Bispecific Single Chain Antibodies With Specificity For High Molecular Weight Target Antigens
Kufer; Peter ; et al.
U.S. patent application number 16/034134 was filed with the patent office on 2019-02-07 for bispecific single chain antibodies with specificity for high molecular weight target antigens. The applicant listed for this patent is AMGEN RESEARCH (MUNICH) GMBH. Invention is credited to Claudia Blumel, Roman Kischel, Peter Kufer.
| Application Number | 20190040133 16/034134 |
| Document ID | / |
| Family ID | 42073957 |
| Filed Date | 2019-02-07 |


View All Diagrams
| United States Patent Application | 20190040133 |
| Kind Code | A1 |
| Kufer; Peter ; et al. | February 7, 2019 |
BISPECIFIC SINGLE CHAIN ANTIBODIES WITH SPECIFICITY FOR HIGH MOLECULAR WEIGHT TARGET ANTIGENS
Abstract
The present invention provides a method for the selection of bispecific single chain antibodies comprising a first binding domain capable of binding to an epitope of CD3 and a second binding domain capable of binding to the extracellular domain cell surface antigens with a high molecular weight extracellular domain. Moreover, the invention provides bispecific single chain antibodies produced by the use of the method of the invention, nucleic acid molecules encoding these antibodies, vectors comprising such nucleic acid molecules and methods for the production of the antibodies. Furthermore, the invention provides pharmaceutical compositions comprising bispecific single chain antibodies of the invention, medical uses of the same and methods for the treatment of diseases comprising the administration of bispecific single chain antibodies of the invention.
| Inventors: | Kufer; Peter; (Munich, DE) ; Blumel; Claudia; (Munich, DE) ; Kischel; Roman; (Munich, DE) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 42073957 | ||||||||||
| Appl. No.: | 16/034134 | ||||||||||
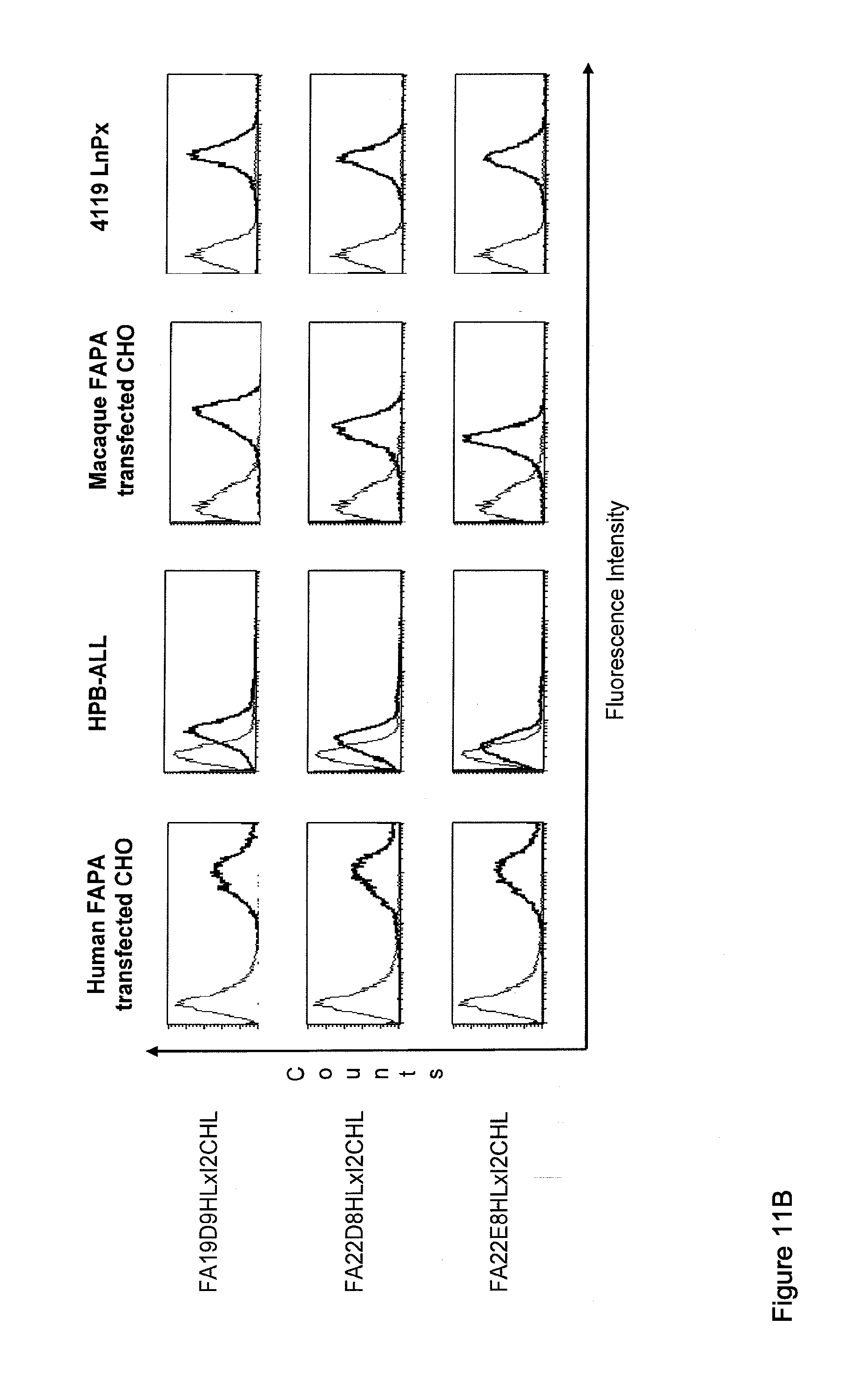
| Filed: | July 12, 2018 |
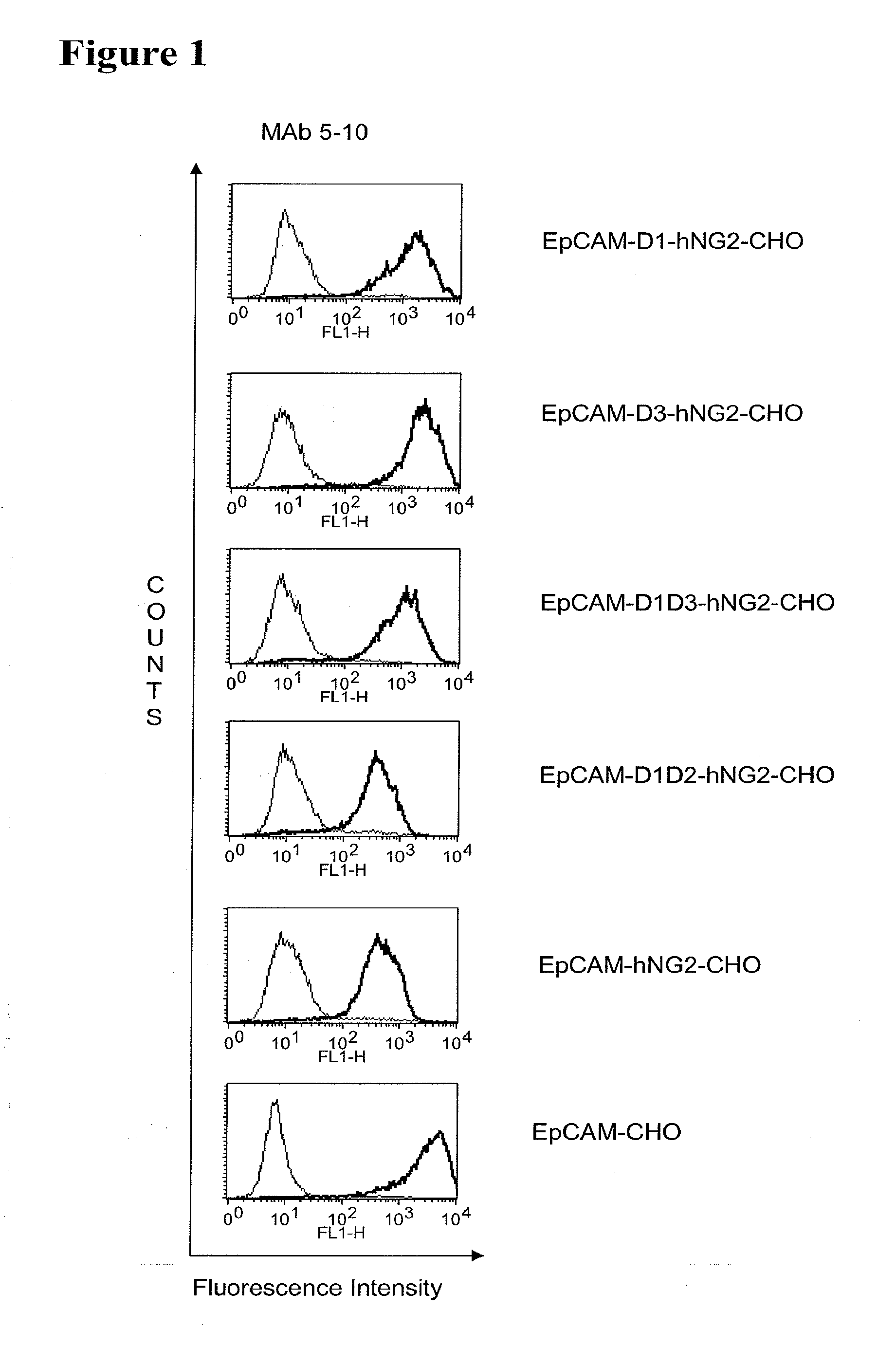
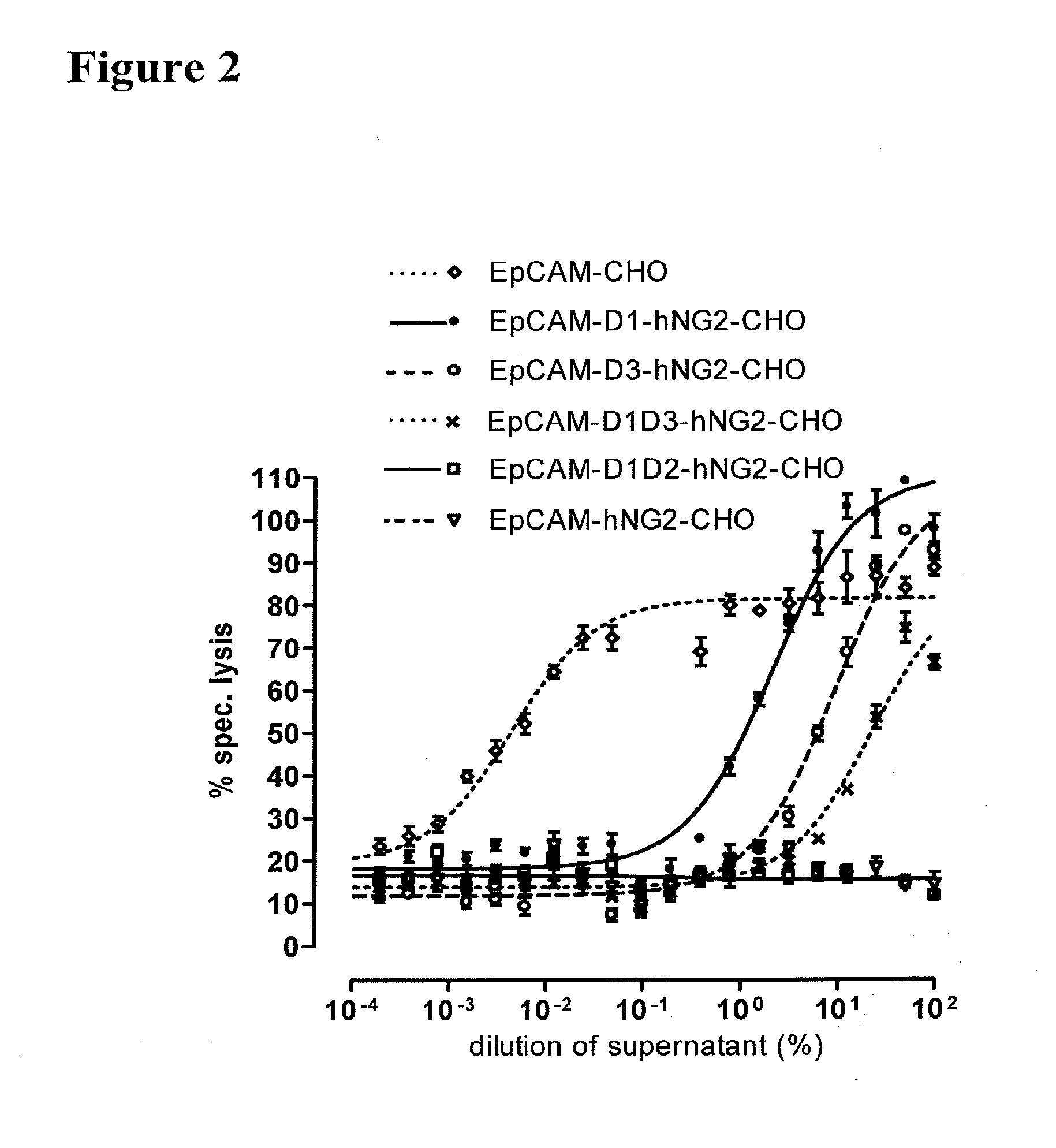
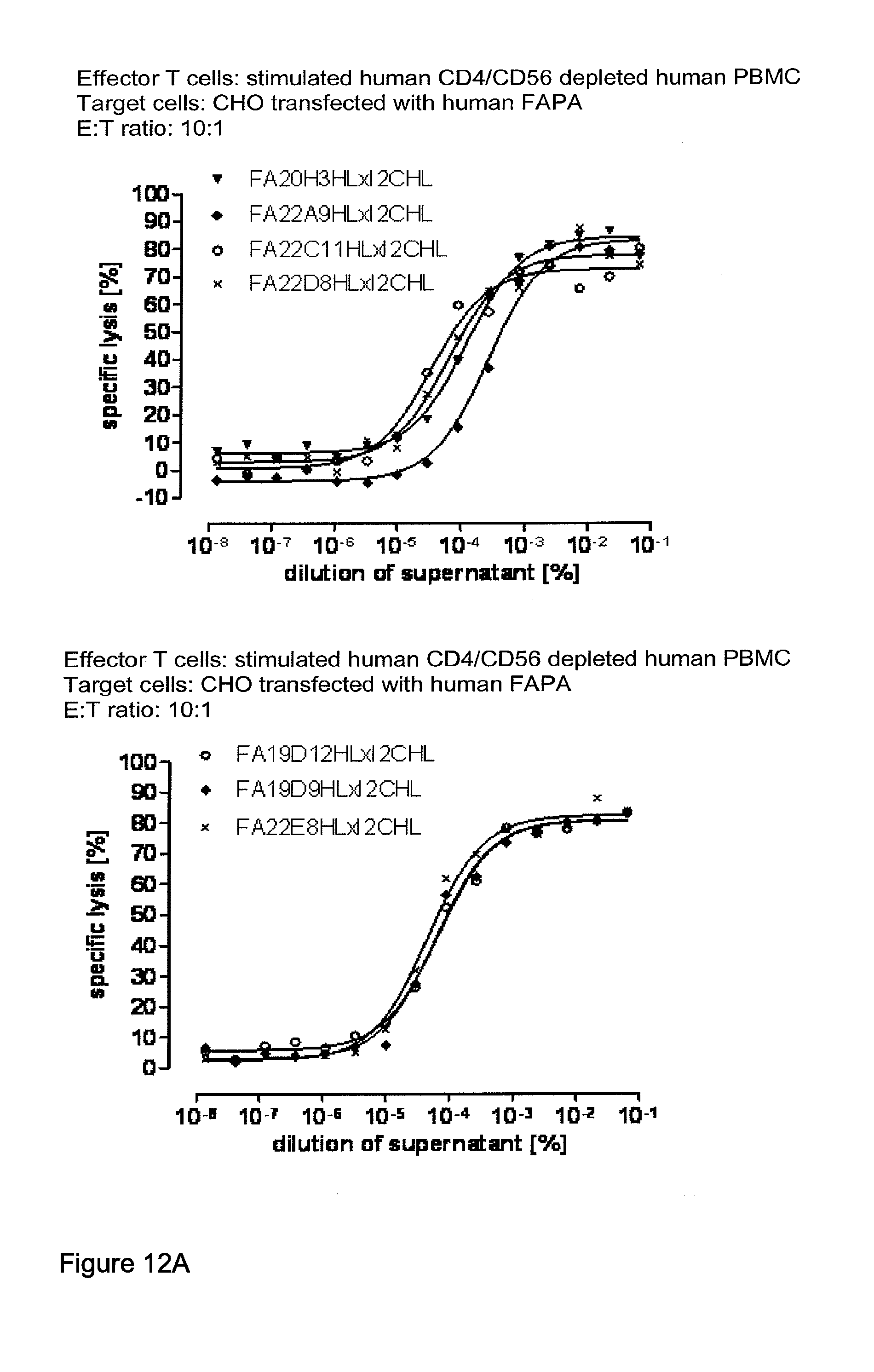
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 14991189 | Jan 8, 2016 | 10047159 | ||
| 16034134 | ||||
| 13122271 | Jul 14, 2011 | 9260522 | ||
| PCT/EP2009/062794 | Oct 1, 2009 | |||
| 14991189 | ||||
| 61101933 | Oct 1, 2008 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | C07K 16/2863 20130101; C07K 16/3069 20130101; C07K 16/2851 20130101; C07K 2317/31 20130101; C07K 2317/622 20130101; C12N 15/1037 20130101; A61K 39/39558 20130101; C07K 2317/732 20130101; A61P 35/00 20180101; C07K 16/005 20130101; C07K 2317/34 20130101; C07K 16/2809 20130101; A61K 2039/505 20130101; A61P 35/02 20180101 |
| International Class: | C07K 16/28 20060101 C07K016/28; C12N 15/10 20060101 C12N015/10; C07K 16/30 20060101 C07K016/30; C07K 16/00 20060101 C07K016/00 |
Claims
1-17. (canceled)
18. A bispecific single chain antibody comprising a first domain binding domain capable of binding to CD3 epsilon (CD3.epsilon.) of human and non-chimpanzee primate and a second domain binding domain capable of binding to (a) the extracellular domain of the mutated human prostate-specific membrane antigen (PSMA) comprising the amino acid sequence of SEQ ID NO: 447 but not to the extracellular domain of the rodent PSMA; (b) the extracellular domain of the mutated human fibroblast activation protein alpha (FAP.alpha.) chimera comprising the amino acid sequence of SEQ ID NO: 448 but not to the extracellular domain of the rodent FAP.alpha.; (c) the four Ig domains (SEQ ID NO: 436), a cystein-rich domain (SEQ ID NO: 437), or the beta-chain of a sema domain (SEQ ID NO: 438) of the extracellular domain of c-MET; (d) the mucin domain (SEQ ID NO: 440), the three EGF-like domains (SEQ ID NO: 441), or the Sushi/SCR/CCP domain (SEQ ID NO: 442) of the extracellular domain of TEM1; and (e) the three fibronectin type III domains (SEQ ID NO: 444), or the L2 domain (SEQ ID NO: 445) of the extracellular domain of insulin-like growth factor 1 receptor (IGF-1R).
19. The bispecific single chain antibody of claim 18, wherein the first domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises an amino acid sequence selected from the group consisting of SEQ ID NOs: 23, 25, 41, 43, 59, 61, 77, 79, 95, 97, 113, 115, 131, 133, 149, 151, 167, 169, 185 and 187.
20. The bispecific single chain antibody of claim 18, wherein the second domain comprises a VL region comprising CDR-L1, CDR-L2 and CDR-L3 selected from the group consisting of: (a) CDR-L1 as depicted in SEQ ID NO. 269, CDR-L2 as depicted in SEQ ID NO: 270 and CDR-L3 as depicted in SEQ ID NO. 271; (b) CDR-L1 as depicted in SEQ ID NO. 283, CDR-L2 as depicted in SEQ ID NO: 284 and CDR-L3 as depicted in SEQ ID NO. 285; (c) CDR-L1 as depicted in SEQ ID NO. 297, CDR-L2 as depicted in SEQ ID NO: 298 and CDR-L3 as depicted in SEQ ID NO. 299; (d) CDR-L1 as depicted in SEQ ID NO. 311, CDR-L2 as depicted in SEQ ID NO: 312 and CDR-L3 as depicted in SEQ ID NO. 313; (e) CDR-L1 as depicted in SEQ ID NO. 325, CDR-L2 as depicted in SEQ ID NO. 326 and CDR-L3 as depicted in SEQ ID NO. 327; (f) CDR-L1 as depicted in SEQ ID NO. 255, CDR-L2 as depicted in SEQ ID NO. 256 and CDR-L3 as depicted in SEQ ID NO. 257; and (g) CDR-L1 as depicted in SEQ ID NO. 481, CDR-L2 as depicted in SEQ ID NO. 482 and CDR-L3 as depicted in SEQ ID NO. 483.
21. The bispecific single chain antibody of claim 18, wherein the second domain comprises a VH region comprising CDR-H1, CDR-H2 and CDR-H3 selected from the group consisting of: (a) CDR-H1 as depicted in SEQ ID NO. 274, CDR-H2 as depicted in SEQ ID NO: 275 and CDR-H3 as depicted in SEQ ID NO. 276; (b) CDR-H1 as depicted in SEQ ID NO. 288, CDR-H2 as depicted in SEQ ID NO: 289 and CDR-H3 as depicted in SEQ ID NO. 290; (c) CDR-H1 as depicted in SEQ ID NO. 302, CDR-H2 as depicted in SEQ ID NO: 303 and CDR-H3 as depicted in SEQ ID NO. 304; (d) CDR-H1 as depicted in SEQ ID NO. 316, CDR-H2 as depicted in SEQ ID NO: 317 and CDR-H3 as depicted in SEQ ID NO. 318; (e) CDR-H1 as depicted in SEQ ID NO. 330, CDR-H2 as depicted in SEQ ID NO: 331 and CDR-H3 as depicted in SEQ ID NO. 332; (f) CDR-H1 as depicted in SEQ ID NO. 260, CDR-H2 as depicted in SEQ ID NO: 261 and CDR-H3 as depicted in SEQ ID NO. 262; and (g) CDR-H1 as depicted in SEQ ID NO. 476, CDR-H2 as depicted in SEQ ID NO: 477 and CDR-H3 as depicted in SEQ ID NO. 478.
22. The bispecific single chain antibody of claim 18, wherein the second domain comprises a VL region and a VH region selected from the group consisting of: (a) a VL region as depicted in SEQ ID NO. 268 and a VH region as depicted in SEQ ID NO. 273; (b) a VL region as depicted in SEQ ID NO. 282 and a VH region as depicted in SEQ ID NO. 287; (c) a VL region as depicted in SEQ ID NO. 296 and a VH region as depicted in SEQ ID NO. 301; (d) a VL region as depicted in SEQ ID NO. 310 and a VH region as depicted in SEQ ID NO. 315; (e) a VL region as depicted in SEQ ID NO. 324 and a VH region as depicted in SEQ ID NO. 329; (f) a VL region as depicted in SEQ ID NO. 254 and a VH region as depicted in SEQ ID NO. 259; and (g) a VL region as depicted in SEQ ID NO. 480 and a VH region as depicted in SEQ ID NO. 475.
23. The bispecific single chain antibody of claim 18, wherein the second domain comprises an amino acid sequence selected from the group consisting of SEQ ID NOs: 278, 292, 306, 320, 334, 485 and 264.
24. The bispecific single chain antibody molecule of claim 23, wherein the bispecific single chain antibody molecule comprises a sequence selected from the group consisting of: (a) an amino acid sequence as depicted in any of SEQ ID NOs: 280, 294, 308, 322, 336, 266 or 487; (b) an amino acid sequence encoded by a nucleic acid sequence as depicted in any of SEQ ID NOs: 281, 295, 267, 309, 323, 337 or 488; and (c) an amino acid sequence at least 90% identical, more preferred at least 95% identical, most preferred at least 96% identical to the amino acid sequence of (a) or (b).
25. (canceled)
26. The bispecific single chain antibody molecule of claim 18, wherein the bispecific single chain antibody molecule comprises a group of the following sequences as CDR H1, CDR H2, CDR H3, CDR L1, CDR L2 and CDR L3 in the second binding domain selected from the group consisting of: a) CDR H1-3 of SEQ ID NO: -808-810 and CDR L1-3 of SEQ ID NO: -813-815; b) CDR H1-3 of SEQ ID NO: 794-796 and CDR L1-3 of SEQ ID NO: 799-801; c) CDR H1-3 of SEQ ID NO: 738-740 and CDR L1-3 of SEQ ID NO: 743-745; d) CDR H1-3 of SEQ ID NO: 752-754 and CDR L1-3 of SEQ ID NO: 757-759; e) CDR H1-3 of SEQ ID NO: 822-824 and CDR L1-3 of SEQ ID NO: 827-829; f) CDR H1-3 of SEQ ID NO: 766-768 and CDR L1-3 of SEQ ID NO: 771-773; and g) CDR H1-3 of SEQ ID NO: 780-782 and CDR L1-3 of SEQ ID NO: 785-787.
27. The bispecific single chain antibody molecule of claim 26, wherein the bispecific single chain antibody molecule comprises a sequence selected from the group consisting of: (a) an amino acid sequence as depicted in any of SEQ ID NOs: 819, 805, 749, 763, 833, 777 or 791; (b) an amino acid sequence encoded by a nucleic acid sequence as depicted in any of SEQ ID NOs: 820, 806, 750, 764, 834, 778 or 792; and (c) an amino acid sequence at least 90% identical, more preferred at least 95% identical, most preferred at least 96% identical to the amino acid sequence of (a) or (b).
28-29. (canceled)
30. The bispecific single chain antibody molecule of claim 18, wherein the bispecific single chain antibody molecule comprises a group of the following sequences as CDR H1, CDR H2, CDR H3, CDR L1, CDR L2 and CDR L3 in the second binding domain selected from the group consisting of: a) CDR H1-3 of SEQ ID NO: 500-502 and CDR L1-3 of SEQ ID NO: 1505-507; b) CDR H1-3 of SEQ ID NO: 514-516 and CDR L1-3 of SEQ ID NO: 519-521; c) CDR H1-3 of SEQ ID NO: 528-530 and CDR L1-3 of SEQ ID NO: 533-535; d) CDR H1-3 of SEQ ID NO: 542-544 and CDR L1-3 of SEQ ID NO: 547-549; e) CDR H1-3 of SEQ ID NO: 556-558 and CDR L1-3 of SEQ ID NO: 561-563; f) CDR H1-3 of SEQ ID NO: 570-572 and CDR L1-3 of SEQ ID NO: 575-577; g) CDR H1-3 of SEQ ID NO: 584-586 and CDR L1-3 of SEQ ID NO: 589-591; h) CDR H1-3 of SEQ ID NO: 598-600 and CDR L1-3 of SEQ ID NO: 603-605; i) CDR H1-3 of SEQ ID NO: 612-614 and CDR L1-3 of SEQ ID NO: 617-619; j) CDR H1-3 of SEQ ID NO: 626-628 and CDR L1-3 of SEQ ID NO: 631-633; k) CDR H1-3 of SEQ ID NO: 640-642 and CDR L1-3 of SEQ ID NO: 645-647; I) CDR H1-3 of SEQ ID NO: 654-656 and CDR L1-3 of SEQ ID NO: 659-661; m) CDR H1-3 of SEQ ID NO: 668-670 and CDR L1-3 of SEQ ID NO: 673-675; n) CDR H1-3 of SEQ ID NO: 682-684 and CDR L1-3 of SEQ ID NO: 687-689; o) CDR H1-3 of SEQ ID NO: 696-698 and CDR L1-3 of SEQ ID NO: 701-703; p) CDR H1-3 of SEQ ID NO: 710-712 and CDR L1-3 of SEQ ID NO: 715-717; and q) CDR H1-3 of SEQ ID NO: 724-726 and CDR L1-3 of SEQ ID NO: 729-731.
31. The bispecific single chain antibody molecule of claim 30, wherein the bispecific single chain antibody molecule comprises a sequence selected from the group consisting of: (a) an amino acid sequence as depicted in SEQ ID NO: 511, 525, 539, 553, 567 or 581; (b) an amino acid sequence encoded by a nucleic acid sequence as depicted in SEQ ID NO: 512, 526, 540, 554, 568 or 582; and (c) an amino acid sequence at least 90% identical, more preferred at least 95% identical, most preferred at least 96% identical to the amino acid sequence of (a) or (b).
32-35. (canceled)
36. The bispecific single chain antibody molecule of claim 18, wherein the bispecific single chain antibody molecule comprises a group of the following sequences as CDR H1, CDR H2, CDR H3, CDR L1, CDR L2 and CDR L3 in the second binding domain selected from the group consisting of: a) CDR H1-3 of SEQ ID NO: 836-838 and CDR L1-3 of SEQ ID NO: 841-843; and b) CDR H1-3 of SEQ ID NO: 850-852 and CDR L1-3 of SEQ ID NO: 855-857.
37. The bispecific single chain antibody molecule of claim 36, wherein the bispecific single chain antibody molecule comprises a sequence selected from the group consisting of: (a) the amino acid sequence of SEQ ID NO: 847 or 861; (b) an amino acid sequence encoded by the nucleic acid sequence of SEQ ID NO: 848 or 862; and (c) an amino acid sequence at least 90% identical to the amino acid sequence of (a) or (b).
38. (canceled)
39. A nucleic acid sequence encoding the bispecific single chain antibody molecule of claim 18.
40. A vector comprising the nucleic acid sequence of claim 39.
41-42. (canceled)
43. A host transformed or transfected with the nucleic acid of claim 39.
44. A process for producing a bispecific single chain antibody molecule, said process comprising culturing the host of claim 43 under conditions allowing the expression of the the bispecific single chain antibody molecule.
45. A composition comprising the bispecific single chain antibody molecule of claim 18 and a pharmaceutically acceptable carrier.
46. (canceled)
47. A method for preventing, treating or ameliorating a cancer or autoimmune disease comprising administering an effective amount of the bispecific single chain antibody molecule of claim 18.
48-55. (canceled)
56. The method of claim 47, wherein said cancer is (a) a solid tumor; (b) a carcinoma, sarcoma, glioblastoma/astrocytoma, melanoma, mesothelioma, Wilms tumor or a hematopoietic malignancy such as leukemia, lymphoma or multiple myeloma; (c) a neuroectodermal tumor; (d) an epithelial cancer; or (e) a bone or soft tissue cancer, or breast, liver, lung, head and neck, colorectal, prostate, leiomyosarcoma, cervical and endometrial cancer, ovarian, prostate, and pancreatic cancer.
57-61. (canceled)
Description
[0001] This application is a Divisional of U.S. application Ser. No. 14/991,189, filed Jan. 8, 2016 (now U.S. Pat. No. 10,047,159), which was a Divisional of U.S. application Ser. No. 13/122,271, filed Jul. 14, 2011 (now U.S. Pat. No. 9,260,522, issued Feb. 16, 2016), which is the U.S. National Phase of International Application No. PCT/EP2009/062794, filed Oct. 1, 2009, which claims benefit of U.S. Provisional Patent Application No. 61/101,933, filed Oct. 1, 2008, each of which is incorporated herein by reference in its entirety.
[0002] The present invention provides a method for the selection of bispecific single chain antibodies comprising a first binding domain capable of binding to an epitope of CD3 and a second binding domain capable of binding to to the extracellular domain cell surface antigens with a high molecular weight extracellular domain. Moreover, the invention provides bispecific single chain antibodies produced by the use of the method of the invention, nucleic acid molecules encoding these antibodies, vectors comprising such nucleic acid molecules and methods for the production of the antibodies. Furthermore, the invention provides pharmaceutical compositions comprising bispecific single chain antibodies of the invention, medical uses of the same and methods for the treatment of diseases comprising the administration of bispecific single chain antibodies of the invention.
[0003] Unifying two antigen binding sites of different specificity into a single construct, bispecific antibodies have the ability to bring together two discrete antigens with exquisite specificity and therefore have great potential as therapeutic agents. This potential was recognized early on, leading to a number of approaches for obtaining such bispecific antibodies. Bispecific antibodies were originally made by fusing two hybridomas, each capable of producing a different immunoglobulin. The resulting hybrid-hybridoma, or quadroma, was capable of producing antibodies bearing the antigen specificity of the first parent hybridoma as well as that of the second parent hybridoma (Milstein et al., (1983) Nature 305, 537). However, the antibodies resulting from quadromas often exhibited undesired properties due to the presence of an Fc antibody portion.
[0004] Largely due to such difficulties, attempts later focused on creating antibody constructs resulting from joining two scFv antibody fragments while omitting the Fc portion present in full immunoglobulins. Each scFv unit in such constructs was made up of one variable domain from each of the heavy (VH) and light (VL) antibody chains, joined with one another via a synthetic polypeptide linker, the latter often being genetically engineered so as to be minimally immunogenic while remaining maximally resistant to proteolysis. Respective scFv units were joined by a number of techniques including incorporation of a short (usually less than 10 amino acids) polypeptide spacer bridging the two scFv units, thereby creating a bispecific single chain antibody. The resulting bispecific single chain antibody is therefore a species containing two VH/VL pairs of different specificity on a single polypeptide chain, wherein the VH and VL domains in a respective scFv unit are separated by a polypeptide linker long enough to allow intramolecular association between these two domains, and wherein the thusly formed scFv units are contiguously tethered to one another through a polypeptide spacer kept short enough to prevent unwanted association between, for example, the VH domain of one scFv unit and the VL of the other scFv unit.
[0005] Bispecific single chain antibodies of the general form described above have the advantage that the nucleotide sequence encoding the four V-domains, two linkers and one spacer can be incorporated into a suitable host expression organism under the control of a single promoter. This increases the flexibility with which these constructs can be designed as well as the degree of experimenter control during their production.
[0006] Remarkable experimental results have been obtained using such bispecific single chain antibodies designed for the treatment of malignancies (Mack, J. Immunol. (1997) 158, 3965-70; Mack, PNAS (1995) 92, 7021-5; Kufer, Cancer Immunol. Immunother. (1997) 45, 193-7; Loffler, Blood (2000) 95, 2098-103) and non-malignant diseases (Bruhl, J. Immunol. (2001) 166, 2420-6); Brischwein et al. J Immunother. (2007) 30(8), 798-807; Bargou, et al. (2008) Science 321, 974). If In such bispecific single chain antibodies, one scFv unit is capable of activating cytotoxic cells, for example cytotoxic T cells, within the immune system by specifically binding to an antigen on the cytotoxic cells, while the other scFv unit specifically binds an antigen on a malignant cell intended for destruction. In this way, such bispecific single chain antibodies have been shown to activate and redirect the immune system's cytotoxic potential to the destruction of pathological, especially malignant cells. In the absence of such a bispecific single chain antibody construct, malignant cells would otherwise proliferate uninhibited.
[0007] When designing a new bispecific single chain antibodies comprising one scFv unit is capable of recruiting cytotoxic cells, for example cytotoxic T cells, while the other scFv unit specifically binds an antigen on a target cell to be eliminated by the recruited cytotoxic cell, it has been observed that different combination of scFv's in the bispecific single chain antibodies show different effectively in the elimination of the target cells. The election of a promising candidate is an intensive and time consuming procedure.
[0008] The present invention provides means and methods for the solution of this problem for a bispecific single chain antibodies binding with one domain to cytotoxic cells, i.e. cytotoxic T cells, and with the second binding domain to target antigens with a high molecular weight extracellular domain.
[0009] Accordingly, the present invention provides in a first embodiment a method for the selection of bispecific single chain antibodies comprising a first binding domain capable of binding to an epitope of CD3 and a second binding domain capable of binding to the extracellular domain cell surface antigens with a high molecular weight extracellular domain. Different binding domains, which may be used as first binding domain, are described in the art and in the appended sequence listing. As apparent from the above, the election of an antigenic domain on a target cell for of preparation of a target cell binding domain of a bispecific single chain antibody is the critical step for the provision of new bispecific single chain antibodies which allow for an efficient elimination of target cells via redirected T cell lysis. A first choice for the election of an antigenic domain on a target cell for of preparation of a target cell binding domain of a bispecific single chain antibody might be a domain, which is easily accessible from a steric point of view. Accordingly, the person skilled in the art would elect in the case cell surface proteins on target cells with a high molecular weight extracellular domain epitopes which are most distant from the target cell surface are most exposed, therefore best accessible for T cells and thus particularly potent in redirecting T cell cytotoxicity. However, it has been surprisingly found that membrane distant epitopes of target cell surface antigens with a high molecular weight extracellular domain show a poor potency of redirecting T cell cytotoxicity.
[0010] The method of the invention provides guidance for the election of antigenic regions of cell surface antigens with a high molecular weight extracellular domain which allow for the selection of bispecific single chain antibodies with a high potency for redirected T cell cytotoxicity. These cell surface antigens with a high molecular weight extracellular domain are type I or type II integral membrane proteins with an extracellular portion of >640 amino acids. The extracellular portion of this group of membrane proteins is independently folded, thus formed by a single continuous stretch of extracellular amino acids adjacent to the transmembrane region in the primary protein sequence. In order to fulfil the requirement of a high molecular weight extracellular domain in the context of the invention, the extracellular domain essentially comprises more than 640 amino acids. Optionally the extracellular domain is charcterized by at least one functionally and/or structurally defined subdomain formed by discontinuous stretches of extracellular amino acids within the primary protein sequence. Examples for such cell surface antigens comprise prostate-specific membrane antigen (PSMA), fibroblast activation protein .alpha. (FAP.alpha.), Hepatocyte Growth Factor Receptor (c-MET), endosialin (TEM1 or CD248) and type 1 insulin-like growth factor receptor (IGF-1R).
[0011] PSMA and FAP.alpha. are cell surface molecules for which the crystal structure and, thus, the three dimensional structure of the extracellular domain are known in the art. These antigens show a compact discontinuous domain composition of the extracellular domain. It has been surprisingly found that bispecific single chain antibodies binding to epitopes with a distance of up to 60 .ANG. from the alpha C-atom of the thirteenth extracellular amino acid as counted from the junction of transmembrane and extracellular region (reference C-atom) show a significant high efficiency in the redirected T cell lysis of target cells. In contrast thereto, the efficiency in the redirected T cell lysis of target cells of bispecific single chain antibodies binding only to epitopes with a distance of more than 60 .ANG. from the reference C-atom is reduced and thus renders such bispecific antibodies unattractive for a clinical development.
[0012] c-MET, TEM1 and IGF-1R are are cell surface molecules having a consecutive sequence of independently folded extracellular domains is formed by a corresponding sequence of continuous stretches of extracellular amino acids within the primary protein sequence. It has been surprisingly found that bispecific single chain antibodies binding to epitopes within the first 640 amino acid residues counted from the junction of transmembrane and extracellular region show a significant high efficiency in the redirected T cell lysis of target cells. In contrast thereto, the efficiency in the redirected T cell lysis of target cells of bispecific single chain antibodies binding only to epitopes within the amino acid recidues above the 640.sup.th amino acid residue counted from the junction of transmembrane and extracellular region is reduced and thus renders such bispecific antibodies unattractive for a clinical development.
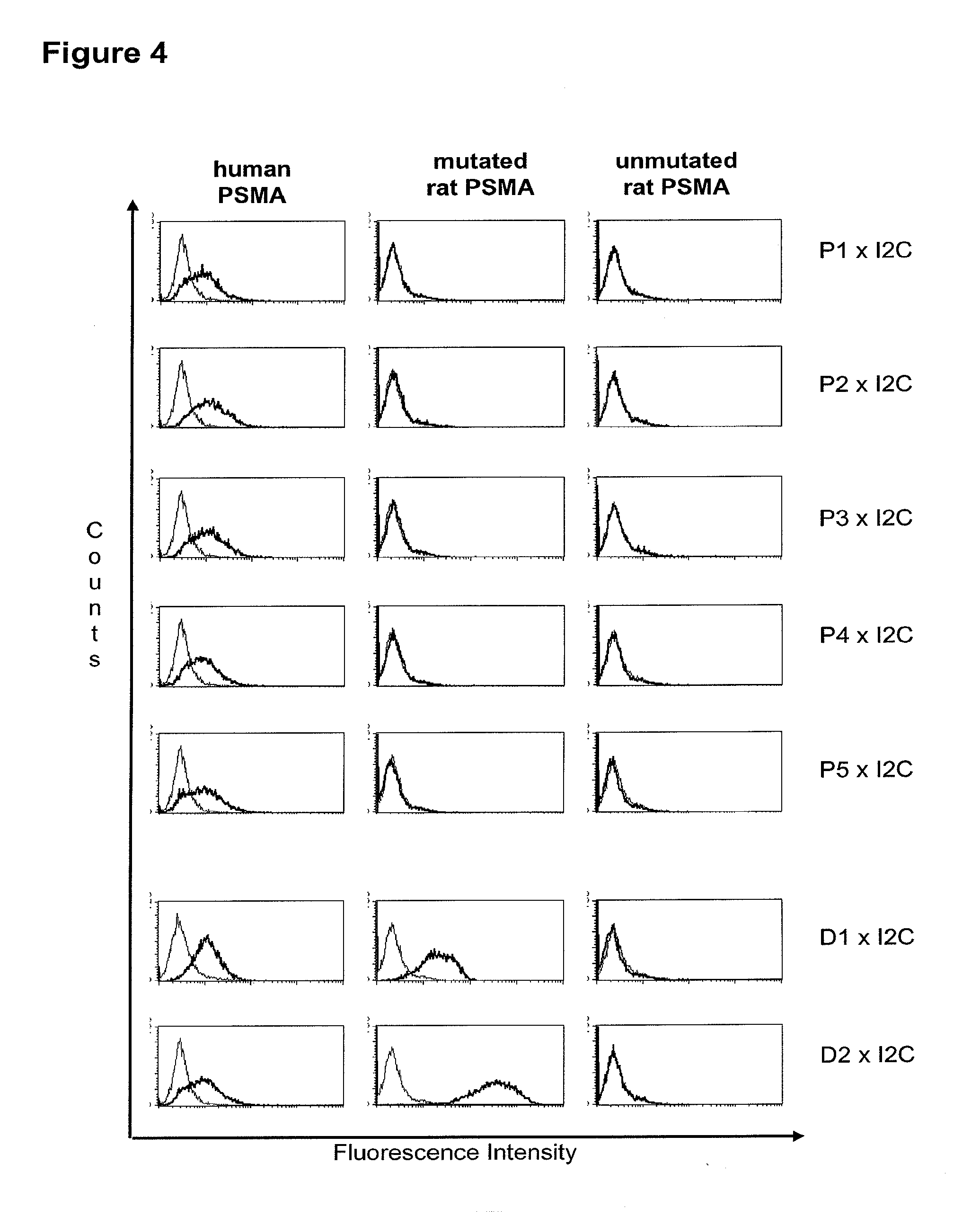
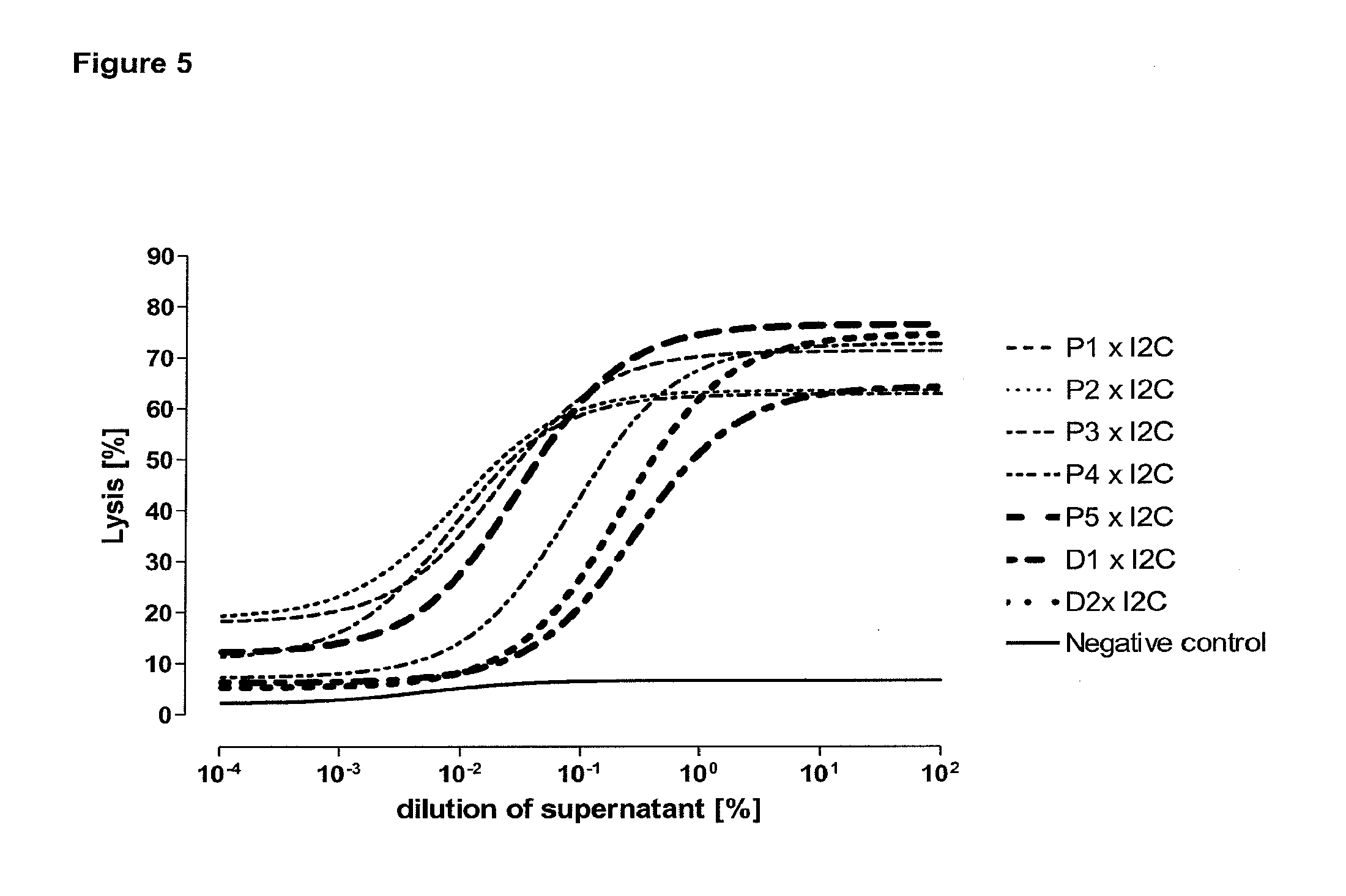
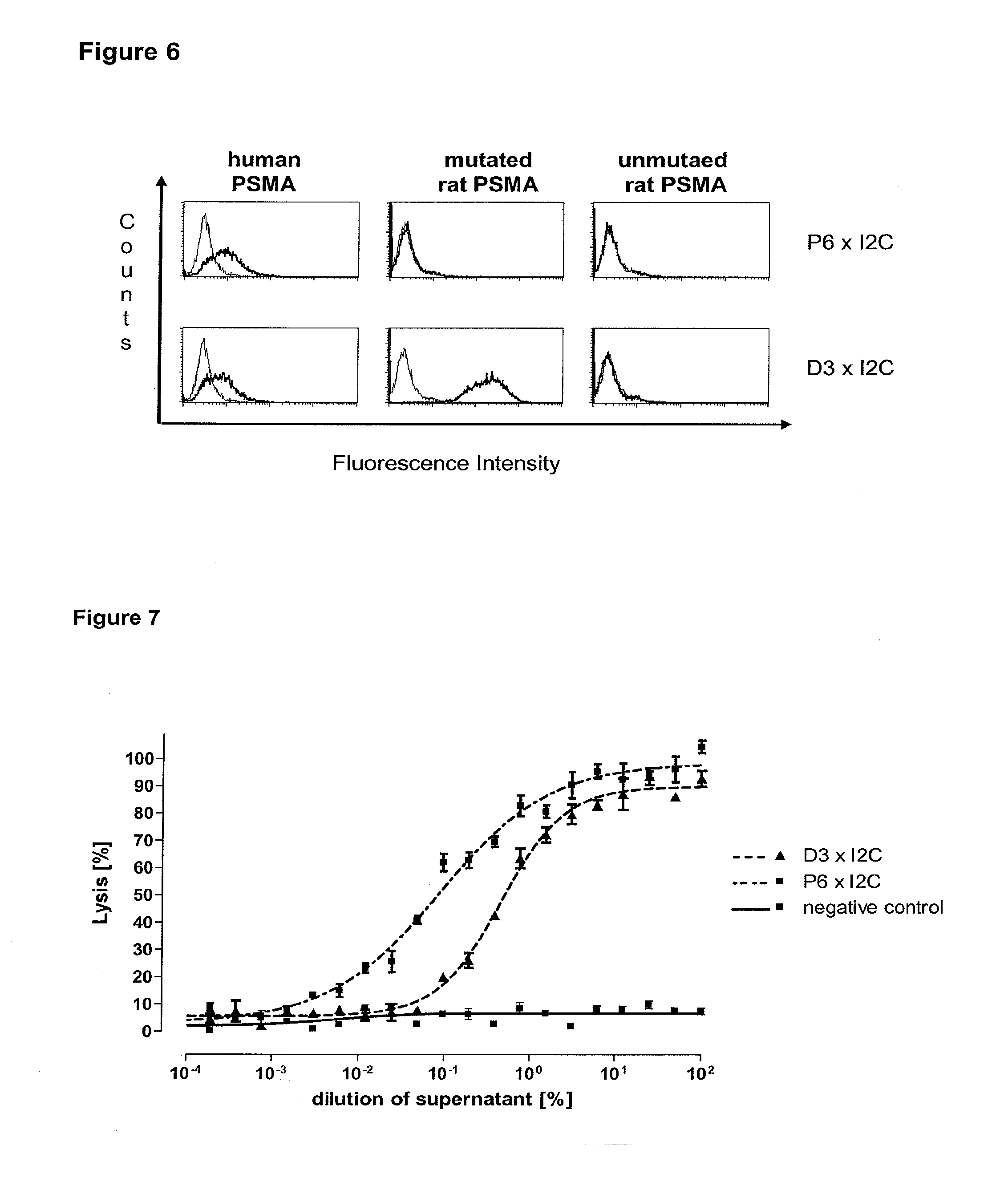
[0013] Based on these findings the invention relates in one embodiment to a method for the selection of bispecific single chain antibodies comprising a first binding domain capable of binding to an epitope of CD3 and a second binding domain capable of binding to the extracellular domain of prostate-specific membrane antigen (PSMA), the method comprising the steps of: [0014] (a) providing at least three types of host cells expressing [0015] (i) the wt human extracellular domain of PSMA (SEQ ID NO: 447) on the cell surface; [0016] (ii) a mutated form of the wt human PSMA on the cell surface, wherein the amino acid residues at positions 140, 169, 191, 308, 334, 339, 344, 624, 626, 716, 717 and 721 are mutated to the corresponding amino acid residues of the wt rodent PSMA; and [0017] (iii) the rodent wt extracellular domain of PSMA on the cell surface; [0018] (b) contacting each type of host cells (i), (ii) and (iii) of step (a) with the bispecific single chain antibodies and effector T cells; and [0019] (c) identifying and isolating the bispecific single chain antibodies that mediate the lysis of host cells expressing wt human extracellular domain of PSMA on the cell surface according to (b)(i) and of host cells expressing mutated form of the wt human PSMA on the cell surface according to (b)(ii) but not of host cells expressing the rodent wt extracellular domain of PSMA on the cell surface according to b(iii).
[0020] As noted above, prostate-specific membrane antigen (PSMA; PSM) is a large antigen falling under the provided definition of cell surface antigens with a high molecular weight extracellular domai. Israeli et al. (Cancer Res. 53: 227-230, 1993) cloned a 2.65-kb cDNA for a prostate-specific membrane antigen detected with a monoclonal antibody raised against the human prostatic carcinoma cell line LNCaP. The PSMA gene encodes a 750-amino acid protein that has an apparent molecular weight of 100 kD (due to posttranslational modification) and is expressed by normal and neoplastic prostate cells. PSMA was originally defined by the monoclonal antibody (MAb) 7E11 derived from immunization with a partially purified membrane preparation from the lymph node prostatic adenocarcinoma (LNCaP) cell line (Horoszewicz et al., Anticancer Res. 7 (1987), 927-35). A 2.65-kb cDNA fragment encoding the PSMA protein was cloned and subsequently mapped to chromosome 11p11.2 (Israeli et al., loc. cit.; O'Keefe et al., Biochem. Biophys. Acta 1443 (1998), 113-127). Initial analysis of PSMA demonstrated widespread expression within the cells of the prostatic secretory epithelium. Immunohistochemical staining demonstrated that PSMA was absent to moderately expressed in hyperplastic and benign tissues, while malignant tissues stained with the greatest intensity (Horoszewicz et al., loc. cit.). Subsequent investigations have recapitulated these results and evinced PSMA expression as a universal feature in practically every prostatic tissue examined to date. These reports further demonstrate that expression of PSMA increases precipitously proportional to tumor aggressiveness (Burger et al., Int. J. Cancer 100 (2002), 228-237; Chang et al., Cancer Res. 59 (1999), 3192-98; Chang et al., Urology 57 (2001), 1179-83), Kawakami and Nakayama, Cancer Res. 57 (1997), 2321-24; Liu et al., Cancer Res. 57 (1997), 3629-34; Lopes et al., Cancer Res. 50 (1990), 6423-29; Silver et al., Clin. Cancer Res. 9 (2003), 6357-62; Sweat et al., Urology 52 (1998), 637-40; Troyer et al., Int. J. Cancer 62 (1995), 552-558; Wright et al., Urology 48 (1996), 326-334). Consistent with the correlation between PSMA expression and tumor stage, increased levels of PSMA are associated with androgen-independent prostate cancer (PCa). Analysis of tissue samples from patients with prostate cancer has demonstrated elevated PSMA levels after physical castration or androgen-deprivation therapy. Unlike expression of prostate specific antigen, which is downregulated after androgen ablation, PSMA expression is significantly increased in both primary and metastatic tumor specimens (Kawakami et al., Wright et al., loc. cit.). Consistent with the elevated expression in androgen-independent tumors, PSMA transcription is also known to be downregulated by steroids, and administration of testosterone mediates a dramatic reduction in PSMA protein and mRNA levels (Israeli et al., Cancer Res. 54 (1994), 1807-11; Wright et al., loc. cit.). PSMA is also highly expressed in secondary prostatic tumors and occult metastatic disease. Immunohistochemical analysis has revealed relatively intense and homogeneous expression of PSMA within metastatic lesions localized to lymph nodes, bone, soft tissue, and lungs compared with benign prostatic tissues (Chang et al. (2001), loc. cit.; Murphy et al., Cancer 78 (1996), 809-818; Sweat et al., loc. cit.). Some reports have also indicated limited PSMA expression in extraprostatic tissues, including a subset of renal proximal tubules, some cells of the intestinal brush-border membrane, and rare cells in the colonic crypts (Chang et al. (1999), Horoszewicz et al., Israeli et al. (1994), Lopes et al., Troyer et al., loc. cit.). However, the levels of PSMA in these tissues are generally two to three orders of magnitude less than those observed in the prostate (Sokoloff et al., Prostate 43 (2000), 150-157). PSMA is also expressed in the tumor-associated neovasculature of most solid cancers examined yet is absent in the normal vascular endothelium (Chang et al. (1999), Liu et al., Silver et al., loc. cit.). Although the significance of PSMA expression within the vasculature is unknown, the specificity for tumor-associated endothelium makes PSMA a potential target for the treatment of many forms of malignancy.
[0021] As apparent from SEQ ID NO: 447 the extracellular domain of PSMA comprises 707 amino acid residues. The 13.sup.th aa as counted from the junction of transmembrane and extracellular region (reference C-atom) is a histidine. The identification of the amino acid residues to be mutated for the mutant human PSMA is described in detail in appended example 2. According to the method of the invention all amino acid residues which do not match between the mouse and the rodent extracellular domain of PSMA and which have a distance of more than 60 .ANG. from the reference C-atom are mutatet from the human sequence to the rodent sequence. This mutation results in a transformation of all antigenic regions with a distance of more than 60 .ANG. from the reference C-atom from the human specific form to the rodent specific form. Antibodies, e.g. bispecific antibodies which are specific for human epitopes comprising antigenic regions with a distance of more than 60 .ANG. from the reference C-atom (specific for membrane distal epitopes) do not bind to the mutant human PSMA and the rodent PSMA. Accordingly, the method of the invention allows for a discrimination of antibodies which bind to epitopes comprising antigenic regions with a distance of more than 60 .ANG. from the reference C-atom (antibodies specific for membrane distal epitopes) and a positive identification and isolation of antibodies specific for epitopes of the human PSMA within a distance of less than 60 .ANG. from the reference C-atom (antibodies specific for membrane proximal epitopes).
[0022] As apparent from the appended examples it has been surprisingly observed that the distance of the epitope from the cell membrane is a critical factor for the cytotoxic potency of a bispecific single chain antibody which engages effector T cells and target cells, such as PSMA cells. The general effect underlying the distance between the epitope, which is bound by an according bispecific single chain antibody, from the cell membrane of a target cell is exemplified in a model in the appended example 1. What came as a surprise according to this example, however, was the large extent of the loss in target cell lysis observed between a target size of 640 aa (D1) and 679 aa (D3). Despite this small difference in target size there was more loss in target cell lysis than from 679 aa (D3) to 1319 aa (D1+D3). Thus, a target size of 640 aa was unexpectedly found as upper threshold for the membrane-distant epitopes of bispecific single chain antibodies, still capable of inducing redirected T cell cytotoxicity with reasonable potency without requiring compensation for the negative influence of more membrane-distance by other properties of the bscAb such as a very high affinity to the target antigen. Moreover, the cytotxic potency relative to the distance of the epitope bound by a bispecific single chain antibody is demonstrated in examples 3 and 4.
[0023] Examples for assays for performing the steps of the method according to the invention are described in the appended examples.
[0024] The invention further relates to a method for the selection of bispecific single chain antibodies comprising a first binding domain capable of binding to an epitope of CD3 and a second binding domain capable of binding to the extracellular domain of fibroblast activation protein .alpha. (FAP.alpha.), the method comprising the steps of: [0025] (a) providing at least three types of host cells expressing [0026] (i) the wt human extracellular domain of FAP.alpha. (SEQ ID NO: 448) on the cell surface; [0027] (ii) a mutated form of the wt human FAP.alpha. on the cell surface, wherein the amino acid residues at positions 144, 185, 186, 229, 267, 273, 274, 278, 284, 301, 328, 329, 331, 335 and 362 are mutated to the corresponding amino acid residues of the wt rodent FAP.alpha.; and [0028] (iii) the rodent wt extracellular domain of FAP.alpha. on the cell surface; [0029] (b) contacting each type of host cells (i), (ii) and (iii) of step (a) with the bispecific single chain antibodies and effector T cells; and [0030] (c) identifying and isolating the bispecific single chain antibodies that mediate the lysis of host cells expressing wt human extracellular domain of FAP.alpha. on the cell surface according to (b)(i) and of host cells expressing mutated form of the wt human FAP.alpha. on the cell surface according to (b)(ii) but not of host cells expressing the rodent wt extracellular domain of FAP.alpha. on the cell surface according to b(iii).
[0031] Another large antigen according to the above definition is the cell surface protease fibroblast activation protein alpha (FAP alpha). In epithelial cancer, invasion and metastasis of malignant epithelial cells into normal tissues is accompanied by adaptive changes in the mesenchyme-derived supporting stroma of the target organs. Altered gene expression in these non-transformed stromal cells has been discussed to provide potential targets for therapy. FAP alpha is such an example for a target of activated tumor fibroblasts in tumor stroma. Fibroblast activation protein alpha is an inducible cell surface glycoprotein that has originally been identified in cultured fibroblasts using monoclonal antibody F19. Immunohistochemical studies have shown that FAP alpha is transiently expressed in certain normal fetal mesenchymal tissues but that normal adult tissues as well as malignant epithelial, neural, and hematopoietic cells are generally FAP alpha-negative. However, most of the common types of epithelial cancers contain abundant FAP alpha-reactive stromal fibroblasts. FAP alpha cDNA was cloned and published in GenBank (Accession number NM_004460). The predicted human FAP alpha protein is a type II integral membrane protein with a large C-terminal extracellular domain, which contains 6 potential N-glycosylation sites, 13 cysteine residues, and 3 segments that correspond to highly conserved catalytic domains of serine proteases; a hydrophobic transmembrane segment; and a short cytoplasmic tail. FAP-alpha shows 48% amino acid identity with dipeptidyl peptidase IV (DPP4) and 30% identity with DPP4-related protein (DPPX). Northern blot analysis detected a 2.8-kb FAP alpha mRNA in fibroblasts. Seprase is a 170-kD integral membrane gelatinase whose expression correlates with the invasiveness of human melanoma and carcinoma cells. Goldstein et al. (Biochim. Biophys. Acta 1361: 11-19, 1997) cloned and characterized the corresponding seprase cDNA. The authors found that seprase and FAP alpha are the same protein and products of the same gene. Pineiro-Sanchez et al. (J. Biol. Chem. 272: 7595-7601, 1997) isolated seprase/FAP alpha protein from the cell membranes and shed vesicles of human melanoma LOX cells. Serine protease inhibitors blocked the gelatinase activity of seprase/FAP alpha, suggesting that seprase/FAP alpha contains a catalytically active serine residue(s). The authors found that seprase/FAP alpha is composed of monomeric, N-glycosylated 97-kD subunits that are proteolytically inactive. They concluded that seprase/FAP alpha is similar to DPP4 in that their proteolytic activities are dependent upon subunit association. Due to its degrading activity of gelatine and heat-denatured type-I and type-IV collagen, a role for seprase/FAP alpha in extracellular matrix remodeling, tumor growth, and metastasis of cancers has been suggested. Moreover, seprase/FAP alpha shows a restricted expression pattern in normal tissues and a uniform expression in the supporting stroma of many malignant tumors. Therefore, seprase/FAP alpha may be used as a target for exploring the concept of tumor stroma targeting for immunotherapy of human epithelial cancer. However, though several clinical trials have been initiated to investigate seprase's/FAP alpha's role as a tumor antigen target, conventional immunotherapy approaches or inhibition of seprase/FAP alpha enzymatic activity so far did not yet result in therapeutic efficacy (see e.g. Welt et al., J. Clin. Oncol. 12:1193-203, 1994; Narra et al., Cancer Biol. Ther. 6, 1691-9, 2007; Henry et al., Clinical Cancer Research 13, 1736-1741, 2007). As apparent from SEQ ID NO: 448 the extracellular domain of FAP.alpha. comprises 734 amino acid residues. The 13.sup.th aa as counted from the junction of transmembrane and extracellular region (reference C-atom) is a methionine. The identification of the amino acid residues to be mutated for the mutant human FAP.alpha. is described in detail in appended example 5. According to the method of the invention all amino acid residues which do not match between the mouse and the rodent extracellular domain of FAP.alpha. and which have a distance of more than 60 .ANG. from the reference C-atom are mutatet from the human sequence to the rodent sequence.
