Antibody Therapeutics That Bind Psma
Gros; Edwige ; et al.
U.S. patent application number 16/138944 was filed with the patent office on 2019-01-10 for antibody therapeutics that bind psma. This patent application is currently assigned to Sorrento Therapeutics, Inc.. The applicant listed for this patent is Sorrento Therapeutics, Inc.. Invention is credited to Edwige Gros, Silpa Yalamanchili, Heyue Zhou.
| Application Number | 20190010250 16/138944 |
| Document ID | / |
| Family ID | 56879307 |
| Filed Date | 2019-01-10 |







| United States Patent Application | 20190010250 |
| Kind Code | A1 |
| Gros; Edwige ; et al. | January 10, 2019 |
ANTIBODY THERAPEUTICS THAT BIND PSMA
Abstract
There is disclosed compositions and methods relating to or derived from anti-PSMA antibodies. More specifically, there is disclosed fully human antibodies that bind PSMA, PSMA-antibody binding fragments and derivatives of such antibodies, and PSMA-binding polypeptides comprising such fragments. Further still, there is disclosed nucleic acids encoding such antibodies, antibody fragments and derivatives and polypeptides, cells comprising such polynucleotides, methods of making such antibodies, antibody fragments and derivatives and polypeptides, and methods of using such antibodies, antibody fragments and derivatives and polypeptides, including methods of treating a disease. There is further disclosed targeted therapies for treatment of prostate cancer having the disclosed anti-PSMA antibodies and fragments thereof targeting the therapeutic agent or cell.
| Inventors: | Gros; Edwige; (San Diego, CA) ; Yalamanchili; Silpa; (San Diego, CA) ; Zhou; Heyue; (San Diego, CA) | ||||||||||
| Applicant: |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Assignee: | Sorrento Therapeutics, Inc. San Diego CA |
||||||||||
| Family ID: | 56879307 | ||||||||||
| Appl. No.: | 16/138944 | ||||||||||
| Filed: | September 21, 2018 |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | ||
|---|---|---|---|---|
| 15066806 | Mar 10, 2016 | 10100126 | ||
| 16138944 | ||||
| 62131227 | Mar 10, 2015 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | A61P 25/00 20180101; C07K 2317/92 20130101; A61P 15/00 20180101; C07K 16/40 20130101; A61P 35/00 20180101; C07K 2317/55 20130101; C07K 2317/21 20130101; A61P 11/00 20180101; A61P 19/00 20180101; C07K 16/3069 20130101; A61K 47/6803 20170801; C07K 2317/73 20130101; A61K 39/39558 20130101; A61K 47/6829 20170801; A61K 47/6869 20170801; A61P 13/08 20180101; A61K 2039/505 20130101; C07K 2317/56 20130101; A61P 35/02 20180101; A61P 1/04 20180101 |
| International Class: | C07K 16/40 20060101 C07K016/40; C07K 16/30 20060101 C07K016/30; A61K 47/68 20170101 A61K047/68 |
Claims
1.-7. (canceled)
8. A method for treating prostate cancer, said method comprising administering an effective amount of a fully human anti-PSMA antibody or antigen-binding fragment thereof, that binds to a PSMA epitope, to a subject in need thereof, such that the prostate cancer is treated, wherein the antibody comprising: a heavy chain variable domain sequence that is at least 95% identical to the amino acid sequence SEQ ID NO. 1; and a light chain variable domain sequence that is at least 95% identical to an amino acid sequence selected from the group consisting of: SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, and SEQ ID NO. 17.
9. (canceled)
10. The method for treating prostate cancer of claim 8, wherein the cancer is selected from the group consisting of: ovarian cancer, colon cancer, breast cancer, lung cancer, myelomas, neuroblastic-derived CNS tumors, monocytic leukemias, B-cell derived leukemias, T-cell derived leukemias, B-cell derived lymphomas, T-cell derived lymphomas, and mast cell derived tumors.
11. The method of claim 8, wherein the antibody comprises a heavy chain/light chain variable domain sequence selected from the group consisting of: SEQ ID NO. 1/SEQ ID NO. 2, SEQ ID NO. 1/SEQ ID NO. 3, SEQ ID NO. 1/SEQ ID NO. 4, SEQ ID NO. 1/SEQ ID NO. 5, SEQ ID NO. 1/SEQ ID NO. 6, SEQ ID NO. 1/SEQ ID NO. 7, SEQ ID NO. 1/SEQ ID NO. 8, SEQ ID NO. 1/SEQ ID NO. 9, SEQ ID NO. 1/SEQ ID NO. 10, SEQ ID NO. 1/SEQ ID NO. 11, SEQ ID NO. 1/SEQ ID NO. 12, SEQ ID NO. 1/SEQ ID NO. 13, SEQ ID NO. 1/SEQ ID NO. 14, SEQ ID NO. 1/SEQ ID NO. 15, SEQ ID NO. 1/SEQ ID NO. 16, and SEQ ID NO. 1/SEQ ID NO. 17.
12.-18. (canceled)
19. A method for treating cancer associated with PSMA expression in a human subject in need thereof, comprising administering an effective amount of the anti-PSMA antibody, or antigen-binding fragment thereof, to the subject, such that the cancer is treated, wherein the antibody comprises a heavy chain variable domain comprising complementarity determining regions (CDRs) as set forth in SEQ ID NO. 1; and comprises a light chain variable domain comprising CDRs as set forth in a light chain variable region amino acid sequence selected from the group consisting of: SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, and SEQ ID NO. 17.
20. The method for treating cancer of claim 19, wherein the cancer is selected from the group consisting of: prostate cancer, ovarian cancer, colon cancer, breast cancer, lung cancer, myelomas, neuroblastic-derived CNS tumors, monocytic leukemias, B-cell derived leukemias, T-cell derived leukemias, B-cell derived lymphomas, T-cell derived lymphomas, and mast cell derived tumors.
21. The method of claim 19, wherein the antibody comprises a heavy chain/light chain variable domain sequence selected from the group consisting of: SEQ ID NO. 1/SEQ ID NO. 2, SEQ ID NO. 1/SEQ ID NO. 3, SEQ ID NO. 1/SEQ ID NO. 4, SEQ ID NO. 1/SEQ ID NO. 5, SEQ ID NO. 1/SEQ ID NO. 6, SEQ ID NO. 1/SEQ ID NO. 7, SEQ ID NO. 1/SEQ ID NO. 8, SEQ ID NO. 1/SEQ ID NO. 9, SEQ ID NO. 1/SEQ ID NO. 10, SEQ ID NO. 1/SEQ ID NO. 11, SEQ ID NO. 1/SEQ ID NO. 12, SEQ ID NO. 1/SEQ ID NO. 13, SEQ ID NO. 1/SEQ ID NO. 14, SEQ ID NO. 1/SEQ ID NO. 15, SEQ ID NO. 1/SEQ ID NO. 16, and SEQ ID NO. 1/SEQ ID NO. 17.
22. The method of claim 8, wherein the antigen-binding fragment is a Fab fragment.
23. The method of claim 8, wherein the antibody is a single chain antibody comprising a peptide linker connecting the heavy and light chain variable domains.
Description
RELATED APPLICATIONS
[0001] This application claims priority to U.S. Provisional Application No. 62/131,227, filed on Mar. 10, 2015, the entire contents of which are incorporated by reference in its entirety herein.
TECHNICAL FIELD
[0002] The present disclosure provides compositions and methods relating to or derived from anti-PSMA (prostate-specific membrane antigen) antibodies. More specifically, the present disclosure provides fully human antibodies that bind PSMA, PSMA-antibody binding fragments and derivatives of such antibodies, and PSMA-binding polypeptides comprising such fragments. Further still, the present disclosure provides nucleic acids encoding such antibodies, antibody fragments and derivatives and polypeptides, cells comprising such polynucleotides, methods of making such antibodies, antibody fragments and derivatives and polypeptides, and methods of using such antibodies, antibody fragments and derivatives and polypeptides, including methods of treating a disease. The present disclosure further provides targeted therapies for treatment of prostate cancer having the disclosed anti-PSMA antibodies and fragments thereof targeting the therapeutic agent or cell.
BACKGROUND
[0003] Prostate cancer is the most prevalent type of cancer and the second leading cause of death from cancer in American men (Landis, S. H. et al. C A Cancer J. Clin. 48:6-29 (1998)). The number of men diagnosed with prostate cancer is steadily increasing as a result of the increasing population of older men as well as a greater awareness of the disease leading to its earlier diagnosis (Parker et al., 1997, CA Cancer J. Clin. 47:5-280). The life time risk for men developing prostate cancer is about 1 in 5 for Caucasians, 1 in 6 for African Americans. High risk groups are represented by those with a positive family history of prostate cancer or African Americans.
[0004] Over a lifetime, more than 2/3 of the men diagnosed with prostate cancer die of the disease (Wingo et al., 1996, CA Cancer J. Clin. 46:113-25). Moreover, many patients who do not succumb to prostate cancer require continuous treatment to ameliorate symptoms such as pain, bleeding and urinary obstruction. Thus, prostate cancer also represents a major cause of suffering and increased health care expenditures.
[0005] Radiation therapy has also been used as an alternative to radical prostatectomy. Patients generally treated by radiation therapy are those who are older and less healthy and those with higher-grade, more clinically advanced tumors. Particularly preferred procedures are external-beam therapy which involves three dimensional, confocal radiation therapy where the field of radiation is designed to conform to the volume of tissue treated; interstitial-radiation therapy where seeds of radioactive compounds are implanted using ultrasound guidance; and a combination of external-beam therapy and interstitial-radiation therapy.
[0006] For treatment of patients with locally advanced disease, hormonal therapy before or following radical prostatectomy or radiation therapy has been utilized. Hormonal therapy is the main form of treating men with disseminated prostate cancer. Orchiectomy reduces serum testosterone concentrations, while estrogen treatment is similarly beneficial. Diethylstilbestrol from estrogen is another useful hormonal therapy which has a disadvantage of causing cardiovascular toxicity. When gonadotropin-releasing hormone agonists are administered testosterone concentrations are ultimately reduced. Flutamide and other nonsteroidal, anti-androgen agents block binding of testosterone to its intracellular receptors. As a result, it blocks the effect of testosterone, increasing serum testosterone concentrations and allows patients to remain potent, a significant problem after radical prostatectomy and radiation treatments.
[0007] Cytotoxic chemotherapy is largely ineffective in treating prostate cancer. Its toxicity makes such therapy unsuitable for elderly patients. In addition, prostate cancer is relatively resistant to cytotoxic agents.
[0008] Relapsed or more advanced disease is also treated with anti-androgen therapy. Unfortunately, almost all tumors become hormone-resistant and progress rapidly in the absence of any effective therapy.
[0009] Accordingly, there is a need for effective therapeutics for prostate cancer which are not overwhelmingly toxic to normal tissues of a patient, and which are effective in selectively eliminating prostate cancer cells.
SUMMARY OF THE INVENTION
[0010] This invention pertains to binding proteins capable of binding to prostate-specific membrane antigen (PSMA), (e.g., human PSMA), including anti-PSMA antibodies, and antigen-binding fragments thereof.
[0011] In one aspect, the present disclosure provides an isolated fully human anti-PSMA antibody of an IgG class that binds to a PSMA epitope, said antibody comprising a heavy chain variable domain sequence that is at least 95% identical to the amino acid sequence SEQ ID NO. 1; and a light chain variable domain sequence that is at least 95% identical to an amino acid sequence selected from the group consisting of: SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, and SEQ ID NO. 17.
[0012] In another aspect, the present disclosure provides a fully human antibody of an IgG class that binds to a PSMA epitope with a binding affinity of at least 10.sup.-6M, and comprises a heavy chain variable domain sequence that is at least 95% identical to the amino acid sequence SEQ ID NO. 1, and comprises a light chain variable domain sequence that is at least 95% identical to the amino acid sequence consisting of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, SEQ ID NO. 17. In one embodiment, the fully human antibody comprises both a heavy chain and a light chain wherein the antibody has a heavy chain/light chain variable domain sequence selected from the group consisting of SEQ ID NO. 1/SEQ ID NO. 2 (called PSA11 herein), SEQ ID NO. 1/SEQ ID NO. 3 (called PSGB11 herein), SEQ ID NO. 1/SEQ ID NO. 4 (called PSGB12 herein), SEQ ID NO. 1/SEQ ID NO. 5 (called PSGC8 herein), SEQ ID NO. 1/SEQ ID NO. 6 (called PSGC9 herein), SEQ ID NO. 1/SEQ ID NO. 7 (called PSGC12 herein), SEQ ID NO. 1/SEQ ID NO. 8 (called PSGD3 herein), SEQ ID NO. 1/SEQ ID NO. 9 (called PSGD4 herein), SEQ ID NO. 1/SEQ ID NO. 10 (called PSGD6 herein), SEQ ID NO. 1/SEQ ID NO. 11 (called PSGE10 herein), SEQ ID NO. 1/SEQ ID NO. 12 (called PSGE11 herein), SEQ ID NO. 1/SEQ ID NO. 13 (called PSGF9 herein), SEQ ID NO. 1/SEQ ID NO. 14 (called PSGF11 herein), SEQ ID NO. 1/SEQ ID NO. 15 (called PSGG6 herein), SEQ ID NO. 1/SEQ ID NO. 16 (called PSGH3 herein), SEQ ID NO. 1/SEQ ID NO. 17 (called PSGH8 herein).
[0013] In another aspect, the present disclosure provides an anti-PSMA Fab fully human antibody fragment, having a variable domain region from a heavy chain and a variable domain region from a light chain, wherein the heavy chain variable domain comprises an amino acid sequence that is at least 95% identical to the amino acid sequence of SEQ ID NO. 1, and comprises a light chain variable domain sequence that is at least 95% identical to an amino acid sequence selected from the group consisting of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, SEQ ID NO. 17. In one embodiment, the fully human antibody Fab fragment comprises both a heavy chain variable domain region and a light chain variable domain region wherein the antibody has a heavy chain/light chain variable domain sequence selected from the group consisting SEQ ID NO. 1/SEQ ID NO. 2, SEQ ID NO. 1/SEQ ID NO. 3, SEQ ID NO. 1/SEQ ID NO. 4, SEQ ID NO. 1/SEQ ID NO. 5, SEQ ID NO. 1/SEQ ID NO. 6, SEQ ID NO. 1/SEQ ID NO. 7, SEQ ID NO. 1/SEQ ID NO. 8, SEQ ID NO. 1/SEQ ID NO. 9, SEQ ID NO. 1/SEQ ID NO. 10, SEQ ID NO. 1/SEQ ID NO. 11, SEQ ID NO. 1/SEQ ID NO. 12, SEQ ID NO. 1/SEQ ID NO. 13, SEQ ID NO. 1/SEQ ID NO. 14, SEQ ID NO. 1/SEQ ID NO. 15, SEQ ID NO. 1/SEQ ID NO. 16, SEQ ID NO. 1/SEQ ID NO. 17.
[0014] In another aspect, the present disclosure provides an anti-PSMA single chain human antibody, comprising a variable domain region from a heavy chain and a variable domain region from a light chain and a peptide linker connection the heavy chain and light chain variable domain regions, wherein the heavy chain variable domain comprises an amino acid sequence that is at least 95% identical to the amino acid sequence of SEQ ID NO. 1, and comprises a light chain variable domain sequence that is at least 95% identical to an amino acid sequence selected from the group consisting of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, SEQ ID NO. 17. In one embodiment, the fully human single chain antibody comprises both a heavy chain variable domain region and a light chain variable domain region, wherein the single chain fully human antibody comprises a heavy chain/light chain variable domain sequence selected from the group consisting of SEQ ID NO. 1/SEQ ID NO. 2, SEQ ID NO. 1/SEQ ID NO. 3, SEQ ID NO. 1/SEQ ID NO. 4, SEQ ID NO. 1/SEQ ID NO. 5, SEQ ID NO. 1/SEQ ID NO. 6, SEQ ID NO. 1/SEQ ID NO. 7, SEQ ID NO. 1/SEQ ID NO. 8, SEQ ID NO. 1/SEQ ID NO. 9, SEQ ID NO. 1/SEQ ID NO. 10, SEQ ID NO. 1/SEQ ID NO. 11, SEQ ID NO. 1/SEQ ID NO. 12, SEQ ID NO. 1/SEQ ID NO. 13, SEQ ID NO. 1/SEQ ID NO. 14, SEQ ID NO. 1/SEQ ID NO. 15, SEQ ID NO. 1/SEQ ID NO. 16, and SEQ ID NO. 1/SEQ ID NO. 17.
[0015] In one embodiment, the invention features an isolated anti-PSMA antibody, or an antigen-binding fragment thereof, comprising a heavy chain variable domain comprising complementarity determining regions (CDRs) as set forth in SEQ ID NO. 1; and comprising a light chain variable domain comprising CDRs as set forth in a light chain variable region amino acid sequence selected from the group consisting of: SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, and SEQ ID NO. 17. In one embodiment, the isolated anti-PSMA antibody, or antigen-binding fragment thereof, is human.
