion by weight of the oral care composition.
[0135] Suitable chelating agents include organic acids and their salts, such as tartaric acid and pharmaceutically-acceptable salts thereof, citric acid and alkali metal citrates and mixtures thereof. Chelating agents are able to complex calcium found in the cell walls of the bacteria. Chelating agents can also disrupt plaque by removing calcium from the calcium bridges which help hold this biomass intact. However, it is possible to use a chelating agent which has an affinity for calcium that is too high, resulting in tooth demineralisation. In certain embodiments the chelating agents have a calcium binding constant of about 101 to about 105 to provide improved cleaning with reduced plaque and calculus formation. The amounts of chelating that may be used in the formulations of the present invention are about 0.1% to about 2.5%, from about 0.5% to about 2.5% or from about 1.0% to about 2.5%. The tartaric acid salt chelating agent can be used alone or in combination with other optional chelating agents.
[0136] Another group of agents particularly suitable for use as chelating agents in the present invention are the water soluble polyphosphates, polyphosphonates, and pyro-phosphates which are useful as anticalculus agents. The pyrophosphate salts used in the present compositions can be any of the alkali metal pyrophosphate salts. An effective amount of pyrophosphate salt useful in the present composition is generally enough to provide at least 1.0% pyrophosphate ion or from about 1.5% to about 6% of such ions. The pyrophosphate salts are described in more detail in Kirk & Othmer, Encyclopedia of Chemical Technology, Second Edition, Volume 15, Interscience Publishers (1968).
[0137] Water soluble polyphosphates such as sodium tripolyphosphate, potassium tripolyphosphate and sodium hexametaphosphate may be used. Other long chain anticalculus agents of this type are described in WO98/22079. Also preferred are the water soluble diphosphonates. Suitable soluble diphosphonates include ethane-1-hydroxy-1,1,-diphosphonate (EHDP) and aza-cycloheptane-diphosphonate (AHP). The tripolyphosphates and diphosphonates are particularly effective as they provide both anti-tartar activity and stain removal activity without building viscosity as much as much as less water soluble chemical stain removal agents and are stable with respect to hydrolysis in water. The soluble polyphosphates and diphosphonates are beneficial as destaining actives. Without wishing to be bound by theory, it is believed that these ingredients remove stain by desorbing stained pellicle from the enamel surface of the tooth. Suitable levels of water soluble polyphosphates and diphosphonates are from about 0.1% to about 10%, from about 1% to about 5%, or from about 1.5% to about 3% by weight of the oral care composition.
[0138] Still another possible group of chelating agents suitable for use in the present invention are the anionic polymeric polycarboxylates. Such materials are well known in the art, being employed in the form of their free acids or partially or preferably fully neutralised water-soluble alkali metal (e.g. potassium and preferably sodium) or ammonium salts. Additional polymeric polycarboxylates are disclosed in U.S. Pat. No. 4,138,477 and U.S. Pat. No. 4,183,914, and include copolymers of maleic anhydride with styrene, isobutylene or ethyl vinyl ether, polyacrylic, polyitaconic and polymaleic acids, and sulphoacrylic oligomers of MW as low as 1,000 available as Uniroyal ND-2.
[0139] Also useful for the present invention are antimicrobial agents. A wide variety of antimicrobial agents can be used, including stannous salts such as stannous pyrophosphate and stannous gluconate; zinc salt, such as zinc lactate and zinc citrate; copper salts, such as copper bisglycinate; quaternary ammonium salts, such as cetyl pyridinium chloride and tetradecylethyl pyridinium chloride; bis-biguanide salts; and nonionic antimicrobial agents such as triclosan. Certain flavour oils, such as thymol, may also have antimicrobial activity. Such agents are disclosed in U.S. Pat. No. 2,946,725 and U.S. Pat. No. 4,051,234. Also useful is sodium chlorite, described in WO 99/43290.
[0140] Antimicrobial agents, if present, are typically included at levels of from about 0.01% to about 10%. Levels of stannous and cationic antimicrobial agents can be kept to less than about 5% or less than about 1% to avoid staining problems.
[0141] In certain embodiments antimicrobial agents are non-cationic antimicrobial agent, such as those described in U.S. Pat. No. 5,037,637. A particularly effective antimicrobial agent is 2',4,4'-trichloro-2-hydroxy-diphenyl ether (triclosan).
[0142] An optional ingredient in the present compositions is a silicone oil. Silicone oils can be useful as plaque barriers, as disclosed in WO 96/19191. Suitable classes of silicone oils include, but are not limited to, dimethicones, dimethiconols, dimethicone copolyols and aminoalkylsilicones. Silicone oils are generally present in a level of from about 0.1% to about 15%, from about 0.5% to about 5%, or from about 0.5% to about 3% by weight.
[0143] Sweetening agents such as sodium saccharin, sodium cyclamate, Acesulfame K, aspartame, sucrose and the like may be included at levels from about 0.1 to 5% by weight. Other additives may also be incorporated including flavours, preservatives, opacifiers and colorants. Typical colorants are D&C Yellow No. 10, FD&C Blue No. 1, FD&C Red No. 40, D&C Red No. 33 and combinations thereof. Levels of the colorant may range from about 0.0001 to about 0.1%.
[0144] The oral care composition preferably comprises at least one nucleic acid aptamer at a level where upon directed use, promotes one or more benefits without detriment to the oral cavity component it is applied to. In certain embodiments of the present invention, said oral care composition comprises between about 0.00001% to about 10% of at least one nucleic acid aptamer. In another embodiment, said oral care composition comprises between about 0.00005% to about 5% of at least one nucleic acid aptamer. In another embodiment, said oral care composition comprises between about 0.0001% to about 1% of at least one nucleic acid aptamer.
[0145] In another embodiment, an oral care composition comprises at least one peptide aptamer; wherein said at least one peptide aptamer has a binding affinity for an oral cavity component selected from the group consisting of: tooth, enamel, dentin, and any other surfaces in the oral cavity. In another embodiment, said at least one peptide aptamer has a binding affinity for tooth.
[0146] The aptamers of the present invention could provide several benefits when bound to an oral cavity component, including, but not limited to, teeth remineralization (e.g. by improving calcium deposition on teeth), teeth acid resistance, appearance and structural changes to teeth, stain prevention (e.g. by repelling teeth staining materials such as dyes or pigments), plaque prevention, tartar prevention, and cavity prevention and treatment. As an example, if aptamers comprising fluorinated nucleotides are degraded or decomposed after binding, they could effectively deliver fluoride ions to teeth, which can provide cavity prevention benefits. Non-limiting examples of fluorinated nucleotides include fluorophosphate nucleotides, 2'-fluoro deoxyribonucleotides, and nucleotides with fluorinated nucleobases.
[0147] The combined use of aptamers that bind to different epitopes of a particular target (e.g. tooth) could provide a greater overall target coverage and/or efficacy across different individuals. Identification of aptamers binding to different epitopes can be achieved by performing a covariance analysis for the change in oligonucleotide frequency during the rounds of SELEX selection as described in Example 3. In certain embodiments of the present invention, an oral care composition comprises at least two different nucleic acid aptamers; wherein said at least two different nucleic acid aptamers have binding affinities for different epitopes of tooth. In another embodiment, said at least two different nucleic acid aptamers are selected from the group consisting of SEQ ID NO 1, SEQ ID NO 9, SEQ ID NO 25, SEQ ID NO 112, SEQ ID NO 120, SEQ ID NO 136, and SEQ ID NO 223 to SEQ ID NO 234.
[0148] The aptamers of the current invention can also be formulated in oral care products to effectively deliver active ingredients to oral cavity components. In certain embodiments of the present invention, a method for delivering one or more oral care active ingredients to the oral cavity comprises administering an oral care composition comprising at least one nucleic acid aptamer and one or more oral care active ingredients; wherein said at least one nucleic acid aptamer and said one or more oral care active ingredients are covalently or non-covalently attached; and wherein said at least one nucleic acid aptamer has a binding affinity for an oral cavity component. Examples of the oral conditions these oral care active ingredients address include, but are not limited to, appearance and structural changes to teeth, whitening, stain prevention and removal, stain bleaching, plaque prevention and removal, tartar prevention and removal, cavity prevention and treatment, inflamed and/or bleeding gums, mucosal wounds, lesions, ulcers, aphthous ulcers, cold sores, and tooth abscesses.
[0149] In another embodiment, said oral cavity component in said method of delivering one or more oral care active ingredients is selected from the group comprising: tooth, enamel, dentin, and any other surfaces in the oral cavity. In another embodiment, said oral cavity component is tooth.
[0150] In another embodiment, a method for delivering one or more oral care active ingredients to the oral cavity comprises administering an oral care composition comprising at least one peptide aptamer and one or more oral care active ingredients; wherein said at least one peptide aptamer and said one or more oral care active ingredients are covalently or non-covalently attached; and wherein said at least one peptide aptamer has a binding affinity for an oral cavity component.
[0151] In another embodiment, said one or more oral care active ingredients are selected from the group comprising: whitening agents, brightening agents, anti-stain agents, anti-cavity agents, anti-erosion agents, anti-tartar agents, anti-calculus agents, anti-plaque agents, teeth remineralizing agents, anti-fracture agents, strengthening agents, abrasion resistance agents, anti-gingivitis agents, anti-microbial agents, anti-bacterial agents, anti-fungal agents, anti-yeast agents, anti-viral, anti-malodor agents, breath freshening agents, flavoring agents, cooling agents, taste enhancement agents, olfactory enhancement agents, anti-adherence agents, smoothness agents, surface modification agents, anti-tooth pain agents, anti-sensitivity agents, anti-inflammatory agents, gum protecting agents, periodontal actives, tissue regeneration agents, anti-blood coagulation agents, anti-clot stabilizer agents, salivary stimulant agents, salivary rheology modification agents, enhanced retention agents, soft/hard tissue targeted agents, tooth/soft tissue cleaning agents, antioxidants, pH modifying agents, H-2 antagonists, analgesics, natural extracts and essential oils, dyes, optical brighteners, cations, phosphates, fluoride ion sources, peptides, nutrients, enzymes, mouth and throat products, and mixtures thereof. The present invention also includes other oral care active ingredients previously disclosed in the art. In another embodiment, said oral care active ingredient is selected from the group consisting of dyes and optical brighteners. In another embodiment, said oral care active ingredient is selected from the group consisting of dyes and optical brighteners and said at least one nucleic acid aptamer has a binding affinity for tooth.
[0152] Non-limiting examples of whitening agents are dyes, optical brighteners, peroxides, metal chlorites, perborates, percarbonates, peroxyacids, and mixtures thereof. Suitable peroxide compounds include hydrogen peroxide, calcium peroxide, carbamide peroxide, and mixtures thereof. Most preferred is carbamide peroxide. Suitable metal chlorites include calcium chlorite, barium chlorite, magnesium chlorite, lithium chlorite, sodium chlorite, and potassium chlorite. Additional whitening actives may be hypochlorite and chlorine dioxide. The preferred chlorite is sodium chlorite.
[0153] Dyes and optical brighteners can provide desirable whitening and other cosmetic effects on teeth. Non-limiting examples of dyes are triarylmethane dyes, including brilliant blue FCF (FD&C blue 1 or D&C blue 4), fast green FCF (FD&C green 3), and patent blue V; indigoid dyes, including indigo carmine (FD&C blue 2); anthraquinone dyes, including sunset violet 13 (D&C violet 2); azoic dyes; xanthene dyes; natural dyes, including chlorophylls, spirulina, and anthocyanins; their derivatives; and mixtures thereof.
[0154] Optical brighteners, also known as fluorescent whitening agents, are organic compounds that are colorless to weakly colored in solution, absorb ultraviolet light (e.g. from daylight, ca. 300-430 nm), and reemit most of the absorbed energy as blue fluorescent light (400-500 nm). Thus, in daylight, optical brighteners can compensate for the often undesirable yellowish tone found in teeth and other materials. Furthermore, since day UV light (not perceived by the eye) is converted to visible light, the brightness of the teeth can be enhanced to produce a luminous white. Non-limiting examples of optical brighteners are derivatives of carbocyles, stilbene and 4,4'-diaminostilbene, including 4,4'-diamino-2,2'-stilbenedisulfonic acid; derivatives of distyrylbenzenes, distyrylbiphenyls, and divinylstilbenes; derivatives of triazinylaminostilbenes; derivatives of stilbenyl-2H-triazoles; derivatives of benzoxazoles, stilbenylbenzoxazoles, and bis(benzoxazoles); derivatives of furans, benzo[b]furans, benzimidazoles, bix(benzo[b]furan-2-yl)biphenyls, and cationic benzimidazoles; derivatives of 1,3-diphenyl-2-pyrazolines; derivatives of coumarins; derivatives of napthalimides; derivatives of 1,3,5-triazin-2-yl; derivatives of bis(benzoxazol-2-yl); and mixtures thereof. A review of commonly used optical brighteners is found in "Optical Brighteners" by Siegrist, A. E., Eckhardt, C., Kaschig, J. and Schmidt, E.; Ullmann's Encyclopedia of Industrial Chemistry, Wiley and Sons, 2003, the contents of which are incorporated herein by reference. In certain embodiments of the present invention, said oral care active ingredient is 4,4'-diamino-2,2'-stilbenedisulfonic acid.
[0155] Non-limiting examples of anti-cavity agents are: a) phosphorus-containing agents, including polyphosphates such as pyrophosphate, tripolyphosphate, trimetaphosphate, and hexametaphosphate; organic phosphates such as glycerophosphate, phytate, 1,6-fructose diphosphate, calcium lactophosphate, casein-phosphopeptide amorphous calcium phosphate (CPP-ACP), and sodium caseinate; phosphoproteins; phosphonates such as ethane hydroxy diphosphonate; and phosphosilicates; b) calcium-containing agents, including calcium lactate; c) anti-microbial agents; d) metals and their cations, including zinc, tin, aluminum, copper, iron, and calcium; e) other organic agents including citrate; and f) fluoride-ion sources agents, including sodium fluoride, stannous fluoride, amine fluorides such as olaflur (amine fluoride 297) and dectaflur, sodium monofluorophosphate, fluorosilicates, fluorozirconates, fluorostannites, fluoroborates, fluorotitanates, and fluorogermanates. Non-limiting examples of cations are Ca.sup.2+, Sn.sup.2+, Sn.sup.4+, Zn.sup.2+, Al.sup.3+, Cu.sup.2+, Fe.sup.2+, and Fe.sup.3+.
[0156] Anti-tartar agents known for use in dental care products also include phosphates, such as pyrophosphates, polyphosphates, polyphosphonates and mixtures thereof. Pyrophosphates are among the best known for use in dental care products. Pyrophosphate ions delivered to the teeth derive from pyrophosphate salts. The pyrophosphate salts useful in the present compositions include the dialkali metal pyrophosphate salts, tetra-alkali metal pyrophosphate salts, and mixtures thereof. Disodium dihydrogen pyrophosphate (Na.sub.2H.sub.2P.sub.2O.sub.7), tetrasodium pyrophosphate (Na.sub.4P.sub.2O.sub.7), and tetrapotassium pyrophosphate (K.sub.4P.sub.207) in their unhydrated as well as hydrated forms are the preferred species. While any of the above-mentioned pyrophosphate salts may be used, tetrasodium pyrophosphate salt is preferred.
[0157] The pyrophosphate salts are described in more detail in Kirk & Othmer, Encyclopedia of Chemical Technology, Third Edition, Volume 17, Wiley-Interscience Publishers (1982). Additional anti-calculus agents include pyrophosphates or polyphosphates disclosed in U.S. Pat. No. 4,590,066 issued to Parran & Sakkab on May 20, 1986; polyacrylates and other polycarboxylates, such as those disclosed in U.S. Pat. No. 3,429,963 issued to Shedlovsky on Feb. 25, 1969, U.S. Pat. No. 4,304,766 issued to Chang on Dec. 8, 1981 and U.S. Pat. No. 4,661,341 issued to Benedict & Sunberg on Apr. 28, 1987; polyepoxysuccinates such as those disclosed in U.S. Pat. No. 4,846,650 issued to Benedict, Bush & Sunberg on Jul. 11, 1989; ethylenediaminetetraacetic acid as disclosed in British Patent No. 490,384 dated Feb. 15, 1937; nitrilotriacetic acid and related compounds as disclosed in U.S. Pat. No. 3,678,154 issued to Widder & Briner on Jul. 18, 1972; polyphosphonates as disclosed in U.S. Pat. No. 3,737,533 issued to Francis on Jun. 5, 1973, U.S. Pat. No. 3,988,443 issued to Ploger, Schmidt-Dunker & Gloxhuber on Oct. 26, 1976 and U.S. Pat. No. 4,877,603 issued to Degenhardt & Kozikowski on Oct. 31, 1989. Anti-calculus phosphates include potassium and sodium pyrophosphates; sodium tripolyphosphate; diphosphonates, such as ethane-1-hydroxy-1,1-diphosphonate, 1-azacycloheptane-1,1-diphosphonate, and linear alkyl diphosphonates; linear carboxylic acids; and sodium zinc citrate.
[0158] Agents that may be used in place of or in combination with the pyrophosphate salt include such known materials as synthetic anionic polymers including polyacrylates and copolymers of maleic anhydride or acid and methyl vinyl ether (e.g., Gantrez), as described, for example, in U.S. Pat. No. 4,627,977, to Gaffar et al., as well as, e.g., polyamino propoane sulfonic acid (AMPS), zinc citrate trihydrate, polyphosphates (e.g., tripolyphosphate; hexametaphosphate), diphosphonates (e.g., EHDP; AHP), polypeptides (such as polyaspartic and polyglutamic acids), and mixtures thereof.
[0159] Fluoride ion sources are well known for use in oral care compositions as anti-cavity agents. Fluoride ions are contained in a number of oral care compositions for this purpose, particularly dentifrices. Patents disclosing such dentifrices include U.S. Pat. No. 3,538,230 to Pader et al; U.S. Pat. No. 3,689,637 to Pader; U.S. Pat. No. 3,711,604 to Colodney et al; U.S. Pat. No. 3,911,104 to Harrison; U.S. Pat. No. 3,935,306 to Roberts et al; and U.S. Pat. No. 4,040,858 to Wason.
[0160] Application of fluoride ions to dental enamel serves to protect teeth against decay. A wide variety of fluoride ion-yielding materials can be employed as sources of soluble fluoride in the instant compositions. Examples of suitable fluoride ion-yielding materials are found in Briner et al; U.S. Pat. No. 3,535,421; issued Oct. 20, 1970 and Widder et al; U.S. Pat. No. 3,678,154; issued Jul. 18, 1972. Preferred fluoride ion sources for use herein include sodium fluoride, potassium fluoride and ammonium fluoride. Sodium fluoride is particularly preferred.
[0161] Anti-microbial agents can also be present in the oral care compositions or substances of the present invention. Such agents may include, but are not limited to, triclosan, 5-chloro-2-(2,4-dichlorophenoxy)-phenol, as described in The Merck Index, 11th ed. (1989), pp. 1529 (entry no. 9573) in U.S. Pat. No. 3,506,720, and in European Patent Application No. 0,251,591 of Beecham Group, PLC, published Jan. 7, 1988; chlorhexidine (Merck Index, no. 2090), alexidine (Merck Index, no. 222); hexetidine (Merck Index, no. 4624); sanguinarine (Merck Index, no. 8320); benzalkonium chloride (Merck Index, no. 1066); salicylanilide (Merck Index, no. 8299); domiphen bromide (Merck Index, no. 3411); cetylpyridinium chloride (CPC) (Merck Index, no. 2024; tetradecylpyridinium chloride (TPC); N-tetradecyl-4-ethylpyridinium chloride (TDEPC); octenidine; delmopinol, octapinol, and other piperidino derivatives; nisin preparations; zinc/stannous ion agents; bacteriocins; antibiotics such as augmentin, amoxicillin, tetracycline, doxycycline, minocycline, and metronidazole; and analogs and salts of the above anti-microbial anti-plaque agents; essential oils inclyding thymol, geraniol, carvacrol, citral, hinokitiol, eucalyptol, catechol (particularly 4-allyl catechol) and mixtures thereof; methyl salicylate; hydrogen peroxide; metal salts of chlorite, and mixtures thereof.
[0162] Non-limiting examples of flavoring and cooling agents are menthol, menthone, methyl acetate, menthofuran, 1,8-cineol, R-(-)-carvone, limonene, dihydrocarvone, methyl salicylate, sugar alcohols or polyols (e.g. xylitol, sorbitol, and erythritol), and their derivatives. A non-limiting example of teeth remineralizing agents is hydroxyapatite nanocrystals.
[0163] Anti-inflammatory agents can also be present in the oral care compositions or substances of the present invention. Such agents may include, but are not limited to, non-steroidal anti-inflammatory agents or NSAIDs such as ketorolac, flurbiprofen, ibuprofen, naproxen, indomethacin, aspirin, ketoprofen, piroxicam and meclofenamic acid. Use of NSAIDs such as ketorolac is claimed in U.S. Pat. No. 5,626,838, issued May 6, 1997. Disclosed therein are methods of preventing and/or treating primary and reoccurring squamous cell carcinoma of the oral cavity or oropharynx by topical administration to the oral cavity or oropharynx an effective amount of an NSAID.
[0164] Nutrients may improve the condition of the oral cavity. Nutrients include minerals, vitamins, oral nutritional supplements, enteral nutritional supplements, and mixtures thereof. Minerals that can be included with the compositions of the present invention include calcium, phosphorus, fluoride, zinc, manganese, potassium and mixtures thereof. These minerals are disclosed in Drug Facts and Comparisons (loose leaf drug information service), Wolters Kluer Company, St. Louis, Mo., (c)1997, pp 10-17. Vitamins can be included with minerals or used separately. Vitamins include Vitamins C and D, thiamine, riboflavin, calcium pantothenate, niacin, folic acid, nicotinamide, pyridoxine, cyanocobalamin, para-aminobenzoic acid, bioflavonoids, and mixtures thereof. Such vitamins are disclosed in Drug Facts and Comparisons (loose leaf drug information service), Wolters Kluer Company, St. Louis, Mo., (c)1997, pp. 3-10. Oral nutritional supplements include amino acids, lipotropics, fish oil, and mixtures thereof, as disclosed in Drug Facts and Comparisons (loose leaf drug information service), Wolters Kluer Company, St. Louis, Mo., (c)1997, pp. 54-54e. Amino acids include L-tryptophan, L-lysine, methionine, threonine, levocarnitine or L-carnitine and mixtures thereof. Lipotropics include, but, are not limited to choline, inositol, betaine, linoleic acid, linolenic acid, and mixtures thereof. Fish oil contains large amounts of omega-3 (N-3) polyunsaturated fatty acids, eicosapentaenoic acid and docosahexaenoic acid. Enteral nutritional supplements include, but, are not limited to protein products, glucose polymers, corn oil, safflower oil, medium chain triglycerides as disclosed in Drug Facts and Comparisons (loose leaf drug information service), Wolters Kluer Company, St. Louis, Mo., (c) 1997, pp. 55-57.
