DIMM for a high bandwidth memory channel
Agarwal , et al. January 5, 2
U.S. patent number 10,884,958 [Application Number 16/017,515] was granted by the patent office on 2021-01-05 for dimm for a high bandwidth memory channel. This patent grant is currently assigned to Intel Corporation. The grantee listed for this patent is Intel Corporation. Invention is credited to Rajat Agarwal, James A. McCall, Bill Nale, George Vergis, Chong J. Zhao.










View All Diagrams
| United States Patent | 10,884,958 |
| Agarwal , et al. | January 5, 2021 |
DIMM for a high bandwidth memory channel
Abstract
A DIMM is described. The DIMM includes circuitry to multiplex write data to different groups of memory chips on the DIMM during a same burst write sequence.
| Inventors: | Agarwal; Rajat (Portland, OR), Nale; Bill (Livermore, CA), Zhao; Chong J. (West Linn, OR), McCall; James A. (Portland, OR), Vergis; George (Portland, OR) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Applicant: |
|
||||||||||
| Assignee: | Intel Corporation (Santa Clara,
CA) |
||||||||||
| Family ID: | 65230392 | ||||||||||
| Appl. No.: | 16/017,515 | ||||||||||
| Filed: | June 25, 2018 |
Prior Publication Data
| Document Identifier | Publication Date | |
|---|---|---|
| US 20190042500 A1 | Feb 7, 2019 | |
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06F 13/28 (20130101); G06F 13/1684 (20130101) |
| Current International Class: | G06F 13/16 (20060101); G06F 13/28 (20060101) |
References Cited [Referenced By]
U.S. Patent Documents
| 6446158 | September 2002 | Karabatsos |
| 6854042 | February 2005 | Karabatsos |
| 7209397 | April 2007 | Ware |
| 7650457 | January 2010 | Ruckerbauer |
| 7861014 | December 2010 | Gower |
| 8806116 | August 2014 | Karamcheti |
| 9368174 | June 2016 | Nishio |
| 9811263 | November 2017 | Teh |
| 2006/0136618 | June 2006 | Gower |
| 2006/0262586 | November 2006 | Solomon et al. |
| 2007/0162715 | July 2007 | Tagawa |
| 2009/0161475 | June 2009 | Kim et al. |
| 2009/0254689 | October 2009 | Karamcheti |
| 2012/0206165 | August 2012 | Ferolito et al. |
| 2014/0032984 | January 2014 | Lee |
| 2014/0192583 | July 2014 | Rajan |
| 2015/0149735 | May 2015 | Nale et al. |
| 2015/0302904 | October 2015 | Yoon |
| 2015/0331817 | November 2015 | Han |
| 2016/0110102 | April 2016 | Lee |
| 2016/0147678 | May 2016 | Nale |
| 2016/0291894 | October 2016 | Yeung et al. |
| 2016/0314085 | October 2016 | Ware |
| 2016/0350002 | December 2016 | Vergis et al. |
| 2017/0092379 | March 2017 | Kim |
| 2017/0160928 | June 2017 | Jaffari |
| 2017/0168746 | June 2017 | Kwon et al. |
| 2017/0177496 | June 2017 | Han et al. |
| 2017/0249991 | August 2017 | Han et al. |
| 2017/0315914 | November 2017 | Muralimanohar et al. |
| 2018/0225235 | August 2018 | Lee |
| 2018/0292991 | October 2018 | Walker |
| 2019/0042095 | February 2019 | Vergis et al. |
| 2019/0042162 | February 2019 | McCall |
| 2019/0042500 | February 2019 | Agarwal |
Attorney, Agent or Firm: Compass IP Law PC
Claims
What is claimed:
1. An apparatus, comprising: a memory controller comprising a memory channel interface to couple to a memory channel, the memory channel interface comprising a first group of data inputs/outputs (I/Os) and second group of data I/Os, the first group of data I/Os to couple to a first dual in-line memory module (DIMM) in only a point-to-point link fashion, the second group of data I/Os to couple to a second DIMM in only a point-to-point link fashion, the memory controller comprising logic circuitry to send first multiplexed write data to the first DIMM that targets different groups of memory chips on the first DIMM during a same first burst write sequence, the memory controller to also concurrently send second multiplexed write data to the second DIMM that targets different groups of memory chips on the second DIMM during a same second burst write sequence and that exists on the memory channel during a same time period that the first burst write sequence exists on the memory channel, wherein, the memory channel interface conforms to an industry standard specification, wherein, the memory channel as described by the industry standard specification comprises a first data bus that is to couple to multiple DIMMs and describes a second data bus that is to couple to the multiple DIMMs, wherein, the first group of I/Os correspond to the first data bus and the second group of I/Os correspond to the second data bus.
2. The apparatus of claim 1 wherein the different groups of memory chips are different ranks of memory chips.
3. The apparatus of claim 1 wherein the different groups of memory chips are different half-ranks of memory chips.
4. The apparatus of claim 1 wherein the memory controller further comprises additional logic circuitry to move second write requests that are targeted to the second DIMM ahead of first write requests that are targeted to the first DIMM, the second write requests received by the memory controller after the first write requests, the first write requests received by the memory controller after other write requests were received by the memory controller, the memory controller to move the second write requests ahead of the first write requests so that the memory controller is able to concurrently send write data to both the first DIMM and the second DIMM.
5. The apparatus of claim 4 wherein the write data is sent over a same third burst write sequencing time period.
6. The apparatus of claim 1 wherein the memory controller comprises a multiplexer, the multiplexer to multiplex, during the same first burst write sequence to the first DIMM, between different target address values having different base address values.
7. The apparatus of claim 6 wherein the multiplexer is to, during a same burst read sequence time period, multiplex reception of read data from the different groups of memory chips on a same one of the first and second DIMMs.
8. The apparatus of claim 7 wherein the multiplexer is to multiplex reception of read data from different groups of memory chips on the other of the first and second DIMMs during the same burst read sequence.
