Determining whether to perform address translation to forward a service request or deny a service request based on blocked service attributes in an IP table in a container-based computing cluster management system
Shimoga Manjunatha , et al. November 24, 2
U.S. patent number 10,848,552 [Application Number 15/994,073] was granted by the patent office on 2020-11-24 for determining whether to perform address translation to forward a service request or deny a service request based on blocked service attributes in an ip table in a container-based computing cluster management system. This patent grant is currently assigned to Hewlett Packard Enterprise Development LP. The grantee listed for this patent is Hewlett Packard Enterprise Development LP. Invention is credited to Koteswara Rao Kelam, Sangeeta Maurya, John Joseph McCann, III, Syed Ahmed Mohiuddin Peerzade, Selvakumar Sanmugam, Pradeep Sathasivam, Praveen Kumar Shimoga Manjunatha, Sonu Sudhakaran, Krishna Mouli Tankala, Ravikumar Vallabhu.
| United States Patent | 10,848,552 |
| Shimoga Manjunatha , et al. | November 24, 2020 |
Determining whether to perform address translation to forward a service request or deny a service request based on blocked service attributes in an IP table in a container-based computing cluster management system
Abstract
In an example, a container cluster management system includes a cluster manager providing access to services provided by containers within a container cluster and a plurality of nodes. Each node has access to an IP table, and is to forward a service request for a service received via the cluster manager to at least one container sub-cluster by translating a destination address of the service request to an IP address of a container sub-cluster. At least one of the nodes comprises a proxy manager, to manage an IP table of the node and a service firewall, to add a service-specific rule to the IP table.
| Inventors: | Shimoga Manjunatha; Praveen Kumar (Bangalore Karnataka, IN), Sudhakaran; Sonu (Bangalore Karnataka, IN), Sanmugam; Selvakumar (Bangalore Karnataka, IN), Tankala; Krishna Mouli (Bangalore Karnataka, IN), Sathasivam; Pradeep (Bangalore Karnataka, IN), McCann, III; John Joseph (Fort Collins, CO), Maurya; Sangeeta (Bangalore Karnataka, IN), Kelam; Koteswara Rao (Bangalore Karnataka, IN), Mohiuddin Peerzade; Syed Ahmed (Bangalore Karnataka, IN), Vallabhu; Ravikumar (Bangalore Karnataka, IN) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Applicant: |
|
||||||||||
| Assignee: | Hewlett Packard Enterprise
Development LP (Houston, TX) |
||||||||||
| Family ID: | 1000005204986 | ||||||||||
| Appl. No.: | 15/994,073 | ||||||||||
| Filed: | May 31, 2018 |
Prior Publication Data
| Document Identifier | Publication Date | |
|---|---|---|
| US 20190306231 A1 | Oct 3, 2019 | |
Foreign Application Priority Data
| Mar 29, 2018 [IN] | 201841012010 | |||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | H04L 61/2007 (20130101); H04L 61/255 (20130101); H04L 67/16 (20130101); G06F 9/5083 (20130101); H04L 63/0281 (20130101); H04L 67/1031 (20130101); H04L 63/0263 (20130101); H04L 67/1034 (20130101); H04L 67/32 (20130101) |
| Current International Class: | H04L 29/08 (20060101); H04L 29/12 (20060101); G06F 9/50 (20060101); H04L 29/06 (20060101) |
References Cited [Referenced By]
U.S. Patent Documents
| 6392990 | May 2002 | Tosey |
| 6801949 | October 2004 | Bruck |
| 7200865 | April 2007 | Roscoe |
| 7299294 | November 2007 | Bruck |
| 7373644 | May 2008 | Aborn |
| 7546354 | June 2009 | Fan |
| 7657501 | February 2010 | Brown |
| 7962582 | June 2011 | Potti |
| 8306951 | November 2012 | Ghosh |
| 8434080 | April 2013 | Yendluri |
| 8706798 | April 2014 | Suchter |
| 8806605 | August 2014 | Chickering |
| 8954979 | February 2015 | Myers |
| 9027087 | May 2015 | Ishaya |
| 9141410 | September 2015 | Leafe |
| 9143530 | September 2015 | Qureshi |
| 9154367 | October 2015 | Kontothanassis |
| 9304999 | April 2016 | Bono |
| 9471798 | October 2016 | Vepa |
| 9529996 | December 2016 | Qureshi |
| 9563480 | February 2017 | Messerli |
| 9634948 | April 2017 | Brown |
| 9692727 | June 2017 | Zhou |
| 9755898 | September 2017 | Jain |
| 9813307 | November 2017 | Walsh |
| 9819699 | November 2017 | Nenov |
| 9870412 | January 2018 | Ghosh |
| 9935829 | April 2018 | Miller |
| 9935834 | April 2018 | Baveja |
| 9985894 | May 2018 | Baveja |
| 10033631 | July 2018 | Baveja |
| 10075429 | September 2018 | Jayanti Venkata |
| 10091112 | October 2018 | Sharma |
| 10091238 | October 2018 | Shieh |
| 10110668 | October 2018 | Sharma |
| 10133619 | November 2018 | Nagpal |
| 10181047 | January 2019 | Lim |
| 10191758 | January 2019 | Ross |
| 10284473 | May 2019 | Sharma |
| 10326672 | June 2019 | Scheib |
| 10333986 | June 2019 | Lian |
| 10348767 | July 2019 | Lee |
| 10367787 | July 2019 | Gupta |
| 10382329 | August 2019 | Thomas |
| 10432638 | October 2019 | Nambiar |
| 10439987 | October 2019 | Church |
| 10445197 | October 2019 | Harpreet |
| 10469389 | November 2019 | Sharma |
| 10491522 | November 2019 | Sharma |
| 10530747 | January 2020 | Saxena |
| 10574513 | February 2020 | Nagarajan |
| 10608881 | March 2020 | Teng |
| 10608990 | March 2020 | Parvanov |
| 10659523 | May 2020 | Joseph |
| 10698714 | June 2020 | Krishnamurthy |
| 10708082 | July 2020 | Bakiaraj |
| 10708230 | July 2020 | Huang |
| 2002/0049859 | April 2002 | Bruckert |
| 2003/0018927 | January 2003 | Gadir |
| 2003/0217134 | November 2003 | Fontoura |
| 2004/0088408 | May 2004 | Tsyganskiy |
| 2004/0215639 | October 2004 | Bamford |
| 2007/0060143 | March 2007 | Bhatti |
| 2007/0083725 | April 2007 | Kasiolas |
| 2010/0287263 | November 2010 | Liu |
| 2011/0071981 | March 2011 | Ghosh |
| 2012/0233668 | September 2012 | Leafe |
| 2013/0046731 | February 2013 | Ghosh |
| 2013/0159487 | June 2013 | Patel |
| 2013/0205028 | August 2013 | Crockett |
| 2013/0212264 | August 2013 | Troppens |
| 2013/0219010 | August 2013 | Mahendran |
| 2013/0326507 | December 2013 | McGrath |
| 2014/0047084 | February 2014 | Breternitz |
| 2014/0130054 | May 2014 | Molkov |
| 2014/0215057 | July 2014 | Walsh |
| 2014/0282889 | September 2014 | Ishaya |
| 2015/0082417 | March 2015 | Bhagwat |
| 2015/0134822 | May 2015 | Bhagwat |
| 2015/0156183 | June 2015 | Beyer |
| 2016/0021026 | January 2016 | Aron |
| 2016/0094668 | March 2016 | Chang |
| 2016/0170668 | June 2016 | Mehra |
| 2016/0212012 | July 2016 | Young |
| 2016/0359697 | December 2016 | Scheib |
| 2017/0004057 | January 2017 | Brown |
| 2017/0093661 | March 2017 | Deulgaonkar |
| 2017/0199770 | July 2017 | Peteva |
| 2017/0331739 | November 2017 | Sharma |
| 2018/0019969 | January 2018 | Murthy |
| 2018/0063025 | March 2018 | Nambiar |
| 2018/0205652 | July 2018 | Saxena |
| 2018/0234459 | August 2018 | Kung |
| 2018/0295036 | October 2018 | Krishnamurthy |
| 2018/0359218 | December 2018 | Church |
| 2018/0367371 | December 2018 | Nagarajan |
| 2019/0097975 | March 2019 | Martz |
| 2020/0099610 | March 2020 | Heron |
| 2020/0106744 | April 2020 | Miriyala |
| 2020/0137185 | April 2020 | Parekh |
| 103957237 | Jul 2014 | CN | |||
| 106888254 | Jun 2017 | CN | |||
| 2012/057956 | May 2012 | WO | |||
Other References
|
Amazon Web Services, Inc., "Elastic Load Balancing," 2017, pp. 1-7. cited by applicant . Armstrong, D., et al., "Towards Energy Aware Cloud Computing Application Construction," Jun. 23, 2017, pp. 1-23. cited by applicant . Banerjee, P. K.; "Deploying a Service on a Kubernetes Cluster," Mar. 8, 2016, pp. 1-10. cited by applicant . Bhatia, J.; "A Dynamic Model for Load Balancing in Cloud Infrastructure," NIRMA University Journal of Engineering and Technology, Jan.-Jun. 2015, pp. 15-19, vol. 4, No. 1. cited by applicant . F5 Networks, Inc. "Load Balancing 101: Nuts and Bolts," White Paper, May 10, 2017, pp. 1-8. cited by applicant . Kabar, N.; "Docker Reference Architecture: Service Discovery and Load Balancing with Docker Universal Control Plane (UCP 1.1)," 2017, pp. 1-16. cited by applicant . Openshift; "Application Health," 2017, pp. 1-2 [online], Retrieved from the Internet on Dec. 5, 2017 at URL: <docs.openshift.com/container-platform/3.4/dev_guide/application_healt- h.html>. cited by applicant . Openshift; "Using a Service External IP to Get Traffic into the Cluster," 2017, pp. 1-7 [online], Retrieved from the Internet on Dec. 5, 2017 at URL: <docs.openshift.com/container-platform/3.4/dev_guide/expose_servi- ce/expose_internal_ip_service.html>. cited by applicant . Scholes, M.; "Deploy an App Into Kubernetes Using Advanced Application Services," Jun. 22, 2017, pp. 1-11. cited by applicant . Slideshare.net; "Kubernetes and Software Load Balancers," Mar. 24, 2017, pp. 1-10 [online], Retrieved from the Internet on Dec. 5, 2017 at URL: <slideshare.net/haproxytech/kubernetes-and-software-load-balancers-735- 98367>. cited by applicant . The Openstack; "Load-Balancing Policy," Dec. 4, 2017, pp. 1-6. cited by applicant . Total Uptime, "Load Balancing and Failover Between AWS Regions," Sep. 19, 2015, pp. 1-3 [online], Total Uptime Technologies, LLC, Retrieved from the Internet on Dec. 5, 2017 at URL: <totaluptime.com/load-balancing-and-failover-between-aws-regions/>. cited by applicant . Michael Churchman, "Load-Balancing in Kubernetes," Aug. 14, 2017, pp. 1-5, Retrieved from the Internet on Apr. 20, 2020 at URL: <web.archive.org/web/20180327002500/http://rancher.com/load-balancing-- in-kubernetes/>. cited by applicant . Coles et al., "Rapid Node Reallocation Between Virtual Clusters for Data Intensive Utility Computing", 2006 IEEE International Conference on Cluster Computing, Sep. 1, 2006 (Sep. 1, 2006), 10 pages. cited by applicant . European Search Report and Search Opinion Received for EP Application No. 19165945.7, dated Jul. 8, 2019, 11 pages. cited by applicant . European Search Report and Search Opinion Received for EP Application No. 19165946.5, dated Jul. 10, 2019, 10 pages. cited by applicant. |
