Cache Return Order Optimization
Kaltenbach; Markus ; et al.
U.S. patent application number 15/878450 was filed with the patent office on 2019-01-17 for cache return order optimization. The applicant listed for this patent is INTERNATIONAL BUSINESS MACHINES CORPORATION. Invention is credited to Markus Kaltenbach, Ulrich Mayer, Siegmund Schlechter, Maxim Scholl.
| Application Number | 20190018792 15/878450 |
| Document ID | / |
| Family ID | 64998954 |
| Filed Date | 2019-01-17 |




| United States Patent Application | 20190018792 |
| Kind Code | A1 |
| Kaltenbach; Markus ; et al. | January 17, 2019 |
CACHE RETURN ORDER OPTIMIZATION
Abstract
Improving operation of a processing unit to access data within a cache system. A first fetch request and one or more subsequent fetch requests are accessed in an instruction stream. An address of data sought by the first fetch requested is obtained. At least a portion of the address of data sought by the first fetch request in inserted in each of the one or more subsequent fetch requests. The portion of the address inserted in each of the one or more subsequent fetch requests is utilized to retrieve the data sought by the first fetch request first in order from the cache system.
| Inventors: | Kaltenbach; Markus; (Holzgerlingen, DE) ; Mayer; Ulrich; (Schoenbuch, DE) ; Schlechter; Siegmund; (Lorch, DE) ; Scholl; Maxim; (Willich, DE) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Family ID: | 64998954 | ||||||||||
| Appl. No.: | 15/878450 | ||||||||||
| Filed: | January 24, 2018 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15649990 | Jul 14, 2017 | |||
| 15878450 | ||||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06F 2212/452 20130101; G06F 12/0895 20130101; G06F 12/0875 20130101; G06F 12/0855 20130101; G06F 2212/60 20130101; G06F 9/30043 20130101; G06F 12/1054 20130101; G06F 9/3824 20130101; G06F 9/3836 20130101 |
| International Class: | G06F 12/1045 20060101 G06F012/1045; G06F 9/38 20060101 G06F009/38; G06F 12/0855 20060101 G06F012/0855; G06F 9/30 20060101 G06F009/30 |
Claims
1. A method of improving operation of a processing unit to access data within a cache system, the method comprising: receiving by a processing unit a stream of pipelined instructions including one or more fetch requests seeking data from a multilevel cache or system memory; breaking up by the processing unit the stream of pipelined instructions during execution into multiple independent fetch requests including a first fetch request and one or more subsequent fetch requests each seeking data existing in different levels of the multilevel level cache system or system memory; accessing by the processing unit the first fetch request and one or more subsequent fetch requests; obtaining by the processing unit a memory address of data sought by the first fetch request, the obtained memory address a logical address where the data is located in the multilevel level cache system or system memory; inserting low order bits of the memory address of data sought from the cache system or main system memory by the first fetch request in each of the one or more subsequent fetch requests seeking data located in the cache system or main system memory; determining, by accessing a first level cache directory indicating data present in the first level cache, that data sought by the first fetch request is not found in the first level cache of the multilevel level cache system; attempting to access a translation look aside buffer providing access to information residing in a higher cache level of the multilevel cache system higher than the first level cache to determine an absolute address or a physical address of the data sought in a higher level cache or system memory, the attempt to access the translation look aside buffer failing to arbitrate access; and utilizing the low order bits portion of the memory address inserted in each of the one or more subsequent fetch requests in place of the memory address contained within each of the one or more subsequent fetch requests to retrieve the data sought by the first fetch request.
Description
BACKGROUND
[0001] The present invention relates generally to the field of computer memory cache access and instruction pipelining, and more particularly to improving processor efficiency in memory caching by modifying addresses of fetch requests to maintain data return order.
BRIEF SUMMARY
[0002] Embodiments of the present invention disclose a method, system, and computer program product for improving operation of a processing unit to access data within a cache system. A first fetch request and one or more subsequent fetch requests are accessed in an instruction stream. An address of data sought by the first fetch requested is obtained. At least a portion of the address of data sought by the first fetch request in inserted in each of the one or more subsequent fetch requests. The portion of the address inserted in each of the one or more subsequent fetch requests is utilized to retrieve the data sought by the first fetch request first in order from the cache system.