9. The apparatus of claim 1 wherein the memory channel interface is a DDR5 memory channel interface and the industry standard specification is a Joint Electron Device Engineering Council (JEDEC) DDR5 industry standard specification.
10. The apparatus of claim 9 wherein the memory controller comprises control register space to disable DDR5 operation in favor of multiplexing between different groups of memory chips on a same DIMM during burst write sequences and burst read sequences.
11. An apparatus, comprising: a dual in-line memory module (DIMM) comprising circuitry to multiplex write data to different groups of memory chips on the DIMM during a same burst write sequence of a memory channel, wherein, the DIMM is to receive some of the write data for a first of the different groups of memory chips in a portion of a single data transfer cycle of the memory channel and receive some of the write data for a second of the different groups of memory chips in another portion of the single data transfer cycle of the memory channel, wherein, the DIMM is to couple to a data bus that is to couple only to a single DIMM, wherein, the memory channel conforms to an industry standard specification that describes a respective data bus that is permitted to be a multi-drop data bus.
12. The apparatus of claim 11 wherein the circuitry comprises a multiplexer.
13. The apparatus of claim 11 wherein the circuitry comprises a buffer to store-and-forward at least some of the write data.
14. The apparatus of claim 11 wherein the different groups of memory chips are different ranks of memory chips.
15. The apparatus of claim 11 wherein the different groups of memory chips are different half-ranks of memory chips.
16. An apparatus, comprising: a memory controller comprising multiplexer circuitry to multiplex data and addresses of different ranks of memory chips on a same dual in-line memory module (DIMM) over a same read or write burst time window on a memory channel, wherein, the memory controller is to correspondingly receive or send less than a full rank width of data for a first of the ranks in a portion of a single data transfer cycle of the memory channel and correspondingly receive or send less than a full rank width of data for a second of the ranks of memory chips in another portion of the single data transfer cycle of the memory channel, wherein, transmission of the less than full rank width for the first rank and transmission of the less than full rank width for the second rank alternate on the memory channel.
17. The apparatus of claim 16 wherein the memory controller comprises a DDR5 memory channel interface, the data and addresses to be multiplexed through the DDR5 channel interface.
18. The apparatus of claim 16 wherein the memory controller is integrated into computing system, comprising: a plurality of processing cores; a solid-state drive; a system memory, the DIMM a component of the system memory, the memory controller coupled between the system memory and the plurality of processing cores.
Description
FIELD OF INVENTION
The field of invention pertains generally to a DIMM for a high bandwidth memory channel.
BACKGROUND
The performance of computing systems is highly dependent on the performance of their system memory. Generally, however, increasing memory channel capacity and memory speed can result in challenges concerning the power consumption of the memory channel implementation. As such, system designers are seeking ways to increase memory channel capacity and bandwidth while keeping power consumption in check.
FIGURES
A better understanding of the present invention can be obtained from the following detailed description in conjunction with the following drawings, in which:
FIG. 1 shows a first prior art DIMM;
FIG. 2 shows a second prior art DIMM;
FIG. 3a shows a third prior art DIMM;
FIG. 3b shows a first layout for a memory channel that interfaces with DIMMs of FIG. 3;
FIG. 4a shows an emerging layout for a memory channel;
FIG. 4b shows an improved layout for a memory channel;
FIG. 4c shows an improved DIMM that is to interface with the improved layout of FIG. 4b;
FIG. 4d compares timing of respective memory channels implemented according to the first layout of FIG. 3b and the improved DIMM of FIG. 4c;
FIG. 4e shows another improved DIMM that is to interface with the improved layout of FIG. 4b;
FIG. 4f compares timing of respective memory channels implemented according to the first layout of FIG. 3b and the improved DIMM of FIG. 4e;
FIG. 4g shows additional information of the timing of FIG. 4f;
FIG. 5a shows a memory controller to interface with the improved DIMM of FIG. 4c;
FIG. 5b shows a memory controller to interface with the improved DIMM of FIG. 4e;
FIG. 6 shows a computing system.
DETAILED DESCRIPTION
As is known in the art, main memory (also referred to as "system memory") in high performance computing systems, such as high performance servers, are often implemented with dual in-line memory modules (DIMMs) that plug into a memory channel. Here, multiple memory channels emanate from a main memory controller and one or more DIMMs are plugged into each memory channel. Each DIMM includes a number of memory chips that define the DIMM's memory storage capacity. The combined memory capacity of the DIMMs that are plugged into the memory controller's memory channels corresponds to the system memory capacity of the system.
Over time the design and structure of DIMMs has changed to meet the ever increasing need of both memory capacity and memory channel bandwidth. FIG. 1 shows a traditional DIMM approach. As observed in FIG. 1, a single "unbuffered" DIMM (UDIMM) 100 has its memory chips directly coupled to the wires of the memory channel bus 101, 102. The UDIMM 100 includes a number of memory chips sufficient to form a data width of at least one rank 103. A rank corresponds to the width of the data bus which generally corresponds to the number of data signals and the number of ECC signals on the memory channel.
As such, the total number of memory chips used on a DIMM is a function of the rank size and the bit width of the memory chips. For example, for a rank having 64 bits of data and 8 bits of ECC, the DIMM can include eighteen ".times.4" (four bit width) memory chips (e.g., 16 chips.times.4 bits/chip=64 bits of data plus 2 chips.times.4 bits/chip to implement 8 bits of ECC), or, nine ".times.8" (eight bit width) memory chips (e.g., 8 chips.times.8 bits/chip=64 bits of data plus 1 chip.times.8 bits/chip to implement 8 bits of ECC).
For simplicity, when referring to FIG. 1 and the ensuing figures, the ECC bits may be ignored and the observed rank width M simply corresponds to the number of data bits on the memory bus. That is, e.g., for a data bus having 64 data bits, the rank=M=64.