Primary Examiner: Murray; Daniel C.
Attorney, Agent or Firm: Hewlett Packard Enterprise Patent Department
Claims
The invention claimed is:
1. A method comprising: receiving, at a node executing on a hardware processor in a container-based computing cluster, a request for a service; determining, by the node, if the request for the service comprises blocked service attributes in an IP table of the node; in response to the request not comprising blocked service attributes, performing, by the node, an address translation to forward the request to a container sub-cluster of the container-based computing cluster; and in response to the request comprising blocked service attributes, denying the request by the node.
2. A method according to claim 1, further comprising advertising at least one of an availability and an accessibility of an IP address of a service to a network.
3. A method according to claim 1, further comprising: adding, by a service firewall of the node, service-specific rules to the IP table.
4. A method according to claim 3, further comprising establishing a cluster manager and a plurality of nodes to provide the container-based computing cluster; and detecting a service creation event adding, by the node, service-specific rules to the IP table follow detection of the service creation event.
5. A method according to claim 3, wherein the service-specific rules restrict address translation to requests specifying a single predetermined port and/or or a single predetermined protocol.
6. The method according to claim 3, wherein the service-specific rules added to the IP table includes a deny rule for accessing the service using a first protocol or a first port.
7. A method according to claim 1, further comprising, in an event of a failure of a first node, reassigning an IP address of the first node to a second node by updating a mapping table associating a virtual router associated with the IP address such that the IP address is associated with the second node.
8. A method according to claim 7, further comprising, in an event that the first node resumes service, reassigning the IP address from the second node to the first node.
9. The method according to claim 1, further comprising monitoring, by a service monitor of the node, for at least one external service; and updating, by a service firewall of the node, the IP table in response to detection of an external service by the service monitor.
10. A non-transitory machine readable medium storing instructions that, when executed by a processor on which a node of a container-based computing cluster is executing, cause the node to: receive a request for a service; determine if the request for the service comprises blocked service attributes in an IP table of the node; respond to the request not comprising blocked service attributes by performing an address translation to forward the request to a container sub-cluster of the container-based computing cluster; and respond to the request comprising blocked service attributes by denying the request.
11. The non-transitory machine readable medium of claim 10 storing instructions that, when executed, cause the node to advertise at least one of an availability and an accessibility of an IP address of a service to a network.
12. The non-transitory machine readable medium of claim 10 storing instructions that, when executed, cause the node to add, by a service firewall, service-specific rules to the IP table.
13. The non-transitory machine readable medium of claim 12, wherein the service-specific rules restrict address translation to requests specifying a single predetermined port or a single predetermined protocol.
14. The non-transitory machine readable medium of claim 10 storing instructions that, when executed, cause the node to respond to a failure of a first node by reassigning an IP address of the first node to a second node by updating a mapping table associating a virtual router associated with the IP address such that the IP address is associated with the second node.
15. The non-transitory machine readable medium of claim 14 storing instructions that, when executed, cause the node to respond to the first node resuming service by reassigning the IP address from the second node to the first node.
16. A system comprising: a processing resource; and a non-transitory machine readable medium storing instructions that, when executed by the processing resource, cause the processing resource to: receive a request for a service, determine if the request for the service comprises blocked service attributes in an IP table of the node, respond to the request not comprising blocked service attributes by performing an address translation to forward the request to a container sub-cluster of the container-based computing cluster, and respond to the request comprising blocked service attributes by denying the request.
17. The system of claim 16, wherein the non-transitory machine readable medium stores instructions that, when executed, cause the processing resource to advertise at least one of an availability and an accessibility of an IP address of a service to a network.
18. The system of claim 16, wherein the non-transitory machine readable medium stores instructions that, when executed, cause the processing resource to add, by a service firewall, service-specific rules to the IP table.
19. The system of claim 18, wherein the service-specific rules restrict address translation to requests specifying a single predetermined port or a single predetermined protocol.
Description
BACKGROUND
Containerized computing systems provide a readily scalable architecture for the individual deployment of a plurality of programs which may utilise the same underlying resource.
BRIEF DESCRIPTION OF DRAWINGS
Non-limiting examples will now be described with reference to the accompanying drawings, in which:
FIG. 1 is a block diagram of an example of a containerized computing management system;
FIG. 2 is a flow chart of an example of a method of managing a containerized computing system;
FIG. 3 is a block diagram of an example of a worker node of a containerized computing system;
FIG. 4 is a block diagram of another example of a worker node of a containerized computing system;
FIG. 5 is a flow chart of another example of a method of managing a containerized computing system;
FIG. 6 is a flow chart of an example of a method of reassigning IP addresses in a containerized computing system; and
FIG. 7 is a block diagram of another example of a containerized computing management system.
DETAILED DESCRIPTION
The following discussion is directed to various examples of the disclosure. The examples disclosed herein should not be interpreted, or otherwise used, as limiting the scope of the disclosure, including the claims. In addition, the following description has broad application, and the discussion of any example is meant only to be descriptive of that example, and not intended to intimate that the scope of the disclosure, including the claims, is limited to that example. Throughout the present disclosure, the terms "a" and "an" are intended to denote at least one of a particular element. In addition, as used herein, the term "includes" means includes but not limited to. The term "based on" means based at least in part on.
Some computing systems employ `containerization`. Containerization can take place at the operating system level. In some examples, mutually isolated computing instances, known as containers (or in some examples, by other terms such as virtualisation engines or partitions), operate as separate computers from the point of view of programs deployed thereon. While a deployed program may utilise, and be aware of, the resources of its container, it may generally be unaware of the resources of any other container, even where an underlying physical resource is shared.
Thus, a computing resource such as a computer, a server, a memory or the like, may have part of its resources allocated to one container and another part allocated to another. Programs running within containers (and in some examples, there may be several programs running within each container) have access only to the resources allocated to the container. Such computing resources allow for ease of scalability and accessibility of the same underlying resource by mutually distrusting entities with little additional overhead. An example of a container manager and deployment system is Kubemetes.