BRIEF DESCRIPTION OF THE DRAWINGS
[0003] FIG. 1 is a flowchart illustrating operational steps to maintain data return order, in an embodiment of the invention.
[0004] FIG. 2 is a functional block diagram displaying an environment for cache return order optimization, in an embodiment of the invention.
[0005] FIG. 3 displays a process of execution of cache return order optimization, in accordance with an embodiment of the invention.
DETAILED DESCRIPTION
[0006] Nearly every modern processor uses memory caching to access more frequently needed data in the fastest manner possible, rather than always directly accessing main system memory. First, second, third, and even, in some processor designs, fourth and even higher level caches each present fast, and progressively larger locations from the processor to store and write data, and even though each cache level is more distant from the microprocessor, all cache levels are closer and allow faster access than accesses from main system memory. The goal of the caches' availability very close to the processor, is to improve memory search times for frequently needed data, with the end result of a reduction of the time needed to execute.
[0007] Cache access, as with other computer processes, occurs via pipelined instructions executed by the processor. Each "stream" of pipelined instructions may include, for example, one or more "fetch" requests, in which data is sought from the cache, as well as various other steps. If data is sought from a certain cache during a fetch request, but is not found, a search in a higher level cache may be scheduled by the processor during a subsequent "fetch" request.
[0008] The stream of pipelined instructions is broken up by a processing unit to multiple independent fetch requests as it is executed, but the data requested by each independent fetch request may exist in different levels of the cache system. It is possible, therefore, that the first fetch request in the stream of pipelined instructions seeks data existing in a higher level of the cache, and, for various reasons, access to this cache level occurs at a later time than access to a lower cache level where the remainder of the data sought by subsequent fetch requests reside. This causes data return order to become askew which leads to slowdowns and even stalls in program execution, while waiting for the sought data from an early fetch request to be returned.
