System and method for addressing overfitting in a neural network
Hinton , et al. July 30, 2
U.S. patent number 10,366,329 [Application Number 15/222,870] was granted by the patent office on 2019-07-30 for system and method for addressing overfitting in a neural network. This patent grant is currently assigned to Google LLC. The grantee listed for this patent is Google LLC. Invention is credited to Geoffrey E. Hinton, Alexander Krizhevsky, Nitish Srivastava, Ilya Sutskever.
| United States Patent | 10,366,329 |
| Hinton , et al. | July 30, 2019 |
System and method for addressing overfitting in a neural network
Abstract
A system for training a neural network. A switch is linked to feature detectors in at least some of the layers of the neural network. For each training case, the switch randomly selectively disables each of the feature detectors in accordance with a preconfigured probability. The weights from each training case are then normalized for applying the neural network to test data.
| Inventors: | Hinton; Geoffrey E. (Toronto, CA), Krizhevsky; Alexander (San Jose, CA), Sutskever; Ilya (San Francisco, CA), Srivastava; Nitish (Toronto, CA) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Applicant: |
|
||||||||||
| Assignee: | Google LLC (Mountain View,
CA) |
||||||||||
| Family ID: | 50975834 | ||||||||||
| Appl. No.: | 15/222,870 | ||||||||||
| Filed: | July 28, 2016 |
Prior Publication Data
| Document Identifier | Publication Date | |
|---|---|---|
| US 20160335540 A1 | Nov 17, 2016 | |
Related U.S. Patent Documents
| Application Number | Filing Date | Patent Number | Issue Date | ||
|---|---|---|---|---|---|
| 14015768 | Aug 30, 2013 | 9406017 | |||
| 61745711 | Dec 24, 2012 | ||||
| Current U.S. Class: | 1/1 |
| Current CPC Class: | G06N 3/0472 (20130101); G06V 10/454 (20220101); G06N 3/082 (20130101); G06K 9/4628 (20130101); G06N 3/0454 (20130101); G06N 3/084 (20130101) |
| Current International Class: | G06N 3/04 (20060101); G06N 3/08 (20060101); G06K 9/46 (20060101) |
Other References
|
Castellano, Giovanna, Anna Maria Fanelli, and Marcello Pelillo. "An iterative pruning algorithm for feedforward neural networks." IEEE Transactions on Neural Networks 8.3 (1997): 519-531. cited by examiner . Rumelhart et al., "Learning Representations by Back-propagating Errors," Nature 323:533-536, Oct. 9, 1986. cited by applicant . Hinton, "Training Products of Experts by Minimizing Contrastive Divergence," Neural Computation 14(8):1771-1800, Aug. 2002. cited by applicant . Ciresan et al., "Deep, Big, Simple Neural Nets for Handwritten Digit Recognition," Neural Computation 22(12):3207-3220, Dec. 2010. cited by applicant . LeCun et al., "Gradient-based Learning Applied to Document Recognition," Proceedings of the IEEE 86(11):2278-2324, Nov. 1998. cited by applicant . Hinton et al., "Reducing the Dimensionality of Data with Neural Networks," Science 313(5768):504-507, Jul. 28, 2006. cited by applicant . Mohamed et al., "Acoustic Modeling Using Deep Belief Networks," IEEE Transactions on Audio, Speech, and Language Processing, 20(1):14-22, Jan. 2012. cited by applicant . Dahl et al., "Context-dependent Pre-trained Deep Neural Networks for Large-vocabulary Speech Recognition," IEEE Transactions on Audio, Speech, and Language Processing, 20:30-42, Jan. 2012. cited by applicant . Jaitly et al., "Application of Pretrained Deep Neural Networks to Large Vocabulary Conversational Speech Recognition," Tech. Rep. 001, Department of Computer Science, University of Toronto, Mar. 12, 2012, 11 pages. cited by applicant . Krizhevsky, "Learning Multiple Layers of Features from Tiny Images," Tech. Rep. 001, Department of Computer Science, University of Toronto, Apr. 8, 2009, 60 pages. cited by applicant . Coates et al., "The Importance of Encoding Versus Training with Sparse Coding and Vector Quantization," ICML, 921-928, 2011. cited by applicant . Deng et al., "ImageNet: A Large-scale Hierarchical Image Database," CVPR 2009, Jun. 20-25, 2009, 248-255. cited by applicant . Sanchez et al., "High-dimensional Signature Compression for Large-scale Image Classification," CVPR 2011, Jun. 20-25, 2011, 1665-1672. cited by applicant . Jacobs et al., "Adaptive Mixtures of Local Experts," Neural Computation 3, 79-87 (1991). cited by applicant . Neal, "Bayesian Learning for Neural Networks," Lecture Notes in Statistics No. 118 (Springer-Verlag, New York, 1996), 195 pages. cited by applicant . Breiman, "Bagging Predictors," Machine Learning 24, 123140 (1996). cited by applicant . Breiman, "Random Forests," Machine Learning 45, 5-32 (2001). cited by applicant . Livnat et al., "A Mixability Theory for the Role of Sex in Evolution," PNAS 105(50):19803-19808 (2008). cited by applicant . Salakhutdinov et al., "A Better Way to Pretrain Deep Boltzmann Machines," Artificial Intelligence and Statistics (2009), 9 pages. cited by applicant . Lewis et al., "Rcvl: A New Benchmark Collection for Text Categorization Research," Journal of Machine Learning 5, 361-397 (2004). cited by applicant . Guo et al., "Stochastic Resonance in Hodgkin-Huxley Neuron Induced by Unreliable Synaptic Transmission," Journal of Theoretical Biology, 308:105-114, Jun. 9, 2012. cited by applicant . Wang et al., "Fast `Dropout` Training for Logistic Regression," Workshop on Log-linear Models at the 26.sup.th Annual Conference on Neural Information Processing Systems, Dec. 8, 2012, Retrieved from the Internet: URL:https://docs.google.com/file/d/0B_9blvt8HjXzbGJTZlpWczRyMGM- /edit [retrieved on Apr. 7, 2014]. cited by applicant . Duda, "NeuroXyce Synapse Device with STDP and Stochastic Transmission Reliability," SAND Report from Sandia National Laboratories, 2012, Retrieved from the Internet: URL:http://www.alexduda.com/2012_SAND.pdf [retrieved on Feb. 5, 2014]. cited by applicant . International Search Report and Written Opinion in International Application No. PCT/US2013/077608, dated Apr. 17, 2014, 11 pages. cited by applicant . Castellano et al., "An Iterative Pruning Algorithm for Feedforward Neural Networks," Neural Networks, IEEE Transactions on 8.3 (1997): 519-531. cited by applicant. |
Primary Examiner: Waldron; Scott A.
Assistant Examiner: Figueroa; Kevin W
Attorney, Agent or Firm: Fish & Richardson P.C.
Parent Case Text
CROSS-REFERENCE TO RELATED APPLICATIONS
This is a continuation of U.S. application Ser. No. 14/015,768, filed on Aug. 30, 2013, which claims priority to U.S. Provisional Application No. 61/745,711, filed on Dec. 24, 2012. The disclosures of the prior applications are considered part of and are incorporated by reference in the disclosure of this application.
Claims
What is claimed is:
1. A system comprising one or more computers and one or more storage devices storing instructions that, when executed by the one or more computers, cause the one or more computers to perform operations for training a neural network with reduced overfitting and in reduced time, the neural network having a plurality of layers, each of the layers including one or more feature detectors each having a corresponding set of weights, and the operations comprising: obtaining, by one or more computers, a plurality of training cases; and training, by the one or more computers, the neural network on the plurality of training cases with reduced overfitting and reduced co-adaptation of feature detectors by reducing reliance of feature detectors in the neural network on other feature detectors in the neural network, comprising: for a first training case of the plurality of training cases: determining a first set of one or more feature detectors to disable during processing of the first training case, disabling the first set of one or more feature detectors in accordance with the determining, processing the first training case using the neural network with the first set of one or more feature detectors disabled to generate a predicted output for the first training case, thereby reducing overfitting and reducing co-adaptation of feature detectors by reducing reliance on the first set of one or more feature detectors by other feature detectors in the neural network; and after processing the first training case using the neural network with the first set of one or more feature detectors disabled and for a second training case of the plurality of training cases: determining a second, different set of one or more feature detectors to disable during processing of the second training case, disabling the second, different set of one or more feature detectors in accordance with the determining, processing the second training case with at least one of the feature detectors in the first set of feature detectors enabled and the second, different set of feature detectors disabled to generate a predicted output for the second training case, thereby reducing overfitting and co-adaptation of feature detectors by reducing reliance on the second set of one or more feature detectors by other feature detectors in the neural network.
2. The system of claim 1, wherein a subset of the feature detectors are associated with respective probabilities of being disabled during processing of each of the training cases, and wherein determining the first set of one or more feature detectors to disable during processing of the first training case comprises: determining whether to disable each of the feature detectors in the subset based on the respective probability associated with the feature detector.
