Systems and methods for unsupervised streaming feature selection in social media
Li , et al. March 9, 2
U.S. patent number 10,942,939 [Application Number 15/412,955] was granted by the patent office on 2021-03-09 for systems and methods for unsupervised streaming feature selection in social media. This patent grant is currently assigned to Arizona Board of Regents on Behalf of Arizona State University. The grantee listed for this patent is ARIZONA BOARD OF REGENTS ON BEHALF OF ARIZONA STATE UNIVERSITY. Invention is credited to Xia Hu, Jundong Li, Huan Liu, Jiliang Tang.



View All Diagrams
| United States Patent | 10,942,939 |
| Li , et al. | March 9, 2021 |
Systems and methods for unsupervised streaming feature selection in social media
Abstract
Systems and methods for exploiting link information in streaming feature selection, resulting in a novel unsupervised streaming feature selection framework are disclosed.
| Inventors: | Li; Jundong (Tempe, AZ), Hu; Xia (Tempe, AZ), Tang; Jiliang (Tempe, AZ), Liu; Huan (Tempe, AZ) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Applicant: |
|
||||||||||
| Assignee: | Arizona Board of Regents on Behalf
of Arizona State University (Tempe, AZ) |
||||||||||
| Family ID: | 1000005410700 | ||||||||||
| Appl. No.: | 15/412,955 | ||||||||||
| Filed: | January 23, 2017 |
Prior Publication Data
| Document Identifier | Publication Date | |
|---|---|---|
| US 20170212943 A1 | Jul 27, 2017 | |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | Issue Date | ||
|---|---|---|---|---|---|
| 62286242 | Jan 22, 2016 | ||||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06F 16/9024 (20190101); G06F 16/9535 (20190101); G06F 16/24578 (20190101); G06F 16/248 (20190101); G06F 16/22 (20190101); G06F 16/24568 (20190101) |
| Current International Class: | G06F 17/00 (20190101); G06F 16/2455 (20190101); G06F 7/00 (20060101); G06F 16/248 (20190101); G06F 16/22 (20190101); G06F 16/901 (20190101); G06F 16/9535 (20190101); G06F 16/2457 (20190101) |
| Field of Search: | ;707/728 |
References Cited [Referenced By]
U.S. Patent Documents
| 6546398 | April 2003 | Simon |
| 6640227 | October 2003 | Andreev |
| 6826539 | November 2004 | Loveland |
| 7480640 | January 2009 | Elad |
| 7920485 | April 2011 | Tung |
| 9082043 | July 2015 | Liu |
| 10319209 | June 2019 | Carlton-Foss |
| 2005/0114313 | May 2005 | Campbell |
| 2012/0311496 | December 2012 | Cao et al. |
| 2013/0073489 | March 2013 | Qin et al. |
| 2014/0072209 | March 2014 | Brumby et al. |
| 2014/0321758 | October 2014 | Liu |
| 2015/0324663 | November 2015 | Liu et al. |
Other References
|
Tang et al., Unsupervised feature selection for linked social media data, Aug. 2012, KDD '12: Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 904-912 https://doi.org/10.1145/2339530.2339673 (Year: 2012). cited by examiner . Airoldi et al, Mixed membership stochastic blockmodel, 2009,. In NIPS, pp. 33-40. (Year: 2009). cited by examiner . Lior Wolf and Amnon Shashua. Feature selection for unsupervised and supervised inference: The emergence of sparsity in a weight-based approach. The Journal of Machine Learning Research, 6:1855-1887, 2005. cited by applicant . Zheng Zhao, Lei Wang, and Huan Liu. Efficient spectral feature selection with minimum redundancy. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2010, Atlanta, Georgia, USA, Jul. 11-15, 2010, 2010. cited by applicant . Chen, X., & Candan, K. S. (2014). GI-NMF: Group incremental non-negative matrix factorization on data streams. Paper presented at the 1119-1128. doi:10.1145/2661829.2662008. cited by applicant . Unsupervised Streaming Feature Selection in Social Media Jundong Li, Xia Hu, Jiliang Tang, Huan Liu in Proceedings of 24th ACM International Conference on Information and Knowledge Management (CIKM), Melbourne, Australia, Oct. 19-23, 2015. cited by applicant . C. C. Aggarwal, J. Han, J. Wang, and P. S. Yu. A framework for projected clustering of high dimensional data streams. In VLDB, pp. 852{863. VLDB Endowment, 2004. cited by applicant . E. M. Airoldi, D. M. Blei, S. E. Fienberg, and E. P. Xing. Mixed membership stochastic blockmodels. In NIPS, pp. 33{40, 2009. cited by applicant . D. Cai, C. Zhang, and X. He. Unsupervised feature selection for multi-cluster data. In KDD, pp. 333{342. ACM, 2010. cited by applicant . X. Chen and K. S. Candan. Lwi-svd: low-rank, windowed, incremental singular value decompositions on time-evolving data sets. In KDD, pp. 987{996. ACM, 2014. cited by applicant . J. Dem_sar. Statistical comparisons of classi_ers over multiple data sets. The Journal of Machine Learning Research, 7:1{30, 2006. cited by applicant . C. Ding and H. Peng. Minimum redundancy feature selection from microarray gene expression data.Journal of bioinformatics and computational biology, 3(02):185{205, 2005. cited by applicant . J. G. Dy and C. E. Brodley. Feature subset selection and order identi_cation for unsupervised learning. In ICML, pp. 247{254, 2000. cited by applicant . L. Gong, J. Zeng, and S. Zhang. Text stream clustering algorithm based on adaptive feature selection. Expert Systems with Applications, 38(3):1393{1399, 2011. cited by applicant . P. K. Gopalan, S. Gerrish, M. Freedman, D. M. Blei, and D. M. Mimno. Scalable inference of overlapping communities. In NIPS, pp. 2249{2257, 2012 cited by applicant . Q. Gu, Z. Li, and J. Han. Generalized_sher score for feature selection. In UAI, pp. 266{273, 2012. cited by applicant . T. Guo, X. Zhu, J. Pei, and C. Zhang. Snoc: streaming network node classi_cation. In ICDM, pp. 150{159. IEEE, 2014. cited by applicant . I. Guyon, J. Weston, S. Barnhill, and V. Vapnik. Gene selection for cancer classi_cation using support vector machines. Machine learning, 46(1-3):389{422, 2002. cited by applicant . X. He, D. Cai, and P. Niyogi. Laplacian score for feature selection. In NIPS, pp. 507{514, 2005. cited by applicant . G. H. John, R. Kohavi, K. Peger, et al. Irrelevant features and the subset selection problem. In ICML, 1994. cited by applicant . Z. Li, Y. Yang, J. Liu, X. Zhou, and H. Lu. Unsupervised feature selection using nonnegative spectral analysis. In AAAI, pp. 1026{1032, 2012. cited by applicant . H. Liu, E.-P. Lim, H. W. Lauw, M.-T. Le, A. Sun, J. Srivastava, and Y. Kim. Predicting trusts among users of online communities: an epinions case study. In EC, pp. 310{319. ACM, 2008. cited by applicant . M. McPherson, L. Smith-Lovin, and J. M. Cook. Birds of a feather: Homophily in social networks. Annual Review of Sociology, pp. 415{444, 2001. cited by applicant . M. E. Newman and M. Girvan. Finding and evaluating community structure in networks. Physical review E, 69(2):026113, 2004. cited by applicant . F. Nie, H. Huang, X. Cai, and C. H. Ding. E_cient and robust feature selection via joint I2, 1-norms minimization. In NIPS, pp. 1813{1821, 2010. cited by applicant . F. Nie, S. Xiang, Y. Jia, C. Zhang, and S. Yan. Trace ratio criterion for feature selection. In AAAI, pp. 671{676, 2008. cited by applicant . H. Peng, F. Long, and C. Ding. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(8):1226{1238, 2005. cited by applicant . S. Perkins, K. Lacker, and J. Theiler. Grafting: Fast, incremental feature selection by gradient descent in function space. The Journal of Machine Learning Research, 3:1333{1356, 2003. cited by applicant . S. Perkins and J. Theiler. Online feature selection using grafting. In ICML, pp. 592{599, 2003. cited by applicant . M. Robnik-_Sikonja and I. Kononenko. Theoretical and empirical analysis of relie_ and rrelie_. Machine Learning, 53(1-2):23{69, 2003. cited by applicant . J. Tang and H. Liu. Unsupervised feature selection for linked social media data. In KDD, pp. 904{912. ACM, 2012. cited by applicant . L. Tang and H. Liu. Relational learning via latent social dimensions. In KDD, pp. 817{826. ACM, 2009. cited by applicant . R. Tibshirani. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B, pp. 267{288, 1996. cited by applicant . J. Wang, Z.-Q. Zhao, X. Hu, Y.-M. Cheung, M. Wang, and X. Wu. Online group feature selection. In IJCAI, pp. 1757{1763. AAAI Press, 2013. cited by applicant . X. Wu, K. Yu, H. Wang, and W. Ding. Online streaming feature selection. In ICML, pp. 1159{1166, 2010. cited by applicant . W. Yang, H. Xu, and A. Theorem. Streaming sparse principal component analysis. In ICML, pp. 494{503, 2015. cited by applicant . Y. Yang, H. T. Shen, Z. Ma, Z. Huang, and X. Zhou. I2, 1-norm regularized discriminative feature selection for unsupervised learning. In IJCAI, pp. 1589{1594, 2011. cited by applicant . Z. Zhao and H. Liu. Spectral feature selection for supervised and unsupervised learning. In ICML, pp. 1151{1157. ACM, 2007. cited by applicant . J. Zhou, D. Foster, R. Stine, and L. Ungar. Streaming feature selection using alpha-investing. In KDD, pp. 384{393. ACM, 2005. cited by applicant . H. Zou and T. Hastie. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B, 67(2):301{320, 2005. cited by applicant . Wang, D., Nie, F., & Huang, H. (Sep. 2014). Unsupervised feature selection via unified trace ratio formulation and k-means clustering (TRACK). In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (pp. 306-321). Springer Berlin Heidelberg. cited by applicant . Du, L., & Shen, Y. D. (Aug. 2015). Unsupervised feature selection with adaptive structure learning. cited by applicant . Jiliang Tang and Huan Liu. "Feature Selection for Social Media Data", ACM Transactions on Knowledge Discovery from Data (TKDD),8(4) pp. 19:1-19:27, 2014. cited by applicant . Jiliang Tang, Xia Hu, Huiji Gao, and Huan Liu. "Discriminant Analysis for Unsupervised Feature Selection", the 14th SIAM International Conference on Data Mining (SDM), 2014. cited by applicant . Wang, S., Tang, J., & Liu, H. (Jan. 2015). Embedded Unsupervised Feature Selection. In AAAI (pp. 470-476). cited by applicant . Christos Boutsidis, Petros Drineas, and Michael W Mahoney. Unsupervised feature selection for the k-means clustering problem. In Advances in Neural Information Processing Systems, pp. 153-161, 2009. cited by applicant . Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and TrendsR in Machine Learning, 3(1):1-122, 2011. cited by applicant . Tom Goldstein, Brendan ODonoghue, and Simon Setzer. Fast alternating direction optimization methods. CAM report, pp. 12-35, 2012. cited by applicant . Quanquan Gu and Jiawei Han. Towards feature selection in network. In Proceedings of the 20th ACM international conference on Information and knowledge management, pp. 1175-1184. ACM, 2011. cited by applicant . Isabelle Guyon and Andr'e Elisseeff. An introduction to variable and feature selection. The Journal of Machine Learning Research, 3:1157-1182, 2003. cited by applicant . Jin Huang, Feiping Nie, Heng Huang, and Chris Ding. Robust manifold nonnegative matrix factorization. ACM Transactions on Knowledge Discovery from Data (TKDD), 8(3):11, 2014. cited by applicant . Jun Liu, Shuiwang Ji, and Jieping Ye. Multi-task feature learning via efficient I 2, 1-norm minimization. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, pp. 339-348. AUAI Press, 2009. cited by applicant . Mingjie Qian and Chengxiang Zhai. Robust unsupervised feature selection. In Proceedings of the Twenty-Third joint international conference on Artificial Intelligence, pp. 1621-1627. AAAI Press, 2013. cited by applicant . Peter H Schonemann. A generalized solution of the orthogonal procrustes problem. Psychometrika, 31(1):1-10, 1966. cited by applicant . Dinesh Singh, Phillip G Febbo, Kenneth Ross, Donald G Jackson, Judith Manola, Christine Ladd, Pablo Tamayo, Andrew A Renshaw, Anthony V D'Amico, Jerome P Richie, et al. Gene expression correlates of clinical prostate cancer behavior. Cancer cell, 1(2):203-209,2002. cited by applicant . Alelyani et al., Feature selection for clustering: A review. In Data Clustering: Algorithms and Applications, pp. 29-60. CRC Press, 2013. cited by applicant . Boyd et al., Convex optimization. Cambridge university press, 2004. cited by applicant . Duda et al., Pattern classification. 2nd. Edition. New York, 2001. cited by applicant . Fodor, DNA sequencing: Massively parallel genomics. 277(5324):393-395, 1997. cited by applicant . Jain et al., Feature selection: Evaluation, application, and small sample performance, 1997. cited by applicant . Liu et al., Computational methods of feature selection. CRC Press, 2007. cited by applicant . Nene et al., Columbia object image library (coil-20). Technical report, Technical Report CUCS-005-96, 1996. cited by applicant . Tang et al., Feature selection for classification: A review. In Data Classification: Algorithms and Applications. 2014. cited by applicant . Tang et al., Feature selection with linked data in social media. In Proceedings of the Twelfth SIAM International Conference on Data Mining, Anaheim, California, USA, Apr. 26-28, 2012., pp. 118-128, 2012. cited by applicant . Von Luxburg, A tutorial on spectral clustering. Statistics and computing, 17(4):395-416, 2007. cited by applicant. |
Primary Examiner: Mamillapalli; Pavan
Attorney, Agent or Firm: Polsinelli PC
Government Interests
GOVERNMENT SUPPORT
The presently disclosed technology was made with government support under contract no. 1217466 awarded by the National Science Foundation. The government has certain rights in the presently disclosed technology.