[0165] Enzymes provide several benefits when used for cleansing of the oral cavity. Proteases break down salivary proteins which are absorbed onto the tooth surface and form the pellicle; the first layer of resulting plaque. Proteases along with lipases destroy bacteria by lysing proteins and lipids which form the structural component of bacterial cell walls and membranes. Dextranases break down the organic skeletal structure produced by bacteria that forms a matrix for bacterial adhesion. Proteases and amylases not only prevent plaque formation but also prevent the development of calculus by breaking-up the carbohydrate-protein complex that binds calcium, preventing mineralization. Enzymes useful in the present invention include any of the commercially available proteases, glucanohydrolases, endoglycosidases, amylases, mutanases, lipases and mucinases or compatible mixtures thereof. Preferred are the proteases, dextranases, endoglycosidases and mutanases, most preferred being papain, endoglycosidase or a mixture of dextranase and mutanase. Additional enzymes suitable for use in the present invention are disclosed in U.S. Pat. No. 5,000,939 to Dring et al.; U.S. Pat. No. 4,992,420 to Neeser; U.S. Pat. No. 4,355,022 to Rabussay; U.S. Pat. No. 4,154,815 to Pader; U.S. Pat. No. 4,058,595 to Colodney; U.S. Pat. No. 3,991,177 to Virda et al. and 3,696,191 to Weeks.
[0166] Other materials that can be used with the present invention include commonly known mouth and throat products. Such products are disclosed in Drug Facts and Comparisons (loose leaf drug information service), Wolters Kluer Company, St. Louis, Mo., (c)1997, pp. 520b-527. These products include anti-fungal, antibiotic and analgesic agents.
[0167] Antioxidants are generally recognized as useful in compositions such as those of the present invention. Antioxidants are disclosed in texts such as Cadenas and Packer, The Handbook of Antioxidants, (c) 1996 by Marcel Dekker, Inc. Antioxidants that may be included in the oral care composition or substance of the present invention include, but are not limited to vitamin E, ascorbic acid, uric acid, carotenoids, Vitamin A, flavonoids and polyphenols, herbal antioxidants, melatonin, aminoindoles, lipoic acids and mixtures thereof.
[0168] In another embodiment, a method for delivering one or more oral care active ingredients to the oral cavity comprises administering an oral care composition comprising: at least one nucleic acid aptamer and one or more nanomaterials; wherein said at least one nucleic acid aptamer and said one or more nanomaterials are covalently or non-covalently attached; and wherein said at least one nucleic acid aptamer has a binding affinity for an oral cavity component.
[0169] In another embodiment, a method for delivering one or more oral care active ingredients to the oral cavity comprises administering an oral care composition comprising: a) at least one nucleic acid aptamer; b) one or more nanomaterials; and c) and one or more oral care active ingredients; wherein said at least one nucleic acid aptamer and said one or more nanomaterials are covalently or non-covalently attached; and wherein said at least one nucleic acid aptamer has a binding affinity for an oral cavity component. In another embodiment, said one or more oral care active ingredients are covalently or non-covalently attached to said one or more nanomaterials. In yet another embodiment, said one or more oral care active ingredients are carried by said one or more nanomaterials.
[0170] Non-limiting examples of nanomaterials are gold nanoparticles, nano-scale iron oxides, carbon nanomaterials (such as single-walled carbon nanotubes and graphene oxide), mesoporous silica nanoparticles, quantum dots, liposomes, poly (lactide-co-glycolic acids) nanoparticles, polymeric micelles, dendrimers, serum albumin nanoparticles, and DNA-based nanomaterials.
[0171] In addition to at least one nucleic acid aptamer, the oral care compositions of the present invention may also include surfactants and/or detergents, polishing agents, abrasive materials, binders, carriers, thickening agents, humectants, salts, and other ingredients. Surfactants or detergents can provide a desirable foaming quality. Suitable surfactants are those which are reasonably stable and foam throughout a wide pH range. The surfactant may be anionic, nonionic, amphoteric, zwitterionic, cationic, or mixtures thereof. Anionic surfactants useful herein include the water-soluble salts of alkyl sulfates having from 8 to 20 carbon atoms in the alkyl radical (e.g., sodium alkyl sulfate) and the water-soluble salts of sulfonated monoglycerides of fatty acids having from 8 to 20 carbon atoms. Sodium lauryl sulfate and sodium coconut monoglyceride sulfonates are examples of anionic surfactants of this type. Other suitable anionic surfactants are sarcosinates, such as sodium lauroyl sarcosinate, taurates, sodium lauryl sulfoacetate, sodium lauroyl isethionate, sodium laureth carboxylate, and sodium dodecyl benzenesulfonate. Mixtures of anionic surfactants can also be employed. Many suitable anionic surfactants are disclosed by Agricola et al., U.S. Pat. No. 3,959,458, issued May 25, 1976, incorporated herein in its entirety by reference. Nonionic surfactants which can be used in the compositions of the present invention can be broadly defined as compounds produced by the condensation of alkylene oxide groups (hydrophilic in nature) with an organic hydrophobic compound which may be aliphatic or alkyl-aromatic in nature. Examples of suitable nonionic surfactants include poloxamers (sold under trade name Pluronic), polyoxyethylene, polyoxyethylene sorbitan esters (sold under trade name Tweens), fatty alcohol ethoxylates, polyethylene oxide condensates of alkyl phenols, products derived from the condensation of ethylene oxide with the reaction product of propylene oxide and ethylene diamine, ethylene oxide condensates of aliphatic alcohols, long chain tertiary amine oxides, long chain tertiary phosphine oxides, long chain dialkyl sulfoxides, and mixtures of such materials. The amphoteric surfactants useful in the present invention can be broadly described as derivatives of aliphatic secondary and tertiary amines in which the aliphatic radical can be a straight chain or branched and wherein one of the aliphatic substituents contains from about 8 to about 18 carbon atoms and one contains an anionic water-solubilizing group, e.g., carboxylate, sulfonate, sulfate, phosphate, or phosphonate. Other suitable amphoteric surfactants are betaines, specifically cocamidopropyl betaine. Mixtures of amphoteric surfactants can also be employed. Many of these suitable nonionic and amphoteric surfactants are disclosed by Gieske et al., U.S. Pat. No. 4,051,234, issued Sep. 27, 1977, incorporated herein by reference in its entirety. The present composition typically comprises one or more surfactants each at a level of from about 0.25% to about 12%, preferably from about 0.5% to about 8%, and most preferably from about 1% to about 6%, by weight of the composition.
[0172] The binder system, generally, is a primary factor that determines the rheological characteristics of the oral care composition. The binder also acts to keep any solid phase of an oral care component suspended, thus preventing separation of the solid phase portion of the oral care component from the liquid phase portion. Additionally, the binder can provide body or thickness to the oral care composition. Thus, in some instances, a binder can also provide a thickening function to an oral care composition. Examples of binders include sodium carboxymethyl-cellulose, cellulose ether, xanthan gum, carrageenan, sodium alginate, carbopol, or silicates such as hydrous sodium lithium magnesium silicate. Other examples of suitable binders include polymers such as hydroxypropyl methylcellulose, hydroxyethyl cellulose, guar gum, tragacanth gum, karaya gum, arabic gum, Irish moss, starch, and alginate. Alternatively, the binder can include a clay, for example, a synthetic clay such as a hectorite, or a natural clay. Each of the binders can be used alone or in combination with other binders.
[0173] Non-limiting examples of thickening agents include thickening silica, polymers, clays, and combinations thereof. Thickening silica, for example, SILODENT 15 hydrated silica, in the amount between about 4% to about 8% by weight (e.g., about 6%) provide desirable in-mouth characteristics. The phrase "in-mouth characteristics" as described herein relates to the body and thickness of the dentifrice as it foams in the mouth of a user.
[0174] Non-limiting examples of polishing agents include abrasive materials, such as carbonates (e.g., sodium bicarbonate, calcium carbonate) water-colloidal silica, precipitated silicas (e.g., hydrated silica), sodium aluminosilicates, silica grades containing alumina, hydrated alumina, dicalcium phosphates, calcium hydrogen phosphates, calcium pyrophosphate, calcium pyrophosphate (beta phase), hydroxyapatite, insoluble sodium metaphosphate, and magnesiums (e.g., trimagnesium phosphate). A suitable amount of polishing agent is an amount that safely provides good polishing and cleaning and which, when combined with other ingredients gives a smooth, flowable, and not excessively gritty composition. In general, when polishing agents are included, they are present in an amount from about 5% to about 50% by weight (e.g., from about 5% to about 35%, or from about 7% to about 25%).
[0175] Examples of carriers include water, polyethylene glycol, glycerin, polypropylene glycol, starches, sucrose, alcohols (e.g., methanol, ethanol, isopropanol, etc.), or combinations thereof. Examples of combinations include various water and alcohol combinations and various polyethylene glycol and polypropylene glycol combinations. In general, the amount of carrier included is determined based on the concentration of the binder system along with the amount of dissolved salts, surfactants, and dispersed phase.
[0176] Generally, humectants are polyols. Examples of humectants include glycerin, sorbitol propyleneglycol, xylitol, lactitol, polypropylene glycol, polyethylene glycol, hydrogenated corn syrup and mixtures thereof. In general, when humectants are included they can be present in an amount from about 10% to about 60% by weight.
[0177] Examples of buffers and salts include primary, secondary, or tertiary alkali metal phosphates, citric acid, sodium citrate, sodium saccharin, tetrasodium pyrophosphate, sodium hydroxide, and the like. The oral care compositions of the present invention may also include active ingredients, for example, to prevent cavities, to whiten teeth, to freshen breath, to deliver oral medication, and to provide other therapeutic and cosmetic benefits such as those described above. Examples of active ingredients include the following: anti-caries agents (e.g., water soluble fluoride salts, fluorosilicates, fluorozirconates, fluorostannites, fluoroborates, fluorotitanates, fluorogermanates, mixed halides and casine); anti-tartar agents; anti-calculus agents (e.g. alkali-metal pyrophosphates, hypophosphite-containing polymers, organic phosphocitrates, phosphocitrates, polyphosphates); anti-bacterial agents (e.g., bacteriocins, antibodies, enzymes); anti-bacterial enhancing agents; anti-microbial agents (e.g., Triclosan, chlorhexidine, copper-, zinc- and stannous salts such as zinc citrate, zinc sulfate, zinc glycinate, sanguinarine extract, metronidazole, quaternary ammonium compounds, such as cetylpyridinium chloride; bis-guanides, such as chlorhexidine digluconate, hexetidine, octenidine, alexidine; and halogenated bisphenolic compounds, such as 2,2' methylenbis-(4-chloro-6-bromophenol)); desensitizing agents (e.g., potassium citrate, potassium chloride, potassium tartrate, potassium bicarbonate, potassium oxalate, potassium nitrate and strontium salts); whitening agents (e.g., bleaching agents such as peroxy compounds, e.g. potassium peroxydiphosphate); anti-plaque agents; gum protecting agents (e.g., vegetable oils such as sunflower oil, rape seed oil, soybean oil and safflower oil, and other oils such as silicone oils and hydrocarbon oils). The gum protection agent may be an agent capable of improving the permeability barrier of the gums. Other active ingredients include wound healing agents (e.g., urea, allantoin, panthenol, alkali metal thiocyanates, chamomile-based actives and acetylsalicylic acid derivatives, ibuprofen, flurbiprofen, aspirin, indomethacin etc.); tooth buffering agents; demineralization agents; anti-inflammatory agents; anti-malodor agent; breath freshing agents; and agents for the treatment of oral conditions such as gingivitis or periodontitis.
[0178] The oral care compositions of the present invention may also include one or more of other ingredients, comprising: phenolic compounds (e.g., phenol and its homologues, including 2-methyl-phenol, 3-methyl-phenol. 4-methyl-phenol, 4-ethyl-phenol, 2,4-dimethol-phenol, and 3,4-dimethol-phenol); sweetening agents (e.g., sodium saccharin, sodium cyclamate, sucrose, lactose, maltose, and fructose); flavors (e.g., peppermint oil, spearmint oil, eucalyptus oil, aniseed oil, fennel oil, caraway oil, methyl acetate, cinnamaldehyde, anethol, vanillin, thymol and other natural or nature-identical essential oils or synthetic flavors); preservatives (e.g., p-hydroxybenzoic acid methyl, ethyl, or propyl ester, sodium sorbate, sodium benzoate, bromochlorophene, triclosan, hexetidine, phenyl silicylate, biguanides, and peroxides); opacifying and coloring agents such as titanium dioxide or FD&C dyes; and vitamins such as retinol, tocopherol or ascorbic acid.
[0179] An example of synthesizing aptamers that can be used in oral care compositions, such as dentifrice, is shown below.
Aptamer Preparation:
[0180] Aptamers SEQ ID NO 1, SEQ ID NO 9, and SEQ ID NO 25 are synthesized by enzymatic transcription from the corresponding double stranded DNA templates using a mixture of 15 mM 2'-fluoro CTP, 15 mM 2'-fluoro UTP, 5 mM ATP, 5 mM GTP, a mutant T7 polymerase (T7 R&DNA), and other standard reagents are used. The aptamers are then cleaned up with a Zymo RNA cleanup column, following manufacturer's instructions, and eluted on the reaction buffer (e.g. phosphate buffered saline (PBS) with EDTA: 10 mM sodium phosphate, 0.15 M NaCl, 10 mM EDTA, pH 7.2).
Conjugation Reaction:
[0181] First, a solution of 4,4'-diamino-2,2'-stilbenedisulfonic acid (0.25 M) and imidazole (0.1 M) in water (pH 6) is prepared. Then, EDC (1-ethyl-3-[3-dimethylaminopropyl]carbodiimide hydrochloride) is weighed in a reaction vial and mixed with an aliquot of an aptamer solution prepared as above. An aliquot of the amine/imidazole solution is added immediately to the reaction vial and vortexed until all the components are dissolved. An additional aliquot of imidazole solution (0.1 M, pH 6) is added to the reaction vial and the reaction mixture is incubated at room temperature for at least 2 hours. Following incubation, the unreacted EDC and its by-products and imidazole are separated from the modified aptamer by dialysis or by using a spin desalting column and a suitable buffer (e.g. 10 mM sodium phosphate, 0.15 M NaCl, 10 mM EDTA, pH 7.2). Additional details about the conjugation protocols are described in "Hermanson G. T. (2008). Bioconjugate Techniques. 2nd Edition. pp. 969-1002, Academic Press, San Diego.", the content of which is incorporated herein by reference.
[0182] The produced modified aptamer is conjugated with 4,4'-diamino-2,2'-stilbenedisulfonic acid at the 5'-end and can be formulated in an oral care composition (e.g. dentifrice) to provide teeth whitening benefits when contacted with teeth.
[0183] An example of a potential dentifrice formulation comprising one or more aptamers of the present invention is shown below in TABLE 1. Sample dentifrice formulations can be prepared using standard methods known in the art using the components listed in TABLE 1.
TABLE-US-00001 TABLE 1 Weight % of Components Composition Sorbitol solution (70%) 32.577 Sodium hydroxide (50% soln.) 1.740 Water QS Saccharin sodium 0.450 Xanthan gum 0.300 Sodium fluoride 0.243 Carboxymethylcellulose 1.050 Sodium acid pyrophosphate 3.190 Carbomer 0.300 Flavor 1.4 Sodium lauryl sulfate (28% soln.) 6.000 Mica titanium dioxide 0.400 Aptamer 0.1-0.01 Silica 22 Total 100
EXAMPLES
Example 1. Aptamers Design
A. Preparation of the Immobilization Field
[0184] The immobilization field was prepared by synthesizing a random library of eight nucleotide oligonucleotides with a disulfide group on the 5'-end (immobilization field library) as described elsewhere (PLoS One. 2018 Jan. 5; 13(1):e0190212). In brief, the 8-mer thiolated random oligonucleotide library was dissolved in 50 .mu.L of 1.times.PBS buffer (pH 7.4) at a final concentration of 10 .mu.M. The surface of a gold coated glass slide with dimensions of 7 mm.times.10 mm.times.0.3 mm (Xantec, Germany). was treated with five sequential 10 .mu.L drops of the immobilization field library. The slide was then allowed to incubate for 1 hour in the dark at room temperature in order to facilitate conjugation of the immobilization field library onto the gold surface.
[0185] After this incubation period, the immobilization field library was considered to have been conjugated onto the gold surface. The remaining solution was removed, and the surface was allowed to dry at room temperature.
[0186] The remaining surface was then blocked with short thiol terminated polyethylene glycol (PEG-SH) with molecular formula: CH.sub.3O--(CH.sub.2CH.sub.2O).sub.n--CH.sub.2CH.sub.2SH and an average molecular weight of 550 daltons. An aliquot of 50 .mu.L of the PEG-SH solution in 1.times.PBS buffer at a concentration of 286 .mu.M was applied to the chip and allowed to incubate overnight at room temperature with gentle shaking. This process was repeated in a second blocking step, with an incubation period of 30 minutes at room temperature with gentle shaking.
[0187] Following blocking of the chip, the latter was washed with 600 .mu.L of 1.times.HEPES buffer (10 mM HEPES, pH 7.4, 120 mM NaCl, 5 mM KCl, 5 mM MgCl.sub.2) for 5 minutes with shaking at room temperature.
B. Library Preparation
[0188] A DNA library of about 10.sup.15 different sequences, containing a random region of 40 nucleotides flanked by two conserved regions, i.e. T7 promoter sequence at the 5'-end (5'-GGGAAGAGAAGGACATATGAT-3') and a 3' reverse primer recognition sequence (5'-TTGACTAGTACATGACCACTT-3'), was transcribed to RNA using a mixture of 3:1 2'-fluoro pyrimidines nucleotides and natural purine nucleotides and a mutant T7 polymerase (T7 R&DNA).
[0189] An aliquot of the transcribed selection library comprising about 10.sup.15 RNA sequences was diluted in 50 .mu.L of 1.times. selection buffer (10 mM cacodylate buffer, 120 mM NaCl, 5 mM KCl, 50 .mu.M SnF.sub.2). An equimolar number of oligonucleotides complementary to the conserved regions of the library sequences (T7 promoter primer and 3' reverse primer) or blockers was added and incubated with the selection library in a total volume of 100 .mu.L. This solution was heated for 10 minutes at 45.degree. C. to ensure removal of any secondary or tertiary structures which could interfere with the proper annealing of the blockers to the selection library. The blockers were then allowed to anneal to the selection library by allowing the mixture to equilibrate to room temperature for 15 minutes.
[0190] This blocked selection library was then exposed to the immobilization field in five sequential 10 .mu.L drops. The blocked selection library was incubated on the immobilization field for 30 minutes with slow shaking in an incubator at room temperature. The solution remaining on top after this time period was removed and discarded. The chip was washed twice with the addition of 50 .mu.L of selection buffer. The buffer was pipetted over the chip and then discarded.
[0191] The blocked selection library sequences which were bound to the immobilization field were recovered from the chip by applying 50 .mu.L of 60% DMSO and incubating for 10 min at room temperature. The solution was removed to a fresh tube, and the process was repeated two more times. The three elution solutions were combined (150 .mu.L in total). The RNA sequences were then cleaned up with a Zymo RNA cleanup column (Zymo Research, Irvine, Calif.), following manufacturer's instructions. The purified selection library was eluted with 35 .mu.L of water and combined with 10 .mu.L of 5.times. selection buffer and 5 .mu.L of 500 .mu.M SnF.sub.2.
C. Aptamer Selection
[0192] A clean unerupted third molar tooth was washed with three successive applications of 1 mL water and dipped into a sample of human saliva collected from several individuals. Saliva was pipetted over regions of the tooth that appeared to not be coated. The 50 .mu.L library solution prepared as described above (section B) was pipetted into a depression on a microscope slide (concavity slides, 3.2 mm thick; United Scientific) and the tooth was placed in this depression. The slide was then placed in a shaking incubator at 50 rpm, 37.degree. C., for 1 hour. The tooth was removed and washed twice with 1 mL each of selection buffer. Then the tooth was placed on a fresh depression slide and 50 .mu.L of 60% DMSO was added to elute bound sequences. This elution process was repeated and the two elution solutions were combined (100 .mu.L in total). The eluted RNA library was cleaned up with a Zymo RNA clean up column, following manufacturer's instructions. The library was reverse transcribed into DNA with Protoscript RT II enzyme and PCR amplified in a two-step process. First, four separate PCR reactions were performed with different numbers of sequential PCR cycles (e.g. 4, 6, 8, and 10 cycles). Then, the products of each of these PCR reactions were analyzed by gel electrophoresis to determine the optimum number of cycles required for amplification, i.e. as high a yield as possible without the appearance of any concatemers of the PCR product. Then, this number of PCR cycles was applied for library amplification to complete the selection round.
[0193] The library was split into two aliquots to perform two experiments under the same conditions (Experiment A and Experiment B). The selection process was repeated eleven more times. Dentifrice (Crest Cavity Protection) was added at a concentration of 0.322% in the selection buffer during selection rounds 6, 9, and 12.