3. The system of claim 2, wherein training the neural network further comprises: adjusting the weights of each of the feature detectors in the neural network to generate trained values for each weight in the set of weights corresponding to the feature detector.
4. The system of claim 3, the operations further comprising: normalizing the trained weights for each of the feature detectors in the subset, wherein normalizing the trained weights comprises multiplying the trained values of the weights for each of the one or more feature detectors in the subset by a respective probability of the feature detector not being disabled during processing of each of the training cases.
5. The system of claim 2, wherein the subset includes feature detectors in a first layer of the plurality of layers and feature detectors in one or more second layers of the plurality of layers, wherein the feature detectors in the first layer are associated with a first probability and wherein the feature detectors in the one or more second layers are associated with a second, different probability.
6. The system of claim 5, wherein the first layer is an input layer of the neural network and the one or more second layers are hidden layers of the neural network.
7. The system of claim 5, wherein the first layer and the one or more second layers are hidden layers of the neural network.
8. The system of claim 1, wherein determining the first set of one or more feature detectors to disable during processing of the first training case comprises: determining to disable the same feature detectors that were disabled during processing of a preceding training case.
9. The system of claim 1, wherein training the neural network comprises training the neural network to perform speech recognition.
10. The system of claim 1, wherein training the neural network comprises training the neural network to perform image classification.
11. The system of claim 1, wherein training the neural network comprises training the neural network to perform object recognition.
12. A non-transitory computer storage medium encoded with a computer program, the program comprising instructions that when executed by one or more computers cause the one or more computers to perform operations for reducing overfitting during training of a neural network, the operations comprising: obtaining, by one or more computers, a plurality of training cases; and training, by the one or more computers, the neural network on the plurality of training cases with reduced overfitting and reduced co-adaptation of feature detectors by reducing reliance of feature detectors in the neural network on other feature detectors in the neural network, comprising: for a first training case of the plurality of training cases: determining a first set of one or more feature detectors to disable during processing of the first training case, disabling the first set of one or more feature detectors in accordance with the determining, processing the first training case using the neural network with the first set of one or more feature detectors disabled to generate a predicted output for the first training case, thereby reducing overfitting and co-adaptation of feature detectors by reducing reliance on the first set of one or more feature detectors by other feature detectors in the neural network; and after processing the first training case using the neural network with the first set of one or more feature detectors disabled and for a second training case of the plurality of training cases: determining a second, different set of one or more feature detectors to disable during processing of the second training case, disabling the second, different set of one or more feature detectors in accordance with the determining, processing the second training case with at least one of the feature detectors in the first set of feature detectors enabled and the second, different set of feature detectors disabled to generate a predicted output for the second training case, thereby reducing overfitting and co-adaptation of feature detectors by reducing reliance on the second set of one or more feature detectors by other feature detectors in the neural network.
13. The non-transitory computer storage medium of claim 12, wherein training the neural network comprises training the neural network to perform speech recognition.
14. The non-transitory computer storage medium of claim 12, wherein training the neural network comprises training the neural network to perform image classification.
15. The non-transitory computer storage medium of claim 12, wherein training the neural network comprises training the neural network to perform object recognition.
16. The non-transitory computer storage medium of claim 12, wherein a subset of the feature detectors are associated with respective probabilities of being disabled during processing of each of the training cases, and wherein determining the first set of one or more feature detectors to disable during processing of the first training case comprises: determining whether to disable each of the feature detectors in the subset based on the respective probability associated with the feature detector.
17. The non-transitory computer storage medium of claim 16, wherein training the neural network further comprises: adjusting the weights of each of the feature detectors in the neural network to generate trained values for each weight in the set of weights corresponding to the feature detector.
18. The non-transitory computer storage medium of claim 17, the operations further comprising: normalizing the trained weights for each of the feature detectors in the subset, wherein normalizing the trained weights comprises multiplying the trained values of the weights for each of the one or more feature detectors in the subset by a respective probability of the feature detector not being disabled during processing of each of the training cases.
19. The non-transitory computer storage medium of claim 16, wherein the subset includes feature detectors in a first layer of the plurality of layers and feature detectors in one or more second layers of the plurality of layers, wherein the feature detectors in the first layer are associated with a first probability and wherein the feature detectors in the one or more second layers are associated with a second, different probability.
Description
TECHNICAL FIELD
The following relates generally to neural networks and more specifically to training a neural network.