[0016] The present disclosure further provides a method for treating a prostate cancer, comprising administering an anti-PSMA antibody used to target a chemical or cellular therapeutic payload, wherein the anti-PSMA antibody has a heavy chain variable domain sequence that is at least 95% identical to the amino acid sequence SEQ ID NO. 1, and that has a light chain variable domain sequence that is at least 95% identical to the amino acid consisting of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, SEQ ID NO. 17, combinations thereof.
[0017] The present disclosure further provides a method for treating a prostate cancer, comprising administering an anti-PSMA antibody Fab fully human fragment used to target a chemical or cellular therapeutic payload, wherein the Fab fully human antibody fragment comprises a heavy chain variable domain sequence that is at least 95% identical to the amino acid sequence SEQ ID NO. 1, and comprises a light chain variable domain sequence that is at least 95% identical to an amino acid sequence selected from the group consisting of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, SEQ ID NO. 17.
[0018] The present disclosure also provides a method for treating a prostate cancer, comprising administering an anti-PSMA single chain human antibody used to target a chemical or cellular therapeutic payload, wherein the anti-PSMA antibody single chain human antibody comprises a heavy chain variable domain sequence that is at least 95% identical to the amino acid sequence SEQ ID NO. 1, and comprises a light chain variable domain sequence that is at least 95% identical to the amino acid sequence consisting of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, SEQ ID NO. 17.
[0019] In one embodiment, the fully human antibody comprises both a heavy chain and a light chain, wherein the antibody has a heavy chain/light chain variable domain sequence selected from the group consisting of SEQ ID NO. 1/SEQ ID NO. 2 (called PSA11 herein), SEQ ID NO. 1/SEQ ID NO. 3 (called PSGB11 herein), SEQ ID NO. 1/SEQ ID NO. 4 (called PSGB12 herein), SEQ ID NO. 1/SEQ ID NO. 5 (called PSGC8 herein), SEQ ID NO. 1/SEQ ID NO. 6 (called PSGC9 herein), SEQ ID NO. 1/SEQ ID NO. 7 (called PSGC12 herein), SEQ ID NO. 1/SEQ ID NO. 8 (called PSGD3 herein), SEQ ID NO. 1/SEQ ID NO. 9 (called PSGD4 herein), SEQ ID NO. 1/SEQ ID NO. 10 (called PSGD6 herein), SEQ ID NO. 1/SEQ ID NO. 11 (called PSGE10 herein), SEQ ID NO. 1/SEQ ID NO. 12 (called PSGE11 herein), SEQ ID NO. 1/SEQ ID NO. 13 (called PSGF9 herein), SEQ ID NO. 1/SEQ ID NO. 14 (called PSGF11 herein), SEQ ID NO. 1/SEQ ID NO. 15 (called PSGG6 herein), SEQ ID NO. 1/SEQ ID NO. 16 (called PSGH3 herein), and SEQ ID NO. 1/SEQ ID NO. 17 (called PSGH8 herein). In one embodiment, the fully human single chain antibody has both a heavy chain variable domain region and a light chain variable domain region, wherein the single chain fully human antibody has a heavy chain/light chain variable domain sequence selected from the group consisting of SEQ ID NO. 1/SEQ ID NO. 2, SEQ ID NO. 1/SEQ ID NO. 3, SEQ ID NO. 1/SEQ ID NO. 4, SEQ ID NO. 1/SEQ ID NO. 5, SEQ ID NO. 1/SEQ ID NO. 6, SEQ ID NO. 1/SEQ ID NO. 7, SEQ ID NO. 1/SEQ ID NO. 8, SEQ ID NO. 1/SEQ ID NO. 9, SEQ ID NO. 1/SEQ ID NO. 10, SEQ ID NO. 1/SEQ ID NO. 11, SEQ ID NO. 1/SEQ ID NO. 12, SEQ ID NO. 1/SEQ ID NO. 13, SEQ ID NO. 1/SEQ ID NO. 14, SEQ ID NO. 1/SEQ ID NO. 15, SEQ ID NO. 1/SEQ ID NO. 16, and SEQ ID NO. 1/SEQ ID NO. 17.
[0020] The present invention further provides in another aspect, a method for treating cancer, said method comprising administering an anti-PSMA antibody, or antibody fragment of any one of the aspects or embodiments described herein, to a subject in need thereof. In one embodiment, the cancer is selected from the group consisting of ovarian cancer, colon cancer, breast cancer, lung cancer, myeloma, neuroblastic-derived CNS tumor, monocytic leukemia, B-cell derived leukemia, T-cell derived leukemia, B-cell derived lymphoma, T-cell derived lymphoma, and mast cell derived tumor.
[0021] In certain embodiments, the anti-PSMA antibody is used to treat a broad spectrum of mammalian cancers, including, for example, ovarian, colon, breast, lung cancers, myelomas, neuroblastic-derived CNS tumors, monocytic leukemias, B-cell derived leukemias, T-cell derived leukemias, B-cell derived lymphomas, T-cell derived lymphomas, mast cell derived tumors, and combinations thereof.
[0022] The present invention also provides in another aspect, a method for treating prostate cancer, said method comprising administering an anti-PSMA antibody, or antibody fragment of any one of the aspects or embodiments described herein, to a subject in need thereof.
[0023] In certain embodiments, the antibody, or antigen-binding fragment thereof, of the invention has a binding affinity (K.sub.D) of at least 1.times.10.sup.-6M. In other embodiments, the antibody, or antigen-binding fragment thereof, of the invention has a K.sub.D of at least 1.times.10.sup.-7 M. In other embodiments, the antibody, or antigen-binding fragment thereof, of the invention has a K.sub.D of at least 1.times.10.sup.-8M.
[0024] In certain embodiments, the antibody is an IgG1 isotype. In other embodiments, the antibody is an IgG4 isotype.
[0025] In certain embodiments, the antibody, or antigen-binding fragment, described herein is recombinant.
[0026] In certain embodiments, the antibody, or antigen-binding fragment, described herein is a human antibody, or antigen binding fragment of an antibody.
[0027] The invention also provides pharmaceutical compositions comprising an effective amount of an anti-PSMA antibody or fragment disclosed herein, and a pharmaceutically acceptable carrier.
DESCRIPTION OF THE DRAWINGS
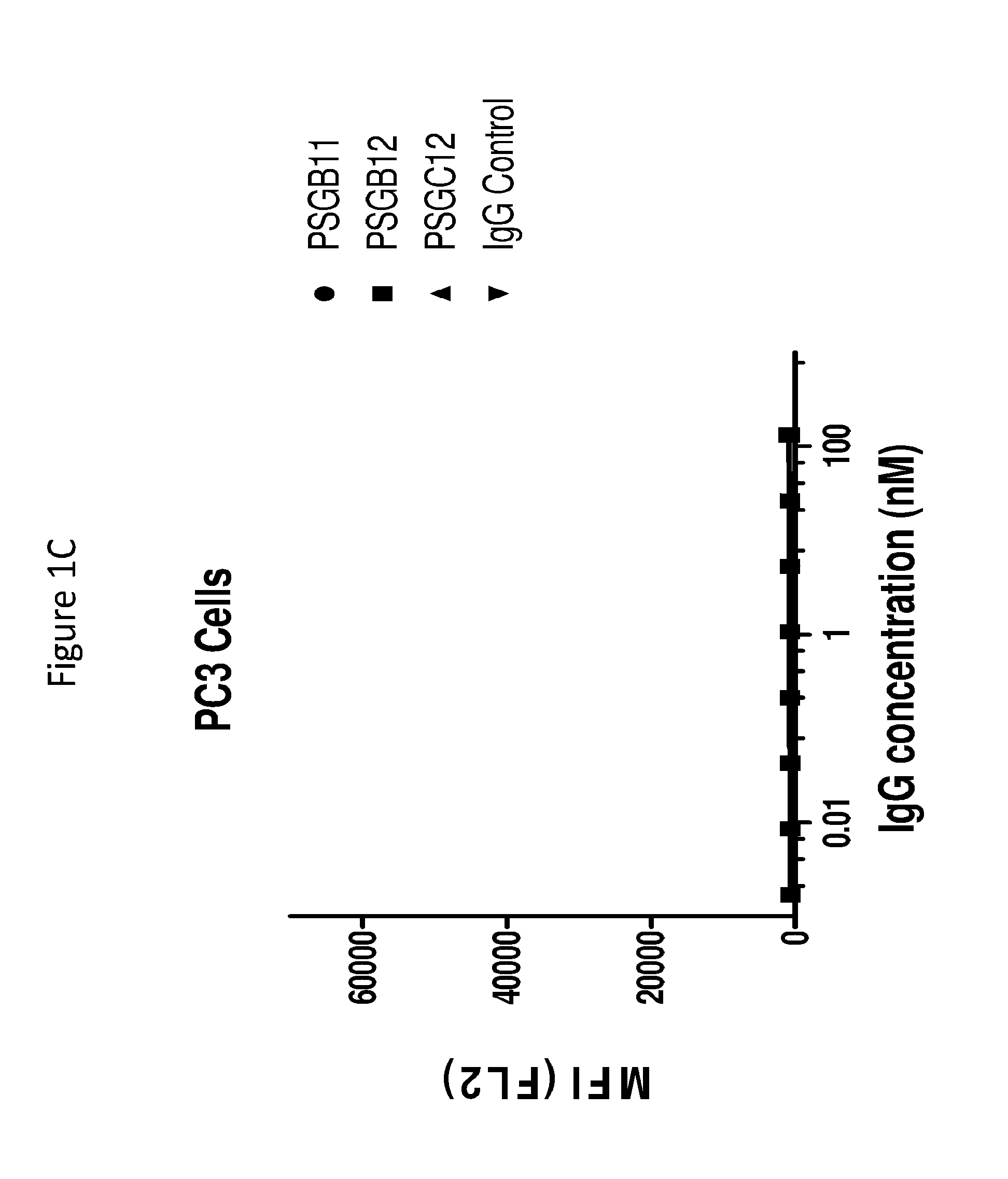
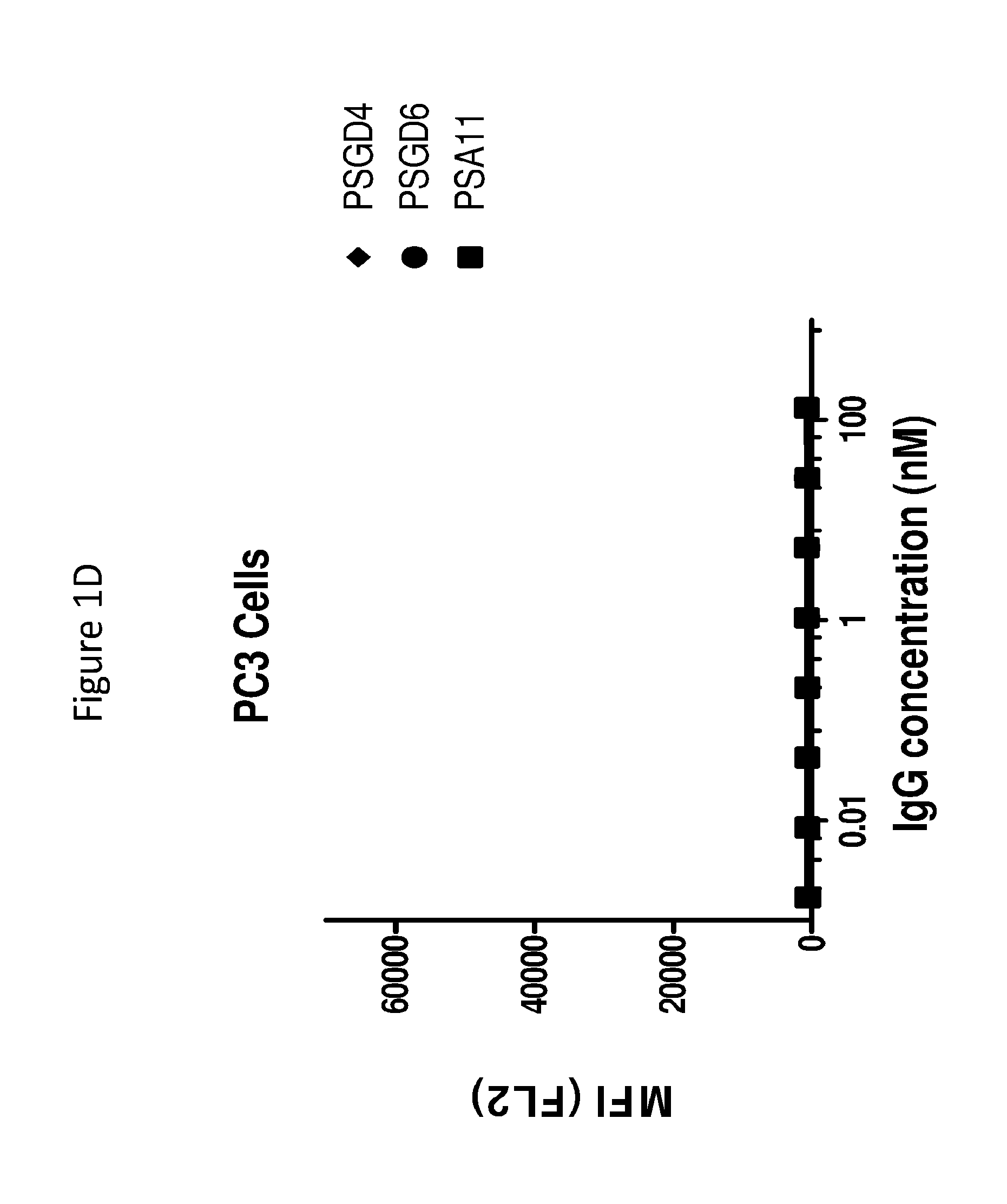
[0028] FIGS. 1A to 1D graphically depict binding of anti-PSMA antibodies to PSMA-positive cells (LNCaP) (as described in FIGS. 1A and 1B), and PSMA-negative normal human fibroblast cells (PC3), (as described in FIGS. 1C and 1D).
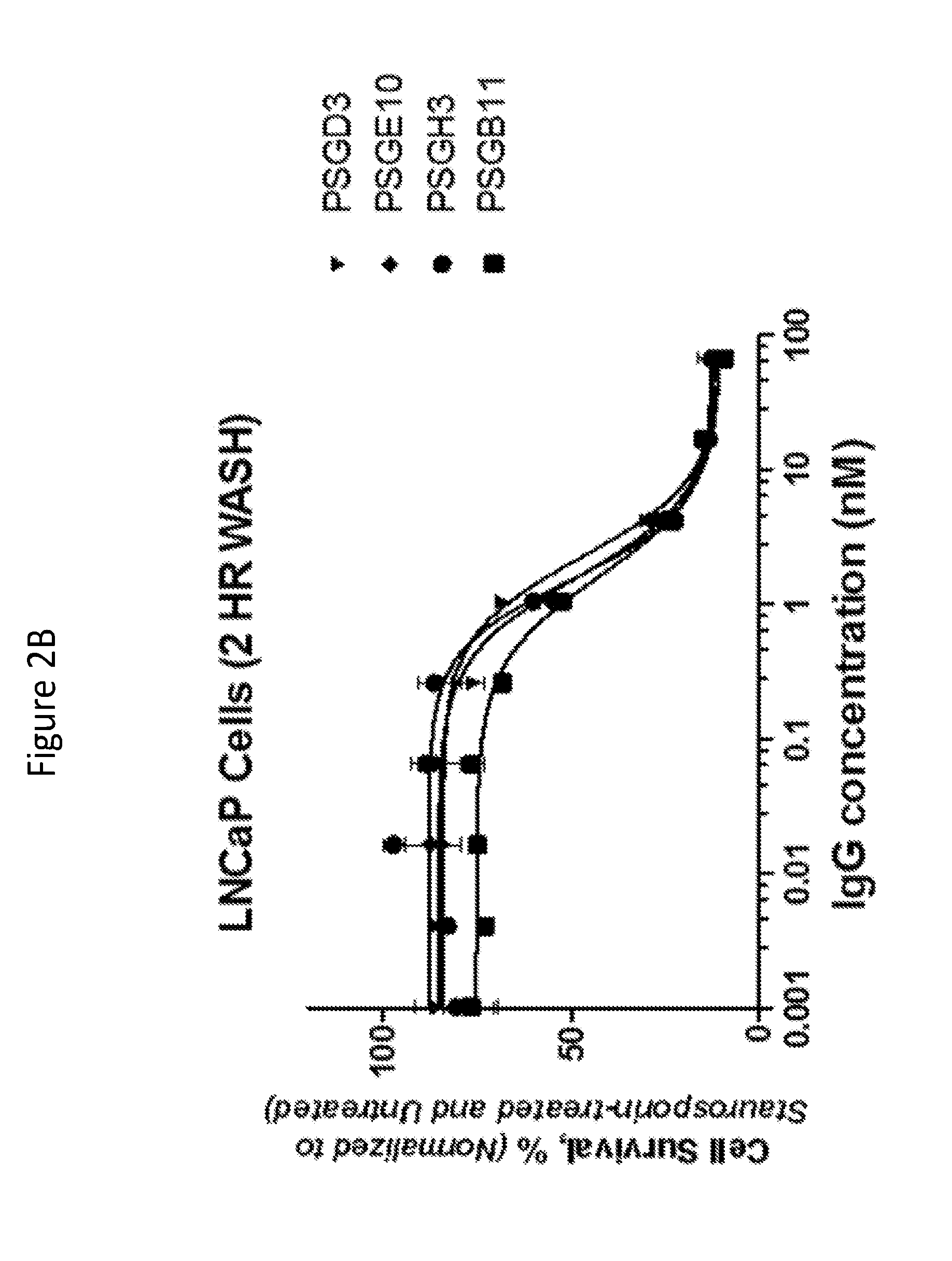
[0029] FIGS. 2A to 2C illustrate cytotoxic potential of anti-PSMA antibodies PSGF9, PSGC9, PSGD6, (shown in FIG. 2A); PSGD3, PSGE10, PSGH3, PSGB11, (shown in FIG. 2B); and PSGD4 and PSGB12 (shown in FIG. 2C) complexed with Protein G (PG)-MMAF molecules on PSMA-overexpressing LNCaP cancer cells.