[0194] Negative selections against coffee and wine were also performed. During selection rounds 7 and 10, an aliquot of 5 .mu.L of instant coffee was added to the library solution (for a final 1:10 dilution) and the mixture was incubated with the immobilization field for 30 minutes with shaking in an incubator at room temperature. Oligonucleotides with specificity for molecules present in the coffee are not expected to bind the immobilization field. Thus, the solution remaining on top after this time period was removed and discarded. The chip was washed twice with the addition of 50 .mu.L of selection buffer. The buffer was pipetted onto the surface and then discarded. The library sequences which were bound to the immobilization field were recovered from the chip by applying 50 .mu.L of 60% DMSO and incubating for 10 min at room temperature. The solution was removed to a fresh tube, and the process was repeated two more times. The three elution solutions were combined (150 .mu.L in total). The RNA sequences were then cleaned up with a Zymo RNA cleanup column, following manufacturer's instructions. The library was reverse transcribed into DNA with Protoscript RT II enzyme and PCR amplified in a two-step process, as described above, to complete the selection cycle. The same process was performed with wine during selection rounds 8 and 11.
D. Aptamers Sequencing
[0195] Aliquots of selection rounds 7 to 12 for both experiments were prepared for next generation sequencing (NGS) analysis. A total of more than 23 million sequences were analyzed. The number of sequences captured was much lower for selection rounds 11 and 12 as a function of the increased stringency of selection. One indication that a selection was successful is the observation that the copy number of certain sequences increased over selection rounds (see FIG. 1 and FIG. 2). In the graphs shown in FIGS. 1 and 2, the top 20 sequences based on the frequency on round 12 of the selection process were graphed. For instance, for FIG. 1, the sequences are OC1R-A1 to OC1R-A20 in order from the top line to the bottom line (based on round 12). FIG. 1 shows the enrichment trajectories of the top twenty sequences in terms of copy number across different selection rounds for Experiment A. FIG. 2 shows the enrichment trajectories of the top twenty sequences in terms of copy number across different selection rounds for Experiment B. The top sequences in terms of copy number for every selection experiment are listed in TABLE 2. Interestingly, the top 15 sequences, based on copy number, in selection experiment A were also identified in the top 40 sequences of selection experiment B. Furthermore, the top 2 sequences in both experiments were identical, but in the reverse ranking.
Example 2. RNA Aptamers Binding
[0196] DNA oligonucleotides encoding for selected aptamers (OC1R-B1/OC1R-A2,OC1R-B9, and OC1R-B25/OC1R-A9) and one encoding for a negative control aptamer (Neg) were transcribed to RNA using a mixture of 1 mM biotinylated UTP, 15 mM 2'-fluoro CTP, 14 mM 2'-fluoro UTP, 5 mM ATP, 5 mM GTP, a mutant T7 polymerase (T7 R&DNA), and other standard reagents. The modified RNA oligonucleotides were then cleaned up with a Zymo RNA cleanup column, following manufacturer's instructions. An aliquot of 250 .mu.L of 1 .mu.M modified RNA in 1.times. binding buffer (10 mM cacodylate buffer, 120 mM NaCl, 5 mM KCl, 50 .mu.M SnF.sub.2, and 0.322% dentifrice) was placed in the depression of a microscope slide (concavity slides, 3.2 mm thick; United Scientific, Waukegan, Ill.). Separately, a clean unerupted third molar tooth was washed with water, dried, and coated with human saliva collected fresh from several. The tooth was then placed into the depression of the slide containing the modified RNA and incubated for 30 minutes at room temperature. The tooth was removed from the slide and washed twice with 250 .mu.L of binding buffer.
[0197] A solution of streptavidin-horse radish peroxidase (HRP) in binding buffer was prepared and an aliquot of 250 .mu.L was placed into the depression of a clean slide (concavity slides, 3.2 mm thick; United Scientific). The tooth was also placed into the same depression and incubated for 30 minutes at room temperature. After incubation, the tooth was washed with 2 mL of binding buffer. Finally, to detect aptamer binding, the tooth was immersed into a solution of 10.times. LumiGLO.RTM. (Cell Signaling Technology, Danvers, Mass.) and 10.times. hydrogen peroxide (50:50 mixture of 20.times. stocks). Only aptamers that bind to the tooth generated chemoluminescence in darkness (see FIGS. 3A-3D). FIGS. 3A-3D show the binding of different aptamers to teeth as demonstrated by the chemoluminescence of the teeth in darkness. FIG. 3A shows a negative control. FIG. 3B shows the binding of the aptamer identified as "OC1R-B1" to teeth. FIG. 3C shows the binding of the aptamer identified as "OC1R-B9" to teeth. FIG. 3D shows the binding of the aptamer identified as "OC1R-B25/OC1R-A9" to teeth.
Example 3. Covariance Analysis of Sequences
[0198] A covariance analysis for the change in sequence frequency was performed on the top 100 aptamers of Experiment B. First, for each selection round, the frequency data was normalized by dividing the observed frequency of each aptamer by the average of the frequencies of the top 100 aptamers. This normalization allowed eliminating potential differences caused by PCR amplification prior to NGS analysis among different selection rounds. Then, the normalized values of each aptamer in selection round 7 were subtracted from the normalized values of the corresponding aptamer in selection rounds 8 to 12. The resulting matrix was used for the correlation analysis.
[0199] A Pearson correlation across the selection rounds was performed. Since a different tooth was used in each selection round, it is reasonable to assume that the covariance among aptamer frequencies would be due to covariance in the abundance of the epitope within the tooth that they bind to. Thus, each cluster of covarying aptamers corresponds to a group of aptamers that bind to a different epitope within the tooth. An Euclidean distance matrix from the correlation matrix was generated and used as the basis for clustering with a Ward.D2 algorithm (see FIG. 4). FIG. 4 shows a correlation matrix ordered by clustering (Ward.D2 method) for enrichment trajectories of top 100 aptamers of Experiment B. These analyses were performed with the software R.
[0200] Based on FIG. 4, five different epitopes are likely the binding sites of the selected aptamers. The sequences numbers (SEQ ID NOs) of such aptamers for each cluster/epitope are listed below:
Cluster A: 29, 66, 4, 89, 3, 31, 1, 49, 69, 75, 81, 5, 41, 37, 6, 8, 14, 21, 61
Cluster B: 16, 24, 33, 76, 45, 36, 52, 51, 15, 93
Cluster C: 87, 9, 62, 77, 79, 35, 73, 7, 78, 98, 55, 59, 71, 18, 95, 53, 13, 20, 23, 30, 84, 22, 34
Cluster D: 12, 17, 11, 39, 82, 27, 10, 26, 38, 92, 65, 56, 88, 42, 47, 28, 63, 91, 32, 96, 46, 60
Cluster E: 99, 43, 80, 100, 44, 97, 58, 67, 74, 85, 86, 19, 90, 50, 25, 83, 54, 40, 48, 72, 64, 57, 68, 94, 2, 70
[0201] The covariance analysis suggests that aptamers OC1R-B1 (SEQ ID NO 1), OC1R-B9 (SEQ ID NO 9), and OC1R-B25/OC1R-A9 (SEQ ID NO 25) bind to different epitopes within a tooth. Furthermore, aptamers within cluster A likely bind to the same epitope as OC1R-B1, aptamers within cluster C likely bind to the same epitope as OC1R-B9, and aptamers within cluster E likely bind to the same epitope as OC1R-B25 (or OC1R-A9). Aptamers in clusters B and D probably bind to epitopes different than the aptamers described above.
[0202] It should be noted that a significant negative correlation among clusters was observed, which could be caused by the variation in the chemical composition of the enamel of the teeth used in this study. This variation could be due to either natural variation among individuals from whom the teeth were extracted or differences on post-extraction treatment of the teeth.
[0203] The combined use of aptamers from different clusters could provide a greater overall tooth coverage and/or efficacy across different individuals and it is included as one of the embodiment of the present invention. Aptamers binding to different teeth epitopes can be selected using the information from this example. Furthermore, the use of these aptamers could be used to diagnose the chemical composition of teeth enamel in vivo.
Example 4. Motif and Predicted Structure Analysis
[0204] Aptamers bind to target molecules on the basis of the lowest free-energy shape that they form. The lowest free energy shape is a function of homology between regions within the single stranded sequence. These regions of homology fold back onto each other and thus create the secondary and tertiary shape of the aptamer that is crucial to enable binding. We characterized the core characteristics of these aptamers through a combined analysis of conserved motif sequences and their effect on the predicted structure of the whole aptamer. A motif in this context is defined as a contiguous sequence of nucleotides of a defined length. For this example, we considered each possible overlapping six nucleotide motif within the random region of each aptamer characterized.
[0205] The frequency of motifs of six or more nucleotides from the random regions of aptamers OC1R-B1, OC1R-B9, and OC1R-A9 within a subset of the selection library (top 1,000 oligonucleotides in terms of copy number) was determined. Since these aptamers were all selected for binding to the same target (teeth), it stands to reason that motifs within this library that were present at higher frequencies than a random distribution would represent key sequences within the aptamers that were selected for. Moreover, predicted structures containing these sequences should be reasonably expected to represent structures that have been selected for. As such, an analysis of the selection of motif sequences and the predicted structures that they form provides a basis for a more general understanding of the necessary requirements for aptamers that have the capacity to bind to teeth.
[0206] The prediction of the secondary structures of the aptamers was performed with RNAstructure (https://rna.urmc.rochester.edu/RNAstructureWeb/Servers/Predictl/Predictl- .html).
[0207] A. Analysis of the Role of Conserved Motifs on Structure within the Aptamer OC1R-B1:
[0208] The results of motif analysis are presented in FIG. 5. The overlapping six nucleotide motifs comprising the random region of the aptamer are provided consecutively along the x axis in this figure. The y axis provides a statistical significance (Z value) for each motif in the library. The Z value was computed as the observed frequency of this motif in the library minus the average of the frequency for all motifs in the library and this subtractant was divided by the standard deviation of all motifs in the library to provide the Z value. Thus, a Z value of 2 represents a frequency of this motif in the library that is two standard deviations greater than the average value for all motifs.
[0209] In FIG. 5, it is clear that the sequence UUCCUA and the sequence UUUAUCUU were conserved at a level that represented more than two standard deviations from the average. These two conserved sequences were separated by a G and U consecutively that were not conserved. These two consensus sequences can be joined by considering these non-conserved nucleotides as N's.
TABLE-US-00002 SEQ ID NO 235: 5' UUCCUANNUUUAUCUU 3'.
[0210] The lowest free energy predicted structure of the OC1R-B1 aptamer is shown in FIG. 6. The numbers in FIGS. 6, 8, 10, 11, 12, 18A-18D, 19A-19C, 20A and 20B indicate the position along the sequence from the 5'-end to the 3'-end; and are useful to track and align oligos. It appears that the consensus motif is key to the creation of a small loop between stems, as well as the joining of the two ends of the aptamer. The sequence of the stem (double stranded regions) itself is of importance as alteration of this sequence while maintaining double stranded structure can destroy binding capacity. It is thought that the sequence nature of the double stranded region is important in terms of the stacking energy of the bases and that this stacking energy is affected by events such as binding elsewhere in the aptamer. The conserved motif noted as SEQ ID NO 235 is highlighted in a box. SEQ ID NO's 235 to 244 are shown in TABLE 5.
[0211] Given that we have shown that the DNA version of this aptamer also binds effectively to teeth (see Example 7), it stands to reason that the conclusions arrived at within this example regarding conserved motifs in the RNA sequence would apply to the DNA sequence as well. Thus, any sequences containing the corresponding deoxyribonucleotide motif
TABLE-US-00003 SEQ ID NO 236: 5'-TTCCTANNTTTATCTT-3'
are also expected to bind to teeth and are included as embodiments of the present invention.
[0212] B. Analysis of the Role of Conserved Motifs on Structure within the Aptamer OC1R-B9:
[0213] The analysis of the role of conserved motifs on structure within aptamer OC1R-B9 was performed in a manner identical to that described for OC1R-B1. FIG. 7 provides a summary of the motif analysis for aptamer OC1R-B9. There is a ten nucleotide motif near the 5' end of the aptamer that was present at a frequency that was more than two standard deviations from the overall average motif frequency in the selected libraries,
TABLE-US-00004 SEQ ID NO 237: 5'-UUCGCANAAG-3'.
This sequence has a single degenerate nucleotide within it. There is an additional highly conserved 14 nucleotide motif near the 3' end of the random sequence,
TABLE-US-00005 SEQ ID NO 238: 5'-UGCGGCANGCGCGU-3'.
[0214] This sequence also contains one degenerate nucleotide. The predicted secondary structure of OC1R-B9 and its conserved motifs is illustrated in FIG. 8. It is clear in this figure that the two consensus motifs are related to each other, each comprising a different side of the same double stranded secondary structure. Sequences containing any of these motifs are also expected to bind to teeth and are included as embodiments of the present invention. Given that we demonstrated that the DNA version of this aptamer also bound to teeth, it stands to reason that the same consensus motifs within the DNA version of this aptamer would be necessary core elements for the binding function. Thus, any sequences containing any of the corresponding deoxyribonucleotide motifs:
TABLE-US-00006 SEQ ID NO 239: 5'-TTCGCANAAG-3' SEQ ID NO 240: 5'-TGCGGCANGCGCGT-3'
are also expected to bind to teeth and are included as embodiments of the present invention.
[0215] C. Analysis of the Role of Conserved Motifs on Structure within Aptamer OC1R-A9:
The motif analysis and predicted secondary structure for the aptamer OC1R-A9 were performed in a manner identical to that described for aptamer OC1R-B1 and OC1R-B9. The motif analysis for the aptamer OC1R-A9 is provided in FIG. 9. In FIG. 9, as described in Section A above, the y axis provides a statistical significance (Z value) for each motif in the library. The Z value was computed as the observed frequency of this motif in the library minus the average of the frequency for all motifs in the library and this subtractant was divided by the standard deviation of all motifs in the library to provide the Z value." The ten nucleotide motif,
TABLE-US-00007 SEQ ID NO 241: 5'-CUUUUCUUCC-3'
was present at a frequency that was more than two standard deviations from the overall average frequency of motifs within this selected library. The role of this motif on the structure of the aptamer is provided in FIG. 10. It is clear that this motif is responsible for the formation of a double stranded region within the aptamer. Therefore, it stands to reason that this double stranded region within the aptamer is necessary for binding to teeth. This motif within the DNA version of this aptamer, OC1D-A9 is also responsible for the formation of a double stranded region (FIG. 11). Therefore, sequences containing this motif are also expected to bind to teeth and are included as embodiments of the present invention. Therefore, it stands to reason that any DNA sequences containing the corresponding deoxyribonucleotide motif
TABLE-US-00008 SEQ ID NO 242: 5'-CTTTTCTTCC-3'
are also expected to bind to teeth and are included as embodiments of the present invention.
[0216] D. Analysis of Common Motifs within Aptamer Library:
[0217] A search for common motifs within the top 10,000 sequences in terms of frequency from Experiment B was performed. The lead motif identified in terms of significant deviation from random distribution was SEQ ID NO 243.
TABLE-US-00009 SEQ ID NO 243: 5'-GCGCGCGC-3'
This motif was found in each of the following sequences, in which the 5'- and 3'-primer recognition sequences were eliminated for simplicity. Oligonucleotides comprising the motif SEQ ID NO 243 are included as an embodiment of the current invention.
TABLE-US-00010 OC1R-B71 AAGCCGGCCCGGGAACAUGUCACGCGCGCGCGCAAAGUAG OC1R-B125 GAAUUAUGAUAGACUAUGAGUCAAUAGCGCGCGCUGGAGG OC1R-B181 CACCGGGUGACGAAACGGCGCGCGCGCUAGCCUGCUAGCA OC1R-B190 ACACCGAGGGACUGAAUGGGGAGGCCGCGCGCGCUGAGGG OC1R-B302 AAGUCAGGACGCGAUGGGUGCGCGCGCGCGUGCGACAUAA OC1R-B306 ACGGCGCGCGCAGGCUACCACUACUGACUCGGCAAUGAUA OC1R-B316 CAACACUGCGCGCGCCGGACAACAAGCGAUUCCUGAGUAC OC1R-B317 CAACUCGACCUGCGCGCGCCUACCCCCAAACUCAACUACC OC1R-B338 CGAGGGUUAGAUCGGGGCGCGCGCACUUGUGGUUGUCCAA OC1R-B348 GAACGAGAGGCGCGCGCUGGUGGACCGGGGGAUAGGGGAU OC1R-B390 AACCGGUCAACACGAUCCUGAGCGCGCGCACGGAUGAAUU OC1R-B394 AACGGGCAUGACAGCCUCACGCCAAGGCGCGCGCGGGUAA OC1R-B395 AACGUCAAAAAACACUGCGCGCGCUGGAUAGAUGAACGUA OC1R-B404 ACAAAGCAGCCAGCGCGCGCUUGACCCGGAGAGUAGCACA OC1R-B463 CAUCCAUGCGCGCGCAGGGGUUAAGCGAGGGUCCUCCAUG OC1R-B497 CUCCGCGCGCGCACUUACCAUCUCUUCGUAAGGAAGUCGA OC1R-B606 AACCUGCAUUAGGCGCGCGCGCGUAGUUGGCACAGCUGUG OC1R-B690 AGCCAGCAGAAUGCCAACCAACGUAGCCGAGGCGCGCGCA OC1R-B875 CUGCUCUCCGGGCGCGCGCACCAACCUCUAGGCAGCUUGG OC1R-B952 GGCAGGGUAAUCUGGGCUGCGCGCGCACCUACAAUGGCUA OC1R-B973 GUGCAAGUUAUGAGAUUGGACGCACCGCGCGCGCAGCCUU OC1R-B986 UAAAGUUGGGUUCGGGGGCGCGCGCACUUCAUCACGACUA OC1R-B1115 UUUCACGCUUCCUGCGCGCGCUAGUGGCAACUCUACCUCC
[0218] Any sequences containing the corresponding deoxyribonucleotide motif
TABLE-US-00011 SEQ ID NO 244: 5'-GCGCGCGC-3'
are also expected to bind to teeth and are included as embodiments of the present invention.
Example 5. Analysis of Sequences Similarity
[0219] Alignment of SEQ ID NO 1 to SEQ ID NO 111 was performed using the software Align X, a component of Vector NTI Advanced 11.5.4 by Themo Fisher Scientific. Several groups of sequences have at least 90%, at least 70%, or at least 50% nucleotide sequence identity as illustrated in the alignments of FIGS. 12, 13, and 14. In these alignments, only the central variable region of the aptamers is included for simplicity. Thus, oligonucleotides with at least 50%, at least 70%, or at least 90% nucleotide sequence identity to sequences selected from the group consisting of SEQ ID NO 1 to SEQ ID NO 111 are included as embodiments of the current invention. FIG. 12 shows the alignment of exemplary sequences with at least 90% nucleotide sequence identity that were identified during the selection process. FIG. 13 shows the alignment of exemplary sequences with at least 70% nucleotide sequence identity that were identified during the selection process. FIG. 14 shows the alignment of exemplary sequences with at least 50% nucleotide sequence identity that were identified during the selection process.
Example 7. DNA Aptamers Binding
[0220] Selected DNA aptamers (OC1D-B1/OC1D-A2, OC1D-B9, and OC1D-B25/OC1D-A9) were chemically synthesized with a FAM fluorophore on the 5'end (Eurofins). An aliquot of 250 .mu.L of 1 .mu.M DNA aptamer in 1.times. binding buffer (10 mM cacodylate buffer, 120 mM NaCl, 5 mM KCl, 50 .mu.M SnF.sub.2, and 0.322% toothpaste; pH 7.2) was placed in the depression of a microscope slide (concavity slides, 3.2 mm thick; United Scientific). Separately, a clean unerupted third molar tooth was washed with water, dried, and coated with human saliva collected fresh from several individuals. The tooth was then placed into the depression of the slide containing the DNA aptamer and incubated for 20 minutes at room temperature. The amount of aptamer bound was determined by measuring the fluorescence remaining in the solution after the tooth was removed (see FIG. 15). The tooth was removed from the slide and washed several times with 250 .mu.L of neutral binding buffer. The fluorescence of each wash solution was measured (see FIG. 16). Bound aptamers were recovered by washing the teeth with two aliquots of 250 mM NaOH. The fluorescence of each elution solution was also measured (see FIG. 17). Not all the aptamer incubated with the teeth was recovered probably due to very strong binding or adsorption inside the teeth.
[0221] Given that we have shown that the DNA version of aptamers OC1R-B1/OC1R-A2, OC1R-B9, and OC1R-B25/OC1R-A9 also bind effectively to teeth, it stands to reason that the conclusions arrived at within this example would apply to the DNA versions of the remaining selected aptamers (SEQ ID NO: 112 to SEQ ID NO: 222), included herein as part of the invention and listed in Table 3.
Example 8. Truncation of Aptamers
[0222] Starting from the predicted secondary structure of the selected aptamers (OC1D-B1, OC1D-B9, and OC1D-A9), smaller oligonucleotides comprising some of the secondary structure elements were designed. Consideration of consensus motifs within these predicted structures was included in the design of the truncated aptamers (FIGS. 5 to 10). The truncated aptamers all contained highly selected motif sequences that were involved in stem/loop structures within the original aptamers. These selected structures were conserved in the truncated aptamers.
[0223] For instance, aptamers OC1D-B1.1, OC1D-B1.2, and OC1D-B1.3 were derived from aptamer OC1D-B1 (see FIGS. 18A-18D). OC1D-B1.1 comprises completely the bent stem/loop structure of the structure, OC1D-B1.2 comprises just the top of the bent stem/loop structure, while OC1D-B1.3 comprises the tight stem/loop structure. Aptamers OC1D-B9.1 and OC1D-B9.2 were derived from aptamer OC1D-B9 (see FIGS. 19A-19C) and correspond to its two-bottom stem/loop substructures. Aptamer OC1D-A9.1 was derived from aptamer OC1D-A9 (see FIGS. 20A and 20B) with a view to maintain the conserved motif element in a minimal aptamer.
[0224] FIGS. 21A-21C illustrate the binding results for each of these truncated aptamers to teeth. These binding assays were performed and analyzed in a manner identical to that described previously for the full-length aptamers (see Example 7). For aptamers from OC1D-B1, the truncated aptamer containing the entire bent stem/loop structure (OC1D-B1.1) performed better on teeth compared to the other two. This provides confirmation that the conserved motif identified in the RNA aptamer is conserved and key to the function of this aptamer as well. For aptamers from OC1D-B9, only the truncated aptamer OC1D-B9.2 containing the bottom bent stem/loop structure binds well on teeth. This corresponds well to the higher level of statistical significance associated with the conserved motif within OC1D-B9.2 compared to the conserved motif within OC1D-B9.1. Finally, truncated aptamer OC1D-A9.1 has a higher binding affinity than the parent aptamer, but not as high as other truncated aptamers. The list of sequences of truncated aptamers is included in TABLE 4.