UDIMMs traditionally only have storage capacity for two separate ranks of memory chips, where, one side of the DIMM has the memory chips for a first rank and the other side of the DIMM has the memory chips for a second rank. Here, a memory chip has a certain amount of storage space which correlates with the total number of different addresses that can be provided to the memory chip. A memory structure composed of the appropriate number of memory chips to interface with the data bus width (eighteen.times.4 memory chips or nine.times.8 memory chips in the aforementioned example) corresponds to a rank of memory chips. A rank of memory chips can therefore separately store a number of transfers from the data bus consistently with its address space. For example, if a rank of memory chips is implemented with memory chips that support 256M different addresses, the rank of memory chips can store the information of 256M different bus transfers.
Notably, the memory chips used to implement both ranks of memory chips are coupled to the memory channel 101, 102 in a multi-drop fashion. As such, the UDIMM 100 can present as much as two memory chips of load to each wire of the memory channel data bus 101 (one memory chip load for each rank of memory chips).
Similarly, the command and address signals for both ranks of memory chips are coupled to the memory channel's command address (CA) bus 102 in multi-drop form. The control signals that are carried on the CA bus 102 include, to name a few, a row address strobe signal (RAS), column address strobe signal (CAS), a write enable (WE) signal and a plurality of address (ADDR) signals. Some of the signals on the CA bus 102 typically have stringent timing margins. As such, if more than one DIMM is plugged into a memory channel, the loading that is presented on the CA bus 102 can sufficiently disturb the quality of the CA signals and limit the memory channel's performance.
FIG. 2 shows a later generation DIMM, referred to as a register DIMM 200 (RDIMM), that includes register and redrive circuitry 205 to address the aforementioned limit on memory channel performance presented by loading of the CA bus 202. Here, the register and redrive circuitry 205 acts as a single load per DIMM on each CA bus 202 wire as opposed to one load per rank of memory chips (as with the UDIMM). As such, whereas a nominal dual rank UDIMM will present one load on each wire of the memory channel's CA bus 202 for memory chip on the UDIMM (because each memory chip on the UDIMM is wired to the CA bus 202), by contrast, a dual rank RDIMM with an identical set of memory chips, etc. will present only one chip load on each of the memory channel's CA bus 202 wires.
In operation, the register and redrive circuitry 205 latches and/or redrives the CA signals from the memory channel's CA bus 202 to the memory chips of the particular rank of memory chips on the DIMM that the CA signals are specifically being sent to. Here, for each memory access (read or write access with corresponding address) that is issued on the memory channel, the corresponding set of CA signals include chip select signals (CS) and/or other signals that specifically identify not only a particular DIMM on the channel but also a particular rank on the identified DIMM that is targeted by the access. The register and redrive circuitry 205 therefore includes logic circuitry that monitors these signals and recognizes when its corresponding DIMM is being accessed. When the logic circuitry recognizes that its DIMM is being targeted, the logic further resolves the CA signals to identify a particular rank of memory chips on the DIMM that is being targeted by the access. The register and redrive circuitry then effectively routes the CA signals that are on the memory channel to the memory chips of the specific targeted rank of memory chips on the DIMM 200.
A problem with the RDIMM 200, however, is that the signal wires for the memory channel's data bus 201 (DQ) are also coupled to the DIMM's ranks of memory chips 203_1 through 203_X in a multi-drop form. That is, for each rank of memory chips that is disposed on the RDIMM, the RDIMM will present one memory chip load on each DQ signal wire. Thus, similar to the UDIMM, the number of ranks of memory chips that can be disposed on an RDIMM is traditionally limited (e.g., to two ranks of memory chips) to keep the loading on the memory channel data bus 201 per RDIMM in check.
FIG. 3a shows an even later generation DIMM, referred to as a load reduced DIMM (LRDIMM) 300, in which both the CA bus wires 302 and the DQ bus wires 301 are presented with only a single load by the LRDIMM 300. Here, similar to the register and redrive circuitry of the RDIMM, the LRDIMM includes buffer circuitry 306 that stores and forwards data that is to be passed between the memory channel data bus 301 and the particular rank of memory chips 303 that is being targeted by an access. The register and redrive circuitry 305 activates whichever rank of memory chips is targeted by a particular access and the data associated with that access appears at the "back side" of the buffer circuitry 306.
With only a single point load for both the DQ and CA wires 301, 302 on the memory channel, the memory capacity of the LRDIMM 300 is free to expand its memory storage capacity beyond only two ranks of memory chips (e.g. four ranks on a single DDR4 DIMM). With more ranks of memory chips per DIMM and/or a generalized insensitivity to the number of memory chips per DIMM (at least from a signal loading perspective), new memory chip packaging technologies that strive to pack more chips into a volume of space have received heightened attention is recent years. For example, stacked chip packaging solutions can be integrated on an LRDIMM to form, e.g., a 3 Dimensional Stacking (3 DS) LRDIMM.
Even with memory capacity per DIMM being greatly expanded with the emergence of LRDIMMs, memory channel bandwidth remains limited with LRDIMMs because multiple LRDIMMs can plug into a same memory channel. That is, a multi-drop approach still exists on the memory channel in that more than one DIMM can couple to the CA and DQ wires of a same memory channel.
Here, FIG. 3b shows a high performance memory channel layout 310 in which two DIMM slots 311_1, 311_2 are coupled to a same memory channel. The particular layout of FIG. 3b is consistent with the Joint Electron Device Engineering Council (JEDEC) Double Date Rate 4 (DDR4) memory standard. As can be seen from the layout 310 of FIG. 3b, if a respective LRDIMM is plugged into each of the two slots 311_1, 311_2, each CA bus wire and DQ bus wire will have two loads (one from each LRDIMM). If the loading could be further reduced, the timing margins of the CA and DQ signals could likewise be increased, which, in turn, would provide higher memory channel frequencies and corresponding memory channel bandwidth (read/write operations could be performed in less time).