[0030] FIG. 2D illustrates the non-specific cell killing effect observed on normal human fibroblasts (PC3) with various anti-PSMA antibodies complexed with Protein G-MMAF molecules.
[0031] FIG. 3 graphically depicts affinity binding characteristics of anti-PSMA antibody PSA11.
[0032] FIG. 4 graphically depicts affinity binding characteristics of anti-PSMA antibody PSGB11.
DETAILED DESCRIPTION
Definitions
[0033] The terms "peptide," "polypeptide" and "protein" each refers to a molecule comprising two or more amino acid residues joined to each other by peptide bonds. These terms encompass, e.g., native and artificial proteins, protein fragments and polypeptide analogs (such as muteins, variants, and fusion proteins) of a protein sequence as well as post-translationally, or otherwise covalently or non-covalently, modified proteins. A peptide, polypeptide, or protein may be monomeric or polymeric.
[0034] A "variant" of a polypeptide (for example, a variant of an antibody) comprises an amino acid sequence wherein one or more amino acid residues are inserted into, deleted from and/or substituted into the amino acid sequence relative to another polypeptide sequence. Disclosed variants include, for example, fusion proteins.
[0035] A "derivative" of a polypeptide is a polypeptide (e.g., an antibody) that has been chemically modified, e.g., via conjugation to another chemical moiety (such as, for example, polyethylene glycol or albumin, e.g., human serum albumin), phosphorylation, and glycosylation. Unless otherwise indicated, the term "antibody" includes, in addition to antibodies comprising two full-length heavy chains and two full-length light chains, derivatives, variants, fragments, and muteins thereof, examples of which are described below.
[0036] An "antigen binding protein" is a protein comprising a portion that binds to an antigen and, optionally, a scaffold or framework portion that allows the antigen binding portion to adopt a conformation that promotes binding of the antigen binding protein to the antigen. Examples of antigen binding proteins include antibodies, antibody fragments (e.g., an antigen binding portion of an antibody), antibody derivatives, and antibody analogs. The antigen binding protein can comprise, for example, an alternative protein scaffold or artificial scaffold with grafted CDRs or CDR derivatives. Such scaffolds include, but are not limited to, antibody-derived scaffolds comprising mutations introduced to, for example, stabilize the three-dimensional structure of the antigen binding protein as well as wholly synthetic scaffolds comprising, for example, a biocompatible polymer. See, for example, Korndorfer et al., 2003, Proteins: Structure, Function, and Bioinformatics, Volume 53, Issue 1:121-129; Roque et al., 2004, Biotechnol. Prog. 20:639-654. In addition, peptide antibody mimetics ("PAMs") can be used, as well as scaffolds based on antibody mimetics utilizing fibronection components as a scaffold.
[0037] An antigen binding protein can have, for example, the structure of an immunoglobulin. An "immunoglobulin" is a tetrameric molecule composed of two identical pairs of polypeptide chains, each pair having one "light" (about 25 kDa) and one "heavy" chain (about 50-70 kDa). The amino-terminal portion of each chain includes a variable region of about 100 to 110 or more amino acids primarily responsible for antigen recognition. The carboxy-terminal portion of each chain defines a constant region primarily responsible for effector function. Human light chains are classified as kappa or lambda light chains. Heavy chains are classified as mu, delta, gamma, alpha, or epsilon, and define the antibody's isotype as IgM, IgD, IgG, IgA, and IgE, respectively. Preferably, the anti-PSMA antibodies disclosed herein are characterized by their variable domain region sequences in the heavy V.sub.H and light V.sub.L amino acid sequences. Within light and heavy chains, the variable and constant regions are joined by a "J" region of about 12 or more amino acids, with the heavy chain also including a "D" region of about 10 more amino acids. See generally, Fundamental Immunology Ch. 7 (Paul, W., ed., 2nd ed. Raven Press, N.Y. (1989)). The variable regions of each light/heavy chain pair form the antibody binding site such that an intact immunoglobulin has two binding sites.
[0038] The variable regions of immunoglobulin chains exhibit the same general structure of relatively conserved framework regions (FR) joined by three hypervariable regions, also called complementarity determining regions or CDRs. From N-terminus to C-terminus, both light and heavy chains comprise the domains FR1, CDR1, FR2, CDR2, FR3, CDR3 and FR4. The assignment of amino acids to each domain is in accordance with the definitions of Kabat et al. in Sequences of Proteins of Immunological Interest, 5.sup.th Ed., US Dept. of Health and Human Services, PHS, NIH, NIH Publication no. 91-3242, 1991. Other numbering systems for the amino acids in immunoglobulin chains include IMGT.RTM. (international ImMunoGeneTics information system; Lefranc et al, Dev. Comp. Immunol. 29:185-203; 2005) and AHo (Honegger and Pluckthun, J. Mol. Biol. 309(3):657-670; 2001).
[0039] An "antibody" refers to an intact immunoglobulin or to an antigen binding portion thereof that competes with the intact antibody for specific binding, unless otherwise specified. In one embodiment, an antibody comprises two identical heavy chains each comprising a heavy chain variable domain and heavy chain constant regions C.sub.H1, C.sub.H2 and C.sub.H3; and comprises two identical light chains each comprising a light chain variable domain and a light chain constant region (C.sub.L). In one embodiment, an antibody of the invention comprises a heavy and light chain variable domain sequence selected from those described herein in Table 3.
[0040] In certain embodiments, antibodies can be obtained from sources such as serum or plasma that contain immunoglobulins having varied antigenic specificity. If such antibodies are subjected to affinity purification, they can be enriched for a particular antigenic specificity. Such enriched preparations of antibodies usually are made of less than about 10% antibody having specific binding activity for the particular antigen. Subjecting these preparations to several rounds of affinity purification can increase the proportion of antibody having specific binding activity for the antigen. Antibodies prepared in this manner are often referred to as "monospecific."
[0041] The term "monospecific", as used herein, refers to an antibody that displays an affinity for one particular epitope. Monospecific antibody preparations can be made up of about 10%, 20%, 30%, 40%, 50%, 60%, 70%, 75%, 80%, 85%, 90%, 95%, 97%, 99%, or 99.9% antibody having specific binding activity for the particular antigen.
[0042] In certain embodiments, an antigen binding protein, such as an antibody, may have one or more binding sites. If there is more than one binding site, the binding sites may be identical to one another or may be different. For example, a naturally occurring human immunoglobulin typically has two identical binding sites, while a "bispecific" or "bifunctional" antibody has two different binding sites.
[0043] An "antibody fragment" or "antigen binding fragment of an antibody" comprises a portion of an intact antibody, and preferably comprises the antibody antigen binding or variable domains. Examples of an antibody fragment include a Fab, an Fab', an F(ab')2, an Fv fragment, and a linear antibody.
[0044] Antigen binding portions (or fragments) of an antibody may be produced by recombinant DNA techniques or by enzymatic or chemical cleavage of intact antibodies. Antigen binding portions include, inter alia, Fab, Fab', F(ab').sub.2, Fv, domain antibodies (dAbs), and complementarity determining region (CDR) fragments, single-chain antibodies (scFv), chimeric antibodies, diabodies, triabodies, tetrabodies, and polypeptides that contain at least a portion of an immunoglobulin that is sufficient to confer specific antigen binding to the polypeptide.
[0045] A Fab fragment is a monovalent fragment having the V.sub.L, V.sub.H, C.sub.L and C.sub.H1 domains; a F(ab').sub.2 fragment is a bivalent fragment having two Fab fragments linked by a disulfide bridge at the hinge region; a Fd fragment has the V.sub.H and C.sub.H1 domains; an Fv fragment has the V.sub.L and V.sub.H domains of a single arm of an antibody; and a dAb fragment has a V.sub.H domain, a V.sub.L domain, or an antigen-binding fragment of a V.sub.H or V.sub.L domain (U.S. Pat. Nos. 6,846,634; 6,696,245, US App. Pub. 20/0202512; 2004/0202995; 2004/0038291; 2004/0009507; 20 03/0039958, and Ward et al., Nature 341:544-546, 1989).
[0046] A single-chain antibody (scFv) is an antibody in which a V.sub.L and a V.sub.H region are joined via a linker (e.g., a synthetic sequence of amino acid residues) to form a continuous protein chain wherein the linker is long enough to allow the protein chain to fold back on itself and form a monovalent antigen binding site (see, e.g., Bird et al., 1988, Science 242:423-26 and Huston et al., 1988, Proc. Natl. Acad. Sci. USA 85:5879-83).
[0047] Diabodies are bivalent antibodies comprising two polypeptide chains, wherein each polypeptide chain comprises V.sub.H and V.sub.L domains joined by a linker that is too short to allow for pairing between two domains on the same chain, thus allowing each domain to pair with a complementary domain on another polypeptide chain (see, e.g., Holliger et al., 1993, Proc. Natl. Acad. Sci. USA 90:6444-48, and Poljak et al., 1994, Structure 2:1121-23). If the two polypeptide chains of a diabody are identical, then a diabody resulting from their pairing will have two identical antigen binding sites. Polypeptide chains having different sequences can be used to make a diabody with two different antigen binding sites. Similarly, triabodies and tetrabodies are antibodies comprising three and four polypeptide chains, respectively, and forming three and four antigen binding sites, respectively, which can be the same or different.
[0048] The term "human antibody" includes antibodies that have one or more variable and constant regions derived from human immunoglobulin sequences. In one embodiment, all of the variable and constant domains of the antibody are derived from human immunoglobulin sequences (referred to as "a fully human antibody"). These antibodies may be prepared in a variety of ways, examples of which are described below, including through the immunization with an antigen of interest of a mouse that is genetically modified to express antibodies derived from human heavy and/or light chain-encoding genes. In a preferred embodiment, a fully human antibody is made using recombinant methods such that the glycosylation pattern of the antibody is different than an antibody having the same sequence if it were to exist in nature.
[0049] A "humanized antibody" has a sequence that differs from the sequence of an antibody derived from a non-human species by one or more amino acid substitutions, deletions, and/or additions, such that the humanized antibody is less likely to induce an immune response, and/or induces a less severe immune response, as compared to the non-human species antibody, when it is administered to a human subject. In one embodiment, certain amino acids in the framework and constant domains of the heavy and/or light chains of the non-human species antibody are mutated to produce the humanized antibody. In another embodiment, the constant domain(s) from a human antibody are fused to the variable domain(s) of a non-human species. In another embodiment, one or more amino acid residues in one or more CDR sequences of a non-human antibody are changed to reduce the likely immunogenicity of the non-human antibody when it is administered to a human subject, wherein the changed amino acid residues either are not critical for immunospecific binding of the antibody to its antigen, or the changes to the amino acid sequence that are made are conservative changes, such that the binding of the humanized antibody to the antigen is not significantly worse than the binding of the non-human antibody to the antigen. Examples of how to make humanized antibodies may be found in U.S. Pat. Nos. 6,054,297, 5,886,152 and 5,877,293.
[0050] The term "chimeric antibody" refers to an antibody that contains one or more regions from one antibody and one or more regions from one or more other antibodies. In one embodiment, one or more of the CDRs are derived from a human anti-PSMA antibody. In another embodiment, all of the CDRs are derived from a human anti-PSMA antibody. In another embodiment, the CDRs from more than one human anti-PSMA antibodies are mixed and matched in a chimeric antibody. For instance, a chimeric antibody may comprise a CDR1 from the light chain of a first human anti-PAR-2 antibody, a CDR2 and a CDR3 from the light chain of a second human anti-PSMA antibody, and the CDRs from the heavy chain from a third anti-PSMA antibody. Other combinations are possible.
[0051] Further, the framework regions may be derived from one of the same anti-PSMA antibodies, from one or more different antibodies, such as a human antibody, or from a humanized antibody. In one example of a chimeric antibody, a portion of the heavy and/or light chain is identical with, homologous to, or derived from an antibody from a particular species or belonging to a particular antibody class or subclass, while the remainder of the chain(s) is/are identical with, homologous to, or derived from an antibody (-ies) from another species or belonging to another antibody class or subclass. Also included are fragments of such antibodies that exhibit the desired biological activity (i.e., the ability to specifically bind PSMA).
[0052] A "neutralizing antibody" or an "inhibitory antibody" is an antibody that inhibits the proteolytic activation of PSMA when an excess of the anti-PSMA antibody reduces the amount of activation by at least about 20% using an assay such as those described herein in the Examples. In various embodiments, the antigen binding protein reduces the amount of amount of proteolytic activation of PSMA by at least 30%, 40%, 50%, 60%, 70%, 75%, 80%, 85%, 90%, 95%, 97%, 99%, and 99.9%.
[0053] A "CDR grafted antibody" is an antibody comprising one or more CDRs derived from an antibody of a particular species or isotype and the framework of another antibody of the same or different species or isotype.
[0054] A "multi-specific antibody" is an antibody that recognizes more than one epitope on one or more antigens. A subclass of this type of antibody is a "bi-specific antibody" which recognizes two distinct epitopes on the same or different antigens.
[0055] An antigen binding protein "specifically binds" to an antigen (e.g., PSMA) if it binds to the antigen with a dissociation constant of 1 nanomolar or less.
[0056] An "antigen binding domain, "antigen binding region," or "antigen binding site" is a portion of an antigen binding protein that contains amino acid residues (or other moieties) that interact with an antigen and contribute to the antigen binding protein's specificity and affinity for the antigen. For an antibody that specifically binds to its antigen, this will include at least part of at least one of its CDR domains.
[0057] The term "Fc polypeptide" includes native and mutein forms of polypeptides derived from the Fc region of an antibody. Truncated forms of such polypeptides containing the hinge region that promotes dimerization also are included. Fusion proteins comprising Fc moieties (and oligomers formed therefrom) offer the advantage of facile purification by affinity chromatography over Protein A or Protein G columns.
[0058] An "epitope" is the portion of a molecule that is bound by an antigen binding protein (e.g., by an antibody). An epitope can comprise non-contiguous portions of the molecule (e.g., in a polypeptide, amino acid residues that are not contiguous in the polypeptide's primary sequence but that, in the context of the polypeptide's tertiary and quaternary structure, are near enough to each other to be bound by an antigen binding protein).
[0059] The "percent identity" or "percent homology" of two polynucleotide or two polypeptide sequences is determined by comparing the sequences using the GAP computer program (a part of the GCG Wisconsin Package, version 10.3 (Accelrys, San Diego, Calif.)) using its default parameters.
[0060] The terms "polynucleotide," "oligonucleotide" and "nucleic acid" are used interchangeably throughout and include DNA molecules (e.g., cDNA or genomic DNA), RNA molecules (e.g., mRNA), analogs of the DNA or RNA generated using nucleotide analogs (e.g., peptide nucleic acids and non-naturally occurring nucleotide analogs), and hybrids thereof. The nucleic acid molecule can be single-stranded or double-stranded. In one embodiment, the nucleic acid molecules of the invention comprise a contiguous open reading frame encoding an antibody, or a fragment, derivative, mutein, or variant thereof.
[0061] Two single-stranded polynucleotides are "the complement" of each other if their sequences can be aligned in an anti-parallel orientation such that every nucleotide in one polynucleotide is opposite its complementary nucleotide in the other polynucleotide, without the introduction of gaps, and without unpaired nucleotides at the 5' or the 3' end of either sequence. A polynucleotide is "complementary" to another polynucleotide if the two polynucleotides can hybridize to one another under moderately stringent conditions. Thus, a polynucleotide can be complementary to another polynucleotide without being its complement.
[0062] A "vector" is a nucleic acid that can be used to introduce another nucleic acid linked to it into a cell. One type of vector is a "plasmid," which refers to a linear or circular double stranded DNA molecule into which additional nucleic acid segments can be ligated. Another type of vector is a viral vector (e.g., replication defective retroviruses, adenoviruses and adeno-associated viruses), wherein additional DNA segments can be introduced into the viral genome. Certain vectors are capable of autonomous replication in a host cell into which they are introduced (e.g., bacterial vectors comprising a bacterial origin of replication and episomal mammalian vectors). Other vectors (e.g., non-episomal mammalian vectors) are integrated into the genome of a host cell upon introduction into the host cell, and thereby are replicated along with the host genome. An "expression vector" is a type of vector that can direct the expression of a chosen polynucleotide.