Solutions for load balancing in containerized computing systems include plugins utilising elastic load balancers to provide external access for containerized services. Such plugins are specialised, advanced features which are specifically tailored to a particular implementation/service provider. Moreover, such solutions may introduce latency into the deployment of containerized services.
In examples described herein, a processing resource may include, for example, one processing resource or multiple processing resources included in a single computing device or distributed across multiple computing devices. As used herein, a "processing resource" may be at least one of a central processing unit (CPU), a semiconductor-based microprocessor, a graphics processing unit (GPU), a field-programmable gate array (FPGA) configured to retrieve and execute instructions, other electronic circuitry suitable for the retrieval and execution of instructions stored on a machine-readable storage medium, or a combination thereof. In examples described herein, entities may communicate with one another via direct connections, via one or more computer networks, or a combination thereof. In examples described herein, a computer network may include, for example, a local area network (LAN), a virtual LAN (VLAN), a wireless local area network (WLAN), a virtual private network (VPN), the Internet, or the like, or a combination thereof.
In examples described herein, a "node" entity is a virtualised processing resource, which may run on all or part of a computing device, such as a server, storage array, storage device, desktop or laptop computer, switch, router, or any other processing device or equipment including a processing resource.
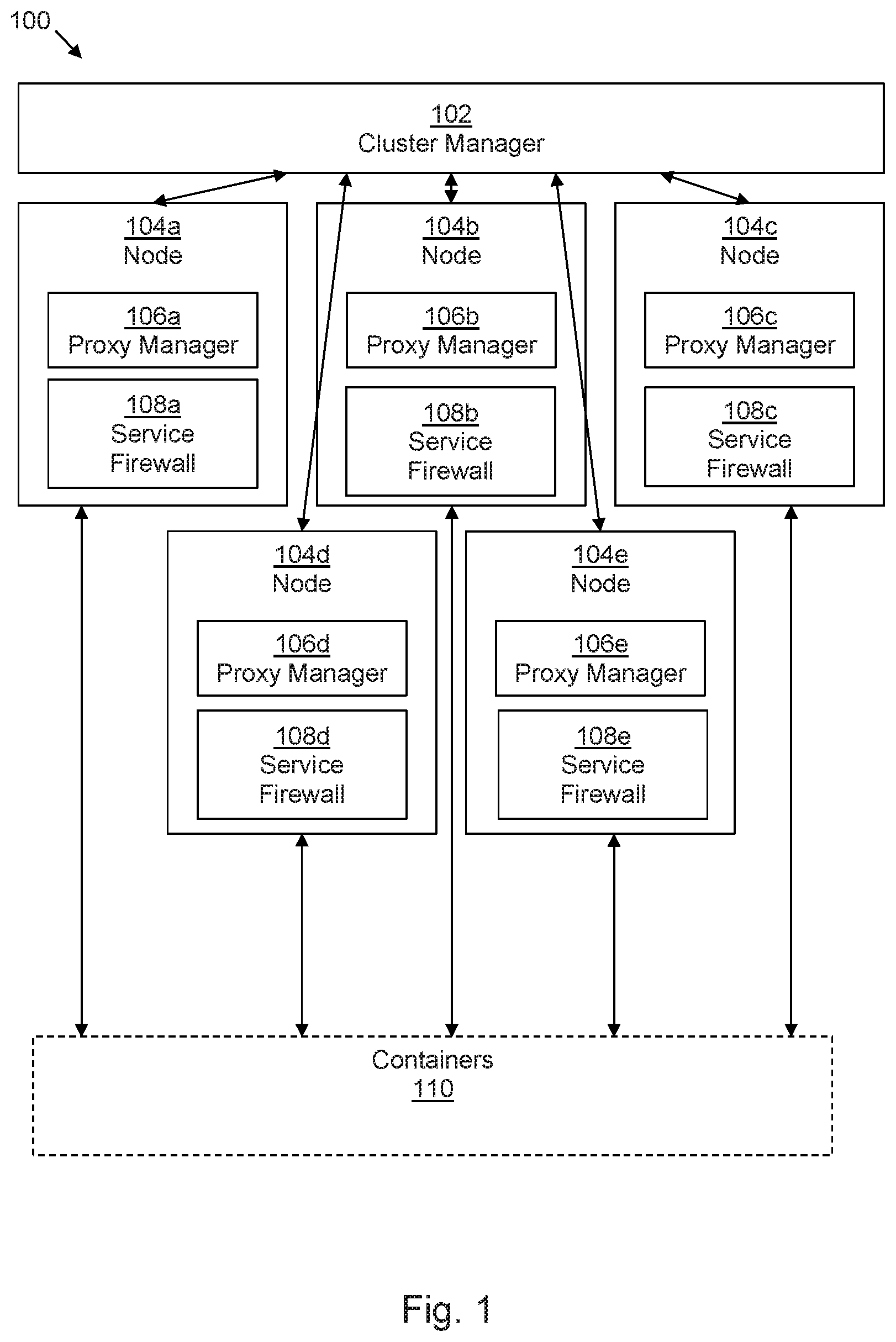
FIG. 1 is an example of a container cluster management system 100 comprising a cluster manager 102 and a plurality of nodes 104a-e. In use of the system 100, the cluster manager 102 provides access to services provided by containers 110.
Each node 104 of the plurality of nodes 104a-e has access to an IP table. The IP table may, for example be stored in a storage resource such as a volatile or non-volatile memory which the node 104 can access. In some examples, a node 104 may be provided as a virtual machine on a processing device and the IP table may be stored in a storage resource of the processing device.
At least one (and in the illustrated example, each) node 104a-e comprises a proxy manager 106a-e and a service firewall 108a-e. Although shown separately herein, a service firewall 108 may constitute part of a proxy manager 106. In use of the system 100, each proxy manager 106 manages the IP table of its node and each service firewall 108 adds service-specific rules to the IP table of its node. While each node is shown as comprising a service firewall 108, this may not be the case in all examples. In some examples, some nodes of the system 100 may comprise a service firewall 108 whereas other nodes of the system 100 may not.
A service may comprise a predetermined set of `pods`, where a pod is a logical host of a set of containers or, expressed another way, a pod comprises a sub-cluster of related containers. For example, a pod's containers may be co-located and co-scheduled, and run in a shared context. Containers within a pod may share an IP address and/or port space, and may be able to communicate with one another (whereas, generally, containers in different pods may have distinct IP addresses and are not typically in direct communication with one another, instead communicating via Pod IP addresses and the like). Applications deployed within a pod may have access to shared `volumes`, which are usually directories, in some examples holding data. Such volumes may be logically considered to be part of a pod, and may have the same life cycle as a pod.
To consider a particular example, a pod may comprise frontend and backend containers, where the frontend containers may provide user interfaces and the like and the backend containers may provide databases, data processing and the like. The containers may work together to provide a service.
A pod (as well as an individual container) may be a temporary configuration. Pods may be created, assigned a unique ID, and scheduled to nodes 104 where they remain until termination (according to restart policy) or deletion. In some examples, if a node 104 fails, the pods scheduled to that node 104 may be scheduled for deletion, after a timeout period.
In use of the system 100, a node 104 forwards service requests for a service received via the cluster manager 102 to at least one container sub-cluster by translating the destination address of the service request to an IP address of a container sub-cluster (which may comprise one or more pods). For example this may utilise Destination Network Address Translation (DNAT) and redirect the incoming traffic to the pod or pods which make up the service identified by the IP address. In some examples, the pods have different IP addresses and, where there is more than one pod, this redirection may be intended to forward traffic to a given pod with a predetermined probability (e.g. an equal probability). A pod's reply may be routed back to a service IP address, i.e. the node 104, and then forwarded thereby to a client.
In this example, the proxy manager 106 manages the IP table of the node and the service firewall 108 adds at least one service-specific rule to the IP table.
This allows load balancing of services through post-routing Destination Network Address Translation (DNAT) rules. In some examples, the at least one rule may comprise a `deny` rule. A deny rule may prevent access to a service via any port and/or using any protocol other than an expected port/protocol. For example, a service may be accessible using an IP address and at least one of a specified port and/or a specified protocol. A deny rule may be configured so as to prevent user access to ports other than the specified port, even if the request comprises the `correct` IP address of the service. Another rule may be provided for protocols other than the specified protocol (for example, User Datagram Protocol (udp), or Transmission Control Protocol (tcp), or any other network protocol). There may be a single specified protocol and/or port for each service.
In some examples, a service may be detected on creation, or may be detected on making its first request to a node 104. In some examples, whenever a service is created, at least one address translation rule (e.g. a DNAT rule, which may comprise a rule for carrying out an address translation) and at least one deny rule may be added to the IP table.
Such a solution de-couples load balancing from a provider (e.g. a cloud provider), and can be handled within the cluster manager 102. The IP table may be a Linux IP table, which may increase the portability and ease of scalability of the solution.