[0009] Presented is a system, method, and computer program product for improving operation of the processing unit by maintaining data return order when executing multiple fetch requests from a multilevel cache.
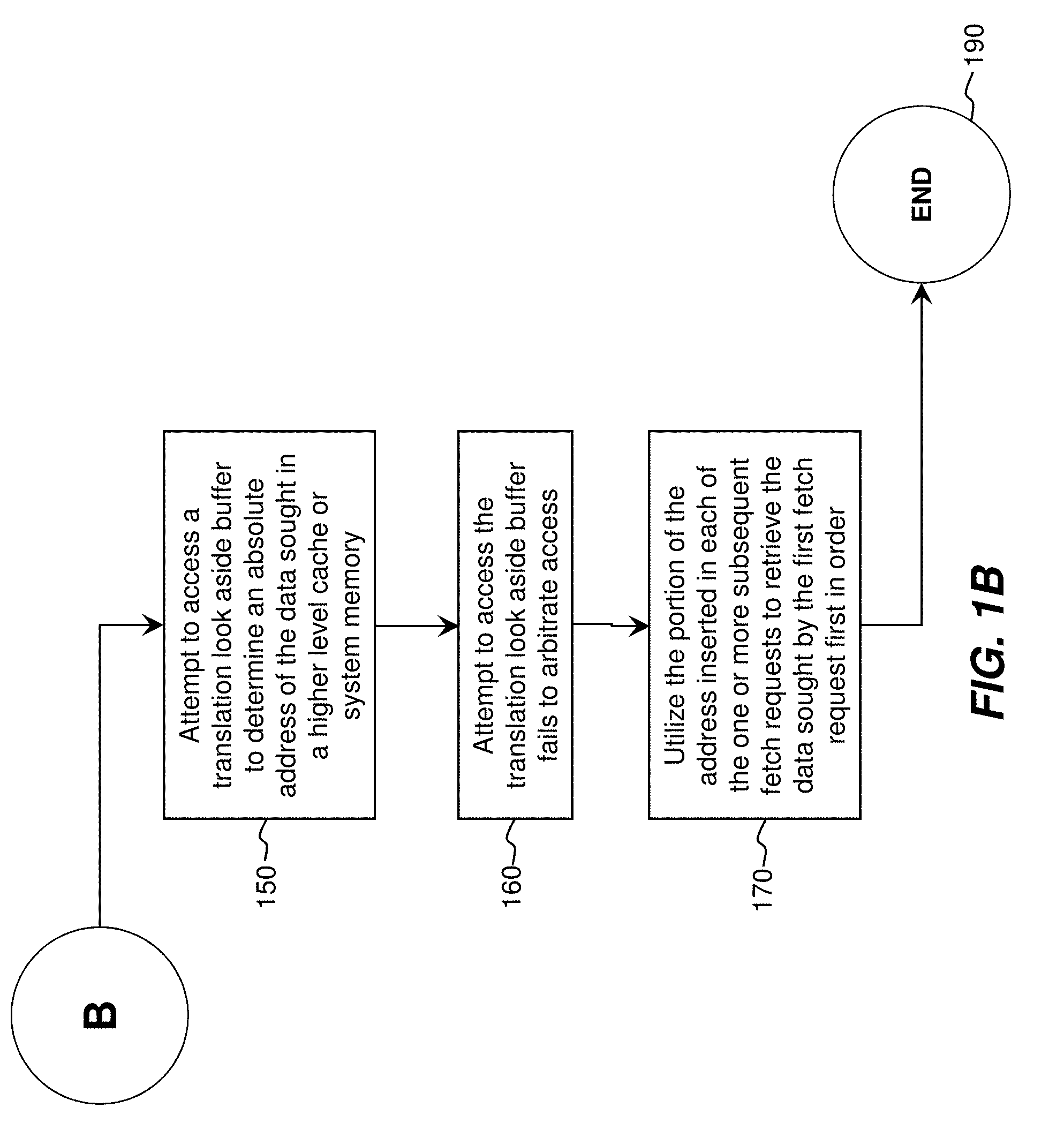
[0010] FIG. 1 is a flowchart illustrating operational steps to maintain data return order, in an embodiment of the invention. At step 100, execution begins. At step 110, a first fetch request and one or more subsequent fetch requests are accessed from an instruction stream. At step 120, an address of data sought by the first fetch request is obtained for further use. For simplicity's sake, shortened addresses such as x40 are used throughout. At step 130, at least a portion of the address sought by the first fetch request is inserted in each of the one or more subsequent fetch requests. At step 140, a determination is made that the data sought by the first fetch request is not found in a first level cache associated with the processing unit.
[0011] At step 150, an attempt to access a translation look aside buffer is made to determine an absolute address of the data sought in a higher level cache or system memory. Alternately, and depending upon the location of the data and system architecture, a logical address may be utilized in seeking the same data. At step 160, an attempt to access the translation look aside buffer fails to arbitrate access. At step 170, and as execution of pipeline stages proceeds, the portion of the address inserted into each of the one or more subsequent fetch requests is utilized to confirm that the data requested by the first fetch request is actually retrieved first. Although simplified addresses such as x40 are used herein, in practice a few low order bits of the address responsible for data return may be inserted. Execution may then proceed to return subsequent data to transfer to a cache line in the first level cache, with the full cache line of data utilized in subsequent execution by the processing unit. The advantage of the present invention is the returning of the first requested data first in time, so as to allow execution to proceed in the fastest manner possible. Execution proceeds to end 190, but may restart immediately and return to start 100.