[0063] A nucleotide sequence is "operably linked" to a regulatory sequence if the regulatory sequence affects the expression (e.g., the level, timing, or location of expression) of the nucleotide sequence. A "regulatory sequence" is a nucleic acid that affects the expression (e.g., the level, timing, or location of expression) of a nucleic acid to which it is operably linked. The regulatory sequence can, for example, exert its effects directly on the regulated nucleic acid, or through the action of one or more other molecules (e.g., polypeptides that bind to the regulatory sequence and/or the nucleic acid). Examples of regulatory sequences include promoters, enhancers and other expression control elements (e.g., polyadenylation signals). Further examples of regulatory sequences are described in, for example, Goeddel, 1990, Gene Expression Technology: Methods in Enzymology 185, Academic Press, San Diego, Calif. and Baron et al., 1995, Nucleic Acids Res. 23:3605-06.
[0064] A "host cell" is a cell that can be used to express a nucleic acid, e.g., a nucleic acid of the invention. A host cell can be a prokaryote, for example, E. coli, or it can be a eukaryote, for example, a single-celled eukaryote (e.g., a yeast or other fungus), a plant cell (e.g., a tobacco or tomato plant cell), an animal cell (e.g., a human cell, a monkey cell, a hamster cell, a rat cell, a mouse cell, or an insect cell) or a hybridoma. Examples of host cells include the COS-7 line of monkey kidney cells (ATCC CRL 1651) (see Gluzman et al., 1981, Cell 23:175), L cells, C127 cells, 3T3 cells (ATCC CCL 163), Chinese hamster ovary (CHO) cells or their derivatives such as Veggie CHO and related cell lines which grow in serum-free media (see Rasmussen et al., 1998, Cytotechnology 28:31) or CHO strain DX-B11, which is deficient in DHFR (see Urlaub et al., 1980, Proc. Natl. Acad. Sci. USA 77:4216-20), HeLa cells, BHK (ATCC CRL 10) cell lines, the CV1/EBNA cell line derived from the African green monkey kidney cell line CV1 (ATCC CCL 70) (see McMahan et al., 1991, EMBO J. 10:2821), human embryonic kidney cells such as 293,293 EBNA or MSR 293, human epidermal A431 cells, human Colo205 cells, other transformed primate cell lines, normal diploid cells, cell strains derived from in vitro culture of primary tissue, primary explants, HL-60, U937, HaK or Jurkat cells. In one embodiment, a host cell is a mammalian host cell. In one embodiment, a host cell is a mammalian host cell, but is not a human host cell. Typically, a host cell is a cultured cell that can be transformed or transfected with a polypeptide-encoding nucleic acid, which can then be expressed in the host cell. The phrase "recombinant host cell" can be used to denote a host cell that has been transformed or transfected with a nucleic acid to be expressed. A host cell also can be a cell that comprises the nucleic acid but does not express it at a desired level unless a regulatory sequence is introduced into the host cell such that it becomes operably linked with the nucleic acid. It is understood that the term host cell refers not only to the particular subject cell but also to the progeny or potential progeny of such a cell. Because certain modifications may occur in succeeding generations due to, e.g., mutation or environmental influence, such progeny may not, in fact, be identical to the parent cell, but are still included within the scope of the term as used herein.
[0065] The term "recombinant antibody" refers to an antibody that is prepared according to standard recombinant expression methods. A recombinant antibody can, for example, be expressed from a cell or cell line transfected with an expression vector (or possibly more than one expression vector) comprising the coding sequence of the antibody, where said coding sequence is not naturally associated with the cell. In one embodiment, a recombinant antibody has a glycosylation pattern that is different than the glycosylation pattern of an antibody having the same sequence if it were to exist in nature. In one embodiment, a recombinant antibody is expressed in a mammalian host cell which is not a human host cell. Notably, individual mammalian host cells have unique glycosylation patterns.
[0066] The term "effective amount" as used herein, refers to that amount of an antibody, or an antigen binding portion thereof that binds PSMA, which is sufficient to effect treatment of a disease when administered to a subject. A therapeutically effective amount of an antibody, or fragment, provided herein will vary depending upon the relative activity of the antibodies and depending upon the subject and disease condition being treated, the weight and age of the subject, the severity of the disease condition, the manner of administration and the like, which can readily be determined by one of ordinary skill in the art.
[0067] The term "isolated" refers to a protein (e.g., an antibody) that is substantially free of other cellular material. In one embodiment, an isolated antibody is substantially free of other proteins from the same species. In one embodiment, an isolated antibody is expressed by a cell from a different species and is substantially free of other proteins from the different species. A protein may be rendered substantially free of naturally associated components (or components associated with the cellular expression system used to produce the antibody) by isolation, using protein purification techniques well known in the art. In one embodiment, the anti-PSMA antibodies, or antigen binding fragments, of the invention are isolated.
PSMA Antigen Binding Proteins
[0068] The present invention pertains to PSMA binding proteins, particularly anti-PSMA antibodies, or antigen-binding portions thereof, that bind PSMA, e.g., human PSMA, and uses thereof. Various aspects of the invention relate to antibodies and antibody fragments, pharmaceutical compositions, nucleic acids, recombinant expression vectors, and host cells for making such antibodies and fragments. Methods of using the antibodies of the invention to detect human PSMA, to inhibit PSMA activity, either in vitro or in vivo, and to prevent or treat disorders such as cancer are also encompassed by the invention. In one embodiment, the antibody of the invention is a human antibody.
[0069] As described in Table 3 below, included in the invention are novel human antibody heavy and light chain variable regions that are specific to PSMA. In one embodiment, the invention provides an anti-PSMA antibody, or an antigen-binding fragment thereof, that comprises a heavy chain having a variable domain comprising an amino acid sequence as set forth in SEQ ID NO:1. In one embodiment, the invention provides an anti-PSMA antibody, or an antigen-binding fragment thereof, that comprises a light chain having a variable domain comprising an amino acid sequence as set forth in any one of SEQ ID Nos: 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 and 17. In one embodiment, the invention provides an anti-PSMA antibody, or an antigen-binding fragment thereof, that comprises a light chain having a variable domain comprising an amino acid sequence as set forth in any one of SEQ ID Nos: 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 and 17; and a heavy chain having a variable domain comprising an amino acid sequence as set forth in SEQ ID NO: 1.
[0070] Complementarity determining regions (CDRs) are known as hypervariable regions both in the light chain and the heavy chain variable domains. The more highly conserved portions of variable domains are called the framework (FR). Complementarity determining regions (CDRs) and framework regions (FR) of a given antibody may be identified using the system described by Kabat et al. supra; Lefranc et al., supra and/or Honegger and Pluckthun, supra. Also familiar to those in the art is the numbering system described in Kabat et al. (1991, NIH Publication 91-3242, National Technical Information Service, Springfield, Va.). In this regard Kabat et al. defined a numbering system for variable domain sequences that is applicable to any antibody. One of ordinary skill in the art can unambiguously assign this system of "Kabat numbering" to any variable domain amino acid sequence, without reliance on any experimental data beyond the sequence itself.
[0071] In certain embodiments, the present invention provides an anti-PSMA antibody comprising the CDRs of the heavy and light chain variable domains described in Table 3 (SEQ ID Nos: 1 to 17). For example, the invention provides an anti-PSMA antibody, or antigen-binding fragment thereof, comprising a heavy chain variable region having the CDRs described in an amino acid sequence as set forth in SEQ ID NO:1. In one embodiment, the invention provides an anti-PSMA antibody, or antigen-binding fragment thereof, comprising a light chain variable region having the CDRs described in an amino acid sequence as set forth in any one of SEQ ID Nos: 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 and 17. In one embodiment, the invention provides an anti-PSMA antibody, or antigen-binding fragment thereof, comprising a light chain variable region having the CDRs described in an amino acid sequence as set forth in any one of SEQ ID Nos: 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 and 17; and a heavy chain variable region having the CDRs described in an amino acid sequence as set forth in SEQ ID NO:1.
[0072] In one embodiment, the present disclosure provides an isolated anti-PSMA antibody, or antigen binding fragment thereof, that comprises a heavy chain comprising a variable domain comprising the amino acid sequence of SEQ ID NO: 1, and a light chain comprising a variable domain comprising an amino acid sequence selected from the group consisting of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, SEQ ID NO. 17.
[0073] In one embodiment, the present disclosure provides a fully human antibody of an IgG class that binds to a PSMA epitope with a binding affinity of 10.sup.-6M or less, that has a heavy chain variable domain sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical, to the amino acid sequence SEQ ID NO. 1, and that has a light chain variable domain sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical, to the amino acid sequence consisting of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, SEQ ID NO. 17, and combinations thereof.
[0074] In one embodiment, the fully human antibody has both a heavy chain and a light chain wherein the antibody has a heavy chain/light chain variable domain sequence selected from the group consisting of SEQ ID NO. 1/SEQ ID NO. 2 (called PSA11 herein), SEQ ID NO. 1/SEQ ID NO. 3 (called PSGB11 herein), SEQ ID NO. 1/SEQ ID NO. 4 (called PSGB12 herein), SEQ ID NO. 1/SEQ ID NO. 5 (called PSGC8 herein), SEQ ID NO. 1/SEQ ID NO. 6 (called PSGC9 herein), SEQ ID NO. 1/SEQ ID NO. 7 (called PSGC12 herein), SEQ ID NO. 1/SEQ ID NO. 8 (called PSGD3 herein), SEQ ID NO. 1/SEQ ID NO. 9 (called PSGD4 herein), SEQ ID NO. 1/SEQ ID NO. 10 (called PSGD6 herein), SEQ ID NO. 1/SEQ ID NO. 11 (called PSGE10 herein), SEQ ID NO. 1/SEQ ID NO. 12 (called PSGE11 herein), SEQ ID NO. 1/SEQ ID NO. 13 (called PSGF9 herein), SEQ ID NO. 1/SEQ ID NO. 14 (called PSGF11 herein), SEQ ID NO. 1/SEQ ID NO. 15 (called PSGG6 herein), SEQ ID NO. 1/SEQ ID NO. 16 (called PSGH3 herein), SEQ ID NO. 1/SEQ ID NO. 17 (called PSGH8 herein), and combinations thereof.
[0075] In one embodiment, the invention provides an anti-PSMA antibody, or an antigen-binding fragment thereof, comprising a heavy chain comprising a CDR3 domain as set forth in SEQ ID NO: 1, and comprising a variable domain comprising an amino acid sequence that is at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% identical to a sequence as set forth in SEQ ID NO: 1. In one embodiment, the invention provides an anti-PSMA antibody, or an antigen-binding fragment thereof, comprising a light chain comprising a CDR3 domain as set forth in any one of SEQ ID Nos: 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 and 17 and comprising a light chain variable domain comprising an amino acid sequence that has at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% identical to a sequence as set forth in any one of SEQ ID Nos: 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 and 17. Thus, in certain embodiments, the CDR3 domain is held constant, while variability may be introduced into the remaining CDRs and/or framework regions of the heavy and/or light chains, while the antibody, or antigen binding fragment thereof, retains the ability to bind to PSMA and retains the functional characteristics, e.g., binding affinity, of the parent.
[0076] In one embodiment, the substitutions made within a heavy or light chain that is at least 95% identical (or at least 96% identical, or at least 97% identical, or at least 98% identical, or at least 99% identical) are conservative amino acid substitutions. A "conservative amino acid substitution" is one in which an amino acid residue is substituted by another amino acid residue having a side chain (R group) with similar chemical properties (e.g., charge or hydrophobicity). In general, a conservative amino acid substitution will not substantially change the functional properties of a protein. In cases where two or more amino acid sequences differ from each other by conservative substitutions, the percent sequence identity or degree of similarity may be adjusted upwards to correct for the conservative nature of the substitution. Means for making this adjustment are well-known to those of skill in the art. See, e.g., Pearson (1994) Methods Mol. Biol. 24: 307-331, herein incorporated by reference. Examples of groups of amino acids that have side chains with similar chemical properties include (1) aliphatic side chains: glycine, alanine, valine, leucine and isoleucine; (2) aliphatic-hydroxyl side chains: serine and threonine; (3) amide-containing side chains: asparagine and glutamine; (4) aromatic side chains: phenylalanine, tyrosine, and tryptophan; (5) basic side chains: lysine, arginine, and histidine; (6) acidic side chains: aspartate and glutamate, and (7) sulfur-containing side chains are cysteine and methionine.
[0077] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having the antigen binding regions of any of the antibodies described in Table 3.
[0078] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSA11. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 2. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 2. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 2. The antibody may further be an IgG1 or an IgG4 isotype.
[0079] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGB11. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 3. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 3. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 3. The antibody may further be an IgG1 or an IgG4 isotype.
[0080] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGB12. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 4. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO:4. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 4. The antibody may further be an IgG1 or an IgG4 isotype.
[0081] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGC8. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 5. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 5. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 5. The antibody may further be an IgG1 or an IgG4 isotype.
[0082] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGC9. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 6. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 6. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 6. The antibody may further be an IgG1 or an IgG4 isotype.
[0083] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGC12. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 7. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 7. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 7. The antibody may further be an IgG1 or an IgG4 isotype.
[0084] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGD3. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 8. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 8. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 8. The antibody may further be an IgG1 or an IgG4 isotype.
[0085] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGD4. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 9. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 9. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 9. The antibody may further be an IgG1 or an IgG4 isotype.
[0086] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGD6. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 10. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 10. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 10. The antibody may further be an IgG1 or an IgG4 isotype.
[0087] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGE10. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 11. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 11. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 11. The antibody may further be an IgG1 or an IgG4 isotype.
[0088] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGE11. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 12. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 12. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 12. The antibody may further be an IgG1 or an IgG4 isotype.
[0089] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGF9. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 13. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 13. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 13. The antibody may further be an IgG1 or an IgG4 isotype.
[0090] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGF11. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 14. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 14. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 14. The antibody may further be an IgG1 or an IgG4 isotype.
[0091] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGG6. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 15. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 15. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 15. The antibody may further be an IgG1 or an IgG4 isotype.
[0092] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGH3. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 16. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 16. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 16. The antibody may further be an IgG1 or an IgG4 isotype.
[0093] In one embodiment, the present invention is directed to an antibody, or an antigen binding fragment thereof, having antigen binding regions of antibody PSGH8. In one embodiment, the invention provides an antibody, or antigen-binding fragment thereof, comprising a heavy chain variable domain sequence as set forth in SEQ ID NO: 1, and a light chain variable domain sequence as set forth in SEQ ID NO: 17. In one embodiment, the invention is directed to an antibody having a heavy chain variable domain comprising the CDRs of SEQ ID NO: 1, and a light chain variable domain comprising the CDRs of SEQ ID NO: 17. In one embodiment, the invention features an isolated human antibody, or antigen-binding fragment thereof, that comprises a heavy chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 1 and comprises a light chain variable region having an amino acid sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical to the sequence set forth in SEQ ID NO: 17. The antibody may further be an IgG1 or an IgG4 isotype.
[0094] Antigen binding proteins (e.g., antibodies, antibody fragments, antibody derivatives, antibody muteins, and antibody variants) are polypeptides that bind to PSMA.
[0095] Antigen-binding fragments of antigen binding proteins of the invention may be produced by conventional techniques. Examples of such fragments include, but are not limited to, Fab and F(ab').sub.2 fragments.
[0096] Single chain antibodies may be formed by linking heavy and light chain variable domain (Fv region) fragments via an amino acid bridge (short peptide linker), resulting in a single polypeptide chain. Such single-chain Fvs (scFvs) have been prepared by fusing DNA encoding a peptide linker between DNAs encoding the two variable domain polypeptides (V.sub.L and V.sub.H). The resulting polypeptides can fold back on themselves to form antigen-binding monomers, or they can form multimers (e.g., dimers, trimers, or tetramers), depending on the length of a flexible linker between the two variable domains (Kortt et al., 1997, Prot. Eng. 10:423; Kortt et al., 2001, Biomol. Eng. 18:95-108). By combining different V.sub.L and V.sub.H-comprising polypeptides, one can form multimeric scFvs that bind to different epitopes (Kriangkum et al., 2001, Biomol. Eng. 18:31-40). Techniques developed for the production of single chain antibodies include those described in U.S. Pat. No. 4,946,778; Bird, 1988, Science 242:423; Huston et al., 1988, Proc. Natl. Acad. Sci. USA 85:5879; Ward et al., 1989, Nature 334:544, de Graaf et al., 2002, Methods Mol. Biol. 178:379-87.
[0097] In certain embodiments, the present disclosure provides a Fab fully human antibody fragment, having a variable domain region from a heavy chain and a variable domain region from a light chain, wherein the heavy chain variable domain sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical, to the amino acid sequence SEQ ID NO. 1, and that has a light chain variable domain sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical, to the amino acid sequence consisting of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, SEQ ID NO. 17, and combinations thereof. In one embodiment, the fully human antibody Fab fragment has both a heavy chain variable domain region and a light chain variable domain region wherein the antibody has a heavy chain/light chain variable domain sequence selected from the group consisting of SEQ ID NO. 1/SEQ ID NO. 2, SEQ ID NO. 1/SEQ ID NO. 3, SEQ ID NO. 1/SEQ ID NO. 4, SEQ ID NO. 1/SEQ ID NO. 5, SEQ ID NO. 1/SEQ ID NO. 6, SEQ ID NO.