[0032] Moreover, the invention relates to a method for the selection of bispecific single chain antibodies comprising a first binding domain capable of binding to an epitope of CD3 and a second binding domain capable of binding to the extracellular domain of Hepatocyte Growth Factor Receptor (c-MET), endosialin (TEM1) and type 1 insulin-like growth factor receptor (IGF-1R), the method comprising the steps of: [0033] (a) identifying the membrane proximal 640 amino acid residues of the human and the rodent homolog of the extracellular domain of c-MET, TEM1 or IGF-1R; [0034] (b) providing host cells expressing [0035] (i) the human wt of the extracellular domain of the extracellular domain of c-MET (SEQ ID NO: 439), TEM1 (SEQ ID NO: 443) or IGF-1R (SEQ ID NO: 446) on the cell surface; [0036] (ii) a fusion protein comprising the human membrane proximal 640 amino acid residues identified in step (a) and the rodent amino acid residues >640 of c-MET, TEM1 or IGF-1R; and [0037] (iii) the rodent wt extracellular domain of c-MET, TEM1 or IGF-1R; [0038] (c) contacting the host cells according to step (b) with the bispecific single chain antibodies and effector T cells; and [0039] (d) identifying and isolating the bispecific single chain antibodies that mediate the lysis of host cells according to (b)(i) and (b)(ii) but not of host cells according to b(iii).
[0040] As described herein above, c-MET, TEM1 and IGF-1R are type I or type II integral membrane proteins with an extracellular portion of more than 640 amino acids. The consecutive sequence of the extracellular domain comprises continuous stretches of extracellular amino acids within the primary protein sequence and independently folded extracellular subdomain formed by a single continuous stretches. Hepatocyte growth factor receptor MET (C-MET) is involved in the progression and spread of numerous human cancer types. The MET oncogene, encoding the receptor tyrosin kinase (RTK) for hepatocyte growth factor (HGF) and Scatter Factor (SF), controls genetic programs leading to cell growth, invasion, and protection from apoptosis. Deregulated activation of MET is critical not only for the acquisition of tumorigenic properties but also for the achievement of the invasive phenotype (Trusolino, L. & Comoglio, P. M. (2002) Nat. Rev. Cancer 2, 289-300). The role of MET in human tumors emerged from several experimental approaches and was unequivocally proven by the discovery of MET-activating mutations in inherited forms of carcinomas (Schmidt et al., Nat. Genet. 16 (1997), 68-73; Kim et al., J. Med. Genet. 40 (2003), e97). MET constitutive activation is frequent in sporadic cancers, and several studies have shown that the MET oncogene is overexpressed in tumors of specific histotypes or is activated through autocrine mechanisms (for a list see http://www.vai.org/met/). Besides, the MET gene is amplified in hematogenous metastases of colorectal carcinomas (Di Renzo et al., Clin. Cancer Res. 1 (1995), 147-154). The Scatter Factor (SF) secreted in culture by fibroblasts, that have the ability to induce intercellular dissociation of epithelial cells, and the Hepatocyte Growth Factor (HGF), a potent mitogen for hepatocytes in culture derived from platelets or from blood of patients with acute liver failure, independently identified as Met ligands turned out to be the same molecule. Met and SF/HGF are widely expressed in a variety of tissues. The expression of Met (the receptor) is normally confined to cells of epithelial origin, while the expression of SF/HGF (the ligand) is restricted to cells of mesenchymal origin. Met is a transmembrane protein produced as a single-chain precursor. The precursor is proteolytically cleaved at a furin site to produce a highly glycosylated and entirely extracellular .alpha.-subunit of 50 kd and a .beta.-subunit of 145 kd with a large extracellular region (involved in binding the ligand), a membrane spanning segment, and an intracellular region (containing the catalytic activity) (Giordano (1989) 339: 155-156). The .alpha. and .beta. chains are disulphide linked. The extracellular portion of Met contains a region of homology to semaphorins (Sema domain, which includes the full .alpha. chain and the N-terminal part of the .beta. chain of Met), a cysteine-rich Met Related Sequence (MRS) followed by glycineproline-rich (G-P) repeats, and four Immunoglobuline-like structures (Birchmeier et al., Nature Rev. 4 (2003), 915-25). The intracellular region of Met contains three regions: (1) a juxtamembrane segment that contains: (a) a serine residue (Ser 985) that, when phosphorylated by protein kinase C or by Ca.sup.2+calmodulin-dependent kinases downregulates the receptor kinase activity Gandino et al., J. Biol. Chem. 269 (1994), 1815-20); and (b) a tyrosine (Tyr 1003) that binds the ubiquitin ligase Cbl responsible for Met polyubiquitination, endocytosis and degradation (Peschard et al., Mol. Cell 8 (2001), 995-1004); (2) the tyrosine kinase domain that, upon receptor activation, undergoes transphosphorylation on Tyr1234 and Tyr1235; (3) the C-terminal region, which comprises two crucial tyrosines (Tyr1349 and Tyr1356) inserted in a degenerate motif that represents a multisubstrate docking site capable of recruiting several downstream adaptors containing Src homology-2 (SH2) domains Met receptor, as most Receptor Tyrosine Kinases (RTKs) use different tyrosines to bind specific signaling molecules. The two tyrosines of the docking sites have been demonstrated to be necessary and sufficient for the signal transduction both in vitro and in vivo (Maina et al., Cell 87 (1996), 531-542; Ponzetto et aL, Cell 77 (1994), 261-71).
[0041] A further example for a molecule having a large extracellular domain is the tumor endothelial marker (TEM) Endosialin (=TEM1). TEMs are overexpressed during tumor angiogenesis (St. Croix et al., Science 289 (2000), 1197-1202). Despite the fact that their functions have not been characterized in detail so far, it is well established that they are strongly expressed on vascular endothelial cells in developing embryos and tumors studies (Carson-Walter et al., Cancer Res. 61: 6649-6655, 2001). Accordingly, Endosialin, a 165-kDa type I transmembrane protein, is expressed on the cell surface of tumor blood vessel endothelium in a broad range of human cancers but not detected in blood vessels or other cell types in many normal tissues. It is a C-type lectin-like molecule of 757 amino acids composed of a signal leader peptide, five globular extracellular domains (including a C-type lectin domain, one domain with similarity to the Sushi/ccp/scr pattern, and three EGF repeats), followed by a mucin like region, a transmembrane segment, and a short cytoplasmic tail (Christian et al., J. Biol. Chem. 276: 7408-7414, 2001). The Endosialin core protein carries abundantly sialylated, O-linked oligosaccharides and is sensitive to O-sialoglycoprotein endopeptidase, placing it in the group of sialomucin-like molecules. The N-terminal 360 amino acids of Endosialin show homology to thrombomodulin, a receptor involved in regulating blood coagulation, and to complement receptor C1qRp. This structural relationship indicates a function for Endosialin as a tumor endothelial receptor. Although Endosialin mRNA is ubiquitously expressed on endothelial cells in normal human and murine somatic tissues, Endosialin protein is largely restricted to the corpus luteum and highly angiogenic tissues such as the granular tissue of healing wounds or tumors (Opaysky et al., J. Biol. Chem. 276 (2001, 38795-38807; Rettig et al., PNAS 89 (1992), 10832-36). Endosialin protein expression is upregulated on tumor endothelial cells of carcinomas (breast, kidney, lung, colorectal, colon, pancreas mesothelioma), sarcomas, and neuroectodermal tumors (melanoma, glioma, neuroblastoma) (Rettig et al., loc. cit.). In addition, Endosialin is expressed at a low level on a subset of tumor stroma fibroblasts (Brady et al., J. Neuropathol. Exp. Neurol. 63 (2004), 1274-83; Opaysky et al., loc. cit.). Because of its restricted normal tissue distribution and abundant expression on tumor endothelial cells of many different types of solid tumors, Endosialin has been discussed as a target for antibody-based antiangiogenic treatment strategies of cancer. However, so far, there are no effective therapeutic approaches using Endosialin as a tumor endothelial target.
[0042] A still further example for a large antigen is the insulin-like growth factor I receptor (IGF-IR or IGF-1R). IGF-IR is a receptor with tyrosine kinase activity having 70% homology with the insulin receptor IR. IGF-IR is a glycoprotein of molecular weight approximately 350,000. It is a hetero-tetrameric receptor of which each half-linked by disulfide bridges-is composed of an extracellular .alpha.-subunit and of a transmembrane [beta]-subunit. IGF-IR binds IGF I and IGF II with a very high affinity but is equally capable of binding to insulin with an affinity 100 to 1000 times less. Conversely, the IR binds insulin with a very high affinity although the ICFs only bind to the insulin receptor with a 100 times lower affinity. The tyrosine kinase domain of IGF-IR and of IR has a very high sequence homology although the zones of weaker homology respectively concern the cysteine-rich region situated on the alpha-subunit and the C-terminal part of the [beta]-subunit. The sequence differences observed in the a-subunit are situated in the binding zone of the ligands and are therefore at the origin of the relative affinities of IGF-IR and of IR for the IGFs and insulin respectively. The differences in the C-terminal part of the [beta]-subunit result in a divergence in the signalling pathways of the two receptors; IGF-IR mediating mitogenic, differentiation and antiapoptosis effects, while the activation of the IR principally involves effects at the level of the metabolic pathways (Baserga et al., Biochim. Biophys. Acta, 1332: F105-126, 1997; Baserga R., Exp. Cell. Res., 253:1-6, 1999). The cytoplasmic tyrosine kinase proteins are activated by the binding of the ligand to the extracellular domain of the receptor. The activation of the kinases in its turn involves the stimulation of different intra-cellular substrates, including IRS-1, IRS-2, Shc and Grb 10 (Peruzzi F. et al., J. Cancer Res. Clin. Oncol., 125:166-173, 1999). The two major substrates of IGF-IR are IRS and Shc which mediate, by the activation of numerous effectors downstream, the majority of the growth and differentiation effects connected with the attachment of the IGFs to this receptor. The availability of substrates can consequently dictate the final biological effect connected with the activation of the IGF-IR. When IRS-1 predominates, the cells tend to proliferate and to transform. When Shc dominates, the cells tend to differentiate (Valentinis B. et al.; J. Biol. Chem. 274:12423-12430, 1999). It seems that the route principally involved for the effects of protection against apoptosis is the phosphatidyl-inositol 3-kinases (PI 3-kinases) route (Prisco M. et al., Horm. Metab. Res., 31:80-89, 1999; Peruzzi F. et al., J. Cancer Res. Clin. Oncol., 125:166-173, 1999). The role of the IGF system in carcinogenesis has become the subject of intensive research in the last ten years. This interest followed the discovery of the fact that in addition to its mitogenic and antiapoptosis properties, IGF-IR seems to be required for the establishment and the maintenance of a transformed phenotype. In fact, it has been well established that an overexpression or a constitutive activation of IGF-IR leads, in a great variety of cells, to a growth of the cells independent of the support in media devoid of fetal calf serum, and to the formation of tumors in nude mice. This in itself is not a unique property since a great variety of products of overexpressed genes can transform cells, including a good number of receptors of growth factors. However, the crucial discovery which has clearly demonstrated the major role played by, IGF-IR in the transformation has been the demonstration that the R-cells, in which the gene coding for IGF-IR has been inactivated, are totally refractory to transformation by different agents which are usually capable of transforming the cells, such as the E5 protein of bovine papilloma virus, an overexpression of EGFR or of PDGFR, the T antigen of SV 40, activated ras or the combination of these two last factors (Sell C. et al., Proc. Natl. Acad. Sci., USA, 90: 11217-11221, 1993; Sell C. et al., Mol. Cell. Biol., 14:3604-3612, 1994; Morrione A. J., Virol., 69:5300-5303, 1995; Coppola D. et al., Mol. Cell. Biol., 14:458a-4595, 1994; DeAngelis T et al., J. Cell. Physiol., 164:214-221, 1995). IGF-IR is expressed in a great variety of tumors and of tumor lines and the IGFs amplify the tumor growth via their attachment to IGF-IR. Other arguments in favor of the role of IGF-IR in carcinogenesis come from studies using murine monoclonal antibodies directed against the receptor or using negative dominants of IGF-IR. In effect, murine monoclonal antibodies directed against IGF-IR inhibit the proliferation of numerous cell lines in culture and the growth of tumor cells in vivo (Arteaga C. et al., Cancer Res., 49:6237-6241, 1989 Li et al., Biochem. Biophys. Res. Com., 196:92-98, 1993; Zia F et al., J. Cell. Biol., 24:269-275, 1996; Scotlandi K et al., Cancer Res., 58:4127-4131, 1998). It has likewise been shown in the works of Jiang et al. (Oncogene, 18:6071-6077, 1999) that a negative dominant of IGF-IR is capable of inhibiting tumor proliferation.
[0043] The term "cell surface antigen" as used herein denotes a molecule, which is displayed on the surface of a cell. In most cases, this molecule will be located in or on the plasma membrane of the cell such that at least part of this molecule remains accessible from outside the cell in tertiary form. A non-limiting example of a cell surface molecule, which is located in the plasma membrane is a transmembrane protein comprising, in its tertiary conformation, regions of hydrophilicity and hydrophobicity. Here, at least one hydrophobic region allows the cell surface molecule to be embedded, or inserted in the hydrophobic plasma membrane of the cell while the hydrophilic regions extend on either side of the plasma membrane into the cytoplasm and extracellular space, respectively. Non-limiting examples of cell surface molecules which are located on the plasma membrane are proteins which have been modified at a cysteine residue to bear a palmitoyl group, proteins modified at a C-terminal cysteine residue to bear a farnesyl group or proteins which have been modified at the C-terminus to bear a glycosyl phosphatidyl inositol ("GPI") anchor. These groups allow covalent attachment of proteins to the outer surface of the plasma membrane, where they remain accessible for recognition by extracellular molecules such as antibodies. Examples of cell surface antigens are CD3 (in particular CD3.epsilon.), PSMA, FAP.alpha., c-MET, endosialin and IGF-IR. As described herein above, PSMA, FAP.alpha., c-MET, endosialin and IGF-IR are cell surface antigens which are targets for therapy of cancer, including, but not limited to solid tumors.
[0044] In light of this, the target antigens PSMA, FAP.alpha., c-MET, endosialin and IGF-IR can also be characterized as tumor antigens. The term "tumor antigen" as used herein may be understood as those antigens that are presented on tumor cells. These antigens can be presented on the cell surface with an extracellular part, which is often combined with a transmembrane and cytoplasmic part of the molecule. These antigens can sometimes be presented only by tumor cells and never by the normal ones. Tumor antigens can be exclusively expressed on tumor cells or might represent a tumor specific mutation compared to normal cells. In this case, they are called tumor-specific antigens. More common are antigens that are presented by tumor cells and normal cells, and they are called tumor-associated antigens. These tumor-associated antigens can be overexpressed compared to normal cells or are accessible for antibody binding in tumor cells due to the less compact structure of the tumor tissue compared to normal tissue.
[0045] In accordance with the present invention an independently folded protein domain is defined as a discrete portion of a protein formed by a single continuous stretch of amino acids within the primary protein sequence, e.g. known from its crystal structure, to take the "correct conformation" without requiring support by other portions of the protein or predicted to do so by comparison with hidden Markow models in libraries of described sequence domains, such as PFAM (Bateman (2000) Nucleic Acids Res. 28: 263-266) and SMART (Schultz (2000) Nucleic Acids Res. 28: 231-234), sequence similarity searches in data bases with the BLAST and PSI-BLAST tools (Altschul (1997) Nucleic Acids Res. 25: 3389-3402) that rely on the concept of a common evolutionary ancestor among sequentially homologous sequences or any other state-of-the-art domain prediction method. Independently folded domains of the same protein chain are often joined by a flexible segment of amino acids, with each half of the flexible segment counting to its adjacent independently folded protein domain. Independently folded domains of the same protein may be connected in a precursor molecule by a protease cleavage site and after proteolytical processing may lie on two different connected protein chains in the mature molecule. Independently folded protein domains may comprise functionally and/or structurally defined subdomains which do not take their correct conformation without requiring support by other portions of the protein because they are formed by discontinuous stretches of extracellular amino acids within the primary protein sequence or kept in their correct conformation by adjacent or other portions of the protein.
[0046] Ther term "method for the selection", respectively the term "selecting" denotes in the context of the present invention the identification and isolation of one or more bispecific single chain antibodies from a population of candidate antibodies. In particular, the candidate antibodies are tested in separate settings for the binding and the mediation of cytotoxicity for each of the three different host cell populations. Populations of bispecific single chain antibodies to be tested and methods for the generation of such populations are described in the appended examples. Since the method of the invention allows for the isolation of one ore more bispecific single chain antibodies the method is also understood as a method for the production of bispecific single chain antibodies of the invention. Of course, such method for the production involves the production of the population of bispecific single chain antibodies, from which the one or more, which bind to the membrane proximal epitopes, are isolated.
[0047] As used herein, a "bispecific single chain antibody" denotes a single polypeptide chain comprising two binding domains. Each binding domain comprises one variable region from an antibody heavy chain ("VH region"), wherein the VH region of the first binding domain specifically binds to the CD3 molecule, and the VH region of the second binding domain specifically binds to the extracellular domain of a membrane protein on a target cell, e.g. to PSMA, FAP.alpha., c-MET, endosialin/TEM1 or IGF-1R. The two binding domains are optionally linked to one another by a short polypeptide spacer. A non-limiting example for a polypeptide spacer is Gly-Gly-Gly-Gly-Ser (G-G-G-G-S) and repeats thereof. Each binding domain may additionally comprise one variable region from an antibody light chain ("VL region"), the VH region and VL region within each of the first and second binding domains being linked to one another via a polypeptide linker, for example of the type disclosed and claimed in EP 623679 B1, but in any case long enough to allow the VH region and VL region of the first binding domain and the VH region and VL region of the second binding domain to pair with one another such that, together, they are able to specifically bind to the respective first and second binding domains.
[0048] The term "protein" is well known in the art and describes biological compounds. Proteins comprise one or more amino acid chains (polypeptides), whereby the amino acids are bound among one another via a peptide bond. The term "polypeptide" as used herein describes a group of molecules, which consists of more than 30 amino acids. In accordance with the invention, the group of polypeptides comprises "proteins" as long as the proteins consist of a single polypeptide chain. Also in line with the definition the term "polypeptide" describes fragments of proteins as long as these fragments consist of more than 30 amino acids. Polypeptides may further form multimers such as dimers, trimers and higher oligomers, i.e. consisting of more than one polypeptide molecule. Polypeptide molecules forming such dimers, trimers etc. may be identical or non-identical. The corresponding higher order structures of such multimers are, consequently, termed homo- or heterodimers, homo- or heterotrimers etc. An example for a hereteromultimer is an antibody molecule, which, in its naturally occurring form, consists of two identical light polypeptide chains and two identical heavy polypeptide chains. The terms "polypeptide" and "protein" also refer to naturally modified polypeptides/proteins wherein the modification is effected e.g. by post-translational modifications like glycosylation, acetylation, phosphorylation and the like. Such modifications are well known in the art.
[0049] The term "binding domain" characterizes in connection with the present invention a domain of a polypeptide which specifically binds to/interacts with a given target structure/antigen/epitope. Thus, the binding domain is an "antigen-interaction-site". The term "antigen-interaction-site" defines, in accordance with the present invention, a motif of a polypeptide, which is able to specifically interact with a specific antigen or a specific group of antigens, e.g. the identical antigen in different species. Said binding/interaction is also understood to define a "specific recognition". The term "specifically recognizing" means in accordance with this invention that the antibody molecule is capable of specifically interacting with and/or binding to at least two, preferably at least three, more preferably at least four amino acids of an antigen, e.g. the human CD3 antigen and the target antigens as defined herein. Such binding may be exemplified by the specificity of a "lock-and-key-principle". Thus, specific motifs in the amino acid sequence of the binding domain and the antigen bind to each other as a result of their primary, secondary or tertiary structure as well as the result of secondary modifications of said structure. The specific interaction of the antigen-interaction-site with its specific antigen may result as well in a simple binding of said site to the antigen. Moreover, the specific interaction of the binding domain/antigen-interaction-site with its specific antigen may alternatively result in the initiation of a signal, e.g. due to the induction of a change of the conformation of the antigen, an oligomerization of the antigen, etc.
[0050] The term "antibody" comprises derivatives or functional fragments thereof which still retain the binding specificity. Techniques for the production of antibodies are well known in the art and described, e.g. in Harlow and Lane "Antibodies, A Laboratory Manual", Cold Spring Harbor Laboratory Press, 1988 and Harlow and Lane "Using Antibodies: A Laboratory Manual" Cold Spring Harbor Laboratory Press, 1999. The term "antibody" also comprises immunoglobulins (Ig's) of different classes (i.e. IgA, IgG, IgM, IgD and IgE) and subclasses (such as IgG1, IgG2 etc.).
[0051] The definition of the term "antibody" also includes embodiments such as chimeric, single chain and humanized antibodies, as well as antibody fragments, like, inter alia, Fab fragments. Antibody fragments or derivatives further comprise F(ab').sub.2, Fv, scFv fragments or single domain antibodies, single variable domain antibodies or immunoglobulin single variable domain comprising merely one variable domain, which might be VH or VL, that specifically bind to an antigen or epitope independently of other V regions or domains; see, for example, Harlow and Lane (1988) and (1999), loc. cit. Such immunoglobulin single variable domain encompasses not only an isolated antibody single variable domain polypeptide, but also larger polypeptides that comprise one or more monomers of an antibody single variable domain polypeptide sequence.
[0052] Various procedures are known in the art and may be used for the production of such antibodies and/or fragments. Thus, the (antibody) derivatives can also be produced by peptidomimetics. Further, techniques described for the production of single chain antibodies (see, inter alia, U.S. Pat. No. 4,946,778) can be adapted to produce single chain antibodies specific for elected polypeptide(s). Also, transgenic animals may be used to express humanized or human antibodies specific for polypeptides and fusion proteins of this invention. For the preparation of monoclonal antibodies, any technique, providing antibodies produced by continuous cell line cultures can be used. Examples for such techniques include the hybridoma technique (Kohler and Milstein Nature 256 (1975), 495-497), the trioma technique, the human B-cell hybridoma technique (Kozbor, Immunology Today 4 (1983), 72) and the EBV-hybridoma technique to produce human monoclonal antibodies (Cole et al., Monoclonal Antibodies and Cancer Therapy, Alan R. Liss, Inc. (1985), 77-96). Surface plasmon resonance as employed in the BIAcore system can be used to increase the efficiency of phage antibodies which bind to an epitope of a target polypeptide, such as CD3 (epsilon), PSMA or FAP.alpha., c-MET, TEM1 or IGF-1R (Schier, Human Antibodies Hybridomas 7 (1996), 97-105; Malmborg, J. Immunol. Methods 183 (1995), 7-13). It is also envisaged in the context of this invention that the term "antibody" comprises antibody constructs, which may be expressed in a host as described herein below, e.g. antibody constructs which may be transfected and/or transduced via, inter alia, viruses or plasmid vectors.
[0053] The term "specific interaction" as used in accordance with the present invention means that the binding domain does not or does not significantly cross-react with polypeptides which have similar structure as those bound by the binding domain, and which might be expressed by the same cells as the polypeptide of interest. Cross-reactivity of a panel of binding domains under investigation may be tested, for example, by assessing binding of said panel of binding domains under conventional conditions (see, e.g., Harlow and Lane, Antibodies: A Laboratory Manual, Cold Spring Harbor Laboratory Press, 1988 and Using Antibodies: A Laboratory Manual, Cold Spring Harbor Laboratory Press, 1999). Examples for the specific interaction of a binding domain with a specific antigen comprise the specificity of a ligand for its receptor. Said definition particularly comprises the interaction of ligands, which induce a signal upon binding to its specific receptor. Examples for said interaction, which is also particularly comprised by said definition, is the interaction of an antigenic determinant (epitope) with the binding domain (antigenic binding site) of an antibody.
[0054] According to a preferred embodiment of the method of the invention the first binding domain binds to CD3 epsilon (CD3.epsilon.) of human and non-chimpanzee primate. In this context it is particularly preferred that the first binding domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain binds to an epitope, which is part of an amino acid sequence comprised in the group consisting of SEQ ID NOs. 2, 4, 6, and 8.
[0055] As used herein, "human" and "man" refers to the species Homo sapiens. As far as the medical uses of the constructs described herein are concerned, human patients are to be treated with the same molecule.
[0056] The term "human" antibody as used herein is to be understood as meaning that the bispecific single chain antibody as defined herein, comprises (an) amino acid sequence(s) contained in the human germline antibody repertoire. For the purposes of definition herein, said bispecific single chain antibody may therefore be considered human if it consists of such (a) human germline amino acid sequence(s), i.e. if the amino acid sequence(s) of the bispecific single chain antibody in question is (are) identical to (an) expressed human germline amino acid sequence(s). A bispecific single chain antibody as defined herein may also be regarded as human if it consists of (a) sequence(s) that deviate(s) from its (their) closest human germline sequence(s) by no more than would be expected due to the imprint of somatic hypermutation. Additionally, the antibodies of many non-human mammals, for example rodents such as mice and rats, comprise VH CDR3 amino acid sequences which one may expect to exist in the expressed human antibody repertoire as well. Any such sequence(s) of human or non-human origin which may be expected to exist in the expressed human repertoire would also be considered "human" for the purposes of the present invention.
[0057] Though T cell-engaging bispecific single chain antibodies described in the art have great therapeutic potential for the treatment of malignant diseases, most of these bispecific molecules are limited in that they are species specific and recognize only human antigen, and--due to genetic similarity--likely the chimpanzee counterpart. The advantage of the preferred embodiment of the invention is the provision of a bispecific single chain antibody comprising a binding domain exhibiting cross-species specificity to human and non-chimpanzee primate of the CD3 epsilon chain.
[0058] Herein described examples for preferred first binding domains bind to an N-terminal 1-27 amino acid residue polypeptide fragment of the extracellular domain of CD3 epsilon. This 1-27 amino acid residue polypeptide fragment was surprisingly identified which--in contrast to all other known epitopes of CD3 epsilon described in the art--maintains its three-dimensional structural integrity when taken out of its native environment in the CD3 complex (and optionally fused to a heterologous amino acid sequence such as EpCAM or an immunoglobulin Fc part).
[0059] The present invention, therefore, provides for a bispecific single chain antibody molecule comprising a first binding domain capable of binding to an epitope of an N-terminal 1-27 amino acid residue polypeptide fragment of the extracellular domain of CD3 epsilon (which CD3 epsilon is, for example, taken out of its native environment and/or comprised by (presented on the surface of) a T-cell) of human and at least one non-chimpanzee primate CD3 epsilon chain, wherein the epitope is part of an amino acid sequence comprised in the group consisting of SEQ ID NOs. 2, 4, 6, and 8; and a second binding domain capable of binding to prostate-specific membrane antigen (PSMA). Preferred non-chimpanzee primates are mentioned herein elsewhere. At least one (or a selection thereof or all) primate(s) selected from Callithrix jacchus; Saguinus oedipus, Saimiri sciureus, and Macaca fascicularis (either SEQ ID 863 or 864 or both), is (are) particularily preferred. Macaca mulatta, also known as Rhesus Monkey is also envisaged as another preferred primate. It is thus envisaged that antibodies of the invention bind to (are capable of binding to) the context independent epitope of an N-terminal 1-27 amino acid residue polypeptide fragment of the extracellular domain of CD3 epsilon of human and Callithrix jacchus, Saguinus oedipus, Saimiri sciureus, and Macaca fascicularis (either SEQ ID 863 or 864 or both), and optionally also to Macaca mulatta. A bispecific single chain antibody molecule comprising a first binding domain as defined herein can be obtained (is obtainable by) or can be manufactured in accordance with the protocol set out in the appended Examples (in particular Example 2). To this end, it is envisaged to (a) immunize mice with an N-terminal 1-27 amino acid residue polypeptide fragment of the extracellular domain of CD3 epsilon of human and/or Saimiri sciureus; (b) generation of an immune murine antibody scFv library; (c) identification of CD3 epsilon specific binders by testing the capability to bind to at least SEQ ID NOs. 2, 4, 6, and 8.
[0060] The context-independence of the CD3 epitope provided herein corresponds to the first 27 N-terminal amino acids of CD3 epsilon or functional fragments of this 27 amino acid stretch. The phrase "context-independent," as used herein in relation to the CD3 epitope means that binding of the herein described inventive binding molecules/antibody molecules does not lead to a change or modification of the conformation, sequence, or structure surrounding the antigenic determinant or epitope. In contrast, the CD3 epitope recognized by a conventional CD3 binding molecule (e.g. as disclosed in WO 99/54440 or WO 04/106380) is localized on the CD3 epsilon chain C-terminally to the N-terminal 1-27 amino acids of the context-independent epitope, where it only takes the correct conformation if it is embedded within the rest of the epsilon chain and held in the right sterical position by heterodimerization of the epsilon chain with either the CD3 gamma or delta chain. Anti-CD3 binding domains as part of bispecific single chain molecules as provided herein and generated (and directed) against a context-independent CD3 epitope provide for a surprising clinical improvement with regard to T cell redistribution and, thus, a more favourable safety profile. Without being bound by theory, since the CD3 epitope is context-independent, forming an autonomous selfsufficient subdomain without much influence on the rest of the CD3 complex, the CD3 binding domain of the bispecific single chain molecules provided herein induces less allosteric changes in CD3 conformation than the conventional CD3 binding molecules (like molecules provided in WO 99/54440 or WO 04/106380), which recognize context-dependent CD3 epitopes.
[0061] The context-independence of the CD3 epitope which is recognized by the CD3 binding domain of the bispecific single chain antibodies of the invention, respectively isolated by the method of the invention, is associated with less or no T cell redistribution (T cell redistribution equates with an initial episode of drop and subsequent recovery of absolute T cell counts) during the starting phase of treatment with said bispecific single chain antibody. This results in a better safety profile of the bispecific single chain antibodies of the invention compared to conventional CD3 binding molecules known in the art, which recognize context-dependent CD3 epitopes. Particularly, because T cell redistribution during the starting phase of treatment with CD3 binding molecules is a major risk factor for adverse events, like CNS adverse events, the bispecific single chain antibodies of the invention by recognizing a context-independent rather than a context-dependent CD3 epitope has a substantial safety advantage over the CD3 binding molecules known in the art. Patients with such CNS adverse events related to T cell redistribution during the starting phase of treatment with conventional CD3 binding molecules usually suffer from confusion and disorientation, in some cases also from urinary incontinence. Confusion is a change in mental status in which the patient is not able to think with his or her usual level of clarity. The patient usually has difficulties to concentrate and thinking is not only blurred and unclear but often significantly slowed down. Patients with CNS adverse events related to T cell redistribution during the starting phase of treatment with conventional CD3 binding molecules may also suffer from loss of memory. Frequently, the confusion leads to the loss of ability to recognize people, places, time or the date. Feelings of disorientation are common in confusion, and the decision-making ability is impaired. CNS adverse events related to T cell redistribution during the starting phase of treatment with conventional CD3 binding molecules may further comprise blurred speech and/or word finding difficulties. This disorder may impair both, the expression and understanding of language as well as reading and writing. Besides urinary incontinence, vertigo and dizziness may also accompany CNS adverse events related to T cell redistribution during the starting phase of treatment with conventional CD3 binding molecules in some patients.
[0062] The maintenance of the three-dimensional structure within the mentioned 27 amino acid N-terminal polypeptide fragment of CD3 epsilon can be used for the generation of, preferably human, binding domains which are capable of binding to the N-terminal CD3 epsilon polypeptide fragment in vitro and to the native (CD3 epsilon subunit of the) CD3 complex on T cells in vivo with the same binding affinity. These data strongly indicate that the N-terminal fragment as described herein forms a tertiary conformation, which is similar to its structure normally existing in vivo. A very sensitive test for the importance of the structural integrity of the amino acids 1-27 of the N-terminal polypeptide fragment of CD3 epsilon was performed. Individual amino acids of amino acids 1-27 of the N-terminal polypeptide fragment of CD3 epsilon were changed to alanine (alanine scanning) to test the sensitivity of the amino acids 1-27 of the N-terminal polypeptide fragment of CD3 epsilon for minor disruptions.
[0063] Unexpectedly, it has been found that the thus isolated, preferably human, bispecific single chain antibody of the invention not only recognizes the human N-terminal fragment of CD3 epsilon, but also the corresponding homologous fragments of CD3 epsilon of various primates, including New-World Monkeys (Marmoset, Callithrix jacchus; Saguinus oedipus; Saimiri sciureus) and Old-World Monkeys (Macaca fascicularis, also known as Cynomolgus Monkey; or Macaca mulatta, also known as Rhesus Monkey). Thus, multi-primate specificity of the bispecific single chain antibodies of the invention can be detected. The multi-primate specificity of the biding domains of the invention is defined herein as cross-species specificity.
[0064] The amino acid sequence of the aformentioned N-terminal fragments of CD3 epsilon are depicted in SEQ ID No. 2 (human), SEQ ID No. 4 (Callithrix jacchus); SEQ ID No. 6 (Saguinus oedipus); SEQ ID No. 8 (Saimiri sciureus); SEQ ID No. 863 QDGNEEMGSITQTPYQVSISGTTILTC or SEQ ID No. 864 QDGNEEMGSITQTPYQVSISGTTVILT (Macaca fascicularis, also known as Cynomolgus Monkey), and SEQ ID No. 865 QDGNEEMGSITQTPYHVSISGTTVILT (Macaca mulatta, also known as Rhesus Monkey).
[0065] The term "cross-species specificity" or "interspecies specificity" as used herein means binding of a binding domain described herein to the same target molecule in humans and non-chimpanzee primates. Thus, "cross-species specificity" or "interspecies specificity" is to be understood as an interspecies reactivity to the same molecule "X" expressed in different species, but not to a molecule other than "X". Cross-species specificity of a monoclonal antibody recognizing e.g. human CD3 epsilon, to a non-chimpanzee primate CD3 epsilon, e.g. macaque CD3 epsilon, can be determined, for instance, by FACS analysis. The FACS analysis is carried out in a way that the respective monoclonal antibody is tested for binding to human and non-chimpanzee primate cells, e.g. macaque cells, expressing said human and non-chimpanzee primate CD3 epsilon antigens, respectively. An appropriate assay is shown in the following examples. The above-mentioned subject matter applies mutatis mutandis for the targe antigens PSMA, FAP.alpha., endosialin (TEM1), c-MET and IGF-1R: Cross-species specificity of a monoclonal antibody recognizing e.g. human PSMA, to a non-chimpanzee primate PSMA, e.g. macaque PSMA, can be determined, for instance, by FACS analysis. The FACS analysis is carried out in a way that the respective monoclonal antibody is tested for binding to human and non-chimpanzee primate cells, e.g. macaque cells, expressing said human and non-chimpanzee primate PSMA antigens, respectively.
[0066] As used herein, CD3 epsilon denotes a molecule expressed as part of the T cell receptor and has the meaning as typically ascribed to it in the prior art. In human, it encompasses in individual or independently combined form all known CD3 subunits, for example CD3 epsilon, CD3 delta, CD3 gamma, CD3 zeta, CD3 alpha and CD3 beta. The non-chimpanzee primate, non-human CD3 antigens as referred to herein are, for example, Macaca fascicularis CD3 and Macaca mulatta CD3. In Macaca fascicularis, it encompasses CD3 epsilon FN-18 negative and CD3 epsilon FN-18 positive, CD3 gamma and CD3 delta. In Macaca mulatta, it encompasses CD3 epsilon, CD3 gamma and CD3 delta. Preferably, said CD3 as used herein is CD3 epsilon.
[0067] The human CD3 epsilon is indicated in GenBank Accession No. NM_000733 and comprises SEQ ID NO. 1. The human CD3 gamma is indicated in GenBank Accession NO. NM_000073. The human CD3 delta is indicated in GenBank Accession No. NM_000732.
[0068] The CD3 epsilon "FN-18 negative" of Macaca fascicularis (i.e. CD3 epsilon not recognized by monoclonal antibody FN-18 due to a polymorphism as set forth above) is indicated in GenBank Accession No. AB073994.
[0069] The CD3 epsilon "FN-18 positive" of Macaca fascicularis (i.e. CD3 epsilon recognized by monoclonal antibody FN-18) is indicated in GenBank Accession No. AB073993. The CD3 gamma of Macaca fascicularis is indicated in GenBank Accession No. AB073992. The CD3 delta of Macaca fascicularis is indicated in GenBank Accession No. AB073991.
[0070] The nucleic acid sequences and amino acid sequences of the respective CD3 epsilon, gamma and delta homologs of Macaca mulatta can be identified and isolated by recombinant techniques described in the art (Sambrook et al. Molecular Cloning: A Laboratory Manual; Cold Spring Harbor Laboratory Press, 3.sup.rd edition 2001). This applies mutatis mutandis to the CD3 epsilon, gamma and delta homologs of other non-chimpanzee primates as defined herein. The identification of the amino acid sequence of Callithrix jacchus, Saimiri sciureus and Saguinus oedipus is described in the appended examples. The amino acid sequence of the extracellular domain of the CD3 epsilon of Callithrix jacchus is depicted in SEQ ID NO: 3, the one of Saguinus oedipus is depicted in SEQ ID NO: 5 and the one of Saimiri sciureus is depicted in SEQ ID NO: 7.
[0071] In line with the above, the term "epitope" defines an antigenic determinant, which is specifically bound/identified by a binding domain as defined herein. The binding domain may specifically bind to/interact with conformational or continuous epitopes, which are unique for the target structure, e.g. the human and non-chimpanzee primate CD3 epsilon chain. A conformational or discontinuous epitope is characterized for polypeptide antigens by the presence of two or more discrete amino acid residues which are separated in the primary sequence, but come together on the surface of the molecule when the polypeptide folds into the native protein/antigen (Sela, (1969) Science 166, 1365 and Laver, (1990) Cell 61, 553-6). The two or more discrete amino acid residues contributing to the epitope are present on separate sections of one or more polypeptide chain(s). These residues come together on the surface of the molecule when the polypeptide chain(s) fold(s) into a three-dimensional structure to constitute the epitope. In contrast, a continuous or linear epitope consists of two or more discrete amino acid residues, which are present in a single linear segment of a polypeptide chain. Within the present invention, a "context-dependent" CD3 epitope refers to the conformation of said epitope. Such a context-dependent epitope, localized on the epsilon chain of CD3, can only develop its correct conformation if it is embedded within the rest of the epsilon chain and held in the right position by heterodimerization of the epsilon chain with either CD3 gamma or delta chain. In contrast, a context-independent CD3 epitope as provided herein refers to an N-terminal 1-27 amino acid residue polypeptide or a functional fragment thereof of CD3 epsilon. This N-terminal 1-27 amino acid residue polypeptide or a functional fragment thereof maintains its three-dimensional structural integrity and correct conformation when taken out of its native environment in the CD3 complex. The context-independency of the N-terminal 1-27 amino acid residue polypeptide or a functional fragment thereof, which is part of the extracellular domain of CD3 epsilon, represents, thus, an epitope which is completely different to the epitopes of CD3 epsilon described in connection with a method for the preparation of human binding molecules in WO 2004/106380. Said method used solely expressed recombinant CD3 epsilon. The conformation of this solely expressed recombinant CD3 epsilon differed from that adopted in its natural form, that is, the form in which the CD3 epsilon subunit of the TCR/CD3 complex exists as part of a noncovalent complex with either the CD3 delta or the CD3-gamma subunit of the TCR/CD3 complex. When such solely expressed recombinant CD3 epsilon protein is used as an antigen for selection of antibodies from an antibody library, antibodies specific for this antigen are identified from the library although such a library does not contain antibodies with specificity for self-antigens/autoantigens. This is due to the fact that solely expressed recombinant CD3 epsilon protein does not exist in vivo; it is not an autoantigen. Consequently, subpopulations of B cells expressing antibodies specific for this protein have not been depleted in vivo; an antibody library constructed from such B cells would contain genetic material for antibodies specific for solely expressed recombinant CD3 epsilon protein.
[0072] However, since the context-independent N-terminal 1-27 amino acid residue polypeptide or a functional fragment thereof is an epitope, which folds in its native form, binding domains in line with the present invention cannot be identified by methods based on the approach described in WO 2004/106380. Therefore, it could be verified in tests that binding molecules as disclosed in WO 2004/106380 are not capable of binding to the N-terminal 1-27 amino acid residues of the CD3 epsilon chain. Hence, conventional anti-CD3 binding molecules or anti-CD3 antibody molecules (e.g. as disclosed in WO 99/54440) bind CD3 epsilon chain at a position which is more C-terminally located than the context-independent N-terminal 1-27 amino acid residue polypeptide or a functional fragment provided herein. Prior art antibody molecules OKT3 and UCHT-1 have also a specificity for the epsilon-subunit of the TCR/CD3 complex between amino acid residues 35 to 85 and, accordingly, the epitope of these antibodies is also more C-terminally located. In addition, UCHT-1 binds to the CD3 epsilon chain in a region between amino acid residues 43 to 77 (Tunnacliffe, Int. Immunol. 1 (1989), 546-50; Kjer-Nielsen, PNAS 101, (2004), 7675-7680; Salmeron, J. Immunol. 147 (1991), 3047-52). Therefore, prior art anti-CD3 molecules do not bind to and are not directed against the herein defined context-independent N-terminal 1-27 amino acid residue epitope (or a functional fragment thereof). In particular, the state of the art fails to provide anti-CD3 molecules which specifically binds to the context-independent N-terminal 1-27 amino acid residue epitope and which are cross-species specific, i.e. bind to human and non-chimpanzee primate CD3 epsilon.
[0073] As used herein, the term "humanized", "humanization", "human-like" or grammatically related variants thereof are used interchangeably to refer to a bispecific single chain antibody comprising in at least one of its binding domains at least one complementarity determining region ("CDR") from a non-human antibody or fragment thereof. Humanization approaches are described for example in WO 91/09968 and U.S. Pat. No. 6,407,213. As non-limiting examples, the term encompasses the case in which a variable region of at least one binding domain comprises a single CDR region, for example the third CDR region of the VH (CDRH3), from another non-human animal, for example a rodent, as well as the case in which a or both variable region/s comprise at each of their respective first, second and third CDRs the CDRs from said non-human animal. In the event that all CDRs of a binding domain of the bispecific single chain antibody have been replaced by their corresponding equivalents from, for example, a rodent, one typically speaks of "CDR-grafting", and this term is to be understood as being encompassed by the term "humanized" or grammatically related variants thereof as used herein. The term "humanized" or grammatically related variants thereof also encompasses cases in which, in addition to replacement of one or more CDR regions within a VH and/or VL of the first and/or second binding domain further mutation/s (e.g. substitutions) of at least one single amino acid residue/s within the framework ("FR") regions between the CDRs has/have been effected such that the amino acids at that/those positions correspond/s to the amino acid/s at that/those position/s in the animal from which the CDR regions used for replacement is/are derived. As is known in the art, such individual mutations are often made in the framework regions following CDR-grafting in order to restore the original binding affinity of the non-human antibody used as a CDR-donor for its target molecule. The term "humanized" may further encompass (an) amino acid substitution(s) in the CDR regions from a non-human animal to the amino acid(s) of a corresponding CDR region from a human antibody, in addition to the amino acid substitutions in the framework regions as described above.
[0074] As used herein, the term "homolog" or "homology" is to be understood as follows: Homology among proteins and DNA is often concluded on the basis of sequence similarity, especially in bioinformatics. For example, in general, if two or more genes have highly similar DNA sequences, it is likely that they are homologous. But sequence similarity may arise from different ancestors: short sequences may be similar by chance, and sequences may be similar because both were selected to bind to a particular protein, such as a transcription factor. Such sequences are similar but not homologous. Sequence regions that are homologous are also called conserved. This is not to be confused with conservation in amino acid sequences in which the amino acid at a specific position has changed but the physio-chemical properties of the amino acid remain unchanged. Homologous sequences are of two types: orthologous and paralogous. Homologous sequences are orthologous if they were separated by a speciation event: when a species diverges into two separate species, the divergent copies of a single gene in the resulting species are said to be orthologous. Orthologs, or orthologous genes, are genes in different species that are similar to each other because they originated from a common ancestor. The strongest evidence that two similar genes are orthologous is the result of a phylogenetic analysis of the gene lineage. Genes that are found within one clade are orthologs, descended from a common ancestor. Orthologs often, but not always, have the same function. Orthologous sequences provide useful information in taxonomic classification studies of organisms. The pattern of genetic divergence can be used to trace the relatedness of organisms. Two organisms that are very closely related are likely to display very similar DNA sequences between two orthologs. Conversely, an organism that is further removed evolutionarily from another organism is likely to display a greater divergence in the sequence of the orthologs being studied. Homologous sequences are paralogous if they were separated by a gene duplication event: if a gene in an organism is duplicated to occupy two different positions in the same genome, then the two copies are paralogous. A set of sequences that are paralogous are called paralogs of each other. Paralogs typically have the same or similar function, but sometimes do not: due to lack of the original selective pressure upon one copy of the duplicated gene, this copy is free to mutate and acquire new functions. An example can be found in rodents such as rats and mice. Rodents have a pair of paralogous insulin genes, although it is unclear if any divergence in function has occurred. Paralogous genes often belong to the same species, but this is not necessary: for example, the hemoglobin gene of humans and the myoglobin gene of chimpanzees are paralogs. This is a common problem in bioinformatics: when genomes of different species have been sequenced and homologous genes have been found, one can not immediately conclude that these genes have the same or similar function, as they could be paralogs whose function has diverged.
[0075] As used herein, a "non-chimpanzee primate" or "non-chimp primate" or grammatical variants thereof refers to any primate animal (i.e. not human) other than chimpanzee, i.e. other than an animal of belonging to the genus Pan, and including the species Pan paniscus and Pan troglodytes, also known as Anthropopithecus troglodytes or Simia satyrus. It will be understood, however, that it is possible that the antibodies of the invention can also bind with their first and/or second binding domain to the respective epitopes/fragments etc. of said chimpanzees. The intention is merely to avoid animal tests which are carried out with chimpanzees, if desired. It is thus also envisaged that in another embodiment the antibodies of the present invention also bind with their first and/or second binding domain to the respective epitopes of chimpanzees. A "primate", "primate species", "primates" or grammatical variants thereof denote/s an order of eutherian mammals divided into the two suborders of prosimians and anthropoids and comprising apes, monkeys and lemurs. Specifically, "primates" as used herein comprises the suborder Strepsirrhini (non-tarsier prosimians), including the infraorder Lemuriformes (itself including the superfamilies Cheirogaleoidea and Lemuroidea), the infraorder Chiromyiformes (itself including the family Daubentoniidae) and the infraorder Lorisiformes (itself including the families Lorisidae and Galagidae). "Primates" as used herein also comprises the suborder Haplorrhini, including the infraorder Tarsiiformes (itself including the family Tarsiidae), the infraorder Simiiformes (itself including the Platyrrhini, or New-World monkeys, and the Catarrhini, including the Cercopithecidea, or Old-World Monkeys).
[0076] The non-chimpanzee primate species may be understood within the meaning of the invention to be a lemur, a tarsier, a gibbon, a marmoset (belonging to New-World Monkeys of the family Cebidae) or an Old-World Monkey (belonging to the superfamily Cercopithecoidea).
[0077] As used herein, an "Old-World Monkey" comprises any monkey falling in the superfamily Cercopithecoidea, itself subdivided into the families: the Cercopithecinae, which are mainly African but include the diverse genus of macaques which are Asian and North African; and the Colobinae, which include most of the Asian genera but also the African colobus monkeys.
[0078] Specifically, within the subfamily Cercopithecinae, an advantageous non-chimpanzee primate may be from the Tribe Cercopithecini, within the genus Allenopithecus (Allen's Swamp Monkey, Allenopithecus nigroviridis); within the genus Miopithecus (Angolan Talapoin, Miopithecus talapoin; Gabon Talapoin, Miopithecus ogouensis); within the genus Erythrocebus (Patas Monkey, Erythrocebus patas); within the genus Chlorocebus (Green Monkey, Chlorocebus sabaceus; Grivet, Chlorocebus aethiops; Bale Mountains Vervet, Chlorocebus djamdjamensis; Tantalus Monkey, Chlorocebus tantalus; Vervet Monkey, Chlorocebus pygerythrus; Malbrouck, Chlorocebus cynosuros); or within the genus Cercopithecus (Dryas Monkey or Salongo Monkey, Cercopithecus dryas; Diana Monkey, Cercopithecus diana; Roloway Monkey, Cercopithecus roloway; Greater Spot-nosed Monkey, Cercopithecus nictitans; Blue Monkey, Cercopithecus mitis; Silver Monkey, Cercopithecus doggetti; Golden Monkey, Cercopithecus kandti; Sykes's Monkey, Cercopithecus albogularis; Mona Monkey, Cercopithecus mona; Campbell's Mona Monkey, Cercopithecus campbelli; Lowe's Mona Monkey, Cercopithecus lowei; Crested Mona Monkey, Cercopithecus pogonias; Wolf's Mona Monkey, Cercopithecus wolfi; Dent's Mona Monkey, Cercopithecus denti; Lesser Spot-nosed Monkey, Cercopithecus petaurista; White-throated Guenon, Cercopithecus erythrogaster; Sclater's Guenon, Cercopithecus sclateri; Red-eared Guenon, Cercopithecus erythrotis; Moustached Guenon, Cercopithecus cephus; Red-tailed Monkey, Cercopithecus ascanius; L'Hoest's Monkey, Cercopithecus lhoesti; Preuss's Monkey, Cercopithecus preussi; Sun-tailed Monkey, Cercopithecus solatus; Hamlyn's Monkey or Owl-faced Monkey, Cercopithecus hamlyni; De Brazza's Monkey, Cercopithecus neglectus).
[0079] Alternatively, an advantageous non-chimpanzee primate, also within the subfamily Cercopithecinae but within the Tribe Papionini, may be from within the genus Macaca (Barbary Macaque, Macaca sylvanus; Lion-tailed Macaque, Macaca silenus; Southern Pig-tailed Macaque or Beruk, Macaca nemestrina; Northern Pig-tailed Macaque, Macaca leonina; Pagai Island Macaque or Bokkoi, Macaca pagensis; Siberut Macaque, Macaca siberu; Moor Macaque, Macaca maura; Booted Macaque, Macaca ochreata; Tonkean Macaque, Macaca tonkeana; Heck's Macaque, Macaca hecki; Gorontalo Macaque, Macaca nigriscens; Celebes Crested Macaque or Black "Ape", Macaca nigra; Cynomolgus monkey or Crab-eating Macaque or Long-tailed Macaque or Kera, Macaca fascicularis; Stump-tailed Macaque or Bear Macaque, Macaca arctoides; Rhesus Macaque, Macaca mulatta; Formosan Rock Macaque, Macaca cyclopis; Japanese Macaque, Macaca fuscata; Toque Macaque, Macaca sinica; Bonnet Macaque, Macaca radiata; Barbary Macaque, Macaca sylvanmus; Assam Macaque, Macaca assamensis; Tibetan Macaque or Milne-Edwards' Macaque, Macaca thibetana; Arunachal Macaque or Munzala, Macaca munzala); within the genus Lophocebus (Gray-cheeked Mangabey, Lophocebus albigena; Lophocebus albigena albigena; Lophocebus albigena osmani; Lophocebus albigena johnstoni; Black Crested Mangabey, Lophocebus aterrimus; Opdenbosch's Mangabey, Lophocebus opdenboschi; Highland Mangabey, Lophocebus kipunji); within the genus Papio (Hamadryas Baboon, Papio hamadryas; Guinea Baboon, Papio papio; Olive Baboon, Papio anubis; Yellow Baboon, Papio cynocephalus; Chacma Baboon, Papio ursinus); within the genus Theropithecus (Gelada, Theropithecus gelada); within the genus Cercocebus (Sooty Mangabey, Cercocebus atys; Cercocebus atys atys; Cercocebus atys lunulatus; Collared Mangabey, Cercocebus torquatus; Agile Mangabey, Cercocebus agilis; Golden-bellied Mangabey, Cercocebus chrysogaster; Tana River Mangabey, Cercocebus galeritus; Sanje Mangabey, Cercocebus sanjei); or within the genus Mandrillus (Mandrill, Mandrillus sphinx; Drill, Mandrillus leucophaeus).
[0080] Most preferred is Macaca fascicularis (also known as Cynomolgus monkey and, therefore, in the Examples named "Cynomolgus") and Macaca mulatta (rhesus monkey, named "rhesus").
[0081] Within the subfamily Colobinae, an advantageous non-chimpanzee primate may be from the African group, within the genus Colobus (Black Colobus, Colobus satanas; Angola Colobus, Colobus angolensis; King Colobus, Colobus polykomos; Ursine Colobus, Colobus vellerosus; Mantled Guereza, Colobus guereza); within the genus Piliocolobus (Western Red Colobus, Piliocolobus badius; Piliocolobus badius badius; Piliocolobus badius temminckii; Piliocolobus badius waldronae; Pennant's Colobus, Piliocolobus pennantii; Piliocolobus pennantii pennantii; Piliocolobus pennantii epieni; Piliocolobus pennantii bouvieri; Preuss's Red Colobus, Piliocolobus preussi; Thollon's Red Colobus, Piliocolobus tholloni; Central African Red Colobus, Piliocolobus foai; Piliocolobus foai foai; Piliocolobus foai ellioti; Piliocolobus foai oustaleti; Piliocolobus foai semlikiensis; Piliocolobus foai parmentierorum; Ugandan Red Colobus, Piliocolobus tephrosceles; Uzyngwa Red Colobus, Piliocolobus gordonorum; Zanzibar Red Colobus, Piliocolobus kirkii; Tana River Red Colobus, Piliocolobus rufomitratus); or within the genus Procolobus (Olive Colobus, Procolobus verus).
[0082] Within the subfamily Colobinae, an advantageous non-chimpanzee primate may alternatively be from the Langur (leaf monkey) group, within the genus Semnopithecus (Nepal Gray Langur, Semnopithecus schistaceus; Kashmir Gray Langur, Semnopithecus ajax; Tarai Gray Langur, Semnopithecus hector; Northern Plains Gray Langur, Semnopithecus entellus; Black-footed Gray Langur, Semnopithecus hypoleucos; Southern Plains Gray Langur, Semnopithecus dussumieri; Tufted Gray Langur, Semnopithecus priam); within the T. vetulus group or the genus Trachypithecus (Purple-faced Langur, Trachypithecus vetulus; Nilgiri Langur, Trachypithecus johnii); within the T. cristatus group of the genus Trachypithecus (Javan Lutung, Trachypithecus auratus; Silvery Leaf Monkey or Silvery Lutung, Trachypithecus cristatus; Indochinese Lutung, Trachypithecus germaini; Tenasserim Lutung, Trachypithecus barbel); within the T. obscurus group of the genus Trachypithecus (Dusky Leaf Monkey or Spectacled Leaf Monkey, Trachypithecus obscurus; Phayre's Leaf Monkey, Trachypithecus phayrei); within the T. pileatus group of the genus Trachypithecus (Capped Langur, Trachypithecus pileatus; Shortridge's Langur, Trachypithecus shortridgei; Gee's Golden Langur, Trachypithecus geei); within the T. francoisi group of the genus Trachypithecus (Francois' Langur, Trachypithecus francoisi; Hatinh Langur, Trachypithecus hatinhensis; White-headed Langur, Trachypithecus poliocephalus; Laotian Langur, Trachypithecus laotum; Delacour's Langur, Trachypithecus delacouri; Indochinese Black Langur, Trachypithecus ebenus); or within the genus Presbytis (Sumatran Surili, Presbytis melalophos; Banded Surili, Presbytis femoralis; Sarawak Surili, Presbytis chrysomelas; White-thighed Surili, Presbytis siamensis; White-fronted Surili, Presbytis frontata; Javan Surili, Presbytis comata; Thomas's Langur, Presbytis thomasi; Hose's Langur, Presbytis hosei; Maroon Leaf Monkey, Presbytis rubicunda; Mentawai Langur or Joja, Presbytis potenziani; Natuna Island Surili, Presbytis natunae).
[0083] Within the subfamily Colobinae, an advantageous non-chimpanzee primate may alternatively be from the Odd-Nosed group, within the genus Pygathrix (Red-shanked Douc, Pygathrix nemaeus; Black-shanked Douc, Pygathrix nigripes; Gray-shanked Douc, Pygathrix cinerea); within the genus Rhinopithecus (Golden Snub-nosed Monkey, Rhinopithecus roxellana; Black Snub-nosed Monkey, Rhinopithecus bieti; Gray Snub-nosed Monkey, Rhinopithecus brelichi; Tonkin Snub-nosed Langur, Rhinopithecus avunculus); within the genus Nasalis (Proboscis Monkey, Nasalis larvatus); or within the genus Simias (Pig-tailed Langur, Simias concolor).
[0084] As used herein, the term "marmoset" denotes any New-World Monkeys of the genus Callithrix, for example belonging to the Atlantic marmosets of subgenus Callithrix (sic!) (Common Marmoset, Callithrix (Callithrix) jacchus; Black-tufted Marmoset, Callithrix (Callithrix) penicillata; Wied's Marmoset, Callithrix (Callithrix) kuhlii; White-headed Marmoset, Callithrix (Callithrix) geoffroyi; Buffy-headed Marmoset, Callithrix (Callithrix) flaviceps; Buffy-tufted Marmoset, Callithrix (Callithrix) aurita); belonging to the Amazonian marmosets of subgenus Mico (Rio Acari Marmoset, Callithrix (Mico) acariensis; Manicore Marmoset, Callithrix (Mico) manicorensis; Silvery Marmoset, Callithrix (Mico) argentata; White Marmoset, Callithrix (Mico) leucippe; Emilia's Marmoset, Callithrix (Mico) emiliae; Black-headed Marmoset, Callithrix (Mico) nigriceps; Marca's Marmoset, Callithrix (Mico)marcai; Black-tailed Marmoset, Callithrix (Mico) melanura; Santarem Marmoset, Callithrix (Mico) humeralifera; Maues Marmoset, Callithrix (Mico) mauesi; Gold-and-white Marmoset, Callithrix (Mico) chrysoleuca; Hershkovitz's Marmoset, Callithrix (Mico) intermedia; Satere Marmoset, Callithrix (Mico) saterei); Roosmalens' Dwarf Marmoset belonging to the subgenus Callibella (Callithrix (Callibella) humilis); or the Pygmy Marmoset belonging to the subgenus Cebuella (Callithrix (Cebuella) pygmaea).
[0085] Other genera of the New-World Monkeys comprise tamarins of the genus Saguinus (comprising the S. oedipus-group, the S. midas group, the S. nigricollis group, the S. mystax group, the S. bicolor group and the S. inustus group) and squirrel monkeys of the genus Saimiri (e.g. Saimiri sciureus, Saimiri oerstedii, Saimiri ustus, Saimiri boliviensis, Saimiri vanzolini).
[0086] Advantageously, the present invention provides also target antigenxCD3 bispecific single chain antibodies comprising a second binding domain which binds both to the human target antigen and to the macaque target antigen homolog, i.e. the homolog of a non-chimpanzee primate. In a preferred embodiment, the bispecific single chain antibody thus comprises a second binding domain exhibiting cross-species specificity to the human and a non-chimpanzee primate target antigen. In this case, the identical bispecific single chain antibody molecule can be used both for preclinical evaluation of safety, activity and/or pharmacokinetic profile of these binding domains in primates and as drug in humans. Put in other words, the same molecule can be used in preclinical animal studies as well as in clinical studies in humans. This leads to highly comparable results and a much-increased predictive power of the animal studies compared to species-specific surrogate molecules. Since both the CD3 and the target antigen binding domain of the target antigenxCD3 bispecific single chain antibody of the invention are cross-species specific, i.e. reactive with the human and non-chimpanzee primates' antigens, it can be used both for preclinical evaluation of safety, activity and/or pharmacokinetic profile of these binding domains in primates and--in the identical form--as drug in humans. It will be understood that in a preferred embodiment, the cross-species specificity of the first and second binding domain of the antibodies of the invention is identical.
[0087] It has been found in the present invention that it is possible to generate a, preferably human, target antigenxCD3 bispecific single chain antibody wherein the identical molecule can be used in preclinical animal testing, as well as clinical studies and even in therapy in human. This is due to the unexpected identification of the, preferably human, target antigenxCD3 bispecific single chain antibody, which, in addition to binding to human CD3 epsilon and target antigen, respectively, (and due to genetic similarity likely to the chimpanzee counterpart), also binds to the homologs of said antigens of non-chimpanzee primates, including New-World Monkeys and Old-World Monkeys. The preferably human, target antigenxCD3 bispecific single chain antibody of the invention can be used as therapeutic agent against various diseases, including, but not limited, to cancer. In view of the above, the need to construct a surrogate target antigenxCD3 bispecific single chain antibody for testing in a phylogenetic distant (from humans) species disappears. As a result, the identical molecule can be used in animal preclinical testing as is intended to be administered to humans in clinical testing as well as following market approval and therapeutic drug administration. The ability to use the same molecule for preclinical animal testing as in later administration to humans virtually eliminates, or at least greatly reduces, the danger that the data obtained in preclinical animal testing have limited applicability to the human case. In short, obtaining preclinical safety data in animals using the same molecule as will actually be administered to humans does much to ensure the applicability of the data to a human-relevant scenario. In contrast, in conventional approaches using surrogate molecules, said surrogate molecules have to be molecularly adapted to the animal test system used for preclinical safety assessment. Thus, the molecule to be used in human therapy in fact differs in sequence and also likely in structure from the surrogate molecule used in preclinical testing in pharmacokinetic parameters and/or biological activity, with the consequence that data obtained in preclinical animal testing have limited applicability/transferability to the human case. The use of surrogate molecules requires the construction, production, purification and characterization of a completely new construct. This leads to additional development costs and time necessary to obtain that molecule. In sum, surrogates have to be developed separately in addition to the actual drug to be used in human therapy, so that two lines of development for two molecules have to be carried out. Therefore, a major advantage of the, preferably human, target antigenxCD3 bispecific single chain antibody of the invention exhibiting cross-species specificity described herein is that the identical molecule can be used for therapeutic agents in humans and in preclinical animal testing.
[0088] It is preferred that at least one of said first or second binding domains of the bispecific single chain antibody of the invention is CDR-grafted, humanized or human, as set forth in more detail below. Preferably, both the first and second binding domains of the bispecific single chain antibody of the invention are CDR-grafted, humanized or human. For the preferably human, target antigenxCD3 bispecific single chain antibody of the invention, the generation of an immune reaction against said binding molecule is excluded to the maximum possible extent upon administration of the molecule to human patients.