Parent Case Text
CROSS REFERENCE TO RELATED APPLICATIONS
This is a non-provisional application that claims benefit to U.S. provisional application Ser. No. 62/286,242 filed on Jan. 22, 2016, which is herein incorporated by reference in its entirety.
Claims
What is claimed is:
1. A method for managing high-dimensional data in streaming social media, the method comprising: generating, by a processor, a model for unsupervised streaming feature selection from high-dimensional data defining a set of linked data instances, by: modeling link information associated with the set of linked data instances via extracting social latent factors, by, for each of the set of linked data instances, assigning a k-dimensional social latent vector at a time step t of a plurality of time steps, and modeling feature information of the high-dimensional data by generating a data matrix for the high-dimensional data, the data matrix representing similarities in features between different ones of the set of data instances, wherein the feature information is modeled to be consistent with the social latent factors, each of the set of features dynamically generated and arriving at the time step t from a social media stream; and selecting, by the processor and utilizing both of the feature information and the link information of the model, a subset of features at each of the plurality of time steps to facilitate clustering including, including utilizing the social latent factors as a constraint to perform feature selection through a regression model as the social latent factors are extracted for each of the set of linked data instances.
2. The method of claim 1, wherein the social latent factors are extracted based on a mixed membership stochastic blockmodel.
3. The method of claim 1, wherein each of the plurality of data instances is associated with a latent factor vector, the latent factor vectors of the plurality of data instances interacting with each other to form one or more social relationships.
4. The method of claim 3, wherein the social latent factors are extracted from the one or more social relationships using a scalable interference algorithm.
5. The method of claim 1, wherein the social latent factors are extracted using a scalable interference algorithm.
6. The method of claim 1, wherein the link information is a directed graph or an undirected graph.
7. The method of claim 1, wherein a subset of the most relevant features is identified at the time step given each social latent factor for the plurality of data instances.
8. The method of claim 1, wherein selecting one or more relevant features in the social media stream from the one or more features through a regression model includes modeling feature information based on feature similarity between the plurality of data instances.
9. The method of claim 1, further comprising: identifying a new feature.
10. The method of claim 9, wherein identifying the new feature includes determining whether to select the new feature from the one or more relevant features.
11. The method of claim 1, further comprising: determining whether to discard one or more existing features.
Description
FIELD
The present disclosure generally relates to feature selection and in particular to systems and methods for unsupervised feature selection in social media.
BACKGROUND
The rapid growth and popularity of social media services such as Twitter and Facebook provide a platform for people to perform online social activities by sharing information and communicating with others. Massive amounts of high-dimensional data (blogs, posts, images, etc.) are user generated and quickly disseminated. It is desirable and of great importance to reduce the dimensionality of social media data for many learning tasks due to the curse of dimensionality. One way to resolve this problem is feature selection, which aims to select a subset of relevant features for a compact and accurate representation.
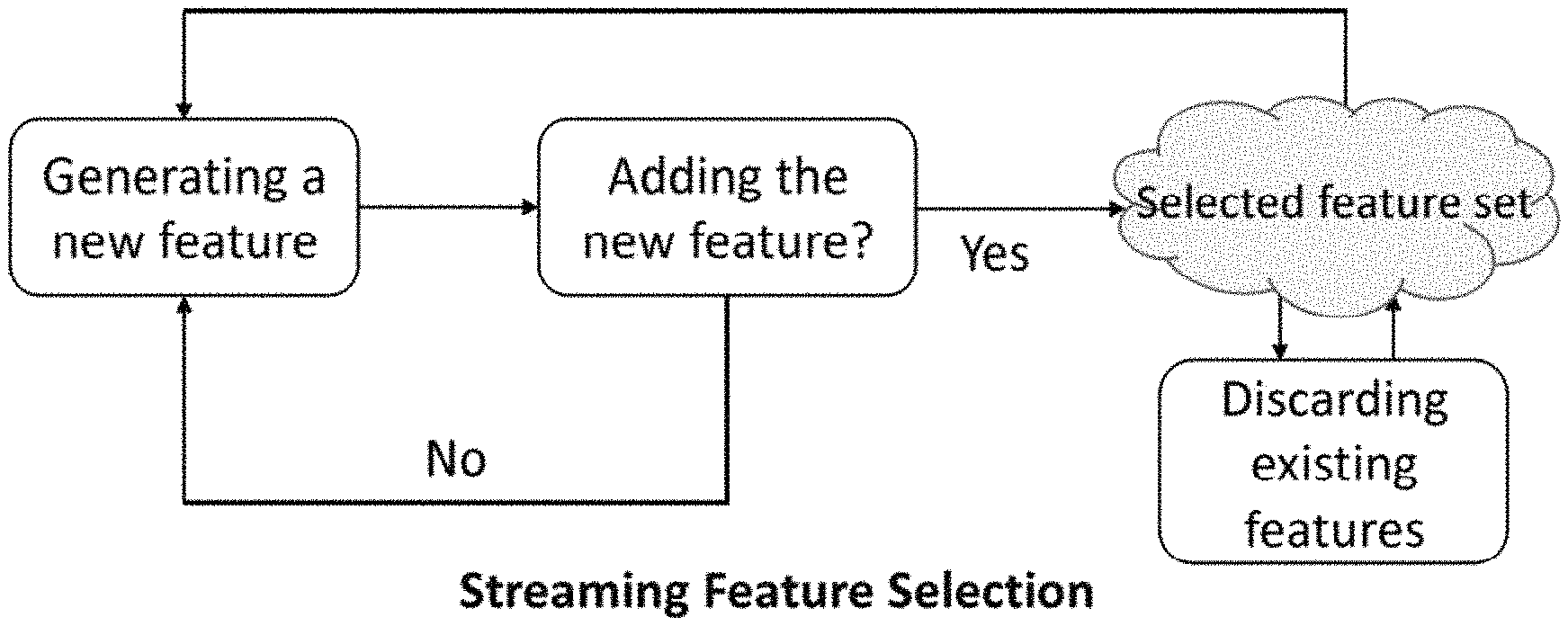
Traditional feature selection assumes that all features are static and known in advance. However, this assumption is invalid in many real-world applications especially in social media which is imbued with high-velocity streaming features. In social media, features are generated dynamically, new features are sequentially added and the size of features is unknown in most cases. For example, Twitter produces more than 320 million tweets every day and a large amount of slang words (features) are continuously being user generated. These slang words promptly grab users' attention and become popular in a short time. It is not practical to wait until all features are available before performing feature selection. Another example is that after earthquakes, topics (features) like "Nepal" emerge as hot topics in social media shortly afterwards, thus traditional batch-mode feature selection can hardly capture and select such features in a timely manner. Therefore, it could be more appealing to perform streaming feature selection (SFS) to rapidly adapt to the changes.
In SFS, the number of instances is considered to be constant while candidate features arrive one at a time. The task is to timely select a subset of relevant features from all features seen so far. Instead of searching for the whole feature space which is costly, SFS processes a new feature upon its arrival. A general framework of streaming feature selection is presented in FIG. 1. At each time step, a typical SFS algorithm first determines whether to accept the most recently arrived feature. If the feature is added to the selected feature set, it then determines whether to discard some existing features from the selected feature set. The process repeats until no new features show up anymore. The vast majority of existing streaming feature selection algorithms is supervised which utilize label information to guide feature selection process. However, in social media, it is easy to a mass vast quantities of unlabeled data, while it is time and labor consuming to obtain labels. To deal with large-scale unlabeled data in social media, unsupervised streaming feature selection is desirable. However, unsupervised streaming feature selection is particularly difficult and challenging because: (1) without any label information, it is difficult to assess the importance of features; and (2) features are usually not predefined, but are generated dynamically, hence it cannot be carried out by directly applying traditional unsupervised feature selection algorithms.
On the other hand, link information is abundant in social media. As observed by homophily from social sciences, linked instances are likely to share similar features (or attributes). Therefore, as label information for supervised streaming feature selection, link information could provide helpful constraints to enable unsupervised streaming feature selection. However, linked social media data is inherently not independent and identically distributed (i.i.d.), while existing streaming feature selection are based on the data i.i.d assumption, it is challenging to exploit link information for streaming feature selection. It is with these observations in mind, among others, that various aspects of the present disclosure were conceived and developed.