A next generation JEDEC memory interface standard, referred to as DDR5, is taking the approach of physically splitting both the CA bus and the DQ bus into two separate multi-drop busses as depicted in FIG. 4a. Here, comparing FIG. 3b with FIG. 4a, note that whereas the layout of FIG. 3b depicts a single N bit wide CA bus that is multi-dropped to two DIMM slots 311_1, 311_2 and a single M bit wide DQ data bus that is also multi-dropped to the two DIMM slots 311_1, 311_2; by contrast, the DDR5 layout of FIG. 4a consists of two separate N/2 bit wide CA busses that are multi-dropped to two DIMM slots 411_1, 411_2 and two separate M/2 bit wide DQ data busses that are multi-dropped to the DIMM slots 411_1, 411_2.
Again, for simplicity, ECC bits are ignored and M=64 in both FIGS. 3b and 4a for DDR4 and DDR5 implementations, respectively. As such, whereas DDR4 has a single 64 bit wide data bus, by contrast, DDR5 has two 32 bit wide data busses (DQ_1 and DQ_2). A "rank" in a DDR5 system therefore corresponds to 32 bits and not 64 bits (the width of both the DQ_1 and DQ_2 data busses is M/2=64/2=32 bits). Likewise, a rank of memory chips for a DDR5 system accepts 32 bits of data from a sub-channel in a single transfer rather than 64 as in DDR4.
A concern, however, is that the JEDEC DDR5 layout of FIG. 4a still adopts a multi-drop bus approach. That is both pairs of CA and DQ busses, as observed in FIG. 4a, multi-drop to both DIMM slots 411_1, 411_2. With both the CA and DQ busses adopting a multi-drop approach, there is no fundamental increase in operating frequency of the channel nor corresponding increase in data rate of the DDR5 memory channel as compared to the earlier channel of FIG. 3b. That is, in terms of data rate, the physical layout of FIG. 4a will generally possess the same physical limitations as the earlier generation memory channel of FIG. 3b.
FIG. 4b therefore shows an improved memory channel approach that conforms to the DDR5 host side interface 430 (at least in terms of CA and DQ bus wire-count, pin-out and/or signaling) but in which the different DIMMs do not couple to the interface 430 in a multi-drop fashion. Instead, comparing FIG. 4a and FIG. 4b, the data bus of the memory channel in FIG. 4b is split into a pair of point-to-point (P2P) data busses DQ_1, DQ_2 that each connect a different DIMM to the host. With point-to-point links rather than multi-drop busses being incorporated into the improved layout of FIG. 4b, the layout of FIG. 4b should be able to exhibit faster operating frequencies and/or data rates than the nominal DDR5 approach of FIG. 4a.
FIG. 4c shows an improved DIMM 400, referred to as enhanced LRDIMM (eLRDIMM), that can be plugged into either of the slots 421_1, 421_2 of the improved memory channel design of FIG. 4b. Here, the eLRDIMM 400 of FIG. 4c is designed to multiplex 32 bit transfers over a same burst time window to two different ranks of memory chips. More specifically, the DIMM 400 is designed to multiplex data transfers between one rank of memory chips from group 409_1 (rank_0 or rank_1) and one rank of memory chips from group 409_2 (rank_2 or rank_3).
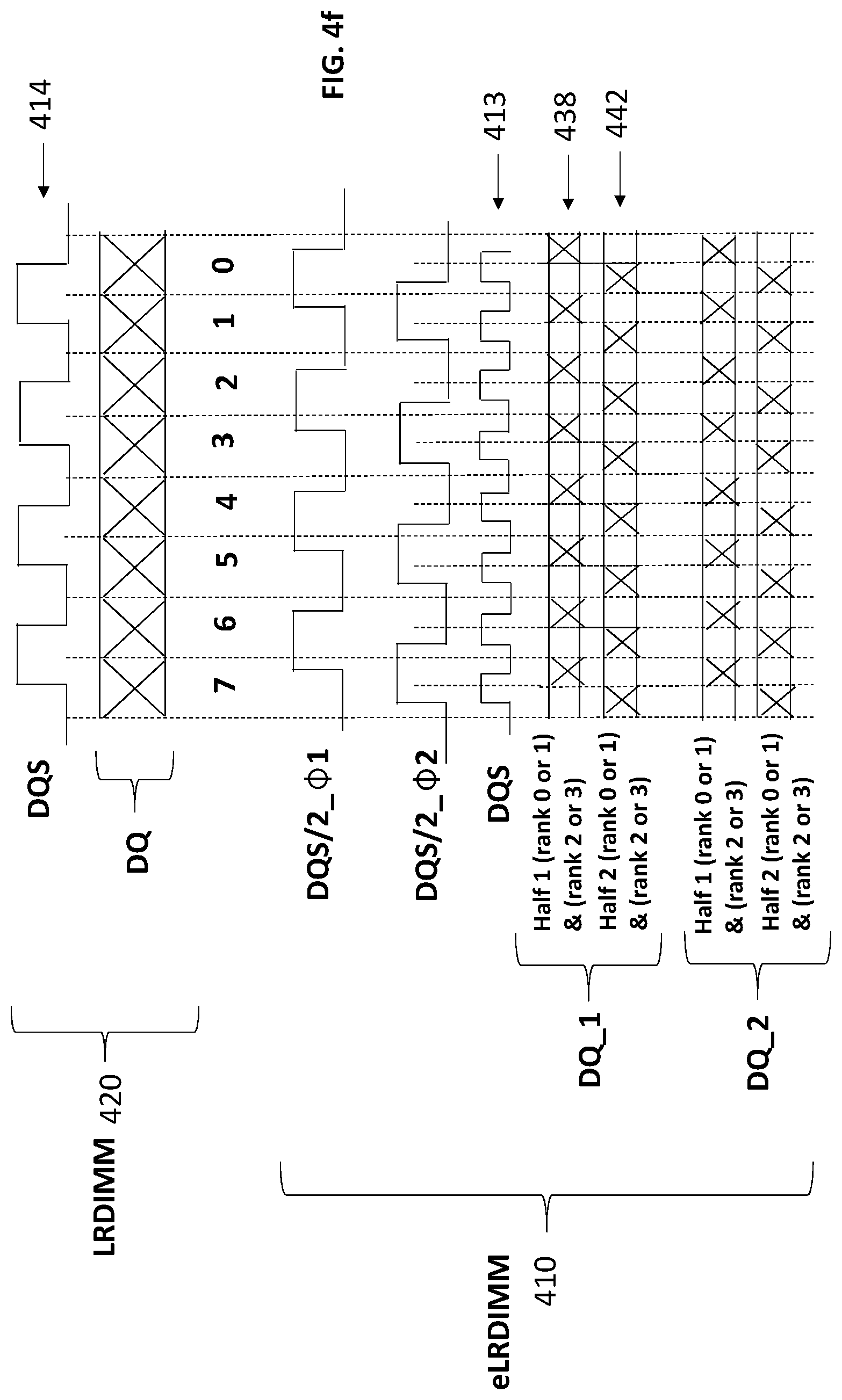
FIG. 4d shows a high level view of the write timing. Inset 410 shows a write transfer as performed by the improved eLRDIMM 400 of FIG. 4c, while, inset 420 shows a write transfer for the prior art DDR4 LRDIMM 300 of FIG. 3a as a point of comparison. As observed at inset 420, the prior art DDR4 LRDIMM 300 receives eight transfers of 64 bits over eight cycles 0 through 7 to effect a total burst of 512 bits.