[0012] FIG. 2 is a functional block diagram displaying an environment for cache return order optimization, in an embodiment of the invention. The processing unit is displayed 200. Displayed also is an L1 cache directory 210, translation look aside buffer 2 ("TLB2") 220, and translation look aside buffer 3 ("TLB3") for providing access, respectively, to an L1 cache 240, an L2 cache 250, and an L3 cache 260. The processing unit 200 utilizes for fast access the L1 cache 240, the L2 cache 250, and the L3 cache 260 (versus direct accesses to system memory). The L1 cache 240 is closest to the processing unit 200, with the fastest data transfer rate between the L1 cache 240 and the processing unit 200, but with the smallest amount of storage space available. The L2 cache 250 is an intermediate distance from the processing unit 200, with an intermediate data transfer rate between the L2 cache 250 and the processing unit 200, and an intermediate amount of storage space available. The L3 cache 260 is the farthest distance from the processing unit 200, with the slowest data transfer rate between the processing unit 200 and the L3 cache 260, but the largest amount of storage space available.
[0013] The L1 cache directory 210 provides access to information residing in the L1 cache 240. The L1 cache directory 210 also identifies whether data is present within the L1 cache 240 (i.e. whether a fetch request will "hit" or "miss"). If data is not present to respond to a fetch attempted from the processing unit 200, the L1 cache directory 210 may identify which higher level cache to access of the L2 cache 250 and the L3 cache 260. Data in the L1 cache 240 is accessible via logical addresses (also referred to as "virtual addresses"), and may operate on cache line granularity. Translation look aside buffer 2 220 provides access to information residing in the L2 cache 250. Translation look aside buffer 3 230 provides access to information residing in the L3 cache 260. Data in the L2 cache 250 and the L3 cache 260 are accessible via absolute addresses (also referred to as "physical addresses"). The translation look aside buffer 2 220 and translation look aside buffer 3 230 service many potential requestors, including the processing unit 200, an instruction cache, multiple load-store units, etc., but are only single-ported so cannot service multiple requests simultaneously. Access to the TLB2 220 and TLB3 230 must therefore be successfully "arbitrated" by the processing unit 200 in order to process a fetch request.
[0014] When accessing and executing a first fetch request and subsequent fetch requests, the processing unit 200 first accesses the L1 cache directory 210 to see if the data is present in the L1 cache directory 210. If the processing unit 200 determines the data requested by the first fetch request is not present in the L1 cache 240, the L1 cache directory 210 may indicate that the data is located in the L2 cache 250 or the L3 cache 260. The processing unit 200 may then access TLB2 220 or TLB3 230 to determine the address of the data.
[0015] If the data is located in the L2 cache 250 or L3 cache 260, the data requested by the fetch request may be loaded after retrieval into a cache line of the L1 cache 240, with an entire line being loaded into the cache line of the L1 cache 240 to support fast continuation (as requested by one or more subsequent fetch requests), although only the data requested by the first fetch request is truly necessary. Data following the first fetch request is loaded in the pre-determined order, with "wrap-around" supported to fill the cache line of the L1 cache 240. If, for example, data requested at x80 was requested in the first fetch request, x90, xA0, xB0, xC0, xD0, xE0, xF0, x00, x10, x20, x30, x40, x50, x60, x70 are also subsequently requested by subsequent fetch requests (with wrap-around occurring at x00 . . . ) to fill the cache line of the L1 cache 240, and support fast availability of potentially useful data in the vicinity of the first fetch request at x80 via the L1 cache 240 after retrieval.
[0016] Depending upon how the first fetch request and one or more subsequent fetch requests in an instruction stream are processed by the TLB2 220 and TLB3 230, and where arbitration is granted first for the subsequent fetch requests (based upon other requests from the load-store unit, etc.), it is possible information requested in subsequent fetch requests is loaded first into the L1 cache 240, while waiting for data in the first fetch request which was truly necessary to begin with. By inserting at least a portion of the address of the data sought by the first fetch request in each of the subsequent fetch requests, the presently disclosed invention confirms that the data in the first fetch requests and subsequent requests is loaded in the correct order, to maximize speed and minimize power consumption by the processing unit 200. This process is further discussed in connection with FIG. 3.