BRIEF DESCRIPTION OF THE DRAWINGS
FIG. 1 is a simplified illustration showing a framework for a streaming feature selection consisting to two phases;
FIG. 2 is a simplified illustration showing a framework of unsupervised streaming feature selection in social media;
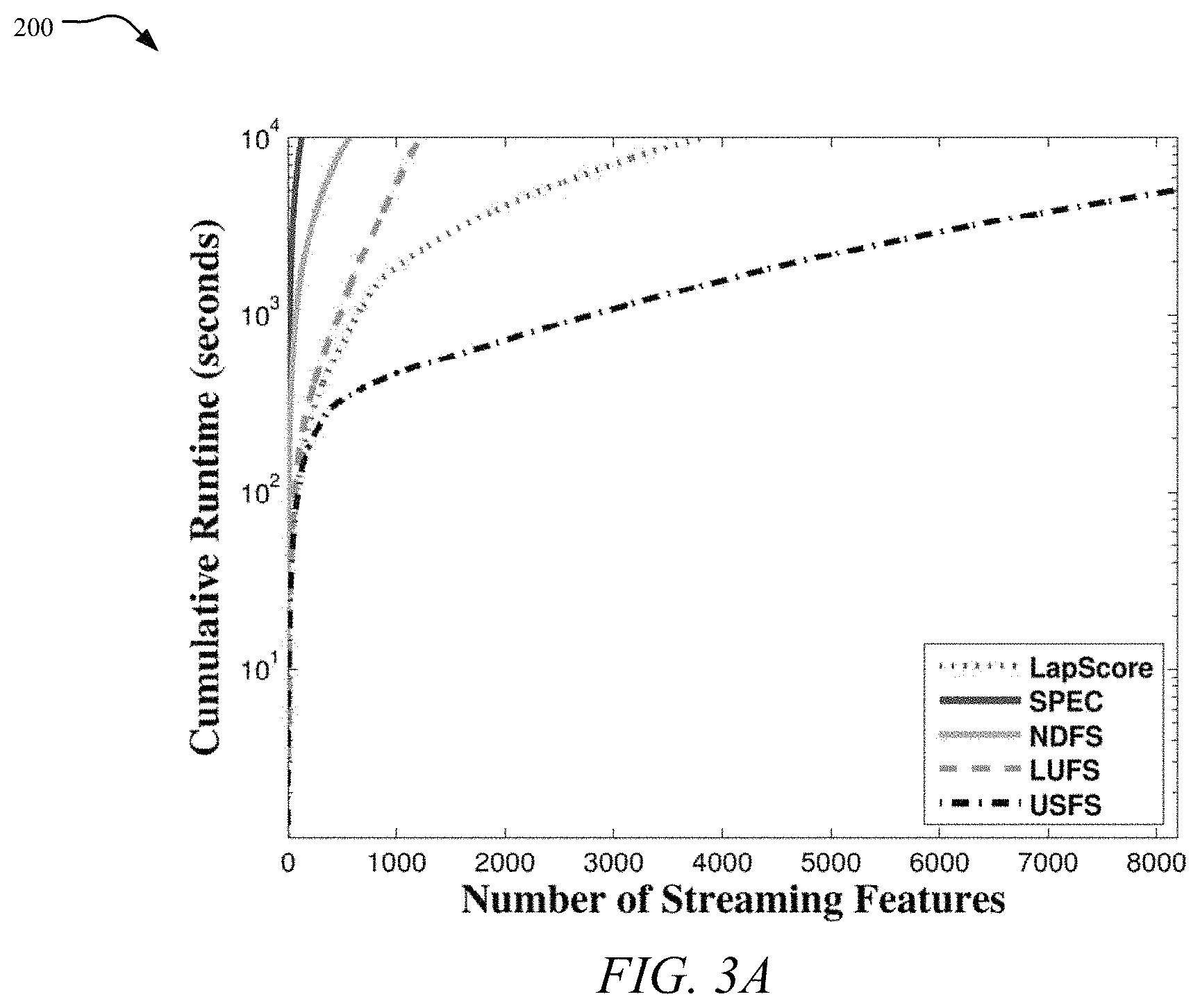
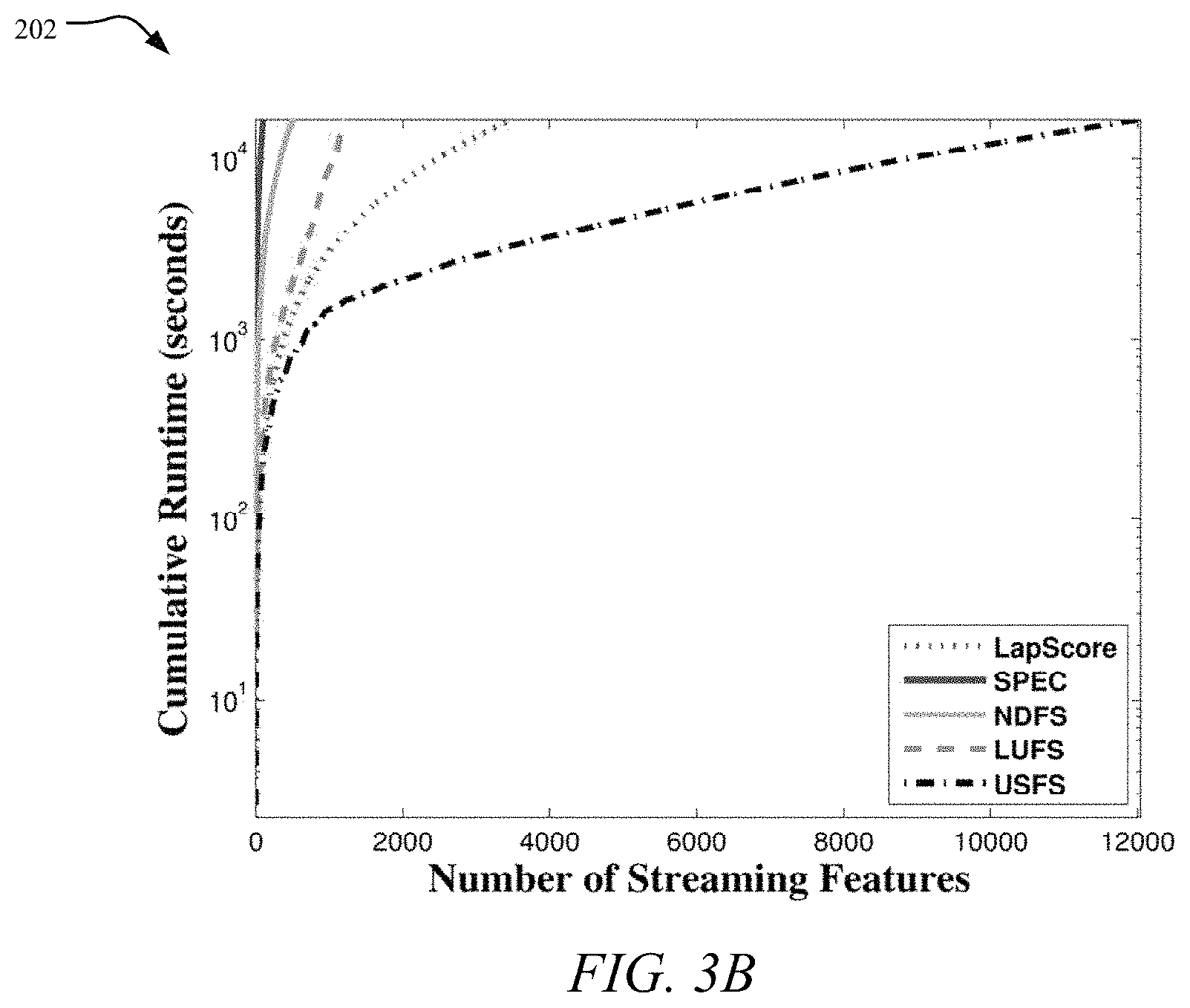
FIG. 3A is a graph showing the cumulative runtime on BlogCatalog dataset, while FIG. 3B is a graph showing a cumulative runtime on Flickr dataset;
FIGS. 4A and 4B are graphs showing the effect of # social latent factors;
FIGS. 5A and 5B are graphs showing the effect of .alpha.;
FIGS. 6A and 6B are graphs showing the effect of .beta.;
FIGS. 7A and 7B are graphs showing the effect of .gamma.;
FIG. 8 depicts an example network environment that may implement various systems and methods of the presently disclosed technology; and
FIG. 9 shows an example computing system that may implement various systems and methods of the presently disclosed technology.
Corresponding reference characters indicate corresponding elements among the view of the drawings. The headings used in the figures do not limit the scope of the claims.
DETAILED DESCRIPTION
Aspects of the present disclosure involve systems and methods for unsupervised feature selection in social media using an unsupervised streaming feature selection framework ("USFS framework 100"). In one aspect, the systems and methods described herein link exploit link information for feature selection and perform streaming feature selection in unsupervised scenarios. The presently disclosed technology utilizes link information to enable unsupervised streaming feature selection in social media. Further, an unsupervised streaming feature selection framework, which exploits link and feature information simultaneously to select features dynamically and efficiently. An empirical demonstration of the efficacy and efficiency of the USFS framework 100 on real-world social media datasets is provided herein.
To begin a detailed description of an example USFS framework 100, reference is made to FIG. 2. In one implementation, the framework 100 generates a data matrix for high-dimensional data. The data matrix has a plurality of data instances and link information denoted between the plurality of data instances, and each of the data instances are associated with a set of one or more features that are dynamically generated and arrive at a time step from a social media stream. The framework 100 extracts social latent factors for each of the plurality of data instances from the link information and selecting one or more relevant features in the social media stream from the one or more features through a regression model using the social latent factors as a constraint during unsupervised streaming feature selection.
In this disclosure, bold uppercase characters denote matrices, bold lowercase characters denote vectors, normal lowercase characters denote scalars. For an arbitrary matrix A R.sup.n.times.d, a.sub.i and a.sup.j mean the i-th row and j-th column of matrix A, respectively. A.sub.ij or a.sup.j.sub.i denotes the (i, j)-th of matrix A. A.sup.(t) denotes the matrix of A at time step t, (a.sup.(t)).sub.i and (a.sup.(t)).sup.j represent i-th row and j-th column of matrix A.sup.(t), respectively. Tr(A) is the trace of matrix A if it is square, the Frobenius norm of the matrix A R.sup.n.times.d is defined as .parallel.A.parallel..sub.F= {square root over (.SIGMA..sub.i=1.sup.n.SIGMA..sub.j=1.sup.aA.sub.ij.sup.2)}.
Let ={u.sub.1, u.sub.2, . . . , u.sub.n} denote a set of n linked data instances. It is assumed features are dynamically generated and one feature arrives at each time step, thus, at time step t, each linked data instance is associated with a set of t features .sup.(t)={f.sub.1, f.sub.2, . . . , f.sub.t}. Then at the next time step t+1, each linked instance is tied with a new feature set .sup.(t+1)={f.sub.1, f.sub.2, . . . , f.sub.t, f.sub.t+1}. The data representation at time step t and t+1 can be represented as X.sup.(t)=[f.sub.1, f.sub.2, . . . , f.sub.t] and X.sup.(t+1)=[f.sub.1, f.sub.2, . . . , f.sub.t, f.sub.t+1], where f.sub.1, . . . , f.sub.t, f.sub.t+1 are the feature vectors corresponding to features f.sub.1, . . . , f.sub.t, f.sub.t+1. The link information is denoted between instances in a matrix M.di-elect cons..sup.n.times.n, where M.sub.ij=1 if u.sub.i and u.sub.j are linked, otherwise M.sub.ij=0. The link information can either be a directed or an undirected graph. It should be noted that the dynamics of link information is not considered and the reason is that link information does not change as fast as feature information; for example, the friend circles of most users are often stable once they are established.
With these notations, the task of unsupervised streaming feature selection in social media focuses on finding a subset of most relevant features S.sup.(t).sup.(t) at each time step t to facilitate clustering by utilizing both the feature information .sup.(t) and the link information M.
Unsupervised Streaming Feature Selection in Social Media
The work flow of the USFS framework 100 is shown in FIG. 2. It can be observed that it consists of three components. The first component shows the representation of data. There is a set of linked instances (for example) u.sub.1, u.sub.2, . . . , u.sub.5); for each linked instance, its features arrive through a streaming fashion, for example, u.sub.1, u.sub.2, . . . , u.sub.5 are associated with features f.sub.1, f.sub.2 . . . , f.sub.t at time step t; are associated with features f.sub.1, f.sub.2, . . . , f.sub.t+i at time step t+i. The second component shows the process of the algorithm. It will be discussed how to model link information via extracting social latent factors and how to use them as a constraint through a regression model. Then it will be discussed how to model feature information to make it consistent with social latent factors. Finally, it will be shown how to efficiently test new feature and existing features discussed herein. After that, as shown in the third component, a subset of relevant features will be obtained at each time step (for example, S.sup.(t) at time step t).
Modeling Link Information
Social media users connect to each other due to different factors such as movie fans, football enthusiasts, colleagues and each factor should be related to certain features (or attributes) of users. Therefore, extracting these factors from link information should be very useful to steer the unsupervised streaming feature selection. However, in most cases, these hidden factors are not explicitly available in social media data.
Uncovering hidden social factors has been extensively studied. In this disclosure, the social latent factors will be extracted for each instance based on the mixed membership stochastic blockmodel. In the blockmodel, it is assumed that there exists a number of latent factors, and these latent factors interact with each other with certain probabilities to form social relationships. More specially, each instance is associated with a k-dimensional latent factor vector .pi..sub.i.di-elect cons..sup.k where .pi..sub.ig denotes the probability of u.sub.i in factor g. This means that each instance can simultaneously be sided with multiple latent factors with different affiliation strength. For each instance, the indicator vector z.sub.i.fwdarw.j denotes the latent factor membership of u.sub.i when it links to u.sub.j and z.sub.i.rarw.j denotes the latent factor membership of u.sub.i when it is linked from u.sub.j. The interaction strength between different latent factors is encoded in a k.times.k stochastic matrix B, in which each element is between 0 and 1. Then the observed link information is generated according to the following process:
For each linked instance u.sub.i, Draw a k dimensional vector .pi..sub.i.about.Dirichlet(.theta.).
For each pair of linked instance (i, j).di-elect cons..times., Draw indicator vector z.sub.i.fwdarw.j.about.Multinomial(.pi..sub.i). Draw indicator vector z.sub.i.rarw.j.about.Multinomial(.pi..sub.j). Draw the relationship between u.sub.i and u.sub.j, M.sub.i,j.about.Bernoulli (z.sub.i.fwdarw.jBz.sub.i.rarw.j).
A scalable inference algorithm is used to obtain the social latent factors II=[.pi..sub.1, .pi..sub.2, . . . , .pi..sub.n].sup.T.di-elect cons..sup.n.times.k for all n instances efficiently.
As the social latent factors are obtained for each linked instances, the framework takes advantage of them as a constraint to perform feature selection through a regression model. The importance of each feature is measured by its ability to differentiate different social latent factors. At time step t, given each social latent factor .pi..sup.i (a column of II) for all instances, a subset is found of most relevant features by the following minimization problem:
.function..times..function..times..times..times..function..pi..alpha..tim- es..times..times..times..times..PI..alpha..times..times. ##EQU00001##
where X.sup.(f).di-elect cons..sup.n.times.t, W.sup.(t).di-elect cons..sup.t.times.k is a mapping matrix which assigns each instance a k-dimensional social latent vector at time step t. Each column of W.sup.(t), i.e., (w.sup.(t)).sup.i.di-elect cons..sup.i contains coefficients of t different features in approximating the i-th social latent vector of II. .alpha. is a parameter which controls the trade-off between the loss function and the l.sub.1-norm. One main advantage of l.sub.1-norm regression is that it leads some coefficients of (w.sup.(t)).sup.i to be exact zero. This property makes it to be suitable for feature selection, as features can be selected with corresponding non-zero coefficients.