TABLE-US-00012 TABLE 2 List of top sequences from selection experiments A and B. All the pyrimidine nucleotides are fluorinated at the 2' position of the pentose group. Copy SEQ ID NO Name Total Sequence Number 1 OC1R-B1 GGGAAGAGAAGGACAUAUGAUUCAUGUGAGAUGA 16160 or OC1R- UGUGUGUUCCUAGUUUUAUCUUGCUCUUUGACUA A2 GUACAUGACCACUU 2 OC1R-B2 GGGAAGAGAAGGACAUAUGAUUAGGCUAACUGUU 7945 or OC1R- CAGGGAUUUGAUAUGCAUGAGGAGCACUUGACUA A1 GUACAUGACCACUU 3 OC1R-B3 GGGAAGAGAAGGACAUAUGAUCCGCUCUAAAGUA 7939 or OC1R- CCAACCGCGGGAGCUAAAUGCAAGCCGUUGACUAG A19 UACAUGACCACUU 4 OC1R-B4 GGGAAGAGAAGGACAUAUGAUUGUGUCAGGCUCU 4041 AGAGUCUAGACGGCCGGGGUCCCGGAUUUGACUA GUACAUGACCACUU 5 OC1R-B5 GGGAAGAGAAGGACAUAUGAUCCUUAUGUCUAGC 2867 GGCCUUACGCGAUUAGUGGCGUUUUGUUUGACUA GUACAUGACCACUU 6 OC1R-B6 GGGAAGAGAAGGACAUAUGAUCUUUAUGUAUUAU 1841 CAGUCAUACCGGACGCAGCCCGCUGGAUUGACUAG UACAUGACCACUU 7 OC1R-B7 GGGAAGAGAAGGACAUAUGAUUGUGUUAUUACAC 1464 or OC1R- UUCGUGAUUUUCCUUGCUUUUCUAUUUUUGACUA A3 GUACAUGACCACUU 8 OC1R-B8 GGGAAGAGAAGGACAUAUGAUCCAACAUCUAAAG 1373 UACUGGUCGCCUAGGGAGACUGUUCGGUUGACUA GUACAUGACCACUU 9 OC1R-B9 GGGAAGAGAAGGACAUAUGAUGCUAUAUUCGCAA 851 AAGCAGGCUGAGUGCGGCAGGCGCGUGUUGACUA GUACAUGACCACUU 10 OC1R- GGGAAGAGAAGGACAUAUGAUUCAUUCAUUCGCA 759 B10 ACACAAUUGUAUUCGCAUCUGCGAUUUUUGACUA GUACAUGACCACUU 11 OC1R- GGGAAGAGAAGGACAUAUGAUCUUUCUCUUUUCU 561 B11 or AAUAUUUAAUUUAUUGGGUACCAAUUUUUGACUA OC1R- GUACAUGACCACUU A11 12 OC1R- GGGAAGAGAAGGACAUAUGAUCUUUGUUUCGCAU 425 B12 or ACGUUUUCUUUUUCUCUCUUCUUAUUUUUGACUA OC1R-A7 GUACAUGACCACUU 13 OC1R- GGGAAGAGAAGGACAUAUGAUUAUUCUGUUCUUC 402 B13 or AAAAAUCUUUUAGCGUAUACGCUAUUUUUGACUA OC1R-A5 GUACAUGACCACUU 14 OC1R- GGGAAGAGAAGGACAUAUGAUUUCCUUAUGUUCG 396 B14 GUCAACAGGGACUGCUGCAGCACCGGCUUGACUAG UACAUGACCACUU 15 OC1R- GGGAAGAGAAGGACAUAUGAUUAAGCGCACUCAA 371 B15 CAGGGUCUAUGAUCCGCGCCGAUCAUGUUGACUAG UACAUGACCACUU 16 OC1R- GGGAAGAGAAGGACAUAUGAUCCGCUUUCCAUUG 357 B16 or AGAUUAUAAGCUGUUAGAGACUUAUUUUUGACUA OC1R- GUACAUGACCACUU A15 17 OC1R- GGGAAGAGAAGGACAUAUGAUUUUCGAAACGUUU 353 B17 or CUUUCAAGUUCUUAAUCAUUCCCAUUUUUGACUA OC1R-A8 GUACAUGACCACUU 18 OC1R- GGGAAGAGAAGGACAUAUGAUCAUUAGAUGCGCA 297 B18 GUUCGAAGCCGGUACAGCUGGCGCGCGUUGACUAG UACAUGACCACUU 19 OC1R- GGGAAGAGAAGGACAUAUGAUAAAGAAUAACCUU 290 B19 AAAAUAACACCACCGCCUCACAGCAUAUUGACUAG UACAUGACCACUU 20 OC1R- GGGAAGAGAAGGACAUAUGAUAAAUUGAUCUAUU 282 B20 or CUUUUCGGUGCUAUUUAUCUUCCAUUUUUGACUA OC1R-A6 GUACAUGACCACUU 21 OC1R- GGGAAGAGAAGGACAUAUGAUCUACUCGCGCGGC 282 B21 GGACAAAAGCGCAACCCAGCACCCAUGUUGACUAG UACAUGACCACUU 22 OC1R- GGGAAGAGAAGGACAUAUGAUUCUUAGUUUGUAA 255 B22 or UUACUUUUCCUUCCUUUUAUUCUAUUUUUGACUA OC1R- GUACAUGACCACUU A10 23 OC1R- GGGAAGAGAAGGACAUAUGAUAACCCGCGCAGAC 227 B23 UUACAAGCGCGCAAAAAAAGGGUACGUUUGACUA GUACAUGACCACUU 24 OC1R- GGGAAGAGAAGGACAUAUGAUAUUCCUUUAUGCC 209 B24 or GCAUCAUUUUAUUGUUUAUGACAAUUUUUGACUA OC1R- GUACAUGACCACUU A23 25 OC1R- GGGAAGAGAAGGACAUAUGAUAUUUCGUACUACU 209 B25 or UUUCUUCCAAGCUUCAAUCGCCCAUUUUUGACUAG OC1R-A9 UACAUGACCACUU 26 OC1R- GGGAAGAGAAGGACAUAUGAUUCACUCAUUCGCA 198 B26 or ACACAAUUGUAUUCGCAUCUGCGAUUUUUGACUA OC1R- GUACAUGACCACUU A24 27 OC1R- GGGAAGAGAAGGACAUAUGAUAUUAUUUCCACAG 190 B27 or UUCCUUUAUCCACACAUCUUCUCAUUUUUGACUAG OC1R- UACAUGACCACUU A12 28 OC1R- GGGAAGAGAAGGACAUAUGAUAAACUCGUUAUCU 187 B28 AUUCGUUUAUUUGCAUCUCUUUCAUUUUUGACUA GUACAUGACCACUU 29 OC1R- GGGAAGAGAAGGACAUAUGAUCCAACCUCUAAAG 185 B29 UACUGGUCGCCUAGGGAGACUGUUCGGUUGACUA GUACAUGACCACUU 30 OC1R- GGGAAGAGAAGGACAUAUGAUUUCCUUUUUGCUA 179 B30 UUUCCGUUAAUGUAAACUCUCCUAUUUUUGACUA OC1R- GUACAUGACCACUU A13 31 OC1R- GGGAAGAGAAGGACAUAUGAUCCUUAUGGCCUAG 167 B31 UAGGGAUCCGGGCGCCGACCAGCGCGAUUGACUAG UACAUGACCACUU 32 OC1R- GGGAAGAGAAGGACAUAUGAUCGUCUGUCUUCUU 153 B32 CGAAUACGUUUUGGGCUAAGCCCAUUUUUGACUA OC1R- GUACAUGACCACUU A18 33 OC1R- GGGAAGAGAAGGACAUAUGAUUCAACCAAACUGC 143 B33 CGACGACCGAGGUAUGUCCUUAUGUACUUGACUA GUACAUGACCACUU 34 OC1R- GGGAAGAGAAGGACAUAUGAUUACGGGUCUGAGC 142 B34 AAAAGCGAAGGAAGCAGGCGCAGGGAUUUGACUA GUACAUGACCACUU 35 OC1R- GGGAAGAGAAGGACAUAUGAUUCUCUCAUUCGCA 134 B35 or ACACAAUUGUAUUCGCAUCUGCGAUUUUUGACUA OC1R-A4 GUACAUGACCACUU 36 OC1R- GGGAAGAGAAGGACAUAUGAUGCUCUAAAGUACU 127 B36 AAGCGUUUGCGCCGAUGCCCGGACCGCUUGACUAG UACAUGACCACUU 37 OC1R- GGGAAGAGAAGGACAUAUGAUACUUCAUUAAUGU 126 B37 GAGGCCGUCAGGGGGCAACCUUCGAGCUUGACUAG UACAUGACCACUU 38 OC1R- GGGAAGAGAAGGACAUAUGAUUCCUUAUUCUUGU 126 B38 UACUACUUUCUUUUCCUAUUUUUUUCUUUGACUA GUACAUGACCACUU 39 OC1R- GGGAAGAGAAGGACAUAUGAUCGUUAUUUUCAUU 125 B39 or UUCUUGUUCCCCAUAUGCCCAGGCGCAUUGACUAG OC1R- UACAUGACCACUU A14 40 OC1R- GGGAAGAGAAGGACAUAUGAUACCAGCGGCGUAG 120 B40 AAACGUACAGCUCGCCUGUAACGCCUGUUGACUAG UACAUGACCACUU 41 OC1R- GGGAAGAGAAGGACAUAUGAUCGAUAUGGGUGCG 107 B41 GGAAUGUACGUUCACCGAAUAUGCUCCUUGACUA GUACAUGACCACUU 42 OC1R- GGGAAGAGAAGGACAUAUGAUUAACAGUGCGUAG 95 B42 UCAUAUCGAAUGUUUAUCUUCCUAUUUUUGACUA GUACAUGACCACUU 43 OC1R- GGGAAGAGAAGGACAUAUGAUCAGACUCUCGCCC 94 B43 AAUUCGCAAGGCGUUGCAUUGCGAUUUUUGACUA GUACAUGACCACUU 44 OC1R- GGGAAGAGAAGGACAUAUGAUUUCCAACUCUCCA 88 B44 CGAGAGCAUGGGUCGAAUGACUCAUUUUUGACUA GUACAUGACCACUU 45 OC1R- GGGAAGAGAAGGACAUAUGAUGCAUCGCGCGUCA 86 B45 CUCAACUCGUGAUUACCGAGGGCGCCGUUGACUAG UACAUGACCACUU 46 OC1R- GGGAAGAGAAGGACAUAUGAUCUGAAUCUUUCCG 82 B46 CAGCCCUGUCCUUUUAAAGACAGGUUUUUGACUA GUACAUGACCACUU 47 OC1R- GGGAAGAGAAGGACAUAUGAUUUUGUUACUUACU 70 B47 UCGUCUAUCUUCUGUUGCACACAGUUUUUGACUA GUACAUGACCACUU 48 OC1R- GGGAAGAGAAGGACAUAUGAUUCAAAUCUUCAGC 69 B48 GAUAAUGGCACAAUUUCCGCGCCAUUUUUGACUA GUACAUGACCACUU 49 OC1R- GGGAAGAGAAGGACAUAUGAUUUAUGUGAGAUGA 67 B49 UGUGUGUUCCUAGUUUUAUCUUGCUCUUUGACUA GUACAUGACCACUU 50 OC1R- GGGAAGAGAAGGACAUAUGAUCCACUUUUCCAUU 62 B50 AACUGUUGCGGGCAAGUAGCACCGUUUUUGACUA GUACAUGACCACUU 51 OC1R- GGGAAGAGAAGGACAUAUGAUAGAGAAGACCAUU 59 B51 CGGAAAGAGCUGCGUGUCCUUAUGUACUUGACUA GUACAUGACCACUU 52 OC1R- GGGAAGAGAAGGACAUAUGAUUCUUAUGUAGCAA 58 B52 GCAAAAUGUGCCGCCGAGCCGACGCCAUUGACUAG UACAUGACCACUU 53 OC1R- GGGAAGAGAAGGACAUAUGAUAAGCGCAUAAUAA 56 B53 GCCAGCCAGUUCUUGGCGCGCGGGGUAUUGACUAG UACAUGACCACUU 54 OC1R- GGGAAGAGAAGGACAUAUGAUUAGUCCGCAUUUC 56 B54 UAUUUUCUAUAUGGCUUACUGCCAUUUUUGACUA GUACAUGACCACUU 55 OC1R- GGGAAGAGAAGGACAUAUGAUAUAAAGAACACGC 44 B55 AAAACCACCCGGACACCCGGUGCCGUGUUGACUAG UACAUGACCACUU 56 OC1R- GGGAAGAGAAGGACAUAUGAUACACAGGCGGUGG 42 B56 AGCCGAAGGGCACCGGGACAAACCGACUUGACUAG UACAUGACCACUU 57 OC1R- GGGAAGAGAAGGACAUAUGAUAGUUCCGGCGCAG 39 B57 CAGCGUCCUCACGUUUUACGUGCCCCAUUGACUAG UACAUGACCACUU 58 OC1R- GGGAAGAGAAGGACAUAUGAUGACCGUCGCGAUC 39 B58 GUUUAUAAUGUUCUGGAUCUUUCAUUUUUGACUA GUACAUGACCACUU 59 OC1R- GGGAAGAGAAGGACAUAUGAUAAGUGGGGCCCCG 37
B59 ACGACUUUUCCUUCCUCUCUUCCGGCAUUGACUAG UACAUGACCACUU 60 OC1R- GGGAAGAGAAGGACAUAUGAUAUCAACAUACCAA 37 B60 AAUGUCAUUUCCAAUCUUUUCCCAUUUUUGACUA GUACAUGACCACUU 61 OC1R- GGGAAGAGAAGGACAUAUGAUAGCGAACAAACAA 36 B61 GGGUGCCCAGGCCCCCUUCGCACAUCGUUGACUAG UACAUGACCACUU 62 OC1R- GGGAAGAGAAGGACAUAUGAUCCUCUGUAACGCA 35 B62 AAGUCAAGUCGCGCAAGGCCGCCCGCGUUGACUAG UACAUGACCACUU 63 OC1R- GGGAAGAGAAGGACAUAUGAUCUUCAUCUGCGAU 35 B63 UACGGUACACUUUAGUGUAUCGUUUUUUUGACUA GUACAUGACCACUU 64 OC1R- GGGAAGAGAAGGACAUAUGAUGCCUAUGUGCUAG 35 B64 AUGCAGCAGCAACCGCCGGCGACUGGAUUGACUAG UACAUGACCACUU 65 OC1R- GGGAAGAGAAGGACAUAUGAUCCGCGCCCUAACCU 33 B65 UCUGACCAAGCUUCCCUGGCACUUGGUUGACUAGU ACAUGACCACUU 66 OC1R- GGGAAGAGAAGGACAUAUGAUCCUUAUGUAUUAU 33 B66 CAGUCAUACCGGACGCAGCCCGCUGGAUUGACUAG UACAUGACCACUU 67 OC1R- GGGAAGAGAAGGACAUAUGAUCUAAUCUAUACUG 33 B67 GCUGCUAACGCUUUUUCUUUUCCAUUUUUGACUA GUACAUGACCACUU 68 OC1R- GGGAAGAGAAGGACAUAUGAUCAGUUUACGCGGA 32 B68 GUCGUUUGUGUCCAUUUCUUCUCAUUUUUGACUA GUACAUGACCACUU 69 OC1R- GGGAAGAGAAGGACAUAUGAUUCACGUGAGAUGA 32 B69 UGUGUGUUCCUAGUUUUAUCUUGCUCUUUGACUA GUACAUGACCACUU 70 OC1R- GGGAAGAGAAGGACAUAUGAUUCCUUGUGUACCG 32 B70 CUCCGAAUGUGCUCCAGCGCGCCUCGGUUGACUAG UACAUGACCACUU 71 OC1R- GGGAAGAGAAGGACAUAUGAUAAGCCGGCCCGGG 31 B71 AACAUGUCACGCGCGCGCGCAAAGUAGUUGACUAG UACAUGACCACUU 72 OC1R- GGGAAGAGAAGGACAUAUGAUCCUGGAUUUCCGA 31 B72 AAUUAGAGUGCCGUUUCGUUACGGUUUUUGACUA GUACAUGACCACUU 73 OC1R- GGGAAGAGAAGGACAUAUGAUCGUGUCAUCCGCA 31 B73 CAAGGAGGCCUGCAUGGCAGGGACACGUUGACUA GUACAUGACCACUU 74 OC1R- GGGAAGAGAAGGACAUAUGAUGAGUAGACUUUUU 31 B74 GUAUCAUUUUUUUAUCGUAAGAUAUUUUUGACUA GUACAUGACCACUU 75 OC1R- GGGAAGAGAAGGACAUAUGAUCCAUGUGAGAUGA 30 B75 UGUGUGUUCCUAGUUUUAUCUUGCUCUUUGACUA GUACAUGACCACUU 76 OC1R- GGGAAGAGAAGGACAUAUGAUCUUUGCUCUAGAG 29 B76 UGUAGUCUAUGAGGGACAAGGUAGCCAUUGACUA GUACAUGACCACUU 77 OC1R- GGGAAGAGAAGGACAUAUGAUGUUGGUUUUCUUU 29 B77 CUCUUUCUUUUCUUUCUCUUUCUAUUUUUGACUA GUACAUGACCACUU 78 OC1R- GGGAAGAGAAGGACAUAUGAUCAAUCGGGCGGGG 28 B78 GUAAGAGGCGUGCGCAGCGUGGAGGUGUUGACUA GUACAUGACCACUU 79 OC1R- GGGAAGAGAAGGACAUAUGAUCACCGUGGUGCGC 27 B79 AAAGCCGCAACGAGAACUGCGGAAUCGUUGACUA GUACAUGACCACUU 80 OC1R- GGGAAGAGAAGGACAUAUGAUUGCUUUAAGUCUU 26 B80 UUUAUCAUUUUGUUUCCUUCAUUUUUUUUGACUA GUACAUGACCACUU 81 OC1R- GGGAAGAGAAGGACAUAUGAUCGACUAGUUAUAC 25 B81 UGCAAAGGCUAUAAGCGCGAGCGCGCGUUGACUA GUACAUGACCACUU 82 OC1R- GGGAAGAGAAGGACAUAUGAUGAGUAAUAGAUGG 25 B82 CGUACACAAAUCGGAUACGACGAGCGCUUGACUAG UACAUGACCACUU 83 OC1R- GGGAAGAGAAGGACAUAUGAUUUUCGCUUCAAGA 25 B83 UUCCCAACGCCUUGUAAGUCAAGGUUUUUGACUA GUACAUGACCACUU 84 OC1R- GGGAAGAGAAGGACAUAUGAUGUGUGAGAUGAGC 24 B84 CCCUGGACCAGACGCACGCUCGCACUGUUGACUAG UACAUGACCACUU 85 OC1R- GGGAAGAGAAGGACAUAUGAUCAGGAUGCGGCGC 23 B85 CGGUAAUUGACUUCCCCCUACGUAGGAUUGACUAG UACAUGACCACUU 86 OC1R- GGGAAGAGAAGGACAUAUGAUCAGGGACCCGGCC 22 B86 GGUGCAUCUCCUUCUUUAGCGUACGCCUUGACUAG UACAUGACCACUU 87 OC1R- GGGAAGAGAAGGACAUAUGAUCUGCUCUAAAGUA 22 B87 CCAACCGCGGGAGCUAAAUGCAAGCCGUUGACUAG UACAUGACCACUU 88 OC1R- GGGAAGAGAAGGACAUAUGAUGAUUGCCAUGCAU 22 B88 UAGGGGGGGACGCGCGCGAAAGGGAGAUUGACUA GUACAUGACCACUU 89 OC1R- GGGAAGAGAAGGACAUAUGAUUCGCUCUAAAGUA 22 B89 CCAACCGCGGGAGCUAAAUGCAAGCCGUUGACUAG UACAUGACCACUU 90 OC1R- GGGAAGAGAAGGACAUAUGAUAAAAAACCGGGGU 21 B90 UCUUAAUUUUCAUUGUUCGUCGUACUUUUGACUA GUACAUGACCACUU 91 OC1R- GGGAAGAGAAGGACAUAUGAUAACCCAUUGGUGA 21 B91 AUCGCAACCACAGCCAGCCCGGCGCGAUUGACUAG UACAUGACCACUU 92 OC1R- GGGAAGAGAAGGACAUAUGAUCGAAGUGAGGGGA 21 B92 UCGCGCGGGGUGCACCUAAAUAUGGGAUUGACUA GUACAUGACCACUU 93 OC1R- GGGAAGAGAAGGACAUAUGAUAGCCUUAUGUACU 20 B93 AUAGAAGUCAGCUAUCCGCCGCACAAUUUGACUAG UACAUGACCACUU 94 OC1R- GGGAAGAGAAGGACAUAUGAUCGUUGUUUUUCCC 20 B94 AAAGCUCGUUAGCAUUCAUUCCUAUUUUUGACUA GUACAUGACCACUU 95 OC1R- GGGAAGAGAAGGACAUAUGAUGAUCAUCAGCGGA 20 B95 AAGCACGAAACGCCACGGGCCGCGGCAUUGACUAG UACAUGACCACUU 96 OC1R- GGGAAGAGAAGGACAUAUGAUUCCUUCCUAUUGA 20 B96 CAAUGCGCCCGGGCCUCUUCAAUUGUAUUGACUAG UACAUGACCACUU 97 OC1R- GGGAAGAGAAGGACAUAUGAUAGUUGCCGCGCGG 18 B97 CGCAAGAUUGGAGAGUCCCGGGCUGUAUUGACUA GUACAUGACCACUU 98 OC1R- GGGAAGAGAAGGACAUAUGAUCAUAAGUUCGUUC 18 B98 AUUCCGUUAACACGCGUAUGGCGUUUUUUGACUA GUACAUGACCACUU 99 OC1R- GGGAAGAGAAGGACAUAUGAUCCUUUGUCUCCAA 18 B99 AUCUUAGGACUGAAUGAGUGCCUAUUUUUGACUA GUACAUGACCACUU 100 OC1R- GGGAAGAGAAGGACAUAUGAUCUUCUUUGAGAAU 18 B100 UCUCUUUUUACAAUUCCGGCGCCGUGAUUGACUAG UACAUGACCACUU 101 OC1R- GGGAAGAGAAGGACAUAUGAUUAGGCUAACUGUU 3130 A16 UAGGGAUUUGAUAUGCAUGAGGAGCACUUGACUA GUACAUGACCACUU 102 OC1R- GGGAAGAGAAGGACAUAUGAUCGUCUGUCUUCUU 2970 A17 CGAAUACGUUUUGGGCUAAGCCCAUUUUUGACUA GUACAUGACCACUU 103 OC1R- GGGAAGAGAAGGACAUAUGAUUAGGCUAACUGCU 2753 A20 CAGGGAUUUGAUAUGCAUGAGGAGCACUUGACUA GUACAUGACCACUU 104 OC1R- GGGAAGAGAAGGACAUAUGAUUAGGCUAACUGUU 2642 A21 CAGGGACUUGAUAUGCAUGAGGAGCACUUGACUA GUACAUGACCACUU 105 OC1R- GGGAAGAGAAGGACAUAUGAUUAGGCUCACUGUU 2627 A22 CAGGGAUUUGAUAUGCAUGAGGAGCACUUGACUA GUACAUGACCACUU 106 OC1R- GGGAAGAGAAGGACAUAUGAUUAGGCUAACUGUU 2250 A25 CAGGGAUUUGAUAUGCAUGGGGAGCACUUGACUA GUACAUGACCACUU 107 OC1R- GGGAAGAGAAGGACAUAUGAUUUCUUCCUAUUGA 2195 A26 CGAUGCGCCCGGGCCUCUUCAAUUGUAUUGACUAG UACAUGACCACUU 108 OC1R- GGGAAGAGAAGGACAUAUGAUUAGGCUAACUGUU 2156 A27 CGGGGAUUUGAUAUGCAUGAGGAGCACUUGACUA GUACAUGACCACUU 109 OC1R- GGGAAGAGAAGGACAUAUGAUUAGGCUAACUGUU 2074 A28 CAGGGAUUUGAUAUGCACGAGGAGCACUUGACUA GUACAUGACCACUU 110 OC1R- GGGAAGAGAAGGACAUAUGAUUAGGUUAACUGUU 2042 A29 CAGGGAUUUGAUAUGCAUGAGGAGCACUUGACUA GUACAUGACCACUU 111 OC1R- GGGAAGAGAAGGACAUAUGAUUAGGCUAACUGUU 2031 A30 CAGGGAUUUGAUGUGCAUGAGGAGCACUUGACUA GUACAUGACCACUU