BACKGROUND
A feedforward, artificial neural network uses layers of non-linear "hidden" units between its inputs and its outputs. Each unit has a weight that is determined during learning, which can be referred to as a training stage. In the training stage, a training set of data (a training set of inputs each having a known output) is processed by the neural network. Thus, it is intended that the neural network learn how to provide an output for new input data by generalizing the information it learns in the training stage from the training data. Generally, once learning is complete, a validation set is processed by the neural network to validate the results of learning. Finally, test data (i.e., data for which generating an output is desired) can be processed by a validated neural network.
The purpose of learning is to adapt the weights on the incoming connections of hidden units to learn feature detectors that enable it to predict the correct output when given an input vector. If the relationship between the input and the correct output is complicated and the network has enough hidden units to model it accurately, there will typically be many different settings of the weights that can model the training set almost perfectly, especially if there is only a limited amount of labeled training data. Each of these weight vectors will make different predictions on held-out test data and almost all of them will do worse on the test data than on the training data because the feature detectors have been tuned to work well together on the training data but not on the test data.
This occurs because of the overfitting problem, which occurs when the neural network simply memorizes the training data that it is provided, rather than generalizing well to new examples. Generally, the overfitting problem is increasingly likely to occur as the complexity of the neural network increases.
Overfitting can be mitigated by providing the neural network with more training data. However, the collection of training data is a laborious and expensive task.