It is known that the number of selected features is usually bounded by the number of data instances, which is unrealistic in many applications. Besides, features in social media usually have strong pairwise correlations, such as synonyms or antonyms words in text data. It is known to randomly select features from a group and discards the others. Therefore, we employ the elastic net on the basis of Equation (1):
.function..times..function..times..times..PI..alpha..times..times..beta..- times. ##EQU00002##
where the regularization term
.beta..times. ##EQU00003## controls the robustness of the learned model. Modeling Feature Information
In Twitter, if two users post similar contents (features), they are more likely to share similar social latent factors, like hobbies, education background, etc. The similarity of social latent factors reflects the correlation of two linked instances in the feature space. In other words, social latent factors of two instances are more likely to be consistent when their feature similarity (like textual similarity) is high. To model the feature information, a graph g is constructed to represent the feature similarity between different data instances. The adjacency matrix A.di-elect cons..sup.n.times.n of the graph g at time step t is defined as:
.times..times..di-elect cons. .function..times..times..times..times..di-elect cons. .function. ##EQU00004##
where (x.sup.(t)).sub.i, indicates the feature information of u.sub.i,.sub.p((x.sup.(t)).sub.i) represents p-nearest neighbors of (x.sup.(t)).sub.i. Then feature information can be modeled by minimizing the following term:
.times..times..times..times..times..times..times..times..times..function.- .times..times..times..times..times..function..times..times..function..time- s. ##EQU00005##
where D.sup.(t).di-elect cons..sup.n.times.n is a diagonal matrix with D.sub.ii.sup.(t)=.SIGMA..sub.j=1.sup.nA.sub.ij.sup.(t), L.sup.(t)=D.sup.(t)-A.sup.(t) is the Laplacian matrix. Since the Laplacian matrix in Equation (3) is positive-semi-definite, Equation (3) can also be written as:
.function..times..times..function..times..times..times. ##EQU00006##
The optimization formulation, which integrates feature information, is defined as:
.function..times..function..times..times..PI. .alpha..times..times..beta..times..gamma..times..times..times. ##EQU00007##
where .gamma. is the regularization parameter to balance link information and feature information.
Streaming Feature Selection Framework
The objective function in Equation (5) at time step t is parameterized by a transformation matrix W.sup.(t). It can be further decomposed into a series of k sub-problems which correspond to k social latent factors:
.times..function..times..function..pi. .alpha..times..beta..times..gamma..times..function..times. ##EQU00008##
where i=1, . . . , k. By solving each sub-problem in Equation (6), a subset of features can be selected at time t. Next it is introduced how to efficiently perform feature selection when a new feature f.sub.t+1 is generated at a new time step t+1. Following common steps of supervised streaming feature selection, the USFS framework 100 will test: (1) whether the new feature should be selected; and (2) whether some existing features should be discarded.
Testing New Features
It can be observed from Equation (6) that at time step t+1, incorporating a new feature feature f.sub.t+1 involves adding a new non-zero weight value (w.sup.(t+1)).sub.t+1.sup.i to the model, which incurs a penalty increasing .alpha..parallel.(w.sup.(t+1)).sub.t+1.sup.i.parallel..sub.l on the l.sub.1 regularization term. The addition of the new feature f.sub.t+1 reduces the overall objective function value in Equation (6) only when the overall reduction from the first, third, and forth term outweighs the increase of l.sub.1 penalty .alpha..parallel.(w.sup.(t)).sub.t+1.sup.t.parallel..sub.i.
A stagewise is adopted as a way to check newly arrived features. Let ((w.sup.(t+1)).sup.i) denotes the objective function of Equation (6) at time step t+1:
.times..function..times..function..pi. .alpha..times..beta..times..gamma..times..function..times. ##EQU00009## then the derivative of ((w.sup.(t+1)).sup.i) with respect to (w.sup.(t+1)).sub.t+1.sup.i is as follows:
.differential..function..differential..times..times..function..pi..beta..- function..times..gamma..function..times..times..function..alpha..times..ti- mes..times..times..function..pi..beta..function..times..gamma..function..t- imes..times..function..+-..alpha. ##EQU00010##
In Equation (8), the derivative of l.sub.1-norm term .alpha..parallel.(w.sup.(t+1)).sub.t.parallel..sub.1 w.r.t. (w.sup.(t+1)).sub.t+1.sup.i is not smooth. Here the sign of the derivative, i.e., sign(w.sup.(t+1)).sub.t+1.sup.i is discussed. When the new feature f.sub.t+1 arrives, its feature coefficient (w.sup.(t+1)).sub.t+1.sup.i is first set to be zero and add it to the model, if: [(X.sup.(t+1)).sup.T(X.sup.(t+1)(w.sup.(t+1)).sup.i-.pi..sup.i)+.beta.(w.- sup.(t+1)).sup.i+.gamma.(X.sup.(t+1)).sup.TL.sup.(t+1)X.sup.(t+1)(w.sup.(t- +1)).sup.i].sub.t+1-.alpha.>0, (9)
it is easy to verify that:
.differential..function..differential.> ##EQU00011##
In order to reduce the objective function value ((w.sup.(t+1)).sup.i), the value of (w.sup.(t+1)).sub.t+1.sup.i is required to be slightly reduced to make it negative, and then the sign of (w.sup.(t+1)).sub.t+1.sup.i will be negative. For the same reason, if: [(X.sup.(t+1)).sup.T(X.sup.(t+1)(w.sup.(t+1)).sup.i-.pi..sup.i)+.beta.(w.- sup.(t+1)).sup.i+.gamma.(X.sup.(t+1)).sup.TL.sup.(t+1)X.sup.(t+1)(w.sup.(t- +1)).sup.i].sub.t+1+.alpha.>0, (11) then:
.differential..function..differential.< ##EQU00012##
the sign of (w.sup.(t+1)).sub.t+1.sup.i will be positive. If both of previous conditions are not satisfied, it is impossible to reduce the objective function value ((w.sup.(t+1)).sup.i) by making (w.sup.(t+1)).sub.t+1.sup.i as a small disturbance around 0. In other words, for the new feature f.sub.t+1, we need to check: |[(X.sup.(t+1)).sup.T(X.sup.(t+1)(w.sup.(t+1)).sup.i-.pi..sup.i)+.beta.(w- .sup.(t+1)).sup.i+.gamma.(X.sup.(t+1)).sup.TL.sup.(t+1)X.sup.(t+1)(w.sup.(- t+1)).sup.i].sub.t+1|>.alpha.. (13)
As the condition in Equation (13) is satisfied, it indicates that the addition of the new feature f.sub.t+1 will reduce the objective function value ((w.sup.(t+1)).sup.i), therefore the new feature is included in the model described in Equation (7).
Testing Existing Features
In social media, when new features are continuously being generated, they may take place of some existing features since new features can better reflect the interests of users, etc. Old features become outdated as a result, therefore, in the unsupervised streaming feature selection framework 100, it is investigated if it is necessary to remove any existing selected features.
After a new feature is accepted and added to the model, Equation (7) is optimized with respect to existing feature weights, such that the optimization may force some feature weights to be zero. If the feature weight obtains a zero value, it indicates that the existence of the feature is not likely to reduce the objective function value and the feature can be removed. Here it is discussed how to solve the optimization problem in Equation (7). The objective function in Equation (7) is convex and the gradient with respect to (w.sup.(t+1)).sub.t+1.sup.i can be easily obtained as Equation (8), then a global optimum solution can be achieved. A Broyden-Fletcher-Goldfarb-Shanno (BFGS) quasi-newton method is used to solve the optimization problem. Unlike traditional Newton's method, which requires the calculation of second derivatives (the Hessian), BFGS only needs the gradient of the objective function to be computed at each iteration. Therefore, it is more efficient than Newton's methods especially when Hessian evaluation is slow.
The minimization problem in Equation (7) can be generalized to the following form: min f(x),x.di-elect cons..sup.n. (14)
At each iteration, the optimal solution x is updated as: x.sub.m+1=x.sub.m-.delta..sub.mH.sub.mg.sub.m, (15)
where H.sub.m=B.sub.m.sup.-1, B.sub.m is an approximation to the Hessian matric (B.sub.m.apprxeq.[.gradient..sup.2f(x.sub.m)]), g.sub.m=.gradient.f(x.sub.m) is the gradient and .delta..sub.m is the step size that can be determined by line search. Let the vectors s.sub.m and c.sub.m be: s.sub.m=x.sub.m+1-x.sub.m,c.sub.m=g.sub.+1-g.sub.m, (16)
the next Hessian approximation has to meet the secant equation: B.sub.m+1s.sub.m=c.sub.m. (17)
By pre-multiplying the secant equation s.sub.m.sup.T at both sides, the following curvature condition is obtained:
.times..times. >.times.> ##EQU00013##
If the curvature condition is satisfied, B.sub.m+1 in the secant equation has at least one solution, which can be updated by the following way:
.times..times..times..times..times..times..times. ##EQU00014##
Its inverse, i.e., H.sub.m+1, can be updated efficiently by Sherman-Morrison formula:
.times..times..times..times..times..times..times..times..times..times..ti- mes. ##EQU00015##
With these, the BFGS algorithm to solve Equation (7) is illustrated in Algorithm 1.
TABLE-US-00001 Algorithm 1 BFGS to optimize Eq. (7) Input: Starting point x.sub.0, convergence threshold , initial inverse Hessian approximation H.sub.0 Output: Optimal solution x* 1: m .rarw. 0 2: g.sub.m = .gradient.f(x.sub.m) 3: while ||g.sub.m|| > do 4: Obtain a direction p.sub.m = -H.sub.mg.sub.m 5: Compute x.sub.m+1 = x.sub.m + .delta..sub.mp.sub.m, where .delta..sub.m is chosen by line search to meet curvature condition 6: g.sub.m+1 = .gradient.f(x.sub.m+1) 7: s.sub.m = x.sub.m+1 - x.sub.m 8: c.sub.m = g.sub.m+1 - g.sub.m 9: .times..times..times..times..times..times..times..times..times..time- s..times. ##EQU00016## 10: m .rarw. m + 1 11: end while 12: return x.sub.m
Feature Selection by the USFS Framework 100
By solving all k sub-problems at time step t+1, the sparse coefficient matrix W=[(w.sup.(t+1)).sup.1, . . . , (w.sup.(t+1)).sup.k] is obtained. Since each sub-problem is solved separately, the number of non-zero weights in each (w.sup.(t+1)).sup.i (i=1, . . . , k) is not necessarily to be the same. For each feature f.sub.i, if any of the k corresponding feature weight coefficients (w.sup.(t+1)).sub.j.sup.i (i=1, 2, . . . , k) is nonzero, the feature is included in the final model, otherwise the feature is not selected. If f.sub.j is selected, its feature score at time step t+1 is defined as: FScore(j).sup.(t+1)=max((w.sup.(t+1)).sub.j.sup.1, . . . ,(w.sup.(t+1)).sub.j.sup.k) (21)
The selected features are then sorted according to their feature scores in a descending order, the higher the feature score, the more important the feature is.
The pseudo code of the unsupervised streaming feature selection framework 100 for social media data is illustrated in Algorithm 2. It efficiently performs unsupervised feature selection when a new feature f.sub.t+1 arrives. In line 1, we obtain the social latent factor matrix II using the link information M. The algorithm to check new feature and existing features is illustrated in lines 2-8. More specifically, for each sub-problem, the gradient condition is first checked, this step decides whether the new feature (line 3) is accepted. If the condition is satisfied (line 4), the new feature is included in the model (line 5) and the model is re-optimized with respect to all existing feature weights (line 6). At last, when the new feature is included in the model, it updates the Laplacian matrix (line 10), calculates the feature scores, and updates the selected feature set (lines 11-12).