There may be minimal lag in implementing the rules; updating the IP table is an efficient process and therefore the solution may be lightweight and easily maintainable. In some examples, deny rules may be structured so as to deny access to a service via any port other than a predetermined port (in some example, a predetermined single port). In such an example, security may be enhanced. In some examples, deny rules may be structured so as to deny access to a service using any protocol other than a predetermined protocol (in some example, a predetermined single protocol). In some examples, deny rules may be structured so as to deny access to a service using any protocol or port combination other than a predetermined protocol and port combination. The predetermined port/protocol may be specified in a service specification, which may be stored or accessible to the cluster manager 102.
Each of the cluster manager 102, nodes 104a-e, proxy manager 106 and/or the service firewall 108 may be any combination of hardware and programming to implement the described functionalities. In examples described herein, such combinations of hardware and programming may be implemented in a number of different ways. For example, programming may be processing resource executable instructions stored on at least one non-transitory machine-readable storage medium and the hardware may include at least one processing resource to execute those instructions. In some examples, the hardware may also include other electronic circuitry to at least partially implement at least one of the cluster manager 102, nodes 104a-e, proxy manager 106 and/or the service firewall 108. In some examples, the at least one machine-readable storage medium may store instructions that, when executed by the at least one processing resource, at least partially implement some or all of the cluster manager 102, nodes 104a-e, proxy manager 106 and/or the service firewall 108. In such examples, a computing device at least partially implementing the processing cluster manager 102 and/or a node 104a-e may include the at least one machine-readable storage medium storing the instructions and the at least one processing resource to execute the instructions. In other examples, cluster manager 102, nodes 104a-e, proxy manager 106 and/or the service firewall 108 may be implemented by electronic circuitry.
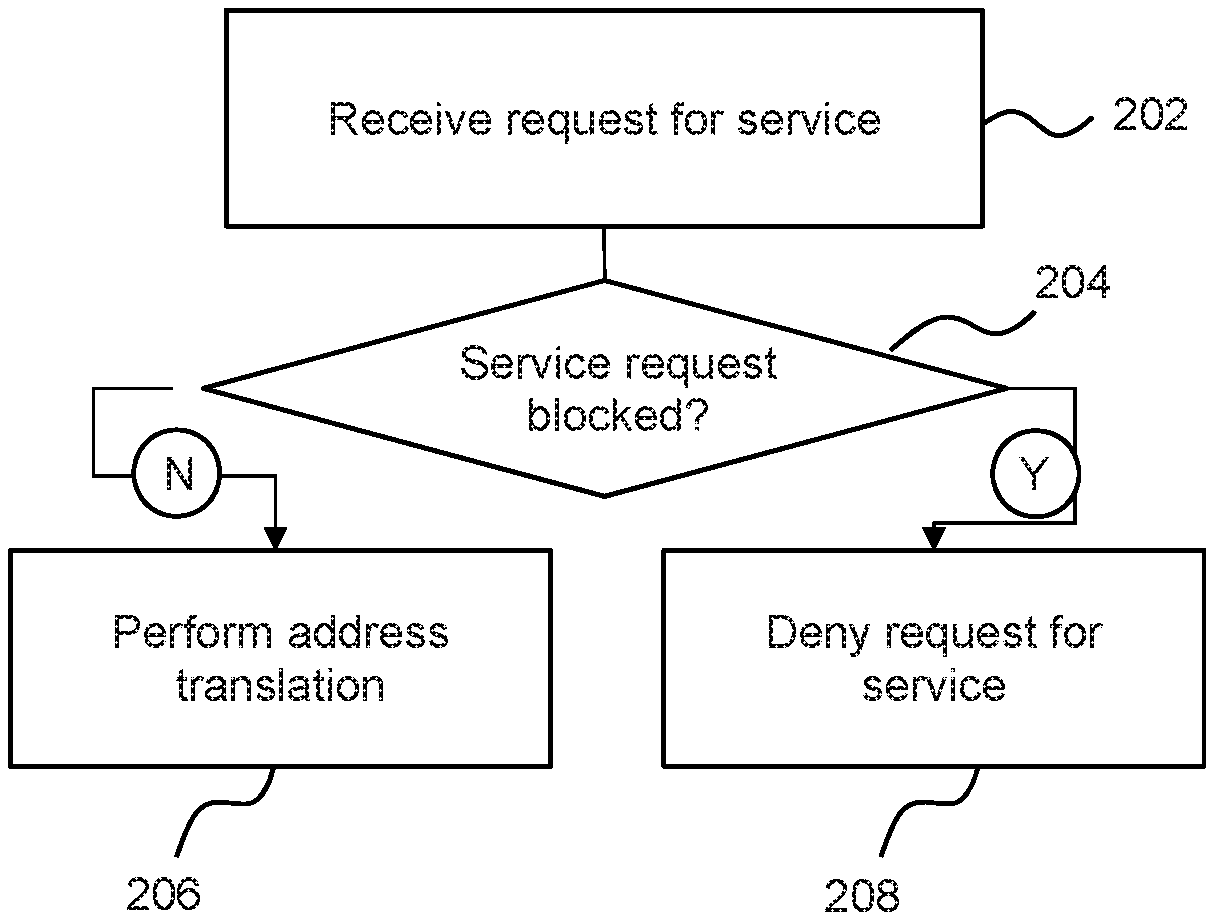
FIG. 2 is a flowchart showing an example of a method, which may be a method of managing a container-based computing cluster. Block 202 comprises receiving, at a node of a container-based computing cluster, a request for a service. Block 204 comprises determining if the service request comprises blocked service attributes. For example, this may comprise determining if a request for a service is a request to access the service via a port or protocol which is listed as a blocked port or protocol in a deny rule of an IP table of the node. In another examples, a port or protocol may be defined as an accepted port or protocol, and only such ports or protocols may be accepted for forwarding. When the port or protocol is not a blocked a port or protocol, an address translation is performed to forward the request to a container sub-duster of the container-based computing cluster in block 206. Otherwise (i.e. when the request is a blocked request), block 208 comprises denying the request for the service.
For example, a service request may be made by referring to a protocol, an IP address of the service and the port. Such a request may have the format: <PROTOCOL>://<IP Address>:<Port>, and the identity of the IP address as well as the port and/or protocol may be defined in a service specification. Port(s) and/or protocol(s) other than the specified port and/or protocol may be specified (positively or negatively) within one or a set of deny rules.
For example, the IP table may be initialised as follows: A: sudo iptables -t nat -N KUBE-MARK-DROP-LB
This inserts a new rule called "KUBE-MARK-DROP-LB" B: sudo iptables -t nat -A KUBE-MARK-DROP-LB -j MARK --set-xmark 0x8000/0x8000
This rule specifies that packets marked with a 32 bit value (in this example, 0x8000, but this value could be different in other examples) should be dropped. This value is a value which is utilised in Kubemetes to identify and drop packages, although in principle another value could be used. C: sudo iptables -t nat -A KUBE-MARK-DROP-LB -j ACCEPT
Packets with other values may however be accepted in this rule chain, so that they will be forwarded to the next rule set for onward processing.
Then, on creation of a service, the following code may be executed: D: sudo iptables -t nat -N<SERVICE-NAME_NAMESPACE>
This creates a new chain with a unique name based on a combination of the service name and a namespace value. This chain will identify packets to forward to the KUBE-MARK-DROP-LB chain described above. E: sudo iptables -t nat -l PREROUTING --destination <ExtIP> -j <SERVICE-NAME_NAMESPACE>
This inserts a rule in a rule chain "PREROUTING", which captures and redirects any packet with a destination address <ExtIP> to the new chain <SERVICE-NAME_NAMESPACE>
F: sudo iptables -t nat -A <SERVICE-NAME_NAMESPACE> -p < PROTOCOL> -m multiport --dports <SER-PORT,NODE-PORT> -j RETURN
This appends a rule to the new chain <SERVICE-NAME_NAMESPACE> which returns the processing of the packet to the standard processing route for address translation if the protocol matches <PROTOCOL> and destination ports match <SER-PORT, NODE-PORT>
G: sudo iptables -t nat -A <SERVICE-NAME> -j KUBE-MARK-DROP-LB
This serves to forward any packets which have not be redirected for normal processing at F to the "KUBE-MARK-DROP-LB" chain described above. The package will be marked using the value 0x8000 (although in principle other markings could be used), such that the packet will be dropped by KUBE-MARK-DROP-LB.
In other words, a packet directed to a particular external IP address (ExtIP) will be captured by rule E and handled by the chain <SERVICE-NAME_NAMESPACE>. If this packet specifies a protocol which matches <PROTOCOL> and destination ports which match <SER-PORT, NODE-PORT>, it is accepted and forwarded for address translation by rule F. If however it does not, it will be forwarded to the chain KUBE-MARK-DROP-LB, where, if it contains a value 0x8000, it will be dropped.