[0098] 1/SEQ ID NO. 7, SEQ ID NO. 1/SEQ ID NO. 8, SEQ ID NO. 1/SEQ ID NO. 9, SEQ ID NO. 1/SEQ ID NO. 10, SEQ ID NO. 1/SEQ ID NO. 11, SEQ ID NO. 1/SEQ ID NO. 12, SEQ ID NO. 1/SEQ ID NO. 13, SEQ ID NO. 1/SEQ ID NO. 14, SEQ ID NO. 1/SEQ ID NO. 15, SEQ ID NO. 1/SEQ ID NO. 16, SEQ ID NO. 1/SEQ ID NO. 17, and combinations thereof.
[0099] In one embodiment, the present disclosure provides a single chain human antibody, having a variable domain region from a heavy chain and a variable domain region from a light chain and a peptide linker connection the heavy chain and light chain variable domain regions, wherein the heavy chain variable domain sequence is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical, to the amino acid sequence of SEQ ID NO. 1, and wherein the light chain variable domain sequence is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical, to an amino acid sequence selected from the group consisting of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, SEQ ID NO. 17, and combinations thereof. In one embodiment, the fully human single chain antibody has both a heavy chain variable domain region and a light chain variable domain region, wherein the single chain fully human antibody has a heavy chain/light chain variable domain sequence selected from the group consisting of SEQ ID NO. 1/SEQ ID NO. 2, SEQ ID NO. 1/SEQ ID NO. 3, SEQ ID NO. 1/SEQ ID NO. 4, SEQ ID NO. 1/SEQ ID NO. 5, SEQ ID NO. 1/SEQ ID NO. 6, SEQ ID NO. 1/SEQ ID NO. 7, SEQ ID NO. 1/SEQ ID NO. 8, SEQ ID NO. 1/SEQ ID NO. 9, SEQ ID NO. 1/SEQ ID NO. 10, SEQ ID NO. 1/SEQ ID NO. 11, SEQ ID NO. 1/SEQ ID NO. 12, SEQ ID NO. 1/SEQ ID NO. 13, SEQ ID NO. 1/SEQ ID NO. 14, SEQ ID NO. 1/SEQ ID NO. 15, SEQ ID NO. 1/SEQ ID NO. 16, SEQ ID NO. 1/SEQ ID NO. 17, and combinations thereof.
[0100] Techniques are known for deriving an antibody of a different subclass or isotype from an antibody of interest, i.e., subclass switching. Thus, IgG antibodies may be derived from an IgM antibody, for example, and vice versa. Such techniques allow the preparation of new antibodies that possess the antigen-binding properties of a given antibody (the parent antibody), but also exhibit biological properties associated with an antibody isotype or subclass different from that of the parent antibody. Recombinant DNA techniques may be employed. Cloned DNA encoding particular antibody polypeptides may be employed in such procedures, e.g., DNA encoding the constant domain of an antibody of the desired isotype (Lantto et al., 2002, Methods Mol. Biol. 178:303-16). Moreover, if an IgG4 is desired, it may also be desired to introduce a point mutation (CPSC->CPPC) (SEQ ID NOS 18 and 19, respectively) in the hinge region (Bloom et al., 1997, Protein Science 6:407) to alleviate a tendency to form intra-H chain disulfide bonds that can lead to heterogeneity in the IgG4 antibodies. Thus, in one embodiment, the antibody of the invention is a human IgG1 antibody. Thus, in one embodiment, the antibody of the invention is a human IgG4 antibody.
[0101] The present disclosure provides a number of antibodies structurally characterized by the amino acid sequences of their variable domain regions. However, the amino acid sequences can undergo some changes while retaining their high degree of binding to their specific targets. More specifically, many amino acids in the variable domain region can be changed with conservative substitutions and it is predictable that the binding characteristics of the resulting antibody will not differ from the binding characteristics of the wild type antibody sequence. There are many amino acids in an antibody variable domain that do not directly interact with the antigen or impact antigen binding and are not critical for determining antibody structure. For example, a predicted nonessential amino acid residue in any of the disclosed antibodies is preferably replaced with another amino acid residue from the same class. Methods of identifying amino acid conservative substitutions which do not eliminate antigen binding are well-known in the art (see, e.g., Brummell et al., Biochem. 32: 1180-1187 (1993); Kobayashi et al. Protein Eng. 12(10):879-884 (1999); and Burks et al. Proc. Natl. Acad. Sci. USA 94:412-417 (1997)). Near et al. Mol. Immunol. 30:369-377, 1993 explains how to impact or not impact binding through site-directed mutagenesis. Near et al. only mutated residues that they thought had a high probability of changing antigen binding. Most had a modest or negative effect on binding affinity (Near et al. Table 3) and binding to different forms of digoxin (Near et al. Table 2). Thus, the invention also includes, in certain embodiments, variable sequences having at least 95% identity, at least 96% identity, at least 97% identity, at least 98% identity, or at least 99% identity to those sequences disclosed herein.
[0102] In certain embodiments, an antibody, or antigen-binding fragment thereof, provided herein has a binding affinity (K.sub.D) of 1.times.10.sup.-6 M or less; 5.times.10.sup.-7 M or less' 1.times.10.sup.-7 M or less; 5.times.10.sup.-8 M or less; 1.times.10.sup.-8 M or less; 5.times.10.sup.-9 M or less; or 1.times.10.sup.-9 M or less. In one embodiment, the antibody, or antigen-binding fragment thereof, of the invention as a K.sub.D from 1.times.10.sup.-7 M to 1.times.10.sup.-10 M. In one embodiment, the antibody, or antigen-binding fragment thereof, of the invention as a K.sub.D from 1.times.10.sup.-8 M to 1.times.10.sup.-10 M.
[0103] Those of ordinary skill in the art will appreciate standard methods known for determining the K.sub.D of an antibody, or fragment thereof. For example, in one embodiment, K.sub.D is measured by a radiolabeled antigen binding assay (RIA). In one embodiment, an RIA is performed with the Fab version of an antibody of interest and its antigen. For example, solution binding affinity of Fabs for antigen is measured by equilibrating Fab with a minimal concentration of (.sup.125I)-labeled antigen in the presence of a titration series of unlabeled antigen, then capturing bound antigen with an anti-Fab antibody-coated plate (see, e.g., Chen et al., J. Mol. Biol. 293:865-881(1999)).
[0104] According to another embodiment, K.sub.D is measured using a BIACORE surface plasmon resonance assay. The term "surface plasmon resonance", as used herein, refers to an optical phenomenon that allows for the analysis of real-time interactions by detection of alterations in protein concentrations within a biosensor matrix, for example using the BIACORE system (Biacore Life Sciences division of GE Healthcare, Piscataway, N.J.).
[0105] In particular embodiments, antigen binding proteins of the present invention have a K.sub.a for PSMA of at least 10.sup.6. In other embodiments, the antigen binding proteins exhibit a K.sub.a of at least 10.sup.7, at least 10.sup.8, at least 10.sup.9, or at least 10.sup.10. In another embodiment, the antigen binding protein exhibits a K.sub.a substantially the same as that of an antibody described herein in the Examples.
[0106] In another embodiment, the present disclosure provides an antigen binding protein that has a low dissociation rate from PSMA. In one embodiment, the antigen binding protein has a K.sub.off of 1.times.10.sup.-4 to .sup.-1 or lower. In another embodiment, the K.sub.off is 5.times.10.sup.-5 to .sup.-1 or lower. In another embodiment, the K.sub.off is substantially the same as an antibody described herein. In another embodiment, the antigen binding protein binds to PSMA with substantially the same K.sub.off as an antibody described herein.
[0107] In another aspect, the present disclosure provides an antigen binding protein that inhibits an activity of PSMA. In one embodiment, the antigen binding protein has an IC.sub.50 of 1000 nM or lower. In another embodiment, the IC.sub.50 is 100 nM or lower; in another embodiment, the IC.sub.50 is 10 nM or lower. In another embodiment, the IC.sub.50 is substantially the same as that of an antibody described herein in the Examples. In another embodiment, the antigen binding protein inhibits an activity of PSMA with substantially the same IC.sub.50 as an antibody described herein.
[0108] In another aspect, the present disclosure provides an antigen binding protein that binds to PSMA expressed on the surface of a cell and, when so bound, inhibits PSMA signaling activity in the cell without causing a significant reduction in the amount of PSMA on the surface of the cell. Any method for determining or estimating the amount of PSMA on the surface and/or in the interior of the cell can be used. In other embodiments, binding of the antigen binding protein to the PSMA-expressing cell causes less than about 75%, 50%, 40%, 30%, 20%, 15%, 10%, 5%, 1%, or 0.1% of the cell-surface PSMA to be internalized.
[0109] In another aspect, the present disclosure provides an antigen binding protein having a half-life of at least one day in vitro or in vivo (e.g., when administered to a human subject). In one embodiment, the antigen binding protein has a half-life of at least three days. In another embodiment, the antigen binding protein has a half-life of four days or longer. In another embodiment, the antigen binding protein has a half-life of eight days or longer. In another embodiment, the antigen binding protein is derivatized or modified such that it has a longer half-life as compared to the underivatized or unmodified antigen binding protein. In another embodiment, the antigen binding protein contains one or more point mutations to increase serum half life, such as described in WO00/09560, incorporated by reference herein.
[0110] The present disclosure further provides multi-specific antigen binding proteins, for example, bispecific antigen binding protein, e.g., antigen binding protein that bind to two different epitopes of PSMA, or to an epitope of PSMA and an epitope of another molecule, via two different antigen binding sites or regions. Moreover, bispecific antigen binding protein as disclosed herein can comprise a PSMA binding site from one of the herein-described antibodies and a second PSMA binding region from another of the herein-described antibodies, including those described herein by reference to other publications. Alternatively, a bispecific antigen binding protein may comprise an antigen binding site from one of the herein described antibodies and a second antigen binding site from another PSMA antibody that is known in the art, or from an antibody that is prepared by known methods or the methods described herein.
[0111] Numerous methods of preparing bispecific antibodies are known in the art. Such methods include the use of hybrid-hybridomas as described by Milstein et al., 1983, Nature 305:537, and chemical coupling of antibody fragments (Brennan et al., 1985, Science 229:81; Glennie et al., 1987, J. Immunol. 139:2367; U.S. Pat. No. 6,010,902). Moreover, bispecific antibodies can be produced via recombinant means, for example by using leucine zipper moieties (i.e., from the Fos and Jun proteins, which preferentially form heterodimers; Kostelny et al., 1992, J. Immunol. 148:1547) or other lock and key interactive domain structures as described in U.S. Pat. No. 5,582,996. Additional useful techniques include those described in U.S. Pat. Nos. 5,959,083; and 5,807,706.
[0112] In another aspect, the antigen binding protein comprises a derivative of an antibody. The derivatized antibody can comprise any molecule or substance that imparts a desired property to the antibody, such as increased half-life in a particular use. The derivatized antibody can comprise, for example, a detectable (or labeling) moiety (e.g., a radioactive, colorimetric, antigenic or enzymatic molecule, a detectable bead (such as a magnetic or electrodense (e.g., gold) bead), or a molecule that binds to another molecule (e.g., biotin or streptavidin), a therapeutic or diagnostic moiety (e.g., a radioactive, cytotoxic, or pharmaceutically active moiety), or a molecule that increases the suitability of the antibody for a particular use (e.g., administration to a subject, such as a human subject, or other in vivo or in vitro uses). Examples of molecules that can be used to derivatize an antibody include albumin (e g, human serum albumin) and polyethylene glycol (PEG). Albumin-linked and PEGylated derivatives of antibodies can be prepared using techniques well known in the art. In one embodiment, the antibody is conjugated or otherwise linked to transthyretin (TTR) or a TTR variant. The TTR or TTR variant can be chemically modified with, for example, a chemical selected from the group consisting of dextran, poly(n-vinyl pyrrolidone), polyethylene glycols, propropylene glycol homopolymers, polypropylene oxide/ethylene oxide co-polymers, polyoxyethylated polyols and polyvinyl alcohols.
[0113] An alternative approach to antibody-targeted therapy is to utilize anti-PSMA antibodies of the invention for delivery of cytotoxic drugs specifically to PSMA antigen-expressing cancer cells. In one embodiment, an anti-PSMA antibody, or fragment, of the invention is conjugated to a cytotoxic agent via a linker, to form an anti-PSMA Antibody Drug Conjugate (ADC). An alternative approach to antibody-targeted therapy is to utilize anti-PSMA antibodies for delivery of cytotoxic drugs specifically to PSMA antigen-expressing cancer cells. Various cytotoxic drugs are known in the art which can be conjugated with any of the antibodies disclosed herein to form an ADC, including, but not limited to, an auristatin. Auristatins, such as Monomethyl auristatin E (MMAE) and Monomethyl auristatin F (MMAF) are antimitotic agents that inhibit cell division by blocking the polymerization of tubulin (Francisco et al. Blood. 2003 Aug. 15; 102(4):1458-65; Smith et al. Mol Cancer Ther Jun. 2006 5; 1474-82). Antibody-drug conjugates (ADCs) composed of the auristatin MMAF linked to an anti-PSMA antibody, as described in Example 2 below, showed potent anti-tumor activity in PSMA-expressing tumor cell lines. Thus, in one embodiment, an anti-PSMA antibody, or fragment thereof, of the invention is conjugated to an auristatin, e.g., MMAF.
[0114] Oligomers that contain one or more antigen binding proteins may be employed as PSMA antagonists. Oligomers may be in the form of covalently-linked or non-covalently-linked dimers, trimers, or higher oligomers. Oligomers comprising two or more antigen binding protein are contemplated for use, with one example being a homodimer. Other oligomers include heterodimers, homotrimers, heterotrimers, homotetramers, heterotetramers, etc.
[0115] One embodiment is directed to oligomers comprising multiple antigen binding proteins joined via covalent or non-covalent interactions between peptide moieties fused to the antigen binding proteins. Such peptides may be peptide linkers (spacers), or peptides that have the property of promoting oligomerization. Leucine zippers and certain polypeptides derived from antibodies are among the peptides that can promote oligomerization of antigen binding proteins attached thereto, as described in more detail below.
[0116] In particular embodiments, the oligomers comprise from two to four antigen binding proteins. The antigen binding proteins of the oligomer may be in any form, such as any of the forms described above, e.g., variants or fragments. Preferably, the oligomers comprise antigen binding proteins that have PSMA binding activity.
[0117] In one embodiment, an oligomer is prepared using polypeptides derived from immunoglobulins. Preparation of Fusion Proteins Comprising Certain Heterologous Polypeptides Fused to Various Portions of antibody-derived polypeptides (including the Fc domain) has been described, e.g., by Ashkenazi et al., 1991, Proc. Natl. Acad. Sci. USA 88:10535; Byrn et al., 1990, Nature 344:677; and Hollenbaugh et al., 1992 "Construction of Immunoglobulin Fusion Proteins", in Current Protocols in Immunology, Suppl. 4, pages 10.19.1-10.19.11.
[0118] One embodiment is directed to a dimer comprising two fusion proteins created by fusing a PSMA binding fragment of an anti-PSMA antibody to the Fc region of an antibody. The dimer can be made by, for example, inserting a gene fusion encoding the fusion protein into an appropriate expression vector, expressing the gene fusion in host cells transformed with the recombinant expression vector, and allowing the expressed fusion protein to assemble much like antibody molecules, whereupon interchain disulfide bonds form between the Fc moieties to yield the dimer.
[0119] Another method for preparing oligomeric antigen binding proteins involves use of a leucine zipper. Leucine zipper domains are peptides that promote oligomerization of the proteins in which they are found. Leucine zippers were originally identified in several DNA-binding proteins (Landschulz et al., 1988, Science 240:1759), and have since been found in a variety of different proteins. Among the known leucine zippers are naturally occurring peptides and derivatives thereof that dimerize or trimerize. Examples of leucine zipper domains suitable for producing soluble oligomeric proteins are described in WO 94/10308, and the leucine zipper derived from lung surfactant protein D (SPD) described in Hoppe et al., 1994, FEBS Letters 344:191. The use of a modified leucine zipper that allows for stable trimerization of a heterologous protein fused thereto is described in Fanslow et al., 1994, Semin. Immunol. 6:267-78. In one approach, recombinant fusion proteins comprising an anti-PSMA antibody fragment or derivative fused to a leucine zipper peptide are expressed in suitable host cells, and the soluble oligomeric anti-PSMA antibody fragments or derivatives that form are recovered from the culture supernatant.
[0120] Antigen binding proteins directed against PSMA can be used, for example, in assays to detect the presence of PSMA polypeptides, either in vitro or in vivo. The antigen binding proteins also may be employed in purifying PSMA proteins by immunoaffinity chromatography. Blocking antigen binding proteins can be used in the methods disclosed herein. Such antigen binding proteins that function as PSMA antagonists may be employed in treating any PSMA-induced condition, including but not limited to various cancers.
[0121] Antigen binding proteins may be employed in an in vitro procedure, or administered in vivo to inhibit PSMA-induced biological activity. Disorders caused or exacerbated (directly or indirectly) by the proteolytic activation of PSMA, examples of which are provided herein, thus may be treated. In one embodiment, the present invention provides a therapeutic method comprising in vivo administration of a PSMA blocking antigen binding protein to a mammal in need thereof in an amount effective for reducing a PSMA-induced biological activity.