[0089] Another major advantage of the, preferably human, target antigenxCD3 bispecific single chain antibody of the invention is its applicability for preclinical testing in various primates. The behavior of a drug candidate in animals should ideally be indicative of the expected behavior of this drug candidate upon administration to humans. As a result, the data obtained from such preclinical testing should therefore generally have a highly predictive power for the human case. However, as learned from the tragic outcome of the recent Phase I clinical trial on TGN1412 (a CD28 monoclonal antibody), a drug candidate may act differently in a primate species than in humans: Whereas in preclinical testing of said antibody no or only limited adverse effects have been observed in animal studies performed with cynomolgus monkeys, six human patients developed multiple organ failure upon administration of said antibody (Lancet 368 (2006), 2206-7). The results of these dramatic, non-desired negative events suggest that it may not be sufficient to limit preclinical testing to only one (non-chimpanzee primate) species. The fact that the target antigenxCD3 bispecific single chain antibody of the invention binds to a series of New-World and Old-World Monkeys may help to overcome the problems faced in the case mentioned above. Accordingly, the present invention provides means and methods for minimizing species differences in effects when drugs for human therapy are being developed and tested.
[0090] With the, preferably human, cross-species specific target antigenxCD3 bispecific single chain antibody of the invention it is also no longer necessary to adapt the test animal to the drug candidate intended for administration to humans, such as e.g. the creation of transgenic animals. The, preferably human, target antigenxCD3 bispecific single chain antibody of the invention exhibiting cross-species specificity according to the uses and the methods of invention can be directly used for preclinical testing in non-chimpanzee primates, without any genetic manipulation of the animals. As well known to those skilled in the art, approaches in which the test animal is adapted to the drug candidate always bear the risk that the results obtained in the preclinical safety testing are less representative and predictive for humans due to the modification of the animal. For example, in transgenic animals, the proteins encoded by the transgenes are often highly over-expressed. Thus, data obtained for the biological activity of an antibody against this protein antigen may be limited in their predictive value for humans in which the protein is expressed at much lower, more physiological levels.
[0091] A further advantage of the uses of the preferably human target antigenxCD3 bispecific single chain antibody of the invention exhibiting cross-species specificity is the fact that chimpanzees as an endangered species are avoided for animal testing.
[0092] Chimpanzees are the closest relatives to humans and were recently grouped into the family of hominids based on the genome sequencing data (Wildman et al., PNAS 100 (2003), 7181). Therefore, data obtained with chimpanzee is generally considered to be highly predictive for humans. However, due to their status as endangered species, the number of chimpanzees, which can be used for medical experiments, is highly restricted. As stated above, maintenance of chimpanzees for animal testing is therefore both costly and ethically problematic. The uses of the, preferably human, target antigenxCD3 bispecific single chain antibody of the invention avoid both ethical objections and financial burden during preclinical testing without prejudicing the quality, i.e. applicability, of the animal testing data obtained. In light of this, the uses of the, preferably human, target antigenxCD3 bispecific single chain antibody of the invention provide for a reasonable alternative for studies in chimpanzees.
[0093] A still further advantage of the, preferably human, target antigenxCD3 bispecific single chain antibody of the invention is the ability of extracting multiple blood samples when using it as part of animal preclinical testing, for example in the course of pharmacokinetic animal studies. Multiple blood extractions can be much more readily obtained with a non-chimpanzee primate than with lower animals, e.g. a mouse. The extraction of multiple blood samples allows continuous testing of blood parameters for the determination of the biological effects induced by the, preferably human, target antigenxCD3 bispecific single chain antibody of the invention. Furthermore, the extraction of multiple blood samples enables the researcher to evaluate the pharmacokinetic profile of the, preferably human, target antigenxCD3 bispecific single chain antibody of the invention as defined herein. In addition, potential side effects, which may be induced by said, preferably human, target antigenxCD3 bispecific single chain antibody of the invention reflected in blood parameters can be measured in different blood samples extracted during the course of the administration of said antibody. This allows the determination of the potential toxicity profile of the, preferably human, target antigenxCD3 bispecific single chain antibody of the invention as defined herein.
[0094] The advantages of the, preferably human, target antigenxCD3 bispecific single chain antibody of the invention as defined herein exhibiting cross-species specificity may be briefly summarized as follows: First, the, preferably human, target antigenxCD3 bispecific single chain antibody of the invention as defined herein used in preclinical testing is the same as the one used in human therapy. Thus, it is no longer necessary to develop two independent molecules, which may differ in their pharmacokinetic properties and biological activity. This is highly advantageous in that e.g. the pharmacokinetic results are more directly transferable and applicable to the human setting than e.g. in conventional surrogate approaches.
[0095] Second, the uses of the, preferably human, target antigenxCD3 bispecific single chain antibody of the invention as defined herein for the preparation of therapeutics in human is less cost- and labor-intensive than surrogate approaches.
[0096] Third, the, preferably human, target antigenxCD3 bispecific single chain antibody of the invention as defined herein can be used for preclinical testing not only in one primate species, but in a series of different primate species, thereby limiting the risk of potential species differences between primates and human.
[0097] Fourth, chimpanzee as an endangered species for animal testing can be avoided if desired.
[0098] Fifth, multiple blood samples can be extracted for extensive pharmacokinetic studies.
[0099] Sixth, due to the human origin of the, preferably human, binding molecules according to a preferred embodiment of the invention, the generation of an immune reaction against said binding molecules is minimalized when administered to human patients. Induction of an immune response with antibodies specific for a drug candidate derived from a non-human species as e.g. a mouse leading to the development of human-anti-mouse antibodies (HAMAs) against therapeutic molecules of murine origin is excluded.
[0100] Last but not least, the therapeutic use of the target antigenxCD3 bispecific single chain antibody of the invention provides a novel and inventive therapeutic approach for cancer, preferably solid tumors, more preferably carcinomas and prostate cancer.
[0101] As shown in the following examples, the target antigenxCD3 bispecific single chain antibody of the invention provides an advantageous tool in order to kill target antigen-expressing human target cells, e.g. cancer cells. Moreover, the cytotoxic activity of the target antigenxCD3 bispecific single chain antibody of the invention is higher than the activity of antibodies described in the art for the exemplified targets.
[0102] It is further preferred for the method of the invention that the first binding domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises a VL region comprising CDR-L1, CDR-L2 and CDR-L3 selected from: (a) CDR-L1 as depicted in SEQ ID NO. 27, CDR-L2 as depicted in SEQ ID NO. 28 and CDR-L3 as depicted in SEQ ID NO. 29; [0103] (b) CDR-L1 as depicted in SEQ ID NO. 117, CDR-L2 as depicted in SEQ ID NO. 118 and CDR-L3 as depicted in SEQ ID NO. 119; and [0104] (c) CDR-L1 as depicted in SEQ ID NO. 153, CDR-L2 as depicted in SEQ ID NO.
[0105] 154 and CDR-L3 as depicted in SEQ ID NO. 155.
[0106] More preferably, the first binding domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises a VL region selected from the group consisting of a VL region as depicted in SEQ ID NO. 35, 39, 125, 129, 161 or 165.
[0107] It is alternatively preferred for the method of the invention that the first binding domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises a VH region comprising CDR-H 1, CDR-H2 and CDR-H3 selected from:
[0108] (a) CDR-H1 as depicted in SEQ ID NO. 12, CDR-H2 as depicted in SEQ ID NO. 13 and CDR-H3 as depicted in SEQ ID NO. 14;
[0109] (b) CDR-H1 as depicted in SEQ ID NO. 30, CDR-H2 as depicted in SEQ ID NO. 31 and CDR-H3 as depicted in SEQ ID NO. 32;
[0110] (c) CDR-H1 as depicted in SEQ ID NO. 48, CDR-H2 as depicted in SEQ ID NO. 49 and CDR-H3 as depicted in SEQ ID NO. 50;
[0111] (d) CDR-H1 as depicted in SEQ ID NO. 66, CDR-H2 as depicted in SEQ ID NO. 67 and CDR-H3 as depicted in SEQ ID NO. 68;
[0112] (e) CDR-H1 as depicted in SEQ ID NO. 84, CDR-H2 as depicted in SEQ ID NO. 85 and CDR-H3 as depicted in SEQ ID NO. 86;
[0113] (f) CDR-H1 as depicted in SEQ ID NO. 102, CDR-H2 as depicted in SEQ ID NO. 103 and CDR-H3 as depicted in SEQ ID NO. 104;
[0114] (g) CDR-H1 as depicted in SEQ ID NO. 120, CDR-H2 as depicted in SEQ ID NO. 121 and CDR-H3 as depicted in SEQ ID NO. 122;
[0115] (h) CDR-H1 as depicted in SEQ ID NO. 138, CDR-H2 as depicted in SEQ ID NO. 139 and CDR-H3 as depicted in SEQ ID NO. 140;
[0116] (i) CDR-H1 as depicted in SEQ ID NO. 156, CDR-H2 as depicted in SEQ ID NO.
[0117] 157 and CDR-H3 as depicted in SEQ ID NO. 158; and
[0118] (j) CDR-H1 as depicted in SEQ ID NO. 174, CDR-H2 as depicted in SEQ ID NO.
[0119] 175 and CDR-H3 as depicted in SEQ ID NO. 176.
[0120] More preferably, the binding domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises a VH region selected from the group consisting of a VH region as depicted in SEQ ID NO. 15, 19, 33, 37, 51, 55, 69, 73, 87, 91, 105, 109, 123, 127, 141, 145, 159, 163, 177 or 181.
[0121] It is preferred for the method of the invention that the first binding domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises a VL region and a VH region selected from the group consisting of: [0122] (a) a VL region as depicted in SEQ ID NO. 17 or 21 and a VH region as depicted in SEQ ID NO. 15 or 19; [0123] (b) a VL region as depicted in SEQ ID NO. 35 or 39 and a VH region as depicted in SEQ ID NO. 33 or 37; [0124] (c) a VL region as depicted in SEQ ID NO. 53 or 57 and a VH region as depicted in SEQ ID NO. 51 or 55;
[0125] (d) a VL region as depicted in SEQ ID NO. 71 or 75 and a VH region as depicted in SEQ ID NO. 69 or 73; [0126] (e) a VL region as depicted in SEQ ID NO. 89 or 93 and a VH region as depicted in SEQ ID NO. 87 or 91; [0127] (f) a VL region as depicted in SEQ ID NO. 107 or 111 and a VH region as depicted in SEQ ID NO. 105 or 109; [0128] (g) a VL region as depicted in SEQ ID NO. 125 or 129 and a VH region as depicted in SEQ ID NO. 123 or 127; [0129] (h) a VL region as depicted in SEQ ID NO. 143 or 147 and a VH region as depicted in SEQ ID NO. 141 or 145;
[0130] (i) a VL region as depicted in SEQ ID NO. 161 or 165 and a VH region as depicted in SEQ ID NO. 159 or 163; and [0131] (j) a VL region as depicted in SEQ ID NO. 179 or 183 and a VH region as depicted in SEQ ID NO. 177 or 181.
[0132] More preferably, the first binding domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises an amino acid sequence selected from the group consisting of SEQ ID NOs: 23, 25, 41, 43, 59, 61, 77, 79, 95, 97, 113, 115, 131, 133, 149, 151, 167, 169, 185 or 187.
[0133] As already discussed herein above, it is also preferred for the method of the invention that also the second binding domain binds to epitopes/binding sites in the extracellular domain of a high molecular weight antigen of human and non-chimpanzee primate.
[0134] In a preferred embodiment of the method of the invention the second binding domain binds to epitopes/binding sites in the extracellular domain of c-MET. This target antigen and its expression characteristics have been described herein above. The MET tyrosine kinase receptor with an extracellular region of 908 aa with the following sequential arrangement of independently folded extracellular domains from membrane-proximal to membrane-distal: Four Ig domains of together 362 aa (residues 563-924), a cystein-rich domain of 42 aa (residues 520-561), the beta-chain of a sema domain of 212 aa (residues 308-519) and the alpha-chain of the sema domain of 282 aa (residues 25-307). Accordingly, it is preferred for the method of the invention, that the second binging domain binds to epitopes/binding sites in the four Ig domains (SEQ ID NO: 436), a cystein-rich domain (SEQ ID NO: 437), or the beta-chain of a sema domain (SEQ ID NO: 438) of the extracellular domain of c-MET, which are all below the 640 aa-threshold.
[0135] In an alternatively preferred embodiment of the method of the invention the second binding domain binds to epitopes/binding sites in the extracellular domain of endosialin (TEM1). This target antigen and its expression characteristics have been described herein above. For endosialin a extracellular domain consisting of 665 aa and the following sequential arrangement of independently folded extracellular domains from membrane-proximal to membrane-distal is described in the art: a mucin domain of 326 aa (residues 360-685), three EGF-like domains of together 116 aa (residues 235-350), a Sushi/SCR/CCP domain of 55 aa (residues 176-230) and a C-type lectin domain of 129 aa (residues 29-157). Accordingly, it is preferred for the method of the invention that the second binging domain binds to epitopes/binding sites in the mucin domain (SEQ ID NO: 440), the three EGF-like domains (SEQ ID NO: 441), or the Sushi/SCR/CCP domain (SEQ ID NO: 442) of the extracellular domain of TEM1.
[0136] According to a further alternatively preferred embodiment of the method of the invention the second binding domain binds to epitopes/binding sites in the extracellular domain of IGF-1R. This target antigen and its expression characteristics have been described herein above. For endosialin a extracellular domain consisting of 905 aa and the following sequential arrangement of independently folded extracellular domains from membrane-proximal to membrane-distal is described in the art: three fibronectin type III domains of together 447 aa (residues 460-906), an L2 domain of 160 aa (residues 300-459), a cystein-rich domain of 149 aa (residues 151-299) and an L1 domain of 150 aa (residues 1-150). Accordingly, it is preferred for the method of the invention that the second binging domain binds to epitopes/binding sites in the three fibronectin type III domains (SEQ ID NO: 444), and the L2 domain (SEQ ID NO: 445) of the extracellular domain of IGF-1R.
[0137] An alternative embodiment of the invention reltes to a bispecific single chain antibody comprising a first domain binding domain capable of binding to CD3 epsilon (CD3.epsilon.) of human and non-chimpanzee primate and a second domain binding domain capable of binding to the extracellular domain of the mutated human PSMA having an amino acid sequence as depicted in SEQ ID NO: 447 but not to the extracellular domain of the rodent PSMA. In other words, the bispecific antibody of the invention specifically binds to membrane proximal epitopes, i.e. epitopes formed only by amino acid resides of the extracellular domain of PSMA, the alpha C-atom of which has a distance of less than 60 .ANG. from the reference C-atom (the alpha C-atom of the 13.sup.th aa as counted from the junction of transmembrane and extracellular region). The specific superior characteristics of these PSMAxCD3 bispecific single chain antibodies have been described herein above. Moreover, corresponding antibodies are exemplified and characterized in the appended examples.
[0138] It is preferred for the bispecific ingle chain antibody comprising a first domain binding domain capable of binding to CD3 epsilon (CD3.epsilon.) and a second domain binding domain capable of binding to the extracellular domain of the mutated human PSMA having an amino acid sequence as depicted in SEQ ID NO: 447 but not to the extracellular domain of the rodent PSMA that the first domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises an amino acid sequence selected from the group consisting of SEQ ID NOs: 23, 25, 41, 43, 59, 61, 77, 79, 95, 97, 113, 115, 131, 133, 149, 151, 167, 169, 185 or 187. It is preferred for the bispecific single chain antibodies that the second domain comprises a VL region comprising CDR-L1, CDR-L2 and CDR-L3 selected from:
[0139] (a) CDR-L1 as depicted in SEQ ID NO. 269, CDR-L2 as depicted in SEQ ID NO: 270 and CDR-L3 as depicted in SEQ ID NO. 271;
[0140] (b) CDR-L1 as depicted in SEQ ID NO. 283, CDR-L2 as depicted in SEQ ID NO: 284 and CDR-L3 as depicted in SEQ ID NO. 285;
[0141] (c) CDR-L1 as depicted in SEQ ID NO. 297, CDR-L2 as depicted in SEQ ID NO: 298 and CDR-L3 as depicted in SEQ ID NO. 299;
[0142] (d) CDR-L1 as depicted in SEQ ID NO. 311, CDR-L2 as depicted in SEQ ID NO: 312 and CDR-L3 as depicted in SEQ ID NO. 313;
[0143] (e) CDR-L1 as depicted in SEQ ID NO. 325, CDR-L2 as depicted in SEQ ID NO. 326 and CDR-L3 as depicted in SEQ ID NO. 327;
[0144] (f) CDR-L1 as depicted in SEQ ID NO. 255, CDR-L2 as depicted in SEQ ID NO.
[0145] 256 and CDR-L3 as depicted in SEQ ID NO. 257; and
[0146] (g) CDR-L1 as depicted in SEQ ID NO. 481, CDR-L2 as depicted in SEQ ID NO. 482 and CDR-L3 as depicted in SEQ ID NO. 483.
[0147] It is also preferred for the bispecific single chain antibodies of the invention that the second domain comprises a VH region comprising CDR-H1, CDR-H2 and CDR-H3 selected from: [0148] (a) CDR-H1 as depicted in SEQ ID NO. 274, CDR-H2 as depicted in SEQ ID NO:
[0149] 275 and CDR-H3 as depicted in SEQ ID NO. 276; [0150] (b) CDR-H1 as depicted in SEQ ID NO. 288, CDR-H2 as depicted in SEQ ID NO:
[0151] 289 and CDR-H3 as depicted in SEQ ID NO. 290; [0152] (c) CDR-H1 as depicted in SEQ ID NO. 302, CDR-H2 as depicted in SEQ ID NO:
[0153] 303 and CDR-H3 as depicted in SEQ ID NO. 304; [0154] (d) CDR-H1 as depicted in SEQ ID NO. 316, CDR-H2 as depicted in SEQ ID NO: 317 and CDR-H3 as depicted in SEQ ID NO. 318;
[0155] (e) CDR-H1 as depicted in SEQ ID NO. 330, CDR-H2 as depicted in SEQ ID NO:
[0156] 331 and CDR-H3 as depicted in SEQ ID NO. 332; [0157] (f) CDR-H1 as depicted in SEQ ID NO. 260, CDR-H2 as depicted in SEQ ID NO:
[0158] 261 and CDR-H3 as depicted in SEQ ID NO. 262; and [0159] (g) CDR-H1 as depicted in SEQ ID NO. 476, CDR-H2 as depicted in SEQ ID NO:
[0160] 477 and CDR-H3 as depicted in SEQ ID NO. 478.
[0161] In a further preferred embodiment of a bispecific single chain antibody of the invention the second domain comprises a VL region and a VH region selected from the group consisting of: [0162] (a) a VL region as depicted in SEQ ID NO. 268 and a VH region as depicted in SEQ ID NO. 273; [0163] (b) a VL region as depicted in SEQ ID NO. 282 and a VH region as depicted in SEQ ID NO. 287;
[0164] (c) a VL region as depicted in SEQ ID NO. 296 and a VH region as depicted in SEQ ID NO. 301; [0165] (d) a VL region as depicted in SEQ ID NO. 310 and a VH region as depicted in SEQ ID NO. 315; [0166] (e) a VL region as depicted in SEQ ID NO. 324 and a VH region as depicted in SEQ ID NO. 329; [0167] (f) a VL region as depicted in SEQ ID NO. 254 and a VH region as depicted in SEQ ID NO. 259; and [0168] (g) a VL region as depicted in SEQ ID NO. 480 and a VH region as depicted in SEQ ID NO. 475.
[0169] More preferably, the second domain comprises an amino acid sequence selected from the group consisting of SEQ ID NOs: 278, 292, 306, 320, 334, 485 or 264. It is preferred for the bispecific single chain antibody comprising a first domain binding domain capable of binding to CD3 epsilon (CD3.epsilon.) of human and non-chimpanzee primate and a second domain binding domain capable of binding to the extracellular domain of the mutated human PSMA chimera that the first domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises an amino acid sequence selected from the group consisting of SEQ ID NOs: 23, 25, 41, 43, 59, 61, 77, 79, 95, 97, 113, 115, 131, 133, 149, 151, 167, 169, 185 or 187.
[0170] A particularly preferred embodiment of the invention concerns an above characterized polypeptide, wherein the bispecific single chain antibody molecule comprises a sequence selected from: [0171] (a) an amino acid sequence as depicted in any of SEQ ID NOs. 280, 294, 308, 322, 336, 266 or 487; [0172] (b) an amino acid sequence encoded by a nucleic acid sequence as depicted in any of SEQ ID NOs: 281, 295, 309, 267, 323, 337 or 488; and [0173] (c) an amino acid sequence at least 90% identical, more preferred at least 95% identical, most preferred at least 96% identical to the amino acid sequence of (a) or (b).
[0174] The invention relates to a bispecific single chain antibody molecule comprising an amino acid sequence as depicted in any of SEQ ID NOs: 280, 294, 266, 308, 322, 336 or 487, as well as to an amino acid sequences at least 85% identical, preferably 90%, more preferred at least 95% identical, most preferred at least 96, 97, 98, or 99% identical to the amino acid sequence of SEQ ID NOs: 280, 294, 266, 308, 322, 336 or 487. The invention relates also to the corresponding nucleic acid sequences as depicted in any of SEQ ID NOs: 281, 295, 267, 309, 323, 337 or 488, as well as to nucleic acid sequences at least 85% identical, preferably 90%, more preferred at least 95% identical, most preferred at least 96, 97, 98, or 99% identical to the nucleic acid sequences shown in SEQ ID NOs: 281, 295, 267, 309, 323, 337 or 488. Preferred domain arrangements in the PSMAxCD3 bispecific single chain antibody constructs of the invention are shown in the following examples.
[0175] In a preferred embodiment of the invention, the bispecific single chain antibodies are cross-species specific for CD3 epsilon and for the human and non-chimpanzee primate cell surface antigen PSMA, recognized by their second binding domain.
[0176] In an alternative embodiemt the invention provides a bispecific single chain antibody comprising a first domain binding domain capable of binding to CD3 epsilon (CD3.epsilon.) of human and non-chimpanzee primate and a second domain binding domain capable of binding to the extracellular domain of the mutated human FAP.alpha. chimera having an amino acid sequence as depicted in SEQ ID NO: 448 but not to the extracellular domain of the rodent FAP.alpha.. In other words, the bispecific antibody of the invention specifically binds to membrane proximal epitopes, i.e. epitopes formed only by amino acid resides of the extracellular domain of FAP.alpha., the alpha C-atom of which has a distance of less than 60 .ANG. from the reference C-atom (the alpha C-atom of the 13.sup.th aa as counted from the junction of transmembrane and extracellular region).
[0177] According to a preferred embodiment of the invention an above characterized bispecific single chain antibody molecule comprises a group of the following sequences as CDR H1, CDR H2, CDR H3, CDR L1, CDR L2 and CDR L3 in the second binding domain selected from: CDR H1-3 of SEQ ID NO: 1137-1139 and CDR L1-3 of SEQ ID NO: 1132-1134.
[0178] The sequences of the corresponding VL- and VH-regions of the second binding domain of the bispecific single chain antibody molecule of the invention as well as of the respective scFvs are shown in the sequence listing.
[0179] According to a preferred embodiment of the invention an above characterized bispecific single chain antibody molecule comprises a group of the following sequences as CDR H1, CDR H2, CDR H3, CDR L1, CDR L2 and CDR L3 in the second binding domain selected from the group consisting of:
[0180] a) CDR H1-3 of SEQ ID NO: 808-810 and CDR L1-3 of SEQ ID NO: -813-815;
[0181] b) CDR H1-3 of SEQ ID NO: 794-796 and CDR L1-3 of SEQ ID NO: 799-801, [0182] c) CDR H1-3 of SEQ ID NO: 738-740 and CDR L1-3 of SEQ ID NO: 743-745; [0183] d) CDR H1-3 of SEQ ID NO: 752-754 and CDR L1-3 of SEQ ID NO: 757-759; [0184] e) CDR H1-3 of SEQ ID NO: 822-824 and CDR L1-3 of SEQ ID NO: 827-829; [0185] f) CDR H1-3 of SEQ ID NO: 766-768 and CDR L1-3 of SEQ ID NO: 771-773; and [0186] g) CDR H1-3 of SEQ ID NO: 780-782 and CDR L1-3 of SEQ ID NO: 785-787.
[0187] In the bispecific single chain antibody molecule of the invention the binding domains are arranged in the order VL-VH--VH-VL, VL-VH-VL-VH, VH-VL-VH-VL or VH-VL-VL-VH, as exemplified in the appended examples. Preferably, the binding domains are arranged in the order VH FAP alpha-VL FAP alpha-VH CD3-VL CD3 or VL FAP alpha-VH FAP alpha-VH CD3-VL CD3. More preferred, the binding domains are arranged in the order VL FAP alpha-VH FAP alpha-VH CD3-VL CD3.
[0188] It is preferred for the bispecific single chain antibody comprising a first domain binding domain capable of binding to CD3 epsilon (CD3.epsilon.) of human and non-chimpanzee primate and a second domain binding domain capable of binding to the extracellular domain of the mutated human FAP.alpha. chimera that the first domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises an amino acid sequence selected from the group consisting of SEQ ID NOs: 23, 25, 41, 43, 59, 61, 77, 79, 95, 97, 113, 115, 131, 133, 149, 151, 167, 169, 185 or 187.
[0189] A particularly preferred embodiment of the invention concerns an above characterized polypeptide, wherein the bispecific single chain antibody molecule comprises a sequence selected from: [0190] (a) an amino acid sequence as depicted in any of SEQ ID NOs. 819, 805, 749, 763, 833, 777 or 791; [0191] (b) an amino acid sequence encoded by a nucleic acid sequence as depicted in any of SEQ ID NOs: 820, 806, 750, 764, 834, 778 or 792; and [0192] (c) an amino acid sequence at least 90% identical, more preferred at least 95%) identical, most preferred at least 96% identical to the amino acid sequence of (a) or (b).
[0193] The invention relates to a bispecific single chain antibody molecule comprising an amino acid sequence as depicted in any of SEQ ID NOs: 819, 805, 749, 763, 833, 777 or 791, as well as to an amino acid sequences at least 85% identical, preferably 90%, more preferred at least 95% identical, most preferred at least 96, 97, 98, or 99%) identical to the amino acid sequence of SEQ ID NOs: 819, 805, 749, 763, 833, 777 or 791. The invention relates also to the corresponding nucleic acid sequences as depicted in any of SEQ ID NOs: 820, 806, 750, 764, 834, 778 or 792, as well as to nucleic acid sequences at least 85% identical, preferably 90%, more preferred at least 95% identical, most preferred at least 96, 97, 98, or 99% identical to the nucleic acid sequences shown in SEQ ID NOs: 820, 806, 750, 764, 834, 778 or 792. Preferred domain arrangements in the FAPaxCD3 bispecific single chain antibody constructs of the invention are shown in the following examples.
[0194] In a further alternative embodiement the invention provides a bispecific single chain antibody comprising a first domain binding domain capable of binding to CD3 epsilon (CD3.epsilon.) of human and non-chimpanzee primate and a second domain binding domain capable of binding to the four Ig domains (SEQ ID NO: 436), a cystein-rich domain (SEQ ID NO: 437), or the beta-chain of a sema domain (SEQ ID NO: 438) of the extracellular domain of c-MET.
[0195] According to a preferred embodiment of the invention an above characterized bispecific single chain antibody molecule comprises a group of the following sequences as CDR H1, CDR H2, CDR H3, CDR L1, CDR L2 and CDR L3 in the second binding domain selected from the group consisting of:
[0196] a) CDR H1-3 of SEQ ID NO: -500-502 and CDR L1-3 of SEQ ID NO: -505-507;
[0197] b) CDR H1-3 of SEQ ID NO: 514-516 and CDR L1-3 of SEQ ID NO: 519-521; [0198] c) CDR H1-3 of SEQ ID NO: 528-530 and CDR L1-3 of SEQ ID NO: 533-535; [0199] d) CDR H1-3 of SEQ ID NO: 542-544 and CDR L1-3 of SEQ ID NO: 547-549;
[0200] e) CDR H1-3 of SEQ ID NO: 556-558 and CDR L1-3 of SEQ ID NO: 561-563;
[0201] f) CDR H1-3 of SEQ ID NO: 570-572 and CDR L1-3 of SEQ ID NO: 575-577;
[0202] g) CDR H1-3 of SEQ ID NO: 584-586 and CDR L1-3 of SEQ ID NO: 589-591; [0203] h) CDR H1-3 of SEQ ID NO: 598-600 and CDR L1-3 of SEQ ID NO: 603-605; [0204] i) CDR H1-3 of SEQ ID NO: 612-614 and CDR L1-3 of SEQ ID NO: 617-619;
[0205] j) CDR H1-3 of SEQ ID NO: 626-628 and CDR L1-3 of SEQ ID NO: 631-633;
[0206] k) CDR H1-3 of SEQ ID NO: 640-642 and CDR L1-3 of SEQ ID NO: 645-647; [0207] I) CDR H1-3 of SEQ ID NO: 654-656 and CDR L1-3 of SEQ ID NO: 659-661; [0208] m) CDR H1-3 of SEQ ID NO: 668-670 and CDR L1-3 of SEQ ID NO: 673-675; [0209] n) CDR H1-3 of SEQ ID NO: 682-684 and CDR L1-3 of SEQ ID NO: 687-689; [0210] o) CDR H1-3 of SEQ ID NO: 696-698 and CDR L1-3 of SEQ ID NO: 701-703; [0211] p) CDR H1-3 of SEQ ID NO: 710-712 and CDR L1-3 of SEQ ID NO: 715-717; and [0212] q) CDR H1-3 of SEQ ID NO: 724-726 and CDR L1-3 of SEQ ID NO: 729-731.
[0213] The sequences of the corresponding VL- and VH-regions of the second binding domain of the bispecific single chain antibody molecule of the invention as well as of the respective scFvs are shown in the sequence listing.
[0214] In the bispecific single chain antibody molecule of the invention the binding domains are arranged in the order VL-VH--VH-VL, VL-VH-VL-VH, VH-VL-VH-VL or VH-VL-VL-VH, as exemplified in the appended examples. Preferably, the binding domains are arranged in the order VH C-MET-VL C-MET-VH CD3-VL CD3 or VL C-MET-VH C-MET-VH CD3-VL CD3.
[0215] More preferably, the first domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises an amino acid sequence selected from the group consisting of SEQ ID NOs: 23, 25, 41, 43, 59, 61, 77, 79, 95, 97, 113, 115, 131, 133, 149, 151, 167, 169, 185 or 187.
[0216] A particularly preferred embodiment of the invention concerns an above characterized polypeptide, wherein the bispecific single chain antibody molecule comprises a sequence selected from:
[0217] (a) an amino acid sequence as depicted in any of SEQ ID NOs. 511, 525, 539, 553, 567 or 581;
[0218] (b) an amino acid sequence encoded by a nucleic acid sequence as depicted in any of SEQ ID NOs: 512, 526, 540, 554, 568 or 582; and
[0219] (c) an amino acid sequence at least 90% identical, more preferred at least 95% identical, most preferred at least 96% identical to the amino acid sequence of (a) or (b).
[0220] The invention relates to a bispecific single chain antibody molecule comprising an amino acid sequence as depicted in any of SEQ ID NOs: 511, 525, 539, 553, 567 or 581, as well as to an amino acid sequences at least 85% identical, preferably 90%, more preferred at least 95% identical, most preferred at least 96, 97, 98, or 99%) identical to the amino acid sequence of SEQ ID NOs: 511, 525, 539, 553, 567 or 581.
[0221] The invention relates also to the corresponding nucleic acid sequences as depicted in any of SEQ ID NOs: 512, 526, 540, 554, 568 or 582 as well as to nucleic acid sequences at least 85% identical, preferably 90%, more preferred at least 95% identical, most preferred at least 96, 97, 98, or 99% identical to the nucleic acid sequences shown in SEQ ID NOs: 512, 526, 540, 554, 568 or 582.
[0222] Preferred domain arrangements in the c-METxCD3 bispecific single chain antibody constructs of the invention are shown in the following examples.
[0223] According to an alternative embodiment the invention provides a bispecific single chain antibody comprising a first domain binding domain capable of binding to CD3 epsilon (CD3.epsilon.) of human and non-chimpanzee primate and a second domain binding domain capable of binding to the mucin domain (SEQ ID NO: 440), the three EGF-like domains (SEQ ID NO: 441), or the Sushi/SCR/CCP domain (SEQ ID NO: 442) of the extracellular domain of endosialin (TEM1).
[0224] Preferably the first domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises an amino acid sequence selected from the group consisting of SEQ ID NOs: 23, 25, 41, 43, 59, 61, 77, 79, 95, 97, 113, 115, 131, 133, 149, 151, 167, 169, 185 or 187.
[0225] Moreover, in an alternative embodiment the invention provides a bispecific single chain antibody comprising a first domain binding domain capable of binding to CD3 epsilon (CD3.epsilon.) of human and non-chimpanzee primate and a second domain binding domain capable of binding to the three fibronectin type III domains (SEQ ID NO: 444), the L2 domain (SEQ ID NO: 445) of the extracellular domain of IGF-1R.
[0226] According to a preferred embodiment of the invention an above characterized bispecific single chain antibody molecule comprises a group of the following sequences as CDR H1, CDR H2, CDR H3, CDR L1, CDR L2 and CDR L3 in the second binding domain selected from the group consisting of: [0227] a) CDR H1-3 of SEQ ID NO: -836-838 and CDR L1-3 of SEQ ID NO: -841-843; and [0228] b) CDR H1-3 of SEQ ID NO: 850-852 and CDR L1-3 of SEQ ID NO: 855-857.
[0229] The sequences of the corresponding VL- and VH-regions of the second binding domain of the bispecific single chain antibody molecule of the invention as well as of the respective scFvs are shown in the sequence listing.
[0230] In the bispecific single chain antibody molecule of the invention the binding domains are arranged in the order VL-VH--VH-VL, VL-VH-VL-VH, VH-VL-VH-VL or VH-VL-VL-VH, as exemplified in the appended examples. Preferably, the binding domains are arranged in the order VH IGF-1R-VL IGF-1R-VH CD3-VL CD3 or VL IGF-1R-VH IGF-1R-VH CD3-VL CD3.
[0231] Preferably, the first domain capable of binding to an epitope of human and non-chimpanzee primate CD3.epsilon. chain comprises an amino acid sequence selected from the group consisting of SEQ ID NOs: 23, 25, 41, 43, 59, 61, 77, 79, 95, 97, 113, 115, 131, 133, 149, 151, 167, 169, 185 or 187.
[0232] A particularly preferred embodiment of the invention concerns an above characterized polypeptide, wherein the bispecific single chain antibody molecule comprises a sequence selected from:
[0233] (a) an amino acid sequence as depicted in any of SEQ ID NOs: 847 or 861;
[0234] (b) an amino acid sequence encoded by a nucleic acid sequence as depicted in any of SEQ ID NOs: 848, or 862; and
[0235] (c) an amino acid sequence at least 90% identical, more preferred at least 95% identical, most preferred at least 96% identical to the amino acid sequence of (a) or (b).
[0236] The invention relates to a bispecific single chain antibody molecule comprising an amino acid sequence as depicted in any of SEQ ID NOs: 847 or 861, as well as to an amino acid sequences at least 85% identical, preferably 90%, more preferred at least 95% identical, most preferred at least 96, 97, 98, or 99% identical to the amino acid sequence of SEQ ID NOs: 847 or 861. The invention relates also to the corresponding nucleic acid sequences as depicted in any of SEQ ID NOs: 848, or 862 as well as to nucleic acid sequences at least 85% identical, preferably 90%, more preferred at least 95% identical, most preferred at least 96, 97, 98, or 99%) identical to the nucleic acid sequences shown in SEQ ID NOs: 848, or 862. Preferred domain arrangements in the IGF-1RxCD3 bispecific single chain antibody constructs of the invention are shown in the following examples.
[0237] The invention relates to bispecific single chain antibody molecule comprising the above identified amino acid sequences, as well as to amino acid sequences at least 85% identical, preferably 90%, more preferred at least 95% identical, most preferred at least 96, 97, 98, or 99% identical to the amino acid sequence of said sequences. As described herein above, the specificity of an antibody is generally understood to be determined by the CDR sequences. Accordingly, in order to maintain the specificity of a given group of CDRs, e.g three CDRs of a heavy chain and three CDRs of a light chain, the sequence of these CDRs has to be conserved. Accordingly variants of bispecific single antibodies as identified herein, which also fall under the present invention are preferably variants having more than one amino acid substituions in FR regions instead of the CDRs. It is to be understood that the sequence identity is determined over the entire nucleotide or amino acid sequence. For sequence alignments, for example, the programs Gap or BestFit can be used (Needleman and Wunsch J. Mol. Biol. 48 (1970), 443-453; Smith and Waterman, Adv. Appl. Math 2 (1981), 482-489), which is contained in the GCG software package (Genetics Computer Group, 575 Science Drive, Madison, Wis., USA 53711 (1991). It is a routine method for those skilled in the art to determine and identify a nucleotide or amino acid sequence having e.g. 85% (90%, 95%, 96%, 97%, 98% or 99%) sequence identity to the nucleotide or amino acid sequences of the bispecific single single chain antibody of the invention by using e.g. one of the above mentioned programs. For example, according to Crick's Wobble hypothesis, the 5' base on the anti-codon is not as spatially confined as the other two bases, and could thus have non-standard base pairing. Put in other words: the third position in a codon triplet may vary so that two triplets which differ in this third position may encode the same amino acid residue. Said hypothesis is well known to the person skilled in the art (see e.g. http://en.wikipedia.org/wiki/Wobble_Hypothesis; Crick, J Mol Biol 19 (1966): 548-55).
[0238] In an alternative embodiment the present invention provides a nucleic acid sequence encoding an above described bispecific single chain antibody molecule of the invention.
[0239] The present invention also relates to a vector comprising the nucleic acid molecule of the present invention.
[0240] Many suitable vectors are known to those skilled in molecular biology, the choice of which would depend on the function desired and include plasmids, cosmids, viruses, bacteriophages and other vectors used conventionally in genetic engineering. Methods which are well known to those skilled in the art can be used to construct various plasmids and vectors; see, for example, the techniques described in Sambrook et al. (loc cit.) and Ausubel, Current Protocols in Molecular Biology, Green Publishing Associates and Wiley Interscience, N.Y. (1989), (1994). Alternatively, the polynucleotides and vectors of the invention can be reconstituted into liposomes for delivery to target cells. As discussed in further details below, a cloning vector was used to isolate individual sequences of DNA. Relevant sequences can be transferred into expression vectors where expression of a particular polypeptide is required. Typical cloning vectors include pBluescript SK, pGEM, pUC9, pBR322 and pGBT9. Typical expression vectors include pTRE, pCAL-n-EK, pESP-1, pOP13CAT.
[0241] Preferably said vector comprises a nucleic acid sequence which is a regulatory sequence operably linked to said nucleic acid sequence defined herein.
[0242] The term "regulatory sequence" refers to DNA sequences, which are necessary to effect the expression of coding sequences to which they are ligated. The nature of such control sequences differs depending upon the host organism. In prokaryotes, control sequences generally include promoter, ribosomal binding site, and terminators. In eukaryotes generally control sequences include promoters, terminators and, in some instances, enhancers, transactivators or transcription factors. The term "control sequence" is intended to include, at a minimum, all components the presence of which are necessary for expression, and may also include additional advantageous components.
[0243] The term "operably linked" refers to a juxtaposition wherein the components so described are in a relationship permitting them to function in their intended manner. A control sequence "operably linked" to a coding sequence is ligated in such a way that expression of the coding sequence is achieved under conditions compatible with the control sequences. In case the control sequence is a promoter, it is obvious for a skilled person that double-stranded nucleic acid is preferably used.
[0244] Thus, the recited vector is preferably an expression vector. An "expression vector" is a construct that can be used to transform a selected host and provides for expression of a coding sequence in the selected host. Expression vectors can for instance be cloning vectors, binary vectors or integrating vectors. Expression comprises transcription of the nucleic acid molecule preferably into a translatable mRNA. Regulatory elements ensuring expression in prokaryotes and/or eukaryotic cells are well known to those skilled in the art. In the case of eukaryotic cells they comprise normally promoters ensuring initiation of transcription and optionally poly-A signals ensuring termination of transcription and stabilization of the transcript. Possible regulatory elements permitting expression in prokaryotic host cells comprise, e.g., the P.sub.L, lac, trp or tac promoter in E. coli, and examples of regulatory elements permitting expression in eukaryotic host cells are the AOX1 or GAL1 promoter in yeast or the CMV-, SV40-, RSV-promoter (Rous sarcoma virus), CMV-enhancer, SV40-enhancer or a globin intron in mammalian and other animal cells.
[0245] Beside elements, which are responsible for the initiation of transcription such regulatory elements may also comprise transcription termination signals, such as the SV40-poly-A site or the tk-poly-A site, downstream of the polynucleotide. Furthermore, depending on the expression system used leader sequences capable of directing the polypeptide to a cellular compartment or secreting it into the medium may be added to the coding sequence of the recited nucleic acid sequence and are well known in the art; see also the appended Examples. The leader sequence(s) is (are) assembled in appropriate phase with translation, initiation and termination sequences, and preferably, a leader sequence capable of directing secretion of translated protein, or a portion thereof, into the periplasmic space or extracellular medium. Optionally, the heterologous sequence can encode a fusion protein including an N-terminal identification peptide imparting desired characteristics, e.g., stabilization or simplified purification of expressed recombinant product; see supra. In this context, suitable expression vectors are known in the art such as Okayama-Berg cDNA expression vector pcDV1 (Pharmacia), pCDM8, pRc/CMV, pcDNA1, pcDNA3 (In-vitrogene), pEF-DHFR, pEF-ADA or pEF-neo (Mack et al. PNAS (1995) 92, 7021-7025 and Raum et al. Cancer Immunol Immunother (2001) 50(3), 141-150) or pSPORT1 (GIBCO BRL).
[0246] Preferably, the expression control sequences will be eukaryotic promoter systems in vectors capable of transforming of transfecting eukaryotic host cells, but control sequences for prokaryotic hosts may also be used. Once the vector has been incorporated into the appropriate host, the host is maintained under conditions suitable for high level expression of the nucleotide sequences, and as desired, the collection and purification of the bispecific single chain antibody molecule of the invention may follow; see, e.g., the appended examples.
[0247] An alternative expression system, which can be used to express a cell cycle interacting protein is an insect system. In one such system, Autographa californica nuclear polyhedrosis virus (AcNPV) is used as a vector to express foreign genes in Spodoptera frugiperda cells or in Trichoplusia larvae. The coding sequence of a recited nucleic acid molecule may be cloned into a nonessential region of the virus, such as the polyhedrin gene, and placed under control of the polyhedrin promoter. Successful insertion of said coding sequence will render the polyhedrin gene inactive and produce recombinant virus lacking coat protein coat. The recombinant viruses are then used to infect S. frugiperda cells or Trichoplusia larvae in which the protein of the invention is expressed (Smith, J. Virol. 46 (1983), 584; Engelhard, Proc. Nat. Acad. Sci. USA 91 (1994), 3224-3227).
[0248] Additional regulatory elements may include transcriptional as well as translational enhancers. Advantageously, the above-described vectors of the invention comprise a selectable and/or scorable marker.
[0249] Selectable marker genes useful for the selection of transformed cells and, e.g., plant tissue and plants are well known to those skilled in the art and comprise, for example, antimetabolite resistance as the basis of selection for dhfr, which confers resistance to methotrexate (Reiss, Plant Physiol. (Life Sci. Adv.) 13 (1994), 143-149);
[0250] npt, which confers resistance to the aminoglycosides neomycin, kanamycin and paromycin (Herrera-Estrella, EMBO J. 2 (1983), 987-995) and hygro, which confers resistance to hygromycin (Marsh, Gene 32 (1984), 481-485). Additional selectable genes have been described, namely trpB, which allows cells to utilize indole in place of tryptophan; hisD, which allows cells to utilize histinol in place of histidine (Hartman, Proc. Natl. Acad. Sci. USA 85 (1988), 8047); mannose-6-phosphate isomerase which allows cells to utilize mannose (WO 94/20627) and ODC (ornithine decarboxylase) which confers resistance to the ornithine decarboxylase inhibitor, 2-(difluoromethyl)-DL-ornithine, DFMO (McConlogue, 1987, In: Current Communications in Molecular Biology, Cold Spring Harbor Laboratory ed.) or deaminase from Aspergillus terreus which confers resistance to Blasticidin S (Tamura, Biosci. Biotechnol. Biochem. 59 (1995), 2336-2338).
[0251] Useful scorable markers are also known to those skilled in the art and are commercially available. Advantageously, said marker is a gene encoding luciferase (Giacomin, Pl. Sci. 116 (1996), 59-72; Scikantha, J. Bact. 178 (1996), 121), green fluorescent protein (Gerdes, FEBS Lett. 389 (1996), 44-47) or .beta.-glucuronidase (Jefferson, EMBO J. 6 (1987), 3901-3907). This embodiment is particularly useful for simple and rapid screening of cells, tissues and organisms containing a recited vector.
[0252] As described above, the recited nucleic acid molecule can be used alone or as part of a vector to express the bispecific single chain antibody molecule of the invention in cells, for, e.g., purification but also for gene therapy purposes. The nucleic acid molecules or vectors containing the DNA sequence(s) encoding any one of the above described bispecific single chain antibody molecule of the invention is introduced into the cells which in turn produce the polypeptide of interest. Gene therapy, which is based on introducing therapeutic genes into cells by ex-vivo or in-vivo techniques is one of the most important applications of gene transfer. Suitable vectors, methods or gene-delivery systems for in-vitro or in-vivo gene therapy are described in the literature and are known to the person skilled in the art; see, e.g., Giordano, Nature Medicine 2 (1996), 534-539; Schaper, Circ. Res. 79 (1996), 911-919; Anderson, Science 256 (1992), 808-813; Verma, Nature 389 (1994), 239; Isner, Lancet 348 (1996), 370-374; Muhlhauser, Circ. Res. 77 (1995), 1077-1086; Onodera, Blood 91 (1998), 30-36; Verma, Gene Ther. 5 (1998), 692-699; Nabel, Ann. N.Y. Acad. Sci. 811 (1997), 289-292; Verzeletti, Hum. Gene Ther. 9 (1998), 2243-51; Wang, Nature Medicine 2 (1996), 714-716; WO 94/29469; WO 97/00957, U.S. Pat. No. 5,580,859; U.S. Pat. No. 5,589,466; or Schaper, Current Opinion in Biotechnology 7 (1996), 635-640; dos Santos Coura and Nardi Virol J. (2007), 4:99. The recited nucleic acid molecules and vectors may be designed for direct introduction or for introduction via liposomes, or viral vectors (e.g., adenoviral, retroviral) into the cell. Preferably, said cell is a germ line cell, embryonic cell, or egg cell or derived there from, most preferably said cell is a stem cell. An example for an embryonic stem cell can be, inter alia, a stem cell as described in Nagy, Proc. Natl. Acad. Sci. USA 90 (1993), 8424-8428.
[0253] The invention also provides for a host transformed or transfected with a vector of the invention. Said host may be produced by introducing the above described vector of the invention or the above described nucleic acid molecule of the invention into the host. The presence of at least one vector or at least one nucleic acid molecule in the host may mediate the expression of a gene encoding the above described single chain antibody constructs.
[0254] The described nucleic acid molecule or vector of the invention, which is introduced in the host may either integrate into the genome of the host or it may be maintained extrachromosomally.
[0255] The host can be any prokaryote or eukaryotic cell.
[0256] The term "prokaryote" is meant to include all bacteria, which can be transformed or transfected with DNA or RNA molecules for the expression of a protein of the invention. Prokaryotic hosts may include gram negative as well as gram positive bacteria such as, for example, E. coli, S. typhimurium, Serratia marcescens and Bacillus subtilis. The term "eukaryotic" is meant to include yeast, higher plant, insect and preferably mammalian cells. Depending upon the host employed in a recombinant production procedure, the protein encoded by the polynucleotide of the present invention may be glycosylated or may be non-glycosylated. Especially preferred is the use of a plasmid or a virus containing the coding sequence of the bispecific single chain antibody molecule of the invention and genetically fused thereto an N-terminal FLAG-tag and/or C-terminal His-tag. Preferably, the length of said FLAG-tag is about 4 to 8 amino acids, most preferably 8 amino acids. An above described polynucleotide can be used to transform or transfect the host using any of the techniques commonly known to those of ordinary skill in the art. Furthermore, methods for preparing fused, operably linked genes and expressing them in, e.g., mammalian cells and bacteria are well-known in the art (Sambrook, loc cit.).
[0257] Preferably, said the host is a bacterium or an insect, fungal, plant or animal cell.
[0258] It is particularly envisaged that the recited host may be a mammalian cell. Particularly preferred host cells comprise CHO cells, COS cells, myeloma cell lines like SP2/0 or NS/0. As illustrated in the appended examples, particularly preferred are CHO-cells as hosts.
[0259] More preferably said host cell is a human cell or human cell line, e.g. per.c6 (Kroos, Biotechnol. Prog., 2003, 19:163-168).
[0260] In a further embodiment, the present invention thus relates to a process for the production of a bispecific single chain antibody molecule of the invention, said process comprising culturing a host of the invention under conditions allowing the expression of the bispecific single chain antibody molecule of the invention and recovering the produced polypeptide from the culture.
[0261] The transformed hosts can be grown in fermentors and cultured according to techniques known in the art to achieve optimal cell growth. The bispecific single chain antibody molecule of the invention can then be isolated from the growth medium, cellular lysates, or cellular membrane fractions. The isolation and purification of the, e.g., microbially expressed bispecific single chain antibody molecules may be by any conventional means such as, for example, preparative chromatographic separations and immunological separations such as those involving the use of monoclonal or polyclonal antibodies directed, e.g., against a tag of the bispecific single chain antibody molecule of the invention or as described in the appended examples.
[0262] The conditions for the culturing of a host, which allow the expression are known in the art to depend on the host system and the expression system/vector used in such process. The parameters to be modified in order to achieve conditions allowing the expression of a recombinant polypeptide are known in the art. Thus, suitable conditions can be determined by the person skilled in the art in the absence of further inventive input.
[0263] Once expressed, the bispecific single chain antibody molecule of the invention can be purified according to standard procedures of the art, including ammonium sulfate precipitation, affinity columns, column chromatography, gel electrophoresis and the like; see, Scopes, "Protein Purification", Springer-Verlag, N.Y. (1982). Substantially pure polypeptides of at least about 90 to 95% homogeneity are preferred, and 98 to 99% or more homogeneity are most preferred, for pharmaceutical uses. Once purified, partially or to homogeneity as desired, the bispecific single chain antibody molecule of the invention may then be used therapeutically (including extracorporeally) or in developing and performing assay procedures. Furthermore, examples for methods for the recovery of the bispecific single chain antibody molecule of the invention from a culture are described in detail in the appended examples.
[0264] Furthermore, the invention provides for a composition comprising a bispecific single chain antibody molecule of the invention or a bispecific single chain antibody as produced by the process disclosed above. Preferably, said composition is a pharmaceutical composition.
[0265] The invention provides also for a bispecific single chain antibody molecule as defined herein, or produced according to the process as defined herein, wherein said bispecific single chain antibody molecule is for use in the prevention, treatment or amelioration of cancer. Preferably, said cancer is a solid tumor, more preferably a carcinoma or prostate cancer. It is preferred that the bispecific single chain is further comprising suitable formulations of carriers, stabilizers and/or excipients. Moreover, it is preferred that said bispecific single chain antibody molecule is suitable to be administered in combination with an additional drug. Said drug may be a non-proteinaceous compound or a proteinaceous compound and may be administered simultaneously or non-simultaneously with the bispecific single chain antibody molecule as defined herein.
[0266] In accordance with the invention, the term "pharmaceutical composition" relates to a composition for administration to a patient, preferably a human patient. The particular preferred pharmaceutical composition of this invention comprises bispecific single chain antibodies directed against and generated against context-independent CD3 epitopes. Preferably, the pharmaceutical composition comprises suitable formulations of carriers, stabilizers and/or excipients. In a preferred embodiment, the pharmaceutical composition comprises a composition for parenteral, transdermal, intraluminal, intraarterial, intrathecal and/or intranasal administration or by direct injection into tissue. It is in particular envisaged that said composition is administered to a patient via infusion or injection. Administration of the suitable compositions may be effected by different ways, e.g., by intravenous, intraperitoneal, subcutaneous, intramuscular, topical or intradermal administration. In particular, the present invention provides for an uninterrupted administration of the suitable composition. As a non-limiting example, uninterrupted, i.e. continuous administration may be realized by a small pump system worn by the patient for metering the influx of therapeutic agent into the body of the patient. The pharmaceutical composition comprising the bispecific single chain antibodies directed against and generated against context-independent CD3 epitopes of the invention can be administered by using said pump systems. Such pump systems are generally known in the art, and commonly rely on periodic exchange of cartridges containing the therapeutic agent to be infused. When exchanging the cartridge in such a pump system, a temporary interruption of the otherwise uninterrupted flow of therapeutic agent into the body of the patient may ensue. In such a case, the phase of administration prior to cartridge replacement and the phase of administration following cartridge replacement would still be considered within the meaning of the pharmaceutical means and methods of the invention together make up one "uninterrupted administration" of such therapeutic agent.
[0267] The continuous or uninterrupted administration of these bispecific single chain antibodies directed against and generated against context-independent CD3 epitopes of this invention may be intravenuous or subcutaneous by way of a fluid delivery device or small pump system including a fluid driving mechanism for driving fluid out of a reservoir and an actuating mechanism for actuating the driving mechanism. Pump systems for subcutaneous administration may include a needle or a cannula for penetrating the skin of a patient and delivering the suitable composition into the patient's body. Said pump systems may be directly fixed or attached to the skin of the patient independently of a vein, artery or blood vessel, thereby allowing a direct contact between the pump system and the skin of the patient. The pump system can be attached to the skin of the patient for 24 hours up to several days. The pump system may be of small size with a reservoir for small volumes. As a non-limiting example, the volume of the reservoir for the suitable pharmaceutical composition to be administered can be between 0.1 and 50 ml.
[0268] The continuous administration may be transdermal by way of a patch worn on the skin and replaced at intervals. One of skill in the art is aware of patch systems for drug delivery suitable for this purpose. It is of note that transdermal administration is especially amenable to uninterrupted administration, as exchange of a first exhausted patch can advantageously be accomplished simultaneously with the placement of a new, second patch, for example on the surface of the skin immediately adjacent to the first exhausted patch and immediately prior to removal of the first exhausted patch. Issues of flow interruption or power cell failure do not arise.
[0269] The composition of the present invention, comprising in particular bispecific single chain antibodies preferably directed against and generated against context-independent CD3 epitopes may further comprise a pharmaceutically acceptable carrier. Examples of suitable pharmaceutical carriers are well known in the art and include solutions, e.g. phosphate buffered saline solutions, water, emulsions, such as oil/water emulsions, various types of wetting agents, sterile solutions, liposomes, etc. Compositions comprising such carriers can be formulated by well known conventional methods. Formulations can comprise carbohydrates, buffer solutions, amino acids and/or surfactants. Carbohydrates may be non-reducing sugars, preferably trehalose, sucrose, octasulfate, sorbitol or xylitol. Such formulations may be used for continuous administrations which may be intravenuous or subcutaneous with and/or without pump systems. Amino acids may be charged amino acids, preferably lysine, lysine acetate, arginine, glutamate and/or histidine. Surfactants may be detergents, preferably with a molecular weight of >1.2 KD and/or a polyether, preferably with a molecular weight of >3 KD. Non-limiting examples for preferred detergents are Tween 20, Tween 40, Tween 60, Tween 80 or Tween 85. Non-limiting examples for preferred polyethers are PEG 3000, PEG 3350, PEG 4000 or PEG 5000. Buffer systems used in the present invention can have a preferred pH of 5-9 and may comprise citrate, succinate, phosphate, histidine and acetate. The compositions of the present invention can be administered to the subject at a suitable dose which can be determined e.g. by dose escalating studies by administration of increasing doses of the bispecific single chain antibody molecule of the invention exhibiting cross-species specificity described herein to non-chimpanzee primates, for instance macaques. As set forth above, the bispecific single chain antibody molecule of the invention exhibiting cross-species specificity described herein can be advantageously used in identical form in preclinical testing in non-chimpanzee primates and as drug in humans. These compositions can also be administered in combination with other proteinaceous and non-proteinaceous drugs. These drugs may be administered simultaneously with the composition comprising the bispecific single chain antibody molecule of the invention as defined herein or separately before or after administration of said polypeptide in timely defined intervals and doses. The dosage regimen will be determined by the attending physician and clinical factors. As is well known in the medical arts, dosages for any one patient depend upon many factors, including the patient's size, body surface area, age, the particular compound to be administered, sex, time and route of administration, general health, and other drugs being administered concurrently. Preparations for parenteral administration include sterile aqueous or non-aqueous solutions, suspensions, and emulsions. Examples of non-aqueous solvents are propylene glycol, polyethylene glycol, vegetable oils such as olive oil, and injectable organic esters such as ethyl oleate. Aqueous carriers include water, alcoholic/aqueous solutions, emulsions or suspensions, including saline and buffered media. Parenteral vehicles include sodium chloride solution, Ringer's dextrose, dextrose and sodium chloride, lactated Ringer's, or fixed oils. Intravenous vehicles include fluid and nutrient replenishers, electrolyte replenishers (such as those based on Ringer's dextrose), and the like. Preservatives and other additives may also be present such as, for example, antimicrobials, anti-oxidants, chelating agents, inert gases and the like. In addition, the composition of the present invention might comprise proteinaceous carriers, like, e.g., serum albumin or immunoglobulin, preferably of human origin. It is envisaged that the composition of the invention might comprise, in addition to the bispecific single chain antibody molecule of the invention defined herein, further biologically active agents, depending on the intended use of the composition. Such agents might be drugs acting on the gastro-intestinal system, drugs acting as cytostatica, drugs preventing hyperurikemia, drugs inhibiting immunoreactions (e.g. corticosteroids), drugs modulating the inflammatory response, drugs acting on the circulatory system and/or agents such as cytokines known in the art.
[0270] The biological activity of the pharmaceutical composition defined herein can be determined for instance by cytotoxicity assays, as described in the following examples, in WO 99/54440 or by Schlereth et al. (Cancer Immunol. Immunother. 20 (2005), 1-12). "Efficacy" or "in vivo efficacy" as used herein refers to the response to therapy by the pharmaceutical composition of the invention, using e.g. standardized NCI response criteria. The success or in vivo efficacy of the therapy using a pharmaceutical composition of the invention refers to the effectiveness of the composition for its intended purpose, i.e. the ability of the composition to cause its desired effect, i.e. depletion of pathologic cells, e.g. tumor cells. The in vivo efficacy may be monitored by established standard methods for the respective disease entities including, but not limited to white blood cell counts, differentials, Fluorescence Activated Cell Sorting, bone marrow aspiration. In addition, various disease specific clinical chemistry parameters and other established standard methods may be used. Furthermore, computer-aided tomography, X-ray, nuclear magnetic resonance tomography (e.g. for National Cancer Institute-criteria based response assessment [Cheson B D, Horning S J, Coiffier B, Shipp M A, Fisher R I, Connors J M, Lister T A, Vose J, Grillo-Lopez A, Hagenbeek A, Cabanillas F, Klippensten D, Hiddemann W, Castellino R, Harris N L, Armitage J O, Carter W, Hoppe R, Canellos G P. Report of an international workshop to standardize response criteria for non-Hodgkin's lymphomas. NCI Sponsored International Working Group. J Clin Oncol. 1999 April; 17(4):1244]), positron-emission tomography scanning, white blood cell counts, differentials, Fluorescence Activated Cell Sorting, bone marrow aspiration, lymph node biopsies/histologies, and various cancer specific clinical chemistry parameters (e.g. lactate dehydrogenase) and other established standard methods may be used.
[0271] Another major challenge in the development of drugs such as the pharmaceutical composition of the invention is the predictable modulation of pharmacokinetic properties. To this end, a pharmacokinetic profile of the drug candidate, i.e. a profile of the pharmacokinetic parameters that effect the ability of a particular drug to treat a given condition, is established. Pharmacokinetic parameters of the drug influencing the ability of a drug for treating a certain disease entity include, but are not limited to: half-life, volume of distribution, hepatic first-pass metabolism and the degree of blood serum binding. The efficacy of a given drug agent can be influenced by each of the parameters mentioned above.
[0272] "Half-life" means the time where 50% of an administered drug are eliminated through biological processes, e.g. metabolism, excretion, etc.
[0273] By "hepatic first-pass metabolism" is meant the propensity of a drug to be metabolized upon first contact with the liver, i.e. during its first pass through the liver.
[0274] "Volume of distribution" means the degree of retention of a drug throughout the various compartments of the body, like e.g. intracellular and extracellular spaces, tissues and organs, etc. and the distribution of the drug within these compartments.
[0275] "Degree of blood serum binding" means the propensity of a drug to interact with and bind to blood serum proteins, such as albumin, leading to a reduction or loss of biological activity of the drug.
[0276] Pharmacokinetic parameters also include bioavailability, lag time (Tlag), Tmax, absorption rates, more onset and/or Cmax for a given amount of drug administered.
[0277] "Bioavailability" means the amount of a drug in the blood compartment.
[0278] "Lag time" means the time delay between the administration of the drug and its detection and measurability in blood or plasma.
[0279] "Tmax" is the time after which maximal blood concentration of the drug is reached, and "Cmax" is the blood concentration maximally obtained with a given drug. The time to reach a blood or tissue concentration of the drug which is required for its biological effect is influenced by all parameters. Pharmacokinetik parameters of bispecific single chain antibodies exhibiting cross-species specificity, which may be determined in preclinical animal testing in non-chimpanzee primates as outlined above are also set forth e.g. in the publication by Schlereth et al. (Cancer Immunol. Immunother. 20 (2005), 1-12).
[0280] The term "toxicity" as used herein refers to the toxic effects of a drug manifested in adverse events or severe adverse events. These side events might refer to a lack of tolerability of the drug in general and/or a lack of local tolerance after administration. Toxicity could also include teratogenic or carcinogenic effects caused by the drug.