[0017] FIG. 3 displays a process of execution of cache return order optimization, in accordance with an embodiment of the invention. Displayed 410 is a process of execution without the benefit of the presently disclosed invention. As displayed 411-419, a first fetch request 1 411 and subsequent fetch requests 412, 413, 415, 417, and 419 are being executed. The first fetch request 1 411 is requesting data at address x40. Subsequent fetch request 2 412 is requesting data at address x60. Subsequent fetch request 3 413 is requesting data at address x80. Subsequent fetch request 4 415 is requesting data at xA0. Subsequent fetch request 5 417 is requesting data at xC0. Subsequent fetch request 6 419 is requesting data at xE0.
[0018] In this process of execution 410, fetch requests are executed at instruction cycle i2. First fetch request 1 411 would execute at instruction cycle i2 (431), but due to not arbitrating access to a translation look aside buffer, the first fetch request 1 411 is not executed. Subsequent fetch request 2 412 would execute at instruction cycle i2 (433), but again due to not arbitrating access to the translation look aside buffer, subsequent fetch request 2 412 is not executed. Subsequent fetch request 3 413 executes at instruction cycle i2 (435), and successfully arbitrates access to the translation look aside buffer. Data at address x80 is therefore successfully returned by subsequent fetch request 3 413. Subsequent fetches 415, 417, 419 successfully arbitrate access to the translation look aside buffer, and wrap around occurs to return the remainder of data.
[0019] The data return order is displayed 425, as x80, x90, xA0, xB0, xC0, xD0, xE0, xF0, x00, x10, x20, x30, x40, x50, x60, x70. Thus, even though the first fetch request 1 411 was for data at x40, the first data returned is at x80, as displayed 427. The data at x40 was returned 429, much later, after receiving a restart indication (not shown here). Multiple fetches and other instructions may have been executed in the interim, leading to systematic delays, stalls, and possibly increased power consumption due to not receiving the first requested data x40 first.
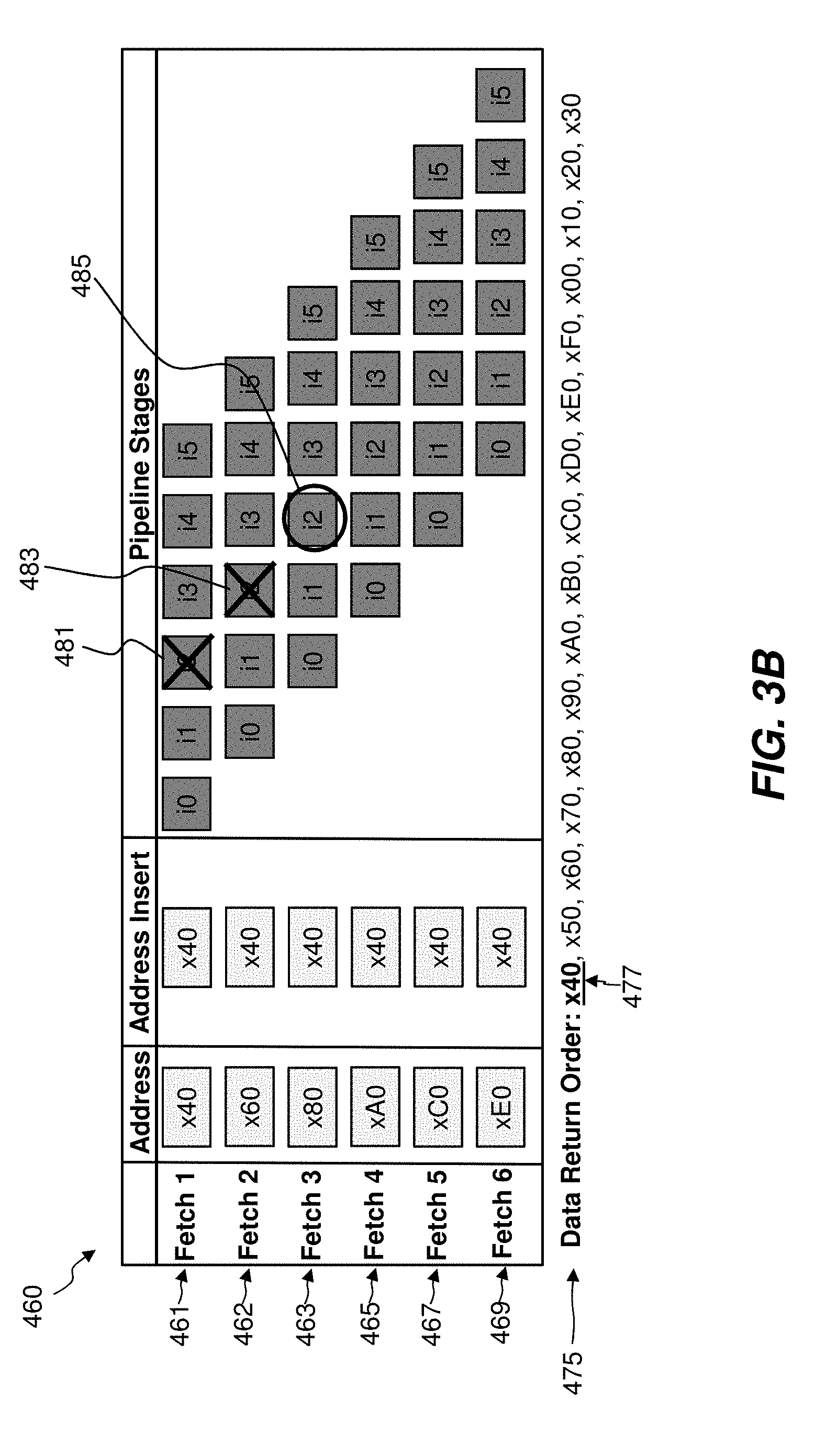