One proposed approach to reduce the error on the test set is to average the predictions produced by many separate trained networks and then to apply each of these networks to the test data, but this is computationally expensive during both training and testing.
It is an object of the following to obviate or mitigate at least one of the foregoing issues.
SUMMARY
In one aspect, a system for training a neural network is provided, the system comprising a switch linked to a plurality of feature detectors of the neural network, the switch operable to randomly selectively disable each of the plurality of feature detectors for each of a plurality of training cases.
In another aspect, a method for training a neural network is provided.
DESCRIPTION OF DRAWINGS
The features of the invention will become more apparent in the following detailed description in which reference is made to the appended drawings wherein:
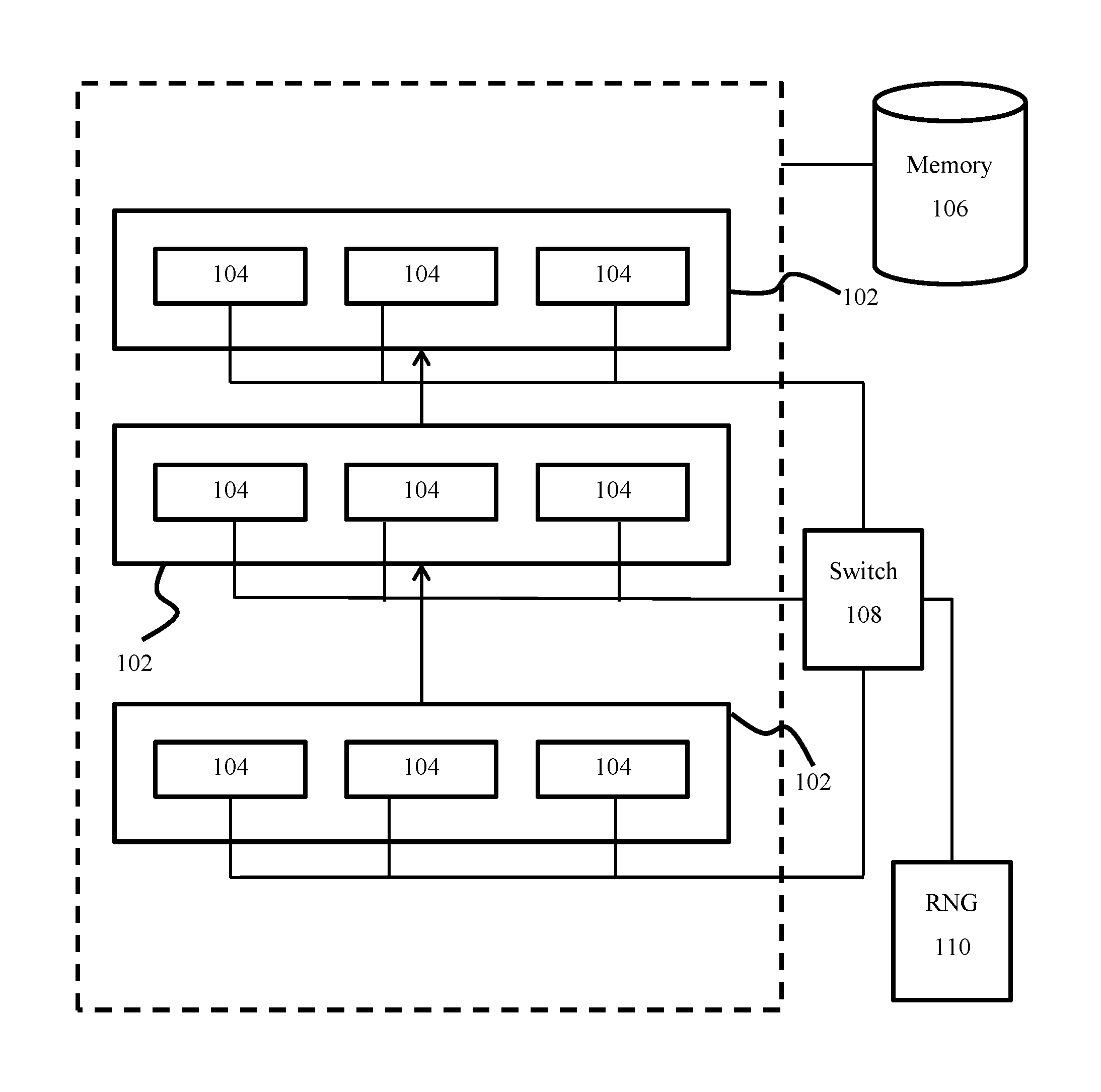
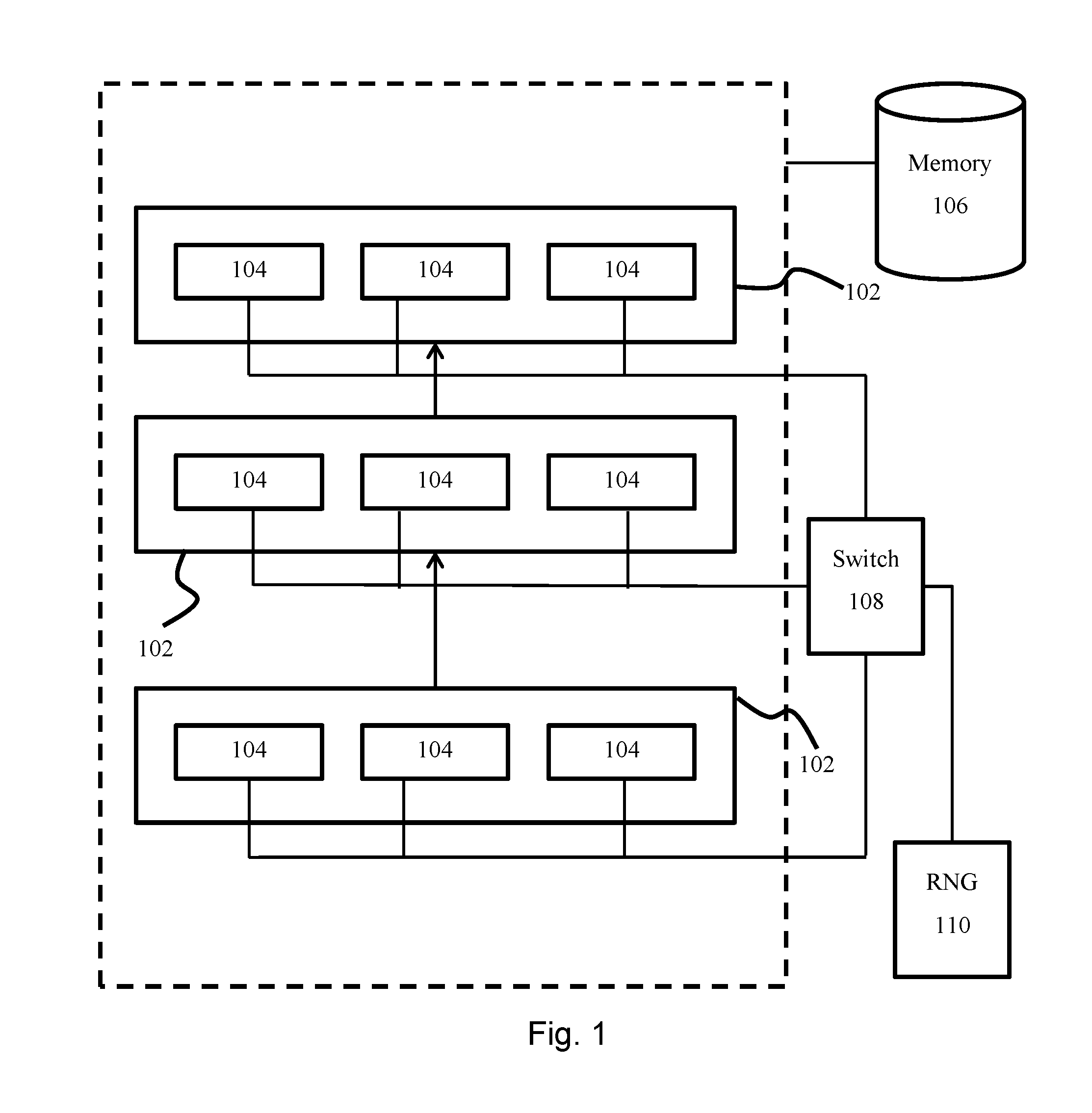
FIG. 1 is an architecture diagram of a system for training a neural network; and
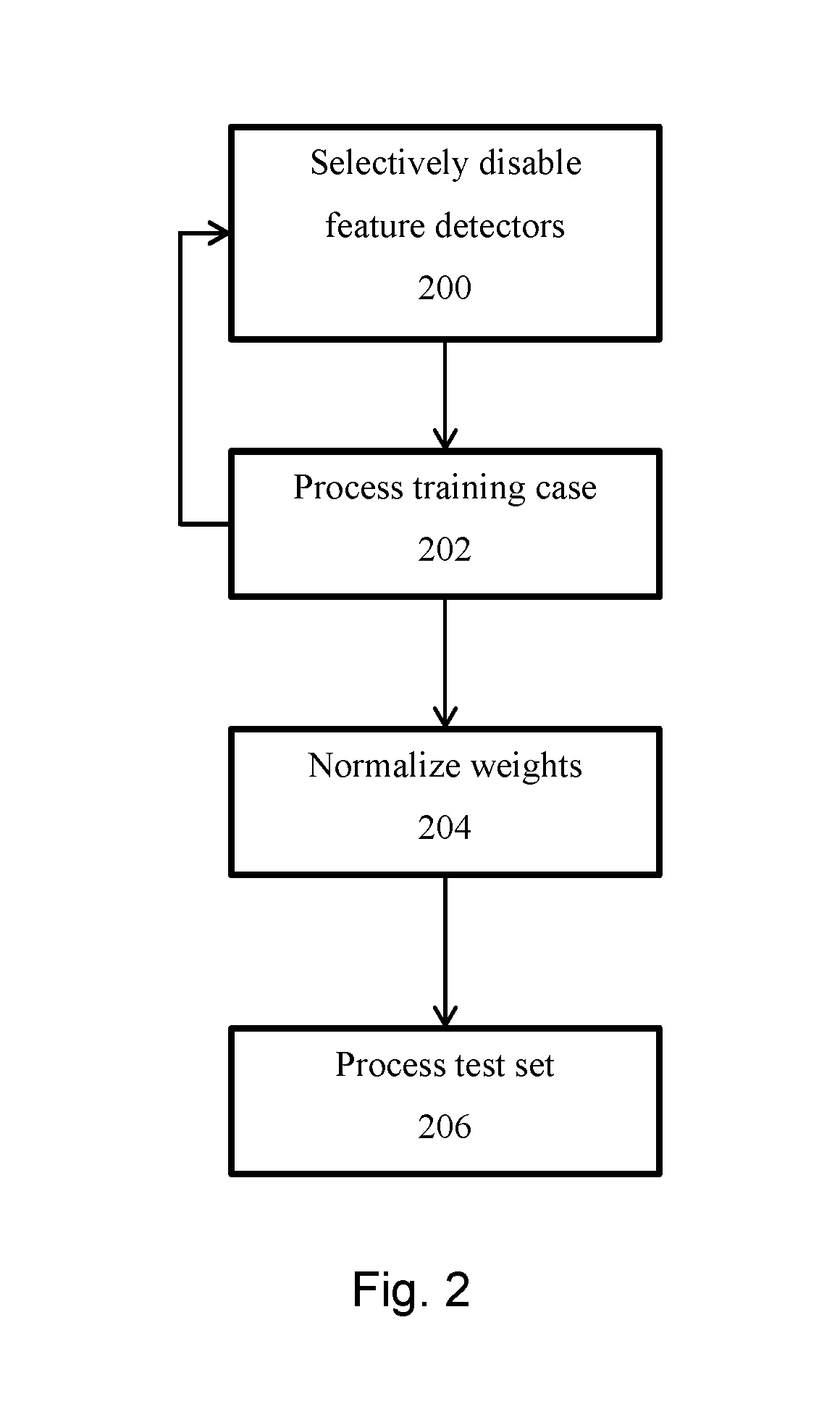
FIG. 2 is a flowchart for training a neural network.