[0281] The term "safety", "in vivo safety" or "tolerability" as used herein defines the administration of a drug without inducing severe adverse events directly after administration (local tolerance) and during a longer period of application of the drug. "Safety", "in vivo safety" or "tolerability" can be evaluated e.g. at regular intervals during the treatment and follow-up period. Measurements include clinical evaluation, e.g. organ manifestations, and screening of laboratory abnormalities. Clinical evaluation may be carried out and deviating to normal findings recorded/coded according to NCI-CTC and/or MedDRA standards. Organ manifestations may include criteria such as allergy/immunology, blood/bone marrow, cardiac arrhythmia, coagulation and the like, as set forth e.g. in the Common Terminology Criteria for adverse events v3.0 (CTCAE). Laboratory parameters which may be tested include for instance haematology, clinical chemistry, coagulation profile and urine analysis and examination of other body fluids such as serum, plasma, lymphoid or spinal fluid, liquor and the like. Safety can thus be assessed e.g. by physical examination, imaging techniques (i.e. ultrasound, x-ray, CT scans, Magnetic Resonance Imaging (MRI), other measures with technical devices (i.e. electrocardiogram), vital signs, by measuring laboratory parameters and recording adverse events. For example, adverse events in non-chimpanzee primates in the uses and methods according to the invention may be examined by histopathological and/or histochemical methods.
[0282] The term "effective and non-toxic dose" as used herein refers to a tolerable dose of the bispecific single chain antibody as defined herein which is high enough to cause depletion of pathologic cells, tumor elimination, tumor shrinkage or stabilization of disease without or essentially without major toxic effects. Such effective and non-toxic doses may be determined e.g. by dose escalation studies described in the art and should be below the dose inducing severe adverse side events (dose limiting toxicity, DLT).
[0283] The above terms are also referred to e.g. in the Preclinical safety evaluation of biotechnology-derived pharmaceuticals S6; ICH Harmonised Tripartite Guideline; ICH Steering Committee meeting on Jul. 16, 1997.
[0284] Moreover, the invention relates to a pharmaceutical composition comprising a bispecific single chain antibody molecule of this invention or produced according to the process according to the invention for the prevention, treatment or amelioration of cancer or an autoimmune disease. Preferably, said cancer is a: [0285] (a) a solid tumor, more preferably a carcinoma or prostate cancer; [0286] (b) a carcinoma, sarcoma, glioblastoma/astrocytoma, melanoma, mesothelioma, Wilms tumor or a hematopoietic malignancy such as leukemia, lymphoma or multiple myeloma; [0287] (c) carcinomas (breast, kidney, lung, colorectal, colon, pancreas mesothelioma), sarcomas, and neuroectodermal tumors (melanoma, glioma, neuroblastoma); [0288] (d) epithelial cancer; or [0289] (e) bone or soft tissue cancer (e.g. Ewing sarcoma), breast, liver, lung, head and neck, colorectal, prostate, leiomyosarcoma, cervical and endometrial cancer, ovarian, prostate, and pancreatic cancer.
[0290] Preferably, said pharmaceutical composition further comprises suitable formulations of carriers, stabilizers and/or excipients.
[0291] A further aspect of the invention relates to a use of a bispecific single chain antibody molecule/polypeptide as defined herein above or produced according to a process defined herein above, for the preparation of a pharmaceutical composition for the prevention, treatment or amelioration of a disease. Preferably, said disease is cancer. More preferably, said cancer is a solid tumor, preferably a carcinoma or prostate cancer.
[0292] In another preferred embodiment of use of the bispecific single chain antibody molecule of the invention said pharmaceutical composition is suitable to be administered in combination with an additional drug, i.e. as part of a co-therapy. In said co-therapy, an active agent may be optionally included in the same pharmaceutical composition as the bispecific single chain antibody molecule of the invention, or may be included in a separate pharmaceutical composition. In this latter case, said separate pharmaceutical composition is suitable for administration prior to, simultaneously as or following administration of said pharmaceutical composition comprising the bispecific single chain antibody molecule of the invention. The additional drug or pharmaceutical composition may be a non-proteinaceous compound or a proteinaceous compound. In the case that the additional drug is a proteinaceous compound, it is advantageous that the proteinaceous compound be capable of providing an activation signal for immune effector cells.
[0293] Preferably, said proteinaceous compound or non-proteinaceous compound may be administered simultaneously or non-simultaneously with the bispecific single chain antibody molecule of the invention, a nucleic acid molecule as defined hereinabove, a vector as defined as defined hereinabove, or a host as defined as defined hereinabove.
[0294] Another aspect of the invention relates to a method for the prevention, treatment or amelioration of a disease in a subject in the need thereof, said method comprising the step of administration of an effective amount of a pharmaceutical composition of the invention. Preferably, said disease is cancer or an autoimmune disease. Preferably, said cancer is [0295] (a) a solid tumor, more preferably a carcinoma or prostate cancer; [0296] (b) a carcinoma, sarcoma, glioblastoma/astrocytoma, melanoma, mesothelioma, Wilms tumor or a hematopoietic malignancy such as leukemia, lymphoma or multiple myeloma; [0297] (c) carcinomas (breast, kidney, lung, colorectal, colon, pancreas mesothelioma), sarcomas, and neuroectodermal tumors (melanoma, glioma, neuroblastoma); [0298] (d) epithelial cancer; or [0299] (e) bone or soft tissue cancer (e.g. Ewing sarcoma), breast, liver, lung, head and neck, colorectal, prostate, leiomyosarcoma, cervical and endometrial cancer, ovarian, prostate, and pancreatic cancer.
[0300] In another preferred embodiment of the method of the invention said pharmaceutical composition is suitable to be administered in combination with an additional drug, i.e. as part of a co-therapy. In said co-therapy, an active agent may be optionally included in the same pharmaceutical composition as the bispecific single chain antibody molecule of the invention, or may be included in a separate pharmaceutical composition. In this latter case, said separate pharmaceutical composition is suitable for administration prior to, simultaneously as or following administration of said pharmaceutical composition comprising the bispecific single chain antibody molecule of the invention. The additional drug or pharmaceutical composition may be a non-proteinaceous compound or a proteinaceous compound. In the case that the additional drug is a proteinaceous compound, it is advantageous that the proteinaceous compound be capable of providing an activation signal for immune effector cells.
[0301] Preferably, said proteinaceous compound or non-proteinaceous compound may be administered simultaneously or non-simultaneously with the bispecific single chain antibody molecule of the invention, a nucleic acid molecule as defined hereinabove, a vector as defined as defined hereinabove, or a host as defined as defined hereinabove.
[0302] It is preferred for the above described method of the invention that said subject is a human.
[0303] In a further aspect, the invention relates to a kit comprising a bispecific single chain antibody molecule of the invention, a nucleic acid molecule of the invention, a vector of the invention, or a host of the invention.
[0304] These and other embodiments are disclosed and encompassed by the description and Examples of the present invention. Recombinant techniques and methods in immunology are described e.g. in Sambrook et al. Molecular Cloning: A Laboratory Manual; Cold Spring Harbor Laboratory Press, 3.sup.rd edition 2001; Lefkovits; Immunology Methods Manual; The Comprehensive Sourcebook of Techniques; Academic Press, 1997; Golemis; Protein-Protein Interactions: A Molecular Cloning Manual; Cold Spring Laboratory Press, 2002. Further literature concerning any one of the antibodies, methods, uses and compounds to be employed in accordance with the present invention may be retrieved from public libraries and databases, using for example electronic devices. For example, the public database "Medline", available on the Internet, may be utilized, for example under http://www.ncbi.nlm.nih.gov/PubMed/medline.html. Further databases and addresses such as http://www.ncbi.nlm.nih.gov/or listed at the EMBL-services homepage under http://www.embl.de/services/index.html are known to the person skilled in the art and can also be obtained using, e. g., http://www.google.com.
[0305] The figures show:
[0306] FIG. 1
[0307] Flowcytometry of CHO cells transfected with native human EpCAM (positive control) and different EpCAM-hNG2 fusion proteins, respectively. Staining with the murine parental IgG1 antibody MAb 5-10 (bold lines) directed against human EpCAM was performed as described (Brischwein (2007) J Immunother 30: 798-807). PBS/2% FCS instead of MAb 5-10 was used as negative control (thin lines).
[0308] FIG. 2
[0309] T cell cytotoxicity redirected by bscAb 5-10.times.I2C against CHO cells transfected with human EpCAM (positive control) and different EpCAM-hNG2 fusion proteins as measured in a chromium 51 (.sup.51Cr) release assay (y-axis). Stimulated human CD4/CD56 depleted PBMC served as effector T cells. Effector- to target cell ratio was 10:1. BscAb 5-10.times.I2C was used as culture supernatant at different dilutions as indicated on the x-axis. Assay duration was 18 hours.
[0310] FIG. 3
[0311] Amino acid sequence alignment of full-length mature human and rat PSMA. Mismatching homologous amino acid positions are underlined and highlighted by bold character style. Numbering of amino acid positions refers to human PSMA and starts with the amino acid methionine encoded by the start codon of human PSMA. Intracellular domain aa 1-aa 19; transmembrane domain aa 20-aa 43; extracellular domain aa 44-aa 750.
[0312] FIG. 4
[0313] FACS binding analysis of I2C-based anti-human PSMA-bscAbs on CHO cells transfected with (unmutated) human PSMA, rat PSMA mutated to the homologous human amino acid at every mismatched amino acid position with a membrane-distance of .gtoreq.60 .ANG., and unmutated rat PSMA. The bold lines show staining by cell culture supernatant of CHO cells transfected with PSMA-directed bispecific antibody constructs. Cell culture supernatant of untransfected CHO cells served as negative control (thin lines). PSMA-directed bscAbs P1.times.I2C, P2.times.I2C, P3.times.I2C, P4.times.I2C and P5.times.I2C bind to (unmutated) human PSMA but neither to unmutated nor to mutated rat PSMA and thus confirms a membrane-distance of <60 .ANG. for the PSMA-epitope of each of these bispecific constructs. By contrast, PSMA-directed bscAbs D1.times.I2C and D2.times.I2C do not bind to unmutated rat PSMA but to (unmutated) human and mutated rat PSMA consistent with PSMA-epitopes of a membrane-distance .gtoreq.60 .ANG..
[0314] FIG. 5
[0315] T cell cytotoxicity redirected by I2C-based PSMA-directed bscAbs to CHO cells transfected with human PSMA as measured in a chromium 51 (.sup.51Cr) release assay. As source of effector T cells stimulated human CD4/CD56 depleted PBMC were used. The effector-to-target cell ratio was 10:1. PSMA-directed bscAbs were used as cell culture supernatants from transfected CHO cells at different dilutions as indicated. The assay duration was 18 hours. PSMA-directed bscAbs P1.times.I2C, P2.times.I2C, P3.times.I2C, P4.times.I2C and P5.times.I2C, whose PSMA-epitopes have a membrane-distance of <60 .ANG. are substantially more potent in redirecting T cell cytotoxicity than PSMA-directed bscAbs D1.times.I2C and D2.times.I2C, whose PSMA-epitopes have a membrane-distance of .gtoreq.60 .ANG..
[0316] FIG. 6
[0317] FACS binding analysis of I2C-based anti-human PSMA-bscAbs on CHO cells transfected with (unmutated) human PSMA, rat PSMA mutated to the homologous human amino acid at every mismatched amino acid position with a membrane-distance of .gtoreq.60 .ANG., and unmutated rat PSMA. The bold lines show staining by cell culture supernatant of CHO cells transfected with PSMA-directed bispecific antibody constructs. Cell culture supernatant of untransfected CHO cells served as negative control (thin lines). The PSMA-directed bscAb P6.times.I2C binds to (unmutated) human PSMA but neither to unmutated nor to mutated rat PSMA and thus confirms a membrane-distance of <60 .ANG. for the PSMA-epitope of this bispecific construct. By contrast, PSMA-directed bscAb D3.times.I2C does not bind to unmutated rat PSMA but to (unmutated) human and mutated rat PSMA consistent with a PSMA-epitope of a membrane-distance .gtoreq.60 .ANG..
[0318] FIG. 7
[0319] T cell cytotoxicity redirected by I2C-based PSMA-directed bscAbs to CHO cells transfected with human PSMA as measured in a chromium 51 (.sup.51Cr) release assay. As source of effector T cells stimulated human CD4/CD56 depleted PBMC were used. The effector-to-target cell ratio was 10:1. PSMA-directed bscAbs were used as cell culture supernatants from transfected CHO cells at different dilutions as indicated. The assay duration was 18 hours. PSMA-directed bscAb P6.times.I2C, whose PSMA-epitope has a membrane-distance of <60 .ANG. is substantially more potent in redirecting T cell cytotoxicity than PSMA-directed bscAb D3.times.I2C, whose PSMA-epitope has a membrane-distance of .gtoreq.60 .ANG..
[0320] FIG. 8
[0321] FACS binding analysis of I2C-based bscAbs directed to membrane-proximal PSMA-epitopes on CHO cells transfected with macaque PSMA, the CD3 positive human T cell leukemia cell line HPB-ALL and the CD3 positive macaque T cell line 4119LnPx. The bold lines show staining by cell culture supernatant of CHO cells transfected with designated PSMA-directed bispecific antibody constructs. Cell culture supernatant of untransfected CHO cells served as negative control (thin lines). The designated PSMA-directed bscAbs in addition to human PSMA also bind to macaque PSMA, human CD3 and macaque CD3.
[0322] FIG. 9
[0323] Amino acid sequence alignment of full-length mature human and murine FAP.alpha.. Mismatching homologous amino acid positions are underlined and highlighted by bold character style. Numbering of amino acid positions refers to human FAPalpha and starts with the amino acid methionine encoded by the start codon of human FAPalpha. Intracellular domain aa 1-aa 9; transmembrane domain aa 10-aa 26; extracellular domain aa 27-aa 760.
[0324] FIG. 10
[0325] FACS binding analysis of cell surface expression on CHO cells expressing the murine FAPalpha antigen as described in Example 6.3 and CHO cells expressing the mutated human FAPalpha antigen with murine membrane-distal epitopes as described in Example 6.4, respectively. The FACS staining was performed as described in Examples 6.3 and 6.4. The bold lines represent cells incubated with the detection antibodies--the Penta His antibody in case of murine FAPalpha and the anti-FLAG M2 antibody in case of the mutated human FAPalpha antigen with murine membrane-distal epitopes. The thin lines represent the negative controls. For both cell lines the overlay of the histograms for the anti-FLAG M2 antibody and the Penta His antibody, respectively, shows a significant expression level of the respective antigen. Expression levels were comparable for the two cell lines.
[0326] FIGS. 11A-11B
[0327] FACS binding analysis of designated bispecific single chain constructs to CHO cells expressing human FAPalpha as described in Example 6.1, the human CD3+ T cell line HPB-ALL, CHO cells expressing macaque FAPalpha as described in Example 6.15 and the macaque T cell line 4119LnPx, respectively. The FACS staining was performed as described in Examples 6.13 and 6.16. The bold lines represent cells incubated with cell culture supernatant of transfected cells expressing the bispecific antibody constructs. The thin lines represent the negative controls. Supernatant of untransfected CHO cells was used as negative control. For each bispecific single chain construct the overlays of the histograms show specific binding of the construct to human and macaque FAPalpha and human and macaque CD3.
[0328] FIGS. 12A-12C
[0329] The diagrams show results of chromium release assays measuring cytotoxic activity induced by designated FAPalpha specific single chain constructs redirected to the indicated target cell lines generated as described in Examples 6.1, 6.3 and 6.4. Effector cells were also used as indicated. The assays were performed as described in Example 6.14. The diagrams clearly demonstrate for each construct the potent recruitment of cytotoxic activity of human effector T cells against target cells positive for human FAPalpha and target cells positive for the mutated human FAPalpha antigen with murine membrane-distal epitopes. No significant recruitment of cytotoxic activity of human effector T cells against target cells positive for murine FAPalpha was detectable.
[0330] FIGS. 13A-13C
[0331] FACS binding analysis of designated bispecific single chain constructs to CHO cells expressing human c-MET as described in Example 7.17, the human CD3+ T cell line HPB-ALL, CHO cells expressing macaque c-MET as described in Example 7.17 and the macaque T cell line 4119LnPx, respectively. The FACS staining was performed as described in Examples 7.13 and 7.16. The bold lines represent cells incubated with cell culture supernatant of transfected cells expressing the bispecific antibody constructs. The filled histograms show the negative controls. Supernatant of untransfected CHO cells was used as negative control. For each bispecific single chain construct the overlays of the histograms show specific binding of the construct to human and macaque c-MET and human and macaque CD3.
[0332] FIGS. 14A-14D
[0333] FACS binding analysis of designated bispecific single chain constructs to CHO cells expressing the murine c-MET antigen as described in Example 7.17, CHO cells expressing the mutated human c-MET antigen with murine membrane-distal epitopes as described in Example 7.17 and CHO cells expressing the mutated murine c-MET antigen with human membrane-distal epitopes as described in Example 7.17, respectively. The FACS staining was performed as described in Example 7.13. The bold lines represent cells incubated with cell culture supernatant of transfected cells expressing the bispecific antibody constructs. The filled histograms show the negative controls. Supernatant of untransfected CHO cells was used as negative control. An anti-FLAG M2 antibody was used to detect expression levels of the respective antigens. For each cell line the overlay of the histograms for the anti-FLAG M2 antibody shows high expression levels of the respective antigen. Expression levels were comparable for the three cell lines. For each bispecific single chain construct the overlays of the histograms show specific binding of the construct to the mutated human c-MET antigen with murine membrane-distal epitopes but not to the mutated murine c-MET antigen with human membrane-distal epitopes and not to the murine c-MET antigen.
[0334] FIGS. 15A-15C
[0335] The diagrams show results of chromium release assays measuring cytotoxic activity induced by designated c-MET specific single chain constructs redirected to the indicated target cell lines generated as described in Example 7.17. Effector cells were also used as indicated. The assays were performed as described in Example 7.14. The diagrams clearly demonstrate for each construct the potent recruitment of cytotoxic activity of human effector T cells against target cells positive for human c-MET. No significant recruitment of cytotoxic activity of human effector T cells against target cells positive for murine c-MET and target cells positive for the mutated murine c-MET antigen with human membrane-distal epitopes, respectively, was detectable.
[0336] FIGS. 16A-16F
[0337] FACS binding analysis of designated cross-species specific scFv antibodies to CHO cells expressing human c-MET as described in Example 7.17, CHO cells expressing the murine c-MET antigen as described in Example 7.17, CHO cells expressing the mutated human c-MET antigen with murine membrane-distal epitopes as described in Example 7.17 and CHO cells expressing the mutated murine c-MET antigen with human membrane-distal epitopes as described in Example 7.17, respectively. The FACS staining was performed as described in Example 7.9. The bold lines represent cells incubated with periplasmic preparations containing the c-MET specific scFv antibodies. The filled histograms show the negative controls. The Buffer used for periplasmic preparations was used as negative control. For each c-MET specific scFv antibody the overlays of the histograms show specific binding of the construct to human c-MET and human c-MET with murine membrane-distal epitopes. No significant binding to cells positive for murine c-MET and to cells positive for the mutated murine c-MET with human membrane-distal epitopes, respectively, was detectable.
[0338] FIG. 17
[0339] FACS binding analysis of designated bispecific single chain constructs to CHO cells expressing human IGF-1R as described in Example 9.1, the human CD3+ T cell line HPB-ALL, CHO cells expressing macaque IGF-1R as described in Example 9.15 and the macaque T cell line 4119LnPx, respectively. The FACS staining was performed as described in Examples 9.13 and 9.16. The bold lines represent cells incubated with cell culture supernatant of transfected cells expressing the bispecific antibody constructs. The filled histograms show the negative controls. Supernatant of untransfected CHO cells was used as negative control. For each bispecific single chain construct the overlays of the histograms show specific binding of the construct to human and macaque IGF-1R and human and macaque CD3.
[0340] FIG. 18
[0341] FACS binding analysis of designated bispecific single chain constructs to CHO cells expressing the murine IGF-1R antigen as described in Example 9.3, CHO cells expressing the mutated human IGF-1R antigen with murine membrane-distal epitopes as described in Example 9.4 and CHO cells expressing the mutated murine IGF-1R antigen with human membrane-distal epitopes as described in Example 9.5, respectively. The FACS staining was performed as described in Example 9.13. The bold lines represent cells incubated with cell culture supernatant of transfected cells expressing the bispecific antibody constructs. The filled histograms show the negative controls. Supernatant of untransfected CHO cells was used as negative control. For each bispecific single chain construct the overlays of the histograms show specific binding of the construct to the mutated human IGF-1R antigen with murine membrane-distal epitopes but not to the mutated murine IGF-1R antigen with human membrane-distal epitopes and not to the murine IGF-1R antigen.
[0342] FIG. 19
[0343] The diagrams show results of chromium release assays measuring cytotoxic activity induced by designated IGF-1R specific single chain constructs redirected to the CHO cells expressing human IGF-1R as described in Example 9.1. Effector cells were used as indicated. The assays were performed as described in Example 9.14. The diagrams clearly demonstrate for each construct the potent recruitment of cytotoxic activity of human effector T cells against target cells positive for human IGF-1R.
[0344] FIGS. 20A-20B
[0345] FACS binding analysis of designated bispecific single chain constructs to CHO cells expressing designated human/rat PSMA chimeras as described in Example 10.2.1. The FACS staining was performed as described in Example 10.2.2. The bold lines represent cells incubated with cell culture supernatant of transfected cells expressing the bispecific antibody constructs. The filled histograms show the negative controls. Supernatant of untransfected CHO cells was used as negative control. For each bispecific single chain construct the overlays of the histograms show specific binding of the construct to the chimeric constructs huPSMArat140-169, huPSMArat281-284, huPSMArat300-344, huPSMArat683-690 and huPSMArat716-750. Compared with the signals obtained for the other bispecific single chain construct there is a clear lack of binding for the bispecific single chain antibody construct PSMA-P7 HL.times.I2C HL to the chimeric PSMA construct huPSMArat598-617.
[0346] FIG. 21
[0347] The Figure shows binding signals obtained with periplasmic preparations of the scFv antibody of the PSMA specific binder of PSMA-D4 HL.times.I2C HL to 15-mer peptides spanning over the extracellular domain of human PSMA and overlapping with their neighboring peptides by 14 amino acids. Signals obtained for the peptides are plotted on on the X-axis in order of the N-terminal peptides on the left to the C-terminal peptides on the right. Strength of ELISA signals using His detection is plotted on the Y-axis. The ELISA was performed as described in Example 10.3. A distinc maximum signal is detectable for the peptide spanning over the amino acids threonine 334 to threonine 339.
[0348] FIG. 22
[0349] The diagram shows results of a CytoTox-Glo.TM. cytotoxicity assay measuring cytotoxic activity of unstimulated human T cells induced by designated PSMA specific bispecific single chain constructs against CHO cells expressing human PSMA as described in Example 2.1. The assay was performed as described in Example X.4. The diagram clearly demonstrates the superior cytotoxic activity of PSMA bispecific single chain antibody PSMA-P7 HL.times.I2C HL directed at a membrane-proximal target epitope of human PSMA over PSMA bispecific single chain antibody PSMA-D4 HL.times.I2C HL directed at a membrane-distal target epitope of human PSMA.
TABLE LEGENDS
Table 1
[0350] All extracellular amino acids of human PSMA mismatching with the homologous rat PSMA amino acid sequence. Those mismatched extracellular human PSMA amino acids, whose alpha C-atoms have a distance of .gtoreq.60 .ANG. from the alpha C-atom of the thirteenth extracellular human PSMA amino acid (i.e. the reference aa) as counted from the junction of transmembrane and extracellular region are marked in bold. The distances between alpha C-atoms of two amino acids within human PSMA were determined using the crystal structure of human PSMA (accession No 1Z8L; obtained from the RCSB pdb, protein data bank of the Research Collaboratory for Structural Bioinformatics; http://www.rcsb.org/pdb) and the "measure distance mode" of the software "3D molecule viewer" (a component of Vector NTI Suite 8.0, Informax Inc.). Numbering of amino acid positions refers to human PSMA and starts with the amino acid methionine encoded by the start codon of human PSMA. The reference aa is histidine at position 56.
Table 2
[0351] All extracellular amino acids of human FAPalpha mismatching with the homologous murine FAPalpha amino acid sequence. Those mismatched extracellular human FAPalpha amino acids, whose alpha C-atoms have a distance of .gtoreq.60 .ANG. from the alpha C-atom of the thirteenth extracellular human FAPalpha amino acid (i.e. the reference aa) as counted from the junction of transmembrane and extracellular region are marked in bold. The distances between alpha C-atoms of two amino acids within human FAPalpha were determined using the crystal structure of human FAPalpha (Accession No 1Z68; obtained from the RCSB pdb, protein data bank of the Research Collaboratory for Structural Bioinformatics; http://www.rcsb.org/pdb) and the "measure distance mode" of the software "3D molecule viewer" (a component of Vector NTI Suite 8.0, Informax Inc.). Numbering of amino acid positions refers to human FAPalpha and starts with the amino acid methionine encoded by the start codon of human FAPalpha. The reference aa is methionine at position 39.
[0352] The present invention is additionally described by way of the following illustrative non-limiting examples that provide a better understanding of the present invention and of its many advantages.
EXAMPLES
[0353] 1. Cytotxicity with Respect to the Distance of the Target Cell Epitopes Distance from the Target Cell Membrane
1.1. Generation of CHO Cells Expressing the Human EpCAM Antigen
[0354] The sequence of the human EpCAM antigen ('NM_002354, Homo sapiens tumor-associated calcium signal transducer 1 (TACSTD1), mRNA, National Center for Biotechnology Information, http://www.ncbi.nlm.nih.gov/entrez) was used to obtain a synthetic molecule by gene synthesis according to standard protocols. The gene synthesis fragment was also designed as to contain a Kozak site for eukaryotic expression of the construct and and restriction sites at the beginning and the end of the DNA. The introduced restriction sites XbaI at the 5' end and SalI at the 3' end were utilised in the following cloning procedures. The gene synthesis fragment was cloned via XbaI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures were carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence was transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells was performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct was induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
1.2. Generation of CHO Cells Expressing EpCAM-hNG2 Fusion Proteins
[0355] The coding sequences of EpCAM-hNG2 fusion proteins EpCAM-D1-hNG2 (SEQ ID Nos 189 and 190), EpCAM-D3-hNG2 (SEQ ID Nos 191 and 192), EpCAM-D1D3-hNG2 (SEQ ID Nos 193 and 194), EpCAM-D1D2-hNG2 (SEQ ID Nos 195 and 196) and EpCAM-hNG2 (SEQ ID Nos 197 and 198) were obtained by gene synthesis according to standard protocols. The gene synthesis fragment was designed as to contain first the coding sequence of an immunoglobulin leader peptide followed subsequently by human EpCAM, the respective extracellular part of human NG2 and the transmembrane and cytoplasmic domain of the human NG2 (Pluschke (1996) PNAS 93: 9710-9715). The different components were connected by short peptide linkers. The gene synthesis fragments were also designed as to introduce restriction sites at the 5' end (Eco RI) and at the 3' end (Sal I) for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures were carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). For each EpCAM-hNG2 fusion protein .alpha. clone with sequence-verified nucleotide sequence was transfected into DHFR deficient CHO cells for eukaryotic expression. Eukaryotic protein expression in DHFR deficient CHO cells was performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct was induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
1.3. Generation of the EpCAM and CD3 Bispecific Single Antibody 5-10.times.I2C
[0356] The bispecific single chain antibody 5-10.times.I2C comprising the scFv binding domain 5-10 (in VL-VH arrangement) directed at human EpCAM (Brischwein (2007) J Immunother 30: 798-807) and the scFv binding domain I2C (in VL-VH arrangement) directed at CD3epsilon on human T cells was obtained by gene synthesis. The gene synthesis fragment was designed as to contain first a Kozak site for eukaryotic expression of the construct, followed by a 19 amino acid immunoglobulin leader peptide, followed in frame by the coding sequence of the bispecific single chain antibody 5-10.times.I2C, followed in frame by the coding sequence of a 6 histidine tag and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 199 and 200). The gene synthesis fragment was also designed as to introduce suitable restriction sites at the beginning (EcoRI) and at the end of the fragment (Sal I) for cloning of the gene synthesis fragment into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures were carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence was transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells was performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct was induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX. After two passages of stationary culture cell culture supernatant was collected and used in the subsequent experiments.
1.4. Flowcytometry of CHO Cells Transfected with Different EpCAM-hNG2 Fusion Proteins
[0357] The presence of the EpCAM-epitope of bispecific single chain antibody 5-10.times.I2C on the CHO cells transfected with native EpCAM and the EpCAM-hNG2 fusion proteins EpCAM-D1-hNG2, EpCAM-D3-hNG2, EpCAM-D1 D3-hNG2, EpCAM-D1 D2-hNG2 and EpCAM-hNG2, respectively, was confirmed by flowcytometry with the murine parental IgG1 antibody Mab 5-10 as described (Brischwein (2007) J Immunother 30: 798-807). The result is shown in FIG. 1.
1.5. T Cell Cytotoxicity Redirected by bscAb 5-10.times.I2C Against CHO Cells Transfected with Different EpCAM-hNG2 Fusion Proteins
[0358] T cell cytotoxicity redirected by bscAb 5-10.times.I2C against CHO cells transfected with different EpCAM-hNG2 fusion proteins was measured in a chromium 51 (.sup.51Cr) release in vitro cytotoxicity assay. As source of effector T cells stimulated human CD4/CD56 depleted PBMC were used. Stimulated human PBMC were obtained as follows: A Petri dish (145 mm diameter, Greiner bio-one GmbH, Kremsmunster) was coated with a commercially available anti-CD3 specific antibody (e.g. OKT3, Orthoclone) in a final concentration of 1 .mu.g/ml for 1 hour at 37.degree. C. Unbound protein was removed by one washing step with PBS. The fresh PBMC were isolated from peripheral blood (30-50 ml human blood) by Ficoll gradient centrifugation according to standard protocols. 3-5.times.10.sup.7 PBMC were added to the precoated petri dish in 120 ml of RPMI 1640 with stabilized glutamine/10% FCS/IL-2 20 U/ml (Proleukin, Chiron) and stimulated for 2 days. On the third day the cells were collected and washed once with RPMI 1640. IL-2 was added to a final concentration of 20 U/ml and the cells were cultured again for one day in the same cell culture medium as above.
[0359] By depletion of CD4+ T cells and CD56+NK cells according to standard protocols CD8+ cytotoxic T lymphocytes (CTLs) were enriched. Target cells were washed twice with PBS and labelled with 11.1 MBq .sup.51Cr in a final volume of 100 .mu.l RPMI with 50% FCS for 60 minutes at 37.degree. C. Subsequently the labelled target cells were washed 3 times with 5 ml RPMI and then used in the cytotoxicity assay. The assay was performed in a 96 well plate in a total volume of 250 .mu.l supplemented RPMI (as above) with an E:T ratio of 10:1. BscAb 5-10.times.I2C was added as culture supernatant from transfected CHO cells at different dilutions. The assay time was 18 hours. Cytotoxicity was measured as relative values of released chromium related to the difference of maximum lysis (addition of Triton-X) and spontaneous lysis (without effector cells). All measurements were carried out in quadruplicates. Measurement of released chromium activity was performed with a Wizard 3'' gammacounter (Perkin Elmer Life Sciences GmbH, Koln, Germany). Analysis of the experimental data was performed with Prism 4 for Windows (version 4.02, GraphPad Software Inc., San Diego, Calif., USA). Sigmoidal dose response curves typically had R.sup.2 values >0.90 as determined by the software. As shown in FIG. 2 the T cell cytotoxicity redirected by bscAb 5-10.times.I2C against the indicated target cells critically depends on the varying distance of the target EpCAM epitope of bsc 5-10.times.I2C in the different EpCAM-hNG2 model antigens from the target cell membrane. The descending order of T cell cytotoxicity with increasing membrane distance of the target epitope as given in parentheses is EpCAM-CHO (positive control)>EpCAM-D1-hNG2 (640 aa)>EpCAM-D3-hNG2 (679 aa)>EpCAM-D1 D3-hNG2 (871 aa). There was no cytotoxic activity detectable against CHO cells expressing EpCAM-D1 D2-hNG2 (1511 aa) or EpCAM-hNG2 (2190 aa).
2. Generation of Bispecific Single Chain Antibodies Directed at Membrane-Proximal Target Epitopes of Human PSMA
2.1 Generation of CHO Cells Expressing Human PSMA
[0360] The coding sequence of human PSMA as published in GenBank (Accession number NM_004476) is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the human PSMA protein and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 201 and 202). The gene synthesis fragment is also designed as to introduce restriction sites at the beginning and at the end of the fragment. The introduced restriction sites, XbaI at the 5' end and SalI at the 3' end, are utilized in the following cloning procedures. The gene synthesis fragment is cloned via XbaI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
2.2 Generation of a Soluble Human PSMA Fusion Protein
[0361] The coding sequence of human PSMA as described in Example 2.1 and the coding sequence of murine Lag3 as published in GenBank (Accession number NM_008479) are used for the construction of an artificial cDNA sequence encoding a soluble fusion protein of human PSMA and murine Lag3. To generate a construct for expression of the soluble human PSMA fusion protein .alpha. cDNA fragment is obtained by gene synthesis according to standard protocols (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 203 and 204). The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the murine Lag3 protein from amino acid 1 to 441 corresponding to the signal peptide and extracellular domains of murine Lag3, followed in frame by the coding sequence of an artificial Ser.sub.1-Gly.sub.4-Ser.sub.1-linker, followed in frame by the coding sequence of the human PSMA protein from amino acid 44 to 750 corresponding to the extracellular domains of human PSMA, followed in frame by the coding sequence of an artificial Ser.sub.1-Gly.sub.1-linker, followed in frame by the coding sequence of a 6 histidine tag and a stop codon. The gene synthesis fragment is also designed as to introduce restriction sites at the beginning and at the end of the fragment. The introduced restriction sites, XbaI at the 5' end and SalI at the 3' end, are utilized in the following cloning procedures. The gene synthesis fragment is cloned via XbaI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are all carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX. After two passages of stationary culture the cells are grown in roller bottles with nucleoside-free HyQ PF CHO liquid soy medium (with 4.0 mM L-Glutamine with 0.1% Pluronic F--68; HyClone) for 7 days before harvest. The cells are removed by centrifugation and the supernatant containing the expressed protein is stored at -20.degree. C. Alternatively a clone of the expression plasmid with sequence-verified nucleotide sequence is used for transfection and protein expression in the FreeStyle 293 Expression System (Invitrogen GmbH, Karlsruhe, Germany) according to the manufacturer's protocol. Supernatant containing the expressed protein is obtained, cells are removed by centrifugation and the supernatant is stored at -20.degree. C.
[0362] Purification of the soluble human PSMA fusion protein is performed as follows: Akta.RTM. Explorer System (GE Health Systems) and Unicorn.RTM. Software are used for chromatography. Immobilized metal affinity chromatography ("IMAC") is performed using a Fractogel EMD Chelate.RTM. (Merck) which is loaded with ZnCl.sub.2 according to the protocol provided by the manufacturer. The column is equilibrated with buffer A (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl) and the cell culture supernatant (500 ml) is applied to the column (10 ml) at a flow rate of 3 ml/min. The column is washed with buffer A to remove unbound sample. Bound protein is eluted using a two step gradient of buffer B (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl, 0.5 M Imidazole) according to the following procedure:
[0363] Step 1: 20% buffer B in 6 column volumes
[0364] Step 2: 100% buffer B in 6 column volumes
[0365] Eluted protein fractions from step 2 are pooled for further purification. All chemicals are of research grade and purchased from Sigma (Deisenhofen) or Merck (Darmstadt).
[0366] Gel filtration chromatography is performed on a HiLoad 16/60 Superdex 200 prep grade column (GE/Amersham) equilibrated with Equi-buffer (25 mM Citrate, 200 mM Lysine, 5% Glycerol, pH 7.2). Eluted protein samples (flow rate 1 ml/min) are subjected to standard SDS-PAGE and Western Blot for detection. Prior to purification, the column is calibrated for molecular weight determination (molecular weight marker kit, Sigma MW GF-200). Protein concentrations are determined using OD280 nm.
2.3 Generation of CHO Cells Expressing Rat PSMA
[0367] The sequence of rat PSMA (NM_057185, Rattus norvegicus folate hydrolase (Folh1), mRNA, National Center for Biotechnology Information, http://www.ncbi.nlm.nih.gov/entrez) is used to obtain a synthetic cDNA molecule by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the complete coding sequence of the rat PSMA antigen, followed in frame by the coding sequence of a FLAG-tag and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 205 and 206). The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (SalI) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct.
[0368] Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
[0369] 2.4 Generation of CHO Cells Expressing a Mutated Human PSMA Antigen with Rat Membrane-Distal Epitopes
[0370] The coding sequence of a mutated human PSMA antigen with rat membrane-distal epitopes is obtained by gene synthesis according to standard protocols The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the complete coding sequence of the human PSMA antigen mutated at 12 specific amino acid positions as explained below, followed in frame by the coding sequence of a FLAG tag and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 207 and 208). All extracellular amino acids of human PSMA mismatching with the homologous rat sequence, whose alpha C-atoms have a distance of .gtoreq.60 .ANG. from the alpha C-atom of the thirteenth extracellular amino acid (i.e. the reference aa) as counted from the junction of transmembrane and extracellular region, are mutated to the homologous mismatched rat amino acid. This applies to the 12 amino acids that are listed in table Table 1 and marked in bold. The homologous mismatched amino acids between human and rat PSMA are identified by sequence alignment as shown in FIG. 3. The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (Xba I) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
[0371] 2.5 Generation of CHO Cells Expressing a Mutated Rat PSMA Antigen with Human Membrane-Distal Epitopes
[0372] The coding sequence of a mutated rat PSMA antigen with human membrane-distal epitopes is obtained by gene synthesis according to standard protocols The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the complete coding sequence of the rat PSMA antigen mutated at the same 12 specific extracellular amino acid positions as identified in the foregoing Example 2.4 to the respective homologous human amino acid, followed in frame by the coding sequence of a FLAG tag and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 209 and 210). The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI I) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566.
[0373] Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
[0374] 2.6 Immunization of mice using a soluble human PSMA fusion protein Twelve weeks old F1 mice from BALB/c.times.C57BL/6 crossings are immunized with the soluble human PSMA fusion protein as described in Example 2.2 To this end for each animal 40 .mu.g of the soluble human PSMA fusion protein are mixed with 10 nmol of a thioate-modified CpG-Oligonucleotide (5'-tccatgacgttcctgatgct-3') in 300 .mu.l PBS and are injected intraperitoneally. Mice receive booster immunizations after 21, 42 and optionally 63 days in the same way. Ten days after the first booster immunization, blood samples are taken and antibody serum titers against human PSMA are tested by flow cytometry according to standard protocols. To this end 200.000 cells of the human PSMA transfected CHO cells as described in Example 2.1 are incubated for 30 min on ice with 50 .mu.l of serum of the immunized animals diluted 1:1000 in PBS with 2% FCS. The cells are washed twice in PBS with 2% FCS and binding of serum antibodies is detected with an mouse Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Serum of the animals obtained prior to immunization is used as a negative control. Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg).
[0375] FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0376] Animals demonstrating significant serum reactivity against human PSMA as determined by the FACS analysis are used in the subsequent experiment.
[0377] 2.7 Generation of an immune murine antibody scFv library: Construction of a combinatorial antibody library and phage display Three days after the last booster immunization spleen cells of reactive animals are harvested for the preparation of total RNA according to standard protocols. A library of murine immunoglobulin (Ig) light chain (kappa) variable region (VK) and
[0378] Ig heavy chain variable region (VH) DNA-fragments is constructed by RT-PCR on murine spleen RNA using VK- and VH specific primers. cDNA is synthesized according to standard protocols.
[0379] The primers are designed in a way to give rise to a 5'-XhoI and a 3'-BstElI recognition site for the amplified heavy chain V-fragments and to a 5'-SacI and a 3'-SpeI recognition site for amplified VK DNA fragments.
[0380] For the PCR-amplification of the VH DNA-fragments eight different 5'-VH-family specific primers (MVH1(GC)AG GTG CAG CTC GAG GAG TCA GGA CCT SEQ ID NO: 211; MVH2 GAG GTC CAG CTC GAG CAG TCT GGA CCT SEQ ID NO: 212; MVH3 CAG GTC CAA CTC GAG CAG CCT GGG GCT SEQ ID NO: 213; MVH4 GAG GTT CAG CTC GAG CAG TCT GGG GCA SEQ ID NO: 214; MVH5 GA(AG) GTG AAG CTC GAG GAG TCT GGA GGA SEQ ID NO: 215; MVH6 GAG GTG AAG CTT CTC GAG TCT GGA GGT SEQ ID NO: 216; MVH7 GAA GTG AAG CTC GAG GAG TCT GGG GGA SEQ ID NO: 217; MVH8 GAG GTT CAG CTC GAG CAG TCT GGA GCT SEQ ID NO: 218) are each combined with one 3'-VH primer (3'MuVHBstElI tga gga gac ggt gac cgt ggt ccc ttg gcc cca g SEQ ID NO: 219); for the PCR amplification of the VK-chain fragments seven different 5'-VK-family specific primers (MUVK1 CCA GTT CCG AGC TCG TTG TGA CTC AGG AAT CT SEQ ID NO: 220; MUVK2 CCA GTT CCG AGC TCG TGT TGA CGC AGC CGC CC SEQ ID NO: 221; MUVK3 CCA GTT CCG AGC TCG TGC TCA CCC AGT CTC CA SEQ ID NO: 222; MUVK4 CCA GTT CCG AGC TCC AGA TGA CCC AGT CTC CA SEQ ID NO: 223; MUVK5 CCA GAT GTG AGC TCG TGA TGA CCC AGA CTC CA SEQ ID NO: 224; MUVK6 CCA GAT GTG AGC TCG TCA TGA CCC AGT CTC CA SEQ ID NO: 225; MUVK7 CCA GTT CCG AGC TCG TGA TGA CAC AGT CTC CA SEQ ID NO: 226) are each combined with one 3'-VK primer (3'MuVkHindIII/BsiW1 tgg tgc act agt cgt acg ttt gat ctc aag ctt ggt ccc SEQ ID NO: 227).
[0381] The following PCR program is used for amplification: denaturation at 94.degree. C. for 20 sec; primer annealing at 52.degree. C. for 50 sec and primer extension at 72.degree. C. for 60 sec and 40 cycles, followed by a 10 min final extension at 72.degree. C.
[0382] 450 ng of the kappa light chain fragments (SacI-SpeI digested) are ligated with 1400 ng of the phagemid pComb3H5Bhis (SacI-SpeI digested; large fragment). The resulting combinatorial antibody library is then transformed into 300 .mu.l of electrocompetent Escherichia coli XL1 Blue cells by electroporation (2.5 kV, 0.2 cm gap cuvette, 25 .mu.FD, 200 Ohm, Biorad gene-pulser) resulting in a library size of more than 10.sup.7 independent clones. After one hour of phenotype expression, positive transformants are selected for carbenicillin resistance encoded by the pComb3H5BHis vector in 100 ml of liquid super broth (SB)-culture over night. Cells are then harvested by centrifugation and plasmid preparation is carried out using a commercially available plasmid preparation kit (Qiagen).
[0383] 2800 ng of this plasmid-DNA containing the VK-library (XhoI-BstElI digested; large fragment) are ligated with 900 ng of the heavy chain V-fragments (XhoI-BstElI digested) and again transformed into two 300 .mu.l aliquots of electrocompetent E. coli XL1 Blue cells by electroporation (2.5 kV, 0.2 cm gap cuvette, 25 .mu.FD, 200 Ohm) resulting in a total VH-VK scFv (single chain variable fragment) library size of more than 10.sup.7 independent clones.
[0384] After phenotype expression and slow adaptation to carbenicillin, the E. coli cells containing the antibody library are transferred into SB-Carbenicillin (SB with 50 .mu.g/mL carbenicillin) selection medium. The E. coli cells containing the antibody library are then infected with an infectious dose of 10.sup.12 particles of helper phage VCSM13 resulting in the production and secretion of filamentous M13 phage, wherein each phage particle contains single stranded pComb3H5BHis-DNA encoding a murine scFv-fragment and displays the corresponding scFv-protein as a translational fusion to phage coat protein III. This pool of phages displaying the antibody library is later used for the selection of antigen binding entities.
[0385] 2.8 Phage Display Based Selection of Membrane-Proximal Target Binders on CHO Cells Expressing the Mutated Human PSMA Antigen with Rat Membrane-Distal Epitopes
[0386] The phage library carrying the cloned scFv-repertoire is harvested from the respective culture supernatant by PEG8000/NaCl precipitation and centrifugation. Approximately 10.sup.11 to 10.sup.12 scFv phage particles are resuspended in 0.4 ml of PBS/0.1% BSA and incubated with 10.sup.5 to 10.sup.7 CHO cells expressing the mutated human PSMA antigen with rat membrane-distal epitopes as described in example 2.4 for 1 hour on ice under slow agitation. These CHO cells are grown beforehand, harvested by centrifugation, washed in PBS and resuspended in PBS/1% FCS (containing Na Azide). scFv phage which do not specifically bind to the CHO cells are eliminated by up to five washing steps with PBS/1% FCS (containing Na Azide). After washing, binding entities are eluted from the cells by resuspending the cells in HCl-glycine pH 2.2 (10 min incubation with subsequent vortexing) and after neutralization with 2 M Tris pH 12, the eluate is used for infection of a fresh uninfected E. coli XL1 Blue culture (OD600>0.5). The E. coli culture containing E. coli cells successfully transduced with a phagemid copy, encoding a murine scFv-fragment, are again selected for carbenicillin resistance and subsequently infected with VCMS 13 helper phage to start the second round of antibody display and in vitro selection. Typically a total of 4 to 5 rounds of selections are carried out.
2.9 Screening for Membrane-Proximal Target Binders on CHO Cells Expressing the Human PSMA Antigen, the Rat PSMA Antigen and the Mutated Rat PSMA Antigen with Human Membrane-Distal Epitopes
[0387] Plasmid DNA corresponding to 4 and 5 rounds of panning is isolated from E. coli cultures after selection. For the production of soluble scFv-protein, VH-VL-DNA fragments are excised from the plasmids (XhoI-SpeI). These fragments are cloned via the same restriction sites in the plasmid pComb3H5BFlag/His differing from the original pComb3H5BHis in that the expression construct (e.g. scFv) includes a Flag-tag (TGDYKDDDDK) between the scFv and the His6-tag and the additional phage proteins are deleted. After ligation, each pool (different rounds of panning) of plasmid DNA is transformed into 100 .mu.l heat shock competent E. coli TG1 or XLI blue and plated onto carbenicillin LB-agar. Single colonies are picked into 100 .mu.l of LB carb (LB with 50 .mu.g/ml carbenicillin).
[0388] After induction with 1 mM IPTG E. coli transformed with pComb3H5BFlag/His containing a VL- and VH-segment produce soluble scFv in sufficient amounts. Due to a suitable signal sequence, the scFv is exported into the periplasma where it folds into a functional conformation.
[0389] Single E. coli bacterial colonies from the transformation plates are picked for periplasmic small scale preparations and grown in SB-medium (e.g. 10 ml) supplemented with 20 mM MgCl.sub.2 and carbenicillin 50 .mu.g/ml (and re-dissolved in PBS (e.g. 1 ml) after harvesting. A temperature shock is applied by four rounds of freezing at -70.degree. C. and thawing at 37.degree. C. whereby the outer membrane of the bacteria is destroyed and the soluble periplasmic proteins including the scFvs are released into the supernatant. After elimination of intact cells and cell-debris by centrifugation, the supernatant containing the murine anti-human PSMA-scFvs is collected and used for further examination.
[0390] Screening of the isolated scFvs for membrane-proximal target binders is performed by flow cytometry on CHO cells expressing the human PSMA antigen as described in Example 2.1, the rat PSMA antigen as described in Example 2.3 and the mutated rat PSMA antigen with human membrane-distal epitopes as described in Example 2.5.
[0391] For flow cytometry 2.5.times.10.sup.5 cells of the respective cell lines are incubated with 50 .mu.l supernatant. The binding of the constructs is detected with an anti-His antibody (Penta-His Antibody, BSA free, Qiagen GmbH, Hilden, FRG) at 2 .mu.g/ml in 50 .mu.l PBS with 2% FCS. As a second step reagent a R-Phycoerythrin-conjugated affinity purified F(ab')2 fragment, goat anti-mouse IgG (Fc-gamma fragment specific), diluted 1:100 in 50 .mu.l PBS with 2% FCS (Dianova, Hamburg, FRG) is used. The samples are measured on a FACSscan (BD biosciences, Heidelberg, FRG).
[0392] Only constructs which show binding to CHO cells expressing the human PSMA antigen and do not show binding to CHO cells expressing the rat PSMA antigen and also do not show binding to CHO cells expressing the mutated rat PSMA antigen with human membrane-distal epitopes are selected for further use.
2.10 Generation of Human/Humanized Equivalents of Non-Human scFvs to Membrane-Proximal Target Epitopes of Human PSMA
[0393] The VH region of a murine anti-PSMA scFv to a membrane-proximal target epitope of human PSMA is aligned against human antibody germline amino acid sequences.
[0394] The human antibody germline VH sequence is chosen which has the closest homology to the non-human VH and a direct alignment of the two amino acid sequences is performed. There are a number of framework residues of the non-human VH that differ from the human VH framework regions ("different framework positions"). Some of these residues may contribute to the binding and activity of the antibody to its target.
[0395] To construct a library that contains the murine CDRs and at every framework position that differs from the chosen human VH sequence both possible residues (the human and the maternal murine amino acid residue), degenerated oligonucleotides are synthesized. These oligonucleotides incorporate at the differing positions the human residue with a probability of 75% and the murine residue with a probability of 25%. For one human VH e.g. six of these oligonucleotides have to be synthesized that overlap in a terminal stretch of approximately 20 nucleotides. To this end every second primer is an antisense primer. Restriction sites within the oligonucleotides needed for later cloning are deleted.
[0396] These primers may have a length of 60 to 90 nucleotides, depending on the number of primers that are needed to span over the whole V sequence.
[0397] These e.g. six primers are mixed in equal amounts (e.g. 1 .mu.l of each primer (primer stocks 20 to 100 .mu.M) to a 20 .mu.l PCR reaction) and added to a PCR mix consisting of PCR buffer, nucleotides and Taq polymerase. This mix is incubated at 94.degree. C. for 3 minutes, 65.degree. C. for 1 minute, 62.degree. C. for 1 minute, 59.degree. C. for 1 minute, 56.degree. C. for 1 minute, 52.degree. C. for 1 minute, 50.degree. C. for 1 minute and at 72.degree. C. for 10 minutes in a PCR cycler. Subsequently the product is run in an agarose gel electrophoresis and the product of a size from 200 to 400 base pairs isolated from the gel according to standard methods.
[0398] This PCR product is then used as a template for a standard PCR reaction using primers that incorporate suitable N-terminal and C-terminal cloning restriction sites. The DNA fragment of the correct size (for a VH approximately 350 nucleotides) is isolated by agarose gel electrophoresis according to standard methods. In this way sufficient VH DNA fragment is amplified. This VH fragment is now a pool of VH fragments that have each one a different amount of human and murine residues at the respective differing framework positions (pool of humanized VH). The same procedure is performed for the VL region of the murine anti-PSMA scFv to a membrane-proximal target epitope of human PSMA (pool of humanized VL).
[0399] The pool of humanized VH is then combined with the pool of humanized VL in the phage display vector pComb3H5Bhis to form a library of functional scFvs from which--after display on filamentous phage--anti-PSMA binders to membrane-proximal target epitopes of human PSMA are selected, screened, identified and confirmed as described above for the parental non-human (murine) anti-PSMA scFv. Single clones are then analyzed for favorable properties and amino acid sequence. Those scFvs, which are closest in amino acid sequence homology to human germline V-segments, are preferred.
[0400] Human/humanized anti-PSMA scFvs to membrane-proximal target epitopes of human PSMA are converted into recombinant bispecific single chain antibodies and further characterized as follows.
2.11 Generation of I2C-Based Bispecific Single Chain Antibodies Directed at Membrane-Proximal Target Epitopes of Human PSMA
[0401] Anti-PSMA scFvs to membrane-proximal target epitopes of human PSMA with favorable properties and amino acid sequence are converted into recombinant bispecific single chain antibodies by joining them via a Gly.sub.4Ser.sub.1-linker with the CD3 specific scFv I2C (SEQ ID NO: 185) to result in constructs with the domain arrangement VH.sub.PSMA-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.PSMA-Ser.sub.1Gly.sub.4Ser.- sub.1-VH.sub.CD3-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.CD3. Alternatively further constructs with different domain arrangements can be generated according to standard protocolls. For expression in CHO cells the coding sequences of (i) an N-terminal immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence and (ii) a C-terminal His6-tag followed by a stop codon are both attached in frame to the nucleotide sequence encoding the bispecific single chain antibodies prior to insertion of the resulting DNA-fragment as obtained by gene synthesis into the multiple cloning site of the expression vector pEF-DHFR (Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
2.12 Expression and Purification of Bispecific Single Chain Antibody Molecules Directed at Membrane-Proximal Target Epitopes of Human PSMA
[0402] Bispecific single chain antibody molecules are expressed in Chinese hamster ovary cells (CHO). Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the constructs is induced by addition of increasing concentrations of MTX up to final concentrations of 20 nM MTX. After two passages of stationary culture cell culture supernatant is collected and used in the subsequent experiments. To generate supernatant for purification after two passages of stationary culture the cells are grown in roller bottles with nucleoside-free HyQ PF CHO liquid soy medium (with 4.0 mM L-Glutamine with 0.1% Pluronic F-68; HyClone) for 7 days before harvest. The cells are removed by centrifugation and the supernatant containing the expressed protein is stored at -20.degree. C. Alternatively, constructs are transiently expressed in HEK 293 cells. Transfection is performed with 293fectin reagent (Invitrogen, #12347-019) according to the manufacturer's protocol. Furthermore the constructs are alternatively expressed in transiently transfected DHFR deficient CHO cells using for example FuGENE.RTM. HD Transfection Reagent (Roche Diagnostics GmbH, Cat. No. 04709691001) according to the manufacturer's protocol.
[0403] Akta.RTM. Explorer System (GE Health Systems) and Unicorn.RTM. Software are used for chromatography. Immobilized metal affinity chromatography ("IMAC") is performed using a Fractogel EMD Chelate.RTM. (Merck) which is loaded with ZnCl.sub.2 according to the protocol provided by the manufacturer. The column is equilibrated with buffer A (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl) and the cell culture supernatant (500 ml) is applied to the column (10 ml) at a flow rate of 3 ml/min. The column is washed with buffer A to remove unbound sample. Bound protein is eluted using a two step gradient of buffer B (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl, 0.5 M Imidazole) according to the following procedure:
[0404] Step 1: 20% buffer B in 6 column volumes
[0405] Step 2: 100% buffer B in 6 column volumes
[0406] Eluted protein fractions from step 2 are pooled for further purification. All chemicals are of research grade and purchased from Sigma (Deisenhofen) or Merck (Darmstadt).
[0407] Gel filtration chromatography is performed on a HiLoad 16/60 Superdex 200 prep grade column (GE/Amersham) equilibrated with Equi-buffer (25 mM Citrate, 200 mM Lysine, 5% Glycerol, pH 7.2). Eluted protein samples (flow rate 1 ml/min) are subjected to standard SDS-PAGE and Western Blot for detection. Prior to purification, the column is calibrated for molecular weight determination (molecular weight marker kit, Sigma MW GF-200). Protein concentrations are determined using OD280 nm.
[0408] Purified bispecific single chain antibody protein is analyzed in SDS PAGE under reducing conditions performed with pre-cast 4-12% Bis Tris gels (Invitrogen). Sample preparation and application are performed according to the protocol provided by the manufacturer. The molecular weight is determined with MultiMark protein standard (Invitrogen). The gel is stained with colloidal Coomassie (Invitrogen protocol). The purity of the isolated protein is typically >95% as determined by SDS-PAGE.
[0409] The bispecific single chain antibody has a molecular weight of about 52 kDa under native conditions as determined by gel filtration in PBS.
[0410] Western Blot is performed using an Optitran.RTM. BA-S83 membrane and the Invitrogen Blot Module according to the protocol provided by the manufacturer. The antibody used is directed against the His Tag (Penta His, Qiagen) and a Goat-anti-mouse Ig labeled with alkaline phosphatase (AP) (Sigma) is used as second step reagent, and BCIP/NBT (Sigma) as substrate. A band detected at 52 kD corresponds to purified bispecific single chain antibodies.
2.13 Flow Cytometric Binding Analysis of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human PSMA
[0411] In order to test the functionality of bispecific antibody constructs regarding the capability to bind to CD3 and to membrane-proximal target epitopes of human PSMA, respectively, a FACS analysis is performed. For this purpose CHO cells transfected with human PSMA as described in Example 2.1 and the human CD3 positive T cell leukemia cell line HPB-ALL (DSMZ, Braunschweig, ACC483) are used. For confirmation of binding to membrane-proximal target epitopes of human PSMA--in addition--CHO cells expressing the rat PSMA antigen as described in Example 2.3 and CHO cells expressing the mutated rat PSMA antigen with human membrane-distal epitopes as described in Example 2.5 are used. 200.000 cells of the respective cell lines are incubated for 30 min on ice with 50 .mu.l of cell culture supernatant of transfected cells expressing the bispecific antibody constructs. The cells are washed twice in PBS with 2% FCS and binding of the construct is detected with a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS).
[0412] After washing, bound anti His antibodies are detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Supernatant of untransfected cells is used as a negative control.
[0413] Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0414] Only those constructs that show bispecific binding to human CD3 as well as to human PSMA and neither bind to the rat PSMA antigen nor to the mutated rat PSMA antigen with human membrane-distal epitopes are selected for further use.
2.14 Bioactivity of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human PSMA
[0415] Bioactivity of generated bispecific single chain antibodies is analyzed by chromium 51 (.sup.51Cr) release in vitro cytotoxicity assays using the CHO cells transfected with human PSMA described in Example 2.1. As effector cells stimulated human CD4/CD56 depleted PBMC are used.
[0416] Stimulated human PBMC are obtained as follows:
[0417] A Petri dish (145 mm diameter, Greiner bio-one GmbH, Kremsmunster) is coated with a commercially available anti-CD3 specific antibody (e.g. OKT3, Orthoclone) in a final concentration of 1 .mu.g/ml for 1 hour at 37.degree. C. Unbound protein is removed by one washing step with PBS. The fresh PBMC are isolated from peripheral blood (30-50 ml human blood) by Ficoll gradient centrifugation according to standard protocols. 3-5.times.10.sup.7 PBMC are added to the precoated petri dish in 120 ml of RPMI 1640 with stabilized glutamine/10% FCS/IL-2 20 U/ml (Proleukin, Chiron) and stimulated for 2 days. On the third day the cells are collected and washed once with RPMI 1640. IL 2 is added to a final concentration of 20 U/ml and the cells are cultivated again for one day in the same cell culture medium as above.
[0418] By depletion of CD4+ T cells and CD56+NK cells according to standard protocols CD8+ cytotoxic T lymphocytes (CTLs) are enriched.
[0419] Target cells are washed twice with PBS and labeled with 11.1 MBq .sup.51Cr in a final volume of 100 .mu.l RPMI with 50% FCS for 60 minutes at 37.degree. C. Subsequently the labeled target cells are washed 3 times with 5 ml RPMI and then used in the cytotoxicity assay. The assay is performed in a 96 well plate in a total volume of 250 .mu.l supplemented RPMI (as above) with an E:T ratio of 10:1. 1 .mu.g/ml of purified bispecific single chain antibody molecule and 20 threefold dilutions thereof are applied. The assay time is 18 hours. Cytotoxicity is measured as relative values of released chromium in the supernatant related to the difference of maximum lysis (addition of Triton-X) and spontaneous lysis (without effector cells). All measurements are done in quadruplicates. Measurement of chromium activity in the supernatants is performed with a Wizard 3'' gammacounter (Perkin Elmer Life Sciences GmbH, Koln, Germany). Analysis of the experimental data is performed with Prism 4 for Windows (version 4.02, GraphPad Software Inc., San Diego, Calif., USA). Sigmoidal dose response curves typically have R.sup.2 values >0.90 as determined by the software. EC50 values calculated by the analysis program are used for comparison of bioactivity.
[0420] Only those constructs showing potent recruitment of cytotoxic activity of effector T cells against target cells positive for PSMA are selected for further use.
2.15 Generation of CHO Cells Expressing Macaque PSMA
[0421] The cDNA sequence of macaque PSMA is obtained by a set of five PCRs on cDNA from macaque monkey prostate prepared according to standard protocols. The following reaction conditions: 1 cycle at 94.degree. C. for 2 minutes followed by 40 cycles with 94.degree. C. for 1 minute, 52.degree. C. for 1 minute and 72.degree. C. for 1.5 minutes followed by a terminal cycle of 72.degree. C. for 3 minutes and the following primers are used:
TABLE-US-00001 1. forward primer: SEQ ID NO: 228 5'-cactgtggcccaggttcgagg-3' reverse primer: SEQ ID NO: 229 5'-gacataccacacaaattcaatacgg-3' 2. forward primer: SEQ ID NO: 230 5'-gctctgctcgcgccgagatgtgg-3' reverse primer: SEQ ID NO: 231 5'-acgctggacaccacctccagg-3' 3. forward primer: SEQ ID NO: 232 5'-ggttctactgagtgggcagagg-3' reverse primer: SEQ ID NO: 233 5'-acttgttgtggctgcttggagc-3' 4. forward primer: SEQ ID NO: 234 5'-gggtgaagtcctatccagatgg-3' reverse primer: SEQ ID NO: 235 5'-gtgctctgcctgaagcaattcc-3' 5. forward primer: SEQ ID NO: 236 5'-ctcggcttcctcttcgggtgg-3' reverse primer: SEQ ID NO: 237 5'-gcatattcatttgctgggtaacctgg-3'
[0422] Those PCRs generate five overlapping fragments, which are isolated and sequenced according to standard protocols using the PCR primers, and thereby provided a portion of the cDNA sequence coding macaque PSMA from codon 3 to the last codon of the mature protein. To generate a construct for expression of macaque PSMA a cDNA fragment is obtained by gene synthesis according to standard protocols (the cDNA and amino acid sequence of the construct is listed under SEQ ID NO: 238 and 239). In this construct the coding sequence of macaque PSMA from amino acid 3 to the last amino acid of the mature PSMA protein followed by a stop codon is fused in frame to the coding sequence of the first two amino acids of the human PSMA protein. The gene synthesis fragment is also designed as to contain a Kozak site for eukaryotic expression of the construct and restriction sites at the beginning and the end of the fragment containing the cDNA. The introduced restriction sites, XbaI at the 5' end and SalI at the 3' end, are utilised in the following cloning procedures. The gene synthesis fragment is cloned via XbaI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
2.16 Flow Cytometric Analysis of Cross-Species Specificity of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human PSMA
[0423] In order to test the cross-species specificity of bispecific antibodies directed at membrane-proximal target epitopes of human PSMA the capability of the constructs to bind to macaque PSMA and macaque CD3, respectively, is investigated by FACS analysis. For this purpose the macaque PSMA transfected CHO cells as described in example 2.15 and the macaque T cell line 4119LnPx (kindly provided by Prof Fickenscher, Hygiene Institute, Virology, Erlangen-Nuernberg; published in Knappe A, et al., and Fickenscher H., Blood 2000, 95, 3256-61) are used. 200.000 cells of the respective cell lines are incubated for 30 min on ice with with 50 .mu.l of cell culture supernatant of transfected cells expressing the cross-species specific bispecific antibody constructs. The cells are washed twice in PBS with 2% FCS and binding of the construct is detected with a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS). After washing, bound anti His antibodies are detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Supernatant of untransfected cells is used as a negative control. Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg).