Time Complexity Analysis
Time Complexity for All Streaming Features
The mixed membership stochastic model to extract social latent factors has a time complexity of O(n.sup.2k.sup.2). Assuming the total number of streaming features is t and the number of obtained features is s, the time complexity of updating
TABLE-US-00002 Algorithm 2 Unsupervised streaming feature selection framework (USFS) Input: New feature f.sub.t+1 at time t + 1, feature weigth ma- trix W.sup.(t) at previous time step t, link information M, parameters .alpha., .beta., .gamma., number of social latent factors k, number of nearest neighbors p Output: Selected feature subset S.sup.(t+1) at time step t + 1 1: Obtain social latent factors II from M 2: for each social latent factor .pi..sup.1(l = 1,...,k) do 3: compute gradient g for f.sub.t+1 according to Eq. (8) 4: if abs(g) > .alpha. then 5: add feature f.sub.t+1 to the model 6: optimize the model via BFGS in Algorithm 1 7: end if 8: end for 9: if feature f.sub.t+1 is accepted then 10: update Laplacian matrix L.sup.(t+1) 11: obtain feature scores according to Eq. (21) 12: sort features by scores and update S.sup.(t+1) 13: end if 14: return S.sup.(t+1)
Laplacian matrix is bounded by O(n.sup.2st). At each time step, the gradient condition in Equation (13) is checked. The time complexity upper bound of the gradient checking over all t time steps is O(n.sup.2kst). Since the model in Eq. (7) is optimized when the new feature is accepted, the total time of optimization with BFGS is O(n.sup.2s.sup.2t) in the worst case when the selected s features are the latest arrived s features.
Overall, the total time complexity of the USFS framework 100 is O(n.sup.2k.sup.2)+O(n.sup.2st)+O(n.sup.2kst)+O(n.sup.2s.sup.2t). Since k<<t and s<<t, the upper bound of the overall time complexity is O(n.sup.2s.sup.2t). However, it only provides an upper bound, in real-world applications, the time complexity could be much lower than this upper bound. The efficiency of the USFS framework 100 will be empirically shown in the experiments.
Time Complexity for an Individual Feature
For the newly generated feature, suppose there are already s features in the model, if its previous feature is added in the model, the time complexity of gradient test is O(n.sup.2ks), otherwise the time complexity is only O(n). To test existing features via BFGS, the time complexity is O(n.sup.2s.sup.2).
EXPERIMENTS
In this section, experiments were conducted to evaluate the performance of the USFS framework 100. In particular, the following questions were addressed: 1) how is the quality of selected features by USFS framework 100 compared with the state-of-the-art unsupervised feature selection algorithms? 2) how efficient is the USFS framework 100? Before introducing the details of experiments, the datasets and experimental settings were first introduced.
Datasets
Two real-world social media datasets BlogCatalog and Flickr were used for experimental evaluation. Some statistics of the datasets are listed in Table 1.
TABLE-US-00003 TABLE 1 Detailed information of datasets. BlogCatalog Flickr # of Users 5,196 7,575 # of Features 8,189 12,047 # of Links 171,743 239,738 # of Ave Degree 66.11 63.30 # of Classes 0 0
BlogCatalog: BlogCatalog is a social blog directory which manages bloggers and their blogs. Bloggers are associated with sets of tags, which provide feature information. Users in blogcatalog follow each other which form the social link information. Bloggers can also register their blogs under predefined categories, which are used as ground truth for validation in our work.
Flickr: Flickr is an image hosting and sharing website, the key features in Flickr are tags, user can specify the list of tags to reflect their interests. Similar to blogcatalog, users in Flickr can interact with others. Photos are organized under prespecified categories, which are used as the ground truth.
Experimental Settings
Following a standard way to assess unsupervised feature selection, the clustering performance is used to evaluate the quality of selected features. Two commonly used clustering performance evaluation metrics, i.e., accuracy (ACC) and normalized mutual information (NMI) are used in this paper.
To the best of our knowledge, this is study streaming feature selection in social media. To investigate the effectiveness and the efficiency of the USFS framework 100, the following state-of-the-art unsupervised feature selection algorithms were selected as baseline methods: LapScore: Laplacian score evaluates feature importance by its ability to preserve the local manifold structure of data. SPEC: Features are selected by spectral analysis [and SPEC can be considered as an extension of Laplacian score method. NDFS: Nonnegative Discriminative Unsupervised Feature Selection which selects features via a joint nonnegative spectral analysis as well as l.sub.2,1-norm regularization. LUFS: LUFS utilizes both content information and link information to perform feature selection in an unsupervised scenario.
For LapScore, NDFS and USFS, a previous work was used to specify the number of neighborhood size to be 5 to construct the Laplacian matrix on the data instances. NDFS and LUFS have different regularization parameters and so these regularization parameters were set according to the suggestions from previous studies. For the USFS framework 100, the number of social latent factors was set as the number of clusters. There are three important regularization parameters .alpha., .beta. and .gamma. in USFS framework 100 .alpha. controls the sparsity of the model, .beta. is the parameter for elastic net which controls the robustness of the model, and .gamma. balances the contribution of the link information and feature information. In the experiments, .alpha.=10, .beta.=0.1, .gamma.=0.1 was empirically set and more details about the effects of these parameters on the USFS framework 100 will be discussed herein.
All experiments are conducted on a machine with 16 GB RAM and Intel Core i7-4770 CPU.
Quality of Selected Features