Like reference symbols in the various drawings indicate like elements.
DETAILED DESCRIPTION
Embodiments will now be described with reference to the figures. It will be appreciated that for simplicity and clarity of illustration, where considered appropriate, reference numerals may be repeated among the figures to indicate corresponding or analogous elements. In addition, numerous specific details are set forth in order to provide a thorough understanding of the embodiments described herein. However, it will be understood by those of ordinary skill in the art that the embodiments described herein may be practiced without these specific details. In other instances, well-known methods, procedures and components have not been described in detail so as not to obscure the embodiments described herein. Also, the description is not to be considered as limiting the scope of the embodiments described herein.
It will also be appreciated that any module, unit, component, server, computer, terminal or device exemplified herein that executes instructions may include or otherwise have access to computer readable media such as storage media, computer storage media, or data storage devices (removable and/or non-removable) such as, for example, magnetic disks, optical disks, or tape. Computer storage media may include volatile and non-volatile, removable and non-removable media implemented in any method or technology for storage of information, such as computer readable instructions, data structures, program modules, or other data. Examples of computer storage media include RAM, ROM, EEPROM, flash memory or other memory technology, CD-ROM, digital versatile disks (DVD) or other optical storage, magnetic cassettes, magnetic tape, magnetic disk storage or other magnetic storage devices, or any other medium which can be used to store the desired information and which can be accessed by an application, module, or both. Any such computer storage media may be part of the device or accessible or connectable thereto. Any application or module herein described may be implemented using computer readable/executable instructions that may be stored or otherwise held by such computer readable media.
It has been found that overfitting may be reduced by selectively disabling a randomly (or pseudorandomly) selected subset of feature detectors in a neural network during each training case of the training stage, and adapting the weights of each feature detector accordingly during application of the neural network in the test stage. It has been found that the foregoing approach may prevent complex co-adaptations between feature detectors, for example where a particular feature detector is only helpful in the context of several other specific feature detectors. Although it is preferred that the selective disabling of feature detectors be changed for each training case, it is contemplated herein that disabling of particular feature detectors may be held constant for a plurality of training cases.
Referring now to FIG. 1, a feedforward neural network (100) having a plurality of layers (102) is shown. Each layer comprises one or more feature detectors (104), each of which may be associated with activation functions and weights for each parameter input to the respective feature detector (104). Generally, the output of a feature detectors of layer i may be provided as input to one or more feature detector of layer i+1.
The neural network is implemented by one or more processors. Each feature detector may be considered as a processing "node" and one or more nodes may be implemented by a processor. Further, a memory (106) may be provided for storing activations and learned weights for each feature detector. The memory (106) may further store a training set comprising training data. The training data may, for example, be used for image classification in which case the training data may comprise images with known classifications. The memory (106) may further store a validation set comprising validation data.
During the training stage, the neural network learns optimal weights for each feature detector. An optimal configuration can then be applied to test data. Exemplary applications of such a neural network include image classification, object recognition and speech recognition.
A switch (108) is linked to at least a subset of the feature detectors. The switch is operable to selectively disable each feature detector in the neural network to which it is linked, with a learned or preconfigured probability. A random number generator (110) is linked to the switch and provides the switch with a random value that enables the switch to selectively disable each linked feature detector. The possible values generated by the random number generator (110) each correspond to a decision of whether to disable any particular feature detector in accordance with the preconfigured probability.
In an embodiment, the switch (108) is linked to all feature detectors of the hidden layers. In another embodiment, the switch (108) is linked to all feature detectors of the input layers. In yet another embodiment, the switch (108) may be linked to all feature detectors in both the hidden and input layers. In yet further embodiments, the switch (108) may be linked to the feature detectors of a subset of the input and hidden layers. In another aspect, the switch may be connected to all hidden layers that are fully connected layers.