Therefore, if a request received in block 202 has an IP address as defined in the service specification but with a different port or protocol, such deny rule(s) may be applied such that the request is dropped (block 208). In some examples, as shown in the rule set above, there may be a single port or protocol which is allowed (i.e. not in a deny rule) for each service as identified by its IP address. I.e. the blocked ports and protocols are described negatively, with reference to an accepted port and protocol.
Such a method may be carried out by a node 104 of a system 100 as described in relation to FIG. 1.
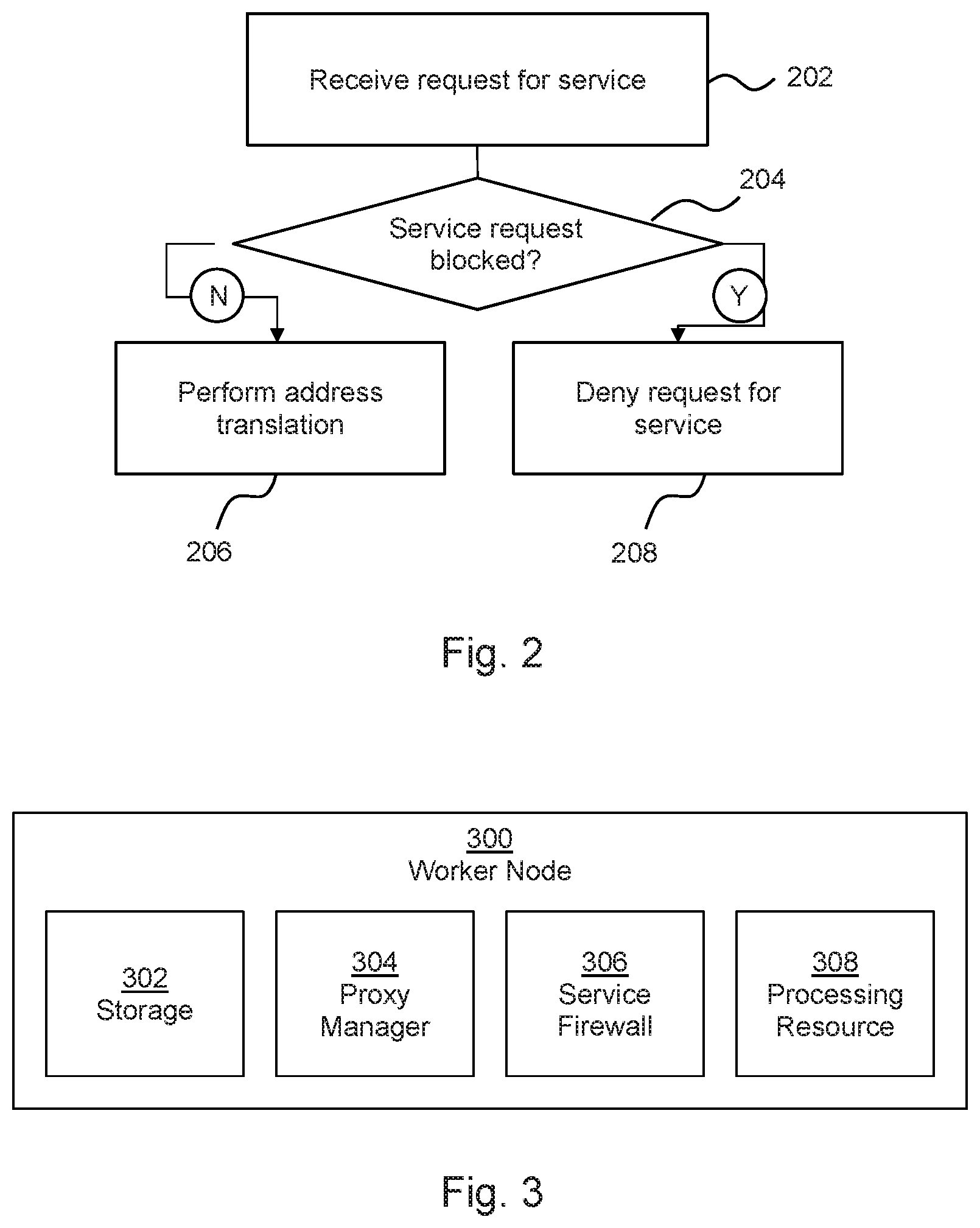
FIG. 3 shows an example of a worker node 300 for deployment in a container cluster management system. The worker node 300 comprise storage 302 to store an IP table. For example, this may comprise non-volatile and/or volatile memory. The worker node 300 further comprises a proxy manager 304, which, when the node 300 is deployed, manages an IP table of the node stored in the storage 302, and a service firewall 306. In this example, when the node 300 is deployed, the service firewall 306 blocks a service request for a service by adding a deny rule for the service to the IP table. In some examples, the service firewall 306 is provided by the proxy manager 304.
The worker node 300 further comprises a processing resource 308 to forward a service request to at least one container sub-cluster by translating the destination address of the service request to an IP address of a container sub-cluster (e.g. a `pod` as described above) using the IP table, unless the service request is a blocked service request. Such a node 300 may provide a node 104 of FIG. 1, or may carry out the method of FIG. 2.
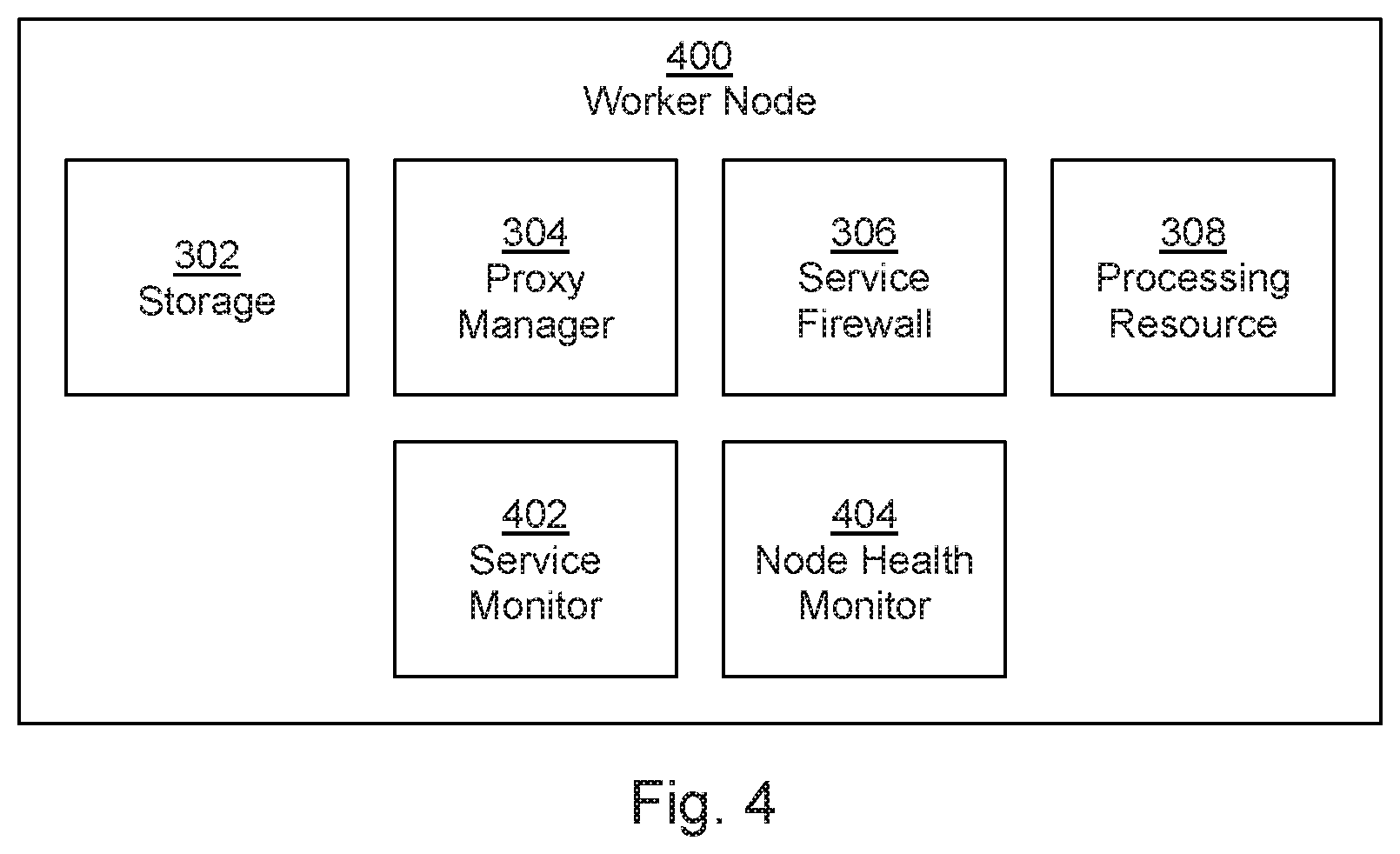
FIG. 4 is another example of a worker node 400. In addition to the storage 302, proxy manager 304, service firewall 306 and processing resource 308, the node 400 further comprises a service monitor 402 and a node health monitor 404.