TABLE-US-00013 TABLE 3 List of deoxyribonucleotides aptamers based on the top sequences from selection experiments A and B. SEQ ID NO Name Total Sequence 112 OC1D- GGGAAGAGAAGGACATATGATTCATGTGAGATGATGTGTGTTCCTAG B1 or TTTTATCTTGCTCTTTGACTAGTACATGACCACTT OC1D- A2 113 OC1D- GGGAAGAGAAGGACATATGATTAGGCTAACTGTTCAGGGATTTGATA B2 or TGCATGAGGAGCACTTGACTAGTACATGACCACTT OC1D- A1 114 OC1D- GGGAAGAGAAGGACATATGATCCGCTCTAAAGTACCAACCGCGGGA B3 or GCTAAATGCAAGCCGTTGACTAGTACATGACCACTT OC1D- A19 115 OC1D- GGGAAGAGAAGGACATATGATTGTGTCAGGCTCTAGAGTCTAGACGG B4 CCGGGGTCCCGGATTTGACTAGTACATGACCACTT 116 OC1D- GGGAAGAGAAGGACATATGATCCTTATGTCTAGCGGCCTTACGCGAT B5 TAGTGGCGTTTTGTTTGACTAGTACATGACCACTT 117 OC1D- GGGAAGAGAAGGACATATGATCTTTATGTATTATCAGTCATACCGGA B6 CGCAGCCCGCTGGATTGACTAGTACATGACCACTT 118 OC1D- GGGAAGAGAAGGACATATGATTGTGTTATTACACTTCGTGATTTTCCT B7 or TGCTTTTCTATTTTTGACTAGTACATGACCACTT OC1D- A3 119 OC1D- GGGAAGAGAAGGACATATGATCCAACATCTAAAGTACTGGTCGCCTA B8 GGGAGACTGTTCGGTTGACTAGTACATGACCACTT 120 OC1D- GGGAAGAGAAGGACATATGATGCTATATTCGCAAAAGCAGGCTGAG B9 TGCGGCAGGCGCGTGTTGACTAGTACATGACCACTT 121 OC1D- GGGAAGAGAAGGACATATGATTCATTCATTCGCAACACAATTGTATT B10 CGCATCTGCGATTTTTGACTAGTACATGACCACTT 122 OC1D- GGGAAGAGAAGGACATATGATCTTTCTCTTTTCTAATATTTAATTTAT B11 or TGGGTACCAATTTTTGACTAGTACATGACCACTT OC1D- A11 123 OC1D- GGGAAGAGAAGGACATATGATCTTTGTTTCGCATACGTTTTCTTTTTC B12 or TCTCTTCTTATTTTTGACTAGTACATGACCACTT OC1D- A7 124 OC1D- GGGAAGAGAAGGACATATGATTATTCTGTTCTTCAAAAATCTTTTAG B13 or CGTATACGCTATTTTTGACTAGTACATGACCACTT OC1D- A5 125 OC1D- GGGAAGAGAAGGACATATGATTTCCTTATGTTCGGTCAACAGGGACT B14 GCTGCAGCACCGGCTTGACTAGTACATGACCACTT 126 OC1D- GGGAAGAGAAGGACATATGATTAAGCGCACTCAACAGGGTCTATGA B15 TCCGCGCCGATCATGTTGACTAGTACATGACCACTT 127 OC1D- GGGAAGAGAAGGACATATGATCCGCTTTCCATTGAGATTATAAGCTG B16 or TTAGAGACTTATTTTTGACTAGTACATGACCACTT OC1D- A15 128 OC1D- GGGAAGAGAAGGACATATGATTTTCGAAACGTTTCTTTCAAGTTCTT B17 or AATCATTCCCATTTTTGACTAGTACATGACCACTT OC1D- A8 129 OC1D- GGGAAGAGAAGGACATATGATCATTAGATGCGCAGTTCGAAGCCGG B18 TACAGCTGGCGCGCGTTGACTAGTACATGACCACTT 130 OC1D- GGGAAGAGAAGGACATATGATAAAGAATAACCTTAAAATAACACCA B19 CCGCCTCACAGCATATTGACTAGTACATGACCACTT 131 OC1D- GGGAAGAGAAGGACATATGATAAATTGATCTATTCTTTTCGGTGCTA B20 or TTTATCTTCCATTTTTGACTAGTACATGACCACTT OC1D- A6 132 OC1D- GGGAAGAGAAGGACATATGATCTACTCGCGCGGCGGACAAAAGCGC B21 AACCCAGCACCCATGTTGACTAGTACATGACCACTT 133 OC1D- GGGAAGAGAAGGACATATGATTCTTAGTTTGTAATTACTTTTCCTTCC B22 or TTTTATTCTATTTTTGACTAGTACATGACCACTT OC1D- A10 134 OC1D- GGGAAGAGAAGGACATATGATAACCCGCGCAGACTTACAAGCGCGC B23 AAAAAAAGGGTACGTTTGACTAGTACATGACCACTT 135 OC1D- GGGAAGAGAAGGACATATGATATTCCTTTATGCCGCATCATTTTATTG B24 or TTTATGACAATTTTTGACTAGTACATGACCACTT OC1D- A23 136 OC1D- GGGAAGAGAAGGACATATGATATTTCGTACTACTTTTCTTCCAAGCTT B25 or CAATCGCCCATTTTTGACTAGTACATGACCACTT OC1D- A9 137 OC1D- GGGAAGAGAAGGACATATGATTCACTCATTCGCAACACAATTGTATT B26 or CGCATCTGCGATTTTTGACTAGTACATGACCACTT OC1D- A24 138 OC1D- GGGAAGAGAAGGACATATGATATTATTTCCACAGTTCCTTTATCCAC B27 or ACATCTTCTCATTTTTGACTAGTACATGACCACTT OC1D- A12 139 OC1D- GGGAAGAGAAGGACATATGATAAACTCGTTATCTATTCGTTTATTTG B28 CATCTCTTTCATTTTTGACTAGTACATGACCACTT 140 OC1D- GGGAAGAGAAGGACATATGATCCAACCTCTAAAGTACTGGTCGCCTA B29 GGGAGACTGTTCGGTTGACTAGTACATGACCACTT 141 OC1D- GGGAAGAGAAGGACATATGATTTCCTTTTTGCTATTTCCGTTAATGTA B30 AACTCTCCTATTTTTGACTAGTACATGACCACTT OC1D- A13 142 OC1D- GGGAAGAGAAGGACATATGATCCTTATGGCCTAGTAGGGATCCGGGC B31 GCCGACCAGCGCGATTGACTAGTACATGACCACTT 143 OC1D- GGGAAGAGAAGGACATATGATCGTCTGTCTTCTTCGAATACGTTTTG B32 GGCTAAGCCCATTTTTGACTAGTACATGACCACTT OC1D- A18 144 OC1D- GGGAAGAGAAGGACATATGATTCAACCAAACTGCCGACGACCGAGG B33 TATGTCCTTATGTACTTGACTAGTACATGACCACTT 145 OC1D- GGGAAGAGAAGGACATATGATTACGGGTCTGAGCAAAAGCGAAGGA B34 AGCAGGCGCAGGGATTTGACTAGTACATGACCACTT 146 OC1D- GGGAAGAGAAGGACATATGATTCTCTCATTCGCAACACAATTGTATT B35 or CGCATCTGCGATTTTTGACTAGTACATGACCACTT OC1D- A4 147 OC1D- GGGAAGAGAAGGACATATGATGCTCTAAAGTACTAAGCGTTTGCGCC B36 GATGCCCGGACCGCTTGACTAGTACATGACCACTT 148 OC1D- GGGAAGAGAAGGACATATGATACTTCATTAATGTGAGGCCGTCAGGG B37 GGCAACCTTCGAGCTTGACTAGTACATGACCACTT 149 OC1D- GGGAAGAGAAGGACATATGATTCCTTATTCTTGTTACTACTTTCTTTT B38 CCTATTTTTTTCTTTGACTAGTACATGACCACTT 150 OC1D- GGGAAGAGAAGGACATATGATCGTTATTTTCATTTTCTTGTTCCCCAT B39 or ATGCCCAGGCGCATTGACTAGTACATGACCACTT OC1D- A14 151 OC1D- GGGAAGAGAAGGACATATGATACCAGCGGCGTAGAAACGTACAGCT B40 CGCCTGTAACGCCTGTTGACTAGTACATGACCACTT 152 OC1D- GGGAAGAGAAGGACATATGATCGATATGGGTGCGGGAATGTACGTT B41 CACCGAATATGCTCCTTGACTAGTACATGACCACTT 153 OC1D- GGGAAGAGAAGGACATATGATTAACAGTGCGTAGTCATATCGAATGT B42 TTATCTTCCTATTTTTGACTAGTACATGACCACTT 154 OC1D- GGGAAGAGAAGGACATATGATCAGACTCTCGCCCAATTCGCAAGGC B43 GTTGCATTGCGATTTTTGACTAGTACATGACCACTT 155 OC1D- GGGAAGAGAAGGACATATGATTTCCAACTCTCCACGAGAGCATGGGT B44 CGAATGACTCATTTTTGACTAGTACATGACCACTT 156 OC1D- GGGAAGAGAAGGACATATGATGCATCGCGCGTCACTCAACTCGTGAT B45 TACCGAGGGCGCCGTTGACTAGTACATGACCACTT 157 OC1D- GGGAAGAGAAGGACATATGATCTGAATCTTTCCGCAGCCCTGTCCTT B46 TTAAAGACAGGTTTTTGACTAGTACATGACCACTT 158 OC1D- GGGAAGAGAAGGACATATGATTTTGTTACTTACTTCGTCTATCTTCTG B47 TTGCACACAGTTTTTGACTAGTACATGACCACTT 159 OC1D- GGGAAGAGAAGGACATATGATTCAAATCTTCAGCGATAATGGCACA B48 ATTTCCGCGCCATTTTTGACTAGTACATGACCACTT 160 OC1D- GGGAAGAGAAGGACATATGATTTATGTGAGATGATGTGTGTTCCTAG B49 TTTTATCTTGCTCTTTGACTAGTACATGACCACTT 161 OC1D- GGGAAGAGAAGGACATATGATCCACTTTTCCATTAACTGTTGCGGGC B50 AAGTAGCACCGTTTTTGACTAGTACATGACCACTT 162 OC1D- GGGAAGAGAAGGACATATGATAGAGAAGACCATTCGGAAAGAGCTG B51 CGTGTCCTTATGTACTTGACTAGTACATGACCACTT 163 OC1D- GGGAAGAGAAGGACATATGATTCTTATGTAGCAAGCAAAATGTGCCG B52 CCGAGCCGACGCCATTGACTAGTACATGACCACTT 164 OC1D- GGGAAGAGAAGGACATATGATAAGCGCATAATAAGCCAGCCAGTTC B53 TTGGCGCGCGGGGTATTGACTAGTACATGACCACTT 165 OC1D- GGGAAGAGAAGGACATATGATTAGTCCGCATTTCTATTTTCTATATG B54 GCTTACTGCCATTTTTGACTAGTACATGACCACTT 166 OC1D- GGGAAGAGAAGGACATATGATATAAAGAACACGCAAAACCACCCGG B55 ACACCCGGTGCCGTGTTGACTAGTACATGACCACTT 167 OC1D- GGGAAGAGAAGGACATATGATACACAGGCGGTGGAGCCGAAGGGCA B56 CCGGGACAAACCGACTTGACTAGTACATGACCACTT 168 OC1D- GGGAAGAGAAGGACATATGATAGTTCCGGCGCAGCAGCGTCCTCAC B57 GTTTTACGTGCCCCATTGACTAGTACATGACCACTT 169 OC1D- GGGAAGAGAAGGACATATGATGACCGTCGCGATCGTTTATAATGTTC B58 TGGATCTTTCATTTTTGACTAGTACATGACCACTT 170 OC1D- GGGAAGAGAAGGACATATGATAAGTGGGGCCCCGACGACTTTTCCTT B59 CCTCTCTTCCGGCATTGACTAGTACATGACCACTT 171 OC1D- GGGAAGAGAAGGACATATGATATCAACATACCAAAATGTCATTTCCA B60 ATCTTTTCCCATTTTTGACTAGTACATGACCACTT 172 OC1D- GGGAAGAGAAGGACATATGATAGCGAACAAACAAGGGTGCCCAGGC B61 CCCCTTCGCACATCGTTGACTAGTACATGACCACTT 173 OC1D- GGGAAGAGAAGGACATATGATCCTCTGTAACGCAAAGTCAAGTCGC B62 GCAAGGCCGCCCGCGTTGACTAGTACATGACCACTT 174 OC1D- GGGAAGAGAAGGACATATGATCTTCATCTGCGATTACGGTACACTTT B63 AGTGTATCGTTTTTTTGACTAGTACATGACCACTT 175 OC1D- GGGAAGAGAAGGACATATGATGCCTATGTGCTAGATGCAGCAGCAA B64 CCGCCGGCGACTGGATTGACTAGTACATGACCACTT 176 OC1D- GGGAAGAGAAGGACATATGATCCGCGCCCTAACCTTCTGACCAAGCT B65 TCCCTGGCACTTGGTTGACTAGTACATGACCACTT 177 OC1D- GGGAAGAGAAGGACATATGATCCTTATGTATTATCAGTCATACCGGA B66 CGCAGCCCGCTGGATTGACTAGTACATGACCACTT 178 OC1D- GGGAAGAGAAGGACATATGATCTAATCTATACTGGCTGCTAACGCTT B67 TTTCTTTTCCATTTTTGACTAGTACATGACCACTT 179 OC1D- GGGAAGAGAAGGACATATGATCAGTTTACGCGGAGTCGTTTGTGTCC B68 ATTTCTTCTCATTTTTGACTAGTACATGACCACTT 180 OC1D- GGGAAGAGAAGGACATATGATTCACGTGAGATGATGTGTGTTCCTAG
B69 TTTTATCTTGCTCTTTGACTAGTACATGACCACTT 181 OC1D- GGGAAGAGAAGGACATATGATTCCTTGTGTACCGCTCCGAATGTGCT B70 CCAGCGCGCCTCGGTTGACTAGTACATGACCACTT 182 OC1D- GGGAAGAGAAGGACATATGATAAGCCGGCCCGGGAACATGTCACGC B71 GCGCGCGCAAAGTAGTTGACTAGTACATGACCACTT 183 OC1D- GGGAAGAGAAGGACATATGATCCTGGATTTCCGAAATTAGAGTGCCG B72 TTTCGTTACGGTTTTTGACTAGTACATGACCACTT 184 OC1D- GGGAAGAGAAGGACATATGATCGTGTCATCCGCACAAGGAGGCCTG B73 CATGGCAGGGACACGTTGACTAGTACATGACCACTT 185 OC1D- GGGAAGAGAAGGACATATGATGAGTAGACTTTTTGTATCATTTTTTTA B74 TCGTAAGATATTTTTGACTAGTACATGACCACTT 186 OC1D- GGGAAGAGAAGGACATATGATCCATGTGAGATGATGTGTGTTCCTAG B75 TTTTATCTTGCTCTTTGACTAGTACATGACCACTT 187 OC1D- GGGAAGAGAAGGACATATGATCTTTGCTCTAGAGTGTAGTCTATGAG B76 GGACAAGGTAGCCATTGACTAGTACATGACCACTT 188 OC1D- GGGAAGAGAAGGACATATGATGTTGGTTTTCTTTCTCTTTCTTTTCTTT B77 CTCTTTCTATTTTTGACTAGTACATGACCACTT 189 OC1D- GGGAAGAGAAGGACATATGATCAATCGGGCGGGGGTAAGAGGCGTG B78 CGCAGCGTGGAGGTGTTGACTAGTACATGACCACTT 190 OC1D- GGGAAGAGAAGGACATATGATCACCGTGGTGCGCAAAGCCGCAACG B79 AGAACTGCGGAATCGTTGACTAGTACATGACCACTT 191 OC1D- GGGAAGAGAAGGACATATGATTGCTTTAAGTCTTTTTATCATTTTGTT B80 TCCTTCATTTTTTTTGACTAGTACATGACCACTT 192 OC1D- GGGAAGAGAAGGACATATGATCGACTAGTTATACTGCAAAGGCTATA B81 AGCGCGAGCGCGCGTTGACTAGTACATGACCACTT 193 OC1D- GGGAAGAGAAGGACATATGATGAGTAATAGATGGCGTACACAAATC B82 GGATACGACGAGCGCTTGACTAGTACATGACCACTT 194 OC1D- GGGAAGAGAAGGACATATGATTTTCGCTTCAAGATTCCCAACGCCTT B83 GTAAGTCAAGGTTTTTGACTAGTACATGACCACTT 195 OC1D- GGGAAGAGAAGGACATATGATGTGTGAGATGAGCCCCTGGACCAGA B84 CGCACGCTCGCACTGTTGACTAGTACATGACCACTT 196 OC1D- GGGAAGAGAAGGACATATGATCAGGATGCGGCGCCGGTAATTGACT B85 TCCCCCTACGTAGGATTGACTAGTACATGACCACTT 197 OC1D- GGGAAGAGAAGGACATATGATCAGGGACCCGGCCGGTGCATCTCCTT B86 CTTTAGCGTACGCCTTGACTAGTACATGACCACTT 198 OC1D- GGGAAGAGAAGGACATATGATCTGCTCTAAAGTACCAACCGCGGGA B87 GCTAAATGCAAGCCGTTGACTAGTACATGACCACTT 199 OC1D- GGGAAGAGAAGGACATATGATGATTGCCATGCATTAGGGGGGGACG B88 CGCGCGAAAGGGAGATTGACTAGTACATGACCACTT 200 OC1D- GGGAAGAGAAGGACATATGATTCGCTCTAAAGTACCAACCGCGGGA B89 GCTAAATGCAAGCCGTTGACTAGTACATGACCACTT 201 OC1D- GGGAAGAGAAGGACATATGATAAAAAACCGGGGTTCTTAATTTTCAT B90 TGTTCGTCGTACTTTTGACTAGTACATGACCACTT 202 OC1D- GGGAAGAGAAGGACATATGATAACCCATTGGTGAATCGCAACCACA B91 GCCAGCCCGGCGCGATTGACTAGTACATGACCACTT 203 OC1D- GGGAAGAGAAGGACATATGATCGAAGTGAGGGGATCGCGCGGGGTG B92 CACCTAAATATGGGATTGACTAGTACATGACCACTT 204 OC1D- GGGAAGAGAAGGACATATGATAGCCTTATGTACTATAGAAGTCAGCT B93 ATCCGCCGCACAATTTGACTAGTACATGACCACTT 205 OC1D- GGGAAGAGAAGGACATATGATCGTTGTTTTTCCCAAAGCTCGTTAGC B94 ATTCATTCCTATTTTTGACTAGTACATGACCACTT 206 OC1D- GGGAAGAGAAGGACATATGATGATCATCAGCGGAAAGCACGAAACG B95 CCACGGGCCGCGGCATTGACTAGTACATGACCACTT 207 OC1D- GGGAAGAGAAGGACATATGATTCCTTCCTATTGACAATGCGCCCGGG B96 CCTCTTCAATTGTATTGACTAGTACATGACCACTT 208 OC1D- GGGAAGAGAAGGACATATGATAGTTGCCGCGCGGCGCAAGATTGGA B97 GAGTCCCGGGCTGTATTGACTAGTACATGACCACTT 209 OC1D- GGGAAGAGAAGGACATATGATCATAAGTTCGTTCATTCCGTTAACAC B98 GCGTATGGCGTTTTTTGACTAGTACATGACCACTT 210 OC1D- GGGAAGAGAAGGACATATGATCCTTTGTCTCCAAATCTTAGGACTGA B99 ATGAGTGCCTATTTTTGACTAGTACATGACCACTT 211 OC1D- GGGAAGAGAAGGACATATGATCTTCTTTGAGAATTCTCTTTTTACAAT B100 TCCGGCGCCGTGATTGACTAGTACATGACCACTT 212 OC1D- GGGAAGAGAAGGACATATGATTAGGCTAACTGTTTAGGGATTTGATA A16 TGCATGAGGAGCACTTGACTAGTACATGACCACTT 213 OC1D- GGGAAGAGAAGGACATATGATCGTCTGTCTTCTTCGAATACGTTTTG A17 GGCTAAGCCCATTTTTGACTAGTACATGACCACTT 214 OC1D- GGGAAGAGAAGGACATATGATTAGGCTAACTGCTCAGGGATTTGATA A20 TGCATGAGGAGCACTTGACTAGTACATGACCACTT 215 OC1D- GGGAAGAGAAGGACATATGATTAGGCTAACTGTTCAGGGACTTGATA A21 TGCATGAGGAGCACTTGACTAGTACATGACCACTT 216 OC1D- GGGAAGAGAAGGACATATGATTAGGCTCACTGTTCAGGGATTTGATA A22 TGCATGAGGAGCACTTGACTAGTACATGACCACTT 217 OC1D- GGGAAGAGAAGGACATATGATTAGGCTAACTGTTCAGGGATTTGATA A25 TGCATGGGGAGCACTTGACTAGTACATGACCACTT 218 OC1D- GGGAAGAGAAGGACATATGATTTCTTCCTATTGACGATGCGCCCGGG A26 CCTCTTCAATTGTATTGACTAGTACATGACCACTT 219 OC1D- GGGAAGAGAAGGACATATGATTAGGCTAACTGTTCGGGGATTTGATA A27 TGCATGAGGAGCACTTGACTAGTACATGACCACTT 220 OC1D- GGGAAGAGAAGGACATATGATTAGGCTAACTGTTCAGGGATTTGATA A28 TGCACGAGGAGCACTTGACTAGTACATGACCACTT 221 OC1D- GGGAAGAGAAGGACATATGATTAGGTTAACTGTTCAGGGATTTGATA A29 TGCATGAGGAGCACTTGACTAGTACATGACCACTT 222 OC1D- GGGAAGAGAAGGACATATGATTAGGCTAACTGTTCAGGGATTTGATG A30 TGCATGAGGAGCACTTGACTAGTACATGACCACTT 112 OC1D- GGGAAGAGAAGGACATATGATTCATGTGAGATGATGTGTGTTCCTAG B1 or TTTTATCTTGCTCTTTGACTAGTACATGACCACTT OC1D- A2 113 OC1D- GGGAAGAGAAGGACATATGATTAGGCTAACTGTTCAGGGATTTGATA B2 or TGCATGAGGAGCACTTGACTAGTACATGACCACTT OC1D- A1 114 OC1D- GGGAAGAGAAGGACATATGATCCGCTCTAAAGTACCAACCGCGGGA B3 or GCTAAATGCAAGCCGTTGACTAGTACATGACCACTT OC1D- A19 115 OC1D- GGGAAGAGAAGGACATATGATTGTGTCAGGCTCTAGAGTCTAGACGG B4 CCGGGGTCCCGGATTTGACTAGTACATGACCACTT 116 OC1D- GGGAAGAGAAGGACATATGATCCTTATGTCTAGCGGCCTTACGCGAT B5 TAGTGGCGTTTTGTTTGACTAGTACATGACCACTT 117 OC1D- GGGAAGAGAAGGACATATGATCTTTATGTATTATCAGTCATACCGGA B6 CGCAGCCCGCTGGATTGACTAGTACATGACCACTT 118 OC1D- GGGAAGAGAAGGACATATGATTGTGTTATTACACTTCGTGATTTTCCT B7 or TGCTTTTCTATTTTTGACTAGTACATGACCACTT OC1D- A3 119 OC1D- GGGAAGAGAAGGACATATGATCCAACATCTAAAGTACTGGTCGCCTA B8 GGGAGACTGTTCGGTTGACTAGTACATGACCACTT 120 OC1D- GGGAAGAGAAGGACATATGATGCTATATTCGCAAAAGCAGGCTGAG B9 TGCGGCAGGCGCGTGTTGACTAGTACATGACCACTT 121 OC1D- GGGAAGAGAAGGACATATGATTCATTCATTCGCAACACAATTGTATT B10 CGCATCTGCGATTTTTGACTAGTACATGACCACTT 122 OC1D- GGGAAGAGAAGGACATATGATCTTTCTCTTTTCTAATATTTAATTTAT B11 or TGGGTACCAATTTTTGACTAGTACATGACCACTT OC1D- A11 123 OC1D- GGGAAGAGAAGGACATATGATCTTTGTTTCGCATACGTTTTCTTTTTC B12 or TCTCTTCTTATTTTTGACTAGTACATGACCACTT OC1D- A7 124 OC1D- GGGAAGAGAAGGACATATGATTATTCTGTTCTTCAAAAATCTTTTAG B13 or CGTATACGCTATTTTTGACTAGTACATGACCACTT OC1D- A5 125 OC1D- GGGAAGAGAAGGACATATGATTTCCTTATGTTCGGTCAACAGGGACT B14 GCTGCAGCACCGGCTTGACTAGTACATGACCACTT 126 OC1D- GGGAAGAGAAGGACATATGATTAAGCGCACTCAACAGGGTCTATGA B15 TCCGCGCCGATCATGTTGACTAGTACATGACCACTT 127 OC1D- GGGAAGAGAAGGACATATGATCCGCTTTCCATTGAGATTATAAGCTG B16 or TTAGAGACTTATTTTTGACTAGTACATGACCACTT OC1D- A15 128 OC1D- GGGAAGAGAAGGACATATGATTTTCGAAACGTTTCTTTCAAGTTCTT B17 or AATCATTCCCATTTTTGACTAGTACATGACCACTT OC1D- A8 129 OC1D- GGGAAGAGAAGGACATATGATCATTAGATGCGCAGTTCGAAGCCGG B18 TACAGCTGGCGCGCGTTGACTAGTACATGACCACTT 130 OC1D- GGGAAGAGAAGGACATATGATAAAGAATAACCTTAAAATAACACCA B19 CCGCCTCACAGCATATTGACTAGTACATGACCACTT