[0424] FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
Example 3
3.1. Generation of PSMA- and CD3-Directed Bispecific Single Antibodies
[0425] Bispecific single chain antibodes comprising either scFv binding domain P1, P2, P3, P4 or P5 against a PSMA-epitope of <60 .ANG. membrane-distance or scFv binding domain D1 or D2 against a PSMA-epitope of .gtoreq.60 .ANG. membrane-distance and the scFv binding domain I2C directed at CD3epsilon on human T cells were obtained by gene synthesis. The gene synthesis fragments were designed as to contain first a Kozak site for eukaryotic expression of the construct, followed by a 19 amino acid immunoglobulin leader peptide, followed in frame by the coding sequence of the bispecific single chain antibody, followed in frame by the coding sequence of a 6 histidine tag and a stop codon. The variable region arrangements as well as the SEQ ID Nos of the cDNA- and amino acid sequences are listed in the table 3 below.
TABLE-US-00002 TABLE 3 SEQ ID Formats of protein constructs (nucl/prot) (N .fwdarw. C) 281/280 PSMA-P1 LH .times. I2C HL 295/294 PSMA-P2 LH .times. I2C HL 309/308 PSMA-P3 LH .times. I2C HL 323/322 PSMA-P4 LH .times. I2C HL 337/336 PSMA-P5 LH .times. I2C HL 351/350 PSMA-D1 LH .times. I2C HL 365/364 PSMA-D2 LH .times. I2C HL
[0426] The gene synthesis fragments were also designed as to introduce suitable restriction sites at the beginning (EcoRI) and at the end of the fragment (Sal I) for cloning of the gene synthesis fragment into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures were carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence was transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells was performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct was induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX. After two passages of stationary culture cell culture supernatant was collected and used in the subsequent experiments.
3.2. Membrane-Distance <60 .ANG. or .gtoreq.60 .ANG. of PSMA-Epitopes Recognized by I2C-Based PSMA-Directed bscAbs
[0427] Epitope confirmation of PSMA-directed bispecific single antibodies was carried out by flowcytometry on CHO cells transfected with (unmutated) human PSMA, unmutated rat PSMA and rat PSMA mutated to the homologous human amino acid at every mismatched amino acid position with a membrane-distance of 60 .ANG. as described in Example 2.
[0428] 200,000 cells of each CHO-transfectant were incubated for 30 min on ice with 50 .mu.l of cell culture supernatant of transfected cells expressing the PSMA-directed bispecific antibody constructs. The cells were washed twice in PBS with 2% FCS and binding of the construct was detected with a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS). After washing, bound anti His antibodies were detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Cell culture medium was used as a negative control. Flowcytometry was performed on a FACS-Calibur apparatus, the CellQuest software was used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity were performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0429] FIG. 4 shows, that PSMA-directed bscAbs P1.times.I2C, P2.times.I2C, P3.times.I2C, P4.times.I2C and P5.times.I2C bind to (unmutated) human PSMA but neither to unmutated nor to mutated rat PSMA and thus confirms a membrane-distance of <60 .ANG. for the PSMA-epitope of each of these bispecific constructs. By contrast, PSMA-directed bscAbs D1.times.I2C and D2.times.I2C do not bind to unmutated rat PSMA but to (unmutated) human and mutated rat PSMA consistent with PSMA-epitopes of a membrane-distance .gtoreq.60 .ANG..
3.3. Relative T Cell Cytotoxicity Redirected by I2C-Based PSMA-Directed bscAbs with PSMA-Epitopes of a Membrane-Distance <60 .ANG. and .gtoreq.60 .ANG.
[0430] T cell cytotoxicity redirected by I2C-based PSMA-directed bscAbs against CHO cells transfected with human PSMA was measured in a chromium 51 (.sup.51Cr) release assay. As source of effector T cells stimulated human CD4/CD56 depleted PBMC were used. Stimulated human PBMC were obtained as follows: A Petri dish (145 mm diameter, Greiner bio-one GmbH, Kremsmunster) was coated with a commercially available anti-CD3 specific antibody (e.g. OKT3, Orthoclone) in a final concentration of 1 .mu.g/ml for 1 hour at 37.degree. C. Unbound protein was removed by one washing step with PBS. The fresh PBMC were isolated from peripheral blood (30-50 ml human blood) by Ficoll gradient centrifugation according to standard protocols. 3-5.times.10.sup.7 PBMC were added to the precoated petri dish in 120 ml of RPMI 1640 with stabilized glutamine/10% FCS/IL-2 20 U/ml (Proleukin, Chiron) and stimulated for 2 days. On the third day the cells were collected and washed once with RPMI 1640. IL-2 was added to a final concentration of 20 U/ml and the cells were cultured again for one day in the same cell culture medium as above.
[0431] By depletion of CD4+ T cells and CD56+NK cells according to standard protocols CD8+ cytotoxic T lymphocytes (CTLs) were enriched. Target cells were washed twice with PBS and labelled with 11.1 MBq .sup.51Cr in a final volume of 100 .mu.l RPMI with 50% FCS for 60 minutes at 37.degree. C. Subsequently the labelled target cells were washed 3 times with 5 ml RPMI and then used in the cytotoxicity assay. The assay was performed in a 96 well plate in a total volume of 250 .mu.l supplemented RPMI (as above) with an E:T cell ratio of 10:1. I2C-based PSMA-directed bscAbs were added as culture supernatants from transfected CHO cells at different dilutions. The assay time was 18 hours. Cytotoxicity was measured as relative values of released chromium related to the difference of maximum lysis (addition of Triton-X) and spontaneous lysis (without effector cells). All measurements were carried out in quadruplicates. Measurement of released chromium activity was performed with a Wizard 3'' gammacounter (Perkin Elmer Life Sciences GmbH, Koln, Germany). Analysis of the experimental data was performed with Prism 4 for Windows (version 4.02, GraphPad Software Inc., San Diego, Calif., USA). Sigmoidal dose response curves typically had R.sup.2 values >0.90 as determined by the software.
[0432] As shown in FIG. 5 all 5 PSMA-directed bscAbs, whose PSMA-epitopes have a membrane-distance of <60 .ANG. are substantially more potent in redirecting T cell cytotoxicity than the other two PSMA-directed bscAbs, whose PSMA-epitopes have a membrane-distance of .gtoreq.60 .ANG..
4. Generation of Additional Bispecific Single Antibodies Directed at CD3 and Membrane-Proximal Target Epitopes of Human PSMA
[0433] The human antibody germline VH sequence VH1 1-03 (http://vbase.mrc-cpe.cam.ac.uk/) is chosen as framework context for CDRH1 (SEQ ID NO 260), CDRH2 (SEQ ID NO 261) and CDRH3 (SEQ ID NO 262). For VH1 1-03 the following degenerated oligonucleotides have to be synthesized that overlap in a terminal stretch of approximately 15-20 nucleotides (to this end every second primer is an antisense primer):
TABLE-US-00003 5'P6-VH-A-XhoI (SEQ ID NO: 449) CTT GAT CTC GAG TCC GGC SCT GAG STG RWG AAG CCT GGC GCC TCC GTG AAG RTG TCC TGC AAG GCC TCC GGC TAC 3'P6-VH-B (SEQ ID NO: 450) CCA TTC CAG CMS CTG GCC GGG TKY CTG TYT CAC CCA GTG CAT CAC GTA GCC GGT GAA GGT GTA GCC GGA GGC CTT GCA 5'P6-VH-C (SEQ ID NO: 451) CCC GGC CAG SKG CTG GAA TGG ATS GGC TAC ATC AAC CCT TAC AAC GAC GTG ACC CGG TAC AAC GGC AAG TTC AAG 3'P6-VH-D (SEQ ID NO: 452) TTC CAT GTA GGC GGT GGA GGM GKA CKT GTC KCT GGT AAK GGT GRC TYT GCC CTT GAA CTT GCC GTT GTA 5'P6-VH-E (SEQ ID NO: 453) TCC ACC GCC TAC ATG GAA CTG TCC RGC CTG ASG TCT GAG GAC ACC GCC GTG TAC TAC TGC GCC AGG GGC 3'P6-VH-F-BstEII (SEQ ID NO: 454) CGA TAC GGT GAC CAG AGT GCC TCT GCC CCA GGA GTC GAA GTA GTA CCA GTT CTC GCC CCT GGC GCA GTA GTA
[0434] This primer-set spans over the whole VH sequence.
[0435] Within this set primers are mixed in equal amounts (e.g. 1 .mu.l of each primer (primer stocks 20 to 100 .mu.M) to a 20 .mu.l PCR reaction) and added to a PCR mix consisting of PCR buffer, nucleotides and Taq polymerase. This mix is incubated at 94.degree. C. for 3 minutes, 65.degree. C. for 1 minute, 62.degree. C. for 1 minute, 59.degree. C. for 1 minute, 56.degree. C. for 1 minute, 52.degree. C. for 1 minute, 50.degree. C. for 1 minute and at 72.degree. C. for 10 minutes in a PCR cycler. Subsequently the product is run in an agarose gel electrophoresis and the product of a size from 200 to 400 isolated from the gel according to standard methods.
[0436] The VH PCR product is then used as a template for a standard PCR reaction using primers that incorporate N-terminal and C-terminal suitable cloning restriction sites. The DNA fragment of the correct size (for a VH approximately 350 nucleotides) is isolated by agarose gel electrophoresis according to standard methods. In this way sufficient VH DNA fragment is amplified.
[0437] The human antibody germline VL sequence VklI A1 (http://vbase.mrc-cpe.cam.ac.uk/) is chosen as framework context for CDRL1 (SEQ ID NO: 255), CDRL2 (SEQ ID NO: 256) and CDRL3 (SEQ ID NO: 257). For VklI A1 the following degenerated oligonucleotides have to be synthesized that overlap in a terminal stretch of approximately 15-20 nucleotides (to this end every second primer is an antisense primer):
TABLE-US-00004 5'P6-VL-A-SacI (SEQ ID NO: 455) CTT GAT GAG CTC GTG ATG ACC CAG TCT CCA SYC TCC CTG SCT GTG ACT CTG GGC CAG CSG GCC TCC ATC TCT TGC CGG 3'P6-VL-B (SEQ ID NO: 456) CCA GTG CAT GAA GGT GTT GTC GTA GGA GTC GAT GGA CTC GGA GGC CCG GCA AGA GAT GGA GGC 5'P6-VL-C (SEQ ID NO: 457) ACC TTC ATG CAC TGG TWT CAG CAG ARG CCT GGC CAG YCT CCT MRC CKG CTG ATC TWC CGG GCC TCT ATC CTG GAA 3'P6-VL-D (SEQ ID NO: 458) CAG GGT GAA GTC GGT GCC GGA GCC AGA GCC GGA GAA CCG GKC AGG GAY GCC GGA TTC CAG GAT AGA GGC CCG 5'P6-VL-E (SEQ ID NO: 459) ACC GAC TTC ACC CTG AMA ATC TMC CST GTG GAG GCC GAS GAC GTG GSC RYC TAC TAC TGC CAC CAG 3'P6-VL-F-BsiWI/SpeI (SEQ ID NO: 460) ACT CAG ACT AGT CGT ACG CTT GAT TTC CAG CTT GGT CCC TCC GCC GAA GGT GTA AGG GTC CTC GAT GGA CTG GTG GCA GTA GTA
[0438] This primer-set spans over the whole corresponding VL sequence.
[0439] Within this set primers are mixed in equal amounts (e.g. 1 .mu.l of each primer (primer stocks 20 to 100 .mu.M) to a 20 .mu.l PCR reaction) and added to a PCR mix consisting of PCR buffer, nucleotides and Taq polymerase. This mix is incubated at 94.degree. C. for 3 minutes, 65.degree. C. for 1 minute, 62.degree. C. for 1 minute, 59.degree. C. for 1 minute, 56.degree. C. for 1 minute, 52.degree. C. for 1 minute, 50.degree. C. for 1 minute and at 72.degree. C. for 10 minutes in a PCR cycler. Subsequently the product is run in an agarose gel electrophoresis and the product of a size from 200 to 400 isolated from the gel according to standard methods.
[0440] The VL PCR product is then used as a template for a standard PCR reaction using primers that incorporate N-terminal and C-terminal suitable cloning restriction sites.
[0441] The DNA fragment of the correct size (for a VL approximately 330 nucleotides) is isolated by agarose gel electrophoresis according to standard methods. In this way sufficient VL DNA fragment is amplified.
[0442] The final VH1 1-03-based VH PCR product (i.e. the repertoire of human/humanized VH) is combined with the final VklI A1-based VL PCR product (i.e. the repertoire of human/humanized VL) in the phage display vector pComb3H5Bhis. This VH-VL combination forms a library of functional scFvs from which--after display on filamentous phage--anti-PSMA binders are selected, screened, identified and confirmed as described in the following:
[0443] 450 ng of the light chain fragments (SacI-SpeI digested) are ligated with 1400 ng of the phagemid pComb3H5Bhis (SacI-SpeI digested; large fragment). The resulting combinatorial antibody library is then transformed into 300 ul of electrocompetent Escherichia coli XL1 Blue cells by electroporation (2.5 kV, 0.2 cm gap cuvette, 25 uFD, 200 Ohm, Biorad gene-pulser) resulting in a library size of more than 10.sup.7 independent clones. After one hour of phenotype expression, positive transformants are selected for carbenicilline resistance encoded by the pComb3H5BHis vector in 100 ml of liquid super broth (SB)-culture over night. Cells are then harvested by centrifugation and plasmid preparation is carried out using a commercially available plasmid preparation kit (Qiagen).
[0444] 2800 ng of this plasmid-DNA containing the VL-library (XhoI-BstElI digested; large fragment) are ligated with 900 ng of the heavy chain V-fragments (XhoI-BstElI digested) and again transformed into two 300 ul aliquots of electrocompetent E. coli XL1 Blue cells by electroporation (2.5 kV, 0.2 cm gap cuvette, 25 uFD, 200 Ohm) resulting in a total VH-VL scFv (single chain variable fragment) library size of more than 10.sup.7 independent clones.
[0445] After phenotype expression and slow adaptation to carbenicilline, the E. coli cells containing the antibody library are transferred into SB-carbenicilline (SB with 50 ug/mL carbenicilline) selection medium. The E. coli cells containing the antibody library is then infected with an infectious dose of 10.sup.12 particles of helper phage VCSM13 resulting in the production and secretion of filamentous M13 phage, wherein phage particle contains single stranded pComb3H5BHis-DNA encoding a scFv-fragment and displayed the corresponding scFv-protein as a translational fusion to phage coat protein III. This pool of phages displaying the antibody library is used for the selection of antigen binding entities.
[0446] For this purpose the phage library carrying the cloned scFv-repertoire is harvested from the respective culture supernatant by PEG8000/NaCl precipitation and centrifugation. Approximately 10.sup.11 to 10.sup.12 scFv phage particles are resuspended in 0.4 ml of PBS/0.1% BSA and incubated with 10.sup.5 to 10.sup.7 PSMA-positive human prostate cancer cell line LNCaP (ATCC No. CRL-1740) for 1 hour on ice under slow agitation. These LNCaP cells are harvested beforehand by centrifugation, washed in PBS and resuspended in PBS/1% FCS (containing 0.05% Na Azide). scFv phage which do not specifically bind to LNCaP cells are eliminated by up to five washing steps with PBS/1% FCS (containing 0.05% Na Azide). After washing, binding entities are eluted from the cells by resuspending the cells in HCl-glycine pH 2.2 (10 min incubation with subsequent vortexing) and after neutralization with 2 M Tris pH 12, the eluate is used for infection of a fresh uninfected E. coli XL1 Blue culture (OD600>0.5). The E. coli culture containing E. coli cells successfully transduced with a phagemid copy, encoding a human/humanized scFv-fragment, are again selected for carbenicilline resistance and subsequently infected with VCMS 13 helper phage to start the second round of antibody display and in vitro selection. A total of 4 to 5 rounds of selections are carried out, normally.
[0447] In order to screen for PSMA specific binders plasmid DNA corresponding to 4 and 5 rounds of panning is isolated from E. coli cultures after selection. For the production of soluble scFv-protein, VH-VL-DNA fragments are excised from the plasmids (XhoI-SpeI). These fragments are cloned via the same restriction sites into the plasmid pComb3H5BFlag/His differing from the original pComb3H5BHis in that the expression construct (i.e. the scFv) includes a Flag-tag (DYKDDDDK) at its C-terminus before the His6-tag and that phage protein III/N2 domain and protein III/CT domain had been deleted. After ligation, each pool (different rounds of panning) of plasmid DNA is transformed into 100 .mu.l heat shock competent E. coli TG1 or XLI blue and plated onto carbenicilline LB-agar. Single colonies are picked into 100 .mu.l of LB carb (50 ug/ml carbenicilline).
[0448] E. coli transformed with pComb3H5BFlag/His containing a VL- and VH-segment produce soluble scFv in sufficient amounts after induction with 1 mM IPTG. Due to a suitable signal sequence, the scFv-chain is exported into the periplasma where it folds into a functional conformation.
[0449] Single E. coli TG1 bacterial colonies from the transformation plates are picked for periplasmic small scale preparations and grown in SB-medium (e.g. 10 ml) supplemented with 20 mM MgCl.sub.2 and carbenicilline 50 .mu.g/ml (and re-dissolved in PBS (e.g. 1 ml) after harvesting. By four rounds of freezing at -70.degree. C. and thawing at 37.degree. C., the outer membrane of the bacteria is destroyed by temperature shock and the soluble periplasmic proteins including the scFvs are released into the supernatant. After elimination of intact cells and cell-debris by centrifugation, the supernatant containing the anti-PSMA scFvs is collected and used for the identification of PSMA specific binders as follows:
[0450] Binding of scFvs to PSMA is tested by flow cytometry on the PSMA-positive human prostate cancer cell line LNCaP (ATCC No. CRL-1740). A periplasmic small scale preparation as described above without any grown bacteria is used as negative control.
[0451] For flow cytometry 2.5.times.10.sup.5 cells are incubated with 50 ul of scFv periplasmic preparation or with 5 .mu.g/ml of purified scFv in 50 .mu.l PBS with 2% FCS. The binding of scFv is detected with an anti-His antibody (Penta-His Antibody, BSA free, Qiagen GmbH, Hilden, FRG) at 2 .mu.g/ml in 50 .mu.l PBS with 2% FCS. As a second step reagent a R-Phycoerythrin-conjugated affinity purified F(ab')2 fragment, goat anti-mouse IgG (Fc-gamma fragment specific), diluted 1:100 in 50 .mu.l PBS with 2% FCS (Dianova, Hamburg, FRG) is used. The samples are measured on a FACSscan (BD biosciences, Heidelberg, FRG).
[0452] Single clones are then analyzed for favourable properties and amino acid sequence. PSMA specific scFvs are converted into recombinant bispecific single chain antibodies by joining them via a Gly.sub.4Ser.sub.1-linker with the CD3 specific scFv I2C (SEQ ID NO: 185) or any other CD3 specific scFv of the invention to result in constructs with the domain arrangement VH.sub.PSMA-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.PSMA-Ser.sub.1Gly.sub.4Ser.- sub.1-VH.sub.CD3-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.CD3 or alternative domain arrangements such as VL.sub.PSMA-(Gly.sub.4Ser.sub.1).sub.3-VH.sub.PSMA-Gly.sub.4Ser.sub.1-VH.- sub.CD3-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.CD3. For expression in CHO cells the coding sequences of (i) an N-terminal immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence and (ii) a C-terminal His.sub.6-tag followed by a stop codon are both attached in frame to the nucleotide sequence encoding the bispecific single chain antibodies prior to insertion of the resulting DNA-fragment as obtained by gene synthesis into the multiple cloning site of the expression vector pEF-DHFR (Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). Transfection of the generated expression plasmids is carried out as described in Example 3.1. Protein expression and purification of bispecific antibody constructs, flow cytometric confirmation of binding to CD3 and to membrane-proximal target epitopes of human PSMA as well as the analysis of bioactivity by cytotoxicity assay are performed as described in Example 2. All other state of the art procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)).
[0453] Only those bispecific antibody constructs that bind to CD3 and to membrane-proximal target epitopes of human PSMA and show potent recruitment of cytotoxic activity of effector T cells against target cells positive for PSMA are selected for further use.
Example 4
4.1. Generation of PSMA- and CD3-Directed Bispecific Single Chain Antibodies
[0454] Bispecific single chain antibodes comprising either scFv binding domain P6 against a PSMA-epitope of <60 .ANG. membrane-distance or scFv binding domain D3 against a PSMA-epitope of .gtoreq.60 .ANG. membrane-distance and the scFv binding domain I2C directed at CD3epsilon on human T cells were obtained by gene synthesis. The gene synthesis fragments were designed as to contain first a Kozak site for eukaryotic expression of the construct, followed by a 19 amino acid immunoglobulin leader peptide, followed in frame by the coding sequence of the bispecific single chain antibody, followed in frame by the coding sequence of a 6 histidine tag and a stop codon. The variable region arrangements as well as the SEQ ID Nos of the cDNA- and amino acid sequences are listed in the table 4 below.
TABLE-US-00005 TABLE 4 SEQ ID Formats of protein constructs (nucl/prot) (N .fwdarw. C) 267/266 PSMA-P6 LH .times. I2C HL 253/252 PSMA-D3 LH .times. I2C HL
[0455] The gene synthesis fragments were also designed as to introduce suitable restriction sites at the beginning (EcoRI) and at the end of the fragment (Sal I) for cloning of the gene synthesis fragment into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures were carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence was transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells was performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct was induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX. After two passages of stationary culture cell culture supernatant was collected and used in the subsequent experiments.
4.2. Membrane-Distance <60 .ANG. or .gtoreq.60 .ANG. of PSMA-Epitopes Recognized by I2C-Based PSMA-Directed bscAbs
[0456] Epitope confirmation of PSMA-directed bispecific single antibodies was carried out by flowcytometry on CHO cells transfected with (unmutated) human PSMA, unmutated rat PSMA and rat PSMA mutated to the homologous human amino acid at every mismatched amino acid position with a membrane-distance of .gtoreq.60 .ANG. as described in Example 2.
[0457] 200,000 cells of each CHO-transfectant were incubated for 30 min on ice with 50 .mu.l of cell culture supernatant of transfected cells expressing the PSMA-directed bispecific antibody constructs. The cells were washed twice in PBS with 2% FCS and binding of the construct was detected with a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS). After washing, bound anti His antibodies were detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Cell culture medium was used as a negative control. Flowcytometry was performed on a FACS-Calibur apparatus, the CellQuest software was used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity were performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0458] FIG. 6 shows, that PSMA-directed bscAb P6.times.I2C binds to (unmutated) human PSMA but neither to unmutated nor to mutated rat PSMA and thus confirms a membrane-distance of <60 .ANG. for the PSMA-epitope of this bispecific construct. By contrast, PSMA-directed bscAb D3.times.I2C does not bind to unmutated rat PSMA but to (unmutated) human and mutated rat PSMA consistent with a PSMA-epitope of a membrane-distance .gtoreq.60 .ANG..
4.3. Relative T Cell Cytotoxicity Redirected by I2C-Based PSMA-Directed bscAbs with PSMA-Epitopes of a Membrane-Distance <60 .ANG. and .gtoreq.60 .ANG.
[0459] T cell cytotoxicity redirected by I2C-based PSMA-directed bscAbs against CHO cells transfected with human PSMA was measured in a chromium 51 (.sup.51Cr) release assay. As source of effector T cells stimulated human CD4/CD56 depleted PBMC were used. Stimulated human PBMC were obtained as follows: A Petri dish (145 mm diameter, Greiner bio-one GmbH, Kremsmunster) was coated with a commercially available anti-CD3 specific antibody (e.g. OKT3, Orthoclone) in a final concentration of 1 .mu.g/ml for 1 hour at 37.degree. C. Unbound protein was removed by one washing step with PBS. The fresh PBMC were isolated from peripheral blood (30-50 ml human blood) by Ficoll gradient centrifugation according to standard protocols. 3-5.times.10.sup.7 PBMC were added to the precoated petri dish in 120 ml of RPMI 1640 with stabilized glutamine/10% FCS/IL-2 20 U/ml (Proleukin, Chiron) and stimulated for 2 days. On the third day the cells were collected and washed once with RPMI 1640. IL-2 was added to a final concentration of 20 U/ml and the cells were cultured again for one day in the same cell culture medium as above.
[0460] By depletion of CD4+ T cells and CD56+NK cells according to standard protocols CD8+ cytotoxic T lymphocytes (CTLs) were enriched. Target cells were washed twice with PBS and labelled with 11.1 MBq .sup.51Cr in a final volume of 100 .mu.l RPMI with 50% FCS for 60 minutes at 37.degree. C. Subsequently the labelled target cells were washed 3 times with 5 ml RPMI and then used in the cytotoxicity assay. The assay was performed in a 96 well plate in a total volume of 250 .mu.l supplemented RPMI (as above) with an E:T cell ratio of 10:1. I2C-based PSMA-directed bscAbs were added as culture supernatants from transfected CHO cells at different dilutions. The assay time was 18 hours. Cytotoxicity was measured as relative values of released chromium related to the difference of maximum lysis (addition of Triton-X) and spontaneous lysis (without effector cells). All measurements were carried out in quadruplicates. Measurement of released chromium activity was performed with a Wizard 3'' gammacounter (Perkin Elmer Life Sciences GmbH, Koln, Germany). Analysis of the experimental data was performed with Prism 4 for Windows (version 4.02, GraphPad Software Inc., San Diego, Calif., USA). Sigmoidal dose response curves typically had R.sup.2 values >0.90 as determined by the software. As shown in FIG. 7 the PSMA-directed bscAb P6.times.I2C, whose PSMA-epitope has a membrane-distance of <60 .ANG. is substantially more potent in redirecting T cell cytotoxicity than PSMA-directed bscAb D3.times.I2C, whose PSMA-epitope has a membrane-distance of .gtoreq.60 .ANG..
Example 5: Crossreactive Binding to Human and Non-Chimpanzee Primate PSMA and CD3 of I2C-Based bscAbs Against Membrane-Proximal PSMA-Eptitopes
5.1. Cloning and Expression of Cyno PSMA Antigen on CHO Cells
[0461] The cDNA sequence of macaque PSMA was obtained as described in Example 2.15 As described above, these PCRs generated five overlapping fragments, which were isolated and sequenced according to standard protocols using the PCR primers, and thereby provided a portion of the cDNA sequence coding macaque PSMA from codon 3 to the last codon of the mature protein. To generate a construct for expression of macaque PSMA a cDNA fragment was obtained by gene synthesis according to standard protocols (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 238 and 239). In this construct the coding sequence of macaque PSMA from amino acid 3 to the last amino acid of the mature PSMA protein followed by a stop codon was fused in frame to the coding sequence of the first two amino acids of the human PSMA protein. The gene synthesis fragment was also designed as to contain a Kozak site for eukaryotic expression of the construct and restriction sites at the beginning and the end of the fragment containing the cDNA. The introduced restriction sites, XbaI at the 5' end and SalI at the 3' end, were utilised in the following cloning procedures. The gene synthesis fragment was cloned via XbaI and SalI into a plasmid designated pEF-DHFR following standard protocols. The aforementioned procedures were carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence was transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells was performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct was induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
5.2. Flow Cytometric Binding Analysis of I2C-Based bscAbs Against Membrane-Proximal Eptitopes of Human PSMA on Non-Chimanzee Primate PSMA and on Human and Non-Chimpanzee Primate CD3
[0462] Binding of bscAbs P1.times.I2C, P2.times.I2C, P3.times.I2C, P4.times.I2C, P5.times.I2C and P6.times.I2C directed against membrane-proximal PSMA-epitopes to CHO cells expressing human PSMA is shown by flowcytometry in Examples 3 and 4.
[0463] Binding of these bscAbs to macaque PSMA as well as to human and macaque CD3 was analysed by flowcytometry using CHO cells transfected with macaque PSMA, the human CD3 positive T cell leukemia cell line HPB-ALL (DSMZ, Braunschweig, ACC483) and the CD3 positive macaque T cell line 4119LnPx (kindly provided by Prof Fickenscher, Hygiene Institute, Virology, Erlangen-Nuernberg; published in Knappe A, et al., and Fickenscher H., Blood 2000, 95, 3256-61). Results are shown in FIG. 8. 200,000 cells of the respective cell population were incubated for 30 min on ice with 50 .mu.l of cell culture supernatant of CHO cells transfected with the PSMA-directed bispecific antibody constructs. The cells were washed twice in PBS and binding of the construct was detected with an unlabeled murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS). After washing, bound anti His antibodies were detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in 50 .mu.l PBS with 2% FCS. Fresh culture medium was used as a negative control.
[0464] Flow cytometry was performed on a FACS-Calibur apparatus, the CellQuest software was used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity were performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
6. Generation of Bispecific Single Chain Antibodies Directed at Membrane-Proximal Target Epitopes of Human FAPalpha
6.1 Generation of CHO Cells Expressing Human FAPalpha
[0465] The coding sequence of human FAPalpha as published in GenBank (Accession number NM_004460) is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the human FAPalpha protein and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 366 and 367). The gene synthesis fragment is also designed as to introduce restriction sites at the beginning and at the end of the fragment. The introduced restriction sites, XmaI at the 5' end and SalI at the 3' end, are utilized in the following cloning procedures. The gene synthesis fragment is cloned via XmaI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
6.2 Generation of a Soluble Human FAPalpha Fusion Protein
[0466] The coding sequence of human FAPalpha as described in Example 6.1 and the coding sequence of murine Lag3 as published in GenBank (Accession number NM_008479) are used for the construction of an artificial cDNA sequence encoding a soluble fusion protein of human FAPalpha and murine Lag3. To generate a construct for expression of the soluble human FAPalpha fusion protein .alpha. cDNA fragment is obtained by gene synthesis according to standard protocols (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 368 369). The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the murine Lag3 protein from amino acid 1 to 441 corresponding to the signal peptide and extracellular domains of murine Lag3, followed in frame by the coding sequence of an artificial Ser.sub.1-Gly.sub.4-Ser.sub.1-linker, followed in frame by the coding sequence of the human FAPalpha protein from amino acid 27 to 760 corresponding to the extracellular domains of human FAPalpha, followed in frame by the coding sequence of an artificial Ser.sub.1-Gly.sub.1-linker, followed in frame by the coding sequence of a 6 histidine tag and a stop codon. The gene synthesis fragment is also designed as to introduce restriction sites at the beginning and at the end of the fragment. The introduced restriction sites, SpeI at the 5' end and SalI at the 3' end, are utilized in the following cloning procedures. The gene synthesis fragment is cloned via SpeI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are all carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX. After two passages of stationary culture the cells are grown in roller bottles with nucleoside-free HyQ PF CHO liquid soy medium (with 4.0 mM L-Glutamine with 0.1% Pluronic F--68; HyClone) for 7 days before harvest. The cells are removed by centrifugation and the supernatant containing the expressed protein is stored at -20.degree. C. Alternatively a clone of the expression plasmid with sequence-verified nucleotide sequence is used for transfection and protein expression in the FreeStyle 293 Expression System (Invitrogen GmbH, Karlsruhe, Germany) according to the manufacturer's protocol. Supernatant containing the expressed protein is obtained, cells are removed by centrifugation and the supernatant is stored at -20.degree. C. Purification of the soluble human FAPalpha fusion protein is performed as follows:
[0467] Akta.RTM. Explorer System (GE Health Systems) and Unicorn.RTM. Software are used for chromatography. Immobilized metal affinity chromatography ("IMAC") is performed using a Fractogel EMD Chelate.RTM. (Merck) which is loaded with ZnCl.sub.2 according to the protocol provided by the manufacturer. The column is equilibrated with buffer A (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl) and the cell culture supernatant (500 ml) is applied to the column (10 ml) at a flow rate of 3 ml/min. The column is washed with buffer A to remove unbound sample. Bound protein is eluted using a two step gradient of buffer B (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl, 0.5 M Imidazole) according to the following procedure:
[0468] Step 1: 20% buffer B in 6 column volumes
[0469] Step 2: 100% buffer B in 6 column volumes
[0470] Eluted protein fractions from step 2 are pooled for further purification. All chemicals are of research grade and purchased from Sigma (Deisenhofen) or Merck (Darmstadt).
[0471] Gel filtration chromatography is performed on a HiLoad 16/60 Superdex 200 prep grade column (GE/Amersham) equilibrated with Equi-buffer (25 mM Citrate, 200 mM Lysine, 5% Glycerol, pH 7.2). Eluted protein samples (flow rate 1 ml/min) are subjected to standard SDS-PAGE and Western Blot for detection. Prior to purification, the column is calibrated for molecular weight determination (molecular weight marker kit, Sigma MW GF-200). Protein concentrations are determined using OD280 nm.
6.3 Generation of CHO Cells Expressing Murine FAPalpha
[0472] The sequence of murine FAPalpha (NM_007986, Mus musculus fibroblast activation protein (Fap), mRNA, National Center for Biotechnology Information, http://www.ncbi.nlm.nih.gov/entrez) is used to obtain a synthetic cDNA molecule by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the complete murine FAPalpha antigen, followed in frame by the coding sequence of a FLAG-tag and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 370 and 371). An alternative construct identical to the aforementioned construct except for a C-terminal 6 Histidine-tag instead of the FLAG-tag is also generated. The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX. Cell surface expression of murine FAPalpha by the generated transfectants is confirmed by flow cytometric binding analysis performed as described herein. In the case of the construct with the 6 Histidine tag a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS) was used and detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin. Expression of murine FAPalpha was confirmed as shown in FIG. 10.
6.4 Generation of CHO Cells Expressing a Mutated Human FAPalpha Antigen with Murine Membrane-Distal Epitopes
[0473] The coding sequence of a mutated human FAPalpha antigen with murine membrane-distal epitopes is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the complete human FAPalpha antigen mutated at 15 specific amino acid positions as explained below, followed in frame by the coding sequence of a FLAG-tag and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 372 and 373). All extracellular amino acids of human FAPalpha mismatching with the homologous murine sequence, whose alpha C-atoms have a distance of 60 .ANG. from the alpha C-atom of the thirteenth extracellular amino acid (i.e. the reference aa) as counted from the junction of transmembrane and extracellular region, are mutated to the homologous mismatched murine amino acid. This applies to the 15 amino acids that are listed in table 2 and marked in bold. The homologous mismatched amino acids between human and murine FAPalpha are identified by sequence alignment as shown in FIG. 9. The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). Internal restriction sites are removed by silent mutation of the coding sequence in the gene synthesis fragment. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
[0474] Cell surface expression of mutated human FAPalpha with murine membrane-distal epitopes by the generated transfectants is confirmed by flow cytometric binding analysis performed as described herein using an anti-FLAG M2 antibody (Sigma-Aldrich, Inc.; diluted 1:900 in 50 .mu.l PBS with 2% FCS) detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin. Expression of mutated human FAPalpha with murine membrane-distal epitopes was confirmed as shown in FIG. 10.
6.5 Generation of CHO Cells Expressing a Mutated Murine FAPalpha Antigen with Human Membrane-Distal Epitopes
[0475] The coding sequence of a mutated murine FAPalpha antigen with human membrane-distal epitopes is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the complete murine FAPalpha antigen mutated at the same 15 specific extracellular amino acid positions as identified in the foregoing Example 6.4 to the respective homologous human amino acid, followed in frame by the coding sequence of a FLAG tag and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 374 and 375). The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
6.6 Immunization of Mice Using a Soluble Human FAPalpha Fusion Protein
[0476] Twelve weeks old F1 mice from BALB/c.times.C57BL/6 crossings are immunized with the soluble human FAPalpha fusion protein as described in Example 6.2. To this end for each animal 40 .mu.g of the soluble human FAPalpha fusion protein are mixed with 10 nmol of a thioate-modified CpG-Oligonucleotide (5'-tccatgacgttcctgatgct-3') in 300 .mu.l PBS and are injected intraperitoneally. Mice receive booster immunizations after 21, 42 and optionally 63 days in the same way. Ten days after the first booster immunization, blood samples are taken and antibody serum titers against human FAPalpha are tested by flow cytometry according to standard protocols. To this end 200.000 cells of the human FAPalpha transfected CHO cells as described in Example 6.1 are incubated for 30 min on ice with 50 .mu.l of serum of the immunized animals diluted 1:1000 in PBS with 2% FCS. The cells are washed twice in PBS with 2% FCS and binding of serum antibodies is detected with a mouse Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Serum of the animals obtained prior to immunization is used as a negative control.
[0477] Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0478] Animals demonstrating significant serum reactivity against human FAPalpha as determined by the FACS analysis are used in the subsequent experiment.
6.7 Generation of an Immune Murine Antibody scFv Library: Construction of a Combinatorial Antibody Library and Phage Display
[0479] Three days after the last booster immunization spleen cells of reactive animals are harvested for the preparation of total RNA according to standard protocols.
[0480] A library of murine immunoglobulin (Ig) light chain (kappa) variable region (VK) and Ig heavy chain variable region (VH) DNA-fragments is constructed by RT-PCR on murine spleen RNA using VK- and VH specific primers. cDNA is synthesized according to standard protocols, see example 2.7.
[0481] 450 ng of the kappa light chain fragments (SacI-SpeI digested) are ligated with 1400 ng of the phagemid pComb3H5Bhis (SacI-SpeI digested; large fragment). The resulting combinatorial antibody library is then transformed into 300 .mu.l of electrocompetent Escherichia coli XL1 Blue cells by electroporation (2.5 kV, 0.2 cm gap cuvette, 25 .mu.FD, 200 Ohm, Biorad gene-pulser) resulting in a library size of more than 10.sup.7 independent clones. After one hour of phenotype expression, positive transformants are selected for carbenicillin resistance encoded by the pComb3H5BHis vector in 100 ml of liquid super broth (SB)-culture over night. Cells are then harvested by centrifugation and plasmid preparation is carried out using a commercially available plasmid preparation kit (Qiagen).
[0482] 2800 ng of this plasmid-DNA containing the VK-library (XhoI-BstElI digested; large fragment) are ligated with 900 ng of the heavy chain V-fragments (XhoI-BstElI digested) and again transformed into two 300 .mu.l aliquots of electrocompetent E. coli XL1 Blue cells by electroporation (2.5 kV, 0.2 cm gap cuvette, 25 .mu.FD, 200 Ohm) resulting in a total VH-VK scFv (single chain variable fragment) library size of more than 10.sup.7 independent clones.
[0483] After phenotype expression and slow adaptation to carbenicillin, the E. coli cells containing the antibody library are transferred into SB-Carbenicillin (SB with 50 .mu.g/mL carbenicillin) selection medium. The E. coli cells containing the antibody library are then infected with an infectious dose of 10.sup.12 particles of helper phage VCSM13 resulting in the production and secretion of filamentous M13 phage, wherein each phage particle contains single stranded pComb3H5BHis-DNA encoding a murine scFv-fragment and displays the corresponding scFv-protein as a translational fusion to phage coat protein III. This pool of phages displaying the antibody library is later used for the selection of antigen binding entities.
6.8 Phage Display Based Selection of Membrane-Proximal Target Binders on CHO Cells Expressing the Mutated Human FAPalpha Antigen with Murine Membrane-Distal Epitopes
[0484] The phage library carrying the cloned scFv-repertoire is harvested from the respective culture supernatant by PEG8000/NaCl precipitation and centrifugation. Approximately 10.sup.11 to 10.sup.12 scFv phage particles are resuspended in 0.4 ml of PBS/0.1% BSA and incubated with 10.sup.5 to 10.sup.7 CHO cells expressing the mutated human FAPalpha antigen with murine membrane-distal epitopes as described in example 6.4 for 1 hour on ice under slow agitation. These CHO cells are grown beforehand, harvested by centrifugation, washed in PBS and resuspended in PBS/1% FCS (containing Na Azide). scFv phage which do not specifically bind to the CHO cells are eliminated by up to five washing steps with PBS/1% FCS (containing Na Azide). After washing, binding entities are eluted from the cells by resuspending the cells in HCl-glycine pH 2.2 (10 min incubation with subsequent vortexing) and after neutralization with 2 M Tris pH 12, the eluate is used for infection of a fresh uninfected E. coli XL1 Blue culture (OD600>0.5). The E. coli culture containing E. coli cells successfully transduced with a phagemid copy, encoding a murine scFv-fragment, are again selected for carbenicillin resistance and subsequently infected with VCMS 13 helper phage to start the second round of antibody display and in vitro selection. Typically a total of 4 to 5 rounds of selections are carried out.
6.9 Screening for Membrane-Proximal Target Binders on CHO Cells Expressing the Human FAPalpha Antigen, the Murine FAPalpha Antigen and the Mutated Murine FAPalpha Antigen with Human Membrane-Distal Epitopes
[0485] Plasmid DNA corresponding to 4 and 5 rounds of panning is isolated from E. coli cultures after selection. For the production of soluble scFv-protein, VH-VL-DNA fragments are excised from the plasmids (XhoI-SpeI). These fragments are cloned via the same restriction sites in the plasmid pComb3H5BFlag/His differing from the original pComb3H5BHis in that the expression construct (e.g. scFv) includes a Flag-tag (TGDYKDDDDK) between the scFv and the His6-tag and the additional phage proteins are deleted. After ligation, each pool (different rounds of panning) of plasmid DNA is transformed into 100 .mu.l heat shock competent E. coli TG1 or XLI blue and plated onto carbenicillin LB-agar. Single colonies are picked into 100 .mu.l of LB carb (LB with 50 .mu.g/ml carbenicillin).
[0486] After induction with 1 mM IPTG E. coli transformed with pComb3H5BFlag/His containing a VL- and VH-segment produce soluble scFv in sufficient amounts. Due to a suitable signal sequence, the scFv is exported into the periplasma where it folds into a functional conformation.
[0487] Single E. coli bacterial colonies from the transformation plates are picked for periplasmic small scale preparations and grown in SB-medium (e.g. 10 ml) supplemented with 20 mM MgCl.sub.2 and carbenicillin 50 .mu.g/ml (and re-dissolved in PBS (e.g. 1 ml) after harvesting. A temperature shock is applied by four rounds of freezing at -70.degree. C. and thawing at 37.degree. C. whereby the outer membrane of the bacteria is destroyed and the soluble periplasmic proteins including the scFvs are released into the supernatant. After elimination of intact cells and cell-debris by centrifugation, the supernatant containing the murine anti-human FAPalpha-scFvs is collected and used for further examination.
[0488] Screening of the isolated scFvs for membrane-proximal target binders is performed by flow cytometry on CHO cells expressing the human FAPalpha antigen as described in Example 6.1, the murine FAPalpha antigen as described in Example 6.3 and the mutated murine FAPalpha antigen with human membrane-distal epitopes as described in Example 6.5.
[0489] For flow cytometry 2.5.times.10.sup.5 cells of the respective cell lines are incubated with 50 .mu.l supernatant. The binding of the constructs is detected with an anti-His antibody (Penta-His Antibody, BSA free, Qiagen GmbH, Hilden, FRG) at 2 .mu.g/ml in 50 .mu.l PBS with 2% FCS. As a second step reagent an R-Phycoerythrin-conjugated affinity purified F(ab')2 fragment, goat anti-mouse IgG (Fc-gamma fragment specific), diluted 1:100 in 50 .mu.l PBS with 2% FCS (Dianova, Hamburg, FRG) is used. The samples are measured on a FACSscan (BD biosciences, Heidelberg, FRG).
[0490] Only constructs which show binding to CHO cells expressing the human FAPalpha antigen and do not show binding to CHO cells expressing the murine FAPalpha antigen and also do not show binding to CHO cells expressing the mutated murine FAPalpha antigen with human membrane-distal epitopes are selected for further use.
6.10 Generation of Human/Humanized Equivalents of Non-Human scFvs to Membrane-Proximal Target Epitopes of Human FAPalpha
[0491] The VH region of a murine anti-FAPalpha scFv to a membrane-proximal target epitope of human FAPalpha is aligned against human antibody germline amino acid sequences. The human antibody germline VH sequence is chosen which has the closest homology to the non-human VH and a direct alignment of the two amino acid sequences is performed. There are a number of framework residues of the non-human VH that differ from the human VH framework regions ("different framework positions"). Some of these residues may contribute to the binding and activity of the antibody to its target.
[0492] To construct a library that contains the murine CDRs and at every framework position that differs from the chosen human VH sequence both possible residues (the human and the maternal murine amino acid residue), degenerated oligonucleotides are synthesized. These oligonucleotides incorporate at the differing positions the human residue with a probability of 75% and the murine residue with a probability of 25%. For one human VH e.g. six of these oligonucleotides have to be synthesized that overlap in a terminal stretch of approximately 20 nucleotides. To this end every second primer is an antisense primer. Restriction sites within the oligonucleotides needed for later cloning are deleted.
[0493] These primers may have a length of 60 to 90 nucleotides, depending on the number of primers that are needed to span over the whole V sequence.
[0494] These e.g. six primers are mixed in equal amounts (e.g. 1 .mu.l of each primer (primer stocks 20 to 100 .mu.M) to a 20 .mu.l PCR reaction) and added to a PCR mix consisting of PCR buffer, nucleotides and Taq polymerase. This mix is incubated at 94.degree. C. for 3 minutes, 65.degree. C. for 1 minute, 62.degree. C. for 1 minute, 59.degree. C. for 1 minute, 56.degree. C. for 1 minute, 52.degree. C. for 1 minute, 50.degree. C. for 1 minute and at 72.degree. C. for 10 minutes in a PCR cycler. Subsequently the product is run in an agarose gel electrophoresis and the product of a size from 200 to 400 base pairs isolated from the gel according to standard methods.
[0495] This PCR product is then used as a template for a standard PCR reaction using primers that incorporate suitable N-terminal and C-terminal cloning restriction sites. The DNA fragment of the correct size (for a VH approximately 350 nucleotides) is isolated by agarose gel electrophoresis according to standard methods. In this way sufficient VH DNA fragment is amplified. This VH fragment is now a pool of VH fragments that have each one a different amount of human and murine residues at the respective differing framework positions (pool of humanized VH). The same procedure is performed for the VL region of the murine anti-FAPalpha scFv to a membrane-proximal target epitope of human FAPalpha (pool of humanized VL). The pool of humanized VH is then combined with the pool of humanized VL in the phage display vector pComb3H5Bhis to form a library of functional scFvs from which--after display on filamentous phage--anti-FAPalpha binders to membrane-proximal target epitopes of human FAPalpha are selected, screened, identified and confirmed as described above for the parental non-human (murine) anti-FAPalpha scFv. Single clones are then analyzed for favorable properties and amino acid sequence. Those scFvs, which are closest in amino acid sequence homology to human germline V-segments, are preferred.
[0496] Human/humanized anti-FAPalpha scFvs to membrane-proximal target epitopes of human FAPalpha are converted into recombinant bispecific single chain antibodies and further characterized as follows.
6.11 Generation of I2C-Based Bispecific Single Chain Antibodies Directed at Membrane-Proximal Target Epitopes of Human FAPalpha
[0497] Anti-FAPalpha scFvs to membrane-proximal target epitopes of human FAPalpha with favorable properties and amino acid sequence are converted into recombinant bispecific single chain antibodies by joining them via a Gly.sub.4Ser.sub.1-linker with the CD3 specific scFv I2C (SEQ ID NO: 185) to result in constructs with the domain arrangement VH.sub.FAPalpha-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.FAPalpha-Ser.sub.1Gly.s- ub.4Ser.sub.1-VH.sub.CD3-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.CD3.
[0498] I2C-based bispecific single chain antibodies directed at membrane-proximal target epitopes of human FAPalpha were designed as set out in the following Table 5:
TABLE-US-00006 TABLE 5 Formats of I2C-based bispecific single chain antibodies directed at membrane-proximal target epitopes of human FAPalpha SEQ ID Formats of protein constructs (nucl/prot) (N .fwdarw. C) 820/819 FA19D12HL .times. I2CHL 806/805 FA20H3HL .times. I2CHL 750/749 FA22A9HL .times. I2CHL 764/763 FA22C11HL .times. I2CHL 834/833 FA19D9HL .times. I2CHL 778/777 FA22D8HL .times. I2CHL 792/791 FA22E8HL .times. I2CHL
[0499] Alternatively further constructs with different domain arrangements can be generated according to standard protocolls. For expression in CHO cells the coding sequences of (i) an N-terminal immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence and (ii) a C-terminal His6-tag followed by a stop codon are both attached in frame to the nucleotide sequence encoding the bispecific single chain antibodies prior to insertion of the resulting DNA-fragment as obtained by gene synthesis into the multiple cloning site of the expression vector pEF-DHFR (Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
6.12 Expression and Purification of Bispecific Single Chain Antibody Molecules Directed at Membrane-Proximal Target Epitopes of Human FAPalpha
[0500] Bispecific single chain antibody molecules are expressed in Chinese hamster ovary cells (CHO). Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the constructs is induced by addition of increasing concentrations of MTX up to final concentrations of 20 nM MTX. After two passages of stationary culture cell culture supernatant is collected and used in the subsequent experiments. To generate supernatant for purification after two passages of stationary culture the cells are grown in roller bottles with nucleoside-free HyQ PF CHO liquid soy medium (with 4.0 mM L-Glutamine with 0.1% Pluronic F-68; HyClone) for 7 days before harvest. The cells are removed by centrifugation and the supernatant containing the expressed protein is stored at -20.degree. C. Alternatively, constructs are transiently expressed in HEK 293 cells. Transfection is performed with 293fectin reagent (Invitrogen, #12347-019) according to the manufacturer's protocol. Furthermore the constructs are alternatively expressed in transiently transfected DHFR deficient CHO cells using for example FuGENE.RTM. HD Transfection Reagent (Roche Diagnostics GmbH, Cat. No. 04709691001) according to the manufacturer's protocol.
[0501] Akta.RTM. Explorer System (GE Health Systems) and Unicorn.RTM. Software are used for chromatography. Immobilized metal affinity chromatography ("IMAC") is performed using a Fractogel EMD Chelate.RTM. (Merck) which is loaded with ZnCl.sub.2 according to the protocol provided by the manufacturer. The column is equilibrated with buffer A (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl) and the cell culture supernatant (500 ml) is applied to the column (10 ml) at a flow rate of 3 ml/min. The column is washed with buffer A to remove unbound sample. Bound protein is eluted using a two step gradient of buffer B (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl, 0.5 M Imidazole) according to the following procedure:
[0502] Step 1: 20% buffer B in 6 column volumes
[0503] Step 2: 100% buffer B in 6 column volumes
[0504] Eluted protein fractions from step 2 are pooled for further purification. All chemicals are of research grade and purchased from Sigma (Deisenhofen) or Merck (Darmstadt).
[0505] Gel filtration chromatography is performed on a HiLoad 16/60 Superdex 200 prep grade column (GE/Amersham) equilibrated with Equi-buffer (25 mM Citrate, 200 mM Lysine, 5% Glycerol, pH 7.2). Eluted protein samples (flow rate 1 ml/min) are subjected to standard SDS-PAGE and Western Blot for detection. Prior to purification, the column is calibrated for molecular weight determination (molecular weight marker kit, Sigma MW GF-200). Protein concentrations are determined using OD280 nm.
[0506] Purified bispecific single chain antibody protein is analyzed in SDS PAGE under reducing conditions performed with pre-cast 4-12% Bis Tris gels (Invitrogen). Sample preparation and application are performed according to the protocol provided by the manufacturer. The molecular weight is determined with MultiMark protein standard (Invitrogen). The gel is stained with colloidal Coomassie (Invitrogen protocol). The purity of the isolated protein is typically >95% as determined by SDS-PAGE. The bispecific single chain antibody has a molecular weight of about 52 kDa under native conditions as determined by gel filtration in PBS.
[0507] Western Blot is performed using an Optitran.RTM. BA-S83 membrane and the Invitrogen Blot Module according to the protocol provided by the manufacturer. The antibody used is directed against the His Tag (Penta His, Qiagen) and a Goat-anti-mouse Ig labeled with alkaline phosphatase (AP) (Sigma) is used as second step reagent, and BCIP/NBT (Sigma) as substrate. A band detected at 52 kD corresponds to purified bispecific single chain antibodies.
6.13 Flow Cytometric Binding Analysis of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human FAPalpha
[0508] In order to test the functionality of bispecific antibody constructs regarding the capability to bind to CD3 and to human FAPalpha, respectively, a FACS analysis is performed. For this purpose CHO cells transfected with human FAPalpha as described in Example 6.1 and the human CD3 positive T cell leukemia cell line HPB-ALL (DSMZ, Braunschweig, ACC483) are used. 200.000 cells of the respective cell lines are incubated for 30 min on ice with 50 .mu.l of cell culture supernatant of transfected cells expressing the bispecific antibody constructs. The cells are washed twice in PBS with 2% FCS and binding of the construct is detected with a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS). After washing, bound anti His antibodies are detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Supernatant of untransfected cells is used as a negative control.
[0509] Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0510] Only those constructs that show bispecific binding to human CD3 as well as to human FAPalpha are selected for further use.
[0511] The bispecific binding of the single chain molecules listed above was clearly detectable as shown in FIG. 11. In the FACS analysis all constructs showed binding to human CD3 and human FAPA compared to the negative control.
6.14 Bioactivity of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human FAPalpha
[0512] Bioactivity of generated bispecific single chain antibodies is analyzed by chromium 51 (.sup.51Cr) release in vitro cytotoxicity assays using the CHO cells transfected with human FAPalpha described in Example 6.1. To confirm that significant bioactivity is only recruited by binding to membrane-proximal target epitopes of human FAPalpha --in addition--CHO cells expressing the murine FAPalpha antigen as described in Example 6.3 and CHO cells expressing the mutated human FAPalpha antigen with murine membrane-distal epitopes as described in Example 6.4 are used. As effector cells stimulated human CD4/CD56 depleted PBMC are used.
[0513] Stimulated human PBMC are obtained as follows:
[0514] A Petri dish (145 mm diameter, Greiner bio-one GmbH, Kremsmunster) is coated with a commercially available anti-CD3 specific antibody (e.g. OKT3, Orthoclone) in a final concentration of 1 .mu.g/ml for 1 hour at 37.degree. C. Unbound protein is removed by one washing step with PBS. The fresh PBMC are isolated from peripheral blood (30-50 ml human blood) by Ficoll gradient centrifugation according to standard protocols. 3-5.times.10.sup.7 PBMC are added to the precoated petri dish in 120 ml of RPMI 1640 with stabilized glutamine/10% FCS/IL-2 20 U/ml (Proleukin, Chiron) and stimulated for 2 days. On the third day the cells are collected and washed once with RPMI 1640. IL 2 is added to a final concentration of 20 U/ml and the cells are cultivated again for one day in the same cell culture medium as above.
[0515] By depletion of CD4+ T cells and CD56+NK cells according to standard protocols CD8+ cytotoxic T lymphocytes (CTLs) are enriched.
[0516] Target cells are washed twice with PBS and labeled with 11.1 MBq .sup.51Cr in a final volume of 100 .mu.l RPMI with 50% FCS for 60 minutes at 37.degree. C. Subsequently the labeled target cells are washed 3 times with 5 ml RPMI and then used in the cytotoxicity assay. The assay is performed in a 96 well plate in a total volume of 250 .mu.l supplemented RPMI (as above) with an E:T ratio of 10:1. Supernatant of cells expressing the bispecific single chain antibody molecules in a final concentration of 6,6% and 14 threefold dilutions thereof are applied. The assay time is 18 hours. Cytotoxicity is measured as relative values of released chromium in the supernatant related to the difference of maximum lysis (addition of Triton-X) and spontaneous lysis (without effector cells). All measurements are done in quadruplicates. Measurement of chromium activity in the supernatants is performed with a Wizard 3'' gammacounter (Perkin Elmer Life Sciences GmbH, Koln, Germany). Analysis of the experimental data is performed with Prism 4 for Windows (version 4.02, GraphPad Software Inc., San Diego, Calif., USA). Sigmoidal dose response curves typically have R.sup.2 values >0.90 as determined by the software.
[0517] Only those constructs showing potent recruitment of cytotoxic activity of effector T cells against target cells positive for FAPalpha are selected for further use. As shown in FIG. 12 all of the generated bispecific antibodies directed at membrane-proximal target epitopes of human FAPalpha demonstrated cytotoxic activity against human FAPA positive target cells and target cells positive for the mutated human FAPalpha antigen with murine membrane-distal epitopes elicited by stimulated human CD4/CD56 depleted PBMC but did not recruit significant cytotoxic activity against murine FAPalpha positive target cells. Thereby specific recruitment of cytotoxic activity via binding to membrane-proximal target epitopes of human FAPalpha was confirmed.
6.15 Generation of CHO Cells Expressing Macaque FAPalpha
[0518] The cDNA sequence of macaque FAPalpha is obtained by a set of four PCRs on cDNA from macaque monkey skin prepared according to standard protocols. The following reaction conditions: 1 cycle at 94.degree. C. for 3 minutes followed by 40 cycles with 94.degree. C. for 0.5 minutes, 56.degree. C. for 0.5 minutes and 72.degree. C. for 3 minutes followed by a terminal cycle of 72.degree. C. for 3 minutes and the following primers are used:
TABLE-US-00007 1. forward primer: SEQ ID NO: 376 5'-cagcttccaactacaaagacagac-3' reverse primer: SEQ ID NO: 377 5'-tttcctcttcataaacccagtctgg-3' 2. forward primer: SEQ ID NO: 378 5'-ttgaaacaaagaccaggagatccacc-3' reverse primer: SEQ ID NO: 379 5'-agatggcaagtaacacacttcttgc-3' 3. forward primer: SEQ ID NO: 380 5'-gaagaaacatctacagaattagcattgg-3' reverse primer: SEQ ID NO: 381 5'-cacatttgaaaagaccagttccagatgc-3' 4. forward primer: SEQ ID NO: 382 5'-agattacagctgtcagaaaattcatagaaatgg-3' reverse primer: SEQ ID NO: 383 5'-atataaggttttcagattctgatacaggc-3'
[0519] These PCRs generate four overlapping fragments, which are isolated and sequenced according to standard protocols using the PCR primers, and thereby provided the cDNA sequence coding macaque FAPalpha. To generate a construct for expression of macaque FAPalpha a cDNA fragment is obtained by gene synthesis according to standard protocols (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 384 and 385). This construct contains the complete coding sequence of macaque FAPalpha followed by a stop codon. The gene synthesis fragment is also designed as to contain a Kozak site for eukaryotic expression of the construct and restriction sites at the beginning and the end of the fragment containing the cDNA. The introduced restriction sites, EcoRI at the 5' end and SalI at the 3' end, are utilised in the following cloning procedures. The gene synthesis fragment is cloned via EcoRI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
6.16 Flow Cytometric Analysis of Cross-Species Specificity of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human FAPalpha
[0520] In order to test the cross-species specificity of bispecific antibodies directed at membrane-proximal target epitopes of human FAPalpha the capability of the constructs to bind to macaque FAPalpha and macaque CD3, respectively, is investigated by FACS analysis. For this purpose the macaque FAPalpha transfected CHO cells as described in example 6.15 and the macaque T cell line 4119LnPx (kindly provided by Prof Fickenscher, Hygiene Institute, Virology, Erlangen-Nuernberg; published in Knappe A, et al., and Fickenscher H., Blood 2000, 95, 3256-61) are used. 200.000 cells of the respective cell lines are incubated for 30 min on ice with with 50 .mu.l of cell culture supernatant of transfected cells expressing the cross-species specific bispecific antibody constructs. The cells are washed twice in PBS with 2% FCS and binding of the construct is detected with a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS). After washing, bound anti His antibodies are detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Supernatant of untransfected cells is used as a negative control.
[0521] Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0522] The cross-species specific binding of the single chain molecules listed above was clearly detectable as shown in FIG. 11. In the FACS analysis all constructs showed binding to macaque CD3 and macaque FAPA compared to the negative control.
7. Generation of Bispecific Single Chain Antibodies Directed at Membrane-Proximal Target Epitopes of Human c-MET 7.1 Generation of CHO Cells Expressing Human c-MET
[0523] The coding sequence of human c-MET as published in GenBank (Accession number NM_000245) is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the human c-MET protein and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 368 and 387). The gene synthesis fragment is also designed as to introduce restriction sites at the beginning and at the end of the fragment. The introduced restriction sites, EcoRI at the 5' end and SalI at the 3' end, are utilized in the following cloning procedures. Internal restriction sites are removed by silent mutation of the coding sequence in the gene synthesis fragment. The gene synthesis fragment is cloned via EcoRI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
7.2 Generation of a Soluble Human c-MET Fusion Protein
[0524] The modified coding sequence of human c-MET as described in Example 7.1 is used for the construction of an artificial cDNA sequence encoding a soluble fusion protein of human c-MET and murine IgG1 Fc. To generate a construct for expression of the soluble human c-MET fusion protein .alpha. cDNA fragment is obtained by gene synthesis according to standard protocols (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 388 and 389). The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the human c-MET protein from amino acid 1 to 932 corresponding to the signal peptide and extracellular domains of human c-MET, followed in frame by the coding sequence of an artificial Ser.sub.1-Gly.sub.4-Ser.sub.1-linker, followed in frame by the coding sequence of the hinge region and Fc gamma portion of murine IgG1, followed in frame by the coding sequence of a 6 histidine tag and a stop codon. The gene synthesis fragment is also designed as to introduce restriction sites at the beginning and at the end of the fragment. The introduced restriction sites, EcoRI at the 5' end and SalI at the 3' end, are utilized in the following cloning procedures. The gene synthesis fragment is cloned via EcoRI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are all carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX. After two passages of stationary culture the cells are grown in roller bottles with nucleoside-free HyQ PF CHO liquid soy medium (with 4.0 mM L-Glutamine with 0.1% Pluronic F--68; HyClone) for 7 days before harvest. The cells are removed by centrifugation and the supernatant containing the expressed protein is stored at -20.degree. C. Alternatively a clone of the expression plasmid with sequence-verified nucleotide sequence is used for transfection and protein expression in the FreeStyle 293 Expression System (Invitrogen GmbH, Karlsruhe, Germany) according to the manufacturer's protocol. Supernatant containing the expressed protein is obtained, cells are removed by centrifugation and the supernatant is stored at -20.degree. C.