The service monitor 402 monitors for at least one external service. On detection of a service, the service firewall 306 is triggered to update the IP table in response to the detection. Detection of a service may for example comprise receiving a notification, which may be generated by a container management system with which the service monitor or associated apparatus is registered or associated (for example, the cluster manager 102). Such notifications may be generated for update and delete events, as well as for create events. In some examples, the service monitor 402 may comprise a component of the service firewall 306. In some examples, the node health monitor 404 monitors the operational status of the node 400 and provides a healthcheck message indicative of normal operation when in a normal operational state. The message may for example be provided to a cluster manager, such as the cluster manager 102 of FIG. 1, and/or to at least one other node 104. The node health monitor 404 may also, in some examples, monitor the health of other nodes 104, 400.
Each of the node 400, proxy manager 304, service firewall 306, processing resources 308, service monitor 402 and the node health monitor 404 may be any combination of hardware and programming to implement the described functionalities. In examples described herein, such combinations of hardware and programming may be implemented in a number of different ways. For example, programming may be processing resource executable instructions stored on at least one non-transitory machine-readable storage medium and the hardware may include at least one processing resource to execute those instructions. In some examples, the hardware may also include other electronic circuitry to at least partially implement at least one of the node 400, proxy manager 304, service firewall 306, processing resources 308, service monitor 402 and the node health monitor 404. In some examples, the at least one machine-readable storage medium may store instructions that, when executed by the at least one processing resource, at least partially implement some or all of the node 400, proxy manager 304, service firewall 306, processing resources 308, service monitor 402 and the node health monitor 404. In such examples, a computing device at least partially implementing the node 400 may include the at least one machine-readable storage medium storing the instructions and the at least one processing resource to execute the instructions. In other examples, the node 400, proxy manager 304, service firewall 306, processing resources 308, service monitor 402 and/or the node health monitor 404 may be implemented by electronic circuitry.
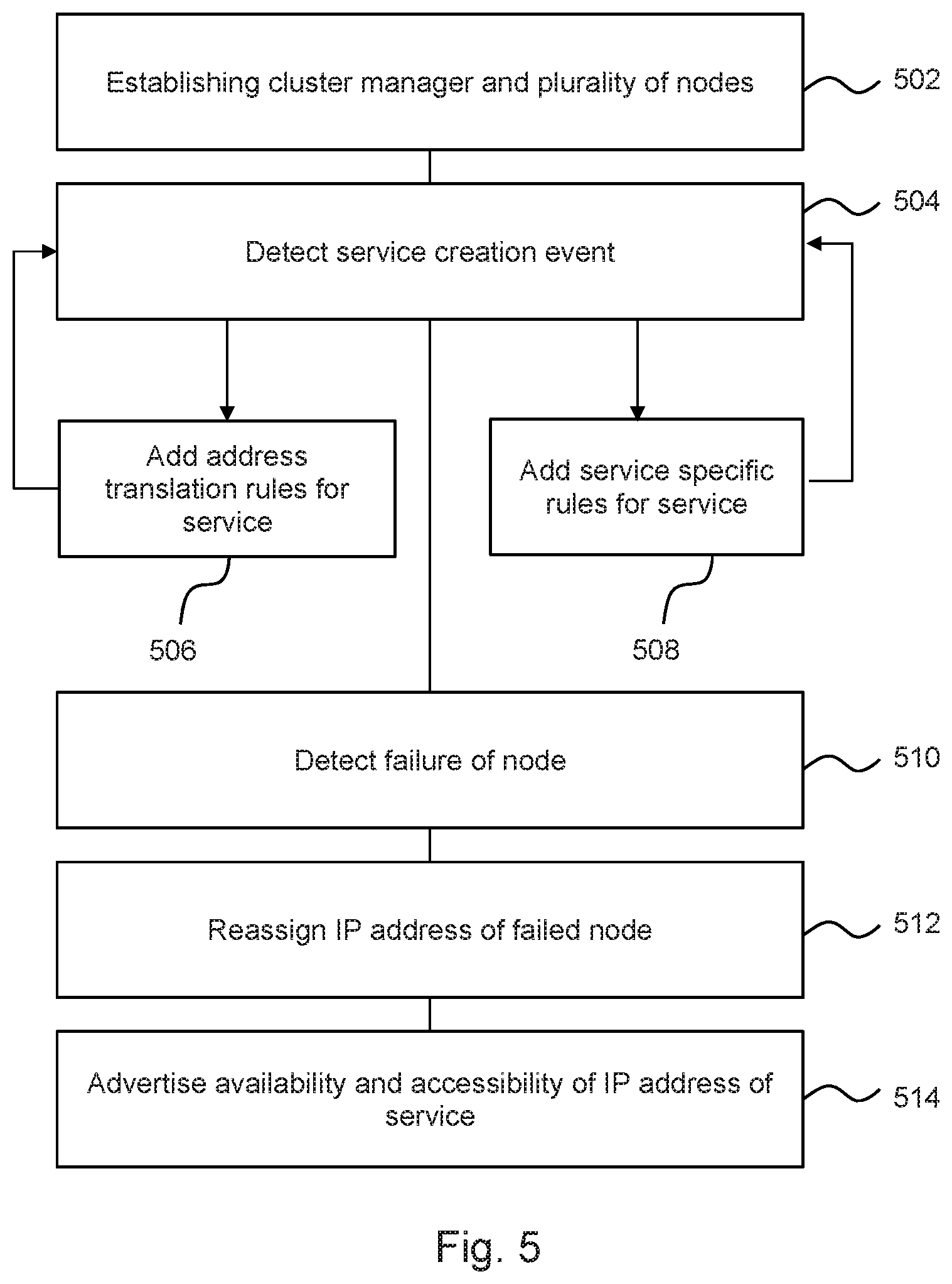
FIG. 5 is an example of a method, which may in some examples be carried out at least in part by a node 400.
The method comprises, in block 502, establishing a cluster manager and a plurality of nodes. Block 504 comprises detecting a service creation event, for example on receipt of a notification from a cluster management entity such as a cluster manager 102. Block 506 comprises adding address translation rules for a first detected service to an IP table of a node. In some examples, the address translation rules may be added at a plurality of nodes. In block 508, service-specific `deny` or `block` rules are added to the IP table of at least one node (and in some examples, for a plurality of nodes) for the service.
For the sake of example, a service specific rule DNAT rule added in block 506 may comprise, in a Kubemetes container system:
-A KUBE-SERVICES -d 10.142.137.200/32 -p tcp -m comment --comment "default/nginx: external IP" -m tcp -dport 80 -m physdev ! --physdev-is-in -m addrtype ! --src-type LOCAL -j KUBE-SVC-4N57TFCL4MD7ZTDA
This rule checks if a request is received on IP address 10.142.137.200 and with protocol tcp and on port 80. If the request is received on IP address 10.142.137.200 but with a protocol other than tcp and/or a port other than port 80, the packet may be diverted to other rule chains as set out above.
If the packet is accepted, the request is forwarded to another rule set -KUBE-SVC-4N57TFCL4MD7ZTDA, in this example comprising three rules set out below. In turn, if an IP table has been established in a manner to drop packets which are associated with that IP address, but associated with any protocol other than tcp and any port other than port 80, such packets will be dropped.
In this example, the three rules of the further rule set are:
-A KUBE-SVC-4N57TFCL4MD7ZTDA -m comment --comment "default/nginx:" -m statistic
--mode random --probability 0.25000000000 -j KUBE-SEP-YWXOX2RATT4U5XWP
-A KUBE-SVC-4N57TFCL4MD7ZTDA -m comment --comment "default/nginx:" -m statistic
--mode random --probability 0.33332999982 -j KUBE-SEP-62W5WRRO7TZHHJIR
-A KUBE-SVC-4N57TFCL4MD7ZTDA -m comment --comment "default/nginx:" -m statistic
-mode random -probability 0.50000000000 -j KUBE-SEP-XL4V4VLBKROVH7NR
This rule set directs the request to a rule of a second rule set on a probability basis. The probability is decided based on the number of backend processing entities. The second rule set, in which the address translation is carried out, may be as follows:
-A KUBE-SEP-YWXOX2RATT4U5XWP -p tcp -m comment --comment "default/nginx:" -m tcp -j DNA T --to-destination 10.32.0.4:80
-A KUBE-SEP-XL4V4VLBKROVH7NR -p tcp -m comment --comment "default/nginx:" -m tcp j DNAT --to-destination 10.36.0.5:80
-A KUBE-SEP-62W5WRRO7TZHHJIR -p tcp -m comment --comment "default/nginx:" -m tcp j DNAT --to-destination 10.36.0.4:80
Each of the above three rules of the second rule set redirects the request to a particular backend.