By contrast, referring to the improved eLRDIMM write process of inset 410, the transfer process over a single data bus (DQ_1) consists of two multiplexed data streams 408, 412 that target different ranks of memory chips of the eLRDIMM that is coupled to the data bus (eLRDIMM 1). In particular, referring to FIG. 4c, data stream 408 targets one of rank 0 and rank 1, and, data stream 412 targets one of rank 2 and rank 3. A multiplexer 407 on the eLRDIMM provides the multiplexing between the data transfers on the DQ_1 bus and the two targeted ranks of memory chips.
More specifically, during a first cycle (0) of the eLRDIMM data strobe (DQS) signal 413, a first 32 bit transfer on the DQ_1 bus targets a first rank of memory chips within group 409_1 at base address A. During a second immediately following DQS cycle (1), a second 32 bit transfer on the DQ_1 bus targets a second rank of memory chips within group 409_2 at base address B. During a third immediately following DQS cycle (3), a third 32 bit transfer on the DQ_1 bus targets the first rank of memory chips within group 409_1 at incremented address A+1. During a fourth immediately following DQS cycle, a fourth 32 bit transfer on the DQ_1 bus targets a fourth rank of memory chips within group 409_2 at incremented base address B+1.
The process continues until 512 bits have been transferred for both targeted ranks of memory chips which corresponds to 16 cycles for each of the targeted ranks of memory chips (32 bits per transfer.times.16 transfers=512 bits) which, in turn, corresponds to 32 total cycles of the DQS signal 413 because of the multiplexing activity. FIG. 4d therefore only shows half of a complete 512 transfer per targeted rank of memory chips (only eight cycles per targeted rank is depicted).
Note that the total amount of data transferred on the DQ_1 bus by the eLRDIMM process 420 over the depicted eight cycles (256 bits for each of streams 408 and 412=512 total bits) is the same as the total amount of data transferred by the prior art DDR4 process 410 (64 bits per transfer.times.8 transfers=512 bits). However, because there are two separate DQ data busses with an eLRDIMM interface 430 (DQ_1 and DQ_2), two different eLRDIMMs can be accessed simultaneously (eLRDIMM 1 on DQ_1 and eLRDIMM 2 on DQ_2) thereby doubling the bandwidth of the overall eLRDIMM memory interface 430 from the perspective of the host as compared to a DDR4 interface.
That is, when accounting for both DQ_1 and DQ_2, the eLRDIMM write process 420 transfers twice as much data as the prior art DDR4 process 410. Thus, the doubled speed of the eLRDIMM DQS signal 413 as compared to the prior art DDR4 DQS signal translates into a doubling of total data rate through the interface 430 from the perspective of the host. The higher frequency DQS signal 413 and associated data signals on the DQ_1 and DQ_2 busses with the eLRDIMM approach 410 is achievable because, as discussed above with respect to FIG. 4b, a multi-drop bus approach is not undertaken on either of the DQ_1 and DQ_2 busses which permits higher frequency signals to exist on these busses.
Importantly, the speed/frequency of the memory chips on the eLRDIMM need not double. Here, the multiplexing activity of the eLRDIMM effects transfer to each of the targeted ranks of memory chips once per DQS cycle. As such, with only one transfer per DQS cycle, both the ranks of targeted memory chips operate at approximately the same frequency/speed as the memory chips of the prior art LRDIMM 300 of FIG. 3a.
The eLRDIMM approach 410 also transfers the combined data targeted for both ranks of memory chips according to a double data rate technique on the DQ_1 and DQ_2 busses (both rising and falling edges of the DQS signal 413 corresponds to DQS cycles). The multiplexing activity on the eLRDIMM, however, causes the memory chips themselves to be accessed according to a double data rate technique with a clock having a frequency that is one half the frequency of the DQS signal 413 (each memory chip experiences a data transfer on the rising and falling edge of a clock resembling slower clock 414). These clocks are represented by the DQS/2_.PHI.31 and DQS/2_.PHI.32 signals in FIG. 4d.