[0525] For purification of the soluble human c-MET fusion protein .alpha. goat anti-mouse Fc affinity column is prepared according to standard protocols using a commercially available affinity purified goat anti-mouse IgG Fc fragment specific antibody with minimal cross-reaction to human, bovine and horse serum proteins (Jackson ImmunoResearch Europe Ltd.). Using this affinity column the fusion protein is isolated out of cell culture supernatant on an Akta Explorer System (GE Amersham) and eluted by citric acid. The eluate is neutralized and concentrated.
7.3 Generation of CHO Cells Expressing Murine c-MET
[0526] The sequence of murine c-MET (NM_008591 Mus musculus met proto-oncogene (Met), mRNA, National Center for Biotechnology Information, http://www.ncbi.nlm.nih.gov/entrez) is used to obtain a synthetic cDNA molecule by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain the coding sequence of an immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence, followed in frame by the coding sequence of a FLAG tag, followed in frame by the complete coding sequence of the mature murine c-MET (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 390 and 391). The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) Internal restriction sites are removed by silent mutation of the coding sequence in the gene synthesis fragment. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
7.4 Generation of CHO Cells Expressing a Mutated Human c-MET Antigen with Murine Membrane-Distal Epitopes
[0527] The coding sequence of a mutated human c-MET antigen with murine membrane-distal epitopes is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain the coding sequence of an immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence, followed in frame by the coding sequence of a FLAG tag, followed in frame by the coding sequence of the alpha-chain of the sema domain of mature murine c-MET followed in frame by human c-MET from the beta-chain of the sema domain to the stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 392 and 393). The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). Internal restriction sites are removed by silent mutation of the coding sequence in the gene synthesis fragment. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
7.5 Generation of CHO Cells Expressing a Mutated Murine c-MET Antigen with Human Membrane-Distal Epitopes
[0528] The coding sequence of a mutated murine c-MET antigen with human membrane-distal epitopes is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain the coding sequence of an immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence, followed in frame by the coding sequence of a FLAG tag, followed in frame by the coding sequence of the alpha-chain of the sema domain of mature human c-MET, followed in frame by murine c-MET from the beta-chain of the sema domain to the stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 394 and 395). The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). Internal restriction sites are removed by silent mutation of the coding sequence in the gene synthesis fragment. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
7.6 Immunization of Mice Using a Soluble Human c-MET Fusion Protein
[0529] Twelve weeks old F1 mice from BALB/c.times.C57BL/6 crossings are immunized with the soluble human c-MET fusion protein as described in Example 7.2. To this end for each animal 40 .mu.g of the soluble human c-MET fusion protein are mixed with 10 nmol of a thioate-modified CpG-Oligonucleotide (5'-tccatgacgttcctgatgct-3') in 300 .mu.l PBS and are injected intraperitoneally. Mice receive booster immunizations after 21, 42 and optionally 63 days in the same way. Ten days after the first booster immunization, blood samples are taken and antibody serum titers against human c-MET are tested by flow cytometry according to standard protocols. To this end 200.000 cells of the human c-MET transfected CHO cells as described in Example 7.17 are incubated for 30 min on ice with 50 .mu.l of serum of the immunized animals diluted 1:1000 in PBS with 2% FCS. The cells are washed twice in PBS with 2% FCS and binding of serum antibodies is detected with an mouse Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Serum of the animals obtained prior to immunization is used as a negative control.
[0530] Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0531] Animals demonstrating significant serum reactivity against human c-MET as determined by the FACS analysis are used in the subsequent experiment.
7.7 Generation of an Immune Murine Antibody scFv Library: Construction of a Combinatorial Antibody Library and Phage Display
[0532] Three days after the last booster immunization spleen cells of reactive animals are harvested for the preparation of total RNA according to standard protocols.
[0533] A library of murine immunoglobulin (Ig) light chain (kappa) variable region (VK) and Ig heavy chain variable region (VH) DNA-fragments is constructed by RT-PCR on murine spleen RNA using VK- and VH specific primers. cDNA is synthesized according to standard protocols, see example 2.7.
[0534] 450 ng of the kappa light chain fragments (SacI-SpeI digested) are ligated with 1400 ng of the phagemid pComb3H5Bhis (SacI-SpeI digested; large fragment). The resulting combinatorial antibody library is then transformed into 300 .mu.l of electrocompetent Escherichia coli XL1 Blue cells by electroporation (2.5 kV, 0.2 cm gap cuvette, 25 .mu.FD, 200 Ohm, Biorad gene-pulser) resulting in a library size of more than 10.sup.7 independent clones. After one hour of phenotype expression, positive transformants are selected for carbenicillin resistance encoded by the pComb3H5BHis vector in 100 ml of liquid super broth (SB)-culture over night. Cells are then harvested by centrifugation and plasmid preparation is carried out using a commercially available plasmid preparation kit (Qiagen).
[0535] 2800 ng of this plasmid-DNA containing the VK-library (XhoI-BstElI digested; large fragment) are ligated with 900 ng of the heavy chain V-fragments (XhoI-BstElI digested) and again transformed into two 300 .mu.l aliquots of electrocompetent E. coli XL1 Blue cells by electroporation (2.5 kV, 0.2 cm gap cuvette, 25 .mu.FD, 200 Ohm) resulting in a total VH-VK scFv (single chain variable fragment) library size of more than 10.sup.7 independent clones.
[0536] After phenotype expression and slow adaptation to carbenicillin, the E. coli cells containing the antibody library are transferred into SB-Carbenicillin (SB with 50 .mu.g/mL carbenicillin) selection medium. The E. coli cells containing the antibody library are then infected with an infectious dose of 10.sup.12 particles of helper phage VCSM13 resulting in the production and secretion of filamentous M13 phage, wherein each phage particle contains single stranded pComb3H5BHis-DNA encoding a murine scFv-fragment and displays the corresponding scFv-protein as a translational fusion to phage coat protein III. This pool of phages displaying the antibody library is later used for the selection of antigen binding entities.
7.8 Phage Display Based Selection of Membrane-Proximal Target Binders on CHO Cells Expressing the Mutated Human c-MET Antigen with Murine Membrane-Distal Epitopes
[0537] The phage library carrying the cloned scFv-repertoire is harvested from the respective culture supernatant by PEG8000/NaCl precipitation and centrifugation. Approximately 10.sup.11 to 10.sup.12 scFv phage particles are resuspended in 0.4 ml of PBS/0.1% BSA and incubated with 10.sup.5 to 10.sup.7 CHO cells expressing the mutated human c-MET antigen with murine membrane-distal epitopes as described in example 7.17 for 1 hour on ice under slow agitation. These CHO cells are grown beforehand, harvested by centrifugation, washed in PBS and resuspended in PBS/1% FCS (containing Na Azide). scFv phage which do not specifically bind to the CHO cells are eliminated by up to five washing steps with PBS/1% FCS (containing Na Azide). After washing, binding entities are eluted from the cells by resuspending the cells in HCl-glycine pH 2.2 (10 min incubation with subsequent vortexing) and after neutralization with 2 M Tris pH 12, the eluate is used for infection of a fresh uninfected E. coli XL1 Blue culture (OD600>0.5). The E. coli culture containing E. coli cells successfully transduced with a phagemid copy, encoding a murine scFv-fragment, are again selected for carbenicillin resistance and subsequently infected with VCMS 13 helper phage to start the second round of antibody display and in vitro selection. Typically a total of 4 to 5 rounds of selections are carried out.
7.9 Screening for Membrane-Proximal Target Binders on CHO Cells Expressing the Human c-MET Antigen, the Murine c-MET Antigen, the Mutated Human c-MET Antigen with Murine Membrane-Distal Epitopes and the Mutated Murine c-MET Antigen with Human Membrane-Distal Epitopes
[0538] Plasmid DNA corresponding to 4 and 5 rounds of panning is isolated from E. coli cultures after selection. For the production of soluble scFv-protein, VH-VL-DNA fragments are excised from the plasmids (XhoI-SpeI). These fragments are cloned via the same restriction sites in the plasmid pComb3H5BFlag/His differing from the original pComb3H5BHis in that the expression construct (e.g. scFv) includes a Flag-tag (TGDYKDDDDK) between the scFv and the His6-tag and the additional phage proteins are deleted. After ligation, each pool (different rounds of panning) of plasmid DNA is transformed into 100 .mu.l heat shock competent E. coli TG1 or XLI blue and plated onto carbenicillin LB-agar. Single colonies are picked into 100 .mu.l of LB carb (LB with 50 .mu.g/ml carbenicillin).
[0539] After induction with 1 mM IPTG E. coli transformed with pComb3H5BFlag/His containing a VL- and VH-segment produce soluble scFv in sufficient amounts. Due to a suitable signal sequence, the scFv is exported into the periplasma where it folds into a functional conformation.
[0540] Single E. coli bacterial colonies from the transformation plates are picked for periplasmic small scale preparations and grown in SB-medium (e.g. 10 ml) supplemented with 20 mM MgCl.sub.2 and carbenicillin 50 .mu.g/ml (and re-dissolved in PBS (e.g. 1 ml) after harvesting. A temperature shock is applied by four rounds of freezing at -70.degree. C. and thawing at 37.degree. C. whereby the outer membrane of the bacteria is destroyed and the soluble periplasmic proteins including the scFvs are released into the supernatant. After elimination of intact cells and cell-debris by centrifugation, the supernatant containing the murine anti-human c-MET-scFvs is collected and used for further examination.
[0541] Screening of the isolated scFvs for membrane-proximal target binders is performed by flow cytometry on CHO cells expressing the human c-MET antigen as described in Example 7.17, the murine c-MET antigen as described in Example 7.17, the mutated human c-MET antigen with murine membrane-distal epitopes as described in Example 7.17 and the mutated murine c-MET antigen with human membrane-distal epitopes as described in Example 7.17.
[0542] For flow cytometry 2.5.times.10.sup.5 cells of the respective cell lines are incubated with 50 .mu.l supernatant. The binding of the constructs is detected with an anti-His antibody (Penta-His Antibody, BSA free, Qiagen GmbH, Hilden, FRG) at 2 .mu.g/ml in 50 .mu.l PBS with 2% FCS. As a second step reagent a R-Phycoerythrin-conjugated affinity purified F(ab')2 fragment, goat anti-mouse IgG (Fc-gamma fragment specific), diluted 1:100 in 50 .mu.l PBS with 2% FCS (Dianova, Hamburg, FRG) is used. The samples are measured on a FACSscan (BD biosciences, Heidelberg, FRG).
[0543] Only constructs which show binding to CHO cells expressing the human c-MET antigen and show binding to CHO cells expressing the mutated human c-MET antigen with murine membrane-distal epitopes and do not show binding to CHO cells expressing the murine c-MET antigen and also do not show binding to CHO cells expressing the mutated murine c-MET antigen with human membrane-distal epitopes are selected for further use.
[0544] scFv specific for membrane proximal epitopes of human cMET were generated as described above and designated as set out in the following Table 6:
TABLE-US-00008 TABLE 6 Designation of single chain antibody fragments SEQ ID (nucl/prot) Designation 734/733 ME06F2HL 720/719 ME06E10HL 706/705 ME06D2HL 692/691 ME06D1HL 664/663 ME06C7HL 650/649 ME06C6HL 678/677 ME06B7HL 636/635 ME05F6HL 622/621 ME05B7HL 608/607 ME99B1HL 594/593 ME75H6HL
[0545] Membrane-proximal target binding of the single chain molecules listed above was clearly detectable as shown in FIG. 16. In the FACS analysis all constructs showed binding to the human c-MET antigen and showed binding to the mutated human c-MET antigen with murine membrane-distal epitopes and did not show binding to the murine c-MET antigen and did also not show binding to the mutated murine c-MET antigen with human membrane-distal epitopes as compared to the negative control.
7.10 Generation of Human/Humanized Equivalents of Non-Human scFvs to Membrane-Proximal Target Epitopes of Human c-MET
[0546] The VH region of a murine anti-c-MET scFv to a membrane-proximal target epitope of human c-MET is aligned against human antibody germline amino acid sequences. The human antibody germline VH sequence is chosen which has the closest homology to the non-human VH and a direct alignment of the two amino acid sequences is performed. There are a number of framework residues of the non-human VH that differ from the human VH framework regions ("different framework positions"). Some of these residues may contribute to the binding and activity of the antibody to its target.
[0547] To construct a library that contains the murine CDRs and at every framework position that differs from the chosen human VH sequence both possible residues (the human and the maternal murine amino acid residue), degenerated oligonucleotides are synthesized. These oligonucleotides incorporate at the differing positions the human residue with a probability of 75% and the murine residue with a probability of 25%. For one human VH e.g. six of these oligonucleotides have to be synthesized that overlap in a terminal stretch of approximately 20 nucleotides. To this end every second primer is an antisense primer. Restriction sites within the oligonucleotides needed for later cloning are deleted.
[0548] These primers may have a length of 60 to 90 nucleotides, depending on the number of primers that are needed to span over the whole V sequence.
[0549] These e.g. six primers are mixed in equal amounts (e.g. 1 .mu.l of each primer (primer stocks 20 to 100 .mu.M) to a 20 .mu.l PCR reaction) and added to a PCR mix consisting of PCR buffer, nucleotides and Taq polymerase. This mix is incubated at 94.degree. C. for 3 minutes, 65.degree. C. for 1 minute, 62.degree. C. for 1 minute, 59.degree. C. for 1 minute, 56.degree. C. for 1 minute, 52.degree. C. for 1 minute, 50.degree. C. for 1 minute and at 72.degree. C. for 10 minutes in a PCR cycler. Subsequently the product is run in an agarose gel electrophoresis and the product of a size from 200 to 400 base pairs isolated from the gel according to standard methods.
[0550] This PCR product is then used as a template for a standard PCR reaction using primers that incorporate suitable N-terminal and C-terminal cloning restriction sites.
[0551] The DNA fragment of the correct size (for a VH approximately 350 nucleotides) is isolated by agarose gel electrophoresis according to standard methods. In this way sufficient VH DNA fragment is amplified. This VH fragment is now a pool of VH fragments that have each one a different amount of human and murine residues at the respective differing framework positions (pool of humanized VH). The same procedure is performed for the VL region of the murine anti-c-MET scFv to a membrane-proximal target epitope of human c-MET (pool of humanized VL).
[0552] The pool of humanized VH is then combined with the pool of humanized VL in the phage display vector pComb3H5Bhis to form a library of functional scFvs from which--after display on filamentous phage--anti-c-MET binders to membrane-proximal target epitopes of human c-MET are selected, screened, identified and confirmed as described above for the parental non-human (murine) anti-c-MET scFv. Single clones are then analyzed for favorable properties and amino acid sequence. Those scFvs, which are closest in amino acid sequence homology to human germline V-segments, are preferred.
[0553] Human/humanized anti-c-MET scFvs to membrane-proximal target epitopes of human c-MET are converted into recombinant bispecific single chain antibodies and further characterized as follows.
7.11 Generation of I2C-Based Bispecific Single Chain Antibodies Directed at Membrane-Proximal Target Epitopes of Human c-MET
[0554] Anti-c-MET scFvs to membrane-proximal target epitopes of human c-MET with favorable properties and amino acid sequence are converted into recombinant bispecific single chain antibodies by joining them via a Gly.sub.4Ser.sub.1-linker with the CD3 specific scFv I2C (SEQ ID NO: 185) to result in constructs with the domain arrangement VH.sub.c-MET-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.c-MET-Ser.sub.1Gly.sub.4Se- r.sub.1-VH.sub.CD3-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.CD3.
[0555] I2C-based bispecific single chain antibodies directed at membrane-proximal target epitopes of human c-MET were designed as set out in the following Table 7:
TABLE-US-00009 TABLE 7 Formats of I2C-based bispecific single chain antibodies directed at membrane-proximal target epitopes of human c-MET SEQ ID Formats of protein constructs (nucl/prot) (N .fwdarw. C) 512/511 ME86H11HL .times. I2CHL 526/525 ME62A12HL .times. I2CHL 540/539 ME63F2HL .times. I2CHL 554/553 ME62D11HL .times. I2CHL 568/567 ME62C10HL .times. I2CHL 582/581 ME62A4HL .times. I2CHL
[0556] Alternatively further constructs with different domain arrangements can be generated according to standard protocolls. For expression in CHO cells the coding sequences of (i) an N-terminal immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence and (ii) a C-terminal His6-tag followed by a stop codon are both attached in frame to the nucleotide sequence encoding the bispecific single chain antibodies prior to insertion of the resulting DNA-fragment as obtained by gene synthesis into the multiple cloning site of the expression vector pEF-DHFR (Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
7.12 Expression and Purification of Bispecific Single Chain Antibody Molecules Directed at Membrane-Proximal Target Epitopes of Human c-MET
[0557] Bispecific single chain antibody molecules are expressed in Chinese hamster ovary cells (CHO). Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the constructs is induced by addition of increasing concentrations of MTX up to final concentrations of 20 nM MTX. After two passages of stationary culture cell culture supernatant is collected and used in the subsequent experiments. To generate supernatant for purification after two passages of stationary culture the cells are grown in roller bottles with nucleoside-free HyQ PF CHO liquid soy medium (with 4.0 mM L-Glutamine with 0.1% Pluronic F-68; HyClone) for 7 days before harvest. The cells are removed by centrifugation and the supernatant containing the expressed protein is stored at -20.degree. C. Alternatively, constructs are transiently expressed in HEK 293 cells. Transfection is performed with 293fectin reagent (Invitrogen, #12347-019) according to the manufacturer's protocol. Furthermore the constructs are alternatively expressed in transiently transfected DHFR deficient CHO cells using for example FuGENE.RTM. HD Transfection Reagent (Roche Diagnostics GmbH, Cat. No. 04709691001) according to the manufacturer's protocol.
[0558] Akta.RTM. Explorer System (GE Health Systems) and Unicorn.RTM. Software are used for chromatography. Immobilized metal affinity chromatography ("IMAC") is performed using a Fractogel EMD Chelate.RTM. (Merck) which is loaded with ZnCl.sub.2 according to the protocol provided by the manufacturer. The column is equilibrated with buffer A (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl) and the cell culture supernatant (500 ml) is applied to the column (10 ml) at a flow rate of 3 ml/min. The column is washed with buffer A to remove unbound sample. Bound protein is eluted using a two step gradient of buffer B (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl, 0.5 M Imidazole) according to the following procedure:
[0559] Step 1: 20% buffer B in 6 column volumes
[0560] Step 2: 100% buffer B in 6 column volumes
[0561] Eluted protein fractions from step 2 are pooled for further purification. All chemicals are of research grade and purchased from Sigma (Deisenhofen) or Merck (Darmstadt).
[0562] Gel filtration chromatography is performed on a HiLoad 16/60 Superdex 200 prep grade column (GE/Amersham) equilibrated with Equi-buffer (25 mM Citrate, 200 mM Lysine, 5% Glycerol, pH 7.2). Eluted protein samples (flow rate 1 ml/min) are subjected to standard SDS-PAGE and Western Blot for detection. Prior to purification, the column is calibrated for molecular weight determination (molecular weight marker kit, Sigma MW GF-200). Protein concentrations are determined using OD280 nm.
[0563] Purified bispecific single chain antibody protein is analyzed in SDS PAGE under reducing conditions performed with pre-cast 4-12% Bis Tris gels (Invitrogen). Sample preparation and application are performed according to the protocol provided by the manufacturer. The molecular weight is determined with MultiMark protein standard (Invitrogen). The gel is stained with colloidal Coomassie (Invitrogen protocol). The purity of the isolated protein is typically >95% as determined by SDS-PAGE.
[0564] The bispecific single chain antibody has a molecular weight of about 52 kDa under native conditions as determined by gel filtration in PBS.
[0565] Western Blot is performed using an Optitran.RTM. BA-S83 membrane and the Invitrogen Blot Module according to the protocol provided by the manufacturer. The antibody used is directed against the His Tag (Penta His, Qiagen) and a Goat-anti-mouse Ig labeled with alkaline phosphatase (AP) (Sigma) is used as second step reagent, and BCIP/NBT (Sigma) as substrate. A band detected at 52 kD corresponds to purified bispecific single chain antibodies.
7.13 Flow Cytometric Binding Analysis of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human c-MET
[0566] In order to test the functionality of bispecific antibody constructs regarding the capability to bind to CD3 and to membrane-proximal target epitopes of human c-MET, respectively, a FACS analysis is performed. For this purpose CHO cells transfected with human c-MET as described in Example 7.17 and the human CD3 positive T cell leukemia cell line HPB-ALL (DSMZ, Braunschweig, ACC483) are used. For confirmation of binding to membrane-proximal target epitopes of human c-MET--in addition--CHO cells expressing the murine c-MET antigen as described in Example 7.17, CHO cells expressing the mutated human c-MET antigen with murine membrane-distal epitopes as described in Example 7.17 and CHO cells expressing the mutated murine c-MET antigen with human membrane-distal epitopes as described in Example 7.17 are used. 200.000 cells of the respective cell lines are incubated for 30 min on ice with 50 .mu.l of cell culture supernatant of transfected cells expressing the bispecific antibody constructs. The cells are washed twice in PBS with 2% FCS and binding of the construct is detected with a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS). After washing, bound anti His antibodies are detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Supernatant of untransfected cells is used as a negative control.
[0567] Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0568] Only those constructs that show bispecific binding to human CD3 as well as to human c-MET and neither bind to the murine c-MET antigen nor to the mutated murine c-MET antigen with human membrane-distal epitopes are selected for further use.
[0569] The bispecific binding of the single chain molecules listed above was clearly detectable as shown in FIG. 13. In the FACS analysis all constructs showed binding to human CD3 and human c-MET compared to the negative control.
[0570] Membrane-proximal target binding of the single chain molecules listed above was clearly detectable as shown in FIG. 14. In the FACS analysis all constructs showed binding to the mutated human c-MET antigen with murine membrane-distal epitopes and did not show binding to the murine c-MET antigen and did also not show binding to the mutated murine c-MET antigen with human membrane-distal epitopes as compared to the negative control. Expression of the c-MET antigens was confirmed by detection with an anti-FLAG M2 antibody as described herein. In the FACS analysis also shown in FIG. 14 CHO cells transfected with the murine c-MET antigen, the mutated murine c-MET antigen with human membrane-distal epitopes and the mutated human c-MET antigen with murine membrane-distal epitopes, respectively, showed comparable expression of the antigens as detected with the anti-FLAG antibody.
7.14 Bioactivity of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human c-MET
[0571] Bioactivity of generated bispecific single chain antibodies is analyzed by chromium 51 (.sup.51Cr) release in vitro cytotoxicity assays using the CHO cells transfected with human c-MET described in Example 7.17. To confirm that significant bioactivity is only recruited by binding to membrane-proximal target epitopes of human c-MET--in addition--CHO cells expressing murine c-MET and the mutated murine c-MET antigen with human membrane-distal epitopes, respectively, both as described in Example 7.17 are used. As effector cells stimulated human CD4/CD56 depleted PBMC are used.
[0572] Stimulated human PBMC are obtained as follows:
[0573] A Petri dish (145 mm diameter, Greiner bio-one GmbH, Kremsmunster) is coated with a commercially available anti-CD3 specific antibody (e.g. OKT3, Orthoclone) in a final concentration of 1 .mu.g/ml for 1 hour at 37.degree. C. Unbound protein is removed by one washing step with PBS. The fresh PBMC are isolated from peripheral blood (30-50 ml human blood) by Ficoll gradient centrifugation according to standard protocols. 3-5.times.10.sup.7 PBMC are added to the precoated petri dish in 120 ml of RPMI 1640 with stabilized glutamine/10% FCS/IL-2 20 U/ml (Proleukin, Chiron) and stimulated for 2 days. On the third day the cells are collected and washed once with RPMI 1640. IL 2 is added to a final concentration of 20 U/ml and the cells are cultivated again for one day in the same cell culture medium as above.
[0574] By depletion of CD4+ T cells and CD56+NK cells according to standard protocols CD8+ cytotoxic T lymphocytes (CTLs) are enriched.
[0575] Target cells are washed twice with PBS and labeled with 11.1 MBq .sup.51Cr in a final volume of 100 .mu.l RPMI with 50% FCS for 60 minutes at 37.degree. C. Subsequently the labeled target cells are washed 3 times with 5 ml RPMI and then used in the cytotoxicity assay. The assay is performed in a 96 well plate in a total volume of 250 .mu.l supplemented RPMI (as above) with an E:T ratio of 10:1. Supernatant of cells expressing the bispecific single chain antibody molecules in a final concentration of 50% and 20 threefold dilutions thereof are applied. The assay time is 18 hours. Cytotoxicity is measured as relative values of released chromium in the supernatant related to the difference of maximum lysis (addition of Triton-X) and spontaneous lysis (without effector cells). All measurements are done in quadruplicates. Measurement of chromium activity in the supernatants is performed with a Wizard 3'' gammacounter (Perkin Elmer Life Sciences GmbH, Koln, Germany). Analysis of the experimental data is performed with Prism 4 for Windows (version 4.02, GraphPad Software Inc., San Diego, Calif., USA). Sigmoidal dose response curves typically have R.sup.2 values >0.90 as determined by the software.
[0576] Only those constructs showing potent recruitment of cytotoxic activity of effector T cells against target cells positive for c-MET are selected for further use.
[0577] As shown in FIG. 15 all of the generated bispecific antibodies directed at membrane-proximal target epitopes of human c-MET demonstrated cytotoxic activity against human c-MET positive target cells elicited by stimulated human CD4/CD56 depleted PBMC but did not recruit significant cytotoxic activity against murine c-MET positive target cells and target cells positive for the mutated murine c-MET antigen with human membrane-distal epitopes. Thereby specific recruitment of cytotoxic activity via binding to membrane-proximal target epitopes of human c-MET was confirmed.
7.15 Generation of CHO Cells Expressing Macaque c-MET
[0578] The cDNA sequence of macaque c-MET is obtained by a set of 5 PCRs on cDNA from macaque monkey Liver prepared according to standard protocols. The following reaction conditions: 1 cycle at 94.degree. C. for 2 minutes followed by 40 cycles with 94.degree. C. for 1 minute, 56.degree. C. for 1 minute and 72.degree. C. for 3 minutes followed by a terminal cycle of 72.degree. C. for 3 minutes and the following primers are used:
TABLE-US-00010 1. forward primer: SEQ ID NO: 396 5'-aggaattcaccatgaaggcccccgctgtgcttgcacc-3' reverse primer: SEQ ID NO: 397 5'-ctccagaggcatttccatgtagg-3' 2. forward primer: SEQ ID NO: 398 5'-gtccaaagggaaactctagatgc-3' reverse primer: SEQ ID NO: 399 5'-ggagacactggatgggagtccagg-3' 3. forward primer: SEQ ID NO: 400 5'-catcagagggtcgcttcatgcagg-3' reverse primer: SEQ ID NO: 401 5'-gctttggttttcagggggagttgc-3' 4. forward primer: SEQ ID NO: 402 5'-atccaaccaaatcttttattagtggtgg-3' reverse primer: SEQ ID NO: 403 5'-gacttcattgaaatgcacaatcagg-3' 5. forward primer: SEQ ID NO: 404 5'-tgctctaaatccagagctggtcc-3' reverse primer: SEQ ID NO: 405 5'-gtcagataagaaattccttagaatcc-3'
[0579] These PCRs generate five overlapping fragments, which are isolated and sequenced according to standard protocols using the PCR primers, and thereby provide a portion of the cDNA sequence coding macaque c-MET from codon 10 of the leader peptide to the last codon of the mature protein. To generate a construct for expression of macaque c-MET a cDNA fragment is obtained by gene synthesis according to standard protocols (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 406 and 407). In this construct the coding sequence of macaque c-MET from amino acid 10 of the leader peptide to the last amino acid of the mature c-MET protein followed by a stop codon is fused in frame to the coding sequence of the amino acids 1 to 9 of the leader peptide of the human c-MET protein. The gene synthesis fragment is also designed as to contain a Kozak site for eukaryotic expression of the construct and restriction sites at the beginning and the end of the fragment containing the cDNA. The introduced restriction sites, EcoRI at the 5' end and SalI at the 3' end, are utilised in the following cloning procedures. Internal restriction sites are removed by silent mutation of the coding sequence in the gene synthesis fragment. The gene synthesis fragment is cloned via EcoRI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
7.16 Flow Cytometric Analysis of Cross-Species Specificity of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human c-MET
[0580] In order to test the cross-species specificity of bispecific antibodies directed at membrane-proximal target epitopes of human c-MET the capability of the constructs to bind to macaque c-MET and macaque CD3, respectively, is investigated by FACS analysis. For this purpose the macaque c-MET transfected CHO cells as described in example 7.17 and the macaque T cell line 4119LnPx (kindly provided by Prof Fickenscher, Hygiene Institute, Virology, Erlangen-Nuernberg; published in Knappe A, et al., and Fickenscher H., Blood 2000, 95, 3256-61) are used. 200.000 cells of the respective cell lines are incubated for 30 min on ice with with 50 .mu.l of cell culture supernatant of transfected cells expressing the cross-species specific bispecific antibody constructs. The cells are washed twice in PBS with 2% FCS and binding of the construct is detected with a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS). After washing, bound anti His antibodies are detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Supernatant of untransfected cells is used as a negative control. Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0581] The cross-species specific binding of the single chain molecules listed above was clearly detectable as shown in FIG. 13. In the FACS analysis all constructs showed binding to macaque CD3 and macaque c-MET compared to the negative control.
7.17 Generation of CHO Cells with Enhanced Expression of Extracellular Domains of Human c-MET, Macaque c-MET, Murine c-MET, Mutated Murine c-MET with Human Membrane-Distal Epitopes and Mutated Human c-MET with Murine Membrane-Distal Epitopes, Respectively
[0582] The modified coding sequences of human c-MET, macaque c-MET, murine c-MET, mutated murine c-MET with human membrane-distal epitopes and mutated human c-MET with murine membrane-distal epitopes as described above are used for the construction of artificial cDNA sequences encoding fusion proteins of the extracellular domains of human c-MET, macaque c-MET, murine c-MET, mutated murine c-MET with human membrane-distal epitopes and mutated human c-MET with murine membrane-distal epitopes, respectively, with a truncated variant of human EpCAM. To generate constructs for expression of these c-MET fusion proteins cDNA fragments are obtained by gene synthesis according to standard protocols (the cDNA and amino acid sequences of the constructs are listed under SEQ ID Nos 489 and 490 for human c-MET, 491 and 492 for macaque c-MET, 493 and 494 for murine c-MET, 495 and 496 for mutated murine c-MET with human membrane-distal epitopes and 497 and 498 for mutated human c-MET with murine membrane-distal epitopes). The gene synthesis fragments are designed as to contain first a Kozak site for eukaryotic expression of the construct, followed by the coding sequence of a 19 amino acid immunoglobulin leader peptide, followed in frame by the coding sequence of a FLAG tag (only in the case of the murine and the mutated human and mutated murine constructs), followed in frame by the coding sequence of the extracellular domains of human c-MET, macaque c-MET, murine c-MET, mutated murine c-MET with human membrane-distal epitopes and mutated human c-MET with murine membrane-distal epitopes, respectively, followed in frame by the coding sequence of an artificial Ser.sub.1-Gly.sub.4-Ser.sub.1-Gly.sub.1-linker, followed in frame by the coding sequence of the transmembrane domain and intracellular domain of human EpCAM (as published in GenBank; Accession number NM_002354; amino acids 266 to 314 [as counted from the start codon] except for a point mutation at position 279 with isoleucine instead of valine) and a stop codon. The gene synthesis fragments are also designed as to introduce restriction sites at the beginning and at the end of the fragment. The introduced restriction sites, EcoRI at the 5' end and SalI at the 3' end, are utilized in the following cloning procedures. The gene synthesis fragments are cloned via EcoRI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. Clones with sequence-verified nucleotide sequence are transfected into DHFR deficient CHO cells for eukaryotic expression of the constructs. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the constructs is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
8. Generation of Bispecific Single Chain Antibodies Directed at Membrane-Proximal Target Epitopes of Human Endosialin
8.1 Generation of CHO Cells Expressing Human Endosialin
[0583] The coding sequence of human Endosialin as published in GenBank (Accession number NM_020404) is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the human Endosialin protein, followed in frame by the coding sequence of a Flag tag and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 408 and 409). The gene synthesis fragment is also designed as to introduce restriction sites at the beginning and at the end of the fragment. The introduced restriction sites, EcoRI at the 5' end and XbaI at the 3' end, are utilized in the following cloning procedures. The gene synthesis fragment is cloned via EcoRI and XbaI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
8.2 Generation of a Soluble Human Endosialin Fusion Protein
[0584] The coding sequence of human Endosialin as described in Example 8.1 is used for the construction of an artificial cDNA sequence encoding a soluble fusion protein of human Endosialin and murine IgG1 Fc. To generate a construct for expression of the soluble human Endosialin fusion protein .alpha. cDNA fragment is obtained by gene synthesis according to standard protocols (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 410 and 411). The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the human Endosialin protein from amino acid 1 to 685 corresponding to the signal peptide and extracellular domains of human Endosialin, followed in frame by the coding sequence of an artificial Thr.sub.1-Gly.sub.4-Ser.sub.1-linker, followed in frame by the coding sequence of the hinge region and Fc gamma portion of murine IgG1, followed in frame by the coding sequence of a 6 histidine tag and a stop codon. The gene synthesis fragment is also designed as to introduce restriction sites at the beginning and at the end of the fragment. The introduced restriction sites, EcoRI at the 5' end and XbaI at the 3' end, are utilized in the following cloning procedures. The gene synthesis fragment is cloned via EcoRI and XbaI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are all carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX. After two passages of stationary culture the cells are grown in roller bottles with nucleoside-free HyQ PF CHO liquid soy medium (with 4.0 mM L-Glutamine with 0.1% Pluronic F--68; HyClone) for 7 days before harvest. The cells are removed by centrifugation and the supernatant containing the expressed protein is stored at -20.degree. C. Alternatively a clone of the expression plasmid with sequence-verified nucleotide sequence is used for transfection and protein expression in the FreeStyle 293 Expression System (Invitrogen GmbH, Karlsruhe, Germany) according to the manufacturer's protocol. Supernatant containing the expressed protein is obtained, cells are removed by centrifugation and the supernatant is stored at -20.degree. C.
[0585] For purification of the soluble human Endosialin fusion protein .alpha. goat anti-mouse Fc affinity column is prepared according to standard protocols using a commercially available affinity purified goat anti-mouse IgG Fc fragment specific antibody with minimal cross-reaction to human, bovine and horse serum proteins (Jackson ImmunoResearch Europe Ltd.). Using this affinity column the fusion protein is isolated out of cell culture supernatant on an Akta Explorer System (GE Amersham) and eluted by citric acid. The eluate is neutralized and concentrated.
8.3 Generation of CHO Cells Expressing the Murine Endosialin Antigen
[0586] The sequence of murine Endosialin (NM_054042 Mus musculus Endosialin antigen, endosialin (Cd248), mRNA; National Center for Biotechnology Information, http://www.ncbi.nlm.nih.gov/entrez) is used to obtain a synthetic cDNA molecule by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain the coding sequence of an immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence, followed in frame by the coding sequence of a FLAG tag, followed in frame by the complete coding sequence of mature murine endosialin (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 412 and 413). The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
8.4 Generation of CHO Cells Expressing a Mutated Human Endosialin Antigen with Murine Membrane-Distal Epitopes
[0587] The coding sequence of a mutated human Endosialin antigen with murine membrane-distal epitopes is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain the coding sequence of an immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence, followed in frame by the coding sequence of a FLAG tag, followed in frame by the coding sequence of the C-type lectin domain of mature murine endosialin followed in frame by human endosialin from the Sushi/SCR/CCP domain to the stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 414 and 415). The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
8.5 Generation of CHO Cells Expressing a Mutated Murine Endosialin Antigen with Human Membrane-Distal Epitopes
[0588] The coding sequence of a mutated murine Endosialin antigen with human membrane-distal epitopes is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain the coding sequence of an immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence, followed in frame by the coding sequence of a FLAG tag, followed in frame by the coding sequence of the C-type lectin domain of mature human endosialin followed in frame by murine endosialin from the Sushi/SCR/CCP domain to the stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 416 and 417). The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). Internal restriction sites are removed by silent mutation of the coding sequence in the gene synthesis fragment. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
8.6 Immunization of Mice Using a Soluble Human Endosialin Fusion Protein
[0589] Twelve weeks old F1 mice from BALB/c.times.C57BL/6 crossings are immunized with the soluble human Endosialin fusion protein as described in Example 8.2. To this end for each animal 40 .mu.g of the soluble human Endosialin fusion protein are mixed with 10 nmol of a thioate-modified CpG-Oligonucleotide (5'-tccatgacgttcctgatgct-3') in 300 .mu.l PBS and are injected intraperitoneally. Mice receive booster immunizations after 21, 42 and optionally 63 days in the same way. Ten days after the first booster immunization, blood samples are taken and antibody serum titers against human Endosialin are tested by flow cytometry according to standard protocols. To this end 200.000 cells of the human Endosialin transfected CHO cells as described in Example 8.1 are incubated for 30 min on ice with 50 .mu.l of serum of the immunized animals diluted 1:1000 in PBS with 2% FCS. The cells are washed twice in PBS with 2% FCS and binding of serum antibodies is detected with an mouse Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Serum of the animals obtained prior to immunization is used as a negative control.
[0590] Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0591] Animals demonstrating significant serum reactivity against human Endosialin as determined by the FACS analysis are used in the subsequent experiment.
8.7 Generation of an Immune Murine Antibody scFv Library: Construction of a Combinatorial Antibody Library and Phage Display
[0592] Three days after the last booster immunization spleen cells of reactive animals are harvested for the preparation of total RNA according to standard protocols. A library of murine immunoglobulin (Ig) light chain (kappa) variable region (VK) and Ig heavy chain variable region (VH) DNA-fragments is constructed by RT-PCR on murine spleen RNA using VK- and VH specific primers. cDNA is synthesized according to standard protocols, see example 2.7.
[0593] 450 ng of the kappa light chain fragments (SacI-SpeI digested) are ligated with 1400 ng of the phagemid pComb3H5Bhis (SacI-SpeI digested; large fragment). The resulting combinatorial antibody library is then transformed into 300 .mu.l of electrocompetent Escherichia coli XL1 Blue cells by electroporation (2.5 kV, 0.2 cm gap cuvette, 25 .mu.FD, 200 Ohm, Biorad gene-pulser) resulting in a library size of more than 10.sup.7 independent clones. After one hour of phenotype expression, positive transformants are selected for carbenicillin resistance encoded by the pComb3H5BHis vector in 100 ml of liquid super broth (SB)-culture over night. Cells are then harvested by centrifugation and plasmid preparation is carried out using a commercially available plasmid preparation kit (Qiagen).
[0594] 2800 ng of this plasmid-DNA containing the VK-library (XhoI-BstElI digested; large fragment) are ligated with 900 ng of the heavy chain V-fragments (XhoI-BstElI digested) and again transformed into two 300 .mu.l aliquots of electrocompetent E. coli XL1 Blue cells by electroporation (2.5 kV, 0.2 cm gap cuvette, 25 .mu.FD, 200 Ohm) resulting in a total VH-VK scFv (single chain variable fragment) library size of more than 10.sup.7 independent clones.
[0595] After phenotype expression and slow adaptation to carbenicillin, the E. coli cells containing the antibody library are transferred into SB-Carbenicillin (SB with 50 .mu.g/mL carbenicillin) selection medium. The E. coli cells containing the antibody library are then infected with an infectious dose of 10.sup.12 particles of helper phage VCSM13 resulting in the production and secretion of filamentous M13 phage, wherein each phage particle contains single stranded pComb3H5BHis-DNA encoding a murine scFv-fragment and displays the corresponding scFv-protein as a translational fusion to phage coat protein III. This pool of phages displaying the antibody library is later used for the selection of antigen binding entities.
8.8 Phage Display Based Selection of Membrane-Proximal Target Binders on CHO Cells Expressing the Mutated Human Endosialin Antigen with Murine Membrane-Distal Epitopes
[0596] The phage library carrying the cloned scFv-repertoire is harvested from the respective culture supernatant by PEG8000/NaCl precipitation and centrifugation. Approximately 10.sup.11 to 10.sup.12 scFv phage particles are resuspended in 0.4 ml of PBS/0.1% BSA and incubated with 10.sup.5 to 10.sup.7 CHO cells expressing the mutated human Endosialin antigen with murine membrane-distal epitopes as described in example 8.4 for 1 hour on ice under slow agitation. These CHO cells are grown beforehand, harvested by centrifugation, washed in PBS and resuspended in PBS/1% FCS (containing Na Azide). scFv phage which do not specifically bind to the CHO cells are eliminated by up to five washing steps with PBS/1% FCS (containing Na Azide). After washing, binding entities are eluted from the cells by resuspending the cells in HCl-glycine pH 2.2 (10 min incubation with subsequent vortexing) and after neutralization with 2 M Tris pH 12, the eluate is used for infection of a fresh uninfected E. coli XL1 Blue culture (OD600>0.5). The E. coli culture containing E. coli cells successfully transduced with a phagemid copy, encoding a murine scFv-fragment, are again selected for carbenicillin resistance and subsequently infected with VCMS 13 helper phage to start the second round of antibody display and in vitro selection. Typically a total of 4 to 5 rounds of selections are carried out.
8.9 Screening for Membrane-Proximal Target Binders on CHO Cells Expressing the Human Endosialin Antigen, the Murine Endosialin Antigen and the Mutated Murine Endosialin Antigen with Human Membrane-Distal Epitopes
[0597] Plasmid DNA corresponding to 4 and 5 rounds of panning is isolated from E. coli cultures after selection. For the production of soluble scFv-protein, VH-VL-DNA fragments are excised from the plasmids (XhoI-SpeI). These fragments are cloned via the same restriction sites in the plasmid pComb3H5BFlag/His differing from the original pComb3H5BHis in that the expression construct (e.g. scFv) includes a Flag-tag (TGDYKDDDDK) between the scFv and the His6-tag and the additional phage proteins are deleted. After ligation, each pool (different rounds of panning) of plasmid DNA is transformed into 100 .mu.l heat shock competent E. coli TG1 or XLI blue and plated onto carbenicillin LB-agar. Single colonies are picked into 100 .mu.l of LB carb (LB with 50 .mu.g/ml carbenicillin).
[0598] After induction with 1 mM IPTG E. coli transformed with pComb3H5BFlag/His containing a VL- and VH-segment produce soluble scFv in sufficient amounts. Due to a suitable signal sequence, the scFv is exported into the periplasma where it folds into a functional conformation.
[0599] Single E. coli bacterial colonies from the transformation plates are picked for periplasmic small scale preparations and grown in SB-medium (e.g. 10 ml) supplemented with 20 mM MgCl.sub.2 and carbenicillin 50 .mu.g/ml (and re-dissolved in PBS (e.g. 1 ml) after harvesting. A temperature shock is applied by four rounds of freezing at -70.degree. C. and thawing at 37.degree. C. whereby the outer membrane of the bacteria is destroyed and the soluble periplasmic proteins including the scFvs are released into the supernatant. After elimination of intact cells and cell-debris by centrifugation, the supernatant containing the murine anti-human Endosialin-scFvs is collected and used for further examination.
[0600] Screening of the isolated scFvs for membrane-proximal target binders is performed by flow cytometry on CHO cells expressing the human Endosialin antigen as described in Example 8.1, the murine Endosialin antigen as described in Example 8.3 and the mutated murine Endosialin antigen with human membrane-distal epitopes as described in Example 8.5.
[0601] For flow cytometry 2.5.times.10.sup.5 cells of the respective cell lines are incubated with 50 .mu.l supernatant. The binding of the constructs is detected with an anti-His antibody (Penta-His Antibody, BSA free, Qiagen GmbH, Hilden, FRG) at 2 .mu.g/ml in 50 .mu.l PBS with 2% FCS. As a second step reagent a R-Phycoerythrin-conjugated affinity purified F(ab')2 fragment, goat anti-mouse IgG (Fc-gamma fragment specific), diluted 1:100 in 50 .mu.l PBS with 2% FCS (Dianova, Hamburg, FRG) is used. The samples are measured on a FACSscan (BD biosciences, Heidelberg, FRG).
[0602] Only constructs which show binding to CHO cells expressing the human Endosialin antigen and do not show binding to CHO cells expressing the murine Endosialin antigen and also do not show binding to CHO cells expressing the mutated murine Endosialin antigen with human membrane-distal epitopes are selected for further use.
8.10 Generation of Human/Humanized Equivalents of Non-Human scFvs to Membrane-Proximal Target Epitopes of Human Endosialin
[0603] The VH region of a murine anti-Endosialin scFv to a membrane-proximal target epitope of human Endosialin is aligned against human antibody germline amino acid sequences. The human antibody germline VH sequence is chosen which has the closest homology to the non-human VH and a direct alignment of the two amino acid sequences is performed. There are a number of framework residues of the non-human VH that differ from the human VH framework regions ("different framework positions"). Some of these residues may contribute to the binding and activity of the antibody to its target.
[0604] To construct a library that contains the murine CDRs and at every framework position that differs from the chosen human VH sequence both possible residues (the human and the maternal murine amino acid residue), degenerated oligonucleotides are synthesized. These oligonucleotides incorporate at the differing positions the human residue with a probability of 75% and the murine residue with a probability of 25%. For one human VH e.g. six of these oligonucleotides have to be synthesized that overlap in a terminal stretch of approximately 20 nucleotides. To this end every second primer is an antisense primer. Restriction sites within the oligonucleotides needed for later cloning are deleted.
[0605] These primers may have a length of 60 to 90 nucleotides, depending on the number of primers that are needed to span over the whole V sequence.
[0606] These e.g. six primers are mixed in equal amounts (e.g. 1 .mu.l of each primer (primer stocks 20 to 100 .mu.M) to a 20 .mu.l PCR reaction) and added to a PCR mix consisting of PCR buffer, nucleotides and Taq polymerase. This mix is incubated at 94.degree. C. for 3 minutes, 65.degree. C. for 1 minute, 62.degree. C. for 1 minute, 59.degree. C. for 1 minute, 56.degree. C. for 1 minute, 52.degree. C. for 1 minute, 50.degree. C. for 1 minute and at 72.degree. C. for 10 minutes in a PCR cycler. Subsequently the product is run in an agarose gel electrophoresis and the product of a size from 200 to 400 base pairs isolated from the gel according to standard methods.
[0607] This PCR product is then used as a template for a standard PCR reaction using primers that incorporate suitable N-terminal and C-terminal cloning restriction sites. The DNA fragment of the correct size (for a VH approximately 350 nucleotides) is isolated by agarose gel electrophoresis according to standard methods. In this way sufficient VH DNA fragment is amplified. This VH fragment is now a pool of VH fragments that have each one a different amount of human and murine residues at the respective differing framework positions (pool of humanized VH). The same procedure is performed for the VL region of the murine anti-Endosialin scFv to a membrane-proximal target epitope of human Endosialin (pool of humanized VL).
[0608] The pool of humanized VH is then combined with the pool of humanized VL in the phage display vector pComb3H5Bhis to form a library of functional scFvs from which--after display on filamentous phage--anti-Endosialin binders to membrane-proximal target epitopes of human Endosialin are selected, screened, identified and confirmed as described above for the parental non-human (murine) anti-Endosialin scFv. Single clones are then analyzed for favorable properties and amino acid sequence. Those scFvs, which are closest in amino acid sequence homology to human germline V-segments, are preferred.
[0609] Human/humanized anti-Endosialin scFvs to membrane-proximal target epitopes of human Endosialin are converted into recombinant bispecific single chain antibodies and further characterized as follows.
8.11 Generation of I2C-Based Bispecific Single Chain Antibodies Directed at Membrane-Proximal Target Epitopes of Human Endosialin
[0610] Anti-Endosialin scFvs to membrane-proximal target epitopes of human Endosialin with favorable properties and amino acid sequence are converted into recombinant bispecific single chain antibodies by joining them via a Gly.sub.4Ser.sub.1-linker with the CD3 specific scFv I2C (SEQ ID NO: 185) to result in constructs with the domain arrangement VH.sub.Endosialin-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.Endosialin-Ser.sub.1 Gly.sub.4Ser.sub.1-VH.sub.CD3-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.CD3. Alternatively further constructs with different domain arrangements can be generated according to standard protocolls. For expression in CHO cells the coding sequences of (i) an N-terminal immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence and (ii) a C-terminal His6-tag followed by a stop codon are both attached in frame to the nucleotide sequence encoding the bispecific single chain antibodies prior to insertion of the resulting DNA-fragment as obtained by gene synthesis into the multiple cloning site of the expression vector pEF-DHFR (Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
8.12 Expression and Purification of Bispecific Single Chain Antibody Molecules Directed at Membrane-Proximal Target Epitopes of Human Endosialin
[0611] Bispecific single chain antibody molecules are expressed in Chinese hamster ovary cells (CHO). Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the constructs is induced by addition of increasing concentrations of MTX up to final concentrations of 20 nM MTX. After two passages of stationary culture cell culture supernatant is collected and used in the subsequent experiments. To generate supernatant for purification after two passages of stationary culture the cells are grown in roller bottles with nucleoside-free HyQ PF CHO liquid soy medium (with 4.0 mM L-Glutamine with 0.1% Pluronic F-68; HyClone) for 7 days before harvest. The cells are removed by centrifugation and the supernatant containing the expressed protein is stored at -20.degree. C. Alternatively, constructs are transiently expressed in HEK 293 cells. Transfection is performed with 293fectin reagent (Invitrogen, #12347-019) according to the manufacturer's protocol. Furthermore the constructs are alternatively expressed in transiently transfected DHFR deficient CHO cells using for example FuGENE.RTM. HD Transfection Reagent (Roche Diagnostics GmbH, Cat. No. 04709691001) according to the manufacturer's protocol.
[0612] Akta.RTM. Explorer System (GE Health Systems) and Unicorn.RTM. Software are used for chromatography. Immobilized metal affinity chromatography ("IMAC") is performed using a Fractogel EMD Chelate.RTM. (Merck) which is loaded with ZnCl.sub.2 according to the protocol provided by the manufacturer. The column is equilibrated with buffer A (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl) and the cell culture supernatant (500 ml) is applied to the column (10 ml) at a flow rate of 3 ml/min. The column is washed with buffer A to remove unbound sample. Bound protein is eluted using a two step gradient of buffer B (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl, 0.5 M Imidazole) according to the following procedure:
[0613] Step 1: 20% buffer B in 6 column volumes
[0614] Step 2: 100% buffer B in 6 column volumes
[0615] Eluted protein fractions from step 2 are pooled for further purification. All chemicals are of research grade and purchased from Sigma (Deisenhofen) or Merck (Darmstadt).
[0616] Gel filtration chromatography is performed on a HiLoad 16/60 Superdex 200 prep grade column (GE/Amersham) equilibrated with Equi-buffer (25 mM Citrate, 200 mM Lysine, 5% Glycerol, pH 7.2). Eluted protein samples (flow rate 1 ml/min) are subjected to standard SDS-PAGE and Western Blot for detection. Prior to purification, the column is calibrated for molecular weight determination (molecular weight marker kit, Sigma MW GF-200). Protein concentrations are determined using OD280 nm.
[0617] Purified bispecific single chain antibody protein is analyzed in SDS PAGE under reducing conditions performed with pre-cast 4-12% Bis Tris gels (Invitrogen). Sample preparation and application are performed according to the protocol provided by the manufacturer. The molecular weight is determined with MultiMark protein standard (Invitrogen). The gel is stained with colloidal Coomassie (Invitrogen protocol). The purity of the isolated protein is typically >95% as determined by SDS-PAGE. The bispecific single chain antibody has a molecular weight of about 52 kDa under native conditions as determined by gel filtration in PBS.
[0618] Western Blot is performed using an Optitran.RTM. BA-S83 membrane and the Invitrogen Blot Module according to the protocol provided by the manufacturer. The antibody used is directed against the His Tag (Penta His, Qiagen) and a Goat-anti-mouse Ig labeled with alkaline phosphatase (AP) (Sigma) is used as second step reagent, and BCIP/NBT (Sigma) as substrate. A band detected at 52 kD corresponds to purified bispecific single chain antibodies.
8.13 Flow Cytometric Binding Analysis of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human Endosialin
[0619] In order to test the functionality of bispecific antibody constructs regarding the capability to bind to CD3 and to membrane-proximal target epitopes of human Endosialin, respectively, a FACS analysis is performed. For this purpose CHO cells transfected with human Endosialin as described in Example 8.1 and the human CD3 positive T cell leukemia cell line HPB-ALL (DSMZ, Braunschweig, ACC483) are used. For confirmation of binding to membrane-proximal target epitopes of human Endosialin--in addition--CHO cells expressing the murine Endosialin antigen as described in Example 8.3 and CHO cells expressing the mutated murine Endosialin antigen with human membrane-distal epitopes as described in Example 8.5 are used. 200.000 cells of the respective cell lines are incubated for 30 min on ice with 50 .mu.l of cell culture supernatant of transfected cells expressing the bispecific antibody constructs. The cells are washed twice in PBS with 2% FCS and binding of the construct is detected with a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS). After washing, bound anti His antibodies are detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Supernatant of untransfected cells is used as a negative control. Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0620] Only those constructs that show bispecific binding to human CD3 as well as to human Endosialin and neither bind to the murine Endosialin antigen nor to the mutated murine Endosialin antigen with human membrane-distal epitopes are selected for further use.
8.14 Bioactivity of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human Endosialin
[0621] Bioactivity of generated bispecific single chain antibodies is analyzed by chromium 51 (.sup.51Cr) release in vitro cytotoxicity assays using the CHO cells transfected with human Endosialin described in Example 8.1. As effector cells stimulated human CD4/CD56 depleted PBMC are used.
[0622] Stimulated human PBMC are obtained as follows:
[0623] A Petri dish (145 mm diameter, Greiner bio-one GmbH, Kremsmunster) is coated with a commercially available anti-CD3 specific antibody (e.g. OKT3, Orthoclone) in a final concentration of 1 .mu.g/ml for 1 hour at 37.degree. C. Unbound protein is removed by one washing step with PBS. The fresh PBMC are isolated from peripheral blood (30-50 ml human blood) by Ficoll gradient centrifugation according to standard protocols. 3-5.times.10.sup.7 PBMC are added to the precoated petri dish in 120 ml of RPMI 1640 with stabilized glutamine/10% FCS/IL-2 20 U/ml (Proleukin, Chiron) and stimulated for 2 days. On the third day the cells are collected and washed once with RPMI 1640. IL 2 is added to a final concentration of 20 U/ml and the cells are cultivated again for one day in the same cell culture medium as above.
[0624] By depletion of CD4+ T cells and CD56+NK cells according to standard protocols CD8+ cytotoxic T lymphocytes (CTLs) are enriched.
[0625] Target cells are washed twice with PBS and labeled with 11.1 MBq .sup.51Cr in a final volume of 100 .mu.l RPMI with 50% FCS for 60 minutes at 37.degree. C. Subsequently the labeled target cells are washed 3 times with 5 ml RPMI and then used in the cytotoxicity assay. The assay is performed in a 96 well plate in a total volume of 250 .mu.l supplemented RPMI (as above) with an E:T ratio of 10:1. 1 .mu.g/ml of purified bispecific single chain antibody molecule and 20 threefold dilutions thereof are applied. The assay time is 18 hours. Cytotoxicity is measured as relative values of released chromium in the supernatant related to the difference of maximum lysis (addition of Triton-X) and spontaneous lysis (without effector cells). All measurements are done in quadruplicates. Measurement of chromium activity in the supernatants is performed with a Wizard 3'' gammacounter (Perkin Elmer Life Sciences GmbH, Koln, Germany). Analysis of the experimental data is performed with Prism 4 for Windows (version 4.02, GraphPad Software Inc., San Diego, California, USA). Sigmoidal dose response curves typically have R.sup.2 values >0.90 as determined by the software. EC50 values calculated by the analysis program are used for comparison of bioactivity.
[0626] Only those constructs showing potent recruitment of cytotoxic activity of effector T cells against target cells positive for Endosialin are selected for further use.
8.15 Generation of CHO Cells Expressing Macaque Endosialin
[0627] The cDNA sequence of macaque Endosialin is obtained by a set of 2 PCRs on cDNA from macaque monkey colon prepared according to standard protocols. The following reaction conditions: 1 cycle at 95.degree. C. for 5 minutes followed by 40 cycles with 95.degree. C. for 45 seconds, 50.degree. C. for 45 seconds and 72.degree. C. for 2 minutes followed by a terminal cycle of 72.degree. C. for 5 minutes and the following primers are used for the first PCR:
TABLE-US-00011 forward primer: SEQ ID NO: 418 5'-atatgaattcgccaccatgctgctgcgcctgttgctggcc-3' reverse primer: SEQ ID NO: 419 5'-gtcttcatcttcctcatcctcccc-3'
[0628] The following reaction conditions: 1 cycle at 95.degree. C. for 5 minutes followed by 40 cycles with 95.degree. C. for 45 seconds, 58.degree. C. for 45 seconds and 72.degree. C. for 2 minutes followed by a terminal cycle of 72.degree. C. for 5 minutes and the following primers are used for the second PCR:
TABLE-US-00012 forward primer: SEQ ID NO: 420 5'-gtcaactacgttggtggcttcgagtg-3' reverse primer: SEQ ID NO: 421 5'-ggtctagatcacttatcgtcatcatctttgtagtccacgctggttc tgcaggtctgc-3'
[0629] The PCR reactions are performed under addition of PCR grade betain to a final concentration of 1 M. Those PCRs generate two overlapping fragments, which are isolated and sequenced according to standard protocols using the PCR primers, and thereby provided a portion of the cDNA sequence coding macaque Endosialin from codon 9 of the leader peptide to codon 733 of the mature protein. To generate a construct for expression of macaque Endosialin a cDNA fragment is obtained by gene synthesis according to standard protocols (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 422 and 423). In this construct the coding sequence of macaque Endosialin from amino acid 9 of the leader peptide to amino acid 733 of the mature protein, followed in frame by the coding sequence of amino acid 734 to the last amino acid of the mature human Endosialin protein, followed in frame by the coding sequence of a FLAG tag and a stop codon is fused in frame to the coding sequence of the amino acids 1 to 8 of the leader peptide of the human Endosialin protein. The gene synthesis fragment is also designed as to contain a Kozak site for eukaryotic expression of the construct and restriction sites at the beginning and the end of the fragment containing the cDNA. The introduced restriction sites, EcoRI at the 5' end and XbaI at the 3' end, are utilised in the following cloning procedures. The gene synthesis fragment is cloned via EcoRI and XbaI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
8.16 Flow Cytometric Analysis of Cross-Species Specificity of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human Endosialin
[0630] In order to test the cross-species specificity of bispecific antibodies directed at membrane-proximal target epitopes of human Endosialin the capability of the constructs to bind to macaque Endosialin and macaque CD3, respectively, is investigated by FACS analysis. For this purpose the macaque Endosialin transfected CHO cells as described in example 8.15 and the macaque T cell line 4119LnPx (kindly provided by Prof Fickenscher, Hygiene Institute, Virology, Erlangen-Nuernberg; published in Knappe A, et al., and Fickenscher H., Blood 2000, 95, 3256-61) are used. 200.000 cells of the respective cell lines are incubated for 30 min on ice with with 50 .mu.l of cell culture supernatant of transfected cells expressing the cross-species specific bispecific antibody constructs. The cells are washed twice in PBS with 2% FCS and binding of the construct is detected with a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS). After washing, bound anti His antibodies are detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Supernatant of untransfected cells is used as a negative control.
[0631] Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
9. Generation of Bispecific Single Chain Antibodies Directed at Membrane-Proximal Target Epitopes of Human IGF-1R
9.1 Generation of CHO Cells Expressing Human IGF-1R
[0632] The coding sequence of human IGF-1R as published in GenBank (Accession number NM_000875) is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the human IGF-1R protein and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 424 and 425). The gene synthesis fragment is also designed as to introduce restriction sites at the beginning and at the end of the fragment. The introduced restriction sites, EcoRI at the 5' end and SalI at the 3' end, are utilized in the following cloning procedures. An internal restriction site is removed by silent mutation of the coding sequence in the gene synthesis fragment (BspEl: nucleotide 18 from A to C). The gene synthesis fragment is cloned via EcoRI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
9.2 Generation of a Soluble Human IGF-1R Fusion Protein
[0633] The modified coding sequence of human IGF-1R as described in Example 9.1 is used for the construction of an artificial cDNA sequence encoding a soluble fusion protein of human IGF-1R and murine IgG1 Fc. To generate a construct for expression of the soluble human IGF-1R fusion protein .alpha. cDNA fragment is obtained by gene synthesis according to standard protocols (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 426 and 427). The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the human IGF-1R protein from amino acid 1 to 935 corresponding to the signal peptide and extracellular domains of human IGF-1R, followed in frame by the coding sequence of an artificial Ser.sub.1-Gly.sub.4-Ser.sub.1-linker, followed in frame by the coding sequence of the hinge region and Fc gamma portion of murine IgG1, followed in frame by the coding sequence of a 6 histidine tag and a stop codon. The gene synthesis fragment is also designed as to introduce restriction sites at the beginning and at the end of the fragment. The introduced restriction sites, EcoRI at the 5' end and SalI at the 3' end, are utilized in the following cloning procedures. The gene synthesis fragment is cloned via EcoRI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are all carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX. After two passages of stationary culture the cells are grown in roller bottles with nucleoside-free HyQ PF CHO liquid soy medium (with 4.0 mM L-Glutamine with 0.1% Pluronic F--68; HyClone) for 7 days before harvest. The cells are removed by centrifugation and the supernatant containing the expressed protein is stored at -20.degree. C. Alternatively a clone of the expression plasmid with sequence-verified nucleotide sequence is used for transfection and protein expression in the FreeStyle 293 Expression System (Invitrogen GmbH, Karlsruhe, Germany) according to the manufacturer's protocol. Supernatant containing the expressed protein is obtained, cells are removed by centrifugation and the supernatant is stored at -20.degree. C. For purification of the soluble human IGF-1R fusion protein .alpha. goat anti-mouse Fc affinity column is prepared according to standard protocols using a commercially available affinity purified goat anti-mouse IgG Fc fragment specific antibody with minimal cross-reaction to human, bovine and horse serum proteins (Jackson ImmunoResearch Europe Ltd.). Using this affinity column the fusion protein is isolated out of cell culture supernatant on an Akta Explorer System (GE Amersham) and eluted by citric acid. The eluate is neutralized and concentrated.