TABLE-US-00014 TABLE 4 List of truncated aptamers. SEQ ID NO Name Sequence 223 OC1D-B1.1 ATGTGTGTTCCTAGTTTTATCTTGCTCTTTGACTA GTACATGACCACTTG 224 OC1D-B1.2 TTCCTAGTTTTATCTTGCTCTTTGACTAGTA 225 OC1D-B1.3 GGACATATGATTCATGTGAGA 226 OC1D-B9.1 TTCGCAAAAGCAGGCTGAGTGCGGC 227 OC1D-B9.2 CAGGCGCGTGTTGACTAGTACATGACCAC 228 OC1D-A9.1 GGGAAGAGAAGGACATATGATATTTCGTACTACTT TTCTTCCAA 229 OC1R-B1.1 AUGUGUGUUCCUAGUUUUAUCUUGCUCUUUGACUA GUACAUGACCACUUG 230 OC1R-B1.2 UUCCUAGUUUUAUCUUGCUCUUUGACUAGUA 231 OC1R-B1.3 GGACAUAUGAUUCAUGUGAGA 232 OC1R-B9.1 UUCGCAAAAGCAGGCUGAGUGCGGC 233 OC1R-B9.2 CAGGCGCGUGUUGACUAGUACAUGACCAC 234 OC1R-A9.1 GGGAAGAGAAGGACAUAUGAUAUUUCGUACUACUU UUCUUCCAA
TABLE-US-00015 TABLE 5 List of Conserved Motif Sequences SEQ ID NO Sequence 235 UUCCUANNUUUAUCUU 236 TTCCTANNTTTATCTT 237 UUCGCANAAG 238 UGCGGCANGCGCGU 239 TTCGCANAAG 240 TGCGGCANGCGCGT 241 CUUUUCUUCC 242 CTTTTCTTCC 243 NGCGCGCGCN 244 NGCGCGCGCN
Sequence CWU 1
1
244182RNAArtificial SequenceSynthetic aptamer sequence 1gggaagagaa
ggacauauga uucaugugag augaugugug uuccuaguuu uaucuugcuc 60uuugacuagu
acaugaccac uu 82282RNAArtificial SequenceSynthetic aptamer sequence
2gggaagagaa ggacauauga uuaggcuaac uguucaggga uuugauaugc augaggagca
60cuugacuagu acaugaccac uu 82382RNAArtificial SequenceSynthetic
aptamer sequence 3gggaagagaa ggacauauga uccgcucuaa aguaccaacc
gcgggagcua aaugcaagcc 60guugacuagu acaugaccac uu 82482RNAArtificial
SequenceSynthetic aptamer sequence 4gggaagagaa ggacauauga
uugugucagg cucuagaguc uagacggccg gggucccgga 60uuugacuagu acaugaccac
uu 82582RNAArtificial SequenceSynthetic aptamer sequence
5gggaagagaa ggacauauga uccuuauguc uagcggccuu acgcgauuag uggcguuuug
60uuugacuagu acaugaccac uu 82682RNAArtificial SequenceSynthetic
aptamer sequence 6gggaagagaa ggacauauga ucuuuaugua uuaucaguca
uaccggacgc agcccgcugg 60auugacuagu acaugaccac uu 82782RNAArtificial
SequenceSynthetic aptamer sequence 7gggaagagaa ggacauauga
uuguguuauu acacuucgug auuuuccuug cuuuucuauu 60uuugacuagu acaugaccac
uu 82882RNAArtificial SequenceSynthetic aptamer sequence
8gggaagagaa ggacauauga uccaacaucu aaaguacugg ucgccuaggg agacuguucg
60guugacuagu acaugaccac uu 82982RNAArtificial SequenceSynthetic
aptamer sequence 9gggaagagaa ggacauauga ugcuauauuc gcaaaagcag
gcugagugcg gcaggcgcgu 60guugacuagu acaugaccac uu
821082RNAArtificial SequenceSynthetic aptamer sequence 10gggaagagaa
ggacauauga uucauucauu cgcaacacaa uuguauucgc aucugcgauu 60uuugacuagu
acaugaccac uu 821182RNAArtificial SequenceSynthetic aptamer
sequence 11gggaagagaa ggacauauga ucuuucucuu uucuaauauu uaauuuauug
gguaccaauu 60uuugacuagu acaugaccac uu 821282RNAArtificial
SequenceSynthetic aptamer sequence 12gggaagagaa ggacauauga
ucuuuguuuc gcauacguuu ucuuuuucuc ucuucuuauu 60uuugacuagu acaugaccac
uu 821382RNAArtificial SequenceSynthetic aptamer sequence
13gggaagagaa ggacauauga uuauucuguu cuucaaaaau cuuuuagcgu auacgcuauu
60uuugacuagu acaugaccac uu 821482RNAArtificial SequenceSynthetic
aptamer sequence 14gggaagagaa ggacauauga uuuccuuaug uucggucaac
agggacugcu gcagcaccgg 60cuugacuagu acaugaccac uu
821582RNAArtificial SequenceSynthetic aptamer sequence 15gggaagagaa
ggacauauga uuaagcgcac ucaacagggu cuaugauccg cgccgaucau 60guugacuagu
acaugaccac uu 821682RNAArtificial SequenceSynthetic aptamer
sequence 16gggaagagaa ggacauauga uccgcuuucc auugagauua uaagcuguua
gagacuuauu 60uuugacuagu acaugaccac uu 821782RNAArtificial
SequenceSynthetic aptamer sequence 17gggaagagaa ggacauauga
uuuucgaaac guuucuuuca aguucuuaau cauucccauu 60uuugacuagu acaugaccac
uu 821882RNAArtificial SequenceSynthetic aptamer sequence
18gggaagagaa ggacauauga ucauuagaug cgcaguucga agccgguaca gcuggcgcgc
60guugacuagu acaugaccac uu 821982RNAArtificial SequenceSynthetic
aptamer sequence 19gggaagagaa ggacauauga uaaagaauaa ccuuaaaaua
acaccaccgc cucacagcau 60auugacuagu acaugaccac uu
822082RNAArtificial SequenceSynthetic aptamer sequence 20gggaagagaa
ggacauauga uaaauugauc uauucuuuuc ggugcuauuu aucuuccauu 60uuugacuagu
acaugaccac uu 822182RNAArtificial SequenceSynthetic aptamer
sequence 21gggaagagaa ggacauauga ucuacucgcg cggcggacaa aagcgcaacc
cagcacccau 60guugacuagu acaugaccac uu 822282RNAArtificial
SequenceSynthetic aptamer sequence 22gggaagagaa ggacauauga
uucuuaguuu guaauuacuu uuccuuccuu uuauucuauu 60uuugacuagu acaugaccac
uu 822382RNAArtificial SequenceSynthetic aptamer sequence
23gggaagagaa ggacauauga uaacccgcgc agacuuacaa gcgcgcaaaa aaaggguacg
60uuugacuagu acaugaccac uu 822482RNAArtificial SequenceSynthetic
aptamer sequence 24gggaagagaa ggacauauga uauuccuuua ugccgcauca
uuuuauuguu uaugacaauu 60uuugacuagu acaugaccac uu
822582RNAArtificial SequenceSynthetic aptamer sequence 25gggaagagaa
ggacauauga uauuucguac uacuuuucuu ccaagcuuca aucgcccauu 60uuugacuagu
acaugaccac uu 822682RNAArtificial SequenceSynthetic aptamer
sequence 26gggaagagaa ggacauauga uucacucauu cgcaacacaa uuguauucgc
aucugcgauu 60uuugacuagu acaugaccac uu 822782RNAArtificial
SequenceSynthetic aptamer sequence 27gggaagagaa ggacauauga
uauuauuucc acaguuccuu uauccacaca ucuucucauu 60uuugacuagu acaugaccac
uu 822882RNAArtificial SequenceSynthetic aptamer sequence
28gggaagagaa ggacauauga uaaacucguu aucuauucgu uuauuugcau cucuuucauu
60uuugacuagu acaugaccac uu 822982RNAArtificial SequenceSynthetic
aptamer sequence 29gggaagagaa ggacauauga uccaaccucu aaaguacugg
ucgccuaggg agacuguucg 60guugacuagu acaugaccac uu
823082RNAArtificial SequenceSynthetic aptamer sequence 30gggaagagaa
ggacauauga uuuccuuuuu gcuauuuccg uuaauguaaa cucuccuauu 60uuugacuagu
acaugaccac uu 823182RNAArtificial SequenceSynthetic aptamer
sequence 31gggaagagaa ggacauauga uccuuauggc cuaguaggga uccgggcgcc
gaccagcgcg 60auugacuagu acaugaccac uu 823282RNAArtificial
SequenceSynthetic aptamer sequence 32gggaagagaa ggacauauga
ucgucugucu ucuucgaaua cguuuugggc uaagcccauu 60uuugacuagu acaugaccac
uu 823382RNAArtificial SequenceSynthetic aptamer sequence
33gggaagagaa ggacauauga uucaaccaaa cugccgacga ccgagguaug uccuuaugua
60cuugacuagu acaugaccac uu 823482RNAArtificial SequenceSynthetic
aptamer sequence 34gggaagagaa ggacauauga uuacgggucu gagcaaaagc
gaaggaagca ggcgcaggga 60uuugacuagu acaugaccac uu
823582RNAArtificial SequenceSynthetic aptamer sequence 35gggaagagaa
ggacauauga uucucucauu cgcaacacaa uuguauucgc aucugcgauu 60uuugacuagu
acaugaccac uu 823682RNAArtificial SequenceSynthetic aptamer
sequence 36gggaagagaa ggacauauga ugcucuaaag uacuaagcgu uugcgccgau
gcccggaccg 60cuugacuagu acaugaccac uu 823782RNAArtificial
SequenceSynthetic aptamer sequence 37gggaagagaa ggacauauga
uacuucauua augugaggcc gucagggggc aaccuucgag 60cuugacuagu acaugaccac
uu 823882RNAArtificial SequenceSynthetic aptamer sequence
38gggaagagaa ggacauauga uuccuuauuc uuguuacuac uuucuuuucc uauuuuuuuc
60uuugacuagu acaugaccac uu 823982RNAArtificial SequenceSynthetic
aptamer sequence 39gggaagagaa ggacauauga ucguuauuuu cauuuucuug
uuccccauau gcccaggcgc 60auugacuagu acaugaccac uu
824082RNAArtificial SequenceSynthetic aptamer sequence 40gggaagagaa
ggacauauga uaccagcggc guagaaacgu acagcucgcc uguaacgccu 60guugacuagu
acaugaccac uu 824182RNAArtificial SequenceSynthetic aptamer
sequence 41gggaagagaa ggacauauga ucgauauggg ugcgggaaug uacguucacc
gaauaugcuc 60cuugacuagu acaugaccac uu 824282RNAArtificial
SequenceSynthetic aptamer sequence 42gggaagagaa ggacauauga
uuaacagugc guagucauau cgaauguuua ucuuccuauu 60uuugacuagu acaugaccac
uu 824382RNAArtificial SequenceSynthetic aptamer sequence
43gggaagagaa ggacauauga ucagacucuc gcccaauucg caaggcguug cauugcgauu
60uuugacuagu acaugaccac uu 824482RNAArtificial SequenceSynthetic
aptamer sequence 44gggaagagaa ggacauauga uuuccaacuc uccacgagag
caugggucga augacucauu 60uuugacuagu acaugaccac uu
824582RNAArtificial SequenceSynthetic aptamer sequence 45gggaagagaa
ggacauauga ugcaucgcgc gucacucaac ucgugauuac cgagggcgcc 60guugacuagu
acaugaccac uu 824682RNAArtificial SequenceSynthetic aptamer
sequence 46gggaagagaa ggacauauga ucugaaucuu uccgcagccc uguccuuuua
aagacagguu 60uuugacuagu acaugaccac uu 824782RNAArtificial
SequenceSynthetic aptamer sequence 47gggaagagaa ggacauauga
uuuuguuacu uacuucgucu aucuucuguu gcacacaguu 60uuugacuagu acaugaccac
uu 824882RNAArtificial SequenceSynthetic aptamer sequence
48gggaagagaa ggacauauga uucaaaucuu cagcgauaau ggcacaauuu ccgcgccauu
60uuugacuagu acaugaccac uu 824982RNAArtificial SequenceSynthetic
aptamer sequence 49gggaagagaa ggacauauga uuuaugugag augaugugug
uuccuaguuu uaucuugcuc 60uuugacuagu acaugaccac uu
825082RNAArtificial SequenceSynthetic aptamer sequence 50gggaagagaa
ggacauauga uccacuuuuc cauuaacugu ugcgggcaag uagcaccguu 60uuugacuagu
acaugaccac uu 825182RNAArtificial SequenceSynthetic aptamer
sequence 51gggaagagaa ggacauauga uagagaagac cauucggaaa gagcugcgug
uccuuaugua 60cuugacuagu acaugaccac uu 825282RNAArtificial
SequenceSynthetic aptamer sequence 52gggaagagaa ggacauauga
uucuuaugua gcaagcaaaa ugugccgccg agccgacgcc 60auugacuagu acaugaccac
uu 825382RNAArtificial SequenceSynthetic aptamer sequence
53gggaagagaa ggacauauga uaagcgcaua auaagccagc caguucuugg cgcgcggggu
60auugacuagu acaugaccac uu 825482RNAArtificial SequenceSynthetic
aptamer sequence 54gggaagagaa ggacauauga uuaguccgca uuucuauuuu
cuauauggcu uacugccauu 60uuugacuagu acaugaccac uu
825582RNAArtificial SequenceSynthetic aptamer sequence 55gggaagagaa
ggacauauga uauaaagaac acgcaaaacc acccggacac ccggugccgu 60guugacuagu
acaugaccac uu 825682RNAArtificial SequenceSynthetic aptamer
sequence 56gggaagagaa ggacauauga uacacaggcg guggagccga agggcaccgg
gacaaaccga 60cuugacuagu acaugaccac uu 825782RNAArtificial
SequenceSynthetic aptamer sequence 57gggaagagaa ggacauauga
uaguuccggc gcagcagcgu ccucacguuu uacgugcccc 60auugacuagu acaugaccac
uu 825882RNAArtificial SequenceSynthetic aptamer sequence
58gggaagagaa ggacauauga ugaccgucgc gaucguuuau aauguucugg aucuuucauu
60uuugacuagu acaugaccac uu 825982RNAArtificial SequenceSynthetic
aptamer sequence 59gggaagagaa ggacauauga uaaguggggc cccgacgacu
uuuccuuccu cucuuccggc 60auugacuagu acaugaccac uu
826082RNAArtificial SequenceSynthetic aptamer sequence 60gggaagagaa
ggacauauga uaucaacaua ccaaaauguc auuuccaauc uuuucccauu 60uuugacuagu
acaugaccac uu 826182RNAArtificial SequenceSynthetic aptamer
sequence 61gggaagagaa ggacauauga uagcgaacaa acaagggugc ccaggccccc
uucgcacauc 60guugacuagu acaugaccac uu 826282RNAArtificial
SequenceSynthetic aptamer sequence 62gggaagagaa ggacauauga
uccucuguaa cgcaaaguca agucgcgcaa ggccgcccgc 60guugacuagu acaugaccac
uu 826382RNAArtificial SequenceSynthetic aptamer sequence
63gggaagagaa ggacauauga ucuucaucug cgauuacggu acacuuuagu guaucguuuu
60uuugacuagu acaugaccac uu 826482RNAArtificial SequenceSynthetic
aptamer sequence 64gggaagagaa ggacauauga ugccuaugug cuagaugcag
cagcaaccgc cggcgacugg 60auugacuagu acaugaccac uu
826582RNAArtificial SequenceSynthetic aptamer sequence 65gggaagagaa
ggacauauga uccgcgcccu aaccuucuga ccaagcuucc cuggcacuug 60guugacuagu
acaugaccac uu 826682RNAArtificial SequenceSynthetic aptamer
sequence 66gggaagagaa ggacauauga uccuuaugua uuaucaguca uaccggacgc
agcccgcugg 60auugacuagu acaugaccac uu 826782RNAArtificial
SequenceSynthetic aptamer sequence 67gggaagagaa ggacauauga
ucuaaucuau acuggcugcu aacgcuuuuu cuuuuccauu 60uuugacuagu acaugaccac
uu 826882RNAArtificial SequenceSynthetic aptamer sequence
68gggaagagaa ggacauauga ucaguuuacg cggagucguu uguguccauu ucuucucauu
60uuugacuagu acaugaccac uu 826982RNAArtificial SequenceSynthetic
aptamer sequence 69gggaagagaa ggacauauga uucacgugag augaugugug
uuccuaguuu uaucuugcuc 60uuugacuagu acaugaccac uu
827082RNAArtificial SequenceSynthetic aptamer sequence 70gggaagagaa
ggacauauga uuccuugugu accgcuccga augugcucca gcgcgccucg 60guugacuagu
acaugaccac uu 827182RNAArtificial SequenceSynthetic aptamer
sequence 71gggaagagaa ggacauauga uaagccggcc cgggaacaug ucacgcgcgc
gcgcaaagua 60guugacuagu acaugaccac uu 827282RNAArtificial
SequenceSynthetic aptamer sequence 72gggaagagaa ggacauauga
uccuggauuu ccgaaauuag agugccguuu cguuacgguu 60uuugacuagu acaugaccac
uu 827382RNAArtificial SequenceSynthetic aptamer sequence
73gggaagagaa ggacauauga ucgugucauc cgcacaagga ggccugcaug gcagggacac
60guugacuagu acaugaccac uu 827482RNAArtificial SequenceSynthetic
aptamer sequence 74gggaagagaa ggacauauga ugaguagacu uuuuguauca
uuuuuuuauc guaagauauu 60uuugacuagu acaugaccac uu
827582RNAArtificial SequenceSynthetic aptamer sequence 75gggaagagaa
ggacauauga uccaugugag augaugugug uuccuaguuu uaucuugcuc 60uuugacuagu
acaugaccac uu 827682RNAArtificial SequenceSynthetic aptamer
sequence 76gggaagagaa ggacauauga ucuuugcucu agaguguagu cuaugaggga