[0122] In certain embodiments of the invention, antigen binding proteins include fully human monoclonal antibodies that inhibit a biological activity of PSMA.
[0123] Antigen binding proteins, including antibodies and antibody fragments described herein, may be prepared by any of a number of conventional techniques. For example, they may be purified from cells that naturally express them (e.g., an antibody can be purified from a hybridoma that produces it), or produced in recombinant expression systems, using any technique known in the art. See, for example, Monoclonal Antibodies, Hybridomas: A New Dimension in Biological Analyses, Kennet et al. (eds.), Plenum Press, New York (1980); and Antibodies: A Laboratory Manual, Harlow and Land (eds.), Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., (1988).
[0124] Any expression system known in the art can be used to make the recombinant polypeptides, including antibodies and antibody fragments described herein, of the invention. In general, host cells are transformed with a recombinant expression vector that comprises DNA encoding a desired polypeptide. Among the host cells that may be employed are prokaryotes, yeast or higher eukaryotic cells. Prokaryotes include gram negative or gram positive organisms, for example E. coli or bacilli. Higher eukaryotic cells include insect cells and established cell lines of mammalian origin. Examples of suitable mammalian host cell lines include the COS-7 line of monkey kidney cells (ATCC CRL 1651) (Gluzman et al., 1981, Cell 23:175), L cells, 293 cells, C127 cells, 3T3 cells (ATCC CCL 163), Chinese hamster ovary (CHO) cells, HeLa cells, BHK (ATCC CRL 10) cell lines, and the CV1/EBNA cell line derived from the African green monkey kidney cell line CV1 (ATCC CCL 70) as described by McMahan et al., 1991, EMBO J. 10: 2821. Appropriate cloning and expression vectors for use with bacterial, fungal, yeast, and mammalian cellular hosts are described by Pouwels et al. (Cloning Vectors: A Laboratory Manual, Elsevier, N.Y., 1985).
[0125] The transformed cells can be cultured under conditions that promote expression of the polypeptide, and the polypeptide recovered by conventional protein purification procedures. One such purification procedure includes the use of affinity chromatography, e.g., over a matrix having all or a portion (e.g., the extracellular domain) of PSMA bound thereto. Polypeptides contemplated for use herein include substantially homogeneous recombinant mammalian anti-PSMA antibody polypeptides substantially free of contaminating endogenous materials.
[0126] Antigen binding proteins may be prepared, and screened for desired properties, by any of a number of known techniques. Certain of the techniques involve isolating a nucleic acid encoding a polypeptide chain (or portion thereof) of an antigen binding protein of interest (e.g., an anti-PSMA antibody), and manipulating the nucleic acid through recombinant DNA technology. The nucleic acid may be fused to another nucleic acid of interest, or altered (e.g., by mutagenesis or other conventional techniques) to add, delete, or substitute one or more amino acid residues, for example.
[0127] Polypeptides of the present disclosure can be produced using any standard methods known in the art. In one example, the polypeptides are produced by recombinant DNA methods by inserting a nucleic acid sequence (e.g., a cDNA) encoding the polypeptide into a recombinant expression vector and expressing the DNA sequence under conditions promoting expression.
[0128] Nucleic acids encoding any of the various polypeptides disclosed herein may be synthesized chemically. Codon usage may be selected so as to improve expression in a cell. Such codon usage will depend on the cell type selected. Specialized codon usage patterns have been developed for E. coli and other bacteria, as well as mammalian cells, plant cells, yeast cells and insect cells. See for example: Mayfield et al., Proc. Natl. Acad. Sci. USA. 2003 100(2):438-42; Sinclair et al. Protein Expr. Purif. 2002 (1):96-105; Connell N D. Curr. Opin. Biotechnol. 2001 12(5):446-9; Makrides et al. Microbiol. Rev. 1996 60(3):512-38; and Sharp et al. Yeast. 1991 7(7):657-78.
[0129] In one embodiment, the invention features nucleic acids encoding the antibodies or antibody fragments described herein. For example, in one embodiment, the invention includes a nucleic acid encoding a heavy chain variable domain as set forth in SEQ ID NO: 1 and/or a light chain variable domain as set forth in any one of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, and SEQ ID NO. 17.
[0130] General techniques for nucleic acid manipulation are described for example in Sambrook et al., Molecular Cloning: A Laboratory Manual, Vols. 1-3, Cold Spring Harbor Laboratory Press, 2 ed., 1989, or F. Ausubel et al., Current Protocols in Molecular Biology (Green Publishing and Wiley-Interscience: New York, 1987) and periodic updates, herein incorporated by reference. The DNA encoding the polypeptide is operably linked to suitable transcriptional or translational regulatory elements derived from mammalian, viral, or insect genes. Such regulatory elements include a transcriptional promoter, an optional operator sequence to control transcription, a sequence encoding suitable mRNA ribosomal binding sites, and sequences that control the termination of transcription and translation. The ability to replicate in a host, usually conferred by an origin of replication, and a selection gene to facilitate recognition of transformants is additionally incorporated.
[0131] The recombinant DNA can also include any type of protein tag sequence that may be useful for purifying the protein. Examples of protein tags include but are not limited to a histidine tag, a FLAG tag, a myc tag, an HA tag, or a GST tag. Appropriate cloning and expression vectors for use with bacterial, fungal, yeast, and mammalian cellular hosts can be found in Cloning Vectors: A Laboratory Manual, (Elsevier, N.Y., 1985).
[0132] The expression construct is introduced into the host cell using a method appropriate to the host cell. A variety of methods for introducing nucleic acids into host cells are known in the art, including, but not limited to, electroporation; transfection employing calcium chloride, rubidium chloride, calcium phosphate, DEAE-dextran, or other substances; microprojectile bombardment; lipofection; and infection (where the vector is an infectious agent). Suitable host cells include prokaryotes, yeast, mammalian cells, or bacterial cells.
[0133] Suitable bacteria include gram negative or gram positive organisms, for example, E. coli or Bacillus spp. Yeast, preferably from the Saccharomyces species, such as S. cerevisiae, may also be used for production of polypeptides. Various mammalian or insect cell culture systems can also be employed to express recombinant proteins. Baculovirus systems for production of heterologous proteins in insect cells are reviewed by Luckow and Summers, (Bio/Technology, 6:47, 1988). Examples of suitable mammalian host cell lines include endothelial cells, COS-7 monkey kidney cells, CV-1, L cells, C127, 3T3, Chinese hamster ovary (CHO), human embryonic kidney cells, HeLa, 293, 293T, and BHK cell lines. Purified polypeptides are prepared by culturing suitable host/vector systems to express the recombinant proteins. In some embodiments, the small size of many of the polypeptides disclosed herein would make expression in E. coli as the preferred method for expression. The protein is then purified from culture media or cell extracts.
[0134] Proteins disclosed herein can also be produced using cell-translation systems. For such purposes the nucleic acids encoding the polypeptide must be modified to allow in vitro transcription to produce mRNA and to allow cell-free translation of the mRNA in the particular cell-free system being utilized (eukaryotic such as a mammalian or yeast cell-free translation system or prokaryotic such as a bacterial cell-free translation system. PSMA-binding polypeptides can also be produced by chemical synthesis (e.g., by the methods described in Solid Phase Peptide Synthesis, 2nd ed., 1984, The Pierce Chemical Co., Rockford, Ill.). Modifications to the protein can also be produced by chemical synthesis.
[0135] The polypeptides of the present disclosure can be purified by isolation/purification methods for proteins generally known in the field of protein chemistry. Non-limiting examples include extraction, recrystallization, salting out (e.g., with ammonium sulfate or sodium sulfate), centrifugation, dialysis, ultrafiltration, adsorption chromatography, ion exchange chromatography, hydrophobic chromatography, normal phase chromatography, reversed-phase chromatography, gel filtration, gel permeation chromatography, affinity chromatography, electrophoresis, countercurrent distribution or any combinations of these. After purification, polypeptides may be exchanged into different buffers and/or concentrated by any of a variety of methods known to the art, including, but not limited to, filtration and dialysis. The purified polypeptide is preferably at least 85% pure, more preferably at least 95% pure, and most preferably at least 98% pure. Regardless of the exact numerical value of the purity, the polypeptide is sufficiently pure for use as a pharmaceutical product.
[0136] In certain embodiments, the present disclosure provides monoclonal antibodies that bind to PSMA. Monoclonal antibodies may be produced using any technique known in the art, e.g., by immortalizing spleen cells harvested from the transgenic animal after completion of the immunization schedule. The spleen cells can be immortalized using any technique known in the art, e.g., by fusing them with myeloma cells to produce hybridomas. Myeloma cells for use in hybridoma-producing fusion procedures preferably are non-antibody-producing, have high fusion efficiency, and enzyme deficiencies that render them incapable of growing in certain selective media which support the growth of only the desired fused cells (hybridomas). Examples of suitable cell lines for use in mouse fusions include Sp-20, P3-X63/Ag8, P3-X63-Ag8.653, NS1/1.Ag 4 1, Sp210-Ag14, FO, NSO/U, MPC-11, MPC11-X45-GTG 1.7 and S194/5XX0 Bul; examples of cell lines used in rat fusions include R210.RCY3, Y3-Ag 1.2.3, IR983F and 48210. Other cell lines useful for cell fusions are U-266, GM1500-GRG2, LICR-LON-HMy2 and UC729-6.
[0137] Fragments or analogs of antibodies can be readily prepared by those of ordinary skill in the art following the teachings of this specification and using techniques known in the art. Preferred amino- and carboxy-termini of fragments or analogs occur near boundaries of functional domains. Structural and functional domains can be identified by comparison of the nucleotide and/or amino acid sequence data to public or proprietary sequence databases. Computerized comparison methods can be used to identify sequence motifs or predicted protein conformation domains that occur in other proteins of known structure and/or function. Methods to identify protein sequences that fold into a known three-dimensional structure are known. See, Bowie et al., 1991, Science 253:164.
Post-Translational Modifications of Polypeptides
[0138] In certain embodiments, the binding polypeptides of the invention may further comprise post-translational modifications. Exemplary post-translational protein modifications include phosphorylation, acetylation, methylation, ADP-ribosylation, ubiquitination, glycosylation, carbonylation, sumoylation, biotinylation or addition of a polypeptide side chain or of a hydrophobic group. As a result, the modified soluble polypeptides may contain non-amino acid elements, such as lipids, poly- or mono-saccharide, and phosphates. A preferred form of glycosylation is sialylation, which conjugates one or more sialic acid moieties to the polypeptide. Sialic acid moieties improve solubility and serum half-life while also reducing the possible immunogeneticity of the protein. See Raju et al. Biochemistry. 2001 31; 40(30):8868-76.
[0139] In one embodiment, modified forms of the subject soluble polypeptides comprise linking the subject soluble polypeptides to nonproteinaceous polymers. In one embodiment, the polymer is polyethylene glycol ("PEG"), polypropylene glycol, or polyoxyalkylenes, in the manner as set forth in U.S. Pat. Nos. 4,640,835; 4,496,689; 4,301,144; 4,670,417; 4,791,192 or 4,179,337.
[0140] PEG is a water soluble polymer that is commercially available or can be prepared by ring-opening polymerization of ethylene glycol according to methods well known in the art (Sandler and Karo, Polymer Synthesis, Academic Press, New York, Vol. 3, pages 138-161). The term "PEG" is used broadly to encompass any polyethylene glycol molecule, without regard to size or to modification at an end of the PEG, and can be represented by the formula: X--O(CH.sub.2CH.sub.2O).sub.n--CH.sub.2CH.sub.2OH (1), where n is 20 to 2300 and X is H or a terminal modification, e.g., a C.sub.1-4 alkyl. In one embodiment, the PEG of the invention terminates on one end with hydroxy or methoxy, i.e., X is H or CH.sub.3 ("methoxy PEG"). A PEG can contain further chemical groups which are necessary for binding reactions; which results from the chemical synthesis of the molecule; or which is a spacer for optimal distance of parts of the molecule. In addition, such a PEG can consist of one or more PEG side-chains which are linked together. PEGs with more than one PEG chain are called multi-armed or branched PEGs. Branched PEGs can be prepared, for example, by the addition of polyethylene oxide to various polyols, including glycerol, pentaerythriol, and sorbitol. For example, a four-armed branched PEG can be prepared from pentaerythriol and ethylene oxide. Branched PEG are described in, for example, EP-A 0 473 084 and U.S. Pat. No. 5,932,462. One form of PEGs includes two PEG side-chains (PEG2) linked via the primary amino groups of a lysine (Monfardini et al., Bioconjugate Chem. 6 (1995) 62-69).
[0141] The serum clearance rate of PEG-modified polypeptide may be decreased by about 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, or even 90%, relative to the clearance rate of the unmodified binding polypeptide. The PEG-modified polypeptide may have a half-life (t.sub.1/2) which is enhanced relative to the half-life of the unmodified protein. The half-life of PEG-binding polypeptide may be enhanced by at least 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 125%, 150%, 175%, 200%, 250%, 300%, 400% or 500%, or even by 1000% relative to the half-life of the unmodified binding polypeptide. In some embodiments, the protein half-life is determined in vitro, such as in a buffered saline solution or in serum. In other embodiments, the protein half-life is an in vivo half life, such as the half-life of the protein in the serum or other bodily fluid of an animal.
Therapeutic Methods, Formulations and Modes of Administration
[0142] The present disclosure provides a method for treating cancer, comprising administering an anti-PSMA antibody, or antibody fragment, as described herein. The present disclosure further provides a method for treating a prostate cancer, comprising administering an anti-PSMA antibody, or an antibody fragment as described herein.
[0143] Studies have demonstrated PSMA expression in many types of prostate tissue and increased PSMA expression in cancer tissue (Chang, S. Rev Urol. 2004; 6(Suppl 10): S13-S18; Silver et al. Clin Cancer Res. 1997; 3:81-85; Troyer et al. Int J Cancer. 1995; 62:552-558; Haffner et al. Hum Pathol. 2009 December; 40(12):1754-61). Accordingly, in one embodiment, the anti-PSMA antibodies and antibody fragments of the invention are used to treat cancer associated with increased PSMA expression.
[0144] Any of the antibodies disclosed herein may be used in such methods. For example, the methods may be performed using a fully human antibody of an IgG class that binds to a PSMA epitope with a binding affinity of at least 10.sup.-6M, a Fab fully human antibody fragment, having a variable domain region from a heavy chain and a variable domain region from a light chain, a single chain human antibody, having a variable domain region from a heavy chain and a variable domain region from a light chain and a peptide linker connection the heavy chain and light chain variable domain regions, including the heavy and light chain variable regions (and CDRs within said sequences) described in SEQ ID Nos. 1-17 (Table 3).
[0145] In one embodiment, the antibodies disclosed herein are used to target a chemical or cellular therapeutic payload, wherein the anti-PSMA antibody comprises a heavy chain variable domain sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical, to the amino acid sequence SEQ ID NO. 1, and comprising a light chain variable domain sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical, to an amino acid sequences selected from the group consisting of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, and SEQ ID NO. 17.
[0146] In one embodiment, the methods described herein include the use of a fully human Fab antibody fragment comprising a heavy chain variable domain sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical, to the amino acid sequence SEQ ID NO. 1, and comprising a light chain variable domain sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical, to an amino acid sequence selected from the group consisting SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, and SEQ ID NO. 17.
[0147] In one embodiment, the methods described herein include the use of a single chain human antibody comprising a heavy chain variable domain sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical, to the amino acid sequence SEQ ID NO. 1, and comprising a light chain variable domain sequence that is at least 95% identical, at least 96% identical, at least 97% identical, at least 98% identical, or at least 99% identical, to an amino acid sequence selected from the group consisting of SEQ ID NO. 2, SEQ ID NO. 3, SEQ ID NO. 4, SEQ ID NO. 5, SEQ ID NO. 6, SEQ ID NO. 8, SEQ ID NO. 8, SEQ ID NO. 9, SEQ ID NO. 10, SEQ ID NO. 11, SEQ ID NO. 12, SEQ ID NO. 13, SEQ ID NO. 14, SEQ ID NO. 15, SEQ ID NO. 16, and SEQ ID NO. 17.
[0148] In one embodiment, the fully human antibody has both a heavy chain and a light chain wherein the antibody comprises a heavy chain/light chain variable domain sequence selected from the group consisting of SEQ ID NO. 1/SEQ ID NO. 2, SEQ ID NO. 1/SEQ ID NO. 3, SEQ ID NO. 1/SEQ ID NO. 4, SEQ ID NO. 1/SEQ ID NO. 5, SEQ ID NO. 1/SEQ ID NO. 6, SEQ ID NO. 1/SEQ ID NO. 7, SEQ ID NO. 1/SEQ ID NO. 8, SEQ ID NO. 1/SEQ ID NO. 9, SEQ ID NO. 1/SEQ ID NO. 10, SEQ ID NO. 1/SEQ ID NO. 11, SEQ ID NO. 1/SEQ ID NO. 12, SEQ ID NO. 1/SEQ ID NO. 13, SEQ ID NO. 1/SEQ ID NO. 14, SEQ ID NO. 1/SEQ ID NO. 15, SEQ ID NO. 1/SEQ ID NO. 16, and SEQ ID NO. 1/SEQ ID NO. 17.