Following streaming feature selection settings that assume features arrive one at a time, all features were divided into 9 groups where the first {20%, . . . , 90%, 100%} were chosen as streaming features. In each group, feature selection was performed with traditional unsupervised feature selection algorithm as well as the USFS framework 100. How many features the USFS framework 100 selects are recorded and the same number is specified as that of selected features by traditional unsupervised feature selection algorithms for a fair comparison.
After obtaining the feature selection results, K-means clustering is performed based on the chosen features. The K-means algorithm is repeated 20 times and report average results because K-means may converge to local minima. The clustering results are evaluated by both accuracy (ACC) and normalized mutual information (NMI). The higher the ACC and NMI values are, the better feature selection performance is. The comparison results are shown in Table 2 and Table 3 for BlogCatalog and Flickr, respectively. Note that the number in parentheses in the table indicates the number of selected features determined by USFS framework 100. The following observations were made: USFS framework 100 tends to accept new features at the very beginning, then it becomes increasingly difficult for newly generated features to alternate previous decisions since existing features already provide us enough information. For example, no new features are accepted anymore after the number of selected features reaches 275 and 670 in BlogCatalog and Flickr, respectively. USFS framework 100 consistently outperforms all baseline methods on both datasets with significant performance gain in most cases. The reason is that traditional unsupervised feature selection algorithms are based on the i.i.d. assumption which is invalid in linked social media data. The USFS framework 100 takes advantage of link information to guide the unsupervised streaming feature selection. It can also be observed that when feature information is scarce (for example 20%), link information could better complement feature information for feature selection. A pair-wise wilcoxon signed-rank test was also performed between the USFS framework 100 and other baseline methods on different proportions of streaming features and the test results show that the USFS framework 100 is significantly better (with both 0.01 and 0.05 significance level). For baseline methods, clustering performance gradually decreases when features are continuously generated. While for USFS framework 100, the clustering performance is relatively more stable when the proportion of streaming features varies from 20% to 100%. The number of selected features by the USFS framework 100 is also very stable, which varies from 236 to 275 in BlogCatalog and 562 to 670 in Flickr, respectively. It demonstrates the effectiveness of streaming feature selection, with a large amount of streaming features, a small set of relevant features can only be dynamically maintained without deteriorating the performance. Efficiency Performance Comparison
To evaluate the efficiency of the USFS framework 100, the running times of different methods are compared in graphs 200 and 202 shown in FIGS. 3A-3B. As LapScore, SPEC, NDFS and LUFS are not designed for dealing with streaming features, the feature selection process is rerun at each time step. For both datasets, we set the cumulative running time threshold to be around 10.sup.4 seconds since all methods except USFS take more than 50 hours. As can be observed, the USFS framework 100 is perform significantly faster than other baseline methods, the average processing time for each feature in BlogCatalog and Flickr is only 0.62 seconds and 1.37 seconds, respectively.
The cumulative running time of the USFS framework 100 was also recorded when the cumulative running time of other methods arrived at the threshold (10.sup.4 seconds). The results show that in BlogCatalog, the USFS framework 100 is 7.times., 20.times., 29.times., 76.times. faster than LapScore, LUFS, NDFS, SPEC, respectively; in Flickr, the USFS framework 100 is 5.times., 11.times., 20.times., 75.times. faster than LapScore, LUFS, NDFS, and SPEC, respectively. The difference is becoming larger as the curve of the USFS framework 100 shown in FIGS. 3A and 3B are getting smoother when streaming features continuously arrive.
Effects of Parameters
As discussed herein, the USFS framework 100 has four important parameters: the number of social latent factors k, and parameters .alpha., .beta. and .gamma. in Equation (6). To investigate the effects of these parameters, we vary one parameter each time and fix the other three to see how the parameter affects the feature selection performance in terms of clustering with different number of selected features. The parameter study was performed only on BlogCatalog dataset to save space since similar observations were made with the Flickr dataset.
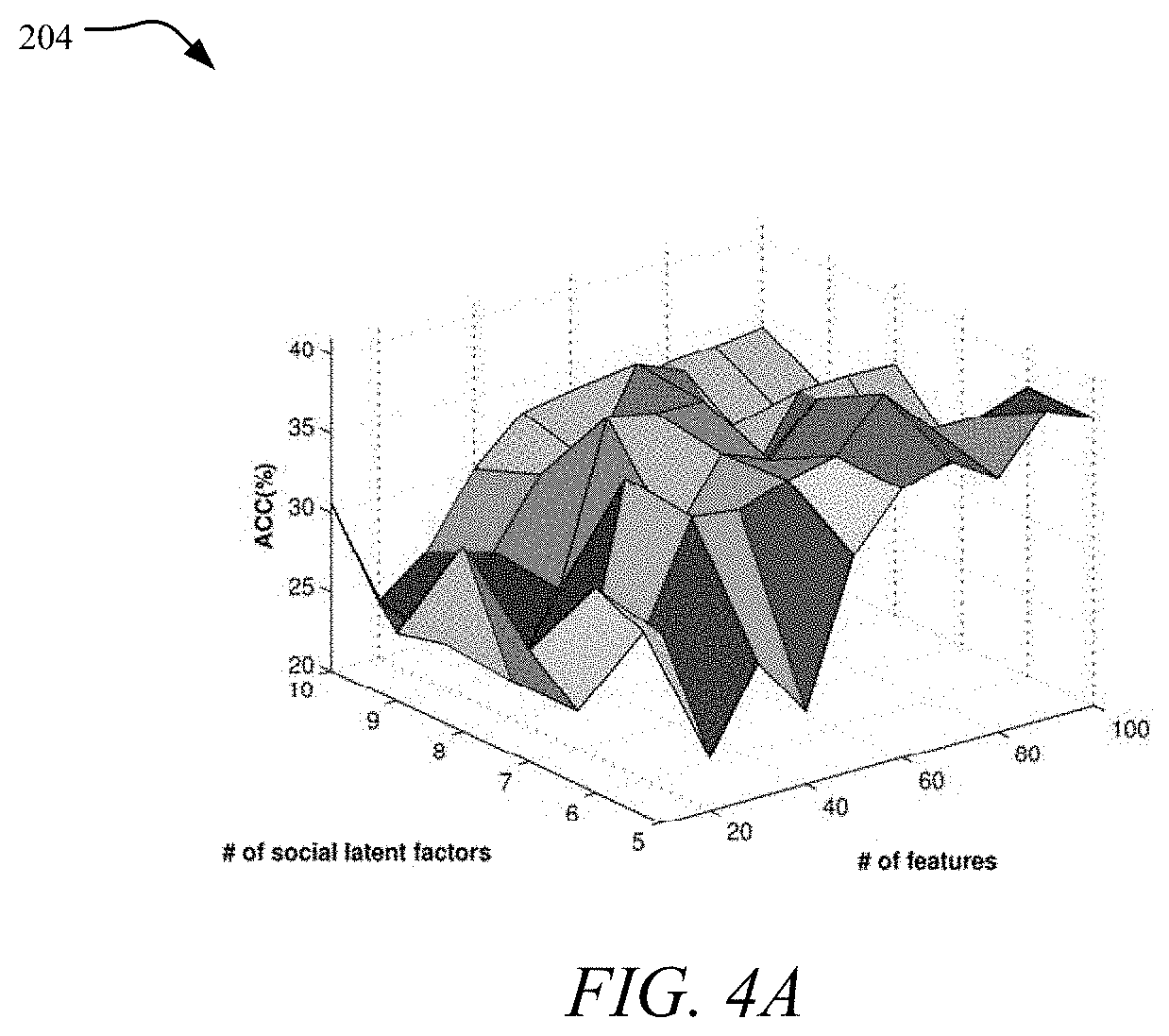
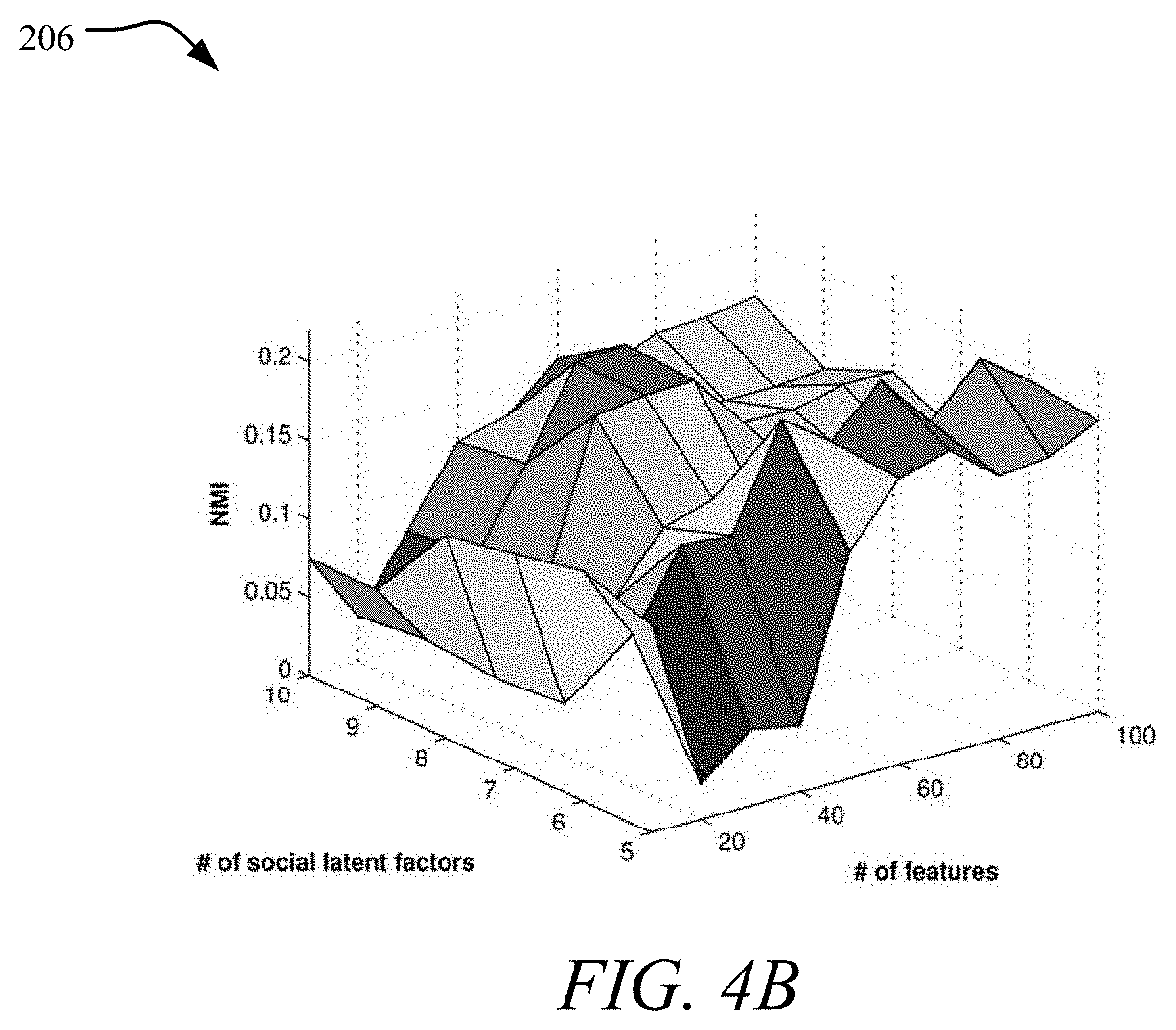
First, the number of social latent factors k was varied from 5 to 10 while fix the other three parameters (.alpha.=10, .beta.=0.1, .gamma.=0.1). The clustering performance in terms of Accuracy and NMI is illustrated in graphs 204 and 206 shown in FIGS. 4A and 4B. The clustering performance is the best when the number of social latent factors is close to the number of clusters, which is 6 in BlogCatalog.
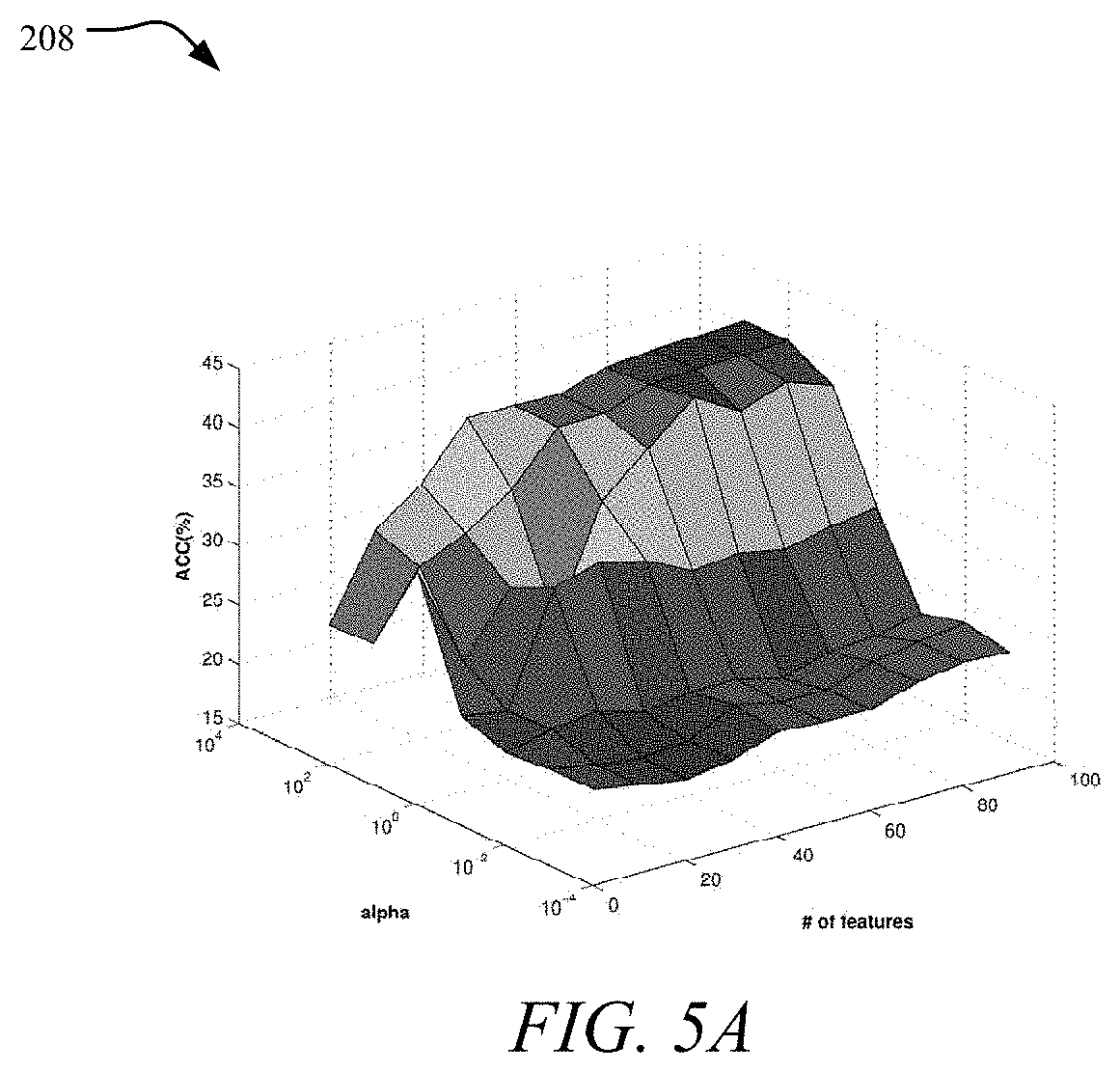
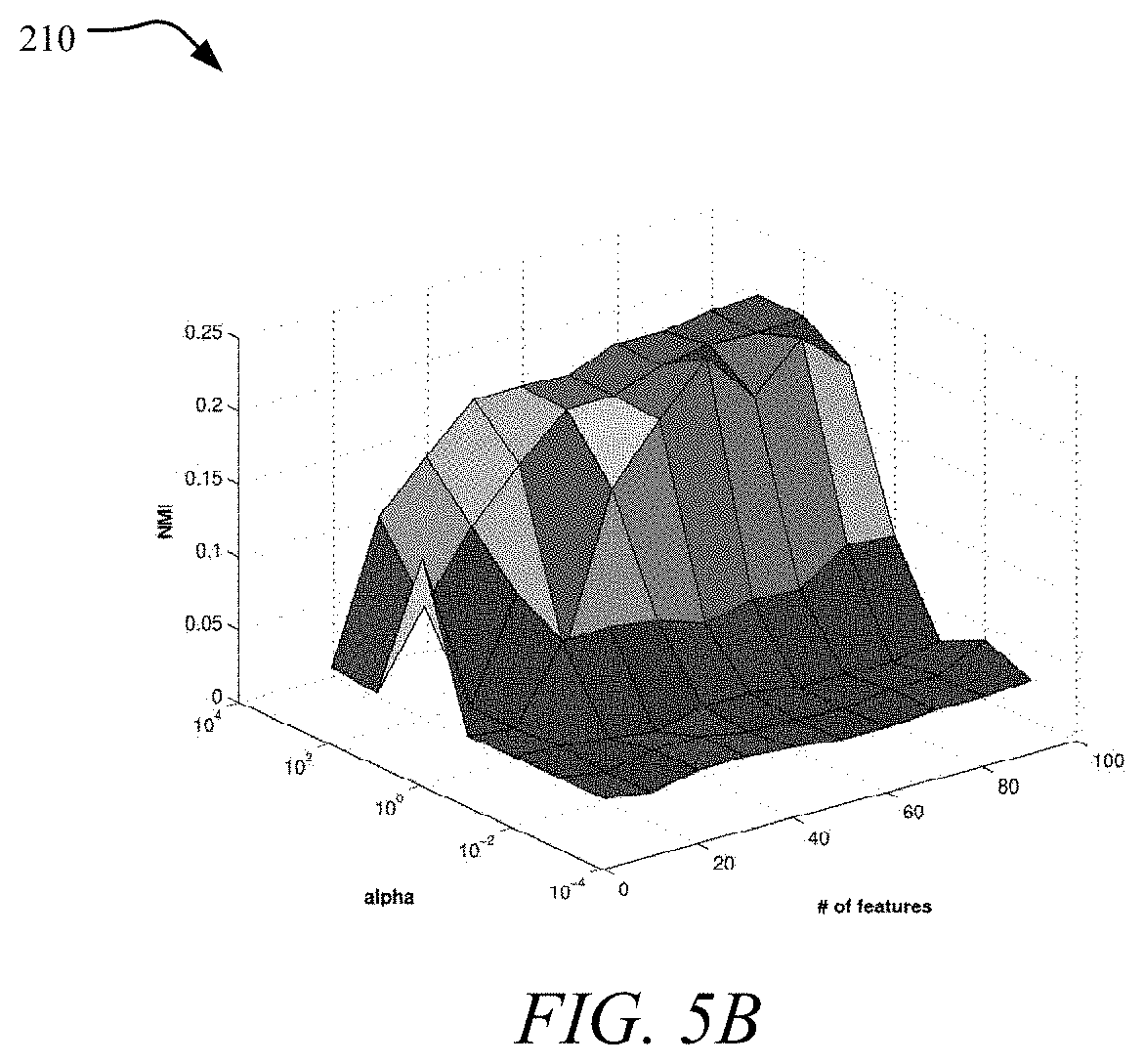
To assess the effect of parameter .alpha. which controls the model sparseness, we vary .alpha. as {0.001, 0.01, 0.1, 1, 10, 100, 1000} while fix k=6, .beta.=0.1, .gamma.=0.1, performance variance between .alpha. and number of selected features is presented in graphs 208 and 210 shown in FIGS. 5A and 5B. With the increase of .alpha., the clustering performance rises rapidly and then keeps stable between the range of 10 to 1000. A high value of .alpha. indicates that it is not easy for new features to pass the gradient test in Equation (13), thus the accepted features are more relevant and meaningful.