caagguagcc 60auugacuagu acaugaccac uu 827782RNAArtificial
SequenceSynthetic aptamer sequence 77gggaagagaa ggacauauga
uguugguuuu cuuucucuuu cuuuucuuuc ucuuucuauu 60uuugacuagu acaugaccac
uu 827882RNAArtificial SequenceSynthetic aptamer sequence
78gggaagagaa ggacauauga ucaaucgggc ggggguaaga ggcgugcgca gcguggaggu
60guugacuagu acaugaccac uu 827982RNAArtificial SequenceSynthetic
aptamer sequence 79gggaagagaa ggacauauga ucaccguggu gcgcaaagcc
gcaacgagaa cugcggaauc 60guugacuagu acaugaccac uu
828082RNAArtificial SequenceSynthetic aptamer sequence 80gggaagagaa
ggacauauga uugcuuuaag ucuuuuuauc auuuuguuuc cuucauuuuu 60uuugacuagu
acaugaccac uu 828182RNAArtificial SequenceSynthetic aptamer
sequence 81gggaagagaa ggacauauga ucgacuaguu auacugcaaa ggcuauaagc
gcgagcgcgc 60guugacuagu acaugaccac uu 828282RNAArtificial
SequenceSynthetic aptamer sequence 82gggaagagaa ggacauauga
ugaguaauag auggcguaca caaaucggau acgacgagcg 60cuugacuagu acaugaccac
uu 828382RNAArtificial SequenceSynthetic aptamer sequence
83gggaagagaa ggacauauga uuuucgcuuc aagauuccca acgccuugua agucaagguu
60uuugacuagu acaugaccac uu 828482RNAArtificial SequenceSynthetic
aptamer sequence 84gggaagagaa ggacauauga ugugugagau gagccccugg
accagacgca cgcucgcacu 60guugacuagu
acaugaccac uu 828582RNAArtificial SequenceSynthetic aptamer
sequence 85gggaagagaa ggacauauga ucaggaugcg gcgccgguaa uugacuuccc
ccuacguagg 60auugacuagu acaugaccac uu 828682RNAArtificial
SequenceSynthetic aptamer sequence 86gggaagagaa ggacauauga
ucagggaccc ggccggugca ucuccuucuu uagcguacgc 60cuugacuagu acaugaccac
uu 828782RNAArtificial SequenceSynthetic aptamer sequence
87gggaagagaa ggacauauga ucugcucuaa aguaccaacc gcgggagcua aaugcaagcc
60guugacuagu acaugaccac uu 828882RNAArtificial SequenceSynthetic
aptamer sequence 88gggaagagaa ggacauauga ugauugccau gcauuagggg
gggacgcgcg cgaaagggag 60auugacuagu acaugaccac uu
828982RNAArtificial SequenceSynthetic aptamer sequence 89gggaagagaa
ggacauauga uucgcucuaa aguaccaacc gcgggagcua aaugcaagcc 60guugacuagu
acaugaccac uu 829082RNAArtificial SequenceSynthetic aptamer
sequence 90gggaagagaa ggacauauga uaaaaaaccg ggguucuuaa uuuucauugu
ucgucguacu 60uuugacuagu acaugaccac uu 829182RNAArtificial
SequenceSynthetic aptamer sequence 91gggaagagaa ggacauauga
uaacccauug gugaaucgca accacagcca gcccggcgcg 60auugacuagu acaugaccac
uu 829282RNAArtificial SequenceSynthetic aptamer sequence
92gggaagagaa ggacauauga ucgaagugag gggaucgcgc ggggugcacc uaaauauggg
60auugacuagu acaugaccac uu 829382RNAArtificial SequenceSynthetic
aptamer sequence 93gggaagagaa ggacauauga uagccuuaug uacuauagaa
gucagcuauc cgccgcacaa 60uuugacuagu acaugaccac uu
829482RNAArtificial SequenceSynthetic aptamer sequence 94gggaagagaa
ggacauauga ucguuguuuu ucccaaagcu cguuagcauu cauuccuauu 60uuugacuagu
acaugaccac uu 829582RNAArtificial SequenceSynthetic aptamer
sequence 95gggaagagaa ggacauauga ugaucaucag cggaaagcac gaaacgccac
gggccgcggc 60auugacuagu acaugaccac uu 829682RNAArtificial
SequenceSynthetic aptamer sequence 96gggaagagaa ggacauauga
uuccuuccua uugacaaugc gcccgggccu cuucaauugu 60auugacuagu acaugaccac
uu 829782RNAArtificial SequenceSynthetic aptamer sequence
97gggaagagaa ggacauauga uaguugccgc gcggcgcaag auuggagagu cccgggcugu
60auugacuagu acaugaccac uu 829882RNAArtificial SequenceSynthetic
aptamer sequence 98gggaagagaa ggacauauga ucauaaguuc guucauuccg
uuaacacgcg uauggcguuu 60uuugacuagu acaugaccac uu
829982RNAArtificial SequenceSynthetic aptamer sequence 99gggaagagaa
ggacauauga uccuuugucu ccaaaucuua ggacugaaug agugccuauu 60uuugacuagu
acaugaccac uu 8210082RNAArtificial SequenceSynthetic aptamer
sequence 100gggaagagaa ggacauauga ucuucuuuga gaauucucuu uuuacaauuc
cggcgccgug 60auugacuagu acaugaccac uu 8210182RNAArtificial
SequenceSynthetic aptamer sequence 101gggaagagaa ggacauauga
uuaggcuaac uguuuaggga uuugauaugc augaggagca 60cuugacuagu acaugaccac
uu 8210282RNAArtificial SequenceSynthetic aptamer sequence
102gggaagagaa ggacauauga uuaggcuaac uguucaggga guugauaugc
augaggagca 60cuugacuagu acaugaccac uu 8210382RNAArtificial
SequenceSynthetic aptamer sequence 103gggaagagaa ggacauauga
uuaggcuaac ugcucaggga uuugauaugc augaggagca 60cuugacuagu acaugaccac
uu 8210482RNAArtificial SequenceSynthetic aptamer sequence
104gggaagagaa ggacauauga uuaggcuaac uguucaggga cuugauaugc
augaggagca 60cuugacuagu acaugaccac uu 8210582RNAArtificial
SequenceSynthetic aptamer sequence 105gggaagagaa ggacauauga
uuaggcucac uguucaggga uuugauaugc augaggagca 60cuugacuagu acaugaccac
uu 8210682RNAArtificial SequenceSynthetic aptamer sequence
106gggaagagaa ggacauauga uuaggcuaac uguucaggga uuugauaugc
auggggagca 60cuugacuagu acaugaccac uu 8210782RNAArtificial
SequenceSynthetic aptamer sequence 107gggaagagaa ggacauauga
uuucuuccua uugacgaugc gcccgggccu cuucaauugu 60auugacuagu acaugaccac
uu 8210882RNAArtificial SequenceSynthetic aptamer sequence
108gggaagagaa ggacauauga uuaggcuaac uguucgggga uuugauaugc
augaggagca 60cuugacuagu acaugaccac uu 8210982RNAArtificial
SequenceSynthetic aptamer sequence 109gggaagagaa ggacauauga
uuaggcuaac uguucaggga uuugauaugc acgaggagca 60cuugacuagu acaugaccac
uu 8211082RNAArtificial SequenceSynthetic aptamer sequence
110gggaagagaa ggacauauga uuagguuaac uguucaggga uuugauaugc
augaggagca 60cuugacuagu acaugaccac uu 8211182RNAArtificial
SequenceSynthetic aptamer sequence 111gggaagagaa ggacauauga
uuaggcuaac uguucaggga uuugaugugc augaggagca 60cuugacuagu acaugaccac
uu 8211282DNAArtificial SequenceSynthetic aptamer sequence
112gggaagagaa ggacatatga ttcatgtgag atgatgtgtg ttcctagttt
tatcttgctc 60tttgactagt acatgaccac tt 8211382DNAArtificial
SequenceSynthetic aptamer sequence 113gggaagagaa ggacatatga
ttaggctaac tgttcaggga tttgatatgc atgaggagca 60cttgactagt acatgaccac
tt 8211482DNAArtificial SequenceSynthetic aptamer sequence
114gggaagagaa ggacatatga tccgctctaa agtaccaacc gcgggagcta
aatgcaagcc 60gttgactagt acatgaccac tt 8211582DNAArtificial
SequenceSynthetic aptamer sequence 115gggaagagaa ggacatatga
ttgtgtcagg ctctagagtc tagacggccg gggtcccgga 60tttgactagt acatgaccac
tt 8211682DNAArtificial SequenceSynthetic aptamer sequence
116gggaagagaa ggacatatga tccttatgtc tagcggcctt acgcgattag
tggcgttttg 60tttgactagt acatgaccac tt 8211782DNAArtificial
SequenceSynthetic aptamer sequence 117gggaagagaa ggacatatga
tctttatgta ttatcagtca taccggacgc agcccgctgg 60attgactagt acatgaccac
tt 8211882DNAArtificial SequenceSynthetic aptamer sequence
118gggaagagaa ggacatatga ttgtgttatt acacttcgtg attttccttg
cttttctatt 60tttgactagt acatgaccac tt 8211982DNAArtificial
SequenceSynthetic aptamer sequence 119gggaagagaa ggacatatga
tccaacatct aaagtactgg tcgcctaggg agactgttcg 60gttgactagt acatgaccac
tt 8212082DNAArtificial SequenceSynthetic aptamer sequence
120gggaagagaa ggacatatga tgctatattc gcaaaagcag gctgagtgcg
gcaggcgcgt 60gttgactagt acatgaccac tt 8212182DNAArtificial
SequenceSynthetic aptamer sequence 121gggaagagaa ggacatatga
ttcattcatt cgcaacacaa ttgtattcgc atctgcgatt 60tttgactagt acatgaccac
tt 8212282DNAArtificial SequenceSynthetic aptamer sequence
122gggaagagaa ggacatatga tctttctctt ttctaatatt taatttattg
ggtaccaatt 60tttgactagt acatgaccac tt 8212382DNAArtificial
SequenceSynthetic aptamer sequence 123gggaagagaa ggacatatga
tctttgtttc gcatacgttt tctttttctc tcttcttatt 60tttgactagt acatgaccac
tt 8212482DNAArtificial SequenceSynthetic aptamer sequence
124gggaagagaa ggacatatga ttattctgtt cttcaaaaat cttttagcgt
atacgctatt 60tttgactagt acatgaccac tt 8212582DNAArtificial
SequenceSynthetic aptamer sequence 125gggaagagaa ggacatatga
tttccttatg ttcggtcaac agggactgct gcagcaccgg 60cttgactagt acatgaccac
tt 8212682DNAArtificial SequenceSynthetic aptamer sequence
126gggaagagaa ggacatatga ttaagcgcac tcaacagggt ctatgatccg
cgccgatcat 60gttgactagt acatgaccac tt 8212782DNAArtificial
SequenceSynthetic aptamer sequence 127gggaagagaa ggacatatga
tccgctttcc attgagatta taagctgtta gagacttatt 60tttgactagt acatgaccac
tt 8212882DNAArtificial SequenceSynthetic aptamer sequence
128gggaagagaa ggacatatga ttttcgaaac gtttctttca agttcttaat
cattcccatt 60tttgactagt acatgaccac tt 8212982DNAArtificial
SequenceSynthetic aptamer sequence 129gggaagagaa ggacatatga
tcattagatg cgcagttcga agccggtaca gctggcgcgc 60gttgactagt acatgaccac
tt 8213082DNAArtificial SequenceSynthetic aptamer sequence
130gggaagagaa ggacatatga taaagaataa ccttaaaata acaccaccgc
ctcacagcat 60attgactagt acatgaccac tt 8213182DNAArtificial
SequenceSynthetic aptamer sequence 131gggaagagaa ggacatatga
taaattgatc tattcttttc ggtgctattt atcttccatt 60tttgactagt acatgaccac
tt 8213282DNAArtificial SequenceSynthetic aptamer sequence
132gggaagagaa ggacatatga tctactcgcg cggcggacaa aagcgcaacc
cagcacccat 60gttgactagt acatgaccac tt 8213382DNAArtificial
SequenceSynthetic aptamer sequence 133gggaagagaa ggacatatga
ttcttagttt gtaattactt ttccttcctt ttattctatt 60tttgactagt acatgaccac
tt 8213482DNAArtificial SequenceSynthetic aptamer sequence
134gggaagagaa ggacatatga taacccgcgc agacttacaa gcgcgcaaaa
aaagggtacg 60tttgactagt acatgaccac tt 8213582DNAArtificial
SequenceSynthetic aptamer sequence 135gggaagagaa ggacatatga
tattccttta tgccgcatca ttttattgtt tatgacaatt 60tttgactagt acatgaccac
tt 8213682DNAArtificial SequenceSynthetic aptamer sequence
136gggaagagaa ggacatatga tatttcgtac tacttttctt ccaagcttca
atcgcccatt 60tttgactagt acatgaccac tt 8213782DNAArtificial
SequenceSynthetic aptamer sequence 137gggaagagaa ggacatatga
ttcactcatt cgcaacacaa ttgtattcgc atctgcgatt 60tttgactagt acatgaccac
tt 8213882DNAArtificial SequenceSynthetic aptamer sequence
138gggaagagaa ggacatatga tattatttcc acagttcctt tatccacaca
tcttctcatt 60tttgactagt acatgaccac tt 8213982DNAArtificial
SequenceSynthetic aptamer sequence 139gggaagagaa ggacatatga
taaactcgtt atctattcgt ttatttgcat ctctttcatt 60tttgactagt acatgaccac
tt 8214082DNAArtificial SequenceSynthetic aptamer sequence
140gggaagagaa ggacatatga tccaacctct aaagtactgg tcgcctaggg
agactgttcg 60gttgactagt acatgaccac tt 8214182DNAArtificial
SequenceSynthetic aptamer sequence 141gggaagagaa ggacatatga
tttccttttt gctatttccg ttaatgtaaa ctctcctatt 60tttgactagt acatgaccac
tt 8214282DNAArtificial SequenceSynthetic aptamer sequence
142gggaagagaa ggacatatga tccttatggc ctagtaggga tccgggcgcc
gaccagcgcg 60attgactagt acatgaccac tt 8214382DNAArtificial
SequenceSynthetic aptamer sequence 143gggaagagaa ggacatatga
tcgtctgtct tcttcgaata cgttttgggc taagcccatt 60tttgactagt acatgaccac
tt 8214482DNAArtificial SequenceSynthetic aptamer sequence
144gggaagagaa ggacatatga ttcaaccaaa ctgccgacga ccgaggtatg
tccttatgta 60cttgactagt acatgaccac tt 8214582DNAArtificial
SequenceSynthetic aptamer sequence 145gggaagagaa ggacatatga
ttacgggtct gagcaaaagc gaaggaagca ggcgcaggga 60tttgactagt acatgaccac
tt 8214682DNAArtificial SequenceSynthetic aptamer sequence
146gggaagagaa ggacatatga ttctctcatt cgcaacacaa ttgtattcgc
atctgcgatt 60tttgactagt acatgaccac tt 8214782DNAArtificial
SequenceSynthetic aptamer sequence 147gggaagagaa ggacatatga
tgctctaaag tactaagcgt ttgcgccgat gcccggaccg 60cttgactagt acatgaccac
tt 8214882DNAArtificial SequenceSynthetic aptamer sequence
148gggaagagaa ggacatatga tacttcatta atgtgaggcc gtcagggggc
aaccttcgag 60cttgactagt acatgaccac tt 8214982DNAArtificial
SequenceSynthetic aptamer sequence 149gggaagagaa ggacatatga
ttccttattc ttgttactac tttcttttcc tatttttttc 60tttgactagt acatgaccac
tt 8215082DNAArtificial SequenceSynthetic aptamer sequence
150gggaagagaa ggacatatga tcgttatttt cattttcttg ttccccatat
gcccaggcgc 60attgactagt acatgaccac tt 8215182DNAArtificial
SequenceSynthetic aptamer sequence 151gggaagagaa ggacatatga
taccagcggc gtagaaacgt acagctcgcc tgtaacgcct 60gttgactagt acatgaccac
tt 8215282DNAArtificial SequenceSynthetic aptamer sequence
152gggaagagaa ggacatatga tcgatatggg tgcgggaatg tacgttcacc
gaatatgctc 60cttgactagt acatgaccac tt 8215382DNAArtificial
SequenceSynthetic aptamer sequence 153gggaagagaa ggacatatga
ttaacagtgc gtagtcatat cgaatgttta tcttcctatt 60tttgactagt acatgaccac
tt 8215482DNAArtificial SequenceSynthetic aptamer sequence
154gggaagagaa ggacatatga tcagactctc gcccaattcg caaggcgttg
cattgcgatt 60tttgactagt acatgaccac tt 8215582DNAArtificial
SequenceSynthetic aptamer sequence 155gggaagagaa ggacatatga
tttccaactc tccacgagag catgggtcga atgactcatt 60tttgactagt acatgaccac
tt 8215682DNAArtificial SequenceSynthetic aptamer sequence
156gggaagagaa ggacatatga tgcatcgcgc gtcactcaac tcgtgattac
cgagggcgcc 60gttgactagt acatgaccac tt 8215782DNAArtificial
SequenceSynthetic aptamer sequence 157gggaagagaa ggacatatga
tctgaatctt tccgcagccc tgtcctttta aagacaggtt 60tttgactagt acatgaccac
tt 8215882DNAArtificial SequenceSynthetic aptamer sequence