[0149] In one embodiment, the fully human antibody Fab fragment comprises both a heavy chain variable domain region and a light chain variable domain region wherein the antibody comprises a heavy chain/light chain variable domain sequence selected from the group consisting of SEQ ID NO. 1/SEQ ID NO. 2, SEQ ID NO. 1/SEQ ID NO. 3, SEQ ID NO. 1/SEQ ID NO. 4, SEQ ID NO. 1/SEQ ID NO. 5, SEQ ID NO. 1/SEQ ID NO. 6, SEQ ID NO. 1/SEQ ID NO. 7, SEQ ID NO. 1/SEQ ID NO. 8, SEQ ID NO. 1/SEQ ID NO. 9, SEQ ID NO. 1/SEQ ID NO. 10, SEQ ID NO. 1/SEQ ID NO. 11, SEQ ID NO. 1/SEQ ID NO. 12, SEQ ID NO. 1/SEQ ID NO. 13, SEQ ID NO. 1/SEQ ID NO. 14, SEQ ID NO. 1/SEQ ID NO. 15, SEQ ID NO. 1/SEQ ID NO. 16, and SEQ ID NO. 1/SEQ ID NO. 17.
[0150] In one embodiment, the fully human single chain antibody comprises both a heavy chain variable domain region and a light chain variable domain region, wherein the single chain fully human antibody comprises a heavy chain/light chain variable domain sequence selected from the group consisting of SEQ ID NO. 1/SEQ ID NO. 2, SEQ ID NO. 1/SEQ ID NO. 3, SEQ ID NO. 1/SEQ ID NO. 4, SEQ ID NO. 1/SEQ ID NO. 5, SEQ ID NO. 1/SEQ ID NO. 6, SEQ ID NO. 1/SEQ ID NO. 7, SEQ ID NO. 1/SEQ ID NO. 8, SEQ ID NO. 1/SEQ ID NO. 9, SEQ ID NO. 1/SEQ ID NO. 10, SEQ ID NO. 1/SEQ ID NO. 11, SEQ ID NO. 1/SEQ ID NO. 12, SEQ ID NO. 1/SEQ ID NO. 13, SEQ ID NO. 1/SEQ ID NO. 14, SEQ ID NO. 1/SEQ ID NO. 15, SEQ ID NO. 1/SEQ ID NO. 16, and SEQ ID NO. 1/SEQ ID NO. 17.
[0151] In one embodiment, cancer which can be treated using the antibodies and fragments disclosed herein include, but are not limited to, ovarian cancer, colon cancer, breast cancer, lung cancer, myelomas, neuroblastic-derived CNS tumors, monocytic leukemias, B-cell derived leukemias, T-cell derived leukemias, B-cell derived lymphomas, T-cell derived lymphomas, and mast cell derived tumors.
[0152] In one embodiment, the anti-PSMA antibodies and antibody fragments of the invention are used to treat prostate cancer.
[0153] The PSMA antibodies, and antibody fragments, described herein are useful in treating, delaying the progression of, preventing relapse of or alleviating a symptom of a cancer or other neoplastic condition, including, hematological malignancies and/or PSMA+tumors. The PSMA antibodies described herein are useful in treating a cancer selected from the group consisting of non-Hodgkin's lymphoma (NHL), acute lymphocytic leukemia (ALL), acute myeloid leukemia (AML), chronic lymphocytic leukemia (CLL), chronic myelogenous leukemia (CML), multiple myeloma (MM), breast cancer, ovarian cancer, head and neck cancer, bladder cancer, melanoma, colorectal cancer, pancreatic cancer, lung cancer, leiomyoma, leiomyosarcoma, glioma, glioblastoma, and solid tumors, wherein solid tumors are selected from the group consisting of breast tumors, ovarian tumors, lung tumors, pancreatic tumors, prostate tumors, melanoma tumors, colorectal tumors, lung tumors, head and neck tumors, bladder tumors, esophageal tumors, liver tumors, and kidney tumors.
[0154] As used herein, "hematological cancer" refers to a cancer of the blood, and includes leukemia, lymphoma and myeloma among others. "Leukemia" refers to a cancer of the blood in which too many white blood cells that are ineffective in fighting infection are made, thus crowding out the other parts that make up the blood, such as platelets and red blood cells. It is understood that cases of leukemia are classified as acute or chronic. As such, antibodies and fragments of the invention may be used to treat a subject having a hematological cancer.
[0155] Certain forms of leukemia include, acute lymphocytic leukemia (ALL); acute myeloid leukemia (AML); chronic lymphocytic leukemia (CLL); chronic myelogenous leukemia (CML); Myeloproliferative disorder/neoplasm (MPDS); and myelodysplasia syndrome. "Lymphoma" may refer to a Hodgkin's lymphoma, both indolent and aggressive non-Hodgkin's lymphoma, Burkitt's lymphoma, and follicular lymphoma (small cell and large cell), among others. Myeloma may refer to multiple myeloma (MM), giant cell myeloma, heavy-chain myeloma, and light chain or Bence-Jones myeloma.
[0156] The present disclosure features methods for treating or preventing the S. aureus infection comprising administering an anti-PSMA polypeptide. Techniques and dosages for administration vary depending on the type of specific polypeptide and the specific condition being treated but can be readily determined by the skilled artisan. In general, regulatory agencies require that a protein reagent to be used as a therapeutic is formulated so as to have acceptably low levels of pyrogens. Accordingly, therapeutic formulations will generally be distinguished from other formulations in that they are substantially pyrogen free, or at least contain no more than acceptable levels of pyrogen as determined by the appropriate regulatory agency (e.g., FDA).
[0157] Therapeutic compositions of the present disclosure may be administered with a pharmaceutically acceptable diluent, carrier, or excipient, in unit dosage form. Administration may be parenteral (e.g., intravenous, subcutaneous), oral, or topical, as non-limiting examples. In addition, any gene therapy technique, using nucleic acids encoding the polypeptides of the invention, may be employed, such as naked DNA delivery, recombinant genes and vectors, cell-based delivery, including ex vivo manipulation of patients' cells, and the like.
[0158] The composition can be in the form of a pill, tablet, capsule, liquid, or sustained release tablet for oral administration; or a liquid for intravenous, subcutaneous or parenteral administration; gel, lotion, ointment, cream, or a polymer or other sustained release vehicle for local administration.
[0159] In certain embodiments, the disclosed antibodies are administered by inhalation, but aerosolization of full IgG antibodies may prove limiting due to their molecular size (.about.150 kDa).
[0160] Methods well known in the art for making formulations are found, for example, in "Remington: The Science and Practice of Pharmacy" (20th ed., ed. A. R. Gennaro A R., 2000, Lippincott Williams & Wilkins, Philadelphia, Pa.). Formulations for parenteral administration may, for example, contain excipients, sterile water, saline, polyalkylene glycols such as polyethylene glycol, oils of vegetable origin, or hydrogenated napthalenes. Biocompatible, biodegradable lactide polymer, lactide/glycolide copolymer, or polyoxyethylene-polyoxypropylene copolymers may be used to control the release of the compounds. Nanoparticulate formulations (e.g., biodegradable nanoparticles, solid lipid nanoparticles, liposomes) may be used to control the biodistribution of the compounds. Other potentially useful parenteral delivery systems include ethylene-vinyl acetate copolymer particles, osmotic pumps, implantable infusion systems, and liposomes. The concentration of the compound in the formulation varies depending upon a number of factors, including the dosage of the drug to be administered, and the route of administration.
[0161] The polypeptide may be optionally administered as a pharmaceutically acceptable salt, such as non-toxic acid addition salts or metal complexes that are commonly used in the pharmaceutical industry. Examples of acid addition salts include organic acids such as acetic, lactic, pamoic, maleic, citric, malic, ascorbic, succinic, benzoic, palmitic, suberic, salicylic, tartaric, methanesulfonic, toluenesulfonic, or trifluoroacetic acids or the like; polymeric acids such as tannic acid, carboxymethyl cellulose, or the like; and inorganic acid such as hydrochloric acid, hydrobromic acid, sulfuric acid phosphoric acid, or the like. Metal complexes include zinc, iron, and the like. In one example, the polypeptide is formulated in the presence of sodium acetate to increase thermal stability.
[0162] Formulations for oral use include tablets containing the active ingredient(s) in a mixture with non-toxic pharmaceutically acceptable excipients. These excipients may be, for example, inert diluents or fillers (e.g., sucrose and sorbitol), lubricating agents, glidants, and anti-adhesives (e.g., magnesium stearate, zinc stearate, stearic acid, silicas, hydrogenated vegetable oils, or talc).
[0163] Formulations for oral use may also be provided as chewable tablets, or as hard gelatin capsules wherein the active ingredient is mixed with an inert solid diluent, or as soft gelatin capsules wherein the active ingredient is mixed with water or an oil medium.
[0164] A therapeutically effective dose refers to a dose that produces the therapeutic effects for which it is administered. The exact dose will depend on the disorder to be treated, and may be ascertained by one skilled in the art using known techniques. In general, the polypeptide is administered at about 0.01 .mu.g/kg to about 50 mg/kg per day, preferably 0.01 mg/kg to about 30 mg/kg per day, most preferably 0.1 mg/kg to about 20 mg/kg per day. The polypeptide may be given daily (e.g., once, twice, three times, or four times daily) or preferably less frequently (e.g., weekly, every two weeks, every three weeks, monthly, or quarterly). In addition, as is known in the art, adjustments for age as well as the body weight, general health, sex, diet, time of administration, drug interaction, and the severity of the disease may be necessary, and will be ascertainable with routine experimentation by those skilled in the art.
[0165] A PSMA binding polypeptide, as disclosed herein, can be administered alone or in combination with one or more additional therapies such as chemotherapy radiotherapy, immunotherapy, surgical intervention, or any combination of these. Long-term therapy is equally possible as is adjuvant therapy in the context of other treatment strategies, as described above.
[0166] In certain embodiments of such methods, one or more polypeptide therapeutic agents can be administered, together (simultaneously) or at different times (sequentially). In addition, polypeptide therapeutic agents can be administered with another type of compounds for treating cancer or for inhibiting angiogenesis.
[0167] In certain embodiments, the subject anti-PSMA antibodies agents of the invention can be used alone.
[0168] In certain embodiments, the binding polypeptides of fragments thereof can be labeled or unlabeled for diagnostic purposes. Typically, diagnostic assays entail detecting the formation of a complex resulting from the binding of a binding polypeptide to PSMA. The binding polypeptides or fragments can be directly labeled, similar to antibodies. A variety of labels can be employed, including, but not limited to, radionuclides, fluorescers, enzymes, enzyme substrates, enzyme cofactors, enzyme inhibitors and ligands (e.g., biotin, haptens). Numerous appropriate immunoassays are known to the skilled artisan (see, for example, U.S. Pat. Nos. 3,817,827; 3,850,752; 3,901,654; and 4,098,876). When unlabeled, the binding polypeptides can be used in assays, such as agglutination assays. Unlabeled binding polypeptides can also be used in combination with another (one or more) suitable reagent which can be used to detect the binding polypeptide, such as a labeled antibody reactive with the binding polypeptide or other suitable reagent (e.g., labeled protein A).
[0169] In one embodiment, the binding polypeptides of the present invention can be utilized in enzyme immunoassays, wherein the subject polypeptides are conjugated to an enzyme. When a biological sample comprising a PSMA protein is combined with the subject binding polypeptides, binding occurs between the binding polypeptides and the PSMA protein. In one embodiment, a sample containing cells expressing a PSMA protein (e.g., endothelial cells) is combined with the subject antibodies, and binding occurs between the binding polypeptides and cells bearing a PSMA protein recognized by the binding polypeptide. These bound cells can be separated from unbound reagents and the presence of the binding polypeptide-enzyme conjugate specifically bound to the cells can be determined, for example, by contacting the sample with a substrate of the enzyme which produces a color or other detectable change when acted on by the enzyme. In another embodiment, the subject binding polypeptides can be unlabeled, and a second, labeled polypeptide (e.g., an antibody) can be added which recognizes the subject binding polypeptide.
[0170] In certain aspects, kits for use in detecting the presence of a PSMA protein in a biological sample can also be prepared. Such kits will include a PSMA binding polypeptide which binds to a PSMA protein or portion of said receptor, as well as one or more ancillary reagents suitable for detecting the presence of a complex between the binding polypeptide and the receptor protein or portions thereof. The polypeptide compositions of the present invention can be provided in lyophilized form, either alone or in combination with additional antibodies specific for other epitopes. The binding polypeptides and/or antibodies, which can be labeled or unlabeled, can be included in the kits with adjunct ingredients (e.g., buffers, such as Tris, phosphate and carbonate, stabilizers, excipients, biocides and/or inert proteins, e.g., bovine serum albumin). For example, the binding polypeptides and/or antibodies can be provided as a lyophilized mixture with the adjunct ingredients, or the adjunct ingredients can be separately provided for combination by the user. Generally these adjunct materials will be present in less than about 5% weight based on the amount of active binding polypeptide or antibody, and usually will be present in a total amount of at least about 0.001% weight based on polypeptide or antibody concentration. Where a second antibody capable of binding to the binding polypeptide is employed, such antibody can be provided in the kit, for instance in a separate vial or container. The second antibody, if present, is typically labeled, and can be formulated in an analogous manner with the antibody formulations described above.
[0171] Polypeptide sequences are indicated using standard one- or three-letter abbreviations. Unless otherwise indicated, each polypeptide sequence has amino termini at the left and a carboxy termini at the right; each single-stranded nucleic acid sequence, and the top strand of each double-stranded nucleic acid sequence, has a 5' termini at the left and a 3' termini at the right. A particular polypeptide sequence also can be described by explaining how it differs from a reference sequence.
[0172] Having now described the present invention in detail, the same will be more clearly understood by reference to the following examples, which are included for purposes of illustration only and are not intended to be limiting of the invention.
Example 1
[0173] Human anti-PSMA antibodies were identified, and the amino acid sequences of the light chain and heavy chain variable regions are described in Table 3 below.
[0174] This example illustrates the binding of anti-PSMA antibodies to endogenous human PSMA expressed on LNCaP human prostate cancer cells, as assayed by flow cytometry. EC.sub.50 values for antibodies were determined as follows.
[0175] PSMA expressing LNCaP cells were harvested with enzyme-free Cell Dissociation Buffer (GIBCO) and transferred to V-Bottom 96 well-plates (50,000 cells/well). Cells were incubated on ice for 45 min with serial dilutions of anti-PSMA antibodies PSGB11, PSGB12, PSGC12, PSGD4, PSGD6 and PSA11 in FACS buffer (PBS+2% FBS)+NaN.sub.3. The control antibody (clg) was a negative control, and was an isotype matched, nonspecific (i.e., does not bind to PSMA and also did not bind the cells) antibody. After 1 wash in FACS buffer, a 1:1000 dilution of Phycoerythrin conjugated anti-Human IgG (y-chain specific) was added and incubated for 30 min Following a final wash, fluorescence intensity was measured on an Intellicyt High Throughput Flow Cytometer (HTFC).
[0176] Data were analyzed using Graphpad Prism software and non-linear regression fit. Data points are shown as the median fluorescence intensity (MFI) of positively labeled cells+/-Standard Error. EC.sub.50 values are reported as the concentration of antibody to achieve 50% of maximal PSMA antibodies binding to PSMA expressing cells.
[0177] In parallel, cell binding was also assessed with the same method on PC3, a prostate cancer cell line that does not express human PSMA endogenously, and thus served as a negative control.
[0178] The results from the binding assays for both cancer, PSMA-specific LNCaP cells and negative control PC3 cells are provided in FIG. 1 (A-D). As shown in FIGS. 1A and B, anti-PSMA antibodies PSGB11, PSGB12, PSGC12, PSGD4, PSGD6 and PSA11 strongly bound PSMA-expressing LNCaP cells relative to the negative IgG control (see FIG. 1A). Furthermore, as described in Figures (C) and (D), anti-PSMA antibodies PSGB11, PSGB12, PSGC12, PSGD4, PSGD6 and PSA11 showed little to no binding to cells not expressing human PSMA (PC3 cells), as the cells showed similar results to the negative control antibody (see FIG. 1(C)). Thus, the results in FIG. 1(A-D) show that the antibodies were specific to PSMA expressing cells, including PSMA expressing cancer cells.
[0179] In addition, the anti-PSMA antibodies identified herein displayed EC.sub.50 values in the nanomolar range for LNCaP PSMA expressing cells, as described below in Table 1. These data demonstrate strong and specific binding of the antibodies described in Table 3 to endogenous PSMA.
TABLE-US-00001 TABLE 1 Anti-PSMA Binding to LNCaP Antibodies cells (EC.sub.50, nM) PSA11 2.4 PSGF9 2.08 PSGC9 2.05 PSGD6 1.92 PSGD3 3.15 PSGE10 1.92 PSGH3 3.72 PSGD4 1.59 PSGB12 3.46 PSGB11 1.98 PSGE11 553.70 PSGC8 3.84 PSG6 6.95 PSGH8 2.13 PSGG6 1.3 PSGB11 1.83 PSGC12 2.84
Example 2
[0180] This example illustrates in vitro data showing the assessment of anti-PSMA antibodies in a cytotoxicity assay using secondary antibody-drug conjugate technique ("Secondary Antibody-Drug Conjugates as Tools for ADC Discovery". Helen Mao, Poster, IBC 24.sup.th Annual, 2013). This example demonstrates the potential of anti-PSMA antibodies to be used as antibody drug conjugates.