The DQS/2_.PHI.31 and DQS/2_.PHI.32 signals indicate that the different targeted ranks of memory chips that are multiplexed over a same burst window can be accessed at different time with respect to one another. For example, the rank of memory chips from the first group 409_1 is accessed at a first clock phase and the rank of memory chirp from the second group 409_1 is accessed at a second (e.g., lagging) clock phase. In such embodiments, ranks of data emerge from the buffering logic circuitry 406 in the sequence order in which they are received from the data bus (in the case of a write). The multiplexer 407 then steers the data to the correct target of memory chips. Here, the register and redrive circuitry 405 may craft the correct channel select input to the multiplexer 407 and memory chip access signals to the correct rank of memory chips to effect the correct multiplexing activity.
Other approaches may choose to access the different targeted ranks of memory chips that are multiplexed over a same burst window in phase with one another (at the same time). For example, according to approach, the buffering logic circuitry 406 may, e.g., impose a store-and-forward approach to one of the targeted rank's data streams to eliminate the phase difference that exists between the respective data streams of the pair of targeted ranks on the data bus. For example, referring to FIG. 4d, the data targeted to the rank of memory chips in the first group 409_1 (represented by stream 408) may be delayed by the buffer circuitry 406 for one cycle of the DQS signal 413 which, in turn, temporarily aligns the data with the data that is targeted to the rank of memory chips in the second group 409_2 (represent by stream 412). Data from both streams can then be simultaneously written into both targeted ranks of memory chips.
Note that this approach may obviate the existence of any actual multiplexing circuitry 406. That is, the multiplexing activity of the eLRDIMM is logically (rather than actually) effected with the store and forwarding performed by the buffer circuitry. As such, multiplexing circuitry should be understood to include not only actual multiplexing circuitry (such as multiplexer 407) but also circuitry designed to eliminate phase differences in data through store-and-forwarding (which may be performed by buffer circuitry 406). Other embodiments may include both actual multiplexing circuitry and store-and-forwarding circuitry. In embodiments that do use actual multiplexing circuitry, such actual multiplexing circuitry may be physically integrated into the buffer semiconductor chips used to implement buffer circuitry 406.
To reiterate, in actual DDR5 implementations, the rank size is 32 bits which corresponds to the amount of data that is transferred on the data bus per DQS cycle. However, the size of the data bus is larger than that to accommodate the ECC bits (e.g., 32 bits data plus 8 bits ECC=40 total data bus bits). The ranks of memory chips are likewise designed with a data width to accommodate both data and ECC (e.g., 40 bits wide).
Although the above description has been directed to a write process, a read process can transpire by reading data from selected ranks on both DIMMs consistent with the techniques described above. As with writes, the pair of targeted ranks of memory chips may be accessed out-of-phase with one another (e.g., with actual multiplexing circuitry and no store-and-forwarding in the read direction in the buffer circuitry) or simultaneously with one another (e.g., with store-and-forwarding in the read direction in the buffer circuitry).
FIG. 4e shows another eLRDIMM embodiment in which the data bus simultaneously transfers two "half ranks" for both of the targeted rank of memory chips. For example, again using a DDR5 example, the data bus physically includes wiring for 32 data bits of transfer. During any single transfer on the bus, however, a first group of 16 bits are for a first targeted rank of memory chips and a second group of 16 bits are for a second targeted rank of memory chips. The multiplexing that is performed on the eLRDIMM, therefore, is "within a rank" in that two consecutive 16 bit transfers on the data bus are multiplexed up (in the case of a write) or down (in the case of a read) between the data bus and a 32 bit wide targeted rank of memory chips.
The eLRDIMM therefore consists of two separate 16 bit wide data interfaces 421, 422 each having dedicated logic that multiplexes between two different 16 bit halves of a targeted rank of memory chips. In the particular eLRDIMM embodiment of FIG. 4e, for any particular burst write sequence, the first 16 bit wide interface 421 multiplexes between rank halves of either the rank_0 rank of memory chips or the rank_1 rank of memory chips, and, the second 16 bit wide interface 422 multiplexes between rank halves of either the rank_2 rank of memory chips or the rank_3 rank of memory chips.
FIG. 4f shows a corresponding timing diagram. Here, both of the DQ_1 and DQ_2 data busses are observed to multiplex between: 1) a first data stream 438 that simultaneously carries a first half rank for rank 0 or rank 1 and a first half rank for rank 2 or rank 3; and, 2) a second data stream 442 that simultaneously carries a second half rank for rank 0 or rank 1 and a second half rank for rank 2 or rank 3. Again, in the case of DDR5, a half rank corresponds to 16 bits. With two half ranks being simultaneously carried during any particular DQS cycle, 32 data bits are transferred per cycle.