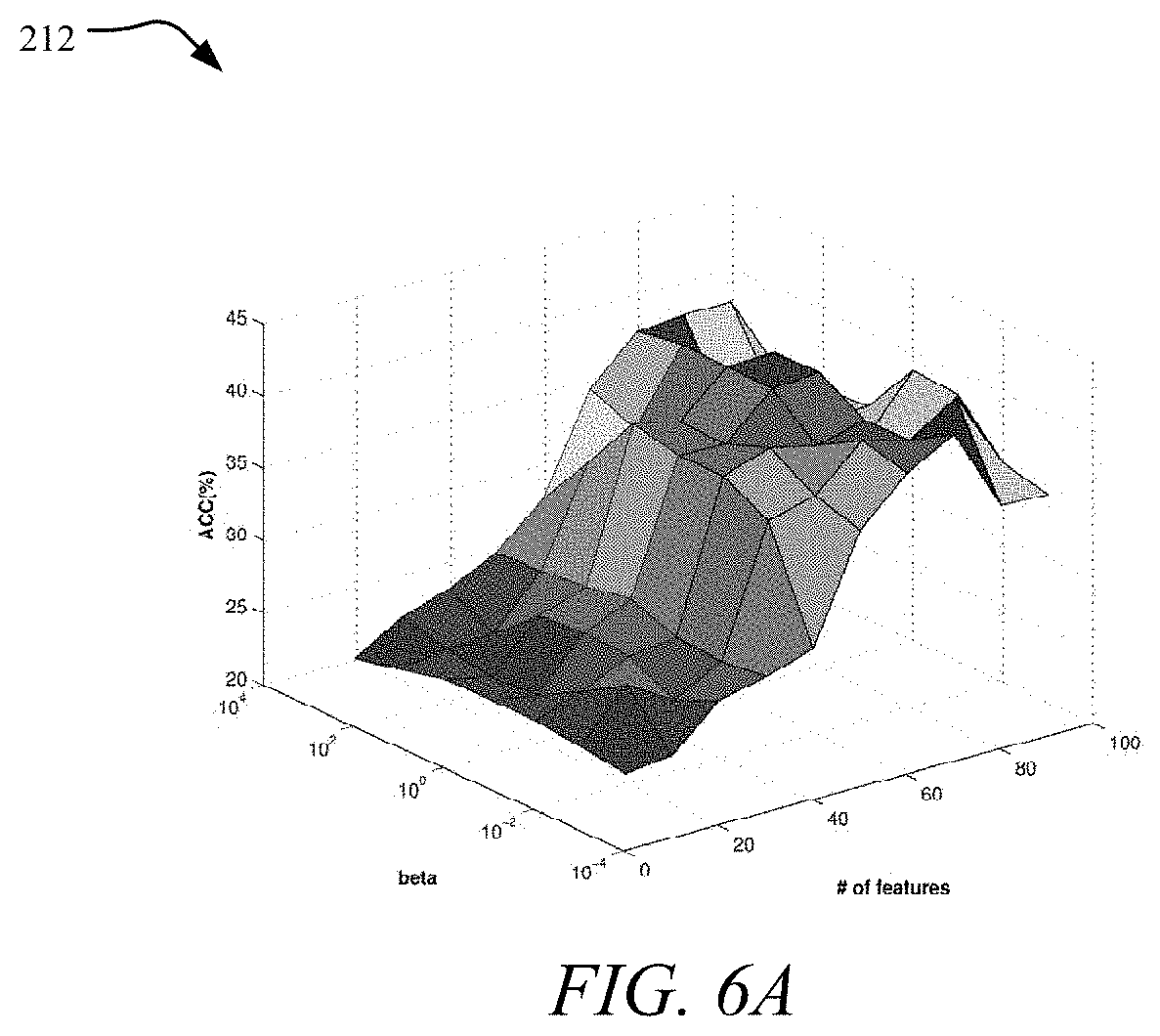
The effect of parameter .beta. was studied which makes the model more robust. Similar to the setting of .alpha., .beta. is also in the range of {0.001, 0.01, 0.1, 1, 10, 100, 1000} and k=6, .alpha.=10, .gamma.=0.1. The results are shown in graphs 212 and 214 shown in FIGS. 6A and 6B. It is shown that clustering performance is much more sensitive to the number of selected features than to .beta.. The performance is relatively higher when .beta. is between 0.1 and 10.
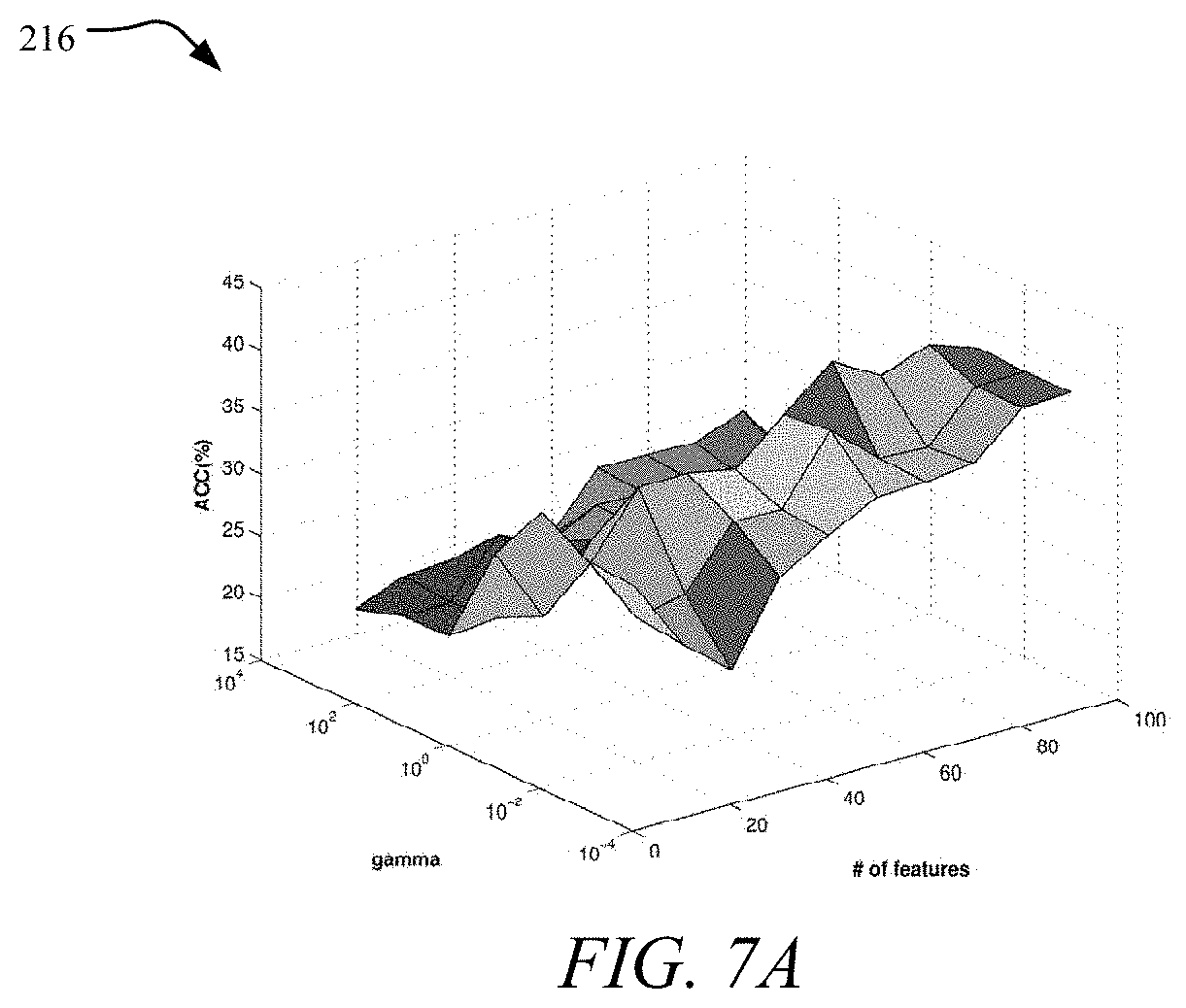
In addition, the trade-off between link information and feature information was evaluated by varying .gamma. in {0.001, 0.01, 0.1, 1, 10, 100, 1000} while fix k=6, .alpha.=10, .beta.=0.1. The results are presented in graphs 216 and 218 shown in FIGS. 7A and 7B. As shown in the figure, in most cases, the clustering performance first increases, reaches its peak and then it gradually decreases. The best performance was achieved when .gamma. is around 0.1. These observations suggest the importance of both link information and feature information in unsupervised streaming feature selection.
TABLE-US-00004 TABLE 2 Clustering results with different feature selection algorithms on BlogCatalog dataset. 20%(259) 30%(260) 40%(270) 50%(271) 60%(272) 70%(272) 80%(274) 90%(275) 1- 00%(276) Accuracy LapScore 87.96 28.60 22.88 23.00 23.36 26.98 26.33 26.73 26.00 SPEC 30.10 29.50 24.79 21.48 18.88 10.63 18.34 18.30 18.01 NDFS 30.89 25.37 28.07 26.44 25.42 26.00 23.69 23.85 23.78 LUFS 24.65 24.11 22.27 22.84 22.50 20.71 21.61 20.71 20.48 USFS 40.65 39.61 40.57 40.61 40.67 40.67 40.78 40.84 40.84 NMI LapScore 0.1451 0.0600 0.0474 0.0610 0.0507 0.0743 0.0675 0.0793 0.0682 SPEC 0.0606 0.0765 0.0397 0.0143 0.0951 0.0098 0.0032 0.0029 0.0019 NDFS 0.1475 0.1250 0.1193 0.1092 0.1284 0.1006 0.1125 0.1130 0.1160 LUFS 0.0574 0.0033 0.0488 0.0490 0.0462 0.0492 0.0462 0.0345 0.0287 USFS 0.2028 0.1861 0.2828 0.2026 0.2042 0.2042 0.2059 0.2072 0.2072
TABLE-US-00005 TABLE 3 Clustering results with different feature selection algorithms on Flickr dataset. 20%(640) 30%(666) 40%(670) 50%(670) 60%(670) 70%(670) 80%(670) 90%(670) 1- 00%(670) Accuracy LapScore 25.06 19.30 21.27 17.52 15.27 13.58 13.53 12.73 12.07 SPEC 25.52 20.26 17.50 15.46 13.53 14.11 13.94 13.53 13.07 NDFS 22.30 29.50 26.79 25.29 25.64 28.01 25.97 29.08 20.48 LUFS 27.13 22.11 19.19 24.00 24.79 19.97 16.22 19.24 23.99 USFS 27.22 29.50 28.37 28.37 28.37 28.37 28.37 28.37 28.37 NMI LapScore 0.1072 0.0629 0.0786 0.0521 0.0308 0.0143 0.0172 0.0100 0.0040 SPEC 0.0854 0.0546 0.0326 0.0246 0.0117 0.0152 0.0118 0.0109 0.0083 NDFS 0.0876 0.1260 0.1073 0.0876 0.0853 0.1207 0.1236 0.1152 0.0663 LUFS 0.1129 0.0958 0.0550 0.1015 0.1023 0.0602 0.0535 0.0524 0.0913 USFS 0.1285 0.1368 0.1262 0.1262 0.1262 0.1262 0.1262 0.1262 0.1262
FIG. 8 illustrates an example network environment 300 for implementing the various systems and methods, as described herein. As depicted in FIG. 8, a communications network 302 (e.g., the Internet) is used by one or more computing or data storage devices for implementing the systems and methods for managing high-dimensional data using the framework 100. In one implementation, one or more databases 302, such as a storage cluster, one or more computing devices 304, and/or other network components or computing devices described herein are communicatively connected to the communications network 302. Examples of the computing devices 304 include a terminal, personal computer, a mobile device, a smart-phone, a tablet, a multimedia console, a gaming console, a set top box, etc.
A server 306 hosts the system. In one implementation, the server 306 also hosts a website or an application that users may visit to access the high-dimensional data and/or the framework 100. The server 306 may be one single server, a plurality of servers 306 with each such server 306 being a physical server or a virtual machine, or a collection of both physical servers and virtual machines. In another implementation, a cloud hosts one or more components of the system. The computing devices 304, the server 306, and other resources connected to the communications network 302 may access one or more additional servers for access to one or more websites, applications, web services interfaces, etc. that are used for data management. In one implementation, the server 306 also hosts a search engine that the system uses for accessing and modifying information, including without limitation, high-dimensional data and/or algorithms of the framework 100.
Referring to FIG. 9, a detailed description of an example computing system 400 having one or more computing units that may implement various systems and methods discussed herein is provided. The computing system 400 may be applicable to the computing device 304, the server 306, and other computing or network devices. It will be appreciated that specific implementations of these devices may be of differing possible specific computing architectures not all of which are specifically discussed herein but will be understood by those of ordinary skill in the art.
The computer system 400 may be a computing system is capable of executing a computer program product to execute a computer process. Data and program files may be input to the computer system 400, which reads the files and executes the programs therein. Some of the elements of the computer system 400 are shown in FIG. 9, including one or more hardware processors 402, one or more data storage devices 404, one or more memory devices 408, and/or one or more ports 408-410. Additionally, other elements that will be recognized by those skilled in the art may be included in the computing system 400 but are not explicitly depicted in FIG. 9 or discussed further herein. Various elements of the computer system 400 may communicate with one another by way of one or more communication buses, point-to-point communication paths, or other communication means not explicitly depicted in FIG. 9.