9.3 Generation of CHO Cells Expressing Murine IGF-1R
[0634] The sequence of murine IGF-1R (NM_010513 Mus musculus insulin-like growth factor I receptor (Igf1r), mRNA, National Center for Biotechnology Information, http://www.ncbi.nlm.nih.gov/entrez) is used to obtain a synthetic cDNA molecule by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain the coding sequence of an immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence, followed in frame by the coding sequence of a FLAG tag, followed in frame by the complete coding sequence of mature murine IGF-1R (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 428 and 429). The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
9.4 Generation of CHO Cells Expressing a Mutated Human IGF-1R Antigen with Murine Membrane-Distal Epitopes
[0635] The coding sequence of a mutated human IGF-1R antigen with murine membrane-distal epitopes is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain the coding sequence of an immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence, followed in frame by the coding sequence of a FLAG tag, followed in frame by the coding sequence of the L1 domain and the cysteine-rich domain of mature murine IGF-1R followed in frame by human IGF-1R from the L2 domain to the stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 430 and 431). The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
9.5 Generation of CHO Cells Expressing a Mutated Murine IGF-1R Antigen with Human Membrane-Distal Epitopes
[0636] The coding sequence of a mutated murine IGF-1R antigen with human membrane-distal epitopes is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain the coding sequence of an immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence, followed in frame by the coding sequence of a FLAG tag, followed in frame by the L1 domain and the cysteine-rich domain of mature human IGF-1R followed in frame by murine IGF-1R from the L2 domain to the stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 432 and 433). The gene synthesis fragment is also designed as to introduce restriction sites at the 5' end (EcoRI) and at the 3' end (Sal I) of the cDNA fragment for cloning into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification for increased antigen expression is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
9.6 Immunization of Mice Using a Soluble Human IGF-1R Fusion Protein
[0637] Twelve weeks old F1 mice from BALB/c.times.C57BL/6 crossings are immunized with the soluble human IGF-1R fusion protein as described in Example 9.2. To this end for each animal 40 .mu.g of the soluble human IGF-1R fusion protein are mixed with 10 nmol of a thioate-modified CpG-Oligonucleotide (5'-tccatgacgttcctgatgct-3') in 300 .mu.l PBS and are injected intraperitoneally. Mice receive booster immunizations after 21, 42 and optionally 63 days in the same way. Ten days after the first booster immunization, blood samples are taken and antibody serum titers against human IGF-1R are tested by flow cytometry according to standard protocols. To this end 200.000 cells of the human IGF-1R transfected CHO cells as described in Example 9.1 are incubated for 30 min on ice with 50 .mu.l of serum of the immunized animals diluted 1:1000 in PBS with 2% FCS. The cells are washed twice in PBS with 2% FCS and binding of serum antibodies is detected with an mouse Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Serum of the animals obtained prior to immunization is used as a negative control. Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0638] Animals demonstrating significant serum reactivity against human IGF-1R as determined by the FACS analysis are used in the subsequent experiment.
9.7 Generation of an Immune Murine Antibody scFv Library: Construction of a Combinatorial Antibody Library and Phage Display
[0639] Three days after the last booster immunization spleen cells of reactive animals are harvested for the preparation of total RNA according to standard protocols.
[0640] A library of murine immunoglobulin (Ig) light chain (kappa) variable region (VK) and Ig heavy chain variable region (VH) DNA-fragments is constructed by RT-PCR on murine spleen RNA using VK- and VH specific primers. cDNA is synthesized according to standard protocols, see example 2.7.
[0641] 450 ng of the kappa light chain fragments (SacI-SpeI digested) are ligated with 1400 ng of the phagemid pComb3H5Bhis (SacI-SpeI digested; large fragment). The resulting combinatorial antibody library is then transformed into 300 .mu.l of electrocompetent Escherichia coli XL1 Blue cells by electroporation (2.5 kV, 0.2 cm gap cuvette, 25 .mu.FD, 200 Ohm, Biorad gene-pulser) resulting in a library size of more than 10.sup.7 independent clones. After one hour of phenotype expression, positive transformants are selected for carbenicillin resistance encoded by the pComb3H5BHis vector in 100 ml of liquid super broth (SB)-culture over night. Cells are then harvested by centrifugation and plasmid preparation is carried out using a commercially available plasmid preparation kit (Qiagen).
[0642] 2800 ng of this plasmid-DNA containing the VK-library (XhoI-BstElI digested; large fragment) are ligated with 900 ng of the heavy chain V-fragments (XhoI-BstElI digested) and again transformed into two 300 .mu.l aliquots of electrocompetent E. coli XL1 Blue cells by electroporation (2.5 kV, 0.2 cm gap cuvette, 25 .mu.FD, 200 Ohm) resulting in a total VH-VK scFv (single chain variable fragment) library size of more than 10.sup.7 independent clones.
[0643] After phenotype expression and slow adaptation to carbenicillin, the E. coli cells containing the antibody library are transferred into SB-Carbenicillin (SB with 50 .mu.g/mL carbenicillin) selection medium. The E. coli cells containing the antibody library are then infected with an infectious dose of 10.sup.12 particles of helper phage VCSM13 resulting in the production and secretion of filamentous M13 phage, wherein each phage particle contains single stranded pComb3H5BHis-DNA encoding a murine scFv-fragment and displays the corresponding scFv-protein as a translational fusion to phage coat protein III. This pool of phages displaying the antibody library is later used for the selection of antigen binding entities.
9.8 Phage Display Based Selection of Membrane-Proximal Target Binders on CHO Cells Expressing the Mutated Human IGF-1R Antigen with Murine Membrane-Distal Epitopes
[0644] The phage library carrying the cloned scFv-repertoire is harvested from the respective culture supernatant by PEG8000/NaCl precipitation and centrifugation. Approximately 10.sup.11 to 10.sup.12 scFv phage particles are resuspended in 0.4 ml of PBS/0.1% BSA and incubated with 10.sup.5 to 10.sup.7 CHO cells expressing the mutated human IGF-1R antigen with murine membrane-distal epitopes as described in example 9.4 for 1 hour on ice under slow agitation. These CHO cells are grown beforehand, harvested by centrifugation, washed in PBS and resuspended in PBS/1% FCS (containing Na Azide). scFv phage which do not specifically bind to the CHO cells are eliminated by up to five washing steps with PBS/1% FCS (containing Na Azide). After washing, binding entities are eluted from the cells by resuspending the cells in HCl-glycine pH 2.2 (10 min incubation with subsequent vortexing) and after neutralization with 2 M Tris pH 12, the eluate is used for infection of a fresh uninfected E. coli XL1 Blue culture (OD600>0.5). The E. coli culture containing E. coli cells successfully transduced with a phagemid copy, encoding a murine scFv-fragment, are again selected for carbenicillin resistance and subsequently infected with VCMS 13 helper phage to start the second round of antibody display and in vitro selection. Typically a total of 4 to 5 rounds of selections are carried out.
9.9 Screening for Membrane-Proximal Target Binders on CHO Cells Expressing the Human IGF-1R Antigen, the Murine IGF-1R Antigen and the Mutated Murine IGF-1R Antigen with Human Membrane-Distal Epitopes
[0645] Plasmid DNA corresponding to 4 and 5 rounds of panning is isolated from E. coli cultures after selection. For the production of soluble scFv-protein, VH-VL-DNA fragments are excised from the plasmids (XhoI-SpeI). These fragments are cloned via the same restriction sites in the plasmid pComb3H5BFlag/His differing from the original pComb3H5BHis in that the expression construct (e.g. scFv) includes a Flag-tag (TGDYKDDDDK) between the scFv and the His6-tag and the additional phage proteins are deleted. After ligation, each pool (different rounds of panning) of plasmid DNA is transformed into 100 .mu.l heat shock competent E. coli TG1 or XLI blue and plated onto carbenicillin LB-agar. Single colonies are picked into 100 .mu.l of LB carb (LB with 50 .mu.g/ml carbenicillin).
[0646] After induction with 1 mM IPTG E. coli transformed with pComb3H5BFlag/His containing a VL- and VH-segment produce soluble scFv in sufficient amounts. Due to a suitable signal sequence, the scFv is exported into the periplasma where it folds into a functional conformation.
[0647] Single E. coli bacterial colonies from the transformation plates are picked for periplasmic small scale preparations and grown in SB-medium (e.g. 10 ml) supplemented with 20 mM MgCl.sub.2 and carbenicillin 50 .mu.g/ml (and re-dissolved in PBS (e.g. 1 ml) after harvesting. A temperature shock is applied by four rounds of freezing at -70.degree. C. and thawing at 37.degree. C. whereby the outer membrane of the bacteria is destroyed and the soluble periplasmic proteins including the scFvs are released into the supernatant. After elimination of intact cells and cell-debris by centrifugation, the supernatant containing the murine anti-human IGF-1R-scFvs is collected and used for further examination.
[0648] Screening of the isolated scFvs for membrane-proximal target binders is performed by flow cytometry on CHO cells expressing the human IGF-1R antigen as described in Example 9.1, the murine IGF-1R antigen as described in Example 9.3 and the mutated murine IGF-1R antigen with human membrane-distal epitopes as described in Example 9.5.
[0649] For flow cytometry 2.5.times.10.sup.5 cells of the respective cell lines are incubated with 50 .mu.l supernatant. The binding of the constructs is detected with an anti-His antibody (Penta-His Antibody, BSA free, Qiagen GmbH, Hilden, FRG) at 2 .mu.g/ml in 50 .mu.l PBS with 2% FCS. As a second step reagent a R-Phycoerythrin-conjugated affinity purified F(ab')2 fragment, goat anti-mouse IgG (Fc-gamma fragment specific), diluted 1:100 in 50 .mu.l PBS with 2% FCS (Dianova, Hamburg, FRG) is used. The samples are measured on a FACSscan (BD biosciences, Heidelberg, FRG).
[0650] Only constructs which show binding to CHO cells expressing the human IGF-1R antigen and do not show binding to CHO cells expressing the murine IGF-1R antigen and also do not show binding to CHO cells expressing the mutated murine IGF-1R antigen with human membrane-distal epitopes are selected for further use.
9.10 Generation of Human/Humanized Equivalents of Non-Human scFvs to Membrane-Proximal Target Epitopes of Human IGF-1R
[0651] The VH region of a murine anti-IGF-1R scFv to a membrane-proximal target epitope of human IGF-1R is aligned against human antibody germline amino acid sequences. The human antibody germline VH sequence is chosen which has the closest homology to the non-human VH and a direct alignment of the two amino acid sequences is performed. There are a number of framework residues of the non-human VH that differ from the human VH framework regions ("different framework positions"). Some of these residues may contribute to the binding and activity of the antibody to its target.
[0652] To construct a library that contains the murine CDRs and at every framework position that differs from the chosen human VH sequence both possible residues (the human and the maternal murine amino acid residue), degenerated oligonucleotides are synthesized. These oligonucleotides incorporate at the differing positions the human residue with a probability of 75% and the murine residue with a probability of 25%. For one human VH e.g. six of these oligonucleotides have to be synthesized that overlap in a terminal stretch of approximately 20 nucleotides. To this end every second primer is an antisense primer. Restriction sites within the oligonucleotides needed for later cloning are deleted.
[0653] These primers may have a length of 60 to 90 nucleotides, depending on the number of primers that are needed to span over the whole V sequence.
[0654] These e.g. six primers are mixed in equal amounts (e.g. 1 .mu.l of each primer (primer stocks 20 to 100 .mu.M) to a 20 .mu.l PCR reaction) and added to a PCR mix consisting of PCR buffer, nucleotides and Taq polymerase. This mix is incubated at 94.degree. C. for 3 minutes, 65.degree. C. for 1 minute, 62.degree. C. for 1 minute, 59.degree. C. for 1 minute, 56.degree. C. for 1 minute, 52.degree. C. for 1 minute, 50.degree. C. for 1 minute and at 72.degree. C. for 10 minutes in a PCR cycler. Subsequently the product is run in an agarose gel electrophoresis and the product of a size from 200 to 400 base pairs isolated from the gel according to standard methods.
[0655] This PCR product is then used as a template for a standard PCR reaction using primers that incorporate suitable N-terminal and C-terminal cloning restriction sites. The DNA fragment of the correct size (for a VH approximately 350 nucleotides) is isolated by agarose gel electrophoresis according to standard methods. In this way sufficient VH DNA fragment is amplified. This VH fragment is now a pool of VH fragments that have each one a different amount of human and murine residues at the respective differing framework positions (pool of humanized VH). The same procedure is performed for the VL region of the murine anti-IGF-1R scFv to a membrane-proximal target epitope of human IGF-1R (pool of humanized VL).
[0656] The pool of humanized VH is then combined with the pool of humanized VL in the phage display vector pComb3H5Bhis to form a library of functional scFvs from which after display on filamentous phage--anti-IGF-1R binders to membrane-proximal target epitopes of human IGF-1R are selected, screened, identified and confirmed as described above for the parental non-human (murine) anti-IGF-1R scFv. Single clones are then analyzed for favorable properties and amino acid sequence. Those scFvs, which are closest in amino acid sequence homology to human germline V-segments, are preferred.
[0657] Human/humanized anti-IGF-1R scFvs to membrane-proximal target epitopes of human IGF-1R are converted into recombinant bispecific single chain antibodies and further characterized as follows.
9.11 Generation of I2C-Based Bispecific Single Chain Antibodies Directed at Membrane-Proximal Target Epitopes of Human IGF-1R
[0658] Anti-IGF-1R scFvs to membrane-proximal target epitopes of human IGF-1R with favorable properties and amino acid sequence are converted into recombinant bispecific single chain antibodies by joining them via a Gly.sub.4Ser.sub.1-linker with the CD3 specific scFv I2C (SEQ ID) to result in constructs with the domain arrangement VH.sub.IGF-1R-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.IGF-1R-Ser.sub.1Gly.sub.4- Ser.sub.1-VH.sub.CD3-(Gly.sub.4Ser.sub.1).sub.3-VL.sub.CD3.
[0659] I2C-based bispecific single chain antibodies directed at membrane-proximal target epitopes of human IGF-1R were designed as set out in the following Table 8:
TABLE-US-00013 TABLE 8 Formats of I2C-based bispecific single chain antibodies directed at membrane-proximal target epitopes of human IGF-1R SEQ ID Formats of protein constructs (nucl/prot) (N .fwdarw. C) 848/847 IGF1R12HL .times. I2CHL 862/861 IGF1R24HL .times. I2CHL
[0660] Alternatively further constructs with different domain arrangements can be generated according to standard protocolls. For expression in CHO cells the coding sequences of (i) an N-terminal immunoglobulin heavy chain leader comprising a start codon embedded within a Kozak consensus sequence and (ii) a C-terminal His6-tag followed by a stop codon are both attached in frame to the nucleotide sequence encoding the bispecific single chain antibodies prior to insertion of the resulting DNA-fragment as obtained by gene synthesis into the multiple cloning site of the expression vector pEF-DHFR (Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
9.12 Expression and Purification of Bispecific Single Chain Antibody Molecules Directed at Membrane-Proximal Target Epitopes of Human IGF-1R
[0661] Bispecific single chain antibody molecules are expressed in Chinese hamster ovary cells (CHO). Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the constructs is induced by addition of increasing concentrations of MTX up to final concentrations of 20 nM MTX. After two passages of stationary culture cell culture supernatant is collected and used in the subsequent experiments. To generate supernatant for purification after two passages of stationary culture the cells are grown in roller bottles with nucleoside-free HyQ PF CHO liquid soy medium (with 4.0 mM L-Glutamine with 0.1% Pluronic F-68; HyClone) for 7 days before harvest. The cells are removed by centrifugation and the supernatant containing the expressed protein is stored at -20.degree. C. Alternatively, constructs are transiently expressed in HEK 293 cells. Transfection is performed with 293fectin reagent (Invitrogen, #12347-019) according to the manufacturer's protocol. Furthermore the constructs are alternatively expressed in transiently transfected DHFR deficient CHO cells using for example FuGENE.RTM. HD Transfection Reagent (Roche Diagnostics GmbH, Cat. No. 04709691001) according to the manufacturer's protocol. Akta.RTM. Explorer System (GE Health Systems) and Unicorn.RTM. Software are used for chromatography. Immobilized metal affinity chromatography ("IMAC") is performed using a Fractogel EMD Chelate.RTM. (Merck) which is loaded with ZnCl.sub.2 according to the protocol provided by the manufacturer. The column is equilibrated with buffer A (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl) and the cell culture supernatant (500 ml) is applied to the column (10 ml) at a flow rate of 3 ml/min. The column is washed with buffer A to remove unbound sample. Bound protein is eluted using a two step gradient of buffer B (20 mM sodium phosphate buffer pH 7.2, 0.1 M NaCl, 0.5 M Imidazole) according to the following procedure:
Step 1: 20% buffer B in 6 column volumes Step 2: 100% buffer B in 6 column volumes
[0662] Eluted protein fractions from step 2 are pooled for further purification. All chemicals are of research grade and purchased from Sigma (Deisenhofen) or Merck (Darmstadt).
[0663] Gel filtration chromatography is performed on a HiLoad 16/60 Superdex 200 prep grade column (GE/Amersham) equilibrated with Equi-buffer (25 mM Citrate, 200 mM Lysine, 5% Glycerol, pH 7.2). Eluted protein samples (flow rate 1 ml/min) are subjected to standard SDS-PAGE and Western Blot for detection. Prior to purification, the column is calibrated for molecular weight determination (molecular weight marker kit, Sigma MW GF-200). Protein concentrations are determined using OD280 nm.
[0664] Purified bispecific single chain antibody protein is analyzed in SDS PAGE under reducing conditions performed with pre-cast 4-12% Bis Tris gels (Invitrogen). Sample preparation and application are performed according to the protocol provided by the manufacturer. The molecular weight is determined with MultiMark protein standard (Invitrogen). The gel is stained with colloidal Coomassie (Invitrogen protocol). The purity of the isolated protein is typically >95% as determined by SDS-PAGE.
[0665] The bispecific single chain antibody has a molecular weight of about 52 kDa under native conditions as determined by gel filtration in PBS.
[0666] Western Blot is performed using an Optitran.RTM. BA-S83 membrane and the Invitrogen Blot Module according to the protocol provided by the manufacturer. The antibody used is directed against the His Tag (Penta His, Qiagen) and a Goat-anti-mouse Ig labeled with alkaline phosphatase (AP) (Sigma) is used as second step reagent, and BCIP/NBT (Sigma) as substrate. A band detected at 52 kD corresponds to purified bispecific single chain antibodies.
[0667] 9.13 Flow Cytometric Binding Analysis of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human IGF-1R
[0668] In order to test the functionality of bispecific antibody constructs regarding the capability to bind to CD3 and to membrane-proximal target epitopes of human IGF-1R, respectively, a FACS analysis is performed. For this purpose CHO cells transfected with human IGF-1R as described in Example 9.1 and the human CD3 positive T cell leukemia cell line HPB-ALL (DSMZ, Braunschweig, ACC483) are used. For confirmation of binding to membrane-proximal target epitopes of human IGF-1R--in addition--CHO cells expressing the murine IGF-1R antigen as described in Example 9.3, CHO cells expressing the mutated human IGF-1R antigen with murine membrane-distal epitopes as described in Example 9.4 and CHO cells expressing the mutated murine IGF-1R antigen with human membrane-distal epitopes as described in Example 9.5 are used. 200.000 cells of the respective cell lines are incubated for 30 min on ice with 50 .mu.l of cell culture supernatant of transfected cells expressing the bispecific antibody constructs. The cells are washed twice in PBS with 2% FCS and binding of the construct is detected with a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS). After washing, bound anti His antibodies are detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Supernatant of untransfected cells is used as a negative control.
[0669] Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0670] Only those constructs that show bispecific binding to human CD3 as well as to human IGF-1R and neither bind to the murine IGF-1R antigen nor to the mutated murine IGF-1R antigen with human membrane-distal epitopes are selected for further use.
[0671] The bispecific binding of the single chain molecules listed above was clearly detectable as shown in FIG. 17. In the FACS analysis all constructs showed binding to human CD3 and human IGF-1R compared to the negative control. Membrane-proximal target binding of the single chain molecules listed above was clearly detectable as shown in FIG. 19. In the FACS analysis all constructs showed binding to the mutated human IGF-1R antigen with murine membrane-distal epitopes and did not show binding to the murine IGF-1R antigen and did also not show binding to the mutated murine IGF-1R antigen with human membrane-distal epitopes as compared to the negative control.
[0672] 9.14 Bioactivity of bispecific antibodies directed at membrane-proximal target epitopes of human IGF-1R