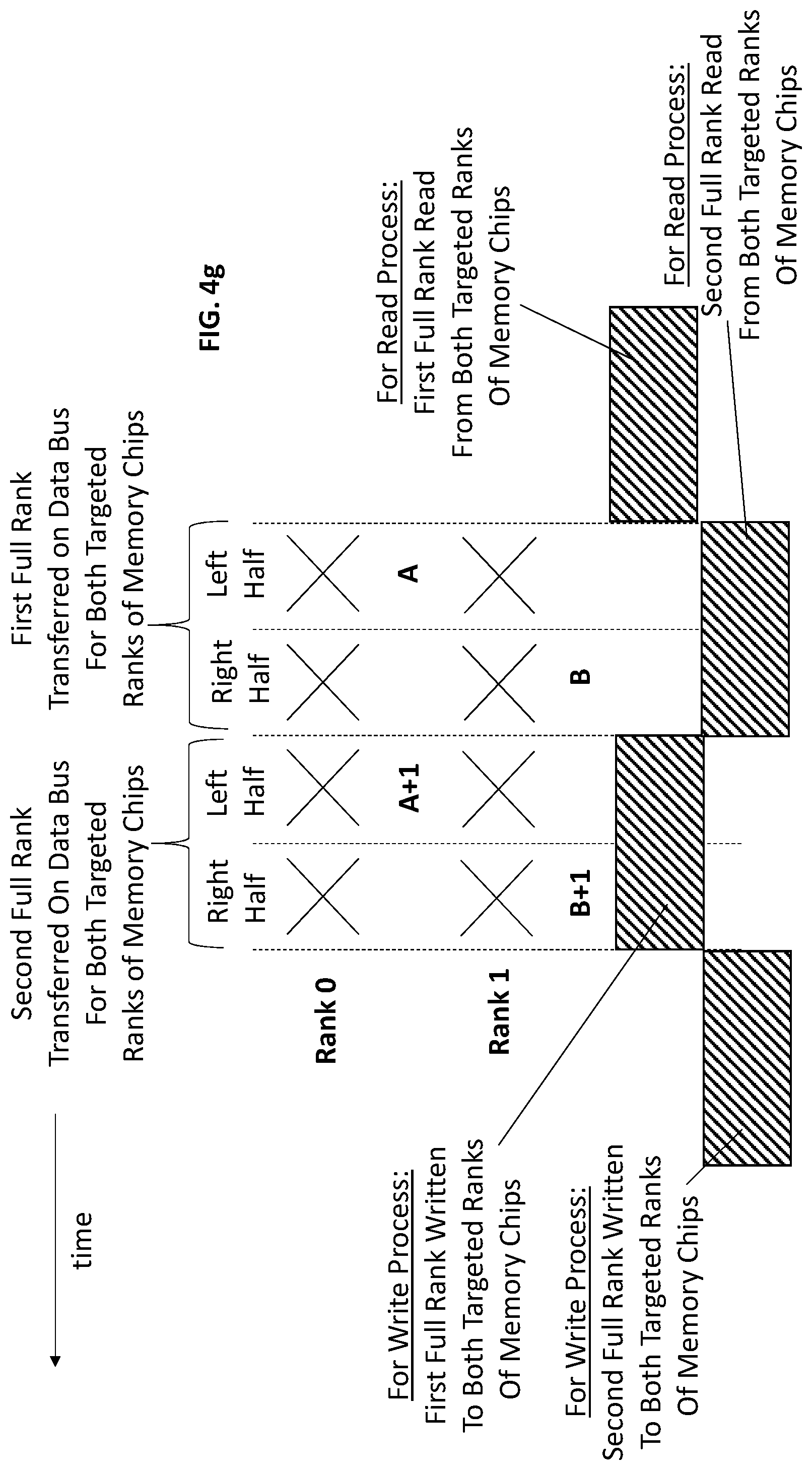
FIG. 4g shows additional detail for a particular data bus transfer with the eLRDIMM embodiment of FIG. 4e. Here, notably, the addresses for the different targeted ranks of memory chips (A and B) are multiplexed on the CA bus over consecutive DQS cycles. FIG. 4g also depicts relative timings between data bus transfers and memory accesses for both write and read processes. Similar to the eLRDIMM of FIG. 4c, multiplexing of half ranks may be accomplished with actual multiplexing circuitry (e.g., multiplexers 427, 429) or logical multiplexing circuitry (e.g., store-and-forwarding with buffer circuits 426, 428) or some combination of both. Actual multiplexer circuitry may be integrated into buffer semiconductor chips.
FIG. 5a shows an exemplary memory controller 501 that is capable of driving a memory channel as described above having the eLRDIMM of FIG. 4c plugged into its DQ_1 and DQ_2 data busses. The memory controller comprises first and second memory interfaces 504_1, 504_2 that each comprise a pair of DQ point-to-point link interfaces for corresponding to a respective DIMM in a point-to-point fashion as discussed above. Each interface therefore includes first and second groups of input/outputs (I/Os) to respective couple to first and second DQ point-to-point links.
As observed in FIG. 5a the memory controller receives memory read and memory write requests at input node 502. Scheduler and address mapping circuitry 503 orders and directs the requests to an appropriate memory channel interface (e.g., interface 504_1 or 504_2). Notably, each memory channel interface includes its own address mapping logic circuitry (not shown in FIG. 5a for illustrative ease) to map each request to its correct DIMM slot (said another way, the correct one of DQ_1 and DQ_2). As such, with two separate DQ channels that terminate at two separate DIMM slots, the memory interface circuitry 504_1 itself has to map the addresses of the requests it receives to a particular one of the DQ channels/DIMM slots.
Here, an inbound queue 505_1, 505_2 precedes each interface 504_1, 504_2 and the address mapping circuitry of an interface may pull requests out-of-order from the queue to keep both DIMMs that are coupled to the interface busy (e.g., if the front of the queue contains requests that map to only one of the DQ busses, the address mapping logic may pull a request from deeper back in the queue that maps to the other DQ channel). Such pulling of requests may further take into account the multiplexing activity on any particular DQ bus. For instance, as described with respect to the eLRDIMM implementation of FIG. 4c, the eLRDIMM is constructed to concurrently multiplex between two different groups of ranks of memory chips, a "left" group 409_1 and a "right" group 409_2.
Here, certain higher order bits of a request's address may map to one or the other of these groups 409_1, 409_2. In order to keep a particular one of the DQ busses at maximum capacity when possible, the interface's address mapping logic circuitry may service requests out-of-order from the interface's queue so that requests whose addresses map to different groups of a same eLRDIMM (same DQ bus) can be serviced concurrently and multiplexed on the eLRDIMM's particular DQ bus.
Likewise, the memory interface circuitry 504_1 includes a pair of multiplexer circuits 506_1 and 506_2, one for each DQ bus (DQ_1 and DQ_2), to multiplex data from two different rank groups to/from a same DQ bus during a same burst transfer process as described above. As described above, both multiplexers 506_1, 506_2 may concurrently operate to concurrently transfer the data of four data ranks between the interface 504_1 and the pair of DIMM slots it is coupled to during a same burst transfer sequence. Multiplexing may be done actually or logically (e.g., with store-and-forward circuitry).