The processor 402 may include, for example, a central processing unit (CPU), a microprocessor, a microcontroller, a digital signal processor (DSP), and/or one or more internal levels of cache. There may be one or more processors 402, such that the processor 402 comprises a single central-processing unit, or a plurality of processing units capable of executing instructions and performing operations in parallel with each other, commonly referred to as a parallel processing environment.
The computer system 400 may be a conventional computer, a distributed computer, or any other type of computer, such as one or more external computers made available via a cloud computing architecture. The presently described technology is optionally implemented in software stored on the data stored device(s) 404, stored on the memory device(s) 406, and/or communicated via one or more of the ports 408-410, thereby transforming the computer system 400 in FIG. 9 to a special purpose machine for implementing the operations described herein. Examples of the computer system 400 include personal computers, terminals, workstations, mobile phones, tablets, laptops, personal computers, multimedia consoles, gaming consoles, set top boxes, and the like.
The one or more data storage devices 404 may include any non-volatile data storage device capable of storing data generated or employed within the computing system 400, such as computer executable instructions for performing a computer process, which may include instructions of both application programs and an operating system (OS) that manages the various components of the computing system 400. The data storage devices 404 may include, without limitation, magnetic disk drives, optical disk drives, solid state drives (SSDs), flash drives, and the like. The data storage devices 404 may include removable data storage media, non-removable data storage media, and/or external storage devices made available via a wired or wireless network architecture with such computer program products, including one or more database management products, web server products, application server products, and/or other additional software components. Examples of removable data storage media include Compact Disc Read-Only Memory (CD-ROM), Digital Versatile Disc Read-Only Memory (DVD-ROM), magneto-optical disks, flash drives, and the like. Examples of non-removable data storage media include internal magnetic hard disks, SSDs, and the like. The one or more memory devices 406 may include volatile memory (e.g., dynamic random access memory (DRAM), static random access memory (SRAM), etc.) and/or non-volatile memory (e.g., read-only memory (ROM), flash memory, etc.).
Computer program products containing mechanisms to effectuate the systems and methods in accordance with the presently described technology may reside in the data storage devices 404 and/or the memory devices 406, which may be referred to as machine-readable media. It will be appreciated that machine-readable media may include any tangible non-transitory medium that is capable of storing or encoding instructions to perform any one or more of the operations of the present disclosure for execution by a machine or that is capable of storing or encoding data structures and/or modules utilized by or associated with such instructions. Machine-readable media may include a single medium or multiple media (e.g., a centralized or distributed database, and/or associated caches and servers) that store the one or more executable instructions or data structures.
In some implementations, the computer system 400 includes one or more ports, such as an input/output (I/O) port 408 and a communication port 410, for communicating with other computing, network, or vehicle devices. It will be appreciated that the ports 408-410 may be combined or separate and that more or fewer ports may be included in the computer system 400.
The I/O port 408 may be connected to an I/O device, or other device, by which information is input to or output from the computing system 400. Such I/O devices may include, without limitation, one or more input devices, output devices, and/or environment transducer devices.
In one implementation, the input devices convert a human-generated signal, such as, human voice, physical movement, physical touch or pressure, and/or the like, into electrical signals as input data into the computing system 400 via the I/O port 408. Similarly, the output devices may convert electrical signals received from computing system 400 via the I/O port 408 into signals that may be sensed as output by a human, such as sound, light, and/or touch. The input device may be an alphanumeric input device, including alphanumeric and other keys for communicating information and/or command selections to the processor 402 via the I/O port 408. The input device may be another type of user input device including, but not limited to: direction and selection control devices, such as a mouse, a trackball, cursor direction keys, a joystick, and/or a wheel; one or more sensors, such as a camera, a microphone, a positional sensor, an orientation sensor, a gravitational sensor, an inertial sensor, and/or an accelerometer; and/or a touch-sensitive display screen ("touchscreen"). The output devices may include, without limitation, a display, a touchscreen, a speaker, a tactile and/or haptic output device, and/or the like. In some implementations, the input device and the output device may be the same device, for example, in the case of a touchscreen.
The environment transducer devices convert one form of energy or signal into another for input into or output from the computing system 400 via the I/O port 408. For example, an electrical signal generated within the computing system 400 may be converted to another type of signal, and/or vice-versa. In one implementation, the environment transducer devices sense characteristics or aspects of an environment local to or remote from the computing device 400, such as, light, sound, temperature, pressure, magnetic field, electric field, chemical properties, physical movement, orientation, acceleration, gravity, and/or the like. Further, the environment transducer devices may generate signals to impose some effect on the environment either local to or remote from the example computing device 400, such as, physical movement of some object (e.g., a mechanical actuator), heating or cooling of a substance, adding a chemical substance, and/or the like.
In one implementation, a communication port 410 is connected to a network by way of which the computer system 400 may receive network data useful in executing the methods and systems set out herein as well as transmitting information and network configuration changes determined thereby. Stated differently, the communication port 410 connects the computer system 400 to one or more communication interface devices configured to transmit and/or receive information between the computing system 400 and other devices by way of one or more wired or wireless communication networks or connections. Examples of such networks or connections include, without limitation, Universal Serial Bus (USB), Ethernet, Wi-Fi, Bluetooth.RTM., Near Field Communication (NFC), Long-Term Evolution (LTE), and so on. One or more such communication interface devices may be utilized via the communication port 410 to communicate one or more other machines, either directly over a point-to-point communication path, over a wide area network (WAN) (e.g., the Internet), over a local area network (LAN), over a cellular (e.g., third generation (3G) or fourth generation (4G)) network, or over another communication means. Further, the communication port 410 may communicate with an antenna or other link for electromagnetic signal transmission and/or reception.
In an example implementation, the framework 100 algorithms, and other software and/or modules and services may be embodied by instructions stored on the data storage devices 404 and/or the memory devices 406 and executed by the processor 402.
The system set forth in FIG. 9 is but one possible example of a computer system that may employ or be configured in accordance with aspects of the present disclosure. It will be appreciated that other non-transitory tangible computer-readable storage media storing computer-executable instructions for implementing the presently disclosed technology on a computing system may be utilized.
In the present disclosure, the methods disclosed may be implemented as sets of instructions or software readable by a device. Further, it is understood that the specific order or hierarchy of steps in the methods disclosed are instances of example approaches. Based upon design preferences, it is understood that the specific order or hierarchy of steps in the method can be rearranged while remaining within the disclosed subject matter. The accompanying method claims present elements of the various steps in a sample order, and are not necessarily meant to be limited to the specific order or hierarchy presented.
The described disclosure may be provided as a computer program product, or software, that may include a non-transitory machine-readable medium having stored thereon instructions, which may be used to program a computer system (or other electronic devices) to perform a process according to the present disclosure. A machine-readable medium includes any mechanism for storing information in a form (e.g., software, processing application) readable by a machine (e.g., a computer). The machine-readable medium may include, but is not limited to, magnetic storage medium, optical storage medium; magneto-optical storage medium, read only memory (ROM); random access memory (RAM); erasable programmable memory (e.g., EPROM and EEPROM); flash memory; or other types of medium suitable for storing electronic instructions.
While the present disclosure has been described with reference to various implementations, it will be understood that these implementations are illustrative and that the scope of the present disclosure is not limited to them. Many variations, modifications, additions, and improvements are possible. More generally, embodiments in accordance with the present disclosure have been described in the context of particular implementations. Functionality may be separated or combined in blocks differently in various embodiments of the disclosure or described with different terminology. These and other variations, modifications, additions, and improvements may fall within the scope of the disclosure as defined in the claims that follow.
* * * * *
References
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012

D00013
D00014

M00001
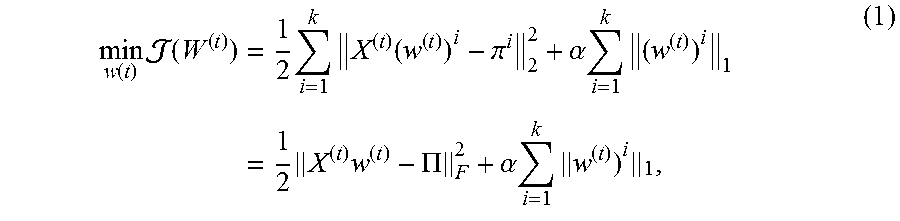
M00002
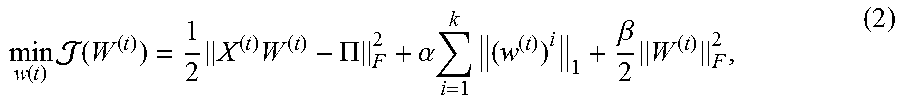
M00003

M00004

M00005

M00006
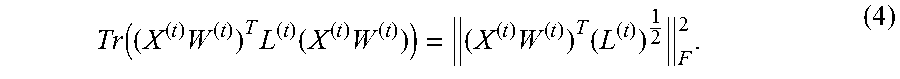
M00007
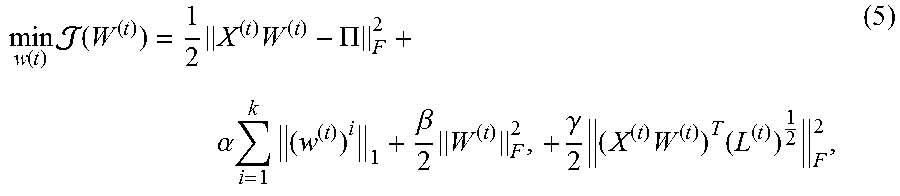
M00008
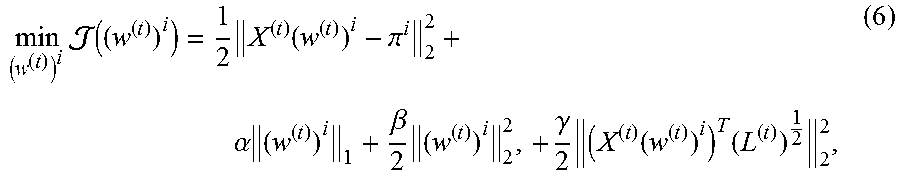
M00009
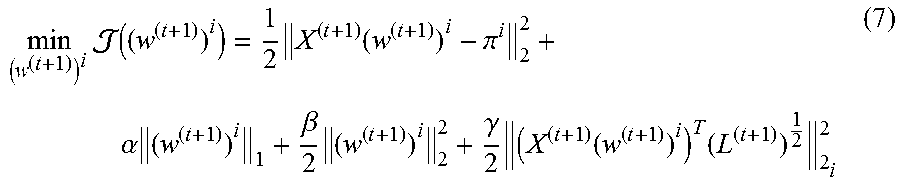
M00010
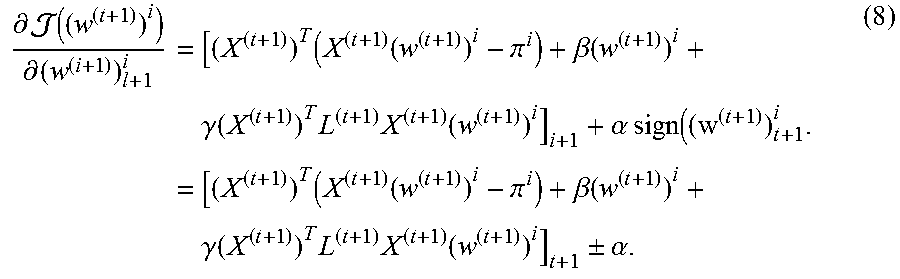
M00011

M00012

M00013

M00014
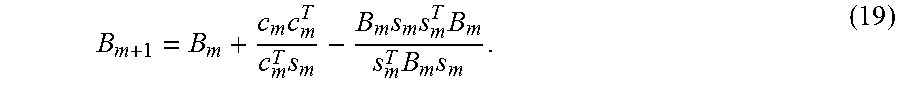
M00015
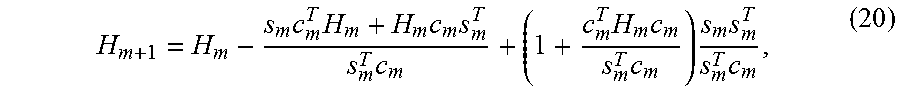
M00016
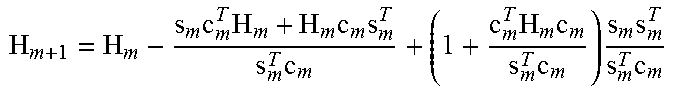
P00001

P00002
P00003
P00004
P00005
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.