158gggaagagaa ggacatatga ttttgttact tacttcgtct atcttctgtt
gcacacagtt 60tttgactagt acatgaccac tt 8215982DNAArtificial
SequenceSynthetic aptamer sequence 159gggaagagaa ggacatatga
ttcaaatctt cagcgataat ggcacaattt ccgcgccatt 60tttgactagt acatgaccac
tt 8216082DNAArtificial SequenceSynthetic aptamer sequence
160gggaagagaa ggacatatga tttatgtgag atgatgtgtg ttcctagttt
tatcttgctc 60tttgactagt acatgaccac tt 8216182DNAArtificial
SequenceSynthetic aptamer sequence 161gggaagagaa ggacatatga
tccacttttc cattaactgt tgcgggcaag tagcaccgtt 60tttgactagt acatgaccac
tt 8216282DNAArtificial SequenceSynthetic aptamer sequence
162gggaagagaa ggacatatga tagagaagac cattcggaaa gagctgcgtg
tccttatgta 60cttgactagt acatgaccac tt 8216382DNAArtificial
SequenceSynthetic aptamer sequence 163gggaagagaa ggacatatga
ttcttatgta gcaagcaaaa tgtgccgccg agccgacgcc 60attgactagt acatgaccac
tt 8216482DNAArtificial SequenceSynthetic aptamer sequence
164gggaagagaa ggacatatga taagcgcata ataagccagc cagttcttgg
cgcgcggggt 60attgactagt acatgaccac tt 8216582DNAArtificial
SequenceSynthetic aptamer sequence 165gggaagagaa ggacatatga
ttagtccgca tttctatttt ctatatggct tactgccatt 60tttgactagt acatgaccac
tt 8216682DNAArtificial SequenceSynthetic aptamer sequence
166gggaagagaa ggacatatga tataaagaac acgcaaaacc acccggacac
ccggtgccgt 60gttgactagt acatgaccac tt 8216782DNAArtificial
SequenceSynthetic aptamer sequence 167gggaagagaa ggacatatga
tacacaggcg gtggagccga agggcaccgg gacaaaccga 60cttgactagt acatgaccac
tt 8216882DNAArtificial SequenceSynthetic aptamer sequence
168gggaagagaa
ggacatatga tagttccggc gcagcagcgt cctcacgttt tacgtgcccc 60attgactagt
acatgaccac tt 8216982DNAArtificial SequenceSynthetic aptamer
sequence 169gggaagagaa ggacatatga tgaccgtcgc gatcgtttat aatgttctgg
atctttcatt 60tttgactagt acatgaccac tt 8217082DNAArtificial
SequenceSynthetic aptamer sequence 170gggaagagaa ggacatatga
taagtggggc cccgacgact tttccttcct ctcttccggc 60attgactagt acatgaccac
tt 8217182DNAArtificial SequenceSynthetic aptamer sequence
171gggaagagaa ggacatatga tatcaacata ccaaaatgtc atttccaatc
ttttcccatt 60tttgactagt acatgaccac tt 8217282DNAArtificial
SequenceSynthetic aptamer sequence 172gggaagagaa ggacatatga
tagcgaacaa acaagggtgc ccaggccccc ttcgcacatc 60gttgactagt acatgaccac
tt 8217382DNAArtificial SequenceSynthetic aptamer sequence
173gggaagagaa ggacatatga tcctctgtaa cgcaaagtca agtcgcgcaa
ggccgcccgc 60gttgactagt acatgaccac tt 8217482DNAArtificial
SequenceSynthetic aptamer sequence 174gggaagagaa ggacatatga
tcttcatctg cgattacggt acactttagt gtatcgtttt 60tttgactagt acatgaccac
tt 8217582DNAArtificial SequenceSynthetic aptamer sequence
175gggaagagaa ggacatatga tgcctatgtg ctagatgcag cagcaaccgc
cggcgactgg 60attgactagt acatgaccac tt 8217682DNAArtificial
SequenceSynthetic aptamer sequence 176gggaagagaa ggacatatga
tccgcgccct aaccttctga ccaagcttcc ctggcacttg 60gttgactagt acatgaccac
tt 8217782DNAArtificial SequenceSynthetic aptamer sequence
177gggaagagaa ggacatatga tccttatgta ttatcagtca taccggacgc
agcccgctgg 60attgactagt acatgaccac tt 8217882DNAArtificial
SequenceSynthetic aptamer sequence 178gggaagagaa ggacatatga
tctaatctat actggctgct aacgcttttt cttttccatt 60tttgactagt acatgaccac
tt 8217982DNAArtificial SequenceSynthetic aptamer sequence
179gggaagagaa ggacatatga tcagtttacg cggagtcgtt tgtgtccatt
tcttctcatt 60tttgactagt acatgaccac tt 8218082DNAArtificial
SequenceSynthetic aptamer sequence 180gggaagagaa ggacatatga
ttcacgtgag atgatgtgtg ttcctagttt tatcttgctc 60tttgactagt acatgaccac
tt 8218182DNAArtificial SequenceSynthetic aptamer sequence
181gggaagagaa ggacatatga ttccttgtgt accgctccga atgtgctcca
gcgcgcctcg 60gttgactagt acatgaccac tt 8218282DNAArtificial
SequenceSynthetic aptamer sequence 182gggaagagaa ggacatatga
taagccggcc cgggaacatg tcacgcgcgc gcgcaaagta 60gttgactagt acatgaccac
tt 8218382DNAArtificial SequenceSynthetic aptamer sequence
183gggaagagaa ggacatatga tcctggattt ccgaaattag agtgccgttt
cgttacggtt 60tttgactagt acatgaccac tt 8218482DNAArtificial
SequenceSynthetic aptamer sequence 184gggaagagaa ggacatatga
tcgtgtcatc cgcacaagga ggcctgcatg gcagggacac 60gttgactagt acatgaccac
tt 8218582DNAArtificial SequenceSynthetic aptamer sequence
185gggaagagaa ggacatatga tgagtagact ttttgtatca tttttttatc
gtaagatatt 60tttgactagt acatgaccac tt 8218682DNAArtificial
SequenceSynthetic aptamer sequence 186gggaagagaa ggacatatga
tccatgtgag atgatgtgtg ttcctagttt tatcttgctc 60tttgactagt acatgaccac
tt 8218782DNAArtificial SequenceSynthetic aptamer sequence
187gggaagagaa ggacatatga tctttgctct agagtgtagt ctatgaggga
caaggtagcc 60attgactagt acatgaccac tt 8218882DNAArtificial
SequenceSynthetic aptamer sequence 188gggaagagaa ggacatatga
tgttggtttt ctttctcttt cttttctttc tctttctatt 60tttgactagt acatgaccac
tt 8218982DNAArtificial SequenceSynthetic aptamer sequence
189gggaagagaa ggacatatga tcaatcgggc gggggtaaga ggcgtgcgca
gcgtggaggt 60gttgactagt acatgaccac tt 8219082DNAArtificial
SequenceSynthetic aptamer sequence 190gggaagagaa ggacatatga
tcaccgtggt gcgcaaagcc gcaacgagaa ctgcggaatc 60gttgactagt acatgaccac
tt 8219182DNAArtificial SequenceSynthetic aptamer sequence
191gggaagagaa ggacatatga ttgctttaag tctttttatc attttgtttc
cttcattttt 60tttgactagt acatgaccac tt 8219282DNAArtificial
SequenceSynthetic aptamer sequence 192gggaagagaa ggacatatga
tcgactagtt atactgcaaa ggctataagc gcgagcgcgc 60gttgactagt acatgaccac
tt 8219382DNAArtificial SequenceSynthetic aptamer sequence
193gggaagagaa ggacatatga tgagtaatag atggcgtaca caaatcggat
acgacgagcg 60cttgactagt acatgaccac tt 8219482DNAArtificial
SequenceSynthetic aptamer sequence 194gggaagagaa ggacatatga
ttttcgcttc aagattccca acgccttgta agtcaaggtt 60tttgactagt acatgaccac
tt 8219582DNAArtificial SequenceSynthetic aptamer sequence
195gggaagagaa ggacatatga tgtgtgagat gagcccctgg accagacgca
cgctcgcact 60gttgactagt acatgaccac tt 8219682DNAArtificial
SequenceSynthetic aptamer sequence 196gggaagagaa ggacatatga
tcaggatgcg gcgccggtaa ttgacttccc cctacgtagg 60attgactagt acatgaccac
tt 8219782DNAArtificial SequenceSynthetic aptamer sequence
197gggaagagaa ggacatatga tcagggaccc ggccggtgca tctccttctt
tagcgtacgc 60cttgactagt acatgaccac tt 8219882DNAArtificial
SequenceSynthetic aptamer sequence 198gggaagagaa ggacatatga
tctgctctaa agtaccaacc gcgggagcta aatgcaagcc 60gttgactagt acatgaccac
tt 8219982DNAArtificial SequenceSynthetic aptamer sequence
199gggaagagaa ggacatatga tgattgccat gcattagggg gggacgcgcg
cgaaagggag 60attgactagt acatgaccac tt 8220082DNAArtificial
SequenceSynthetic aptamer sequence 200gggaagagaa ggacatatga
ttcgctctaa agtaccaacc gcgggagcta aatgcaagcc 60gttgactagt acatgaccac
tt 8220182DNAArtificial SequenceSynthetic aptamer sequence
201gggaagagaa ggacatatga taaaaaaccg gggttcttaa ttttcattgt
tcgtcgtact 60tttgactagt acatgaccac tt 8220282DNAArtificial
SequenceSynthetic aptamer sequence 202gggaagagaa ggacatatga
taacccattg gtgaatcgca accacagcca gcccggcgcg 60attgactagt acatgaccac
tt 8220382DNAArtificial SequenceSynthetic aptamer sequence
203gggaagagaa ggacatatga tcgaagtgag gggatcgcgc ggggtgcacc
taaatatggg 60attgactagt acatgaccac tt 8220482DNAArtificial
SequenceSynthetic aptamer sequence 204gggaagagaa ggacatatga
tagccttatg tactatagaa gtcagctatc cgccgcacaa 60tttgactagt acatgaccac
tt 8220582DNAArtificial SequenceSynthetic aptamer sequence
205gggaagagaa ggacatatga tcgttgtttt tcccaaagct cgttagcatt
cattcctatt 60tttgactagt acatgaccac tt 8220682DNAArtificial
SequenceSynthetic aptamer sequence 206gggaagagaa ggacatatga
tgatcatcag cggaaagcac gaaacgccac gggccgcggc 60attgactagt acatgaccac
tt 8220782DNAArtificial SequenceSynthetic aptamer sequence
207gggaagagaa ggacatatga ttccttccta ttgacaatgc gcccgggcct
cttcaattgt 60attgactagt acatgaccac tt 8220882DNAArtificial
SequenceSynthetic aptamer sequence 208gggaagagaa ggacatatga
tagttgccgc gcggcgcaag attggagagt cccgggctgt 60attgactagt acatgaccac
tt 8220982DNAArtificial SequenceSynthetic aptamer sequence
209gggaagagaa ggacatatga tcataagttc gttcattccg ttaacacgcg
tatggcgttt 60tttgactagt acatgaccac tt 8221082DNAArtificial
SequenceSynthetic aptamer sequence 210gggaagagaa ggacatatga
tcctttgtct ccaaatctta ggactgaatg agtgcctatt 60tttgactagt acatgaccac
tt 8221182DNAArtificial SequenceSynthetic aptamer sequence
211gggaagagaa ggacatatga tcttctttga gaattctctt tttacaattc
cggcgccgtg 60attgactagt acatgaccac tt 8221282DNAArtificial
SequenceSynthetic aptamer sequence 212gggaagagaa ggacatatga
ttaggctaac tgtttaggga tttgatatgc atgaggagca 60cttgactagt acatgaccac
tt 8221382DNAArtificial SequenceSynthetic aptamer sequence
213gggaagagaa ggacatatga tcgtctgtct tcttcgaata cgttttgggc
taagcccatt 60tttgactagt acatgaccac tt 8221482DNAArtificial
SequenceSynthetic aptamer sequence 214gggaagagaa ggacatatga
ttaggctaac tgctcaggga tttgatatgc atgaggagca 60cttgactagt acatgaccac
tt 8221582DNAArtificial SequenceSynthetic aptamer sequence
215gggaagagaa ggacatatga ttaggctaac tgttcaggga cttgatatgc
atgaggagca 60cttgactagt acatgaccac tt 8221682DNAArtificial
SequenceSynthetic aptamer sequence 216gggaagagaa ggacatatga
ttaggctcac tgttcaggga tttgatatgc atgaggagca 60cttgactagt acatgaccac
tt 8221782DNAArtificial SequenceSynthetic aptamer sequence
217gggaagagaa ggacatatga ttaggctaac tgttcaggga tttgatatgc
atggggagca 60cttgactagt acatgaccac tt 8221882DNAArtificial
SequenceSynthetic aptamer sequence 218gggaagagaa ggacatatga
tttcttccta ttgacgatgc gcccgggcct cttcaattgt 60attgactagt acatgaccac
tt 8221982DNAArtificial SequenceSynthetic aptamer sequence
219gggaagagaa ggacatatga ttaggctaac tgttcgggga tttgatatgc
atgaggagca 60cttgactagt acatgaccac tt 8222082DNAArtificial
SequenceSynthetic aptamer sequence 220gggaagagaa ggacatatga
ttaggctaac tgttcaggga tttgatatgc acgaggagca 60cttgactagt acatgaccac
tt 8222182DNAArtificial SequenceSynthetic aptamer sequence
221gggaagagaa ggacatatga ttaggttaac tgttcaggga tttgatatgc
atgaggagca 60cttgactagt acatgaccac tt 8222282DNAArtificial
SequenceSynthetic aptamer sequence 222gggaagagaa ggacatatga
ttaggctaac tgttcaggga tttgatgtgc atgaggagca 60cttgactagt acatgaccac
tt 8222350DNAArtificial SequenceSynthetic aptamer sequence
223atgtgtgttc ctagttttat cttgctcttt gactagtaca tgaccacttg
5022431DNAArtificial SequenceSynthetic aptamer sequence
224ttcctagttt tatcttgctc tttgactagt a 3122521DNAArtificial
SequenceSynthetic aptamer sequence 225ggacatatga ttcatgtgag a
2122625DNAArtificial SequenceSynthetic aptamer sequence
226ttcgcaaaag caggctgagt gcggc 2522729DNAArtificial
SequenceSynthetic aptamer sequence 227caggcgcgtg ttgactagta
catgaccac 2922844DNAArtificial SequenceSynthetic aptamer sequence
228gggaagagaa ggacatatga tatttcgtac tacttttctt ccaa
4422950RNAArtificial SequenceSynthetic aptamer sequence
229auguguguuc cuaguuuuau cuugcucuuu gacuaguaca ugaccacuug
5023031RNAArtificial SequenceSynthetic aptamer sequence
230uuccuaguuu uaucuugcuc uuugacuagu a 3123121RNAArtificial
SequenceSynthetic aptamer sequence 231ggacauauga uucaugugag a
2123225RNAArtificial SequenceSynthetic aptamer sequence
232uucgcaaaag caggcugagu gcggc 2523329RNAArtificial
SequenceSynthetic aptamer sequence 233caggcgcgug uugacuagua
caugaccac 2923444RNAArtificial SequenceSynthetic aptamer sequence
234gggaagagaa ggacauauga uauuucguac uacuuuucuu ccaa
4423516RNAArtificial SequenceSynthetic aptamer
sequencemisc_feature(7)..(8)n is a, c, g, or u 235uuccuannuu uaucuu
1623616DNAArtificial SequenceSynthetic aptamer
sequencemisc_feature(7)..(8)n is a, c, g, or t 236ttcctanntt tatctt
1623710RNAArtificial SequenceSynthetic aptamer
sequencemisc_feature(7)..(7)n is a, c, g, or u 237uucgcanaag
1023814RNAArtificial SequenceSynthetic aptamer
sequencemisc_feature(8)..(8)n is a, c, g, or u 238ugcggcangc gcgu
1423910DNAArtificial SequenceSynthetic aptamer
sequencemisc_feature(7)..(7)n is a, c, g, or t 239ttcgcanaag
1024014DNAArtificial SequenceSynthetic aptamer
sequencemisc_feature(8)..(8)n is a, c, g, or t 240tgcggcangc gcgt
1424110RNAArtificial SequenceSynthetic aptamer sequence
241cuuuucuucc 1024210DNAArtificial SequenceSynthetic aptamer
sequence 242cttttcttcc 1024310RNAArtificial SequenceSynthetic
aptamer sequencemisc_feature(1)..(1)n is a, c, g, or
umisc_feature(10)..(10)n is a, c, g, or u 243ngcgcgcgcn
1024410DNAArtificial SequenceSynthetic aptamer
sequencemisc_feature(1)..(1)n is a, c, g, or
tmisc_feature(10)..(10)n is a, c, g, or t 244ngcgcgcgcn 10
References
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012

D00013

D00014

D00015

D00016

D00017
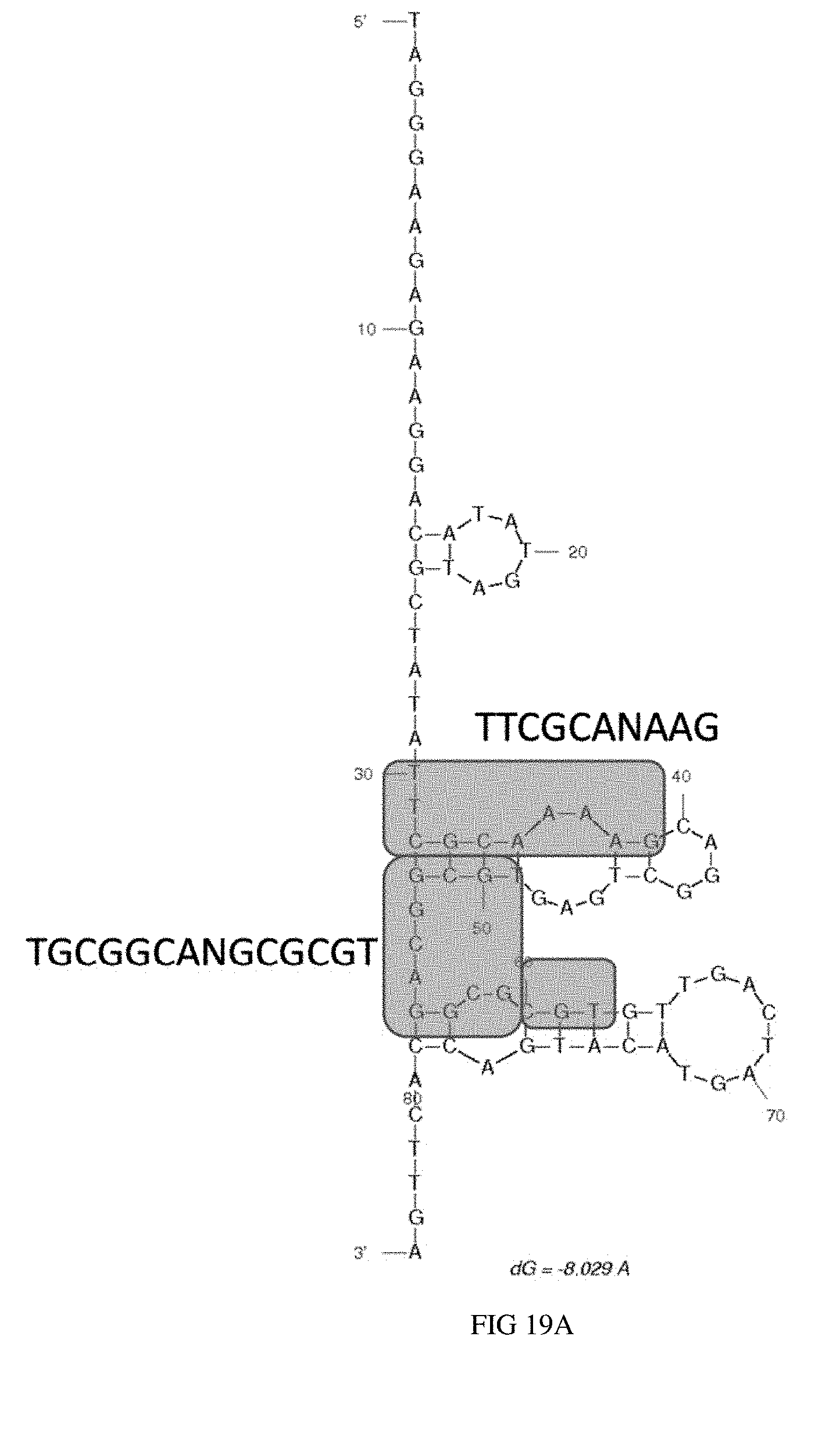
D00018

D00019

D00020
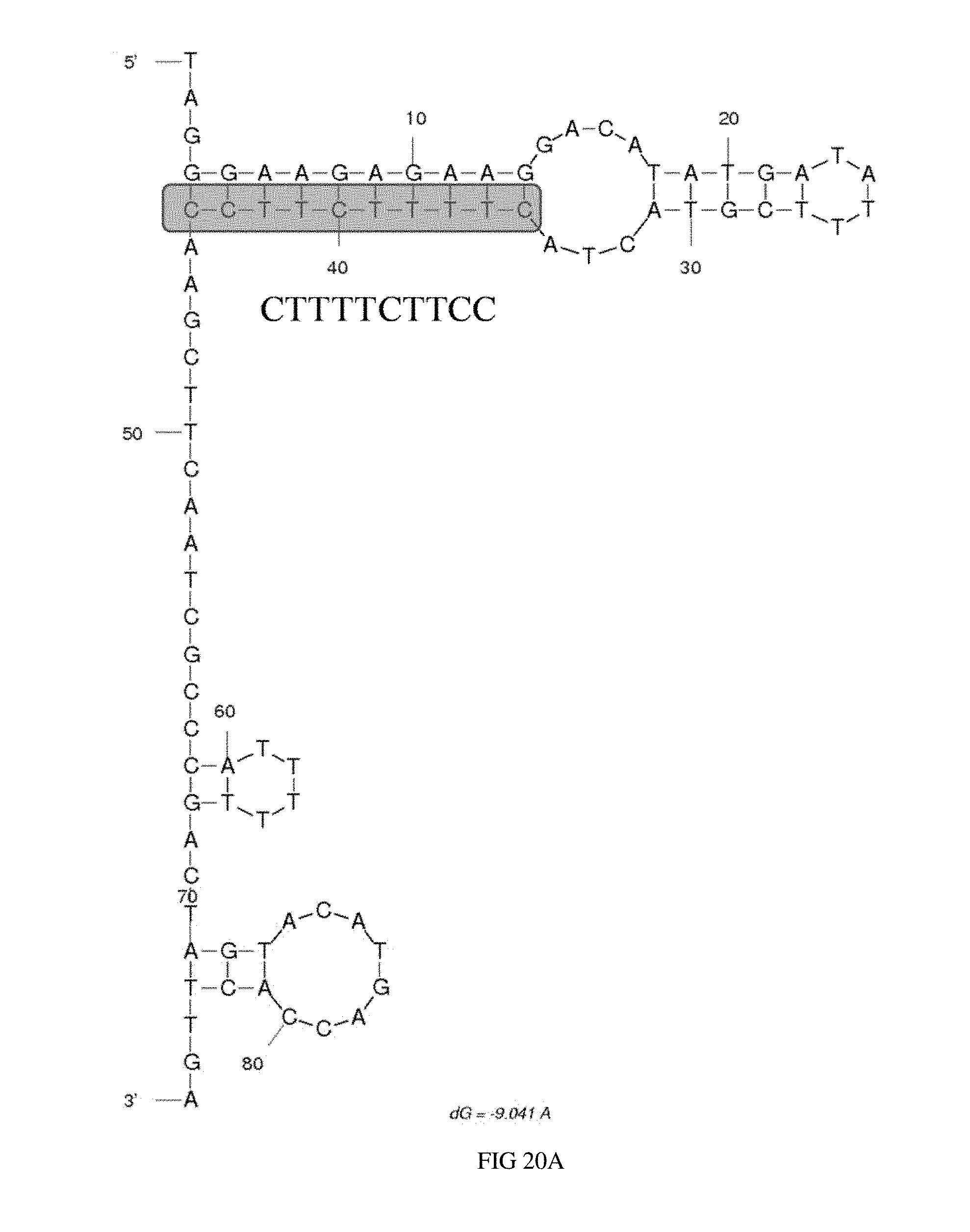
D00021

D00022

D00023

S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.