[0181] PSMA-expressing prostate cancer cells (LNCaP, ATCC CRL-1740.TM.) were harvested with enzyme-free Cell Dissociation Buffer (GIBCO), seeded into white 96-Well Clear Bottom plates (2,000 cells/well in 90 .mu.l) and allowed to adhere overnight at 37.degree. C. Anti-PSMA antibodies PSGF9, PSGC9, PSGD6, PSGD3, PSGE10, PSGH3, PSGB11, PSGD4, PSGB12 and PSA11 were used in the experiment. Antibodies were pre-complexed with Protein G(PG)-MMAF (Monomethyl auristatin F, Concortis Biosystems) in cell culture media, at a 1:4 molar ratio. The control antibody (cIg) was an isotype matched, nonspecific (i.e., does not bind to PSMA) antibody. PGMMAF alone was used as a negative control. After 10 min at room temperature, serial dilutions of the antibody-ProteinG-MMAF complex were prepared in cell culture media, incubated 10 more minutes at room temperature, and added to cells (10 .mu.l/well) in triplicate. In some experiments, plates were incubated at 37.degree. C. for 4 days ("No wash method"). In other experiments ("2-hours-wash method"), plates were incubated at 37.degree. C. for two hours, media was aspirated. Then cells were washed once with full media, and left in fresh full media before being incubated at 37.degree. C. for 4 days. For all experiments, cell proliferation was then analyzed as follows: 100 .mu.l of Cell Titer Glo buffer (Promega) was added to each well. Plates were incubated with shaking at room temperature for 20 min Luminescence signal was then measured on a Flexstation 3 plate reader (Molecular Device). Data were reported as relative Luminescent Units. Dose-response curves were generated in GraphPad prism, and IC.sub.50 values were calculated using non-linear regression fit (Log (inhibitor) vs. response--Variable slope equation).
[0182] The results are shown in FIG. 2(A-C) and below in Table 2. The results described in FIG. 2A-C show that anti-PSMA ADCs comprising antibodies PSGF9, PSGC9, PSGD6, (FIG. 2A); PSGD3, PSGE10, PSGH3, PSGB11, (FIG. 2B); PSGD4, PSGB12 and PSA11 (FIG. 2C), each conjugated to MMAF can induce cell killing in LNCaP cancer cells. In contrast, MMAF alone and the IgG control (see FIG. 2A) had little to no effect on cell death and had high rates of cell survival.
[0183] The same methods were used with PSMA-negative prostate cancer cells (PC-3, ATCC CRL-1435) to assess the non-specificity of cell killing of anti-PSMA antibodies (PSGF9, PSGC9, PSGD6, PSGD3, PSGE10, PSGH3, PSGB11, PSGD4, PSGB12 and PSA11)/Protein G-MMAF complexes. The results, shown in FIG. 2D, indicate that anti-PSMA antibodies do not induce cell killing when complexed with a cytotoxin such as MMAF in PSMA negative cancer cells. Thus, FIGS. 1 and 2 show that little to no non-specific cell killing is observed on cells not overexpressing PSMA, suggesting a good selectivity index for future PSMA antibody drug conjugate (ADC). Altogether, this illustrates the potential of PSMA antibodies as antibody-drug conjugates.
[0184] IC.sub.50 values for the anti-PSMA-MMAF ADCs were determined and are described below in Table 2. To verify that the cell killing observed for these types of secondary conjugates was due to the specifically internalized conjugates tested, unbound conjugates were washed out (2-hours-wash method in Table 2). As described in Table 2, the IC.sub.50 values were in the nanomolar range.
TABLE-US-00002 TABLE 2 Cell killing, No wash Cell killing, 2-hours-wash Antibodies method (IC.sub.50, nM) method (IC.sub.50, nM) PSA11 0.08 1.55 PSGB11 0.04 1.60 PSGB12 0.05 1.66 PSGC9 0.06 1.22 PSGD3 0.12 2.24 PSGD4 0.06 2.09 PSGD6 0.04 1.13 PSGE10 0.08 1.58 PSGF9 0.13 1.33 PSGH3 0.06 1.51
Example 3
[0185] In addition to the ability of the anti-PSMA antibodies described herein to bind to PSMA and also to induce cell death when conjugated to a toxin, the affinity values for antibodies PSA11 and PSGB11 were determined on Octet. As described in FIG. 3, anti-PSMA antibody PSA11 had an K.sub.D of about 6.7.times.10.sup.-10 M, and antibody PSA11 (described in FIG. 4) had a K.sub.D of about 6.8.times.10.sup.-10 M.
[0186] Specifically, an amine Reactive Second-Generation (AR2G) sensor was coated with antibody (15 ug/ml in acetic buffer, pH5.0) using Sulfo-N-hydroxysuccinimide/N-Ethyl-N'-(3-dimethylaminopropyl)carbodiimide hydrochloride (Sulfo-NHS/EDC) coupling methodology. The sensors were quenched with 1M pH 8.5 ethanolamine Data was collected by moving sensors to serially diluted recombinant human PSMA/His (in PBS buffer) wells, then the data was dissociated by transferring the sensors to PBS wells. A 1:1 binding model was used to fit the data. Results from the assay are provided in FIGS. 3 and 4.
TABLE-US-00003 TABLE 3 Amino Acid Heavy and Light Chain Variable Domains Heavy chain variable domain Light chain variable domain PSA11 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS VIWMTQSPSSVSASVGDRVTITCRASQGISS YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKAPKLLIYAASNLQSGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTISSLQPEDFATYYCQQANS YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS FPLTFGGGTKVDIK SEQ ID NO. 1 SEQ ID NO. 2 PSGB11 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS EIVLTQSPSTLSASVGDRVTITCRASQSISS YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKAPRLLIYAASILQRGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSETDFTLTISSLQPEDLATYYCQETYS YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS NLFTFGPGTKVDIK SEQ ID NO. 1 SEQ ID NO. 3 PSGB12 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS DVVMTQSPSTLSASVGDRVTITCRASQSISS YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKAPKLLIFAASSLQSGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFALTISSLQPEDFATYYCQESYS YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS IPWTFGQGTKVEIK SEQ ID NO. 1 SEQ ID NO. 4 PSGC8 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS AIRMTQSPSSVSASVGDRVTITCRASQGISS YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKAPKLLIYAASSLQSGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTISSLKPEDFATYYCQQANS YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS FPRALTFGGGTKVEIK SEQ ID NO. 1 SEQ ID NO. 5 PSGC9 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS AIRMTQSPSTLSASVGDRVTITCRASQNIYG YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKAPELLIYAASSLQSGYPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTINSLQPEDFATYYCQQSYT YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS IPFTFGPGTKVDIK SEQ ID NO. 1 SEQ ID NO. 6 PSGC12 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS DIVMTQSPSSVSASVGDRVTITCRASQDVGT YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGRAPKLLIYVASSLQSGYPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTISSLQPEDSATYYCQQAKG YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS IPYTFGQGTKLEIK SEQ ID NO. 1 SEQ ID NO. 7 PSGD3 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS DIVMTQSPSSVSASVGDRVTITCRASQDINN YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKAGKAPKLLIYVATKLQNGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLSISNLQPEDFATYYCQQAKS YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS FPYTFGQGTKLEIK SEQ ID NO. 1 SEQ ID NO. 8 PSGD4 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS DIVMTQSPSSLSASVGDRVSITCRASQGIST YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKAPDLLIYAASNLQSGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTISSLQPEDFATYYCQQANS YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS FPLTFGGGTKVEIK SEQ ID NO. 1 SEQ ID NO. 9 PSGD6 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS DIVMTQSPSSVSASVGDRVTITCRASQAISS YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKAPKLLIYAASSLQSGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTISSLQPEDFATYYCQQAYS YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS FPVTFGPGTKVDIK SEQ ID NO. 1 SEQ ID NO. 10 PSGE10 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS DVVMTQSPSSVSASVGDRVTITCRASQGISS YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKAPKLLIYAASTLQSGYPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTINNLQPEDFATYYCQQTAS YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS FPINFGGGTKVEIK SEQ ID NO. 1 SEQ ID NO. 11 PSGE11 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS DIVMTQSPSTLSASVGDRVTITCRASQSISN YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKPPKLLIYAASSLQSGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTISSLQPEDFATYYCQQSYR YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS SLTFAGGTKVEIK SEQ ID NO. 1 SEQ ID NO. 12 PSGF9 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS AIQMTQSPSSVSASVGDRVTITCRASQGISS YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKAPKLLIYAASSLQSGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTISSLQPEDIATYYCQESYS YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS TPFTFGPGTKVDIK SEQ ID NO. 1 SEQ ID NO. 13 PSGF11 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS DIQMTQSPSYVSASVGDRVTITCRASQGVSH YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKAPKLLIYAASRLQSGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTISSLQPEDFATYYCQQAYS YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS FPLTFGQGTKLEIK SEQ ID NO. 1 SEQ ID NO. 14 PSGG6 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS EIVLTQSPSSLSASVGDRVTITCRASQGISS YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD YLAWYQQKPGKAPKLLIYAASTLQSGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTISSLQPEDFATYYCQQLNS YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS YPRGITFGQGTKLEIK SEQ ID NO. 1 SEQ ID NO. 15 PSGH3 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS DIVMTQSPSSVSASVGDRVTITCRASQGISN YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKAPKLLIYVASSLQSGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTISSLQPEDFATYYCQQANS YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS FPITFGQGTRLEIK SEQ ID NO. 1 SEQ ID NO. 16 PSGH8 QVQLVQSGGGLVQPGGSLRLSCAASGFTFSS DIVMTQSPSSLSASVGDRVTITCRASQGISS YWMSWVRQAPGKGLEWVANIKQDGSEKYYVD WLAWYQQKPGKAPKLLIYAASSLQSGVPSRF SVKGRFTISRDNAKNSLYLQMNSLRAEDTAV SGSGSGTDFTLTINSLQPEDFATYYCQQASG YYCARVWDYYYDSSGDAFDIWGQGTMVTVSS FPFTFGPGTKVDIK SEQ ID NO. 1 SEQ ID NO. 17
INCORPORATION BY REFERENCE
[0187] The contents of all references, patents, pending patent applications and published patents, cited throughout this application are hereby expressly incorporated by reference.
Sequence CWU 1
1
191124PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 1Gln Val Gln Leu Val Gln Ser Gly Gly Gly Leu
Val Gln Pro Gly Gly 1 5 10 15 Ser Leu Arg Leu Ser Cys Ala Ala Ser
Gly Phe Thr Phe Ser Ser Tyr 20 25 30 Trp Met Ser Trp Val Arg Gln
Ala Pro Gly Lys Gly Leu Glu Trp Val 35 40 45 Ala Asn Ile Lys Gln
Asp Gly Ser Glu Lys Tyr Tyr Val Asp Ser Val 50 55 60 Lys Gly Arg
Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr 65 70 75 80 Leu
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys 85 90
95 Ala Arg Val Trp Asp Tyr Tyr Tyr Asp Ser Ser Gly Asp Ala Phe Asp
100 105 110 Ile Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser 115 120
2107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 2Val Ile Trp Met Thr Gln Ser Pro Ser Ser Val
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Gly Ile Ser Ser Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45 Tyr Ala Ala Ser Asn
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro Leu 85 90
95 Thr Phe Gly Gly Gly Thr Lys Val Asp Ile Lys 100 105
3107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 3Glu Ile Val Leu Thr Gln Ser Pro Ser Thr Leu
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Ser Ile Ser Ser Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Arg Leu Leu Ile 35 40 45 Tyr Ala Ala Ser Ile
Leu Gln Arg Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Glu Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro 65 70 75 80 Glu
Asp Leu Ala Thr Tyr Tyr Cys Gln Glu Thr Tyr Ser Asn Leu Phe 85 90
95 Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys 100 105
4107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 4Asp Val Val Met Thr Gln Ser Pro Ser Thr Leu
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Ser Ile Ser Ser Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45 Phe Ala Ala Ser Ser
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Ala Leu Thr Ile Ser Ser Leu Gln Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Glu Ser Tyr Ser Ile Pro Trp 85 90
95 Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys 100 105
5109PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 5Ala Ile Arg Met Thr Gln Ser Pro Ser Ser Val
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Gly Ile Ser Ser Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45 Tyr Ala Ala Ser Ser
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Lys Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro Arg 85 90
95 Ala Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys 100 105
6107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 6Ala Ile Arg Met Thr Gln Ser Pro Ser Thr Leu
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Asn Ile Tyr Gly Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Glu Leu Leu Ile 35 40 45 Tyr Ala Ala Ser Ser
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Asn Ser Leu Gln Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Thr Ile Pro Phe 85 90
95 Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys 100 105
7107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 7Asp Ile Val Met Thr Gln Ser Pro Ser Ser Val
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Asp Val Gly Thr Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Arg Ala Pro Lys Leu Leu Ile 35 40 45 Tyr Val Ala Ser Ser
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro 65 70 75 80 Glu
Asp Ser Ala Thr Tyr Tyr Cys Gln Gln Ala Lys Gly Ile Pro Tyr 85 90
95 Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys 100 105
8107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 8Asp Ile Val Met Thr Gln Ser Pro Ser Ser Val
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Asp Ile Asn Asn Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Ala Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45 Tyr Val Ala Thr Lys
Leu Gln Asn Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Ser Ile Ser Asn Leu Gln Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Lys Ser Phe Pro Tyr 85 90
95 Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys 100 105
9107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 9Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Ser Ile Thr Cys Arg Ala
Ser Gln Gly Ile Ser Thr Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Asp Leu Leu Ile 35 40 45 Tyr Ala Ala Ser Asn
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro Leu 85 90
95 Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys 100 105
10107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 10Asp Ile Val Met Thr Gln Ser Pro Ser Ser Val
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Ala Ile Ser Ser Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45 Tyr Ala Ala Ser Ser
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Tyr Ser Phe Pro Val 85 90
95 Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys 100 105
11107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 11Asp Val Val Met Thr Gln Ser Pro Ser Ser Val
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Gly Ile Ser Ser Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45 Tyr Ala Ala Ser Thr
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Asn Asn Leu Gln Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Thr Ala Ser Phe Pro Ile 85 90
95 Asn Phe Gly Gly Gly Thr Lys Val Glu Ile Lys 100 105
12106PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 12Asp Ile Val Met Thr Gln Ser Pro Ser Thr Leu
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Ser Ile Ser Asn Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Pro Pro Lys Leu Leu Ile 35 40 45 Tyr Ala Ala Ser Ser
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ser Tyr Arg Ser Leu Thr 85 90
95 Phe Ala Gly Gly Thr Lys Val Glu Ile Lys 100 105
13107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 13Ala Ile Gln Met Thr Gln Ser Pro Ser Ser Val
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Gly Ile Ser Ser Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45 Tyr Ala Ala Ser Ser
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro 65 70 75 80 Glu
Asp Ile Ala Thr Tyr Tyr Cys Gln Glu Ser Tyr Ser Thr Pro Phe 85 90
95 Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys 100 105
14107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 14Asp Ile Gln Met Thr Gln Ser Pro Ser Tyr Val
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Gly Val Ser His Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45 Tyr Ala Ala Ser Arg
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Tyr Ser Phe Pro Leu 85 90
95 Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys 100 105
15109PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 15Glu Ile Val Leu Thr Gln Ser Pro Ser Ser Leu
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Gly Ile Ser Ser Tyr 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45 Tyr Ala Ala Ser Thr
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Leu Asn Ser Tyr Pro Arg 85 90
95 Gly Ile Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys 100 105
16107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 16Asp Ile Val Met Thr Gln Ser Pro Ser Ser Val
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Gly Ile Ser Asn Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45 Tyr Val Ala Ser Ser
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro Ile 85 90
95 Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys 100 105
17107PRTArtificial SequenceDescription of Artificial Sequence
Synthetic polypeptide 17Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu
Ser Ala Ser Val Gly 1 5 10 15 Asp Arg Val Thr Ile Thr Cys Arg Ala
Ser Gln Gly Ile Ser Ser Trp 20 25 30 Leu Ala Trp Tyr Gln Gln Lys
Pro Gly Lys Ala Pro Lys Leu Leu Ile 35 40 45 Tyr Ala Ala Ser Ser
Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly 50 55 60 Ser Gly Ser
Gly Thr Asp Phe Thr Leu Thr Ile Asn Ser Leu Gln Pro 65 70 75 80 Glu
Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Ser Gly Phe Pro Phe 85 90
95 Thr Phe Gly Pro Gly Thr Lys Val Asp Ile Lys 100 105
184PRTUnknownDescription of Unknown Hinge region sequence 18Cys Pro
Ser Cys 1 194PRTUnknownDescription of Unknown Hinge region sequence
19Cys Pro Pro Cys 1
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
S00001
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.