[0020] Displayed 460 is a process of execution with the benefit of the presently disclosed invention. As displayed 461-469, a first fetch request 1 461 and subsequent fetch requests 462, 463, 465, 467, and 469 are being executed. The first fetch request 1 461 is requesting data at address x40. Since the first fetch request 1 461 is requesting data at x40, in the presently disclosed invention, the address of data sought by the first fetch request 1 461 is inserted in all subsequent fetch requests 462, 463, 465, 467, 469 to maintain order of the retrieved data when retrieving from higher level caches such as the L2 cache 250 or L3 cache 260. Subsequent fetch request 2 462 is requesting data at address x60. Subsequent fetch request 3 463 is requesting data at address x80. Subsequent fetch request 4 465 is requesting data at xA0. Subsequent fetch request 5 467 is requesting data at xC0. Subsequent fetch request 6 469 is requesting data at xE0. Address insert x40 remains associated with all subsequent fetch requests 462-469, to ascertain that x40 is retrieved first.
[0021] In this process of execution 460, as previously with 410, fetch requests are executed at instruction cycle i2. First fetch request 1 461 would execute at instruction cycle i2 (481), but due to not arbitrating access to a translation look aside buffer, the first fetch request 1 461 is not executed. Subsequent fetch request 2 462 would execute at instruction cycle i2 (483), but again due to not arbitrating access to the translation look aside buffer, subsequent fetch request 2 462 is not executed. Subsequent fetch request 3 463 executes at instruction cycle i2 (485), and successfully arbitrates access to the translation look aside buffer. Data at address x40 is successfully returned by subsequent fetch request 3 463, since the address insert is utilized in fetch request 3 463. Subsequent fetches 465, 467, 469 successfully arbitrate access to the translation look aside buffer, and wrap around occurs to return the remainder of data.
[0022] The data return order is displayed 475, as x40, x50, x60, x70, x80, x90, xA0, xB0, xC0, xD0, xE0, xF0, x00, x10, x20, x30. This is the correct order, with the first requested data x40 returned first in the data return order 475, as displayed 477. The fewest possible number of fetches have been executed, leading to a minimum of system delay. The returned data may be utilized in a line of the L1 cache 240, or in another way based upon system architecture.
[0023] Based on the foregoing, a computer system, method and program product have been disclosed for cache return order optimization. However, numerous modifications and substitutions can be made without deviating from the scope of the present invention. The embodiment(s) herein may be combined, altered, or portions removed. Therefore, the present invention has been disclosed by way of example and not limitation.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.