Each memory interface 504_1, 504_2 also includes signal generation logic circuitry to generate the appropriate CA and DQ signals for each DIMM consistent with the teachings above. The memory controller 501 may include configuration register space (not depicted in FIG. 5 for illustrative ease) whose corresponding information is used to configure each memory interface. In an embodiment, the register space is used to define whether the memory interfaces are to operate in an eLRDIMM mode as described above, or, operate according to a DDR5 mode. If the later is specified, the multiplexing activity of the memory controller is disabled and data for only a single rank of memory chips is propagated on any DQ_1 or DQ_2 bus during a burst transfer.
FIG. 5b shows an embodiment of a memory controller that is designed to communicate with the eLRDIMM embodiment of FIG. 4e. For simplicity, circuitry that feeds only one of an interface's DQ busses is depicted per interface. Here, the memory controller operates as described above in FIG. 5a except that the transfers for left and right groups of memory chips of a same eLRDIMM are simultaneously transferred on different halves of the DQ bus that the eLRDIMM is connected to (in FIG. 4e, rank_0 and rank_1 correspond to the left rank group and rank_2 and rank_3 correspond to the right rank group). As such, there is a left rank group channel and a right rank group channel that physically append to one another at the DQ interface. Both channels have respective multiplexers 516_1, 516_2 to multiplex between halves of a same targeted rank as described above with respect to FIGS. 4e and 4f.
Here, address mapping circuitry within an interface 514 may cause the interface to service requests out-of-order not only to keep different DQ busses busy but also to promote multiplexing on any particular DQ bus. As such, again, the address mapping circuitry will look to pull requests directed to different rank groups of a same eLRDIMM together so that they can multiplex together on the eLRDIMM's DQ bus.
Although discussions above has been directed to a particular DDR5 implementation specifying, e.g., number of cycles per burst transaction, number of DIMM slots per interface, 2:1 multiplexing ratio, memory chip clock being half the channel clock, etc., it is pertinent to recognize that other embodiments may exist having different numbers for these and other features than those described above. For example, a DIMM that architecturally groups ranks in groups of four may use a 4:1 multiplexing ratio and its memory chips that receive a DQS/4 clock. Embodiments also exist having values of M other than 64 or rank sizes other than 32.
FIG. 6 provides an exemplary depiction of a computing system 600 (e.g., a smartphone, a tablet computer, a laptop computer, a desktop computer, a server computer, etc.). As observed in FIG. 6, the basic computing system 600 may include a central processing unit 601 (which may include, e.g., a plurality of general purpose processing cores 615_1 through 615_X) and a main memory controller 617 disposed on a multi-core processor or applications processor, system memory 602, a display 603 (e.g., touchscreen, flat-panel), a local wired point-to-point link (e.g., USB) interface 604, various network I/O functions 605 (such as an Ethernet interface and/or cellular modem subsystem), a wireless local area network (e.g., WiFi) interface 606, a wireless point-to-point link (e.g., Bluetooth) interface 607 and a Global Positioning System interface 608, various sensors 609_1 through 609_Y, one or more cameras 610, a battery 611, a power management control unit 612, a speaker and microphone 613 and an audio coder/decoder 614.
An applications processor or multi-core processor 650 may include one or more general purpose processing cores 615 within its CPU 601, one or more graphical processing units 616, a memory management function 617 (e.g., a memory controller) and an I/O control function 618. The general purpose processing cores 615 typically execute the operating system and application software of the computing system. The graphics processing unit 616 typically executes graphics intensive functions to, e.g., generate graphics information that is presented on the display 603. The memory control function 617 interfaces with the system memory 602 to write/read data to/from system memory 602. The power management control unit 612 generally controls the power consumption of the system 600.
Each of the touchscreen display 603, the communication interfaces 604-507, the GPS interface 608, the sensors 609, the camera(s) 610, and the speaker/microphone codec 613, 614 all can be viewed as various forms of I/O (input and/or output) relative to the overall computing system including, where appropriate, an integrated peripheral device as well (e.g., the one or more cameras 610). Depending on implementation, various ones of these I/O components may be integrated on the applications processor/multi-core processor 650 or may be located off the die or outside the package of the applications processor/multi-core processor 650. The computing system also includes non-volatile storage 620 which may be the mass storage component of the system.
The main memory control function 617 (e.g., main memory controller, system memory controller) may be designed consistent with the teachings above describing a host side memory interface that is able to multiplex data directed to/from different ranks of memory chips through a same host side memory interface during a same burst transfer to/from, e.g., an eLRDIMMs as described above.
Embodiments of the invention may include various processes as set forth above. The processes may be embodied in machine-executable instructions. The instructions can be used to cause a general-purpose or special-purpose processor to perform certain processes. Alternatively, these processes may be performed by specific/custom hardware components that contain hardwired logic circuitry or programmable logic circuitry (e.g., field programmable gate array (FPGA), programmable logic device (PLD)) for performing the processes, or by any combination of programmed computer components and custom hardware components.
Elements of the present invention may also be provided as a machine-readable medium for storing the machine-executable instructions. The machine-readable medium may include, but is not limited to, floppy diskettes, optical disks, CD-ROMs, and magneto-optical disks, FLASH memory, ROMs, RAMs, EPROMs, EEPROMs, magnetic or optical cards, propagation media or other type of media/machine-readable medium suitable for storing electronic instructions. For example, the present invention may be downloaded as a computer program which may be transferred from a remote computer (e.g., a server) to a requesting computer (e.g., a client) by way of data signals embodied in a carrier wave or other propagation medium via a communication link (e.g., a modem or network connection).
In the foregoing specification, the invention has been described with reference to specific exemplary embodiments thereof. It will, however, be evident that various modifications and changes may be made thereto without departing from the broader spirit and scope of the invention as set forth in the appended claims. The specification and drawings are, accordingly, to be regarded in an illustrative rather than a restrictive sense.
* * * * *
D00000
D00001
D00002
D00003
D00004
D00005
D00006
D00007
D00008
D00009
D00010
D00011
D00012

D00013

D00014

XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.