Referring now to FIG. 2, during the training stage, a plurality of training cases are input, one at a time, to the neural network in order to train the neural network. For each such training case, the switch selectively disables a subset of the feature detectors to which it is linked (200). In particular embodiments, the switch is configured to disable each such feature detector in accordance with a preconfigured probability. In a more specific embodiment, feature detectors in hidden layers may be selectively disabled with probability 0.5 (that is, on average, each feature detector will be enabled for half of the training cases and disabled for the other half of the training cases) while feature detectors of input layers are disabled with probability 0.2 (that is, on average, these feature detectors will be enabled for 80% of training cases and disabled for 20% of training cases). Therefore, in this example, for each training case, each hidden layer feature detector is randomly omitted from the network with a probability of 0.5 and each input layer feature detector is randomly omitted from the network with a probability 0.2, so each hidden or input feature detector cannot rely on other hidden or input feature detectors being present. Thus, co-adaptation of feature detectors may be reduced.
Each training case is then processed by the neural network, one at a time (202). For each such training case, the switch may reconfigure the neural network by selectively disabling each linked feature detector.
Once the training set has been learned by the neural network, the switch may enable all feature detectors and normalize their outgoing weights (204). Normalization comprises reducing the outgoing weights of each feature detector or input by multiplying them by the probability that the feature detector or input was not disabled. In an example, if the feature detectors of each hidden layer were selectively disabled with probability 0.5 in the training stage, the outgoing weights are halved for the test case since approximately twice as many feature detectors will be enabled. A similar approach is applied to the input layers.
The test set may then be processed by the neural network (206).
It has been found that the foregoing method provides results similar to performing model averaging with neural networks but is operable to do so with increased efficiency. The described method may enable the training of a plurality of different networks in a reduced time as compared to model averaging.
In another aspect, a stochastic gradient descent process may be applied for training the neural network on mini-batches of training cases. However, in this example, the penalty term that is normally used to prevent the weights from growing too large may be modified, such that instead of penalizing the squared length (L2 norm) of the whole weight vector, an upper bound may be set on the L2 norm of the incoming weight vector for each individual hidden unit. If a weight-update violates this constraint, the incoming weights of the hidden unit may be renormalized by division. Using a constraint rather than a penalty prevents weights from growing very large regardless of how large the proposed weight-update is. Thus, it may be possible to start with a very large learning rate which decays during learning, thus allowing a thorough search of the weight-space.
Further, performance may be improved by implementing separate L2 constraints on the incoming weights of each hidden unit and further improved by also dropping out a random 20% of the pixels.
In further aspects, performance of the neural network on the test set may be improved by enhancing the training data with transformed images or by wiring knowledge about spatial transformations into a convolutional neural network or by using generative pre-training to extract useful features from the training images without using the labels, or a combination thereof
The foregoing method may further be combined with generative pre-training, though it may be beneficial to apply a small learning rate and no weight constraints to avoid losing the feature detectors discovered by the pre-training fine-tuned using standard back-propagation.
In addition, for speech recognition and object recognition datasets the architecture of the neural network may be adapted by evaluating the performance of a plurality of the more optimal learned neural networks on the validation set and then selecting the architecture that performs best on the validation set as the one to apply to the test set.
In further examples, for datasets in which the required input-output mapping has several suitably different regimes, performance may be further improved by adapting the preconfigured probabilities to be a learned function of the input.
In another aspect, the switch may select hidden units in blocks so that all of the hidden units within a block are always either selected or not selected together. The blocks may comprise units in a single hidden layer or may comprise units in more than one hidden layer.
In another aspect, a plurality of switches may be provided to control blocks of hidden units or inputs, including blocks of size 1, and a hidden unit or input is only used in the forward pass if it is selected by all of the switches that are capable of selecting it.
Example embodiments are now described for applying the foregoing system to particular test data. However, it will be appreciated that alternative neural network configurations may be implemented for such test data, and further neural network configurations may be implemented for other applications. In addition, the type of neural network implemented is not limited merely to feedforward neural networks but can also be applied to any neural networks, including convolutional neural networks, recurrent neural networks, auto-encoders and Boltzmann machines.
* * * * *
References
D00000
D00001
D00002
XML
uspto.report is an independent third-party trademark research tool that is not affiliated, endorsed, or sponsored by the United States Patent and Trademark Office (USPTO) or any other governmental organization. The information provided by uspto.report is based on publicly available data at the time of writing and is intended for informational purposes only.
While we strive to provide accurate and up-to-date information, we do not guarantee the accuracy, completeness, reliability, or suitability of the information displayed on this site. The use of this site is at your own risk. Any reliance you place on such information is therefore strictly at your own risk.
All official trademark data, including owner information, should be verified by visiting the official USPTO website at www.uspto.gov. This site is not intended to replace professional legal advice and should not be used as a substitute for consulting with a legal professional who is knowledgeable about trademark law.