Service specific deny rules may, for example, deny access to a service unless the request specifies a protocol and/or port which is not associated with a deny rule.
Block 510 comprises detecting a failure of a node and block 512 comprises reassigning the IP address of the failed node to another node. While in this example, node failure is detected, in another example, it may be determined that a node has become unhealthy. This provides for high-availability of the cluster. This may comprise updating a mapping table. In some examples, this may comprise updating a virtual router to node mapping table (a Node_ID-to-VRID mapping table, as described in greater detail below).
Block 514 comprises advertising at least one of an availability and an accessibility of an IP address of a service to a network. Advertising an availability may comprise sending or responding to a Virtual Router Redundancy Protocol (VRRP) advertisement. This may be carried out at any time, and in some examples periodically.
An example of reassigning an IP address, for example as set out in relation to blocks 510 and 512, is now discussed. Such methods may be used in conjunction with the described service specific rules such as deny rules, or separately therefrom. In other words, the methods of block 510 and 512 may be provided separately from the methods describe in blocks 502 to 508 and in block 514. In examples, there may be n nodes, each of which have IP addresses configured for a specific service, and this information may be held in a mapping table. Consider a scenario where:
Service-1 and service-2 have their IP addresses configured on node-1.
Service-3 and service-4 have their IP addresses configured on node-2.
Service-5 and service-6 have their IP addresses configured on node-3.
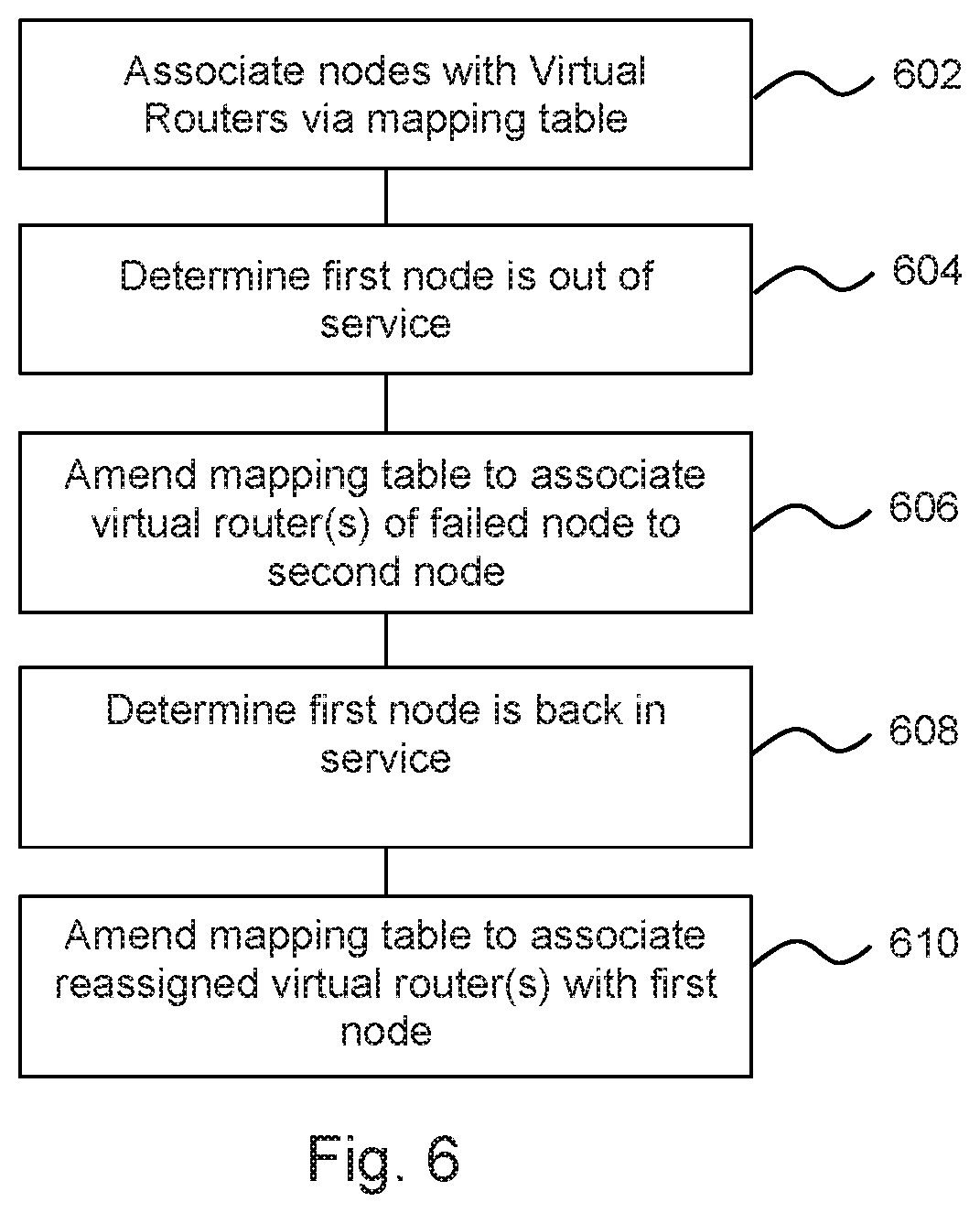
If one of the nodes fail (which may be a total failure or a partial failure, i.e. the node is unhealthy), the IP addresses which were configured on the failed node may be configured on any one of the other two nodes. In this way high availability is achieved. An example of reassigning an IP address, for example in the event of that a node fails, or becomes unhealthy, may comprise utilising a mapping table associated with a node, as is now discussed with reference to FIG. 6.
In block 602, nodes are with associated Virtual Routers via a mapping table.
In one example it may be that each load balancing node 104, 400 (i.e. each node comprising a proxy manager 106 and a service firewall 108 as described above) is associated with at least one virtual router. There may be a virtual router associated with each service (although, as described below, there may be multiple instances of each virtual router).
In one example, each load balancing node 104 may act as a Master node for a virtual router. In some examples, at least one node 104 may act as a back-up node for a virtual router. In some examples, each node acts as a potential back-up node for each virtual router.
In some examples, if there are n worker nodes 104, 400, there may be n instances of a particular virtual router, where n is an integer. Each instance is provided on a different node 104, 400, and one of the nodes acts as the master node for that virtual router. In some examples, cluster manager 102 may determine which node 104 is the master node for each virtual router.
For example in a case where there are three load-balancing/worker nodes, a first node, Node_ID1, may initially be the master node for a virtual router VR_ID1, which is associated with a first service, and a back-up node for virtual routers VR_ID2 and VR_ID3 which are associated with a second and third service respectively. A second node, Node_ID2, may initially be the master node for VR_ID2, and a back-up node for VR_ID1 and VR_ID3. A third node, Node_ID3, may initially be the master node for VR_ID3, and a back-up node for VR_ID1 and VR_ID2.
The mapping between master nodes and virtual routers may be held in a Node_ID-to-VRID mapping table, which may in some examples be managed by the cluster manager 102. The cluster manager 102 may also determine which external IP address(es) is/are associated with each virtual router in a VRID-to-IP address mapping table, for example as configuration information. In some examples, the configuration may also define which interface to use to send advertisements and/or a virtual IP address for each instance of the virtual router.
Each load balancing node 104 may be configured to monitor the mappings between the VR IDs and the IP addresses. In the event of a change (e.g. a node goes out of service), the `mastership` of the virtual router for which that node is the master node may be reassigned to another node. In some examples, the new master node may be determined using an `election` process between the nodes.
For example, in the case that the first node, Node_ID1, goes out of service (block 604), the second node, Node_ID2, may be elected to act as master for virtual router VR_ID1 (and therefore is the master node for both virtual routers VR_ID1 and VR_ID2). The VRID-to-IP address mapping table may then be updated (block 606).
The IP addresses associated with the failed node may also be reassigned to the new `master` node, based on the VRID-to-IP address mapping table. In practice, to effect this change, a background process (in some example, a so-called `daemon`) may be reloaded with the new configuration.
The VRID-to-IP address mapping table may change if there are changes in services. For example, if a new service is added then the IP address of that service is mapped to a VRID and appended to the list of IP addresses that are already mapped to that VRID.
If a service is deleted then the VRID-to-IP address mapping table may be updated by removing the corresponding IP address.
In some examples, if the originally designated master node for a virtual router resumes service, it will `reclaim` its mastership of the virtual router, and the IP addresses associated with that router by the VRID-to-IP mapping table will migrate back to the originally designated master node. This may for example be achieved by setting a priority level associated with each virtual router on each node, such that the originally designated node has a higher priority level than the other nodes.
In such an example, a background process may, by reassigning the `mastership` of a virtual router, cause the associated IP addresses to be reconfigured on a new node. This is relatively simple to implement, and provides for a high-availability cluster. For example, it may automatically allow a load to be rebalanced when a node comes back on line.