[0673] Bioactivity of generated bispecific single chain antibodies is analyzed by chromium 51 (51Cr) release in vitro cytotoxicity assays using the CHO cells transfected with human IGF-1R described in Example 9.1. As effector cells stimulated human CD4/CD56 depleted PBMC are used.
[0674] Stimulated human PBMC are obtained as follows:
[0675] A Petri dish (145 mm diameter, Greiner bio-one GmbH, Kremsmunster) is coated with a commercially available anti-CD3 specific antibody (e.g. OKT3, Orthoclone) in a final concentration of 1 .mu.g/ml for 1 hour at 37.degree. C. Unbound protein is removed by one washing step with PBS. The fresh PBMC are isolated from peripheral blood (30-50 ml human blood) by Ficoll gradient centrifugation according to standard protocols. 3-5.times.10.sup.7 PBMC are added to the precoated petri dish in 120 ml of RPMI 1640 with stabilized glutamine/10% FCS/IL-2 20 U/ml (Proleukin, Chiron) and stimulated for 2 days. On the third day the cells are collected and washed once with RPMI 1640. IL 2 is added to a final concentration of 20 U/ml and the cells are cultivated again for one day in the same cell culture medium as above.
[0676] By depletion of CD4+ T cells and CD56+NK cells according to standard protocols CD8+ cytotoxic T lymphocytes (CTLs) are enriched.
[0677] Target cells are washed twice with PBS and labeled with 11.1 MBq 51Cr in a final volume of 100 .mu.l RPMI with 50% FCS for 60 minutes at 37.degree. C. Subsequently the labeled target cells are washed 3 times with 5 ml RPMI and then used in the cytotoxicity assay. The assay is performed in a 96 well plate in a total volume of 250 .mu.l supplemented RPMI (as above) with an E:T ratio of 10:1. Supernatant of cells expressing the bispecific single chain antibody molecules in a final concentration of 50% and 20 twofold dilutions thereof are applied. The assay time is 18 hours. Cytotoxicity is measured as relative values of released chromium in the supernatant related to the difference of maximum lysis (addition of Triton-X) and spontaneous lysis (without effector cells). All measurements are done in quadruplicates. Measurement of chromium activity in the supernatants is performed with a Wizard 3'' gammacounter (Perkin Elmer Life Sciences GmbH, Koln, Germany). Analysis of the experimental data is performed with Prism 4 for Windows (version 4.02, GraphPad Software Inc., San Diego, Calif., USA). Sigmoidal dose response curves typically have R.sup.2 values >0.90 as determined by the software.
[0678] Only those constructs showing potent recruitment of cytotoxic activity of effector T cells against target cells positive for IGF-1R are selected for further use.
9.15 Generation of CHO Cells Expressing Macaque IGF-1R
[0679] The coding sequence of macaque IGF-1R as published in GenBank (Accession number XM_001100407) is obtained by gene synthesis according to standard protocols. The gene synthesis fragment is designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the macaque IGF-1R protein and a stop codon (the cDNA and amino acid sequence of the construct is listed under SEQ ID Nos 434 and 435). The gene synthesis fragment is also designed as to introduce restriction sites at the beginning and at the end of the fragment. The introduced restriction sites, EcoRI at the 5' end and SalI at the 3' end, are utilized in the following cloning procedures. The gene synthesis fragment is cloned via EcoRI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures are carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence is transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells is performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct is induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
9.16 Flow Cytometric Analysis of Cross-Species Specificity of Bispecific Antibodies Directed at Membrane-Proximal Target Epitopes of Human IGF-1R
[0680] In order to test the cross-species specificity of bispecific antibodies directed at membrane-proximal target epitopes of human IGF-1R the capability of the constructs to bind to macaque IGF-1R and macaque CD3, respectively, is investigated by FACS analysis. For this purpose the macaque IGF-1R transfected CHO cells as described in example 9.15 and the macaque T cell line 4119LnPx (kindly provided by Prof Fickenscher, Hygiene Institute, Virology, Erlangen-Nuernberg; published in Knappe A, et al., and Fickenscher H., Blood 2000, 95, 3256-61) are used. 200.000 cells of the respective cell lines are incubated for 30 min on ice with with 50 .mu.l of cell culture supernatant of transfected cells expressing the cross-species specific bispecific antibody constructs. The cells are washed twice in PBS with 2% FCS and binding of the construct is detected with a murine Penta His antibody (Qiagen; diluted 1:20 in 50 .mu.l PBS with 2% FCS). After washing, bound anti His antibodies are detected with an Fc gamma-specific antibody (Dianova) conjugated to phycoerythrin, diluted 1:100 in PBS with 2% FCS. Supernatant of untransfected cells is used as a negative control.
[0681] Flow cytometry is performed on a FACS-Calibur apparatus, the CellQuest software is used to acquire and analyze the data (Becton Dickinson biosciences, Heidelberg). FACS staining and measuring of the fluorescence intensity are performed as described in Current Protocols in Immunology (Coligan, Kruisbeek, Margulies, Shevach and Strober, Wiley-Interscience, 2002).
[0682] The cross-species specific binding of the single chain molecules listed above was clearly detectable as shown in FIG. 17. In the FACS analysis all constructs showed binding to macaque CD3 and macaque IGF-1R compared to the negative control. Human/humanized equivalents of scFvs specific for IGF-1R contained in the bispecific single chain molecules are generated as described herein. Cloning of binding molecules based on these human/humanized scFvs and expression and purification of these bispecific single chain molecules is performed as described above. Flow cytometric analysis of bispecific binding and analysis of bioactivity by chromium 51 (51Cr) release in vitro cytotoxicity assays is performed as described above. Based on demonstrated bispecific binding and recruited cytotoxicity binding molecules are selected for further use.
Example 10
10.1. Generation of PSMA- and CD3-Directed Bispecific Single Chain Antibodies
[0683] Bispecific single chain antibodes comprising either scFv binding domain P7 against a PSMA-epitope with <60 .ANG. membrane-distance or scFv binding domain D4 against a PSMA-epitope with .gtoreq.60 .ANG. membrane-distance and the scFv binding domain I2C directed at CD3epsilon on human T cells were obtained by gene synthesis. The gene synthesis fragments were designed as to contain first a Kozak site for eukaryotic expression of the construct, followed by a 19 amino acid immunoglobulin leader peptide, followed in frame by the coding sequence of the bispecific single chain antibody, followed in frame by the coding sequence of a 6 histidine tag and a stop codon. The variable region arrangements as well as the SEQ ID Nos of the cDNA- and amino acid sequences are listed in the table 9 below.
TABLE-US-00014 SEQ ID Formats of protein constructs (nucl/prot) (N .fwdarw. C) 488/487 PSMA-P7 HL .times. I2C HL 474/473 PSMA-D4 HL .times. I2C HL
[0684] The gene synthesis fragments were also designed as to introduce suitable restriction sites at the beginning (EcoRI) and at the end of the fragment (Sal I) for cloning of the gene synthesis fragment into the mammalian cell expression vector pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150). The aforementioned procedures were carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence was transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells was performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct was induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX. After two passages of stationary culture cell culture supernatant was collected and used in the subsequent experiments.
10.2 Epitope Mapping of the PSMA- and CD3-Reactive Bispecific Single Chain Antibody Molecule PSMA-P7 HL.times.I2C HL
[0685] A PSMA-epitope with <60 .ANG. membrane-distance of bispecific single chain antibody PSMA-P7 HL.times.I2C HL was confirmed by epitope mapping using chimeric PSMA constructs.
10.2.1 Generation of CHO Cells Expressing Human/Rat PSMA Chimeras
[0686] PSMA of rattus norvegicus, which is not bound by PSMA bispecific single chain antibody PSMA-P7 HL.times.I2C HL, was used for making chimeras with human PSMA. Thus, creating a chimera in the region containing the binding epitope of a PSMA bispecific single chain antibody leads to loss of binding of said bispecific single chain antibody to the respective PSMA construct.
[0687] The coding sequence of human PSMA as published in GenBank (Accession number NM_004476) and the coding sequence of rat PSMA (NM_057185, Rattus norvegicus folate hydrolase (Folh1), mRNA, National Center for Biotechnology Information, http://www.ncbi.nlm.nih.gov/entrez) were used for generation of the chimeric constructs.
[0688] A set of 6 chimeric cDNA constructs was designed and generated by gene synthesis according to standard protocols. In the constructs segments of the coding sequences for the amino acids 140 to 169, 281 to 284, 300 to 344, 589 to 617, 683 to 690 and 716 to 750, respectively, were exchanged for the homologous sequences of rat PSMA.
[0689] Chimeric PSMA constructs were generated as described above and designated as set out in the following Table 10:
TABLE-US-00015 TABLE 10 Designation of chimeric PSMA constructs SEQ ID (nucl/prot) Designation 461/462 huPSMArat140-169 463/464 huPSMArat281-284 465/466 huPSMArat300-344 467/468 huPSMArat598-617 469/470 huPSMArat683-690 471/472 huPSMArat716-750
[0690] The gene synthesis fragments were designed as to contain first a Kozak site for eukaryotic expression of the construct followed by the coding sequence of the chimeric PSMA proteins, followed in frame by the coding sequence of a FLAG-tag and a stop codon. The gene synthesis fragments were also designed as to introduce restriction sites at the beginning and at the end of the fragments. The introduced restriction sites, EcoRI at the 5' end and SalI at the 3' end, were utilized in the following cloning procedures. Undesirable internal restriction sites were removed by silent mutation of the coding sequence in the gene synthesis fragments. The gene synthesis fragments were cloned via EcoRI and SalI into a plasmid designated pEF-DHFR (pEF-DHFR is described in Raum et al. Cancer Immunol Immunother 50 (2001) 141-150) following standard protocols. The aforementioned procedures were carried out according to standard protocols (Sambrook, Molecular Cloning; A Laboratory Manual, 3rd edition, Cold Spring Harbour Laboratory Press, Cold Spring Harbour, New York (2001)). A clone with sequence-verified nucleotide sequence was transfected into DHFR deficient CHO cells for eukaryotic expression of the construct. Eukaryotic protein expression in DHFR deficient CHO cells was performed as described by Kaufmann R. J. (1990) Methods Enzymol. 185, 537-566. Gene amplification of the construct was induced by increasing concentrations of methotrexate (MTX) to a final concentration of up to 20 nM MTX.
10.2.2 Flow Cytometric Binding Analysis for Epitope Mapping of the PSMA- and CD3-Reactive Bispecific Single Chain Antibody Molecule PSMA-P7 HL.times.I2C HL Using Chimeric PSMA Proteins
[0691] In order to determine the binding epitope of the PSMA bispecific single chain antibody PSMA-P7 HL.times.I2C HL a FACS analysis was performed. For this purpose CHO cells transfected with human/rat chimeric PSMA molecules as described in Example 10.2.1 above were used. FACS analysis with supernatant of CHO cells expressing PSMA-P7 HL.times.I2C HL was performed as described herein. Detection of binding of PSMA-P7 HL.times.I2C HL was performed using a murine Penta His antibody and as second step reagent an Fc gamma-specific antibody conjugated to phycoerythrin. Supernatant of untransfected cells was used as a negative control. Supernatant of CHO cells expressing the bispecific single chain antibody construct PSMA-D4 HL.times.I2C HL cross-reactive with rat PSMA was used as control for expression of the chimeric PSMA constructs.
[0692] As shown in FIG. 20 both PSMA bispecific single chain antibodies, PSMA-P7 HL.times.I2C HL and PSMA-D4 HL.times.I2C HL, showed binding to the chimeric constructs hu PSMArat140-169, hu PSMArat281-284, huPSMArat300-344, hu PSMArat683-690 and huPSMArat716-750. As furthermore shown in FIG. 20 there is a lack of binding for PSMA-P7 HL.times.I2C HL to the construct huPSMArat598-617, which demonstrates the presence of its binding epitope in the region of amino acids 598 to 617 of human PSMA.
[0693] As shown in Table 1 the amino acids 598 to 617 constitute a membrane proximal epitope as defined herein. In conclusion the results of the mapping based on chimeric PSMA constructs demonstrate that bispecific single-chain antibody PSMA-P7 HL.times.I2C HL recognizes a membrane-proximal target epitope of human PSMA with <60 .ANG. membrane-distance as defined herein.
10.3 Epitope Mapping of the PSMA- and CD3-Reactive Bispecific Single Chain Antibody Molecule PSMA-D4 HL.times.I2C HL
[0694] A PSMA-epitope with 60 .ANG. membrane-distance of bispecific single chain antibody PSMA-D4 HL.times.I2C HL was confirmed by epitope mapping using a peptide scanning approach. Peptide scanning uses overlapping peptides of a given protein and analyses antibody binding to immobilized peptides by enzyme-linked immunosorbent assays (ELISAs). The epitope mapping experiments with the PSMA bispecific single chain antibody PSMA-D4 HL.times.I2C HL were performed as described in detail in Bernard et al. 2004, J. Biol. Chem., 279: 24313-22 and Teeling et al. 2006, J Immunol., 177: 362-71.
[0695] In brief, 693 different 15-mer peptides were synthesized that span the entire extracellular amino acid sequence of human PSMA and overlap with each neighboring 15-mer peptide by 14 amino acids. These peptides were coated to ELISA wells in a 384-well plate format. For this series of experiments, the anti-PSMA scFv fragment of bispecific single chain antibody PSMA-D4 HL.times.I2C HL was produced in E. coli and used for ELISA as crude periplasmic extracts prepared as described herein. The scFv antibody was incubated with the peptides and specific binding detected using an anti-His antibody. Binding signals were measured in a 384-well ELISA reader. As shown in the FIG. 21 a clear maximum signal was obtained for a peptide spanning over the amino acids threonine 334 to threonine 339, which demonstrates the presence of binding epitope of PSMA-D4 HL.times.I2C HL in the region of amino acids 334 to 339 of human PSMA. As shown in Table 1 threonine 334 and threonine 339 constitute a membrane-distal epitope as defined herein.
[0696] In conclusion the results of the mapping based on peptide scanning demonstrate that bispecific single-chain antibody PSMA-D4 HL.times.I2C HL recognizes a membrane-distal target epitope of human PSMA with 60 .ANG. membrane-distance as defined herein.
10.4 Comparative Analysis of Cytotoxic Activity of Bispecific Antibodies Single-Chain Antibodies Directed at Membrane-Proximal and Membrane-Distal Target Epitopes of Human PSMA
[0697] Bioactivity of bispecific single chain antibodies was analyzed by a CytoTox-Glo.TM. cytotoxicity assay with unstimulated human PBMC using the CHO cells transfected with human PSMA described in Example 2.1. As effector cells unstimulated human PBMC were used.
[0698] Unstimulated human PBMC were obtained as follows:
[0699] Human peripheral blood mononuclear cells (PBMC) were prepared by Ficoll density gradient centrifugation from enriched lymphocyte preparations (buffy coats), a side product of blood banks collecting blood for transfusions. Buffy coats were supplied by a local blood bank and PBMC were prepared on the same day of blood collection. After Ficoll density centrifugation and extensive washes with Dulbecco's PBS (Gibco), remaining erythrocytes were removed from PBMC via incubation with erythrocyte lysis buffer (155 mM NH4Cl, 10 mM KHCO3, 100 .mu.M EDTA). Platelets were removed via the supernatant upon centrifugation of PBMC at 100.times.g. Remaining lymphocytes mainly encompass B and T lymphocytes, NK cells and monocytes. PBMC were kept in culture at 37.degree. C. and 5% CO2 in RPMI medium (Gibco) with 10% FBS (Gibco). All procedures were performed according to standard protocols (Current Protocols in Immunology; Coligan, Kruisbeek, Margulies, Shevach and Strober; Wiley-Interscience, 2002)
[0700] The CytoTox-Glo.TM. cytotoxicity assay (Kit from Promega) was used according to the instructions provided by the manufacturer.
[0701] Each measurement was performed in triplicates with defined dilution series of purified PSMA specific bispecific antibodies (0.001 ng/ml to 250 ng/ml) and appropriate controls to define spontaneous lysis (effector and target cells without bispecific antibodies) and maximum lysis (addition of detergent digitonin to cells). 10000/well target and 100000/well effector cells were mixed in a defined ratio with effector cells in excess (E:T ratio of 10:1). After incubation at 37.degree. C. for 20-24 hours CytoTox-Glo cytotoxicity assay reagent (AAF-GIo.TM.; part of the CytoTox-Glo Kit from Promega) was added to all wells. The cells and the reagent were mixed by orbital shaking and incubated at room temperature for 1 hour. Determination of the number of dead cells was performed subsequently by measuring luminescence with a plate reader (TECAN Spectrafluorometer). The measured signal correlates directly with the amount of lysed cells.
[0702] On the basis of those measured values the cytotoxicity values of every individual sample were calculated according to following formula:
S[%]=(V-B)/(M-B)
[0703] Wherein S is specific toxicity, V is the measured value, B is the average of blank values and M is the average of maximum lysis.
[0704] As shown in FIG. 22 the bispecific antibody PSMA-P7 HL.times.I2C HL directed at a membrane-proximal target epitope of human PSMA (as shown in Example 10.2) demonstrated superior cytotoxic activity against human PSMA positive target cells as compared to the bispecific single-chain antibody PSMA-D4 HL.times.I2C HL directed at membrane-distal target epitope of human PSMA (as shown in Example 10.3).
TABLE-US-00016 TABLE 1 aa distance to aa of pos. HUM RAT reference (.ANG.) 63 D Q 11.7 79 Q R 35.75 80 I T 37.16 87 E Q 40.16 88 Q H 37.46 91 Q E 33.93 97 Q H 25.2 98 S A 24.96 107 S L 21.07 111 A S 31.1 112 H D 34.65 140 N K 62.43 144 F A 51.27 146 P L 50.14 147 P S 47.22 154 V I 44.73 157 I V 44.61 161 F Y 48.85 169 M T 62.96 191 D V 68.07 207 K V 46.97 225 V I 56.52 236 A V 45.34 258 I V 46.85 281 R H 50.31 282 G E 52.65 283 I F 52.92 284 A T 55.82 300 Y D 56.23 308 K H 67.6 320 R K 58.61 322 S G 56.59 334 T A 73.45 339 T K 75.1 344 M L 60.7 349 T Y 52.3 351 E K 48.1 363 R K 15.8 380 S A 35.47 401 S T 11.76 408 E K 7.93 438 N H 31.19 471 Y H 25.5 475 H Y 23.2 482 K P 20.44 495 E D 27.54 498 T K 30.45 499 K E 33.18 504 P T 38.15 507 S T 35.93 542 E K 42.23 543 T N 42.97 546 F V 43.56 548 G S 39.02 569 M T 28.15 582 G A 14.07 598 R Q 31.22 599 D S 30.9 603 V A 36.05 605 R K 40.9 607 Y H 41.38 609 D E 45.95 610 K T 45.84 613 S N 51.09 617 K N 56.75 624 T A 64.88 626 S M 60.97 627 V I 57.43 637 K N 42.63 641 E D 38.71 642 I V 36.92 647 S N 29.22 648 E Q 30.75 653 F L 26.85 660 V L 26.27 663 M I 26.27 664 M L 26.99 670 F Y 28.76 683 D G 49.46 690 V I 40.04 716 E N 60.95 717 S N 62.54 721 P T 64.1 726 G R 58.11 733 Y S 49.53 734 V I 46.73 747 S R 35.94 750 A D 38.19
TABLE-US-00017 TABLE 2 aa distance to aa of pos. HUM MU reference (.ANG.) 57 F Y 30.42 64 G E 46.67 72 A E 30.96 74 N D 35.61 78 L F 42.46 84 G R 42.58 85 Q E 43.72 88 T I 43.24 93 R S 43.31 101 S T 38.96 102 N D 40.41 136 S Q 55.96 144 N Y 61.64 185 F Y 64.38 186 N T 63.68 191 K R 57.71 217 N D 58.09 224 A V 56.62 229 T S 60.5 233 V I 54.23 242 E G 49.32 264 I V 59.95 267 I V 63.87 273 A H 70.89 274 Y H 72.78 278 Q M 66.9 284 A E 67.3 300 T S 59 301 D S 60.96 328 Q H 72.16 329 T A 69.98 331 D E 68.26 335 T N 67.63 339 I V 59.27 356 V A 50.4 359 Y Q 56.3 362 I T 60.49 399 N Y 41.15 417 E G 35.94 431 S N 56.56 432 Y S 57.15 457 D Y 47.06 458 Y K 48.96 471 I L 19.07 486 K Q 33.08 487 I V 29.68 497 A S 11.55 499 K R 7.95 506 E V 18.65 512 E K 37.64 513 V D 39.8 514 D G 43.57 515 E G 44.32 516 I L 41.48 518 L F 34.87 550 R K 27.19 559 S T 15.7 567 M I 19.02 584 L F 42.67 586 Y H 46.36 601 I L 36.05 616 K E 31.12 659 V I 49.32 661 T S 47.68 736 L I 32.18 739 L R 28.95 741 T Q 27.16
Sequence CWU 0 SQTB SEQUENCE LISTING The patent application
contains a lengthy "Sequence Listing" section. A copy of the
"Sequence Listing" is available in electronic form from the USPTO
web site
(http://seqdata.uspto.gov/?pageRequest=docDetail&DocID=US20190040133A1).
An electronic copy of the "Sequence Listing" will also be available
from the USPTO upon request and payment of the fee set forth in 37
CFR 1.19(b)(3).
0 SQTB SEQUENCE LISTING The patent application contains a lengthy
"Sequence Listing" section. A copy of the "Sequence Listing" is
available in electronic form from the USPTO web site
(http://seqdata.uspto.gov/?pageRequest=docDetail&DocID=US20190040133A1).
An electronic copy of the "Sequence Listing" will also be available
from the USPTO upon request and payment of the fee set forth in 37
CFR 1.19(b)(3).
References
-
vai.org/met
-
en.wikipedia.org/wiki/Wobble_Hypothesis
-
ncbi.nlm.nih.gov/PubMed/medline.html
-
-
embl.de/services/index.htmlareknowntothepersonskilledintheartandcanalsobeobtainedusing
-
google.com
-
rcsb.org/pdb
-
-
vbase.mrc-cpe.cam.ac.uk
-
seqdata.uspto.gov/?pageRequest=docDetail&DocID=US20190040133A1
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012
D00013
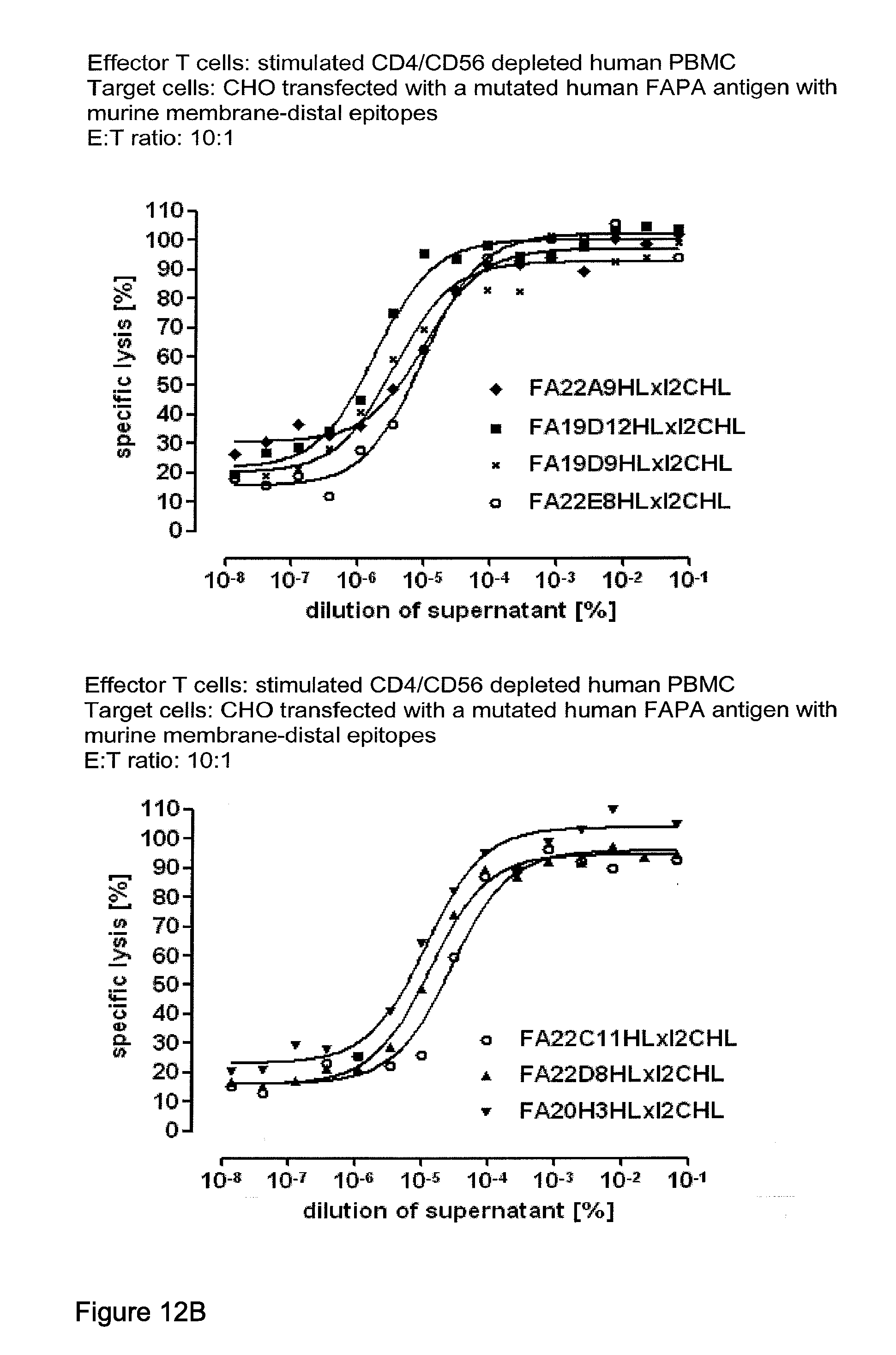
D00014
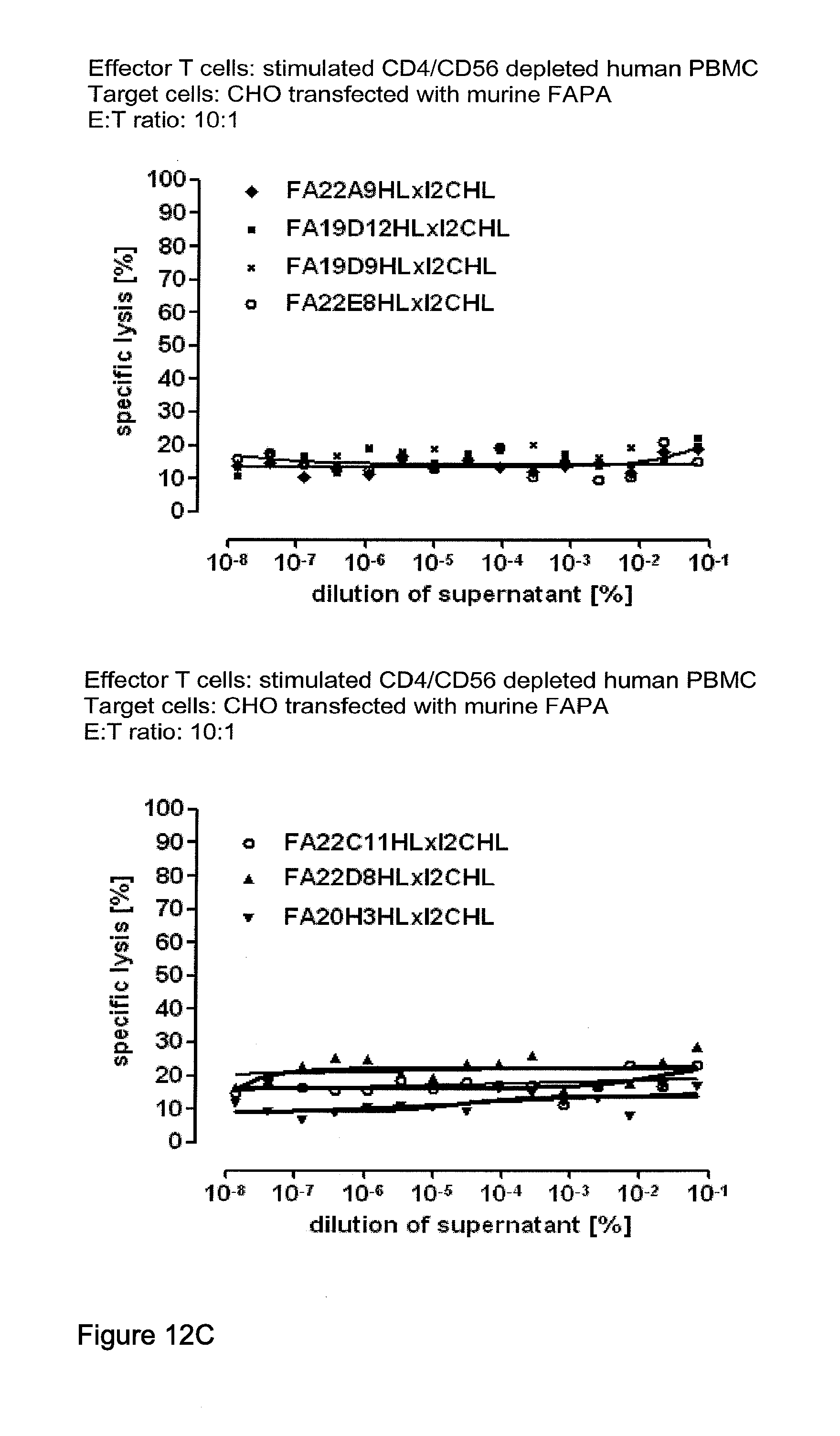
D00015
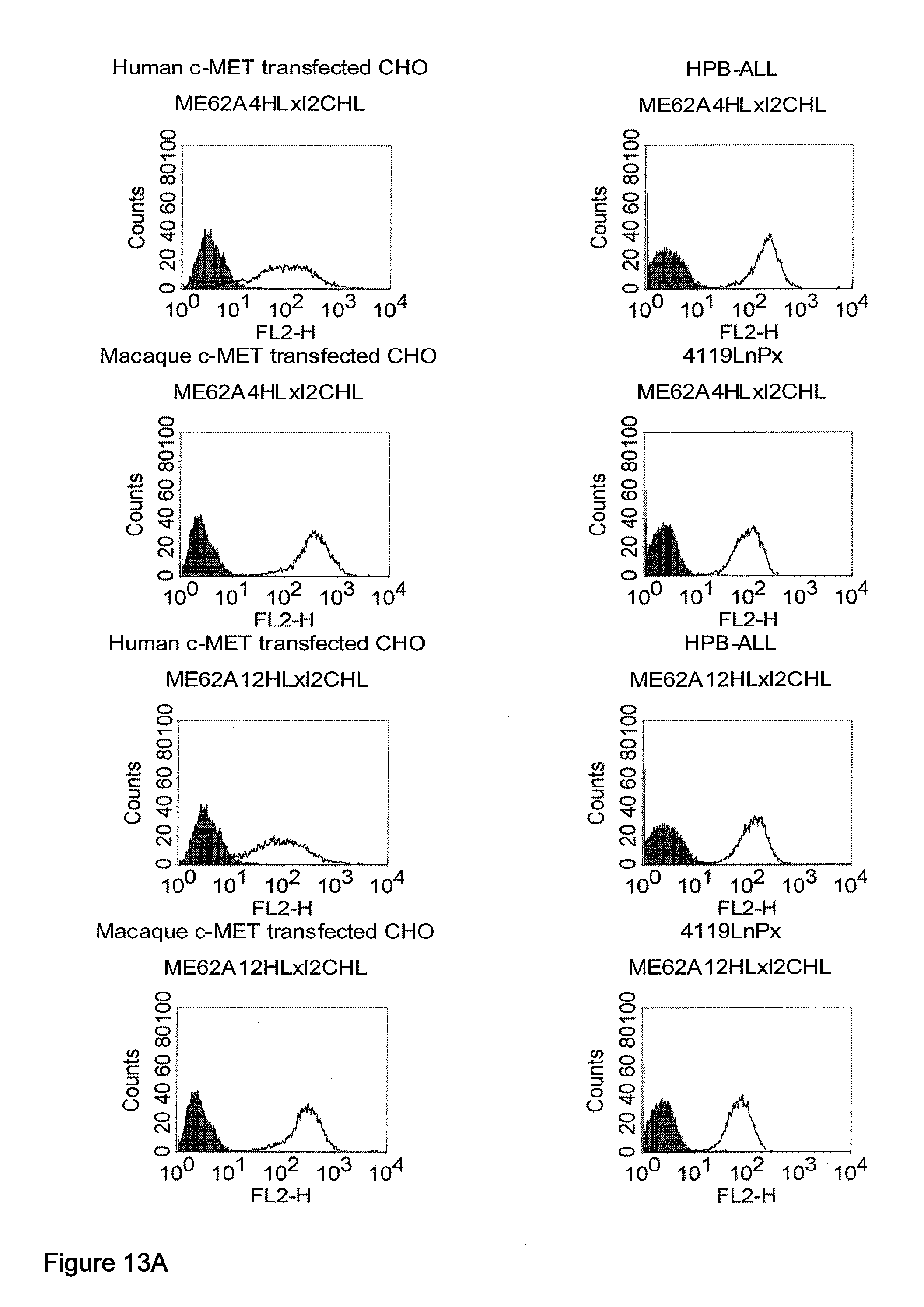
D00016
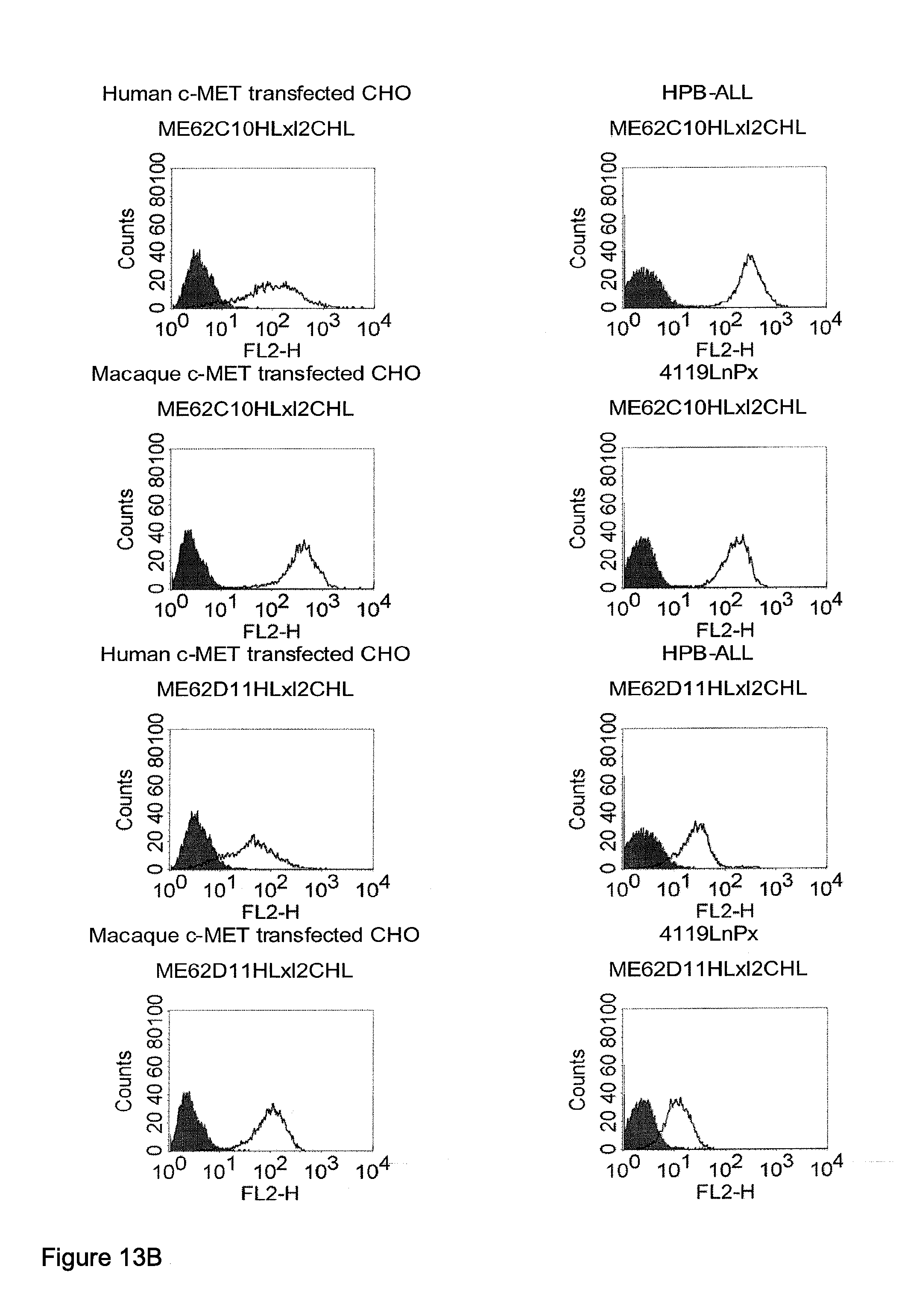
D00017
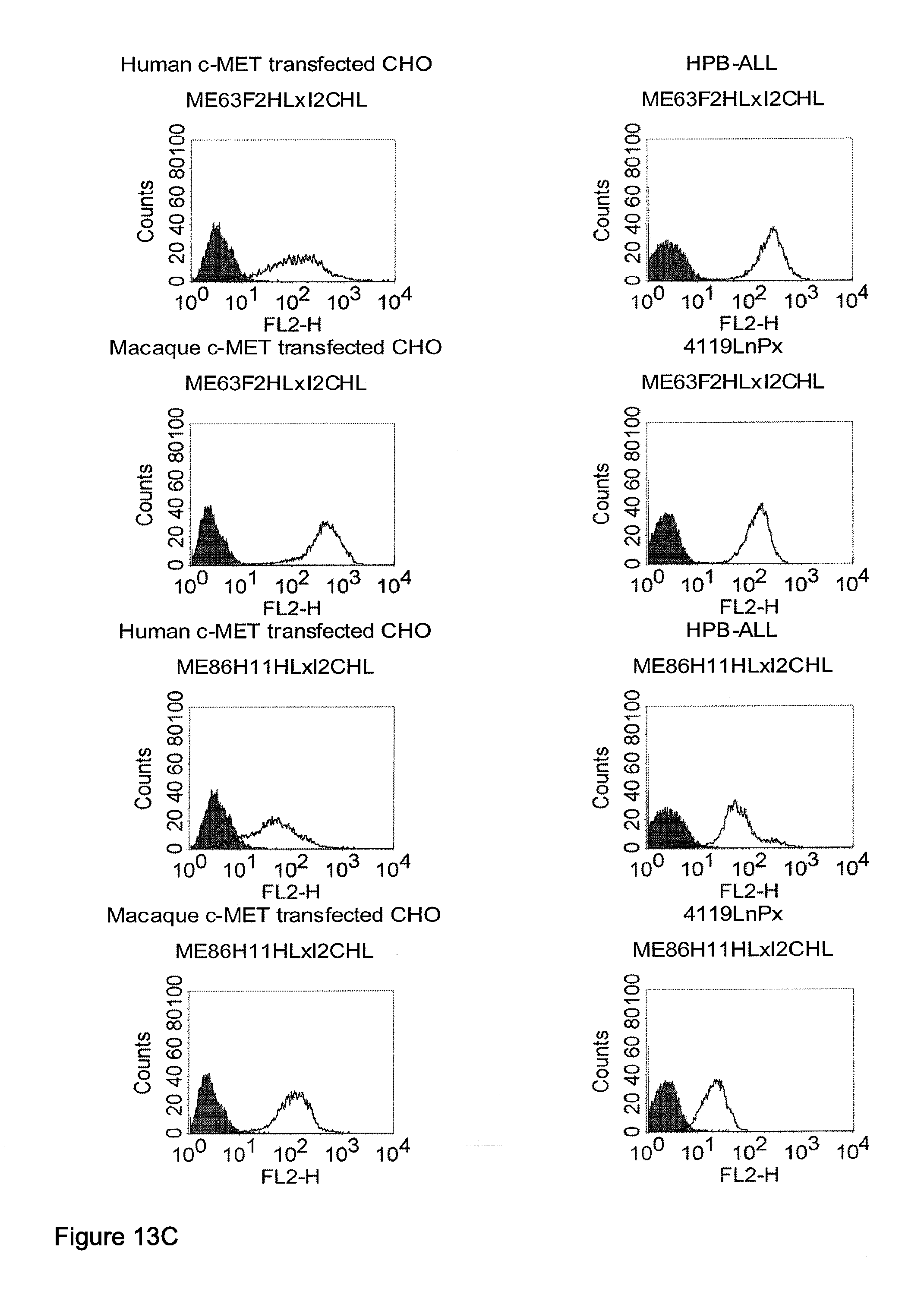
D00018
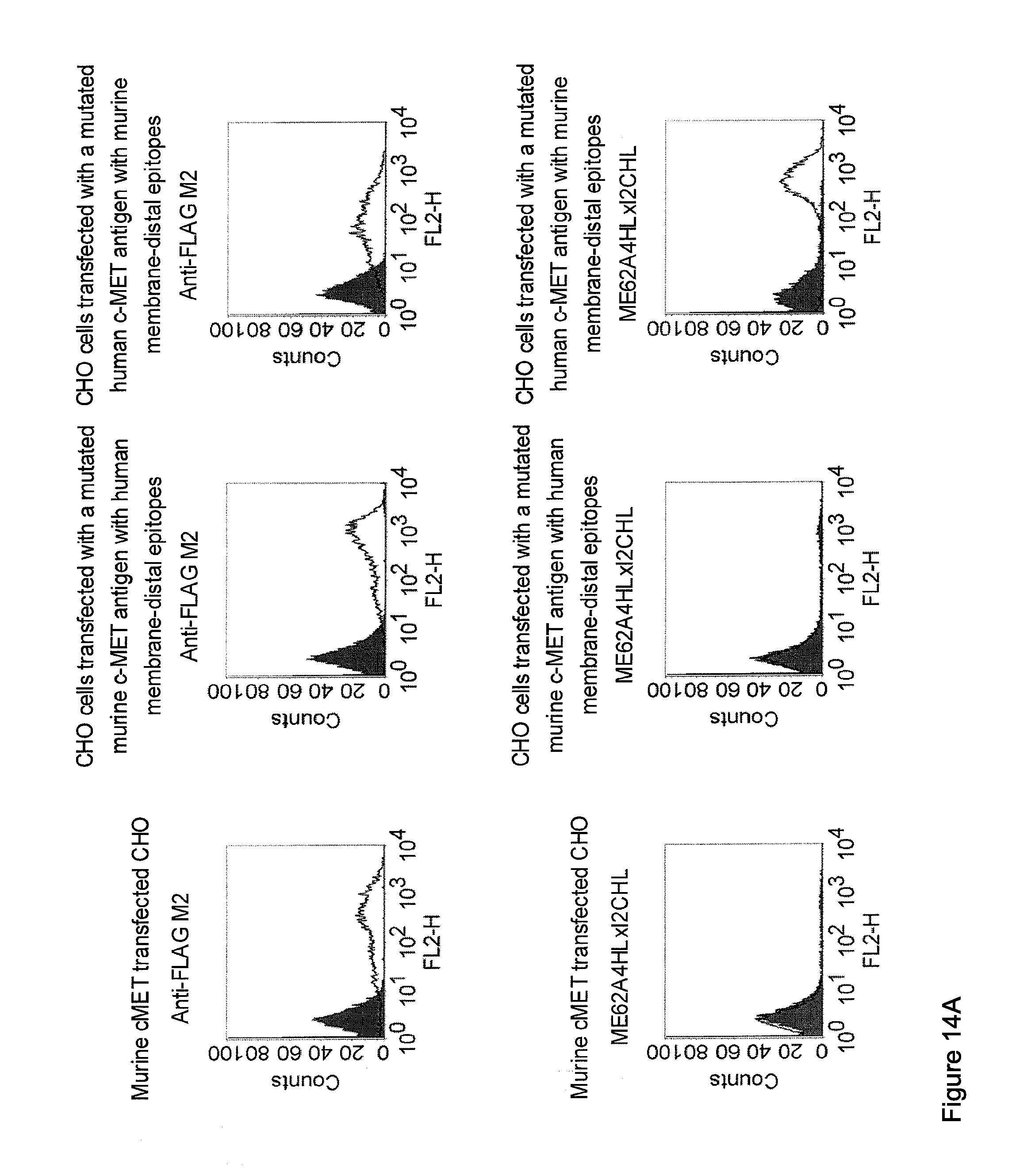
D00019
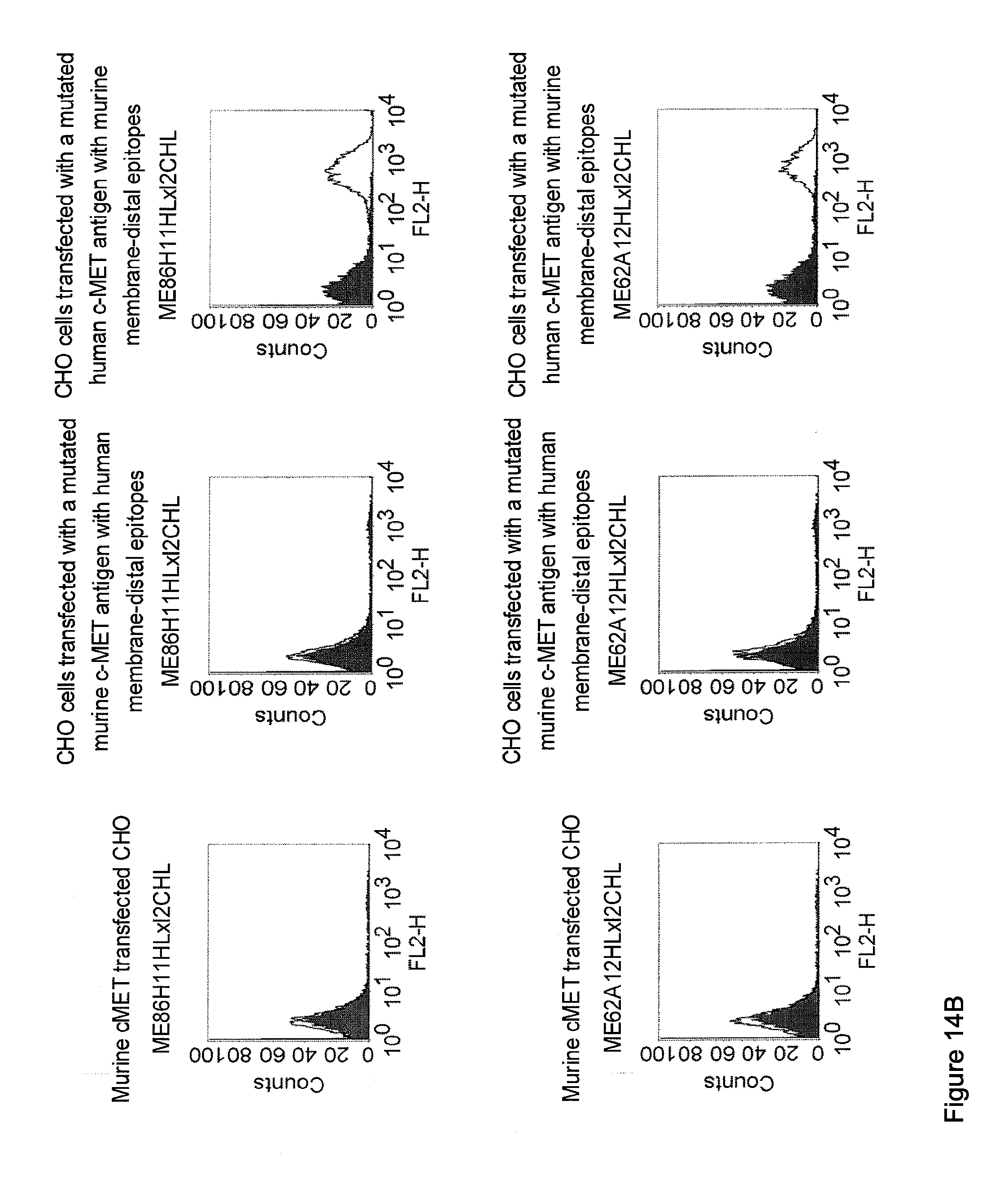
D00020
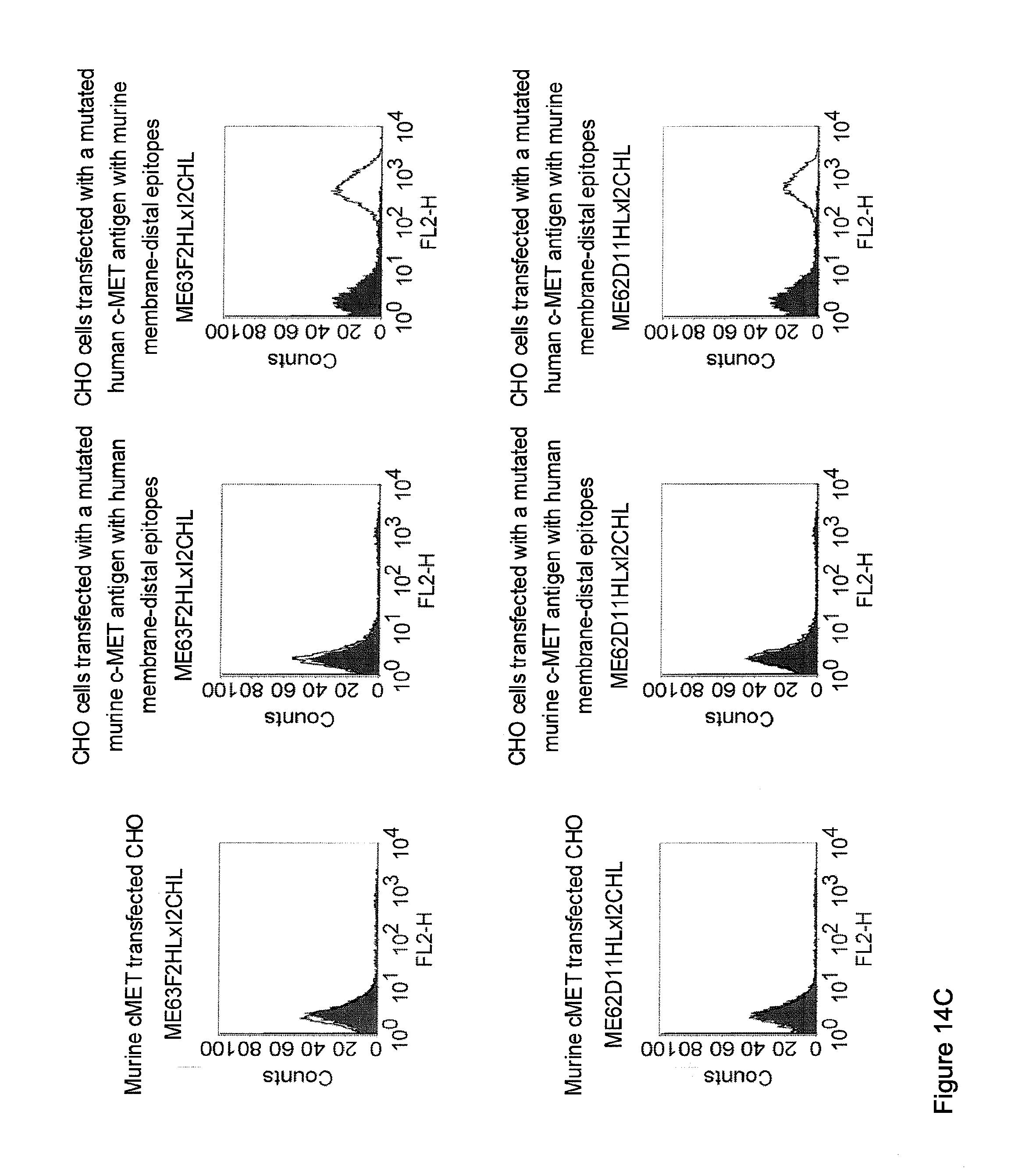
D00021
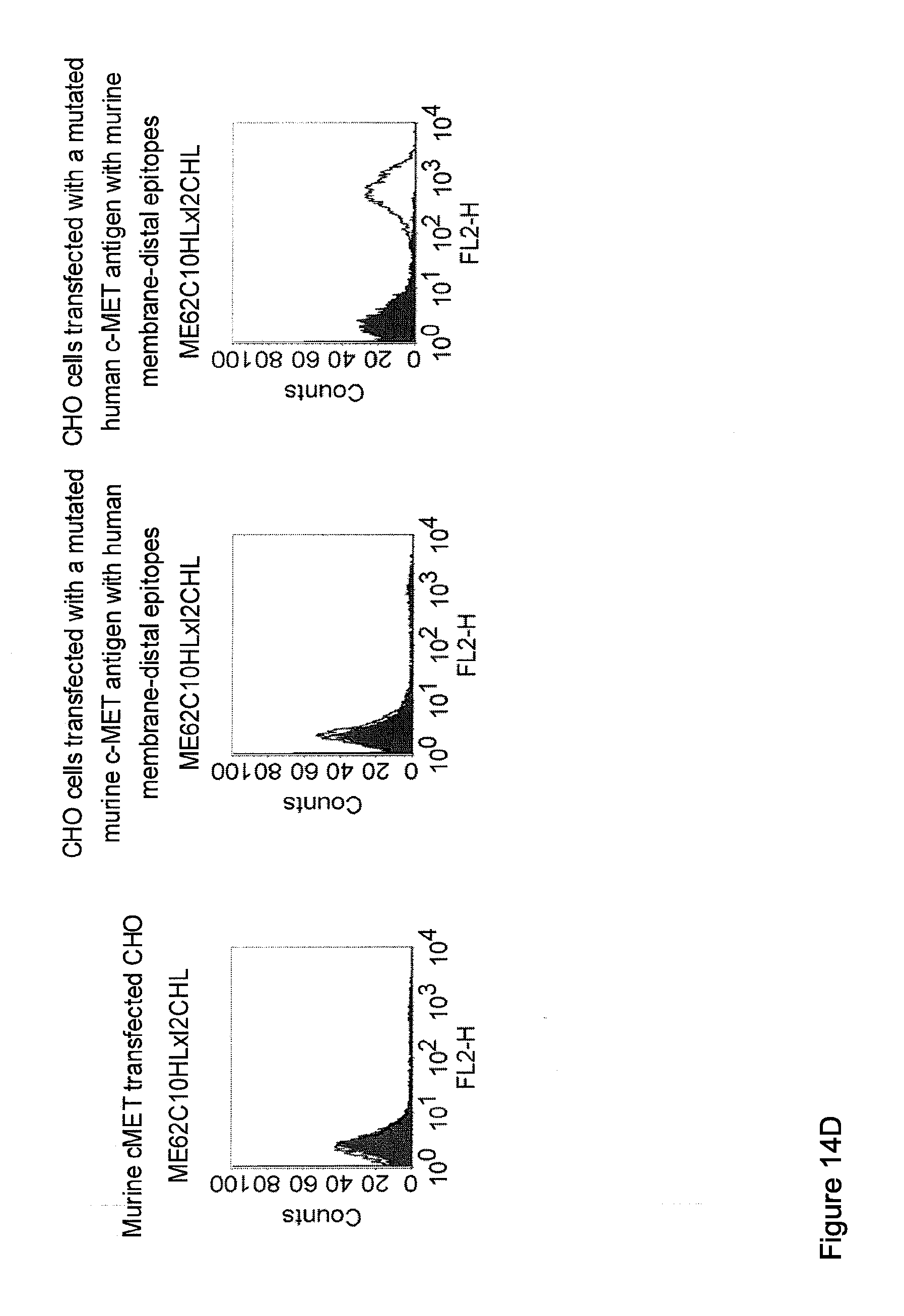
D00022
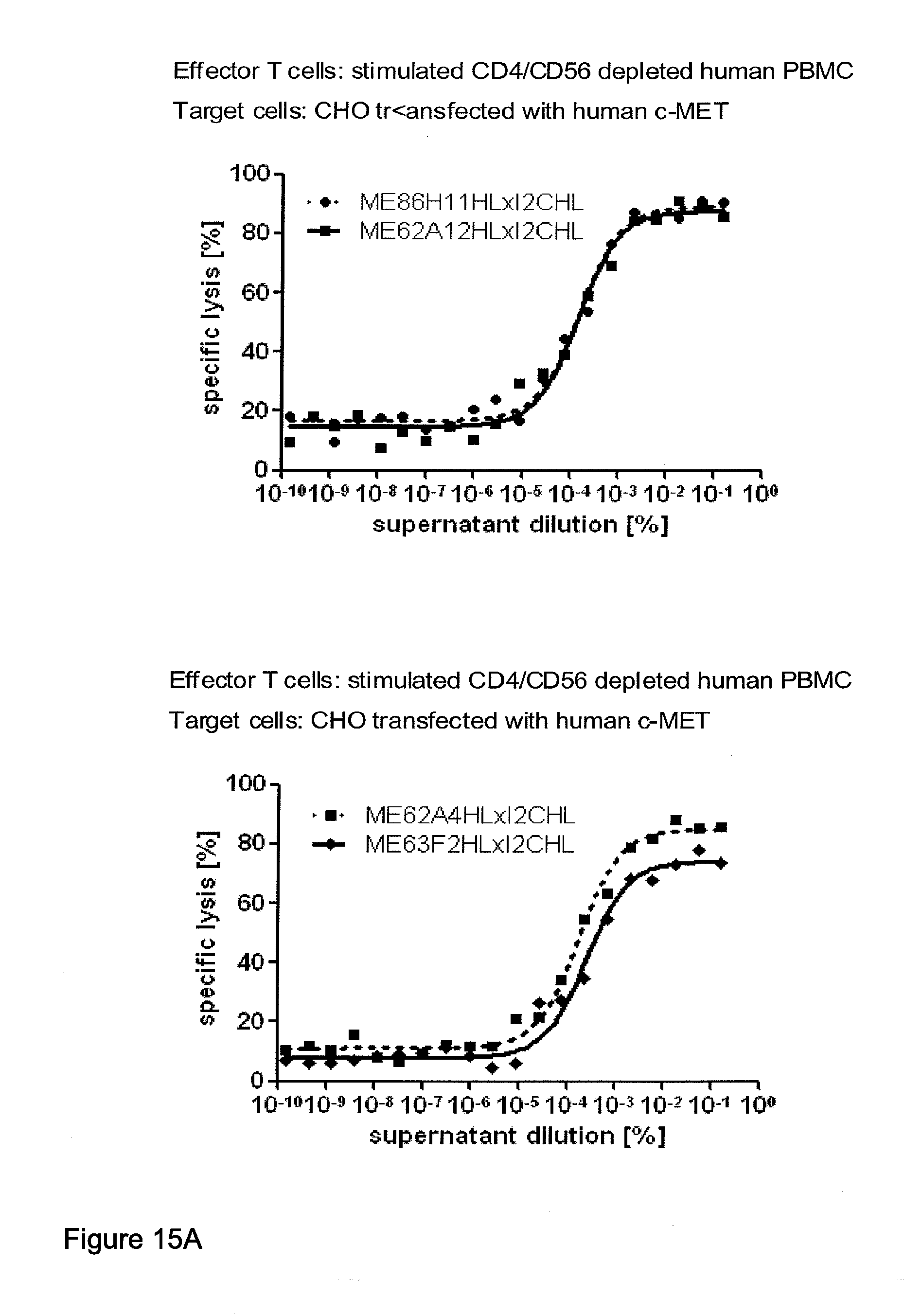
D00023
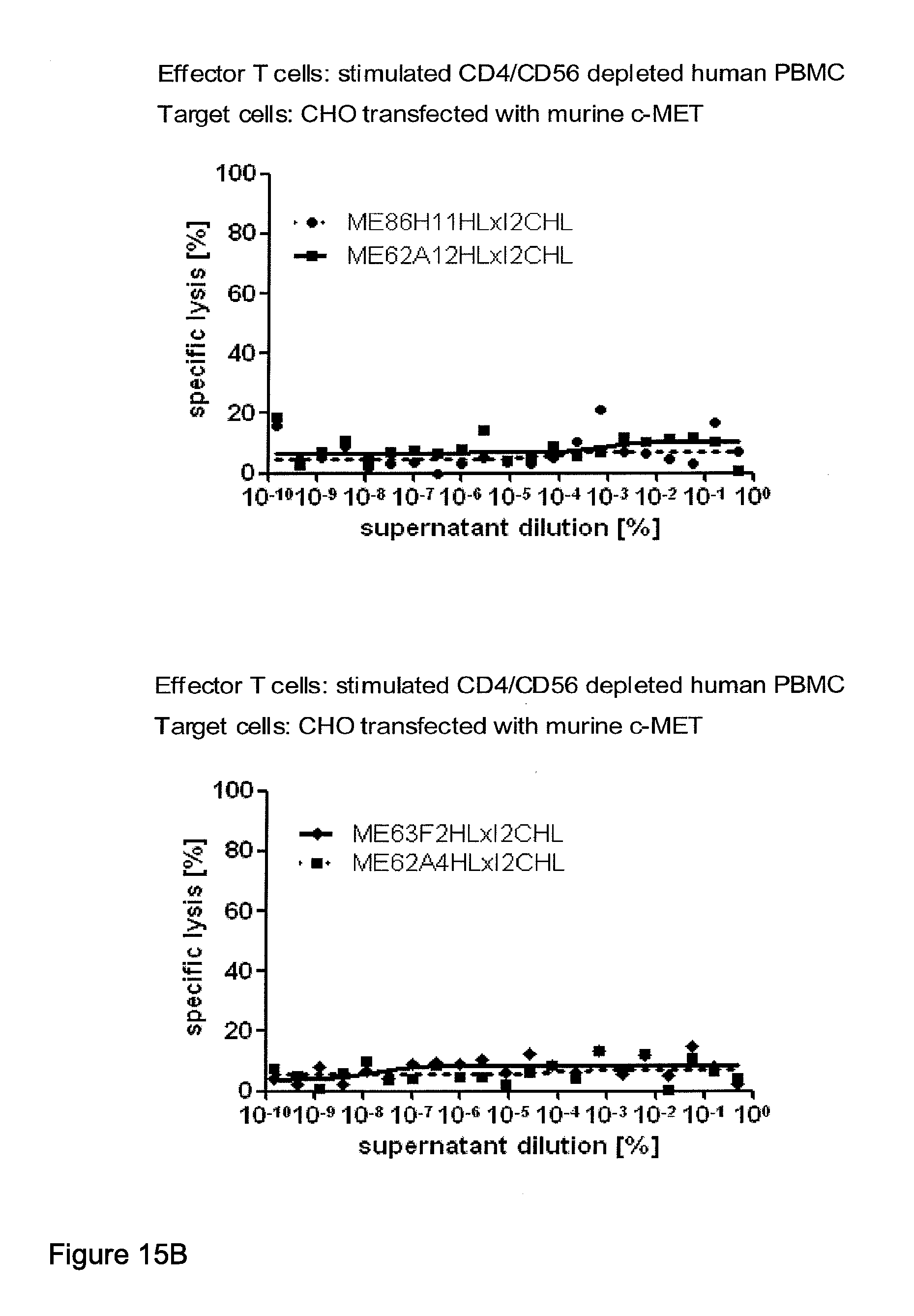
D00024
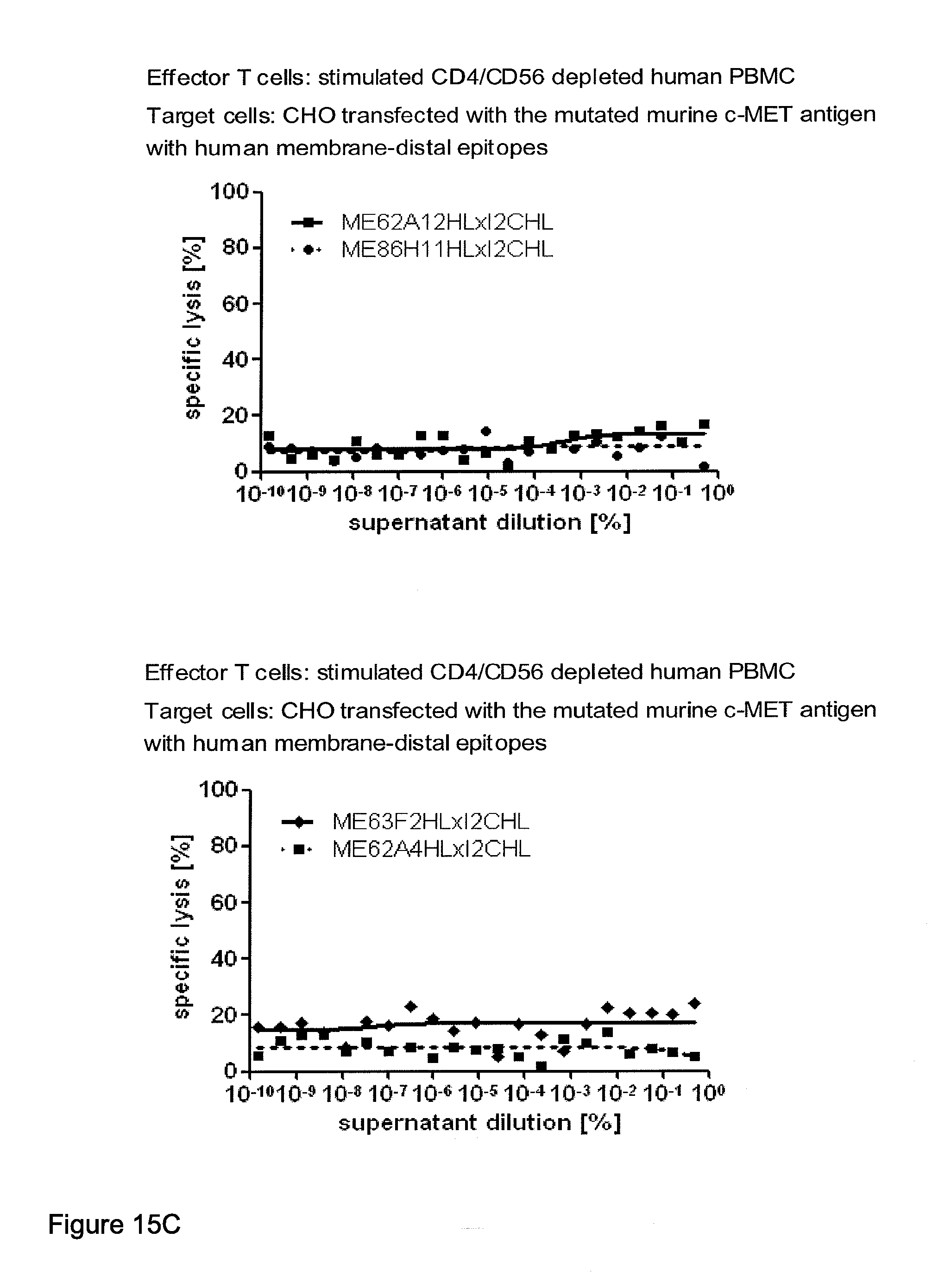
D00025
D00026
D00027
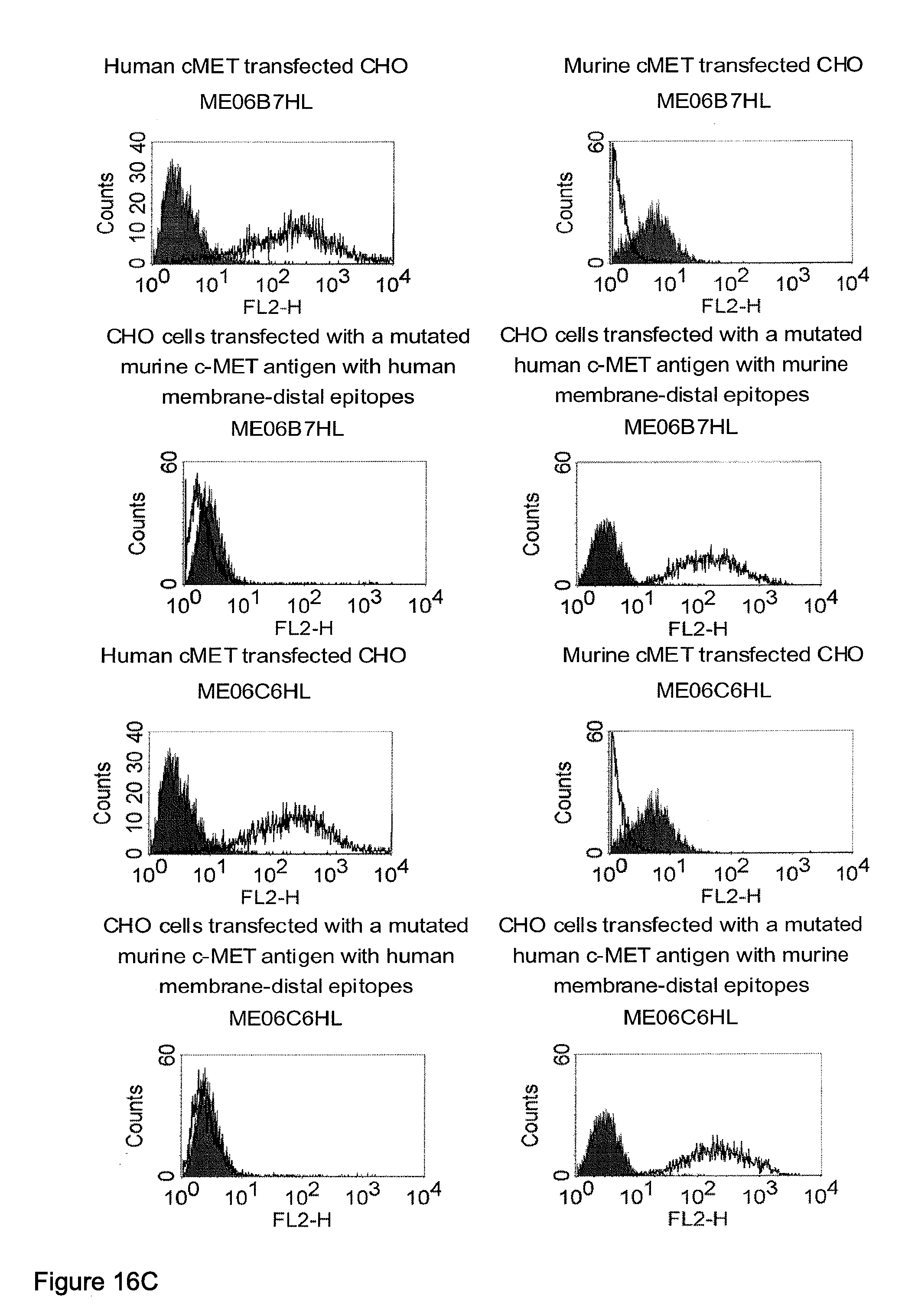
D00028
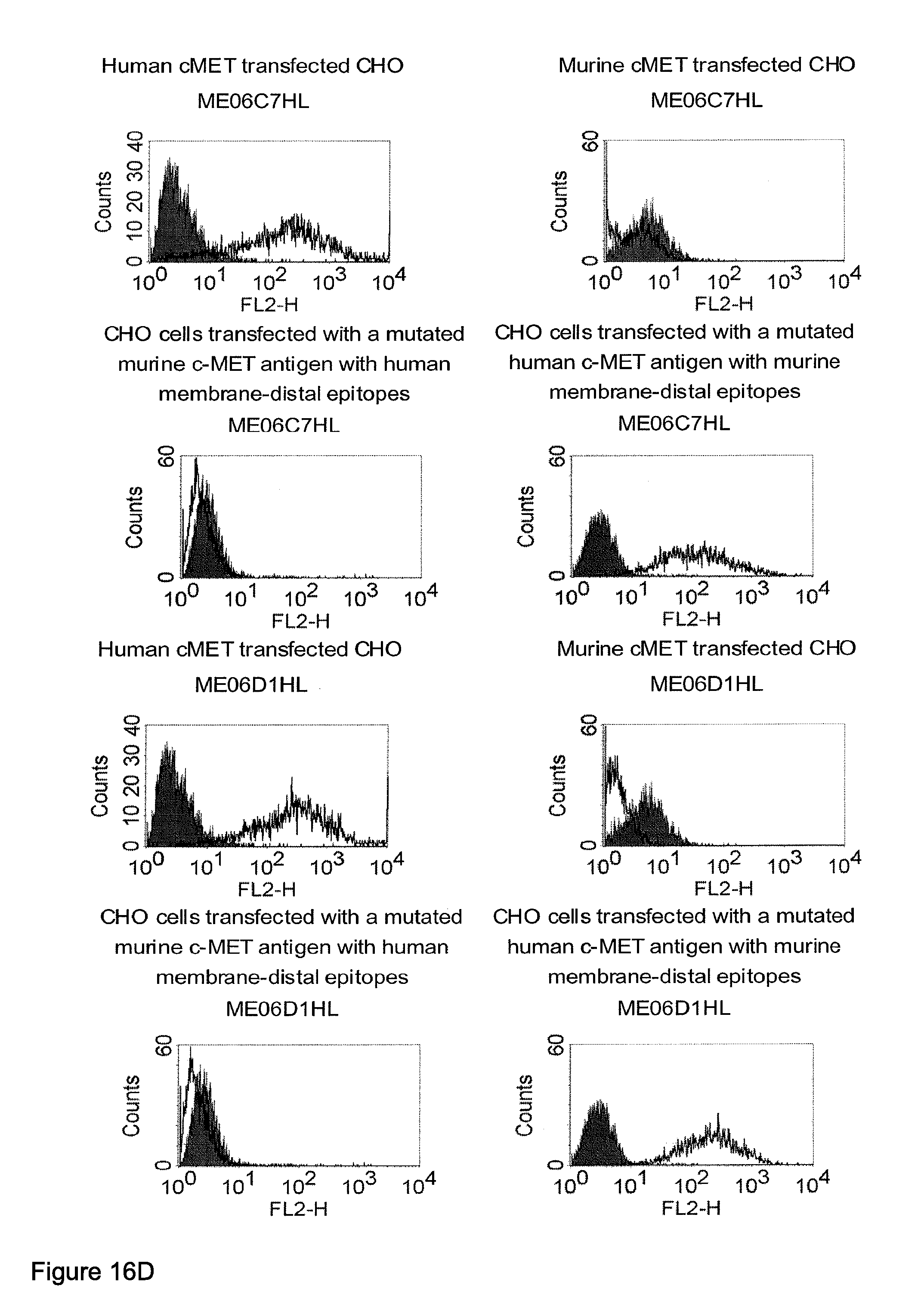
D00029
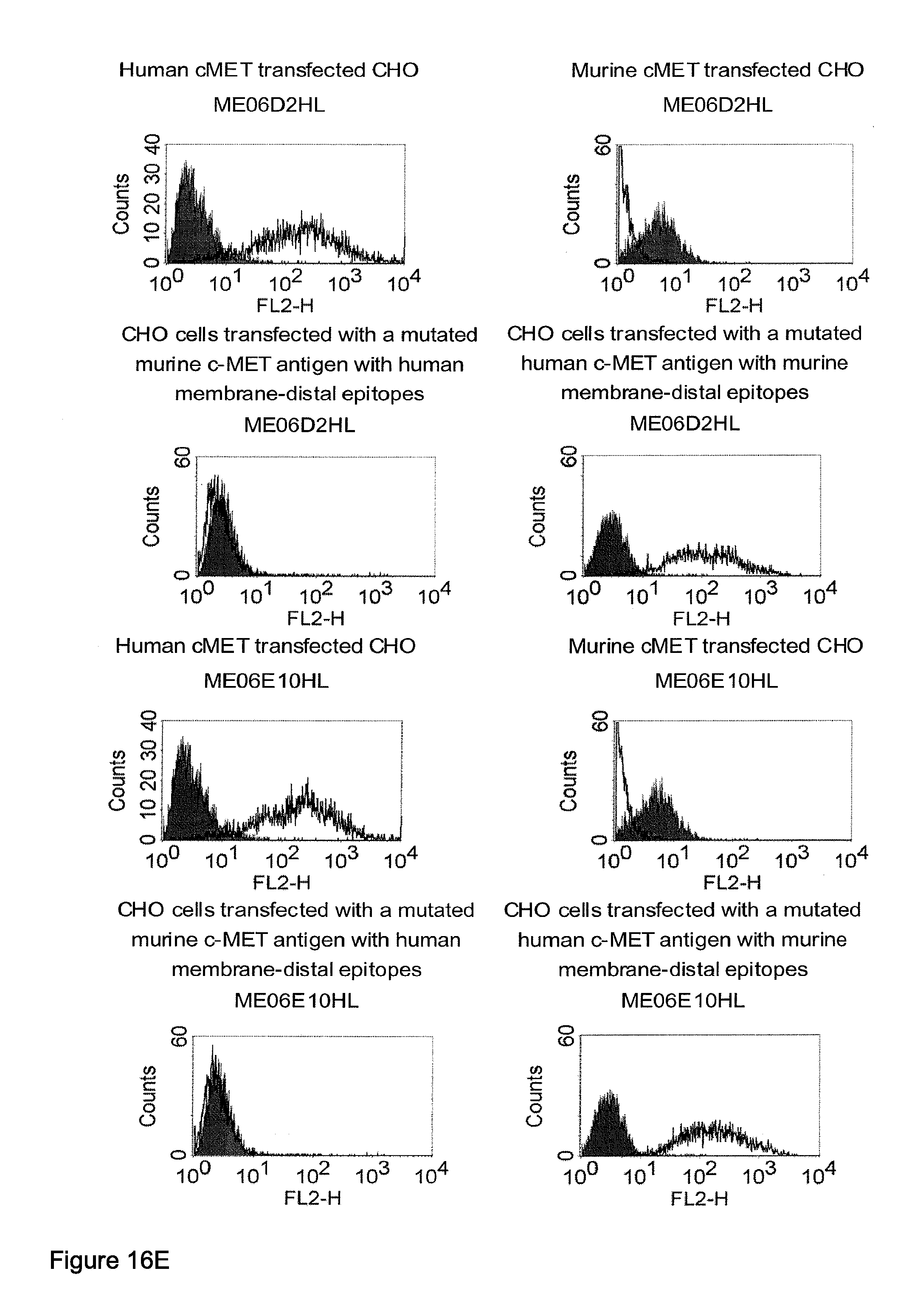
D00030
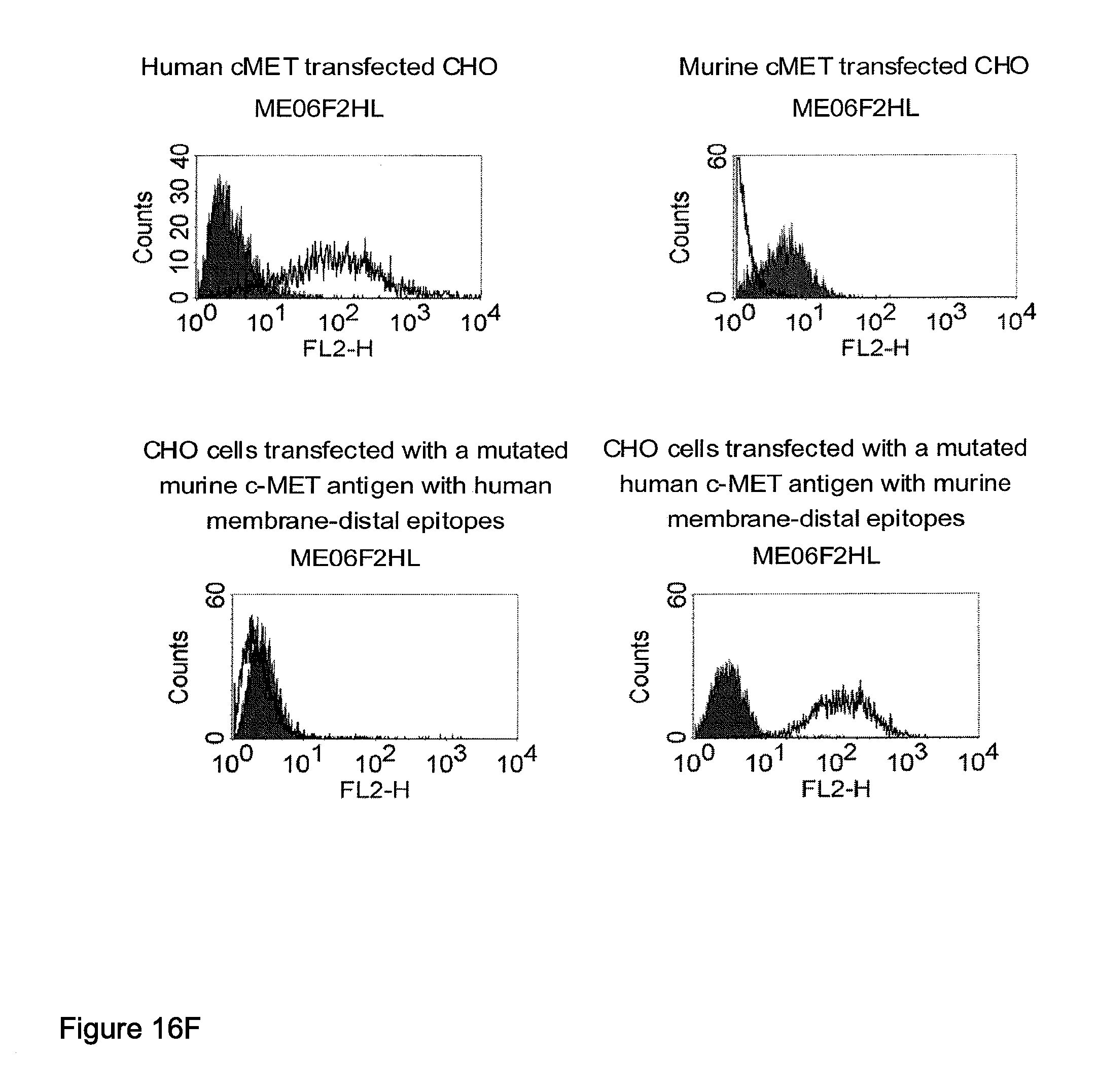
D00031
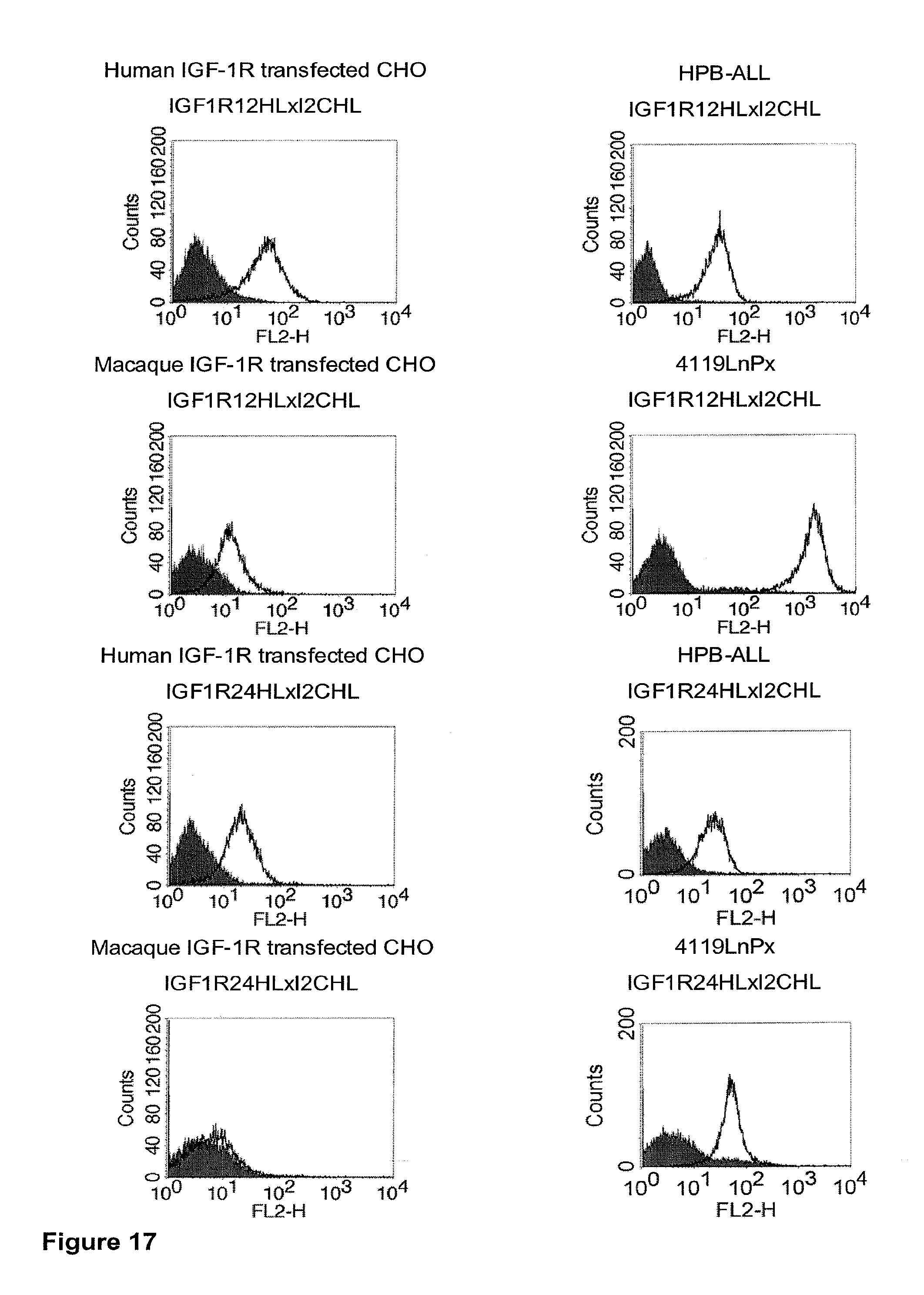
D00032
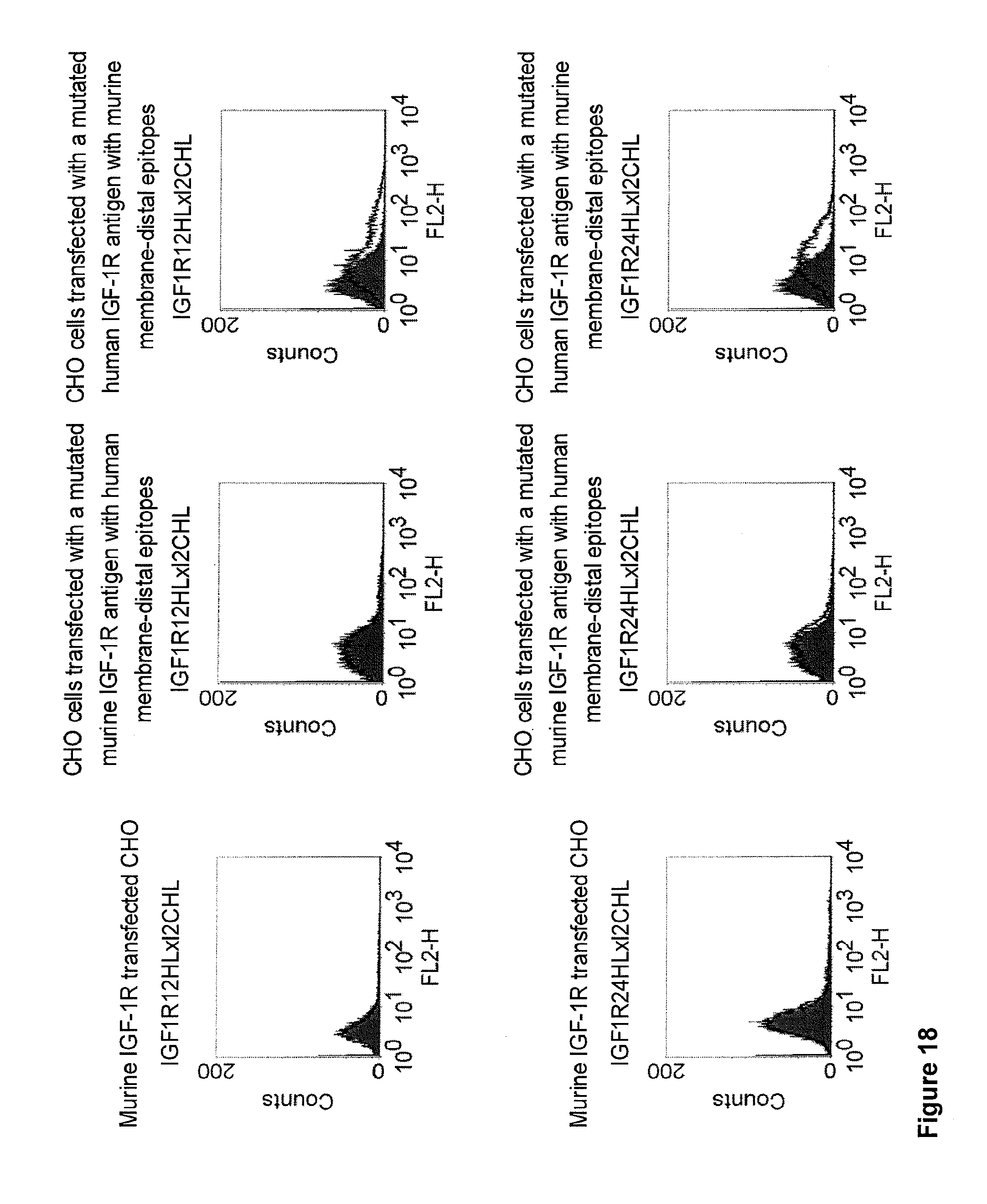
D00033
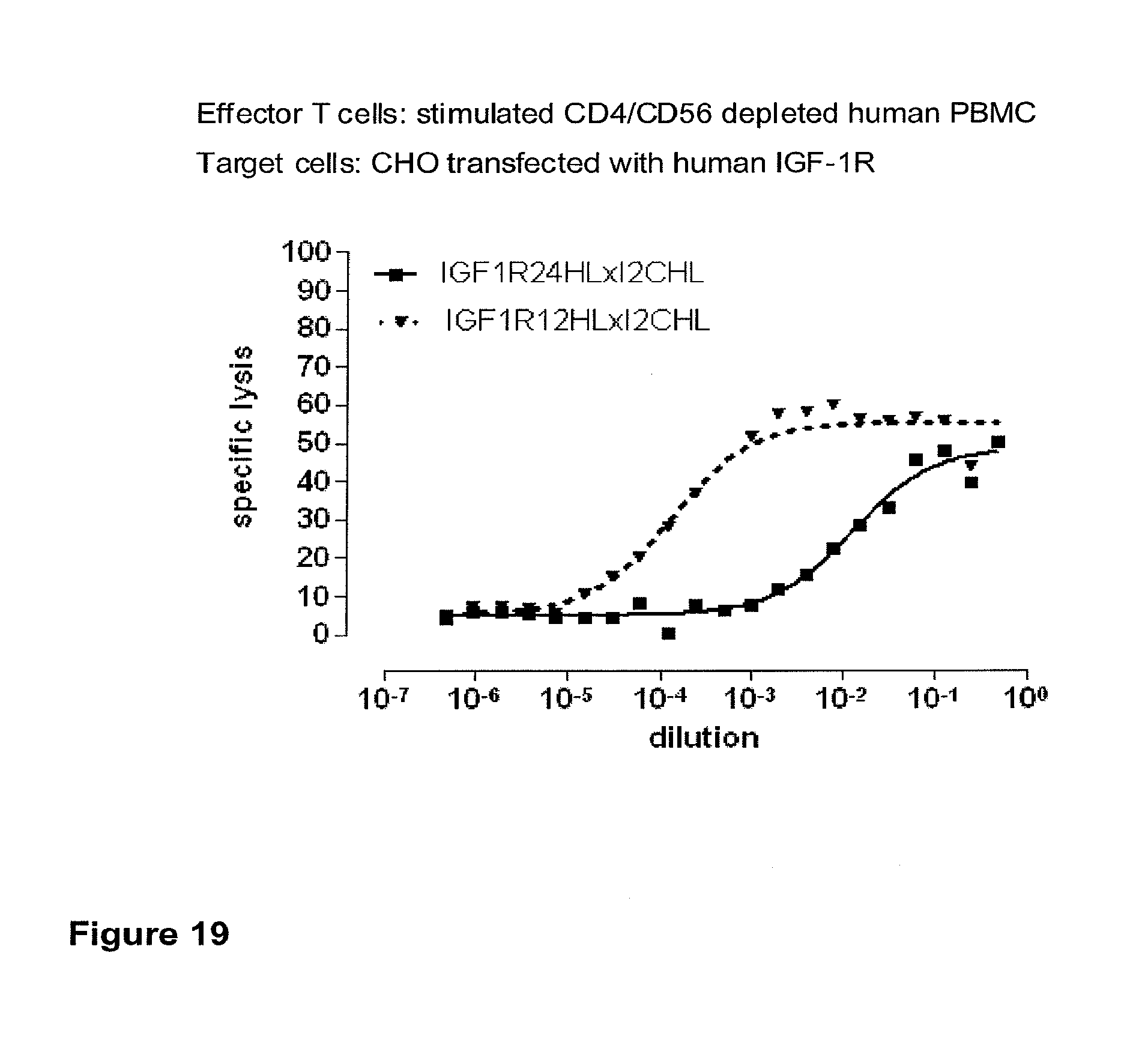
D00034
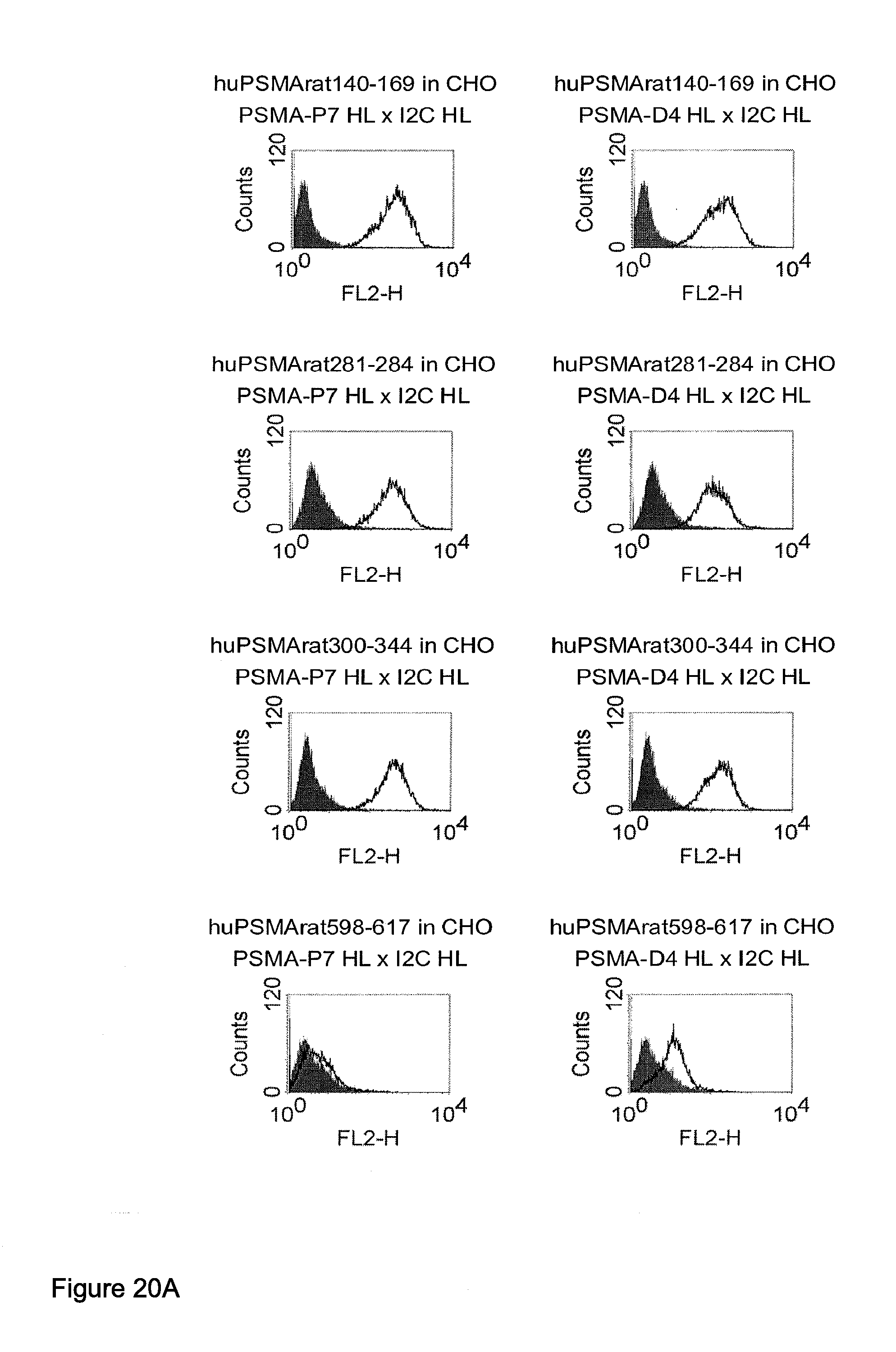
D00035
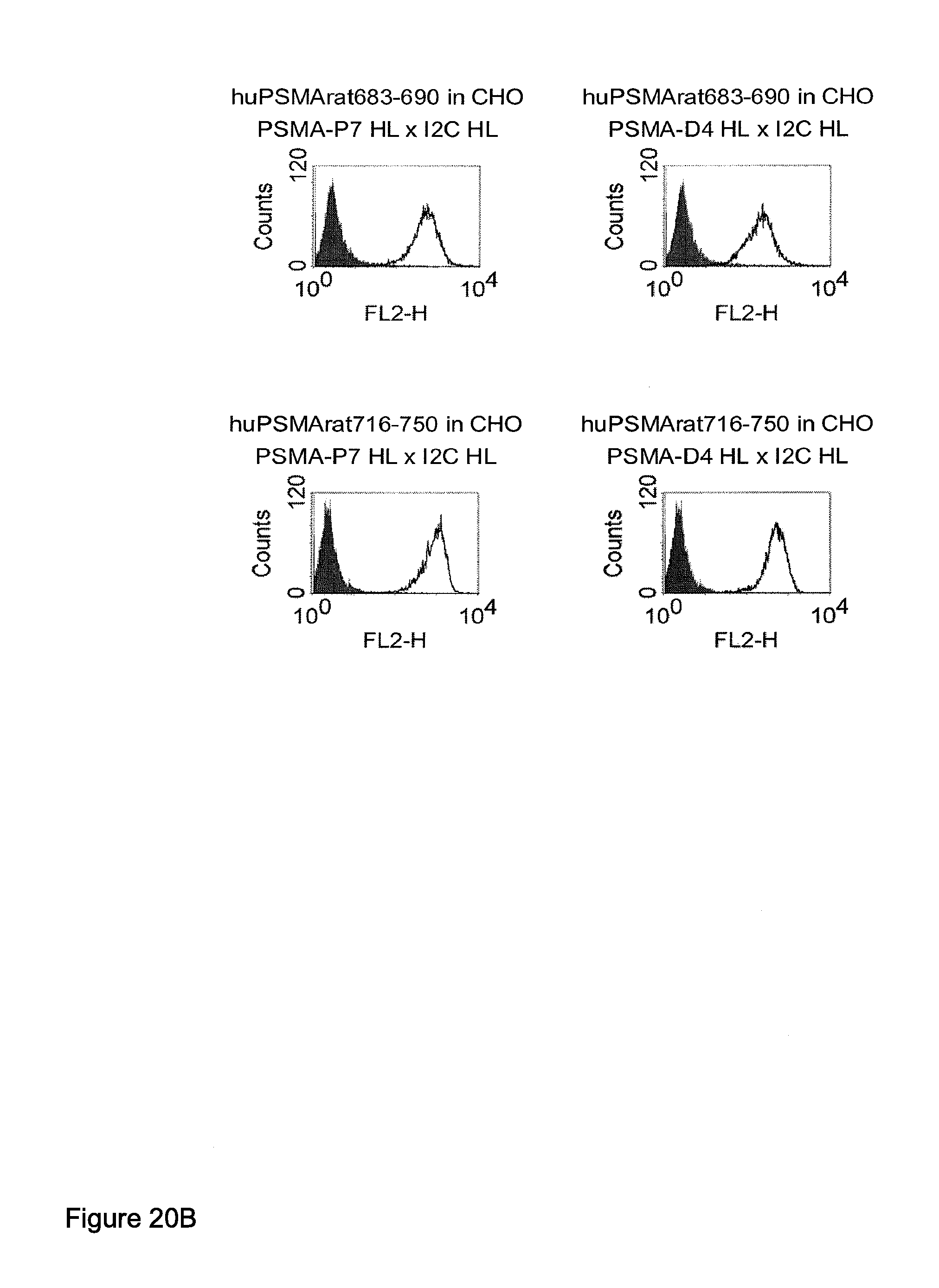
D00036
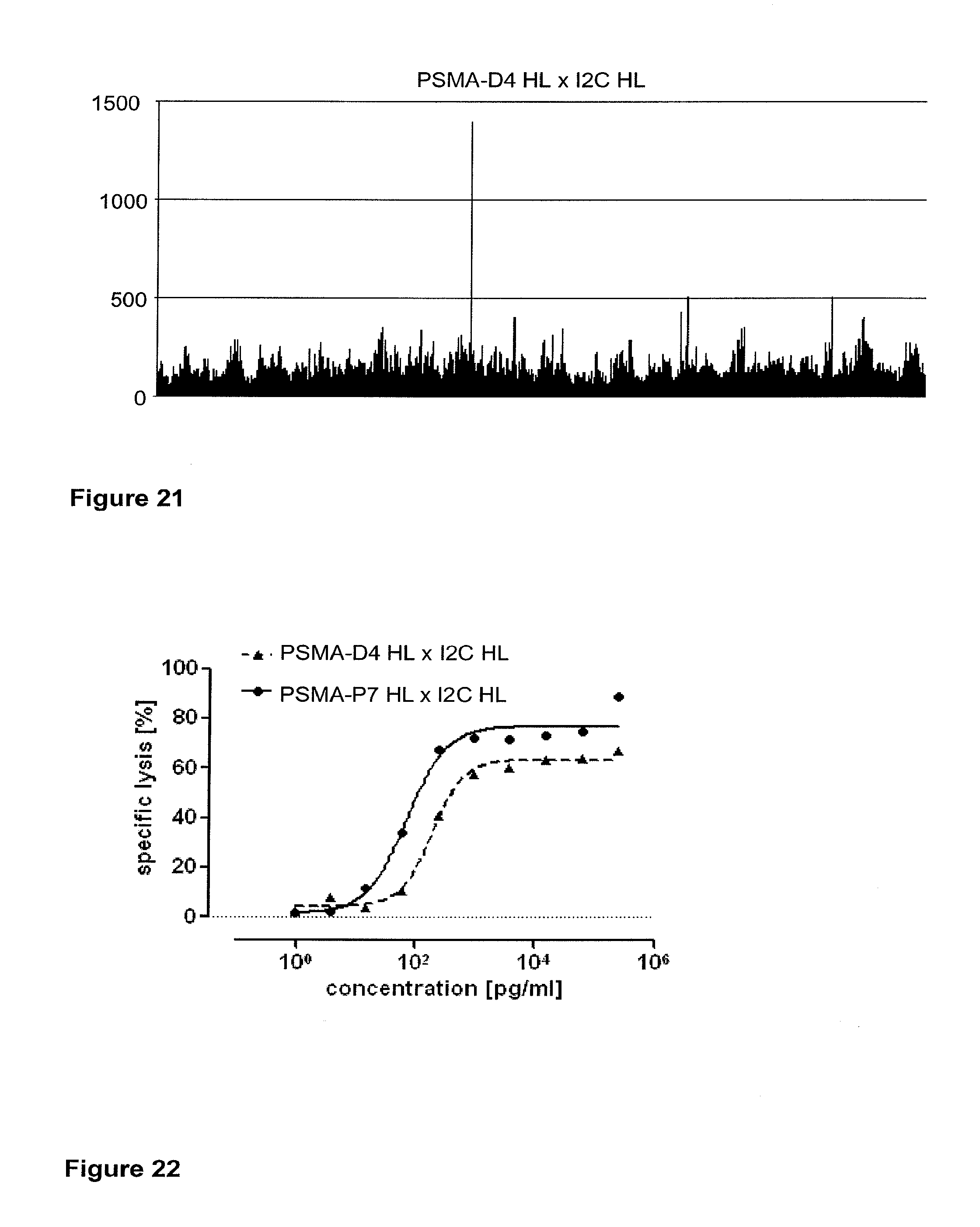
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.