In the example above, this may mean that in the case that the first node Node_ID1 comes back into service (block 608), it may reclaim the mastership for virtual router VR_ID1 from the second node Node_ID2. In such an example, the Node_ID-to-VRID mapping table may be altered to reflect the change (block 610).
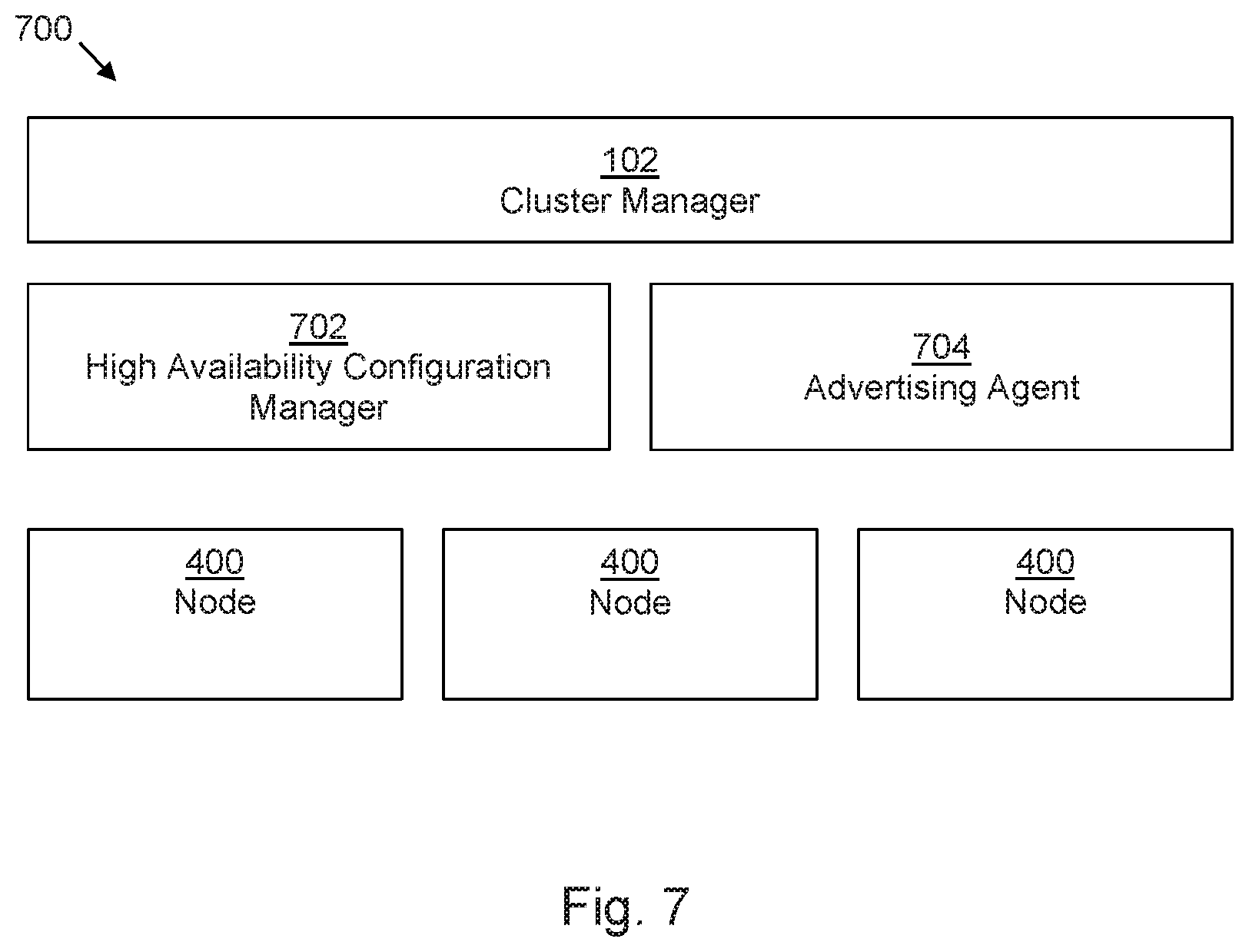
FIG. 7 shows another example of a container cluster management system 700, in this example comprising the cluster manager 102 of FIG. 1 and a plurality of nodes 400 as described in relation to FIG. 4. In this example, the container cluster management system 700 further comprises a high availability configuration manager 702 to, in the event of a failure of a node, reassign the IP address of the failed node to another node. For example this may operate a process such as keepalived or proxy ARP. In some examples, this may comprise executing a method as described in FIG. 6. In addition, the container cluster management system 700 comprises an advertisement agent 704 to advertise at least one of an availability of the node (for example, as a Virtual Router Redundancy Protocol (VRRP) advertisement/response) and an accessibility of an IP address of a service to a network, for example as described in relation to block 514 above.
The high availability configuration manager 702 may be configured as a backend process (e.g. at least one `daemon`, such as keepalived), which responds to changes in a node_ID-to-VRID mapping table by reassigning the mastership of a virtual router to another node (for example, following an election of another node, or some other designation process), and thereby configuring the IP addresses associated with that virtual router on another node. In some examples, the backend process may be reloaded to effect the changes. In some examples, at least some functions of the high availability configuration manager 702 may be provided on a node 400, which may be a load balancing node 104 as described above. In other examples, other types of worker node (e.g. those without a service firewall) may be provided in the container cluster management system 700 in addition or instead of the nodes as described in FIGS. 1, 3 and 4
Examples in the present disclosure can be provided as methods, systems or machine readable instructions, such as any combination of software, hardware, firmware or the like.
In some examples, a machine readable medium may be provided which comprises instructions to cause a processing resource to perform the functionalities described above in relation to one or more blocks of FIG. 2, or 5. In some examples, the instructions may comprise the programming of any of the functional modules described in relation to FIGS. 1 and 3 and 4 and 7. In such examples, processing resource may comprise the hardware of any of the functional modules described in relation to FIGS. 1, 3, 4 and 7. As used herein, a "machine readable storage medium" may be any electronic, magnetic, optical, or other physical storage apparatus to contain or store information such as executable instructions, data, and the like. For example, any machine-readable storage medium described herein may be any of Random Access Memory (RAM), volatile memory, non-volatile memory, flash memory, a storage drive (e.g., a hard disk drive (HDD)), a solid state drive, any type of storage disc (e.g., a compact disc, a DVD, etc.), and the like, or a combination thereof. Further, any machine-readable storage medium described herein may be non-transitory. In examples described herein, a machine-readable storage medium or media may be part of an article (or article of manufacture). An article or article of manufacture may refer to any manufactured single component or multiple components.
The machine readable instructions may, for example, be executed by a general purpose computer, a special purpose computer, an embedded processor or processors of other programmable data processing devices to realize the functions described in the description and diagrams. In particular, a processor or processing circuitry may execute the machine readable instructions. Thus functional modules of the apparatus may be implemented by a processing resource executing machine readable instructions stored in a memory, or a processing resource operating in accordance with instructions embedded in logic circuitry. The methods and functional modules may all be performed by a single processor or divided amongst several processors.
Such machine readable instructions may also be stored in a computer readable storage medium that can guide the computer or other programmable data processing devices to operate in a specific mode.
Machine readable instructions may also be loaded onto a computer or other programmable data processing devices, so that the computer or other programmable data processing devices perform a series of operations to produce computer-implemented processing, thus the instructions executed on the computer or other programmable devices realize functions specified by flow(s) in the flow charts and/or block(s) in the block diagrams.
Further, the teachings herein may be implemented in the form of a computer software product, the computer software product being stored in a storage medium and comprising a plurality of instructions for making a computer device implement the methods recited in the examples of the present disclosure.
The present disclosure is described with reference to flow charts and block diagrams of the method, devices and systems according to examples of the present disclosure. Although the flow diagrams described above show a specific order of execution, the order of execution may differ from that which is depicted. Blocks described in relation to one flow chart may be combined with those of another flow chart. It shall be understood that at least some flows and/or blocks in the flow charts and/or block diagrams, as well as combinations of the flows and/or diagrams in the flow charts and/or block diagrams can be realized by machine readable instructions.
While the method, apparatus and related aspects have been described with reference to certain examples, various modifications, changes, omissions, and substitutions can be made without departing from the spirit of the present disclosure. It is intended, therefore, that the method, apparatus and related aspects be limited by the scope of the following claims and their equivalents. It should be noted that the above-mentioned examples illustrate rather than limit what is described herein, and that those skilled in the art will be able to design many alternative implementations without departing from the scope of the appended claims. Features described in relation to one example may be combined with features of another example.
The word "comprising" does not exclude the presence of elements other than those listed in a claim, "a" or "an" does not exclude a plurality, and a single processor or other processing resource may fulfil the functions of several units recited in the claims.
The features of any dependent claim may be combined with the features of any of the independent claims or other dependent claims, in any combination.
* * * * *
References
D00000
D00001
D00002
D00003
D00004
D00005
D00006
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.